[llvm-branch-commits] [mlir] [mlir][Transforms][NFC] Simplify `BlockTypeConversionRewrite` (PR #83286)
Matthias Springer via llvm-branch-commits
llvm-branch-commits at lists.llvm.org
Mon Mar 4 00:58:16 PST 2024
Ingo =?utf-8?q?Müller?= <ingomueller at google.com>,Michael Liao
<michael.hliao at gmail.com>,Alexey Bataev <a.bataev at outlook.com>,Ivan Kosarev
<ivan.kosarev at amd.com>,Alexey Bataev
<5361294+alexey-bataev at users.noreply.github.com>,
Timm =?utf-8?q?Bäder?= <tbaeder at redhat.com>,Petar Avramovic
<Petar.Avramovic at amd.com>,Quinn Dawkins <quinn.dawkins at gmail.com>,Alexey
Bataev <a.bataev at outlook.com>,Diego Caballero <diegocaballero at google.com>,Florian
Hahn <flo at fhahn.com>,Leandro Lupori <leandro.lupori at linaro.org>,Walter
Erquinigo <a20012251 at gmail.com>,Lukacma <Marian.Lukac at arm.com>,SivanShani-Arm
<sivan.shani at arm.com>,Leandro Lupori <leandro.lupori at linaro.org>,
Timm =?utf-8?q?Bäder?= <tbaeder at redhat.com>,srcarroll
<50210727+srcarroll at users.noreply.github.com>,Paul T Robinson
<paul.robinson at sony.com>,Michael Jones <michaelrj at google.com>,Han-Chung Wang
<hanhan0912 at gmail.com>,Jason Eckhardt <jeckhardt at nvidia.com>,Cyndy Ishida
<cyndy_ishida at apple.com>,Alexandros Lamprineas
<alexandros.lamprineas at arm.com>,LLVM GN Syncbot <llvmgnsyncbot at gmail.com>,Cyndy
Ishida <cyndy_ishida at apple.com>,Nilanjana Basu <n_basu at apple.com>,Aart Bik
<39774503+aartbik at users.noreply.github.com>,Slava Zakharin
<szakharin at nvidia.com>,Kevin Frei <kevinfrei at users.noreply.github.com>,Simon
Pilgrim <llvm-dev at redking.me.uk>,Patrick Dougherty
<patrick.dougherty.0208 at gmail.com>,Arthur Eubanks <aeubanks at google.com>,Benoit
Jacob <jacob.benoit.1 at gmail.com>,Paul Kirth <paulkirth at google.com>,Nikolas
Klauser <nikolasklauser at berlin.de>,Marius Brehler
<marius.brehler at iml.fraunhofer.de>,Zequan Wu <zequanwu at google.com>,ChiaHungDuan
<chiahungduan at google.com>,Nikolas Klauser <nikolasklauser at berlin.de>,David
Green <david.green at arm.com>,Aart Bik
<39774503+aartbik at users.noreply.github.com>,Fangrui Song <i at maskray.me>,Nick
Desaulniers <nickdesaulniers at users.noreply.github.com>,Jordan Rupprecht
<rupprecht at google.com>,Jon Roelofs <jonathan_roelofs at apple.com>,Nick
Desaulniers <nickdesaulniers at users.noreply.github.com>,Joe Nash
<Sisyph at users.noreply.github.com>,Joseph Huber <huberjn at outlook.com>,Petr
Hosek <phosek at google.com>,Aart Bik
<39774503+aartbik at users.noreply.github.com>,Cyndy Ishida
<cyndy_ishida at apple.com>,Nico Weber <thakis at chromium.org>,Max191
<44243577+Max191 at users.noreply.github.com>,OverMighty
<its.overmighty at gmail.com>,Nick Desaulniers
<nickdesaulniers at users.noreply.github.com>,Aart Bik
<39774503+aartbik at users.noreply.github.com>,Craig Topper
<craig.topper at sifive.com>,Craig Topper <craig.topper at sifive.com>,Fangrui
Song <i at maskray.me>,Fangrui Song <i at maskray.me>,Jonas Devlieghere
<jonas at devlieghere.com>,Stanislav Mekhanoshin
<rampitec at users.noreply.github.com>,Shilei Tian <i at tianshilei.me>,Fangrui
Song <i at maskray.me>,Peiming Liu
<36770114+PeimingLiu at users.noreply.github.com>,jimingham <jingham at apple.com>,ChiaHungDuan
<chiahungduan at google.com>,Aart Bik
<39774503+aartbik at users.noreply.github.com>,Alex Langford
<alangford at apple.com>,Peiming Liu
<36770114+PeimingLiu at users.noreply.github.com>,Uday Bondhugula
<uday at polymagelabs.com>,"Henrik G. Olsson" <hnrklssn at gmail.com>,Nick
Desaulniers <nickdesaulniers at users.noreply.github.com>,Changpeng Fang
<changpeng.fang at amd.com>,jimingham <jingham at apple.com>,Shengchen Kan
<shengchen.kan at intel.com>,Shengchen Kan <shengchen.kan at intel.com>,lifengxiang1025
<lifengxiang.1025 at bytedance.com>,Paul Kirth <paulkirth at google.com>,Matt
Arsenault <Matthew.Arsenault at amd.com>,XinWang10
<108658776+XinWang10 at users.noreply.github.com>,Maksim Panchenko <maks at fb.com>
=?utf-8?q?,?=Maksim Panchenko <maks at fb.com>,Yeting Kuo
<46629943+yetingk at users.noreply.github.com>,Matt Arsenault
<Matthew.Arsenault at amd.com>,Jonas Devlieghere <jonas at devlieghere.com>,Jonas
Devlieghere <jonas at devlieghere.com>,=?utf-8?q?Dávid_Ferenc_Szabó?=,Craig
Topper <craig.topper at sifive.com>,SunilKuravinakop
<98882378+SunilKuravinakop at users.noreply.github.com>,Animesh Kumar
<108114634+animeshk-amd at users.noreply.github.com>,Shih-Po Hung
<shihpo.hung at sifive.com>,Dominik =?utf-8?q?Wójt?= <dominik.wojt at arm.com>
=?utf-8?q?,?=jeanPerier <jperier at nvidia.com>,
Timm =?utf-8?q?Bäder?= <tbaeder at redhat.com>,Matt Arsenault
<Matthew.Arsenault at amd.com>,Guillaume Chatelet <gchatelet at google.com>,
kadir =?utf-8?q?çetinkaya?= <kadircet at google.com>,Sudharsan Veeravalli
<quic_svs at quicinc.com>,Tomas Matheson <tomas.matheson at arm.com>,Chen Zheng
<czhengsz at cn.ibm.com>,Alexander Belyaev
<32522095+pifon2a at users.noreply.github.com>,Benjamin Maxwell
<benjamin.maxwell at arm.com>,Simon Pilgrim <llvm-dev at redking.me.uk>,Simon
Pilgrim <llvm-dev at redking.me.uk>,Sudharsan Veeravalli <quic_svs at quicinc.com>,Matt
Arsenault <Matthew.Arsenault at amd.com>,Alexander Belyaev
<32522095+pifon2a at users.noreply.github.com>,Jay Foad <jay.foad at amd.com>,Samuel
Tebbs <samuel.tebbs at arm.com>,Mitch Phillips <mitchp at google.com>,Jay Foad
<jay.foad at amd.com>,Nicolai =?utf-8?q?Hähnle?= <nicolai.haehnle at amd.com>,Simon
Pilgrim <llvm-dev at redking.me.uk>,Simon Pilgrim <llvm-dev at redking.me.uk>,Florian
Hahn <flo at fhahn.com>,Joseph Huber <huberjn at outlook.com>,David Green
<david.green at arm.com>,Petar Avramovic <Petar.Avramovic at amd.com>,Jeremy Morse
<jeremy.morse at sony.com>,Benjamin Maxwell <benjamin.maxwell at arm.com>,Dani
<daniel.kiss at arm.com>,Erich Keane <ekeane at nvidia.com>,Vinayak Dev
<104419489+vinayakdsci at users.noreply.github.com>,"S. Bharadwaj Yadavalli"
<Bharadwaj.Yadavalli at microsoft.com>,David Spickett
<david.spickett at linaro.org>,Stephen Tozer <stephen.tozer at sony.com>,Petar
Avramovic <Petar.Avramovic at amd.com>,Stephen Tozer <stephen.tozer at sony.com>,Jeremy
Morse <jeremy.morse at sony.com>,RicoAfoat
<51285519+RicoAfoat at users.noreply.github.com>,Michael Maitland
<michaeltmaitland at gmail.com>,David Spickett <david.spickett at linaro.org>,Farzon
Lotfi <1802579+farzonl at users.noreply.github.com>,Louis Dionne
<ldionne.2 at gmail.com>,Tuan Chuong Goh <chuong.goh at arm.com>,Simon Pilgrim
<llvm-dev at redking.me.uk>,Sander de Smalen <sander.desmalen at arm.com>,Devajith
Valaparambil Sreeramaswamy <devajithvs at gmail.com>,Louis Dionne
<ldionne.2 at gmail.com>,Sumanth Gundapaneni <sgundapa at quicinc.com>,Jonathan
Thackray <jonathan.thackray at arm.com>,Jonas Devlieghere
<jonas at devlieghere.com>,Jonas Devlieghere <jonas at devlieghere.com>,chuongg3
<chuong.goh at arm.com>,Francesco Petrogalli <francesco.petrogalli at apple.com>,Jeremy
Morse <jeremy.morse at sony.com>,Sirraide <aeternalmail at gmail.com>,Jeremy Morse
<jeremy.morse at sony.com>,Craig Topper <craig.topper at sifive.com>,erichkeane
<ekeane at nvidia.com>,Slava Zakharin <szakharin at nvidia.com>,SunilKuravinakop
<98882378+SunilKuravinakop at users.noreply.github.com>,Jonas Devlieghere
<jonas at devlieghere.com>,Alexey Bataev <a.bataev at outlook.com>,Jason Eckhardt
<jeckhardt at nvidia.com>,Kalesh Singh <kaleshsingh96 at gmail.com>,Farzon Lotfi
<1802579+farzonl at users.noreply.github.com>,Farzon Lotfi
<1802579+farzonl at users.noreply.github.com>,Arthur Eubanks
<aeubanks at google.com>,Yinying Li
<107574043+yinying-lisa-li at users.noreply.github.com>,Alexey Bataev
<a.bataev at outlook.com>,lntue <35648136+lntue at users.noreply.github.com>,
Danny =?utf-8?q?Mösch?= <danny.moesch at icloud.com>,LLVM GN Syncbot
<llvmgnsyncbot at gmail.com>,Guillaume Chatelet <gchatelet at google.com>,Aiden
Grossman <agrossman154 at yahoo.com>,Piotr Zegar <me at piotrzegar.pl>,Guillaume
Chatelet <gchatelet at google.com>,Peter Klausler
<35819229+klausler at users.noreply.github.com>,Fangrui Song <i at maskray.me>,Shubham
Sandeep Rastogi <srastogi22 at apple.com>,Mehdi Amini <joker.eph at gmail.com>,Aiden
Grossman <agrossman154 at yahoo.com>,Teresa Johnson <tejohnson at google.com>,Michael
Buch <michaelbuch12 at gmail.com>,Reid Kleckner <rnk at google.com>,Michael Buch
<michaelbuch12 at gmail.com>,Mircea Trofin <mtrofin at google.com>,Paul Kirth
<paulkirth at google.com>,Leon Clark <PeddleSpam at users.noreply.github.com>,Slava
Zakharin <szakharin at nvidia.com>,Matthias Braun <matze at braunis.de>,Sumanth
Gundapaneni <sgundapa at quicinc.com>,LLVM GN Syncbot <llvmgnsyncbot at gmail.com>,Mehdi
Amini <joker.eph at gmail.com>,Andrei Homescu <ahomescu at google.com>,Florian
Mayer <fmayer at google.com>,Mehdi Amini <joker.eph at gmail.com>,Mircea Trofin
<mtrofin at google.com>,Kai Luo <lkail at cn.ibm.com>,ZijunZhaoCCK
<88353225+ZijunZhaoCCK at users.noreply.github.com>,"Felix (Ting Wang)"
<Ting.Wang.SH at ibm.com>,Yinying Li
<107574043+yinying-lisa-li at users.noreply.github.com>,Jason Molenda
<jmolenda at apple.com>,David CARLIER <devnexen at gmail.com>,Jason Molenda
<jmolenda at apple.com>,Kirill Stoimenov
<87100199+kstoimenov at users.noreply.github.com>,David CARLIER
<devnexen at gmail.com>,lntue <35648136+lntue at users.noreply.github.com>,Alexander
M <iammorjj at gmail.com>,jameshu15869
<55058507+jameshu15869 at users.noreply.github.com>,Chelsea Cassanova
<chelsea_cassanova at apple.com>,Wang Pengcheng <wangpengcheng.pp at bytedance.com>
=?utf-8?q?,?=Jason Molenda <jmolenda at apple.com>,Brandon Wu
<brandon.wu at sifive.com>,Cyndy Ishida <cyndy_ishida at apple.com>,Cyndy Ishida
<cyndy_ishida at apple.com>,Douglas Yung <douglas.yung at sony.com>,Matthias Gehre
<matthias.gehre at amd.com>,Matthias Gehre <matthias.gehre at amd.com>,
=?utf-8?q?Balázs_Kéri?= <balazs.keri at ericsson.com>,David CARLIER
<devnexen at gmail.com>,"Dhruv Chawla (work)" <dhruvc at nvidia.com>,Shengchen Kan
<shengchen.kan at intel.com>,martinboehme <mboehme at google.com>,
Timm =?utf-8?q?Bäder?= <tbaeder at redhat.com>,Nick Anderson
<nickleus27 at gmail.com>,chuongg3 <chuong.goh at arm.com>,Pravin Jagtap
<prjagtap at amd.com>,Alexandros Lamprineas <alexandros.lamprineas at arm.com>,
Timm =?utf-8?q?Bäder?= <tbaeder at redhat.com>,David CARLIER
<devnexen at gmail.com>,Nikita Popov <npopov at redhat.com>,Jie Fu
<jiefu at tencent.com>,David Spickett <david.spickett at linaro.org>,Simon Pilgrim
<llvm-dev at redking.me.uk>,Sergei Barannikov <barannikov88 at gmail.com>,Benjamin
Maxwell <benjamin.maxwell at arm.com>,Pavel Iliin <Pavel.Iliin at arm.com>,Jay
Foad <jay.foad at amd.com>,Tom Eccles <tom.eccles at arm.com>,
Martin =?utf-8?q?Storsjö?= <martin at martin.st>,David Green
<david.green at arm.com>,David CARLIER <devnexen at gmail.com>,David Green
<david.green at arm.com>,Alexey Bataev
<5361294+alexey-bataev at users.noreply.github.com>,Marius Brehler
<marius.brehler at iml.fraunhofer.de>,Alexey Bataev
<5361294+alexey-bataev at users.noreply.github.com>,Pierre van Houtryve
<pierre.vanhoutryve at amd.com>,Alfie Richards
<156316945+AlfieRichardsArm at users.noreply.github.com>,Shengchen Kan
<shengchen.kan at intel.com>,Martin Wehking <martin.wehking at codeplay.com>,Nikolas
Klauser <nikolasklauser at berlin.de>,zhijian lin <zhijian at ca.ibm.com>,
Timm =?utf-8?q?Bäder?= <tbaeder at redhat.com>,
Timm =?utf-8?q?Bäder?= <tbaeder at redhat.com>,Simon Pilgrim
<RKSimon at users.noreply.github.com>,Florian Hahn <flo at fhahn.com>,Alexey
Bataev <a.bataev at outlook.com>,Benjamin Kramer <benny.kra at googlemail.com>,
Timm =?utf-8?q?Bäder?= <tbaeder at redhat.com>,
Timm =?utf-8?q?Bäder?= <tbaeder at redhat.com>,
Timm =?utf-8?q?Bäder?= <tbaeder at redhat.com>,Erich Keane
<ekeane at nvidia.com>,Timm =?utf-8?q?Bäder?= <tbaeder at redhat.com>,Erich
Keane <ekeane at nvidia.com>,Mats Petersson <mats.petersson at arm.com>,Vinayak
Dev <104419489+vinayakdsci at users.noreply.github.com>,Joseph Huber
<huberjn at outlook.com>,Martin Wehking <martin.wehking at codeplay.com>,Jonas
Devlieghere <jonas at devlieghere.com>,Daniil Kovalev
<dkovalev at accesssoftek.com>,Joseph Huber <huberjn at outlook.com>,Fangrui Song
<i at maskray.me>,Timm =?utf-8?q?Bäder?= <tbaeder at redhat.com>,Craig Topper
<craig.topper at sifive.com>,Kirill Stoimenov <kstoimenov at google.com>,Jay Foad
<jay.foad at amd.com>,Farzon Lotfi <1802579+farzonl at users.noreply.github.com>,Slava
Zakharin <szakharin at nvidia.com>,Francesco Petrogalli
<francesco.petrogalli at apple.com>,Mircea Trofin <mtrofin at google.com>,Alexey
Bataev <5361294+alexey-bataev at users.noreply.github.com>,Farzon Lotfi
<1802579+farzonl at users.noreply.github.com>,Changpeng Fang
<changpeng.fang at amd.com>,sylvain-audi
<62035306+sylvain-audi at users.noreply.github.com>,Alexey Bataev
<5361294+alexey-bataev at users.noreply.github.com>,Chelsea Cassanova
<chelsea_cassanova at apple.com>,Alexey Bataev <a.bataev at outlook.com>,Joseph
Huber <huberjn at outlook.com>,Jonas Devlieghere <jonas at devlieghere.com>,Fangrui
Song <i at maskray.me>,Simon Pilgrim <llvm-dev at redking.me.uk>,Simon Pilgrim
<llvm-dev at redking.me.uk>,Simon Pilgrim <RKSimon at users.noreply.github.com>,yelleyee
<22870466+yelleyee at users.noreply.github.com>,Florian Hahn <flo at fhahn.com>,Michael
Liao <michael.hliao at gmail.com>,Hui <hui.xie0621 at gmail.com>,Fabian Schiebel
<52407375+fabianbs96 at users.noreply.github.com>,Fangrui Song <i at maskray.me>,Fangrui
Song <i at maskray.me>,Fangrui Song <i at maskray.me>,Florian Hahn <flo at fhahn.com>,rayroudc
<rayroudc at gmail.com>,Alexandros Lamprineas <alexandros.lamprineas at arm.com>,Noah
Goldstein <goldstein.w.n at gmail.com>,Noah Goldstein <goldstein.w.n at gmail.com>,Joseph
Huber <huberjn at outlook.com>,Peter Klausler
<35819229+klausler at users.noreply.github.com>,alx32
<103613512+alx32 at users.noreply.github.com>,Peter Klausler
<35819229+klausler at users.noreply.github.com>,erichkeane <ekeane at nvidia.com>,Peter
Klausler <35819229+klausler at users.noreply.github.com>,Peter Klausler
<35819229+klausler at users.noreply.github.com>,Cyndy Ishida
<cyndy_ishida at apple.com>,Peter Klausler
<35819229+klausler at users.noreply.github.com>,Cyndy Ishida
<cyndy_ishida at apple.com>,Peter Klausler
<35819229+klausler at users.noreply.github.com>,Peter Klausler
<35819229+klausler at users.noreply.github.com>,Peter Klausler
<35819229+klausler at users.noreply.github.com>,Peter Klausler
<35819229+klausler at users.noreply.github.com>,Peter Klausler
<35819229+klausler at users.noreply.github.com>,Peter Klausler
<35819229+klausler at users.noreply.github.com>,Farzon Lotfi
<1802579+farzonl at users.noreply.github.com>,Fangrui Song <i at maskray.me>,Peter
Klausler <35819229+klausler at users.noreply.github.com>,Peter Klausler
<35819229+klausler at users.noreply.github.com>,Fangrui Song <i at maskray.me>,Peter
Klausler <35819229+klausler at users.noreply.github.com>,Peter Klausler
<35819229+klausler at users.noreply.github.com>,Jan Svoboda
<jan_svoboda at apple.com>,Jan Svoboda <jan_svoboda at apple.com>,Jan Svoboda
<jan_svoboda at apple.com>,Jan Svoboda <jan_svoboda at apple.com>,Jan Svoboda
<jan_svoboda at apple.com>,Jan Svoboda <jan_svoboda at apple.com>,Peter Klausler
<35819229+klausler at users.noreply.github.com>,Peter Klausler
<35819229+klausler at users.noreply.github.com>,Joseph Huber
<huberjn at outlook.com>,Sergei Barannikov <barannikov88 at gmail.com>,Joseph
Huber <huberjn at outlook.com>,lntue <35648136+lntue at users.noreply.github.com>,Alexander
Richardson <alexrichardson at google.com>,Alex Richardson
<alexrichardson at google.com>,Daniil Kovalev <dkovalev at accesssoftek.com>,Joseph
Huber <huberjn at outlook.com>,Shih-Po Hung <shihpo.hung at sifive.com>,Daniil
Kovalev <dkovalev at accesssoftek.com>,
=?utf-8?b?V8OBTkcgWHXEm3J1w6w=?= <git at xen0n.name>,Daniil Kovalev
<dkovalev at accesssoftek.com>,Michael Spencer <bigcheesegs at gmail.com>,Daniil
Kovalev <dkovalev at accesssoftek.com>,Florian Hahn <flo at fhahn.com>,Simon
Pilgrim <RKSimon at users.noreply.github.com>,David Green <david.green at arm.com>,Hui
<hui.xie1990 at gmail.com>,Timm =?utf-8?q?Bäder?= <tbaeder at redhat.com>,
Timm =?utf-8?q?Bäder?= <tbaeder at redhat.com>,
Timm =?utf-8?q?Bäder?= <tbaeder at redhat.com>,
Timm =?utf-8?q?Bäder?= <tbaeder at redhat.com>,
Timm =?utf-8?q?Bäder?= <tbaeder at redhat.com>,Fangrui Song <i at maskray.me>,
=?utf-8?q?Michał_Górny?= <mgorny at gentoo.org>,Bjorn Pettersson
<bjorn.a.pettersson at ericsson.com>,Matthias Gehre <matthias.gehre at amd.com>,Owen
Pan <owenpiano at gmail.com>,Mehdi Amini <joker.eph at gmail.com>,MagentaTreehouse
<99200384+MagentaTreehouse at users.noreply.github.com>,Quinn Dawkins
<quinn.dawkins at gmail.com>,Mircea Trofin <mtrofin at google.com>,Matthias Gehre
<matthias.gehre at amd.com>,Artem Tyurin <artem.tyurin at gmail.com>,Craig Topper
<craig.topper at sifive.com>,Craig Topper <craig.topper at sifive.com>,Craig
Topper <craig.topper at sifive.com>,Brad Smith <brad at comstyle.com>,Mehdi Amini
<joker.eph at gmail.com>,George Koehler <kernigh at gmail.com>,Mehdi Amini
<joker.eph at gmail.com>,Mehdi Amini <joker.eph at gmail.com>,Mehdi Amini
<joker.eph at gmail.com>,Mehdi Amini <joker.eph at gmail.com>,Alex Richardson
<alexrichardson at google.com>,Mehdi Amini <joker.eph at gmail.com>,Mehdi Amini
<joker.eph at gmail.com>,Shengchen Kan <shengchen.kan at intel.com>,Quinn Dawkins
<quinn.dawkins at gmail.com>,David Green <david.green at arm.com>,AMS21
<AMS21.github at gmail.com>,Jacques Pienaar <jpienaar at google.com>,Mark de Wever
<koraq at xs4all.nl>,Jacques Pienaar <jpienaar at google.com>,NAKAMURA Takumi
<geek4civic at gmail.com>,Jacques Pienaar <jpienaar at google.com>,Jacques Pienaar
<jpienaar at google.com>,Mark de Wever <koraq at xs4all.nl>,David Green
<david.green at arm.com>,Mark de Wever <koraq at xs4all.nl>,Nikolas Klauser
<nikolasklauser at berlin.de>,Nikolas Klauser <nikolasklauser at berlin.de>,Nikolas
Klauser <nikolasklauser at berlin.de>,Aiden Grossman <agrossman154 at yahoo.com>,LLVM
GN Syncbot <llvmgnsyncbot at gmail.com>,Florian Hahn <flo at fhahn.com>,David
Majnemer <david.majnemer at gmail.com>,Po-yao Chang <poyaoc97 at gmail.com>,Lu
Weining <luweining at loongson.cn>,Chen Zheng <czhengsz at cn.ibm.com>,Yeting Kuo
<46629943+yetingk at users.noreply.github.com>,Matthias Springer <me at m-sp.org>,Matthias
Springer <springerm at google.com>
Message-ID:
In-Reply-To: <llvm.org/llvm/llvm-project/pull/83286 at github.com>
https://github.com/matthias-springer updated https://github.com/llvm/llvm-project/pull/83286
>From 8e51b22ce21b01ae0be8267c5da3703ffd3b2c5b Mon Sep 17 00:00:00 2001
From: chuongg3 <chuong.goh at arm.com>
Date: Wed, 28 Feb 2024 13:55:27 +0000
Subject: [PATCH 001/406] [AArch64][GlobalISel] Legalize G_LOAD for v4s8 Vector
(#82989)
Lowers `v4s8 = G_LOAD %ptr ptr` into
`s32 = G_LOAD %ptr ptr`
`v4s8 = G_BITCAST s32`
---
.../AArch64/GISel/AArch64LegalizerInfo.cpp | 8 +++++-
llvm/test/CodeGen/AArch64/load.ll | 27 +++++++++++--------
2 files changed, 23 insertions(+), 12 deletions(-)
diff --git a/llvm/lib/Target/AArch64/GISel/AArch64LegalizerInfo.cpp b/llvm/lib/Target/AArch64/GISel/AArch64LegalizerInfo.cpp
index 3205484bb0631d..91323e456a5ef8 100644
--- a/llvm/lib/Target/AArch64/GISel/AArch64LegalizerInfo.cpp
+++ b/llvm/lib/Target/AArch64/GISel/AArch64LegalizerInfo.cpp
@@ -388,8 +388,14 @@ AArch64LegalizerInfo::AArch64LegalizerInfo(const AArch64Subtarget &ST)
.clampMaxNumElements(0, s32, 4)
.clampMaxNumElements(0, s64, 2)
.clampMaxNumElements(0, p0, 2)
+ // TODO: Use BITCAST for v2i8, v2i16 after G_TRUNC gets sorted out
+ .bitcastIf(typeInSet(0, {v4s8}),
+ [=](const LegalityQuery &Query) {
+ const LLT VecTy = Query.Types[0];
+ return std::pair(0, LLT::scalar(VecTy.getSizeInBits()));
+ })
.customIf(IsPtrVecPred)
- .scalarizeIf(typeIs(0, v2s16), 0);
+ .scalarizeIf(typeInSet(0, {v2s16, v2s8}), 0);
getActionDefinitionsBuilder(G_STORE)
.customIf([=](const LegalityQuery &Query) {
diff --git a/llvm/test/CodeGen/AArch64/load.ll b/llvm/test/CodeGen/AArch64/load.ll
index d82c1fe55a2dd2..7f4540d915ab37 100644
--- a/llvm/test/CodeGen/AArch64/load.ll
+++ b/llvm/test/CodeGen/AArch64/load.ll
@@ -1,9 +1,6 @@
; NOTE: Assertions have been autogenerated by utils/update_llc_test_checks.py UTC_ARGS: --version 4
; RUN: llc -mtriple=aarch64-none-linux-gnu %s -o - | FileCheck %s --check-prefixes=CHECK,CHECK-SD
-; RUN: llc -mtriple=aarch64-none-linux-gnu -global-isel -global-isel-abort=2 %s -o - 2>&1 | FileCheck %s --check-prefixes=CHECK,CHECK-GI
-
-; CHECK-GI: warning: Instruction selection used fallback path for load_v2i8
-; CHECK-GI-NEXT: warning: Instruction selection used fallback path for load_v4i8
+; RUN: llc -mtriple=aarch64-none-linux-gnu -global-isel %s -o - | FileCheck %s --check-prefixes=CHECK,CHECK-GI
; ===== Legal Scalars =====
@@ -111,13 +108,21 @@ define <2 x i64> @load_v2i64(ptr %ptr){
; ===== Smaller/Larger Width Vectors with Legal Element Sizes =====
define <2 x i8> @load_v2i8(ptr %ptr, <2 x i8> %b){
-; CHECK-LABEL: load_v2i8:
-; CHECK: // %bb.0:
-; CHECK-NEXT: ld1 { v0.b }[0], [x0]
-; CHECK-NEXT: add x8, x0, #1
-; CHECK-NEXT: ld1 { v0.b }[4], [x8]
-; CHECK-NEXT: // kill: def $d0 killed $d0 killed $q0
-; CHECK-NEXT: ret
+; CHECK-SD-LABEL: load_v2i8:
+; CHECK-SD: // %bb.0:
+; CHECK-SD-NEXT: ld1 { v0.b }[0], [x0]
+; CHECK-SD-NEXT: add x8, x0, #1
+; CHECK-SD-NEXT: ld1 { v0.b }[4], [x8]
+; CHECK-SD-NEXT: // kill: def $d0 killed $d0 killed $q0
+; CHECK-SD-NEXT: ret
+;
+; CHECK-GI-LABEL: load_v2i8:
+; CHECK-GI: // %bb.0:
+; CHECK-GI-NEXT: ldr b0, [x0]
+; CHECK-GI-NEXT: ldr b1, [x0, #1]
+; CHECK-GI-NEXT: mov v0.s[1], v1.s[0]
+; CHECK-GI-NEXT: // kill: def $d0 killed $d0 killed $q0
+; CHECK-GI-NEXT: ret
%a = load <2 x i8>, ptr %ptr
ret <2 x i8> %a
}
>From 9e1432069555d70e1f0148742e565b31d3ba8695 Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?Ingo=20M=C3=BCller?= <ingomueller at google.com>
Date: Wed, 28 Feb 2024 13:54:19 +0000
Subject: [PATCH 002/406] [bazel] Fix breakage from
915fce040271c77df1ff9b2c8797c441cec0d18d.
That commit (from #82189) introduces a new dependency but does not
declare it in the BUILD files.
---
utils/bazel/llvm-project-overlay/mlir/BUILD.bazel | 1 +
1 file changed, 1 insertion(+)
diff --git a/utils/bazel/llvm-project-overlay/mlir/BUILD.bazel b/utils/bazel/llvm-project-overlay/mlir/BUILD.bazel
index f58808476cbbca..7860ccd0406a13 100644
--- a/utils/bazel/llvm-project-overlay/mlir/BUILD.bazel
+++ b/utils/bazel/llvm-project-overlay/mlir/BUILD.bazel
@@ -4111,6 +4111,7 @@ cc_library(
includes = ["include"],
deps = [
":AffineDialect",
+ ":AffineTransforms",
":AffineUtils",
":ArithDialect",
":ConversionPassIncGen",
>From a8364c9e17b46ec339e97cc00877c58a7bdf6089 Mon Sep 17 00:00:00 2001
From: Michael Liao <michael.hliao at gmail.com>
Date: Wed, 28 Feb 2024 09:29:59 -0500
Subject: [PATCH 003/406] [mlir] Fix shared builds. NFC
---
mlir/lib/Conversion/AffineToStandard/CMakeLists.txt | 3 ++-
1 file changed, 2 insertions(+), 1 deletion(-)
diff --git a/mlir/lib/Conversion/AffineToStandard/CMakeLists.txt b/mlir/lib/Conversion/AffineToStandard/CMakeLists.txt
index 2ba0f30b1190ee..f41e3ca27ee4dd 100644
--- a/mlir/lib/Conversion/AffineToStandard/CMakeLists.txt
+++ b/mlir/lib/Conversion/AffineToStandard/CMakeLists.txt
@@ -12,12 +12,13 @@ add_mlir_conversion_library(MLIRAffineToStandard
LINK_LIBS PUBLIC
MLIRAffineDialect
+ MLIRAffineTransforms
MLIRAffineUtils
MLIRArithDialect
MLIRIR
MLIRMemRefDialect
- MLIRSCFDialect
MLIRPass
+ MLIRSCFDialect
MLIRTransforms
MLIRVectorDialect
)
>From c89d51112d329a4a37ff6dbcda7002853847c8a3 Mon Sep 17 00:00:00 2001
From: Alexey Bataev <a.bataev at outlook.com>
Date: Wed, 28 Feb 2024 06:07:58 -0800
Subject: [PATCH 004/406] [SLP]Use It->second.first for BWSz, NFC.
---
llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp b/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
index de4e56ff80659a..2b7d518c1c1a78 100644
--- a/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
+++ b/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
@@ -9364,7 +9364,7 @@ InstructionCost BoUpSLP::getTreeCost(ArrayRef<Value *> VectorizedVals) {
VectorCasts
.insert(std::make_pair(ScalarTE, FTy->getElementType()))
.second) {
- unsigned BWSz = It->second.second;
+ unsigned BWSz = It->second.first;
unsigned DstBWSz = DL->getTypeSizeInBits(FTy->getElementType());
unsigned VecOpcode;
if (DstBWSz < BWSz)
@@ -9376,7 +9376,7 @@ InstructionCost BoUpSLP::getTreeCost(ArrayRef<Value *> VectorizedVals) {
InstructionCost C = TTI->getCastInstrCost(
VecOpcode, FTy,
FixedVectorType::get(
- IntegerType::get(FTy->getContext(), It->second.first),
+ IntegerType::get(FTy->getContext(), BWSz),
FTy->getNumElements()),
TTI::CastContextHint::None, CostKind);
LLVM_DEBUG(dbgs() << "SLP: Adding cost " << C
>From 680c780a367bfe1c0cdf786250fd7f565ef6d23d Mon Sep 17 00:00:00 2001
From: Ivan Kosarev <ivan.kosarev at amd.com>
Date: Wed, 28 Feb 2024 16:44:34 +0200
Subject: [PATCH 005/406] [AMDGPU][AsmParser] Support structured HWREG
operands. (#82805)
Symbolic values are to be supported separately.
---
.../AMDGPU/AsmParser/AMDGPUAsmParser.cpp | 215 +++++++++++-------
.../Target/AMDGPU/Utils/AMDGPUBaseInfo.cpp | 10 -
llvm/lib/Target/AMDGPU/Utils/AMDGPUBaseInfo.h | 9 -
llvm/test/MC/AMDGPU/gfx1011_err.s | 2 +-
llvm/test/MC/AMDGPU/gfx1030_err.s | 2 +-
llvm/test/MC/AMDGPU/gfx10_err_pos.s | 10 +-
llvm/test/MC/AMDGPU/gfx940_asm_features.s | 10 +-
llvm/test/MC/AMDGPU/gfx940_err.s | 12 +-
llvm/test/MC/AMDGPU/sopk-err.s | 173 +++++++++++---
llvm/test/MC/AMDGPU/sopk.s | 49 +++-
10 files changed, 343 insertions(+), 149 deletions(-)
diff --git a/llvm/lib/Target/AMDGPU/AsmParser/AMDGPUAsmParser.cpp b/llvm/lib/Target/AMDGPU/AsmParser/AMDGPUAsmParser.cpp
index b7b471d8dc7b39..18d51087ff5fba 100644
--- a/llvm/lib/Target/AMDGPU/AsmParser/AMDGPUAsmParser.cpp
+++ b/llvm/lib/Target/AMDGPU/AsmParser/AMDGPUAsmParser.cpp
@@ -1685,24 +1685,48 @@ class AMDGPUAsmParser : public MCTargetAsmParser {
private:
struct OperandInfoTy {
SMLoc Loc;
- int64_t Id;
+ int64_t Val;
bool IsSymbolic = false;
bool IsDefined = false;
- OperandInfoTy(int64_t Id_) : Id(Id_) {}
+ OperandInfoTy(int64_t Val) : Val(Val) {}
};
+ struct StructuredOpField : OperandInfoTy {
+ StringLiteral Id;
+ StringLiteral Desc;
+ unsigned Width;
+ bool IsDefined = false;
+
+ StructuredOpField(StringLiteral Id, StringLiteral Desc, unsigned Width,
+ int64_t Default)
+ : OperandInfoTy(Default), Id(Id), Desc(Desc), Width(Width) {}
+ virtual ~StructuredOpField() = default;
+
+ bool Error(AMDGPUAsmParser &Parser, const Twine &Err) const {
+ Parser.Error(Loc, "invalid " + Desc + ": " + Err);
+ return false;
+ }
+
+ virtual bool validate(AMDGPUAsmParser &Parser) const {
+ if (IsSymbolic && Val == OPR_ID_UNSUPPORTED)
+ return Error(Parser, "not supported on this GPU");
+ if (!isUIntN(Width, Val))
+ return Error(Parser, "only " + Twine(Width) + "-bit values are legal");
+ return true;
+ }
+ };
+
+ ParseStatus parseStructuredOpFields(ArrayRef<StructuredOpField *> Fields);
+ bool validateStructuredOpFields(ArrayRef<const StructuredOpField *> Fields);
+
bool parseSendMsgBody(OperandInfoTy &Msg, OperandInfoTy &Op, OperandInfoTy &Stream);
bool validateSendMsg(const OperandInfoTy &Msg,
const OperandInfoTy &Op,
const OperandInfoTy &Stream);
- bool parseHwregBody(OperandInfoTy &HwReg,
- OperandInfoTy &Offset,
- OperandInfoTy &Width);
- bool validateHwreg(const OperandInfoTy &HwReg,
- const OperandInfoTy &Offset,
- const OperandInfoTy &Width);
+ ParseStatus parseHwregFunc(OperandInfoTy &HwReg, OperandInfoTy &Offset,
+ OperandInfoTy &Width);
SMLoc getFlatOffsetLoc(const OperandVector &Operands) const;
SMLoc getSMEMOffsetLoc(const OperandVector &Operands) const;
@@ -7197,71 +7221,44 @@ bool AMDGPUOperand::isDepCtr() const { return isS16Imm(); }
// hwreg
//===----------------------------------------------------------------------===//
-bool
-AMDGPUAsmParser::parseHwregBody(OperandInfoTy &HwReg,
- OperandInfoTy &Offset,
- OperandInfoTy &Width) {
+ParseStatus AMDGPUAsmParser::parseHwregFunc(OperandInfoTy &HwReg,
+ OperandInfoTy &Offset,
+ OperandInfoTy &Width) {
using namespace llvm::AMDGPU::Hwreg;
+ if (!trySkipId("hwreg", AsmToken::LParen))
+ return ParseStatus::NoMatch;
+
// The register may be specified by name or using a numeric code
HwReg.Loc = getLoc();
if (isToken(AsmToken::Identifier) &&
- (HwReg.Id = getHwregId(getTokenStr(), getSTI())) != OPR_ID_UNKNOWN) {
+ (HwReg.Val = getHwregId(getTokenStr(), getSTI())) != OPR_ID_UNKNOWN) {
HwReg.IsSymbolic = true;
lex(); // skip register name
- } else if (!parseExpr(HwReg.Id, "a register name")) {
- return false;
+ } else if (!parseExpr(HwReg.Val, "a register name")) {
+ return ParseStatus::Failure;
}
if (trySkipToken(AsmToken::RParen))
- return true;
+ return ParseStatus::Success;
// parse optional params
if (!skipToken(AsmToken::Comma, "expected a comma or a closing parenthesis"))
- return false;
+ return ParseStatus::Failure;
Offset.Loc = getLoc();
- if (!parseExpr(Offset.Id))
- return false;
+ if (!parseExpr(Offset.Val))
+ return ParseStatus::Failure;
if (!skipToken(AsmToken::Comma, "expected a comma"))
- return false;
+ return ParseStatus::Failure;
Width.Loc = getLoc();
- return parseExpr(Width.Id) &&
- skipToken(AsmToken::RParen, "expected a closing parenthesis");
-}
-
-bool
-AMDGPUAsmParser::validateHwreg(const OperandInfoTy &HwReg,
- const OperandInfoTy &Offset,
- const OperandInfoTy &Width) {
-
- using namespace llvm::AMDGPU::Hwreg;
+ if (!parseExpr(Width.Val) ||
+ !skipToken(AsmToken::RParen, "expected a closing parenthesis"))
+ return ParseStatus::Failure;
- if (HwReg.IsSymbolic) {
- if (HwReg.Id == OPR_ID_UNSUPPORTED) {
- Error(HwReg.Loc,
- "specified hardware register is not supported on this GPU");
- return false;
- }
- } else {
- if (!isValidHwreg(HwReg.Id)) {
- Error(HwReg.Loc,
- "invalid code of hardware register: only 6-bit values are legal");
- return false;
- }
- }
- if (!isValidHwregOffset(Offset.Id)) {
- Error(Offset.Loc, "invalid bit offset: only 5-bit values are legal");
- return false;
- }
- if (!isValidHwregWidth(Width.Id)) {
- Error(Width.Loc,
- "invalid bitfield width: only values from 1 to 32 are legal");
- return false;
- }
- return true;
+ return ParseStatus::Success;
}
ParseStatus AMDGPUAsmParser::parseHwreg(OperandVector &Operands) {
@@ -7270,24 +7267,40 @@ ParseStatus AMDGPUAsmParser::parseHwreg(OperandVector &Operands) {
int64_t ImmVal = 0;
SMLoc Loc = getLoc();
- if (trySkipId("hwreg", AsmToken::LParen)) {
- OperandInfoTy HwReg(OPR_ID_UNKNOWN);
- OperandInfoTy Offset(HwregOffset::Default);
- OperandInfoTy Width(HwregSize::Default);
- if (parseHwregBody(HwReg, Offset, Width) &&
- validateHwreg(HwReg, Offset, Width)) {
- ImmVal = HwregEncoding::encode(HwReg.Id, Offset.Id, Width.Id);
- } else {
- return ParseStatus::Failure;
+ StructuredOpField HwReg("id", "hardware register", HwregId::Width,
+ HwregId::Default);
+ StructuredOpField Offset("offset", "bit offset", HwregOffset::Width,
+ HwregOffset::Default);
+ struct : StructuredOpField {
+ using StructuredOpField::StructuredOpField;
+ bool validate(AMDGPUAsmParser &Parser) const override {
+ if (!isUIntN(Width, Val - 1))
+ return Error(Parser, "only values from 1 to 32 are legal");
+ return true;
}
- } else if (parseExpr(ImmVal, "a hwreg macro")) {
- if (ImmVal < 0 || !isUInt<16>(ImmVal))
- return Error(Loc, "invalid immediate: only 16-bit values are legal");
- } else {
- return ParseStatus::Failure;
+ } Width("size", "bitfield width", HwregSize::Width, HwregSize::Default);
+ ParseStatus Res = parseStructuredOpFields({&HwReg, &Offset, &Width});
+
+ if (Res.isNoMatch())
+ Res = parseHwregFunc(HwReg, Offset, Width);
+
+ if (Res.isSuccess()) {
+ if (!validateStructuredOpFields({&HwReg, &Offset, &Width}))
+ return ParseStatus::Failure;
+ ImmVal = HwregEncoding::encode(HwReg.Val, Offset.Val, Width.Val);
}
- Operands.push_back(AMDGPUOperand::CreateImm(this, ImmVal, Loc, AMDGPUOperand::ImmTyHwreg));
+ if (Res.isNoMatch() &&
+ parseExpr(ImmVal, "a hwreg macro, structured immediate"))
+ Res = ParseStatus::Success;
+
+ if (!Res.isSuccess())
+ return ParseStatus::Failure;
+
+ if (!isUInt<16>(ImmVal))
+ return Error(Loc, "invalid immediate: only 16-bit values are legal");
+ Operands.push_back(
+ AMDGPUOperand::CreateImm(this, ImmVal, Loc, AMDGPUOperand::ImmTyHwreg));
return ParseStatus::Success;
}
@@ -7307,10 +7320,10 @@ AMDGPUAsmParser::parseSendMsgBody(OperandInfoTy &Msg,
Msg.Loc = getLoc();
if (isToken(AsmToken::Identifier) &&
- (Msg.Id = getMsgId(getTokenStr(), getSTI())) != OPR_ID_UNKNOWN) {
+ (Msg.Val = getMsgId(getTokenStr(), getSTI())) != OPR_ID_UNKNOWN) {
Msg.IsSymbolic = true;
lex(); // skip message name
- } else if (!parseExpr(Msg.Id, "a message name")) {
+ } else if (!parseExpr(Msg.Val, "a message name")) {
return false;
}
@@ -7318,16 +7331,16 @@ AMDGPUAsmParser::parseSendMsgBody(OperandInfoTy &Msg,
Op.IsDefined = true;
Op.Loc = getLoc();
if (isToken(AsmToken::Identifier) &&
- (Op.Id = getMsgOpId(Msg.Id, getTokenStr())) >= 0) {
+ (Op.Val = getMsgOpId(Msg.Val, getTokenStr())) >= 0) {
lex(); // skip operation name
- } else if (!parseExpr(Op.Id, "an operation name")) {
+ } else if (!parseExpr(Op.Val, "an operation name")) {
return false;
}
if (trySkipToken(AsmToken::Comma)) {
Stream.IsDefined = true;
Stream.Loc = getLoc();
- if (!parseExpr(Stream.Id))
+ if (!parseExpr(Stream.Val))
return false;
}
}
@@ -7347,17 +7360,17 @@ AMDGPUAsmParser::validateSendMsg(const OperandInfoTy &Msg,
bool Strict = Msg.IsSymbolic;
if (Strict) {
- if (Msg.Id == OPR_ID_UNSUPPORTED) {
+ if (Msg.Val == OPR_ID_UNSUPPORTED) {
Error(Msg.Loc, "specified message id is not supported on this GPU");
return false;
}
} else {
- if (!isValidMsgId(Msg.Id, getSTI())) {
+ if (!isValidMsgId(Msg.Val, getSTI())) {
Error(Msg.Loc, "invalid message id");
return false;
}
}
- if (Strict && (msgRequiresOp(Msg.Id, getSTI()) != Op.IsDefined)) {
+ if (Strict && (msgRequiresOp(Msg.Val, getSTI()) != Op.IsDefined)) {
if (Op.IsDefined) {
Error(Op.Loc, "message does not support operations");
} else {
@@ -7365,16 +7378,16 @@ AMDGPUAsmParser::validateSendMsg(const OperandInfoTy &Msg,
}
return false;
}
- if (!isValidMsgOp(Msg.Id, Op.Id, getSTI(), Strict)) {
+ if (!isValidMsgOp(Msg.Val, Op.Val, getSTI(), Strict)) {
Error(Op.Loc, "invalid operation id");
return false;
}
- if (Strict && !msgSupportsStream(Msg.Id, Op.Id, getSTI()) &&
+ if (Strict && !msgSupportsStream(Msg.Val, Op.Val, getSTI()) &&
Stream.IsDefined) {
Error(Stream.Loc, "message operation does not support streams");
return false;
}
- if (!isValidMsgStream(Msg.Id, Op.Id, Stream.Id, getSTI(), Strict)) {
+ if (!isValidMsgStream(Msg.Val, Op.Val, Stream.Val, getSTI(), Strict)) {
Error(Stream.Loc, "invalid message stream id");
return false;
}
@@ -7393,7 +7406,7 @@ ParseStatus AMDGPUAsmParser::parseSendMsg(OperandVector &Operands) {
OperandInfoTy Stream(STREAM_ID_NONE_);
if (parseSendMsgBody(Msg, Op, Stream) &&
validateSendMsg(Msg, Op, Stream)) {
- ImmVal = encodeMsg(Msg.Id, Op.Id, Stream.Id);
+ ImmVal = encodeMsg(Msg.Val, Op.Val, Stream.Val);
} else {
return ParseStatus::Failure;
}
@@ -7730,6 +7743,48 @@ AMDGPUAsmParser::getConstLoc(const OperandVector &Operands) const {
return getOperandLoc(Test, Operands);
}
+ParseStatus
+AMDGPUAsmParser::parseStructuredOpFields(ArrayRef<StructuredOpField *> Fields) {
+ if (!trySkipToken(AsmToken::LCurly))
+ return ParseStatus::NoMatch;
+
+ bool First = true;
+ while (!trySkipToken(AsmToken::RCurly)) {
+ if (!First &&
+ !skipToken(AsmToken::Comma, "comma or closing brace expected"))
+ return ParseStatus::Failure;
+
+ StringRef Id = getTokenStr();
+ SMLoc IdLoc = getLoc();
+ if (!skipToken(AsmToken::Identifier, "field name expected") ||
+ !skipToken(AsmToken::Colon, "colon expected"))
+ return ParseStatus::Failure;
+
+ auto I =
+ find_if(Fields, [Id](StructuredOpField *F) { return F->Id == Id; });
+ if (I == Fields.end())
+ return Error(IdLoc, "unknown field");
+ if ((*I)->IsDefined)
+ return Error(IdLoc, "duplicate field");
+
+ // TODO: Support symbolic values.
+ (*I)->Loc = getLoc();
+ if (!parseExpr((*I)->Val))
+ return ParseStatus::Failure;
+ (*I)->IsDefined = true;
+
+ First = false;
+ }
+ return ParseStatus::Success;
+}
+
+bool AMDGPUAsmParser::validateStructuredOpFields(
+ ArrayRef<const StructuredOpField *> Fields) {
+ return all_of(Fields, [this](const StructuredOpField *F) {
+ return F->validate(*this);
+ });
+}
+
//===----------------------------------------------------------------------===//
// swizzle
//===----------------------------------------------------------------------===//
diff --git a/llvm/lib/Target/AMDGPU/Utils/AMDGPUBaseInfo.cpp b/llvm/lib/Target/AMDGPU/Utils/AMDGPUBaseInfo.cpp
index 177d99a0ac0abe..963dc2882fcc0d 100644
--- a/llvm/lib/Target/AMDGPU/Utils/AMDGPUBaseInfo.cpp
+++ b/llvm/lib/Target/AMDGPU/Utils/AMDGPUBaseInfo.cpp
@@ -1700,16 +1700,6 @@ int64_t getHwregId(const StringRef Name, const MCSubtargetInfo &STI) {
return (Idx < 0) ? Idx : Opr[Idx].Encoding;
}
-bool isValidHwreg(int64_t Id) { return 0 <= Id && isUInt<HwregId::Width>(Id); }
-
-bool isValidHwregOffset(int64_t Offset) {
- return 0 <= Offset && isUInt<HwregOffset::Width>(Offset);
-}
-
-bool isValidHwregWidth(int64_t Width) {
- return 0 <= (Width - 1) && isUInt<HwregSize::Width>(Width - 1);
-}
-
StringRef getHwreg(unsigned Id, const MCSubtargetInfo &STI) {
int Idx = getOprIdx<const MCSubtargetInfo &>(Id, Opr, OPR_SIZE, STI);
return (Idx < 0) ? "" : Opr[Idx].Name;
diff --git a/llvm/lib/Target/AMDGPU/Utils/AMDGPUBaseInfo.h b/llvm/lib/Target/AMDGPU/Utils/AMDGPUBaseInfo.h
index 9a6d0834679eae..b2fc7d874fe588 100644
--- a/llvm/lib/Target/AMDGPU/Utils/AMDGPUBaseInfo.h
+++ b/llvm/lib/Target/AMDGPU/Utils/AMDGPUBaseInfo.h
@@ -1068,15 +1068,6 @@ using HwregEncoding = EncodingFields<HwregId, HwregOffset, HwregSize>;
LLVM_READONLY
int64_t getHwregId(const StringRef Name, const MCSubtargetInfo &STI);
-LLVM_READNONE
-bool isValidHwreg(int64_t Id);
-
-LLVM_READNONE
-bool isValidHwregOffset(int64_t Offset);
-
-LLVM_READNONE
-bool isValidHwregWidth(int64_t Width);
-
LLVM_READNONE
StringRef getHwreg(unsigned Id, const MCSubtargetInfo &STI);
diff --git a/llvm/test/MC/AMDGPU/gfx1011_err.s b/llvm/test/MC/AMDGPU/gfx1011_err.s
index 4b37aaf221e395..a86e48a29c78f7 100644
--- a/llvm/test/MC/AMDGPU/gfx1011_err.s
+++ b/llvm/test/MC/AMDGPU/gfx1011_err.s
@@ -17,7 +17,7 @@ v_dot8c_i32_i4 v5, v1, v2 dpp8:[7,6,5,4,3,2,1,0] fi:1
// GFX10: :[[@LINE-1]]:{{[0-9]+}}: error: instruction not supported on this GPU
s_getreg_b32 s2, hwreg(HW_REG_SHADER_CYCLES)
-// GFX10: :[[@LINE-1]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
+// GFX10: :[[@LINE-1]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
v_fma_legacy_f32 v0, v1, v2, v3
// GFX10: :[[@LINE-1]]:{{[0-9]+}}: error: instruction not supported on this GPU
diff --git a/llvm/test/MC/AMDGPU/gfx1030_err.s b/llvm/test/MC/AMDGPU/gfx1030_err.s
index ba8784a39c3698..f4ab5fe5b14a92 100644
--- a/llvm/test/MC/AMDGPU/gfx1030_err.s
+++ b/llvm/test/MC/AMDGPU/gfx1030_err.s
@@ -25,7 +25,7 @@ s_get_waveid_in_workgroup s0
// GFX10: :[[@LINE-1]]:{{[0-9]+}}: error: instruction not supported on this GPU
s_getreg_b32 s2, hwreg(HW_REG_XNACK_MASK)
-// GFX10: :[[@LINE-1]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
+// GFX10: :[[@LINE-1]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
v_mac_f32 v0, v1, v2
// GFX10: :[[@LINE-1]]:{{[0-9]+}}: error: instruction not supported on this GPU
diff --git a/llvm/test/MC/AMDGPU/gfx10_err_pos.s b/llvm/test/MC/AMDGPU/gfx10_err_pos.s
index 1d34f00ee0f921..c2679db3b2acfa 100644
--- a/llvm/test/MC/AMDGPU/gfx10_err_pos.s
+++ b/llvm/test/MC/AMDGPU/gfx10_err_pos.s
@@ -448,7 +448,7 @@ ds_swizzle_b32 v8, v2 offset:SWZ(QUAD_PERM, 0, 1, 2, 3)
// expected a hwreg macro or an absolute expression
s_setreg_b32 undef, s2
-// CHECK: :[[@LINE-1]]:{{[0-9]+}}: error: expected a hwreg macro or an absolute expression
+// CHECK: :[[@LINE-1]]:{{[0-9]+}}: error: expected a hwreg macro, structured immediate or an absolute expression
// CHECK-NEXT:{{^}}s_setreg_b32 undef, s2
// CHECK-NEXT:{{^}} ^
@@ -621,10 +621,10 @@ s_setreg_b32 hwreg(3,0,33), s2
// CHECK-NEXT:{{^}} ^
//==============================================================================
-// invalid code of hardware register: only 6-bit values are legal
+// invalid hardware register: only 6-bit values are legal
s_setreg_b32 hwreg(0x40), s2
-// CHECK: :[[@LINE-1]]:{{[0-9]+}}: error: invalid code of hardware register: only 6-bit values are legal
+// CHECK: :[[@LINE-1]]:{{[0-9]+}}: error: invalid hardware register: only 6-bit values are legal
// CHECK-NEXT:{{^}}s_setreg_b32 hwreg(0x40), s2
// CHECK-NEXT:{{^}} ^
@@ -1158,10 +1158,10 @@ v_movrels_b32_sdwa v0, shared_base
// CHECK-NEXT:{{^}} ^
//==============================================================================
-// specified hardware register is not supported on this GPU
+// invalid hardware register: not supported on this GPU
s_getreg_b32 s2, hwreg(HW_REG_SHADER_CYCLES)
-// CHECK: :[[@LINE-1]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
+// CHECK: :[[@LINE-1]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
// CHECK-NEXT:{{^}}s_getreg_b32 s2, hwreg(HW_REG_SHADER_CYCLES)
// CHECK-NEXT:{{^}} ^
diff --git a/llvm/test/MC/AMDGPU/gfx940_asm_features.s b/llvm/test/MC/AMDGPU/gfx940_asm_features.s
index 5ee9480677be92..e208b6cf903d38 100644
--- a/llvm/test/MC/AMDGPU/gfx940_asm_features.s
+++ b/llvm/test/MC/AMDGPU/gfx940_asm_features.s
@@ -197,23 +197,23 @@ scratch_load_lds_ushort v2, off
// GFX940: scratch_load_lds_sshort v2, off ; encoding: [0x00,0x60,0xa4,0xdc,0x02,0x00,0x7f,0x00]
scratch_load_lds_sshort v2, off
-// NOT-GFX940: :[[@LINE+2]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
+// NOT-GFX940: :[[@LINE+2]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
// GFX940: s_getreg_b32 s1, hwreg(HW_REG_XCC_ID) ; encoding: [0x14,0xf8,0x81,0xb8]
s_getreg_b32 s1, hwreg(HW_REG_XCC_ID)
-// NOT-GFX940: :[[@LINE+2]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
+// NOT-GFX940: :[[@LINE+2]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
// GFX940: s_getreg_b32 s1, hwreg(HW_REG_SQ_PERF_SNAPSHOT_DATA) ; encoding: [0x15,0xf8,0x81,0xb8]
s_getreg_b32 s1, hwreg(HW_REG_SQ_PERF_SNAPSHOT_DATA)
-// NOT-GFX940: :[[@LINE+2]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
+// NOT-GFX940: :[[@LINE+2]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
// GFX940: s_getreg_b32 s1, hwreg(HW_REG_SQ_PERF_SNAPSHOT_DATA1) ; encoding: [0x16,0xf8,0x81,0xb8]
s_getreg_b32 s1, hwreg(HW_REG_SQ_PERF_SNAPSHOT_DATA1)
-// NOT-GFX940: :[[@LINE+2]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
+// NOT-GFX940: :[[@LINE+2]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
// GFX940: s_getreg_b32 s1, hwreg(HW_REG_SQ_PERF_SNAPSHOT_PC_LO) ; encoding: [0x17,0xf8,0x81,0xb8]
s_getreg_b32 s1, hwreg(HW_REG_SQ_PERF_SNAPSHOT_PC_LO)
-// NOT-GFX940: :[[@LINE+2]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
+// NOT-GFX940: :[[@LINE+2]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
// GFX940: s_getreg_b32 s1, hwreg(HW_REG_SQ_PERF_SNAPSHOT_PC_HI) ; encoding: [0x18,0xf8,0x81,0xb8]
s_getreg_b32 s1, hwreg(HW_REG_SQ_PERF_SNAPSHOT_PC_HI)
diff --git a/llvm/test/MC/AMDGPU/gfx940_err.s b/llvm/test/MC/AMDGPU/gfx940_err.s
index 515b89513a8048..000f3decf96071 100644
--- a/llvm/test/MC/AMDGPU/gfx940_err.s
+++ b/llvm/test/MC/AMDGPU/gfx940_err.s
@@ -97,22 +97,22 @@ v_cvt_pk_fp8_f32 v1, v2, v3 mul:2
// GFX940: :[[@LINE-1]]:{{[0-9]+}}: error: not a valid operand.
s_getreg_b32 s1, hwreg(HW_REG_FLAT_SCR_LO)
-// GFX940: :[[@LINE-1]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
+// GFX940: :[[@LINE-1]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
s_getreg_b32 s1, hwreg(HW_REG_FLAT_SCR_HI)
-// GFX940: :[[@LINE-1]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
+// GFX940: :[[@LINE-1]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
s_getreg_b32 s1, hwreg(HW_REG_XNACK_MASK)
-// GFX940: :[[@LINE-1]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
+// GFX940: :[[@LINE-1]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
s_getreg_b32 s1, hwreg(HW_REG_HW_ID1)
-// GFX940: :[[@LINE-1]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
+// GFX940: :[[@LINE-1]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
s_getreg_b32 s1, hwreg(HW_REG_HW_ID2)
-// GFX940: :[[@LINE-1]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
+// GFX940: :[[@LINE-1]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
s_getreg_b32 s1, hwreg(HW_REG_POPS_PACKER)
-// GFX940: :[[@LINE-1]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
+// GFX940: :[[@LINE-1]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
ds_ordered_count v5, v1 offset:65535 gds
// GFX940: :[[@LINE-1]]:{{[0-9]+}}: error: instruction not supported on this GPU
diff --git a/llvm/test/MC/AMDGPU/sopk-err.s b/llvm/test/MC/AMDGPU/sopk-err.s
index 504ee1d11cbc97..cd92343b0e7fe7 100644
--- a/llvm/test/MC/AMDGPU/sopk-err.s
+++ b/llvm/test/MC/AMDGPU/sopk-err.s
@@ -5,48 +5,127 @@
// RUN: not llvm-mc -triple=amdgcn -mcpu=gfx1010 -show-encoding %s | FileCheck -check-prefix=GFX10 %s
// RUN: not llvm-mc -triple=amdgcn -mcpu=gfx1100 -show-encoding %s | FileCheck -check-prefix=GFX11 %s
-// RUN: not llvm-mc -triple=amdgcn %s 2>&1 | FileCheck -check-prefixes=GCN,SICIVI-ERR --implicit-check-not=error: %s
-// RUN: not llvm-mc -triple=amdgcn -mcpu=tahiti %s 2>&1 | FileCheck -check-prefixes=GCN,SICIVI-ERR --implicit-check-not=error: %s
-// RUN: not llvm-mc -triple=amdgcn -mcpu=tonga %s 2>&1 | FileCheck -check-prefixes=GCN,SICIVI-ERR --implicit-check-not=error: %s
-// RUN: not llvm-mc -triple=amdgcn -mcpu=gfx900 %s 2>&1 | FileCheck -check-prefixes=GCN,GFX9-ERR --implicit-check-not=error: %s
-// RUN: not llvm-mc -triple=amdgcn -mcpu=gfx1010 %s 2>&1 | FileCheck -check-prefixes=GCN,GFX10-ERR --implicit-check-not=error: %s
-// RUN: not llvm-mc -triple=amdgcn -mcpu=gfx1100 %s 2>&1 | FileCheck -check-prefixes=GCN,GFX11-ERR --implicit-check-not=error: %s
+// RUN: not llvm-mc -triple=amdgcn %s 2>&1 | FileCheck -check-prefixes=GCN,SICIVI-ERR --implicit-check-not=error: --strict-whitespace %s
+// RUN: not llvm-mc -triple=amdgcn -mcpu=tahiti %s 2>&1 | FileCheck -check-prefixes=GCN,SICIVI-ERR --implicit-check-not=error: --strict-whitespace %s
+// RUN: not llvm-mc -triple=amdgcn -mcpu=tonga %s 2>&1 | FileCheck -check-prefixes=GCN,SICIVI-ERR --implicit-check-not=error: --strict-whitespace %s
+// RUN: not llvm-mc -triple=amdgcn -mcpu=gfx900 %s 2>&1 | FileCheck -check-prefixes=GCN,GFX9-ERR --implicit-check-not=error: --strict-whitespace %s
+// RUN: not llvm-mc -triple=amdgcn -mcpu=gfx1010 %s 2>&1 | FileCheck -check-prefixes=GCN,GFX10-ERR --implicit-check-not=error: --strict-whitespace %s
+// RUN: not llvm-mc -triple=amdgcn -mcpu=gfx1100 %s 2>&1 | FileCheck -check-prefixes=GCN,GFX11-ERR --implicit-check-not=error: --strict-whitespace %s
s_setreg_b32 0x1f803, s2
// GCN: :[[@LINE-1]]:{{[0-9]+}}: error: invalid immediate: only 16-bit values are legal
+// GCN-NEXT: {{^}}s_setreg_b32 0x1f803, s2
+// GCN-NEXT: {{^}} ^
s_setreg_b32 typo(0x40), s2
-// GCN: :[[@LINE-1]]:{{[0-9]+}}: error: expected a hwreg macro or an absolute expression
+// GCN: :[[@LINE-1]]:{{[0-9]+}}: error: expected a hwreg macro, structured immediate or an absolute expression
+// GCN-NEXT: {{^}}s_setreg_b32 typo(0x40), s2
+// GCN-NEXT: {{^}} ^
s_setreg_b32 hwreg(0x40), s2
-// GCN: :[[@LINE-1]]:{{[0-9]+}}: error: invalid code of hardware register: only 6-bit values are legal
+// GCN: :[[@LINE-1]]:{{[0-9]+}}: error: invalid hardware register: only 6-bit values are legal
+// GCN-NEXT: {{^}}s_setreg_b32 hwreg(0x40), s2
+// GCN-NEXT: {{^}} ^
+
+s_setreg_b32 {id: 0x40}, s2
+// GCN: :[[@LINE-1]]:{{[0-9]+}}: error: invalid hardware register: only 6-bit values are legal
+// GCN-NEXT: {{^}}s_setreg_b32 {id: 0x40}, s2
+// GCN-NEXT: {{^}} ^
s_setreg_b32 hwreg(HW_REG_WRONG), s2
// GCN: :[[@LINE-1]]:{{[0-9]+}}: error: expected a register name or an absolute expression
+// GCN-NEXT: {{^}}s_setreg_b32 hwreg(HW_REG_WRONG), s2
+// GCN-NEXT: {{^}} ^
s_setreg_b32 hwreg(1 2,3), s2
// GCN: :[[@LINE-1]]:{{[0-9]+}}: error: expected a comma or a closing parenthesis
+// GCN-NEXT: {{^}}s_setreg_b32 hwreg(1 2,3), s2
+// GCN-NEXT: {{^}} ^
s_setreg_b32 hwreg(1,2 3), s2
// GCN: :[[@LINE-1]]:{{[0-9]+}}: error: expected a comma
+// GCN-NEXT: {{^}}s_setreg_b32 hwreg(1,2 3), s2
+// GCN-NEXT: {{^}} ^
s_setreg_b32 hwreg(1,2,3, s2
// GCN: :[[@LINE-1]]:{{[0-9]+}}: error: expected a closing parenthesis
+// GCN-NEXT: {{^}}s_setreg_b32 hwreg(1,2,3, s2
+// GCN-NEXT: {{^}} ^
+
+s_setreg_b32 {id: 1 offset: 2, size: 3}, s2
+// GCN: :[[@LINE-1]]:{{[0-9]+}}: error: comma or closing brace expected
+// GCN-NEXT: {{^}}s_setreg_b32 {id: 1 offset: 2, size: 3}, s2
+// GCN-NEXT: {{^}} ^
+
+s_setreg_b32 {id: 1 offset: 2, size: 3}, s2
+// GCN: :[[@LINE-1]]:{{[0-9]+}}: error: comma or closing brace expected
+// GCN-NEXT: {{^}}s_setreg_b32 {id: 1 offset: 2, size: 3}, s2
+// GCN-NEXT: {{^}} ^
+
+s_setreg_b32 {id 1, offset: 2, size: 3}, s2
+// GCN: :[[@LINE-1]]:{{[0-9]+}}: error: colon expected
+// GCN-NEXT: {{^}}s_setreg_b32 {id 1, offset: 2, size: 3}, s2
+// GCN-NEXT: {{^}} ^
+
+s_setreg_b32 {id: 1, offset: 2, size: 3, s2
+// GCN: :[[@LINE-1]]:{{[0-9]+}}: error: colon expected
+// GCN-NEXT: {{^}}s_setreg_b32 {id: 1, offset: 2, size: 3, s2
+// GCN-NEXT: {{^}} ^
+
+s_setreg_b32 {id: 1, offset: 2, blah: 3}, s2
+// GCN: :[[@LINE-1]]:{{[0-9]+}}: error: unknown field
+// GCN-NEXT: {{^}}s_setreg_b32 {id: 1, offset: 2, blah: 3}, s2
+// GCN-NEXT: {{^}} ^
+
+s_setreg_b32 {id: 1, id: 2}, s2
+// GCN: :[[@LINE-1]]:{{[0-9]+}}: error: duplicate field
+// GCN-NEXT: {{^}}s_setreg_b32 {id: 1, id: 2}, s2
+// GCN-NEXT: {{^}} ^
s_setreg_b32 hwreg(3,32,32), s2
// GCN: :[[@LINE-1]]:{{[0-9]+}}: error: invalid bit offset: only 5-bit values are legal
+// GCN-NEXT: {{^}}s_setreg_b32 hwreg(3,32,32), s2
+// GCN-NEXT: {{^}} ^
+
+s_setreg_b32 {id: 3, offset: 32, size: 32}, s2
+// GCN: :[[@LINE-1]]:{{[0-9]+}}: error: invalid bit offset: only 5-bit values are legal
+// GCN-NEXT: {{^}}s_setreg_b32 {id: 3, offset: 32, size: 32}, s2
+// GCN-NEXT: {{^}} ^
s_setreg_b32 hwreg(3,0,33), s2
// GCN: :[[@LINE-1]]:{{[0-9]+}}: error: invalid bitfield width: only values from 1 to 32 are legal
+// GCN-NEXT: {{^}}s_setreg_b32 hwreg(3,0,33), s2
+// GCN-NEXT: {{^}} ^
+
+s_setreg_b32 {id: 3, offset: 0, size: 33}, s2
+// GCN: :[[@LINE-1]]:{{[0-9]+}}: error: invalid bitfield width: only values from 1 to 32 are legal
+// GCN-NEXT: {{^}}s_setreg_b32 {id: 3, offset: 0, size: 33}, s2
+// GCN-NEXT: {{^}} ^
s_setreg_imm32_b32 0x1f803, 0xff
// GCN: :[[@LINE-1]]:{{[0-9]+}}: error: invalid immediate: only 16-bit values are legal
+// GCN-NEXT: {{^}}s_setreg_imm32_b32 0x1f803, 0xff
+// GCN-NEXT: {{^}} ^
s_setreg_imm32_b32 hwreg(3,0,33), 0xff
// GCN: :[[@LINE-1]]:{{[0-9]+}}: error: invalid bitfield width: only values from 1 to 32 are legal
+// GCN-NEXT: {{^}}s_setreg_imm32_b32 hwreg(3,0,33), 0xff
+// GCN-NEXT: {{^}} ^
+
+s_setreg_imm32_b32 {id: 3, offset: 0, size: 33}, 0xff
+// GCN: :[[@LINE-1]]:{{[0-9]+}}: error: invalid bitfield width: only values from 1 to 32 are legal
+// GCN-NEXT: {{^}}s_setreg_imm32_b32 {id: 3, offset: 0, size: 33}, 0xff
+// GCN-NEXT: {{^}} ^
s_getreg_b32 s2, hwreg(3,32,32)
// GCN: :[[@LINE-1]]:{{[0-9]+}}: error: invalid bit offset: only 5-bit values are legal
+// GCN-NEXT: {{^}}s_getreg_b32 s2, hwreg(3,32,32)
+// GCN-NEXT: {{^}} ^
+
+s_getreg_b32 s2, {id: 3, offset: 32, size: 32}
+// GCN: :[[@LINE-1]]:{{[0-9]+}}: error: invalid bit offset: only 5-bit values are legal
+// GCN-NEXT: {{^}}s_getreg_b32 s2, {id: 3, offset: 32, size: 32}
+// GCN-NEXT: {{^}} ^
s_cbranch_i_fork s[2:3], 0x6
// SICI: s_cbranch_i_fork s[2:3], 6 ; encoding: [0x06,0x00,0x82,0xb8]
@@ -57,69 +136,109 @@ s_cbranch_i_fork s[2:3], 0x6
s_getreg_b32 s2, hwreg(HW_REG_SH_MEM_BASES)
// GFX10: s_getreg_b32 s2, hwreg(HW_REG_SH_MEM_BASES) ; encoding: [0x0f,0xf8,0x02,0xb9]
-// SICIVI-ERR: :[[@LINE-2]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
+// SICIVI-ERR: :[[@LINE-2]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
+// SICIVI-ERR-NEXT: {{^}}s_getreg_b32 s2, hwreg(HW_REG_SH_MEM_BASES)
+// SICIVI-ERR-NEXT: {{^}} ^
// GFX9: s_getreg_b32 s2, hwreg(HW_REG_SH_MEM_BASES) ; encoding: [0x0f,0xf8,0x82,0xb8]
// GFX11: s_getreg_b32 s2, hwreg(HW_REG_SH_MEM_BASES) ; encoding: [0x0f,0xf8,0x82,0xb8]
s_getreg_b32 s2, hwreg(HW_REG_TBA_LO)
// GFX10: s_getreg_b32 s2, hwreg(HW_REG_TBA_LO) ; encoding: [0x10,0xf8,0x02,0xb9]
-// SICIVI-ERR: :[[@LINE-2]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
-// GFX11-ERR: :[[@LINE-3]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
+// SICIVI-ERR: :[[@LINE-2]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
+// SICIVI-ERR-NEXT: {{^}}s_getreg_b32 s2, hwreg(HW_REG_TBA_LO)
+// SICIVI-ERR-NEXT: {{^}} ^
+// GFX11-ERR: :[[@LINE-5]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
+// GFX11-ERR-NEXT: {{^}}s_getreg_b32 s2, hwreg(HW_REG_TBA_LO)
+// GFX11-ERR-NEXT: {{^}} ^
// GFX9: s_getreg_b32 s2, hwreg(HW_REG_TBA_LO) ; encoding: [0x10,0xf8,0x82,0xb8]
s_getreg_b32 s2, hwreg(HW_REG_TBA_HI)
// GFX10: s_getreg_b32 s2, hwreg(HW_REG_TBA_HI) ; encoding: [0x11,0xf8,0x02,0xb9]
-// SICIVI-ERR: :[[@LINE-2]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
-// GFX11-ERR: :[[@LINE-3]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
+// SICIVI-ERR: :[[@LINE-2]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
+// SICIVI-ERR-NEXT: {{^}}s_getreg_b32 s2, hwreg(HW_REG_TBA_HI)
+// SICIVI-ERR-NEXT: {{^}} ^
+// GFX11-ERR: :[[@LINE-5]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
+// GFX11-ERR-NEXT: {{^}}s_getreg_b32 s2, hwreg(HW_REG_TBA_HI)
+// GFX11-ERR-NEXT: {{^}} ^
// GFX9: s_getreg_b32 s2, hwreg(HW_REG_TBA_HI) ; encoding: [0x11,0xf8,0x82,0xb8]
s_getreg_b32 s2, hwreg(HW_REG_TMA_LO)
// GFX10: s_getreg_b32 s2, hwreg(HW_REG_TMA_LO) ; encoding: [0x12,0xf8,0x02,0xb9]
-// SICIVI-ERR: :[[@LINE-2]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
-// GFX11-ERR: :[[@LINE-3]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
+// SICIVI-ERR: :[[@LINE-2]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
+// SICIVI-ERR-NEXT: {{^}}s_getreg_b32 s2, hwreg(HW_REG_TMA_LO)
+// SICIVI-ERR-NEXT: {{^}} ^
+// GFX11-ERR: :[[@LINE-5]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
+// GFX11-ERR-NEXT: {{^}}s_getreg_b32 s2, hwreg(HW_REG_TMA_LO)
+// GFX11-ERR-NEXT: {{^}} ^
// GFX9: s_getreg_b32 s2, hwreg(HW_REG_TMA_LO) ; encoding: [0x12,0xf8,0x82,0xb8]
s_getreg_b32 s2, hwreg(HW_REG_TMA_HI)
// GFX10: s_getreg_b32 s2, hwreg(HW_REG_TMA_HI) ; encoding: [0x13,0xf8,0x02,0xb9]
-// SICIVI-ERR: :[[@LINE-2]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
-// GFX11-ERR: :[[@LINE-3]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
+// SICIVI-ERR: :[[@LINE-2]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
+// SICIVI-ERR-NEXT: {{^}}s_getreg_b32 s2, hwreg(HW_REG_TMA_HI)
+// SICIVI-ERR-NEXT: {{^}} ^
+// GFX11-ERR: :[[@LINE-5]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
+// GFX11-ERR-NEXT: {{^}}s_getreg_b32 s2, hwreg(HW_REG_TMA_HI)
+// GFX11-ERR-NEXT: {{^}} ^
// GFX9: s_getreg_b32 s2, hwreg(HW_REG_TMA_HI) ; encoding: [0x13,0xf8,0x82,0xb8]
s_getreg_b32 s2, hwreg(HW_REG_FLAT_SCR_LO)
// GFX10: s_getreg_b32 s2, hwreg(HW_REG_FLAT_SCR_LO) ; encoding: [0x14,0xf8,0x02,0xb9]
-// SICIVI-ERR: :[[@LINE-2]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
-// GFX9-ERR: :[[@LINE-3]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
+// SICIVI-ERR: :[[@LINE-2]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
+// SICIVI-ERR-NEXT: {{^}}s_getreg_b32 s2, hwreg(HW_REG_FLAT_SCR_LO)
+// SICIVI-ERR-NEXT: {{^}} ^
+// GFX9-ERR: :[[@LINE-5]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
+// GFX9-ERR-NEXT: {{^}}s_getreg_b32 s2, hwreg(HW_REG_FLAT_SCR_LO)
+// GFX9-ERR-NEXT: {{^}} ^
// GFX11: s_getreg_b32 s2, hwreg(HW_REG_FLAT_SCR_LO) ; encoding: [0x14,0xf8,0x82,0xb8]
s_getreg_b32 s2, hwreg(HW_REG_FLAT_SCR_HI)
// GFX10: s_getreg_b32 s2, hwreg(HW_REG_FLAT_SCR_HI) ; encoding: [0x15,0xf8,0x02,0xb9]
-// SICIVI-ERR: :[[@LINE-2]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
-// GFX9-ERR: :[[@LINE-3]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
+// SICIVI-ERR: :[[@LINE-2]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
+// SICIVI-ERR-NEXT: {{^}}s_getreg_b32 s2, hwreg(HW_REG_FLAT_SCR_HI)
+// SICIVI-ERR-NEXT: {{^}} ^
+// GFX9-ERR: :[[@LINE-5]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
+// GFX9-ERR-NEXT: {{^}}s_getreg_b32 s2, hwreg(HW_REG_FLAT_SCR_HI)
+// GFX9-ERR-NEXT: {{^}} ^
// GFX11: s_getreg_b32 s2, hwreg(HW_REG_FLAT_SCR_HI) ; encoding: [0x15,0xf8,0x82,0xb8]
s_getreg_b32 s2, hwreg(HW_REG_XNACK_MASK)
// GFX10: s_getreg_b32 s2, hwreg(HW_REG_XNACK_MASK) ; encoding: [0x16,0xf8,0x02,0xb9]
-// SICIVI-ERR: :[[@LINE-2]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
-// GFX9-ERR: :[[@LINE-3]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
-// GFX11-ERR: :[[@LINE-4]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
+// SICIVI-ERR: :[[@LINE-2]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
+// SICIVI-ERR-NEXT: {{^}}s_getreg_b32 s2, hwreg(HW_REG_XNACK_MASK)
+// SICIVI-ERR-NEXT: {{^}} ^
+// GFX9-ERR: :[[@LINE-5]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
+// GFX11-ERR: :[[@LINE-6]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
s_getreg_b32 s2, hwreg(HW_REG_POPS_PACKER)
// GFX10: s_getreg_b32 s2, hwreg(HW_REG_POPS_PACKER) ; encoding: [0x19,0xf8,0x02,0xb9]
-// SICIVI-ERR: :[[@LINE-2]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
-// GFX9-ERR: :[[@LINE-3]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
-// GFX11-ERR: :[[@LINE-4]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
+// SICIVI-ERR: :[[@LINE-2]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
+// SICIVI-ERR-NEXT: {{^}}s_getreg_b32 s2, hwreg(HW_REG_POPS_PACKER)
+// SICIVI-ERR-NEXT: {{^}} ^
+// GFX9-ERR: :[[@LINE-5]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
+// GFX11-ERR: :[[@LINE-6]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
s_cmpk_le_u32 s2, -1
// GCN: :[[@LINE-1]]:{{[0-9]+}}: error: invalid operand for instruction
+// GCN-NEXT: {{^}}s_cmpk_le_u32 s2, -1
+// GCN-NEXT: {{^}} ^
s_cmpk_le_u32 s2, 0x1ffff
// GCN: :[[@LINE-1]]:{{[0-9]+}}: error: invalid operand for instruction
+// GCN-NEXT: {{^}}s_cmpk_le_u32 s2, 0x1ffff
+// GCN-NEXT: {{^}} ^
s_cmpk_le_u32 s2, 0x10000
// GCN: :[[@LINE-1]]:{{[0-9]+}}: error: invalid operand for instruction
+// GCN-NEXT: {{^}}s_cmpk_le_u32 s2, 0x10000
+// GCN-NEXT: {{^}} ^
s_mulk_i32 s2, 0xFFFFFFFFFFFF0000
// GCN: :[[@LINE-1]]:{{[0-9]+}}: error: invalid operand for instruction
+// GCN-NEXT: {{^}}s_mulk_i32 s2, 0xFFFFFFFFFFFF0000
+// GCN-NEXT: {{^}} ^
s_mulk_i32 s2, 0x10000
// GCN: :[[@LINE-1]]:{{[0-9]+}}: error: invalid operand for instruction
+// GCN-NEXT: {{^}}s_mulk_i32 s2, 0x10000
+// GCN-NEXT: {{^}} ^
diff --git a/llvm/test/MC/AMDGPU/sopk.s b/llvm/test/MC/AMDGPU/sopk.s
index 2b20c35aa7719a..c912b83ca61c27 100644
--- a/llvm/test/MC/AMDGPU/sopk.s
+++ b/llvm/test/MC/AMDGPU/sopk.s
@@ -158,6 +158,12 @@ s_getreg_b32 s2, hwreg(51, 1, 31)
// GFX10: s_getreg_b32 s2, hwreg(51, 1, 31) ; encoding: [0x73,0xf0,0x02,0xb9]
// GFX11: s_getreg_b32 s2, hwreg(51, 1, 31) ; encoding: [0x73,0xf0,0x82,0xb8]
+s_getreg_b32 s2, {id: 51, offset: 1, size: 31}
+// SICI: s_getreg_b32 s2, hwreg(51, 1, 31) ; encoding: [0x73,0xf0,0x02,0xb9]
+// VI9: s_getreg_b32 s2, hwreg(51, 1, 31) ; encoding: [0x73,0xf0,0x82,0xb8]
+// GFX10: s_getreg_b32 s2, hwreg(51, 1, 31) ; encoding: [0x73,0xf0,0x02,0xb9]
+// GFX11: s_getreg_b32 s2, hwreg(51, 1, 31) ; encoding: [0x73,0xf0,0x82,0xb8]
+
// HW register code of unknown HW register, default offset/width
s_getreg_b32 s2, hwreg(51)
// SICI: s_getreg_b32 s2, hwreg(51) ; encoding: [0x33,0xf8,0x02,0xb9]
@@ -165,6 +171,27 @@ s_getreg_b32 s2, hwreg(51)
// GFX10: s_getreg_b32 s2, hwreg(51) ; encoding: [0x33,0xf8,0x02,0xb9]
// GFX11: s_getreg_b32 s2, hwreg(51) ; encoding: [0x33,0xf8,0x82,0xb8]
+// Structured form using default values.
+s_getreg_b32 s2, {id: 51}
+// SICI: s_getreg_b32 s2, hwreg(51) ; encoding: [0x33,0xf8,0x02,0xb9]
+// VI9: s_getreg_b32 s2, hwreg(51) ; encoding: [0x33,0xf8,0x82,0xb8]
+// GFX10: s_getreg_b32 s2, hwreg(51) ; encoding: [0x33,0xf8,0x02,0xb9]
+// GFX11: s_getreg_b32 s2, hwreg(51) ; encoding: [0x33,0xf8,0x82,0xb8]
+
+// Fields may come in any order.
+s_getreg_b32 s2, {size: 32, id: 51}
+// SICI: s_getreg_b32 s2, hwreg(51) ; encoding: [0x33,0xf8,0x02,0xb9]
+// VI9: s_getreg_b32 s2, hwreg(51) ; encoding: [0x33,0xf8,0x82,0xb8]
+// GFX10: s_getreg_b32 s2, hwreg(51) ; encoding: [0x33,0xf8,0x02,0xb9]
+// GFX11: s_getreg_b32 s2, hwreg(51) ; encoding: [0x33,0xf8,0x82,0xb8]
+
+// Empty field lists are allowed.
+s_getreg_b32 s2, {}
+// SICI: s_getreg_b32 s2, hwreg(0) ; encoding: [0x00,0xf8,0x02,0xb9]
+// VI9: s_getreg_b32 s2, hwreg(0) ; encoding: [0x00,0xf8,0x82,0xb8]
+// GFX10: s_getreg_b32 s2, hwreg(0) ; encoding: [0x00,0xf8,0x02,0xb9]
+// GFX11: s_getreg_b32 s2, hwreg(0) ; encoding: [0x00,0xf8,0x82,0xb8]
+
// HW register code of unknown HW register, valid symbolic name range but no name available
s_getreg_b32 s2, hwreg(10)
// SICI: s_getreg_b32 s2, hwreg(10) ; encoding: [0x0a,0xf8,0x02,0xb9]
@@ -271,17 +298,17 @@ s_setreg_b32 hwreg(HW_REG_HW_ID), s2
// SICI: s_setreg_b32 hwreg(HW_REG_HW_ID), s2 ; encoding: [0x04,0xf8,0x82,0xb9]
// VI9: s_setreg_b32 hwreg(HW_REG_HW_ID), s2 ; encoding: [0x04,0xf8,0x02,0xb9]
// GFX10: s_setreg_b32 hwreg(HW_REG_HW_ID1), s2 ; encoding: [0x17,0xf8,0x82,0xb9]
-// NOGFX11: :[[@LINE-4]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
+// NOGFX11: :[[@LINE-4]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
s_setreg_b32 hwreg(HW_REG_HW_ID1), s2
-// NOSICIVI: :[[@LINE-1]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
-// NOGFX9: :[[@LINE-2]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
+// NOSICIVI: :[[@LINE-1]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
+// NOGFX9: :[[@LINE-2]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
// GFX10: s_setreg_b32 hwreg(HW_REG_HW_ID1), s2 ; encoding: [0x17,0xf8,0x82,0xb9]
// GFX11: s_setreg_b32 hwreg(HW_REG_HW_ID1), s2 ; encoding: [0x17,0xf8,0x02,0xb9]
s_setreg_b32 hwreg(HW_REG_HW_ID2), s2
-// NOSICIVI: :[[@LINE-1]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
-// NOGFX9: :[[@LINE-2]]:{{[0-9]+}}: error: specified hardware register is not supported on this GPU
+// NOSICIVI: :[[@LINE-1]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
+// NOGFX9: :[[@LINE-2]]:{{[0-9]+}}: error: invalid hardware register: not supported on this GPU
// GFX10: s_setreg_b32 hwreg(HW_REG_HW_ID2), s2 ; encoding: [0x18,0xf8,0x82,0xb9]
// GFX11: s_setreg_b32 hwreg(HW_REG_HW_ID2), s2 ; encoding: [0x18,0xf8,0x02,0xb9]
@@ -427,12 +454,24 @@ s_getreg_b32 s2, hwreg(reg + 1, offset - 1, width + 1)
// GFX10: s_getreg_b32 s2, hwreg(51, 1, 31) ; encoding: [0x73,0xf0,0x02,0xb9]
// GFX11: s_getreg_b32 s2, hwreg(51, 1, 31) ; encoding: [0x73,0xf0,0x82,0xb8]
+s_getreg_b32 s2, {id: reg + 1, offset: offset - 1, size: width + 1}
+// SICI: s_getreg_b32 s2, hwreg(51, 1, 31) ; encoding: [0x73,0xf0,0x02,0xb9]
+// VI9: s_getreg_b32 s2, hwreg(51, 1, 31) ; encoding: [0x73,0xf0,0x82,0xb8]
+// GFX10: s_getreg_b32 s2, hwreg(51, 1, 31) ; encoding: [0x73,0xf0,0x02,0xb9]
+// GFX11: s_getreg_b32 s2, hwreg(51, 1, 31) ; encoding: [0x73,0xf0,0x82,0xb8]
+
s_getreg_b32 s2, hwreg(1 + reg, -1 + offset, 1 + width)
// SICI: s_getreg_b32 s2, hwreg(51, 1, 31) ; encoding: [0x73,0xf0,0x02,0xb9]
// VI9: s_getreg_b32 s2, hwreg(51, 1, 31) ; encoding: [0x73,0xf0,0x82,0xb8]
// GFX10: s_getreg_b32 s2, hwreg(51, 1, 31) ; encoding: [0x73,0xf0,0x02,0xb9]
// GFX11: s_getreg_b32 s2, hwreg(51, 1, 31) ; encoding: [0x73,0xf0,0x82,0xb8]
+s_getreg_b32 s2, {id: 1 + reg, offset: -1 + offset, size: 1 + width}
+// SICI: s_getreg_b32 s2, hwreg(51, 1, 31) ; encoding: [0x73,0xf0,0x02,0xb9]
+// VI9: s_getreg_b32 s2, hwreg(51, 1, 31) ; encoding: [0x73,0xf0,0x82,0xb8]
+// GFX10: s_getreg_b32 s2, hwreg(51, 1, 31) ; encoding: [0x73,0xf0,0x02,0xb9]
+// GFX11: s_getreg_b32 s2, hwreg(51, 1, 31) ; encoding: [0x73,0xf0,0x82,0xb8]
+
//===----------------------------------------------------------------------===//
// Instructions
//===----------------------------------------------------------------------===//
>From fdd60c7b961cd7beb2aaa4c5d0c559c34bbfafe8 Mon Sep 17 00:00:00 2001
From: Alexey Bataev <5361294+alexey-bataev at users.noreply.github.com>
Date: Wed, 28 Feb 2024 10:15:52 -0500
Subject: [PATCH 006/406] [LV][NFC]Preselect folding style while chosing the
max VF, NFC.
Selects the tail-folding style while choosing the max vector
factor and storing it in the data member rather than calculating it each
time upon getTailFoldingStyle call.
Part of https://github.com/llvm/llvm-project/pull/76172
Reviewers: ayalz, fhahn
Reviewed By: fhahn
Pull Request: https://github.com/llvm/llvm-project/pull/81885
---
.../Transforms/Vectorize/LoopVectorize.cpp | 42 +++++++++++++------
1 file changed, 30 insertions(+), 12 deletions(-)
diff --git a/llvm/lib/Transforms/Vectorize/LoopVectorize.cpp b/llvm/lib/Transforms/Vectorize/LoopVectorize.cpp
index 2e76adb83bd503..e5bce7299a970f 100644
--- a/llvm/lib/Transforms/Vectorize/LoopVectorize.cpp
+++ b/llvm/lib/Transforms/Vectorize/LoopVectorize.cpp
@@ -1510,19 +1510,36 @@ class LoopVectorizationCostModel {
}
/// Returns the TailFoldingStyle that is best for the current loop.
- TailFoldingStyle
- getTailFoldingStyle(bool IVUpdateMayOverflow = true) const {
- if (!CanFoldTailByMasking)
- return TailFoldingStyle::None;
+ TailFoldingStyle getTailFoldingStyle(bool IVUpdateMayOverflow = true) const {
+ return IVUpdateMayOverflow ? ChosenTailFoldingStyle.first
+ : ChosenTailFoldingStyle.second;
+ }
+
+ /// Selects and saves TailFoldingStyle for 2 options - if IV update may
+ /// overflow or not.
+ void setTailFoldinStyles() {
+ assert(ChosenTailFoldingStyle.first == TailFoldingStyle::None &&
+ ChosenTailFoldingStyle.second == TailFoldingStyle::None &&
+ "Tail folding must not be selected yet.");
+ if (!Legal->prepareToFoldTailByMasking())
+ return;
- if (ForceTailFoldingStyle.getNumOccurrences())
- return ForceTailFoldingStyle;
+ if (ForceTailFoldingStyle.getNumOccurrences()) {
+ ChosenTailFoldingStyle.first = ChosenTailFoldingStyle.second =
+ ForceTailFoldingStyle;
+ return;
+ }
- return TTI.getPreferredTailFoldingStyle(IVUpdateMayOverflow);
+ ChosenTailFoldingStyle.first =
+ TTI.getPreferredTailFoldingStyle(/*IVUpdateMayOverflow=*/true);
+ ChosenTailFoldingStyle.second =
+ TTI.getPreferredTailFoldingStyle(/*IVUpdateMayOverflow=*/false);
}
/// Returns true if all loop blocks should be masked to fold tail loop.
bool foldTailByMasking() const {
+ // TODO: check if it is possible to check for None style independent of
+ // IVUpdateMayOverflow flag in getTailFoldingStyle.
return getTailFoldingStyle() != TailFoldingStyle::None;
}
@@ -1675,8 +1692,10 @@ class LoopVectorizationCostModel {
/// iterations to execute in the scalar loop.
ScalarEpilogueLowering ScalarEpilogueStatus = CM_ScalarEpilogueAllowed;
- /// All blocks of loop are to be masked to fold tail of scalar iterations.
- bool CanFoldTailByMasking = false;
+ /// Control finally chosen tail folding style. The first element is used if
+ /// the IV update may overflow, the second element - if it does not.
+ std::pair<TailFoldingStyle, TailFoldingStyle> ChosenTailFoldingStyle =
+ std::make_pair(TailFoldingStyle::None, TailFoldingStyle::None);
/// A map holding scalar costs for different vectorization factors. The
/// presence of a cost for an instruction in the mapping indicates that the
@@ -4633,10 +4652,9 @@ LoopVectorizationCostModel::computeMaxVF(ElementCount UserVF, unsigned UserIC) {
// found modulo the vectorization factor is not zero, try to fold the tail
// by masking.
// FIXME: look for a smaller MaxVF that does divide TC rather than masking.
- if (Legal->prepareToFoldTailByMasking()) {
- CanFoldTailByMasking = true;
+ setTailFoldinStyles();
+ if (foldTailByMasking())
return MaxFactors;
- }
// If there was a tail-folding hint/switch, but we can't fold the tail by
// masking, fallback to a vectorization with a scalar epilogue.
>From cb6c0f1d28c0d1915d1ca9a198254e3828af2384 Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?Timm=20B=C3=A4der?= <tbaeder at redhat.com>
Date: Wed, 28 Feb 2024 13:06:41 +0100
Subject: [PATCH 007/406] [clang][Interp] Ignore ArrayDecay ops for null
pointers
Just don't do anything and let later operations handle the diagnostics.
---
clang/lib/AST/Interp/Interp.h | 2 +-
clang/test/AST/Interp/cxx11.cpp | 2 ++
2 files changed, 3 insertions(+), 1 deletion(-)
diff --git a/clang/lib/AST/Interp/Interp.h b/clang/lib/AST/Interp/Interp.h
index db52f6649c18ba..241d5941e143ee 100644
--- a/clang/lib/AST/Interp/Interp.h
+++ b/clang/lib/AST/Interp/Interp.h
@@ -1933,7 +1933,7 @@ inline bool ArrayElemPop(InterpState &S, CodePtr OpPC, uint32_t Index) {
inline bool ArrayDecay(InterpState &S, CodePtr OpPC) {
const Pointer &Ptr = S.Stk.pop<Pointer>();
- if (Ptr.isDummy()) {
+ if (Ptr.isZero() || Ptr.isDummy()) {
S.Stk.push<Pointer>(Ptr);
return true;
}
diff --git a/clang/test/AST/Interp/cxx11.cpp b/clang/test/AST/Interp/cxx11.cpp
index 29098ea694c688..993e3618a37848 100644
--- a/clang/test/AST/Interp/cxx11.cpp
+++ b/clang/test/AST/Interp/cxx11.cpp
@@ -28,3 +28,5 @@ struct S {
};
constexpr S s = { 5 };
constexpr const int *p = &s.m + 1;
+
+constexpr const int *np2 = &(*(int(*)[4])nullptr)[0]; // ok
>From 3e35ba53e20dbbd3ccc191d71ed75d52dc36ec59 Mon Sep 17 00:00:00 2001
From: Petar Avramovic <Petar.Avramovic at amd.com>
Date: Wed, 28 Feb 2024 16:18:04 +0100
Subject: [PATCH 008/406] AMDGPU/GFX12: Insert waitcnts before stores with
scope_sys (#82996)
Insert waitcnts for loads and atomics before stores with system scope.
Scope is field in instruction encoding and corresponds to desired
coherence level in cache hierarchy.
Intrinsic stores can set scope in cache policy operand.
If volatile keyword is used on generic stores memory legalizer will set
scope to system. Generic stores, by default, get lowest scope level.
Waitcnts are not required if it is guaranteed that memory is cached.
For example vulkan shaders can guarantee this.
TODO: implement flag for frontends to give us a hint not to insert
waits.
Expecting vulkan flag to be implemented as vulkan:private MMRA.
---
llvm/lib/Target/AMDGPU/SIInstrInfo.h | 2 +
llvm/lib/Target/AMDGPU/SIMemoryLegalizer.cpp | 47 +++++++++++++++++++
llvm/lib/Target/AMDGPU/SOPInstructions.td | 1 +
.../CodeGen/AMDGPU/GlobalISel/flat-scratch.ll | 8 ++++
llvm/test/CodeGen/AMDGPU/clamp.ll | 1 +
llvm/test/CodeGen/AMDGPU/flat-scratch.ll | 20 ++++++++
.../lower-work-group-id-intrinsics-hsa.ll | 1 +
llvm/test/CodeGen/AMDGPU/omod.ll | 2 +-
.../AMDGPU/vgpr-mark-last-scratch-load.ll | 4 ++
.../wait-before-stores-with-scope_sys.ll | 26 ++++++++++
.../wait-before-stores-with-scope_sys.mir | 43 +++++++++++++++++
11 files changed, 154 insertions(+), 1 deletion(-)
create mode 100644 llvm/test/CodeGen/AMDGPU/wait-before-stores-with-scope_sys.ll
create mode 100644 llvm/test/CodeGen/AMDGPU/wait-before-stores-with-scope_sys.mir
diff --git a/llvm/lib/Target/AMDGPU/SIInstrInfo.h b/llvm/lib/Target/AMDGPU/SIInstrInfo.h
index d774826c1d08c0..a8a33a5fecb413 100644
--- a/llvm/lib/Target/AMDGPU/SIInstrInfo.h
+++ b/llvm/lib/Target/AMDGPU/SIInstrInfo.h
@@ -949,6 +949,8 @@ class SIInstrInfo final : public AMDGPUGenInstrInfo {
return AMDGPU::S_WAIT_BVHCNT;
case AMDGPU::S_WAIT_DSCNT_soft:
return AMDGPU::S_WAIT_DSCNT;
+ case AMDGPU::S_WAIT_KMCNT_soft:
+ return AMDGPU::S_WAIT_KMCNT;
default:
return Opcode;
}
diff --git a/llvm/lib/Target/AMDGPU/SIMemoryLegalizer.cpp b/llvm/lib/Target/AMDGPU/SIMemoryLegalizer.cpp
index f62e808b33e42b..4069a368f68719 100644
--- a/llvm/lib/Target/AMDGPU/SIMemoryLegalizer.cpp
+++ b/llvm/lib/Target/AMDGPU/SIMemoryLegalizer.cpp
@@ -312,6 +312,10 @@ class SICacheControl {
SIMemOp Op, bool IsVolatile,
bool IsNonTemporal) const = 0;
+ virtual bool expandSystemScopeStore(MachineBasicBlock::iterator &MI) const {
+ return false;
+ };
+
/// Inserts any necessary instructions at position \p Pos relative
/// to instruction \p MI to ensure memory instructions before \p Pos of kind
/// \p Op associated with address spaces \p AddrSpace have completed. Used
@@ -589,6 +593,15 @@ class SIGfx12CacheControl : public SIGfx11CacheControl {
bool setScope(const MachineBasicBlock::iterator MI,
AMDGPU::CPol::CPol Value) const;
+ // Stores with system scope (SCOPE_SYS) need to wait for:
+ // - loads or atomics(returning) - wait for {LOAD|SAMPLE|BVH|KM}CNT==0
+ // - non-returning-atomics - wait for STORECNT==0
+ // TODO: SIInsertWaitcnts will not always be able to remove STORECNT waits
+ // since it does not distinguish atomics-with-return from regular stores.
+ // There is no need to wait if memory is cached (mtype != UC).
+ bool
+ insertWaitsBeforeSystemScopeStore(const MachineBasicBlock::iterator MI) const;
+
public:
SIGfx12CacheControl(const GCNSubtarget &ST) : SIGfx11CacheControl(ST) {}
@@ -603,6 +616,8 @@ class SIGfx12CacheControl : public SIGfx11CacheControl {
SIAtomicAddrSpace AddrSpace, SIMemOp Op,
bool IsVolatile,
bool IsNonTemporal) const override;
+
+ bool expandSystemScopeStore(MachineBasicBlock::iterator &MI) const override;
};
class SIMemoryLegalizer final : public MachineFunctionPass {
@@ -2194,6 +2209,22 @@ bool SIGfx12CacheControl::setScope(const MachineBasicBlock::iterator MI,
return false;
}
+bool SIGfx12CacheControl::insertWaitsBeforeSystemScopeStore(
+ const MachineBasicBlock::iterator MI) const {
+ // TODO: implement flag for frontend to give us a hint not to insert waits.
+
+ MachineBasicBlock &MBB = *MI->getParent();
+ const DebugLoc &DL = MI->getDebugLoc();
+
+ BuildMI(MBB, MI, DL, TII->get(S_WAIT_LOADCNT_soft)).addImm(0);
+ BuildMI(MBB, MI, DL, TII->get(S_WAIT_SAMPLECNT_soft)).addImm(0);
+ BuildMI(MBB, MI, DL, TII->get(S_WAIT_BVHCNT_soft)).addImm(0);
+ BuildMI(MBB, MI, DL, TII->get(S_WAIT_KMCNT_soft)).addImm(0);
+ BuildMI(MBB, MI, DL, TII->get(S_WAIT_STORECNT_soft)).addImm(0);
+
+ return true;
+}
+
bool SIGfx12CacheControl::insertWait(MachineBasicBlock::iterator &MI,
SIAtomicScope Scope,
SIAtomicAddrSpace AddrSpace, SIMemOp Op,
@@ -2364,6 +2395,9 @@ bool SIGfx12CacheControl::enableVolatileAndOrNonTemporal(
if (IsVolatile) {
Changed |= setScope(MI, AMDGPU::CPol::SCOPE_SYS);
+ if (Op == SIMemOp::STORE)
+ Changed |= insertWaitsBeforeSystemScopeStore(MI);
+
// Ensure operation has completed at system scope to cause all volatile
// operations to be visible outside the program in a global order. Do not
// request cross address space as only the global address space can be
@@ -2381,6 +2415,15 @@ bool SIGfx12CacheControl::enableVolatileAndOrNonTemporal(
return Changed;
}
+bool SIGfx12CacheControl::expandSystemScopeStore(
+ MachineBasicBlock::iterator &MI) const {
+ MachineOperand *CPol = TII->getNamedOperand(*MI, OpName::cpol);
+ if (CPol && ((CPol->getImm() & CPol::SCOPE) == CPol::SCOPE_SYS))
+ return insertWaitsBeforeSystemScopeStore(MI);
+
+ return false;
+}
+
bool SIMemoryLegalizer::removeAtomicPseudoMIs() {
if (AtomicPseudoMIs.empty())
return false;
@@ -2467,6 +2510,10 @@ bool SIMemoryLegalizer::expandStore(const SIMemOpInfo &MOI,
Changed |= CC->enableVolatileAndOrNonTemporal(
MI, MOI.getInstrAddrSpace(), SIMemOp::STORE, MOI.isVolatile(),
MOI.isNonTemporal());
+
+ // GFX12 specific, scope(desired coherence domain in cache hierarchy) is
+ // instruction field, do not confuse it with atomic scope.
+ Changed |= CC->expandSystemScopeStore(MI);
return Changed;
}
diff --git a/llvm/lib/Target/AMDGPU/SOPInstructions.td b/llvm/lib/Target/AMDGPU/SOPInstructions.td
index 0fe2845f8edc31..b5de311f8c58ce 100644
--- a/llvm/lib/Target/AMDGPU/SOPInstructions.td
+++ b/llvm/lib/Target/AMDGPU/SOPInstructions.td
@@ -1601,6 +1601,7 @@ let SubtargetPredicate = isGFX12Plus in {
def S_WAIT_SAMPLECNT_soft : SOPP_Pseudo <"s_soft_wait_samplecnt", (ins s16imm:$simm16), "$simm16">;
def S_WAIT_BVHCNT_soft : SOPP_Pseudo <"s_soft_wait_bvhcnt", (ins s16imm:$simm16), "$simm16">;
def S_WAIT_DSCNT_soft : SOPP_Pseudo <"s_soft_wait_dscnt", (ins s16imm:$simm16), "$simm16">;
+ def S_WAIT_KMCNT_soft : SOPP_Pseudo <"s_soft_wait_kmcnt", (ins s16imm:$simm16), "$simm16">;
}
def S_SETHALT : SOPP_Pseudo <"s_sethalt" , (ins i32imm:$simm16), "$simm16",
diff --git a/llvm/test/CodeGen/AMDGPU/GlobalISel/flat-scratch.ll b/llvm/test/CodeGen/AMDGPU/GlobalISel/flat-scratch.ll
index 921bdb5015c79a..63e7339d829e1d 100644
--- a/llvm/test/CodeGen/AMDGPU/GlobalISel/flat-scratch.ll
+++ b/llvm/test/CodeGen/AMDGPU/GlobalISel/flat-scratch.ll
@@ -256,6 +256,7 @@ define void @store_load_vindex_foo(i32 %idx) {
; GFX12-NEXT: v_lshlrev_b32_e32 v0, 2, v0
; GFX12-NEXT: s_delay_alu instid0(VALU_DEP_2)
; GFX12-NEXT: v_lshlrev_b32_e32 v1, 2, v1
+; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_store_b32 v0, v2, s32 scope:SCOPE_SYS
; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_load_b32 v0, v1, s32 scope:SCOPE_SYS
@@ -607,6 +608,7 @@ define void @store_load_vindex_small_offset_foo(i32 %idx) {
; GFX12-NEXT: scratch_load_b32 v3, off, s32 scope:SCOPE_SYS
; GFX12-NEXT: s_wait_loadcnt 0x0
; GFX12-NEXT: v_lshlrev_b32_e32 v1, 2, v1
+; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_store_b32 v0, v2, s32 offset:256 scope:SCOPE_SYS
; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_load_b32 v0, v1, s32 offset:256 scope:SCOPE_SYS
@@ -921,6 +923,7 @@ define void @store_load_vindex_large_offset_foo(i32 %idx) {
; GFX12-NEXT: scratch_load_b32 v3, off, s32 scope:SCOPE_SYS
; GFX12-NEXT: s_wait_loadcnt 0x0
; GFX12-NEXT: v_lshlrev_b32_e32 v1, 2, v1
+; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_store_b32 v0, v2, s32 offset:16384 scope:SCOPE_SYS
; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_load_b32 v0, v1, s32 offset:16384 scope:SCOPE_SYS
@@ -1089,6 +1092,7 @@ define void @store_load_large_imm_offset_foo() {
; GFX12-NEXT: s_wait_bvhcnt 0x0
; GFX12-NEXT: s_wait_kmcnt 0x0
; GFX12-NEXT: v_dual_mov_b32 v0, 13 :: v_dual_mov_b32 v1, 15
+; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_store_b32 off, v0, s32 scope:SCOPE_SYS
; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_store_b32 off, v1, s32 offset:16000 scope:SCOPE_SYS
@@ -1242,6 +1246,7 @@ define void @store_load_i64_aligned(ptr addrspace(5) nocapture %arg) {
; GFX12-NEXT: s_wait_kmcnt 0x0
; GFX12-NEXT: v_mov_b32_e32 v1, 15
; GFX12-NEXT: v_mov_b32_e32 v2, 0
+; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_store_b64 v0, v[1:2], off scope:SCOPE_SYS
; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_load_b64 v[0:1], v0, off scope:SCOPE_SYS
@@ -1306,6 +1311,7 @@ define void @store_load_i64_unaligned(ptr addrspace(5) nocapture %arg) {
; GFX12-NEXT: s_wait_kmcnt 0x0
; GFX12-NEXT: v_mov_b32_e32 v1, 15
; GFX12-NEXT: v_mov_b32_e32 v2, 0
+; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_store_b64 v0, v[1:2], off scope:SCOPE_SYS
; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_load_b64 v[0:1], v0, off scope:SCOPE_SYS
@@ -1389,6 +1395,7 @@ define void @store_load_v3i32_unaligned(ptr addrspace(5) nocapture %arg) {
; GFX12-NEXT: s_mov_b32 s0, 1
; GFX12-NEXT: v_dual_mov_b32 v3, s2 :: v_dual_mov_b32 v2, s1
; GFX12-NEXT: v_mov_b32_e32 v1, s0
+; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_store_b96 v0, v[1:3], off scope:SCOPE_SYS
; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_load_b96 v[0:2], v0, off scope:SCOPE_SYS
@@ -1478,6 +1485,7 @@ define void @store_load_v4i32_unaligned(ptr addrspace(5) nocapture %arg) {
; GFX12-NEXT: s_mov_b32 s0, 1
; GFX12-NEXT: v_dual_mov_b32 v4, s3 :: v_dual_mov_b32 v3, s2
; GFX12-NEXT: v_dual_mov_b32 v2, s1 :: v_dual_mov_b32 v1, s0
+; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_store_b128 v0, v[1:4], off scope:SCOPE_SYS
; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_load_b128 v[0:3], v0, off scope:SCOPE_SYS
diff --git a/llvm/test/CodeGen/AMDGPU/clamp.ll b/llvm/test/CodeGen/AMDGPU/clamp.ll
index 7c1c24f4a67dfa..dfadd8d205b04e 100644
--- a/llvm/test/CodeGen/AMDGPU/clamp.ll
+++ b/llvm/test/CodeGen/AMDGPU/clamp.ll
@@ -525,6 +525,7 @@ define amdgpu_kernel void @v_clamp_multi_use_max_f32(ptr addrspace(1) %out, ptr
; GFX12-NEXT: v_max_num_f32_e32 v1, 0, v1
; GFX12-NEXT: v_min_num_f32_e32 v2, 1.0, v1
; GFX12-NEXT: global_store_b32 v0, v2, s[0:1]
+; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: global_store_b32 v[0:1], v1, off scope:SCOPE_SYS
; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: s_nop 0
diff --git a/llvm/test/CodeGen/AMDGPU/flat-scratch.ll b/llvm/test/CodeGen/AMDGPU/flat-scratch.ll
index 687d8456569229..850be72f06c7d0 100644
--- a/llvm/test/CodeGen/AMDGPU/flat-scratch.ll
+++ b/llvm/test/CodeGen/AMDGPU/flat-scratch.ll
@@ -893,6 +893,7 @@ define void @store_load_vindex_foo(i32 %idx) {
; GFX12-NEXT: v_lshlrev_b32_e32 v0, 2, v0
; GFX12-NEXT: s_delay_alu instid0(VALU_DEP_2)
; GFX12-NEXT: v_lshlrev_b32_e32 v1, 2, v1
+; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_store_b32 v0, v2, s32 scope:SCOPE_SYS
; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_load_b32 v0, v1, s32 scope:SCOPE_SYS
@@ -964,6 +965,7 @@ define void @store_load_vindex_foo(i32 %idx) {
; GFX12-PAL-NEXT: v_lshlrev_b32_e32 v0, 2, v0
; GFX12-PAL-NEXT: s_delay_alu instid0(VALU_DEP_2)
; GFX12-PAL-NEXT: v_lshlrev_b32_e32 v1, 2, v1
+; GFX12-PAL-NEXT: s_wait_storecnt 0x0
; GFX12-PAL-NEXT: scratch_store_b32 v0, v2, s32 scope:SCOPE_SYS
; GFX12-PAL-NEXT: s_wait_storecnt 0x0
; GFX12-PAL-NEXT: scratch_load_b32 v0, v1, s32 scope:SCOPE_SYS
@@ -2137,6 +2139,7 @@ define void @store_load_vindex_small_offset_foo(i32 %idx) {
; GFX12-NEXT: scratch_load_b32 v3, off, s32 scope:SCOPE_SYS
; GFX12-NEXT: s_wait_loadcnt 0x0
; GFX12-NEXT: v_lshlrev_b32_e32 v1, 2, v1
+; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_store_b32 v0, v2, s32 offset:256 scope:SCOPE_SYS
; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_load_b32 v0, v1, s32 offset:256 scope:SCOPE_SYS
@@ -2221,6 +2224,7 @@ define void @store_load_vindex_small_offset_foo(i32 %idx) {
; GFX12-PAL-NEXT: scratch_load_b32 v3, off, s32 scope:SCOPE_SYS
; GFX12-PAL-NEXT: s_wait_loadcnt 0x0
; GFX12-PAL-NEXT: v_lshlrev_b32_e32 v1, 2, v1
+; GFX12-PAL-NEXT: s_wait_storecnt 0x0
; GFX12-PAL-NEXT: scratch_store_b32 v0, v2, s32 offset:256 scope:SCOPE_SYS
; GFX12-PAL-NEXT: s_wait_storecnt 0x0
; GFX12-PAL-NEXT: scratch_load_b32 v0, v1, s32 offset:256 scope:SCOPE_SYS
@@ -3382,6 +3386,7 @@ define void @store_load_vindex_large_offset_foo(i32 %idx) {
; GFX12-NEXT: scratch_load_b32 v3, off, s32 scope:SCOPE_SYS
; GFX12-NEXT: s_wait_loadcnt 0x0
; GFX12-NEXT: v_lshlrev_b32_e32 v1, 2, v1
+; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_store_b32 v0, v2, s32 offset:16384 scope:SCOPE_SYS
; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_load_b32 v0, v1, s32 offset:16384 scope:SCOPE_SYS
@@ -3468,6 +3473,7 @@ define void @store_load_vindex_large_offset_foo(i32 %idx) {
; GFX12-PAL-NEXT: scratch_load_b32 v3, off, s32 scope:SCOPE_SYS
; GFX12-PAL-NEXT: s_wait_loadcnt 0x0
; GFX12-PAL-NEXT: v_lshlrev_b32_e32 v1, 2, v1
+; GFX12-PAL-NEXT: s_wait_storecnt 0x0
; GFX12-PAL-NEXT: scratch_store_b32 v0, v2, s32 offset:16384 scope:SCOPE_SYS
; GFX12-PAL-NEXT: s_wait_storecnt 0x0
; GFX12-PAL-NEXT: scratch_load_b32 v0, v1, s32 offset:16384 scope:SCOPE_SYS
@@ -3714,6 +3720,7 @@ define void @store_load_large_imm_offset_foo() {
; GFX12-NEXT: s_wait_bvhcnt 0x0
; GFX12-NEXT: s_wait_kmcnt 0x0
; GFX12-NEXT: v_dual_mov_b32 v0, 13 :: v_dual_mov_b32 v1, 15
+; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_store_b32 off, v0, s32 scope:SCOPE_SYS
; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_store_b32 off, v1, s32 offset:16000 scope:SCOPE_SYS
@@ -3789,6 +3796,7 @@ define void @store_load_large_imm_offset_foo() {
; GFX12-PAL-NEXT: s_wait_bvhcnt 0x0
; GFX12-PAL-NEXT: s_wait_kmcnt 0x0
; GFX12-PAL-NEXT: v_dual_mov_b32 v0, 13 :: v_dual_mov_b32 v1, 15
+; GFX12-PAL-NEXT: s_wait_storecnt 0x0
; GFX12-PAL-NEXT: scratch_store_b32 off, v0, s32 scope:SCOPE_SYS
; GFX12-PAL-NEXT: s_wait_storecnt 0x0
; GFX12-PAL-NEXT: scratch_store_b32 off, v1, s32 offset:16000 scope:SCOPE_SYS
@@ -3998,6 +4006,7 @@ define void @store_load_i64_aligned(ptr addrspace(5) nocapture %arg) {
; GFX12-NEXT: s_wait_bvhcnt 0x0
; GFX12-NEXT: s_wait_kmcnt 0x0
; GFX12-NEXT: v_dual_mov_b32 v1, 15 :: v_dual_mov_b32 v2, 0
+; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_store_b64 v0, v[1:2], off scope:SCOPE_SYS
; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_load_b64 v[0:1], v0, off scope:SCOPE_SYS
@@ -4055,6 +4064,7 @@ define void @store_load_i64_aligned(ptr addrspace(5) nocapture %arg) {
; GFX12-PAL-NEXT: s_wait_bvhcnt 0x0
; GFX12-PAL-NEXT: s_wait_kmcnt 0x0
; GFX12-PAL-NEXT: v_dual_mov_b32 v1, 15 :: v_dual_mov_b32 v2, 0
+; GFX12-PAL-NEXT: s_wait_storecnt 0x0
; GFX12-PAL-NEXT: scratch_store_b64 v0, v[1:2], off scope:SCOPE_SYS
; GFX12-PAL-NEXT: s_wait_storecnt 0x0
; GFX12-PAL-NEXT: scratch_load_b64 v[0:1], v0, off scope:SCOPE_SYS
@@ -4107,6 +4117,7 @@ define void @store_load_i64_unaligned(ptr addrspace(5) nocapture %arg) {
; GFX12-NEXT: s_wait_bvhcnt 0x0
; GFX12-NEXT: s_wait_kmcnt 0x0
; GFX12-NEXT: v_dual_mov_b32 v1, 15 :: v_dual_mov_b32 v2, 0
+; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_store_b64 v0, v[1:2], off scope:SCOPE_SYS
; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_load_b64 v[0:1], v0, off scope:SCOPE_SYS
@@ -4164,6 +4175,7 @@ define void @store_load_i64_unaligned(ptr addrspace(5) nocapture %arg) {
; GFX12-PAL-NEXT: s_wait_bvhcnt 0x0
; GFX12-PAL-NEXT: s_wait_kmcnt 0x0
; GFX12-PAL-NEXT: v_dual_mov_b32 v1, 15 :: v_dual_mov_b32 v2, 0
+; GFX12-PAL-NEXT: s_wait_storecnt 0x0
; GFX12-PAL-NEXT: scratch_store_b64 v0, v[1:2], off scope:SCOPE_SYS
; GFX12-PAL-NEXT: s_wait_storecnt 0x0
; GFX12-PAL-NEXT: scratch_load_b64 v[0:1], v0, off scope:SCOPE_SYS
@@ -4220,6 +4232,7 @@ define void @store_load_v3i32_unaligned(ptr addrspace(5) nocapture %arg) {
; GFX12-NEXT: s_wait_kmcnt 0x0
; GFX12-NEXT: v_dual_mov_b32 v1, 1 :: v_dual_mov_b32 v2, 2
; GFX12-NEXT: v_mov_b32_e32 v3, 3
+; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_store_b96 v0, v[1:3], off scope:SCOPE_SYS
; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_load_b96 v[0:2], v0, off scope:SCOPE_SYS
@@ -4282,6 +4295,7 @@ define void @store_load_v3i32_unaligned(ptr addrspace(5) nocapture %arg) {
; GFX12-PAL-NEXT: s_wait_kmcnt 0x0
; GFX12-PAL-NEXT: v_dual_mov_b32 v1, 1 :: v_dual_mov_b32 v2, 2
; GFX12-PAL-NEXT: v_mov_b32_e32 v3, 3
+; GFX12-PAL-NEXT: s_wait_storecnt 0x0
; GFX12-PAL-NEXT: scratch_store_b96 v0, v[1:3], off scope:SCOPE_SYS
; GFX12-PAL-NEXT: s_wait_storecnt 0x0
; GFX12-PAL-NEXT: scratch_load_b96 v[0:2], v0, off scope:SCOPE_SYS
@@ -4340,6 +4354,7 @@ define void @store_load_v4i32_unaligned(ptr addrspace(5) nocapture %arg) {
; GFX12-NEXT: s_wait_kmcnt 0x0
; GFX12-NEXT: v_dual_mov_b32 v1, 1 :: v_dual_mov_b32 v2, 2
; GFX12-NEXT: v_dual_mov_b32 v3, 3 :: v_dual_mov_b32 v4, 4
+; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_store_b128 v0, v[1:4], off scope:SCOPE_SYS
; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_load_b128 v[0:3], v0, off scope:SCOPE_SYS
@@ -4405,6 +4420,7 @@ define void @store_load_v4i32_unaligned(ptr addrspace(5) nocapture %arg) {
; GFX12-PAL-NEXT: s_wait_kmcnt 0x0
; GFX12-PAL-NEXT: v_dual_mov_b32 v1, 1 :: v_dual_mov_b32 v2, 2
; GFX12-PAL-NEXT: v_dual_mov_b32 v3, 3 :: v_dual_mov_b32 v4, 4
+; GFX12-PAL-NEXT: s_wait_storecnt 0x0
; GFX12-PAL-NEXT: scratch_store_b128 v0, v[1:4], off scope:SCOPE_SYS
; GFX12-PAL-NEXT: s_wait_storecnt 0x0
; GFX12-PAL-NEXT: scratch_load_b128 v[0:3], v0, off scope:SCOPE_SYS
@@ -4456,6 +4472,7 @@ define void @store_load_i32_negative_unaligned(ptr addrspace(5) nocapture %arg)
; GFX12-NEXT: s_wait_bvhcnt 0x0
; GFX12-NEXT: s_wait_kmcnt 0x0
; GFX12-NEXT: v_mov_b32_e32 v1, 1
+; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_store_b8 v0, v1, off offset:-1 scope:SCOPE_SYS
; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_load_u8 v0, v0, off offset:-1 scope:SCOPE_SYS
@@ -4523,6 +4540,7 @@ define void @store_load_i32_negative_unaligned(ptr addrspace(5) nocapture %arg)
; GFX12-PAL-NEXT: s_wait_bvhcnt 0x0
; GFX12-PAL-NEXT: s_wait_kmcnt 0x0
; GFX12-PAL-NEXT: v_mov_b32_e32 v1, 1
+; GFX12-PAL-NEXT: s_wait_storecnt 0x0
; GFX12-PAL-NEXT: scratch_store_b8 v0, v1, off offset:-1 scope:SCOPE_SYS
; GFX12-PAL-NEXT: s_wait_storecnt 0x0
; GFX12-PAL-NEXT: scratch_load_u8 v0, v0, off offset:-1 scope:SCOPE_SYS
@@ -4576,6 +4594,7 @@ define void @store_load_i32_large_negative_unaligned(ptr addrspace(5) nocapture
; GFX12-NEXT: s_wait_bvhcnt 0x0
; GFX12-NEXT: s_wait_kmcnt 0x0
; GFX12-NEXT: v_mov_b32_e32 v1, 1
+; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_store_b8 v0, v1, off offset:-4225 scope:SCOPE_SYS
; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: scratch_load_u8 v0, v0, off offset:-4225 scope:SCOPE_SYS
@@ -4644,6 +4663,7 @@ define void @store_load_i32_large_negative_unaligned(ptr addrspace(5) nocapture
; GFX12-PAL-NEXT: s_wait_bvhcnt 0x0
; GFX12-PAL-NEXT: s_wait_kmcnt 0x0
; GFX12-PAL-NEXT: v_mov_b32_e32 v1, 1
+; GFX12-PAL-NEXT: s_wait_storecnt 0x0
; GFX12-PAL-NEXT: scratch_store_b8 v0, v1, off offset:-4225 scope:SCOPE_SYS
; GFX12-PAL-NEXT: s_wait_storecnt 0x0
; GFX12-PAL-NEXT: scratch_load_u8 v0, v0, off offset:-4225 scope:SCOPE_SYS
diff --git a/llvm/test/CodeGen/AMDGPU/lower-work-group-id-intrinsics-hsa.ll b/llvm/test/CodeGen/AMDGPU/lower-work-group-id-intrinsics-hsa.ll
index afa914c8375f64..9547f08d3eba6b 100644
--- a/llvm/test/CodeGen/AMDGPU/lower-work-group-id-intrinsics-hsa.ll
+++ b/llvm/test/CodeGen/AMDGPU/lower-work-group-id-intrinsics-hsa.ll
@@ -269,6 +269,7 @@ define void @workgroup_ids_device_func(ptr addrspace(1) %outx, ptr addrspace(1)
; GFX12-NEXT: v_dual_mov_b32 v6, ttmp9 :: v_dual_mov_b32 v7, s0
; GFX12-NEXT: s_lshr_b32 s1, ttmp7, 16
; GFX12-NEXT: v_mov_b32_e32 v8, s1
+; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: global_store_b32 v[0:1], v6, off scope:SCOPE_SYS
; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: global_store_b32 v[2:3], v7, off scope:SCOPE_SYS
diff --git a/llvm/test/CodeGen/AMDGPU/omod.ll b/llvm/test/CodeGen/AMDGPU/omod.ll
index fa1ca66ef4156c..769d035858ca83 100644
--- a/llvm/test/CodeGen/AMDGPU/omod.ll
+++ b/llvm/test/CodeGen/AMDGPU/omod.ll
@@ -651,8 +651,8 @@ define amdgpu_ps void @v_omod_mul4_multi_use_f32(float %a) #0 {
; GFX12-NEXT: v_add_f32_e32 v0, 1.0, v0
; GFX12-NEXT: s_delay_alu instid0(VALU_DEP_1)
; GFX12-NEXT: v_mul_f32_e32 v1, 4.0, v0
-; GFX12-NEXT: s_clause 0x1
; GFX12-NEXT: global_store_b32 v[0:1], v1, off
+; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: global_store_b32 v[0:1], v0, off scope:SCOPE_SYS
; GFX12-NEXT: s_wait_storecnt 0x0
; GFX12-NEXT: s_nop 0
diff --git a/llvm/test/CodeGen/AMDGPU/vgpr-mark-last-scratch-load.ll b/llvm/test/CodeGen/AMDGPU/vgpr-mark-last-scratch-load.ll
index 137bd0f5d9f14e..4efa1e9353ab3a 100644
--- a/llvm/test/CodeGen/AMDGPU/vgpr-mark-last-scratch-load.ll
+++ b/llvm/test/CodeGen/AMDGPU/vgpr-mark-last-scratch-load.ll
@@ -28,6 +28,7 @@ define amdgpu_cs void @max_6_vgprs(ptr addrspace(1) %p) "amdgpu-num-vgpr"="6" {
; CHECK-NEXT: scratch_store_b32 off, v0, off offset:12 ; 4-byte Folded Spill
; CHECK-NEXT: ;;#ASMSTART
; CHECK-NEXT: ;;#ASMEND
+; CHECK-NEXT: s_wait_storecnt 0x0
; CHECK-NEXT: global_store_b32 v[0:1], v5, off scope:SCOPE_SYS
; CHECK-NEXT: s_wait_storecnt 0x0
; CHECK-NEXT: scratch_load_b32 v0, off, off th:TH_LOAD_LU ; 4-byte Folded Reload
@@ -116,6 +117,7 @@ define amdgpu_cs void @max_11_vgprs_branch(ptr addrspace(1) %p, i32 %tmp) "amdgp
; CHECK-NEXT: scratch_store_b32 off, v0, off offset:32 ; 4-byte Folded Spill
; CHECK-NEXT: ;;#ASMSTART
; CHECK-NEXT: ;;#ASMEND
+; CHECK-NEXT: s_wait_storecnt 0x0
; CHECK-NEXT: global_store_b32 v[0:1], v10, off scope:SCOPE_SYS
; CHECK-NEXT: s_wait_storecnt 0x0
; CHECK-NEXT: scratch_load_b32 v0, off, off offset:16 th:TH_LOAD_LU ; 4-byte Folded Reload
@@ -174,6 +176,7 @@ define amdgpu_cs void @max_11_vgprs_branch(ptr addrspace(1) %p, i32 %tmp) "amdgp
; CHECK-NEXT: scratch_store_b32 off, v0, off offset:32 ; 4-byte Folded Spill
; CHECK-NEXT: ;;#ASMSTART
; CHECK-NEXT: ;;#ASMEND
+; CHECK-NEXT: s_wait_storecnt 0x0
; CHECK-NEXT: global_store_b32 v[0:1], v10, off scope:SCOPE_SYS
; CHECK-NEXT: s_wait_storecnt 0x0
; CHECK-NEXT: scratch_load_b32 v0, off, off offset:16 th:TH_LOAD_LU ; 4-byte Folded Reload
@@ -208,6 +211,7 @@ define amdgpu_cs void @max_11_vgprs_branch(ptr addrspace(1) %p, i32 %tmp) "amdgp
; CHECK-NEXT: s_or_b32 exec_lo, exec_lo, s0
; CHECK-NEXT: scratch_load_b32 v0, off, off th:TH_LOAD_LU ; 4-byte Folded Reload
; CHECK-NEXT: s_wait_loadcnt 0x0
+; CHECK-NEXT: s_wait_storecnt 0x0
; CHECK-NEXT: global_store_b32 v[0:1], v0, off scope:SCOPE_SYS
; CHECK-NEXT: s_wait_storecnt 0x0
; CHECK-NEXT: scratch_load_b32 v0, off, off offset:4 th:TH_LOAD_LU ; 4-byte Folded Reload
diff --git a/llvm/test/CodeGen/AMDGPU/wait-before-stores-with-scope_sys.ll b/llvm/test/CodeGen/AMDGPU/wait-before-stores-with-scope_sys.ll
new file mode 100644
index 00000000000000..e6fbe97f8dc0a5
--- /dev/null
+++ b/llvm/test/CodeGen/AMDGPU/wait-before-stores-with-scope_sys.ll
@@ -0,0 +1,26 @@
+; NOTE: Assertions have been autogenerated by utils/update_llc_test_checks.py UTC_ARGS: --version 4
+; RUN: llc -global-isel=0 -march=amdgcn -mcpu=gfx1200 -verify-machineinstrs < %s | FileCheck -check-prefix=GFX12 %s
+; RUN: llc -global-isel=1 -march=amdgcn -mcpu=gfx1200 -verify-machineinstrs < %s | FileCheck -check-prefix=GFX12 %s
+
+define amdgpu_ps void @intrinsic_store_system_scope(i32 %val, <4 x i32> inreg %rsrc, i32 %vindex, i32 %voffset, i32 inreg %soffset) {
+; GFX12-LABEL: intrinsic_store_system_scope:
+; GFX12: ; %bb.0:
+; GFX12-NEXT: buffer_store_b32 v0, v[1:2], s[0:3], s4 idxen offen scope:SCOPE_SYS
+; GFX12-NEXT: s_nop 0
+; GFX12-NEXT: s_sendmsg sendmsg(MSG_DEALLOC_VGPRS)
+; GFX12-NEXT: s_endpgm
+ call void @llvm.amdgcn.struct.buffer.store.i32(i32 %val, <4 x i32> %rsrc, i32 %vindex, i32 %voffset, i32 %soffset, i32 24)
+ ret void
+}
+
+define amdgpu_ps void @generic_store_volatile(i32 %val, ptr addrspace(1) %out) {
+; GFX12-LABEL: generic_store_volatile:
+; GFX12: ; %bb.0:
+; GFX12-NEXT: global_store_b32 v[1:2], v0, off scope:SCOPE_SYS
+; GFX12-NEXT: s_wait_storecnt 0x0
+; GFX12-NEXT: s_nop 0
+; GFX12-NEXT: s_sendmsg sendmsg(MSG_DEALLOC_VGPRS)
+; GFX12-NEXT: s_endpgm
+ store volatile i32 %val, ptr addrspace(1) %out
+ ret void
+}
diff --git a/llvm/test/CodeGen/AMDGPU/wait-before-stores-with-scope_sys.mir b/llvm/test/CodeGen/AMDGPU/wait-before-stores-with-scope_sys.mir
new file mode 100644
index 00000000000000..acf8bd3a6ab563
--- /dev/null
+++ b/llvm/test/CodeGen/AMDGPU/wait-before-stores-with-scope_sys.mir
@@ -0,0 +1,43 @@
+# NOTE: Assertions have been autogenerated by utils/update_mir_test_checks.py UTC_ARGS: --version 4
+# RUN: llc -mtriple=amdgcn -mcpu=gfx1200 -run-pass=si-memory-legalizer %s -o - | FileCheck -check-prefix=GFX12 %s
+
+---
+name: intrinsic_store_system_scope
+body: |
+ bb.0:
+ liveins: $sgpr0, $sgpr1, $sgpr2, $sgpr3, $sgpr4, $vgpr0, $vgpr1, $vgpr2
+
+ ; GFX12-LABEL: name: intrinsic_store_system_scope
+ ; GFX12: liveins: $sgpr0, $sgpr1, $sgpr2, $sgpr3, $sgpr4, $vgpr0, $vgpr1, $vgpr2
+ ; GFX12-NEXT: {{ $}}
+ ; GFX12-NEXT: S_WAIT_LOADCNT_soft 0
+ ; GFX12-NEXT: S_WAIT_SAMPLECNT_soft 0
+ ; GFX12-NEXT: S_WAIT_BVHCNT_soft 0
+ ; GFX12-NEXT: S_WAIT_KMCNT_soft 0
+ ; GFX12-NEXT: S_WAIT_STORECNT_soft 0
+ ; GFX12-NEXT: BUFFER_STORE_DWORD_VBUFFER_BOTHEN_exact killed renamable $vgpr0, killed renamable $vgpr1_vgpr2, killed renamable $sgpr0_sgpr1_sgpr2_sgpr3, killed renamable $sgpr4, 0, 24, 0, implicit $exec :: (dereferenceable store (s32), align 1, addrspace 8)
+ ; GFX12-NEXT: S_ENDPGM 0
+ BUFFER_STORE_DWORD_VBUFFER_BOTHEN_exact killed renamable $vgpr0, killed renamable $vgpr1_vgpr2, killed renamable $sgpr0_sgpr1_sgpr2_sgpr3, killed renamable $sgpr4, 0, 24, 0, implicit $exec :: (dereferenceable store (s32), align 1, addrspace 8)
+ S_ENDPGM 0
+...
+
+---
+name: generic_store_volatile
+body: |
+ bb.0:
+ liveins: $vgpr0, $vgpr1, $vgpr2
+
+ ; GFX12-LABEL: name: generic_store_volatile
+ ; GFX12: liveins: $vgpr0, $vgpr1, $vgpr2
+ ; GFX12-NEXT: {{ $}}
+ ; GFX12-NEXT: S_WAIT_LOADCNT_soft 0
+ ; GFX12-NEXT: S_WAIT_SAMPLECNT_soft 0
+ ; GFX12-NEXT: S_WAIT_BVHCNT_soft 0
+ ; GFX12-NEXT: S_WAIT_KMCNT_soft 0
+ ; GFX12-NEXT: S_WAIT_STORECNT_soft 0
+ ; GFX12-NEXT: GLOBAL_STORE_DWORD killed renamable $vgpr1_vgpr2, killed renamable $vgpr0, 0, 24, implicit $exec :: (volatile store (s32), addrspace 1)
+ ; GFX12-NEXT: S_WAIT_STORECNT_soft 0
+ ; GFX12-NEXT: S_ENDPGM 0
+ GLOBAL_STORE_DWORD killed renamable $vgpr1_vgpr2, killed renamable $vgpr0, 0, 0, implicit $exec :: (volatile store (s32), addrspace 1)
+ S_ENDPGM 0
+...
>From 6067129fbe8944d5bd39dc1bc2331ce5ed6ecee8 Mon Sep 17 00:00:00 2001
From: Quinn Dawkins <quinn.dawkins at gmail.com>
Date: Wed, 28 Feb 2024 10:52:57 -0500
Subject: [PATCH 009/406] Revert "[mlir][vector] Add a pattern to fuse
extract(constant_mask) (#81057)" (#83275)
This reverts commit 5cdb8c0c8854d08ac7ca131ce3e8d78a32eb6716.
This pattern is producing incorrect IR. For example,
```mlir
func.func @extract_subvector_from_constant_mask() -> vector<16xi1> {
%mask = vector.constant_mask [2, 3] : vector<16x16xi1>
%extract = vector.extract %mask[8] : vector<16xi1> from vector<16x16xi1>
return %extract : vector<16xi1>
}
```
Canonicalizes to
```mlir
func.func @extract_subvector_from_constant_mask() -> vector<16xi1> {
%0 = vector.constant_mask [3] : vector<16xi1>
return %0 : vector<16xi1>
}
```
Where it should be a zero mask because the extraction index (8) is
greater than the constant mask size along that dim (2).
---
mlir/lib/Dialect/Vector/IR/VectorOps.cpp | 74 +---------------------
mlir/test/Dialect/Vector/canonicalize.mlir | 73 ---------------------
2 files changed, 1 insertion(+), 146 deletions(-)
diff --git a/mlir/lib/Dialect/Vector/IR/VectorOps.cpp b/mlir/lib/Dialect/Vector/IR/VectorOps.cpp
index 8c341a347ff662..5be6a628904cdf 100644
--- a/mlir/lib/Dialect/Vector/IR/VectorOps.cpp
+++ b/mlir/lib/Dialect/Vector/IR/VectorOps.cpp
@@ -2040,77 +2040,6 @@ class ExtractOpFromCreateMask final : public OpRewritePattern<ExtractOp> {
}
};
-// Patterns to rewrite ExtractOp(ConstantMaskOp)
-//
-// When the result of ExtractOp is a subvector of input, we can rewrite it as
-// a ConstantMaskOp with subvector ranks.
-//
-// ExtractOp(ConstantMaskOp) -> ConstantMaskOp
-//
-// When the result of ExtractOp is a scalar, we can get the scalar value
-// directly.
-//
-// ExtractOp(ConstantMaskOp) -> ConstantOp
-class ExtractOpFromConstantMask final : public OpRewritePattern<ExtractOp> {
-public:
- using OpRewritePattern::OpRewritePattern;
-
- LogicalResult matchAndRewrite(ExtractOp extractOp,
- PatternRewriter &rewriter) const override {
- auto constantMaskOp =
- extractOp.getVector().getDefiningOp<vector::ConstantMaskOp>();
- if (!constantMaskOp)
- return failure();
-
- // All indices must be static.
- ArrayRef<int64_t> extractOpPos = extractOp.getStaticPosition();
- unsigned dynamicPosCount =
- llvm::count_if(extractOpPos, ShapedType::isDynamic);
- // If there is any dynamic position in ExtractOp, we cannot determine the
- // scalar value.
- if (dynamicPosCount)
- return failure();
-
- ArrayRef<Attribute> maskDimSizes =
- constantMaskOp.getMaskDimSizes().getValue();
- Type resultTy = extractOp.getResult().getType();
- if (resultTy.isa<mlir::VectorType>()) {
- auto resultVectorTy = resultTy.cast<mlir::VectorType>();
- int64_t resultRank = resultVectorTy.getRank();
- int64_t n = maskDimSizes.size();
- std::vector<int64_t> indices;
- for (auto i = n - resultRank; i < n; ++i)
- indices.push_back(cast<IntegerAttr>(maskDimSizes[i]).getInt());
-
- rewriter.replaceOpWithNewOp<vector::ConstantMaskOp>(
- extractOp, resultVectorTy,
- vector::getVectorSubscriptAttr(rewriter, indices));
-
- return success();
- } else if (resultTy.isa<mlir::IntegerType>()) {
- // ConstantMaskOp creates and returns a vector mask where elements of the
- // result vector are set to ‘0’ or ‘1’, based on whether the element
- // indices are contained within a hyper-rectangular region.
- // We go through ExtractOp static positions to determine the position is
- // within the hyper-rectangular region or not.
- Type boolType = rewriter.getI1Type();
- IntegerAttr setAttr = IntegerAttr::get(boolType, 1);
- for (size_t i = 0, end = extractOpPos.size(); i < end; ++i) {
- if (cast<IntegerAttr>(maskDimSizes[i]).getInt() <= extractOpPos[i]) {
- setAttr = IntegerAttr::get(boolType, 0);
- break;
- }
- }
-
- rewriter.replaceOpWithNewOp<arith::ConstantOp>(extractOp, boolType,
- setAttr);
- return success();
- }
-
- return failure();
- }
-};
-
// Folds extract(shape_cast(..)) into shape_cast when the total element count
// does not change.
LogicalResult foldExtractFromShapeCastToShapeCast(ExtractOp extractOp,
@@ -2137,8 +2066,7 @@ LogicalResult foldExtractFromShapeCastToShapeCast(ExtractOp extractOp,
void ExtractOp::getCanonicalizationPatterns(RewritePatternSet &results,
MLIRContext *context) {
results.add<ExtractOpSplatConstantFolder, ExtractOpNonSplatConstantFolder,
- ExtractOpFromBroadcast, ExtractOpFromCreateMask,
- ExtractOpFromConstantMask>(context);
+ ExtractOpFromBroadcast, ExtractOpFromCreateMask>(context);
results.add(foldExtractFromShapeCastToShapeCast);
}
diff --git a/mlir/test/Dialect/Vector/canonicalize.mlir b/mlir/test/Dialect/Vector/canonicalize.mlir
index dc486181ebe960..e6f045e12e5197 100644
--- a/mlir/test/Dialect/Vector/canonicalize.mlir
+++ b/mlir/test/Dialect/Vector/canonicalize.mlir
@@ -2567,76 +2567,3 @@ func.func @load_store_forwarding_rank_mismatch(%v0: vector<4x1x1xf32>, %arg0: te
tensor<4x4x4xf32>, vector<1x100x4x5xf32>
return %r : vector<1x100x4x5xf32>
}
-
-// -----
-
-// CHECK-LABEL: func.func @extract_true_from_constant_mask() -> i1 {
-func.func @extract_true_from_constant_mask() -> i1 {
-// CHECK: %[[TRUE:.*]] = arith.constant true
-// CHECK-NEXT: return %[[TRUE]] : i1
- %mask = vector.constant_mask [2, 2, 3] : vector<4x4x4xi1>
- %extract = vector.extract %mask[1, 1, 2] : i1 from vector<4x4x4xi1>
- return %extract : i1
-}
-
-// -----
-
-// CHECK-LABEL: func.func @extract_false_from_constant_mask() -> i1 {
-func.func @extract_false_from_constant_mask() -> i1 {
-// CHECK: %[[FALSE:.*]] = arith.constant false
-// CHECK-NEXT: return %[[FALSE]] : i1
- %mask = vector.constant_mask [2, 2, 3] : vector<4x4x4xi1>
- %extract = vector.extract %mask[1, 2, 2] : i1 from vector<4x4x4xi1>
- return %extract : i1
-}
-
-// -----
-
-// CHECK-LABEL: func.func @extract_from_create_mask() -> i1 {
-func.func @extract_from_create_mask() -> i1 {
-// CHECK: %[[TRUE:.*]] = arith.constant true
-// CHECK-NEXT: return %[[TRUE]] : i1
- %c2 = arith.constant 2 : index
- %c3 = arith.constant 3 : index
- %mask = vector.create_mask %c2, %c2, %c3 : vector<4x4x4xi1>
- %extract = vector.extract %mask[1, 1, 2] : i1 from vector<4x4x4xi1>
- return %extract : i1
-}
-
-// -----
-
-// CHECK-LABEL: func.func @extract_subvector_from_constant_mask() ->
-// CHECK-SAME: vector<6xi1> {
-func.func @extract_subvector_from_constant_mask() -> vector<6xi1> {
-// CHECK: %[[S0:.*]] = vector.constant_mask [4] : vector<6xi1>
-// CHECK-NEXT: return %[[S0]] : vector<6xi1>
- %mask = vector.constant_mask [2, 3, 4] : vector<4x5x6xi1>
- %extract = vector.extract %mask[1, 2] : vector<6xi1> from vector<4x5x6xi1>
- return %extract : vector<6xi1>
-}
-
-// -----
-
-// CHECK-LABEL: func.func @extract_scalar_with_dynamic_positions(
-// CHECK-SAME: %[[INDEX:.*]]: index) -> i1 {
-func.func @extract_scalar_with_dynamic_positions(%index: index) -> i1 {
-// CHECK: %[[S0:.*]] = vector.constant_mask [2, 2, 3] : vector<4x4x4xi1>
-// CHECK-NEXT: %[[S1:.*]] = vector.extract %[[S0]][1, 1, %[[INDEX]]] : i1 from vector<4x4x4xi1>
-// CHECK-NEXT: return %[[S1]] : i1
- %mask = vector.constant_mask [2, 2, 3] : vector<4x4x4xi1>
- %extract = vector.extract %mask[1, 1, %index] : i1 from vector<4x4x4xi1>
- return %extract : i1
-}
-
-// -----
-
-// CHECK-LABEL: func.func @extract_subvector_with_dynamic_positions
-// CHECK-SAME: %[[INDEX:.*]]: index) -> vector<6xi1> {
-func.func @extract_subvector_with_dynamic_positions(%index: index) -> vector<6xi1> {
-// CHECK: %[[S0:.*]] = vector.constant_mask [2, 3, 4] : vector<4x5x6xi1>
-// CHECK-NEXT: %[[S1:.*]] = vector.extract %[[S0]][1, %[[INDEX]]] : vector<6xi1> from vector<4x5x6xi1>
-// CHECK-NEXT: return %[[S1]] : vector<6xi1>
- %mask = vector.constant_mask [2, 3, 4] : vector<4x5x6xi1>
- %extract = vector.extract %mask[1, %index] : vector<6xi1> from vector<4x5x6xi1>
- return %extract : vector<6xi1>
-}
>From 80cff273906b200eed2f779913f49a64cad8c0c6 Mon Sep 17 00:00:00 2001
From: Alexey Bataev <a.bataev at outlook.com>
Date: Wed, 28 Feb 2024 07:27:39 -0800
Subject: [PATCH 010/406] [LV][NFC]Fix a misprint, NFC.
---
llvm/lib/Transforms/Vectorize/LoopVectorize.cpp | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/llvm/lib/Transforms/Vectorize/LoopVectorize.cpp b/llvm/lib/Transforms/Vectorize/LoopVectorize.cpp
index e5bce7299a970f..6b16923213c86e 100644
--- a/llvm/lib/Transforms/Vectorize/LoopVectorize.cpp
+++ b/llvm/lib/Transforms/Vectorize/LoopVectorize.cpp
@@ -1517,7 +1517,7 @@ class LoopVectorizationCostModel {
/// Selects and saves TailFoldingStyle for 2 options - if IV update may
/// overflow or not.
- void setTailFoldinStyles() {
+ void setTailFoldingStyles() {
assert(ChosenTailFoldingStyle.first == TailFoldingStyle::None &&
ChosenTailFoldingStyle.second == TailFoldingStyle::None &&
"Tail folding must not be selected yet.");
@@ -4652,7 +4652,7 @@ LoopVectorizationCostModel::computeMaxVF(ElementCount UserVF, unsigned UserIC) {
// found modulo the vectorization factor is not zero, try to fold the tail
// by masking.
// FIXME: look for a smaller MaxVF that does divide TC rather than masking.
- setTailFoldinStyles();
+ setTailFoldingStyles();
if (foldTailByMasking())
return MaxFactors;
>From 4623c114fb51e48b5cbb352adecb60d76077cb0a Mon Sep 17 00:00:00 2001
From: Diego Caballero <diegocaballero at google.com>
Date: Wed, 28 Feb 2024 08:15:47 -0800
Subject: [PATCH 011/406] [mlir][Vector] Support vector.insert in bubbling
bitcast patterns (#82843)
This PR is adds support for `vector.insert` to the patterns that bubble up and down `vector.bitcat` ops across `vector.extract/extract_slice/insert_slice` ops.
---
.../Vector/Transforms/VectorTransforms.cpp | 74 ++++++++++++++++++-
.../Dialect/Vector/vector-transforms.mlir | 45 +++++++++++
2 files changed, 117 insertions(+), 2 deletions(-)
diff --git a/mlir/lib/Dialect/Vector/Transforms/VectorTransforms.cpp b/mlir/lib/Dialect/Vector/Transforms/VectorTransforms.cpp
index 74dd1dfaca0da8..a2d4e216633181 100644
--- a/mlir/lib/Dialect/Vector/Transforms/VectorTransforms.cpp
+++ b/mlir/lib/Dialect/Vector/Transforms/VectorTransforms.cpp
@@ -710,6 +710,76 @@ struct BubbleDownBitCastForStridedSliceExtract
}
};
+// Shuffles vector.bitcast op before vector.insert_strided_slice op.
+//
+// This transforms IR like:
+// %0 = vector.insert %val, %dst[4] : vector<32xi4> into vector<8x32xi4>
+// %1 = vector.bitcast %0 : vector<8x32xi4> to vector<8x16xi8>
+// Into:
+// %0 = vector.bitcast %val : vector<32xi4> to vector<16xi8>
+// %1 = vector.bitcast %dst : vector<8x32xi4> to vector<8x16xi8>
+// %2 = vector.insert %0, %1 [4] : vector<16xi8> into vector<8x16xi8>
+//
+struct BubbleUpBitCastForInsert : public OpRewritePattern<vector::BitCastOp> {
+ using OpRewritePattern::OpRewritePattern;
+
+ LogicalResult matchAndRewrite(vector::BitCastOp bitcastOp,
+ PatternRewriter &rewriter) const override {
+ VectorType castSrcType = bitcastOp.getSourceVectorType();
+ VectorType castDstType = bitcastOp.getResultVectorType();
+
+ // 0-D and scalable vectors are not supported yet.
+ if (castSrcType.getRank() == 0 || castSrcType.isScalable() ||
+ castDstType.isScalable())
+ return failure();
+
+ int64_t castSrcLastDim = castSrcType.getShape().back();
+ int64_t castDstLastDim = castDstType.getShape().back();
+ bool isNumElemsShrink = castSrcLastDim >= castDstLastDim;
+ int64_t ratio;
+ if (isNumElemsShrink) {
+ assert(castSrcLastDim % castDstLastDim == 0);
+ ratio = castSrcLastDim / castDstLastDim;
+ } else {
+ assert(castDstLastDim % castSrcLastDim == 0);
+ ratio = castDstLastDim / castSrcLastDim;
+ }
+
+ auto insertOp = bitcastOp.getSource().getDefiningOp<vector::InsertOp>();
+ if (!insertOp)
+ return failure();
+
+ // Only vector sources are supported for now.
+ auto insertSrcType = dyn_cast<VectorType>(insertOp.getSourceType());
+ if (!insertSrcType)
+ return failure();
+
+ // Bitcast the source.
+ SmallVector<int64_t> srcDims(insertSrcType.getShape());
+ srcDims.back() =
+ isNumElemsShrink ? srcDims.back() / ratio : srcDims.back() * ratio;
+ VectorType newCastSrcType =
+ VectorType::get(srcDims, castDstType.getElementType());
+ auto newCastSrcOp = rewriter.create<vector::BitCastOp>(
+ bitcastOp.getLoc(), newCastSrcType, insertOp.getSource());
+
+ SmallVector<int64_t> dstDims(insertOp.getDestVectorType().getShape());
+ dstDims.back() =
+ isNumElemsShrink ? dstDims.back() / ratio : dstDims.back() * ratio;
+ VectorType newCastDstType =
+ VectorType::get(dstDims, castDstType.getElementType());
+
+ // Bitcast the destination.
+ auto newCastDstOp = rewriter.create<vector::BitCastOp>(
+ bitcastOp.getLoc(), newCastDstType, insertOp.getDest());
+
+ // Generate new insert.
+ rewriter.replaceOpWithNewOp<vector::InsertOp>(
+ bitcastOp, newCastSrcOp, newCastDstOp, insertOp.getMixedPosition());
+ return success();
+ }
+};
+
// Shuffles vector.bitcast op before vector.insert_strided_slice op.
//
// This transforms IR like:
@@ -1782,8 +1852,8 @@ void mlir::vector::populateBubbleVectorBitCastOpPatterns(
RewritePatternSet &patterns, PatternBenefit benefit) {
patterns.add<BubbleDownVectorBitCastForExtract,
BubbleDownBitCastForStridedSliceExtract,
- BubbleUpBitCastForStridedSliceInsert>(patterns.getContext(),
- benefit);
+ BubbleUpBitCastForInsert, BubbleUpBitCastForStridedSliceInsert>(
+ patterns.getContext(), benefit);
}
void mlir::vector::populateBreakDownVectorBitCastOpPatterns(
diff --git a/mlir/test/Dialect/Vector/vector-transforms.mlir b/mlir/test/Dialect/Vector/vector-transforms.mlir
index ea10bd56390c78..eda6a5cc40d999 100644
--- a/mlir/test/Dialect/Vector/vector-transforms.mlir
+++ b/mlir/test/Dialect/Vector/vector-transforms.mlir
@@ -339,6 +339,51 @@ func.func @bubble_down_bitcast_in_strided_slice_extract_odd_size(%arg0: vector<4
return %0: vector<3xf16>
}
+// CHECK-LABEL: func.func @bubble_up_bitcast_in_insert_i4_i8(
+// CHECK-SAME: %[[VAL:.*]]: vector<32xi4>,
+// CHECK-SAME: %[[DST:.*]]: vector<8x32xi4>) -> vector<8x16xi8> {
+func.func @bubble_up_bitcast_in_insert_i4_i8(%val: vector<32xi4>, %src: vector<8x32xi4>) -> vector<8x16xi8> {
+// CHECK: %[[BC_VAL:.*]] = vector.bitcast %[[VAL]] : vector<32xi4> to vector<16xi8>
+// CHECK: %[[BC_DST:.*]] = vector.bitcast %[[DST]] : vector<8x32xi4> to vector<8x16xi8>
+// CHECK: vector.insert %[[BC_VAL]], %[[BC_DST]] [4] : vector<16xi8> into vector<8x16xi8>
+ %0 = vector.insert %val, %src[4] : vector<32xi4> into vector<8x32xi4>
+ %1 = vector.bitcast %0 : vector<8x32xi4> to vector<8x16xi8>
+ return %1 : vector<8x16xi8>
+}
+
+// CHECK-LABEL: func.func @bubble_up_bitcast_in_insert_i8_i4(
+// CHECK-SAME: %[[VAL:.*]]: vector<16xi8>,
+// CHECK-SAME: %[[DST:.*]]: vector<8x16xi8>) -> vector<8x32xi4> {
+func.func @bubble_up_bitcast_in_insert_i8_i4(%val: vector<16xi8>, %src: vector<8x16xi8>) -> vector<8x32xi4> {
+// CHECK: %[[BC_VAL:.*]] = vector.bitcast %[[VAL]] : vector<16xi8> to vector<32xi4>
+// CHECK: %[[BC_DST:.*]] = vector.bitcast %[[DST]] : vector<8x16xi8> to vector<8x32xi4>
+// CHECK: vector.insert %[[BC_VAL]], %[[BC_DST]] [4] : vector<32xi4> into vector<8x32xi4>
+ %0 = vector.insert %val, %src[4] : vector<16xi8> into vector<8x16xi8>
+ %1 = vector.bitcast %0 : vector<8x16xi8> to vector<8x32xi4>
+ return %1 : vector<8x32xi4>
+}
+
+// CHECK-LABEL: func.func @bubble_up_bitcast_in_insert_i32_f32(
+// CHECK-SAME: %[[VAL:.*]]: vector<16xi32>,
+// CHECK-SAME: %[[DST:.*]]: vector<8x16xi32>) -> vector<8x16xf32> {
+func.func @bubble_up_bitcast_in_insert_i32_f32(%val: vector<16xi32>, %src: vector<8x16xi32>) -> vector<8x16xf32> {
+// CHECK: %[[BC_VAL:.*]] = vector.bitcast %[[VAL]] : vector<16xi32> to vector<16xf32>
+// CHECK: %[[BC_DST:.*]] = vector.bitcast %[[DST]] : vector<8x16xi32> to vector<8x16xf32>
+// CHECK: vector.insert %[[BC_VAL]], %[[BC_DST]] [4] : vector<16xf32> into vector<8x16xf32>
+ %0 = vector.insert %val, %src[4] : vector<16xi32> into vector<8x16xi32>
+ %1 = vector.bitcast %0 : vector<8x16xi32> to vector<8x16xf32>
+ return %1 : vector<8x16xf32>
+}
+
+// CHECK-LABEL: func.func @bubble_up_bitcast_in_insert_scalar(
+func.func @bubble_up_bitcast_in_insert_scalar(%val: i8, %src: vector<8x16xi8>) -> vector<8x32xi4> {
+// CHECK: vector.insert
+// CHECK-NEXT: vector.bitcast
+ %0 = vector.insert %val, %src[4, 8] : i8 into vector<8x16xi8>
+ %1 = vector.bitcast %0 : vector<8x16xi8> to vector<8x32xi4>
+ return %1 : vector<8x32xi4>
+}
+
// CHECK-LABEL: func @bubble_up_bitcast_in_strided_slice_insert
// CHECK-SAME: (%[[DST:.+]]: vector<8xf16>, %[[SRC1:.+]]: vector<4xf16>, %[[SRC2:.+]]: vector<4xf16>)
func.func @bubble_up_bitcast_in_strided_slice_insert(%dst: vector<8xf16>, %src1: vector<4xf16>, %src2: vector<4xf16>) -> vector<4xf32> {
>From 3fac0562f8bdf193f039945eb40c51a5e6c24de1 Mon Sep 17 00:00:00 2001
From: Florian Hahn <flo at fhahn.com>
Date: Wed, 28 Feb 2024 16:27:56 +0000
Subject: [PATCH 012/406] [VPlan] Reset trip count when replacing ExpandSCEV
recipe.
Otherwise accessing the trip count may accesses freed memory.
Fixes https://lab.llvm.org/buildbot/#/builders/74/builds/26239 and
others.
---
llvm/lib/Transforms/Vectorize/LoopVectorize.cpp | 2 ++
llvm/lib/Transforms/Vectorize/VPlan.h | 8 ++++++++
2 files changed, 10 insertions(+)
diff --git a/llvm/lib/Transforms/Vectorize/LoopVectorize.cpp b/llvm/lib/Transforms/Vectorize/LoopVectorize.cpp
index 6b16923213c86e..ea77b6018c0d15 100644
--- a/llvm/lib/Transforms/Vectorize/LoopVectorize.cpp
+++ b/llvm/lib/Transforms/Vectorize/LoopVectorize.cpp
@@ -10093,6 +10093,8 @@ bool LoopVectorizePass::processLoop(Loop *L) {
auto *ExpandedVal = BestEpiPlan.getVPValueOrAddLiveIn(
ExpandedSCEVs.find(ExpandR->getSCEV())->second);
ExpandR->replaceAllUsesWith(ExpandedVal);
+ if (BestEpiPlan.getTripCount() == ExpandR)
+ BestEpiPlan.resetTripCount(ExpandedVal);
ExpandR->eraseFromParent();
}
diff --git a/llvm/lib/Transforms/Vectorize/VPlan.h b/llvm/lib/Transforms/Vectorize/VPlan.h
index 47cebecdb27083..16c09a83e777dd 100644
--- a/llvm/lib/Transforms/Vectorize/VPlan.h
+++ b/llvm/lib/Transforms/Vectorize/VPlan.h
@@ -2931,6 +2931,14 @@ class VPlan {
return TripCount;
}
+ /// Resets the trip count for the VPlan. The caller must make sure all uses of
+ /// the original trip count have been replaced.
+ void resetTripCount(VPValue *NewTripCount) {
+ assert(TripCount && NewTripCount && TripCount->getNumUsers() == 0 &&
+ "TripCount always must be set");
+ TripCount = NewTripCount;
+ }
+
/// The backedge taken count of the original loop.
VPValue *getOrCreateBackedgeTakenCount() {
if (!BackedgeTakenCount)
>From 64422cf826354ee1d586c2484ec72d66db898e75 Mon Sep 17 00:00:00 2001
From: Leandro Lupori <leandro.lupori at linaro.org>
Date: Wed, 28 Feb 2024 13:33:42 -0300
Subject: [PATCH 013/406] [llvm][mlir][OMPIRBuilder] Translate omp.single's
copyprivate (#80488)
Use the new copyprivate list from omp.single to emit calls to
__kmpc_copyprivate, during the creation of the single operation
in OMPIRBuilder.
This is patch 4 of 4, to add support for COPYPRIVATE in Flang.
Original PR: https://github.com/llvm/llvm-project/pull/73128
---
flang/test/Integration/OpenMP/copyprivate.f90 | 97 +++++++++++
.../llvm/Frontend/OpenMP/OMPIRBuilder.h | 6 +-
llvm/lib/Frontend/OpenMP/OMPIRBuilder.cpp | 33 +++-
.../Frontend/OpenMPIRBuilderTest.cpp | 153 +++++++++++++++++-
.../OpenMP/OpenMPToLLVMIRTranslation.cpp | 16 +-
mlir/test/Target/LLVMIR/openmp-llvm.mlir | 37 +++++
6 files changed, 330 insertions(+), 12 deletions(-)
create mode 100644 flang/test/Integration/OpenMP/copyprivate.f90
diff --git a/flang/test/Integration/OpenMP/copyprivate.f90 b/flang/test/Integration/OpenMP/copyprivate.f90
new file mode 100644
index 00000000000000..9318b743a95290
--- /dev/null
+++ b/flang/test/Integration/OpenMP/copyprivate.f90
@@ -0,0 +1,97 @@
+!===----------------------------------------------------------------------===!
+! This directory can be used to add Integration tests involving multiple
+! stages of the compiler (for eg. from Fortran to LLVM IR). It should not
+! contain executable tests. We should only add tests here sparingly and only
+! if there is no other way to test. Repeat this message in each test that is
+! added to this directory and sub-directories.
+!===----------------------------------------------------------------------===!
+
+!RUN: %flang_fc1 -emit-llvm -fopenmp %s -o - | FileCheck %s
+
+!CHECK-DAG: define void @_copy_box_Uxi32(ptr %{{.*}}, ptr %{{.*}})
+!CHECK-DAG: define void @_copy_10xi32(ptr %{{.*}}, ptr %{{.*}})
+!CHECK-DAG: define void @_copy_i64(ptr %{{.*}}, ptr %{{.*}})
+!CHECK-DAG: define void @_copy_box_Uxi64(ptr %{{.*}}, ptr %{{.*}})
+!CHECK-DAG: define void @_copy_f32(ptr %{{.*}}, ptr %{{.*}})
+!CHECK-DAG: define void @_copy_2x3xf32(ptr %{{.*}}, ptr %{{.*}})
+!CHECK-DAG: define void @_copy_z32(ptr %{{.*}}, ptr %{{.*}})
+!CHECK-DAG: define void @_copy_10xz32(ptr %{{.*}}, ptr %{{.*}})
+!CHECK-DAG: define void @_copy_l32(ptr %{{.*}}, ptr %{{.*}})
+!CHECK-DAG: define void @_copy_5xl32(ptr %{{.*}}, ptr %{{.*}})
+!CHECK-DAG: define void @_copy_c8x8(ptr %{{.*}}, ptr %{{.*}})
+!CHECK-DAG: define void @_copy_10xc8x8(ptr %{{.*}}, ptr %{{.*}})
+!CHECK-DAG: define void @_copy_c16x5(ptr %{{.*}}, ptr %{{.*}})
+!CHECK-DAG: define void @_copy_rec__QFtest_typesTdt(ptr %{{.*}}, ptr %{{.*}})
+!CHECK-DAG: define void @_copy_box_heap_Uxi32(ptr %{{.*}}, ptr %{{.*}})
+!CHECK-DAG: define void @_copy_box_ptr_Uxc8x9(ptr %{{.*}}, ptr %{{.*}})
+
+!CHECK-LABEL: define void @_copy_i32(
+!CHECK-SAME: ptr %[[DST:.*]], ptr %[[SRC:.*]]) {
+!CHECK-NEXT: %[[SRC_VAL:.*]] = load i32, ptr %[[SRC]]
+!CHECK-NEXT: store i32 %[[SRC_VAL]], ptr %[[DST]]
+!CHECK-NEXT: ret void
+!CHECK-NEXT: }
+
+!CHECK-LABEL: define internal void @test_scalar_..omp_par({{.*}})
+!CHECK: %[[I:.*]] = alloca i32, i64 1
+!CHECK: %[[J:.*]] = alloca i32, i64 1
+!CHECK: %[[DID_IT:.*]] = alloca i32
+!CHECK: store i32 0, ptr %[[DID_IT]]
+!CHECK: %[[THREAD_NUM1:.*]] = call i32 @__kmpc_global_thread_num(ptr @[[LOC:.*]])
+!CHECK: %[[RET:.*]] = call i32 @__kmpc_single({{.*}})
+!CHECK: %[[NOT_ZERO:.*]] = icmp ne i32 %[[RET]], 0
+!CHECK: br i1 %[[NOT_ZERO]], label %[[OMP_REGION_BODY:.*]], label %[[OMP_REGION_END:.*]]
+
+!CHECK: [[OMP_REGION_END]]:
+!CHECK: %[[THREAD_NUM2:.*]] = call i32 @__kmpc_global_thread_num(ptr @[[LOC:.*]])
+!CHECK: %[[DID_IT_VAL:.*]] = load i32, ptr %[[DID_IT]]
+!CHECK: call void @__kmpc_copyprivate(ptr @[[LOC]], i32 %[[THREAD_NUM2]], i64 0, ptr %[[I]], ptr @_copy_i32, i32 %[[DID_IT_VAL]])
+!CHECK: %[[THREAD_NUM3:.*]] = call i32 @__kmpc_global_thread_num(ptr @[[LOC]])
+!CHECK: %[[DID_IT_VAL2:.*]] = load i32, ptr %[[DID_IT]]
+!CHECK: call void @__kmpc_copyprivate(ptr @[[LOC]], i32 %[[THREAD_NUM3]], i64 0, ptr %[[J]], ptr @_copy_i32, i32 %[[DID_IT_VAL2]])
+
+!CHECK: [[OMP_REGION_BODY]]:
+!CHECK: br label %[[OMP_SINGLE_REGION:.*]]
+!CHECK: [[OMP_SINGLE_REGION]]:
+!CHECK: store i32 11, ptr %[[I]]
+!CHECK: store i32 22, ptr %[[J]]
+!CHECK: br label %[[OMP_REGION_CONT3:.*]]
+!CHECK: [[OMP_REGION_CONT3:.*]]:
+!CHECK: store i32 1, ptr %[[DID_IT]]
+!CHECK: call void @__kmpc_end_single(ptr @[[LOC]], i32 %[[THREAD_NUM1]])
+!CHECK: br label %[[OMP_REGION_END]]
+subroutine test_scalar()
+ integer :: i, j
+
+ !$omp parallel private(i, j)
+ !$omp single
+ i = 11
+ j = 22
+ !$omp end single copyprivate(i, j)
+ !$omp end parallel
+end subroutine
+
+subroutine test_types(a, n)
+ integer :: a(:), n
+ integer(4) :: i4, i4a(10)
+ integer(8) :: i8, i8a(n)
+ real :: r, ra(2, 3)
+ complex :: z, za(10)
+ logical :: l, la(5)
+ character(kind=1, len=8) :: c1, c1a(10)
+ character(kind=2, len=5) :: c2
+
+ type dt
+ integer :: i
+ real :: r
+ end type
+ type(dt) :: t
+
+ integer, allocatable :: aloc(:)
+ character(kind=1, len=9), pointer :: ptr(:)
+
+ !$omp parallel private(a, i4, i4a, i8, i8a, r, ra, z, za, l, la, c1, c1a, c2, t, aloc, ptr)
+ !$omp single
+ !$omp end single copyprivate(a, i4, i4a, i8, i8a, r, ra, z, za, l, la, c1, c1a, c2, t, aloc, ptr)
+ !$omp end parallel
+end subroutine
diff --git a/llvm/include/llvm/Frontend/OpenMP/OMPIRBuilder.h b/llvm/include/llvm/Frontend/OpenMP/OMPIRBuilder.h
index 589a9066ac57af..5bbaa8c208b8cd 100644
--- a/llvm/include/llvm/Frontend/OpenMP/OMPIRBuilder.h
+++ b/llvm/include/llvm/Frontend/OpenMP/OMPIRBuilder.h
@@ -1834,13 +1834,15 @@ class OpenMPIRBuilder {
/// \param BodyGenCB Callback that will generate the region code.
/// \param FiniCB Callback to finalize variable copies.
/// \param IsNowait If false, a barrier is emitted.
- /// \param DidIt Local variable used as a flag to indicate 'single' thread
+ /// \param CPVars copyprivate variables.
+ /// \param CPFuncs copy functions to use for each copyprivate variable.
///
/// \returns The insertion position *after* the single call.
InsertPointTy createSingle(const LocationDescription &Loc,
BodyGenCallbackTy BodyGenCB,
FinalizeCallbackTy FiniCB, bool IsNowait,
- llvm::Value *DidIt);
+ ArrayRef<llvm::Value *> CPVars = {},
+ ArrayRef<llvm::Function *> CPFuncs = {});
/// Generator for '#omp master'
///
diff --git a/llvm/lib/Frontend/OpenMP/OMPIRBuilder.cpp b/llvm/lib/Frontend/OpenMP/OMPIRBuilder.cpp
index 09f59c81123ea5..d65ed8c11d86cc 100644
--- a/llvm/lib/Frontend/OpenMP/OMPIRBuilder.cpp
+++ b/llvm/lib/Frontend/OpenMP/OMPIRBuilder.cpp
@@ -4047,13 +4047,17 @@ OpenMPIRBuilder::createCopyPrivate(const LocationDescription &Loc,
OpenMPIRBuilder::InsertPointTy OpenMPIRBuilder::createSingle(
const LocationDescription &Loc, BodyGenCallbackTy BodyGenCB,
- FinalizeCallbackTy FiniCB, bool IsNowait, llvm::Value *DidIt) {
+ FinalizeCallbackTy FiniCB, bool IsNowait, ArrayRef<llvm::Value *> CPVars,
+ ArrayRef<llvm::Function *> CPFuncs) {
if (!updateToLocation(Loc))
return Loc.IP;
- // If needed (i.e. not null), initialize `DidIt` with 0
- if (DidIt) {
+ // If needed allocate and initialize `DidIt` with 0.
+ // DidIt: flag variable: 1=single thread; 0=not single thread.
+ llvm::Value *DidIt = nullptr;
+ if (!CPVars.empty()) {
+ DidIt = Builder.CreateAlloca(llvm::Type::getInt32Ty(Builder.getContext()));
Builder.CreateStore(Builder.getInt32(0), DidIt);
}
@@ -4070,17 +4074,36 @@ OpenMPIRBuilder::InsertPointTy OpenMPIRBuilder::createSingle(
Function *ExitRTLFn = getOrCreateRuntimeFunctionPtr(OMPRTL___kmpc_end_single);
Instruction *ExitCall = Builder.CreateCall(ExitRTLFn, Args);
+ auto FiniCBWrapper = [&](InsertPointTy IP) {
+ FiniCB(IP);
+
+ // The thread that executes the single region must set `DidIt` to 1.
+ // This is used by __kmpc_copyprivate, to know if the caller is the
+ // single thread or not.
+ if (DidIt)
+ Builder.CreateStore(Builder.getInt32(1), DidIt);
+ };
+
// generates the following:
// if (__kmpc_single()) {
// .... single region ...
// __kmpc_end_single
// }
+ // __kmpc_copyprivate
// __kmpc_barrier
- EmitOMPInlinedRegion(OMPD, EntryCall, ExitCall, BodyGenCB, FiniCB,
+ EmitOMPInlinedRegion(OMPD, EntryCall, ExitCall, BodyGenCB, FiniCBWrapper,
/*Conditional*/ true,
/*hasFinalize*/ true);
- if (!IsNowait)
+
+ if (DidIt) {
+ for (size_t I = 0, E = CPVars.size(); I < E; ++I)
+ // NOTE BufSize is currently unused, so just pass 0.
+ createCopyPrivate(LocationDescription(Builder.saveIP(), Loc.DL),
+ /*BufSize=*/ConstantInt::get(Int64, 0), CPVars[I],
+ CPFuncs[I], DidIt);
+ // NOTE __kmpc_copyprivate already inserts a barrier
+ } else if (!IsNowait)
createBarrier(LocationDescription(Builder.saveIP(), Loc.DL),
omp::Directive::OMPD_unknown, /* ForceSimpleCall */ false,
/* CheckCancelFlag */ false);
diff --git a/llvm/unittests/Frontend/OpenMPIRBuilderTest.cpp b/llvm/unittests/Frontend/OpenMPIRBuilderTest.cpp
index d923b25fda9f96..fdbe8df783b117 100644
--- a/llvm/unittests/Frontend/OpenMPIRBuilderTest.cpp
+++ b/llvm/unittests/Frontend/OpenMPIRBuilderTest.cpp
@@ -3327,8 +3327,8 @@ TEST_F(OpenMPIRBuilderTest, SingleDirective) {
EXPECT_NE(IPBB->end(), IP.getPoint());
};
- Builder.restoreIP(OMPBuilder.createSingle(
- Builder, BodyGenCB, FiniCB, /*IsNowait*/ false, /*DidIt*/ nullptr));
+ Builder.restoreIP(
+ OMPBuilder.createSingle(Builder, BodyGenCB, FiniCB, /*IsNowait*/ false));
Value *EntryBBTI = EntryBB->getTerminator();
EXPECT_NE(EntryBBTI, nullptr);
EXPECT_TRUE(isa<BranchInst>(EntryBBTI));
@@ -3417,8 +3417,8 @@ TEST_F(OpenMPIRBuilderTest, SingleDirectiveNowait) {
EXPECT_NE(IPBB->end(), IP.getPoint());
};
- Builder.restoreIP(OMPBuilder.createSingle(
- Builder, BodyGenCB, FiniCB, /*IsNowait*/ true, /*DidIt*/ nullptr));
+ Builder.restoreIP(
+ OMPBuilder.createSingle(Builder, BodyGenCB, FiniCB, /*IsNowait*/ true));
Value *EntryBBTI = EntryBB->getTerminator();
EXPECT_NE(EntryBBTI, nullptr);
EXPECT_TRUE(isa<BranchInst>(EntryBBTI));
@@ -3464,6 +3464,151 @@ TEST_F(OpenMPIRBuilderTest, SingleDirectiveNowait) {
EXPECT_EQ(ExitBarrier, nullptr);
}
+// Helper class to check each instruction of a BB.
+class BBInstIter {
+ BasicBlock *BB;
+ BasicBlock::iterator BBI;
+
+public:
+ BBInstIter(BasicBlock *BB) : BB(BB), BBI(BB->begin()) {}
+
+ bool hasNext() const { return BBI != BB->end(); }
+
+ template <typename InstTy> InstTy *next() {
+ if (!hasNext())
+ return nullptr;
+ Instruction *Cur = &*BBI++;
+ if (!isa<InstTy>(Cur))
+ return nullptr;
+ return cast<InstTy>(Cur);
+ }
+};
+
+TEST_F(OpenMPIRBuilderTest, SingleDirectiveCopyPrivate) {
+ using InsertPointTy = OpenMPIRBuilder::InsertPointTy;
+ OpenMPIRBuilder OMPBuilder(*M);
+ OMPBuilder.initialize();
+ F->setName("func");
+ IRBuilder<> Builder(BB);
+
+ OpenMPIRBuilder::LocationDescription Loc({Builder.saveIP(), DL});
+
+ AllocaInst *PrivAI = nullptr;
+
+ BasicBlock *EntryBB = nullptr;
+ BasicBlock *ThenBB = nullptr;
+
+ Value *CPVar = Builder.CreateAlloca(F->arg_begin()->getType());
+ Builder.CreateStore(F->arg_begin(), CPVar);
+
+ FunctionType *CopyFuncTy = FunctionType::get(
+ Builder.getVoidTy(), {Builder.getPtrTy(), Builder.getPtrTy()}, false);
+ Function *CopyFunc =
+ Function::Create(CopyFuncTy, Function::PrivateLinkage, "copy_var", *M);
+
+ auto BodyGenCB = [&](InsertPointTy AllocaIP, InsertPointTy CodeGenIP) {
+ if (AllocaIP.isSet())
+ Builder.restoreIP(AllocaIP);
+ else
+ Builder.SetInsertPoint(&*(F->getEntryBlock().getFirstInsertionPt()));
+ PrivAI = Builder.CreateAlloca(F->arg_begin()->getType());
+ Builder.CreateStore(F->arg_begin(), PrivAI);
+
+ llvm::BasicBlock *CodeGenIPBB = CodeGenIP.getBlock();
+ llvm::Instruction *CodeGenIPInst = &*CodeGenIP.getPoint();
+ EXPECT_EQ(CodeGenIPBB->getTerminator(), CodeGenIPInst);
+
+ Builder.restoreIP(CodeGenIP);
+
+ // collect some info for checks later
+ ThenBB = Builder.GetInsertBlock();
+ EntryBB = ThenBB->getUniquePredecessor();
+
+ // simple instructions for body
+ Value *PrivLoad =
+ Builder.CreateLoad(PrivAI->getAllocatedType(), PrivAI, "local.use");
+ Builder.CreateICmpNE(F->arg_begin(), PrivLoad);
+ };
+
+ auto FiniCB = [&](InsertPointTy IP) {
+ BasicBlock *IPBB = IP.getBlock();
+ // IP must be before the unconditional branch to ExitBB
+ EXPECT_NE(IPBB->end(), IP.getPoint());
+ };
+
+ Builder.restoreIP(OMPBuilder.createSingle(Builder, BodyGenCB, FiniCB,
+ /*IsNowait*/ false, {CPVar},
+ {CopyFunc}));
+ Value *EntryBBTI = EntryBB->getTerminator();
+ EXPECT_NE(EntryBBTI, nullptr);
+ EXPECT_TRUE(isa<BranchInst>(EntryBBTI));
+ BranchInst *EntryBr = cast<BranchInst>(EntryBB->getTerminator());
+ EXPECT_TRUE(EntryBr->isConditional());
+ EXPECT_EQ(EntryBr->getSuccessor(0), ThenBB);
+ BasicBlock *ExitBB = ThenBB->getUniqueSuccessor();
+ EXPECT_EQ(EntryBr->getSuccessor(1), ExitBB);
+
+ CmpInst *CondInst = cast<CmpInst>(EntryBr->getCondition());
+ EXPECT_TRUE(isa<CallInst>(CondInst->getOperand(0)));
+
+ CallInst *SingleEntryCI = cast<CallInst>(CondInst->getOperand(0));
+ EXPECT_EQ(SingleEntryCI->arg_size(), 2U);
+ EXPECT_EQ(SingleEntryCI->getCalledFunction()->getName(), "__kmpc_single");
+ EXPECT_TRUE(isa<GlobalVariable>(SingleEntryCI->getArgOperand(0)));
+
+ // check ThenBB
+ BBInstIter ThenBBI(ThenBB);
+ // load PrivAI
+ auto *PrivLI = ThenBBI.next<LoadInst>();
+ EXPECT_NE(PrivLI, nullptr);
+ EXPECT_EQ(PrivLI->getPointerOperand(), PrivAI);
+ // icmp
+ EXPECT_TRUE(ThenBBI.next<ICmpInst>());
+ // store 1, DidIt
+ auto *DidItSI = ThenBBI.next<StoreInst>();
+ EXPECT_NE(DidItSI, nullptr);
+ EXPECT_EQ(DidItSI->getValueOperand(),
+ ConstantInt::get(Type::getInt32Ty(Ctx), 1));
+ Value *DidIt = DidItSI->getPointerOperand();
+ // call __kmpc_end_single
+ auto *SingleEndCI = ThenBBI.next<CallInst>();
+ EXPECT_NE(SingleEndCI, nullptr);
+ EXPECT_EQ(SingleEndCI->getCalledFunction()->getName(), "__kmpc_end_single");
+ EXPECT_EQ(SingleEndCI->arg_size(), 2U);
+ EXPECT_TRUE(isa<GlobalVariable>(SingleEndCI->getArgOperand(0)));
+ EXPECT_EQ(SingleEndCI->getArgOperand(1), SingleEntryCI->getArgOperand(1));
+ // br ExitBB
+ auto *ExitBBBI = ThenBBI.next<BranchInst>();
+ EXPECT_NE(ExitBBBI, nullptr);
+ EXPECT_TRUE(ExitBBBI->isUnconditional());
+ EXPECT_EQ(ExitBBBI->getOperand(0), ExitBB);
+ EXPECT_FALSE(ThenBBI.hasNext());
+
+ // check ExitBB
+ BBInstIter ExitBBI(ExitBB);
+ // call __kmpc_global_thread_num
+ auto *ThreadNumCI = ExitBBI.next<CallInst>();
+ EXPECT_NE(ThreadNumCI, nullptr);
+ EXPECT_EQ(ThreadNumCI->getCalledFunction()->getName(),
+ "__kmpc_global_thread_num");
+ // load DidIt
+ auto *DidItLI = ExitBBI.next<LoadInst>();
+ EXPECT_NE(DidItLI, nullptr);
+ EXPECT_EQ(DidItLI->getPointerOperand(), DidIt);
+ // call __kmpc_copyprivate
+ auto *CopyPrivateCI = ExitBBI.next<CallInst>();
+ EXPECT_NE(CopyPrivateCI, nullptr);
+ EXPECT_EQ(CopyPrivateCI->arg_size(), 6U);
+ EXPECT_TRUE(isa<AllocaInst>(CopyPrivateCI->getArgOperand(3)));
+ EXPECT_EQ(CopyPrivateCI->getArgOperand(3), CPVar);
+ EXPECT_TRUE(isa<Function>(CopyPrivateCI->getArgOperand(4)));
+ EXPECT_EQ(CopyPrivateCI->getArgOperand(4), CopyFunc);
+ EXPECT_TRUE(isa<LoadInst>(CopyPrivateCI->getArgOperand(5)));
+ DidItLI = cast<LoadInst>(CopyPrivateCI->getArgOperand(5));
+ EXPECT_EQ(DidItLI->getOperand(0), DidIt);
+ EXPECT_FALSE(ExitBBI.hasNext());
+}
+
TEST_F(OpenMPIRBuilderTest, OMPAtomicReadFlt) {
OpenMPIRBuilder OMPBuilder(*M);
OMPBuilder.initialize();
diff --git a/mlir/lib/Target/LLVMIR/Dialect/OpenMP/OpenMPToLLVMIRTranslation.cpp b/mlir/lib/Target/LLVMIR/Dialect/OpenMP/OpenMPToLLVMIRTranslation.cpp
index 8c20689c4a39dd..fd1de274da60e8 100644
--- a/mlir/lib/Target/LLVMIR/Dialect/OpenMP/OpenMPToLLVMIRTranslation.cpp
+++ b/mlir/lib/Target/LLVMIR/Dialect/OpenMP/OpenMPToLLVMIRTranslation.cpp
@@ -667,8 +667,22 @@ convertOmpSingle(omp::SingleOp &singleOp, llvm::IRBuilderBase &builder,
moduleTranslation, bodyGenStatus);
};
auto finiCB = [&](InsertPointTy codeGenIP) {};
+
+ // Handle copyprivate
+ Operation::operand_range cpVars = singleOp.getCopyprivateVars();
+ std::optional<ArrayAttr> cpFuncs = singleOp.getCopyprivateFuncs();
+ llvm::SmallVector<llvm::Value *> llvmCPVars;
+ llvm::SmallVector<llvm::Function *> llvmCPFuncs;
+ for (size_t i = 0, e = cpVars.size(); i < e; ++i) {
+ llvmCPVars.push_back(moduleTranslation.lookupValue(cpVars[i]));
+ auto llvmFuncOp = SymbolTable::lookupNearestSymbolFrom<LLVM::LLVMFuncOp>(
+ singleOp, cast<SymbolRefAttr>((*cpFuncs)[i]));
+ llvmCPFuncs.push_back(
+ moduleTranslation.lookupFunction(llvmFuncOp.getName()));
+ }
+
builder.restoreIP(moduleTranslation.getOpenMPBuilder()->createSingle(
- ompLoc, bodyCB, finiCB, singleOp.getNowait(), /*DidIt=*/nullptr));
+ ompLoc, bodyCB, finiCB, singleOp.getNowait(), llvmCPVars, llvmCPFuncs));
return bodyGenStatus;
}
diff --git a/mlir/test/Target/LLVMIR/openmp-llvm.mlir b/mlir/test/Target/LLVMIR/openmp-llvm.mlir
index 39a1e036e85c02..12bd108ba86cb6 100644
--- a/mlir/test/Target/LLVMIR/openmp-llvm.mlir
+++ b/mlir/test/Target/LLVMIR/openmp-llvm.mlir
@@ -2186,6 +2186,43 @@ llvm.func @single_nowait(%x: i32, %y: i32, %zaddr: !llvm.ptr) {
// -----
+llvm.func @copy_i32(!llvm.ptr, !llvm.ptr)
+llvm.func @copy_f32(!llvm.ptr, !llvm.ptr)
+
+// CHECK-LABEL: @single_copyprivate
+// CHECK-SAME: (ptr %[[ip:.*]], ptr %[[fp:.*]])
+llvm.func @single_copyprivate(%ip: !llvm.ptr, %fp: !llvm.ptr) {
+ // CHECK: %[[didit_addr:.*]] = alloca i32
+ // CHECK: store i32 0, ptr %[[didit_addr]]
+ // CHECK: call i32 @__kmpc_single
+ omp.single copyprivate(%ip -> @copy_i32 : !llvm.ptr, %fp -> @copy_f32 : !llvm.ptr) {
+ // CHECK: %[[i:.*]] = load i32, ptr %[[ip]]
+ %i = llvm.load %ip : !llvm.ptr -> i32
+ // CHECK: %[[i2:.*]] = add i32 %[[i]], %[[i]]
+ %i2 = llvm.add %i, %i : i32
+ // CHECK: store i32 %[[i2]], ptr %[[ip]]
+ llvm.store %i2, %ip : i32, !llvm.ptr
+ // CHECK: %[[f:.*]] = load float, ptr %[[fp]]
+ %f = llvm.load %fp : !llvm.ptr -> f32
+ // CHECK: %[[f2:.*]] = fadd float %[[f]], %[[f]]
+ %f2 = llvm.fadd %f, %f : f32
+ // CHECK: store float %[[f2]], ptr %[[fp]]
+ llvm.store %f2, %fp : f32, !llvm.ptr
+ // CHECK: store i32 1, ptr %[[didit_addr]]
+ // CHECK: call void @__kmpc_end_single
+ // CHECK: %[[didit:.*]] = load i32, ptr %[[didit_addr]]
+ // CHECK: call void @__kmpc_copyprivate({{.*}}, ptr %[[ip]], ptr @copy_i32, i32 %[[didit]])
+ // CHECK: %[[didit2:.*]] = load i32, ptr %[[didit_addr]]
+ // CHECK: call void @__kmpc_copyprivate({{.*}}, ptr %[[fp]], ptr @copy_f32, i32 %[[didit2]])
+ // CHECK-NOT: call void @__kmpc_barrier
+ omp.terminator
+ }
+ // CHECK: ret void
+ llvm.return
+}
+
+// -----
+
// CHECK: @_QFsubEx = internal global i32 undef
// CHECK: @_QFsubEx.cache = common global ptr null
>From cd344a4c20e295d49f8163ec9a0656c1061a6e42 Mon Sep 17 00:00:00 2001
From: Walter Erquinigo <a20012251 at gmail.com>
Date: Wed, 28 Feb 2024 11:43:36 -0500
Subject: [PATCH 014/406] [LLDB] Fix completion of space-only lines in the REPL
on Linux (#83203)
https://github.com/modularml/mojo/issues/1796 discovered that if you try
to complete a space-only line in the REPL on Linux, LLDB crashes. I
suspect that editline doesn't behave the same way on linux and on
darwin, because I can't replicate this on darwin.
Adding a boundary check in the completion code prevents the crash from
happening.
---
lldb/source/Host/common/Editline.cpp | 5 +++-
lldb/test/API/repl/clang/TestClangREPL.py | 32 ++++++++++++++++-------
2 files changed, 27 insertions(+), 10 deletions(-)
diff --git a/lldb/source/Host/common/Editline.cpp b/lldb/source/Host/common/Editline.cpp
index ce707e530d008b..e66271e8a6ee99 100644
--- a/lldb/source/Host/common/Editline.cpp
+++ b/lldb/source/Host/common/Editline.cpp
@@ -1029,8 +1029,11 @@ unsigned char Editline::TabCommand(int ch) {
case CompletionMode::Normal: {
std::string to_add = completion.GetCompletion();
// Terminate the current argument with a quote if it started with a quote.
- if (!request.GetParsedLine().empty() && request.GetParsedArg().IsQuoted())
+ Args &parsedLine = request.GetParsedLine();
+ if (!parsedLine.empty() && request.GetCursorIndex() < parsedLine.size() &&
+ request.GetParsedArg().IsQuoted()) {
to_add.push_back(request.GetParsedArg().GetQuoteChar());
+ }
to_add.push_back(' ');
el_deletestr(m_editline, request.GetCursorArgumentPrefix().size());
el_insertstr(m_editline, to_add.c_str());
diff --git a/lldb/test/API/repl/clang/TestClangREPL.py b/lldb/test/API/repl/clang/TestClangREPL.py
index 0b67955a7833c6..c37557fb94735d 100644
--- a/lldb/test/API/repl/clang/TestClangREPL.py
+++ b/lldb/test/API/repl/clang/TestClangREPL.py
@@ -1,7 +1,6 @@
-import lldb
from lldbsuite.test.decorators import *
-from lldbsuite.test.lldbtest import *
from lldbsuite.test.lldbpexpect import PExpectTest
+from lldbsuite.test.lldbtest import *
class TestCase(PExpectTest):
@@ -17,13 +16,7 @@ def expect_repl(self, expr, substrs=[]):
self.current_repl_line_number += 1
self.child.expect_exact(str(self.current_repl_line_number) + ">")
- # PExpect uses many timeouts internally and doesn't play well
- # under ASAN on a loaded machine..
- @skipIfAsan
- @skipIf(oslist=["linux"], archs=["arm", "aarch64"]) # Randomly fails on buildbot
- @skipIfEditlineSupportMissing
- def test_basic_completion(self):
- """Test that we can complete a simple multiline expression"""
+ def start_repl(self):
self.build()
self.current_repl_line_number = 1
@@ -41,6 +34,14 @@ def test_basic_completion(self):
self.child.send("expression --repl -l c --\n")
self.child.expect_exact("1>")
+ # PExpect uses many timeouts internally and doesn't play well
+ # under ASAN on a loaded machine..
+ @skipIfAsan
+ @skipIf(oslist=["linux"], archs=["arm", "aarch64"]) # Randomly fails on buildbot
+ @skipIfEditlineSupportMissing
+ def test_basic_completion(self):
+ """Test that we can complete a simple multiline expression"""
+ self.start_repl()
# Try evaluating a simple expression.
self.expect_repl("3 + 3", substrs=["(int) $0 = 6"])
@@ -54,3 +55,16 @@ def test_basic_completion(self):
self.expect_repl("$persistent + 10", substrs=["(long) $2 = 17"])
self.quit()
+
+ # PExpect uses many timeouts internally and doesn't play well
+ # under ASAN on a loaded machine..
+ @skipIfAsan
+ @skipIf(oslist=["linux"], archs=["arm", "aarch64"]) # Randomly fails on buildbot
+ @skipIfEditlineSupportMissing
+ def test_completion_with_space_only_line(self):
+ """Test that we don't crash when completing lines with spaces only"""
+ self.start_repl()
+
+ self.child.send(" ")
+ self.child.send("\t")
+ self.expect_repl("3 + 3", substrs=["(int) $0 = 6"])
>From 26402777ebf4eb3d8f3d5a45943b451c740b2d76 Mon Sep 17 00:00:00 2001
From: Lukacma <Marian.Lukac at arm.com>
Date: Wed, 28 Feb 2024 16:45:39 +0000
Subject: [PATCH 015/406] [AArch64] Optimized generated assembly for bool to
svbool_t conversions (#83001)
In certain cases Legalizer was generating `AND(WHILELO, SPLAT 1)` instruction pattern, when `WHILELO` would be sufficient.
---
.../Target/AArch64/AArch64ISelLowering.cpp | 6 +--
.../AArch64/sve-intrinsics-reinterpret.ll | 42 ++++++++++++++++++-
2 files changed, 43 insertions(+), 5 deletions(-)
diff --git a/llvm/lib/Target/AArch64/AArch64ISelLowering.cpp b/llvm/lib/Target/AArch64/AArch64ISelLowering.cpp
index b86661c8a4e0d4..c21bc3a4abbc00 100644
--- a/llvm/lib/Target/AArch64/AArch64ISelLowering.cpp
+++ b/llvm/lib/Target/AArch64/AArch64ISelLowering.cpp
@@ -271,11 +271,9 @@ static bool isMergePassthruOpcode(unsigned Opc) {
static bool isZeroingInactiveLanes(SDValue Op) {
switch (Op.getOpcode()) {
default:
- // We guarantee i1 splat_vectors to zero the other lanes by
- // implementing it with ptrue and possibly a punpklo for nxv1i1.
- if (ISD::isConstantSplatVectorAllOnes(Op.getNode()))
- return true;
return false;
+ // We guarantee i1 splat_vectors to zero the other lanes
+ case ISD::SPLAT_VECTOR:
case AArch64ISD::PTRUE:
case AArch64ISD::SETCC_MERGE_ZERO:
return true;
diff --git a/llvm/test/CodeGen/AArch64/sve-intrinsics-reinterpret.ll b/llvm/test/CodeGen/AArch64/sve-intrinsics-reinterpret.ll
index 82bf756f822898..c7c102f5d567d9 100644
--- a/llvm/test/CodeGen/AArch64/sve-intrinsics-reinterpret.ll
+++ b/llvm/test/CodeGen/AArch64/sve-intrinsics-reinterpret.ll
@@ -1,4 +1,4 @@
-; NOTE: Assertions have been autogenerated by utils/update_llc_test_checks.py
+; NOTE: Assertions have been autogenerated by utils/update_llc_test_checks.py UTC_ARGS: --version 2
; RUN: llc -mtriple=aarch64-linux-gnu -mattr=+sve < %s | FileCheck %s
; RUN: llc -mtriple=aarch64-linux-gnu -mattr=+sme < %s | FileCheck %s
@@ -150,6 +150,46 @@ define <vscale x 16 x i1> @chained_reinterpret() {
ret <vscale x 16 x i1> %out
}
+define <vscale x 16 x i1> @reinterpret_scalar_bool_h(i1 %x){
+; CHECK-LABEL: reinterpret_scalar_bool_h:
+; CHECK: // %bb.0:
+; CHECK-NEXT: // kill: def $w0 killed $w0 def $x0
+; CHECK-NEXT: sbfx x8, x0, #0, #1
+; CHECK-NEXT: whilelo p0.h, xzr, x8
+; CHECK-NEXT: ret
+ %.splatinsert = insertelement <vscale x 8 x i1> poison, i1 %x, i64 0
+ %.splat = shufflevector <vscale x 8 x i1> %.splatinsert, <vscale x 8 x i1> poison, <vscale x 8 x i32> zeroinitializer
+ %out = tail call <vscale x 16 x i1> @llvm.aarch64.sve.convert.to.svbool.nxv8i1(<vscale x 8 x i1> %.splat)
+ ret <vscale x 16 x i1> %out
+}
+
+define <vscale x 16 x i1> @reinterpret_scalar_bool_s(i1 %x){
+; CHECK-LABEL: reinterpret_scalar_bool_s:
+; CHECK: // %bb.0:
+; CHECK-NEXT: // kill: def $w0 killed $w0 def $x0
+; CHECK-NEXT: sbfx x8, x0, #0, #1
+; CHECK-NEXT: whilelo p0.s, xzr, x8
+; CHECK-NEXT: ret
+ %.splatinsert = insertelement <vscale x 4 x i1> poison, i1 %x, i64 0
+ %.splat = shufflevector <vscale x 4 x i1> %.splatinsert, <vscale x 4 x i1> poison, <vscale x 4 x i32> zeroinitializer
+ %out = tail call <vscale x 16 x i1> @llvm.aarch64.sve.convert.to.svbool.nxv4i1(<vscale x 4 x i1> %.splat)
+ ret <vscale x 16 x i1> %out
+}
+
+define <vscale x 16 x i1> @reinterpret_scalar_bool_q(i1 %x){
+; CHECK-LABEL: reinterpret_scalar_bool_q:
+; CHECK: // %bb.0:
+; CHECK-NEXT: // kill: def $w0 killed $w0 def $x0
+; CHECK-NEXT: sbfx x8, x0, #0, #1
+; CHECK-NEXT: whilelo p0.d, xzr, x8
+; CHECK-NEXT: ret
+ %.splatinsert = insertelement <vscale x 2 x i1> poison, i1 %x, i64 0
+ %.splat = shufflevector <vscale x 2 x i1> %.splatinsert, <vscale x 2 x i1> poison, <vscale x 2 x i32> zeroinitializer
+ %out = tail call <vscale x 16 x i1> @llvm.aarch64.sve.convert.to.svbool.nxv2i1(<vscale x 2 x i1> %.splat)
+ ret <vscale x 16 x i1> %out
+}
+
+
declare <vscale x 8 x i1> @llvm.aarch64.sve.ptrue.nxv8i1(i32 immarg)
declare <vscale x 16 x i1> @llvm.aarch64.sve.ptrue.nxv16i1(i32 immarg)
declare <vscale x 8 x i1> @llvm.aarch64.sve.cmpgt.nxv8i16(<vscale x 8 x i1>, <vscale x 8 x i16>, <vscale x 8 x i16>)
>From 634b0243b8f7acc85af4f16b70e91d86ded4dc83 Mon Sep 17 00:00:00 2001
From: SivanShani-Arm <sivan.shani at arm.com>
Date: Wed, 28 Feb 2024 17:02:51 +0000
Subject: [PATCH 016/406] [llvm][arm] add T1 and T2 assembly options for vlldm
and vlstm (#83116)
T1 allows for an optional registers list, the register list must be {d0-d15}.
T2 defines a mandatory register list, the register list must be {d0-d31}.
The requirements for T1/T2 are as follows:
T1 T2
Require: v8-M.Main, v8.1-M.Main,
secure state secure state
16 D Regs valid valid
32 D Regs UNDEFINED valid
No D Regs NOP NOP
---
llvm/lib/Target/ARM/ARMExpandPseudoInsts.cpp | 57 +++++++++-----
llvm/lib/Target/ARM/ARMInstrFormats.td | 31 ++++++++
llvm/lib/Target/ARM/ARMInstrVFP.td | 64 +++++++++++-----
.../lib/Target/ARM/AsmParser/ARMAsmParser.cpp | 76 ++++++++++++++++---
.../ARM/Disassembler/ARMDisassembler.cpp | 23 ++++++
.../ARM/MCTargetDesc/ARMInstPrinter.cpp | 32 ++++++++
.../CodeGen/ARM/cmse-vlldm-no-reorder.mir | 4 +-
llvm/test/CodeGen/ARM/vlldm-vlstm-uops.mir | 9 +--
llvm/test/MC/ARM/thumbv8m.s | 8 +-
llvm/test/MC/ARM/vlstm-vlldm-8.1m.s | 11 +++
llvm/test/MC/ARM/vlstm-vlldm-8m.s | 17 +++++
llvm/test/MC/ARM/vlstm-vlldm-diag.s | 61 +++++++++++++++
.../ARM/armv8.1m-vlldm_vlstm-8.1.main.txt | 11 +++
.../ARM/armv8.1m-vlldm_vlstm-8.main.txt | 17 +++++
.../unittests/Target/ARM/MachineInstrTest.cpp | 2 +
15 files changed, 362 insertions(+), 61 deletions(-)
create mode 100644 llvm/test/MC/ARM/vlstm-vlldm-8.1m.s
create mode 100644 llvm/test/MC/ARM/vlstm-vlldm-8m.s
create mode 100644 llvm/test/MC/ARM/vlstm-vlldm-diag.s
create mode 100644 llvm/test/MC/Disassembler/ARM/armv8.1m-vlldm_vlstm-8.1.main.txt
create mode 100644 llvm/test/MC/Disassembler/ARM/armv8.1m-vlldm_vlstm-8.main.txt
diff --git a/llvm/lib/Target/ARM/ARMExpandPseudoInsts.cpp b/llvm/lib/Target/ARM/ARMExpandPseudoInsts.cpp
index f0b69b0b09809f..e78ea63c3b4a56 100644
--- a/llvm/lib/Target/ARM/ARMExpandPseudoInsts.cpp
+++ b/llvm/lib/Target/ARM/ARMExpandPseudoInsts.cpp
@@ -1468,15 +1468,21 @@ void ARMExpandPseudo::CMSESaveClearFPRegsV8(
if (passesFPReg)
assert(STI->hasFPRegs() && "Subtarget needs fpregs");
- // Lazy store all fp registers to the stack.
+ // Lazy store all fp registers to the stack
// This executes as NOP in the absence of floating-point support.
- MachineInstrBuilder VLSTM = BuildMI(MBB, MBBI, DL, TII->get(ARM::VLSTM))
- .addReg(ARM::SP)
- .add(predOps(ARMCC::AL));
- for (auto R : {ARM::VPR, ARM::FPSCR, ARM::FPSCR_NZCV, ARM::Q0, ARM::Q1,
- ARM::Q2, ARM::Q3, ARM::Q4, ARM::Q5, ARM::Q6, ARM::Q7})
- VLSTM.addReg(R, RegState::Implicit |
- (LiveRegs.contains(R) ? 0 : RegState::Undef));
+ MachineInstrBuilder VLSTM =
+ BuildMI(MBB, MBBI, DL, TII->get(ARM::VLSTM))
+ .addReg(ARM::SP)
+ .add(predOps(ARMCC::AL))
+ .addImm(0); // Represents a pseoudo register list, has no effect on
+ // the encoding.
+ // Mark non-live registers as undef
+ for (MachineOperand &MO : VLSTM->implicit_operands()) {
+ if (MO.isReg() && !MO.isDef()) {
+ Register Reg = MO.getReg();
+ MO.setIsUndef(!LiveRegs.contains(Reg));
+ }
+ }
// Restore all arguments
for (const auto &Regs : ClearedFPRegs) {
@@ -1563,14 +1569,20 @@ void ARMExpandPseudo::CMSESaveClearFPRegsV81(MachineBasicBlock &MBB,
.addImm(CMSE_FP_SAVE_SIZE >> 2)
.add(predOps(ARMCC::AL));
- // Lazy store all FP registers to the stack
- MachineInstrBuilder VLSTM = BuildMI(MBB, MBBI, DL, TII->get(ARM::VLSTM))
- .addReg(ARM::SP)
- .add(predOps(ARMCC::AL));
- for (auto R : {ARM::VPR, ARM::FPSCR, ARM::FPSCR_NZCV, ARM::Q0, ARM::Q1,
- ARM::Q2, ARM::Q3, ARM::Q4, ARM::Q5, ARM::Q6, ARM::Q7})
- VLSTM.addReg(R, RegState::Implicit |
- (LiveRegs.contains(R) ? 0 : RegState::Undef));
+ // Lazy store all fp registers to the stack.
+ MachineInstrBuilder VLSTM =
+ BuildMI(MBB, MBBI, DL, TII->get(ARM::VLSTM))
+ .addReg(ARM::SP)
+ .add(predOps(ARMCC::AL))
+ .addImm(0); // Represents a pseoudo register list, has no effect on
+ // the encoding.
+ // Mark non-live registers as undef
+ for (MachineOperand &MO : VLSTM->implicit_operands()) {
+ if (MO.isReg() && MO.isImplicit() && !MO.isDef()) {
+ Register Reg = MO.getReg();
+ MO.setIsUndef(!LiveRegs.contains(Reg));
+ }
+ }
} else {
// Push all the callee-saved registers (s16-s31).
MachineInstrBuilder VPUSH =
@@ -1673,9 +1685,12 @@ void ARMExpandPseudo::CMSERestoreFPRegsV8(
// Lazy load fp regs from stack.
// This executes as NOP in the absence of floating-point support.
- MachineInstrBuilder VLLDM = BuildMI(MBB, MBBI, DL, TII->get(ARM::VLLDM))
- .addReg(ARM::SP)
- .add(predOps(ARMCC::AL));
+ MachineInstrBuilder VLLDM =
+ BuildMI(MBB, MBBI, DL, TII->get(ARM::VLLDM))
+ .addReg(ARM::SP)
+ .add(predOps(ARMCC::AL))
+ .addImm(0); // Represents a pseoudo register list, has no effect on
+ // the encoding.
if (STI->fixCMSE_CVE_2021_35465()) {
auto Bundler = MIBundleBuilder(MBB, VLLDM);
@@ -1757,7 +1772,9 @@ void ARMExpandPseudo::CMSERestoreFPRegsV81(
// Load FP registers from stack.
BuildMI(MBB, MBBI, DL, TII->get(ARM::VLLDM))
.addReg(ARM::SP)
- .add(predOps(ARMCC::AL));
+ .add(predOps(ARMCC::AL))
+ .addImm(0); // Represents a pseoudo register list, has no effect on the
+ // encoding.
// Pop the stack space
BuildMI(MBB, MBBI, DL, TII->get(ARM::tADDspi), ARM::SP)
diff --git a/llvm/lib/Target/ARM/ARMInstrFormats.td b/llvm/lib/Target/ARM/ARMInstrFormats.td
index 14e315534570d2..404085820a6660 100644
--- a/llvm/lib/Target/ARM/ARMInstrFormats.td
+++ b/llvm/lib/Target/ARM/ARMInstrFormats.td
@@ -1749,6 +1749,37 @@ class AXSI4<dag oops, dag iops, IndexMode im, InstrItinClass itin,
let Inst{8} = 0; // Single precision
}
+// Single Precision with fixed registers.
+// For when the registers-to-be-stored/loaded are fixed, e.g. VLLDM and VLSTM
+class AXSI4FR<string asm, bit et, bit load>
+ : InstARM<AddrMode4, 4, IndexModeNone, VFPLdStMulFrm, VFPDomain, "", NoItinerary> {
+ // Instruction operands.
+ bits<4> Rn;
+ bits<13> regs; // Does not affect encoding, for assembly/disassembly only.
+ list<Predicate> Predicates = [HasVFP2];
+ let OutOperandList = (outs);
+ let InOperandList = (ins GPRnopc:$Rn, pred:$p, dpr_reglist:$regs);
+ let AsmString = asm;
+ let Pattern = [];
+ let DecoderNamespace = "VFP";
+ // Encode instruction operands.
+ let Inst{19-16} = Rn;
+ let Inst{31-28} = 0b1110;
+ let Inst{27-25} = 0b110;
+ let Inst{24} = 0b0;
+ let Inst{23} = 0b0;
+ let Inst{22} = 0b0;
+ let Inst{21} = 0b1;
+ let Inst{20} = load; // Distinguishes vlldm from vlstm
+ let Inst{15-12} = 0b0000;
+ let Inst{11-9} = 0b101;
+ let Inst{8} = 0; // Single precision
+ let Inst{7} = et; // encoding type, 0 for T1 and 1 for T2.
+ let Inst{6-0} = 0b0000000;
+ let mayLoad = load;
+ let mayStore = !eq(load, 0);
+}
+
// Double precision, unary
class ADuI<bits<5> opcod1, bits<2> opcod2, bits<4> opcod3, bits<2> opcod4,
bit opcod5, dag oops, dag iops, InstrItinClass itin, string opc,
diff --git a/llvm/lib/Target/ARM/ARMInstrVFP.td b/llvm/lib/Target/ARM/ARMInstrVFP.td
index 55d3efbd9b9a2b..3094a4db2b4d12 100644
--- a/llvm/lib/Target/ARM/ARMInstrVFP.td
+++ b/llvm/lib/Target/ARM/ARMInstrVFP.td
@@ -313,29 +313,51 @@ def : MnemonicAlias<"vstm", "vstmia">;
//===----------------------------------------------------------------------===//
// Lazy load / store multiple Instructions
//
-def VLLDM : AXSI4<(outs), (ins GPRnopc:$Rn, pred:$p), IndexModeNone,
- NoItinerary, "vlldm${p}\t$Rn", "", []>,
+// VLLDM and VLSTM:
+// 2 encoding options:
+// T1 (bit 7 is 0):
+// T1 takes an optional dpr_reglist, must be '{d0-d15}' (exactly)
+// T1 require v8-M.Main, secure state, target with 16 D registers (or with no D registers - NOP)
+// T2 (bit 7 is 1):
+// T2 takes a mandatory dpr_reglist, must be '{d0-d31}' (exactly)
+// T2 require v8.1-M.Main, secure state, target with 16/32 D registers (or with no D registers - NOP)
+// (source: Arm v8-M ARM, DDI0553B.v ID16122022)
+
+def VLLDM : AXSI4FR<"vlldm${p}\t$Rn, $regs", 0, 1>,
Requires<[HasV8MMainline, Has8MSecExt]> {
- let Inst{24-23} = 0b00;
- let Inst{22} = 0;
- let Inst{21} = 1;
- let Inst{20} = 1;
- let Inst{15-12} = 0;
- let Inst{7-0} = 0;
- let mayLoad = 1;
- let Defs = [Q0, Q1, Q2, Q3, Q4, Q5, Q6, Q7, VPR, FPSCR, FPSCR_NZCV];
-}
-
-def VLSTM : AXSI4<(outs), (ins GPRnopc:$Rn, pred:$p), IndexModeNone,
- NoItinerary, "vlstm${p}\t$Rn", "", []>,
+ let Defs = [VPR, FPSCR, FPSCR_NZCV, D0, D1, D2, D3, D4, D5, D6, D7, D8, D9, D10, D11, D12, D13, D14, D15];
+ let DecoderMethod = "DecodeLazyLoadStoreMul";
+}
+// T1: assembly does not contains the register list.
+def : InstAlias<"vlldm${p}\t$Rn", (VLLDM GPRnopc:$Rn, pred:$p, 0)>,
+ Requires<[HasV8MMainline, Has8MSecExt]>;
+// T2: assembly must contains the register list.
+// The register list has no effect on the encoding, it is for assembly/disassembly purposes only.
+def VLLDM_T2 : AXSI4FR<"vlldm${p}\t$Rn, $regs", 1, 1>,
+ Requires<[HasV8_1MMainline, Has8MSecExt]> {
+ let Defs = [VPR, FPSCR, FPSCR_NZCV, D0, D1, D2, D3, D4, D5, D6, D7, D8, D9, D10, D11, D12, D13, D14, D15,
+ D16, D17, D18, D19, D20, D21, D22, D23, D24, D25, D26, D27, D28, D29, D30, D31];
+ let DecoderMethod = "DecodeLazyLoadStoreMul";
+}
+// T1: assembly contains the register list.
+// The register list has no effect on the encoding, it is for assembly/disassembly purposes only.
+def VLSTM : AXSI4FR<"vlstm${p}\t$Rn, $regs", 0, 0>,
Requires<[HasV8MMainline, Has8MSecExt]> {
- let Inst{24-23} = 0b00;
- let Inst{22} = 0;
- let Inst{21} = 1;
- let Inst{20} = 0;
- let Inst{15-12} = 0;
- let Inst{7-0} = 0;
- let mayStore = 1;
+ let Defs = [VPR, FPSCR, FPSCR_NZCV];
+ let Uses = [VPR, FPSCR, FPSCR_NZCV, D0, D1, D2, D3, D4, D5, D6, D7, D8, D9, D10, D11, D12, D13, D14, D15];
+ let DecoderMethod = "DecodeLazyLoadStoreMul";
+}
+// T1: assembly does not contain the register list.
+def : InstAlias<"vlstm${p}\t$Rn", (VLSTM GPRnopc:$Rn, pred:$p, 0)>,
+ Requires<[HasV8MMainline, Has8MSecExt]>;
+// T2: assembly must contain the register list.
+// The register list has no effect on the encoding, it is for assembly/disassembly purposes only.
+def VLSTM_T2 : AXSI4FR<"vlstm${p}\t$Rn, $regs", 1, 0>,
+ Requires<[HasV8_1MMainline, Has8MSecExt]> {
+ let Defs = [VPR, FPSCR, FPSCR_NZCV];
+ let Uses = [VPR, FPSCR, FPSCR_NZCV, D0, D1, D2, D3, D4, D5, D6, D7, D8, D9, D10, D11, D12, D13, D14, D15,
+ D16, D17, D18, D19, D20, D21, D22, D23, D24, D25, D26, D27, D28, D29, D30, D31];
+ let DecoderMethod = "DecodeLazyLoadStoreMul";
}
def : InstAlias<"vpush${p} $r", (VSTMDDB_UPD SP, pred:$p, dpr_reglist:$r), 0>,
diff --git a/llvm/lib/Target/ARM/AsmParser/ARMAsmParser.cpp b/llvm/lib/Target/ARM/AsmParser/ARMAsmParser.cpp
index 37bfb76a494dee..5efbaf0d41060c 100644
--- a/llvm/lib/Target/ARM/AsmParser/ARMAsmParser.cpp
+++ b/llvm/lib/Target/ARM/AsmParser/ARMAsmParser.cpp
@@ -450,11 +450,12 @@ class ARMAsmParser : public MCTargetAsmParser {
bool validatetSTMRegList(const MCInst &Inst, const OperandVector &Operands,
unsigned ListNo);
- int tryParseRegister();
+ int tryParseRegister(bool AllowOutofBoundReg = false);
bool tryParseRegisterWithWriteBack(OperandVector &);
int tryParseShiftRegister(OperandVector &);
bool parseRegisterList(OperandVector &, bool EnforceOrder = true,
- bool AllowRAAC = false);
+ bool AllowRAAC = false,
+ bool AllowOutOfBoundReg = false);
bool parseMemory(OperandVector &);
bool parseOperand(OperandVector &, StringRef Mnemonic);
bool parseImmExpr(int64_t &Out);
@@ -4072,7 +4073,7 @@ ParseStatus ARMAsmParser::tryParseRegister(MCRegister &Reg, SMLoc &StartLoc,
/// Try to parse a register name. The token must be an Identifier when called,
/// and if it is a register name the token is eaten and the register number is
/// returned. Otherwise return -1.
-int ARMAsmParser::tryParseRegister() {
+int ARMAsmParser::tryParseRegister(bool AllowOutOfBoundReg) {
MCAsmParser &Parser = getParser();
const AsmToken &Tok = Parser.getTok();
if (Tok.isNot(AsmToken::Identifier)) return -1;
@@ -4116,7 +4117,8 @@ int ARMAsmParser::tryParseRegister() {
}
// Some FPUs only have 16 D registers, so D16-D31 are invalid
- if (!hasD32() && RegNum >= ARM::D16 && RegNum <= ARM::D31)
+ if (!AllowOutOfBoundReg && !hasD32() && RegNum >= ARM::D16 &&
+ RegNum <= ARM::D31)
return -1;
Parser.Lex(); // Eat identifier token.
@@ -4456,7 +4458,7 @@ insertNoDuplicates(SmallVectorImpl<std::pair<unsigned, unsigned>> &Regs,
/// Parse a register list.
bool ARMAsmParser::parseRegisterList(OperandVector &Operands, bool EnforceOrder,
- bool AllowRAAC) {
+ bool AllowRAAC, bool AllowOutOfBoundReg) {
MCAsmParser &Parser = getParser();
if (Parser.getTok().isNot(AsmToken::LCurly))
return TokError("Token is not a Left Curly Brace");
@@ -4510,7 +4512,7 @@ bool ARMAsmParser::parseRegisterList(OperandVector &Operands, bool EnforceOrder,
return Error(RegLoc, "pseudo-register not allowed");
Parser.Lex(); // Eat the minus.
SMLoc AfterMinusLoc = Parser.getTok().getLoc();
- int EndReg = tryParseRegister();
+ int EndReg = tryParseRegister(AllowOutOfBoundReg);
if (EndReg == -1)
return Error(AfterMinusLoc, "register expected");
if (EndReg == ARM::RA_AUTH_CODE)
@@ -4545,7 +4547,7 @@ bool ARMAsmParser::parseRegisterList(OperandVector &Operands, bool EnforceOrder,
RegLoc = Parser.getTok().getLoc();
int OldReg = Reg;
const AsmToken RegTok = Parser.getTok();
- Reg = tryParseRegister();
+ Reg = tryParseRegister(AllowOutOfBoundReg);
if (Reg == -1)
return Error(RegLoc, "register expected");
if (!AllowRAAC && Reg == ARM::RA_AUTH_CODE)
@@ -6085,8 +6087,11 @@ bool ARMAsmParser::parseOperand(OperandVector &Operands, StringRef Mnemonic) {
}
case AsmToken::LBrac:
return parseMemory(Operands);
- case AsmToken::LCurly:
- return parseRegisterList(Operands, !Mnemonic.starts_with("clr"));
+ case AsmToken::LCurly: {
+ bool AllowOutOfBoundReg = Mnemonic == "vlldm" || Mnemonic == "vlstm";
+ return parseRegisterList(Operands, !Mnemonic.starts_with("clr"), false,
+ AllowOutOfBoundReg);
+ }
case AsmToken::Dollar:
case AsmToken::Hash: {
// #42 -> immediate
@@ -7596,6 +7601,33 @@ bool ARMAsmParser::validateInstruction(MCInst &Inst,
const unsigned Opcode = Inst.getOpcode();
switch (Opcode) {
+ case ARM::VLLDM:
+ case ARM::VLLDM_T2:
+ case ARM::VLSTM:
+ case ARM::VLSTM_T2: {
+ // Since in some cases both T1 and T2 are valid, tablegen can not always
+ // pick the correct instruction.
+ if (Operands.size() == 4) { // a register list has been provided
+ ARMOperand &Op = static_cast<ARMOperand &>(
+ *Operands[3]); // the register list, a dpr_reglist
+ assert(Op.isDPRRegList());
+ auto &RegList = Op.getRegList();
+ // T2 requires v8.1-M.Main (cannot be handled by tablegen)
+ if (RegList.size() == 32 && !hasV8_1MMainline()) {
+ return Error(Op.getEndLoc(), "T2 version requires v8.1-M.Main");
+ }
+ // When target has 32 D registers, T1 is undefined.
+ if (hasD32() && RegList.size() != 32) {
+ return Error(Op.getEndLoc(), "operand must be exactly {d0-d31}");
+ }
+ // When target has 16 D registers, both T1 and T2 are valid.
+ if (!hasD32() && (RegList.size() != 16 && RegList.size() != 32)) {
+ return Error(Op.getEndLoc(),
+ "operand must be exactly {d0-d15} (T1) or {d0-d31} (T2)");
+ }
+ }
+ return false;
+ }
case ARM::t2IT: {
// Encoding is unpredictable if it ever results in a notional 'NV'
// predicate. Since we don't parse 'NV' directly this means an 'AL'
@@ -8731,6 +8763,32 @@ bool ARMAsmParser::processInstruction(MCInst &Inst,
}
switch (Inst.getOpcode()) {
+ case ARM::VLLDM:
+ case ARM::VLSTM: {
+ // In some cases both T1 and T2 are valid, causing tablegen pick T1 instead
+ // of T2
+ if (Operands.size() == 4) { // a register list has been provided
+ ARMOperand &Op = static_cast<ARMOperand &>(
+ *Operands[3]); // the register list, a dpr_reglist
+ assert(Op.isDPRRegList());
+ auto &RegList = Op.getRegList();
+ // When the register list is {d0-d31} the instruction has to be the T2
+ // variant
+ if (RegList.size() == 32) {
+ const unsigned Opcode =
+ (Inst.getOpcode() == ARM::VLLDM) ? ARM::VLLDM_T2 : ARM::VLSTM_T2;
+ MCInst TmpInst;
+ TmpInst.setOpcode(Opcode);
+ TmpInst.addOperand(Inst.getOperand(0));
+ TmpInst.addOperand(Inst.getOperand(1));
+ TmpInst.addOperand(Inst.getOperand(2));
+ TmpInst.addOperand(Inst.getOperand(3));
+ Inst = TmpInst;
+ return true;
+ }
+ }
+ return false;
+ }
// Alias for alternate form of 'ldr{,b}t Rt, [Rn], #imm' instruction.
case ARM::LDRT_POST:
case ARM::LDRBT_POST: {
diff --git a/llvm/lib/Target/ARM/Disassembler/ARMDisassembler.cpp b/llvm/lib/Target/ARM/Disassembler/ARMDisassembler.cpp
index 604f22d7111900..705f3cbce12f02 100644
--- a/llvm/lib/Target/ARM/Disassembler/ARMDisassembler.cpp
+++ b/llvm/lib/Target/ARM/Disassembler/ARMDisassembler.cpp
@@ -700,6 +700,9 @@ DecodeMVEOverlappingLongShift(MCInst &Inst, unsigned Insn, uint64_t Address,
static DecodeStatus DecodeT2AddSubSPImm(MCInst &Inst, unsigned Insn,
uint64_t Address,
const MCDisassembler *Decoder);
+static DecodeStatus DecodeLazyLoadStoreMul(MCInst &Inst, unsigned Insn,
+ uint64_t Address,
+ const MCDisassembler *Decoder);
#include "ARMGenDisassemblerTables.inc"
@@ -7030,3 +7033,23 @@ static DecodeStatus DecodeT2AddSubSPImm(MCInst &Inst, unsigned Insn,
return DS;
}
+
+static DecodeStatus DecodeLazyLoadStoreMul(MCInst &Inst, unsigned Insn,
+ uint64_t Address,
+ const MCDisassembler *Decoder) {
+ DecodeStatus S = MCDisassembler::Success;
+
+ const unsigned Rn = fieldFromInstruction(Insn, 16, 4);
+ // Adding Rn, holding memory location to save/load to/from, the only argument
+ // that is being encoded.
+ // '$Rn' in the assembly.
+ if (!Check(S, DecodeGPRRegisterClass(Inst, Rn, Address, Decoder)))
+ return MCDisassembler::Fail;
+ // An optional predicate, '$p' in the assembly.
+ DecodePredicateOperand(Inst, ARMCC::AL, Address, Decoder);
+ // An immediate that represents a floating point registers list. '$regs' in
+ // the assembly.
+ Inst.addOperand(MCOperand::createImm(0)); // Arbitrary value, has no effect.
+
+ return S;
+}
diff --git a/llvm/lib/Target/ARM/MCTargetDesc/ARMInstPrinter.cpp b/llvm/lib/Target/ARM/MCTargetDesc/ARMInstPrinter.cpp
index fbd067d79af0b3..24e627cd9a4e1f 100644
--- a/llvm/lib/Target/ARM/MCTargetDesc/ARMInstPrinter.cpp
+++ b/llvm/lib/Target/ARM/MCTargetDesc/ARMInstPrinter.cpp
@@ -91,6 +91,38 @@ void ARMInstPrinter::printInst(const MCInst *MI, uint64_t Address,
unsigned Opcode = MI->getOpcode();
switch (Opcode) {
+ case ARM::VLLDM: {
+ const MCOperand &Reg = MI->getOperand(0);
+ O << '\t' << "vlldm" << '\t';
+ printRegName(O, Reg.getReg());
+ O << ", "
+ << "{d0 - d15}";
+ return;
+ }
+ case ARM::VLLDM_T2: {
+ const MCOperand &Reg = MI->getOperand(0);
+ O << '\t' << "vlldm" << '\t';
+ printRegName(O, Reg.getReg());
+ O << ", "
+ << "{d0 - d31}";
+ return;
+ }
+ case ARM::VLSTM: {
+ const MCOperand &Reg = MI->getOperand(0);
+ O << '\t' << "vlstm" << '\t';
+ printRegName(O, Reg.getReg());
+ O << ", "
+ << "{d0 - d15}";
+ return;
+ }
+ case ARM::VLSTM_T2: {
+ const MCOperand &Reg = MI->getOperand(0);
+ O << '\t' << "vlstm" << '\t';
+ printRegName(O, Reg.getReg());
+ O << ", "
+ << "{d0 - d31}";
+ return;
+ }
// Check for MOVs and print canonical forms, instead.
case ARM::MOVsr: {
// FIXME: Thumb variants?
diff --git a/llvm/test/CodeGen/ARM/cmse-vlldm-no-reorder.mir b/llvm/test/CodeGen/ARM/cmse-vlldm-no-reorder.mir
index 2bc4288884f192..d006aa9ba38e84 100644
--- a/llvm/test/CodeGen/ARM/cmse-vlldm-no-reorder.mir
+++ b/llvm/test/CodeGen/ARM/cmse-vlldm-no-reorder.mir
@@ -89,7 +89,7 @@ body: |
# CHECK: $sp = t2STMDB_UPD $sp, 14 /* CC::al */, $noreg, $r4, $r5, $r6, undef $r7, $r8, $r9, $r10, $r11
# CHECK-NEXT: $r0 = t2BICri $r0, 1, 14 /* CC::al */, $noreg, $noreg
# CHECK-NEXT: $sp = tSUBspi $sp, 34, 14 /* CC::al */, $noreg
-# CHECK-NEXT: VLSTM $sp, 14 /* CC::al */, $noreg, implicit undef $vpr, implicit undef $fpscr, implicit undef $fpscr_nzcv, implicit undef $q0, implicit undef $q1, implicit undef $q2, implicit undef $q3, implicit undef $q4, implicit undef $q5, implicit undef $q6, implicit undef $q7
+# CHECK-NEXT: VLSTM $sp, 14 /* CC::al */, $noreg, 0, implicit-def $vpr, implicit-def $fpscr, implicit-def $fpscr_nzcv, implicit undef $vpr, implicit undef $fpscr, implicit undef $fpscr_nzcv, implicit undef $d0, implicit undef $d1, implicit undef $d2, implicit undef $d3, implicit undef $d4, implicit undef $d5, implicit undef $d6, implicit undef $d7, implicit $d8, implicit $d9, implicit $d10, implicit $d11, implicit $d12, implicit $d13, implicit $d14, implicit $d15
# CHECK-NEXT: $r1 = tMOVr $r0, 14 /* CC::al */, $noreg
# CHECK-NEXT: $r2 = tMOVr $r0, 14 /* CC::al */, $noreg
# CHECK-NEXT: $r3 = tMOVr $r0, 14 /* CC::al */, $noreg
@@ -105,7 +105,7 @@ body: |
# CHECK-NEXT: t2MSR_M 3072, $r0, 14 /* CC::al */, $noreg, implicit-def $cpsr
# CHECK-NEXT: tBLXNSr 14 /* CC::al */, $noreg, killed $r0, csr_aapcs, implicit-def $lr, implicit $sp, implicit-def dead $lr, implicit $sp, implicit-def $sp, implicit-def $s0
# CHECK-NEXT: $r12 = VMOVRS $s0, 14 /* CC::al */, $noreg
-# CHECK-NEXT: VLLDM $sp, 14 /* CC::al */, $noreg, implicit-def $q0, implicit-def $q1, implicit-def $q2, implicit-def $q3, implicit-def $q4, implicit-def $q5, implicit-def $q6, implicit-def $q7, implicit-def $vpr, implicit-def $fpscr, implicit-def $fpscr_nzcv
+# CHECK-NEXT: VLLDM $sp, 14 /* CC::al */, $noreg, 0, implicit-def $vpr, implicit-def $fpscr, implicit-def $fpscr_nzcv, implicit-def $d0, implicit-def $d1, implicit-def $d2, implicit-def $d3, implicit-def $d4, implicit-def $d5, implicit-def $d6, implicit-def $d7, implicit-def $d8, implicit-def $d9, implicit-def $d10, implicit-def $d11, implicit-def $d12, implicit-def $d13, implicit-def $d14, implicit-def $d15
# CHECK-NEXT: $s0 = VMOVSR $r12, 14 /* CC::al */, $noreg
# CHECK-NEXT: $sp = tADDspi $sp, 34, 14 /* CC::al */, $noreg
# CHECK-NEXT: $sp = t2LDMIA_UPD $sp, 14 /* CC::al */, $noreg, def $r4, def $r5, def $r6, def $r7, def $r8, def $r9, def $r10, def $r11
diff --git a/llvm/test/CodeGen/ARM/vlldm-vlstm-uops.mir b/llvm/test/CodeGen/ARM/vlldm-vlstm-uops.mir
index 8c49a531674115..ad53addcc21a35 100644
--- a/llvm/test/CodeGen/ARM/vlldm-vlstm-uops.mir
+++ b/llvm/test/CodeGen/ARM/vlldm-vlstm-uops.mir
@@ -2,7 +2,7 @@
--- |
target triple = "thumbv8m.main-arm-none-eabi"
- define hidden void @foo(ptr nocapture %baz) local_unnamed_addr #0 {
+ define hidden void @foo(void ()* nocapture %baz) local_unnamed_addr #0 {
entry:
%call = call i32 @bar() #0
%tobool = icmp eq i32 %call, 0
@@ -55,14 +55,13 @@ body: |
tBL 14, $noreg, @bar, csr_aapcs, implicit-def dead $lr, implicit $sp, implicit-def $sp, implicit-def dead $r0
bb.2.land.end:
- liveins: $r4
-
+ liveins: $r4, $vpr, $fpscr, $fpscr_nzcv, $d0, $d1, $d2, $d3, $d4, $d5, $d6, $d7, $d8, $d9, $d10, $d11, $d12, $d13, $d14, $d15
$sp = t2STMDB_UPD $sp, 14, $noreg, $r4, killed $r5, killed $r6, killed $r7, killed $r8, killed $r9, killed $r10, killed $r11
$r4 = t2BICri $r4, 1, 14, $noreg, $noreg
$sp = tSUBspi $sp, 34, 14, $noreg
- VLSTM $sp, 14, $noreg
+ VLSTM $sp, 14, $noreg, 0, implicit-def $vpr, implicit-def $fpscr, implicit-def $fpscr_nzcv, implicit $vpr, implicit $fpscr, implicit $fpscr_nzcv, implicit $d0, implicit $d1, implicit $d2, implicit $d3, implicit $d4, implicit $d5, implicit $d6, implicit $d7, implicit $d8, implicit $d9, implicit $d10, implicit $d11, implicit $d12, implicit $d13, implicit $d14, implicit $d15
tBLXNSr 14, $noreg, killed $r4, csr_aapcs, implicit-def $lr, implicit $sp, implicit-def dead $lr, implicit $sp, implicit-def $sp
- VLLDM $sp, 14, $noreg, implicit-def $q0, implicit-def $q1, implicit-def $q2, implicit-def $q3, implicit-def $q4, implicit-def $q5, implicit-def $q6, implicit-def $q7, implicit-def $vpr, implicit-def $fpscr, implicit-def $fpscr_nzcv
+ VLLDM $sp, 14, $noreg, 0, implicit-def $vpr, implicit-def $fpscr, implicit-def $fpscr_nzcv, implicit-def $d0, implicit-def $d1, implicit-def $d2, implicit-def $d3, implicit-def $d4, implicit-def $d5, implicit-def $d6, implicit-def $d7, implicit-def $d8, implicit-def $d9, implicit-def $d10, implicit-def $d11, implicit-def $d12, implicit-def $d13, implicit-def $d14, implicit-def $d15
$sp = tADDspi $sp, 34, 14, $noreg
$sp = t2LDMIA_UPD $sp, 14, $noreg, def $r4, def $r5, def $r6, def $r7, def $r8, def $r9, def $r10, def $r11
$sp = t2LDMIA_RET $sp, 14, $noreg, def $r4, def $pc
diff --git a/llvm/test/MC/ARM/thumbv8m.s b/llvm/test/MC/ARM/thumbv8m.s
index 0e9ab4a9b3bf91..f03dd03dae3a4f 100644
--- a/llvm/test/MC/ARM/thumbv8m.s
+++ b/llvm/test/MC/ARM/thumbv8m.s
@@ -184,13 +184,13 @@ ttat r0, r1
// 'Lazy Load/Store Multiple'
// UNDEF-BASELINE: error: instruction requires: armv8m.main
-// CHECK-MAINLINE: vlldm r5 @ encoding: [0x35,0xec,0x00,0x0a]
-// CHECK-MAINLINE_DSP: vlldm r5 @ encoding: [0x35,0xec,0x00,0x0a]
+// CHECK-MAINLINE: vlldm r5, {d0 - d15} @ encoding: [0x35,0xec,0x00,0x0a]
+// CHECK-MAINLINE_DSP: vlldm r5, {d0 - d15} @ encoding: [0x35,0xec,0x00,0x0a]
vlldm r5
// UNDEF-BASELINE: error: instruction requires: armv8m.main
-// CHECK-MAINLINE: vlstm r10 @ encoding: [0x2a,0xec,0x00,0x0a]
-// CHECK-MAINLINE_DSP: vlstm r10 @ encoding: [0x2a,0xec,0x00,0x0a]
+// CHECK-MAINLINE: vlstm r10, {d0 - d15} @ encoding: [0x2a,0xec,0x00,0x0a]
+// CHECK-MAINLINE_DSP: vlstm r10, {d0 - d15} @ encoding: [0x2a,0xec,0x00,0x0a]
vlstm r10
// New SYSm's
diff --git a/llvm/test/MC/ARM/vlstm-vlldm-8.1m.s b/llvm/test/MC/ARM/vlstm-vlldm-8.1m.s
new file mode 100644
index 00000000000000..4e35883ffe4332
--- /dev/null
+++ b/llvm/test/MC/ARM/vlstm-vlldm-8.1m.s
@@ -0,0 +1,11 @@
+// RUN: llvm-mc -triple=armv8.1m.main-arm-none-eabi -mcpu=generic -show-encoding %s \
+// RUN: | FileCheck --check-prefixes=CHECK %s
+
+// RUN: llvm-mc -triple=thumbv8.1m.main-none-eabi -mcpu=generic -show-encoding %s \
+// RUN: | FileCheck --check-prefixes=CHECK %s
+
+vlstm r8, {d0 - d31}
+// CHECK: vlstm r8, {d0 - d31} @ encoding: [0x28,0xec,0x80,0x0a]
+
+vlldm r8, {d0 - d31}
+// CHECK: vlldm r8, {d0 - d31} @ encoding: [0x38,0xec,0x80,0x0a]
diff --git a/llvm/test/MC/ARM/vlstm-vlldm-8m.s b/llvm/test/MC/ARM/vlstm-vlldm-8m.s
new file mode 100644
index 00000000000000..bbc95318aeb3d0
--- /dev/null
+++ b/llvm/test/MC/ARM/vlstm-vlldm-8m.s
@@ -0,0 +1,17 @@
+// RUN: llvm-mc -triple=armv8m.main-arm-none-eabi -mcpu=generic -show-encoding %s \
+// RUN: | FileCheck --check-prefixes=CHECK %s
+
+// RUN: llvm-mc -triple=thumbv8m.main-none-eabi -mcpu=generic -show-encoding %s \
+// RUN: | FileCheck --check-prefixes=CHECK %s
+
+vlstm r8, {d0 - d15}
+// CHECK: vlstm r8, {d0 - d15} @ encoding: [0x28,0xec,0x00,0x0a]
+
+vlldm r8, {d0 - d15}
+// CHECK: vlldm r8, {d0 - d15} @ encoding: [0x38,0xec,0x00,0x0a]
+
+vlstm r8
+// CHECK: vlstm r8, {d0 - d15} @ encoding: [0x28,0xec,0x00,0x0a]
+
+vlldm r8
+// CHECK: vlldm r8, {d0 - d15} @ encoding: [0x38,0xec,0x00,0x0a]
diff --git a/llvm/test/MC/ARM/vlstm-vlldm-diag.s b/llvm/test/MC/ARM/vlstm-vlldm-diag.s
new file mode 100644
index 00000000000000..b57f535c6a25cf
--- /dev/null
+++ b/llvm/test/MC/ARM/vlstm-vlldm-diag.s
@@ -0,0 +1,61 @@
+// RUN: not llvm-mc -triple=armv8.1m.main-arm-none-eabi -mcpu=generic -show-encoding %s 2>&1 >/dev/null \
+// RUN: | FileCheck --check-prefixes=ERR %s
+
+// RUN: not llvm-mc -triple=armv8.1m.main-arm-none-eabi -mcpu=generic -show-encoding %s 2>&1 >/dev/null \
+// RUN: | FileCheck --check-prefixes=ERRT2 %s
+
+vlstm r8, {d0 - d11}
+// ERR: error: operand must be exactly {d0-d15} (T1) or {d0-d31} (T2)
+// ERR-NEXT: vlstm r8, {d0 - d11}
+
+vlldm r8, {d0 - d11}
+// ERR: error: operand must be exactly {d0-d15} (T1) or {d0-d31} (T2)
+// ERR-NEXT: vlldm r8, {d0 - d11}
+
+vlstm r8, {d3 - d15}
+// ERR: error: operand must be exactly {d0-d15} (T1) or {d0-d31} (T2)
+// ERR-NEXT: vlstm r8, {d3 - d15}
+
+vlldm r8, {d3 - d15}
+// ERR: error: operand must be exactly {d0-d15} (T1) or {d0-d31} (T2)
+// ERR-NEXT: vlldm r8, {d3 - d15}
+
+vlstm r8, {d0 - d29}
+// ERR: error: operand must be exactly {d0-d15} (T1) or {d0-d31} (T2)
+// ERR-NEXT: vlstm r8, {d0 - d29}
+
+vlldm r8, {d0 - d29}
+// ERR: error: operand must be exactly {d0-d15} (T1) or {d0-d31} (T2)
+// ERR-NEXT: vlldm r8, {d0 - d29}
+
+vlstm r8, {d3 - d31}
+// ERR: error: operand must be exactly {d0-d15} (T1) or {d0-d31} (T2)
+// ERR-NEXT: vlstm r8, {d3 - d31}
+
+vlldm r8, {d3 - d31}
+// ERR: error: operand must be exactly {d0-d15} (T1) or {d0-d31} (T2)
+// ERR-NEXT: vlldm r8, {d3 - d31}
+
+vlstm r8, {d0 - d35}
+// ERR: error: register expected
+// ERR-NEXT: vlstm r8, {d0 - d35}
+
+vlldm r8, {d0 - d35}
+// ERR: error: register expected
+// ERR-NEXT: vlldm r8, {d0 - d35}
+
+vlstm pc
+// ERR: error: operand must be a register in range [r0, r14]
+// ERR-NEXT: vlstm pc
+
+vlldm pc
+// ERR: error: operand must be a register in range [r0, r14]
+// ERR-NEXT: vlldm pc
+
+vlstm pc
+// ERRT2: error: operand must be a register in range [r0, r14]
+// ERRT2-NEXT: vlstm pc
+
+vlldm pc
+// ERRT2: error: operand must be a register in range [r0, r14]
+// ERRT2-NEXT: vlldm pc
\ No newline at end of file
diff --git a/llvm/test/MC/Disassembler/ARM/armv8.1m-vlldm_vlstm-8.1.main.txt b/llvm/test/MC/Disassembler/ARM/armv8.1m-vlldm_vlstm-8.1.main.txt
new file mode 100644
index 00000000000000..6b9882454c06a3
--- /dev/null
+++ b/llvm/test/MC/Disassembler/ARM/armv8.1m-vlldm_vlstm-8.1.main.txt
@@ -0,0 +1,11 @@
+// RUN: llvm-mc -triple=armv8.1m.main-arm-none-eabi -mcpu=generic -show-encoding -disassemble %s \
+// RUN: | FileCheck %s --check-prefixes=CHECK-DISS
+
+// RUN: llvm-mc -triple=thumbv8.1m.main-none-eabi -mcpu=generic -show-encoding -disassemble %s \
+// RUN: | FileCheck %s --check-prefixes=CHECK-DISS
+
+[0x28,0xec,0x80,0x0a]
+// CHECK-DISS: vlstm r8, {d0 - d31} @ encoding: [0x28,0xec,0x80,0x0a]
+
+[0x38,0xec,0x80,0x0a]
+// CHECK-DISS: vlldm r8, {d0 - d31} @ encoding: [0x38,0xec,0x80,0x0a]
\ No newline at end of file
diff --git a/llvm/test/MC/Disassembler/ARM/armv8.1m-vlldm_vlstm-8.main.txt b/llvm/test/MC/Disassembler/ARM/armv8.1m-vlldm_vlstm-8.main.txt
new file mode 100644
index 00000000000000..1e28d5284c5b2a
--- /dev/null
+++ b/llvm/test/MC/Disassembler/ARM/armv8.1m-vlldm_vlstm-8.main.txt
@@ -0,0 +1,17 @@
+// RUN: llvm-mc -triple=armv8m.main-arm-none-eabi -mcpu=generic -show-encoding -disassemble %s \
+// RUN: | FileCheck %s --check-prefixes=CHECK-DISS
+
+// RUN: llvm-mc -triple=thumbv8m.main-none-eabi -mcpu=generic -show-encoding -disassemble %s \
+// RUN: | FileCheck %s --check-prefixes=CHECK-DISS
+
+[0x28,0xec,0x00,0x0a]
+// CHECK-DISS: vlstm r8, {d0 - d15} @ encoding: [0x28,0xec,0x00,0x0a]
+
+[0x38,0xec,0x00,0x0a]
+// CHECK-DISS: vlldm r8, {d0 - d15} @ encoding: [0x38,0xec,0x00,0x0a]
+
+[0x28,0xec,0x00,0x0a]
+// CHECK-DISS: vlstm r8, {d0 - d15} @ encoding: [0x28,0xec,0x00,0x0a]
+
+[0x38,0xec,0x00,0x0a]
+// CHECK-DISS: vlldm r8, {d0 - d15} @ encoding: [0x38,0xec,0x00,0x0a]
\ No newline at end of file
diff --git a/llvm/unittests/Target/ARM/MachineInstrTest.cpp b/llvm/unittests/Target/ARM/MachineInstrTest.cpp
index aeb25bf012d034..3a76054ca4f36d 100644
--- a/llvm/unittests/Target/ARM/MachineInstrTest.cpp
+++ b/llvm/unittests/Target/ARM/MachineInstrTest.cpp
@@ -1126,7 +1126,9 @@ TEST(MachineInstr, HasSideEffects) {
VLDR_VPR_post,
VLDR_VPR_pre,
VLLDM,
+ VLLDM_T2,
VLSTM,
+ VLSTM_T2,
VMRS,
VMRS_FPCXTNS,
VMRS_FPCXTS,
>From 28162b7832b87c85faedfca661e47d60e74337e9 Mon Sep 17 00:00:00 2001
From: Leandro Lupori <leandro.lupori at linaro.org>
Date: Wed, 28 Feb 2024 14:04:23 -0300
Subject: [PATCH 017/406] [flang][OpenMP] Fix copyprivate test on ppc64le
---
flang/test/Integration/OpenMP/copyprivate.f90 | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/flang/test/Integration/OpenMP/copyprivate.f90 b/flang/test/Integration/OpenMP/copyprivate.f90
index 9318b743a95290..d32319a18c28bb 100644
--- a/flang/test/Integration/OpenMP/copyprivate.f90
+++ b/flang/test/Integration/OpenMP/copyprivate.f90
@@ -26,7 +26,7 @@
!CHECK-DAG: define void @_copy_box_ptr_Uxc8x9(ptr %{{.*}}, ptr %{{.*}})
!CHECK-LABEL: define void @_copy_i32(
-!CHECK-SAME: ptr %[[DST:.*]], ptr %[[SRC:.*]]) {
+!CHECK-SAME: ptr %[[DST:.*]], ptr %[[SRC:.*]]){{.*}} {
!CHECK-NEXT: %[[SRC_VAL:.*]] = load i32, ptr %[[SRC]]
!CHECK-NEXT: store i32 %[[SRC_VAL]], ptr %[[DST]]
!CHECK-NEXT: ret void
>From 95e036956f0a610027907df9a8f99d1f3c3b4cf5 Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?Timm=20B=C3=A4der?= <tbaeder at redhat.com>
Date: Wed, 28 Feb 2024 16:14:49 +0100
Subject: [PATCH 018/406] [clang][Interp] Note UB when converting Inf to
integer
The F.isFinite() check here was introduced back when the first
floating point implementation was pushed, but I don't think it's
necessary and it fixes the attached test case.
---
clang/lib/AST/Interp/Interp.h | 2 +-
clang/test/AST/Interp/cxx20.cpp | 9 +++++++++
2 files changed, 10 insertions(+), 1 deletion(-)
diff --git a/clang/lib/AST/Interp/Interp.h b/clang/lib/AST/Interp/Interp.h
index 241d5941e143ee..13e004371f912c 100644
--- a/clang/lib/AST/Interp/Interp.h
+++ b/clang/lib/AST/Interp/Interp.h
@@ -1680,7 +1680,7 @@ bool CastFloatingIntegral(InterpState &S, CodePtr OpPC) {
auto Status = F.convertToInteger(Result);
// Float-to-Integral overflow check.
- if ((Status & APFloat::opStatus::opInvalidOp) && F.isFinite()) {
+ if ((Status & APFloat::opStatus::opInvalidOp)) {
const Expr *E = S.Current->getExpr(OpPC);
QualType Type = E->getType();
diff --git a/clang/test/AST/Interp/cxx20.cpp b/clang/test/AST/Interp/cxx20.cpp
index 2c28e53784c5c6..000ffe39eb94a7 100644
--- a/clang/test/AST/Interp/cxx20.cpp
+++ b/clang/test/AST/Interp/cxx20.cpp
@@ -765,3 +765,12 @@ namespace FailingDestructor {
f<D{0, false}>(); // both-error {{no matching function}}
}
}
+
+
+void overflowInSwitchCase(int n) {
+ switch (n) {
+ case (int)(float)1e300: // both-error {{constant expression}} \
+ // both-note {{value +Inf is outside the range of representable values of type 'int'}}
+ break;
+ }
+}
>From b6f4dd9ee8cd4aa2c41622d75790df9341d9e043 Mon Sep 17 00:00:00 2001
From: srcarroll <50210727+srcarroll at users.noreply.github.com>
Date: Wed, 28 Feb 2024 11:19:06 -0600
Subject: [PATCH 019/406] [mlir][transform] Implement
`FlattenElementwiseLinalgOp` transform op (#81431)
A `transform.structured.flatten_elementwise` op is implemented for
flattening the iteration space and (applicable) operands/results to a
single dimension.
---
.../Linalg/TransformOps/LinalgTransformOps.td | 43 +++++++
.../Dialect/Linalg/Transforms/Transforms.h | 10 +-
.../TransformOps/LinalgTransformOps.cpp | 25 ++++
.../Linalg/Transforms/ElementwiseOpFusion.cpp | 114 ++++++++++--------
.../Dialect/Linalg/flatten-elementwise.mlir | 99 +++++++++++++++
5 files changed, 241 insertions(+), 50 deletions(-)
create mode 100644 mlir/test/Dialect/Linalg/flatten-elementwise.mlir
diff --git a/mlir/include/mlir/Dialect/Linalg/TransformOps/LinalgTransformOps.td b/mlir/include/mlir/Dialect/Linalg/TransformOps/LinalgTransformOps.td
index 309573a562872f..53ed31877c6f24 100644
--- a/mlir/include/mlir/Dialect/Linalg/TransformOps/LinalgTransformOps.td
+++ b/mlir/include/mlir/Dialect/Linalg/TransformOps/LinalgTransformOps.td
@@ -2295,6 +2295,49 @@ def ConvertConv2DToImg2ColOp : Op<Transform_Dialect,
}];
}
+//===----------------------------------------------------------------------===//
+// FlattenElementwiseLinalgOp
+//===----------------------------------------------------------------------===//
+
+def FlattenElementwiseLinalgOp : Op<Transform_Dialect,
+ "structured.flatten_elementwise",
+ [FunctionalStyleTransformOpTrait,
+ MemoryEffectsOpInterface,
+ TransformOpInterface,
+ TransformEachOpTrait,
+ ReportTrackingListenerFailuresOpTrait]> {
+ let description = [{
+ Flattens the iteration space and (applicable) operands of elementwise
+ linalg ops to a single dimension.
+
+ Returns one handle:
+ - Flattened linalg operation.
+
+ #### Return modes:
+
+ Returns a definite failure if target is not isolated from above.
+ Returns a silenceable failure if the pattern application failed.
+ }];
+
+ let arguments = (ins TransformHandleTypeInterface:$target);
+ let results = (outs TransformHandleTypeInterface:$transformed);
+
+ let assemblyFormat =
+ "$target attr-dict `:` functional-type($target, results)";
+
+ let builders = [
+ OpBuilder<(ins "Value":$target)>
+ ];
+
+ let extraClassDeclaration = [{
+ ::mlir::DiagnosedSilenceableFailure applyToOne(
+ ::mlir::transform::TransformRewriter &rewriter,
+ ::mlir::linalg::LinalgOp target,
+ ::mlir::transform::ApplyToEachResultList &results,
+ ::mlir::transform::TransformState &state);
+ }];
+}
+
//===----------------------------------------------------------------------===//
// Transpose Conv2D
//===----------------------------------------------------------------------===//
diff --git a/mlir/include/mlir/Dialect/Linalg/Transforms/Transforms.h b/mlir/include/mlir/Dialect/Linalg/Transforms/Transforms.h
index a848d12fbbb50e..65cf19e7a4fcd6 100644
--- a/mlir/include/mlir/Dialect/Linalg/Transforms/Transforms.h
+++ b/mlir/include/mlir/Dialect/Linalg/Transforms/Transforms.h
@@ -1074,6 +1074,11 @@ bool isDimSequencePreserved(AffineMap map, ReassociationIndicesRef dimSequence);
bool areDimSequencesPreserved(ArrayRef<AffineMap> maps,
ArrayRef<ReassociationIndices> dimSequences);
+struct CollapseResult {
+ SmallVector<Value> results;
+ LinalgOp collapsedOp;
+};
+
/// Collapses dimensions of linalg.generic/linalg.copy operation. A precondition
/// to calling this method is that for each list in `foldedIterationDim`, the
/// sequence of dimensions is contiguous in domains of all `indexing_maps` of
@@ -1081,9 +1086,8 @@ bool areDimSequencesPreserved(ArrayRef<AffineMap> maps,
/// When valid, the method also collapses the operands of the op. Returns
/// replacement values of the results of the original `linalgOp` by inserting
/// reshapes to get back values of compatible types.
-template <typename LinalgType>
-FailureOr<SmallVector<Value>>
-collapseOpIterationDims(LinalgType op,
+FailureOr<CollapseResult>
+collapseOpIterationDims(LinalgOp op,
ArrayRef<ReassociationIndices> foldedIterationDims,
RewriterBase &rewriter);
diff --git a/mlir/lib/Dialect/Linalg/TransformOps/LinalgTransformOps.cpp b/mlir/lib/Dialect/Linalg/TransformOps/LinalgTransformOps.cpp
index 299965bcfc3ab3..ef9cd5561665fc 100644
--- a/mlir/lib/Dialect/Linalg/TransformOps/LinalgTransformOps.cpp
+++ b/mlir/lib/Dialect/Linalg/TransformOps/LinalgTransformOps.cpp
@@ -3244,6 +3244,31 @@ DiagnosedSilenceableFailure transform::ConvertConv2DToImg2ColOp::applyToOne(
return DiagnosedSilenceableFailure::success();
}
+//===----------------------------------------------------------------------===//
+// FlattenElementwiseLinalgOp.
+//===----------------------------------------------------------------------===//
+
+DiagnosedSilenceableFailure transform::FlattenElementwiseLinalgOp::applyToOne(
+ transform::TransformRewriter &rewriter, linalg::LinalgOp target,
+ transform::ApplyToEachResultList &results,
+ transform::TransformState &state) {
+ rewriter.setInsertionPoint(target);
+ if (target.getNumLoops() <= 1)
+ return DiagnosedSilenceableFailure::success();
+ ReassociationIndices reassociation(target.getNumLoops());
+ std::iota(reassociation.begin(), reassociation.end(), 0);
+ auto maybeFlattened =
+ (isElementwise(target))
+ ? collapseOpIterationDims(target, reassociation, rewriter)
+ : FailureOr<CollapseResult>(rewriter.notifyMatchFailure(
+ target, "only elementwise flattening is supported"));
+ if (failed(maybeFlattened))
+ return emitDefaultSilenceableFailure(target);
+ results.push_back(maybeFlattened->collapsedOp);
+ rewriter.replaceOp(target, maybeFlattened->results);
+ return DiagnosedSilenceableFailure::success();
+}
+
//===----------------------------------------------------------------------===//
// TransposeConv2DOp
//===----------------------------------------------------------------------===//
diff --git a/mlir/lib/Dialect/Linalg/Transforms/ElementwiseOpFusion.cpp b/mlir/lib/Dialect/Linalg/Transforms/ElementwiseOpFusion.cpp
index 4977940cfbd797..4797bfb2267d7f 100644
--- a/mlir/lib/Dialect/Linalg/Transforms/ElementwiseOpFusion.cpp
+++ b/mlir/lib/Dialect/Linalg/Transforms/ElementwiseOpFusion.cpp
@@ -1446,24 +1446,20 @@ void generateCollapsedIndexingRegion(Location loc, Block *block,
}
}
-template <typename LinalgType>
-Operation *createCollapsedOp(LinalgType op,
- const CollapsingInfo &collapsingInfo,
- RewriterBase &rewriter) {
- static_assert(llvm::is_one_of<LinalgType, GenericOp, CopyOp>::value,
- "unsupported linalg op type to create");
+void collapseOperandsAndResults(LinalgOp op,
+ const CollapsingInfo &collapsingInfo,
+ RewriterBase &rewriter,
+ SmallVectorImpl<Value> &inputOperands,
+ SmallVectorImpl<Value> &outputOperands,
+ SmallVectorImpl<Type> &resultTypes) {
Location loc = op->getLoc();
-
- // Get the input operands.
