[llvm] [MachineScheduler] Experimental option to partially disable pre-ra scheduling. (PR #90181)
Jonas Paulsson via llvm-commits
llvm-commits at lists.llvm.org
Fri Apr 26 02:05:33 PDT 2024
https://github.com/JonPsson1 created https://github.com/llvm/llvm-project/pull/90181
I found a big regression on SPEC/cactus which comes from enabling the machine scheduler before register allocation - cactus ran 8% faster by just disabling the pre-ra machine scheduler. The reason seems to be that it prdoduces a schedule that gives heavily increased spilling during register allocation. I have experimented quite a bit with the scheduler heuristics but do not yet have an overall solution to this. This is merely a first step that enables experimentally to disable scheduling of bigger regions.
This is actually relevant not only for SystemZ (@greened @efriedma-quic @asb @ecnelises @uweigand @dominik-steenken @arsenm @michaelmaitland):
```
clang -c -S /dev/null -o -O3 -target s390x-linux-gnu -march=z16 ./ML_BSSN_RHS.ii -mllvm --stats -w |& grep spilled
338 regalloc - Number of spilled snippets
2888 regalloc - Number of spilled live ranges
clang -c -S /dev/null -o -O3 -target s390x-linux-gnu -march=z16 ./ML_BSSN_RHS.ii -mllvm --stats -w -mllvm -nosched-above=350 |& grep spilled
352 regalloc - Number of spilled snippets
1872 regalloc - Number of spilled live ranges
clang -c -S /dev/null -o -O3 -target aarch64 ./ML_BSSN_RHS.ii -mllvm --stats -w |& grep spilled
555 regalloc - Number of spilled snippets
5038 regalloc - Number of spilled live ranges
clang -c -S /dev/null -o -O3 -target aarch64 ./ML_BSSN_RHS.ii -mllvm --stats -w -mllvm -nosched-above=350 |& grep spilled
566 regalloc - Number of spilled snippets
2228 regalloc - Number of spilled live ranges
clang -c -S /dev/null -o -O3 -target powerpc64-unknown-linux-gnu -mcpu=pwr9 ./ML_BSSN_RHS.ii -mllvm --stats -w |& grep spilled
331 regalloc - Number of spilled snippets
4213 regalloc - Number of spilled live ranges
clang -c -S /dev/null -o -O3 -target powerpc64-unknown-linux-gnu -mcpu=pwr9 ./ML_BSSN_RHS.ii -mllvm --stats -w -mllvm -nosched-above=350 |& grep spilled
180 regalloc - Number of spilled snippets
915 regalloc - Number of spilled live ranges
```
With this setting, I see a 9% speedup on cactus on SystemZ / z16. I think it would be interesting to try this on at least aarch64 and PowerPC as well, given the reduced spilling. Of course, maybe some other number than 350 would be optimal, but it looks like a good start. Would anyone be willing to do this?