- SmallVector<Value> inputOperands =
+ inputOperands =
llvm::map_to_vector(op.getDpsInputOperands(), [&](OpOperand *opOperand) {
return getCollapsedOpOperand(loc, op, opOperand, collapsingInfo,
rewriter);
});
// Get the output operands and result types.
- SmallVector<Type> resultTypes;
- SmallVector<Value> outputOperands;
resultTypes.reserve(op.getNumDpsInits());
outputOperands.reserve(op.getNumDpsInits());
for (OpOperand &output : op.getDpsInitsMutable()) {
@@ -1475,41 +1471,69 @@ Operation *createCollapsedOp(LinalgType op,
if (!op.hasPureBufferSemantics())
resultTypes.push_back(newOutput.getType());
}
+}
- if (isa<linalg::CopyOp>(op)) {
- return rewriter.create<linalg::CopyOp>(loc, inputOperands[0],
- outputOperands[0]);
- }
+/// Clone a `LinalgOp` to a collapsed version of same name
+template <typename OpTy>
+OpTy cloneToCollapsedOp(RewriterBase &rewriter, OpTy origOp,
+ const CollapsingInfo &collapsingInfo) {
+ return nullptr;
+}
- // Get the iterator types for the operand.
- SmallVector<utils::IteratorType> iteratorTypes =
- getCollapsedOpIteratorTypes(op.getIteratorTypesArray(), collapsingInfo);
+/// Collapse any `LinalgOp` that does not require any specialization such as
+/// indexing_maps, iterator_types, etc.
+template <>
+LinalgOp cloneToCollapsedOp<LinalgOp>(RewriterBase &rewriter, LinalgOp origOp,
+ const CollapsingInfo &collapsingInfo) {
+ SmallVector<Value> inputOperands, outputOperands;
+ SmallVector<Type> resultTypes;
+ collapseOperandsAndResults(origOp, collapsingInfo, rewriter, inputOperands,
+ outputOperands, resultTypes);
+ return cast<LinalgOp>(clone(
+ rewriter, origOp, resultTypes,
+ llvm::to_vector(llvm::concat<Value>(inputOperands, outputOperands))));
+}
- // Get the indexing maps.
- auto indexingMaps =
- llvm::map_to_vector(op.getIndexingMapsArray(), [&](AffineMap map) {
+/// Collapse a `GenericOp`
+template <>
+GenericOp cloneToCollapsedOp<GenericOp>(RewriterBase &rewriter,
+ GenericOp origOp,
+ const CollapsingInfo &collapsingInfo) {
+ SmallVector<Value> inputOperands, outputOperands;
+ SmallVector<Type> resultTypes;
+ collapseOperandsAndResults(origOp, collapsingInfo, rewriter, inputOperands,
+ outputOperands, resultTypes);
+ SmallVector<AffineMap> indexingMaps(
+ llvm::map_range(origOp.getIndexingMapsArray(), [&](AffineMap map) {
return getCollapsedOpIndexingMap(map, collapsingInfo);
- });
+ }));
+
+ SmallVector<utils::IteratorType> iteratorTypes(getCollapsedOpIteratorTypes(
+ origOp.getIteratorTypesArray(), collapsingInfo));
- Operation *collapsedOp = rewriter.create<linalg::GenericOp>(
- loc, resultTypes, inputOperands, outputOperands, indexingMaps,
+ GenericOp collapsedOp = rewriter.create<linalg::GenericOp>(
+ origOp.getLoc(), resultTypes, inputOperands, outputOperands, indexingMaps,
iteratorTypes, [](OpBuilder &builder, Location loc, ValueRange args) {});
- Block *origOpBlock = &op->getRegion(0).front();
+ Block *origOpBlock = &origOp->getRegion(0).front();
Block *collapsedOpBlock = &collapsedOp->getRegion(0).front();
rewriter.mergeBlocks(origOpBlock, collapsedOpBlock,
collapsedOpBlock->getArguments());
-
return collapsedOp;
}
+LinalgOp createCollapsedOp(LinalgOp op, const CollapsingInfo &collapsingInfo,
+ RewriterBase &rewriter) {
+ if (GenericOp genericOp = dyn_cast<GenericOp>(op.getOperation())) {
+ return cloneToCollapsedOp(rewriter, genericOp, collapsingInfo);
+ } else {
+ return cloneToCollapsedOp(rewriter, op, collapsingInfo);
+ }
+}
+
/// Implementation of fusion with reshape operation by collapsing dimensions.
-template <typename LinalgType>
-FailureOr<SmallVector<Value>> mlir::linalg::collapseOpIterationDims(
- LinalgType op, ArrayRef<ReassociationIndices> foldedIterationDims,
+FailureOr<CollapseResult> mlir::linalg::collapseOpIterationDims(
+ LinalgOp op, ArrayRef<ReassociationIndices> foldedIterationDims,
RewriterBase &rewriter) {
- static_assert(llvm::is_one_of<LinalgType, GenericOp, CopyOp>::value,
- "unsupported linalg op type to collapse");
-
// Bail on trivial no-op cases.
if (op.getNumLoops() <= 1 || foldedIterationDims.empty() ||
llvm::all_of(foldedIterationDims, [](ReassociationIndicesRef foldedDims) {
@@ -1538,8 +1562,7 @@ FailureOr<SmallVector<Value>> mlir::linalg::collapseOpIterationDims(
}
// Bail on non-canonical ranges.
- SmallVector<Range> loopRanges =
- cast<LinalgOp>(op.getOperation()).createLoopRanges(rewriter, op.getLoc());
+ SmallVector<Range> loopRanges = op.createLoopRanges(rewriter, op.getLoc());
auto opFoldIsConstantValue = [](OpFoldResult ofr, int64_t value) {
if (auto attr = llvm::dyn_cast_if_present<Attribute>(ofr))
return cast<IntegerAttr>(attr).getInt() == value;
@@ -1555,8 +1578,7 @@ FailureOr<SmallVector<Value>> mlir::linalg::collapseOpIterationDims(
op, "expected all loop ranges to have zero start and unit stride");
}
- LinalgType collapsedOp = cast<LinalgType>(
- createCollapsedOp<LinalgType>(op, collapsingInfo, rewriter));
+ LinalgOp collapsedOp = createCollapsedOp(op, collapsingInfo, rewriter);
Location loc = op->getLoc();
if (collapsedOp.hasIndexSemantics()) {
@@ -1597,7 +1619,7 @@ FailureOr<SmallVector<Value>> mlir::linalg::collapseOpIterationDims(
results.push_back(collapsedOpResult);
}
}
- return results;
+ return CollapseResult{results, collapsedOp};
}
namespace {
@@ -1629,15 +1651,14 @@ class FoldWithProducerReshapeOpByCollapsing
continue;
}
- std::optional<SmallVector<Value>> replacements =
- collapseOpIterationDims<linalg::GenericOp>(
- genericOp, collapsableIterationDims, rewriter);
- if (!replacements) {
+ std::optional<CollapseResult> collapseResult = collapseOpIterationDims(
+ genericOp, collapsableIterationDims, rewriter);
+ if (!collapseResult) {
return rewriter.notifyMatchFailure(
genericOp, "failed to do the fusion by collapsing transformation");
}
- rewriter.replaceOp(genericOp, *replacements);
+ rewriter.replaceOp(genericOp, collapseResult->results);
return success();
}
return failure();
@@ -1671,13 +1692,12 @@ class CollapseLinalgDimensions : public OpRewritePattern<LinalgType> {
op, "specified dimensions cannot be collapsed");
}
- std::optional<SmallVector<Value>> replacements =
- collapseOpIterationDims<LinalgType>(op, collapsableIterationDims,
- rewriter);
- if (!replacements) {
+ std::optional<CollapseResult> collapseResult =
+ collapseOpIterationDims(op, collapsableIterationDims, rewriter);
+ if (!collapseResult) {
return rewriter.notifyMatchFailure(op, "failed to collapse dimensions");
}
- rewriter.replaceOp(op, *replacements);
+ rewriter.replaceOp(op, collapseResult->results);
return success();
}
diff --git a/mlir/test/Dialect/Linalg/flatten-elementwise.mlir b/mlir/test/Dialect/Linalg/flatten-elementwise.mlir
new file mode 100644
index 00000000000000..858c133dd536ca
--- /dev/null
+++ b/mlir/test/Dialect/Linalg/flatten-elementwise.mlir
@@ -0,0 +1,99 @@
+// RUN: mlir-opt %s -transform-interpreter -split-input-file | FileCheck %s
+
+// CHECK-LABEL: func.func @fill(
+// CHECK-SAME: %[[ARG0:.*]]: f32,
+// CHECK-SAME: %[[ARG1:.*]]: memref<32x7xf32>
+// CHECK-NEXT: %[[FLATTENED:.*]] = memref.collapse_shape %[[ARG1]] {{\[}}[0, 1]]
+// CHECK-NEXT: linalg.fill ins(%[[ARG0]] : f32) outs(%[[FLATTENED]] : memref<224xf32>)
+func.func @fill(%cst: f32, %arg: memref<32x7xf32>) {
+ linalg.fill ins(%cst: f32) outs(%arg: memref<32x7xf32>)
+ return
+}
+
+module attributes {transform.with_named_sequence} {
+ transform.named_sequence @__transform_main(%arg1: !transform.any_op {transform.readonly}) {
+ %0 = transform.structured.match interface{LinalgOp} in %arg1 : (!transform.any_op) -> !transform.any_op
+ %flattened = transform.structured.flatten_elementwise %0
+ : (!transform.any_op) -> !transform.any_op
+ transform.yield
+ }
+}
+
+// -----
+
+// CHECK-LABEL: func.func @fill_tensor(
+// CHECK-SAME: %[[ARG0:.*]]: f32,
+// CHECK-SAME: %[[ARG1:.*]]: tensor<32x7xf32>
+// CHECK-NEXT: %[[FLATTENED:.*]] = tensor.collapse_shape %[[ARG1]] {{\[}}[0, 1]]
+// CHECK-NEXT: %[[FLATTENED_RESULT:.*]] = linalg.fill ins(%[[ARG0]] : f32) outs(%[[FLATTENED]] : tensor<224xf32>)
+// CHECK-NEXT: %[[RESULT:.*]] = tensor.expand_shape %[[FLATTENED_RESULT]] {{\[}}[0, 1]]
+func.func @fill_tensor(%cst: f32, %arg: tensor<32x7xf32>) -> tensor<32x7xf32> {
+ %0 = linalg.fill ins(%cst: f32) outs(%arg: tensor<32x7xf32>) -> tensor<32x7xf32>
+ return %0 : tensor<32x7xf32>
+}
+
+module attributes {transform.with_named_sequence} {
+ transform.named_sequence @__transform_main(%arg1: !transform.any_op {transform.readonly}) {
+ %0 = transform.structured.match interface{LinalgOp} in %arg1 : (!transform.any_op) -> !transform.any_op
+ %flattened = transform.structured.flatten_elementwise %0
+ : (!transform.any_op) -> !transform.any_op
+ transform.yield
+ }
+}
+
+// -----
+
+// CHECK-LABEL: func.func @map(
+// CHECK-SAME: %[[ARG0:[a-zA-Z0-9_]*]]: memref<32x7xf32>
+// CHECK-SAME: %[[ARG1:[a-zA-Z0-9_]*]]: memref<32x7xf32>
+// CHECK-SAME: %[[ARG2:[a-zA-Z0-9_]*]]: memref<32x7xf32>
+// CHECK-NEXT: %[[FLATTENED_0:.*]] = memref.collapse_shape %[[ARG0]] {{\[}}[0, 1]]
+// CHECK-NEXT: %[[FLATTENED_1:.*]] = memref.collapse_shape %[[ARG1]] {{\[}}[0, 1]]
+// CHECK-NEXT: %[[FLATTENED_2:.*]] = memref.collapse_shape %[[ARG2]] {{\[}}[0, 1]]
+// CHECK-NEXT: linalg.map { arith.addf } ins(%[[FLATTENED_0]], %[[FLATTENED_1]] : memref<224xf32>, memref<224xf32>) outs(%[[FLATTENED_2]] : memref<224xf32>)
+func.func @map(%arg0: memref<32x7xf32>, %arg1: memref<32x7xf32>, %arg2: memref<32x7xf32>) {
+ linalg.map {arith.addf} ins(%arg0, %arg1: memref<32x7xf32>, memref<32x7xf32>) outs(%arg2: memref<32x7xf32>)
+ return
+}
+
+module attributes {transform.with_named_sequence} {
+ transform.named_sequence @__transform_main(%arg1: !transform.any_op {transform.readonly}) {
+ %0 = transform.structured.match interface{LinalgOp} in %arg1 : (!transform.any_op) -> !transform.any_op
+ %flattened = transform.structured.flatten_elementwise %0
+ : (!transform.any_op) -> !transform.any_op
+ transform.yield
+ }
+}
+
+// -----
+
+// CHECK: #[[$MAP0:.*]] = affine_map<(d0) -> (d0)>
+// CHECK-LABEL: func.func @generic
+// CHECK-SAME: %[[ARG0:[a-zA-Z0-9_]*]]: memref<32x7xf32>
+// CHECK-SAME: %[[ARG1:[a-zA-Z0-9_]*]]: memref<32x7xf32>
+// CHECK-SAME: %[[ARG2:[a-zA-Z0-9_]*]]: memref<32x7xf32>
+// CHECK-NEXT: %[[FLATTENED_0:.*]] = memref.collapse_shape %[[ARG0]] {{\[}}[0, 1]]
+// CHECK-NEXT: %[[FLATTENED_1:.*]] = memref.collapse_shape %[[ARG1]] {{\[}}[0, 1]]
+// CHECK-NEXT: %[[FLATTENED_2:.*]] = memref.collapse_shape %[[ARG2]] {{\[}}[0, 1]]
+// CHECK-NEXT: linalg.generic {indexing_maps = [#[[$MAP0]], #[[$MAP0]], #[[$MAP0]]], iterator_types = ["parallel"]} ins(%[[FLATTENED_0]], %[[FLATTENED_1]] : memref<224xf32>, memref<224xf32>) outs(%[[FLATTENED_2]] : memref<224xf32>)
+// CHECK-NEXT: ^bb0(%[[A:.*]]: f32, %[[B:.*]]: f32, %[[C:.*]]: f32)
+// CHECK-NEXT: %[[SUM:.*]] = arith.addf %[[A]], %[[B]]
+// CHECK-NEXT: linalg.yield %[[SUM]]
+#map = affine_map<(d0, d1) -> (d0, d1)>
+func.func @generic( %arg0: memref<32x7xf32>, %arg1: memref<32x7xf32>, %arg2: memref<32x7xf32>) {
+ linalg.generic {indexing_maps = [#map, #map, #map], iterator_types = ["parallel", "parallel"]} ins(%arg0, %arg1: memref<32x7xf32>, memref<32x7xf32>) outs(%arg2: memref<32x7xf32>) {
+ ^bb0(%a: f32, %b: f32, %c: f32):
+ %0 = arith.addf %a, %b : f32
+ linalg.yield %0 : f32
+ }
+ return
+}
+
+module attributes {transform.with_named_sequence} {
+ transform.named_sequence @__transform_main(%arg1: !transform.any_op {transform.readonly}) {
+ %0 = transform.structured.match interface{LinalgOp} in %arg1 : (!transform.any_op) -> !transform.any_op
+ %flattened = transform.structured.flatten_elementwise %0
+ : (!transform.any_op) -> !transform.any_op
+ transform.yield
+ }
+}
>From 15b6908afa9b74ae62821ff44179d659277eef69 Mon Sep 17 00:00:00 2001
From: Paul T Robinson <paul.robinson at sony.com>
Date: Wed, 28 Feb 2024 09:36:28 -0800
Subject: [PATCH 020/406] [Headers][X86] Make brief descriptions briefer
(#82422)
In Sony's document processing, the first "paragraph" of the description
is duplicated into a Brief Description section. Add paragraph breaks to make
those brief descriptions less verbose.
In fmaintrin.h we were including the \code blocks, which are
inappropriate for a brief description. While I was in there, change
\code to \code{.operation} which the Intel document processing wants.
---
clang/lib/Headers/emmintrin.h | 121 +++++++++++++------------
clang/lib/Headers/fmaintrin.h | 48 ++++++----
clang/lib/Headers/mmintrin.h | 148 +++++++++++++++----------------
clang/lib/Headers/prfchwintrin.h | 16 ++--
clang/lib/Headers/smmintrin.h | 20 ++---
clang/lib/Headers/tmmintrin.h | 36 ++++----
6 files changed, 201 insertions(+), 188 deletions(-)
diff --git a/clang/lib/Headers/emmintrin.h b/clang/lib/Headers/emmintrin.h
index 96e3ebdecbdf83..1d451b5f5b25de 100644
--- a/clang/lib/Headers/emmintrin.h
+++ b/clang/lib/Headers/emmintrin.h
@@ -2099,9 +2099,11 @@ static __inline__ __m128i __DEFAULT_FN_ATTRS _mm_add_epi64(__m128i __a,
}
/// Adds, with saturation, the corresponding elements of two 128-bit
-/// signed [16 x i8] vectors, saving each sum in the corresponding element of
-/// a 128-bit result vector of [16 x i8]. Positive sums greater than 0x7F are
-/// saturated to 0x7F. Negative sums less than 0x80 are saturated to 0x80.
+/// signed [16 x i8] vectors, saving each sum in the corresponding element
+/// of a 128-bit result vector of [16 x i8].
+///
+/// Positive sums greater than 0x7F are saturated to 0x7F. Negative sums
+/// less than 0x80 are saturated to 0x80.
///
/// \headerfile <x86intrin.h>
///
@@ -2119,10 +2121,11 @@ static __inline__ __m128i __DEFAULT_FN_ATTRS _mm_adds_epi8(__m128i __a,
}
/// Adds, with saturation, the corresponding elements of two 128-bit
-/// signed [8 x i16] vectors, saving each sum in the corresponding element of
-/// a 128-bit result vector of [8 x i16]. Positive sums greater than 0x7FFF
-/// are saturated to 0x7FFF. Negative sums less than 0x8000 are saturated to
-/// 0x8000.
+/// signed [8 x i16] vectors, saving each sum in the corresponding element
+/// of a 128-bit result vector of [8 x i16].
+///
+/// Positive sums greater than 0x7FFF are saturated to 0x7FFF. Negative sums
+/// less than 0x8000 are saturated to 0x8000.
///
/// \headerfile <x86intrin.h>
///
@@ -2141,8 +2144,10 @@ static __inline__ __m128i __DEFAULT_FN_ATTRS _mm_adds_epi16(__m128i __a,
/// Adds, with saturation, the corresponding elements of two 128-bit
/// unsigned [16 x i8] vectors, saving each sum in the corresponding element
-/// of a 128-bit result vector of [16 x i8]. Positive sums greater than 0xFF
-/// are saturated to 0xFF. Negative sums are saturated to 0x00.
+/// of a 128-bit result vector of [16 x i8].
+///
+/// Positive sums greater than 0xFF are saturated to 0xFF. Negative sums are
+/// saturated to 0x00.
///
/// \headerfile <x86intrin.h>
///
@@ -2161,8 +2166,10 @@ static __inline__ __m128i __DEFAULT_FN_ATTRS _mm_adds_epu8(__m128i __a,
/// Adds, with saturation, the corresponding elements of two 128-bit
/// unsigned [8 x i16] vectors, saving each sum in the corresponding element
-/// of a 128-bit result vector of [8 x i16]. Positive sums greater than
-/// 0xFFFF are saturated to 0xFFFF. Negative sums are saturated to 0x0000.
+/// of a 128-bit result vector of [8 x i16].
+///
+/// Positive sums greater than 0xFFFF are saturated to 0xFFFF. Negative sums
+/// are saturated to 0x0000.
///
/// \headerfile <x86intrin.h>
///
@@ -2518,10 +2525,12 @@ static __inline__ __m128i __DEFAULT_FN_ATTRS _mm_sub_epi64(__m128i __a,
return (__m128i)((__v2du)__a - (__v2du)__b);
}
-/// Subtracts corresponding 8-bit signed integer values in the input and
-/// returns the differences in the corresponding bytes in the destination.
-/// Differences greater than 0x7F are saturated to 0x7F, and differences less
-/// than 0x80 are saturated to 0x80.
+/// Subtracts, with saturation, corresponding 8-bit signed integer values in
+/// the input and returns the differences in the corresponding bytes in the
+/// destination.
+///
+/// Differences greater than 0x7F are saturated to 0x7F, and differences
+/// less than 0x80 are saturated to 0x80.
///
/// \headerfile <x86intrin.h>
///
@@ -2538,8 +2547,10 @@ static __inline__ __m128i __DEFAULT_FN_ATTRS _mm_subs_epi8(__m128i __a,
return (__m128i)__builtin_elementwise_sub_sat((__v16qs)__a, (__v16qs)__b);
}
-/// Subtracts corresponding 16-bit signed integer values in the input and
-/// returns the differences in the corresponding bytes in the destination.
+/// Subtracts, with saturation, corresponding 16-bit signed integer values in
+/// the input and returns the differences in the corresponding bytes in the
+/// destination.
+///
/// Differences greater than 0x7FFF are saturated to 0x7FFF, and values less
/// than 0x8000 are saturated to 0x8000.
///
@@ -2558,9 +2569,11 @@ static __inline__ __m128i __DEFAULT_FN_ATTRS _mm_subs_epi16(__m128i __a,
return (__m128i)__builtin_elementwise_sub_sat((__v8hi)__a, (__v8hi)__b);
}
-/// Subtracts corresponding 8-bit unsigned integer values in the input
-/// and returns the differences in the corresponding bytes in the
-/// destination. Differences less than 0x00 are saturated to 0x00.
+/// Subtracts, with saturation, corresponding 8-bit unsigned integer values in
+/// the input and returns the differences in the corresponding bytes in the
+/// destination.
+///
+/// Differences less than 0x00 are saturated to 0x00.
///
/// \headerfile <x86intrin.h>
///
@@ -2577,9 +2590,11 @@ static __inline__ __m128i __DEFAULT_FN_ATTRS _mm_subs_epu8(__m128i __a,
return (__m128i)__builtin_elementwise_sub_sat((__v16qu)__a, (__v16qu)__b);
}
-/// Subtracts corresponding 16-bit unsigned integer values in the input
-/// and returns the differences in the corresponding bytes in the
-/// destination. Differences less than 0x0000 are saturated to 0x0000.
+/// Subtracts, with saturation, corresponding 16-bit unsigned integer values in
+/// the input and returns the differences in the corresponding bytes in the
+/// destination.
+///
+/// Differences less than 0x0000 are saturated to 0x0000.
///
/// \headerfile <x86intrin.h>
///
@@ -4050,26 +4065,22 @@ void _mm_mfence(void);
} // extern "C"
#endif
-/// Converts 16-bit signed integers from both 128-bit integer vector
-/// operands into 8-bit signed integers, and packs the results into the
-/// destination. Positive values greater than 0x7F are saturated to 0x7F.
-/// Negative values less than 0x80 are saturated to 0x80.
+/// Converts, with saturation, 16-bit signed integers from both 128-bit integer
+/// vector operands into 8-bit signed integers, and packs the results into
+/// the destination.
+///
+/// Positive values greater than 0x7F are saturated to 0x7F. Negative values
+/// less than 0x80 are saturated to 0x80.
///
/// \headerfile <x86intrin.h>
///
/// This intrinsic corresponds to the <c> VPACKSSWB / PACKSSWB </c> instruction.
///
/// \param __a
-/// A 128-bit integer vector of [8 x i16]. Each 16-bit element is treated as
-/// a signed integer and is converted to a 8-bit signed integer with
-/// saturation. Values greater than 0x7F are saturated to 0x7F. Values less
-/// than 0x80 are saturated to 0x80. The converted [8 x i8] values are
+/// A 128-bit integer vector of [8 x i16]. The converted [8 x i8] values are
/// written to the lower 64 bits of the result.
/// \param __b
-/// A 128-bit integer vector of [8 x i16]. Each 16-bit element is treated as
-/// a signed integer and is converted to a 8-bit signed integer with
-/// saturation. Values greater than 0x7F are saturated to 0x7F. Values less
-/// than 0x80 are saturated to 0x80. The converted [8 x i8] values are
+/// A 128-bit integer vector of [8 x i16]. The converted [8 x i8] values are
/// written to the higher 64 bits of the result.
/// \returns A 128-bit vector of [16 x i8] containing the converted values.
static __inline__ __m128i __DEFAULT_FN_ATTRS _mm_packs_epi16(__m128i __a,
@@ -4077,26 +4088,22 @@ static __inline__ __m128i __DEFAULT_FN_ATTRS _mm_packs_epi16(__m128i __a,
return (__m128i)__builtin_ia32_packsswb128((__v8hi)__a, (__v8hi)__b);
}
-/// Converts 32-bit signed integers from both 128-bit integer vector
-/// operands into 16-bit signed integers, and packs the results into the
-/// destination. Positive values greater than 0x7FFF are saturated to 0x7FFF.
-/// Negative values less than 0x8000 are saturated to 0x8000.
+/// Converts, with saturation, 32-bit signed integers from both 128-bit integer
+/// vector operands into 16-bit signed integers, and packs the results into
+/// the destination.
+///
+/// Positive values greater than 0x7FFF are saturated to 0x7FFF. Negative
+/// values less than 0x8000 are saturated to 0x8000.
///
/// \headerfile <x86intrin.h>
///
/// This intrinsic corresponds to the <c> VPACKSSDW / PACKSSDW </c> instruction.
///
/// \param __a
-/// A 128-bit integer vector of [4 x i32]. Each 32-bit element is treated as
-/// a signed integer and is converted to a 16-bit signed integer with
-/// saturation. Values greater than 0x7FFF are saturated to 0x7FFF. Values
-/// less than 0x8000 are saturated to 0x8000. The converted [4 x i16] values
+/// A 128-bit integer vector of [4 x i32]. The converted [4 x i16] values
/// are written to the lower 64 bits of the result.
/// \param __b
-/// A 128-bit integer vector of [4 x i32]. Each 32-bit element is treated as
-/// a signed integer and is converted to a 16-bit signed integer with
-/// saturation. Values greater than 0x7FFF are saturated to 0x7FFF. Values
-/// less than 0x8000 are saturated to 0x8000. The converted [4 x i16] values
+/// A 128-bit integer vector of [4 x i32]. The converted [4 x i16] values
/// are written to the higher 64 bits of the result.
/// \returns A 128-bit vector of [8 x i16] containing the converted values.
static __inline__ __m128i __DEFAULT_FN_ATTRS _mm_packs_epi32(__m128i __a,
@@ -4104,26 +4111,22 @@ static __inline__ __m128i __DEFAULT_FN_ATTRS _mm_packs_epi32(__m128i __a,
return (__m128i)__builtin_ia32_packssdw128((__v4si)__a, (__v4si)__b);
}
-/// Converts 16-bit signed integers from both 128-bit integer vector
-/// operands into 8-bit unsigned integers, and packs the results into the
-/// destination. Values greater than 0xFF are saturated to 0xFF. Values less
-/// than 0x00 are saturated to 0x00.
+/// Converts, with saturation, 16-bit signed integers from both 128-bit integer
+/// vector operands into 8-bit unsigned integers, and packs the results into
+/// the destination.
+///
+/// Values greater than 0xFF are saturated to 0xFF. Values less than 0x00
+/// are saturated to 0x00.
///
/// \headerfile <x86intrin.h>
///
/// This intrinsic corresponds to the <c> VPACKUSWB / PACKUSWB </c> instruction.
///
/// \param __a
-/// A 128-bit integer vector of [8 x i16]. Each 16-bit element is treated as
-/// a signed integer and is converted to an 8-bit unsigned integer with
-/// saturation. Values greater than 0xFF are saturated to 0xFF. Values less
-/// than 0x00 are saturated to 0x00. The converted [8 x i8] values are
+/// A 128-bit integer vector of [8 x i16]. The converted [8 x i8] values are
/// written to the lower 64 bits of the result.
/// \param __b
-/// A 128-bit integer vector of [8 x i16]. Each 16-bit element is treated as
-/// a signed integer and is converted to an 8-bit unsigned integer with
-/// saturation. Values greater than 0xFF are saturated to 0xFF. Values less
-/// than 0x00 are saturated to 0x00. The converted [8 x i8] values are
+/// A 128-bit integer vector of [8 x i16]. The converted [8 x i8] values are
/// written to the higher 64 bits of the result.
/// \returns A 128-bit vector of [16 x i8] containing the converted values.
static __inline__ __m128i __DEFAULT_FN_ATTRS _mm_packus_epi16(__m128i __a,
diff --git a/clang/lib/Headers/fmaintrin.h b/clang/lib/Headers/fmaintrin.h
index ea832fac4f9922..22d1a780bbfd4e 100644
--- a/clang/lib/Headers/fmaintrin.h
+++ b/clang/lib/Headers/fmaintrin.h
@@ -60,7 +60,8 @@ _mm_fmadd_pd(__m128d __A, __m128d __B, __m128d __C)
/// Computes a scalar multiply-add of the single-precision values in the
/// low 32 bits of 128-bit vectors of [4 x float].
-/// \code
+///
+/// \code{.operation}
/// result[31:0] = (__A[31:0] * __B[31:0]) + __C[31:0]
/// result[127:32] = __A[127:32]
/// \endcode
@@ -88,7 +89,8 @@ _mm_fmadd_ss(__m128 __A, __m128 __B, __m128 __C)
/// Computes a scalar multiply-add of the double-precision values in the
/// low 64 bits of 128-bit vectors of [2 x double].
-/// \code
+///
+/// \code{.operation}
/// result[63:0] = (__A[63:0] * __B[63:0]) + __C[63:0]
/// result[127:64] = __A[127:64]
/// \endcode
@@ -156,7 +158,8 @@ _mm_fmsub_pd(__m128d __A, __m128d __B, __m128d __C)
/// Computes a scalar multiply-subtract of the single-precision values in
/// the low 32 bits of 128-bit vectors of [4 x float].
-/// \code
+///
+/// \code{.operation}
/// result[31:0] = (__A[31:0] * __B[31:0]) - __C[31:0]
/// result[127:32] = __A[127:32]
/// \endcode
@@ -184,7 +187,8 @@ _mm_fmsub_ss(__m128 __A, __m128 __B, __m128 __C)
/// Computes a scalar multiply-subtract of the double-precision values in
/// the low 64 bits of 128-bit vectors of [2 x double].
-/// \code
+///
+/// \code{.operation}
/// result[63:0] = (__A[63:0] * __B[63:0]) - __C[63:0]
/// result[127:64] = __A[127:64]
/// \endcode
@@ -252,7 +256,8 @@ _mm_fnmadd_pd(__m128d __A, __m128d __B, __m128d __C)
/// Computes a scalar negated multiply-add of the single-precision values in
/// the low 32 bits of 128-bit vectors of [4 x float].
-/// \code
+///
+/// \code{.operation}
/// result[31:0] = -(__A[31:0] * __B[31:0]) + __C[31:0]
/// result[127:32] = __A[127:32]
/// \endcode
@@ -280,7 +285,8 @@ _mm_fnmadd_ss(__m128 __A, __m128 __B, __m128 __C)
/// Computes a scalar negated multiply-add of the double-precision values
/// in the low 64 bits of 128-bit vectors of [2 x double].
-/// \code
+///
+/// \code{.operation}
/// result[63:0] = -(__A[63:0] * __B[63:0]) + __C[63:0]
/// result[127:64] = __A[127:64]
/// \endcode
@@ -348,7 +354,8 @@ _mm_fnmsub_pd(__m128d __A, __m128d __B, __m128d __C)
/// Computes a scalar negated multiply-subtract of the single-precision
/// values in the low 32 bits of 128-bit vectors of [4 x float].
-/// \code
+///
+/// \code{.operation}
/// result[31:0] = -(__A[31:0] * __B[31:0]) - __C[31:0]
/// result[127:32] = __A[127:32]
/// \endcode
@@ -376,7 +383,8 @@ _mm_fnmsub_ss(__m128 __A, __m128 __B, __m128 __C)
/// Computes a scalar negated multiply-subtract of the double-precision
/// values in the low 64 bits of 128-bit vectors of [2 x double].
-/// \code
+///
+/// \code{.operation}
/// result[63:0] = -(__A[63:0] * __B[63:0]) - __C[63:0]
/// result[127:64] = __A[127:64]
/// \endcode
@@ -404,7 +412,8 @@ _mm_fnmsub_sd(__m128d __A, __m128d __B, __m128d __C)
/// Computes a multiply with alternating add/subtract of 128-bit vectors of
/// [4 x float].
-/// \code
+///
+/// \code{.operation}
/// result[31:0] = (__A[31:0] * __B[31:0]) - __C[31:0]
/// result[63:32] = (__A[63:32] * __B[63:32]) + __C[63:32]
/// result[95:64] = (__A[95:64] * __B[95:64]) - __C[95:64]
@@ -430,7 +439,8 @@ _mm_fmaddsub_ps(__m128 __A, __m128 __B, __m128 __C)
/// Computes a multiply with alternating add/subtract of 128-bit vectors of
/// [2 x double].
-/// \code
+///
+/// \code{.operation}
/// result[63:0] = (__A[63:0] * __B[63:0]) - __C[63:0]
/// result[127:64] = (__A[127:64] * __B[127:64]) + __C[127:64]
/// \endcode
@@ -454,7 +464,8 @@ _mm_fmaddsub_pd(__m128d __A, __m128d __B, __m128d __C)
/// Computes a multiply with alternating add/subtract of 128-bit vectors of
/// [4 x float].
-/// \code
+///
+/// \code{.operation}
/// result[31:0] = (__A[31:0] * __B[31:0]) + __C[31:0]
/// result[63:32] = (__A[63:32] * __B[63:32]) - __C[63:32]
/// result[95:64] = (__A[95:64] * __B[95:64]) + __C[95:64]
@@ -480,7 +491,8 @@ _mm_fmsubadd_ps(__m128 __A, __m128 __B, __m128 __C)
/// Computes a multiply with alternating add/subtract of 128-bit vectors of
/// [2 x double].
-/// \code
+///
+/// \code{.operation}
/// result[63:0] = (__A[63:0] * __B[63:0]) + __C[63:0]
/// result[127:64] = (__A[127:64] * __B[127:64]) - __C[127:64]
/// \endcode
@@ -664,7 +676,8 @@ _mm256_fnmsub_pd(__m256d __A, __m256d __B, __m256d __C)
/// Computes a multiply with alternating add/subtract of 256-bit vectors of
/// [8 x float].
-/// \code
+///
+/// \code{.operation}
/// result[31:0] = (__A[31:0] * __B[31:0]) - __C[31:0]
/// result[63:32] = (__A[63:32] * __B[63:32]) + __C[63:32]
/// result[95:64] = (__A[95:64] * __B[95:64]) - __C[95:64]
@@ -694,7 +707,8 @@ _mm256_fmaddsub_ps(__m256 __A, __m256 __B, __m256 __C)
/// Computes a multiply with alternating add/subtract of 256-bit vectors of
/// [4 x double].
-/// \code
+///
+/// \code{.operation}
/// result[63:0] = (__A[63:0] * __B[63:0]) - __C[63:0]
/// result[127:64] = (__A[127:64] * __B[127:64]) + __C[127:64]
/// result[191:128] = (__A[191:128] * __B[191:128]) - __C[191:128]
@@ -720,7 +734,8 @@ _mm256_fmaddsub_pd(__m256d __A, __m256d __B, __m256d __C)
/// Computes a vector multiply with alternating add/subtract of 256-bit
/// vectors of [8 x float].
-/// \code
+///
+/// \code{.operation}
/// result[31:0] = (__A[31:0] * __B[31:0]) + __C[31:0]
/// result[63:32] = (__A[63:32] * __B[63:32]) - __C[63:32]
/// result[95:64] = (__A[95:64] * __B[95:64]) + __C[95:64]
@@ -750,7 +765,8 @@ _mm256_fmsubadd_ps(__m256 __A, __m256 __B, __m256 __C)
/// Computes a vector multiply with alternating add/subtract of 256-bit
/// vectors of [4 x double].
-/// \code
+///
+/// \code{.operation}
/// result[63:0] = (__A[63:0] * __B[63:0]) + __C[63:0]
/// result[127:64] = (__A[127:64] * __B[127:64]) - __C[127:64]
/// result[191:128] = (__A[191:128] * __B[191:128]) + __C[191:128]
diff --git a/clang/lib/Headers/mmintrin.h b/clang/lib/Headers/mmintrin.h
index 08849f01071aea..962d24738e7aa4 100644
--- a/clang/lib/Headers/mmintrin.h
+++ b/clang/lib/Headers/mmintrin.h
@@ -105,28 +105,23 @@ _mm_cvtm64_si64(__m64 __m)
return (long long)__m;
}
-/// Converts 16-bit signed integers from both 64-bit integer vector
-/// parameters of [4 x i16] into 8-bit signed integer values, and constructs
-/// a 64-bit integer vector of [8 x i8] as the result. Positive values
-/// greater than 0x7F are saturated to 0x7F. Negative values less than 0x80
-/// are saturated to 0x80.
+/// Converts, with saturation, 16-bit signed integers from both 64-bit integer
+/// vector parameters of [4 x i16] into 8-bit signed integer values, and
+/// constructs a 64-bit integer vector of [8 x i8] as the result.
+///
+/// Positive values greater than 0x7F are saturated to 0x7F. Negative values
+/// less than 0x80 are saturated to 0x80.
///
/// \headerfile <x86intrin.h>
///
/// This intrinsic corresponds to the <c> PACKSSWB </c> instruction.
///
/// \param __m1
-/// A 64-bit integer vector of [4 x i16]. Each 16-bit element is treated as a
-/// 16-bit signed integer and is converted to an 8-bit signed integer with
-/// saturation. Positive values greater than 0x7F are saturated to 0x7F.
-/// Negative values less than 0x80 are saturated to 0x80. The converted
-/// [4 x i8] values are written to the lower 32 bits of the result.
+/// A 64-bit integer vector of [4 x i16]. The converted [4 x i8] values are
+/// written to the lower 32 bits of the result.
/// \param __m2
-/// A 64-bit integer vector of [4 x i16]. Each 16-bit element is treated as a
-/// 16-bit signed integer and is converted to an 8-bit signed integer with
-/// saturation. Positive values greater than 0x7F are saturated to 0x7F.
-/// Negative values less than 0x80 are saturated to 0x80. The converted
-/// [4 x i8] values are written to the upper 32 bits of the result.
+/// A 64-bit integer vector of [4 x i16]. The converted [4 x i8] values are
+/// written to the upper 32 bits of the result.
/// \returns A 64-bit integer vector of [8 x i8] containing the converted
/// values.
static __inline__ __m64 __DEFAULT_FN_ATTRS
@@ -135,28 +130,23 @@ _mm_packs_pi16(__m64 __m1, __m64 __m2)
return (__m64)__builtin_ia32_packsswb((__v4hi)__m1, (__v4hi)__m2);
}
-/// Converts 32-bit signed integers from both 64-bit integer vector
-/// parameters of [2 x i32] into 16-bit signed integer values, and constructs
-/// a 64-bit integer vector of [4 x i16] as the result. Positive values
-/// greater than 0x7FFF are saturated to 0x7FFF. Negative values less than
-/// 0x8000 are saturated to 0x8000.
+/// Converts, with saturation, 32-bit signed integers from both 64-bit integer
+/// vector parameters of [2 x i32] into 16-bit signed integer values, and
+/// constructs a 64-bit integer vector of [4 x i16] as the result.
+///
+/// Positive values greater than 0x7FFF are saturated to 0x7FFF. Negative
+/// values less than 0x8000 are saturated to 0x8000.
///
/// \headerfile <x86intrin.h>
///
/// This intrinsic corresponds to the <c> PACKSSDW </c> instruction.
///
/// \param __m1
-/// A 64-bit integer vector of [2 x i32]. Each 32-bit element is treated as a
-/// 32-bit signed integer and is converted to a 16-bit signed integer with
-/// saturation. Positive values greater than 0x7FFF are saturated to 0x7FFF.
-/// Negative values less than 0x8000 are saturated to 0x8000. The converted
-/// [2 x i16] values are written to the lower 32 bits of the result.
+/// A 64-bit integer vector of [2 x i32]. The converted [2 x i16] values are
+/// written to the lower 32 bits of the result.
/// \param __m2
-/// A 64-bit integer vector of [2 x i32]. Each 32-bit element is treated as a
-/// 32-bit signed integer and is converted to a 16-bit signed integer with
-/// saturation. Positive values greater than 0x7FFF are saturated to 0x7FFF.
-/// Negative values less than 0x8000 are saturated to 0x8000. The converted
-/// [2 x i16] values are written to the upper 32 bits of the result.
+/// A 64-bit integer vector of [2 x i32]. The converted [2 x i16] values are
+/// written to the upper 32 bits of the result.
/// \returns A 64-bit integer vector of [4 x i16] containing the converted
/// values.
static __inline__ __m64 __DEFAULT_FN_ATTRS
@@ -165,28 +155,23 @@ _mm_packs_pi32(__m64 __m1, __m64 __m2)
return (__m64)__builtin_ia32_packssdw((__v2si)__m1, (__v2si)__m2);
}
-/// Converts 16-bit signed integers from both 64-bit integer vector
-/// parameters of [4 x i16] into 8-bit unsigned integer values, and
-/// constructs a 64-bit integer vector of [8 x i8] as the result. Values
-/// greater than 0xFF are saturated to 0xFF. Values less than 0 are saturated
-/// to 0.
+/// Converts, with saturation, 16-bit signed integers from both 64-bit integer
+/// vector parameters of [4 x i16] into 8-bit unsigned integer values, and
+/// constructs a 64-bit integer vector of [8 x i8] as the result.
+///
+/// Values greater than 0xFF are saturated to 0xFF. Values less than 0 are
+/// saturated to 0.
///
/// \headerfile <x86intrin.h>
///
/// This intrinsic corresponds to the <c> PACKUSWB </c> instruction.
///
/// \param __m1
-/// A 64-bit integer vector of [4 x i16]. Each 16-bit element is treated as a
-/// 16-bit signed integer and is converted to an 8-bit unsigned integer with
-/// saturation. Values greater than 0xFF are saturated to 0xFF. Values less
-/// than 0 are saturated to 0. The converted [4 x i8] values are written to
-/// the lower 32 bits of the result.
+/// A 64-bit integer vector of [4 x i16]. The converted [4 x i8] values are
+/// written to the lower 32 bits of the result.
/// \param __m2
-/// A 64-bit integer vector of [4 x i16]. Each 16-bit element is treated as a
-/// 16-bit signed integer and is converted to an 8-bit unsigned integer with
-/// saturation. Values greater than 0xFF are saturated to 0xFF. Values less
-/// than 0 are saturated to 0. The converted [4 x i8] values are written to
-/// the upper 32 bits of the result.
+/// A 64-bit integer vector of [4 x i16]. The converted [4 x i8] values are
+/// written to the upper 32 bits of the result.
/// \returns A 64-bit integer vector of [8 x i8] containing the converted
/// values.
static __inline__ __m64 __DEFAULT_FN_ATTRS
@@ -400,11 +385,13 @@ _mm_add_pi32(__m64 __m1, __m64 __m2)
return (__m64)__builtin_ia32_paddd((__v2si)__m1, (__v2si)__m2);
}
-/// Adds each 8-bit signed integer element of the first 64-bit integer
-/// vector of [8 x i8] to the corresponding 8-bit signed integer element of
-/// the second 64-bit integer vector of [8 x i8]. Positive sums greater than
-/// 0x7F are saturated to 0x7F. Negative sums less than 0x80 are saturated to
-/// 0x80. The results are packed into a 64-bit integer vector of [8 x i8].
+/// Adds, with saturation, each 8-bit signed integer element of the first
+/// 64-bit integer vector of [8 x i8] to the corresponding 8-bit signed
+/// integer element of the second 64-bit integer vector of [8 x i8].
+///
+/// Positive sums greater than 0x7F are saturated to 0x7F. Negative sums
+/// less than 0x80 are saturated to 0x80. The results are packed into a
+/// 64-bit integer vector of [8 x i8].
///
/// \headerfile <x86intrin.h>
///
@@ -422,12 +409,13 @@ _mm_adds_pi8(__m64 __m1, __m64 __m2)
return (__m64)__builtin_ia32_paddsb((__v8qi)__m1, (__v8qi)__m2);
}
-/// Adds each 16-bit signed integer element of the first 64-bit integer
-/// vector of [4 x i16] to the corresponding 16-bit signed integer element of
-/// the second 64-bit integer vector of [4 x i16]. Positive sums greater than
-/// 0x7FFF are saturated to 0x7FFF. Negative sums less than 0x8000 are
-/// saturated to 0x8000. The results are packed into a 64-bit integer vector
-/// of [4 x i16].
+/// Adds, with saturation, each 16-bit signed integer element of the first
+/// 64-bit integer vector of [4 x i16] to the corresponding 16-bit signed
+/// integer element of the second 64-bit integer vector of [4 x i16].
+///
+/// Positive sums greater than 0x7FFF are saturated to 0x7FFF. Negative sums
+/// less than 0x8000 are saturated to 0x8000. The results are packed into a
+/// 64-bit integer vector of [4 x i16].
///
/// \headerfile <x86intrin.h>
///
@@ -445,11 +433,12 @@ _mm_adds_pi16(__m64 __m1, __m64 __m2)
return (__m64)__builtin_ia32_paddsw((__v4hi)__m1, (__v4hi)__m2);
}
-/// Adds each 8-bit unsigned integer element of the first 64-bit integer
-/// vector of [8 x i8] to the corresponding 8-bit unsigned integer element of
-/// the second 64-bit integer vector of [8 x i8]. Sums greater than 0xFF are
-/// saturated to 0xFF. The results are packed into a 64-bit integer vector of
-/// [8 x i8].
+/// Adds, with saturation, each 8-bit unsigned integer element of the first
+/// 64-bit integer vector of [8 x i8] to the corresponding 8-bit unsigned
+/// integer element of the second 64-bit integer vector of [8 x i8].
+///
+/// Sums greater than 0xFF are saturated to 0xFF. The results are packed
+/// into a 64-bit integer vector of [8 x i8].
///
/// \headerfile <x86intrin.h>
///
@@ -467,11 +456,12 @@ _mm_adds_pu8(__m64 __m1, __m64 __m2)
return (__m64)__builtin_ia32_paddusb((__v8qi)__m1, (__v8qi)__m2);
}
-/// Adds each 16-bit unsigned integer element of the first 64-bit integer
-/// vector of [4 x i16] to the corresponding 16-bit unsigned integer element
-/// of the second 64-bit integer vector of [4 x i16]. Sums greater than
-/// 0xFFFF are saturated to 0xFFFF. The results are packed into a 64-bit
-/// integer vector of [4 x i16].
+/// Adds, with saturation, each 16-bit unsigned integer element of the first
+/// 64-bit integer vector of [4 x i16] to the corresponding 16-bit unsigned
+/// integer element of the second 64-bit integer vector of [4 x i16].
+///
+/// Sums greater than 0xFFFF are saturated to 0xFFFF. The results are packed
+/// into a 64-bit integer vector of [4 x i16].
///
/// \headerfile <x86intrin.h>
///
@@ -552,12 +542,13 @@ _mm_sub_pi32(__m64 __m1, __m64 __m2)
return (__m64)__builtin_ia32_psubd((__v2si)__m1, (__v2si)__m2);
}
-/// Subtracts each 8-bit signed integer element of the second 64-bit
-/// integer vector of [8 x i8] from the corresponding 8-bit signed integer
-/// element of the first 64-bit integer vector of [8 x i8]. Positive results
-/// greater than 0x7F are saturated to 0x7F. Negative results less than 0x80
-/// are saturated to 0x80. The results are packed into a 64-bit integer
-/// vector of [8 x i8].
+/// Subtracts, with saturation, each 8-bit signed integer element of the second
+/// 64-bit integer vector of [8 x i8] from the corresponding 8-bit signed
+/// integer element of the first 64-bit integer vector of [8 x i8].
+///
+/// Positive results greater than 0x7F are saturated to 0x7F. Negative
+/// results less than 0x80 are saturated to 0x80. The results are packed
+/// into a 64-bit integer vector of [8 x i8].
///
/// \headerfile <x86intrin.h>
///
@@ -575,12 +566,13 @@ _mm_subs_pi8(__m64 __m1, __m64 __m2)
return (__m64)__builtin_ia32_psubsb((__v8qi)__m1, (__v8qi)__m2);
}
-/// Subtracts each 16-bit signed integer element of the second 64-bit
-/// integer vector of [4 x i16] from the corresponding 16-bit signed integer
-/// element of the first 64-bit integer vector of [4 x i16]. Positive results
-/// greater than 0x7FFF are saturated to 0x7FFF. Negative results less than
-/// 0x8000 are saturated to 0x8000. The results are packed into a 64-bit
-/// integer vector of [4 x i16].
+/// Subtracts, with saturation, each 16-bit signed integer element of the
+/// second 64-bit integer vector of [4 x i16] from the corresponding 16-bit
+/// signed integer element of the first 64-bit integer vector of [4 x i16].
+///
+/// Positive results greater than 0x7FFF are saturated to 0x7FFF. Negative
+/// results less than 0x8000 are saturated to 0x8000. The results are packed
+/// into a 64-bit integer vector of [4 x i16].
///
/// \headerfile <x86intrin.h>
///
diff --git a/clang/lib/Headers/prfchwintrin.h b/clang/lib/Headers/prfchwintrin.h
index d2f91aa0123e0e..8a13784543c5f1 100644
--- a/clang/lib/Headers/prfchwintrin.h
+++ b/clang/lib/Headers/prfchwintrin.h
@@ -15,9 +15,10 @@
#define __PRFCHWINTRIN_H
/// Loads a memory sequence containing the specified memory address into
-/// all data cache levels. The cache-coherency state is set to exclusive.
-/// Data can be read from and written to the cache line without additional
-/// delay.
+/// all data cache levels.
+///
+/// The cache-coherency state is set to exclusive. Data can be read from
+/// and written to the cache line without additional delay.
///
/// \headerfile <x86intrin.h>
///
@@ -32,10 +33,11 @@ _m_prefetch(void *__P)
}
/// Loads a memory sequence containing the specified memory address into
-/// the L1 data cache and sets the cache-coherency to modified. This
-/// provides a hint to the processor that the cache line will be modified.
-/// It is intended for use when the cache line will be written to shortly
-/// after the prefetch is performed.
+/// the L1 data cache and sets the cache-coherency state to modified.
+///
+/// This provides a hint to the processor that the cache line will be
+/// modified. It is intended for use when the cache line will be written to
+/// shortly after the prefetch is performed.
///
/// Note that the effect of this intrinsic is dependent on the processor
/// implementation.
diff --git a/clang/lib/Headers/smmintrin.h b/clang/lib/Headers/smmintrin.h
index 005d7db9c3c308..c52ffb77e33d5c 100644
--- a/clang/lib/Headers/smmintrin.h
+++ b/clang/lib/Headers/smmintrin.h
@@ -1431,8 +1431,10 @@ static __inline__ __m128i __DEFAULT_FN_ATTRS _mm_cvtepu32_epi64(__m128i __V) {
}
/* SSE4 Pack with Unsigned Saturation. */
-/// Converts 32-bit signed integers from both 128-bit integer vector
-/// operands into 16-bit unsigned integers, and returns the packed result.
+/// Converts, with saturation, 32-bit signed integers from both 128-bit integer
+/// vector operands into 16-bit unsigned integers, and returns the packed
+/// result.
+///
/// Values greater than 0xFFFF are saturated to 0xFFFF. Values less than
/// 0x0000 are saturated to 0x0000.
///
@@ -1441,17 +1443,11 @@ static __inline__ __m128i __DEFAULT_FN_ATTRS _mm_cvtepu32_epi64(__m128i __V) {
/// This intrinsic corresponds to the <c> VPACKUSDW / PACKUSDW </c> instruction.
///
/// \param __V1
-/// A 128-bit vector of [4 x i32]. Each 32-bit element is treated as a
-/// signed integer and is converted to a 16-bit unsigned integer with
-/// saturation. Values greater than 0xFFFF are saturated to 0xFFFF. Values
-/// less than 0x0000 are saturated to 0x0000. The converted [4 x i16] values
-/// are written to the lower 64 bits of the result.
+/// A 128-bit vector of [4 x i32]. The converted [4 x i16] values are
+/// written to the lower 64 bits of the result.
/// \param __V2
-/// A 128-bit vector of [4 x i32]. Each 32-bit element is treated as a
-/// signed integer and is converted to a 16-bit unsigned integer with
-/// saturation. Values greater than 0xFFFF are saturated to 0xFFFF. Values
-/// less than 0x0000 are saturated to 0x0000. The converted [4 x i16] values
-/// are written to the higher 64 bits of the result.
+/// A 128-bit vector of [4 x i32]. The converted [4 x i16] values are
+/// written to the higher 64 bits of the result.
/// \returns A 128-bit vector of [8 x i16] containing the converted values.
static __inline__ __m128i __DEFAULT_FN_ATTRS _mm_packus_epi32(__m128i __V1,
__m128i __V2) {
diff --git a/clang/lib/Headers/tmmintrin.h b/clang/lib/Headers/tmmintrin.h
index 7d8dc46c57bfeb..bf8327b692d1cf 100644
--- a/clang/lib/Headers/tmmintrin.h
+++ b/clang/lib/Headers/tmmintrin.h
@@ -271,10 +271,11 @@ _mm_hadd_pi32(__m64 __a, __m64 __b)
return (__m64)__builtin_ia32_phaddd((__v2si)__a, (__v2si)__b);
}
-/// Horizontally adds the adjacent pairs of values contained in 2 packed
-/// 128-bit vectors of [8 x i16]. Positive sums greater than 0x7FFF are
-/// saturated to 0x7FFF. Negative sums less than 0x8000 are saturated to
-/// 0x8000.
+/// Horizontally adds, with saturation, the adjacent pairs of values contained
+/// in two packed 128-bit vectors of [8 x i16].
+///
+/// Positive sums greater than 0x7FFF are saturated to 0x7FFF. Negative sums
+/// less than 0x8000 are saturated to 0x8000.
///
/// \headerfile <x86intrin.h>
///
@@ -296,10 +297,11 @@ _mm_hadds_epi16(__m128i __a, __m128i __b)
return (__m128i)__builtin_ia32_phaddsw128((__v8hi)__a, (__v8hi)__b);
}
-/// Horizontally adds the adjacent pairs of values contained in 2 packed
-/// 64-bit vectors of [4 x i16]. Positive sums greater than 0x7FFF are
-/// saturated to 0x7FFF. Negative sums less than 0x8000 are saturated to
-/// 0x8000.
+/// Horizontally adds, with saturation, the adjacent pairs of values contained
+/// in two packed 64-bit vectors of [4 x i16].
+///
+/// Positive sums greater than 0x7FFF are saturated to 0x7FFF. Negative sums
+/// less than 0x8000 are saturated to 0x8000.
///
/// \headerfile <x86intrin.h>
///
@@ -413,10 +415,11 @@ _mm_hsub_pi32(__m64 __a, __m64 __b)
return (__m64)__builtin_ia32_phsubd((__v2si)__a, (__v2si)__b);
}
-/// Horizontally subtracts the adjacent pairs of values contained in 2
-/// packed 128-bit vectors of [8 x i16]. Positive differences greater than
-/// 0x7FFF are saturated to 0x7FFF. Negative differences less than 0x8000 are
-/// saturated to 0x8000.
+/// Horizontally subtracts, with saturation, the adjacent pairs of values
+/// contained in two packed 128-bit vectors of [8 x i16].
+///
+/// Positive differences greater than 0x7FFF are saturated to 0x7FFF.
+/// Negative differences less than 0x8000 are saturated to 0x8000.
///
/// \headerfile <x86intrin.h>
///
@@ -438,10 +441,11 @@ _mm_hsubs_epi16(__m128i __a, __m128i __b)
return (__m128i)__builtin_ia32_phsubsw128((__v8hi)__a, (__v8hi)__b);
}
-/// Horizontally subtracts the adjacent pairs of values contained in 2
-/// packed 64-bit vectors of [4 x i16]. Positive differences greater than
-/// 0x7FFF are saturated to 0x7FFF. Negative differences less than 0x8000 are
-/// saturated to 0x8000.
+/// Horizontally subtracts, with saturation, the adjacent pairs of values
+/// contained in two packed 64-bit vectors of [4 x i16].
+///
+/// Positive differences greater than 0x7FFF are saturated to 0x7FFF.
+/// Negative differences less than 0x8000 are saturated to 0x8000.
///
/// \headerfile <x86intrin.h>
///
>From 9da9b5f86750fc5286a89cc75f5f731affec7dfa Mon Sep 17 00:00:00 2001
From: Michael Jones <michaelrj at google.com>
Date: Wed, 28 Feb 2024 09:43:44 -0800
Subject: [PATCH 021/406] [libc][docs] Document policy for non-standard func
(#83212)
As encountered with <sys/queue.h>, we need a policy for how to handle
implementing functions that users need, but has no specific standard. In
that case, we should treat existing implementations as the standard and
try to match their behavior as best as possible.
---
libc/docs/dev/undefined_behavior.rst | 3 ++-
1 file changed, 2 insertions(+), 1 deletion(-)
diff --git a/libc/docs/dev/undefined_behavior.rst b/libc/docs/dev/undefined_behavior.rst
index 0cb25c7f2a2336..6e73a305e8e054 100644
--- a/libc/docs/dev/undefined_behavior.rst
+++ b/libc/docs/dev/undefined_behavior.rst
@@ -20,6 +20,7 @@ guidelines and the resulting code should behave predictably even in unexpected
situations.
#. Follow the standards.
+ #. If there is no standard, first ask yourself if this implementation is necessary (are there users who need this functionality?). If it truly is, then match existing implementations. Creating competing designs just causes confusion (see the history of qsort_r).
#. Avoid giving an incorrect answer.
#. In general, correct answer > correct answer (wrong format) > no answer > crash the program >>>>>>> incorrect answer.
#. The C library is called frequently in performance critical situations, and so can't afford to do thorough error checking and correction.
@@ -61,7 +62,7 @@ Often the standard will imply an intended behavior through what it states is und
Ignoring Bug-For-Bug Compatibility
----------------------------------
-Any long running implementations will have bugs and deviations from the standard. Hyrum's Law states that “all observable behaviors of your system will be depended on by somebody” which includes these bugs. An example of a long-standing bug is glibc's scanf float parsing behavior. The behavior is specifically defined in the standard, but it isn't adhered to by all libc implementations. There is a longstanding bug in glibc where it incorrectly parses the string 100er and this caused the C standard to add that specific example to the definition for scanf. The intended behavior is for scanf, when parsing a float, to parse the longest possibly valid prefix and then accept it if and only if that complete parsed value is a float. In the case of 100er the longest possibly valid prefix is 100e but the float parsed from that string is only 100. Since there is no number after the e it shouldn't be included in the float, so scanf should return a parsing error. For LLVM's libc it was decided to follow the standard, even though glibc's version is slightly simpler to implement and this edge case is rare. Following the standard must be the first priority, since that's the goal of the library.
+Any long running implementations will have bugs and deviations from the standard. Hyrum's Law states that “all observable behaviors of your system will be depended on by somebody” which includes these bugs. An example of a long-standing bug is glibc's scanf float parsing behavior. The behavior is specifically defined in the standard, but it isn't adhered to by all libc implementations. There is a longstanding bug in glibc where it incorrectly parses the string 100er and this caused the C standard to add that specific example to the definition for scanf. The intended behavior is for scanf, when parsing a float, to parse the longest possibly valid prefix and then accept it if and only if that complete parsed value is a float. In the case of 100er the longest possibly valid prefix is 100e but the float parsed from that string is only 100. Since there is no number after the e it shouldn't be included in the float, so scanf should return a parsing error. For LLVM's libc it was decided to follow the standard, even though glibc's version is slightly simpler to implement and this edge case is rare. Following the standard must be the first priority, since that's the goal of the library. If there is no standard, then matching another implementation (even bug-for-bug) may be necessary, but before you implement an unstandardized function first consider if anyone will actually use it at all.
Design Decisions
================
>From 46bd65a0509fefdf50d44f63640a7b8bd8ad0d14 Mon Sep 17 00:00:00 2001
From: Han-Chung Wang <hanhan0912 at gmail.com>
Date: Wed, 28 Feb 2024 09:45:09 -0800
Subject: [PATCH 022/406] [mlir][LinAlg] Vectorize reverse-like ops using
vector.gather ops. (#83205)
The reverse op is treated as a VectorMemoryAccessKind::Contiguous load.
It is contiguous slice, but we'll need to compute indices differently
and apply a reverse at vector level. It takes non-trivial efforts for
the approach. The revision flips the case to use vector.gather.
Otherwise there are functionality issues. E.g., the below example loaded
`2, 3, 4` (which is a bug), but what we want is `2, 1, 0`.
Before vectorization:
```mlir
func.func @vectorize_reverse_like_tensor_extract(%arg0: tensor<1x2x3xf32>, %arg1: tensor<1x1x3xf32>, %arg2: index) -> tensor<1x1x3xf32> {
%c1 = arith.constant 1 : index
%c0 = arith.constant 0 : index
%c2 = arith.constant 2 : index
%0 = linalg.generic {indexing_maps = [#map], iterator_types = ["parallel", "parallel", "parallel"]} outs(%arg1 : tensor<1x1x3xf32>) {
^bb0(%out: f32):
%1 = linalg.index 1 : index
%2 = linalg.index 0 : index
%3 = affine.apply #map1(%1, %2, %arg2)
%4 = linalg.index 2 : index
%5 = arith.subi %c2, %4 : index
%extracted = tensor.extract %arg0[%c0, %3, %5] : tensor<1x2x3xf32>
linalg.yield %extracted : f32
} -> tensor<1x1x3xf32>
return %0 : tensor<1x1x3xf32>
}
```
Partial IR after vectorization:
```
%5 = vector.constant_mask [1, 1, 3] : vector<1x1x4xi1>
%6 = vector.broadcast %arg0 : index to vector<1x1x4xindex>
%7 = vector.shape_cast %6 : vector<1x1x4xindex> to vector<4xindex>
%8 = vector.extractelement %7[%c0_i32 : i32] : vector<4xindex>
%9 = vector.transfer_read %3[%c0, %8, %c2], %cst, %5 {in_bounds = [true, true, true]} : tensor<1x2x3xf32>, vector<1x1x4xf32>
```
---
.../Linalg/Transforms/Vectorization.cpp | 3 +-
.../Linalg/vectorize-tensor-extract.mlir | 45 +++++++++++++++++++
2 files changed, 46 insertions(+), 2 deletions(-)
diff --git a/mlir/lib/Dialect/Linalg/Transforms/Vectorization.cpp b/mlir/lib/Dialect/Linalg/Transforms/Vectorization.cpp
index ac043e87223dfe..1e703dacfd0c75 100644
--- a/mlir/lib/Dialect/Linalg/Transforms/Vectorization.cpp
+++ b/mlir/lib/Dialect/Linalg/Transforms/Vectorization.cpp
@@ -891,8 +891,7 @@ static bool isContiguousLoadIdx(LinalgOp &linalgOp, Value &val,
// Conservatively reject Ops that could lead to indices with stride other
// than 1.
- if (!isa<arith::AddIOp, arith::SubIOp, arith::ConstantOp, linalg::IndexOp>(
- ancestor))
+ if (!isa<arith::AddIOp, arith::ConstantOp, linalg::IndexOp>(ancestor))
return false;
bool result = false;
diff --git a/mlir/test/Dialect/Linalg/vectorize-tensor-extract.mlir b/mlir/test/Dialect/Linalg/vectorize-tensor-extract.mlir
index 96953c234a0873..85e1c56dd45a0d 100644
--- a/mlir/test/Dialect/Linalg/vectorize-tensor-extract.mlir
+++ b/mlir/test/Dialect/Linalg/vectorize-tensor-extract.mlir
@@ -550,3 +550,48 @@ module attributes {transform.with_named_sequence} {
transform.yield
}
}
+
+// -----
+
+#map = affine_map<(d0, d1, d2) -> (d0, d1, d2)>
+#map1 = affine_map<(d0, d1, d2) -> (d0 + d1 + d2)>
+func.func @vectorize_reverse_like_tensor_extract(%arg0: tensor<1x2x3xf32>, %arg1: tensor<1x1x3xf32>, %arg2: index) -> tensor<1x1x3xf32> {
+ %c1 = arith.constant 1 : index
+ %c0 = arith.constant 0 : index
+ %c2 = arith.constant 2 : index
+ %0 = linalg.generic {indexing_maps = [#map], iterator_types = ["parallel", "parallel", "parallel"]} outs(%arg1 : tensor<1x1x3xf32>) {
+ ^bb0(%out: f32):
+ %1 = linalg.index 1 : index
+ %2 = linalg.index 0 : index
+ %3 = affine.apply #map1(%1, %2, %arg2)
+ %4 = linalg.index 2 : index
+ %5 = arith.subi %c2, %4 : index
+ %extracted = tensor.extract %arg0[%c0, %3, %5] : tensor<1x2x3xf32>
+ linalg.yield %extracted : f32
+ } -> tensor<1x1x3xf32>
+ return %0 : tensor<1x1x3xf32>
+}
+// CHECK-LABEL: func.func @vectorize_reverse_like_tensor_extract
+// CHECK-SAME: %[[ARG0:[0-9a-zA-Z]*]]
+// CHECK-SAME: %[[ARG1:[0-9a-zA-Z]*]]
+// CHECK-SAME: %[[ARG2:[0-9a-zA-Z]*]]
+// CHECK-DAG: %[[CST:.+]] = arith.constant dense<3> : vector<1x1x3xindex>
+// CHECK-DAG: %[[C0:.+]] = arith.constant 0 : index
+// CHECK-DAG: %[[MASK:.*]] = arith.constant dense<true> : vector<1x1x3xi1>
+// CHECK-DAG: %[[PASSTHRU:.*]] = arith.constant dense<0.000000e+00> : vector<1x1x3xf32>
+// CHECK-DAG: %[[INIT_IDX:.+]] = arith.constant dense<[2, 1, 0]> : vector<3xindex>
+// CHECK: %[[T0:.+]] = vector.broadcast %[[ARG2]] : index to vector<1x1x3xindex>
+// CHECK: %[[T1:.+]] = arith.muli %[[T0]], %[[CST]] : vector<1x1x3xindex>
+// CHECK: %[[T2:.+]] = vector.broadcast %[[INIT_IDX]]
+// CHECK: %[[T3:.+]] = arith.addi %[[T2]], %[[T1]]
+// CHECK: %[[GATHER:.*]] = vector.gather %[[ARG0]][%[[C0]], %[[C0]], %[[C0]]] [%[[T3]]], %[[MASK]], %[[PASSTHRU]]
+// CHECK: vector.transfer_write %[[GATHER]]
+
+module attributes {transform.with_named_sequence} {
+ transform.named_sequence @__transform_main(%arg1: !transform.any_op {transform.readonly}) {
+ %0 = transform.structured.match ops{["linalg.generic"]} in %arg1 : (!transform.any_op) -> !transform.any_op
+ %1 = transform.get_parent_op %0 {isolated_from_above} : (!transform.any_op) -> !transform.any_op
+ %2 = transform.structured.vectorize_children_and_apply_patterns %1 { vectorize_nd_extract } : (!transform.any_op) -> !transform.any_op
+ transform.yield
+ }
+}
>From ad43ea3328dad844c245caf93509c2facba1ec32 Mon Sep 17 00:00:00 2001
From: Jason Eckhardt <jeckhardt at nvidia.com>
Date: Wed, 28 Feb 2024 11:47:18 -0600
Subject: [PATCH 023/406] [TableGen] Add support for DefaultMode in per-HwMode
encode/decode. (#83029)
Currently the decoder and encoder emitters will crash if DefaultMode is
used within an EncodingByHwMode. As can be done today for
RegInfoByHwMode and ValueTypeByHwMode, this patch adds support for this
usage in EncodingByHwMode:
let EncodingInfos =
EncodingByHwMode<[ModeA, DefaultMode], [EncA, EncDefault]>;
---
llvm/test/TableGen/HwModeEncodeDecode3.td | 168 ++++++++++++++++++++++
llvm/utils/TableGen/CodeEmitterGen.cpp | 8 +-
llvm/utils/TableGen/CodeGenHwModes.h | 5 +
llvm/utils/TableGen/DecoderEmitter.cpp | 10 +-
4 files changed, 183 insertions(+), 8 deletions(-)
create mode 100644 llvm/test/TableGen/HwModeEncodeDecode3.td
diff --git a/llvm/test/TableGen/HwModeEncodeDecode3.td b/llvm/test/TableGen/HwModeEncodeDecode3.td
new file mode 100644
index 00000000000000..406e52d25be706
--- /dev/null
+++ b/llvm/test/TableGen/HwModeEncodeDecode3.td
@@ -0,0 +1,168 @@
+// RUN: llvm-tblgen -gen-emitter -I %p/../../include %s | \
+// RUN: FileCheck %s --check-prefix=ENCODER
+// RUN: llvm-tblgen -gen-disassembler -I %p/../../include %s | \
+// RUN: FileCheck %s --check-prefix=DECODER
+// RUN: llvm-tblgen -gen-disassembler --suppress-per-hwmode-duplicates -I \
+// RUN: %p/../../include %s | FileCheck %s --check-prefix=DECODER-SUPPRESS
+
+include "llvm/Target/Target.td"
+
+def archInstrInfo : InstrInfo { }
+
+def arch : Target {
+ let InstructionSet = archInstrInfo;
+}
+
+def Myi32 : Operand<i32> {
+ let DecoderMethod = "DecodeMyi32";
+}
+
+def HasA : Predicate<"Subtarget->hasA()">;
+def HasB : Predicate<"Subtarget->hasB()">;
+
+def ModeA : HwMode<"+a", [HasA]>;
+def ModeB : HwMode<"+b", [HasB]>;
+
+
+def fooTypeEncDefault : InstructionEncoding {
+ let Size = 8;
+ field bits<64> SoftFail = 0;
+ bits<64> Inst;
+ bits<8> factor;
+ let Inst{7...0} = factor;
+ let Inst{3...2} = 0b10;
+ let Inst{1...0} = 0b00;
+}
+
+def fooTypeEncA : InstructionEncoding {
+ let Size = 4;
+ field bits<32> SoftFail = 0;
+ bits<32> Inst;
+ bits<8> factor;
+ let Inst{7...0} = factor;
+ let Inst{3...2} = 0b11;
+ let Inst{1...0} = 0b00;
+}
+
+def fooTypeEncB : InstructionEncoding {
+ let Size = 4;
+ field bits<32> SoftFail = 0;
+ bits<32> Inst;
+ bits<8> factor;
+ let Inst{15...8} = factor;
+ let Inst{1...0} = 0b11;
+}
+
+// Test for DefaultMode as a selector.
+def foo : Instruction {
+ let OutOperandList = (outs);
+ let InOperandList = (ins i32imm:$factor);
+ let EncodingInfos = EncodingByHwMode<
+ [ModeA, ModeB, DefaultMode], [fooTypeEncA, fooTypeEncB, fooTypeEncDefault]
+ >;
+ let AsmString = "foo $factor";
+}
+
+def bar: Instruction {
+ let OutOperandList = (outs);
+ let InOperandList = (ins i32imm:$factor);
+ let Size = 4;
+ bits<32> Inst;
+ bits<32> SoftFail;
+ bits<8> factor;
+ let Inst{31...24} = factor;
+ let Inst{1...0} = 0b10;
+ let AsmString = "bar $factor";
+}
+
+def baz : Instruction {
+ let OutOperandList = (outs);
+ let InOperandList = (ins i32imm:$factor);
+ bits<32> Inst;
+ let EncodingInfos = EncodingByHwMode<
+ [ModeB], [fooTypeEncA]
+ >;
+ let AsmString = "foo $factor";
+}
+
+def unrelated: Instruction {
+ let OutOperandList = (outs);
+ let DecoderNamespace = "Alt";
+ let InOperandList = (ins i32imm:$factor);
+ let Size = 4;
+ bits<32> Inst;
+ bits<32> SoftFail;
+ bits<8> factor;
+ let Inst{31...24} = factor;
+ let Inst{1...0} = 0b10;
+ let AsmString = "unrelated $factor";
+}
+
+
+// DECODER-LABEL: DecoderTableAlt_DefaultMode32[] =
+// DECODER-DAG: Opcode: unrelated
+// DECODER-LABEL: DecoderTableAlt_ModeA32[] =
+// DECODER-DAG: Opcode: unrelated
+// DECODER-LABEL: DecoderTableAlt_ModeB32[] =
+// DECODER-DAG: Opcode: unrelated
+// DECODER-LABEL: DecoderTable_DefaultMode32[] =
+// DECODER-DAG: Opcode: bar
+// DECODER-LABEL: DecoderTable_DefaultMode64[] =
+// DECODER-DAG: Opcode: fooTypeEncDefault:foo
+// DECODER-LABEL: DecoderTable_ModeA32[] =
+// DECODER-DAG: Opcode: fooTypeEncA:foo
+// DECODER-DAG: Opcode: bar
+// DECODER-LABEL: DecoderTable_ModeB32[] =
+// DECODER-DAG: Opcode: fooTypeEncB:foo
+// DECODER-DAG: Opcode: fooTypeEncA:baz
+// DECODER-DAG: Opcode: bar
+
+
+// DECODER-SUPPRESS-LABEL: DecoderTableAlt_AllModes32[] =
+// DECODER-SUPPRESS-DAG: Opcode: unrelated
+// DECODER-SUPPRESS-LABEL: DecoderTable_AllModes32[] =
+// DECODER-SUPPRESS-DAG: Opcode: bar
+// DECODER-SUPPRESS-LABEL: DecoderTable_DefaultMode64[] =
+// DECODER-SUPPRESS-NOT: Opcode: bar
+// DECODER-SUPPRESS-DAG: Opcode: fooTypeEncDefault:foo
+// DECODER-SUPPRESS-LABEL: DecoderTable_ModeA32[] =
+// DECODER-SUPPRESS-DAG: Opcode: fooTypeEncA:foo
+// DECODER-SUPPRESS-NOT: Opcode: bar
+// DECODER-SUPPRESS-LABEL: DecoderTable_ModeB32[] =
+// DECODER-SUPPRESS-DAG: Opcode: fooTypeEncB:foo
+// DECODER-SUPPRESS-DAG: Opcode: fooTypeEncA:baz
+// DECODER-SUPPRESS-NOT: Opcode: bar
+
+// ENCODER-LABEL: static const uint64_t InstBits_DefaultMode[] = {
+// ENCODER: UINT64_C(2), // bar
+// ENCODER: UINT64_C(0), // baz
+// ENCODER: UINT64_C(8), // foo
+// ENCODER: UINT64_C(2), // unrelated
+
+// ENCODER-LABEL: static const uint64_t InstBits_ModeA[] = {
+// ENCODER: UINT64_C(2), // bar
+// ENCODER: UINT64_C(0), // baz
+// ENCODER: UINT64_C(12), // foo
+// ENCODER: UINT64_C(2), // unrelated
+
+// ENCODER-LABEL: static const uint64_t InstBits_ModeB[] = {
+// ENCODER: UINT64_C(2), // bar
+// ENCODER: UINT64_C(12), // baz
+// ENCODER: UINT64_C(3), // foo
+// ENCODER: UINT64_C(2), // unrelated
+
+// ENCODER: unsigned HwMode = STI.getHwMode();
+// ENCODER: switch (HwMode) {
+// ENCODER: default: llvm_unreachable("Unknown hardware mode!"); break;
+// ENCODER: case 0: InstBits = InstBits_DefaultMode; break;
+// ENCODER: case 1: InstBits = InstBits_ModeA; break;
+// ENCODER: case 2: InstBits = InstBits_ModeB; break;
+// ENCODER: };
+
+// ENCODER: case ::foo: {
+// ENCODER: switch (HwMode) {
+// ENCODER: default: llvm_unreachable("Unhandled HwMode");
+// ENCODER: case 0: {
+// ENCODER: case 1: {
+// ENCODER: case 2: {
+
diff --git a/llvm/utils/TableGen/CodeEmitterGen.cpp b/llvm/utils/TableGen/CodeEmitterGen.cpp
index d80761d5fe35d2..1e80eb6b1ad50e 100644
--- a/llvm/utils/TableGen/CodeEmitterGen.cpp
+++ b/llvm/utils/TableGen/CodeEmitterGen.cpp
@@ -365,8 +365,8 @@ void CodeEmitterGen::emitInstructionBaseValues(
if (HwMode == -1)
o << " static const uint64_t InstBits[] = {\n";
else
- o << " static const uint64_t InstBits_" << HWM.getMode(HwMode).Name
- << "[] = {\n";
+ o << " static const uint64_t InstBits_"
+ << HWM.getModeName(HwMode, /*IncludeDefault=*/true) << "[] = {\n";
for (const CodeGenInstruction *CGI : NumberedInstructions) {
Record *R = CGI->TheDef;
@@ -495,8 +495,8 @@ void CodeEmitterGen::run(raw_ostream &o) {
o << " switch (HwMode) {\n";
o << " default: llvm_unreachable(\"Unknown hardware mode!\"); break;\n";
for (unsigned I : HwModes) {
- o << " case " << I << ": InstBits = InstBits_" << HWM.getMode(I).Name
- << "; break;\n";
+ o << " case " << I << ": InstBits = InstBits_"
+ << HWM.getModeName(I, /*IncludeDefault=*/true) << "; break;\n";
}
o << " };\n";
}
diff --git a/llvm/utils/TableGen/CodeGenHwModes.h b/llvm/utils/TableGen/CodeGenHwModes.h
index 56639f741ede11..23723b7bd4af55 100644
--- a/llvm/utils/TableGen/CodeGenHwModes.h
+++ b/llvm/utils/TableGen/CodeGenHwModes.h
@@ -52,6 +52,11 @@ struct CodeGenHwModes {
assert(Id != 0 && "Mode id of 0 is reserved for the default mode");
return Modes[Id - 1];
}
+ StringRef getModeName(unsigned Id, bool IncludeDefault = false) const {
+ if (IncludeDefault && Id == CodeGenHwModes::DefaultMode)
+ return DefaultModeName;
+ return getMode(Id).Name;
+ }
const HwModeSelect &getHwModeSelect(Record *R) const;
const std::map<Record *, HwModeSelect> &getHwModeSelects() const {
return ModeSelects;
diff --git a/llvm/utils/TableGen/DecoderEmitter.cpp b/llvm/utils/TableGen/DecoderEmitter.cpp
index 4ce5a73d775668..27ff84bce4058e 100644
--- a/llvm/utils/TableGen/DecoderEmitter.cpp
+++ b/llvm/utils/TableGen/DecoderEmitter.cpp
@@ -2461,8 +2461,9 @@ collectHwModesReferencedForEncodings(const CodeGenHwModes &HWM,
BV.set(P.first);
}
}
- transform(BV.set_bits(), std::back_inserter(Names),
- [&HWM](const int &M) { return HWM.getMode(M).Name; });
+ transform(BV.set_bits(), std::back_inserter(Names), [&HWM](const int &M) {
+ return HWM.getModeName(M, /*IncludeDefault=*/true);
+ });
}
// Emits disassembler code for instruction decoding.
@@ -2503,8 +2504,9 @@ void DecoderEmitter::run(raw_ostream &o) {
if (DefInit *DI = dyn_cast_or_null<DefInit>(RV->getValue())) {
EncodingInfoByHwMode EBM(DI->getDef(), HWM);
for (auto &KV : EBM)
- NumberedEncodings.emplace_back(KV.second, NumberedInstruction,
- HWM.getMode(KV.first).Name);
+ NumberedEncodings.emplace_back(
+ KV.second, NumberedInstruction,
+ HWM.getModeName(KV.first, /*IncludeDefault=*/true));
continue;
}
}
>From c6cbf81c84b00ab0107a09f5b2d0183458a367b8 Mon Sep 17 00:00:00 2001
From: Cyndy Ishida <cyndy_ishida at apple.com>
Date: Wed, 28 Feb 2024 09:47:45 -0800
Subject: [PATCH 024/406] [InstallAPI] Hookup Input files & basic ASTVisitor
(#82552)
This patch takes in json files as input to determine that header files
to process, and in which order, to pass along for CC1 invocations. This
patch also includes an ASTVisitor to collect simple global variables.
---
clang/include/clang/InstallAPI/Context.h | 22 ++++-
clang/include/clang/InstallAPI/Frontend.h | 48 ++++++++++
clang/include/clang/InstallAPI/HeaderFile.h | 23 +++++
clang/include/clang/InstallAPI/Visitor.h | 51 ++++++++++
clang/lib/InstallAPI/CMakeLists.txt | 3 +
clang/lib/InstallAPI/Frontend.cpp | 58 ++++++++++++
clang/lib/InstallAPI/Visitor.cpp | 94 +++++++++++++++++++
clang/test/InstallAPI/basic.test | 5 +
clang/test/InstallAPI/variables.test | 63 +++++++++++++
.../clang-installapi/ClangInstallAPI.cpp | 76 +++++++++++++--
clang/tools/clang-installapi/Options.cpp | 29 ++++++
clang/tools/clang-installapi/Options.h | 8 ++
12 files changed, 472 insertions(+), 8 deletions(-)
create mode 100644 clang/include/clang/InstallAPI/Frontend.h
create mode 100644 clang/include/clang/InstallAPI/Visitor.h
create mode 100644 clang/lib/InstallAPI/Frontend.cpp
create mode 100644 clang/lib/InstallAPI/Visitor.cpp
create mode 100644 clang/test/InstallAPI/variables.test
diff --git a/clang/include/clang/InstallAPI/Context.h b/clang/include/clang/InstallAPI/Context.h
index 7d105920734fde..3e2046642c7fe8 100644
--- a/clang/include/clang/InstallAPI/Context.h
+++ b/clang/include/clang/InstallAPI/Context.h
@@ -9,6 +9,9 @@
#ifndef LLVM_CLANG_INSTALLAPI_CONTEXT_H
#define LLVM_CLANG_INSTALLAPI_CONTEXT_H
+#include "clang/Basic/Diagnostic.h"
+#include "clang/Basic/FileManager.h"
+#include "clang/InstallAPI/HeaderFile.h"
#include "llvm/TextAPI/InterfaceFile.h"
#include "llvm/TextAPI/RecordVisitor.h"
#include "llvm/TextAPI/RecordsSlice.h"
@@ -24,8 +27,23 @@ struct InstallAPIContext {
/// Library attributes that are typically passed as linker inputs.
llvm::MachO::RecordsSlice::BinaryAttrs BA;
- /// Active target triple to parse.
- llvm::Triple TargetTriple{};
+ /// All headers that represent a library.
+ HeaderSeq InputHeaders;
+
+ /// Active language mode to parse in.
+ Language LangMode = Language::ObjC;
+
+ /// Active header access type.
+ HeaderType Type = HeaderType::Unknown;
+
+ /// Active TargetSlice for symbol record collection.
+ std::shared_ptr<llvm::MachO::RecordsSlice> Slice;
+
+ /// FileManager for all I/O operations.
+ FileManager *FM = nullptr;
+
+ /// DiagnosticsEngine for all error reporting.
+ DiagnosticsEngine *Diags = nullptr;
/// File Path of output location.
llvm::StringRef OutputLoc{};
diff --git a/clang/include/clang/InstallAPI/Frontend.h b/clang/include/clang/InstallAPI/Frontend.h
new file mode 100644
index 00000000000000..7ee87ae028d079
--- /dev/null
+++ b/clang/include/clang/InstallAPI/Frontend.h
@@ -0,0 +1,48 @@
+//===- InstallAPI/Frontend.h -----------------------------------*- C++ -*-===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+///
+/// Top level wrappers for InstallAPI frontend operations.
+///
+//===----------------------------------------------------------------------===//
+
+#ifndef LLVM_CLANG_INSTALLAPI_FRONTEND_H
+#define LLVM_CLANG_INSTALLAPI_FRONTEND_H
+
+#include "clang/AST/ASTConsumer.h"
+#include "clang/Frontend/CompilerInstance.h"
+#include "clang/Frontend/FrontendActions.h"
+#include "clang/InstallAPI/Context.h"
+#include "clang/InstallAPI/Visitor.h"
+#include "llvm/ADT/Twine.h"
+#include "llvm/Support/MemoryBuffer.h"
+
+namespace clang {
+namespace installapi {
+
+/// Create a buffer that contains all headers to scan
+/// for global symbols with.
+std::unique_ptr<llvm::MemoryBuffer>
+createInputBuffer(const InstallAPIContext &Ctx);
+
+class InstallAPIAction : public ASTFrontendAction {
+public:
+ explicit InstallAPIAction(llvm::MachO::RecordsSlice &Records)
+ : Records(Records) {}
+
+ std::unique_ptr<ASTConsumer> CreateASTConsumer(CompilerInstance &CI,
+ StringRef InFile) override {
+ return std::make_unique<InstallAPIVisitor>(CI.getASTContext(), Records);
+ }
+
+private:
+ llvm::MachO::RecordsSlice &Records;
+};
+} // namespace installapi
+} // namespace clang
+
+#endif // LLVM_CLANG_INSTALLAPI_FRONTEND_H
diff --git a/clang/include/clang/InstallAPI/HeaderFile.h b/clang/include/clang/InstallAPI/HeaderFile.h
index fc64a43b3def5c..70e83bbb3e76f6 100644
--- a/clang/include/clang/InstallAPI/HeaderFile.h
+++ b/clang/include/clang/InstallAPI/HeaderFile.h
@@ -15,6 +15,7 @@
#include "clang/Basic/LangStandard.h"
#include "llvm/ADT/StringRef.h"
+#include "llvm/Support/ErrorHandling.h"
#include "llvm/Support/Regex.h"
#include <optional>
#include <string>
@@ -32,6 +33,20 @@ enum class HeaderType {
Project,
};
+inline StringRef getName(const HeaderType T) {
+ switch (T) {
+ case HeaderType::Public:
+ return "Public";
+ case HeaderType::Private:
+ return "Private";
+ case HeaderType::Project:
+ return "Project";
+ case HeaderType::Unknown:
+ return "Unknown";
+ }
+ llvm_unreachable("unexpected header type");
+}
+
class HeaderFile {
/// Full input path to header.
std::string FullPath;
@@ -52,6 +67,14 @@ class HeaderFile {
static llvm::Regex getFrameworkIncludeRule();
+ HeaderType getType() const { return Type; }
+ StringRef getIncludeName() const { return IncludeName; }
+ StringRef getPath() const { return FullPath; }
+
+ bool useIncludeName() const {
+ return Type != HeaderType::Project && !IncludeName.empty();
+ }
+
bool operator==(const HeaderFile &Other) const {
return std::tie(Type, FullPath, IncludeName, Language) ==
std::tie(Other.Type, Other.FullPath, Other.IncludeName,
diff --git a/clang/include/clang/InstallAPI/Visitor.h b/clang/include/clang/InstallAPI/Visitor.h
new file mode 100644
index 00000000000000..95d669688e4f9c
--- /dev/null
+++ b/clang/include/clang/InstallAPI/Visitor.h
@@ -0,0 +1,51 @@
+//===- InstallAPI/Visitor.h -----------------------------------*- C++ -*-===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+///
+/// ASTVisitor Interface for InstallAPI frontend operations.
+///
+//===----------------------------------------------------------------------===//
+
+#ifndef LLVM_CLANG_INSTALLAPI_VISITOR_H
+#define LLVM_CLANG_INSTALLAPI_VISITOR_H
+
+#include "clang/AST/Mangle.h"
+#include "clang/AST/RecursiveASTVisitor.h"
+#include "clang/Basic/TargetInfo.h"
+#include "clang/Frontend/FrontendActions.h"
+#include "llvm/ADT/Twine.h"
+#include "llvm/TextAPI/RecordsSlice.h"
+
+namespace clang {
+namespace installapi {
+
+/// ASTVisitor for collecting declarations that represent global symbols.
+class InstallAPIVisitor final : public ASTConsumer,
+ public RecursiveASTVisitor<InstallAPIVisitor> {
+public:
+ InstallAPIVisitor(ASTContext &ASTCtx, llvm::MachO::RecordsSlice &Slice)
+ : Slice(Slice),
+ MC(ItaniumMangleContext::create(ASTCtx, ASTCtx.getDiagnostics())),
+ Layout(ASTCtx.getTargetInfo().getDataLayoutString()) {}
+ void HandleTranslationUnit(ASTContext &ASTCtx) override;
+
+ /// Collect global variables.
+ bool VisitVarDecl(const VarDecl *D);
+
+private:
+ std::string getMangledName(const NamedDecl *D) const;
+ std::string getBackendMangledName(llvm::Twine Name) const;
+
+ llvm::MachO::RecordsSlice &Slice;
+ std::unique_ptr<clang::ItaniumMangleContext> MC;
+ StringRef Layout;
+};
+
+} // namespace installapi
+} // namespace clang
+
+#endif // LLVM_CLANG_INSTALLAPI_VISITOR_H
diff --git a/clang/lib/InstallAPI/CMakeLists.txt b/clang/lib/InstallAPI/CMakeLists.txt
index fdc4f064f29e95..19fc4c3abde53a 100644
--- a/clang/lib/InstallAPI/CMakeLists.txt
+++ b/clang/lib/InstallAPI/CMakeLists.txt
@@ -1,11 +1,14 @@
set(LLVM_LINK_COMPONENTS
Support
TextAPI
+ Core
)
add_clang_library(clangInstallAPI
FileList.cpp
+ Frontend.cpp
HeaderFile.cpp
+ Visitor.cpp
LINK_LIBS
clangAST
diff --git a/clang/lib/InstallAPI/Frontend.cpp b/clang/lib/InstallAPI/Frontend.cpp
new file mode 100644
index 00000000000000..9f675ef7d1bd22
--- /dev/null
+++ b/clang/lib/InstallAPI/Frontend.cpp
@@ -0,0 +1,58 @@
+//===- Frontend.cpp ---------------------------------------------*- C++ -*-===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+
+#include "clang/InstallAPI/Frontend.h"
+#include "clang/AST/Availability.h"
+#include "llvm/ADT/SmallString.h"
+#include "llvm/ADT/StringRef.h"
+
+using namespace llvm;
+using namespace llvm::MachO;
+
+namespace clang::installapi {
+
+static StringRef getFileExtension(clang::Language Lang) {
+ switch (Lang) {
+ default:
+ llvm_unreachable("Unexpected language option.");
+ case clang::Language::C:
+ return ".c";
+ case clang::Language::CXX:
+ return ".cpp";
+ case clang::Language::ObjC:
+ return ".m";
+ case clang::Language::ObjCXX:
+ return ".mm";
+ }
+}
+
+std::unique_ptr<MemoryBuffer> createInputBuffer(const InstallAPIContext &Ctx) {
+ assert(Ctx.Type != HeaderType::Unknown &&
+ "unexpected access level for parsing");
+ SmallString<4096> Contents;
+ raw_svector_ostream OS(Contents);
+ for (const HeaderFile &H : Ctx.InputHeaders) {
+ if (H.getType() != Ctx.Type)
+ continue;
+ if (Ctx.LangMode == Language::C || Ctx.LangMode == Language::CXX)
+ OS << "#include ";
+ else
+ OS << "#import ";
+ if (H.useIncludeName())
+ OS << "<" << H.getIncludeName() << ">";
+ else
+ OS << "\"" << H.getPath() << "\"";
+ }
+ if (Contents.empty())
+ return nullptr;
+
+ return llvm::MemoryBuffer::getMemBufferCopy(
+ Contents, "installapi-includes" + getFileExtension(Ctx.LangMode));
+}
+
+} // namespace clang::installapi
diff --git a/clang/lib/InstallAPI/Visitor.cpp b/clang/lib/InstallAPI/Visitor.cpp
new file mode 100644
index 00000000000000..9b333a6142ae8f
--- /dev/null
+++ b/clang/lib/InstallAPI/Visitor.cpp
@@ -0,0 +1,94 @@
+//===- Visitor.cpp ---------------------------------------------*- C++ -*-===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+
+#include "clang/InstallAPI/Visitor.h"
+#include "clang/AST/Availability.h"
+#include "clang/Basic/Linkage.h"
+#include "llvm/ADT/SmallString.h"
+#include "llvm/ADT/StringRef.h"
+#include "llvm/IR/DataLayout.h"
+#include "llvm/IR/Mangler.h"
+
+using namespace llvm;
+using namespace llvm::MachO;
+
+namespace clang::installapi {
+
+// Exported NamedDecl needs to have externally visibiliy linkage and
+// default visibility from LinkageComputer.
+static bool isExported(const NamedDecl *D) {
+ auto LV = D->getLinkageAndVisibility();
+ return isExternallyVisible(LV.getLinkage()) &&
+ (LV.getVisibility() == DefaultVisibility);
+}
+
+static SymbolFlags getFlags(bool WeakDef, bool ThreadLocal) {
+ SymbolFlags Result = SymbolFlags::None;
+ if (WeakDef)
+ Result |= SymbolFlags::WeakDefined;
+ if (ThreadLocal)
+ Result |= SymbolFlags::ThreadLocalValue;
+
+ return Result;
+}
+
+void InstallAPIVisitor::HandleTranslationUnit(ASTContext &ASTCtx) {
+ if (ASTCtx.getDiagnostics().hasErrorOccurred())
+ return;
+
+ auto *D = ASTCtx.getTranslationUnitDecl();
+ TraverseDecl(D);
+}
+
+std::string InstallAPIVisitor::getMangledName(const NamedDecl *D) const {
+ SmallString<256> Name;
+ if (MC->shouldMangleDeclName(D)) {
+ raw_svector_ostream NStream(Name);
+ MC->mangleName(D, NStream);
+ } else
+ Name += D->getNameAsString();
+
+ return getBackendMangledName(Name);
+}
+
+std::string InstallAPIVisitor::getBackendMangledName(Twine Name) const {
+ SmallString<256> FinalName;
+ Mangler::getNameWithPrefix(FinalName, Name, DataLayout(Layout));
+ return std::string(FinalName);
+}
+
+/// Collect all global variables.
+bool InstallAPIVisitor::VisitVarDecl(const VarDecl *D) {
+ // Skip function parameters.
+ if (isa<ParmVarDecl>(D))
+ return true;
+
+ // Skip variables in records. They are handled seperately for C++.
+ if (D->getDeclContext()->isRecord())
+ return true;
+
+ // Skip anything inside functions or methods.
+ if (!D->isDefinedOutsideFunctionOrMethod())
+ return true;
+
+ // If this is a template but not specialization or instantiation, skip.
+ if (D->getASTContext().getTemplateOrSpecializationInfo(D) &&
+ D->getTemplateSpecializationKind() == TSK_Undeclared)
+ return true;
+
+ // TODO: Capture SourceLocation & Availability for Decls.
+ const RecordLinkage Linkage =
+ isExported(D) ? RecordLinkage::Exported : RecordLinkage::Internal;
+ const bool WeakDef = D->hasAttr<WeakAttr>();
+ const bool ThreadLocal = D->getTLSKind() != VarDecl::TLS_None;
+ Slice.addGlobal(getMangledName(D), Linkage, GlobalRecord::Kind::Variable,
+ getFlags(WeakDef, ThreadLocal));
+ return true;
+}
+
+} // namespace clang::installapi
diff --git a/clang/test/InstallAPI/basic.test b/clang/test/InstallAPI/basic.test
index 22b04792ca2c30..5b41ccd517b0af 100644
--- a/clang/test/InstallAPI/basic.test
+++ b/clang/test/InstallAPI/basic.test
@@ -16,6 +16,11 @@
// CHECK-NOT: warning:
//--- basic_inputs.json
+{
+ "headers": [
+ ],
+ "version": "3"
+}
//--- expected.tbd
{
diff --git a/clang/test/InstallAPI/variables.test b/clang/test/InstallAPI/variables.test
new file mode 100644
index 00000000000000..6272867911f18b
--- /dev/null
+++ b/clang/test/InstallAPI/variables.test
@@ -0,0 +1,63 @@
+// RUN: rm -rf %t
+// RUN: split-file %s %t
+// RUN: sed -e "s|SRC_DIR|%/t|g" %t/vars_inputs.json.in > %t/vars_inputs.json
+
+/// Check multiple targets are captured.
+// RUN: clang-installapi -target arm64-apple-macos13.1 -target arm64e-apple-macos13.1 \
+// RUN: -fapplication-extension -install_name /usr/lib/vars.dylib \
+// RUN: %t/vars_inputs.json -o %t/vars.tbd 2>&1 | FileCheck %s --allow-empty
+// RUN: llvm-readtapi -compare %t/vars.tbd %t/expected.tbd 2>&1 | FileCheck %s --allow-empty
+
+// CHECK-NOT: error:
+// CHECK-NOT: warning:
+
+//--- vars.h
+extern int foo;
+
+//--- vars_inputs.json.in
+{
+ "headers": [ {
+ "path" : "SRC_DIR/vars.h",
+ "type" : "public"
+ }],
+ "version": "3"
+}
+
+//--- expected.tbd
+{
+ "main_library": {
+ "compatibility_versions": [
+ {
+ "version": "0"
+ }],
+ "current_versions": [
+ {
+ "version": "0"
+ }],
+ "install_names": [
+ {
+ "name": "/usr/lib/vars.dylib"
+ }
+ ],
+ "exported_symbols": [
+ {
+ "data": {
+ "global": [
+ "_foo"
+ ]
+ }
+ }
+ ],
+ "target_info": [
+ {
+ "min_deployment": "13.1",
+ "target": "arm64-macos"
+ },
+ {
+ "min_deployment": "13.1",
+ "target": "arm64e-macos"
+ }
+ ]
+ },
+ "tapi_tbd_version": 5
+}
diff --git a/clang/tools/clang-installapi/ClangInstallAPI.cpp b/clang/tools/clang-installapi/ClangInstallAPI.cpp
index fc23ffd7ae6b9c..43c9fca0a82eec 100644
--- a/clang/tools/clang-installapi/ClangInstallAPI.cpp
+++ b/clang/tools/clang-installapi/ClangInstallAPI.cpp
@@ -12,12 +12,14 @@
//===----------------------------------------------------------------------===//
#include "Options.h"
-#include "clang/Basic/DiagnosticIDs.h"
+#include "clang/Basic/Diagnostic.h"
+#include "clang/Basic/DiagnosticFrontend.h"
#include "clang/Driver/Driver.h"
#include "clang/Driver/DriverDiagnostic.h"
-#include "clang/Frontend/CompilerInstance.h"
+#include "clang/Driver/Tool.h"
#include "clang/Frontend/TextDiagnosticPrinter.h"
-#include "clang/InstallAPI/Context.h"
+#include "clang/InstallAPI/Frontend.h"
+#include "clang/Tooling/Tooling.h"
#include "llvm/ADT/ArrayRef.h"
#include "llvm/Option/Option.h"
#include "llvm/Support/CommandLine.h"
@@ -27,7 +29,9 @@
#include "llvm/Support/Process.h"
#include "llvm/Support/Signals.h"
#include "llvm/TargetParser/Host.h"
+#include "llvm/TextAPI/RecordVisitor.h"
#include "llvm/TextAPI/TextAPIWriter.h"
+#include <memory>
using namespace clang;
using namespace clang::installapi;
@@ -35,6 +39,36 @@ using namespace clang::driver::options;
using namespace llvm::opt;
using namespace llvm::MachO;
+static bool runFrontend(StringRef ProgName, bool Verbose,
+ const InstallAPIContext &Ctx,
+ llvm::vfs::InMemoryFileSystem *FS,
+ const ArrayRef<std::string> InitialArgs) {
+
+ std::unique_ptr<llvm::MemoryBuffer> ProcessedInput = createInputBuffer(Ctx);
+ // Skip invoking cc1 when there are no header inputs.
+ if (!ProcessedInput)
+ return true;
+
+ if (Verbose)
+ llvm::errs() << getName(Ctx.Type) << " Headers:\n"
+ << ProcessedInput->getBuffer() << "\n\n";
+
+ std::string InputFile = ProcessedInput->getBufferIdentifier().str();
+ FS->addFile(InputFile, /*ModTime=*/0, std::move(ProcessedInput));
+ // Reconstruct arguments with unique values like target triple or input
+ // headers.
+ std::vector<std::string> Args = {ProgName.data(), "-target",
+ Ctx.Slice->getTriple().str().c_str()};
+ llvm::copy(InitialArgs, std::back_inserter(Args));
+ Args.push_back(InputFile);
+
+ // Create & run invocation.
+ clang::tooling::ToolInvocation Invocation(
+ std::move(Args), std::make_unique<InstallAPIAction>(*Ctx.Slice), Ctx.FM);
+
+ return Invocation.run();
+}
+
static bool run(ArrayRef<const char *> Args, const char *ProgName) {
// Setup Diagnostics engine.
IntrusiveRefCntPtr<DiagnosticOptions> DiagOpts = new DiagnosticOptions();
@@ -48,9 +82,15 @@ static bool run(ArrayRef<const char *> Args, const char *ProgName) {
new clang::DiagnosticIDs(), DiagOpts.get(),
new clang::TextDiagnosticPrinter(llvm::errs(), DiagOpts.get()));
- // Create file manager for all file operations.
+ // Create file manager for all file operations and holding in-memory generated
+ // inputs.
+ llvm::IntrusiveRefCntPtr<llvm::vfs::OverlayFileSystem> OverlayFileSystem(
+ new llvm::vfs::OverlayFileSystem(llvm::vfs::getRealFileSystem()));
+ llvm::IntrusiveRefCntPtr<llvm::vfs::InMemoryFileSystem> InMemoryFileSystem(
+ new llvm::vfs::InMemoryFileSystem);
+ OverlayFileSystem->pushOverlay(InMemoryFileSystem);
IntrusiveRefCntPtr<clang::FileManager> FM(
- new FileManager(clang::FileSystemOptions()));
+ new FileManager(clang::FileSystemOptions(), OverlayFileSystem));
// Set up driver to parse input arguments.
auto DriverArgs = llvm::ArrayRef(Args).slice(1);
@@ -71,7 +111,10 @@ static bool run(ArrayRef<const char *> Args, const char *ProgName) {
Options Opts(*Diag, FM.get(), ArgList);
if (Diag->hasErrorOccurred())
return EXIT_FAILURE;
+
InstallAPIContext Ctx = Opts.createContext();
+ if (Diag->hasErrorOccurred())
+ return EXIT_FAILURE;
// Set up compilation.
std::unique_ptr<CompilerInstance> CI(new CompilerInstance());
@@ -80,6 +123,21 @@ static bool run(ArrayRef<const char *> Args, const char *ProgName) {
if (!CI->hasDiagnostics())
return EXIT_FAILURE;
+ // Execute and gather AST results.
+ llvm::MachO::Records FrontendResults;
+ for (const auto &[Targ, Trip] : Opts.DriverOpts.Targets) {
+ for (const HeaderType Type :
+ {HeaderType::Public, HeaderType::Private, HeaderType::Project}) {
+ Ctx.Slice = std::make_shared<RecordsSlice>(Trip);
+ Ctx.Type = Type;
+ if (!runFrontend(ProgName, Opts.DriverOpts.Verbose, Ctx,
+ InMemoryFileSystem.get(), Opts.getClangFrontendArgs()))
+ return EXIT_FAILURE;
+ FrontendResults.emplace_back(std::move(Ctx.Slice));
+ }
+ }
+
+ // After symbols have been collected, prepare to write output.
auto Out = CI->createOutputFile(Ctx.OutputLoc, /*Binary=*/false,
/*RemoveFileOnSignal=*/false,
/*UseTemporary=*/false,
@@ -88,7 +146,13 @@ static bool run(ArrayRef<const char *> Args, const char *ProgName) {
return EXIT_FAILURE;
// Assign attributes for serialization.
- InterfaceFile IF;
+ auto Symbols = std::make_unique<SymbolSet>();
+ for (const auto &FR : FrontendResults) {
+ SymbolConverter Converter(Symbols.get(), FR->getTarget());
+ FR->visit(Converter);
+ }
+
+ InterfaceFile IF(std::move(Symbols));
for (const auto &TargetInfo : Opts.DriverOpts.Targets) {
IF.addTarget(TargetInfo.first);
IF.setFromBinaryAttrs(Ctx.BA, TargetInfo.first);
diff --git a/clang/tools/clang-installapi/Options.cpp b/clang/tools/clang-installapi/Options.cpp
index 562a643edfcf40..7d45e999448d9f 100644
--- a/clang/tools/clang-installapi/Options.cpp
+++ b/clang/tools/clang-installapi/Options.cpp
@@ -9,6 +9,7 @@
#include "Options.h"
#include "clang/Driver/Driver.h"
#include "clang/Frontend/FrontendDiagnostic.h"
+#include "clang/InstallAPI/FileList.h"
#include "llvm/Support/Program.h"
#include "llvm/TargetParser/Host.h"
@@ -68,6 +69,8 @@ bool Options::processDriverOptions(InputArgList &Args) {
}
}
+ DriverOpts.Verbose = Args.hasArgNoClaim(OPT_v);
+
return true;
}
@@ -104,10 +107,21 @@ Options::Options(DiagnosticsEngine &Diag, FileManager *FM,
if (!processLinkerOptions(ArgList))
return;
+
+ /// Any remaining arguments should be handled by invoking the clang frontend.
+ for (const Arg *A : ArgList) {
+ if (A->isClaimed())
+ continue;
+ FrontendArgs.emplace_back(A->getAsString(ArgList));
+ }
+ FrontendArgs.push_back("-fsyntax-only");
}
InstallAPIContext Options::createContext() {
InstallAPIContext Ctx;
+ Ctx.FM = FM;
+ Ctx.Diags = Diags;
+
// InstallAPI requires two level namespacing.
Ctx.BA.TwoLevelNamespace = true;
@@ -116,6 +130,21 @@ InstallAPIContext Options::createContext() {
Ctx.BA.AppExtensionSafe = LinkerOpts.AppExtensionSafe;
Ctx.FT = DriverOpts.OutFT;
Ctx.OutputLoc = DriverOpts.OutputPath;
+
+ // Process inputs.
+ for (const std::string &ListPath : DriverOpts.FileLists) {
+ auto Buffer = FM->getBufferForFile(ListPath);
+ if (auto Err = Buffer.getError()) {
+ Diags->Report(diag::err_cannot_open_file) << ListPath;
+ return Ctx;
+ }
+ if (auto Err = FileListReader::loadHeaders(std::move(Buffer.get()),
+ Ctx.InputHeaders)) {
+ Diags->Report(diag::err_cannot_open_file) << ListPath;
+ return Ctx;
+ }
+ }
+
return Ctx;
}
diff --git a/clang/tools/clang-installapi/Options.h b/clang/tools/clang-installapi/Options.h
index 4a84166a6c91b1..f68addf1972880 100644
--- a/clang/tools/clang-installapi/Options.h
+++ b/clang/tools/clang-installapi/Options.h
@@ -43,6 +43,9 @@ struct DriverOptions {
/// \brief File encoding to print.
llvm::MachO::FileType OutFT = llvm::MachO::FileType::TBD_V5;
+
+ /// \brief Print verbose output.
+ bool Verbose = false;
};
struct LinkerOptions {
@@ -78,9 +81,14 @@ class Options {
Options(clang::DiagnosticsEngine &Diag, FileManager *FM,
llvm::opt::InputArgList &Args);
+ /// \brief Get CC1 arguments after extracting out the irrelevant
+ /// ones.
+ std::vector<std::string> &getClangFrontendArgs() { return FrontendArgs; }
+
private:
DiagnosticsEngine *Diags;
FileManager *FM;
+ std::vector<std::string> FrontendArgs;
};
} // namespace installapi
>From b42b7c8a123863d86db9abc8b6a1340b920f6573 Mon Sep 17 00:00:00 2001
From: Alexandros Lamprineas <alexandros.lamprineas at arm.com>
Date: Wed, 28 Feb 2024 17:49:59 +0000
Subject: [PATCH 025/406] [clang] Refactor target attribute mangling. (#81893)
Before this patch all of the 'target', 'target_version' and
'target_clones' attributes were sharing a common mangling logic across
different targets. However we would like to differenciate this logic,
therefore I have moved the default path to ABIInfo and provided
overrides for AArch64. This way we can resolve feature aliases without
affecting the name mangling. The PR #80540 demonstrates a motivating
case.
---
clang/lib/CodeGen/ABIInfo.cpp | 52 ++++++++++++
clang/lib/CodeGen/ABIInfo.h | 10 +++
clang/lib/CodeGen/CodeGenModule.cpp | 111 ++++----------------------
clang/lib/CodeGen/Targets/AArch64.cpp | 40 ++++++++++
4 files changed, 118 insertions(+), 95 deletions(-)
diff --git a/clang/lib/CodeGen/ABIInfo.cpp b/clang/lib/CodeGen/ABIInfo.cpp
index 1b56cf7c596d06..efcff958ce5452 100644
--- a/clang/lib/CodeGen/ABIInfo.cpp
+++ b/clang/lib/CodeGen/ABIInfo.cpp
@@ -184,6 +184,58 @@ ABIArgInfo ABIInfo::getNaturalAlignIndirectInReg(QualType Ty,
/*ByVal*/ false, Realign);
}
+void ABIInfo::appendAttributeMangling(TargetAttr *Attr,
+ raw_ostream &Out) const {
+ if (Attr->isDefaultVersion())
+ return;
+ appendAttributeMangling(Attr->getFeaturesStr(), Out);
+}
+
+void ABIInfo::appendAttributeMangling(TargetVersionAttr *Attr,
+ raw_ostream &Out) const {
+ appendAttributeMangling(Attr->getNamesStr(), Out);
+}
+
+void ABIInfo::appendAttributeMangling(TargetClonesAttr *Attr, unsigned Index,
+ raw_ostream &Out) const {
+ appendAttributeMangling(Attr->getFeatureStr(Index), Out);
+ Out << '.' << Attr->getMangledIndex(Index);
+}
+
+void ABIInfo::appendAttributeMangling(StringRef AttrStr,
+ raw_ostream &Out) const {
+ if (AttrStr == "default") {
+ Out << ".default";
+ return;
+ }
+
+ Out << '.';
+ const TargetInfo &TI = CGT.getTarget();
+ ParsedTargetAttr Info = TI.parseTargetAttr(AttrStr);
+
+ llvm::sort(Info.Features, [&TI](StringRef LHS, StringRef RHS) {
+ // Multiversioning doesn't allow "no-${feature}", so we can
+ // only have "+" prefixes here.
+ assert(LHS.starts_with("+") && RHS.starts_with("+") &&
+ "Features should always have a prefix.");
+ return TI.multiVersionSortPriority(LHS.substr(1)) >
+ TI.multiVersionSortPriority(RHS.substr(1));
+ });
+
+ bool IsFirst = true;
+ if (!Info.CPU.empty()) {
+ IsFirst = false;
+ Out << "arch_" << Info.CPU;
+ }
+
+ for (StringRef Feat : Info.Features) {
+ if (!IsFirst)
+ Out << '_';
+ IsFirst = false;
+ Out << Feat.substr(1);
+ }
+}
+
// Pin the vtable to this file.
SwiftABIInfo::~SwiftABIInfo() = default;
diff --git a/clang/lib/CodeGen/ABIInfo.h b/clang/lib/CodeGen/ABIInfo.h
index b9a5ef6e436693..ff4ae44a42c332 100644
--- a/clang/lib/CodeGen/ABIInfo.h
+++ b/clang/lib/CodeGen/ABIInfo.h
@@ -9,6 +9,7 @@
#ifndef LLVM_CLANG_LIB_CODEGEN_ABIINFO_H
#define LLVM_CLANG_LIB_CODEGEN_ABIINFO_H
+#include "clang/AST/Attr.h"
#include "clang/AST/CharUnits.h"
#include "clang/AST/Type.h"
#include "llvm/IR/CallingConv.h"
@@ -111,6 +112,15 @@ class ABIInfo {
CodeGen::ABIArgInfo getNaturalAlignIndirectInReg(QualType Ty,
bool Realign = false) const;
+
+ virtual void appendAttributeMangling(TargetAttr *Attr,
+ raw_ostream &Out) const;
+ virtual void appendAttributeMangling(TargetVersionAttr *Attr,
+ raw_ostream &Out) const;
+ virtual void appendAttributeMangling(TargetClonesAttr *Attr, unsigned Index,
+ raw_ostream &Out) const;
+ virtual void appendAttributeMangling(StringRef AttrStr,
+ raw_ostream &Out) const;
};
/// Target specific hooks for defining how a type should be passed or returned
diff --git a/clang/lib/CodeGen/CodeGenModule.cpp b/clang/lib/CodeGen/CodeGenModule.cpp
index d16d12fac8b03c..82a97ecfaa0078 100644
--- a/clang/lib/CodeGen/CodeGenModule.cpp
+++ b/clang/lib/CodeGen/CodeGenModule.cpp
@@ -1727,59 +1727,6 @@ static void AppendCPUSpecificCPUDispatchMangling(const CodeGenModule &CGM,
Out << ".resolver";
}
-static void AppendTargetVersionMangling(const CodeGenModule &CGM,
- const TargetVersionAttr *Attr,
- raw_ostream &Out) {
- if (Attr->isDefaultVersion()) {
- Out << ".default";
- return;
- }
- Out << "._";
- const TargetInfo &TI = CGM.getTarget();
- llvm::SmallVector<StringRef, 8> Feats;
- Attr->getFeatures(Feats);
- llvm::stable_sort(Feats, [&TI](const StringRef FeatL, const StringRef FeatR) {
- return TI.multiVersionSortPriority(FeatL) <
- TI.multiVersionSortPriority(FeatR);
- });
- for (const auto &Feat : Feats) {
- Out << 'M';
- Out << Feat;
- }
-}
-
-static void AppendTargetMangling(const CodeGenModule &CGM,
- const TargetAttr *Attr, raw_ostream &Out) {
- if (Attr->isDefaultVersion())
- return;
-
- Out << '.';
- const TargetInfo &Target = CGM.getTarget();
- ParsedTargetAttr Info = Target.parseTargetAttr(Attr->getFeaturesStr());
- llvm::sort(Info.Features, [&Target](StringRef LHS, StringRef RHS) {
- // Multiversioning doesn't allow "no-${feature}", so we can
- // only have "+" prefixes here.
- assert(LHS.starts_with("+") && RHS.starts_with("+") &&
- "Features should always have a prefix.");
- return Target.multiVersionSortPriority(LHS.substr(1)) >
- Target.multiVersionSortPriority(RHS.substr(1));
- });
-
- bool IsFirst = true;
-
- if (!Info.CPU.empty()) {
- IsFirst = false;
- Out << "arch_" << Info.CPU;
- }
-
- for (StringRef Feat : Info.Features) {
- if (!IsFirst)
- Out << '_';
- IsFirst = false;
- Out << Feat.substr(1);
- }
-}
-
// Returns true if GD is a function decl with internal linkage and
// needs a unique suffix after the mangled name.
static bool isUniqueInternalLinkageDecl(GlobalDecl GD,
@@ -1789,41 +1736,6 @@ static bool isUniqueInternalLinkageDecl(GlobalDecl GD,
(CGM.getFunctionLinkage(GD) == llvm::GlobalValue::InternalLinkage);
}
-static void AppendTargetClonesMangling(const CodeGenModule &CGM,
- const TargetClonesAttr *Attr,
- unsigned VersionIndex,
- raw_ostream &Out) {
- const TargetInfo &TI = CGM.getTarget();
- if (TI.getTriple().isAArch64()) {
- StringRef FeatureStr = Attr->getFeatureStr(VersionIndex);
- if (FeatureStr == "default") {
- Out << ".default";
- return;
- }
- Out << "._";
- SmallVector<StringRef, 8> Features;
- FeatureStr.split(Features, "+");
- llvm::stable_sort(Features,
- [&TI](const StringRef FeatL, const StringRef FeatR) {
- return TI.multiVersionSortPriority(FeatL) <
- TI.multiVersionSortPriority(FeatR);
- });
- for (auto &Feat : Features) {
- Out << 'M';
- Out << Feat;
- }
- } else {
- Out << '.';
- StringRef FeatureStr = Attr->getFeatureStr(VersionIndex);
- if (FeatureStr.starts_with("arch="))
- Out << "arch_" << FeatureStr.substr(sizeof("arch=") - 1);
- else
- Out << FeatureStr;
-
- Out << '.' << Attr->getMangledIndex(VersionIndex);
- }
-}
-
static std::string getMangledNameImpl(CodeGenModule &CGM, GlobalDecl GD,
const NamedDecl *ND,
bool OmitMultiVersionMangling = false) {
@@ -1877,16 +1789,25 @@ static std::string getMangledNameImpl(CodeGenModule &CGM, GlobalDecl GD,
FD->getAttr<CPUSpecificAttr>(),
GD.getMultiVersionIndex(), Out);
break;
- case MultiVersionKind::Target:
- AppendTargetMangling(CGM, FD->getAttr<TargetAttr>(), Out);
+ case MultiVersionKind::Target: {
+ auto *Attr = FD->getAttr<TargetAttr>();
+ const ABIInfo &Info = CGM.getTargetCodeGenInfo().getABIInfo();
+ Info.appendAttributeMangling(Attr, Out);
break;
- case MultiVersionKind::TargetVersion:
- AppendTargetVersionMangling(CGM, FD->getAttr<TargetVersionAttr>(), Out);
+ }
+ case MultiVersionKind::TargetVersion: {
+ auto *Attr = FD->getAttr<TargetVersionAttr>();
+ const ABIInfo &Info = CGM.getTargetCodeGenInfo().getABIInfo();
+ Info.appendAttributeMangling(Attr, Out);
break;
- case MultiVersionKind::TargetClones:
- AppendTargetClonesMangling(CGM, FD->getAttr<TargetClonesAttr>(),
- GD.getMultiVersionIndex(), Out);
+ }
+ case MultiVersionKind::TargetClones: {
+ auto *Attr = FD->getAttr<TargetClonesAttr>();
+ unsigned Index = GD.getMultiVersionIndex();
+ const ABIInfo &Info = CGM.getTargetCodeGenInfo().getABIInfo();
+ Info.appendAttributeMangling(Attr, Index, Out);
break;
+ }
case MultiVersionKind::None:
llvm_unreachable("None multiversion type isn't valid here");
}
diff --git a/clang/lib/CodeGen/Targets/AArch64.cpp b/clang/lib/CodeGen/Targets/AArch64.cpp
index 94f8e7be2ee6eb..adfdd516351901 100644
--- a/clang/lib/CodeGen/Targets/AArch64.cpp
+++ b/clang/lib/CodeGen/Targets/AArch64.cpp
@@ -9,6 +9,7 @@
#include "ABIInfoImpl.h"
#include "TargetInfo.h"
#include "clang/Basic/DiagnosticFrontend.h"
+#include "llvm/TargetParser/AArch64TargetParser.h"
using namespace clang;
using namespace clang::CodeGen;
@@ -75,6 +76,12 @@ class AArch64ABIInfo : public ABIInfo {
bool allowBFloatArgsAndRet() const override {
return getTarget().hasBFloat16Type();
}
+
+ using ABIInfo::appendAttributeMangling;
+ void appendAttributeMangling(TargetClonesAttr *Attr, unsigned Index,
+ raw_ostream &Out) const override;
+ void appendAttributeMangling(StringRef AttrStr,
+ raw_ostream &Out) const override;
};
class AArch64SwiftABIInfo : public SwiftABIInfo {
@@ -857,6 +864,39 @@ void AArch64TargetCodeGenInfo::checkFunctionCallABI(
<< Callee->getDeclName();
}
+void AArch64ABIInfo::appendAttributeMangling(TargetClonesAttr *Attr,
+ unsigned Index,
+ raw_ostream &Out) const {
+ appendAttributeMangling(Attr->getFeatureStr(Index), Out);
+}
+
+void AArch64ABIInfo::appendAttributeMangling(StringRef AttrStr,
+ raw_ostream &Out) const {
+ if (AttrStr == "default") {
+ Out << ".default";
+ return;
+ }
+
+ Out << "._";
+ SmallVector<StringRef, 8> Features;
+ AttrStr.split(Features, "+");
+ for (auto &Feat : Features)
+ Feat = Feat.trim();
+
+ // FIXME: It was brought up in #79316 that sorting the features which are
+ // used for mangling based on their multiversion priority is not a good
+ // practice. Changing the feature priorities will break the ABI. Perhaps
+ // it would be preferable to perform a lexicographical sort instead.
+ const TargetInfo &TI = CGT.getTarget();
+ llvm::sort(Features, [&TI](const StringRef LHS, const StringRef RHS) {
+ return TI.multiVersionSortPriority(LHS) < TI.multiVersionSortPriority(RHS);
+ });
+
+ for (auto &Feat : Features)
+ if (auto Ext = llvm::AArch64::parseArchExtension(Feat))
+ Out << 'M' << Ext->Name;
+}
+
std::unique_ptr<TargetCodeGenInfo>
CodeGen::createAArch64TargetCodeGenInfo(CodeGenModule &CGM,
AArch64ABIKind Kind) {
>From f9b079972c234c90df4b28990d5b2e51184e0b64 Mon Sep 17 00:00:00 2001
From: LLVM GN Syncbot <llvmgnsyncbot at gmail.com>
Date: Wed, 28 Feb 2024 17:54:20 +0000
Subject: [PATCH 026/406] [gn build] Port c6cbf81c84b0
---
llvm/utils/gn/secondary/clang/lib/InstallAPI/BUILD.gn | 2 ++
1 file changed, 2 insertions(+)
diff --git a/llvm/utils/gn/secondary/clang/lib/InstallAPI/BUILD.gn b/llvm/utils/gn/secondary/clang/lib/InstallAPI/BUILD.gn
index fbff113613d269..5e533bf23ec475 100644
--- a/llvm/utils/gn/secondary/clang/lib/InstallAPI/BUILD.gn
+++ b/llvm/utils/gn/secondary/clang/lib/InstallAPI/BUILD.gn
@@ -8,6 +8,8 @@ static_library("InstallAPI") {
]
sources = [
"FileList.cpp",
+ "Frontend.cpp",
"HeaderFile.cpp",
+ "Visitor.cpp",
]
}
>From 6101cf3164d77cfa4e2df75bf5262da9a2fb3d0a Mon Sep 17 00:00:00 2001
From: Cyndy Ishida <cyndy_ishida at apple.com>
Date: Wed, 28 Feb 2024 10:01:03 -0800
Subject: [PATCH 027/406] [InstallAPI] add missing link to clangAST
Appeases bots.
---
clang/tools/clang-installapi/CMakeLists.txt | 1 +
1 file changed, 1 insertion(+)
diff --git a/clang/tools/clang-installapi/CMakeLists.txt b/clang/tools/clang-installapi/CMakeLists.txt
index b8384c92c104f6..e05f4eac3ad198 100644
--- a/clang/tools/clang-installapi/CMakeLists.txt
+++ b/clang/tools/clang-installapi/CMakeLists.txt
@@ -14,6 +14,7 @@ add_clang_tool(clang-installapi
clang_target_link_libraries(clang-installapi
PRIVATE
+ clangAST
clangInstallAPI
clangBasic
clangDriver
>From 1c211bc76e8b6a3261c62e5b6c2b75b7b90386b0 Mon Sep 17 00:00:00 2001
From: Nilanjana Basu <n_basu at apple.com>
Date: Wed, 28 Feb 2024 10:17:25 -0800
Subject: [PATCH 028/406] [LV] Remove unused configuration option (#82955)
Recent set of changes (PR #67725) in loop interleaving algorithm caused removal of the loop trip count threshold for allowing interleaving. Therefore configuration option interleave-small-loop-scalar-reduction is no longer needed.
---
llvm/lib/Transforms/Vectorize/LoopVectorize.cpp | 9 +--------
.../Transforms/LoopVectorize/PowerPC/interleave_IC.ll | 4 ++--
2 files changed, 3 insertions(+), 10 deletions(-)
diff --git a/llvm/lib/Transforms/Vectorize/LoopVectorize.cpp b/llvm/lib/Transforms/Vectorize/LoopVectorize.cpp
index ea77b6018c0d15..b81cd508663c32 100644
--- a/llvm/lib/Transforms/Vectorize/LoopVectorize.cpp
+++ b/llvm/lib/Transforms/Vectorize/LoopVectorize.cpp
@@ -315,12 +315,6 @@ static cl::opt<bool> EnableLoadStoreRuntimeInterleave(
cl::desc(
"Enable runtime interleaving until load/store ports are saturated"));
-/// Interleave small loops with scalar reductions.
-static cl::opt<bool> InterleaveSmallLoopScalarReduction(
- "interleave-small-loop-scalar-reduction", cl::init(false), cl::Hidden,
- cl::desc("Enable interleaving for loops with small iteration counts that "
- "contain scalar reductions to expose ILP."));
-
/// The number of stores in a loop that are allowed to need predication.
static cl::opt<unsigned> NumberOfStoresToPredicate(
"vectorize-num-stores-pred", cl::init(1), cl::Hidden,
@@ -5495,8 +5489,7 @@ LoopVectorizationCostModel::selectInterleaveCount(ElementCount VF,
// If there are scalar reductions and TTI has enabled aggressive
// interleaving for reductions, we will interleave to expose ILP.
- if (InterleaveSmallLoopScalarReduction && VF.isScalar() &&
- AggressivelyInterleaveReductions) {
+ if (VF.isScalar() && AggressivelyInterleaveReductions) {
LLVM_DEBUG(dbgs() << "LV: Interleaving to expose ILP.\n");
// Interleave no less than SmallIC but not as aggressive as the normal IC
// to satisfy the rare situation when resources are too limited.
diff --git a/llvm/test/Transforms/LoopVectorize/PowerPC/interleave_IC.ll b/llvm/test/Transforms/LoopVectorize/PowerPC/interleave_IC.ll
index 7121c85dd59be4..c12b3b122ba74c 100644
--- a/llvm/test/Transforms/LoopVectorize/PowerPC/interleave_IC.ll
+++ b/llvm/test/Transforms/LoopVectorize/PowerPC/interleave_IC.ll
@@ -1,5 +1,5 @@
-; RUN: opt < %s -passes=loop-vectorize -S -mcpu=pwr9 -interleave-small-loop-scalar-reduction=true 2>&1 | FileCheck %s
-; RUN: opt < %s -passes='loop-vectorize' -S -mcpu=pwr9 -interleave-small-loop-scalar-reduction=true 2>&1 | FileCheck %s
+; RUN: opt < %s -passes=loop-vectorize -S -mcpu=pwr9 2>&1 | FileCheck %s
+; RUN: opt < %s -passes='loop-vectorize' -S -mcpu=pwr9 2>&1 | FileCheck %s
; CHECK-LABEL: vector.body
; CHECK: load double, ptr
>From c1b8c6cf41df4a148e7a89c3a3c7e8049b0a47af Mon Sep 17 00:00:00 2001
From: Aart Bik <39774503+aartbik at users.noreply.github.com>
Date: Wed, 28 Feb 2024 10:18:21 -0800
Subject: [PATCH 029/406] [mlir][vector][print] do not append newline to
printing pure strings (#83213)
Since the vector.print str provides no punctuation control, it is
slightly more flexible to let the client of this operation decide
whether there should be a trailing newline. This allows for printing
like
vector.print str "nse = "
vector.print %nse : index
as
nse = 42
---
.../VectorToLLVM/ConvertVectorToLLVM.cpp | 3 ++-
...t-wide-int-emulation-compare-results-i16.mlir | 2 +-
.../Dialect/Linalg/CPU/ArmSME/fill-2d.mlir | 2 +-
.../Linalg/CPU/ArmSME/use-too-many-tiles.mlir | 10 +++++-----
.../CPU/ArmSME/Emulated/test-setArmSVLBits.mlir | 8 ++++----
.../CPU/ArmSME/load-store-128-bit-tile.mlir | 8 ++++----
.../Vector/CPU/ArmSME/test-load-vertical.mlir | 8 ++++----
.../CPU/ArmSME/test-multi-tile-transpose.mlir | 8 ++++----
.../Vector/CPU/ArmSME/test-outerproduct-f32.mlir | 16 ++++++++--------
.../Vector/CPU/ArmSME/test-outerproduct-f64.mlir | 16 ++++++++--------
.../Vector/CPU/ArmSME/test-transfer-read-2d.mlir | 12 ++++++------
.../CPU/ArmSME/test-transfer-write-2d.mlir | 2 +-
.../Vector/CPU/ArmSME/test-transpose.mlir | 8 ++++----
.../Dialect/Vector/CPU/ArmSME/tile_fill.mlir | 4 ++--
.../Vector/CPU/ArmSME/vector-load-store.mlir | 8 ++++----
.../CPU/ArmSVE/arrays-of-scalable-vectors.mlir | 12 ++++++------
.../Dialect/Vector/CPU/test-print-str.mlir | 4 ++--
17 files changed, 66 insertions(+), 65 deletions(-)
diff --git a/mlir/lib/Conversion/VectorToLLVM/ConvertVectorToLLVM.cpp b/mlir/lib/Conversion/VectorToLLVM/ConvertVectorToLLVM.cpp
index 19cc914efae005..337f8bb6ab99ed 100644
--- a/mlir/lib/Conversion/VectorToLLVM/ConvertVectorToLLVM.cpp
+++ b/mlir/lib/Conversion/VectorToLLVM/ConvertVectorToLLVM.cpp
@@ -1532,7 +1532,8 @@ class VectorPrintOpConversion : public ConvertOpToLLVMPattern<vector::PrintOp> {
auto punct = printOp.getPunctuation();
if (auto stringLiteral = printOp.getStringLiteral()) {
LLVM::createPrintStrCall(rewriter, loc, parent, "vector_print_str",
- *stringLiteral, *getTypeConverter());
+ *stringLiteral, *getTypeConverter(),
+ /*addNewline=*/false);
} else if (punct != PrintPunctuation::NoPunctuation) {
emitCall(rewriter, printOp->getLoc(), [&] {
switch (punct) {
diff --git a/mlir/test/Integration/Dialect/Arith/CPU/test-wide-int-emulation-compare-results-i16.mlir b/mlir/test/Integration/Dialect/Arith/CPU/test-wide-int-emulation-compare-results-i16.mlir
index 15bafeda67403e..437e49a6b81446 100644
--- a/mlir/test/Integration/Dialect/Arith/CPU/test-wide-int-emulation-compare-results-i16.mlir
+++ b/mlir/test/Integration/Dialect/Arith/CPU/test-wide-int-emulation-compare-results-i16.mlir
@@ -26,7 +26,7 @@ func.func @check_results(%lhs : i16, %rhs : i16, %res0 : i16, %res1 : i16) -> ()
%mismatch = arith.cmpi ne, %res0, %res1 : i16
scf.if %mismatch -> () {
vector.print %res1 : i16
- vector.print str "Mismatch"
+ vector.print str "Mismatch\n"
}
return
}
diff --git a/mlir/test/Integration/Dialect/Linalg/CPU/ArmSME/fill-2d.mlir b/mlir/test/Integration/Dialect/Linalg/CPU/ArmSME/fill-2d.mlir
index 12f13e8dbc4a9f..881e2799b5b06b 100644
--- a/mlir/test/Integration/Dialect/Linalg/CPU/ArmSME/fill-2d.mlir
+++ b/mlir/test/Integration/Dialect/Linalg/CPU/ArmSME/fill-2d.mlir
@@ -88,7 +88,7 @@ func.func @entry() {
}
// CHECK: SME: END OF TEST OUTPUT
- vector.print str "SME: END OF TEST OUTPUT"
+ vector.print str "SME: END OF TEST OUTPUT\n"
return
}
diff --git a/mlir/test/Integration/Dialect/Linalg/CPU/ArmSME/use-too-many-tiles.mlir b/mlir/test/Integration/Dialect/Linalg/CPU/ArmSME/use-too-many-tiles.mlir
index ee3866de303e03..588b44a36c29f3 100644
--- a/mlir/test/Integration/Dialect/Linalg/CPU/ArmSME/use-too-many-tiles.mlir
+++ b/mlir/test/Integration/Dialect/Linalg/CPU/ArmSME/use-too-many-tiles.mlir
@@ -24,23 +24,23 @@ func.func @use_too_many_tiles(%a: memref<?x?xi16>, %b: memref<?x?xi16>, %c: mem
// CHECK-LABEL: tile_a:
// CHECK-COUNT-8: ( 0, 0, 0, 0, 0, 0, 0, 0
- vector.print str "tile_a:"
+ vector.print str "tile_a:\n"
vector.print %tile_a : vector<[8]x[8]xi16>
// CHECK-LABEL: tile_b:
// CHECK-COUNT-8: ( 1, 1, 1, 1, 1, 1, 1, 1
- vector.print str "tile_b:"
+ vector.print str "tile_b:\n"
vector.print %tile_b : vector<[8]x[8]xi16>
// CHECK-LABEL: tile_c:
// CHECK-COUNT-8: ( 2, 2, 2, 2, 2, 2, 2, 2
- vector.print str "tile_c:"
+ vector.print str "tile_c:\n"
vector.print %tile_c : vector<[8]x[8]xi16>
// CHECK-LABEL: tile_d:
// CHECK-COUNT-8: ( 3, 3, 3, 3, 3, 3, 3, 3
- vector.print str "tile_d:"
+ vector.print str "tile_d:\n"
vector.print %tile_d : vector<[8]x[8]xi16>
// CHECK-LABEL: tile_e:
// CHECK-COUNT-8: ( 4, 4, 4, 4, 4, 4, 4, 4
- vector.print str "tile_e:"
+ vector.print str "tile_e:\n"
vector.print %tile_e : vector<[8]x[8]xi16>
return
}
diff --git a/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/Emulated/test-setArmSVLBits.mlir b/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/Emulated/test-setArmSVLBits.mlir
index 415181171e27b8..1794564a6a7244 100644
--- a/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/Emulated/test-setArmSVLBits.mlir
+++ b/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/Emulated/test-setArmSVLBits.mlir
@@ -12,13 +12,13 @@ func.func @checkSVL() {
%svl_h = arm_sme.streaming_vl <half>
%svl_w = arm_sme.streaming_vl <word>
%svl_d = arm_sme.streaming_vl <double>
- vector.print str "SVL.b"
+ vector.print str "SVL.b\n"
vector.print %svl_b : index
- vector.print str "SVL.h"
+ vector.print str "SVL.h\n"
vector.print %svl_h : index
- vector.print str "SVL.w"
+ vector.print str "SVL.w\n"
vector.print %svl_w : index
- vector.print str "SVL.d"
+ vector.print str "SVL.d\n"
vector.print %svl_d : index
return
}
diff --git a/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/load-store-128-bit-tile.mlir b/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/load-store-128-bit-tile.mlir
index 2b8899b6c6fc32..41e724844fe403 100644
--- a/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/load-store-128-bit-tile.mlir
+++ b/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/load-store-128-bit-tile.mlir
@@ -53,13 +53,13 @@ func.func @test_load_store_zaq0() {
// CHECK-LABEL: INITIAL TILE A:
// CHECK: ( 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7 )
- vector.print str "INITIAL TILE A:"
+ vector.print str "INITIAL TILE A:\n"
func.call @print_i8s(%tile_a_bytes, %zaq_size_bytes) : (memref<?xi8>, index) -> ()
vector.print punctuation <newline>
// CHECK-LABEL: INITIAL TILE B:
// CHECK: ( 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64 )
- vector.print str "INITIAL TILE B:"
+ vector.print str "INITIAL TILE B:\n"
func.call @print_i8s(%tile_b_bytes, %zaq_size_bytes) : (memref<?xi8>, index) -> ()
vector.print punctuation <newline>
@@ -68,13 +68,13 @@ func.func @test_load_store_zaq0() {
// CHECK-LABEL: FINAL TILE A:
// CHECK: ( 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7 )
- vector.print str "FINAL TILE A:"
+ vector.print str "FINAL TILE A:\n"
func.call @print_i8s(%tile_a_bytes, %zaq_size_bytes) : (memref<?xi8>, index) -> ()
vector.print punctuation <newline>
// CHECK-LABEL: FINAL TILE B:
// CHECK: ( 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7 )
- vector.print str "FINAL TILE B:"
+ vector.print str "FINAL TILE B:\n"
func.call @print_i8s(%tile_b_bytes, %zaq_size_bytes) : (memref<?xi8>, index) -> ()
return
diff --git a/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-load-vertical.mlir b/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-load-vertical.mlir
index 27be801252b812..68c31ac1dd8e9c 100644
--- a/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-load-vertical.mlir
+++ b/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-load-vertical.mlir
@@ -49,12 +49,12 @@ func.func @entry() {
// CHECK-NEXT: ( 2, 2, 2, 2
// CHECK-NEXT: ( 3, 3, 3, 3
// CHECK: TILE END
- vector.print str "TILE BEGIN"
+ vector.print str "TILE BEGIN\n"
scf.for %i = %c0 to %za_s_size step %svl_s {
%tileslice = vector.load %mem1[%i] : memref<?xi32>, vector<[4]xi32>
vector.print %tileslice : vector<[4]xi32>
}
- vector.print str "TILE END"
+ vector.print str "TILE END\n"
// 2. VERTICAL LAYOUT
// Dump "mem2". The smallest SVL is 128-bits so the tile will be at least
@@ -66,9 +66,9 @@ func.func @entry() {
// CHECK-NEXT: ( 0, 1, 2, 3
// CHECK-NEXT: ( 0, 1, 2, 3
// CHECK: TILE END
- vector.print str "TILE BEGIN"
+ vector.print str "TILE BEGIN\n"
vector.print %0 : vector<[4]x[4]xi32>
- vector.print str "TILE END"
+ vector.print str "TILE END\n"
return
}
diff --git a/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-multi-tile-transpose.mlir b/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-multi-tile-transpose.mlir
index 9d836d93c85bb7..cd48f2a9ebfd89 100644
--- a/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-multi-tile-transpose.mlir
+++ b/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-multi-tile-transpose.mlir
@@ -46,12 +46,12 @@ func.func @testTransposedReadWithMask(%maskRows: index, %maskCols: index) {
vector.transfer_write %readTransposed, %outDyn[%c0, %c0] {in_bounds = [true, true]} : vector<[16]x[4]xf32>, memref<?x?xf32>
/// Print the input memref.
- vector.print str "Input memref:"
+ vector.print str "Input memref:\n"
%inUnranked = memref.cast %inDyn : memref<?x?xf32> to memref<*xf32>
call @printMemrefF32(%inUnranked) : (memref<*xf32>) -> ()
/// Print the result memref.
- vector.print str "Masked transposed result:"
+ vector.print str "Masked transposed result:\n"
%outUnranked = memref.cast %outDyn : memref<?x?xf32> to memref<*xf32>
call @printMemrefF32(%outUnranked) : (memref<*xf32>) -> ()
@@ -84,12 +84,12 @@ func.func @testTransposedWriteWithMask(%maskRows: index, %maskCols: index) {
: vector<[16]x[4]xf32>, memref<?x?xf32>
/// Print the input memref.
- vector.print str "Input memref:"
+ vector.print str "Input memref:\n"
%inUnranked = memref.cast %inDyn : memref<?x?xf32> to memref<*xf32>
call @printMemrefF32(%inUnranked) : (memref<*xf32>) -> ()
/// Print the result memref.
- vector.print str "Masked transposed result:"
+ vector.print str "Masked transposed result:\n"
%outUnranked = memref.cast %outDyn : memref<?x?xf32> to memref<*xf32>
call @printMemrefF32(%outUnranked) : (memref<*xf32>) -> ()
diff --git a/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-outerproduct-f32.mlir b/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-outerproduct-f32.mlir
index 7e7869d1c957aa..fb6c06cfd69999 100644
--- a/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-outerproduct-f32.mlir
+++ b/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-outerproduct-f32.mlir
@@ -35,9 +35,9 @@ func.func @test_outerproduct_no_accumulator_4x4xf32() {
// WITHOUT-ACC-NEXT: ( 0, 2, 4, 6
// WITHOUT-ACC-NEXT: ( 0, 3, 6, 9
// WITHOUT-ACC: TILE END
- vector.print str "TILE BEGIN"
+ vector.print str "TILE BEGIN\n"
vector.print %tile : vector<[4]x[4]xf32>
- vector.print str "TILE END"
+ vector.print str "TILE END\n"
return
}
@@ -60,9 +60,9 @@ func.func @test_outerproduct_with_accumulator_4x4xf32() {
// WITH-ACC-NEXT: ( 10, 12, 14, 16
// WITH-ACC-NEXT: ( 10, 13, 16, 19
// WITH-ACC: TILE END
- vector.print str "TILE BEGIN"
+ vector.print str "TILE BEGIN\n"
vector.print %tile : vector<[4]x[4]xf32>
- vector.print str "TILE END"
+ vector.print str "TILE END\n"
return
}
@@ -91,9 +91,9 @@ func.func @test_masked_outerproduct_no_accumulator_4x4xf32() {
// WITH-MASK-NEXT: ( 3, 6, 0, 0
// WITH-MASK-NEXT: ( 0, 0, 0, 0
// WITH-MASK: TILE END
- vector.print str "TILE BEGIN"
+ vector.print str "TILE BEGIN\n"
vector.print %tile : vector<[4]x[4]xf32>
- vector.print str "TILE END"
+ vector.print str "TILE END\n"
return
}
@@ -124,9 +124,9 @@ func.func @test_masked_outerproduct_with_accumulator_4x4xf32() {
// WITH-MASK-AND-ACC-NEXT: ( 10, 10, 10, 10
// WITH-MASK-AND-ACC-NEXT: ( 10, 10, 10, 10
// WITH-MASK-AND-ACC: TILE END
- vector.print str "TILE BEGIN"
+ vector.print str "TILE BEGIN\n"
vector.print %tile : vector<[4]x[4]xf32>
- vector.print str "TILE END"
+ vector.print str "TILE END\n"
return
}
diff --git a/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-outerproduct-f64.mlir b/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-outerproduct-f64.mlir
index 46bf799232ae3a..b8458606d3f324 100644
--- a/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-outerproduct-f64.mlir
+++ b/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-outerproduct-f64.mlir
@@ -40,9 +40,9 @@ func.func @test_outerproduct_no_accumulator_2x2xf64() {
// CHECK-NEXT: ( 1, 2
// CHECK-NEXT: ( 2, 4
// CHECK: TILE END
- vector.print str "TILE BEGIN"
+ vector.print str "TILE BEGIN\n"
vector.print %tile : vector<[2]x[2]xf64>
- vector.print str "TILE END"
+ vector.print str "TILE END\n"
return
}
@@ -66,9 +66,9 @@ func.func @test_outerproduct_with_accumulator_2x2xf64() {
// WITH-ACC-NEXT: ( 11, 12
// WITH-ACC-NEXT: ( 12, 14
// WITH-ACC: TILE END
- vector.print str "TILE BEGIN"
+ vector.print str "TILE BEGIN\n"
vector.print %tile : vector<[2]x[2]xf64>
- vector.print str "TILE END"
+ vector.print str "TILE END\n"
return
}
@@ -96,9 +96,9 @@ func.func @test_masked_outerproduct_no_accumulator_2x2xf64() {
// WITH-MASK-NEXT: ( 1, 0
// WITH-MASK-NEXT: ( 2, 0
// WITH-MASK: TILE END
- vector.print str "TILE BEGIN"
+ vector.print str "TILE BEGIN\n"
vector.print %tile : vector<[2]x[2]xf64>
- vector.print str "TILE END"
+ vector.print str "TILE END\n"
return
}
@@ -127,9 +127,9 @@ func.func @test_masked_outerproduct_with_accumulator_2x2xf64() {
// WITH-MASK-AND-ACC-NEXT: ( 11, 12
// WITH-MASK-AND-ACC-NEXT: ( 10, 10
// WITH-MASK-AND-ACC: TILE END
- vector.print str "TILE BEGIN"
+ vector.print str "TILE BEGIN\n"
vector.print %tile : vector<[2]x[2]xf64>
- vector.print str "TILE END"
+ vector.print str "TILE END\n"
return
}
diff --git a/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-transfer-read-2d.mlir b/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-transfer-read-2d.mlir
index 52f56883cad9c1..7421521b96bf92 100644
--- a/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-transfer-read-2d.mlir
+++ b/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-transfer-read-2d.mlir
@@ -14,7 +14,7 @@ func.func @transfer_read_2d(%A : memref<?x?xf32>, %base1: index, %base2: index)
%0 = vector.transfer_read %A[%base1, %base2], %pad {in_bounds=[true, true]} :
memref<?x?xf32>, vector<[4]x[4]xf32>
- vector.print str "TILE BEGIN:"
+ vector.print str "TILE BEGIN:\n"
vector.print %0: vector<[4]x[4]xf32>
return
@@ -27,7 +27,7 @@ func.func @transfer_read_2d_transposed(%A : memref<?x?xf32>, %base1: index, %bas
{permutation_map = affine_map<(d0, d1) -> (d1, d0)>, in_bounds=[true, true]}
: memref<?x?xf32>, vector<[4]x[4]xf32>
- vector.print str "TILE BEGIN:"
+ vector.print str "TILE BEGIN:\n"
vector.print %0 : vector<[4]x[4]xf32>
return
@@ -42,7 +42,7 @@ func.func @transfer_read_2d_mask(%A : memref<?x?xf32>, %base1: index, %base2: in
%0 = vector.transfer_read %A[%base1, %base2], %pad, %mask
{in_bounds = [true, true]} : memref<?x?xf32>, vector<[4]x[4]xf32>
- vector.print str "TILE BEGIN:"
+ vector.print str "TILE BEGIN:\n"
vector.print %0: vector<[4]x[4]xf32>
return
@@ -58,7 +58,7 @@ func.func @transfer_read_2d_mask_transposed(%A : memref<?x?xf32>, %base1: index,
{permutation_map = affine_map<(d0, d1) -> (d1, d0)>, in_bounds=[true, true]}
: memref<?x?xf32>, vector<[4]x[4]xf32>
- vector.print str "TILE BEGIN:"
+ vector.print str "TILE BEGIN:\n"
vector.print %0: vector<[4]x[4]xf32>
return
@@ -73,7 +73,7 @@ func.func @transfer_read_2d_mask_non_zero_pad(%A : memref<?x?xf32>, %base1: inde
%0 = vector.transfer_read %A[%base1, %base2], %pad, %mask
{in_bounds = [true, true]} : memref<?x?xf32>, vector<[4]x[4]xf32>
- vector.print str "TILE BEGIN:"
+ vector.print str "TILE BEGIN:\n"
vector.print %0: vector<[4]x[4]xf32>
return
@@ -89,7 +89,7 @@ func.func @transfer_read_2d_mask_non_zero_pad_transposed(%A : memref<?x?xf32>, %
{permutation_map = affine_map<(d0, d1) -> (d1, d0)>, in_bounds=[true, true]}
: memref<?x?xf32>, vector<[4]x[4]xf32>
- vector.print str "TILE BEGIN:"
+ vector.print str "TILE BEGIN:\n"
vector.print %0: vector<[4]x[4]xf32>
return
diff --git a/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-transfer-write-2d.mlir b/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-transfer-write-2d.mlir
index 710cc6672f0057..2fef705861f28e 100644
--- a/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-transfer-write-2d.mlir
+++ b/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-transfer-write-2d.mlir
@@ -51,7 +51,7 @@ func.func @transfer_write_2d_mask_transposed(%A : memref<?x?xf32>, %base1: index
func.func @load_and_print(%A : memref<?x?xf32>, %base1: index, %base2: index) {
%0 = vector.load %A[%base1, %base2] : memref<?x?xf32>, vector<[4]x[4]xf32>
- vector.print str "TILE BEGIN:"
+ vector.print str "TILE BEGIN:\n"
vector.print %0: vector<[4]x[4]xf32>
return
diff --git a/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-transpose.mlir b/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-transpose.mlir
index 88bc0d0709d489..177c96f1d8aae6 100644
--- a/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-transpose.mlir
+++ b/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-transpose.mlir
@@ -51,9 +51,9 @@ func.func @entry() {
// CHECK-NEXT: ( 2, 2, 2, 2
// CHECK-NEXT: ( 3, 3, 3, 3
// CHECK: TILE END
- vector.print str "TILE BEGIN"
+ vector.print str "TILE BEGIN\n"
vector.print %tile : vector<[4]x[4]xi32>
- vector.print str "TILE END"
+ vector.print str "TILE END\n"
// Dump the transposed tile. The smallest SVL is 128-bits so the tile will be
// at least 4x4xi32.
@@ -64,9 +64,9 @@ func.func @entry() {
// CHECK-NEXT: ( 0, 1, 2, 3
// CHECK-NEXT: ( 0, 1, 2, 3
// CHECK: TILE END
- vector.print str "TILE BEGIN"
+ vector.print str "TILE BEGIN\n"
vector.print %transposed_tile : vector<[4]x[4]xi32>
- vector.print str "TILE END"
+ vector.print str "TILE END\n"
return
}
diff --git a/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/tile_fill.mlir b/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/tile_fill.mlir
index e14917486d845d..3d74508cd23b57 100644
--- a/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/tile_fill.mlir
+++ b/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/tile_fill.mlir
@@ -23,9 +23,9 @@ func.func @entry() -> i32 {
// CHECK-NEXT: ( 123, 123, 123, 123
// CHECK-NEXT: ( 123, 123, 123, 123
// CHECK: TILE END
- vector.print str "TILE BEGIN"
+ vector.print str "TILE BEGIN\n"
vector.print %tile : vector<[4]x[4]xi32>
- vector.print str "TILE END"
+ vector.print str "TILE END\n"
%c0_i32 = arith.constant 0 : i32
return %c0_i32 : i32
diff --git a/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/vector-load-store.mlir b/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/vector-load-store.mlir
index b29790db14ddc4..48080fd0a26a2b 100644
--- a/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/vector-load-store.mlir
+++ b/mlir/test/Integration/Dialect/Vector/CPU/ArmSME/vector-load-store.mlir
@@ -255,7 +255,7 @@ func.func @load_store_two_za_s_tiles() -> i32 {
// CHECK-NEXT: ( 1, 1, 1, 1
// CHECK-NEXT: ( 1, 1, 1, 1
// CHECK: TILE END
- vector.print str "TILE BEGIN"
+ vector.print str "TILE BEGIN\n"
scf.for %i = %c0 to %size_of_two_tiles step %svl_s {
%av = vector.load %mem2[%i] : memref<?xi32>, vector<[4]xi32>
vector.print %av : vector<[4]xi32>
@@ -263,11 +263,11 @@ func.func @load_store_two_za_s_tiles() -> i32 {
%tileSizeMinusStep = arith.subi %size_of_tile, %svl_s : index
%isNextTile = arith.cmpi eq, %i, %tileSizeMinusStep : index
scf.if %isNextTile {
- vector.print str "TILE END"
- vector.print str "TILE BEGIN"
+ vector.print str "TILE END\n"
+ vector.print str "TILE BEGIN\n"
}
}
- vector.print str "TILE END"
+ vector.print str "TILE END\n"
return %c0_i32 : i32
}
diff --git a/mlir/test/Integration/Dialect/Vector/CPU/ArmSVE/arrays-of-scalable-vectors.mlir b/mlir/test/Integration/Dialect/Vector/CPU/ArmSVE/arrays-of-scalable-vectors.mlir
index c486bf0de5d352..afb23e8e520660 100644
--- a/mlir/test/Integration/Dialect/Vector/CPU/ArmSVE/arrays-of-scalable-vectors.mlir
+++ b/mlir/test/Integration/Dialect/Vector/CPU/ArmSVE/arrays-of-scalable-vectors.mlir
@@ -24,7 +24,7 @@ func.func @read_and_print_2d_vector(%memref: memref<3x?xf32>) {
/// Print each of the vectors.
/// vscale is >= 1, so at least 8 elements will be printed.
- vector.print str "read_and_print_2d_vector()"
+ vector.print str "read_and_print_2d_vector()\n"
// CHECK-LABEL: read_and_print_2d_vector()
// CHECK: ( 8, 8, 8, 8, 8, 8, 8, 8
vector.print %row0 : vector<[8]xf32>
@@ -62,21 +62,21 @@ func.func @add_arrays_of_scalable_vectors(%a: memref<1x2x?xf32>, %b: memref<1x2x
// CHECK-LABEL: Vector A
// CHECK-NEXT: ( 5, 5, 5, 5
// CHECK-NEXT: ( 5, 5, 5, 5
- vector.print str "\nVector A"
+ vector.print str "\nVector A\n"
%vector_a = vector.transfer_read %a[%c0, %c0, %c0], %cst, %mask_a {in_bounds = [true, true, true]} : memref<1x2x?xf32>, vector<1x2x[4]xf32>
func.call @print_1x2xVSCALExf32(%vector_a) : (vector<1x2x[4]xf32>) -> ()
// CHECK-LABEL: Vector B
// CHECK-NEXT: ( 4, 4, 4, 4
// CHECK-NEXT: ( 4, 4, 4, 4
- vector.print str "\nVector B"
+ vector.print str "\nVector B\n"
%vector_b = vector.transfer_read %b[%c0, %c0, %c0], %cst, %mask_b {in_bounds = [true, true, true]} : memref<1x2x?xf32>, vector<1x2x[4]xf32>
func.call @print_1x2xVSCALExf32(%vector_b) : (vector<1x2x[4]xf32>) -> ()
// CHECK-LABEL: Sum
// CHECK-NEXT: ( 9, 9, 9, 9
// CHECK-NEXT: ( 9, 9, 9, 9
- vector.print str "\nSum"
+ vector.print str "\nSum\n"
%sum = arith.addf %vector_a, %vector_b : vector<1x2x[4]xf32>
func.call @print_1x2xVSCALExf32(%sum) : (vector<1x2x[4]xf32>) -> ()
@@ -97,7 +97,7 @@ func.func @entry() {
linalg.fill ins(%f32_8 : f32) outs(%test_1_memref :memref<3x?xf32>)
- vector.print str "=> Print and read 2D arrays of scalable vectors:"
+ vector.print str "=> Print and read 2D arrays of scalable vectors:\n"
func.call @read_and_print_2d_vector(%test_1_memref) : (memref<3x?xf32>) -> ()
vector.print str "\n====================\n"
@@ -109,7 +109,7 @@ func.func @entry() {
linalg.fill ins(%f32_5 : f32) outs(%test_2_memref_a :memref<1x2x?xf32>)
linalg.fill ins(%f32_4 : f32) outs(%test_2_memref_b :memref<1x2x?xf32>)
- vector.print str "=> Reading and adding two 3D arrays of scalable vectors:"
+ vector.print str "=> Reading and adding two 3D arrays of scalable vectors:\n"
func.call @add_arrays_of_scalable_vectors(
%test_2_memref_a, %test_2_memref_b) : (memref<1x2x?xf32>, memref<1x2x?xf32>) -> ()
diff --git a/mlir/test/Integration/Dialect/Vector/CPU/test-print-str.mlir b/mlir/test/Integration/Dialect/Vector/CPU/test-print-str.mlir
index 78d6609ccaf9a9..25a44f22c2dc0b 100644
--- a/mlir/test/Integration/Dialect/Vector/CPU/test-print-str.mlir
+++ b/mlir/test/Integration/Dialect/Vector/CPU/test-print-str.mlir
@@ -7,8 +7,8 @@
func.func @entry() {
// CHECK: Hello, World!
- vector.print str "Hello, World!"
+ vector.print str "Hello, World!\n"
// CHECK-NEXT: Bye!
- vector.print str "Bye!"
+ vector.print str "Bye!\n"
return
}
>From baf6725b38491222f40a3c40bd27e57b0dd7f1f9 Mon Sep 17 00:00:00 2001
From: Slava Zakharin <szakharin at nvidia.com>
Date: Wed, 28 Feb 2024 10:39:14 -0800
Subject: [PATCH 030/406] [flang][runtime] Support NORM2 for REAL(16) with
FortranFloat128Math lib. (#83219)
Changed the lowering to call Norm2DimReal16 for REAL(16).
Added the corresponding entry point to FortranFloat128Math,
which required some restructuring in the related templates.
---
flang/include/flang/Runtime/reduction.h | 5 +-
.../Optimizer/Builder/Runtime/Reduction.cpp | 25 +++-
flang/runtime/Float128Math/CMakeLists.txt | 1 +
flang/runtime/Float128Math/math-entries.h | 16 +++
flang/runtime/Float128Math/norm2.cpp | 59 +++++++++
flang/runtime/extrema.cpp | 107 ++--------------
flang/runtime/reduction-templates.h | 115 ++++++++++++++++++
flang/runtime/tools.h | 11 +-
flang/test/Lower/Intrinsics/norm2.f90 | 16 +++
9 files changed, 256 insertions(+), 99 deletions(-)
create mode 100644 flang/runtime/Float128Math/norm2.cpp
diff --git a/flang/include/flang/Runtime/reduction.h b/flang/include/flang/Runtime/reduction.h
index 6d62f4016937e0..5b607765857523 100644
--- a/flang/include/flang/Runtime/reduction.h
+++ b/flang/include/flang/Runtime/reduction.h
@@ -364,9 +364,12 @@ double RTDECL(Norm2_8)(
#if LDBL_MANT_DIG == 64
long double RTDECL(Norm2_10)(
const Descriptor &, const char *source, int line, int dim = 0);
-#elif LDBL_MANT_DIG == 113
+#endif
+#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
long double RTDECL(Norm2_16)(
const Descriptor &, const char *source, int line, int dim = 0);
+void RTDECL(Norm2DimReal16)(
+ Descriptor &, const Descriptor &, int dim, const char *source, int line);
#endif
void RTDECL(Norm2Dim)(
Descriptor &, const Descriptor &, int dim, const char *source, int line);
diff --git a/flang/lib/Optimizer/Builder/Runtime/Reduction.cpp b/flang/lib/Optimizer/Builder/Runtime/Reduction.cpp
index fabbff818b6f0e..66fbaddcbda1aa 100644
--- a/flang/lib/Optimizer/Builder/Runtime/Reduction.cpp
+++ b/flang/lib/Optimizer/Builder/Runtime/Reduction.cpp
@@ -149,6 +149,22 @@ struct ForcedNorm2Real16 {
}
};
+/// Placeholder for real*16 version of Norm2Dim Intrinsic
+struct ForcedNorm2DimReal16 {
+ static constexpr const char *name = ExpandAndQuoteKey(RTNAME(Norm2DimReal16));
+ static constexpr fir::runtime::FuncTypeBuilderFunc getTypeModel() {
+ return [](mlir::MLIRContext *ctx) {
+ auto boxTy =
+ fir::runtime::getModel<const Fortran::runtime::Descriptor &>()(ctx);
+ auto strTy = fir::ReferenceType::get(mlir::IntegerType::get(ctx, 8));
+ auto intTy = mlir::IntegerType::get(ctx, 8 * sizeof(int));
+ return mlir::FunctionType::get(
+ ctx, {fir::ReferenceType::get(boxTy), boxTy, intTy, strTy, intTy},
+ mlir::NoneType::get(ctx));
+ };
+ }
+};
+
/// Placeholder for real*10 version of Product Intrinsic
struct ForcedProductReal10 {
static constexpr const char *name = ExpandAndQuoteKey(RTNAME(ProductReal10));
@@ -876,7 +892,14 @@ mlir::Value fir::runtime::genMinval(fir::FirOpBuilder &builder,
void fir::runtime::genNorm2Dim(fir::FirOpBuilder &builder, mlir::Location loc,
mlir::Value resultBox, mlir::Value arrayBox,
mlir::Value dim) {
- auto func = fir::runtime::getRuntimeFunc<mkRTKey(Norm2Dim)>(loc, builder);
+ mlir::func::FuncOp func;
+ auto ty = arrayBox.getType();
+ auto arrTy = fir::dyn_cast_ptrOrBoxEleTy(ty);
+ auto eleTy = arrTy.cast<fir::SequenceType>().getEleTy();
+ if (eleTy.isF128())
+ func = fir::runtime::getRuntimeFunc<ForcedNorm2DimReal16>(loc, builder);
+ else
+ func = fir::runtime::getRuntimeFunc<mkRTKey(Norm2Dim)>(loc, builder);
auto fTy = func.getFunctionType();
auto sourceFile = fir::factory::locationToFilename(builder, loc);
auto sourceLine =
diff --git a/flang/runtime/Float128Math/CMakeLists.txt b/flang/runtime/Float128Math/CMakeLists.txt
index 8d276e8f122728..f11678cd70b769 100644
--- a/flang/runtime/Float128Math/CMakeLists.txt
+++ b/flang/runtime/Float128Math/CMakeLists.txt
@@ -69,6 +69,7 @@ set(sources
log.cpp
log10.cpp
lround.cpp
+ norm2.cpp
pow.cpp
round.cpp
sin.cpp
diff --git a/flang/runtime/Float128Math/math-entries.h b/flang/runtime/Float128Math/math-entries.h
index 83298674c4971f..a0d81d0cbb5407 100644
--- a/flang/runtime/Float128Math/math-entries.h
+++ b/flang/runtime/Float128Math/math-entries.h
@@ -54,6 +54,7 @@ namespace Fortran::runtime {
};
// Define fallback callers.
+DEFINE_FALLBACK(Abs)
DEFINE_FALLBACK(Acos)
DEFINE_FALLBACK(Acosh)
DEFINE_FALLBACK(Asin)
@@ -99,6 +100,7 @@ DEFINE_FALLBACK(Yn)
// Use STD math functions. They provide IEEE-754 128-bit float
// support either via 'long double' or __float128.
// The Bessel's functions are not present in STD namespace.
+DEFINE_SIMPLE_ALIAS(Abs, std::abs)
DEFINE_SIMPLE_ALIAS(Acos, std::acos)
DEFINE_SIMPLE_ALIAS(Acosh, std::acosh)
DEFINE_SIMPLE_ALIAS(Asin, std::asin)
@@ -155,6 +157,7 @@ DEFINE_SIMPLE_ALIAS(Yn, ynl)
#elif HAS_QUADMATHLIB
// Define wrapper callers for libquadmath.
#include "quadmath.h"
+DEFINE_SIMPLE_ALIAS(Abs, fabsq)
DEFINE_SIMPLE_ALIAS(Acos, acosq)
DEFINE_SIMPLE_ALIAS(Acosh, acoshq)
DEFINE_SIMPLE_ALIAS(Asin, asinq)
@@ -191,6 +194,19 @@ DEFINE_SIMPLE_ALIAS(Y0, y0q)
DEFINE_SIMPLE_ALIAS(Y1, y1q)
DEFINE_SIMPLE_ALIAS(Yn, ynq)
#endif
+
+extern "C" {
+// Declarations of the entry points that might be referenced
+// within the Float128Math library itself.
+// Note that not all of these entry points are actually
+// defined in this library. Some of them are used just
+// as template parameters to call the corresponding callee directly.
+CppTypeFor<TypeCategory::Real, 16> RTDECL(AbsF128)(
+ CppTypeFor<TypeCategory::Real, 16> x);
+CppTypeFor<TypeCategory::Real, 16> RTDECL(SqrtF128)(
+ CppTypeFor<TypeCategory::Real, 16> x);
+} // extern "C"
+
} // namespace Fortran::runtime
#endif // FORTRAN_RUNTIME_FLOAT128MATH_MATH_ENTRIES_H_
diff --git a/flang/runtime/Float128Math/norm2.cpp b/flang/runtime/Float128Math/norm2.cpp
new file mode 100644
index 00000000000000..17453bd2d6cbd7
--- /dev/null
+++ b/flang/runtime/Float128Math/norm2.cpp
@@ -0,0 +1,59 @@
+//===-- runtime/Float128Math/norm2.cpp ------------------------------------===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+
+#include "math-entries.h"
+#include "reduction-templates.h"
+#include <cmath>
+
+#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
+
+namespace {
+using namespace Fortran::runtime;
+
+using AccumType = Norm2AccumType<16>;
+
+struct ABSTy {
+ static AccumType compute(AccumType x) {
+ return Sqrt<RTNAME(AbsF128)>::invoke(x);
+ }
+};
+
+struct SQRTTy {
+ static AccumType compute(AccumType x) {
+ return Sqrt<RTNAME(SqrtF128)>::invoke(x);
+ }
+};
+
+using Float128Norm2Accumulator = Norm2Accumulator<16, ABSTy, SQRTTy>;
+} // namespace
+
+namespace Fortran::runtime {
+extern "C" {
+
+CppTypeFor<TypeCategory::Real, 16> RTDEF(Norm2_16)(
+ const Descriptor &x, const char *source, int line, int dim) {
+ auto accumulator{::Float128Norm2Accumulator(x)};
+ return GetTotalReduction<TypeCategory::Real, 16>(
+ x, source, line, dim, nullptr, accumulator, "NORM2");
+}
+
+void RTDEF(Norm2DimReal16)(Descriptor &result, const Descriptor &x, int dim,
+ const char *source, int line) {
+ Terminator terminator{source, line};
+ auto type{x.type().GetCategoryAndKind()};
+ RUNTIME_CHECK(terminator, type);
+ RUNTIME_CHECK(
+ terminator, type->first == TypeCategory::Real && type->second == 16);
+ DoMaxMinNorm2<TypeCategory::Real, 16, ::Float128Norm2Accumulator>(
+ result, x, dim, nullptr, "NORM2", terminator);
+}
+
+} // extern "C"
+} // namespace Fortran::runtime
+
+#endif
diff --git a/flang/runtime/extrema.cpp b/flang/runtime/extrema.cpp
index 3fdc8e159866d1..fc2b4e165cb269 100644
--- a/flang/runtime/extrema.cpp
+++ b/flang/runtime/extrema.cpp
@@ -528,35 +528,6 @@ inline RT_API_ATTRS CppTypeFor<CAT, KIND> TotalNumericMaxOrMin(
NumericExtremumAccumulator<CAT, KIND, IS_MAXVAL>{x}, intrinsic);
}
-template <TypeCategory CAT, int KIND, typename ACCUMULATOR>
-static RT_API_ATTRS void DoMaxMinNorm2(Descriptor &result, const Descriptor &x,
- int dim, const Descriptor *mask, const char *intrinsic,
- Terminator &terminator) {
- using Type = CppTypeFor<CAT, KIND>;
- ACCUMULATOR accumulator{x};
- if (dim == 0 || x.rank() == 1) {
- // Total reduction
-
- // Element size of the destination descriptor is the same
- // as the element size of the source.
- result.Establish(x.type(), x.ElementBytes(), nullptr, 0, nullptr,
- CFI_attribute_allocatable);
- if (int stat{result.Allocate()}) {
- terminator.Crash(
- "%s: could not allocate memory for result; STAT=%d", intrinsic, stat);
- }
- DoTotalReduction<Type>(x, dim, mask, accumulator, intrinsic, terminator);
- accumulator.GetResult(result.OffsetElement<Type>());
- } else {
- // Partial reduction
-
- // Element size of the destination descriptor is the same
- // as the element size of the source.
- PartialReduction<ACCUMULATOR, CAT, KIND>(result, x, x.ElementBytes(), dim,
- mask, terminator, intrinsic, accumulator);
- }
-}
-
template <TypeCategory CAT, bool IS_MAXVAL> struct MaxOrMinHelper {
template <int KIND> struct Functor {
RT_API_ATTRS void operator()(Descriptor &result, const Descriptor &x,
@@ -802,66 +773,11 @@ RT_EXT_API_GROUP_END
// NORM2
-RT_VAR_GROUP_BEGIN
-
-// Use at least double precision for accumulators.
-// Don't use __float128, it doesn't work with abs() or sqrt() yet.
-static constexpr RT_CONST_VAR_ATTRS int largestLDKind {
-#if LDBL_MANT_DIG == 113
- 16
-#elif LDBL_MANT_DIG == 64
- 10
-#else
- 8
-#endif
-};
-
-RT_VAR_GROUP_END
-
-template <int KIND> class Norm2Accumulator {
-public:
- using Type = CppTypeFor<TypeCategory::Real, KIND>;
- using AccumType =
- CppTypeFor<TypeCategory::Real, std::clamp(KIND, 8, largestLDKind)>;
- explicit RT_API_ATTRS Norm2Accumulator(const Descriptor &array)
- : array_{array} {}
- RT_API_ATTRS void Reinitialize() { max_ = sum_ = 0; }
- template <typename A>
- RT_API_ATTRS void GetResult(A *p, int /*zeroBasedDim*/ = -1) const {
- // m * sqrt(1 + sum((others(:)/m)**2))
- *p = static_cast<Type>(max_ * std::sqrt(1 + sum_));
- }
- RT_API_ATTRS bool Accumulate(Type x) {
- auto absX{std::abs(static_cast<AccumType>(x))};
- if (!max_) {
- max_ = absX;
- } else if (absX > max_) {
- auto t{max_ / absX}; // < 1.0
- auto tsq{t * t};
- sum_ *= tsq; // scale sum to reflect change to the max
- sum_ += tsq; // include a term for the previous max
- max_ = absX;
- } else { // absX <= max_
- auto t{absX / max_};
- sum_ += t * t;
- }
- return true;
- }
- template <typename A>
- RT_API_ATTRS bool AccumulateAt(const SubscriptValue at[]) {
- return Accumulate(*array_.Element<A>(at));
- }
-
-private:
- const Descriptor &array_;
- AccumType max_{0}; // value (m) with largest magnitude
- AccumType sum_{0}; // sum((others(:)/m)**2)
-};
-
template <int KIND> struct Norm2Helper {
RT_API_ATTRS void operator()(Descriptor &result, const Descriptor &x, int dim,
const Descriptor *mask, Terminator &terminator) const {
- DoMaxMinNorm2<TypeCategory::Real, KIND, Norm2Accumulator<KIND>>(
+ DoMaxMinNorm2<TypeCategory::Real, KIND,
+ typename Norm2AccumulatorGetter<KIND>::Type>(
result, x, dim, mask, "NORM2", terminator);
}
};
@@ -872,26 +788,27 @@ RT_EXT_API_GROUP_BEGIN
// TODO: REAL(2 & 3)
CppTypeFor<TypeCategory::Real, 4> RTDEF(Norm2_4)(
const Descriptor &x, const char *source, int line, int dim) {
- return GetTotalReduction<TypeCategory::Real, 4>(
- x, source, line, dim, nullptr, Norm2Accumulator<4>{x}, "NORM2");
+ return GetTotalReduction<TypeCategory::Real, 4>(x, source, line, dim, nullptr,
+ Norm2AccumulatorGetter<4>::create(x), "NORM2");
}
CppTypeFor<TypeCategory::Real, 8> RTDEF(Norm2_8)(
const Descriptor &x, const char *source, int line, int dim) {
- return GetTotalReduction<TypeCategory::Real, 8>(
- x, source, line, dim, nullptr, Norm2Accumulator<8>{x}, "NORM2");
+ return GetTotalReduction<TypeCategory::Real, 8>(x, source, line, dim, nullptr,
+ Norm2AccumulatorGetter<8>::create(x), "NORM2");
}
#if LDBL_MANT_DIG == 64
CppTypeFor<TypeCategory::Real, 10> RTDEF(Norm2_10)(
const Descriptor &x, const char *source, int line, int dim) {
- return GetTotalReduction<TypeCategory::Real, 10>(
- x, source, line, dim, nullptr, Norm2Accumulator<10>{x}, "NORM2");
+ return GetTotalReduction<TypeCategory::Real, 10>(x, source, line, dim,
+ nullptr, Norm2AccumulatorGetter<10>::create(x), "NORM2");
}
#endif
#if LDBL_MANT_DIG == 113
+// The __float128 implementation resides in FortranFloat128Math library.
CppTypeFor<TypeCategory::Real, 16> RTDEF(Norm2_16)(
const Descriptor &x, const char *source, int line, int dim) {
- return GetTotalReduction<TypeCategory::Real, 16>(
- x, source, line, dim, nullptr, Norm2Accumulator<16>{x}, "NORM2");
+ return GetTotalReduction<TypeCategory::Real, 16>(x, source, line, dim,
+ nullptr, Norm2AccumulatorGetter<16>::create(x), "NORM2");
}
#endif
@@ -901,7 +818,7 @@ void RTDEF(Norm2Dim)(Descriptor &result, const Descriptor &x, int dim,
auto type{x.type().GetCategoryAndKind()};
RUNTIME_CHECK(terminator, type);
if (type->first == TypeCategory::Real) {
- ApplyFloatingPointKind<Norm2Helper, void>(
+ ApplyFloatingPointKind<Norm2Helper, void, true>(
type->second, terminator, result, x, dim, nullptr, terminator);
} else {
terminator.Crash("NORM2: bad type code %d", x.type().raw());
diff --git a/flang/runtime/reduction-templates.h b/flang/runtime/reduction-templates.h
index 7d0f82d59a084d..0891bc021ff753 100644
--- a/flang/runtime/reduction-templates.h
+++ b/flang/runtime/reduction-templates.h
@@ -25,6 +25,7 @@
#include "tools.h"
#include "flang/Runtime/cpp-type.h"
#include "flang/Runtime/descriptor.h"
+#include <algorithm>
namespace Fortran::runtime {
@@ -332,5 +333,119 @@ template <typename ACCUMULATOR> struct PartialLocationHelper {
};
};
+// NORM2 templates
+
+RT_VAR_GROUP_BEGIN
+
+// Use at least double precision for accumulators.
+// Don't use __float128, it doesn't work with abs() or sqrt() yet.
+static constexpr RT_CONST_VAR_ATTRS int Norm2LargestLDKind {
+#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
+ 16
+#elif LDBL_MANT_DIG == 64
+ 10
+#else
+ 8
+#endif
+};
+
+RT_VAR_GROUP_END
+
+template <TypeCategory CAT, int KIND, typename ACCUMULATOR>
+inline RT_API_ATTRS void DoMaxMinNorm2(Descriptor &result, const Descriptor &x,
+ int dim, const Descriptor *mask, const char *intrinsic,
+ Terminator &terminator) {
+ using Type = CppTypeFor<CAT, KIND>;
+ ACCUMULATOR accumulator{x};
+ if (dim == 0 || x.rank() == 1) {
+ // Total reduction
+
+ // Element size of the destination descriptor is the same
+ // as the element size of the source.
+ result.Establish(x.type(), x.ElementBytes(), nullptr, 0, nullptr,
+ CFI_attribute_allocatable);
+ if (int stat{result.Allocate()}) {
+ terminator.Crash(
+ "%s: could not allocate memory for result; STAT=%d", intrinsic, stat);
+ }
+ DoTotalReduction<Type>(x, dim, mask, accumulator, intrinsic, terminator);
+ accumulator.GetResult(result.OffsetElement<Type>());
+ } else {
+ // Partial reduction
+
+ // Element size of the destination descriptor is the same
+ // as the element size of the source.
+ PartialReduction<ACCUMULATOR, CAT, KIND>(result, x, x.ElementBytes(), dim,
+ mask, terminator, intrinsic, accumulator);
+ }
+}
+
+// The data type used by Norm2Accumulator.
+template <int KIND>
+using Norm2AccumType =
+ CppTypeFor<TypeCategory::Real, std::clamp(KIND, 8, Norm2LargestLDKind)>;
+
+template <int KIND, typename ABS, typename SQRT> class Norm2Accumulator {
+public:
+ using Type = CppTypeFor<TypeCategory::Real, KIND>;
+ using AccumType = Norm2AccumType<KIND>;
+ explicit RT_API_ATTRS Norm2Accumulator(const Descriptor &array)
+ : array_{array} {}
+ RT_API_ATTRS void Reinitialize() { max_ = sum_ = 0; }
+ template <typename A>
+ RT_API_ATTRS void GetResult(A *p, int /*zeroBasedDim*/ = -1) const {
+ // m * sqrt(1 + sum((others(:)/m)**2))
+ *p = static_cast<Type>(max_ * SQRT::compute(1 + sum_));
+ }
+ RT_API_ATTRS bool Accumulate(Type x) {
+ auto absX{ABS::compute(static_cast<AccumType>(x))};
+ if (!max_) {
+ max_ = absX;
+ } else if (absX > max_) {
+ auto t{max_ / absX}; // < 1.0
+ auto tsq{t * t};
+ sum_ *= tsq; // scale sum to reflect change to the max
+ sum_ += tsq; // include a term for the previous max
+ max_ = absX;
+ } else { // absX <= max_
+ auto t{absX / max_};
+ sum_ += t * t;
+ }
+ return true;
+ }
+ template <typename A>
+ RT_API_ATTRS bool AccumulateAt(const SubscriptValue at[]) {
+ return Accumulate(*array_.Element<A>(at));
+ }
+
+private:
+ const Descriptor &array_;
+ AccumType max_{0}; // value (m) with largest magnitude
+ AccumType sum_{0}; // sum((others(:)/m)**2)
+};
+
+// Helper class for creating Norm2Accumulator instance
+// based on the given KIND. This helper returns and instance
+// that uses std::abs and std::sqrt for the computations.
+template <int KIND> class Norm2AccumulatorGetter {
+ using AccumType = Norm2AccumType<KIND>;
+
+public:
+ struct ABSTy {
+ static constexpr RT_API_ATTRS AccumType compute(AccumType &&x) {
+ return std::abs(std::forward<AccumType>(x));
+ }
+ };
+ struct SQRTTy {
+ static constexpr RT_API_ATTRS AccumType compute(AccumType &&x) {
+ return std::sqrt(std::forward<AccumType>(x));
+ }
+ };
+
+ using Type = Norm2Accumulator<KIND, ABSTy, SQRTTy>;
+
+ static RT_API_ATTRS Type create(const Descriptor &x) { return Type(x); }
+};
+
} // namespace Fortran::runtime
#endif // FORTRAN_RUNTIME_REDUCTION_TEMPLATES_H_
diff --git a/flang/runtime/tools.h b/flang/runtime/tools.h
index 89e5069995748b..c1f89cadca06e7 100644
--- a/flang/runtime/tools.h
+++ b/flang/runtime/tools.h
@@ -266,7 +266,8 @@ inline RT_API_ATTRS RESULT ApplyIntegerKind(
}
}
-template <template <int KIND> class FUNC, typename RESULT, typename... A>
+template <template <int KIND> class FUNC, typename RESULT,
+ bool NEEDSMATH = false, typename... A>
inline RT_API_ATTRS RESULT ApplyFloatingPointKind(
int kind, Terminator &terminator, A &&...x) {
switch (kind) {
@@ -287,7 +288,13 @@ inline RT_API_ATTRS RESULT ApplyFloatingPointKind(
break;
case 16:
if constexpr (HasCppTypeFor<TypeCategory::Real, 16>) {
- return FUNC<16>{}(std::forward<A>(x)...);
+ // If FUNC implemenation relies on FP math functions,
+ // then we should not be here. The compiler should have
+ // generated a call to an entry in FortranFloat128Math
+ // library.
+ if constexpr (!NEEDSMATH) {
+ return FUNC<16>{}(std::forward<A>(x)...);
+ }
}
break;
}
diff --git a/flang/test/Lower/Intrinsics/norm2.f90 b/flang/test/Lower/Intrinsics/norm2.f90
index f14cad59d5bd3b..0d125e36f6650a 100644
--- a/flang/test/Lower/Intrinsics/norm2.f90
+++ b/flang/test/Lower/Intrinsics/norm2.f90
@@ -76,3 +76,19 @@ subroutine norm2_test_dim_3(a,r)
! CHECK-DAG: %[[addr:.*]] = fir.box_addr %[[box]] : (!fir.box<!fir.heap<!fir.array<?x?xf32>>>) -> !fir.heap<!fir.array<?x?xf32>>
! CHECK-DAG: fir.freemem %[[addr]]
end subroutine norm2_test_dim_3
+
+! CHECK-LABEL: func @_QPnorm2_test_real16(
+! CHECK-SAME: %[[arg0:.*]]: !fir.box<!fir.array<?x?x?xf128>>{{.*}}, %[[arg1:.*]]: !fir.box<!fir.array<?x?xf128>>{{.*}})
+subroutine norm2_test_real16(a,r)
+ real(16) :: a(:,:,:)
+ real(16) :: r(:,:)
+ ! CHECK-DAG: %[[dim:.*]] = arith.constant 3 : i32
+ ! CHECK-DAG: %[[r:.*]] = fir.alloca !fir.box<!fir.heap<!fir.array<?x?xf128>>>
+ ! CHECK-DAG: %[[res:.*]] = fir.convert %[[r]] : (!fir.ref<!fir.box<!fir.heap<!fir.array<?x?xf128>>>>) -> !fir.ref<!fir.box<none>>
+ ! CHECK: %[[arr:.*]] = fir.convert %[[arg0]] : (!fir.box<!fir.array<?x?x?xf128>>) -> !fir.box<none>
+ r = norm2(a,dim=3)
+ ! CHECK: %{{.*}} = fir.call @_FortranANorm2DimReal16(%[[res]], %[[arr]], %[[dim]], %{{.*}}, %{{.*}}) {{.*}} : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, !fir.ref<i8>, i32) -> none
+ ! CHECK: %[[box:.*]] = fir.load %[[r]] : !fir.ref<!fir.box<!fir.heap<!fir.array<?x?xf128>>>>
+ ! CHECK-DAG: %[[addr:.*]] = fir.box_addr %[[box]] : (!fir.box<!fir.heap<!fir.array<?x?xf128>>>) -> !fir.heap<!fir.array<?x?xf128>>
+ ! CHECK-DAG: fir.freemem %[[addr]]
+end subroutine norm2_test_real16
>From 6244dfef5cd45f1395c66abbe061c6a7eb002676 Mon Sep 17 00:00:00 2001
From: Kevin Frei <kevinfrei at users.noreply.github.com>
Date: Wed, 28 Feb 2024 10:43:49 -0800
Subject: [PATCH 031/406] llvm-dwarfdump --verify aggregated output to JSON
file (#81762)
In order to make tooling around dwarf health easier, I've added an `--verify-json` option to `llvm-dwarfdump --verify` that will spit out error summary data with counts to a JSON file.
I've added the same capability to `llvm-gsymutil` in a [different PR.](https://github.com/llvm/llvm-project/pull/81763)
The format of the json is:
``` json
{
"error-categories": {
"<first category description>": {"count": 1234},
"<next category description>": {"count":4321}
},
"error-count": 5555
}
```
for a clean run:
``` json
{
"error-categories": {},
"error-count": 0
}
```
---------
Co-authored-by: Kevin Frei <freik at meta.com>
---
llvm/include/llvm/DebugInfo/DIContext.h | 1 +
llvm/lib/DebugInfo/DWARF/DWARFVerifier.cpp | 29 +++++++++++++++++++-
llvm/tools/llvm-dwarfdump/llvm-dwarfdump.cpp | 14 ++++++++--
3 files changed, 41 insertions(+), 3 deletions(-)
diff --git a/llvm/include/llvm/DebugInfo/DIContext.h b/llvm/include/llvm/DebugInfo/DIContext.h
index 288ddf77bdfda7..b75dc8db54336b 100644
--- a/llvm/include/llvm/DebugInfo/DIContext.h
+++ b/llvm/include/llvm/DebugInfo/DIContext.h
@@ -206,6 +206,7 @@ struct DIDumpOptions {
bool IsEH = false;
bool DumpNonSkeleton = false;
bool ShowAggregateErrors = false;
+ std::string JsonErrSummaryFile;
std::function<llvm::StringRef(uint64_t DwarfRegNum, bool IsEH)>
GetNameForDWARFReg;
diff --git a/llvm/lib/DebugInfo/DWARF/DWARFVerifier.cpp b/llvm/lib/DebugInfo/DWARF/DWARFVerifier.cpp
index 20ef59e7b4422e..520debe513d9f1 100644
--- a/llvm/lib/DebugInfo/DWARF/DWARFVerifier.cpp
+++ b/llvm/lib/DebugInfo/DWARF/DWARFVerifier.cpp
@@ -29,7 +29,9 @@
#include "llvm/Support/DJB.h"
#include "llvm/Support/Error.h"
#include "llvm/Support/ErrorHandling.h"
+#include "llvm/Support/FileSystem.h"
#include "llvm/Support/FormatVariadic.h"
+#include "llvm/Support/JSON.h"
#include "llvm/Support/WithColor.h"
#include "llvm/Support/raw_ostream.h"
#include <map>
@@ -2026,12 +2028,37 @@ void OutputCategoryAggregator::EnumerateResults(
}
void DWARFVerifier::summarize() {
- if (ErrorCategory.GetNumCategories() && DumpOpts.ShowAggregateErrors) {
+ if (DumpOpts.ShowAggregateErrors && ErrorCategory.GetNumCategories()) {
error() << "Aggregated error counts:\n";
ErrorCategory.EnumerateResults([&](StringRef s, unsigned count) {
error() << s << " occurred " << count << " time(s).\n";
});
}
+ if (!DumpOpts.JsonErrSummaryFile.empty()) {
+ std::error_code EC;
+ raw_fd_ostream JsonStream(DumpOpts.JsonErrSummaryFile, EC,
+ sys::fs::OF_Text);
+ if (EC) {
+ error() << "unable to open json summary file '"
+ << DumpOpts.JsonErrSummaryFile
+ << "' for writing: " << EC.message() << '\n';
+ return;
+ }
+
+ llvm::json::Object Categories;
+ uint64_t ErrorCount = 0;
+ ErrorCategory.EnumerateResults([&](StringRef Category, unsigned Count) {
+ llvm::json::Object Val;
+ Val.try_emplace("count", Count);
+ Categories.try_emplace(Category, std::move(Val));
+ ErrorCount += Count;
+ });
+ llvm::json::Object RootNode;
+ RootNode.try_emplace("error-categories", std::move(Categories));
+ RootNode.try_emplace("error-count", ErrorCount);
+
+ JsonStream << llvm::json::Value(std::move(RootNode));
+ }
}
raw_ostream &DWARFVerifier::error() const { return WithColor::error(OS); }
diff --git a/llvm/tools/llvm-dwarfdump/llvm-dwarfdump.cpp b/llvm/tools/llvm-dwarfdump/llvm-dwarfdump.cpp
index 2b438a8b134613..2bfc9705368e46 100644
--- a/llvm/tools/llvm-dwarfdump/llvm-dwarfdump.cpp
+++ b/llvm/tools/llvm-dwarfdump/llvm-dwarfdump.cpp
@@ -286,6 +286,8 @@ static opt<bool> Verify("verify", desc("Verify the DWARF debug info."),
cat(DwarfDumpCategory));
static opt<ErrorDetailLevel> ErrorDetails(
"error-display", init(Unspecified),
+ desc("Set the level of detail and summary to display when verifying "
+ "(implies --verify)"),
values(clEnumValN(NoDetailsOrSummary, "quiet",
"Only display whether errors occurred."),
clEnumValN(NoDetailsOnlySummary, "summary",
@@ -295,6 +297,11 @@ static opt<ErrorDetailLevel> ErrorDetails(
clEnumValN(BothDetailsAndSummary, "full",
"Display each error as well as a summary. [default]")),
cat(DwarfDumpCategory));
+static opt<std::string> JsonErrSummaryFile(
+ "verify-json", init(""),
+ desc("Output JSON-formatted error summary to the specified file. "
+ "(Implies --verify)"),
+ value_desc("filename.json"), cat(DwarfDumpCategory));
static opt<bool> Quiet("quiet", desc("Use with -verify to not emit to STDOUT."),
cat(DwarfDumpCategory));
static opt<bool> DumpUUID("uuid", desc("Show the UUID for each architecture."),
@@ -349,6 +356,7 @@ static DIDumpOptions getDumpOpts(DWARFContext &C) {
ErrorDetails != NoDetailsOrSummary;
DumpOpts.ShowAggregateErrors = ErrorDetails != OnlyDetailsNoSummary &&
ErrorDetails != NoDetailsOnlySummary;
+ DumpOpts.JsonErrSummaryFile = JsonErrSummaryFile;
return DumpOpts.noImplicitRecursion();
}
return DumpOpts;
@@ -834,8 +842,10 @@ int main(int argc, char **argv) {
"-verbose is currently not supported";
return 1;
}
- if (!Verify && ErrorDetails != Unspecified)
- WithColor::warning() << "-error-detail has no affect without -verify";
+ // -error-detail and -json-summary-file both imply -verify
+ if (ErrorDetails != Unspecified || !JsonErrSummaryFile.empty()) {
+ Verify = true;
+ }
std::error_code EC;
ToolOutputFile OutputFile(OutputFilename, EC, sys::fs::OF_TextWithCRLF);
>From b4bc19e2e6b7d0de9cb5f0578269085a76e99d3f Mon Sep 17 00:00:00 2001
From: Simon Pilgrim <llvm-dev at redking.me.uk>
Date: Wed, 28 Feb 2024 18:49:12 +0000
Subject: [PATCH 032/406] [X86] Add tests showing failure to demand only the
sign bit of a sitofp/uitofp node
sitofp - if we only demand the signbit, then we can try to use the source integer
uitofp - signbit is guaranteed to be zero
Noticed while reviewing #82290
---
.../CodeGen/X86/combine-sse41-intrinsics.ll | 47 +++++++++++++++++++
1 file changed, 47 insertions(+)
diff --git a/llvm/test/CodeGen/X86/combine-sse41-intrinsics.ll b/llvm/test/CodeGen/X86/combine-sse41-intrinsics.ll
index 7039e33c00935d..cbb5bd09c2399a 100644
--- a/llvm/test/CodeGen/X86/combine-sse41-intrinsics.ll
+++ b/llvm/test/CodeGen/X86/combine-sse41-intrinsics.ll
@@ -160,6 +160,53 @@ define <16 x i8> @demandedelts_pblendvb(<16 x i8> %a0, <16 x i8> %a1, <16 x i8>
ret <16 x i8> %5
}
+define <4 x float> @demandedbits_sitofp_blendvps(<4 x float> %a0, <4 x float> %a1, <4 x i32> %a2) {
+; SSE-LABEL: demandedbits_sitofp_blendvps:
+; SSE: # %bb.0:
+; SSE-NEXT: movaps %xmm0, %xmm3
+; SSE-NEXT: cvtdq2ps %xmm2, %xmm0
+; SSE-NEXT: blendvps %xmm0, %xmm1, %xmm3
+; SSE-NEXT: movaps %xmm3, %xmm0
+; SSE-NEXT: retq
+;
+; AVX-LABEL: demandedbits_sitofp_blendvps:
+; AVX: # %bb.0:
+; AVX-NEXT: vcvtdq2ps %xmm2, %xmm2
+; AVX-NEXT: vblendvps %xmm2, %xmm1, %xmm0, %xmm0
+; AVX-NEXT: retq
+ %cvt = sitofp <4 x i32> %a2 to <4 x float>
+ %sel = tail call noundef <4 x float> @llvm.x86.sse41.blendvps(<4 x float> %a0, <4 x float> %a1, <4 x float> %cvt)
+ ret <4 x float> %sel
+}
+
+define <4 x float> @demandedbits_uitofp_blendvps(<4 x float> %a0, <4 x float> %a1, <4 x i32> %a2) {
+; SSE-LABEL: demandedbits_uitofp_blendvps:
+; SSE: # %bb.0:
+; SSE-NEXT: movaps %xmm0, %xmm3
+; SSE-NEXT: movdqa {{.*#+}} xmm0 = [1258291200,1258291200,1258291200,1258291200]
+; SSE-NEXT: pblendw {{.*#+}} xmm0 = xmm2[0],xmm0[1],xmm2[2],xmm0[3],xmm2[4],xmm0[5],xmm2[6],xmm0[7]
+; SSE-NEXT: psrld $16, %xmm2
+; SSE-NEXT: pblendw {{.*#+}} xmm2 = xmm2[0],mem[1],xmm2[2],mem[3],xmm2[4],mem[5],xmm2[6],mem[7]
+; SSE-NEXT: subps {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm2
+; SSE-NEXT: addps %xmm2, %xmm0
+; SSE-NEXT: blendvps %xmm0, %xmm1, %xmm3
+; SSE-NEXT: movaps %xmm3, %xmm0
+; SSE-NEXT: retq
+;
+; AVX-LABEL: demandedbits_uitofp_blendvps:
+; AVX: # %bb.0:
+; AVX-NEXT: vpblendw {{.*#+}} xmm3 = xmm2[0],mem[1],xmm2[2],mem[3],xmm2[4],mem[5],xmm2[6],mem[7]
+; AVX-NEXT: vpsrld $16, %xmm2, %xmm2
+; AVX-NEXT: vpblendw {{.*#+}} xmm2 = xmm2[0],mem[1],xmm2[2],mem[3],xmm2[4],mem[5],xmm2[6],mem[7]
+; AVX-NEXT: vsubps {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm2, %xmm2
+; AVX-NEXT: vaddps %xmm2, %xmm3, %xmm2
+; AVX-NEXT: vblendvps %xmm2, %xmm1, %xmm0, %xmm0
+; AVX-NEXT: retq
+ %cvt = uitofp <4 x i32> %a2 to <4 x float>
+ %sel = tail call noundef <4 x float> @llvm.x86.sse41.blendvps(<4 x float> %a0, <4 x float> %a1, <4 x float> %cvt)
+ ret <4 x float> %sel
+}
+
define <2 x i64> @demandedbits_blendvpd(i64 %a0, i64 %a2, <2 x double> %a3) {
; SSE-LABEL: demandedbits_blendvpd:
; SSE: # %bb.0:
>From 782147e82ab3e2d0e22f729ea4e54eeed7b3cb96 Mon Sep 17 00:00:00 2001
From: Patrick Dougherty <patrick.dougherty.0208 at gmail.com>
Date: Wed, 28 Feb 2024 12:53:12 -0600
Subject: [PATCH 033/406] [CMake][LIT] Add option to run lit testsuites in
parallel (#82899)
Currently `add_lit_target` sets the `USES_TERMINAL` CMake option. When
using Ninja, this forces all lit testsuite targets into the
single-threaded `console` pool.
This PR adds a new option `LLVM_PARALLEL_LIT` which drops the
`USES_TERMINAL` flag, allowing Ninja to run them in parallel.
The default setting (`LLVM_PARALLEL_LIT=OFF`) retains the existing
behavior of serial testsuite execution.
---
llvm/CMakeLists.txt | 2 ++
llvm/cmake/modules/AddLLVM.cmake | 17 ++++++++++++-----
llvm/docs/CMake.rst | 6 ++++++
3 files changed, 20 insertions(+), 5 deletions(-)
diff --git a/llvm/CMakeLists.txt b/llvm/CMakeLists.txt
index f5f7d3f3253fd3..651f17879fad24 100644
--- a/llvm/CMakeLists.txt
+++ b/llvm/CMakeLists.txt
@@ -718,6 +718,8 @@ if(LLVM_INDIVIDUAL_TEST_COVERAGE)
endif()
set(LLVM_LIT_ARGS "${LIT_ARGS_DEFAULT}" CACHE STRING "Default options for lit")
+option(LLVM_PARALLEL_LIT "Enable multiple lit suites to run in parallel" OFF)
+
# On Win32 hosts, provide an option to specify the path to the GnuWin32 tools.
if( WIN32 AND NOT CYGWIN )
set(LLVM_LIT_TOOLS_DIR "" CACHE PATH "Path to GnuWin32 tools")
diff --git a/llvm/cmake/modules/AddLLVM.cmake b/llvm/cmake/modules/AddLLVM.cmake
index 3bc78b0dc9355a..0f1734a64ee6e6 100644
--- a/llvm/cmake/modules/AddLLVM.cmake
+++ b/llvm/cmake/modules/AddLLVM.cmake
@@ -1947,11 +1947,18 @@ function(add_lit_target target comment)
list(APPEND LIT_COMMAND --param ${param})
endforeach()
if (ARG_UNPARSED_ARGUMENTS)
- add_custom_target(${target}
- COMMAND ${LIT_COMMAND} ${ARG_UNPARSED_ARGUMENTS}
- COMMENT "${comment}"
- USES_TERMINAL
- )
+ if (LLVM_PARALLEL_LIT)
+ add_custom_target(${target}
+ COMMAND ${LIT_COMMAND} ${ARG_UNPARSED_ARGUMENTS}
+ COMMENT "${comment}"
+ )
+ else()
+ add_custom_target(${target}
+ COMMAND ${LIT_COMMAND} ${ARG_UNPARSED_ARGUMENTS}
+ COMMENT "${comment}"
+ USES_TERMINAL
+ )
+ endif()
else()
add_custom_target(${target}
COMMAND ${CMAKE_COMMAND} -E echo "${target} does nothing, no tools built.")
diff --git a/llvm/docs/CMake.rst b/llvm/docs/CMake.rst
index abef4f8103140f..35c47989a7eef0 100644
--- a/llvm/docs/CMake.rst
+++ b/llvm/docs/CMake.rst
@@ -762,6 +762,12 @@ enabled sub-projects. Nearly all of these variable names begin with
**LLVM_PARALLEL_LINK_JOBS**:STRING
Define the maximum number of concurrent link jobs.
+**LLVM_PARALLEL_LIT**:BOOL
+ Defaults to ``OFF``. If set to ``OFF``, lit testsuites will be configured
+ with CMake's ``USES_TERMINAL`` flag to give direct access to the terminal. If
+ set to ``ON``, that flag will be removed allowing Ninja to schedule multiple
+ lit testsuites in parallel.
+
**LLVM_RAM_PER_COMPILE_JOB**:STRING
Calculates the amount of Ninja compile jobs according to available resources.
Value has to be in MB, overwrites LLVM_PARALLEL_COMPILE_JOBS. Compile jobs
>From 2eb63982e88b9ed8336158d35884b1a1d04a0f78 Mon Sep 17 00:00:00 2001
From: Arthur Eubanks <aeubanks at google.com>
Date: Wed, 28 Feb 2024 10:53:47 -0800
Subject: [PATCH 034/406] [SROA] Unfold gep of index phi (#83087)
If a gep has only one phi as one of its operands and the remaining
indexes are constant, we can unfold `gep ptr, (phi idx1, idx2)` to `phi
((gep ptr, idx1), (gep ptr, idx2))`.
Take care not to unfold recursive phis.
Followup to #80983.
---
llvm/lib/Transforms/Scalar/SROA.cpp | 115 ++++++++++------
llvm/test/Transforms/SROA/phi-and-select.ll | 20 +--
llvm/test/Transforms/SROA/phi-gep.ll | 141 +++++++++++++++++---
3 files changed, 207 insertions(+), 69 deletions(-)
diff --git a/llvm/lib/Transforms/Scalar/SROA.cpp b/llvm/lib/Transforms/Scalar/SROA.cpp
index fad70e8bf2861f..c7b9ce2e93120a 100644
--- a/llvm/lib/Transforms/Scalar/SROA.cpp
+++ b/llvm/lib/Transforms/Scalar/SROA.cpp
@@ -3956,11 +3956,11 @@ class AggLoadStoreRewriter : public InstVisitor<AggLoadStoreRewriter, bool> {
return false;
}
- // Fold gep (select cond, ptr1, ptr2), idx
+ // Unfold gep (select cond, ptr1, ptr2), idx
// => select cond, gep(ptr1, idx), gep(ptr2, idx)
// and gep ptr, (select cond, idx1, idx2)
// => select cond, gep(ptr, idx1), gep(ptr, idx2)
- bool foldGEPSelect(GetElementPtrInst &GEPI) {
+ bool unfoldGEPSelect(GetElementPtrInst &GEPI) {
// Check whether the GEP has exactly one select operand and all indices
// will become constant after the transform.
SelectInst *Sel = dyn_cast<SelectInst>(GEPI.getPointerOperand());
@@ -4029,67 +4029,100 @@ class AggLoadStoreRewriter : public InstVisitor<AggLoadStoreRewriter, bool> {
return true;
}
- // Fold gep (phi ptr1, ptr2) => phi gep(ptr1), gep(ptr2)
- bool foldGEPPhi(GetElementPtrInst &GEPI) {
- if (!GEPI.hasAllConstantIndices())
- return false;
+ // Unfold gep (phi ptr1, ptr2), idx
+ // => phi ((gep ptr1, idx), (gep ptr2, idx))
+ // and gep ptr, (phi idx1, idx2)
+ // => phi ((gep ptr, idx1), (gep ptr, idx2))
+ bool unfoldGEPPhi(GetElementPtrInst &GEPI) {
+ // To prevent infinitely expanding recursive phis, bail if the GEP pointer
+ // operand (looking through the phi if it is the phi we want to unfold) is
+ // an instruction besides an alloca.
+ PHINode *Phi = dyn_cast<PHINode>(GEPI.getPointerOperand());
+ auto IsInvalidPointerOperand = [](Value *V) {
+ return isa<Instruction>(V) && !isa<AllocaInst>(V);
+ };
+ if (Phi) {
+ if (any_of(Phi->operands(), IsInvalidPointerOperand))
+ return false;
+ } else {
+ if (IsInvalidPointerOperand(GEPI.getPointerOperand()))
+ return false;
+ }
+ // Check whether the GEP has exactly one phi operand (including the pointer
+ // operand) and all indices will become constant after the transform.
+ for (Value *Op : GEPI.indices()) {
+ if (auto *SI = dyn_cast<PHINode>(Op)) {
+ if (Phi)
+ return false;
- PHINode *PHI = cast<PHINode>(GEPI.getPointerOperand());
- if (GEPI.getParent() != PHI->getParent() ||
- llvm::any_of(PHI->incoming_values(), [](Value *In) {
- Instruction *I = dyn_cast<Instruction>(In);
- return !I || isa<GetElementPtrInst>(I) || isa<PHINode>(I) ||
- succ_empty(I->getParent()) ||
- !I->getParent()->isLegalToHoistInto();
- }))
+ Phi = SI;
+ if (!all_of(Phi->incoming_values(),
+ [](Value *V) { return isa<ConstantInt>(V); }))
+ return false;
+ continue;
+ }
+
+ if (!isa<ConstantInt>(Op))
+ return false;
+ }
+
+ if (!Phi)
return false;
LLVM_DEBUG(dbgs() << " Rewriting gep(phi) -> phi(gep):\n";
- dbgs() << " original: " << *PHI << "\n";
+ dbgs() << " original: " << *Phi << "\n";
dbgs() << " " << GEPI << "\n";);
- SmallVector<Value *, 4> Index(GEPI.indices());
- bool IsInBounds = GEPI.isInBounds();
- IRB.SetInsertPoint(GEPI.getParent(), GEPI.getParent()->getFirstNonPHIIt());
- PHINode *NewPN = IRB.CreatePHI(GEPI.getType(), PHI->getNumIncomingValues(),
- PHI->getName() + ".sroa.phi");
- for (unsigned I = 0, E = PHI->getNumIncomingValues(); I != E; ++I) {
- BasicBlock *B = PHI->getIncomingBlock(I);
- Value *NewVal = nullptr;
- int Idx = NewPN->getBasicBlockIndex(B);
- if (Idx >= 0) {
- NewVal = NewPN->getIncomingValue(Idx);
- } else {
- Instruction *In = cast<Instruction>(PHI->getIncomingValue(I));
+ auto GetNewOps = [&](Value *PhiOp) {
+ SmallVector<Value *> NewOps;
+ for (Value *Op : GEPI.operands())
+ if (Op == Phi)
+ NewOps.push_back(PhiOp);
+ else
+ NewOps.push_back(Op);
+ return NewOps;
+ };
- IRB.SetInsertPoint(In->getParent(), std::next(In->getIterator()));
- Type *Ty = GEPI.getSourceElementType();
- NewVal = IRB.CreateGEP(Ty, In, Index, In->getName() + ".sroa.gep",
- IsInBounds);
- }
- NewPN->addIncoming(NewVal, B);
+ IRB.SetInsertPoint(Phi);
+ PHINode *NewPhi = IRB.CreatePHI(GEPI.getType(), Phi->getNumIncomingValues(),
+ Phi->getName() + ".sroa.phi");
+
+ bool IsInBounds = GEPI.isInBounds();
+ Type *SourceTy = GEPI.getSourceElementType();
+ // We only handle arguments, constants, and static allocas here, so we can
+ // insert GEPs at the beginning of the function after static allocas.
+ IRB.SetInsertPointPastAllocas(GEPI.getFunction());
+ for (unsigned I = 0, E = Phi->getNumIncomingValues(); I != E; ++I) {
+ Value *Op = Phi->getIncomingValue(I);
+ BasicBlock *BB = Phi->getIncomingBlock(I);
+ SmallVector<Value *> NewOps = GetNewOps(Op);
+
+ Value *NewGEP =
+ IRB.CreateGEP(SourceTy, NewOps[0], ArrayRef(NewOps).drop_front(),
+ Phi->getName() + ".sroa.gep", IsInBounds);
+ NewPhi->addIncoming(NewGEP, BB);
}
Visited.erase(&GEPI);
- GEPI.replaceAllUsesWith(NewPN);
+ GEPI.replaceAllUsesWith(NewPhi);
GEPI.eraseFromParent();
- Visited.insert(NewPN);
- enqueueUsers(*NewPN);
+ Visited.insert(NewPhi);
+ enqueueUsers(*NewPhi);
LLVM_DEBUG(dbgs() << " to: ";
for (Value *In
- : NewPN->incoming_values()) dbgs()
+ : NewPhi->incoming_values()) dbgs()
<< "\n " << *In;
- dbgs() << "\n " << *NewPN << '\n');
+ dbgs() << "\n " << *NewPhi << '\n');
return true;
}
bool visitGetElementPtrInst(GetElementPtrInst &GEPI) {
- if (foldGEPSelect(GEPI))
+ if (unfoldGEPSelect(GEPI))
return true;
- if (isa<PHINode>(GEPI.getPointerOperand()) && foldGEPPhi(GEPI))
+ if (unfoldGEPPhi(GEPI))
return true;
enqueueUsers(GEPI);
diff --git a/llvm/test/Transforms/SROA/phi-and-select.ll b/llvm/test/Transforms/SROA/phi-and-select.ll
index 54cfb10793a1ac..7c8b27c9de9c0b 100644
--- a/llvm/test/Transforms/SROA/phi-and-select.ll
+++ b/llvm/test/Transforms/SROA/phi-and-select.ll
@@ -114,13 +114,13 @@ define i32 @test3(i32 %x) {
; CHECK-LABEL: @test3(
; CHECK-NEXT: entry:
; CHECK-NEXT: switch i32 [[X:%.*]], label [[BB0:%.*]] [
-; CHECK-NEXT: i32 1, label [[BB1:%.*]]
-; CHECK-NEXT: i32 2, label [[BB2:%.*]]
-; CHECK-NEXT: i32 3, label [[BB3:%.*]]
-; CHECK-NEXT: i32 4, label [[BB4:%.*]]
-; CHECK-NEXT: i32 5, label [[BB5:%.*]]
-; CHECK-NEXT: i32 6, label [[BB6:%.*]]
-; CHECK-NEXT: i32 7, label [[BB7:%.*]]
+; CHECK-NEXT: i32 1, label [[BB1:%.*]]
+; CHECK-NEXT: i32 2, label [[BB2:%.*]]
+; CHECK-NEXT: i32 3, label [[BB3:%.*]]
+; CHECK-NEXT: i32 4, label [[BB4:%.*]]
+; CHECK-NEXT: i32 5, label [[BB5:%.*]]
+; CHECK-NEXT: i32 6, label [[BB6:%.*]]
+; CHECK-NEXT: i32 7, label [[BB7:%.*]]
; CHECK-NEXT: ]
; CHECK: bb0:
; CHECK-NEXT: br label [[EXIT:%.*]]
@@ -733,6 +733,7 @@ define void @PR20822(i1 %c1, i1 %c2, ptr %ptr) {
; CHECK-LABEL: @PR20822(
; CHECK-NEXT: entry:
; CHECK-NEXT: [[F_SROA_0:%.*]] = alloca i32, align 4
+; CHECK-NEXT: [[F1_SROA_GEP:%.*]] = getelementptr inbounds [[STRUCT_S:%.*]], ptr [[PTR:%.*]], i32 0, i32 0
; CHECK-NEXT: br i1 [[C1:%.*]], label [[IF_END:%.*]], label [[FOR_COND:%.*]]
; CHECK: for.cond:
; CHECK-NEXT: br label [[IF_END]]
@@ -742,9 +743,8 @@ define void @PR20822(i1 %c1, i1 %c2, ptr %ptr) {
; CHECK: if.then2:
; CHECK-NEXT: br label [[IF_THEN5]]
; CHECK: if.then5:
-; CHECK-NEXT: [[F1:%.*]] = phi ptr [ [[PTR:%.*]], [[IF_THEN2]] ], [ [[F_SROA_0]], [[IF_END]] ]
-; CHECK-NEXT: [[DOTFCA_0_GEP:%.*]] = getelementptr inbounds [[STRUCT_S:%.*]], ptr [[F1]], i32 0, i32 0
-; CHECK-NEXT: store i32 0, ptr [[DOTFCA_0_GEP]], align 4
+; CHECK-NEXT: [[F1_SROA_PHI:%.*]] = phi ptr [ [[F1_SROA_GEP]], [[IF_THEN2]] ], [ [[F_SROA_0]], [[IF_END]] ]
+; CHECK-NEXT: store i32 0, ptr [[F1_SROA_PHI]], align 4
; CHECK-NEXT: ret void
;
entry:
diff --git a/llvm/test/Transforms/SROA/phi-gep.ll b/llvm/test/Transforms/SROA/phi-gep.ll
index c5aa1cdd9cf654..78071dcdafb49d 100644
--- a/llvm/test/Transforms/SROA/phi-gep.ll
+++ b/llvm/test/Transforms/SROA/phi-gep.ll
@@ -65,15 +65,13 @@ end:
define i32 @test_sroa_phi_gep_poison(i1 %cond) {
; CHECK-LABEL: @test_sroa_phi_gep_poison(
; CHECK-NEXT: entry:
-; CHECK-NEXT: [[A:%.*]] = alloca [[PAIR:%.*]], align 4
; CHECK-NEXT: br i1 [[COND:%.*]], label [[IF_THEN:%.*]], label [[END:%.*]]
; CHECK: if.then:
+; CHECK-NEXT: [[PHI_SROA_PHI_SROA_SPECULATE_LOAD_IF_THEN:%.*]] = load i32, ptr poison, align 4
; CHECK-NEXT: br label [[END]]
; CHECK: end:
-; CHECK-NEXT: [[PHI:%.*]] = phi ptr [ [[A]], [[ENTRY:%.*]] ], [ poison, [[IF_THEN]] ]
-; CHECK-NEXT: [[GEP:%.*]] = getelementptr inbounds [[PAIR]], ptr [[PHI]], i32 0, i32 1
-; CHECK-NEXT: [[LOAD:%.*]] = load i32, ptr [[GEP]], align 4
-; CHECK-NEXT: ret i32 [[LOAD]]
+; CHECK-NEXT: [[PHI_SROA_PHI_SROA_SPECULATED:%.*]] = phi i32 [ undef, [[ENTRY:%.*]] ], [ [[PHI_SROA_PHI_SROA_SPECULATE_LOAD_IF_THEN]], [[IF_THEN]] ]
+; CHECK-NEXT: ret i32 [[PHI_SROA_PHI_SROA_SPECULATED]]
;
entry:
%a = alloca %pair, align 4
@@ -94,17 +92,13 @@ end:
define i32 @test_sroa_phi_gep_global(i1 %cond) {
; CHECK-LABEL: @test_sroa_phi_gep_global(
; CHECK-NEXT: entry:
-; CHECK-NEXT: [[A:%.*]] = alloca [[PAIR:%.*]], align 4
-; CHECK-NEXT: [[GEP_A:%.*]] = getelementptr inbounds [[PAIR]], ptr [[A]], i32 0, i32 1
-; CHECK-NEXT: store i32 1, ptr [[GEP_A]], align 4
; CHECK-NEXT: br i1 [[COND:%.*]], label [[IF_THEN:%.*]], label [[END:%.*]]
; CHECK: if.then:
+; CHECK-NEXT: [[PHI_SROA_PHI_SROA_SPECULATE_LOAD_IF_THEN:%.*]] = load i32, ptr getelementptr inbounds ([[PAIR:%.*]], ptr @g, i32 0, i32 1), align 4
; CHECK-NEXT: br label [[END]]
; CHECK: end:
-; CHECK-NEXT: [[PHI:%.*]] = phi ptr [ [[A]], [[ENTRY:%.*]] ], [ @g, [[IF_THEN]] ]
-; CHECK-NEXT: [[GEP:%.*]] = getelementptr inbounds [[PAIR]], ptr [[PHI]], i32 0, i32 1
-; CHECK-NEXT: [[LOAD:%.*]] = load i32, ptr [[GEP]], align 4
-; CHECK-NEXT: ret i32 [[LOAD]]
+; CHECK-NEXT: [[PHI_SROA_PHI_SROA_SPECULATED:%.*]] = phi i32 [ 1, [[ENTRY:%.*]] ], [ [[PHI_SROA_PHI_SROA_SPECULATE_LOAD_IF_THEN]], [[IF_THEN]] ]
+; CHECK-NEXT: ret i32 [[PHI_SROA_PHI_SROA_SPECULATED]]
;
entry:
%a = alloca %pair, align 4
@@ -245,7 +239,7 @@ define i32 @test_sroa_invoke_phi_gep(i1 %cond) personality ptr @__gxx_personalit
; CHECK-NEXT: br i1 [[COND:%.*]], label [[CALL:%.*]], label [[END:%.*]]
; CHECK: call:
; CHECK-NEXT: [[B:%.*]] = invoke ptr @foo()
-; CHECK-NEXT: to label [[END]] unwind label [[INVOKE_CATCH:%.*]]
+; CHECK-NEXT: to label [[END]] unwind label [[INVOKE_CATCH:%.*]]
; CHECK: end:
; CHECK-NEXT: [[PHI:%.*]] = phi ptr [ [[A]], [[ENTRY:%.*]] ], [ [[B]], [[CALL]] ]
; CHECK-NEXT: [[GEP:%.*]] = getelementptr inbounds [[PAIR]], ptr [[PHI]], i32 0, i32 1
@@ -253,7 +247,7 @@ define i32 @test_sroa_invoke_phi_gep(i1 %cond) personality ptr @__gxx_personalit
; CHECK-NEXT: ret i32 [[LOAD]]
; CHECK: invoke_catch:
; CHECK-NEXT: [[RES:%.*]] = landingpad { ptr, i32 }
-; CHECK-NEXT: catch ptr null
+; CHECK-NEXT: catch ptr null
; CHECK-NEXT: ret i32 0
;
entry:
@@ -468,10 +462,10 @@ define i32 @test_sroa_phi_gep_multiple_values_from_same_block(i32 %arg) {
; CHECK-LABEL: @test_sroa_phi_gep_multiple_values_from_same_block(
; CHECK-NEXT: bb.1:
; CHECK-NEXT: switch i32 [[ARG:%.*]], label [[BB_3:%.*]] [
-; CHECK-NEXT: i32 1, label [[BB_2:%.*]]
-; CHECK-NEXT: i32 2, label [[BB_2]]
-; CHECK-NEXT: i32 3, label [[BB_4:%.*]]
-; CHECK-NEXT: i32 4, label [[BB_4]]
+; CHECK-NEXT: i32 1, label [[BB_2:%.*]]
+; CHECK-NEXT: i32 2, label [[BB_2]]
+; CHECK-NEXT: i32 3, label [[BB_4:%.*]]
+; CHECK-NEXT: i32 4, label [[BB_4]]
; CHECK-NEXT: ]
; CHECK: bb.2:
; CHECK-NEXT: br label [[BB_4]]
@@ -504,6 +498,117 @@ bb.4: ; preds = %bb.1, %bb.1, %bb
ret i32 %load
}
+define i64 @test_phi_idx_mem2reg_const(i1 %arg) {
+; CHECK-LABEL: @test_phi_idx_mem2reg_const(
+; CHECK-NEXT: bb:
+; CHECK-NEXT: br i1 [[ARG:%.*]], label [[BB1:%.*]], label [[BB2:%.*]]
+; CHECK: bb1:
+; CHECK-NEXT: br label [[END:%.*]]
+; CHECK: bb2:
+; CHECK-NEXT: br label [[END]]
+; CHECK: end:
+; CHECK-NEXT: [[PHI_SROA_PHI_SROA_SPECULATED:%.*]] = phi i64 [ 2, [[BB1]] ], [ 3, [[BB2]] ]
+; CHECK-NEXT: [[PHI:%.*]] = phi i64 [ 0, [[BB1]] ], [ 1, [[BB2]] ]
+; CHECK-NEXT: ret i64 [[PHI_SROA_PHI_SROA_SPECULATED]]
+;
+bb:
+ %alloca = alloca [2 x i64], align 8
+ %gep1 = getelementptr inbounds i64, ptr %alloca, i64 1
+ store i64 2, ptr %alloca
+ store i64 3, ptr %gep1
+ br i1 %arg, label %bb1, label %bb2
+
+bb1:
+ br label %end
+
+bb2:
+ br label %end
+
+end:
+ %phi = phi i64 [ 0, %bb1 ], [ 1, %bb2 ]
+ %getelementptr = getelementptr inbounds i64, ptr %alloca, i64 %phi
+ %load = load i64, ptr %getelementptr
+ ret i64 %load
+}
+
+define i64 @test_phi_idx_mem2reg_not_const(i1 %arg, i64 %idx) {
+; CHECK-LABEL: @test_phi_idx_mem2reg_not_const(
+; CHECK-NEXT: bb:
+; CHECK-NEXT: [[ALLOCA:%.*]] = alloca [2 x i64], align 8
+; CHECK-NEXT: [[GEP1:%.*]] = getelementptr inbounds i64, ptr [[ALLOCA]], i64 1
+; CHECK-NEXT: store i64 2, ptr [[ALLOCA]], align 4
+; CHECK-NEXT: store i64 3, ptr [[GEP1]], align 4
+; CHECK-NEXT: br i1 [[ARG:%.*]], label [[BB1:%.*]], label [[BB2:%.*]]
+; CHECK: bb1:
+; CHECK-NEXT: br label [[END:%.*]]
+; CHECK: bb2:
+; CHECK-NEXT: br label [[END]]
+; CHECK: end:
+; CHECK-NEXT: [[PHI:%.*]] = phi i64 [ 0, [[BB1]] ], [ [[IDX:%.*]], [[BB2]] ]
+; CHECK-NEXT: [[GETELEMENTPTR:%.*]] = getelementptr inbounds i64, ptr [[ALLOCA]], i64 [[PHI]]
+; CHECK-NEXT: [[LOAD:%.*]] = load i64, ptr [[GETELEMENTPTR]], align 4
+; CHECK-NEXT: ret i64 [[LOAD]]
+;
+bb:
+ %alloca = alloca [2 x i64], align 8
+ %gep1 = getelementptr inbounds i64, ptr %alloca, i64 1
+ store i64 2, ptr %alloca
+ store i64 3, ptr %gep1
+ br i1 %arg, label %bb1, label %bb2
+
+bb1:
+ br label %end
+
+bb2:
+ br label %end
+
+end:
+ %phi = phi i64 [ 0, %bb1 ], [ %idx, %bb2 ]
+ %getelementptr = getelementptr inbounds i64, ptr %alloca, i64 %phi
+ %load = load i64, ptr %getelementptr
+ ret i64 %load
+}
+
+define i64 @test_phi_mem2reg_pointer_op_is_non_const_gep(i1 %arg, i64 %idx) {
+; CHECK-LABEL: @test_phi_mem2reg_pointer_op_is_non_const_gep(
+; CHECK-NEXT: bb:
+; CHECK-NEXT: [[ALLOCA:%.*]] = alloca [2 x i64], align 8
+; CHECK-NEXT: [[GEP1:%.*]] = getelementptr inbounds i64, ptr [[ALLOCA]], i64 1
+; CHECK-NEXT: store i64 2, ptr [[ALLOCA]], align 4
+; CHECK-NEXT: store i64 3, ptr [[GEP1]], align 4
+; CHECK-NEXT: br i1 [[ARG:%.*]], label [[BB1:%.*]], label [[BB2:%.*]]
+; CHECK: bb1:
+; CHECK-NEXT: br label [[END:%.*]]
+; CHECK: bb2:
+; CHECK-NEXT: br label [[END]]
+; CHECK: end:
+; CHECK-NEXT: [[PHI:%.*]] = phi i64 [ 0, [[BB1]] ], [ 1, [[BB2]] ]
+; CHECK-NEXT: [[GETELEMENTPTR:%.*]] = getelementptr inbounds i64, ptr [[ALLOCA]], i64 [[IDX:%.*]]
+; CHECK-NEXT: [[GETELEMENTPTR2:%.*]] = getelementptr inbounds i64, ptr [[GETELEMENTPTR]], i64 [[PHI]]
+; CHECK-NEXT: [[LOAD:%.*]] = load i64, ptr [[GETELEMENTPTR]], align 4
+; CHECK-NEXT: ret i64 [[LOAD]]
+;
+bb:
+ %alloca = alloca [2 x i64], align 8
+ %gep1 = getelementptr inbounds i64, ptr %alloca, i64 1
+ store i64 2, ptr %alloca
+ store i64 3, ptr %gep1
+ br i1 %arg, label %bb1, label %bb2
+
+bb1:
+ br label %end
+
+bb2:
+ br label %end
+
+end:
+ %phi = phi i64 [ 0, %bb1 ], [ 1, %bb2 ]
+ %getelementptr = getelementptr inbounds i64, ptr %alloca, i64 %idx
+ %getelementptr2 = getelementptr inbounds i64, ptr %getelementptr, i64 %phi
+ %load = load i64, ptr %getelementptr
+ ret i64 %load
+}
+
declare ptr @foo()
declare i32 @__gxx_personality_v0(...)
>From 9c7cde64e6556f8a04dc4a14cbfb2b277d5ab4d9 Mon Sep 17 00:00:00 2001
From: Benoit Jacob <jacob.benoit.1 at gmail.com>
Date: Wed, 28 Feb 2024 13:56:18 -0500
Subject: [PATCH 035/406] Fix the lowering of `arith.truncf : f32 to bf16`.
(#83180)
This lowering was not correctly handling the case where saturation of
the mantissa results in an increase of the exponent value. The new code
borrows, with credit, the idea from
https://github.com/pytorch/pytorch/blob/e1502c0cdbfd17548c612f25d5a65b1e4b86224d/c10/util/BFloat16.h#L60-L79
and adds comments to explain the magic trick going on here and why it's
correct. Hat tip to its original author, whom I believe to be
@Maratyszcza.
A testcase was also requiring a tie to be broken upwards in a case where
"to nearest-even" required going downward. The fact that it used to pass
suggests that there was another bug in the old code.
---
.../Dialect/Arith/Transforms/ExpandOps.cpp | 98 +++++++++----------
mlir/test/Dialect/Arith/expand-ops.mlir | 45 +++------
.../mlir-cpu-runner/expand-arith-ops.mlir | 47 ++++++---
3 files changed, 96 insertions(+), 94 deletions(-)
diff --git a/mlir/lib/Dialect/Arith/Transforms/ExpandOps.cpp b/mlir/lib/Dialect/Arith/Transforms/ExpandOps.cpp
index 8deb8f028ba458..7f246daf99ff3c 100644
--- a/mlir/lib/Dialect/Arith/Transforms/ExpandOps.cpp
+++ b/mlir/lib/Dialect/Arith/Transforms/ExpandOps.cpp
@@ -261,68 +261,62 @@ struct BFloat16TruncFOpConverter : public OpRewritePattern<arith::TruncFOp> {
return rewriter.notifyMatchFailure(op, "not a trunc of f32 to bf16.");
}
- Type i1Ty = b.getI1Type();
Type i16Ty = b.getI16Type();
Type i32Ty = b.getI32Type();
Type f32Ty = b.getF32Type();
if (auto shapedTy = dyn_cast<ShapedType>(operandTy)) {
- i1Ty = shapedTy.clone(i1Ty);
i16Ty = shapedTy.clone(i16Ty);
i32Ty = shapedTy.clone(i32Ty);
f32Ty = shapedTy.clone(f32Ty);
}
- Value bitcast = b.create<arith::BitcastOp>(i32Ty, operand);
-
- Value c23 = createConst(op.getLoc(), i32Ty, 23, rewriter);
- Value c31 = createConst(op.getLoc(), i32Ty, 31, rewriter);
- Value c23Mask = createConst(op.getLoc(), i32Ty, (1 << 23) - 1, rewriter);
- Value expMask =
- createConst(op.getLoc(), i32Ty, ((1 << 8) - 1) << 23, rewriter);
- Value expMax =
- createConst(op.getLoc(), i32Ty, ((1 << 8) - 2) << 23, rewriter);
-
- // Grab the sign bit.
- Value sign = b.create<arith::ShRUIOp>(bitcast, c31);
-
- // Our mantissa rounding value depends on the sign bit and the last
- // truncated bit.
- Value cManRound = createConst(op.getLoc(), i32Ty, (1 << 15), rewriter);
- cManRound = b.create<arith::SubIOp>(cManRound, sign);
-
- // Grab out the mantissa and directly apply rounding.
- Value man = b.create<arith::AndIOp>(bitcast, c23Mask);
- Value manRound = b.create<arith::AddIOp>(man, cManRound);
-
- // Grab the overflow bit and shift right if we overflow.
- Value roundBit = b.create<arith::ShRUIOp>(manRound, c23);
- Value manNew = b.create<arith::ShRUIOp>(manRound, roundBit);
-
- // Grab the exponent and round using the mantissa's carry bit.
- Value exp = b.create<arith::AndIOp>(bitcast, expMask);
- Value expCarry = b.create<arith::AddIOp>(exp, manRound);
- expCarry = b.create<arith::AndIOp>(expCarry, expMask);
-
- // If the exponent is saturated, we keep the max value.
- Value expCmp =
- b.create<arith::CmpIOp>(arith::CmpIPredicate::uge, exp, expMax);
- exp = b.create<arith::SelectOp>(expCmp, exp, expCarry);
-
- // If the exponent is max and we rolled over, keep the old mantissa.
- Value roundBitBool = b.create<arith::TruncIOp>(i1Ty, roundBit);
- Value keepOldMan = b.create<arith::AndIOp>(expCmp, roundBitBool);
- man = b.create<arith::SelectOp>(keepOldMan, man, manNew);
-
- // Assemble the now rounded f32 value (as an i32).
- Value rounded = b.create<arith::ShLIOp>(sign, c31);
- rounded = b.create<arith::OrIOp>(rounded, exp);
- rounded = b.create<arith::OrIOp>(rounded, man);
-
+ // Algorithm borrowed from this excellent code:
+ // https://github.com/pytorch/pytorch/blob/e1502c0cdbfd17548c612f25d5a65b1e4b86224d/c10/util/BFloat16.h#L60-L79
+ // There is a magic idea there, to let the addition of the rounding_bias to
+ // the mantissa simply overflow into the exponent bits. It's a bit of an
+ // aggressive, obfuscating optimization, but it is well-tested code, and it
+ // results in more concise and efficient IR.
+ // The case of NaN is handled separately (see isNaN and the final select).
+ // The case of infinities is NOT handled separately, which deserves an
+ // explanation. As the encoding of infinities has zero mantissa, the
+ // rounding-bias addition never carries into the exponent so that just gets
+ // truncated away, and as bfloat16 and float32 have the same number of
+ // exponent bits, that simple truncation is the desired outcome for
+ // infinities.
+ Value isNan =
+ b.create<arith::CmpFOp>(arith::CmpFPredicate::UNE, operand, operand);
+ // Constant used to make the rounding bias.
+ Value c7FFF = createConst(op.getLoc(), i32Ty, 0x7fff, rewriter);
+ // Constant used to generate a quiet NaN.
+ Value c7FC0_i16 = createConst(op.getLoc(), i16Ty, 0x7fc0, rewriter);
+ // Small constants used to address bits.
Value c16 = createConst(op.getLoc(), i32Ty, 16, rewriter);
- Value shr = b.create<arith::ShRUIOp>(rounded, c16);
- Value trunc = b.create<arith::TruncIOp>(i16Ty, shr);
- Value result = b.create<arith::BitcastOp>(resultTy, trunc);
-
+ Value c1 = createConst(op.getLoc(), i32Ty, 1, rewriter);
+ // Reinterpret the input f32 value as bits.
+ Value bitcast = b.create<arith::BitcastOp>(i32Ty, operand);
+ // Read bit 16 as a value in {0,1}.
+ Value bit16 =
+ b.create<arith::AndIOp>(b.create<arith::ShRUIOp>(bitcast, c16), c1);
+ // Determine the rounding bias to add as either 0x7fff or 0x8000 depending
+ // on bit 16, implementing the tie-breaking "to nearest even".
+ Value roundingBias = b.create<arith::AddIOp>(bit16, c7FFF);
+ // Add the rounding bias. Generally we want this to be added to the
+ // mantissa, but nothing prevents this to from carrying into the exponent
+ // bits, which would feel like a bug, but this is the magic trick here:
+ // when that happens, the mantissa gets reset to zero and the exponent
+ // gets incremented by the carry... which is actually exactly what we
+ // want.
+ Value biased = b.create<arith::AddIOp>(bitcast, roundingBias);
+ // Now that the rounding-bias has been added, truncating the low bits
+ // yields the correctly rounded result.
+ Value biasedAndShifted = b.create<arith::ShRUIOp>(biased, c16);
+ Value normalCaseResult_i16 =
+ b.create<arith::TruncIOp>(i16Ty, biasedAndShifted);
+ // Select either the above-computed result, or a quiet NaN constant
+ // if the input was NaN.
+ Value select =
+ b.create<arith::SelectOp>(isNan, c7FC0_i16, normalCaseResult_i16);
+ Value result = b.create<arith::BitcastOp>(resultTy, select);
rewriter.replaceOp(op, result);
return success();
}
diff --git a/mlir/test/Dialect/Arith/expand-ops.mlir b/mlir/test/Dialect/Arith/expand-ops.mlir
index 046e8ff64fba6d..91f652e5a270e3 100644
--- a/mlir/test/Dialect/Arith/expand-ops.mlir
+++ b/mlir/test/Dialect/Arith/expand-ops.mlir
@@ -255,36 +255,21 @@ func.func @truncf_f32(%arg0 : f32) -> bf16 {
}
// CHECK-LABEL: @truncf_f32
-
-// CHECK-DAG: %[[C16:.+]] = arith.constant 16
-// CHECK-DAG: %[[C32768:.+]] = arith.constant 32768
-// CHECK-DAG: %[[C2130706432:.+]] = arith.constant 2130706432
-// CHECK-DAG: %[[C2139095040:.+]] = arith.constant 2139095040
-// CHECK-DAG: %[[C8388607:.+]] = arith.constant 8388607
-// CHECK-DAG: %[[C31:.+]] = arith.constant 31
-// CHECK-DAG: %[[C23:.+]] = arith.constant 23
-// CHECK-DAG: %[[BITCAST:.+]] = arith.bitcast %arg0
-// CHECK-DAG: %[[SIGN:.+]] = arith.shrui %[[BITCAST:.+]], %[[C31]]
-// CHECK-DAG: %[[ROUND:.+]] = arith.subi %[[C32768]], %[[SIGN]]
-// CHECK-DAG: %[[MANTISSA:.+]] = arith.andi %[[BITCAST]], %[[C8388607]]
-// CHECK-DAG: %[[ROUNDED:.+]] = arith.addi %[[MANTISSA]], %[[ROUND]]
-// CHECK-DAG: %[[ROLL:.+]] = arith.shrui %[[ROUNDED]], %[[C23]]
-// CHECK-DAG: %[[SHR:.+]] = arith.shrui %[[ROUNDED]], %[[ROLL]]
-// CHECK-DAG: %[[EXP:.+]] = arith.andi %0, %[[C2139095040]]
-// CHECK-DAG: %[[EXPROUND:.+]] = arith.addi %[[EXP]], %[[ROUNDED]]
-// CHECK-DAG: %[[EXPROLL:.+]] = arith.andi %[[EXPROUND]], %[[C2139095040]]
-// CHECK-DAG: %[[EXPMAX:.+]] = arith.cmpi uge, %[[EXP]], %[[C2130706432]]
-// CHECK-DAG: %[[EXPNEW:.+]] = arith.select %[[EXPMAX]], %[[EXP]], %[[EXPROLL]]
-// CHECK-DAG: %[[OVERFLOW_B:.+]] = arith.trunci %[[ROLL]]
-// CHECK-DAG: %[[KEEP_MAN:.+]] = arith.andi %[[EXPMAX]], %[[OVERFLOW_B]]
-// CHECK-DAG: %[[MANNEW:.+]] = arith.select %[[KEEP_MAN]], %[[MANTISSA]], %[[SHR]]
-// CHECK-DAG: %[[NEWSIGN:.+]] = arith.shli %[[SIGN]], %[[C31]]
-// CHECK-DAG: %[[WITHEXP:.+]] = arith.ori %[[NEWSIGN]], %[[EXPNEW]]
-// CHECK-DAG: %[[WITHMAN:.+]] = arith.ori %[[WITHEXP]], %[[MANNEW]]
-// CHECK-DAG: %[[SHIFT:.+]] = arith.shrui %[[WITHMAN]], %[[C16]]
-// CHECK-DAG: %[[TRUNC:.+]] = arith.trunci %[[SHIFT]]
-// CHECK-DAG: %[[RES:.+]] = arith.bitcast %[[TRUNC]]
-// CHECK: return %[[RES]]
+// CHECK-DAG: %[[C1:.+]] = arith.constant 1 : i32
+// CHECK-DAG: %[[C16:.+]] = arith.constant 16 : i32
+// CHECK-DAG: %[[C7FC0_i16:.+]] = arith.constant 32704 : i16
+// CHECK-DAG: %[[C7FFF:.+]] = arith.constant 32767 : i32
+// CHECK-DAG: %[[ISNAN:.+]] = arith.cmpf une, %arg0, %arg0 : f32
+// CHECK-DAG: %[[BITCAST:.+]] = arith.bitcast %arg0 : f32 to i32
+// CHECK-DAG: %[[SHRUI:.+]] = arith.shrui %[[BITCAST]], %[[C16]] : i32
+// CHECK-DAG: %[[BIT16:.+]] = arith.andi %[[SHRUI]], %[[C1]] : i32
+// CHECK-DAG: %[[ROUNDING_BIAS:.+]] = arith.addi %[[BIT16]], %[[C7FFF]] : i32
+// CHECK-DAG: %[[BIASED:.+]] = arith.addi %[[BITCAST]], %[[ROUNDING_BIAS]] : i32
+// CHECK-DAG: %[[BIASED_SHIFTED:.+]] = arith.shrui %[[BIASED]], %[[C16]] : i32
+// CHECK-DAG: %[[NORMAL_CASE_RESULT_i16:.+]] = arith.trunci %[[BIASED_SHIFTED]] : i32 to i16
+// CHECK-DAG: %[[SELECT:.+]] = arith.select %[[ISNAN]], %[[C7FC0_i16]], %[[NORMAL_CASE_RESULT_i16]] : i16
+// CHECK-DAG: %[[RESULT:.+]] = arith.bitcast %[[SELECT]] : i16 to bf16
+// CHECK: return %[[RESULT]]
// -----
diff --git a/mlir/test/mlir-cpu-runner/expand-arith-ops.mlir b/mlir/test/mlir-cpu-runner/expand-arith-ops.mlir
index 44141cc4eeaf42..0bf6523c5e5d5c 100644
--- a/mlir/test/mlir-cpu-runner/expand-arith-ops.mlir
+++ b/mlir/test/mlir-cpu-runner/expand-arith-ops.mlir
@@ -13,10 +13,21 @@ func.func @trunc_bf16(%a : f32) {
}
func.func @main() {
- // CHECK: 1.00781
- %roundOneI = arith.constant 0x3f808000 : i32
- %roundOneF = arith.bitcast %roundOneI : i32 to f32
- call @trunc_bf16(%roundOneF): (f32) -> ()
+ // Note: this is a tie (low 16 bits are 0x8000). We expect the rounding behavior
+ // to break ties "to nearest-even", which in this case means downwards,
+ // since bit 16 is not set.
+ // CHECK: 1
+ %value_1_00391_I = arith.constant 0x3f808000 : i32
+ %value_1_00391_F = arith.bitcast %value_1_00391_I : i32 to f32
+ call @trunc_bf16(%value_1_00391_F): (f32) -> ()
+
+ // Note: this is a tie (low 16 bits are 0x8000). We expect the rounding behavior
+ // to break ties "to nearest-even", which in this case means upwards,
+ // since bit 16 is set.
+ // CHECK-NEXT: 1.01562
+ %value_1_01172_I = arith.constant 0x3f818000 : i32
+ %value_1_01172_F = arith.bitcast %value_1_01172_I : i32 to f32
+ call @trunc_bf16(%value_1_01172_F): (f32) -> ()
// CHECK-NEXT: -1
%noRoundNegOneI = arith.constant 0xbf808000 : i32
@@ -38,15 +49,27 @@ func.func @main() {
%neginff = arith.bitcast %neginfi : i32 to f32
call @trunc_bf16(%neginff): (f32) -> ()
+ // Note: this rounds upwards. As the mantissa was already saturated, this rounding
+ // causes the exponent to be incremented. As the exponent was already the
+ // maximum exponent value for finite values, this increment of the exponent
+ // causes this to overflow to +inf.
+ // CHECK-NEXT: inf
+ %big_overflowing_i = arith.constant 0x7f7fffff : i32
+ %big_overflowing_f = arith.bitcast %big_overflowing_i : i32 to f32
+ call @trunc_bf16(%big_overflowing_f): (f32) -> ()
+
+ // Same as the previous testcase but negative.
+ // CHECK-NEXT: -inf
+ %negbig_overflowing_i = arith.constant 0xff7fffff : i32
+ %negbig_overflowing_f = arith.bitcast %negbig_overflowing_i : i32 to f32
+ call @trunc_bf16(%negbig_overflowing_f): (f32) -> ()
+
+ // In contrast to the previous two testcases, the upwards-rounding here
+ // does not cause overflow.
// CHECK-NEXT: 3.38953e+38
- %bigi = arith.constant 0x7f7fffff : i32
- %bigf = arith.bitcast %bigi : i32 to f32
- call @trunc_bf16(%bigf): (f32) -> ()
-
- // CHECK-NEXT: -3.38953e+38
- %negbigi = arith.constant 0xff7fffff : i32
- %negbigf = arith.bitcast %negbigi : i32 to f32
- call @trunc_bf16(%negbigf): (f32) -> ()
+ %big_nonoverflowing_i = arith.constant 0x7f7effff : i32
+ %big_nonoverflowing_f = arith.bitcast %big_nonoverflowing_i : i32 to f32
+ call @trunc_bf16(%big_nonoverflowing_f): (f32) -> ()
// CHECK-NEXT: 1.625
%exprolli = arith.constant 0x3fcfffff : i32
>From 777ac46ddbc318b5d5820d278a2e4dc2213699d8 Mon Sep 17 00:00:00 2001
From: Paul Kirth <paulkirth at google.com>
Date: Wed, 28 Feb 2024 11:12:13 -0800
Subject: [PATCH 036/406] [llvm] Remove pipeline checks for optsize for
DFAJumpThreadingPass
The pass itself checks whether to apply the optimization based on the
minsize attribute, so there isn't much functional benefit to preventing
the pass from being added. Gating the pass gets added to the pass
pipeline complicates the interaction with -enable-dfa-jump-thread, as
well.
Reviewers: aeubanks
Reviewed By: aeubanks
Pull Request: https://github.com/llvm/llvm-project/pull/83318
---
llvm/lib/Passes/PassBuilderPipelines.cpp | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/llvm/lib/Passes/PassBuilderPipelines.cpp b/llvm/lib/Passes/PassBuilderPipelines.cpp
index 142bd50b3798e0..991c3ac8f7446c 100644
--- a/llvm/lib/Passes/PassBuilderPipelines.cpp
+++ b/llvm/lib/Passes/PassBuilderPipelines.cpp
@@ -707,7 +707,7 @@ PassBuilder::buildFunctionSimplificationPipeline(OptimizationLevel Level,
// Re-consider control flow based optimizations after redundancy elimination,
// redo DCE, etc.
- if (EnableDFAJumpThreading && Level.getSizeLevel() == 0)
+ if (EnableDFAJumpThreading)
FPM.addPass(DFAJumpThreadingPass());
FPM.addPass(JumpThreadingPass());
>From 21c7bc51e9ed2402a3a2f7a88d63cc8f5c2e303c Mon Sep 17 00:00:00 2001
From: Nikolas Klauser <nikolasklauser at berlin.de>
Date: Wed, 28 Feb 2024 20:33:20 +0100
Subject: [PATCH 037/406] [libc++] Use __integer_pack to implement
integer_sequence on GCC (#82983)
This significantly simplifies the implementation.
---
libcxx/include/__utility/integer_sequence.h | 87 +++----------------
.../make_integer_seq_fallback.pass.cpp | 19 ----
.../make_integer_seq_fallback.verify.cpp | 24 -----
3 files changed, 12 insertions(+), 118 deletions(-)
delete mode 100644 libcxx/test/std/utilities/intseq/intseq.make/make_integer_seq_fallback.pass.cpp
delete mode 100644 libcxx/test/std/utilities/intseq/intseq.make/make_integer_seq_fallback.verify.cpp
diff --git a/libcxx/include/__utility/integer_sequence.h b/libcxx/include/__utility/integer_sequence.h
index e63f3f265b7d5e..ccce9433e7a801 100644
--- a/libcxx/include/__utility/integer_sequence.h
+++ b/libcxx/include/__utility/integer_sequence.h
@@ -31,65 +31,16 @@ struct __integer_sequence {
using __to_tuple_indices = __tuple_indices<(_Values + _Sp)...>;
};
-#if !__has_builtin(__make_integer_seq) || defined(_LIBCPP_TESTING_FALLBACK_MAKE_INTEGER_SEQUENCE)
-
-namespace __detail {
-
-template <typename _Tp, size_t... _Extra>
-struct __repeat;
-template <typename _Tp, _Tp... _Np, size_t... _Extra>
-struct __repeat<__integer_sequence<_Tp, _Np...>, _Extra...> {
- typedef _LIBCPP_NODEBUG __integer_sequence<
- _Tp,
- _Np...,
- sizeof...(_Np) + _Np...,
- 2 * sizeof...(_Np) + _Np...,
- 3 * sizeof...(_Np) + _Np...,
- 4 * sizeof...(_Np) + _Np...,
- 5 * sizeof...(_Np) + _Np...,
- 6 * sizeof...(_Np) + _Np...,
- 7 * sizeof...(_Np) + _Np...,
- _Extra...>
- type;
-};
-
-template <size_t _Np>
-struct __parity;
-template <size_t _Np>
-struct __make : __parity<_Np % 8>::template __pmake<_Np> {};
-
-// clang-format off
-template<> struct __make<0> { typedef __integer_sequence<size_t> type; };
-template<> struct __make<1> { typedef __integer_sequence<size_t, 0> type; };
-template<> struct __make<2> { typedef __integer_sequence<size_t, 0, 1> type; };
-template<> struct __make<3> { typedef __integer_sequence<size_t, 0, 1, 2> type; };
-template<> struct __make<4> { typedef __integer_sequence<size_t, 0, 1, 2, 3> type; };
-template<> struct __make<5> { typedef __integer_sequence<size_t, 0, 1, 2, 3, 4> type; };
-template<> struct __make<6> { typedef __integer_sequence<size_t, 0, 1, 2, 3, 4, 5> type; };
-template<> struct __make<7> { typedef __integer_sequence<size_t, 0, 1, 2, 3, 4, 5, 6> type; };
-
-template<> struct __parity<0> { template<size_t _Np> struct __pmake : __repeat<typename __make<_Np / 8>::type> {}; };
-template<> struct __parity<1> { template<size_t _Np> struct __pmake : __repeat<typename __make<_Np / 8>::type, _Np - 1> {}; };
-template<> struct __parity<2> { template<size_t _Np> struct __pmake : __repeat<typename __make<_Np / 8>::type, _Np - 2, _Np - 1> {}; };
-template<> struct __parity<3> { template<size_t _Np> struct __pmake : __repeat<typename __make<_Np / 8>::type, _Np - 3, _Np - 2, _Np - 1> {}; };
-template<> struct __parity<4> { template<size_t _Np> struct __pmake : __repeat<typename __make<_Np / 8>::type, _Np - 4, _Np - 3, _Np - 2, _Np - 1> {}; };
-template<> struct __parity<5> { template<size_t _Np> struct __pmake : __repeat<typename __make<_Np / 8>::type, _Np - 5, _Np - 4, _Np - 3, _Np - 2, _Np - 1> {}; };
-template<> struct __parity<6> { template<size_t _Np> struct __pmake : __repeat<typename __make<_Np / 8>::type, _Np - 6, _Np - 5, _Np - 4, _Np - 3, _Np - 2, _Np - 1> {}; };
-template<> struct __parity<7> { template<size_t _Np> struct __pmake : __repeat<typename __make<_Np / 8>::type, _Np - 7, _Np - 6, _Np - 5, _Np - 4, _Np - 3, _Np - 2, _Np - 1> {}; };
-// clang-format on
-
-} // namespace __detail
-
-#endif
-
#if __has_builtin(__make_integer_seq)
template <size_t _Ep, size_t _Sp>
using __make_indices_imp =
typename __make_integer_seq<__integer_sequence, size_t, _Ep - _Sp>::template __to_tuple_indices<_Sp>;
-#else
+#elif __has_builtin(__integer_pack)
template <size_t _Ep, size_t _Sp>
-using __make_indices_imp = typename __detail::__make<_Ep - _Sp>::type::template __to_tuple_indices<_Sp>;
-
+using __make_indices_imp =
+ typename __integer_sequence<size_t, __integer_pack(_Ep - _Sp)...>::template __to_tuple_indices<_Sp>;
+#else
+# error "No known way to get an integer pack from the compiler"
#endif
#if _LIBCPP_STD_VER >= 14
@@ -104,34 +55,20 @@ struct _LIBCPP_TEMPLATE_VIS integer_sequence {
template <size_t... _Ip>
using index_sequence = integer_sequence<size_t, _Ip...>;
-# if __has_builtin(__make_integer_seq) && !defined(_LIBCPP_TESTING_FALLBACK_MAKE_INTEGER_SEQUENCE)
+# if __has_builtin(__make_integer_seq)
template <class _Tp, _Tp _Ep>
-using __make_integer_sequence _LIBCPP_NODEBUG = __make_integer_seq<integer_sequence, _Tp, _Ep>;
-
-# else
+using make_integer_sequence _LIBCPP_NODEBUG = __make_integer_seq<integer_sequence, _Tp, _Ep>;
-template <typename _Tp, _Tp _Np>
-using __make_integer_sequence_unchecked _LIBCPP_NODEBUG =
- typename __detail::__make<_Np>::type::template __convert<integer_sequence, _Tp>;
+# elif __has_builtin(__integer_pack)
-template <class _Tp, _Tp _Ep>
-struct __make_integer_sequence_checked {
- static_assert(is_integral<_Tp>::value, "std::make_integer_sequence can only be instantiated with an integral type");
- static_assert(0 <= _Ep, "std::make_integer_sequence must have a non-negative sequence length");
- // Workaround GCC bug by preventing bad installations when 0 <= _Ep
- // https://gcc.gnu.org/bugzilla/show_bug.cgi?id=68929
- typedef _LIBCPP_NODEBUG __make_integer_sequence_unchecked<_Tp, 0 <= _Ep ? _Ep : 0> type;
-};
-
-template <class _Tp, _Tp _Ep>
-using __make_integer_sequence _LIBCPP_NODEBUG = typename __make_integer_sequence_checked<_Tp, _Ep>::type;
+template <class _Tp, _Tp _SequenceSize>
+using make_integer_sequence _LIBCPP_NODEBUG = integer_sequence<_Tp, __integer_pack(_SequenceSize)...>;
+# else
+# error "No known way to get an integer pack from the compiler"
# endif
-template <class _Tp, _Tp _Np>
-using make_integer_sequence = __make_integer_sequence<_Tp, _Np>;
-
template <size_t _Np>
using make_index_sequence = make_integer_sequence<size_t, _Np>;
diff --git a/libcxx/test/std/utilities/intseq/intseq.make/make_integer_seq_fallback.pass.cpp b/libcxx/test/std/utilities/intseq/intseq.make/make_integer_seq_fallback.pass.cpp
deleted file mode 100644
index ceeb4dd3eeec41..00000000000000
--- a/libcxx/test/std/utilities/intseq/intseq.make/make_integer_seq_fallback.pass.cpp
+++ /dev/null
@@ -1,19 +0,0 @@
-//===----------------------------------------------------------------------===//
-//
-// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
-// See https://llvm.org/LICENSE.txt for license information.
-// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
-//
-//===----------------------------------------------------------------------===//
-
-// <utility>
-
-// template<class T, T N>
-// using make_integer_sequence = integer_sequence<T, 0, 1, ..., N-1>;
-
-// UNSUPPORTED: c++03, c++11
-
-#define _LIBCPP_TESTING_FALLBACK_MAKE_INTEGER_SEQUENCE
-#include "make_integer_seq.pass.cpp"
-
-#include "test_macros.h"
diff --git a/libcxx/test/std/utilities/intseq/intseq.make/make_integer_seq_fallback.verify.cpp b/libcxx/test/std/utilities/intseq/intseq.make/make_integer_seq_fallback.verify.cpp
deleted file mode 100644
index 32a4a5431333e2..00000000000000
--- a/libcxx/test/std/utilities/intseq/intseq.make/make_integer_seq_fallback.verify.cpp
+++ /dev/null
@@ -1,24 +0,0 @@
-//===----------------------------------------------------------------------===//
-//
-// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
-// See https://llvm.org/LICENSE.txt for license information.
-// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
-//
-//===----------------------------------------------------------------------===//
-
-// <utility>
-
-// template<class T, T N>
-// using make_integer_sequence = integer_sequence<T, 0, 1, ..., N-1>;
-
-// UNSUPPORTED: c++03, c++11
-
-// This test hangs during recursive template instantiation with libstdc++
-// UNSUPPORTED: stdlib=libstdc++
-
-// ADDITIONAL_COMPILE_FLAGS: -D_LIBCPP_TESTING_FALLBACK_MAKE_INTEGER_SEQUENCE
-
-#include <utility>
-
-typedef std::make_integer_sequence<int, -3> MakeSeqT;
-MakeSeqT i; // expected-error-re@*:* {{static assertion failed{{.*}}std::make_integer_sequence must have a non-negative sequence length}}
>From b81bb0e1d0acc3db64557ed699ccba751b8b511a Mon Sep 17 00:00:00 2001
From: Marius Brehler <marius.brehler at iml.fraunhofer.de>
Date: Wed, 28 Feb 2024 20:41:05 +0100
Subject: [PATCH 038/406] [mlir][EmitC] Add logical operators (#83123)
This adds operations for the logical operators AND, NOT and OR.
---
mlir/include/mlir/Dialect/EmitC/IR/EmitC.td | 64 +++++++++++++++++++++
mlir/lib/Target/Cpp/TranslateToCpp.cpp | 30 +++++++++-
mlir/test/Dialect/EmitC/invalid_ops.mlir | 24 ++++++++
mlir/test/Dialect/EmitC/ops.mlir | 7 +++
mlir/test/Target/Cpp/logical_operators.mlir | 14 +++++
5 files changed, 138 insertions(+), 1 deletion(-)
create mode 100644 mlir/test/Target/Cpp/logical_operators.mlir
diff --git a/mlir/include/mlir/Dialect/EmitC/IR/EmitC.td b/mlir/include/mlir/Dialect/EmitC/IR/EmitC.td
index c50fdf397a0fec..7b9fbb494e895a 100644
--- a/mlir/include/mlir/Dialect/EmitC/IR/EmitC.td
+++ b/mlir/include/mlir/Dialect/EmitC/IR/EmitC.td
@@ -658,6 +658,70 @@ def EmitC_LiteralOp : EmitC_Op<"literal", [Pure]> {
let assemblyFormat = "$value attr-dict `:` type($result)";
}
+def EmitC_LogicalAndOp : EmitC_BinaryOp<"logical_and", []> {
+ let summary = "Logical and operation";
+ let description = [{
+ With the `logical_and` operation the logical operator && (and) can
+ be applied.
+
+ Example:
+
+ ```mlir
+ %0 = emitc.logical_and %arg0, %arg1 : i32, i32
+ ```
+ ```c++
+ // Code emitted for the operation above.
+ bool v3 = v1 && v2;
+ ```
+ }];
+
+ let results = (outs I1);
+ let assemblyFormat = "operands attr-dict `:` type(operands)";
+}
+
+def EmitC_LogicalNotOp : EmitC_Op<"logical_not", []> {
+ let summary = "Logical not operation";
+ let description = [{
+ With the `logical_not` operation the logical operator ! (negation) can
+ be applied.
+
+ Example:
+
+ ```mlir
+ %0 = emitc.logical_not %arg0 : i32
+ ```
+ ```c++
+ // Code emitted for the operation above.
+ bool v2 = !v1;
+ ```
+ }];
+
+ let arguments = (ins AnyType);
+ let results = (outs I1);
+ let assemblyFormat = "operands attr-dict `:` type(operands)";
+}
+
+def EmitC_LogicalOrOp : EmitC_BinaryOp<"logical_or", []> {
+ let summary = "Logical or operation";
+ let description = [{
+ With the `logical_or` operation the logical operator || (inclusive or)
+ can be applied.
+
+ Example:
+
+ ```mlir
+ %0 = emitc.logical_or %arg0, %arg1 : i32, i32
+ ```
+ ```c++
+ // Code emitted for the operation above.
+ bool v3 = v1 || v2;
+ ```
+ }];
+
+ let results = (outs I1);
+ let assemblyFormat = "operands attr-dict `:` type(operands)";
+}
+
def EmitC_MulOp : EmitC_BinaryOp<"mul", []> {
let summary = "Multiplication operation";
let description = [{
diff --git a/mlir/lib/Target/Cpp/TranslateToCpp.cpp b/mlir/lib/Target/Cpp/TranslateToCpp.cpp
index 2ba3dec0a9a57f..16aa136c5a4e28 100644
--- a/mlir/lib/Target/Cpp/TranslateToCpp.cpp
+++ b/mlir/lib/Target/Cpp/TranslateToCpp.cpp
@@ -627,6 +627,33 @@ static LogicalResult printOperation(CppEmitter &emitter,
return success();
}
+static LogicalResult printOperation(CppEmitter &emitter,
+ emitc::LogicalAndOp logicalAndOp) {
+ Operation *operation = logicalAndOp.getOperation();
+ return printBinaryOperation(emitter, operation, "&&");
+}
+
+static LogicalResult printOperation(CppEmitter &emitter,
+ emitc::LogicalNotOp logicalNotOp) {
+ raw_ostream &os = emitter.ostream();
+
+ if (failed(emitter.emitAssignPrefix(*logicalNotOp.getOperation())))
+ return failure();
+
+ os << "!";
+
+ if (failed(emitter.emitOperand(logicalNotOp.getOperand())))
+ return failure();
+
+ return success();
+}
+
+static LogicalResult printOperation(CppEmitter &emitter,
+ emitc::LogicalOrOp logicalOrOp) {
+ Operation *operation = logicalOrOp.getOperation();
+ return printBinaryOperation(emitter, operation, "||");
+}
+
static LogicalResult printOperation(CppEmitter &emitter, emitc::ForOp forOp) {
raw_indented_ostream &os = emitter.ostream();
@@ -1284,7 +1311,8 @@ LogicalResult CppEmitter::emitOperation(Operation &op, bool trailingSemicolon) {
emitc::CallOpaqueOp, emitc::CastOp, emitc::CmpOp,
emitc::ConstantOp, emitc::DeclareFuncOp, emitc::DivOp,
emitc::ExpressionOp, emitc::ForOp, emitc::FuncOp, emitc::IfOp,
- emitc::IncludeOp, emitc::MulOp, emitc::RemOp, emitc::ReturnOp,
+ emitc::IncludeOp, emitc::LogicalAndOp, emitc::LogicalNotOp,
+ emitc::LogicalOrOp, emitc::MulOp, emitc::RemOp, emitc::ReturnOp,
emitc::SubOp, emitc::VariableOp, emitc::VerbatimOp>(
[&](auto op) { return printOperation(*this, op); })
// Func ops.
diff --git a/mlir/test/Dialect/EmitC/invalid_ops.mlir b/mlir/test/Dialect/EmitC/invalid_ops.mlir
index 121a2163d38320..5f64b535d684f3 100644
--- a/mlir/test/Dialect/EmitC/invalid_ops.mlir
+++ b/mlir/test/Dialect/EmitC/invalid_ops.mlir
@@ -331,3 +331,27 @@ emitc.declare_func @bar
// expected-error at +1 {{'emitc.declare_func' op requires attribute 'sym_name'}}
"emitc.declare_func"() : () -> ()
+
+// -----
+
+func.func @logical_and_resulterror(%arg0: i32, %arg1: i32) {
+ // expected-error @+1 {{'emitc.logical_and' op result #0 must be 1-bit signless integer, but got 'i32'}}
+ %0 = "emitc.logical_and"(%arg0, %arg1) : (i32, i32) -> i32
+ return
+}
+
+// -----
+
+func.func @logical_not_resulterror(%arg0: i32) {
+ // expected-error @+1 {{'emitc.logical_not' op result #0 must be 1-bit signless integer, but got 'i32'}}
+ %0 = "emitc.logical_not"(%arg0) : (i32) -> i32
+ return
+}
+
+// -----
+
+func.func @logical_or_resulterror(%arg0: i32, %arg1: i32) {
+ // expected-error @+1 {{'emitc.logical_or' op result #0 must be 1-bit signless integer, but got 'i32'}}
+ %0 = "emitc.logical_or"(%arg0, %arg1) : (i32, i32) -> i32
+ return
+}
diff --git a/mlir/test/Dialect/EmitC/ops.mlir b/mlir/test/Dialect/EmitC/ops.mlir
index 93119be14c908b..045fb24cb67f8d 100644
--- a/mlir/test/Dialect/EmitC/ops.mlir
+++ b/mlir/test/Dialect/EmitC/ops.mlir
@@ -117,6 +117,13 @@ func.func @cmp(%arg0 : i32, %arg1 : f32, %arg2 : i64, %arg3 : f64, %arg4 : !emit
return
}
+func.func @logical(%arg0: i32, %arg1: i32) {
+ %0 = emitc.logical_and %arg0, %arg1 : i32, i32
+ %1 = emitc.logical_not %arg0 : i32
+ %2 = emitc.logical_or %arg0, %arg1 : i32, i32
+ return
+}
+
func.func @test_if(%arg0: i1, %arg1: f32) {
emitc.if %arg0 {
%0 = emitc.call_opaque "func_const"(%arg1) : (f32) -> i32
diff --git a/mlir/test/Target/Cpp/logical_operators.mlir b/mlir/test/Target/Cpp/logical_operators.mlir
new file mode 100644
index 00000000000000..7083dc218fca99
--- /dev/null
+++ b/mlir/test/Target/Cpp/logical_operators.mlir
@@ -0,0 +1,14 @@
+// RUN: mlir-translate -mlir-to-cpp %s | FileCheck %s
+
+func.func @logical(%arg0: i32, %arg1: i32) -> () {
+ %0 = emitc.logical_and %arg0, %arg1 : i32, i32
+ %1 = emitc.logical_not %arg0 : i32
+ %2 = emitc.logical_or %arg0, %arg1 : i32, i32
+
+ return
+}
+
+// CHECK-LABEL: void logical
+// CHECK-NEXT: bool [[V2:[^ ]*]] = [[V0:[^ ]*]] && [[V1:[^ ]*]];
+// CHECK-NEXT: bool [[V3:[^ ]*]] = ![[V0]];
+// CHECK-NEXT: bool [[V4:[^ ]*]] = [[V0]] || [[V1]];
>From 2cacc7a61095577ff42177373d46c8cb8df0cb1f Mon Sep 17 00:00:00 2001
From: Zequan Wu <zequanwu at google.com>
Date: Wed, 28 Feb 2024 14:56:55 -0500
Subject: [PATCH 039/406] [lldb-dap] Deduplicate watchpoints starting at the
same address on SetDataBreakpointsRequest. (#83192)
If a SetDataBreakpointsRequest contains a list data breakpoints which
have duplicate starting addresses, the current behaviour is returning
`{verified: true}` to both watchpoints with duplicated starting
addresses. This confuses the client and what actually happens in lldb is
the second one overwrite the first one.
This fixes it by letting the last watchpoint at given address have
`{verified: true}` and all previous watchpoints at the same address
should have `{verfied: false}` at response.
---
.../TestDAP_setDataBreakpoints.py | 45 +++++++++++++++++++
lldb/tools/lldb-dap/Watchpoint.cpp | 23 +++++-----
lldb/tools/lldb-dap/Watchpoint.h | 5 +++
lldb/tools/lldb-dap/lldb-dap.cpp | 16 ++++++-
4 files changed, 78 insertions(+), 11 deletions(-)
diff --git a/lldb/test/API/tools/lldb-dap/databreakpoint/TestDAP_setDataBreakpoints.py b/lldb/test/API/tools/lldb-dap/databreakpoint/TestDAP_setDataBreakpoints.py
index 17cdad89aa6d10..52c0bbfb33dad8 100644
--- a/lldb/test/API/tools/lldb-dap/databreakpoint/TestDAP_setDataBreakpoints.py
+++ b/lldb/test/API/tools/lldb-dap/databreakpoint/TestDAP_setDataBreakpoints.py
@@ -12,6 +12,51 @@ def setUp(self):
lldbdap_testcase.DAPTestCaseBase.setUp(self)
self.accessTypes = ["read", "write", "readWrite"]
+ @skipIfWindows
+ @skipIfRemote
+ def test_duplicate_start_addresses(self):
+ """Test setDataBreakpoints with multiple watchpoints starting at the same addresses."""
+ program = self.getBuildArtifact("a.out")
+ self.build_and_launch(program)
+ source = "main.cpp"
+ first_loop_break_line = line_number(source, "// first loop breakpoint")
+ self.set_source_breakpoints(source, [first_loop_break_line])
+ self.continue_to_next_stop()
+ self.dap_server.get_stackFrame()
+ # Test setting write watchpoint using expressions: &x, arr+2
+ response_x = self.dap_server.request_dataBreakpointInfo(0, "&x")
+ response_arr_2 = self.dap_server.request_dataBreakpointInfo(0, "arr+2")
+ # Test response from dataBreakpointInfo request.
+ self.assertEquals(response_x["body"]["dataId"].split("/")[1], "4")
+ self.assertEquals(response_x["body"]["accessTypes"], self.accessTypes)
+ self.assertEquals(response_arr_2["body"]["dataId"].split("/")[1], "4")
+ self.assertEquals(response_arr_2["body"]["accessTypes"], self.accessTypes)
+ # The first one should be overwritten by the third one as they start at
+ # the same address. This is indicated by returning {verified: False} for
+ # the first one.
+ dataBreakpoints = [
+ {"dataId": response_x["body"]["dataId"], "accessType": "read"},
+ {"dataId": response_arr_2["body"]["dataId"], "accessType": "write"},
+ {"dataId": response_x["body"]["dataId"], "accessType": "write"},
+ ]
+ set_response = self.dap_server.request_setDataBreakpoint(dataBreakpoints)
+ self.assertEquals(
+ set_response["body"]["breakpoints"],
+ [{"verified": False}, {"verified": True}, {"verified": True}],
+ )
+
+ self.continue_to_next_stop()
+ x_val = self.dap_server.get_local_variable_value("x")
+ i_val = self.dap_server.get_local_variable_value("i")
+ self.assertEquals(x_val, "2")
+ self.assertEquals(i_val, "1")
+
+ self.continue_to_next_stop()
+ arr_2 = self.dap_server.get_local_variable_child("arr", "[2]")
+ i_val = self.dap_server.get_local_variable_value("i")
+ self.assertEquals(arr_2["value"], "42")
+ self.assertEquals(i_val, "2")
+
@skipIfWindows
@skipIfRemote
def test_expression(self):
diff --git a/lldb/tools/lldb-dap/Watchpoint.cpp b/lldb/tools/lldb-dap/Watchpoint.cpp
index 2f176e0da84f15..21765509449140 100644
--- a/lldb/tools/lldb-dap/Watchpoint.cpp
+++ b/lldb/tools/lldb-dap/Watchpoint.cpp
@@ -16,17 +16,11 @@ Watchpoint::Watchpoint(const llvm::json::Object &obj) : BreakpointBase(obj) {
llvm::StringRef dataId = GetString(obj, "dataId");
std::string accessType = GetString(obj, "accessType").str();
auto [addr_str, size_str] = dataId.split('/');
- lldb::addr_t addr;
- size_t size;
llvm::to_integer(addr_str, addr, 16);
llvm::to_integer(size_str, size);
- lldb::SBWatchpointOptions options;
options.SetWatchpointTypeRead(accessType != "write");
if (accessType != "read")
options.SetWatchpointTypeWrite(lldb::eWatchpointWriteTypeOnModify);
- wp = g_dap.target.WatchpointCreateByAddress(addr, size, options, error);
- SetCondition();
- SetHitCondition();
}
void Watchpoint::SetCondition() { wp.SetCondition(condition.c_str()); }
@@ -38,11 +32,20 @@ void Watchpoint::SetHitCondition() {
}
void Watchpoint::CreateJsonObject(llvm::json::Object &object) {
- if (error.Success()) {
- object.try_emplace("verified", true);
- } else {
+ if (!error.IsValid() || error.Fail()) {
object.try_emplace("verified", false);
- EmplaceSafeString(object, "message", error.GetCString());
+ if (error.Fail())
+ EmplaceSafeString(object, "message", error.GetCString());
+ } else {
+ object.try_emplace("verified", true);
}
}
+
+void Watchpoint::SetWatchpoint() {
+ wp = g_dap.target.WatchpointCreateByAddress(addr, size, options, error);
+ if (!condition.empty())
+ SetCondition();
+ if (!hitCondition.empty())
+ SetHitCondition();
+}
} // namespace lldb_dap
diff --git a/lldb/tools/lldb-dap/Watchpoint.h b/lldb/tools/lldb-dap/Watchpoint.h
index 026b07d67241ce..4d2e58ed753360 100644
--- a/lldb/tools/lldb-dap/Watchpoint.h
+++ b/lldb/tools/lldb-dap/Watchpoint.h
@@ -17,6 +17,9 @@
namespace lldb_dap {
struct Watchpoint : public BreakpointBase {
+ lldb::addr_t addr;
+ size_t size;
+ lldb::SBWatchpointOptions options;
// The LLDB breakpoint associated wit this watchpoint.
lldb::SBWatchpoint wp;
lldb::SBError error;
@@ -28,6 +31,8 @@ struct Watchpoint : public BreakpointBase {
void SetCondition() override;
void SetHitCondition() override;
void CreateJsonObject(llvm::json::Object &object) override;
+
+ void SetWatchpoint();
};
} // namespace lldb_dap
diff --git a/lldb/tools/lldb-dap/lldb-dap.cpp b/lldb/tools/lldb-dap/lldb-dap.cpp
index c6a275bcf8140c..55f8c920e60016 100644
--- a/lldb/tools/lldb-dap/lldb-dap.cpp
+++ b/lldb/tools/lldb-dap/lldb-dap.cpp
@@ -2880,15 +2880,29 @@ void request_setDataBreakpoints(const llvm::json::Object &request) {
const auto *breakpoints = arguments->getArray("breakpoints");
llvm::json::Array response_breakpoints;
g_dap.target.DeleteAllWatchpoints();
+ std::vector<Watchpoint> watchpoints;
if (breakpoints) {
for (const auto &bp : *breakpoints) {
const auto *bp_obj = bp.getAsObject();
if (bp_obj) {
Watchpoint wp(*bp_obj);
- AppendBreakpoint(&wp, response_breakpoints);
+ watchpoints.push_back(wp);
}
}
}
+ // If two watchpoints start at the same address, the latter overwrite the
+ // former. So, we only enable those at first-seen addresses when iterating
+ // backward.
+ std::set<lldb::addr_t> addresses;
+ for (auto iter = watchpoints.rbegin(); iter != watchpoints.rend(); ++iter) {
+ if (addresses.count(iter->addr) == 0) {
+ iter->SetWatchpoint();
+ addresses.insert(iter->addr);
+ }
+ }
+ for (auto wp : watchpoints)
+ AppendBreakpoint(&wp, response_breakpoints);
+
llvm::json::Object body;
body.try_emplace("breakpoints", std::move(response_breakpoints));
response.try_emplace("body", std::move(body));
>From 1a7776abe6ca01996e8050dcdc8350d686a5749f Mon Sep 17 00:00:00 2001
From: ChiaHungDuan <chiahungduan at google.com>
Date: Wed, 28 Feb 2024 12:09:49 -0800
Subject: [PATCH 040/406] Reland "[scudo] Store more blocks in each
TransferBatch" (#83078) (#83081)
This reverts commit 056d62be38c5db3d8332ac300c4ff29214126697.
Fixed the number of bytes copied in moveNToArray()
---
.../lib/scudo/standalone/allocator_common.h | 7 +
compiler-rt/lib/scudo/standalone/primary32.h | 106 ++++++------
compiler-rt/lib/scudo/standalone/primary64.h | 153 ++++++++++--------
.../scudo/standalone/tests/primary_test.cpp | 34 ++--
4 files changed, 159 insertions(+), 141 deletions(-)
diff --git a/compiler-rt/lib/scudo/standalone/allocator_common.h b/compiler-rt/lib/scudo/standalone/allocator_common.h
index 95f4776ac596dc..4d39956bf90503 100644
--- a/compiler-rt/lib/scudo/standalone/allocator_common.h
+++ b/compiler-rt/lib/scudo/standalone/allocator_common.h
@@ -40,6 +40,7 @@ template <class SizeClassAllocator> struct TransferBatch {
B->Count = static_cast<u16>(B->Count - N);
}
void clear() { Count = 0; }
+ bool empty() { return Count == 0; }
void add(CompactPtrT P) {
DCHECK_LT(Count, MaxNumCached);
Batch[Count++] = P;
@@ -48,6 +49,12 @@ template <class SizeClassAllocator> struct TransferBatch {
memcpy(Array, Batch, sizeof(Batch[0]) * Count);
clear();
}
+
+ void moveNToArray(CompactPtrT *Array, u16 N) {
+ DCHECK_LE(N, Count);
+ memcpy(Array, Batch + Count - N, sizeof(Batch[0]) * N);
+ Count -= N;
+ }
u16 getCount() const { return Count; }
bool isEmpty() const { return Count == 0U; }
CompactPtrT get(u16 I) const {
diff --git a/compiler-rt/lib/scudo/standalone/primary32.h b/compiler-rt/lib/scudo/standalone/primary32.h
index 4d03b282d000de..c86e75b8fd66a8 100644
--- a/compiler-rt/lib/scudo/standalone/primary32.h
+++ b/compiler-rt/lib/scudo/standalone/primary32.h
@@ -191,38 +191,21 @@ template <typename Config> class SizeClassAllocator32 {
return BlockSize > PageSize;
}
- // Note that the `MaxBlockCount` will be used when we support arbitrary blocks
- // count. Now it's the same as the number of blocks stored in the
- // `TransferBatch`.
u16 popBlocks(CacheT *C, uptr ClassId, CompactPtrT *ToArray,
- UNUSED const u16 MaxBlockCount) {
- TransferBatchT *B = popBatch(C, ClassId);
- if (!B)
- return 0;
-
- const u16 Count = B->getCount();
- DCHECK_GT(Count, 0U);
- B->moveToArray(ToArray);
-
- if (ClassId != SizeClassMap::BatchClassId)
- C->deallocate(SizeClassMap::BatchClassId, B);
-
- return Count;
- }
-
- TransferBatchT *popBatch(CacheT *C, uptr ClassId) {
+ const u16 MaxBlockCount) {
DCHECK_LT(ClassId, NumClasses);
SizeClassInfo *Sci = getSizeClassInfo(ClassId);
ScopedLock L(Sci->Mutex);
- TransferBatchT *B = popBatchImpl(C, ClassId, Sci);
- if (UNLIKELY(!B)) {
+
+ u16 PopCount = popBlocksImpl(C, ClassId, Sci, ToArray, MaxBlockCount);
+ if (UNLIKELY(PopCount == 0)) {
if (UNLIKELY(!populateFreeList(C, ClassId, Sci)))
- return nullptr;
- B = popBatchImpl(C, ClassId, Sci);
- // if `populateFreeList` succeeded, we are supposed to get free blocks.
- DCHECK_NE(B, nullptr);
+ return 0U;
+ PopCount = popBlocksImpl(C, ClassId, Sci, ToArray, MaxBlockCount);
+ DCHECK_NE(PopCount, 0U);
}
- return B;
+
+ return PopCount;
}
// Push the array of free blocks to the designated batch group.
@@ -510,7 +493,7 @@ template <typename Config> class SizeClassAllocator32 {
// by TransferBatch is also free for use. We don't need to recycle the
// TransferBatch. Note that the correctness is maintained by the invariant,
//
- // The unit of each popBatch() request is entire TransferBatch. Return
+ // Each popBlocks() request returns the entire TransferBatch. Returning
// part of the blocks in a TransferBatch is invalid.
//
// This ensures that TransferBatch won't leak the address itself while it's
@@ -634,7 +617,7 @@ template <typename Config> class SizeClassAllocator32 {
BG->Batches.push_front(TB);
BG->PushedBlocks = 0;
BG->BytesInBGAtLastCheckpoint = 0;
- BG->MaxCachedPerBatch = CacheT::getMaxCached(getSizeByClassId(ClassId));
+ BG->MaxCachedPerBatch = TransferBatchT::MaxNumCached;
return BG;
};
@@ -726,14 +709,11 @@ template <typename Config> class SizeClassAllocator32 {
InsertBlocks(Cur, Array + Size - Count, Count);
}
- // Pop one TransferBatch from a BatchGroup. The BatchGroup with the smallest
- // group id will be considered first.
- //
- // The region mutex needs to be held while calling this method.
- TransferBatchT *popBatchImpl(CacheT *C, uptr ClassId, SizeClassInfo *Sci)
+ u16 popBlocksImpl(CacheT *C, uptr ClassId, SizeClassInfo *Sci,
+ CompactPtrT *ToArray, const u16 MaxBlockCount)
REQUIRES(Sci->Mutex) {
if (Sci->FreeListInfo.BlockList.empty())
- return nullptr;
+ return 0U;
SinglyLinkedList<TransferBatchT> &Batches =
Sci->FreeListInfo.BlockList.front()->Batches;
@@ -746,33 +726,57 @@ template <typename Config> class SizeClassAllocator32 {
// Block used by `BatchGroup` is from BatchClassId. Turn the block into
// `TransferBatch` with single block.
TransferBatchT *TB = reinterpret_cast<TransferBatchT *>(BG);
- TB->clear();
- TB->add(
- compactPtr(SizeClassMap::BatchClassId, reinterpret_cast<uptr>(TB)));
+ ToArray[0] =
+ compactPtr(SizeClassMap::BatchClassId, reinterpret_cast<uptr>(TB));
Sci->FreeListInfo.PoppedBlocks += 1;
- return TB;
+ return 1U;
}
+ // So far, instead of always filling the blocks to `MaxBlockCount`, we only
+ // examine single `TransferBatch` to minimize the time spent on the primary
+ // allocator. Besides, the sizes of `TransferBatch` and
+ // `CacheT::getMaxCached()` may also impact the time spent on accessing the
+ // primary allocator.
+ // TODO(chiahungduan): Evaluate if we want to always prepare `MaxBlockCount`
+ // blocks and/or adjust the size of `TransferBatch` according to
+ // `CacheT::getMaxCached()`.
TransferBatchT *B = Batches.front();
- Batches.pop_front();
DCHECK_NE(B, nullptr);
DCHECK_GT(B->getCount(), 0U);
- if (Batches.empty()) {
- BatchGroupT *BG = Sci->FreeListInfo.BlockList.front();
- Sci->FreeListInfo.BlockList.pop_front();
-
- // We don't keep BatchGroup with zero blocks to avoid empty-checking while
- // allocating. Note that block used by constructing BatchGroup is recorded
- // as free blocks in the last element of BatchGroup::Batches. Which means,
- // once we pop the last TransferBatch, the block is implicitly
- // deallocated.
+ // BachClassId should always take all blocks in the TransferBatch. Read the
+ // comment in `pushBatchClassBlocks()` for more details.
+ const u16 PopCount = ClassId == SizeClassMap::BatchClassId
+ ? B->getCount()
+ : Min(MaxBlockCount, B->getCount());
+ B->moveNToArray(ToArray, PopCount);
+
+ // TODO(chiahungduan): The deallocation of unused BatchClassId blocks can be
+ // done without holding `Mutex`.
+ if (B->empty()) {
+ Batches.pop_front();
+ // `TransferBatch` of BatchClassId is self-contained, no need to
+ // deallocate. Read the comment in `pushBatchClassBlocks()` for more
+ // details.
if (ClassId != SizeClassMap::BatchClassId)
- C->deallocate(SizeClassMap::BatchClassId, BG);
+ C->deallocate(SizeClassMap::BatchClassId, B);
+
+ if (Batches.empty()) {
+ BatchGroupT *BG = Sci->FreeListInfo.BlockList.front();
+ Sci->FreeListInfo.BlockList.pop_front();
+
+ // We don't keep BatchGroup with zero blocks to avoid empty-checking
+ // while allocating. Note that block used for constructing BatchGroup is
+ // recorded as free blocks in the last element of BatchGroup::Batches.
+ // Which means, once we pop the last TransferBatch, the block is
+ // implicitly deallocated.
+ if (ClassId != SizeClassMap::BatchClassId)
+ C->deallocate(SizeClassMap::BatchClassId, BG);
+ }
}
- Sci->FreeListInfo.PoppedBlocks += B->getCount();
- return B;
+ Sci->FreeListInfo.PoppedBlocks += PopCount;
+ return PopCount;
}
NOINLINE bool populateFreeList(CacheT *C, uptr ClassId, SizeClassInfo *Sci)
diff --git a/compiler-rt/lib/scudo/standalone/primary64.h b/compiler-rt/lib/scudo/standalone/primary64.h
index 9a642d23620e1e..d89a2e6a4e5c8d 100644
--- a/compiler-rt/lib/scudo/standalone/primary64.h
+++ b/compiler-rt/lib/scudo/standalone/primary64.h
@@ -12,6 +12,7 @@
#include "allocator_common.h"
#include "bytemap.h"
#include "common.h"
+#include "condition_variable.h"
#include "list.h"
#include "local_cache.h"
#include "mem_map.h"
@@ -22,8 +23,6 @@
#include "string_utils.h"
#include "thread_annotations.h"
-#include "condition_variable.h"
-
namespace scudo {
// SizeClassAllocator64 is an allocator tuned for 64-bit address space.
@@ -221,41 +220,24 @@ template <typename Config> class SizeClassAllocator64 {
DCHECK_EQ(BlocksInUse, BatchClassUsedInFreeLists);
}
- // Note that the `MaxBlockCount` will be used when we support arbitrary blocks
- // count. Now it's the same as the number of blocks stored in the
- // `TransferBatch`.
u16 popBlocks(CacheT *C, uptr ClassId, CompactPtrT *ToArray,
- UNUSED const u16 MaxBlockCount) {
- TransferBatchT *B = popBatch(C, ClassId);
- if (!B)
- return 0;
-
- const u16 Count = B->getCount();
- DCHECK_GT(Count, 0U);
- B->moveToArray(ToArray);
-
- if (ClassId != SizeClassMap::BatchClassId)
- C->deallocate(SizeClassMap::BatchClassId, B);
-
- return Count;
- }
-
- TransferBatchT *popBatch(CacheT *C, uptr ClassId) {
+ const u16 MaxBlockCount) {
DCHECK_LT(ClassId, NumClasses);
RegionInfo *Region = getRegionInfo(ClassId);
+ u16 PopCount = 0;
{
ScopedLock L(Region->FLLock);
- TransferBatchT *B = popBatchImpl(C, ClassId, Region);
- if (LIKELY(B))
- return B;
+ PopCount = popBlocksImpl(C, ClassId, Region, ToArray, MaxBlockCount);
+ if (PopCount != 0U)
+ return PopCount;
}
bool ReportRegionExhausted = false;
- TransferBatchT *B = nullptr;
if (conditionVariableEnabled()) {
- B = popBatchWithCV(C, ClassId, Region, ReportRegionExhausted);
+ PopCount = popBlocksWithCV(C, ClassId, Region, ToArray, MaxBlockCount,
+ ReportRegionExhausted);
} else {
while (true) {
// When two threads compete for `Region->MMLock`, we only want one of
@@ -264,13 +246,15 @@ template <typename Config> class SizeClassAllocator64 {
ScopedLock ML(Region->MMLock);
{
ScopedLock FL(Region->FLLock);
- if ((B = popBatchImpl(C, ClassId, Region)))
- break;
+ PopCount = popBlocksImpl(C, ClassId, Region, ToArray, MaxBlockCount);
+ if (PopCount != 0U)
+ return PopCount;
}
const bool RegionIsExhausted = Region->Exhausted;
if (!RegionIsExhausted)
- B = populateFreeListAndPopBatch(C, ClassId, Region);
+ PopCount = populateFreeListAndPopBlocks(C, ClassId, Region, ToArray,
+ MaxBlockCount);
ReportRegionExhausted = !RegionIsExhausted && Region->Exhausted;
break;
}
@@ -286,7 +270,7 @@ template <typename Config> class SizeClassAllocator64 {
reportOutOfBatchClass();
}
- return B;
+ return PopCount;
}
// Push the array of free blocks to the designated batch group.
@@ -640,7 +624,7 @@ template <typename Config> class SizeClassAllocator64 {
// by TransferBatch is also free for use. We don't need to recycle the
// TransferBatch. Note that the correctness is maintained by the invariant,
//
- // The unit of each popBatch() request is entire TransferBatch. Return
+ // Each popBlocks() request returns the entire TransferBatch. Returning
// part of the blocks in a TransferBatch is invalid.
//
// This ensures that TransferBatch won't leak the address itself while it's
@@ -763,7 +747,7 @@ template <typename Config> class SizeClassAllocator64 {
BG->Batches.push_front(TB);
BG->PushedBlocks = 0;
BG->BytesInBGAtLastCheckpoint = 0;
- BG->MaxCachedPerBatch = CacheT::getMaxCached(getSizeByClassId(ClassId));
+ BG->MaxCachedPerBatch = TransferBatchT::MaxNumCached;
return BG;
};
@@ -855,9 +839,10 @@ template <typename Config> class SizeClassAllocator64 {
InsertBlocks(Cur, Array + Size - Count, Count);
}
- TransferBatchT *popBatchWithCV(CacheT *C, uptr ClassId, RegionInfo *Region,
- bool &ReportRegionExhausted) {
- TransferBatchT *B = nullptr;
+ u16 popBlocksWithCV(CacheT *C, uptr ClassId, RegionInfo *Region,
+ CompactPtrT *ToArray, const u16 MaxBlockCount,
+ bool &ReportRegionExhausted) {
+ u16 PopCount = 0;
while (true) {
// We only expect one thread doing the freelist refillment and other
@@ -878,7 +863,8 @@ template <typename Config> class SizeClassAllocator64 {
const bool RegionIsExhausted = Region->Exhausted;
if (!RegionIsExhausted)
- B = populateFreeListAndPopBatch(C, ClassId, Region);
+ PopCount = populateFreeListAndPopBlocks(C, ClassId, Region, ToArray,
+ MaxBlockCount);
ReportRegionExhausted = !RegionIsExhausted && Region->Exhausted;
{
@@ -905,7 +891,8 @@ template <typename Config> class SizeClassAllocator64 {
// blocks were used up right after the refillment. Therefore, we have to
// check if someone is still populating the freelist.
ScopedLock FL(Region->FLLock);
- if (LIKELY(B = popBatchImpl(C, ClassId, Region)))
+ PopCount = popBlocksImpl(C, ClassId, Region, ToArray, MaxBlockCount);
+ if (PopCount != 0U)
break;
if (!Region->isPopulatingFreeList)
@@ -918,21 +905,19 @@ template <typename Config> class SizeClassAllocator64 {
// `pushBatchClassBlocks()` and `mergeGroupsToReleaseBack()`.
Region->FLLockCV.wait(Region->FLLock);
- if (LIKELY(B = popBatchImpl(C, ClassId, Region)))
+ PopCount = popBlocksImpl(C, ClassId, Region, ToArray, MaxBlockCount);
+ if (PopCount != 0U)
break;
}
- return B;
+ return PopCount;
}
- // Pop one TransferBatch from a BatchGroup. The BatchGroup with the smallest
- // group id will be considered first.
- //
- // The region mutex needs to be held while calling this method.
- TransferBatchT *popBatchImpl(CacheT *C, uptr ClassId, RegionInfo *Region)
+ u16 popBlocksImpl(CacheT *C, uptr ClassId, RegionInfo *Region,
+ CompactPtrT *ToArray, const u16 MaxBlockCount)
REQUIRES(Region->FLLock) {
if (Region->FreeListInfo.BlockList.empty())
- return nullptr;
+ return 0U;
SinglyLinkedList<TransferBatchT> &Batches =
Region->FreeListInfo.BlockList.front()->Batches;
@@ -945,39 +930,64 @@ template <typename Config> class SizeClassAllocator64 {
// Block used by `BatchGroup` is from BatchClassId. Turn the block into
// `TransferBatch` with single block.
TransferBatchT *TB = reinterpret_cast<TransferBatchT *>(BG);
- TB->clear();
- TB->add(
- compactPtr(SizeClassMap::BatchClassId, reinterpret_cast<uptr>(TB)));
+ ToArray[0] =
+ compactPtr(SizeClassMap::BatchClassId, reinterpret_cast<uptr>(TB));
Region->FreeListInfo.PoppedBlocks += 1;
- return TB;
+ return 1U;
}
+ // So far, instead of always filling blocks to `MaxBlockCount`, we only
+ // examine single `TransferBatch` to minimize the time spent in the primary
+ // allocator. Besides, the sizes of `TransferBatch` and
+ // `CacheT::getMaxCached()` may also impact the time spent on accessing the
+ // primary allocator.
+ // TODO(chiahungduan): Evaluate if we want to always prepare `MaxBlockCount`
+ // blocks and/or adjust the size of `TransferBatch` according to
+ // `CacheT::getMaxCached()`.
TransferBatchT *B = Batches.front();
- Batches.pop_front();
DCHECK_NE(B, nullptr);
DCHECK_GT(B->getCount(), 0U);
- if (Batches.empty()) {
- BatchGroupT *BG = Region->FreeListInfo.BlockList.front();
- Region->FreeListInfo.BlockList.pop_front();
-
- // We don't keep BatchGroup with zero blocks to avoid empty-checking while
- // allocating. Note that block used by constructing BatchGroup is recorded
- // as free blocks in the last element of BatchGroup::Batches. Which means,
- // once we pop the last TransferBatch, the block is implicitly
- // deallocated.
+ // BachClassId should always take all blocks in the TransferBatch. Read the
+ // comment in `pushBatchClassBlocks()` for more details.
+ const u16 PopCount = ClassId == SizeClassMap::BatchClassId
+ ? B->getCount()
+ : Min(MaxBlockCount, B->getCount());
+ B->moveNToArray(ToArray, PopCount);
+
+ // TODO(chiahungduan): The deallocation of unused BatchClassId blocks can be
+ // done without holding `FLLock`.
+ if (B->empty()) {
+ Batches.pop_front();
+ // `TransferBatch` of BatchClassId is self-contained, no need to
+ // deallocate. Read the comment in `pushBatchClassBlocks()` for more
+ // details.
if (ClassId != SizeClassMap::BatchClassId)
- C->deallocate(SizeClassMap::BatchClassId, BG);
+ C->deallocate(SizeClassMap::BatchClassId, B);
+
+ if (Batches.empty()) {
+ BatchGroupT *BG = Region->FreeListInfo.BlockList.front();
+ Region->FreeListInfo.BlockList.pop_front();
+
+ // We don't keep BatchGroup with zero blocks to avoid empty-checking
+ // while allocating. Note that block used for constructing BatchGroup is
+ // recorded as free blocks in the last element of BatchGroup::Batches.
+ // Which means, once we pop the last TransferBatch, the block is
+ // implicitly deallocated.
+ if (ClassId != SizeClassMap::BatchClassId)
+ C->deallocate(SizeClassMap::BatchClassId, BG);
+ }
}
- Region->FreeListInfo.PoppedBlocks += B->getCount();
+ Region->FreeListInfo.PoppedBlocks += PopCount;
- return B;
+ return PopCount;
}
- // Refill the freelist and return one batch.
- NOINLINE TransferBatchT *populateFreeListAndPopBatch(CacheT *C, uptr ClassId,
- RegionInfo *Region)
+ NOINLINE u16 populateFreeListAndPopBlocks(CacheT *C, uptr ClassId,
+ RegionInfo *Region,
+ CompactPtrT *ToArray,
+ const u16 MaxBlockCount)
REQUIRES(Region->MMLock) EXCLUDES(Region->FLLock) {
const uptr Size = getSizeByClassId(ClassId);
const u16 MaxCount = CacheT::getMaxCached(Size);
@@ -994,7 +1004,7 @@ template <typename Config> class SizeClassAllocator64 {
const uptr RegionBase = RegionBeg - getRegionBaseByClassId(ClassId);
if (UNLIKELY(RegionBase + MappedUser + MapSize > RegionSize)) {
Region->Exhausted = true;
- return nullptr;
+ return 0U;
}
if (UNLIKELY(!Region->MemMapInfo.MemMap.remap(
@@ -1002,7 +1012,7 @@ template <typename Config> class SizeClassAllocator64 {
MAP_ALLOWNOMEM | MAP_RESIZABLE |
(useMemoryTagging<Config>(Options.load()) ? MAP_MEMTAG
: 0)))) {
- return nullptr;
+ return 0U;
}
Region->MemMapInfo.MappedUser += MapSize;
C->getStats().add(StatMapped, MapSize);
@@ -1049,8 +1059,9 @@ template <typename Config> class SizeClassAllocator64 {
pushBatchClassBlocks(Region, ShuffleArray, NumberOfBlocks);
}
- TransferBatchT *B = popBatchImpl(C, ClassId, Region);
- DCHECK_NE(B, nullptr);
+ const u16 PopCount =
+ popBlocksImpl(C, ClassId, Region, ToArray, MaxBlockCount);
+ DCHECK_NE(PopCount, 0U);
// Note that `PushedBlocks` and `PoppedBlocks` are supposed to only record
// the requests from `PushBlocks` and `PopBatch` which are external
@@ -1062,7 +1073,7 @@ template <typename Config> class SizeClassAllocator64 {
C->getStats().add(StatFree, AllocatedUser);
Region->MemMapInfo.AllocatedUser += AllocatedUser;
- return B;
+ return PopCount;
}
void getStats(ScopedString *Str, uptr ClassId, RegionInfo *Region)
@@ -1186,7 +1197,7 @@ template <typename Config> class SizeClassAllocator64 {
}
// Note that we have extracted the `GroupsToRelease` from region freelist.
- // It's safe to let pushBlocks()/popBatches() access the remaining region
+ // It's safe to let pushBlocks()/popBlocks() access the remaining region
// freelist. In the steps 3 and 4, we will temporarily release the FLLock
// and lock it again before step 5.
diff --git a/compiler-rt/lib/scudo/standalone/tests/primary_test.cpp b/compiler-rt/lib/scudo/standalone/tests/primary_test.cpp
index 18171511758a14..f64a5143b30d46 100644
--- a/compiler-rt/lib/scudo/standalone/tests/primary_test.cpp
+++ b/compiler-rt/lib/scudo/standalone/tests/primary_test.cpp
@@ -237,7 +237,6 @@ struct SmallRegionsConfig {
// For the 32-bit one, it requires actually exhausting memory, so we skip it.
TEST(ScudoPrimaryTest, Primary64OOM) {
using Primary = scudo::SizeClassAllocator64<SmallRegionsConfig>;
- using TransferBatch = Primary::TransferBatchT;
Primary Allocator;
Allocator.init(/*ReleaseToOsInterval=*/-1);
typename Primary::CacheT Cache;
@@ -245,29 +244,26 @@ TEST(ScudoPrimaryTest, Primary64OOM) {
Stats.init();
Cache.init(&Stats, &Allocator);
bool AllocationFailed = false;
- std::vector<TransferBatch *> Batches;
+ std::vector<void *> Blocks;
const scudo::uptr ClassId = Primary::SizeClassMap::LargestClassId;
const scudo::uptr Size = Primary::getSizeByClassId(ClassId);
- typename Primary::CacheT::CompactPtrT Blocks[TransferBatch::MaxNumCached];
+ const scudo::u16 MaxCachedBlockCount = Primary::CacheT::getMaxCached(Size);
for (scudo::uptr I = 0; I < 10000U; I++) {
- TransferBatch *B = Allocator.popBatch(&Cache, ClassId);
- if (!B) {
- AllocationFailed = true;
- break;
+ for (scudo::uptr J = 0; J < MaxCachedBlockCount; ++J) {
+ void *Ptr = Cache.allocate(ClassId);
+ if (Ptr == nullptr) {
+ AllocationFailed = true;
+ break;
+ }
+ memset(Ptr, 'B', Size);
+ Blocks.push_back(Ptr);
}
- for (scudo::u16 J = 0; J < B->getCount(); J++)
- memset(Allocator.decompactPtr(ClassId, B->get(J)), 'B', Size);
- Batches.push_back(B);
- }
- while (!Batches.empty()) {
- TransferBatch *B = Batches.back();
- Batches.pop_back();
- const scudo::u16 Count = B->getCount();
- B->moveToArray(Blocks);
- Allocator.pushBlocks(&Cache, ClassId, Blocks, Count);
- Cache.deallocate(Primary::SizeClassMap::BatchClassId, B);
}
+
+ for (auto *Ptr : Blocks)
+ Cache.deallocate(ClassId, Ptr);
+
Cache.destroy(nullptr);
Allocator.releaseToOS(scudo::ReleaseToOS::Force);
scudo::ScopedString Str;
@@ -342,7 +338,7 @@ SCUDO_TYPED_TEST(ScudoPrimaryTest, PrimaryThreaded) {
V.push_back(std::make_pair(ClassId, P));
}
- // Try to interleave pushBlocks(), popBatch() and releaseToOS().
+ // Try to interleave pushBlocks(), popBlocks() and releaseToOS().
Allocator->releaseToOS(scudo::ReleaseToOS::Force);
while (!V.empty()) {
>From 153003416696c2464d296594dac5a36a5a60bac5 Mon Sep 17 00:00:00 2001
From: Nikolas Klauser <nikolasklauser at berlin.de>
Date: Wed, 28 Feb 2024 21:14:35 +0100
Subject: [PATCH 041/406] [libc++] Remove unnecessary includes from <atomic>
(#82880)
This reduces the include time of `<atomic>` from 135ms to 88ms.
---
libcxx/include/__atomic/aliases.h | 1 -
libcxx/include/__config | 5 +++++
libcxx/include/__thread/support/pthread.h | 5 ++++-
libcxx/include/atomic | 1 +
libcxx/test/libcxx/transitive_includes/cxx23.csv | 1 -
libcxx/test/libcxx/transitive_includes/cxx26.csv | 1 -
6 files changed, 10 insertions(+), 4 deletions(-)
diff --git a/libcxx/include/__atomic/aliases.h b/libcxx/include/__atomic/aliases.h
index db34f5ec02d744..e27e09af6b77d9 100644
--- a/libcxx/include/__atomic/aliases.h
+++ b/libcxx/include/__atomic/aliases.h
@@ -18,7 +18,6 @@
#include <__type_traits/make_unsigned.h>
#include <cstddef>
#include <cstdint>
-#include <cstdlib>
#if !defined(_LIBCPP_HAS_NO_PRAGMA_SYSTEM_HEADER)
# pragma GCC system_header
diff --git a/libcxx/include/__config b/libcxx/include/__config
index 942bbe7cbb93cb..53ff113a16b2a8 100644
--- a/libcxx/include/__config
+++ b/libcxx/include/__config
@@ -460,6 +460,11 @@ _LIBCPP_HARDENING_MODE_DEBUG
# define __has_constexpr_builtin(x) 0
# endif
+// This checks wheter a Clang module is built
+# ifndef __building_module
+# define __building_module(...) 0
+# endif
+
// '__is_identifier' returns '0' if '__x' is a reserved identifier provided by
// the compiler and '1' otherwise.
# ifndef __is_identifier
diff --git a/libcxx/include/__thread/support/pthread.h b/libcxx/include/__thread/support/pthread.h
index d0b8367e448f48..d8e3f938ddf629 100644
--- a/libcxx/include/__thread/support/pthread.h
+++ b/libcxx/include/__thread/support/pthread.h
@@ -30,7 +30,10 @@
// so libc++'s <math.h> usually absorbs atomic_wide_counter.h into the
// module with <math.h> and makes atomic_wide_counter.h invisible.
// Include <math.h> here to work around that.
-#include <math.h>
+// This checks wheter a Clang module is built
+#if __building_module(std)
+# include <math.h>
+#endif
#ifndef _LIBCPP_HAS_NO_PRAGMA_SYSTEM_HEADER
# pragma GCC system_header
diff --git a/libcxx/include/atomic b/libcxx/include/atomic
index 2e8f5b521a55eb..2dac69377b77f0 100644
--- a/libcxx/include/atomic
+++ b/libcxx/include/atomic
@@ -620,6 +620,7 @@ template <class T>
#if !defined(_LIBCPP_REMOVE_TRANSITIVE_INCLUDES) && _LIBCPP_STD_VER <= 20
# include <cmath>
# include <compare>
+# include <cstdlib>
# include <cstring>
# include <type_traits>
#endif
diff --git a/libcxx/test/libcxx/transitive_includes/cxx23.csv b/libcxx/test/libcxx/transitive_includes/cxx23.csv
index 44b5f78beea48b..49b3ac265487d7 100644
--- a/libcxx/test/libcxx/transitive_includes/cxx23.csv
+++ b/libcxx/test/libcxx/transitive_includes/cxx23.csv
@@ -30,7 +30,6 @@ array stdexcept
array version
atomic cstddef
atomic cstdint
-atomic cstdlib
atomic cstring
atomic ctime
atomic limits
diff --git a/libcxx/test/libcxx/transitive_includes/cxx26.csv b/libcxx/test/libcxx/transitive_includes/cxx26.csv
index 44b5f78beea48b..49b3ac265487d7 100644
--- a/libcxx/test/libcxx/transitive_includes/cxx26.csv
+++ b/libcxx/test/libcxx/transitive_includes/cxx26.csv
@@ -30,7 +30,6 @@ array stdexcept
array version
atomic cstddef
atomic cstdint
-atomic cstdlib
atomic cstring
atomic ctime
atomic limits
>From b339c88120429df738d198d7535bc59f65f11edb Mon Sep 17 00:00:00 2001
From: David Green <david.green at arm.com>
Date: Wed, 28 Feb 2024 20:31:26 +0000
Subject: [PATCH 042/406] [AArch64] Add some base aes intrinsic tests. NFC
Including commutative tests.
---
llvm/test/CodeGen/AArch64/aes.ll | 43 ++++++++++++++++++++++++++++++++
1 file changed, 43 insertions(+)
create mode 100644 llvm/test/CodeGen/AArch64/aes.ll
diff --git a/llvm/test/CodeGen/AArch64/aes.ll b/llvm/test/CodeGen/AArch64/aes.ll
new file mode 100644
index 00000000000000..2bef28de895baf
--- /dev/null
+++ b/llvm/test/CodeGen/AArch64/aes.ll
@@ -0,0 +1,43 @@
+; NOTE: Assertions have been autogenerated by utils/update_llc_test_checks.py UTC_ARGS: --version 4
+; RUN: llc %s -o - -mtriple=aarch64 -mattr=+aes | FileCheck %s
+
+declare <16 x i8> @llvm.aarch64.crypto.aese(<16 x i8> %d, <16 x i8> %k)
+declare <16 x i8> @llvm.aarch64.crypto.aesd(<16 x i8> %d, <16 x i8> %k)
+
+define <16 x i8> @aese(<16 x i8> %a, <16 x i8> %b) {
+; CHECK-LABEL: aese:
+; CHECK: // %bb.0:
+; CHECK-NEXT: aese v0.16b, v1.16b
+; CHECK-NEXT: ret
+ %r = call <16 x i8> @llvm.aarch64.crypto.aese(<16 x i8> %a, <16 x i8> %b)
+ ret <16 x i8> %r
+}
+
+define <16 x i8> @aese_c(<16 x i8> %a, <16 x i8> %b) {
+; CHECK-LABEL: aese_c:
+; CHECK: // %bb.0:
+; CHECK-NEXT: aese v1.16b, v0.16b
+; CHECK-NEXT: mov v0.16b, v1.16b
+; CHECK-NEXT: ret
+ %r = call <16 x i8> @llvm.aarch64.crypto.aese(<16 x i8> %b, <16 x i8> %a)
+ ret <16 x i8> %r
+}
+
+define <16 x i8> @aesd(<16 x i8> %a, <16 x i8> %b) {
+; CHECK-LABEL: aesd:
+; CHECK: // %bb.0:
+; CHECK-NEXT: aesd v0.16b, v1.16b
+; CHECK-NEXT: ret
+ %r = call <16 x i8> @llvm.aarch64.crypto.aesd(<16 x i8> %a, <16 x i8> %b)
+ ret <16 x i8> %r
+}
+
+define <16 x i8> @aesd_c(<16 x i8> %a, <16 x i8> %b) {
+; CHECK-LABEL: aesd_c:
+; CHECK: // %bb.0:
+; CHECK-NEXT: aesd v1.16b, v0.16b
+; CHECK-NEXT: mov v0.16b, v1.16b
+; CHECK-NEXT: ret
+ %r = call <16 x i8> @llvm.aarch64.crypto.aesd(<16 x i8> %b, <16 x i8> %a)
+ ret <16 x i8> %r
+}
>From d37affb06f2709ee46a86568a77ae6fea7fb4424 Mon Sep 17 00:00:00 2001
From: Aart Bik <39774503+aartbik at users.noreply.github.com>
Date: Wed, 28 Feb 2024 12:33:26 -0800
Subject: [PATCH 043/406] [mlir][sparse] add a sparse_tensor.print operation
(#83321)
This operation is mainly used for testing and debugging purposes but
provides a very convenient way to quickly inspect the contents of a
sparse tensor (all components over all stored levels).
Example:
[ [ 1, 0, 2, 0, 0, 0, 0, 0 ],
[ 0, 0, 0, 0, 0, 0, 0, 0 ],
[ 0, 0, 0, 0, 0, 0, 0, 0 ],
[ 0, 0, 3, 4, 0, 5, 0, 0 ]
when stored sparse as DCSC prints as
---- Sparse Tensor ----
nse = 5
pos[0] : ( 0, 4, )
crd[0] : ( 0, 2, 3, 5, )
pos[1] : ( 0, 1, 3, 4, 5, )
crd[1] : ( 0, 0, 3, 3, 3, )
values : ( 1, 2, 3, 4, 5, )
----
---
.../SparseTensor/IR/SparseTensorOps.td | 22 ++
.../Transforms/SparseTensorRewriting.cpp | 95 +++++++-
.../SparseTensor/CPU/sparse_print.mlir | 215 ++++++++++++++++++
3 files changed, 331 insertions(+), 1 deletion(-)
create mode 100755 mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_print.mlir
diff --git a/mlir/include/mlir/Dialect/SparseTensor/IR/SparseTensorOps.td b/mlir/include/mlir/Dialect/SparseTensor/IR/SparseTensorOps.td
index 3127cf1b1bcf69..9007e4e98e3163 100644
--- a/mlir/include/mlir/Dialect/SparseTensor/IR/SparseTensorOps.td
+++ b/mlir/include/mlir/Dialect/SparseTensor/IR/SparseTensorOps.td
@@ -1453,4 +1453,26 @@ def SparseTensor_ForeachOp : SparseTensor_Op<"foreach",
let hasVerifier = 1;
}
+//===----------------------------------------------------------------------===//
+// Sparse Tensor Debugging Operations.
+//===----------------------------------------------------------------------===//
+
+def SparseTensor_PrintOp : SparseTensor_Op<"print">,
+ Arguments<(ins AnySparseTensor:$tensor)> {
+ string summary = "Prints a sparse tensor (for testing and debugging)";
+ string description = [{
+ Prints the individual components of a sparse tensors (the positions,
+ coordinates, and values components) to stdout for testing and debugging
+ purposes. This operation lowers to just a few primitives in a light-weight
+ runtime support to simplify supporting this operation on new platforms.
+
+ Example:
+
+ ```mlir
+ sparse_tensor.print %tensor : tensor<1024x1024xf64, #CSR>
+ ```
+ }];
+ let assemblyFormat = "$tensor attr-dict `:` type($tensor)";
+}
+
#endif // SPARSETENSOR_OPS
diff --git a/mlir/lib/Dialect/SparseTensor/Transforms/SparseTensorRewriting.cpp b/mlir/lib/Dialect/SparseTensor/Transforms/SparseTensorRewriting.cpp
index 1bcc131781d34d..c95b7b015b3725 100644
--- a/mlir/lib/Dialect/SparseTensor/Transforms/SparseTensorRewriting.cpp
+++ b/mlir/lib/Dialect/SparseTensor/Transforms/SparseTensorRewriting.cpp
@@ -21,9 +21,11 @@
#include "mlir/Dialect/MemRef/IR/MemRef.h"
#include "mlir/Dialect/SCF/IR/SCF.h"
#include "mlir/Dialect/SparseTensor/IR/SparseTensor.h"
+#include "mlir/Dialect/SparseTensor/IR/SparseTensorStorageLayout.h"
#include "mlir/Dialect/SparseTensor/IR/SparseTensorType.h"
#include "mlir/Dialect/SparseTensor/Transforms/Passes.h"
#include "mlir/Dialect/Tensor/IR/Tensor.h"
+#include "mlir/Dialect/Vector/IR/VectorOps.h"
#include "mlir/IR/AffineMap.h"
#include "mlir/IR/Matchers.h"
#include "mlir/Support/LLVM.h"
@@ -598,6 +600,96 @@ struct GenSemiRingReduction : public OpRewritePattern<GenericOp> {
}
};
+/// Sparse rewriting rule for the print operator. This operation is mainly used
+/// for debugging and testing. As such, it lowers to the vector.print operation
+/// which only require very light-weight runtime support.
+struct PrintRewriter : public OpRewritePattern<PrintOp> {
+public:
+ using OpRewritePattern::OpRewritePattern;
+ LogicalResult matchAndRewrite(PrintOp op,
+ PatternRewriter &rewriter) const override {
+ Location loc = op.getLoc();
+ auto tensor = op.getTensor();
+ auto stt = getSparseTensorType(tensor);
+ // Header with NSE.
+ auto nse = rewriter.create<NumberOfEntriesOp>(loc, tensor);
+ rewriter.create<vector::PrintOp>(
+ loc, rewriter.getStringAttr("---- Sparse Tensor ----\nnse = "));
+ rewriter.create<vector::PrintOp>(loc, nse);
+ // Use the "codegen" foreach loop construct to iterate over
+ // all typical sparse tensor components for printing.
+ foreachFieldAndTypeInSparseTensor(stt, [&rewriter, &loc,
+ &tensor](Type tp, FieldIndex,
+ SparseTensorFieldKind kind,
+ Level l, LevelType) {
+ switch (kind) {
+ case SparseTensorFieldKind::StorageSpec: {
+ break;
+ }
+ case SparseTensorFieldKind::PosMemRef: {
+ auto lvl = constantIndex(rewriter, loc, l);
+ rewriter.create<vector::PrintOp>(loc, rewriter.getStringAttr("pos["));
+ rewriter.create<vector::PrintOp>(
+ loc, lvl, vector::PrintPunctuation::NoPunctuation);
+ rewriter.create<vector::PrintOp>(loc, rewriter.getStringAttr("] : "));
+ auto pos = rewriter.create<ToPositionsOp>(loc, tp, tensor, l);
+ printContents(rewriter, loc, tp, pos);
+ break;
+ }
+ case SparseTensorFieldKind::CrdMemRef: {
+ auto lvl = constantIndex(rewriter, loc, l);
+ rewriter.create<vector::PrintOp>(loc, rewriter.getStringAttr("crd["));
+ rewriter.create<vector::PrintOp>(
+ loc, lvl, vector::PrintPunctuation::NoPunctuation);
+ rewriter.create<vector::PrintOp>(loc, rewriter.getStringAttr("] : "));
+ auto crd = rewriter.create<ToCoordinatesOp>(loc, tp, tensor, l);
+ printContents(rewriter, loc, tp, crd);
+ break;
+ }
+ case SparseTensorFieldKind::ValMemRef: {
+ rewriter.create<vector::PrintOp>(loc,
+ rewriter.getStringAttr("values : "));
+ auto val = rewriter.create<ToValuesOp>(loc, tp, tensor);
+ printContents(rewriter, loc, tp, val);
+ break;
+ }
+ }
+ return true;
+ });
+ rewriter.create<vector::PrintOp>(loc, rewriter.getStringAttr("----\n"));
+ rewriter.eraseOp(op);
+ return success();
+ }
+
+private:
+ // Helper to print contents of a single memref. Note that for the "push_back"
+ // vectors, this prints the full capacity, not just the size. This is done
+ // on purpose, so that clients see how much storage has been allocated in
+ // total. Contents of the extra capacity in the buffer may be uninitialized
+ // (unless the flag enable-buffer-initialization is set to true).
+ //
+ // Generates code to print:
+ // ( a0, a1, ... )
+ static void printContents(PatternRewriter &rewriter, Location loc, Type tp,
+ Value vec) {
+ // Open bracket.
+ rewriter.create<vector::PrintOp>(loc, vector::PrintPunctuation::Open);
+ // For loop over elements.
+ auto zero = constantIndex(rewriter, loc, 0);
+ auto size = rewriter.create<memref::DimOp>(loc, vec, zero);
+ auto step = constantIndex(rewriter, loc, 1);
+ auto forOp = rewriter.create<scf::ForOp>(loc, zero, size, step);
+ rewriter.setInsertionPointToStart(forOp.getBody());
+ auto idx = forOp.getInductionVar();
+ auto val = rewriter.create<memref::LoadOp>(loc, vec, idx);
+ rewriter.create<vector::PrintOp>(loc, val, vector::PrintPunctuation::Comma);
+ rewriter.setInsertionPointAfter(forOp);
+ // Close bracket and end of line.
+ rewriter.create<vector::PrintOp>(loc, vector::PrintPunctuation::Close);
+ rewriter.create<vector::PrintOp>(loc, vector::PrintPunctuation::NewLine);
+ }
+};
+
/// Sparse rewriting rule for sparse-to-sparse reshape operator.
struct TensorReshapeRewriter : public OpRewritePattern<tensor::ReshapeOp> {
public:
@@ -1284,7 +1376,8 @@ struct OutRewriter : public OpRewritePattern<OutOp> {
void mlir::populatePreSparsificationRewriting(RewritePatternSet &patterns) {
patterns.add<FoldInvariantYield, FuseSparseMultiplyOverAdd, FuseTensorCast,
- GenSemiRingReduction, GenSemiRingSelect>(patterns.getContext());
+ GenSemiRingReduction, GenSemiRingSelect, PrintRewriter>(
+ patterns.getContext());
}
void mlir::populateLowerSparseOpsToForeachPatterns(RewritePatternSet &patterns,
diff --git a/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_print.mlir b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_print.mlir
new file mode 100755
index 00000000000000..797a04bb9ff862
--- /dev/null
+++ b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_print.mlir
@@ -0,0 +1,215 @@
+//--------------------------------------------------------------------------------------------------
+// WHEN CREATING A NEW TEST, PLEASE JUST COPY & PASTE WITHOUT EDITS.
+//
+// Set-up that's shared across all tests in this directory. In principle, this
+// config could be moved to lit.local.cfg. However, there are downstream users that
+// do not use these LIT config files. Hence why this is kept inline.
+//
+// DEFINE: %{sparsifier_opts} = enable-runtime-library=true
+// DEFINE: %{sparsifier_opts_sve} = enable-arm-sve=true %{sparsifier_opts}
+// DEFINE: %{compile} = mlir-opt %s --sparsifier="%{sparsifier_opts}"
+// DEFINE: %{compile_sve} = mlir-opt %s --sparsifier="%{sparsifier_opts_sve}"
+// DEFINE: %{run_libs} = -shared-libs=%mlir_c_runner_utils,%mlir_runner_utils
+// DEFINE: %{run_opts} = -e main -entry-point-result=void
+// DEFINE: %{run} = mlir-cpu-runner %{run_opts} %{run_libs}
+// DEFINE: %{run_sve} = %mcr_aarch64_cmd --march=aarch64 --mattr="+sve" %{run_opts} %{run_libs}
+//
+// DEFINE: %{env} =
+//--------------------------------------------------------------------------------------------------
+
+// RUN: %{compile} | %{run} | FileCheck %s
+//
+// Do the same run, but now with direct IR generation.
+// REDEFINE: %{sparsifier_opts} = enable-runtime-library=false enable-buffer-initialization=true
+// RUN: %{compile} | %{run} | FileCheck %s
+//
+
+#AllDense = #sparse_tensor.encoding<{
+ map = (i, j) -> (
+ i : dense,
+ j : dense
+ )
+}>
+
+#AllDenseT = #sparse_tensor.encoding<{
+ map = (i, j) -> (
+ j : dense,
+ i : dense
+ )
+}>
+
+#CSR = #sparse_tensor.encoding<{
+ map = (i, j) -> (
+ i : dense,
+ j : compressed
+ )
+}>
+
+#DCSR = #sparse_tensor.encoding<{
+ map = (i, j) -> (
+ i : compressed,
+ j : compressed
+ )
+}>
+
+#CSC = #sparse_tensor.encoding<{
+ map = (i, j) -> (
+ j : dense,
+ i : compressed
+ )
+}>
+
+#DCSC = #sparse_tensor.encoding<{
+ map = (i, j) -> (
+ j : compressed,
+ i : compressed
+ )
+}>
+
+#BSR = #sparse_tensor.encoding<{
+ map = (i, j) -> (
+ i floordiv 2 : compressed,
+ j floordiv 4 : compressed,
+ i mod 2 : dense,
+ j mod 4 : dense
+ )
+}>
+
+#BSRC = #sparse_tensor.encoding<{
+ map = (i, j) -> (
+ i floordiv 2 : compressed,
+ j floordiv 4 : compressed,
+ j mod 4 : dense,
+ i mod 2 : dense
+ )
+}>
+
+#BSC = #sparse_tensor.encoding<{
+ map = (i, j) -> (
+ j floordiv 4 : compressed,
+ i floordiv 2 : compressed,
+ i mod 2 : dense,
+ j mod 4 : dense
+ )
+}>
+
+#BSCC = #sparse_tensor.encoding<{
+ map = (i, j) -> (
+ j floordiv 4 : compressed,
+ i floordiv 2 : compressed,
+ j mod 4 : dense,
+ i mod 2 : dense
+ )
+}>
+
+module {
+
+ //
+ // Main driver that tests sparse tensor storage.
+ //
+ func.func @main() {
+ %x = arith.constant dense <[
+ [ 1, 0, 2, 0, 0, 0, 0, 0 ],
+ [ 0, 0, 0, 0, 0, 0, 0, 0 ],
+ [ 0, 0, 0, 0, 0, 0, 0, 0 ],
+ [ 0, 0, 3, 4, 0, 5, 0, 0 ] ]> : tensor<4x8xi32>
+
+ %a = sparse_tensor.convert %x : tensor<4x8xi32> to tensor<4x8xi32, #CSR>
+ %b = sparse_tensor.convert %x : tensor<4x8xi32> to tensor<4x8xi32, #DCSR>
+ %c = sparse_tensor.convert %x : tensor<4x8xi32> to tensor<4x8xi32, #CSC>
+ %d = sparse_tensor.convert %x : tensor<4x8xi32> to tensor<4x8xi32, #DCSC>
+ %e = sparse_tensor.convert %x : tensor<4x8xi32> to tensor<4x8xi32, #BSR>
+ %f = sparse_tensor.convert %x : tensor<4x8xi32> to tensor<4x8xi32, #BSRC>
+ %g = sparse_tensor.convert %x : tensor<4x8xi32> to tensor<4x8xi32, #BSC>
+ %h = sparse_tensor.convert %x : tensor<4x8xi32> to tensor<4x8xi32, #BSCC>
+
+ //
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 5
+ // CHECK-NEXT: pos[1] : ( 0, 2, 2, 2, 5,
+ // CHECK-NEXT: crd[1] : ( 0, 2, 2, 3, 5,
+ // CHECK-NEXT: values : ( 1, 2, 3, 4, 5,
+ // CHECK-NEXT: ----
+ sparse_tensor.print %a : tensor<4x8xi32, #CSR>
+
+ // CHECK-NEXT: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 5
+ // CHECK-NEXT: pos[0] : ( 0, 2,
+ // CHECK-NEXT: crd[0] : ( 0, 3,
+ // CHECK-NEXT: pos[1] : ( 0, 2, 5,
+ // CHECK-NEXT: crd[1] : ( 0, 2, 2, 3, 5,
+ // CHECK-NEXT: values : ( 1, 2, 3, 4, 5,
+ // CHECK-NEXT: ----
+ sparse_tensor.print %b : tensor<4x8xi32, #DCSR>
+
+ // CHECK-NEXT: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 5
+ // CHECK-NEXT: pos[1] : ( 0, 1, 1, 3, 4, 4, 5, 5, 5,
+ // CHECK-NEXT: crd[1] : ( 0, 0, 3, 3, 3,
+ // CHECK-NEXT: values : ( 1, 2, 3, 4, 5,
+ // CHECK-NEXT: ----
+ sparse_tensor.print %c : tensor<4x8xi32, #CSC>
+
+ // CHECK-NEXT: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 5
+ // CHECK-NEXT: pos[0] : ( 0, 4,
+ // CHECK-NEXT: crd[0] : ( 0, 2, 3, 5,
+ // CHECK-NEXT: pos[1] : ( 0, 1, 3, 4, 5,
+ // CHECK-NEXT: crd[1] : ( 0, 0, 3, 3, 3,
+ // CHECK-NEXT: values : ( 1, 2, 3, 4, 5,
+ // CHECK-NEXT: ----
+ sparse_tensor.print %d : tensor<4x8xi32, #DCSC>
+
+ // CHECK-NEXT: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 24
+ // CHECK-NEXT: pos[0] : ( 0, 2,
+ // CHECK-NEXT: crd[0] : ( 0, 1,
+ // CHECK-NEXT: pos[1] : ( 0, 1, 3,
+ // CHECK-NEXT: crd[1] : ( 0, 0, 1,
+ // CHECK-NEXT: values : ( 1, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 4, 0, 0, 0, 0, 0, 5, 0, 0,
+ // CHECK-NEXT: ----
+ sparse_tensor.print %e : tensor<4x8xi32, #BSR>
+
+ // CHECK-NEXT: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 24
+ // CHECK-NEXT: pos[0] : ( 0, 2,
+ // CHECK-NEXT: crd[0] : ( 0, 1,
+ // CHECK-NEXT: pos[1] : ( 0, 1, 3,
+ // CHECK-NEXT: crd[1] : ( 0, 0, 1,
+ // CHECK-NEXT: values : ( 1, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 3, 0, 4, 0, 0, 0, 5, 0, 0, 0, 0,
+ // CHECK-NEXT: ----
+ sparse_tensor.print %f : tensor<4x8xi32, #BSRC>
+
+ // CHECK-NEXT: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 24
+ // CHECK-NEXT: pos[0] : ( 0, 2,
+ // CHECK-NEXT: crd[0] : ( 0, 1,
+ // CHECK-NEXT: pos[1] : ( 0, 2, 3,
+ // CHECK-NEXT: crd[1] : ( 0, 1, 1,
+ // CHECK-NEXT: values : ( 1, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 4, 0, 0, 0, 0, 0, 5, 0, 0,
+ // CHECK-NEXT: ----
+ sparse_tensor.print %g : tensor<4x8xi32, #BSC>
+
+ // CHECK-NEXT: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 24
+ // CHECK-NEXT: pos[0] : ( 0, 2,
+ // CHECK-NEXT: crd[0] : ( 0, 1,
+ // CHECK-NEXT: pos[1] : ( 0, 2, 3,
+ // CHECK-NEXT: crd[1] : ( 0, 1, 1,
+ // CHECK-NEXT: values : ( 1, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 3, 0, 4, 0, 0, 0, 5, 0, 0, 0, 0,
+ // CHECK-NEXT: ----
+ sparse_tensor.print %h : tensor<4x8xi32, #BSCC>
+
+ // Release the resources.
+ bufferization.dealloc_tensor %a : tensor<4x8xi32, #CSR>
+ bufferization.dealloc_tensor %b : tensor<4x8xi32, #DCSR>
+ bufferization.dealloc_tensor %c : tensor<4x8xi32, #CSC>
+ bufferization.dealloc_tensor %d : tensor<4x8xi32, #DCSC>
+ bufferization.dealloc_tensor %e : tensor<4x8xi32, #BSR>
+ bufferization.dealloc_tensor %f : tensor<4x8xi32, #BSRC>
+ bufferization.dealloc_tensor %g : tensor<4x8xi32, #BSC>
+ bufferization.dealloc_tensor %h : tensor<4x8xi32, #BSCC>
+
+ return
+ }
+}
>From d1f04443b14f3cfc565656fb14d283f729d95344 Mon Sep 17 00:00:00 2001
From: Fangrui Song <i at maskray.me>
Date: Wed, 28 Feb 2024 12:49:15 -0800
Subject: [PATCH 044/406] [Bazel] Port clangInstallAPI changes #82293 and
#82552
---
utils/bazel/llvm-project-overlay/clang/BUILD.bazel | 3 ++-
1 file changed, 2 insertions(+), 1 deletion(-)
diff --git a/utils/bazel/llvm-project-overlay/clang/BUILD.bazel b/utils/bazel/llvm-project-overlay/clang/BUILD.bazel
index 18af1af657f9e6..6d3904f84673e5 100644
--- a/utils/bazel/llvm-project-overlay/clang/BUILD.bazel
+++ b/utils/bazel/llvm-project-overlay/clang/BUILD.bazel
@@ -1843,7 +1843,6 @@ cc_library(
":driver",
":driver_options_inc_gen",
":edit",
- ":install_api",
":lex",
":parse",
":sema",
@@ -2066,7 +2065,9 @@ cc_library(
deps = [
":ast",
":basic",
+ ":frontend",
":support",
+ "//llvm:Core",
"//llvm:Support",
"//llvm:TextAPI",
],
>From 330793c91d08e6ac60334e4813746db898b9407e Mon Sep 17 00:00:00 2001
From: Nick Desaulniers <nickdesaulniers at users.noreply.github.com>
Date: Wed, 28 Feb 2024 12:53:56 -0800
Subject: [PATCH 045/406] [libc] fix clang-tidy llvm-header-guard warnings
(#82679)
Towards the goal of getting `ninja libc-lint` back to green, fix the numerous
instances of:
warning: header guard does not follow preferred style [llvm-header-guard]
This is because many of our header guards start with `__LLVM` rather than
`LLVM`.
To filter just these warnings:
$ ninja -k2000 libc-lint 2>&1 | grep llvm-header-guard
To automatically apply fixits:
$ find libc/src libc/include libc/test -name \*.h | \
xargs -n1 -I {} clang-tidy {} -p build/compile_commands.json \
-checks='-*,llvm-header-guard' --fix --quiet
Some manual cleanup is still necessary as headers that were missing header
guards outright will have them inserted before the license block (we prefer
them after).
---
libc/include/__llvm-libc-common.h | 6 +++---
libc/include/llvm-libc-macros/containerof-macro.h | 6 +++---
libc/include/llvm-libc-macros/fcntl-macros.h | 6 +++---
libc/include/llvm-libc-macros/features-macros.h | 6 +++---
libc/include/llvm-libc-macros/fenv-macros.h | 6 +++---
libc/include/llvm-libc-macros/file-seek-macros.h | 6 +++---
libc/include/llvm-libc-macros/float-macros.h | 6 +++---
.../include/llvm-libc-macros/generic-error-number-macros.h | 6 +++---
libc/include/llvm-libc-macros/gpu/time-macros.h | 6 +++---
libc/include/llvm-libc-macros/inttypes-macros.h | 6 +++---
libc/include/llvm-libc-macros/limits-macros.h | 6 +++---
libc/include/llvm-libc-macros/linux/fcntl-macros.h | 6 +++---
libc/include/llvm-libc-macros/linux/sched-macros.h | 6 +++---
libc/include/llvm-libc-macros/linux/signal-macros.h | 6 +++---
libc/include/llvm-libc-macros/linux/sys-ioctl-macros.h | 6 +++---
libc/include/llvm-libc-macros/linux/sys-random-macros.h | 6 +++---
libc/include/llvm-libc-macros/linux/sys-resource-macros.h | 5 +++++
libc/include/llvm-libc-macros/linux/sys-socket-macros.h | 6 +++---
libc/include/llvm-libc-macros/linux/sys-stat-macros.h | 6 +++---
libc/include/llvm-libc-macros/linux/sys-time-macros.h | 6 +++---
libc/include/llvm-libc-macros/linux/sys-wait-macros.h | 6 +++---
libc/include/llvm-libc-macros/linux/termios-macros.h | 6 +++---
libc/include/llvm-libc-macros/linux/time-macros.h | 6 +++---
libc/include/llvm-libc-macros/linux/unistd-macros.h | 6 +++---
libc/include/llvm-libc-macros/math-macros.h | 6 +++---
libc/include/llvm-libc-macros/null-macro.h | 6 +++---
libc/include/llvm-libc-macros/offsetof-macro.h | 6 +++---
libc/include/llvm-libc-macros/sched-macros.h | 6 +++---
libc/include/llvm-libc-macros/signal-macros.h | 6 +++---
libc/include/llvm-libc-macros/stdckdint-macros.h | 6 +++---
libc/include/llvm-libc-macros/stdfix-macros.h | 6 +++---
libc/include/llvm-libc-macros/stdio-macros.h | 6 +++---
libc/include/llvm-libc-macros/stdlib-macros.h | 6 +++---
libc/include/llvm-libc-macros/sys-auxv-macros.h | 6 +++---
libc/include/llvm-libc-macros/sys-ioctl-macros.h | 6 +++---
libc/include/llvm-libc-macros/sys-mman-macros.h | 6 +++---
libc/include/llvm-libc-macros/sys-queue-macros.h | 6 +++---
libc/include/llvm-libc-macros/sys-random-macros.h | 6 +++---
libc/include/llvm-libc-macros/sys-resource-macros.h | 6 +++---
libc/include/llvm-libc-macros/sys-select-macros.h | 6 +++---
libc/include/llvm-libc-macros/sys-socket-macros.h | 6 +++---
libc/include/llvm-libc-macros/sys-stat-macros.h | 6 +++---
libc/include/llvm-libc-macros/sys-time-macros.h | 6 +++---
libc/include/llvm-libc-macros/sys-wait-macros.h | 6 +++---
libc/include/llvm-libc-macros/termios-macros.h | 6 +++---
libc/include/llvm-libc-macros/time-macros.h | 6 +++---
libc/include/llvm-libc-macros/unistd-macros.h | 6 +++---
libc/include/llvm-libc-macros/wchar-macros.h | 6 +++---
libc/include/llvm-libc-types/ACTION.h | 6 +++---
libc/include/llvm-libc-types/DIR.h | 6 +++---
libc/include/llvm-libc-types/ENTRY.h | 6 +++---
libc/include/llvm-libc-types/FILE.h | 6 +++---
libc/include/llvm-libc-types/__atexithandler_t.h | 6 +++---
libc/include/llvm-libc-types/__atfork_callback_t.h | 6 +++---
libc/include/llvm-libc-types/__bsearchcompare_t.h | 6 +++---
libc/include/llvm-libc-types/__call_once_func_t.h | 6 +++---
libc/include/llvm-libc-types/__exec_argv_t.h | 6 +++---
libc/include/llvm-libc-types/__exec_envp_t.h | 6 +++---
libc/include/llvm-libc-types/__futex_word.h | 6 +++---
libc/include/llvm-libc-types/__getoptargv_t.h | 6 +++---
libc/include/llvm-libc-types/__mutex_type.h | 6 +++---
libc/include/llvm-libc-types/__pthread_once_func_t.h | 6 +++---
libc/include/llvm-libc-types/__pthread_start_t.h | 6 +++---
libc/include/llvm-libc-types/__pthread_tss_dtor_t.h | 6 +++---
libc/include/llvm-libc-types/__qsortcompare_t.h | 6 +++---
libc/include/llvm-libc-types/__qsortrcompare_t.h | 6 +++---
libc/include/llvm-libc-types/__sighandler_t.h | 6 +++---
libc/include/llvm-libc-types/__thread_type.h | 6 +++---
libc/include/llvm-libc-types/blkcnt_t.h | 6 +++---
libc/include/llvm-libc-types/blksize_t.h | 6 +++---
libc/include/llvm-libc-types/cc_t.h | 6 +++---
libc/include/llvm-libc-types/clock_t.h | 6 +++---
libc/include/llvm-libc-types/clockid_t.h | 6 +++---
libc/include/llvm-libc-types/cnd_t.h | 6 +++---
libc/include/llvm-libc-types/cookie_io_functions_t.h | 6 +++---
libc/include/llvm-libc-types/cpu_set_t.h | 6 +++---
libc/include/llvm-libc-types/dev_t.h | 6 +++---
libc/include/llvm-libc-types/div_t.h | 6 +++---
libc/include/llvm-libc-types/double_t.h | 6 +++---
libc/include/llvm-libc-types/fd_set.h | 6 +++---
libc/include/llvm-libc-types/fenv_t.h | 6 +++---
libc/include/llvm-libc-types/fexcept_t.h | 6 +++---
libc/include/llvm-libc-types/float128.h | 6 +++---
libc/include/llvm-libc-types/float_t.h | 6 +++---
libc/include/llvm-libc-types/gid_t.h | 6 +++---
libc/include/llvm-libc-types/ino_t.h | 6 +++---
libc/include/llvm-libc-types/jmp_buf.h | 6 +++---
libc/include/llvm-libc-types/ldiv_t.h | 6 +++---
libc/include/llvm-libc-types/lldiv_t.h | 6 +++---
libc/include/llvm-libc-types/mode_t.h | 6 +++---
libc/include/llvm-libc-types/mtx_t.h | 6 +++---
libc/include/llvm-libc-types/nlink_t.h | 6 +++---
libc/include/llvm-libc-types/off64_t.h | 6 +++---
libc/include/llvm-libc-types/off_t.h | 6 +++---
libc/include/llvm-libc-types/once_flag.h | 6 +++---
libc/include/llvm-libc-types/pid_t.h | 6 +++---
libc/include/llvm-libc-types/posix_spawn_file_actions_t.h | 6 +++---
libc/include/llvm-libc-types/posix_spawnattr_t.h | 6 +++---
libc/include/llvm-libc-types/pthread_attr_t.h | 6 +++---
libc/include/llvm-libc-types/pthread_key_t.h | 6 +++---
libc/include/llvm-libc-types/pthread_mutex_t.h | 6 +++---
libc/include/llvm-libc-types/pthread_mutexattr_t.h | 6 +++---
libc/include/llvm-libc-types/pthread_once_t.h | 6 +++---
libc/include/llvm-libc-types/pthread_t.h | 6 +++---
libc/include/llvm-libc-types/rlim_t.h | 6 +++---
libc/include/llvm-libc-types/rpc_opcodes_t.h | 6 +++---
libc/include/llvm-libc-types/sa_family_t.h | 6 +++---
libc/include/llvm-libc-types/sig_atomic_t.h | 6 +++---
libc/include/llvm-libc-types/siginfo_t.h | 6 +++---
libc/include/llvm-libc-types/sigset_t.h | 6 +++---
libc/include/llvm-libc-types/size_t.h | 6 +++---
libc/include/llvm-libc-types/socklen_t.h | 6 +++---
libc/include/llvm-libc-types/speed_t.h | 6 +++---
libc/include/llvm-libc-types/ssize_t.h | 6 +++---
libc/include/llvm-libc-types/stack_t.h | 6 +++---
libc/include/llvm-libc-types/struct_dirent.h | 6 +++---
libc/include/llvm-libc-types/struct_epoll_data.h | 6 +++---
libc/include/llvm-libc-types/struct_epoll_event.h | 6 +++---
libc/include/llvm-libc-types/struct_hsearch_data.h | 6 +++---
libc/include/llvm-libc-types/struct_rlimit.h | 6 +++---
libc/include/llvm-libc-types/struct_rusage.h | 6 +++---
libc/include/llvm-libc-types/struct_sched_param.h | 6 +++---
libc/include/llvm-libc-types/struct_sigaction.h | 6 +++---
libc/include/llvm-libc-types/struct_sockaddr.h | 6 +++---
libc/include/llvm-libc-types/struct_sockaddr_un.h | 6 +++---
libc/include/llvm-libc-types/struct_stat.h | 6 +++---
libc/include/llvm-libc-types/struct_timespec.h | 6 +++---
libc/include/llvm-libc-types/struct_timeval.h | 6 +++---
libc/include/llvm-libc-types/struct_tm.h | 6 +++---
libc/include/llvm-libc-types/struct_utsname.h | 6 +++---
libc/include/llvm-libc-types/suseconds_t.h | 6 +++---
libc/include/llvm-libc-types/tcflag_t.h | 6 +++---
libc/include/llvm-libc-types/test_rpc_opcodes_t.h | 6 +++---
libc/include/llvm-libc-types/thrd_start_t.h | 6 +++---
libc/include/llvm-libc-types/thrd_t.h | 6 +++---
libc/include/llvm-libc-types/time_t.h | 6 +++---
libc/include/llvm-libc-types/tss_dtor_t.h | 6 +++---
libc/include/llvm-libc-types/tss_t.h | 6 +++---
libc/include/llvm-libc-types/uid_t.h | 6 +++---
libc/include/llvm-libc-types/union_sigval.h | 6 +++---
libc/include/llvm-libc-types/wchar_t.h | 6 +++---
libc/include/llvm-libc-types/wint_t.h | 6 +++---
libc/include/sys/queue.h | 6 +++---
libc/src/__support/CPP/type_traits/is_fixed_point.h | 2 +-
libc/src/__support/FPUtil/fpbits_str.h | 6 +++---
libc/src/__support/GPU/generic/utils.h | 6 +++---
libc/src/__support/GPU/utils.h | 6 +++---
libc/src/__support/HashTable/table.h | 6 +++---
libc/src/__support/OSUtil/gpu/io.h | 2 +-
libc/src/__support/RPC/rpc_util.h | 6 +++---
libc/src/__support/StringUtil/message_mapper.h | 6 +++---
libc/src/__support/StringUtil/platform_errors.h | 6 +++---
libc/src/__support/StringUtil/platform_signals.h | 6 +++---
.../__support/StringUtil/tables/linux_extension_errors.h | 6 +++---
.../__support/StringUtil/tables/linux_extension_signals.h | 6 +++---
.../__support/StringUtil/tables/linux_platform_errors.h | 6 +++---
.../__support/StringUtil/tables/linux_platform_signals.h | 6 +++---
.../__support/StringUtil/tables/minimal_platform_errors.h | 6 +++---
.../__support/StringUtil/tables/minimal_platform_signals.h | 6 +++---
libc/src/__support/StringUtil/tables/posix_errors.h | 6 +++---
libc/src/__support/StringUtil/tables/posix_signals.h | 6 +++---
libc/src/__support/StringUtil/tables/signal_table.h | 6 +++---
libc/src/__support/StringUtil/tables/stdc_errors.h | 6 +++---
libc/src/__support/StringUtil/tables/stdc_signals.h | 6 +++---
libc/src/__support/fixed_point/fx_bits.h | 6 +++---
libc/src/__support/fixed_point/fx_rep.h | 6 +++---
libc/src/__support/memory_size.h | 5 +++++
libc/src/__support/threads/gpu/mutex.h | 6 +++---
libc/src/assert/assert.h | 7 ++++++-
libc/src/gpu/rpc_host_call.h | 2 +-
libc/src/math/amdgpu/declarations.h | 6 +++---
libc/src/math/amdgpu/platform.h | 6 +++---
libc/src/math/copysignf128.h | 2 +-
libc/src/math/generic/exp_utils.h | 6 +++---
libc/src/math/nvptx/declarations.h | 6 +++---
libc/src/math/nvptx/nvptx.h | 6 +++---
libc/src/search/hsearch/global.h | 5 +++++
libc/src/string/memory_utils/aarch64/inline_memcpy.h | 6 +++---
libc/src/string/memory_utils/riscv/inline_memmove.h | 6 +++---
libc/test/UnitTest/ExecuteFunction.h | 6 +++---
libc/test/UnitTest/FPExceptMatcher.h | 6 +++---
libc/test/UnitTest/FPMatcher.h | 6 +++---
libc/test/UnitTest/LibcTest.h | 6 +++---
libc/test/UnitTest/MemoryMatcher.h | 6 +++---
libc/test/UnitTest/PlatformDefs.h | 6 +++---
libc/test/UnitTest/RoundingModeUtils.h | 6 +++---
libc/test/UnitTest/StringUtils.h | 6 +++---
libc/test/UnitTest/Test.h | 6 +++---
libc/test/integration/src/spawn/test_binary_properties.h | 6 +++---
libc/test/src/math/FAbsTest.h | 5 +++++
libc/test/src/math/FMaxTest.h | 5 +++++
libc/test/src/math/FMinTest.h | 5 +++++
libc/test/src/math/FloorTest.h | 5 +++++
libc/test/src/math/RandUtils.h | 5 +++++
libc/test/src/math/RoundTest.h | 5 +++++
libc/test/src/math/TruncTest.h | 5 +++++
libc/test/src/math/differential_testing/Timer.h | 6 +++---
libc/test/src/math/in_float_range_test_helper.h | 6 +++---
libc/test/src/math/smoke/CeilTest.h | 5 +++++
libc/test/src/math/smoke/CopySignTest.h | 5 +++++
libc/test/src/math/smoke/FAbsTest.h | 5 +++++
libc/test/src/math/smoke/FMaxTest.h | 5 +++++
libc/test/src/math/smoke/FMinTest.h | 5 +++++
libc/test/src/math/smoke/FloorTest.h | 5 +++++
libc/test/src/math/smoke/RIntTest.h | 6 +++---
libc/test/src/math/smoke/RoundTest.h | 5 +++++
libc/test/src/math/smoke/RoundToIntegerTest.h | 6 +++---
libc/test/src/math/smoke/TruncTest.h | 5 +++++
libc/test/src/time/TmHelper.h | 6 +++---
libc/utils/MPFRWrapper/MPFRUtils.h | 6 +++---
210 files changed, 661 insertions(+), 566 deletions(-)
diff --git a/libc/include/__llvm-libc-common.h b/libc/include/__llvm-libc-common.h
index 6b883ee21a8c49..3af0b08e9e8668 100644
--- a/libc/include/__llvm-libc-common.h
+++ b/libc/include/__llvm-libc-common.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC___COMMON_H
-#define LLVM_LIBC___COMMON_H
+#ifndef LLVM_LIBC_COMMON_H
+#define LLVM_LIBC_COMMON_H
#ifdef __cplusplus
@@ -51,4 +51,4 @@
#endif // __cplusplus
-#endif // LLVM_LIBC___COMMON_H
+#endif // LLVM_LIBC_COMMON_H
diff --git a/libc/include/llvm-libc-macros/containerof-macro.h b/libc/include/llvm-libc-macros/containerof-macro.h
index ea91fa7097a4f2..62724abd3b0f11 100644
--- a/libc/include/llvm-libc-macros/containerof-macro.h
+++ b/libc/include/llvm-libc-macros/containerof-macro.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_CONTAINEROF_MACRO_H
-#define __LLVM_LIBC_MACROS_CONTAINEROF_MACRO_H
+#ifndef LLVM_LIBC_MACROS_CONTAINEROF_MACRO_H
+#define LLVM_LIBC_MACROS_CONTAINEROF_MACRO_H
#include <llvm-libc-macros/offsetof-macro.h>
@@ -17,4 +17,4 @@
(type *)(void *)((const char *)__ptr - offsetof(type, member)); \
})
-#endif // __LLVM_LIBC_MACROS_CONTAINEROF_MACRO_H
+#endif // LLVM_LIBC_MACROS_CONTAINEROF_MACRO_H
diff --git a/libc/include/llvm-libc-macros/fcntl-macros.h b/libc/include/llvm-libc-macros/fcntl-macros.h
index 448dcc0a813536..4bd03a7e3e2b29 100644
--- a/libc/include/llvm-libc-macros/fcntl-macros.h
+++ b/libc/include/llvm-libc-macros/fcntl-macros.h
@@ -1,8 +1,8 @@
-#ifndef __LLVM_LIBC_MACROS_FCNTL_MACROS_H
-#define __LLVM_LIBC_MACROS_FCNTL_MACROS_H
+#ifndef LLVM_LIBC_MACROS_FCNTL_MACROS_H
+#define LLVM_LIBC_MACROS_FCNTL_MACROS_H
#ifdef __linux__
#include "linux/fcntl-macros.h"
#endif
-#endif // __LLVM_LIBC_MACROS_FCNTL_MACROS_H
+#endif // LLVM_LIBC_MACROS_FCNTL_MACROS_H
diff --git a/libc/include/llvm-libc-macros/features-macros.h b/libc/include/llvm-libc-macros/features-macros.h
index 2938b3ccb95b29..5bc87a68fc0ba8 100644
--- a/libc/include/llvm-libc-macros/features-macros.h
+++ b/libc/include/llvm-libc-macros/features-macros.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_FEATURES_MACROS_H
-#define __LLVM_LIBC_MACROS_FEATURES_MACROS_H
+#ifndef LLVM_LIBC_MACROS_FEATURES_MACROS_H
+#define LLVM_LIBC_MACROS_FEATURES_MACROS_H
#define __LLVM_LIBC__ 1
-#endif // __LLVM_LIBC_MACROS_FEATURES_MACROS_H
+#endif // LLVM_LIBC_MACROS_FEATURES_MACROS_H
diff --git a/libc/include/llvm-libc-macros/fenv-macros.h b/libc/include/llvm-libc-macros/fenv-macros.h
index cc0ea344b1702b..72ac660cd98cba 100644
--- a/libc/include/llvm-libc-macros/fenv-macros.h
+++ b/libc/include/llvm-libc-macros/fenv-macros.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_FENV_MACROS_H
-#define __LLVM_LIBC_MACROS_FENV_MACROS_H
+#ifndef LLVM_LIBC_MACROS_FENV_MACROS_H
+#define LLVM_LIBC_MACROS_FENV_MACROS_H
#define FE_DIVBYZERO 1
#define FE_INEXACT 2
@@ -24,4 +24,4 @@
#define FE_DFL_ENV ((fenv_t *)-1)
-#endif // __LLVM_LIBC_MACROS_FENV_MACROS_H
+#endif // LLVM_LIBC_MACROS_FENV_MACROS_H
diff --git a/libc/include/llvm-libc-macros/file-seek-macros.h b/libc/include/llvm-libc-macros/file-seek-macros.h
index 04f397982f460d..676cb7511407ff 100644
--- a/libc/include/llvm-libc-macros/file-seek-macros.h
+++ b/libc/include/llvm-libc-macros/file-seek-macros.h
@@ -6,11 +6,11 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_FILE_SEEK_MACROS_H
-#define __LLVM_LIBC_MACROS_FILE_SEEK_MACROS_H
+#ifndef LLVM_LIBC_MACROS_FILE_SEEK_MACROS_H
+#define LLVM_LIBC_MACROS_FILE_SEEK_MACROS_H
#define SEEK_SET 0
#define SEEK_CUR 1
#define SEEK_END 2
-#endif // __LLVM_LIBC_MACROS_FILE_SEEK_MACROS_H
+#endif // LLVM_LIBC_MACROS_FILE_SEEK_MACROS_H
diff --git a/libc/include/llvm-libc-macros/float-macros.h b/libc/include/llvm-libc-macros/float-macros.h
index 86ec4939393086..a51eab0c7ed2f3 100644
--- a/libc/include/llvm-libc-macros/float-macros.h
+++ b/libc/include/llvm-libc-macros/float-macros.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_FLOAT_MACROS_H
-#define __LLVM_LIBC_MACROS_FLOAT_MACROS_H
+#ifndef LLVM_LIBC_MACROS_FLOAT_MACROS_H
+#define LLVM_LIBC_MACROS_FLOAT_MACROS_H
// Suppress `#include_next is a language extension` warnings.
#ifdef __clang__
@@ -169,4 +169,4 @@
// TODO: Add FLT16 and FLT128 constants.
-#endif // __LLVM_LIBC_MACROS_FLOAT_MACROS_H
+#endif // LLVM_LIBC_MACROS_FLOAT_MACROS_H
diff --git a/libc/include/llvm-libc-macros/generic-error-number-macros.h b/libc/include/llvm-libc-macros/generic-error-number-macros.h
index 3805c95cbb2a5c..7ee0352669b8a9 100644
--- a/libc/include/llvm-libc-macros/generic-error-number-macros.h
+++ b/libc/include/llvm-libc-macros/generic-error-number-macros.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_GENERIC_ERROR_NUMBER_MACROS_H
-#define __LLVM_LIBC_MACROS_GENERIC_ERROR_NUMBER_MACROS_H
+#ifndef LLVM_LIBC_MACROS_GENERIC_ERROR_NUMBER_MACROS_H
+#define LLVM_LIBC_MACROS_GENERIC_ERROR_NUMBER_MACROS_H
#define EPERM 1
#define ENOENT 2
@@ -45,4 +45,4 @@
#define ERANGE 34
#define EILSEQ 35
-#endif // __LLVM_LIBC_MACROS_GENERIC_ERROR_NUMBER_MACROS_H
+#endif // LLVM_LIBC_MACROS_GENERIC_ERROR_NUMBER_MACROS_H
diff --git a/libc/include/llvm-libc-macros/gpu/time-macros.h b/libc/include/llvm-libc-macros/gpu/time-macros.h
index baf2ea5f41324f..c3dc812f90a3be 100644
--- a/libc/include/llvm-libc-macros/gpu/time-macros.h
+++ b/libc/include/llvm-libc-macros/gpu/time-macros.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_GPU_TIME_MACROS_H
-#define __LLVM_LIBC_MACROS_GPU_TIME_MACROS_H
+#ifndef LLVM_LIBC_MACROS_GPU_TIME_MACROS_H
+#define LLVM_LIBC_MACROS_GPU_TIME_MACROS_H
#define CLOCKS_PER_SEC 1000000
-#endif // __LLVM_LIBC_MACROS_GPU_TIME_MACROS_H
+#endif // LLVM_LIBC_MACROS_GPU_TIME_MACROS_H
diff --git a/libc/include/llvm-libc-macros/inttypes-macros.h b/libc/include/llvm-libc-macros/inttypes-macros.h
index fc3e2517f19471..8e7d4f558a63b6 100644
--- a/libc/include/llvm-libc-macros/inttypes-macros.h
+++ b/libc/include/llvm-libc-macros/inttypes-macros.h
@@ -5,8 +5,8 @@
// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_INTTYPES_MACROS_H
-#define __LLVM_LIBC_MACROS_INTTYPES_MACROS_H
+#ifndef LLVM_LIBC_MACROS_INTTYPES_MACROS_H
+#define LLVM_LIBC_MACROS_INTTYPES_MACROS_H
// fprintf/scanf format macros.
// POSIX.1-2008, Technical Corrigendum 1, XBD/TC1-2008/0050 [211] is applied.
@@ -286,4 +286,4 @@
#define SCNxMAX __UINTMAX_FMTx__
#define SCNxPTR __UINTPTR_FMTx__
-#endif // __LLVM_LIBC_MACROS_INTTYPES_MACROS_H
+#endif // LLVM_LIBC_MACROS_INTTYPES_MACROS_H
diff --git a/libc/include/llvm-libc-macros/limits-macros.h b/libc/include/llvm-libc-macros/limits-macros.h
index 3b4df58ae4a143..95f0f5f0baa58e 100644
--- a/libc/include/llvm-libc-macros/limits-macros.h
+++ b/libc/include/llvm-libc-macros/limits-macros.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_LIMITS_MACROS_H
-#define __LLVM_LIBC_MACROS_LIMITS_MACROS_H
+#ifndef LLVM_LIBC_MACROS_LIMITS_MACROS_H
+#define LLVM_LIBC_MACROS_LIMITS_MACROS_H
// Define all C23 macro constants of limits.h
@@ -225,4 +225,4 @@
#define ULLONG_MIN 0ULL
#endif // ULLONG_MIN
-#endif // __LLVM_LIBC_MACROS_LIMITS_MACROS_H
+#endif // LLVM_LIBC_MACROS_LIMITS_MACROS_H
diff --git a/libc/include/llvm-libc-macros/linux/fcntl-macros.h b/libc/include/llvm-libc-macros/linux/fcntl-macros.h
index 495c5ec780edb0..1d4e5bbbdc770a 100644
--- a/libc/include/llvm-libc-macros/linux/fcntl-macros.h
+++ b/libc/include/llvm-libc-macros/linux/fcntl-macros.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_LINUX_FCNTL_MACROS_H
-#define __LLVM_LIBC_MACROS_LINUX_FCNTL_MACROS_H
+#ifndef LLVM_LIBC_MACROS_LINUX_FCNTL_MACROS_H
+#define LLVM_LIBC_MACROS_LINUX_FCNTL_MACROS_H
// File creation flags
#define O_CLOEXEC 02000000
@@ -68,4 +68,4 @@
#define F_GETFL 3
#define F_SETFL 4
-#endif // __LLVM_LIBC_MACROS_LINUX_FCNTL_MACROS_H
+#endif // LLVM_LIBC_MACROS_LINUX_FCNTL_MACROS_H
diff --git a/libc/include/llvm-libc-macros/linux/sched-macros.h b/libc/include/llvm-libc-macros/linux/sched-macros.h
index 0c574440ccbcf7..ace620049ca0c6 100644
--- a/libc/include/llvm-libc-macros/linux/sched-macros.h
+++ b/libc/include/llvm-libc-macros/linux/sched-macros.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_LINUX_SCHED_MACROS_H
-#define __LLVM_LIBC_MACROS_LINUX_SCHED_MACROS_H
+#ifndef LLVM_LIBC_MACROS_LINUX_SCHED_MACROS_H
+#define LLVM_LIBC_MACROS_LINUX_SCHED_MACROS_H
// Definitions of SCHED_* macros must match was linux as at:
// https://elixir.bootlin.com/linux/latest/source/include/uapi/linux/sched.h
@@ -26,4 +26,4 @@
#define CPU_COUNT_S(setsize, set) __sched_getcpucount(setsize, set)
#define CPU_COUNT(set) CPU_COUNT_S(sizeof(cpu_set_t), set)
-#endif // __LLVM_LIBC_MACROS_LINUX_SCHED_MACROS_H
+#endif // LLVM_LIBC_MACROS_LINUX_SCHED_MACROS_H
diff --git a/libc/include/llvm-libc-macros/linux/signal-macros.h b/libc/include/llvm-libc-macros/linux/signal-macros.h
index deb190ec375998..e379fc41efd02f 100644
--- a/libc/include/llvm-libc-macros/linux/signal-macros.h
+++ b/libc/include/llvm-libc-macros/linux/signal-macros.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_LINUX_SIGNUM_MACROS_H
-#define __LLVM_LIBC_MACROS_LINUX_SIGNUM_MACROS_H
+#ifndef LLVM_LIBC_MACROS_LINUX_SIGNAL_MACROS_H
+#define LLVM_LIBC_MACROS_LINUX_SIGNAL_MACROS_H
#define SIGHUP 1
#define SIGINT 2
@@ -101,4 +101,4 @@
#define CLD_STOPPED 5 // child has stopped
#define CLD_CONTINUED 6 // stopped child has continued
-#endif // __LLVM_LIBC_MACROS_LINUX_SIGNUM_MACROS_H
+#endif // LLVM_LIBC_MACROS_LINUX_SIGNAL_MACROS_H
diff --git a/libc/include/llvm-libc-macros/linux/sys-ioctl-macros.h b/libc/include/llvm-libc-macros/linux/sys-ioctl-macros.h
index 8f13a0ef4ad305..5eb779aeeca561 100644
--- a/libc/include/llvm-libc-macros/linux/sys-ioctl-macros.h
+++ b/libc/include/llvm-libc-macros/linux/sys-ioctl-macros.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_LINUX_SYS_IOCTL_MACROS_H
-#define __LLVM_LIBC_MACROS_LINUX_SYS_IOCTL_MACROS_H
+#ifndef LLVM_LIBC_MACROS_LINUX_SYS_IOCTL_MACROS_H
+#define LLVM_LIBC_MACROS_LINUX_SYS_IOCTL_MACROS_H
// TODO (michaelrj): Finish defining these macros.
// Just defining this macro for the moment since it's all that we need right
@@ -16,4 +16,4 @@
// think is worth digging into right now.
#define TIOCGETD 0x5424
-#endif // __LLVM_LIBC_MACROS_LINUX_SYS_IOCTL_MACROS_H
+#endif // LLVM_LIBC_MACROS_LINUX_SYS_IOCTL_MACROS_H
diff --git a/libc/include/llvm-libc-macros/linux/sys-random-macros.h b/libc/include/llvm-libc-macros/linux/sys-random-macros.h
index 1337f8b606fcf8..9261e87bdbf6f6 100644
--- a/libc/include/llvm-libc-macros/linux/sys-random-macros.h
+++ b/libc/include/llvm-libc-macros/linux/sys-random-macros.h
@@ -6,12 +6,12 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_LINUX_SYS_RANDOM_MACROS_H
-#define __LLVM_LIBC_MACROS_LINUX_SYS_RANDOM_MACROS_H
+#ifndef LLVM_LIBC_MACROS_LINUX_SYS_RANDOM_MACROS_H
+#define LLVM_LIBC_MACROS_LINUX_SYS_RANDOM_MACROS_H
// Getrandom flags
#define GRND_RANDOM 0x0001
#define GRND_NONBLOCK 0x0002
#define GRND_INSECURE 0x0004
-#endif // __LLVM_LIBC_MACROS_LINUX_SYS_RANDOM_MACROS_H
+#endif // LLVM_LIBC_MACROS_LINUX_SYS_RANDOM_MACROS_H
diff --git a/libc/include/llvm-libc-macros/linux/sys-resource-macros.h b/libc/include/llvm-libc-macros/linux/sys-resource-macros.h
index dd265530ada26c..c9d93c30c35a41 100644
--- a/libc/include/llvm-libc-macros/linux/sys-resource-macros.h
+++ b/libc/include/llvm-libc-macros/linux/sys-resource-macros.h
@@ -6,6 +6,9 @@
//
//===----------------------------------------------------------------------===//
+#ifndef LLVM_LIBC_MACROS_LINUX_SYS_RESOURCE_MACROS_H
+#define LLVM_LIBC_MACROS_LINUX_SYS_RESOURCE_MACROS_H
+
#define RLIMIT_CPU 0
#define RLIMIT_FSIZE 1
#define RLIMIT_DATA 2
@@ -24,3 +27,5 @@
#define RLIMIT_RTTIME 15
#define RLIM_INFINITY (~0UL)
+
+#endif // LLVM_LIBC_MACROS_LINUX_SYS_RESOURCE_MACROS_H
diff --git a/libc/include/llvm-libc-macros/linux/sys-socket-macros.h b/libc/include/llvm-libc-macros/linux/sys-socket-macros.h
index 7de410225b7126..f335200a103bb0 100644
--- a/libc/include/llvm-libc-macros/linux/sys-socket-macros.h
+++ b/libc/include/llvm-libc-macros/linux/sys-socket-macros.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_LINUX_SYS_SOCKET_MACROS_H
-#define __LLVM_LIBC_MACROS_LINUX_SYS_SOCKET_MACROS_H
+#ifndef LLVM_LIBC_MACROS_LINUX_SYS_SOCKET_MACROS_H
+#define LLVM_LIBC_MACROS_LINUX_SYS_SOCKET_MACROS_H
// IEEE Std 1003.1-2017 - basedefs/sys_socket.h.html
// Macro values come from the Linux syscall interface.
@@ -25,4 +25,4 @@
#define SOCK_SEQPACKET 5
#define SOCK_PACKET 10
-#endif // __LLVM_LIBC_MACROS_LINUX_SYS_SOCKET_MACROS_H
+#endif // LLVM_LIBC_MACROS_LINUX_SYS_SOCKET_MACROS_H
diff --git a/libc/include/llvm-libc-macros/linux/sys-stat-macros.h b/libc/include/llvm-libc-macros/linux/sys-stat-macros.h
index 48606cfa08ce93..3013121d0f3cb3 100644
--- a/libc/include/llvm-libc-macros/linux/sys-stat-macros.h
+++ b/libc/include/llvm-libc-macros/linux/sys-stat-macros.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_LINUX_SYS_STAT_MACROS_H
-#define __LLVM_LIBC_MACROS_LINUX_SYS_STAT_MACROS_H
+#ifndef LLVM_LIBC_MACROS_LINUX_SYS_STAT_MACROS_H
+#define LLVM_LIBC_MACROS_LINUX_SYS_STAT_MACROS_H
// Definitions from linux/stat.h
#define S_IFMT 0170000
@@ -45,4 +45,4 @@
#define S_IWOTH 00002
#define S_IXOTH 00001
-#endif // __LLVM_LIBC_MACROS_LINUX_SYS_STAT_MACROS_H
+#endif // LLVM_LIBC_MACROS_LINUX_SYS_STAT_MACROS_H
diff --git a/libc/include/llvm-libc-macros/linux/sys-time-macros.h b/libc/include/llvm-libc-macros/linux/sys-time-macros.h
index 06ae43f0e0054c..e97819594adcb1 100644
--- a/libc/include/llvm-libc-macros/linux/sys-time-macros.h
+++ b/libc/include/llvm-libc-macros/linux/sys-time-macros.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_LINUX_SYS_TIME_MACROS_H
-#define __LLVM_LIBC_MACROS_LINUX_SYS_TIME_MACROS_H
+#ifndef LLVM_LIBC_MACROS_LINUX_SYS_TIME_MACROS_H
+#define LLVM_LIBC_MACROS_LINUX_SYS_TIME_MACROS_H
// Add two timevals and put the result in timeval_ptr_result. If the resulting
// usec value is greater than 999,999 then the microseconds are turned into full
@@ -50,4 +50,4 @@
? ((timeval_ptr_a)->tv_usec CMP(timeval_ptr_b)->tv_usec) \
: ((timeval_ptr_a)->tv_sec CMP(timeval_ptr_b)->tv_sec))
-#endif // __LLVM_LIBC_MACROS_LINUX_SYS_TIME_MACROS_H
+#endif // LLVM_LIBC_MACROS_LINUX_SYS_TIME_MACROS_H
diff --git a/libc/include/llvm-libc-macros/linux/sys-wait-macros.h b/libc/include/llvm-libc-macros/linux/sys-wait-macros.h
index 3e6c6f53cc7171..c101638fdae340 100644
--- a/libc/include/llvm-libc-macros/linux/sys-wait-macros.h
+++ b/libc/include/llvm-libc-macros/linux/sys-wait-macros.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_LINUX_SYS_WAIT_MACROS_H
-#define __LLVM_LIBC_MACROS_LINUX_SYS_WAIT_MACROS_H
+#ifndef LLVM_LIBC_MACROS_LINUX_SYS_WAIT_MACROS_H
+#define LLVM_LIBC_MACROS_LINUX_SYS_WAIT_MACROS_H
// Wait flags
#define WNOHANG 1 // Do not block
@@ -41,4 +41,4 @@
#define P_PGID 2
#define P_PIDFD 3
-#endif // __LLVM_LIBC_MACROS_LINUX_SYS_WAIT_MACROS_H
+#endif // LLVM_LIBC_MACROS_LINUX_SYS_WAIT_MACROS_H
diff --git a/libc/include/llvm-libc-macros/linux/termios-macros.h b/libc/include/llvm-libc-macros/linux/termios-macros.h
index 17e380ebecffe3..668cfe27abaabf 100644
--- a/libc/include/llvm-libc-macros/linux/termios-macros.h
+++ b/libc/include/llvm-libc-macros/linux/termios-macros.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_LINUX_TERMIOS_MACROS_H
-#define __LLVM_LIBC_MACROS_LINUX_TERMIOS_MACROS_H
+#ifndef LLVM_LIBC_MACROS_LINUX_TERMIOS_MACROS_H
+#define LLVM_LIBC_MACROS_LINUX_TERMIOS_MACROS_H
// Below are generic definitions of symbolic bit-masks, modes etc. They serve
// most architectures including x86_64, aarch64 but have to be adjusted for few
@@ -164,4 +164,4 @@
#define TCIOFF 2 // Suspend output
#define TCION 3 // Restart output
-#endif // __LLVM_LIBC_MACROS_LINUX_TERMIOS_MACROS_H
+#endif // LLVM_LIBC_MACROS_LINUX_TERMIOS_MACROS_H
diff --git a/libc/include/llvm-libc-macros/linux/time-macros.h b/libc/include/llvm-libc-macros/linux/time-macros.h
index ace27cb2e9eb4b..407a1eb30eeaf7 100644
--- a/libc/include/llvm-libc-macros/linux/time-macros.h
+++ b/libc/include/llvm-libc-macros/linux/time-macros.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_LINUX_TIME_MACROS_H
-#define __LLVM_LIBC_MACROS_LINUX_TIME_MACROS_H
+#ifndef LLVM_LIBC_MACROS_LINUX_TIME_MACROS_H
+#define LLVM_LIBC_MACROS_LINUX_TIME_MACROS_H
// clock type macros
#define CLOCK_REALTIME 0
@@ -23,4 +23,4 @@
#define CLOCKS_PER_SEC 1000000
-#endif //__LLVM_LIBC_MACROS_LINUX_TIME_MACROS_H
+#endif // LLVM_LIBC_MACROS_LINUX_TIME_MACROS_H
diff --git a/libc/include/llvm-libc-macros/linux/unistd-macros.h b/libc/include/llvm-libc-macros/linux/unistd-macros.h
index cfdfb9a93ee9b0..c5109df435e68d 100644
--- a/libc/include/llvm-libc-macros/linux/unistd-macros.h
+++ b/libc/include/llvm-libc-macros/linux/unistd-macros.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_LINUX_UNISTD_MACROS_H
-#define __LLVM_LIBC_MACROS_LINUX_UNISTD_MACROS_H
+#ifndef LLVM_LIBC_MACROS_LINUX_UNISTD_MACROS_H
+#define LLVM_LIBC_MACROS_LINUX_UNISTD_MACROS_H
// Values for mode argument to the access(...) function.
#define F_OK 0
@@ -27,4 +27,4 @@
(long)(arg4), (long)(arg5), (long)(arg6))
#define syscall(...) __syscall_helper(__VA_ARGS__, 0, 1, 2, 3, 4, 5, 6)
-#endif // __LLVM_LIBC_MACROS_LINUX_UNISTD_MACROS_H
+#endif // LLVM_LIBC_MACROS_LINUX_UNISTD_MACROS_H
diff --git a/libc/include/llvm-libc-macros/math-macros.h b/libc/include/llvm-libc-macros/math-macros.h
index 9f8edd954b7e0f..e67fe4d11b4493 100644
--- a/libc/include/llvm-libc-macros/math-macros.h
+++ b/libc/include/llvm-libc-macros/math-macros.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_MATH_MACROS_H
-#define __LLVM_LIBC_MACROS_MATH_MACROS_H
+#ifndef LLVM_LIBC_MACROS_MATH_MACROS_H
+#define LLVM_LIBC_MACROS_MATH_MACROS_H
#include "limits-macros.h"
@@ -38,4 +38,4 @@
#define math_errhandling (MATH_ERRNO | MATH_ERREXCEPT)
#endif
-#endif // __LLVM_LIBC_MACROS_MATH_MACROS_H
+#endif // LLVM_LIBC_MACROS_MATH_MACROS_H
diff --git a/libc/include/llvm-libc-macros/null-macro.h b/libc/include/llvm-libc-macros/null-macro.h
index b83fc05c614dfb..416d4e865fc583 100644
--- a/libc/include/llvm-libc-macros/null-macro.h
+++ b/libc/include/llvm-libc-macros/null-macro.h
@@ -6,10 +6,10 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_NULL_MACRO_H
-#define __LLVM_LIBC_MACROS_NULL_MACRO_H
+#ifndef LLVM_LIBC_MACROS_NULL_MACRO_H
+#define LLVM_LIBC_MACROS_NULL_MACRO_H
#define __need_NULL
#include <stddef.h>
-#endif // __LLVM_LIBC_MACROS_NULL_MACRO_H
+#endif // LLVM_LIBC_MACROS_NULL_MACRO_H
diff --git a/libc/include/llvm-libc-macros/offsetof-macro.h b/libc/include/llvm-libc-macros/offsetof-macro.h
index eeceb3db110b6b..208c06b29cb642 100644
--- a/libc/include/llvm-libc-macros/offsetof-macro.h
+++ b/libc/include/llvm-libc-macros/offsetof-macro.h
@@ -6,10 +6,10 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_OFFSETOF_MACRO_H
-#define __LLVM_LIBC_MACROS_OFFSETOF_MACRO_H
+#ifndef LLVM_LIBC_MACROS_OFFSETOF_MACRO_H
+#define LLVM_LIBC_MACROS_OFFSETOF_MACRO_H
#define __need_offsetof
#include <stddef.h>
-#endif // __LLVM_LIBC_MACROS_OFFSETOF_MACRO_H
+#endif // LLVM_LIBC_MACROS_OFFSETOF_MACRO_H
diff --git a/libc/include/llvm-libc-macros/sched-macros.h b/libc/include/llvm-libc-macros/sched-macros.h
index 760edd9feb723d..0f643029816c1f 100644
--- a/libc/include/llvm-libc-macros/sched-macros.h
+++ b/libc/include/llvm-libc-macros/sched-macros.h
@@ -6,11 +6,11 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_SCHED_MACROS_H
-#define __LLVM_LIBC_MACROS_SCHED_MACROS_H
+#ifndef LLVM_LIBC_MACROS_SCHED_MACROS_H
+#define LLVM_LIBC_MACROS_SCHED_MACROS_H
#ifdef __linux__
#include "linux/sched-macros.h"
#endif
-#endif // __LLVM_LIBC_MACROS_SCHED_MACROS_H
+#endif // LLVM_LIBC_MACROS_SCHED_MACROS_H
diff --git a/libc/include/llvm-libc-macros/signal-macros.h b/libc/include/llvm-libc-macros/signal-macros.h
index 525032b3c5b161..7ab605baa54c2e 100644
--- a/libc/include/llvm-libc-macros/signal-macros.h
+++ b/libc/include/llvm-libc-macros/signal-macros.h
@@ -6,11 +6,11 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_SIGNUM_MACROS_H
-#define __LLVM_LIBC_MACROS_SIGNUM_MACROS_H
+#ifndef LLVM_LIBC_MACROS_SIGNAL_MACROS_H
+#define LLVM_LIBC_MACROS_SIGNAL_MACROS_H
#ifdef __linux__
#include "linux/signal-macros.h"
#endif
-#endif // __LLVM_LIBC_MACROS_SIGNUM_MACROS_H
+#endif // LLVM_LIBC_MACROS_SIGNAL_MACROS_H
diff --git a/libc/include/llvm-libc-macros/stdckdint-macros.h b/libc/include/llvm-libc-macros/stdckdint-macros.h
index 03b73aeeb6710a..694412290bbca0 100644
--- a/libc/include/llvm-libc-macros/stdckdint-macros.h
+++ b/libc/include/llvm-libc-macros/stdckdint-macros.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_STDCKDINT_MACROS_H
-#define __LLVM_LIBC_MACROS_STDCKDINT_MACROS_H
+#ifndef LLVM_LIBC_MACROS_STDCKDINT_MACROS_H
+#define LLVM_LIBC_MACROS_STDCKDINT_MACROS_H
// We need to use __builtin_*_overflow from GCC/Clang to implement the overflow
// macros. Check __GNUC__ for availability of such builtins.
@@ -22,4 +22,4 @@
#define ckd_mul(R, A, B) __builtin_mul_overflow((A), (B), (R))
#endif // __STDC_VERSION_STDCKDINT_H__
#endif // __GNUC__
-#endif // __LLVM_LIBC_MACROS_STDCKDINT_MACROS_H
+#endif // LLVM_LIBC_MACROS_STDCKDINT_MACROS_H
diff --git a/libc/include/llvm-libc-macros/stdfix-macros.h b/libc/include/llvm-libc-macros/stdfix-macros.h
index 11c18f83b8c57b..554ebe544a42ed 100644
--- a/libc/include/llvm-libc-macros/stdfix-macros.h
+++ b/libc/include/llvm-libc-macros/stdfix-macros.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_STDFIX_MACROS_H
-#define __LLVM_LIBC_MACROS_STDFIX_MACROS_H
+#ifndef LLVM_LIBC_MACROS_STDFIX_MACROS_H
+#define LLVM_LIBC_MACROS_STDFIX_MACROS_H
#ifdef __FRACT_FBIT__
// _Fract and _Accum types are available
@@ -325,4 +325,4 @@
#endif // LIBC_COMPILER_HAS_FIXED_POINT
-#endif // __LLVM_LIBC_MACROS_STDFIX_MACROS_H
+#endif // LLVM_LIBC_MACROS_STDFIX_MACROS_H
diff --git a/libc/include/llvm-libc-macros/stdio-macros.h b/libc/include/llvm-libc-macros/stdio-macros.h
index b2c62ec7cff2a6..db747c5d5d6755 100644
--- a/libc/include/llvm-libc-macros/stdio-macros.h
+++ b/libc/include/llvm-libc-macros/stdio-macros.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_STDIO_MACROS_H
-#define __LLVM_LIBC_MACROS_STDIO_MACROS_H
+#ifndef LLVM_LIBC_MACROS_STDIO_MACROS_H
+#define LLVM_LIBC_MACROS_STDIO_MACROS_H
#define BUFSIZ 1024
-#endif // __LLVM_LIBC_MACROS_STDIO_MACROS_H
+#endif // LLVM_LIBC_MACROS_STDIO_MACROS_H
diff --git a/libc/include/llvm-libc-macros/stdlib-macros.h b/libc/include/llvm-libc-macros/stdlib-macros.h
index a7625aa187c910..5fcbfef97b3285 100644
--- a/libc/include/llvm-libc-macros/stdlib-macros.h
+++ b/libc/include/llvm-libc-macros/stdlib-macros.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_STDLIB_MACROS_H
-#define __LLVM_LIBC_MACROS_STDLIB_MACROS_H
+#ifndef LLVM_LIBC_MACROS_STDLIB_MACROS_H
+#define LLVM_LIBC_MACROS_STDLIB_MACROS_H
#ifndef NULL
#define __need_NULL
@@ -19,4 +19,4 @@
#define RAND_MAX 2147483647
-#endif // __LLVM_LIBC_MACROS_STDLIB_MACROS_H
+#endif // LLVM_LIBC_MACROS_STDLIB_MACROS_H
diff --git a/libc/include/llvm-libc-macros/sys-auxv-macros.h b/libc/include/llvm-libc-macros/sys-auxv-macros.h
index a57c6018ea0a9d..2dcaa2f1a8ee87 100644
--- a/libc/include/llvm-libc-macros/sys-auxv-macros.h
+++ b/libc/include/llvm-libc-macros/sys-auxv-macros.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_AUXV_MACROS_H
-#define __LLVM_LIBC_MACROS_AUXV_MACROS_H
+#ifndef LLVM_LIBC_MACROS_SYS_AUXV_MACROS_H
+#define LLVM_LIBC_MACROS_SYS_AUXV_MACROS_H
// Macros defining the aux vector indexes.
#define AT_NULL 0
@@ -40,4 +40,4 @@
#define AT_MINSIGSTKSZ 51
#endif
-#endif // __LLVM_LIBC_MACROS_AUXV_MACROS_H
+#endif // LLVM_LIBC_MACROS_SYS_AUXV_MACROS_H
diff --git a/libc/include/llvm-libc-macros/sys-ioctl-macros.h b/libc/include/llvm-libc-macros/sys-ioctl-macros.h
index c273fab36e3fe5..4a5f9651231fb8 100644
--- a/libc/include/llvm-libc-macros/sys-ioctl-macros.h
+++ b/libc/include/llvm-libc-macros/sys-ioctl-macros.h
@@ -6,11 +6,11 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_SYS_IOCTL_MACROS_H
-#define __LLVM_LIBC_MACROS_SYS_IOCTL_MACROS_H
+#ifndef LLVM_LIBC_MACROS_SYS_IOCTL_MACROS_H
+#define LLVM_LIBC_MACROS_SYS_IOCTL_MACROS_H
#ifdef __linux__
#include "linux/sys-ioctl-macros.h"
#endif
-#endif // __LLVM_LIBC_MACROS_SYS_IOCTL_MACROS_H
+#endif // LLVM_LIBC_MACROS_SYS_IOCTL_MACROS_H
diff --git a/libc/include/llvm-libc-macros/sys-mman-macros.h b/libc/include/llvm-libc-macros/sys-mman-macros.h
index 4ffc112f4e4dee..a6dc6d96b5b79d 100644
--- a/libc/include/llvm-libc-macros/sys-mman-macros.h
+++ b/libc/include/llvm-libc-macros/sys-mman-macros.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_SYS_MMAN_MACROS_H
-#define __LLVM_LIBC_MACROS_SYS_MMAN_MACROS_H
+#ifndef LLVM_LIBC_MACROS_SYS_MMAN_MACROS_H
+#define LLVM_LIBC_MACROS_SYS_MMAN_MACROS_H
// Use definitions from <linux/mman.h> to dispatch arch-specific flag values.
// For example, MCL_CURRENT/MCL_FUTURE/MCL_ONFAULT are different on different
@@ -45,4 +45,4 @@
#define POSIX_MADV_DONTNEED MADV_DONTNEED
#endif
-#endif // __LLVM_LIBC_MACROS_SYS_MMAN_MACROS_H
+#endif // LLVM_LIBC_MACROS_SYS_MMAN_MACROS_H
diff --git a/libc/include/llvm-libc-macros/sys-queue-macros.h b/libc/include/llvm-libc-macros/sys-queue-macros.h
index 7da643cb725330..fcac265333fc82 100644
--- a/libc/include/llvm-libc-macros/sys-queue-macros.h
+++ b/libc/include/llvm-libc-macros/sys-queue-macros.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_SYS_QUEUE_MACROS_H
-#define __LLVM_LIBC_MACROS_SYS_QUEUE_MACROS_H
+#ifndef LLVM_LIBC_MACROS_SYS_QUEUE_MACROS_H
+#define LLVM_LIBC_MACROS_SYS_QUEUE_MACROS_H
#include <llvm-libc-macros/containerof-macro.h>
#include <llvm-libc-macros/null-macro.h>
@@ -259,4 +259,4 @@
(head2)->stqh_last = &STAILQ_FIRST(head2); \
} while (0)
-#endif // __LLVM_LIBC_MACROS_SYS_QUEUE_MACROS_H
+#endif // LLVM_LIBC_MACROS_SYS_QUEUE_MACROS_H
diff --git a/libc/include/llvm-libc-macros/sys-random-macros.h b/libc/include/llvm-libc-macros/sys-random-macros.h
index e87128d0d0fcb3..9b1a8edb4f79db 100644
--- a/libc/include/llvm-libc-macros/sys-random-macros.h
+++ b/libc/include/llvm-libc-macros/sys-random-macros.h
@@ -6,11 +6,11 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_SYS_RANDOM_MACROS_H
-#define __LLVM_LIBC_MACROS_SYS_RANDOM_MACROS_H
+#ifndef LLVM_LIBC_MACROS_SYS_RANDOM_MACROS_H
+#define LLVM_LIBC_MACROS_SYS_RANDOM_MACROS_H
#ifdef __linux__
#include "linux/sys-random-macros.h"
#endif
-#endif // __LLVM_LIBC_MACROS_SYS_RANDOM_MACROS_H
+#endif // LLVM_LIBC_MACROS_SYS_RANDOM_MACROS_H
diff --git a/libc/include/llvm-libc-macros/sys-resource-macros.h b/libc/include/llvm-libc-macros/sys-resource-macros.h
index 272723a955a76a..1ce01cdd1e8384 100644
--- a/libc/include/llvm-libc-macros/sys-resource-macros.h
+++ b/libc/include/llvm-libc-macros/sys-resource-macros.h
@@ -6,11 +6,11 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_SYS_RESOURCE_MACROS_H
-#define __LLVM_LIBC_MACROS_SYS_RESOURCE_MACROS_H
+#ifndef LLVM_LIBC_MACROS_SYS_RESOURCE_MACROS_H
+#define LLVM_LIBC_MACROS_SYS_RESOURCE_MACROS_H
#ifdef __linux__
#include "linux/sys-resource-macros.h"
#endif
-#endif // __LLVM_LIBC_MACROS_SYS_RESOURCE_MACROS_H
+#endif // LLVM_LIBC_MACROS_SYS_RESOURCE_MACROS_H
diff --git a/libc/include/llvm-libc-macros/sys-select-macros.h b/libc/include/llvm-libc-macros/sys-select-macros.h
index 5d6592c1c281c4..d54e5300d12eba 100644
--- a/libc/include/llvm-libc-macros/sys-select-macros.h
+++ b/libc/include/llvm-libc-macros/sys-select-macros.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_SYS_SELECT_MACROS_H
-#define __LLVM_LIBC_MACROS_SYS_SELECT_MACROS_H
+#ifndef LLVM_LIBC_MACROS_SYS_SELECT_MACROS_H
+#define LLVM_LIBC_MACROS_SYS_SELECT_MACROS_H
#define FD_SETSIZE 1024
#define __FD_SET_WORD_TYPE unsigned long
@@ -32,4 +32,4 @@
#define FD_ISSET(fd, set) \
(int)(((set)->__set[__FD_WORD(fd)] & __FD_MASK(fd)) != 0)
-#endif // __LLVM_LIBC_MACROS_SYS_SELECT_MACROS_H
+#endif // LLVM_LIBC_MACROS_SYS_SELECT_MACROS_H
diff --git a/libc/include/llvm-libc-macros/sys-socket-macros.h b/libc/include/llvm-libc-macros/sys-socket-macros.h
index 2032360990631c..6b1d28070b43ec 100644
--- a/libc/include/llvm-libc-macros/sys-socket-macros.h
+++ b/libc/include/llvm-libc-macros/sys-socket-macros.h
@@ -6,11 +6,11 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_SYS_SOCKET_MACROS_H
-#define __LLVM_LIBC_MACROS_SYS_SOCKET_MACROS_H
+#ifndef LLVM_LIBC_MACROS_SYS_SOCKET_MACROS_H
+#define LLVM_LIBC_MACROS_SYS_SOCKET_MACROS_H
#ifdef __linux__
#include "linux/sys-socket-macros.h"
#endif
-#endif // __LLVM_LIBC_MACROS_SYS_SOCKET_MACROS_H
+#endif // LLVM_LIBC_MACROS_SYS_SOCKET_MACROS_H
diff --git a/libc/include/llvm-libc-macros/sys-stat-macros.h b/libc/include/llvm-libc-macros/sys-stat-macros.h
index 64f63c33b3e5b8..c47c9612705e9e 100644
--- a/libc/include/llvm-libc-macros/sys-stat-macros.h
+++ b/libc/include/llvm-libc-macros/sys-stat-macros.h
@@ -6,11 +6,11 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_SYS_STAT_MACROS_H
-#define __LLVM_LIBC_MACROS_SYS_STAT_MACROS_H
+#ifndef LLVM_LIBC_MACROS_SYS_STAT_MACROS_H
+#define LLVM_LIBC_MACROS_SYS_STAT_MACROS_H
#ifdef __linux__
#include "linux/sys-stat-macros.h"
#endif
-#endif // __LLVM_LIBC_MACROS_SYS_STAT_MACROS_H
+#endif // LLVM_LIBC_MACROS_SYS_STAT_MACROS_H
diff --git a/libc/include/llvm-libc-macros/sys-time-macros.h b/libc/include/llvm-libc-macros/sys-time-macros.h
index 8e463170330847..36d7d5adafc95a 100644
--- a/libc/include/llvm-libc-macros/sys-time-macros.h
+++ b/libc/include/llvm-libc-macros/sys-time-macros.h
@@ -6,11 +6,11 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_SYS_TIME_MACROS_H
-#define __LLVM_LIBC_MACROS_SYS_TIME_MACROS_H
+#ifndef LLVM_LIBC_MACROS_SYS_TIME_MACROS_H
+#define LLVM_LIBC_MACROS_SYS_TIME_MACROS_H
#ifdef __linux__
#include "linux/sys-time-macros.h"
#endif
-#endif // __LLVM_LIBC_MACROS_SYS_TIME_MACROS_H
+#endif // LLVM_LIBC_MACROS_SYS_TIME_MACROS_H
diff --git a/libc/include/llvm-libc-macros/sys-wait-macros.h b/libc/include/llvm-libc-macros/sys-wait-macros.h
index ea58fccecaffb5..c418a7930b69e7 100644
--- a/libc/include/llvm-libc-macros/sys-wait-macros.h
+++ b/libc/include/llvm-libc-macros/sys-wait-macros.h
@@ -6,11 +6,11 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_SYS_WAIT_MACROS_H
-#define __LLVM_LIBC_MACROS_SYS_WAIT_MACROS_H
+#ifndef LLVM_LIBC_MACROS_SYS_WAIT_MACROS_H
+#define LLVM_LIBC_MACROS_SYS_WAIT_MACROS_H
#ifdef __linux__
#include "linux/sys-wait-macros.h"
#endif
-#endif // __LLVM_LIBC_MACROS_SYS_WAIT_MACROS_H
+#endif // LLVM_LIBC_MACROS_SYS_WAIT_MACROS_H
diff --git a/libc/include/llvm-libc-macros/termios-macros.h b/libc/include/llvm-libc-macros/termios-macros.h
index c99982837a57a2..1067e8a574747e 100644
--- a/libc/include/llvm-libc-macros/termios-macros.h
+++ b/libc/include/llvm-libc-macros/termios-macros.h
@@ -6,11 +6,11 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_TERMIOS_MACROS_H
-#define __LLVM_LIBC_MACROS_TERMIOS_MACROS_H
+#ifndef LLVM_LIBC_MACROS_TERMIOS_MACROS_H
+#define LLVM_LIBC_MACROS_TERMIOS_MACROS_H
#ifdef __linux__
#include "linux/termios-macros.h"
#endif
-#endif // __LLVM_LIBC_MACROS_TERMIOS_MACROS_H
+#endif // LLVM_LIBC_MACROS_TERMIOS_MACROS_H
diff --git a/libc/include/llvm-libc-macros/time-macros.h b/libc/include/llvm-libc-macros/time-macros.h
index c3bd7aa24f56c3..6d49ed484d5d48 100644
--- a/libc/include/llvm-libc-macros/time-macros.h
+++ b/libc/include/llvm-libc-macros/time-macros.h
@@ -1,5 +1,5 @@
-#ifndef __LLVM_LIBC_MACROS_TIME_MACROS_H
-#define __LLVM_LIBC_MACROS_TIME_MACROS_H
+#ifndef LLVM_LIBC_MACROS_TIME_MACROS_H
+#define LLVM_LIBC_MACROS_TIME_MACROS_H
#if defined(__AMDGPU__) || defined(__NVPTX__)
#include "gpu/time-macros.h"
@@ -7,4 +7,4 @@
#include "linux/time-macros.h"
#endif
-#endif // __LLVM_LIBC_MACROS_TIME_MACROS_H
+#endif // LLVM_LIBC_MACROS_TIME_MACROS_H
diff --git a/libc/include/llvm-libc-macros/unistd-macros.h b/libc/include/llvm-libc-macros/unistd-macros.h
index dbcac0f5e72dcb..4f27f075fcc61b 100644
--- a/libc/include/llvm-libc-macros/unistd-macros.h
+++ b/libc/include/llvm-libc-macros/unistd-macros.h
@@ -1,8 +1,8 @@
-#ifndef __LLVM_LIBC_MACROS_UNISTD_MACROS_H
-#define __LLVM_LIBC_MACROS_UNISTD_MACROS_H
+#ifndef LLVM_LIBC_MACROS_UNISTD_MACROS_H
+#define LLVM_LIBC_MACROS_UNISTD_MACROS_H
#ifdef __linux__
#include "linux/unistd-macros.h"
#endif
-#endif // __LLVM_LIBC_MACROS_UNISTD_MACROS_H
+#endif // LLVM_LIBC_MACROS_UNISTD_MACROS_H
diff --git a/libc/include/llvm-libc-macros/wchar-macros.h b/libc/include/llvm-libc-macros/wchar-macros.h
index adca41eb012272..5b211f5276b628 100644
--- a/libc/include/llvm-libc-macros/wchar-macros.h
+++ b/libc/include/llvm-libc-macros/wchar-macros.h
@@ -6,11 +6,11 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_MACROS_WCHAR_MACROS_H
-#define __LLVM_LIBC_MACROS_WCHAR_MACROS_H
+#ifndef LLVM_LIBC_MACROS_WCHAR_MACROS_H
+#define LLVM_LIBC_MACROS_WCHAR_MACROS_H
#ifndef WEOF
#define WEOF 0xffffffffu
#endif
-#endif // __LLVM_LIBC_MACROS_WCHAR_MACROS_H
+#endif // LLVM_LIBC_MACROS_WCHAR_MACROS_H
diff --git a/libc/include/llvm-libc-types/ACTION.h b/libc/include/llvm-libc-types/ACTION.h
index 7181a59b177d6b..1ddce208df1c3e 100644
--- a/libc/include/llvm-libc-types/ACTION.h
+++ b/libc/include/llvm-libc-types/ACTION.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_ACTION_H__
-#define __LLVM_LIBC_TYPES_ACTION_H__
+#ifndef LLVM_LIBC_TYPES_ACTION_H
+#define LLVM_LIBC_TYPES_ACTION_H
typedef enum { FIND, ENTER } ACTION;
-#endif // __LLVM_LIBC_TYPES_ACTION_H__
+#endif // LLVM_LIBC_TYPES_ACTION_H
diff --git a/libc/include/llvm-libc-types/DIR.h b/libc/include/llvm-libc-types/DIR.h
index 0a2cf27d248545..855446db6f53fb 100644
--- a/libc/include/llvm-libc-types/DIR.h
+++ b/libc/include/llvm-libc-types/DIR.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_DIR_H__
-#define __LLVM_LIBC_TYPES_DIR_H__
+#ifndef LLVM_LIBC_TYPES_DIR_H
+#define LLVM_LIBC_TYPES_DIR_H
typedef struct DIR DIR;
-#endif // __LLVM_LIBC_TYPES_DIR_H__
+#endif // LLVM_LIBC_TYPES_DIR_H
diff --git a/libc/include/llvm-libc-types/ENTRY.h b/libc/include/llvm-libc-types/ENTRY.h
index 0ccb5938207acc..ccbd777e2475b5 100644
--- a/libc/include/llvm-libc-types/ENTRY.h
+++ b/libc/include/llvm-libc-types/ENTRY.h
@@ -6,12 +6,12 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_ENTRY_H__
-#define __LLVM_LIBC_TYPES_ENTRY_H__
+#ifndef LLVM_LIBC_TYPES_ENTRY_H
+#define LLVM_LIBC_TYPES_ENTRY_H
typedef struct {
char *key;
void *data;
} ENTRY;
-#endif // __LLVM_LIBC_TYPES_ENTRY_H__
+#endif // LLVM_LIBC_TYPES_ENTRY_H
diff --git a/libc/include/llvm-libc-types/FILE.h b/libc/include/llvm-libc-types/FILE.h
index 1c1ff97ec86a56..f1d2e4f726c7dd 100644
--- a/libc/include/llvm-libc-types/FILE.h
+++ b/libc/include/llvm-libc-types/FILE.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_FILE_H__
-#define __LLVM_LIBC_TYPES_FILE_H__
+#ifndef LLVM_LIBC_TYPES_FILE_H
+#define LLVM_LIBC_TYPES_FILE_H
typedef struct FILE FILE;
-#endif // __LLVM_LIBC_TYPES_FILE_H__
+#endif // LLVM_LIBC_TYPES_FILE_H
diff --git a/libc/include/llvm-libc-types/__atexithandler_t.h b/libc/include/llvm-libc-types/__atexithandler_t.h
index a9887b6abf708a..01aed676c2a700 100644
--- a/libc/include/llvm-libc-types/__atexithandler_t.h
+++ b/libc/include/llvm-libc-types/__atexithandler_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_ATEXITHANDLER_T_H__
-#define __LLVM_LIBC_TYPES_ATEXITHANDLER_T_H__
+#ifndef LLVM_LIBC_TYPES___ATEXITHANDLER_T_H
+#define LLVM_LIBC_TYPES___ATEXITHANDLER_T_H
typedef void (*__atexithandler_t)(void);
-#endif // __LLVM_LIBC_TYPES_ATEXITHANDLER_T_H__
+#endif // LLVM_LIBC_TYPES___ATEXITHANDLER_T_H
diff --git a/libc/include/llvm-libc-types/__atfork_callback_t.h b/libc/include/llvm-libc-types/__atfork_callback_t.h
index 3da66c23feb0d5..ae2d0ca39d5320 100644
--- a/libc/include/llvm-libc-types/__atfork_callback_t.h
+++ b/libc/include/llvm-libc-types/__atfork_callback_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_ATFORK_CALLBACK_T_H__
-#define __LLVM_LIBC_TYPES_ATFORK_CALLBACK_T_H__
+#ifndef LLVM_LIBC_TYPES___ATFORK_CALLBACK_T_H
+#define LLVM_LIBC_TYPES___ATFORK_CALLBACK_T_H
typedef void (*__atfork_callback_t)(void);
-#endif // __LLVM_LIBC_TYPES_ATFORK_CALLBACK_T_H__
+#endif // LLVM_LIBC_TYPES___ATFORK_CALLBACK_T_H
diff --git a/libc/include/llvm-libc-types/__bsearchcompare_t.h b/libc/include/llvm-libc-types/__bsearchcompare_t.h
index 40ebc7f3566882..0b1987be1fdd64 100644
--- a/libc/include/llvm-libc-types/__bsearchcompare_t.h
+++ b/libc/include/llvm-libc-types/__bsearchcompare_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_BSEARCHCOMPARE_T_H__
-#define __LLVM_LIBC_TYPES_BSEARCHCOMPARE_T_H__
+#ifndef LLVM_LIBC_TYPES___BSEARCHCOMPARE_T_H
+#define LLVM_LIBC_TYPES___BSEARCHCOMPARE_T_H
typedef int (*__bsearchcompare_t)(const void *, const void *);
-#endif // __LLVM_LIBC_TYPES_BSEARCHCOMPARE_T_H__
+#endif // LLVM_LIBC_TYPES___BSEARCHCOMPARE_T_H
diff --git a/libc/include/llvm-libc-types/__call_once_func_t.h b/libc/include/llvm-libc-types/__call_once_func_t.h
index bc8ed8331bd802..6d278da4f1d3f5 100644
--- a/libc/include/llvm-libc-types/__call_once_func_t.h
+++ b/libc/include/llvm-libc-types/__call_once_func_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_CALL_ONCE_FUNC_T_H__
-#define __LLVM_LIBC_TYPES_CALL_ONCE_FUNC_T_H__
+#ifndef LLVM_LIBC_TYPES___CALL_ONCE_FUNC_T_H
+#define LLVM_LIBC_TYPES___CALL_ONCE_FUNC_T_H
typedef void (*__call_once_func_t)(void);
-#endif // __LLVM_LIBC_TYPES_CALL_ONCE_FUNC_T_H__
+#endif // LLVM_LIBC_TYPES___CALL_ONCE_FUNC_T_H
diff --git a/libc/include/llvm-libc-types/__exec_argv_t.h b/libc/include/llvm-libc-types/__exec_argv_t.h
index 35b687d9685d4e..4eff583768afb1 100644
--- a/libc/include/llvm-libc-types/__exec_argv_t.h
+++ b/libc/include/llvm-libc-types/__exec_argv_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_EXEC_ARGV_T_H__
-#define __LLVM_LIBC_TYPES_EXEC_ARGV_T_H__
+#ifndef LLVM_LIBC_TYPES___EXEC_ARGV_T_H
+#define LLVM_LIBC_TYPES___EXEC_ARGV_T_H
typedef char *const __exec_argv_t[];
-#endif // __LLVM_LIBC_TYPES_EXEC_ARGV_T_H__
+#endif // LLVM_LIBC_TYPES___EXEC_ARGV_T_H
diff --git a/libc/include/llvm-libc-types/__exec_envp_t.h b/libc/include/llvm-libc-types/__exec_envp_t.h
index 06eb2ddcb1fbd3..89e02754c4e4f4 100644
--- a/libc/include/llvm-libc-types/__exec_envp_t.h
+++ b/libc/include/llvm-libc-types/__exec_envp_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_EXEC_ENVP_T_H__
-#define __LLVM_LIBC_TYPES_EXEC_ENVP_T_H__
+#ifndef LLVM_LIBC_TYPES___EXEC_ENVP_T_H
+#define LLVM_LIBC_TYPES___EXEC_ENVP_T_H
typedef char *const __exec_envp_t[];
-#endif // __LLVM_LIBC_TYPES_EXEC_ENVP_T_H__
+#endif // LLVM_LIBC_TYPES___EXEC_ENVP_T_H
diff --git a/libc/include/llvm-libc-types/__futex_word.h b/libc/include/llvm-libc-types/__futex_word.h
index 85130ab4976ba3..04023c7e2d5ff0 100644
--- a/libc/include/llvm-libc-types/__futex_word.h
+++ b/libc/include/llvm-libc-types/__futex_word.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_FUTEX_WORD_H__
-#define __LLVM_LIBC_TYPES_FUTEX_WORD_H__
+#ifndef LLVM_LIBC_TYPES___FUTEX_WORD_H
+#define LLVM_LIBC_TYPES___FUTEX_WORD_H
typedef struct {
// Futex word should be aligned appropriately to allow target atomic
@@ -17,4 +17,4 @@ typedef struct {
: _Alignof(__UINT32_TYPE__)) __UINT32_TYPE__ __word;
} __futex_word;
-#endif // __LLVM_LIBC_TYPES_FUTEX_WORD_H__
+#endif // LLVM_LIBC_TYPES___FUTEX_WORD_H
diff --git a/libc/include/llvm-libc-types/__getoptargv_t.h b/libc/include/llvm-libc-types/__getoptargv_t.h
index 81c67286c3a766..c26b9e9fa619dd 100644
--- a/libc/include/llvm-libc-types/__getoptargv_t.h
+++ b/libc/include/llvm-libc-types/__getoptargv_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_GETOPTARGV_T_H__
-#define __LLVM_LIBC_TYPES_GETOPTARGV_T_H__
+#ifndef LLVM_LIBC_TYPES___GETOPTARGV_T_H
+#define LLVM_LIBC_TYPES___GETOPTARGV_T_H
typedef char *const __getoptargv_t[];
-#endif // __LLVM_LIBC_TYPES_GETOPTARGV_T_H__
+#endif // LLVM_LIBC_TYPES___GETOPTARGV_T_H
diff --git a/libc/include/llvm-libc-types/__mutex_type.h b/libc/include/llvm-libc-types/__mutex_type.h
index a7ed8f843c3aa5..d27bf5db83776b 100644
--- a/libc/include/llvm-libc-types/__mutex_type.h
+++ b/libc/include/llvm-libc-types/__mutex_type.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES___MUTEX_T_H
-#define __LLVM_LIBC_TYPES___MUTEX_T_H
+#ifndef LLVM_LIBC_TYPES___MUTEX_TYPE_H
+#define LLVM_LIBC_TYPES___MUTEX_TYPE_H
#include <llvm-libc-types/__futex_word.h>
@@ -26,4 +26,4 @@ typedef struct {
#endif
} __mutex_type;
-#endif // __LLVM_LIBC_TYPES___MUTEX_T_H
+#endif // LLVM_LIBC_TYPES___MUTEX_TYPE_H
diff --git a/libc/include/llvm-libc-types/__pthread_once_func_t.h b/libc/include/llvm-libc-types/__pthread_once_func_t.h
index 5ace5cb7f151ba..7575029f08c22b 100644
--- a/libc/include/llvm-libc-types/__pthread_once_func_t.h
+++ b/libc/include/llvm-libc-types/__pthread_once_func_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_PTHREAD_ONCE_FUNC_T_H__
-#define __LLVM_LIBC_TYPES_PTHREAD_ONCE_FUNC_T_H__
+#ifndef LLVM_LIBC_TYPES___PTHREAD_ONCE_FUNC_T_H
+#define LLVM_LIBC_TYPES___PTHREAD_ONCE_FUNC_T_H
typedef void (*__pthread_once_func_t)(void);
-#endif // __LLVM_LIBC_TYPES_PTHREAD_ONCE_FUNC_T_H__
+#endif // LLVM_LIBC_TYPES___PTHREAD_ONCE_FUNC_T_H
diff --git a/libc/include/llvm-libc-types/__pthread_start_t.h b/libc/include/llvm-libc-types/__pthread_start_t.h
index 1e05f9b497299c..6b7ae40b1b7760 100644
--- a/libc/include/llvm-libc-types/__pthread_start_t.h
+++ b/libc/include/llvm-libc-types/__pthread_start_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_PTHREAD_START_T_H__
-#define __LLVM_LIBC_TYPES_PTHREAD_START_T_H__
+#ifndef LLVM_LIBC_TYPES___PTHREAD_START_T_H
+#define LLVM_LIBC_TYPES___PTHREAD_START_T_H
typedef void *(*__pthread_start_t)(void *);
-#endif // __LLVM_LIBC_TYPES_PTHREAD_START_T_H__
+#endif // LLVM_LIBC_TYPES___PTHREAD_START_T_H
diff --git a/libc/include/llvm-libc-types/__pthread_tss_dtor_t.h b/libc/include/llvm-libc-types/__pthread_tss_dtor_t.h
index 1b54d31a79771a..c67b6045936d07 100644
--- a/libc/include/llvm-libc-types/__pthread_tss_dtor_t.h
+++ b/libc/include/llvm-libc-types/__pthread_tss_dtor_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_PTHREAD_TSS_DTOR_T_H__
-#define __LLVM_LIBC_TYPES_PTHREAD_TSS_DTOR_T_H__
+#ifndef LLVM_LIBC_TYPES___PTHREAD_TSS_DTOR_T_H
+#define LLVM_LIBC_TYPES___PTHREAD_TSS_DTOR_T_H
typedef void (*__pthread_tss_dtor_t)(void *);
-#endif // __LLVM_LIBC_TYPES_PTHREAD_TSS_DTOR_T_H__
+#endif // LLVM_LIBC_TYPES___PTHREAD_TSS_DTOR_T_H
diff --git a/libc/include/llvm-libc-types/__qsortcompare_t.h b/libc/include/llvm-libc-types/__qsortcompare_t.h
index 82bd4cc1fcd032..48fc9ccb44097e 100644
--- a/libc/include/llvm-libc-types/__qsortcompare_t.h
+++ b/libc/include/llvm-libc-types/__qsortcompare_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_QSORTCOMPARE_T_H__
-#define __LLVM_LIBC_TYPES_QSORTCOMPARE_T_H__
+#ifndef LLVM_LIBC_TYPES___QSORTCOMPARE_T_H
+#define LLVM_LIBC_TYPES___QSORTCOMPARE_T_H
typedef int (*__qsortcompare_t)(const void *, const void *);
-#endif // __LLVM_LIBC_TYPES_QSORTCOMPARE_T_H__
+#endif // LLVM_LIBC_TYPES___QSORTCOMPARE_T_H
diff --git a/libc/include/llvm-libc-types/__qsortrcompare_t.h b/libc/include/llvm-libc-types/__qsortrcompare_t.h
index febf79d9f90bfe..f6b058864359bd 100644
--- a/libc/include/llvm-libc-types/__qsortrcompare_t.h
+++ b/libc/include/llvm-libc-types/__qsortrcompare_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_QSORTRCOMPARE_T_H__
-#define __LLVM_LIBC_TYPES_QSORTRCOMPARE_T_H__
+#ifndef LLVM_LIBC_TYPES___QSORTRCOMPARE_T_H
+#define LLVM_LIBC_TYPES___QSORTRCOMPARE_T_H
typedef int (*__qsortrcompare_t)(const void *, const void *, void *);
-#endif // __LLVM_LIBC_TYPES_QSORTRCOMPARE_T_H__
+#endif // LLVM_LIBC_TYPES___QSORTRCOMPARE_T_H
diff --git a/libc/include/llvm-libc-types/__sighandler_t.h b/libc/include/llvm-libc-types/__sighandler_t.h
index bd0ad98d852950..9c1ac997fc4ee0 100644
--- a/libc/include/llvm-libc-types/__sighandler_t.h
+++ b/libc/include/llvm-libc-types/__sighandler_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_SIGHANDLER_T_H__
-#define __LLVM_LIBC_TYPES_SIGHANDLER_T_H__
+#ifndef LLVM_LIBC_TYPES___SIGHANDLER_T_H
+#define LLVM_LIBC_TYPES___SIGHANDLER_T_H
typedef void (*__sighandler_t)(int);
-#endif // __LLVM_LIBC_TYPES_SIGHANDLER_T_H__
+#endif // LLVM_LIBC_TYPES___SIGHANDLER_T_H
diff --git a/libc/include/llvm-libc-types/__thread_type.h b/libc/include/llvm-libc-types/__thread_type.h
index da5b898e5750fc..645573f544a99b 100644
--- a/libc/include/llvm-libc-types/__thread_type.h
+++ b/libc/include/llvm-libc-types/__thread_type.h
@@ -6,11 +6,11 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_THREAD_TYPE_H__
-#define __LLVM_LIBC_TYPES_THREAD_TYPE_H__
+#ifndef LLVM_LIBC_TYPES___THREAD_TYPE_H
+#define LLVM_LIBC_TYPES___THREAD_TYPE_H
typedef struct {
void *__attrib;
} __thread_type;
-#endif // __LLVM_LIBC_TYPES_THREAD_TYPE_H__
+#endif // LLVM_LIBC_TYPES___THREAD_TYPE_H
diff --git a/libc/include/llvm-libc-types/blkcnt_t.h b/libc/include/llvm-libc-types/blkcnt_t.h
index acd8d3467ec576..9dea8f033d6d68 100644
--- a/libc/include/llvm-libc-types/blkcnt_t.h
+++ b/libc/include/llvm-libc-types/blkcnt_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_BLKCNT_T_H__
-#define __LLVM_LIBC_TYPES_BLKCNT_T_H__
+#ifndef LLVM_LIBC_TYPES_BLKCNT_T_H
+#define LLVM_LIBC_TYPES_BLKCNT_T_H
typedef __INTPTR_TYPE__ blkcnt_t;
-#endif // __LLVM_LIBC_TYPES_BLKCNT_T_H__
+#endif // LLVM_LIBC_TYPES_BLKCNT_T_H
diff --git a/libc/include/llvm-libc-types/blksize_t.h b/libc/include/llvm-libc-types/blksize_t.h
index 99ddac56194a80..7caa9705cca396 100644
--- a/libc/include/llvm-libc-types/blksize_t.h
+++ b/libc/include/llvm-libc-types/blksize_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_BLKSIZE_T_H__
-#define __LLVM_LIBC_TYPES_BLKSIZE_T_H__
+#ifndef LLVM_LIBC_TYPES_BLKSIZE_T_H
+#define LLVM_LIBC_TYPES_BLKSIZE_T_H
typedef __INTPTR_TYPE__ blksize_t;
-#endif // __LLVM_LIBC_TYPES_BLKSIZE_T_H__
+#endif // LLVM_LIBC_TYPES_BLKSIZE_T_H
diff --git a/libc/include/llvm-libc-types/cc_t.h b/libc/include/llvm-libc-types/cc_t.h
index e08523cc3ec9e9..40d99ad22da2e7 100644
--- a/libc/include/llvm-libc-types/cc_t.h
+++ b/libc/include/llvm-libc-types/cc_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_CC_T_H__
-#define __LLVM_LIBC_TYPES_CC_T_H__
+#ifndef LLVM_LIBC_TYPES_CC_T_H
+#define LLVM_LIBC_TYPES_CC_T_H
typedef unsigned char cc_t;
-#endif // __LLVM_LIBC_TYPES_CC_T_H__
+#endif // LLVM_LIBC_TYPES_CC_T_H
diff --git a/libc/include/llvm-libc-types/clock_t.h b/libc/include/llvm-libc-types/clock_t.h
index b7969d602c6b38..8759ee999fb508 100644
--- a/libc/include/llvm-libc-types/clock_t.h
+++ b/libc/include/llvm-libc-types/clock_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_CLOCK_T_H__
-#define __LLVM_LIBC_TYPES_CLOCK_T_H__
+#ifndef LLVM_LIBC_TYPES_CLOCK_T_H
+#define LLVM_LIBC_TYPES_CLOCK_T_H
typedef long clock_t;
-#endif // __LLVM_LIBC_TYPES_CLOCK_T_H__
+#endif // LLVM_LIBC_TYPES_CLOCK_T_H
diff --git a/libc/include/llvm-libc-types/clockid_t.h b/libc/include/llvm-libc-types/clockid_t.h
index ddaceb664ec125..4b059599502c44 100644
--- a/libc/include/llvm-libc-types/clockid_t.h
+++ b/libc/include/llvm-libc-types/clockid_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_CLOCKID_T_H__
-#define __LLVM_LIBC_TYPES_CLOCKID_T_H__
+#ifndef LLVM_LIBC_TYPES_CLOCKID_T_H
+#define LLVM_LIBC_TYPES_CLOCKID_T_H
typedef int clockid_t;
-#endif // __LLVM_LIBC_TYPES_CLOCKID_T_H__
+#endif // LLVM_LIBC_TYPES_CLOCKID_T_H
diff --git a/libc/include/llvm-libc-types/cnd_t.h b/libc/include/llvm-libc-types/cnd_t.h
index 09a29ac43dee62..1159ac43579215 100644
--- a/libc/include/llvm-libc-types/cnd_t.h
+++ b/libc/include/llvm-libc-types/cnd_t.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_CND_T_H__
-#define __LLVM_LIBC_TYPES_CND_T_H__
+#ifndef LLVM_LIBC_TYPES_CND_T_H
+#define LLVM_LIBC_TYPES_CND_T_H
#include "mtx_t.h"
@@ -17,4 +17,4 @@ typedef struct {
mtx_t __qmtx;
} cnd_t;
-#endif // __LLVM_LIBC_TYPES_CND_T_H__
+#endif // LLVM_LIBC_TYPES_CND_T_H
diff --git a/libc/include/llvm-libc-types/cookie_io_functions_t.h b/libc/include/llvm-libc-types/cookie_io_functions_t.h
index df904162a89709..f9fa1a2d50ed05 100644
--- a/libc/include/llvm-libc-types/cookie_io_functions_t.h
+++ b/libc/include/llvm-libc-types/cookie_io_functions_t.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_COOKIE_IO_FUNCTIONS_T_H
-#define __LLVM_LIBC_TYPES_COOKIE_IO_FUNCTIONS_T_H
+#ifndef LLVM_LIBC_TYPES_COOKIE_IO_FUNCTIONS_T_H
+#define LLVM_LIBC_TYPES_COOKIE_IO_FUNCTIONS_T_H
#include <llvm-libc-types/off64_t.h>
#include <llvm-libc-types/size_t.h>
@@ -25,4 +25,4 @@ typedef struct {
cookie_close_function_t *close;
} cookie_io_functions_t;
-#endif // __LLVM_LIBC_TYPES_COOKIE_IO_FUNCTIONS_T_H
+#endif // LLVM_LIBC_TYPES_COOKIE_IO_FUNCTIONS_T_H
diff --git a/libc/include/llvm-libc-types/cpu_set_t.h b/libc/include/llvm-libc-types/cpu_set_t.h
index 79f694aeda60fd..e7f52597e147e1 100644
--- a/libc/include/llvm-libc-types/cpu_set_t.h
+++ b/libc/include/llvm-libc-types/cpu_set_t.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_CPU_SET_T_H
-#define __LLVM_LIBC_TYPES_CPU_SET_T_H
+#ifndef LLVM_LIBC_TYPES_CPU_SET_T_H
+#define LLVM_LIBC_TYPES_CPU_SET_T_H
typedef struct {
// If a processor with more than 1024 CPUs is to be supported in future,
@@ -15,4 +15,4 @@ typedef struct {
unsigned long __mask[128 / sizeof(unsigned long)];
} cpu_set_t;
-#endif // __LLVM_LIBC_TYPES_CPU_SET_T_H
+#endif // LLVM_LIBC_TYPES_CPU_SET_T_H
diff --git a/libc/include/llvm-libc-types/dev_t.h b/libc/include/llvm-libc-types/dev_t.h
index 9fbc41a49b8984..3181e3415f2ef4 100644
--- a/libc/include/llvm-libc-types/dev_t.h
+++ b/libc/include/llvm-libc-types/dev_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_DEV_T_H__
-#define __LLVM_LIBC_TYPES_DEV_T_H__
+#ifndef LLVM_LIBC_TYPES_DEV_T_H
+#define LLVM_LIBC_TYPES_DEV_T_H
typedef __UINT64_TYPE__ dev_t;
-#endif // __LLVM_LIBC_TYPES_DEV_T_H__
+#endif // LLVM_LIBC_TYPES_DEV_T_H
diff --git a/libc/include/llvm-libc-types/div_t.h b/libc/include/llvm-libc-types/div_t.h
index e495a1c3f9dcc6..450603d69f35f6 100644
--- a/libc/include/llvm-libc-types/div_t.h
+++ b/libc/include/llvm-libc-types/div_t.h
@@ -6,12 +6,12 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_DIV_T_H__
-#define __LLVM_LIBC_TYPES_DIV_T_H__
+#ifndef LLVM_LIBC_TYPES_DIV_T_H
+#define LLVM_LIBC_TYPES_DIV_T_H
typedef struct {
int quot;
int rem;
} div_t;
-#endif // __LLVM_LIBC_TYPES_DIV_T_H__
+#endif // LLVM_LIBC_TYPES_DIV_T_H
diff --git a/libc/include/llvm-libc-types/double_t.h b/libc/include/llvm-libc-types/double_t.h
index 2aa471de4840f1..c4ad08afddfa78 100644
--- a/libc/include/llvm-libc-types/double_t.h
+++ b/libc/include/llvm-libc-types/double_t.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_DOUBLE_T_H__
-#define __LLVM_LIBC_TYPES_DOUBLE_T_H__
+#ifndef LLVM_LIBC_TYPES_DOUBLE_T_H
+#define LLVM_LIBC_TYPES_DOUBLE_T_H
#if !defined(__FLT_EVAL_METHOD__) || __FLT_EVAL_METHOD__ == 0
#define __LLVM_LIBC_DOUBLE_T double
@@ -21,4 +21,4 @@
typedef __LLVM_LIBC_DOUBLE_T double_t;
-#endif // __LLVM_LIBC_TYPES_DOUBLE_T_H__
+#endif // LLVM_LIBC_TYPES_DOUBLE_T_H
diff --git a/libc/include/llvm-libc-types/fd_set.h b/libc/include/llvm-libc-types/fd_set.h
index 54e3fc654c0677..58fc438bbdd285 100644
--- a/libc/include/llvm-libc-types/fd_set.h
+++ b/libc/include/llvm-libc-types/fd_set.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_FD_SET_H__
-#define __LLVM_LIBC_TYPES_FD_SET_H__
+#ifndef LLVM_LIBC_TYPES_FD_SET_H
+#define LLVM_LIBC_TYPES_FD_SET_H
#include <llvm-libc-macros/sys-select-macros.h> // FD_SETSIZE
@@ -15,4 +15,4 @@ typedef struct {
__FD_SET_WORD_TYPE __set[__FD_SET_ARRAYSIZE];
} fd_set;
-#endif // __LLVM_LIBC_TYPES_FD_SET_H__
+#endif // LLVM_LIBC_TYPES_FD_SET_H
diff --git a/libc/include/llvm-libc-types/fenv_t.h b/libc/include/llvm-libc-types/fenv_t.h
index 86fcf2e49a7fff..c83f23894c0c81 100644
--- a/libc/include/llvm-libc-types/fenv_t.h
+++ b/libc/include/llvm-libc-types/fenv_t.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_FENV_T_H__
-#define __LLVM_LIBC_TYPES_FENV_T_H__
+#ifndef LLVM_LIBC_TYPES_FENV_T_H
+#define LLVM_LIBC_TYPES_FENV_T_H
#ifdef __aarch64__
typedef struct {
@@ -33,4 +33,4 @@ typedef struct {
#error "fenv_t not defined for your platform"
#endif
-#endif // __LLVM_LIBC_TYPES_FENV_T_H__
+#endif // LLVM_LIBC_TYPES_FENV_T_H
diff --git a/libc/include/llvm-libc-types/fexcept_t.h b/libc/include/llvm-libc-types/fexcept_t.h
index 6e7969c1be0a82..60687bd1318aa4 100644
--- a/libc/include/llvm-libc-types/fexcept_t.h
+++ b/libc/include/llvm-libc-types/fexcept_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_FEXCEPT_T_H__
-#define __LLVM_LIBC_TYPES_FEXCEPT_T_H__
+#ifndef LLVM_LIBC_TYPES_FEXCEPT_T_H
+#define LLVM_LIBC_TYPES_FEXCEPT_T_H
typedef int fexcept_t;
-#endif // __LLVM_LIBC_TYPES_FEXCEPT_T_H__
+#endif // LLVM_LIBC_TYPES_FEXCEPT_T_H
diff --git a/libc/include/llvm-libc-types/float128.h b/libc/include/llvm-libc-types/float128.h
index 1907a5e3ece727..e2dc18c040d99e 100644
--- a/libc/include/llvm-libc-types/float128.h
+++ b/libc/include/llvm-libc-types/float128.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_FLOAT128_H__
-#define __LLVM_LIBC_TYPES_FLOAT128_H__
+#ifndef LLVM_LIBC_TYPES_FLOAT128_H
+#define LLVM_LIBC_TYPES_FLOAT128_H
#include "llvm-libc-macros/float-macros.h" // LDBL_MANT_DIG
@@ -34,4 +34,4 @@ typedef __float128 float128;
typedef long double float128;
#endif
-#endif // __LLVM_LIBC_TYPES_FLOAT128_H__
+#endif // LLVM_LIBC_TYPES_FLOAT128_H
diff --git a/libc/include/llvm-libc-types/float_t.h b/libc/include/llvm-libc-types/float_t.h
index 8df3bf05f6a129..5027249c30d387 100644
--- a/libc/include/llvm-libc-types/float_t.h
+++ b/libc/include/llvm-libc-types/float_t.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_FLOAT_T_H__
-#define __LLVM_LIBC_TYPES_FLOAT_T_H__
+#ifndef LLVM_LIBC_TYPES_FLOAT_T_H
+#define LLVM_LIBC_TYPES_FLOAT_T_H
#if !defined(__FLT_EVAL_METHOD__) || __FLT_EVAL_METHOD__ == 0
#define __LLVM_LIBC_FLOAT_T float
@@ -21,4 +21,4 @@
typedef __LLVM_LIBC_FLOAT_T float_t;
-#endif // __LLVM_LIBC_TYPES_FLOAT_T_H__
+#endif // LLVM_LIBC_TYPES_FLOAT_T_H
diff --git a/libc/include/llvm-libc-types/gid_t.h b/libc/include/llvm-libc-types/gid_t.h
index 664aee020a4e79..cfe36ce9906b85 100644
--- a/libc/include/llvm-libc-types/gid_t.h
+++ b/libc/include/llvm-libc-types/gid_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_GID_T_H__
-#define __LLVM_LIBC_TYPES_GID_T_H__
+#ifndef LLVM_LIBC_TYPES_GID_T_H
+#define LLVM_LIBC_TYPES_GID_T_H
typedef __UINT32_TYPE__ gid_t;
-#endif // __LLVM_LIBC_TYPES_GID_T_H__
+#endif // LLVM_LIBC_TYPES_GID_T_H
diff --git a/libc/include/llvm-libc-types/ino_t.h b/libc/include/llvm-libc-types/ino_t.h
index 0f5abd96c2b742..148bd67f98fef7 100644
--- a/libc/include/llvm-libc-types/ino_t.h
+++ b/libc/include/llvm-libc-types/ino_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_INO_T_H__
-#define __LLVM_LIBC_TYPES_INO_T_H__
+#ifndef LLVM_LIBC_TYPES_INO_T_H
+#define LLVM_LIBC_TYPES_INO_T_H
typedef __UINTPTR_TYPE__ ino_t;
-#endif // __LLVM_LIBC_TYPES_INO_T_H__
+#endif // LLVM_LIBC_TYPES_INO_T_H
diff --git a/libc/include/llvm-libc-types/jmp_buf.h b/libc/include/llvm-libc-types/jmp_buf.h
index 6af4e8ebad92ca..29a1df9ad6823a 100644
--- a/libc/include/llvm-libc-types/jmp_buf.h
+++ b/libc/include/llvm-libc-types/jmp_buf.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_JMP_BUF_H__
-#define __LLVM_LIBC_TYPES_JMP_BUF_H__
+#ifndef LLVM_LIBC_TYPES_JMP_BUF_H
+#define LLVM_LIBC_TYPES_JMP_BUF_H
typedef struct {
#ifdef __x86_64__
@@ -39,4 +39,4 @@ typedef struct {
typedef __jmp_buf jmp_buf[1];
-#endif // __LLVM_LIBC_TYPES_JMP_BUF_H__
+#endif // LLVM_LIBC_TYPES_JMP_BUF_H
diff --git a/libc/include/llvm-libc-types/ldiv_t.h b/libc/include/llvm-libc-types/ldiv_t.h
index 9bd8d253330a06..5c64ec10d91850 100644
--- a/libc/include/llvm-libc-types/ldiv_t.h
+++ b/libc/include/llvm-libc-types/ldiv_t.h
@@ -6,12 +6,12 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_LDIV_T_H__
-#define __LLVM_LIBC_TYPES_LDIV_T_H__
+#ifndef LLVM_LIBC_TYPES_LDIV_T_H
+#define LLVM_LIBC_TYPES_LDIV_T_H
typedef struct {
long quot;
long rem;
} ldiv_t;
-#endif // __LLVM_LIBC_TYPES_LDIV_T_H__
+#endif // LLVM_LIBC_TYPES_LDIV_T_H
diff --git a/libc/include/llvm-libc-types/lldiv_t.h b/libc/include/llvm-libc-types/lldiv_t.h
index 109304d1207872..5b8dcbef94708f 100644
--- a/libc/include/llvm-libc-types/lldiv_t.h
+++ b/libc/include/llvm-libc-types/lldiv_t.h
@@ -6,12 +6,12 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_LLDIV_T_H__
-#define __LLVM_LIBC_TYPES_LLDIV_T_H__
+#ifndef LLVM_LIBC_TYPES_LLDIV_T_H
+#define LLVM_LIBC_TYPES_LLDIV_T_H
typedef struct {
long long quot;
long long rem;
} lldiv_t;
-#endif // __LLVM_LIBC_TYPES_LLDIV_T_H__
+#endif // LLVM_LIBC_TYPES_LLDIV_T_H
diff --git a/libc/include/llvm-libc-types/mode_t.h b/libc/include/llvm-libc-types/mode_t.h
index 20037bb9ac8fc6..fe09060d9a6e87 100644
--- a/libc/include/llvm-libc-types/mode_t.h
+++ b/libc/include/llvm-libc-types/mode_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_MODE_T_H
-#define __LLVM_LIBC_TYPES_MODE_T_H
+#ifndef LLVM_LIBC_TYPES_MODE_T_H
+#define LLVM_LIBC_TYPES_MODE_T_H
typedef unsigned mode_t;
-#endif // __LLVM_LIBC_TYPES_MODE_T_H
+#endif // LLVM_LIBC_TYPES_MODE_T_H
diff --git a/libc/include/llvm-libc-types/mtx_t.h b/libc/include/llvm-libc-types/mtx_t.h
index ac6453eeabf034..0f3882c26b6bc2 100644
--- a/libc/include/llvm-libc-types/mtx_t.h
+++ b/libc/include/llvm-libc-types/mtx_t.h
@@ -6,11 +6,11 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_MTX_T_H__
-#define __LLVM_LIBC_TYPES_MTX_T_H__
+#ifndef LLVM_LIBC_TYPES_MTX_T_H
+#define LLVM_LIBC_TYPES_MTX_T_H
#include <llvm-libc-types/__mutex_type.h>
typedef __mutex_type mtx_t;
-#endif // __LLVM_LIBC_TYPES_MTX_T_H__
+#endif // LLVM_LIBC_TYPES_MTX_T_H
diff --git a/libc/include/llvm-libc-types/nlink_t.h b/libc/include/llvm-libc-types/nlink_t.h
index 1826144b3c88cf..7e0016a9af95fb 100644
--- a/libc/include/llvm-libc-types/nlink_t.h
+++ b/libc/include/llvm-libc-types/nlink_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_NLINK_T_H__
-#define __LLVM_LIBC_TYPES_NLINK_T_H__
+#ifndef LLVM_LIBC_TYPES_NLINK_T_H
+#define LLVM_LIBC_TYPES_NLINK_T_H
typedef __UINTPTR_TYPE__ nlink_t;
-#endif // __LLVM_LIBC_TYPES_NLINK_T_H__
+#endif // LLVM_LIBC_TYPES_NLINK_T_H
diff --git a/libc/include/llvm-libc-types/off64_t.h b/libc/include/llvm-libc-types/off64_t.h
index 0f95caa19cca22..669698a8c05f89 100644
--- a/libc/include/llvm-libc-types/off64_t.h
+++ b/libc/include/llvm-libc-types/off64_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_OFF64_T_H__
-#define __LLVM_LIBC_TYPES_OFF64_T_H__
+#ifndef LLVM_LIBC_TYPES_OFF64_T_H
+#define LLVM_LIBC_TYPES_OFF64_T_H
typedef __INT64_TYPE__ off64_t;
-#endif // __LLVM_LIBC_TYPES_OFF64_T_H__
+#endif // LLVM_LIBC_TYPES_OFF64_T_H
diff --git a/libc/include/llvm-libc-types/off_t.h b/libc/include/llvm-libc-types/off_t.h
index 111b29aa68d875..63224b6831d557 100644
--- a/libc/include/llvm-libc-types/off_t.h
+++ b/libc/include/llvm-libc-types/off_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_OFF_T_H__
-#define __LLVM_LIBC_TYPES_OFF_T_H__
+#ifndef LLVM_LIBC_TYPES_OFF_T_H
+#define LLVM_LIBC_TYPES_OFF_T_H
typedef __INT64_TYPE__ off_t;
-#endif // __LLVM_LIBC_TYPES_OFF_T_H__
+#endif // LLVM_LIBC_TYPES_OFF_T_H
diff --git a/libc/include/llvm-libc-types/once_flag.h b/libc/include/llvm-libc-types/once_flag.h
index 77bab28338a02c..cb801128461023 100644
--- a/libc/include/llvm-libc-types/once_flag.h
+++ b/libc/include/llvm-libc-types/once_flag.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_ONCE_FLAG_H__
-#define __LLVM_LIBC_TYPES_ONCE_FLAG_H__
+#ifndef LLVM_LIBC_TYPES_ONCE_FLAG_H
+#define LLVM_LIBC_TYPES_ONCE_FLAG_H
#include <llvm-libc-types/__futex_word.h>
@@ -17,4 +17,4 @@ typedef __futex_word once_flag;
#error "Once flag type not defined for the target platform."
#endif
-#endif // __LLVM_LIBC_TYPES_ONCE_FLAG_H__
+#endif // LLVM_LIBC_TYPES_ONCE_FLAG_H
diff --git a/libc/include/llvm-libc-types/pid_t.h b/libc/include/llvm-libc-types/pid_t.h
index d78fde74f34ad0..0397bd24903293 100644
--- a/libc/include/llvm-libc-types/pid_t.h
+++ b/libc/include/llvm-libc-types/pid_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_PID_t_H__
-#define __LLVM_LIBC_TYPES_PID_t_H__
+#ifndef LLVM_LIBC_TYPES_PID_T_H
+#define LLVM_LIBC_TYPES_PID_T_H
typedef __INT32_TYPE__ pid_t;
-#endif // __LLVM_LIBC_TYPES_PID_t_H__
+#endif // LLVM_LIBC_TYPES_PID_T_H
diff --git a/libc/include/llvm-libc-types/posix_spawn_file_actions_t.h b/libc/include/llvm-libc-types/posix_spawn_file_actions_t.h
index 55adbd198de85c..3062da3a54b566 100644
--- a/libc/include/llvm-libc-types/posix_spawn_file_actions_t.h
+++ b/libc/include/llvm-libc-types/posix_spawn_file_actions_t.h
@@ -6,12 +6,12 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_POSIX_SPAWN_FILE_ACTIONS_T_T_H
-#define __LLVM_LIBC_TYPES_POSIX_SPAWN_FILE_ACTIONS_T_T_H
+#ifndef LLVM_LIBC_TYPES_POSIX_SPAWN_FILE_ACTIONS_T_H
+#define LLVM_LIBC_TYPES_POSIX_SPAWN_FILE_ACTIONS_T_H
typedef struct {
void *__front;
void *__back;
} posix_spawn_file_actions_t;
-#endif // __LLVM_LIBC_TYPES_POSIX_SPAWN_FILE_ACTIONS_T_T_H
+#endif // LLVM_LIBC_TYPES_POSIX_SPAWN_FILE_ACTIONS_T_H
diff --git a/libc/include/llvm-libc-types/posix_spawnattr_t.h b/libc/include/llvm-libc-types/posix_spawnattr_t.h
index f1bcb3e1434f85..47cadc7cdda17b 100644
--- a/libc/include/llvm-libc-types/posix_spawnattr_t.h
+++ b/libc/include/llvm-libc-types/posix_spawnattr_t.h
@@ -6,11 +6,11 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_POSIX_SPAWNATTR_T_H
-#define __LLVM_LIBC_TYPES_POSIX_SPAWNATTR_T_H
+#ifndef LLVM_LIBC_TYPES_POSIX_SPAWNATTR_T_H
+#define LLVM_LIBC_TYPES_POSIX_SPAWNATTR_T_H
typedef struct {
// This data structure will be populated as required.
} posix_spawnattr_t;
-#endif // __LLVM_LIBC_TYPES_POSIX_SPAWNATTR_T_H
+#endif // LLVM_LIBC_TYPES_POSIX_SPAWNATTR_T_H
diff --git a/libc/include/llvm-libc-types/pthread_attr_t.h b/libc/include/llvm-libc-types/pthread_attr_t.h
index 7bf8a5402f283f..66c04de04a99b2 100644
--- a/libc/include/llvm-libc-types/pthread_attr_t.h
+++ b/libc/include/llvm-libc-types/pthread_attr_t.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_PTHREAD_ATTR_T_H
-#define __LLVM_LIBC_TYPES_PTHREAD_ATTR_T_H
+#ifndef LLVM_LIBC_TYPES_PTHREAD_ATTR_T_H
+#define LLVM_LIBC_TYPES_PTHREAD_ATTR_T_H
#include <llvm-libc-types/size_t.h>
@@ -18,4 +18,4 @@ typedef struct {
size_t __guardsize;
} pthread_attr_t;
-#endif // __LLVM_LIBC_TYPES_PTHREAD_ATTR_T_H
+#endif // LLVM_LIBC_TYPES_PTHREAD_ATTR_T_H
diff --git a/libc/include/llvm-libc-types/pthread_key_t.h b/libc/include/llvm-libc-types/pthread_key_t.h
index 351e37614a01ee..e73c7e26c17cca 100644
--- a/libc/include/llvm-libc-types/pthread_key_t.h
+++ b/libc/include/llvm-libc-types/pthread_key_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_PTHREAD_KEY_T_H__
-#define __LLVM_LIBC_TYPES_PTHREAD_KEY_T_H__
+#ifndef LLVM_LIBC_TYPES_PTHREAD_KEY_T_H
+#define LLVM_LIBC_TYPES_PTHREAD_KEY_T_H
typedef unsigned int pthread_key_t;
-#endif // __LLVM_LIBC_TYPES_PTHREAD_KEY_T_H__
+#endif // LLVM_LIBC_TYPES_PTHREAD_KEY_T_H
diff --git a/libc/include/llvm-libc-types/pthread_mutex_t.h b/libc/include/llvm-libc-types/pthread_mutex_t.h
index 65e43538cd27d4..b1eb21f24fac52 100644
--- a/libc/include/llvm-libc-types/pthread_mutex_t.h
+++ b/libc/include/llvm-libc-types/pthread_mutex_t.h
@@ -6,11 +6,11 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_PTHREAD_MUTEX_T_H
-#define __LLVM_LIBC_TYPES_PTHREAD_MUTEX_T_H
+#ifndef LLVM_LIBC_TYPES_PTHREAD_MUTEX_T_H
+#define LLVM_LIBC_TYPES_PTHREAD_MUTEX_T_H
#include <llvm-libc-types/__mutex_type.h>
typedef __mutex_type pthread_mutex_t;
-#endif // __LLVM_LIBC_TYPES_PTHREAD_MUTEX_T_H
+#endif // LLVM_LIBC_TYPES_PTHREAD_MUTEX_T_H
diff --git a/libc/include/llvm-libc-types/pthread_mutexattr_t.h b/libc/include/llvm-libc-types/pthread_mutexattr_t.h
index be1ff5611ed4a7..8f159a61420c7e 100644
--- a/libc/include/llvm-libc-types/pthread_mutexattr_t.h
+++ b/libc/include/llvm-libc-types/pthread_mutexattr_t.h
@@ -6,11 +6,11 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_PTHREAD_MUTEXATTR_T_H
-#define __LLVM_LIBC_TYPES_PTHREAD_MUTEXATTR_T_H
+#ifndef LLVM_LIBC_TYPES_PTHREAD_MUTEXATTR_T_H
+#define LLVM_LIBC_TYPES_PTHREAD_MUTEXATTR_T_H
// pthread_mutexattr_t is a collection bit mapped flags. The mapping is internal
// detail of the libc implementation.
typedef unsigned int pthread_mutexattr_t;
-#endif // __LLVM_LIBC_TYPES_PTHREAD_MUTEXATTR_T_H
+#endif // LLVM_LIBC_TYPES_PTHREAD_MUTEXATTR_T_H
diff --git a/libc/include/llvm-libc-types/pthread_once_t.h b/libc/include/llvm-libc-types/pthread_once_t.h
index 6d65f8f7405219..3fe78b7ddff662 100644
--- a/libc/include/llvm-libc-types/pthread_once_t.h
+++ b/libc/include/llvm-libc-types/pthread_once_t.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_PTHREAD_ONCE_T_H__
-#define __LLVM_LIBC_TYPES_PTHREAD_ONCE_T_H__
+#ifndef LLVM_LIBC_TYPES_PTHREAD_ONCE_T_H
+#define LLVM_LIBC_TYPES_PTHREAD_ONCE_T_H
#include <llvm-libc-types/__futex_word.h>
@@ -17,4 +17,4 @@ typedef __futex_word pthread_once_t;
#error "Once flag type not defined for the target platform."
#endif
-#endif // __LLVM_LIBC_TYPES_PTHREAD_ONCE_T_H__
+#endif // LLVM_LIBC_TYPES_PTHREAD_ONCE_T_H
diff --git a/libc/include/llvm-libc-types/pthread_t.h b/libc/include/llvm-libc-types/pthread_t.h
index 8130491274efb0..72c14e1c2eea8f 100644
--- a/libc/include/llvm-libc-types/pthread_t.h
+++ b/libc/include/llvm-libc-types/pthread_t.h
@@ -6,11 +6,11 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_PTHREAD_T_H__
-#define __LLVM_LIBC_TYPES_PTHREAD_T_H__
+#ifndef LLVM_LIBC_TYPES_PTHREAD_T_H
+#define LLVM_LIBC_TYPES_PTHREAD_T_H
#include <llvm-libc-types/__thread_type.h>
typedef __thread_type pthread_t;
-#endif // __LLVM_LIBC_TYPES_PTHREAD_T_H__
+#endif // LLVM_LIBC_TYPES_PTHREAD_T_H
diff --git a/libc/include/llvm-libc-types/rlim_t.h b/libc/include/llvm-libc-types/rlim_t.h
index 4e5acfb24c1b5b..016ec7bdc5b1d5 100644
--- a/libc/include/llvm-libc-types/rlim_t.h
+++ b/libc/include/llvm-libc-types/rlim_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_RLIM_T_H__
-#define __LLVM_LIBC_TYPES_RLIM_T_H__
+#ifndef LLVM_LIBC_TYPES_RLIM_T_H
+#define LLVM_LIBC_TYPES_RLIM_T_H
typedef __UINT64_TYPE__ rlim_t;
-#endif // __LLVM_LIBC_TYPES_RLIM_T_H__
+#endif // LLVM_LIBC_TYPES_RLIM_T_H
diff --git a/libc/include/llvm-libc-types/rpc_opcodes_t.h b/libc/include/llvm-libc-types/rpc_opcodes_t.h
index 7b85428dd3445e..919ea039c18e32 100644
--- a/libc/include/llvm-libc-types/rpc_opcodes_t.h
+++ b/libc/include/llvm-libc-types/rpc_opcodes_t.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_RPC_OPCODE_H__
-#define __LLVM_LIBC_TYPES_RPC_OPCODE_H__
+#ifndef LLVM_LIBC_TYPES_RPC_OPCODES_T_H
+#define LLVM_LIBC_TYPES_RPC_OPCODES_T_H
typedef enum {
RPC_NOOP = 0,
@@ -34,4 +34,4 @@ typedef enum {
RPC_LAST = 0xFFFF,
} rpc_opcode_t;
-#endif // __LLVM_LIBC_TYPES_RPC_OPCODE_H__
+#endif // LLVM_LIBC_TYPES_RPC_OPCODES_T_H
diff --git a/libc/include/llvm-libc-types/sa_family_t.h b/libc/include/llvm-libc-types/sa_family_t.h
index 52b69957b0d3fa..0a010b678ddbea 100644
--- a/libc/include/llvm-libc-types/sa_family_t.h
+++ b/libc/include/llvm-libc-types/sa_family_t.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_SA_FAMILY_T_H__
-#define __LLVM_LIBC_TYPES_SA_FAMILY_T_H__
+#ifndef LLVM_LIBC_TYPES_SA_FAMILY_T_H
+#define LLVM_LIBC_TYPES_SA_FAMILY_T_H
// The posix standard only says of sa_family_t that it must be unsigned. The
// linux man page for "address_families" lists approximately 32 different
@@ -16,4 +16,4 @@
typedef unsigned short sa_family_t;
-#endif // __LLVM_LIBC_TYPES_SA_FAMILY_T_H__
+#endif // LLVM_LIBC_TYPES_SA_FAMILY_T_H
diff --git a/libc/include/llvm-libc-types/sig_atomic_t.h b/libc/include/llvm-libc-types/sig_atomic_t.h
index 324629c1b55c31..2ef37580679126 100644
--- a/libc/include/llvm-libc-types/sig_atomic_t.h
+++ b/libc/include/llvm-libc-types/sig_atomic_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_SIG_ATOMIC_T_H__
-#define __LLVM_LIBC_TYPES_SIG_ATOMIC_T_H__
+#ifndef LLVM_LIBC_TYPES_SIG_ATOMIC_T_H
+#define LLVM_LIBC_TYPES_SIG_ATOMIC_T_H
typedef int sig_atomic_t;
-#endif // __LLVM_LIBC_TYPES_SIG_ATOMIC_T_H__
+#endif // LLVM_LIBC_TYPES_SIG_ATOMIC_T_H
diff --git a/libc/include/llvm-libc-types/siginfo_t.h b/libc/include/llvm-libc-types/siginfo_t.h
index ef8af78a88be69..935ef4bbcb723b 100644
--- a/libc/include/llvm-libc-types/siginfo_t.h
+++ b/libc/include/llvm-libc-types/siginfo_t.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_SIGINFO_T_H__
-#define __LLVM_LIBC_TYPES_SIGINFO_T_H__
+#ifndef LLVM_LIBC_TYPES_SIGINFO_T_H
+#define LLVM_LIBC_TYPES_SIGINFO_T_H
#include <llvm-libc-types/clock_t.h>
#include <llvm-libc-types/pid_t.h>
@@ -106,4 +106,4 @@ typedef struct {
#define si_syscall _sifields._sigsys._syscall
#define si_arch _sifields._sigsys._arch
-#endif // __LLVM_LIBC_TYPES_SIGINFO_T_H__
+#endif // LLVM_LIBC_TYPES_SIGINFO_T_H
diff --git a/libc/include/llvm-libc-types/sigset_t.h b/libc/include/llvm-libc-types/sigset_t.h
index bcfbc29996ae42..f159c6c6c6435b 100644
--- a/libc/include/llvm-libc-types/sigset_t.h
+++ b/libc/include/llvm-libc-types/sigset_t.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_SIGSET_T_H__
-#define __LLVM_LIBC_TYPES_SIGSET_T_H__
+#ifndef LLVM_LIBC_TYPES_SIGSET_T_H
+#define LLVM_LIBC_TYPES_SIGSET_T_H
#include <llvm-libc-macros/signal-macros.h>
@@ -17,4 +17,4 @@ typedef struct {
unsigned long __signals[__NSIGSET_WORDS];
} sigset_t;
-#endif // __LLVM_LIBC_TYPES_SIGSET_T_H__
+#endif // LLVM_LIBC_TYPES_SIGSET_T_H
diff --git a/libc/include/llvm-libc-types/size_t.h b/libc/include/llvm-libc-types/size_t.h
index 8eaf194e057272..3b31b0820f2372 100644
--- a/libc/include/llvm-libc-types/size_t.h
+++ b/libc/include/llvm-libc-types/size_t.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_SIZE_T_H__
-#define __LLVM_LIBC_TYPES_SIZE_T_H__
+#ifndef LLVM_LIBC_TYPES_SIZE_T_H
+#define LLVM_LIBC_TYPES_SIZE_T_H
// Since __need_size_t is defined, we get the definition of size_t from the
// standalone C header stddef.h. Also, because __need_size_t is defined,
@@ -16,4 +16,4 @@
#include <stddef.h>
#undef __need_size_t
-#endif // __LLVM_LIBC_TYPES_SIZE_T_H__
+#endif // LLVM_LIBC_TYPES_SIZE_T_H
diff --git a/libc/include/llvm-libc-types/socklen_t.h b/libc/include/llvm-libc-types/socklen_t.h
index 3134a53390e71e..5357747f5b8366 100644
--- a/libc/include/llvm-libc-types/socklen_t.h
+++ b/libc/include/llvm-libc-types/socklen_t.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_SOCKLEN_T_H__
-#define __LLVM_LIBC_TYPES_SOCKLEN_T_H__
+#ifndef LLVM_LIBC_TYPES_SOCKLEN_T_H
+#define LLVM_LIBC_TYPES_SOCKLEN_T_H
// The posix standard only says of socklen_t that it must be an integer type of
// width of at least 32 bits. The long type is defined as being at least 32
@@ -15,4 +15,4 @@
typedef unsigned long socklen_t;
-#endif // __LLVM_LIBC_TYPES_SOCKLEN_T_H__
+#endif // LLVM_LIBC_TYPES_SOCKLEN_T_H
diff --git a/libc/include/llvm-libc-types/speed_t.h b/libc/include/llvm-libc-types/speed_t.h
index b4ec13df27b558..9875d3b82a692b 100644
--- a/libc/include/llvm-libc-types/speed_t.h
+++ b/libc/include/llvm-libc-types/speed_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_SPEED_T_H__
-#define __LLVM_LIBC_TYPES_SPEED_T_H__
+#ifndef LLVM_LIBC_TYPES_SPEED_T_H
+#define LLVM_LIBC_TYPES_SPEED_T_H
typedef unsigned int speed_t;
-#endif // __LLVM_LIBC_TYPES_SPEED_T_H__
+#endif // LLVM_LIBC_TYPES_SPEED_T_H
diff --git a/libc/include/llvm-libc-types/ssize_t.h b/libc/include/llvm-libc-types/ssize_t.h
index b8874538b1bf45..41e4b6d2c500ad 100644
--- a/libc/include/llvm-libc-types/ssize_t.h
+++ b/libc/include/llvm-libc-types/ssize_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_SSIZE_T_H__
-#define __LLVM_LIBC_TYPES_SSIZE_T_H__
+#ifndef LLVM_LIBC_TYPES_SSIZE_T_H
+#define LLVM_LIBC_TYPES_SSIZE_T_H
typedef __INT64_TYPE__ ssize_t;
-#endif // __LLVM_LIBC_TYPES_SSIZE_T_H__
+#endif // LLVM_LIBC_TYPES_SSIZE_T_H
diff --git a/libc/include/llvm-libc-types/stack_t.h b/libc/include/llvm-libc-types/stack_t.h
index f564d9134010bf..5fa4d3a6d3dc94 100644
--- a/libc/include/llvm-libc-types/stack_t.h
+++ b/libc/include/llvm-libc-types/stack_t.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_STACK_T_H__
-#define __LLVM_LIBC_TYPES_STACK_T_H__
+#ifndef LLVM_LIBC_TYPES_STACK_T_H
+#define LLVM_LIBC_TYPES_STACK_T_H
#include <llvm-libc-types/size_t.h>
@@ -19,4 +19,4 @@ typedef struct {
size_t ss_size;
} stack_t;
-#endif // __LLVM_LIBC_TYPES_STACK_T_H__
+#endif // LLVM_LIBC_TYPES_STACK_T_H
diff --git a/libc/include/llvm-libc-types/struct_dirent.h b/libc/include/llvm-libc-types/struct_dirent.h
index de54a2262446f5..3c5b361c3cbcf5 100644
--- a/libc/include/llvm-libc-types/struct_dirent.h
+++ b/libc/include/llvm-libc-types/struct_dirent.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_STRUCT_DIRENT_H__
-#define __LLVM_LIBC_TYPES_STRUCT_DIRENT_H__
+#ifndef LLVM_LIBC_TYPES_STRUCT_DIRENT_H
+#define LLVM_LIBC_TYPES_STRUCT_DIRENT_H
#include <llvm-libc-types/ino_t.h>
#include <llvm-libc-types/off_t.h>
@@ -26,4 +26,4 @@ struct dirent {
char d_name[1];
};
-#endif // __LLVM_LIBC_TYPES_STRUCT_DIRENT_H__
+#endif // LLVM_LIBC_TYPES_STRUCT_DIRENT_H
diff --git a/libc/include/llvm-libc-types/struct_epoll_data.h b/libc/include/llvm-libc-types/struct_epoll_data.h
index c363171089f116..7200276a141e56 100644
--- a/libc/include/llvm-libc-types/struct_epoll_data.h
+++ b/libc/include/llvm-libc-types/struct_epoll_data.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_EPOLL_DATA_H__
-#define __LLVM_LIBC_TYPES_EPOLL_DATA_H__
+#ifndef LLVM_LIBC_TYPES_STRUCT_EPOLL_DATA_H
+#define LLVM_LIBC_TYPES_STRUCT_EPOLL_DATA_H
union epoll_data {
void *ptr;
@@ -18,4 +18,4 @@ union epoll_data {
typedef union epoll_data epoll_data_t;
-#endif // __LLVM_LIBC_TYPES_EPOLL_DATA_H__
+#endif // LLVM_LIBC_TYPES_STRUCT_EPOLL_DATA_H
diff --git a/libc/include/llvm-libc-types/struct_epoll_event.h b/libc/include/llvm-libc-types/struct_epoll_event.h
index edfa026fa982a1..6fc5b410348a11 100644
--- a/libc/include/llvm-libc-types/struct_epoll_event.h
+++ b/libc/include/llvm-libc-types/struct_epoll_event.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_EPOLL_EVENT_H__
-#define __LLVM_LIBC_TYPES_EPOLL_EVENT_H__
+#ifndef LLVM_LIBC_TYPES_STRUCT_EPOLL_EVENT_H
+#define LLVM_LIBC_TYPES_STRUCT_EPOLL_EVENT_H
#include <llvm-libc-types/struct_epoll_data.h>
@@ -16,4 +16,4 @@ typedef struct epoll_event {
epoll_data_t data;
} epoll_event;
-#endif // __LLVM_LIBC_TYPES_EPOLL_EVENT_H__
+#endif // LLVM_LIBC_TYPES_STRUCT_EPOLL_EVENT_H
diff --git a/libc/include/llvm-libc-types/struct_hsearch_data.h b/libc/include/llvm-libc-types/struct_hsearch_data.h
index 7e2a7232fce535..cdb1d0c5da14c4 100644
--- a/libc/include/llvm-libc-types/struct_hsearch_data.h
+++ b/libc/include/llvm-libc-types/struct_hsearch_data.h
@@ -6,12 +6,12 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_STRUCT_HSEARCH_DATA_H__
-#define __LLVM_LIBC_TYPES_STRUCT_HSEARCH_DATA_H__
+#ifndef LLVM_LIBC_TYPES_STRUCT_HSEARCH_DATA_H
+#define LLVM_LIBC_TYPES_STRUCT_HSEARCH_DATA_H
struct hsearch_data {
void *__opaque;
unsigned int __unused[2];
};
-#endif // __LLVM_LIBC_TYPES_STRUCT_HSEARCH_DATA_H__
+#endif // LLVM_LIBC_TYPES_STRUCT_HSEARCH_DATA_H
diff --git a/libc/include/llvm-libc-types/struct_rlimit.h b/libc/include/llvm-libc-types/struct_rlimit.h
index 4fe0aa6cdf0b17..e093d9f306c984 100644
--- a/libc/include/llvm-libc-types/struct_rlimit.h
+++ b/libc/include/llvm-libc-types/struct_rlimit.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_STRUCT_RLIMIT_H__
-#define __LLVM_LIBC_TYPES_STRUCT_RLIMIT_H__
+#ifndef LLVM_LIBC_TYPES_STRUCT_RLIMIT_H
+#define LLVM_LIBC_TYPES_STRUCT_RLIMIT_H
#include <llvm-libc-types/rlim_t.h>
@@ -16,4 +16,4 @@ struct rlimit {
rlim_t rlim_max;
};
-#endif // __LLVM_LIBC_TYPES_STRUCT_RLIMIT_H__
+#endif // LLVM_LIBC_TYPES_STRUCT_RLIMIT_H
diff --git a/libc/include/llvm-libc-types/struct_rusage.h b/libc/include/llvm-libc-types/struct_rusage.h
index 43f345792205dd..21ea8b1061c296 100644
--- a/libc/include/llvm-libc-types/struct_rusage.h
+++ b/libc/include/llvm-libc-types/struct_rusage.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_STRUCT_RUSAGE_H__
-#define __LLVM_LIBC_TYPES_STRUCT_RUSAGE_H__
+#ifndef LLVM_LIBC_TYPES_STRUCT_RUSAGE_H
+#define LLVM_LIBC_TYPES_STRUCT_RUSAGE_H
#include <llvm-libc-types/struct_timeval.h>
@@ -34,4 +34,4 @@ struct rusage {
#endif
};
-#endif // __LLVM_LIBC_TYPES_STRUCT_RUSAGE_H__
+#endif // LLVM_LIBC_TYPES_STRUCT_RUSAGE_H
diff --git a/libc/include/llvm-libc-types/struct_sched_param.h b/libc/include/llvm-libc-types/struct_sched_param.h
index 4f31881ceeb6c9..0521a4df652f15 100644
--- a/libc/include/llvm-libc-types/struct_sched_param.h
+++ b/libc/include/llvm-libc-types/struct_sched_param.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_STRUCT_SCHED_PARAM_H__
-#define __LLVM_LIBC_TYPES_STRUCT_SCHED_PARAM_H__
+#ifndef LLVM_LIBC_TYPES_STRUCT_SCHED_PARAM_H
+#define LLVM_LIBC_TYPES_STRUCT_SCHED_PARAM_H
#include <llvm-libc-types/pid_t.h>
#include <llvm-libc-types/struct_timespec.h>
@@ -18,4 +18,4 @@ struct sched_param {
int sched_priority;
};
-#endif // __LLVM_LIBC_TYPES_STRUCT_SCHED_PARAM_H__
+#endif // LLVM_LIBC_TYPES_STRUCT_SCHED_PARAM_H
diff --git a/libc/include/llvm-libc-types/struct_sigaction.h b/libc/include/llvm-libc-types/struct_sigaction.h
index 3940f14ffa8424..54d2995f4ecd08 100644
--- a/libc/include/llvm-libc-types/struct_sigaction.h
+++ b/libc/include/llvm-libc-types/struct_sigaction.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_SIGACTION_H__
-#define __LLVM_LIBC_TYPES_SIGACTION_H__
+#ifndef LLVM_LIBC_TYPES_STRUCT_SIGACTION_H
+#define LLVM_LIBC_TYPES_STRUCT_SIGACTION_H
#include <llvm-libc-types/siginfo_t.h>
#include <llvm-libc-types/sigset_t.h>
@@ -27,4 +27,4 @@ struct sigaction {
typedef void (*__sighandler_t)(int);
-#endif // __LLVM_LIBC_TYPES_SIGACTION_H__
+#endif // LLVM_LIBC_TYPES_STRUCT_SIGACTION_H
diff --git a/libc/include/llvm-libc-types/struct_sockaddr.h b/libc/include/llvm-libc-types/struct_sockaddr.h
index 9a6214c7d3e6b9..074b1ae50ef073 100644
--- a/libc/include/llvm-libc-types/struct_sockaddr.h
+++ b/libc/include/llvm-libc-types/struct_sockaddr.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_STRUCT_SOCKADDR_H__
-#define __LLVM_LIBC_TYPES_STRUCT_SOCKADDR_H__
+#ifndef LLVM_LIBC_TYPES_STRUCT_SOCKADDR_H
+#define LLVM_LIBC_TYPES_STRUCT_SOCKADDR_H
#include <llvm-libc-types/sa_family_t.h>
@@ -18,4 +18,4 @@ struct sockaddr {
char sa_data[];
};
-#endif // __LLVM_LIBC_TYPES_STRUCT_SOCKADDR_H__
+#endif // LLVM_LIBC_TYPES_STRUCT_SOCKADDR_H
diff --git a/libc/include/llvm-libc-types/struct_sockaddr_un.h b/libc/include/llvm-libc-types/struct_sockaddr_un.h
index 9c3efea279256e..4332419a5b7155 100644
--- a/libc/include/llvm-libc-types/struct_sockaddr_un.h
+++ b/libc/include/llvm-libc-types/struct_sockaddr_un.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_STRUCT_SOCKADDR_UN_H__
-#define __LLVM_LIBC_TYPES_STRUCT_SOCKADDR_UN_H__
+#ifndef LLVM_LIBC_TYPES_STRUCT_SOCKADDR_UN_H
+#define LLVM_LIBC_TYPES_STRUCT_SOCKADDR_UN_H
#include <llvm-libc-types/sa_family_t.h>
@@ -19,4 +19,4 @@ struct sockaddr_un {
char sun_path[108]; /* Pathname */
};
-#endif // __LLVM_LIBC_TYPES_STRUCT_SOCKADDR_UN_H__
+#endif // LLVM_LIBC_TYPES_STRUCT_SOCKADDR_UN_H
diff --git a/libc/include/llvm-libc-types/struct_stat.h b/libc/include/llvm-libc-types/struct_stat.h
index baaef15d996490..3539fb5b920e36 100644
--- a/libc/include/llvm-libc-types/struct_stat.h
+++ b/libc/include/llvm-libc-types/struct_stat.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_STRUCT_STAT_H__
-#define __LLVM_LIBC_TYPES_STRUCT_STAT_H__
+#ifndef LLVM_LIBC_TYPES_STRUCT_STAT_H
+#define LLVM_LIBC_TYPES_STRUCT_STAT_H
#include <llvm-libc-types/blkcnt_t.h>
#include <llvm-libc-types/blksize_t.h>
@@ -36,4 +36,4 @@ struct stat {
blkcnt_t st_blocks;
};
-#endif // __LLVM_LIBC_TYPES_STRUCT_STAT_H__
+#endif // LLVM_LIBC_TYPES_STRUCT_STAT_H
diff --git a/libc/include/llvm-libc-types/struct_timespec.h b/libc/include/llvm-libc-types/struct_timespec.h
index 1fa6272d3df924..5d56d9c9468b4f 100644
--- a/libc/include/llvm-libc-types/struct_timespec.h
+++ b/libc/include/llvm-libc-types/struct_timespec.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_TIMESPEC_H__
-#define __LLVM_LIBC_TYPES_TIMESPEC_H__
+#ifndef LLVM_LIBC_TYPES_STRUCT_TIMESPEC_H
+#define LLVM_LIBC_TYPES_STRUCT_TIMESPEC_H
#include <llvm-libc-types/time_t.h>
@@ -17,4 +17,4 @@ struct timespec {
long tv_nsec; /* Nanoseconds. */
};
-#endif // __LLVM_LIBC_TYPES_TIMESPEC_H__
+#endif // LLVM_LIBC_TYPES_STRUCT_TIMESPEC_H
diff --git a/libc/include/llvm-libc-types/struct_timeval.h b/libc/include/llvm-libc-types/struct_timeval.h
index 756fecabb6ace4..6a0b7bbaf8254d 100644
--- a/libc/include/llvm-libc-types/struct_timeval.h
+++ b/libc/include/llvm-libc-types/struct_timeval.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_TIMEVAL_H__
-#define __LLVM_LIBC_TYPES_TIMEVAL_H__
+#ifndef LLVM_LIBC_TYPES_STRUCT_TIMEVAL_H
+#define LLVM_LIBC_TYPES_STRUCT_TIMEVAL_H
#include <llvm-libc-types/suseconds_t.h>
#include <llvm-libc-types/time_t.h>
@@ -17,4 +17,4 @@ struct timeval {
suseconds_t tv_usec; // Micro seconds
};
-#endif // __LLVM_LIBC_TYPES_TIMEVAL_H__
+#endif // LLVM_LIBC_TYPES_STRUCT_TIMEVAL_H
diff --git a/libc/include/llvm-libc-types/struct_tm.h b/libc/include/llvm-libc-types/struct_tm.h
index 953e12e819c3a0..9fef7c5718ea4a 100644
--- a/libc/include/llvm-libc-types/struct_tm.h
+++ b/libc/include/llvm-libc-types/struct_tm.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_TM_H__
-#define __LLVM_LIBC_TYPES_TM_H__
+#ifndef LLVM_LIBC_TYPES_STRUCT_TM_H
+#define LLVM_LIBC_TYPES_STRUCT_TM_H
struct tm {
int tm_sec; // seconds after the minute
@@ -21,4 +21,4 @@ struct tm {
int tm_isdst; // Daylight Saving Time flag
};
-#endif // __LLVM_LIBC_TYPES_TM_H__
+#endif // LLVM_LIBC_TYPES_STRUCT_TM_H
diff --git a/libc/include/llvm-libc-types/struct_utsname.h b/libc/include/llvm-libc-types/struct_utsname.h
index bfd1ad9ceddb7a..e474171c728590 100644
--- a/libc/include/llvm-libc-types/struct_utsname.h
+++ b/libc/include/llvm-libc-types/struct_utsname.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_STRUCT_UTSNAME_H__
-#define __LLVM_LIBC_TYPES_STRUCT_UTSNAME_H__
+#ifndef LLVM_LIBC_TYPES_STRUCT_UTSNAME_H
+#define LLVM_LIBC_TYPES_STRUCT_UTSNAME_H
#if defined(__linux__)
#define __UTS_NAME_LENGTH 65
@@ -31,4 +31,4 @@ struct utsname {
#undef __UTS_NAME_LENGTH
-#endif // __LLVM_LIBC_TYPES_STRUCT_UTSNAME_H__
+#endif // LLVM_LIBC_TYPES_STRUCT_UTSNAME_H
diff --git a/libc/include/llvm-libc-types/suseconds_t.h b/libc/include/llvm-libc-types/suseconds_t.h
index d7298ed74a4cd0..32ecc9f537d008 100644
--- a/libc/include/llvm-libc-types/suseconds_t.h
+++ b/libc/include/llvm-libc-types/suseconds_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_SUSECONDS_T_H__
-#define __LLVM_LIBC_TYPES_SUSECONDS_T_H__
+#ifndef LLVM_LIBC_TYPES_SUSECONDS_T_H
+#define LLVM_LIBC_TYPES_SUSECONDS_T_H
typedef __INT32_TYPE__ suseconds_t;
-#endif // __LLVM_LIBC_TYPES_SUSECONDS_T_H__
+#endif // LLVM_LIBC_TYPES_SUSECONDS_T_H
diff --git a/libc/include/llvm-libc-types/tcflag_t.h b/libc/include/llvm-libc-types/tcflag_t.h
index 7c2ce215420863..2978487df4343f 100644
--- a/libc/include/llvm-libc-types/tcflag_t.h
+++ b/libc/include/llvm-libc-types/tcflag_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_TCFLAG_T_H__
-#define __LLVM_LIBC_TYPES_TCFLAG_T_H__
+#ifndef LLVM_LIBC_TYPES_TCFLAG_T_H
+#define LLVM_LIBC_TYPES_TCFLAG_T_H
typedef unsigned int tcflag_t;
-#endif // __LLVM_LIBC_TYPES_TCFLAG_T_H__
+#endif // LLVM_LIBC_TYPES_TCFLAG_T_H
diff --git a/libc/include/llvm-libc-types/test_rpc_opcodes_t.h b/libc/include/llvm-libc-types/test_rpc_opcodes_t.h
index ec4eb260879971..7129768dc8b988 100644
--- a/libc/include/llvm-libc-types/test_rpc_opcodes_t.h
+++ b/libc/include/llvm-libc-types/test_rpc_opcodes_t.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_TEST_RPC_OPCODE_H__
-#define __LLVM_LIBC_TYPES_TEST_RPC_OPCODE_H__
+#ifndef LLVM_LIBC_TYPES_TEST_RPC_OPCODES_T_H
+#define LLVM_LIBC_TYPES_TEST_RPC_OPCODES_T_H
// We consider the first 32768 opcodes as reserved for libc purposes. We allow
// extensions to use any other number without conflicting with anything else.
@@ -18,4 +18,4 @@ typedef enum : unsigned short {
RPC_TEST_STREAM,
} rpc_test_opcode_t;
-#endif // __LLVM_LIBC_TYPES_TEST_RPC_OPCODE_H__
+#endif // LLVM_LIBC_TYPES_TEST_RPC_OPCODES_T_H
diff --git a/libc/include/llvm-libc-types/thrd_start_t.h b/libc/include/llvm-libc-types/thrd_start_t.h
index 83fc32cbd1f879..1fb21bccc036b8 100644
--- a/libc/include/llvm-libc-types/thrd_start_t.h
+++ b/libc/include/llvm-libc-types/thrd_start_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_THRD_START_T_H__
-#define __LLVM_LIBC_TYPES_THRD_START_T_H__
+#ifndef LLVM_LIBC_TYPES_THRD_START_T_H
+#define LLVM_LIBC_TYPES_THRD_START_T_H
typedef int (*thrd_start_t)(void *);
-#endif // __LLVM_LIBC_TYPES_THRD_START_T_H__
+#endif // LLVM_LIBC_TYPES_THRD_START_T_H
diff --git a/libc/include/llvm-libc-types/thrd_t.h b/libc/include/llvm-libc-types/thrd_t.h
index 0743106c48c648..2e0f9a0d75ad7c 100644
--- a/libc/include/llvm-libc-types/thrd_t.h
+++ b/libc/include/llvm-libc-types/thrd_t.h
@@ -6,11 +6,11 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_THRD_T_H__
-#define __LLVM_LIBC_TYPES_THRD_T_H__
+#ifndef LLVM_LIBC_TYPES_THRD_T_H
+#define LLVM_LIBC_TYPES_THRD_T_H
#include <llvm-libc-types/__thread_type.h>
typedef __thread_type thrd_t;
-#endif // __LLVM_LIBC_TYPES_THRD_T_H__
+#endif // LLVM_LIBC_TYPES_THRD_T_H
diff --git a/libc/include/llvm-libc-types/time_t.h b/libc/include/llvm-libc-types/time_t.h
index 2b3ccd4d802471..59953b343ba963 100644
--- a/libc/include/llvm-libc-types/time_t.h
+++ b/libc/include/llvm-libc-types/time_t.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_TIME_T_H__
-#define __LLVM_LIBC_TYPES_TIME_T_H__
+#ifndef LLVM_LIBC_TYPES_TIME_T_H
+#define LLVM_LIBC_TYPES_TIME_T_H
#if (defined(__arm__) || defined(_M_ARM))
typedef __INTPTR_TYPE__ time_t;
@@ -15,4 +15,4 @@ typedef __INTPTR_TYPE__ time_t;
typedef __INT64_TYPE__ time_t;
#endif
-#endif // __LLVM_LIBC_TYPES_TIME_T_H__
+#endif // LLVM_LIBC_TYPES_TIME_T_H
diff --git a/libc/include/llvm-libc-types/tss_dtor_t.h b/libc/include/llvm-libc-types/tss_dtor_t.h
index f80661b588ba3f..c54b34e7d8b781 100644
--- a/libc/include/llvm-libc-types/tss_dtor_t.h
+++ b/libc/include/llvm-libc-types/tss_dtor_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_TSS_DTOR_T_H__
-#define __LLVM_LIBC_TYPES_TSS_DTOR_T_H__
+#ifndef LLVM_LIBC_TYPES_TSS_DTOR_T_H
+#define LLVM_LIBC_TYPES_TSS_DTOR_T_H
typedef void (*tss_dtor_t)(void *);
-#endif // __LLVM_LIBC_TYPES_TSS_DTOR_T_H__
+#endif // LLVM_LIBC_TYPES_TSS_DTOR_T_H
diff --git a/libc/include/llvm-libc-types/tss_t.h b/libc/include/llvm-libc-types/tss_t.h
index 868ec1ac112889..92bc7ef451cac3 100644
--- a/libc/include/llvm-libc-types/tss_t.h
+++ b/libc/include/llvm-libc-types/tss_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_TSS_T_H__
-#define __LLVM_LIBC_TYPES_TSS_T_H__
+#ifndef LLVM_LIBC_TYPES_TSS_T_H
+#define LLVM_LIBC_TYPES_TSS_T_H
typedef unsigned int tss_t;
-#endif // __LLVM_LIBC_TYPES_TSS_T_H__
+#endif // LLVM_LIBC_TYPES_TSS_T_H
diff --git a/libc/include/llvm-libc-types/uid_t.h b/libc/include/llvm-libc-types/uid_t.h
index ae9fac2a4288c8..4f6c6479186bad 100644
--- a/libc/include/llvm-libc-types/uid_t.h
+++ b/libc/include/llvm-libc-types/uid_t.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_UID_T_H__
-#define __LLVM_LIBC_TYPES_UID_T_H__
+#ifndef LLVM_LIBC_TYPES_UID_T_H
+#define LLVM_LIBC_TYPES_UID_T_H
typedef __UINT32_TYPE__ uid_t;
-#endif // __LLVM_LIBC_TYPES_UID_T_H__
+#endif // LLVM_LIBC_TYPES_UID_T_H
diff --git a/libc/include/llvm-libc-types/union_sigval.h b/libc/include/llvm-libc-types/union_sigval.h
index ccc9f2e5d0fb27..5f83cd2203081f 100644
--- a/libc/include/llvm-libc-types/union_sigval.h
+++ b/libc/include/llvm-libc-types/union_sigval.h
@@ -6,12 +6,12 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_UNION_SIGVAL_H__
-#define __LLVM_LIBC_TYPES_UNION_SIGVAL_H__
+#ifndef LLVM_LIBC_TYPES_UNION_SIGVAL_H
+#define LLVM_LIBC_TYPES_UNION_SIGVAL_H
union sigval {
int sival_int;
void *sival_ptr;
};
-#endif // __LLVM_LIBC_TYPES_UNION_SIGVAL_H__
+#endif // LLVM_LIBC_TYPES_UNION_SIGVAL_H
diff --git a/libc/include/llvm-libc-types/wchar_t.h b/libc/include/llvm-libc-types/wchar_t.h
index 9efb5cd8e6652f..3e9a70b8afe6a6 100644
--- a/libc/include/llvm-libc-types/wchar_t.h
+++ b/libc/include/llvm-libc-types/wchar_t.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_WCHAR_T_H__
-#define __LLVM_LIBC_TYPES_WCHAR_T_H__
+#ifndef LLVM_LIBC_TYPES_WCHAR_T_H
+#define LLVM_LIBC_TYPES_WCHAR_T_H
// Since __need_wchar_t is defined, we get the definition of wchar_t from the
// standalone C header stddef.h. Also, because __need_wchar_t is defined,
@@ -16,4 +16,4 @@
#include <stddef.h>
#undef __need_wchar_t
-#endif // __LLVM_LIBC_TYPES_WCHAR_T_H__
+#endif // LLVM_LIBC_TYPES_WCHAR_T_H
diff --git a/libc/include/llvm-libc-types/wint_t.h b/libc/include/llvm-libc-types/wint_t.h
index cf6ccd7e1ae765..2758685a084575 100644
--- a/libc/include/llvm-libc-types/wint_t.h
+++ b/libc/include/llvm-libc-types/wint_t.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef __LLVM_LIBC_TYPES_WINT_T_H__
-#define __LLVM_LIBC_TYPES_WINT_T_H__
+#ifndef LLVM_LIBC_TYPES_WINT_T_H
+#define LLVM_LIBC_TYPES_WINT_T_H
// Since __need_wint_t is defined, we get the definition of wint_t from the
// standalone C header stddef.h. Also, because __need_wint_t is defined,
@@ -16,4 +16,4 @@
#include <stddef.h>
#undef __need_wint_t
-#endif // __LLVM_LIBC_TYPES_WINT_T_H__
+#endif // LLVM_LIBC_TYPES_WINT_T_H
diff --git a/libc/include/sys/queue.h b/libc/include/sys/queue.h
index 2a4dc37712d6d9..1cde35e77a04e3 100644
--- a/libc/include/sys/queue.h
+++ b/libc/include/sys/queue.h
@@ -6,9 +6,9 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_SYS_QUEUE_H
-#define LLVM_LIBC_SYS_QUEUE_H
+#ifndef SYS_QUEUE_H
+#define SYS_QUEUE_H
#include <llvm-libc-macros/sys-queue-macros.h>
-#endif // LLVM_LIBC_SYS_QUEUE_H
+#endif // SYS_QUEUE_H
diff --git a/libc/src/__support/CPP/type_traits/is_fixed_point.h b/libc/src/__support/CPP/type_traits/is_fixed_point.h
index e139e6477e2e7e..09dba8b7ecbcd4 100644
--- a/libc/src/__support/CPP/type_traits/is_fixed_point.h
+++ b/libc/src/__support/CPP/type_traits/is_fixed_point.h
@@ -43,4 +43,4 @@ LIBC_INLINE_VAR constexpr bool is_fixed_point_v = is_fixed_point<T>::value;
} // namespace LIBC_NAMESPACE::cpp
-#endif // LLVM_LIBC_SRC___SUPPORT_CPP_TYPE_TRAITS_IS_INTEGRAL_H
+#endif // LLVM_LIBC_SRC___SUPPORT_CPP_TYPE_TRAITS_IS_FIXED_POINT_H
diff --git a/libc/src/__support/FPUtil/fpbits_str.h b/libc/src/__support/FPUtil/fpbits_str.h
index a1654cddad7464..212265bb9ad4a8 100644
--- a/libc/src/__support/FPUtil/fpbits_str.h
+++ b/libc/src/__support/FPUtil/fpbits_str.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_SRC___SUPPORT_FPUTIL_FP_BITS_STR_H
-#define LLVM_LIBC_SRC___SUPPORT_FPUTIL_FP_BITS_STR_H
+#ifndef LLVM_LIBC_SRC___SUPPORT_FPUTIL_FPBITS_STR_H
+#define LLVM_LIBC_SRC___SUPPORT_FPUTIL_FPBITS_STR_H
#include "src/__support/CPP/string.h"
#include "src/__support/CPP/type_traits.h"
@@ -73,4 +73,4 @@ template <typename T> LIBC_INLINE cpp::string str(fputil::FPBits<T> x) {
} // namespace LIBC_NAMESPACE
-#endif // LLVM_LIBC_SRC___SUPPORT_FPUTIL_FP_BITS_STR_H
+#endif // LLVM_LIBC_SRC___SUPPORT_FPUTIL_FPBITS_STR_H
diff --git a/libc/src/__support/GPU/generic/utils.h b/libc/src/__support/GPU/generic/utils.h
index 58db88dce1ca8c..c6c3c01cf7d5f0 100644
--- a/libc/src/__support/GPU/generic/utils.h
+++ b/libc/src/__support/GPU/generic/utils.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_SRC___SUPPORT_GPU_GENERIC_IO_H
-#define LLVM_LIBC_SRC___SUPPORT_GPU_GENERIC_IO_H
+#ifndef LLVM_LIBC_SRC___SUPPORT_GPU_GENERIC_UTILS_H
+#define LLVM_LIBC_SRC___SUPPORT_GPU_GENERIC_UTILS_H
#include "src/__support/common.h"
@@ -78,4 +78,4 @@ LIBC_INLINE uint32_t get_cluster_id() { return 0; }
} // namespace gpu
} // namespace LIBC_NAMESPACE
-#endif
+#endif // LLVM_LIBC_SRC___SUPPORT_GPU_GENERIC_UTILS_H
diff --git a/libc/src/__support/GPU/utils.h b/libc/src/__support/GPU/utils.h
index 6505b18dbd331e..0f9167cdee0663 100644
--- a/libc/src/__support/GPU/utils.h
+++ b/libc/src/__support/GPU/utils.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_SRC___SUPPORT_GPU_UTIL_H
-#define LLVM_LIBC_SRC___SUPPORT_GPU_UTIL_H
+#ifndef LLVM_LIBC_SRC___SUPPORT_GPU_UTILS_H
+#define LLVM_LIBC_SRC___SUPPORT_GPU_UTILS_H
#include "src/__support/macros/properties/architectures.h"
@@ -34,4 +34,4 @@ LIBC_INLINE bool is_first_lane(uint64_t lane_mask) {
} // namespace gpu
} // namespace LIBC_NAMESPACE
-#endif // LLVM_LIBC_SRC___SUPPORT_OSUTIL_IO_H
+#endif // LLVM_LIBC_SRC___SUPPORT_GPU_UTILS_H
diff --git a/libc/src/__support/HashTable/table.h b/libc/src/__support/HashTable/table.h
index e2a26d0e2b5f36..07fcd42c97f3e7 100644
--- a/libc/src/__support/HashTable/table.h
+++ b/libc/src/__support/HashTable/table.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_SRC___SUPPORT_HASHTABLE_table_H
-#define LLVM_LIBC_SRC___SUPPORT_HASHTABLE_table_H
+#ifndef LLVM_LIBC_SRC___SUPPORT_HASHTABLE_TABLE_H
+#define LLVM_LIBC_SRC___SUPPORT_HASHTABLE_TABLE_H
#include "llvm-libc-types/ENTRY.h"
#include "src/__support/CPP/bit.h" // bit_ceil
@@ -351,4 +351,4 @@ struct HashTable {
} // namespace internal
} // namespace LIBC_NAMESPACE
-#endif // LLVM_LIBC_SRC___SUPPORT_HASHTABLE_table_H
+#endif // LLVM_LIBC_SRC___SUPPORT_HASHTABLE_TABLE_H
diff --git a/libc/src/__support/OSUtil/gpu/io.h b/libc/src/__support/OSUtil/gpu/io.h
index d6c89cf45e3a55..e5562eb74a67db 100644
--- a/libc/src/__support/OSUtil/gpu/io.h
+++ b/libc/src/__support/OSUtil/gpu/io.h
@@ -18,4 +18,4 @@ void write_to_stderr(cpp::string_view msg);
} // namespace LIBC_NAMESPACE
-#endif // LLVM_LIBC_SRC___SUPPORT_OSUTIL_LINUX_IO_H
+#endif // LLVM_LIBC_SRC___SUPPORT_OSUTIL_GPU_IO_H
diff --git a/libc/src/__support/RPC/rpc_util.h b/libc/src/__support/RPC/rpc_util.h
index 11d2f751355d34..7a9901af83e739 100644
--- a/libc/src/__support/RPC/rpc_util.h
+++ b/libc/src/__support/RPC/rpc_util.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_SRC___SUPPORT_RPC_RPC_UTILS_H
-#define LLVM_LIBC_SRC___SUPPORT_RPC_RPC_UTILS_H
+#ifndef LLVM_LIBC_SRC___SUPPORT_RPC_RPC_UTIL_H
+#define LLVM_LIBC_SRC___SUPPORT_RPC_RPC_UTIL_H
#include "src/__support/CPP/type_traits.h"
#include "src/__support/GPU/utils.h"
@@ -69,4 +69,4 @@ LIBC_INLINE void rpc_memcpy(void *dst, const void *src, size_t count) {
} // namespace rpc
} // namespace LIBC_NAMESPACE
-#endif
+#endif // LLVM_LIBC_SRC___SUPPORT_RPC_RPC_UTIL_H
diff --git a/libc/src/__support/StringUtil/message_mapper.h b/libc/src/__support/StringUtil/message_mapper.h
index c93a57c6256784..dd91839fb92006 100644
--- a/libc/src/__support/StringUtil/message_mapper.h
+++ b/libc/src/__support/StringUtil/message_mapper.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_MESSAGE_MAPPER_H
-#define LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_MESSAGE_MAPPER_H
+#ifndef LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_MESSAGE_MAPPER_H
+#define LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_MESSAGE_MAPPER_H
#include "src/__support/CPP/array.h"
#include "src/__support/CPP/optional.h"
@@ -100,4 +100,4 @@ constexpr MsgTable<N1 + N2> operator+(const MsgTable<N1> &t1,
} // namespace LIBC_NAMESPACE
-#endif // LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_MESSAGE_MAPPER_H
+#endif // LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_MESSAGE_MAPPER_H
diff --git a/libc/src/__support/StringUtil/platform_errors.h b/libc/src/__support/StringUtil/platform_errors.h
index dfa841ce5d8234..32e8414b3e3ded 100644
--- a/libc/src/__support/StringUtil/platform_errors.h
+++ b/libc/src/__support/StringUtil/platform_errors.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_PLATFORM_ERROR_TABLE_H
-#define LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_PLATFORM_ERROR_TABLE_H
+#ifndef LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_PLATFORM_ERRORS_H
+#define LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_PLATFORM_ERRORS_H
#if defined(__linux__) || defined(__Fuchsia__)
#include "tables/linux_platform_errors.h"
@@ -15,4 +15,4 @@
#include "tables/minimal_platform_errors.h"
#endif
-#endif // LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_PLATFORM_ERROR_TABLE_H
+#endif // LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_PLATFORM_ERRORS_H
diff --git a/libc/src/__support/StringUtil/platform_signals.h b/libc/src/__support/StringUtil/platform_signals.h
index 0a1c3f6bef2515..52da082649bf36 100644
--- a/libc/src/__support/StringUtil/platform_signals.h
+++ b/libc/src/__support/StringUtil/platform_signals.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_PLATFORM_SIGNAL_TABLE_H
-#define LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_PLATFORM_SIGNAL_TABLE_H
+#ifndef LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_PLATFORM_SIGNALS_H
+#define LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_PLATFORM_SIGNALS_H
#if defined(__linux__) || defined(__Fuchsia__)
#include "tables/linux_platform_signals.h"
@@ -15,4 +15,4 @@
#include "tables/minimal_platform_signals.h"
#endif
-#endif // LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_PLATFORM_SIGNAL_TABLE_H
+#endif // LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_PLATFORM_SIGNALS_H
diff --git a/libc/src/__support/StringUtil/tables/linux_extension_errors.h b/libc/src/__support/StringUtil/tables/linux_extension_errors.h
index 4964fa47efd531..f48968892e9671 100644
--- a/libc/src/__support/StringUtil/tables/linux_extension_errors.h
+++ b/libc/src/__support/StringUtil/tables/linux_extension_errors.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_LINUX_EXTENSION_ERRORS_H
-#define LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_LINUX_EXTENSION_ERRORS_H
+#ifndef LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_LINUX_EXTENSION_ERRORS_H
+#define LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_LINUX_EXTENSION_ERRORS_H
#include "src/__support/StringUtil/message_mapper.h"
@@ -72,4 +72,4 @@ constexpr MsgTable<52> LINUX_ERRORS = {
} // namespace LIBC_NAMESPACE
-#endif // LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_LINUX_EXTENSION_ERRORS_H
+#endif // LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_LINUX_EXTENSION_ERRORS_H
diff --git a/libc/src/__support/StringUtil/tables/linux_extension_signals.h b/libc/src/__support/StringUtil/tables/linux_extension_signals.h
index 633d0e2ed53827..3f9f0c66ff24b3 100644
--- a/libc/src/__support/StringUtil/tables/linux_extension_signals.h
+++ b/libc/src/__support/StringUtil/tables/linux_extension_signals.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_LINUX_EXTENSION_SIGNALS_H
-#define LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_LINUX_EXTENSION_SIGNALS_H
+#ifndef LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_LINUX_EXTENSION_SIGNALS_H
+#define LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_LINUX_EXTENSION_SIGNALS_H
#include "src/__support/StringUtil/message_mapper.h"
@@ -30,4 +30,4 @@ LIBC_INLINE_VAR constexpr const MsgTable<3> LINUX_SIGNALS = {
} // namespace LIBC_NAMESPACE
-#endif // LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_LINUX_EXTENSION_SIGNALS_H
+#endif // LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_LINUX_EXTENSION_SIGNALS_H
diff --git a/libc/src/__support/StringUtil/tables/linux_platform_errors.h b/libc/src/__support/StringUtil/tables/linux_platform_errors.h
index a9ae2e8100a1b3..a7bb545d3bf92b 100644
--- a/libc/src/__support/StringUtil/tables/linux_platform_errors.h
+++ b/libc/src/__support/StringUtil/tables/linux_platform_errors.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_LINUX_PLATFORM_ERRORS_H
-#define LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_LINUX_PLATFORM_ERRORS_H
+#ifndef LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_LINUX_PLATFORM_ERRORS_H
+#define LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_LINUX_PLATFORM_ERRORS_H
#include "linux_extension_errors.h"
#include "posix_errors.h"
@@ -20,4 +20,4 @@ LIBC_INLINE_VAR constexpr auto PLATFORM_ERRORS =
} // namespace LIBC_NAMESPACE
-#endif // LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_LINUX_PLATFORM_ERRORS_H
+#endif // LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_LINUX_PLATFORM_ERRORS_H
diff --git a/libc/src/__support/StringUtil/tables/linux_platform_signals.h b/libc/src/__support/StringUtil/tables/linux_platform_signals.h
index 1daaa9cc62852e..f12d31f222b09d 100644
--- a/libc/src/__support/StringUtil/tables/linux_platform_signals.h
+++ b/libc/src/__support/StringUtil/tables/linux_platform_signals.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_LINUX_PLATFORM_SIGNALS_H
-#define LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_LINUX_PLATFORM_SIGNALS_H
+#ifndef LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_LINUX_PLATFORM_SIGNALS_H
+#define LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_LINUX_PLATFORM_SIGNALS_H
#include "linux_extension_signals.h"
#include "posix_signals.h"
@@ -20,4 +20,4 @@ LIBC_INLINE_VAR constexpr auto PLATFORM_SIGNALS =
} // namespace LIBC_NAMESPACE
-#endif // LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_LINUX_PLATFORM_SIGNALS_H
+#endif // LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_LINUX_PLATFORM_SIGNALS_H
diff --git a/libc/src/__support/StringUtil/tables/minimal_platform_errors.h b/libc/src/__support/StringUtil/tables/minimal_platform_errors.h
index 1cfd9e2e944d46..c5672c4d875f59 100644
--- a/libc/src/__support/StringUtil/tables/minimal_platform_errors.h
+++ b/libc/src/__support/StringUtil/tables/minimal_platform_errors.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_MINIMAL_PLATFORM_ERRORS_H
-#define LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_MINIMAL_PLATFORM_ERRORS_H
+#ifndef LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_MINIMAL_PLATFORM_ERRORS_H
+#define LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_MINIMAL_PLATFORM_ERRORS_H
#include "stdc_errors.h"
@@ -17,4 +17,4 @@ LIBC_INLINE_VAR constexpr auto PLATFORM_ERRORS = STDC_ERRORS;
} // namespace LIBC_NAMESPACE
-#endif // LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_MINIMAL_PLATFORM_ERRORS_H
+#endif // LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_MINIMAL_PLATFORM_ERRORS_H
diff --git a/libc/src/__support/StringUtil/tables/minimal_platform_signals.h b/libc/src/__support/StringUtil/tables/minimal_platform_signals.h
index 7fcf91bfee8525..7fe0dccfc465e9 100644
--- a/libc/src/__support/StringUtil/tables/minimal_platform_signals.h
+++ b/libc/src/__support/StringUtil/tables/minimal_platform_signals.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_MINIMAL_PLATFORM_SIGNALS_H
-#define LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_MINIMAL_PLATFORM_SIGNALS_H
+#ifndef LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_MINIMAL_PLATFORM_SIGNALS_H
+#define LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_MINIMAL_PLATFORM_SIGNALS_H
#include "stdc_signals.h"
@@ -17,4 +17,4 @@ LIBC_INLINE_VAR constexpr auto PLATFORM_SIGNALS = STDC_SIGNALS;
} // namespace LIBC_NAMESPACE
-#endif // LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_MINIMAL_PLATFORM_SIGNALS_H
+#endif // LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_MINIMAL_PLATFORM_SIGNALS_H
diff --git a/libc/src/__support/StringUtil/tables/posix_errors.h b/libc/src/__support/StringUtil/tables/posix_errors.h
index 3ade7aaab4f0de..3cb6de394ea367 100644
--- a/libc/src/__support/StringUtil/tables/posix_errors.h
+++ b/libc/src/__support/StringUtil/tables/posix_errors.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_POSIX_ERRORS_H
-#define LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_POSIX_ERRORS_H
+#ifndef LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_POSIX_ERRORS_H
+#define LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_POSIX_ERRORS_H
#include "src/__support/StringUtil/message_mapper.h"
@@ -96,4 +96,4 @@ LIBC_INLINE_VAR constexpr MsgTable<76> POSIX_ERRORS = {
} // namespace LIBC_NAMESPACE
-#endif // LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_POSIX_ERRORS_H
+#endif // LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_POSIX_ERRORS_H
diff --git a/libc/src/__support/StringUtil/tables/posix_signals.h b/libc/src/__support/StringUtil/tables/posix_signals.h
index 2fba2d963f4b9b..b9535cbeb6f69f 100644
--- a/libc/src/__support/StringUtil/tables/posix_signals.h
+++ b/libc/src/__support/StringUtil/tables/posix_signals.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_POSIX_SIGNALS_H
-#define LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_POSIX_SIGNALS_H
+#ifndef LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_POSIX_SIGNALS_H
+#define LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_POSIX_SIGNALS_H
#include "src/__support/CPP/array.h"
#include "src/__support/StringUtil/message_mapper.h"
@@ -43,4 +43,4 @@ LIBC_INLINE_VAR constexpr MsgTable<22> POSIX_SIGNALS = {
} // namespace LIBC_NAMESPACE
-#endif // LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_POSIX_SIGNALS_H
+#endif // LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_POSIX_SIGNALS_H
diff --git a/libc/src/__support/StringUtil/tables/signal_table.h b/libc/src/__support/StringUtil/tables/signal_table.h
index 5035c54770c5c7..d7ffbc63722e5b 100644
--- a/libc/src/__support/StringUtil/tables/signal_table.h
+++ b/libc/src/__support/StringUtil/tables/signal_table.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_SIGNAL_TABLE_H
-#define LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_SIGNAL_TABLE_H
+#ifndef LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_SIGNAL_TABLE_H
+#define LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_SIGNAL_TABLE_H
#include "src/__support/StringUtil/message_mapper.h"
@@ -36,4 +36,4 @@ LIBC_INLINE_VAR constexpr auto PLATFORM_SIGNALS = []() {
} // namespace LIBC_NAMESPACE::internal
-#endif // LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_SIGNAL_TABLE_H
+#endif // LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_SIGNAL_TABLE_H
diff --git a/libc/src/__support/StringUtil/tables/stdc_errors.h b/libc/src/__support/StringUtil/tables/stdc_errors.h
index f0fc78710b18a6..a9c1527834550f 100644
--- a/libc/src/__support/StringUtil/tables/stdc_errors.h
+++ b/libc/src/__support/StringUtil/tables/stdc_errors.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_STDC_ERRORS_H
-#define LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_STDC_ERRORS_H
+#ifndef LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_STDC_ERRORS_H
+#define LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_STDC_ERRORS_H
#include "src/__support/StringUtil/message_mapper.h"
@@ -24,4 +24,4 @@ LIBC_INLINE_VAR constexpr const MsgTable<4> STDC_ERRORS = {
} // namespace LIBC_NAMESPACE
-#endif // LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_LINUX_ERRORS_H
+#endif // LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_STDC_ERRORS_H
diff --git a/libc/src/__support/StringUtil/tables/stdc_signals.h b/libc/src/__support/StringUtil/tables/stdc_signals.h
index 773f182140ef93..7c93b45a441c3c 100644
--- a/libc/src/__support/StringUtil/tables/stdc_signals.h
+++ b/libc/src/__support/StringUtil/tables/stdc_signals.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_STDC_SIGNALS_H
-#define LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_STDC_SIGNALS_H
+#ifndef LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_STDC_SIGNALS_H
+#define LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_STDC_SIGNALS_H
#include <signal.h> // For signal numbers
@@ -26,4 +26,4 @@ LIBC_INLINE_VAR constexpr const MsgTable<6> STDC_SIGNALS = {
} // namespace LIBC_NAMESPACE
-#endif // LLVM_LIBC_SRC___SUPPORT_STRING_UTIL_TABLES_LINUX_SIGNALS_H
+#endif // LLVM_LIBC_SRC___SUPPORT_STRINGUTIL_TABLES_STDC_SIGNALS_H
diff --git a/libc/src/__support/fixed_point/fx_bits.h b/libc/src/__support/fixed_point/fx_bits.h
index 0c8d03beb84ae5..6fdbc6f6ece63f 100644
--- a/libc/src/__support/fixed_point/fx_bits.h
+++ b/libc/src/__support/fixed_point/fx_bits.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_SRC___SUPPORT_FIXEDPOINT_FXBITS_H
-#define LLVM_LIBC_SRC___SUPPORT_FIXEDPOINT_FXBITS_H
+#ifndef LLVM_LIBC_SRC___SUPPORT_FIXED_POINT_FX_BITS_H
+#define LLVM_LIBC_SRC___SUPPORT_FIXED_POINT_FX_BITS_H
#include "llvm-libc-macros/stdfix-macros.h"
#include "src/__support/CPP/bit.h"
@@ -165,4 +165,4 @@ template <typename T> LIBC_INLINE constexpr T round(T x, int n) {
#endif // LIBC_COMPILER_HAS_FIXED_POINT
-#endif // LLVM_LIBC_SRC___SUPPORT_FIXEDPOINT_FXBITS_H
+#endif // LLVM_LIBC_SRC___SUPPORT_FIXED_POINT_FX_BITS_H
diff --git a/libc/src/__support/fixed_point/fx_rep.h b/libc/src/__support/fixed_point/fx_rep.h
index 7d18f14a8c483a..e1fee62f335eb9 100644
--- a/libc/src/__support/fixed_point/fx_rep.h
+++ b/libc/src/__support/fixed_point/fx_rep.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_SRC___SUPPORT_FIXEDPOINT_FXREP_H
-#define LLVM_LIBC_SRC___SUPPORT_FIXEDPOINT_FXREP_H
+#ifndef LLVM_LIBC_SRC___SUPPORT_FIXED_POINT_FX_REP_H
+#define LLVM_LIBC_SRC___SUPPORT_FIXED_POINT_FX_REP_H
#include "llvm-libc-macros/stdfix-macros.h"
#include "src/__support/CPP/type_traits.h"
@@ -273,4 +273,4 @@ struct FXRep<unsigned long sat accum> : FXRep<unsigned long accum> {};
#endif // LIBC_COMPILER_HAS_FIXED_POINT
-#endif // LLVM_LIBC_SRC___SUPPORT_FIXEDPOINT_FXREP_H
+#endif // LLVM_LIBC_SRC___SUPPORT_FIXED_POINT_FX_REP_H
diff --git a/libc/src/__support/memory_size.h b/libc/src/__support/memory_size.h
index 94aee2520afaa1..7bd16a1695be9a 100644
--- a/libc/src/__support/memory_size.h
+++ b/libc/src/__support/memory_size.h
@@ -6,6 +6,9 @@
//
//===----------------------------------------------------------------------===//
+#ifndef LLVM_LIBC_SRC___SUPPORT_MEMORY_SIZE_H
+#define LLVM_LIBC_SRC___SUPPORT_MEMORY_SIZE_H
+
#include "src/__support/CPP/bit.h" // has_single_bit
#include "src/__support/CPP/limits.h"
#include "src/__support/CPP/type_traits.h"
@@ -83,3 +86,5 @@ class SafeMemSize {
};
} // namespace internal
} // namespace LIBC_NAMESPACE
+
+#endif // LLVM_LIBC_SRC___SUPPORT_MEMORY_SIZE_H
diff --git a/libc/src/__support/threads/gpu/mutex.h b/libc/src/__support/threads/gpu/mutex.h
index 7a23604b5b986a..71d0ef04cbfe56 100644
--- a/libc/src/__support/threads/gpu/mutex.h
+++ b/libc/src/__support/threads/gpu/mutex.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_SRC___SUPPORT_THREAD_GPU_MUTEX_H
-#define LLVM_LIBC_SRC___SUPPORT_THREAD_GPU_MUTEX_H
+#ifndef LLVM_LIBC_SRC___SUPPORT_THREADS_GPU_MUTEX_H
+#define LLVM_LIBC_SRC___SUPPORT_THREADS_GPU_MUTEX_H
#include "src/__support/macros/attributes.h"
#include "src/__support/threads/mutex_common.h"
@@ -28,4 +28,4 @@ struct Mutex {
} // namespace LIBC_NAMESPACE
-#endif
+#endif // LLVM_LIBC_SRC___SUPPORT_THREADS_GPU_MUTEX_H
diff --git a/libc/src/assert/assert.h b/libc/src/assert/assert.h
index 0318a934acca49..0daf9c4e1e6166 100644
--- a/libc/src/assert/assert.h
+++ b/libc/src/assert/assert.h
@@ -6,6 +6,9 @@
//
//===----------------------------------------------------------------------===//
+#ifndef LLVM_LIBC_SRC_ASSERT_ASSERT_H
+#define LLVM_LIBC_SRC_ASSERT_ASSERT_H
+
#include "src/assert/__assert_fail.h"
// There is no header guard here since assert is intended to be capable of being
@@ -21,4 +24,6 @@
((e) ? (void)0 \
: LIBC_NAMESPACE::__assert_fail(#e, __FILE__, __LINE__, \
__PRETTY_FUNCTION__))
-#endif
+#endif // NDEBUG
+
+#endif // LLVM_LIBC_SRC_ASSERT_ASSERT_H
diff --git a/libc/src/gpu/rpc_host_call.h b/libc/src/gpu/rpc_host_call.h
index 14393ab95dc13a..473d90ba48fd0d 100644
--- a/libc/src/gpu/rpc_host_call.h
+++ b/libc/src/gpu/rpc_host_call.h
@@ -17,4 +17,4 @@ void rpc_host_call(void *fn, void *buffer, size_t size);
} // namespace LIBC_NAMESPACE
-#endif // LLVM_LIBC_SRC_GPU_RPC_H_HOST_CALL
+#endif // LLVM_LIBC_SRC_GPU_RPC_HOST_CALL_H
diff --git a/libc/src/math/amdgpu/declarations.h b/libc/src/math/amdgpu/declarations.h
index 780d5f0a114032..5d7f3c9609d238 100644
--- a/libc/src/math/amdgpu/declarations.h
+++ b/libc/src/math/amdgpu/declarations.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_SRC_MATH_GPU_AMDGPU_DECLARATIONS_H
-#define LLVM_LIBC_SRC_MATH_GPU_AMDGPU_DECLARATIONS_H
+#ifndef LLVM_LIBC_SRC_MATH_AMDGPU_DECLARATIONS_H
+#define LLVM_LIBC_SRC_MATH_AMDGPU_DECLARATIONS_H
#include "platform.h"
@@ -83,4 +83,4 @@ float __ocml_tgamma_f32(float);
} // namespace LIBC_NAMESPACE
-#endif // LLVM_LIBC_SRC_MATH_GPU_AMDGPU_DECLARATIONS_H
+#endif // LLVM_LIBC_SRC_MATH_AMDGPU_DECLARATIONS_H
diff --git a/libc/src/math/amdgpu/platform.h b/libc/src/math/amdgpu/platform.h
index e5a9f810cd1072..29d6cac1fa492c 100644
--- a/libc/src/math/amdgpu/platform.h
+++ b/libc/src/math/amdgpu/platform.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_SRC_MATH_GPU_AMDGPU_PLATFORM_H
-#define LLVM_LIBC_SRC_MATH_GPU_AMDGPU_PLATFORM_H
+#ifndef LLVM_LIBC_SRC_MATH_AMDGPU_PLATFORM_H
+#define LLVM_LIBC_SRC_MATH_AMDGPU_PLATFORM_H
#include "src/__support/macros/attributes.h"
@@ -51,4 +51,4 @@ extern const LIBC_INLINE_VAR uint32_t __oclc_ISA_version = 9000;
} // namespace LIBC_NAMESPACE
-#endif // LLVM_LIBC_SRC_MATH_GPU_AMDGPU_PLATFORM_H
+#endif // LLVM_LIBC_SRC_MATH_AMDGPU_PLATFORM_H
diff --git a/libc/src/math/copysignf128.h b/libc/src/math/copysignf128.h
index 5e40657de33be3..0eda56a1cebbb0 100644
--- a/libc/src/math/copysignf128.h
+++ b/libc/src/math/copysignf128.h
@@ -17,4 +17,4 @@ float128 copysignf128(float128 x, float128 y);
} // namespace LIBC_NAMESPACE
-#endif // LLVM_LIBC_SRC_MATH_COPYSIGN_H
+#endif // LLVM_LIBC_SRC_MATH_COPYSIGNF128_H
diff --git a/libc/src/math/generic/exp_utils.h b/libc/src/math/generic/exp_utils.h
index 49d9a8192d344a..405678c356f36e 100644
--- a/libc/src/math/generic/exp_utils.h
+++ b/libc/src/math/generic/exp_utils.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_SRC_MATH_EXP_UTILS_H
-#define LLVM_LIBC_SRC_MATH_EXP_UTILS_H
+#ifndef LLVM_LIBC_SRC_MATH_GENERIC_EXP_UTILS_H
+#define LLVM_LIBC_SRC_MATH_GENERIC_EXP_UTILS_H
#include <stdint.h>
@@ -30,4 +30,4 @@ extern const Exp2fDataTable exp2f_data;
} // namespace LIBC_NAMESPACE
-#endif // LLVM_LIBC_SRC_MATH_EXP_UTILS_H
+#endif // LLVM_LIBC_SRC_MATH_GENERIC_EXP_UTILS_H
diff --git a/libc/src/math/nvptx/declarations.h b/libc/src/math/nvptx/declarations.h
index 9cb2be67b85b1a..d41b16c8eec9fd 100644
--- a/libc/src/math/nvptx/declarations.h
+++ b/libc/src/math/nvptx/declarations.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_SRC_MATH_GPU_NVPTX_DECLARATIONS_H
-#define LLVM_LIBC_SRC_MATH_GPU_NVPTX_DECLARATIONS_H
+#ifndef LLVM_LIBC_SRC_MATH_NVPTX_DECLARATIONS_H
+#define LLVM_LIBC_SRC_MATH_NVPTX_DECLARATIONS_H
namespace LIBC_NAMESPACE {
@@ -86,4 +86,4 @@ float __nv_tgammaf(float);
} // namespace LIBC_NAMESPACE
-#endif // LLVM_LIBC_SRC_MATH_GPU_NVPTX_DECLARATIONS_H
+#endif // LLVM_LIBC_SRC_MATH_NVPTX_DECLARATIONS_H
diff --git a/libc/src/math/nvptx/nvptx.h b/libc/src/math/nvptx/nvptx.h
index 110d570a84a393..5f9b32f311eabb 100644
--- a/libc/src/math/nvptx/nvptx.h
+++ b/libc/src/math/nvptx/nvptx.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_SRC_MATH_GPU_NVPTX_H
-#define LLVM_LIBC_SRC_MATH_GPU_NVPTX_H
+#ifndef LLVM_LIBC_SRC_MATH_NVPTX_NVPTX_H
+#define LLVM_LIBC_SRC_MATH_NVPTX_NVPTX_H
#include "declarations.h"
@@ -99,4 +99,4 @@ LIBC_INLINE float tgammaf(float x) { return __nv_tgammaf(x); }
} // namespace internal
} // namespace LIBC_NAMESPACE
-#endif // LLVM_LIBC_SRC_MATH_GPU_NVPTX_H
+#endif // LLVM_LIBC_SRC_MATH_NVPTX_NVPTX_H
diff --git a/libc/src/search/hsearch/global.h b/libc/src/search/hsearch/global.h
index 292008cb0c8075..9579195a2f3e7b 100644
--- a/libc/src/search/hsearch/global.h
+++ b/libc/src/search/hsearch/global.h
@@ -6,8 +6,13 @@
//
//===----------------------------------------------------------------------===//
+#ifndef LLVM_LIBC_SRC_SEARCH_HSEARCH_GLOBAL_H
+#define LLVM_LIBC_SRC_SEARCH_HSEARCH_GLOBAL_H
+
namespace LIBC_NAMESPACE {
namespace internal {
extern struct HashTable *global_hash_table;
}
} // namespace LIBC_NAMESPACE
+
+#endif // LLVM_LIBC_SRC_SEARCH_HSEARCH_GLOBAL_H
diff --git a/libc/src/string/memory_utils/aarch64/inline_memcpy.h b/libc/src/string/memory_utils/aarch64/inline_memcpy.h
index 0a159f476cd61c..ea1a03f4fa0bf7 100644
--- a/libc/src/string/memory_utils/aarch64/inline_memcpy.h
+++ b/libc/src/string/memory_utils/aarch64/inline_memcpy.h
@@ -5,8 +5,8 @@
// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
//
//===----------------------------------------------------------------------===//
-#ifndef LIBC_SRC_STRING_MEMORY_UTILS_AARCH64_INLINE_MEMCPY_H
-#define LIBC_SRC_STRING_MEMORY_UTILS_AARCH64_INLINE_MEMCPY_H
+#ifndef LLVM_LIBC_SRC_STRING_MEMORY_UTILS_AARCH64_INLINE_MEMCPY_H
+#define LLVM_LIBC_SRC_STRING_MEMORY_UTILS_AARCH64_INLINE_MEMCPY_H
#include "src/__support/macros/config.h" // LIBC_INLINE
#include "src/string/memory_utils/op_builtin.h"
@@ -45,4 +45,4 @@ inline_memcpy_aarch64(Ptr __restrict dst, CPtr __restrict src, size_t count) {
} // namespace LIBC_NAMESPACE
-#endif // LIBC_SRC_STRING_MEMORY_UTILS_AARCH64_INLINE_MEMCPY_H
+#endif // LLVM_LIBC_SRC_STRING_MEMORY_UTILS_AARCH64_INLINE_MEMCPY_H
diff --git a/libc/src/string/memory_utils/riscv/inline_memmove.h b/libc/src/string/memory_utils/riscv/inline_memmove.h
index 1c26917a96d9d1..1a95a8ebba07ca 100644
--- a/libc/src/string/memory_utils/riscv/inline_memmove.h
+++ b/libc/src/string/memory_utils/riscv/inline_memmove.h
@@ -5,8 +5,8 @@
// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
//
//===----------------------------------------------------------------------===//
-#ifndef LIBC_SRC_STRING_MEMORY_UTILS_RISCV_INLINE_MEMMOVE_H
-#define LIBC_SRC_STRING_MEMORY_UTILS_RISCV_INLINE_MEMMOVE_H
+#ifndef LLVM_LIBC_SRC_STRING_MEMORY_UTILS_RISCV_INLINE_MEMMOVE_H
+#define LLVM_LIBC_SRC_STRING_MEMORY_UTILS_RISCV_INLINE_MEMMOVE_H
#include "src/__support/macros/attributes.h" // LIBC_INLINE
#include "src/__support/macros/properties/architectures.h" // LIBC_TARGET_ARCH_IS_RISCV64
@@ -24,4 +24,4 @@ inline_memmove_riscv(Ptr __restrict dst, CPtr __restrict src, size_t count) {
} // namespace LIBC_NAMESPACE
-#endif // LIBC_SRC_STRING_MEMORY_UTILS_RISCV_INLINE_MEMMOVE_H
+#endif // LLVM_LIBC_SRC_STRING_MEMORY_UTILS_RISCV_INLINE_MEMMOVE_H
diff --git a/libc/test/UnitTest/ExecuteFunction.h b/libc/test/UnitTest/ExecuteFunction.h
index 2129e63a3a0029..95950567e74a24 100644
--- a/libc/test/UnitTest/ExecuteFunction.h
+++ b/libc/test/UnitTest/ExecuteFunction.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_UTILS_TESTUTILS_EXECUTEFUNCTION_H
-#define LLVM_LIBC_UTILS_TESTUTILS_EXECUTEFUNCTION_H
+#ifndef LLVM_LIBC_TEST_UNITTEST_EXECUTEFUNCTION_H
+#define LLVM_LIBC_TEST_UNITTEST_EXECUTEFUNCTION_H
#include <stdint.h>
@@ -49,4 +49,4 @@ const char *signal_as_string(int signum);
} // namespace testutils
} // namespace LIBC_NAMESPACE
-#endif // LLVM_LIBC_UTILS_TESTUTILS_EXECUTEFUNCTION_H
+#endif // LLVM_LIBC_TEST_UNITTEST_EXECUTEFUNCTION_H
diff --git a/libc/test/UnitTest/FPExceptMatcher.h b/libc/test/UnitTest/FPExceptMatcher.h
index 98c4f737d17275..d36e98d22d4b4e 100644
--- a/libc/test/UnitTest/FPExceptMatcher.h
+++ b/libc/test/UnitTest/FPExceptMatcher.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_UTILS_UNITTEST_FPEXCEPTMATCHER_H
-#define LLVM_LIBC_UTILS_UNITTEST_FPEXCEPTMATCHER_H
+#ifndef LLVM_LIBC_TEST_UNITTEST_FPEXCEPTMATCHER_H
+#define LLVM_LIBC_TEST_UNITTEST_FPEXCEPTMATCHER_H
#ifndef LIBC_COPT_TEST_USE_FUCHSIA
@@ -61,4 +61,4 @@ class FPExceptMatcher : public Matcher<bool> {
#define ASSERT_RAISES_FP_EXCEPT(func) ASSERT_DEATH(func, WITH_SIGNAL(SIGFPE))
#endif // LIBC_COPT_TEST_USE_FUCHSIA
-#endif // LLVM_LIBC_UTILS_UNITTEST_FPEXCEPTMATCHER_H
+#endif // LLVM_LIBC_TEST_UNITTEST_FPEXCEPTMATCHER_H
diff --git a/libc/test/UnitTest/FPMatcher.h b/libc/test/UnitTest/FPMatcher.h
index c4a1cfa1bc1d48..4525b9e830195e 100644
--- a/libc/test/UnitTest/FPMatcher.h
+++ b/libc/test/UnitTest/FPMatcher.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_UTILS_UNITTEST_FPMATCHER_H
-#define LLVM_LIBC_UTILS_UNITTEST_FPMATCHER_H
+#ifndef LLVM_LIBC_TEST_UNITTEST_FPMATCHER_H
+#define LLVM_LIBC_TEST_UNITTEST_FPMATCHER_H
#include "src/__support/CPP/type_traits.h"
#include "src/__support/FPUtil/FEnvImpl.h"
@@ -210,4 +210,4 @@ template <typename T> struct FPTest : public Test {
} \
} while (0)
-#endif // LLVM_LIBC_UTILS_UNITTEST_FPMATCHER_H
+#endif // LLVM_LIBC_TEST_UNITTEST_FPMATCHER_H
diff --git a/libc/test/UnitTest/LibcTest.h b/libc/test/UnitTest/LibcTest.h
index 00e34a4da85852..639f6005832576 100644
--- a/libc/test/UnitTest/LibcTest.h
+++ b/libc/test/UnitTest/LibcTest.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_UTILS_UNITTEST_LIBCTEST_H
-#define LLVM_LIBC_UTILS_UNITTEST_LIBCTEST_H
+#ifndef LLVM_LIBC_TEST_UNITTEST_LIBCTEST_H
+#define LLVM_LIBC_TEST_UNITTEST_LIBCTEST_H
// This is defined as a simple macro in test.h so that it exists for platforms
// that don't use our test infrastructure. It's defined as a proper function
@@ -493,4 +493,4 @@ CString libc_make_test_file_path_func(const char *file_name);
#define WITH_SIGNAL(X) X
-#endif // LLVM_LIBC_UTILS_UNITTEST_LIBCTEST_H
+#endif // LLVM_LIBC_TEST_UNITTEST_LIBCTEST_H
diff --git a/libc/test/UnitTest/MemoryMatcher.h b/libc/test/UnitTest/MemoryMatcher.h
index cf861a6757ae17..c548bafb7ae4d6 100644
--- a/libc/test/UnitTest/MemoryMatcher.h
+++ b/libc/test/UnitTest/MemoryMatcher.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_UTILS_UNITTEST_MEMORY_MATCHER_H
-#define LLVM_LIBC_UTILS_UNITTEST_MEMORY_MATCHER_H
+#ifndef LLVM_LIBC_TEST_UNITTEST_MEMORYMATCHER_H
+#define LLVM_LIBC_TEST_UNITTEST_MEMORYMATCHER_H
#include "src/__support/CPP/span.h"
@@ -66,4 +66,4 @@ class MemoryMatcher : public Matcher<MemoryView> {
#endif
-#endif // LLVM_LIBC_UTILS_UNITTEST_MEMORY_MATCHER_H
+#endif // LLVM_LIBC_TEST_UNITTEST_MEMORYMATCHER_H
diff --git a/libc/test/UnitTest/PlatformDefs.h b/libc/test/UnitTest/PlatformDefs.h
index 40472f4eb4eb43..f9911b1557698a 100644
--- a/libc/test/UnitTest/PlatformDefs.h
+++ b/libc/test/UnitTest/PlatformDefs.h
@@ -6,11 +6,11 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_UTILS_UNITTEST_PLATFORMDEFS_H
-#define LLVM_LIBC_UTILS_UNITTEST_PLATFORMDEFS_H
+#ifndef LLVM_LIBC_TEST_UNITTEST_PLATFORMDEFS_H
+#define LLVM_LIBC_TEST_UNITTEST_PLATFORMDEFS_H
#if !defined(_WIN32)
#define ENABLE_SUBPROCESS_TESTS
#endif
-#endif // LLVM_LIBC_UTILS_UNITTEST_PLATFORMDEFS_H
+#endif // LLVM_LIBC_TEST_UNITTEST_PLATFORMDEFS_H
diff --git a/libc/test/UnitTest/RoundingModeUtils.h b/libc/test/UnitTest/RoundingModeUtils.h
index d1c3c6ff400a54..b986c98fa2e5e2 100644
--- a/libc/test/UnitTest/RoundingModeUtils.h
+++ b/libc/test/UnitTest/RoundingModeUtils.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_UTILS_TESTUTILS_ROUNDINGMODEUTILS_H
-#define LLVM_LIBC_UTILS_TESTUTILS_ROUNDINGMODEUTILS_H
+#ifndef LLVM_LIBC_TEST_UNITTEST_ROUNDINGMODEUTILS_H
+#define LLVM_LIBC_TEST_UNITTEST_ROUNDINGMODEUTILS_H
#include <stdint.h>
@@ -34,4 +34,4 @@ template <RoundingMode R> struct ForceRoundingModeTest : ForceRoundingMode {
} // namespace fputil
} // namespace LIBC_NAMESPACE
-#endif // LLVM_LIBC_UTILS_TESTUTILS_ROUNDINGMODEUTILS_H
+#endif // LLVM_LIBC_TEST_UNITTEST_ROUNDINGMODEUTILS_H
diff --git a/libc/test/UnitTest/StringUtils.h b/libc/test/UnitTest/StringUtils.h
index ac28926d51cd89..54cff97ceafb4e 100644
--- a/libc/test/UnitTest/StringUtils.h
+++ b/libc/test/UnitTest/StringUtils.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_UTILS_UNITTEST_SIMPLE_STRING_CONV_H
-#define LLVM_LIBC_UTILS_UNITTEST_SIMPLE_STRING_CONV_H
+#ifndef LLVM_LIBC_TEST_UNITTEST_STRINGUTILS_H
+#define LLVM_LIBC_TEST_UNITTEST_STRINGUTILS_H
#include "src/__support/CPP/string.h"
#include "src/__support/CPP/type_traits.h"
@@ -33,4 +33,4 @@ int_to_hex(T value, size_t length = sizeof(T) * 2) {
} // namespace LIBC_NAMESPACE
-#endif // LLVM_LIBC_UTILS_UNITTEST_SIMPLE_STRING_CONV_H
+#endif // LLVM_LIBC_TEST_UNITTEST_STRINGUTILS_H
diff --git a/libc/test/UnitTest/Test.h b/libc/test/UnitTest/Test.h
index 61021b9d0e13a8..f7ce3cfa5cf622 100644
--- a/libc/test/UnitTest/Test.h
+++ b/libc/test/UnitTest/Test.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_UTILS_UNITTEST_TEST_H
-#define LLVM_LIBC_UTILS_UNITTEST_TEST_H
+#ifndef LLVM_LIBC_TEST_UNITTEST_TEST_H
+#define LLVM_LIBC_TEST_UNITTEST_TEST_H
// This macro takes a file name and returns a value implicitly castable to
// a const char*. That const char* is the path to a file with the provided name
@@ -24,4 +24,4 @@
#include "LibcTest.h"
#endif
-#endif // LLVM_LIBC_UTILS_UNITTEST_TEST_H
+#endif // LLVM_LIBC_TEST_UNITTEST_TEST_H
diff --git a/libc/test/integration/src/spawn/test_binary_properties.h b/libc/test/integration/src/spawn/test_binary_properties.h
index f1521c218c0cbf..8e6a1fe6747c8d 100644
--- a/libc/test/integration/src/spawn/test_binary_properties.h
+++ b/libc/test/integration/src/spawn/test_binary_properties.h
@@ -6,10 +6,10 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LIBC_TEST_INTEGRATION_SRC_SPAWN_TEST_BINARY_PROPERTIES_H
-#define LIBC_TEST_INTEGRATION_SRC_SPAWN_TEST_BINARY_PROPERTIES_H
+#ifndef LLVM_LIBC_TEST_INTEGRATION_SRC_SPAWN_TEST_BINARY_PROPERTIES_H
+#define LLVM_LIBC_TEST_INTEGRATION_SRC_SPAWN_TEST_BINARY_PROPERTIES_H
constexpr int CHILD_FD = 10;
constexpr char TEXT[] = "Hello, posix_spawn";
-#endif // LIBC_TEST_INTEGRATION_SRC_SPAWN_TEST_BINARY_PROPERTIES_H
+#endif // LLVM_LIBC_TEST_INTEGRATION_SRC_SPAWN_TEST_BINARY_PROPERTIES_H
diff --git a/libc/test/src/math/FAbsTest.h b/libc/test/src/math/FAbsTest.h
index bf3052afc816fb..54f5f87e08e7e3 100644
--- a/libc/test/src/math/FAbsTest.h
+++ b/libc/test/src/math/FAbsTest.h
@@ -6,6 +6,9 @@
//
//===----------------------------------------------------------------------===//
+#ifndef LLVM_LIBC_TEST_SRC_MATH_FABSTEST_H
+#define LLVM_LIBC_TEST_SRC_MATH_FABSTEST_H
+
#include "test/UnitTest/FPMatcher.h"
#include "test/UnitTest/Test.h"
#include "utils/MPFRWrapper/MPFRUtils.h"
@@ -47,3 +50,5 @@ template <typename T> class FAbsTest : public LIBC_NAMESPACE::testing::Test {
using LlvmLibcFAbsTest = FAbsTest<T>; \
TEST_F(LlvmLibcFAbsTest, SpecialNumbers) { testSpecialNumbers(&func); } \
TEST_F(LlvmLibcFAbsTest, Range) { testRange(&func); }
+
+#endif // LLVM_LIBC_TEST_SRC_MATH_FABSTEST_H
diff --git a/libc/test/src/math/FMaxTest.h b/libc/test/src/math/FMaxTest.h
index edc46ae5bb0fe3..f8046f380f5fd5 100644
--- a/libc/test/src/math/FMaxTest.h
+++ b/libc/test/src/math/FMaxTest.h
@@ -6,6 +6,9 @@
//
//===----------------------------------------------------------------------===//
+#ifndef LLVM_LIBC_TEST_SRC_MATH_FMAXTEST_H
+#define LLVM_LIBC_TEST_SRC_MATH_FMAXTEST_H
+
#include "test/UnitTest/FPMatcher.h"
#include "test/UnitTest/Test.h"
#include "utils/MPFRWrapper/MPFRUtils.h"
@@ -83,3 +86,5 @@ template <typename T> class FMaxTest : public LIBC_NAMESPACE::testing::Test {
TEST_F(LlvmLibcFMaxTest, NegInfArg) { testNegInfArg(&func); } \
TEST_F(LlvmLibcFMaxTest, BothZero) { testBothZero(&func); } \
TEST_F(LlvmLibcFMaxTest, Range) { testRange(&func); }
+
+#endif // LLVM_LIBC_TEST_SRC_MATH_FMAXTEST_H
diff --git a/libc/test/src/math/FMinTest.h b/libc/test/src/math/FMinTest.h
index 5ff583604ebc52..7a6534f320c92a 100644
--- a/libc/test/src/math/FMinTest.h
+++ b/libc/test/src/math/FMinTest.h
@@ -6,6 +6,9 @@
//
//===----------------------------------------------------------------------===//
+#ifndef LLVM_LIBC_TEST_SRC_MATH_FMINTEST_H
+#define LLVM_LIBC_TEST_SRC_MATH_FMINTEST_H
+
#include "test/UnitTest/FPMatcher.h"
#include "test/UnitTest/Test.h"
#include "utils/MPFRWrapper/MPFRUtils.h"
@@ -83,3 +86,5 @@ template <typename T> class FMinTest : public LIBC_NAMESPACE::testing::Test {
TEST_F(LlvmLibcFMinTest, NegInfArg) { testNegInfArg(&func); } \
TEST_F(LlvmLibcFMinTest, BothZero) { testBothZero(&func); } \
TEST_F(LlvmLibcFMinTest, Range) { testRange(&func); }
+
+#endif // LLVM_LIBC_TEST_SRC_MATH_FMINTEST_H
diff --git a/libc/test/src/math/FloorTest.h b/libc/test/src/math/FloorTest.h
index 5e459ebd492891..66b37d69d7ba3d 100644
--- a/libc/test/src/math/FloorTest.h
+++ b/libc/test/src/math/FloorTest.h
@@ -6,6 +6,9 @@
//
//===----------------------------------------------------------------------===//
+#ifndef LLVM_LIBC_TEST_SRC_MATH_FLOORTEST_H
+#define LLVM_LIBC_TEST_SRC_MATH_FLOORTEST_H
+
#include "test/UnitTest/FPMatcher.h"
#include "test/UnitTest/Test.h"
#include "utils/MPFRWrapper/MPFRUtils.h"
@@ -82,3 +85,5 @@ template <typename T> class FloorTest : public LIBC_NAMESPACE::testing::Test {
TEST_F(LlvmLibcFloorTest, RoundedNubmers) { testRoundedNumbers(&func); } \
TEST_F(LlvmLibcFloorTest, Fractions) { testFractions(&func); } \
TEST_F(LlvmLibcFloorTest, Range) { testRange(&func); }
+
+#endif // LLVM_LIBC_TEST_SRC_MATH_FLOORTEST_H
diff --git a/libc/test/src/math/RandUtils.h b/libc/test/src/math/RandUtils.h
index 05236ead2aced1..fecbd8eaabf2cd 100644
--- a/libc/test/src/math/RandUtils.h
+++ b/libc/test/src/math/RandUtils.h
@@ -6,6 +6,9 @@
//
//===----------------------------------------------------------------------===//
+#ifndef LLVM_LIBC_TEST_SRC_MATH_RANDUTILS_H
+#define LLVM_LIBC_TEST_SRC_MATH_RANDUTILS_H
+
namespace LIBC_NAMESPACE {
namespace testutils {
@@ -14,3 +17,5 @@ int rand();
} // namespace testutils
} // namespace LIBC_NAMESPACE
+
+#endif // LLVM_LIBC_TEST_SRC_MATH_RANDUTILS_H
diff --git a/libc/test/src/math/RoundTest.h b/libc/test/src/math/RoundTest.h
index 4860464be9089d..b255ecc4fa84e8 100644
--- a/libc/test/src/math/RoundTest.h
+++ b/libc/test/src/math/RoundTest.h
@@ -6,6 +6,9 @@
//
//===----------------------------------------------------------------------===//
+#ifndef LLVM_LIBC_TEST_SRC_MATH_ROUNDTEST_H
+#define LLVM_LIBC_TEST_SRC_MATH_ROUNDTEST_H
+
#include "test/UnitTest/FPMatcher.h"
#include "test/UnitTest/Test.h"
#include "utils/MPFRWrapper/MPFRUtils.h"
@@ -82,3 +85,5 @@ template <typename T> class RoundTest : public LIBC_NAMESPACE::testing::Test {
TEST_F(LlvmLibcRoundTest, RoundedNubmers) { testRoundedNumbers(&func); } \
TEST_F(LlvmLibcRoundTest, Fractions) { testFractions(&func); } \
TEST_F(LlvmLibcRoundTest, Range) { testRange(&func); }
+
+#endif // LLVM_LIBC_TEST_SRC_MATH_ROUNDTEST_H
diff --git a/libc/test/src/math/TruncTest.h b/libc/test/src/math/TruncTest.h
index 0d99363526e8a5..6d0ea1182ec11b 100644
--- a/libc/test/src/math/TruncTest.h
+++ b/libc/test/src/math/TruncTest.h
@@ -6,6 +6,9 @@
//
//===----------------------------------------------------------------------===//
+#ifndef LLVM_LIBC_TEST_SRC_MATH_TRUNCTEST_H
+#define LLVM_LIBC_TEST_SRC_MATH_TRUNCTEST_H
+
#include "test/UnitTest/FPMatcher.h"
#include "test/UnitTest/Test.h"
#include "utils/MPFRWrapper/MPFRUtils.h"
@@ -82,3 +85,5 @@ template <typename T> class TruncTest : public LIBC_NAMESPACE::testing::Test {
TEST_F(LlvmLibcTruncTest, RoundedNubmers) { testRoundedNumbers(&func); } \
TEST_F(LlvmLibcTruncTest, Fractions) { testFractions(&func); } \
TEST_F(LlvmLibcTruncTest, Range) { testRange(&func); }
+
+#endif // LLVM_LIBC_TEST_SRC_MATH_TRUNCTEST_H
diff --git a/libc/test/src/math/differential_testing/Timer.h b/libc/test/src/math/differential_testing/Timer.h
index d4acff7ba0eb18..0d9518c37d9e0f 100644
--- a/libc/test/src/math/differential_testing/Timer.h
+++ b/libc/test/src/math/differential_testing/Timer.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_UTILS_TESTUTILS_TIMER_H
-#define LLVM_LIBC_UTILS_TESTUTILS_TIMER_H
+#ifndef LLVM_LIBC_TEST_SRC_MATH_DIFFERENTIAL_TESTING_TIMER_H
+#define LLVM_LIBC_TEST_SRC_MATH_DIFFERENTIAL_TESTING_TIMER_H
#include <stdint.h>
@@ -30,4 +30,4 @@ class Timer {
} // namespace testing
} // namespace LIBC_NAMESPACE
-#endif // LLVM_LIBC_UTILS_TESTUTILS_TIMER_H
+#endif // LLVM_LIBC_TEST_SRC_MATH_DIFFERENTIAL_TESTING_TIMER_H
diff --git a/libc/test/src/math/in_float_range_test_helper.h b/libc/test/src/math/in_float_range_test_helper.h
index 5f345c0cf17af0..35e039e74af5c3 100644
--- a/libc/test/src/math/in_float_range_test_helper.h
+++ b/libc/test/src/math/in_float_range_test_helper.h
@@ -2,8 +2,8 @@
// Created by kirill on 8/30/22.