This is a screenshot of some of my own personal experimental measurements on SPEC17/SystemZ:
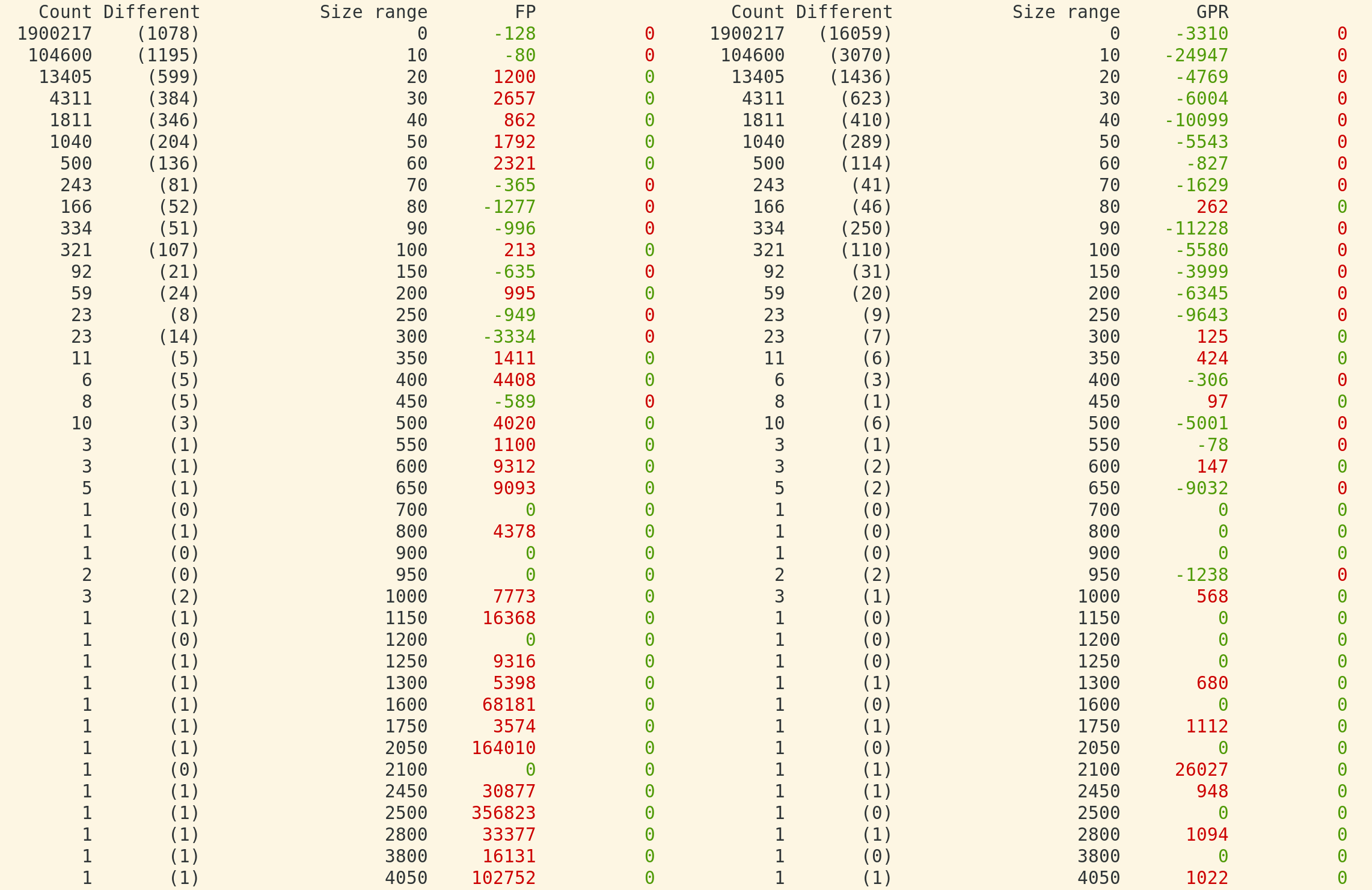
I have during scheduling counted the register overlaps before and after the scheduling of a region, both for FP and GPR registers (on SystemZ). This is a summary which from left to right shows the total number of regions of a particular size(-interval), then in parenthesis the number of regions where the resulting register overlaps where different (the size ranges is first in steps of 10, and then in bigger steps. Only size intervals with something changing are printed (some bigger ones are omitted). The FP / GPR columns show the overall results - green / negative is good as overlaps decreased, while red shows the scheduler strategy has increased overlaps.
If overlaps increase, that means register pressure will increase and more spilling will typically result. As can be seen, the results are only satisfactory for the upper right hand corner - the GPR register pressure in small (common) regions. Bigger regions (rare) with FP is really bad. This overlap measurement unit is sort of an integral (sum) of all the overlaps across the region at point of each instruction.
A first next step might be to disable big regions non-experimentally for now on SystemZ. In the long run, I am hoping to have better general heuristics that works also on big regions. Some thoughts:
- I was hoping that ilp-min would remedy this situation, but to my surprise it did not. It is actually a lot worse that the default strategy overall on SPEC/SystemZ, as well as on the cactus file, for register spilling.