//
-#ifndef LLVM_IN_FLOAT_RANGE_TEST_HELPER_H
-#define LLVM_IN_FLOAT_RANGE_TEST_HELPER_H
+#ifndef LLVM_LIBC_TEST_SRC_MATH_IN_FLOAT_RANGE_TEST_HELPER_H
+#define LLVM_LIBC_TEST_SRC_MATH_IN_FLOAT_RANGE_TEST_HELPER_H
#include <stdint.h>
@@ -23,4 +23,4 @@
} \
}
-#endif // LLVM_IN_FLOAT_RANGE_TEST_HELPER_H
+#endif // LLVM_LIBC_TEST_SRC_MATH_IN_FLOAT_RANGE_TEST_HELPER_H
diff --git a/libc/test/src/math/smoke/CeilTest.h b/libc/test/src/math/smoke/CeilTest.h
index c10fd281601435..5248dbca503701 100644
--- a/libc/test/src/math/smoke/CeilTest.h
+++ b/libc/test/src/math/smoke/CeilTest.h
@@ -6,6 +6,9 @@
//
//===----------------------------------------------------------------------===//
+#ifndef LLVM_LIBC_TEST_SRC_MATH_SMOKE_CEILTEST_H
+#define LLVM_LIBC_TEST_SRC_MATH_SMOKE_CEILTEST_H
+
#include "test/UnitTest/FPMatcher.h"
#include "test/UnitTest/Test.h"
@@ -66,3 +69,5 @@ template <typename T> class CeilTest : public LIBC_NAMESPACE::testing::Test {
TEST_F(LlvmLibcCeilTest, SpecialNumbers) { testSpecialNumbers(&func); } \
TEST_F(LlvmLibcCeilTest, RoundedNubmers) { testRoundedNumbers(&func); } \
TEST_F(LlvmLibcCeilTest, Fractions) { testFractions(&func); }
+
+#endif // LLVM_LIBC_TEST_SRC_MATH_SMOKE_CEILTEST_H
diff --git a/libc/test/src/math/smoke/CopySignTest.h b/libc/test/src/math/smoke/CopySignTest.h
index 1108a45ae673e5..9ee34338ba8073 100644
--- a/libc/test/src/math/smoke/CopySignTest.h
+++ b/libc/test/src/math/smoke/CopySignTest.h
@@ -6,6 +6,9 @@
//
//===----------------------------------------------------------------------===//
+#ifndef LLVM_LIBC_TEST_SRC_MATH_SMOKE_COPYSIGNTEST_H
+#define LLVM_LIBC_TEST_SRC_MATH_SMOKE_COPYSIGNTEST_H
+
#include "test/UnitTest/FPMatcher.h"
#include "test/UnitTest/Test.h"
@@ -52,3 +55,5 @@ class CopySignTest : public LIBC_NAMESPACE::testing::Test {
using LlvmLibcCopySignTest = CopySignTest<T>; \
TEST_F(LlvmLibcCopySignTest, SpecialNumbers) { testSpecialNumbers(&func); } \
TEST_F(LlvmLibcCopySignTest, Range) { testRange(&func); }
+
+#endif // LLVM_LIBC_TEST_SRC_MATH_SMOKE_COPYSIGNTEST_H
diff --git a/libc/test/src/math/smoke/FAbsTest.h b/libc/test/src/math/smoke/FAbsTest.h
index 7d905baefe8514..cf05882e22f97d 100644
--- a/libc/test/src/math/smoke/FAbsTest.h
+++ b/libc/test/src/math/smoke/FAbsTest.h
@@ -6,6 +6,9 @@
//
//===----------------------------------------------------------------------===//
+#ifndef LLVM_LIBC_TEST_SRC_MATH_SMOKE_FABSTEST_H
+#define LLVM_LIBC_TEST_SRC_MATH_SMOKE_FABSTEST_H
+
#include "test/UnitTest/FPMatcher.h"
#include "test/UnitTest/Test.h"
@@ -35,3 +38,5 @@ template <typename T> class FAbsTest : public LIBC_NAMESPACE::testing::Test {
#define LIST_FABS_TESTS(T, func) \
using LlvmLibcFAbsTest = FAbsTest<T>; \
TEST_F(LlvmLibcFAbsTest, SpecialNumbers) { testSpecialNumbers(&func); }
+
+#endif // LLVM_LIBC_TEST_SRC_MATH_SMOKE_FABSTEST_H
diff --git a/libc/test/src/math/smoke/FMaxTest.h b/libc/test/src/math/smoke/FMaxTest.h
index 1a376af2e0b7b4..98fae06ee2a0fd 100644
--- a/libc/test/src/math/smoke/FMaxTest.h
+++ b/libc/test/src/math/smoke/FMaxTest.h
@@ -6,6 +6,9 @@
//
//===----------------------------------------------------------------------===//
+#ifndef LLVM_LIBC_TEST_SRC_MATH_SMOKE_FMAXTEST_H
+#define LLVM_LIBC_TEST_SRC_MATH_SMOKE_FMAXTEST_H
+
#include "test/UnitTest/FPMatcher.h"
#include "test/UnitTest/Test.h"
@@ -80,3 +83,5 @@ template <typename T> class FMaxTest : public LIBC_NAMESPACE::testing::Test {
TEST_F(LlvmLibcFMaxTest, NegInfArg) { testNegInfArg(&func); } \
TEST_F(LlvmLibcFMaxTest, BothZero) { testBothZero(&func); } \
TEST_F(LlvmLibcFMaxTest, Range) { testRange(&func); }
+
+#endif // LLVM_LIBC_TEST_SRC_MATH_SMOKE_FMAXTEST_H
diff --git a/libc/test/src/math/smoke/FMinTest.h b/libc/test/src/math/smoke/FMinTest.h
index add2544424a016..b1ffe38829f438 100644
--- a/libc/test/src/math/smoke/FMinTest.h
+++ b/libc/test/src/math/smoke/FMinTest.h
@@ -6,6 +6,9 @@
//
//===----------------------------------------------------------------------===//
+#ifndef LLVM_LIBC_TEST_SRC_MATH_SMOKE_FMINTEST_H
+#define LLVM_LIBC_TEST_SRC_MATH_SMOKE_FMINTEST_H
+
#include "test/UnitTest/FPMatcher.h"
#include "test/UnitTest/Test.h"
@@ -80,3 +83,5 @@ template <typename T> class FMinTest : public LIBC_NAMESPACE::testing::Test {
TEST_F(LlvmLibcFMinTest, NegInfArg) { testNegInfArg(&func); } \
TEST_F(LlvmLibcFMinTest, BothZero) { testBothZero(&func); } \
TEST_F(LlvmLibcFMinTest, Range) { testRange(&func); }
+
+#endif // LLVM_LIBC_TEST_SRC_MATH_SMOKE_FMINTEST_H
diff --git a/libc/test/src/math/smoke/FloorTest.h b/libc/test/src/math/smoke/FloorTest.h
index 1c1b62c2dcda2a..610f5c206ed3a0 100644
--- a/libc/test/src/math/smoke/FloorTest.h
+++ b/libc/test/src/math/smoke/FloorTest.h
@@ -6,6 +6,9 @@
//
//===----------------------------------------------------------------------===//
+#ifndef LLVM_LIBC_TEST_SRC_MATH_SMOKE_FLOORTEST_H
+#define LLVM_LIBC_TEST_SRC_MATH_SMOKE_FLOORTEST_H
+
#include "test/UnitTest/FPMatcher.h"
#include "test/UnitTest/Test.h"
@@ -66,3 +69,5 @@ template <typename T> class FloorTest : public LIBC_NAMESPACE::testing::Test {
TEST_F(LlvmLibcFloorTest, SpecialNumbers) { testSpecialNumbers(&func); } \
TEST_F(LlvmLibcFloorTest, RoundedNubmers) { testRoundedNumbers(&func); } \
TEST_F(LlvmLibcFloorTest, Fractions) { testFractions(&func); }
+
+#endif // LLVM_LIBC_TEST_SRC_MATH_SMOKE_FLOORTEST_H
diff --git a/libc/test/src/math/smoke/RIntTest.h b/libc/test/src/math/smoke/RIntTest.h
index 233164b4124743..4c90dffa39cb15 100644
--- a/libc/test/src/math/smoke/RIntTest.h
+++ b/libc/test/src/math/smoke/RIntTest.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_TEST_SRC_MATH_RINTTEST_H
-#define LLVM_LIBC_TEST_SRC_MATH_RINTTEST_H
+#ifndef LLVM_LIBC_TEST_SRC_MATH_SMOKE_RINTTEST_H
+#define LLVM_LIBC_TEST_SRC_MATH_SMOKE_RINTTEST_H
#include "src/__support/FPUtil/FEnvImpl.h"
#include "src/__support/FPUtil/FPBits.h"
@@ -54,4 +54,4 @@ class RIntTestTemplate : public LIBC_NAMESPACE::testing::Test {
using LlvmLibcRIntTest = RIntTestTemplate<F>; \
TEST_F(LlvmLibcRIntTest, specialNumbers) { testSpecialNumbers(&func); }
-#endif // LLVM_LIBC_TEST_SRC_MATH_RINTTEST_H
+#endif // LLVM_LIBC_TEST_SRC_MATH_SMOKE_RINTTEST_H
diff --git a/libc/test/src/math/smoke/RoundTest.h b/libc/test/src/math/smoke/RoundTest.h
index 2e95f182ce948b..d2a5906b1e29ea 100644
--- a/libc/test/src/math/smoke/RoundTest.h
+++ b/libc/test/src/math/smoke/RoundTest.h
@@ -6,6 +6,9 @@
//
//===----------------------------------------------------------------------===//
+#ifndef LLVM_LIBC_TEST_SRC_MATH_SMOKE_ROUNDTEST_H
+#define LLVM_LIBC_TEST_SRC_MATH_SMOKE_ROUNDTEST_H
+
#include "test/UnitTest/FPMatcher.h"
#include "test/UnitTest/Test.h"
@@ -66,3 +69,5 @@ template <typename T> class RoundTest : public LIBC_NAMESPACE::testing::Test {
TEST_F(LlvmLibcRoundTest, SpecialNumbers) { testSpecialNumbers(&func); } \
TEST_F(LlvmLibcRoundTest, RoundedNubmers) { testRoundedNumbers(&func); } \
TEST_F(LlvmLibcRoundTest, Fractions) { testFractions(&func); }
+
+#endif // LLVM_LIBC_TEST_SRC_MATH_SMOKE_ROUNDTEST_H
diff --git a/libc/test/src/math/smoke/RoundToIntegerTest.h b/libc/test/src/math/smoke/RoundToIntegerTest.h
index 59694131f7f5dd..e86533ca09e178 100644
--- a/libc/test/src/math/smoke/RoundToIntegerTest.h
+++ b/libc/test/src/math/smoke/RoundToIntegerTest.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_TEST_SRC_MATH_ROUNDTOINTEGERTEST_H
-#define LLVM_LIBC_TEST_SRC_MATH_ROUNDTOINTEGERTEST_H
+#ifndef LLVM_LIBC_TEST_SRC_MATH_SMOKE_ROUNDTOINTEGERTEST_H
+#define LLVM_LIBC_TEST_SRC_MATH_SMOKE_ROUNDTOINTEGERTEST_H
#include "src/__support/FPUtil/FEnvImpl.h"
#include "src/__support/FPUtil/FPBits.h"
@@ -169,4 +169,4 @@ class RoundToIntegerTestTemplate : public LIBC_NAMESPACE::testing::Test {
#define LIST_ROUND_TO_INTEGER_TESTS_WITH_MODES(F, I, func) \
LIST_ROUND_TO_INTEGER_TESTS_HELPER(F, I, func, true)
-#endif // LLVM_LIBC_TEST_SRC_MATH_ROUNDTOINTEGERTEST_H
+#endif // LLVM_LIBC_TEST_SRC_MATH_SMOKE_ROUNDTOINTEGERTEST_H
diff --git a/libc/test/src/math/smoke/TruncTest.h b/libc/test/src/math/smoke/TruncTest.h
index 8334a7b7c0f90d..71b1ab9df3f08b 100644
--- a/libc/test/src/math/smoke/TruncTest.h
+++ b/libc/test/src/math/smoke/TruncTest.h
@@ -6,6 +6,9 @@
//
//===----------------------------------------------------------------------===//
+#ifndef LLVM_LIBC_TEST_SRC_MATH_SMOKE_TRUNCTEST_H
+#define LLVM_LIBC_TEST_SRC_MATH_SMOKE_TRUNCTEST_H
+
#include "test/UnitTest/FPMatcher.h"
#include "test/UnitTest/Test.h"
@@ -66,3 +69,5 @@ template <typename T> class TruncTest : public LIBC_NAMESPACE::testing::Test {
TEST_F(LlvmLibcTruncTest, SpecialNumbers) { testSpecialNumbers(&func); } \
TEST_F(LlvmLibcTruncTest, RoundedNubmers) { testRoundedNumbers(&func); } \
TEST_F(LlvmLibcTruncTest, Fractions) { testFractions(&func); }
+
+#endif // LLVM_LIBC_TEST_SRC_MATH_SMOKE_TRUNCTEST_H
diff --git a/libc/test/src/time/TmHelper.h b/libc/test/src/time/TmHelper.h
index d8e638d8dbaffb..16210944bf15f9 100644
--- a/libc/test/src/time/TmHelper.h
+++ b/libc/test/src/time/TmHelper.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_TEST_SRC_TIME_TM_HELPER_H
-#define LLVM_LIBC_TEST_SRC_TIME_TM_HELPER_H
+#ifndef LLVM_LIBC_TEST_SRC_TIME_TMHELPER_H
+#define LLVM_LIBC_TEST_SRC_TIME_TMHELPER_H
#include <time.h>
@@ -40,4 +40,4 @@ static inline void initialize_tm_data(struct tm *tm_data, int year, int month,
} // namespace tmhelper
} // namespace LIBC_NAMESPACE
-#endif // LLVM_LIBC_TEST_SRC_TIME_TM_HELPER_H
+#endif // LLVM_LIBC_TEST_SRC_TIME_TMHELPER_H
diff --git a/libc/utils/MPFRWrapper/MPFRUtils.h b/libc/utils/MPFRWrapper/MPFRUtils.h
index 25e6b0ba9ac08b..6164d78fa5adc4 100644
--- a/libc/utils/MPFRWrapper/MPFRUtils.h
+++ b/libc/utils/MPFRWrapper/MPFRUtils.h
@@ -6,8 +6,8 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_UTILS_TESTUTILS_MPFRUTILS_H
-#define LLVM_LIBC_UTILS_TESTUTILS_MPFRUTILS_H
+#ifndef LLVM_LIBC_UTILS_MPFRWRAPPER_MPFRUTILS_H
+#define LLVM_LIBC_UTILS_MPFRWRAPPER_MPFRUTILS_H
#include "src/__support/CPP/type_traits.h"
#include "test/UnitTest/RoundingModeUtils.h"
@@ -426,4 +426,4 @@ template <typename T> bool round_to_long(T x, RoundingMode mode, long &result);
} \
}
-#endif // LLVM_LIBC_UTILS_TESTUTILS_MPFRUTILS_H
+#endif // LLVM_LIBC_UTILS_MPFRWRAPPER_MPFRUTILS_H
>From 249cf356ef21d0b6ed0d1fa962f3fc5a9e3fcc9e Mon Sep 17 00:00:00 2001
From: Jordan Rupprecht <rupprecht at google.com>
Date: Wed, 28 Feb 2024 15:00:41 -0600
Subject: [PATCH 046/406] [lldb][test][NFC] Add option to exclude third_party
packages (#83191)
The goal here is to remove the third_party/Python/module tree, which
LLDB tests only use to `import pexpect`. This package is available on
`pip`, and I believe should not be hard to obtain.
However, in case it isn't easily available, deleting the tree right now
could cause disruption. This introduces a
`LLDB_TEST_USE_VENDOR_PACKAGES` cmake param that can be enabled, and the
tests will continue loading that tree. By default, it is enabled,
meaning there's really no change here. A followup change will disable it
by default once all known build bots are updated to include this
package. When disabled, an eager cmake check runs that makes sure
`pexpect` is available before waiting for the test to fail in an obscure
way.
Later, this option will go away, and when it does, we can delete the
tree too. Ideally this is not disruptive, and we can remove it in a week
or two.
---
lldb/cmake/modules/LLDBConfig.cmake | 2 ++
lldb/test/API/lit.cfg.py | 3 +++
lldb/test/API/lit.site.cfg.py.in | 1 +
lldb/test/CMakeLists.txt | 17 ++++++++++++++++-
lldb/use_lldb_suite_root.py | 4 +++-
lldb/utils/lldb-dotest/CMakeLists.txt | 1 +
lldb/utils/lldb-dotest/lldb-dotest.in | 5 +++++
7 files changed, 31 insertions(+), 2 deletions(-)
diff --git a/lldb/cmake/modules/LLDBConfig.cmake b/lldb/cmake/modules/LLDBConfig.cmake
index a758261073ac57..93c8ffe4b7d8a0 100644
--- a/lldb/cmake/modules/LLDBConfig.cmake
+++ b/lldb/cmake/modules/LLDBConfig.cmake
@@ -67,6 +67,8 @@ option(LLDB_SKIP_STRIP "Whether to skip stripping of binaries when installing ll
option(LLDB_SKIP_DSYM "Whether to skip generating a dSYM when installing lldb." OFF)
option(LLDB_ENFORCE_STRICT_TEST_REQUIREMENTS
"Fail to configure if certain requirements are not met for testing." OFF)
+option(LLDB_TEST_USE_VENDOR_PACKAGES
+ "Use packages from lldb/third_party/Python/module instead of system deps." ON)
set(LLDB_GLOBAL_INIT_DIRECTORY "" CACHE STRING
"Path to the global lldbinit directory. Relative paths are resolved relative to the
diff --git a/lldb/test/API/lit.cfg.py b/lldb/test/API/lit.cfg.py
index 12675edc0fd3b9..f9497b632fc504 100644
--- a/lldb/test/API/lit.cfg.py
+++ b/lldb/test/API/lit.cfg.py
@@ -309,3 +309,6 @@ def delete_module_cache(path):
# Propagate XDG_CACHE_HOME
if "XDG_CACHE_HOME" in os.environ:
config.environment["XDG_CACHE_HOME"] = os.environ["XDG_CACHE_HOME"]
+
+if is_configured("use_vendor_packages"):
+ config.environment["LLDB_TEST_USE_VENDOR_PACKAGES"] = "1"
diff --git a/lldb/test/API/lit.site.cfg.py.in b/lldb/test/API/lit.site.cfg.py.in
index 053331dc4881f7..c2602acd2ef85a 100644
--- a/lldb/test/API/lit.site.cfg.py.in
+++ b/lldb/test/API/lit.site.cfg.py.in
@@ -38,6 +38,7 @@ config.libcxx_include_target_dir = "@LIBCXX_GENERATED_INCLUDE_TARGET_DIR@"
# The API tests use their own module caches.
config.lldb_module_cache = os.path.join("@LLDB_TEST_MODULE_CACHE_LLDB@", "lldb-api")
config.clang_module_cache = os.path.join("@LLDB_TEST_MODULE_CACHE_CLANG@", "lldb-api")
+config.use_vendor_packages = @LLDB_TEST_USE_VENDOR_PACKAGES@
# Plugins
lldb_build_intel_pt = '@LLDB_BUILD_INTEL_PT@'
diff --git a/lldb/test/CMakeLists.txt b/lldb/test/CMakeLists.txt
index 1aa8843b6a2e78..d8cbb24b6c9b81 100644
--- a/lldb/test/CMakeLists.txt
+++ b/lldb/test/CMakeLists.txt
@@ -26,6 +26,20 @@ if(LLDB_ENFORCE_STRICT_TEST_REQUIREMENTS)
endforeach()
endif()
+# The "pexpect" package should come from the system environment, not from the
+# LLDB tree. However, we delay the deletion of it from the tree in case
+# users/buildbots don't have the package yet and need some time to install it.
+if (NOT LLDB_TEST_USE_VENDOR_PACKAGES)
+ lldb_find_python_module(pexpect)
+ if (NOT PY_pexpect_FOUND)
+ message(FATAL_ERROR
+ "Python module 'pexpect' not found. Please install it via pip or via "
+ "your operating system's package manager. For a temporary workaround, "
+ "use a version from the LLDB tree with "
+ "`LLDB_TEST_USE_VENDOR_PACKAGES=ON`")
+ endif()
+endif()
+
if(LLDB_BUILT_STANDALONE)
# In order to run check-lldb-* we need the correct map_config directives in
# llvm-lit. Because this is a standalone build, LLVM doesn't know about LLDB,
@@ -240,7 +254,8 @@ llvm_canonicalize_cmake_booleans(
LLDB_HAS_LIBCXX
LLDB_TOOL_LLDB_SERVER_BUILD
LLDB_USE_SYSTEM_DEBUGSERVER
- LLDB_IS_64_BITS)
+ LLDB_IS_64_BITS
+ LLDB_TEST_USE_VENDOR_PACKAGES)
# Configure the individual test suites.
add_subdirectory(API)
diff --git a/lldb/use_lldb_suite_root.py b/lldb/use_lldb_suite_root.py
index fd42f63a3c7f30..b8f8acf5dd94a4 100644
--- a/lldb/use_lldb_suite_root.py
+++ b/lldb/use_lldb_suite_root.py
@@ -21,5 +21,7 @@ def add_lldbsuite_packages_dir(lldb_root):
lldb_root = os.path.dirname(inspect.getfile(inspect.currentframe()))
-add_third_party_module_dirs(lldb_root)
+# Use environment variables to avoid plumbing flags, lit configs, etc.
+if os.getenv("LLDB_TEST_USE_VENDOR_PACKAGES"):
+ add_third_party_module_dirs(lldb_root)
add_lldbsuite_packages_dir(lldb_root)
diff --git a/lldb/utils/lldb-dotest/CMakeLists.txt b/lldb/utils/lldb-dotest/CMakeLists.txt
index 09f41dbce421ec..2ba40f009cc92a 100644
--- a/lldb/utils/lldb-dotest/CMakeLists.txt
+++ b/lldb/utils/lldb-dotest/CMakeLists.txt
@@ -10,6 +10,7 @@ set(LLDB_LIBS_DIR "${LLVM_LIBRARY_OUTPUT_INTDIR}")
llvm_canonicalize_cmake_booleans(
LLDB_BUILD_INTEL_PT
LLDB_HAS_LIBCXX
+ LLDB_TEST_USE_VENDOR_PACKAGES
)
if ("libcxx" IN_LIST LLVM_ENABLE_RUNTIMES)
diff --git a/lldb/utils/lldb-dotest/lldb-dotest.in b/lldb/utils/lldb-dotest/lldb-dotest.in
index 5cd49d253b9937..9291f59b41982d 100755
--- a/lldb/utils/lldb-dotest/lldb-dotest.in
+++ b/lldb/utils/lldb-dotest/lldb-dotest.in
@@ -1,4 +1,5 @@
#!@Python3_EXECUTABLE@
+import os
import subprocess
import sys
@@ -17,8 +18,12 @@ has_libcxx = @LLDB_HAS_LIBCXX@
libcxx_libs_dir = "@LIBCXX_LIBRARY_DIR@"
libcxx_include_dir = "@LIBCXX_GENERATED_INCLUDE_DIR@"
libcxx_include_target_dir = "@LIBCXX_GENERATED_INCLUDE_TARGET_DIR@"
+use_vendor_packages = @LLDB_TEST_USE_VENDOR_PACKAGES@
if __name__ == '__main__':
+ if use_vendor_packages:
+ os.putenv("LLDB_TEST_USE_VENDOR_PACKAGES", "1")
+
wrapper_args = sys.argv[1:]
dotest_args = []
# split on an empty string will produce [''] and if you
>From 5b91647e3f82c9747c42c3239b7d7f3ade4542a7 Mon Sep 17 00:00:00 2001
From: Jon Roelofs <jonathan_roelofs at apple.com>
Date: Wed, 28 Feb 2024 13:03:35 -0800
Subject: [PATCH 047/406] Allow .alt_entry symbols to pass the .cfi nesting
check (#82268)
A symbol with an `N_ALT_ENTRY` attribute may be defined in the middle of
a subsection, so it is reasonable to opt them out of the
`.cfi_{start,end}proc` nesting check.
Fixes: https://github.com/llvm/llvm-project/issues/82261
---
llvm/lib/MC/MCParser/AsmParser.cpp | 4 +++-
llvm/test/MC/AArch64/cfi-bad-nesting-darwin.s | 6 +++++-
2 files changed, 8 insertions(+), 2 deletions(-)
diff --git a/llvm/lib/MC/MCParser/AsmParser.cpp b/llvm/lib/MC/MCParser/AsmParser.cpp
index a1c32eee328643..76a3e501f45909 100644
--- a/llvm/lib/MC/MCParser/AsmParser.cpp
+++ b/llvm/lib/MC/MCParser/AsmParser.cpp
@@ -44,6 +44,7 @@
#include "llvm/MC/MCSection.h"
#include "llvm/MC/MCStreamer.h"
#include "llvm/MC/MCSymbol.h"
+#include "llvm/MC/MCSymbolMachO.h"
#include "llvm/MC/MCTargetOptions.h"
#include "llvm/MC/MCValue.h"
#include "llvm/Support/Casting.h"
@@ -1950,7 +1951,8 @@ bool AsmParser::parseStatement(ParseStatementInfo &Info,
Lex();
}
- if (MAI.hasSubsectionsViaSymbols() && CFIStartProcLoc && Sym->isExternal())
+ if (MAI.hasSubsectionsViaSymbols() && CFIStartProcLoc &&
+ Sym->isExternal() && !cast<MCSymbolMachO>(Sym)->isAltEntry())
return Error(StartTokLoc, "non-private labels cannot appear between "
".cfi_startproc / .cfi_endproc pairs") &&
Error(*CFIStartProcLoc, "previous .cfi_startproc was here");
diff --git a/llvm/test/MC/AArch64/cfi-bad-nesting-darwin.s b/llvm/test/MC/AArch64/cfi-bad-nesting-darwin.s
index 235b7d44809929..3a5af86defc592 100644
--- a/llvm/test/MC/AArch64/cfi-bad-nesting-darwin.s
+++ b/llvm/test/MC/AArch64/cfi-bad-nesting-darwin.s
@@ -8,6 +8,10 @@
.p2align 2
_locomotive:
.cfi_startproc
+ ; An N_ALT_ENTRY symbol can be defined in the middle of a subsection, so
+ ; these are opted out of the .cfi_{start,end}proc nesting check.
+ .alt_entry _engineer
+_engineer:
ret
; It is invalid to have a non-private label between .cfi_startproc and
@@ -17,7 +21,7 @@ _locomotive:
.p2align 2
_caboose:
; DARWIN: [[#@LINE-1]]:1: error: non-private labels cannot appear between .cfi_startproc / .cfi_endproc pairs
-; DARWIN: [[#@LINE-10]]:2: error: previous .cfi_startproc was here
+; DARWIN: [[#@LINE-14]]:2: error: previous .cfi_startproc was here
ret
.cfi_endproc
>From 4df364bc93af49ae413ec1ae8328f34ac70730c4 Mon Sep 17 00:00:00 2001
From: Nick Desaulniers <nickdesaulniers at users.noreply.github.com>
Date: Wed, 28 Feb 2024 13:19:40 -0800
Subject: [PATCH 048/406] [libc] remove header guard for assert.h (#83334)
It's meant to be included multiple times! Maybe use a NOLINT rule to
suppress
clang-tidy's llvm-header-guard lint warning.
---
libc/src/assert/assert.h | 6 +-----
1 file changed, 1 insertion(+), 5 deletions(-)
diff --git a/libc/src/assert/assert.h b/libc/src/assert/assert.h
index 0daf9c4e1e6166..6f352af1988b37 100644
--- a/libc/src/assert/assert.h
+++ b/libc/src/assert/assert.h
@@ -1,3 +1,4 @@
+// NOLINT(llvm-header-guard) https://github.com/llvm/llvm-project/issues/83339
//===-- Internal header for assert ------------------------------*- C++ -*-===//
//
// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
@@ -6,9 +7,6 @@
//
//===----------------------------------------------------------------------===//
-#ifndef LLVM_LIBC_SRC_ASSERT_ASSERT_H
-#define LLVM_LIBC_SRC_ASSERT_ASSERT_H
-
#include "src/assert/__assert_fail.h"
// There is no header guard here since assert is intended to be capable of being
@@ -25,5 +23,3 @@
: LIBC_NAMESPACE::__assert_fail(#e, __FILE__, __LINE__, \
__PRETTY_FUNCTION__))
#endif // NDEBUG
-
-#endif // LLVM_LIBC_SRC_ASSERT_ASSERT_H
>From caca8d33a9d5e6fe75980c4ae1cb13de2e460590 Mon Sep 17 00:00:00 2001
From: Joe Nash <Sisyph at users.noreply.github.com>
Date: Wed, 28 Feb 2024 16:37:39 -0500
Subject: [PATCH 049/406] [vim] Fix command already exists on opening multiple
mir buffers (#82410)
When using the vim syntax for mir, an error occurs in nvim when opening
multiple .mir buffers. delcommand HiLink in the mir syntax file to avoid
the issue.
To reproduce:
Open an .mir file, for example
llvm/test/Codegen/X86/expand-post-ra-pseudo.mir
Open another mir file from within nvim, for example peephole.mir
```
Error detected while processing function 335[30]..<SNR>43_callback[25]..function 335[30]..<SNR>43_callback:
line 23:
Vim(command):E174: Command already exists: add ! to replace it: HiLink hi def link <args>
```
---
llvm/utils/vim/syntax/mir.vim | 2 ++
1 file changed, 2 insertions(+)
diff --git a/llvm/utils/vim/syntax/mir.vim b/llvm/utils/vim/syntax/mir.vim
index 51ac4982b7c95e..024a795a23c54c 100644
--- a/llvm/utils/vim/syntax/mir.vim
+++ b/llvm/utils/vim/syntax/mir.vim
@@ -43,6 +43,8 @@ if version >= 508 || !exists("did_c_syn_inits")
endif
HiLink mirSpecialComment SpecialComment
+
+ delcommand HiLink
endif
let b:current_syntax = "mir"
>From 1977404d20ab29ff78a58d8c0f1f4c5e7aef6b16 Mon Sep 17 00:00:00 2001
From: Joseph Huber <huberjn at outlook.com>
Date: Wed, 28 Feb 2024 15:39:27 -0600
Subject: [PATCH 050/406] [OpenMP] Respect LLVM per-target install directories
(#83282)
Summary:
One recurring problem we have with the OpenMP libraries is that they are
potentially conflicting with ones found on the system, this occurs when
there are two copies and one is used for linking that it not attached to
the correspoding clang compiler. LLVM already uses target specific
directories for this, like with libc++, which are always searched first.
This patch changes the install directory to be
`lib/x86_64-unknown-linux-gnu` for example.
Notable changes would be that users will need to change their
LD_LIBRARY_PATH settings optionally, or use default rt-rpath options.
This should fix problems were users are linking the wrong versions of
static libraries
---
clang/lib/Driver/ToolChains/CommonArgs.cpp | 10 +++++-----
clang/lib/Driver/ToolChains/CommonArgs.h | 3 ++-
clang/lib/Driver/ToolChains/Cuda.cpp | 2 +-
openmp/CMakeLists.txt | 12 +++++++++---
4 files changed, 17 insertions(+), 10 deletions(-)
diff --git a/clang/lib/Driver/ToolChains/CommonArgs.cpp b/clang/lib/Driver/ToolChains/CommonArgs.cpp
index faceee85a2f8dc..382c8b3612a0af 100644
--- a/clang/lib/Driver/ToolChains/CommonArgs.cpp
+++ b/clang/lib/Driver/ToolChains/CommonArgs.cpp
@@ -2763,13 +2763,13 @@ void tools::addOpenMPDeviceRTL(const Driver &D,
const llvm::opt::ArgList &DriverArgs,
llvm::opt::ArgStringList &CC1Args,
StringRef BitcodeSuffix,
- const llvm::Triple &Triple) {
+ const llvm::Triple &Triple,
+ const ToolChain &HostTC) {
SmallVector<StringRef, 8> LibraryPaths;
- // Add path to clang lib / lib64 folder.
- SmallString<256> DefaultLibPath = llvm::sys::path::parent_path(D.Dir);
- llvm::sys::path::append(DefaultLibPath, CLANG_INSTALL_LIBDIR_BASENAME);
- LibraryPaths.emplace_back(DefaultLibPath.c_str());
+ // Check all of the standard library search paths used by the compiler.
+ for (const auto &LibPath : HostTC.getFilePaths())
+ LibraryPaths.emplace_back(LibPath);
// Add user defined library paths from LIBRARY_PATH.
std::optional<std::string> LibPath =
diff --git a/clang/lib/Driver/ToolChains/CommonArgs.h b/clang/lib/Driver/ToolChains/CommonArgs.h
index 2db0f889ca8209..b8f649aab4bdd2 100644
--- a/clang/lib/Driver/ToolChains/CommonArgs.h
+++ b/clang/lib/Driver/ToolChains/CommonArgs.h
@@ -214,7 +214,8 @@ void addMachineOutlinerArgs(const Driver &D, const llvm::opt::ArgList &Args,
void addOpenMPDeviceRTL(const Driver &D, const llvm::opt::ArgList &DriverArgs,
llvm::opt::ArgStringList &CC1Args,
- StringRef BitcodeSuffix, const llvm::Triple &Triple);
+ StringRef BitcodeSuffix, const llvm::Triple &Triple,
+ const ToolChain &HostTC);
void addOutlineAtomicsArgs(const Driver &D, const ToolChain &TC,
const llvm::opt::ArgList &Args,
diff --git a/clang/lib/Driver/ToolChains/Cuda.cpp b/clang/lib/Driver/ToolChains/Cuda.cpp
index ff3687ca7dae33..177fd6310e7ee2 100644
--- a/clang/lib/Driver/ToolChains/Cuda.cpp
+++ b/clang/lib/Driver/ToolChains/Cuda.cpp
@@ -903,7 +903,7 @@ void CudaToolChain::addClangTargetOptions(
return;
addOpenMPDeviceRTL(getDriver(), DriverArgs, CC1Args, GpuArch.str(),
- getTriple());
+ getTriple(), HostTC);
}
}
diff --git a/openmp/CMakeLists.txt b/openmp/CMakeLists.txt
index 03068af22629f7..3c4ff76ad6d161 100644
--- a/openmp/CMakeLists.txt
+++ b/openmp/CMakeLists.txt
@@ -46,9 +46,15 @@ if (OPENMP_STANDALONE_BUILD)
set(CMAKE_CXX_EXTENSIONS NO)
else()
set(OPENMP_ENABLE_WERROR ${LLVM_ENABLE_WERROR})
- # If building in tree, we honor the same install suffix LLVM uses.
- set(OPENMP_INSTALL_LIBDIR "lib${LLVM_LIBDIR_SUFFIX}" CACHE STRING
- "Path where built OpenMP libraries should be installed.")
+
+ # When building in tree we install the runtime according to the LLVM settings.
+ if(LLVM_ENABLE_PER_TARGET_RUNTIME_DIR AND NOT APPLE)
+ set(OPENMP_INSTALL_LIBDIR lib${LLVM_LIBDIR_SUFFIX}/${LLVM_DEFAULT_TARGET_TRIPLE} CACHE STRING
+ "Path where built openmp libraries should be installed.")
+ else()
+ set(OPENMP_INSTALL_LIBDIR "lib${LLVM_LIBDIR_SUFFIX}" CACHE STRING
+ "Path where built OpenMP libraries should be installed.")
+ endif()
if (NOT MSVC)
set(OPENMP_TEST_C_COMPILER ${LLVM_RUNTIME_OUTPUT_INTDIR}/clang)
>From 68f0edfa359fde3fb4f5ec391a4afe96f3905aaf Mon Sep 17 00:00:00 2001
From: Petr Hosek <phosek at google.com>
Date: Wed, 28 Feb 2024 13:53:51 -0800
Subject: [PATCH 051/406] [libc] Include assert.h on baremetal targets (#83324)
Many baremetal applications use asserts.
---
libc/config/baremetal/api.td | 36 +++++++++++++++++++++
libc/config/baremetal/arm/entrypoints.txt | 3 ++
libc/config/baremetal/arm/headers.txt | 1 +
libc/config/baremetal/riscv/entrypoints.txt | 3 ++
libc/config/baremetal/riscv/headers.txt | 1 +
5 files changed, 44 insertions(+)
diff --git a/libc/config/baremetal/api.td b/libc/config/baremetal/api.td
index d6897fbecaac70..3da83d9eb30cff 100644
--- a/libc/config/baremetal/api.td
+++ b/libc/config/baremetal/api.td
@@ -2,6 +2,42 @@ include "config/public_api.td"
include "spec/stdc.td"
+def AssertMacro : MacroDef<"assert"> {
+ let Defn = [{
+ #undef assert
+
+ #ifdef NDEBUG
+ #define assert(e) (void)0
+ #else
+
+ #ifdef __cplusplus
+ extern "C"
+ #endif
+ _Noreturn void __assert_fail(const char *, const char *, unsigned, const char *) __NOEXCEPT;
+
+ #define assert(e) \
+ ((e) ? (void)0 : __assert_fail(#e, __FILE__, __LINE__, __PRETTY_FUNCTION__))
+
+ #endif
+ }];
+}
+
+def StaticAssertMacro : MacroDef<"static_assert"> {
+ let Defn = [{
+ #ifndef __cplusplus
+ #undef static_assert
+ #define static_assert _Static_assert
+ #endif
+ }];
+}
+
+def AssertAPI : PublicAPI<"assert.h"> {
+ let Macros = [
+ AssertMacro,
+ StaticAssertMacro,
+ ];
+}
+
def CTypeAPI : PublicAPI<"ctype.h"> {
}
diff --git a/libc/config/baremetal/arm/entrypoints.txt b/libc/config/baremetal/arm/entrypoints.txt
index 608ac46034306b..a61d9feac2938d 100644
--- a/libc/config/baremetal/arm/entrypoints.txt
+++ b/libc/config/baremetal/arm/entrypoints.txt
@@ -1,4 +1,7 @@
set(TARGET_LIBC_ENTRYPOINTS
+ # assert.h entrypoints
+ libc.src.assert.__assert_fail
+
# ctype.h entrypoints
libc.src.ctype.isalnum
libc.src.ctype.isalpha
diff --git a/libc/config/baremetal/arm/headers.txt b/libc/config/baremetal/arm/headers.txt
index 38899fabd980c9..4c02ac84018d85 100644
--- a/libc/config/baremetal/arm/headers.txt
+++ b/libc/config/baremetal/arm/headers.txt
@@ -1,4 +1,5 @@
set(TARGET_PUBLIC_HEADERS
+ libc.include.assert
libc.include.ctype
libc.include.fenv
libc.include.errno
diff --git a/libc/config/baremetal/riscv/entrypoints.txt b/libc/config/baremetal/riscv/entrypoints.txt
index 2f299e992be09a..533f9f9f368506 100644
--- a/libc/config/baremetal/riscv/entrypoints.txt
+++ b/libc/config/baremetal/riscv/entrypoints.txt
@@ -1,4 +1,7 @@
set(TARGET_LIBC_ENTRYPOINTS
+ # assert.h entrypoints
+ libc.src.assert.__assert_fail
+
# ctype.h entrypoints
libc.src.ctype.isalnum
libc.src.ctype.isalpha
diff --git a/libc/config/baremetal/riscv/headers.txt b/libc/config/baremetal/riscv/headers.txt
index 38899fabd980c9..4c02ac84018d85 100644
--- a/libc/config/baremetal/riscv/headers.txt
+++ b/libc/config/baremetal/riscv/headers.txt
@@ -1,4 +1,5 @@
set(TARGET_PUBLIC_HEADERS
+ libc.include.assert
libc.include.ctype
libc.include.fenv
libc.include.errno
>From 8394ec9ff1d58b361961e3a8990d0e080ba6c7f2 Mon Sep 17 00:00:00 2001
From: Aart Bik <39774503+aartbik at users.noreply.github.com>
Date: Wed, 28 Feb 2024 14:05:40 -0800
Subject: [PATCH 052/406] [mlir][sparse] add a few more cases to
sparse_tensor.print test (#83338)
---
.../SparseTensor/CPU/sparse_print.mlir | 58 ++++++++++++++++++-
1 file changed, 56 insertions(+), 2 deletions(-)
diff --git a/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_print.mlir b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_print.mlir
index 797a04bb9ff862..79728fdb0f8cde 100755
--- a/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_print.mlir
+++ b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_print.mlir
@@ -102,6 +102,24 @@
)
}>
+#BSR0 = #sparse_tensor.encoding<{
+ map = (i, j) -> (
+ i floordiv 2 : dense,
+ j floordiv 4 : compressed,
+ i mod 2 : dense,
+ j mod 4 : dense
+ )
+}>
+
+#BSC0 = #sparse_tensor.encoding<{
+ map = (i, j) -> (
+ j floordiv 4 : dense,
+ i floordiv 2 : compressed,
+ i mod 2 : dense,
+ j mod 4 : dense
+ )
+}>
+
module {
//
@@ -114,6 +132,21 @@ module {
[ 0, 0, 0, 0, 0, 0, 0, 0 ],
[ 0, 0, 3, 4, 0, 5, 0, 0 ] ]> : tensor<4x8xi32>
+ %XO = sparse_tensor.convert %x : tensor<4x8xi32> to tensor<4x8xi32, #AllDense>
+ %XT = sparse_tensor.convert %x : tensor<4x8xi32> to tensor<4x8xi32, #AllDenseT>
+
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 32
+ // CHECK-NEXT: values : ( 1, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 4, 0, 5, 0, 0,
+ // CHECK-NEXT: ----
+ sparse_tensor.print %XO : tensor<4x8xi32, #AllDense>
+
+ // CHECK-NEXT: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 32
+ // CHECK-NEXT: values : ( 1, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0, 3, 0, 0, 0, 4, 0, 0, 0, 0, 0, 0, 0, 5, 0, 0, 0, 0, 0, 0, 0, 0,
+ // CHECK-NEXT: ----
+ sparse_tensor.print %XT : tensor<4x8xi32, #AllDenseT>
+
%a = sparse_tensor.convert %x : tensor<4x8xi32> to tensor<4x8xi32, #CSR>
%b = sparse_tensor.convert %x : tensor<4x8xi32> to tensor<4x8xi32, #DCSR>
%c = sparse_tensor.convert %x : tensor<4x8xi32> to tensor<4x8xi32, #CSC>
@@ -122,9 +155,10 @@ module {
%f = sparse_tensor.convert %x : tensor<4x8xi32> to tensor<4x8xi32, #BSRC>
%g = sparse_tensor.convert %x : tensor<4x8xi32> to tensor<4x8xi32, #BSC>
%h = sparse_tensor.convert %x : tensor<4x8xi32> to tensor<4x8xi32, #BSCC>
+ %i = sparse_tensor.convert %x : tensor<4x8xi32> to tensor<4x8xi32, #BSR0>
+ %j = sparse_tensor.convert %x : tensor<4x8xi32> to tensor<4x8xi32, #BSC0>
- //
- // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: ---- Sparse Tensor ----
// CHECK-NEXT: nse = 5
// CHECK-NEXT: pos[1] : ( 0, 2, 2, 2, 5,
// CHECK-NEXT: crd[1] : ( 0, 2, 2, 3, 5,
@@ -200,7 +234,25 @@ module {
// CHECK-NEXT: ----
sparse_tensor.print %h : tensor<4x8xi32, #BSCC>
+ // CHECK-NEXT: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 24
+ // CHECK-NEXT: pos[1] : ( 0, 1, 3,
+ // CHECK-NEXT: crd[1] : ( 0, 0, 1,
+ // CHECK-NEXT: values : ( 1, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 4, 0, 0, 0, 0, 0, 5, 0, 0,
+ // CHECK-NEXT: ----
+ sparse_tensor.print %i : tensor<4x8xi32, #BSR0>
+
+ // CHECK-NEXT: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 24
+ // CHECK-NEXT: pos[1] : ( 0, 2, 3,
+ // CHECK-NEXT: crd[1] : ( 0, 1, 1,
+ // CHECK-NEXT: values : ( 1, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 4, 0, 0, 0, 0, 0, 5, 0, 0,
+ // CHECK-NEXT: ----
+ sparse_tensor.print %j : tensor<4x8xi32, #BSC0>
+
// Release the resources.
+ bufferization.dealloc_tensor %XO : tensor<4x8xi32, #AllDense>
+ bufferization.dealloc_tensor %XT : tensor<4x8xi32, #AllDenseT>
bufferization.dealloc_tensor %a : tensor<4x8xi32, #CSR>
bufferization.dealloc_tensor %b : tensor<4x8xi32, #DCSR>
bufferization.dealloc_tensor %c : tensor<4x8xi32, #CSC>
@@ -209,6 +261,8 @@ module {
bufferization.dealloc_tensor %f : tensor<4x8xi32, #BSRC>
bufferization.dealloc_tensor %g : tensor<4x8xi32, #BSC>
bufferization.dealloc_tensor %h : tensor<4x8xi32, #BSCC>
+ bufferization.dealloc_tensor %i : tensor<4x8xi32, #BSR0>
+ bufferization.dealloc_tensor %j : tensor<4x8xi32, #BSC0>
return
}
>From 14faf0d4aa841aafd0d1982391114bc35fda7e59 Mon Sep 17 00:00:00 2001
From: Cyndy Ishida <cyndy_ishida at apple.com>
Date: Wed, 28 Feb 2024 14:24:42 -0800
Subject: [PATCH 053/406] [TextAPI][InstallAPI] Fix documentation typos, NFC
---
clang/lib/InstallAPI/Visitor.cpp | 2 +-
llvm/include/llvm/TextAPI/RecordsSlice.h | 7 ++++---
2 files changed, 5 insertions(+), 4 deletions(-)
diff --git a/clang/lib/InstallAPI/Visitor.cpp b/clang/lib/InstallAPI/Visitor.cpp
index 9b333a6142ae8f..3806a69b52399b 100644
--- a/clang/lib/InstallAPI/Visitor.cpp
+++ b/clang/lib/InstallAPI/Visitor.cpp
@@ -19,7 +19,7 @@ using namespace llvm::MachO;
namespace clang::installapi {
-// Exported NamedDecl needs to have externally visibiliy linkage and
+// Exported NamedDecl needs to have external linkage and
// default visibility from LinkageComputer.
static bool isExported(const NamedDecl *D) {
auto LV = D->getLinkageAndVisibility();
diff --git a/llvm/include/llvm/TextAPI/RecordsSlice.h b/llvm/include/llvm/TextAPI/RecordsSlice.h
index 5b214d0bfff567..57b23e5ea29e71 100644
--- a/llvm/include/llvm/TextAPI/RecordsSlice.h
+++ b/llvm/include/llvm/TextAPI/RecordsSlice.h
@@ -50,9 +50,9 @@ class RecordsSlice {
/// Add non-ObjC global record.
///
/// \param Name The name of symbol.
- /// \param Flags The flags that describe attributes of the symbol.
- /// \param GV The kind of global.
/// \param Linkage The linkage of symbol.
+ /// \param GV The kind of global.
+ /// \param Flags The flags that describe attributes of the symbol.
/// \return The non-owning pointer to added record in slice.
GlobalRecord *addGlobal(StringRef Name, RecordLinkage Linkage,
GlobalRecord::Kind GV,
@@ -69,6 +69,7 @@ class RecordsSlice {
/// Add ObjC IVar record.
///
+ /// \param Container Owning pointer for instance variable.
/// \param Name The name of ivar, not symbol.
/// \param Linkage The linkage of symbol.
/// \return The non-owning pointer to added record in slice.
@@ -93,7 +94,7 @@ class RecordsSlice {
/// Find ObjC Category.
///
/// \param ClassToExtend The name of class, not full symbol name.
- /// \param Categories The name of category.
+ /// \param Category The name of category.
/// \return The non-owning pointer to record in slice.
ObjCCategoryRecord *findObjCCategory(StringRef ClassToExtend,
StringRef Category) const;
>From dc456ce4f2ad6ebe883c301758d8eb95fcd16a0a Mon Sep 17 00:00:00 2001
From: Nico Weber <thakis at chromium.org>
Date: Wed, 28 Feb 2024 17:35:21 -0500
Subject: [PATCH 054/406] [gn] port 249cf356ef21
---
llvm/utils/gn/secondary/lldb/test/BUILD.gn | 3 ++-
1 file changed, 2 insertions(+), 1 deletion(-)
diff --git a/llvm/utils/gn/secondary/lldb/test/BUILD.gn b/llvm/utils/gn/secondary/lldb/test/BUILD.gn
index 06ef7383ad3b55..414ea4933c519d 100644
--- a/llvm/utils/gn/secondary/lldb/test/BUILD.gn
+++ b/llvm/utils/gn/secondary/lldb/test/BUILD.gn
@@ -60,7 +60,8 @@ write_lit_cfg("lit_api_site_cfg") {
"LLDB_TEST_COMMON_ARGS=",
"LLDB_TEST_USER_ARGS=",
"LLDB_ENABLE_PYTHON=0",
- "LLDB_HAS_LIBCXX=0", # FIXME: support this (?)
+ "LLDB_HAS_LIBCXX=False", # FIXME: support this (?)
+ "LLDB_TEST_USE_VENDOR_PACKAGES=False",
"LLDB_LIBS_DIR=", # FIXME: for shared builds only (?)
"LLDB_TEST_ARCH=$current_cpu",
"LLDB_TEST_COMPILER=" + rebase_path("$root_build_dir/bin/clang"),
>From e3b93a16201d96745a2c64523801a2b1eb43b4c0 Mon Sep 17 00:00:00 2001
From: Max191 <44243577+Max191 at users.noreply.github.com>
Date: Wed, 28 Feb 2024 17:39:22 -0500
Subject: [PATCH 055/406] [mlir] Fix bug in pack and unpack op canonicalization
for folding dynamic dims (#82539)
This PR fixes a bug in the inference of pack and unpack static shapes
that should be using an inverse permutation.
---
mlir/lib/Dialect/Tensor/IR/TensorOps.cpp | 16 ++++++----
mlir/test/Dialect/Tensor/canonicalize.mlir | 35 ++++++++++++++++++----
2 files changed, 39 insertions(+), 12 deletions(-)
diff --git a/mlir/lib/Dialect/Tensor/IR/TensorOps.cpp b/mlir/lib/Dialect/Tensor/IR/TensorOps.cpp
index e6efec14e31a60..fe2f250e6b9290 100644
--- a/mlir/lib/Dialect/Tensor/IR/TensorOps.cpp
+++ b/mlir/lib/Dialect/Tensor/IR/TensorOps.cpp
@@ -4012,15 +4012,17 @@ static bool inferStaticShape(PackOp packOp, SmallVectorImpl<int64_t> &srcShape,
llvm::SmallSetVector<int64_t, 4> innerDims;
innerDims.insert(packOp.getInnerDimsPos().begin(),
packOp.getInnerDimsPos().end());
- auto outerDimsPerm = packOp.getOuterDimsPerm();
+ SmallVector<int64_t> inverseOuterDimsPerm;
+ if (!packOp.getOuterDimsPerm().empty())
+ inverseOuterDimsPerm = invertPermutationVector(packOp.getOuterDimsPerm());
int srcRank = packOp.getSourceRank();
for (auto i : llvm::seq<int64_t>(0, srcRank)) {
if (innerDims.contains(i))
continue;
int64_t srcPos = i;
int64_t destPos = i;
- if (!outerDimsPerm.empty())
- destPos = outerDimsPerm[srcPos];
+ if (!inverseOuterDimsPerm.empty())
+ destPos = inverseOuterDimsPerm[srcPos];
if (ShapedType::isDynamic(srcShape[srcPos]) ==
ShapedType::isDynamic(destShape[destPos])) {
continue;
@@ -4240,15 +4242,17 @@ static bool inferStaticShape(UnPackOp op, SmallVectorImpl<int64_t> &srcShape,
op.getDestType().getShape().end());
llvm::SmallSetVector<int64_t, 4> innerDims;
innerDims.insert(op.getInnerDimsPos().begin(), op.getInnerDimsPos().end());
- auto outerDimsPerm = op.getOuterDimsPerm();
+ SmallVector<int64_t> inverseOuterDimsPerm;
+ if (!op.getOuterDimsPerm().empty())
+ inverseOuterDimsPerm = invertPermutationVector(op.getOuterDimsPerm());
int destRank = op.getDestRank();
for (auto i : llvm::seq<int64_t>(0, destRank)) {
if (innerDims.contains(i))
continue;
int64_t srcPos = i;
int64_t destPos = i;
- if (!outerDimsPerm.empty())
- srcPos = outerDimsPerm[destPos];
+ if (!inverseOuterDimsPerm.empty())
+ srcPos = inverseOuterDimsPerm[destPos];
if (ShapedType::isDynamic(srcShape[srcPos]) ==
ShapedType::isDynamic(destShape[destPos])) {
continue;
diff --git a/mlir/test/Dialect/Tensor/canonicalize.mlir b/mlir/test/Dialect/Tensor/canonicalize.mlir
index e123c77aabd57c..d17c23adfb14d8 100644
--- a/mlir/test/Dialect/Tensor/canonicalize.mlir
+++ b/mlir/test/Dialect/Tensor/canonicalize.mlir
@@ -822,7 +822,7 @@ func.func @infer_src_shape_pack(%src: tensor<?x?x?x?xf32>, %dest: tensor<10x20x3
// CHECK-LABEL: func.func @infer_src_shape_pack
// CHECK-SAME: %[[SRC:[0-9a-zA-Z]+]]
// CHECK-SAME: %[[DEST:[0-9a-zA-Z]+]]
-// CHECK: %[[CAST_SRC:.+]] = tensor.cast %[[SRC]] : tensor<?x?x?x?xf32> to tensor<30x20x?x10xf32>
+// CHECK: %[[CAST_SRC:.+]] = tensor.cast %[[SRC]] : tensor<?x?x?x?xf32> to tensor<40x20x?x30xf32>
// CHECK: %[[PACK:.+]] = tensor.pack %[[CAST_SRC]] {{.+}} into %[[DEST]]
// CHECK: return %[[PACK]]
@@ -841,13 +841,24 @@ func.func @infer_dest_shape_pack(%src: tensor<30x20x?x10xf32>, %dest: tensor<?x?
// CHECK-LABEL: func.func @infer_dest_shape_pack
// CHECK-SAME: %[[SRC:[0-9a-zA-Z]+]]
// CHECK-SAME: %[[DEST:[0-9a-zA-Z]+]]
-// CHECK: %[[CAST_DEST:.+]] = tensor.cast %[[DEST]] : tensor<?x?x?x?x16xf32> to tensor<10x20x30x?x16xf32>
+// CHECK: %[[CAST_DEST:.+]] = tensor.cast %[[DEST]] : tensor<?x?x?x?x16xf32> to tensor<?x20x10x30x16xf32>
// CHECK: %[[PACK:.+]] = tensor.pack %[[SRC]] {{.+}} into %[[CAST_DEST]]
-// CHECK: %[[CAST_PACK:.+]] = tensor.cast %[[PACK]] : tensor<10x20x30x?x16xf32> to tensor<?x?x?x?x16xf32>
+// CHECK: %[[CAST_PACK:.+]] = tensor.cast %[[PACK]] : tensor<?x20x10x30x16xf32> to tensor<?x?x?x?x16xf32>
// CHECK: return %[[CAST_PACK]]
// -----
+func.func @no_infer_pack_shape(%arg0: tensor<?x32x100xf32>, %arg1: index) -> tensor<32x7x?x16x1xf32> {
+ %cst = arith.constant 0.000000e+00 : f32
+ %0 = tensor.empty(%arg1) : tensor<32x7x?x16x1xf32>
+ %pack = tensor.pack %arg0 padding_value(%cst : f32) outer_dims_perm = [1, 2, 0] inner_dims_pos = [2, 0] inner_tiles = [16, 1] into %0 : tensor<?x32x100xf32> -> tensor<32x7x?x16x1xf32>
+ return %pack : tensor<32x7x?x16x1xf32>
+}
+// CHECK-LABEL: func.func @no_infer_pack_shape
+// CHECK-NOT: tensor.cast
+
+// -----
+
func.func @fold_padding_value_pack_negative1(%arg0: tensor<1200x499999xf32>) -> tensor<31250x1200x16x1xf32> {
%cst = arith.constant 0.000000e+00 : f32
%0 = tensor.empty() : tensor<31250x1200x16x1xf32>
@@ -920,9 +931,9 @@ func.func @infer_dest_shape_unpack(%src: tensor<10x20x30x40x16xf32>, %dest: tens
// CHECK-LABEL: func.func @infer_dest_shape_unpack
// CHECK-SAME: %[[SRC:[0-9a-zA-Z]+]]
// CHECK-SAME: %[[DEST:[0-9a-zA-Z]+]]
-// CHECK: %[[CAST_DEST:.+]] = tensor.cast %[[DEST]] : tensor<?x?x?x?xf32> to tensor<30x20x?x10xf32>
+// CHECK: %[[CAST_DEST:.+]] = tensor.cast %[[DEST]] : tensor<?x?x?x?xf32> to tensor<40x20x?x30xf32>
// CHECK: %[[UNPACK:.+]] = tensor.unpack %[[SRC]] {{.+}} into %[[CAST_DEST]]
-// CHECK: %[[CAST_UNPACK:.+]] = tensor.cast %[[UNPACK]] : tensor<30x20x?x10xf32> to tensor<?x?x?x?xf32>
+// CHECK: %[[CAST_UNPACK:.+]] = tensor.cast %[[UNPACK]] : tensor<40x20x?x30xf32> to tensor<?x?x?x?xf32>
// CHECK: return %[[CAST_UNPACK]]
// -----
@@ -938,12 +949,24 @@ func.func @infer_src_shape_unpack(%src: tensor<?x?x?x?x16xf32>, %dest: tensor<30
// CHECK-LABEL: func.func @infer_src_shape_unpack
// CHECK-SAME: %[[SRC:[0-9a-zA-Z]+]]
// CHECK-SAME: %[[DEST:[0-9a-zA-Z]+]]
-// CHECK: %[[CAST_SRC:.+]] = tensor.cast %[[SRC]] : tensor<?x?x?x?x16xf32> to tensor<10x20x30x?x16xf32>
+// CHECK: %[[CAST_SRC:.+]] = tensor.cast %[[SRC]] : tensor<?x?x?x?x16xf32> to tensor<?x20x10x30x16xf32>
// CHECK: %[[UNPACK:.+]] = tensor.unpack %[[CAST_SRC]]
// CHECK: return %[[UNPACK]]
// -----
+func.func @no_infer_unpack_shape(%arg1: tensor<32x7x?x16x1xf32>, %arg2: index) -> tensor<?x32x100xf32> {
+ %cst = arith.constant 0.000000e+00 : f32
+ %0 = tensor.empty(%arg2) : tensor<?x32x100xf32>
+ %unpack = tensor.unpack %arg1 outer_dims_perm = [1, 2, 0] inner_dims_pos = [2, 0] inner_tiles = [16, 1] into %0 : tensor<32x7x?x16x1xf32> -> tensor<?x32x100xf32>
+ return %unpack : tensor<?x32x100xf32>
+}
+// CHECK-LABEL: func.func @no_infer_unpack_shape
+// CHECK-NOT: tensor.cast
+
+// -----
+
+
// CHECK-LABEL: func @fold_overlapping_insert
// CHECK-SAME: %[[INPUT:.+]]: tensor<?x?x?xf32>, %{{.+}}: tensor<4x?x8xf32>, %[[SLICE2:.+]]: tensor<4x?x8xf32>
func.func @fold_overlapping_insert(%input : tensor<?x?x?xf32>, %slice1: tensor<4x?x8xf32>, %slice2: tensor<4x?x8xf32>, %i: index, %size: index) -> (tensor<?x?x?xf32>) {
>From fc8d48106387b8b79531902788ef93571f924da7 Mon Sep 17 00:00:00 2001
From: OverMighty <its.overmighty at gmail.com>
Date: Wed, 28 Feb 2024 22:46:06 +0000
Subject: [PATCH 056/406] [clang] Fix __builtin_popcountg not matching GCC
(#83313)
Our implementation previously accepted signed arguments and performed
integer promotion on the argument. GCC's implementation requires an
unsigned argument and does not perform integer promotion on it.
---
clang/docs/LanguageExtensions.rst | 8 +++---
clang/include/clang/Basic/Builtins.td | 2 +-
.../clang/Basic/DiagnosticSemaKinds.td | 2 +-
clang/lib/Sema/SemaChecking.cpp | 14 +++++++---
clang/test/CodeGen/builtins.c | 28 +++++++++----------
clang/test/Sema/builtin-popcountg.c | 17 ++++++++---
6 files changed, 43 insertions(+), 28 deletions(-)
diff --git a/clang/docs/LanguageExtensions.rst b/clang/docs/LanguageExtensions.rst
index 2a177814c4df7a..bcd69198eafdbe 100644
--- a/clang/docs/LanguageExtensions.rst
+++ b/clang/docs/LanguageExtensions.rst
@@ -3477,7 +3477,7 @@ builtin, the mangler emits their usual pattern without any special treatment.
-----------------------
``__builtin_popcountg`` returns the number of 1 bits in the argument. The
-argument can be of any integer type.
+argument can be of any unsigned integer type.
**Syntax**:
@@ -3489,20 +3489,20 @@ argument can be of any integer type.
.. code-block:: c++
- int x = 1;
+ unsigned int x = 1;
int x_pop = __builtin_popcountg(x);
unsigned long y = 3;
int y_pop = __builtin_popcountg(y);
- _BitInt(128) z = 7;
+ unsigned _BitInt(128) z = 7;
int z_pop = __builtin_popcountg(z);
**Description**:
``__builtin_popcountg`` is meant to be a type-generic alternative to the
``__builtin_popcount{,l,ll}`` builtins, with support for other integer types,
-such as ``__int128`` and C23 ``_BitInt(N)``.
+such as ``unsigned __int128`` and C23 ``unsigned _BitInt(N)``.
Multiprecision Arithmetic Builtins
----------------------------------
diff --git a/clang/include/clang/Basic/Builtins.td b/clang/include/clang/Basic/Builtins.td
index 3bc35c5bb38ecf..2fbc56d49a59a1 100644
--- a/clang/include/clang/Basic/Builtins.td
+++ b/clang/include/clang/Basic/Builtins.td
@@ -690,7 +690,7 @@ def Popcount : Builtin, BitInt_Long_LongLongTemplate {
def Popcountg : Builtin {
let Spellings = ["__builtin_popcountg"];
- let Attributes = [NoThrow, Const];
+ let Attributes = [NoThrow, Const, CustomTypeChecking];
let Prototype = "int(...)";
}
diff --git a/clang/include/clang/Basic/DiagnosticSemaKinds.td b/clang/include/clang/Basic/DiagnosticSemaKinds.td
index c8141fefb8edba..f726805dc02bd9 100644
--- a/clang/include/clang/Basic/DiagnosticSemaKinds.td
+++ b/clang/include/clang/Basic/DiagnosticSemaKinds.td
@@ -11984,7 +11984,7 @@ def err_builtin_invalid_arg_type: Error <
"signed integer or floating point type|vector type|"
"floating point type|"
"vector of integers|"
- "type of integer}1 (was %2)">;
+ "type of unsigned integer}1 (was %2)">;
def err_builtin_matrix_disabled: Error<
"matrix types extension is disabled. Pass -fenable-matrix to enable it">;
diff --git a/clang/lib/Sema/SemaChecking.cpp b/clang/lib/Sema/SemaChecking.cpp
index 0de76ee119cf81..979b63884359fc 100644
--- a/clang/lib/Sema/SemaChecking.cpp
+++ b/clang/lib/Sema/SemaChecking.cpp
@@ -2190,17 +2190,23 @@ static bool SemaBuiltinCpu(Sema &S, const TargetInfo &TI, CallExpr *TheCall,
}
/// Checks that __builtin_popcountg was called with a single argument, which is
-/// an integer.
+/// an unsigned integer.
static bool SemaBuiltinPopcountg(Sema &S, CallExpr *TheCall) {
if (checkArgCount(S, TheCall, 1))
return true;
- Expr *Arg = TheCall->getArg(0);
+ ExprResult ArgRes = S.DefaultLvalueConversion(TheCall->getArg(0));
+ if (ArgRes.isInvalid())
+ return true;
+
+ Expr *Arg = ArgRes.get();
+ TheCall->setArg(0, Arg);
+
QualType ArgTy = Arg->getType();
- if (!ArgTy->isIntegerType()) {
+ if (!ArgTy->isUnsignedIntegerType()) {
S.Diag(Arg->getBeginLoc(), diag::err_builtin_invalid_arg_type)
- << 1 << /*integer ty*/ 7 << ArgTy;
+ << 1 << /*unsigned integer ty*/ 7 << ArgTy;
return true;
}
return false;
diff --git a/clang/test/CodeGen/builtins.c b/clang/test/CodeGen/builtins.c
index 73866116e07e72..4f9641d357b7ba 100644
--- a/clang/test/CodeGen/builtins.c
+++ b/clang/test/CodeGen/builtins.c
@@ -948,14 +948,14 @@ void test_builtin_popcountg(unsigned char uc, unsigned short us,
volatile int pop;
pop = __builtin_popcountg(uc);
// CHECK: %1 = load i8, ptr %uc.addr, align 1
- // CHECK-NEXT: %conv = zext i8 %1 to i32
- // CHECK-NEXT: %2 = call i32 @llvm.ctpop.i32(i32 %conv)
- // CHECK-NEXT: store volatile i32 %2, ptr %pop, align 4
+ // CHECK-NEXT: %2 = call i8 @llvm.ctpop.i8(i8 %1)
+ // CHECK-NEXT: %cast = sext i8 %2 to i32
+ // CHECK-NEXT: store volatile i32 %cast, ptr %pop, align 4
pop = __builtin_popcountg(us);
// CHECK-NEXT: %3 = load i16, ptr %us.addr, align 2
- // CHECK-NEXT: %conv1 = zext i16 %3 to i32
- // CHECK-NEXT: %4 = call i32 @llvm.ctpop.i32(i32 %conv1)
- // CHECK-NEXT: store volatile i32 %4, ptr %pop, align 4
+ // CHECK-NEXT: %4 = call i16 @llvm.ctpop.i16(i16 %3)
+ // CHECK-NEXT: %cast1 = sext i16 %4 to i32
+ // CHECK-NEXT: store volatile i32 %cast1, ptr %pop, align 4
pop = __builtin_popcountg(ui);
// CHECK-NEXT: %5 = load i32, ptr %ui.addr, align 4
// CHECK-NEXT: %6 = call i32 @llvm.ctpop.i32(i32 %5)
@@ -963,23 +963,23 @@ void test_builtin_popcountg(unsigned char uc, unsigned short us,
pop = __builtin_popcountg(ul);
// CHECK-NEXT: %7 = load i64, ptr %ul.addr, align 8
// CHECK-NEXT: %8 = call i64 @llvm.ctpop.i64(i64 %7)
- // CHECK-NEXT: %cast = trunc i64 %8 to i32
- // CHECK-NEXT: store volatile i32 %cast, ptr %pop, align 4
+ // CHECK-NEXT: %cast2 = trunc i64 %8 to i32
+ // CHECK-NEXT: store volatile i32 %cast2, ptr %pop, align 4
pop = __builtin_popcountg(ull);
// CHECK-NEXT: %9 = load i64, ptr %ull.addr, align 8
// CHECK-NEXT: %10 = call i64 @llvm.ctpop.i64(i64 %9)
- // CHECK-NEXT: %cast2 = trunc i64 %10 to i32
- // CHECK-NEXT: store volatile i32 %cast2, ptr %pop, align 4
+ // CHECK-NEXT: %cast3 = trunc i64 %10 to i32
+ // CHECK-NEXT: store volatile i32 %cast3, ptr %pop, align 4
pop = __builtin_popcountg(ui128);
// CHECK-NEXT: %11 = load i128, ptr %ui128.addr, align 16
// CHECK-NEXT: %12 = call i128 @llvm.ctpop.i128(i128 %11)
- // CHECK-NEXT: %cast3 = trunc i128 %12 to i32
- // CHECK-NEXT: store volatile i32 %cast3, ptr %pop, align 4
+ // CHECK-NEXT: %cast4 = trunc i128 %12 to i32
+ // CHECK-NEXT: store volatile i32 %cast4, ptr %pop, align 4
pop = __builtin_popcountg(ubi128);
// CHECK-NEXT: %13 = load i128, ptr %ubi128.addr, align 8
// CHECK-NEXT: %14 = call i128 @llvm.ctpop.i128(i128 %13)
- // CHECK-NEXT: %cast4 = trunc i128 %14 to i32
- // CHECK-NEXT: store volatile i32 %cast4, ptr %pop, align 4
+ // CHECK-NEXT: %cast5 = trunc i128 %14 to i32
+ // CHECK-NEXT: store volatile i32 %cast5, ptr %pop, align 4
// CHECK-NEXT: ret void
}
diff --git a/clang/test/Sema/builtin-popcountg.c b/clang/test/Sema/builtin-popcountg.c
index e18b910046ff0c..9d095927d24e1a 100644
--- a/clang/test/Sema/builtin-popcountg.c
+++ b/clang/test/Sema/builtin-popcountg.c
@@ -1,14 +1,23 @@
-// RUN: %clang_cc1 -triple=x86_64-pc-linux-gnu -fsyntax-only -verify -Wpedantic %s
+// RUN: %clang_cc1 -std=c23 -triple=x86_64-pc-linux-gnu -fsyntax-only -verify -Wpedantic %s
typedef int int2 __attribute__((ext_vector_type(2)));
-void test_builtin_popcountg(int i, double d, int2 i2) {
+void test_builtin_popcountg(short s, int i, __int128 i128, _BitInt(128) bi128,
+ double d, int2 i2) {
__builtin_popcountg();
// expected-error at -1 {{too few arguments to function call, expected 1, have 0}}
__builtin_popcountg(i, i);
// expected-error at -1 {{too many arguments to function call, expected 1, have 2}}
+ __builtin_popcountg(s);
+ // expected-error at -1 {{1st argument must be a type of unsigned integer (was 'short')}}
+ __builtin_popcountg(i);
+ // expected-error at -1 {{1st argument must be a type of unsigned integer (was 'int')}}
+ __builtin_popcountg(i128);
+ // expected-error at -1 {{1st argument must be a type of unsigned integer (was '__int128')}}
+ __builtin_popcountg(bi128);
+ // expected-error at -1 {{1st argument must be a type of unsigned integer (was '_BitInt(128)')}}
__builtin_popcountg(d);
- // expected-error at -1 {{1st argument must be a type of integer (was 'double')}}
+ // expected-error at -1 {{1st argument must be a type of unsigned integer (was 'double')}}
__builtin_popcountg(i2);
- // expected-error at -1 {{1st argument must be a type of integer (was 'int2' (vector of 2 'int' values))}}
+ // expected-error at -1 {{1st argument must be a type of unsigned integer (was 'int2' (vector of 2 'int' values))}}
}
>From 6f8d826b746242802a2368cac26896dfebd6f5a1 Mon Sep 17 00:00:00 2001
From: Nick Desaulniers <nickdesaulniers at users.noreply.github.com>
Date: Wed, 28 Feb 2024 14:52:02 -0800
Subject: [PATCH 057/406] [libc] fix
readability-identifier-naming.ConstexprFunctionCase (#83345)
Codify that we use lower_case for
readability-identifier-naming.ConstexprFunctionCase and then fix the 11
violations (rather than codify UPPER_CASE and have to fix the 170 violations).
---
libc/.clang-tidy | 2 +
libc/src/__support/FPUtil/FPBits.h | 112 +++++++++---------
.../string/memory_utils/aarch64/inline_bcmp.h | 2 +-
.../memory_utils/aarch64/inline_memcmp.h | 2 +-
.../memory_utils/generic/aligned_access.h | 4 +-
.../memory_utils/generic/byte_per_byte.h | 6 +-
libc/src/string/memory_utils/op_aarch64.h | 10 +-
libc/src/string/memory_utils/op_builtin.h | 16 +--
libc/src/string/memory_utils/op_generic.h | 10 +-
libc/src/string/memory_utils/utils.h | 4 +-
.../string/memory_utils/x86_64/inline_bcmp.h | 2 +-
.../memory_utils/x86_64/inline_memcmp.h | 2 +-
12 files changed, 87 insertions(+), 85 deletions(-)
diff --git a/libc/.clang-tidy b/libc/.clang-tidy
index 5adada9a3f59a8..dbde88928ee636 100644
--- a/libc/.clang-tidy
+++ b/libc/.clang-tidy
@@ -26,5 +26,7 @@ CheckOptions:
value: UPPER_CASE
- key: readability-identifier-naming.ConstexprVariableCase
value: UPPER_CASE
+ - key: readability-identifier-naming.ConstexprFunctionCase
+ value: lower_case
- key: readability-identifier-naming.GetConfigPerFile
value: true
diff --git a/libc/src/__support/FPUtil/FPBits.h b/libc/src/__support/FPUtil/FPBits.h
index b3179a24c74749..fb5ff6a4153c90 100644
--- a/libc/src/__support/FPUtil/FPBits.h
+++ b/libc/src/__support/FPUtil/FPBits.h
@@ -239,23 +239,23 @@ template <FPType fp_type> struct FPStorage : public FPLayout<fp_type> {
// An opaque type to store a floating point exponent.
// We define special values but it is valid to create arbitrary values as long
- // as they are in the range [MIN, MAX].
+ // as they are in the range [min, max].
struct Exponent : public TypedInt<int32_t> {
using UP = TypedInt<int32_t>;
using UP::UP;
- LIBC_INLINE static constexpr auto SUBNORMAL() {
+ LIBC_INLINE static constexpr auto subnormal() {
return Exponent(-EXP_BIAS);
}
- LIBC_INLINE static constexpr auto MIN() { return Exponent(1 - EXP_BIAS); }
- LIBC_INLINE static constexpr auto ZERO() { return Exponent(0); }
- LIBC_INLINE static constexpr auto MAX() { return Exponent(EXP_BIAS); }
- LIBC_INLINE static constexpr auto INF() { return Exponent(EXP_BIAS + 1); }
+ LIBC_INLINE static constexpr auto min() { return Exponent(1 - EXP_BIAS); }
+ LIBC_INLINE static constexpr auto zero() { return Exponent(0); }
+ LIBC_INLINE static constexpr auto max() { return Exponent(EXP_BIAS); }
+ LIBC_INLINE static constexpr auto inf() { return Exponent(EXP_BIAS + 1); }
};
// An opaque type to store a floating point biased exponent.
// We define special values but it is valid to create arbitrary values as long
- // as they are in the range [BITS_ALL_ZEROES, BITS_ALL_ONES].
- // Values greater than BITS_ALL_ONES are truncated.
+ // as they are in the range [zero, bits_all_ones].
+ // Values greater than bits_all_ones are truncated.
struct BiasedExponent : public TypedInt<uint32_t> {
using UP = TypedInt<uint32_t>;
using UP::UP;
@@ -269,13 +269,13 @@ template <FPType fp_type> struct FPStorage : public FPLayout<fp_type> {
}
LIBC_INLINE constexpr BiasedExponent &operator++() {
- LIBC_ASSERT(*this != BiasedExponent(Exponent::INF()));
+ LIBC_ASSERT(*this != BiasedExponent(Exponent::inf()));
++UP::value;
return *this;
}
LIBC_INLINE constexpr BiasedExponent &operator--() {
- LIBC_ASSERT(*this != BiasedExponent(Exponent::SUBNORMAL()));
+ LIBC_ASSERT(*this != BiasedExponent(Exponent::subnormal()));
--UP::value;
return *this;
}
@@ -283,9 +283,9 @@ template <FPType fp_type> struct FPStorage : public FPLayout<fp_type> {
// An opaque type to store a floating point significand.
// We define special values but it is valid to create arbitrary values as long
- // as they are in the range [ZERO, BITS_ALL_ONES].
+ // as they are in the range [zero, bits_all_ones].
// Note that the semantics of the Significand are implementation dependent.
- // Values greater than BITS_ALL_ONES are truncated.
+ // Values greater than bits_all_ones are truncated.
struct Significand : public TypedInt<StorageType> {
using UP = TypedInt<StorageType>;
using UP::UP;
@@ -305,16 +305,16 @@ template <FPType fp_type> struct FPStorage : public FPLayout<fp_type> {
return Significand(StorageType(a.to_storage_type() >> shift));
}
- LIBC_INLINE static constexpr auto ZERO() {
+ LIBC_INLINE static constexpr auto zero() {
return Significand(StorageType(0));
}
- LIBC_INLINE static constexpr auto LSB() {
+ LIBC_INLINE static constexpr auto lsb() {
return Significand(StorageType(1));
}
- LIBC_INLINE static constexpr auto MSB() {
+ LIBC_INLINE static constexpr auto msb() {
return Significand(StorageType(1) << (SIG_LEN - 1));
}
- LIBC_INLINE static constexpr auto BITS_ALL_ONES() {
+ LIBC_INLINE static constexpr auto bits_all_ones() {
return Significand(SIG_MASK);
}
};
@@ -393,58 +393,58 @@ struct FPRepSem : public FPStorage<fp_type> {
public:
// Builders
LIBC_INLINE static constexpr RetT zero(Sign sign = Sign::POS) {
- return RetT(encode(sign, Exponent::SUBNORMAL(), Significand::ZERO()));
+ return RetT(encode(sign, Exponent::subnormal(), Significand::zero()));
}
LIBC_INLINE static constexpr RetT one(Sign sign = Sign::POS) {
- return RetT(encode(sign, Exponent::ZERO(), Significand::ZERO()));
+ return RetT(encode(sign, Exponent::zero(), Significand::zero()));
}
LIBC_INLINE static constexpr RetT min_subnormal(Sign sign = Sign::POS) {
- return RetT(encode(sign, Exponent::SUBNORMAL(), Significand::LSB()));
+ return RetT(encode(sign, Exponent::subnormal(), Significand::lsb()));
}
LIBC_INLINE static constexpr RetT max_subnormal(Sign sign = Sign::POS) {
return RetT(
- encode(sign, Exponent::SUBNORMAL(), Significand::BITS_ALL_ONES()));
+ encode(sign, Exponent::subnormal(), Significand::bits_all_ones()));
}
LIBC_INLINE static constexpr RetT min_normal(Sign sign = Sign::POS) {
- return RetT(encode(sign, Exponent::MIN(), Significand::ZERO()));
+ return RetT(encode(sign, Exponent::min(), Significand::zero()));
}
LIBC_INLINE static constexpr RetT max_normal(Sign sign = Sign::POS) {
- return RetT(encode(sign, Exponent::MAX(), Significand::BITS_ALL_ONES()));
+ return RetT(encode(sign, Exponent::max(), Significand::bits_all_ones()));
}
LIBC_INLINE static constexpr RetT inf(Sign sign = Sign::POS) {
- return RetT(encode(sign, Exponent::INF(), Significand::ZERO()));
+ return RetT(encode(sign, Exponent::inf(), Significand::zero()));
}
LIBC_INLINE static constexpr RetT signaling_nan(Sign sign = Sign::POS,
StorageType v = 0) {
- return RetT(encode(sign, Exponent::INF(),
- (v ? Significand(v) : (Significand::MSB() >> 1))));
+ return RetT(encode(sign, Exponent::inf(),
+ (v ? Significand(v) : (Significand::msb() >> 1))));
}
LIBC_INLINE static constexpr RetT quiet_nan(Sign sign = Sign::POS,
StorageType v = 0) {
return RetT(
- encode(sign, Exponent::INF(), Significand::MSB() | Significand(v)));
+ encode(sign, Exponent::inf(), Significand::msb() | Significand(v)));
}
// Observers
LIBC_INLINE constexpr bool is_zero() const { return exp_sig_bits() == 0; }
LIBC_INLINE constexpr bool is_nan() const {
- return exp_sig_bits() > encode(Exponent::INF(), Significand::ZERO());
+ return exp_sig_bits() > encode(Exponent::inf(), Significand::zero());
}
LIBC_INLINE constexpr bool is_quiet_nan() const {
- return exp_sig_bits() >= encode(Exponent::INF(), Significand::MSB());
+ return exp_sig_bits() >= encode(Exponent::inf(), Significand::msb());
}
LIBC_INLINE constexpr bool is_signaling_nan() const {
return is_nan() && !is_quiet_nan();
}
LIBC_INLINE constexpr bool is_inf() const {
- return exp_sig_bits() == encode(Exponent::INF(), Significand::ZERO());
+ return exp_sig_bits() == encode(Exponent::inf(), Significand::zero());
}
LIBC_INLINE constexpr bool is_finite() const {
- return exp_bits() != encode(Exponent::INF());
+ return exp_bits() != encode(Exponent::inf());
}
LIBC_INLINE
constexpr bool is_subnormal() const {
- return exp_bits() == encode(Exponent::SUBNORMAL());
+ return exp_bits() == encode(Exponent::subnormal());
}
LIBC_INLINE constexpr bool is_normal() const {
return is_finite() && !is_subnormal();
@@ -493,37 +493,37 @@ struct FPRepSem<FPType::X86_Binary80, RetT>
public:
// Builders
LIBC_INLINE static constexpr RetT zero(Sign sign = Sign::POS) {
- return RetT(encode(sign, Exponent::SUBNORMAL(), Significand::ZERO()));
+ return RetT(encode(sign, Exponent::subnormal(), Significand::zero()));
}
LIBC_INLINE static constexpr RetT one(Sign sign = Sign::POS) {
- return RetT(encode(sign, Exponent::ZERO(), Significand::MSB()));
+ return RetT(encode(sign, Exponent::zero(), Significand::msb()));
}
LIBC_INLINE static constexpr RetT min_subnormal(Sign sign = Sign::POS) {
- return RetT(encode(sign, Exponent::SUBNORMAL(), Significand::LSB()));
+ return RetT(encode(sign, Exponent::subnormal(), Significand::lsb()));
}
LIBC_INLINE static constexpr RetT max_subnormal(Sign sign = Sign::POS) {
- return RetT(encode(sign, Exponent::SUBNORMAL(),
- Significand::BITS_ALL_ONES() ^ Significand::MSB()));
+ return RetT(encode(sign, Exponent::subnormal(),
+ Significand::bits_all_ones() ^ Significand::msb()));
}
LIBC_INLINE static constexpr RetT min_normal(Sign sign = Sign::POS) {
- return RetT(encode(sign, Exponent::MIN(), Significand::MSB()));
+ return RetT(encode(sign, Exponent::min(), Significand::msb()));
}
LIBC_INLINE static constexpr RetT max_normal(Sign sign = Sign::POS) {
- return RetT(encode(sign, Exponent::MAX(), Significand::BITS_ALL_ONES()));
+ return RetT(encode(sign, Exponent::max(), Significand::bits_all_ones()));
}
LIBC_INLINE static constexpr RetT inf(Sign sign = Sign::POS) {
- return RetT(encode(sign, Exponent::INF(), Significand::MSB()));
+ return RetT(encode(sign, Exponent::inf(), Significand::msb()));
}
LIBC_INLINE static constexpr RetT signaling_nan(Sign sign = Sign::POS,
StorageType v = 0) {
- return RetT(encode(sign, Exponent::INF(),
- Significand::MSB() |
- (v ? Significand(v) : (Significand::MSB() >> 2))));
+ return RetT(encode(sign, Exponent::inf(),
+ Significand::msb() |
+ (v ? Significand(v) : (Significand::msb() >> 2))));
}
LIBC_INLINE static constexpr RetT quiet_nan(Sign sign = Sign::POS,
StorageType v = 0) {
- return RetT(encode(sign, Exponent::INF(),
- Significand::MSB() | (Significand::MSB() >> 1) |
+ return RetT(encode(sign, Exponent::inf(),
+ Significand::msb() | (Significand::msb() >> 1) |
Significand(v)));
}
@@ -541,33 +541,33 @@ struct FPRepSem<FPType::X86_Binary80, RetT>
// - Quiet Not a Number
// - Unnormal
// This can be reduced to the following logic:
- if (exp_bits() == encode(Exponent::INF()))
+ if (exp_bits() == encode(Exponent::inf()))
return !is_inf();
- if (exp_bits() != encode(Exponent::SUBNORMAL()))
- return (sig_bits() & encode(Significand::MSB())) == 0;
+ if (exp_bits() != encode(Exponent::subnormal()))
+ return (sig_bits() & encode(Significand::msb())) == 0;
return false;
}
LIBC_INLINE constexpr bool is_quiet_nan() const {
return exp_sig_bits() >=
- encode(Exponent::INF(),
- Significand::MSB() | (Significand::MSB() >> 1));
+ encode(Exponent::inf(),
+ Significand::msb() | (Significand::msb() >> 1));
}
LIBC_INLINE constexpr bool is_signaling_nan() const {
return is_nan() && !is_quiet_nan();
}
LIBC_INLINE constexpr bool is_inf() const {
- return exp_sig_bits() == encode(Exponent::INF(), Significand::MSB());
+ return exp_sig_bits() == encode(Exponent::inf(), Significand::msb());
}
LIBC_INLINE constexpr bool is_finite() const {
return !is_inf() && !is_nan();
}
LIBC_INLINE
constexpr bool is_subnormal() const {
- return exp_bits() == encode(Exponent::SUBNORMAL());
+ return exp_bits() == encode(Exponent::subnormal());
}
LIBC_INLINE constexpr bool is_normal() const {
const auto exp = exp_bits();
- if (exp == encode(Exponent::SUBNORMAL()) || exp == encode(Exponent::INF()))
+ if (exp == encode(Exponent::subnormal()) || exp == encode(Exponent::inf()))
return false;
return get_implicit_bit();
}
@@ -578,7 +578,7 @@ struct FPRepSem<FPType::X86_Binary80, RetT>
} else if (exp_sig_bits() == max_subnormal().uintval()) {
return min_normal(sign());
} else if (sig_bits() == SIG_MASK) {
- return RetT(encode(sign(), ++biased_exponent(), Significand::ZERO()));
+ return RetT(encode(sign(), ++biased_exponent(), Significand::zero()));
} else {
return RetT(bits + StorageType(1));
}
@@ -715,9 +715,9 @@ struct FPRepImpl : public FPRepSem<fp_type, RetT> {
LIBC_INLINE constexpr int get_explicit_exponent() const {
Exponent exponent(UP::biased_exponent());
if (is_zero())
- exponent = Exponent::ZERO();
- if (exponent == Exponent::SUBNORMAL())
- exponent = Exponent::MIN();
+ exponent = Exponent::zero();
+ if (exponent == Exponent::subnormal())
+ exponent = Exponent::min();
return static_cast<int32_t>(exponent);
}
diff --git a/libc/src/string/memory_utils/aarch64/inline_bcmp.h b/libc/src/string/memory_utils/aarch64/inline_bcmp.h
index 8e0827f1361fe4..b80b5781876343 100644
--- a/libc/src/string/memory_utils/aarch64/inline_bcmp.h
+++ b/libc/src/string/memory_utils/aarch64/inline_bcmp.h
@@ -27,7 +27,7 @@ namespace LIBC_NAMESPACE {
}
switch (count) {
case 0:
- return BcmpReturnType::ZERO();
+ return BcmpReturnType::zero();
case 1:
return generic::Bcmp<uint8_t>::block(p1, p2);
case 2:
diff --git a/libc/src/string/memory_utils/aarch64/inline_memcmp.h b/libc/src/string/memory_utils/aarch64/inline_memcmp.h
index 839c8ec13854f2..d0e0bd7cf025f9 100644
--- a/libc/src/string/memory_utils/aarch64/inline_memcmp.h
+++ b/libc/src/string/memory_utils/aarch64/inline_memcmp.h
@@ -50,7 +50,7 @@ inline_memcmp_aarch64_neon_gt16(CPtr p1, CPtr p2, size_t count) {
LIBC_INLINE MemcmpReturnType inline_memcmp_aarch64(CPtr p1, CPtr p2,
size_t count) {
if (count == 0)
- return MemcmpReturnType::ZERO();
+ return MemcmpReturnType::zero();
if (count == 1)
return generic::Memcmp<uint8_t>::block(p1, p2);
if (count == 2)
diff --git a/libc/src/string/memory_utils/generic/aligned_access.h b/libc/src/string/memory_utils/generic/aligned_access.h
index 65bc63f6cbe557..b6ece816756c55 100644
--- a/libc/src/string/memory_utils/generic/aligned_access.h
+++ b/libc/src/string/memory_utils/generic/aligned_access.h
@@ -135,7 +135,7 @@ inline_bcmp_aligned_access_32bit(CPtr p1, CPtr p2, size_t count) {
uint32_t a = load32_aligned<uint32_t>(p1, offset);
uint32_t b = load32_aligned(p2, offset, p2_alignment);
if (a != b)
- return BcmpReturnType::NONZERO();
+ return BcmpReturnType::nonzero();
}
return inline_bcmp_byte_per_byte(p1, p2, count, offset);
}
@@ -154,7 +154,7 @@ inline_bcmp_aligned_access_64bit(CPtr p1, CPtr p2, size_t count) {
uint64_t a = load64_aligned<uint64_t>(p1, offset);
uint64_t b = load64_aligned(p2, offset, p2_alignment);
if (a != b)
- return BcmpReturnType::NONZERO();
+ return BcmpReturnType::nonzero();
}
return inline_bcmp_byte_per_byte(p1, p2, count, offset);
}
diff --git a/libc/src/string/memory_utils/generic/byte_per_byte.h b/libc/src/string/memory_utils/generic/byte_per_byte.h
index a666c5da313604..948da8ab2a8702 100644
--- a/libc/src/string/memory_utils/generic/byte_per_byte.h
+++ b/libc/src/string/memory_utils/generic/byte_per_byte.h
@@ -56,8 +56,8 @@ inline_bcmp_byte_per_byte(CPtr p1, CPtr p2, size_t count, size_t offset = 0) {
LIBC_LOOP_NOUNROLL
for (; offset < count; ++offset)
if (p1[offset] != p2[offset])
- return BcmpReturnType::NONZERO();
- return BcmpReturnType::ZERO();
+ return BcmpReturnType::zero();
+ return BcmpReturnType::zero();
}
[[maybe_unused]] LIBC_INLINE MemcmpReturnType
@@ -70,7 +70,7 @@ inline_memcmp_byte_per_byte(CPtr p1, CPtr p2, size_t count, size_t offset = 0) {
if (diff)
return diff;
}
- return MemcmpReturnType::ZERO();
+ return MemcmpReturnType::zero();
}
} // namespace LIBC_NAMESPACE
diff --git a/libc/src/string/memory_utils/op_aarch64.h b/libc/src/string/memory_utils/op_aarch64.h
index 3aae328945dd2c..6a2013b2a8faeb 100644
--- a/libc/src/string/memory_utils/op_aarch64.h
+++ b/libc/src/string/memory_utils/op_aarch64.h
@@ -108,7 +108,7 @@ template <size_t Size> struct Bcmp {
} else {
static_assert(cpp::always_false<decltype(Size)>, "SIZE not implemented");
}
- return BcmpReturnType::ZERO();
+ return BcmpReturnType::zero();
}
LIBC_INLINE static BcmpReturnType tail(CPtr p1, CPtr p2, size_t count) {
@@ -154,7 +154,7 @@ template <size_t Size> struct Bcmp {
} else {
static_assert(cpp::always_false<decltype(Size)>, "SIZE not implemented");
}
- return BcmpReturnType::ZERO();
+ return BcmpReturnType::zero();
}
LIBC_INLINE static BcmpReturnType loop_and_tail(CPtr p1, CPtr p2,
@@ -217,7 +217,7 @@ LIBC_INLINE MemcmpReturnType cmp<uint64_t>(CPtr p1, CPtr p2, size_t offset) {
const auto b = load_be<uint64_t>(p2, offset);
if (a != b)
return a > b ? 1 : -1;
- return MemcmpReturnType::ZERO();
+ return MemcmpReturnType::zero();
}
///////////////////////////////////////////////////////////////////////////////
@@ -245,7 +245,7 @@ LIBC_INLINE MemcmpReturnType cmp<uint8x16_t>(CPtr p1, CPtr p2, size_t offset) {
return cmp_neq_uint64_t(a, b);
offset += sizeof(uint64_t);
}
- return MemcmpReturnType::ZERO();
+ return MemcmpReturnType::zero();
}
///////////////////////////////////////////////////////////////////////////////
@@ -262,7 +262,7 @@ LIBC_INLINE MemcmpReturnType cmp<uint8x16x2_t>(CPtr p1, CPtr p2,
return cmp_neq_uint64_t(a, b);
offset += sizeof(uint64_t);
}
- return MemcmpReturnType::ZERO();
+ return MemcmpReturnType::zero();
}
} // namespace LIBC_NAMESPACE::generic
diff --git a/libc/src/string/memory_utils/op_builtin.h b/libc/src/string/memory_utils/op_builtin.h
index 3c17eef781e576..75dd4de53a4700 100644
--- a/libc/src/string/memory_utils/op_builtin.h
+++ b/libc/src/string/memory_utils/op_builtin.h
@@ -105,22 +105,22 @@ template <size_t Size> struct Bcmp {
LIBC_INLINE static BcmpReturnType block(CPtr, CPtr) {
static_assert(cpp::always_false<decltype(Size)>,
"Missing __builtin_memcmp_inline");
- return BcmpReturnType::ZERO();
+ return BcmpReturnType::zero();
}
LIBC_INLINE static BcmpReturnType tail(CPtr, CPtr, size_t) {
static_assert(cpp::always_false<decltype(Size)>, "Not implemented");
- return BcmpReturnType::ZERO();
+ return BcmpReturnType::zero();
}
LIBC_INLINE static BcmpReturnType head_tail(CPtr, CPtr, size_t) {
static_assert(cpp::always_false<decltype(Size)>, "Not implemented");
- return BcmpReturnType::ZERO();
+ return BcmpReturnType::zero();
}
LIBC_INLINE static BcmpReturnType loop_and_tail(CPtr, CPtr, size_t) {
static_assert(cpp::always_false<decltype(Size)>, "Not implemented");
- return BcmpReturnType::ZERO();
+ return BcmpReturnType::zero();
}
};
@@ -132,22 +132,22 @@ template <size_t Size> struct Memcmp {
LIBC_INLINE static MemcmpReturnType block(CPtr, CPtr) {
static_assert(cpp::always_false<decltype(Size)>,
"Missing __builtin_memcmp_inline");
- return MemcmpReturnType::ZERO();
+ return MemcmpReturnType::zero();
}
LIBC_INLINE static MemcmpReturnType tail(CPtr, CPtr, size_t) {
static_assert(cpp::always_false<decltype(Size)>, "Not implemented");
- return MemcmpReturnType::ZERO();
+ return MemcmpReturnType::zero();
}
LIBC_INLINE static MemcmpReturnType head_tail(CPtr, CPtr, size_t) {
static_assert(cpp::always_false<decltype(Size)>, "Not implemented");
- return MemcmpReturnType::ZERO();
+ return MemcmpReturnType::zero();
}
LIBC_INLINE static MemcmpReturnType loop_and_tail(CPtr, CPtr, size_t) {
static_assert(cpp::always_false<decltype(Size)>, "Not implemented");
- return MemcmpReturnType::ZERO();
+ return MemcmpReturnType::zero();
}
};
diff --git a/libc/src/string/memory_utils/op_generic.h b/libc/src/string/memory_utils/op_generic.h
index db218f8577ab58..c7dbd5dd1d6cce 100644
--- a/libc/src/string/memory_utils/op_generic.h
+++ b/libc/src/string/memory_utils/op_generic.h
@@ -390,7 +390,7 @@ template <typename T> struct Memcmp {
if constexpr (cmp_is_expensive<T>::value) {
if (!eq<T>(p1, p2, offset))
return cmp_neq<T>(p1, p2, offset);
- return MemcmpReturnType::ZERO();
+ return MemcmpReturnType::zero();
} else {
return cmp<T>(p1, p2, offset);
}
@@ -443,7 +443,7 @@ template <typename T> struct Memcmp {
for (; offset < count; offset += SIZE)
if (auto value = cmp<T>(p1, p2, offset))
return value;
- return MemcmpReturnType::ZERO();
+ return MemcmpReturnType::zero();
}
}
@@ -475,7 +475,7 @@ template <typename T, typename... TS> struct MemcmpSequence {
if constexpr (sizeof...(TS) > 0)
return MemcmpSequence<TS...>::block(p1 + sizeof(T), p2 + sizeof(T));
else
- return MemcmpReturnType::ZERO();
+ return MemcmpReturnType::zero();
}
};
@@ -521,7 +521,7 @@ template <typename T> struct Bcmp {
for (; offset < count; offset += SIZE)
if (const auto value = neq<T>(p1, p2, offset))
return value;
- return BcmpReturnType::ZERO();
+ return BcmpReturnType::zero();
}
}
@@ -547,7 +547,7 @@ template <typename T, typename... TS> struct BcmpSequence {
if constexpr (sizeof...(TS) > 0)
return BcmpSequence<TS...>::block(p1 + sizeof(T), p2 + sizeof(T));
else
- return BcmpReturnType::ZERO();
+ return BcmpReturnType::zero();
}
};
diff --git a/libc/src/string/memory_utils/utils.h b/libc/src/string/memory_utils/utils.h
index 543d45b7c4e33e..701a84375ea8e7 100644
--- a/libc/src/string/memory_utils/utils.h
+++ b/libc/src/string/memory_utils/utils.h
@@ -130,8 +130,8 @@ template <typename T> struct StrictIntegralType {
}
// Helper to get the zero value.
- LIBC_INLINE static constexpr StrictIntegralType ZERO() { return {T(0)}; }
- LIBC_INLINE static constexpr StrictIntegralType NONZERO() { return {T(1)}; }
+ LIBC_INLINE static constexpr StrictIntegralType zero() { return {T(0)}; }
+ LIBC_INLINE static constexpr StrictIntegralType nonzero() { return {T(1)}; }
private:
T value;
diff --git a/libc/src/string/memory_utils/x86_64/inline_bcmp.h b/libc/src/string/memory_utils/x86_64/inline_bcmp.h
index 31aff86e60598e..58eaedbbe015f9 100644
--- a/libc/src/string/memory_utils/x86_64/inline_bcmp.h
+++ b/libc/src/string/memory_utils/x86_64/inline_bcmp.h
@@ -58,7 +58,7 @@ inline_bcmp_x86_avx512bw_gt16(CPtr p1, CPtr p2, size_t count) {
[[maybe_unused]] LIBC_INLINE BcmpReturnType inline_bcmp_x86(CPtr p1, CPtr p2,
size_t count) {
if (count == 0)
- return BcmpReturnType::ZERO();
+ return BcmpReturnType::zero();
if (count == 1)
return generic::Bcmp<uint8_t>::block(p1, p2);
if (count == 2)
diff --git a/libc/src/string/memory_utils/x86_64/inline_memcmp.h b/libc/src/string/memory_utils/x86_64/inline_memcmp.h
index d5fa77cdbbcdc0..6a315adcd566cd 100644
--- a/libc/src/string/memory_utils/x86_64/inline_memcmp.h
+++ b/libc/src/string/memory_utils/x86_64/inline_memcmp.h
@@ -59,7 +59,7 @@ inline_memcmp_x86_avx512bw_gt16(CPtr p1, CPtr p2, size_t count) {
LIBC_INLINE MemcmpReturnType inline_memcmp_x86(CPtr p1, CPtr p2, size_t count) {
if (count == 0)
- return MemcmpReturnType::ZERO();
+ return MemcmpReturnType::zero();
if (count == 1)
return generic::Memcmp<uint8_t>::block(p1, p2);
if (count == 2)
>From 8dfa1d878d015dd7f466d6eadbaca6c46fc8d7a9 Mon Sep 17 00:00:00 2001
From: Aart Bik <39774503+aartbik at users.noreply.github.com>
Date: Wed, 28 Feb 2024 14:52:43 -0800
Subject: [PATCH 058/406] [mlir][sparse] add roundtrip and invalid tests for
sparse_tensor.print (#83349)
---
mlir/test/Dialect/SparseTensor/invalid.mlir | 10 ++++++++++
mlir/test/Dialect/SparseTensor/roundtrip.mlir | 17 +++++++++++++++++
2 files changed, 27 insertions(+)
diff --git a/mlir/test/Dialect/SparseTensor/invalid.mlir b/mlir/test/Dialect/SparseTensor/invalid.mlir
index f85bc5111d7a27..395b812a7685b7 100644
--- a/mlir/test/Dialect/SparseTensor/invalid.mlir
+++ b/mlir/test/Dialect/SparseTensor/invalid.mlir
@@ -1027,3 +1027,13 @@ func.func @sparse_reinterpret_map(%t0 : tensor<6x12xi32, #BSR>) -> tensor<3x4x2x
to tensor<3x4x2x4xi32, #DSDD>
return %t1 : tensor<3x4x2x4xi32, #DSDD>
}
+
+// -----
+
+#CSR = #sparse_tensor.encoding<{map = (d0, d1) -> (d0 : compressed, d1 : compressed)}>
+
+func.func @sparse_print(%arg0: tensor<10x10xf64>) {
+ // expected-error at +1 {{'sparse_tensor.print' op operand #0 must be sparse tensor of any type values}}
+ sparse_tensor.print %arg0 : tensor<10x10xf64>
+ return
+}
diff --git a/mlir/test/Dialect/SparseTensor/roundtrip.mlir b/mlir/test/Dialect/SparseTensor/roundtrip.mlir
index 476fa1b08a39d8..f4a58df1d4d2d6 100644
--- a/mlir/test/Dialect/SparseTensor/roundtrip.mlir
+++ b/mlir/test/Dialect/SparseTensor/roundtrip.mlir
@@ -705,8 +705,25 @@ func.func @sparse_lvl(%arg0: index, %t : tensor<?x?xi32, #BSR>) -> index {
map = (i, j, k, l) -> (i: dense, j: compressed, k: dense, l: dense)
}>
+// CHECK-LABEL: func.func @sparse_reinterpret_map(
+// CHECK-SAME: %[[A0:.*]]: tensor<6x12xi32, #sparse{{[0-9]*}}>)
+// CHECK: %[[VAL:.*]] = sparse_tensor.reinterpret_map %[[A0]]
+// CHECK: return %[[VAL]]
func.func @sparse_reinterpret_map(%t0 : tensor<6x12xi32, #BSR>) -> tensor<3x4x2x3xi32, #DSDD> {
%t1 = sparse_tensor.reinterpret_map %t0 : tensor<6x12xi32, #BSR>
to tensor<3x4x2x3xi32, #DSDD>
return %t1 : tensor<3x4x2x3xi32, #DSDD>
}
+
+// -----
+
+#CSR = #sparse_tensor.encoding<{map = (d0, d1) -> (d0 : compressed, d1 : compressed)}>
+
+// CHECK-LABEL: func.func @sparse_print(
+// CHECK-SAME: %[[A0:.*]]: tensor<10x10xf64, #sparse{{[0-9]*}}>)
+// CHECK: sparse_tensor.print %[[A0]]
+// CHECK: return
+func.func @sparse_print(%arg0: tensor<10x10xf64, #CSR>) {
+ sparse_tensor.print %arg0 : tensor<10x10xf64, #CSR>
+ return
+}
>From e7a303e3cf7f205184c9d9d878791661260f9852 Mon Sep 17 00:00:00 2001
From: Craig Topper <craig.topper at sifive.com>
Date: Wed, 28 Feb 2024 15:02:48 -0800
Subject: [PATCH 059/406] [SelectionDAG] Remove unused
getIndexedStridedLoadVP/getIndexedStridedStoreVP functions. NFC (#82847)
These appear to have been copied from getIndexedLoadVP/getIndexedStoreVP
which in turn were copied from the non-VP versions.
---
llvm/include/llvm/CodeGen/SelectionDAG.h | 6 ---
.../lib/CodeGen/SelectionDAG/SelectionDAG.cpp | 52 -------------------
2 files changed, 58 deletions(-)
diff --git a/llvm/include/llvm/CodeGen/SelectionDAG.h b/llvm/include/llvm/CodeGen/SelectionDAG.h
index 2fc1ceafa927fd..25e6c525b672a1 100644
--- a/llvm/include/llvm/CodeGen/SelectionDAG.h
+++ b/llvm/include/llvm/CodeGen/SelectionDAG.h
@@ -1488,9 +1488,6 @@ class SelectionDAG {
SDValue Chain, SDValue Ptr, SDValue Stride,
SDValue Mask, SDValue EVL, EVT MemVT,
MachineMemOperand *MMO, bool IsExpanding = false);
- SDValue getIndexedStridedLoadVP(SDValue OrigLoad, const SDLoc &DL,
- SDValue Base, SDValue Offset,
- ISD::MemIndexedMode AM);
SDValue getStridedStoreVP(SDValue Chain, const SDLoc &DL, SDValue Val,
SDValue Ptr, SDValue Offset, SDValue Stride,
SDValue Mask, SDValue EVL, EVT MemVT,
@@ -1501,9 +1498,6 @@ class SelectionDAG {
SDValue Ptr, SDValue Stride, SDValue Mask,
SDValue EVL, EVT SVT, MachineMemOperand *MMO,
bool IsCompressing = false);
- SDValue getIndexedStridedStoreVP(SDValue OrigStore, const SDLoc &DL,
- SDValue Base, SDValue Offset,
- ISD::MemIndexedMode AM);
SDValue getGatherVP(SDVTList VTs, EVT VT, const SDLoc &dl,
ArrayRef<SDValue> Ops, MachineMemOperand *MMO,
diff --git a/llvm/lib/CodeGen/SelectionDAG/SelectionDAG.cpp b/llvm/lib/CodeGen/SelectionDAG/SelectionDAG.cpp
index e150f27240d7f0..e3e7de1573c818 100644
--- a/llvm/lib/CodeGen/SelectionDAG/SelectionDAG.cpp
+++ b/llvm/lib/CodeGen/SelectionDAG/SelectionDAG.cpp
@@ -9106,26 +9106,6 @@ SDValue SelectionDAG::getExtStridedLoadVP(
Stride, Mask, EVL, MemVT, MMO, IsExpanding);
}
-SDValue SelectionDAG::getIndexedStridedLoadVP(SDValue OrigLoad, const SDLoc &DL,
- SDValue Base, SDValue Offset,
- ISD::MemIndexedMode AM) {
- auto *SLD = cast<VPStridedLoadSDNode>(OrigLoad);
- assert(SLD->getOffset().isUndef() &&
- "Strided load is already a indexed load!");
- // Don't propagate the invariant or dereferenceable flags.
- auto MMOFlags =
- SLD->getMemOperand()->getFlags() &
- ~(MachineMemOperand::MOInvariant | MachineMemOperand::MODereferenceable);
- MachineFunction &MF = getMachineFunction();
- MachineMemOperand *MMO = MF.getMachineMemOperand(
- SLD->getPointerInfo(), MMOFlags, SLD->getMemOperand()->getSize(),
- SLD->getOriginalAlign(), SLD->getAAInfo());
- return getStridedLoadVP(AM, SLD->getExtensionType(), OrigLoad.getValueType(),
- DL, SLD->getChain(), Base, Offset, SLD->getStride(),
- SLD->getMask(), SLD->getVectorLength(),
- SLD->getMemoryVT(), MMO, SLD->isExpandingLoad());
-}
-
SDValue SelectionDAG::getStridedStoreVP(SDValue Chain, const SDLoc &DL,
SDValue Val, SDValue Ptr,
SDValue Offset, SDValue Stride,
@@ -9211,38 +9191,6 @@ SDValue SelectionDAG::getTruncStridedStoreVP(SDValue Chain, const SDLoc &DL,
return V;
}
-SDValue SelectionDAG::getIndexedStridedStoreVP(SDValue OrigStore,
- const SDLoc &DL, SDValue Base,
- SDValue Offset,
- ISD::MemIndexedMode AM) {
- auto *SST = cast<VPStridedStoreSDNode>(OrigStore);
- assert(SST->getOffset().isUndef() &&
- "Strided store is already an indexed store!");
- SDVTList VTs = getVTList(Base.getValueType(), MVT::Other);
- SDValue Ops[] = {
- SST->getChain(), SST->getValue(), Base, Offset, SST->getStride(),
- SST->getMask(), SST->getVectorLength()};
- FoldingSetNodeID ID;
- AddNodeIDNode(ID, ISD::EXPERIMENTAL_VP_STRIDED_STORE, VTs, Ops);
- ID.AddInteger(SST->getMemoryVT().getRawBits());
- ID.AddInteger(SST->getRawSubclassData());
- ID.AddInteger(SST->getPointerInfo().getAddrSpace());
- void *IP = nullptr;
- if (SDNode *E = FindNodeOrInsertPos(ID, DL, IP))
- return SDValue(E, 0);
-
- auto *N = newSDNode<VPStridedStoreSDNode>(
- DL.getIROrder(), DL.getDebugLoc(), VTs, AM, SST->isTruncatingStore(),
- SST->isCompressingStore(), SST->getMemoryVT(), SST->getMemOperand());
- createOperands(N, Ops);
-
- CSEMap.InsertNode(N, IP);
- InsertNode(N);
- SDValue V(N, 0);
- NewSDValueDbgMsg(V, "Creating new node: ", this);
- return V;
-}
-
SDValue SelectionDAG::getGatherVP(SDVTList VTs, EVT VT, const SDLoc &dl,
ArrayRef<SDValue> Ops, MachineMemOperand *MMO,
ISD::MemIndexType IndexType) {
>From c345198c7a68cb76e82dbc04d0e91476cb0edc70 Mon Sep 17 00:00:00 2001
From: Craig Topper <craig.topper at sifive.com>
Date: Wed, 28 Feb 2024 15:06:20 -0800
Subject: [PATCH 060/406] [RISCV] Add a command line option to disable cost per
use for compressed registers. (#83320)
I've seen cases where the cost per use increase the number of spills.
Disabling improves the codegen for #79918.
I propose adding this option to allow easier experimentation.
---
llvm/lib/Target/RISCV/RISCVRegisterInfo.cpp | 7 ++++++-
1 file changed, 6 insertions(+), 1 deletion(-)
diff --git a/llvm/lib/Target/RISCV/RISCVRegisterInfo.cpp b/llvm/lib/Target/RISCV/RISCVRegisterInfo.cpp
index 9d1f01dffaaf47..a68674b221d38e 100644
--- a/llvm/lib/Target/RISCV/RISCVRegisterInfo.cpp
+++ b/llvm/lib/Target/RISCV/RISCVRegisterInfo.cpp
@@ -30,6 +30,8 @@
using namespace llvm;
+static cl::opt<bool> DisableCostPerUse("riscv-disable-cost-per-use",
+ cl::init(false), cl::Hidden);
static cl::opt<bool>
DisableRegAllocHints("riscv-disable-regalloc-hints", cl::Hidden,
cl::init(false),
@@ -712,7 +714,10 @@ void RISCVRegisterInfo::getOffsetOpcodes(const StackOffset &Offset,
unsigned
RISCVRegisterInfo::getRegisterCostTableIndex(const MachineFunction &MF) const {
- return MF.getSubtarget<RISCVSubtarget>().hasStdExtCOrZca() ? 1 : 0;
+ return MF.getSubtarget<RISCVSubtarget>().hasStdExtCOrZca() &&
+ !DisableCostPerUse
+ ? 1
+ : 0;
}
// Add two address hints to improve chances of being able to use a compressed
>From ff07c9b701dc6372f82d989d01768051e848b30d Mon Sep 17 00:00:00 2001
From: Fangrui Song <i at maskray.me>
Date: Wed, 28 Feb 2024 15:12:31 -0800
Subject: [PATCH 061/406] [Driver] Unify InstalledDir and Dir (#80527)
`Driver::ClangExecutable` is derived from:
* (-canonical-prefixes default): `realpath` on the executable path
* (-no-canonical-prefixes) argv[0] (consult PATH if argv[0] is a word)
`Dir` and `ResourceDir` are derived from `ClangExecutable`. Both
variables are used to derive certain include and library paths.
`InstalledDir` is a related concept used to derive certain other paths.
`InstalledDir` is weird in the -canonical-prefixes mode: Clang
calls `make_absolute` but does not follow symlinks
(FIXME from 9ade6a9a747c49383ac747bd8ffaa6a0beaef71c).
This causes some search and library paths to be mix-and-matched.
The "Do a PATH lookup, if there are no directory components." logic
makes things worse.
`InstalledDir` is different when you invoke it via `PATH`:
```
% which clang
/usr/bin/clang
% clang -v |& grep InstalledDir
InstalledDir: /usr/bin
% /usr/lib/llvm-16/bin/clang -v |& grep InstalledDir
InstalledDir: /usr/lib/llvm-16/bin
```
I believe `InstalledDir` was a partial solution to
`-no-canonical-prefixes` and should be eventually removed.
This patch removes `SetInstallDir` and relies on Driver::Driver to set
`InstalledDir` to `Dir`. The behavior for regular file `clang` or
`-no-canonical-prefixes` is unchanged.
If a user creates a symlink to the regular file `clang` and uses the
default `-canonical-prefixes`, they now consistently get search and
library paths relative to the regular file `clang`, not mix-and-match
paths.
If a user creates a symlink to the regular file `clang` and replaces
some directorys from the actual installation, they should change the
symlink to a wrapper that calls the underlying clang with
`-no-canonical-prefixes`.
---
clang/include/clang/Driver/Driver.h | 3 +--
.../Driver/darwin-header-search-libcxx.cpp | 2 +-
clang/test/Driver/mingw-sysroot.cpp | 12 ++++++----
clang/test/Driver/no-canonical-prefixes.c | 2 +-
clang/test/Driver/program-path-priority.c | 13 +++++++----
clang/test/Driver/rocm-detect.hip | 4 ++--
clang/tools/driver/driver.cpp | 23 -------------------
7 files changed, 20 insertions(+), 39 deletions(-)
diff --git a/clang/include/clang/Driver/Driver.h b/clang/include/clang/Driver/Driver.h
index a5ca637853a6ae..73cf326101ffd5 100644
--- a/clang/include/clang/Driver/Driver.h
+++ b/clang/include/clang/Driver/Driver.h
@@ -160,7 +160,7 @@ class Driver {
/// Target and driver mode components extracted from clang executable name.
ParsedClangName ClangNameParts;
- /// The path to the installed clang directory, if any.
+ /// TODO: Remove this in favor of Dir.
std::string InstalledDir;
/// The path to the compiler resource directory.
@@ -433,7 +433,6 @@ class Driver {
return InstalledDir.c_str();
return Dir.c_str();
}
- void setInstalledDir(StringRef Value) { InstalledDir = std::string(Value); }
bool isSaveTempsEnabled() const { return SaveTemps != SaveTempsNone; }
bool isSaveTempsObj() const { return SaveTemps == SaveTempsObj; }
diff --git a/clang/test/Driver/darwin-header-search-libcxx.cpp b/clang/test/Driver/darwin-header-search-libcxx.cpp
index 70cc06090a993d..5695f53683bab3 100644
--- a/clang/test/Driver/darwin-header-search-libcxx.cpp
+++ b/clang/test/Driver/darwin-header-search-libcxx.cpp
@@ -193,7 +193,7 @@
// RUN: ln -sf %t/install/bin/clang %t/symlinked1/bin/clang
// RUN: mkdir -p %t/symlinked1/include/c++/v1
-// RUN: %t/symlinked1/bin/clang -### %s -fsyntax-only 2>&1 \
+// RUN: %t/symlinked1/bin/clang -### %s -no-canonical-prefixes -fsyntax-only 2>&1 \
// RUN: --target=x86_64-apple-darwin \
// RUN: -stdlib=libc++ \
// RUN: -isysroot %S/Inputs/basic_darwin_sdk_usr_cxx_v1 \
diff --git a/clang/test/Driver/mingw-sysroot.cpp b/clang/test/Driver/mingw-sysroot.cpp
index 50152b2ca210d2..5d512e66697097 100644
--- a/clang/test/Driver/mingw-sysroot.cpp
+++ b/clang/test/Driver/mingw-sysroot.cpp
@@ -50,10 +50,12 @@
// CHECK_TESTROOT_GCC_EXPLICIT: "-internal-isystem" "{{[^"]+}}/testroot-gcc{{/|\\\\}}include"
-// If there's a matching sysroot next to the clang binary itself, prefer that
+// If -no-canonical-prefixes and there's a matching sysroot next to the clang binary itself, prefer that
// over a gcc in the path:
-// RUN: env "PATH=%T/testroot-gcc/bin:%PATH%" %T/testroot-clang/bin/x86_64-w64-mingw32-clang -target x86_64-w64-mingw32 -rtlib=compiler-rt -stdlib=libstdc++ --sysroot="" -c -### %s 2>&1 | FileCheck -check-prefix=CHECK_TESTROOT_CLANG %s
+// RUN: env "PATH=%T/testroot-gcc/bin:%PATH%" %T/testroot-clang/bin/x86_64-w64-mingw32-clang --target=x86_64-w64-mingw32 -rtlib=compiler-rt -stdlib=libstdc++ --sysroot="" -c -### %s 2>&1 | FileCheck -check-prefix=CHECK_TESTROOT_GCC2 %s
+// RUN: env "PATH=%T/testroot-gcc/bin:%PATH%" %T/testroot-clang/bin/x86_64-w64-mingw32-clang --target=x86_64-w64-mingw32 -rtlib=compiler-rt -stdlib=libstdc++ --sysroot="" -c -### %s -no-canonical-prefixes 2>&1 | FileCheck -check-prefix=CHECK_TESTROOT_CLANG %s
+// CHECK_TESTROOT_GCC2: "{{[^"]+}}/testroot-gcc{{/|\\\\}}x86_64-w64-mingw32{{/|\\\\}}include"
// CHECK_TESTROOT_CLANG: "{{[^"]+}}/testroot-clang{{/|\\\\}}x86_64-w64-mingw32{{/|\\\\}}include"
@@ -82,7 +84,7 @@
// that indicates that we did choose the right base, even if this particular directory
// actually doesn't exist here.
-// RUN: env "PATH=%T/testroot-gcc/bin:%PATH%" %T/testroot-clang-native/bin/clang -target x86_64-w64-mingw32 -rtlib=compiler-rt -stdlib=libstdc++ --sysroot="" -c -### %s 2>&1 | FileCheck -check-prefix=CHECK_TESTROOT_CLANG_NATIVE %s
+// RUN: env "PATH=%T/testroot-gcc/bin:%PATH%" %T/testroot-clang-native/bin/clang -no-canonical-prefixes --target=x86_64-w64-mingw32 -rtlib=compiler-rt -stdlib=libstdc++ --sysroot="" -c -### %s 2>&1 | FileCheck -check-prefix=CHECK_TESTROOT_CLANG_NATIVE %s
// CHECK_TESTROOT_CLANG_NATIVE: "{{[^"]+}}/testroot-clang-native{{/|\\\\}}x86_64-w64-mingw32{{/|\\\\}}include"
@@ -93,12 +95,12 @@
// that defaults to x86_64 mingw, but it's easier to test this in cross setups
// with symlinks, like the other tests here.)
-// RUN: env "PATH=%T/testroot-gcc/bin:%PATH%" %T/testroot-clang/bin/x86_64-w64-mingw32-clang --target=x86_64-w64-mingw32 -m32 -rtlib=compiler-rt -stdlib=libstdc++ --sysroot="" -c -### %s 2>&1 | FileCheck -check-prefix=CHECK_TESTROOT_CLANG_I686 %s
+// RUN: env "PATH=%T/testroot-gcc/bin:%PATH%" %T/testroot-clang/bin/x86_64-w64-mingw32-clang -no-canonical-prefixes --target=x86_64-w64-mingw32 -m32 -rtlib=compiler-rt -stdlib=libstdc++ --sysroot="" -c -### %s 2>&1 | FileCheck -check-prefix=CHECK_TESTROOT_CLANG_I686 %s
// CHECK_TESTROOT_CLANG_I686: "{{[^"]+}}/testroot-clang{{/|\\\\}}i686-w64-mingw32{{/|\\\\}}include"
// If the user calls clang with a custom literal triple, make sure this maps
// to sysroots with the matching spelling.
-// RUN: %T/testroot-custom-triple/bin/clang --target=x86_64-w64-mingw32foo -rtlib=compiler-rt -stdlib=libstdc++ --sysroot="" -c -### %s 2>&1 | FileCheck -check-prefix=CHECK_TESTROOT_CUSTOM_TRIPLE %s
+// RUN: %T/testroot-custom-triple/bin/clang -no-canonical-prefixes --target=x86_64-w64-mingw32foo -rtlib=compiler-rt -stdlib=libstdc++ --sysroot="" -c -### %s 2>&1 | FileCheck -check-prefix=CHECK_TESTROOT_CUSTOM_TRIPLE %s
// CHECK_TESTROOT_CUSTOM_TRIPLE: "{{[^"]+}}/testroot-custom-triple{{/|\\\\}}x86_64-w64-mingw32foo{{/|\\\\}}include"
diff --git a/clang/test/Driver/no-canonical-prefixes.c b/clang/test/Driver/no-canonical-prefixes.c
index fb54f85f959ae2..669e56639284a7 100644
--- a/clang/test/Driver/no-canonical-prefixes.c
+++ b/clang/test/Driver/no-canonical-prefixes.c
@@ -26,7 +26,7 @@
// RUN: | FileCheck --check-prefix=NON-CANONICAL %s
//
// FIXME: This should really be '.real'.
-// CANONICAL: InstalledDir: {{.*}}.fake
+// CANONICAL: InstalledDir: {{.*}}bin
// CANONICAL: {{[/|\\]*}}clang{{.*}}" -cc1
//
// NON-CANONICAL: InstalledDir: .{{$}}
diff --git a/clang/test/Driver/program-path-priority.c b/clang/test/Driver/program-path-priority.c
index ee931dd7a9a35c..c940c4ced94420 100644
--- a/clang/test/Driver/program-path-priority.c
+++ b/clang/test/Driver/program-path-priority.c
@@ -36,7 +36,7 @@
// RUN: touch %t/notreal-none-elf-gcc && chmod +x %t/notreal-none-elf-gcc
// RUN: env "PATH=" %t/clang -### -target notreal-none-elf %s 2>&1 | \
// RUN: FileCheck --check-prefix=PROG_PATH_NOTREAL_GCC %s
-// PROG_PATH_NOTREAL_GCC: notreal-none-elf-gcc"
+// PROG_PATH_NOTREAL_GCC: notreal-none-unknown-elf
/// <triple>-gcc on the PATH is found
// RUN: mkdir -p %t/env
@@ -57,7 +57,7 @@
// RUN: touch %t/gcc && chmod +x %t/gcc
// RUN: env "PATH=" %t/clang -### -target notreal-none-elf %s 2>&1 | \
// RUN: FileCheck --check-prefix=NOTREAL_GCC_PREFERRED %s
-// NOTREAL_GCC_PREFERRED: notreal-none-elf-gcc"
+// NOTREAL_GCC_PREFERRED: notreal-none-unknown-elf"
// NOTREAL_GCC_PREFERRED-NOT: /gcc"
/// <triple>-gcc on the PATH is preferred to gcc in program path
@@ -125,6 +125,9 @@
/// Only if there is nothing in the prefix will we search other paths
/// -f in case $DEFAULT_TRIPLE == %target_triple
// RUN: rm -f %t/prefix/$DEFAULT_TRIPLE-gcc %t/prefix/%target_triple-gcc %t/prefix/gcc
-// RUN: env "PATH=" %t/clang -### -target notreal-none-elf %s -B %t/prefix 2>&1 | \
-// RUN: FileCheck --check-prefix=EMPTY_PREFIX_DIR %s
-// EMPTY_PREFIX_DIR: notreal-none-elf-gcc"
+// RUN: env "PATH=" %t/clang -### -canonical-prefixes --target=notreal-none-elf %s -B %t/prefix 2>&1 | \
+// RUN: FileCheck --check-prefix=EMPTY_PREFIX_DIR1 %s
+// EMPTY_PREFIX_DIR1: gcc"
+// RUN: env "PATH=" %t/clang -### -no-canonical-prefixes --target=notreal-none-elf %s -B %t/prefix 2>&1 | \
+// RUN: FileCheck --check-prefix=EMPTY_PREFIX_DIR2 %s
+// EMPTY_PREFIX_DIR2: notreal-none-elf-gcc"
diff --git a/clang/test/Driver/rocm-detect.hip b/clang/test/Driver/rocm-detect.hip
index 0db994af556f3a..8b15c322e3fb36 100644
--- a/clang/test/Driver/rocm-detect.hip
+++ b/clang/test/Driver/rocm-detect.hip
@@ -102,7 +102,7 @@
// RUN: rm -rf %t/rocm-spack
// RUN: cp -r %S/Inputs/rocm-spack %t
// RUN: ln -fs %clang %t/rocm-spack/llvm-amdgpu-4.0.0-ieagcs7inf7runpyfvepqkurasoglq4z/bin/clang
-// RUN: %t/rocm-spack/llvm-amdgpu-4.0.0-ieagcs7inf7runpyfvepqkurasoglq4z/bin/clang -### -v \
+// RUN: %t/rocm-spack/llvm-amdgpu-4.0.0-ieagcs7inf7runpyfvepqkurasoglq4z/bin/clang -### -no-canonical-prefixes -v \
// RUN: -resource-dir=%t/rocm-spack/llvm-amdgpu-4.0.0-ieagcs7inf7runpyfvepqkurasoglq4z/lib/clang \
// RUN: -target x86_64-linux-gnu --cuda-gpu-arch=gfx900 --print-rocm-search-dirs %s 2>&1 \
// RUN: | FileCheck -check-prefixes=SPACK %s
@@ -111,7 +111,7 @@
// ROCm release. --hip-path and --rocm-device-lib-path can be used to specify them.
// RUN: cp -r %t/rocm-spack/hip-* %t/rocm-spack/hip-4.0.0-abcd
-// RUN: %t/rocm-spack/llvm-amdgpu-4.0.0-ieagcs7inf7runpyfvepqkurasoglq4z/bin/clang -### -v \
+// RUN: %t/rocm-spack/llvm-amdgpu-4.0.0-ieagcs7inf7runpyfvepqkurasoglq4z/bin/clang -### -no-canonical-prefixes -v \
// RUN: -target x86_64-linux-gnu --cuda-gpu-arch=gfx900 \
// RUN: --hip-path=%t/rocm-spack/hip-4.0.0-abcd \
// RUN: %s 2>&1 | FileCheck -check-prefixes=SPACK-SET %s
diff --git a/clang/tools/driver/driver.cpp b/clang/tools/driver/driver.cpp
index 0dfb512adb0cc6..376025e3605be8 100644
--- a/clang/tools/driver/driver.cpp
+++ b/clang/tools/driver/driver.cpp
@@ -323,28 +323,6 @@ static void FixupDiagPrefixExeName(TextDiagnosticPrinter *DiagClient,
DiagClient->setPrefix(std::string(ExeBasename));
}
-static void SetInstallDir(SmallVectorImpl<const char *> &argv,
- Driver &TheDriver, bool CanonicalPrefixes) {
- // Attempt to find the original path used to invoke the driver, to determine
- // the installed path. We do this manually, because we want to support that
- // path being a symlink.
- SmallString<128> InstalledPath(argv[0]);
-
- // Do a PATH lookup, if there are no directory components.
- if (llvm::sys::path::filename(InstalledPath) == InstalledPath)
- if (llvm::ErrorOr<std::string> Tmp = llvm::sys::findProgramByName(
- llvm::sys::path::filename(InstalledPath.str())))
- InstalledPath = *Tmp;
-
- // FIXME: We don't actually canonicalize this, we just make it absolute.
- if (CanonicalPrefixes)
- llvm::sys::fs::make_absolute(InstalledPath);
-
- StringRef InstalledPathParent(llvm::sys::path::parent_path(InstalledPath));
- if (llvm::sys::fs::exists(InstalledPathParent))
- TheDriver.setInstalledDir(InstalledPathParent);
-}
-
static int ExecuteCC1Tool(SmallVectorImpl<const char *> &ArgV,
const llvm::ToolContext &ToolContext) {
// If we call the cc1 tool from the clangDriver library (through
@@ -484,7 +462,6 @@ int clang_main(int Argc, char **Argv, const llvm::ToolContext &ToolContext) {
ProcessWarningOptions(Diags, *DiagOpts, /*ReportDiags=*/false);
Driver TheDriver(Path, llvm::sys::getDefaultTargetTriple(), Diags);
- SetInstallDir(Args, TheDriver, CanonicalPrefixes);
auto TargetAndMode = ToolChain::getTargetAndModeFromProgramName(ProgName);
TheDriver.setTargetAndMode(TargetAndMode);
// If -canonical-prefixes is set, GetExecutablePath will have resolved Path
>From 0f76d9fb5fbfea92da7647af70d78165c71c0700 Mon Sep 17 00:00:00 2001
From: Fangrui Song <i at maskray.me>
Date: Wed, 28 Feb 2024 15:17:31 -0800
Subject: [PATCH 062/406] clang-installapi: remove setInstalledDir
---
clang/tools/clang-installapi/ClangInstallAPI.cpp | 1 -
1 file changed, 1 deletion(-)
diff --git a/clang/tools/clang-installapi/ClangInstallAPI.cpp b/clang/tools/clang-installapi/ClangInstallAPI.cpp
index 43c9fca0a82eec..ff031e0236d0bc 100644
--- a/clang/tools/clang-installapi/ClangInstallAPI.cpp
+++ b/clang/tools/clang-installapi/ClangInstallAPI.cpp
@@ -96,7 +96,6 @@ static bool run(ArrayRef<const char *> Args, const char *ProgName) {
auto DriverArgs = llvm::ArrayRef(Args).slice(1);
clang::driver::Driver Driver(ProgName, llvm::sys::getDefaultTargetTriple(),
*Diag, "clang installapi tool");
- Driver.setInstalledDir(llvm::sys::path::parent_path(ProgName));
auto TargetAndMode =
clang::driver::ToolChain::getTargetAndModeFromProgramName(ProgName);
Driver.setTargetAndMode(TargetAndMode);
>From d3173f4ab61c17337908eb7df3f1c515ddcd428c Mon Sep 17 00:00:00 2001
From: Jonas Devlieghere <jonas at devlieghere.com>
Date: Wed, 28 Feb 2024 15:23:55 -0800
Subject: [PATCH 063/406] [lldb] Remove -d(ebug) mode from the lldb driver
(#83330)
The -d(ebug) option broke 5 years ago when I migrated the driver to
libOption. Since then, we were never check if the option is set. We were
incorrectly toggling the internal variable (m_debug_mode) based on
OPT_no_use_colors instead.
Given that the functionality doesn't seem particularly useful and nobody
noticed it has been broken for 5 years, I'm just removing the flag.
---
lldb/test/Shell/Driver/TestHelp.test | 2 --
lldb/tools/driver/Driver.cpp | 15 ---------------
lldb/tools/driver/Driver.h | 1 -
3 files changed, 18 deletions(-)
diff --git a/lldb/test/Shell/Driver/TestHelp.test b/lldb/test/Shell/Driver/TestHelp.test
index 0f73fdf0374fdd..2521b31a618836 100644
--- a/lldb/test/Shell/Driver/TestHelp.test
+++ b/lldb/test/Shell/Driver/TestHelp.test
@@ -37,8 +37,6 @@ CHECK: --arch
CHECK: -a
CHECK: --core
CHECK: -c
-CHECK: --debug
-CHECK: -d
CHECK: --editor
CHECK: -e
CHECK: --file
diff --git a/lldb/tools/driver/Driver.cpp b/lldb/tools/driver/Driver.cpp
index c63ff0ff597e5c..9286abb27e1332 100644
--- a/lldb/tools/driver/Driver.cpp
+++ b/lldb/tools/driver/Driver.cpp
@@ -188,7 +188,6 @@ SBError Driver::ProcessArgs(const opt::InputArgList &args, bool &exiting) {
if (args.hasArg(OPT_no_use_colors)) {
m_debugger.SetUseColor(false);
WithColor::setAutoDetectFunction(disable_color);
- m_option_data.m_debug_mode = true;
}
if (args.hasArg(OPT_version)) {
@@ -455,16 +454,7 @@ int Driver::MainLoop() {
// Process lldbinit files before handling any options from the command line.
SBCommandReturnObject result;
sb_interpreter.SourceInitFileInGlobalDirectory(result);
- if (m_option_data.m_debug_mode) {
- result.PutError(m_debugger.GetErrorFile());
- result.PutOutput(m_debugger.GetOutputFile());
- }
-
sb_interpreter.SourceInitFileInHomeDirectory(result, m_option_data.m_repl);
- if (m_option_data.m_debug_mode) {
- result.PutError(m_debugger.GetErrorFile());
- result.PutOutput(m_debugger.GetOutputFile());
- }
// Source the local .lldbinit file if it exists and we're allowed to source.
// Here we want to always print the return object because it contains the
@@ -536,11 +526,6 @@ int Driver::MainLoop() {
"or -s) are ignored in REPL mode.\n";
}
- if (m_option_data.m_debug_mode) {
- result.PutError(m_debugger.GetErrorFile());
- result.PutOutput(m_debugger.GetOutputFile());
- }
-
const bool handle_events = true;
const bool spawn_thread = false;
diff --git a/lldb/tools/driver/Driver.h b/lldb/tools/driver/Driver.h
index d5779b3c2c91b5..83e0d8a41cfdb1 100644
--- a/lldb/tools/driver/Driver.h
+++ b/lldb/tools/driver/Driver.h
@@ -75,7 +75,6 @@ class Driver : public lldb::SBBroadcaster {
std::vector<InitialCmdEntry> m_after_file_commands;
std::vector<InitialCmdEntry> m_after_crash_commands;
- bool m_debug_mode = false;
bool m_source_quietly = false;
bool m_print_version = false;
bool m_print_python_path = false;
>From d7b73c8d012cd19bcbd35a33df9e45e3cdddbfad Mon Sep 17 00:00:00 2001
From: Stanislav Mekhanoshin <rampitec at users.noreply.github.com>
Date: Wed, 28 Feb 2024 15:42:31 -0800
Subject: [PATCH 064/406] [AMDGPU] Copy WaveSizePredicate into VOP3_Real. NFCI.
(#83352)
---
llvm/lib/Target/AMDGPU/VOPInstructions.td | 1 +
1 file changed, 1 insertion(+)
diff --git a/llvm/lib/Target/AMDGPU/VOPInstructions.td b/llvm/lib/Target/AMDGPU/VOPInstructions.td
index 918bdb9506b04d..fa8d46608f5d11 100644
--- a/llvm/lib/Target/AMDGPU/VOPInstructions.td
+++ b/llvm/lib/Target/AMDGPU/VOPInstructions.td
@@ -190,6 +190,7 @@ class VOP3_Real <VOP_Pseudo ps, int EncodingFamily, string asm_name = ps.Mnemoni
// copy relevant pseudo op flags
let SubtargetPredicate = ps.SubtargetPredicate;
+ let WaveSizePredicate = ps.WaveSizePredicate;
let OtherPredicates = ps.OtherPredicates;
let AsmMatchConverter = ps.AsmMatchConverter;
let AsmVariantName = ps.AsmVariantName;
>From 191fd2d9db46ba41308f0b2b342b2dc268d7be6f Mon Sep 17 00:00:00 2001
From: Shilei Tian <i at tianshilei.me>
Date: Wed, 28 Feb 2024 18:47:02 -0500
Subject: [PATCH 065/406] [NFC][AMDGPU] Move the rem tests in `div_i128.ll`
into `rem_i128.ll` (#83307)
---
llvm/test/CodeGen/AMDGPU/div_i128.ll | 3003 -------------------------
llvm/test/CodeGen/AMDGPU/rem_i128.ll | 3014 ++++++++++++++++++++++++++
2 files changed, 3014 insertions(+), 3003 deletions(-)
create mode 100644 llvm/test/CodeGen/AMDGPU/rem_i128.ll
diff --git a/llvm/test/CodeGen/AMDGPU/div_i128.ll b/llvm/test/CodeGen/AMDGPU/div_i128.ll
index 5296ad3ab51d31..2f3d5d9d140c2c 100644
--- a/llvm/test/CodeGen/AMDGPU/div_i128.ll
+++ b/llvm/test/CodeGen/AMDGPU/div_i128.ll
@@ -2310,2860 +2310,6 @@ define i128 @v_udiv_i128_vv(i128 %lhs, i128 %rhs) {
ret i128 %div
}
-define i128 @v_srem_i128_vv(i128 %lhs, i128 %rhs) {
-; GFX9-LABEL: v_srem_i128_vv:
-; GFX9: ; %bb.0: ; %_udiv-special-cases
-; GFX9-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
-; GFX9-NEXT: v_ashrrev_i32_e32 v20, 31, v3
-; GFX9-NEXT: v_xor_b32_e32 v0, v0, v20
-; GFX9-NEXT: v_xor_b32_e32 v10, v2, v20
-; GFX9-NEXT: v_xor_b32_e32 v1, v1, v20
-; GFX9-NEXT: v_sub_co_u32_e32 v2, vcc, v0, v20
-; GFX9-NEXT: v_xor_b32_e32 v9, v3, v20
-; GFX9-NEXT: v_subb_co_u32_e32 v3, vcc, v1, v20, vcc
-; GFX9-NEXT: v_ashrrev_i32_e32 v8, 31, v7
-; GFX9-NEXT: v_subb_co_u32_e32 v0, vcc, v10, v20, vcc
-; GFX9-NEXT: v_xor_b32_e32 v4, v4, v8
-; GFX9-NEXT: v_subb_co_u32_e32 v1, vcc, v9, v20, vcc
-; GFX9-NEXT: v_xor_b32_e32 v5, v5, v8
-; GFX9-NEXT: v_sub_co_u32_e32 v23, vcc, v4, v8
-; GFX9-NEXT: v_xor_b32_e32 v6, v6, v8
-; GFX9-NEXT: v_subb_co_u32_e32 v21, vcc, v5, v8, vcc
-; GFX9-NEXT: v_xor_b32_e32 v7, v7, v8
-; GFX9-NEXT: v_subb_co_u32_e32 v4, vcc, v6, v8, vcc
-; GFX9-NEXT: v_subb_co_u32_e32 v5, vcc, v7, v8, vcc
-; GFX9-NEXT: v_or_b32_e32 v7, v21, v5
-; GFX9-NEXT: v_or_b32_e32 v6, v23, v4
-; GFX9-NEXT: v_cmp_eq_u64_e32 vcc, 0, v[6:7]
-; GFX9-NEXT: v_or_b32_e32 v7, v3, v1
-; GFX9-NEXT: v_or_b32_e32 v6, v2, v0
-; GFX9-NEXT: v_cmp_eq_u64_e64 s[4:5], 0, v[6:7]
-; GFX9-NEXT: v_ffbh_u32_e32 v6, v4
-; GFX9-NEXT: v_add_u32_e32 v6, 32, v6
-; GFX9-NEXT: v_ffbh_u32_e32 v7, v5
-; GFX9-NEXT: v_min_u32_e32 v6, v6, v7
-; GFX9-NEXT: v_ffbh_u32_e32 v7, v23
-; GFX9-NEXT: v_add_u32_e32 v7, 32, v7
-; GFX9-NEXT: v_ffbh_u32_e32 v8, v21
-; GFX9-NEXT: v_min_u32_e32 v7, v7, v8
-; GFX9-NEXT: s_or_b64 s[4:5], vcc, s[4:5]
-; GFX9-NEXT: v_add_co_u32_e32 v7, vcc, 64, v7
-; GFX9-NEXT: v_addc_co_u32_e64 v8, s[6:7], 0, 0, vcc
-; GFX9-NEXT: v_cmp_ne_u64_e32 vcc, 0, v[4:5]
-; GFX9-NEXT: v_ffbh_u32_e32 v9, v1
-; GFX9-NEXT: v_cndmask_b32_e32 v6, v7, v6, vcc
-; GFX9-NEXT: v_ffbh_u32_e32 v7, v0
-; GFX9-NEXT: v_add_u32_e32 v7, 32, v7
-; GFX9-NEXT: v_min_u32_e32 v7, v7, v9
-; GFX9-NEXT: v_ffbh_u32_e32 v9, v2
-; GFX9-NEXT: v_add_u32_e32 v9, 32, v9
-; GFX9-NEXT: v_ffbh_u32_e32 v10, v3
-; GFX9-NEXT: v_min_u32_e32 v9, v9, v10
-; GFX9-NEXT: v_cndmask_b32_e64 v8, v8, 0, vcc
-; GFX9-NEXT: v_add_co_u32_e32 v9, vcc, 64, v9
-; GFX9-NEXT: v_addc_co_u32_e64 v10, s[6:7], 0, 0, vcc
-; GFX9-NEXT: v_cmp_ne_u64_e32 vcc, 0, v[0:1]
-; GFX9-NEXT: s_mov_b64 s[6:7], 0x7f
-; GFX9-NEXT: v_cndmask_b32_e32 v7, v9, v7, vcc
-; GFX9-NEXT: v_cndmask_b32_e64 v10, v10, 0, vcc
-; GFX9-NEXT: v_sub_co_u32_e32 v6, vcc, v6, v7
-; GFX9-NEXT: v_subb_co_u32_e32 v7, vcc, v8, v10, vcc
-; GFX9-NEXT: v_mov_b32_e32 v9, 0
-; GFX9-NEXT: v_subbrev_co_u32_e32 v8, vcc, 0, v9, vcc
-; GFX9-NEXT: v_subbrev_co_u32_e32 v9, vcc, 0, v9, vcc
-; GFX9-NEXT: v_cmp_lt_u64_e32 vcc, s[6:7], v[6:7]
-; GFX9-NEXT: v_or_b32_e32 v13, v7, v9
-; GFX9-NEXT: v_cndmask_b32_e64 v10, 0, 1, vcc
-; GFX9-NEXT: v_cmp_ne_u64_e32 vcc, 0, v[8:9]
-; GFX9-NEXT: v_mov_b32_e32 v22, v20
-; GFX9-NEXT: v_cndmask_b32_e64 v11, 0, 1, vcc
-; GFX9-NEXT: v_cmp_eq_u64_e32 vcc, 0, v[8:9]
-; GFX9-NEXT: v_cndmask_b32_e32 v10, v11, v10, vcc
-; GFX9-NEXT: v_and_b32_e32 v10, 1, v10
-; GFX9-NEXT: v_cmp_eq_u32_e32 vcc, 1, v10
-; GFX9-NEXT: v_xor_b32_e32 v10, 0x7f, v6
-; GFX9-NEXT: v_or_b32_e32 v12, v10, v8
-; GFX9-NEXT: s_or_b64 s[4:5], s[4:5], vcc
-; GFX9-NEXT: v_cmp_ne_u64_e32 vcc, 0, v[12:13]
-; GFX9-NEXT: s_xor_b64 s[6:7], s[4:5], -1
-; GFX9-NEXT: v_cndmask_b32_e64 v11, v1, 0, s[4:5]
-; GFX9-NEXT: v_cndmask_b32_e64 v12, v0, 0, s[4:5]
-; GFX9-NEXT: v_cndmask_b32_e64 v10, v3, 0, s[4:5]
-; GFX9-NEXT: v_cndmask_b32_e64 v13, v2, 0, s[4:5]
-; GFX9-NEXT: s_and_b64 s[4:5], s[6:7], vcc
-; GFX9-NEXT: s_and_saveexec_b64 s[8:9], s[4:5]
-; GFX9-NEXT: s_cbranch_execz .LBB2_6
-; GFX9-NEXT: ; %bb.1: ; %udiv-bb1
-; GFX9-NEXT: v_add_co_u32_e32 v24, vcc, 1, v6
-; GFX9-NEXT: v_addc_co_u32_e32 v25, vcc, 0, v7, vcc
-; GFX9-NEXT: v_addc_co_u32_e32 v26, vcc, 0, v8, vcc
-; GFX9-NEXT: v_sub_u32_e32 v13, 0x7f, v6
-; GFX9-NEXT: v_addc_co_u32_e32 v27, vcc, 0, v9, vcc
-; GFX9-NEXT: v_sub_u32_e32 v11, 64, v13
-; GFX9-NEXT: v_or_b32_e32 v8, v25, v27
-; GFX9-NEXT: v_or_b32_e32 v7, v24, v26
-; GFX9-NEXT: v_lshlrev_b64 v[9:10], v13, v[0:1]
-; GFX9-NEXT: v_lshrrev_b64 v[11:12], v11, v[2:3]
-; GFX9-NEXT: v_sub_u32_e32 v6, 63, v6
-; GFX9-NEXT: v_cmp_ne_u64_e32 vcc, 0, v[7:8]
-; GFX9-NEXT: v_lshlrev_b64 v[6:7], v6, v[2:3]
-; GFX9-NEXT: v_or_b32_e32 v8, v10, v12
-; GFX9-NEXT: v_or_b32_e32 v9, v9, v11
-; GFX9-NEXT: v_cmp_gt_u32_e64 s[4:5], 64, v13
-; GFX9-NEXT: v_cmp_eq_u32_e64 s[6:7], 0, v13
-; GFX9-NEXT: v_lshlrev_b64 v[12:13], v13, v[2:3]
-; GFX9-NEXT: v_cndmask_b32_e64 v7, v7, v8, s[4:5]
-; GFX9-NEXT: v_cndmask_b32_e64 v6, v6, v9, s[4:5]
-; GFX9-NEXT: v_mov_b32_e32 v8, 0
-; GFX9-NEXT: v_mov_b32_e32 v10, 0
-; GFX9-NEXT: v_cndmask_b32_e64 v7, v7, v1, s[6:7]
-; GFX9-NEXT: v_cndmask_b32_e64 v6, v6, v0, s[6:7]
-; GFX9-NEXT: v_cndmask_b32_e64 v13, 0, v13, s[4:5]
-; GFX9-NEXT: v_mov_b32_e32 v9, 0
-; GFX9-NEXT: v_mov_b32_e32 v11, 0
-; GFX9-NEXT: v_cndmask_b32_e64 v12, 0, v12, s[4:5]
-; GFX9-NEXT: s_and_saveexec_b64 s[4:5], vcc
-; GFX9-NEXT: s_xor_b64 s[6:7], exec, s[4:5]
-; GFX9-NEXT: s_cbranch_execz .LBB2_5
-; GFX9-NEXT: ; %bb.2: ; %udiv-preheader
-; GFX9-NEXT: v_sub_u32_e32 v10, 64, v24
-; GFX9-NEXT: v_lshrrev_b64 v[8:9], v24, v[2:3]
-; GFX9-NEXT: v_lshlrev_b64 v[10:11], v10, v[0:1]
-; GFX9-NEXT: v_cmp_gt_u32_e32 vcc, 64, v24
-; GFX9-NEXT: v_or_b32_e32 v10, v8, v10
-; GFX9-NEXT: v_subrev_u32_e32 v8, 64, v24
-; GFX9-NEXT: v_or_b32_e32 v11, v9, v11
-; GFX9-NEXT: v_lshrrev_b64 v[8:9], v8, v[0:1]
-; GFX9-NEXT: v_cmp_eq_u32_e64 s[4:5], 0, v24
-; GFX9-NEXT: v_cndmask_b32_e32 v9, v9, v11, vcc
-; GFX9-NEXT: v_cndmask_b32_e64 v15, v9, v3, s[4:5]
-; GFX9-NEXT: v_cndmask_b32_e32 v10, v8, v10, vcc
-; GFX9-NEXT: v_lshrrev_b64 v[8:9], v24, v[0:1]
-; GFX9-NEXT: v_cndmask_b32_e64 v14, v10, v2, s[4:5]
-; GFX9-NEXT: v_cndmask_b32_e32 v17, 0, v9, vcc
-; GFX9-NEXT: v_cndmask_b32_e32 v16, 0, v8, vcc
-; GFX9-NEXT: v_add_co_u32_e32 v28, vcc, -1, v23
-; GFX9-NEXT: v_addc_co_u32_e32 v29, vcc, -1, v21, vcc
-; GFX9-NEXT: v_addc_co_u32_e32 v30, vcc, -1, v4, vcc
-; GFX9-NEXT: v_mov_b32_e32 v18, 0
-; GFX9-NEXT: v_mov_b32_e32 v10, 0
-; GFX9-NEXT: v_addc_co_u32_e32 v31, vcc, -1, v5, vcc
-; GFX9-NEXT: s_mov_b64 s[4:5], 0
-; GFX9-NEXT: v_mov_b32_e32 v19, 0
-; GFX9-NEXT: v_mov_b32_e32 v11, 0
-; GFX9-NEXT: v_mov_b32_e32 v9, 0
-; GFX9-NEXT: .LBB2_3: ; %udiv-do-while
-; GFX9-NEXT: ; =>This Inner Loop Header: Depth=1
-; GFX9-NEXT: v_lshrrev_b32_e32 v32, 31, v15
-; GFX9-NEXT: v_lshlrev_b64 v[14:15], 1, v[14:15]
-; GFX9-NEXT: v_lshrrev_b32_e32 v33, 31, v7
-; GFX9-NEXT: v_lshlrev_b64 v[6:7], 1, v[6:7]
-; GFX9-NEXT: v_lshrrev_b32_e32 v8, 31, v13
-; GFX9-NEXT: v_lshlrev_b64 v[16:17], 1, v[16:17]
-; GFX9-NEXT: v_or_b32_e32 v14, v14, v33
-; GFX9-NEXT: v_or3_b32 v6, v6, v8, v10
-; GFX9-NEXT: v_sub_co_u32_e32 v8, vcc, v28, v14
-; GFX9-NEXT: v_or_b32_e32 v16, v16, v32
-; GFX9-NEXT: v_subb_co_u32_e32 v8, vcc, v29, v15, vcc
-; GFX9-NEXT: v_subb_co_u32_e32 v8, vcc, v30, v16, vcc
-; GFX9-NEXT: v_lshlrev_b64 v[12:13], 1, v[12:13]
-; GFX9-NEXT: v_subb_co_u32_e32 v8, vcc, v31, v17, vcc
-; GFX9-NEXT: v_ashrrev_i32_e32 v8, 31, v8
-; GFX9-NEXT: v_or_b32_e32 v12, v18, v12
-; GFX9-NEXT: v_and_b32_e32 v18, v8, v23
-; GFX9-NEXT: v_or_b32_e32 v13, v19, v13
-; GFX9-NEXT: v_and_b32_e32 v19, v8, v21
-; GFX9-NEXT: v_sub_co_u32_e32 v14, vcc, v14, v18
-; GFX9-NEXT: v_and_b32_e32 v32, v8, v4
-; GFX9-NEXT: v_subb_co_u32_e32 v15, vcc, v15, v19, vcc
-; GFX9-NEXT: v_and_b32_e32 v33, v8, v5
-; GFX9-NEXT: v_subb_co_u32_e32 v16, vcc, v16, v32, vcc
-; GFX9-NEXT: v_subb_co_u32_e32 v17, vcc, v17, v33, vcc
-; GFX9-NEXT: v_add_co_u32_e32 v24, vcc, -1, v24
-; GFX9-NEXT: v_addc_co_u32_e32 v25, vcc, -1, v25, vcc
-; GFX9-NEXT: v_addc_co_u32_e32 v26, vcc, -1, v26, vcc
-; GFX9-NEXT: v_addc_co_u32_e32 v27, vcc, -1, v27, vcc
-; GFX9-NEXT: v_or_b32_e32 v18, v24, v26
-; GFX9-NEXT: v_or_b32_e32 v19, v25, v27
-; GFX9-NEXT: v_cmp_eq_u64_e32 vcc, 0, v[18:19]
-; GFX9-NEXT: v_and_b32_e32 v8, 1, v8
-; GFX9-NEXT: v_mov_b32_e32 v19, v9
-; GFX9-NEXT: v_or3_b32 v7, v7, 0, v11
-; GFX9-NEXT: s_or_b64 s[4:5], vcc, s[4:5]
-; GFX9-NEXT: v_mov_b32_e32 v18, v8
-; GFX9-NEXT: s_andn2_b64 exec, exec, s[4:5]
-; GFX9-NEXT: s_cbranch_execnz .LBB2_3
-; GFX9-NEXT: ; %bb.4: ; %Flow
-; GFX9-NEXT: s_or_b64 exec, exec, s[4:5]
-; GFX9-NEXT: .LBB2_5: ; %Flow2
-; GFX9-NEXT: s_or_b64 exec, exec, s[6:7]
-; GFX9-NEXT: v_lshlrev_b64 v[14:15], 1, v[12:13]
-; GFX9-NEXT: v_lshlrev_b64 v[6:7], 1, v[6:7]
-; GFX9-NEXT: v_lshrrev_b32_e32 v12, 31, v13
-; GFX9-NEXT: v_or3_b32 v11, v7, 0, v11
-; GFX9-NEXT: v_or3_b32 v12, v6, v12, v10
-; GFX9-NEXT: v_or_b32_e32 v10, v9, v15
-; GFX9-NEXT: v_or_b32_e32 v13, v8, v14
-; GFX9-NEXT: .LBB2_6: ; %Flow3
-; GFX9-NEXT: s_or_b64 exec, exec, s[8:9]
-; GFX9-NEXT: v_mul_lo_u32 v16, v13, v5
-; GFX9-NEXT: v_mad_u64_u32 v[5:6], s[4:5], v23, v13, 0
-; GFX9-NEXT: v_mov_b32_e32 v15, 0
-; GFX9-NEXT: v_mad_u64_u32 v[7:8], s[4:5], v13, v4, 0
-; GFX9-NEXT: v_mov_b32_e32 v14, v6
-; GFX9-NEXT: v_mad_u64_u32 v[13:14], s[4:5], v21, v13, v[14:15]
-; GFX9-NEXT: v_mul_lo_u32 v9, v10, v4
-; GFX9-NEXT: v_mul_lo_u32 v11, v11, v23
-; GFX9-NEXT: v_mov_b32_e32 v4, v14
-; GFX9-NEXT: v_mov_b32_e32 v14, v15
-; GFX9-NEXT: v_mad_u64_u32 v[13:14], s[4:5], v23, v10, v[13:14]
-; GFX9-NEXT: v_add3_u32 v8, v8, v16, v9
-; GFX9-NEXT: v_mad_u64_u32 v[6:7], s[4:5], v12, v23, v[7:8]
-; GFX9-NEXT: v_mov_b32_e32 v8, v14
-; GFX9-NEXT: v_add_co_u32_e32 v8, vcc, v4, v8
-; GFX9-NEXT: v_addc_co_u32_e64 v9, s[4:5], 0, 0, vcc
-; GFX9-NEXT: v_mul_lo_u32 v12, v12, v21
-; GFX9-NEXT: v_mad_u64_u32 v[8:9], s[4:5], v21, v10, v[8:9]
-; GFX9-NEXT: v_add3_u32 v4, v11, v7, v12
-; GFX9-NEXT: v_add_co_u32_e32 v6, vcc, v8, v6
-; GFX9-NEXT: v_addc_co_u32_e32 v4, vcc, v9, v4, vcc
-; GFX9-NEXT: v_mov_b32_e32 v7, v13
-; GFX9-NEXT: v_sub_co_u32_e32 v2, vcc, v2, v5
-; GFX9-NEXT: v_subb_co_u32_e32 v3, vcc, v3, v7, vcc
-; GFX9-NEXT: v_subb_co_u32_e32 v0, vcc, v0, v6, vcc
-; GFX9-NEXT: v_subb_co_u32_e32 v1, vcc, v1, v4, vcc
-; GFX9-NEXT: v_xor_b32_e32 v5, v0, v20
-; GFX9-NEXT: v_xor_b32_e32 v0, v2, v20
-; GFX9-NEXT: v_xor_b32_e32 v4, v1, v22
-; GFX9-NEXT: v_xor_b32_e32 v1, v3, v22
-; GFX9-NEXT: v_sub_co_u32_e32 v0, vcc, v0, v20
-; GFX9-NEXT: v_subb_co_u32_e32 v1, vcc, v1, v22, vcc
-; GFX9-NEXT: v_subb_co_u32_e32 v2, vcc, v5, v20, vcc
-; GFX9-NEXT: v_subb_co_u32_e32 v3, vcc, v4, v22, vcc
-; GFX9-NEXT: s_setpc_b64 s[30:31]
-;
-; GFX9-O0-LABEL: v_srem_i128_vv:
-; GFX9-O0: ; %bb.0: ; %_udiv-special-cases
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
-; GFX9-O0-NEXT: s_xor_saveexec_b64 s[4:5], -1
-; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 offset:348 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:352 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v8, off, s[0:3], s32 offset:356 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v16, off, s[0:3], s32 offset:360 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_mov_b64 exec, s[4:5]
-; GFX9-O0-NEXT: ; implicit-def: $vgpr8 : SGPR spill to VGPR lane
-; GFX9-O0-NEXT: v_mov_b32_e32 v8, v6
-; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:120 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:116 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: v_mov_b32_e32 v14, v2
-; GFX9-O0-NEXT: buffer_load_dword v2, off, s[0:3], s32 offset:120 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v1
-; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:116 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v0
-; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
-; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v5
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr4 killed $vgpr4 def $vgpr4_vgpr5 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v6
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr8 killed $vgpr8 def $vgpr8_vgpr9 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v9, v7
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr14 killed $vgpr14 def $vgpr14_vgpr15 killed $exec
-; GFX9-O0-NEXT: s_waitcnt vmcnt(1)
-; GFX9-O0-NEXT: v_mov_b32_e32 v15, v1
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4_sgpr5
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4_sgpr5
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4_sgpr5
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4_sgpr5
-; GFX9-O0-NEXT: s_mov_b32 s4, 63
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v14
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v15
-; GFX9-O0-NEXT: v_ashrrev_i64 v[12:13], s4, v[6:7]
-; GFX9-O0-NEXT: buffer_store_dword v12, off, s[0:3], s32 offset:108 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v13, off, s[0:3], s32 offset:112 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v12
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v13
-; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:100 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v7, off, s[0:3], s32 offset:104 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v8
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v9
-; GFX9-O0-NEXT: v_ashrrev_i64 v[6:7], s4, v[6:7]
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v15
-; GFX9-O0-NEXT: v_mov_b32_e32 v10, v13
-; GFX9-O0-NEXT: v_xor_b32_e64 v1, v1, v10
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, v14
-; GFX9-O0-NEXT: v_xor_b32_e64 v13, v11, v12
-; GFX9-O0-NEXT: ; kill: def $vgpr13 killed $vgpr13 def $vgpr13_vgpr14 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v14, v1
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v5
-; GFX9-O0-NEXT: v_xor_b32_e64 v1, v1, v10
-; GFX9-O0-NEXT: ; kill: def $vgpr4 killed $vgpr4 killed $vgpr4_vgpr5 killed $exec
-; GFX9-O0-NEXT: v_xor_b32_e64 v15, v4, v12
-; GFX9-O0-NEXT: ; kill: def $vgpr15 killed $vgpr15 def $vgpr15_vgpr16 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v16, v1
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v9
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v7
-; GFX9-O0-NEXT: v_xor_b32_e64 v1, v1, v4
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v8
-; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 killed $vgpr6_vgpr7 killed $exec
-; GFX9-O0-NEXT: v_xor_b32_e64 v7, v5, v6
-; GFX9-O0-NEXT: ; kill: def $vgpr7 killed $vgpr7 def $vgpr7_vgpr8 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v8, v1
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v3
-; GFX9-O0-NEXT: v_xor_b32_e64 v1, v1, v4
-; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 killed $vgpr2_vgpr3 killed $exec
-; GFX9-O0-NEXT: v_xor_b32_e64 v2, v2, v6
-; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v1
-; GFX9-O0-NEXT: v_mov_b32_e32 v9, v15
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v16
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, v13
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v14
-; GFX9-O0-NEXT: v_sub_co_u32_e32 v9, vcc, v9, v12
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v1, vcc, v1, v10, vcc
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v13, vcc, v11, v12, vcc
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v5, vcc, v5, v10, vcc
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr13 killed $vgpr13 def $vgpr13_vgpr14 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v14, v5
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr9 killed $vgpr9 def $vgpr9_vgpr10 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v10, v1
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v2
-; GFX9-O0-NEXT: ; kill: def $vgpr3 killed $vgpr3 killed $vgpr2_vgpr3 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v7
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v8
-; GFX9-O0-NEXT: v_sub_co_u32_e32 v1, vcc, v1, v6
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v3, vcc, v3, v4, vcc
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v11, vcc, v5, v6, vcc
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v2, vcc, v2, v4, vcc
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 def $vgpr11_vgpr12 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, v2
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr1 killed $vgpr1 def $vgpr1_vgpr2 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
-; GFX9-O0-NEXT: buffer_store_dword v9, off, s[0:3], s32 offset:92 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v10, off, s[0:3], s32 offset:96 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v13, off, s[0:3], s32 offset:84 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v14, off, s[0:3], s32 offset:88 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:76 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:80 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v11, off, s[0:3], s32 offset:68 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v12, off, s[0:3], s32 offset:72 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v11
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v12
-; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:60 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:64 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v1
-; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:52 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:56 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v13
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v14
-; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:44 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:48 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v9
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v10
-; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:36 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:40 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v12
-; GFX9-O0-NEXT: v_mov_b32_e32 v8, v2
-; GFX9-O0-NEXT: v_or_b32_e64 v3, v8, v7
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v11
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v1
-; GFX9-O0-NEXT: v_or_b32_e64 v1, v5, v6
-; GFX9-O0-NEXT: ; kill: def $vgpr1 killed $vgpr1 def $vgpr1_vgpr2 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
-; GFX9-O0-NEXT: s_mov_b64 s[6:7], 0
-; GFX9-O0-NEXT: v_writelane_b32 v0, s6, 0
-; GFX9-O0-NEXT: v_writelane_b32 v0, s7, 1
-; GFX9-O0-NEXT: v_cmp_eq_u64_e64 s[4:5], v[1:2], s[6:7]
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v14
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v10
-; GFX9-O0-NEXT: v_or_b32_e64 v15, v4, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v13
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v9
-; GFX9-O0-NEXT: v_or_b32_e64 v9, v3, v1
-; GFX9-O0-NEXT: ; kill: def $vgpr9 killed $vgpr9 def $vgpr9_vgpr10 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v10, v15
-; GFX9-O0-NEXT: v_cmp_eq_u64_e64 s[8:9], v[9:10], s[6:7]
-; GFX9-O0-NEXT: s_or_b64 s[4:5], s[4:5], s[8:9]
-; GFX9-O0-NEXT: v_ffbh_u32_e64 v6, v6
-; GFX9-O0-NEXT: s_mov_b32 s9, 32
-; GFX9-O0-NEXT: v_add_u32_e64 v6, v6, s9
-; GFX9-O0-NEXT: v_ffbh_u32_e64 v7, v7
-; GFX9-O0-NEXT: v_min_u32_e64 v6, v6, v7
-; GFX9-O0-NEXT: s_mov_b32 s8, 0
-; GFX9-O0-NEXT: ; implicit-def: $sgpr10
-; GFX9-O0-NEXT: v_mov_b32_e32 v9, s8
-; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 def $vgpr6_vgpr7 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v9
-; GFX9-O0-NEXT: v_mov_b32_e32 v10, v7
-; GFX9-O0-NEXT: v_ffbh_u32_e64 v5, v5
-; GFX9-O0-NEXT: v_add_u32_e64 v5, v5, s9
-; GFX9-O0-NEXT: v_ffbh_u32_e64 v8, v8
-; GFX9-O0-NEXT: v_min_u32_e64 v15, v5, v8
-; GFX9-O0-NEXT: ; implicit-def: $sgpr10
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, s8
-; GFX9-O0-NEXT: ; kill: def $vgpr15 killed $vgpr15 def $vgpr15_vgpr16 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v16, v5
-; GFX9-O0-NEXT: s_mov_b64 s[10:11], 64
-; GFX9-O0-NEXT: v_mov_b32_e32 v8, v15
-; GFX9-O0-NEXT: s_mov_b32 s12, s10
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v16
-; GFX9-O0-NEXT: s_mov_b32 s14, s11
-; GFX9-O0-NEXT: v_add_co_u32_e64 v8, s[12:13], v8, s12
-; GFX9-O0-NEXT: v_mov_b32_e32 v9, s14
-; GFX9-O0-NEXT: v_addc_co_u32_e64 v5, s[12:13], v5, v9, s[12:13]
-; GFX9-O0-NEXT: ; kill: def $vgpr8 killed $vgpr8 def $vgpr8_vgpr9 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v9, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v9
-; GFX9-O0-NEXT: v_cmp_ne_u64_e64 s[12:13], v[11:12], s[6:7]
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v5, v10, s[12:13]
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v6
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v8
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v9, v6, v7, s[12:13]
-; GFX9-O0-NEXT: ; implicit-def: $sgpr12
-; GFX9-O0-NEXT: ; implicit-def: $sgpr12
-; GFX9-O0-NEXT: ; kill: def $vgpr9 killed $vgpr9 def $vgpr9_vgpr10 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v10, v5
-; GFX9-O0-NEXT: v_ffbh_u32_e64 v5, v1
-; GFX9-O0-NEXT: v_add_u32_e64 v5, v5, s9
-; GFX9-O0-NEXT: v_ffbh_u32_e64 v6, v2
-; GFX9-O0-NEXT: v_min_u32_e64 v6, v5, v6
-; GFX9-O0-NEXT: ; implicit-def: $sgpr12
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, s8
-; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 def $vgpr6_vgpr7 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v8, v7
-; GFX9-O0-NEXT: v_ffbh_u32_e64 v5, v3
-; GFX9-O0-NEXT: v_add_u32_e64 v5, v5, s9
-; GFX9-O0-NEXT: v_ffbh_u32_e64 v11, v4
-; GFX9-O0-NEXT: v_min_u32_e64 v15, v5, v11
-; GFX9-O0-NEXT: ; implicit-def: $sgpr9
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, s8
-; GFX9-O0-NEXT: ; kill: def $vgpr15 killed $vgpr15 def $vgpr15_vgpr16 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v16, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, v15
-; GFX9-O0-NEXT: s_mov_b32 s8, s10
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v16
-; GFX9-O0-NEXT: s_mov_b32 s10, s11
-; GFX9-O0-NEXT: v_add_co_u32_e64 v11, s[8:9], v11, s8
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, s10
-; GFX9-O0-NEXT: v_addc_co_u32_e64 v5, s[8:9], v5, v12, s[8:9]
-; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 def $vgpr11_vgpr12 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v12
-; GFX9-O0-NEXT: v_cmp_ne_u64_e64 s[8:9], v[13:14], s[6:7]
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v5, v8, s[8:9]
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v6
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v11
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v6, v6, v7, s[8:9]
-; GFX9-O0-NEXT: ; implicit-def: $sgpr8
-; GFX9-O0-NEXT: ; implicit-def: $sgpr8
-; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 def $vgpr6_vgpr7 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v8, v6
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v9
-; GFX9-O0-NEXT: ; kill: def $vgpr7 killed $vgpr7 killed $vgpr6_vgpr7 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v10
-; GFX9-O0-NEXT: s_mov_b32 s10, s6
-; GFX9-O0-NEXT: s_mov_b32 s11, s7
-; GFX9-O0-NEXT: v_sub_co_u32_e32 v5, vcc, v5, v8
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v9, vcc, v6, v7, vcc
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, s10
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, s10
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v8, vcc, v6, v7, vcc
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, s11
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, s11
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v7, vcc, v6, v7, vcc
-; GFX9-O0-NEXT: ; implicit-def: $sgpr8
-; GFX9-O0-NEXT: ; implicit-def: $sgpr8
-; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v9
-; GFX9-O0-NEXT: ; implicit-def: $sgpr8
-; GFX9-O0-NEXT: ; implicit-def: $sgpr8
-; GFX9-O0-NEXT: ; kill: def $vgpr8 killed $vgpr8 def $vgpr8_vgpr9 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v9, v7
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, v9
-; GFX9-O0-NEXT: v_mov_b32_e32 v10, v8
-; GFX9-O0-NEXT: buffer_store_dword v10, off, s[0:3], s32 offset:28 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v11, off, s[0:3], s32 offset:32 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, v6
-; GFX9-O0-NEXT: v_mov_b32_e32 v10, v5
-; GFX9-O0-NEXT: buffer_store_dword v10, off, s[0:3], s32 offset:20 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v11, off, s[0:3], s32 offset:24 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_mov_b64 s[8:9], s[6:7]
-; GFX9-O0-NEXT: v_cmp_eq_u64_e64 s[8:9], v[8:9], s[8:9]
-; GFX9-O0-NEXT: s_mov_b64 s[12:13], 0x7f
-; GFX9-O0-NEXT: s_mov_b64 s[14:15], s[12:13]
-; GFX9-O0-NEXT: v_cmp_gt_u64_e64 s[14:15], v[5:6], s[14:15]
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v10, 0, 1, s[14:15]
-; GFX9-O0-NEXT: s_mov_b64 s[14:15], s[6:7]
-; GFX9-O0-NEXT: v_cmp_ne_u64_e64 s[14:15], v[8:9], s[14:15]
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v7, 0, 1, s[14:15]
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v7, v7, v10, s[8:9]
-; GFX9-O0-NEXT: v_and_b32_e64 v7, 1, v7
-; GFX9-O0-NEXT: v_cmp_eq_u32_e64 s[8:9], v7, 1
-; GFX9-O0-NEXT: s_or_b64 s[8:9], s[4:5], s[8:9]
-; GFX9-O0-NEXT: s_mov_b64 s[4:5], -1
-; GFX9-O0-NEXT: s_xor_b64 s[4:5], s[8:9], s[4:5]
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v6
-; GFX9-O0-NEXT: s_mov_b32 s14, s13
-; GFX9-O0-NEXT: v_xor_b32_e64 v7, v7, s14
-; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 killed $vgpr5_vgpr6 killed $exec
-; GFX9-O0-NEXT: ; kill: def $sgpr12 killed $sgpr12 killed $sgpr12_sgpr13
-; GFX9-O0-NEXT: v_xor_b32_e64 v5, v5, s12
-; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v7
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v6
-; GFX9-O0-NEXT: v_mov_b32_e32 v10, v9
-; GFX9-O0-NEXT: v_or_b32_e64 v7, v7, v10
-; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 killed $vgpr5_vgpr6 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v8
-; GFX9-O0-NEXT: v_or_b32_e64 v5, v5, v6
-; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v7
-; GFX9-O0-NEXT: v_cmp_ne_u64_e64 s[6:7], v[5:6], s[6:7]
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, s11
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v2, v5, s[8:9]
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, s10
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v1, v1, v2, s[8:9]
-; GFX9-O0-NEXT: ; implicit-def: $sgpr12
-; GFX9-O0-NEXT: ; implicit-def: $sgpr12
-; GFX9-O0-NEXT: ; kill: def $vgpr1 killed $vgpr1 def $vgpr1_vgpr2 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, s11
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v4, v5, s[8:9]
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, s10
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v3, v3, v4, s[8:9]
-; GFX9-O0-NEXT: ; implicit-def: $sgpr8
-; GFX9-O0-NEXT: ; implicit-def: $sgpr8
-; GFX9-O0-NEXT: ; kill: def $vgpr3 killed $vgpr3 def $vgpr3_vgpr4 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v5
-; GFX9-O0-NEXT: s_and_b64 s[6:7], s[4:5], s[6:7]
-; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:12 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:16 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:4 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:8 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_mov_b64 s[4:5], exec
-; GFX9-O0-NEXT: v_writelane_b32 v0, s4, 2
-; GFX9-O0-NEXT: v_writelane_b32 v0, s5, 3
-; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
-; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
-; GFX9-O0-NEXT: s_and_b64 s[4:5], s[4:5], s[6:7]
-; GFX9-O0-NEXT: s_mov_b64 exec, s[4:5]
-; GFX9-O0-NEXT: s_cbranch_execz .LBB2_3
-; GFX9-O0-NEXT: s_branch .LBB2_8
-; GFX9-O0-NEXT: .LBB2_1: ; %Flow
-; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
-; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: v_readlane_b32 s4, v0, 4
-; GFX9-O0-NEXT: v_readlane_b32 s5, v0, 5
-; GFX9-O0-NEXT: s_or_b64 exec, exec, s[4:5]
-; GFX9-O0-NEXT: ; %bb.2: ; %Flow
-; GFX9-O0-NEXT: buffer_load_dword v6, off, s[0:3], s32 offset:156 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v7, off, s[0:3], s32 offset:160 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v4, off, s[0:3], s32 offset:164 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v5, off, s[0:3], s32 offset:168 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v2, off, s[0:3], s32 offset:172 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v3, off, s[0:3], s32 offset:176 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 offset:180 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:184 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_waitcnt vmcnt(6)
-; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:148 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v7, off, s[0:3], s32 offset:152 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:140 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:144 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:132 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:136 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 offset:124 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:128 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_branch .LBB2_5
-; GFX9-O0-NEXT: .LBB2_3: ; %Flow2
-; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
-; GFX9-O0-NEXT: buffer_load_dword v4, off, s[0:3], s32 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: v_readlane_b32 s4, v4, 2
-; GFX9-O0-NEXT: v_readlane_b32 s5, v4, 3
-; GFX9-O0-NEXT: s_or_b64 exec, exec, s[4:5]
-; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 offset:12 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:16 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v2, off, s[0:3], s32 offset:4 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v3, off, s[0:3], s32 offset:8 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:196 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:200 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 offset:188 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:192 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_branch .LBB2_9
-; GFX9-O0-NEXT: .LBB2_4: ; %udiv-loop-exit
-; GFX9-O0-NEXT: buffer_load_dword v5, off, s[0:3], s32 offset:204 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v6, off, s[0:3], s32 offset:208 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v7, off, s[0:3], s32 offset:212 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v8, off, s[0:3], s32 offset:216 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 offset:220 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:224 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v9, off, s[0:3], s32 offset:228 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v10, off, s[0:3], s32 offset:232 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_mov_b32 s4, 1
-; GFX9-O0-NEXT: s_waitcnt vmcnt(2)
-; GFX9-O0-NEXT: v_lshlrev_b64 v[2:3], s4, v[0:1]
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: v_lshlrev_b64 v[9:10], s4, v[9:10]
-; GFX9-O0-NEXT: s_mov_b32 s4, 63
-; GFX9-O0-NEXT: v_lshrrev_b64 v[0:1], s4, v[0:1]
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, v1
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v10
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, v8
-; GFX9-O0-NEXT: v_or3_b32 v4, v4, v11, v12
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v0
-; GFX9-O0-NEXT: v_mov_b32_e32 v0, v9
-; GFX9-O0-NEXT: v_or3_b32 v0, v0, v1, v7
-; GFX9-O0-NEXT: ; kill: def $vgpr0 killed $vgpr0 def $vgpr0_vgpr1 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v4
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v3
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v6
-; GFX9-O0-NEXT: v_or_b32_e64 v4, v4, v7
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v5
-; GFX9-O0-NEXT: v_or_b32_e64 v2, v2, v3
-; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v4
-; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:12 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:16 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 offset:4 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:8 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_branch .LBB2_3
-; GFX9-O0-NEXT: .LBB2_5: ; %Flow1
-; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
-; GFX9-O0-NEXT: buffer_load_dword v8, off, s[0:3], s32 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: v_readlane_b32 s4, v8, 6
-; GFX9-O0-NEXT: v_readlane_b32 s5, v8, 7
-; GFX9-O0-NEXT: s_or_b64 exec, exec, s[4:5]
-; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 offset:148 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:152 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v2, off, s[0:3], s32 offset:140 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v3, off, s[0:3], s32 offset:144 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v4, off, s[0:3], s32 offset:132 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v5, off, s[0:3], s32 offset:136 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v6, off, s[0:3], s32 offset:124 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v7, off, s[0:3], s32 offset:128 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:212 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v7, off, s[0:3], s32 offset:216 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:204 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:208 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:228 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:232 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 offset:220 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:224 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_branch .LBB2_4
-; GFX9-O0-NEXT: .LBB2_6: ; %udiv-do-while
-; GFX9-O0-NEXT: ; =>This Inner Loop Header: Depth=1
-; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
-; GFX9-O0-NEXT: buffer_load_dword v16, off, s[0:3], s32 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: v_readlane_b32 s6, v16, 8
-; GFX9-O0-NEXT: v_readlane_b32 s7, v16, 9
-; GFX9-O0-NEXT: buffer_load_dword v6, off, s[0:3], s32 offset:236 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v7, off, s[0:3], s32 offset:240 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 offset:244 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:248 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v23, off, s[0:3], s32 offset:252 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v24, off, s[0:3], s32 offset:256 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v2, off, s[0:3], s32 offset:260 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v3, off, s[0:3], s32 offset:264 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v17, off, s[0:3], s32 offset:268 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v18, off, s[0:3], s32 offset:272 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v8, off, s[0:3], s32 offset:276 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v9, off, s[0:3], s32 offset:280 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v27, off, s[0:3], s32 offset:284 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v28, off, s[0:3], s32 offset:288 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v25, off, s[0:3], s32 offset:292 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v26, off, s[0:3], s32 offset:296 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v19, off, s[0:3], s32 offset:52 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v20, off, s[0:3], s32 offset:56 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v21, off, s[0:3], s32 offset:60 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v22, off, s[0:3], s32 offset:64 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v14, off, s[0:3], s32 offset:300 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v15, off, s[0:3], s32 offset:304 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v11, off, s[0:3], s32 offset:308 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v12, off, s[0:3], s32 offset:312 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_mov_b32 s4, 63
-; GFX9-O0-NEXT: s_waitcnt vmcnt(16)
-; GFX9-O0-NEXT: v_lshrrev_b64 v[29:30], s4, v[2:3]
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v30
-; GFX9-O0-NEXT: s_mov_b32 s5, 1
-; GFX9-O0-NEXT: v_lshlrev_b64 v[23:24], s5, v[23:24]
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v24
-; GFX9-O0-NEXT: v_or_b32_e64 v4, v4, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v10, v29
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v23
-; GFX9-O0-NEXT: v_or_b32_e64 v23, v5, v10
-; GFX9-O0-NEXT: ; kill: def $vgpr23 killed $vgpr23 def $vgpr23_vgpr24 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v24, v4
-; GFX9-O0-NEXT: v_lshlrev_b64 v[29:30], s5, v[2:3]
-; GFX9-O0-NEXT: v_lshrrev_b64 v[4:5], s4, v[6:7]
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v30
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v5
-; GFX9-O0-NEXT: v_or_b32_e64 v2, v2, v3
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v29
-; GFX9-O0-NEXT: ; kill: def $vgpr4 killed $vgpr4 killed $vgpr4_vgpr5 killed $exec
-; GFX9-O0-NEXT: v_or_b32_e64 v4, v3, v4
-; GFX9-O0-NEXT: ; kill: def $vgpr4 killed $vgpr4 def $vgpr4_vgpr5 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v2
-; GFX9-O0-NEXT: v_lshlrev_b64 v[2:3], s5, v[0:1]
-; GFX9-O0-NEXT: v_lshlrev_b64 v[29:30], s5, v[6:7]
-; GFX9-O0-NEXT: v_lshrrev_b64 v[0:1], s4, v[0:1]
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v1
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v30
-; GFX9-O0-NEXT: s_waitcnt vmcnt(10)
-; GFX9-O0-NEXT: v_mov_b32_e32 v10, v28
-; GFX9-O0-NEXT: v_or3_b32 v6, v6, v7, v10
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v0
-; GFX9-O0-NEXT: v_mov_b32_e32 v0, v29
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v27
-; GFX9-O0-NEXT: v_or3_b32 v0, v0, v1, v7
-; GFX9-O0-NEXT: ; kill: def $vgpr0 killed $vgpr0 def $vgpr0_vgpr1 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v6
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v3
-; GFX9-O0-NEXT: s_waitcnt vmcnt(8)
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v26
-; GFX9-O0-NEXT: v_or_b32_e64 v6, v6, v7
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v25
-; GFX9-O0-NEXT: v_or_b32_e64 v2, v2, v3
-; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v6
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v4
-; GFX9-O0-NEXT: v_mov_b32_e32 v10, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v23
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v24
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: v_mov_b32_e32 v13, v11
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, v14
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v15
-; GFX9-O0-NEXT: v_sub_co_u32_e32 v13, vcc, v13, v6
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v12, vcc, v12, v10, vcc
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v11, vcc, v11, v4, vcc
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v7, vcc, v7, v5, vcc
-; GFX9-O0-NEXT: ; implicit-def: $sgpr5
-; GFX9-O0-NEXT: ; implicit-def: $sgpr5
-; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 def $vgpr11_vgpr12 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, v7
-; GFX9-O0-NEXT: v_ashrrev_i64 v[13:14], s4, v[11:12]
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v14
-; GFX9-O0-NEXT: s_mov_b64 s[4:5], 1
-; GFX9-O0-NEXT: s_mov_b32 s8, s5
-; GFX9-O0-NEXT: v_and_b32_e64 v12, v7, s8
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, v13
-; GFX9-O0-NEXT: ; kill: def $sgpr4 killed $sgpr4 killed $sgpr4_sgpr5
-; GFX9-O0-NEXT: v_and_b32_e64 v14, v11, s4
-; GFX9-O0-NEXT: ; kill: def $vgpr14 killed $vgpr14 def $vgpr14_vgpr15 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v15, v12
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, 0
-; GFX9-O0-NEXT: v_mov_b32_e32 v13, 0
-; GFX9-O0-NEXT: v_mov_b32_e32 v23, v22
-; GFX9-O0-NEXT: v_and_b32_e64 v23, v7, v23
-; GFX9-O0-NEXT: v_and_b32_e64 v21, v11, v21
-; GFX9-O0-NEXT: ; kill: def $vgpr21 killed $vgpr21 def $vgpr21_vgpr22 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v22, v23
-; GFX9-O0-NEXT: v_mov_b32_e32 v23, v20
-; GFX9-O0-NEXT: v_and_b32_e64 v7, v7, v23
-; GFX9-O0-NEXT: v_and_b32_e64 v23, v11, v19
-; GFX9-O0-NEXT: ; kill: def $vgpr23 killed $vgpr23 def $vgpr23_vgpr24 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v24, v7
-; GFX9-O0-NEXT: v_mov_b32_e32 v20, v23
-; GFX9-O0-NEXT: v_mov_b32_e32 v19, v24
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, v21
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v22
-; GFX9-O0-NEXT: v_sub_co_u32_e32 v6, vcc, v6, v20
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v10, vcc, v10, v19, vcc
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v4, vcc, v4, v11, vcc
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v7, vcc, v5, v7, vcc
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr4 killed $vgpr4 def $vgpr4_vgpr5 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v7
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 def $vgpr6_vgpr7 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v10
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, v8
-; GFX9-O0-NEXT: ; kill: def $vgpr9 killed $vgpr9 killed $vgpr8_vgpr9 killed $exec
-; GFX9-O0-NEXT: s_mov_b64 s[8:9], -1
-; GFX9-O0-NEXT: s_mov_b32 s5, s8
-; GFX9-O0-NEXT: s_mov_b32 s4, s9
-; GFX9-O0-NEXT: v_mov_b32_e32 v10, v17
-; GFX9-O0-NEXT: v_mov_b32_e32 v8, v18
-; GFX9-O0-NEXT: v_mov_b32_e32 v17, s5
-; GFX9-O0-NEXT: v_add_co_u32_e32 v20, vcc, v11, v17
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, s4
-; GFX9-O0-NEXT: v_addc_co_u32_e32 v9, vcc, v9, v11, vcc
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, s5
-; GFX9-O0-NEXT: v_addc_co_u32_e32 v17, vcc, v10, v11, vcc
-; GFX9-O0-NEXT: v_mov_b32_e32 v10, s4
-; GFX9-O0-NEXT: v_addc_co_u32_e32 v8, vcc, v8, v10, vcc
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr20 killed $vgpr20 def $vgpr20_vgpr21 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v21, v9
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr17 killed $vgpr17 def $vgpr17_vgpr18 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v18, v8
-; GFX9-O0-NEXT: v_mov_b32_e32 v8, v17
-; GFX9-O0-NEXT: v_mov_b32_e32 v9, v18
-; GFX9-O0-NEXT: v_mov_b32_e32 v10, v20
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, v21
-; GFX9-O0-NEXT: v_mov_b32_e32 v22, v18
-; GFX9-O0-NEXT: v_mov_b32_e32 v19, v21
-; GFX9-O0-NEXT: v_or_b32_e64 v19, v19, v22
-; GFX9-O0-NEXT: v_mov_b32_e32 v18, v17
-; GFX9-O0-NEXT: v_mov_b32_e32 v17, v20
-; GFX9-O0-NEXT: v_or_b32_e64 v17, v17, v18
-; GFX9-O0-NEXT: ; kill: def $vgpr17 killed $vgpr17 def $vgpr17_vgpr18 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v18, v19
-; GFX9-O0-NEXT: v_cmp_eq_u64_e64 s[4:5], v[17:18], v[12:13]
-; GFX9-O0-NEXT: s_or_b64 s[4:5], s[4:5], s[6:7]
-; GFX9-O0-NEXT: v_mov_b32_e32 v18, v3
-; GFX9-O0-NEXT: v_mov_b32_e32 v17, v2
-; GFX9-O0-NEXT: buffer_store_dword v17, off, s[0:3], s32 offset:156 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v18, off, s[0:3], s32 offset:160 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: v_mov_b32_e32 v18, v1
-; GFX9-O0-NEXT: v_mov_b32_e32 v17, v0
-; GFX9-O0-NEXT: buffer_store_dword v17, off, s[0:3], s32 offset:164 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v18, off, s[0:3], s32 offset:168 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: v_mov_b32_e32 v18, v15
-; GFX9-O0-NEXT: v_mov_b32_e32 v17, v14
-; GFX9-O0-NEXT: buffer_store_dword v17, off, s[0:3], s32 offset:172 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v18, off, s[0:3], s32 offset:176 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: v_mov_b32_e32 v18, v13
-; GFX9-O0-NEXT: v_mov_b32_e32 v17, v12
-; GFX9-O0-NEXT: buffer_store_dword v17, off, s[0:3], s32 offset:180 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v18, off, s[0:3], s32 offset:184 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_mov_b64 s[6:7], s[4:5]
-; GFX9-O0-NEXT: v_writelane_b32 v16, s6, 4
-; GFX9-O0-NEXT: v_writelane_b32 v16, s7, 5
-; GFX9-O0-NEXT: s_mov_b64 s[6:7], s[4:5]
-; GFX9-O0-NEXT: v_writelane_b32 v16, s6, 8
-; GFX9-O0-NEXT: v_writelane_b32 v16, s7, 9
-; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
-; GFX9-O0-NEXT: buffer_store_dword v16, off, s[0:3], s32 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
-; GFX9-O0-NEXT: buffer_store_dword v14, off, s[0:3], s32 offset:292 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v15, off, s[0:3], s32 offset:296 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v12, off, s[0:3], s32 offset:284 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v13, off, s[0:3], s32 offset:288 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v10, off, s[0:3], s32 offset:276 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v11, off, s[0:3], s32 offset:280 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v8, off, s[0:3], s32 offset:268 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v9, off, s[0:3], s32 offset:272 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:260 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v7, off, s[0:3], s32 offset:264 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:252 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:256 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:244 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:248 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 offset:236 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:240 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_andn2_b64 exec, exec, s[4:5]
-; GFX9-O0-NEXT: s_cbranch_execnz .LBB2_6
-; GFX9-O0-NEXT: s_branch .LBB2_1
-; GFX9-O0-NEXT: .LBB2_7: ; %udiv-preheader
-; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 offset:316 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:320 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v2, off, s[0:3], s32 offset:324 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v3, off, s[0:3], s32 offset:328 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v8, off, s[0:3], s32 offset:332 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v9, off, s[0:3], s32 offset:336 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v10, off, s[0:3], s32 offset:340 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v11, off, s[0:3], s32 offset:344 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
-; GFX9-O0-NEXT: buffer_load_dword v16, off, s[0:3], s32 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
-; GFX9-O0-NEXT: buffer_load_dword v17, off, s[0:3], s32 offset:60 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v18, off, s[0:3], s32 offset:64 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v13, off, s[0:3], s32 offset:52 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v14, off, s[0:3], s32 offset:56 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v19, off, s[0:3], s32 offset:44 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v20, off, s[0:3], s32 offset:48 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v21, off, s[0:3], s32 offset:36 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v22, off, s[0:3], s32 offset:40 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_waitcnt vmcnt(9)
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v10
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: v_lshrrev_b64 v[6:7], v4, v[21:22]
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v7
-; GFX9-O0-NEXT: s_mov_b32 s6, 64
-; GFX9-O0-NEXT: v_sub_u32_e64 v12, s6, v4
-; GFX9-O0-NEXT: v_lshlrev_b64 v[23:24], v12, v[19:20]
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, v24
-; GFX9-O0-NEXT: v_or_b32_e64 v5, v5, v12
-; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 killed $vgpr6_vgpr7 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v23
-; GFX9-O0-NEXT: v_or_b32_e64 v6, v6, v7
-; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 def $vgpr6_vgpr7 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, v7
-; GFX9-O0-NEXT: v_cmp_lt_u32_e64 s[4:5], v4, s6
-; GFX9-O0-NEXT: v_sub_u32_e64 v5, v4, s6
-; GFX9-O0-NEXT: v_lshrrev_b64 v[23:24], v5, v[19:20]
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v24
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v5, v12, s[4:5]
-; GFX9-O0-NEXT: s_mov_b32 s6, 0
-; GFX9-O0-NEXT: v_cmp_eq_u32_e64 s[6:7], v4, s6
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, v22
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v5, v12, s[6:7]
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v6
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v23
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v6, v6, v7, s[4:5]
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v21
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v6, v6, v7, s[6:7]
-; GFX9-O0-NEXT: ; implicit-def: $sgpr6
-; GFX9-O0-NEXT: ; implicit-def: $sgpr6
-; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 def $vgpr6_vgpr7 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v5
-; GFX9-O0-NEXT: v_lshrrev_b64 v[4:5], v4, v[19:20]
-; GFX9-O0-NEXT: v_mov_b32_e32 v15, v5
-; GFX9-O0-NEXT: s_mov_b64 s[6:7], 0
-; GFX9-O0-NEXT: s_mov_b32 s8, s7
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, s8
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v12, v12, v15, s[4:5]
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v4
-; GFX9-O0-NEXT: s_mov_b32 s8, s6
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, s8
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v4, v4, v5, s[4:5]
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr4 killed $vgpr4 def $vgpr4_vgpr5 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v12
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, v13
-; GFX9-O0-NEXT: v_mov_b32_e32 v15, v14
-; GFX9-O0-NEXT: s_mov_b64 s[8:9], -1
-; GFX9-O0-NEXT: s_mov_b32 s5, s8
-; GFX9-O0-NEXT: s_mov_b32 s4, s9
-; GFX9-O0-NEXT: v_mov_b32_e32 v14, v17
-; GFX9-O0-NEXT: v_mov_b32_e32 v13, v18
-; GFX9-O0-NEXT: v_mov_b32_e32 v17, s5
-; GFX9-O0-NEXT: v_add_co_u32_e32 v12, vcc, v12, v17
-; GFX9-O0-NEXT: v_mov_b32_e32 v17, s4
-; GFX9-O0-NEXT: v_addc_co_u32_e32 v17, vcc, v15, v17, vcc
-; GFX9-O0-NEXT: v_mov_b32_e32 v15, s5
-; GFX9-O0-NEXT: v_addc_co_u32_e32 v14, vcc, v14, v15, vcc
-; GFX9-O0-NEXT: v_mov_b32_e32 v15, s4
-; GFX9-O0-NEXT: v_addc_co_u32_e32 v13, vcc, v13, v15, vcc
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr14 killed $vgpr14 def $vgpr14_vgpr15 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v15, v13
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr12 killed $vgpr12 def $vgpr12_vgpr13 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v13, v17
-; GFX9-O0-NEXT: s_mov_b64 s[8:9], s[6:7]
-; GFX9-O0-NEXT: buffer_store_dword v14, off, s[0:3], s32 offset:300 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v15, off, s[0:3], s32 offset:304 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v12, off, s[0:3], s32 offset:308 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v13, off, s[0:3], s32 offset:312 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_mov_b64 s[4:5], s[6:7]
-; GFX9-O0-NEXT: v_mov_b32_e32 v15, s9
-; GFX9-O0-NEXT: v_mov_b32_e32 v14, s8
-; GFX9-O0-NEXT: v_mov_b32_e32 v13, s7
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, s6
-; GFX9-O0-NEXT: v_writelane_b32 v16, s4, 8
-; GFX9-O0-NEXT: v_writelane_b32 v16, s5, 9
-; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
-; GFX9-O0-NEXT: buffer_store_dword v16, off, s[0:3], s32 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
-; GFX9-O0-NEXT: buffer_store_dword v14, off, s[0:3], s32 offset:292 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v15, off, s[0:3], s32 offset:296 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v12, off, s[0:3], s32 offset:284 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v13, off, s[0:3], s32 offset:288 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v10, off, s[0:3], s32 offset:276 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v11, off, s[0:3], s32 offset:280 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v8, off, s[0:3], s32 offset:268 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v9, off, s[0:3], s32 offset:272 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:260 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v7, off, s[0:3], s32 offset:264 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:252 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:256 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:244 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:248 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 offset:236 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:240 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_branch .LBB2_6
-; GFX9-O0-NEXT: .LBB2_8: ; %udiv-bb1
-; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
-; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
-; GFX9-O0-NEXT: buffer_load_dword v7, off, s[0:3], s32 offset:36 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v8, off, s[0:3], s32 offset:40 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v11, off, s[0:3], s32 offset:44 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v12, off, s[0:3], s32 offset:48 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v5, off, s[0:3], s32 offset:28 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v6, off, s[0:3], s32 offset:32 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:20 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v2, off, s[0:3], s32 offset:24 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_mov_b64 s[6:7], 1
-; GFX9-O0-NEXT: s_mov_b32 s5, s6
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v1
-; GFX9-O0-NEXT: s_mov_b32 s4, s7
-; GFX9-O0-NEXT: s_mov_b64 s[6:7], 0
-; GFX9-O0-NEXT: s_mov_b32 s8, s6
-; GFX9-O0-NEXT: s_mov_b32 s9, s7
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v6
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, s5
-; GFX9-O0-NEXT: v_add_co_u32_e32 v9, vcc, v4, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, s4
-; GFX9-O0-NEXT: v_addc_co_u32_e32 v2, vcc, v2, v5, vcc
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, s8
-; GFX9-O0-NEXT: v_addc_co_u32_e32 v1, vcc, v1, v5, vcc
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, s9
-; GFX9-O0-NEXT: v_addc_co_u32_e32 v3, vcc, v3, v5, vcc
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr9 killed $vgpr9 def $vgpr9_vgpr10 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v10, v2
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr1 killed $vgpr1 def $vgpr1_vgpr2 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v1
-; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:332 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:336 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v9
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v10
-; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:340 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:344 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_mov_b32 s4, 0x7f
-; GFX9-O0-NEXT: v_sub_u32_e64 v3, s4, v4
-; GFX9-O0-NEXT: v_lshlrev_b64 v[5:6], v3, v[11:12]
-; GFX9-O0-NEXT: v_mov_b32_e32 v13, v6
-; GFX9-O0-NEXT: s_mov_b32 s4, 64
-; GFX9-O0-NEXT: v_sub_u32_e64 v14, s4, v3
-; GFX9-O0-NEXT: v_lshrrev_b64 v[14:15], v14, v[7:8]
-; GFX9-O0-NEXT: v_mov_b32_e32 v16, v15
-; GFX9-O0-NEXT: v_or_b32_e64 v13, v13, v16
-; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 killed $vgpr5_vgpr6 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v14
-; GFX9-O0-NEXT: v_or_b32_e64 v5, v5, v6
-; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v13
-; GFX9-O0-NEXT: v_mov_b32_e32 v15, v6
-; GFX9-O0-NEXT: v_cmp_lt_u32_e64 s[4:5], v3, s4
-; GFX9-O0-NEXT: s_mov_b32 s10, 63
-; GFX9-O0-NEXT: v_sub_u32_e64 v4, s10, v4
-; GFX9-O0-NEXT: v_lshlrev_b64 v[13:14], v4, v[7:8]
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v14
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v4, v4, v15, s[4:5]
-; GFX9-O0-NEXT: s_mov_b32 s10, 0
-; GFX9-O0-NEXT: v_cmp_eq_u32_e64 s[10:11], v3, s10
-; GFX9-O0-NEXT: v_mov_b32_e32 v15, v12
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v4, v4, v15, s[10:11]
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v13
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v5, v6, s[4:5]
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v11
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v5, v6, s[10:11]
-; GFX9-O0-NEXT: ; implicit-def: $sgpr10
-; GFX9-O0-NEXT: ; implicit-def: $sgpr10
-; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v4
-; GFX9-O0-NEXT: v_lshlrev_b64 v[7:8], v3, v[7:8]
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v8
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, s9
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v3, v3, v4, s[4:5]
-; GFX9-O0-NEXT: ; kill: def $vgpr7 killed $vgpr7 killed $vgpr7_vgpr8 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, s8
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v7, v4, v7, s[4:5]
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr7 killed $vgpr7 def $vgpr7_vgpr8 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v8, v3
-; GFX9-O0-NEXT: buffer_store_dword v7, off, s[0:3], s32 offset:324 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v8, off, s[0:3], s32 offset:328 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:316 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:320 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v10
-; GFX9-O0-NEXT: v_or_b32_e64 v3, v3, v4
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v1
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v9
-; GFX9-O0-NEXT: v_or_b32_e64 v1, v1, v2
-; GFX9-O0-NEXT: ; kill: def $vgpr1 killed $vgpr1 def $vgpr1_vgpr2 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
-; GFX9-O0-NEXT: v_cmp_ne_u64_e64 s[4:5], v[1:2], s[6:7]
-; GFX9-O0-NEXT: s_mov_b64 s[8:9], s[6:7]
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, s8
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, s9
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, s6
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, s7
-; GFX9-O0-NEXT: buffer_store_dword v7, off, s[0:3], s32 offset:148 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v8, off, s[0:3], s32 offset:152 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:140 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:144 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:132 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:136 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:124 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:128 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_mov_b64 s[6:7], exec
-; GFX9-O0-NEXT: s_and_b64 s[4:5], s[6:7], s[4:5]
-; GFX9-O0-NEXT: s_xor_b64 s[6:7], s[4:5], s[6:7]
-; GFX9-O0-NEXT: v_writelane_b32 v0, s6, 6
-; GFX9-O0-NEXT: v_writelane_b32 v0, s7, 7
-; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
-; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
-; GFX9-O0-NEXT: s_mov_b64 exec, s[4:5]
-; GFX9-O0-NEXT: s_cbranch_execz .LBB2_5
-; GFX9-O0-NEXT: s_branch .LBB2_7
-; GFX9-O0-NEXT: .LBB2_9: ; %udiv-end
-; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
-; GFX9-O0-NEXT: buffer_load_dword v4, off, s[0:3], s32 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
-; GFX9-O0-NEXT: buffer_load_dword v7, off, s[0:3], s32 offset:108 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v8, off, s[0:3], s32 offset:112 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v9, off, s[0:3], s32 offset:100 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v10, off, s[0:3], s32 offset:104 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v13, off, s[0:3], s32 offset:84 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v14, off, s[0:3], s32 offset:88 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v15, off, s[0:3], s32 offset:92 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v16, off, s[0:3], s32 offset:96 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v19, off, s[0:3], s32 offset:76 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v20, off, s[0:3], s32 offset:80 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v11, off, s[0:3], s32 offset:196 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v12, off, s[0:3], s32 offset:200 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v5, off, s[0:3], s32 offset:188 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v6, off, s[0:3], s32 offset:192 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v17, off, s[0:3], s32 offset:68 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v18, off, s[0:3], s32 offset:72 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_mov_b32 s4, 32
-; GFX9-O0-NEXT: s_waitcnt vmcnt(2)
-; GFX9-O0-NEXT: v_lshrrev_b64 v[0:1], s4, v[5:6]
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v0
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: v_mov_b32_e32 v0, v17
-; GFX9-O0-NEXT: v_mul_lo_u32 v3, v1, v0
-; GFX9-O0-NEXT: v_lshrrev_b64 v[17:18], s4, v[17:18]
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v17
-; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 killed $vgpr5_vgpr6 killed $exec
-; GFX9-O0-NEXT: v_mul_lo_u32 v2, v5, v2
-; GFX9-O0-NEXT: v_mad_u64_u32 v[17:18], s[6:7], v5, v0, 0
-; GFX9-O0-NEXT: v_mov_b32_e32 v0, v18
-; GFX9-O0-NEXT: v_add3_u32 v2, v0, v2, v3
-; GFX9-O0-NEXT: ; implicit-def: $sgpr5
-; GFX9-O0-NEXT: ; implicit-def: $sgpr6
-; GFX9-O0-NEXT: ; implicit-def: $sgpr6
-; GFX9-O0-NEXT: v_mov_b32_e32 v0, s5
-; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v0
-; GFX9-O0-NEXT: v_lshlrev_b64 v[2:3], s4, v[2:3]
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v3
-; GFX9-O0-NEXT: ; kill: def $vgpr17 killed $vgpr17 killed $vgpr17_vgpr18 killed $exec
-; GFX9-O0-NEXT: s_mov_b32 s5, 0
-; GFX9-O0-NEXT: ; implicit-def: $sgpr6
-; GFX9-O0-NEXT: v_mov_b32_e32 v0, s5
-; GFX9-O0-NEXT: ; kill: def $vgpr17 killed $vgpr17 def $vgpr17_vgpr18 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v18, v0
-; GFX9-O0-NEXT: v_mov_b32_e32 v0, v18
-; GFX9-O0-NEXT: v_or_b32_e64 v0, v0, v6
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v17
-; GFX9-O0-NEXT: v_or_b32_e64 v17, v2, v3
-; GFX9-O0-NEXT: ; kill: def $vgpr17 killed $vgpr17 def $vgpr17_vgpr18 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v18, v0
-; GFX9-O0-NEXT: v_lshrrev_b64 v[2:3], s4, v[19:20]
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v11
-; GFX9-O0-NEXT: v_mul_lo_u32 v3, v2, v6
-; GFX9-O0-NEXT: v_lshrrev_b64 v[11:12], s4, v[11:12]
-; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 killed $vgpr11_vgpr12 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v0, v19
-; GFX9-O0-NEXT: v_mul_lo_u32 v11, v11, v0
-; GFX9-O0-NEXT: v_mad_u64_u32 v[19:20], s[6:7], v2, v0, 0
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v20
-; GFX9-O0-NEXT: v_add3_u32 v2, v2, v3, v11
-; GFX9-O0-NEXT: ; implicit-def: $sgpr6
-; GFX9-O0-NEXT: ; implicit-def: $sgpr7
-; GFX9-O0-NEXT: ; implicit-def: $sgpr7
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, s6
-; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v11
-; GFX9-O0-NEXT: v_lshlrev_b64 v[2:3], s4, v[2:3]
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, v3
-; GFX9-O0-NEXT: ; kill: def $vgpr19 killed $vgpr19 killed $vgpr19_vgpr20 killed $exec
-; GFX9-O0-NEXT: ; implicit-def: $sgpr6
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, s5
-; GFX9-O0-NEXT: ; kill: def $vgpr19 killed $vgpr19 def $vgpr19_vgpr20 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v20, v11
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, v20
-; GFX9-O0-NEXT: v_or_b32_e64 v11, v11, v12
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v19
-; GFX9-O0-NEXT: v_or_b32_e64 v2, v2, v3
-; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v11
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, v17
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v18
-; GFX9-O0-NEXT: v_add_co_u32_e64 v17, s[6:7], v11, v12
-; GFX9-O0-NEXT: v_addc_co_u32_e64 v2, s[6:7], v2, v3, s[6:7]
-; GFX9-O0-NEXT: ; kill: def $vgpr17 killed $vgpr17 def $vgpr17_vgpr18 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v18, v2
-; GFX9-O0-NEXT: v_mad_u64_u32 v[19:20], s[6:7], v6, v1, 0
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v19
-; GFX9-O0-NEXT: ; implicit-def: $sgpr6
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, s5
-; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v11
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, v3
-; GFX9-O0-NEXT: v_mov_b32_e32 v19, v20
-; GFX9-O0-NEXT: ; implicit-def: $sgpr6
-; GFX9-O0-NEXT: ; implicit-def: $sgpr7
-; GFX9-O0-NEXT: ; implicit-def: $sgpr7
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, s6
-; GFX9-O0-NEXT: ; kill: def $vgpr19 killed $vgpr19 def $vgpr19_vgpr20 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v20, v12
-; GFX9-O0-NEXT: v_lshlrev_b64 v[19:20], s4, v[19:20]
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, v20
-; GFX9-O0-NEXT: v_or_b32_e64 v11, v11, v12
-; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 killed $vgpr2_vgpr3 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v19
-; GFX9-O0-NEXT: v_or_b32_e64 v2, v2, v3
-; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v11
-; GFX9-O0-NEXT: v_mad_u64_u32 v[19:20], s[6:7], v6, v5, 0
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, v19
-; GFX9-O0-NEXT: ; implicit-def: $sgpr6
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, s5
-; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 def $vgpr11_vgpr12 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, v6
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v12
-; GFX9-O0-NEXT: v_mov_b32_e32 v19, v20
-; GFX9-O0-NEXT: ; implicit-def: $sgpr6
-; GFX9-O0-NEXT: ; implicit-def: $sgpr7
-; GFX9-O0-NEXT: ; implicit-def: $sgpr7
-; GFX9-O0-NEXT: v_mov_b32_e32 v21, s6
-; GFX9-O0-NEXT: ; kill: def $vgpr19 killed $vgpr19 def $vgpr19_vgpr20 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v20, v21
-; GFX9-O0-NEXT: v_lshlrev_b64 v[19:20], s4, v[19:20]
-; GFX9-O0-NEXT: v_mov_b32_e32 v21, v20
-; GFX9-O0-NEXT: v_or_b32_e64 v6, v6, v21
-; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 killed $vgpr11_vgpr12 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, v19
-; GFX9-O0-NEXT: v_or_b32_e64 v23, v11, v12
-; GFX9-O0-NEXT: ; kill: def $vgpr23 killed $vgpr23 def $vgpr23_vgpr24 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v24, v6
-; GFX9-O0-NEXT: v_mad_u64_u32 v[11:12], s[6:7], v0, v5, 0
-; GFX9-O0-NEXT: v_mov_b32_e32 v21, v12
-; GFX9-O0-NEXT: ; implicit-def: $sgpr6
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, s5
-; GFX9-O0-NEXT: ; kill: def $vgpr21 killed $vgpr21 def $vgpr21_vgpr22 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v22, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v23
-; GFX9-O0-NEXT: v_mov_b32_e32 v20, v21
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v24
-; GFX9-O0-NEXT: v_mov_b32_e32 v19, v22
-; GFX9-O0-NEXT: v_add_co_u32_e64 v5, s[6:7], v5, v20
-; GFX9-O0-NEXT: v_addc_co_u32_e64 v19, s[6:7], v6, v19, s[6:7]
-; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v19
-; GFX9-O0-NEXT: v_mov_b32_e32 v19, v6
-; GFX9-O0-NEXT: s_mov_b64 s[6:7], 0xffffffff
-; GFX9-O0-NEXT: s_mov_b32 s8, s7
-; GFX9-O0-NEXT: v_and_b32_e64 v19, v19, s8
-; GFX9-O0-NEXT: v_mov_b32_e32 v20, v5
-; GFX9-O0-NEXT: ; kill: def $sgpr6 killed $sgpr6 killed $sgpr6_sgpr7
-; GFX9-O0-NEXT: v_and_b32_e64 v21, v20, s6
-; GFX9-O0-NEXT: ; kill: def $vgpr21 killed $vgpr21 def $vgpr21_vgpr22 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v22, v19
-; GFX9-O0-NEXT: v_mad_u64_u32 v[19:20], s[6:7], v0, v1, 0
-; GFX9-O0-NEXT: v_mov_b32_e32 v23, v19
-; GFX9-O0-NEXT: ; implicit-def: $sgpr6
-; GFX9-O0-NEXT: v_mov_b32_e32 v0, s5
-; GFX9-O0-NEXT: ; kill: def $vgpr23 killed $vgpr23 def $vgpr23_vgpr24 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v24, v0
-; GFX9-O0-NEXT: v_mov_b32_e32 v0, v24
-; GFX9-O0-NEXT: v_mov_b32_e32 v19, v20
-; GFX9-O0-NEXT: ; implicit-def: $sgpr6
-; GFX9-O0-NEXT: ; implicit-def: $sgpr7
-; GFX9-O0-NEXT: ; implicit-def: $sgpr7
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, s6
-; GFX9-O0-NEXT: ; kill: def $vgpr19 killed $vgpr19 def $vgpr19_vgpr20 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v20, v1
-; GFX9-O0-NEXT: v_lshlrev_b64 v[19:20], s4, v[19:20]
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v20
-; GFX9-O0-NEXT: v_or_b32_e64 v0, v0, v1
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v23
-; GFX9-O0-NEXT: ; kill: def $vgpr19 killed $vgpr19 killed $vgpr19_vgpr20 killed $exec
-; GFX9-O0-NEXT: v_or_b32_e64 v23, v1, v19
-; GFX9-O0-NEXT: ; kill: def $vgpr23 killed $vgpr23 def $vgpr23_vgpr24 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v24, v0
-; GFX9-O0-NEXT: v_mov_b32_e32 v0, v23
-; GFX9-O0-NEXT: v_mov_b32_e32 v20, v21
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v24
-; GFX9-O0-NEXT: v_mov_b32_e32 v19, v22
-; GFX9-O0-NEXT: v_add_co_u32_e64 v0, s[6:7], v0, v20
-; GFX9-O0-NEXT: v_addc_co_u32_e64 v19, s[6:7], v1, v19, s[6:7]
-; GFX9-O0-NEXT: ; kill: def $vgpr0 killed $vgpr0 def $vgpr0_vgpr1 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v19
-; GFX9-O0-NEXT: v_lshrrev_b64 v[21:22], s4, v[0:1]
-; GFX9-O0-NEXT: v_lshrrev_b64 v[5:6], s4, v[5:6]
-; GFX9-O0-NEXT: v_mov_b32_e32 v19, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v20, v21
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v6
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v22
-; GFX9-O0-NEXT: v_add_co_u32_e64 v19, s[6:7], v19, v20
-; GFX9-O0-NEXT: v_addc_co_u32_e64 v5, s[6:7], v5, v6, s[6:7]
-; GFX9-O0-NEXT: ; kill: def $vgpr19 killed $vgpr19 def $vgpr19_vgpr20 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v20, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v19
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v20
-; GFX9-O0-NEXT: v_add_co_u32_e64 v19, s[6:7], v5, v6
-; GFX9-O0-NEXT: v_addc_co_u32_e64 v2, s[6:7], v2, v3, s[6:7]
-; GFX9-O0-NEXT: ; kill: def $vgpr19 killed $vgpr19 def $vgpr19_vgpr20 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v20, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v19
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v17
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v20
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v18
-; GFX9-O0-NEXT: v_add_co_u32_e64 v2, s[6:7], v2, v6
-; GFX9-O0-NEXT: v_addc_co_u32_e64 v5, s[6:7], v3, v5, s[6:7]
-; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v5
-; GFX9-O0-NEXT: v_lshlrev_b64 v[0:1], s4, v[0:1]
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v1
-; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 killed $vgpr11_vgpr12 killed $exec
-; GFX9-O0-NEXT: ; implicit-def: $sgpr6
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, s5
-; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 def $vgpr11_vgpr12 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v12
-; GFX9-O0-NEXT: v_or_b32_e64 v5, v5, v6
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v0
-; GFX9-O0-NEXT: v_mov_b32_e32 v0, v11
-; GFX9-O0-NEXT: v_or_b32_e64 v0, v0, v1
-; GFX9-O0-NEXT: ; kill: def $vgpr0 killed $vgpr0 def $vgpr0_vgpr1 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, v0
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, v1
-; GFX9-O0-NEXT: v_mov_b32_e32 v0, v15
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v16
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v13
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v14
-; GFX9-O0-NEXT: v_sub_co_u32_e32 v0, vcc, v0, v12
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v3, vcc, v3, v11, vcc
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v5, vcc, v5, v6, vcc
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v2, vcc, v1, v2, vcc
-; GFX9-O0-NEXT: ; implicit-def: $sgpr5
-; GFX9-O0-NEXT: ; implicit-def: $sgpr5
-; GFX9-O0-NEXT: ; kill: def $vgpr0 killed $vgpr0 def $vgpr0_vgpr1 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v3
-; GFX9-O0-NEXT: ; implicit-def: $sgpr5
-; GFX9-O0-NEXT: ; implicit-def: $sgpr5
-; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v6
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v10
-; GFX9-O0-NEXT: v_xor_b32_e64 v3, v3, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v9
-; GFX9-O0-NEXT: v_xor_b32_e64 v9, v6, v5
-; GFX9-O0-NEXT: ; kill: def $vgpr9 killed $vgpr9 def $vgpr9_vgpr10 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v10, v3
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v1
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v8
-; GFX9-O0-NEXT: v_xor_b32_e64 v3, v3, v6
-; GFX9-O0-NEXT: ; kill: def $vgpr0 killed $vgpr0 killed $vgpr0_vgpr1 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v8, v7
-; GFX9-O0-NEXT: v_xor_b32_e64 v0, v0, v8
-; GFX9-O0-NEXT: ; kill: def $vgpr0 killed $vgpr0 def $vgpr0_vgpr1 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v3
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v0
-; GFX9-O0-NEXT: v_mov_b32_e32 v0, v1
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v9
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v10
-; GFX9-O0-NEXT: v_sub_co_u32_e32 v7, vcc, v7, v8
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v0, vcc, v0, v6, vcc
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v5, vcc, v3, v5, vcc
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v1, vcc, v1, v2, vcc
-; GFX9-O0-NEXT: ; implicit-def: $sgpr5
-; GFX9-O0-NEXT: ; implicit-def: $sgpr5
-; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v1
-; GFX9-O0-NEXT: ; implicit-def: $sgpr5
-; GFX9-O0-NEXT: ; implicit-def: $sgpr5
-; GFX9-O0-NEXT: ; kill: def $vgpr7 killed $vgpr7 def $vgpr7_vgpr8 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v8, v0
-; GFX9-O0-NEXT: v_mov_b32_e32 v0, v7
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v5
-; GFX9-O0-NEXT: v_lshrrev_b64 v[7:8], s4, v[7:8]
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v7
-; GFX9-O0-NEXT: v_lshrrev_b64 v[5:6], s4, v[5:6]
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v5
-; GFX9-O0-NEXT: ; kill: killed $vgpr4
-; GFX9-O0-NEXT: s_xor_saveexec_b64 s[4:5], -1
-; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 offset:348 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_nop 0
-; GFX9-O0-NEXT: buffer_load_dword v4, off, s[0:3], s32 offset:352 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v8, off, s[0:3], s32 offset:356 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v16, off, s[0:3], s32 offset:360 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_mov_b64 exec, s[4:5]
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: s_setpc_b64 s[30:31]
- %div = srem i128 %lhs, %rhs
- ret i128 %div
-}
-
-define i128 @v_urem_i128_vv(i128 %lhs, i128 %rhs) {
-; GFX9-LABEL: v_urem_i128_vv:
-; GFX9: ; %bb.0: ; %_udiv-special-cases
-; GFX9-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
-; GFX9-NEXT: v_or_b32_e32 v9, v5, v7
-; GFX9-NEXT: v_or_b32_e32 v8, v4, v6
-; GFX9-NEXT: v_cmp_eq_u64_e32 vcc, 0, v[8:9]
-; GFX9-NEXT: v_or_b32_e32 v9, v1, v3
-; GFX9-NEXT: v_or_b32_e32 v8, v0, v2
-; GFX9-NEXT: v_cmp_eq_u64_e64 s[4:5], 0, v[8:9]
-; GFX9-NEXT: v_ffbh_u32_e32 v8, v6
-; GFX9-NEXT: v_add_u32_e32 v8, 32, v8
-; GFX9-NEXT: v_ffbh_u32_e32 v9, v7
-; GFX9-NEXT: v_min_u32_e32 v8, v8, v9
-; GFX9-NEXT: v_ffbh_u32_e32 v9, v4
-; GFX9-NEXT: v_add_u32_e32 v9, 32, v9
-; GFX9-NEXT: v_ffbh_u32_e32 v10, v5
-; GFX9-NEXT: v_min_u32_e32 v9, v9, v10
-; GFX9-NEXT: s_or_b64 s[4:5], vcc, s[4:5]
-; GFX9-NEXT: v_add_co_u32_e32 v9, vcc, 64, v9
-; GFX9-NEXT: v_addc_co_u32_e64 v10, s[6:7], 0, 0, vcc
-; GFX9-NEXT: v_cmp_ne_u64_e32 vcc, 0, v[6:7]
-; GFX9-NEXT: v_ffbh_u32_e32 v11, v3
-; GFX9-NEXT: v_cndmask_b32_e32 v8, v9, v8, vcc
-; GFX9-NEXT: v_ffbh_u32_e32 v9, v2
-; GFX9-NEXT: v_add_u32_e32 v9, 32, v9
-; GFX9-NEXT: v_min_u32_e32 v9, v9, v11
-; GFX9-NEXT: v_ffbh_u32_e32 v11, v0
-; GFX9-NEXT: v_add_u32_e32 v11, 32, v11
-; GFX9-NEXT: v_ffbh_u32_e32 v12, v1
-; GFX9-NEXT: v_min_u32_e32 v11, v11, v12
-; GFX9-NEXT: v_cndmask_b32_e64 v10, v10, 0, vcc
-; GFX9-NEXT: v_add_co_u32_e32 v11, vcc, 64, v11
-; GFX9-NEXT: v_addc_co_u32_e64 v12, s[6:7], 0, 0, vcc
-; GFX9-NEXT: v_cmp_ne_u64_e32 vcc, 0, v[2:3]
-; GFX9-NEXT: s_mov_b64 s[6:7], 0x7f
-; GFX9-NEXT: v_cndmask_b32_e32 v9, v11, v9, vcc
-; GFX9-NEXT: v_cndmask_b32_e64 v12, v12, 0, vcc
-; GFX9-NEXT: v_sub_co_u32_e32 v8, vcc, v8, v9
-; GFX9-NEXT: v_subb_co_u32_e32 v9, vcc, v10, v12, vcc
-; GFX9-NEXT: v_mov_b32_e32 v11, 0
-; GFX9-NEXT: v_subbrev_co_u32_e32 v10, vcc, 0, v11, vcc
-; GFX9-NEXT: v_subbrev_co_u32_e32 v11, vcc, 0, v11, vcc
-; GFX9-NEXT: v_cmp_lt_u64_e32 vcc, s[6:7], v[8:9]
-; GFX9-NEXT: v_cndmask_b32_e64 v12, 0, 1, vcc
-; GFX9-NEXT: v_cmp_ne_u64_e32 vcc, 0, v[10:11]
-; GFX9-NEXT: v_cndmask_b32_e64 v13, 0, 1, vcc
-; GFX9-NEXT: v_cmp_eq_u64_e32 vcc, 0, v[10:11]
-; GFX9-NEXT: v_cndmask_b32_e32 v12, v13, v12, vcc
-; GFX9-NEXT: v_and_b32_e32 v12, 1, v12
-; GFX9-NEXT: v_cmp_eq_u32_e32 vcc, 1, v12
-; GFX9-NEXT: v_xor_b32_e32 v12, 0x7f, v8
-; GFX9-NEXT: v_or_b32_e32 v13, v9, v11
-; GFX9-NEXT: v_or_b32_e32 v12, v12, v10
-; GFX9-NEXT: s_or_b64 s[4:5], s[4:5], vcc
-; GFX9-NEXT: v_cmp_ne_u64_e32 vcc, 0, v[12:13]
-; GFX9-NEXT: s_xor_b64 s[6:7], s[4:5], -1
-; GFX9-NEXT: v_cndmask_b32_e64 v15, v3, 0, s[4:5]
-; GFX9-NEXT: v_cndmask_b32_e64 v14, v2, 0, s[4:5]
-; GFX9-NEXT: v_cndmask_b32_e64 v13, v1, 0, s[4:5]
-; GFX9-NEXT: v_cndmask_b32_e64 v12, v0, 0, s[4:5]
-; GFX9-NEXT: s_and_b64 s[4:5], s[6:7], vcc
-; GFX9-NEXT: s_and_saveexec_b64 s[8:9], s[4:5]
-; GFX9-NEXT: s_cbranch_execz .LBB3_6
-; GFX9-NEXT: ; %bb.1: ; %udiv-bb1
-; GFX9-NEXT: v_add_co_u32_e32 v22, vcc, 1, v8
-; GFX9-NEXT: v_addc_co_u32_e32 v23, vcc, 0, v9, vcc
-; GFX9-NEXT: v_addc_co_u32_e32 v24, vcc, 0, v10, vcc
-; GFX9-NEXT: v_sub_u32_e32 v15, 0x7f, v8
-; GFX9-NEXT: v_addc_co_u32_e32 v25, vcc, 0, v11, vcc
-; GFX9-NEXT: v_sub_u32_e32 v13, 64, v15
-; GFX9-NEXT: v_or_b32_e32 v10, v23, v25
-; GFX9-NEXT: v_or_b32_e32 v9, v22, v24
-; GFX9-NEXT: v_lshlrev_b64 v[11:12], v15, v[2:3]
-; GFX9-NEXT: v_lshrrev_b64 v[13:14], v13, v[0:1]
-; GFX9-NEXT: v_sub_u32_e32 v8, 63, v8
-; GFX9-NEXT: v_cmp_ne_u64_e32 vcc, 0, v[9:10]
-; GFX9-NEXT: v_lshlrev_b64 v[8:9], v8, v[0:1]
-; GFX9-NEXT: v_or_b32_e32 v10, v12, v14
-; GFX9-NEXT: v_or_b32_e32 v11, v11, v13
-; GFX9-NEXT: v_cmp_gt_u32_e64 s[4:5], 64, v15
-; GFX9-NEXT: v_cndmask_b32_e64 v9, v9, v10, s[4:5]
-; GFX9-NEXT: v_cndmask_b32_e64 v8, v8, v11, s[4:5]
-; GFX9-NEXT: v_lshlrev_b64 v[10:11], v15, v[0:1]
-; GFX9-NEXT: v_cmp_eq_u32_e64 s[6:7], 0, v15
-; GFX9-NEXT: v_mov_b32_e32 v12, 0
-; GFX9-NEXT: v_mov_b32_e32 v14, 0
-; GFX9-NEXT: v_cndmask_b32_e64 v9, v9, v3, s[6:7]
-; GFX9-NEXT: v_cndmask_b32_e64 v8, v8, v2, s[6:7]
-; GFX9-NEXT: v_cndmask_b32_e64 v11, 0, v11, s[4:5]
-; GFX9-NEXT: v_mov_b32_e32 v13, 0
-; GFX9-NEXT: v_mov_b32_e32 v15, 0
-; GFX9-NEXT: v_cndmask_b32_e64 v10, 0, v10, s[4:5]
-; GFX9-NEXT: s_and_saveexec_b64 s[4:5], vcc
-; GFX9-NEXT: s_xor_b64 s[6:7], exec, s[4:5]
-; GFX9-NEXT: s_cbranch_execz .LBB3_5
-; GFX9-NEXT: ; %bb.2: ; %udiv-preheader
-; GFX9-NEXT: v_sub_u32_e32 v14, 64, v22
-; GFX9-NEXT: v_lshrrev_b64 v[12:13], v22, v[0:1]
-; GFX9-NEXT: v_lshlrev_b64 v[14:15], v14, v[2:3]
-; GFX9-NEXT: v_cmp_gt_u32_e32 vcc, 64, v22
-; GFX9-NEXT: v_or_b32_e32 v14, v12, v14
-; GFX9-NEXT: v_subrev_u32_e32 v12, 64, v22
-; GFX9-NEXT: v_or_b32_e32 v15, v13, v15
-; GFX9-NEXT: v_lshrrev_b64 v[12:13], v12, v[2:3]
-; GFX9-NEXT: v_cmp_eq_u32_e64 s[4:5], 0, v22
-; GFX9-NEXT: v_cndmask_b32_e32 v13, v13, v15, vcc
-; GFX9-NEXT: v_cndmask_b32_e64 v17, v13, v1, s[4:5]
-; GFX9-NEXT: v_cndmask_b32_e32 v14, v12, v14, vcc
-; GFX9-NEXT: v_lshrrev_b64 v[12:13], v22, v[2:3]
-; GFX9-NEXT: v_cndmask_b32_e64 v16, v14, v0, s[4:5]
-; GFX9-NEXT: v_cndmask_b32_e32 v19, 0, v13, vcc
-; GFX9-NEXT: v_cndmask_b32_e32 v18, 0, v12, vcc
-; GFX9-NEXT: v_add_co_u32_e32 v26, vcc, -1, v4
-; GFX9-NEXT: v_addc_co_u32_e32 v27, vcc, -1, v5, vcc
-; GFX9-NEXT: v_addc_co_u32_e32 v28, vcc, -1, v6, vcc
-; GFX9-NEXT: v_mov_b32_e32 v20, 0
-; GFX9-NEXT: v_mov_b32_e32 v14, 0
-; GFX9-NEXT: v_addc_co_u32_e32 v29, vcc, -1, v7, vcc
-; GFX9-NEXT: s_mov_b64 s[4:5], 0
-; GFX9-NEXT: v_mov_b32_e32 v21, 0
-; GFX9-NEXT: v_mov_b32_e32 v15, 0
-; GFX9-NEXT: v_mov_b32_e32 v13, 0
-; GFX9-NEXT: .LBB3_3: ; %udiv-do-while
-; GFX9-NEXT: ; =>This Inner Loop Header: Depth=1
-; GFX9-NEXT: v_lshrrev_b32_e32 v12, 31, v11
-; GFX9-NEXT: v_lshlrev_b64 v[10:11], 1, v[10:11]
-; GFX9-NEXT: v_lshlrev_b64 v[18:19], 1, v[18:19]
-; GFX9-NEXT: v_or_b32_e32 v10, v20, v10
-; GFX9-NEXT: v_lshrrev_b32_e32 v20, 31, v17
-; GFX9-NEXT: v_lshlrev_b64 v[16:17], 1, v[16:17]
-; GFX9-NEXT: v_or_b32_e32 v18, v18, v20
-; GFX9-NEXT: v_lshrrev_b32_e32 v20, 31, v9
-; GFX9-NEXT: v_or_b32_e32 v16, v16, v20
-; GFX9-NEXT: v_sub_co_u32_e32 v20, vcc, v26, v16
-; GFX9-NEXT: v_subb_co_u32_e32 v20, vcc, v27, v17, vcc
-; GFX9-NEXT: v_subb_co_u32_e32 v20, vcc, v28, v18, vcc
-; GFX9-NEXT: v_subb_co_u32_e32 v20, vcc, v29, v19, vcc
-; GFX9-NEXT: v_ashrrev_i32_e32 v30, 31, v20
-; GFX9-NEXT: v_and_b32_e32 v20, v30, v4
-; GFX9-NEXT: v_sub_co_u32_e32 v16, vcc, v16, v20
-; GFX9-NEXT: v_and_b32_e32 v20, v30, v5
-; GFX9-NEXT: v_subb_co_u32_e32 v17, vcc, v17, v20, vcc
-; GFX9-NEXT: v_and_b32_e32 v20, v30, v6
-; GFX9-NEXT: v_subb_co_u32_e32 v18, vcc, v18, v20, vcc
-; GFX9-NEXT: v_and_b32_e32 v20, v30, v7
-; GFX9-NEXT: v_subb_co_u32_e32 v19, vcc, v19, v20, vcc
-; GFX9-NEXT: v_add_co_u32_e32 v22, vcc, -1, v22
-; GFX9-NEXT: v_addc_co_u32_e32 v23, vcc, -1, v23, vcc
-; GFX9-NEXT: v_addc_co_u32_e32 v24, vcc, -1, v24, vcc
-; GFX9-NEXT: v_addc_co_u32_e32 v25, vcc, -1, v25, vcc
-; GFX9-NEXT: v_or_b32_e32 v11, v21, v11
-; GFX9-NEXT: v_lshlrev_b64 v[8:9], 1, v[8:9]
-; GFX9-NEXT: v_or_b32_e32 v20, v22, v24
-; GFX9-NEXT: v_or_b32_e32 v21, v23, v25
-; GFX9-NEXT: v_cmp_eq_u64_e32 vcc, 0, v[20:21]
-; GFX9-NEXT: v_or3_b32 v8, v8, v12, v14
-; GFX9-NEXT: v_and_b32_e32 v12, 1, v30
-; GFX9-NEXT: v_mov_b32_e32 v21, v13
-; GFX9-NEXT: v_or3_b32 v9, v9, 0, v15
-; GFX9-NEXT: s_or_b64 s[4:5], vcc, s[4:5]
-; GFX9-NEXT: v_mov_b32_e32 v20, v12
-; GFX9-NEXT: s_andn2_b64 exec, exec, s[4:5]
-; GFX9-NEXT: s_cbranch_execnz .LBB3_3
-; GFX9-NEXT: ; %bb.4: ; %Flow
-; GFX9-NEXT: s_or_b64 exec, exec, s[4:5]
-; GFX9-NEXT: .LBB3_5: ; %Flow2
-; GFX9-NEXT: s_or_b64 exec, exec, s[6:7]
-; GFX9-NEXT: v_lshlrev_b64 v[16:17], 1, v[10:11]
-; GFX9-NEXT: v_lshlrev_b64 v[8:9], 1, v[8:9]
-; GFX9-NEXT: v_lshrrev_b32_e32 v10, 31, v11
-; GFX9-NEXT: v_or3_b32 v15, v9, 0, v15
-; GFX9-NEXT: v_or3_b32 v14, v8, v10, v14
-; GFX9-NEXT: v_or_b32_e32 v13, v13, v17
-; GFX9-NEXT: v_or_b32_e32 v12, v12, v16
-; GFX9-NEXT: .LBB3_6: ; %Flow3
-; GFX9-NEXT: s_or_b64 exec, exec, s[8:9]
-; GFX9-NEXT: v_mul_lo_u32 v19, v12, v7
-; GFX9-NEXT: v_mad_u64_u32 v[7:8], s[4:5], v4, v12, 0
-; GFX9-NEXT: v_mov_b32_e32 v17, 0
-; GFX9-NEXT: v_mad_u64_u32 v[9:10], s[4:5], v12, v6, 0
-; GFX9-NEXT: v_mov_b32_e32 v16, v8
-; GFX9-NEXT: v_mad_u64_u32 v[11:12], s[4:5], v5, v12, v[16:17]
-; GFX9-NEXT: v_mul_lo_u32 v18, v13, v6
-; GFX9-NEXT: v_mul_lo_u32 v16, v15, v4
-; GFX9-NEXT: v_mov_b32_e32 v6, v12
-; GFX9-NEXT: v_mov_b32_e32 v12, v17
-; GFX9-NEXT: v_mad_u64_u32 v[11:12], s[4:5], v4, v13, v[11:12]
-; GFX9-NEXT: v_add3_u32 v10, v10, v19, v18
-; GFX9-NEXT: v_mad_u64_u32 v[8:9], s[4:5], v14, v4, v[9:10]
-; GFX9-NEXT: v_mov_b32_e32 v4, v12
-; GFX9-NEXT: v_mul_lo_u32 v10, v14, v5
-; GFX9-NEXT: v_add_co_u32_e32 v14, vcc, v6, v4
-; GFX9-NEXT: v_addc_co_u32_e64 v15, s[4:5], 0, 0, vcc
-; GFX9-NEXT: v_mad_u64_u32 v[4:5], s[4:5], v5, v13, v[14:15]
-; GFX9-NEXT: v_add3_u32 v6, v16, v9, v10
-; GFX9-NEXT: v_add_co_u32_e32 v4, vcc, v4, v8
-; GFX9-NEXT: v_addc_co_u32_e32 v5, vcc, v5, v6, vcc
-; GFX9-NEXT: v_mov_b32_e32 v6, v11
-; GFX9-NEXT: v_sub_co_u32_e32 v0, vcc, v0, v7
-; GFX9-NEXT: v_subb_co_u32_e32 v1, vcc, v1, v6, vcc
-; GFX9-NEXT: v_subb_co_u32_e32 v2, vcc, v2, v4, vcc
-; GFX9-NEXT: v_subb_co_u32_e32 v3, vcc, v3, v5, vcc
-; GFX9-NEXT: s_setpc_b64 s[30:31]
-;
-; GFX9-O0-LABEL: v_urem_i128_vv:
-; GFX9-O0: ; %bb.0: ; %_udiv-special-cases
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
-; GFX9-O0-NEXT: s_xor_saveexec_b64 s[4:5], -1
-; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 offset:328 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:332 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v8, off, s[0:3], s32 offset:336 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v16, off, s[0:3], s32 offset:340 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_mov_b64 exec, s[4:5]
-; GFX9-O0-NEXT: ; implicit-def: $vgpr8 : SGPR spill to VGPR lane
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, v6
-; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:100 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: v_mov_b32_e32 v13, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v1
-; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:100 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: v_mov_b32_e32 v9, v0
-; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
-; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr9 killed $vgpr9 def $vgpr9_vgpr10 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v10, v2
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr13 killed $vgpr13 def $vgpr13_vgpr14 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v14, v3
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr1 killed $vgpr1 def $vgpr1_vgpr2 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v5
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 def $vgpr11_vgpr12 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, v7
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4_sgpr5
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4_sgpr5
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4_sgpr5
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4_sgpr5
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v13
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v14
-; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:92 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:96 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v9
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v10
-; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:84 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:88 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v11
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v12
-; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:76 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:80 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v1
-; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:68 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:72 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v11
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v12
-; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:60 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:64 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v1
-; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:52 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:56 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v13
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v14
-; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:44 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:48 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v9
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v10
-; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:36 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:40 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v12
-; GFX9-O0-NEXT: v_mov_b32_e32 v8, v2
-; GFX9-O0-NEXT: v_or_b32_e64 v3, v8, v7
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v11
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v1
-; GFX9-O0-NEXT: v_or_b32_e64 v1, v5, v6
-; GFX9-O0-NEXT: ; kill: def $vgpr1 killed $vgpr1 def $vgpr1_vgpr2 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
-; GFX9-O0-NEXT: s_mov_b64 s[6:7], 0
-; GFX9-O0-NEXT: v_writelane_b32 v0, s6, 0
-; GFX9-O0-NEXT: v_writelane_b32 v0, s7, 1
-; GFX9-O0-NEXT: v_cmp_eq_u64_e64 s[4:5], v[1:2], s[6:7]
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v14
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v10
-; GFX9-O0-NEXT: v_or_b32_e64 v15, v4, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v13
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v9
-; GFX9-O0-NEXT: v_or_b32_e64 v9, v3, v1
-; GFX9-O0-NEXT: ; kill: def $vgpr9 killed $vgpr9 def $vgpr9_vgpr10 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v10, v15
-; GFX9-O0-NEXT: v_cmp_eq_u64_e64 s[8:9], v[9:10], s[6:7]
-; GFX9-O0-NEXT: s_or_b64 s[4:5], s[4:5], s[8:9]
-; GFX9-O0-NEXT: v_ffbh_u32_e64 v6, v6
-; GFX9-O0-NEXT: s_mov_b32 s9, 32
-; GFX9-O0-NEXT: v_add_u32_e64 v6, v6, s9
-; GFX9-O0-NEXT: v_ffbh_u32_e64 v7, v7
-; GFX9-O0-NEXT: v_min_u32_e64 v6, v6, v7
-; GFX9-O0-NEXT: s_mov_b32 s8, 0
-; GFX9-O0-NEXT: ; implicit-def: $sgpr10
-; GFX9-O0-NEXT: v_mov_b32_e32 v9, s8
-; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 def $vgpr6_vgpr7 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v9
-; GFX9-O0-NEXT: v_mov_b32_e32 v10, v7
-; GFX9-O0-NEXT: v_ffbh_u32_e64 v5, v5
-; GFX9-O0-NEXT: v_add_u32_e64 v5, v5, s9
-; GFX9-O0-NEXT: v_ffbh_u32_e64 v8, v8
-; GFX9-O0-NEXT: v_min_u32_e64 v15, v5, v8
-; GFX9-O0-NEXT: ; implicit-def: $sgpr10
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, s8
-; GFX9-O0-NEXT: ; kill: def $vgpr15 killed $vgpr15 def $vgpr15_vgpr16 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v16, v5
-; GFX9-O0-NEXT: s_mov_b64 s[10:11], 64
-; GFX9-O0-NEXT: v_mov_b32_e32 v8, v15
-; GFX9-O0-NEXT: s_mov_b32 s12, s10
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v16
-; GFX9-O0-NEXT: s_mov_b32 s14, s11
-; GFX9-O0-NEXT: v_add_co_u32_e64 v8, s[12:13], v8, s12
-; GFX9-O0-NEXT: v_mov_b32_e32 v9, s14
-; GFX9-O0-NEXT: v_addc_co_u32_e64 v5, s[12:13], v5, v9, s[12:13]
-; GFX9-O0-NEXT: ; kill: def $vgpr8 killed $vgpr8 def $vgpr8_vgpr9 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v9, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v9
-; GFX9-O0-NEXT: s_mov_b64 s[12:13], s[6:7]
-; GFX9-O0-NEXT: v_cmp_ne_u64_e64 s[12:13], v[11:12], s[12:13]
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v5, v10, s[12:13]
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v6
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v8
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v9, v6, v7, s[12:13]
-; GFX9-O0-NEXT: ; implicit-def: $sgpr12
-; GFX9-O0-NEXT: ; implicit-def: $sgpr12
-; GFX9-O0-NEXT: ; kill: def $vgpr9 killed $vgpr9 def $vgpr9_vgpr10 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v10, v5
-; GFX9-O0-NEXT: v_ffbh_u32_e64 v5, v1
-; GFX9-O0-NEXT: v_add_u32_e64 v5, v5, s9
-; GFX9-O0-NEXT: v_ffbh_u32_e64 v6, v2
-; GFX9-O0-NEXT: v_min_u32_e64 v6, v5, v6
-; GFX9-O0-NEXT: ; implicit-def: $sgpr12
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, s8
-; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 def $vgpr6_vgpr7 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v8, v7
-; GFX9-O0-NEXT: v_ffbh_u32_e64 v5, v3
-; GFX9-O0-NEXT: v_add_u32_e64 v5, v5, s9
-; GFX9-O0-NEXT: v_ffbh_u32_e64 v11, v4
-; GFX9-O0-NEXT: v_min_u32_e64 v15, v5, v11
-; GFX9-O0-NEXT: ; implicit-def: $sgpr9
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, s8
-; GFX9-O0-NEXT: ; kill: def $vgpr15 killed $vgpr15 def $vgpr15_vgpr16 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v16, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, v15
-; GFX9-O0-NEXT: s_mov_b32 s8, s10
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v16
-; GFX9-O0-NEXT: s_mov_b32 s10, s11
-; GFX9-O0-NEXT: v_add_co_u32_e64 v11, s[8:9], v11, s8
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, s10
-; GFX9-O0-NEXT: v_addc_co_u32_e64 v5, s[8:9], v5, v12, s[8:9]
-; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 def $vgpr11_vgpr12 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v12
-; GFX9-O0-NEXT: s_mov_b64 s[8:9], s[6:7]
-; GFX9-O0-NEXT: v_cmp_ne_u64_e64 s[8:9], v[13:14], s[8:9]
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v5, v8, s[8:9]
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v6
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v11
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v6, v6, v7, s[8:9]
-; GFX9-O0-NEXT: ; implicit-def: $sgpr8
-; GFX9-O0-NEXT: ; implicit-def: $sgpr8
-; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 def $vgpr6_vgpr7 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v8, v6
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v9
-; GFX9-O0-NEXT: ; kill: def $vgpr7 killed $vgpr7 killed $vgpr6_vgpr7 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v10
-; GFX9-O0-NEXT: s_mov_b32 s10, s6
-; GFX9-O0-NEXT: s_mov_b32 s11, s7
-; GFX9-O0-NEXT: v_sub_co_u32_e32 v5, vcc, v5, v8
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v9, vcc, v6, v7, vcc
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, s10
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, s10
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v8, vcc, v6, v7, vcc
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, s11
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, s11
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v7, vcc, v6, v7, vcc
-; GFX9-O0-NEXT: ; implicit-def: $sgpr8
-; GFX9-O0-NEXT: ; implicit-def: $sgpr8
-; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v9
-; GFX9-O0-NEXT: ; implicit-def: $sgpr8
-; GFX9-O0-NEXT: ; implicit-def: $sgpr8
-; GFX9-O0-NEXT: ; kill: def $vgpr8 killed $vgpr8 def $vgpr8_vgpr9 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v9, v7
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, v9
-; GFX9-O0-NEXT: v_mov_b32_e32 v10, v8
-; GFX9-O0-NEXT: buffer_store_dword v10, off, s[0:3], s32 offset:28 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v11, off, s[0:3], s32 offset:32 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, v6
-; GFX9-O0-NEXT: v_mov_b32_e32 v10, v5
-; GFX9-O0-NEXT: buffer_store_dword v10, off, s[0:3], s32 offset:20 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v11, off, s[0:3], s32 offset:24 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_mov_b64 s[8:9], s[6:7]
-; GFX9-O0-NEXT: v_cmp_eq_u64_e64 s[8:9], v[8:9], s[8:9]
-; GFX9-O0-NEXT: s_mov_b64 s[12:13], 0x7f
-; GFX9-O0-NEXT: s_mov_b64 s[14:15], s[12:13]
-; GFX9-O0-NEXT: v_cmp_gt_u64_e64 s[14:15], v[5:6], s[14:15]
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v10, 0, 1, s[14:15]
-; GFX9-O0-NEXT: s_mov_b64 s[14:15], s[6:7]
-; GFX9-O0-NEXT: v_cmp_ne_u64_e64 s[14:15], v[8:9], s[14:15]
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v7, 0, 1, s[14:15]
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v7, v7, v10, s[8:9]
-; GFX9-O0-NEXT: v_and_b32_e64 v7, 1, v7
-; GFX9-O0-NEXT: v_cmp_eq_u32_e64 s[8:9], v7, 1
-; GFX9-O0-NEXT: s_or_b64 s[8:9], s[4:5], s[8:9]
-; GFX9-O0-NEXT: s_mov_b64 s[4:5], -1
-; GFX9-O0-NEXT: s_xor_b64 s[4:5], s[8:9], s[4:5]
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v6
-; GFX9-O0-NEXT: s_mov_b32 s14, s13
-; GFX9-O0-NEXT: v_xor_b32_e64 v7, v7, s14
-; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 killed $vgpr5_vgpr6 killed $exec
-; GFX9-O0-NEXT: ; kill: def $sgpr12 killed $sgpr12 killed $sgpr12_sgpr13
-; GFX9-O0-NEXT: v_xor_b32_e64 v5, v5, s12
-; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v7
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v6
-; GFX9-O0-NEXT: v_mov_b32_e32 v10, v9
-; GFX9-O0-NEXT: v_or_b32_e64 v7, v7, v10
-; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 killed $vgpr5_vgpr6 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v8
-; GFX9-O0-NEXT: v_or_b32_e64 v5, v5, v6
-; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v7
-; GFX9-O0-NEXT: v_cmp_ne_u64_e64 s[6:7], v[5:6], s[6:7]
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, s11
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v2, v5, s[8:9]
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, s10
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v1, v1, v2, s[8:9]
-; GFX9-O0-NEXT: ; implicit-def: $sgpr12
-; GFX9-O0-NEXT: ; implicit-def: $sgpr12
-; GFX9-O0-NEXT: ; kill: def $vgpr1 killed $vgpr1 def $vgpr1_vgpr2 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, s11
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v4, v5, s[8:9]
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, s10
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v3, v3, v4, s[8:9]
-; GFX9-O0-NEXT: ; implicit-def: $sgpr8
-; GFX9-O0-NEXT: ; implicit-def: $sgpr8
-; GFX9-O0-NEXT: ; kill: def $vgpr3 killed $vgpr3 def $vgpr3_vgpr4 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v5
-; GFX9-O0-NEXT: s_and_b64 s[6:7], s[4:5], s[6:7]
-; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:12 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:16 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:4 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:8 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_mov_b64 s[4:5], exec
-; GFX9-O0-NEXT: v_writelane_b32 v0, s4, 2
-; GFX9-O0-NEXT: v_writelane_b32 v0, s5, 3
-; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
-; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
-; GFX9-O0-NEXT: s_and_b64 s[4:5], s[4:5], s[6:7]
-; GFX9-O0-NEXT: s_mov_b64 exec, s[4:5]
-; GFX9-O0-NEXT: s_cbranch_execz .LBB3_3
-; GFX9-O0-NEXT: s_branch .LBB3_8
-; GFX9-O0-NEXT: .LBB3_1: ; %Flow
-; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
-; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: v_readlane_b32 s4, v0, 4
-; GFX9-O0-NEXT: v_readlane_b32 s5, v0, 5
-; GFX9-O0-NEXT: s_or_b64 exec, exec, s[4:5]
-; GFX9-O0-NEXT: ; %bb.2: ; %Flow
-; GFX9-O0-NEXT: buffer_load_dword v6, off, s[0:3], s32 offset:136 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v7, off, s[0:3], s32 offset:140 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v4, off, s[0:3], s32 offset:144 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v5, off, s[0:3], s32 offset:148 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v2, off, s[0:3], s32 offset:152 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v3, off, s[0:3], s32 offset:156 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 offset:160 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:164 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_waitcnt vmcnt(6)
-; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:128 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v7, off, s[0:3], s32 offset:132 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:120 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:124 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:112 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:116 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 offset:104 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:108 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_branch .LBB3_5
-; GFX9-O0-NEXT: .LBB3_3: ; %Flow2
-; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
-; GFX9-O0-NEXT: buffer_load_dword v4, off, s[0:3], s32 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: v_readlane_b32 s4, v4, 2
-; GFX9-O0-NEXT: v_readlane_b32 s5, v4, 3
-; GFX9-O0-NEXT: s_or_b64 exec, exec, s[4:5]
-; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 offset:12 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:16 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v2, off, s[0:3], s32 offset:4 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v3, off, s[0:3], s32 offset:8 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:176 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:180 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 offset:168 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:172 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_branch .LBB3_9
-; GFX9-O0-NEXT: .LBB3_4: ; %udiv-loop-exit
-; GFX9-O0-NEXT: buffer_load_dword v5, off, s[0:3], s32 offset:184 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v6, off, s[0:3], s32 offset:188 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v7, off, s[0:3], s32 offset:192 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v8, off, s[0:3], s32 offset:196 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 offset:200 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:204 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v9, off, s[0:3], s32 offset:208 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v10, off, s[0:3], s32 offset:212 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_mov_b32 s4, 1
-; GFX9-O0-NEXT: s_waitcnt vmcnt(2)
-; GFX9-O0-NEXT: v_lshlrev_b64 v[2:3], s4, v[0:1]
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: v_lshlrev_b64 v[9:10], s4, v[9:10]
-; GFX9-O0-NEXT: s_mov_b32 s4, 63
-; GFX9-O0-NEXT: v_lshrrev_b64 v[0:1], s4, v[0:1]
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, v1
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v10
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, v8
-; GFX9-O0-NEXT: v_or3_b32 v4, v4, v11, v12
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v0
-; GFX9-O0-NEXT: v_mov_b32_e32 v0, v9
-; GFX9-O0-NEXT: v_or3_b32 v0, v0, v1, v7
-; GFX9-O0-NEXT: ; kill: def $vgpr0 killed $vgpr0 def $vgpr0_vgpr1 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v4
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v3
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v6
-; GFX9-O0-NEXT: v_or_b32_e64 v4, v4, v7
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v5
-; GFX9-O0-NEXT: v_or_b32_e64 v2, v2, v3
-; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v4
-; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:12 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:16 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 offset:4 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:8 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_branch .LBB3_3
-; GFX9-O0-NEXT: .LBB3_5: ; %Flow1
-; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
-; GFX9-O0-NEXT: buffer_load_dword v8, off, s[0:3], s32 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: v_readlane_b32 s4, v8, 6
-; GFX9-O0-NEXT: v_readlane_b32 s5, v8, 7
-; GFX9-O0-NEXT: s_or_b64 exec, exec, s[4:5]
-; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 offset:128 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:132 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v2, off, s[0:3], s32 offset:120 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v3, off, s[0:3], s32 offset:124 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v4, off, s[0:3], s32 offset:112 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v5, off, s[0:3], s32 offset:116 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v6, off, s[0:3], s32 offset:104 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v7, off, s[0:3], s32 offset:108 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:192 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v7, off, s[0:3], s32 offset:196 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:184 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:188 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:208 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:212 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 offset:200 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:204 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_branch .LBB3_4
-; GFX9-O0-NEXT: .LBB3_6: ; %udiv-do-while
-; GFX9-O0-NEXT: ; =>This Inner Loop Header: Depth=1
-; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
-; GFX9-O0-NEXT: buffer_load_dword v16, off, s[0:3], s32 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: v_readlane_b32 s6, v16, 8
-; GFX9-O0-NEXT: v_readlane_b32 s7, v16, 9
-; GFX9-O0-NEXT: buffer_load_dword v6, off, s[0:3], s32 offset:216 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v7, off, s[0:3], s32 offset:220 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 offset:224 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:228 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v23, off, s[0:3], s32 offset:232 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v24, off, s[0:3], s32 offset:236 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v2, off, s[0:3], s32 offset:240 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v3, off, s[0:3], s32 offset:244 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v17, off, s[0:3], s32 offset:248 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v18, off, s[0:3], s32 offset:252 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v8, off, s[0:3], s32 offset:256 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v9, off, s[0:3], s32 offset:260 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v27, off, s[0:3], s32 offset:264 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v28, off, s[0:3], s32 offset:268 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v25, off, s[0:3], s32 offset:272 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v26, off, s[0:3], s32 offset:276 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v19, off, s[0:3], s32 offset:52 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v20, off, s[0:3], s32 offset:56 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v21, off, s[0:3], s32 offset:60 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v22, off, s[0:3], s32 offset:64 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v14, off, s[0:3], s32 offset:280 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v15, off, s[0:3], s32 offset:284 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v11, off, s[0:3], s32 offset:288 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v12, off, s[0:3], s32 offset:292 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_mov_b32 s4, 63
-; GFX9-O0-NEXT: s_waitcnt vmcnt(16)
-; GFX9-O0-NEXT: v_lshrrev_b64 v[29:30], s4, v[2:3]
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v30
-; GFX9-O0-NEXT: s_mov_b32 s5, 1
-; GFX9-O0-NEXT: v_lshlrev_b64 v[23:24], s5, v[23:24]
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v24
-; GFX9-O0-NEXT: v_or_b32_e64 v4, v4, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v10, v29
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v23
-; GFX9-O0-NEXT: v_or_b32_e64 v23, v5, v10
-; GFX9-O0-NEXT: ; kill: def $vgpr23 killed $vgpr23 def $vgpr23_vgpr24 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v24, v4
-; GFX9-O0-NEXT: v_lshlrev_b64 v[29:30], s5, v[2:3]
-; GFX9-O0-NEXT: v_lshrrev_b64 v[4:5], s4, v[6:7]
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v30
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v5
-; GFX9-O0-NEXT: v_or_b32_e64 v2, v2, v3
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v29
-; GFX9-O0-NEXT: ; kill: def $vgpr4 killed $vgpr4 killed $vgpr4_vgpr5 killed $exec