- The default MachineSchedStrategy does many things that make sense mostly on an in-order target, it seems to me. An out-of-order target would primarily like to reduce spilling, and secondarily also do things like critical path / height adjustments and try to balance out usages of processor resources.
- The default scheduler does a cycle based decision and puts SUs in Pending if it is not cycle-ready even though it is possible to schedule it. The alternative would be to put all available SUs in Available, and thus make it possible to reduce live ranges, by e.g. scheduling a load immediately next to its user.
- It seems to me that there should be an OOO strategy that should never increase spilling (hopefully improve it), while increasing ILP in a sensible manner. It shouldn't worry too much about cycle exact scheduling or processor resources balancing. Has anyone else worked on this also?
- While building the sched graph, it tracks the register pressures and decides what should be the critical pressure set during scheduling. The cactus example is an FP intensive region, but in the given *input* order the GPR registers are instead deemed to be the more important during scheduling (This is however not the real problem in this case).
- Overall SPEC/SystemZ shows an 18% in spilled FP live ranges with machine-scheduler enabled, while the rest (GPR) is about the same. This is too much to ignore, of course.
- I have done quite some experimenting with this and have been able to get even some additional improvement on cactus/SystemZ by a simpler scheduling strategy (12%). It goes bottom-up, always schedules a load lower, and pushes stores up a bit, to decrease the overlapping of registers. In addition, it also adds a height/depth heuristic which gives the additional performance improvement. I did try bi-directional extensively but to my surprise that was not helpful. This is quite tricky to get right it seems, and I would be happy to collaborate with anyone else interested in this.
>From 2bfad9b3e50bb5770e64160c181b80f12a0c5465 Mon Sep 17 00:00:00 2001
From: Jonas Paulsson <paulson1 at linux.ibm.com>
Date: Wed, 24 Apr 2024 17:21:42 +0200
Subject: [PATCH 1/2] -nosched-above
---
llvm/include/llvm/CodeGen/MachineScheduler.h | 17 +++++++++++++++++
llvm/include/llvm/CodeGen/ScheduleDAGInstrs.h | 5 +++++
llvm/include/llvm/CodeGen/TargetSubtargetInfo.h | 10 ++++++++++
llvm/lib/CodeGen/MachineScheduler.cpp | 10 +++++++++-
llvm/lib/Target/SystemZ/SystemZSubtarget.cpp | 16 ++++++++++++++++
llvm/lib/Target/SystemZ/SystemZSubtarget.h | 6 ++++++
6 files changed, 63 insertions(+), 1 deletion(-)
diff --git a/llvm/include/llvm/CodeGen/MachineScheduler.h b/llvm/include/llvm/CodeGen/MachineScheduler.h
index 9cca6b3a571c3b..acf3937cb37626 100644
--- a/llvm/include/llvm/CodeGen/MachineScheduler.h
+++ b/llvm/include/llvm/CodeGen/MachineScheduler.h
@@ -241,6 +241,12 @@ class MachineSchedStrategy {
/// Tell the strategy that MBB is about to be processed.
virtual void enterMBB(MachineBasicBlock *MBB) {};
+ virtual bool disableForRegionPreRA(MachineBasicBlock::iterator begin,
+ MachineBasicBlock::iterator end,
+ unsigned regioninstrs) const {
+ return false;
+ }
+
/// Tell the strategy that current MBB is done.
virtual void leaveMBB() {};
@@ -487,6 +493,13 @@ class ScheduleDAGMILive : public ScheduleDAGMI {
MachineBasicBlock::iterator end,
unsigned regioninstrs) override;
+ bool disableForRegion(MachineBasicBlock *bb,
+ MachineBasicBlock::iterator begin,
+ MachineBasicBlock::iterator end,
+ unsigned regioninstrs) const override {
+ return SchedImpl->disableForRegionPreRA(begin, end, regioninstrs);
+ }
+
/// Implement ScheduleDAGInstrs interface for scheduling a sequence of
/// reorderable instructions.
void schedule() override;
@@ -1219,6 +1232,10 @@ class GenericScheduler : public GenericSchedulerBase {
void dumpPolicy() const override;
+ bool disableForRegionPreRA(MachineBasicBlock::iterator Begin,
+ MachineBasicBlock::iterator End,
+ unsigned NumRegionInstrs) const override;
+
bool shouldTrackPressure() const override {
return RegionPolicy.ShouldTrackPressure;
}
diff --git a/llvm/include/llvm/CodeGen/ScheduleDAGInstrs.h b/llvm/include/llvm/CodeGen/ScheduleDAGInstrs.h
index 32ff15fc75936a..6594048b8f8a29 100644
--- a/llvm/include/llvm/CodeGen/ScheduleDAGInstrs.h
+++ b/llvm/include/llvm/CodeGen/ScheduleDAGInstrs.h
@@ -319,6 +319,11 @@ namespace llvm {
MachineBasicBlock::iterator end,
unsigned regioninstrs);
+ virtual bool disableForRegion(MachineBasicBlock *bb,
+ MachineBasicBlock::iterator begin,
+ MachineBasicBlock::iterator end,
+ unsigned regioninstrs) const { return false; }
+
/// Called when the scheduler has finished scheduling the current region.
virtual void exitRegion();
diff --git a/llvm/include/llvm/CodeGen/TargetSubtargetInfo.h b/llvm/include/llvm/CodeGen/TargetSubtargetInfo.h
index 5023e29ce145ac..9d74a2ec578048 100644
--- a/llvm/include/llvm/CodeGen/TargetSubtargetInfo.h
+++ b/llvm/include/llvm/CodeGen/TargetSubtargetInfo.h
@@ -16,6 +16,7 @@
#include "llvm/ADT/ArrayRef.h"
#include "llvm/ADT/SmallVector.h"
#include "llvm/ADT/StringRef.h"
+#include "llvm/CodeGen/MachineBasicBlock.h"
#include "llvm/CodeGen/MacroFusion.h"
#include "llvm/CodeGen/PBQPRAConstraint.h"
#include "llvm/CodeGen/SchedulerRegistry.h"
@@ -229,6 +230,15 @@ class TargetSubtargetInfo : public MCSubtargetInfo {
virtual void overrideSchedPolicy(MachineSchedPolicy &Policy,
unsigned NumRegionInstrs) const {}
+ /// Allow the subtarget to leave a region untouched. This has purposefully
+ /// been left a bit untangled from other methods as this is hopefully
+ /// just a temporary solution.
+ virtual bool disableForRegionPreRA(MachineBasicBlock::iterator Begin,
+ MachineBasicBlock::iterator End,
+ unsigned NumRegionInstrs) const {
+ return false;
+ }
+
// Perform target-specific adjustments to the latency of a schedule
// dependency.
// If a pair of operands is associated with the schedule dependency, DefOpIdx
diff --git a/llvm/lib/CodeGen/MachineScheduler.cpp b/llvm/lib/CodeGen/MachineScheduler.cpp
index 78d581c8ceadfd..443319946bc59c 100644
--- a/llvm/lib/CodeGen/MachineScheduler.cpp
+++ b/llvm/lib/CodeGen/MachineScheduler.cpp
@@ -641,7 +641,8 @@ void MachineSchedulerBase::scheduleRegions(ScheduleDAGInstrs &Scheduler,
Scheduler.enterRegion(&*MBB, I, RegionEnd, NumRegionInstrs);
// Skip empty scheduling regions (0 or 1 schedulable instructions).
- if (I == RegionEnd || I == std::prev(RegionEnd)) {
+ if (I == RegionEnd || I == std::prev(RegionEnd) ||
+ Scheduler.disableForRegion(&*MBB, I, RegionEnd, NumRegionInstrs)) {
// Close the current region. Bundle the terminator if needed.
// This invalidates 'RegionEnd' and 'I'.