-; GFX9-O0-NEXT: v_or_b32_e64 v4, v3, v4
-; GFX9-O0-NEXT: ; kill: def $vgpr4 killed $vgpr4 def $vgpr4_vgpr5 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v2
-; GFX9-O0-NEXT: v_lshlrev_b64 v[2:3], s5, v[0:1]
-; GFX9-O0-NEXT: v_lshlrev_b64 v[29:30], s5, v[6:7]
-; GFX9-O0-NEXT: v_lshrrev_b64 v[0:1], s4, v[0:1]
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v1
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v30
-; GFX9-O0-NEXT: s_waitcnt vmcnt(10)
-; GFX9-O0-NEXT: v_mov_b32_e32 v10, v28
-; GFX9-O0-NEXT: v_or3_b32 v6, v6, v7, v10
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v0
-; GFX9-O0-NEXT: v_mov_b32_e32 v0, v29
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v27
-; GFX9-O0-NEXT: v_or3_b32 v0, v0, v1, v7
-; GFX9-O0-NEXT: ; kill: def $vgpr0 killed $vgpr0 def $vgpr0_vgpr1 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v6
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v3
-; GFX9-O0-NEXT: s_waitcnt vmcnt(8)
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v26
-; GFX9-O0-NEXT: v_or_b32_e64 v6, v6, v7
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v25
-; GFX9-O0-NEXT: v_or_b32_e64 v2, v2, v3
-; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v6
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v4
-; GFX9-O0-NEXT: v_mov_b32_e32 v10, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v23
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v24
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: v_mov_b32_e32 v13, v11
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, v14
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v15
-; GFX9-O0-NEXT: v_sub_co_u32_e32 v13, vcc, v13, v6
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v12, vcc, v12, v10, vcc
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v11, vcc, v11, v4, vcc
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v7, vcc, v7, v5, vcc
-; GFX9-O0-NEXT: ; implicit-def: $sgpr5
-; GFX9-O0-NEXT: ; implicit-def: $sgpr5
-; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 def $vgpr11_vgpr12 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, v7
-; GFX9-O0-NEXT: v_ashrrev_i64 v[13:14], s4, v[11:12]
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v14
-; GFX9-O0-NEXT: s_mov_b64 s[4:5], 1
-; GFX9-O0-NEXT: s_mov_b32 s8, s5
-; GFX9-O0-NEXT: v_and_b32_e64 v12, v7, s8
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, v13
-; GFX9-O0-NEXT: ; kill: def $sgpr4 killed $sgpr4 killed $sgpr4_sgpr5
-; GFX9-O0-NEXT: v_and_b32_e64 v14, v11, s4
-; GFX9-O0-NEXT: ; kill: def $vgpr14 killed $vgpr14 def $vgpr14_vgpr15 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v15, v12
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, 0
-; GFX9-O0-NEXT: v_mov_b32_e32 v13, 0
-; GFX9-O0-NEXT: v_mov_b32_e32 v23, v22
-; GFX9-O0-NEXT: v_and_b32_e64 v23, v7, v23
-; GFX9-O0-NEXT: v_and_b32_e64 v21, v11, v21
-; GFX9-O0-NEXT: ; kill: def $vgpr21 killed $vgpr21 def $vgpr21_vgpr22 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v22, v23
-; GFX9-O0-NEXT: v_mov_b32_e32 v23, v20
-; GFX9-O0-NEXT: v_and_b32_e64 v7, v7, v23
-; GFX9-O0-NEXT: v_and_b32_e64 v23, v11, v19
-; GFX9-O0-NEXT: ; kill: def $vgpr23 killed $vgpr23 def $vgpr23_vgpr24 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v24, v7
-; GFX9-O0-NEXT: v_mov_b32_e32 v20, v23
-; GFX9-O0-NEXT: v_mov_b32_e32 v19, v24
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, v21
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v22
-; GFX9-O0-NEXT: v_sub_co_u32_e32 v6, vcc, v6, v20
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v10, vcc, v10, v19, vcc
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v4, vcc, v4, v11, vcc
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v7, vcc, v5, v7, vcc
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr4 killed $vgpr4 def $vgpr4_vgpr5 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v7
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 def $vgpr6_vgpr7 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v10
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, v8
-; GFX9-O0-NEXT: ; kill: def $vgpr9 killed $vgpr9 killed $vgpr8_vgpr9 killed $exec
-; GFX9-O0-NEXT: s_mov_b64 s[8:9], -1
-; GFX9-O0-NEXT: s_mov_b32 s5, s8
-; GFX9-O0-NEXT: s_mov_b32 s4, s9
-; GFX9-O0-NEXT: v_mov_b32_e32 v10, v17
-; GFX9-O0-NEXT: v_mov_b32_e32 v8, v18
-; GFX9-O0-NEXT: v_mov_b32_e32 v17, s5
-; GFX9-O0-NEXT: v_add_co_u32_e32 v20, vcc, v11, v17
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, s4
-; GFX9-O0-NEXT: v_addc_co_u32_e32 v9, vcc, v9, v11, vcc
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, s5
-; GFX9-O0-NEXT: v_addc_co_u32_e32 v17, vcc, v10, v11, vcc
-; GFX9-O0-NEXT: v_mov_b32_e32 v10, s4
-; GFX9-O0-NEXT: v_addc_co_u32_e32 v8, vcc, v8, v10, vcc
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr20 killed $vgpr20 def $vgpr20_vgpr21 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v21, v9
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr17 killed $vgpr17 def $vgpr17_vgpr18 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v18, v8
-; GFX9-O0-NEXT: v_mov_b32_e32 v8, v17
-; GFX9-O0-NEXT: v_mov_b32_e32 v9, v18
-; GFX9-O0-NEXT: v_mov_b32_e32 v10, v20
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, v21
-; GFX9-O0-NEXT: v_mov_b32_e32 v22, v18
-; GFX9-O0-NEXT: v_mov_b32_e32 v19, v21
-; GFX9-O0-NEXT: v_or_b32_e64 v19, v19, v22
-; GFX9-O0-NEXT: v_mov_b32_e32 v18, v17
-; GFX9-O0-NEXT: v_mov_b32_e32 v17, v20
-; GFX9-O0-NEXT: v_or_b32_e64 v17, v17, v18
-; GFX9-O0-NEXT: ; kill: def $vgpr17 killed $vgpr17 def $vgpr17_vgpr18 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v18, v19
-; GFX9-O0-NEXT: v_cmp_eq_u64_e64 s[4:5], v[17:18], v[12:13]
-; GFX9-O0-NEXT: s_or_b64 s[4:5], s[4:5], s[6:7]
-; GFX9-O0-NEXT: v_mov_b32_e32 v18, v3
-; GFX9-O0-NEXT: v_mov_b32_e32 v17, v2
-; GFX9-O0-NEXT: buffer_store_dword v17, off, s[0:3], s32 offset:136 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v18, off, s[0:3], s32 offset:140 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: v_mov_b32_e32 v18, v1
-; GFX9-O0-NEXT: v_mov_b32_e32 v17, v0
-; GFX9-O0-NEXT: buffer_store_dword v17, off, s[0:3], s32 offset:144 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v18, off, s[0:3], s32 offset:148 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: v_mov_b32_e32 v18, v15
-; GFX9-O0-NEXT: v_mov_b32_e32 v17, v14
-; GFX9-O0-NEXT: buffer_store_dword v17, off, s[0:3], s32 offset:152 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v18, off, s[0:3], s32 offset:156 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: v_mov_b32_e32 v18, v13
-; GFX9-O0-NEXT: v_mov_b32_e32 v17, v12
-; GFX9-O0-NEXT: buffer_store_dword v17, off, s[0:3], s32 offset:160 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v18, off, s[0:3], s32 offset:164 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_mov_b64 s[6:7], s[4:5]
-; GFX9-O0-NEXT: v_writelane_b32 v16, s6, 4
-; GFX9-O0-NEXT: v_writelane_b32 v16, s7, 5
-; GFX9-O0-NEXT: s_mov_b64 s[6:7], s[4:5]
-; GFX9-O0-NEXT: v_writelane_b32 v16, s6, 8
-; GFX9-O0-NEXT: v_writelane_b32 v16, s7, 9
-; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
-; GFX9-O0-NEXT: buffer_store_dword v16, off, s[0:3], s32 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
-; GFX9-O0-NEXT: buffer_store_dword v14, off, s[0:3], s32 offset:272 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v15, off, s[0:3], s32 offset:276 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v12, off, s[0:3], s32 offset:264 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v13, off, s[0:3], s32 offset:268 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v10, off, s[0:3], s32 offset:256 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v11, off, s[0:3], s32 offset:260 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v8, off, s[0:3], s32 offset:248 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v9, off, s[0:3], s32 offset:252 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:240 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v7, off, s[0:3], s32 offset:244 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:232 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:236 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:224 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:228 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 offset:216 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:220 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_andn2_b64 exec, exec, s[4:5]
-; GFX9-O0-NEXT: s_cbranch_execnz .LBB3_6
-; GFX9-O0-NEXT: s_branch .LBB3_1
-; GFX9-O0-NEXT: .LBB3_7: ; %udiv-preheader
-; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 offset:296 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:300 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v2, off, s[0:3], s32 offset:304 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v3, off, s[0:3], s32 offset:308 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v8, off, s[0:3], s32 offset:312 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v9, off, s[0:3], s32 offset:316 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v10, off, s[0:3], s32 offset:320 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v11, off, s[0:3], s32 offset:324 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
-; GFX9-O0-NEXT: buffer_load_dword v16, off, s[0:3], s32 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
-; GFX9-O0-NEXT: buffer_load_dword v17, off, s[0:3], s32 offset:60 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v18, off, s[0:3], s32 offset:64 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v13, off, s[0:3], s32 offset:52 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v14, off, s[0:3], s32 offset:56 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v19, off, s[0:3], s32 offset:44 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v20, off, s[0:3], s32 offset:48 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v21, off, s[0:3], s32 offset:36 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v22, off, s[0:3], s32 offset:40 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_waitcnt vmcnt(9)
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v10
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: v_lshrrev_b64 v[6:7], v4, v[21:22]
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v7
-; GFX9-O0-NEXT: s_mov_b32 s6, 64
-; GFX9-O0-NEXT: v_sub_u32_e64 v12, s6, v4
-; GFX9-O0-NEXT: v_lshlrev_b64 v[23:24], v12, v[19:20]
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, v24
-; GFX9-O0-NEXT: v_or_b32_e64 v5, v5, v12
-; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 killed $vgpr6_vgpr7 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v23
-; GFX9-O0-NEXT: v_or_b32_e64 v6, v6, v7
-; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 def $vgpr6_vgpr7 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, v7
-; GFX9-O0-NEXT: v_cmp_lt_u32_e64 s[4:5], v4, s6
-; GFX9-O0-NEXT: v_sub_u32_e64 v5, v4, s6
-; GFX9-O0-NEXT: v_lshrrev_b64 v[23:24], v5, v[19:20]
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v24
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v5, v12, s[4:5]
-; GFX9-O0-NEXT: s_mov_b32 s6, 0
-; GFX9-O0-NEXT: v_cmp_eq_u32_e64 s[6:7], v4, s6
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, v22
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v5, v12, s[6:7]
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v6
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v23
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v6, v6, v7, s[4:5]
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v21
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v6, v6, v7, s[6:7]
-; GFX9-O0-NEXT: ; implicit-def: $sgpr6
-; GFX9-O0-NEXT: ; implicit-def: $sgpr6
-; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 def $vgpr6_vgpr7 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v5
-; GFX9-O0-NEXT: v_lshrrev_b64 v[4:5], v4, v[19:20]
-; GFX9-O0-NEXT: v_mov_b32_e32 v15, v5
-; GFX9-O0-NEXT: s_mov_b64 s[6:7], 0
-; GFX9-O0-NEXT: s_mov_b32 s8, s7
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, s8
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v12, v12, v15, s[4:5]
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v4
-; GFX9-O0-NEXT: s_mov_b32 s8, s6
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, s8
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v4, v4, v5, s[4:5]
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr4 killed $vgpr4 def $vgpr4_vgpr5 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v12
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, v13
-; GFX9-O0-NEXT: v_mov_b32_e32 v15, v14
-; GFX9-O0-NEXT: s_mov_b64 s[8:9], -1
-; GFX9-O0-NEXT: s_mov_b32 s5, s8
-; GFX9-O0-NEXT: s_mov_b32 s4, s9
-; GFX9-O0-NEXT: v_mov_b32_e32 v14, v17
-; GFX9-O0-NEXT: v_mov_b32_e32 v13, v18
-; GFX9-O0-NEXT: v_mov_b32_e32 v17, s5
-; GFX9-O0-NEXT: v_add_co_u32_e32 v12, vcc, v12, v17
-; GFX9-O0-NEXT: v_mov_b32_e32 v17, s4
-; GFX9-O0-NEXT: v_addc_co_u32_e32 v17, vcc, v15, v17, vcc
-; GFX9-O0-NEXT: v_mov_b32_e32 v15, s5
-; GFX9-O0-NEXT: v_addc_co_u32_e32 v14, vcc, v14, v15, vcc
-; GFX9-O0-NEXT: v_mov_b32_e32 v15, s4
-; GFX9-O0-NEXT: v_addc_co_u32_e32 v13, vcc, v13, v15, vcc
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr14 killed $vgpr14 def $vgpr14_vgpr15 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v15, v13
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr12 killed $vgpr12 def $vgpr12_vgpr13 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v13, v17
-; GFX9-O0-NEXT: s_mov_b64 s[8:9], s[6:7]
-; GFX9-O0-NEXT: buffer_store_dword v14, off, s[0:3], s32 offset:280 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v15, off, s[0:3], s32 offset:284 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v12, off, s[0:3], s32 offset:288 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v13, off, s[0:3], s32 offset:292 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_mov_b64 s[4:5], s[6:7]
-; GFX9-O0-NEXT: v_mov_b32_e32 v15, s9
-; GFX9-O0-NEXT: v_mov_b32_e32 v14, s8
-; GFX9-O0-NEXT: v_mov_b32_e32 v13, s7
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, s6
-; GFX9-O0-NEXT: v_writelane_b32 v16, s4, 8
-; GFX9-O0-NEXT: v_writelane_b32 v16, s5, 9
-; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
-; GFX9-O0-NEXT: buffer_store_dword v16, off, s[0:3], s32 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
-; GFX9-O0-NEXT: buffer_store_dword v14, off, s[0:3], s32 offset:272 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v15, off, s[0:3], s32 offset:276 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v12, off, s[0:3], s32 offset:264 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v13, off, s[0:3], s32 offset:268 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v10, off, s[0:3], s32 offset:256 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v11, off, s[0:3], s32 offset:260 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v8, off, s[0:3], s32 offset:248 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v9, off, s[0:3], s32 offset:252 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:240 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v7, off, s[0:3], s32 offset:244 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:232 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:236 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:224 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:228 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 offset:216 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:220 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_branch .LBB3_6
-; GFX9-O0-NEXT: .LBB3_8: ; %udiv-bb1
-; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
-; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
-; GFX9-O0-NEXT: buffer_load_dword v7, off, s[0:3], s32 offset:36 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v8, off, s[0:3], s32 offset:40 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v11, off, s[0:3], s32 offset:44 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v12, off, s[0:3], s32 offset:48 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v5, off, s[0:3], s32 offset:28 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v6, off, s[0:3], s32 offset:32 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:20 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v2, off, s[0:3], s32 offset:24 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_mov_b64 s[6:7], 1
-; GFX9-O0-NEXT: s_mov_b32 s5, s6
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v1
-; GFX9-O0-NEXT: s_mov_b32 s4, s7
-; GFX9-O0-NEXT: s_mov_b64 s[6:7], 0
-; GFX9-O0-NEXT: s_mov_b32 s8, s6
-; GFX9-O0-NEXT: s_mov_b32 s9, s7
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v6
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, s5
-; GFX9-O0-NEXT: v_add_co_u32_e32 v9, vcc, v4, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, s4
-; GFX9-O0-NEXT: v_addc_co_u32_e32 v2, vcc, v2, v5, vcc
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, s8
-; GFX9-O0-NEXT: v_addc_co_u32_e32 v1, vcc, v1, v5, vcc
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, s9
-; GFX9-O0-NEXT: v_addc_co_u32_e32 v3, vcc, v3, v5, vcc
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr9 killed $vgpr9 def $vgpr9_vgpr10 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v10, v2
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr1 killed $vgpr1 def $vgpr1_vgpr2 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v1
-; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:312 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:316 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v9
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v10
-; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:320 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:324 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_mov_b32 s4, 0x7f
-; GFX9-O0-NEXT: v_sub_u32_e64 v3, s4, v4
-; GFX9-O0-NEXT: v_lshlrev_b64 v[5:6], v3, v[11:12]
-; GFX9-O0-NEXT: v_mov_b32_e32 v13, v6
-; GFX9-O0-NEXT: s_mov_b32 s4, 64
-; GFX9-O0-NEXT: v_sub_u32_e64 v14, s4, v3
-; GFX9-O0-NEXT: v_lshrrev_b64 v[14:15], v14, v[7:8]
-; GFX9-O0-NEXT: v_mov_b32_e32 v16, v15
-; GFX9-O0-NEXT: v_or_b32_e64 v13, v13, v16
-; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 killed $vgpr5_vgpr6 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v14
-; GFX9-O0-NEXT: v_or_b32_e64 v5, v5, v6
-; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v13
-; GFX9-O0-NEXT: v_mov_b32_e32 v15, v6
-; GFX9-O0-NEXT: v_cmp_lt_u32_e64 s[4:5], v3, s4
-; GFX9-O0-NEXT: s_mov_b32 s10, 63
-; GFX9-O0-NEXT: v_sub_u32_e64 v4, s10, v4
-; GFX9-O0-NEXT: v_lshlrev_b64 v[13:14], v4, v[7:8]
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v14
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v4, v4, v15, s[4:5]
-; GFX9-O0-NEXT: s_mov_b32 s10, 0
-; GFX9-O0-NEXT: v_cmp_eq_u32_e64 s[10:11], v3, s10
-; GFX9-O0-NEXT: v_mov_b32_e32 v15, v12
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v4, v4, v15, s[10:11]
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v13
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v5, v6, s[4:5]
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v11
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v5, v6, s[10:11]
-; GFX9-O0-NEXT: ; implicit-def: $sgpr10
-; GFX9-O0-NEXT: ; implicit-def: $sgpr10
-; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v4
-; GFX9-O0-NEXT: v_lshlrev_b64 v[7:8], v3, v[7:8]
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v8
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, s9
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v3, v3, v4, s[4:5]
-; GFX9-O0-NEXT: ; kill: def $vgpr7 killed $vgpr7 killed $vgpr7_vgpr8 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, s8
-; GFX9-O0-NEXT: v_cndmask_b32_e64 v7, v4, v7, s[4:5]
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr7 killed $vgpr7 def $vgpr7_vgpr8 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v8, v3
-; GFX9-O0-NEXT: buffer_store_dword v7, off, s[0:3], s32 offset:304 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v8, off, s[0:3], s32 offset:308 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:296 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:300 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v10
-; GFX9-O0-NEXT: v_or_b32_e64 v3, v3, v4
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v1
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v9
-; GFX9-O0-NEXT: v_or_b32_e64 v1, v1, v2
-; GFX9-O0-NEXT: ; kill: def $vgpr1 killed $vgpr1 def $vgpr1_vgpr2 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
-; GFX9-O0-NEXT: v_cmp_ne_u64_e64 s[4:5], v[1:2], s[6:7]
-; GFX9-O0-NEXT: s_mov_b64 s[8:9], s[6:7]
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, s8
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, s9
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, s6
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, s7
-; GFX9-O0-NEXT: buffer_store_dword v7, off, s[0:3], s32 offset:128 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v8, off, s[0:3], s32 offset:132 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:120 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:124 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:112 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:116 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:104 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:108 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_mov_b64 s[6:7], exec
-; GFX9-O0-NEXT: s_and_b64 s[4:5], s[6:7], s[4:5]
-; GFX9-O0-NEXT: s_xor_b64 s[6:7], s[4:5], s[6:7]
-; GFX9-O0-NEXT: v_writelane_b32 v0, s6, 6
-; GFX9-O0-NEXT: v_writelane_b32 v0, s7, 7
-; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
-; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
-; GFX9-O0-NEXT: s_mov_b64 exec, s[4:5]
-; GFX9-O0-NEXT: s_cbranch_execz .LBB3_5
-; GFX9-O0-NEXT: s_branch .LBB3_7
-; GFX9-O0-NEXT: .LBB3_9: ; %udiv-end
-; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
-; GFX9-O0-NEXT: buffer_load_dword v4, off, s[0:3], s32 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
-; GFX9-O0-NEXT: buffer_load_dword v9, off, s[0:3], s32 offset:92 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v10, off, s[0:3], s32 offset:96 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 offset:84 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:88 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v15, off, s[0:3], s32 offset:68 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v16, off, s[0:3], s32 offset:72 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v11, off, s[0:3], s32 offset:176 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v12, off, s[0:3], s32 offset:180 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v7, off, s[0:3], s32 offset:168 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v8, off, s[0:3], s32 offset:172 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v13, off, s[0:3], s32 offset:76 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v14, off, s[0:3], s32 offset:80 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_mov_b32 s4, 32
-; GFX9-O0-NEXT: s_waitcnt vmcnt(2)
-; GFX9-O0-NEXT: v_lshrrev_b64 v[2:3], s4, v[7:8]
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v2
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v13
-; GFX9-O0-NEXT: v_mul_lo_u32 v5, v6, v2
-; GFX9-O0-NEXT: v_lshrrev_b64 v[13:14], s4, v[13:14]
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v13
-; GFX9-O0-NEXT: ; kill: def $vgpr7 killed $vgpr7 killed $vgpr7_vgpr8 killed $exec
-; GFX9-O0-NEXT: v_mul_lo_u32 v3, v7, v3
-; GFX9-O0-NEXT: v_mad_u64_u32 v[13:14], s[6:7], v7, v2, 0
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v14
-; GFX9-O0-NEXT: v_add3_u32 v2, v2, v3, v5
-; GFX9-O0-NEXT: ; implicit-def: $sgpr5
-; GFX9-O0-NEXT: ; implicit-def: $sgpr6
-; GFX9-O0-NEXT: ; implicit-def: $sgpr6
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, s5
-; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v5
-; GFX9-O0-NEXT: v_lshlrev_b64 v[17:18], s4, v[2:3]
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v18
-; GFX9-O0-NEXT: ; kill: def $vgpr13 killed $vgpr13 killed $vgpr13_vgpr14 killed $exec
-; GFX9-O0-NEXT: s_mov_b32 s5, 0
-; GFX9-O0-NEXT: ; implicit-def: $sgpr6
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, s5
-; GFX9-O0-NEXT: ; kill: def $vgpr13 killed $vgpr13 def $vgpr13_vgpr14 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v14, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v14
-; GFX9-O0-NEXT: v_or_b32_e64 v2, v2, v3
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v17
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v13
-; GFX9-O0-NEXT: v_or_b32_e64 v13, v3, v5
-; GFX9-O0-NEXT: ; kill: def $vgpr13 killed $vgpr13 def $vgpr13_vgpr14 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v14, v2
-; GFX9-O0-NEXT: v_lshrrev_b64 v[2:3], s4, v[15:16]
-; GFX9-O0-NEXT: v_mov_b32_e32 v8, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v11
-; GFX9-O0-NEXT: v_mul_lo_u32 v3, v2, v8
-; GFX9-O0-NEXT: v_lshrrev_b64 v[11:12], s4, v[11:12]
-; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 killed $vgpr11_vgpr12 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v15
-; GFX9-O0-NEXT: v_mul_lo_u32 v11, v11, v5
-; GFX9-O0-NEXT: v_mad_u64_u32 v[15:16], s[6:7], v2, v5, 0
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v16
-; GFX9-O0-NEXT: v_add3_u32 v2, v2, v3, v11
-; GFX9-O0-NEXT: ; implicit-def: $sgpr6
-; GFX9-O0-NEXT: ; implicit-def: $sgpr7
-; GFX9-O0-NEXT: ; implicit-def: $sgpr7
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, s6
-; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v11
-; GFX9-O0-NEXT: v_lshlrev_b64 v[2:3], s4, v[2:3]
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, v3
-; GFX9-O0-NEXT: ; kill: def $vgpr15 killed $vgpr15 killed $vgpr15_vgpr16 killed $exec
-; GFX9-O0-NEXT: ; implicit-def: $sgpr6
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, s5
-; GFX9-O0-NEXT: ; kill: def $vgpr15 killed $vgpr15 def $vgpr15_vgpr16 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v16, v11
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, v16
-; GFX9-O0-NEXT: v_or_b32_e64 v11, v11, v12
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v15
-; GFX9-O0-NEXT: v_or_b32_e64 v2, v2, v3
-; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v11
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, v13
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v14
-; GFX9-O0-NEXT: v_add_co_u32_e64 v13, s[6:7], v11, v12
-; GFX9-O0-NEXT: v_addc_co_u32_e64 v2, s[6:7], v2, v3, s[6:7]
-; GFX9-O0-NEXT: ; kill: def $vgpr13 killed $vgpr13 def $vgpr13_vgpr14 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v14, v2
-; GFX9-O0-NEXT: v_mad_u64_u32 v[15:16], s[6:7], v8, v6, 0
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v15
-; GFX9-O0-NEXT: ; implicit-def: $sgpr6
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, s5
-; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v11
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, v3
-; GFX9-O0-NEXT: v_mov_b32_e32 v15, v16
-; GFX9-O0-NEXT: ; implicit-def: $sgpr6
-; GFX9-O0-NEXT: ; implicit-def: $sgpr7
-; GFX9-O0-NEXT: ; implicit-def: $sgpr7
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, s6
-; GFX9-O0-NEXT: ; kill: def $vgpr15 killed $vgpr15 def $vgpr15_vgpr16 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v16, v12
-; GFX9-O0-NEXT: v_lshlrev_b64 v[15:16], s4, v[15:16]
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, v16
-; GFX9-O0-NEXT: v_or_b32_e64 v11, v11, v12
-; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 killed $vgpr2_vgpr3 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v15
-; GFX9-O0-NEXT: v_or_b32_e64 v2, v2, v3
-; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v11
-; GFX9-O0-NEXT: v_mad_u64_u32 v[15:16], s[6:7], v8, v7, 0
-; GFX9-O0-NEXT: v_mov_b32_e32 v11, v15
-; GFX9-O0-NEXT: ; implicit-def: $sgpr6
-; GFX9-O0-NEXT: v_mov_b32_e32 v8, s5
-; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 def $vgpr11_vgpr12 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, v8
-; GFX9-O0-NEXT: v_mov_b32_e32 v8, v12
-; GFX9-O0-NEXT: v_mov_b32_e32 v15, v16
-; GFX9-O0-NEXT: ; implicit-def: $sgpr6
-; GFX9-O0-NEXT: ; implicit-def: $sgpr7
-; GFX9-O0-NEXT: ; implicit-def: $sgpr7
-; GFX9-O0-NEXT: v_mov_b32_e32 v17, s6
-; GFX9-O0-NEXT: ; kill: def $vgpr15 killed $vgpr15 def $vgpr15_vgpr16 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v16, v17
-; GFX9-O0-NEXT: v_lshlrev_b64 v[15:16], s4, v[15:16]
-; GFX9-O0-NEXT: v_mov_b32_e32 v17, v16
-; GFX9-O0-NEXT: v_or_b32_e64 v8, v8, v17
-; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 killed $vgpr11_vgpr12 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, v15
-; GFX9-O0-NEXT: v_or_b32_e64 v19, v11, v12
-; GFX9-O0-NEXT: ; kill: def $vgpr19 killed $vgpr19 def $vgpr19_vgpr20 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v20, v8
-; GFX9-O0-NEXT: v_mad_u64_u32 v[11:12], s[6:7], v5, v7, 0
-; GFX9-O0-NEXT: v_mov_b32_e32 v17, v12
-; GFX9-O0-NEXT: ; implicit-def: $sgpr6
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, s5
-; GFX9-O0-NEXT: ; kill: def $vgpr17 killed $vgpr17 def $vgpr17_vgpr18 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v18, v7
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v19
-; GFX9-O0-NEXT: v_mov_b32_e32 v16, v17
-; GFX9-O0-NEXT: v_mov_b32_e32 v8, v20
-; GFX9-O0-NEXT: v_mov_b32_e32 v15, v18
-; GFX9-O0-NEXT: v_add_co_u32_e64 v7, s[6:7], v7, v16
-; GFX9-O0-NEXT: v_addc_co_u32_e64 v15, s[6:7], v8, v15, s[6:7]
-; GFX9-O0-NEXT: ; kill: def $vgpr7 killed $vgpr7 def $vgpr7_vgpr8 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v8, v15
-; GFX9-O0-NEXT: v_mov_b32_e32 v15, v8
-; GFX9-O0-NEXT: s_mov_b64 s[6:7], 0xffffffff
-; GFX9-O0-NEXT: s_mov_b32 s8, s7
-; GFX9-O0-NEXT: v_and_b32_e64 v15, v15, s8
-; GFX9-O0-NEXT: v_mov_b32_e32 v16, v7
-; GFX9-O0-NEXT: ; kill: def $sgpr6 killed $sgpr6 killed $sgpr6_sgpr7
-; GFX9-O0-NEXT: v_and_b32_e64 v17, v16, s6
-; GFX9-O0-NEXT: ; kill: def $vgpr17 killed $vgpr17 def $vgpr17_vgpr18 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v18, v15
-; GFX9-O0-NEXT: v_mad_u64_u32 v[15:16], s[6:7], v5, v6, 0
-; GFX9-O0-NEXT: v_mov_b32_e32 v19, v15
-; GFX9-O0-NEXT: ; implicit-def: $sgpr6
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, s5
-; GFX9-O0-NEXT: ; kill: def $vgpr19 killed $vgpr19 def $vgpr19_vgpr20 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v20, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v20
-; GFX9-O0-NEXT: v_mov_b32_e32 v15, v16
-; GFX9-O0-NEXT: ; implicit-def: $sgpr6
-; GFX9-O0-NEXT: ; implicit-def: $sgpr7
-; GFX9-O0-NEXT: ; implicit-def: $sgpr7
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, s6
-; GFX9-O0-NEXT: ; kill: def $vgpr15 killed $vgpr15 def $vgpr15_vgpr16 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v16, v6
-; GFX9-O0-NEXT: v_lshlrev_b64 v[15:16], s4, v[15:16]
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v16
-; GFX9-O0-NEXT: v_or_b32_e64 v5, v5, v6
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v19
-; GFX9-O0-NEXT: ; kill: def $vgpr15 killed $vgpr15 killed $vgpr15_vgpr16 killed $exec
-; GFX9-O0-NEXT: v_or_b32_e64 v19, v6, v15
-; GFX9-O0-NEXT: ; kill: def $vgpr19 killed $vgpr19 def $vgpr19_vgpr20 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v20, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v19
-; GFX9-O0-NEXT: v_mov_b32_e32 v16, v17
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v20
-; GFX9-O0-NEXT: v_mov_b32_e32 v15, v18
-; GFX9-O0-NEXT: v_add_co_u32_e64 v5, s[6:7], v5, v16
-; GFX9-O0-NEXT: v_addc_co_u32_e64 v15, s[6:7], v6, v15, s[6:7]
-; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v15
-; GFX9-O0-NEXT: v_lshrrev_b64 v[17:18], s4, v[5:6]
-; GFX9-O0-NEXT: v_lshrrev_b64 v[7:8], s4, v[7:8]
-; GFX9-O0-NEXT: v_mov_b32_e32 v15, v7
-; GFX9-O0-NEXT: v_mov_b32_e32 v16, v17
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v8
-; GFX9-O0-NEXT: v_mov_b32_e32 v8, v18
-; GFX9-O0-NEXT: v_add_co_u32_e64 v15, s[6:7], v15, v16
-; GFX9-O0-NEXT: v_addc_co_u32_e64 v7, s[6:7], v7, v8, s[6:7]
-; GFX9-O0-NEXT: ; kill: def $vgpr15 killed $vgpr15 def $vgpr15_vgpr16 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v16, v7
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v8, v15
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v16
-; GFX9-O0-NEXT: v_add_co_u32_e64 v15, s[6:7], v7, v8
-; GFX9-O0-NEXT: v_addc_co_u32_e64 v2, s[6:7], v2, v3, s[6:7]
-; GFX9-O0-NEXT: ; kill: def $vgpr15 killed $vgpr15 def $vgpr15_vgpr16 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v16, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v15
-; GFX9-O0-NEXT: v_mov_b32_e32 v8, v13
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v16
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v14
-; GFX9-O0-NEXT: v_add_co_u32_e64 v2, s[6:7], v2, v8
-; GFX9-O0-NEXT: v_addc_co_u32_e64 v7, s[6:7], v3, v7, s[6:7]
-; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v7
-; GFX9-O0-NEXT: v_lshlrev_b64 v[6:7], s4, v[5:6]
-; GFX9-O0-NEXT: v_mov_b32_e32 v8, v7
-; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 killed $vgpr11_vgpr12 killed $exec
-; GFX9-O0-NEXT: ; implicit-def: $sgpr6
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, s5
-; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 def $vgpr11_vgpr12 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v12, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v12
-; GFX9-O0-NEXT: v_or_b32_e64 v5, v5, v8
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v6
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v11
-; GFX9-O0-NEXT: v_or_b32_e64 v6, v6, v7
-; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 def $vgpr6_vgpr7 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
-; GFX9-O0-NEXT: v_mov_b32_e32 v8, v6
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v7
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v0
-; GFX9-O0-NEXT: v_mov_b32_e32 v0, v1
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v9
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v10
-; GFX9-O0-NEXT: v_sub_co_u32_e32 v7, vcc, v7, v8
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v0, vcc, v0, v6, vcc
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v5, vcc, v3, v5, vcc
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v1, vcc, v1, v2, vcc
-; GFX9-O0-NEXT: ; implicit-def: $sgpr5
-; GFX9-O0-NEXT: ; implicit-def: $sgpr5
-; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v1
-; GFX9-O0-NEXT: ; implicit-def: $sgpr5
-; GFX9-O0-NEXT: ; implicit-def: $sgpr5
-; GFX9-O0-NEXT: ; kill: def $vgpr7 killed $vgpr7 def $vgpr7_vgpr8 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v8, v0
-; GFX9-O0-NEXT: v_mov_b32_e32 v0, v7
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v5
-; GFX9-O0-NEXT: v_lshrrev_b64 v[7:8], s4, v[7:8]
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v7
-; GFX9-O0-NEXT: v_lshrrev_b64 v[5:6], s4, v[5:6]
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v5
-; GFX9-O0-NEXT: ; kill: killed $vgpr4
-; GFX9-O0-NEXT: s_xor_saveexec_b64 s[4:5], -1
-; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 offset:328 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_nop 0
-; GFX9-O0-NEXT: buffer_load_dword v4, off, s[0:3], s32 offset:332 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v8, off, s[0:3], s32 offset:336 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: buffer_load_dword v16, off, s[0:3], s32 offset:340 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: s_mov_b64 exec, s[4:5]
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: s_setpc_b64 s[30:31]
- %div = urem i128 %lhs, %rhs
- ret i128 %div
-}
-
define i128 @v_sdiv_i128_v_pow2k(i128 %lhs) {
; GFX9-LABEL: v_sdiv_i128_v_pow2k:
; GFX9: ; %bb.0:
@@ -5246,106 +2392,6 @@ define i128 @v_sdiv_i128_v_pow2k(i128 %lhs) {
ret i128 %div
}
-define i128 @v_srem_i128_v_pow2k(i128 %lhs) {
-; GFX9-LABEL: v_srem_i128_v_pow2k:
-; GFX9: ; %bb.0:
-; GFX9-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
-; GFX9-NEXT: v_ashrrev_i32_e32 v4, 31, v3
-; GFX9-NEXT: v_mov_b32_e32 v5, v4
-; GFX9-NEXT: v_lshrrev_b64 v[4:5], 31, v[4:5]
-; GFX9-NEXT: v_add_co_u32_e32 v4, vcc, v0, v4
-; GFX9-NEXT: v_addc_co_u32_e32 v4, vcc, v1, v5, vcc
-; GFX9-NEXT: v_addc_co_u32_e32 v5, vcc, 0, v2, vcc
-; GFX9-NEXT: v_addc_co_u32_e32 v6, vcc, 0, v3, vcc
-; GFX9-NEXT: v_and_b32_e32 v4, -2, v4
-; GFX9-NEXT: v_subrev_co_u32_e32 v0, vcc, 0, v0
-; GFX9-NEXT: v_subb_co_u32_e32 v1, vcc, v1, v4, vcc
-; GFX9-NEXT: v_subb_co_u32_e32 v2, vcc, v2, v5, vcc
-; GFX9-NEXT: v_subb_co_u32_e32 v3, vcc, v3, v6, vcc
-; GFX9-NEXT: s_setpc_b64 s[30:31]
-;
-; GFX9-O0-LABEL: v_srem_i128_v_pow2k:
-; GFX9-O0: ; %bb.0:
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v1
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 def $vgpr6_vgpr7 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v3
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr0 killed $vgpr0 def $vgpr0_vgpr1 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v2
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4_sgpr5
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4_sgpr5
-; GFX9-O0-NEXT: v_mov_b32_e32 v5, v0
-; GFX9-O0-NEXT: v_mov_b32_e32 v0, v1
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v6
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v7
-; GFX9-O0-NEXT: s_mov_b32 s4, 63
-; GFX9-O0-NEXT: v_ashrrev_i64 v[6:7], s4, v[6:7]
-; GFX9-O0-NEXT: s_mov_b32 s4, 31
-; GFX9-O0-NEXT: v_lshrrev_b64 v[6:7], s4, v[6:7]
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v6
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v7
-; GFX9-O0-NEXT: s_mov_b64 s[6:7], 0
-; GFX9-O0-NEXT: s_mov_b32 s5, s6
-; GFX9-O0-NEXT: s_mov_b32 s4, s7
-; GFX9-O0-NEXT: v_add_co_u32_e32 v6, vcc, v5, v4
-; GFX9-O0-NEXT: v_addc_co_u32_e32 v4, vcc, v0, v2, vcc
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, s5
-; GFX9-O0-NEXT: v_addc_co_u32_e32 v8, vcc, v3, v2, vcc
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, s4
-; GFX9-O0-NEXT: v_addc_co_u32_e32 v2, vcc, v1, v2, vcc
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 def $vgpr6_vgpr7 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v4
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v7
-; GFX9-O0-NEXT: s_mov_b32 s6, -2
-; GFX9-O0-NEXT: s_mov_b32 s4, 0
-; GFX9-O0-NEXT: ; kill: def $sgpr4 killed $sgpr4 def $sgpr4_sgpr5
-; GFX9-O0-NEXT: s_mov_b32 s5, s6
-; GFX9-O0-NEXT: s_mov_b32 s6, s5
-; GFX9-O0-NEXT: v_and_b32_e64 v4, v4, s6
-; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 killed $vgpr6_vgpr7 killed $exec
-; GFX9-O0-NEXT: ; kill: def $sgpr4 killed $sgpr4 killed $sgpr4_sgpr5
-; GFX9-O0-NEXT: v_and_b32_e64 v9, v6, s4
-; GFX9-O0-NEXT: ; kill: def $vgpr9 killed $vgpr9 def $vgpr9_vgpr10 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v10, v4
-; GFX9-O0-NEXT: v_mov_b32_e32 v7, v9
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v10
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr8 killed $vgpr8 def $vgpr8_vgpr9 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v9, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v8
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v9
-; GFX9-O0-NEXT: v_sub_co_u32_e32 v5, vcc, v5, v7
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v0, vcc, v0, v6, vcc
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v3, vcc, v3, v4, vcc
-; GFX9-O0-NEXT: v_subb_co_u32_e32 v1, vcc, v1, v2, vcc
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr3 killed $vgpr3 def $vgpr3_vgpr4 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v4, v1
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v6, v0
-; GFX9-O0-NEXT: v_mov_b32_e32 v0, v5
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
-; GFX9-O0-NEXT: s_mov_b32 s4, 32
-; GFX9-O0-NEXT: v_lshrrev_b64 v[5:6], s4, v[5:6]
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v5
-; GFX9-O0-NEXT: v_lshrrev_b64 v[3:4], s4, v[3:4]
-; GFX9-O0-NEXT: ; kill: def $vgpr3 killed $vgpr3 killed $vgpr3_vgpr4 killed $exec
-; GFX9-O0-NEXT: s_setpc_b64 s[30:31]
- %div = srem i128 %lhs, 8589934592
- ret i128 %div
-}
-
define i128 @v_udiv_i128_v_pow2k(i128 %lhs) {
; GFX9-LABEL: v_udiv_i128_v_pow2k:
; GFX9: ; %bb.0:
@@ -5392,55 +2438,6 @@ define i128 @v_udiv_i128_v_pow2k(i128 %lhs) {
ret i128 %div
}
-define i128 @v_urem_i128_v_pow2k(i128 %lhs) {
-; GFX9-LABEL: v_urem_i128_v_pow2k:
-; GFX9: ; %bb.0:
-; GFX9-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
-; GFX9-NEXT: v_and_b32_e32 v1, 1, v1
-; GFX9-NEXT: v_mov_b32_e32 v2, 0
-; GFX9-NEXT: v_mov_b32_e32 v3, 0
-; GFX9-NEXT: s_setpc_b64 s[30:31]
-;
-; GFX9-O0-LABEL: v_urem_i128_v_pow2k:
-; GFX9-O0: ; %bb.0:
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
-; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 ; 4-byte Folded Spill
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, v2
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v1
-; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 ; 4-byte Folded Reload
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr3 killed $vgpr3 def $vgpr3_vgpr4 killed $exec
-; GFX9-O0-NEXT: ; kill: def $vgpr4 killed $vgpr1 killed $exec
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4
-; GFX9-O0-NEXT: ; kill: def $vgpr0 killed $vgpr0 def $vgpr0_vgpr1 killed $exec
-; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
-; GFX9-O0-NEXT: v_mov_b32_e32 v1, v2
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4_sgpr5
-; GFX9-O0-NEXT: ; implicit-def: $sgpr4_sgpr5
-; GFX9-O0-NEXT: s_mov_b32 s6, 1
-; GFX9-O0-NEXT: s_mov_b32 s4, -1
-; GFX9-O0-NEXT: ; kill: def $sgpr4 killed $sgpr4 def $sgpr4_sgpr5
-; GFX9-O0-NEXT: s_mov_b32 s5, s6
-; GFX9-O0-NEXT: s_mov_b32 s6, s5
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v1
-; GFX9-O0-NEXT: v_and_b32_e64 v3, v2, s6
-; GFX9-O0-NEXT: ; kill: def $sgpr4 killed $sgpr4 killed $sgpr4_sgpr5
-; GFX9-O0-NEXT: ; kill: def $vgpr0 killed $vgpr0 killed $vgpr0_vgpr1 killed $exec
-; GFX9-O0-NEXT: v_and_b32_e64 v1, v0, s4
-; GFX9-O0-NEXT: ; kill: def $vgpr1 killed $vgpr1 def $vgpr1_vgpr2 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
-; GFX9-O0-NEXT: s_mov_b32 s4, 32
-; GFX9-O0-NEXT: v_lshrrev_b64 v[1:2], s4, v[1:2]
-; GFX9-O0-NEXT: ; kill: def $vgpr1 killed $vgpr1 killed $vgpr1_vgpr2 killed $exec
-; GFX9-O0-NEXT: v_mov_b32_e32 v3, 0
-; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
-; GFX9-O0-NEXT: s_setpc_b64 s[30:31]
- %div = urem i128 %lhs, 8589934592
- ret i128 %div
-}
-
;; NOTE: These prefixes are unused and the list is autogenerated. Do not add tests below this line:
; GFX9-SDAG: {{.*}}
; GFX9-SDAG-O0: {{.*}}
diff --git a/llvm/test/CodeGen/AMDGPU/rem_i128.ll b/llvm/test/CodeGen/AMDGPU/rem_i128.ll
new file mode 100644
index 00000000000000..6ba66ccf71868e
--- /dev/null
+++ b/llvm/test/CodeGen/AMDGPU/rem_i128.ll
@@ -0,0 +1,3014 @@
+; NOTE: Assertions have been autogenerated by utils/update_llc_test_checks.py UTC_ARGS: --version 4
+; RUN: llc -global-isel=0 -mtriple=amdgcn-amd-amdhsa -mcpu=gfx900 -o - %s | FileCheck -check-prefixes=GFX9,GFX9-SDAG %s
+; RUN: llc -O0 -global-isel=0 -mtriple=amdgcn-amd-amdhsa -mcpu=gfx900 -o - %s | FileCheck -check-prefixes=GFX9-O0,GFX9-SDAG-O0 %s
+
+; FIXME: GlobalISel missing the power-of-2 cases in legalization. https://github.com/llvm/llvm-project/issues/80671
+; xUN: llc -global-isel=1 -mtriple=amdgcn-amd-amdhsa -mcpu=gfx900 -o - %s | FileCheck -check-prefixes=GFX9,GFX9 %s
+; xUN: llc -O0 -global-isel=1 -mtriple=amdgcn-amd-amdhsa -mcpu=gfx900 -o - %s | FileCheck -check-prefixes=GFX9-O0,GFX9-O0 %s}}
+
+define i128 @v_srem_i128_vv(i128 %lhs, i128 %rhs) {
+; GFX9-LABEL: v_srem_i128_vv:
+; GFX9: ; %bb.0: ; %_udiv-special-cases
+; GFX9-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
+; GFX9-NEXT: v_ashrrev_i32_e32 v20, 31, v3
+; GFX9-NEXT: v_xor_b32_e32 v0, v0, v20
+; GFX9-NEXT: v_xor_b32_e32 v10, v2, v20
+; GFX9-NEXT: v_xor_b32_e32 v1, v1, v20
+; GFX9-NEXT: v_sub_co_u32_e32 v2, vcc, v0, v20
+; GFX9-NEXT: v_xor_b32_e32 v9, v3, v20
+; GFX9-NEXT: v_subb_co_u32_e32 v3, vcc, v1, v20, vcc
+; GFX9-NEXT: v_ashrrev_i32_e32 v8, 31, v7
+; GFX9-NEXT: v_subb_co_u32_e32 v0, vcc, v10, v20, vcc
+; GFX9-NEXT: v_xor_b32_e32 v4, v4, v8
+; GFX9-NEXT: v_subb_co_u32_e32 v1, vcc, v9, v20, vcc
+; GFX9-NEXT: v_xor_b32_e32 v5, v5, v8
+; GFX9-NEXT: v_sub_co_u32_e32 v23, vcc, v4, v8
+; GFX9-NEXT: v_xor_b32_e32 v6, v6, v8
+; GFX9-NEXT: v_subb_co_u32_e32 v21, vcc, v5, v8, vcc
+; GFX9-NEXT: v_xor_b32_e32 v7, v7, v8
+; GFX9-NEXT: v_subb_co_u32_e32 v4, vcc, v6, v8, vcc
+; GFX9-NEXT: v_subb_co_u32_e32 v5, vcc, v7, v8, vcc
+; GFX9-NEXT: v_or_b32_e32 v7, v21, v5
+; GFX9-NEXT: v_or_b32_e32 v6, v23, v4
+; GFX9-NEXT: v_cmp_eq_u64_e32 vcc, 0, v[6:7]
+; GFX9-NEXT: v_or_b32_e32 v7, v3, v1
+; GFX9-NEXT: v_or_b32_e32 v6, v2, v0
+; GFX9-NEXT: v_cmp_eq_u64_e64 s[4:5], 0, v[6:7]
+; GFX9-NEXT: v_ffbh_u32_e32 v6, v4
+; GFX9-NEXT: v_add_u32_e32 v6, 32, v6
+; GFX9-NEXT: v_ffbh_u32_e32 v7, v5
+; GFX9-NEXT: v_min_u32_e32 v6, v6, v7
+; GFX9-NEXT: v_ffbh_u32_e32 v7, v23
+; GFX9-NEXT: v_add_u32_e32 v7, 32, v7
+; GFX9-NEXT: v_ffbh_u32_e32 v8, v21
+; GFX9-NEXT: v_min_u32_e32 v7, v7, v8
+; GFX9-NEXT: s_or_b64 s[4:5], vcc, s[4:5]
+; GFX9-NEXT: v_add_co_u32_e32 v7, vcc, 64, v7
+; GFX9-NEXT: v_addc_co_u32_e64 v8, s[6:7], 0, 0, vcc
+; GFX9-NEXT: v_cmp_ne_u64_e32 vcc, 0, v[4:5]
+; GFX9-NEXT: v_ffbh_u32_e32 v9, v1
+; GFX9-NEXT: v_cndmask_b32_e32 v6, v7, v6, vcc
+; GFX9-NEXT: v_ffbh_u32_e32 v7, v0
+; GFX9-NEXT: v_add_u32_e32 v7, 32, v7
+; GFX9-NEXT: v_min_u32_e32 v7, v7, v9
+; GFX9-NEXT: v_ffbh_u32_e32 v9, v2
+; GFX9-NEXT: v_add_u32_e32 v9, 32, v9
+; GFX9-NEXT: v_ffbh_u32_e32 v10, v3
+; GFX9-NEXT: v_min_u32_e32 v9, v9, v10
+; GFX9-NEXT: v_cndmask_b32_e64 v8, v8, 0, vcc
+; GFX9-NEXT: v_add_co_u32_e32 v9, vcc, 64, v9
+; GFX9-NEXT: v_addc_co_u32_e64 v10, s[6:7], 0, 0, vcc
+; GFX9-NEXT: v_cmp_ne_u64_e32 vcc, 0, v[0:1]
+; GFX9-NEXT: s_mov_b64 s[6:7], 0x7f
+; GFX9-NEXT: v_cndmask_b32_e32 v7, v9, v7, vcc
+; GFX9-NEXT: v_cndmask_b32_e64 v10, v10, 0, vcc
+; GFX9-NEXT: v_sub_co_u32_e32 v6, vcc, v6, v7
+; GFX9-NEXT: v_subb_co_u32_e32 v7, vcc, v8, v10, vcc
+; GFX9-NEXT: v_mov_b32_e32 v9, 0
+; GFX9-NEXT: v_subbrev_co_u32_e32 v8, vcc, 0, v9, vcc
+; GFX9-NEXT: v_subbrev_co_u32_e32 v9, vcc, 0, v9, vcc
+; GFX9-NEXT: v_cmp_lt_u64_e32 vcc, s[6:7], v[6:7]
+; GFX9-NEXT: v_or_b32_e32 v13, v7, v9
+; GFX9-NEXT: v_cndmask_b32_e64 v10, 0, 1, vcc
+; GFX9-NEXT: v_cmp_ne_u64_e32 vcc, 0, v[8:9]
+; GFX9-NEXT: v_mov_b32_e32 v22, v20
+; GFX9-NEXT: v_cndmask_b32_e64 v11, 0, 1, vcc
+; GFX9-NEXT: v_cmp_eq_u64_e32 vcc, 0, v[8:9]
+; GFX9-NEXT: v_cndmask_b32_e32 v10, v11, v10, vcc
+; GFX9-NEXT: v_and_b32_e32 v10, 1, v10
+; GFX9-NEXT: v_cmp_eq_u32_e32 vcc, 1, v10
+; GFX9-NEXT: v_xor_b32_e32 v10, 0x7f, v6
+; GFX9-NEXT: v_or_b32_e32 v12, v10, v8
+; GFX9-NEXT: s_or_b64 s[4:5], s[4:5], vcc
+; GFX9-NEXT: v_cmp_ne_u64_e32 vcc, 0, v[12:13]
+; GFX9-NEXT: s_xor_b64 s[6:7], s[4:5], -1
+; GFX9-NEXT: v_cndmask_b32_e64 v11, v1, 0, s[4:5]
+; GFX9-NEXT: v_cndmask_b32_e64 v12, v0, 0, s[4:5]
+; GFX9-NEXT: v_cndmask_b32_e64 v10, v3, 0, s[4:5]
+; GFX9-NEXT: v_cndmask_b32_e64 v13, v2, 0, s[4:5]
+; GFX9-NEXT: s_and_b64 s[4:5], s[6:7], vcc
+; GFX9-NEXT: s_and_saveexec_b64 s[8:9], s[4:5]
+; GFX9-NEXT: s_cbranch_execz .LBB0_6
+; GFX9-NEXT: ; %bb.1: ; %udiv-bb1
+; GFX9-NEXT: v_add_co_u32_e32 v24, vcc, 1, v6
+; GFX9-NEXT: v_addc_co_u32_e32 v25, vcc, 0, v7, vcc
+; GFX9-NEXT: v_addc_co_u32_e32 v26, vcc, 0, v8, vcc
+; GFX9-NEXT: v_sub_u32_e32 v13, 0x7f, v6
+; GFX9-NEXT: v_addc_co_u32_e32 v27, vcc, 0, v9, vcc
+; GFX9-NEXT: v_sub_u32_e32 v11, 64, v13
+; GFX9-NEXT: v_or_b32_e32 v8, v25, v27
+; GFX9-NEXT: v_or_b32_e32 v7, v24, v26
+; GFX9-NEXT: v_lshlrev_b64 v[9:10], v13, v[0:1]
+; GFX9-NEXT: v_lshrrev_b64 v[11:12], v11, v[2:3]
+; GFX9-NEXT: v_sub_u32_e32 v6, 63, v6
+; GFX9-NEXT: v_cmp_ne_u64_e32 vcc, 0, v[7:8]
+; GFX9-NEXT: v_lshlrev_b64 v[6:7], v6, v[2:3]
+; GFX9-NEXT: v_or_b32_e32 v8, v10, v12
+; GFX9-NEXT: v_or_b32_e32 v9, v9, v11
+; GFX9-NEXT: v_cmp_gt_u32_e64 s[4:5], 64, v13
+; GFX9-NEXT: v_cmp_eq_u32_e64 s[6:7], 0, v13
+; GFX9-NEXT: v_lshlrev_b64 v[12:13], v13, v[2:3]
+; GFX9-NEXT: v_cndmask_b32_e64 v7, v7, v8, s[4:5]
+; GFX9-NEXT: v_cndmask_b32_e64 v6, v6, v9, s[4:5]
+; GFX9-NEXT: v_mov_b32_e32 v8, 0
+; GFX9-NEXT: v_mov_b32_e32 v10, 0
+; GFX9-NEXT: v_cndmask_b32_e64 v7, v7, v1, s[6:7]
+; GFX9-NEXT: v_cndmask_b32_e64 v6, v6, v0, s[6:7]
+; GFX9-NEXT: v_cndmask_b32_e64 v13, 0, v13, s[4:5]
+; GFX9-NEXT: v_mov_b32_e32 v9, 0
+; GFX9-NEXT: v_mov_b32_e32 v11, 0
+; GFX9-NEXT: v_cndmask_b32_e64 v12, 0, v12, s[4:5]
+; GFX9-NEXT: s_and_saveexec_b64 s[4:5], vcc
+; GFX9-NEXT: s_xor_b64 s[6:7], exec, s[4:5]
+; GFX9-NEXT: s_cbranch_execz .LBB0_5
+; GFX9-NEXT: ; %bb.2: ; %udiv-preheader
+; GFX9-NEXT: v_sub_u32_e32 v10, 64, v24
+; GFX9-NEXT: v_lshrrev_b64 v[8:9], v24, v[2:3]
+; GFX9-NEXT: v_lshlrev_b64 v[10:11], v10, v[0:1]
+; GFX9-NEXT: v_cmp_gt_u32_e32 vcc, 64, v24
+; GFX9-NEXT: v_or_b32_e32 v10, v8, v10
+; GFX9-NEXT: v_subrev_u32_e32 v8, 64, v24
+; GFX9-NEXT: v_or_b32_e32 v11, v9, v11
+; GFX9-NEXT: v_lshrrev_b64 v[8:9], v8, v[0:1]
+; GFX9-NEXT: v_cmp_eq_u32_e64 s[4:5], 0, v24
+; GFX9-NEXT: v_cndmask_b32_e32 v9, v9, v11, vcc
+; GFX9-NEXT: v_cndmask_b32_e64 v15, v9, v3, s[4:5]
+; GFX9-NEXT: v_cndmask_b32_e32 v10, v8, v10, vcc
+; GFX9-NEXT: v_lshrrev_b64 v[8:9], v24, v[0:1]
+; GFX9-NEXT: v_cndmask_b32_e64 v14, v10, v2, s[4:5]
+; GFX9-NEXT: v_cndmask_b32_e32 v17, 0, v9, vcc
+; GFX9-NEXT: v_cndmask_b32_e32 v16, 0, v8, vcc
+; GFX9-NEXT: v_add_co_u32_e32 v28, vcc, -1, v23
+; GFX9-NEXT: v_addc_co_u32_e32 v29, vcc, -1, v21, vcc
+; GFX9-NEXT: v_addc_co_u32_e32 v30, vcc, -1, v4, vcc
+; GFX9-NEXT: v_mov_b32_e32 v18, 0
+; GFX9-NEXT: v_mov_b32_e32 v10, 0
+; GFX9-NEXT: v_addc_co_u32_e32 v31, vcc, -1, v5, vcc
+; GFX9-NEXT: s_mov_b64 s[4:5], 0
+; GFX9-NEXT: v_mov_b32_e32 v19, 0
+; GFX9-NEXT: v_mov_b32_e32 v11, 0
+; GFX9-NEXT: v_mov_b32_e32 v9, 0
+; GFX9-NEXT: .LBB0_3: ; %udiv-do-while
+; GFX9-NEXT: ; =>This Inner Loop Header: Depth=1
+; GFX9-NEXT: v_lshrrev_b32_e32 v32, 31, v15
+; GFX9-NEXT: v_lshlrev_b64 v[14:15], 1, v[14:15]
+; GFX9-NEXT: v_lshrrev_b32_e32 v33, 31, v7
+; GFX9-NEXT: v_lshlrev_b64 v[6:7], 1, v[6:7]
+; GFX9-NEXT: v_lshrrev_b32_e32 v8, 31, v13
+; GFX9-NEXT: v_lshlrev_b64 v[16:17], 1, v[16:17]
+; GFX9-NEXT: v_or_b32_e32 v14, v14, v33
+; GFX9-NEXT: v_or3_b32 v6, v6, v8, v10
+; GFX9-NEXT: v_sub_co_u32_e32 v8, vcc, v28, v14
+; GFX9-NEXT: v_or_b32_e32 v16, v16, v32
+; GFX9-NEXT: v_subb_co_u32_e32 v8, vcc, v29, v15, vcc
+; GFX9-NEXT: v_subb_co_u32_e32 v8, vcc, v30, v16, vcc
+; GFX9-NEXT: v_lshlrev_b64 v[12:13], 1, v[12:13]
+; GFX9-NEXT: v_subb_co_u32_e32 v8, vcc, v31, v17, vcc
+; GFX9-NEXT: v_ashrrev_i32_e32 v8, 31, v8
+; GFX9-NEXT: v_or_b32_e32 v12, v18, v12
+; GFX9-NEXT: v_and_b32_e32 v18, v8, v23
+; GFX9-NEXT: v_or_b32_e32 v13, v19, v13
+; GFX9-NEXT: v_and_b32_e32 v19, v8, v21
+; GFX9-NEXT: v_sub_co_u32_e32 v14, vcc, v14, v18
+; GFX9-NEXT: v_and_b32_e32 v32, v8, v4
+; GFX9-NEXT: v_subb_co_u32_e32 v15, vcc, v15, v19, vcc
+; GFX9-NEXT: v_and_b32_e32 v33, v8, v5
+; GFX9-NEXT: v_subb_co_u32_e32 v16, vcc, v16, v32, vcc
+; GFX9-NEXT: v_subb_co_u32_e32 v17, vcc, v17, v33, vcc
+; GFX9-NEXT: v_add_co_u32_e32 v24, vcc, -1, v24
+; GFX9-NEXT: v_addc_co_u32_e32 v25, vcc, -1, v25, vcc
+; GFX9-NEXT: v_addc_co_u32_e32 v26, vcc, -1, v26, vcc
+; GFX9-NEXT: v_addc_co_u32_e32 v27, vcc, -1, v27, vcc
+; GFX9-NEXT: v_or_b32_e32 v18, v24, v26
+; GFX9-NEXT: v_or_b32_e32 v19, v25, v27
+; GFX9-NEXT: v_cmp_eq_u64_e32 vcc, 0, v[18:19]
+; GFX9-NEXT: v_and_b32_e32 v8, 1, v8
+; GFX9-NEXT: v_mov_b32_e32 v19, v9
+; GFX9-NEXT: v_or3_b32 v7, v7, 0, v11
+; GFX9-NEXT: s_or_b64 s[4:5], vcc, s[4:5]
+; GFX9-NEXT: v_mov_b32_e32 v18, v8
+; GFX9-NEXT: s_andn2_b64 exec, exec, s[4:5]
+; GFX9-NEXT: s_cbranch_execnz .LBB0_3
+; GFX9-NEXT: ; %bb.4: ; %Flow
+; GFX9-NEXT: s_or_b64 exec, exec, s[4:5]
+; GFX9-NEXT: .LBB0_5: ; %Flow2
+; GFX9-NEXT: s_or_b64 exec, exec, s[6:7]
+; GFX9-NEXT: v_lshlrev_b64 v[14:15], 1, v[12:13]
+; GFX9-NEXT: v_lshlrev_b64 v[6:7], 1, v[6:7]
+; GFX9-NEXT: v_lshrrev_b32_e32 v12, 31, v13
+; GFX9-NEXT: v_or3_b32 v11, v7, 0, v11
+; GFX9-NEXT: v_or3_b32 v12, v6, v12, v10
+; GFX9-NEXT: v_or_b32_e32 v10, v9, v15
+; GFX9-NEXT: v_or_b32_e32 v13, v8, v14
+; GFX9-NEXT: .LBB0_6: ; %Flow3
+; GFX9-NEXT: s_or_b64 exec, exec, s[8:9]
+; GFX9-NEXT: v_mul_lo_u32 v16, v13, v5
+; GFX9-NEXT: v_mad_u64_u32 v[5:6], s[4:5], v23, v13, 0
+; GFX9-NEXT: v_mov_b32_e32 v15, 0
+; GFX9-NEXT: v_mad_u64_u32 v[7:8], s[4:5], v13, v4, 0
+; GFX9-NEXT: v_mov_b32_e32 v14, v6
+; GFX9-NEXT: v_mad_u64_u32 v[13:14], s[4:5], v21, v13, v[14:15]
+; GFX9-NEXT: v_mul_lo_u32 v9, v10, v4
+; GFX9-NEXT: v_mul_lo_u32 v11, v11, v23
+; GFX9-NEXT: v_mov_b32_e32 v4, v14
+; GFX9-NEXT: v_mov_b32_e32 v14, v15
+; GFX9-NEXT: v_mad_u64_u32 v[13:14], s[4:5], v23, v10, v[13:14]
+; GFX9-NEXT: v_add3_u32 v8, v8, v16, v9
+; GFX9-NEXT: v_mad_u64_u32 v[6:7], s[4:5], v12, v23, v[7:8]
+; GFX9-NEXT: v_mov_b32_e32 v8, v14
+; GFX9-NEXT: v_add_co_u32_e32 v8, vcc, v4, v8
+; GFX9-NEXT: v_addc_co_u32_e64 v9, s[4:5], 0, 0, vcc
+; GFX9-NEXT: v_mul_lo_u32 v12, v12, v21
+; GFX9-NEXT: v_mad_u64_u32 v[8:9], s[4:5], v21, v10, v[8:9]
+; GFX9-NEXT: v_add3_u32 v4, v11, v7, v12
+; GFX9-NEXT: v_add_co_u32_e32 v6, vcc, v8, v6
+; GFX9-NEXT: v_addc_co_u32_e32 v4, vcc, v9, v4, vcc
+; GFX9-NEXT: v_mov_b32_e32 v7, v13
+; GFX9-NEXT: v_sub_co_u32_e32 v2, vcc, v2, v5
+; GFX9-NEXT: v_subb_co_u32_e32 v3, vcc, v3, v7, vcc
+; GFX9-NEXT: v_subb_co_u32_e32 v0, vcc, v0, v6, vcc
+; GFX9-NEXT: v_subb_co_u32_e32 v1, vcc, v1, v4, vcc
+; GFX9-NEXT: v_xor_b32_e32 v5, v0, v20
+; GFX9-NEXT: v_xor_b32_e32 v0, v2, v20
+; GFX9-NEXT: v_xor_b32_e32 v4, v1, v22
+; GFX9-NEXT: v_xor_b32_e32 v1, v3, v22
+; GFX9-NEXT: v_sub_co_u32_e32 v0, vcc, v0, v20
+; GFX9-NEXT: v_subb_co_u32_e32 v1, vcc, v1, v22, vcc
+; GFX9-NEXT: v_subb_co_u32_e32 v2, vcc, v5, v20, vcc
+; GFX9-NEXT: v_subb_co_u32_e32 v3, vcc, v4, v22, vcc
+; GFX9-NEXT: s_setpc_b64 s[30:31]
+;
+; GFX9-O0-LABEL: v_srem_i128_vv:
+; GFX9-O0: ; %bb.0: ; %_udiv-special-cases
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
+; GFX9-O0-NEXT: s_xor_saveexec_b64 s[4:5], -1
+; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 offset:348 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:352 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v8, off, s[0:3], s32 offset:356 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v16, off, s[0:3], s32 offset:360 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_mov_b64 exec, s[4:5]
+; GFX9-O0-NEXT: ; implicit-def: $vgpr8 : SGPR spill to VGPR lane
+; GFX9-O0-NEXT: v_mov_b32_e32 v8, v6
+; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:120 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:116 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: v_mov_b32_e32 v14, v2
+; GFX9-O0-NEXT: buffer_load_dword v2, off, s[0:3], s32 offset:120 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v1
+; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:116 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v0
+; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
+; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v5
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr4 killed $vgpr4 def $vgpr4_vgpr5 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v6
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr8 killed $vgpr8 def $vgpr8_vgpr9 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v9, v7
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr14 killed $vgpr14 def $vgpr14_vgpr15 killed $exec
+; GFX9-O0-NEXT: s_waitcnt vmcnt(1)
+; GFX9-O0-NEXT: v_mov_b32_e32 v15, v1
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4_sgpr5
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4_sgpr5
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4_sgpr5
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4_sgpr5
+; GFX9-O0-NEXT: s_mov_b32 s4, 63
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v14
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v15
+; GFX9-O0-NEXT: v_ashrrev_i64 v[12:13], s4, v[6:7]
+; GFX9-O0-NEXT: buffer_store_dword v12, off, s[0:3], s32 offset:108 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v13, off, s[0:3], s32 offset:112 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v12
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v13
+; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:100 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v7, off, s[0:3], s32 offset:104 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v8
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v9
+; GFX9-O0-NEXT: v_ashrrev_i64 v[6:7], s4, v[6:7]
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v15
+; GFX9-O0-NEXT: v_mov_b32_e32 v10, v13
+; GFX9-O0-NEXT: v_xor_b32_e64 v1, v1, v10
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, v14
+; GFX9-O0-NEXT: v_xor_b32_e64 v13, v11, v12
+; GFX9-O0-NEXT: ; kill: def $vgpr13 killed $vgpr13 def $vgpr13_vgpr14 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v14, v1
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v5
+; GFX9-O0-NEXT: v_xor_b32_e64 v1, v1, v10
+; GFX9-O0-NEXT: ; kill: def $vgpr4 killed $vgpr4 killed $vgpr4_vgpr5 killed $exec
+; GFX9-O0-NEXT: v_xor_b32_e64 v15, v4, v12
+; GFX9-O0-NEXT: ; kill: def $vgpr15 killed $vgpr15 def $vgpr15_vgpr16 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v16, v1
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v9
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v7
+; GFX9-O0-NEXT: v_xor_b32_e64 v1, v1, v4
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v8
+; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 killed $vgpr6_vgpr7 killed $exec
+; GFX9-O0-NEXT: v_xor_b32_e64 v7, v5, v6
+; GFX9-O0-NEXT: ; kill: def $vgpr7 killed $vgpr7 def $vgpr7_vgpr8 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v8, v1
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v3
+; GFX9-O0-NEXT: v_xor_b32_e64 v1, v1, v4
+; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 killed $vgpr2_vgpr3 killed $exec
+; GFX9-O0-NEXT: v_xor_b32_e64 v2, v2, v6
+; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v1
+; GFX9-O0-NEXT: v_mov_b32_e32 v9, v15
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v16
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, v13
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v14
+; GFX9-O0-NEXT: v_sub_co_u32_e32 v9, vcc, v9, v12
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v1, vcc, v1, v10, vcc
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v13, vcc, v11, v12, vcc
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v5, vcc, v5, v10, vcc
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr13 killed $vgpr13 def $vgpr13_vgpr14 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v14, v5
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr9 killed $vgpr9 def $vgpr9_vgpr10 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v10, v1
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v2
+; GFX9-O0-NEXT: ; kill: def $vgpr3 killed $vgpr3 killed $vgpr2_vgpr3 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v7
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v8
+; GFX9-O0-NEXT: v_sub_co_u32_e32 v1, vcc, v1, v6
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v3, vcc, v3, v4, vcc
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v11, vcc, v5, v6, vcc
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v2, vcc, v2, v4, vcc
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 def $vgpr11_vgpr12 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, v2
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr1 killed $vgpr1 def $vgpr1_vgpr2 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
+; GFX9-O0-NEXT: buffer_store_dword v9, off, s[0:3], s32 offset:92 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v10, off, s[0:3], s32 offset:96 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v13, off, s[0:3], s32 offset:84 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v14, off, s[0:3], s32 offset:88 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:76 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:80 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v11, off, s[0:3], s32 offset:68 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v12, off, s[0:3], s32 offset:72 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v11
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v12
+; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:60 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:64 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v1
+; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:52 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:56 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v13
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v14
+; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:44 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:48 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v9
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v10
+; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:36 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:40 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v12
+; GFX9-O0-NEXT: v_mov_b32_e32 v8, v2
+; GFX9-O0-NEXT: v_or_b32_e64 v3, v8, v7
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v11
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v1
+; GFX9-O0-NEXT: v_or_b32_e64 v1, v5, v6
+; GFX9-O0-NEXT: ; kill: def $vgpr1 killed $vgpr1 def $vgpr1_vgpr2 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
+; GFX9-O0-NEXT: s_mov_b64 s[6:7], 0
+; GFX9-O0-NEXT: v_writelane_b32 v0, s6, 0
+; GFX9-O0-NEXT: v_writelane_b32 v0, s7, 1
+; GFX9-O0-NEXT: v_cmp_eq_u64_e64 s[4:5], v[1:2], s[6:7]
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v14
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v10
+; GFX9-O0-NEXT: v_or_b32_e64 v15, v4, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v13
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v9
+; GFX9-O0-NEXT: v_or_b32_e64 v9, v3, v1
+; GFX9-O0-NEXT: ; kill: def $vgpr9 killed $vgpr9 def $vgpr9_vgpr10 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v10, v15
+; GFX9-O0-NEXT: v_cmp_eq_u64_e64 s[8:9], v[9:10], s[6:7]
+; GFX9-O0-NEXT: s_or_b64 s[4:5], s[4:5], s[8:9]
+; GFX9-O0-NEXT: v_ffbh_u32_e64 v6, v6
+; GFX9-O0-NEXT: s_mov_b32 s9, 32
+; GFX9-O0-NEXT: v_add_u32_e64 v6, v6, s9
+; GFX9-O0-NEXT: v_ffbh_u32_e64 v7, v7
+; GFX9-O0-NEXT: v_min_u32_e64 v6, v6, v7
+; GFX9-O0-NEXT: s_mov_b32 s8, 0
+; GFX9-O0-NEXT: ; implicit-def: $sgpr10
+; GFX9-O0-NEXT: v_mov_b32_e32 v9, s8
+; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 def $vgpr6_vgpr7 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v9
+; GFX9-O0-NEXT: v_mov_b32_e32 v10, v7
+; GFX9-O0-NEXT: v_ffbh_u32_e64 v5, v5
+; GFX9-O0-NEXT: v_add_u32_e64 v5, v5, s9
+; GFX9-O0-NEXT: v_ffbh_u32_e64 v8, v8
+; GFX9-O0-NEXT: v_min_u32_e64 v15, v5, v8
+; GFX9-O0-NEXT: ; implicit-def: $sgpr10
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, s8
+; GFX9-O0-NEXT: ; kill: def $vgpr15 killed $vgpr15 def $vgpr15_vgpr16 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v16, v5
+; GFX9-O0-NEXT: s_mov_b64 s[10:11], 64
+; GFX9-O0-NEXT: v_mov_b32_e32 v8, v15
+; GFX9-O0-NEXT: s_mov_b32 s12, s10
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v16
+; GFX9-O0-NEXT: s_mov_b32 s14, s11
+; GFX9-O0-NEXT: v_add_co_u32_e64 v8, s[12:13], v8, s12
+; GFX9-O0-NEXT: v_mov_b32_e32 v9, s14
+; GFX9-O0-NEXT: v_addc_co_u32_e64 v5, s[12:13], v5, v9, s[12:13]
+; GFX9-O0-NEXT: ; kill: def $vgpr8 killed $vgpr8 def $vgpr8_vgpr9 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v9, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v9
+; GFX9-O0-NEXT: v_cmp_ne_u64_e64 s[12:13], v[11:12], s[6:7]
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v5, v10, s[12:13]
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v6
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v8
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v9, v6, v7, s[12:13]
+; GFX9-O0-NEXT: ; implicit-def: $sgpr12
+; GFX9-O0-NEXT: ; implicit-def: $sgpr12
+; GFX9-O0-NEXT: ; kill: def $vgpr9 killed $vgpr9 def $vgpr9_vgpr10 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v10, v5
+; GFX9-O0-NEXT: v_ffbh_u32_e64 v5, v1
+; GFX9-O0-NEXT: v_add_u32_e64 v5, v5, s9
+; GFX9-O0-NEXT: v_ffbh_u32_e64 v6, v2
+; GFX9-O0-NEXT: v_min_u32_e64 v6, v5, v6
+; GFX9-O0-NEXT: ; implicit-def: $sgpr12
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, s8
+; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 def $vgpr6_vgpr7 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v8, v7
+; GFX9-O0-NEXT: v_ffbh_u32_e64 v5, v3
+; GFX9-O0-NEXT: v_add_u32_e64 v5, v5, s9
+; GFX9-O0-NEXT: v_ffbh_u32_e64 v11, v4
+; GFX9-O0-NEXT: v_min_u32_e64 v15, v5, v11
+; GFX9-O0-NEXT: ; implicit-def: $sgpr9
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, s8
+; GFX9-O0-NEXT: ; kill: def $vgpr15 killed $vgpr15 def $vgpr15_vgpr16 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v16, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, v15
+; GFX9-O0-NEXT: s_mov_b32 s8, s10
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v16
+; GFX9-O0-NEXT: s_mov_b32 s10, s11
+; GFX9-O0-NEXT: v_add_co_u32_e64 v11, s[8:9], v11, s8
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, s10
+; GFX9-O0-NEXT: v_addc_co_u32_e64 v5, s[8:9], v5, v12, s[8:9]
+; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 def $vgpr11_vgpr12 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v12
+; GFX9-O0-NEXT: v_cmp_ne_u64_e64 s[8:9], v[13:14], s[6:7]
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v5, v8, s[8:9]
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v6
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v11
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v6, v6, v7, s[8:9]
+; GFX9-O0-NEXT: ; implicit-def: $sgpr8
+; GFX9-O0-NEXT: ; implicit-def: $sgpr8
+; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 def $vgpr6_vgpr7 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v8, v6
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v9
+; GFX9-O0-NEXT: ; kill: def $vgpr7 killed $vgpr7 killed $vgpr6_vgpr7 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v10
+; GFX9-O0-NEXT: s_mov_b32 s10, s6
+; GFX9-O0-NEXT: s_mov_b32 s11, s7
+; GFX9-O0-NEXT: v_sub_co_u32_e32 v5, vcc, v5, v8
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v9, vcc, v6, v7, vcc
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, s10
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, s10
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v8, vcc, v6, v7, vcc
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, s11
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, s11
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v7, vcc, v6, v7, vcc
+; GFX9-O0-NEXT: ; implicit-def: $sgpr8
+; GFX9-O0-NEXT: ; implicit-def: $sgpr8
+; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v9
+; GFX9-O0-NEXT: ; implicit-def: $sgpr8
+; GFX9-O0-NEXT: ; implicit-def: $sgpr8
+; GFX9-O0-NEXT: ; kill: def $vgpr8 killed $vgpr8 def $vgpr8_vgpr9 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v9, v7
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, v9
+; GFX9-O0-NEXT: v_mov_b32_e32 v10, v8
+; GFX9-O0-NEXT: buffer_store_dword v10, off, s[0:3], s32 offset:28 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v11, off, s[0:3], s32 offset:32 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, v6
+; GFX9-O0-NEXT: v_mov_b32_e32 v10, v5
+; GFX9-O0-NEXT: buffer_store_dword v10, off, s[0:3], s32 offset:20 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v11, off, s[0:3], s32 offset:24 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_mov_b64 s[8:9], s[6:7]
+; GFX9-O0-NEXT: v_cmp_eq_u64_e64 s[8:9], v[8:9], s[8:9]
+; GFX9-O0-NEXT: s_mov_b64 s[12:13], 0x7f
+; GFX9-O0-NEXT: s_mov_b64 s[14:15], s[12:13]
+; GFX9-O0-NEXT: v_cmp_gt_u64_e64 s[14:15], v[5:6], s[14:15]
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v10, 0, 1, s[14:15]
+; GFX9-O0-NEXT: s_mov_b64 s[14:15], s[6:7]
+; GFX9-O0-NEXT: v_cmp_ne_u64_e64 s[14:15], v[8:9], s[14:15]
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v7, 0, 1, s[14:15]
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v7, v7, v10, s[8:9]
+; GFX9-O0-NEXT: v_and_b32_e64 v7, 1, v7
+; GFX9-O0-NEXT: v_cmp_eq_u32_e64 s[8:9], v7, 1
+; GFX9-O0-NEXT: s_or_b64 s[8:9], s[4:5], s[8:9]
+; GFX9-O0-NEXT: s_mov_b64 s[4:5], -1
+; GFX9-O0-NEXT: s_xor_b64 s[4:5], s[8:9], s[4:5]
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v6
+; GFX9-O0-NEXT: s_mov_b32 s14, s13
+; GFX9-O0-NEXT: v_xor_b32_e64 v7, v7, s14
+; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 killed $vgpr5_vgpr6 killed $exec
+; GFX9-O0-NEXT: ; kill: def $sgpr12 killed $sgpr12 killed $sgpr12_sgpr13
+; GFX9-O0-NEXT: v_xor_b32_e64 v5, v5, s12
+; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v7
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v6
+; GFX9-O0-NEXT: v_mov_b32_e32 v10, v9
+; GFX9-O0-NEXT: v_or_b32_e64 v7, v7, v10
+; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 killed $vgpr5_vgpr6 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v8
+; GFX9-O0-NEXT: v_or_b32_e64 v5, v5, v6
+; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v7
+; GFX9-O0-NEXT: v_cmp_ne_u64_e64 s[6:7], v[5:6], s[6:7]
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, s11
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v2, v5, s[8:9]
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, s10
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v1, v1, v2, s[8:9]
+; GFX9-O0-NEXT: ; implicit-def: $sgpr12
+; GFX9-O0-NEXT: ; implicit-def: $sgpr12
+; GFX9-O0-NEXT: ; kill: def $vgpr1 killed $vgpr1 def $vgpr1_vgpr2 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, s11
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v4, v5, s[8:9]
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, s10
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v3, v3, v4, s[8:9]
+; GFX9-O0-NEXT: ; implicit-def: $sgpr8
+; GFX9-O0-NEXT: ; implicit-def: $sgpr8
+; GFX9-O0-NEXT: ; kill: def $vgpr3 killed $vgpr3 def $vgpr3_vgpr4 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v5
+; GFX9-O0-NEXT: s_and_b64 s[6:7], s[4:5], s[6:7]
+; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:12 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:16 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:4 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:8 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_mov_b64 s[4:5], exec
+; GFX9-O0-NEXT: v_writelane_b32 v0, s4, 2
+; GFX9-O0-NEXT: v_writelane_b32 v0, s5, 3
+; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
+; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
+; GFX9-O0-NEXT: s_and_b64 s[4:5], s[4:5], s[6:7]
+; GFX9-O0-NEXT: s_mov_b64 exec, s[4:5]
+; GFX9-O0-NEXT: s_cbranch_execz .LBB0_3
+; GFX9-O0-NEXT: s_branch .LBB0_8
+; GFX9-O0-NEXT: .LBB0_1: ; %Flow
+; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
+; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: v_readlane_b32 s4, v0, 4
+; GFX9-O0-NEXT: v_readlane_b32 s5, v0, 5
+; GFX9-O0-NEXT: s_or_b64 exec, exec, s[4:5]
+; GFX9-O0-NEXT: ; %bb.2: ; %Flow
+; GFX9-O0-NEXT: buffer_load_dword v6, off, s[0:3], s32 offset:156 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v7, off, s[0:3], s32 offset:160 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v4, off, s[0:3], s32 offset:164 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v5, off, s[0:3], s32 offset:168 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v2, off, s[0:3], s32 offset:172 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v3, off, s[0:3], s32 offset:176 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 offset:180 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:184 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_waitcnt vmcnt(6)
+; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:148 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v7, off, s[0:3], s32 offset:152 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:140 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:144 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:132 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:136 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 offset:124 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:128 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_branch .LBB0_5
+; GFX9-O0-NEXT: .LBB0_3: ; %Flow2
+; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
+; GFX9-O0-NEXT: buffer_load_dword v4, off, s[0:3], s32 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: v_readlane_b32 s4, v4, 2
+; GFX9-O0-NEXT: v_readlane_b32 s5, v4, 3
+; GFX9-O0-NEXT: s_or_b64 exec, exec, s[4:5]
+; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 offset:12 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:16 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v2, off, s[0:3], s32 offset:4 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v3, off, s[0:3], s32 offset:8 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:196 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:200 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 offset:188 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:192 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_branch .LBB0_9
+; GFX9-O0-NEXT: .LBB0_4: ; %udiv-loop-exit
+; GFX9-O0-NEXT: buffer_load_dword v5, off, s[0:3], s32 offset:204 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v6, off, s[0:3], s32 offset:208 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v7, off, s[0:3], s32 offset:212 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v8, off, s[0:3], s32 offset:216 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 offset:220 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:224 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v9, off, s[0:3], s32 offset:228 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v10, off, s[0:3], s32 offset:232 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_mov_b32 s4, 1
+; GFX9-O0-NEXT: s_waitcnt vmcnt(2)
+; GFX9-O0-NEXT: v_lshlrev_b64 v[2:3], s4, v[0:1]
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: v_lshlrev_b64 v[9:10], s4, v[9:10]
+; GFX9-O0-NEXT: s_mov_b32 s4, 63
+; GFX9-O0-NEXT: v_lshrrev_b64 v[0:1], s4, v[0:1]
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, v1
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v10
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, v8
+; GFX9-O0-NEXT: v_or3_b32 v4, v4, v11, v12
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v0
+; GFX9-O0-NEXT: v_mov_b32_e32 v0, v9
+; GFX9-O0-NEXT: v_or3_b32 v0, v0, v1, v7
+; GFX9-O0-NEXT: ; kill: def $vgpr0 killed $vgpr0 def $vgpr0_vgpr1 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v4
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v3
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v6
+; GFX9-O0-NEXT: v_or_b32_e64 v4, v4, v7
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v5
+; GFX9-O0-NEXT: v_or_b32_e64 v2, v2, v3
+; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v4
+; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:12 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:16 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 offset:4 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:8 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_branch .LBB0_3
+; GFX9-O0-NEXT: .LBB0_5: ; %Flow1
+; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
+; GFX9-O0-NEXT: buffer_load_dword v8, off, s[0:3], s32 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: v_readlane_b32 s4, v8, 6
+; GFX9-O0-NEXT: v_readlane_b32 s5, v8, 7
+; GFX9-O0-NEXT: s_or_b64 exec, exec, s[4:5]
+; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 offset:148 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:152 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v2, off, s[0:3], s32 offset:140 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v3, off, s[0:3], s32 offset:144 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v4, off, s[0:3], s32 offset:132 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v5, off, s[0:3], s32 offset:136 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v6, off, s[0:3], s32 offset:124 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v7, off, s[0:3], s32 offset:128 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:212 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v7, off, s[0:3], s32 offset:216 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:204 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:208 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:228 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:232 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 offset:220 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:224 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_branch .LBB0_4
+; GFX9-O0-NEXT: .LBB0_6: ; %udiv-do-while
+; GFX9-O0-NEXT: ; =>This Inner Loop Header: Depth=1
+; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
+; GFX9-O0-NEXT: buffer_load_dword v16, off, s[0:3], s32 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: v_readlane_b32 s6, v16, 8
+; GFX9-O0-NEXT: v_readlane_b32 s7, v16, 9
+; GFX9-O0-NEXT: buffer_load_dword v6, off, s[0:3], s32 offset:236 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v7, off, s[0:3], s32 offset:240 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 offset:244 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:248 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v23, off, s[0:3], s32 offset:252 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v24, off, s[0:3], s32 offset:256 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v2, off, s[0:3], s32 offset:260 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v3, off, s[0:3], s32 offset:264 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v17, off, s[0:3], s32 offset:268 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v18, off, s[0:3], s32 offset:272 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v8, off, s[0:3], s32 offset:276 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v9, off, s[0:3], s32 offset:280 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v27, off, s[0:3], s32 offset:284 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v28, off, s[0:3], s32 offset:288 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v25, off, s[0:3], s32 offset:292 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v26, off, s[0:3], s32 offset:296 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v19, off, s[0:3], s32 offset:52 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v20, off, s[0:3], s32 offset:56 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v21, off, s[0:3], s32 offset:60 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v22, off, s[0:3], s32 offset:64 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v14, off, s[0:3], s32 offset:300 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v15, off, s[0:3], s32 offset:304 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v11, off, s[0:3], s32 offset:308 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v12, off, s[0:3], s32 offset:312 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_mov_b32 s4, 63
+; GFX9-O0-NEXT: s_waitcnt vmcnt(16)
+; GFX9-O0-NEXT: v_lshrrev_b64 v[29:30], s4, v[2:3]
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v30
+; GFX9-O0-NEXT: s_mov_b32 s5, 1
+; GFX9-O0-NEXT: v_lshlrev_b64 v[23:24], s5, v[23:24]
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v24
+; GFX9-O0-NEXT: v_or_b32_e64 v4, v4, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v10, v29
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v23
+; GFX9-O0-NEXT: v_or_b32_e64 v23, v5, v10
+; GFX9-O0-NEXT: ; kill: def $vgpr23 killed $vgpr23 def $vgpr23_vgpr24 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v24, v4
+; GFX9-O0-NEXT: v_lshlrev_b64 v[29:30], s5, v[2:3]
+; GFX9-O0-NEXT: v_lshrrev_b64 v[4:5], s4, v[6:7]
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v30
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v5
+; GFX9-O0-NEXT: v_or_b32_e64 v2, v2, v3
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v29
+; GFX9-O0-NEXT: ; kill: def $vgpr4 killed $vgpr4 killed $vgpr4_vgpr5 killed $exec
+; GFX9-O0-NEXT: v_or_b32_e64 v4, v3, v4
+; GFX9-O0-NEXT: ; kill: def $vgpr4 killed $vgpr4 def $vgpr4_vgpr5 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v2
+; GFX9-O0-NEXT: v_lshlrev_b64 v[2:3], s5, v[0:1]
+; GFX9-O0-NEXT: v_lshlrev_b64 v[29:30], s5, v[6:7]
+; GFX9-O0-NEXT: v_lshrrev_b64 v[0:1], s4, v[0:1]
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v1
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v30
+; GFX9-O0-NEXT: s_waitcnt vmcnt(10)
+; GFX9-O0-NEXT: v_mov_b32_e32 v10, v28
+; GFX9-O0-NEXT: v_or3_b32 v6, v6, v7, v10
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v0
+; GFX9-O0-NEXT: v_mov_b32_e32 v0, v29
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v27
+; GFX9-O0-NEXT: v_or3_b32 v0, v0, v1, v7
+; GFX9-O0-NEXT: ; kill: def $vgpr0 killed $vgpr0 def $vgpr0_vgpr1 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v6
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v3
+; GFX9-O0-NEXT: s_waitcnt vmcnt(8)
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v26
+; GFX9-O0-NEXT: v_or_b32_e64 v6, v6, v7
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v25
+; GFX9-O0-NEXT: v_or_b32_e64 v2, v2, v3
+; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v6
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v4
+; GFX9-O0-NEXT: v_mov_b32_e32 v10, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v23
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v24
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: v_mov_b32_e32 v13, v11
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, v14
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v15
+; GFX9-O0-NEXT: v_sub_co_u32_e32 v13, vcc, v13, v6
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v12, vcc, v12, v10, vcc
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v11, vcc, v11, v4, vcc
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v7, vcc, v7, v5, vcc
+; GFX9-O0-NEXT: ; implicit-def: $sgpr5
+; GFX9-O0-NEXT: ; implicit-def: $sgpr5
+; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 def $vgpr11_vgpr12 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, v7
+; GFX9-O0-NEXT: v_ashrrev_i64 v[13:14], s4, v[11:12]
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v14
+; GFX9-O0-NEXT: s_mov_b64 s[4:5], 1
+; GFX9-O0-NEXT: s_mov_b32 s8, s5
+; GFX9-O0-NEXT: v_and_b32_e64 v12, v7, s8
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, v13
+; GFX9-O0-NEXT: ; kill: def $sgpr4 killed $sgpr4 killed $sgpr4_sgpr5
+; GFX9-O0-NEXT: v_and_b32_e64 v14, v11, s4
+; GFX9-O0-NEXT: ; kill: def $vgpr14 killed $vgpr14 def $vgpr14_vgpr15 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v15, v12
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, 0
+; GFX9-O0-NEXT: v_mov_b32_e32 v13, 0
+; GFX9-O0-NEXT: v_mov_b32_e32 v23, v22
+; GFX9-O0-NEXT: v_and_b32_e64 v23, v7, v23
+; GFX9-O0-NEXT: v_and_b32_e64 v21, v11, v21
+; GFX9-O0-NEXT: ; kill: def $vgpr21 killed $vgpr21 def $vgpr21_vgpr22 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v22, v23
+; GFX9-O0-NEXT: v_mov_b32_e32 v23, v20
+; GFX9-O0-NEXT: v_and_b32_e64 v7, v7, v23
+; GFX9-O0-NEXT: v_and_b32_e64 v23, v11, v19
+; GFX9-O0-NEXT: ; kill: def $vgpr23 killed $vgpr23 def $vgpr23_vgpr24 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v24, v7
+; GFX9-O0-NEXT: v_mov_b32_e32 v20, v23
+; GFX9-O0-NEXT: v_mov_b32_e32 v19, v24
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, v21
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v22
+; GFX9-O0-NEXT: v_sub_co_u32_e32 v6, vcc, v6, v20
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v10, vcc, v10, v19, vcc
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v4, vcc, v4, v11, vcc
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v7, vcc, v5, v7, vcc
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr4 killed $vgpr4 def $vgpr4_vgpr5 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v7
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 def $vgpr6_vgpr7 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v10
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, v8
+; GFX9-O0-NEXT: ; kill: def $vgpr9 killed $vgpr9 killed $vgpr8_vgpr9 killed $exec
+; GFX9-O0-NEXT: s_mov_b64 s[8:9], -1
+; GFX9-O0-NEXT: s_mov_b32 s5, s8
+; GFX9-O0-NEXT: s_mov_b32 s4, s9
+; GFX9-O0-NEXT: v_mov_b32_e32 v10, v17
+; GFX9-O0-NEXT: v_mov_b32_e32 v8, v18
+; GFX9-O0-NEXT: v_mov_b32_e32 v17, s5
+; GFX9-O0-NEXT: v_add_co_u32_e32 v20, vcc, v11, v17
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, s4
+; GFX9-O0-NEXT: v_addc_co_u32_e32 v9, vcc, v9, v11, vcc
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, s5
+; GFX9-O0-NEXT: v_addc_co_u32_e32 v17, vcc, v10, v11, vcc
+; GFX9-O0-NEXT: v_mov_b32_e32 v10, s4
+; GFX9-O0-NEXT: v_addc_co_u32_e32 v8, vcc, v8, v10, vcc
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr20 killed $vgpr20 def $vgpr20_vgpr21 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v21, v9
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr17 killed $vgpr17 def $vgpr17_vgpr18 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v18, v8
+; GFX9-O0-NEXT: v_mov_b32_e32 v8, v17
+; GFX9-O0-NEXT: v_mov_b32_e32 v9, v18
+; GFX9-O0-NEXT: v_mov_b32_e32 v10, v20
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, v21
+; GFX9-O0-NEXT: v_mov_b32_e32 v22, v18
+; GFX9-O0-NEXT: v_mov_b32_e32 v19, v21
+; GFX9-O0-NEXT: v_or_b32_e64 v19, v19, v22
+; GFX9-O0-NEXT: v_mov_b32_e32 v18, v17
+; GFX9-O0-NEXT: v_mov_b32_e32 v17, v20
+; GFX9-O0-NEXT: v_or_b32_e64 v17, v17, v18
+; GFX9-O0-NEXT: ; kill: def $vgpr17 killed $vgpr17 def $vgpr17_vgpr18 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v18, v19
+; GFX9-O0-NEXT: v_cmp_eq_u64_e64 s[4:5], v[17:18], v[12:13]
+; GFX9-O0-NEXT: s_or_b64 s[4:5], s[4:5], s[6:7]
+; GFX9-O0-NEXT: v_mov_b32_e32 v18, v3
+; GFX9-O0-NEXT: v_mov_b32_e32 v17, v2
+; GFX9-O0-NEXT: buffer_store_dword v17, off, s[0:3], s32 offset:156 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v18, off, s[0:3], s32 offset:160 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: v_mov_b32_e32 v18, v1
+; GFX9-O0-NEXT: v_mov_b32_e32 v17, v0
+; GFX9-O0-NEXT: buffer_store_dword v17, off, s[0:3], s32 offset:164 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v18, off, s[0:3], s32 offset:168 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: v_mov_b32_e32 v18, v15
+; GFX9-O0-NEXT: v_mov_b32_e32 v17, v14
+; GFX9-O0-NEXT: buffer_store_dword v17, off, s[0:3], s32 offset:172 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v18, off, s[0:3], s32 offset:176 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: v_mov_b32_e32 v18, v13
+; GFX9-O0-NEXT: v_mov_b32_e32 v17, v12
+; GFX9-O0-NEXT: buffer_store_dword v17, off, s[0:3], s32 offset:180 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v18, off, s[0:3], s32 offset:184 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_mov_b64 s[6:7], s[4:5]
+; GFX9-O0-NEXT: v_writelane_b32 v16, s6, 4
+; GFX9-O0-NEXT: v_writelane_b32 v16, s7, 5
+; GFX9-O0-NEXT: s_mov_b64 s[6:7], s[4:5]
+; GFX9-O0-NEXT: v_writelane_b32 v16, s6, 8
+; GFX9-O0-NEXT: v_writelane_b32 v16, s7, 9
+; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
+; GFX9-O0-NEXT: buffer_store_dword v16, off, s[0:3], s32 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
+; GFX9-O0-NEXT: buffer_store_dword v14, off, s[0:3], s32 offset:292 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v15, off, s[0:3], s32 offset:296 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v12, off, s[0:3], s32 offset:284 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v13, off, s[0:3], s32 offset:288 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v10, off, s[0:3], s32 offset:276 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v11, off, s[0:3], s32 offset:280 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v8, off, s[0:3], s32 offset:268 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v9, off, s[0:3], s32 offset:272 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:260 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v7, off, s[0:3], s32 offset:264 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:252 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:256 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:244 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:248 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 offset:236 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:240 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_andn2_b64 exec, exec, s[4:5]
+; GFX9-O0-NEXT: s_cbranch_execnz .LBB0_6
+; GFX9-O0-NEXT: s_branch .LBB0_1
+; GFX9-O0-NEXT: .LBB0_7: ; %udiv-preheader
+; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 offset:316 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:320 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v2, off, s[0:3], s32 offset:324 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v3, off, s[0:3], s32 offset:328 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v8, off, s[0:3], s32 offset:332 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v9, off, s[0:3], s32 offset:336 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v10, off, s[0:3], s32 offset:340 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v11, off, s[0:3], s32 offset:344 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
+; GFX9-O0-NEXT: buffer_load_dword v16, off, s[0:3], s32 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
+; GFX9-O0-NEXT: buffer_load_dword v17, off, s[0:3], s32 offset:60 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v18, off, s[0:3], s32 offset:64 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v13, off, s[0:3], s32 offset:52 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v14, off, s[0:3], s32 offset:56 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v19, off, s[0:3], s32 offset:44 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v20, off, s[0:3], s32 offset:48 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v21, off, s[0:3], s32 offset:36 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v22, off, s[0:3], s32 offset:40 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_waitcnt vmcnt(9)
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v10
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: v_lshrrev_b64 v[6:7], v4, v[21:22]
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v7
+; GFX9-O0-NEXT: s_mov_b32 s6, 64
+; GFX9-O0-NEXT: v_sub_u32_e64 v12, s6, v4
+; GFX9-O0-NEXT: v_lshlrev_b64 v[23:24], v12, v[19:20]
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, v24
+; GFX9-O0-NEXT: v_or_b32_e64 v5, v5, v12
+; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 killed $vgpr6_vgpr7 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v23
+; GFX9-O0-NEXT: v_or_b32_e64 v6, v6, v7
+; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 def $vgpr6_vgpr7 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, v7
+; GFX9-O0-NEXT: v_cmp_lt_u32_e64 s[4:5], v4, s6
+; GFX9-O0-NEXT: v_sub_u32_e64 v5, v4, s6
+; GFX9-O0-NEXT: v_lshrrev_b64 v[23:24], v5, v[19:20]
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v24
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v5, v12, s[4:5]
+; GFX9-O0-NEXT: s_mov_b32 s6, 0
+; GFX9-O0-NEXT: v_cmp_eq_u32_e64 s[6:7], v4, s6
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, v22
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v5, v12, s[6:7]
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v6
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v23
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v6, v6, v7, s[4:5]
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v21
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v6, v6, v7, s[6:7]
+; GFX9-O0-NEXT: ; implicit-def: $sgpr6
+; GFX9-O0-NEXT: ; implicit-def: $sgpr6
+; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 def $vgpr6_vgpr7 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v5
+; GFX9-O0-NEXT: v_lshrrev_b64 v[4:5], v4, v[19:20]
+; GFX9-O0-NEXT: v_mov_b32_e32 v15, v5
+; GFX9-O0-NEXT: s_mov_b64 s[6:7], 0
+; GFX9-O0-NEXT: s_mov_b32 s8, s7
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, s8
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v12, v12, v15, s[4:5]
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v4
+; GFX9-O0-NEXT: s_mov_b32 s8, s6
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, s8
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v4, v4, v5, s[4:5]
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr4 killed $vgpr4 def $vgpr4_vgpr5 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v12
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, v13
+; GFX9-O0-NEXT: v_mov_b32_e32 v15, v14
+; GFX9-O0-NEXT: s_mov_b64 s[8:9], -1
+; GFX9-O0-NEXT: s_mov_b32 s5, s8
+; GFX9-O0-NEXT: s_mov_b32 s4, s9
+; GFX9-O0-NEXT: v_mov_b32_e32 v14, v17
+; GFX9-O0-NEXT: v_mov_b32_e32 v13, v18
+; GFX9-O0-NEXT: v_mov_b32_e32 v17, s5
+; GFX9-O0-NEXT: v_add_co_u32_e32 v12, vcc, v12, v17
+; GFX9-O0-NEXT: v_mov_b32_e32 v17, s4
+; GFX9-O0-NEXT: v_addc_co_u32_e32 v17, vcc, v15, v17, vcc
+; GFX9-O0-NEXT: v_mov_b32_e32 v15, s5
+; GFX9-O0-NEXT: v_addc_co_u32_e32 v14, vcc, v14, v15, vcc
+; GFX9-O0-NEXT: v_mov_b32_e32 v15, s4
+; GFX9-O0-NEXT: v_addc_co_u32_e32 v13, vcc, v13, v15, vcc
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr14 killed $vgpr14 def $vgpr14_vgpr15 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v15, v13
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr12 killed $vgpr12 def $vgpr12_vgpr13 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v13, v17
+; GFX9-O0-NEXT: s_mov_b64 s[8:9], s[6:7]
+; GFX9-O0-NEXT: buffer_store_dword v14, off, s[0:3], s32 offset:300 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v15, off, s[0:3], s32 offset:304 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v12, off, s[0:3], s32 offset:308 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v13, off, s[0:3], s32 offset:312 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_mov_b64 s[4:5], s[6:7]
+; GFX9-O0-NEXT: v_mov_b32_e32 v15, s9
+; GFX9-O0-NEXT: v_mov_b32_e32 v14, s8
+; GFX9-O0-NEXT: v_mov_b32_e32 v13, s7
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, s6
+; GFX9-O0-NEXT: v_writelane_b32 v16, s4, 8
+; GFX9-O0-NEXT: v_writelane_b32 v16, s5, 9
+; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
+; GFX9-O0-NEXT: buffer_store_dword v16, off, s[0:3], s32 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
+; GFX9-O0-NEXT: buffer_store_dword v14, off, s[0:3], s32 offset:292 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v15, off, s[0:3], s32 offset:296 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v12, off, s[0:3], s32 offset:284 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v13, off, s[0:3], s32 offset:288 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v10, off, s[0:3], s32 offset:276 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v11, off, s[0:3], s32 offset:280 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v8, off, s[0:3], s32 offset:268 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v9, off, s[0:3], s32 offset:272 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:260 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v7, off, s[0:3], s32 offset:264 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:252 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:256 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:244 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:248 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 offset:236 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:240 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_branch .LBB0_6
+; GFX9-O0-NEXT: .LBB0_8: ; %udiv-bb1
+; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
+; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
+; GFX9-O0-NEXT: buffer_load_dword v7, off, s[0:3], s32 offset:36 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v8, off, s[0:3], s32 offset:40 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v11, off, s[0:3], s32 offset:44 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v12, off, s[0:3], s32 offset:48 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v5, off, s[0:3], s32 offset:28 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v6, off, s[0:3], s32 offset:32 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:20 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v2, off, s[0:3], s32 offset:24 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_mov_b64 s[6:7], 1
+; GFX9-O0-NEXT: s_mov_b32 s5, s6
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v1
+; GFX9-O0-NEXT: s_mov_b32 s4, s7
+; GFX9-O0-NEXT: s_mov_b64 s[6:7], 0
+; GFX9-O0-NEXT: s_mov_b32 s8, s6
+; GFX9-O0-NEXT: s_mov_b32 s9, s7
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v6
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, s5
+; GFX9-O0-NEXT: v_add_co_u32_e32 v9, vcc, v4, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, s4
+; GFX9-O0-NEXT: v_addc_co_u32_e32 v2, vcc, v2, v5, vcc
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, s8
+; GFX9-O0-NEXT: v_addc_co_u32_e32 v1, vcc, v1, v5, vcc
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, s9
+; GFX9-O0-NEXT: v_addc_co_u32_e32 v3, vcc, v3, v5, vcc
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr9 killed $vgpr9 def $vgpr9_vgpr10 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v10, v2
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr1 killed $vgpr1 def $vgpr1_vgpr2 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v1
+; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:332 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:336 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v9
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v10
+; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:340 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:344 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_mov_b32 s4, 0x7f
+; GFX9-O0-NEXT: v_sub_u32_e64 v3, s4, v4
+; GFX9-O0-NEXT: v_lshlrev_b64 v[5:6], v3, v[11:12]
+; GFX9-O0-NEXT: v_mov_b32_e32 v13, v6
+; GFX9-O0-NEXT: s_mov_b32 s4, 64
+; GFX9-O0-NEXT: v_sub_u32_e64 v14, s4, v3
+; GFX9-O0-NEXT: v_lshrrev_b64 v[14:15], v14, v[7:8]
+; GFX9-O0-NEXT: v_mov_b32_e32 v16, v15
+; GFX9-O0-NEXT: v_or_b32_e64 v13, v13, v16
+; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 killed $vgpr5_vgpr6 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v14
+; GFX9-O0-NEXT: v_or_b32_e64 v5, v5, v6
+; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v13
+; GFX9-O0-NEXT: v_mov_b32_e32 v15, v6
+; GFX9-O0-NEXT: v_cmp_lt_u32_e64 s[4:5], v3, s4
+; GFX9-O0-NEXT: s_mov_b32 s10, 63
+; GFX9-O0-NEXT: v_sub_u32_e64 v4, s10, v4
+; GFX9-O0-NEXT: v_lshlrev_b64 v[13:14], v4, v[7:8]
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v14
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v4, v4, v15, s[4:5]
+; GFX9-O0-NEXT: s_mov_b32 s10, 0
+; GFX9-O0-NEXT: v_cmp_eq_u32_e64 s[10:11], v3, s10
+; GFX9-O0-NEXT: v_mov_b32_e32 v15, v12
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v4, v4, v15, s[10:11]
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v13
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v5, v6, s[4:5]
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v11
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v5, v6, s[10:11]
+; GFX9-O0-NEXT: ; implicit-def: $sgpr10
+; GFX9-O0-NEXT: ; implicit-def: $sgpr10
+; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v4
+; GFX9-O0-NEXT: v_lshlrev_b64 v[7:8], v3, v[7:8]
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v8
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, s9
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v3, v3, v4, s[4:5]
+; GFX9-O0-NEXT: ; kill: def $vgpr7 killed $vgpr7 killed $vgpr7_vgpr8 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, s8
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v7, v4, v7, s[4:5]
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr7 killed $vgpr7 def $vgpr7_vgpr8 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v8, v3
+; GFX9-O0-NEXT: buffer_store_dword v7, off, s[0:3], s32 offset:324 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v8, off, s[0:3], s32 offset:328 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:316 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:320 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v10
+; GFX9-O0-NEXT: v_or_b32_e64 v3, v3, v4
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v1
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v9
+; GFX9-O0-NEXT: v_or_b32_e64 v1, v1, v2
+; GFX9-O0-NEXT: ; kill: def $vgpr1 killed $vgpr1 def $vgpr1_vgpr2 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
+; GFX9-O0-NEXT: v_cmp_ne_u64_e64 s[4:5], v[1:2], s[6:7]
+; GFX9-O0-NEXT: s_mov_b64 s[8:9], s[6:7]
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, s8
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, s9
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, s6
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, s7
+; GFX9-O0-NEXT: buffer_store_dword v7, off, s[0:3], s32 offset:148 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v8, off, s[0:3], s32 offset:152 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:140 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:144 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:132 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:136 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:124 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:128 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_mov_b64 s[6:7], exec
+; GFX9-O0-NEXT: s_and_b64 s[4:5], s[6:7], s[4:5]
+; GFX9-O0-NEXT: s_xor_b64 s[6:7], s[4:5], s[6:7]
+; GFX9-O0-NEXT: v_writelane_b32 v0, s6, 6
+; GFX9-O0-NEXT: v_writelane_b32 v0, s7, 7
+; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
+; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
+; GFX9-O0-NEXT: s_mov_b64 exec, s[4:5]
+; GFX9-O0-NEXT: s_cbranch_execz .LBB0_5
+; GFX9-O0-NEXT: s_branch .LBB0_7
+; GFX9-O0-NEXT: .LBB0_9: ; %udiv-end
+; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
+; GFX9-O0-NEXT: buffer_load_dword v4, off, s[0:3], s32 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
+; GFX9-O0-NEXT: buffer_load_dword v7, off, s[0:3], s32 offset:108 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v8, off, s[0:3], s32 offset:112 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v9, off, s[0:3], s32 offset:100 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v10, off, s[0:3], s32 offset:104 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v13, off, s[0:3], s32 offset:84 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v14, off, s[0:3], s32 offset:88 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v15, off, s[0:3], s32 offset:92 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v16, off, s[0:3], s32 offset:96 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v19, off, s[0:3], s32 offset:76 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v20, off, s[0:3], s32 offset:80 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v11, off, s[0:3], s32 offset:196 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v12, off, s[0:3], s32 offset:200 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v5, off, s[0:3], s32 offset:188 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v6, off, s[0:3], s32 offset:192 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v17, off, s[0:3], s32 offset:68 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v18, off, s[0:3], s32 offset:72 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_mov_b32 s4, 32
+; GFX9-O0-NEXT: s_waitcnt vmcnt(2)
+; GFX9-O0-NEXT: v_lshrrev_b64 v[0:1], s4, v[5:6]
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v0
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: v_mov_b32_e32 v0, v17
+; GFX9-O0-NEXT: v_mul_lo_u32 v3, v1, v0
+; GFX9-O0-NEXT: v_lshrrev_b64 v[17:18], s4, v[17:18]
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v17
+; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 killed $vgpr5_vgpr6 killed $exec
+; GFX9-O0-NEXT: v_mul_lo_u32 v2, v5, v2
+; GFX9-O0-NEXT: v_mad_u64_u32 v[17:18], s[6:7], v5, v0, 0
+; GFX9-O0-NEXT: v_mov_b32_e32 v0, v18
+; GFX9-O0-NEXT: v_add3_u32 v2, v0, v2, v3
+; GFX9-O0-NEXT: ; implicit-def: $sgpr5
+; GFX9-O0-NEXT: ; implicit-def: $sgpr6
+; GFX9-O0-NEXT: ; implicit-def: $sgpr6
+; GFX9-O0-NEXT: v_mov_b32_e32 v0, s5
+; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v0
+; GFX9-O0-NEXT: v_lshlrev_b64 v[2:3], s4, v[2:3]
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v3
+; GFX9-O0-NEXT: ; kill: def $vgpr17 killed $vgpr17 killed $vgpr17_vgpr18 killed $exec
+; GFX9-O0-NEXT: s_mov_b32 s5, 0
+; GFX9-O0-NEXT: ; implicit-def: $sgpr6
+; GFX9-O0-NEXT: v_mov_b32_e32 v0, s5
+; GFX9-O0-NEXT: ; kill: def $vgpr17 killed $vgpr17 def $vgpr17_vgpr18 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v18, v0
+; GFX9-O0-NEXT: v_mov_b32_e32 v0, v18
+; GFX9-O0-NEXT: v_or_b32_e64 v0, v0, v6
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v17
+; GFX9-O0-NEXT: v_or_b32_e64 v17, v2, v3
+; GFX9-O0-NEXT: ; kill: def $vgpr17 killed $vgpr17 def $vgpr17_vgpr18 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v18, v0
+; GFX9-O0-NEXT: v_lshrrev_b64 v[2:3], s4, v[19:20]
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v11
+; GFX9-O0-NEXT: v_mul_lo_u32 v3, v2, v6
+; GFX9-O0-NEXT: v_lshrrev_b64 v[11:12], s4, v[11:12]
+; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 killed $vgpr11_vgpr12 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v0, v19
+; GFX9-O0-NEXT: v_mul_lo_u32 v11, v11, v0
+; GFX9-O0-NEXT: v_mad_u64_u32 v[19:20], s[6:7], v2, v0, 0
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v20
+; GFX9-O0-NEXT: v_add3_u32 v2, v2, v3, v11
+; GFX9-O0-NEXT: ; implicit-def: $sgpr6
+; GFX9-O0-NEXT: ; implicit-def: $sgpr7
+; GFX9-O0-NEXT: ; implicit-def: $sgpr7
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, s6
+; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v11
+; GFX9-O0-NEXT: v_lshlrev_b64 v[2:3], s4, v[2:3]
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, v3
+; GFX9-O0-NEXT: ; kill: def $vgpr19 killed $vgpr19 killed $vgpr19_vgpr20 killed $exec
+; GFX9-O0-NEXT: ; implicit-def: $sgpr6
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, s5
+; GFX9-O0-NEXT: ; kill: def $vgpr19 killed $vgpr19 def $vgpr19_vgpr20 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v20, v11
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, v20
+; GFX9-O0-NEXT: v_or_b32_e64 v11, v11, v12
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v19
+; GFX9-O0-NEXT: v_or_b32_e64 v2, v2, v3
+; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v11
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, v17
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v18
+; GFX9-O0-NEXT: v_add_co_u32_e64 v17, s[6:7], v11, v12
+; GFX9-O0-NEXT: v_addc_co_u32_e64 v2, s[6:7], v2, v3, s[6:7]
+; GFX9-O0-NEXT: ; kill: def $vgpr17 killed $vgpr17 def $vgpr17_vgpr18 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v18, v2
+; GFX9-O0-NEXT: v_mad_u64_u32 v[19:20], s[6:7], v6, v1, 0
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v19
+; GFX9-O0-NEXT: ; implicit-def: $sgpr6
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, s5
+; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v11
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, v3
+; GFX9-O0-NEXT: v_mov_b32_e32 v19, v20
+; GFX9-O0-NEXT: ; implicit-def: $sgpr6
+; GFX9-O0-NEXT: ; implicit-def: $sgpr7
+; GFX9-O0-NEXT: ; implicit-def: $sgpr7
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, s6
+; GFX9-O0-NEXT: ; kill: def $vgpr19 killed $vgpr19 def $vgpr19_vgpr20 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v20, v12
+; GFX9-O0-NEXT: v_lshlrev_b64 v[19:20], s4, v[19:20]
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, v20
+; GFX9-O0-NEXT: v_or_b32_e64 v11, v11, v12
+; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 killed $vgpr2_vgpr3 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v19
+; GFX9-O0-NEXT: v_or_b32_e64 v2, v2, v3
+; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v11
+; GFX9-O0-NEXT: v_mad_u64_u32 v[19:20], s[6:7], v6, v5, 0
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, v19
+; GFX9-O0-NEXT: ; implicit-def: $sgpr6
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, s5
+; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 def $vgpr11_vgpr12 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, v6
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v12
+; GFX9-O0-NEXT: v_mov_b32_e32 v19, v20
+; GFX9-O0-NEXT: ; implicit-def: $sgpr6
+; GFX9-O0-NEXT: ; implicit-def: $sgpr7
+; GFX9-O0-NEXT: ; implicit-def: $sgpr7
+; GFX9-O0-NEXT: v_mov_b32_e32 v21, s6
+; GFX9-O0-NEXT: ; kill: def $vgpr19 killed $vgpr19 def $vgpr19_vgpr20 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v20, v21
+; GFX9-O0-NEXT: v_lshlrev_b64 v[19:20], s4, v[19:20]
+; GFX9-O0-NEXT: v_mov_b32_e32 v21, v20
+; GFX9-O0-NEXT: v_or_b32_e64 v6, v6, v21
+; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 killed $vgpr11_vgpr12 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, v19
+; GFX9-O0-NEXT: v_or_b32_e64 v23, v11, v12
+; GFX9-O0-NEXT: ; kill: def $vgpr23 killed $vgpr23 def $vgpr23_vgpr24 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v24, v6
+; GFX9-O0-NEXT: v_mad_u64_u32 v[11:12], s[6:7], v0, v5, 0
+; GFX9-O0-NEXT: v_mov_b32_e32 v21, v12
+; GFX9-O0-NEXT: ; implicit-def: $sgpr6
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, s5
+; GFX9-O0-NEXT: ; kill: def $vgpr21 killed $vgpr21 def $vgpr21_vgpr22 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v22, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v23
+; GFX9-O0-NEXT: v_mov_b32_e32 v20, v21
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v24
+; GFX9-O0-NEXT: v_mov_b32_e32 v19, v22
+; GFX9-O0-NEXT: v_add_co_u32_e64 v5, s[6:7], v5, v20
+; GFX9-O0-NEXT: v_addc_co_u32_e64 v19, s[6:7], v6, v19, s[6:7]
+; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v19
+; GFX9-O0-NEXT: v_mov_b32_e32 v19, v6
+; GFX9-O0-NEXT: s_mov_b64 s[6:7], 0xffffffff
+; GFX9-O0-NEXT: s_mov_b32 s8, s7
+; GFX9-O0-NEXT: v_and_b32_e64 v19, v19, s8
+; GFX9-O0-NEXT: v_mov_b32_e32 v20, v5
+; GFX9-O0-NEXT: ; kill: def $sgpr6 killed $sgpr6 killed $sgpr6_sgpr7
+; GFX9-O0-NEXT: v_and_b32_e64 v21, v20, s6
+; GFX9-O0-NEXT: ; kill: def $vgpr21 killed $vgpr21 def $vgpr21_vgpr22 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v22, v19
+; GFX9-O0-NEXT: v_mad_u64_u32 v[19:20], s[6:7], v0, v1, 0
+; GFX9-O0-NEXT: v_mov_b32_e32 v23, v19
+; GFX9-O0-NEXT: ; implicit-def: $sgpr6
+; GFX9-O0-NEXT: v_mov_b32_e32 v0, s5
+; GFX9-O0-NEXT: ; kill: def $vgpr23 killed $vgpr23 def $vgpr23_vgpr24 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v24, v0
+; GFX9-O0-NEXT: v_mov_b32_e32 v0, v24
+; GFX9-O0-NEXT: v_mov_b32_e32 v19, v20
+; GFX9-O0-NEXT: ; implicit-def: $sgpr6
+; GFX9-O0-NEXT: ; implicit-def: $sgpr7
+; GFX9-O0-NEXT: ; implicit-def: $sgpr7
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, s6
+; GFX9-O0-NEXT: ; kill: def $vgpr19 killed $vgpr19 def $vgpr19_vgpr20 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v20, v1
+; GFX9-O0-NEXT: v_lshlrev_b64 v[19:20], s4, v[19:20]
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v20
+; GFX9-O0-NEXT: v_or_b32_e64 v0, v0, v1
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v23
+; GFX9-O0-NEXT: ; kill: def $vgpr19 killed $vgpr19 killed $vgpr19_vgpr20 killed $exec
+; GFX9-O0-NEXT: v_or_b32_e64 v23, v1, v19
+; GFX9-O0-NEXT: ; kill: def $vgpr23 killed $vgpr23 def $vgpr23_vgpr24 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v24, v0
+; GFX9-O0-NEXT: v_mov_b32_e32 v0, v23
+; GFX9-O0-NEXT: v_mov_b32_e32 v20, v21
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v24
+; GFX9-O0-NEXT: v_mov_b32_e32 v19, v22
+; GFX9-O0-NEXT: v_add_co_u32_e64 v0, s[6:7], v0, v20
+; GFX9-O0-NEXT: v_addc_co_u32_e64 v19, s[6:7], v1, v19, s[6:7]
+; GFX9-O0-NEXT: ; kill: def $vgpr0 killed $vgpr0 def $vgpr0_vgpr1 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v19
+; GFX9-O0-NEXT: v_lshrrev_b64 v[21:22], s4, v[0:1]
+; GFX9-O0-NEXT: v_lshrrev_b64 v[5:6], s4, v[5:6]
+; GFX9-O0-NEXT: v_mov_b32_e32 v19, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v20, v21
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v6
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v22
+; GFX9-O0-NEXT: v_add_co_u32_e64 v19, s[6:7], v19, v20
+; GFX9-O0-NEXT: v_addc_co_u32_e64 v5, s[6:7], v5, v6, s[6:7]
+; GFX9-O0-NEXT: ; kill: def $vgpr19 killed $vgpr19 def $vgpr19_vgpr20 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v20, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v19
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v20
+; GFX9-O0-NEXT: v_add_co_u32_e64 v19, s[6:7], v5, v6
+; GFX9-O0-NEXT: v_addc_co_u32_e64 v2, s[6:7], v2, v3, s[6:7]
+; GFX9-O0-NEXT: ; kill: def $vgpr19 killed $vgpr19 def $vgpr19_vgpr20 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v20, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v19
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v17
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v20
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v18
+; GFX9-O0-NEXT: v_add_co_u32_e64 v2, s[6:7], v2, v6
+; GFX9-O0-NEXT: v_addc_co_u32_e64 v5, s[6:7], v3, v5, s[6:7]
+; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v5
+; GFX9-O0-NEXT: v_lshlrev_b64 v[0:1], s4, v[0:1]
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v1
+; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 killed $vgpr11_vgpr12 killed $exec
+; GFX9-O0-NEXT: ; implicit-def: $sgpr6
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, s5
+; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 def $vgpr11_vgpr12 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v12
+; GFX9-O0-NEXT: v_or_b32_e64 v5, v5, v6
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v0
+; GFX9-O0-NEXT: v_mov_b32_e32 v0, v11
+; GFX9-O0-NEXT: v_or_b32_e64 v0, v0, v1
+; GFX9-O0-NEXT: ; kill: def $vgpr0 killed $vgpr0 def $vgpr0_vgpr1 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, v0
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, v1
+; GFX9-O0-NEXT: v_mov_b32_e32 v0, v15
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v16
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v13
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v14
+; GFX9-O0-NEXT: v_sub_co_u32_e32 v0, vcc, v0, v12
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v3, vcc, v3, v11, vcc
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v5, vcc, v5, v6, vcc
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v2, vcc, v1, v2, vcc
+; GFX9-O0-NEXT: ; implicit-def: $sgpr5
+; GFX9-O0-NEXT: ; implicit-def: $sgpr5
+; GFX9-O0-NEXT: ; kill: def $vgpr0 killed $vgpr0 def $vgpr0_vgpr1 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v3
+; GFX9-O0-NEXT: ; implicit-def: $sgpr5
+; GFX9-O0-NEXT: ; implicit-def: $sgpr5
+; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v6
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v10
+; GFX9-O0-NEXT: v_xor_b32_e64 v3, v3, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v9
+; GFX9-O0-NEXT: v_xor_b32_e64 v9, v6, v5
+; GFX9-O0-NEXT: ; kill: def $vgpr9 killed $vgpr9 def $vgpr9_vgpr10 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v10, v3
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v1
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v8
+; GFX9-O0-NEXT: v_xor_b32_e64 v3, v3, v6
+; GFX9-O0-NEXT: ; kill: def $vgpr0 killed $vgpr0 killed $vgpr0_vgpr1 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v8, v7
+; GFX9-O0-NEXT: v_xor_b32_e64 v0, v0, v8
+; GFX9-O0-NEXT: ; kill: def $vgpr0 killed $vgpr0 def $vgpr0_vgpr1 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v3
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v0
+; GFX9-O0-NEXT: v_mov_b32_e32 v0, v1
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v9
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v10
+; GFX9-O0-NEXT: v_sub_co_u32_e32 v7, vcc, v7, v8
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v0, vcc, v0, v6, vcc
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v5, vcc, v3, v5, vcc
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v1, vcc, v1, v2, vcc
+; GFX9-O0-NEXT: ; implicit-def: $sgpr5
+; GFX9-O0-NEXT: ; implicit-def: $sgpr5
+; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v1
+; GFX9-O0-NEXT: ; implicit-def: $sgpr5
+; GFX9-O0-NEXT: ; implicit-def: $sgpr5
+; GFX9-O0-NEXT: ; kill: def $vgpr7 killed $vgpr7 def $vgpr7_vgpr8 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v8, v0
+; GFX9-O0-NEXT: v_mov_b32_e32 v0, v7
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v5
+; GFX9-O0-NEXT: v_lshrrev_b64 v[7:8], s4, v[7:8]
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v7
+; GFX9-O0-NEXT: v_lshrrev_b64 v[5:6], s4, v[5:6]
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v5
+; GFX9-O0-NEXT: ; kill: killed $vgpr4
+; GFX9-O0-NEXT: s_xor_saveexec_b64 s[4:5], -1
+; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 offset:348 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_nop 0
+; GFX9-O0-NEXT: buffer_load_dword v4, off, s[0:3], s32 offset:352 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v8, off, s[0:3], s32 offset:356 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v16, off, s[0:3], s32 offset:360 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_mov_b64 exec, s[4:5]
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: s_setpc_b64 s[30:31]
+ %div = srem i128 %lhs, %rhs
+ ret i128 %div
+}
+
+define i128 @v_urem_i128_vv(i128 %lhs, i128 %rhs) {
+; GFX9-LABEL: v_urem_i128_vv:
+; GFX9: ; %bb.0: ; %_udiv-special-cases
+; GFX9-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
+; GFX9-NEXT: v_or_b32_e32 v9, v5, v7
+; GFX9-NEXT: v_or_b32_e32 v8, v4, v6
+; GFX9-NEXT: v_cmp_eq_u64_e32 vcc, 0, v[8:9]
+; GFX9-NEXT: v_or_b32_e32 v9, v1, v3
+; GFX9-NEXT: v_or_b32_e32 v8, v0, v2
+; GFX9-NEXT: v_cmp_eq_u64_e64 s[4:5], 0, v[8:9]
+; GFX9-NEXT: v_ffbh_u32_e32 v8, v6
+; GFX9-NEXT: v_add_u32_e32 v8, 32, v8
+; GFX9-NEXT: v_ffbh_u32_e32 v9, v7
+; GFX9-NEXT: v_min_u32_e32 v8, v8, v9
+; GFX9-NEXT: v_ffbh_u32_e32 v9, v4
+; GFX9-NEXT: v_add_u32_e32 v9, 32, v9
+; GFX9-NEXT: v_ffbh_u32_e32 v10, v5
+; GFX9-NEXT: v_min_u32_e32 v9, v9, v10
+; GFX9-NEXT: s_or_b64 s[4:5], vcc, s[4:5]
+; GFX9-NEXT: v_add_co_u32_e32 v9, vcc, 64, v9
+; GFX9-NEXT: v_addc_co_u32_e64 v10, s[6:7], 0, 0, vcc
+; GFX9-NEXT: v_cmp_ne_u64_e32 vcc, 0, v[6:7]
+; GFX9-NEXT: v_ffbh_u32_e32 v11, v3
+; GFX9-NEXT: v_cndmask_b32_e32 v8, v9, v8, vcc
+; GFX9-NEXT: v_ffbh_u32_e32 v9, v2
+; GFX9-NEXT: v_add_u32_e32 v9, 32, v9
+; GFX9-NEXT: v_min_u32_e32 v9, v9, v11
+; GFX9-NEXT: v_ffbh_u32_e32 v11, v0
+; GFX9-NEXT: v_add_u32_e32 v11, 32, v11
+; GFX9-NEXT: v_ffbh_u32_e32 v12, v1
+; GFX9-NEXT: v_min_u32_e32 v11, v11, v12
+; GFX9-NEXT: v_cndmask_b32_e64 v10, v10, 0, vcc
+; GFX9-NEXT: v_add_co_u32_e32 v11, vcc, 64, v11
+; GFX9-NEXT: v_addc_co_u32_e64 v12, s[6:7], 0, 0, vcc
+; GFX9-NEXT: v_cmp_ne_u64_e32 vcc, 0, v[2:3]
+; GFX9-NEXT: s_mov_b64 s[6:7], 0x7f
+; GFX9-NEXT: v_cndmask_b32_e32 v9, v11, v9, vcc
+; GFX9-NEXT: v_cndmask_b32_e64 v12, v12, 0, vcc
+; GFX9-NEXT: v_sub_co_u32_e32 v8, vcc, v8, v9
+; GFX9-NEXT: v_subb_co_u32_e32 v9, vcc, v10, v12, vcc
+; GFX9-NEXT: v_mov_b32_e32 v11, 0
+; GFX9-NEXT: v_subbrev_co_u32_e32 v10, vcc, 0, v11, vcc
+; GFX9-NEXT: v_subbrev_co_u32_e32 v11, vcc, 0, v11, vcc
+; GFX9-NEXT: v_cmp_lt_u64_e32 vcc, s[6:7], v[8:9]
+; GFX9-NEXT: v_cndmask_b32_e64 v12, 0, 1, vcc
+; GFX9-NEXT: v_cmp_ne_u64_e32 vcc, 0, v[10:11]
+; GFX9-NEXT: v_cndmask_b32_e64 v13, 0, 1, vcc
+; GFX9-NEXT: v_cmp_eq_u64_e32 vcc, 0, v[10:11]
+; GFX9-NEXT: v_cndmask_b32_e32 v12, v13, v12, vcc
+; GFX9-NEXT: v_and_b32_e32 v12, 1, v12
+; GFX9-NEXT: v_cmp_eq_u32_e32 vcc, 1, v12
+; GFX9-NEXT: v_xor_b32_e32 v12, 0x7f, v8
+; GFX9-NEXT: v_or_b32_e32 v13, v9, v11
+; GFX9-NEXT: v_or_b32_e32 v12, v12, v10
+; GFX9-NEXT: s_or_b64 s[4:5], s[4:5], vcc
+; GFX9-NEXT: v_cmp_ne_u64_e32 vcc, 0, v[12:13]
+; GFX9-NEXT: s_xor_b64 s[6:7], s[4:5], -1
+; GFX9-NEXT: v_cndmask_b32_e64 v15, v3, 0, s[4:5]
+; GFX9-NEXT: v_cndmask_b32_e64 v14, v2, 0, s[4:5]
+; GFX9-NEXT: v_cndmask_b32_e64 v13, v1, 0, s[4:5]
+; GFX9-NEXT: v_cndmask_b32_e64 v12, v0, 0, s[4:5]
+; GFX9-NEXT: s_and_b64 s[4:5], s[6:7], vcc
+; GFX9-NEXT: s_and_saveexec_b64 s[8:9], s[4:5]
+; GFX9-NEXT: s_cbranch_execz .LBB1_6
+; GFX9-NEXT: ; %bb.1: ; %udiv-bb1
+; GFX9-NEXT: v_add_co_u32_e32 v22, vcc, 1, v8
+; GFX9-NEXT: v_addc_co_u32_e32 v23, vcc, 0, v9, vcc
+; GFX9-NEXT: v_addc_co_u32_e32 v24, vcc, 0, v10, vcc
+; GFX9-NEXT: v_sub_u32_e32 v15, 0x7f, v8
+; GFX9-NEXT: v_addc_co_u32_e32 v25, vcc, 0, v11, vcc
+; GFX9-NEXT: v_sub_u32_e32 v13, 64, v15
+; GFX9-NEXT: v_or_b32_e32 v10, v23, v25
+; GFX9-NEXT: v_or_b32_e32 v9, v22, v24
+; GFX9-NEXT: v_lshlrev_b64 v[11:12], v15, v[2:3]
+; GFX9-NEXT: v_lshrrev_b64 v[13:14], v13, v[0:1]
+; GFX9-NEXT: v_sub_u32_e32 v8, 63, v8
+; GFX9-NEXT: v_cmp_ne_u64_e32 vcc, 0, v[9:10]
+; GFX9-NEXT: v_lshlrev_b64 v[8:9], v8, v[0:1]
+; GFX9-NEXT: v_or_b32_e32 v10, v12, v14
+; GFX9-NEXT: v_or_b32_e32 v11, v11, v13
+; GFX9-NEXT: v_cmp_gt_u32_e64 s[4:5], 64, v15
+; GFX9-NEXT: v_cndmask_b32_e64 v9, v9, v10, s[4:5]
+; GFX9-NEXT: v_cndmask_b32_e64 v8, v8, v11, s[4:5]
+; GFX9-NEXT: v_lshlrev_b64 v[10:11], v15, v[0:1]
+; GFX9-NEXT: v_cmp_eq_u32_e64 s[6:7], 0, v15
+; GFX9-NEXT: v_mov_b32_e32 v12, 0
+; GFX9-NEXT: v_mov_b32_e32 v14, 0
+; GFX9-NEXT: v_cndmask_b32_e64 v9, v9, v3, s[6:7]
+; GFX9-NEXT: v_cndmask_b32_e64 v8, v8, v2, s[6:7]
+; GFX9-NEXT: v_cndmask_b32_e64 v11, 0, v11, s[4:5]
+; GFX9-NEXT: v_mov_b32_e32 v13, 0
+; GFX9-NEXT: v_mov_b32_e32 v15, 0
+; GFX9-NEXT: v_cndmask_b32_e64 v10, 0, v10, s[4:5]
+; GFX9-NEXT: s_and_saveexec_b64 s[4:5], vcc
+; GFX9-NEXT: s_xor_b64 s[6:7], exec, s[4:5]
+; GFX9-NEXT: s_cbranch_execz .LBB1_5
+; GFX9-NEXT: ; %bb.2: ; %udiv-preheader
+; GFX9-NEXT: v_sub_u32_e32 v14, 64, v22
+; GFX9-NEXT: v_lshrrev_b64 v[12:13], v22, v[0:1]
+; GFX9-NEXT: v_lshlrev_b64 v[14:15], v14, v[2:3]
+; GFX9-NEXT: v_cmp_gt_u32_e32 vcc, 64, v22
+; GFX9-NEXT: v_or_b32_e32 v14, v12, v14
+; GFX9-NEXT: v_subrev_u32_e32 v12, 64, v22
+; GFX9-NEXT: v_or_b32_e32 v15, v13, v15
+; GFX9-NEXT: v_lshrrev_b64 v[12:13], v12, v[2:3]
+; GFX9-NEXT: v_cmp_eq_u32_e64 s[4:5], 0, v22
+; GFX9-NEXT: v_cndmask_b32_e32 v13, v13, v15, vcc
+; GFX9-NEXT: v_cndmask_b32_e64 v17, v13, v1, s[4:5]
+; GFX9-NEXT: v_cndmask_b32_e32 v14, v12, v14, vcc
+; GFX9-NEXT: v_lshrrev_b64 v[12:13], v22, v[2:3]
+; GFX9-NEXT: v_cndmask_b32_e64 v16, v14, v0, s[4:5]
+; GFX9-NEXT: v_cndmask_b32_e32 v19, 0, v13, vcc
+; GFX9-NEXT: v_cndmask_b32_e32 v18, 0, v12, vcc
+; GFX9-NEXT: v_add_co_u32_e32 v26, vcc, -1, v4
+; GFX9-NEXT: v_addc_co_u32_e32 v27, vcc, -1, v5, vcc
+; GFX9-NEXT: v_addc_co_u32_e32 v28, vcc, -1, v6, vcc
+; GFX9-NEXT: v_mov_b32_e32 v20, 0
+; GFX9-NEXT: v_mov_b32_e32 v14, 0
+; GFX9-NEXT: v_addc_co_u32_e32 v29, vcc, -1, v7, vcc
+; GFX9-NEXT: s_mov_b64 s[4:5], 0
+; GFX9-NEXT: v_mov_b32_e32 v21, 0
+; GFX9-NEXT: v_mov_b32_e32 v15, 0
+; GFX9-NEXT: v_mov_b32_e32 v13, 0
+; GFX9-NEXT: .LBB1_3: ; %udiv-do-while
+; GFX9-NEXT: ; =>This Inner Loop Header: Depth=1
+; GFX9-NEXT: v_lshrrev_b32_e32 v12, 31, v11
+; GFX9-NEXT: v_lshlrev_b64 v[10:11], 1, v[10:11]
+; GFX9-NEXT: v_lshlrev_b64 v[18:19], 1, v[18:19]
+; GFX9-NEXT: v_or_b32_e32 v10, v20, v10
+; GFX9-NEXT: v_lshrrev_b32_e32 v20, 31, v17
+; GFX9-NEXT: v_lshlrev_b64 v[16:17], 1, v[16:17]
+; GFX9-NEXT: v_or_b32_e32 v18, v18, v20
+; GFX9-NEXT: v_lshrrev_b32_e32 v20, 31, v9
+; GFX9-NEXT: v_or_b32_e32 v16, v16, v20
+; GFX9-NEXT: v_sub_co_u32_e32 v20, vcc, v26, v16
+; GFX9-NEXT: v_subb_co_u32_e32 v20, vcc, v27, v17, vcc
+; GFX9-NEXT: v_subb_co_u32_e32 v20, vcc, v28, v18, vcc
+; GFX9-NEXT: v_subb_co_u32_e32 v20, vcc, v29, v19, vcc
+; GFX9-NEXT: v_ashrrev_i32_e32 v30, 31, v20
+; GFX9-NEXT: v_and_b32_e32 v20, v30, v4
+; GFX9-NEXT: v_sub_co_u32_e32 v16, vcc, v16, v20
+; GFX9-NEXT: v_and_b32_e32 v20, v30, v5
+; GFX9-NEXT: v_subb_co_u32_e32 v17, vcc, v17, v20, vcc
+; GFX9-NEXT: v_and_b32_e32 v20, v30, v6
+; GFX9-NEXT: v_subb_co_u32_e32 v18, vcc, v18, v20, vcc
+; GFX9-NEXT: v_and_b32_e32 v20, v30, v7
+; GFX9-NEXT: v_subb_co_u32_e32 v19, vcc, v19, v20, vcc
+; GFX9-NEXT: v_add_co_u32_e32 v22, vcc, -1, v22
+; GFX9-NEXT: v_addc_co_u32_e32 v23, vcc, -1, v23, vcc
+; GFX9-NEXT: v_addc_co_u32_e32 v24, vcc, -1, v24, vcc
+; GFX9-NEXT: v_addc_co_u32_e32 v25, vcc, -1, v25, vcc
+; GFX9-NEXT: v_or_b32_e32 v11, v21, v11
+; GFX9-NEXT: v_lshlrev_b64 v[8:9], 1, v[8:9]
+; GFX9-NEXT: v_or_b32_e32 v20, v22, v24
+; GFX9-NEXT: v_or_b32_e32 v21, v23, v25
+; GFX9-NEXT: v_cmp_eq_u64_e32 vcc, 0, v[20:21]
+; GFX9-NEXT: v_or3_b32 v8, v8, v12, v14
+; GFX9-NEXT: v_and_b32_e32 v12, 1, v30
+; GFX9-NEXT: v_mov_b32_e32 v21, v13
+; GFX9-NEXT: v_or3_b32 v9, v9, 0, v15
+; GFX9-NEXT: s_or_b64 s[4:5], vcc, s[4:5]
+; GFX9-NEXT: v_mov_b32_e32 v20, v12
+; GFX9-NEXT: s_andn2_b64 exec, exec, s[4:5]
+; GFX9-NEXT: s_cbranch_execnz .LBB1_3
+; GFX9-NEXT: ; %bb.4: ; %Flow
+; GFX9-NEXT: s_or_b64 exec, exec, s[4:5]
+; GFX9-NEXT: .LBB1_5: ; %Flow2
+; GFX9-NEXT: s_or_b64 exec, exec, s[6:7]
+; GFX9-NEXT: v_lshlrev_b64 v[16:17], 1, v[10:11]
+; GFX9-NEXT: v_lshlrev_b64 v[8:9], 1, v[8:9]
+; GFX9-NEXT: v_lshrrev_b32_e32 v10, 31, v11
+; GFX9-NEXT: v_or3_b32 v15, v9, 0, v15
+; GFX9-NEXT: v_or3_b32 v14, v8, v10, v14
+; GFX9-NEXT: v_or_b32_e32 v13, v13, v17
+; GFX9-NEXT: v_or_b32_e32 v12, v12, v16
+; GFX9-NEXT: .LBB1_6: ; %Flow3
+; GFX9-NEXT: s_or_b64 exec, exec, s[8:9]
+; GFX9-NEXT: v_mul_lo_u32 v19, v12, v7
+; GFX9-NEXT: v_mad_u64_u32 v[7:8], s[4:5], v4, v12, 0
+; GFX9-NEXT: v_mov_b32_e32 v17, 0
+; GFX9-NEXT: v_mad_u64_u32 v[9:10], s[4:5], v12, v6, 0
+; GFX9-NEXT: v_mov_b32_e32 v16, v8
+; GFX9-NEXT: v_mad_u64_u32 v[11:12], s[4:5], v5, v12, v[16:17]
+; GFX9-NEXT: v_mul_lo_u32 v18, v13, v6
+; GFX9-NEXT: v_mul_lo_u32 v16, v15, v4
+; GFX9-NEXT: v_mov_b32_e32 v6, v12
+; GFX9-NEXT: v_mov_b32_e32 v12, v17
+; GFX9-NEXT: v_mad_u64_u32 v[11:12], s[4:5], v4, v13, v[11:12]
+; GFX9-NEXT: v_add3_u32 v10, v10, v19, v18
+; GFX9-NEXT: v_mad_u64_u32 v[8:9], s[4:5], v14, v4, v[9:10]
+; GFX9-NEXT: v_mov_b32_e32 v4, v12
+; GFX9-NEXT: v_mul_lo_u32 v10, v14, v5
+; GFX9-NEXT: v_add_co_u32_e32 v14, vcc, v6, v4
+; GFX9-NEXT: v_addc_co_u32_e64 v15, s[4:5], 0, 0, vcc
+; GFX9-NEXT: v_mad_u64_u32 v[4:5], s[4:5], v5, v13, v[14:15]
+; GFX9-NEXT: v_add3_u32 v6, v16, v9, v10
+; GFX9-NEXT: v_add_co_u32_e32 v4, vcc, v4, v8
+; GFX9-NEXT: v_addc_co_u32_e32 v5, vcc, v5, v6, vcc
+; GFX9-NEXT: v_mov_b32_e32 v6, v11
+; GFX9-NEXT: v_sub_co_u32_e32 v0, vcc, v0, v7
+; GFX9-NEXT: v_subb_co_u32_e32 v1, vcc, v1, v6, vcc
+; GFX9-NEXT: v_subb_co_u32_e32 v2, vcc, v2, v4, vcc
+; GFX9-NEXT: v_subb_co_u32_e32 v3, vcc, v3, v5, vcc
+; GFX9-NEXT: s_setpc_b64 s[30:31]
+;
+; GFX9-O0-LABEL: v_urem_i128_vv:
+; GFX9-O0: ; %bb.0: ; %_udiv-special-cases
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
+; GFX9-O0-NEXT: s_xor_saveexec_b64 s[4:5], -1
+; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 offset:328 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:332 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v8, off, s[0:3], s32 offset:336 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v16, off, s[0:3], s32 offset:340 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_mov_b64 exec, s[4:5]
+; GFX9-O0-NEXT: ; implicit-def: $vgpr8 : SGPR spill to VGPR lane
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, v6
+; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:100 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: v_mov_b32_e32 v13, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v1
+; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:100 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: v_mov_b32_e32 v9, v0
+; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
+; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr9 killed $vgpr9 def $vgpr9_vgpr10 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v10, v2
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr13 killed $vgpr13 def $vgpr13_vgpr14 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v14, v3
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr1 killed $vgpr1 def $vgpr1_vgpr2 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v5
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 def $vgpr11_vgpr12 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, v7
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4_sgpr5
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4_sgpr5
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4_sgpr5
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4_sgpr5
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v13
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v14
+; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:92 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:96 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v9
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v10
+; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:84 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:88 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v11
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v12
+; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:76 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:80 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v1
+; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:68 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:72 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v11
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v12
+; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:60 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:64 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v1
+; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:52 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:56 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v13
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v14
+; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:44 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:48 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v9
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v10
+; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:36 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:40 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v12
+; GFX9-O0-NEXT: v_mov_b32_e32 v8, v2
+; GFX9-O0-NEXT: v_or_b32_e64 v3, v8, v7
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v11
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v1
+; GFX9-O0-NEXT: v_or_b32_e64 v1, v5, v6
+; GFX9-O0-NEXT: ; kill: def $vgpr1 killed $vgpr1 def $vgpr1_vgpr2 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
+; GFX9-O0-NEXT: s_mov_b64 s[6:7], 0
+; GFX9-O0-NEXT: v_writelane_b32 v0, s6, 0
+; GFX9-O0-NEXT: v_writelane_b32 v0, s7, 1
+; GFX9-O0-NEXT: v_cmp_eq_u64_e64 s[4:5], v[1:2], s[6:7]
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v14
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v10
+; GFX9-O0-NEXT: v_or_b32_e64 v15, v4, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v13
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v9
+; GFX9-O0-NEXT: v_or_b32_e64 v9, v3, v1
+; GFX9-O0-NEXT: ; kill: def $vgpr9 killed $vgpr9 def $vgpr9_vgpr10 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v10, v15
+; GFX9-O0-NEXT: v_cmp_eq_u64_e64 s[8:9], v[9:10], s[6:7]
+; GFX9-O0-NEXT: s_or_b64 s[4:5], s[4:5], s[8:9]
+; GFX9-O0-NEXT: v_ffbh_u32_e64 v6, v6
+; GFX9-O0-NEXT: s_mov_b32 s9, 32
+; GFX9-O0-NEXT: v_add_u32_e64 v6, v6, s9
+; GFX9-O0-NEXT: v_ffbh_u32_e64 v7, v7
+; GFX9-O0-NEXT: v_min_u32_e64 v6, v6, v7
+; GFX9-O0-NEXT: s_mov_b32 s8, 0
+; GFX9-O0-NEXT: ; implicit-def: $sgpr10
+; GFX9-O0-NEXT: v_mov_b32_e32 v9, s8
+; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 def $vgpr6_vgpr7 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v9
+; GFX9-O0-NEXT: v_mov_b32_e32 v10, v7
+; GFX9-O0-NEXT: v_ffbh_u32_e64 v5, v5
+; GFX9-O0-NEXT: v_add_u32_e64 v5, v5, s9
+; GFX9-O0-NEXT: v_ffbh_u32_e64 v8, v8
+; GFX9-O0-NEXT: v_min_u32_e64 v15, v5, v8
+; GFX9-O0-NEXT: ; implicit-def: $sgpr10
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, s8
+; GFX9-O0-NEXT: ; kill: def $vgpr15 killed $vgpr15 def $vgpr15_vgpr16 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v16, v5
+; GFX9-O0-NEXT: s_mov_b64 s[10:11], 64
+; GFX9-O0-NEXT: v_mov_b32_e32 v8, v15
+; GFX9-O0-NEXT: s_mov_b32 s12, s10
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v16
+; GFX9-O0-NEXT: s_mov_b32 s14, s11
+; GFX9-O0-NEXT: v_add_co_u32_e64 v8, s[12:13], v8, s12
+; GFX9-O0-NEXT: v_mov_b32_e32 v9, s14
+; GFX9-O0-NEXT: v_addc_co_u32_e64 v5, s[12:13], v5, v9, s[12:13]
+; GFX9-O0-NEXT: ; kill: def $vgpr8 killed $vgpr8 def $vgpr8_vgpr9 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v9, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v9
+; GFX9-O0-NEXT: s_mov_b64 s[12:13], s[6:7]
+; GFX9-O0-NEXT: v_cmp_ne_u64_e64 s[12:13], v[11:12], s[12:13]
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v5, v10, s[12:13]
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v6
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v8
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v9, v6, v7, s[12:13]
+; GFX9-O0-NEXT: ; implicit-def: $sgpr12
+; GFX9-O0-NEXT: ; implicit-def: $sgpr12
+; GFX9-O0-NEXT: ; kill: def $vgpr9 killed $vgpr9 def $vgpr9_vgpr10 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v10, v5
+; GFX9-O0-NEXT: v_ffbh_u32_e64 v5, v1
+; GFX9-O0-NEXT: v_add_u32_e64 v5, v5, s9
+; GFX9-O0-NEXT: v_ffbh_u32_e64 v6, v2
+; GFX9-O0-NEXT: v_min_u32_e64 v6, v5, v6
+; GFX9-O0-NEXT: ; implicit-def: $sgpr12
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, s8
+; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 def $vgpr6_vgpr7 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v8, v7
+; GFX9-O0-NEXT: v_ffbh_u32_e64 v5, v3
+; GFX9-O0-NEXT: v_add_u32_e64 v5, v5, s9
+; GFX9-O0-NEXT: v_ffbh_u32_e64 v11, v4
+; GFX9-O0-NEXT: v_min_u32_e64 v15, v5, v11
+; GFX9-O0-NEXT: ; implicit-def: $sgpr9
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, s8
+; GFX9-O0-NEXT: ; kill: def $vgpr15 killed $vgpr15 def $vgpr15_vgpr16 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v16, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, v15
+; GFX9-O0-NEXT: s_mov_b32 s8, s10
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v16
+; GFX9-O0-NEXT: s_mov_b32 s10, s11
+; GFX9-O0-NEXT: v_add_co_u32_e64 v11, s[8:9], v11, s8
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, s10
+; GFX9-O0-NEXT: v_addc_co_u32_e64 v5, s[8:9], v5, v12, s[8:9]
+; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 def $vgpr11_vgpr12 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v12
+; GFX9-O0-NEXT: s_mov_b64 s[8:9], s[6:7]
+; GFX9-O0-NEXT: v_cmp_ne_u64_e64 s[8:9], v[13:14], s[8:9]
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v5, v8, s[8:9]
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v6
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v11
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v6, v6, v7, s[8:9]
+; GFX9-O0-NEXT: ; implicit-def: $sgpr8
+; GFX9-O0-NEXT: ; implicit-def: $sgpr8
+; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 def $vgpr6_vgpr7 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v8, v6
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v9
+; GFX9-O0-NEXT: ; kill: def $vgpr7 killed $vgpr7 killed $vgpr6_vgpr7 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v10
+; GFX9-O0-NEXT: s_mov_b32 s10, s6
+; GFX9-O0-NEXT: s_mov_b32 s11, s7
+; GFX9-O0-NEXT: v_sub_co_u32_e32 v5, vcc, v5, v8
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v9, vcc, v6, v7, vcc
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, s10
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, s10
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v8, vcc, v6, v7, vcc
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, s11
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, s11
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v7, vcc, v6, v7, vcc
+; GFX9-O0-NEXT: ; implicit-def: $sgpr8
+; GFX9-O0-NEXT: ; implicit-def: $sgpr8
+; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v9
+; GFX9-O0-NEXT: ; implicit-def: $sgpr8
+; GFX9-O0-NEXT: ; implicit-def: $sgpr8
+; GFX9-O0-NEXT: ; kill: def $vgpr8 killed $vgpr8 def $vgpr8_vgpr9 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v9, v7
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, v9
+; GFX9-O0-NEXT: v_mov_b32_e32 v10, v8
+; GFX9-O0-NEXT: buffer_store_dword v10, off, s[0:3], s32 offset:28 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v11, off, s[0:3], s32 offset:32 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, v6
+; GFX9-O0-NEXT: v_mov_b32_e32 v10, v5
+; GFX9-O0-NEXT: buffer_store_dword v10, off, s[0:3], s32 offset:20 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v11, off, s[0:3], s32 offset:24 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_mov_b64 s[8:9], s[6:7]
+; GFX9-O0-NEXT: v_cmp_eq_u64_e64 s[8:9], v[8:9], s[8:9]
+; GFX9-O0-NEXT: s_mov_b64 s[12:13], 0x7f
+; GFX9-O0-NEXT: s_mov_b64 s[14:15], s[12:13]
+; GFX9-O0-NEXT: v_cmp_gt_u64_e64 s[14:15], v[5:6], s[14:15]
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v10, 0, 1, s[14:15]
+; GFX9-O0-NEXT: s_mov_b64 s[14:15], s[6:7]
+; GFX9-O0-NEXT: v_cmp_ne_u64_e64 s[14:15], v[8:9], s[14:15]
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v7, 0, 1, s[14:15]
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v7, v7, v10, s[8:9]
+; GFX9-O0-NEXT: v_and_b32_e64 v7, 1, v7
+; GFX9-O0-NEXT: v_cmp_eq_u32_e64 s[8:9], v7, 1
+; GFX9-O0-NEXT: s_or_b64 s[8:9], s[4:5], s[8:9]
+; GFX9-O0-NEXT: s_mov_b64 s[4:5], -1
+; GFX9-O0-NEXT: s_xor_b64 s[4:5], s[8:9], s[4:5]
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v6
+; GFX9-O0-NEXT: s_mov_b32 s14, s13
+; GFX9-O0-NEXT: v_xor_b32_e64 v7, v7, s14
+; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 killed $vgpr5_vgpr6 killed $exec
+; GFX9-O0-NEXT: ; kill: def $sgpr12 killed $sgpr12 killed $sgpr12_sgpr13
+; GFX9-O0-NEXT: v_xor_b32_e64 v5, v5, s12
+; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v7
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v6
+; GFX9-O0-NEXT: v_mov_b32_e32 v10, v9
+; GFX9-O0-NEXT: v_or_b32_e64 v7, v7, v10
+; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 killed $vgpr5_vgpr6 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v8
+; GFX9-O0-NEXT: v_or_b32_e64 v5, v5, v6
+; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v7
+; GFX9-O0-NEXT: v_cmp_ne_u64_e64 s[6:7], v[5:6], s[6:7]
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, s11
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v2, v5, s[8:9]
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, s10
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v1, v1, v2, s[8:9]
+; GFX9-O0-NEXT: ; implicit-def: $sgpr12
+; GFX9-O0-NEXT: ; implicit-def: $sgpr12
+; GFX9-O0-NEXT: ; kill: def $vgpr1 killed $vgpr1 def $vgpr1_vgpr2 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, s11
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v4, v5, s[8:9]
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, s10
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v3, v3, v4, s[8:9]
+; GFX9-O0-NEXT: ; implicit-def: $sgpr8
+; GFX9-O0-NEXT: ; implicit-def: $sgpr8
+; GFX9-O0-NEXT: ; kill: def $vgpr3 killed $vgpr3 def $vgpr3_vgpr4 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v5
+; GFX9-O0-NEXT: s_and_b64 s[6:7], s[4:5], s[6:7]
+; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:12 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:16 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:4 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:8 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_mov_b64 s[4:5], exec
+; GFX9-O0-NEXT: v_writelane_b32 v0, s4, 2
+; GFX9-O0-NEXT: v_writelane_b32 v0, s5, 3
+; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
+; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
+; GFX9-O0-NEXT: s_and_b64 s[4:5], s[4:5], s[6:7]
+; GFX9-O0-NEXT: s_mov_b64 exec, s[4:5]
+; GFX9-O0-NEXT: s_cbranch_execz .LBB1_3
+; GFX9-O0-NEXT: s_branch .LBB1_8
+; GFX9-O0-NEXT: .LBB1_1: ; %Flow
+; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
+; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: v_readlane_b32 s4, v0, 4
+; GFX9-O0-NEXT: v_readlane_b32 s5, v0, 5
+; GFX9-O0-NEXT: s_or_b64 exec, exec, s[4:5]
+; GFX9-O0-NEXT: ; %bb.2: ; %Flow
+; GFX9-O0-NEXT: buffer_load_dword v6, off, s[0:3], s32 offset:136 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v7, off, s[0:3], s32 offset:140 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v4, off, s[0:3], s32 offset:144 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v5, off, s[0:3], s32 offset:148 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v2, off, s[0:3], s32 offset:152 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v3, off, s[0:3], s32 offset:156 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 offset:160 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:164 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_waitcnt vmcnt(6)
+; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:128 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v7, off, s[0:3], s32 offset:132 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:120 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:124 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:112 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:116 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 offset:104 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:108 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_branch .LBB1_5
+; GFX9-O0-NEXT: .LBB1_3: ; %Flow2
+; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
+; GFX9-O0-NEXT: buffer_load_dword v4, off, s[0:3], s32 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: v_readlane_b32 s4, v4, 2
+; GFX9-O0-NEXT: v_readlane_b32 s5, v4, 3
+; GFX9-O0-NEXT: s_or_b64 exec, exec, s[4:5]
+; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 offset:12 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:16 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v2, off, s[0:3], s32 offset:4 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v3, off, s[0:3], s32 offset:8 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:176 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:180 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 offset:168 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:172 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_branch .LBB1_9
+; GFX9-O0-NEXT: .LBB1_4: ; %udiv-loop-exit
+; GFX9-O0-NEXT: buffer_load_dword v5, off, s[0:3], s32 offset:184 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v6, off, s[0:3], s32 offset:188 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v7, off, s[0:3], s32 offset:192 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v8, off, s[0:3], s32 offset:196 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 offset:200 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:204 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v9, off, s[0:3], s32 offset:208 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v10, off, s[0:3], s32 offset:212 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_mov_b32 s4, 1
+; GFX9-O0-NEXT: s_waitcnt vmcnt(2)
+; GFX9-O0-NEXT: v_lshlrev_b64 v[2:3], s4, v[0:1]
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: v_lshlrev_b64 v[9:10], s4, v[9:10]
+; GFX9-O0-NEXT: s_mov_b32 s4, 63
+; GFX9-O0-NEXT: v_lshrrev_b64 v[0:1], s4, v[0:1]
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, v1
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v10
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, v8
+; GFX9-O0-NEXT: v_or3_b32 v4, v4, v11, v12
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v0
+; GFX9-O0-NEXT: v_mov_b32_e32 v0, v9
+; GFX9-O0-NEXT: v_or3_b32 v0, v0, v1, v7
+; GFX9-O0-NEXT: ; kill: def $vgpr0 killed $vgpr0 def $vgpr0_vgpr1 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v4
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v3
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v6
+; GFX9-O0-NEXT: v_or_b32_e64 v4, v4, v7
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v5
+; GFX9-O0-NEXT: v_or_b32_e64 v2, v2, v3
+; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v4
+; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:12 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:16 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 offset:4 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:8 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_branch .LBB1_3
+; GFX9-O0-NEXT: .LBB1_5: ; %Flow1
+; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
+; GFX9-O0-NEXT: buffer_load_dword v8, off, s[0:3], s32 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: v_readlane_b32 s4, v8, 6
+; GFX9-O0-NEXT: v_readlane_b32 s5, v8, 7
+; GFX9-O0-NEXT: s_or_b64 exec, exec, s[4:5]
+; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 offset:128 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:132 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v2, off, s[0:3], s32 offset:120 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v3, off, s[0:3], s32 offset:124 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v4, off, s[0:3], s32 offset:112 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v5, off, s[0:3], s32 offset:116 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v6, off, s[0:3], s32 offset:104 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v7, off, s[0:3], s32 offset:108 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:192 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v7, off, s[0:3], s32 offset:196 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:184 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:188 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:208 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:212 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 offset:200 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:204 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_branch .LBB1_4
+; GFX9-O0-NEXT: .LBB1_6: ; %udiv-do-while
+; GFX9-O0-NEXT: ; =>This Inner Loop Header: Depth=1
+; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
+; GFX9-O0-NEXT: buffer_load_dword v16, off, s[0:3], s32 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: v_readlane_b32 s6, v16, 8
+; GFX9-O0-NEXT: v_readlane_b32 s7, v16, 9
+; GFX9-O0-NEXT: buffer_load_dword v6, off, s[0:3], s32 offset:216 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v7, off, s[0:3], s32 offset:220 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 offset:224 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:228 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v23, off, s[0:3], s32 offset:232 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v24, off, s[0:3], s32 offset:236 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v2, off, s[0:3], s32 offset:240 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v3, off, s[0:3], s32 offset:244 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v17, off, s[0:3], s32 offset:248 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v18, off, s[0:3], s32 offset:252 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v8, off, s[0:3], s32 offset:256 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v9, off, s[0:3], s32 offset:260 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v27, off, s[0:3], s32 offset:264 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v28, off, s[0:3], s32 offset:268 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v25, off, s[0:3], s32 offset:272 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v26, off, s[0:3], s32 offset:276 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v19, off, s[0:3], s32 offset:52 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v20, off, s[0:3], s32 offset:56 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v21, off, s[0:3], s32 offset:60 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v22, off, s[0:3], s32 offset:64 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v14, off, s[0:3], s32 offset:280 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v15, off, s[0:3], s32 offset:284 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v11, off, s[0:3], s32 offset:288 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v12, off, s[0:3], s32 offset:292 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_mov_b32 s4, 63
+; GFX9-O0-NEXT: s_waitcnt vmcnt(16)
+; GFX9-O0-NEXT: v_lshrrev_b64 v[29:30], s4, v[2:3]
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v30
+; GFX9-O0-NEXT: s_mov_b32 s5, 1
+; GFX9-O0-NEXT: v_lshlrev_b64 v[23:24], s5, v[23:24]
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v24
+; GFX9-O0-NEXT: v_or_b32_e64 v4, v4, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v10, v29
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v23
+; GFX9-O0-NEXT: v_or_b32_e64 v23, v5, v10
+; GFX9-O0-NEXT: ; kill: def $vgpr23 killed $vgpr23 def $vgpr23_vgpr24 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v24, v4
+; GFX9-O0-NEXT: v_lshlrev_b64 v[29:30], s5, v[2:3]
+; GFX9-O0-NEXT: v_lshrrev_b64 v[4:5], s4, v[6:7]
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v30
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v5
+; GFX9-O0-NEXT: v_or_b32_e64 v2, v2, v3
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v29
+; GFX9-O0-NEXT: ; kill: def $vgpr4 killed $vgpr4 killed $vgpr4_vgpr5 killed $exec
+; GFX9-O0-NEXT: v_or_b32_e64 v4, v3, v4
+; GFX9-O0-NEXT: ; kill: def $vgpr4 killed $vgpr4 def $vgpr4_vgpr5 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v2
+; GFX9-O0-NEXT: v_lshlrev_b64 v[2:3], s5, v[0:1]
+; GFX9-O0-NEXT: v_lshlrev_b64 v[29:30], s5, v[6:7]
+; GFX9-O0-NEXT: v_lshrrev_b64 v[0:1], s4, v[0:1]
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v1
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v30
+; GFX9-O0-NEXT: s_waitcnt vmcnt(10)
+; GFX9-O0-NEXT: v_mov_b32_e32 v10, v28
+; GFX9-O0-NEXT: v_or3_b32 v6, v6, v7, v10
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v0
+; GFX9-O0-NEXT: v_mov_b32_e32 v0, v29
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v27
+; GFX9-O0-NEXT: v_or3_b32 v0, v0, v1, v7
+; GFX9-O0-NEXT: ; kill: def $vgpr0 killed $vgpr0 def $vgpr0_vgpr1 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v6
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v3
+; GFX9-O0-NEXT: s_waitcnt vmcnt(8)
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v26
+; GFX9-O0-NEXT: v_or_b32_e64 v6, v6, v7
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v25
+; GFX9-O0-NEXT: v_or_b32_e64 v2, v2, v3
+; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v6
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v4
+; GFX9-O0-NEXT: v_mov_b32_e32 v10, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v23
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v24
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: v_mov_b32_e32 v13, v11
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, v14
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v15
+; GFX9-O0-NEXT: v_sub_co_u32_e32 v13, vcc, v13, v6
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v12, vcc, v12, v10, vcc
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v11, vcc, v11, v4, vcc
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v7, vcc, v7, v5, vcc
+; GFX9-O0-NEXT: ; implicit-def: $sgpr5
+; GFX9-O0-NEXT: ; implicit-def: $sgpr5
+; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 def $vgpr11_vgpr12 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, v7
+; GFX9-O0-NEXT: v_ashrrev_i64 v[13:14], s4, v[11:12]
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v14
+; GFX9-O0-NEXT: s_mov_b64 s[4:5], 1
+; GFX9-O0-NEXT: s_mov_b32 s8, s5
+; GFX9-O0-NEXT: v_and_b32_e64 v12, v7, s8
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, v13
+; GFX9-O0-NEXT: ; kill: def $sgpr4 killed $sgpr4 killed $sgpr4_sgpr5
+; GFX9-O0-NEXT: v_and_b32_e64 v14, v11, s4
+; GFX9-O0-NEXT: ; kill: def $vgpr14 killed $vgpr14 def $vgpr14_vgpr15 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v15, v12
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, 0
+; GFX9-O0-NEXT: v_mov_b32_e32 v13, 0
+; GFX9-O0-NEXT: v_mov_b32_e32 v23, v22
+; GFX9-O0-NEXT: v_and_b32_e64 v23, v7, v23
+; GFX9-O0-NEXT: v_and_b32_e64 v21, v11, v21
+; GFX9-O0-NEXT: ; kill: def $vgpr21 killed $vgpr21 def $vgpr21_vgpr22 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v22, v23
+; GFX9-O0-NEXT: v_mov_b32_e32 v23, v20
+; GFX9-O0-NEXT: v_and_b32_e64 v7, v7, v23
+; GFX9-O0-NEXT: v_and_b32_e64 v23, v11, v19
+; GFX9-O0-NEXT: ; kill: def $vgpr23 killed $vgpr23 def $vgpr23_vgpr24 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v24, v7
+; GFX9-O0-NEXT: v_mov_b32_e32 v20, v23
+; GFX9-O0-NEXT: v_mov_b32_e32 v19, v24
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, v21
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v22
+; GFX9-O0-NEXT: v_sub_co_u32_e32 v6, vcc, v6, v20
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v10, vcc, v10, v19, vcc
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v4, vcc, v4, v11, vcc
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v7, vcc, v5, v7, vcc
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr4 killed $vgpr4 def $vgpr4_vgpr5 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v7
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 def $vgpr6_vgpr7 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v10
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, v8
+; GFX9-O0-NEXT: ; kill: def $vgpr9 killed $vgpr9 killed $vgpr8_vgpr9 killed $exec
+; GFX9-O0-NEXT: s_mov_b64 s[8:9], -1
+; GFX9-O0-NEXT: s_mov_b32 s5, s8
+; GFX9-O0-NEXT: s_mov_b32 s4, s9
+; GFX9-O0-NEXT: v_mov_b32_e32 v10, v17
+; GFX9-O0-NEXT: v_mov_b32_e32 v8, v18
+; GFX9-O0-NEXT: v_mov_b32_e32 v17, s5
+; GFX9-O0-NEXT: v_add_co_u32_e32 v20, vcc, v11, v17
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, s4
+; GFX9-O0-NEXT: v_addc_co_u32_e32 v9, vcc, v9, v11, vcc
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, s5
+; GFX9-O0-NEXT: v_addc_co_u32_e32 v17, vcc, v10, v11, vcc
+; GFX9-O0-NEXT: v_mov_b32_e32 v10, s4
+; GFX9-O0-NEXT: v_addc_co_u32_e32 v8, vcc, v8, v10, vcc
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr20 killed $vgpr20 def $vgpr20_vgpr21 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v21, v9
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr17 killed $vgpr17 def $vgpr17_vgpr18 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v18, v8
+; GFX9-O0-NEXT: v_mov_b32_e32 v8, v17
+; GFX9-O0-NEXT: v_mov_b32_e32 v9, v18
+; GFX9-O0-NEXT: v_mov_b32_e32 v10, v20
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, v21
+; GFX9-O0-NEXT: v_mov_b32_e32 v22, v18
+; GFX9-O0-NEXT: v_mov_b32_e32 v19, v21
+; GFX9-O0-NEXT: v_or_b32_e64 v19, v19, v22
+; GFX9-O0-NEXT: v_mov_b32_e32 v18, v17
+; GFX9-O0-NEXT: v_mov_b32_e32 v17, v20
+; GFX9-O0-NEXT: v_or_b32_e64 v17, v17, v18
+; GFX9-O0-NEXT: ; kill: def $vgpr17 killed $vgpr17 def $vgpr17_vgpr18 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v18, v19
+; GFX9-O0-NEXT: v_cmp_eq_u64_e64 s[4:5], v[17:18], v[12:13]
+; GFX9-O0-NEXT: s_or_b64 s[4:5], s[4:5], s[6:7]
+; GFX9-O0-NEXT: v_mov_b32_e32 v18, v3
+; GFX9-O0-NEXT: v_mov_b32_e32 v17, v2
+; GFX9-O0-NEXT: buffer_store_dword v17, off, s[0:3], s32 offset:136 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v18, off, s[0:3], s32 offset:140 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: v_mov_b32_e32 v18, v1
+; GFX9-O0-NEXT: v_mov_b32_e32 v17, v0
+; GFX9-O0-NEXT: buffer_store_dword v17, off, s[0:3], s32 offset:144 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v18, off, s[0:3], s32 offset:148 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: v_mov_b32_e32 v18, v15
+; GFX9-O0-NEXT: v_mov_b32_e32 v17, v14
+; GFX9-O0-NEXT: buffer_store_dword v17, off, s[0:3], s32 offset:152 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v18, off, s[0:3], s32 offset:156 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: v_mov_b32_e32 v18, v13
+; GFX9-O0-NEXT: v_mov_b32_e32 v17, v12
+; GFX9-O0-NEXT: buffer_store_dword v17, off, s[0:3], s32 offset:160 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v18, off, s[0:3], s32 offset:164 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_mov_b64 s[6:7], s[4:5]
+; GFX9-O0-NEXT: v_writelane_b32 v16, s6, 4
+; GFX9-O0-NEXT: v_writelane_b32 v16, s7, 5
+; GFX9-O0-NEXT: s_mov_b64 s[6:7], s[4:5]
+; GFX9-O0-NEXT: v_writelane_b32 v16, s6, 8
+; GFX9-O0-NEXT: v_writelane_b32 v16, s7, 9
+; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
+; GFX9-O0-NEXT: buffer_store_dword v16, off, s[0:3], s32 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
+; GFX9-O0-NEXT: buffer_store_dword v14, off, s[0:3], s32 offset:272 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v15, off, s[0:3], s32 offset:276 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v12, off, s[0:3], s32 offset:264 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v13, off, s[0:3], s32 offset:268 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v10, off, s[0:3], s32 offset:256 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v11, off, s[0:3], s32 offset:260 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v8, off, s[0:3], s32 offset:248 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v9, off, s[0:3], s32 offset:252 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:240 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v7, off, s[0:3], s32 offset:244 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:232 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:236 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:224 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:228 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 offset:216 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:220 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_andn2_b64 exec, exec, s[4:5]
+; GFX9-O0-NEXT: s_cbranch_execnz .LBB1_6
+; GFX9-O0-NEXT: s_branch .LBB1_1
+; GFX9-O0-NEXT: .LBB1_7: ; %udiv-preheader
+; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 offset:296 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:300 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v2, off, s[0:3], s32 offset:304 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v3, off, s[0:3], s32 offset:308 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v8, off, s[0:3], s32 offset:312 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v9, off, s[0:3], s32 offset:316 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v10, off, s[0:3], s32 offset:320 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v11, off, s[0:3], s32 offset:324 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
+; GFX9-O0-NEXT: buffer_load_dword v16, off, s[0:3], s32 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
+; GFX9-O0-NEXT: buffer_load_dword v17, off, s[0:3], s32 offset:60 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v18, off, s[0:3], s32 offset:64 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v13, off, s[0:3], s32 offset:52 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v14, off, s[0:3], s32 offset:56 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v19, off, s[0:3], s32 offset:44 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v20, off, s[0:3], s32 offset:48 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v21, off, s[0:3], s32 offset:36 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v22, off, s[0:3], s32 offset:40 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_waitcnt vmcnt(9)
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v10
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: v_lshrrev_b64 v[6:7], v4, v[21:22]
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v7
+; GFX9-O0-NEXT: s_mov_b32 s6, 64
+; GFX9-O0-NEXT: v_sub_u32_e64 v12, s6, v4
+; GFX9-O0-NEXT: v_lshlrev_b64 v[23:24], v12, v[19:20]
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, v24
+; GFX9-O0-NEXT: v_or_b32_e64 v5, v5, v12
+; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 killed $vgpr6_vgpr7 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v23
+; GFX9-O0-NEXT: v_or_b32_e64 v6, v6, v7
+; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 def $vgpr6_vgpr7 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, v7
+; GFX9-O0-NEXT: v_cmp_lt_u32_e64 s[4:5], v4, s6
+; GFX9-O0-NEXT: v_sub_u32_e64 v5, v4, s6
+; GFX9-O0-NEXT: v_lshrrev_b64 v[23:24], v5, v[19:20]
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v24
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v5, v12, s[4:5]
+; GFX9-O0-NEXT: s_mov_b32 s6, 0
+; GFX9-O0-NEXT: v_cmp_eq_u32_e64 s[6:7], v4, s6
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, v22
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v5, v12, s[6:7]
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v6
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v23
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v6, v6, v7, s[4:5]
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v21
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v6, v6, v7, s[6:7]
+; GFX9-O0-NEXT: ; implicit-def: $sgpr6
+; GFX9-O0-NEXT: ; implicit-def: $sgpr6
+; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 def $vgpr6_vgpr7 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v5
+; GFX9-O0-NEXT: v_lshrrev_b64 v[4:5], v4, v[19:20]
+; GFX9-O0-NEXT: v_mov_b32_e32 v15, v5
+; GFX9-O0-NEXT: s_mov_b64 s[6:7], 0
+; GFX9-O0-NEXT: s_mov_b32 s8, s7
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, s8
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v12, v12, v15, s[4:5]
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v4
+; GFX9-O0-NEXT: s_mov_b32 s8, s6
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, s8
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v4, v4, v5, s[4:5]
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr4 killed $vgpr4 def $vgpr4_vgpr5 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v12
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, v13
+; GFX9-O0-NEXT: v_mov_b32_e32 v15, v14
+; GFX9-O0-NEXT: s_mov_b64 s[8:9], -1
+; GFX9-O0-NEXT: s_mov_b32 s5, s8
+; GFX9-O0-NEXT: s_mov_b32 s4, s9
+; GFX9-O0-NEXT: v_mov_b32_e32 v14, v17
+; GFX9-O0-NEXT: v_mov_b32_e32 v13, v18
+; GFX9-O0-NEXT: v_mov_b32_e32 v17, s5
+; GFX9-O0-NEXT: v_add_co_u32_e32 v12, vcc, v12, v17
+; GFX9-O0-NEXT: v_mov_b32_e32 v17, s4
+; GFX9-O0-NEXT: v_addc_co_u32_e32 v17, vcc, v15, v17, vcc
+; GFX9-O0-NEXT: v_mov_b32_e32 v15, s5
+; GFX9-O0-NEXT: v_addc_co_u32_e32 v14, vcc, v14, v15, vcc
+; GFX9-O0-NEXT: v_mov_b32_e32 v15, s4
+; GFX9-O0-NEXT: v_addc_co_u32_e32 v13, vcc, v13, v15, vcc
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr14 killed $vgpr14 def $vgpr14_vgpr15 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v15, v13
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr12 killed $vgpr12 def $vgpr12_vgpr13 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v13, v17
+; GFX9-O0-NEXT: s_mov_b64 s[8:9], s[6:7]
+; GFX9-O0-NEXT: buffer_store_dword v14, off, s[0:3], s32 offset:280 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v15, off, s[0:3], s32 offset:284 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v12, off, s[0:3], s32 offset:288 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v13, off, s[0:3], s32 offset:292 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_mov_b64 s[4:5], s[6:7]
+; GFX9-O0-NEXT: v_mov_b32_e32 v15, s9
+; GFX9-O0-NEXT: v_mov_b32_e32 v14, s8
+; GFX9-O0-NEXT: v_mov_b32_e32 v13, s7
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, s6
+; GFX9-O0-NEXT: v_writelane_b32 v16, s4, 8
+; GFX9-O0-NEXT: v_writelane_b32 v16, s5, 9
+; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
+; GFX9-O0-NEXT: buffer_store_dword v16, off, s[0:3], s32 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
+; GFX9-O0-NEXT: buffer_store_dword v14, off, s[0:3], s32 offset:272 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v15, off, s[0:3], s32 offset:276 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v12, off, s[0:3], s32 offset:264 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v13, off, s[0:3], s32 offset:268 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v10, off, s[0:3], s32 offset:256 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v11, off, s[0:3], s32 offset:260 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v8, off, s[0:3], s32 offset:248 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v9, off, s[0:3], s32 offset:252 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:240 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v7, off, s[0:3], s32 offset:244 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:232 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:236 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:224 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:228 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 offset:216 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:220 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_branch .LBB1_6
+; GFX9-O0-NEXT: .LBB1_8: ; %udiv-bb1
+; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
+; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
+; GFX9-O0-NEXT: buffer_load_dword v7, off, s[0:3], s32 offset:36 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v8, off, s[0:3], s32 offset:40 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v11, off, s[0:3], s32 offset:44 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v12, off, s[0:3], s32 offset:48 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v5, off, s[0:3], s32 offset:28 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v6, off, s[0:3], s32 offset:32 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:20 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v2, off, s[0:3], s32 offset:24 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_mov_b64 s[6:7], 1
+; GFX9-O0-NEXT: s_mov_b32 s5, s6
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v1
+; GFX9-O0-NEXT: s_mov_b32 s4, s7
+; GFX9-O0-NEXT: s_mov_b64 s[6:7], 0
+; GFX9-O0-NEXT: s_mov_b32 s8, s6
+; GFX9-O0-NEXT: s_mov_b32 s9, s7
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v6
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, s5
+; GFX9-O0-NEXT: v_add_co_u32_e32 v9, vcc, v4, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, s4
+; GFX9-O0-NEXT: v_addc_co_u32_e32 v2, vcc, v2, v5, vcc
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, s8
+; GFX9-O0-NEXT: v_addc_co_u32_e32 v1, vcc, v1, v5, vcc
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, s9
+; GFX9-O0-NEXT: v_addc_co_u32_e32 v3, vcc, v3, v5, vcc
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr9 killed $vgpr9 def $vgpr9_vgpr10 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v10, v2
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr1 killed $vgpr1 def $vgpr1_vgpr2 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v1
+; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:312 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:316 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v9
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v10
+; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:320 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:324 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_mov_b32 s4, 0x7f
+; GFX9-O0-NEXT: v_sub_u32_e64 v3, s4, v4
+; GFX9-O0-NEXT: v_lshlrev_b64 v[5:6], v3, v[11:12]
+; GFX9-O0-NEXT: v_mov_b32_e32 v13, v6
+; GFX9-O0-NEXT: s_mov_b32 s4, 64
+; GFX9-O0-NEXT: v_sub_u32_e64 v14, s4, v3
+; GFX9-O0-NEXT: v_lshrrev_b64 v[14:15], v14, v[7:8]
+; GFX9-O0-NEXT: v_mov_b32_e32 v16, v15
+; GFX9-O0-NEXT: v_or_b32_e64 v13, v13, v16
+; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 killed $vgpr5_vgpr6 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v14
+; GFX9-O0-NEXT: v_or_b32_e64 v5, v5, v6
+; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v13
+; GFX9-O0-NEXT: v_mov_b32_e32 v15, v6
+; GFX9-O0-NEXT: v_cmp_lt_u32_e64 s[4:5], v3, s4
+; GFX9-O0-NEXT: s_mov_b32 s10, 63
+; GFX9-O0-NEXT: v_sub_u32_e64 v4, s10, v4
+; GFX9-O0-NEXT: v_lshlrev_b64 v[13:14], v4, v[7:8]
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v14
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v4, v4, v15, s[4:5]
+; GFX9-O0-NEXT: s_mov_b32 s10, 0
+; GFX9-O0-NEXT: v_cmp_eq_u32_e64 s[10:11], v3, s10
+; GFX9-O0-NEXT: v_mov_b32_e32 v15, v12
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v4, v4, v15, s[10:11]
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v13
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v5, v6, s[4:5]
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v11
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v5, v5, v6, s[10:11]
+; GFX9-O0-NEXT: ; implicit-def: $sgpr10
+; GFX9-O0-NEXT: ; implicit-def: $sgpr10
+; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v4
+; GFX9-O0-NEXT: v_lshlrev_b64 v[7:8], v3, v[7:8]
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v8
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, s9
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v3, v3, v4, s[4:5]
+; GFX9-O0-NEXT: ; kill: def $vgpr7 killed $vgpr7 killed $vgpr7_vgpr8 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, s8
+; GFX9-O0-NEXT: v_cndmask_b32_e64 v7, v4, v7, s[4:5]
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr7 killed $vgpr7 def $vgpr7_vgpr8 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v8, v3
+; GFX9-O0-NEXT: buffer_store_dword v7, off, s[0:3], s32 offset:304 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v8, off, s[0:3], s32 offset:308 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:296 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:300 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v10
+; GFX9-O0-NEXT: v_or_b32_e64 v3, v3, v4
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v1
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v9
+; GFX9-O0-NEXT: v_or_b32_e64 v1, v1, v2
+; GFX9-O0-NEXT: ; kill: def $vgpr1 killed $vgpr1 def $vgpr1_vgpr2 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
+; GFX9-O0-NEXT: v_cmp_ne_u64_e64 s[4:5], v[1:2], s[6:7]
+; GFX9-O0-NEXT: s_mov_b64 s[8:9], s[6:7]
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, s8
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, s9
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, s6
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, s7
+; GFX9-O0-NEXT: buffer_store_dword v7, off, s[0:3], s32 offset:128 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v8, off, s[0:3], s32 offset:132 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v5, off, s[0:3], s32 offset:120 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v6, off, s[0:3], s32 offset:124 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 offset:112 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v4, off, s[0:3], s32 offset:116 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: buffer_store_dword v1, off, s[0:3], s32 offset:104 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v2, off, s[0:3], s32 offset:108 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_mov_b64 s[6:7], exec
+; GFX9-O0-NEXT: s_and_b64 s[4:5], s[6:7], s[4:5]
+; GFX9-O0-NEXT: s_xor_b64 s[6:7], s[4:5], s[6:7]
+; GFX9-O0-NEXT: v_writelane_b32 v0, s6, 6
+; GFX9-O0-NEXT: v_writelane_b32 v0, s7, 7
+; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
+; GFX9-O0-NEXT: buffer_store_dword v0, off, s[0:3], s32 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
+; GFX9-O0-NEXT: s_mov_b64 exec, s[4:5]
+; GFX9-O0-NEXT: s_cbranch_execz .LBB1_5
+; GFX9-O0-NEXT: s_branch .LBB1_7
+; GFX9-O0-NEXT: .LBB1_9: ; %udiv-end
+; GFX9-O0-NEXT: s_or_saveexec_b64 s[18:19], -1
+; GFX9-O0-NEXT: buffer_load_dword v4, off, s[0:3], s32 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_mov_b64 exec, s[18:19]
+; GFX9-O0-NEXT: buffer_load_dword v9, off, s[0:3], s32 offset:92 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v10, off, s[0:3], s32 offset:96 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 offset:84 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 offset:88 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v15, off, s[0:3], s32 offset:68 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v16, off, s[0:3], s32 offset:72 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v11, off, s[0:3], s32 offset:176 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v12, off, s[0:3], s32 offset:180 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v7, off, s[0:3], s32 offset:168 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v8, off, s[0:3], s32 offset:172 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v13, off, s[0:3], s32 offset:76 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v14, off, s[0:3], s32 offset:80 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_mov_b32 s4, 32
+; GFX9-O0-NEXT: s_waitcnt vmcnt(2)
+; GFX9-O0-NEXT: v_lshrrev_b64 v[2:3], s4, v[7:8]
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v2
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v13
+; GFX9-O0-NEXT: v_mul_lo_u32 v5, v6, v2
+; GFX9-O0-NEXT: v_lshrrev_b64 v[13:14], s4, v[13:14]
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v13
+; GFX9-O0-NEXT: ; kill: def $vgpr7 killed $vgpr7 killed $vgpr7_vgpr8 killed $exec
+; GFX9-O0-NEXT: v_mul_lo_u32 v3, v7, v3
+; GFX9-O0-NEXT: v_mad_u64_u32 v[13:14], s[6:7], v7, v2, 0
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v14
+; GFX9-O0-NEXT: v_add3_u32 v2, v2, v3, v5
+; GFX9-O0-NEXT: ; implicit-def: $sgpr5
+; GFX9-O0-NEXT: ; implicit-def: $sgpr6
+; GFX9-O0-NEXT: ; implicit-def: $sgpr6
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, s5
+; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v5
+; GFX9-O0-NEXT: v_lshlrev_b64 v[17:18], s4, v[2:3]
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v18
+; GFX9-O0-NEXT: ; kill: def $vgpr13 killed $vgpr13 killed $vgpr13_vgpr14 killed $exec
+; GFX9-O0-NEXT: s_mov_b32 s5, 0
+; GFX9-O0-NEXT: ; implicit-def: $sgpr6
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, s5
+; GFX9-O0-NEXT: ; kill: def $vgpr13 killed $vgpr13 def $vgpr13_vgpr14 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v14, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v14
+; GFX9-O0-NEXT: v_or_b32_e64 v2, v2, v3
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v17
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v13
+; GFX9-O0-NEXT: v_or_b32_e64 v13, v3, v5
+; GFX9-O0-NEXT: ; kill: def $vgpr13 killed $vgpr13 def $vgpr13_vgpr14 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v14, v2
+; GFX9-O0-NEXT: v_lshrrev_b64 v[2:3], s4, v[15:16]
+; GFX9-O0-NEXT: v_mov_b32_e32 v8, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v11
+; GFX9-O0-NEXT: v_mul_lo_u32 v3, v2, v8
+; GFX9-O0-NEXT: v_lshrrev_b64 v[11:12], s4, v[11:12]
+; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 killed $vgpr11_vgpr12 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v15
+; GFX9-O0-NEXT: v_mul_lo_u32 v11, v11, v5
+; GFX9-O0-NEXT: v_mad_u64_u32 v[15:16], s[6:7], v2, v5, 0
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v16
+; GFX9-O0-NEXT: v_add3_u32 v2, v2, v3, v11
+; GFX9-O0-NEXT: ; implicit-def: $sgpr6
+; GFX9-O0-NEXT: ; implicit-def: $sgpr7
+; GFX9-O0-NEXT: ; implicit-def: $sgpr7
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, s6
+; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v11
+; GFX9-O0-NEXT: v_lshlrev_b64 v[2:3], s4, v[2:3]
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, v3
+; GFX9-O0-NEXT: ; kill: def $vgpr15 killed $vgpr15 killed $vgpr15_vgpr16 killed $exec
+; GFX9-O0-NEXT: ; implicit-def: $sgpr6
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, s5
+; GFX9-O0-NEXT: ; kill: def $vgpr15 killed $vgpr15 def $vgpr15_vgpr16 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v16, v11
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, v16
+; GFX9-O0-NEXT: v_or_b32_e64 v11, v11, v12
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v15
+; GFX9-O0-NEXT: v_or_b32_e64 v2, v2, v3
+; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v11
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, v13
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v14
+; GFX9-O0-NEXT: v_add_co_u32_e64 v13, s[6:7], v11, v12
+; GFX9-O0-NEXT: v_addc_co_u32_e64 v2, s[6:7], v2, v3, s[6:7]
+; GFX9-O0-NEXT: ; kill: def $vgpr13 killed $vgpr13 def $vgpr13_vgpr14 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v14, v2
+; GFX9-O0-NEXT: v_mad_u64_u32 v[15:16], s[6:7], v8, v6, 0
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v15
+; GFX9-O0-NEXT: ; implicit-def: $sgpr6
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, s5
+; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v11
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, v3
+; GFX9-O0-NEXT: v_mov_b32_e32 v15, v16
+; GFX9-O0-NEXT: ; implicit-def: $sgpr6
+; GFX9-O0-NEXT: ; implicit-def: $sgpr7
+; GFX9-O0-NEXT: ; implicit-def: $sgpr7
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, s6
+; GFX9-O0-NEXT: ; kill: def $vgpr15 killed $vgpr15 def $vgpr15_vgpr16 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v16, v12
+; GFX9-O0-NEXT: v_lshlrev_b64 v[15:16], s4, v[15:16]
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, v16
+; GFX9-O0-NEXT: v_or_b32_e64 v11, v11, v12
+; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 killed $vgpr2_vgpr3 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v15
+; GFX9-O0-NEXT: v_or_b32_e64 v2, v2, v3
+; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v11
+; GFX9-O0-NEXT: v_mad_u64_u32 v[15:16], s[6:7], v8, v7, 0
+; GFX9-O0-NEXT: v_mov_b32_e32 v11, v15
+; GFX9-O0-NEXT: ; implicit-def: $sgpr6
+; GFX9-O0-NEXT: v_mov_b32_e32 v8, s5
+; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 def $vgpr11_vgpr12 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, v8
+; GFX9-O0-NEXT: v_mov_b32_e32 v8, v12
+; GFX9-O0-NEXT: v_mov_b32_e32 v15, v16
+; GFX9-O0-NEXT: ; implicit-def: $sgpr6
+; GFX9-O0-NEXT: ; implicit-def: $sgpr7
+; GFX9-O0-NEXT: ; implicit-def: $sgpr7
+; GFX9-O0-NEXT: v_mov_b32_e32 v17, s6
+; GFX9-O0-NEXT: ; kill: def $vgpr15 killed $vgpr15 def $vgpr15_vgpr16 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v16, v17
+; GFX9-O0-NEXT: v_lshlrev_b64 v[15:16], s4, v[15:16]
+; GFX9-O0-NEXT: v_mov_b32_e32 v17, v16
+; GFX9-O0-NEXT: v_or_b32_e64 v8, v8, v17
+; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 killed $vgpr11_vgpr12 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, v15
+; GFX9-O0-NEXT: v_or_b32_e64 v19, v11, v12
+; GFX9-O0-NEXT: ; kill: def $vgpr19 killed $vgpr19 def $vgpr19_vgpr20 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v20, v8
+; GFX9-O0-NEXT: v_mad_u64_u32 v[11:12], s[6:7], v5, v7, 0
+; GFX9-O0-NEXT: v_mov_b32_e32 v17, v12
+; GFX9-O0-NEXT: ; implicit-def: $sgpr6
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, s5
+; GFX9-O0-NEXT: ; kill: def $vgpr17 killed $vgpr17 def $vgpr17_vgpr18 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v18, v7
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v19
+; GFX9-O0-NEXT: v_mov_b32_e32 v16, v17
+; GFX9-O0-NEXT: v_mov_b32_e32 v8, v20
+; GFX9-O0-NEXT: v_mov_b32_e32 v15, v18
+; GFX9-O0-NEXT: v_add_co_u32_e64 v7, s[6:7], v7, v16
+; GFX9-O0-NEXT: v_addc_co_u32_e64 v15, s[6:7], v8, v15, s[6:7]
+; GFX9-O0-NEXT: ; kill: def $vgpr7 killed $vgpr7 def $vgpr7_vgpr8 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v8, v15
+; GFX9-O0-NEXT: v_mov_b32_e32 v15, v8
+; GFX9-O0-NEXT: s_mov_b64 s[6:7], 0xffffffff
+; GFX9-O0-NEXT: s_mov_b32 s8, s7
+; GFX9-O0-NEXT: v_and_b32_e64 v15, v15, s8
+; GFX9-O0-NEXT: v_mov_b32_e32 v16, v7
+; GFX9-O0-NEXT: ; kill: def $sgpr6 killed $sgpr6 killed $sgpr6_sgpr7
+; GFX9-O0-NEXT: v_and_b32_e64 v17, v16, s6
+; GFX9-O0-NEXT: ; kill: def $vgpr17 killed $vgpr17 def $vgpr17_vgpr18 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v18, v15
+; GFX9-O0-NEXT: v_mad_u64_u32 v[15:16], s[6:7], v5, v6, 0
+; GFX9-O0-NEXT: v_mov_b32_e32 v19, v15
+; GFX9-O0-NEXT: ; implicit-def: $sgpr6
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, s5
+; GFX9-O0-NEXT: ; kill: def $vgpr19 killed $vgpr19 def $vgpr19_vgpr20 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v20, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v20
+; GFX9-O0-NEXT: v_mov_b32_e32 v15, v16
+; GFX9-O0-NEXT: ; implicit-def: $sgpr6
+; GFX9-O0-NEXT: ; implicit-def: $sgpr7
+; GFX9-O0-NEXT: ; implicit-def: $sgpr7
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, s6
+; GFX9-O0-NEXT: ; kill: def $vgpr15 killed $vgpr15 def $vgpr15_vgpr16 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v16, v6
+; GFX9-O0-NEXT: v_lshlrev_b64 v[15:16], s4, v[15:16]
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v16
+; GFX9-O0-NEXT: v_or_b32_e64 v5, v5, v6
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v19
+; GFX9-O0-NEXT: ; kill: def $vgpr15 killed $vgpr15 killed $vgpr15_vgpr16 killed $exec
+; GFX9-O0-NEXT: v_or_b32_e64 v19, v6, v15
+; GFX9-O0-NEXT: ; kill: def $vgpr19 killed $vgpr19 def $vgpr19_vgpr20 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v20, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v19
+; GFX9-O0-NEXT: v_mov_b32_e32 v16, v17
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v20
+; GFX9-O0-NEXT: v_mov_b32_e32 v15, v18
+; GFX9-O0-NEXT: v_add_co_u32_e64 v5, s[6:7], v5, v16
+; GFX9-O0-NEXT: v_addc_co_u32_e64 v15, s[6:7], v6, v15, s[6:7]
+; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v15
+; GFX9-O0-NEXT: v_lshrrev_b64 v[17:18], s4, v[5:6]
+; GFX9-O0-NEXT: v_lshrrev_b64 v[7:8], s4, v[7:8]
+; GFX9-O0-NEXT: v_mov_b32_e32 v15, v7
+; GFX9-O0-NEXT: v_mov_b32_e32 v16, v17
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v8
+; GFX9-O0-NEXT: v_mov_b32_e32 v8, v18
+; GFX9-O0-NEXT: v_add_co_u32_e64 v15, s[6:7], v15, v16
+; GFX9-O0-NEXT: v_addc_co_u32_e64 v7, s[6:7], v7, v8, s[6:7]
+; GFX9-O0-NEXT: ; kill: def $vgpr15 killed $vgpr15 def $vgpr15_vgpr16 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v16, v7
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v8, v15
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v16
+; GFX9-O0-NEXT: v_add_co_u32_e64 v15, s[6:7], v7, v8
+; GFX9-O0-NEXT: v_addc_co_u32_e64 v2, s[6:7], v2, v3, s[6:7]
+; GFX9-O0-NEXT: ; kill: def $vgpr15 killed $vgpr15 def $vgpr15_vgpr16 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v16, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v15
+; GFX9-O0-NEXT: v_mov_b32_e32 v8, v13
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v16
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v14
+; GFX9-O0-NEXT: v_add_co_u32_e64 v2, s[6:7], v2, v8
+; GFX9-O0-NEXT: v_addc_co_u32_e64 v7, s[6:7], v3, v7, s[6:7]
+; GFX9-O0-NEXT: ; kill: def $vgpr2 killed $vgpr2 def $vgpr2_vgpr3 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v7
+; GFX9-O0-NEXT: v_lshlrev_b64 v[6:7], s4, v[5:6]
+; GFX9-O0-NEXT: v_mov_b32_e32 v8, v7
+; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 killed $vgpr11_vgpr12 killed $exec
+; GFX9-O0-NEXT: ; implicit-def: $sgpr6
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, s5
+; GFX9-O0-NEXT: ; kill: def $vgpr11 killed $vgpr11 def $vgpr11_vgpr12 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v12, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v12
+; GFX9-O0-NEXT: v_or_b32_e64 v5, v5, v8
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v6
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v11
+; GFX9-O0-NEXT: v_or_b32_e64 v6, v6, v7
+; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 def $vgpr6_vgpr7 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
+; GFX9-O0-NEXT: v_mov_b32_e32 v8, v6
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v7
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v0
+; GFX9-O0-NEXT: v_mov_b32_e32 v0, v1
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v9
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v10
+; GFX9-O0-NEXT: v_sub_co_u32_e32 v7, vcc, v7, v8
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v0, vcc, v0, v6, vcc
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v5, vcc, v3, v5, vcc
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v1, vcc, v1, v2, vcc
+; GFX9-O0-NEXT: ; implicit-def: $sgpr5
+; GFX9-O0-NEXT: ; implicit-def: $sgpr5
+; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v1
+; GFX9-O0-NEXT: ; implicit-def: $sgpr5
+; GFX9-O0-NEXT: ; implicit-def: $sgpr5
+; GFX9-O0-NEXT: ; kill: def $vgpr7 killed $vgpr7 def $vgpr7_vgpr8 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v8, v0
+; GFX9-O0-NEXT: v_mov_b32_e32 v0, v7
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v5
+; GFX9-O0-NEXT: v_lshrrev_b64 v[7:8], s4, v[7:8]
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v7
+; GFX9-O0-NEXT: v_lshrrev_b64 v[5:6], s4, v[5:6]
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v5
+; GFX9-O0-NEXT: ; kill: killed $vgpr4
+; GFX9-O0-NEXT: s_xor_saveexec_b64 s[4:5], -1
+; GFX9-O0-NEXT: buffer_load_dword v0, off, s[0:3], s32 offset:328 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_nop 0
+; GFX9-O0-NEXT: buffer_load_dword v4, off, s[0:3], s32 offset:332 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v8, off, s[0:3], s32 offset:336 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: buffer_load_dword v16, off, s[0:3], s32 offset:340 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: s_mov_b64 exec, s[4:5]
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: s_setpc_b64 s[30:31]
+ %div = urem i128 %lhs, %rhs
+ ret i128 %div
+}
+
+define i128 @v_srem_i128_v_pow2k(i128 %lhs) {
+; GFX9-LABEL: v_srem_i128_v_pow2k:
+; GFX9: ; %bb.0:
+; GFX9-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
+; GFX9-NEXT: v_ashrrev_i32_e32 v4, 31, v3
+; GFX9-NEXT: v_mov_b32_e32 v5, v4
+; GFX9-NEXT: v_lshrrev_b64 v[4:5], 31, v[4:5]
+; GFX9-NEXT: v_add_co_u32_e32 v4, vcc, v0, v4
+; GFX9-NEXT: v_addc_co_u32_e32 v4, vcc, v1, v5, vcc
+; GFX9-NEXT: v_addc_co_u32_e32 v5, vcc, 0, v2, vcc
+; GFX9-NEXT: v_addc_co_u32_e32 v6, vcc, 0, v3, vcc
+; GFX9-NEXT: v_and_b32_e32 v4, -2, v4
+; GFX9-NEXT: v_subrev_co_u32_e32 v0, vcc, 0, v0
+; GFX9-NEXT: v_subb_co_u32_e32 v1, vcc, v1, v4, vcc
+; GFX9-NEXT: v_subb_co_u32_e32 v2, vcc, v2, v5, vcc
+; GFX9-NEXT: v_subb_co_u32_e32 v3, vcc, v3, v6, vcc
+; GFX9-NEXT: s_setpc_b64 s[30:31]
+;
+; GFX9-O0-LABEL: v_srem_i128_v_pow2k:
+; GFX9-O0: ; %bb.0:
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v1
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 def $vgpr6_vgpr7 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v3
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr0 killed $vgpr0 def $vgpr0_vgpr1 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v2
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4_sgpr5
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4_sgpr5
+; GFX9-O0-NEXT: v_mov_b32_e32 v5, v0
+; GFX9-O0-NEXT: v_mov_b32_e32 v0, v1
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v6
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v7
+; GFX9-O0-NEXT: s_mov_b32 s4, 63
+; GFX9-O0-NEXT: v_ashrrev_i64 v[6:7], s4, v[6:7]
+; GFX9-O0-NEXT: s_mov_b32 s4, 31
+; GFX9-O0-NEXT: v_lshrrev_b64 v[6:7], s4, v[6:7]
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v6
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v7
+; GFX9-O0-NEXT: s_mov_b64 s[6:7], 0
+; GFX9-O0-NEXT: s_mov_b32 s5, s6
+; GFX9-O0-NEXT: s_mov_b32 s4, s7
+; GFX9-O0-NEXT: v_add_co_u32_e32 v6, vcc, v5, v4
+; GFX9-O0-NEXT: v_addc_co_u32_e32 v4, vcc, v0, v2, vcc
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, s5
+; GFX9-O0-NEXT: v_addc_co_u32_e32 v8, vcc, v3, v2, vcc
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, s4
+; GFX9-O0-NEXT: v_addc_co_u32_e32 v2, vcc, v1, v2, vcc
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 def $vgpr6_vgpr7 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v4
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v7
+; GFX9-O0-NEXT: s_mov_b32 s6, -2
+; GFX9-O0-NEXT: s_mov_b32 s4, 0
+; GFX9-O0-NEXT: ; kill: def $sgpr4 killed $sgpr4 def $sgpr4_sgpr5
+; GFX9-O0-NEXT: s_mov_b32 s5, s6
+; GFX9-O0-NEXT: s_mov_b32 s6, s5
+; GFX9-O0-NEXT: v_and_b32_e64 v4, v4, s6
+; GFX9-O0-NEXT: ; kill: def $vgpr6 killed $vgpr6 killed $vgpr6_vgpr7 killed $exec
+; GFX9-O0-NEXT: ; kill: def $sgpr4 killed $sgpr4 killed $sgpr4_sgpr5
+; GFX9-O0-NEXT: v_and_b32_e64 v9, v6, s4
+; GFX9-O0-NEXT: ; kill: def $vgpr9 killed $vgpr9 def $vgpr9_vgpr10 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v10, v4
+; GFX9-O0-NEXT: v_mov_b32_e32 v7, v9
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v10
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr8 killed $vgpr8 def $vgpr8_vgpr9 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v9, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v8
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v9
+; GFX9-O0-NEXT: v_sub_co_u32_e32 v5, vcc, v5, v7
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v0, vcc, v0, v6, vcc
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v3, vcc, v3, v4, vcc
+; GFX9-O0-NEXT: v_subb_co_u32_e32 v1, vcc, v1, v2, vcc
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr3 killed $vgpr3 def $vgpr3_vgpr4 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v4, v1
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr5 killed $vgpr5 def $vgpr5_vgpr6 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v6, v0
+; GFX9-O0-NEXT: v_mov_b32_e32 v0, v5
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
+; GFX9-O0-NEXT: s_mov_b32 s4, 32
+; GFX9-O0-NEXT: v_lshrrev_b64 v[5:6], s4, v[5:6]
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v5
+; GFX9-O0-NEXT: v_lshrrev_b64 v[3:4], s4, v[3:4]
+; GFX9-O0-NEXT: ; kill: def $vgpr3 killed $vgpr3 killed $vgpr3_vgpr4 killed $exec
+; GFX9-O0-NEXT: s_setpc_b64 s[30:31]
+ %div = srem i128 %lhs, 8589934592
+ ret i128 %div
+}
+
+define i128 @v_urem_i128_v_pow2k(i128 %lhs) {
+; GFX9-LABEL: v_urem_i128_v_pow2k:
+; GFX9: ; %bb.0:
+; GFX9-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
+; GFX9-NEXT: v_and_b32_e32 v1, 1, v1
+; GFX9-NEXT: v_mov_b32_e32 v2, 0
+; GFX9-NEXT: v_mov_b32_e32 v3, 0
+; GFX9-NEXT: s_setpc_b64 s[30:31]
+;
+; GFX9-O0-LABEL: v_urem_i128_v_pow2k:
+; GFX9-O0: ; %bb.0:
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
+; GFX9-O0-NEXT: buffer_store_dword v3, off, s[0:3], s32 ; 4-byte Folded Spill
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, v2
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v1
+; GFX9-O0-NEXT: buffer_load_dword v1, off, s[0:3], s32 ; 4-byte Folded Reload
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr3 killed $vgpr3 def $vgpr3_vgpr4 killed $exec
+; GFX9-O0-NEXT: ; kill: def $vgpr4 killed $vgpr1 killed $exec
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4
+; GFX9-O0-NEXT: ; kill: def $vgpr0 killed $vgpr0 def $vgpr0_vgpr1 killed $exec
+; GFX9-O0-NEXT: s_waitcnt vmcnt(0)
+; GFX9-O0-NEXT: v_mov_b32_e32 v1, v2
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4_sgpr5
+; GFX9-O0-NEXT: ; implicit-def: $sgpr4_sgpr5
+; GFX9-O0-NEXT: s_mov_b32 s6, 1
+; GFX9-O0-NEXT: s_mov_b32 s4, -1
+; GFX9-O0-NEXT: ; kill: def $sgpr4 killed $sgpr4 def $sgpr4_sgpr5
+; GFX9-O0-NEXT: s_mov_b32 s5, s6
+; GFX9-O0-NEXT: s_mov_b32 s6, s5
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v1
+; GFX9-O0-NEXT: v_and_b32_e64 v3, v2, s6
+; GFX9-O0-NEXT: ; kill: def $sgpr4 killed $sgpr4 killed $sgpr4_sgpr5
+; GFX9-O0-NEXT: ; kill: def $vgpr0 killed $vgpr0 killed $vgpr0_vgpr1 killed $exec
+; GFX9-O0-NEXT: v_and_b32_e64 v1, v0, s4
+; GFX9-O0-NEXT: ; kill: def $vgpr1 killed $vgpr1 def $vgpr1_vgpr2 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
+; GFX9-O0-NEXT: s_mov_b32 s4, 32
+; GFX9-O0-NEXT: v_lshrrev_b64 v[1:2], s4, v[1:2]
+; GFX9-O0-NEXT: ; kill: def $vgpr1 killed $vgpr1 killed $vgpr1_vgpr2 killed $exec
+; GFX9-O0-NEXT: v_mov_b32_e32 v3, 0
+; GFX9-O0-NEXT: v_mov_b32_e32 v2, v3
+; GFX9-O0-NEXT: s_setpc_b64 s[30:31]
+ %div = urem i128 %lhs, 8589934592
+ ret i128 %div
+}
+
+;; NOTE: These prefixes are unused and the list is autogenerated. Do not add tests below this line:
+; GFX9-SDAG: {{.*}}
+; GFX9-SDAG-O0: {{.*}}
>From 43b7dfcc1dbdf904b1c507e03e5c34d527b5a344 Mon Sep 17 00:00:00 2001
From: Fangrui Song <i at maskray.me>
Date: Wed, 28 Feb 2024 15:56:43 -0800
Subject: [PATCH 066/406] Revert "[SROA] Unfold gep of index phi (#83087)"
This reverts commit 2eb63982e88b9ed8336158d35884b1a1d04a0f78.
This caused verifier error
```
Instruction does not dominate all uses!
```
for some projects using Halide.
The verifier error happens inside `Halide::Internal::CodeGen_LLVM::optimize_module`
and looks like a genuine SROA issue.
---
llvm/lib/Transforms/Scalar/SROA.cpp | 115 ++++++----------
llvm/test/Transforms/SROA/phi-and-select.ll | 20 +--
llvm/test/Transforms/SROA/phi-gep.ll | 141 +++-----------------
3 files changed, 69 insertions(+), 207 deletions(-)
diff --git a/llvm/lib/Transforms/Scalar/SROA.cpp b/llvm/lib/Transforms/Scalar/SROA.cpp
index c7b9ce2e93120a..fad70e8bf2861f 100644
--- a/llvm/lib/Transforms/Scalar/SROA.cpp
+++ b/llvm/lib/Transforms/Scalar/SROA.cpp
@@ -3956,11 +3956,11 @@ class AggLoadStoreRewriter : public InstVisitor<AggLoadStoreRewriter, bool> {
return false;
}
- // Unfold gep (select cond, ptr1, ptr2), idx
+ // Fold gep (select cond, ptr1, ptr2), idx
// => select cond, gep(ptr1, idx), gep(ptr2, idx)
// and gep ptr, (select cond, idx1, idx2)
// => select cond, gep(ptr, idx1), gep(ptr, idx2)
- bool unfoldGEPSelect(GetElementPtrInst &GEPI) {
+ bool foldGEPSelect(GetElementPtrInst &GEPI) {
// Check whether the GEP has exactly one select operand and all indices
// will become constant after the transform.
SelectInst *Sel = dyn_cast<SelectInst>(GEPI.getPointerOperand());
@@ -4029,100 +4029,67 @@ class AggLoadStoreRewriter : public InstVisitor<AggLoadStoreRewriter, bool> {
return true;
}
- // Unfold gep (phi ptr1, ptr2), idx
- // => phi ((gep ptr1, idx), (gep ptr2, idx))
- // and gep ptr, (phi idx1, idx2)
- // => phi ((gep ptr, idx1), (gep ptr, idx2))
- bool unfoldGEPPhi(GetElementPtrInst &GEPI) {
- // To prevent infinitely expanding recursive phis, bail if the GEP pointer
- // operand (looking through the phi if it is the phi we want to unfold) is
- // an instruction besides an alloca.
- PHINode *Phi = dyn_cast<PHINode>(GEPI.getPointerOperand());
- auto IsInvalidPointerOperand = [](Value *V) {
- return isa<Instruction>(V) && !isa<AllocaInst>(V);
- };
- if (Phi) {
- if (any_of(Phi->operands(), IsInvalidPointerOperand))
- return false;
- } else {
- if (IsInvalidPointerOperand(GEPI.getPointerOperand()))
- return false;
- }
- // Check whether the GEP has exactly one phi operand (including the pointer
- // operand) and all indices will become constant after the transform.
- for (Value *Op : GEPI.indices()) {
- if (auto *SI = dyn_cast<PHINode>(Op)) {
- if (Phi)
- return false;
-
- Phi = SI;
- if (!all_of(Phi->incoming_values(),
- [](Value *V) { return isa<ConstantInt>(V); }))
- return false;
- continue;
- }
-
- if (!isa<ConstantInt>(Op))
- return false;
- }
+ // Fold gep (phi ptr1, ptr2) => phi gep(ptr1), gep(ptr2)
+ bool foldGEPPhi(GetElementPtrInst &GEPI) {
+ if (!GEPI.hasAllConstantIndices())
+ return false;
- if (!Phi)
+ PHINode *PHI = cast<PHINode>(GEPI.getPointerOperand());
+ if (GEPI.getParent() != PHI->getParent() ||
+ llvm::any_of(PHI->incoming_values(), [](Value *In) {
+ Instruction *I = dyn_cast<Instruction>(In);
+ return !I || isa<GetElementPtrInst>(I) || isa<PHINode>(I) ||
+ succ_empty(I->getParent()) ||
+ !I->getParent()->isLegalToHoistInto();
+ }))
return false;
LLVM_DEBUG(dbgs() << " Rewriting gep(phi) -> phi(gep):\n";
- dbgs() << " original: " << *Phi << "\n";
+ dbgs() << " original: " << *PHI << "\n";
dbgs() << " " << GEPI << "\n";);
- auto GetNewOps = [&](Value *PhiOp) {
- SmallVector<Value *> NewOps;
- for (Value *Op : GEPI.operands())
- if (Op == Phi)
- NewOps.push_back(PhiOp);
- else
- NewOps.push_back(Op);
- return NewOps;
- };
-
- IRB.SetInsertPoint(Phi);
- PHINode *NewPhi = IRB.CreatePHI(GEPI.getType(), Phi->getNumIncomingValues(),
- Phi->getName() + ".sroa.phi");
-
+ SmallVector<Value *, 4> Index(GEPI.indices());
bool IsInBounds = GEPI.isInBounds();
- Type *SourceTy = GEPI.getSourceElementType();
- // We only handle arguments, constants, and static allocas here, so we can
- // insert GEPs at the beginning of the function after static allocas.
- IRB.SetInsertPointPastAllocas(GEPI.getFunction());
- for (unsigned I = 0, E = Phi->getNumIncomingValues(); I != E; ++I) {
- Value *Op = Phi->getIncomingValue(I);
- BasicBlock *BB = Phi->getIncomingBlock(I);
- SmallVector<Value *> NewOps = GetNewOps(Op);
-
- Value *NewGEP =
- IRB.CreateGEP(SourceTy, NewOps[0], ArrayRef(NewOps).drop_front(),
- Phi->getName() + ".sroa.gep", IsInBounds);
- NewPhi->addIncoming(NewGEP, BB);
+ IRB.SetInsertPoint(GEPI.getParent(), GEPI.getParent()->getFirstNonPHIIt());
+ PHINode *NewPN = IRB.CreatePHI(GEPI.getType(), PHI->getNumIncomingValues(),
+ PHI->getName() + ".sroa.phi");
+ for (unsigned I = 0, E = PHI->getNumIncomingValues(); I != E; ++I) {
+ BasicBlock *B = PHI->getIncomingBlock(I);
+ Value *NewVal = nullptr;
+ int Idx = NewPN->getBasicBlockIndex(B);
+ if (Idx >= 0) {
+ NewVal = NewPN->getIncomingValue(Idx);
+ } else {
+ Instruction *In = cast<Instruction>(PHI->getIncomingValue(I));
+
+ IRB.SetInsertPoint(In->getParent(), std::next(In->getIterator()));
+ Type *Ty = GEPI.getSourceElementType();
+ NewVal = IRB.CreateGEP(Ty, In, Index, In->getName() + ".sroa.gep",
+ IsInBounds);
+ }
+ NewPN->addIncoming(NewVal, B);
}
Visited.erase(&GEPI);
- GEPI.replaceAllUsesWith(NewPhi);
+ GEPI.replaceAllUsesWith(NewPN);
GEPI.eraseFromParent();
- Visited.insert(NewPhi);
- enqueueUsers(*NewPhi);
+ Visited.insert(NewPN);
+ enqueueUsers(*NewPN);
LLVM_DEBUG(dbgs() << " to: ";
for (Value *In
- : NewPhi->incoming_values()) dbgs()
+ : NewPN->incoming_values()) dbgs()
<< "\n " << *In;
- dbgs() << "\n " << *NewPhi << '\n');
+ dbgs() << "\n " << *NewPN << '\n');
return true;
}
bool visitGetElementPtrInst(GetElementPtrInst &GEPI) {
- if (unfoldGEPSelect(GEPI))
+ if (foldGEPSelect(GEPI))
return true;
- if (unfoldGEPPhi(GEPI))
+ if (isa<PHINode>(GEPI.getPointerOperand()) && foldGEPPhi(GEPI))
return true;
enqueueUsers(GEPI);
diff --git a/llvm/test/Transforms/SROA/phi-and-select.ll b/llvm/test/Transforms/SROA/phi-and-select.ll
index 7c8b27c9de9c0b..54cfb10793a1ac 100644
--- a/llvm/test/Transforms/SROA/phi-and-select.ll
+++ b/llvm/test/Transforms/SROA/phi-and-select.ll
@@ -114,13 +114,13 @@ define i32 @test3(i32 %x) {
; CHECK-LABEL: @test3(
; CHECK-NEXT: entry:
; CHECK-NEXT: switch i32 [[X:%.*]], label [[BB0:%.*]] [
-; CHECK-NEXT: i32 1, label [[BB1:%.*]]
-; CHECK-NEXT: i32 2, label [[BB2:%.*]]
-; CHECK-NEXT: i32 3, label [[BB3:%.*]]
-; CHECK-NEXT: i32 4, label [[BB4:%.*]]
-; CHECK-NEXT: i32 5, label [[BB5:%.*]]
-; CHECK-NEXT: i32 6, label [[BB6:%.*]]
-; CHECK-NEXT: i32 7, label [[BB7:%.*]]
+; CHECK-NEXT: i32 1, label [[BB1:%.*]]
+; CHECK-NEXT: i32 2, label [[BB2:%.*]]
+; CHECK-NEXT: i32 3, label [[BB3:%.*]]
+; CHECK-NEXT: i32 4, label [[BB4:%.*]]
+; CHECK-NEXT: i32 5, label [[BB5:%.*]]
+; CHECK-NEXT: i32 6, label [[BB6:%.*]]
+; CHECK-NEXT: i32 7, label [[BB7:%.*]]
; CHECK-NEXT: ]
; CHECK: bb0:
; CHECK-NEXT: br label [[EXIT:%.*]]
@@ -733,7 +733,6 @@ define void @PR20822(i1 %c1, i1 %c2, ptr %ptr) {
; CHECK-LABEL: @PR20822(
; CHECK-NEXT: entry:
; CHECK-NEXT: [[F_SROA_0:%.*]] = alloca i32, align 4
-; CHECK-NEXT: [[F1_SROA_GEP:%.*]] = getelementptr inbounds [[STRUCT_S:%.*]], ptr [[PTR:%.*]], i32 0, i32 0
; CHECK-NEXT: br i1 [[C1:%.*]], label [[IF_END:%.*]], label [[FOR_COND:%.*]]
; CHECK: for.cond:
; CHECK-NEXT: br label [[IF_END]]
@@ -743,8 +742,9 @@ define void @PR20822(i1 %c1, i1 %c2, ptr %ptr) {
; CHECK: if.then2:
; CHECK-NEXT: br label [[IF_THEN5]]
; CHECK: if.then5:
-; CHECK-NEXT: [[F1_SROA_PHI:%.*]] = phi ptr [ [[F1_SROA_GEP]], [[IF_THEN2]] ], [ [[F_SROA_0]], [[IF_END]] ]
-; CHECK-NEXT: store i32 0, ptr [[F1_SROA_PHI]], align 4
+; CHECK-NEXT: [[F1:%.*]] = phi ptr [ [[PTR:%.*]], [[IF_THEN2]] ], [ [[F_SROA_0]], [[IF_END]] ]
+; CHECK-NEXT: [[DOTFCA_0_GEP:%.*]] = getelementptr inbounds [[STRUCT_S:%.*]], ptr [[F1]], i32 0, i32 0
+; CHECK-NEXT: store i32 0, ptr [[DOTFCA_0_GEP]], align 4
; CHECK-NEXT: ret void
;
entry:
diff --git a/llvm/test/Transforms/SROA/phi-gep.ll b/llvm/test/Transforms/SROA/phi-gep.ll
index 78071dcdafb49d..c5aa1cdd9cf654 100644
--- a/llvm/test/Transforms/SROA/phi-gep.ll
+++ b/llvm/test/Transforms/SROA/phi-gep.ll
@@ -65,13 +65,15 @@ end:
define i32 @test_sroa_phi_gep_poison(i1 %cond) {
; CHECK-LABEL: @test_sroa_phi_gep_poison(
; CHECK-NEXT: entry:
+; CHECK-NEXT: [[A:%.*]] = alloca [[PAIR:%.*]], align 4
; CHECK-NEXT: br i1 [[COND:%.*]], label [[IF_THEN:%.*]], label [[END:%.*]]
; CHECK: if.then:
-; CHECK-NEXT: [[PHI_SROA_PHI_SROA_SPECULATE_LOAD_IF_THEN:%.*]] = load i32, ptr poison, align 4
; CHECK-NEXT: br label [[END]]
; CHECK: end:
-; CHECK-NEXT: [[PHI_SROA_PHI_SROA_SPECULATED:%.*]] = phi i32 [ undef, [[ENTRY:%.*]] ], [ [[PHI_SROA_PHI_SROA_SPECULATE_LOAD_IF_THEN]], [[IF_THEN]] ]
-; CHECK-NEXT: ret i32 [[PHI_SROA_PHI_SROA_SPECULATED]]
+; CHECK-NEXT: [[PHI:%.*]] = phi ptr [ [[A]], [[ENTRY:%.*]] ], [ poison, [[IF_THEN]] ]
+; CHECK-NEXT: [[GEP:%.*]] = getelementptr inbounds [[PAIR]], ptr [[PHI]], i32 0, i32 1
+; CHECK-NEXT: [[LOAD:%.*]] = load i32, ptr [[GEP]], align 4
+; CHECK-NEXT: ret i32 [[LOAD]]
;
entry:
%a = alloca %pair, align 4
@@ -92,13 +94,17 @@ end:
define i32 @test_sroa_phi_gep_global(i1 %cond) {
; CHECK-LABEL: @test_sroa_phi_gep_global(
; CHECK-NEXT: entry:
+; CHECK-NEXT: [[A:%.*]] = alloca [[PAIR:%.*]], align 4
+; CHECK-NEXT: [[GEP_A:%.*]] = getelementptr inbounds [[PAIR]], ptr [[A]], i32 0, i32 1
+; CHECK-NEXT: store i32 1, ptr [[GEP_A]], align 4
; CHECK-NEXT: br i1 [[COND:%.*]], label [[IF_THEN:%.*]], label [[END:%.*]]
; CHECK: if.then:
-; CHECK-NEXT: [[PHI_SROA_PHI_SROA_SPECULATE_LOAD_IF_THEN:%.*]] = load i32, ptr getelementptr inbounds ([[PAIR:%.*]], ptr @g, i32 0, i32 1), align 4
; CHECK-NEXT: br label [[END]]
; CHECK: end:
-; CHECK-NEXT: [[PHI_SROA_PHI_SROA_SPECULATED:%.*]] = phi i32 [ 1, [[ENTRY:%.*]] ], [ [[PHI_SROA_PHI_SROA_SPECULATE_LOAD_IF_THEN]], [[IF_THEN]] ]
-; CHECK-NEXT: ret i32 [[PHI_SROA_PHI_SROA_SPECULATED]]
+; CHECK-NEXT: [[PHI:%.*]] = phi ptr [ [[A]], [[ENTRY:%.*]] ], [ @g, [[IF_THEN]] ]
+; CHECK-NEXT: [[GEP:%.*]] = getelementptr inbounds [[PAIR]], ptr [[PHI]], i32 0, i32 1
+; CHECK-NEXT: [[LOAD:%.*]] = load i32, ptr [[GEP]], align 4
+; CHECK-NEXT: ret i32 [[LOAD]]
;
entry:
%a = alloca %pair, align 4
@@ -239,7 +245,7 @@ define i32 @test_sroa_invoke_phi_gep(i1 %cond) personality ptr @__gxx_personalit
; CHECK-NEXT: br i1 [[COND:%.*]], label [[CALL:%.*]], label [[END:%.*]]
; CHECK: call:
; CHECK-NEXT: [[B:%.*]] = invoke ptr @foo()
-; CHECK-NEXT: to label [[END]] unwind label [[INVOKE_CATCH:%.*]]
+; CHECK-NEXT: to label [[END]] unwind label [[INVOKE_CATCH:%.*]]
; CHECK: end:
; CHECK-NEXT: [[PHI:%.*]] = phi ptr [ [[A]], [[ENTRY:%.*]] ], [ [[B]], [[CALL]] ]
; CHECK-NEXT: [[GEP:%.*]] = getelementptr inbounds [[PAIR]], ptr [[PHI]], i32 0, i32 1
@@ -247,7 +253,7 @@ define i32 @test_sroa_invoke_phi_gep(i1 %cond) personality ptr @__gxx_personalit
; CHECK-NEXT: ret i32 [[LOAD]]
; CHECK: invoke_catch:
; CHECK-NEXT: [[RES:%.*]] = landingpad { ptr, i32 }
-; CHECK-NEXT: catch ptr null
+; CHECK-NEXT: catch ptr null
; CHECK-NEXT: ret i32 0
;
entry:
@@ -462,10 +468,10 @@ define i32 @test_sroa_phi_gep_multiple_values_from_same_block(i32 %arg) {
; CHECK-LABEL: @test_sroa_phi_gep_multiple_values_from_same_block(
; CHECK-NEXT: bb.1:
; CHECK-NEXT: switch i32 [[ARG:%.*]], label [[BB_3:%.*]] [
-; CHECK-NEXT: i32 1, label [[BB_2:%.*]]
-; CHECK-NEXT: i32 2, label [[BB_2]]
-; CHECK-NEXT: i32 3, label [[BB_4:%.*]]
-; CHECK-NEXT: i32 4, label [[BB_4]]
+; CHECK-NEXT: i32 1, label [[BB_2:%.*]]
+; CHECK-NEXT: i32 2, label [[BB_2]]
+; CHECK-NEXT: i32 3, label [[BB_4:%.*]]
+; CHECK-NEXT: i32 4, label [[BB_4]]
; CHECK-NEXT: ]
; CHECK: bb.2:
; CHECK-NEXT: br label [[BB_4]]
@@ -498,117 +504,6 @@ bb.4: ; preds = %bb.1, %bb.1, %bb
ret i32 %load
}
-define i64 @test_phi_idx_mem2reg_const(i1 %arg) {
-; CHECK-LABEL: @test_phi_idx_mem2reg_const(
-; CHECK-NEXT: bb:
-; CHECK-NEXT: br i1 [[ARG:%.*]], label [[BB1:%.*]], label [[BB2:%.*]]
-; CHECK: bb1:
-; CHECK-NEXT: br label [[END:%.*]]
-; CHECK: bb2:
-; CHECK-NEXT: br label [[END]]
-; CHECK: end:
-; CHECK-NEXT: [[PHI_SROA_PHI_SROA_SPECULATED:%.*]] = phi i64 [ 2, [[BB1]] ], [ 3, [[BB2]] ]
-; CHECK-NEXT: [[PHI:%.*]] = phi i64 [ 0, [[BB1]] ], [ 1, [[BB2]] ]
-; CHECK-NEXT: ret i64 [[PHI_SROA_PHI_SROA_SPECULATED]]
-;
-bb:
- %alloca = alloca [2 x i64], align 8
- %gep1 = getelementptr inbounds i64, ptr %alloca, i64 1
- store i64 2, ptr %alloca
- store i64 3, ptr %gep1
- br i1 %arg, label %bb1, label %bb2
-
-bb1:
- br label %end
-
-bb2:
- br label %end
-
-end:
- %phi = phi i64 [ 0, %bb1 ], [ 1, %bb2 ]
- %getelementptr = getelementptr inbounds i64, ptr %alloca, i64 %phi
- %load = load i64, ptr %getelementptr
- ret i64 %load
-}
-
-define i64 @test_phi_idx_mem2reg_not_const(i1 %arg, i64 %idx) {
-; CHECK-LABEL: @test_phi_idx_mem2reg_not_const(
-; CHECK-NEXT: bb:
-; CHECK-NEXT: [[ALLOCA:%.*]] = alloca [2 x i64], align 8
-; CHECK-NEXT: [[GEP1:%.*]] = getelementptr inbounds i64, ptr [[ALLOCA]], i64 1
-; CHECK-NEXT: store i64 2, ptr [[ALLOCA]], align 4
-; CHECK-NEXT: store i64 3, ptr [[GEP1]], align 4
-; CHECK-NEXT: br i1 [[ARG:%.*]], label [[BB1:%.*]], label [[BB2:%.*]]
-; CHECK: bb1:
-; CHECK-NEXT: br label [[END:%.*]]
-; CHECK: bb2:
-; CHECK-NEXT: br label [[END]]
-; CHECK: end:
-; CHECK-NEXT: [[PHI:%.*]] = phi i64 [ 0, [[BB1]] ], [ [[IDX:%.*]], [[BB2]] ]
-; CHECK-NEXT: [[GETELEMENTPTR:%.*]] = getelementptr inbounds i64, ptr [[ALLOCA]], i64 [[PHI]]
-; CHECK-NEXT: [[LOAD:%.*]] = load i64, ptr [[GETELEMENTPTR]], align 4
-; CHECK-NEXT: ret i64 [[LOAD]]
-;
-bb:
- %alloca = alloca [2 x i64], align 8
- %gep1 = getelementptr inbounds i64, ptr %alloca, i64 1
- store i64 2, ptr %alloca
- store i64 3, ptr %gep1
- br i1 %arg, label %bb1, label %bb2
-
-bb1:
- br label %end
-
-bb2:
- br label %end
-
-end:
- %phi = phi i64 [ 0, %bb1 ], [ %idx, %bb2 ]
- %getelementptr = getelementptr inbounds i64, ptr %alloca, i64 %phi
- %load = load i64, ptr %getelementptr
- ret i64 %load
-}
-
-define i64 @test_phi_mem2reg_pointer_op_is_non_const_gep(i1 %arg, i64 %idx) {
-; CHECK-LABEL: @test_phi_mem2reg_pointer_op_is_non_const_gep(
-; CHECK-NEXT: bb:
-; CHECK-NEXT: [[ALLOCA:%.*]] = alloca [2 x i64], align 8
-; CHECK-NEXT: [[GEP1:%.*]] = getelementptr inbounds i64, ptr [[ALLOCA]], i64 1
-; CHECK-NEXT: store i64 2, ptr [[ALLOCA]], align 4
-; CHECK-NEXT: store i64 3, ptr [[GEP1]], align 4
-; CHECK-NEXT: br i1 [[ARG:%.*]], label [[BB1:%.*]], label [[BB2:%.*]]
-; CHECK: bb1:
-; CHECK-NEXT: br label [[END:%.*]]
-; CHECK: bb2:
-; CHECK-NEXT: br label [[END]]
-; CHECK: end:
-; CHECK-NEXT: [[PHI:%.*]] = phi i64 [ 0, [[BB1]] ], [ 1, [[BB2]] ]
-; CHECK-NEXT: [[GETELEMENTPTR:%.*]] = getelementptr inbounds i64, ptr [[ALLOCA]], i64 [[IDX:%.*]]
-; CHECK-NEXT: [[GETELEMENTPTR2:%.*]] = getelementptr inbounds i64, ptr [[GETELEMENTPTR]], i64 [[PHI]]
-; CHECK-NEXT: [[LOAD:%.*]] = load i64, ptr [[GETELEMENTPTR]], align 4
-; CHECK-NEXT: ret i64 [[LOAD]]
-;
-bb:
- %alloca = alloca [2 x i64], align 8
- %gep1 = getelementptr inbounds i64, ptr %alloca, i64 1
- store i64 2, ptr %alloca
- store i64 3, ptr %gep1
- br i1 %arg, label %bb1, label %bb2
-
-bb1:
- br label %end
-
-bb2:
- br label %end
-
-end:
- %phi = phi i64 [ 0, %bb1 ], [ 1, %bb2 ]
- %getelementptr = getelementptr inbounds i64, ptr %alloca, i64 %idx
- %getelementptr2 = getelementptr inbounds i64, ptr %getelementptr, i64 %phi
- %load = load i64, ptr %getelementptr
- ret i64 %load
-}
-
declare ptr @foo()
declare i32 @__gxx_personality_v0(...)
>From 6bc7c9df7f45642071f2b59a222ba009dc81eb99 Mon Sep 17 00:00:00 2001
From: Peiming Liu <36770114+PeimingLiu at users.noreply.github.com>
Date: Wed, 28 Feb 2024 16:10:20 -0800
Subject: [PATCH 067/406] [mlir][sparse] infer returned type for
sparse_tensor.to_[buffer] ops (#83343)
The sparse structure buffers might not always be memrefs with rank == 1
with the presence of batch levels.