Scheduler.exitRegion();
@@ -3334,6 +3335,13 @@ void GenericScheduler::dumpPolicy() const {
#endif
}
+bool GenericScheduler::disableForRegionPreRA(MachineBasicBlock::iterator Begin,
+ MachineBasicBlock::iterator End,
+ unsigned NumRegionInstrs) const {
+ const MachineFunction &MF = *Begin->getMF();
+ return MF.getSubtarget().disableForRegionPreRA(Begin, End, NumRegionInstrs);
+}
+
/// Set IsAcyclicLatencyLimited if the acyclic path is longer than the cyclic
/// critical path by more cycles than it takes to drain the instruction buffer.
/// We estimate an upper bounds on in-flight instructions as:
diff --git a/llvm/lib/Target/SystemZ/SystemZSubtarget.cpp b/llvm/lib/Target/SystemZ/SystemZSubtarget.cpp
index d0badd3692e406..e09ca747e4fe2e 100644
--- a/llvm/lib/Target/SystemZ/SystemZSubtarget.cpp
+++ b/llvm/lib/Target/SystemZ/SystemZSubtarget.cpp
@@ -72,6 +72,22 @@ SystemZSubtarget::SystemZSubtarget(const Triple &TT, const std::string &CPU,
InstrInfo(initializeSubtargetDependencies(CPU, TuneCPU, FS)),
TLInfo(TM, *this), FrameLowering(SystemZFrameLowering::create(*this)) {}
+
+// EXPERIMENTAL
+cl::opt<unsigned> NoSchedAbove("nosched-above", cl::init(~0U));
+bool SystemZSubtarget::disableForRegionPreRA(MachineBasicBlock::iterator Begin,
+ MachineBasicBlock::iterator End,
+ unsigned NumRegionInstrs) const {
+ // It seems that the generic scheduler currently can increase spilling heavily
+ // with big / huge regions. Disable it until it is fixed.
+ if (NumRegionInstrs > NoSchedAbove) {
+ LLVM_DEBUG(dbgs() << "Disabling pre-ra mischeduling of region with "
+ << NumRegionInstrs << " instructions\n";);
+ return true;
+ }
+ return false;
+}
+
bool SystemZSubtarget::enableSubRegLiveness() const {
return UseSubRegLiveness;
}
diff --git a/llvm/lib/Target/SystemZ/SystemZSubtarget.h b/llvm/lib/Target/SystemZ/SystemZSubtarget.h
index 5fa7c8f194ebf3..c5749405cc71a3 100644
--- a/llvm/lib/Target/SystemZ/SystemZSubtarget.h
+++ b/llvm/lib/Target/SystemZ/SystemZSubtarget.h
@@ -89,6 +89,12 @@ class SystemZSubtarget : public SystemZGenSubtargetInfo {
// "source" order scheduler.
bool enableMachineScheduler() const override { return true; }
+ // Don't use pre-ra mischeduler for huge regions where it creates a lot of
+ // spilling (temporary solution).
+ bool disableForRegionPreRA(MachineBasicBlock::iterator Begin,
+ MachineBasicBlock::iterator End,
+ unsigned NumRegionInstrs) const override;
+
// This is important for reducing register pressure in vector code.
bool useAA() const override { return true; }
>From 3d2fa294f440e97d2aec1bce8aabb8e5c91c8f82 Mon Sep 17 00:00:00 2001
From: Jonas Paulsson <paulson1 at linux.ibm.com>
Date: Fri, 26 Apr 2024 08:53:31 +0200
Subject: [PATCH 2/2] In MachineScheduler instead of Subtarget.
---
llvm/include/llvm/CodeGen/MachineScheduler.h | 14 +----------
.../llvm/CodeGen/TargetSubtargetInfo.h | 10 --------
llvm/lib/CodeGen/MachineScheduler.cpp | 24 +++++++++++++------
llvm/lib/Target/SystemZ/SystemZSubtarget.cpp | 16 -------------
llvm/lib/Target/SystemZ/SystemZSubtarget.h | 6 -----
5 files changed, 18 insertions(+), 52 deletions(-)
diff --git a/llvm/include/llvm/CodeGen/MachineScheduler.h b/llvm/include/llvm/CodeGen/MachineScheduler.h
index acf3937cb37626..77b432f6a48fb7 100644
--- a/llvm/include/llvm/CodeGen/MachineScheduler.h
+++ b/llvm/include/llvm/CodeGen/MachineScheduler.h
@@ -241,12 +241,6 @@ class MachineSchedStrategy {
/// Tell the strategy that MBB is about to be processed.
virtual void enterMBB(MachineBasicBlock *MBB) {};
- virtual bool disableForRegionPreRA(MachineBasicBlock::iterator begin,
- MachineBasicBlock::iterator end,
- unsigned regioninstrs) const {
- return false;
- }
-
/// Tell the strategy that current MBB is done.
virtual void leaveMBB() {};
@@ -496,9 +490,7 @@ class ScheduleDAGMILive : public ScheduleDAGMI {
bool disableForRegion(MachineBasicBlock *bb,
MachineBasicBlock::iterator begin,
MachineBasicBlock::iterator end,
- unsigned regioninstrs) const override {
- return SchedImpl->disableForRegionPreRA(begin, end, regioninstrs);
- }
+ unsigned regioninstrs) const override;
/// Implement ScheduleDAGInstrs interface for scheduling a sequence of
/// reorderable instructions.
@@ -1232,10 +1224,6 @@ class GenericScheduler : public GenericSchedulerBase {
void dumpPolicy() const override;
- bool disableForRegionPreRA(MachineBasicBlock::iterator Begin,
- MachineBasicBlock::iterator End,
- unsigned NumRegionInstrs) const override;
-
bool shouldTrackPressure() const override {
return RegionPolicy.ShouldTrackPressure;
}
diff --git a/llvm/include/llvm/CodeGen/TargetSubtargetInfo.h b/llvm/include/llvm/CodeGen/TargetSubtargetInfo.h
index 9d74a2ec578048..5023e29ce145ac 100644
--- a/llvm/include/llvm/CodeGen/TargetSubtargetInfo.h
+++ b/llvm/include/llvm/CodeGen/TargetSubtargetInfo.h
@@ -16,7 +16,6 @@
#include "llvm/ADT/ArrayRef.h"
#include "llvm/ADT/SmallVector.h"
#include "llvm/ADT/StringRef.h"
-#include "llvm/CodeGen/MachineBasicBlock.h"
#include "llvm/CodeGen/MacroFusion.h"
#include "llvm/CodeGen/PBQPRAConstraint.h"
#include "llvm/CodeGen/SchedulerRegistry.h"
@@ -230,15 +229,6 @@ class TargetSubtargetInfo : public MCSubtargetInfo {
virtual void overrideSchedPolicy(MachineSchedPolicy &Policy,
unsigned NumRegionInstrs) const {}
- /// Allow the subtarget to leave a region untouched. This has purposefully
- /// been left a bit untangled from other methods as this is hopefully
- /// just a temporary solution.
- virtual bool disableForRegionPreRA(MachineBasicBlock::iterator Begin,
- MachineBasicBlock::iterator End,
- unsigned NumRegionInstrs) const {
- return false;
- }
-
// Perform target-specific adjustments to the latency of a schedule
// dependency.
// If a pair of operands is associated with the schedule dependency, DefOpIdx
diff --git a/llvm/lib/CodeGen/MachineScheduler.cpp b/llvm/lib/CodeGen/MachineScheduler.cpp
index 443319946bc59c..95a74a6bbb7ca3 100644
--- a/llvm/lib/CodeGen/MachineScheduler.cpp
+++ b/llvm/lib/CodeGen/MachineScheduler.cpp
@@ -1253,6 +1253,23 @@ void ScheduleDAGMILive::enterRegion(MachineBasicBlock *bb,
"ShouldTrackLaneMasks requires ShouldTrackPressure");
}
+// EXPERIMENTAL: It seems that GenericScheduler currently often increases
+// spilling heavily with huge regions (like >350 instructions). This option
+// makes any sched region bigger than its value have pre-ra scheduling
+// skipped.