---
.../SparseTensor/IR/SparseTensorOps.td | 20 +-
.../SparseTensor/IR/SparseTensorDialect.cpp | 65 +++++++
.../Transforms/SparseTensorCodegen.cpp | 12 +-
.../Transforms/SparseTensorRewriting.cpp | 27 +--
.../SparseTensor/CPU/sparse_insert_3d.mlir | 171 ++++--------------
5 files changed, 132 insertions(+), 163 deletions(-)
diff --git a/mlir/include/mlir/Dialect/SparseTensor/IR/SparseTensorOps.td b/mlir/include/mlir/Dialect/SparseTensor/IR/SparseTensorOps.td
index 9007e4e98e3163..3a5447d29f866d 100644
--- a/mlir/include/mlir/Dialect/SparseTensor/IR/SparseTensorOps.td
+++ b/mlir/include/mlir/Dialect/SparseTensor/IR/SparseTensorOps.td
@@ -257,9 +257,10 @@ def SparseTensor_ReinterpretMapOp : SparseTensor_Op<"reinterpret_map", [NoMemory
let hasVerifier = 1;
}
-def SparseTensor_ToPositionsOp : SparseTensor_Op<"positions", [Pure]>,
+def SparseTensor_ToPositionsOp : SparseTensor_Op<"positions",
+ [Pure, DeclareOpInterfaceMethods<InferTypeOpInterface>]>,
Arguments<(ins AnySparseTensor:$tensor, LevelAttr:$level)>,
- Results<(outs AnyStridedMemRefOfRank<1>:$result)> {
+ Results<(outs AnyNon0RankedMemRef:$result)> {
let summary = "Extracts the `level`-th positions array of the `tensor`";
let description = [{
Returns the positions array of the tensor's storage at the given
@@ -283,9 +284,10 @@ def SparseTensor_ToPositionsOp : SparseTensor_Op<"positions", [Pure]>,
let hasVerifier = 1;
}
-def SparseTensor_ToCoordinatesOp : SparseTensor_Op<"coordinates", [Pure]>,
+def SparseTensor_ToCoordinatesOp : SparseTensor_Op<"coordinates",
+ [Pure, DeclareOpInterfaceMethods<InferTypeOpInterface>]>,
Arguments<(ins AnySparseTensor:$tensor, LevelAttr:$level)>,
- Results<(outs AnyStridedMemRefOfRank<1>:$result)> {
+ Results<(outs AnyNon0RankedMemRef:$result)> {
let summary = "Extracts the `level`-th coordinates array of the `tensor`";
let description = [{
Returns the coordinates array of the tensor's storage at the given
@@ -309,9 +311,10 @@ def SparseTensor_ToCoordinatesOp : SparseTensor_Op<"coordinates", [Pure]>,
let hasVerifier = 1;
}
-def SparseTensor_ToCoordinatesBufferOp : SparseTensor_Op<"coordinates_buffer", [Pure]>,
+def SparseTensor_ToCoordinatesBufferOp : SparseTensor_Op<"coordinates_buffer",
+ [Pure, DeclareOpInterfaceMethods<InferTypeOpInterface>]>,
Arguments<(ins AnySparseTensor:$tensor)>,
- Results<(outs AnyStridedMemRefOfRank<1>:$result)> {
+ Results<(outs AnyNon0RankedMemRef:$result)> {
let summary = "Extracts the linear coordinates array from a tensor";
let description = [{
Returns the linear coordinates array for a sparse tensor with
@@ -340,9 +343,10 @@ def SparseTensor_ToCoordinatesBufferOp : SparseTensor_Op<"coordinates_buffer", [
let hasVerifier = 1;
}
-def SparseTensor_ToValuesOp : SparseTensor_Op<"values", [Pure]>,
+def SparseTensor_ToValuesOp : SparseTensor_Op<"values",
+ [Pure, DeclareOpInterfaceMethods<InferTypeOpInterface>]>,
Arguments<(ins AnySparseTensor:$tensor)>,
- Results<(outs AnyStridedMemRefOfRank<1>:$result)> {
+ Results<(outs AnyNon0RankedMemRef:$result)> {
let summary = "Extracts numerical values array from a tensor";
let description = [{
Returns the values array of the sparse storage format for the given
diff --git a/mlir/lib/Dialect/SparseTensor/IR/SparseTensorDialect.cpp b/mlir/lib/Dialect/SparseTensor/IR/SparseTensorDialect.cpp
index 69c3413f35ea9c..232635ca84a47e 100644
--- a/mlir/lib/Dialect/SparseTensor/IR/SparseTensorDialect.cpp
+++ b/mlir/lib/Dialect/SparseTensor/IR/SparseTensorDialect.cpp
@@ -1445,6 +1445,38 @@ OpFoldResult ReinterpretMapOp::fold(FoldAdaptor adaptor) {
return {};
}
+template <typename ToBufferOp>
+static LogicalResult inferSparseBufferType(ValueRange ops, DictionaryAttr attr,
+ OpaqueProperties prop,
+ RegionRange region,
+ SmallVectorImpl<mlir::Type> &ret) {
+ typename ToBufferOp::Adaptor adaptor(ops, attr, prop, region);
+ SparseTensorType stt = getSparseTensorType(adaptor.getTensor());
+ Type elemTp = nullptr;
+ bool withStride = false;
+ if constexpr (std::is_same_v<ToBufferOp, ToPositionsOp>) {
+ elemTp = stt.getPosType();
+ } else if constexpr (std::is_same_v<ToBufferOp, ToCoordinatesOp> ||
+ std::is_same_v<ToBufferOp, ToCoordinatesBufferOp>) {
+ elemTp = stt.getCrdType();
+ if constexpr (std::is_same_v<ToBufferOp, ToCoordinatesOp>)
+ withStride = stt.getAoSCOOStart() <= adaptor.getLevel();
+ } else if constexpr (std::is_same_v<ToBufferOp, ToValuesOp>) {
+ elemTp = stt.getElementType();
+ }
+
+ assert(elemTp && "unhandled operation.");
+ SmallVector<int64_t> bufShape = stt.getBatchLvlShape();
+ bufShape.push_back(ShapedType::kDynamic);
+
+ auto layout = withStride ? StridedLayoutAttr::StridedLayoutAttr::get(
+ stt.getContext(), ShapedType::kDynamic,
+ {ShapedType::kDynamic})
+ : StridedLayoutAttr();
+ ret.emplace_back(MemRefType::get(bufShape, elemTp, layout));
+ return success();
+}
+
LogicalResult ToPositionsOp::verify() {
auto stt = getSparseTensorType(getTensor());
if (failed(lvlIsInBounds(getLevel(), getTensor())))
@@ -1454,6 +1486,14 @@ LogicalResult ToPositionsOp::verify() {
return success();
}
+LogicalResult
+ToPositionsOp::inferReturnTypes(MLIRContext *ctx, std::optional<Location> loc,
+ ValueRange ops, DictionaryAttr attr,
+ OpaqueProperties prop, RegionRange region,
+ SmallVectorImpl<mlir::Type> &ret) {
+ return inferSparseBufferType<ToPositionsOp>(ops, attr, prop, region, ret);
+}
+
LogicalResult ToCoordinatesOp::verify() {
auto stt = getSparseTensorType(getTensor());
if (failed(lvlIsInBounds(getLevel(), getTensor())))
@@ -1463,6 +1503,14 @@ LogicalResult ToCoordinatesOp::verify() {
return success();
}
+LogicalResult
+ToCoordinatesOp::inferReturnTypes(MLIRContext *ctx, std::optional<Location> loc,
+ ValueRange ops, DictionaryAttr attr,
+ OpaqueProperties prop, RegionRange region,
+ SmallVectorImpl<mlir::Type> &ret) {
+ return inferSparseBufferType<ToCoordinatesOp>(ops, attr, prop, region, ret);
+}
+
LogicalResult ToCoordinatesBufferOp::verify() {
auto stt = getSparseTensorType(getTensor());
if (stt.getAoSCOOStart() >= stt.getLvlRank())
@@ -1470,6 +1518,14 @@ LogicalResult ToCoordinatesBufferOp::verify() {
return success();
}
+LogicalResult ToCoordinatesBufferOp::inferReturnTypes(
+ MLIRContext *ctx, std::optional<Location> loc, ValueRange ops,
+ DictionaryAttr attr, OpaqueProperties prop, RegionRange region,
+ SmallVectorImpl<mlir::Type> &ret) {
+ return inferSparseBufferType<ToCoordinatesBufferOp>(ops, attr, prop, region,
+ ret);
+}
+
LogicalResult ToValuesOp::verify() {
auto stt = getSparseTensorType(getTensor());
auto mtp = getMemRefType(getResult());
@@ -1478,6 +1534,15 @@ LogicalResult ToValuesOp::verify() {
return success();
}
+LogicalResult ToValuesOp::inferReturnTypes(MLIRContext *ctx,
+ std::optional<Location> loc,
+ ValueRange ops, DictionaryAttr attr,
+ OpaqueProperties prop,
+ RegionRange region,
+ SmallVectorImpl<mlir::Type> &ret) {
+ return inferSparseBufferType<ToValuesOp>(ops, attr, prop, region, ret);
+}
+
LogicalResult ToSliceOffsetOp::verify() {
auto rank = getRankedTensorType(getSlice()).getRank();
if (rank <= getDim().getSExtValue() || getDim().getSExtValue() < 0)
diff --git a/mlir/lib/Dialect/SparseTensor/Transforms/SparseTensorCodegen.cpp b/mlir/lib/Dialect/SparseTensor/Transforms/SparseTensorCodegen.cpp
index d5eec4ae67e798..4e3393195813c3 100644
--- a/mlir/lib/Dialect/SparseTensor/Transforms/SparseTensorCodegen.cpp
+++ b/mlir/lib/Dialect/SparseTensor/Transforms/SparseTensorCodegen.cpp
@@ -1058,17 +1058,9 @@ class SparseToCoordinatesConverter
// Replace the requested coordinates access with corresponding field.
// The cast_op is inserted by type converter to intermix 1:N type
// conversion.
- Location loc = op.getLoc();
auto desc = getDescriptorFromTensorTuple(adaptor.getTensor());
- Value field = desc.getCrdMemRefOrView(rewriter, loc, op.getLevel());
-
- // Insert a cast to bridge the actual type to the user expected type. If the
- // actual type and the user expected type aren't compatible, the compiler or
- // the runtime will issue an error.
- Type resType = op.getResult().getType();
- if (resType != field.getType())
- field = rewriter.create<memref::CastOp>(loc, resType, field);
- rewriter.replaceOp(op, field);
+ rewriter.replaceOp(
+ op, desc.getCrdMemRefOrView(rewriter, op.getLoc(), op.getLevel()));
return success();
}
diff --git a/mlir/lib/Dialect/SparseTensor/Transforms/SparseTensorRewriting.cpp b/mlir/lib/Dialect/SparseTensor/Transforms/SparseTensorRewriting.cpp
index c95b7b015b3725..6ff21468e05764 100644
--- a/mlir/lib/Dialect/SparseTensor/Transforms/SparseTensorRewriting.cpp
+++ b/mlir/lib/Dialect/SparseTensor/Transforms/SparseTensorRewriting.cpp
@@ -618,10 +618,10 @@ struct PrintRewriter : public OpRewritePattern<PrintOp> {
rewriter.create<vector::PrintOp>(loc, nse);
// Use the "codegen" foreach loop construct to iterate over
// all typical sparse tensor components for printing.
- foreachFieldAndTypeInSparseTensor(stt, [&rewriter, &loc,
- &tensor](Type tp, FieldIndex,
- SparseTensorFieldKind kind,
- Level l, LevelType) {
+ foreachFieldAndTypeInSparseTensor(stt, [&rewriter, &loc, &tensor,
+ &stt](Type, FieldIndex,
+ SparseTensorFieldKind kind,
+ Level l, LevelType) {
switch (kind) {
case SparseTensorFieldKind::StorageSpec: {
break;
@@ -632,8 +632,8 @@ struct PrintRewriter : public OpRewritePattern<PrintOp> {
rewriter.create<vector::PrintOp>(
loc, lvl, vector::PrintPunctuation::NoPunctuation);
rewriter.create<vector::PrintOp>(loc, rewriter.getStringAttr("] : "));
- auto pos = rewriter.create<ToPositionsOp>(loc, tp, tensor, l);
- printContents(rewriter, loc, tp, pos);
+ auto pos = rewriter.create<ToPositionsOp>(loc, tensor, l);
+ printContents(rewriter, loc, pos);
break;
}
case SparseTensorFieldKind::CrdMemRef: {
@@ -642,15 +642,20 @@ struct PrintRewriter : public OpRewritePattern<PrintOp> {
rewriter.create<vector::PrintOp>(
loc, lvl, vector::PrintPunctuation::NoPunctuation);
rewriter.create<vector::PrintOp>(loc, rewriter.getStringAttr("] : "));
- auto crd = rewriter.create<ToCoordinatesOp>(loc, tp, tensor, l);
- printContents(rewriter, loc, tp, crd);
+ Value crd = nullptr;
+ // TODO: eliminates ToCoordinateBufferOp!
+ if (stt.getAoSCOOStart() == l)
+ crd = rewriter.create<ToCoordinatesBufferOp>(loc, tensor);
+ else
+ crd = rewriter.create<ToCoordinatesOp>(loc, tensor, l);
+ printContents(rewriter, loc, crd);
break;
}
case SparseTensorFieldKind::ValMemRef: {
rewriter.create<vector::PrintOp>(loc,
rewriter.getStringAttr("values : "));
- auto val = rewriter.create<ToValuesOp>(loc, tp, tensor);
- printContents(rewriter, loc, tp, val);
+ auto val = rewriter.create<ToValuesOp>(loc, tensor);
+ printContents(rewriter, loc, val);
break;
}
}
@@ -670,7 +675,7 @@ struct PrintRewriter : public OpRewritePattern<PrintOp> {
//
// Generates code to print:
// ( a0, a1, ... )
- static void printContents(PatternRewriter &rewriter, Location loc, Type tp,
+ static void printContents(PatternRewriter &rewriter, Location loc,
Value vec) {
// Open bracket.
rewriter.create<vector::PrintOp>(loc, vector::PrintPunctuation::Open);
diff --git a/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_insert_3d.mlir b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_insert_3d.mlir
index c141df64c22e76..3a32ff28527001 100644
--- a/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_insert_3d.mlir
+++ b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_insert_3d.mlir
@@ -45,91 +45,6 @@
module {
-
- func.func @dump(%arg0: tensor<5x4x3xf64, #TensorCSR>) {
- %c0 = arith.constant 0 : index
- %fu = arith.constant 99.0 : f64
- %p0 = sparse_tensor.positions %arg0 { level = 0 : index } : tensor<5x4x3xf64, #TensorCSR> to memref<?xindex>
- %i0 = sparse_tensor.coordinates %arg0 { level = 0 : index } : tensor<5x4x3xf64, #TensorCSR> to memref<?xindex>
- %p2 = sparse_tensor.positions %arg0 { level = 2 : index } : tensor<5x4x3xf64, #TensorCSR> to memref<?xindex>
- %i2 = sparse_tensor.coordinates %arg0 { level = 2 : index } : tensor<5x4x3xf64, #TensorCSR> to memref<?xindex>
- %v = sparse_tensor.values %arg0 : tensor<5x4x3xf64, #TensorCSR> to memref<?xf64>
- %vp0 = vector.transfer_read %p0[%c0], %c0: memref<?xindex>, vector<2xindex>
- vector.print %vp0 : vector<2xindex>
- %vi0 = vector.transfer_read %i0[%c0], %c0: memref<?xindex>, vector<2xindex>
- vector.print %vi0 : vector<2xindex>
- %vp2 = vector.transfer_read %p2[%c0], %c0: memref<?xindex>, vector<9xindex>
- vector.print %vp2 : vector<9xindex>
- %vi2 = vector.transfer_read %i2[%c0], %c0: memref<?xindex>, vector<5xindex>
- vector.print %vi2 : vector<5xindex>
- %vv = vector.transfer_read %v[%c0], %fu: memref<?xf64>, vector<5xf64>
- vector.print %vv : vector<5xf64>
- return
- }
-
- func.func @dump_row(%arg0: tensor<5x4x3xf64, #TensorRow>) {
- %c0 = arith.constant 0 : index
- %fu = arith.constant 99.0 : f64
- %p0 = sparse_tensor.positions %arg0 { level = 0 : index } : tensor<5x4x3xf64, #TensorRow> to memref<?xindex>
- %i0 = sparse_tensor.coordinates %arg0 { level = 0 : index } : tensor<5x4x3xf64, #TensorRow> to memref<?xindex>
- %p1 = sparse_tensor.positions %arg0 { level = 1 : index } : tensor<5x4x3xf64, #TensorRow> to memref<?xindex>
- %i1 = sparse_tensor.coordinates %arg0 { level = 1 : index } : tensor<5x4x3xf64, #TensorRow> to memref<?xindex>
- %v = sparse_tensor.values %arg0 : tensor<5x4x3xf64, #TensorRow> to memref<?xf64>
- %vp0 = vector.transfer_read %p0[%c0], %c0: memref<?xindex>, vector<2xindex>
- vector.print %vp0 : vector<2xindex>
- %vi0 = vector.transfer_read %i0[%c0], %c0: memref<?xindex>, vector<2xindex>
- vector.print %vi0 : vector<2xindex>
- %vp1 = vector.transfer_read %p1[%c0], %c0: memref<?xindex>, vector<3xindex>
- vector.print %vp1 : vector<3xindex>
- %vi1 = vector.transfer_read %i1[%c0], %c0: memref<?xindex>, vector<4xindex>
- vector.print %vi1 : vector<4xindex>
- %vv = vector.transfer_read %v[%c0], %fu: memref<?xf64>, vector<12xf64>
- vector.print %vv : vector<12xf64>
- return
- }
-
-func.func @dump_ccoo(%arg0: tensor<5x4x3xf64, #CCoo>) {
- %c0 = arith.constant 0 : index
- %fu = arith.constant 99.0 : f64
- %p0 = sparse_tensor.positions %arg0 { level = 0 : index } : tensor<5x4x3xf64, #CCoo> to memref<?xindex>
- %i0 = sparse_tensor.coordinates %arg0 { level = 0 : index } : tensor<5x4x3xf64, #CCoo> to memref<?xindex>
- %p1 = sparse_tensor.positions %arg0 { level = 1 : index } : tensor<5x4x3xf64, #CCoo> to memref<?xindex>
- %i1 = sparse_tensor.coordinates %arg0 { level = 1 : index } : tensor<5x4x3xf64, #CCoo> to memref<?xindex>
- %i2 = sparse_tensor.coordinates %arg0 { level = 2 : index } : tensor<5x4x3xf64, #CCoo> to memref<?xindex>
- %v = sparse_tensor.values %arg0 : tensor<5x4x3xf64, #CCoo> to memref<?xf64>
- %vp0 = vector.transfer_read %p0[%c0], %c0: memref<?xindex>, vector<2xindex>
- vector.print %vp0 : vector<2xindex>
- %vi0 = vector.transfer_read %i0[%c0], %c0: memref<?xindex>, vector<2xindex>
- vector.print %vi0 : vector<2xindex>
- %vp1 = vector.transfer_read %p1[%c0], %c0: memref<?xindex>, vector<3xindex>
- vector.print %vp1 : vector<3xindex>
- %vi1 = vector.transfer_read %i1[%c0], %c0: memref<?xindex>, vector<5xindex>
- vector.print %vi1 : vector<5xindex>
- %vi2 = vector.transfer_read %i2[%c0], %c0: memref<?xindex>, vector<5xindex>
- vector.print %vi2 : vector<5xindex>
- %vv = vector.transfer_read %v[%c0], %fu: memref<?xf64>, vector<5xf64>
- vector.print %vv : vector<5xf64>
- return
- }
-
-func.func @dump_dcoo(%arg0: tensor<5x4x3xf64, #DCoo>) {
- %c0 = arith.constant 0 : index
- %fu = arith.constant 99.0 : f64
- %p1 = sparse_tensor.positions %arg0 { level = 1 : index } : tensor<5x4x3xf64, #DCoo> to memref<?xindex>
- %i1 = sparse_tensor.coordinates %arg0 { level = 1 : index } : tensor<5x4x3xf64, #DCoo> to memref<?xindex>
- %i2 = sparse_tensor.coordinates %arg0 { level = 2 : index } : tensor<5x4x3xf64, #DCoo> to memref<?xindex>
- %v = sparse_tensor.values %arg0 : tensor<5x4x3xf64, #DCoo> to memref<?xf64>
- %vp1 = vector.transfer_read %p1[%c0], %c0: memref<?xindex>, vector<6xindex>
- vector.print %vp1 : vector<6xindex>
- %vi1 = vector.transfer_read %i1[%c0], %c0: memref<?xindex>, vector<5xindex>
- vector.print %vi1 : vector<5xindex>
- %vi2 = vector.transfer_read %i2[%c0], %c0: memref<?xindex>, vector<5xindex>
- vector.print %vi2 : vector<5xindex>
- %vv = vector.transfer_read %v[%c0], %fu: memref<?xf64>, vector<5xf64>
- vector.print %vv : vector<5xf64>
- return
-}
-
//
// Main driver.
//
@@ -145,13 +60,14 @@ func.func @dump_dcoo(%arg0: tensor<5x4x3xf64, #DCoo>) {
%f4 = arith.constant 4.4 : f64
%f5 = arith.constant 5.5 : f64
- //
- // CHECK: ( 0, 2 )
- // CHECK-NEXT: ( 3, 4 )
- // CHECK-NEXT: ( 0, 2, 2, 2, 3, 3, 3, 4, 5 )
- // CHECK-NEXT: ( 1, 2, 1, 2, 2 )
- // CHECK-NEXT: ( 1.1, 2.2, 3.3, 4.4, 5.5 )
- //
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 5
+ // CHECK-NEXT: pos[0] : ( 0, 2
+ // CHECK-NEXT: crd[0] : ( 3, 4
+ // CHECK-NEXT: pos[2] : ( 0, 2, 2, 2, 3, 3, 3, 4, 5
+ // CHECK-NEXT: crd[2] : ( 1, 2, 1, 2, 2
+ // CHECK-NEXT: values : ( 1.1, 2.2, 3.3, 4.4, 5.5
+ // CHECK-NEXT: ----
%tensora = tensor.empty() : tensor<5x4x3xf64, #TensorCSR>
%tensor1 = sparse_tensor.insert %f1 into %tensora[%c3, %c0, %c1] : tensor<5x4x3xf64, #TensorCSR>
%tensor2 = sparse_tensor.insert %f2 into %tensor1[%c3, %c0, %c2] : tensor<5x4x3xf64, #TensorCSR>
@@ -159,15 +75,16 @@ func.func @dump_dcoo(%arg0: tensor<5x4x3xf64, #DCoo>) {
%tensor4 = sparse_tensor.insert %f4 into %tensor3[%c4, %c2, %c2] : tensor<5x4x3xf64, #TensorCSR>
%tensor5 = sparse_tensor.insert %f5 into %tensor4[%c4, %c3, %c2] : tensor<5x4x3xf64, #TensorCSR>
%tensorm = sparse_tensor.load %tensor5 hasInserts : tensor<5x4x3xf64, #TensorCSR>
- call @dump(%tensorm) : (tensor<5x4x3xf64, #TensorCSR>) -> ()
-
- //
- // CHECK-NEXT: ( 0, 2 )
- // CHECK-NEXT: ( 3, 4 )
- // CHECK-NEXT: ( 0, 2, 4 )
- // CHECK-NEXT: ( 0, 3, 2, 3 )
- // CHECK-NEXT: ( 0, 1.1, 2.2, 0, 3.3, 0, 0, 0, 4.4, 0, 0, 5.5 )
- //
+ sparse_tensor.print %tensorm : tensor<5x4x3xf64, #TensorCSR>
+
+ // CHECK-NEXT: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 12
+ // CHECK-NEXT: pos[0] : ( 0, 2
+ // CHECK-NEXT: crd[0] : ( 3, 4
+ // CHECK-NEXT: pos[1] : ( 0, 2, 4
+ // CHECK-NEXT: crd[1] : ( 0, 3, 2, 3
+ // CHECK-NEXT: values : ( 0, 1.1, 2.2, 0, 3.3, 0, 0, 0, 4.4, 0, 0, 5.5
+ // CHECK-NEXT: ----
%rowa = tensor.empty() : tensor<5x4x3xf64, #TensorRow>
%row1 = sparse_tensor.insert %f1 into %rowa[%c3, %c0, %c1] : tensor<5x4x3xf64, #TensorRow>
%row2 = sparse_tensor.insert %f2 into %row1[%c3, %c0, %c2] : tensor<5x4x3xf64, #TensorRow>
@@ -175,15 +92,16 @@ func.func @dump_dcoo(%arg0: tensor<5x4x3xf64, #DCoo>) {
%row4 = sparse_tensor.insert %f4 into %row3[%c4, %c2, %c2] : tensor<5x4x3xf64, #TensorRow>
%row5 = sparse_tensor.insert %f5 into %row4[%c4, %c3, %c2] : tensor<5x4x3xf64, #TensorRow>
%rowm = sparse_tensor.load %row5 hasInserts : tensor<5x4x3xf64, #TensorRow>
- call @dump_row(%rowm) : (tensor<5x4x3xf64, #TensorRow>) -> ()
-
- //
- // CHECK: ( 0, 2 )
- // CHECK-NEXT: ( 3, 4 )
- // CHECK-NEXT: ( 0, 3, 5 )
- // CHECK-NEXT: ( 0, 0, 3, 2, 3 )
- // CHECK-NEXT: ( 1, 2, 1, 2, 2 )
- // CHECK-NEXT: ( 1.1, 2.2, 3.3, 4.4, 5.5 )
+ sparse_tensor.print %rowm : tensor<5x4x3xf64, #TensorRow>
+
+ // CHECK-NEXT: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 5
+ // CHECK-NEXT: pos[0] : ( 0, 2
+ // CHECK-NEXT: crd[0] : ( 3, 4
+ // CHECK-NEXT: pos[1] : ( 0, 3, 5
+ // CHECK-NEXT: crd[1] : ( 0, 1, 0, 2, 3, 1, 2, 2, 3, 2
+ // CHECK-NEXT: values : ( 1.1, 2.2, 3.3, 4.4, 5.5
+ // CHECK-NEXT: ----
%ccoo = tensor.empty() : tensor<5x4x3xf64, #CCoo>
%ccoo1 = sparse_tensor.insert %f1 into %ccoo[%c3, %c0, %c1] : tensor<5x4x3xf64, #CCoo>
%ccoo2 = sparse_tensor.insert %f2 into %ccoo1[%c3, %c0, %c2] : tensor<5x4x3xf64, #CCoo>
@@ -191,13 +109,14 @@ func.func @dump_dcoo(%arg0: tensor<5x4x3xf64, #DCoo>) {
%ccoo4 = sparse_tensor.insert %f4 into %ccoo3[%c4, %c2, %c2] : tensor<5x4x3xf64, #CCoo>
%ccoo5 = sparse_tensor.insert %f5 into %ccoo4[%c4, %c3, %c2] : tensor<5x4x3xf64, #CCoo>
%ccoom = sparse_tensor.load %ccoo5 hasInserts : tensor<5x4x3xf64, #CCoo>
- call @dump_ccoo(%ccoom) : (tensor<5x4x3xf64, #CCoo>) -> ()
-
- //
- // CHECK-NEXT: ( 0, 0, 0, 0, 3, 5 )
- // CHECK-NEXT: ( 0, 0, 3, 2, 3 )
- // CHECK-NEXT: ( 1, 2, 1, 2, 2 )
- // CHECK-NEXT: ( 1.1, 2.2, 3.3, 4.4, 5.5 )
+ sparse_tensor.print %ccoom : tensor<5x4x3xf64, #CCoo>
+
+ // CHECK-NEXT: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 5
+ // CHECK-NEXT: pos[1] : ( 0, 0, 0, 0, 3, 5
+ // CHECK-NEXT: crd[1] : ( 0, 1, 0, 2, 3, 1, 2, 2, 3, 2
+ // CHECK-NEXT: values : ( 1.1, 2.2, 3.3, 4.4, 5.5
+ // CHECK-NEXT: ----
%dcoo = tensor.empty() : tensor<5x4x3xf64, #DCoo>
%dcoo1 = sparse_tensor.insert %f1 into %dcoo[%c3, %c0, %c1] : tensor<5x4x3xf64, #DCoo>
%dcoo2 = sparse_tensor.insert %f2 into %dcoo1[%c3, %c0, %c2] : tensor<5x4x3xf64, #DCoo>
@@ -205,23 +124,7 @@ func.func @dump_dcoo(%arg0: tensor<5x4x3xf64, #DCoo>) {
%dcoo4 = sparse_tensor.insert %f4 into %dcoo3[%c4, %c2, %c2] : tensor<5x4x3xf64, #DCoo>
%dcoo5 = sparse_tensor.insert %f5 into %dcoo4[%c4, %c3, %c2] : tensor<5x4x3xf64, #DCoo>
%dcoom = sparse_tensor.load %dcoo5 hasInserts : tensor<5x4x3xf64, #DCoo>
- call @dump_dcoo(%dcoom) : (tensor<5x4x3xf64, #DCoo>) -> ()
-
- // NOE sanity check.
- //
- // CHECK-NEXT: 5
- // CHECK-NEXT: 12
- // CHECK-NEXT: 5
- // CHECK-NEXT: 5
- //
- %noe1 = sparse_tensor.number_of_entries %tensorm : tensor<5x4x3xf64, #TensorCSR>
- vector.print %noe1 : index
- %noe2 = sparse_tensor.number_of_entries %rowm : tensor<5x4x3xf64, #TensorRow>
- vector.print %noe2 : index
- %noe3 = sparse_tensor.number_of_entries %ccoom : tensor<5x4x3xf64, #CCoo>
- vector.print %noe3 : index
- %noe4 = sparse_tensor.number_of_entries %dcoom : tensor<5x4x3xf64, #DCoo>
- vector.print %noe4 : index
+ sparse_tensor.print %dcoom : tensor<5x4x3xf64, #DCoo>
// Release resources.
bufferization.dealloc_tensor %tensorm : tensor<5x4x3xf64, #TensorCSR>
>From 97281708ac176e0464b770686ee314af4da0a3d5 Mon Sep 17 00:00:00 2001
From: jimingham <jingham at apple.com>
Date: Wed, 28 Feb 2024 16:14:19 -0800
Subject: [PATCH 068/406] Change `image list -r` so that it actually shows the
ref count and whether the image is in the shared cache. (#83341)
The help for the `-r` option to `image list` says:
-r[<width>] ( --ref-count=[<width>] )
Display the reference count if the module is still in the shared module
cache.
but that's not what it actually does. It unconditionally shows the
use_count for all Module shared pointers, regardless of whether they are
still in the shared module cache or whether they are just in the
ModuleCollection and other entities are keeping them alive. That seems
like a more useful behavior, but then it is also useful to know what's
in the shared cache, so I changed this to:
-r[<width>] ( --ref-count=[<width>] )
Display whether the module is still in the the shared module cache
(Y/N), and its shared pointer use_count.
So instead of just `{5}` you will see `{Y 5}` if it is in the shared
cache and `{N 5}` if not.
I didn't add tests for this because I'm not sure how much we want to fix
shared cache behavior in the testsuite.
---
lldb/source/Commands/CommandObjectTarget.cpp | 8 ++++++--
lldb/source/Commands/Options.td | 4 ++--
2 files changed, 8 insertions(+), 4 deletions(-)
diff --git a/lldb/source/Commands/CommandObjectTarget.cpp b/lldb/source/Commands/CommandObjectTarget.cpp
index 45265577e8b61c..b2346c2402a81d 100644
--- a/lldb/source/Commands/CommandObjectTarget.cpp
+++ b/lldb/source/Commands/CommandObjectTarget.cpp
@@ -3376,15 +3376,19 @@ class CommandObjectTargetModulesList : public CommandObjectParsed {
case 'r': {
size_t ref_count = 0;
+ char in_shared_cache = 'Y';
+
ModuleSP module_sp(module->shared_from_this());
+ if (!ModuleList::ModuleIsInCache(module))
+ in_shared_cache = 'N';
if (module_sp) {
// Take one away to make sure we don't count our local "module_sp"
ref_count = module_sp.use_count() - 1;
}
if (width)
- strm.Printf("{%*" PRIu64 "}", width, (uint64_t)ref_count);
+ strm.Printf("{%c %*" PRIu64 "}", in_shared_cache, width, (uint64_t)ref_count);
else
- strm.Printf("{%" PRIu64 "}", (uint64_t)ref_count);
+ strm.Printf("{%c %" PRIu64 "}", in_shared_cache, (uint64_t)ref_count);
} break;
case 's':
diff --git a/lldb/source/Commands/Options.td b/lldb/source/Commands/Options.td
index ad4321d9a386cc..91d5eea830dedf 100644
--- a/lldb/source/Commands/Options.td
+++ b/lldb/source/Commands/Options.td
@@ -936,8 +936,8 @@ let Command = "target modules list" in {
OptionalArg<"Width">, Desc<"Display the modification time with optional "
"width of the module.">;
def target_modules_list_ref_count : Option<"ref-count", "r">, Group<1>,
- OptionalArg<"Width">, Desc<"Display the reference count if the module is "
- "still in the shared module cache.">;
+ OptionalArg<"Width">, Desc<"Display whether the module is still in the "
+ "the shared module cache (Y/N), and its shared pointer use_count.">;
def target_modules_list_pointer : Option<"pointer", "p">, Group<1>,
OptionalArg<"None">, Desc<"Display the module pointer.">;
def target_modules_list_global : Option<"global", "g">, Group<1>,
>From f83f7128b3c98e5d1d1995bfa18c43c6b32c18bb Mon Sep 17 00:00:00 2001
From: ChiaHungDuan <chiahungduan at google.com>
Date: Wed, 28 Feb 2024 16:15:31 -0800
Subject: [PATCH 069/406] [scudo][NFC] Explicit type casting to avoid compiler
warning (#83355)
---
compiler-rt/lib/scudo/standalone/allocator_common.h | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/compiler-rt/lib/scudo/standalone/allocator_common.h b/compiler-rt/lib/scudo/standalone/allocator_common.h
index 4d39956bf90503..2b77516ad11cae 100644
--- a/compiler-rt/lib/scudo/standalone/allocator_common.h
+++ b/compiler-rt/lib/scudo/standalone/allocator_common.h
@@ -53,7 +53,7 @@ template <class SizeClassAllocator> struct TransferBatch {
void moveNToArray(CompactPtrT *Array, u16 N) {
DCHECK_LE(N, Count);
memcpy(Array, Batch + Count - N, sizeof(Batch[0]) * N);
- Count -= N;
+ Count = static_cast<u16>(Count - N);
}
u16 getCount() const { return Count; }
bool isEmpty() const { return Count == 0U; }
>From fdf44b37774ede4e15b12508753aca16008b718d Mon Sep 17 00:00:00 2001
From: Aart Bik <39774503+aartbik at users.noreply.github.com>
Date: Wed, 28 Feb 2024 16:40:46 -0800
Subject: [PATCH 070/406] [mlir][sparse] migrate integration tests to
sparse_tensor.print (#83357)
This is first step (of many) cleaning up our tests to use the new and
exciting sparse_tensor.print operation instead of lengthy extraction +
print ops.
---
.../Dialect/SparseTensor/CPU/block.mlir | 45 +++++-----
.../SparseTensor/CPU/block_majors.mlir | 85 ++++++++-----------
.../SparseTensor/CPU/dense_output.mlir | 18 ++--
.../SparseTensor/CPU/dense_output_bf16.mlir | 24 ++----
.../SparseTensor/CPU/dense_output_f16.mlir | 24 ++----
.../SparseTensor/CPU/sparse_re_im.mlir | 46 +++++-----
6 files changed, 103 insertions(+), 139 deletions(-)
diff --git a/mlir/test/Integration/Dialect/SparseTensor/CPU/block.mlir b/mlir/test/Integration/Dialect/SparseTensor/CPU/block.mlir
index 6468c4b45d2479..1184d407541b6f 100644
--- a/mlir/test/Integration/Dialect/SparseTensor/CPU/block.mlir
+++ b/mlir/test/Integration/Dialect/SparseTensor/CPU/block.mlir
@@ -10,7 +10,7 @@
// DEFINE: %{compile} = mlir-opt %s --sparsifier="%{sparsifier_opts}"
// DEFINE: %{compile_sve} = mlir-opt %s --sparsifier="%{sparsifier_opts_sve}"
// DEFINE: %{run_libs} = -shared-libs=%mlir_c_runner_utils,%mlir_runner_utils
-// DEFINE: %{run_opts} = -e entry -entry-point-result=void
+// DEFINE: %{run_opts} = -e main -entry-point-result=void
// DEFINE: %{run} = mlir-cpu-runner %{run_opts} %{run_libs}
// DEFINE: %{run_sve} = %mcr_aarch64_cmd --march=aarch64 --mattr="+sve" %{run_opts} %{run_libs}
//
@@ -82,38 +82,39 @@ module {
return %0 : tensor<?x?xf64, #BSR>
}
- func.func @entry() {
+ func.func @main() {
%c0 = arith.constant 0 : index
%f0 = arith.constant 0.0 : f64
%fileName = call @getTensorFilename(%c0) : (index) -> (!Filename)
%A = sparse_tensor.new %fileName : !Filename to tensor<?x?xf64, #BSR>
- // CHECK: ( 0, 2, 3 )
- // CHECK-NEXT: ( 0, 2, 1 )
- // CHECK-NEXT: ( 1, 2, 0, 3, 4, 0, 0, 5, 6, 7, 8, 0 )
- %pos = sparse_tensor.positions %A {level = 1 : index } : tensor<?x?xf64, #BSR> to memref<?xindex>
- %vecp = vector.transfer_read %pos[%c0], %c0 : memref<?xindex>, vector<3xindex>
- vector.print %vecp : vector<3xindex>
- %crd = sparse_tensor.coordinates %A {level = 1 : index } : tensor<?x?xf64, #BSR> to memref<?xindex>
- %vecc = vector.transfer_read %crd[%c0], %c0 : memref<?xindex>, vector<3xindex>
- vector.print %vecc : vector<3xindex>
- %val = sparse_tensor.values %A : tensor<?x?xf64, #BSR> to memref<?xf64>
- %vecv = vector.transfer_read %val[%c0], %f0 : memref<?xf64>, vector<12xf64>
- vector.print %vecv : vector<12xf64>
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 12
+ // CHECK-NEXT: pos[1] : ( 0, 2, 3,
+ // CHECK-NEXT: crd[1] : ( 0, 2, 1,
+ // CHECK-NEXT: values : ( 1, 2, 0, 3, 4, 0, 0, 5, 6, 7, 8, 0,
+ // CHECK-NEXT: ----
+ sparse_tensor.print %A : tensor<?x?xf64, #BSR>
- // CHECK-NEXT: ( 1, 2, 0, 3, 4, 0, 0, 5, 6, 7, 8, 0 )
+ // CHECK-NEXT: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 12
+ // CHECK-NEXT: pos[1] : ( 0, 2, 3,
+ // CHECK-NEXT: crd[1] : ( 0, 2, 1
+ // CHECK-NEXT: values : ( 1, 2, 0, 3, 4, 0, 0, 5, 6, 7, 8, 0,
+ // CHECK-NEXT: ----
%t1 = sparse_tensor.reinterpret_map %A : tensor<?x?xf64, #BSR>
to tensor<?x?x2x2xf64, #DSDD>
- %vdsdd = sparse_tensor.values %t1 : tensor<?x?x2x2xf64, #DSDD> to memref<?xf64>
- %vecdsdd = vector.transfer_read %vdsdd[%c0], %f0 : memref<?xf64>, vector<12xf64>
- vector.print %vecdsdd : vector<12xf64>
+ sparse_tensor.print %t1 : tensor<?x?x2x2xf64, #DSDD>
- // CHECK-NEXT: ( 3, 6, 0, 9, 12, 0, 0, 15, 18, 21, 24, 0 )
+ // CHECK-NEXT: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 12
+ // CHECK-NEXT: pos[1] : ( 0, 2, 3,
+ // CHECK-NEXT: crd[1] : ( 0, 2, 1,
+ // CHECK-NEXT: values : ( 3, 6, 0, 9, 12, 0, 0, 15, 18, 21, 24, 0,
+ // CHECK-NEXT: ----
%As = call @scale(%A) : (tensor<?x?xf64, #BSR>) -> (tensor<?x?xf64, #BSR>)
- %vals = sparse_tensor.values %As : tensor<?x?xf64, #BSR> to memref<?xf64>
- %vecs = vector.transfer_read %vals[%c0], %f0 : memref<?xf64>, vector<12xf64>
- vector.print %vecs : vector<12xf64>
+ sparse_tensor.print %As : tensor<?x?xf64, #BSR>
// Release the resources.
bufferization.dealloc_tensor %A: tensor<?x?xf64, #BSR>
diff --git a/mlir/test/Integration/Dialect/SparseTensor/CPU/block_majors.mlir b/mlir/test/Integration/Dialect/SparseTensor/CPU/block_majors.mlir
index cb06f099dd3703..f8e83b5019679f 100755
--- a/mlir/test/Integration/Dialect/SparseTensor/CPU/block_majors.mlir
+++ b/mlir/test/Integration/Dialect/SparseTensor/CPU/block_majors.mlir
@@ -102,9 +102,15 @@
//
module {
- // CHECK: ( 0, 1, 2 )
- // CHECK-NEXT: ( 0, 2 )
- // CHECK-NEXT: ( 1, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 4, 5, 0, 0, 0, 0, 0, 0, 0, 0, 6, 7 )
+
+ //
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 24
+ // CHECK-NEXT: pos[1] : ( 0, 1, 2,
+ // CHECK-NEXT: crd[1] : ( 0, 2,
+ // CHECK-NEXT: values : ( 1, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 4, 5, 0, 0, 0, 0, 0, 0, 0, 0, 6, 7,
+ // CHECK-NEXT: ----
+ //
func.func @foo1() {
// Build.
%c0 = arith.constant 0 : index
@@ -115,23 +121,20 @@ module {
> : tensor<6x16xf64>
%s1 = sparse_tensor.convert %m : tensor<6x16xf64> to tensor<?x?xf64, #BSR_row_rowmajor>
// Test.
- %pos1 = sparse_tensor.positions %s1 {level = 1 : index } : tensor<?x?xf64, #BSR_row_rowmajor> to memref<?xindex>
- %vecp1 = vector.transfer_read %pos1[%c0], %c0 : memref<?xindex>, vector<3xindex>
- vector.print %vecp1 : vector<3xindex>
- %crd1 = sparse_tensor.coordinates %s1 {level = 1 : index } : tensor<?x?xf64, #BSR_row_rowmajor> to memref<?xindex>
- %vecc1 = vector.transfer_read %crd1[%c0], %c0 : memref<?xindex>, vector<2xindex>
- vector.print %vecc1 : vector<2xindex>
- %val1 = sparse_tensor.values %s1 : tensor<?x?xf64, #BSR_row_rowmajor> to memref<?xf64>
- %vecv1 = vector.transfer_read %val1[%c0], %f0 : memref<?xf64>, vector<24xf64>
- vector.print %vecv1 : vector<24xf64>
+ sparse_tensor.print %s1 : tensor<?x?xf64, #BSR_row_rowmajor>
// Release.
bufferization.dealloc_tensor %s1: tensor<?x?xf64, #BSR_row_rowmajor>
return
}
- // CHECK-NEXT: ( 0, 1, 2 )
- // CHECK-NEXT: ( 0, 2 )
- // CHECK-NEXT: ( 1, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 3, 4, 0, 0, 5, 0, 0, 0, 0, 6, 0, 0, 7 )
+ //
+ // CHECK-NEXT: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 24
+ // CHECK-NEXT: pos[1] : ( 0, 1, 2,
+ // CHECK-NEXT: crd[1] : ( 0, 2,
+ // CHECK-NEXT: values : ( 1, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 3, 4, 0, 0, 5, 0, 0, 0, 0, 6, 0, 0, 7,
+ // CHECK-NEXT: ----
+ //
func.func @foo2() {
// Build.
%c0 = arith.constant 0 : index
@@ -142,23 +145,20 @@ module {
> : tensor<6x16xf64>
%s2 = sparse_tensor.convert %m : tensor<6x16xf64> to tensor<?x?xf64, #BSR_row_colmajor>
// Test.
- %pos2 = sparse_tensor.positions %s2 {level = 1 : index } : tensor<?x?xf64, #BSR_row_colmajor> to memref<?xindex>
- %vecp2 = vector.transfer_read %pos2[%c0], %c0 : memref<?xindex>, vector<3xindex>
- vector.print %vecp2 : vector<3xindex>
- %crd2 = sparse_tensor.coordinates %s2 {level = 1 : index } : tensor<?x?xf64, #BSR_row_colmajor> to memref<?xindex>
- %vecc2 = vector.transfer_read %crd2[%c0], %c0 : memref<?xindex>, vector<2xindex>
- vector.print %vecc2 : vector<2xindex>
- %val2 = sparse_tensor.values %s2 : tensor<?x?xf64, #BSR_row_colmajor> to memref<?xf64>
- %vecv2 = vector.transfer_read %val2[%c0], %f0 : memref<?xf64>, vector<24xf64>
- vector.print %vecv2 : vector<24xf64>
+ sparse_tensor.print %s2 : tensor<?x?xf64, #BSR_row_colmajor>
// Release.
bufferization.dealloc_tensor %s2: tensor<?x?xf64, #BSR_row_colmajor>
return
}
- // CHECK-NEXT: ( 0, 1, 1, 2, 2 )
- // CHECK-NEXT: ( 0, 1 )
- // CHECK-NEXT: ( 1, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 4, 5, 0, 0, 0, 0, 0, 0, 0, 0, 6, 7 )
+ //
+ // CHECK-NEXT: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 24
+ // CHECK-NEXT: pos[1] : ( 0, 1, 1, 2, 2,
+ // CHECK-NEXT: crd[1] : ( 0, 1,
+ // CHECK-NEXT: values : ( 1, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 4, 5, 0, 0, 0, 0, 0, 0, 0, 0, 6, 7,
+ // CHECK-NEXT: ----
+ //
func.func @foo3() {
// Build.
%c0 = arith.constant 0 : index
@@ -169,23 +169,20 @@ module {
> : tensor<6x16xf64>
%s3 = sparse_tensor.convert %m : tensor<6x16xf64> to tensor<?x?xf64, #BSR_col_rowmajor>
// Test.
- %pos3 = sparse_tensor.positions %s3 {level = 1 : index } : tensor<?x?xf64, #BSR_col_rowmajor> to memref<?xindex>
- %vecp3 = vector.transfer_read %pos3[%c0], %c0 : memref<?xindex>, vector<5xindex>
- vector.print %vecp3 : vector<5xindex>
- %crd3 = sparse_tensor.coordinates %s3 {level = 1 : index } : tensor<?x?xf64, #BSR_col_rowmajor> to memref<?xindex>
- %vecc3 = vector.transfer_read %crd3[%c0], %c0 : memref<?xindex>, vector<2xindex>
- vector.print %vecc3 : vector<2xindex>
- %val3 = sparse_tensor.values %s3 : tensor<?x?xf64, #BSR_col_rowmajor> to memref<?xf64>
- %vecv3 = vector.transfer_read %val3[%c0], %f0 : memref<?xf64>, vector<24xf64>
- vector.print %vecv3 : vector<24xf64>
+ sparse_tensor.print %s3 : tensor<?x?xf64, #BSR_col_rowmajor>
// Release.
bufferization.dealloc_tensor %s3: tensor<?x?xf64, #BSR_col_rowmajor>
return
}
- // CHECK-NEXT: ( 0, 1, 1, 2, 2 )
- // CHECK-NEXT: ( 0, 1 )
- // CHECK-NEXT: ( 1, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 3, 4, 0, 0, 5, 0, 0, 0, 0, 6, 0, 0, 7 )
+ //
+ // CHECK-NEXT: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 24
+ // CHECK-NEXT: pos[1] : ( 0, 1, 1, 2, 2,
+ // CHECK-NEXT: crd[1] : ( 0, 1,
+ // CHECK-NEXT: values : ( 1, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 3, 4, 0, 0, 5, 0, 0, 0, 0, 6, 0, 0, 7,
+ // CHECK-NEXT: ----
+ //
func.func @foo4() {
// Build.
%c0 = arith.constant 0 : index
@@ -196,15 +193,7 @@ module {
> : tensor<6x16xf64>
%s4 = sparse_tensor.convert %m : tensor<6x16xf64> to tensor<?x?xf64, #BSR_col_colmajor>
// Test.
- %pos4 = sparse_tensor.positions %s4 {level = 1 : index } : tensor<?x?xf64, #BSR_col_colmajor> to memref<?xindex>
- %vecp4 = vector.transfer_read %pos4[%c0], %c0 : memref<?xindex>, vector<5xindex>
- vector.print %vecp4 : vector<5xindex>
- %crd4 = sparse_tensor.coordinates %s4 {level = 1 : index } : tensor<?x?xf64, #BSR_col_colmajor> to memref<?xindex>
- %vecc4 = vector.transfer_read %crd4[%c0], %c0 : memref<?xindex>, vector<2xindex>
- vector.print %vecc4 : vector<2xindex>
- %val4 = sparse_tensor.values %s4 : tensor<?x?xf64, #BSR_col_colmajor> to memref<?xf64>
- %vecv4 = vector.transfer_read %val4[%c0], %f0 : memref<?xf64>, vector<24xf64>
- vector.print %vecv4 : vector<24xf64>
+ sparse_tensor.print %s4 : tensor<?x?xf64, #BSR_col_colmajor>
// Release.
bufferization.dealloc_tensor %s4: tensor<?x?xf64, #BSR_col_colmajor>
return
diff --git a/mlir/test/Integration/Dialect/SparseTensor/CPU/dense_output.mlir b/mlir/test/Integration/Dialect/SparseTensor/CPU/dense_output.mlir
index 5f6524a4b7af9e..c6ee0ce0705021 100644
--- a/mlir/test/Integration/Dialect/SparseTensor/CPU/dense_output.mlir
+++ b/mlir/test/Integration/Dialect/SparseTensor/CPU/dense_output.mlir
@@ -10,7 +10,7 @@
// DEFINE: %{compile} = mlir-opt %s --sparsifier="%{sparsifier_opts}"
// DEFINE: %{compile_sve} = mlir-opt %s --sparsifier="%{sparsifier_opts_sve}"
// DEFINE: %{run_libs} = -shared-libs=%mlir_c_runner_utils,%mlir_runner_utils
-// DEFINE: %{run_opts} = -e entry -entry-point-result=void
+// DEFINE: %{run_opts} = -e main -entry-point-result=void
// DEFINE: %{run} = mlir-cpu-runner %{run_opts} %{run_libs}
// DEFINE: %{run_sve} = %mcr_aarch64_cmd --march=aarch64 --mattr="+sve" %{run_opts} %{run_libs}
//
@@ -83,12 +83,11 @@ module {
}
func.func private @getTensorFilename(index) -> (!Filename)
- func.func private @printMemref1dF64(%ptr : memref<?xf64>) attributes { llvm.emit_c_interface }
//
// Main driver that reads matrix from file and calls the kernel.
//
- func.func @entry() {
+ func.func @main() {
%d0 = arith.constant 0.0 : f64
%c0 = arith.constant 0 : index
%c1 = arith.constant 1 : index
@@ -104,14 +103,13 @@ module {
//
// Print the linearized 5x5 result for verification.
- // CHECK: 25
- // CHECK: [2, 0, 0, 2.8, 0, 0, 4, 0, 0, 5, 0, 0, 6, 0, 0, 8.2, 0, 0, 8, 0, 0, 10.4, 0, 0, 10
//
- %n = sparse_tensor.number_of_entries %0 : tensor<?x?xf64, #DenseMatrix>
- vector.print %n : index
- %m = sparse_tensor.values %0
- : tensor<?x?xf64, #DenseMatrix> to memref<?xf64>
- call @printMemref1dF64(%m) : (memref<?xf64>) -> ()
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 25
+ // CHECK-NEXT: values : ( 2, 0, 0, 2.8, 0, 0, 4, 0, 0, 5, 0, 0, 6, 0, 0, 8.2, 0, 0, 8, 0, 0, 10.4, 0, 0, 10,
+ // CHECK-NEXT: ----
+ //
+ sparse_tensor.print %0 : tensor<?x?xf64, #DenseMatrix>
// Release the resources.
bufferization.dealloc_tensor %a : tensor<?x?xf64, #SparseMatrix>
diff --git a/mlir/test/Integration/Dialect/SparseTensor/CPU/dense_output_bf16.mlir b/mlir/test/Integration/Dialect/SparseTensor/CPU/dense_output_bf16.mlir
index 81cd2d81cbbc32..0b34ff581016da 100644
--- a/mlir/test/Integration/Dialect/SparseTensor/CPU/dense_output_bf16.mlir
+++ b/mlir/test/Integration/Dialect/SparseTensor/CPU/dense_output_bf16.mlir
@@ -10,7 +10,7 @@
// DEFINE: %{compile} = mlir-opt %s --sparsifier="%{sparsifier_opts}"
// DEFINE: %{compile_sve} = mlir-opt %s --sparsifier="%{sparsifier_opts_sve}"
// DEFINE: %{run_libs} = -shared-libs=%mlir_c_runner_utils,%mlir_runner_utils
-// DEFINE: %{run_opts} = -e entry -entry-point-result=void
+// DEFINE: %{run_opts} = -e main -entry-point-result=void
// DEFINE: %{run} = mlir-cpu-runner %{run_opts} %{run_libs}
// DEFINE: %{run_sve} = %mcr_aarch64_cmd --march=aarch64 --mattr="+sve" %{run_opts} %{run_libs}
//
@@ -67,20 +67,8 @@ module {
return %0 : tensor<?xbf16, #DenseVector>
}
- // Dumps a dense vector of type bf16.
- func.func @dump_vec(%arg0: tensor<?xbf16, #DenseVector>) {
- // Dump the values array to verify only sparse contents are stored.
- %c0 = arith.constant 0 : index
- %d0 = arith.constant -1.0 : bf16
- %0 = sparse_tensor.values %arg0 : tensor<?xbf16, #DenseVector> to memref<?xbf16>
- %1 = vector.transfer_read %0[%c0], %d0: memref<?xbf16>, vector<32xbf16>
- %f1 = arith.extf %1: vector<32xbf16> to vector<32xf32>
- vector.print %f1 : vector<32xf32>
- return
- }
-
// Driver method to call and verify the kernel.
- func.func @entry() {
+ func.func @main() {
%c0 = arith.constant 0 : index
// Setup sparse vectors.
@@ -103,8 +91,12 @@ module {
//
// Verify the result.
//
- // CHECK: ( 1, 11, 0, 2, 13, 0, 0, 0, 0, 0, 14, 3, 0, 0, 0, 0, 15, 4, 16, 0, 5, 6, 0, 0, 0, 0, 0, 0, 7, 8, 0, 9 )
- call @dump_vec(%0) : (tensor<?xbf16, #DenseVector>) -> ()
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 32
+ // CHECK-NEXT: values : ( 1, 11, 0, 2, 13, 0, 0, 0, 0, 0, 14, 3, 0, 0, 0, 0, 15, 4, 16, 0, 5, 6, 0, 0, 0, 0, 0, 0, 7, 8, 0, 9,
+ // CHECK-NEXT: ----
+ //
+ sparse_tensor.print %0 : tensor<?xbf16, #DenseVector>
// Release the resources.
bufferization.dealloc_tensor %sv1 : tensor<?xbf16, #SparseVector>
diff --git a/mlir/test/Integration/Dialect/SparseTensor/CPU/dense_output_f16.mlir b/mlir/test/Integration/Dialect/SparseTensor/CPU/dense_output_f16.mlir
index b320afdb885842..495682169c2909 100644
--- a/mlir/test/Integration/Dialect/SparseTensor/CPU/dense_output_f16.mlir
+++ b/mlir/test/Integration/Dialect/SparseTensor/CPU/dense_output_f16.mlir
@@ -10,7 +10,7 @@
// DEFINE: %{compile} = mlir-opt %s --sparsifier="%{sparsifier_opts}"
// DEFINE: %{compile_sve} = mlir-opt %s --sparsifier="%{sparsifier_opts_sve}"
// DEFINE: %{run_libs} = -shared-libs=%mlir_c_runner_utils,%mlir_runner_utils
-// DEFINE: %{run_opts} = -e entry -entry-point-result=void
+// DEFINE: %{run_opts} = -e main -entry-point-result=void
// DEFINE: %{run} = mlir-cpu-runner %{run_opts} %{run_libs}
// DEFINE: %{run_sve} = %mcr_aarch64_cmd --march=aarch64 --mattr="+sve" %{run_opts} %{run_libs}
//
@@ -68,20 +68,8 @@ module {
return %0 : tensor<?xf16, #DenseVector>
}
- // Dumps a dense vector of type f16.
- func.func @dump_vec(%arg0: tensor<?xf16, #DenseVector>) {
- // Dump the values array to verify only sparse contents are stored.
- %c0 = arith.constant 0 : index
- %d0 = arith.constant -1.0 : f16
- %0 = sparse_tensor.values %arg0 : tensor<?xf16, #DenseVector> to memref<?xf16>
- %1 = vector.transfer_read %0[%c0], %d0: memref<?xf16>, vector<32xf16>
- %f1 = arith.extf %1: vector<32xf16> to vector<32xf32>
- vector.print %f1 : vector<32xf32>
- return
- }
-
// Driver method to call and verify the kernel.
- func.func @entry() {
+ func.func @main() {
%c0 = arith.constant 0 : index
// Setup sparse vectors.
@@ -104,8 +92,12 @@ module {
//
// Verify the result.
//
- // CHECK: ( 1, 11, 0, 2, 13, 0, 0, 0, 0, 0, 14, 3, 0, 0, 0, 0, 15, 4, 16, 0, 5, 6, 0, 0, 0, 0, 0, 0, 7, 8, 0, 9 )
- call @dump_vec(%0) : (tensor<?xf16, #DenseVector>) -> ()
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 32
+ // CHECK-NEXT: values : ( 1, 11, 0, 2, 13, 0, 0, 0, 0, 0, 14, 3, 0, 0, 0, 0, 15, 4, 16, 0, 5, 6, 0, 0, 0, 0, 0, 0, 7, 8, 0, 9,
+ // CHECK-NEXT: ----
+ //
+ sparse_tensor.print %0 : tensor<?xf16, #DenseVector>
// Release the resources.
bufferization.dealloc_tensor %sv1 : tensor<?xf16, #SparseVector>
diff --git a/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_re_im.mlir b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_re_im.mlir
index b44ffc30c3b1ee..1860fc1c7027a1 100644
--- a/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_re_im.mlir
+++ b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_re_im.mlir
@@ -10,7 +10,7 @@
// DEFINE: %{compile} = mlir-opt %s --sparsifier="%{sparsifier_opts}"
// DEFINE: %{compile_sve} = mlir-opt %s --sparsifier="%{sparsifier_opts_sve}"
// DEFINE: %{run_libs} = -shared-libs=%mlir_c_runner_utils,%mlir_runner_utils
-// DEFINE: %{run_opts} = -e entry -entry-point-result=void
+// DEFINE: %{run_opts} = -e main -entry-point-result=void
// DEFINE: %{run} = mlir-cpu-runner %{run_opts} %{run_libs}
// DEFINE: %{run_sve} = %mcr_aarch64_cmd --march=aarch64 --mattr="+sve" %{run_opts} %{run_libs}
//
@@ -72,22 +72,7 @@ module {
return %0 : tensor<?xf32, #SparseVector>
}
- func.func @dump(%arg0: tensor<?xf32, #SparseVector>) {
- %c0 = arith.constant 0 : index
- %d0 = arith.constant -1.0 : f32
- %n = sparse_tensor.number_of_entries %arg0 : tensor<?xf32, #SparseVector>
- vector.print %n : index
- %values = sparse_tensor.values %arg0 : tensor<?xf32, #SparseVector> to memref<?xf32>
- %0 = vector.transfer_read %values[%c0], %d0: memref<?xf32>, vector<3xf32>
- vector.print %0 : vector<3xf32>
- %coordinates = sparse_tensor.coordinates %arg0 { level = 0 : index } : tensor<?xf32, #SparseVector> to memref<?xindex>
- %1 = vector.transfer_read %coordinates[%c0], %c0: memref<?xindex>, vector<3xindex>
- vector.print %1 : vector<3xindex>
- return
- }
-
- // Driver method to call and verify functions cim and cre.
- func.func @entry() {
+ func.func @main() {
// Setup sparse vectors.
%v1 = arith.constant sparse<
[ [0], [20], [31] ],
@@ -104,20 +89,27 @@ module {
//
// Verify the results.
//
- // CHECK: 3
- // CHECK-NEXT: ( 5.13, 3, 5 )
- // CHECK-NEXT: ( 0, 20, 31 )
- // CHECK-NEXT: 3
- // CHECK-NEXT: ( 2, 4, 6 )
- // CHECK-NEXT: ( 0, 20, 31 )
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 3
+ // CHECK-NEXT: pos[0] : ( 0, 3,
+ // CHECK-NEXT: crd[0] : ( 0, 20, 31,
+ // CHECK-NEXT: values : ( 5.13, 3, 5,
+ // CHECK-NEXT: ----
+ //
+ // CHECK-NEXT: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 3
+ // CHECK-NEXT: pos[0] : ( 0, 3,
+ // CHECK-NEXT: crd[0] : ( 0, 20, 31,
+ // CHECK-NEXT: values : ( 2, 4, 6,
+ // CHECK-NEXT: ----
//
- call @dump(%0) : (tensor<?xf32, #SparseVector>) -> ()
- call @dump(%1) : (tensor<?xf32, #SparseVector>) -> ()
+ sparse_tensor.print %0 : tensor<?xf32, #SparseVector>
+ sparse_tensor.print %1 : tensor<?xf32, #SparseVector>
// Release the resources.
bufferization.dealloc_tensor %sv1 : tensor<?xcomplex<f32>, #SparseVector>
- bufferization.dealloc_tensor %0 : tensor<?xf32, #SparseVector>
- bufferization.dealloc_tensor %1 : tensor<?xf32, #SparseVector>
+ bufferization.dealloc_tensor %0 : tensor<?xf32, #SparseVector>
+ bufferization.dealloc_tensor %1 : tensor<?xf32, #SparseVector>
return
}
}
>From f7a544dd5f515c2f9b312142f573806cc8e64145 Mon Sep 17 00:00:00 2001
From: Alex Langford <alangford at apple.com>
Date: Wed, 28 Feb 2024 16:54:32 -0800
Subject: [PATCH 071/406] [lldb] Ignore swig warnings about shadowed overloads
(#83317)
This specifically addresses the warnings:
$LLVM/lldb/include/lldb/API/SBCommandReturnObject.h:119: Warning 509:
Overloaded method lldb::SBCommandReturnObject::PutCString(char const *)
effectively ignored,
$LLVM/lldb/include/lldb/API/SBCommandReturnObject.h:119: Warning 509: as
it is shadowed by lldb::SBCommandReturnObject::PutCString(char const
*,int).
There is exactly one declaration of SBCommandReturnObject::PutCString.
The second parameter (of type `int`) has default value `-1`. Without
investigating why SWIG believes there are 2 method declarations, I
believe it is safe to ignore this warning. It does not appear to
actually impact functionality in any way.
rdar://117744660
---
lldb/bindings/CMakeLists.txt | 6 +++++-
1 file changed, 5 insertions(+), 1 deletion(-)
diff --git a/lldb/bindings/CMakeLists.txt b/lldb/bindings/CMakeLists.txt
index b44ed59aa662b2..296eae1ae77f86 100644
--- a/lldb/bindings/CMakeLists.txt
+++ b/lldb/bindings/CMakeLists.txt
@@ -23,7 +23,11 @@ endif()
set(SWIG_COMMON_FLAGS
-c++
- -w361,362 # Ignore warnings about ignored operator overloads
+ # Ignored warnings:
+ # 361: operator! ignored.
+ # 362: operator= ignored.
+ # 509: Overloaded method declaration effectively ignored, shadowed by previous declaration.
+ -w361,362,509
-features autodoc
-I${LLDB_SOURCE_DIR}/include
-I${CMAKE_CURRENT_SOURCE_DIR}
>From 1a0986f0f7a18cef78852e91e73ec577ea05d8c4 Mon Sep 17 00:00:00 2001
From: Peiming Liu <36770114+PeimingLiu at users.noreply.github.com>
Date: Wed, 28 Feb 2024 16:55:28 -0800
Subject: [PATCH 072/406] =?UTF-8?q?[mlir][sparse]=20code=20cleanup=20(usin?=
=?UTF-8?q?g=20inferred=20type=20to=20construct=20to=5F[buf=E2=80=A6=20(#8?=
=?UTF-8?q?3361)?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
…fer] op).
---
.../Transforms/SparseGPUCodegen.cpp | 18 +++++-----
.../Transforms/Utils/CodegenUtils.cpp | 35 -------------------
.../Transforms/Utils/CodegenUtils.h | 27 --------------
.../Transforms/Utils/LoopEmitter.cpp | 2 +-
.../Transforms/Utils/SparseTensorLevel.cpp | 12 +++----
5 files changed, 16 insertions(+), 78 deletions(-)
diff --git a/mlir/lib/Dialect/SparseTensor/Transforms/SparseGPUCodegen.cpp b/mlir/lib/Dialect/SparseTensor/Transforms/SparseGPUCodegen.cpp
index cdee8a46f551b8..cb75f6a0ea8801 100644
--- a/mlir/lib/Dialect/SparseTensor/Transforms/SparseGPUCodegen.cpp
+++ b/mlir/lib/Dialect/SparseTensor/Transforms/SparseGPUCodegen.cpp
@@ -496,11 +496,11 @@ static Value genFirstPosOrCrds(OpBuilder &builder, Location loc, Value a,
if (format == CuSparseFormat::kCOO) {
// Library uses SoA COO, direct IR uses AoS COO.
if (enableRT)
- return genToCoordinates(builder, loc, a, 0);
- return genToCoordinatesBuffer(builder, loc, a);
+ return builder.create<ToCoordinatesOp>(loc, a, 0);
+ return builder.create<ToCoordinatesBufferOp>(loc, a);
}
// Formats CSR/CSC and BSR use positions at 1.
- return genToPositions(builder, loc, a, 1);
+ return builder.create<ToPositionsOp>(loc, a, 1);
}
/// Generates the second coordinates of a sparse matrix.
@@ -510,7 +510,7 @@ static Value genSecondCrds(OpBuilder &builder, Location loc, Value a,
if (isCOO && !enableRT)
return Value(); // nothing needed
// Formats CSR/CSC and BSR use coordinates at 1.
- return genToCoordinates(builder, loc, a, 1);
+ return builder.create<ToCoordinatesOp>(loc, a, 1);
}
/// Generates the sparse matrix handle.
@@ -584,7 +584,7 @@ static LogicalResult rewriteSpMV(PatternRewriter &rewriter,
Value szX = linalg::createOrFoldDimOp(rewriter, loc, a, 1);
Value memR = genFirstPosOrCrds(rewriter, loc, a, format, enableRT);
Value memC = genSecondCrds(rewriter, loc, a, format, enableRT); // or empty
- Value memV = genToValues(rewriter, loc, a);
+ Value memV = rewriter.create<ToValuesOp>(loc, a);
Value rowA = genAllocCopy(rewriter, loc, memR, tokens);
Value colA = memC ? genAllocCopy(rewriter, loc, memC, tokens) : Value();
Value valA = genAllocCopy(rewriter, loc, memV, tokens);
@@ -682,7 +682,7 @@ static LogicalResult rewriteSpMM(PatternRewriter &rewriter,
Value szn = linalg::createOrFoldDimOp(rewriter, loc, b, 1);
Value memR = genFirstPosOrCrds(rewriter, loc, a, format, enableRT);
Value memC = genSecondCrds(rewriter, loc, a, format, enableRT); // or empty
- Value memV = genToValues(rewriter, loc, a);
+ Value memV = rewriter.create<ToValuesOp>(loc, a);
Value rowA = genAllocCopy(rewriter, loc, memR, tokens);
Value colA = memC ? genAllocCopy(rewriter, loc, memC, tokens) : Value();
Value valA = genAllocCopy(rewriter, loc, memV, tokens);
@@ -785,10 +785,10 @@ static LogicalResult rewriteSpGEMM(PatternRewriter &rewriter,
Value szn = linalg::createOrFoldDimOp(rewriter, loc, b, 1);
Value amemR = genFirstPosOrCrds(rewriter, loc, a, format, enableRT);
Value amemC = genSecondCrds(rewriter, loc, a, format, enableRT); // not empty
- Value amemV = genToValues(rewriter, loc, a);
+ Value amemV = rewriter.create<ToValuesOp>(loc, a);
Value bmemR = genFirstPosOrCrds(rewriter, loc, b, format, enableRT);
Value bmemC = genSecondCrds(rewriter, loc, b, format, enableRT); // not empty
- Value bmemV = genToValues(rewriter, loc, b);
+ Value bmemV = rewriter.create<ToValuesOp>(loc, b);
Value rowA = genAllocCopy(rewriter, loc, amemR, tokens);
Value colA = genAllocCopy(rewriter, loc, amemC, tokens);
Value valA = genAllocCopy(rewriter, loc, amemV, tokens);
@@ -1081,7 +1081,7 @@ static LogicalResult rewriteSDDMM(PatternRewriter &rewriter,
Value matB = genAllocCopy(rewriter, loc, bufB, tokens);
Value memR = genFirstPosOrCrds(rewriter, loc, c, format, enableRT);
Value memC = genSecondCrds(rewriter, loc, c, format, enableRT); // or empty
- Value memV = genToValues(rewriter, loc, c);
+ Value memV = rewriter.create<ToValuesOp>(loc, c);
Value rowC = genAllocCopy(rewriter, loc, memR, tokens);
Value colC = memC ? genAllocCopy(rewriter, loc, memC, tokens) : Value();
Value valC = genAllocCopy(rewriter, loc, memV, tokens);
diff --git a/mlir/lib/Dialect/SparseTensor/Transforms/Utils/CodegenUtils.cpp b/mlir/lib/Dialect/SparseTensor/Transforms/Utils/CodegenUtils.cpp
index b888dfadb9c714..fa570159ba41ca 100644
--- a/mlir/lib/Dialect/SparseTensor/Transforms/Utils/CodegenUtils.cpp
+++ b/mlir/lib/Dialect/SparseTensor/Transforms/Utils/CodegenUtils.cpp
@@ -554,41 +554,6 @@ sparse_tensor::genToMemref(OpBuilder &builder, Location loc, Value tensor) {
.getResult();
}
-Value sparse_tensor::genToPositions(OpBuilder &builder, Location loc,
- Value tensor, Level lvl) {
- const auto srcTp = getSparseTensorType(tensor);
- const Type posTp = srcTp.getPosType();
- const Type memTp = get1DMemRefType(posTp, /*withLayout=*/false);
- return builder.create<ToPositionsOp>(loc, memTp, tensor,
- builder.getIndexAttr(lvl));
-}
-
-Value sparse_tensor::genToCoordinates(OpBuilder &builder, Location loc,
- Value tensor, Level lvl) {
- const auto srcTp = getSparseTensorType(tensor);
- const Type crdTp = srcTp.getCrdType();
- const Type memTp =
- get1DMemRefType(crdTp, /*withLayout=*/lvl >= srcTp.getAoSCOOStart());
- return builder.create<ToCoordinatesOp>(loc, memTp, tensor,
- builder.getIndexAttr(lvl));
-}
-
-Value sparse_tensor::genToCoordinatesBuffer(OpBuilder &builder, Location loc,
- Value tensor) {
- const auto srcTp = getSparseTensorType(tensor);
- const Type crdTp = srcTp.getCrdType();
- const Type memTp = get1DMemRefType(crdTp, /*withLayout=*/false);
- return builder.create<ToCoordinatesBufferOp>(loc, memTp, tensor);
-}
-
-Value sparse_tensor::genToValues(OpBuilder &builder, Location loc,
- Value tensor) {
- RankedTensorType srcTp = getRankedTensorType(tensor);
- Type valTp = get1DMemRefType(srcTp.getElementType(),
- /*withLayout=*/false);
- return builder.create<ToValuesOp>(loc, valTp, tensor);
-}
-
Value sparse_tensor::genValMemSize(OpBuilder &builder, Location loc,
Value tensor) {
return getDescriptorFromTensorTuple(tensor).getValMemSize(builder, loc);
diff --git a/mlir/lib/Dialect/SparseTensor/Transforms/Utils/CodegenUtils.h b/mlir/lib/Dialect/SparseTensor/Transforms/Utils/CodegenUtils.h
index cc119bc7045595..e8f6bd1c5eaeb1 100644
--- a/mlir/lib/Dialect/SparseTensor/Transforms/Utils/CodegenUtils.h
+++ b/mlir/lib/Dialect/SparseTensor/Transforms/Utils/CodegenUtils.h
@@ -228,17 +228,6 @@ void deallocDenseTensor(OpBuilder &builder, Location loc, Value buffer);
void sizesFromSrc(OpBuilder &builder, SmallVectorImpl<Value> &sizes,
Location loc, Value src);
-/// Generates a 1D MemRefType with a dynamic size. When withLayout is set, the
-/// returned memref has a layout has unknown strides and offsets. Otherwise,
-/// a memref with a standard unit stride zero offset layout is returned.
-inline MemRefType get1DMemRefType(Type etp, bool withLayout) {
- auto layout = withLayout ? StridedLayoutAttr::StridedLayoutAttr::get(
- etp.getContext(), ShapedType::kDynamic,
- {ShapedType::kDynamic})
- : StridedLayoutAttr();
- return MemRefType::get(ShapedType::kDynamic, etp, layout);
-}
-
/// Scans to top of generated loop.
Operation *getTop(Operation *op);
@@ -281,22 +270,6 @@ void storeAll(OpBuilder &builder, Location loc, Value mem, ValueRange vs,
TypedValue<BaseMemRefType> genToMemref(OpBuilder &builder, Location loc,
Value tensor);
-/// Infers the result type and generates `ToPositionsOp`.
-Value genToPositions(OpBuilder &builder, Location loc, Value tensor, Level lvl);
-
-/// Infers the result type and generates `ToCoordinatesOp`. If the
-/// level is within a COO region, the result type is a memref with unknown
-/// stride and offset. Otherwise, the result type is a memref without
-/// any specified layout.
-Value genToCoordinates(OpBuilder &builder, Location loc, Value tensor,
- Level lvl);
-
-/// Infers the result type and generates `ToCoordinatesBufferOp`.
-Value genToCoordinatesBuffer(OpBuilder &builder, Location loc, Value tensor);
-
-/// Infers the result type and generates `ToValuesOp`.
-Value genToValues(OpBuilder &builder, Location loc, Value tensor);
-
/// Generates code to retrieve the values size for the sparse tensor.
Value genValMemSize(OpBuilder &builder, Location loc, Value tensor);
diff --git a/mlir/lib/Dialect/SparseTensor/Transforms/Utils/LoopEmitter.cpp b/mlir/lib/Dialect/SparseTensor/Transforms/Utils/LoopEmitter.cpp
index 0ead135c90d305..812c288a20c2df 100644
--- a/mlir/lib/Dialect/SparseTensor/Transforms/Utils/LoopEmitter.cpp
+++ b/mlir/lib/Dialect/SparseTensor/Transforms/Utils/LoopEmitter.cpp
@@ -259,7 +259,7 @@ void LoopEmitter::initializeLoopEmit(
// Annotated sparse tensors.
// We also need the value buffer for all-dense annotated "sparse"
// tensors.
- valBuffer[t] = genToValues(builder, loc, tensor);
+ valBuffer[t] = builder.create<ToValuesOp>(loc, tensor);
}
// NOTE: we can also prepare for 0 lvl here in advance, this will hoist
// some loop preparation from tensor iteration, but will also (undesirably)
diff --git a/mlir/lib/Dialect/SparseTensor/Transforms/Utils/SparseTensorLevel.cpp b/mlir/lib/Dialect/SparseTensor/Transforms/Utils/SparseTensorLevel.cpp
index 011d814cd90094..8edacaa9981ef8 100644
--- a/mlir/lib/Dialect/SparseTensor/Transforms/Utils/SparseTensorLevel.cpp
+++ b/mlir/lib/Dialect/SparseTensor/Transforms/Utils/SparseTensorLevel.cpp
@@ -1281,21 +1281,21 @@ sparse_tensor::makeSparseTensorLevel(OpBuilder &b, Location l, Value t,
case LevelFormat::Batch:
llvm_unreachable("not implemented");
case LevelFormat::Compressed: {
- Value pos = genToPositions(b, l, t, lvl);
- Value crd = genToCoordinates(b, l, t, lvl);
+ Value pos = b.create<ToPositionsOp>(l, t, lvl);
+ Value crd = b.create<ToCoordinatesOp>(l, t, lvl);
return std::make_unique<CompressedLevel>(tid, lvl, lt, sz, pos, crd);
}
case LevelFormat::LooseCompressed: {
- Value pos = genToPositions(b, l, t, lvl);
- Value crd = genToCoordinates(b, l, t, lvl);
+ Value pos = b.create<ToPositionsOp>(l, t, lvl);
+ Value crd = b.create<ToCoordinatesOp>(l, t, lvl);
return std::make_unique<LooseCompressedLevel>(tid, lvl, lt, sz, pos, crd);
}
case LevelFormat::Singleton: {
- Value crd = genToCoordinates(b, l, t, lvl);
+ Value crd = b.create<ToCoordinatesOp>(l, t, lvl);
return std::make_unique<SingletonLevel>(tid, lvl, lt, sz, crd);
}
case LevelFormat::NOutOfM: {
- Value crd = genToCoordinates(b, l, t, lvl);
+ Value crd = b.create<ToCoordinatesOp>(l, t, lvl);
return std::make_unique<NOutOfMLevel>(tid, lvl, lt, sz, crd);
}
case LevelFormat::Undef:
>From 2679d3793b264b2884cf5c9492e3311f08f41de3 Mon Sep 17 00:00:00 2001
From: Uday Bondhugula <uday at polymagelabs.com>
Date: Thu, 29 Feb 2024 06:32:42 +0530
Subject: [PATCH 073/406] [MLIR][Affine] Add test pass for affine
isContiguousAccess (#82923)
`isContiguousAccess` is an important affine analysis utility but is only
tested very indirectly via passes like vectorization and is not exposed.
Expose it and add a test pass for it that'll make it easier/feasible to
write test cases. This is especially needed since the utility can be
significantly enhanced in power, and we need a test pass to exercise it
directly.
This pass can in the future be used to test the utility of invariant
accesses as well.
---
.../Dialect/Affine/Analysis/LoopAnalysis.h | 20 +++++
.../Dialect/Affine/Analysis/LoopAnalysis.cpp | 54 +++++-------
mlir/test/Dialect/Affine/access-analysis.mlir | 67 +++++++++++++++
mlir/test/lib/Dialect/Affine/CMakeLists.txt | 2 +
.../lib/Dialect/Affine/TestAccessAnalysis.cpp | 83 +++++++++++++++++++
mlir/tools/mlir-opt/mlir-opt.cpp | 2 +
6 files changed, 197 insertions(+), 31 deletions(-)
create mode 100644 mlir/test/Dialect/Affine/access-analysis.mlir
create mode 100644 mlir/test/lib/Dialect/Affine/TestAccessAnalysis.cpp
diff --git a/mlir/include/mlir/Dialect/Affine/Analysis/LoopAnalysis.h b/mlir/include/mlir/Dialect/Affine/Analysis/LoopAnalysis.h
index 92f3d5a2c4925b..1f64b57cac5782 100644
--- a/mlir/include/mlir/Dialect/Affine/Analysis/LoopAnalysis.h
+++ b/mlir/include/mlir/Dialect/Affine/Analysis/LoopAnalysis.h
@@ -60,6 +60,26 @@ uint64_t getLargestDivisorOfTripCount(AffineForOp forOp);
DenseSet<Value, DenseMapInfo<Value>>
getInvariantAccesses(Value iv, ArrayRef<Value> indices);
+/// Given:
+/// 1. an induction variable `iv` of type AffineForOp;
+/// 2. a `memoryOp` of type const LoadOp& or const StoreOp&;
+/// determines whether `memoryOp` has a contiguous access along `iv`. Contiguous
+/// is defined as either invariant or varying only along a unique MemRef dim.
+/// Upon success, the unique MemRef dim is written in `memRefDim` (or -1 to
+/// convey the memRef access is invariant along `iv`).
+///
+/// Prerequisites:
+/// 1. `memRefDim` ~= nullptr;
+/// 2. `iv` of the proper type;
+/// 3. the MemRef accessed by `memoryOp` has no layout map or at most an
+/// identity layout map.
+///
+/// Currently only supports no layout map or identity layout map in the memref.
+/// Returns false if the memref has a non-identity layoutMap. This behavior is
+/// conservative.
+template <typename LoadOrStoreOp>
+bool isContiguousAccess(Value iv, LoadOrStoreOp memoryOp, int *memRefDim);
+
using VectorizableLoopFun = std::function<bool(AffineForOp)>;
/// Checks whether the loop is structurally vectorizable; i.e.:
diff --git a/mlir/lib/Dialect/Affine/Analysis/LoopAnalysis.cpp b/mlir/lib/Dialect/Affine/Analysis/LoopAnalysis.cpp
index e645afe7cd3e8f..fc0515ba95f4fe 100644
--- a/mlir/lib/Dialect/Affine/Analysis/LoopAnalysis.cpp
+++ b/mlir/lib/Dialect/Affine/Analysis/LoopAnalysis.cpp
@@ -195,43 +195,25 @@ DenseSet<Value> mlir::affine::getInvariantAccesses(Value iv,
return res;
}
-/// Given:
-/// 1. an induction variable `iv` of type AffineForOp;
-/// 2. a `memoryOp` of type const LoadOp& or const StoreOp&;
-/// determines whether `memoryOp` has a contiguous access along `iv`. Contiguous
-/// is defined as either invariant or varying only along a unique MemRef dim.
-/// Upon success, the unique MemRef dim is written in `memRefDim` (or -1 to
-/// convey the memRef access is invariant along `iv`).
-///
-/// Prerequisites:
-/// 1. `memRefDim` ~= nullptr;
-/// 2. `iv` of the proper type;
-/// 3. the MemRef accessed by `memoryOp` has no layout map or at most an
-/// identity layout map.
-///
-/// Currently only supports no layoutMap or identity layoutMap in the MemRef.
-/// Returns false if the MemRef has a non-identity layoutMap or more than 1
-/// layoutMap. This is conservative.
-///
-// TODO: check strides.
+// TODO: check access stride.
template <typename LoadOrStoreOp>
-static bool isContiguousAccess(Value iv, LoadOrStoreOp memoryOp,
- int *memRefDim) {
- static_assert(
- llvm::is_one_of<LoadOrStoreOp, AffineLoadOp, AffineStoreOp>::value,
- "Must be called on either LoadOp or StoreOp");
+bool mlir::affine::isContiguousAccess(Value iv, LoadOrStoreOp memoryOp,
+ int *memRefDim) {
+ static_assert(llvm::is_one_of<LoadOrStoreOp, AffineReadOpInterface,
+ AffineWriteOpInterface>::value,
+ "Must be called on either an affine read or write op");
assert(memRefDim && "memRefDim == nullptr");
auto memRefType = memoryOp.getMemRefType();
if (!memRefType.getLayout().isIdentity())
- return memoryOp.emitError("NYI: non-trivial layoutMap"), false;
+ return memoryOp.emitError("NYI: non-trivial layout map"), false;
int uniqueVaryingIndexAlongIv = -1;
auto accessMap = memoryOp.getAffineMap();
SmallVector<Value, 4> mapOperands(memoryOp.getMapOperands());
unsigned numDims = accessMap.getNumDims();
for (unsigned i = 0, e = memRefType.getRank(); i < e; ++i) {
- // Gather map operands used result expr 'i' in 'exprOperands'.
+ // Gather map operands used in result expr 'i' in 'exprOperands'.
SmallVector<Value, 4> exprOperands;
auto resultExpr = accessMap.getResult(i);
resultExpr.walk([&](AffineExpr expr) {
@@ -241,7 +223,7 @@ static bool isContiguousAccess(Value iv, LoadOrStoreOp memoryOp,
exprOperands.push_back(mapOperands[numDims + symExpr.getPosition()]);
});
// Check access invariance of each operand in 'exprOperands'.
- for (auto exprOperand : exprOperands) {
+ for (Value exprOperand : exprOperands) {
if (!isAccessIndexInvariant(iv, exprOperand)) {
if (uniqueVaryingIndexAlongIv != -1) {
// 2+ varying indices -> do not vectorize along iv.
@@ -259,6 +241,13 @@ static bool isContiguousAccess(Value iv, LoadOrStoreOp memoryOp,
return true;
}
+template bool mlir::affine::isContiguousAccess(Value iv,
+ AffineReadOpInterface loadOp,
+ int *memRefDim);
+template bool mlir::affine::isContiguousAccess(Value iv,
+ AffineWriteOpInterface loadOp,
+ int *memRefDim);
+
template <typename LoadOrStoreOp>
static bool isVectorElement(LoadOrStoreOp memoryOp) {
auto memRefType = memoryOp.getMemRefType();
@@ -344,10 +333,13 @@ bool mlir::affine::isVectorizableLoopBody(
auto load = dyn_cast<AffineLoadOp>(op);
auto store = dyn_cast<AffineStoreOp>(op);
int thisOpMemRefDim = -1;
- bool isContiguous = load ? isContiguousAccess(loop.getInductionVar(), load,
- &thisOpMemRefDim)
- : isContiguousAccess(loop.getInductionVar(), store,
- &thisOpMemRefDim);
+ bool isContiguous =
+ load ? isContiguousAccess(loop.getInductionVar(),
+ cast<AffineReadOpInterface>(*load),
+ &thisOpMemRefDim)
+ : isContiguousAccess(loop.getInductionVar(),
+ cast<AffineWriteOpInterface>(*store),
+ &thisOpMemRefDim);
if (thisOpMemRefDim != -1) {
// If memory accesses vary across different dimensions then the loop is
// not vectorizable.
diff --git a/mlir/test/Dialect/Affine/access-analysis.mlir b/mlir/test/Dialect/Affine/access-analysis.mlir
new file mode 100644
index 00000000000000..68310b9323535a
--- /dev/null
+++ b/mlir/test/Dialect/Affine/access-analysis.mlir
@@ -0,0 +1,67 @@
+// RUN: mlir-opt %s -split-input-file -test-affine-access-analysis -verify-diagnostics | FileCheck %s
+
+// CHECK-LABEL: func @loop_1d
+func.func @loop_1d(%A : memref<?x?xf32>, %B : memref<?x?x?xf32>) {
+ %c0 = arith.constant 0 : index
+ %M = memref.dim %A, %c0 : memref<?x?xf32>
+ affine.for %i = 0 to %M {
+ affine.for %j = 0 to %M {
+ affine.load %A[%c0, %i] : memref<?x?xf32>
+ // expected-remark at above {{contiguous along loop 0}}
+ affine.load %A[%c0, 8 * %i + %j] : memref<?x?xf32>
+ // expected-remark at above {{contiguous along loop 1}}
+ // Note/FIXME: access stride isn't being checked.
+ // expected-remark at -3 {{contiguous along loop 0}}
+
+ // These are all non-contiguous along both loops. Nothing is emitted.
+ affine.load %A[%i, %c0] : memref<?x?xf32>
+ // Note/FIXME: access stride isn't being checked.
+ affine.load %A[%i, 8 * %j] : memref<?x?xf32>
+ // expected-remark at above {{contiguous along loop 1}}
+ affine.load %A[%j, 4 * %i] : memref<?x?xf32>
+ // expected-remark at above {{contiguous along loop 0}}
+ }
+ }
+ return
+}
+
+// -----
+
+#map = affine_map<(d0) -> (d0 * 16)>
+#map1 = affine_map<(d0) -> (d0 * 16 + 16)>
+#map2 = affine_map<(d0) -> (d0)>
+#map3 = affine_map<(d0) -> (d0 + 1)>
+
+func.func @tiled(%arg0: memref<*xf32>) {
+ %alloc = memref.alloc() {alignment = 64 : i64} : memref<1x224x224x64xf32>
+ %cast = memref.cast %arg0 : memref<*xf32> to memref<64xf32>
+ affine.for %arg1 = 0 to 4 {
+ affine.for %arg2 = 0 to 224 {
+ affine.for %arg3 = 0 to 14 {
+ %alloc_0 = memref.alloc() : memref<1x16x1x16xf32>
+ affine.for %arg4 = #map(%arg1) to #map1(%arg1) {
+ affine.for %arg5 = #map(%arg3) to #map1(%arg3) {
+ %0 = affine.load %cast[%arg4] : memref<64xf32>
+ // expected-remark at above {{contiguous along loop 3}}
+ affine.store %0, %alloc_0[0, %arg1 * -16 + %arg4, 0, %arg3 * -16 + %arg5] : memref<1x16x1x16xf32>
+ // expected-remark at above {{contiguous along loop 4}}
+ // expected-remark at above {{contiguous along loop 2}}
+ }
+ }
+ affine.for %arg4 = #map(%arg1) to #map1(%arg1) {
+ affine.for %arg5 = #map2(%arg2) to #map3(%arg2) {
+ affine.for %arg6 = #map(%arg3) to #map1(%arg3) {
+ %0 = affine.load %alloc_0[0, %arg1 * -16 + %arg4, -%arg2 + %arg5, %arg3 * -16 + %arg6] : memref<1x16x1x16xf32>
+ // expected-remark at above {{contiguous along loop 5}}
+ // expected-remark at above {{contiguous along loop 2}}
+ affine.store %0, %alloc[0, %arg5, %arg6, %arg4] : memref<1x224x224x64xf32>
+ // expected-remark at above {{contiguous along loop 3}}
+ }
+ }
+ }
+ memref.dealloc %alloc_0 : memref<1x16x1x16xf32>
+ }
+ }
+ }
+ return
+}
diff --git a/mlir/test/lib/Dialect/Affine/CMakeLists.txt b/mlir/test/lib/Dialect/Affine/CMakeLists.txt
index af9f312694abc9..14960a45d39bab 100644
--- a/mlir/test/lib/Dialect/Affine/CMakeLists.txt
+++ b/mlir/test/lib/Dialect/Affine/CMakeLists.txt
@@ -3,6 +3,7 @@ add_mlir_library(MLIRAffineTransformsTestPasses
TestAffineDataCopy.cpp
TestAffineLoopUnswitching.cpp
TestAffineLoopParametricTiling.cpp
+ TestAccessAnalysis.cpp
TestDecomposeAffineOps.cpp
TestReifyValueBounds.cpp
TestLoopFusion.cpp
@@ -21,6 +22,7 @@ add_mlir_library(MLIRAffineTransformsTestPasses
LINK_LIBS PUBLIC
MLIRArithTransforms
+ MLIRAffineAnalysis
MLIRAffineTransforms
MLIRAffineUtils
MLIRIR
diff --git a/mlir/test/lib/Dialect/Affine/TestAccessAnalysis.cpp b/mlir/test/lib/Dialect/Affine/TestAccessAnalysis.cpp
new file mode 100644
index 00000000000000..b38046299d504a
--- /dev/null
+++ b/mlir/test/lib/Dialect/Affine/TestAccessAnalysis.cpp
@@ -0,0 +1,83 @@
+//===- TestAccessAnalysis.cpp - Test affine access analysis utility -------===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+//
+// This file implements a pass to test affine access analysis utilities.
+//
+//===----------------------------------------------------------------------===//
+#include "mlir/Dialect/Affine/Analysis/LoopAnalysis.h"
+#include "mlir/Dialect/Affine/Analysis/Utils.h"
+#include "mlir/Dialect/Affine/LoopFusionUtils.h"
+#include "mlir/Dialect/Func/IR/FuncOps.h"
+#include "mlir/Pass/Pass.h"
+
+#define PASS_NAME "test-affine-access-analysis"
+
+using namespace mlir;
+using namespace mlir::affine;
+
+namespace {
+
+struct TestAccessAnalysis
+ : public PassWrapper<TestAccessAnalysis, OperationPass<func::FuncOp>> {
+ MLIR_DEFINE_EXPLICIT_INTERNAL_INLINE_TYPE_ID(TestAccessAnalysis)
+
+ StringRef getArgument() const final { return PASS_NAME; }
+ StringRef getDescription() const final {
+ return "Tests affine memory access analysis utility";
+ }
+
+ void runOnOperation() override;
+};
+
+} // namespace
+
+/// Gathers all affine load/store ops in loop nest rooted at 'forOp' into
+/// 'loadAndStoreOps'.
+static void
+gatherLoadsAndStores(AffineForOp forOp,
+ SmallVectorImpl<Operation *> &loadAndStoreOps) {
+ forOp.walk([&](Operation *op) {
+ if (isa<AffineReadOpInterface, AffineWriteOpInterface>(op))
+ loadAndStoreOps.push_back(op);
+ });
+}
+
+void TestAccessAnalysis::runOnOperation() {
+ SmallVector<Operation *> loadStores;
+ SmallVector<AffineForOp> enclosingOps;
+ // Go over all top-level affine.for ops and test each contained affine
+ // access's contiguity along every surrounding loop IV.
+ for (auto forOp : getOperation().getOps<AffineForOp>()) {
+ loadStores.clear();
+ gatherLoadsAndStores(forOp, loadStores);
+ for (Operation *memOp : loadStores) {
+ enclosingOps.clear();
+ getAffineForIVs(*memOp, &enclosingOps);
+ for (unsigned d = 0, e = enclosingOps.size(); d < e; d++) {
+ int memRefDim;
+ bool isContiguous;
+ if (auto read = dyn_cast<AffineReadOpInterface>(memOp)) {
+ isContiguous = isContiguousAccess(enclosingOps[d].getInductionVar(),
+ read, &memRefDim);
+ } else {
+ isContiguous = isContiguousAccess(enclosingOps[d].getInductionVar(),
+ cast<AffineWriteOpInterface>(memOp),
+ &memRefDim);
+ }
+ if (isContiguous && memRefDim == 0)
+ memOp->emitRemark("contiguous along loop ") << d << '\n';
+ }
+ }
+ }
+}
+
+namespace mlir {
+void registerTestAffineAccessAnalysisPass() {
+ PassRegistration<TestAccessAnalysis>();
+}
+} // namespace mlir
diff --git a/mlir/tools/mlir-opt/mlir-opt.cpp b/mlir/tools/mlir-opt/mlir-opt.cpp
index 4dfa05cc8ca885..0ba1a3a534e35c 100644
--- a/mlir/tools/mlir-opt/mlir-opt.cpp
+++ b/mlir/tools/mlir-opt/mlir-opt.cpp
@@ -43,6 +43,7 @@ void registerSliceAnalysisTestPass();
void registerSymbolTestPasses();
void registerRegionTestPasses();
void registerTestAffineDataCopyPass();
+void registerTestAffineAccessAnalysisPass();
void registerTestAffineReifyValueBoundsPass();
void registerTestAffineLoopUnswitchingPass();
void registerTestAffineWalk();
@@ -169,6 +170,7 @@ void registerTestPasses() {
registerSymbolTestPasses();
registerRegionTestPasses();
registerTestAffineDataCopyPass();
+ registerTestAffineAccessAnalysisPass();
registerTestAffineLoopUnswitchingPass();
registerTestAffineReifyValueBoundsPass();
registerTestAffineWalk();
>From 6a65b44322ee7ba816283c31f8d71559592ca5e7 Mon Sep 17 00:00:00 2001
From: "Henrik G. Olsson" <hnrklssn at gmail.com>
Date: Wed, 28 Feb 2024 17:08:36 -0800
Subject: [PATCH 074/406] [UTC] Don't leave dangling CHECK-SAME when removing
CHECK lines (#82569)
When removing only lines that are global value CHECK lines, a related
CHECK-SAME line could be left dangling without a previous line to belong
to.
Resolves #78517
---
.../Inputs/global_remove_same.ll | 15 +++++++++++++++
.../Inputs/global_remove_same.ll.expected | 13 +++++++++++++
.../update_test_checks/global_remove_same.test | 4 ++++
llvm/utils/UpdateTestChecks/common.py | 15 +++++++++++++--
llvm/utils/update_test_checks.py | 10 +++++++++-
5 files changed, 54 insertions(+), 3 deletions(-)
create mode 100644 llvm/test/tools/UpdateTestChecks/update_test_checks/Inputs/global_remove_same.ll
create mode 100644 llvm/test/tools/UpdateTestChecks/update_test_checks/Inputs/global_remove_same.ll.expected
create mode 100644 llvm/test/tools/UpdateTestChecks/update_test_checks/global_remove_same.test
diff --git a/llvm/test/tools/UpdateTestChecks/update_test_checks/Inputs/global_remove_same.ll b/llvm/test/tools/UpdateTestChecks/update_test_checks/Inputs/global_remove_same.ll
new file mode 100644
index 00000000000000..d3d13ae2622e6f
--- /dev/null
+++ b/llvm/test/tools/UpdateTestChecks/update_test_checks/Inputs/global_remove_same.ll
@@ -0,0 +1,15 @@
+; RUN: opt -S < %s | FileCheck %s
+
+define i32 @foo() {
+; CHECK-LABEL: @foo(
+; CHECK-NEXT: [[RESULT:%.*]] = call i32 @bar(i32 0, i32 1)
+; CHECK-NEXT: ret i32 [[RESULT]]
+;
+ %result = call i32 @bar(i32 0, i32 1)
+ ret i32 %result
+}
+
+declare i32 @bar(i32, i32)
+; CHECK-LABEL: @bar(
+; CHECK-SAME: i32
+; CHECK-SAME: i32
diff --git a/llvm/test/tools/UpdateTestChecks/update_test_checks/Inputs/global_remove_same.ll.expected b/llvm/test/tools/UpdateTestChecks/update_test_checks/Inputs/global_remove_same.ll.expected
new file mode 100644
index 00000000000000..e76efaedd172c1
--- /dev/null
+++ b/llvm/test/tools/UpdateTestChecks/update_test_checks/Inputs/global_remove_same.ll.expected
@@ -0,0 +1,13 @@
+; NOTE: Assertions have been autogenerated by utils/update_test_checks.py
+; RUN: opt -S < %s | FileCheck %s
+
+define i32 @foo() {
+; CHECK-LABEL: @foo(
+; CHECK-NEXT: [[RESULT:%.*]] = call i32 @bar(i32 0, i32 1)
+; CHECK-NEXT: ret i32 [[RESULT]]
+;
+ %result = call i32 @bar(i32 0, i32 1)
+ ret i32 %result
+}
+
+declare i32 @bar(i32, i32)
diff --git a/llvm/test/tools/UpdateTestChecks/update_test_checks/global_remove_same.test b/llvm/test/tools/UpdateTestChecks/update_test_checks/global_remove_same.test
new file mode 100644
index 00000000000000..5d447babddea4f
--- /dev/null
+++ b/llvm/test/tools/UpdateTestChecks/update_test_checks/global_remove_same.test
@@ -0,0 +1,4 @@
+## Basic test checking global checks split over multiple lines are removed together
+# RUN: cp -f %S/Inputs/global_remove_same.ll %t.ll && %update_test_checks %t.ll
+# RUN: diff -u %t.ll %S/Inputs/global_remove_same.ll.expected
+
diff --git a/llvm/utils/UpdateTestChecks/common.py b/llvm/utils/UpdateTestChecks/common.py
index 4a02a92f824e65..53777523ec2a58 100644
--- a/llvm/utils/UpdateTestChecks/common.py
+++ b/llvm/utils/UpdateTestChecks/common.py
@@ -388,7 +388,12 @@ def itertests(
def should_add_line_to_output(
- input_line, prefix_set, skip_global_checks=False, comment_marker=";"
+ input_line,
+ prefix_set,
+ *,
+ skip_global_checks=False,
+ skip_same_checks=False,
+ comment_marker=";",
):
# Skip any blank comment lines in the IR.
if not skip_global_checks and input_line.strip() == comment_marker:
@@ -402,9 +407,14 @@ def should_add_line_to_output(
# And skip any CHECK lines. We're building our own.
m = CHECK_RE.match(input_line)
if m and m.group(1) in prefix_set:
+ if skip_same_checks and CHECK_SAME_RE.match(input_line):
+ # The previous CHECK line was removed, so don't leave this dangling
+ return False
if skip_global_checks:
+ # Skip checks only if they are of global value definitions
global_ir_value_re = re.compile(r"(\[\[|@)", flags=(re.M))
- return not global_ir_value_re.search(input_line)
+ is_global = global_ir_value_re.search(input_line)
+ return not is_global
return False
return True
@@ -483,6 +493,7 @@ def invoke_tool(exe, cmd_args, ir, preprocess_cmd=None, verbose=False):
CHECK_RE = re.compile(
r"^\s*(?://|[;#])\s*([^:]+?)(?:-NEXT|-NOT|-DAG|-LABEL|-SAME|-EMPTY)?:"
)
+CHECK_SAME_RE = re.compile(r"^\s*(?://|[;#])\s*([^:]+?)(?:-SAME)?:")
UTC_ARGS_KEY = "UTC_ARGS:"
UTC_ARGS_CMD = re.compile(r".*" + UTC_ARGS_KEY + r"\s*(?P<cmd>.*)\s*$")
diff --git a/llvm/utils/update_test_checks.py b/llvm/utils/update_test_checks.py
index 06c247c8010a90..b5077d79351378 100755
--- a/llvm/utils/update_test_checks.py
+++ b/llvm/utils/update_test_checks.py
@@ -235,6 +235,7 @@ def main():
)
else:
# "Normal" mode.
+ dropped_previous_line = False
for input_line_info in ti.iterlines(output_lines):
input_line = input_line_info.line
args = input_line_info.args
@@ -282,7 +283,10 @@ def main():
has_checked_pre_function_globals = True
if common.should_add_line_to_output(
- input_line, prefix_set, not is_in_function
+ input_line,
+ prefix_set,
+ skip_global_checks=not is_in_function,
+ skip_same_checks=dropped_previous_line,
):
# This input line of the function body will go as-is into the output.
# Except make leading whitespace uniform: 2 spaces.
@@ -290,9 +294,13 @@ def main():
r" ", input_line
)
output_lines.append(input_line)
+ dropped_previous_line = False
if input_line.strip() == "}":
is_in_function = False
continue
+ else:
+ # If we are removing a check line, and the next line is CHECK-SAME, it MUST also be removed
+ dropped_previous_line = True
if is_in_function:
continue
>From 27352e600aab6a50939db77a6eacc94a5057d66f Mon Sep 17 00:00:00 2001
From: Nick Desaulniers <nickdesaulniers at users.noreply.github.com>
Date: Wed, 28 Feb 2024 17:13:05 -0800
Subject: [PATCH 075/406] [libc] fix typo introduced in
inline_bcmp_byte_per_byte (#83356)
My global find+replace was overzealous and broke post submit unit tests.
Link: #83345
---
libc/src/string/memory_utils/generic/byte_per_byte.h | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/libc/src/string/memory_utils/generic/byte_per_byte.h b/libc/src/string/memory_utils/generic/byte_per_byte.h
index 948da8ab2a8702..9515398794df40 100644
--- a/libc/src/string/memory_utils/generic/byte_per_byte.h
+++ b/libc/src/string/memory_utils/generic/byte_per_byte.h
@@ -56,7 +56,7 @@ inline_bcmp_byte_per_byte(CPtr p1, CPtr p2, size_t count, size_t offset = 0) {
LIBC_LOOP_NOUNROLL
for (; offset < count; ++offset)
if (p1[offset] != p2[offset])
- return BcmpReturnType::zero();
+ return BcmpReturnType::nonzero();
return BcmpReturnType::zero();
}
>From 0fe4b9dae81695dd44c3392e52e1454864a9c001 Mon Sep 17 00:00:00 2001
From: Changpeng Fang <changpeng.fang at amd.com>
Date: Wed, 28 Feb 2024 17:24:23 -0800
Subject: [PATCH 076/406] AMDGPU: Copy a few Predicates from Pseudo to Real
(#83365)
WaveSizePredicate for DS_Reaf and FLAT_Real
OtherPredicates for MTBUF_Real
---
llvm/lib/Target/AMDGPU/BUFInstructions.td | 1 +
llvm/lib/Target/AMDGPU/DSInstructions.td | 1 +
llvm/lib/Target/AMDGPU/FLATInstructions.td | 1 +
3 files changed, 3 insertions(+)
diff --git a/llvm/lib/Target/AMDGPU/BUFInstructions.td b/llvm/lib/Target/AMDGPU/BUFInstructions.td
index 7f812ed7871bda..7d4d619788d392 100644
--- a/llvm/lib/Target/AMDGPU/BUFInstructions.td
+++ b/llvm/lib/Target/AMDGPU/BUFInstructions.td
@@ -127,6 +127,7 @@ class MTBUF_Real <MTBUF_Pseudo ps, string real_name = ps.Mnemonic> :
// copy relevant pseudo op flags
let UseNamedOperandTable = ps.UseNamedOperandTable;
let SubtargetPredicate = ps.SubtargetPredicate;
+ let OtherPredicates = ps.OtherPredicates;
let AsmMatchConverter = ps.AsmMatchConverter;
let Constraints = ps.Constraints;
let DisableEncoding = ps.DisableEncoding;
diff --git a/llvm/lib/Target/AMDGPU/DSInstructions.td b/llvm/lib/Target/AMDGPU/DSInstructions.td
index 074e13317ef89d..e6d27c2e64690d 100644
--- a/llvm/lib/Target/AMDGPU/DSInstructions.td
+++ b/llvm/lib/Target/AMDGPU/DSInstructions.td
@@ -63,6 +63,7 @@ class DS_Real <DS_Pseudo ps, string opName = ps.Mnemonic> :
// copy relevant pseudo op flags
let GWS = ps.GWS;
let SubtargetPredicate = ps.SubtargetPredicate;
+ let WaveSizePredicate = ps.WaveSizePredicate;
let OtherPredicates = ps.OtherPredicates;
let SchedRW = ps.SchedRW;
let mayLoad = ps.mayLoad;
diff --git a/llvm/lib/Target/AMDGPU/FLATInstructions.td b/llvm/lib/Target/AMDGPU/FLATInstructions.td
index a7082f550ccb2d..8a6016862426a9 100644
--- a/llvm/lib/Target/AMDGPU/FLATInstructions.td
+++ b/llvm/lib/Target/AMDGPU/FLATInstructions.td
@@ -153,6 +153,7 @@ class VFLAT_Real <bits<8> op, FLAT_Pseudo ps, string opName = ps.Mnemonic> :
// copy relevant pseudo op flags
let SubtargetPredicate = ps.SubtargetPredicate;
+ let WaveSizePredicate = ps.WaveSizePredicate;
let AsmMatchConverter = ps.AsmMatchConverter;
let OtherPredicates = ps.OtherPredicates;
let TSFlags = ps.TSFlags;
>From 5784bf85bc5143266565586ece0113cd773a8616 Mon Sep 17 00:00:00 2001
From: jimingham <jingham at apple.com>
Date: Wed, 28 Feb 2024 17:26:29 -0800
Subject: [PATCH 077/406] Fix interactive use of "command script add". (#83350)
There was a think-o in a previous commit that made us only able to
define 1 line commands when using command script add interactively.
There was also no test for this feature, so I fixed the think-o and
added a test.
---
.../Python/ScriptInterpreterPython.cpp | 2 +-
.../commands/command/script/TestCommandScript.py | 14 ++++++++++++++
.../test/API/commands/command/script/cmd_file.lldb | 4 ++++
3 files changed, 19 insertions(+), 1 deletion(-)
create mode 100644 lldb/test/API/commands/command/script/cmd_file.lldb
diff --git a/lldb/source/Plugins/ScriptInterpreter/Python/ScriptInterpreterPython.cpp b/lldb/source/Plugins/ScriptInterpreter/Python/ScriptInterpreterPython.cpp
index a1ad3f569ec71a..ce52f359524785 100644
--- a/lldb/source/Plugins/ScriptInterpreter/Python/ScriptInterpreterPython.cpp
+++ b/lldb/source/Plugins/ScriptInterpreter/Python/ScriptInterpreterPython.cpp
@@ -1417,7 +1417,7 @@ bool ScriptInterpreterPythonImpl::GenerateScriptAliasFunction(
sstr.Printf("def %s (debugger, args, exe_ctx, result, internal_dict):",
auto_generated_function_name.c_str());
- if (!GenerateFunction(sstr.GetData(), user_input, /*is_callback=*/true)
+ if (!GenerateFunction(sstr.GetData(), user_input, /*is_callback=*/false)
.Success())
return false;
diff --git a/lldb/test/API/commands/command/script/TestCommandScript.py b/lldb/test/API/commands/command/script/TestCommandScript.py
index 850552032902fd..fdd5216a1c6cc5 100644
--- a/lldb/test/API/commands/command/script/TestCommandScript.py
+++ b/lldb/test/API/commands/command/script/TestCommandScript.py
@@ -216,3 +216,17 @@ def test_persistence(self):
# The result object will be replaced by an empty result object (in the
# "Started" state).
self.expect("script str(persistence.result_copy)", substrs=["Started"])
+
+ def test_interactive(self):
+ """
+ Test that we can add multiple lines interactively.
+ """
+ interp = self.dbg.GetCommandInterpreter()
+ cmd_file = self.getSourcePath("cmd_file.lldb")
+ result = lldb.SBCommandReturnObject()
+ interp.HandleCommand(f"command source {cmd_file}", result)
+ self.assertCommandReturn(result, "Sourcing the command should cause no errors.")
+ self.assertTrue(interp.UserCommandExists("my_cmd"), "Command defined.")
+ interp.HandleCommand("my_cmd", result)
+ self.assertCommandReturn(result, "Running the command succeeds")
+ self.assertIn("My Command Result", result.GetOutput(), "Command was correct")
diff --git a/lldb/test/API/commands/command/script/cmd_file.lldb b/lldb/test/API/commands/command/script/cmd_file.lldb
new file mode 100644
index 00000000000000..1589a7cfe0b8d9
--- /dev/null
+++ b/lldb/test/API/commands/command/script/cmd_file.lldb
@@ -0,0 +1,4 @@
+command script add my_cmd
+result.PutCString("My Command Result")
+result.SetStatus(lldb.eReturnStatusSuccessFinishResult)
+DONE
>From 273cfd377b96f721c9e280bdc67c6f9e6e2e383b Mon Sep 17 00:00:00 2001
From: Shengchen Kan <shengchen.kan at intel.com>
Date: Thu, 29 Feb 2024 10:03:08 +0800
Subject: [PATCH 078/406] [X86][NFC] Avoid duplicated code in
X86ExpandPseudo.cpp by using macro GET_EGPR_IF_ENABLED
---
llvm/lib/Target/X86/X86ExpandPseudo.cpp | 17 +++++++----------
1 file changed, 7 insertions(+), 10 deletions(-)
diff --git a/llvm/lib/Target/X86/X86ExpandPseudo.cpp b/llvm/lib/Target/X86/X86ExpandPseudo.cpp
index 95c4b02842ac57..6ff65107c48ce4 100644
--- a/llvm/lib/Target/X86/X86ExpandPseudo.cpp
+++ b/llvm/lib/Target/X86/X86ExpandPseudo.cpp
@@ -264,7 +264,7 @@ bool X86ExpandPseudo::ExpandMI(MachineBasicBlock &MBB,
MachineInstr &MI = *MBBI;
unsigned Opcode = MI.getOpcode();
const DebugLoc &DL = MBBI->getDebugLoc();
- bool HasEGPR = STI->hasEGPR();
+#define GET_EGPR_IF_ENABLED(OPC) (STI->hasEGPR() ? OPC##_EVEX : OPC)
switch (Opcode) {
default:
return false;
@@ -468,12 +468,10 @@ bool X86ExpandPseudo::ExpandMI(MachineBasicBlock &MBB,
Register Reg1 = TRI->getSubReg(Reg, X86::sub_mask_1);
auto MIBLo =
- BuildMI(MBB, MBBI, DL,
- TII->get(HasEGPR ? X86::KMOVWkm_EVEX : X86::KMOVWkm))
+ BuildMI(MBB, MBBI, DL, TII->get(GET_EGPR_IF_ENABLED(X86::KMOVWkm)))
.addReg(Reg0, RegState::Define | getDeadRegState(DstIsDead));
auto MIBHi =
- BuildMI(MBB, MBBI, DL,
- TII->get(HasEGPR ? X86::KMOVWkm_EVEX : X86::KMOVWkm))
+ BuildMI(MBB, MBBI, DL, TII->get(GET_EGPR_IF_ENABLED(X86::KMOVWkm)))
.addReg(Reg1, RegState::Define | getDeadRegState(DstIsDead));
for (int i = 0; i < X86::AddrNumOperands; ++i) {
@@ -505,10 +503,10 @@ bool X86ExpandPseudo::ExpandMI(MachineBasicBlock &MBB,
Register Reg0 = TRI->getSubReg(Reg, X86::sub_mask_0);
Register Reg1 = TRI->getSubReg(Reg, X86::sub_mask_1);
- auto MIBLo = BuildMI(MBB, MBBI, DL,
- TII->get(HasEGPR ? X86::KMOVWmk_EVEX : X86::KMOVWmk));
- auto MIBHi = BuildMI(MBB, MBBI, DL,
- TII->get(HasEGPR ? X86::KMOVWmk_EVEX : X86::KMOVWmk));
+ auto MIBLo =
+ BuildMI(MBB, MBBI, DL, TII->get(GET_EGPR_IF_ENABLED(X86::KMOVWmk)));
+ auto MIBHi =
+ BuildMI(MBB, MBBI, DL, TII->get(GET_EGPR_IF_ENABLED(X86::KMOVWmk)));
for (int i = 0; i < X86::AddrNumOperands; ++i) {
MIBLo.add(MBBI->getOperand(i));
@@ -556,7 +554,6 @@ bool X86ExpandPseudo::ExpandMI(MachineBasicBlock &MBB,
case TargetOpcode::ICALL_BRANCH_FUNNEL:
ExpandICallBranchFunnel(&MBB, MBBI);
return true;
-#define GET_EGPR_IF_ENABLED(OPC) (STI->hasEGPR() ? OPC##_EVEX : OPC)
case X86::PLDTILECFGV: {
MI.setDesc(TII->get(GET_EGPR_IF_ENABLED(X86::LDTILECFG)));
return true;
>From 265e49d1f41766b66883327a3306b7cd5caeec6e Mon Sep 17 00:00:00 2001
From: Shengchen Kan <shengchen.kan at intel.com>
Date: Thu, 29 Feb 2024 10:29:32 +0800
Subject: [PATCH 079/406] [X86][NFC] Lowercase first letter of function names
in X86ExpandPseudo.cpp
---
llvm/lib/Target/X86/X86ExpandPseudo.cpp | 32 ++++++++++++-------------
1 file changed, 16 insertions(+), 16 deletions(-)
diff --git a/llvm/lib/Target/X86/X86ExpandPseudo.cpp b/llvm/lib/Target/X86/X86ExpandPseudo.cpp
index 6ff65107c48ce4..b9fb3fdb239eef 100644
--- a/llvm/lib/Target/X86/X86ExpandPseudo.cpp
+++ b/llvm/lib/Target/X86/X86ExpandPseudo.cpp
@@ -61,22 +61,22 @@ class X86ExpandPseudo : public MachineFunctionPass {
}
private:
- void ExpandICallBranchFunnel(MachineBasicBlock *MBB,
+ void expandICallBranchFunnel(MachineBasicBlock *MBB,
MachineBasicBlock::iterator MBBI);
void expandCALL_RVMARKER(MachineBasicBlock &MBB,
MachineBasicBlock::iterator MBBI);
- bool ExpandMI(MachineBasicBlock &MBB, MachineBasicBlock::iterator MBBI);
- bool ExpandMBB(MachineBasicBlock &MBB);
+ bool expandMI(MachineBasicBlock &MBB, MachineBasicBlock::iterator MBBI);
+ bool expandMBB(MachineBasicBlock &MBB);
/// This function expands pseudos which affects control flow.
/// It is done in separate pass to simplify blocks navigation in main
- /// pass(calling ExpandMBB).
- bool ExpandPseudosWhichAffectControlFlow(MachineFunction &MF);
+ /// pass(calling expandMBB).
+ bool expandPseudosWhichAffectControlFlow(MachineFunction &MF);
/// Expand X86::VASTART_SAVE_XMM_REGS into set of xmm copying instructions,
/// placed into separate block guarded by check for al register(for SystemV
/// abi).
- void ExpandVastartSaveXmmRegs(
+ void expandVastartSaveXmmRegs(
MachineBasicBlock *EntryBlk,
MachineBasicBlock::iterator VAStartPseudoInstr) const;
};
@@ -87,7 +87,7 @@ char X86ExpandPseudo::ID = 0;
INITIALIZE_PASS(X86ExpandPseudo, DEBUG_TYPE, X86_EXPAND_PSEUDO_NAME, false,
false)
-void X86ExpandPseudo::ExpandICallBranchFunnel(
+void X86ExpandPseudo::expandICallBranchFunnel(
MachineBasicBlock *MBB, MachineBasicBlock::iterator MBBI) {
MachineBasicBlock *JTMBB = MBB;
MachineInstr *JTInst = &*MBBI;
@@ -259,7 +259,7 @@ void X86ExpandPseudo::expandCALL_RVMARKER(MachineBasicBlock &MBB,
/// If \p MBBI is a pseudo instruction, this method expands
/// it to the corresponding (sequence of) actual instruction(s).
/// \returns true if \p MBBI has been expanded.
-bool X86ExpandPseudo::ExpandMI(MachineBasicBlock &MBB,
+bool X86ExpandPseudo::expandMI(MachineBasicBlock &MBB,
MachineBasicBlock::iterator MBBI) {
MachineInstr &MI = *MBBI;
unsigned Opcode = MI.getOpcode();
@@ -552,7 +552,7 @@ bool X86ExpandPseudo::ExpandMI(MachineBasicBlock &MBB,
return true;
}
case TargetOpcode::ICALL_BRANCH_FUNNEL:
- ExpandICallBranchFunnel(&MBB, MBBI);
+ expandICallBranchFunnel(&MBB, MBBI);
return true;
case X86::PLDTILECFGV: {
MI.setDesc(TII->get(GET_EGPR_IF_ENABLED(X86::LDTILECFG)));
@@ -631,7 +631,7 @@ bool X86ExpandPseudo::ExpandMI(MachineBasicBlock &MBB,
// | |
// | |
//
-void X86ExpandPseudo::ExpandVastartSaveXmmRegs(
+void X86ExpandPseudo::expandVastartSaveXmmRegs(
MachineBasicBlock *EntryBlk,
MachineBasicBlock::iterator VAStartPseudoInstr) const {
assert(VAStartPseudoInstr->getOpcode() == X86::VASTART_SAVE_XMM_REGS);
@@ -716,27 +716,27 @@ void X86ExpandPseudo::ExpandVastartSaveXmmRegs(
/// Expand all pseudo instructions contained in \p MBB.
/// \returns true if any expansion occurred for \p MBB.
-bool X86ExpandPseudo::ExpandMBB(MachineBasicBlock &MBB) {
+bool X86ExpandPseudo::expandMBB(MachineBasicBlock &MBB) {
bool Modified = false;
// MBBI may be invalidated by the expansion.
MachineBasicBlock::iterator MBBI = MBB.begin(), E = MBB.end();
while (MBBI != E) {
MachineBasicBlock::iterator NMBBI = std::next(MBBI);
- Modified |= ExpandMI(MBB, MBBI);
+ Modified |= expandMI(MBB, MBBI);
MBBI = NMBBI;
}
return Modified;
}
-bool X86ExpandPseudo::ExpandPseudosWhichAffectControlFlow(MachineFunction &MF) {
+bool X86ExpandPseudo::expandPseudosWhichAffectControlFlow(MachineFunction &MF) {
// Currently pseudo which affects control flow is only
// X86::VASTART_SAVE_XMM_REGS which is located in Entry block.
// So we do not need to evaluate other blocks.
for (MachineInstr &Instr : MF.front().instrs()) {
if (Instr.getOpcode() == X86::VASTART_SAVE_XMM_REGS) {
- ExpandVastartSaveXmmRegs(&(MF.front()), Instr);
+ expandVastartSaveXmmRegs(&(MF.front()), Instr);
return true;
}
}
@@ -751,10 +751,10 @@ bool X86ExpandPseudo::runOnMachineFunction(MachineFunction &MF) {
X86FI = MF.getInfo<X86MachineFunctionInfo>();
X86FL = STI->getFrameLowering();
- bool Modified = ExpandPseudosWhichAffectControlFlow(MF);
+ bool Modified = expandPseudosWhichAffectControlFlow(MF);
for (MachineBasicBlock &MBB : MF)
- Modified |= ExpandMBB(MBB);
+ Modified |= expandMBB(MBB);
return Modified;
}
>From daf3079222b09683a24dd5b11815f6467ae41b8d Mon Sep 17 00:00:00 2001
From: lifengxiang1025 <lifengxiang.1025 at bytedance.com>
Date: Thu, 29 Feb 2024 10:42:06 +0800
Subject: [PATCH 080/406] [ThinLTO] Add metedata 'thinlto_src_module' and
'thinlto_src_file' (#83110)
Originally, when `EnableImportMetadata` enabled, `SourceFileName` will
be recorded as `thinlto_src_module`. Now `SourceFileName` will be
recorded as `thinlto_src_file` and `ModuleIdentifier` will be recorded
as `thinlto_src_module`.
---
llvm/lib/Transforms/IPO/FunctionImport.cpp | 19 ++++++++++++---
llvm/test/ThinLTO/X86/visibility-elf.ll | 6 ++---
llvm/test/ThinLTO/X86/visibility-macho.ll | 4 ++--
.../Transforms/FunctionImport/funcimport.ll | 23 ++++++++++---------
llvm/test/Transforms/Inline/inline_stats.ll | 4 ++--
5 files changed, 35 insertions(+), 21 deletions(-)
diff --git a/llvm/lib/Transforms/IPO/FunctionImport.cpp b/llvm/lib/Transforms/IPO/FunctionImport.cpp
index 49b3f2b085e18f..5c7a74dadb46a8 100644
--- a/llvm/lib/Transforms/IPO/FunctionImport.cpp
+++ b/llvm/lib/Transforms/IPO/FunctionImport.cpp
@@ -125,7 +125,8 @@ static cl::opt<bool> ComputeDead("compute-dead", cl::init(true), cl::Hidden,
static cl::opt<bool> EnableImportMetadata(
"enable-import-metadata", cl::init(false), cl::Hidden,
- cl::desc("Enable import metadata like 'thinlto_src_module'"));
+ cl::desc("Enable import metadata like 'thinlto_src_module' and "
+ "'thinlto_src_file'"));
/// Summary file to use for function importing when using -function-import from
/// the command line.
@@ -1643,9 +1644,15 @@ Expected<bool> FunctionImporter::importFunctions(
if (Error Err = F.materialize())
return std::move(Err);
if (EnableImportMetadata) {
- // Add 'thinlto_src_module' metadata for statistics and debugging.
+ // Add 'thinlto_src_module' and 'thinlto_src_file' metadata for
+ // statistics and debugging.
F.setMetadata(
"thinlto_src_module",
+ MDNode::get(DestModule.getContext(),
+ {MDString::get(DestModule.getContext(),
+ SrcModule->getModuleIdentifier())}));
+ F.setMetadata(
+ "thinlto_src_file",
MDNode::get(DestModule.getContext(),
{MDString::get(DestModule.getContext(),
SrcModule->getSourceFileName())}));
@@ -1687,9 +1694,15 @@ Expected<bool> FunctionImporter::importFunctions(
<< GO->getName() << " from "
<< SrcModule->getSourceFileName() << "\n");
if (EnableImportMetadata) {
- // Add 'thinlto_src_module' metadata for statistics and debugging.
+ // Add 'thinlto_src_module' and 'thinlto_src_file' metadata for
+ // statistics and debugging.
Fn->setMetadata(
"thinlto_src_module",
+ MDNode::get(DestModule.getContext(),
+ {MDString::get(DestModule.getContext(),
+ SrcModule->getModuleIdentifier())}));
+ Fn->setMetadata(
+ "thinlto_src_file",
MDNode::get(DestModule.getContext(),
{MDString::get(DestModule.getContext(),
SrcModule->getSourceFileName())}));
diff --git a/llvm/test/ThinLTO/X86/visibility-elf.ll b/llvm/test/ThinLTO/X86/visibility-elf.ll
index aa11c3e06ff3bd..fc7439bf001b14 100644
--- a/llvm/test/ThinLTO/X86/visibility-elf.ll
+++ b/llvm/test/ThinLTO/X86/visibility-elf.ll
@@ -36,12 +36,12 @@ declare void @ext(ptr)
;; Currently the visibility is not propagated onto an unimported function,
;; because we don't have summaries for declarations.
; CHECK: declare extern_weak void @not_imported()
-; CHECK: define available_externally hidden void @hidden_def_ref() !thinlto_src_module !0
-; CHECK: define available_externally hidden void @hidden_def_weak_ref() !thinlto_src_module !0
+; CHECK: define available_externally hidden void @hidden_def_ref() !thinlto_src_module !0 !thinlto_src_file !1
+; CHECK: define available_externally hidden void @hidden_def_weak_ref() !thinlto_src_module !0 !thinlto_src_file !1
;; This can be hidden, but we cannot communicate the declaration's visibility
;; to other modules because declarations don't have summaries, and the IRLinker
;; overrides it when importing the protected def.
-; CHECK: define available_externally protected void @protected_def_hidden_ref() !thinlto_src_module !0
+; CHECK: define available_externally protected void @protected_def_hidden_ref() !thinlto_src_module !0 !thinlto_src_file !1
; CHECK2: define hidden i32 @hidden_def_weak_def()
; CHECK2: define protected void @protected_def_weak_def()
diff --git a/llvm/test/ThinLTO/X86/visibility-macho.ll b/llvm/test/ThinLTO/X86/visibility-macho.ll
index d41ab4f1ef3989..1a48b477c96dc0 100644
--- a/llvm/test/ThinLTO/X86/visibility-macho.ll
+++ b/llvm/test/ThinLTO/X86/visibility-macho.ll
@@ -30,8 +30,8 @@ declare void @ext(ptr)
;; Currently the visibility is not propagated onto an unimported function,
;; because we don't have summaries for declarations.
; CHECK: declare extern_weak dso_local void @not_imported()
-; CHECK: define available_externally hidden void @hidden_def_ref() !thinlto_src_module !0
-; CHECK: define available_externally hidden void @hidden_def_weak_ref() !thinlto_src_module !0
+; CHECK: define available_externally hidden void @hidden_def_ref() !thinlto_src_module !0 !thinlto_src_file !1
+; CHECK: define available_externally hidden void @hidden_def_weak_ref() !thinlto_src_module !0 !thinlto_src_file !1
; CHECK2: define hidden i32 @hidden_def_weak_def()
; CHECK2: define hidden void @hidden_def_ref()
diff --git a/llvm/test/Transforms/FunctionImport/funcimport.ll b/llvm/test/Transforms/FunctionImport/funcimport.ll
index 01298258c62e99..a0968a67f5ce84 100644
--- a/llvm/test/Transforms/FunctionImport/funcimport.ll
+++ b/llvm/test/Transforms/FunctionImport/funcimport.ll
@@ -57,7 +57,7 @@ declare void @linkoncealias(...) #1
; CHECK-DAG: define available_externally void @linkoncealias()
; INSTLIMDEF-DAG: Import referencestatics
-; INSTLIMDEF-DAG: define available_externally i32 @referencestatics(i32 %i) !thinlto_src_module !0 {
+; INSTLIMDEF-DAG: define available_externally i32 @referencestatics(i32 %i) !thinlto_src_module !0 !thinlto_src_file !1 {
; INSTLIM5-DAG: declare i32 @referencestatics(...)
declare i32 @referencestatics(...) #1
@@ -66,27 +66,27 @@ declare i32 @referencestatics(...) #1
; Ensure that the call is to the properly-renamed function.
; INSTLIMDEF-DAG: Import staticfunc
; INSTLIMDEF-DAG: %call = call i32 @staticfunc.llvm.
-; INSTLIMDEF-DAG: define available_externally hidden i32 @staticfunc.llvm.{{.*}} !thinlto_src_module !0 {
+; INSTLIMDEF-DAG: define available_externally hidden i32 @staticfunc.llvm.{{.*}} !thinlto_src_module !0 !thinlto_src_file !1 {
; INSTLIMDEF-DAG: Import referenceglobals
-; CHECK-DAG: define available_externally i32 @referenceglobals(i32 %i) !thinlto_src_module !0 {
+; CHECK-DAG: define available_externally i32 @referenceglobals(i32 %i) !thinlto_src_module !0 !thinlto_src_file !1 {
declare i32 @referenceglobals(...) #1
; The import of referenceglobals will expose call to globalfunc1 that
; should in turn be imported.
; INSTLIMDEF-DAG: Import globalfunc1
-; CHECK-DAG: define available_externally void @globalfunc1() !thinlto_src_module !0
+; CHECK-DAG: define available_externally void @globalfunc1() !thinlto_src_module !0 !thinlto_src_file !1
; INSTLIMDEF-DAG: Import referencecommon
-; CHECK-DAG: define available_externally i32 @referencecommon(i32 %i) !thinlto_src_module !0 {
+; CHECK-DAG: define available_externally i32 @referencecommon(i32 %i) !thinlto_src_module !0 !thinlto_src_file !1 {
declare i32 @referencecommon(...) #1
; INSTLIMDEF-DAG: Import setfuncptr
-; CHECK-DAG: define available_externally void @setfuncptr() !thinlto_src_module !0 {
+; CHECK-DAG: define available_externally void @setfuncptr() !thinlto_src_module !0 !thinlto_src_file !1 {
declare void @setfuncptr(...) #1
; INSTLIMDEF-DAG: Import callfuncptr
-; CHECK-DAG: define available_externally void @callfuncptr() !thinlto_src_module !0 {
+; CHECK-DAG: define available_externally void @callfuncptr() !thinlto_src_module !0 !thinlto_src_file !1 {
declare void @callfuncptr(...) #1
; Ensure that all uses of local variable @P which has used in setfuncptr
@@ -97,7 +97,7 @@ declare void @callfuncptr(...) #1
; Ensure that @referencelargelinkonce definition is pulled in, but later we
; also check that the linkonceodr function is not.
-; CHECK-DAG: define available_externally void @referencelargelinkonce() !thinlto_src_module !0 {
+; CHECK-DAG: define available_externally void @referencelargelinkonce() !thinlto_src_module !0 !thinlto_src_file !1 {
; INSTLIM5-DAG: declare void @linkonceodr()
declare void @referencelargelinkonce(...)
@@ -110,13 +110,13 @@ declare void @weakfunc(...) #1
declare void @linkoncefunc2(...) #1
; INSTLIMDEF-DAG: Import funcwithpersonality
-; INSTLIMDEF-DAG: define available_externally hidden void @funcwithpersonality.llvm.{{.*}}() personality ptr @__gxx_personality_v0 !thinlto_src_module !0 {
+; INSTLIMDEF-DAG: define available_externally hidden void @funcwithpersonality.llvm.{{.*}}() personality ptr @__gxx_personality_v0 !thinlto_src_module !0 !thinlto_src_file !1 {
; INSTLIM5-DAG: declare hidden void @funcwithpersonality.llvm.{{.*}}()
; We can import variadic functions without a va_start, since the inliner
; can handle them.
; INSTLIMDEF-DAG: Import variadic_no_va_start
-; CHECK-DAG: define available_externally void @variadic_no_va_start(...) !thinlto_src_module !0 {
+; CHECK-DAG: define available_externally void @variadic_no_va_start(...) !thinlto_src_module !0 !thinlto_src_file !1 {
declare void @variadic_no_va_start(...)
; We can import variadic functions with a va_start, since the inliner
@@ -128,7 +128,8 @@ declare void @variadic_va_start(...)
; INSTLIMDEF-DAG: 15 function-import - Number of functions imported
; INSTLIMDEF-DAG: 4 function-import - Number of global variables imported
-; CHECK-DAG: !0 = !{!"{{.*}}/Inputs/funcimport.ll"}
+; CHECK-DAG: !0 = !{!"{{.*}}.bc"}
+; CHECK-DAG: !1 = !{!"{{.*}}/Inputs/funcimport.ll"}
; The actual GUID values will depend on path to test.
; GUID-DAG: GUID {{.*}} is weakalias
diff --git a/llvm/test/Transforms/Inline/inline_stats.ll b/llvm/test/Transforms/Inline/inline_stats.ll
index c779054c3b1ec3..41c12b3015f727 100644
--- a/llvm/test/Transforms/Inline/inline_stats.ll
+++ b/llvm/test/Transforms/Inline/inline_stats.ll
@@ -44,7 +44,7 @@ define void @internal3() {
declare void @external_decl()
-define void @external1() alwaysinline !thinlto_src_module !0 {
+define void @external1() alwaysinline !thinlto_src_module !0 !thinlto_src_file !1 {
call fastcc void @internal2()
call fastcc void @external2();
call void @external_decl();
@@ -87,7 +87,7 @@ define void @external_big() noinline !thinlto_src_module !1 {
}
; It should not be imported, but it should not break anything.
-define void @external_notcalled() !thinlto_src_module !0 {
+define void @external_notcalled() !thinlto_src_module !0 !thinlto_src_file !1 {
call void @external_notcalled()
ret void
}
>From 7d8b50aaab8e0f935e3cb1f3f397e98b9e3ee241 Mon Sep 17 00:00:00 2001
From: Paul Kirth <paulkirth at google.com>
Date: Wed, 28 Feb 2024 19:11:55 -0800
Subject: [PATCH 081/406] [clang][fat-lto-objects] Make module flags match
non-FatLTO pipelines (#83159)
In addition to being rather hard to follow, there isn't a good reason
why FatLTO shouldn't just share the same code for setting module flags
for (Thin)LTO. This patch simplifies the logic and makes sure we use set
these flags in a consistent way, independent of FatLTO.
Additionally, we now test that output in the .llvm.lto section actually
matches the output from Full and Thin LTO compilation.
---
clang/lib/CodeGen/BackendUtil.cpp | 32 ++++++++++++++--------------
clang/test/CodeGen/fat-lto-objects.c | 21 +++++++++++++++++-
2 files changed, 36 insertions(+), 17 deletions(-)
diff --git a/clang/lib/CodeGen/BackendUtil.cpp b/clang/lib/CodeGen/BackendUtil.cpp
index a310825240237c..056f790d41853d 100644
--- a/clang/lib/CodeGen/BackendUtil.cpp
+++ b/clang/lib/CodeGen/BackendUtil.cpp
@@ -186,6 +186,14 @@ class EmitAssemblyHelper {
TargetTriple.getVendor() != llvm::Triple::Apple;
}
+ /// Check whether we should emit a flag for UnifiedLTO.
+ /// The UnifiedLTO module flag should be set when UnifiedLTO is enabled for
+ /// ThinLTO or Full LTO with module summaries.
+ bool shouldEmitUnifiedLTOModueFlag() const {
+ return CodeGenOpts.UnifiedLTO &&
+ (CodeGenOpts.PrepareForThinLTO || shouldEmitRegularLTOSummary());
+ }
+
public:
EmitAssemblyHelper(DiagnosticsEngine &_Diags,
const HeaderSearchOptions &HeaderSearchOpts,
@@ -1036,7 +1044,8 @@ void EmitAssemblyHelper::RunOptimizationPipeline(
if (!actionRequiresCodeGen(Action) && CodeGenOpts.VerifyModule)
MPM.addPass(VerifierPass());
- if (Action == Backend_EmitBC || Action == Backend_EmitLL) {
+ if (Action == Backend_EmitBC || Action == Backend_EmitLL ||
+ CodeGenOpts.FatLTO) {
if (CodeGenOpts.PrepareForThinLTO && !CodeGenOpts.DisableLLVMPasses) {
if (!TheModule->getModuleFlag("EnableSplitLTOUnit"))
TheModule->addModuleFlag(llvm::Module::Error, "EnableSplitLTOUnit",
@@ -1047,11 +1056,9 @@ void EmitAssemblyHelper::RunOptimizationPipeline(
if (!ThinLinkOS)
return;
}
- if (CodeGenOpts.UnifiedLTO)
- TheModule->addModuleFlag(llvm::Module::Error, "UnifiedLTO", uint32_t(1));
MPM.addPass(ThinLTOBitcodeWriterPass(
*OS, ThinLinkOS ? &ThinLinkOS->os() : nullptr));
- } else {
+ } else if (Action == Backend_EmitLL) {
MPM.addPass(PrintModulePass(*OS, "", CodeGenOpts.EmitLLVMUseLists,
/*EmitLTOSummary=*/true));
}
@@ -1065,24 +1072,17 @@ void EmitAssemblyHelper::RunOptimizationPipeline(
if (!TheModule->getModuleFlag("EnableSplitLTOUnit"))
TheModule->addModuleFlag(llvm::Module::Error, "EnableSplitLTOUnit",
uint32_t(1));
- if (CodeGenOpts.UnifiedLTO)
- TheModule->addModuleFlag(llvm::Module::Error, "UnifiedLTO", uint32_t(1));
}
- if (Action == Backend_EmitBC)
+ if (Action == Backend_EmitBC) {
MPM.addPass(BitcodeWriterPass(*OS, CodeGenOpts.EmitLLVMUseLists,
EmitLTOSummary));
- else
+ } else if (Action == Backend_EmitLL) {
MPM.addPass(PrintModulePass(*OS, "", CodeGenOpts.EmitLLVMUseLists,
EmitLTOSummary));
+ }
}
- }
- if (CodeGenOpts.FatLTO) {
- // Set the EnableSplitLTOUnit and UnifiedLTO module flags, since FatLTO
- // uses a different action than Backend_EmitBC or Backend_EmitLL.
- if (!TheModule->getModuleFlag("EnableSplitLTOUnit"))
- TheModule->addModuleFlag(llvm::Module::Error, "EnableSplitLTOUnit",
- uint32_t(CodeGenOpts.EnableSplitLTOUnit));
- if (CodeGenOpts.UnifiedLTO && !TheModule->getModuleFlag("UnifiedLTO"))
+
+ if (shouldEmitUnifiedLTOModueFlag())
TheModule->addModuleFlag(llvm::Module::Error, "UnifiedLTO", uint32_t(1));
}
diff --git a/clang/test/CodeGen/fat-lto-objects.c b/clang/test/CodeGen/fat-lto-objects.c
index afce798c5c8194..b50567c024fc8c 100644
--- a/clang/test/CodeGen/fat-lto-objects.c
+++ b/clang/test/CodeGen/fat-lto-objects.c
@@ -11,10 +11,11 @@
// RUN: llvm-objcopy --dump-section=.llvm.lto=%t.full.split.bc %t.full.split.o
// RUN: llvm-dis %t.full.split.bc -o - | FileCheck %s --check-prefixes=FULL,SPLIT,NOUNIFIED
+/// Full LTO always sets EnableSplitLTOUnit when the summary is used.
// RUN: %clang -cc1 -triple x86_64-unknown-linux-gnu -flto=full -ffat-lto-objects -emit-obj < %s -o %t.full.nosplit.o
// RUN: llvm-readelf -S %t.full.nosplit.o | FileCheck %s --check-prefixes=ELF
// RUN: llvm-objcopy --dump-section=.llvm.lto=%t.full.nosplit.bc %t.full.nosplit.o
-// RUN: llvm-dis %t.full.nosplit.bc -o - | FileCheck %s --check-prefixes=FULL,NOSPLIT,NOUNIFIED
+// RUN: llvm-dis %t.full.nosplit.bc -o - | FileCheck %s --check-prefixes=FULL,SPLIT,NOUNIFIED
// RUN: %clang -cc1 -triple x86_64-unknown-linux-gnu -flto=thin -fsplit-lto-unit -ffat-lto-objects -emit-obj < %s -o %t.thin.split.o
// RUN: llvm-readelf -S %t.thin.split.o | FileCheck %s --check-prefixes=ELF
@@ -34,6 +35,21 @@
// RUN: %clang -cc1 -triple x86_64-unknown-linux-gnu -flto=full -ffat-lto-objects -fsplit-lto-unit -S < %s -o - \
// RUN: | FileCheck %s --check-prefixes=ASM
+/// Make sure that FatLTO generates .llvm.lto sections that are the same as the output from normal LTO compilations
+// RUN: %clang -O2 --target=x86_64-unknown-linux-gnu -fPIE -flto=full -ffat-lto-objects -c %s -o %t.fatlto.full.o
+// RUN: llvm-objcopy --dump-section=.llvm.lto=%t.fatlto.full.bc %t.fatlto.full.o
+// RUN: llvm-dis < %t.fatlto.full.bc -o %t.fatlto.full.ll
+// RUN: %clang -O2 --target=x86_64-unknown-linux-gnu -fPIE -flto=full -c %s -o %t.nofat.full.bc
+// RUN: llvm-dis < %t.nofat.full.bc -o %t.nofat.full.ll
+// RUN: diff %t.fatlto.full.ll %t.nofat.full.ll
+
+// RUN: %clang -O2 --target=x86_64-unknown-linux-gnu -fPIE -flto=thin -ffat-lto-objects -c %s -o %t.fatlto.thin.o
+// RUN: llvm-objcopy --dump-section=.llvm.lto=%t.fatlto.thin.bc %t.fatlto.thin.o
+// RUN: llvm-dis < %t.fatlto.thin.bc -o %t.fatlto.thin.ll
+// RUN: %clang -O2 --target=x86_64-unknown-linux-gnu -fPIE -flto=thin -c %s -o %t.nofat.thin.bc
+// RUN: llvm-dis < %t.nofat.thin.bc -o %t.nofat.thin.ll
+// RUN: diff %t.fatlto.thin.ll %t.nofat.thin.ll
+
/// Be sure we enable split LTO units correctly under -ffat-lto-objects.
// SPLIT: ![[#]] = !{i32 1, !"EnableSplitLTOUnit", i32 1}
// NOSPLIT: ![[#]] = !{i32 1, !"EnableSplitLTOUnit", i32 0}
@@ -51,6 +67,9 @@
// ASM-NEXT: .asciz "BC
// ASM-NEXT: .size .Lllvm.embedded.object
+const char* foo = "foo";
+
int test(void) {
+ const char* bar = "bar";
return 0xabcd;
}
>From f0484e08bdcf64106592808e3ca80404937b4657 Mon Sep 17 00:00:00 2001
From: Matt Arsenault <Matthew.Arsenault at amd.com>
Date: Thu, 29 Feb 2024 09:13:34 +0530
Subject: [PATCH 082/406] AMDGPU: Add scheduling test for gfx940 (#83220)
I'm not sure the f64 fma cases are correct.
---
llvm/test/tools/llvm-mca/AMDGPU/gfx940.s | 189 +++++++++++++++++++++++
1 file changed, 189 insertions(+)
create mode 100644 llvm/test/tools/llvm-mca/AMDGPU/gfx940.s
diff --git a/llvm/test/tools/llvm-mca/AMDGPU/gfx940.s b/llvm/test/tools/llvm-mca/AMDGPU/gfx940.s
new file mode 100644
index 00000000000000..c66d0b44b5e9a6
--- /dev/null
+++ b/llvm/test/tools/llvm-mca/AMDGPU/gfx940.s
@@ -0,0 +1,189 @@
+# RUN: llvm-mca -mtriple=amdgcn -mcpu=gfx940 --timeline --iterations=1 --timeline-max-cycles=0 < %s | FileCheck %s
+
+# CHECK: Iterations: 1
+# CHECK: Instructions: 71
+# CHECK: Total Cycles: 562
+# CHECK: Total uOps: 77
+
+# CHECK: Resources:
+# CHECK: [0] - HWBranch
+# CHECK: [1] - HWExport
+# CHECK: [2] - HWLGKM
+# CHECK: [3] - HWSALU
+# CHECK: [4] - HWVALU
+# CHECK: [5] - HWVMEM
+# CHECK: [6] - HWXDL
+
+v_pk_fma_f32 v[0:1], v[0:1], v[0:1], v[0:1]
+v_pk_mov_b32 v[0:1], v[2:3], v[4:5]
+v_pk_add_f32 v[0:1], v[0:1], v[0:1]
+v_pk_mul_f32 v[0:1], v[0:1], v[0:1]
+v_add_co_u32 v5, s[0:1], v1, v2
+v_sub_co_u32 v5, s[0:1], v1, v2
+v_subrev_co_u32 v5, s[0:1], v1, v2
+v_addc_co_u32 v5, s[0:1], v1, v2, s[2:3]
+v_subb_co_u32 v5, s[0:1], v1, v2, s[2:3]
+v_subbrev_co_u32 v5, s[0:1], v1, v2, s[2:3]
+v_add_u32 v5, v1, v2
+v_sub_u32 v5, v1, v2
+v_subrev_u32 v5, v1, v2
+
+v_mfma_f32_16x16x4_f32 a[0:3], v0, v1, a[2:5]
+v_mfma_f32_16x16x4_f32 v[0:3], v0, v1, v[2:5]
+
+v_mfma_f32_32x32x2_f32 a[0:15], v0, v1, a[18:33]
+v_mfma_f32_32x32x2_f32 v[0:15], v0, v1, v[18:33]
+
+v_mfma_f64_4x4x4_4b_f64 a[0:1], v[0:1], a[2:3], a[2:3]
+v_mfma_f64_4x4x4_4b_f64 v[0:1], v[0:1], v[2:3], v[2:3]
+
+v_mfma_f64_16x16x4_f64 a[0:7], v[0:1], v[2:3], a[0:7]
+v_mfma_f64_16x16x4_f64 v[0:7], v[0:1], v[2:3], v[0:7]
+
+v_mfma_f32_16x16x16_f16 v[0:3], v[4:5], v[6:7], v[0:3]
+v_mfma_f32_16x16x16_f16 a[0:3], v[4:5], v[6:7], a[0:3]
+
+v_mfma_f32_32x32x8_f16 v[0:15], v[4:5], v[6:7], v[0:15]
+v_mfma_f32_32x32x8_f16 a[0:15], v[4:5], v[6:7], a[0:15]
+
+v_mfma_f32_16x16x16_bf16 v[0:3], v[4:5], v[6:7], v[0:3]
+v_mfma_f32_16x16x16_bf16 a[0:3], v[4:5], v[6:7], a[0:3]
+
+v_mfma_f32_32x32x8_bf16 v[0:15], v[4:5], v[6:7], v[0:15]
+v_mfma_f32_32x32x8_bf16 a[0:15], v[4:5], v[6:7], a[0:15]
+
+v_mfma_i32_16x16x32_i8 v[0:3], v[4:5], v[6:7], v[0:3]
+v_mfma_i32_16x16x32_i8 a[0:3], v[4:5], v[6:7], a[0:3]
+
+v_mfma_i32_32x32x16_i8 v[0:15], v[2:3], v[4:5], v[0:15]
+v_mfma_i32_32x32x16_i8 a[0:15], v[2:3], v[4:5], a[0:15]
+
+v_mfma_f32_4x4x4_16b_f16 v[0:3], v[0:1], v[2:3], v[2:5]
+v_mfma_f32_4x4x4_16b_f16 a[0:3], v[0:1], v[2:3], a[2:5]
+
+v_mfma_f32_16x16x4_4b_f16 v[0:15], v[2:3], v[4:5], v[18:33]
+v_mfma_f32_16x16x4_4b_f16 a[0:15], v[2:3], v[4:5], a[18:33]
+
+v_mfma_f32_32x32x4_2b_f16 v[0:31], v[0:1], v[2:3], v[34:65]
+v_mfma_f32_32x32x4_2b_f16 a[0:31], v[0:1], v[2:3], a[34:65]
+
+v_mfma_f32_4x4x4_16b_bf16 v[0:3], v[0:1], v[2:3], v[2:5]
+v_mfma_f32_4x4x4_16b_bf16 a[0:3], v[0:1], v[2:3], a[2:5]
+
+v_mfma_f32_16x16x4_4b_bf16 v[0:15], v[2:3], v[4:5], v[18:33]
+v_mfma_f32_16x16x4_4b_bf16 a[0:15], v[2:3], v[4:5], a[18:33]
+
+v_mfma_f32_32x32x4_2b_bf16 v[0:31], v[0:1], v[2:3], v[34:65]
+v_mfma_f32_32x32x4_2b_bf16 a[0:31], v[0:1], v[2:3], a[34:65]
+
+v_mfma_f32_4x4x1_16b_f32 v[0:3], v0, v1, v[2:5]
+v_mfma_f32_4x4x1_16b_f32 a[0:3], v0, v1, a[2:5]
+
+v_mfma_f32_16x16x1_4b_f32 v[0:15], v0, v1, v[18:33]
+v_mfma_f32_16x16x1_4b_f32 a[0:15], v0, v1, a[18:33]
+
+v_mfma_f32_16x16x4_f32 v[0:3], v0, v1, v[2:5]
+v_mfma_f32_16x16x4_f32 a[0:3], v0, v1, a[2:5]
+
+v_mfma_f32_32x32x1_2b_f32 v[0:31], v0, v1, v[34:65] blgp:7
+v_mfma_f32_32x32x1_2b_f32 a[0:31], v0, v1, a[34:65] blgp:7
+
+v_mfma_f32_32x32x2_f32 v[0:15], v0, v1, v[18:33]
+v_mfma_f32_32x32x2_f32 a[0:15], v0, v1, a[18:33]
+
+v_mfma_i32_4x4x4_16b_i8 v[0:3], v0, v1, v[2:5]
+v_mfma_i32_4x4x4_16b_i8 a[0:3], v0, v1, a[2:5]
+
+v_mfma_i32_16x16x4_4b_i8 v[0:15], v0, v1, v[18:33]
+v_mfma_i32_16x16x4_4b_i8 a[0:15], v0, v1, a[18:33]
+
+v_mfma_i32_32x32x4_2b_i8 v[0:31], v0, v1, v[34:65]
+v_mfma_i32_32x32x4_2b_i8 a[0:31], v0, v1, a[34:65]
+
+v_smfmac_f32_16x16x32_f16 v[10:13], a[2:3], v[4:7], v0 cbsz:3 abid:1
+v_smfmac_f32_16x16x32_f16 a[10:13], v[2:3], a[4:7], v1
+
+v_smfmac_f32_32x32x16_f16 v[10:25], a[2:3], v[4:7], v2 cbsz:3 abid:1
+v_smfmac_f32_32x32x16_f16 a[10:25], v[2:3], a[4:7], v3
+
+v_smfmac_f32_16x16x32_bf16 v[10:13], a[2:3], v[4:7], v4 cbsz:3 abid:1
+v_smfmac_f32_16x16x32_bf16 a[10:13], v[2:3], a[4:7], v5
+
+v_smfmac_i32_16x16x64_i8 v[10:13], a[2:3], v[4:7], v8 cbsz:3 abid:1
+v_smfmac_i32_16x16x64_i8 a[10:13], v[2:3], a[4:7], v9
+
+v_smfmac_i32_32x32x32_i8 v[10:25], a[2:3], v[4:7], v10 cbsz:3 abid:1
+v_smfmac_i32_32x32x32_i8 a[10:25], v[2:3], a[4:7], v11
+
+# CHECK: [0] [1] [2] [3] [4] [5] [6] Instructions:
+# CHECK-NEXT: - - - - 1.00 - - v_pk_fma_f32 v[0:1], v[0:1], v[0:1], v[0:1]
+# CHECK-NEXT: - - - - 1.00 - - v_pk_mov_b32 v[0:1], v[2:3], v[4:5]
+# CHECK-NEXT: - - - - 1.00 - - v_pk_add_f32 v[0:1], v[0:1], v[0:1]
+# CHECK-NEXT: - - - - 1.00 - - v_pk_mul_f32 v[0:1], v[0:1], v[0:1]
+# CHECK-NEXT: - - - 1.00 1.00 - - v_add_co_u32_e64 v5, s[0:1], v1, v2
+# CHECK-NEXT: - - - 1.00 1.00 - - v_sub_co_u32_e64 v5, s[0:1], v1, v2
+# CHECK-NEXT: - - - 1.00 1.00 - - v_subrev_co_u32_e64 v5, s[0:1], v1, v2
+# CHECK-NEXT: - - - 1.00 1.00 - - v_addc_co_u32_e64 v5, s[0:1], v1, v2, s[2:3]
+# CHECK-NEXT: - - - 1.00 1.00 - - v_subb_co_u32_e64 v5, s[0:1], v1, v2, s[2:3]
+# CHECK-NEXT: - - - 1.00 1.00 - - v_subbrev_co_u32_e64 v5, s[0:1], v1, v2, s[2:3]
+# CHECK-NEXT: - - - - 1.00 - - v_add_u32_e32 v5, v1, v2
+# CHECK-NEXT: - - - - 1.00 - - v_sub_u32_e32 v5, v1, v2
+# CHECK-NEXT: - - - - 1.00 - - v_subrev_u32_e32 v5, v1, v2
+# CHECK-NEXT: - - - - - - 8.00 v_mfma_f32_16x16x4_f32 a[0:3], v0, v1, a[2:5]
+# CHECK-NEXT: - - - - - - 8.00 v_mfma_f32_16x16x4_f32 v[0:3], v0, v1, v[2:5]
+# CHECK-NEXT: - - - - - - 16.00 v_mfma_f32_32x32x2_f32 a[0:15], v0, v1, a[18:33]
+# CHECK-NEXT: - - - - - - 16.00 v_mfma_f32_32x32x2_f32 v[0:15], v0, v1, v[18:33]
+# CHECK-NEXT: - - - - 1.00 - - v_mfma_f64_4x4x4_4b_f64 a[0:1], v[0:1], a[2:3], a[2:3]
+# CHECK-NEXT: - - - - 1.00 - - v_mfma_f64_4x4x4_4b_f64 v[0:1], v[0:1], v[2:3], v[2:3]
+# CHECK-NEXT: - - - - 1.00 - - v_mfma_f64_16x16x4_f64 a[0:7], v[0:1], v[2:3], a[0:7]
+# CHECK-NEXT: - - - - 1.00 - - v_mfma_f64_16x16x4_f64 v[0:7], v[0:1], v[2:3], v[0:7]
+# CHECK-NEXT: - - - - - - 4.00 v_mfma_f32_16x16x16_f16 v[0:3], v[4:5], v[6:7], v[0:3]
+# CHECK-NEXT: - - - - - - 4.00 v_mfma_f32_16x16x16_f16 a[0:3], v[4:5], v[6:7], a[0:3]
+# CHECK-NEXT: - - - - - - 8.00 v_mfma_f32_32x32x8_f16 v[0:15], v[4:5], v[6:7], v[0:15]
+# CHECK-NEXT: - - - - - - 8.00 v_mfma_f32_32x32x8_f16 a[0:15], v[4:5], v[6:7], a[0:15]
+# CHECK-NEXT: - - - - - - 4.00 v_mfma_f32_16x16x16_bf16 v[0:3], v[4:5], v[6:7], v[0:3]
+# CHECK-NEXT: - - - - - - 4.00 v_mfma_f32_16x16x16_bf16 a[0:3], v[4:5], v[6:7], a[0:3]
+# CHECK-NEXT: - - - - - - 8.00 v_mfma_f32_32x32x8_bf16 v[0:15], v[4:5], v[6:7], v[0:15]
+# CHECK-NEXT: - - - - - - 8.00 v_mfma_f32_32x32x8_bf16 a[0:15], v[4:5], v[6:7], a[0:15]
+# CHECK-NEXT: - - - - - - 4.00 v_mfma_i32_16x16x32_i8 v[0:3], v[4:5], v[6:7], v[0:3]
+# CHECK-NEXT: - - - - - - 4.00 v_mfma_i32_16x16x32_i8 a[0:3], v[4:5], v[6:7], a[0:3]
+# CHECK-NEXT: - - - - - - 8.00 v_mfma_i32_32x32x16_i8 v[0:15], v[2:3], v[4:5], v[0:15]
+# CHECK-NEXT: - - - - - - 8.00 v_mfma_i32_32x32x16_i8 a[0:15], v[2:3], v[4:5], a[0:15]
+# CHECK-NEXT: - - - - - - 2.00 v_mfma_f32_4x4x4_16b_f16 v[0:3], v[0:1], v[2:3], v[2:5]
+# CHECK-NEXT: - - - - - - 2.00 v_mfma_f32_4x4x4_16b_f16 a[0:3], v[0:1], v[2:3], a[2:5]
+# CHECK-NEXT: - - - - - - 8.00 v_mfma_f32_16x16x4_4b_f16 v[0:15], v[2:3], v[4:5], v[18:33]
+# CHECK-NEXT: - - - - - - 8.00 v_mfma_f32_16x16x4_4b_f16 a[0:15], v[2:3], v[4:5], a[18:33]
+# CHECK-NEXT: - - - - - - 16.00 v_mfma_f32_32x32x4_2b_f16 v[0:31], v[0:1], v[2:3], v[34:65]
+# CHECK-NEXT: - - - - - - 16.00 v_mfma_f32_32x32x4_2b_f16 a[0:31], v[0:1], v[2:3], a[34:65]
+# CHECK-NEXT: - - - - - - 2.00 v_mfma_f32_4x4x4_16b_bf16 v[0:3], v[0:1], v[2:3], v[2:5]
+# CHECK-NEXT: - - - - - - 2.00 v_mfma_f32_4x4x4_16b_bf16 a[0:3], v[0:1], v[2:3], a[2:5]
+# CHECK-NEXT: - - - - - - 8.00 v_mfma_f32_16x16x4_4b_bf16 v[0:15], v[2:3], v[4:5], v[18:33]
+# CHECK-NEXT: - - - - - - 8.00 v_mfma_f32_16x16x4_4b_bf16 a[0:15], v[2:3], v[4:5], a[18:33]
+# CHECK-NEXT: - - - - - - 16.00 v_mfma_f32_32x32x4_2b_bf16 v[0:31], v[0:1], v[2:3], v[34:65]
+# CHECK-NEXT: - - - - - - 16.00 v_mfma_f32_32x32x4_2b_bf16 a[0:31], v[0:1], v[2:3], a[34:65]
+# CHECK-NEXT: - - - - - - 2.00 v_mfma_f32_4x4x1_16b_f32 v[0:3], v0, v1, v[2:5]
+# CHECK-NEXT: - - - - - - 2.00 v_mfma_f32_4x4x1_16b_f32 a[0:3], v0, v1, a[2:5]
+# CHECK-NEXT: - - - - - - 8.00 v_mfma_f32_16x16x1_4b_f32 v[0:15], v0, v1, v[18:33]
+# CHECK-NEXT: - - - - - - 8.00 v_mfma_f32_16x16x1_4b_f32 a[0:15], v0, v1, a[18:33]
+# CHECK-NEXT: - - - - - - 8.00 v_mfma_f32_16x16x4_f32 v[0:3], v0, v1, v[2:5]
+# CHECK-NEXT: - - - - - - 8.00 v_mfma_f32_16x16x4_f32 a[0:3], v0, v1, a[2:5]
+# CHECK-NEXT: - - - - - - 16.00 v_mfma_f32_32x32x1_2b_f32 v[0:31], v0, v1, v[34:65] blgp:7
+# CHECK-NEXT: - - - - - - 16.00 v_mfma_f32_32x32x1_2b_f32 a[0:31], v0, v1, a[34:65] blgp:7
+# CHECK-NEXT: - - - - - - 16.00 v_mfma_f32_32x32x2_f32 v[0:15], v0, v1, v[18:33]
+# CHECK-NEXT: - - - - - - 16.00 v_mfma_f32_32x32x2_f32 a[0:15], v0, v1, a[18:33]
+# CHECK-NEXT: - - - - - - 2.00 v_mfma_i32_4x4x4_16b_i8 v[0:3], v0, v1, v[2:5]
+# CHECK-NEXT: - - - - - - 2.00 v_mfma_i32_4x4x4_16b_i8 a[0:3], v0, v1, a[2:5]
+# CHECK-NEXT: - - - - - - 8.00 v_mfma_i32_16x16x4_4b_i8 v[0:15], v0, v1, v[18:33]
+# CHECK-NEXT: - - - - - - 8.00 v_mfma_i32_16x16x4_4b_i8 a[0:15], v0, v1, a[18:33]
+# CHECK-NEXT: - - - - - - 16.00 v_mfma_i32_32x32x4_2b_i8 v[0:31], v0, v1, v[34:65]
+# CHECK-NEXT: - - - - - - 16.00 v_mfma_i32_32x32x4_2b_i8 a[0:31], v0, v1, a[34:65]
+# CHECK-NEXT: - - - - - - 4.00 v_smfmac_f32_16x16x32_f16 v[10:13], a[2:3], v[4:7], v0 cbsz:3 abid:1
+# CHECK-NEXT: - - - - - - 4.00 v_smfmac_f32_16x16x32_f16 a[10:13], v[2:3], a[4:7], v1
+# CHECK-NEXT: - - - - - - 8.00 v_smfmac_f32_32x32x16_f16 v[10:25], a[2:3], v[4:7], v2 cbsz:3 abid:1
+# CHECK-NEXT: - - - - - - 8.00 v_smfmac_f32_32x32x16_f16 a[10:25], v[2:3], a[4:7], v3
+# CHECK-NEXT: - - - - - - 4.00 v_smfmac_f32_16x16x32_bf16 v[10:13], a[2:3], v[4:7], v4 cbsz:3 abid:1
+# CHECK-NEXT: - - - - - - 4.00 v_smfmac_f32_16x16x32_bf16 a[10:13], v[2:3], a[4:7], v5
+# CHECK-NEXT: - - - - - - 4.00 v_smfmac_i32_16x16x64_i8 v[10:13], a[2:3], v[4:7], v8 cbsz:3 abid:1
+# CHECK-NEXT: - - - - - - 4.00 v_smfmac_i32_16x16x64_i8 a[10:13], v[2:3], a[4:7], v9
+# CHECK-NEXT: - - - - - - 8.00 v_smfmac_i32_32x32x32_i8 v[10:25], a[2:3], v[4:7], v10 cbsz:3 abid:1
+# CHECK-NEXT: - - - - - - 8.00 v_smfmac_i32_32x32x32_i8 a[10:25], v[2:3], a[4:7], v11
>From ffa48f0c945be3c1680b0830d5c0cac146cb954c Mon Sep 17 00:00:00 2001
From: XinWang10 <108658776+XinWang10 at users.noreply.github.com>
Date: Thu, 29 Feb 2024 11:44:41 +0800
Subject: [PATCH 083/406] [X86][MC] Teach disassembler to recognize apx
instructions which ignores W bit (#82747)
Extended VMX instructions and 8 bit apx extended instructions don't need
W bit, they are marked as W ignored in spec.
RFC:
https://discourse.llvm.org/t/rfc-design-for-apx-feature-egpr-and-ndd-support/73031/4
---
llvm/lib/Target/X86/X86InstrSystem.td | 2 +-
llvm/lib/Target/X86/X86InstrUtils.td | 1 +
llvm/lib/Target/X86/X86InstrVMX.td | 4 +-
llvm/test/MC/Disassembler/X86/apx/IgnoreW.txt | 118 ++++++++++++++++++
llvm/utils/TableGen/X86DisassemblerTables.cpp | 2 +
5 files changed, 124 insertions(+), 3 deletions(-)
create mode 100644 llvm/test/MC/Disassembler/X86/apx/IgnoreW.txt
diff --git a/llvm/lib/Target/X86/X86InstrSystem.td b/llvm/lib/Target/X86/X86InstrSystem.td
index d051047ae46548..56293e20567ed1 100644
--- a/llvm/lib/Target/X86/X86InstrSystem.td
+++ b/llvm/lib/Target/X86/X86InstrSystem.td
@@ -716,7 +716,7 @@ def INVPCID64 : I<0x82, MRMSrcMem, (outs), (ins GR64:$src1, i128mem:$src2),
def INVPCID64_EVEX : I<0xF2, MRMSrcMem, (outs), (ins GR64:$src1, i128mem:$src2),
"invpcid\t{$src2, $src1|$src1, $src2}", []>,
- EVEX, NoCD8, T_MAP4, XS, Requires<[In64BitMode]>;
+ EVEX, NoCD8, T_MAP4, XS, WIG, Requires<[In64BitMode]>;
} // SchedRW
let Predicates = [HasINVPCID, NoEGPR] in {
diff --git a/llvm/lib/Target/X86/X86InstrUtils.td b/llvm/lib/Target/X86/X86InstrUtils.td
index 05ddcfbf2726d9..04d9d104ebc4b0 100644
--- a/llvm/lib/Target/X86/X86InstrUtils.td
+++ b/llvm/lib/Target/X86/X86InstrUtils.td
@@ -967,6 +967,7 @@ class ITy<bits<8> o, Format f, X86TypeInfo t, dag outs, dag ins, string m,
!strconcat(m, "{", t.InstrSuffix, "}\t", args), p>, NoCD8 {
let hasSideEffects = 0;
let hasREX_W = t.HasREX_W;
+ let IgnoresW = !if(!eq(t.VT, i8), 1, 0);
}
// BinOpRR - Instructions that read "reg, reg".
diff --git a/llvm/lib/Target/X86/X86InstrVMX.td b/llvm/lib/Target/X86/X86InstrVMX.td
index 7cc468fe15ad4e..da2b3d76a130cf 100644
--- a/llvm/lib/Target/X86/X86InstrVMX.td
+++ b/llvm/lib/Target/X86/X86InstrVMX.td
@@ -24,7 +24,7 @@ def INVEPT64 : I<0x80, MRMSrcMem, (outs), (ins GR64:$src1, i128mem:$src2),
Requires<[In64BitMode]>;
def INVEPT64_EVEX : I<0xF0, MRMSrcMem, (outs), (ins GR64:$src1, i128mem:$src2),
"invept\t{$src2, $src1|$src1, $src2}", []>,
- EVEX, NoCD8, T_MAP4, XS, Requires<[In64BitMode]>;
+ EVEX, NoCD8, T_MAP4, XS, WIG, Requires<[In64BitMode]>;
// 66 0F 38 81
def INVVPID32 : I<0x81, MRMSrcMem, (outs), (ins GR32:$src1, i128mem:$src2),
@@ -35,7 +35,7 @@ def INVVPID64 : I<0x81, MRMSrcMem, (outs), (ins GR64:$src1, i128mem:$src2),
Requires<[In64BitMode]>;
def INVVPID64_EVEX : I<0xF1, MRMSrcMem, (outs), (ins GR64:$src1, i128mem:$src2),
"invvpid\t{$src2, $src1|$src1, $src2}", []>,
- EVEX, NoCD8, T_MAP4, XS, Requires<[In64BitMode]>;
+ EVEX, NoCD8, T_MAP4, XS, WIG, Requires<[In64BitMode]>;
// 0F 01 C1
def VMCALL : I<0x01, MRM_C1, (outs), (ins), "vmcall", []>, TB;
diff --git a/llvm/test/MC/Disassembler/X86/apx/IgnoreW.txt b/llvm/test/MC/Disassembler/X86/apx/IgnoreW.txt
new file mode 100644
index 00000000000000..df41bdf39fd61b
--- /dev/null
+++ b/llvm/test/MC/Disassembler/X86/apx/IgnoreW.txt
@@ -0,0 +1,118 @@
+# RUN: llvm-mc --disassemble %s -triple=x86_64 | FileCheck %s --check-prefixes=ATT
+# RUN: llvm-mc --disassemble %s -triple=x86_64 -x86-asm-syntax=intel --output-asm-variant=1 | FileCheck %s --check-prefixes=INTEL
+
+## invpcid
+
+# ATT: invpcid 123(%rax,%rbx,4), %r9
+# INTEL: invpcid r9, xmmword ptr [rax + 4*rbx + 123]
+0x62,0x74,0xfe,0x08,0xf2,0x4c,0x98,0x7b
+
+# ATT: invpcid 291(%r28,%r29,4), %r19
+# INTEL: invpcid r19, xmmword ptr [r28 + 4*r29 + 291]
+0x62,0x8c,0xfa,0x08,0xf2,0x9c,0xac,0x23,0x01,0x00,0x00
+
+## invept
+
+# ATT: invept 291(%r28,%r29,4), %r19
+# INTEL: invept r19, xmmword ptr [r28 + 4*r29 + 291]
+0x62,0x8c,0xfa,0x08,0xf0,0x9c,0xac,0x23,0x01,0x00,0x00
+
+# ATT: invept 123(%rax,%rbx,4), %r9
+# INTEL: invept r9, xmmword ptr [rax + 4*rbx + 123]
+0x62,0x74,0xfe,0x08,0xf0,0x4c,0x98,0x7b
+
+## invvpid
+
+# ATT: invvpid 291(%r28,%r29,4), %r19
+# INTEL: invvpid r19, xmmword ptr [r28 + 4*r29 + 291]
+0x62,0x8c,0xfa,0x08,0xf1,0x9c,0xac,0x23,0x01,0x00,0x00
+
+# ATT: invvpid 123(%rax,%rbx,4), %r9
+# INTEL: invvpid r9, xmmword ptr [rax + 4*rbx + 123]
+0x62,0x74,0xfe,0x08,0xf1,0x4c,0x98,0x7b
+
+## adc
+
+# ATT: {evex} adcb $123, %bl
+# INTEL: {evex} adc bl, 123
+0x62,0xf4,0xfc,0x08,0x80,0xd3,0x7b
+
+# ATT: adcb $123, %bl, %cl
+# INTEL: adc cl, bl, 123
+0x62,0xf4,0xf4,0x18,0x80,0xd3,0x7b
+
+# ATT: adcb $123, %r16b
+# INTEL: adc r16b, 123
+0xd5,0x18,0x80,0xd0,0x7b
+
+## add
+
+# ATT: {evex} addb $123, %bl
+# INTEL: {evex} add bl, 123
+0x62,0xf4,0xfc,0x08,0x80,0xc3,0x7b
+
+# ATT: {nf} addb $123, %bl
+# INTEL: {nf} add bl, 123
+0x62,0xf4,0xfc,0x0c,0x80,0xc3,0x7b
+
+# ATT: addb $123, %bl, %cl
+# INTEL: add cl, bl, 123
+0x62,0xf4,0xf4,0x18,0x80,0xc3,0x7b
+
+# ATT: {nf} addb $123, %bl, %cl
+# INTEL: {nf} add cl, bl, 123
+0x62,0xf4,0xf4,0x1c,0x80,0xc3,0x7b
+
+# ATT: addb $123, %r16b
+# INTEL: add r16b, 123
+0xd5,0x18,0x80,0xc0,0x7b
+
+## inc
+
+# ATT: {evex} incb %bl
+# INTEL: {evex} inc bl
+0x62,0xf4,0xfc,0x08,0xfe,0xc3
+
+# ATT: {nf} incb %bl
+# INTEL: {nf} inc bl
+0x62,0xf4,0xfc,0x0c,0xfe,0xc3
+
+# ATT: incb %bl, %bl
+# INTEL: inc bl, bl
+0x62,0xf4,0xe4,0x18,0xfe,0xc3
+
+# ATT: {nf} incb %bl, %bl
+# INTEL: {nf} inc bl, bl
+0x62,0xf4,0xe4,0x1c,0xfe,0xc3
+
+# ATT: incb %r16b
+# INTEL: inc r16b
+0xd5,0x18,0xfe,0xc0
+
+## mul
+
+# ATT: {evex} mulb %bl
+# INTEL: {evex} mul bl
+0x62,0xf4,0xfc,0x08,0xf6,0xe3
+
+# ATT: {nf} mulb %bl
+# INTEL: {nf} mul bl
+0x62,0xf4,0xfc,0x0c,0xf6,0xe3
+
+# ATT: mulb %r16b
+# INTEL: mul r16b
+0xd5,0x18,0xf6,0xe0
+
+## imul
+
+# ATT: {evex} imulb %bl
+# INTEL: {evex} imul bl
+0x62,0xf4,0xfc,0x08,0xf6,0xeb
+
+# ATT: {nf} imulb %bl
+# INTEL: {nf} imul bl
+0x62,0xf4,0xfc,0x0c,0xf6,0xeb
+
+# ATT: imulb %r16b
+# INTEL: imul r16b
+0xd5,0x18,0xf6,0xe8
diff --git a/llvm/utils/TableGen/X86DisassemblerTables.cpp b/llvm/utils/TableGen/X86DisassemblerTables.cpp
index a48b9cfe42e37f..f4d282f54ac055 100644
--- a/llvm/utils/TableGen/X86DisassemblerTables.cpp
+++ b/llvm/utils/TableGen/X86DisassemblerTables.cpp
@@ -567,7 +567,9 @@ static inline bool inheritsFrom(InstructionContext child,
case IC_EVEX_L2_W_OPSIZE_KZ_B:
return false;
case IC_EVEX_NF:
+ return WIG && inheritsFrom(child, IC_EVEX_W_NF);
case IC_EVEX_B_NF:
+ return WIG && inheritsFrom(child, IC_EVEX_W_B_NF);
case IC_EVEX_OPSIZE_NF:
case IC_EVEX_OPSIZE_B_NF:
case IC_EVEX_W_NF:
>From 3f2a9e5910c2f485ce18a6d348af30cd44474b48 Mon Sep 17 00:00:00 2001
From: Maksim Panchenko <maks at fb.com>
Date: Wed, 28 Feb 2024 19:51:44 -0800
Subject: [PATCH 084/406] [BOLT] Sort TakenBranches immediately before use.
NFCI (#83333)
Move code that sorts TakenBranches right before the branches are used.
We can populate TakenBranches in pre-CFG post-processing and hence have
to postpone the sorting to a later point in the processing pipeline.
Will add such a pass later. For now it's NFC.
---
bolt/lib/Core/BinaryFunction.cpp | 14 +++++++-------
1 file changed, 7 insertions(+), 7 deletions(-)
diff --git a/bolt/lib/Core/BinaryFunction.cpp b/bolt/lib/Core/BinaryFunction.cpp
index 00df42c11e2239..957a9c2f72e41d 100644
--- a/bolt/lib/Core/BinaryFunction.cpp
+++ b/bolt/lib/Core/BinaryFunction.cpp
@@ -1759,13 +1759,6 @@ void BinaryFunction::postProcessJumpTables() {
}
}
}
-
- // Remove duplicates branches. We can get a bunch of them from jump tables.
- // Without doing jump table value profiling we don't have use for extra
- // (duplicate) branches.
- llvm::sort(TakenBranches);
- auto NewEnd = std::unique(TakenBranches.begin(), TakenBranches.end());
- TakenBranches.erase(NewEnd, TakenBranches.end());
}
bool BinaryFunction::validateExternallyReferencedOffsets() {
@@ -2128,6 +2121,13 @@ Error BinaryFunction::buildCFG(MCPlusBuilder::AllocatorIdTy AllocatorId) {
// e.g. exit(3), etc. Otherwise we'll see a false fall-through
// blocks.
+ // Remove duplicates branches. We can get a bunch of them from jump tables.
+ // Without doing jump table value profiling we don't have a use for extra
+ // (duplicate) branches.
+ llvm::sort(TakenBranches);
+ auto NewEnd = std::unique(TakenBranches.begin(), TakenBranches.end());
+ TakenBranches.erase(NewEnd, TakenBranches.end());
+
for (std::pair<uint32_t, uint32_t> &Branch : TakenBranches) {
LLVM_DEBUG(dbgs() << "registering branch [0x"
<< Twine::utohexstr(Branch.first) << "] -> [0x"
>From d7d564b2fccbdf5b124f93c03c36ae8bfd849589 Mon Sep 17 00:00:00 2001
From: Maksim Panchenko <maks at fb.com>
Date: Wed, 28 Feb 2024 20:04:28 -0800
Subject: [PATCH 085/406] [BOLT] Add BinaryFunction::registerBranch(). NFC
(#83337)
Add an external interface to register a branch in a function that is in
disassembled state. Allows to make custom modifications to the
disassembler. E.g., a pre-CFG pass can add an instruction and register a
branch that will later be used during the CFG construction.
---
bolt/include/bolt/Core/BinaryFunction.h | 8 ++++++++
bolt/lib/Core/BinaryFunction.cpp | 10 ++++++++++
2 files changed, 18 insertions(+)
diff --git a/bolt/include/bolt/Core/BinaryFunction.h b/bolt/include/bolt/Core/BinaryFunction.h
index a177178769e456..c170fa6397cc92 100644
--- a/bolt/include/bolt/Core/BinaryFunction.h
+++ b/bolt/include/bolt/Core/BinaryFunction.h
@@ -2056,6 +2056,14 @@ class BinaryFunction {
/// Returns false if disassembly failed.
Error disassemble();
+ /// An external interface to register a branch while the function is in
+ /// disassembled state. Allows to make custom modifications to the
+ /// disassembler. E.g., a pre-CFG pass can add an instruction and register
+ /// a branch that will later be used during the CFG construction.
+ ///
+ /// Return a label at the branch destination.
+ MCSymbol *registerBranch(uint64_t Src, uint64_t Dst);
+
Error handlePCRelOperand(MCInst &Instruction, uint64_t Address,
uint64_t Size);
diff --git a/bolt/lib/Core/BinaryFunction.cpp b/bolt/lib/Core/BinaryFunction.cpp
index 957a9c2f72e41d..ce4dd29f542b0d 100644
--- a/bolt/lib/Core/BinaryFunction.cpp
+++ b/bolt/lib/Core/BinaryFunction.cpp
@@ -1445,6 +1445,16 @@ Error BinaryFunction::disassemble() {
return Error::success();
}
+MCSymbol *BinaryFunction::registerBranch(uint64_t Src, uint64_t Dst) {
+ assert(CurrentState == State::Disassembled &&
+ "Cannot register branch unless function is in disassembled state.");
+ assert(containsAddress(Src) && containsAddress(Dst) &&
+ "Cannot register external branch.");
+ MCSymbol *Target = getOrCreateLocalLabel(Dst);
+ TakenBranches.emplace_back(Src - getAddress(), Dst - getAddress());
+ return Target;
+}
+
bool BinaryFunction::scanExternalRefs() {
bool Success = true;
bool DisassemblyFailed = false;
>From 14d8c4563e045fc3da82cb7268b1066cfd1bb6f0 Mon Sep 17 00:00:00 2001
From: Yeting Kuo <46629943+yetingk at users.noreply.github.com>
Date: Thu, 29 Feb 2024 12:57:34 +0800
Subject: [PATCH 086/406] [RISCV] Add more intrinsics into canSplatOperand.
(#83106)
This patch adds smin/smax/umin/umax/sadd_sat/ssub_sat/uadd_sat/usub_sat
into canSplatOperand. It can help llvm fold vv instructions with one
splat operand to vx instructions.
---
llvm/lib/Target/RISCV/RISCVISelLowering.cpp | 16 +
.../CodeGen/RISCV/rvv/sink-splat-operands.ll | 2158 ++++++++++++-----
2 files changed, 1582 insertions(+), 592 deletions(-)
diff --git a/llvm/lib/Target/RISCV/RISCVISelLowering.cpp b/llvm/lib/Target/RISCV/RISCVISelLowering.cpp
index dde1882f5eea83..e647f56416bfa6 100644
--- a/llvm/lib/Target/RISCV/RISCVISelLowering.cpp
+++ b/llvm/lib/Target/RISCV/RISCVISelLowering.cpp
@@ -1999,6 +1999,10 @@ bool RISCVTargetLowering::canSplatOperand(Instruction *I, int Operand) const {
case Intrinsic::vp_sdiv:
case Intrinsic::vp_urem:
case Intrinsic::vp_srem:
+ case Intrinsic::ssub_sat:
+ case Intrinsic::vp_ssub_sat:
+ case Intrinsic::usub_sat:
+ case Intrinsic::vp_usub_sat:
return Operand == 1;
// These intrinsics are commutative.
case Intrinsic::vp_add:
@@ -2010,6 +2014,18 @@ bool RISCVTargetLowering::canSplatOperand(Instruction *I, int Operand) const {
case Intrinsic::vp_fmul:
case Intrinsic::vp_icmp:
case Intrinsic::vp_fcmp:
+ case Intrinsic::smin:
+ case Intrinsic::vp_smin:
+ case Intrinsic::umin:
+ case Intrinsic::vp_umin:
+ case Intrinsic::smax:
+ case Intrinsic::vp_smax:
+ case Intrinsic::umax:
+ case Intrinsic::vp_umax:
+ case Intrinsic::sadd_sat:
+ case Intrinsic::vp_sadd_sat:
+ case Intrinsic::uadd_sat:
+ case Intrinsic::vp_uadd_sat:
// These intrinsics have 'vr' versions.
case Intrinsic::vp_sub:
case Intrinsic::vp_fsub:
diff --git a/llvm/test/CodeGen/RISCV/rvv/sink-splat-operands.ll b/llvm/test/CodeGen/RISCV/rvv/sink-splat-operands.ll
index 191f047131fb16..5d09c39dfd6e68 100644
--- a/llvm/test/CodeGen/RISCV/rvv/sink-splat-operands.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/sink-splat-operands.ll
@@ -2849,23 +2849,21 @@ for.body: ; preds = %for.body.preheader,
br i1 %cmp.not, label %for.cond.cleanup, label %for.body
}
-declare <4 x i32> @llvm.vp.mul.v4i32(<4 x i32>, <4 x i32>, <4 x i1>, i32)
+declare <4 x i32> @llvm.smin.v4i32(<4 x i32>, <4 x i32>)
-define void @sink_splat_vp_mul(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
-; CHECK-LABEL: sink_splat_vp_mul:
+define void @sink_splat_min(ptr nocapture %a, i32 signext %x) {
+; CHECK-LABEL: sink_splat_min:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: lui a3, 1
-; CHECK-NEXT: add a3, a0, a3
+; CHECK-NEXT: li a2, 1024
; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: .LBB46_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
-; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
-; CHECK-NEXT: vmul.vx v8, v8, a1, v0.t
-; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vmin.vx v8, v8, a1
; CHECK-NEXT: vse32.v v8, (a0)
-; CHECK-NEXT: addi a0, a0, 16
-; CHECK-NEXT: bne a0, a3, .LBB46_1
+; CHECK-NEXT: addi a2, a2, 4
+; CHECK-NEXT: addi a0, a0, -16
+; CHECK-NEXT: bnez a2, .LBB46_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
@@ -2877,9 +2875,9 @@ vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
%0 = getelementptr inbounds i32, ptr %a, i64 %index
%wide.load = load <4 x i32>, ptr %0, align 4
- %1 = call <4 x i32> @llvm.vp.mul.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat, <4 x i1> %m, i32 %vl)
+ %1 = call <4 x i32> @llvm.smin.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat)
store <4 x i32> %1, ptr %0, align 4
- %index.next = add nuw i64 %index, 4
+ %index.next = sub nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -2887,23 +2885,19 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-declare <4 x i32> @llvm.vp.add.v4i32(<4 x i32>, <4 x i32>, <4 x i1>, i32)
-
-define void @sink_splat_vp_add(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
-; CHECK-LABEL: sink_splat_vp_add:
+define void @sink_splat_min_commute(ptr nocapture %a, i32 signext %x) {
+; CHECK-LABEL: sink_splat_min_commute:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: lui a3, 1
-; CHECK-NEXT: add a3, a0, a3
+; CHECK-NEXT: li a2, 1024
; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: .LBB47_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
-; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
-; CHECK-NEXT: vadd.vx v8, v8, a1, v0.t
-; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vmin.vx v8, v8, a1
; CHECK-NEXT: vse32.v v8, (a0)
-; CHECK-NEXT: addi a0, a0, 16
-; CHECK-NEXT: bne a0, a3, .LBB47_1
+; CHECK-NEXT: addi a2, a2, 4
+; CHECK-NEXT: addi a0, a0, -16
+; CHECK-NEXT: bnez a2, .LBB47_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
@@ -2915,9 +2909,9 @@ vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
%0 = getelementptr inbounds i32, ptr %a, i64 %index
%wide.load = load <4 x i32>, ptr %0, align 4
- %1 = call <4 x i32> @llvm.vp.add.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat, <4 x i1> %m, i32 %vl)
+ %1 = call <4 x i32> @llvm.smin.v4i32(<4 x i32> %broadcast.splat, <4 x i32> %wide.load)
store <4 x i32> %1, ptr %0, align 4
- %index.next = add nuw i64 %index, 4
+ %index.next = sub nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -2925,21 +2919,21 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-define void @sink_splat_vp_add_commute(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
-; CHECK-LABEL: sink_splat_vp_add_commute:
+declare <4 x i32> @llvm.smax.v4i32(<4 x i32>, <4 x i32>)
+
+define void @sink_splat_max(ptr nocapture %a, i32 signext %x) {
+; CHECK-LABEL: sink_splat_max:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: lui a3, 1
-; CHECK-NEXT: add a3, a0, a3
+; CHECK-NEXT: li a2, 1024
; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: .LBB48_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
-; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
-; CHECK-NEXT: vadd.vx v8, v8, a1, v0.t
-; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vmax.vx v8, v8, a1
; CHECK-NEXT: vse32.v v8, (a0)
-; CHECK-NEXT: addi a0, a0, 16
-; CHECK-NEXT: bne a0, a3, .LBB48_1
+; CHECK-NEXT: addi a2, a2, 4
+; CHECK-NEXT: addi a0, a0, -16
+; CHECK-NEXT: bnez a2, .LBB48_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
@@ -2951,9 +2945,9 @@ vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
%0 = getelementptr inbounds i32, ptr %a, i64 %index
%wide.load = load <4 x i32>, ptr %0, align 4
- %1 = call <4 x i32> @llvm.vp.add.v4i32(<4 x i32> %broadcast.splat, <4 x i32> %wide.load, <4 x i1> %m, i32 %vl)
+ %1 = call <4 x i32> @llvm.smax.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat)
store <4 x i32> %1, ptr %0, align 4
- %index.next = add nuw i64 %index, 4
+ %index.next = sub nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -2961,23 +2955,19 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-declare <4 x i32> @llvm.vp.sub.v4i32(<4 x i32>, <4 x i32>, <4 x i1>, i32)
-
-define void @sink_splat_vp_sub(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
-; CHECK-LABEL: sink_splat_vp_sub:
+define void @sink_splat_max_commute(ptr nocapture %a, i32 signext %x) {
+; CHECK-LABEL: sink_splat_max_commute:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: lui a3, 1
-; CHECK-NEXT: add a3, a0, a3
+; CHECK-NEXT: li a2, 1024
; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: .LBB49_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
-; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
-; CHECK-NEXT: vsub.vx v8, v8, a1, v0.t
-; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vmax.vx v8, v8, a1
; CHECK-NEXT: vse32.v v8, (a0)
-; CHECK-NEXT: addi a0, a0, 16
-; CHECK-NEXT: bne a0, a3, .LBB49_1
+; CHECK-NEXT: addi a2, a2, 4
+; CHECK-NEXT: addi a0, a0, -16
+; CHECK-NEXT: bnez a2, .LBB49_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
@@ -2989,9 +2979,9 @@ vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
%0 = getelementptr inbounds i32, ptr %a, i64 %index
%wide.load = load <4 x i32>, ptr %0, align 4
- %1 = call <4 x i32> @llvm.vp.sub.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat, <4 x i1> %m, i32 %vl)
+ %1 = call <4 x i32> @llvm.smax.v4i32(<4 x i32> %broadcast.splat, <4 x i32> %wide.load)
store <4 x i32> %1, ptr %0, align 4
- %index.next = add nuw i64 %index, 4
+ %index.next = sub nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -2999,21 +2989,21 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-define void @sink_splat_vp_rsub(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
-; CHECK-LABEL: sink_splat_vp_rsub:
+declare <4 x i32> @llvm.umin.v4i32(<4 x i32>, <4 x i32>)
+
+define void @sink_splat_umin(ptr nocapture %a, i32 signext %x) {
+; CHECK-LABEL: sink_splat_umin:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: lui a3, 1
-; CHECK-NEXT: add a3, a0, a3
+; CHECK-NEXT: li a2, 1024
; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: .LBB50_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
-; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
-; CHECK-NEXT: vrsub.vx v8, v8, a1, v0.t
-; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vminu.vx v8, v8, a1
; CHECK-NEXT: vse32.v v8, (a0)
-; CHECK-NEXT: addi a0, a0, 16
-; CHECK-NEXT: bne a0, a3, .LBB50_1
+; CHECK-NEXT: addi a2, a2, 4
+; CHECK-NEXT: addi a0, a0, -16
+; CHECK-NEXT: bnez a2, .LBB50_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
@@ -3025,9 +3015,9 @@ vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
%0 = getelementptr inbounds i32, ptr %a, i64 %index
%wide.load = load <4 x i32>, ptr %0, align 4
- %1 = call <4 x i32> @llvm.vp.sub.v4i32(<4 x i32> %broadcast.splat, <4 x i32> %wide.load, <4 x i1> %m, i32 %vl)
+ %1 = call <4 x i32> @llvm.umin.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat)
store <4 x i32> %1, ptr %0, align 4
- %index.next = add nuw i64 %index, 4
+ %index.next = sub nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -3035,23 +3025,19 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-declare <4 x i32> @llvm.vp.shl.v4i32(<4 x i32>, <4 x i32>, <4 x i1>, i32)
-
-define void @sink_splat_vp_shl(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
-; CHECK-LABEL: sink_splat_vp_shl:
+define void @sink_splat_umin_commute(ptr nocapture %a, i32 signext %x) {
+; CHECK-LABEL: sink_splat_umin_commute:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: lui a3, 1
-; CHECK-NEXT: add a3, a0, a3
+; CHECK-NEXT: li a2, 1024
; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: .LBB51_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
-; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
-; CHECK-NEXT: vsll.vx v8, v8, a1, v0.t
-; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vminu.vx v8, v8, a1
; CHECK-NEXT: vse32.v v8, (a0)
-; CHECK-NEXT: addi a0, a0, 16
-; CHECK-NEXT: bne a0, a3, .LBB51_1
+; CHECK-NEXT: addi a2, a2, 4
+; CHECK-NEXT: addi a0, a0, -16
+; CHECK-NEXT: bnez a2, .LBB51_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
@@ -3063,9 +3049,9 @@ vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
%0 = getelementptr inbounds i32, ptr %a, i64 %index
%wide.load = load <4 x i32>, ptr %0, align 4
- %1 = call <4 x i32> @llvm.vp.shl.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat, <4 x i1> %m, i32 %vl)
+ %1 = call <4 x i32> @llvm.umin.v4i32(<4 x i32> %broadcast.splat, <4 x i32> %wide.load)
store <4 x i32> %1, ptr %0, align 4
- %index.next = add nuw i64 %index, 4
+ %index.next = sub nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -3073,23 +3059,21 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-declare <4 x i32> @llvm.vp.lshr.v4i32(<4 x i32>, <4 x i32>, <4 x i1>, i32)
+declare <4 x i32> @llvm.umax.v4i32(<4 x i32>, <4 x i32>)
-define void @sink_splat_vp_lshr(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
-; CHECK-LABEL: sink_splat_vp_lshr:
+define void @sink_splat_umax(ptr nocapture %a, i32 signext %x) {
+; CHECK-LABEL: sink_splat_umax:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: lui a3, 1
-; CHECK-NEXT: add a3, a0, a3
+; CHECK-NEXT: li a2, 1024
; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: .LBB52_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
-; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
-; CHECK-NEXT: vsrl.vx v8, v8, a1, v0.t
-; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vmaxu.vx v8, v8, a1
; CHECK-NEXT: vse32.v v8, (a0)
-; CHECK-NEXT: addi a0, a0, 16
-; CHECK-NEXT: bne a0, a3, .LBB52_1
+; CHECK-NEXT: addi a2, a2, 4
+; CHECK-NEXT: addi a0, a0, -16
+; CHECK-NEXT: bnez a2, .LBB52_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
@@ -3101,9 +3085,9 @@ vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
%0 = getelementptr inbounds i32, ptr %a, i64 %index
%wide.load = load <4 x i32>, ptr %0, align 4
- %1 = call <4 x i32> @llvm.vp.lshr.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat, <4 x i1> %m, i32 %vl)
+ %1 = call <4 x i32> @llvm.umax.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat)
store <4 x i32> %1, ptr %0, align 4
- %index.next = add nuw i64 %index, 4
+ %index.next = sub nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -3111,23 +3095,19 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-declare <4 x i32> @llvm.vp.ashr.v4i32(<4 x i32>, <4 x i32>, <4 x i1>, i32)
-
-define void @sink_splat_vp_ashr(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
-; CHECK-LABEL: sink_splat_vp_ashr:
+define void @sink_splat_umax_commute(ptr nocapture %a, i32 signext %x) {
+; CHECK-LABEL: sink_splat_umax_commute:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: lui a3, 1
-; CHECK-NEXT: add a3, a0, a3
+; CHECK-NEXT: li a2, 1024
; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: .LBB53_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
-; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
-; CHECK-NEXT: vsra.vx v8, v8, a1, v0.t
-; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vmaxu.vx v8, v8, a1
; CHECK-NEXT: vse32.v v8, (a0)
-; CHECK-NEXT: addi a0, a0, 16
-; CHECK-NEXT: bne a0, a3, .LBB53_1
+; CHECK-NEXT: addi a2, a2, 4
+; CHECK-NEXT: addi a0, a0, -16
+; CHECK-NEXT: bnez a2, .LBB53_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
@@ -3139,9 +3119,9 @@ vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
%0 = getelementptr inbounds i32, ptr %a, i64 %index
%wide.load = load <4 x i32>, ptr %0, align 4
- %1 = call <4 x i32> @llvm.vp.ashr.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat, <4 x i1> %m, i32 %vl)
+ %1 = call <4 x i32> @llvm.umax.v4i32(<4 x i32> %broadcast.splat, <4 x i32> %wide.load)
store <4 x i32> %1, ptr %0, align 4
- %index.next = add nuw i64 %index, 4
+ %index.next = sub nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -3149,10 +3129,10 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-declare <4 x float> @llvm.vp.fmul.v4i32(<4 x float>, <4 x float>, <4 x i1>, i32)
+declare <4 x i32> @llvm.sadd.sat.v4i32(<4 x i32>, <4 x i32>)
-define void @sink_splat_vp_fmul(ptr nocapture %a, float %x, <4 x i1> %m, i32 zeroext %vl) {
-; CHECK-LABEL: sink_splat_vp_fmul:
+define void @sink_splat_sadd_sat(ptr nocapture %a, i32 signext %x) {
+; CHECK-LABEL: sink_splat_sadd_sat:
; CHECK: # %bb.0: # %entry
; CHECK-NEXT: lui a2, 1
; CHECK-NEXT: add a2, a0, a2
@@ -3160,25 +3140,23 @@ define void @sink_splat_vp_fmul(ptr nocapture %a, float %x, <4 x i1> %m, i32 zer
; CHECK-NEXT: .LBB54_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
-; CHECK-NEXT: vsetvli zero, a1, e32, m1, ta, ma
-; CHECK-NEXT: vfmul.vf v8, v8, fa0, v0.t
-; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vsadd.vx v8, v8, a1
; CHECK-NEXT: vse32.v v8, (a0)
; CHECK-NEXT: addi a0, a0, 16
; CHECK-NEXT: bne a0, a2, .LBB54_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
- %broadcast.splatinsert = insertelement <4 x float> poison, float %x, i32 0
- %broadcast.splat = shufflevector <4 x float> %broadcast.splatinsert, <4 x float> poison, <4 x i32> zeroinitializer
+ %broadcast.splatinsert = insertelement <4 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <4 x i32> %broadcast.splatinsert, <4 x i32> poison, <4 x i32> zeroinitializer
br label %vector.body
vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
- %0 = getelementptr inbounds float, ptr %a, i64 %index
- %wide.load = load <4 x float>, ptr %0, align 4
- %1 = call <4 x float> @llvm.vp.fmul.v4i32(<4 x float> %wide.load, <4 x float> %broadcast.splat, <4 x i1> %m, i32 %vl)
- store <4 x float> %1, ptr %0, align 4
+ %0 = getelementptr inbounds i32, ptr %a, i64 %index
+ %wide.load = load <4 x i32>, ptr %0, align 4
+ %1 = call <4 x i32> @llvm.sadd.sat.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat)
+ store <4 x i32> %1, ptr %0, align 4
%index.next = add nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -3187,10 +3165,8 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-declare <4 x float> @llvm.vp.fdiv.v4i32(<4 x float>, <4 x float>, <4 x i1>, i32)
-
-define void @sink_splat_vp_fdiv(ptr nocapture %a, float %x, <4 x i1> %m, i32 zeroext %vl) {
-; CHECK-LABEL: sink_splat_vp_fdiv:
+define void @sink_splat_sadd_sat_commute(ptr nocapture %a, i32 signext %x) {
+; CHECK-LABEL: sink_splat_sadd_sat_commute:
; CHECK: # %bb.0: # %entry
; CHECK-NEXT: lui a2, 1
; CHECK-NEXT: add a2, a0, a2
@@ -3198,25 +3174,23 @@ define void @sink_splat_vp_fdiv(ptr nocapture %a, float %x, <4 x i1> %m, i32 zer
; CHECK-NEXT: .LBB55_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
-; CHECK-NEXT: vsetvli zero, a1, e32, m1, ta, ma
-; CHECK-NEXT: vfdiv.vf v8, v8, fa0, v0.t
-; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vsadd.vx v8, v8, a1
; CHECK-NEXT: vse32.v v8, (a0)
; CHECK-NEXT: addi a0, a0, 16
; CHECK-NEXT: bne a0, a2, .LBB55_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
- %broadcast.splatinsert = insertelement <4 x float> poison, float %x, i32 0
- %broadcast.splat = shufflevector <4 x float> %broadcast.splatinsert, <4 x float> poison, <4 x i32> zeroinitializer
+ %broadcast.splatinsert = insertelement <4 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <4 x i32> %broadcast.splatinsert, <4 x i32> poison, <4 x i32> zeroinitializer
br label %vector.body
vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
- %0 = getelementptr inbounds float, ptr %a, i64 %index
- %wide.load = load <4 x float>, ptr %0, align 4
- %1 = call <4 x float> @llvm.vp.fdiv.v4i32(<4 x float> %wide.load, <4 x float> %broadcast.splat, <4 x i1> %m, i32 %vl)
- store <4 x float> %1, ptr %0, align 4
+ %0 = getelementptr inbounds i32, ptr %a, i64 %index
+ %wide.load = load <4 x i32>, ptr %0, align 4
+ %1 = call <4 x i32> @llvm.sadd.sat.v4i32(<4 x i32> %broadcast.splat, <4 x i32> %wide.load)
+ store <4 x i32> %1, ptr %0, align 4
%index.next = add nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -3225,35 +3199,35 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-define void @sink_splat_vp_frdiv(ptr nocapture %a, float %x, <4 x i1> %m, i32 zeroext %vl) {
-; CHECK-LABEL: sink_splat_vp_frdiv:
+declare <4 x i32> @llvm.ssub.sat.v4i32(<4 x i32>, <4 x i32>)
+
+define void @sink_splat_ssub_sat(ptr nocapture %a, i32 signext %x) {
+; CHECK-LABEL: sink_splat_ssub_sat:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: lui a2, 1
-; CHECK-NEXT: add a2, a0, a2
+; CHECK-NEXT: li a2, 1024
; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: .LBB56_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
-; CHECK-NEXT: vsetvli zero, a1, e32, m1, ta, ma
-; CHECK-NEXT: vfrdiv.vf v8, v8, fa0, v0.t
-; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vssub.vx v8, v8, a1
; CHECK-NEXT: vse32.v v8, (a0)
-; CHECK-NEXT: addi a0, a0, 16
-; CHECK-NEXT: bne a0, a2, .LBB56_1
+; CHECK-NEXT: addi a2, a2, 4
+; CHECK-NEXT: addi a0, a0, -16
+; CHECK-NEXT: bnez a2, .LBB56_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
- %broadcast.splatinsert = insertelement <4 x float> poison, float %x, i32 0
- %broadcast.splat = shufflevector <4 x float> %broadcast.splatinsert, <4 x float> poison, <4 x i32> zeroinitializer
+ %broadcast.splatinsert = insertelement <4 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <4 x i32> %broadcast.splatinsert, <4 x i32> poison, <4 x i32> zeroinitializer
br label %vector.body
vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
- %0 = getelementptr inbounds float, ptr %a, i64 %index
- %wide.load = load <4 x float>, ptr %0, align 4
- %1 = call <4 x float> @llvm.vp.fdiv.v4i32(<4 x float> %broadcast.splat, <4 x float> %wide.load, <4 x i1> %m, i32 %vl)
- store <4 x float> %1, ptr %0, align 4
- %index.next = add nuw i64 %index, 4
+ %0 = getelementptr inbounds i32, ptr %a, i64 %index
+ %wide.load = load <4 x i32>, ptr %0, align 4
+ %1 = call <4 x i32> @llvm.ssub.sat.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat)
+ store <4 x i32> %1, ptr %0, align 4
+ %index.next = sub nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -3261,10 +3235,10 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-declare <4 x float> @llvm.vp.fadd.v4i32(<4 x float>, <4 x float>, <4 x i1>, i32)
+declare <4 x i32> @llvm.uadd.sat.v4i32(<4 x i32>, <4 x i32>)
-define void @sink_splat_vp_fadd(ptr nocapture %a, float %x, <4 x i1> %m, i32 zeroext %vl) {
-; CHECK-LABEL: sink_splat_vp_fadd:
+define void @sink_splat_uadd_sat(ptr nocapture %a, i32 signext %x) {
+; CHECK-LABEL: sink_splat_uadd_sat:
; CHECK: # %bb.0: # %entry
; CHECK-NEXT: lui a2, 1
; CHECK-NEXT: add a2, a0, a2
@@ -3272,25 +3246,23 @@ define void @sink_splat_vp_fadd(ptr nocapture %a, float %x, <4 x i1> %m, i32 zer
; CHECK-NEXT: .LBB57_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
-; CHECK-NEXT: vsetvli zero, a1, e32, m1, ta, ma
-; CHECK-NEXT: vfadd.vf v8, v8, fa0, v0.t
-; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vsaddu.vx v8, v8, a1
; CHECK-NEXT: vse32.v v8, (a0)
; CHECK-NEXT: addi a0, a0, 16
; CHECK-NEXT: bne a0, a2, .LBB57_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
- %broadcast.splatinsert = insertelement <4 x float> poison, float %x, i32 0
- %broadcast.splat = shufflevector <4 x float> %broadcast.splatinsert, <4 x float> poison, <4 x i32> zeroinitializer
+ %broadcast.splatinsert = insertelement <4 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <4 x i32> %broadcast.splatinsert, <4 x i32> poison, <4 x i32> zeroinitializer
br label %vector.body
vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
- %0 = getelementptr inbounds float, ptr %a, i64 %index
- %wide.load = load <4 x float>, ptr %0, align 4
- %1 = call <4 x float> @llvm.vp.fadd.v4i32(<4 x float> %wide.load, <4 x float> %broadcast.splat, <4 x i1> %m, i32 %vl)
- store <4 x float> %1, ptr %0, align 4
+ %0 = getelementptr inbounds i32, ptr %a, i64 %index
+ %wide.load = load <4 x i32>, ptr %0, align 4
+ %1 = call <4 x i32> @llvm.uadd.sat.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat)
+ store <4 x i32> %1, ptr %0, align 4
%index.next = add nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -3299,10 +3271,8 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-declare <4 x float> @llvm.vp.fsub.v4i32(<4 x float>, <4 x float>, <4 x i1>, i32)
-
-define void @sink_splat_vp_fsub(ptr nocapture %a, float %x, <4 x i1> %m, i32 zeroext %vl) {
-; CHECK-LABEL: sink_splat_vp_fsub:
+define void @sink_splat_uadd_sat_commute(ptr nocapture %a, i32 signext %x) {
+; CHECK-LABEL: sink_splat_uadd_sat_commute:
; CHECK: # %bb.0: # %entry
; CHECK-NEXT: lui a2, 1
; CHECK-NEXT: add a2, a0, a2
@@ -3310,25 +3280,23 @@ define void @sink_splat_vp_fsub(ptr nocapture %a, float %x, <4 x i1> %m, i32 zer
; CHECK-NEXT: .LBB58_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
-; CHECK-NEXT: vsetvli zero, a1, e32, m1, ta, ma
-; CHECK-NEXT: vfsub.vf v8, v8, fa0, v0.t
-; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vsaddu.vx v8, v8, a1
; CHECK-NEXT: vse32.v v8, (a0)
; CHECK-NEXT: addi a0, a0, 16
; CHECK-NEXT: bne a0, a2, .LBB58_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
- %broadcast.splatinsert = insertelement <4 x float> poison, float %x, i32 0
- %broadcast.splat = shufflevector <4 x float> %broadcast.splatinsert, <4 x float> poison, <4 x i32> zeroinitializer
+ %broadcast.splatinsert = insertelement <4 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <4 x i32> %broadcast.splatinsert, <4 x i32> poison, <4 x i32> zeroinitializer
br label %vector.body
vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
- %0 = getelementptr inbounds float, ptr %a, i64 %index
- %wide.load = load <4 x float>, ptr %0, align 4
- %1 = call <4 x float> @llvm.vp.fsub.v4i32(<4 x float> %wide.load, <4 x float> %broadcast.splat, <4 x i1> %m, i32 %vl)
- store <4 x float> %1, ptr %0, align 4
+ %0 = getelementptr inbounds i32, ptr %a, i64 %index
+ %wide.load = load <4 x i32>, ptr %0, align 4
+ %1 = call <4 x i32> @llvm.uadd.sat.v4i32(<4 x i32> %broadcast.splat, <4 x i32> %wide.load)
+ store <4 x i32> %1, ptr %0, align 4
%index.next = add nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -3337,37 +3305,35 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-declare <4 x float> @llvm.vp.frsub.v4i32(<4 x float>, <4 x float>, <4 x i1>, i32)
+declare <4 x i32> @llvm.usub.sat.v4i32(<4 x i32>, <4 x i32>)
-define void @sink_splat_vp_frsub(ptr nocapture %a, float %x, <4 x i1> %m, i32 zeroext %vl) {
-; CHECK-LABEL: sink_splat_vp_frsub:
+define void @sink_splat_usub_sat(ptr nocapture %a, i32 signext %x) {
+; CHECK-LABEL: sink_splat_usub_sat:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: lui a2, 1
-; CHECK-NEXT: add a2, a0, a2
+; CHECK-NEXT: li a2, 1024
; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: .LBB59_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
-; CHECK-NEXT: vsetvli zero, a1, e32, m1, ta, ma
-; CHECK-NEXT: vfrsub.vf v8, v8, fa0, v0.t
-; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vssubu.vx v8, v8, a1
; CHECK-NEXT: vse32.v v8, (a0)
-; CHECK-NEXT: addi a0, a0, 16
-; CHECK-NEXT: bne a0, a2, .LBB59_1
+; CHECK-NEXT: addi a2, a2, 4
+; CHECK-NEXT: addi a0, a0, -16
+; CHECK-NEXT: bnez a2, .LBB59_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
- %broadcast.splatinsert = insertelement <4 x float> poison, float %x, i32 0
- %broadcast.splat = shufflevector <4 x float> %broadcast.splatinsert, <4 x float> poison, <4 x i32> zeroinitializer
+ %broadcast.splatinsert = insertelement <4 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <4 x i32> %broadcast.splatinsert, <4 x i32> poison, <4 x i32> zeroinitializer
br label %vector.body
vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
- %0 = getelementptr inbounds float, ptr %a, i64 %index
- %wide.load = load <4 x float>, ptr %0, align 4
- %1 = call <4 x float> @llvm.vp.fsub.v4i32(<4 x float> %broadcast.splat, <4 x float> %wide.load, <4 x i1> %m, i32 %vl)
- store <4 x float> %1, ptr %0, align 4
- %index.next = add nuw i64 %index, 4
+ %0 = getelementptr inbounds i32, ptr %a, i64 %index
+ %wide.load = load <4 x i32>, ptr %0, align 4
+ %1 = call <4 x i32> @llvm.usub.sat.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat)
+ store <4 x i32> %1, ptr %0, align 4
+ %index.next = sub nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -3375,10 +3341,10 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-declare <4 x i32> @llvm.vp.udiv.v4i32(<4 x i32>, <4 x i32>, <4 x i1>, i32)
+declare <4 x i32> @llvm.vp.mul.v4i32(<4 x i32>, <4 x i32>, <4 x i1>, i32)
-define void @sink_splat_vp_udiv(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
-; CHECK-LABEL: sink_splat_vp_udiv:
+define void @sink_splat_vp_mul(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_mul:
; CHECK: # %bb.0: # %entry
; CHECK-NEXT: lui a3, 1
; CHECK-NEXT: add a3, a0, a3
@@ -3387,7 +3353,7 @@ define void @sink_splat_vp_udiv(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
-; CHECK-NEXT: vdivu.vx v8, v8, a1, v0.t
+; CHECK-NEXT: vmul.vx v8, v8, a1, v0.t
; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: vse32.v v8, (a0)
; CHECK-NEXT: addi a0, a0, 16
@@ -3403,7 +3369,7 @@ vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
%0 = getelementptr inbounds i32, ptr %a, i64 %index
%wide.load = load <4 x i32>, ptr %0, align 4
- %1 = call <4 x i32> @llvm.vp.udiv.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat, <4 x i1> %m, i32 %vl)
+ %1 = call <4 x i32> @llvm.vp.mul.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat, <4 x i1> %m, i32 %vl)
store <4 x i32> %1, ptr %0, align 4
%index.next = add nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
@@ -3413,10 +3379,10 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-declare <4 x i32> @llvm.vp.sdiv.v4i32(<4 x i32>, <4 x i32>, <4 x i1>, i32)
+declare <4 x i32> @llvm.vp.add.v4i32(<4 x i32>, <4 x i32>, <4 x i1>, i32)
-define void @sink_splat_vp_sdiv(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
-; CHECK-LABEL: sink_splat_vp_sdiv:
+define void @sink_splat_vp_add(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_add:
; CHECK: # %bb.0: # %entry
; CHECK-NEXT: lui a3, 1
; CHECK-NEXT: add a3, a0, a3
@@ -3425,7 +3391,7 @@ define void @sink_splat_vp_sdiv(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
-; CHECK-NEXT: vdiv.vx v8, v8, a1, v0.t
+; CHECK-NEXT: vadd.vx v8, v8, a1, v0.t
; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: vse32.v v8, (a0)
; CHECK-NEXT: addi a0, a0, 16
@@ -3441,7 +3407,7 @@ vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
%0 = getelementptr inbounds i32, ptr %a, i64 %index
%wide.load = load <4 x i32>, ptr %0, align 4
- %1 = call <4 x i32> @llvm.vp.sdiv.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat, <4 x i1> %m, i32 %vl)
+ %1 = call <4 x i32> @llvm.vp.add.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat, <4 x i1> %m, i32 %vl)
store <4 x i32> %1, ptr %0, align 4
%index.next = add nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
@@ -3451,10 +3417,8 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-declare <4 x i32> @llvm.vp.urem.v4i32(<4 x i32>, <4 x i32>, <4 x i1>, i32)
-
-define void @sink_splat_vp_urem(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
-; CHECK-LABEL: sink_splat_vp_urem:
+define void @sink_splat_vp_add_commute(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_add_commute:
; CHECK: # %bb.0: # %entry
; CHECK-NEXT: lui a3, 1
; CHECK-NEXT: add a3, a0, a3
@@ -3463,7 +3427,7 @@ define void @sink_splat_vp_urem(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
-; CHECK-NEXT: vremu.vx v8, v8, a1, v0.t
+; CHECK-NEXT: vadd.vx v8, v8, a1, v0.t
; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: vse32.v v8, (a0)
; CHECK-NEXT: addi a0, a0, 16
@@ -3479,7 +3443,7 @@ vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
%0 = getelementptr inbounds i32, ptr %a, i64 %index
%wide.load = load <4 x i32>, ptr %0, align 4
- %1 = call <4 x i32> @llvm.vp.urem.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat, <4 x i1> %m, i32 %vl)
+ %1 = call <4 x i32> @llvm.vp.add.v4i32(<4 x i32> %broadcast.splat, <4 x i32> %wide.load, <4 x i1> %m, i32 %vl)
store <4 x i32> %1, ptr %0, align 4
%index.next = add nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
@@ -3489,10 +3453,10 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-declare <4 x i32> @llvm.vp.srem.v4i32(<4 x i32>, <4 x i32>, <4 x i1>, i32)
+declare <4 x i32> @llvm.vp.sub.v4i32(<4 x i32>, <4 x i32>, <4 x i1>, i32)
-define void @sink_splat_vp_srem(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
-; CHECK-LABEL: sink_splat_vp_srem:
+define void @sink_splat_vp_sub(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_sub:
; CHECK: # %bb.0: # %entry
; CHECK-NEXT: lui a3, 1
; CHECK-NEXT: add a3, a0, a3
@@ -3501,7 +3465,7 @@ define void @sink_splat_vp_srem(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
-; CHECK-NEXT: vrem.vx v8, v8, a1, v0.t
+; CHECK-NEXT: vsub.vx v8, v8, a1, v0.t
; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: vse32.v v8, (a0)
; CHECK-NEXT: addi a0, a0, 16
@@ -3517,7 +3481,7 @@ vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
%0 = getelementptr inbounds i32, ptr %a, i64 %index
%wide.load = load <4 x i32>, ptr %0, align 4
- %1 = call <4 x i32> @llvm.vp.srem.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat, <4 x i1> %m, i32 %vl)
+ %1 = call <4 x i32> @llvm.vp.sub.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat, <4 x i1> %m, i32 %vl)
store <4 x i32> %1, ptr %0, align 4
%index.next = add nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
@@ -3527,24 +3491,21 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-; Check that we don't sink a splat operand that has no chance of being folded.
-
-define void @sink_splat_vp_srem_commute(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
-; CHECK-LABEL: sink_splat_vp_srem_commute:
+define void @sink_splat_vp_rsub(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_rsub:
; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: lui a3, 1
+; CHECK-NEXT: add a3, a0, a3
; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
-; CHECK-NEXT: vmv.v.x v8, a1
-; CHECK-NEXT: lui a1, 1
-; CHECK-NEXT: add a1, a0, a1
; CHECK-NEXT: .LBB64_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
-; CHECK-NEXT: vle32.v v9, (a0)
+; CHECK-NEXT: vle32.v v8, (a0)
; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
-; CHECK-NEXT: vrem.vv v9, v8, v9, v0.t
+; CHECK-NEXT: vrsub.vx v8, v8, a1, v0.t
; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
-; CHECK-NEXT: vse32.v v9, (a0)
+; CHECK-NEXT: vse32.v v8, (a0)
; CHECK-NEXT: addi a0, a0, 16
-; CHECK-NEXT: bne a0, a1, .LBB64_1
+; CHECK-NEXT: bne a0, a3, .LBB64_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
@@ -3556,7 +3517,7 @@ vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
%0 = getelementptr inbounds i32, ptr %a, i64 %index
%wide.load = load <4 x i32>, ptr %0, align 4
- %1 = call <4 x i32> @llvm.vp.srem.v4i32(<4 x i32> %broadcast.splat, <4 x i32> %wide.load, <4 x i1> %m, i32 %vl)
+ %1 = call <4 x i32> @llvm.vp.sub.v4i32(<4 x i32> %broadcast.splat, <4 x i32> %wide.load, <4 x i1> %m, i32 %vl)
store <4 x i32> %1, ptr %0, align 4
%index.next = add nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
@@ -3566,115 +3527,112 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-declare <4 x float> @llvm.vp.fma.v4f32(<4 x float>, <4 x float>, <4 x float>, <4 x i1>, i32)
+declare <4 x i32> @llvm.vp.shl.v4i32(<4 x i32>, <4 x i32>, <4 x i1>, i32)
-define void @sink_splat_vp_fma(ptr noalias nocapture %a, ptr nocapture readonly %b, float %x, <4 x i1> %m, i32 zeroext %vl) {
-; CHECK-LABEL: sink_splat_vp_fma:
+define void @sink_splat_vp_shl(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_shl:
; CHECK: # %bb.0: # %entry
; CHECK-NEXT: lui a3, 1
-; CHECK-NEXT: add a3, a1, a3
+; CHECK-NEXT: add a3, a0, a3
; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: .LBB65_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
-; CHECK-NEXT: vle32.v v9, (a1)
; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
-; CHECK-NEXT: vfmadd.vf v8, fa0, v9, v0.t
+; CHECK-NEXT: vsll.vx v8, v8, a1, v0.t
; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: vse32.v v8, (a0)
-; CHECK-NEXT: addi a1, a1, 16
; CHECK-NEXT: addi a0, a0, 16
-; CHECK-NEXT: bne a1, a3, .LBB65_1
+; CHECK-NEXT: bne a0, a3, .LBB65_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
- %broadcast.splatinsert = insertelement <4 x float> poison, float %x, i32 0
- %broadcast.splat = shufflevector <4 x float> %broadcast.splatinsert, <4 x float> poison, <4 x i32> zeroinitializer
+ %broadcast.splatinsert = insertelement <4 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <4 x i32> %broadcast.splatinsert, <4 x i32> poison, <4 x i32> zeroinitializer
br label %vector.body
vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
- %0 = getelementptr inbounds float, ptr %a, i64 %index
- %wide.load = load <4 x float>, ptr %0, align 4
- %1 = getelementptr inbounds float, ptr %b, i64 %index
- %wide.load12 = load <4 x float>, ptr %1, align 4
- %2 = call <4 x float> @llvm.vp.fma.v4f32(<4 x float> %wide.load, <4 x float> %broadcast.splat, <4 x float> %wide.load12, <4 x i1> %m, i32 %vl)
- store <4 x float> %2, ptr %0, align 4
+ %0 = getelementptr inbounds i32, ptr %a, i64 %index
+ %wide.load = load <4 x i32>, ptr %0, align 4
+ %1 = call <4 x i32> @llvm.vp.shl.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat, <4 x i1> %m, i32 %vl)
+ store <4 x i32> %1, ptr %0, align 4
%index.next = add nuw i64 %index, 4
- %3 = icmp eq i64 %index.next, 1024
- br i1 %3, label %for.cond.cleanup, label %vector.body
+ %2 = icmp eq i64 %index.next, 1024
+ br i1 %2, label %for.cond.cleanup, label %vector.body
for.cond.cleanup: ; preds = %vector.body
ret void
}
-define void @sink_splat_vp_fma_commute(ptr noalias nocapture %a, ptr nocapture readonly %b, float %x, <4 x i1> %m, i32 zeroext %vl) {
-; CHECK-LABEL: sink_splat_vp_fma_commute:
+declare <4 x i32> @llvm.vp.lshr.v4i32(<4 x i32>, <4 x i32>, <4 x i1>, i32)
+
+define void @sink_splat_vp_lshr(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_lshr:
; CHECK: # %bb.0: # %entry
; CHECK-NEXT: lui a3, 1
-; CHECK-NEXT: add a3, a1, a3
+; CHECK-NEXT: add a3, a0, a3
; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: .LBB66_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
-; CHECK-NEXT: vle32.v v9, (a1)
; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
-; CHECK-NEXT: vfmadd.vf v8, fa0, v9, v0.t
+; CHECK-NEXT: vsrl.vx v8, v8, a1, v0.t
; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: vse32.v v8, (a0)
-; CHECK-NEXT: addi a1, a1, 16
; CHECK-NEXT: addi a0, a0, 16
-; CHECK-NEXT: bne a1, a3, .LBB66_1
+; CHECK-NEXT: bne a0, a3, .LBB66_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
- %broadcast.splatinsert = insertelement <4 x float> poison, float %x, i32 0
- %broadcast.splat = shufflevector <4 x float> %broadcast.splatinsert, <4 x float> poison, <4 x i32> zeroinitializer
+ %broadcast.splatinsert = insertelement <4 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <4 x i32> %broadcast.splatinsert, <4 x i32> poison, <4 x i32> zeroinitializer
br label %vector.body
vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
- %0 = getelementptr inbounds float, ptr %a, i64 %index
- %wide.load = load <4 x float>, ptr %0, align 4
- %1 = getelementptr inbounds float, ptr %b, i64 %index
- %wide.load12 = load <4 x float>, ptr %1, align 4
- %2 = call <4 x float> @llvm.vp.fma.v4f32(<4 x float> %broadcast.splat, <4 x float> %wide.load, <4 x float> %wide.load12, <4 x i1> %m, i32 %vl)
- store <4 x float> %2, ptr %0, align 4
+ %0 = getelementptr inbounds i32, ptr %a, i64 %index
+ %wide.load = load <4 x i32>, ptr %0, align 4
+ %1 = call <4 x i32> @llvm.vp.lshr.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat, <4 x i1> %m, i32 %vl)
+ store <4 x i32> %1, ptr %0, align 4
%index.next = add nuw i64 %index, 4
- %3 = icmp eq i64 %index.next, 1024
- br i1 %3, label %for.cond.cleanup, label %vector.body
+ %2 = icmp eq i64 %index.next, 1024
+ br i1 %2, label %for.cond.cleanup, label %vector.body
for.cond.cleanup: ; preds = %vector.body
ret void
}
+declare <4 x i32> @llvm.vp.ashr.v4i32(<4 x i32>, <4 x i32>, <4 x i1>, i32)
-define void @sink_splat_mul_lmul2(ptr nocapture %a, i64 signext %x) {
-; CHECK-LABEL: sink_splat_mul_lmul2:
+define void @sink_splat_vp_ashr(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_ashr:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: lui a2, 2
-; CHECK-NEXT: add a2, a0, a2
-; CHECK-NEXT: vsetivli zero, 4, e64, m2, ta, ma
+; CHECK-NEXT: lui a3, 1
+; CHECK-NEXT: add a3, a0, a3
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: .LBB67_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
-; CHECK-NEXT: vle64.v v8, (a0)
-; CHECK-NEXT: vmul.vx v8, v8, a1
-; CHECK-NEXT: vse64.v v8, (a0)
-; CHECK-NEXT: addi a0, a0, 32
-; CHECK-NEXT: bne a0, a2, .LBB67_1
+; CHECK-NEXT: vle32.v v8, (a0)
+; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
+; CHECK-NEXT: vsra.vx v8, v8, a1, v0.t
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 16
+; CHECK-NEXT: bne a0, a3, .LBB67_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
- %broadcast.splatinsert = insertelement <4 x i64> poison, i64 %x, i64 0
- %broadcast.splat = shufflevector <4 x i64> %broadcast.splatinsert, <4 x i64> poison, <4 x i32> zeroinitializer
+ %broadcast.splatinsert = insertelement <4 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <4 x i32> %broadcast.splatinsert, <4 x i32> poison, <4 x i32> zeroinitializer
br label %vector.body
vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
- %0 = getelementptr inbounds i64, ptr %a, i64 %index
- %wide.load = load <4 x i64>, ptr %0, align 8
- %1 = mul <4 x i64> %wide.load, %broadcast.splat
- store <4 x i64> %1, ptr %0, align 8
+ %0 = getelementptr inbounds i32, ptr %a, i64 %index
+ %wide.load = load <4 x i32>, ptr %0, align 4
+ %1 = call <4 x i32> @llvm.vp.ashr.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat, <4 x i1> %m, i32 %vl)
+ store <4 x i32> %1, ptr %0, align 4
%index.next = add nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -3683,32 +3641,36 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-define void @sink_splat_add_lmul2(ptr nocapture %a, i64 signext %x) {
-; CHECK-LABEL: sink_splat_add_lmul2:
+declare <4 x float> @llvm.vp.fmul.v4i32(<4 x float>, <4 x float>, <4 x i1>, i32)
+
+define void @sink_splat_vp_fmul(ptr nocapture %a, float %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_fmul:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: lui a2, 2
+; CHECK-NEXT: lui a2, 1
; CHECK-NEXT: add a2, a0, a2
-; CHECK-NEXT: vsetivli zero, 4, e64, m2, ta, ma
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: .LBB68_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
-; CHECK-NEXT: vle64.v v8, (a0)
-; CHECK-NEXT: vadd.vx v8, v8, a1
-; CHECK-NEXT: vse64.v v8, (a0)
-; CHECK-NEXT: addi a0, a0, 32
+; CHECK-NEXT: vle32.v v8, (a0)
+; CHECK-NEXT: vsetvli zero, a1, e32, m1, ta, ma
+; CHECK-NEXT: vfmul.vf v8, v8, fa0, v0.t
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 16
; CHECK-NEXT: bne a0, a2, .LBB68_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
- %broadcast.splatinsert = insertelement <4 x i64> poison, i64 %x, i64 0
- %broadcast.splat = shufflevector <4 x i64> %broadcast.splatinsert, <4 x i64> poison, <4 x i32> zeroinitializer
+ %broadcast.splatinsert = insertelement <4 x float> poison, float %x, i32 0
+ %broadcast.splat = shufflevector <4 x float> %broadcast.splatinsert, <4 x float> poison, <4 x i32> zeroinitializer
br label %vector.body
vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
- %0 = getelementptr inbounds i64, ptr %a, i64 %index
- %wide.load = load <4 x i64>, ptr %0, align 8
- %1 = add <4 x i64> %wide.load, %broadcast.splat
- store <4 x i64> %1, ptr %0, align 8
+ %0 = getelementptr inbounds float, ptr %a, i64 %index
+ %wide.load = load <4 x float>, ptr %0, align 4
+ %1 = call <4 x float> @llvm.vp.fmul.v4i32(<4 x float> %wide.load, <4 x float> %broadcast.splat, <4 x i1> %m, i32 %vl)
+ store <4 x float> %1, ptr %0, align 4
%index.next = add nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -3717,32 +3679,36 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-define void @sink_splat_sub_lmul2(ptr nocapture %a, i64 signext %x) {
-; CHECK-LABEL: sink_splat_sub_lmul2:
+declare <4 x float> @llvm.vp.fdiv.v4i32(<4 x float>, <4 x float>, <4 x i1>, i32)
+
+define void @sink_splat_vp_fdiv(ptr nocapture %a, float %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_fdiv:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: lui a2, 2
+; CHECK-NEXT: lui a2, 1
; CHECK-NEXT: add a2, a0, a2
-; CHECK-NEXT: vsetivli zero, 4, e64, m2, ta, ma
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: .LBB69_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
-; CHECK-NEXT: vle64.v v8, (a0)
-; CHECK-NEXT: vsub.vx v8, v8, a1
-; CHECK-NEXT: vse64.v v8, (a0)
-; CHECK-NEXT: addi a0, a0, 32
+; CHECK-NEXT: vle32.v v8, (a0)
+; CHECK-NEXT: vsetvli zero, a1, e32, m1, ta, ma
+; CHECK-NEXT: vfdiv.vf v8, v8, fa0, v0.t
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 16
; CHECK-NEXT: bne a0, a2, .LBB69_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
- %broadcast.splatinsert = insertelement <4 x i64> poison, i64 %x, i64 0
- %broadcast.splat = shufflevector <4 x i64> %broadcast.splatinsert, <4 x i64> poison, <4 x i32> zeroinitializer
+ %broadcast.splatinsert = insertelement <4 x float> poison, float %x, i32 0
+ %broadcast.splat = shufflevector <4 x float> %broadcast.splatinsert, <4 x float> poison, <4 x i32> zeroinitializer
br label %vector.body
vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
- %0 = getelementptr inbounds i64, ptr %a, i64 %index
- %wide.load = load <4 x i64>, ptr %0, align 8
- %1 = sub <4 x i64> %wide.load, %broadcast.splat
- store <4 x i64> %1, ptr %0, align 8
+ %0 = getelementptr inbounds float, ptr %a, i64 %index
+ %wide.load = load <4 x float>, ptr %0, align 4
+ %1 = call <4 x float> @llvm.vp.fdiv.v4i32(<4 x float> %wide.load, <4 x float> %broadcast.splat, <4 x i1> %m, i32 %vl)
+ store <4 x float> %1, ptr %0, align 4
%index.next = add nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -3751,32 +3717,1007 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-define void @sink_splat_rsub_lmul2(ptr nocapture %a, i64 signext %x) {
-; CHECK-LABEL: sink_splat_rsub_lmul2:
+define void @sink_splat_vp_frdiv(ptr nocapture %a, float %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_frdiv:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: lui a2, 2
+; CHECK-NEXT: lui a2, 1
; CHECK-NEXT: add a2, a0, a2
-; CHECK-NEXT: vsetivli zero, 4, e64, m2, ta, ma
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: .LBB70_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
-; CHECK-NEXT: vle64.v v8, (a0)
-; CHECK-NEXT: vrsub.vx v8, v8, a1
-; CHECK-NEXT: vse64.v v8, (a0)
+; CHECK-NEXT: vle32.v v8, (a0)
+; CHECK-NEXT: vsetvli zero, a1, e32, m1, ta, ma
+; CHECK-NEXT: vfrdiv.vf v8, v8, fa0, v0.t
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 16
+; CHECK-NEXT: bne a0, a2, .LBB70_1
+; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
+; CHECK-NEXT: ret
+entry:
+ %broadcast.splatinsert = insertelement <4 x float> poison, float %x, i32 0
+ %broadcast.splat = shufflevector <4 x float> %broadcast.splatinsert, <4 x float> poison, <4 x i32> zeroinitializer
+ br label %vector.body
+
+vector.body: ; preds = %vector.body, %entry
+ %index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
+ %0 = getelementptr inbounds float, ptr %a, i64 %index
+ %wide.load = load <4 x float>, ptr %0, align 4
+ %1 = call <4 x float> @llvm.vp.fdiv.v4i32(<4 x float> %broadcast.splat, <4 x float> %wide.load, <4 x i1> %m, i32 %vl)
+ store <4 x float> %1, ptr %0, align 4
+ %index.next = add nuw i64 %index, 4
+ %2 = icmp eq i64 %index.next, 1024
+ br i1 %2, label %for.cond.cleanup, label %vector.body
+
+for.cond.cleanup: ; preds = %vector.body
+ ret void
+}
+
+declare <4 x float> @llvm.vp.fadd.v4i32(<4 x float>, <4 x float>, <4 x i1>, i32)
+
+define void @sink_splat_vp_fadd(ptr nocapture %a, float %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_fadd:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: lui a2, 1
+; CHECK-NEXT: add a2, a0, a2
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: .LBB71_1: # %vector.body
+; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: vle32.v v8, (a0)
+; CHECK-NEXT: vsetvli zero, a1, e32, m1, ta, ma
+; CHECK-NEXT: vfadd.vf v8, v8, fa0, v0.t
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 16
+; CHECK-NEXT: bne a0, a2, .LBB71_1
+; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
+; CHECK-NEXT: ret
+entry:
+ %broadcast.splatinsert = insertelement <4 x float> poison, float %x, i32 0
+ %broadcast.splat = shufflevector <4 x float> %broadcast.splatinsert, <4 x float> poison, <4 x i32> zeroinitializer
+ br label %vector.body
+
+vector.body: ; preds = %vector.body, %entry
+ %index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
+ %0 = getelementptr inbounds float, ptr %a, i64 %index
+ %wide.load = load <4 x float>, ptr %0, align 4
+ %1 = call <4 x float> @llvm.vp.fadd.v4i32(<4 x float> %wide.load, <4 x float> %broadcast.splat, <4 x i1> %m, i32 %vl)
+ store <4 x float> %1, ptr %0, align 4
+ %index.next = add nuw i64 %index, 4
+ %2 = icmp eq i64 %index.next, 1024
+ br i1 %2, label %for.cond.cleanup, label %vector.body
+
+for.cond.cleanup: ; preds = %vector.body
+ ret void
+}
+
+declare <4 x float> @llvm.vp.fsub.v4i32(<4 x float>, <4 x float>, <4 x i1>, i32)
+
+define void @sink_splat_vp_fsub(ptr nocapture %a, float %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_fsub:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: lui a2, 1
+; CHECK-NEXT: add a2, a0, a2
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: .LBB72_1: # %vector.body
+; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: vle32.v v8, (a0)
+; CHECK-NEXT: vsetvli zero, a1, e32, m1, ta, ma
+; CHECK-NEXT: vfsub.vf v8, v8, fa0, v0.t
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 16
+; CHECK-NEXT: bne a0, a2, .LBB72_1
+; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
+; CHECK-NEXT: ret
+entry:
+ %broadcast.splatinsert = insertelement <4 x float> poison, float %x, i32 0
+ %broadcast.splat = shufflevector <4 x float> %broadcast.splatinsert, <4 x float> poison, <4 x i32> zeroinitializer
+ br label %vector.body
+
+vector.body: ; preds = %vector.body, %entry
+ %index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
+ %0 = getelementptr inbounds float, ptr %a, i64 %index
+ %wide.load = load <4 x float>, ptr %0, align 4
+ %1 = call <4 x float> @llvm.vp.fsub.v4i32(<4 x float> %wide.load, <4 x float> %broadcast.splat, <4 x i1> %m, i32 %vl)
+ store <4 x float> %1, ptr %0, align 4
+ %index.next = add nuw i64 %index, 4
+ %2 = icmp eq i64 %index.next, 1024
+ br i1 %2, label %for.cond.cleanup, label %vector.body
+
+for.cond.cleanup: ; preds = %vector.body
+ ret void
+}
+
+declare <4 x float> @llvm.vp.frsub.v4i32(<4 x float>, <4 x float>, <4 x i1>, i32)
+
+define void @sink_splat_vp_frsub(ptr nocapture %a, float %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_frsub:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: lui a2, 1
+; CHECK-NEXT: add a2, a0, a2
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: .LBB73_1: # %vector.body
+; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: vle32.v v8, (a0)
+; CHECK-NEXT: vsetvli zero, a1, e32, m1, ta, ma
+; CHECK-NEXT: vfrsub.vf v8, v8, fa0, v0.t
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 16
+; CHECK-NEXT: bne a0, a2, .LBB73_1
+; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
+; CHECK-NEXT: ret
+entry:
+ %broadcast.splatinsert = insertelement <4 x float> poison, float %x, i32 0
+ %broadcast.splat = shufflevector <4 x float> %broadcast.splatinsert, <4 x float> poison, <4 x i32> zeroinitializer
+ br label %vector.body
+
+vector.body: ; preds = %vector.body, %entry
+ %index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
+ %0 = getelementptr inbounds float, ptr %a, i64 %index
+ %wide.load = load <4 x float>, ptr %0, align 4
+ %1 = call <4 x float> @llvm.vp.fsub.v4i32(<4 x float> %broadcast.splat, <4 x float> %wide.load, <4 x i1> %m, i32 %vl)
+ store <4 x float> %1, ptr %0, align 4
+ %index.next = add nuw i64 %index, 4
+ %2 = icmp eq i64 %index.next, 1024
+ br i1 %2, label %for.cond.cleanup, label %vector.body
+
+for.cond.cleanup: ; preds = %vector.body
+ ret void
+}
+
+declare <4 x i32> @llvm.vp.udiv.v4i32(<4 x i32>, <4 x i32>, <4 x i1>, i32)
+
+define void @sink_splat_vp_udiv(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_udiv:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: lui a3, 1
+; CHECK-NEXT: add a3, a0, a3
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: .LBB74_1: # %vector.body
+; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: vle32.v v8, (a0)
+; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
+; CHECK-NEXT: vdivu.vx v8, v8, a1, v0.t
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 16
+; CHECK-NEXT: bne a0, a3, .LBB74_1
+; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
+; CHECK-NEXT: ret
+entry:
+ %broadcast.splatinsert = insertelement <4 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <4 x i32> %broadcast.splatinsert, <4 x i32> poison, <4 x i32> zeroinitializer
+ br label %vector.body
+
+vector.body: ; preds = %vector.body, %entry
+ %index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
+ %0 = getelementptr inbounds i32, ptr %a, i64 %index
+ %wide.load = load <4 x i32>, ptr %0, align 4
+ %1 = call <4 x i32> @llvm.vp.udiv.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat, <4 x i1> %m, i32 %vl)
+ store <4 x i32> %1, ptr %0, align 4
+ %index.next = add nuw i64 %index, 4
+ %2 = icmp eq i64 %index.next, 1024
+ br i1 %2, label %for.cond.cleanup, label %vector.body
+
+for.cond.cleanup: ; preds = %vector.body
+ ret void
+}
+
+declare <4 x i32> @llvm.vp.sdiv.v4i32(<4 x i32>, <4 x i32>, <4 x i1>, i32)
+
+define void @sink_splat_vp_sdiv(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_sdiv:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: lui a3, 1
+; CHECK-NEXT: add a3, a0, a3
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: .LBB75_1: # %vector.body
+; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: vle32.v v8, (a0)
+; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
+; CHECK-NEXT: vdiv.vx v8, v8, a1, v0.t
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 16
+; CHECK-NEXT: bne a0, a3, .LBB75_1
+; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
+; CHECK-NEXT: ret
+entry:
+ %broadcast.splatinsert = insertelement <4 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <4 x i32> %broadcast.splatinsert, <4 x i32> poison, <4 x i32> zeroinitializer
+ br label %vector.body
+
+vector.body: ; preds = %vector.body, %entry
+ %index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
+ %0 = getelementptr inbounds i32, ptr %a, i64 %index
+ %wide.load = load <4 x i32>, ptr %0, align 4
+ %1 = call <4 x i32> @llvm.vp.sdiv.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat, <4 x i1> %m, i32 %vl)
+ store <4 x i32> %1, ptr %0, align 4
+ %index.next = add nuw i64 %index, 4
+ %2 = icmp eq i64 %index.next, 1024
+ br i1 %2, label %for.cond.cleanup, label %vector.body
+
+for.cond.cleanup: ; preds = %vector.body
+ ret void
+}
+
+declare <4 x i32> @llvm.vp.urem.v4i32(<4 x i32>, <4 x i32>, <4 x i1>, i32)
+
+define void @sink_splat_vp_urem(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_urem:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: lui a3, 1
+; CHECK-NEXT: add a3, a0, a3
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: .LBB76_1: # %vector.body
+; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: vle32.v v8, (a0)
+; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
+; CHECK-NEXT: vremu.vx v8, v8, a1, v0.t
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 16
+; CHECK-NEXT: bne a0, a3, .LBB76_1
+; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
+; CHECK-NEXT: ret
+entry:
+ %broadcast.splatinsert = insertelement <4 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <4 x i32> %broadcast.splatinsert, <4 x i32> poison, <4 x i32> zeroinitializer
+ br label %vector.body
+
+vector.body: ; preds = %vector.body, %entry
+ %index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
+ %0 = getelementptr inbounds i32, ptr %a, i64 %index
+ %wide.load = load <4 x i32>, ptr %0, align 4
+ %1 = call <4 x i32> @llvm.vp.urem.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat, <4 x i1> %m, i32 %vl)
+ store <4 x i32> %1, ptr %0, align 4
+ %index.next = add nuw i64 %index, 4
+ %2 = icmp eq i64 %index.next, 1024
+ br i1 %2, label %for.cond.cleanup, label %vector.body
+
+for.cond.cleanup: ; preds = %vector.body
+ ret void
+}
+
+declare <4 x i32> @llvm.vp.srem.v4i32(<4 x i32>, <4 x i32>, <4 x i1>, i32)
+
+define void @sink_splat_vp_srem(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_srem:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: lui a3, 1
+; CHECK-NEXT: add a3, a0, a3
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: .LBB77_1: # %vector.body
+; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: vle32.v v8, (a0)
+; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
+; CHECK-NEXT: vrem.vx v8, v8, a1, v0.t
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 16
+; CHECK-NEXT: bne a0, a3, .LBB77_1
+; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
+; CHECK-NEXT: ret
+entry:
+ %broadcast.splatinsert = insertelement <4 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <4 x i32> %broadcast.splatinsert, <4 x i32> poison, <4 x i32> zeroinitializer
+ br label %vector.body
+
+vector.body: ; preds = %vector.body, %entry
+ %index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
+ %0 = getelementptr inbounds i32, ptr %a, i64 %index
+ %wide.load = load <4 x i32>, ptr %0, align 4
+ %1 = call <4 x i32> @llvm.vp.srem.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat, <4 x i1> %m, i32 %vl)
+ store <4 x i32> %1, ptr %0, align 4
+ %index.next = add nuw i64 %index, 4
+ %2 = icmp eq i64 %index.next, 1024
+ br i1 %2, label %for.cond.cleanup, label %vector.body
+
+for.cond.cleanup: ; preds = %vector.body
+ ret void
+}
+
+; Check that we don't sink a splat operand that has no chance of being folded.