+cl::opt<unsigned> NoSchedAbove("nosched-above", cl::init(~0U));
+bool ScheduleDAGMILive::disableForRegion(MachineBasicBlock *bb,
+ MachineBasicBlock::iterator begin,
+ MachineBasicBlock::iterator end,
+ unsigned regioninstrs) const {
+ if (NumRegionInstrs > NoSchedAbove) {
+ LLVM_DEBUG(dbgs() << "Disabling pre-ra mischeduling of region with "
+ << NumRegionInstrs << " instructions\n";);
+ return true;
+ }
+ return false;
+}
+
// Setup the register pressure trackers for the top scheduled and bottom
// scheduled regions.
void ScheduleDAGMILive::initRegPressure() {
@@ -3335,13 +3352,6 @@ void GenericScheduler::dumpPolicy() const {
#endif
}
-bool GenericScheduler::disableForRegionPreRA(MachineBasicBlock::iterator Begin,
- MachineBasicBlock::iterator End,
- unsigned NumRegionInstrs) const {
- const MachineFunction &MF = *Begin->getMF();
- return MF.getSubtarget().disableForRegionPreRA(Begin, End, NumRegionInstrs);
-}
-
/// Set IsAcyclicLatencyLimited if the acyclic path is longer than the cyclic
/// critical path by more cycles than it takes to drain the instruction buffer.
/// We estimate an upper bounds on in-flight instructions as:
diff --git a/llvm/lib/Target/SystemZ/SystemZSubtarget.cpp b/llvm/lib/Target/SystemZ/SystemZSubtarget.cpp
index e09ca747e4fe2e..d0badd3692e406 100644
--- a/llvm/lib/Target/SystemZ/SystemZSubtarget.cpp
+++ b/llvm/lib/Target/SystemZ/SystemZSubtarget.cpp
@@ -72,22 +72,6 @@ SystemZSubtarget::SystemZSubtarget(const Triple &TT, const std::string &CPU,
InstrInfo(initializeSubtargetDependencies(CPU, TuneCPU, FS)),
TLInfo(TM, *this), FrameLowering(SystemZFrameLowering::create(*this)) {}
-
-// EXPERIMENTAL
-cl::opt<unsigned> NoSchedAbove("nosched-above", cl::init(~0U));
-bool SystemZSubtarget::disableForRegionPreRA(MachineBasicBlock::iterator Begin,
- MachineBasicBlock::iterator End,
- unsigned NumRegionInstrs) const {
- // It seems that the generic scheduler currently can increase spilling heavily
- // with big / huge regions. Disable it until it is fixed.
- if (NumRegionInstrs > NoSchedAbove) {
- LLVM_DEBUG(dbgs() << "Disabling pre-ra mischeduling of region with "
- << NumRegionInstrs << " instructions\n";);
- return true;
- }
- return false;
-}
-
bool SystemZSubtarget::enableSubRegLiveness() const {
return UseSubRegLiveness;
}
diff --git a/llvm/lib/Target/SystemZ/SystemZSubtarget.h b/llvm/lib/Target/SystemZ/SystemZSubtarget.h
index c5749405cc71a3..5fa7c8f194ebf3 100644
--- a/llvm/lib/Target/SystemZ/SystemZSubtarget.h
+++ b/llvm/lib/Target/SystemZ/SystemZSubtarget.h
@@ -89,12 +89,6 @@ class SystemZSubtarget : public SystemZGenSubtargetInfo {
// "source" order scheduler.
bool enableMachineScheduler() const override { return true; }
- // Don't use pre-ra mischeduler for huge regions where it creates a lot of
- // spilling (temporary solution).
- bool disableForRegionPreRA(MachineBasicBlock::iterator Begin,
- MachineBasicBlock::iterator End,
- unsigned NumRegionInstrs) const override;
-
// This is important for reducing register pressure in vector code.
bool useAA() const override { return true; }
More information about the llvm-commits
mailing list