+
+define void @sink_splat_vp_srem_commute(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_srem_commute:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vmv.v.x v8, a1
+; CHECK-NEXT: lui a1, 1
+; CHECK-NEXT: add a1, a0, a1
+; CHECK-NEXT: .LBB78_1: # %vector.body
+; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: vle32.v v9, (a0)
+; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
+; CHECK-NEXT: vrem.vv v9, v8, v9, v0.t
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vse32.v v9, (a0)
+; CHECK-NEXT: addi a0, a0, 16
+; CHECK-NEXT: bne a0, a1, .LBB78_1
+; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
+; CHECK-NEXT: ret
+entry:
+ %broadcast.splatinsert = insertelement <4 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <4 x i32> %broadcast.splatinsert, <4 x i32> poison, <4 x i32> zeroinitializer
+ br label %vector.body
+
+vector.body: ; preds = %vector.body, %entry
+ %index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
+ %0 = getelementptr inbounds i32, ptr %a, i64 %index
+ %wide.load = load <4 x i32>, ptr %0, align 4
+ %1 = call <4 x i32> @llvm.vp.srem.v4i32(<4 x i32> %broadcast.splat, <4 x i32> %wide.load, <4 x i1> %m, i32 %vl)
+ store <4 x i32> %1, ptr %0, align 4
+ %index.next = add nuw i64 %index, 4
+ %2 = icmp eq i64 %index.next, 1024
+ br i1 %2, label %for.cond.cleanup, label %vector.body
+
+for.cond.cleanup: ; preds = %vector.body
+ ret void
+}
+
+declare <4 x float> @llvm.vp.fma.v4f32(<4 x float>, <4 x float>, <4 x float>, <4 x i1>, i32)
+
+define void @sink_splat_vp_fma(ptr noalias nocapture %a, ptr nocapture readonly %b, float %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_fma:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: lui a3, 1
+; CHECK-NEXT: add a3, a1, a3
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: .LBB79_1: # %vector.body
+; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: vle32.v v8, (a0)
+; CHECK-NEXT: vle32.v v9, (a1)
+; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
+; CHECK-NEXT: vfmadd.vf v8, fa0, v9, v0.t
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: addi a1, a1, 16
+; CHECK-NEXT: addi a0, a0, 16
+; CHECK-NEXT: bne a1, a3, .LBB79_1
+; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
+; CHECK-NEXT: ret
+entry:
+ %broadcast.splatinsert = insertelement <4 x float> poison, float %x, i32 0
+ %broadcast.splat = shufflevector <4 x float> %broadcast.splatinsert, <4 x float> poison, <4 x i32> zeroinitializer
+ br label %vector.body
+
+vector.body: ; preds = %vector.body, %entry
+ %index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
+ %0 = getelementptr inbounds float, ptr %a, i64 %index
+ %wide.load = load <4 x float>, ptr %0, align 4
+ %1 = getelementptr inbounds float, ptr %b, i64 %index
+ %wide.load12 = load <4 x float>, ptr %1, align 4
+ %2 = call <4 x float> @llvm.vp.fma.v4f32(<4 x float> %wide.load, <4 x float> %broadcast.splat, <4 x float> %wide.load12, <4 x i1> %m, i32 %vl)
+ store <4 x float> %2, ptr %0, align 4
+ %index.next = add nuw i64 %index, 4
+ %3 = icmp eq i64 %index.next, 1024
+ br i1 %3, label %for.cond.cleanup, label %vector.body
+
+for.cond.cleanup: ; preds = %vector.body
+ ret void
+}
+
+define void @sink_splat_vp_fma_commute(ptr noalias nocapture %a, ptr nocapture readonly %b, float %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_fma_commute:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: lui a3, 1
+; CHECK-NEXT: add a3, a1, a3
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: .LBB80_1: # %vector.body
+; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: vle32.v v8, (a0)
+; CHECK-NEXT: vle32.v v9, (a1)
+; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
+; CHECK-NEXT: vfmadd.vf v8, fa0, v9, v0.t
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: addi a1, a1, 16
+; CHECK-NEXT: addi a0, a0, 16
+; CHECK-NEXT: bne a1, a3, .LBB80_1
+; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
+; CHECK-NEXT: ret
+entry:
+ %broadcast.splatinsert = insertelement <4 x float> poison, float %x, i32 0
+ %broadcast.splat = shufflevector <4 x float> %broadcast.splatinsert, <4 x float> poison, <4 x i32> zeroinitializer
+ br label %vector.body
+
+vector.body: ; preds = %vector.body, %entry
+ %index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
+ %0 = getelementptr inbounds float, ptr %a, i64 %index
+ %wide.load = load <4 x float>, ptr %0, align 4
+ %1 = getelementptr inbounds float, ptr %b, i64 %index
+ %wide.load12 = load <4 x float>, ptr %1, align 4
+ %2 = call <4 x float> @llvm.vp.fma.v4f32(<4 x float> %broadcast.splat, <4 x float> %wide.load, <4 x float> %wide.load12, <4 x i1> %m, i32 %vl)
+ store <4 x float> %2, ptr %0, align 4
+ %index.next = add nuw i64 %index, 4
+ %3 = icmp eq i64 %index.next, 1024
+ br i1 %3, label %for.cond.cleanup, label %vector.body
+
+for.cond.cleanup: ; preds = %vector.body
+ ret void
+}
+
+
+define void @sink_splat_mul_lmul2(ptr nocapture %a, i64 signext %x) {
+; CHECK-LABEL: sink_splat_mul_lmul2:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: lui a2, 2
+; CHECK-NEXT: add a2, a0, a2
+; CHECK-NEXT: vsetivli zero, 4, e64, m2, ta, ma
+; CHECK-NEXT: .LBB81_1: # %vector.body
+; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: vle64.v v8, (a0)
+; CHECK-NEXT: vmul.vx v8, v8, a1
+; CHECK-NEXT: vse64.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 32
+; CHECK-NEXT: bne a0, a2, .LBB81_1
+; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
+; CHECK-NEXT: ret
+entry:
+ %broadcast.splatinsert = insertelement <4 x i64> poison, i64 %x, i64 0
+ %broadcast.splat = shufflevector <4 x i64> %broadcast.splatinsert, <4 x i64> poison, <4 x i32> zeroinitializer
+ br label %vector.body
+
+vector.body: ; preds = %vector.body, %entry
+ %index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
+ %0 = getelementptr inbounds i64, ptr %a, i64 %index
+ %wide.load = load <4 x i64>, ptr %0, align 8
+ %1 = mul <4 x i64> %wide.load, %broadcast.splat
+ store <4 x i64> %1, ptr %0, align 8
+ %index.next = add nuw i64 %index, 4
+ %2 = icmp eq i64 %index.next, 1024
+ br i1 %2, label %for.cond.cleanup, label %vector.body
+
+for.cond.cleanup: ; preds = %vector.body
+ ret void
+}
+
+define void @sink_splat_add_lmul2(ptr nocapture %a, i64 signext %x) {
+; CHECK-LABEL: sink_splat_add_lmul2:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: lui a2, 2
+; CHECK-NEXT: add a2, a0, a2
+; CHECK-NEXT: vsetivli zero, 4, e64, m2, ta, ma
+; CHECK-NEXT: .LBB82_1: # %vector.body
+; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: vle64.v v8, (a0)
+; CHECK-NEXT: vadd.vx v8, v8, a1
+; CHECK-NEXT: vse64.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 32
+; CHECK-NEXT: bne a0, a2, .LBB82_1
+; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
+; CHECK-NEXT: ret
+entry:
+ %broadcast.splatinsert = insertelement <4 x i64> poison, i64 %x, i64 0
+ %broadcast.splat = shufflevector <4 x i64> %broadcast.splatinsert, <4 x i64> poison, <4 x i32> zeroinitializer
+ br label %vector.body
+
+vector.body: ; preds = %vector.body, %entry
+ %index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
+ %0 = getelementptr inbounds i64, ptr %a, i64 %index
+ %wide.load = load <4 x i64>, ptr %0, align 8
+ %1 = add <4 x i64> %wide.load, %broadcast.splat
+ store <4 x i64> %1, ptr %0, align 8
+ %index.next = add nuw i64 %index, 4
+ %2 = icmp eq i64 %index.next, 1024
+ br i1 %2, label %for.cond.cleanup, label %vector.body
+
+for.cond.cleanup: ; preds = %vector.body
+ ret void
+}
+
+define void @sink_splat_sub_lmul2(ptr nocapture %a, i64 signext %x) {
+; CHECK-LABEL: sink_splat_sub_lmul2:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: lui a2, 2
+; CHECK-NEXT: add a2, a0, a2
+; CHECK-NEXT: vsetivli zero, 4, e64, m2, ta, ma
+; CHECK-NEXT: .LBB83_1: # %vector.body
+; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: vle64.v v8, (a0)
+; CHECK-NEXT: vsub.vx v8, v8, a1
+; CHECK-NEXT: vse64.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 32
+; CHECK-NEXT: bne a0, a2, .LBB83_1
+; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
+; CHECK-NEXT: ret
+entry:
+ %broadcast.splatinsert = insertelement <4 x i64> poison, i64 %x, i64 0
+ %broadcast.splat = shufflevector <4 x i64> %broadcast.splatinsert, <4 x i64> poison, <4 x i32> zeroinitializer
+ br label %vector.body
+
+vector.body: ; preds = %vector.body, %entry
+ %index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
+ %0 = getelementptr inbounds i64, ptr %a, i64 %index
+ %wide.load = load <4 x i64>, ptr %0, align 8
+ %1 = sub <4 x i64> %wide.load, %broadcast.splat
+ store <4 x i64> %1, ptr %0, align 8
+ %index.next = add nuw i64 %index, 4
+ %2 = icmp eq i64 %index.next, 1024
+ br i1 %2, label %for.cond.cleanup, label %vector.body
+
+for.cond.cleanup: ; preds = %vector.body
+ ret void
+}
+
+define void @sink_splat_rsub_lmul2(ptr nocapture %a, i64 signext %x) {
+; CHECK-LABEL: sink_splat_rsub_lmul2:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: lui a2, 2
+; CHECK-NEXT: add a2, a0, a2
+; CHECK-NEXT: vsetivli zero, 4, e64, m2, ta, ma
+; CHECK-NEXT: .LBB84_1: # %vector.body
+; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: vle64.v v8, (a0)
+; CHECK-NEXT: vrsub.vx v8, v8, a1
+; CHECK-NEXT: vse64.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 32
+; CHECK-NEXT: bne a0, a2, .LBB84_1
+; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
+; CHECK-NEXT: ret
+entry:
+ %broadcast.splatinsert = insertelement <4 x i64> poison, i64 %x, i64 0
+ %broadcast.splat = shufflevector <4 x i64> %broadcast.splatinsert, <4 x i64> poison, <4 x i32> zeroinitializer
+ br label %vector.body
+
+vector.body: ; preds = %vector.body, %entry
+ %index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
+ %0 = getelementptr inbounds i64, ptr %a, i64 %index
+ %wide.load = load <4 x i64>, ptr %0, align 8
+ %1 = sub <4 x i64> %broadcast.splat, %wide.load
+ store <4 x i64> %1, ptr %0, align 8
+ %index.next = add nuw i64 %index, 4
+ %2 = icmp eq i64 %index.next, 1024
+ br i1 %2, label %for.cond.cleanup, label %vector.body
+
+for.cond.cleanup: ; preds = %vector.body
+ ret void
+}
+
+define void @sink_splat_and_lmul2(ptr nocapture %a, i64 signext %x) {
+; CHECK-LABEL: sink_splat_and_lmul2:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: lui a2, 2
+; CHECK-NEXT: add a2, a0, a2
+; CHECK-NEXT: vsetivli zero, 4, e64, m2, ta, ma
+; CHECK-NEXT: .LBB85_1: # %vector.body
+; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: vle64.v v8, (a0)
+; CHECK-NEXT: vand.vx v8, v8, a1
+; CHECK-NEXT: vse64.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 32
+; CHECK-NEXT: bne a0, a2, .LBB85_1
+; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
+; CHECK-NEXT: ret
+entry:
+ %broadcast.splatinsert = insertelement <4 x i64> poison, i64 %x, i64 0
+ %broadcast.splat = shufflevector <4 x i64> %broadcast.splatinsert, <4 x i64> poison, <4 x i32> zeroinitializer
+ br label %vector.body
+
+vector.body: ; preds = %vector.body, %entry
+ %index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
+ %0 = getelementptr inbounds i64, ptr %a, i64 %index
+ %wide.load = load <4 x i64>, ptr %0, align 8
+ %1 = and <4 x i64> %wide.load, %broadcast.splat
+ store <4 x i64> %1, ptr %0, align 8
+ %index.next = add nuw i64 %index, 4
+ %2 = icmp eq i64 %index.next, 1024
+ br i1 %2, label %for.cond.cleanup, label %vector.body
+
+for.cond.cleanup: ; preds = %vector.body
+ ret void
+}
+
+define void @sink_splat_or_lmul2(ptr nocapture %a, i64 signext %x) {
+; CHECK-LABEL: sink_splat_or_lmul2:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: lui a2, 2
+; CHECK-NEXT: add a2, a0, a2
+; CHECK-NEXT: vsetivli zero, 4, e64, m2, ta, ma
+; CHECK-NEXT: .LBB86_1: # %vector.body
+; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: vle64.v v8, (a0)
+; CHECK-NEXT: vor.vx v8, v8, a1
+; CHECK-NEXT: vse64.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 32
+; CHECK-NEXT: bne a0, a2, .LBB86_1
+; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
+; CHECK-NEXT: ret
+entry:
+ %broadcast.splatinsert = insertelement <4 x i64> poison, i64 %x, i64 0
+ %broadcast.splat = shufflevector <4 x i64> %broadcast.splatinsert, <4 x i64> poison, <4 x i32> zeroinitializer
+ br label %vector.body
+
+vector.body: ; preds = %vector.body, %entry
+ %index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
+ %0 = getelementptr inbounds i64, ptr %a, i64 %index
+ %wide.load = load <4 x i64>, ptr %0, align 8
+ %1 = or <4 x i64> %wide.load, %broadcast.splat
+ store <4 x i64> %1, ptr %0, align 8
+ %index.next = add nuw i64 %index, 4
+ %2 = icmp eq i64 %index.next, 1024
+ br i1 %2, label %for.cond.cleanup, label %vector.body
+
+for.cond.cleanup: ; preds = %vector.body
+ ret void
+}
+
+define void @sink_splat_xor_lmul2(ptr nocapture %a, i64 signext %x) {
+; CHECK-LABEL: sink_splat_xor_lmul2:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: lui a2, 2
+; CHECK-NEXT: add a2, a0, a2
+; CHECK-NEXT: vsetivli zero, 4, e64, m2, ta, ma
+; CHECK-NEXT: .LBB87_1: # %vector.body
+; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: vle64.v v8, (a0)
+; CHECK-NEXT: vxor.vx v8, v8, a1
+; CHECK-NEXT: vse64.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 32
+; CHECK-NEXT: bne a0, a2, .LBB87_1
+; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
+; CHECK-NEXT: ret
+entry:
+ %broadcast.splatinsert = insertelement <4 x i64> poison, i64 %x, i64 0
+ %broadcast.splat = shufflevector <4 x i64> %broadcast.splatinsert, <4 x i64> poison, <4 x i32> zeroinitializer
+ br label %vector.body
+
+vector.body: ; preds = %vector.body, %entry
+ %index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
+ %0 = getelementptr inbounds i64, ptr %a, i64 %index
+ %wide.load = load <4 x i64>, ptr %0, align 8
+ %1 = xor <4 x i64> %wide.load, %broadcast.splat
+ store <4 x i64> %1, ptr %0, align 8
+ %index.next = add nuw i64 %index, 4
+ %2 = icmp eq i64 %index.next, 1024
+ br i1 %2, label %for.cond.cleanup, label %vector.body
+
+for.cond.cleanup: ; preds = %vector.body
+ ret void
+}
+
+define void @sink_splat_mul_lmul8(ptr nocapture %a, i32 signext %x) {
+; CHECK-LABEL: sink_splat_mul_lmul8:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: lui a2, 1
+; CHECK-NEXT: add a2, a0, a2
+; CHECK-NEXT: li a3, 32
+; CHECK-NEXT: vsetvli zero, a3, e32, m8, ta, ma
+; CHECK-NEXT: .LBB88_1: # %vector.body
+; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: vle32.v v8, (a0)
+; CHECK-NEXT: vmul.vx v8, v8, a1
+; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 16
+; CHECK-NEXT: bne a0, a2, .LBB88_1
+; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
+; CHECK-NEXT: ret
+entry:
+ %broadcast.splatinsert = insertelement <32 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <32 x i32> %broadcast.splatinsert, <32 x i32> poison, <32 x i32> zeroinitializer
+ br label %vector.body
+
+vector.body: ; preds = %vector.body, %entry
+ %index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
+ %0 = getelementptr inbounds i32, ptr %a, i64 %index
+ %wide.load = load <32 x i32>, ptr %0, align 4
+ %1 = mul <32 x i32> %wide.load, %broadcast.splat
+ store <32 x i32> %1, ptr %0, align 4
+ %index.next = add nuw i64 %index, 4
+ %2 = icmp eq i64 %index.next, 1024
+ br i1 %2, label %for.cond.cleanup, label %vector.body
+
+for.cond.cleanup: ; preds = %vector.body
+ ret void
+}
+
+define void @sink_splat_add_lmul8(ptr nocapture %a, i32 signext %x) {
+; CHECK-LABEL: sink_splat_add_lmul8:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: lui a2, 1
+; CHECK-NEXT: add a2, a0, a2
+; CHECK-NEXT: li a3, 32
+; CHECK-NEXT: vsetvli zero, a3, e32, m8, ta, ma
+; CHECK-NEXT: .LBB89_1: # %vector.body
+; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: vle32.v v8, (a0)
+; CHECK-NEXT: vadd.vx v8, v8, a1
+; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 16
+; CHECK-NEXT: bne a0, a2, .LBB89_1
+; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
+; CHECK-NEXT: ret
+entry:
+ %broadcast.splatinsert = insertelement <32 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <32 x i32> %broadcast.splatinsert, <32 x i32> poison, <32 x i32> zeroinitializer
+ br label %vector.body
+
+vector.body: ; preds = %vector.body, %entry
+ %index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
+ %0 = getelementptr inbounds i32, ptr %a, i64 %index
+ %wide.load = load <32 x i32>, ptr %0, align 4
+ %1 = add <32 x i32> %wide.load, %broadcast.splat
+ store <32 x i32> %1, ptr %0, align 4
+ %index.next = add nuw i64 %index, 4
+ %2 = icmp eq i64 %index.next, 1024
+ br i1 %2, label %for.cond.cleanup, label %vector.body
+
+for.cond.cleanup: ; preds = %vector.body
+ ret void
+}
+
+define void @sink_splat_sub_lmul8(ptr nocapture %a, i32 signext %x) {
+; CHECK-LABEL: sink_splat_sub_lmul8:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: lui a2, 1
+; CHECK-NEXT: add a2, a0, a2
+; CHECK-NEXT: li a3, 32
+; CHECK-NEXT: vsetvli zero, a3, e32, m8, ta, ma
+; CHECK-NEXT: .LBB90_1: # %vector.body
+; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: vle32.v v8, (a0)
+; CHECK-NEXT: vsub.vx v8, v8, a1
+; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 16
+; CHECK-NEXT: bne a0, a2, .LBB90_1
+; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
+; CHECK-NEXT: ret
+entry:
+ %broadcast.splatinsert = insertelement <32 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <32 x i32> %broadcast.splatinsert, <32 x i32> poison, <32 x i32> zeroinitializer
+ br label %vector.body
+
+vector.body: ; preds = %vector.body, %entry
+ %index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
+ %0 = getelementptr inbounds i32, ptr %a, i64 %index
+ %wide.load = load <32 x i32>, ptr %0, align 4
+ %1 = sub <32 x i32> %wide.load, %broadcast.splat
+ store <32 x i32> %1, ptr %0, align 4
+ %index.next = add nuw i64 %index, 4
+ %2 = icmp eq i64 %index.next, 1024
+ br i1 %2, label %for.cond.cleanup, label %vector.body
+
+for.cond.cleanup: ; preds = %vector.body
+ ret void
+}
+
+define void @sink_splat_rsub_lmul8(ptr nocapture %a, i32 signext %x) {
+; CHECK-LABEL: sink_splat_rsub_lmul8:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: lui a2, 1
+; CHECK-NEXT: add a2, a0, a2
+; CHECK-NEXT: li a3, 32
+; CHECK-NEXT: vsetvli zero, a3, e32, m8, ta, ma
+; CHECK-NEXT: .LBB91_1: # %vector.body
+; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: vle32.v v8, (a0)
+; CHECK-NEXT: vrsub.vx v8, v8, a1
+; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 16
+; CHECK-NEXT: bne a0, a2, .LBB91_1
+; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
+; CHECK-NEXT: ret
+entry:
+ %broadcast.splatinsert = insertelement <32 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <32 x i32> %broadcast.splatinsert, <32 x i32> poison, <32 x i32> zeroinitializer
+ br label %vector.body
+
+vector.body: ; preds = %vector.body, %entry
+ %index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
+ %0 = getelementptr inbounds i32, ptr %a, i64 %index
+ %wide.load = load <32 x i32>, ptr %0, align 4
+ %1 = sub <32 x i32> %broadcast.splat, %wide.load
+ store <32 x i32> %1, ptr %0, align 4
+ %index.next = add nuw i64 %index, 4
+ %2 = icmp eq i64 %index.next, 1024
+ br i1 %2, label %for.cond.cleanup, label %vector.body
+
+for.cond.cleanup: ; preds = %vector.body
+ ret void
+}
+
+define void @sink_splat_and_lmul8(ptr nocapture %a, i32 signext %x) {
+; CHECK-LABEL: sink_splat_and_lmul8:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: lui a2, 1
+; CHECK-NEXT: add a2, a0, a2
+; CHECK-NEXT: li a3, 32
+; CHECK-NEXT: vsetvli zero, a3, e32, m8, ta, ma
+; CHECK-NEXT: .LBB92_1: # %vector.body
+; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: vle32.v v8, (a0)
+; CHECK-NEXT: vand.vx v8, v8, a1
+; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 16
+; CHECK-NEXT: bne a0, a2, .LBB92_1
+; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
+; CHECK-NEXT: ret
+entry:
+ %broadcast.splatinsert = insertelement <32 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <32 x i32> %broadcast.splatinsert, <32 x i32> poison, <32 x i32> zeroinitializer
+ br label %vector.body
+
+vector.body: ; preds = %vector.body, %entry
+ %index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
+ %0 = getelementptr inbounds i32, ptr %a, i64 %index
+ %wide.load = load <32 x i32>, ptr %0, align 4
+ %1 = and <32 x i32> %wide.load, %broadcast.splat
+ store <32 x i32> %1, ptr %0, align 4
+ %index.next = add nuw i64 %index, 4
+ %2 = icmp eq i64 %index.next, 1024
+ br i1 %2, label %for.cond.cleanup, label %vector.body
+
+for.cond.cleanup: ; preds = %vector.body
+ ret void
+}
+
+define void @sink_splat_or_lmul8(ptr nocapture %a, i32 signext %x) {
+; CHECK-LABEL: sink_splat_or_lmul8:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: lui a2, 1
+; CHECK-NEXT: add a2, a0, a2
+; CHECK-NEXT: li a3, 32
+; CHECK-NEXT: vsetvli zero, a3, e32, m8, ta, ma
+; CHECK-NEXT: .LBB93_1: # %vector.body
+; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: vle32.v v8, (a0)
+; CHECK-NEXT: vor.vx v8, v8, a1
+; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 16
+; CHECK-NEXT: bne a0, a2, .LBB93_1
+; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
+; CHECK-NEXT: ret
+entry:
+ %broadcast.splatinsert = insertelement <32 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <32 x i32> %broadcast.splatinsert, <32 x i32> poison, <32 x i32> zeroinitializer
+ br label %vector.body
+
+vector.body: ; preds = %vector.body, %entry
+ %index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
+ %0 = getelementptr inbounds i32, ptr %a, i64 %index
+ %wide.load = load <32 x i32>, ptr %0, align 4
+ %1 = or <32 x i32> %wide.load, %broadcast.splat
+ store <32 x i32> %1, ptr %0, align 4
+ %index.next = add nuw i64 %index, 4
+ %2 = icmp eq i64 %index.next, 1024
+ br i1 %2, label %for.cond.cleanup, label %vector.body
+
+for.cond.cleanup: ; preds = %vector.body
+ ret void
+}
+
+define void @sink_splat_xor_lmul8(ptr nocapture %a, i32 signext %x) {
+; CHECK-LABEL: sink_splat_xor_lmul8:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: lui a2, 1
+; CHECK-NEXT: add a2, a0, a2
+; CHECK-NEXT: li a3, 32
+; CHECK-NEXT: vsetvli zero, a3, e32, m8, ta, ma
+; CHECK-NEXT: .LBB94_1: # %vector.body
+; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: vle32.v v8, (a0)
+; CHECK-NEXT: vxor.vx v8, v8, a1
+; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 16
+; CHECK-NEXT: bne a0, a2, .LBB94_1
+; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
+; CHECK-NEXT: ret
+entry:
+ %broadcast.splatinsert = insertelement <32 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <32 x i32> %broadcast.splatinsert, <32 x i32> poison, <32 x i32> zeroinitializer
+ br label %vector.body
+
+vector.body: ; preds = %vector.body, %entry
+ %index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
+ %0 = getelementptr inbounds i32, ptr %a, i64 %index
+ %wide.load = load <32 x i32>, ptr %0, align 4
+ %1 = xor <32 x i32> %wide.load, %broadcast.splat
+ store <32 x i32> %1, ptr %0, align 4
+ %index.next = add nuw i64 %index, 4
+ %2 = icmp eq i64 %index.next, 1024
+ br i1 %2, label %for.cond.cleanup, label %vector.body
+
+for.cond.cleanup: ; preds = %vector.body
+ ret void
+}
+
+define void @sink_splat_mul_lmulmf2(ptr nocapture %a, i32 signext %x) {
+; CHECK-LABEL: sink_splat_mul_lmulmf2:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: lui a2, 2
+; CHECK-NEXT: add a2, a0, a2
+; CHECK-NEXT: vsetivli zero, 2, e32, mf2, ta, ma
+; CHECK-NEXT: .LBB95_1: # %vector.body
+; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: vle32.v v8, (a0)
+; CHECK-NEXT: vmul.vx v8, v8, a1
+; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 32
+; CHECK-NEXT: bne a0, a2, .LBB95_1
+; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
+; CHECK-NEXT: ret
+entry:
+ %broadcast.splatinsert = insertelement <2 x i32> poison, i32 %x, i64 0
+ %broadcast.splat = shufflevector <2 x i32> %broadcast.splatinsert, <2 x i32> poison, <2 x i32> zeroinitializer
+ br label %vector.body
+
+vector.body: ; preds = %vector.body, %entry
+ %index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
+ %0 = getelementptr inbounds i64, ptr %a, i64 %index
+ %wide.load = load <2 x i32>, ptr %0, align 8
+ %1 = mul <2 x i32> %wide.load, %broadcast.splat
+ store <2 x i32> %1, ptr %0, align 8
+ %index.next = add nuw i64 %index, 4
+ %2 = icmp eq i64 %index.next, 1024
+ br i1 %2, label %for.cond.cleanup, label %vector.body
+
+for.cond.cleanup: ; preds = %vector.body
+ ret void
+}
+
+define void @sink_splat_add_lmulmf2(ptr nocapture %a, i32 signext %x) {
+; CHECK-LABEL: sink_splat_add_lmulmf2:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: lui a2, 2
+; CHECK-NEXT: add a2, a0, a2
+; CHECK-NEXT: vsetivli zero, 2, e32, mf2, ta, ma
+; CHECK-NEXT: .LBB96_1: # %vector.body
+; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: vle32.v v8, (a0)
+; CHECK-NEXT: vadd.vx v8, v8, a1
+; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 32
+; CHECK-NEXT: bne a0, a2, .LBB96_1
+; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
+; CHECK-NEXT: ret
+entry:
+ %broadcast.splatinsert = insertelement <2 x i32> poison, i32 %x, i64 0
+ %broadcast.splat = shufflevector <2 x i32> %broadcast.splatinsert, <2 x i32> poison, <2 x i32> zeroinitializer
+ br label %vector.body
+
+vector.body: ; preds = %vector.body, %entry
+ %index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
+ %0 = getelementptr inbounds i64, ptr %a, i64 %index
+ %wide.load = load <2 x i32>, ptr %0, align 8
+ %1 = add <2 x i32> %wide.load, %broadcast.splat
+ store <2 x i32> %1, ptr %0, align 8
+ %index.next = add nuw i64 %index, 4
+ %2 = icmp eq i64 %index.next, 1024
+ br i1 %2, label %for.cond.cleanup, label %vector.body
+
+for.cond.cleanup: ; preds = %vector.body
+ ret void
+}
+
+define void @sink_splat_sub_lmulmf2(ptr nocapture %a, i32 signext %x) {
+; CHECK-LABEL: sink_splat_sub_lmulmf2:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: lui a2, 2
+; CHECK-NEXT: add a2, a0, a2
+; CHECK-NEXT: vsetivli zero, 2, e32, mf2, ta, ma
+; CHECK-NEXT: .LBB97_1: # %vector.body
+; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: vle32.v v8, (a0)
+; CHECK-NEXT: vsub.vx v8, v8, a1
+; CHECK-NEXT: vse32.v v8, (a0)
; CHECK-NEXT: addi a0, a0, 32
-; CHECK-NEXT: bne a0, a2, .LBB70_1
+; CHECK-NEXT: bne a0, a2, .LBB97_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
- %broadcast.splatinsert = insertelement <4 x i64> poison, i64 %x, i64 0
- %broadcast.splat = shufflevector <4 x i64> %broadcast.splatinsert, <4 x i64> poison, <4 x i32> zeroinitializer
+ %broadcast.splatinsert = insertelement <2 x i32> poison, i32 %x, i64 0
+ %broadcast.splat = shufflevector <2 x i32> %broadcast.splatinsert, <2 x i32> poison, <2 x i32> zeroinitializer
br label %vector.body
vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
%0 = getelementptr inbounds i64, ptr %a, i64 %index
- %wide.load = load <4 x i64>, ptr %0, align 8
- %1 = sub <4 x i64> %broadcast.splat, %wide.load
- store <4 x i64> %1, ptr %0, align 8
+ %wide.load = load <2 x i32>, ptr %0, align 8
+ %1 = sub <2 x i32> %wide.load, %broadcast.splat
+ store <2 x i32> %1, ptr %0, align 8
%index.next = add nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -3785,32 +4726,32 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-define void @sink_splat_and_lmul2(ptr nocapture %a, i64 signext %x) {
-; CHECK-LABEL: sink_splat_and_lmul2:
+define void @sink_splat_rsub_lmulmf2(ptr nocapture %a, i32 signext %x) {
+; CHECK-LABEL: sink_splat_rsub_lmulmf2:
; CHECK: # %bb.0: # %entry
; CHECK-NEXT: lui a2, 2
; CHECK-NEXT: add a2, a0, a2
-; CHECK-NEXT: vsetivli zero, 4, e64, m2, ta, ma
-; CHECK-NEXT: .LBB71_1: # %vector.body
+; CHECK-NEXT: vsetivli zero, 2, e32, mf2, ta, ma
+; CHECK-NEXT: .LBB98_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
-; CHECK-NEXT: vle64.v v8, (a0)
-; CHECK-NEXT: vand.vx v8, v8, a1
-; CHECK-NEXT: vse64.v v8, (a0)
+; CHECK-NEXT: vle32.v v8, (a0)
+; CHECK-NEXT: vrsub.vx v8, v8, a1
+; CHECK-NEXT: vse32.v v8, (a0)
; CHECK-NEXT: addi a0, a0, 32
-; CHECK-NEXT: bne a0, a2, .LBB71_1
+; CHECK-NEXT: bne a0, a2, .LBB98_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
- %broadcast.splatinsert = insertelement <4 x i64> poison, i64 %x, i64 0
- %broadcast.splat = shufflevector <4 x i64> %broadcast.splatinsert, <4 x i64> poison, <4 x i32> zeroinitializer
+ %broadcast.splatinsert = insertelement <2 x i32> poison, i32 %x, i64 0
+ %broadcast.splat = shufflevector <2 x i32> %broadcast.splatinsert, <2 x i32> poison, <2 x i32> zeroinitializer
br label %vector.body
vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
%0 = getelementptr inbounds i64, ptr %a, i64 %index
- %wide.load = load <4 x i64>, ptr %0, align 8
- %1 = and <4 x i64> %wide.load, %broadcast.splat
- store <4 x i64> %1, ptr %0, align 8
+ %wide.load = load <2 x i32>, ptr %0, align 8
+ %1 = sub <2 x i32> %broadcast.splat, %wide.load
+ store <2 x i32> %1, ptr %0, align 8
%index.next = add nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -3819,32 +4760,32 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-define void @sink_splat_or_lmul2(ptr nocapture %a, i64 signext %x) {
-; CHECK-LABEL: sink_splat_or_lmul2:
+define void @sink_splat_and_lmulmf2(ptr nocapture %a, i32 signext %x) {
+; CHECK-LABEL: sink_splat_and_lmulmf2:
; CHECK: # %bb.0: # %entry
; CHECK-NEXT: lui a2, 2
; CHECK-NEXT: add a2, a0, a2
-; CHECK-NEXT: vsetivli zero, 4, e64, m2, ta, ma
-; CHECK-NEXT: .LBB72_1: # %vector.body
+; CHECK-NEXT: vsetivli zero, 2, e32, mf2, ta, ma
+; CHECK-NEXT: .LBB99_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
-; CHECK-NEXT: vle64.v v8, (a0)
-; CHECK-NEXT: vor.vx v8, v8, a1
-; CHECK-NEXT: vse64.v v8, (a0)
+; CHECK-NEXT: vle32.v v8, (a0)
+; CHECK-NEXT: vand.vx v8, v8, a1
+; CHECK-NEXT: vse32.v v8, (a0)
; CHECK-NEXT: addi a0, a0, 32
-; CHECK-NEXT: bne a0, a2, .LBB72_1
+; CHECK-NEXT: bne a0, a2, .LBB99_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
- %broadcast.splatinsert = insertelement <4 x i64> poison, i64 %x, i64 0
- %broadcast.splat = shufflevector <4 x i64> %broadcast.splatinsert, <4 x i64> poison, <4 x i32> zeroinitializer
+ %broadcast.splatinsert = insertelement <2 x i32> poison, i32 %x, i64 0
+ %broadcast.splat = shufflevector <2 x i32> %broadcast.splatinsert, <2 x i32> poison, <2 x i32> zeroinitializer
br label %vector.body
vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
%0 = getelementptr inbounds i64, ptr %a, i64 %index
- %wide.load = load <4 x i64>, ptr %0, align 8
- %1 = or <4 x i64> %wide.load, %broadcast.splat
- store <4 x i64> %1, ptr %0, align 8
+ %wide.load = load <2 x i32>, ptr %0, align 8
+ %1 = and <2 x i32> %wide.load, %broadcast.splat
+ store <2 x i32> %1, ptr %0, align 8
%index.next = add nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -3853,32 +4794,32 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-define void @sink_splat_xor_lmul2(ptr nocapture %a, i64 signext %x) {
-; CHECK-LABEL: sink_splat_xor_lmul2:
+define void @sink_splat_or_lmulmf2(ptr nocapture %a, i32 signext %x) {
+; CHECK-LABEL: sink_splat_or_lmulmf2:
; CHECK: # %bb.0: # %entry
; CHECK-NEXT: lui a2, 2
; CHECK-NEXT: add a2, a0, a2
-; CHECK-NEXT: vsetivli zero, 4, e64, m2, ta, ma
-; CHECK-NEXT: .LBB73_1: # %vector.body
+; CHECK-NEXT: vsetivli zero, 2, e32, mf2, ta, ma
+; CHECK-NEXT: .LBB100_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
-; CHECK-NEXT: vle64.v v8, (a0)
-; CHECK-NEXT: vxor.vx v8, v8, a1
-; CHECK-NEXT: vse64.v v8, (a0)
+; CHECK-NEXT: vle32.v v8, (a0)
+; CHECK-NEXT: vor.vx v8, v8, a1
+; CHECK-NEXT: vse32.v v8, (a0)
; CHECK-NEXT: addi a0, a0, 32
-; CHECK-NEXT: bne a0, a2, .LBB73_1
+; CHECK-NEXT: bne a0, a2, .LBB100_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
- %broadcast.splatinsert = insertelement <4 x i64> poison, i64 %x, i64 0
- %broadcast.splat = shufflevector <4 x i64> %broadcast.splatinsert, <4 x i64> poison, <4 x i32> zeroinitializer
+ %broadcast.splatinsert = insertelement <2 x i32> poison, i32 %x, i64 0
+ %broadcast.splat = shufflevector <2 x i32> %broadcast.splatinsert, <2 x i32> poison, <2 x i32> zeroinitializer
br label %vector.body
vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
%0 = getelementptr inbounds i64, ptr %a, i64 %index
- %wide.load = load <4 x i64>, ptr %0, align 8
- %1 = xor <4 x i64> %wide.load, %broadcast.splat
- store <4 x i64> %1, ptr %0, align 8
+ %wide.load = load <2 x i32>, ptr %0, align 8
+ %1 = or <2 x i32> %wide.load, %broadcast.splat
+ store <2 x i32> %1, ptr %0, align 8
%index.next = add nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -3887,33 +4828,32 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-define void @sink_splat_mul_lmul8(ptr nocapture %a, i32 signext %x) {
-; CHECK-LABEL: sink_splat_mul_lmul8:
+define void @sink_splat_xor_lmulmf2(ptr nocapture %a, i32 signext %x) {
+; CHECK-LABEL: sink_splat_xor_lmulmf2:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: lui a2, 1
+; CHECK-NEXT: lui a2, 2
; CHECK-NEXT: add a2, a0, a2
-; CHECK-NEXT: li a3, 32
-; CHECK-NEXT: vsetvli zero, a3, e32, m8, ta, ma
-; CHECK-NEXT: .LBB74_1: # %vector.body
+; CHECK-NEXT: vsetivli zero, 2, e32, mf2, ta, ma
+; CHECK-NEXT: .LBB101_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
-; CHECK-NEXT: vmul.vx v8, v8, a1
+; CHECK-NEXT: vxor.vx v8, v8, a1
; CHECK-NEXT: vse32.v v8, (a0)
-; CHECK-NEXT: addi a0, a0, 16
-; CHECK-NEXT: bne a0, a2, .LBB74_1
+; CHECK-NEXT: addi a0, a0, 32
+; CHECK-NEXT: bne a0, a2, .LBB101_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
- %broadcast.splatinsert = insertelement <32 x i32> poison, i32 %x, i32 0
- %broadcast.splat = shufflevector <32 x i32> %broadcast.splatinsert, <32 x i32> poison, <32 x i32> zeroinitializer
+ %broadcast.splatinsert = insertelement <2 x i32> poison, i32 %x, i64 0
+ %broadcast.splat = shufflevector <2 x i32> %broadcast.splatinsert, <2 x i32> poison, <2 x i32> zeroinitializer
br label %vector.body
vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
- %0 = getelementptr inbounds i32, ptr %a, i64 %index
- %wide.load = load <32 x i32>, ptr %0, align 4
- %1 = mul <32 x i32> %wide.load, %broadcast.splat
- store <32 x i32> %1, ptr %0, align 4
+ %0 = getelementptr inbounds i64, ptr %a, i64 %index
+ %wide.load = load <2 x i32>, ptr %0, align 8
+ %1 = xor <2 x i32> %wide.load, %broadcast.splat
+ store <2 x i32> %1, ptr %0, align 8
%index.next = add nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -3922,33 +4862,39 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-define void @sink_splat_add_lmul8(ptr nocapture %a, i32 signext %x) {
-; CHECK-LABEL: sink_splat_add_lmul8:
+declare <4 x i1> @llvm.vp.icmp.v4i32(<4 x i32>, <4 x i32>, metadata, <4 x i1>, i32)
+
+define void @sink_splat_vp_icmp(ptr nocapture %x, i32 signext %y, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_icmp:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: lui a2, 1
-; CHECK-NEXT: add a2, a0, a2
-; CHECK-NEXT: li a3, 32
-; CHECK-NEXT: vsetvli zero, a3, e32, m8, ta, ma
-; CHECK-NEXT: .LBB75_1: # %vector.body
+; CHECK-NEXT: vmv1r.v v8, v0
+; CHECK-NEXT: lui a3, 1
+; CHECK-NEXT: add a3, a0, a3
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vmv.v.i v9, 0
+; CHECK-NEXT: .LBB102_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
-; CHECK-NEXT: vle32.v v8, (a0)
-; CHECK-NEXT: vadd.vx v8, v8, a1
-; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: vle32.v v10, (a0)
+; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
+; CHECK-NEXT: vmv1r.v v0, v8
+; CHECK-NEXT: vmseq.vx v0, v10, a1, v0.t
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vse32.v v9, (a0), v0.t
; CHECK-NEXT: addi a0, a0, 16
-; CHECK-NEXT: bne a0, a2, .LBB75_1
+; CHECK-NEXT: bne a0, a3, .LBB102_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
- %broadcast.splatinsert = insertelement <32 x i32> poison, i32 %x, i32 0
- %broadcast.splat = shufflevector <32 x i32> %broadcast.splatinsert, <32 x i32> poison, <32 x i32> zeroinitializer
+ %broadcast.splatinsert = insertelement <4 x i32> poison, i32 %y, i32 0
+ %broadcast.splat = shufflevector <4 x i32> %broadcast.splatinsert, <4 x i32> poison, <4 x i32> zeroinitializer
br label %vector.body
vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
- %0 = getelementptr inbounds i32, ptr %a, i64 %index
- %wide.load = load <32 x i32>, ptr %0, align 4
- %1 = add <32 x i32> %wide.load, %broadcast.splat
- store <32 x i32> %1, ptr %0, align 4
+ %0 = getelementptr inbounds i32, ptr %x, i64 %index
+ %wide.load = load <4 x i32>, ptr %0, align 4
+ %1 = call <4 x i1> @llvm.vp.icmp.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat, metadata !"eq", <4 x i1> %m, i32 %vl)
+ call void @llvm.masked.store.v4i32.p0(<4 x i32> zeroinitializer, ptr %0, i32 4, <4 x i1> %1)
%index.next = add nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -3957,33 +4903,39 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-define void @sink_splat_sub_lmul8(ptr nocapture %a, i32 signext %x) {
-; CHECK-LABEL: sink_splat_sub_lmul8:
+declare <4 x i1> @llvm.vp.fcmp.v4f32(<4 x float>, <4 x float>, metadata, <4 x i1>, i32)
+
+define void @sink_splat_vp_fcmp(ptr nocapture %x, float %y, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_fcmp:
; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: vmv1r.v v8, v0
; CHECK-NEXT: lui a2, 1
; CHECK-NEXT: add a2, a0, a2
-; CHECK-NEXT: li a3, 32
-; CHECK-NEXT: vsetvli zero, a3, e32, m8, ta, ma
-; CHECK-NEXT: .LBB76_1: # %vector.body
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vmv.v.i v9, 0
+; CHECK-NEXT: .LBB103_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
-; CHECK-NEXT: vle32.v v8, (a0)
-; CHECK-NEXT: vsub.vx v8, v8, a1
-; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: vle32.v v10, (a0)
+; CHECK-NEXT: vsetvli zero, a1, e32, m1, ta, ma
+; CHECK-NEXT: vmv1r.v v0, v8
+; CHECK-NEXT: vmfeq.vf v0, v10, fa0, v0.t
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vse32.v v9, (a0), v0.t
; CHECK-NEXT: addi a0, a0, 16
-; CHECK-NEXT: bne a0, a2, .LBB76_1
+; CHECK-NEXT: bne a0, a2, .LBB103_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
- %broadcast.splatinsert = insertelement <32 x i32> poison, i32 %x, i32 0
- %broadcast.splat = shufflevector <32 x i32> %broadcast.splatinsert, <32 x i32> poison, <32 x i32> zeroinitializer
+ %broadcast.splatinsert = insertelement <4 x float> poison, float %y, i32 0
+ %broadcast.splat = shufflevector <4 x float> %broadcast.splatinsert, <4 x float> poison, <4 x i32> zeroinitializer
br label %vector.body
vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
- %0 = getelementptr inbounds i32, ptr %a, i64 %index
- %wide.load = load <32 x i32>, ptr %0, align 4
- %1 = sub <32 x i32> %wide.load, %broadcast.splat
- store <32 x i32> %1, ptr %0, align 4
+ %0 = getelementptr inbounds float, ptr %x, i64 %index
+ %wide.load = load <4 x float>, ptr %0, align 4
+ %1 = call <4 x i1> @llvm.vp.fcmp.v4f32(<4 x float> %wide.load, <4 x float> %broadcast.splat, metadata !"oeq", <4 x i1> %m, i32 %vl)
+ call void @llvm.masked.store.v4f32.p0(<4 x float> zeroinitializer, ptr %0, i32 4, <4 x i1> %1)
%index.next = add nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -3992,33 +4944,36 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-define void @sink_splat_rsub_lmul8(ptr nocapture %a, i32 signext %x) {
-; CHECK-LABEL: sink_splat_rsub_lmul8:
+declare <4 x i32> @llvm.vp.smin.v4i32(<4 x i32>, <4 x i32>, <4 x i1>, i32)
+
+define void @sink_splat_vp_min(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_min:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: lui a2, 1
-; CHECK-NEXT: add a2, a0, a2
-; CHECK-NEXT: li a3, 32
-; CHECK-NEXT: vsetvli zero, a3, e32, m8, ta, ma
-; CHECK-NEXT: .LBB77_1: # %vector.body
+; CHECK-NEXT: lui a3, 1
+; CHECK-NEXT: add a3, a0, a3
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: .LBB104_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
-; CHECK-NEXT: vrsub.vx v8, v8, a1
+; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
+; CHECK-NEXT: vmin.vx v8, v8, a1, v0.t
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: vse32.v v8, (a0)
; CHECK-NEXT: addi a0, a0, 16
-; CHECK-NEXT: bne a0, a2, .LBB77_1
+; CHECK-NEXT: bne a0, a3, .LBB104_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
- %broadcast.splatinsert = insertelement <32 x i32> poison, i32 %x, i32 0
- %broadcast.splat = shufflevector <32 x i32> %broadcast.splatinsert, <32 x i32> poison, <32 x i32> zeroinitializer
+ %broadcast.splatinsert = insertelement <4 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <4 x i32> %broadcast.splatinsert, <4 x i32> poison, <4 x i32> zeroinitializer
br label %vector.body
vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
%0 = getelementptr inbounds i32, ptr %a, i64 %index
- %wide.load = load <32 x i32>, ptr %0, align 4
- %1 = sub <32 x i32> %broadcast.splat, %wide.load
- store <32 x i32> %1, ptr %0, align 4
+ %wide.load = load <4 x i32>, ptr %0, align 4
+ %1 = call <4 x i32> @llvm.vp.smin.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat, <4 x i1> %m, i32 %vl)
+ store <4 x i32> %1, ptr %0, align 4
%index.next = add nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -4027,33 +4982,34 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-define void @sink_splat_and_lmul8(ptr nocapture %a, i32 signext %x) {
-; CHECK-LABEL: sink_splat_and_lmul8:
+define void @sink_splat_vp_min_commute(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_min_commute:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: lui a2, 1
-; CHECK-NEXT: add a2, a0, a2
-; CHECK-NEXT: li a3, 32
-; CHECK-NEXT: vsetvli zero, a3, e32, m8, ta, ma
-; CHECK-NEXT: .LBB78_1: # %vector.body
+; CHECK-NEXT: lui a3, 1
+; CHECK-NEXT: add a3, a0, a3
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: .LBB105_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
-; CHECK-NEXT: vand.vx v8, v8, a1
+; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
+; CHECK-NEXT: vmin.vx v8, v8, a1, v0.t
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: vse32.v v8, (a0)
; CHECK-NEXT: addi a0, a0, 16
-; CHECK-NEXT: bne a0, a2, .LBB78_1
+; CHECK-NEXT: bne a0, a3, .LBB105_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
- %broadcast.splatinsert = insertelement <32 x i32> poison, i32 %x, i32 0
- %broadcast.splat = shufflevector <32 x i32> %broadcast.splatinsert, <32 x i32> poison, <32 x i32> zeroinitializer
+ %broadcast.splatinsert = insertelement <4 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <4 x i32> %broadcast.splatinsert, <4 x i32> poison, <4 x i32> zeroinitializer
br label %vector.body
vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
%0 = getelementptr inbounds i32, ptr %a, i64 %index
- %wide.load = load <32 x i32>, ptr %0, align 4
- %1 = and <32 x i32> %wide.load, %broadcast.splat
- store <32 x i32> %1, ptr %0, align 4
+ %wide.load = load <4 x i32>, ptr %0, align 4
+ %1 = call <4 x i32> @llvm.vp.smin.v4i32(<4 x i32> %broadcast.splat, <4 x i32> %wide.load, <4 x i1> %m, i32 %vl)
+ store <4 x i32> %1, ptr %0, align 4
%index.next = add nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -4062,33 +5018,36 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-define void @sink_splat_or_lmul8(ptr nocapture %a, i32 signext %x) {
-; CHECK-LABEL: sink_splat_or_lmul8:
+declare <4 x i32> @llvm.vp.smax.v4i32(<4 x i32>, <4 x i32>, <4 x i1>, i32)
+
+define void @sink_splat_vp_max(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_max:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: lui a2, 1
-; CHECK-NEXT: add a2, a0, a2
-; CHECK-NEXT: li a3, 32
-; CHECK-NEXT: vsetvli zero, a3, e32, m8, ta, ma
-; CHECK-NEXT: .LBB79_1: # %vector.body
+; CHECK-NEXT: lui a3, 1
+; CHECK-NEXT: add a3, a0, a3
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: .LBB106_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
-; CHECK-NEXT: vor.vx v8, v8, a1
+; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
+; CHECK-NEXT: vmax.vx v8, v8, a1, v0.t
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: vse32.v v8, (a0)
; CHECK-NEXT: addi a0, a0, 16
-; CHECK-NEXT: bne a0, a2, .LBB79_1
+; CHECK-NEXT: bne a0, a3, .LBB106_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
- %broadcast.splatinsert = insertelement <32 x i32> poison, i32 %x, i32 0
- %broadcast.splat = shufflevector <32 x i32> %broadcast.splatinsert, <32 x i32> poison, <32 x i32> zeroinitializer
+ %broadcast.splatinsert = insertelement <4 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <4 x i32> %broadcast.splatinsert, <4 x i32> poison, <4 x i32> zeroinitializer
br label %vector.body
vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
%0 = getelementptr inbounds i32, ptr %a, i64 %index
- %wide.load = load <32 x i32>, ptr %0, align 4
- %1 = or <32 x i32> %wide.load, %broadcast.splat
- store <32 x i32> %1, ptr %0, align 4
+ %wide.load = load <4 x i32>, ptr %0, align 4
+ %1 = call <4 x i32> @llvm.vp.smax.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat, <4 x i1> %m, i32 %vl)
+ store <4 x i32> %1, ptr %0, align 4
%index.next = add nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -4097,33 +5056,34 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-define void @sink_splat_xor_lmul8(ptr nocapture %a, i32 signext %x) {
-; CHECK-LABEL: sink_splat_xor_lmul8:
+define void @sink_splat_vp_max_commute(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_max_commute:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: lui a2, 1
-; CHECK-NEXT: add a2, a0, a2
-; CHECK-NEXT: li a3, 32
-; CHECK-NEXT: vsetvli zero, a3, e32, m8, ta, ma
-; CHECK-NEXT: .LBB80_1: # %vector.body
+; CHECK-NEXT: lui a3, 1
+; CHECK-NEXT: add a3, a0, a3
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: .LBB107_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
-; CHECK-NEXT: vxor.vx v8, v8, a1
+; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
+; CHECK-NEXT: vmax.vx v8, v8, a1, v0.t
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: vse32.v v8, (a0)
; CHECK-NEXT: addi a0, a0, 16
-; CHECK-NEXT: bne a0, a2, .LBB80_1
+; CHECK-NEXT: bne a0, a3, .LBB107_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
- %broadcast.splatinsert = insertelement <32 x i32> poison, i32 %x, i32 0
- %broadcast.splat = shufflevector <32 x i32> %broadcast.splatinsert, <32 x i32> poison, <32 x i32> zeroinitializer
+ %broadcast.splatinsert = insertelement <4 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <4 x i32> %broadcast.splatinsert, <4 x i32> poison, <4 x i32> zeroinitializer
br label %vector.body
vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
%0 = getelementptr inbounds i32, ptr %a, i64 %index
- %wide.load = load <32 x i32>, ptr %0, align 4
- %1 = xor <32 x i32> %wide.load, %broadcast.splat
- store <32 x i32> %1, ptr %0, align 4
+ %wide.load = load <4 x i32>, ptr %0, align 4
+ %1 = call <4 x i32> @llvm.vp.smax.v4i32(<4 x i32> %broadcast.splat, <4 x i32> %wide.load, <4 x i1> %m, i32 %vl)
+ store <4 x i32> %1, ptr %0, align 4
%index.next = add nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -4132,32 +5092,34 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-define void @sink_splat_mul_lmulmf2(ptr nocapture %a, i32 signext %x) {
-; CHECK-LABEL: sink_splat_mul_lmulmf2:
+define void @sink_splat_vp_umin_commute(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_umin_commute:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: lui a2, 2
-; CHECK-NEXT: add a2, a0, a2
-; CHECK-NEXT: vsetivli zero, 2, e32, mf2, ta, ma
-; CHECK-NEXT: .LBB81_1: # %vector.body
+; CHECK-NEXT: lui a3, 1
+; CHECK-NEXT: add a3, a0, a3
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: .LBB108_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
-; CHECK-NEXT: vmul.vx v8, v8, a1
+; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
+; CHECK-NEXT: vminu.vx v8, v8, a1, v0.t
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: vse32.v v8, (a0)
-; CHECK-NEXT: addi a0, a0, 32
-; CHECK-NEXT: bne a0, a2, .LBB81_1
+; CHECK-NEXT: addi a0, a0, 16
+; CHECK-NEXT: bne a0, a3, .LBB108_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
- %broadcast.splatinsert = insertelement <2 x i32> poison, i32 %x, i64 0
- %broadcast.splat = shufflevector <2 x i32> %broadcast.splatinsert, <2 x i32> poison, <2 x i32> zeroinitializer
+ %broadcast.splatinsert = insertelement <4 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <4 x i32> %broadcast.splatinsert, <4 x i32> poison, <4 x i32> zeroinitializer
br label %vector.body
vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
- %0 = getelementptr inbounds i64, ptr %a, i64 %index
- %wide.load = load <2 x i32>, ptr %0, align 8
- %1 = mul <2 x i32> %wide.load, %broadcast.splat
- store <2 x i32> %1, ptr %0, align 8
+ %0 = getelementptr inbounds i32, ptr %a, i64 %index
+ %wide.load = load <4 x i32>, ptr %0, align 4
+ %1 = call <4 x i32> @llvm.vp.umin.v4i32(<4 x i32> %broadcast.splat, <4 x i32> %wide.load, <4 x i1> %m, i32 %vl)
+ store <4 x i32> %1, ptr %0, align 4
%index.next = add nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -4166,32 +5128,36 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-define void @sink_splat_add_lmulmf2(ptr nocapture %a, i32 signext %x) {
-; CHECK-LABEL: sink_splat_add_lmulmf2:
+declare <4 x i32> @llvm.vp.umax.v4i32(<4 x i32>, <4 x i32>, <4 x i1>, i32)
+
+define void @sink_splat_vp_umax(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_umax:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: lui a2, 2
-; CHECK-NEXT: add a2, a0, a2
-; CHECK-NEXT: vsetivli zero, 2, e32, mf2, ta, ma
-; CHECK-NEXT: .LBB82_1: # %vector.body
+; CHECK-NEXT: lui a3, 1
+; CHECK-NEXT: add a3, a0, a3
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: .LBB109_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
-; CHECK-NEXT: vadd.vx v8, v8, a1
+; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
+; CHECK-NEXT: vmaxu.vx v8, v8, a1, v0.t
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: vse32.v v8, (a0)
-; CHECK-NEXT: addi a0, a0, 32
-; CHECK-NEXT: bne a0, a2, .LBB82_1
+; CHECK-NEXT: addi a0, a0, 16
+; CHECK-NEXT: bne a0, a3, .LBB109_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
- %broadcast.splatinsert = insertelement <2 x i32> poison, i32 %x, i64 0
- %broadcast.splat = shufflevector <2 x i32> %broadcast.splatinsert, <2 x i32> poison, <2 x i32> zeroinitializer
+ %broadcast.splatinsert = insertelement <4 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <4 x i32> %broadcast.splatinsert, <4 x i32> poison, <4 x i32> zeroinitializer
br label %vector.body
vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
- %0 = getelementptr inbounds i64, ptr %a, i64 %index
- %wide.load = load <2 x i32>, ptr %0, align 8
- %1 = add <2 x i32> %wide.load, %broadcast.splat
- store <2 x i32> %1, ptr %0, align 8
+ %0 = getelementptr inbounds i32, ptr %a, i64 %index
+ %wide.load = load <4 x i32>, ptr %0, align 4
+ %1 = call <4 x i32> @llvm.vp.umax.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat, <4 x i1> %m, i32 %vl)
+ store <4 x i32> %1, ptr %0, align 4
%index.next = add nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -4200,32 +5166,34 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-define void @sink_splat_sub_lmulmf2(ptr nocapture %a, i32 signext %x) {
-; CHECK-LABEL: sink_splat_sub_lmulmf2:
+define void @sink_splat_vp_umax_commute(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_umax_commute:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: lui a2, 2
-; CHECK-NEXT: add a2, a0, a2
-; CHECK-NEXT: vsetivli zero, 2, e32, mf2, ta, ma
-; CHECK-NEXT: .LBB83_1: # %vector.body
+; CHECK-NEXT: lui a3, 1
+; CHECK-NEXT: add a3, a0, a3
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: .LBB110_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
-; CHECK-NEXT: vsub.vx v8, v8, a1
+; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
+; CHECK-NEXT: vmaxu.vx v8, v8, a1, v0.t
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: vse32.v v8, (a0)
-; CHECK-NEXT: addi a0, a0, 32
-; CHECK-NEXT: bne a0, a2, .LBB83_1
+; CHECK-NEXT: addi a0, a0, 16
+; CHECK-NEXT: bne a0, a3, .LBB110_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
- %broadcast.splatinsert = insertelement <2 x i32> poison, i32 %x, i64 0
- %broadcast.splat = shufflevector <2 x i32> %broadcast.splatinsert, <2 x i32> poison, <2 x i32> zeroinitializer
+ %broadcast.splatinsert = insertelement <4 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <4 x i32> %broadcast.splatinsert, <4 x i32> poison, <4 x i32> zeroinitializer
br label %vector.body
vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
- %0 = getelementptr inbounds i64, ptr %a, i64 %index
- %wide.load = load <2 x i32>, ptr %0, align 8
- %1 = sub <2 x i32> %wide.load, %broadcast.splat
- store <2 x i32> %1, ptr %0, align 8
+ %0 = getelementptr inbounds i32, ptr %a, i64 %index
+ %wide.load = load <4 x i32>, ptr %0, align 4
+ %1 = call <4 x i32> @llvm.vp.umax.v4i32(<4 x i32> %broadcast.splat, <4 x i32> %wide.load, <4 x i1> %m, i32 %vl)
+ store <4 x i32> %1, ptr %0, align 4
%index.next = add nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -4234,32 +5202,36 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-define void @sink_splat_rsub_lmulmf2(ptr nocapture %a, i32 signext %x) {
-; CHECK-LABEL: sink_splat_rsub_lmulmf2:
+declare <4 x i32> @llvm.vp.sadd.sat.v4i32(<4 x i32>, <4 x i32>, <4 x i1>, i32)
+
+define void @sink_splat_vp_sadd_sat(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_sadd_sat:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: lui a2, 2
-; CHECK-NEXT: add a2, a0, a2
-; CHECK-NEXT: vsetivli zero, 2, e32, mf2, ta, ma
-; CHECK-NEXT: .LBB84_1: # %vector.body
+; CHECK-NEXT: lui a3, 1
+; CHECK-NEXT: add a3, a0, a3
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: .LBB111_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
-; CHECK-NEXT: vrsub.vx v8, v8, a1
+; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
+; CHECK-NEXT: vsadd.vx v8, v8, a1, v0.t
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: vse32.v v8, (a0)
-; CHECK-NEXT: addi a0, a0, 32
-; CHECK-NEXT: bne a0, a2, .LBB84_1
+; CHECK-NEXT: addi a0, a0, 16
+; CHECK-NEXT: bne a0, a3, .LBB111_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
- %broadcast.splatinsert = insertelement <2 x i32> poison, i32 %x, i64 0
- %broadcast.splat = shufflevector <2 x i32> %broadcast.splatinsert, <2 x i32> poison, <2 x i32> zeroinitializer
+ %broadcast.splatinsert = insertelement <4 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <4 x i32> %broadcast.splatinsert, <4 x i32> poison, <4 x i32> zeroinitializer
br label %vector.body
vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
- %0 = getelementptr inbounds i64, ptr %a, i64 %index
- %wide.load = load <2 x i32>, ptr %0, align 8
- %1 = sub <2 x i32> %broadcast.splat, %wide.load
- store <2 x i32> %1, ptr %0, align 8
+ %0 = getelementptr inbounds i32, ptr %a, i64 %index
+ %wide.load = load <4 x i32>, ptr %0, align 4
+ %1 = call <4 x i32> @llvm.vp.sadd.sat.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat, <4 x i1> %m, i32 %vl)
+ store <4 x i32> %1, ptr %0, align 4
%index.next = add nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -4268,32 +5240,34 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-define void @sink_splat_and_lmulmf2(ptr nocapture %a, i32 signext %x) {
-; CHECK-LABEL: sink_splat_and_lmulmf2:
+define void @sink_splat_vp_sadd_sat_commute(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_sadd_sat_commute:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: lui a2, 2
-; CHECK-NEXT: add a2, a0, a2
-; CHECK-NEXT: vsetivli zero, 2, e32, mf2, ta, ma
-; CHECK-NEXT: .LBB85_1: # %vector.body
+; CHECK-NEXT: lui a3, 1
+; CHECK-NEXT: add a3, a0, a3
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: .LBB112_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
-; CHECK-NEXT: vand.vx v8, v8, a1
+; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
+; CHECK-NEXT: vsadd.vx v8, v8, a1, v0.t
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: vse32.v v8, (a0)
-; CHECK-NEXT: addi a0, a0, 32
-; CHECK-NEXT: bne a0, a2, .LBB85_1
+; CHECK-NEXT: addi a0, a0, 16
+; CHECK-NEXT: bne a0, a3, .LBB112_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
- %broadcast.splatinsert = insertelement <2 x i32> poison, i32 %x, i64 0
- %broadcast.splat = shufflevector <2 x i32> %broadcast.splatinsert, <2 x i32> poison, <2 x i32> zeroinitializer
+ %broadcast.splatinsert = insertelement <4 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <4 x i32> %broadcast.splatinsert, <4 x i32> poison, <4 x i32> zeroinitializer
br label %vector.body
vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
- %0 = getelementptr inbounds i64, ptr %a, i64 %index
- %wide.load = load <2 x i32>, ptr %0, align 8
- %1 = and <2 x i32> %wide.load, %broadcast.splat
- store <2 x i32> %1, ptr %0, align 8
+ %0 = getelementptr inbounds i32, ptr %a, i64 %index
+ %wide.load = load <4 x i32>, ptr %0, align 4
+ %1 = call <4 x i32> @llvm.vp.sadd.sat.v4i32(<4 x i32> %broadcast.splat, <4 x i32> %wide.load, <4 x i1> %m, i32 %vl)
+ store <4 x i32> %1, ptr %0, align 4
%index.next = add nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -4302,33 +5276,37 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-define void @sink_splat_or_lmulmf2(ptr nocapture %a, i32 signext %x) {
-; CHECK-LABEL: sink_splat_or_lmulmf2:
+declare <4 x i32> @llvm.vp.ssub.sat.v4i32(<4 x i32>, <4 x i32>, <4 x i1>, i32)
+
+define void @sink_splat_vp_ssub_sat(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_ssub_sat:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: lui a2, 2
-; CHECK-NEXT: add a2, a0, a2
-; CHECK-NEXT: vsetivli zero, 2, e32, mf2, ta, ma
-; CHECK-NEXT: .LBB86_1: # %vector.body
+; CHECK-NEXT: li a3, 1024
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: .LBB113_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
-; CHECK-NEXT: vor.vx v8, v8, a1
+; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
+; CHECK-NEXT: vssub.vx v8, v8, a1, v0.t
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: vse32.v v8, (a0)
-; CHECK-NEXT: addi a0, a0, 32
-; CHECK-NEXT: bne a0, a2, .LBB86_1
+; CHECK-NEXT: addi a3, a3, 4
+; CHECK-NEXT: addi a0, a0, -16
+; CHECK-NEXT: bnez a3, .LBB113_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
- %broadcast.splatinsert = insertelement <2 x i32> poison, i32 %x, i64 0
- %broadcast.splat = shufflevector <2 x i32> %broadcast.splatinsert, <2 x i32> poison, <2 x i32> zeroinitializer
+ %broadcast.splatinsert = insertelement <4 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <4 x i32> %broadcast.splatinsert, <4 x i32> poison, <4 x i32> zeroinitializer
br label %vector.body
vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
- %0 = getelementptr inbounds i64, ptr %a, i64 %index
- %wide.load = load <2 x i32>, ptr %0, align 8
- %1 = or <2 x i32> %wide.load, %broadcast.splat
- store <2 x i32> %1, ptr %0, align 8
- %index.next = add nuw i64 %index, 4
+ %0 = getelementptr inbounds i32, ptr %a, i64 %index
+ %wide.load = load <4 x i32>, ptr %0, align 4
+ %1 = call <4 x i32> @llvm.vp.ssub.sat.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat, <4 x i1> %m, i32 %vl)
+ store <4 x i32> %1, ptr %0, align 4
+ %index.next = sub nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -4336,32 +5314,36 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-define void @sink_splat_xor_lmulmf2(ptr nocapture %a, i32 signext %x) {
-; CHECK-LABEL: sink_splat_xor_lmulmf2:
+declare <4 x i32> @llvm.vp.uadd.sat.v4i32(<4 x i32>, <4 x i32>, <4 x i1>, i32)
+
+define void @sink_splat_vp_uadd_sat(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_uadd_sat:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: lui a2, 2
-; CHECK-NEXT: add a2, a0, a2
-; CHECK-NEXT: vsetivli zero, 2, e32, mf2, ta, ma
-; CHECK-NEXT: .LBB87_1: # %vector.body
+; CHECK-NEXT: lui a3, 1
+; CHECK-NEXT: add a3, a0, a3
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: .LBB114_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vle32.v v8, (a0)
-; CHECK-NEXT: vxor.vx v8, v8, a1
+; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
+; CHECK-NEXT: vsaddu.vx v8, v8, a1, v0.t
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; CHECK-NEXT: vse32.v v8, (a0)
-; CHECK-NEXT: addi a0, a0, 32
-; CHECK-NEXT: bne a0, a2, .LBB87_1
+; CHECK-NEXT: addi a0, a0, 16
+; CHECK-NEXT: bne a0, a3, .LBB114_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
- %broadcast.splatinsert = insertelement <2 x i32> poison, i32 %x, i64 0
- %broadcast.splat = shufflevector <2 x i32> %broadcast.splatinsert, <2 x i32> poison, <2 x i32> zeroinitializer
+ %broadcast.splatinsert = insertelement <4 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <4 x i32> %broadcast.splatinsert, <4 x i32> poison, <4 x i32> zeroinitializer
br label %vector.body
vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
- %0 = getelementptr inbounds i64, ptr %a, i64 %index
- %wide.load = load <2 x i32>, ptr %0, align 8
- %1 = xor <2 x i32> %wide.load, %broadcast.splat
- store <2 x i32> %1, ptr %0, align 8
+ %0 = getelementptr inbounds i32, ptr %a, i64 %index
+ %wide.load = load <4 x i32>, ptr %0, align 4
+ %1 = call <4 x i32> @llvm.vp.uadd.sat.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat, <4 x i1> %m, i32 %vl)
+ store <4 x i32> %1, ptr %0, align 4
%index.next = add nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -4370,39 +5352,34 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-declare <4 x i1> @llvm.vp.icmp.v4i32(<4 x i32>, <4 x i32>, metadata, <4 x i1>, i32)
-
-define void @sink_splat_vp_icmp(ptr nocapture %x, i32 signext %y, <4 x i1> %m, i32 zeroext %vl) {
-; CHECK-LABEL: sink_splat_vp_icmp:
+define void @sink_splat_vp_uadd_sat_commute(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_uadd_sat_commute:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: vmv1r.v v8, v0
; CHECK-NEXT: lui a3, 1
; CHECK-NEXT: add a3, a0, a3
; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
-; CHECK-NEXT: vmv.v.i v9, 0
-; CHECK-NEXT: .LBB88_1: # %vector.body
+; CHECK-NEXT: .LBB115_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
-; CHECK-NEXT: vle32.v v10, (a0)
+; CHECK-NEXT: vle32.v v8, (a0)
; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
-; CHECK-NEXT: vmv1r.v v0, v8
-; CHECK-NEXT: vmseq.vx v0, v10, a1, v0.t
+; CHECK-NEXT: vsaddu.vx v8, v8, a1, v0.t
; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
-; CHECK-NEXT: vse32.v v9, (a0), v0.t
+; CHECK-NEXT: vse32.v v8, (a0)
; CHECK-NEXT: addi a0, a0, 16
-; CHECK-NEXT: bne a0, a3, .LBB88_1
+; CHECK-NEXT: bne a0, a3, .LBB115_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
- %broadcast.splatinsert = insertelement <4 x i32> poison, i32 %y, i32 0
+ %broadcast.splatinsert = insertelement <4 x i32> poison, i32 %x, i32 0
%broadcast.splat = shufflevector <4 x i32> %broadcast.splatinsert, <4 x i32> poison, <4 x i32> zeroinitializer
br label %vector.body
vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
- %0 = getelementptr inbounds i32, ptr %x, i64 %index
+ %0 = getelementptr inbounds i32, ptr %a, i64 %index
%wide.load = load <4 x i32>, ptr %0, align 4
- %1 = call <4 x i1> @llvm.vp.icmp.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat, metadata !"eq", <4 x i1> %m, i32 %vl)
- call void @llvm.masked.store.v4i32.p0(<4 x i32> zeroinitializer, ptr %0, i32 4, <4 x i1> %1)
+ %1 = call <4 x i32> @llvm.vp.uadd.sat.v4i32(<4 x i32> %broadcast.splat, <4 x i32> %wide.load, <4 x i1> %m, i32 %vl)
+ store <4 x i32> %1, ptr %0, align 4
%index.next = add nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
@@ -4411,40 +5388,37 @@ for.cond.cleanup: ; preds = %vector.body
ret void
}
-declare <4 x i1> @llvm.vp.fcmp.v4f32(<4 x float>, <4 x float>, metadata, <4 x i1>, i32)
+declare <4 x i32> @llvm.vp.usub.sat.v4i32(<4 x i32>, <4 x i32>, <4 x i1>, i32)
-define void @sink_splat_vp_fcmp(ptr nocapture %x, float %y, <4 x i1> %m, i32 zeroext %vl) {
-; CHECK-LABEL: sink_splat_vp_fcmp:
+define void @sink_splat_vp_usub_sat(ptr nocapture %a, i32 signext %x, <4 x i1> %m, i32 zeroext %vl) {
+; CHECK-LABEL: sink_splat_vp_usub_sat:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: vmv1r.v v8, v0
-; CHECK-NEXT: lui a2, 1
-; CHECK-NEXT: add a2, a0, a2
+; CHECK-NEXT: li a3, 1024
; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
-; CHECK-NEXT: vmv.v.i v9, 0
-; CHECK-NEXT: .LBB89_1: # %vector.body
+; CHECK-NEXT: .LBB116_1: # %vector.body
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
-; CHECK-NEXT: vle32.v v10, (a0)
-; CHECK-NEXT: vsetvli zero, a1, e32, m1, ta, ma
-; CHECK-NEXT: vmv1r.v v0, v8
-; CHECK-NEXT: vmfeq.vf v0, v10, fa0, v0.t
+; CHECK-NEXT: vle32.v v8, (a0)
+; CHECK-NEXT: vsetvli zero, a2, e32, m1, ta, ma
+; CHECK-NEXT: vssubu.vx v8, v8, a1, v0.t
; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
-; CHECK-NEXT: vse32.v v9, (a0), v0.t
-; CHECK-NEXT: addi a0, a0, 16
-; CHECK-NEXT: bne a0, a2, .LBB89_1
+; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: addi a3, a3, 4
+; CHECK-NEXT: addi a0, a0, -16
+; CHECK-NEXT: bnez a3, .LBB116_1
; CHECK-NEXT: # %bb.2: # %for.cond.cleanup
; CHECK-NEXT: ret
entry:
- %broadcast.splatinsert = insertelement <4 x float> poison, float %y, i32 0
- %broadcast.splat = shufflevector <4 x float> %broadcast.splatinsert, <4 x float> poison, <4 x i32> zeroinitializer
+ %broadcast.splatinsert = insertelement <4 x i32> poison, i32 %x, i32 0
+ %broadcast.splat = shufflevector <4 x i32> %broadcast.splatinsert, <4 x i32> poison, <4 x i32> zeroinitializer
br label %vector.body
vector.body: ; preds = %vector.body, %entry
%index = phi i64 [ 0, %entry ], [ %index.next, %vector.body ]
- %0 = getelementptr inbounds float, ptr %x, i64 %index
- %wide.load = load <4 x float>, ptr %0, align 4
- %1 = call <4 x i1> @llvm.vp.fcmp.v4f32(<4 x float> %wide.load, <4 x float> %broadcast.splat, metadata !"oeq", <4 x i1> %m, i32 %vl)
- call void @llvm.masked.store.v4f32.p0(<4 x float> zeroinitializer, ptr %0, i32 4, <4 x i1> %1)
- %index.next = add nuw i64 %index, 4
+ %0 = getelementptr inbounds i32, ptr %a, i64 %index
+ %wide.load = load <4 x i32>, ptr %0, align 4
+ %1 = call <4 x i32> @llvm.vp.usub.sat.v4i32(<4 x i32> %wide.load, <4 x i32> %broadcast.splat, <4 x i1> %m, i32 %vl)
+ store <4 x i32> %1, ptr %0, align 4
+ %index.next = sub nuw i64 %index, 4
%2 = icmp eq i64 %index.next, 1024
br i1 %2, label %for.cond.cleanup, label %vector.body
>From c36cbba6fbe926a4a73f5df318fab991dad7fcc0 Mon Sep 17 00:00:00 2001
From: Matt Arsenault <Matthew.Arsenault at amd.com>
Date: Thu, 29 Feb 2024 10:34:34 +0530
Subject: [PATCH 087/406] Update IEEE-754 2018 draft references to IEEE-754
2019
---
llvm/docs/GlobalISel/GenericOpcode.rst | 8 ++++----
llvm/docs/LangRef.rst | 8 ++++----
llvm/include/llvm/ADT/APFloat.h | 4 ++--
llvm/include/llvm/CodeGen/ISDOpcodes.h | 2 +-
llvm/include/llvm/Target/GenericOpcodes.td | 2 +-
5 files changed, 12 insertions(+), 12 deletions(-)
diff --git a/llvm/docs/GlobalISel/GenericOpcode.rst b/llvm/docs/GlobalISel/GenericOpcode.rst
index 26ff34376fb838..33b0152bd7b49c 100644
--- a/llvm/docs/GlobalISel/GenericOpcode.rst
+++ b/llvm/docs/GlobalISel/GenericOpcode.rst
@@ -536,15 +536,15 @@ G_FMINIMUM
^^^^^^^^^^
NaN-propagating minimum that also treat -0.0 as less than 0.0. While
-FMINNUM_IEEE follow IEEE 754-2008 semantics, FMINIMUM follows IEEE 754-2018
-draft semantics.
+FMINNUM_IEEE follow IEEE 754-2008 semantics, FMINIMUM follows IEEE
+754-2019 semantics.
G_FMAXIMUM
^^^^^^^^^^
NaN-propagating maximum that also treat -0.0 as less than 0.0. While
-FMAXNUM_IEEE follow IEEE 754-2008 semantics, FMAXIMUM follows IEEE 754-2018
-draft semantics.
+FMAXNUM_IEEE follow IEEE 754-2008 semantics, FMAXIMUM follows IEEE
+754-2019 semantics.
G_FADD, G_FSUB, G_FMUL, G_FDIV, G_FREM
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
diff --git a/llvm/docs/LangRef.rst b/llvm/docs/LangRef.rst
index 60e682ae328a8f..f56d4ed28f2855 100644
--- a/llvm/docs/LangRef.rst
+++ b/llvm/docs/LangRef.rst
@@ -15581,7 +15581,7 @@ Semantics:
If either operand is a NaN, returns NaN. Otherwise returns the lesser
of the two arguments. -0.0 is considered to be less than +0.0 for this
intrinsic. Note that these are the semantics specified in the draft of
-IEEE 754-2018.
+IEEE 754-2019.
.. _i_maximum:
@@ -15621,7 +15621,7 @@ Semantics:
If either operand is a NaN, returns NaN. Otherwise returns the greater
of the two arguments. -0.0 is considered to be less than +0.0 for this
intrinsic. Note that these are the semantics specified in the draft of
-IEEE 754-2018.
+IEEE 754-2019.
.. _int_copysign:
@@ -26000,7 +26000,7 @@ The third argument specifies the exception behavior as described above.
Semantics:
""""""""""
-This function follows semantics specified in the draft of IEEE 754-2018.
+This function follows semantics specified in the draft of IEEE 754-2019.
'``llvm.experimental.constrained.minimum``' Intrinsic
@@ -26032,7 +26032,7 @@ The third argument specifies the exception behavior as described above.
Semantics:
""""""""""
-This function follows semantics specified in the draft of IEEE 754-2018.
+This function follows semantics specified in the draft of IEEE 754-2019.
'``llvm.experimental.constrained.ceil``' Intrinsic
diff --git a/llvm/include/llvm/ADT/APFloat.h b/llvm/include/llvm/ADT/APFloat.h
index 8c247bbcec90a2..4edb24586fd7c4 100644
--- a/llvm/include/llvm/ADT/APFloat.h
+++ b/llvm/include/llvm/ADT/APFloat.h
@@ -1411,7 +1411,7 @@ inline APFloat maxnum(const APFloat &A, const APFloat &B) {
return A < B ? B : A;
}
-/// Implements IEEE 754-2018 minimum semantics. Returns the smaller of 2
+/// Implements IEEE 754-2019 minimum semantics. Returns the smaller of 2
/// arguments, propagating NaNs and treating -0 as less than +0.
LLVM_READONLY
inline APFloat minimum(const APFloat &A, const APFloat &B) {
@@ -1424,7 +1424,7 @@ inline APFloat minimum(const APFloat &A, const APFloat &B) {
return B < A ? B : A;
}
-/// Implements IEEE 754-2018 maximum semantics. Returns the larger of 2
+/// Implements IEEE 754-2019 maximum semantics. Returns the larger of 2
/// arguments, propagating NaNs and treating -0 as less than +0.
LLVM_READONLY
inline APFloat maximum(const APFloat &A, const APFloat &B) {
diff --git a/llvm/include/llvm/CodeGen/ISDOpcodes.h b/llvm/include/llvm/CodeGen/ISDOpcodes.h
index 8cb0bc9fd98133..ad876c5db4509a 100644
--- a/llvm/include/llvm/CodeGen/ISDOpcodes.h
+++ b/llvm/include/llvm/CodeGen/ISDOpcodes.h
@@ -978,7 +978,7 @@ enum NodeType {
/// FMINIMUM/FMAXIMUM - NaN-propagating minimum/maximum that also treat -0.0
/// as less than 0.0. While FMINNUM_IEEE/FMAXNUM_IEEE follow IEEE 754-2008
- /// semantics, FMINIMUM/FMAXIMUM follow IEEE 754-2018 draft semantics.
+ /// semantics, FMINIMUM/FMAXIMUM follow IEEE 754-2019 semantics.
FMINIMUM,
FMAXIMUM,
diff --git a/llvm/include/llvm/Target/GenericOpcodes.td b/llvm/include/llvm/Target/GenericOpcodes.td
index 19197f50d9dff9..d2036e478d18f2 100644
--- a/llvm/include/llvm/Target/GenericOpcodes.td
+++ b/llvm/include/llvm/Target/GenericOpcodes.td
@@ -815,7 +815,7 @@ def G_FMAXNUM_IEEE : GenericInstruction {
// FMINIMUM/FMAXIMUM - NaN-propagating minimum/maximum that also treat -0.0
// as less than 0.0. While FMINNUM_IEEE/FMAXNUM_IEEE follow IEEE 754-2008
-// semantics, FMINIMUM/FMAXIMUM follow IEEE 754-2018 draft semantics.
+// semantics, FMINIMUM/FMAXIMUM follow IEEE 754-2019 semantics.
def G_FMINIMUM : GenericInstruction {
let OutOperandList = (outs type0:$dst);
let InOperandList = (ins type0:$src1, type0:$src2);
>From 793300988b7c723bacadce67879ea8bf71c87e70 Mon Sep 17 00:00:00 2001
From: Jonas Devlieghere <jonas at devlieghere.com>
Date: Wed, 28 Feb 2024 21:19:02 -0800
Subject: [PATCH 088/406] [lldb] Add pexpect to
LLDB_ENFORCE_STRICT_TEST_REQUIREMENTS
This executed Alex' idea [1] of adding pexpect to the list of "strict
test requirements" as we're planning to stop vendoring it. This will
ensure all the bots have the package before we toggle the default.
[1] https://github.com/llvm/llvm-project/pull/83191
---
lldb/test/CMakeLists.txt | 3 ++-
1 file changed, 2 insertions(+), 1 deletion(-)
diff --git a/lldb/test/CMakeLists.txt b/lldb/test/CMakeLists.txt
index d8cbb24b6c9b81..4094c87aaa40e8 100644
--- a/lldb/test/CMakeLists.txt
+++ b/lldb/test/CMakeLists.txt
@@ -12,7 +12,8 @@ endif()
if(LLDB_ENFORCE_STRICT_TEST_REQUIREMENTS)
message(STATUS "Enforcing strict test requirements for LLDB")
set(useful_python_modules
- psutil # Lit uses psutil to do per-test timeouts.
+ psutil # Lit uses psutil to do per-test timeouts.
+ pexpect # We no longer vendor pexpect.
)
foreach(module ${useful_python_modules})
lldb_find_python_module(${module})
>From 81d94cad6d655d66adb08805a3bbef5a58125999 Mon Sep 17 00:00:00 2001
From: Jonas Devlieghere <jonas at devlieghere.com>
Date: Wed, 28 Feb 2024 21:23:19 -0800
Subject: [PATCH 089/406] Revert "[lldb] Add pexpect to
LLDB_ENFORCE_STRICT_TEST_REQUIREMENTS"
This reverts commit 793300988b7c723bacadce67879ea8bf71c87e70 as pexpect
is not available on any of the GreenDragon bots.
---
lldb/test/CMakeLists.txt | 3 +--
1 file changed, 1 insertion(+), 2 deletions(-)
diff --git a/lldb/test/CMakeLists.txt b/lldb/test/CMakeLists.txt
index 4094c87aaa40e8..d8cbb24b6c9b81 100644
--- a/lldb/test/CMakeLists.txt
+++ b/lldb/test/CMakeLists.txt
@@ -12,8 +12,7 @@ endif()
if(LLDB_ENFORCE_STRICT_TEST_REQUIREMENTS)
message(STATUS "Enforcing strict test requirements for LLDB")
set(useful_python_modules
- psutil # Lit uses psutil to do per-test timeouts.
- pexpect # We no longer vendor pexpect.
+ psutil # Lit uses psutil to do per-test timeouts.
)
foreach(module ${useful_python_modules})
lldb_find_python_module(${module})
>From 71c06bbb251371b6285f2a0fa337299bbf96a935 Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?D=C3=A1vid=20Ferenc=20Szab=C3=B3?=
<30732159+dfszabo at users.noreply.github.com>
Date: Thu, 29 Feb 2024 06:28:17 +0100
Subject: [PATCH 090/406] [GlobalISel] Combine (X == 0) & (Y == 0) -> (X | Y)
== 0 (#71949)
Also combine (X != 0) | (Y != 0) -> (X | Y) != 0
---
.../include/llvm/Target/GlobalISel/Combine.td | 33 +-
.../combine-2-icmps-of-0-and-or.mir | 1244 +++++++++++++++++
2 files changed, 1276 insertions(+), 1 deletion(-)
create mode 100644 llvm/test/CodeGen/AArch64/GlobalISel/combine-2-icmps-of-0-and-or.mir
diff --git a/llvm/include/llvm/Target/GlobalISel/Combine.td b/llvm/include/llvm/Target/GlobalISel/Combine.td
index 17757ca3e41111..18db7a819540af 100644
--- a/llvm/include/llvm/Target/GlobalISel/Combine.td
+++ b/llvm/include/llvm/Target/GlobalISel/Combine.td
@@ -952,6 +952,37 @@ def redundant_binop_in_equality : GICombineRule<
[{ return Helper.matchRedundantBinOpInEquality(*${root}, ${info}); }]),
(apply [{ Helper.applyBuildFn(*${root}, ${info}); }])>;
+// Transform: (X == 0 & Y == 0) -> (X | Y) == 0
+def double_icmp_zero_and_combine: GICombineRule<
+ (defs root:$root),
+ (match (G_ICMP $d1, $p, $s1, 0),
+ (G_ICMP $d2, $p, $s2, 0),
+ (G_AND $root, $d1, $d2),
+ [{ return ${p}.getPredicate() == CmpInst::ICMP_EQ &&
+ !MRI.getType(${s1}.getReg()).getScalarType().isPointer() &&
+ (MRI.getType(${s1}.getReg()) ==
+ MRI.getType(${s2}.getReg())); }]),
+ (apply (G_OR $ordst, $s1, $s2),
+ (G_ICMP $root, $p, $ordst, 0))
+>;
+
+// Transform: (X != 0 | Y != 0) -> (X | Y) != 0
+def double_icmp_zero_or_combine: GICombineRule<
+ (defs root:$root),
+ (match (G_ICMP $d1, $p, $s1, 0),
+ (G_ICMP $d2, $p, $s2, 0),
+ (G_OR $root, $d1, $d2),
+ [{ return ${p}.getPredicate() == CmpInst::ICMP_NE &&
+ !MRI.getType(${s1}.getReg()).getScalarType().isPointer() &&
+ (MRI.getType(${s1}.getReg()) ==
+ MRI.getType(${s2}.getReg())); }]),
+ (apply (G_OR $ordst, $s1, $s2),
+ (G_ICMP $root, $p, $ordst, 0))
+>;
+
+def double_icmp_zero_and_or_combine : GICombineGroup<[double_icmp_zero_and_combine,
+ double_icmp_zero_or_combine]>;
+
def and_or_disjoint_mask : GICombineRule<
(defs root:$root, build_fn_matchinfo:$info),
(match (wip_match_opcode G_AND):$root,
@@ -1343,7 +1374,7 @@ def all_combines : GICombineGroup<[trivial_combines, insert_vec_elt_combines,
and_or_disjoint_mask, fma_combines, fold_binop_into_select,
sub_add_reg, select_to_minmax, redundant_binop_in_equality,
fsub_to_fneg, commute_constant_to_rhs, match_ands, match_ors,
- combine_concat_vector]>;
+ combine_concat_vector, double_icmp_zero_and_or_combine]>;
// A combine group used to for prelegalizer combiners at -O0. The combines in
// this group have been selected based on experiments to balance code size and
diff --git a/llvm/test/CodeGen/AArch64/GlobalISel/combine-2-icmps-of-0-and-or.mir b/llvm/test/CodeGen/AArch64/GlobalISel/combine-2-icmps-of-0-and-or.mir
new file mode 100644
index 00000000000000..2ce5c693f3dbca
--- /dev/null
+++ b/llvm/test/CodeGen/AArch64/GlobalISel/combine-2-icmps-of-0-and-or.mir
@@ -0,0 +1,1244 @@
+# NOTE: Assertions have been autogenerated by utils/update_mir_test_checks.py
+# RUN: llc -mtriple aarch64 -run-pass=aarch64-prelegalizer-combiner -verify-machineinstrs %s -o - | FileCheck %s
+# REQUIRES: asserts
+
+
+---
+name: valid_and_eq_0_eq_0_s32
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $w0, $w1
+
+ ; CHECK-LABEL: name: valid_and_eq_0_eq_0_s32
+ ; CHECK: liveins: $w0, $w1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(s32) = COPY $w0
+ ; CHECK-NEXT: %y:_(s32) = COPY $w1
+ ; CHECK-NEXT: %zero:_(s32) = G_CONSTANT i32 0
+ ; CHECK-NEXT: [[OR:%[0-9]+]]:_(s32) = G_OR %x, %y
+ ; CHECK-NEXT: %and:_(s1) = G_ICMP intpred(eq), [[OR]](s32), %zero
+ ; CHECK-NEXT: %zext:_(s32) = G_ZEXT %and(s1)
+ ; CHECK-NEXT: $w0 = COPY %zext(s32)
+ ; CHECK-NEXT: RET_ReallyLR implicit $w0
+ %x:_(s32) = COPY $w0
+ %y:_(s32) = COPY $w1
+ %zero:_(s32) = G_CONSTANT i32 0
+ %cmp1:_(s1) = G_ICMP intpred(eq), %x:_(s32), %zero:_
+ %cmp2:_(s1) = G_ICMP intpred(eq), %y:_(s32), %zero:_
+ %and:_(s1) = G_AND %cmp1, %cmp2
+ %zext:_(s32) = G_ZEXT %and:_(s1)
+ $w0 = COPY %zext
+ RET_ReallyLR implicit $w0
+
+...
+---
+name: invalid_and_eq_1_eq_0_s32
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $w0, $w1
+
+ ; CHECK-LABEL: name: invalid_and_eq_1_eq_0_s32
+ ; CHECK: liveins: $w0, $w1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(s32) = COPY $w0
+ ; CHECK-NEXT: %y:_(s32) = COPY $w1
+ ; CHECK-NEXT: %zero:_(s32) = G_CONSTANT i32 0
+ ; CHECK-NEXT: %one:_(s32) = G_CONSTANT i32 1
+ ; CHECK-NEXT: %cmp1:_(s1) = G_ICMP intpred(eq), %x(s32), %one
+ ; CHECK-NEXT: %cmp2:_(s1) = G_ICMP intpred(eq), %y(s32), %zero
+ ; CHECK-NEXT: %and:_(s1) = G_AND %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(s32) = G_ZEXT %and(s1)
+ ; CHECK-NEXT: $w0 = COPY %zext(s32)
+ ; CHECK-NEXT: RET_ReallyLR implicit $w0
+ %x:_(s32) = COPY $w0
+ %y:_(s32) = COPY $w1
+ %zero:_(s32) = G_CONSTANT i32 0
+ %one:_(s32) = G_CONSTANT i32 1
+ %cmp1:_(s1) = G_ICMP intpred(eq), %x:_(s32), %one:_
+ %cmp2:_(s1) = G_ICMP intpred(eq), %y:_(s32), %zero:_
+ %and:_(s1) = G_AND %cmp1, %cmp2
+ %zext:_(s32) = G_ZEXT %and:_(s1)
+ $w0 = COPY %zext
+ RET_ReallyLR implicit $w0
+
+...
+---
+name: invalid_and_eq_0_eq_1_s32
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $w0, $w1
+
+ ; CHECK-LABEL: name: invalid_and_eq_0_eq_1_s32
+ ; CHECK: liveins: $w0, $w1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(s32) = COPY $w0
+ ; CHECK-NEXT: %y:_(s32) = COPY $w1
+ ; CHECK-NEXT: %zero:_(s32) = G_CONSTANT i32 0
+ ; CHECK-NEXT: %one:_(s32) = G_CONSTANT i32 1
+ ; CHECK-NEXT: %cmp1:_(s1) = G_ICMP intpred(eq), %x(s32), %zero
+ ; CHECK-NEXT: %cmp2:_(s1) = G_ICMP intpred(eq), %y(s32), %one
+ ; CHECK-NEXT: %and:_(s1) = G_AND %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(s32) = G_ZEXT %and(s1)
+ ; CHECK-NEXT: $w0 = COPY %zext(s32)
+ ; CHECK-NEXT: RET_ReallyLR implicit $w0
+ %x:_(s32) = COPY $w0
+ %y:_(s32) = COPY $w1
+ %zero:_(s32) = G_CONSTANT i32 0
+ %one:_(s32) = G_CONSTANT i32 1
+ %cmp1:_(s1) = G_ICMP intpred(eq), %x:_(s32), %zero:_
+ %cmp2:_(s1) = G_ICMP intpred(eq), %y:_(s32), %one:_
+ %and:_(s1) = G_AND %cmp1, %cmp2
+ %zext:_(s32) = G_ZEXT %and:_(s1)
+ $w0 = COPY %zext
+ RET_ReallyLR implicit $w0
+
+...
+---
+name: invalid_and_ne_0_eq_0_s32
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $w0, $w1
+
+ ; CHECK-LABEL: name: invalid_and_ne_0_eq_0_s32
+ ; CHECK: liveins: $w0, $w1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(s32) = COPY $w0
+ ; CHECK-NEXT: %y:_(s32) = COPY $w1
+ ; CHECK-NEXT: %zero:_(s32) = G_CONSTANT i32 0
+ ; CHECK-NEXT: %cmp1:_(s1) = G_ICMP intpred(ne), %x(s32), %zero
+ ; CHECK-NEXT: %cmp2:_(s1) = G_ICMP intpred(eq), %y(s32), %zero
+ ; CHECK-NEXT: %and:_(s1) = G_AND %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(s32) = G_ZEXT %and(s1)
+ ; CHECK-NEXT: $w0 = COPY %zext(s32)
+ ; CHECK-NEXT: RET_ReallyLR implicit $w0
+ %x:_(s32) = COPY $w0
+ %y:_(s32) = COPY $w1
+ %zero:_(s32) = G_CONSTANT i32 0
+ %cmp1:_(s1) = G_ICMP intpred(ne), %x:_(s32), %zero:_
+ %cmp2:_(s1) = G_ICMP intpred(eq), %y:_(s32), %zero:_
+ %and:_(s1) = G_AND %cmp1, %cmp2
+ %zext:_(s32) = G_ZEXT %and:_(s1)
+ $w0 = COPY %zext
+ RET_ReallyLR implicit $w0
+
+...
+---
+name: invalid_and_eq_0_ne_0_s32
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $w0, $w1
+
+ ; CHECK-LABEL: name: invalid_and_eq_0_ne_0_s32
+ ; CHECK: liveins: $w0, $w1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(s32) = COPY $w0
+ ; CHECK-NEXT: %y:_(s32) = COPY $w1
+ ; CHECK-NEXT: %zero:_(s32) = G_CONSTANT i32 0
+ ; CHECK-NEXT: %cmp1:_(s1) = G_ICMP intpred(eq), %x(s32), %zero
+ ; CHECK-NEXT: %cmp2:_(s1) = G_ICMP intpred(ne), %y(s32), %zero
+ ; CHECK-NEXT: %and:_(s1) = G_AND %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(s32) = G_ZEXT %and(s1)
+ ; CHECK-NEXT: $w0 = COPY %zext(s32)
+ ; CHECK-NEXT: RET_ReallyLR implicit $w0
+ %x:_(s32) = COPY $w0
+ %y:_(s32) = COPY $w1
+ %zero:_(s32) = G_CONSTANT i32 0
+ %cmp1:_(s1) = G_ICMP intpred(eq), %x:_(s32), %zero:_
+ %cmp2:_(s1) = G_ICMP intpred(ne), %y:_(s32), %zero:_
+ %and:_(s1) = G_AND %cmp1, %cmp2
+ %zext:_(s32) = G_ZEXT %and:_(s1)
+ $w0 = COPY %zext
+ RET_ReallyLR implicit $w0
+
+...
+---
+name: invalid_and_ne_0_ne_0_s32
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $w0, $w1
+
+ ; CHECK-LABEL: name: invalid_and_ne_0_ne_0_s32
+ ; CHECK: liveins: $w0, $w1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(s32) = COPY $w0
+ ; CHECK-NEXT: %y:_(s32) = COPY $w1
+ ; CHECK-NEXT: %zero:_(s32) = G_CONSTANT i32 0
+ ; CHECK-NEXT: %cmp1:_(s1) = G_ICMP intpred(ne), %x(s32), %zero
+ ; CHECK-NEXT: %cmp2:_(s1) = G_ICMP intpred(ne), %y(s32), %zero
+ ; CHECK-NEXT: %and:_(s1) = G_AND %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(s32) = G_ZEXT %and(s1)
+ ; CHECK-NEXT: $w0 = COPY %zext(s32)
+ ; CHECK-NEXT: RET_ReallyLR implicit $w0
+ %x:_(s32) = COPY $w0
+ %y:_(s32) = COPY $w1
+ %zero:_(s32) = G_CONSTANT i32 0
+ %cmp1:_(s1) = G_ICMP intpred(ne), %x:_(s32), %zero:_
+ %cmp2:_(s1) = G_ICMP intpred(ne), %y:_(s32), %zero:_
+ %and:_(s1) = G_AND %cmp1, %cmp2
+ %zext:_(s32) = G_ZEXT %and:_(s1)
+ $w0 = COPY %zext
+ RET_ReallyLR implicit $w0
+
+...
+---
+name: valid_or_ne_0_ne_0_s32
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $w0, $w1
+
+ ; CHECK-LABEL: name: valid_or_ne_0_ne_0_s32
+ ; CHECK: liveins: $w0, $w1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(s32) = COPY $w0
+ ; CHECK-NEXT: %y:_(s32) = COPY $w1
+ ; CHECK-NEXT: %zero:_(s32) = G_CONSTANT i32 0
+ ; CHECK-NEXT: [[OR:%[0-9]+]]:_(s32) = G_OR %x, %y
+ ; CHECK-NEXT: %or:_(s1) = G_ICMP intpred(ne), [[OR]](s32), %zero
+ ; CHECK-NEXT: %zext:_(s32) = G_ZEXT %or(s1)
+ ; CHECK-NEXT: $w0 = COPY %zext(s32)
+ ; CHECK-NEXT: RET_ReallyLR implicit $w0
+ %x:_(s32) = COPY $w0
+ %y:_(s32) = COPY $w1
+ %zero:_(s32) = G_CONSTANT i32 0
+ %cmp1:_(s1) = G_ICMP intpred(ne), %x:_(s32), %zero:_
+ %cmp2:_(s1) = G_ICMP intpred(ne), %y:_(s32), %zero:_
+ %or:_(s1) = G_OR %cmp1, %cmp2
+ %zext:_(s32) = G_ZEXT %or:_(s1)
+ $w0 = COPY %zext
+ RET_ReallyLR implicit $w0
+
+...
+---
+name: invalid_or_ne_1_ne_0_s32
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $w0, $w1
+
+ ; CHECK-LABEL: name: invalid_or_ne_1_ne_0_s32
+ ; CHECK: liveins: $w0, $w1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(s32) = COPY $w0
+ ; CHECK-NEXT: %y:_(s32) = COPY $w1
+ ; CHECK-NEXT: %zero:_(s32) = G_CONSTANT i32 0
+ ; CHECK-NEXT: %one:_(s32) = G_CONSTANT i32 1
+ ; CHECK-NEXT: %cmp1:_(s1) = G_ICMP intpred(ne), %x(s32), %one
+ ; CHECK-NEXT: %cmp2:_(s1) = G_ICMP intpred(ne), %y(s32), %zero
+ ; CHECK-NEXT: %or:_(s1) = G_OR %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(s32) = G_ZEXT %or(s1)
+ ; CHECK-NEXT: $w0 = COPY %zext(s32)
+ ; CHECK-NEXT: RET_ReallyLR implicit $w0
+ %x:_(s32) = COPY $w0
+ %y:_(s32) = COPY $w1
+ %zero:_(s32) = G_CONSTANT i32 0
+ %one:_(s32) = G_CONSTANT i32 1
+ %cmp1:_(s1) = G_ICMP intpred(ne), %x:_(s32), %one:_
+ %cmp2:_(s1) = G_ICMP intpred(ne), %y:_(s32), %zero:_
+ %or:_(s1) = G_OR %cmp1, %cmp2
+ %zext:_(s32) = G_ZEXT %or:_(s1)
+ $w0 = COPY %zext
+ RET_ReallyLR implicit $w0
+
+...
+---
+name: invalid_or_ne_0_ne_1_s32
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $w0, $w1
+
+ ; CHECK-LABEL: name: invalid_or_ne_0_ne_1_s32
+ ; CHECK: liveins: $w0, $w1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(s32) = COPY $w0
+ ; CHECK-NEXT: %y:_(s32) = COPY $w1
+ ; CHECK-NEXT: %zero:_(s32) = G_CONSTANT i32 0
+ ; CHECK-NEXT: %one:_(s32) = G_CONSTANT i32 1
+ ; CHECK-NEXT: %cmp1:_(s1) = G_ICMP intpred(ne), %x(s32), %zero
+ ; CHECK-NEXT: %cmp2:_(s1) = G_ICMP intpred(ne), %y(s32), %one
+ ; CHECK-NEXT: %or:_(s1) = G_OR %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(s32) = G_ZEXT %or(s1)
+ ; CHECK-NEXT: $w0 = COPY %zext(s32)
+ ; CHECK-NEXT: RET_ReallyLR implicit $w0
+ %x:_(s32) = COPY $w0
+ %y:_(s32) = COPY $w1
+ %zero:_(s32) = G_CONSTANT i32 0
+ %one:_(s32) = G_CONSTANT i32 1
+ %cmp1:_(s1) = G_ICMP intpred(ne), %x:_(s32), %zero:_
+ %cmp2:_(s1) = G_ICMP intpred(ne), %y:_(s32), %one:_
+ %or:_(s1) = G_OR %cmp1, %cmp2
+ %zext:_(s32) = G_ZEXT %or:_(s1)
+ $w0 = COPY %zext
+ RET_ReallyLR implicit $w0
+
+...
+---
+name: invalid_or_eq_0_ne_0_s32
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $w0, $w1
+
+ ; CHECK-LABEL: name: invalid_or_eq_0_ne_0_s32
+ ; CHECK: liveins: $w0, $w1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(s32) = COPY $w0
+ ; CHECK-NEXT: %y:_(s32) = COPY $w1
+ ; CHECK-NEXT: %zero:_(s32) = G_CONSTANT i32 0
+ ; CHECK-NEXT: %cmp1:_(s1) = G_ICMP intpred(eq), %x(s32), %zero
+ ; CHECK-NEXT: %cmp2:_(s1) = G_ICMP intpred(ne), %y(s32), %zero
+ ; CHECK-NEXT: %or:_(s1) = G_OR %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(s32) = G_ZEXT %or(s1)
+ ; CHECK-NEXT: $w0 = COPY %zext(s32)
+ ; CHECK-NEXT: RET_ReallyLR implicit $w0
+ %x:_(s32) = COPY $w0
+ %y:_(s32) = COPY $w1
+ %zero:_(s32) = G_CONSTANT i32 0
+ %cmp1:_(s1) = G_ICMP intpred(eq), %x:_(s32), %zero:_
+ %cmp2:_(s1) = G_ICMP intpred(ne), %y:_(s32), %zero:_
+ %or:_(s1) = G_OR %cmp1, %cmp2
+ %zext:_(s32) = G_ZEXT %or:_(s1)
+ $w0 = COPY %zext
+ RET_ReallyLR implicit $w0
+
+...
+---
+name: invalid_or_ne_0_eq_0_s32
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $w0, $w1
+
+ ; CHECK-LABEL: name: invalid_or_ne_0_eq_0_s32
+ ; CHECK: liveins: $w0, $w1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(s32) = COPY $w0
+ ; CHECK-NEXT: %y:_(s32) = COPY $w1
+ ; CHECK-NEXT: %zero:_(s32) = G_CONSTANT i32 0
+ ; CHECK-NEXT: %cmp1:_(s1) = G_ICMP intpred(ne), %x(s32), %zero
+ ; CHECK-NEXT: %cmp2:_(s1) = G_ICMP intpred(eq), %y(s32), %zero
+ ; CHECK-NEXT: %or:_(s1) = G_OR %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(s32) = G_ZEXT %or(s1)
+ ; CHECK-NEXT: $w0 = COPY %zext(s32)
+ ; CHECK-NEXT: RET_ReallyLR implicit $w0
+ %x:_(s32) = COPY $w0
+ %y:_(s32) = COPY $w1
+ %zero:_(s32) = G_CONSTANT i32 0
+ %cmp1:_(s1) = G_ICMP intpred(ne), %x:_(s32), %zero:_
+ %cmp2:_(s1) = G_ICMP intpred(eq), %y:_(s32), %zero:_
+ %or:_(s1) = G_OR %cmp1, %cmp2
+ %zext:_(s32) = G_ZEXT %or:_(s1)
+ $w0 = COPY %zext
+ RET_ReallyLR implicit $w0
+
+...
+
+---
+name: valid_and_eq_0_eq_0_s64
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $x0, $x1
+
+ ; CHECK-LABEL: name: valid_and_eq_0_eq_0_s64
+ ; CHECK: liveins: $x0, $x1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(s64) = COPY $x0
+ ; CHECK-NEXT: %y:_(s64) = COPY $x1
+ ; CHECK-NEXT: %zero:_(s64) = G_CONSTANT i64 0
+ ; CHECK-NEXT: [[OR:%[0-9]+]]:_(s64) = G_OR %x, %y
+ ; CHECK-NEXT: %and:_(s1) = G_ICMP intpred(eq), [[OR]](s64), %zero
+ ; CHECK-NEXT: %zext:_(s64) = G_ZEXT %and(s1)
+ ; CHECK-NEXT: $x0 = COPY %zext(s64)
+ ; CHECK-NEXT: RET_ReallyLR implicit $x0
+ %x:_(s64) = COPY $x0
+ %y:_(s64) = COPY $x1
+ %zero:_(s64) = G_CONSTANT i64 0
+ %cmp1:_(s1) = G_ICMP intpred(eq), %x:_(s64), %zero:_
+ %cmp2:_(s1) = G_ICMP intpred(eq), %y:_(s64), %zero:_
+ %and:_(s1) = G_AND %cmp1, %cmp2
+ %zext:_(s64) = G_ZEXT %and:_(s1)
+ $x0 = COPY %zext
+ RET_ReallyLR implicit $x0
+
+...
+---
+name: invalid_and_eq_1_eq_0_s64
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $x0, $x1
+
+ ; CHECK-LABEL: name: invalid_and_eq_1_eq_0_s64
+ ; CHECK: liveins: $x0, $x1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(s64) = COPY $x0
+ ; CHECK-NEXT: %y:_(s64) = COPY $x1
+ ; CHECK-NEXT: %zero:_(s64) = G_CONSTANT i64 0
+ ; CHECK-NEXT: %one:_(s64) = G_CONSTANT i64 1
+ ; CHECK-NEXT: %cmp1:_(s1) = G_ICMP intpred(eq), %x(s64), %one
+ ; CHECK-NEXT: %cmp2:_(s1) = G_ICMP intpred(eq), %y(s64), %zero
+ ; CHECK-NEXT: %and:_(s1) = G_AND %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(s64) = G_ZEXT %and(s1)
+ ; CHECK-NEXT: $x0 = COPY %zext(s64)
+ ; CHECK-NEXT: RET_ReallyLR implicit $x0
+ %x:_(s64) = COPY $x0
+ %y:_(s64) = COPY $x1
+ %zero:_(s64) = G_CONSTANT i64 0
+ %one:_(s64) = G_CONSTANT i64 1
+ %cmp1:_(s1) = G_ICMP intpred(eq), %x:_(s64), %one:_
+ %cmp2:_(s1) = G_ICMP intpred(eq), %y:_(s64), %zero:_
+ %and:_(s1) = G_AND %cmp1, %cmp2
+ %zext:_(s64) = G_ZEXT %and:_(s1)
+ $x0 = COPY %zext
+ RET_ReallyLR implicit $x0
+
+...
+---
+name: invalid_and_eq_0_eq_1_s64
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $x0, $x1
+
+ ; CHECK-LABEL: name: invalid_and_eq_0_eq_1_s64
+ ; CHECK: liveins: $x0, $x1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(s64) = COPY $x0
+ ; CHECK-NEXT: %y:_(s64) = COPY $x1
+ ; CHECK-NEXT: %zero:_(s64) = G_CONSTANT i64 0
+ ; CHECK-NEXT: %one:_(s64) = G_CONSTANT i64 1
+ ; CHECK-NEXT: %cmp1:_(s1) = G_ICMP intpred(eq), %x(s64), %zero
+ ; CHECK-NEXT: %cmp2:_(s1) = G_ICMP intpred(eq), %y(s64), %one
+ ; CHECK-NEXT: %and:_(s1) = G_AND %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(s64) = G_ZEXT %and(s1)
+ ; CHECK-NEXT: $x0 = COPY %zext(s64)
+ ; CHECK-NEXT: RET_ReallyLR implicit $x0
+ %x:_(s64) = COPY $x0
+ %y:_(s64) = COPY $x1
+ %zero:_(s64) = G_CONSTANT i64 0
+ %one:_(s64) = G_CONSTANT i64 1
+ %cmp1:_(s1) = G_ICMP intpred(eq), %x:_(s64), %zero:_
+ %cmp2:_(s1) = G_ICMP intpred(eq), %y:_(s64), %one:_
+ %and:_(s1) = G_AND %cmp1, %cmp2
+ %zext:_(s64) = G_ZEXT %and:_(s1)
+ $x0 = COPY %zext
+ RET_ReallyLR implicit $x0
+
+...
+---
+name: invalid_and_ne_0_eq_0_s64
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $x0, $x1
+
+ ; CHECK-LABEL: name: invalid_and_ne_0_eq_0_s64
+ ; CHECK: liveins: $x0, $x1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(s64) = COPY $x0
+ ; CHECK-NEXT: %y:_(s64) = COPY $x1
+ ; CHECK-NEXT: %zero:_(s64) = G_CONSTANT i64 0
+ ; CHECK-NEXT: %cmp1:_(s1) = G_ICMP intpred(ne), %x(s64), %zero
+ ; CHECK-NEXT: %cmp2:_(s1) = G_ICMP intpred(eq), %y(s64), %zero
+ ; CHECK-NEXT: %and:_(s1) = G_AND %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(s64) = G_ZEXT %and(s1)
+ ; CHECK-NEXT: $x0 = COPY %zext(s64)
+ ; CHECK-NEXT: RET_ReallyLR implicit $x0
+ %x:_(s64) = COPY $x0
+ %y:_(s64) = COPY $x1
+ %zero:_(s64) = G_CONSTANT i64 0
+ %cmp1:_(s1) = G_ICMP intpred(ne), %x:_(s64), %zero:_
+ %cmp2:_(s1) = G_ICMP intpred(eq), %y:_(s64), %zero:_
+ %and:_(s1) = G_AND %cmp1, %cmp2
+ %zext:_(s64) = G_ZEXT %and:_(s1)
+ $x0 = COPY %zext
+ RET_ReallyLR implicit $x0
+
+...
+---
+name: invalid_and_eq_0_ne_0_s64
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $x0, $x1
+
+ ; CHECK-LABEL: name: invalid_and_eq_0_ne_0_s64
+ ; CHECK: liveins: $x0, $x1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(s64) = COPY $x0
+ ; CHECK-NEXT: %y:_(s64) = COPY $x1
+ ; CHECK-NEXT: %zero:_(s64) = G_CONSTANT i64 0
+ ; CHECK-NEXT: %cmp1:_(s1) = G_ICMP intpred(eq), %x(s64), %zero
+ ; CHECK-NEXT: %cmp2:_(s1) = G_ICMP intpred(ne), %y(s64), %zero
+ ; CHECK-NEXT: %and:_(s1) = G_AND %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(s64) = G_ZEXT %and(s1)
+ ; CHECK-NEXT: $x0 = COPY %zext(s64)
+ ; CHECK-NEXT: RET_ReallyLR implicit $x0
+ %x:_(s64) = COPY $x0
+ %y:_(s64) = COPY $x1
+ %zero:_(s64) = G_CONSTANT i64 0
+ %cmp1:_(s1) = G_ICMP intpred(eq), %x:_(s64), %zero:_
+ %cmp2:_(s1) = G_ICMP intpred(ne), %y:_(s64), %zero:_
+ %and:_(s1) = G_AND %cmp1, %cmp2
+ %zext:_(s64) = G_ZEXT %and:_(s1)
+ $x0 = COPY %zext
+ RET_ReallyLR implicit $x0
+
+...
+---
+name: invalid_and_ne_0_ne_0_s64
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $x0, $x1
+
+ ; CHECK-LABEL: name: invalid_and_ne_0_ne_0_s64
+ ; CHECK: liveins: $x0, $x1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(s64) = COPY $x0
+ ; CHECK-NEXT: %y:_(s64) = COPY $x1
+ ; CHECK-NEXT: %zero:_(s64) = G_CONSTANT i64 0
+ ; CHECK-NEXT: %cmp1:_(s1) = G_ICMP intpred(ne), %x(s64), %zero
+ ; CHECK-NEXT: %cmp2:_(s1) = G_ICMP intpred(ne), %y(s64), %zero
+ ; CHECK-NEXT: %and:_(s1) = G_AND %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(s64) = G_ZEXT %and(s1)
+ ; CHECK-NEXT: $x0 = COPY %zext(s64)
+ ; CHECK-NEXT: RET_ReallyLR implicit $x0
+ %x:_(s64) = COPY $x0
+ %y:_(s64) = COPY $x1
+ %zero:_(s64) = G_CONSTANT i64 0
+ %cmp1:_(s1) = G_ICMP intpred(ne), %x:_(s64), %zero:_
+ %cmp2:_(s1) = G_ICMP intpred(ne), %y:_(s64), %zero:_
+ %and:_(s1) = G_AND %cmp1, %cmp2
+ %zext:_(s64) = G_ZEXT %and:_(s1)
+ $x0 = COPY %zext
+ RET_ReallyLR implicit $x0
+
+...
+---
+name: valid_or_ne_0_ne_0_s64
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $x0, $x1
+
+ ; CHECK-LABEL: name: valid_or_ne_0_ne_0_s64
+ ; CHECK: liveins: $x0, $x1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(s64) = COPY $x0
+ ; CHECK-NEXT: %y:_(s64) = COPY $x1
+ ; CHECK-NEXT: %zero:_(s64) = G_CONSTANT i64 0
+ ; CHECK-NEXT: [[OR:%[0-9]+]]:_(s64) = G_OR %x, %y
+ ; CHECK-NEXT: %or:_(s1) = G_ICMP intpred(ne), [[OR]](s64), %zero
+ ; CHECK-NEXT: %zext:_(s64) = G_ZEXT %or(s1)
+ ; CHECK-NEXT: $x0 = COPY %zext(s64)
+ ; CHECK-NEXT: RET_ReallyLR implicit $x0
+ %x:_(s64) = COPY $x0
+ %y:_(s64) = COPY $x1
+ %zero:_(s64) = G_CONSTANT i64 0
+ %cmp1:_(s1) = G_ICMP intpred(ne), %x:_(s64), %zero:_
+ %cmp2:_(s1) = G_ICMP intpred(ne), %y:_(s64), %zero:_
+ %or:_(s1) = G_OR %cmp1, %cmp2
+ %zext:_(s64) = G_ZEXT %or:_(s1)
+ $x0 = COPY %zext
+ RET_ReallyLR implicit $x0
+
+...
+---
+name: invalid_or_ne_1_ne_0_s64
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $x0, $x1
+
+ ; CHECK-LABEL: name: invalid_or_ne_1_ne_0_s64
+ ; CHECK: liveins: $x0, $x1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(s64) = COPY $x0
+ ; CHECK-NEXT: %y:_(s64) = COPY $x1
+ ; CHECK-NEXT: %zero:_(s64) = G_CONSTANT i64 0
+ ; CHECK-NEXT: %one:_(s64) = G_CONSTANT i64 1
+ ; CHECK-NEXT: %cmp1:_(s1) = G_ICMP intpred(ne), %x(s64), %one
+ ; CHECK-NEXT: %cmp2:_(s1) = G_ICMP intpred(ne), %y(s64), %zero
+ ; CHECK-NEXT: %or:_(s1) = G_OR %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(s64) = G_ZEXT %or(s1)
+ ; CHECK-NEXT: $x0 = COPY %zext(s64)
+ ; CHECK-NEXT: RET_ReallyLR implicit $x0
+ %x:_(s64) = COPY $x0
+ %y:_(s64) = COPY $x1
+ %zero:_(s64) = G_CONSTANT i64 0
+ %one:_(s64) = G_CONSTANT i64 1
+ %cmp1:_(s1) = G_ICMP intpred(ne), %x:_(s64), %one:_
+ %cmp2:_(s1) = G_ICMP intpred(ne), %y:_(s64), %zero:_
+ %or:_(s1) = G_OR %cmp1, %cmp2
+ %zext:_(s64) = G_ZEXT %or:_(s1)
+ $x0 = COPY %zext
+ RET_ReallyLR implicit $x0
+
+...
+---
+name: invalid_or_ne_0_ne_1_s64
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $x0, $x1
+
+ ; CHECK-LABEL: name: invalid_or_ne_0_ne_1_s64
+ ; CHECK: liveins: $x0, $x1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(s64) = COPY $x0
+ ; CHECK-NEXT: %y:_(s64) = COPY $x1
+ ; CHECK-NEXT: %zero:_(s64) = G_CONSTANT i64 0
+ ; CHECK-NEXT: %one:_(s64) = G_CONSTANT i64 1
+ ; CHECK-NEXT: %cmp1:_(s1) = G_ICMP intpred(ne), %x(s64), %zero
+ ; CHECK-NEXT: %cmp2:_(s1) = G_ICMP intpred(ne), %y(s64), %one
+ ; CHECK-NEXT: %or:_(s1) = G_OR %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(s64) = G_ZEXT %or(s1)
+ ; CHECK-NEXT: $x0 = COPY %zext(s64)
+ ; CHECK-NEXT: RET_ReallyLR implicit $x0
+ %x:_(s64) = COPY $x0
+ %y:_(s64) = COPY $x1
+ %zero:_(s64) = G_CONSTANT i64 0
+ %one:_(s64) = G_CONSTANT i64 1
+ %cmp1:_(s1) = G_ICMP intpred(ne), %x:_(s64), %zero:_
+ %cmp2:_(s1) = G_ICMP intpred(ne), %y:_(s64), %one:_
+ %or:_(s1) = G_OR %cmp1, %cmp2
+ %zext:_(s64) = G_ZEXT %or:_(s1)
+ $x0 = COPY %zext
+ RET_ReallyLR implicit $x0
+
+...
+---
+name: invalid_or_eq_0_ne_0_s64
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $x0, $x1
+
+ ; CHECK-LABEL: name: invalid_or_eq_0_ne_0_s64
+ ; CHECK: liveins: $x0, $x1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(s64) = COPY $x0
+ ; CHECK-NEXT: %y:_(s64) = COPY $x1
+ ; CHECK-NEXT: %zero:_(s64) = G_CONSTANT i64 0
+ ; CHECK-NEXT: %cmp1:_(s1) = G_ICMP intpred(eq), %x(s64), %zero
+ ; CHECK-NEXT: %cmp2:_(s1) = G_ICMP intpred(ne), %y(s64), %zero
+ ; CHECK-NEXT: %or:_(s1) = G_OR %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(s64) = G_ZEXT %or(s1)
+ ; CHECK-NEXT: $x0 = COPY %zext(s64)
+ ; CHECK-NEXT: RET_ReallyLR implicit $x0
+ %x:_(s64) = COPY $x0
+ %y:_(s64) = COPY $x1
+ %zero:_(s64) = G_CONSTANT i64 0
+ %cmp1:_(s1) = G_ICMP intpred(eq), %x:_(s64), %zero:_
+ %cmp2:_(s1) = G_ICMP intpred(ne), %y:_(s64), %zero:_
+ %or:_(s1) = G_OR %cmp1, %cmp2
+ %zext:_(s64) = G_ZEXT %or:_(s1)
+ $x0 = COPY %zext
+ RET_ReallyLR implicit $x0
+
+...
+---
+name: invalid_or_ne_0_eq_0_s64
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $x0, $x1
+
+ ; CHECK-LABEL: name: invalid_or_ne_0_eq_0_s64
+ ; CHECK: liveins: $x0, $x1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(s64) = COPY $x0
+ ; CHECK-NEXT: %y:_(s64) = COPY $x1
+ ; CHECK-NEXT: %zero:_(s64) = G_CONSTANT i64 0
+ ; CHECK-NEXT: %cmp1:_(s1) = G_ICMP intpred(ne), %x(s64), %zero
+ ; CHECK-NEXT: %cmp2:_(s1) = G_ICMP intpred(eq), %y(s64), %zero
+ ; CHECK-NEXT: %or:_(s1) = G_OR %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(s64) = G_ZEXT %or(s1)
+ ; CHECK-NEXT: $x0 = COPY %zext(s64)
+ ; CHECK-NEXT: RET_ReallyLR implicit $x0
+ %x:_(s64) = COPY $x0
+ %y:_(s64) = COPY $x1
+ %zero:_(s64) = G_CONSTANT i64 0
+ %cmp1:_(s1) = G_ICMP intpred(ne), %x:_(s64), %zero:_
+ %cmp2:_(s1) = G_ICMP intpred(eq), %y:_(s64), %zero:_
+ %or:_(s1) = G_OR %cmp1, %cmp2
+ %zext:_(s64) = G_ZEXT %or:_(s1)
+ $x0 = COPY %zext
+ RET_ReallyLR implicit $x0
+
+...
+---
+name: valid_and_eq_0_eq_0_vec
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $x0, $x1
+
+ ; CHECK-LABEL: name: valid_and_eq_0_eq_0_vec
+ ; CHECK: liveins: $x0, $x1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(<2 x s32>) = COPY $x0
+ ; CHECK-NEXT: %y:_(<2 x s32>) = COPY $x1
+ ; CHECK-NEXT: %zero_scalar:_(s32) = G_CONSTANT i32 0
+ ; CHECK-NEXT: %zero:_(<2 x s32>) = G_BUILD_VECTOR %zero_scalar(s32), %zero_scalar(s32)
+ ; CHECK-NEXT: [[OR:%[0-9]+]]:_(<2 x s32>) = G_OR %x, %y
+ ; CHECK-NEXT: %and:_(<2 x s1>) = G_ICMP intpred(eq), [[OR]](<2 x s32>), %zero
+ ; CHECK-NEXT: %zext:_(<2 x s32>) = G_ZEXT %and(<2 x s1>)
+ ; CHECK-NEXT: $x0 = COPY %zext(<2 x s32>)
+ ; CHECK-NEXT: RET_ReallyLR implicit $x0
+ %x:_(<2 x s32>) = COPY $x0
+ %y:_(<2 x s32>) = COPY $x1
+ %zero_scalar:_(s32) = G_CONSTANT i32 0
+ %zero:_(<2 x s32>) = G_BUILD_VECTOR %zero_scalar(s32), %zero_scalar(s32)
+ %cmp1:_(<2 x s1>) = G_ICMP intpred(eq), %x:_(<2 x s32>), %zero:_
+ %cmp2:_(<2 x s1>) = G_ICMP intpred(eq), %y:_(<2 x s32>), %zero:_
+ %and:_(<2 x s1>) = G_AND %cmp1, %cmp2
+ %zext:_(<2 x s32>) = G_ZEXT %and:_(<2 x s1>)
+ $x0 = COPY %zext
+ RET_ReallyLR implicit $x0
+
+...
+---
+name: invalid_and_eq_non_0_eq_0_vec
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $x0, $x1
+
+ ; CHECK-LABEL: name: invalid_and_eq_non_0_eq_0_vec
+ ; CHECK: liveins: $x0, $x1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(<2 x s32>) = COPY $x0
+ ; CHECK-NEXT: %y:_(<2 x s32>) = COPY $x1
+ ; CHECK-NEXT: %scalar0:_(s32) = G_CONSTANT i32 0
+ ; CHECK-NEXT: %scalar1:_(s32) = G_CONSTANT i32 1
+ ; CHECK-NEXT: %zero:_(<2 x s32>) = G_BUILD_VECTOR %scalar0(s32), %scalar0(s32)
+ ; CHECK-NEXT: %non_zero:_(<2 x s32>) = G_BUILD_VECTOR %scalar0(s32), %scalar1(s32)
+ ; CHECK-NEXT: %cmp1:_(<2 x s1>) = G_ICMP intpred(eq), %x(<2 x s32>), %non_zero
+ ; CHECK-NEXT: %cmp2:_(<2 x s1>) = G_ICMP intpred(eq), %y(<2 x s32>), %zero
+ ; CHECK-NEXT: %and:_(<2 x s1>) = G_AND %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(<2 x s32>) = G_ZEXT %and(<2 x s1>)
+ ; CHECK-NEXT: $x0 = COPY %zext(<2 x s32>)
+ ; CHECK-NEXT: RET_ReallyLR implicit $x0
+ %x:_(<2 x s32>) = COPY $x0
+ %y:_(<2 x s32>) = COPY $x1
+ %scalar0:_(s32) = G_CONSTANT i32 0
+ %scalar1:_(s32) = G_CONSTANT i32 1
+ %zero:_(<2 x s32>) = G_BUILD_VECTOR %scalar0(s32), %scalar0(s32)
+ %non_zero:_(<2 x s32>) = G_BUILD_VECTOR %scalar0(s32), %scalar1(s32)
+ %cmp1:_(<2 x s1>) = G_ICMP intpred(eq), %x:_(<2 x s32>), %non_zero:_
+ %cmp2:_(<2 x s1>) = G_ICMP intpred(eq), %y:_(<2 x s32>), %zero:_
+ %and:_(<2 x s1>) = G_AND %cmp1, %cmp2
+ %zext:_(<2 x s32>) = G_ZEXT %and:_(<2 x s1>)
+ $x0 = COPY %zext
+ RET_ReallyLR implicit $x0
+
+...
+---
+name: invalid_and_eq_0_eq_non_0_vec
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $x0, $x1
+
+ ; CHECK-LABEL: name: invalid_and_eq_0_eq_non_0_vec
+ ; CHECK: liveins: $x0, $x1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(<2 x s32>) = COPY $x0
+ ; CHECK-NEXT: %y:_(<2 x s32>) = COPY $x1
+ ; CHECK-NEXT: %scalar0:_(s32) = G_CONSTANT i32 0
+ ; CHECK-NEXT: %scalar1:_(s32) = G_CONSTANT i32 1
+ ; CHECK-NEXT: %zero:_(<2 x s32>) = G_BUILD_VECTOR %scalar0(s32), %scalar0(s32)
+ ; CHECK-NEXT: %non_zero:_(<2 x s32>) = G_BUILD_VECTOR %scalar0(s32), %scalar1(s32)
+ ; CHECK-NEXT: %cmp1:_(<2 x s1>) = G_ICMP intpred(eq), %x(<2 x s32>), %zero
+ ; CHECK-NEXT: %cmp2:_(<2 x s1>) = G_ICMP intpred(eq), %y(<2 x s32>), %non_zero
+ ; CHECK-NEXT: %and:_(<2 x s1>) = G_AND %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(<2 x s32>) = G_ZEXT %and(<2 x s1>)
+ ; CHECK-NEXT: $x0 = COPY %zext(<2 x s32>)
+ ; CHECK-NEXT: RET_ReallyLR implicit $x0
+ %x:_(<2 x s32>) = COPY $x0
+ %y:_(<2 x s32>) = COPY $x1
+ %scalar0:_(s32) = G_CONSTANT i32 0
+ %scalar1:_(s32) = G_CONSTANT i32 1
+ %zero:_(<2 x s32>) = G_BUILD_VECTOR %scalar0(s32), %scalar0(s32)
+ %non_zero:_(<2 x s32>) = G_BUILD_VECTOR %scalar0(s32), %scalar1(s32)
+ %cmp1:_(<2 x s1>) = G_ICMP intpred(eq), %x:_(<2 x s32>), %zero:_
+ %cmp2:_(<2 x s1>) = G_ICMP intpred(eq), %y:_(<2 x s32>), %non_zero:_
+ %and:_(<2 x s1>) = G_AND %cmp1, %cmp2
+ %zext:_(<2 x s32>) = G_ZEXT %and:_(<2 x s1>)
+ $x0 = COPY %zext
+ RET_ReallyLR implicit $x0
+
+...
+---
+name: invalid_and_ne_0_eq_0_vec
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $x0, $x1
+
+ ; CHECK-LABEL: name: invalid_and_ne_0_eq_0_vec
+ ; CHECK: liveins: $x0, $x1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(<2 x s32>) = COPY $x0
+ ; CHECK-NEXT: %y:_(<2 x s32>) = COPY $x1
+ ; CHECK-NEXT: %zero_scalar:_(s32) = G_CONSTANT i32 0
+ ; CHECK-NEXT: %zero:_(<2 x s32>) = G_BUILD_VECTOR %zero_scalar(s32), %zero_scalar(s32)
+ ; CHECK-NEXT: %cmp1:_(<2 x s1>) = G_ICMP intpred(ne), %x(<2 x s32>), %zero
+ ; CHECK-NEXT: %cmp2:_(<2 x s1>) = G_ICMP intpred(eq), %y(<2 x s32>), %zero
+ ; CHECK-NEXT: %and:_(<2 x s1>) = G_AND %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(<2 x s32>) = G_ZEXT %and(<2 x s1>)
+ ; CHECK-NEXT: $x0 = COPY %zext(<2 x s32>)
+ ; CHECK-NEXT: RET_ReallyLR implicit $x0
+ %x:_(<2 x s32>) = COPY $x0
+ %y:_(<2 x s32>) = COPY $x1
+ %zero_scalar:_(s32) = G_CONSTANT i32 0
+ %zero:_(<2 x s32>) = G_BUILD_VECTOR %zero_scalar(s32), %zero_scalar(s32)
+ %cmp1:_(<2 x s1>) = G_ICMP intpred(ne), %x:_(<2 x s32>), %zero:_
+ %cmp2:_(<2 x s1>) = G_ICMP intpred(eq), %y:_(<2 x s32>), %zero:_
+ %and:_(<2 x s1>) = G_AND %cmp1, %cmp2
+ %zext:_(<2 x s32>) = G_ZEXT %and:_(<2 x s1>)
+ $x0 = COPY %zext
+ RET_ReallyLR implicit $x0
+
+...
+---
+name: invalid_and_eq_0_ne_0_vec
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $x0, $x1
+
+ ; CHECK-LABEL: name: invalid_and_eq_0_ne_0_vec
+ ; CHECK: liveins: $x0, $x1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(<2 x s32>) = COPY $x0
+ ; CHECK-NEXT: %y:_(<2 x s32>) = COPY $x1
+ ; CHECK-NEXT: %zero_scalar:_(s32) = G_CONSTANT i32 0
+ ; CHECK-NEXT: %zero:_(<2 x s32>) = G_BUILD_VECTOR %zero_scalar(s32), %zero_scalar(s32)
+ ; CHECK-NEXT: %cmp1:_(<2 x s1>) = G_ICMP intpred(eq), %x(<2 x s32>), %zero
+ ; CHECK-NEXT: %cmp2:_(<2 x s1>) = G_ICMP intpred(ne), %y(<2 x s32>), %zero
+ ; CHECK-NEXT: %and:_(<2 x s1>) = G_AND %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(<2 x s32>) = G_ZEXT %and(<2 x s1>)
+ ; CHECK-NEXT: $x0 = COPY %zext(<2 x s32>)
+ ; CHECK-NEXT: RET_ReallyLR implicit $x0
+ %x:_(<2 x s32>) = COPY $x0
+ %y:_(<2 x s32>) = COPY $x1
+ %zero_scalar:_(s32) = G_CONSTANT i32 0
+ %zero:_(<2 x s32>) = G_BUILD_VECTOR %zero_scalar(s32), %zero_scalar(s32)
+ %cmp1:_(<2 x s1>) = G_ICMP intpred(eq), %x:_(<2 x s32>), %zero:_
+ %cmp2:_(<2 x s1>) = G_ICMP intpred(ne), %y:_(<2 x s32>), %zero:_
+ %and:_(<2 x s1>) = G_AND %cmp1, %cmp2
+ %zext:_(<2 x s32>) = G_ZEXT %and:_(<2 x s1>)
+ $x0 = COPY %zext
+ RET_ReallyLR implicit $x0
+
+...
+---
+name: invalid_and_ne_0_ne_0_vec
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $x0, $x1
+
+ ; CHECK-LABEL: name: invalid_and_ne_0_ne_0_vec
+ ; CHECK: liveins: $x0, $x1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(<2 x s32>) = COPY $x0
+ ; CHECK-NEXT: %y:_(<2 x s32>) = COPY $x1
+ ; CHECK-NEXT: %zero_scalar:_(s32) = G_CONSTANT i32 0
+ ; CHECK-NEXT: %zero:_(<2 x s32>) = G_BUILD_VECTOR %zero_scalar(s32), %zero_scalar(s32)
+ ; CHECK-NEXT: %cmp1:_(<2 x s1>) = G_ICMP intpred(ne), %x(<2 x s32>), %zero
+ ; CHECK-NEXT: %cmp2:_(<2 x s1>) = G_ICMP intpred(ne), %y(<2 x s32>), %zero
+ ; CHECK-NEXT: %and:_(<2 x s1>) = G_AND %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(<2 x s32>) = G_ZEXT %and(<2 x s1>)
+ ; CHECK-NEXT: $x0 = COPY %zext(<2 x s32>)
+ ; CHECK-NEXT: RET_ReallyLR implicit $x0
+ %x:_(<2 x s32>) = COPY $x0
+ %y:_(<2 x s32>) = COPY $x1
+ %zero_scalar:_(s32) = G_CONSTANT i32 0
+ %zero:_(<2 x s32>) = G_BUILD_VECTOR %zero_scalar(s32), %zero_scalar(s32)
+ %cmp1:_(<2 x s1>) = G_ICMP intpred(ne), %x:_(<2 x s32>), %zero:_
+ %cmp2:_(<2 x s1>) = G_ICMP intpred(ne), %y:_(<2 x s32>), %zero:_
+ %and:_(<2 x s1>) = G_AND %cmp1, %cmp2
+ %zext:_(<2 x s32>) = G_ZEXT %and:_(<2 x s1>)
+ $x0 = COPY %zext
+ RET_ReallyLR implicit $x0
+
+...
+---
+name: valid_or_ne_0_ne_0_vec
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $x0, $x1
+
+ ; CHECK-LABEL: name: valid_or_ne_0_ne_0_vec
+ ; CHECK: liveins: $x0, $x1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(<2 x s32>) = COPY $x0
+ ; CHECK-NEXT: %y:_(<2 x s32>) = COPY $x1
+ ; CHECK-NEXT: %zero_scalar:_(s32) = G_CONSTANT i32 0
+ ; CHECK-NEXT: %zero:_(<2 x s32>) = G_BUILD_VECTOR %zero_scalar(s32), %zero_scalar(s32)
+ ; CHECK-NEXT: [[OR:%[0-9]+]]:_(<2 x s32>) = G_OR %x, %y
+ ; CHECK-NEXT: %and:_(<2 x s1>) = G_ICMP intpred(ne), [[OR]](<2 x s32>), %zero
+ ; CHECK-NEXT: %zext:_(<2 x s32>) = G_ZEXT %and(<2 x s1>)
+ ; CHECK-NEXT: $x0 = COPY %zext(<2 x s32>)
+ ; CHECK-NEXT: RET_ReallyLR implicit $x0
+ %x:_(<2 x s32>) = COPY $x0
+ %y:_(<2 x s32>) = COPY $x1
+ %zero_scalar:_(s32) = G_CONSTANT i32 0
+ %zero:_(<2 x s32>) = G_BUILD_VECTOR %zero_scalar(s32), %zero_scalar(s32)
+ %cmp1:_(<2 x s1>) = G_ICMP intpred(ne), %x:_(<2 x s32>), %zero:_
+ %cmp2:_(<2 x s1>) = G_ICMP intpred(ne), %y:_(<2 x s32>), %zero:_
+ %and:_(<2 x s1>) = G_OR %cmp1, %cmp2
+ %zext:_(<2 x s32>) = G_ZEXT %and:_(<2 x s1>)
+ $x0 = COPY %zext
+ RET_ReallyLR implicit $x0
+
+...
+---
+name: invalid_or_ne_non_0_ne_0_vec
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $x0, $x1
+
+ ; CHECK-LABEL: name: invalid_or_ne_non_0_ne_0_vec
+ ; CHECK: liveins: $x0, $x1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(<2 x s32>) = COPY $x0
+ ; CHECK-NEXT: %y:_(<2 x s32>) = COPY $x1
+ ; CHECK-NEXT: %scalar0:_(s32) = G_CONSTANT i32 0
+ ; CHECK-NEXT: %scalar1:_(s32) = G_CONSTANT i32 1
+ ; CHECK-NEXT: %zero:_(<2 x s32>) = G_BUILD_VECTOR %scalar0(s32), %scalar0(s32)
+ ; CHECK-NEXT: %non_zero:_(<2 x s32>) = G_BUILD_VECTOR %scalar0(s32), %scalar1(s32)
+ ; CHECK-NEXT: %cmp1:_(<2 x s1>) = G_ICMP intpred(ne), %x(<2 x s32>), %non_zero
+ ; CHECK-NEXT: %cmp2:_(<2 x s1>) = G_ICMP intpred(ne), %y(<2 x s32>), %zero
+ ; CHECK-NEXT: %and:_(<2 x s1>) = G_OR %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(<2 x s32>) = G_ZEXT %and(<2 x s1>)
+ ; CHECK-NEXT: $x0 = COPY %zext(<2 x s32>)
+ ; CHECK-NEXT: RET_ReallyLR implicit $x0
+ %x:_(<2 x s32>) = COPY $x0
+ %y:_(<2 x s32>) = COPY $x1
+ %scalar0:_(s32) = G_CONSTANT i32 0
+ %scalar1:_(s32) = G_CONSTANT i32 1
+ %zero:_(<2 x s32>) = G_BUILD_VECTOR %scalar0(s32), %scalar0(s32)
+ %non_zero:_(<2 x s32>) = G_BUILD_VECTOR %scalar0(s32), %scalar1(s32)
+ %cmp1:_(<2 x s1>) = G_ICMP intpred(ne), %x:_(<2 x s32>), %non_zero:_
+ %cmp2:_(<2 x s1>) = G_ICMP intpred(ne), %y:_(<2 x s32>), %zero:_
+ %and:_(<2 x s1>) = G_OR %cmp1, %cmp2
+ %zext:_(<2 x s32>) = G_ZEXT %and:_(<2 x s1>)
+ $x0 = COPY %zext
+ RET_ReallyLR implicit $x0
+
+...
+---
+name: invalid_or_ne_0_ne_non_0_vec
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $x0, $x1
+
+ ; CHECK-LABEL: name: invalid_or_ne_0_ne_non_0_vec
+ ; CHECK: liveins: $x0, $x1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(<2 x s32>) = COPY $x0
+ ; CHECK-NEXT: %y:_(<2 x s32>) = COPY $x1
+ ; CHECK-NEXT: %scalar0:_(s32) = G_CONSTANT i32 0
+ ; CHECK-NEXT: %scalar1:_(s32) = G_CONSTANT i32 1
+ ; CHECK-NEXT: %zero:_(<2 x s32>) = G_BUILD_VECTOR %scalar0(s32), %scalar0(s32)
+ ; CHECK-NEXT: %non_zero:_(<2 x s32>) = G_BUILD_VECTOR %scalar0(s32), %scalar1(s32)
+ ; CHECK-NEXT: %cmp1:_(<2 x s1>) = G_ICMP intpred(ne), %x(<2 x s32>), %zero
+ ; CHECK-NEXT: %cmp2:_(<2 x s1>) = G_ICMP intpred(ne), %y(<2 x s32>), %non_zero
+ ; CHECK-NEXT: %and:_(<2 x s1>) = G_OR %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(<2 x s32>) = G_ZEXT %and(<2 x s1>)
+ ; CHECK-NEXT: $x0 = COPY %zext(<2 x s32>)
+ ; CHECK-NEXT: RET_ReallyLR implicit $x0
+ %x:_(<2 x s32>) = COPY $x0
+ %y:_(<2 x s32>) = COPY $x1
+ %scalar0:_(s32) = G_CONSTANT i32 0
+ %scalar1:_(s32) = G_CONSTANT i32 1
+ %zero:_(<2 x s32>) = G_BUILD_VECTOR %scalar0(s32), %scalar0(s32)
+ %non_zero:_(<2 x s32>) = G_BUILD_VECTOR %scalar0(s32), %scalar1(s32)
+ %cmp1:_(<2 x s1>) = G_ICMP intpred(ne), %x:_(<2 x s32>), %zero:_
+ %cmp2:_(<2 x s1>) = G_ICMP intpred(ne), %y:_(<2 x s32>), %non_zero:_
+ %and:_(<2 x s1>) = G_OR %cmp1, %cmp2
+ %zext:_(<2 x s32>) = G_ZEXT %and:_(<2 x s1>)
+ $x0 = COPY %zext
+ RET_ReallyLR implicit $x0
+
+...
+---
+name: invalid_or_eq_0_ne_0_vec
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $x0, $x1
+
+ ; CHECK-LABEL: name: invalid_or_eq_0_ne_0_vec
+ ; CHECK: liveins: $x0, $x1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(<2 x s32>) = COPY $x0
+ ; CHECK-NEXT: %y:_(<2 x s32>) = COPY $x1
+ ; CHECK-NEXT: %zero_scalar:_(s32) = G_CONSTANT i32 0
+ ; CHECK-NEXT: %zero:_(<2 x s32>) = G_BUILD_VECTOR %zero_scalar(s32), %zero_scalar(s32)
+ ; CHECK-NEXT: %cmp1:_(<2 x s1>) = G_ICMP intpred(eq), %x(<2 x s32>), %zero
+ ; CHECK-NEXT: %cmp2:_(<2 x s1>) = G_ICMP intpred(ne), %y(<2 x s32>), %zero
+ ; CHECK-NEXT: %and:_(<2 x s1>) = G_OR %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(<2 x s32>) = G_ZEXT %and(<2 x s1>)
+ ; CHECK-NEXT: $x0 = COPY %zext(<2 x s32>)
+ ; CHECK-NEXT: RET_ReallyLR implicit $x0
+ %x:_(<2 x s32>) = COPY $x0
+ %y:_(<2 x s32>) = COPY $x1
+ %zero_scalar:_(s32) = G_CONSTANT i32 0
+ %zero:_(<2 x s32>) = G_BUILD_VECTOR %zero_scalar(s32), %zero_scalar(s32)
+ %cmp1:_(<2 x s1>) = G_ICMP intpred(eq), %x:_(<2 x s32>), %zero:_
+ %cmp2:_(<2 x s1>) = G_ICMP intpred(ne), %y:_(<2 x s32>), %zero:_
+ %and:_(<2 x s1>) = G_OR %cmp1, %cmp2
+ %zext:_(<2 x s32>) = G_ZEXT %and:_(<2 x s1>)
+ $x0 = COPY %zext
+ RET_ReallyLR implicit $x0
+
+...
+---
+name: invalid_or_ne_0_eq_0_vec
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $x0, $x1
+
+ ; CHECK-LABEL: name: invalid_or_ne_0_eq_0_vec
+ ; CHECK: liveins: $x0, $x1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(<2 x s32>) = COPY $x0
+ ; CHECK-NEXT: %y:_(<2 x s32>) = COPY $x1
+ ; CHECK-NEXT: %zero_scalar:_(s32) = G_CONSTANT i32 0
+ ; CHECK-NEXT: %zero:_(<2 x s32>) = G_BUILD_VECTOR %zero_scalar(s32), %zero_scalar(s32)
+ ; CHECK-NEXT: %cmp1:_(<2 x s1>) = G_ICMP intpred(ne), %x(<2 x s32>), %zero
+ ; CHECK-NEXT: %cmp2:_(<2 x s1>) = G_ICMP intpred(eq), %y(<2 x s32>), %zero
+ ; CHECK-NEXT: %and:_(<2 x s1>) = G_OR %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(<2 x s32>) = G_ZEXT %and(<2 x s1>)
+ ; CHECK-NEXT: $x0 = COPY %zext(<2 x s32>)
+ ; CHECK-NEXT: RET_ReallyLR implicit $x0
+ %x:_(<2 x s32>) = COPY $x0
+ %y:_(<2 x s32>) = COPY $x1
+ %zero_scalar:_(s32) = G_CONSTANT i32 0
+ %zero:_(<2 x s32>) = G_BUILD_VECTOR %zero_scalar(s32), %zero_scalar(s32)
+ %cmp1:_(<2 x s1>) = G_ICMP intpred(ne), %x:_(<2 x s32>), %zero:_
+ %cmp2:_(<2 x s1>) = G_ICMP intpred(eq), %y:_(<2 x s32>), %zero:_
+ %and:_(<2 x s1>) = G_OR %cmp1, %cmp2
+ %zext:_(<2 x s32>) = G_ZEXT %and:_(<2 x s1>)
+ $x0 = COPY %zext
+ RET_ReallyLR implicit $x0
+
+...
+---
+name: invalid_or_eq_0_eq_0_vec
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $x0, $x1
+
+ ; CHECK-LABEL: name: invalid_or_eq_0_eq_0_vec
+ ; CHECK: liveins: $x0, $x1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(<2 x s32>) = COPY $x0
+ ; CHECK-NEXT: %y:_(<2 x s32>) = COPY $x1
+ ; CHECK-NEXT: %zero_scalar:_(s32) = G_CONSTANT i32 0
+ ; CHECK-NEXT: %zero:_(<2 x s32>) = G_BUILD_VECTOR %zero_scalar(s32), %zero_scalar(s32)
+ ; CHECK-NEXT: %cmp1:_(<2 x s1>) = G_ICMP intpred(eq), %x(<2 x s32>), %zero
+ ; CHECK-NEXT: %cmp2:_(<2 x s1>) = G_ICMP intpred(eq), %y(<2 x s32>), %zero
+ ; CHECK-NEXT: %and:_(<2 x s1>) = G_OR %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(<2 x s32>) = G_ZEXT %and(<2 x s1>)
+ ; CHECK-NEXT: $x0 = COPY %zext(<2 x s32>)
+ ; CHECK-NEXT: RET_ReallyLR implicit $x0
+ %x:_(<2 x s32>) = COPY $x0
+ %y:_(<2 x s32>) = COPY $x1
+ %zero_scalar:_(s32) = G_CONSTANT i32 0
+ %zero:_(<2 x s32>) = G_BUILD_VECTOR %zero_scalar(s32), %zero_scalar(s32)
+ %cmp1:_(<2 x s1>) = G_ICMP intpred(eq), %x:_(<2 x s32>), %zero:_
+ %cmp2:_(<2 x s1>) = G_ICMP intpred(eq), %y:_(<2 x s32>), %zero:_
+ %and:_(<2 x s1>) = G_OR %cmp1, %cmp2
+ %zext:_(<2 x s32>) = G_ZEXT %and:_(<2 x s1>)
+ $x0 = COPY %zext
+ RET_ReallyLR implicit $x0
+
+...
+---
+name: invalid_p0_src
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $x0, $x1
+
+ ; CHECK-LABEL: name: invalid_p0_src
+ ; CHECK: liveins: $x0, $x1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(p0) = COPY $x0
+ ; CHECK-NEXT: %y:_(p0) = COPY $x1
+ ; CHECK-NEXT: %zero:_(p0) = G_CONSTANT i64 0
+ ; CHECK-NEXT: %cmp1:_(s1) = G_ICMP intpred(eq), %x(p0), %zero
+ ; CHECK-NEXT: %cmp2:_(s1) = G_ICMP intpred(eq), %y(p0), %zero
+ ; CHECK-NEXT: %and:_(s1) = G_AND %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(s64) = G_ZEXT %and(s1)
+ ; CHECK-NEXT: $x0 = COPY %zext(s64)
+ ; CHECK-NEXT: RET_ReallyLR implicit $x0
+ %x:_(p0) = COPY $x0
+ %y:_(p0) = COPY $x1
+ %zero:_(p0) = G_CONSTANT i64 0
+ %cmp1:_(s1) = G_ICMP intpred(eq), %x:_(p0), %zero:_
+ %cmp2:_(s1) = G_ICMP intpred(eq), %y:_(p0), %zero:_
+ %and:_(s1) = G_AND %cmp1, %cmp2
+ %zext:_(s64) = G_ZEXT %and:_(s1)
+ $x0 = COPY %zext
+ RET_ReallyLR implicit $x0
+
+...
+---
+name: invalid_p0_src_vec
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $q0, $q1
+
+ ; CHECK-LABEL: name: invalid_p0_src_vec
+ ; CHECK: liveins: $q0, $q1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(<2 x p0>) = COPY $q0
+ ; CHECK-NEXT: %y:_(<2 x p0>) = COPY $q1
+ ; CHECK-NEXT: %scalar0:_(p0) = G_CONSTANT i64 0
+ ; CHECK-NEXT: %zero:_(<2 x p0>) = G_BUILD_VECTOR %scalar0(p0), %scalar0(p0)
+ ; CHECK-NEXT: %cmp1:_(<2 x s1>) = G_ICMP intpred(eq), %x(<2 x p0>), %zero
+ ; CHECK-NEXT: %cmp2:_(<2 x s1>) = G_ICMP intpred(eq), %y(<2 x p0>), %zero
+ ; CHECK-NEXT: %or:_(<2 x s1>) = G_AND %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(<2 x s64>) = G_ZEXT %or(<2 x s1>)
+ ; CHECK-NEXT: $q0 = COPY %zext(<2 x s64>)
+ ; CHECK-NEXT: RET_ReallyLR implicit $q0
+ %x:_(<2 x p0>) = COPY $q0
+ %y:_(<2 x p0>) = COPY $q1
+ %scalar0:_(p0) = G_CONSTANT i64 0
+ %zero:_(<2 x p0>) = G_BUILD_VECTOR %scalar0(p0), %scalar0(p0)
+ %cmp1:_(<2 x s1>) = G_ICMP intpred(eq), %x:_(<2 x p0>), %zero:_
+ %cmp2:_(<2 x s1>) = G_ICMP intpred(eq), %y:_(<2 x p0>), %zero:_
+ %or:_(<2 x s1>) = G_AND %cmp1, %cmp2
+ %zext:_(<2 x s64>) = G_ZEXT %or:_(<2 x s1>)
+ $q0 = COPY %zext
+ RET_ReallyLR implicit $q0
+
+...
+---
+name: invalid_diff_src_ty
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $w0, $x1
+
+ ; CHECK-LABEL: name: invalid_diff_src_ty
+ ; CHECK: liveins: $w0, $x1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(s32) = COPY $w0
+ ; CHECK-NEXT: %y:_(s64) = COPY $x1
+ ; CHECK-NEXT: %zero_s32:_(s32) = G_CONSTANT i32 0
+ ; CHECK-NEXT: %zero_s64:_(s64) = G_CONSTANT i64 0
+ ; CHECK-NEXT: %cmp1:_(s1) = G_ICMP intpred(eq), %x(s32), %zero_s32
+ ; CHECK-NEXT: %cmp2:_(s1) = G_ICMP intpred(eq), %y(s64), %zero_s64
+ ; CHECK-NEXT: %and:_(s1) = G_AND %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(s64) = G_ZEXT %and(s1)
+ ; CHECK-NEXT: $x0 = COPY %zext(s64)
+ ; CHECK-NEXT: RET_ReallyLR implicit $x0
+ %x:_(s32) = COPY $w0
+ %y:_(s64) = COPY $x1
+ %zero_s32:_(s32) = G_CONSTANT i32 0
+ %zero_s64:_(s64) = G_CONSTANT i64 0
+ %cmp1:_(s1) = G_ICMP intpred(eq), %x:_(s32), %zero_s32:_
+ %cmp2:_(s1) = G_ICMP intpred(eq), %y:_(s64), %zero_s64:_
+ %and:_(s1) = G_AND %cmp1, %cmp2
+ %zext:_(s64) = G_ZEXT %and:_(s1)
+ $x0 = COPY %zext
+ RET_ReallyLR implicit $x0
+
+...
+---
+name: invalid_diff_src_ty_vec
+tracksRegLiveness: true
+legalized: true
+body: |
+ bb.0:
+ liveins: $x0, $q1
+
+ ; CHECK-LABEL: name: invalid_diff_src_ty_vec
+ ; CHECK: liveins: $x0, $q1
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: %x:_(<2 x s32>) = COPY $x0
+ ; CHECK-NEXT: %y:_(<2 x s64>) = COPY $q1
+ ; CHECK-NEXT: %scalar0s32:_(s32) = G_CONSTANT i32 0
+ ; CHECK-NEXT: %scalar0s64:_(s64) = G_CONSTANT i64 0
+ ; CHECK-NEXT: %zero_s32:_(<2 x s32>) = G_BUILD_VECTOR %scalar0s32(s32), %scalar0s32(s32)
+ ; CHECK-NEXT: %zero_s64:_(<2 x s64>) = G_BUILD_VECTOR %scalar0s64(s64), %scalar0s64(s64)
+ ; CHECK-NEXT: %cmp1:_(<2 x s1>) = G_ICMP intpred(eq), %x(<2 x s32>), %zero_s32
+ ; CHECK-NEXT: %cmp2:_(<2 x s1>) = G_ICMP intpred(eq), %y(<2 x s64>), %zero_s64
+ ; CHECK-NEXT: %or:_(<2 x s1>) = G_AND %cmp1, %cmp2
+ ; CHECK-NEXT: %zext:_(<2 x s32>) = G_ZEXT %or(<2 x s1>)
+ ; CHECK-NEXT: $x0 = COPY %zext(<2 x s32>)
+ ; CHECK-NEXT: RET_ReallyLR implicit $x0
+ %x:_(<2 x s32>) = COPY $x0
+ %y:_(<2 x s64>) = COPY $q1
+ %scalar0s32:_(s32) = G_CONSTANT i32 0
+ %scalar0s64:_(s64) = G_CONSTANT i64 0
+ %zero_s32:_(<2 x s32>) = G_BUILD_VECTOR %scalar0s32(s32), %scalar0s32(s32)
+ %zero_s64:_(<2 x s64>) = G_BUILD_VECTOR %scalar0s64(s64), %scalar0s64(s64)
+ %cmp1:_(<2 x s1>) = G_ICMP intpred(eq), %x:_(<2 x s32>), %zero_s32:_
+ %cmp2:_(<2 x s1>) = G_ICMP intpred(eq), %y:_(<2 x s64>), %zero_s64:_
+ %or:_(<2 x s1>) = G_AND %cmp1, %cmp2
+ %zext:_(<2 x s32>) = G_ZEXT %or:_(<2 x s1>)
+ $x0 = COPY %zext
+ RET_ReallyLR implicit $x0
+
+...
>From 95aab69c109adf29e183090c25dc95c773215746 Mon Sep 17 00:00:00 2001
From: Craig Topper <craig.topper at sifive.com>
Date: Wed, 28 Feb 2024 21:46:58 -0800
Subject: [PATCH 091/406] [RISCV] Remove experimental from Zacas. (#83195)
Document that we don't use the double compare and swap instructions due
to ABI concerns.
---
.../test/Preprocessor/riscv-target-features.c | 18 +++++++++---------
llvm/docs/RISCVUsage.rst | 9 ++++++---
llvm/docs/ReleaseNotes.rst | 1 +
llvm/lib/Support/RISCVISAInfo.cpp | 2 +-
llvm/lib/Target/RISCV/RISCVFeatures.td | 2 +-
.../RISCV/atomic-cmpxchg-branch-on-result.ll | 6 +++---
llvm/test/CodeGen/RISCV/atomic-cmpxchg.ll | 12 ++++++------
llvm/test/CodeGen/RISCV/atomic-rmw.ll | 12 ++++++------
llvm/test/CodeGen/RISCV/atomic-signext.ll | 4 ++--
llvm/test/CodeGen/RISCV/attributes.ll | 4 ++--
llvm/test/MC/RISCV/rv32zacas-invalid.s | 2 +-
llvm/test/MC/RISCV/rv32zacas-valid.s | 12 ++++++------
llvm/test/MC/RISCV/rv64zacas-valid.s | 6 +++---
llvm/test/MC/RISCV/rvzabha-zacas-valid.s | 12 ++++++------
llvm/unittests/Support/RISCVISAInfoTest.cpp | 2 +-
15 files changed, 54 insertions(+), 50 deletions(-)
diff --git a/clang/test/Preprocessor/riscv-target-features.c b/clang/test/Preprocessor/riscv-target-features.c
index ea81c662044306..664279cb123949 100644
--- a/clang/test/Preprocessor/riscv-target-features.c
+++ b/clang/test/Preprocessor/riscv-target-features.c
@@ -74,6 +74,7 @@
// CHECK-NOT: __riscv_xventanacondops {{.*$}}
// CHECK-NOT: __riscv_za128rs {{.*$}}
// CHECK-NOT: __riscv_za64rs {{.*$}}
+// CHECK-NOT: __riscv_zacas {{.*$}}
// CHECK-NOT: __riscv_zawrs {{.*$}}
// CHECK-NOT: __riscv_zba {{.*$}}
// CHECK-NOT: __riscv_zbb {{.*$}}
@@ -166,7 +167,6 @@
// CHECK-NOT: __riscv_ssqosid{{.*$}}
// CHECK-NOT: __riscv_supm{{.*$}}
// CHECK-NOT: __riscv_zaamo {{.*$}}
-// CHECK-NOT: __riscv_zacas {{.*$}}
// CHECK-NOT: __riscv_zalasr {{.*$}}
// CHECK-NOT: __riscv_zalrsc {{.*$}}
// CHECK-NOT: __riscv_zcmop {{.*$}}
@@ -660,6 +660,14 @@
// RUN: -o - | FileCheck --check-prefix=CHECK-ZA64RS-EXT %s
// CHECK-ZA64RS-EXT: __riscv_za64rs 1000000{{$}}
+// RUN: %clang --target=riscv32 \
+// RUN: -march=rv32i_zacas1p0 -E -dM %s \
+// RUN: -o - | FileCheck --check-prefix=CHECK-ZACAS-EXT %s
+// RUN: %clang --target=riscv64 \
+// RUN: -march=rv64i_zacas1p0 -E -dM %s \
+// RUN: -o - | FileCheck --check-prefix=CHECK-ZACAS-EXT %s
+// CHECK-ZACAS-EXT: __riscv_zacas 1000000{{$}}
+
// RUN: %clang --target=riscv32-unknown-linux-gnu \
// RUN: -march=rv32izawrs -E -dM %s \
// RUN: -o - | FileCheck --check-prefix=CHECK-ZAWRS-EXT %s
@@ -1485,14 +1493,6 @@
// RUN: -o - | FileCheck --check-prefix=CHECK-ZAAMO-EXT %s
// CHECK-ZAAMO-EXT: __riscv_zaamo 2000{{$}}
-// RUN: %clang --target=riscv32 -menable-experimental-extensions \
-// RUN: -march=rv32i_zacas1p0 -E -dM %s \
-// RUN: -o - | FileCheck --check-prefix=CHECK-ZACAS-EXT %s
-// RUN: %clang --target=riscv64 -menable-experimental-extensions \
-// RUN: -march=rv64i_zacas1p0 -E -dM %s \
-// RUN: -o - | FileCheck --check-prefix=CHECK-ZACAS-EXT %s
-// CHECK-ZACAS-EXT: __riscv_zacas 1000000{{$}}
-
// RUN: %clang --target=riscv32 -menable-experimental-extensions \
// RUN: -march=rv32i_zalasr0p1 -E -dM %s \
// RUN: -o - | FileCheck --check-prefix=CHECK-ZALASR-EXT %s
diff --git a/llvm/docs/RISCVUsage.rst b/llvm/docs/RISCVUsage.rst
index ed443596897aea..8d293b02144307 100644
--- a/llvm/docs/RISCVUsage.rst
+++ b/llvm/docs/RISCVUsage.rst
@@ -117,6 +117,7 @@ on support follow.
``V`` Supported
``Za128rs`` Supported (`See note <#riscv-profiles-extensions-note>`__)
``Za64rs`` Supported (`See note <#riscv-profiles-extensions-note>`__)
+ ``Zacas`` Supported (`See note <#riscv-zacas-note>`__)
``Zawrs`` Assembly Support
``Zba`` Supported
``Zbb`` Supported
@@ -236,6 +237,11 @@ Supported
``Za128rs``, ``Za64rs``, ``Zic64b``, ``Ziccamoa``, ``Ziccif``, ``Zicclsm``, ``Ziccrse``, ``Shcounterenvw``, ``Shgatpa``, ``Shtvala``, ``Shvsatpa``, ``Shvstvala``, ``Shvstvecd``, ``Ssccptr``, ``Sscounterenw``, ``Ssstateen``, ``Ssstrict``, ``Sstvala``, ``Sstvecd``, ``Ssu64xl``, ``Svade``, ``Svbare``
These extensions are defined as part of the `RISC-V Profiles specification <https://github.com/riscv/riscv-profiles/releases/tag/v1.0>`__. They do not introduce any new features themselves, but instead describe existing hardware features.
+ .. _riscv-zacas-note:
+
+``Zacas``
+ amocas.w will be used for i32 cmpxchg. amocas.d will be used i64 cmpxchg on RV64. The compiler will not generate amocas.d on RV32 or amocas.q on RV64 due to ABI compatibilty. These can only be used in the assembler.
+
Experimental Extensions
=======================
@@ -252,9 +258,6 @@ The primary goal of experimental support is to assist in the process of ratifica
``experimental-zabha``
LLVM implements the `v1.0-rc1 draft specification <https://github.com/riscv/riscv-zabha/tree/v1.0-rc1>`__.
-``experimental-zacas``
- LLVM implements the `1.0-rc1 draft specification <https://github.com/riscv/riscv-zacas/releases/tag/v1.0-rc1>`__.
-
``experimental-zalasr``
LLVM implements the `0.0.5 draft specification <https://github.com/mehnadnerd/riscv-zalasr>`__.
diff --git a/llvm/docs/ReleaseNotes.rst b/llvm/docs/ReleaseNotes.rst
index 51b6527f65bb04..8ce6ee5cebb266 100644
--- a/llvm/docs/ReleaseNotes.rst
+++ b/llvm/docs/ReleaseNotes.rst
@@ -103,6 +103,7 @@ Changes to the RISC-V Backend
* Codegen support was added for the Zimop (May-Be-Operations) extension.
* The experimental Ssnpm, Smnpm, Smmpm, Sspm, and Supm 0.8.1 Pointer Masking extensions are supported.
* The experimental Ssqosid extension is supported.
+* Zacas is no longer experimental.
Changes to the WebAssembly Backend
----------------------------------
diff --git a/llvm/lib/Support/RISCVISAInfo.cpp b/llvm/lib/Support/RISCVISAInfo.cpp
index d028302b8c4d94..68f5c36e8fafc6 100644
--- a/llvm/lib/Support/RISCVISAInfo.cpp
+++ b/llvm/lib/Support/RISCVISAInfo.cpp
@@ -109,6 +109,7 @@ static const RISCVSupportedExtension SupportedExtensions[] = {
{"za128rs", {1, 0}},
{"za64rs", {1, 0}},
+ {"zacas", {1, 0}},
{"zawrs", {1, 0}},
{"zba", {1, 0}},
@@ -220,7 +221,6 @@ static const RISCVSupportedExtension SupportedExperimentalExtensions[] = {
{"zaamo", {0, 2}},
{"zabha", {1, 0}},
- {"zacas", {1, 0}},
{"zalasr", {0, 1}},
{"zalrsc", {0, 2}},
diff --git a/llvm/lib/Target/RISCV/RISCVFeatures.td b/llvm/lib/Target/RISCV/RISCVFeatures.td
index bcaf4477749494..9773b2998c7dc4 100644
--- a/llvm/lib/Target/RISCV/RISCVFeatures.td
+++ b/llvm/lib/Target/RISCV/RISCVFeatures.td
@@ -185,7 +185,7 @@ def HasStdExtZabha : Predicate<"Subtarget->hasStdExtZabha()">,
"'Zabha' (Byte and Halfword Atomic Memory Operations)">;
def FeatureStdExtZacas
- : SubtargetFeature<"experimental-zacas", "HasStdExtZacas", "true",
+ : SubtargetFeature<"zacas", "HasStdExtZacas", "true",
"'Zacas' (Atomic Compare-And-Swap Instructions)">;
def HasStdExtZacas : Predicate<"Subtarget->hasStdExtZacas()">,
AssemblerPredicate<(all_of FeatureStdExtZacas),
diff --git a/llvm/test/CodeGen/RISCV/atomic-cmpxchg-branch-on-result.ll b/llvm/test/CodeGen/RISCV/atomic-cmpxchg-branch-on-result.ll
index 90d78779b764d2..18b66499b85fe3 100644
--- a/llvm/test/CodeGen/RISCV/atomic-cmpxchg-branch-on-result.ll
+++ b/llvm/test/CodeGen/RISCV/atomic-cmpxchg-branch-on-result.ll
@@ -1,13 +1,13 @@
; NOTE: Assertions have been autogenerated by utils/update_llc_test_checks.py
; RUN: llc -mtriple=riscv32 -mattr=+a -verify-machineinstrs < %s \
; RUN: | FileCheck -check-prefixes=NOZACAS,RV32IA %s
-; RUN: llc -mtriple=riscv32 -mattr=+a,+experimental-zacas -verify-machineinstrs < %s \
+; RUN: llc -mtriple=riscv32 -mattr=+a,+zacas -verify-machineinstrs < %s \
; RUN: | FileCheck -check-prefixes=ZACAS,RV32IA-ZACAS %s
; RUN: llc -mtriple=riscv64 -mattr=+a -verify-machineinstrs < %s \
; RUN: | FileCheck -check-prefixes=NOZACAS,RV64IA %s
-; RUN: llc -mtriple=riscv64 -mattr=+a,+experimental-zacas -verify-machineinstrs < %s \
+; RUN: llc -mtriple=riscv64 -mattr=+a,+zacas -verify-machineinstrs < %s \
; RUN: | FileCheck -check-prefixes=ZACAS,RV64IA-ZACAS %s
-; RUN: llc -mtriple=riscv64 -mattr=+a,+experimental-zacas,+experimental-zabha -verify-machineinstrs < %s \
+; RUN: llc -mtriple=riscv64 -mattr=+a,+zacas,+experimental-zabha -verify-machineinstrs < %s \
; RUN: | FileCheck -check-prefixes=ZACAS,RV64IA-ZABHA %s
; Test cmpxchg followed by a branch on the cmpxchg success value to see if the
diff --git a/llvm/test/CodeGen/RISCV/atomic-cmpxchg.ll b/llvm/test/CodeGen/RISCV/atomic-cmpxchg.ll
index 8df37bf40975c1..394dffa346ec63 100644
--- a/llvm/test/CodeGen/RISCV/atomic-cmpxchg.ll
+++ b/llvm/test/CodeGen/RISCV/atomic-cmpxchg.ll
@@ -3,25 +3,25 @@
; RUN: | FileCheck -check-prefix=RV32I %s
; RUN: llc -mtriple=riscv32 -mattr=+a -verify-machineinstrs < %s \
; RUN: | FileCheck -check-prefixes=RV32IA,RV32IA-WMO %s
-; RUN: llc -mtriple=riscv32 -mattr=+a,+experimental-zacas -verify-machineinstrs < %s \
+; RUN: llc -mtriple=riscv32 -mattr=+a,+zacas -verify-machineinstrs < %s \
; RUN: | FileCheck -check-prefixes=RV32IA,RV32IA-ZACAS,RV32IA-WMO-ZACAS %s
; RUN: llc -mtriple=riscv32 -mattr=+a,+experimental-ztso -verify-machineinstrs < %s \
; RUN: | FileCheck -check-prefixes=RV32IA,RV32IA-TSO %s
-; RUN: llc -mtriple=riscv32 -mattr=+a,+experimental-ztso,+experimental-zacas -verify-machineinstrs < %s \
+; RUN: llc -mtriple=riscv32 -mattr=+a,+experimental-ztso,+zacas -verify-machineinstrs < %s \
; RUN: | FileCheck -check-prefixes=RV32IA,RV32IA-ZACAS,RV32IA-TSO-ZACAS %s
; RUN: llc -mtriple=riscv64 -verify-machineinstrs < %s \
; RUN: | FileCheck -check-prefix=RV64I %s
; RUN: llc -mtriple=riscv64 -mattr=+a -verify-machineinstrs < %s \
; RUN: | FileCheck -check-prefixes=RV64IA,RV64IA-WMO %s
-; RUN: llc -mtriple=riscv64 -mattr=+a,+experimental-zacas -verify-machineinstrs < %s \
+; RUN: llc -mtriple=riscv64 -mattr=+a,+zacas -verify-machineinstrs < %s \
; RUN: | FileCheck -check-prefixes=RV64IA,RV64IA-ZACAS,RV64IA-WMO-ZACAS %s
-; RUN: llc -mtriple=riscv64 -mattr=+a,+experimental-zacas,+experimental-zabha -verify-machineinstrs < %s \
+; RUN: llc -mtriple=riscv64 -mattr=+a,+zacas,+experimental-zabha -verify-machineinstrs < %s \
; RUN: | FileCheck -check-prefixes=RV64IA,RV64IA-ZABHA,RV64IA-WMO-ZABHA %s
; RUN: llc -mtriple=riscv64 -mattr=+a,+experimental-ztso -verify-machineinstrs < %s \
; RUN: | FileCheck -check-prefixes=RV64IA,RV64IA-TSO %s
-; RUN: llc -mtriple=riscv64 -mattr=+a,+experimental-ztso,+experimental-zacas -verify-machineinstrs < %s \
+; RUN: llc -mtriple=riscv64 -mattr=+a,+experimental-ztso,+zacas -verify-machineinstrs < %s \
; RUN: | FileCheck -check-prefixes=RV64IA,RV64IA-ZACAS,RV64IA-TSO-ZACAS %s
-; RUN: llc -mtriple=riscv64 -mattr=+a,+experimental-ztso,+experimental-zacas,+experimental-zabha -verify-machineinstrs < %s \
+; RUN: llc -mtriple=riscv64 -mattr=+a,+experimental-ztso,+zacas,+experimental-zabha -verify-machineinstrs < %s \
; RUN: | FileCheck -check-prefixes=RV64IA,RV64IA-ZABHA,RV64IA-TSO-ZABHA %s
define void @cmpxchg_i8_monotonic_monotonic(ptr %ptr, i8 %cmp, i8 %val) nounwind {
diff --git a/llvm/test/CodeGen/RISCV/atomic-rmw.ll b/llvm/test/CodeGen/RISCV/atomic-rmw.ll
index ee802507a02f3c..fe530017406133 100644
--- a/llvm/test/CodeGen/RISCV/atomic-rmw.ll
+++ b/llvm/test/CodeGen/RISCV/atomic-rmw.ll
@@ -12,22 +12,22 @@
; RUN: llc -mtriple=riscv64 -mattr=+a,+experimental-ztso -verify-machineinstrs < %s \
; RUN: | FileCheck -check-prefixes=RV64IA,RV64IA-NOZACAS,RV64IA-TSO,RV64IA-TSO-NOZACAS %s
-; RUN: llc -mtriple=riscv32 -mattr=+a,+experimental-zacas -verify-machineinstrs < %s \
+; RUN: llc -mtriple=riscv32 -mattr=+a,+zacas -verify-machineinstrs < %s \
; RUN: | FileCheck -check-prefixes=RV32IA,RV32IA-ZACAS,RV32IA-WMO,RV32IA-WMO-ZACAS %s
-; RUN: llc -mtriple=riscv32 -mattr=+a,+experimental-ztso,+experimental-zacas -verify-machineinstrs < %s \
+; RUN: llc -mtriple=riscv32 -mattr=+a,+experimental-ztso,+zacas -verify-machineinstrs < %s \
; RUN: | FileCheck -check-prefixes=RV32IA,RV32IA-ZACAS,RV32IA-TSO,RV32IA-TSO-ZACAS %s
-; RUN: llc -mtriple=riscv64 -mattr=+a,+experimental-zacas -verify-machineinstrs < %s \
+; RUN: llc -mtriple=riscv64 -mattr=+a,+zacas -verify-machineinstrs < %s \
; RUN: | FileCheck -check-prefixes=RV64IA,RV64IA-ZACAS,RV64IA-WMO,RV64IA-WMO-ZACAS %s
-; RUN: llc -mtriple=riscv64 -mattr=+a,+experimental-ztso,+experimental-zacas -verify-machineinstrs < %s \
+; RUN: llc -mtriple=riscv64 -mattr=+a,+experimental-ztso,+zacas -verify-machineinstrs < %s \
; RUN: | FileCheck -check-prefixes=RV64IA,RV64IA-ZACAS,RV64IA-TSO,RV64IA-TSO-ZACAS %s
; RUN: llc -mtriple=riscv64 -mattr=+a,+experimental-zabha -verify-machineinstrs < %s \
; RUN: | FileCheck -check-prefixes=RV64IA,RV64IA-WMO,RV64IA-WMO-ZABHA,RV64IA-WMO-ZABHA-NOZACAS %s
; RUN: llc -mtriple=riscv64 -mattr=+a,+experimental-ztso,+experimental-zabha -verify-machineinstrs < %s \
; RUN: | FileCheck -check-prefixes=RV64IA,RV64IA-TSO,RV64IA-TSO-ZABHA,RV64IA-TSO-ZABHA-NOZACAS %s
-; RUN: llc -mtriple=riscv64 -mattr=+a,+experimental-zabha,+experimental-zacas -verify-machineinstrs < %s \
+; RUN: llc -mtriple=riscv64 -mattr=+a,+experimental-zabha,+zacas -verify-machineinstrs < %s \
; RUN: | FileCheck -check-prefixes=RV64IA,RV64IA-WMO,RV64IA-WMO-ZABHA,RV64IA-WMO-ZABHA-ZACAS %s
-; RUN: llc -mtriple=riscv64 -mattr=+a,+experimental-ztso,+experimental-zabha,+experimental-zacas -verify-machineinstrs < %s \
+; RUN: llc -mtriple=riscv64 -mattr=+a,+experimental-ztso,+experimental-zabha,+zacas -verify-machineinstrs < %s \
; RUN: | FileCheck -check-prefixes=RV64IA,RV64IA-TSO,RV64IA-TSO-ZABHA,RV64IA-TSO-ZABHA-ZACAS %s
define i8 @atomicrmw_xchg_i8_monotonic(ptr %a, i8 %b) nounwind {
diff --git a/llvm/test/CodeGen/RISCV/atomic-signext.ll b/llvm/test/CodeGen/RISCV/atomic-signext.ll
index 47807f78d176e8..bdf3b28d2d523b 100644
--- a/llvm/test/CodeGen/RISCV/atomic-signext.ll
+++ b/llvm/test/CodeGen/RISCV/atomic-signext.ll
@@ -3,13 +3,13 @@
; RUN: | FileCheck -check-prefix=RV32I %s
; RUN: llc -mtriple=riscv32 -mattr=+a -verify-machineinstrs < %s \
; RUN: | FileCheck -check-prefixes=RV32IA,RV32IA-NOZACAS %s
-; RUN: llc -mtriple=riscv32 -mattr=+a,+experimental-zacas -verify-machineinstrs < %s \
+; RUN: llc -mtriple=riscv32 -mattr=+a,+zacas -verify-machineinstrs < %s \
; RUN: | FileCheck -check-prefixes=RV32IA,RV32IA-ZACAS %s
; RUN: llc -mtriple=riscv64 -verify-machineinstrs < %s \
; RUN: | FileCheck -check-prefix=RV64I %s
; RUN: llc -mtriple=riscv64 -mattr=+a -verify-machineinstrs < %s \
; RUN: | FileCheck -check-prefixes=RV64IA,RV64IA-NOZACAS %s
-; RUN: llc -mtriple=riscv64 -mattr=+a,+experimental-zacas -verify-machineinstrs < %s \
+; RUN: llc -mtriple=riscv64 -mattr=+a,+zacas -verify-machineinstrs < %s \
; RUN: | FileCheck -check-prefixes=RV64IA,RV64IA-ZACAS %s
define signext i8 @atomic_load_i8_unordered(ptr %a) nounwind {
diff --git a/llvm/test/CodeGen/RISCV/attributes.ll b/llvm/test/CodeGen/RISCV/attributes.ll
index 13635a94d6411a..561b0f21dc3770 100644
--- a/llvm/test/CodeGen/RISCV/attributes.ll
+++ b/llvm/test/CodeGen/RISCV/attributes.ll
@@ -111,7 +111,7 @@
; RUN: llc -mtriple=riscv32 -mattr=+experimental-zvfbfmin %s -o - | FileCheck --check-prefixes=CHECK,RV32ZVFBFMIN %s
; RUN: llc -mtriple=riscv32 -mattr=+experimental-zvfbfwma %s -o - | FileCheck --check-prefixes=CHECK,RV32ZVFBFWMA %s
; RUN: llc -mtriple=riscv32 -mattr=+experimental-zaamo %s -o - | FileCheck --check-prefix=RV32ZAAMO %s
-; RUN: llc -mtriple=riscv32 -mattr=+experimental-zacas %s -o - | FileCheck --check-prefix=RV32ZACAS %s
+; RUN: llc -mtriple=riscv32 -mattr=+zacas %s -o - | FileCheck --check-prefix=RV32ZACAS %s
; RUN: llc -mtriple=riscv32 -mattr=+experimental-zalasr %s -o - | FileCheck --check-prefix=RV32ZALASR %s
; RUN: llc -mtriple=riscv32 -mattr=+experimental-zalrsc %s -o - | FileCheck --check-prefix=RV32ZALRSC %s
; RUN: llc -mtriple=riscv32 -mattr=+experimental-zicfilp %s -o - | FileCheck --check-prefix=RV32ZICFILP %s
@@ -240,7 +240,7 @@
; RUN: llc -mtriple=riscv64 -mattr=+experimental-zvfbfmin %s -o - | FileCheck --check-prefixes=CHECK,RV64ZVFBFMIN %s
; RUN: llc -mtriple=riscv64 -mattr=+experimental-zvfbfwma %s -o - | FileCheck --check-prefixes=CHECK,RV64ZVFBFWMA %s
; RUN: llc -mtriple=riscv64 -mattr=+experimental-zaamo %s -o - | FileCheck --check-prefix=RV64ZAAMO %s
-; RUN: llc -mtriple=riscv64 -mattr=+experimental-zacas %s -o - | FileCheck --check-prefix=RV64ZACAS %s
+; RUN: llc -mtriple=riscv64 -mattr=+zacas %s -o - | FileCheck --check-prefix=RV64ZACAS %s
; RUN: llc -mtriple=riscv64 -mattr=+experimental-zalasr %s -o - | FileCheck --check-prefix=RV64ZALASR %s
; RUN: llc -mtriple=riscv64 -mattr=+experimental-zalrsc %s -o - | FileCheck --check-prefix=RV64ZALRSC %s
; RUN: llc -mtriple=riscv64 -mattr=+experimental-zicfilp %s -o - | FileCheck --check-prefix=RV64ZICFILP %s
diff --git a/llvm/test/MC/RISCV/rv32zacas-invalid.s b/llvm/test/MC/RISCV/rv32zacas-invalid.s
index b86246ca2ed180..11d20dacd8a788 100644
--- a/llvm/test/MC/RISCV/rv32zacas-invalid.s
+++ b/llvm/test/MC/RISCV/rv32zacas-invalid.s
@@ -1,4 +1,4 @@
-# RUN: not llvm-mc -triple riscv32 -mattr=+experimental-zacas < %s 2>&1 | FileCheck %s
+# RUN: not llvm-mc -triple riscv32 -mattr=+zacas < %s 2>&1 | FileCheck %s
# Non-zero offsets not supported for the third operand (rs1).
amocas.w a1, a3, 1(a5) # CHECK: :[[@LINE]]:18: error: optional integer offset must be 0
diff --git a/llvm/test/MC/RISCV/rv32zacas-valid.s b/llvm/test/MC/RISCV/rv32zacas-valid.s
index d80b963f0a0477..05a9cdd5cc2188 100644
--- a/llvm/test/MC/RISCV/rv32zacas-valid.s
+++ b/llvm/test/MC/RISCV/rv32zacas-valid.s
@@ -1,12 +1,12 @@
-# RUN: llvm-mc %s -triple=riscv32 -mattr=+experimental-zacas -riscv-no-aliases -show-encoding \
+# RUN: llvm-mc %s -triple=riscv32 -mattr=+zacas -riscv-no-aliases -show-encoding \
# RUN: | FileCheck -check-prefixes=CHECK-ASM,CHECK-ASM-AND-OBJ %s
-# RUN: llvm-mc %s -triple=riscv64 -mattr=+experimental-zacas -riscv-no-aliases -show-encoding \
+# RUN: llvm-mc %s -triple=riscv64 -mattr=+zacas -riscv-no-aliases -show-encoding \
# RUN: | FileCheck -check-prefixes=CHECK-ASM,CHECK-ASM-AND-OBJ %s
-# RUN: llvm-mc -filetype=obj -triple=riscv32 -mattr=+experimental-zacas < %s \
-# RUN: | llvm-objdump --mattr=+experimental-zacas -M no-aliases -d -r - \
+# RUN: llvm-mc -filetype=obj -triple=riscv32 -mattr=+zacas < %s \
+# RUN: | llvm-objdump --mattr=+zacas -M no-aliases -d -r - \
# RUN: | FileCheck --check-prefix=CHECK-ASM-AND-OBJ %s
-# RUN: llvm-mc -filetype=obj -triple=riscv64 -mattr=+experimental-zacas < %s \
-# RUN: | llvm-objdump --mattr=+experimental-zacas -M no-aliases -d -r - \
+# RUN: llvm-mc -filetype=obj -triple=riscv64 -mattr=+zacas < %s \
+# RUN: | llvm-objdump --mattr=+zacas -M no-aliases -d -r - \
# RUN: | FileCheck --check-prefix=CHECK-ASM-AND-OBJ %s
# RUN: not llvm-mc -triple=riscv32 -mattr=+a -show-encoding %s 2>&1 \
# RUN: | FileCheck %s --check-prefix=CHECK-ERROR
diff --git a/llvm/test/MC/RISCV/rv64zacas-valid.s b/llvm/test/MC/RISCV/rv64zacas-valid.s
index 843401b50871af..694f43b9b4407b 100644
--- a/llvm/test/MC/RISCV/rv64zacas-valid.s
+++ b/llvm/test/MC/RISCV/rv64zacas-valid.s
@@ -1,7 +1,7 @@
-# RUN: llvm-mc %s -triple=riscv64 -mattr=+experimental-zacas -riscv-no-aliases -show-encoding \
+# RUN: llvm-mc %s -triple=riscv64 -mattr=+zacas -riscv-no-aliases -show-encoding \
# RUN: | FileCheck -check-prefixes=CHECK-ASM,CHECK-ASM-AND-OBJ %s
-# RUN: llvm-mc -filetype=obj -triple=riscv64 -mattr=+experimental-zacas < %s \
-# RUN: | llvm-objdump --mattr=+experimental-zacas -M no-aliases -d -r - \
+# RUN: llvm-mc -filetype=obj -triple=riscv64 -mattr=+zacas < %s \
+# RUN: | llvm-objdump --mattr=+zacas -M no-aliases -d -r - \
# RUN: | FileCheck --check-prefix=CHECK-ASM-AND-OBJ %s
# RUN: not llvm-mc -triple=riscv64 -mattr=+a -show-encoding %s 2>&1 \
# RUN: | FileCheck %s --check-prefix=CHECK-ERROR
diff --git a/llvm/test/MC/RISCV/rvzabha-zacas-valid.s b/llvm/test/MC/RISCV/rvzabha-zacas-valid.s
index 8ad2f99d3febad..f1f705e625b87a 100644
--- a/llvm/test/MC/RISCV/rvzabha-zacas-valid.s
+++ b/llvm/test/MC/RISCV/rvzabha-zacas-valid.s
@@ -1,12 +1,12 @@
-# RUN: llvm-mc %s -triple=riscv32 -mattr=+experimental-zabha,+experimental-zacas -riscv-no-aliases -show-encoding \
+# RUN: llvm-mc %s -triple=riscv32 -mattr=+experimental-zabha,+zacas -riscv-no-aliases -show-encoding \
# RUN: | FileCheck -check-prefixes=CHECK-ASM,CHECK-ASM-AND-OBJ %s
-# RUN: llvm-mc %s -triple=riscv64 -mattr=+experimental-zabha,+experimental-zacas -riscv-no-aliases -show-encoding \
+# RUN: llvm-mc %s -triple=riscv64 -mattr=+experimental-zabha,+zacas -riscv-no-aliases -show-encoding \
# RUN: | FileCheck -check-prefixes=CHECK-ASM,CHECK-ASM-AND-OBJ %s
-# RUN: llvm-mc -filetype=obj -triple=riscv32 -mattr=+experimental-zabha,+experimental-zacas < %s \
-# RUN: | llvm-objdump --mattr=+experimental-zabha,+experimental-zacas -M no-aliases -d -r - \
+# RUN: llvm-mc -filetype=obj -triple=riscv32 -mattr=+experimental-zabha,+zacas < %s \
+# RUN: | llvm-objdump --mattr=+experimental-zabha,+zacas -M no-aliases -d -r - \
# RUN: | FileCheck --check-prefix=CHECK-ASM-AND-OBJ %s
-# RUN: llvm-mc -filetype=obj -triple=riscv64 -mattr=+experimental-zabha,+experimental-zacas < %s \
-# RUN: | llvm-objdump --mattr=+experimental-zabha,+experimental-zacas -M no-aliases -d -r - \
+# RUN: llvm-mc -filetype=obj -triple=riscv64 -mattr=+experimental-zabha,+zacas < %s \
+# RUN: | llvm-objdump --mattr=+experimental-zabha,+zacas -M no-aliases -d -r - \
# RUN: | FileCheck --check-prefix=CHECK-ASM-AND-OBJ %s
# RUN: not llvm-mc -triple=riscv32 -mattr=+experimental-zabha -show-encoding %s 2>&1 \
# RUN: | FileCheck %s --check-prefix=CHECK-ERROR
diff --git a/llvm/unittests/Support/RISCVISAInfoTest.cpp b/llvm/unittests/Support/RISCVISAInfoTest.cpp
index df4c7f7de8a3d2..82cce23638d5f5 100644
--- a/llvm/unittests/Support/RISCVISAInfoTest.cpp
+++ b/llvm/unittests/Support/RISCVISAInfoTest.cpp
@@ -752,6 +752,7 @@ R"(All available -march extensions for RISC-V
zmmul 1.0
za128rs 1.0
za64rs 1.0
+ zacas 1.0
zawrs 1.0
zfa 1.0
zfh 1.0
@@ -873,7 +874,6 @@ Experimental extensions
zimop 0.1
zaamo 0.2
zabha 1.0
- zacas 1.0
zalasr 0.1
zalrsc 0.2
zfbfmin 1.0
>From 230b06b44e6c7f710ae4817e1f34709454f420c5 Mon Sep 17 00:00:00 2001
From: SunilKuravinakop <98882378+SunilKuravinakop at users.noreply.github.com>
Date: Thu, 29 Feb 2024 11:32:55 +0530
Subject: [PATCH 092/406] [OpenMP] Clang Codegen Interop : Accept multiple init
(#82604)
Modifying clang/lib/CodeGen/CGStmtOpenMP.cpp to accept multiple `init`
clauses with `interop` directive.
---------
Co-authored-by: Sunil Kuravinakop
---
clang/lib/CodeGen/CGStmtOpenMP.cpp | 30 ++++++++++++++---------
clang/test/OpenMP/interop_codegen.cpp | 35 +++++++++++++++++++++++++++
2 files changed, 53 insertions(+), 12 deletions(-)
create mode 100644 clang/test/OpenMP/interop_codegen.cpp
diff --git a/clang/lib/CodeGen/CGStmtOpenMP.cpp b/clang/lib/CodeGen/CGStmtOpenMP.cpp
index 8fd74697de3c0f..ffcd3ae2711e34 100644
--- a/clang/lib/CodeGen/CGStmtOpenMP.cpp
+++ b/clang/lib/CodeGen/CGStmtOpenMP.cpp
@@ -7023,19 +7023,25 @@ void CodeGenFunction::EmitOMPInteropDirective(const OMPInteropDirective &S) {
S.getSingleClause<OMPUseClause>())) &&
"OMPNowaitClause clause is used separately in OMPInteropDirective.");
- if (const auto *C = S.getSingleClause<OMPInitClause>()) {
- llvm::Value *InteropvarPtr =
- EmitLValue(C->getInteropVar()).getPointer(*this);
- llvm::omp::OMPInteropType InteropType = llvm::omp::OMPInteropType::Unknown;
- if (C->getIsTarget()) {
- InteropType = llvm::omp::OMPInteropType::Target;
- } else {
- assert(C->getIsTargetSync() && "Expected interop-type target/targetsync");
- InteropType = llvm::omp::OMPInteropType::TargetSync;
+ auto ItOMPInitClause = S.getClausesOfKind<OMPInitClause>();
+ if (!ItOMPInitClause.empty()) {
+ // Look at the multiple init clauses
+ for (const OMPInitClause *C : ItOMPInitClause) {
+ llvm::Value *InteropvarPtr =
+ EmitLValue(C->getInteropVar()).getPointer(*this);
+ llvm::omp::OMPInteropType InteropType =
+ llvm::omp::OMPInteropType::Unknown;
+ if (C->getIsTarget()) {
+ InteropType = llvm::omp::OMPInteropType::Target;
+ } else {
+ assert(C->getIsTargetSync() &&
+ "Expected interop-type target/targetsync");
+ InteropType = llvm::omp::OMPInteropType::TargetSync;
+ }
+ OMPBuilder.createOMPInteropInit(Builder, InteropvarPtr, InteropType,
+ Device, NumDependences, DependenceList,
+ Data.HasNowaitClause);
}
- OMPBuilder.createOMPInteropInit(Builder, InteropvarPtr, InteropType, Device,
- NumDependences, DependenceList,
- Data.HasNowaitClause);
} else if (const auto *C = S.getSingleClause<OMPDestroyClause>()) {
llvm::Value *InteropvarPtr =
EmitLValue(C->getInteropVar()).getPointer(*this);
diff --git a/clang/test/OpenMP/interop_codegen.cpp b/clang/test/OpenMP/interop_codegen.cpp
new file mode 100644
index 00000000000000..ea83ef8ed4909f
--- /dev/null
+++ b/clang/test/OpenMP/interop_codegen.cpp
@@ -0,0 +1,35 @@
+// expected-no-diagnostics
+// RUN: %clang_cc1 -fopenmp -x c++ -std=c++11 -triple x86_64-unknown-unknown -fopenmp-targets=amdgcn-amd-amdhsa -emit-llvm %s -o - | FileCheck %s
+// RUN: %clang_cc1 -fopenmp -x c++ -std=c++11 -triple x86_64-unknown-unknown -fopenmp-targets=nvptx64-nvidia-cuda -emit-llvm %s -o - | FileCheck %s
+// RUN: %clang_cc1 -verify -fopenmp -x c++ -std=c++11 -triple powerpc64le-unknown-unknown -fopenmp-targets=powerpc64le-ibm-linux-gnu -emit-llvm %s -o - | FileCheck %s
+
+#ifndef HEADER
+#define HEADER
+
+typedef void *omp_interop_t;
+#define omp_interop_none 0
+#define omp_ipr_fr_id -1
+typedef long omp_intptr_t;
+#define NULL 0
+
+extern omp_intptr_t omp_get_interop_int(const omp_interop_t, int, int *);
+
+int main() {
+ omp_interop_t obj = omp_interop_none;
+ omp_interop_t i1 = omp_interop_none;
+ omp_interop_t i2 = omp_interop_none;
+ omp_interop_t i3 = omp_interop_none;
+ omp_interop_t i4 = omp_interop_none;
+ omp_interop_t i5 = omp_interop_none;
+
+ #pragma omp interop init(targetsync: i1) init(targetsync: obj)
+ int id = (int )omp_get_interop_int(obj, omp_ipr_fr_id, NULL);
+ int id1 = (int )omp_get_interop_int(i1, omp_ipr_fr_id, NULL);
+
+
+}
+#endif
+
+// CHECK-LABEL: define {{.+}}main{{.+}}
+// CHECK: call {{.+}}__tgt_interop_init({{.+}}i1{{.*}})
+// CHECK: call {{.+}}__tgt_interop_init({{.+}}obj{{.*}})
>From 3246c44789546fa926784911e349202d8fd8e33b Mon Sep 17 00:00:00 2001
From: Animesh Kumar <108114634+animeshk-amd at users.noreply.github.com>
Date: Thu, 29 Feb 2024 11:54:50 +0530
Subject: [PATCH 093/406] [OpenMP][Clang] Enable inscan modifier for generic
datatypes (#82220)
This patch fixes the #67002 ([OpenMP][Clang] Scan Directive not
supported for Generic types). It disables the Sema checks/analysis that
are run on the helper arrays which go into the implementation of the
`omp scan` directive until the template instantiation happens.
Grateful to @alexey-bataev for suggesting these changes.
---
clang/lib/Sema/SemaOpenMP.cpp | 3 ++-
clang/test/OpenMP/scan_ast_print.cpp | 18 ++++++++++++++++++
2 files changed, 20 insertions(+), 1 deletion(-)
diff --git a/clang/lib/Sema/SemaOpenMP.cpp b/clang/lib/Sema/SemaOpenMP.cpp
index 7f75cfc5b54f35..f4364a259ad57f 100644
--- a/clang/lib/Sema/SemaOpenMP.cpp
+++ b/clang/lib/Sema/SemaOpenMP.cpp
@@ -4962,7 +4962,8 @@ StmtResult Sema::ActOnOpenMPRegionEnd(StmtResult S,
if (RC->getModifier() != OMPC_REDUCTION_inscan)
continue;
for (Expr *E : RC->copy_array_temps())
- MarkDeclarationsReferencedInExpr(E);
+ if (E)
+ MarkDeclarationsReferencedInExpr(E);
}
if (auto *AC = dyn_cast<OMPAlignedClause>(C)) {
for (Expr *E : AC->varlists())
diff --git a/clang/test/OpenMP/scan_ast_print.cpp b/clang/test/OpenMP/scan_ast_print.cpp
index 3bbd3b60c3e8c4..82cb13eb6e70f7 100644
--- a/clang/test/OpenMP/scan_ast_print.cpp
+++ b/clang/test/OpenMP/scan_ast_print.cpp
@@ -17,6 +17,10 @@ T tmain(T argc) {
static T a;
#pragma omp for reduction(inscan, +: a)
for (int i = 0; i < 10; ++i) {
+#pragma omp scan inclusive(a)
+ }
+#pragma omp parallel for reduction(inscan, +:a)
+ for (int i = 0; i < 10; ++i) {
#pragma omp scan inclusive(a)
}
return a + argc;
@@ -25,15 +29,29 @@ T tmain(T argc) {
// CHECK-NEXT: #pragma omp for reduction(inscan, +: a)
// CHECK-NEXT: for (int i = 0; i < 10; ++i) {
// CHECK-NEXT: #pragma omp scan inclusive(a){{$}}
+
+// CHECK: #pragma omp parallel for reduction(inscan, +: a)
+// CHECK-NEXT: for (int i = 0; i < 10; ++i) {
+// CHECK-NEXT: #pragma omp scan inclusive(a){{$}}
+
// CHECK: static int a;
// CHECK-NEXT: #pragma omp for reduction(inscan, +: a)
// CHECK-NEXT: for (int i = 0; i < 10; ++i) {
// CHECK-NEXT: #pragma omp scan inclusive(a)
+
+// CHECK: #pragma omp parallel for reduction(inscan, +: a)
+// CHECK-NEXT: for (int i = 0; i < 10; ++i) {
+// CHECK-NEXT: #pragma omp scan inclusive(a)
+
// CHECK: static char a;
// CHECK-NEXT: #pragma omp for reduction(inscan, +: a)
// CHECK-NEXT: for (int i = 0; i < 10; ++i) {
// CHECK-NEXT: #pragma omp scan inclusive(a)
+// CHECK: #pragma omp parallel for reduction(inscan, +: a)
+// CHECK-NEXT: for (int i = 0; i < 10; ++i) {
+// CHECK-NEXT: #pragma omp scan inclusive(a)
+
int main(int argc, char **argv) {
static int a;
// CHECK: static int a;
>From 6ee9c8afbcc05f61c64c0938281ff11a5e3221cb Mon Sep 17 00:00:00 2001
From: Shih-Po Hung <shihpo.hung at sifive.com>
Date: Thu, 29 Feb 2024 15:41:19 +0800
Subject: [PATCH 094/406] [RISCV][CostModel] Updates reduction and shuffle cost
(#77342)
- Make `andi` cost 1 in SK_Broadcast
- Query the cost of VID_V, VRSUB_VX/VRSUB_VI which would scale with LMUL
---
.../Target/RISCV/RISCVTargetTransformInfo.cpp | 21 +++++++-------
.../Analysis/CostModel/RISCV/rvv-shuffle.ll | 28 +++++++++----------
.../CostModel/RISCV/shuffle-broadcast.ll | 12 ++++----
.../CostModel/RISCV/shuffle-reverse.ll | 12 ++++----
.../RISCV/riscv-vector-reverse.ll | 21 +++++++-------
5 files changed, 48 insertions(+), 46 deletions(-)
diff --git a/llvm/lib/Target/RISCV/RISCVTargetTransformInfo.cpp b/llvm/lib/Target/RISCV/RISCVTargetTransformInfo.cpp
index f04968d82e86e2..2e4e69fb4f920f 100644
--- a/llvm/lib/Target/RISCV/RISCVTargetTransformInfo.cpp
+++ b/llvm/lib/Target/RISCV/RISCVTargetTransformInfo.cpp
@@ -488,9 +488,8 @@ InstructionCost RISCVTTIImpl::getShuffleCost(TTI::ShuffleKind Kind,
// vmv.v.x v8, a0
// vmsne.vi v0, v8, 0
return LT.first *
- (TLI->getLMULCost(LT.second) + // FIXME: should be 1 for andi
- getRISCVInstructionCost({RISCV::VMV_V_X, RISCV::VMSNE_VI},
- LT.second, CostKind));
+ (1 + getRISCVInstructionCost({RISCV::VMV_V_X, RISCV::VMSNE_VI},
+ LT.second, CostKind));
}
// Example sequence:
// vsetivli zero, 2, e8, mf8, ta, mu (ignored)
@@ -502,11 +501,10 @@ InstructionCost RISCVTTIImpl::getShuffleCost(TTI::ShuffleKind Kind,
// vmsne.vi v0, v8, 0
return LT.first *
- (TLI->getLMULCost(LT.second) + // FIXME: this should be 1 for andi
- getRISCVInstructionCost({RISCV::VMV_V_I, RISCV::VMERGE_VIM,
- RISCV::VMV_X_S, RISCV::VMV_V_X,
- RISCV::VMSNE_VI},
- LT.second, CostKind));
+ (1 + getRISCVInstructionCost({RISCV::VMV_V_I, RISCV::VMERGE_VIM,
+ RISCV::VMV_X_S, RISCV::VMV_V_X,
+ RISCV::VMSNE_VI},
+ LT.second, CostKind));
}
if (HasScalar) {
@@ -551,9 +549,12 @@ InstructionCost RISCVTTIImpl::getShuffleCost(TTI::ShuffleKind Kind,
if (LT.second.isFixedLengthVector())
// vrsub.vi has a 5 bit immediate field, otherwise an li suffices
LenCost = isInt<5>(LT.second.getVectorNumElements() - 1) ? 0 : 1;
- // FIXME: replace the constant `2` below with cost of {VID_V,VRSUB_VX}
+ unsigned Opcodes[] = {RISCV::VID_V, RISCV::VRSUB_VX, RISCV::VRGATHER_VV};
+ if (LT.second.isFixedLengthVector() &&
+ isInt<5>(LT.second.getVectorNumElements() - 1))
+ Opcodes[1] = RISCV::VRSUB_VI;
InstructionCost GatherCost =
- 2 + getRISCVInstructionCost(RISCV::VRGATHER_VV, LT.second, CostKind);
+ getRISCVInstructionCost(Opcodes, LT.second, CostKind);
// Mask operation additionally required extend and truncate
InstructionCost ExtendCost = Tp->getElementType()->isIntegerTy(1) ? 3 : 0;
return LT.first * (LenCost + GatherCost + ExtendCost);
diff --git a/llvm/test/Analysis/CostModel/RISCV/rvv-shuffle.ll b/llvm/test/Analysis/CostModel/RISCV/rvv-shuffle.ll
index 30da63b3feec65..7cc7cff0e6e857 100644
--- a/llvm/test/Analysis/CostModel/RISCV/rvv-shuffle.ll
+++ b/llvm/test/Analysis/CostModel/RISCV/rvv-shuffle.ll
@@ -14,7 +14,7 @@ define void @vector_broadcast() {
; CHECK-NEXT: Cost Model: Found an estimated cost of 2 for instruction: %5 = shufflevector <vscale x 4 x i32> undef, <vscale x 4 x i32> undef, <vscale x 4 x i32> zeroinitializer
; CHECK-NEXT: Cost Model: Found an estimated cost of 1 for instruction: %6 = shufflevector <vscale x 1 x i64> undef, <vscale x 1 x i64> undef, <vscale x 1 x i32> zeroinitializer
; CHECK-NEXT: Cost Model: Found an estimated cost of 2 for instruction: %7 = shufflevector <vscale x 2 x i64> undef, <vscale x 2 x i64> undef, <vscale x 2 x i32> zeroinitializer
-; CHECK-NEXT: Cost Model: Found an estimated cost of 11 for instruction: %8 = shufflevector <vscale x 16 x i1> undef, <vscale x 16 x i1> undef, <vscale x 16 x i32> zeroinitializer
+; CHECK-NEXT: Cost Model: Found an estimated cost of 10 for instruction: %8 = shufflevector <vscale x 16 x i1> undef, <vscale x 16 x i1> undef, <vscale x 16 x i32> zeroinitializer
; CHECK-NEXT: Cost Model: Found an estimated cost of 6 for instruction: %9 = shufflevector <vscale x 8 x i1> undef, <vscale x 8 x i1> undef, <vscale x 8 x i32> zeroinitializer
; CHECK-NEXT: Cost Model: Found an estimated cost of 6 for instruction: %10 = shufflevector <vscale x 4 x i1> undef, <vscale x 4 x i1> undef, <vscale x 4 x i32> zeroinitializer
; CHECK-NEXT: Cost Model: Found an estimated cost of 6 for instruction: %11 = shufflevector <vscale x 2 x i1> undef, <vscale x 2 x i1> undef, <vscale x 2 x i32> zeroinitializer
@@ -29,7 +29,7 @@ define void @vector_broadcast() {
; SIZE-NEXT: Cost Model: Found an estimated cost of 1 for instruction: %5 = shufflevector <vscale x 4 x i32> undef, <vscale x 4 x i32> undef, <vscale x 4 x i32> zeroinitializer
; SIZE-NEXT: Cost Model: Found an estimated cost of 1 for instruction: %6 = shufflevector <vscale x 1 x i64> undef, <vscale x 1 x i64> undef, <vscale x 1 x i32> zeroinitializer
; SIZE-NEXT: Cost Model: Found an estimated cost of 1 for instruction: %7 = shufflevector <vscale x 2 x i64> undef, <vscale x 2 x i64> undef, <vscale x 2 x i32> zeroinitializer
-; SIZE-NEXT: Cost Model: Found an estimated cost of 7 for instruction: %8 = shufflevector <vscale x 16 x i1> undef, <vscale x 16 x i1> undef, <vscale x 16 x i32> zeroinitializer
+; SIZE-NEXT: Cost Model: Found an estimated cost of 6 for instruction: %8 = shufflevector <vscale x 16 x i1> undef, <vscale x 16 x i1> undef, <vscale x 16 x i32> zeroinitializer
; SIZE-NEXT: Cost Model: Found an estimated cost of 6 for instruction: %9 = shufflevector <vscale x 8 x i1> undef, <vscale x 8 x i1> undef, <vscale x 8 x i32> zeroinitializer
; SIZE-NEXT: Cost Model: Found an estimated cost of 6 for instruction: %10 = shufflevector <vscale x 4 x i1> undef, <vscale x 4 x i1> undef, <vscale x 4 x i32> zeroinitializer
; SIZE-NEXT: Cost Model: Found an estimated cost of 6 for instruction: %11 = shufflevector <vscale x 2 x i1> undef, <vscale x 2 x i1> undef, <vscale x 2 x i32> zeroinitializer
@@ -78,20 +78,20 @@ declare <vscale x 16 x i32> @llvm.vector.insert.nxv16i32.nxv4i32(<vscale x 16 x
define void @vector_reverse() {
; CHECK-LABEL: 'vector_reverse'
-; CHECK-NEXT: Cost Model: Found an estimated cost of 9 for instruction: %reverse_nxv16i8 = call <vscale x 16 x i8> @llvm.experimental.vector.reverse.nxv16i8(<vscale x 16 x i8> undef)
-; CHECK-NEXT: Cost Model: Found an estimated cost of 21 for instruction: %reverse_nxv32i8 = call <vscale x 32 x i8> @llvm.experimental.vector.reverse.nxv32i8(<vscale x 32 x i8> undef)
+; CHECK-NEXT: Cost Model: Found an estimated cost of 11 for instruction: %reverse_nxv16i8 = call <vscale x 16 x i8> @llvm.experimental.vector.reverse.nxv16i8(<vscale x 16 x i8> undef)
+; CHECK-NEXT: Cost Model: Found an estimated cost of 27 for instruction: %reverse_nxv32i8 = call <vscale x 32 x i8> @llvm.experimental.vector.reverse.nxv32i8(<vscale x 32 x i8> undef)
; CHECK-NEXT: Cost Model: Found an estimated cost of 6 for instruction: %reverse_nxv2i16 = call <vscale x 2 x i16> @llvm.experimental.vector.reverse.nxv2i16(<vscale x 2 x i16> undef)
; CHECK-NEXT: Cost Model: Found an estimated cost of 6 for instruction: %reverse_nxv4i16 = call <vscale x 4 x i16> @llvm.experimental.vector.reverse.nxv4i16(<vscale x 4 x i16> undef)
-; CHECK-NEXT: Cost Model: Found an estimated cost of 9 for instruction: %reverse_nxv8i16 = call <vscale x 8 x i16> @llvm.experimental.vector.reverse.nxv8i16(<vscale x 8 x i16> undef)
-; CHECK-NEXT: Cost Model: Found an estimated cost of 21 for instruction: %reverse_nxv16i16 = call <vscale x 16 x i16> @llvm.experimental.vector.reverse.nxv16i16(<vscale x 16 x i16> undef)
-; CHECK-NEXT: Cost Model: Found an estimated cost of 9 for instruction: %reverse_nxv4i32 = call <vscale x 4 x i32> @llvm.experimental.vector.reverse.nxv4i32(<vscale x 4 x i32> undef)
-; CHECK-NEXT: Cost Model: Found an estimated cost of 21 for instruction: %reverse_nxv8i32 = call <vscale x 8 x i32> @llvm.experimental.vector.reverse.nxv8i32(<vscale x 8 x i32> undef)
-; CHECK-NEXT: Cost Model: Found an estimated cost of 9 for instruction: %reverse_nxv2i64 = call <vscale x 2 x i64> @llvm.experimental.vector.reverse.nxv2i64(<vscale x 2 x i64> undef)
-; CHECK-NEXT: Cost Model: Found an estimated cost of 21 for instruction: %reverse_nxv4i64 = call <vscale x 4 x i64> @llvm.experimental.vector.reverse.nxv4i64(<vscale x 4 x i64> undef)
-; CHECK-NEXT: Cost Model: Found an estimated cost of 69 for instruction: %reverse_nxv8i64 = call <vscale x 8 x i64> @llvm.experimental.vector.reverse.nxv8i64(<vscale x 8 x i64> undef)
-; CHECK-NEXT: Cost Model: Found an estimated cost of 138 for instruction: %reverse_nxv16i64 = call <vscale x 16 x i64> @llvm.experimental.vector.reverse.nxv16i64(<vscale x 16 x i64> undef)
-; CHECK-NEXT: Cost Model: Found an estimated cost of 276 for instruction: %reverse_nxv32i64 = call <vscale x 32 x i64> @llvm.experimental.vector.reverse.nxv32i64(<vscale x 32 x i64> undef)
-; CHECK-NEXT: Cost Model: Found an estimated cost of 12 for instruction: %reverse_nxv16i1 = call <vscale x 16 x i1> @llvm.experimental.vector.reverse.nxv16i1(<vscale x 16 x i1> undef)
+; CHECK-NEXT: Cost Model: Found an estimated cost of 11 for instruction: %reverse_nxv8i16 = call <vscale x 8 x i16> @llvm.experimental.vector.reverse.nxv8i16(<vscale x 8 x i16> undef)
+; CHECK-NEXT: Cost Model: Found an estimated cost of 27 for instruction: %reverse_nxv16i16 = call <vscale x 16 x i16> @llvm.experimental.vector.reverse.nxv16i16(<vscale x 16 x i16> undef)
+; CHECK-NEXT: Cost Model: Found an estimated cost of 11 for instruction: %reverse_nxv4i32 = call <vscale x 4 x i32> @llvm.experimental.vector.reverse.nxv4i32(<vscale x 4 x i32> undef)
+; CHECK-NEXT: Cost Model: Found an estimated cost of 27 for instruction: %reverse_nxv8i32 = call <vscale x 8 x i32> @llvm.experimental.vector.reverse.nxv8i32(<vscale x 8 x i32> undef)
+; CHECK-NEXT: Cost Model: Found an estimated cost of 11 for instruction: %reverse_nxv2i64 = call <vscale x 2 x i64> @llvm.experimental.vector.reverse.nxv2i64(<vscale x 2 x i64> undef)
+; CHECK-NEXT: Cost Model: Found an estimated cost of 27 for instruction: %reverse_nxv4i64 = call <vscale x 4 x i64> @llvm.experimental.vector.reverse.nxv4i64(<vscale x 4 x i64> undef)
+; CHECK-NEXT: Cost Model: Found an estimated cost of 83 for instruction: %reverse_nxv8i64 = call <vscale x 8 x i64> @llvm.experimental.vector.reverse.nxv8i64(<vscale x 8 x i64> undef)
+; CHECK-NEXT: Cost Model: Found an estimated cost of 166 for instruction: %reverse_nxv16i64 = call <vscale x 16 x i64> @llvm.experimental.vector.reverse.nxv16i64(<vscale x 16 x i64> undef)
+; CHECK-NEXT: Cost Model: Found an estimated cost of 332 for instruction: %reverse_nxv32i64 = call <vscale x 32 x i64> @llvm.experimental.vector.reverse.nxv32i64(<vscale x 32 x i64> undef)
+; CHECK-NEXT: Cost Model: Found an estimated cost of 14 for instruction: %reverse_nxv16i1 = call <vscale x 16 x i1> @llvm.experimental.vector.reverse.nxv16i1(<vscale x 16 x i1> undef)
; CHECK-NEXT: Cost Model: Found an estimated cost of 9 for instruction: %reverse_nxv8i1 = call <vscale x 8 x i1> @llvm.experimental.vector.reverse.nxv8i1(<vscale x 8 x i1> undef)
; CHECK-NEXT: Cost Model: Found an estimated cost of 9 for instruction: %reverse_nxv4i1 = call <vscale x 4 x i1> @llvm.experimental.vector.reverse.nxv4i1(<vscale x 4 x i1> undef)
; CHECK-NEXT: Cost Model: Found an estimated cost of 9 for instruction: %reverse_nxv2i1 = call <vscale x 2 x i1> @llvm.experimental.vector.reverse.nxv2i1(<vscale x 2 x i1> undef)
diff --git a/llvm/test/Analysis/CostModel/RISCV/shuffle-broadcast.ll b/llvm/test/Analysis/CostModel/RISCV/shuffle-broadcast.ll
index fc4a6b17d3f826..46bf3152ac5bd3 100644
--- a/llvm/test/Analysis/CostModel/RISCV/shuffle-broadcast.ll
+++ b/llvm/test/Analysis/CostModel/RISCV/shuffle-broadcast.ll
@@ -45,9 +45,9 @@ define void @broadcast_scalable() #0{
; CHECK-NEXT: Cost Model: Found an estimated cost of 6 for instruction: %38 = shufflevector <vscale x 2 x i1> undef, <vscale x 2 x i1> undef, <vscale x 2 x i32> zeroinitializer
; CHECK-NEXT: Cost Model: Found an estimated cost of 6 for instruction: %39 = shufflevector <vscale x 4 x i1> undef, <vscale x 4 x i1> undef, <vscale x 4 x i32> zeroinitializer
; CHECK-NEXT: Cost Model: Found an estimated cost of 6 for instruction: %40 = shufflevector <vscale x 8 x i1> undef, <vscale x 8 x i1> undef, <vscale x 8 x i32> zeroinitializer
-; CHECK-NEXT: Cost Model: Found an estimated cost of 11 for instruction: %41 = shufflevector <vscale x 16 x i1> undef, <vscale x 16 x i1> undef, <vscale x 16 x i32> zeroinitializer
-; CHECK-NEXT: Cost Model: Found an estimated cost of 21 for instruction: %42 = shufflevector <vscale x 32 x i1> undef, <vscale x 32 x i1> undef, <vscale x 32 x i32> zeroinitializer
-; CHECK-NEXT: Cost Model: Found an estimated cost of 41 for instruction: %43 = shufflevector <vscale x 64 x i1> undef, <vscale x 64 x i1> undef, <vscale x 64 x i32> zeroinitializer
+; CHECK-NEXT: Cost Model: Found an estimated cost of 10 for instruction: %41 = shufflevector <vscale x 16 x i1> undef, <vscale x 16 x i1> undef, <vscale x 16 x i32> zeroinitializer
+; CHECK-NEXT: Cost Model: Found an estimated cost of 18 for instruction: %42 = shufflevector <vscale x 32 x i1> undef, <vscale x 32 x i1> undef, <vscale x 32 x i32> zeroinitializer
+; CHECK-NEXT: Cost Model: Found an estimated cost of 34 for instruction: %43 = shufflevector <vscale x 64 x i1> undef, <vscale x 64 x i1> undef, <vscale x 64 x i32> zeroinitializer
; CHECK-NEXT: Cost Model: Found an estimated cost of 0 for instruction: ret void
;
; SIZE-LABEL: 'broadcast_scalable'
@@ -92,9 +92,9 @@ define void @broadcast_scalable() #0{
; SIZE-NEXT: Cost Model: Found an estimated cost of 6 for instruction: %38 = shufflevector <vscale x 2 x i1> undef, <vscale x 2 x i1> undef, <vscale x 2 x i32> zeroinitializer
; SIZE-NEXT: Cost Model: Found an estimated cost of 6 for instruction: %39 = shufflevector <vscale x 4 x i1> undef, <vscale x 4 x i1> undef, <vscale x 4 x i32> zeroinitializer
; SIZE-NEXT: Cost Model: Found an estimated cost of 6 for instruction: %40 = shufflevector <vscale x 8 x i1> undef, <vscale x 8 x i1> undef, <vscale x 8 x i32> zeroinitializer
-; SIZE-NEXT: Cost Model: Found an estimated cost of 7 for instruction: %41 = shufflevector <vscale x 16 x i1> undef, <vscale x 16 x i1> undef, <vscale x 16 x i32> zeroinitializer
-; SIZE-NEXT: Cost Model: Found an estimated cost of 9 for instruction: %42 = shufflevector <vscale x 32 x i1> undef, <vscale x 32 x i1> undef, <vscale x 32 x i32> zeroinitializer
-; SIZE-NEXT: Cost Model: Found an estimated cost of 13 for instruction: %43 = shufflevector <vscale x 64 x i1> undef, <vscale x 64 x i1> undef, <vscale x 64 x i32> zeroinitializer
+; SIZE-NEXT: Cost Model: Found an estimated cost of 6 for instruction: %41 = shufflevector <vscale x 16 x i1> undef, <vscale x 16 x i1> undef, <vscale x 16 x i32> zeroinitializer
+; SIZE-NEXT: Cost Model: Found an estimated cost of 6 for instruction: %42 = shufflevector <vscale x 32 x i1> undef, <vscale x 32 x i1> undef, <vscale x 32 x i32> zeroinitializer
+; SIZE-NEXT: Cost Model: Found an estimated cost of 6 for instruction: %43 = shufflevector <vscale x 64 x i1> undef, <vscale x 64 x i1> undef, <vscale x 64 x i32> zeroinitializer
; SIZE-NEXT: Cost Model: Found an estimated cost of 1 for instruction: ret void
;
%zero = shufflevector <vscale x 1 x half> undef, <vscale x 1 x half> undef, <vscale x 1 x i32> zeroinitializer
diff --git a/llvm/test/Analysis/CostModel/RISCV/shuffle-reverse.ll b/llvm/test/Analysis/CostModel/RISCV/shuffle-reverse.ll
index 146909cc93df1c..e80dbe31683f3d 100644
--- a/llvm/test/Analysis/CostModel/RISCV/shuffle-reverse.ll
+++ b/llvm/test/Analysis/CostModel/RISCV/shuffle-reverse.ll
@@ -20,21 +20,21 @@ define void @reverse() {
; CHECK-NEXT: Cost Model: Found an estimated cost of 3 for instruction: %v2i16 = shufflevector <2 x i16> undef, <2 x i16> undef, <2 x i32> <i32 1, i32 0>
; CHECK-NEXT: Cost Model: Found an estimated cost of 3 for instruction: %v4i16 = shufflevector <4 x i16> undef, <4 x i16> undef, <4 x i32> <i32 3, i32 2, i32 1, i32 0>
; CHECK-NEXT: Cost Model: Found an estimated cost of 3 for instruction: %v8i16 = shufflevector <8 x i16> undef, <8 x i16> undef, <8 x i32> <i32 7, i32 6, i32 5, i32 4, i32 3, i32 2, i32 1, i32 0>
-; CHECK-NEXT: Cost Model: Found an estimated cost of 6 for instruction: %v16i16 = shufflevector <16 x i16> undef, <16 x i16> undef, <16 x i32> <i32 15, i32 14, i32 13, i32 12, i32 11, i32 10, i32 9, i32 8, i32 7, i32 6, i32 5, i32 4, i32 3, i32 2, i32 1, i32 0>
+; CHECK-NEXT: Cost Model: Found an estimated cost of 8 for instruction: %v16i16 = shufflevector <16 x i16> undef, <16 x i16> undef, <16 x i32> <i32 15, i32 14, i32 13, i32 12, i32 11, i32 10, i32 9, i32 8, i32 7, i32 6, i32 5, i32 4, i32 3, i32 2, i32 1, i32 0>
; CHECK-NEXT: Cost Model: Found an estimated cost of 3 for instruction: %v2i32 = shufflevector <2 x i32> undef, <2 x i32> undef, <2 x i32> <i32 1, i32 0>
; CHECK-NEXT: Cost Model: Found an estimated cost of 3 for instruction: %v4i32 = shufflevector <4 x i32> undef, <4 x i32> undef, <4 x i32> <i32 3, i32 2, i32 1, i32 0>
-; CHECK-NEXT: Cost Model: Found an estimated cost of 6 for instruction: %v8i32 = shufflevector <8 x i32> undef, <8 x i32> undef, <8 x i32> <i32 7, i32 6, i32 5, i32 4, i32 3, i32 2, i32 1, i32 0>
+; CHECK-NEXT: Cost Model: Found an estimated cost of 8 for instruction: %v8i32 = shufflevector <8 x i32> undef, <8 x i32> undef, <8 x i32> <i32 7, i32 6, i32 5, i32 4, i32 3, i32 2, i32 1, i32 0>
; CHECK-NEXT: Cost Model: Found an estimated cost of 3 for instruction: %v2i64 = shufflevector <2 x i64> undef, <2 x i64> undef, <2 x i32> <i32 1, i32 0>
-; CHECK-NEXT: Cost Model: Found an estimated cost of 6 for instruction: %v4i64 = shufflevector <4 x i64> undef, <4 x i64> undef, <4 x i32> <i32 3, i32 2, i32 1, i32 0>
+; CHECK-NEXT: Cost Model: Found an estimated cost of 8 for instruction: %v4i64 = shufflevector <4 x i64> undef, <4 x i64> undef, <4 x i32> <i32 3, i32 2, i32 1, i32 0>
; CHECK-NEXT: Cost Model: Found an estimated cost of 3 for instruction: %v2f16 = shufflevector <2 x half> undef, <2 x half> undef, <2 x i32> <i32 1, i32 0>
; CHECK-NEXT: Cost Model: Found an estimated cost of 3 for instruction: %v4f16 = shufflevector <4 x half> undef, <4 x half> undef, <4 x i32> <i32 3, i32 2, i32 1, i32 0>
; CHECK-NEXT: Cost Model: Found an estimated cost of 3 for instruction: %v8f16 = shufflevector <8 x half> undef, <8 x half> undef, <8 x i32> <i32 7, i32 6, i32 5, i32 4, i32 3, i32 2, i32 1, i32 0>
-; CHECK-NEXT: Cost Model: Found an estimated cost of 6 for instruction: %v16f16 = shufflevector <16 x half> undef, <16 x half> undef, <16 x i32> <i32 15, i32 14, i32 13, i32 12, i32 11, i32 10, i32 9, i32 8, i32 7, i32 6, i32 5, i32 4, i32 3, i32 2, i32 1, i32 0>
+; CHECK-NEXT: Cost Model: Found an estimated cost of 8 for instruction: %v16f16 = shufflevector <16 x half> undef, <16 x half> undef, <16 x i32> <i32 15, i32 14, i32 13, i32 12, i32 11, i32 10, i32 9, i32 8, i32 7, i32 6, i32 5, i32 4, i32 3, i32 2, i32 1, i32 0>
; CHECK-NEXT: Cost Model: Found an estimated cost of 3 for instruction: %v2f32 = shufflevector <2 x float> undef, <2 x float> undef, <2 x i32> <i32 1, i32 0>
; CHECK-NEXT: Cost Model: Found an estimated cost of 3 for instruction: %v4f32 = shufflevector <4 x float> undef, <4 x float> undef, <4 x i32> <i32 3, i32 2, i32 1, i32 0>
-; CHECK-NEXT: Cost Model: Found an estimated cost of 6 for instruction: %v8f32 = shufflevector <8 x float> undef, <8 x float> undef, <8 x i32> <i32 7, i32 6, i32 5, i32 4, i32 3, i32 2, i32 1, i32 0>
+; CHECK-NEXT: Cost Model: Found an estimated cost of 8 for instruction: %v8f32 = shufflevector <8 x float> undef, <8 x float> undef, <8 x i32> <i32 7, i32 6, i32 5, i32 4, i32 3, i32 2, i32 1, i32 0>
; CHECK-NEXT: Cost Model: Found an estimated cost of 3 for instruction: %v2f64 = shufflevector <2 x double> undef, <2 x double> undef, <2 x i32> <i32 1, i32 0>
-; CHECK-NEXT: Cost Model: Found an estimated cost of 6 for instruction: %v4f64 = shufflevector <4 x double> undef, <4 x double> undef, <4 x i32> <i32 3, i32 2, i32 1, i32 0>
+; CHECK-NEXT: Cost Model: Found an estimated cost of 8 for instruction: %v4f64 = shufflevector <4 x double> undef, <4 x double> undef, <4 x i32> <i32 3, i32 2, i32 1, i32 0>
; CHECK-NEXT: Cost Model: Found an estimated cost of 0 for instruction: ret void
;
; SIZE-LABEL: 'reverse'
diff --git a/llvm/test/Transforms/LoopVectorize/RISCV/riscv-vector-reverse.ll b/llvm/test/Transforms/LoopVectorize/RISCV/riscv-vector-reverse.ll
index da6dc34e409684..72d9691b2bb877 100644
--- a/llvm/test/Transforms/LoopVectorize/RISCV/riscv-vector-reverse.ll
+++ b/llvm/test/Transforms/LoopVectorize/RISCV/riscv-vector-reverse.ll
@@ -36,10 +36,10 @@ define void @vector_reverse_i64(ptr nocapture noundef writeonly %A, ptr nocaptur
; CHECK-NEXT: LV: Found an estimated cost of 1 for VF vscale x 4 For instruction: %i.0 = add nsw i32 %i.0.in8, -1
; CHECK-NEXT: LV: Found an estimated cost of 1 for VF vscale x 4 For instruction: %idxprom = zext i32 %i.0 to i64
; CHECK-NEXT: LV: Found an estimated cost of 0 for VF vscale x 4 For instruction: %arrayidx = getelementptr inbounds i32, ptr %B, i64 %idxprom
-; CHECK-NEXT: LV: Found an estimated cost of 11 for VF vscale x 4 For instruction: %1 = load i32, ptr %arrayidx, align 4
+; CHECK-NEXT: LV: Found an estimated cost of 13 for VF vscale x 4 For instruction: %1 = load i32, ptr %arrayidx, align 4
; CHECK-NEXT: LV: Found an estimated cost of 2 for VF vscale x 4 For instruction: %add9 = add i32 %1, 1
; CHECK-NEXT: LV: Found an estimated cost of 0 for VF vscale x 4 For instruction: %arrayidx3 = getelementptr inbounds i32, ptr %A, i64 %idxprom
-; CHECK-NEXT: LV: Found an estimated cost of 11 for VF vscale x 4 For instruction: store i32 %add9, ptr %arrayidx3, align 4
+; CHECK-NEXT: LV: Found an estimated cost of 13 for VF vscale x 4 For instruction: store i32 %add9, ptr %arrayidx3, align 4
; CHECK-NEXT: LV: Found an estimated cost of 1 for VF vscale x 4 For instruction: %cmp = icmp ugt i64 %indvars.iv, 1
; CHECK-NEXT: LV: Found an estimated cost of 1 for VF vscale x 4 For instruction: %indvars.iv.next = add nsw i64 %indvars.iv, -1
; CHECK-NEXT: LV: Found an estimated cost of 0 for VF vscale x 4 For instruction: br i1 %cmp, label %for.body, label %for.cond.cleanup.loopexit, !llvm.loop !0
@@ -86,10 +86,10 @@ define void @vector_reverse_i64(ptr nocapture noundef writeonly %A, ptr nocaptur
; CHECK-NEXT: LV: Found an estimated cost of 1 for VF vscale x 4 For instruction: %i.0 = add nsw i32 %i.0.in8, -1
; CHECK-NEXT: LV: Found an estimated cost of 1 for VF vscale x 4 For instruction: %idxprom = zext i32 %i.0 to i64
; CHECK-NEXT: LV: Found an estimated cost of 0 for VF vscale x 4 For instruction: %arrayidx = getelementptr inbounds i32, ptr %B, i64 %idxprom
-; CHECK-NEXT: LV: Found an estimated cost of 11 for VF vscale x 4 For instruction: %1 = load i32, ptr %arrayidx, align 4
+; CHECK-NEXT: LV: Found an estimated cost of 13 for VF vscale x 4 For instruction: %1 = load i32, ptr %arrayidx, align 4
; CHECK-NEXT: LV: Found an estimated cost of 2 for VF vscale x 4 For instruction: %add9 = add i32 %1, 1
; CHECK-NEXT: LV: Found an estimated cost of 0 for VF vscale x 4 For instruction: %arrayidx3 = getelementptr inbounds i32, ptr %A, i64 %idxprom
-; CHECK-NEXT: LV: Found an estimated cost of 11 for VF vscale x 4 For instruction: store i32 %add9, ptr %arrayidx3, align 4
+; CHECK-NEXT: LV: Found an estimated cost of 13 for VF vscale x 4 For instruction: store i32 %add9, ptr %arrayidx3, align 4
; CHECK-NEXT: LV: Found an estimated cost of 1 for VF vscale x 4 For instruction: %cmp = icmp ugt i64 %indvars.iv, 1
; CHECK-NEXT: LV: Found an estimated cost of 1 for VF vscale x 4 For instruction: %indvars.iv.next = add nsw i64 %indvars.iv, -1
; CHECK-NEXT: LV: Found an estimated cost of 0 for VF vscale x 4 For instruction: br i1 %cmp, label %for.body, label %for.cond.cleanup.loopexit, !llvm.loop !0
@@ -112,7 +112,7 @@ define void @vector_reverse_i64(ptr nocapture noundef writeonly %A, ptr nocaptur
; CHECK-NEXT: LV(REG): RegisterClass: RISCV::GPRRC, 1 registers
; CHECK-NEXT: LV: The target has 31 registers of RISCV::GPRRC register class
; CHECK-NEXT: LV: The target has 32 registers of RISCV::VRRC register class
-; CHECK-NEXT: LV: Loop cost is 28
+; CHECK-NEXT: LV: Loop cost is 32
; CHECK-NEXT: LV: IC is 1
; CHECK-NEXT: LV: VF is vscale x 4
; CHECK-NEXT: LV: Not Interleaving.
@@ -122,6 +122,7 @@ define void @vector_reverse_i64(ptr nocapture noundef writeonly %A, ptr nocaptur
; CHECK-NEXT: Executing best plan with VF=vscale x 4, UF=1
; CHECK: LV: Interleaving disabled by the pass manager
; CHECK-NEXT: LV: Vectorizing: innermost loop.
+; CHECK-EMPTY:
;
entry:
%cmp7 = icmp sgt i32 %n, 0
@@ -176,10 +177,10 @@ define void @vector_reverse_f32(ptr nocapture noundef writeonly %A, ptr nocaptur
; CHECK-NEXT: LV: Found an estimated cost of 1 for VF vscale x 4 For instruction: %i.0 = add nsw i32 %i.0.in8, -1
; CHECK-NEXT: LV: Found an estimated cost of 1 for VF vscale x 4 For instruction: %idxprom = zext i32 %i.0 to i64
; CHECK-NEXT: LV: Found an estimated cost of 0 for VF vscale x 4 For instruction: %arrayidx = getelementptr inbounds float, ptr %B, i64 %idxprom
-; CHECK-NEXT: LV: Found an estimated cost of 11 for VF vscale x 4 For instruction: %1 = load float, ptr %arrayidx, align 4
+; CHECK-NEXT: LV: Found an estimated cost of 13 for VF vscale x 4 For instruction: %1 = load float, ptr %arrayidx, align 4
; CHECK-NEXT: LV: Found an estimated cost of 2 for VF vscale x 4 For instruction: %conv1 = fadd float %1, 1.000000e+00
; CHECK-NEXT: LV: Found an estimated cost of 0 for VF vscale x 4 For instruction: %arrayidx3 = getelementptr inbounds float, ptr %A, i64 %idxprom
-; CHECK-NEXT: LV: Found an estimated cost of 11 for VF vscale x 4 For instruction: store float %conv1, ptr %arrayidx3, align 4
+; CHECK-NEXT: LV: Found an estimated cost of 13 for VF vscale x 4 For instruction: store float %conv1, ptr %arrayidx3, align 4
; CHECK-NEXT: LV: Found an estimated cost of 1 for VF vscale x 4 For instruction: %cmp = icmp ugt i64 %indvars.iv, 1
; CHECK-NEXT: LV: Found an estimated cost of 1 for VF vscale x 4 For instruction: %indvars.iv.next = add nsw i64 %indvars.iv, -1
; CHECK-NEXT: LV: Found an estimated cost of 0 for VF vscale x 4 For instruction: br i1 %cmp, label %for.body, label %for.cond.cleanup.loopexit, !llvm.loop !0
@@ -226,10 +227,10 @@ define void @vector_reverse_f32(ptr nocapture noundef writeonly %A, ptr nocaptur
; CHECK-NEXT: LV: Found an estimated cost of 1 for VF vscale x 4 For instruction: %i.0 = add nsw i32 %i.0.in8, -1
; CHECK-NEXT: LV: Found an estimated cost of 1 for VF vscale x 4 For instruction: %idxprom = zext i32 %i.0 to i64
; CHECK-NEXT: LV: Found an estimated cost of 0 for VF vscale x 4 For instruction: %arrayidx = getelementptr inbounds float, ptr %B, i64 %idxprom
-; CHECK-NEXT: LV: Found an estimated cost of 11 for VF vscale x 4 For instruction: %1 = load float, ptr %arrayidx, align 4
+; CHECK-NEXT: LV: Found an estimated cost of 13 for VF vscale x 4 For instruction: %1 = load float, ptr %arrayidx, align 4
; CHECK-NEXT: LV: Found an estimated cost of 2 for VF vscale x 4 For instruction: %conv1 = fadd float %1, 1.000000e+00
; CHECK-NEXT: LV: Found an estimated cost of 0 for VF vscale x 4 For instruction: %arrayidx3 = getelementptr inbounds float, ptr %A, i64 %idxprom
-; CHECK-NEXT: LV: Found an estimated cost of 11 for VF vscale x 4 For instruction: store float %conv1, ptr %arrayidx3, align 4
+; CHECK-NEXT: LV: Found an estimated cost of 13 for VF vscale x 4 For instruction: store float %conv1, ptr %arrayidx3, align 4
; CHECK-NEXT: LV: Found an estimated cost of 1 for VF vscale x 4 For instruction: %cmp = icmp ugt i64 %indvars.iv, 1
; CHECK-NEXT: LV: Found an estimated cost of 1 for VF vscale x 4 For instruction: %indvars.iv.next = add nsw i64 %indvars.iv, -1
; CHECK-NEXT: LV: Found an estimated cost of 0 for VF vscale x 4 For instruction: br i1 %cmp, label %for.body, label %for.cond.cleanup.loopexit, !llvm.loop !0
@@ -252,7 +253,7 @@ define void @vector_reverse_f32(ptr nocapture noundef writeonly %A, ptr nocaptur
; CHECK-NEXT: LV(REG): RegisterClass: RISCV::GPRRC, 1 registers
; CHECK-NEXT: LV: The target has 31 registers of RISCV::GPRRC register class
; CHECK-NEXT: LV: The target has 32 registers of RISCV::VRRC register class
-; CHECK-NEXT: LV: Loop cost is 28
+; CHECK-NEXT: LV: Loop cost is 32
; CHECK-NEXT: LV: IC is 1
; CHECK-NEXT: LV: VF is vscale x 4
; CHECK-NEXT: LV: Not Interleaving.
>From d1a461dbb2293d9258d400b5426f610bb5191228 Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?Dominik=20W=C3=B3jt?= <dominik.wojt at arm.com>
Date: Thu, 29 Feb 2024 08:54:58 +0100
Subject: [PATCH 095/406] [libc++] tests with picolibc: prevent looking for
unneeded "rt" library (#82262)
Picolibc does not provide the clock_gettime function nor the "rt" library.
check_library_exists was invalidly detecting the "rt" library due to cmake issue
present, when cross-compiling[1]. This resulted with "chrono.cpp" trying to link
to the "rt" library and following error:
unable to find library from dependent library specifier: rt
[1] https://gitlab.kitware.com/cmake/cmake/-/issues/18121
---
libcxx/cmake/config-ix.cmake | 7 +++++++
.../time/time.clock/time.clock.file/to_from_sys.pass.cpp | 3 ---
.../test/std/time/time.clock/time.clock.hires/now.pass.cpp | 3 ---
.../time/time.clock/time.clock.system/from_time_t.pass.cpp | 3 ---
.../std/time/time.clock/time.clock.system/now.pass.cpp | 3 ---
.../time/time.clock/time.clock.system/to_time_t.pass.cpp | 3 ---
.../time.point/time.point.nonmember/op_-duration.pass.cpp | 3 ---
7 files changed, 7 insertions(+), 18 deletions(-)
diff --git a/libcxx/cmake/config-ix.cmake b/libcxx/cmake/config-ix.cmake
index 1e8c2f5ce46321..7406fba482e69d 100644
--- a/libcxx/cmake/config-ix.cmake
+++ b/libcxx/cmake/config-ix.cmake
@@ -1,5 +1,6 @@
include(CMakePushCheckState)
include(CheckLibraryExists)
+include(CheckSymbolExists)
include(LLVMCheckCompilerLinkerFlag)
include(CheckCCompilerFlag)
include(CheckCXXCompilerFlag)
@@ -97,6 +98,8 @@ int main(void) { return 0; }
cmake_pop_check_state()
endif()
+check_symbol_exists(__PICOLIBC__ "string.h" PICOLIBC)
+
# Check libraries
if(WIN32 AND NOT MINGW)
# TODO(compnerd) do we want to support an emulation layer that allows for the
@@ -116,6 +119,10 @@ elseif(ANDROID)
set(LIBCXX_HAS_PTHREAD_LIB NO)
set(LIBCXX_HAS_RT_LIB NO)
set(LIBCXX_HAS_ATOMIC_LIB NO)
+elseif(PICOLIBC)
+ set(LIBCXX_HAS_PTHREAD_LIB NO)
+ set(LIBCXX_HAS_RT_LIB NO)
+ set(LIBCXX_HAS_ATOMIC_LIB NO)
else()
check_library_exists(pthread pthread_create "" LIBCXX_HAS_PTHREAD_LIB)
check_library_exists(rt clock_gettime "" LIBCXX_HAS_RT_LIB)
diff --git a/libcxx/test/std/time/time.clock/time.clock.file/to_from_sys.pass.cpp b/libcxx/test/std/time/time.clock/time.clock.file/to_from_sys.pass.cpp
index b1031c81561047..5b1f4659911118 100644
--- a/libcxx/test/std/time/time.clock/time.clock.file/to_from_sys.pass.cpp
+++ b/libcxx/test/std/time/time.clock/time.clock.file/to_from_sys.pass.cpp
@@ -10,9 +10,6 @@
// UNSUPPORTED: availability-filesystem-missing
-// "unable to find library from dependent library specifier: rt"
-// XFAIL: LIBCXX-PICOLIBC-FIXME
-
// <chrono>
//
// file_clock
diff --git a/libcxx/test/std/time/time.clock/time.clock.hires/now.pass.cpp b/libcxx/test/std/time/time.clock/time.clock.hires/now.pass.cpp
index 8625ac58bde559..db1fb55df90721 100644
--- a/libcxx/test/std/time/time.clock/time.clock.hires/now.pass.cpp
+++ b/libcxx/test/std/time/time.clock/time.clock.hires/now.pass.cpp
@@ -6,9 +6,6 @@
//
//===----------------------------------------------------------------------===//
-// "unable to find library from dependent library specifier: rt"
-// XFAIL: LIBCXX-PICOLIBC-FIXME
-
// <chrono>
// high_resolution_clock
diff --git a/libcxx/test/std/time/time.clock/time.clock.system/from_time_t.pass.cpp b/libcxx/test/std/time/time.clock/time.clock.system/from_time_t.pass.cpp
index 5ff667445b1a39..70dd8117e6cef5 100644
--- a/libcxx/test/std/time/time.clock/time.clock.system/from_time_t.pass.cpp
+++ b/libcxx/test/std/time/time.clock/time.clock.system/from_time_t.pass.cpp
@@ -6,9 +6,6 @@
//
//===----------------------------------------------------------------------===//
-// "unable to find library from dependent library specifier: rt"
-// XFAIL: LIBCXX-PICOLIBC-FIXME
-
// <chrono>
// system_clock
diff --git a/libcxx/test/std/time/time.clock/time.clock.system/now.pass.cpp b/libcxx/test/std/time/time.clock/time.clock.system/now.pass.cpp
index 70fbe98d8dfd12..dade6bafa471bb 100644
--- a/libcxx/test/std/time/time.clock/time.clock.system/now.pass.cpp
+++ b/libcxx/test/std/time/time.clock/time.clock.system/now.pass.cpp
@@ -6,9 +6,6 @@
//
//===----------------------------------------------------------------------===//
-// "unable to find library from dependent library specifier: rt"
-// XFAIL: LIBCXX-PICOLIBC-FIXME
-
// <chrono>
// system_clock
diff --git a/libcxx/test/std/time/time.clock/time.clock.system/to_time_t.pass.cpp b/libcxx/test/std/time/time.clock/time.clock.system/to_time_t.pass.cpp
index f3238f7bb1bb52..bf4339c32d1ca9 100644
--- a/libcxx/test/std/time/time.clock/time.clock.system/to_time_t.pass.cpp
+++ b/libcxx/test/std/time/time.clock/time.clock.system/to_time_t.pass.cpp
@@ -6,9 +6,6 @@
//
//===----------------------------------------------------------------------===//
-// "unable to find library from dependent library specifier: rt"
-// XFAIL: LIBCXX-PICOLIBC-FIXME
-
// <chrono>
// system_clock
diff --git a/libcxx/test/std/time/time.point/time.point.nonmember/op_-duration.pass.cpp b/libcxx/test/std/time/time.point/time.point.nonmember/op_-duration.pass.cpp
index 199bdec66878a2..80e9d04a769fde 100644
--- a/libcxx/test/std/time/time.point/time.point.nonmember/op_-duration.pass.cpp
+++ b/libcxx/test/std/time/time.point/time.point.nonmember/op_-duration.pass.cpp
@@ -6,9 +6,6 @@
//
//===----------------------------------------------------------------------===//
-// "unable to find library from dependent library specifier: rt"
-// XFAIL: LIBCXX-PICOLIBC-FIXME
-
// <chrono>
// time_point
>From 325f51237252e6dab8e4e1ea1fa7acbb4faee1cd Mon Sep 17 00:00:00 2001
From: jeanPerier <jperier at nvidia.com>
Date: Thu, 29 Feb 2024 09:47:06 +0100
Subject: [PATCH 096/406] [flang] Set polymorphic entity lowering option on by
default (#83308)
Preliminary patch for https://github.com/llvm/llvm-project/pull/83285 to
turn polymorphism on by default.
Will give a few days warning for people to remove the flag from their
workflow using flang-new.
Also easier to revert if issues with the gfortran test suites.
---
flang/include/flang/Lower/LoweringOptions.def | 4 ++--
flang/test/Driver/flang-experimental-polymorphism-flag.f90 | 4 ++--
2 files changed, 4 insertions(+), 4 deletions(-)
diff --git a/flang/include/flang/Lower/LoweringOptions.def b/flang/include/flang/Lower/LoweringOptions.def
index 503acdac869c7a..9de69ac5c80f52 100644
--- a/flang/include/flang/Lower/LoweringOptions.def
+++ b/flang/include/flang/Lower/LoweringOptions.def
@@ -24,8 +24,8 @@ LOWERINGOPT(Name, Bits, Default)
/// If true, lower transpose without a runtime call.
ENUM_LOWERINGOPT(OptimizeTranspose, unsigned, 1, 1)
-/// If true, enable polymorphic type lowering feature. Off by default.
-ENUM_LOWERINGOPT(PolymorphicTypeImpl, unsigned, 1, 0)
+/// If true, enable polymorphic type lowering feature. On by default.
+ENUM_LOWERINGOPT(PolymorphicTypeImpl, unsigned, 1, 1)
/// If true, lower to High level FIR before lowering to FIR. On by default.
ENUM_LOWERINGOPT(LowerToHighLevelFIR, unsigned, 1, 1)
diff --git a/flang/test/Driver/flang-experimental-polymorphism-flag.f90 b/flang/test/Driver/flang-experimental-polymorphism-flag.f90
index 106e898149a18f..095c1cc929e67b 100644
--- a/flang/test/Driver/flang-experimental-polymorphism-flag.f90
+++ b/flang/test/Driver/flang-experimental-polymorphism-flag.f90
@@ -1,10 +1,10 @@
! Test -flang-experimental-hlfir flag
! RUN: %flang_fc1 -flang-experimental-polymorphism -emit-fir -o - %s | FileCheck %s
-! RUN: not %flang_fc1 -emit-fir -o - %s 2>&1 | FileCheck %s --check-prefix NO-POLYMORPHISM
+! RUN: %flang_fc1 -emit-fir -o - %s 2>&1 | FileCheck %s --check-prefix NO-POLYMORPHISM
! CHECK: func.func @_QPtest(%{{.*}}: !fir.class<none> {fir.bindc_name = "poly"})
subroutine test(poly)
class(*) :: poly
end subroutine test
-! NO-POLYMORPHISM: not yet implemented: support for polymorphic types
+! NO-POLYMORPHISM: func.func @_QPtest
>From ddfc7e225474558613db3604c053fd73f1fdedac Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?Timm=20B=C3=A4der?= <tbaeder at redhat.com>
Date: Wed, 28 Feb 2024 18:09:39 +0100
Subject: [PATCH 097/406] [clang][Interp] Emit more dummy pointers in C++ mode
---
clang/lib/AST/Interp/ByteCodeExprGen.cpp | 15 +++++-------
clang/lib/AST/Interp/Interp.cpp | 30 ++++++++++++++++-------
clang/lib/AST/Interp/Interp.h | 31 ++++++++++++++++--------
clang/test/AST/Interp/arrays.cpp | 5 ++++
clang/test/AST/Interp/c.c | 8 +++---
clang/test/AST/Interp/cxx98.cpp | 3 ++-
6 files changed, 59 insertions(+), 33 deletions(-)
diff --git a/clang/lib/AST/Interp/ByteCodeExprGen.cpp b/clang/lib/AST/Interp/ByteCodeExprGen.cpp
index b151f8d0d7a79c..122b9045a75f6e 100644
--- a/clang/lib/AST/Interp/ByteCodeExprGen.cpp
+++ b/clang/lib/AST/Interp/ByteCodeExprGen.cpp
@@ -3213,12 +3213,6 @@ bool ByteCodeExprGen<Emitter>::VisitDeclRefExpr(const DeclRefExpr *E) {
// we haven't seen yet.
if (Ctx.getLangOpts().CPlusPlus) {
if (const auto *VD = dyn_cast<VarDecl>(D)) {
- // Dummy for static locals
- if (VD->isStaticLocal()) {
- if (std::optional<unsigned> I = P.getOrCreateDummy(D))
- return this->emitGetPtrGlobal(*I, E);
- return false;
- }
// Visit local const variables like normal.
if (VD->isLocalVarDecl() && VD->getType().isConstQualified()) {
if (!this->visitVarDecl(VD))
@@ -3226,6 +3220,9 @@ bool ByteCodeExprGen<Emitter>::VisitDeclRefExpr(const DeclRefExpr *E) {
// Retry.
return this->VisitDeclRefExpr(E);
}
+
+ if (VD->hasExternalStorage())
+ return this->emitInvalidDeclRef(E, E);
}
} else {
if (const auto *VD = dyn_cast<VarDecl>(D);
@@ -3235,11 +3232,11 @@ bool ByteCodeExprGen<Emitter>::VisitDeclRefExpr(const DeclRefExpr *E) {
// Retry.
return this->VisitDeclRefExpr(E);
}
-
- if (std::optional<unsigned> I = P.getOrCreateDummy(D))
- return this->emitGetPtrGlobal(*I, E);
}
+ if (std::optional<unsigned> I = P.getOrCreateDummy(D))
+ return this->emitGetPtrGlobal(*I, E);
+
return this->emitInvalidDeclRef(E, E);
}
diff --git a/clang/lib/AST/Interp/Interp.cpp b/clang/lib/AST/Interp/Interp.cpp
index 5670888c245eb1..4f3cd6cd21a151 100644
--- a/clang/lib/AST/Interp/Interp.cpp
+++ b/clang/lib/AST/Interp/Interp.cpp
@@ -285,10 +285,6 @@ static bool CheckConstant(InterpState &S, CodePtr OpPC, const Pointer &Ptr) {
return CheckConstant(S, OpPC, Ptr.getDeclDesc());
}
-bool CheckDummy(InterpState &S, CodePtr OpPC, const Pointer &Ptr) {
- return !Ptr.isDummy();
-}
-
bool CheckNull(InterpState &S, CodePtr OpPC, const Pointer &Ptr,
CheckSubobjectKind CSK) {
if (!Ptr.isZero())
@@ -595,10 +591,8 @@ bool CheckFloatResult(InterpState &S, CodePtr OpPC, const Floating &Result,
return true;
}
-/// We aleady know the given DeclRefExpr is invalid for some reason,
-/// now figure out why and print appropriate diagnostics.
-bool CheckDeclRef(InterpState &S, CodePtr OpPC, const DeclRefExpr *DR) {
- const ValueDecl *D = DR->getDecl();
+static bool diagnoseUnknownDecl(InterpState &S, CodePtr OpPC,
+ const ValueDecl *D) {
const SourceInfo &E = S.Current->getSource(OpPC);
if (isa<ParmVarDecl>(D)) {
@@ -621,10 +615,28 @@ bool CheckDeclRef(InterpState &S, CodePtr OpPC, const DeclRefExpr *DR) {
return false;
}
}
-
return false;
}
+/// We aleady know the given DeclRefExpr is invalid for some reason,
+/// now figure out why and print appropriate diagnostics.
+bool CheckDeclRef(InterpState &S, CodePtr OpPC, const DeclRefExpr *DR) {
+ const ValueDecl *D = DR->getDecl();
+ return diagnoseUnknownDecl(S, OpPC, D);
+}
+
+bool CheckDummy(InterpState &S, CodePtr OpPC, const Pointer &Ptr) {
+ if (!Ptr.isDummy())
+ return true;
+
+ const Descriptor *Desc = Ptr.getDeclDesc();
+ const ValueDecl *D = Desc->asValueDecl();
+ if (!D)
+ return false;
+
+ return diagnoseUnknownDecl(S, OpPC, D);
+}
+
bool CheckNonNullArgs(InterpState &S, CodePtr OpPC, const Function *F,
const CallExpr *CE, unsigned ArgSize) {
auto Args = llvm::ArrayRef(CE->getArgs(), CE->getNumArgs());
diff --git a/clang/lib/AST/Interp/Interp.h b/clang/lib/AST/Interp/Interp.h
index 13e004371f912c..f379c9869d8d8e 100644
--- a/clang/lib/AST/Interp/Interp.h
+++ b/clang/lib/AST/Interp/Interp.h
@@ -572,7 +572,8 @@ bool IncDecHelper(InterpState &S, CodePtr OpPC, const Pointer &Ptr) {
template <PrimType Name, class T = typename PrimConv<Name>::T>
bool Inc(InterpState &S, CodePtr OpPC) {
const Pointer &Ptr = S.Stk.pop<Pointer>();
-
+ if (Ptr.isDummy())
+ return false;
if (!CheckInitialized(S, OpPC, Ptr, AK_Increment))
return false;
@@ -585,7 +586,8 @@ bool Inc(InterpState &S, CodePtr OpPC) {
template <PrimType Name, class T = typename PrimConv<Name>::T>
bool IncPop(InterpState &S, CodePtr OpPC) {
const Pointer &Ptr = S.Stk.pop<Pointer>();
-
+ if (Ptr.isDummy())
+ return false;
if (!CheckInitialized(S, OpPC, Ptr, AK_Increment))
return false;
@@ -599,7 +601,8 @@ bool IncPop(InterpState &S, CodePtr OpPC) {
template <PrimType Name, class T = typename PrimConv<Name>::T>
bool Dec(InterpState &S, CodePtr OpPC) {
const Pointer &Ptr = S.Stk.pop<Pointer>();
-
+ if (Ptr.isDummy())
+ return false;
if (!CheckInitialized(S, OpPC, Ptr, AK_Decrement))
return false;
@@ -612,7 +615,8 @@ bool Dec(InterpState &S, CodePtr OpPC) {
template <PrimType Name, class T = typename PrimConv<Name>::T>
bool DecPop(InterpState &S, CodePtr OpPC) {
const Pointer &Ptr = S.Stk.pop<Pointer>();
-
+ if (Ptr.isDummy())
+ return false;
if (!CheckInitialized(S, OpPC, Ptr, AK_Decrement))
return false;
@@ -641,7 +645,8 @@ bool IncDecFloatHelper(InterpState &S, CodePtr OpPC, const Pointer &Ptr,
inline bool Incf(InterpState &S, CodePtr OpPC, llvm::RoundingMode RM) {
const Pointer &Ptr = S.Stk.pop<Pointer>();
-
+ if (Ptr.isDummy())
+ return false;
if (!CheckInitialized(S, OpPC, Ptr, AK_Increment))
return false;
@@ -650,7 +655,8 @@ inline bool Incf(InterpState &S, CodePtr OpPC, llvm::RoundingMode RM) {
inline bool IncfPop(InterpState &S, CodePtr OpPC, llvm::RoundingMode RM) {
const Pointer &Ptr = S.Stk.pop<Pointer>();
-
+ if (Ptr.isDummy())
+ return false;
if (!CheckInitialized(S, OpPC, Ptr, AK_Increment))
return false;
@@ -660,6 +666,9 @@ inline bool IncfPop(InterpState &S, CodePtr OpPC, llvm::RoundingMode RM) {
inline bool Decf(InterpState &S, CodePtr OpPC, llvm::RoundingMode RM) {
const Pointer &Ptr = S.Stk.pop<Pointer>();
+ if (Ptr.isDummy())
+ return false;
+
if (!CheckInitialized(S, OpPC, Ptr, AK_Decrement))
return false;
@@ -669,6 +678,8 @@ inline bool Decf(InterpState &S, CodePtr OpPC, llvm::RoundingMode RM) {
inline bool DecfPop(InterpState &S, CodePtr OpPC, llvm::RoundingMode RM) {
const Pointer &Ptr = S.Stk.pop<Pointer>();
+ if (Ptr.isDummy())
+ return false;
if (!CheckInitialized(S, OpPC, Ptr, AK_Decrement))
return false;
@@ -774,9 +785,9 @@ inline bool CmpHelperEQ<Pointer>(InterpState &S, CodePtr OpPC, CompareFn Fn) {
// element in the same array are NOT equal. They have the same Base value,
// but a different Offset. This is a pretty rare case, so we fix this here
// by comparing pointers to the first elements.
- if (LHS.isArrayRoot())
+ if (!LHS.isDummy() && LHS.isArrayRoot())
VL = LHS.atIndex(0).getByteOffset();
- if (RHS.isArrayRoot())
+ if (!RHS.isDummy() && RHS.isArrayRoot())
VR = RHS.atIndex(0).getByteOffset();
S.Stk.push<BoolT>(BoolT::from(Fn(Compare(VL, VR))));
@@ -1895,7 +1906,7 @@ inline bool ArrayElemPtr(InterpState &S, CodePtr OpPC) {
const T &Offset = S.Stk.pop<T>();
const Pointer &Ptr = S.Stk.peek<Pointer>();
- if (!CheckDummy(S, OpPC, Ptr))
+ if (Ptr.isDummy())
return true;
if (!OffsetHelper<T, ArithOp::Add>(S, OpPC, Offset, Ptr))
@@ -1909,7 +1920,7 @@ inline bool ArrayElemPtrPop(InterpState &S, CodePtr OpPC) {
const T &Offset = S.Stk.pop<T>();
const Pointer &Ptr = S.Stk.pop<Pointer>();
- if (!CheckDummy(S, OpPC, Ptr)) {
+ if (Ptr.isDummy()) {
S.Stk.push<Pointer>(Ptr);
return true;
}
diff --git a/clang/test/AST/Interp/arrays.cpp b/clang/test/AST/Interp/arrays.cpp
index e1af2e80e3ad77..2bf6e9ef35119f 100644
--- a/clang/test/AST/Interp/arrays.cpp
+++ b/clang/test/AST/Interp/arrays.cpp
@@ -564,3 +564,8 @@ namespace LocalVLA {
#endif
}
}
+
+char melchizedek[2200000000];
+typedef decltype(melchizedek[1] - melchizedek[0]) ptrdiff_t;
+constexpr ptrdiff_t d1 = &melchizedek[0x7fffffff] - &melchizedek[0]; // ok
+constexpr ptrdiff_t d3 = &melchizedek[0] - &melchizedek[0x80000000u]; // ok
diff --git a/clang/test/AST/Interp/c.c b/clang/test/AST/Interp/c.c
index 2a72c24b43d1cd..260e5bdfeefb2b 100644
--- a/clang/test/AST/Interp/c.c
+++ b/clang/test/AST/Interp/c.c
@@ -33,15 +33,15 @@ const int b = 3;
_Static_assert(b == 3, ""); // pedantic-ref-warning {{not an integer constant expression}} \
// pedantic-expected-warning {{not an integer constant expression}}
-/// FIXME: The new interpreter is missing the "initializer of 'c' unknown" diagnostics.
-const int c; // ref-note {{declared here}} \
- // pedantic-ref-note {{declared here}}
+const int c; // all-note {{declared here}}
_Static_assert(c == 0, ""); // ref-error {{not an integral constant expression}} \
// ref-note {{initializer of 'c' is unknown}} \
// pedantic-ref-error {{not an integral constant expression}} \
// pedantic-ref-note {{initializer of 'c' is unknown}} \
// expected-error {{not an integral constant expression}} \
- // pedantic-expected-error {{not an integral constant expression}}
+ // expected-note {{initializer of 'c' is unknown}} \
+ // pedantic-expected-error {{not an integral constant expression}} \
+ // pedantic-expected-note {{initializer of 'c' is unknown}}
_Static_assert(&c != 0, ""); // ref-warning {{always true}} \
// pedantic-ref-warning {{always true}} \
diff --git a/clang/test/AST/Interp/cxx98.cpp b/clang/test/AST/Interp/cxx98.cpp
index 1acc74a8290a06..73e45372066334 100644
--- a/clang/test/AST/Interp/cxx98.cpp
+++ b/clang/test/AST/Interp/cxx98.cpp
@@ -18,12 +18,13 @@ template struct C<cval>;
/// FIXME: This example does not get properly diagnosed in the new interpreter.
extern const int recurse1;
-const int recurse2 = recurse1; // ref-note {{here}}
+const int recurse2 = recurse1; // both-note {{declared here}}
const int recurse1 = 1;
int array1[recurse1];
int array2[recurse2]; // ref-warning 2{{variable length array}} \
// ref-note {{initializer of 'recurse2' is not a constant expression}} \
// expected-warning {{variable length array}} \
+ // expected-note {{read of non-const variable 'recurse2'}} \
// expected-error {{variable length array}}
int NCI; // both-note {{declared here}}
>From c757ca74176716ff99f340e82e50f0b6a6c9a7e8 Mon Sep 17 00:00:00 2001
From: Matt Arsenault <Matthew.Arsenault at amd.com>
Date: Thu, 29 Feb 2024 14:32:18 +0530
Subject: [PATCH 098/406] AMDGPU: Remove dead declaration
---
llvm/lib/Target/AMDGPU/Utils/AMDGPUBaseInfo.h | 8 --------
1 file changed, 8 deletions(-)
diff --git a/llvm/lib/Target/AMDGPU/Utils/AMDGPUBaseInfo.h b/llvm/lib/Target/AMDGPU/Utils/AMDGPUBaseInfo.h
index b2fc7d874fe588..6edf01d1217f2d 100644
--- a/llvm/lib/Target/AMDGPU/Utils/AMDGPUBaseInfo.h
+++ b/llvm/lib/Target/AMDGPU/Utils/AMDGPUBaseInfo.h
@@ -856,14 +856,6 @@ bool isReadOnlySegment(const GlobalValue *GV);
/// target triple \p TT, false otherwise.
bool shouldEmitConstantsToTextSection(const Triple &TT);
-/// \returns Integer value requested using \p F's \p Name attribute.
-///
-/// \returns \p Default if attribute is not present.
-///
-/// \returns \p Default and emits error if requested value cannot be converted
-/// to integer.
-int getIntegerAttribute(const Function &F, StringRef Name, int Default);
-
/// \returns A pair of integer values requested using \p F's \p Name attribute
/// in "first[,second]" format ("second" is optional unless \p OnlyFirstRequired
/// is false).
>From 53bd411e5144937acec45080697957bf5b22de54 Mon Sep 17 00:00:00 2001
From: Guillaume Chatelet <gchatelet at google.com>
Date: Thu, 29 Feb 2024 10:28:53 +0100
Subject: [PATCH 099/406] [libc][NFC] rename `float.h` macro file to `types.h`
(#83190)
---
.../compiler_features/check_float128.cpp | 2 +-
libc/docs/dev/code_style.rst | 2 +-
libc/src/__support/CPP/CMakeLists.txt | 4 +--
.../CPP/type_traits/is_floating_point.h | 2 +-
libc/src/__support/FPUtil/CMakeLists.txt | 2 +-
libc/src/__support/FPUtil/FPBits.h | 2 +-
.../macros/properties/CMakeLists.txt | 4 +--
.../macros/properties/{float.h => types.h} | 11 ++++----
libc/src/math/ceilf128.h | 2 +-
libc/src/math/copysignf128.h | 2 +-
libc/src/math/fabsf128.h | 2 +-
libc/src/math/fdimf128.h | 2 +-
libc/src/math/floorf128.h | 2 +-
libc/src/math/fmaxf128.h | 2 +-
libc/src/math/fminf128.h | 2 +-
libc/src/math/frexpf128.h | 2 +-
libc/src/math/generic/CMakeLists.txt | 28 +++++++++----------
libc/src/math/ilogbf128.h | 2 +-
libc/src/math/ldexpf128.h | 2 +-
libc/src/math/llogb.h | 2 +-
libc/src/math/llogbf.h | 2 +-
libc/src/math/llogbf128.h | 2 +-
libc/src/math/llogbl.h | 2 +-
libc/src/math/logbf128.h | 2 +-
libc/src/math/roundf128.h | 2 +-
libc/src/math/sqrtf128.h | 2 +-
libc/src/math/truncf128.h | 2 +-
.../llvm-project-overlay/libc/BUILD.bazel | 8 +++---
28 files changed, 50 insertions(+), 51 deletions(-)
rename libc/src/__support/macros/properties/{float.h => types.h} (85%)
diff --git a/libc/cmake/modules/compiler_features/check_float128.cpp b/libc/cmake/modules/compiler_features/check_float128.cpp
index 8b1e3fe04ed4e1..20f889c14f997b 100644
--- a/libc/cmake/modules/compiler_features/check_float128.cpp
+++ b/libc/cmake/modules/compiler_features/check_float128.cpp
@@ -1,4 +1,4 @@
-#include "src/__support/macros/properties/float.h"
+#include "src/__support/macros/properties/types.h"
#ifndef LIBC_COMPILER_HAS_FLOAT128
#error unsupported
diff --git a/libc/docs/dev/code_style.rst b/libc/docs/dev/code_style.rst
index eeeced0359adbc..c76f8874f3aef6 100644
--- a/libc/docs/dev/code_style.rst
+++ b/libc/docs/dev/code_style.rst
@@ -47,7 +47,7 @@ We define two kinds of macros:
e.g., ``LIBC_COMPILER_IS_CLANG``.
* ``cpu_features.h`` - Target cpu feature availability.
e.g., ``LIBC_TARGET_CPU_HAS_AVX2``.
- * ``float.h`` - Floating point type properties and availability.
+ * ``types.h`` - Type properties and availability.
e.g., ``LIBC_COMPILER_HAS_FLOAT128``.
* ``os.h`` - Target os properties.
e.g., ``LIBC_TARGET_OS_IS_LINUX``.
diff --git a/libc/src/__support/CPP/CMakeLists.txt b/libc/src/__support/CPP/CMakeLists.txt
index d747412791bd8e..6c35bc7090819e 100644
--- a/libc/src/__support/CPP/CMakeLists.txt
+++ b/libc/src/__support/CPP/CMakeLists.txt
@@ -153,10 +153,10 @@ add_header_library(
type_traits/type_identity.h
type_traits/void_t.h
DEPENDS
+ libc.include.llvm-libc-macros.stdfix_macros
libc.src.__support.macros.attributes
libc.src.__support.macros.config
- libc.src.__support.macros.properties.float
- libc.include.llvm-libc-macros.stdfix_macros
+ libc.src.__support.macros.properties.types
)
add_header_library(
diff --git a/libc/src/__support/CPP/type_traits/is_floating_point.h b/libc/src/__support/CPP/type_traits/is_floating_point.h
index 3a5260bcab11ee..7f01cc41cae8fe 100644
--- a/libc/src/__support/CPP/type_traits/is_floating_point.h
+++ b/libc/src/__support/CPP/type_traits/is_floating_point.h
@@ -11,7 +11,7 @@
#include "src/__support/CPP/type_traits/is_same.h"
#include "src/__support/CPP/type_traits/remove_cv.h"
#include "src/__support/macros/attributes.h"
-#include "src/__support/macros/properties/float.h"
+#include "src/__support/macros/properties/types.h"
namespace LIBC_NAMESPACE::cpp {
diff --git a/libc/src/__support/FPUtil/CMakeLists.txt b/libc/src/__support/FPUtil/CMakeLists.txt
index 0c932e8ffcd550..f1c6fba22856dd 100644
--- a/libc/src/__support/FPUtil/CMakeLists.txt
+++ b/libc/src/__support/FPUtil/CMakeLists.txt
@@ -33,7 +33,7 @@ add_header_library(
libc.src.__support.CPP.type_traits
libc.src.__support.libc_assert
libc.src.__support.macros.attributes
- libc.src.__support.macros.properties.float
+ libc.src.__support.macros.properties.types
libc.src.__support.math_extras
libc.src.__support.uint128
)
diff --git a/libc/src/__support/FPUtil/FPBits.h b/libc/src/__support/FPUtil/FPBits.h
index fb5ff6a4153c90..1703e9a2bb3317 100644
--- a/libc/src/__support/FPUtil/FPBits.h
+++ b/libc/src/__support/FPUtil/FPBits.h
@@ -15,7 +15,7 @@
#include "src/__support/common.h"
#include "src/__support/libc_assert.h" // LIBC_ASSERT
#include "src/__support/macros/attributes.h" // LIBC_INLINE, LIBC_INLINE_VAR
-#include "src/__support/macros/properties/float.h" // LIBC_COMPILER_HAS_FLOAT128
+#include "src/__support/macros/properties/types.h" // LIBC_COMPILER_HAS_FLOAT128
#include "src/__support/math_extras.h" // mask_trailing_ones
#include <stdint.h>
diff --git a/libc/src/__support/macros/properties/CMakeLists.txt b/libc/src/__support/macros/properties/CMakeLists.txt
index 3c492ab55a90cb..bbc45650f3fca3 100644
--- a/libc/src/__support/macros/properties/CMakeLists.txt
+++ b/libc/src/__support/macros/properties/CMakeLists.txt
@@ -25,9 +25,9 @@ add_header_library(
)
add_header_library(
- float
+ types
HDRS
- float.h
+ types.h
DEPENDS
.architectures
.compiler
diff --git a/libc/src/__support/macros/properties/float.h b/libc/src/__support/macros/properties/types.h
similarity index 85%
rename from libc/src/__support/macros/properties/float.h
rename to libc/src/__support/macros/properties/types.h
index 510f3923749358..e812a9dfcfd8ab 100644
--- a/libc/src/__support/macros/properties/float.h
+++ b/libc/src/__support/macros/properties/types.h
@@ -1,15 +1,14 @@
-//===-- Float type support --------------------------------------*- C++ -*-===//
+//===-- Types support -------------------------------------------*- C++ -*-===//
//
// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
// See https://llvm.org/LICENSE.txt for license information.
// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
//
//===----------------------------------------------------------------------===//
-// Floating point properties are a combination of compiler support, target OS
-// and target architecture.
+// Types detection and support.
-#ifndef LLVM_LIBC_SRC___SUPPORT_MACROS_PROPERTIES_FLOAT_H
-#define LLVM_LIBC_SRC___SUPPORT_MACROS_PROPERTIES_FLOAT_H
+#ifndef LLVM_LIBC_SRC___SUPPORT_MACROS_PROPERTIES_TYPES_H
+#define LLVM_LIBC_SRC___SUPPORT_MACROS_PROPERTIES_TYPES_H
#include "llvm-libc-macros/float-macros.h" // LDBL_MANT_DIG
#include "llvm-libc-types/float128.h" // float128
@@ -60,4 +59,4 @@ using float16 = _Float16;
#define LIBC_COMPILER_HAS_FLOAT128
#endif
-#endif // LLVM_LIBC_SRC___SUPPORT_MACROS_PROPERTIES_FLOAT_H
+#endif // LLVM_LIBC_SRC___SUPPORT_MACROS_PROPERTIES_TYPES_H
diff --git a/libc/src/math/ceilf128.h b/libc/src/math/ceilf128.h
index db8feffc87ba2b..b0c4020718b29d 100644
--- a/libc/src/math/ceilf128.h
+++ b/libc/src/math/ceilf128.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_MATH_CEILF128_H
#define LLVM_LIBC_SRC_MATH_CEILF128_H
-#include "src/__support/macros/properties/float.h"
+#include "src/__support/macros/properties/types.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/math/copysignf128.h b/libc/src/math/copysignf128.h
index 0eda56a1cebbb0..06c194985d720b 100644
--- a/libc/src/math/copysignf128.h
+++ b/libc/src/math/copysignf128.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_MATH_COPYSIGNF128_H
#define LLVM_LIBC_SRC_MATH_COPYSIGNF128_H
-#include "src/__support/macros/properties/float.h"
+#include "src/__support/macros/properties/types.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/math/fabsf128.h b/libc/src/math/fabsf128.h
index 5999757decfdab..0a275025a5cfe7 100644
--- a/libc/src/math/fabsf128.h
+++ b/libc/src/math/fabsf128.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_MATH_FABSF128_H
#define LLVM_LIBC_SRC_MATH_FABSF128_H
-#include "src/__support/macros/properties/float.h"
+#include "src/__support/macros/properties/types.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/math/fdimf128.h b/libc/src/math/fdimf128.h
index c6f488a586dc03..f0485aba4822c5 100644
--- a/libc/src/math/fdimf128.h
+++ b/libc/src/math/fdimf128.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_MATH_FDIMF128_H
#define LLVM_LIBC_SRC_MATH_FDIMF128_H
-#include "src/__support/macros/properties/float.h"
+#include "src/__support/macros/properties/types.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/math/floorf128.h b/libc/src/math/floorf128.h
index 86b9a8e9265e11..b97c4b6c6ceced 100644
--- a/libc/src/math/floorf128.h
+++ b/libc/src/math/floorf128.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_MATH_FLOORF128_H
#define LLVM_LIBC_SRC_MATH_FLOORF128_H
-#include "src/__support/macros/properties/float.h"
+#include "src/__support/macros/properties/types.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/math/fmaxf128.h b/libc/src/math/fmaxf128.h
index 39eaaf616dd5d8..a4407d9655afa7 100644
--- a/libc/src/math/fmaxf128.h
+++ b/libc/src/math/fmaxf128.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_MATH_FMAXF128_H
#define LLVM_LIBC_SRC_MATH_FMAXF128_H
-#include "src/__support/macros/properties/float.h"
+#include "src/__support/macros/properties/types.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/math/fminf128.h b/libc/src/math/fminf128.h
index b3d1bec8e2ad92..d2ed593250a4af 100644
--- a/libc/src/math/fminf128.h
+++ b/libc/src/math/fminf128.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_MATH_FMINF128_H
#define LLVM_LIBC_SRC_MATH_FMINF128_H
-#include "src/__support/macros/properties/float.h"
+#include "src/__support/macros/properties/types.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/math/frexpf128.h b/libc/src/math/frexpf128.h
index 5d70860fa15599..55c4a47cc80ca3 100644
--- a/libc/src/math/frexpf128.h
+++ b/libc/src/math/frexpf128.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_MATH_FREXPF128_H
#define LLVM_LIBC_SRC_MATH_FREXPF128_H
-#include "src/__support/macros/properties/float.h"
+#include "src/__support/macros/properties/types.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/math/generic/CMakeLists.txt b/libc/src/math/generic/CMakeLists.txt
index 120ada8202ab9d..82d2a5e66af781 100644
--- a/libc/src/math/generic/CMakeLists.txt
+++ b/libc/src/math/generic/CMakeLists.txt
@@ -43,7 +43,7 @@ add_entrypoint_object(
COMPILE_OPTIONS
-O3
DEPENDS
- libc.src.__support.macros.properties.float
+ libc.src.__support.macros.properties.types
libc.src.__support.FPUtil.nearest_integer_operations
)
@@ -216,7 +216,7 @@ add_entrypoint_object(
HDRS
../fabsf128.h
DEPENDS
- libc.src.__support.macros.properties.float
+ libc.src.__support.macros.properties.types
libc.src.__support.FPUtil.basic_operations
COMPILE_OPTIONS
-O3
@@ -267,7 +267,7 @@ add_entrypoint_object(
COMPILE_OPTIONS
-O3
DEPENDS
- libc.src.__support.macros.properties.float
+ libc.src.__support.macros.properties.types
libc.src.__support.FPUtil.nearest_integer_operations
)
@@ -316,7 +316,7 @@ add_entrypoint_object(
COMPILE_OPTIONS
-O3
DEPENDS
- libc.src.__support.macros.properties.float
+ libc.src.__support.macros.properties.types
libc.src.__support.FPUtil.nearest_integer_operations
)
@@ -365,7 +365,7 @@ add_entrypoint_object(
COMPILE_OPTIONS
-O3
DEPENDS
- libc.src.__support.macros.properties.float
+ libc.src.__support.macros.properties.types
libc.src.__support.FPUtil.nearest_integer_operations
)
@@ -908,7 +908,7 @@ add_entrypoint_object(
HDRS
../copysignf128.h
DEPENDS
- libc.src.__support.macros.properties.float
+ libc.src.__support.macros.properties.types
libc.src.__support.FPUtil.manipulation_functions
COMPILE_OPTIONS
-O3
@@ -959,7 +959,7 @@ add_entrypoint_object(
COMPILE_OPTIONS
-O3
DEPENDS
- libc.src.__support.macros.properties.float
+ libc.src.__support.macros.properties.types
libc.src.__support.FPUtil.manipulation_functions
)
@@ -1008,7 +1008,7 @@ add_entrypoint_object(
COMPILE_OPTIONS
-O3
DEPENDS
- libc.src.__support.macros.properties.float
+ libc.src.__support.macros.properties.types
libc.src.__support.FPUtil.manipulation_functions
)
@@ -1057,7 +1057,7 @@ add_entrypoint_object(
COMPILE_OPTIONS
-O3
DEPENDS
- libc.src.__support.macros.properties.float
+ libc.src.__support.macros.properties.types
libc.src.__support.FPUtil.manipulation_functions
)
@@ -1106,7 +1106,7 @@ add_entrypoint_object(
COMPILE_OPTIONS
-O3
DEPENDS
- libc.src.__support.macros.properties.float
+ libc.src.__support.macros.properties.types
libc.src.__support.FPUtil.manipulation_functions
)
@@ -1412,7 +1412,7 @@ add_entrypoint_object(
HDRS
../fminf128.h
DEPENDS
- libc.src.__support.macros.properties.float
+ libc.src.__support.macros.properties.types
libc.src.__support.FPUtil.basic_operations
COMPILE_OPTIONS
-O3
@@ -1461,7 +1461,7 @@ add_entrypoint_object(
HDRS
../fmaxf128.h
DEPENDS
- libc.src.__support.macros.properties.float
+ libc.src.__support.macros.properties.types
libc.src.__support.FPUtil.basic_operations
COMPILE_OPTIONS
-O3
@@ -1510,7 +1510,7 @@ add_entrypoint_object(
HDRS
../sqrtf128.h
DEPENDS
- libc.src.__support.macros.properties.float
+ libc.src.__support.macros.properties.types
libc.src.__support.FPUtil.sqrt
COMPILE_OPTIONS
-O3
@@ -1647,7 +1647,7 @@ add_entrypoint_object(
COMPILE_OPTIONS
-O3
DEPENDS
- libc.src.__support.macros.properties.float
+ libc.src.__support.macros.properties.types
libc.src.__support.FPUtil.basic_operations
)
diff --git a/libc/src/math/ilogbf128.h b/libc/src/math/ilogbf128.h
index df1145ffc0f8ab..d8fe3b970973c4 100644
--- a/libc/src/math/ilogbf128.h
+++ b/libc/src/math/ilogbf128.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_MATH_ILOGBF128_H
#define LLVM_LIBC_SRC_MATH_ILOGBF128_H
-#include "src/__support/macros/properties/float.h"
+#include "src/__support/macros/properties/types.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/math/ldexpf128.h b/libc/src/math/ldexpf128.h
index adf9d8f56b3566..7aa6ded3c8e4c6 100644
--- a/libc/src/math/ldexpf128.h
+++ b/libc/src/math/ldexpf128.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_MATH_LDEXPF128_H
#define LLVM_LIBC_SRC_MATH_LDEXPF128_H
-#include "src/__support/macros/properties/float.h"
+#include "src/__support/macros/properties/types.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/math/llogb.h b/libc/src/math/llogb.h
index 2d95877425e568..b51f89fc0416ee 100644
--- a/libc/src/math/llogb.h
+++ b/libc/src/math/llogb.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_MATH_LLOGB_H
#define LLVM_LIBC_SRC_MATH_LLOGB_H
-#include "src/__support/macros/properties/float.h"
+#include "src/__support/macros/properties/types.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/math/llogbf.h b/libc/src/math/llogbf.h
index 512e174b66ee46..af4aa8a5b15c0b 100644
--- a/libc/src/math/llogbf.h
+++ b/libc/src/math/llogbf.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_MATH_LLOGBF_H
#define LLVM_LIBC_SRC_MATH_LLOGBF_H
-#include "src/__support/macros/properties/float.h"
+#include "src/__support/macros/properties/types.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/math/llogbf128.h b/libc/src/math/llogbf128.h
index 7fb74d4bbe7302..ce7c872a63db4e 100644
--- a/libc/src/math/llogbf128.h
+++ b/libc/src/math/llogbf128.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_MATH_LLOGBF128_H
#define LLVM_LIBC_SRC_MATH_LLOGBF128_H
-#include "src/__support/macros/properties/float.h"
+#include "src/__support/macros/properties/types.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/math/llogbl.h b/libc/src/math/llogbl.h
index 4033100fbe3dae..3c323a3af2a93f 100644
--- a/libc/src/math/llogbl.h
+++ b/libc/src/math/llogbl.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_MATH_LLOGBL_H
#define LLVM_LIBC_SRC_MATH_LLOGBL_H
-#include "src/__support/macros/properties/float.h"
+#include "src/__support/macros/properties/types.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/math/logbf128.h b/libc/src/math/logbf128.h
index 8baa076af1bfdb..7823bbd615b89a 100644
--- a/libc/src/math/logbf128.h
+++ b/libc/src/math/logbf128.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_MATH_LOGBF128_H
#define LLVM_LIBC_SRC_MATH_LOGBF128_H
-#include "src/__support/macros/properties/float.h"
+#include "src/__support/macros/properties/types.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/math/roundf128.h b/libc/src/math/roundf128.h
index c67c946cc5e8be..e4aca17d7eb637 100644
--- a/libc/src/math/roundf128.h
+++ b/libc/src/math/roundf128.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_MATH_ROUNDF128_H
#define LLVM_LIBC_SRC_MATH_ROUNDF128_H
-#include "src/__support/macros/properties/float.h"
+#include "src/__support/macros/properties/types.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/math/sqrtf128.h b/libc/src/math/sqrtf128.h
index bccb6bbb6332da..9da9eb69374cb8 100644
--- a/libc/src/math/sqrtf128.h
+++ b/libc/src/math/sqrtf128.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_MATH_SQRTF128_H
#define LLVM_LIBC_SRC_MATH_SQRTF128_H
-#include "src/__support/macros/properties/float.h"
+#include "src/__support/macros/properties/types.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/math/truncf128.h b/libc/src/math/truncf128.h
index c92c8202d4eef7..5eb6116551d1cb 100644
--- a/libc/src/math/truncf128.h
+++ b/libc/src/math/truncf128.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_MATH_TRUNCF128_H
#define LLVM_LIBC_SRC_MATH_TRUNCF128_H
-#include "src/__support/macros/properties/float.h"
+#include "src/__support/macros/properties/types.h"
namespace LIBC_NAMESPACE {
diff --git a/utils/bazel/llvm-project-overlay/libc/BUILD.bazel b/utils/bazel/llvm-project-overlay/libc/BUILD.bazel
index a1a5b7fe9bf406..16ceaadf276fa5 100644
--- a/utils/bazel/llvm-project-overlay/libc/BUILD.bazel
+++ b/utils/bazel/llvm-project-overlay/libc/BUILD.bazel
@@ -80,8 +80,8 @@ libc_support_library(
)
libc_support_library(
- name = "__support_macros_properties_float",
- hdrs = ["src/__support/macros/properties/float.h"],
+ name = "__support_macros_properties_types",
+ hdrs = ["src/__support/macros/properties/types.h"],
deps = [
":__support_macros_properties_architectures",
":__support_macros_properties_compiler",
@@ -332,7 +332,7 @@ libc_support_library(
deps = [
":__support_macros_attributes",
":__support_macros_config",
- ":__support_macros_properties_float",
+ ":__support_macros_properties_types",
":llvm_libc_macros_stdfix_macros",
],
)
@@ -697,7 +697,7 @@ libc_support_library(
":__support_cpp_type_traits",
":__support_libc_assert",
":__support_macros_attributes",
- ":__support_macros_properties_float",
+ ":__support_macros_properties_types",
":__support_math_extras",
":__support_uint128",
],
>From bd595d54219e434acce2c05e97440847d30b5240 Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?kadir=20=C3=A7etinkaya?= <kadircet at google.com>
Date: Thu, 29 Feb 2024 10:37:00 +0100
Subject: [PATCH 100/406] [include-cleaner] Generate references from explicit
functiontemplate specializations (#83392)
---
clang-tools-extra/include-cleaner/lib/WalkAST.cpp | 5 +++++
.../include-cleaner/unittests/WalkASTTest.cpp | 10 ++++------
2 files changed, 9 insertions(+), 6 deletions(-)
diff --git a/clang-tools-extra/include-cleaner/lib/WalkAST.cpp b/clang-tools-extra/include-cleaner/lib/WalkAST.cpp
index 277e6ec5b08900..878067aca0173f 100644
--- a/clang-tools-extra/include-cleaner/lib/WalkAST.cpp
+++ b/clang-tools-extra/include-cleaner/lib/WalkAST.cpp
@@ -228,6 +228,11 @@ class ASTWalker : public RecursiveASTVisitor<ASTWalker> {
// Mark declaration from definition as it needs type-checking.
if (FD->isThisDeclarationADefinition())
report(FD->getLocation(), FD);
+ // Explicit specializaiton/instantiations of a function template requires
+ // primary template.
+ if (clang::isTemplateExplicitInstantiationOrSpecialization(
+ FD->getTemplateSpecializationKind()))
+ report(FD->getLocation(), FD->getPrimaryTemplate());
return true;
}
bool VisitVarDecl(VarDecl *VD) {
diff --git a/clang-tools-extra/include-cleaner/unittests/WalkASTTest.cpp b/clang-tools-extra/include-cleaner/unittests/WalkASTTest.cpp
index e238dc3d902bbe..5dc88157e13af0 100644
--- a/clang-tools-extra/include-cleaner/unittests/WalkASTTest.cpp
+++ b/clang-tools-extra/include-cleaner/unittests/WalkASTTest.cpp
@@ -229,13 +229,9 @@ TEST(WalkAST, FunctionTemplates) {
EXPECT_THAT(testWalk("template<typename T> void foo(T) {}",
"template void ^foo<int>(int);"),
ElementsAre());
- // FIXME: Report specialized template as used from explicit specializations.
- EXPECT_THAT(testWalk("template<typename T> void foo(T);",
+ EXPECT_THAT(testWalk("template<typename T> void $explicit^foo(T);",
"template<> void ^foo<int>(int);"),
- ElementsAre());
- EXPECT_THAT(testWalk("template<typename T> void foo(T) {}",
- "template<typename T> void ^foo(T*) {}"),
- ElementsAre());
+ ElementsAre(Decl::FunctionTemplate));
// Implicit instantiations references most relevant template.
EXPECT_THAT(testWalk(R"cpp(
@@ -510,6 +506,8 @@ TEST(WalkAST, Functions) {
// Definition uses declaration, not the other way around.
testWalk("void $explicit^foo();", "void ^foo() {}");
testWalk("void foo() {}", "void ^foo();");
+ testWalk("template <typename> void $explicit^foo();",
+ "template <typename> void ^foo() {}");
// Unresolved calls marks all the overloads.
testWalk("void $ambiguous^foo(int); void $ambiguous^foo(char);",
>From de5518836e16be3fbfce78394adc96d9bf70f2a5 Mon Sep 17 00:00:00 2001
From: Sudharsan Veeravalli <quic_svs at quicinc.com>
Date: Thu, 29 Feb 2024 15:10:27 +0530
Subject: [PATCH 101/406] [LLDB] Fix crash when using tab completion on class
variables (#83234)
We weren't checking to see if the partial_path was empty before adding
completions and this led to crashes when the class object and a variable
both start with the same substring.
Fixes [#81536](https://github.com/llvm/llvm-project/issues/81536)
---------
Co-authored-by: Michael Buch <michaelbuch12 at gmail.com>
---
lldb/source/Symbol/Variable.cpp | 8 +++++---
.../functionalities/completion/TestCompletion.py | 6 ++++--
lldb/test/API/functionalities/completion/main.cpp | 13 +++++++++----
3 files changed, 18 insertions(+), 9 deletions(-)
diff --git a/lldb/source/Symbol/Variable.cpp b/lldb/source/Symbol/Variable.cpp
index 2bb2ff7db4b721..a33c3433d9e245 100644
--- a/lldb/source/Symbol/Variable.cpp
+++ b/lldb/source/Symbol/Variable.cpp
@@ -509,15 +509,17 @@ static void PrivateAutoCompleteMembers(
CompilerType member_compiler_type = compiler_type.GetFieldAtIndex(
i, member_name, nullptr, nullptr, nullptr);
- if (partial_member_name.empty() ||
- llvm::StringRef(member_name).starts_with(partial_member_name)) {
+ if (partial_member_name.empty()) {
+ request.AddCompletion((prefix_path + member_name).str());
+ } else if (llvm::StringRef(member_name)
+ .starts_with(partial_member_name)) {
if (member_name == partial_member_name) {
PrivateAutoComplete(
frame, partial_path,
prefix_path + member_name, // Anything that has been resolved
// already will be in here
member_compiler_type.GetCanonicalType(), request);
- } else {
+ } else if (partial_path.empty()) {
request.AddCompletion((prefix_path + member_name).str());
}
}
diff --git a/lldb/test/API/functionalities/completion/TestCompletion.py b/lldb/test/API/functionalities/completion/TestCompletion.py
index f71bc73928f0f4..2f6af3cfce109d 100644
--- a/lldb/test/API/functionalities/completion/TestCompletion.py
+++ b/lldb/test/API/functionalities/completion/TestCompletion.py
@@ -60,10 +60,12 @@ def test_dwim_print(self):
def do_test_variable_completion(self, command):
self.complete_from_to(f"{command} fo", f"{command} fooo")
- self.complete_from_to(f"{command} fooo.", f"{command} fooo.")
+ self.complete_from_to(f"{command} fooo.", f"{command} fooo.t")
+ self.complete_from_to(f"{command} fooo.t.", f"{command} fooo.t.x")
self.complete_from_to(f"{command} fooo.dd", f"{command} fooo.dd")
- self.complete_from_to(f"{command} ptr_fooo->", f"{command} ptr_fooo->")
+ self.complete_from_to(f"{command} ptr_fooo->", f"{command} ptr_fooo->t")
+ self.complete_from_to(f"{command} ptr_fooo->t", f"{command} ptr_fooo->t.x")
self.complete_from_to(f"{command} ptr_fooo->dd", f"{command} ptr_fooo->dd")
self.complete_from_to(f"{command} cont", f"{command} container")
diff --git a/lldb/test/API/functionalities/completion/main.cpp b/lldb/test/API/functionalities/completion/main.cpp
index 06ff5773e8a9dc..f925c1d5acf31c 100644
--- a/lldb/test/API/functionalities/completion/main.cpp
+++ b/lldb/test/API/functionalities/completion/main.cpp
@@ -1,12 +1,17 @@
#include <iostream>
+class Baz {
+public:
+ int x;
+};
+
class Foo
{
public:
- int Bar(int x, int y)
- {
- return x + y;
- }
+ Baz t;
+ int temp;
+
+ int Bar(int x, int y) { return x + y; }
};
namespace { int Quux (void) { return 0; } }
>From 03420f570e92ee96133baa8feabc43148e322963 Mon Sep 17 00:00:00 2001
From: Tomas Matheson <tomas.matheson at arm.com>
Date: Thu, 29 Feb 2024 09:48:29 +0000
Subject: [PATCH 102/406] Revert "[llvm][arm] add T1 and T2 assembly options
for vlldm and vlstm (#83116)"
This reverts commit 634b0243b8f7acc85af4f16b70e91d86ded4dc83.
Failing EXPENSIVE_CHECKS builds with "undefined physical register".
---
llvm/lib/Target/ARM/ARMExpandPseudoInsts.cpp | 57 +++++---------
llvm/lib/Target/ARM/ARMInstrFormats.td | 31 --------
llvm/lib/Target/ARM/ARMInstrVFP.td | 64 +++++-----------
.../lib/Target/ARM/AsmParser/ARMAsmParser.cpp | 76 +++----------------
.../ARM/Disassembler/ARMDisassembler.cpp | 23 ------
.../ARM/MCTargetDesc/ARMInstPrinter.cpp | 32 --------
.../CodeGen/ARM/cmse-vlldm-no-reorder.mir | 4 +-
llvm/test/CodeGen/ARM/vlldm-vlstm-uops.mir | 9 ++-
llvm/test/MC/ARM/thumbv8m.s | 8 +-
llvm/test/MC/ARM/vlstm-vlldm-8.1m.s | 11 ---
llvm/test/MC/ARM/vlstm-vlldm-8m.s | 17 -----
llvm/test/MC/ARM/vlstm-vlldm-diag.s | 61 ---------------
.../ARM/armv8.1m-vlldm_vlstm-8.1.main.txt | 11 ---
.../ARM/armv8.1m-vlldm_vlstm-8.main.txt | 17 -----
.../unittests/Target/ARM/MachineInstrTest.cpp | 2 -
15 files changed, 61 insertions(+), 362 deletions(-)
delete mode 100644 llvm/test/MC/ARM/vlstm-vlldm-8.1m.s
delete mode 100644 llvm/test/MC/ARM/vlstm-vlldm-8m.s
delete mode 100644 llvm/test/MC/ARM/vlstm-vlldm-diag.s
delete mode 100644 llvm/test/MC/Disassembler/ARM/armv8.1m-vlldm_vlstm-8.1.main.txt
delete mode 100644 llvm/test/MC/Disassembler/ARM/armv8.1m-vlldm_vlstm-8.main.txt
diff --git a/llvm/lib/Target/ARM/ARMExpandPseudoInsts.cpp b/llvm/lib/Target/ARM/ARMExpandPseudoInsts.cpp
index e78ea63c3b4a56..f0b69b0b09809f 100644
--- a/llvm/lib/Target/ARM/ARMExpandPseudoInsts.cpp
+++ b/llvm/lib/Target/ARM/ARMExpandPseudoInsts.cpp
@@ -1468,21 +1468,15 @@ void ARMExpandPseudo::CMSESaveClearFPRegsV8(
if (passesFPReg)
assert(STI->hasFPRegs() && "Subtarget needs fpregs");
- // Lazy store all fp registers to the stack
+ // Lazy store all fp registers to the stack.
// This executes as NOP in the absence of floating-point support.
- MachineInstrBuilder VLSTM =
- BuildMI(MBB, MBBI, DL, TII->get(ARM::VLSTM))
- .addReg(ARM::SP)
- .add(predOps(ARMCC::AL))
- .addImm(0); // Represents a pseoudo register list, has no effect on
- // the encoding.
- // Mark non-live registers as undef
- for (MachineOperand &MO : VLSTM->implicit_operands()) {
- if (MO.isReg() && !MO.isDef()) {
- Register Reg = MO.getReg();
- MO.setIsUndef(!LiveRegs.contains(Reg));
- }
- }
+ MachineInstrBuilder VLSTM = BuildMI(MBB, MBBI, DL, TII->get(ARM::VLSTM))
+ .addReg(ARM::SP)
+ .add(predOps(ARMCC::AL));
+ for (auto R : {ARM::VPR, ARM::FPSCR, ARM::FPSCR_NZCV, ARM::Q0, ARM::Q1,
+ ARM::Q2, ARM::Q3, ARM::Q4, ARM::Q5, ARM::Q6, ARM::Q7})
+ VLSTM.addReg(R, RegState::Implicit |
+ (LiveRegs.contains(R) ? 0 : RegState::Undef));
// Restore all arguments
for (const auto &Regs : ClearedFPRegs) {
@@ -1569,20 +1563,14 @@ void ARMExpandPseudo::CMSESaveClearFPRegsV81(MachineBasicBlock &MBB,
.addImm(CMSE_FP_SAVE_SIZE >> 2)
.add(predOps(ARMCC::AL));
- // Lazy store all fp registers to the stack.
- MachineInstrBuilder VLSTM =
- BuildMI(MBB, MBBI, DL, TII->get(ARM::VLSTM))
- .addReg(ARM::SP)
- .add(predOps(ARMCC::AL))
- .addImm(0); // Represents a pseoudo register list, has no effect on
- // the encoding.
- // Mark non-live registers as undef
- for (MachineOperand &MO : VLSTM->implicit_operands()) {
- if (MO.isReg() && MO.isImplicit() && !MO.isDef()) {
- Register Reg = MO.getReg();
- MO.setIsUndef(!LiveRegs.contains(Reg));
- }
- }
+ // Lazy store all FP registers to the stack
+ MachineInstrBuilder VLSTM = BuildMI(MBB, MBBI, DL, TII->get(ARM::VLSTM))
+ .addReg(ARM::SP)
+ .add(predOps(ARMCC::AL));
+ for (auto R : {ARM::VPR, ARM::FPSCR, ARM::FPSCR_NZCV, ARM::Q0, ARM::Q1,
+ ARM::Q2, ARM::Q3, ARM::Q4, ARM::Q5, ARM::Q6, ARM::Q7})
+ VLSTM.addReg(R, RegState::Implicit |
+ (LiveRegs.contains(R) ? 0 : RegState::Undef));
} else {
// Push all the callee-saved registers (s16-s31).
MachineInstrBuilder VPUSH =
@@ -1685,12 +1673,9 @@ void ARMExpandPseudo::CMSERestoreFPRegsV8(
// Lazy load fp regs from stack.
// This executes as NOP in the absence of floating-point support.
- MachineInstrBuilder VLLDM =
- BuildMI(MBB, MBBI, DL, TII->get(ARM::VLLDM))
- .addReg(ARM::SP)
- .add(predOps(ARMCC::AL))
- .addImm(0); // Represents a pseoudo register list, has no effect on
- // the encoding.
+ MachineInstrBuilder VLLDM = BuildMI(MBB, MBBI, DL, TII->get(ARM::VLLDM))
+ .addReg(ARM::SP)
+ .add(predOps(ARMCC::AL));
if (STI->fixCMSE_CVE_2021_35465()) {
auto Bundler = MIBundleBuilder(MBB, VLLDM);
@@ -1772,9 +1757,7 @@ void ARMExpandPseudo::CMSERestoreFPRegsV81(
// Load FP registers from stack.
BuildMI(MBB, MBBI, DL, TII->get(ARM::VLLDM))
.addReg(ARM::SP)
- .add(predOps(ARMCC::AL))
- .addImm(0); // Represents a pseoudo register list, has no effect on the
- // encoding.
+ .add(predOps(ARMCC::AL));
// Pop the stack space
BuildMI(MBB, MBBI, DL, TII->get(ARM::tADDspi), ARM::SP)
diff --git a/llvm/lib/Target/ARM/ARMInstrFormats.td b/llvm/lib/Target/ARM/ARMInstrFormats.td
index 404085820a6660..14e315534570d2 100644
--- a/llvm/lib/Target/ARM/ARMInstrFormats.td
+++ b/llvm/lib/Target/ARM/ARMInstrFormats.td
@@ -1749,37 +1749,6 @@ class AXSI4<dag oops, dag iops, IndexMode im, InstrItinClass itin,
let Inst{8} = 0; // Single precision
}
-// Single Precision with fixed registers.
-// For when the registers-to-be-stored/loaded are fixed, e.g. VLLDM and VLSTM
-class AXSI4FR<string asm, bit et, bit load>
- : InstARM<AddrMode4, 4, IndexModeNone, VFPLdStMulFrm, VFPDomain, "", NoItinerary> {
- // Instruction operands.
- bits<4> Rn;
- bits<13> regs; // Does not affect encoding, for assembly/disassembly only.
- list<Predicate> Predicates = [HasVFP2];
- let OutOperandList = (outs);
- let InOperandList = (ins GPRnopc:$Rn, pred:$p, dpr_reglist:$regs);
- let AsmString = asm;
- let Pattern = [];
- let DecoderNamespace = "VFP";
- // Encode instruction operands.
- let Inst{19-16} = Rn;
- let Inst{31-28} = 0b1110;
- let Inst{27-25} = 0b110;
- let Inst{24} = 0b0;
- let Inst{23} = 0b0;
- let Inst{22} = 0b0;
- let Inst{21} = 0b1;
- let Inst{20} = load; // Distinguishes vlldm from vlstm
- let Inst{15-12} = 0b0000;
- let Inst{11-9} = 0b101;
- let Inst{8} = 0; // Single precision
- let Inst{7} = et; // encoding type, 0 for T1 and 1 for T2.
- let Inst{6-0} = 0b0000000;
- let mayLoad = load;
- let mayStore = !eq(load, 0);
-}
-
// Double precision, unary
class ADuI<bits<5> opcod1, bits<2> opcod2, bits<4> opcod3, bits<2> opcod4,
bit opcod5, dag oops, dag iops, InstrItinClass itin, string opc,
diff --git a/llvm/lib/Target/ARM/ARMInstrVFP.td b/llvm/lib/Target/ARM/ARMInstrVFP.td
index 3094a4db2b4d12..55d3efbd9b9a2b 100644
--- a/llvm/lib/Target/ARM/ARMInstrVFP.td
+++ b/llvm/lib/Target/ARM/ARMInstrVFP.td
@@ -313,51 +313,29 @@ def : MnemonicAlias<"vstm", "vstmia">;
//===----------------------------------------------------------------------===//
// Lazy load / store multiple Instructions
//
-// VLLDM and VLSTM:
-// 2 encoding options:
-// T1 (bit 7 is 0):
-// T1 takes an optional dpr_reglist, must be '{d0-d15}' (exactly)
-// T1 require v8-M.Main, secure state, target with 16 D registers (or with no D registers - NOP)
-// T2 (bit 7 is 1):
-// T2 takes a mandatory dpr_reglist, must be '{d0-d31}' (exactly)
-// T2 require v8.1-M.Main, secure state, target with 16/32 D registers (or with no D registers - NOP)
-// (source: Arm v8-M ARM, DDI0553B.v ID16122022)
-
-def VLLDM : AXSI4FR<"vlldm${p}\t$Rn, $regs", 0, 1>,
+def VLLDM : AXSI4<(outs), (ins GPRnopc:$Rn, pred:$p), IndexModeNone,
+ NoItinerary, "vlldm${p}\t$Rn", "", []>,
Requires<[HasV8MMainline, Has8MSecExt]> {
- let Defs = [VPR, FPSCR, FPSCR_NZCV, D0, D1, D2, D3, D4, D5, D6, D7, D8, D9, D10, D11, D12, D13, D14, D15];
- let DecoderMethod = "DecodeLazyLoadStoreMul";
-}
-// T1: assembly does not contains the register list.
-def : InstAlias<"vlldm${p}\t$Rn", (VLLDM GPRnopc:$Rn, pred:$p, 0)>,
- Requires<[HasV8MMainline, Has8MSecExt]>;
-// T2: assembly must contains the register list.
-// The register list has no effect on the encoding, it is for assembly/disassembly purposes only.
-def VLLDM_T2 : AXSI4FR<"vlldm${p}\t$Rn, $regs", 1, 1>,
- Requires<[HasV8_1MMainline, Has8MSecExt]> {
- let Defs = [VPR, FPSCR, FPSCR_NZCV, D0, D1, D2, D3, D4, D5, D6, D7, D8, D9, D10, D11, D12, D13, D14, D15,
- D16, D17, D18, D19, D20, D21, D22, D23, D24, D25, D26, D27, D28, D29, D30, D31];
- let DecoderMethod = "DecodeLazyLoadStoreMul";
-}
-// T1: assembly contains the register list.
-// The register list has no effect on the encoding, it is for assembly/disassembly purposes only.
-def VLSTM : AXSI4FR<"vlstm${p}\t$Rn, $regs", 0, 0>,
+ let Inst{24-23} = 0b00;
+ let Inst{22} = 0;
+ let Inst{21} = 1;
+ let Inst{20} = 1;
+ let Inst{15-12} = 0;
+ let Inst{7-0} = 0;
+ let mayLoad = 1;
+ let Defs = [Q0, Q1, Q2, Q3, Q4, Q5, Q6, Q7, VPR, FPSCR, FPSCR_NZCV];
+}
+
+def VLSTM : AXSI4<(outs), (ins GPRnopc:$Rn, pred:$p), IndexModeNone,
+ NoItinerary, "vlstm${p}\t$Rn", "", []>,
Requires<[HasV8MMainline, Has8MSecExt]> {
- let Defs = [VPR, FPSCR, FPSCR_NZCV];
- let Uses = [VPR, FPSCR, FPSCR_NZCV, D0, D1, D2, D3, D4, D5, D6, D7, D8, D9, D10, D11, D12, D13, D14, D15];
- let DecoderMethod = "DecodeLazyLoadStoreMul";
-}
-// T1: assembly does not contain the register list.
-def : InstAlias<"vlstm${p}\t$Rn", (VLSTM GPRnopc:$Rn, pred:$p, 0)>,
- Requires<[HasV8MMainline, Has8MSecExt]>;
-// T2: assembly must contain the register list.
-// The register list has no effect on the encoding, it is for assembly/disassembly purposes only.
-def VLSTM_T2 : AXSI4FR<"vlstm${p}\t$Rn, $regs", 1, 0>,
- Requires<[HasV8_1MMainline, Has8MSecExt]> {
- let Defs = [VPR, FPSCR, FPSCR_NZCV];
- let Uses = [VPR, FPSCR, FPSCR_NZCV, D0, D1, D2, D3, D4, D5, D6, D7, D8, D9, D10, D11, D12, D13, D14, D15,
- D16, D17, D18, D19, D20, D21, D22, D23, D24, D25, D26, D27, D28, D29, D30, D31];
- let DecoderMethod = "DecodeLazyLoadStoreMul";
+ let Inst{24-23} = 0b00;
+ let Inst{22} = 0;
+ let Inst{21} = 1;
+ let Inst{20} = 0;
+ let Inst{15-12} = 0;
+ let Inst{7-0} = 0;
+ let mayStore = 1;
}
def : InstAlias<"vpush${p} $r", (VSTMDDB_UPD SP, pred:$p, dpr_reglist:$r), 0>,
diff --git a/llvm/lib/Target/ARM/AsmParser/ARMAsmParser.cpp b/llvm/lib/Target/ARM/AsmParser/ARMAsmParser.cpp
index 5efbaf0d41060c..37bfb76a494dee 100644
--- a/llvm/lib/Target/ARM/AsmParser/ARMAsmParser.cpp
+++ b/llvm/lib/Target/ARM/AsmParser/ARMAsmParser.cpp
@@ -450,12 +450,11 @@ class ARMAsmParser : public MCTargetAsmParser {
bool validatetSTMRegList(const MCInst &Inst, const OperandVector &Operands,
unsigned ListNo);
- int tryParseRegister(bool AllowOutofBoundReg = false);
+ int tryParseRegister();
bool tryParseRegisterWithWriteBack(OperandVector &);
int tryParseShiftRegister(OperandVector &);
bool parseRegisterList(OperandVector &, bool EnforceOrder = true,
- bool AllowRAAC = false,
- bool AllowOutOfBoundReg = false);
+ bool AllowRAAC = false);
bool parseMemory(OperandVector &);
bool parseOperand(OperandVector &, StringRef Mnemonic);
bool parseImmExpr(int64_t &Out);
@@ -4073,7 +4072,7 @@ ParseStatus ARMAsmParser::tryParseRegister(MCRegister &Reg, SMLoc &StartLoc,
/// Try to parse a register name. The token must be an Identifier when called,
/// and if it is a register name the token is eaten and the register number is
/// returned. Otherwise return -1.
-int ARMAsmParser::tryParseRegister(bool AllowOutOfBoundReg) {
+int ARMAsmParser::tryParseRegister() {
MCAsmParser &Parser = getParser();
const AsmToken &Tok = Parser.getTok();
if (Tok.isNot(AsmToken::Identifier)) return -1;
@@ -4117,8 +4116,7 @@ int ARMAsmParser::tryParseRegister(bool AllowOutOfBoundReg) {
}
// Some FPUs only have 16 D registers, so D16-D31 are invalid
- if (!AllowOutOfBoundReg && !hasD32() && RegNum >= ARM::D16 &&
- RegNum <= ARM::D31)
+ if (!hasD32() && RegNum >= ARM::D16 && RegNum <= ARM::D31)
return -1;
Parser.Lex(); // Eat identifier token.
@@ -4458,7 +4456,7 @@ insertNoDuplicates(SmallVectorImpl<std::pair<unsigned, unsigned>> &Regs,
/// Parse a register list.
bool ARMAsmParser::parseRegisterList(OperandVector &Operands, bool EnforceOrder,
- bool AllowRAAC, bool AllowOutOfBoundReg) {
+ bool AllowRAAC) {
MCAsmParser &Parser = getParser();
if (Parser.getTok().isNot(AsmToken::LCurly))
return TokError("Token is not a Left Curly Brace");
@@ -4512,7 +4510,7 @@ bool ARMAsmParser::parseRegisterList(OperandVector &Operands, bool EnforceOrder,
return Error(RegLoc, "pseudo-register not allowed");
Parser.Lex(); // Eat the minus.
SMLoc AfterMinusLoc = Parser.getTok().getLoc();
- int EndReg = tryParseRegister(AllowOutOfBoundReg);
+ int EndReg = tryParseRegister();
if (EndReg == -1)
return Error(AfterMinusLoc, "register expected");
if (EndReg == ARM::RA_AUTH_CODE)
@@ -4547,7 +4545,7 @@ bool ARMAsmParser::parseRegisterList(OperandVector &Operands, bool EnforceOrder,
RegLoc = Parser.getTok().getLoc();
int OldReg = Reg;
const AsmToken RegTok = Parser.getTok();
- Reg = tryParseRegister(AllowOutOfBoundReg);
+ Reg = tryParseRegister();
if (Reg == -1)
return Error(RegLoc, "register expected");
if (!AllowRAAC && Reg == ARM::RA_AUTH_CODE)
@@ -6087,11 +6085,8 @@ bool ARMAsmParser::parseOperand(OperandVector &Operands, StringRef Mnemonic) {
}
case AsmToken::LBrac:
return parseMemory(Operands);
- case AsmToken::LCurly: {
- bool AllowOutOfBoundReg = Mnemonic == "vlldm" || Mnemonic == "vlstm";
- return parseRegisterList(Operands, !Mnemonic.starts_with("clr"), false,
- AllowOutOfBoundReg);
- }
+ case AsmToken::LCurly:
+ return parseRegisterList(Operands, !Mnemonic.starts_with("clr"));
case AsmToken::Dollar:
case AsmToken::Hash: {
// #42 -> immediate
@@ -7601,33 +7596,6 @@ bool ARMAsmParser::validateInstruction(MCInst &Inst,
const unsigned Opcode = Inst.getOpcode();
switch (Opcode) {
- case ARM::VLLDM:
- case ARM::VLLDM_T2:
- case ARM::VLSTM:
- case ARM::VLSTM_T2: {
- // Since in some cases both T1 and T2 are valid, tablegen can not always
- // pick the correct instruction.
- if (Operands.size() == 4) { // a register list has been provided
- ARMOperand &Op = static_cast<ARMOperand &>(
- *Operands[3]); // the register list, a dpr_reglist
- assert(Op.isDPRRegList());
- auto &RegList = Op.getRegList();
- // T2 requires v8.1-M.Main (cannot be handled by tablegen)
- if (RegList.size() == 32 && !hasV8_1MMainline()) {
- return Error(Op.getEndLoc(), "T2 version requires v8.1-M.Main");
- }
- // When target has 32 D registers, T1 is undefined.
- if (hasD32() && RegList.size() != 32) {
- return Error(Op.getEndLoc(), "operand must be exactly {d0-d31}");
- }
- // When target has 16 D registers, both T1 and T2 are valid.
- if (!hasD32() && (RegList.size() != 16 && RegList.size() != 32)) {
- return Error(Op.getEndLoc(),
- "operand must be exactly {d0-d15} (T1) or {d0-d31} (T2)");
- }
- }
- return false;
- }
case ARM::t2IT: {
// Encoding is unpredictable if it ever results in a notional 'NV'
// predicate. Since we don't parse 'NV' directly this means an 'AL'
@@ -8763,32 +8731,6 @@ bool ARMAsmParser::processInstruction(MCInst &Inst,
}
switch (Inst.getOpcode()) {
- case ARM::VLLDM:
- case ARM::VLSTM: {
- // In some cases both T1 and T2 are valid, causing tablegen pick T1 instead
- // of T2
- if (Operands.size() == 4) { // a register list has been provided
- ARMOperand &Op = static_cast<ARMOperand &>(
- *Operands[3]); // the register list, a dpr_reglist
- assert(Op.isDPRRegList());
- auto &RegList = Op.getRegList();
- // When the register list is {d0-d31} the instruction has to be the T2
- // variant
- if (RegList.size() == 32) {
- const unsigned Opcode =
- (Inst.getOpcode() == ARM::VLLDM) ? ARM::VLLDM_T2 : ARM::VLSTM_T2;
- MCInst TmpInst;
- TmpInst.setOpcode(Opcode);
- TmpInst.addOperand(Inst.getOperand(0));
- TmpInst.addOperand(Inst.getOperand(1));
- TmpInst.addOperand(Inst.getOperand(2));
- TmpInst.addOperand(Inst.getOperand(3));
- Inst = TmpInst;
- return true;
- }
- }
- return false;
- }
// Alias for alternate form of 'ldr{,b}t Rt, [Rn], #imm' instruction.
case ARM::LDRT_POST:
case ARM::LDRBT_POST: {
diff --git a/llvm/lib/Target/ARM/Disassembler/ARMDisassembler.cpp b/llvm/lib/Target/ARM/Disassembler/ARMDisassembler.cpp
index 705f3cbce12f02..604f22d7111900 100644
--- a/llvm/lib/Target/ARM/Disassembler/ARMDisassembler.cpp
+++ b/llvm/lib/Target/ARM/Disassembler/ARMDisassembler.cpp
@@ -700,9 +700,6 @@ DecodeMVEOverlappingLongShift(MCInst &Inst, unsigned Insn, uint64_t Address,
static DecodeStatus DecodeT2AddSubSPImm(MCInst &Inst, unsigned Insn,
uint64_t Address,
const MCDisassembler *Decoder);
-static DecodeStatus DecodeLazyLoadStoreMul(MCInst &Inst, unsigned Insn,
- uint64_t Address,
- const MCDisassembler *Decoder);
#include "ARMGenDisassemblerTables.inc"
@@ -7033,23 +7030,3 @@ static DecodeStatus DecodeT2AddSubSPImm(MCInst &Inst, unsigned Insn,
return DS;
}
-
-static DecodeStatus DecodeLazyLoadStoreMul(MCInst &Inst, unsigned Insn,
- uint64_t Address,
- const MCDisassembler *Decoder) {
- DecodeStatus S = MCDisassembler::Success;
-
- const unsigned Rn = fieldFromInstruction(Insn, 16, 4);
- // Adding Rn, holding memory location to save/load to/from, the only argument
- // that is being encoded.
- // '$Rn' in the assembly.
- if (!Check(S, DecodeGPRRegisterClass(Inst, Rn, Address, Decoder)))
- return MCDisassembler::Fail;
- // An optional predicate, '$p' in the assembly.
- DecodePredicateOperand(Inst, ARMCC::AL, Address, Decoder);
- // An immediate that represents a floating point registers list. '$regs' in
- // the assembly.
- Inst.addOperand(MCOperand::createImm(0)); // Arbitrary value, has no effect.
-
- return S;
-}
diff --git a/llvm/lib/Target/ARM/MCTargetDesc/ARMInstPrinter.cpp b/llvm/lib/Target/ARM/MCTargetDesc/ARMInstPrinter.cpp
index 24e627cd9a4e1f..fbd067d79af0b3 100644
--- a/llvm/lib/Target/ARM/MCTargetDesc/ARMInstPrinter.cpp
+++ b/llvm/lib/Target/ARM/MCTargetDesc/ARMInstPrinter.cpp
@@ -91,38 +91,6 @@ void ARMInstPrinter::printInst(const MCInst *MI, uint64_t Address,
unsigned Opcode = MI->getOpcode();
switch (Opcode) {
- case ARM::VLLDM: {
- const MCOperand &Reg = MI->getOperand(0);
- O << '\t' << "vlldm" << '\t';
- printRegName(O, Reg.getReg());
- O << ", "
- << "{d0 - d15}";
- return;
- }
- case ARM::VLLDM_T2: {
- const MCOperand &Reg = MI->getOperand(0);
- O << '\t' << "vlldm" << '\t';
- printRegName(O, Reg.getReg());
- O << ", "
- << "{d0 - d31}";
- return;
- }
- case ARM::VLSTM: {
- const MCOperand &Reg = MI->getOperand(0);
- O << '\t' << "vlstm" << '\t';
- printRegName(O, Reg.getReg());
- O << ", "
- << "{d0 - d15}";
- return;
- }
- case ARM::VLSTM_T2: {
- const MCOperand &Reg = MI->getOperand(0);
- O << '\t' << "vlstm" << '\t';
- printRegName(O, Reg.getReg());
- O << ", "
- << "{d0 - d31}";
- return;
- }
// Check for MOVs and print canonical forms, instead.
case ARM::MOVsr: {
// FIXME: Thumb variants?
diff --git a/llvm/test/CodeGen/ARM/cmse-vlldm-no-reorder.mir b/llvm/test/CodeGen/ARM/cmse-vlldm-no-reorder.mir
index d006aa9ba38e84..2bc4288884f192 100644
--- a/llvm/test/CodeGen/ARM/cmse-vlldm-no-reorder.mir
+++ b/llvm/test/CodeGen/ARM/cmse-vlldm-no-reorder.mir
@@ -89,7 +89,7 @@ body: |
# CHECK: $sp = t2STMDB_UPD $sp, 14 /* CC::al */, $noreg, $r4, $r5, $r6, undef $r7, $r8, $r9, $r10, $r11
# CHECK-NEXT: $r0 = t2BICri $r0, 1, 14 /* CC::al */, $noreg, $noreg
# CHECK-NEXT: $sp = tSUBspi $sp, 34, 14 /* CC::al */, $noreg
-# CHECK-NEXT: VLSTM $sp, 14 /* CC::al */, $noreg, 0, implicit-def $vpr, implicit-def $fpscr, implicit-def $fpscr_nzcv, implicit undef $vpr, implicit undef $fpscr, implicit undef $fpscr_nzcv, implicit undef $d0, implicit undef $d1, implicit undef $d2, implicit undef $d3, implicit undef $d4, implicit undef $d5, implicit undef $d6, implicit undef $d7, implicit $d8, implicit $d9, implicit $d10, implicit $d11, implicit $d12, implicit $d13, implicit $d14, implicit $d15
+# CHECK-NEXT: VLSTM $sp, 14 /* CC::al */, $noreg, implicit undef $vpr, implicit undef $fpscr, implicit undef $fpscr_nzcv, implicit undef $q0, implicit undef $q1, implicit undef $q2, implicit undef $q3, implicit undef $q4, implicit undef $q5, implicit undef $q6, implicit undef $q7
# CHECK-NEXT: $r1 = tMOVr $r0, 14 /* CC::al */, $noreg
# CHECK-NEXT: $r2 = tMOVr $r0, 14 /* CC::al */, $noreg
# CHECK-NEXT: $r3 = tMOVr $r0, 14 /* CC::al */, $noreg
@@ -105,7 +105,7 @@ body: |
# CHECK-NEXT: t2MSR_M 3072, $r0, 14 /* CC::al */, $noreg, implicit-def $cpsr
# CHECK-NEXT: tBLXNSr 14 /* CC::al */, $noreg, killed $r0, csr_aapcs, implicit-def $lr, implicit $sp, implicit-def dead $lr, implicit $sp, implicit-def $sp, implicit-def $s0
# CHECK-NEXT: $r12 = VMOVRS $s0, 14 /* CC::al */, $noreg
-# CHECK-NEXT: VLLDM $sp, 14 /* CC::al */, $noreg, 0, implicit-def $vpr, implicit-def $fpscr, implicit-def $fpscr_nzcv, implicit-def $d0, implicit-def $d1, implicit-def $d2, implicit-def $d3, implicit-def $d4, implicit-def $d5, implicit-def $d6, implicit-def $d7, implicit-def $d8, implicit-def $d9, implicit-def $d10, implicit-def $d11, implicit-def $d12, implicit-def $d13, implicit-def $d14, implicit-def $d15
+# CHECK-NEXT: VLLDM $sp, 14 /* CC::al */, $noreg, implicit-def $q0, implicit-def $q1, implicit-def $q2, implicit-def $q3, implicit-def $q4, implicit-def $q5, implicit-def $q6, implicit-def $q7, implicit-def $vpr, implicit-def $fpscr, implicit-def $fpscr_nzcv
# CHECK-NEXT: $s0 = VMOVSR $r12, 14 /* CC::al */, $noreg
# CHECK-NEXT: $sp = tADDspi $sp, 34, 14 /* CC::al */, $noreg
# CHECK-NEXT: $sp = t2LDMIA_UPD $sp, 14 /* CC::al */, $noreg, def $r4, def $r5, def $r6, def $r7, def $r8, def $r9, def $r10, def $r11
diff --git a/llvm/test/CodeGen/ARM/vlldm-vlstm-uops.mir b/llvm/test/CodeGen/ARM/vlldm-vlstm-uops.mir
index ad53addcc21a35..8c49a531674115 100644
--- a/llvm/test/CodeGen/ARM/vlldm-vlstm-uops.mir
+++ b/llvm/test/CodeGen/ARM/vlldm-vlstm-uops.mir
@@ -2,7 +2,7 @@
--- |
target triple = "thumbv8m.main-arm-none-eabi"
- define hidden void @foo(void ()* nocapture %baz) local_unnamed_addr #0 {
+ define hidden void @foo(ptr nocapture %baz) local_unnamed_addr #0 {
entry:
%call = call i32 @bar() #0
%tobool = icmp eq i32 %call, 0
@@ -55,13 +55,14 @@ body: |
tBL 14, $noreg, @bar, csr_aapcs, implicit-def dead $lr, implicit $sp, implicit-def $sp, implicit-def dead $r0
bb.2.land.end:
- liveins: $r4, $vpr, $fpscr, $fpscr_nzcv, $d0, $d1, $d2, $d3, $d4, $d5, $d6, $d7, $d8, $d9, $d10, $d11, $d12, $d13, $d14, $d15
+ liveins: $r4
+
$sp = t2STMDB_UPD $sp, 14, $noreg, $r4, killed $r5, killed $r6, killed $r7, killed $r8, killed $r9, killed $r10, killed $r11
$r4 = t2BICri $r4, 1, 14, $noreg, $noreg
$sp = tSUBspi $sp, 34, 14, $noreg
- VLSTM $sp, 14, $noreg, 0, implicit-def $vpr, implicit-def $fpscr, implicit-def $fpscr_nzcv, implicit $vpr, implicit $fpscr, implicit $fpscr_nzcv, implicit $d0, implicit $d1, implicit $d2, implicit $d3, implicit $d4, implicit $d5, implicit $d6, implicit $d7, implicit $d8, implicit $d9, implicit $d10, implicit $d11, implicit $d12, implicit $d13, implicit $d14, implicit $d15
+ VLSTM $sp, 14, $noreg
tBLXNSr 14, $noreg, killed $r4, csr_aapcs, implicit-def $lr, implicit $sp, implicit-def dead $lr, implicit $sp, implicit-def $sp
- VLLDM $sp, 14, $noreg, 0, implicit-def $vpr, implicit-def $fpscr, implicit-def $fpscr_nzcv, implicit-def $d0, implicit-def $d1, implicit-def $d2, implicit-def $d3, implicit-def $d4, implicit-def $d5, implicit-def $d6, implicit-def $d7, implicit-def $d8, implicit-def $d9, implicit-def $d10, implicit-def $d11, implicit-def $d12, implicit-def $d13, implicit-def $d14, implicit-def $d15
+ VLLDM $sp, 14, $noreg, implicit-def $q0, implicit-def $q1, implicit-def $q2, implicit-def $q3, implicit-def $q4, implicit-def $q5, implicit-def $q6, implicit-def $q7, implicit-def $vpr, implicit-def $fpscr, implicit-def $fpscr_nzcv
$sp = tADDspi $sp, 34, 14, $noreg
$sp = t2LDMIA_UPD $sp, 14, $noreg, def $r4, def $r5, def $r6, def $r7, def $r8, def $r9, def $r10, def $r11
$sp = t2LDMIA_RET $sp, 14, $noreg, def $r4, def $pc
diff --git a/llvm/test/MC/ARM/thumbv8m.s b/llvm/test/MC/ARM/thumbv8m.s
index f03dd03dae3a4f..0e9ab4a9b3bf91 100644
--- a/llvm/test/MC/ARM/thumbv8m.s
+++ b/llvm/test/MC/ARM/thumbv8m.s
@@ -184,13 +184,13 @@ ttat r0, r1
// 'Lazy Load/Store Multiple'
// UNDEF-BASELINE: error: instruction requires: armv8m.main
-// CHECK-MAINLINE: vlldm r5, {d0 - d15} @ encoding: [0x35,0xec,0x00,0x0a]
-// CHECK-MAINLINE_DSP: vlldm r5, {d0 - d15} @ encoding: [0x35,0xec,0x00,0x0a]
+// CHECK-MAINLINE: vlldm r5 @ encoding: [0x35,0xec,0x00,0x0a]
+// CHECK-MAINLINE_DSP: vlldm r5 @ encoding: [0x35,0xec,0x00,0x0a]
vlldm r5
// UNDEF-BASELINE: error: instruction requires: armv8m.main
-// CHECK-MAINLINE: vlstm r10, {d0 - d15} @ encoding: [0x2a,0xec,0x00,0x0a]
-// CHECK-MAINLINE_DSP: vlstm r10, {d0 - d15} @ encoding: [0x2a,0xec,0x00,0x0a]
+// CHECK-MAINLINE: vlstm r10 @ encoding: [0x2a,0xec,0x00,0x0a]
+// CHECK-MAINLINE_DSP: vlstm r10 @ encoding: [0x2a,0xec,0x00,0x0a]
vlstm r10
// New SYSm's
diff --git a/llvm/test/MC/ARM/vlstm-vlldm-8.1m.s b/llvm/test/MC/ARM/vlstm-vlldm-8.1m.s
deleted file mode 100644
index 4e35883ffe4332..00000000000000
--- a/llvm/test/MC/ARM/vlstm-vlldm-8.1m.s
+++ /dev/null
@@ -1,11 +0,0 @@
-// RUN: llvm-mc -triple=armv8.1m.main-arm-none-eabi -mcpu=generic -show-encoding %s \
-// RUN: | FileCheck --check-prefixes=CHECK %s
-
-// RUN: llvm-mc -triple=thumbv8.1m.main-none-eabi -mcpu=generic -show-encoding %s \
-// RUN: | FileCheck --check-prefixes=CHECK %s
-
-vlstm r8, {d0 - d31}
-// CHECK: vlstm r8, {d0 - d31} @ encoding: [0x28,0xec,0x80,0x0a]
-
-vlldm r8, {d0 - d31}
-// CHECK: vlldm r8, {d0 - d31} @ encoding: [0x38,0xec,0x80,0x0a]
diff --git a/llvm/test/MC/ARM/vlstm-vlldm-8m.s b/llvm/test/MC/ARM/vlstm-vlldm-8m.s
deleted file mode 100644
index bbc95318aeb3d0..00000000000000
--- a/llvm/test/MC/ARM/vlstm-vlldm-8m.s
+++ /dev/null
@@ -1,17 +0,0 @@
-// RUN: llvm-mc -triple=armv8m.main-arm-none-eabi -mcpu=generic -show-encoding %s \
-// RUN: | FileCheck --check-prefixes=CHECK %s
-
-// RUN: llvm-mc -triple=thumbv8m.main-none-eabi -mcpu=generic -show-encoding %s \
-// RUN: | FileCheck --check-prefixes=CHECK %s
-
-vlstm r8, {d0 - d15}
-// CHECK: vlstm r8, {d0 - d15} @ encoding: [0x28,0xec,0x00,0x0a]
-
-vlldm r8, {d0 - d15}
-// CHECK: vlldm r8, {d0 - d15} @ encoding: [0x38,0xec,0x00,0x0a]
-
-vlstm r8
-// CHECK: vlstm r8, {d0 - d15} @ encoding: [0x28,0xec,0x00,0x0a]
-
-vlldm r8
-// CHECK: vlldm r8, {d0 - d15} @ encoding: [0x38,0xec,0x00,0x0a]
diff --git a/llvm/test/MC/ARM/vlstm-vlldm-diag.s b/llvm/test/MC/ARM/vlstm-vlldm-diag.s
deleted file mode 100644
index b57f535c6a25cf..00000000000000
--- a/llvm/test/MC/ARM/vlstm-vlldm-diag.s
+++ /dev/null
@@ -1,61 +0,0 @@
-// RUN: not llvm-mc -triple=armv8.1m.main-arm-none-eabi -mcpu=generic -show-encoding %s 2>&1 >/dev/null \
-// RUN: | FileCheck --check-prefixes=ERR %s
-
-// RUN: not llvm-mc -triple=armv8.1m.main-arm-none-eabi -mcpu=generic -show-encoding %s 2>&1 >/dev/null \
-// RUN: | FileCheck --check-prefixes=ERRT2 %s
-
-vlstm r8, {d0 - d11}
-// ERR: error: operand must be exactly {d0-d15} (T1) or {d0-d31} (T2)
-// ERR-NEXT: vlstm r8, {d0 - d11}
-
-vlldm r8, {d0 - d11}
-// ERR: error: operand must be exactly {d0-d15} (T1) or {d0-d31} (T2)
-// ERR-NEXT: vlldm r8, {d0 - d11}
-
-vlstm r8, {d3 - d15}
-// ERR: error: operand must be exactly {d0-d15} (T1) or {d0-d31} (T2)
-// ERR-NEXT: vlstm r8, {d3 - d15}
-
-vlldm r8, {d3 - d15}
-// ERR: error: operand must be exactly {d0-d15} (T1) or {d0-d31} (T2)
-// ERR-NEXT: vlldm r8, {d3 - d15}
-
-vlstm r8, {d0 - d29}
-// ERR: error: operand must be exactly {d0-d15} (T1) or {d0-d31} (T2)
-// ERR-NEXT: vlstm r8, {d0 - d29}
-
-vlldm r8, {d0 - d29}
-// ERR: error: operand must be exactly {d0-d15} (T1) or {d0-d31} (T2)
-// ERR-NEXT: vlldm r8, {d0 - d29}
-
-vlstm r8, {d3 - d31}
-// ERR: error: operand must be exactly {d0-d15} (T1) or {d0-d31} (T2)
-// ERR-NEXT: vlstm r8, {d3 - d31}
-
-vlldm r8, {d3 - d31}
-// ERR: error: operand must be exactly {d0-d15} (T1) or {d0-d31} (T2)
-// ERR-NEXT: vlldm r8, {d3 - d31}
-
-vlstm r8, {d0 - d35}
-// ERR: error: register expected
-// ERR-NEXT: vlstm r8, {d0 - d35}
-
-vlldm r8, {d0 - d35}
-// ERR: error: register expected
-// ERR-NEXT: vlldm r8, {d0 - d35}
-
-vlstm pc
-// ERR: error: operand must be a register in range [r0, r14]
-// ERR-NEXT: vlstm pc
-
-vlldm pc
-// ERR: error: operand must be a register in range [r0, r14]
-// ERR-NEXT: vlldm pc
-
-vlstm pc
-// ERRT2: error: operand must be a register in range [r0, r14]
-// ERRT2-NEXT: vlstm pc
-
-vlldm pc
-// ERRT2: error: operand must be a register in range [r0, r14]
-// ERRT2-NEXT: vlldm pc
\ No newline at end of file
diff --git a/llvm/test/MC/Disassembler/ARM/armv8.1m-vlldm_vlstm-8.1.main.txt b/llvm/test/MC/Disassembler/ARM/armv8.1m-vlldm_vlstm-8.1.main.txt
deleted file mode 100644
index 6b9882454c06a3..00000000000000
--- a/llvm/test/MC/Disassembler/ARM/armv8.1m-vlldm_vlstm-8.1.main.txt
+++ /dev/null
@@ -1,11 +0,0 @@
-// RUN: llvm-mc -triple=armv8.1m.main-arm-none-eabi -mcpu=generic -show-encoding -disassemble %s \
-// RUN: | FileCheck %s --check-prefixes=CHECK-DISS
-
-// RUN: llvm-mc -triple=thumbv8.1m.main-none-eabi -mcpu=generic -show-encoding -disassemble %s \
-// RUN: | FileCheck %s --check-prefixes=CHECK-DISS
-
-[0x28,0xec,0x80,0x0a]
-// CHECK-DISS: vlstm r8, {d0 - d31} @ encoding: [0x28,0xec,0x80,0x0a]
-
-[0x38,0xec,0x80,0x0a]
-// CHECK-DISS: vlldm r8, {d0 - d31} @ encoding: [0x38,0xec,0x80,0x0a]
\ No newline at end of file
diff --git a/llvm/test/MC/Disassembler/ARM/armv8.1m-vlldm_vlstm-8.main.txt b/llvm/test/MC/Disassembler/ARM/armv8.1m-vlldm_vlstm-8.main.txt
deleted file mode 100644
index 1e28d5284c5b2a..00000000000000
--- a/llvm/test/MC/Disassembler/ARM/armv8.1m-vlldm_vlstm-8.main.txt
+++ /dev/null
@@ -1,17 +0,0 @@
-// RUN: llvm-mc -triple=armv8m.main-arm-none-eabi -mcpu=generic -show-encoding -disassemble %s \
-// RUN: | FileCheck %s --check-prefixes=CHECK-DISS
-
-// RUN: llvm-mc -triple=thumbv8m.main-none-eabi -mcpu=generic -show-encoding -disassemble %s \
-// RUN: | FileCheck %s --check-prefixes=CHECK-DISS
-
-[0x28,0xec,0x00,0x0a]
-// CHECK-DISS: vlstm r8, {d0 - d15} @ encoding: [0x28,0xec,0x00,0x0a]
-
-[0x38,0xec,0x00,0x0a]
-// CHECK-DISS: vlldm r8, {d0 - d15} @ encoding: [0x38,0xec,0x00,0x0a]
-
-[0x28,0xec,0x00,0x0a]
-// CHECK-DISS: vlstm r8, {d0 - d15} @ encoding: [0x28,0xec,0x00,0x0a]
-
-[0x38,0xec,0x00,0x0a]
-// CHECK-DISS: vlldm r8, {d0 - d15} @ encoding: [0x38,0xec,0x00,0x0a]
\ No newline at end of file
diff --git a/llvm/unittests/Target/ARM/MachineInstrTest.cpp b/llvm/unittests/Target/ARM/MachineInstrTest.cpp
index 3a76054ca4f36d..aeb25bf012d034 100644
--- a/llvm/unittests/Target/ARM/MachineInstrTest.cpp
+++ b/llvm/unittests/Target/ARM/MachineInstrTest.cpp
@@ -1126,9 +1126,7 @@ TEST(MachineInstr, HasSideEffects) {
VLDR_VPR_post,
VLDR_VPR_pre,
VLLDM,
- VLLDM_T2,
VLSTM,
- VLSTM_T2,
VMRS,
VMRS_FPCXTNS,
VMRS_FPCXTS,
>From 3196005f6bedbed61a86626a9e4f8fee7437a914 Mon Sep 17 00:00:00 2001
From: Chen Zheng <czhengsz at cn.ibm.com>
Date: Thu, 29 Feb 2024 04:41:39 -0500
Subject: [PATCH 103/406] [NFC][PowerPC] use script to regenerate the CHECK
lines
---
llvm/test/CodeGen/PowerPC/crsave.ll | 324 ++++++++++++++++++++++++----
1 file changed, 279 insertions(+), 45 deletions(-)
diff --git a/llvm/test/CodeGen/PowerPC/crsave.ll b/llvm/test/CodeGen/PowerPC/crsave.ll
index 81e7a0adcc8ca1..bde49d02e86ebd 100644
--- a/llvm/test/CodeGen/PowerPC/crsave.ll
+++ b/llvm/test/CodeGen/PowerPC/crsave.ll
@@ -1,3 +1,4 @@
+; NOTE: Assertions have been autogenerated by utils/update_llc_test_checks.py UTC_ARGS: --version 4
; RUN: llc -O0 -frame-pointer=all -mtriple=powerpc-unknown-linux-gnu -mcpu=g5 < %s | FileCheck %s -check-prefix=PPC32
; RUN: llc -O0 -mtriple=powerpc64-unknown-linux-gnu -mcpu=g5 < %s | FileCheck %s -check-prefix=PPC64
; RUN: llc -O0 -mtriple=powerpc64le-unknown-linux-gnu -verify-machineinstrs < %s | FileCheck %s -check-prefix=PPC64-ELFv2
@@ -5,6 +6,101 @@
declare void @foo()
define i32 @test_cr2() nounwind uwtable {
+; PPC32-LABEL: test_cr2:
+; PPC32: # %bb.0: # %entry
+; PPC32-NEXT: mflr 0
+; PPC32-NEXT: stwu 1, -32(1)
+; PPC32-NEXT: stw 31, 28(1)
+; PPC32-NEXT: stw 0, 36(1)
+; PPC32-NEXT: .cfi_def_cfa_offset 32
+; PPC32-NEXT: .cfi_offset r31, -4
+; PPC32-NEXT: .cfi_offset lr, 4
+; PPC32-NEXT: mr 31, 1
+; PPC32-NEXT: .cfi_def_cfa_register r31
+; PPC32-NEXT: mfcr 12
+; PPC32-NEXT: stw 12, 24(31)
+; PPC32-NEXT: li 3, 1
+; PPC32-NEXT: li 4, 2
+; PPC32-NEXT: li 5, 3
+; PPC32-NEXT: li 6, 0
+; PPC32-NEXT: #APP
+; PPC32-EMPTY:
+; PPC32-NEXT: mtcr 6
+; PPC32-NEXT: cmpw 2, 4, 3
+; PPC32-NEXT: mfcr 3
+; PPC32-NEXT: #NO_APP
+; PPC32-NEXT: stw 3, 20(31)
+; PPC32-NEXT: bl foo
+; PPC32-NEXT: lwz 3, 20(31)
+; PPC32-NEXT: lwz 12, 24(31)
+; PPC32-NEXT: mtocrf 32, 12
+; PPC32-NEXT: lwz 0, 36(1)
+; PPC32-NEXT: lwz 31, 28(1)
+; PPC32-NEXT: addi 1, 1, 32
+; PPC32-NEXT: mtlr 0
+; PPC32-NEXT: blr
+;
+; PPC64-LABEL: test_cr2:
+; PPC64: # %bb.0: # %entry
+; PPC64-NEXT: mflr 0
+; PPC64-NEXT: mfcr 12
+; PPC64-NEXT: stw 12, 8(1)
+; PPC64-NEXT: stdu 1, -128(1)
+; PPC64-NEXT: std 0, 144(1)
+; PPC64-NEXT: .cfi_def_cfa_offset 128
+; PPC64-NEXT: .cfi_offset lr, 16
+; PPC64-NEXT: .cfi_offset cr2, 8
+; PPC64-NEXT: li 3, 1
+; PPC64-NEXT: li 4, 2
+; PPC64-NEXT: li 5, 3
+; PPC64-NEXT: li 6, 0
+; PPC64-NEXT: #APP
+; PPC64-EMPTY:
+; PPC64-NEXT: mtcr 6
+; PPC64-NEXT: cmpw 2, 4, 3
+; PPC64-NEXT: mfcr 3
+; PPC64-NEXT: #NO_APP
+; PPC64-NEXT: stw 3, 124(1)
+; PPC64-NEXT: bl foo
+; PPC64-NEXT: nop
+; PPC64-NEXT: lwz 3, 124(1)
+; PPC64-NEXT: addi 1, 1, 128
+; PPC64-NEXT: ld 0, 16(1)
+; PPC64-NEXT: lwz 12, 8(1)
+; PPC64-NEXT: mtocrf 32, 12
+; PPC64-NEXT: mtlr 0
+; PPC64-NEXT: blr
+;
+; PPC64-ELFv2-LABEL: test_cr2:
+; PPC64-ELFv2: # %bb.0: # %entry
+; PPC64-ELFv2-NEXT: mflr 0
+; PPC64-ELFv2-NEXT: mfocrf 12, 32
+; PPC64-ELFv2-NEXT: stw 12, 8(1)
+; PPC64-ELFv2-NEXT: stdu 1, -112(1)
+; PPC64-ELFv2-NEXT: std 0, 128(1)
+; PPC64-ELFv2-NEXT: .cfi_def_cfa_offset 112
+; PPC64-ELFv2-NEXT: .cfi_offset lr, 16
+; PPC64-ELFv2-NEXT: .cfi_offset cr2, 8
+; PPC64-ELFv2-NEXT: li 3, 1
+; PPC64-ELFv2-NEXT: li 4, 2
+; PPC64-ELFv2-NEXT: li 5, 3
+; PPC64-ELFv2-NEXT: li 6, 0
+; PPC64-ELFv2-NEXT: #APP
+; PPC64-ELFv2-EMPTY:
+; PPC64-ELFv2-NEXT: mtcr 6
+; PPC64-ELFv2-NEXT: cmpw 2, 4, 3
+; PPC64-ELFv2-NEXT: mfcr 3
+; PPC64-ELFv2-NEXT: #NO_APP
+; PPC64-ELFv2-NEXT: stw 3, 108(1)
+; PPC64-ELFv2-NEXT: bl foo
+; PPC64-ELFv2-NEXT: nop
+; PPC64-ELFv2-NEXT: lwz 3, 108(1)
+; PPC64-ELFv2-NEXT: addi 1, 1, 112
+; PPC64-ELFv2-NEXT: ld 0, 16(1)
+; PPC64-ELFv2-NEXT: lwz 12, 8(1)
+; PPC64-ELFv2-NEXT: mtocrf 32, 12
+; PPC64-ELFv2-NEXT: mtlr 0
+; PPC64-ELFv2-NEXT: blr
entry:
%ret = alloca i32, align 4
%0 = call i32 asm sideeffect "\0A\09mtcr $4\0A\09cmpw 2,$2,$1\0A\09mfcr $0", "=r,r,r,r,r,~{cr2}"(i32 1, i32 2, i32 3, i32 0) nounwind
@@ -14,27 +110,104 @@ entry:
ret i32 %1
}
-; PPC32-LABEL: test_cr2:
-; PPC32: stwu 1, -32(1)
-; PPC32: stw 31, 28(1)
-; PPC32: mfcr 12
-; PPC32-NEXT: stw 12, 24(31)
-; PPC32: lwz 12, 24(31)
-; PPC32-NEXT: mtocrf 32, 12
-
-; PPC64: .cfi_startproc
-; PPC64: mfcr 12
-; PPC64: stw 12, 8(1)
-; PPC64: stdu 1, -[[AMT:[0-9]+]](1)
-; PPC64: .cfi_def_cfa_offset 128
-; PPC64: .cfi_offset lr, 16
-; PPC64: .cfi_offset cr2, 8
-; PPC64: addi 1, 1, [[AMT]]
-; PPC64: lwz 12, 8(1)
-; PPC64: mtocrf 32, 12
-; PPC64: .cfi_endproc
-
define i32 @test_cr234() nounwind {
+; PPC32-LABEL: test_cr234:
+; PPC32: # %bb.0: # %entry
+; PPC32-NEXT: mflr 0
+; PPC32-NEXT: stwu 1, -32(1)
+; PPC32-NEXT: stw 31, 28(1)
+; PPC32-NEXT: stw 0, 36(1)
+; PPC32-NEXT: mr 31, 1
+; PPC32-NEXT: mfcr 12
+; PPC32-NEXT: stw 12, 24(31)
+; PPC32-NEXT: li 3, 1
+; PPC32-NEXT: li 4, 2
+; PPC32-NEXT: li 5, 3
+; PPC32-NEXT: li 6, 0
+; PPC32-NEXT: #APP
+; PPC32-EMPTY:
+; PPC32-NEXT: mtcr 6
+; PPC32-NEXT: cmpw 2, 4, 3
+; PPC32-NEXT: cmpw 3, 4, 4
+; PPC32-NEXT: cmpw 4, 4, 5
+; PPC32-NEXT: mfcr 3
+; PPC32-NEXT: #NO_APP
+; PPC32-NEXT: stw 3, 20(31)
+; PPC32-NEXT: bl foo
+; PPC32-NEXT: lwz 3, 20(31)
+; PPC32-NEXT: lwz 12, 24(31)
+; PPC32-NEXT: mtocrf 32, 12
+; PPC32-NEXT: mtocrf 16, 12
+; PPC32-NEXT: mtocrf 8, 12
+; PPC32-NEXT: lwz 0, 36(1)
+; PPC32-NEXT: lwz 31, 28(1)
+; PPC32-NEXT: addi 1, 1, 32
+; PPC32-NEXT: mtlr 0
+; PPC32-NEXT: blr
+;
+; PPC64-LABEL: test_cr234:
+; PPC64: # %bb.0: # %entry
+; PPC64-NEXT: mflr 0
+; PPC64-NEXT: mfcr 12
+; PPC64-NEXT: stw 12, 8(1)
+; PPC64-NEXT: stdu 1, -128(1)
+; PPC64-NEXT: std 0, 144(1)
+; PPC64-NEXT: li 3, 1
+; PPC64-NEXT: li 4, 2
+; PPC64-NEXT: li 5, 3
+; PPC64-NEXT: li 6, 0
+; PPC64-NEXT: #APP
+; PPC64-EMPTY:
+; PPC64-NEXT: mtcr 6
+; PPC64-NEXT: cmpw 2, 4, 3
+; PPC64-NEXT: cmpw 3, 4, 4
+; PPC64-NEXT: cmpw 4, 4, 5
+; PPC64-NEXT: mfcr 3
+; PPC64-NEXT: #NO_APP
+; PPC64-NEXT: stw 3, 124(1)
+; PPC64-NEXT: bl foo
+; PPC64-NEXT: nop
+; PPC64-NEXT: lwz 3, 124(1)
+; PPC64-NEXT: addi 1, 1, 128
+; PPC64-NEXT: ld 0, 16(1)
+; PPC64-NEXT: lwz 12, 8(1)
+; PPC64-NEXT: mtocrf 32, 12
+; PPC64-NEXT: mtocrf 16, 12
+; PPC64-NEXT: mtocrf 8, 12
+; PPC64-NEXT: mtlr 0
+; PPC64-NEXT: blr
+;
+; PPC64-ELFv2-LABEL: test_cr234:
+; PPC64-ELFv2: # %bb.0: # %entry
+; PPC64-ELFv2-NEXT: mflr 0
+; PPC64-ELFv2-NEXT: mfcr 12
+; PPC64-ELFv2-NEXT: stw 12, 8(1)
+; PPC64-ELFv2-NEXT: stdu 1, -112(1)
+; PPC64-ELFv2-NEXT: std 0, 128(1)
+; PPC64-ELFv2-NEXT: li 3, 1
+; PPC64-ELFv2-NEXT: li 4, 2
+; PPC64-ELFv2-NEXT: li 5, 3
+; PPC64-ELFv2-NEXT: li 6, 0
+; PPC64-ELFv2-NEXT: #APP
+; PPC64-ELFv2-EMPTY:
+; PPC64-ELFv2-NEXT: mtcr 6
+; PPC64-ELFv2-NEXT: cmpw 2, 4, 3
+; PPC64-ELFv2-NEXT: cmpw 3, 4, 4
+; PPC64-ELFv2-NEXT: cmpw 4, 4, 5
+; PPC64-ELFv2-NEXT: mfcr 3
+; PPC64-ELFv2-NEXT: #NO_APP
+; PPC64-ELFv2-NEXT: stw 3, 108(1)
+; PPC64-ELFv2-NEXT: bl foo
+; PPC64-ELFv2-NEXT: nop
+; PPC64-ELFv2-NEXT: lwz 3, 108(1)
+; PPC64-ELFv2-NEXT: addi 1, 1, 112
+; PPC64-ELFv2-NEXT: ld 0, 16(1)
+; PPC64-ELFv2-NEXT: lwz 12, 8(1)
+; PPC64-ELFv2-NEXT: mtocrf 32, 12
+; PPC64-ELFv2-NEXT: mtocrf 16, 12
+; PPC64-ELFv2-NEXT: mtocrf 8, 12
+; PPC64-ELFv2-NEXT: mtlr 0
+; PPC64-ELFv2-NEXT: blr
entry:
%ret = alloca i32, align 4
%0 = call i32 asm sideeffect "\0A\09mtcr $4\0A\09cmpw 2,$2,$1\0A\09cmpw 3,$2,$2\0A\09cmpw 4,$2,$3\0A\09mfcr $0", "=r,r,r,r,r,~{cr2},~{cr3},~{cr4}"(i32 1, i32 2, i32 3, i32 0) nounwind
@@ -44,41 +217,102 @@ entry:
ret i32 %1
}
-; PPC32-LABEL: test_cr234:
-; PPC32: stwu 1, -32(1)
-; PPC32: stw 31, 28(1)
-; PPC32: mfcr 12
-; PPC32-NEXT: stw 12, 24(31)
-; PPC32: lwz 12, 24(31)
-; PPC32-NEXT: mtocrf 32, 12
-; PPC32-NEXT: mtocrf 16, 12
-; PPC32-NEXT: mtocrf 8, 12
-
-; PPC64: mfcr 12
-; PPC64: stw 12, 8(1)
-; PPC64: stdu 1, -[[AMT:[0-9]+]](1)
-; PPC64: addi 1, 1, [[AMT]]
-; PPC64: lwz 12, 8(1)
-; PPC64: mtocrf 32, 12
-; PPC64: mtocrf 16, 12
-; PPC64: mtocrf 8, 12
-
; Generate mfocrf in prologue when we need to save 1 nonvolatile CR field
define void @cloberOneNvCrField() {
+; PPC32-LABEL: cloberOneNvCrField:
+; PPC32: # %bb.0: # %entry
+; PPC32-NEXT: stwu 1, -32(1)
+; PPC32-NEXT: stw 31, 28(1)
+; PPC32-NEXT: .cfi_def_cfa_offset 32
+; PPC32-NEXT: .cfi_offset r31, -4
+; PPC32-NEXT: mr 31, 1
+; PPC32-NEXT: .cfi_def_cfa_register r31
+; PPC32-NEXT: mfcr 12
+; PPC32-NEXT: stw 12, 24(31)
+; PPC32-NEXT: #APP
+; PPC32-NEXT: # clobbers
+; PPC32-NEXT: #NO_APP
+; PPC32-NEXT: lwz 12, 24(31)
+; PPC32-NEXT: mtocrf 32, 12
+; PPC32-NEXT: lwz 31, 28(1)
+; PPC32-NEXT: addi 1, 1, 32
+; PPC32-NEXT: blr
+;
+; PPC64-LABEL: cloberOneNvCrField:
+; PPC64: # %bb.0: # %entry
+; PPC64-NEXT: mfcr 12
+; PPC64-NEXT: stw 12, 8(1)
+; PPC64-NEXT: #APP
+; PPC64-NEXT: # clobbers
+; PPC64-NEXT: #NO_APP
+; PPC64-NEXT: lwz 12, 8(1)
+; PPC64-NEXT: mtocrf 32, 12
+; PPC64-NEXT: blr
+;
+; PPC64-ELFv2-LABEL: cloberOneNvCrField:
+; PPC64-ELFv2: # %bb.0: # %entry
+; PPC64-ELFv2-NEXT: mfocrf 12, 32
+; PPC64-ELFv2-NEXT: stw 12, 8(1)
+; PPC64-ELFv2-NEXT: #APP
+; PPC64-ELFv2-NEXT: # clobbers
+; PPC64-ELFv2-NEXT: #NO_APP
+; PPC64-ELFv2-NEXT: lwz 12, 8(1)
+; PPC64-ELFv2-NEXT: mtocrf 32, 12
+; PPC64-ELFv2-NEXT: blr
entry:
tail call void asm sideeffect "# clobbers", "~{cr2}"()
ret void
-
-; PPC64-ELFv2-LABEL: @cloberOneNvCrField
-; PPC64-ELFv2: mfocrf [[REG1:[0-9]+]], 32
}
; Generate mfcr in prologue when we need to save all nonvolatile CR field
define void @cloberAllNvCrField() {
+; PPC32-LABEL: cloberAllNvCrField:
+; PPC32: # %bb.0: # %entry
+; PPC32-NEXT: stwu 1, -32(1)
+; PPC32-NEXT: stw 31, 28(1)
+; PPC32-NEXT: .cfi_def_cfa_offset 32
+; PPC32-NEXT: .cfi_offset r31, -4
+; PPC32-NEXT: mr 31, 1
+; PPC32-NEXT: .cfi_def_cfa_register r31
+; PPC32-NEXT: mfcr 12
+; PPC32-NEXT: stw 12, 24(31)
+; PPC32-NEXT: #APP
+; PPC32-NEXT: # clobbers
+; PPC32-NEXT: #NO_APP
+; PPC32-NEXT: lwz 12, 24(31)
+; PPC32-NEXT: mtocrf 32, 12
+; PPC32-NEXT: mtocrf 16, 12
+; PPC32-NEXT: mtocrf 8, 12
+; PPC32-NEXT: lwz 31, 28(1)
+; PPC32-NEXT: addi 1, 1, 32
+; PPC32-NEXT: blr
+;
+; PPC64-LABEL: cloberAllNvCrField:
+; PPC64: # %bb.0: # %entry
+; PPC64-NEXT: mfcr 12
+; PPC64-NEXT: stw 12, 8(1)
+; PPC64-NEXT: #APP
+; PPC64-NEXT: # clobbers
+; PPC64-NEXT: #NO_APP
+; PPC64-NEXT: lwz 12, 8(1)
+; PPC64-NEXT: mtocrf 32, 12
+; PPC64-NEXT: mtocrf 16, 12
+; PPC64-NEXT: mtocrf 8, 12
+; PPC64-NEXT: blr
+;
+; PPC64-ELFv2-LABEL: cloberAllNvCrField:
+; PPC64-ELFv2: # %bb.0: # %entry
+; PPC64-ELFv2-NEXT: mfcr 12
+; PPC64-ELFv2-NEXT: stw 12, 8(1)
+; PPC64-ELFv2-NEXT: #APP
+; PPC64-ELFv2-NEXT: # clobbers
+; PPC64-ELFv2-NEXT: #NO_APP
+; PPC64-ELFv2-NEXT: lwz 12, 8(1)
+; PPC64-ELFv2-NEXT: mtocrf 32, 12
+; PPC64-ELFv2-NEXT: mtocrf 16, 12
+; PPC64-ELFv2-NEXT: mtocrf 8, 12
+; PPC64-ELFv2-NEXT: blr
entry:
tail call void asm sideeffect "# clobbers", "~{cr2},~{cr3},~{cr4}"()
ret void
-
-; PPC64-ELFv2-LABEL: @cloberAllNvCrField
-; PPC64-ELFv2: mfcr [[REG1:[0-9]+]]
}
>From bfcd3fa825dde06e49235620fd157540c6c1b7d7 Mon Sep 17 00:00:00 2001
From: Alexander Belyaev <32522095+pifon2a at users.noreply.github.com>
Date: Thu, 29 Feb 2024 10:57:09 +0100
Subject: [PATCH 104/406] [mlir] Add result name for gpu.block_id and
gpu.thread_id ops. (#83393)
expand-arith-ops.mlir fails on windows, but this is unrelated to this PR
---
mlir/include/mlir/Dialect/GPU/IR/GPUOps.td | 15 ++++++++++++++-
mlir/test/Dialect/GPU/ops.mlir | 15 +++++++++++++++
mlir/test/python/dialects/gpu/dialect.py | 2 +-
3 files changed, 30 insertions(+), 2 deletions(-)
diff --git a/mlir/include/mlir/Dialect/GPU/IR/GPUOps.td b/mlir/include/mlir/Dialect/GPU/IR/GPUOps.td
index 955dd1e20d2488..f38ef4d709ef44 100644
--- a/mlir/include/mlir/Dialect/GPU/IR/GPUOps.td
+++ b/mlir/include/mlir/Dialect/GPU/IR/GPUOps.td
@@ -24,6 +24,7 @@ include "mlir/IR/EnumAttr.td"
include "mlir/IR/SymbolInterfaces.td"
include "mlir/Interfaces/ControlFlowInterfaces.td"
include "mlir/Interfaces/DataLayoutInterfaces.td"
+include "mlir/IR/OpAsmInterface.td"
include "mlir/Interfaces/FunctionInterfaces.td"
include "mlir/Interfaces/InferIntRangeInterface.td"
include "mlir/Interfaces/InferTypeOpInterface.td"
@@ -50,9 +51,21 @@ def GPU_DimensionAttr : EnumAttr<GPU_Dialect, GPU_Dimension, "dim">;
class GPU_IndexOp<string mnemonic, list<Trait> traits = []> :
GPU_Op<mnemonic, !listconcat(traits, [
- Pure, DeclareOpInterfaceMethods<InferIntRangeInterface>])>,
+ Pure,
+ DeclareOpInterfaceMethods<InferIntRangeInterface>,
+ DeclareOpInterfaceMethods<OpAsmOpInterface, ["getAsmResultNames"]>])>,
Arguments<(ins GPU_DimensionAttr:$dimension)>, Results<(outs Index)> {
let assemblyFormat = "$dimension attr-dict";
+ let extraClassDefinition = [{
+ void $cppClass::getAsmResultNames(
+ llvm::function_ref<void(mlir::Value, mlir::StringRef)> setNameFn) {
+ auto dimStr = stringifyDimension(getDimensionAttr().getValue());
+ auto opName = getOperationName();
+ assert(opName.consume_front("gpu."));
+ SmallString<8> resultName({opName, "_", dimStr});
+ setNameFn(getResult(),resultName);
+ }
+ }];
}
def GPU_ClusterDimOp : GPU_IndexOp<"cluster_dim"> {
diff --git a/mlir/test/Dialect/GPU/ops.mlir b/mlir/test/Dialect/GPU/ops.mlir
index 8d249c9e9b9b8a..511b018877476f 100644
--- a/mlir/test/Dialect/GPU/ops.mlir
+++ b/mlir/test/Dialect/GPU/ops.mlir
@@ -59,24 +59,39 @@ module attributes {gpu.container_module} {
gpu.module @kernels {
gpu.func @kernel_1(%arg0 : f32, %arg1 : memref<?xf32, 1>) kernel {
%tIdX = gpu.thread_id x
+ // CHECK: thread_id_x
%tIdY = gpu.thread_id y
+ // CHECK-NEXT: thread_id_y
%tIdZ = gpu.thread_id z
+ // CHECK-NEXT: thread_id_z
%bDimX = gpu.block_dim x
+ // CHECK-NEXT: block_dim_x
%bDimY = gpu.block_dim y
+ // CHECK-NEXT: block_dim_y
%bDimZ = gpu.block_dim z
+ // CHECK-NEXT: block_dim_z
%bIdX = gpu.block_id x
+ // CHECK-NEXT: block_id_x
%bIdY = gpu.block_id y
+ // CHECK-NEXT: block_id_y
%bIdZ = gpu.block_id z
+ // CHECK-NEXT: block_id_z
%gDimX = gpu.grid_dim x
+ // CHECK-NEXT: grid_dim_x
%gDimY = gpu.grid_dim y
+ // CHECK-NEXT: grid_dim_y
%gDimZ = gpu.grid_dim z
+ // CHECK-NEXT: grid_dim_z
%gIdX = gpu.global_id x
+ // CHECK-NEXT: global_id_x
%gIdY = gpu.global_id y
+ // CHECK-NEXT: global_id_y
%gIdZ = gpu.global_id z
+ // CHECK-NEXT: global_id_z
%sgId = gpu.subgroup_id : index
%numSg = gpu.num_subgroups : index
diff --git a/mlir/test/python/dialects/gpu/dialect.py b/mlir/test/python/dialects/gpu/dialect.py
index 0293e8f276be6b..2f49e2e053999b 100644
--- a/mlir/test/python/dialects/gpu/dialect.py
+++ b/mlir/test/python/dialects/gpu/dialect.py
@@ -27,6 +27,6 @@ def testMMAElementWiseAttr():
module = Module.create()
with InsertionPoint(module.body):
gpu.BlockDimOp(gpu.Dimension.y)
- # CHECK: %0 = gpu.block_dim y
+ # CHECK: %block_dim_y = gpu.block_dim y
print(module)
pass
>From afa6b5e5763059c65f21ca2e612df3d02e71ad00 Mon Sep 17 00:00:00 2001
From: Benjamin Maxwell <benjamin.maxwell at arm.com>
Date: Thu, 29 Feb 2024 10:17:26 +0000
Subject: [PATCH 105/406] [mlir][ArmSME] Fix matmul.mlir test after #83213
---
.../Integration/Dialect/Linalg/CPU/ArmSVE/matmul.mlir | 8 ++++----
1 file changed, 4 insertions(+), 4 deletions(-)
diff --git a/mlir/test/Integration/Dialect/Linalg/CPU/ArmSVE/matmul.mlir b/mlir/test/Integration/Dialect/Linalg/CPU/ArmSVE/matmul.mlir
index 22cf15d4f64047..51a0c8f7c945aa 100644
--- a/mlir/test/Integration/Dialect/Linalg/CPU/ArmSVE/matmul.mlir
+++ b/mlir/test/Integration/Dialect/Linalg/CPU/ArmSVE/matmul.mlir
@@ -36,7 +36,7 @@ func.func @matmul_f32() {
// Print and verify the output
// F32-LABEL: SVE: START OF TEST OUTPUT
- vector.print str "SVE: START OF TEST OUTPUT"
+ vector.print str "SVE: START OF TEST OUTPUT\n"
// F32-NEXT: Unranked Memref {{.*}} rank = 2 offset = 0 sizes = [5, 15] strides = [15, 1] data =
// F32-COUNT-5: [29.5788, 29.5788, 29.5788, 29.5788, 29.5788, 29.5788, 29.5788, 29.5788, 29.5788, 29.5788, 29.5788, 29.5788, 29.5788, 29.5788, 29.5788]
@@ -44,7 +44,7 @@ func.func @matmul_f32() {
call @printMemrefF32(%xf) : (tensor<*xf32>) -> ()
// F32-NEXT: SVE: END OF TEST OUTPUT
- vector.print str "SVE: END OF TEST OUTPUT"
+ vector.print str "SVE: END OF TEST OUTPUT\n"
return
}
@@ -73,7 +73,7 @@ func.func @matmul_mixed_ty() {
// Print and verify the output
// MIXED-LABEL: SVE: START OF TEST OUTPUT
- vector.print str "SVE: START OF TEST OUTPUT"
+ vector.print str "SVE: START OF TEST OUTPUT\n"
// MIXED-NEXT: Unranked Memref {{.*}} rank = 2 offset = 0 sizes = [5, 15] strides = [15, 1] data =
// MIXED-COUNT-5: [45387, 45387, 45387, 45387, 45387, 45387, 45387, 45387, 45387, 45387, 45387, 45387, 45387, 45387, 45387]
@@ -81,7 +81,7 @@ func.func @matmul_mixed_ty() {
call @printMemrefI32(%xf) : (tensor<*xi32>) -> ()
// MIXED-NEXT: SVE: END OF TEST OUTPUT
- vector.print str "SVE: END OF TEST OUTPUT"
+ vector.print str "SVE: END OF TEST OUTPUT\n"
return
}
>From 30b63def5096cbee448176cc82ca5f6c995f16c4 Mon Sep 17 00:00:00 2001
From: Simon Pilgrim <llvm-dev at redking.me.uk>
Date: Wed, 28 Feb 2024 22:37:49 +0000
Subject: [PATCH 106/406] [X86] Regenerate tests to add missing avx512 constant
comments
---
llvm/test/CodeGen/X86/avx512fp16-fp-logic.ll | 12 ++++++------
llvm/test/CodeGen/X86/pr34605.ll | 2 +-
llvm/test/CodeGen/X86/pr38803.ll | 2 +-
llvm/test/CodeGen/X86/pr43509.ll | 2 +-
llvm/test/CodeGen/X86/pr57340.ll | 2 +-
llvm/test/CodeGen/X86/pr78897.ll | 4 ++--
llvm/test/CodeGen/X86/select-of-fp-constants.ll | 2 +-
llvm/test/CodeGen/X86/select-of-half-constants.ll | 8 ++++----
8 files changed, 17 insertions(+), 17 deletions(-)
diff --git a/llvm/test/CodeGen/X86/avx512fp16-fp-logic.ll b/llvm/test/CodeGen/X86/avx512fp16-fp-logic.ll
index e2ea8974f6551f..f6fb2fcc957ef2 100644
--- a/llvm/test/CodeGen/X86/avx512fp16-fp-logic.ll
+++ b/llvm/test/CodeGen/X86/avx512fp16-fp-logic.ll
@@ -92,7 +92,7 @@ define half @f6(half %x, i16 %y) {
define half @f7(half %x) {
; CHECK-LABEL: f7:
; CHECK: # %bb.0:
-; CHECK-NEXT: vmovsh {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
+; CHECK-NEXT: vmovsh {{.*#+}} xmm1 = [1.7881E-7,0.0E+0,0.0E+0,0.0E+0,0.0E+0,0.0E+0,0.0E+0,0.0E+0]
; CHECK-NEXT: vandps %xmm1, %xmm0, %xmm0
; CHECK-NEXT: retq
%bc1 = bitcast half %x to i16
@@ -106,7 +106,7 @@ define half @f7(half %x) {
define half @f8(half %x) {
; CHECK-LABEL: f8:
; CHECK: # %bb.0:
-; CHECK-NEXT: vmovsh {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
+; CHECK-NEXT: vmovsh {{.*#+}} xmm1 = [2.3842E-7,0.0E+0,0.0E+0,0.0E+0,0.0E+0,0.0E+0,0.0E+0,0.0E+0]
; CHECK-NEXT: vandps %xmm1, %xmm0, %xmm0
; CHECK-NEXT: retq
%bc1 = bitcast half %x to i16
@@ -171,7 +171,7 @@ define half @xor(half %x, half %y) {
define half @f7_or(half %x) {
; CHECK-LABEL: f7_or:
; CHECK: # %bb.0:
-; CHECK-NEXT: vmovsh {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
+; CHECK-NEXT: vmovsh {{.*#+}} xmm1 = [1.7881E-7,0.0E+0,0.0E+0,0.0E+0,0.0E+0,0.0E+0,0.0E+0,0.0E+0]
; CHECK-NEXT: vorps %xmm1, %xmm0, %xmm0
; CHECK-NEXT: retq
%bc1 = bitcast half %x to i16
@@ -183,7 +183,7 @@ define half @f7_or(half %x) {
define half @f7_xor(half %x) {
; CHECK-LABEL: f7_xor:
; CHECK: # %bb.0:
-; CHECK-NEXT: vmovsh {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
+; CHECK-NEXT: vmovsh {{.*#+}} xmm1 = [1.7881E-7,0.0E+0,0.0E+0,0.0E+0,0.0E+0,0.0E+0,0.0E+0,0.0E+0]
; CHECK-NEXT: vxorps %xmm1, %xmm0, %xmm0
; CHECK-NEXT: retq
%bc1 = bitcast half %x to i16
@@ -199,7 +199,7 @@ define half @f7_xor(half %x) {
define half @movmsk(half %x) {
; CHECK-LABEL: movmsk:
; CHECK: # %bb.0:
-; CHECK-NEXT: vmovsh {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
+; CHECK-NEXT: vmovsh {{.*#+}} xmm1 = [-0.0E+0,0.0E+0,0.0E+0,0.0E+0,0.0E+0,0.0E+0,0.0E+0,0.0E+0]
; CHECK-NEXT: vandps %xmm1, %xmm0, %xmm0
; CHECK-NEXT: retq
%bc1 = bitcast half %x to i16
@@ -271,7 +271,7 @@ define half @fadd_bitcast_fneg(half %x, half %y) {
define half @fsub_bitcast_fneg(half %x, half %y) {
; CHECK-LABEL: fsub_bitcast_fneg:
; CHECK: # %bb.0:
-; CHECK-NEXT: vmovsh {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm2
+; CHECK-NEXT: vmovsh {{.*#+}} xmm2 = [NaN,0.0E+0,0.0E+0,0.0E+0,0.0E+0,0.0E+0,0.0E+0,0.0E+0]
; CHECK-NEXT: vxorps %xmm2, %xmm1, %xmm1
; CHECK-NEXT: vsubsh %xmm1, %xmm0, %xmm0
; CHECK-NEXT: retq
diff --git a/llvm/test/CodeGen/X86/pr34605.ll b/llvm/test/CodeGen/X86/pr34605.ll
index 863b0ffc93a9e4..25dd6a7436a8a9 100644
--- a/llvm/test/CodeGen/X86/pr34605.ll
+++ b/llvm/test/CodeGen/X86/pr34605.ll
@@ -17,7 +17,7 @@ define void @pr34605(ptr nocapture %s, i32 %p) {
; CHECK-NEXT: kmovd %ecx, %k1
; CHECK-NEXT: kmovd %k1, %k1
; CHECK-NEXT: kandq %k1, %k0, %k1
-; CHECK-NEXT: vmovdqu8 {{\.?LCPI[0-9]+_[0-9]+}}, %zmm0 {%k1} {z}
+; CHECK-NEXT: vmovdqu8 {{.*#+}} zmm0 {%k1} {z} = [1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1]
; CHECK-NEXT: vmovdqu64 %zmm0, (%eax)
; CHECK-NEXT: vpxor %xmm0, %xmm0, %xmm0
; CHECK-NEXT: vmovdqu64 %zmm0, 64(%eax)
diff --git a/llvm/test/CodeGen/X86/pr38803.ll b/llvm/test/CodeGen/X86/pr38803.ll
index 61dc228d1d1ff5..ebac8121df913b 100644
--- a/llvm/test/CodeGen/X86/pr38803.ll
+++ b/llvm/test/CodeGen/X86/pr38803.ll
@@ -13,7 +13,7 @@ define dso_local float @_Z3fn2v() {
; CHECK-NEXT: callq _Z1av at PLT
; CHECK-NEXT: # kill: def $al killed $al def $eax
; CHECK-NEXT: kmovd %eax, %k1
-; CHECK-NEXT: vmovss {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0 {%k1} {z}
+; CHECK-NEXT: vmovss {{.*#+}} xmm0 {%k1} {z} = [7.5E-1,0.0E+0,0.0E+0,0.0E+0]
; CHECK-NEXT: cmpl $0, c(%rip)
; CHECK-NEXT: je .LBB0_2
; CHECK-NEXT: # %bb.1: # %if.then
diff --git a/llvm/test/CodeGen/X86/pr43509.ll b/llvm/test/CodeGen/X86/pr43509.ll
index 87ddad03e9c452..a29fe4c6a0465a 100644
--- a/llvm/test/CodeGen/X86/pr43509.ll
+++ b/llvm/test/CodeGen/X86/pr43509.ll
@@ -7,7 +7,7 @@ define <8 x i8> @foo(<8 x float> %arg) {
; CHECK-NEXT: vxorps %xmm1, %xmm1, %xmm1
; CHECK-NEXT: vcmpltps %ymm1, %ymm0, %k1
; CHECK-NEXT: vcmpgtps {{\.?LCPI[0-9]+_[0-9]+}}(%rip){1to8}, %ymm0, %k1 {%k1}
-; CHECK-NEXT: vmovdqu8 {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0 {%k1} {z}
+; CHECK-NEXT: vmovdqu8 {{.*#+}} xmm0 {%k1} {z} = [1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1]
; CHECK-NEXT: vzeroupper
; CHECK-NEXT: retq
bb:
diff --git a/llvm/test/CodeGen/X86/pr57340.ll b/llvm/test/CodeGen/X86/pr57340.ll
index 57f52c8dcdbb06..f373fb9af22b37 100644
--- a/llvm/test/CodeGen/X86/pr57340.ll
+++ b/llvm/test/CodeGen/X86/pr57340.ll
@@ -294,7 +294,7 @@ define void @main.41() local_unnamed_addr #1 {
; CHECK-NEXT: kmovd %eax, %k1
; CHECK-NEXT: kshiftlw $15, %k1, %k1
; CHECK-NEXT: korw %k1, %k0, %k1
-; CHECK-NEXT: vmovdqu8 {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0 {%k1} {z}
+; CHECK-NEXT: vmovdqu8 {{.*#+}} xmm0 {%k1} {z} = [1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1]
; CHECK-NEXT: vmovdqa %xmm0, (%rax)
; CHECK-NEXT: vzeroupper
; CHECK-NEXT: retq
diff --git a/llvm/test/CodeGen/X86/pr78897.ll b/llvm/test/CodeGen/X86/pr78897.ll
index 0c1c3cafc4ea6b..56e4ec2bc8ecbb 100644
--- a/llvm/test/CodeGen/X86/pr78897.ll
+++ b/llvm/test/CodeGen/X86/pr78897.ll
@@ -225,7 +225,7 @@ define <16 x i8> @produceShuffleVectorForByte(i8 zeroext %0) nounwind {
; X86-AVX512-NEXT: pushl %esi
; X86-AVX512-NEXT: vpbroadcastb {{[0-9]+}}(%esp), %xmm0
; X86-AVX512-NEXT: vptestnmb {{\.?LCPI[0-9]+_[0-9]+}}, %xmm0, %k1
-; X86-AVX512-NEXT: vmovdqu8 {{\.?LCPI[0-9]+_[0-9]+}}, %xmm0 {%k1} {z}
+; X86-AVX512-NEXT: vmovdqu8 {{.*#+}} xmm0 {%k1} {z} = [17,17,17,17,17,17,17,17,u,u,u,u,u,u,u,u]
; X86-AVX512-NEXT: vpextrd $1, %xmm0, %eax
; X86-AVX512-NEXT: vmovd %xmm0, %edx
; X86-AVX512-NEXT: movl $286331152, %ecx # imm = 0x11111110
@@ -258,7 +258,7 @@ define <16 x i8> @produceShuffleVectorForByte(i8 zeroext %0) nounwind {
; X64-AVX512: # %bb.0: # %entry
; X64-AVX512-NEXT: vpbroadcastb %edi, %xmm0
; X64-AVX512-NEXT: vptestnmb {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0, %k1
-; X64-AVX512-NEXT: vmovdqu8 {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0 {%k1} {z}
+; X64-AVX512-NEXT: vmovdqu8 {{.*#+}} xmm0 {%k1} {z} = [17,17,17,17,17,17,17,17,u,u,u,u,u,u,u,u]
; X64-AVX512-NEXT: vmovq %xmm0, %rax
; X64-AVX512-NEXT: movabsq $1229782938247303440, %rcx # imm = 0x1111111111111110
; X64-AVX512-NEXT: movabsq $76861433640456465, %rdx # imm = 0x111111111111111
diff --git a/llvm/test/CodeGen/X86/select-of-fp-constants.ll b/llvm/test/CodeGen/X86/select-of-fp-constants.ll
index 76b8ea8e2b8a2b..2cdaa11a22530b 100644
--- a/llvm/test/CodeGen/X86/select-of-fp-constants.ll
+++ b/llvm/test/CodeGen/X86/select-of-fp-constants.ll
@@ -86,7 +86,7 @@ define float @fcmp_select_fp_constants(float %x) nounwind readnone {
; X64-AVX512F: # %bb.0:
; X64-AVX512F-NEXT: vcmpneqss {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0, %k1
; X64-AVX512F-NEXT: vmovss {{.*#+}} xmm0 = [2.3E+1,0.0E+0,0.0E+0,0.0E+0]
-; X64-AVX512F-NEXT: vmovss {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0 {%k1}
+; X64-AVX512F-NEXT: vmovss {{.*#+}} xmm0 {%k1} = [4.2E+1,0.0E+0,0.0E+0,0.0E+0]
; X64-AVX512F-NEXT: retq
%c = fcmp une float %x, -4.0
%r = select i1 %c, float 42.0, float 23.0
diff --git a/llvm/test/CodeGen/X86/select-of-half-constants.ll b/llvm/test/CodeGen/X86/select-of-half-constants.ll
index e22d4c8b792dca..e3d92eb474968a 100644
--- a/llvm/test/CodeGen/X86/select-of-half-constants.ll
+++ b/llvm/test/CodeGen/X86/select-of-half-constants.ll
@@ -6,9 +6,9 @@
define half @fcmp_select_fp_constants_olt(half %x) nounwind readnone {
; X64-AVX512FP16-LABEL: fcmp_select_fp_constants_olt:
; X64-AVX512FP16: # %bb.0:
-; X64-AVX512FP16-NEXT: vmovsh {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
+; X64-AVX512FP16-NEXT: vmovsh {{.*#+}} xmm1 = [4.2E+1,0.0E+0,0.0E+0,0.0E+0,0.0E+0,0.0E+0,0.0E+0,0.0E+0]
; X64-AVX512FP16-NEXT: vcmpltsh {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0, %k1
-; X64-AVX512FP16-NEXT: vmovsh {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
+; X64-AVX512FP16-NEXT: vmovsh {{.*#+}} xmm0 = [2.3E+1,0.0E+0,0.0E+0,0.0E+0,0.0E+0,0.0E+0,0.0E+0,0.0E+0]
; X64-AVX512FP16-NEXT: vmovsh %xmm1, %xmm0, %xmm0 {%k1}
; X64-AVX512FP16-NEXT: retq
%c = fcmp olt half %x, -4.0
@@ -19,9 +19,9 @@ define half @fcmp_select_fp_constants_olt(half %x) nounwind readnone {
define half @fcmp_select_fp_constants_ogt(half %x) nounwind readnone {
; X64-AVX512FP16-LABEL: fcmp_select_fp_constants_ogt:
; X64-AVX512FP16: # %bb.0:
-; X64-AVX512FP16-NEXT: vmovsh {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
+; X64-AVX512FP16-NEXT: vmovsh {{.*#+}} xmm1 = [4.2E+1,0.0E+0,0.0E+0,0.0E+0,0.0E+0,0.0E+0,0.0E+0,0.0E+0]
; X64-AVX512FP16-NEXT: vcmpgtsh {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0, %k1
-; X64-AVX512FP16-NEXT: vmovsh {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
+; X64-AVX512FP16-NEXT: vmovsh {{.*#+}} xmm0 = [2.3E+1,0.0E+0,0.0E+0,0.0E+0,0.0E+0,0.0E+0,0.0E+0,0.0E+0]
; X64-AVX512FP16-NEXT: vmovsh %xmm1, %xmm0, %xmm0 {%k1}
; X64-AVX512FP16-NEXT: retq
%c = fcmp ogt half %x, -4.0
>From 7ff3f9760da7d7c8fe9209280aefb05168efcf20 Mon Sep 17 00:00:00 2001
From: Simon Pilgrim <llvm-dev at redking.me.uk>
Date: Thu, 29 Feb 2024 10:32:37 +0000
Subject: [PATCH 107/406] [X86] getFauxShuffleMask - handle
insert_vector_elt(bitcast(extract_vector_elt(x))) shuffle patterns
If the bitcast is between types of equal scalar size (i.e. fp<->int bitcasts), then we can safely peek through them
Fixes #83289
---
llvm/lib/Target/X86/X86ISelLowering.cpp | 7 +-
.../test/CodeGen/X86/avx512-insert-extract.ll | 18 +-
llvm/test/CodeGen/X86/avx512-vec-cmp.ll | 36 ++--
llvm/test/CodeGen/X86/fpclamptosat_vec.ll | 154 ++++----------
llvm/test/CodeGen/X86/half.ll | 123 ++++-------
llvm/test/CodeGen/X86/pr31088.ll | 12 +-
llvm/test/CodeGen/X86/pr57340.ll | 201 +++++++-----------
.../CodeGen/X86/vector-half-conversions.ll | 22 +-
.../CodeGen/X86/vector-reduce-fmax-nnan.ll | 16 +-
.../CodeGen/X86/vector-reduce-fmin-nnan.ll | 16 +-
.../test/CodeGen/X86/vector-shuffle-128-v4.ll | 6 -
11 files changed, 200 insertions(+), 411 deletions(-)
diff --git a/llvm/lib/Target/X86/X86ISelLowering.cpp b/llvm/lib/Target/X86/X86ISelLowering.cpp
index bec13d1c00ef7d..93088c7cde938b 100644
--- a/llvm/lib/Target/X86/X86ISelLowering.cpp
+++ b/llvm/lib/Target/X86/X86ISelLowering.cpp
@@ -5878,13 +5878,16 @@ static bool getFauxShuffleMask(SDValue N, const APInt &DemandedElts,
}
}
- // Peek through trunc/aext/zext.
+ // Peek through trunc/aext/zext/bitcast.
// TODO: aext shouldn't require SM_SentinelZero padding.
// TODO: handle shift of scalars.
unsigned MinBitsPerElt = Scl.getScalarValueSizeInBits();
while (Scl.getOpcode() == ISD::TRUNCATE ||
Scl.getOpcode() == ISD::ANY_EXTEND ||
- Scl.getOpcode() == ISD::ZERO_EXTEND) {
+ Scl.getOpcode() == ISD::ZERO_EXTEND ||
+ (Scl.getOpcode() == ISD::BITCAST &&
+ Scl.getScalarValueSizeInBits() ==
+ Scl.getOperand(0).getScalarValueSizeInBits())) {
Scl = Scl.getOperand(0);
MinBitsPerElt =
std::min<unsigned>(MinBitsPerElt, Scl.getScalarValueSizeInBits());
diff --git a/llvm/test/CodeGen/X86/avx512-insert-extract.ll b/llvm/test/CodeGen/X86/avx512-insert-extract.ll
index abfe3e6428e663..22aae4de4db9d2 100644
--- a/llvm/test/CodeGen/X86/avx512-insert-extract.ll
+++ b/llvm/test/CodeGen/X86/avx512-insert-extract.ll
@@ -2171,19 +2171,14 @@ define void @test_concat_v2i1(ptr %arg, ptr %arg1, ptr %arg2) nounwind {
; KNL-LABEL: test_concat_v2i1:
; KNL: ## %bb.0:
; KNL-NEXT: vmovq {{.*#+}} xmm0 = mem[0],zero
-; KNL-NEXT: vpextrw $0, %xmm0, %eax
-; KNL-NEXT: movzwl %ax, %eax
-; KNL-NEXT: vmovd %eax, %xmm1
+; KNL-NEXT: vpmovzxwq {{.*#+}} xmm1 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
; KNL-NEXT: vcvtph2ps %xmm1, %xmm1
; KNL-NEXT: vmovss {{.*#+}} xmm2 = [6.0E+0,0.0E+0,0.0E+0,0.0E+0]
; KNL-NEXT: vucomiss %xmm2, %xmm1
; KNL-NEXT: setb %al
; KNL-NEXT: andl $1, %eax
; KNL-NEXT: kmovw %eax, %k0
-; KNL-NEXT: vpsrld $16, %xmm0, %xmm0
-; KNL-NEXT: vpextrw $0, %xmm0, %eax
-; KNL-NEXT: movzwl %ax, %eax
-; KNL-NEXT: vmovd %eax, %xmm0
+; KNL-NEXT: vpshufb {{.*#+}} xmm0 = xmm0[2,3],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
; KNL-NEXT: vcvtph2ps %xmm0, %xmm0
; KNL-NEXT: vucomiss %xmm2, %xmm0
; KNL-NEXT: setb %al
@@ -2212,19 +2207,14 @@ define void @test_concat_v2i1(ptr %arg, ptr %arg1, ptr %arg2) nounwind {
; SKX-LABEL: test_concat_v2i1:
; SKX: ## %bb.0:
; SKX-NEXT: vmovq {{.*#+}} xmm0 = mem[0],zero
-; SKX-NEXT: vpsrld $16, %xmm0, %xmm1
-; SKX-NEXT: vpextrw $0, %xmm1, %eax
-; SKX-NEXT: movzwl %ax, %eax
-; SKX-NEXT: vmovd %eax, %xmm1
+; SKX-NEXT: vpshufb {{.*#+}} xmm1 = xmm0[2,3],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
; SKX-NEXT: vcvtph2ps %xmm1, %xmm1
; SKX-NEXT: vmovss {{.*#+}} xmm2 = [6.0E+0,0.0E+0,0.0E+0,0.0E+0]
; SKX-NEXT: vucomiss %xmm2, %xmm1
; SKX-NEXT: setb %al
; SKX-NEXT: kmovd %eax, %k0
; SKX-NEXT: kshiftlb $1, %k0, %k0
-; SKX-NEXT: vpextrw $0, %xmm0, %eax
-; SKX-NEXT: movzwl %ax, %eax
-; SKX-NEXT: vmovd %eax, %xmm0
+; SKX-NEXT: vpmovzxwq {{.*#+}} xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
; SKX-NEXT: vcvtph2ps %xmm0, %xmm0
; SKX-NEXT: vucomiss %xmm2, %xmm0
; SKX-NEXT: setb %al
diff --git a/llvm/test/CodeGen/X86/avx512-vec-cmp.ll b/llvm/test/CodeGen/X86/avx512-vec-cmp.ll
index f5cca7838bd87e..f3c728a990f514 100644
--- a/llvm/test/CodeGen/X86/avx512-vec-cmp.ll
+++ b/llvm/test/CodeGen/X86/avx512-vec-cmp.ll
@@ -1436,10 +1436,9 @@ define void @half_vec_compare(ptr %x, ptr %y) {
; KNL: ## %bb.0: ## %entry
; KNL-NEXT: vmovd {{.*#+}} xmm0 = mem[0],zero,zero,zero
; KNL-NEXT: ## EVEX TO VEX Compression encoding: [0xc5,0xf9,0x6e,0x07]
-; KNL-NEXT: vpsrld $16, %xmm0, %xmm1 ## encoding: [0xc5,0xf1,0x72,0xd0,0x10]
-; KNL-NEXT: vpextrw $0, %xmm1, %eax ## encoding: [0xc5,0xf9,0xc5,0xc1,0x00]
-; KNL-NEXT: movzwl %ax, %eax ## encoding: [0x0f,0xb7,0xc0]
-; KNL-NEXT: vmovd %eax, %xmm1 ## EVEX TO VEX Compression encoding: [0xc5,0xf9,0x6e,0xc8]
+; KNL-NEXT: vpshufb {{.*#+}} xmm1 = xmm0[2,3],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
+; KNL-NEXT: ## encoding: [0xc4,0xe2,0x79,0x00,0x0d,A,A,A,A]
+; KNL-NEXT: ## fixup A - offset: 5, value: {{\.?LCPI[0-9]+_[0-9]+}}-4, kind: reloc_riprel_4byte
; KNL-NEXT: vcvtph2ps %xmm1, %xmm1 ## encoding: [0xc4,0xe2,0x79,0x13,0xc9]
; KNL-NEXT: xorl %eax, %eax ## encoding: [0x31,0xc0]
; KNL-NEXT: vxorps %xmm2, %xmm2, %xmm2 ## encoding: [0xc5,0xe8,0x57,0xd2]
@@ -1449,9 +1448,8 @@ define void @half_vec_compare(ptr %x, ptr %y) {
; KNL-NEXT: movl $0, %edx ## encoding: [0xba,0x00,0x00,0x00,0x00]
; KNL-NEXT: cmovnel %ecx, %edx ## encoding: [0x0f,0x45,0xd1]
; KNL-NEXT: cmovpl %ecx, %edx ## encoding: [0x0f,0x4a,0xd1]
-; KNL-NEXT: vpextrw $0, %xmm0, %edi ## encoding: [0xc5,0xf9,0xc5,0xf8,0x00]
-; KNL-NEXT: movzwl %di, %edi ## encoding: [0x0f,0xb7,0xff]
-; KNL-NEXT: vmovd %edi, %xmm0 ## EVEX TO VEX Compression encoding: [0xc5,0xf9,0x6e,0xc7]
+; KNL-NEXT: vpmovzxwq %xmm0, %xmm0 ## encoding: [0xc4,0xe2,0x79,0x34,0xc0]
+; KNL-NEXT: ## xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
; KNL-NEXT: vcvtph2ps %xmm0, %xmm0 ## encoding: [0xc4,0xe2,0x79,0x13,0xc0]
; KNL-NEXT: vucomiss %xmm2, %xmm0 ## EVEX TO VEX Compression encoding: [0xc5,0xf8,0x2e,0xc2]
; KNL-NEXT: cmovnel %ecx, %eax ## encoding: [0x0f,0x45,0xc1]
@@ -1468,10 +1466,9 @@ define void @half_vec_compare(ptr %x, ptr %y) {
; AVX512BW: ## %bb.0: ## %entry
; AVX512BW-NEXT: vmovd {{.*#+}} xmm0 = mem[0],zero,zero,zero
; AVX512BW-NEXT: ## EVEX TO VEX Compression encoding: [0xc5,0xf9,0x6e,0x07]
-; AVX512BW-NEXT: vpsrld $16, %xmm0, %xmm1 ## encoding: [0xc5,0xf1,0x72,0xd0,0x10]
-; AVX512BW-NEXT: vpextrw $0, %xmm1, %eax ## EVEX TO VEX Compression encoding: [0xc5,0xf9,0xc5,0xc1,0x00]
-; AVX512BW-NEXT: movzwl %ax, %eax ## encoding: [0x0f,0xb7,0xc0]
-; AVX512BW-NEXT: vmovd %eax, %xmm1 ## EVEX TO VEX Compression encoding: [0xc5,0xf9,0x6e,0xc8]
+; AVX512BW-NEXT: vpshufb {{.*#+}} xmm1 = xmm0[2,3],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
+; AVX512BW-NEXT: ## encoding: [0xc4,0xe2,0x79,0x00,0x0d,A,A,A,A]
+; AVX512BW-NEXT: ## fixup A - offset: 5, value: {{\.?LCPI[0-9]+_[0-9]+}}-4, kind: reloc_riprel_4byte
; AVX512BW-NEXT: vcvtph2ps %xmm1, %xmm1 ## encoding: [0xc4,0xe2,0x79,0x13,0xc9]
; AVX512BW-NEXT: xorl %eax, %eax ## encoding: [0x31,0xc0]
; AVX512BW-NEXT: vxorps %xmm2, %xmm2, %xmm2 ## encoding: [0xc5,0xe8,0x57,0xd2]
@@ -1481,9 +1478,8 @@ define void @half_vec_compare(ptr %x, ptr %y) {
; AVX512BW-NEXT: movl $0, %edx ## encoding: [0xba,0x00,0x00,0x00,0x00]
; AVX512BW-NEXT: cmovnel %ecx, %edx ## encoding: [0x0f,0x45,0xd1]
; AVX512BW-NEXT: cmovpl %ecx, %edx ## encoding: [0x0f,0x4a,0xd1]
-; AVX512BW-NEXT: vpextrw $0, %xmm0, %edi ## EVEX TO VEX Compression encoding: [0xc5,0xf9,0xc5,0xf8,0x00]
-; AVX512BW-NEXT: movzwl %di, %edi ## encoding: [0x0f,0xb7,0xff]
-; AVX512BW-NEXT: vmovd %edi, %xmm0 ## EVEX TO VEX Compression encoding: [0xc5,0xf9,0x6e,0xc7]
+; AVX512BW-NEXT: vpmovzxwq %xmm0, %xmm0 ## encoding: [0xc4,0xe2,0x79,0x34,0xc0]
+; AVX512BW-NEXT: ## xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
; AVX512BW-NEXT: vcvtph2ps %xmm0, %xmm0 ## encoding: [0xc4,0xe2,0x79,0x13,0xc0]
; AVX512BW-NEXT: vucomiss %xmm2, %xmm0 ## EVEX TO VEX Compression encoding: [0xc5,0xf8,0x2e,0xc2]
; AVX512BW-NEXT: cmovnel %ecx, %eax ## encoding: [0x0f,0x45,0xc1]
@@ -1500,10 +1496,9 @@ define void @half_vec_compare(ptr %x, ptr %y) {
; SKX: ## %bb.0: ## %entry
; SKX-NEXT: vmovd {{.*#+}} xmm0 = mem[0],zero,zero,zero
; SKX-NEXT: ## EVEX TO VEX Compression encoding: [0xc5,0xf9,0x6e,0x07]
-; SKX-NEXT: vpsrld $16, %xmm0, %xmm1 ## EVEX TO VEX Compression encoding: [0xc5,0xf1,0x72,0xd0,0x10]
-; SKX-NEXT: vpextrw $0, %xmm1, %eax ## EVEX TO VEX Compression encoding: [0xc5,0xf9,0xc5,0xc1,0x00]
-; SKX-NEXT: movzwl %ax, %eax ## encoding: [0x0f,0xb7,0xc0]
-; SKX-NEXT: vmovd %eax, %xmm1 ## EVEX TO VEX Compression encoding: [0xc5,0xf9,0x6e,0xc8]
+; SKX-NEXT: vpshufb {{.*#+}} xmm1 = xmm0[2,3],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
+; SKX-NEXT: ## EVEX TO VEX Compression encoding: [0xc4,0xe2,0x79,0x00,0x0d,A,A,A,A]
+; SKX-NEXT: ## fixup A - offset: 5, value: {{\.?LCPI[0-9]+_[0-9]+}}-4, kind: reloc_riprel_4byte
; SKX-NEXT: vcvtph2ps %xmm1, %xmm1 ## EVEX TO VEX Compression encoding: [0xc4,0xe2,0x79,0x13,0xc9]
; SKX-NEXT: vxorps %xmm2, %xmm2, %xmm2 ## EVEX TO VEX Compression encoding: [0xc5,0xe8,0x57,0xd2]
; SKX-NEXT: vucomiss %xmm2, %xmm1 ## EVEX TO VEX Compression encoding: [0xc5,0xf8,0x2e,0xca]
@@ -1512,9 +1507,8 @@ define void @half_vec_compare(ptr %x, ptr %y) {
; SKX-NEXT: orb %al, %cl ## encoding: [0x08,0xc1]
; SKX-NEXT: testb %cl, %cl ## encoding: [0x84,0xc9]
; SKX-NEXT: setne %al ## encoding: [0x0f,0x95,0xc0]
-; SKX-NEXT: vpextrw $0, %xmm0, %ecx ## EVEX TO VEX Compression encoding: [0xc5,0xf9,0xc5,0xc8,0x00]
-; SKX-NEXT: movzwl %cx, %ecx ## encoding: [0x0f,0xb7,0xc9]
-; SKX-NEXT: vmovd %ecx, %xmm0 ## EVEX TO VEX Compression encoding: [0xc5,0xf9,0x6e,0xc1]
+; SKX-NEXT: vpmovzxwq %xmm0, %xmm0 ## EVEX TO VEX Compression encoding: [0xc4,0xe2,0x79,0x34,0xc0]
+; SKX-NEXT: ## xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
; SKX-NEXT: vcvtph2ps %xmm0, %xmm0 ## EVEX TO VEX Compression encoding: [0xc4,0xe2,0x79,0x13,0xc0]
; SKX-NEXT: vucomiss %xmm2, %xmm0 ## EVEX TO VEX Compression encoding: [0xc5,0xf8,0x2e,0xc2]
; SKX-NEXT: setp %cl ## encoding: [0x0f,0x9a,0xc1]
diff --git a/llvm/test/CodeGen/X86/fpclamptosat_vec.ll b/llvm/test/CodeGen/X86/fpclamptosat_vec.ll
index c8708ea9b681fe..a3fb71f817ce47 100644
--- a/llvm/test/CodeGen/X86/fpclamptosat_vec.ll
+++ b/llvm/test/CodeGen/X86/fpclamptosat_vec.ll
@@ -699,34 +699,23 @@ define <4 x i32> @stest_f16i32(<4 x half> %x) nounwind {
; AVX2-LABEL: stest_f16i32:
; AVX2: # %bb.0: # %entry
; AVX2-NEXT: vpsrlq $48, %xmm0, %xmm1
-; AVX2-NEXT: vpextrw $0, %xmm1, %eax
-; AVX2-NEXT: movzwl %ax, %eax
-; AVX2-NEXT: vmovd %eax, %xmm1
; AVX2-NEXT: vcvtph2ps %xmm1, %xmm1
-; AVX2-NEXT: vmovshdup {{.*#+}} xmm2 = xmm0[1,1,3,3]
-; AVX2-NEXT: vpextrw $0, %xmm2, %eax
-; AVX2-NEXT: movzwl %ax, %eax
-; AVX2-NEXT: vmovd %eax, %xmm2
; AVX2-NEXT: vcvttss2si %xmm1, %rax
-; AVX2-NEXT: vcvtph2ps %xmm2, %xmm1
+; AVX2-NEXT: vpshufb {{.*#+}} xmm1 = xmm0[4,5],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
+; AVX2-NEXT: vcvtph2ps %xmm1, %xmm1
+; AVX2-NEXT: vcvttss2si %xmm1, %rcx
+; AVX2-NEXT: vpshufb {{.*#+}} xmm1 = xmm0[2,3],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
+; AVX2-NEXT: vcvtph2ps %xmm1, %xmm1
; AVX2-NEXT: vmovq %rax, %xmm2
; AVX2-NEXT: vcvttss2si %xmm1, %rax
-; AVX2-NEXT: vmovq %rax, %xmm1
+; AVX2-NEXT: vmovq %rcx, %xmm1
; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm1 = xmm1[0],xmm2[0]
-; AVX2-NEXT: vpextrw $0, %xmm0, %eax
-; AVX2-NEXT: movzwl %ax, %eax
-; AVX2-NEXT: vmovd %eax, %xmm2
-; AVX2-NEXT: vcvtph2ps %xmm2, %xmm2
-; AVX2-NEXT: vpsrld $16, %xmm0, %xmm0
-; AVX2-NEXT: vpextrw $0, %xmm0, %eax
-; AVX2-NEXT: movzwl %ax, %eax
-; AVX2-NEXT: vmovd %eax, %xmm0
-; AVX2-NEXT: vcvttss2si %xmm2, %rax
+; AVX2-NEXT: vpmovzxwq {{.*#+}} xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
; AVX2-NEXT: vcvtph2ps %xmm0, %xmm0
; AVX2-NEXT: vmovq %rax, %xmm2
; AVX2-NEXT: vcvttss2si %xmm0, %rax
; AVX2-NEXT: vmovq %rax, %xmm0
-; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm0 = xmm2[0],xmm0[0]
+; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm0 = xmm0[0],xmm2[0]
; AVX2-NEXT: vinserti128 $1, %xmm1, %ymm0, %ymm0
; AVX2-NEXT: vpbroadcastq {{.*#+}} ymm1 = [2147483647,2147483647,2147483647,2147483647]
; AVX2-NEXT: vpcmpgtq %ymm0, %ymm1, %ymm2
@@ -849,9 +838,6 @@ define <4 x i32> @utesth_f16i32(<4 x half> %x) nounwind {
; AVX2-LABEL: utesth_f16i32:
; AVX2: # %bb.0: # %entry
; AVX2-NEXT: vpsrlq $48, %xmm0, %xmm1
-; AVX2-NEXT: vpextrw $0, %xmm1, %eax
-; AVX2-NEXT: movzwl %ax, %eax
-; AVX2-NEXT: vmovd %eax, %xmm1
; AVX2-NEXT: vcvtph2ps %xmm1, %xmm2
; AVX2-NEXT: vmovss {{.*#+}} xmm1 = [9.22337203E+18,0.0E+0,0.0E+0,0.0E+0]
; AVX2-NEXT: vsubss %xmm1, %xmm2, %xmm3
@@ -860,37 +846,29 @@ define <4 x i32> @utesth_f16i32(<4 x half> %x) nounwind {
; AVX2-NEXT: movq %rcx, %rdx
; AVX2-NEXT: sarq $63, %rdx
; AVX2-NEXT: andq %rax, %rdx
-; AVX2-NEXT: orq %rcx, %rdx
-; AVX2-NEXT: vmovshdup {{.*#+}} xmm2 = xmm0[1,1,3,3]
-; AVX2-NEXT: vpextrw $0, %xmm2, %eax
-; AVX2-NEXT: movzwl %ax, %eax
-; AVX2-NEXT: vmovd %eax, %xmm2
+; AVX2-NEXT: vpshufb {{.*#+}} xmm2 = xmm0[4,5],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
; AVX2-NEXT: vcvtph2ps %xmm2, %xmm2
+; AVX2-NEXT: orq %rcx, %rdx
; AVX2-NEXT: vsubss %xmm1, %xmm2, %xmm3
; AVX2-NEXT: vcvttss2si %xmm3, %rax
+; AVX2-NEXT: vmovq %rdx, %xmm3
; AVX2-NEXT: vcvttss2si %xmm2, %rcx
-; AVX2-NEXT: vmovq %rdx, %xmm2
-; AVX2-NEXT: vpextrw $0, %xmm0, %edx
-; AVX2-NEXT: movzwl %dx, %edx
-; AVX2-NEXT: vmovd %edx, %xmm3
; AVX2-NEXT: movq %rcx, %rdx
; AVX2-NEXT: sarq $63, %rdx
-; AVX2-NEXT: vcvtph2ps %xmm3, %xmm3
+; AVX2-NEXT: vpshufb {{.*#+}} xmm2 = xmm0[2,3],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
+; AVX2-NEXT: vcvtph2ps %xmm2, %xmm2
; AVX2-NEXT: andq %rax, %rdx
-; AVX2-NEXT: vsubss %xmm1, %xmm3, %xmm4
+; AVX2-NEXT: vsubss %xmm1, %xmm2, %xmm4
; AVX2-NEXT: vcvttss2si %xmm4, %rax
; AVX2-NEXT: orq %rcx, %rdx
; AVX2-NEXT: vmovq %rdx, %xmm4
-; AVX2-NEXT: vcvttss2si %xmm3, %rcx
-; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm2 = xmm4[0],xmm2[0]
+; AVX2-NEXT: vcvttss2si %xmm2, %rcx
+; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm2 = xmm4[0],xmm3[0]
; AVX2-NEXT: movq %rcx, %rdx
; AVX2-NEXT: sarq $63, %rdx
; AVX2-NEXT: andq %rax, %rdx
; AVX2-NEXT: orq %rcx, %rdx
-; AVX2-NEXT: vpsrld $16, %xmm0, %xmm0
-; AVX2-NEXT: vpextrw $0, %xmm0, %eax
-; AVX2-NEXT: movzwl %ax, %eax
-; AVX2-NEXT: vmovd %eax, %xmm0
+; AVX2-NEXT: vpmovzxwq {{.*#+}} xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
; AVX2-NEXT: vcvtph2ps %xmm0, %xmm0
; AVX2-NEXT: vsubss %xmm1, %xmm0, %xmm1
; AVX2-NEXT: vcvttss2si %xmm1, %rax
@@ -901,7 +879,7 @@ define <4 x i32> @utesth_f16i32(<4 x half> %x) nounwind {
; AVX2-NEXT: andq %rax, %rdx
; AVX2-NEXT: orq %rcx, %rdx
; AVX2-NEXT: vmovq %rdx, %xmm1
-; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm0 = xmm0[0],xmm1[0]
+; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm0 = xmm1[0],xmm0[0]
; AVX2-NEXT: vinserti128 $1, %xmm2, %ymm0, %ymm0
; AVX2-NEXT: vbroadcastsd {{.*#+}} ymm1 = [4294967295,4294967295,4294967295,4294967295]
; AVX2-NEXT: vpbroadcastq {{.*#+}} ymm2 = [9223372036854775808,9223372036854775808,9223372036854775808,9223372036854775808]
@@ -1024,34 +1002,23 @@ define <4 x i32> @ustest_f16i32(<4 x half> %x) nounwind {
; AVX2-LABEL: ustest_f16i32:
; AVX2: # %bb.0: # %entry
; AVX2-NEXT: vpsrlq $48, %xmm0, %xmm1
-; AVX2-NEXT: vpextrw $0, %xmm1, %eax
-; AVX2-NEXT: movzwl %ax, %eax
-; AVX2-NEXT: vmovd %eax, %xmm1
; AVX2-NEXT: vcvtph2ps %xmm1, %xmm1
; AVX2-NEXT: vcvttss2si %xmm1, %rax
; AVX2-NEXT: vmovq %rax, %xmm1
-; AVX2-NEXT: vmovshdup {{.*#+}} xmm2 = xmm0[1,1,3,3]
-; AVX2-NEXT: vpextrw $0, %xmm2, %eax
-; AVX2-NEXT: movzwl %ax, %eax
-; AVX2-NEXT: vmovd %eax, %xmm2
+; AVX2-NEXT: vpshufb {{.*#+}} xmm2 = xmm0[4,5],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
; AVX2-NEXT: vcvtph2ps %xmm2, %xmm2
; AVX2-NEXT: vcvttss2si %xmm2, %rax
; AVX2-NEXT: vmovq %rax, %xmm2
; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm1 = xmm2[0],xmm1[0]
-; AVX2-NEXT: vpextrw $0, %xmm0, %eax
-; AVX2-NEXT: movzwl %ax, %eax
-; AVX2-NEXT: vmovd %eax, %xmm2
+; AVX2-NEXT: vpshufb {{.*#+}} xmm2 = xmm0[2,3],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
; AVX2-NEXT: vcvtph2ps %xmm2, %xmm2
; AVX2-NEXT: vcvttss2si %xmm2, %rax
; AVX2-NEXT: vmovq %rax, %xmm2
-; AVX2-NEXT: vpsrld $16, %xmm0, %xmm0
-; AVX2-NEXT: vpextrw $0, %xmm0, %eax
-; AVX2-NEXT: movzwl %ax, %eax
-; AVX2-NEXT: vmovd %eax, %xmm0
+; AVX2-NEXT: vpmovzxwq {{.*#+}} xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
; AVX2-NEXT: vcvtph2ps %xmm0, %xmm0
; AVX2-NEXT: vcvttss2si %xmm0, %rax
; AVX2-NEXT: vmovq %rax, %xmm0
-; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm0 = xmm2[0],xmm0[0]
+; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm0 = xmm0[0],xmm2[0]
; AVX2-NEXT: vinserti128 $1, %xmm1, %ymm0, %ymm0
; AVX2-NEXT: vpbroadcastq {{.*#+}} ymm1 = [4294967295,4294967295,4294967295,4294967295]
; AVX2-NEXT: vpcmpgtq %ymm0, %ymm1, %ymm2
@@ -3347,34 +3314,23 @@ define <4 x i32> @stest_f16i32_mm(<4 x half> %x) nounwind {
; AVX2-LABEL: stest_f16i32_mm:
; AVX2: # %bb.0: # %entry
; AVX2-NEXT: vpsrlq $48, %xmm0, %xmm1
-; AVX2-NEXT: vpextrw $0, %xmm1, %eax
-; AVX2-NEXT: movzwl %ax, %eax
-; AVX2-NEXT: vmovd %eax, %xmm1
; AVX2-NEXT: vcvtph2ps %xmm1, %xmm1
-; AVX2-NEXT: vmovshdup {{.*#+}} xmm2 = xmm0[1,1,3,3]
-; AVX2-NEXT: vpextrw $0, %xmm2, %eax
-; AVX2-NEXT: movzwl %ax, %eax
-; AVX2-NEXT: vmovd %eax, %xmm2
; AVX2-NEXT: vcvttss2si %xmm1, %rax
-; AVX2-NEXT: vcvtph2ps %xmm2, %xmm1
+; AVX2-NEXT: vpshufb {{.*#+}} xmm1 = xmm0[4,5],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
+; AVX2-NEXT: vcvtph2ps %xmm1, %xmm1
+; AVX2-NEXT: vcvttss2si %xmm1, %rcx
+; AVX2-NEXT: vpshufb {{.*#+}} xmm1 = xmm0[2,3],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
+; AVX2-NEXT: vcvtph2ps %xmm1, %xmm1
; AVX2-NEXT: vmovq %rax, %xmm2
; AVX2-NEXT: vcvttss2si %xmm1, %rax
-; AVX2-NEXT: vmovq %rax, %xmm1
+; AVX2-NEXT: vmovq %rcx, %xmm1
; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm1 = xmm1[0],xmm2[0]
-; AVX2-NEXT: vpextrw $0, %xmm0, %eax
-; AVX2-NEXT: movzwl %ax, %eax
-; AVX2-NEXT: vmovd %eax, %xmm2
-; AVX2-NEXT: vcvtph2ps %xmm2, %xmm2
-; AVX2-NEXT: vpsrld $16, %xmm0, %xmm0
-; AVX2-NEXT: vpextrw $0, %xmm0, %eax
-; AVX2-NEXT: movzwl %ax, %eax
-; AVX2-NEXT: vmovd %eax, %xmm0
-; AVX2-NEXT: vcvttss2si %xmm2, %rax
+; AVX2-NEXT: vpmovzxwq {{.*#+}} xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
; AVX2-NEXT: vcvtph2ps %xmm0, %xmm0
; AVX2-NEXT: vmovq %rax, %xmm2
; AVX2-NEXT: vcvttss2si %xmm0, %rax
; AVX2-NEXT: vmovq %rax, %xmm0
-; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm0 = xmm2[0],xmm0[0]
+; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm0 = xmm0[0],xmm2[0]
; AVX2-NEXT: vinserti128 $1, %xmm1, %ymm0, %ymm0
; AVX2-NEXT: vpbroadcastq {{.*#+}} ymm1 = [2147483647,2147483647,2147483647,2147483647]
; AVX2-NEXT: vpcmpgtq %ymm0, %ymm1, %ymm2
@@ -3495,9 +3451,6 @@ define <4 x i32> @utesth_f16i32_mm(<4 x half> %x) nounwind {
; AVX2-LABEL: utesth_f16i32_mm:
; AVX2: # %bb.0: # %entry
; AVX2-NEXT: vpsrlq $48, %xmm0, %xmm1
-; AVX2-NEXT: vpextrw $0, %xmm1, %eax
-; AVX2-NEXT: movzwl %ax, %eax
-; AVX2-NEXT: vmovd %eax, %xmm1
; AVX2-NEXT: vcvtph2ps %xmm1, %xmm2
; AVX2-NEXT: vmovss {{.*#+}} xmm1 = [9.22337203E+18,0.0E+0,0.0E+0,0.0E+0]
; AVX2-NEXT: vsubss %xmm1, %xmm2, %xmm3
@@ -3506,37 +3459,29 @@ define <4 x i32> @utesth_f16i32_mm(<4 x half> %x) nounwind {
; AVX2-NEXT: movq %rcx, %rdx
; AVX2-NEXT: sarq $63, %rdx
; AVX2-NEXT: andq %rax, %rdx
-; AVX2-NEXT: orq %rcx, %rdx
-; AVX2-NEXT: vmovshdup {{.*#+}} xmm2 = xmm0[1,1,3,3]
-; AVX2-NEXT: vpextrw $0, %xmm2, %eax
-; AVX2-NEXT: movzwl %ax, %eax
-; AVX2-NEXT: vmovd %eax, %xmm2
+; AVX2-NEXT: vpshufb {{.*#+}} xmm2 = xmm0[4,5],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
; AVX2-NEXT: vcvtph2ps %xmm2, %xmm2
+; AVX2-NEXT: orq %rcx, %rdx
; AVX2-NEXT: vsubss %xmm1, %xmm2, %xmm3
; AVX2-NEXT: vcvttss2si %xmm3, %rax
+; AVX2-NEXT: vmovq %rdx, %xmm3
; AVX2-NEXT: vcvttss2si %xmm2, %rcx
-; AVX2-NEXT: vmovq %rdx, %xmm2
-; AVX2-NEXT: vpextrw $0, %xmm0, %edx
-; AVX2-NEXT: movzwl %dx, %edx
-; AVX2-NEXT: vmovd %edx, %xmm3
; AVX2-NEXT: movq %rcx, %rdx
; AVX2-NEXT: sarq $63, %rdx
-; AVX2-NEXT: vcvtph2ps %xmm3, %xmm3
+; AVX2-NEXT: vpshufb {{.*#+}} xmm2 = xmm0[2,3],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
+; AVX2-NEXT: vcvtph2ps %xmm2, %xmm2
; AVX2-NEXT: andq %rax, %rdx
-; AVX2-NEXT: vsubss %xmm1, %xmm3, %xmm4
+; AVX2-NEXT: vsubss %xmm1, %xmm2, %xmm4
; AVX2-NEXT: vcvttss2si %xmm4, %rax
; AVX2-NEXT: orq %rcx, %rdx
; AVX2-NEXT: vmovq %rdx, %xmm4
-; AVX2-NEXT: vcvttss2si %xmm3, %rcx
-; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm2 = xmm4[0],xmm2[0]
+; AVX2-NEXT: vcvttss2si %xmm2, %rcx
+; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm2 = xmm4[0],xmm3[0]
; AVX2-NEXT: movq %rcx, %rdx
; AVX2-NEXT: sarq $63, %rdx
; AVX2-NEXT: andq %rax, %rdx
; AVX2-NEXT: orq %rcx, %rdx
-; AVX2-NEXT: vpsrld $16, %xmm0, %xmm0
-; AVX2-NEXT: vpextrw $0, %xmm0, %eax
-; AVX2-NEXT: movzwl %ax, %eax
-; AVX2-NEXT: vmovd %eax, %xmm0
+; AVX2-NEXT: vpmovzxwq {{.*#+}} xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
; AVX2-NEXT: vcvtph2ps %xmm0, %xmm0
; AVX2-NEXT: vsubss %xmm1, %xmm0, %xmm1
; AVX2-NEXT: vcvttss2si %xmm1, %rax
@@ -3547,7 +3492,7 @@ define <4 x i32> @utesth_f16i32_mm(<4 x half> %x) nounwind {
; AVX2-NEXT: andq %rax, %rdx
; AVX2-NEXT: orq %rcx, %rdx
; AVX2-NEXT: vmovq %rdx, %xmm1
-; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm0 = xmm0[0],xmm1[0]
+; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm0 = xmm1[0],xmm0[0]
; AVX2-NEXT: vinserti128 $1, %xmm2, %ymm0, %ymm0
; AVX2-NEXT: vpbroadcastq {{.*#+}} ymm1 = [9223372036854775808,9223372036854775808,9223372036854775808,9223372036854775808]
; AVX2-NEXT: vpxor %ymm1, %ymm0, %ymm1
@@ -3669,34 +3614,23 @@ define <4 x i32> @ustest_f16i32_mm(<4 x half> %x) nounwind {
; AVX2-LABEL: ustest_f16i32_mm:
; AVX2: # %bb.0: # %entry
; AVX2-NEXT: vpsrlq $48, %xmm0, %xmm1
-; AVX2-NEXT: vpextrw $0, %xmm1, %eax
-; AVX2-NEXT: movzwl %ax, %eax
-; AVX2-NEXT: vmovd %eax, %xmm1
; AVX2-NEXT: vcvtph2ps %xmm1, %xmm1
; AVX2-NEXT: vcvttss2si %xmm1, %rax
; AVX2-NEXT: vmovq %rax, %xmm1
-; AVX2-NEXT: vmovshdup {{.*#+}} xmm2 = xmm0[1,1,3,3]
-; AVX2-NEXT: vpextrw $0, %xmm2, %eax
-; AVX2-NEXT: movzwl %ax, %eax
-; AVX2-NEXT: vmovd %eax, %xmm2
+; AVX2-NEXT: vpshufb {{.*#+}} xmm2 = xmm0[4,5],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
; AVX2-NEXT: vcvtph2ps %xmm2, %xmm2
; AVX2-NEXT: vcvttss2si %xmm2, %rax
; AVX2-NEXT: vmovq %rax, %xmm2
; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm1 = xmm2[0],xmm1[0]
-; AVX2-NEXT: vpextrw $0, %xmm0, %eax
-; AVX2-NEXT: movzwl %ax, %eax
-; AVX2-NEXT: vmovd %eax, %xmm2
+; AVX2-NEXT: vpshufb {{.*#+}} xmm2 = xmm0[2,3],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
; AVX2-NEXT: vcvtph2ps %xmm2, %xmm2
; AVX2-NEXT: vcvttss2si %xmm2, %rax
; AVX2-NEXT: vmovq %rax, %xmm2
-; AVX2-NEXT: vpsrld $16, %xmm0, %xmm0
-; AVX2-NEXT: vpextrw $0, %xmm0, %eax
-; AVX2-NEXT: movzwl %ax, %eax
-; AVX2-NEXT: vmovd %eax, %xmm0
+; AVX2-NEXT: vpmovzxwq {{.*#+}} xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
; AVX2-NEXT: vcvtph2ps %xmm0, %xmm0
; AVX2-NEXT: vcvttss2si %xmm0, %rax
; AVX2-NEXT: vmovq %rax, %xmm0
-; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm0 = xmm2[0],xmm0[0]
+; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm0 = xmm0[0],xmm2[0]
; AVX2-NEXT: vinserti128 $1, %xmm1, %ymm0, %ymm0
; AVX2-NEXT: vpbroadcastq {{.*#+}} ymm1 = [4294967295,4294967295,4294967295,4294967295]
; AVX2-NEXT: vpcmpgtq %ymm0, %ymm1, %ymm2
diff --git a/llvm/test/CodeGen/X86/half.ll b/llvm/test/CodeGen/X86/half.ll
index d0853fdc748d29..2e1322446032ff 100644
--- a/llvm/test/CodeGen/X86/half.ll
+++ b/llvm/test/CodeGen/X86/half.ll
@@ -1614,15 +1614,10 @@ define <8 x half> @maxnum_v8f16(<8 x half> %0, <8 x half> %1) #0 {
;
; BWON-F16C-LABEL: maxnum_v8f16:
; BWON-F16C: # %bb.0:
-; BWON-F16C-NEXT: vpsrldq {{.*#+}} xmm2 = xmm1[14,15],zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero
-; BWON-F16C-NEXT: vpextrw $0, %xmm2, %eax
-; BWON-F16C-NEXT: movzwl %ax, %eax
-; BWON-F16C-NEXT: vmovd %eax, %xmm2
+; BWON-F16C-NEXT: vmovdqa {{.*#+}} xmm3 = [10,11,128,128,128,128,128,128,128,128,128,128,128,128,128,128]
+; BWON-F16C-NEXT: vpshufb %xmm3, %xmm1, %xmm2
; BWON-F16C-NEXT: vcvtph2ps %xmm2, %xmm2
-; BWON-F16C-NEXT: vpsrldq {{.*#+}} xmm3 = xmm0[14,15],zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero
-; BWON-F16C-NEXT: vpextrw $0, %xmm3, %eax
-; BWON-F16C-NEXT: movzwl %ax, %eax
-; BWON-F16C-NEXT: vmovd %eax, %xmm3
+; BWON-F16C-NEXT: vpshufb %xmm3, %xmm0, %xmm3
; BWON-F16C-NEXT: vcvtph2ps %xmm3, %xmm3
; BWON-F16C-NEXT: vucomiss %xmm2, %xmm3
; BWON-F16C-NEXT: ja .LBB26_2
@@ -1630,15 +1625,10 @@ define <8 x half> @maxnum_v8f16(<8 x half> %0, <8 x half> %1) #0 {
; BWON-F16C-NEXT: vmovaps %xmm2, %xmm3
; BWON-F16C-NEXT: .LBB26_2:
; BWON-F16C-NEXT: vcvtps2ph $4, %xmm3, %xmm2
-; BWON-F16C-NEXT: vpshufd {{.*#+}} xmm3 = xmm1[3,3,3,3]
-; BWON-F16C-NEXT: vpextrw $0, %xmm3, %eax
-; BWON-F16C-NEXT: movzwl %ax, %eax
-; BWON-F16C-NEXT: vmovd %eax, %xmm3
+; BWON-F16C-NEXT: vmovdqa {{.*#+}} xmm4 = [8,9,128,128,128,128,128,128,128,128,128,128,128,128,128,128]
+; BWON-F16C-NEXT: vpshufb %xmm4, %xmm1, %xmm3
; BWON-F16C-NEXT: vcvtph2ps %xmm3, %xmm3
-; BWON-F16C-NEXT: vpshufd {{.*#+}} xmm4 = xmm0[3,3,3,3]
-; BWON-F16C-NEXT: vpextrw $0, %xmm4, %eax
-; BWON-F16C-NEXT: movzwl %ax, %eax
-; BWON-F16C-NEXT: vmovd %eax, %xmm4
+; BWON-F16C-NEXT: vpshufb %xmm4, %xmm0, %xmm4
; BWON-F16C-NEXT: vcvtph2ps %xmm4, %xmm4
; BWON-F16C-NEXT: vucomiss %xmm3, %xmm4
; BWON-F16C-NEXT: ja .LBB26_4
@@ -1648,49 +1638,33 @@ define <8 x half> @maxnum_v8f16(<8 x half> %0, <8 x half> %1) #0 {
; BWON-F16C-NEXT: vmovd %xmm2, %eax
; BWON-F16C-NEXT: vcvtps2ph $4, %xmm4, %xmm2
; BWON-F16C-NEXT: vmovd %xmm2, %ecx
-; BWON-F16C-NEXT: vpsrldq {{.*#+}} xmm2 = xmm1[10,11,12,13,14,15],zero,zero,zero,zero,zero,zero,zero,zero,zero,zero
-; BWON-F16C-NEXT: vpextrw $0, %xmm2, %edx
-; BWON-F16C-NEXT: movzwl %dx, %edx
-; BWON-F16C-NEXT: vmovd %edx, %xmm2
-; BWON-F16C-NEXT: vcvtph2ps %xmm2, %xmm2
-; BWON-F16C-NEXT: vpsrldq {{.*#+}} xmm3 = xmm0[10,11,12,13,14,15],zero,zero,zero,zero,zero,zero,zero,zero,zero,zero
-; BWON-F16C-NEXT: vpextrw $0, %xmm3, %edx
-; BWON-F16C-NEXT: movzwl %dx, %edx
-; BWON-F16C-NEXT: vmovd %edx, %xmm3
+; BWON-F16C-NEXT: vmovdqa {{.*#+}} xmm2 = [12,13,128,128,128,128,128,128,128,128,128,128,128,128,128,128]
+; BWON-F16C-NEXT: vpshufb %xmm2, %xmm1, %xmm3
; BWON-F16C-NEXT: vcvtph2ps %xmm3, %xmm3
-; BWON-F16C-NEXT: vucomiss %xmm2, %xmm3
+; BWON-F16C-NEXT: vpshufb %xmm2, %xmm0, %xmm2
+; BWON-F16C-NEXT: vcvtph2ps %xmm2, %xmm2
+; BWON-F16C-NEXT: vucomiss %xmm3, %xmm2
; BWON-F16C-NEXT: ja .LBB26_6
; BWON-F16C-NEXT: # %bb.5:
-; BWON-F16C-NEXT: vmovaps %xmm2, %xmm3
+; BWON-F16C-NEXT: vmovaps %xmm3, %xmm2
; BWON-F16C-NEXT: .LBB26_6:
-; BWON-F16C-NEXT: vcvtps2ph $4, %xmm3, %xmm2
+; BWON-F16C-NEXT: vcvtps2ph $4, %xmm2, %xmm2
; BWON-F16C-NEXT: vmovd %xmm2, %edx
-; BWON-F16C-NEXT: vshufpd {{.*#+}} xmm2 = xmm1[1,0]
-; BWON-F16C-NEXT: vpextrw $0, %xmm2, %esi
-; BWON-F16C-NEXT: movzwl %si, %esi
-; BWON-F16C-NEXT: vmovd %esi, %xmm2
+; BWON-F16C-NEXT: vpsrldq {{.*#+}} xmm2 = xmm1[14,15],zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero
+; BWON-F16C-NEXT: vcvtph2ps %xmm2, %xmm3
+; BWON-F16C-NEXT: vpsrldq {{.*#+}} xmm2 = xmm0[14,15],zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero
; BWON-F16C-NEXT: vcvtph2ps %xmm2, %xmm2
-; BWON-F16C-NEXT: vshufpd {{.*#+}} xmm3 = xmm0[1,0]
-; BWON-F16C-NEXT: vpextrw $0, %xmm3, %esi
-; BWON-F16C-NEXT: movzwl %si, %esi
-; BWON-F16C-NEXT: vmovd %esi, %xmm3
-; BWON-F16C-NEXT: vcvtph2ps %xmm3, %xmm3
-; BWON-F16C-NEXT: vucomiss %xmm2, %xmm3
+; BWON-F16C-NEXT: vucomiss %xmm3, %xmm2
; BWON-F16C-NEXT: ja .LBB26_8
; BWON-F16C-NEXT: # %bb.7:
-; BWON-F16C-NEXT: vmovaps %xmm2, %xmm3
+; BWON-F16C-NEXT: vmovaps %xmm3, %xmm2
; BWON-F16C-NEXT: .LBB26_8:
-; BWON-F16C-NEXT: vcvtps2ph $4, %xmm3, %xmm2
+; BWON-F16C-NEXT: vcvtps2ph $4, %xmm2, %xmm2
; BWON-F16C-NEXT: vmovd %xmm2, %esi
-; BWON-F16C-NEXT: vpsrlq $48, %xmm1, %xmm2
-; BWON-F16C-NEXT: vpextrw $0, %xmm2, %edi
-; BWON-F16C-NEXT: movzwl %di, %edi
-; BWON-F16C-NEXT: vmovd %edi, %xmm2
+; BWON-F16C-NEXT: vmovdqa {{.*#+}} xmm3 = [4,5,128,128,128,128,128,128,128,128,128,128,128,128,128,128]
+; BWON-F16C-NEXT: vpshufb %xmm3, %xmm1, %xmm2
; BWON-F16C-NEXT: vcvtph2ps %xmm2, %xmm2
-; BWON-F16C-NEXT: vpsrlq $48, %xmm0, %xmm3
-; BWON-F16C-NEXT: vpextrw $0, %xmm3, %edi
-; BWON-F16C-NEXT: movzwl %di, %edi
-; BWON-F16C-NEXT: vmovd %edi, %xmm3
+; BWON-F16C-NEXT: vpshufb %xmm3, %xmm0, %xmm3
; BWON-F16C-NEXT: vcvtph2ps %xmm3, %xmm6
; BWON-F16C-NEXT: vucomiss %xmm2, %xmm6
; BWON-F16C-NEXT: ja .LBB26_10
@@ -1703,54 +1677,39 @@ define <8 x half> @maxnum_v8f16(<8 x half> %0, <8 x half> %1) #0 {
; BWON-F16C-NEXT: vpinsrw $0, %esi, %xmm0, %xmm5
; BWON-F16C-NEXT: vcvtps2ph $4, %xmm6, %xmm6
; BWON-F16C-NEXT: vmovd %xmm6, %eax
-; BWON-F16C-NEXT: vmovshdup {{.*#+}} xmm6 = xmm1[1,1,3,3]
-; BWON-F16C-NEXT: vpextrw $0, %xmm6, %ecx
-; BWON-F16C-NEXT: movzwl %cx, %ecx
-; BWON-F16C-NEXT: vmovd %ecx, %xmm6
+; BWON-F16C-NEXT: vpsrlq $48, %xmm1, %xmm6
+; BWON-F16C-NEXT: vcvtph2ps %xmm6, %xmm7
+; BWON-F16C-NEXT: vpsrlq $48, %xmm0, %xmm6
; BWON-F16C-NEXT: vcvtph2ps %xmm6, %xmm6
-; BWON-F16C-NEXT: vmovshdup {{.*#+}} xmm7 = xmm0[1,1,3,3]
-; BWON-F16C-NEXT: vpextrw $0, %xmm7, %ecx
-; BWON-F16C-NEXT: movzwl %cx, %ecx
-; BWON-F16C-NEXT: vmovd %ecx, %xmm7
-; BWON-F16C-NEXT: vcvtph2ps %xmm7, %xmm7
-; BWON-F16C-NEXT: vucomiss %xmm6, %xmm7
+; BWON-F16C-NEXT: vucomiss %xmm7, %xmm6
; BWON-F16C-NEXT: ja .LBB26_12
; BWON-F16C-NEXT: # %bb.11:
-; BWON-F16C-NEXT: vmovaps %xmm6, %xmm7
+; BWON-F16C-NEXT: vmovaps %xmm7, %xmm6
; BWON-F16C-NEXT: .LBB26_12:
; BWON-F16C-NEXT: vpunpcklwd {{.*#+}} xmm2 = xmm3[0],xmm2[0],xmm3[1],xmm2[1],xmm3[2],xmm2[2],xmm3[3],xmm2[3]
-; BWON-F16C-NEXT: vpunpcklwd {{.*#+}} xmm3 = xmm5[0],xmm4[0],xmm5[1],xmm4[1],xmm5[2],xmm4[2],xmm5[3],xmm4[3]
+; BWON-F16C-NEXT: vpunpcklwd {{.*#+}} xmm3 = xmm4[0],xmm5[0],xmm4[1],xmm5[1],xmm4[2],xmm5[2],xmm4[3],xmm5[3]
; BWON-F16C-NEXT: vpinsrw $0, %eax, %xmm0, %xmm4
-; BWON-F16C-NEXT: vcvtps2ph $4, %xmm7, %xmm5
+; BWON-F16C-NEXT: vcvtps2ph $4, %xmm6, %xmm5
; BWON-F16C-NEXT: vmovd %xmm5, %eax
; BWON-F16C-NEXT: vpinsrw $0, %eax, %xmm0, %xmm5
-; BWON-F16C-NEXT: vpextrw $0, %xmm1, %eax
-; BWON-F16C-NEXT: movzwl %ax, %eax
-; BWON-F16C-NEXT: vmovd %eax, %xmm6
-; BWON-F16C-NEXT: vcvtph2ps %xmm6, %xmm6
-; BWON-F16C-NEXT: vpextrw $0, %xmm0, %eax
-; BWON-F16C-NEXT: movzwl %ax, %eax
-; BWON-F16C-NEXT: vmovd %eax, %xmm7
+; BWON-F16C-NEXT: vmovdqa {{.*#+}} xmm6 = [2,3,128,128,128,128,128,128,128,128,128,128,128,128,128,128]
+; BWON-F16C-NEXT: vpshufb %xmm6, %xmm1, %xmm7
; BWON-F16C-NEXT: vcvtph2ps %xmm7, %xmm7
-; BWON-F16C-NEXT: vucomiss %xmm6, %xmm7
+; BWON-F16C-NEXT: vpshufb %xmm6, %xmm0, %xmm6
+; BWON-F16C-NEXT: vcvtph2ps %xmm6, %xmm6
+; BWON-F16C-NEXT: vucomiss %xmm7, %xmm6
; BWON-F16C-NEXT: ja .LBB26_14
; BWON-F16C-NEXT: # %bb.13:
-; BWON-F16C-NEXT: vmovaps %xmm6, %xmm7
+; BWON-F16C-NEXT: vmovaps %xmm7, %xmm6
; BWON-F16C-NEXT: .LBB26_14:
-; BWON-F16C-NEXT: vpunpckldq {{.*#+}} xmm2 = xmm3[0],xmm2[0],xmm3[1],xmm2[1]
-; BWON-F16C-NEXT: vpunpcklwd {{.*#+}} xmm3 = xmm5[0],xmm4[0],xmm5[1],xmm4[1],xmm5[2],xmm4[2],xmm5[3],xmm4[3]
-; BWON-F16C-NEXT: vcvtps2ph $4, %xmm7, %xmm4
+; BWON-F16C-NEXT: vpunpckldq {{.*#+}} xmm2 = xmm2[0],xmm3[0],xmm2[1],xmm3[1]
+; BWON-F16C-NEXT: vpunpcklwd {{.*#+}} xmm3 = xmm4[0],xmm5[0],xmm4[1],xmm5[1],xmm4[2],xmm5[2],xmm4[3],xmm5[3]
+; BWON-F16C-NEXT: vcvtps2ph $4, %xmm6, %xmm4
; BWON-F16C-NEXT: vmovd %xmm4, %eax
; BWON-F16C-NEXT: vpinsrw $0, %eax, %xmm0, %xmm4
-; BWON-F16C-NEXT: vpsrld $16, %xmm1, %xmm1
-; BWON-F16C-NEXT: vpextrw $0, %xmm1, %eax
-; BWON-F16C-NEXT: movzwl %ax, %eax
-; BWON-F16C-NEXT: vmovd %eax, %xmm1
+; BWON-F16C-NEXT: vpmovzxwq {{.*#+}} xmm1 = xmm1[0],zero,zero,zero,xmm1[1],zero,zero,zero
; BWON-F16C-NEXT: vcvtph2ps %xmm1, %xmm1
-; BWON-F16C-NEXT: vpsrld $16, %xmm0, %xmm0
-; BWON-F16C-NEXT: vpextrw $0, %xmm0, %eax
-; BWON-F16C-NEXT: movzwl %ax, %eax
-; BWON-F16C-NEXT: vmovd %eax, %xmm0
+; BWON-F16C-NEXT: vpmovzxwq {{.*#+}} xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
; BWON-F16C-NEXT: vcvtph2ps %xmm0, %xmm0
; BWON-F16C-NEXT: vucomiss %xmm1, %xmm0
; BWON-F16C-NEXT: ja .LBB26_16
@@ -1760,7 +1719,7 @@ define <8 x half> @maxnum_v8f16(<8 x half> %0, <8 x half> %1) #0 {
; BWON-F16C-NEXT: vcvtps2ph $4, %xmm0, %xmm0
; BWON-F16C-NEXT: vmovd %xmm0, %eax
; BWON-F16C-NEXT: vpinsrw $0, %eax, %xmm0, %xmm0
-; BWON-F16C-NEXT: vpunpcklwd {{.*#+}} xmm0 = xmm4[0],xmm0[0],xmm4[1],xmm0[1],xmm4[2],xmm0[2],xmm4[3],xmm0[3]
+; BWON-F16C-NEXT: vpunpcklwd {{.*#+}} xmm0 = xmm0[0],xmm4[0],xmm0[1],xmm4[1],xmm0[2],xmm4[2],xmm0[3],xmm4[3]
; BWON-F16C-NEXT: vpunpckldq {{.*#+}} xmm0 = xmm0[0],xmm3[0],xmm0[1],xmm3[1]
; BWON-F16C-NEXT: vpunpcklqdq {{.*#+}} xmm0 = xmm0[0],xmm2[0]
; BWON-F16C-NEXT: retq
diff --git a/llvm/test/CodeGen/X86/pr31088.ll b/llvm/test/CodeGen/X86/pr31088.ll
index fa1014e3ae0da6..a21653bc7330c9 100644
--- a/llvm/test/CodeGen/X86/pr31088.ll
+++ b/llvm/test/CodeGen/X86/pr31088.ll
@@ -41,15 +41,11 @@ define <1 x half> @ir_fadd_v1f16(<1 x half> %arg0, <1 x half> %arg1) nounwind {
;
; F16C-LABEL: ir_fadd_v1f16:
; F16C: # %bb.0:
-; F16C-NEXT: vpextrw $0, %xmm0, %eax
-; F16C-NEXT: vpextrw $0, %xmm1, %ecx
-; F16C-NEXT: movzwl %cx, %ecx
-; F16C-NEXT: vmovd %ecx, %xmm0
-; F16C-NEXT: vcvtph2ps %xmm0, %xmm0
-; F16C-NEXT: movzwl %ax, %eax
-; F16C-NEXT: vmovd %eax, %xmm1
+; F16C-NEXT: vpmovzxwq {{.*#+}} xmm1 = xmm1[0],zero,zero,zero,xmm1[1],zero,zero,zero
; F16C-NEXT: vcvtph2ps %xmm1, %xmm1
-; F16C-NEXT: vaddss %xmm0, %xmm1, %xmm0
+; F16C-NEXT: vpmovzxwq {{.*#+}} xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
+; F16C-NEXT: vcvtph2ps %xmm0, %xmm0
+; F16C-NEXT: vaddss %xmm1, %xmm0, %xmm0
; F16C-NEXT: vcvtps2ph $4, %xmm0, %xmm0
; F16C-NEXT: vmovd %xmm0, %eax
; F16C-NEXT: vpinsrw $0, %eax, %xmm0, %xmm0
diff --git a/llvm/test/CodeGen/X86/pr57340.ll b/llvm/test/CodeGen/X86/pr57340.ll
index f373fb9af22b37..95f839c338e701 100644
--- a/llvm/test/CodeGen/X86/pr57340.ll
+++ b/llvm/test/CodeGen/X86/pr57340.ll
@@ -5,54 +5,43 @@ define void @main.41() local_unnamed_addr #1 {
; CHECK-LABEL: main.41:
; CHECK: # %bb.0: # %entry
; CHECK-NEXT: vpbroadcastw (%rax), %xmm0
-; CHECK-NEXT: vmovdqu (%rax), %ymm2
-; CHECK-NEXT: vinserti128 $1, %xmm0, %ymm0, %ymm3
-; CHECK-NEXT: vpmovsxbw {{.*#+}} ymm1 = [31,0,1,2,3,4,5,6,7,8,9,10,11,12,13,14]
-; CHECK-NEXT: vpermi2w %ymm3, %ymm2, %ymm1
-; CHECK-NEXT: vpextrw $0, %xmm0, %eax
-; CHECK-NEXT: movzwl %ax, %eax
-; CHECK-NEXT: vmovd %eax, %xmm0
-; CHECK-NEXT: vcvtph2ps %xmm0, %xmm0
-; CHECK-NEXT: vmovdqu (%rax), %xmm5
-; CHECK-NEXT: vpextrw $0, %xmm5, %eax
-; CHECK-NEXT: movzwl %ax, %eax
-; CHECK-NEXT: vmovd %eax, %xmm2
+; CHECK-NEXT: vmovdqu (%rax), %ymm1
+; CHECK-NEXT: vinserti128 $1, %xmm0, %ymm0, %ymm2
+; CHECK-NEXT: vpmovsxbw {{.*#+}} ymm3 = [31,0,1,2,3,4,5,6,7,8,9,10,11,12,13,14]
+; CHECK-NEXT: vpermi2w %ymm2, %ymm1, %ymm3
+; CHECK-NEXT: vmovdqu (%rax), %xmm10
+; CHECK-NEXT: vmovdqa {{.*#+}} xmm1 = [2,3,128,128,128,128,128,128,128,128,128,128,128,128,128,128]
+; CHECK-NEXT: vpshufb %xmm1, %xmm10, %xmm2
; CHECK-NEXT: vcvtph2ps %xmm2, %xmm2
-; CHECK-NEXT: vucomiss %xmm0, %xmm2
+; CHECK-NEXT: vpshufb %xmm1, %xmm3, %xmm4
+; CHECK-NEXT: vcvtph2ps %xmm4, %xmm4
+; CHECK-NEXT: vucomiss %xmm4, %xmm2
; CHECK-NEXT: setnp %al
; CHECK-NEXT: sete %cl
; CHECK-NEXT: testb %al, %cl
-; CHECK-NEXT: vpsrld $16, %xmm1, %xmm3
-; CHECK-NEXT: vpextrw $0, %xmm3, %eax
-; CHECK-NEXT: movzwl %ax, %eax
-; CHECK-NEXT: vmovd %eax, %xmm3
-; CHECK-NEXT: vpsrld $16, %xmm5, %xmm4
-; CHECK-NEXT: vpextrw $0, %xmm4, %eax
-; CHECK-NEXT: movzwl %ax, %eax
-; CHECK-NEXT: vmovd %eax, %xmm4
; CHECK-NEXT: setne %al
-; CHECK-NEXT: andl $1, %eax
-; CHECK-NEXT: vcvtph2ps %xmm3, %xmm6
-; CHECK-NEXT: vcvtph2ps %xmm4, %xmm3
-; CHECK-NEXT: kmovw %eax, %k0
-; CHECK-NEXT: vucomiss %xmm6, %xmm3
+; CHECK-NEXT: kmovd %eax, %k0
+; CHECK-NEXT: kshiftlw $15, %k0, %k0
+; CHECK-NEXT: kshiftrw $14, %k0, %k0
+; CHECK-NEXT: vpmovzxwq {{.*#+}} xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
+; CHECK-NEXT: vcvtph2ps %xmm0, %xmm0
+; CHECK-NEXT: vpmovzxwq {{.*#+}} xmm4 = xmm10[0],zero,zero,zero,xmm10[1],zero,zero,zero
+; CHECK-NEXT: vcvtph2ps %xmm4, %xmm11
+; CHECK-NEXT: vucomiss %xmm0, %xmm11
; CHECK-NEXT: setnp %al
; CHECK-NEXT: sete %cl
; CHECK-NEXT: testb %al, %cl
; CHECK-NEXT: setne %al
-; CHECK-NEXT: kmovd %eax, %k1
-; CHECK-NEXT: kshiftlw $15, %k1, %k1
-; CHECK-NEXT: kshiftrw $14, %k1, %k1
-; CHECK-NEXT: korw %k1, %k0, %k0
+; CHECK-NEXT: andl $1, %eax
+; CHECK-NEXT: kmovw %eax, %k1
+; CHECK-NEXT: korw %k0, %k1, %k0
; CHECK-NEXT: movw $-5, %ax
; CHECK-NEXT: kmovd %eax, %k1
; CHECK-NEXT: kandw %k1, %k0, %k0
-; CHECK-NEXT: vprolq $32, %xmm1, %xmm4
-; CHECK-NEXT: vpextrw $0, %xmm4, %eax
-; CHECK-NEXT: movzwl %ax, %eax
-; CHECK-NEXT: vmovd %eax, %xmm4
-; CHECK-NEXT: vcvtph2ps %xmm4, %xmm4
-; CHECK-NEXT: vucomiss %xmm4, %xmm0
+; CHECK-NEXT: vmovdqa {{.*#+}} xmm4 = [4,5,128,128,128,128,128,128,128,128,128,128,128,128,128,128]
+; CHECK-NEXT: vpshufb %xmm4, %xmm3, %xmm5
+; CHECK-NEXT: vcvtph2ps %xmm5, %xmm5
+; CHECK-NEXT: vucomiss %xmm5, %xmm0
; CHECK-NEXT: setnp %al
; CHECK-NEXT: sete %cl
; CHECK-NEXT: testb %al, %cl
@@ -63,18 +52,12 @@ define void @main.41() local_unnamed_addr #1 {
; CHECK-NEXT: korw %k1, %k0, %k0
; CHECK-NEXT: movw $-9, %ax
; CHECK-NEXT: kmovd %eax, %k1
-; CHECK-NEXT: vpsrlq $48, %xmm1, %xmm4
-; CHECK-NEXT: vpextrw $0, %xmm4, %eax
+; CHECK-NEXT: vpsrlq $48, %xmm3, %xmm5
+; CHECK-NEXT: vcvtph2ps %xmm5, %xmm6
+; CHECK-NEXT: vpsrlq $48, %xmm10, %xmm5
+; CHECK-NEXT: vcvtph2ps %xmm5, %xmm5
; CHECK-NEXT: kandw %k1, %k0, %k0
-; CHECK-NEXT: movzwl %ax, %eax
-; CHECK-NEXT: vmovd %eax, %xmm4
-; CHECK-NEXT: vcvtph2ps %xmm4, %xmm6
-; CHECK-NEXT: vpsrlq $48, %xmm5, %xmm4
-; CHECK-NEXT: vpextrw $0, %xmm4, %eax
-; CHECK-NEXT: movzwl %ax, %eax
-; CHECK-NEXT: vmovd %eax, %xmm4
-; CHECK-NEXT: vcvtph2ps %xmm4, %xmm4
-; CHECK-NEXT: vucomiss %xmm6, %xmm4
+; CHECK-NEXT: vucomiss %xmm6, %xmm5
; CHECK-NEXT: setnp %al
; CHECK-NEXT: sete %cl
; CHECK-NEXT: testb %al, %cl
@@ -85,13 +68,11 @@ define void @main.41() local_unnamed_addr #1 {
; CHECK-NEXT: korw %k1, %k0, %k0
; CHECK-NEXT: movw $-17, %ax
; CHECK-NEXT: kmovd %eax, %k1
-; CHECK-NEXT: vpshufd {{.*#+}} xmm6 = xmm1[2,3,0,1]
-; CHECK-NEXT: vpextrw $0, %xmm6, %eax
+; CHECK-NEXT: vmovdqa {{.*#+}} xmm6 = [8,9,128,128,128,128,128,128,128,128,128,128,128,128,128,128]
; CHECK-NEXT: kandw %k1, %k0, %k0
-; CHECK-NEXT: movzwl %ax, %eax
-; CHECK-NEXT: vmovd %eax, %xmm6
-; CHECK-NEXT: vcvtph2ps %xmm6, %xmm6
-; CHECK-NEXT: vucomiss %xmm6, %xmm0
+; CHECK-NEXT: vpshufb %xmm6, %xmm3, %xmm7
+; CHECK-NEXT: vcvtph2ps %xmm7, %xmm7
+; CHECK-NEXT: vucomiss %xmm7, %xmm0
; CHECK-NEXT: setnp %al
; CHECK-NEXT: sete %cl
; CHECK-NEXT: testb %al, %cl
@@ -102,18 +83,13 @@ define void @main.41() local_unnamed_addr #1 {
; CHECK-NEXT: korw %k1, %k0, %k0
; CHECK-NEXT: movw $-33, %ax
; CHECK-NEXT: kmovd %eax, %k1
-; CHECK-NEXT: vpsrldq {{.*#+}} xmm6 = xmm1[10,11,12,13,14,15],zero,zero,zero,zero,zero,zero,zero,zero,zero,zero
-; CHECK-NEXT: vpextrw $0, %xmm6, %eax
-; CHECK-NEXT: movzwl %ax, %eax
-; CHECK-NEXT: vmovd %eax, %xmm6
-; CHECK-NEXT: vcvtph2ps %xmm6, %xmm7
-; CHECK-NEXT: vpsrldq {{.*#+}} xmm6 = xmm5[10,11,12,13,14,15],zero,zero,zero,zero,zero,zero,zero,zero,zero,zero
-; CHECK-NEXT: vpextrw $0, %xmm6, %eax
+; CHECK-NEXT: vmovdqa {{.*#+}} xmm7 = [10,11,128,128,128,128,128,128,128,128,128,128,128,128,128,128]
+; CHECK-NEXT: vpshufb %xmm7, %xmm10, %xmm8
+; CHECK-NEXT: vcvtph2ps %xmm8, %xmm8
; CHECK-NEXT: kandw %k1, %k0, %k0
-; CHECK-NEXT: movzwl %ax, %eax
-; CHECK-NEXT: vmovd %eax, %xmm6
-; CHECK-NEXT: vcvtph2ps %xmm6, %xmm6
-; CHECK-NEXT: vucomiss %xmm7, %xmm6
+; CHECK-NEXT: vpshufb %xmm7, %xmm3, %xmm9
+; CHECK-NEXT: vcvtph2ps %xmm9, %xmm9
+; CHECK-NEXT: vucomiss %xmm9, %xmm8
; CHECK-NEXT: setnp %al
; CHECK-NEXT: sete %cl
; CHECK-NEXT: testb %al, %cl
@@ -124,13 +100,11 @@ define void @main.41() local_unnamed_addr #1 {
; CHECK-NEXT: korw %k1, %k0, %k0
; CHECK-NEXT: movw $-65, %ax
; CHECK-NEXT: kmovd %eax, %k1
+; CHECK-NEXT: vmovdqa {{.*#+}} xmm9 = [12,13,128,128,128,128,128,128,128,128,128,128,128,128,128,128]
+; CHECK-NEXT: vpshufb %xmm9, %xmm3, %xmm12
+; CHECK-NEXT: vcvtph2ps %xmm12, %xmm12
; CHECK-NEXT: kandw %k1, %k0, %k0
-; CHECK-NEXT: vpshufd {{.*#+}} xmm7 = xmm1[3,3,3,3]
-; CHECK-NEXT: vpextrw $0, %xmm7, %eax
-; CHECK-NEXT: movzwl %ax, %eax
-; CHECK-NEXT: vmovd %eax, %xmm7
-; CHECK-NEXT: vcvtph2ps %xmm7, %xmm7
-; CHECK-NEXT: vucomiss %xmm7, %xmm0
+; CHECK-NEXT: vucomiss %xmm12, %xmm0
; CHECK-NEXT: setnp %al
; CHECK-NEXT: sete %cl
; CHECK-NEXT: testb %al, %cl
@@ -142,17 +116,11 @@ define void @main.41() local_unnamed_addr #1 {
; CHECK-NEXT: movw $-129, %ax
; CHECK-NEXT: kmovd %eax, %k1
; CHECK-NEXT: kandw %k1, %k0, %k0
-; CHECK-NEXT: vpsrldq {{.*#+}} xmm7 = xmm1[14,15],zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero
-; CHECK-NEXT: vpextrw $0, %xmm7, %eax
-; CHECK-NEXT: movzwl %ax, %eax
-; CHECK-NEXT: vmovd %eax, %xmm7
-; CHECK-NEXT: vcvtph2ps %xmm7, %xmm7
-; CHECK-NEXT: vpsrldq {{.*#+}} xmm5 = xmm5[14,15],zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero
-; CHECK-NEXT: vpextrw $0, %xmm5, %eax
-; CHECK-NEXT: movzwl %ax, %eax
-; CHECK-NEXT: vmovd %eax, %xmm5
-; CHECK-NEXT: vcvtph2ps %xmm5, %xmm5
-; CHECK-NEXT: vucomiss %xmm7, %xmm5
+; CHECK-NEXT: vpsrldq {{.*#+}} xmm12 = xmm3[14,15],zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero
+; CHECK-NEXT: vcvtph2ps %xmm12, %xmm12
+; CHECK-NEXT: vpsrldq {{.*#+}} xmm10 = xmm10[14,15],zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero
+; CHECK-NEXT: vcvtph2ps %xmm10, %xmm10
+; CHECK-NEXT: vucomiss %xmm12, %xmm10
; CHECK-NEXT: setnp %al
; CHECK-NEXT: sete %cl
; CHECK-NEXT: testb %al, %cl
@@ -163,13 +131,11 @@ define void @main.41() local_unnamed_addr #1 {
; CHECK-NEXT: korw %k1, %k0, %k0
; CHECK-NEXT: movw $-257, %ax # imm = 0xFEFF
; CHECK-NEXT: kmovd %eax, %k1
+; CHECK-NEXT: vextracti128 $1, %ymm3, %xmm3
+; CHECK-NEXT: vpmovzxwq {{.*#+}} xmm12 = xmm3[0],zero,zero,zero,xmm3[1],zero,zero,zero
+; CHECK-NEXT: vcvtph2ps %xmm12, %xmm12
; CHECK-NEXT: kandw %k1, %k0, %k0
-; CHECK-NEXT: vextracti128 $1, %ymm1, %xmm1
-; CHECK-NEXT: vpextrw $0, %xmm1, %eax
-; CHECK-NEXT: movzwl %ax, %eax
-; CHECK-NEXT: vmovd %eax, %xmm7
-; CHECK-NEXT: vcvtph2ps %xmm7, %xmm7
-; CHECK-NEXT: vucomiss %xmm7, %xmm2
+; CHECK-NEXT: vucomiss %xmm12, %xmm11
; CHECK-NEXT: setnp %al
; CHECK-NEXT: sete %cl
; CHECK-NEXT: testb %al, %cl
@@ -181,12 +147,9 @@ define void @main.41() local_unnamed_addr #1 {
; CHECK-NEXT: movw $-513, %ax # imm = 0xFDFF
; CHECK-NEXT: kmovd %eax, %k1
; CHECK-NEXT: kandw %k1, %k0, %k0
-; CHECK-NEXT: vpsrld $16, %xmm1, %xmm2
-; CHECK-NEXT: vpextrw $0, %xmm2, %eax
-; CHECK-NEXT: movzwl %ax, %eax
-; CHECK-NEXT: vmovd %eax, %xmm2
-; CHECK-NEXT: vcvtph2ps %xmm2, %xmm2
-; CHECK-NEXT: vucomiss %xmm2, %xmm3
+; CHECK-NEXT: vpshufb %xmm1, %xmm3, %xmm1
+; CHECK-NEXT: vcvtph2ps %xmm1, %xmm1
+; CHECK-NEXT: vucomiss %xmm1, %xmm2
; CHECK-NEXT: setnp %al
; CHECK-NEXT: sete %cl
; CHECK-NEXT: testb %al, %cl
@@ -197,13 +160,10 @@ define void @main.41() local_unnamed_addr #1 {
; CHECK-NEXT: korw %k1, %k0, %k0
; CHECK-NEXT: movw $-1025, %ax # imm = 0xFBFF
; CHECK-NEXT: kmovd %eax, %k1
-; CHECK-NEXT: vprolq $32, %xmm1, %xmm2
-; CHECK-NEXT: vpextrw $0, %xmm2, %eax
-; CHECK-NEXT: movzwl %ax, %eax
-; CHECK-NEXT: vmovd %eax, %xmm2
-; CHECK-NEXT: vcvtph2ps %xmm2, %xmm2
; CHECK-NEXT: kandw %k1, %k0, %k0
-; CHECK-NEXT: vucomiss %xmm2, %xmm0
+; CHECK-NEXT: vpshufb %xmm4, %xmm3, %xmm1
+; CHECK-NEXT: vcvtph2ps %xmm1, %xmm1
+; CHECK-NEXT: vucomiss %xmm1, %xmm0
; CHECK-NEXT: setnp %al
; CHECK-NEXT: sete %cl
; CHECK-NEXT: testb %al, %cl
@@ -215,12 +175,9 @@ define void @main.41() local_unnamed_addr #1 {
; CHECK-NEXT: movw $-2049, %ax # imm = 0xF7FF
; CHECK-NEXT: kmovd %eax, %k1
; CHECK-NEXT: kandw %k1, %k0, %k0
-; CHECK-NEXT: vpsrlq $48, %xmm1, %xmm2
-; CHECK-NEXT: vpextrw $0, %xmm2, %eax
-; CHECK-NEXT: movzwl %ax, %eax
-; CHECK-NEXT: vmovd %eax, %xmm2
-; CHECK-NEXT: vcvtph2ps %xmm2, %xmm2
-; CHECK-NEXT: vucomiss %xmm2, %xmm4
+; CHECK-NEXT: vpsrlq $48, %xmm3, %xmm1
+; CHECK-NEXT: vcvtph2ps %xmm1, %xmm1
+; CHECK-NEXT: vucomiss %xmm1, %xmm5
; CHECK-NEXT: setnp %al
; CHECK-NEXT: sete %cl
; CHECK-NEXT: testb %al, %cl
@@ -231,13 +188,10 @@ define void @main.41() local_unnamed_addr #1 {
; CHECK-NEXT: korw %k1, %k0, %k0
; CHECK-NEXT: movw $-4097, %ax # imm = 0xEFFF
; CHECK-NEXT: kmovd %eax, %k1
-; CHECK-NEXT: vpshufd {{.*#+}} xmm2 = xmm1[2,3,0,1]
-; CHECK-NEXT: vpextrw $0, %xmm2, %eax
; CHECK-NEXT: kandw %k1, %k0, %k0
-; CHECK-NEXT: movzwl %ax, %eax
-; CHECK-NEXT: vmovd %eax, %xmm2
-; CHECK-NEXT: vcvtph2ps %xmm2, %xmm2
-; CHECK-NEXT: vucomiss %xmm2, %xmm0
+; CHECK-NEXT: vpshufb %xmm6, %xmm3, %xmm1
+; CHECK-NEXT: vcvtph2ps %xmm1, %xmm1
+; CHECK-NEXT: vucomiss %xmm1, %xmm0
; CHECK-NEXT: setnp %al
; CHECK-NEXT: sete %cl
; CHECK-NEXT: testb %al, %cl
@@ -249,12 +203,9 @@ define void @main.41() local_unnamed_addr #1 {
; CHECK-NEXT: movw $-8193, %ax # imm = 0xDFFF
; CHECK-NEXT: kmovd %eax, %k1
; CHECK-NEXT: kandw %k1, %k0, %k0
-; CHECK-NEXT: vpsrldq {{.*#+}} xmm2 = xmm1[10,11,12,13,14,15],zero,zero,zero,zero,zero,zero,zero,zero,zero,zero
-; CHECK-NEXT: vpextrw $0, %xmm2, %eax
-; CHECK-NEXT: movzwl %ax, %eax
-; CHECK-NEXT: vmovd %eax, %xmm2
-; CHECK-NEXT: vcvtph2ps %xmm2, %xmm2
-; CHECK-NEXT: vucomiss %xmm2, %xmm6
+; CHECK-NEXT: vpshufb %xmm7, %xmm3, %xmm1
+; CHECK-NEXT: vcvtph2ps %xmm1, %xmm1
+; CHECK-NEXT: vucomiss %xmm1, %xmm8
; CHECK-NEXT: setnp %al
; CHECK-NEXT: sete %cl
; CHECK-NEXT: testb %al, %cl
@@ -265,13 +216,10 @@ define void @main.41() local_unnamed_addr #1 {
; CHECK-NEXT: korw %k1, %k0, %k0
; CHECK-NEXT: movw $-16385, %ax # imm = 0xBFFF
; CHECK-NEXT: kmovd %eax, %k1
+; CHECK-NEXT: vpshufb %xmm9, %xmm3, %xmm1
+; CHECK-NEXT: vcvtph2ps %xmm1, %xmm1
; CHECK-NEXT: kandw %k1, %k0, %k0
-; CHECK-NEXT: vpshufd {{.*#+}} xmm2 = xmm1[3,3,3,3]
-; CHECK-NEXT: vpextrw $0, %xmm2, %eax
-; CHECK-NEXT: movzwl %ax, %eax
-; CHECK-NEXT: vmovd %eax, %xmm2
-; CHECK-NEXT: vcvtph2ps %xmm2, %xmm2
-; CHECK-NEXT: vucomiss %xmm2, %xmm0
+; CHECK-NEXT: vucomiss %xmm1, %xmm0
; CHECK-NEXT: setnp %al
; CHECK-NEXT: sete %cl
; CHECK-NEXT: testb %al, %cl
@@ -280,13 +228,10 @@ define void @main.41() local_unnamed_addr #1 {
; CHECK-NEXT: kshiftlw $14, %k1, %k1
; CHECK-NEXT: korw %k1, %k0, %k0
; CHECK-NEXT: kshiftlw $1, %k0, %k0
-; CHECK-NEXT: vpsrldq {{.*#+}} xmm0 = xmm1[14,15],zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero
-; CHECK-NEXT: vpextrw $0, %xmm0, %eax
-; CHECK-NEXT: movzwl %ax, %eax
-; CHECK-NEXT: vmovd %eax, %xmm0
+; CHECK-NEXT: vpsrldq {{.*#+}} xmm0 = xmm3[14,15],zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero
; CHECK-NEXT: vcvtph2ps %xmm0, %xmm0
; CHECK-NEXT: kshiftrw $1, %k0, %k0
-; CHECK-NEXT: vucomiss %xmm0, %xmm5
+; CHECK-NEXT: vucomiss %xmm0, %xmm10
; CHECK-NEXT: setnp %al
; CHECK-NEXT: sete %cl
; CHECK-NEXT: testb %al, %cl
diff --git a/llvm/test/CodeGen/X86/vector-half-conversions.ll b/llvm/test/CodeGen/X86/vector-half-conversions.ll
index f59960f06f4a11..3b82df5d5b74d2 100644
--- a/llvm/test/CodeGen/X86/vector-half-conversions.ll
+++ b/llvm/test/CodeGen/X86/vector-half-conversions.ll
@@ -4976,32 +4976,22 @@ define <4 x i32> @fptosi_2f16_to_4i32(<2 x half> %a) nounwind {
;
; F16C-LABEL: fptosi_2f16_to_4i32:
; F16C: # %bb.0:
-; F16C-NEXT: vpextrw $0, %xmm0, %eax
-; F16C-NEXT: movzwl %ax, %eax
-; F16C-NEXT: vmovd %eax, %xmm1
+; F16C-NEXT: vpshufb {{.*#+}} xmm1 = xmm0[2,3],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
; F16C-NEXT: vcvtph2ps %xmm1, %xmm1
-; F16C-NEXT: vpsrld $16, %xmm0, %xmm0
-; F16C-NEXT: vpextrw $0, %xmm0, %eax
-; F16C-NEXT: movzwl %ax, %eax
-; F16C-NEXT: vmovd %eax, %xmm0
+; F16C-NEXT: vpmovzxwq {{.*#+}} xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
; F16C-NEXT: vcvtph2ps %xmm0, %xmm0
-; F16C-NEXT: vunpcklps {{.*#+}} xmm0 = xmm1[0],xmm0[0],xmm1[1],xmm0[1]
+; F16C-NEXT: vunpcklps {{.*#+}} xmm0 = xmm0[0],xmm1[0],xmm0[1],xmm1[1]
; F16C-NEXT: vcvttps2dq %xmm0, %xmm0
; F16C-NEXT: vmovq {{.*#+}} xmm0 = xmm0[0],zero
; F16C-NEXT: retq
;
; AVX512-LABEL: fptosi_2f16_to_4i32:
; AVX512: # %bb.0:
-; AVX512-NEXT: vpextrw $0, %xmm0, %eax
-; AVX512-NEXT: movzwl %ax, %eax
-; AVX512-NEXT: vmovd %eax, %xmm1
+; AVX512-NEXT: vpshufb {{.*#+}} xmm1 = xmm0[2,3],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
; AVX512-NEXT: vcvtph2ps %xmm1, %xmm1
-; AVX512-NEXT: vpsrld $16, %xmm0, %xmm0
-; AVX512-NEXT: vpextrw $0, %xmm0, %eax
-; AVX512-NEXT: movzwl %ax, %eax
-; AVX512-NEXT: vmovd %eax, %xmm0
+; AVX512-NEXT: vpmovzxwq {{.*#+}} xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
; AVX512-NEXT: vcvtph2ps %xmm0, %xmm0
-; AVX512-NEXT: vunpcklps {{.*#+}} xmm0 = xmm1[0],xmm0[0],xmm1[1],xmm0[1]
+; AVX512-NEXT: vunpcklps {{.*#+}} xmm0 = xmm0[0],xmm1[0],xmm0[1],xmm1[1]
; AVX512-NEXT: vcvttps2dq %xmm0, %xmm0
; AVX512-NEXT: vmovq {{.*#+}} xmm0 = xmm0[0],zero
; AVX512-NEXT: retq
diff --git a/llvm/test/CodeGen/X86/vector-reduce-fmax-nnan.ll b/llvm/test/CodeGen/X86/vector-reduce-fmax-nnan.ll
index 71c4427da96253..6e8eefc607ee11 100644
--- a/llvm/test/CodeGen/X86/vector-reduce-fmax-nnan.ll
+++ b/llvm/test/CodeGen/X86/vector-reduce-fmax-nnan.ll
@@ -413,13 +413,9 @@ define half @test_v2f16(<2 x half> %a0) nounwind {
; AVX512F: # %bb.0:
; AVX512F-NEXT: # kill: def $xmm0 killed $xmm0 def $zmm0
; AVX512F-NEXT: vpsrld $16, %xmm0, %xmm1
-; AVX512F-NEXT: vpextrw $0, %xmm0, %eax
-; AVX512F-NEXT: movzwl %ax, %eax
-; AVX512F-NEXT: vmovd %eax, %xmm2
+; AVX512F-NEXT: vpmovzxwq {{.*#+}} xmm2 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
; AVX512F-NEXT: vcvtph2ps %xmm2, %xmm2
-; AVX512F-NEXT: vpextrw $0, %xmm1, %eax
-; AVX512F-NEXT: movzwl %ax, %eax
-; AVX512F-NEXT: vmovd %eax, %xmm3
+; AVX512F-NEXT: vpmovzxwq {{.*#+}} xmm3 = xmm1[0],zero,zero,zero,xmm1[1],zero,zero,zero
; AVX512F-NEXT: vcvtph2ps %xmm3, %xmm3
; AVX512F-NEXT: xorl %eax, %eax
; AVX512F-NEXT: vucomiss %xmm3, %xmm2
@@ -434,13 +430,9 @@ define half @test_v2f16(<2 x half> %a0) nounwind {
; AVX512VL-LABEL: test_v2f16:
; AVX512VL: # %bb.0:
; AVX512VL-NEXT: vpsrld $16, %xmm0, %xmm1
-; AVX512VL-NEXT: vpextrw $0, %xmm0, %eax
-; AVX512VL-NEXT: movzwl %ax, %eax
-; AVX512VL-NEXT: vmovd %eax, %xmm2
+; AVX512VL-NEXT: vpmovzxwq {{.*#+}} xmm2 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
; AVX512VL-NEXT: vcvtph2ps %xmm2, %xmm2
-; AVX512VL-NEXT: vpextrw $0, %xmm1, %eax
-; AVX512VL-NEXT: movzwl %ax, %eax
-; AVX512VL-NEXT: vmovd %eax, %xmm3
+; AVX512VL-NEXT: vpmovzxwq {{.*#+}} xmm3 = xmm1[0],zero,zero,zero,xmm1[1],zero,zero,zero
; AVX512VL-NEXT: vcvtph2ps %xmm3, %xmm3
; AVX512VL-NEXT: xorl %eax, %eax
; AVX512VL-NEXT: vucomiss %xmm3, %xmm2
diff --git a/llvm/test/CodeGen/X86/vector-reduce-fmin-nnan.ll b/llvm/test/CodeGen/X86/vector-reduce-fmin-nnan.ll
index 0b2f9d69f0623c..804ca183ad4c9d 100644
--- a/llvm/test/CodeGen/X86/vector-reduce-fmin-nnan.ll
+++ b/llvm/test/CodeGen/X86/vector-reduce-fmin-nnan.ll
@@ -412,13 +412,9 @@ define half @test_v2f16(<2 x half> %a0) nounwind {
; AVX512F: # %bb.0:
; AVX512F-NEXT: # kill: def $xmm0 killed $xmm0 def $zmm0
; AVX512F-NEXT: vpsrld $16, %xmm0, %xmm1
-; AVX512F-NEXT: vpextrw $0, %xmm0, %eax
-; AVX512F-NEXT: movzwl %ax, %eax
-; AVX512F-NEXT: vmovd %eax, %xmm2
+; AVX512F-NEXT: vpmovzxwq {{.*#+}} xmm2 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
; AVX512F-NEXT: vcvtph2ps %xmm2, %xmm2
-; AVX512F-NEXT: vpextrw $0, %xmm1, %eax
-; AVX512F-NEXT: movzwl %ax, %eax
-; AVX512F-NEXT: vmovd %eax, %xmm3
+; AVX512F-NEXT: vpmovzxwq {{.*#+}} xmm3 = xmm1[0],zero,zero,zero,xmm1[1],zero,zero,zero
; AVX512F-NEXT: vcvtph2ps %xmm3, %xmm3
; AVX512F-NEXT: xorl %eax, %eax
; AVX512F-NEXT: vucomiss %xmm3, %xmm2
@@ -433,13 +429,9 @@ define half @test_v2f16(<2 x half> %a0) nounwind {
; AVX512VL-LABEL: test_v2f16:
; AVX512VL: # %bb.0:
; AVX512VL-NEXT: vpsrld $16, %xmm0, %xmm1
-; AVX512VL-NEXT: vpextrw $0, %xmm0, %eax
-; AVX512VL-NEXT: movzwl %ax, %eax
-; AVX512VL-NEXT: vmovd %eax, %xmm2
+; AVX512VL-NEXT: vpmovzxwq {{.*#+}} xmm2 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
; AVX512VL-NEXT: vcvtph2ps %xmm2, %xmm2
-; AVX512VL-NEXT: vpextrw $0, %xmm1, %eax
-; AVX512VL-NEXT: movzwl %ax, %eax
-; AVX512VL-NEXT: vmovd %eax, %xmm3
+; AVX512VL-NEXT: vpmovzxwq {{.*#+}} xmm3 = xmm1[0],zero,zero,zero,xmm1[1],zero,zero,zero
; AVX512VL-NEXT: vcvtph2ps %xmm3, %xmm3
; AVX512VL-NEXT: xorl %eax, %eax
; AVX512VL-NEXT: vucomiss %xmm3, %xmm2
diff --git a/llvm/test/CodeGen/X86/vector-shuffle-128-v4.ll b/llvm/test/CodeGen/X86/vector-shuffle-128-v4.ll
index 468fec66c028b7..6360c68e62cc94 100644
--- a/llvm/test/CodeGen/X86/vector-shuffle-128-v4.ll
+++ b/llvm/test/CodeGen/X86/vector-shuffle-128-v4.ll
@@ -2012,24 +2012,18 @@ define <4 x i32> @extract3_insert0_v4i32_7123(<4 x i32> %a0, <4 x i32> %a1) {
; SSE2-LABEL: extract3_insert0_v4i32_7123:
; SSE2: # %bb.0:
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm1[3,3,3,3]
-; SSE2-NEXT: movd %xmm1, %eax
-; SSE2-NEXT: movd %eax, %xmm1
; SSE2-NEXT: movss {{.*#+}} xmm0 = xmm1[0],xmm0[1,2,3]
; SSE2-NEXT: retq
;
; SSE3-LABEL: extract3_insert0_v4i32_7123:
; SSE3: # %bb.0:
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm1[3,3,3,3]
-; SSE3-NEXT: movd %xmm1, %eax
-; SSE3-NEXT: movd %eax, %xmm1
; SSE3-NEXT: movss {{.*#+}} xmm0 = xmm1[0],xmm0[1,2,3]
; SSE3-NEXT: retq
;
; SSSE3-LABEL: extract3_insert0_v4i32_7123:
; SSSE3: # %bb.0:
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm1[3,3,3,3]
-; SSSE3-NEXT: movd %xmm1, %eax
-; SSSE3-NEXT: movd %eax, %xmm1
; SSSE3-NEXT: movss {{.*#+}} xmm0 = xmm1[0],xmm0[1,2,3]
; SSSE3-NEXT: retq
;
>From ee297a73b590ee63f0f4ec9f21c5114c106c8467 Mon Sep 17 00:00:00 2001
From: Sudharsan Veeravalli <quic_svs at quicinc.com>
Date: Thu, 29 Feb 2024 16:32:22 +0530
Subject: [PATCH 108/406] [LLDB] Fix test failure introduced by #83234 (#83406)
Missed adding a . in the test check
---
lldb/test/API/functionalities/completion/TestCompletion.py | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/lldb/test/API/functionalities/completion/TestCompletion.py b/lldb/test/API/functionalities/completion/TestCompletion.py
index 2f6af3cfce109d..0d6907e0c3d229 100644
--- a/lldb/test/API/functionalities/completion/TestCompletion.py
+++ b/lldb/test/API/functionalities/completion/TestCompletion.py
@@ -65,7 +65,7 @@ def do_test_variable_completion(self, command):
self.complete_from_to(f"{command} fooo.dd", f"{command} fooo.dd")
self.complete_from_to(f"{command} ptr_fooo->", f"{command} ptr_fooo->t")
- self.complete_from_to(f"{command} ptr_fooo->t", f"{command} ptr_fooo->t.x")
+ self.complete_from_to(f"{command} ptr_fooo->t.", f"{command} ptr_fooo->t.x")
self.complete_from_to(f"{command} ptr_fooo->dd", f"{command} ptr_fooo->dd")
self.complete_from_to(f"{command} cont", f"{command} container")
>From 6cfd3439d4b99be85f647849168e1076a9737170 Mon Sep 17 00:00:00 2001
From: Matt Arsenault <Matthew.Arsenault at amd.com>
Date: Thu, 29 Feb 2024 16:51:33 +0530
Subject: [PATCH 109/406] APFloat: Fix signed zero handling in minnum/maxnum
(#83376)
Follow the 2019 rules and order -0 as less than +0 and +0 as greater
than -0. As currently defined this isn't required for the intrinsics,
but is a better QoI.
This will avoid the workaround in libc added by #83158
---
llvm/include/llvm/ADT/APFloat.h | 14 ++--
llvm/test/CodeGen/AMDGPU/fmaxnum.ll | 2 +-
llvm/test/CodeGen/AMDGPU/fminnum.ll | 2 +-
llvm/test/Transforms/InstCombine/maxnum.ll | 2 +-
llvm/test/Transforms/InstCombine/minnum.ll | 4 +-
.../InstSimplify/ConstProp/min-max.ll | 68 ++++++++++++++++++-
llvm/unittests/ADT/APFloatTest.cpp | 10 +++
7 files changed, 91 insertions(+), 11 deletions(-)
diff --git a/llvm/include/llvm/ADT/APFloat.h b/llvm/include/llvm/ADT/APFloat.h
index 4edb24586fd7c4..deb74cb2fdeb1e 100644
--- a/llvm/include/llvm/ADT/APFloat.h
+++ b/llvm/include/llvm/ADT/APFloat.h
@@ -1389,25 +1389,31 @@ inline APFloat neg(APFloat X) {
return X;
}
-/// Implements IEEE minNum semantics. Returns the smaller of the 2 arguments if
-/// both are not NaN. If either argument is a NaN, returns the other argument.
+/// Implements IEEE-754 2019 minimumNumber semantics. Returns the smaller of the
+/// 2 arguments if both are not NaN. If either argument is a NaN, returns the
+/// other argument. -0 is treated as ordered less than +0.
LLVM_READONLY
inline APFloat minnum(const APFloat &A, const APFloat &B) {
if (A.isNaN())
return B;
if (B.isNaN())
return A;
+ if (A.isZero() && B.isZero() && (A.isNegative() != B.isNegative()))
+ return A.isNegative() ? A : B;
return B < A ? B : A;
}
-/// Implements IEEE maxNum semantics. Returns the larger of the 2 arguments if
-/// both are not NaN. If either argument is a NaN, returns the other argument.
+/// Implements IEEE-754 2019 maximumNumber semantics. Returns the larger of the
+/// 2 arguments if both are not NaN. If either argument is a NaN, returns the
+/// other argument. +0 is treated as ordered greater than -0.
LLVM_READONLY
inline APFloat maxnum(const APFloat &A, const APFloat &B) {
if (A.isNaN())
return B;
if (B.isNaN())
return A;
+ if (A.isZero() && B.isZero() && (A.isNegative() != B.isNegative()))
+ return A.isNegative() ? B : A;
return A < B ? B : A;
}
diff --git a/llvm/test/CodeGen/AMDGPU/fmaxnum.ll b/llvm/test/CodeGen/AMDGPU/fmaxnum.ll
index 09898f1442fb82..38640a18b5aee6 100644
--- a/llvm/test/CodeGen/AMDGPU/fmaxnum.ll
+++ b/llvm/test/CodeGen/AMDGPU/fmaxnum.ll
@@ -152,7 +152,7 @@ define amdgpu_kernel void @constant_fold_fmax_f32_p0_n0(ptr addrspace(1) %out) #
; GCN-LABEL: {{^}}constant_fold_fmax_f32_n0_p0:
; GCN-NOT: v_max_f32_e32
-; GCN: v_bfrev_b32_e32 [[REG:v[0-9]+]], 1{{$}}
+; GCN: v_mov_b32_e32 [[REG:v[0-9]+]], 0{{$}}
; GCN: buffer_store_dword [[REG]]
define amdgpu_kernel void @constant_fold_fmax_f32_n0_p0(ptr addrspace(1) %out) #0 {
%val = call float @llvm.maxnum.f32(float -0.0, float 0.0)
diff --git a/llvm/test/CodeGen/AMDGPU/fminnum.ll b/llvm/test/CodeGen/AMDGPU/fminnum.ll
index 844d26a6225b40..65b311845a6b77 100644
--- a/llvm/test/CodeGen/AMDGPU/fminnum.ll
+++ b/llvm/test/CodeGen/AMDGPU/fminnum.ll
@@ -150,7 +150,7 @@ define amdgpu_kernel void @constant_fold_fmin_f32_p0_p0(ptr addrspace(1) %out) #
; GCN-LABEL: {{^}}constant_fold_fmin_f32_p0_n0:
; GCN-NOT: v_min_f32_e32
-; GCN: v_mov_b32_e32 [[REG:v[0-9]+]], 0
+; GCN: v_bfrev_b32_e32 [[REG:v[0-9]+]], 1{{$}}
; GCN: buffer_store_dword [[REG]]
define amdgpu_kernel void @constant_fold_fmin_f32_p0_n0(ptr addrspace(1) %out) #0 {
%val = call float @llvm.minnum.f32(float 0.0, float -0.0)
diff --git a/llvm/test/Transforms/InstCombine/maxnum.ll b/llvm/test/Transforms/InstCombine/maxnum.ll
index 87288b18cbcd9f..e140a5b405ea84 100644
--- a/llvm/test/Transforms/InstCombine/maxnum.ll
+++ b/llvm/test/Transforms/InstCombine/maxnum.ll
@@ -66,7 +66,7 @@ define float @constant_fold_maxnum_f32_p0_n0() {
define float @constant_fold_maxnum_f32_n0_p0() {
; CHECK-LABEL: @constant_fold_maxnum_f32_n0_p0(
-; CHECK-NEXT: ret float -0.000000e+00
+; CHECK-NEXT: ret float 0.000000e+00
;
%x = call float @llvm.maxnum.f32(float -0.0, float 0.0)
ret float %x
diff --git a/llvm/test/Transforms/InstCombine/minnum.ll b/llvm/test/Transforms/InstCombine/minnum.ll
index 8050f075595272..cc6171b9d8e6cb 100644
--- a/llvm/test/Transforms/InstCombine/minnum.ll
+++ b/llvm/test/Transforms/InstCombine/minnum.ll
@@ -60,7 +60,7 @@ define float @constant_fold_minnum_f32_p0_p0() {
define float @constant_fold_minnum_f32_p0_n0() {
; CHECK-LABEL: @constant_fold_minnum_f32_p0_n0(
-; CHECK-NEXT: ret float 0.000000e+00
+; CHECK-NEXT: ret float -0.000000e+00
;
%x = call float @llvm.minnum.f32(float 0.0, float -0.0)
ret float %x
@@ -199,7 +199,7 @@ define float @minnum_f32_1_minnum_p0_val_fmf3(float %x) {
define float @minnum_f32_p0_minnum_val_n0(float %x) {
; CHECK-LABEL: @minnum_f32_p0_minnum_val_n0(
-; CHECK-NEXT: [[Z:%.*]] = call float @llvm.minnum.f32(float [[X:%.*]], float 0.000000e+00)
+; CHECK-NEXT: [[Z:%.*]] = call float @llvm.minnum.f32(float [[X:%.*]], float -0.000000e+00)
; CHECK-NEXT: ret float [[Z]]
;
%y = call float @llvm.minnum.f32(float %x, float -0.0)
diff --git a/llvm/test/Transforms/InstSimplify/ConstProp/min-max.ll b/llvm/test/Transforms/InstSimplify/ConstProp/min-max.ll
index a5f5d4e12ed842..9120649eb5c4f1 100644
--- a/llvm/test/Transforms/InstSimplify/ConstProp/min-max.ll
+++ b/llvm/test/Transforms/InstSimplify/ConstProp/min-max.ll
@@ -49,6 +49,38 @@ define float @minnum_float() {
ret float %1
}
+define float @minnum_float_p0_n0() {
+; CHECK-LABEL: @minnum_float_p0_n0(
+; CHECK-NEXT: ret float -0.000000e+00
+;
+ %min = call float @llvm.minnum.f32(float 0.0, float -0.0)
+ ret float %min
+}
+
+define float @minnum_float_n0_p0() {
+; CHECK-LABEL: @minnum_float_n0_p0(
+; CHECK-NEXT: ret float -0.000000e+00
+;
+ %min = call float @llvm.minnum.f32(float -0.0, float 0.0)
+ ret float %min
+}
+
+define float @minnum_float_p0_qnan() {
+; CHECK-LABEL: @minnum_float_p0_qnan(
+; CHECK-NEXT: ret float 0.000000e+00
+;
+ %min = call float @llvm.minnum.f32(float 0.0, float 0x7FF8000000000000)
+ ret float %min
+}
+
+define float @minnum_float_qnan_p0() {
+; CHECK-LABEL: @minnum_float_qnan_p0(
+; CHECK-NEXT: ret float 0.000000e+00
+;
+ %min = call float @llvm.minnum.f32(float 0x7FF8000000000000, float 0.0)
+ ret float %min
+}
+
define bfloat @minnum_bfloat() {
; CHECK-LABEL: @minnum_bfloat(
; CHECK-NEXT: ret bfloat 0xR40A0
@@ -95,7 +127,7 @@ define <4 x half> @minnum_half_vec() {
define <4 x float> @minnum_float_zeros_vec() {
; CHECK-LABEL: @minnum_float_zeros_vec(
-; CHECK-NEXT: ret <4 x float> <float 0.000000e+00, float -0.000000e+00, float 0.000000e+00, float -0.000000e+00>
+; CHECK-NEXT: ret <4 x float> <float 0.000000e+00, float -0.000000e+00, float -0.000000e+00, float -0.000000e+00>
;
%1 = call <4 x float> @llvm.minnum.v4f32(<4 x float> <float 0.0, float -0.0, float 0.0, float -0.0>, <4 x float> <float 0.0, float 0.0, float -0.0, float -0.0>)
ret <4 x float> %1
@@ -109,6 +141,38 @@ define float @maxnum_float() {
ret float %1
}
+define float @maxnum_float_p0_n0() {
+; CHECK-LABEL: @maxnum_float_p0_n0(
+; CHECK-NEXT: ret float 0.000000e+00
+;
+ %max = call float @llvm.maxnum.f32(float 0.0, float -0.0)
+ ret float %max
+}
+
+define float @maxnum_float_n0_p0() {
+; CHECK-LABEL: @maxnum_float_n0_p0(
+; CHECK-NEXT: ret float 0.000000e+00
+;
+ %max = call float @llvm.maxnum.f32(float -0.0, float 0.0)
+ ret float %max
+}
+
+define float @maxnum_float_p0_qnan() {
+; CHECK-LABEL: @maxnum_float_p0_qnan(
+; CHECK-NEXT: ret float 0.000000e+00
+;
+ %max = call float @llvm.maxnum.f32(float 0.0, float 0x7FF8000000000000)
+ ret float %max
+}
+
+define float @maxnum_float_qnan_p0() {
+; CHECK-LABEL: @maxnum_float_qnan_p0(
+; CHECK-NEXT: ret float 0.000000e+00
+;
+ %max = call float @llvm.maxnum.f32(float 0x7FF8000000000000, float 0.0)
+ ret float %max
+}
+
define bfloat @maxnum_bfloat() {
; CHECK-LABEL: @maxnum_bfloat(
; CHECK-NEXT: ret bfloat 0xR4228
@@ -155,7 +219,7 @@ define <4 x half> @maxnum_half_vec() {
define <4 x float> @maxnum_float_zeros_vec() {
; CHECK-LABEL: @maxnum_float_zeros_vec(
-; CHECK-NEXT: ret <4 x float> <float 0.000000e+00, float -0.000000e+00, float 0.000000e+00, float -0.000000e+00>
+; CHECK-NEXT: ret <4 x float> <float 0.000000e+00, float 0.000000e+00, float 0.000000e+00, float -0.000000e+00>
;
%1 = call <4 x float> @llvm.maxnum.v4f32(<4 x float> <float 0.0, float -0.0, float 0.0, float -0.0>, <4 x float> <float 0.0, float 0.0, float -0.0, float -0.0>)
ret <4 x float> %1
diff --git a/llvm/unittests/ADT/APFloatTest.cpp b/llvm/unittests/ADT/APFloatTest.cpp
index baf055e503b7e7..6e4dda8351a1b1 100644
--- a/llvm/unittests/ADT/APFloatTest.cpp
+++ b/llvm/unittests/ADT/APFloatTest.cpp
@@ -578,6 +578,11 @@ TEST(APFloatTest, MinNum) {
EXPECT_EQ(1.0, minnum(f2, f1).convertToDouble());
EXPECT_EQ(1.0, minnum(f1, nan).convertToDouble());
EXPECT_EQ(1.0, minnum(nan, f1).convertToDouble());
+
+ APFloat zp(0.0);
+ APFloat zn(-0.0);
+ EXPECT_EQ(-0.0, minnum(zp, zn).convertToDouble());
+ EXPECT_EQ(-0.0, minnum(zn, zp).convertToDouble());
}
TEST(APFloatTest, MaxNum) {
@@ -589,6 +594,11 @@ TEST(APFloatTest, MaxNum) {
EXPECT_EQ(2.0, maxnum(f2, f1).convertToDouble());
EXPECT_EQ(1.0, maxnum(f1, nan).convertToDouble());
EXPECT_EQ(1.0, maxnum(nan, f1).convertToDouble());
+
+ APFloat zp(0.0);
+ APFloat zn(-0.0);
+ EXPECT_EQ(0.0, maxnum(zp, zn).convertToDouble());
+ EXPECT_EQ(0.0, maxnum(zn, zp).convertToDouble());
}
TEST(APFloatTest, Minimum) {
>From fb3e4e78c65ea22b5eda1b4f7e2b5a5e8c6dd5b4 Mon Sep 17 00:00:00 2001
From: Alexander Belyaev <32522095+pifon2a at users.noreply.github.com>
Date: Thu, 29 Feb 2024 12:26:22 +0100
Subject: [PATCH 110/406] [mlir] Remove assert from GPUOps.td. (#83410)
it changes behaviour for debug vs release builds.
---
mlir/include/mlir/Dialect/GPU/IR/GPUOps.td | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/mlir/include/mlir/Dialect/GPU/IR/GPUOps.td b/mlir/include/mlir/Dialect/GPU/IR/GPUOps.td
index f38ef4d709ef44..bb373afa40ad99 100644
--- a/mlir/include/mlir/Dialect/GPU/IR/GPUOps.td
+++ b/mlir/include/mlir/Dialect/GPU/IR/GPUOps.td
@@ -61,7 +61,7 @@ class GPU_IndexOp<string mnemonic, list<Trait> traits = []> :
llvm::function_ref<void(mlir::Value, mlir::StringRef)> setNameFn) {
auto dimStr = stringifyDimension(getDimensionAttr().getValue());
auto opName = getOperationName();
- assert(opName.consume_front("gpu."));
+ opName.consume_front("gpu.");
SmallString<8> resultName({opName, "_", dimStr});
setNameFn(getResult(),resultName);
}
>From 02bad7a858e763be49c257d957dfd70fab18af9e Mon Sep 17 00:00:00 2001
From: Jay Foad <jay.foad at amd.com>
Date: Thu, 29 Feb 2024 11:22:14 +0000
Subject: [PATCH 111/406] [AMDGPU] Simplify !if condition. NFC.
---
llvm/lib/Target/AMDGPU/BUFInstructions.td | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/llvm/lib/Target/AMDGPU/BUFInstructions.td b/llvm/lib/Target/AMDGPU/BUFInstructions.td
index 7d4d619788d392..4b74f3b81e5e78 100644
--- a/llvm/lib/Target/AMDGPU/BUFInstructions.td
+++ b/llvm/lib/Target/AMDGPU/BUFInstructions.td
@@ -2509,7 +2509,7 @@ class MUBUF_Real_Atomic_gfx12_impl<bits<8> op, string ps_name,
multiclass MUBUF_Real_Atomic_gfx11_Renamed_impl<bits<8> op, bit is_return,
string real_name> {
- defvar Rtn = !if(!eq(is_return, 1), "_RTN", "");
+ defvar Rtn = !if(is_return, "_RTN", "");
def _BOTHEN#Rtn#_gfx11 :
MUBUF_Real_Atomic_gfx11_impl<op, NAME # "_BOTHEN" # Rtn, real_name>,
AtomicNoRet<NAME # "_BOTHEN_gfx11", is_return>;
@@ -2526,7 +2526,7 @@ multiclass MUBUF_Real_Atomic_gfx11_Renamed_impl<bits<8> op, bit is_return,
multiclass MUBUF_Real_Atomic_gfx12_Renamed_impl<bits<8> op, bit is_return,
string real_name> {
- defvar Rtn = !if(!eq(is_return, 1), "_RTN", "");
+ defvar Rtn = !if(is_return, "_RTN", "");
def _BOTHEN#Rtn#_gfx12 :
MUBUF_Real_Atomic_gfx12_impl<op, NAME # "_VBUFFER_BOTHEN" # Rtn, real_name>,
AtomicNoRet<NAME # "_BOTHEN_gfx12", is_return>;
>From 72a60e770cee713a47876483798747cb7db58da6 Mon Sep 17 00:00:00 2001
From: Samuel Tebbs <samuel.tebbs at arm.com>
Date: Wed, 28 Feb 2024 15:04:49 +0000
Subject: [PATCH 112/406] [AArch64][NFC] Use regexes in register class tests
Some MIR and IR tests include checks for register class IDs, which are
unnecessary since the register class name is also checked for and that
doesn't change when new classes are added. This patch replaces the
hard-coded register class ID checks with regexes so they don't have to
be updated every time a new class is added.
---
.../GlobalISel/irtranslator-inline-asm.ll | 22 ++++++++--------
.../irtranslator-unwind-inline-asm.ll | 2 +-
llvm/test/CodeGen/AArch64/aarch64-sme2-asm.ll | 6 ++---
.../callbr-asm-outputs-indirect-isel.ll | 26 +++++++++----------
.../emit_fneg_with_non_register_operand.mir | 4 +--
.../CodeGen/AArch64/peephole-insvigpr.mir | 2 +-
6 files changed, 31 insertions(+), 31 deletions(-)
diff --git a/llvm/test/CodeGen/AArch64/GlobalISel/irtranslator-inline-asm.ll b/llvm/test/CodeGen/AArch64/GlobalISel/irtranslator-inline-asm.ll
index ef8e4665364086..42f6570047fc7a 100644
--- a/llvm/test/CodeGen/AArch64/GlobalISel/irtranslator-inline-asm.ll
+++ b/llvm/test/CodeGen/AArch64/GlobalISel/irtranslator-inline-asm.ll
@@ -26,7 +26,7 @@ define void @asm_simple_register_clobber() {
define i64 @asm_register_early_clobber() {
; CHECK-LABEL: name: asm_register_early_clobber
; CHECK: bb.1 (%ir-block.0):
- ; CHECK-NEXT: INLINEASM &"mov $0, 7; mov $1, 7", 1 /* sideeffect attdialect */, 2752523 /* regdef-ec:GPR64common */, def early-clobber %0, 2752523 /* regdef-ec:GPR64common */, def early-clobber %1, !0
+ ; CHECK-NEXT: INLINEASM &"mov $0, 7; mov $1, 7", 1 /* sideeffect attdialect */, {{[0-9]+}} /* regdef-ec:GPR64common */, def early-clobber %0, {{[0-9]+}} /* regdef-ec:GPR64common */, def early-clobber %1, !0
; CHECK-NEXT: [[COPY:%[0-9]+]]:_(s64) = COPY %0
; CHECK-NEXT: [[COPY1:%[0-9]+]]:_(s64) = COPY %1
; CHECK-NEXT: [[ADD:%[0-9]+]]:_(s64) = G_ADD [[COPY]], [[COPY1]]
@@ -54,7 +54,7 @@ entry:
define i32 @test_single_register_output() nounwind ssp {
; CHECK-LABEL: name: test_single_register_output
; CHECK: bb.1.entry:
- ; CHECK-NEXT: INLINEASM &"mov ${0:w}, 7", 0 /* attdialect */, 1703946 /* regdef:GPR32common */, def %0
+ ; CHECK-NEXT: INLINEASM &"mov ${0:w}, 7", 0 /* attdialect */, {{[0-9]+}} /* regdef:GPR32common */, def %0
; CHECK-NEXT: [[COPY:%[0-9]+]]:_(s32) = COPY %0
; CHECK-NEXT: $w0 = COPY [[COPY]](s32)
; CHECK-NEXT: RET_ReallyLR implicit $w0
@@ -66,7 +66,7 @@ entry:
define i64 @test_single_register_output_s64() nounwind ssp {
; CHECK-LABEL: name: test_single_register_output_s64
; CHECK: bb.1.entry:
- ; CHECK-NEXT: INLINEASM &"mov $0, 7", 0 /* attdialect */, 2752522 /* regdef:GPR64common */, def %0
+ ; CHECK-NEXT: INLINEASM &"mov $0, 7", 0 /* attdialect */, {{[0-9]+}} /* regdef:GPR64common */, def %0
; CHECK-NEXT: [[COPY:%[0-9]+]]:_(s64) = COPY %0
; CHECK-NEXT: $x0 = COPY [[COPY]](s64)
; CHECK-NEXT: RET_ReallyLR implicit $x0
@@ -79,7 +79,7 @@ entry:
define float @test_multiple_register_outputs_same() #0 {
; CHECK-LABEL: name: test_multiple_register_outputs_same
; CHECK: bb.1 (%ir-block.0):
- ; CHECK-NEXT: INLINEASM &"mov $0, #0; mov $1, #0", 0 /* attdialect */, 1703946 /* regdef:GPR32common */, def %0, 1703946 /* regdef:GPR32common */, def %1
+ ; CHECK-NEXT: INLINEASM &"mov $0, #0; mov $1, #0", 0 /* attdialect */, {{[0-9]+}} /* regdef:GPR32common */, def %0, {{[0-9]+}} /* regdef:GPR32common */, def %1
; CHECK-NEXT: [[COPY:%[0-9]+]]:_(s32) = COPY %0
; CHECK-NEXT: [[COPY1:%[0-9]+]]:_(s32) = COPY %1
; CHECK-NEXT: [[FADD:%[0-9]+]]:_(s32) = G_FADD [[COPY]], [[COPY1]]
@@ -96,7 +96,7 @@ define float @test_multiple_register_outputs_same() #0 {
define double @test_multiple_register_outputs_mixed() #0 {
; CHECK-LABEL: name: test_multiple_register_outputs_mixed
; CHECK: bb.1 (%ir-block.0):
- ; CHECK-NEXT: INLINEASM &"mov $0, #0; mov $1, #0", 0 /* attdialect */, 1703946 /* regdef:GPR32common */, def %0, 2555914 /* regdef:FPR64 */, def %1
+ ; CHECK-NEXT: INLINEASM &"mov $0, #0; mov $1, #0", 0 /* attdialect */, {{[0-9]+}} /* regdef:GPR32common */, def %0, {{[0-9]+}} /* regdef:FPR64 */, def %1
; CHECK-NEXT: [[COPY:%[0-9]+]]:_(s32) = COPY %0
; CHECK-NEXT: [[COPY1:%[0-9]+]]:_(s64) = COPY %1
; CHECK-NEXT: $d0 = COPY [[COPY1]](s64)
@@ -125,7 +125,7 @@ define zeroext i8 @test_register_output_trunc(ptr %src) nounwind {
; CHECK-NEXT: liveins: $x0
; CHECK-NEXT: {{ $}}
; CHECK-NEXT: [[COPY:%[0-9]+]]:_(p0) = COPY $x0
- ; CHECK-NEXT: INLINEASM &"mov ${0:w}, 32", 0 /* attdialect */, 1703946 /* regdef:GPR32common */, def %1
+ ; CHECK-NEXT: INLINEASM &"mov ${0:w}, 32", 0 /* attdialect */, {{[0-9]+}} /* regdef:GPR32common */, def %1
; CHECK-NEXT: [[COPY1:%[0-9]+]]:_(s32) = COPY %1
; CHECK-NEXT: [[TRUNC:%[0-9]+]]:_(s8) = G_TRUNC [[COPY1]](s32)
; CHECK-NEXT: [[ZEXT:%[0-9]+]]:_(s32) = G_ZEXT [[TRUNC]](s8)
@@ -155,7 +155,7 @@ define void @test_input_register_imm() {
; CHECK: bb.1 (%ir-block.0):
; CHECK-NEXT: [[C:%[0-9]+]]:_(s64) = G_CONSTANT i64 42
; CHECK-NEXT: [[COPY:%[0-9]+]]:gpr64common = COPY [[C]](s64)
- ; CHECK-NEXT: INLINEASM &"mov x0, $0", 1 /* sideeffect attdialect */, 2752521 /* reguse:GPR64common */, [[COPY]]
+ ; CHECK-NEXT: INLINEASM &"mov x0, $0", 1 /* sideeffect attdialect */, {{[0-9]+}} /* reguse:GPR64common */, [[COPY]]
; CHECK-NEXT: RET_ReallyLR
call void asm sideeffect "mov x0, $0", "r"(i64 42)
ret void
@@ -190,7 +190,7 @@ define zeroext i8 @test_input_register(ptr %src) nounwind {
; CHECK-NEXT: {{ $}}
; CHECK-NEXT: [[COPY:%[0-9]+]]:_(p0) = COPY $x0
; CHECK-NEXT: [[COPY1:%[0-9]+]]:gpr64common = COPY [[COPY]](p0)
- ; CHECK-NEXT: INLINEASM &"ldtrb ${0:w}, [$1]", 0 /* attdialect */, 1703946 /* regdef:GPR32common */, def %1, 2752521 /* reguse:GPR64common */, [[COPY1]]
+ ; CHECK-NEXT: INLINEASM &"ldtrb ${0:w}, [$1]", 0 /* attdialect */, {{[0-9]+}} /* regdef:GPR32common */, def %1, {{[0-9]+}} /* reguse:GPR64common */, [[COPY1]]
; CHECK-NEXT: [[COPY2:%[0-9]+]]:_(s32) = COPY %1
; CHECK-NEXT: [[TRUNC:%[0-9]+]]:_(s8) = G_TRUNC [[COPY2]](s32)
; CHECK-NEXT: [[ZEXT:%[0-9]+]]:_(s32) = G_ZEXT [[TRUNC]](s8)
@@ -207,7 +207,7 @@ define i32 @test_memory_constraint(ptr %a) nounwind {
; CHECK-NEXT: liveins: $x0
; CHECK-NEXT: {{ $}}
; CHECK-NEXT: [[COPY:%[0-9]+]]:_(p0) = COPY $x0
- ; CHECK-NEXT: INLINEASM &"ldr $0, $1", 8 /* mayload attdialect */, 1703946 /* regdef:GPR32common */, def %1, 262158 /* mem:m */, [[COPY]](p0)
+ ; CHECK-NEXT: INLINEASM &"ldr $0, $1", 8 /* mayload attdialect */, {{[0-9]+}} /* regdef:GPR32common */, def %1, 262158 /* mem:m */, [[COPY]](p0)
; CHECK-NEXT: [[COPY1:%[0-9]+]]:_(s32) = COPY %1
; CHECK-NEXT: $w0 = COPY [[COPY1]](s32)
; CHECK-NEXT: RET_ReallyLR implicit $w0
@@ -221,7 +221,7 @@ define i16 @test_anyext_input() {
; CHECK-NEXT: [[C:%[0-9]+]]:_(s16) = G_CONSTANT i16 1
; CHECK-NEXT: [[ANYEXT:%[0-9]+]]:_(s32) = G_ANYEXT [[C]](s16)
; CHECK-NEXT: [[COPY:%[0-9]+]]:gpr32common = COPY [[ANYEXT]](s32)
- ; CHECK-NEXT: INLINEASM &"", 1 /* sideeffect attdialect */, 1703946 /* regdef:GPR32common */, def %0, 1703945 /* reguse:GPR32common */, [[COPY]]
+ ; CHECK-NEXT: INLINEASM &"", 1 /* sideeffect attdialect */, {{[0-9]+}} /* regdef:GPR32common */, def %0, {{[0-9]+}} /* reguse:GPR32common */, [[COPY]]
; CHECK-NEXT: [[COPY1:%[0-9]+]]:_(s32) = COPY %0
; CHECK-NEXT: [[TRUNC:%[0-9]+]]:_(s16) = G_TRUNC [[COPY1]](s32)
; CHECK-NEXT: [[ANYEXT1:%[0-9]+]]:_(s32) = G_ANYEXT [[TRUNC]](s16)
@@ -237,7 +237,7 @@ define i16 @test_anyext_input_with_matching_constraint() {
; CHECK-NEXT: [[C:%[0-9]+]]:_(s16) = G_CONSTANT i16 1
; CHECK-NEXT: [[ANYEXT:%[0-9]+]]:_(s32) = G_ANYEXT [[C]](s16)
; CHECK-NEXT: [[COPY:%[0-9]+]]:gpr32common = COPY [[ANYEXT]](s32)
- ; CHECK-NEXT: INLINEASM &"", 1 /* sideeffect attdialect */, 1703946 /* regdef:GPR32common */, def %0, 2147483657 /* reguse tiedto:$0 */, [[COPY]](tied-def 3)
+ ; CHECK-NEXT: INLINEASM &"", 1 /* sideeffect attdialect */, {{[0-9]+}} /* regdef:GPR32common */, def %0, 2147483657 /* reguse tiedto:$0 */, [[COPY]](tied-def 3)
; CHECK-NEXT: [[COPY1:%[0-9]+]]:_(s32) = COPY %0
; CHECK-NEXT: [[TRUNC:%[0-9]+]]:_(s16) = G_TRUNC [[COPY1]](s32)
; CHECK-NEXT: [[ANYEXT1:%[0-9]+]]:_(s32) = G_ANYEXT [[TRUNC]](s16)
diff --git a/llvm/test/CodeGen/AArch64/GlobalISel/irtranslator-unwind-inline-asm.ll b/llvm/test/CodeGen/AArch64/GlobalISel/irtranslator-unwind-inline-asm.ll
index 59eb80ae6146b3..fbffb50bcbc8a3 100644
--- a/llvm/test/CodeGen/AArch64/GlobalISel/irtranslator-unwind-inline-asm.ll
+++ b/llvm/test/CodeGen/AArch64/GlobalISel/irtranslator-unwind-inline-asm.ll
@@ -71,7 +71,7 @@ define void @test2() #0 personality ptr @__gcc_personality_v0 {
; CHECK-NEXT: G_INVOKE_REGION_START
; CHECK-NEXT: EH_LABEL <mcsymbol >
; CHECK-NEXT: [[COPY:%[0-9]+]]:gpr64common = COPY [[DEF]](p0)
- ; CHECK-NEXT: INLINEASM &"", 1 /* sideeffect attdialect */, 2752521 /* reguse:GPR64common */, [[COPY]]
+ ; CHECK-NEXT: INLINEASM &"", 1 /* sideeffect attdialect */, {{[0-9]+}} /* reguse:GPR64common */, [[COPY]]
; CHECK-NEXT: EH_LABEL <mcsymbol >
; CHECK-NEXT: G_BR %bb.2
; CHECK-NEXT: {{ $}}
diff --git a/llvm/test/CodeGen/AArch64/aarch64-sme2-asm.ll b/llvm/test/CodeGen/AArch64/aarch64-sme2-asm.ll
index 8ed7059d2e754c..58299696e78fc2 100644
--- a/llvm/test/CodeGen/AArch64/aarch64-sme2-asm.ll
+++ b/llvm/test/CodeGen/AArch64/aarch64-sme2-asm.ll
@@ -5,7 +5,7 @@ entry:
; CHECK: %0:ppr = COPY $p0
; CHECK: STR_PXI %0, %stack.0.predcnt.addr, 0 :: (store unknown-size into %ir.predcnt.addr, align 2)
; CHECK: %1:pnr_p8to15 = COPY %0
-; CHECK: INLINEASM &"ld1w {z0.s,z1.s,z2.s,z3.s}, $0/z, [x10]", 1 /* sideeffect attdialect */, 458761 /* reguse:PNR_p8to15 */, %1
+; CHECK: INLINEASM &"ld1w {z0.s,z1.s,z2.s,z3.s}, $0/z, [x10]", 1 /* sideeffect attdialect */, {{[0-9]+}} /* reguse:PNR_p8to15 */, %1
; CHECK: RET_ReallyLR
%predcnt.addr = alloca target("aarch64.svcount"), align 2
store target("aarch64.svcount") %predcnt, ptr %predcnt.addr, align 2
@@ -19,7 +19,7 @@ entry:
; CHECK: %0:ppr = COPY $p0
; CHECK: STR_PXI %0, %stack.0.predcnt.addr, 0 :: (store unknown-size into %ir.predcnt.addr, align 2)
; CHECK: %1:pnr = COPY %0
-; CHECK: INLINEASM &"ld1w {z0.s,z1.s,z2.s,z3.s}, $0/z, [x10]", 1 /* sideeffect attdialect */, 262153 /* reguse:PNR */, %1
+; CHECK: INLINEASM &"ld1w {z0.s,z1.s,z2.s,z3.s}, $0/z, [x10]", 1 /* sideeffect attdialect */, {{[0-9]+}} /* reguse:PNR */, %1
; CHECK: RET_ReallyLR
%predcnt.addr = alloca target("aarch64.svcount"), align 2
store target("aarch64.svcount") %predcnt, ptr %predcnt.addr, align 2
@@ -33,7 +33,7 @@ entry:
; CHECK: %0:ppr = COPY $p0
; CHECK: STR_PXI %0, %stack.0.predcnt.addr, 0 :: (store unknown-size into %ir.predcnt.addr, align 2)
; CHECK: %1:pnr_3b = COPY %0
-; CHECK: INLINEASM &"fadd z0.h, $0/m, z0.h, #0.5", 1 /* sideeffect attdialect */, 393225 /* reguse:PNR_3b */, %1
+; CHECK: INLINEASM &"fadd z0.h, $0/m, z0.h, #0.5", 1 /* sideeffect attdialect */, {{[0-9]+}} /* reguse:PNR_3b */, %1
; CHECK: RET_ReallyLR
%predcnt.addr = alloca target("aarch64.svcount"), align 2
store target("aarch64.svcount") %predcnt, ptr %predcnt.addr, align 2
diff --git a/llvm/test/CodeGen/AArch64/callbr-asm-outputs-indirect-isel.ll b/llvm/test/CodeGen/AArch64/callbr-asm-outputs-indirect-isel.ll
index 3b7b5dd3fa7a54..fbe89e70e4d8e2 100644
--- a/llvm/test/CodeGen/AArch64/callbr-asm-outputs-indirect-isel.ll
+++ b/llvm/test/CodeGen/AArch64/callbr-asm-outputs-indirect-isel.ll
@@ -18,7 +18,7 @@ define i32 @test0() {
; CHECK: bb.0.entry:
; CHECK-NEXT: successors: %bb.2(0x80000000), %bb.1(0x00000000)
; CHECK-NEXT: {{ $}}
- ; CHECK-NEXT: INLINEASM_BR &"# $0", 0 /* attdialect */, 1703946 /* regdef:GPR32common */, def %5, 13 /* imm */, %bb.1
+ ; CHECK-NEXT: INLINEASM_BR &"# $0", 0 /* attdialect */, {{[0-9]+}} /* regdef:GPR32common */, def %5, 13 /* imm */, %bb.1
; CHECK-NEXT: [[COPY:%[0-9]+]]:gpr32all = COPY %5
; CHECK-NEXT: B %bb.2
; CHECK-NEXT: {{ $}}
@@ -31,7 +31,7 @@ define i32 @test0() {
; CHECK-NEXT: bb.2.direct:
; CHECK-NEXT: successors: %bb.4(0x80000000), %bb.3(0x00000000)
; CHECK-NEXT: {{ $}}
- ; CHECK-NEXT: INLINEASM_BR &"# $0", 0 /* attdialect */, 1703946 /* regdef:GPR32common */, def %7, 13 /* imm */, %bb.3
+ ; CHECK-NEXT: INLINEASM_BR &"# $0", 0 /* attdialect */, {{[0-9]+}} /* regdef:GPR32common */, def %7, 13 /* imm */, %bb.3
; CHECK-NEXT: [[COPY2:%[0-9]+]]:gpr32all = COPY %7
; CHECK-NEXT: B %bb.4
; CHECK-NEXT: {{ $}}
@@ -107,7 +107,7 @@ define i32 @dont_split1() {
; CHECK: bb.0.entry:
; CHECK-NEXT: successors: %bb.1(0x80000000), %bb.2(0x00000000)
; CHECK-NEXT: {{ $}}
- ; CHECK-NEXT: INLINEASM_BR &"", 0 /* attdialect */, 1703946 /* regdef:GPR32common */, def %1, 13 /* imm */, %bb.2
+ ; CHECK-NEXT: INLINEASM_BR &"", 0 /* attdialect */, {{[0-9]+}} /* regdef:GPR32common */, def %1, 13 /* imm */, %bb.2
; CHECK-NEXT: [[COPY:%[0-9]+]]:gpr32all = COPY %1
; CHECK-NEXT: B %bb.1
; CHECK-NEXT: {{ $}}
@@ -168,7 +168,7 @@ define i32 @dont_split3() {
; CHECK: bb.0.entry:
; CHECK-NEXT: successors: %bb.1(0x80000000), %bb.2(0x00000000)
; CHECK-NEXT: {{ $}}
- ; CHECK-NEXT: INLINEASM_BR &"", 0 /* attdialect */, 1703946 /* regdef:GPR32common */, def %0, 13 /* imm */, %bb.2
+ ; CHECK-NEXT: INLINEASM_BR &"", 0 /* attdialect */, {{[0-9]+}} /* regdef:GPR32common */, def %0, 13 /* imm */, %bb.2
; CHECK-NEXT: B %bb.1
; CHECK-NEXT: {{ $}}
; CHECK-NEXT: bb.1.x:
@@ -194,7 +194,7 @@ define i32 @split_me0() {
; CHECK: bb.0.entry:
; CHECK-NEXT: successors: %bb.2(0x80000000), %bb.1(0x00000000)
; CHECK-NEXT: {{ $}}
- ; CHECK-NEXT: INLINEASM_BR &"", 0 /* attdialect */, 1703946 /* regdef:GPR32common */, def %3, 13 /* imm */, %bb.1
+ ; CHECK-NEXT: INLINEASM_BR &"", 0 /* attdialect */, {{[0-9]+}} /* regdef:GPR32common */, def %3, 13 /* imm */, %bb.1
; CHECK-NEXT: [[COPY:%[0-9]+]]:gpr32all = COPY %3
; CHECK-NEXT: B %bb.2
; CHECK-NEXT: {{ $}}
@@ -244,7 +244,7 @@ define i32 @split_me1(i1 %z) {
; CHECK-NEXT: bb.1.w:
; CHECK-NEXT: successors: %bb.3(0x80000000), %bb.2(0x00000000)
; CHECK-NEXT: {{ $}}
- ; CHECK-NEXT: INLINEASM_BR &"", 0 /* attdialect */, 1703946 /* regdef:GPR32common */, def %5, 13 /* imm */, %bb.2, 13 /* imm */, %bb.2
+ ; CHECK-NEXT: INLINEASM_BR &"", 0 /* attdialect */, {{[0-9]+}} /* regdef:GPR32common */, def %5, 13 /* imm */, %bb.2, 13 /* imm */, %bb.2
; CHECK-NEXT: [[COPY1:%[0-9]+]]:gpr32all = COPY %5
; CHECK-NEXT: B %bb.3
; CHECK-NEXT: {{ $}}
@@ -297,7 +297,7 @@ define i32 @split_me2(i1 %z) {
; CHECK-NEXT: bb.1.w:
; CHECK-NEXT: successors: %bb.3(0x80000000), %bb.2(0x00000000)
; CHECK-NEXT: {{ $}}
- ; CHECK-NEXT: INLINEASM_BR &"", 0 /* attdialect */, 1703946 /* regdef:GPR32common */, def %6, 13 /* imm */, %bb.2, 13 /* imm */, %bb.2
+ ; CHECK-NEXT: INLINEASM_BR &"", 0 /* attdialect */, {{[0-9]+}} /* regdef:GPR32common */, def %6, 13 /* imm */, %bb.2, 13 /* imm */, %bb.2
; CHECK-NEXT: [[COPY2:%[0-9]+]]:gpr32all = COPY %6
; CHECK-NEXT: B %bb.3
; CHECK-NEXT: {{ $}}
@@ -340,7 +340,7 @@ define i32 @dont_split4() {
; CHECK: bb.0.entry:
; CHECK-NEXT: successors: %bb.1(0x80000000), %bb.2(0x00000000)
; CHECK-NEXT: {{ $}}
- ; CHECK-NEXT: INLINEASM_BR &"", 0 /* attdialect */, 1703946 /* regdef:GPR32common */, def %3, 13 /* imm */, %bb.2
+ ; CHECK-NEXT: INLINEASM_BR &"", 0 /* attdialect */, {{[0-9]+}} /* regdef:GPR32common */, def %3, 13 /* imm */, %bb.2
; CHECK-NEXT: [[COPY:%[0-9]+]]:gpr32all = COPY %3
; CHECK-NEXT: B %bb.1
; CHECK-NEXT: {{ $}}
@@ -379,7 +379,7 @@ define i32 @dont_split5() {
; CHECK: bb.0.entry:
; CHECK-NEXT: successors: %bb.2(0x80000000), %bb.1(0x00000000)
; CHECK-NEXT: {{ $}}
- ; CHECK-NEXT: INLINEASM_BR &"", 0 /* attdialect */, 1703946 /* regdef:GPR32common */, def %3, 13 /* imm */, %bb.1
+ ; CHECK-NEXT: INLINEASM_BR &"", 0 /* attdialect */, {{[0-9]+}} /* regdef:GPR32common */, def %3, 13 /* imm */, %bb.1
; CHECK-NEXT: [[COPY:%[0-9]+]]:gpr32all = COPY %3
; CHECK-NEXT: B %bb.2
; CHECK-NEXT: {{ $}}
@@ -410,7 +410,7 @@ define i32 @split_me3() {
; CHECK: bb.0.entry:
; CHECK-NEXT: successors: %bb.2(0x80000000), %bb.1(0x00000000)
; CHECK-NEXT: {{ $}}
- ; CHECK-NEXT: INLINEASM_BR &"", 0 /* attdialect */, 1703946 /* regdef:GPR32common */, def %3, 13 /* imm */, %bb.1
+ ; CHECK-NEXT: INLINEASM_BR &"", 0 /* attdialect */, {{[0-9]+}} /* regdef:GPR32common */, def %3, 13 /* imm */, %bb.1
; CHECK-NEXT: [[COPY:%[0-9]+]]:gpr32all = COPY %3
; CHECK-NEXT: B %bb.2
; CHECK-NEXT: {{ $}}
@@ -456,7 +456,7 @@ define i32 @dont_split6(i32 %0) {
; CHECK-NEXT: {{ $}}
; CHECK-NEXT: [[PHI:%[0-9]+]]:gpr32all = PHI [[COPY]], %bb.0, %2, %bb.2
; CHECK-NEXT: [[COPY1:%[0-9]+]]:gpr32common = COPY [[PHI]]
- ; CHECK-NEXT: INLINEASM_BR &"", 0 /* attdialect */, 1703946 /* regdef:GPR32common */, def %4, 2147483657 /* reguse tiedto:$0 */, [[COPY1]](tied-def 3), 13 /* imm */, %bb.2
+ ; CHECK-NEXT: INLINEASM_BR &"", 0 /* attdialect */, {{[0-9]+}} /* regdef:GPR32common */, def %4, 2147483657 /* reguse tiedto:$0 */, [[COPY1]](tied-def 3), 13 /* imm */, %bb.2
; CHECK-NEXT: [[COPY2:%[0-9]+]]:gpr32all = COPY %4
; CHECK-NEXT: B %bb.3
; CHECK-NEXT: {{ $}}
@@ -491,7 +491,7 @@ define i32 @split_me4() {
; CHECK: bb.0.entry:
; CHECK-NEXT: successors: %bb.2(0x80000000), %bb.1(0x00000000)
; CHECK-NEXT: {{ $}}
- ; CHECK-NEXT: INLINEASM_BR &"", 0 /* attdialect */, 1703946 /* regdef:GPR32common */, def %3, 13 /* imm */, %bb.1
+ ; CHECK-NEXT: INLINEASM_BR &"", 0 /* attdialect */, {{[0-9]+}} /* regdef:GPR32common */, def %3, 13 /* imm */, %bb.1
; CHECK-NEXT: [[COPY:%[0-9]+]]:gpr32all = COPY %3
; CHECK-NEXT: B %bb.2
; CHECK-NEXT: {{ $}}
@@ -522,7 +522,7 @@ define i32 @split_me5() {
; CHECK: bb.0.entry:
; CHECK-NEXT: successors: %bb.2(0x80000000), %bb.1(0x00000000)
; CHECK-NEXT: {{ $}}
- ; CHECK-NEXT: INLINEASM_BR &"", 0 /* attdialect */, 1703946 /* regdef:GPR32common */, def %3, 13 /* imm */, %bb.1
+ ; CHECK-NEXT: INLINEASM_BR &"", 0 /* attdialect */, {{[0-9]+}} /* regdef:GPR32common */, def %3, 13 /* imm */, %bb.1
; CHECK-NEXT: [[COPY:%[0-9]+]]:gpr32all = COPY %3
; CHECK-NEXT: B %bb.2
; CHECK-NEXT: {{ $}}
diff --git a/llvm/test/CodeGen/AArch64/emit_fneg_with_non_register_operand.mir b/llvm/test/CodeGen/AArch64/emit_fneg_with_non_register_operand.mir
index 483dbd2f14d556..92fb053b0db726 100644
--- a/llvm/test/CodeGen/AArch64/emit_fneg_with_non_register_operand.mir
+++ b/llvm/test/CodeGen/AArch64/emit_fneg_with_non_register_operand.mir
@@ -91,10 +91,10 @@ body: |
; CHECK-NEXT: {{ $}}
; CHECK-NEXT: [[LOADgot:%[0-9]+]]:gpr64common = LOADgot target-flags(aarch64-got) @c
; CHECK-NEXT: [[LDRDui:%[0-9]+]]:fpr64 = LDRDui [[LOADgot]], 0 :: (dereferenceable load (s64) from @c)
- ; CHECK-NEXT: INLINEASM &"", 1 /* sideeffect attdialect */, 2359306 /* regdef:WSeqPairsClass_with_sube32_in_MatrixIndexGPR32_12_15 */, def %2, 2147483657 /* reguse tiedto:$0 */, [[LDRDui]](tied-def 3)
+ ; CHECK-NEXT: INLINEASM &"", 1 /* sideeffect attdialect */, {{[0-9]+}} /* regdef:WSeqPairsClass_with_sube32_in_MatrixIndexGPR32_12_15 */, def %2, 2147483657 /* reguse tiedto:$0 */, [[LDRDui]](tied-def 3)
; CHECK-NEXT: [[COPY:%[0-9]+]]:fpr64 = COPY %2
; CHECK-NEXT: [[LDRDui1:%[0-9]+]]:fpr64 = LDRDui [[LOADgot]], 0 :: (dereferenceable load (s64) from @c)
- ; CHECK-NEXT: INLINEASM &"", 1 /* sideeffect attdialect */, 2359306 /* regdef:WSeqPairsClass_with_sube32_in_MatrixIndexGPR32_12_15 */, def %4, 2147483657 /* reguse tiedto:$0 */, [[LDRDui1]](tied-def 3)
+ ; CHECK-NEXT: INLINEASM &"", 1 /* sideeffect attdialect */, {{[0-9]+}} /* regdef:WSeqPairsClass_with_sube32_in_MatrixIndexGPR32_12_15 */, def %4, 2147483657 /* reguse tiedto:$0 */, [[LDRDui1]](tied-def 3)
; CHECK-NEXT: [[FNEGDr:%[0-9]+]]:fpr64 = FNEGDr %2
; CHECK-NEXT: nofpexcept FCMPDrr %4, killed [[FNEGDr]], implicit-def $nzcv, implicit $fpcr
; CHECK-NEXT: Bcc 1, %bb.2, implicit $nzcv
diff --git a/llvm/test/CodeGen/AArch64/peephole-insvigpr.mir b/llvm/test/CodeGen/AArch64/peephole-insvigpr.mir
index 041b2dc6af1277..65148344096cd7 100644
--- a/llvm/test/CodeGen/AArch64/peephole-insvigpr.mir
+++ b/llvm/test/CodeGen/AArch64/peephole-insvigpr.mir
@@ -487,7 +487,7 @@ body: |
; CHECK-NEXT: [[COPY:%[0-9]+]]:gpr64common = COPY $x0
; CHECK-NEXT: [[DEF:%[0-9]+]]:gpr64all = IMPLICIT_DEF
; CHECK-NEXT: [[COPY1:%[0-9]+]]:gpr64sp = COPY [[DEF]]
- ; CHECK-NEXT: INLINEASM &"ldr ${0:s}, $1", 8 /* mayload attdialect */, 2359306 /* regdef:WSeqPairsClass_with_sube32_in_MatrixIndexGPR32_12_15 */, def %1, 262158 /* mem:m */, killed [[COPY1]]
+ ; CHECK-NEXT: INLINEASM &"ldr ${0:s}, $1", 8 /* mayload attdialect */, {{[0-9]+}} /* regdef:WSeqPairsClass_with_sube32_in_MatrixIndexGPR32_12_15 */, def %1, 262158 /* mem:m */, killed [[COPY1]]
; CHECK-NEXT: [[MOVIv2d_ns:%[0-9]+]]:fpr128 = MOVIv2d_ns 0
; CHECK-NEXT: [[COPY2:%[0-9]+]]:fpr64 = COPY [[MOVIv2d_ns]].dsub
; CHECK-NEXT: [[DEF1:%[0-9]+]]:fpr128 = IMPLICIT_DEF
>From 31295bbe83c3ea9d8a3372efe34342a299d1018a Mon Sep 17 00:00:00 2001
From: Mitch Phillips <mitchp at google.com>
Date: Thu, 29 Feb 2024 11:34:37 +0100
Subject: [PATCH 113/406] Revert "AMDGPU: Add scheduling test for gfx940
(#83220)"
This reverts commit f0484e08bdcf64106592808e3ca80404937b4657.
Reason: Broke the sanitizer build bots. See the github comments on
https://github.com/llvm/llvm-project/commit/f0484e08bdcf64106592808e3ca80404937b4657
for more information
---
llvm/test/tools/llvm-mca/AMDGPU/gfx940.s | 189 -----------------------
1 file changed, 189 deletions(-)
delete mode 100644 llvm/test/tools/llvm-mca/AMDGPU/gfx940.s
diff --git a/llvm/test/tools/llvm-mca/AMDGPU/gfx940.s b/llvm/test/tools/llvm-mca/AMDGPU/gfx940.s
deleted file mode 100644
index c66d0b44b5e9a6..00000000000000
--- a/llvm/test/tools/llvm-mca/AMDGPU/gfx940.s
+++ /dev/null
@@ -1,189 +0,0 @@
-# RUN: llvm-mca -mtriple=amdgcn -mcpu=gfx940 --timeline --iterations=1 --timeline-max-cycles=0 < %s | FileCheck %s
-
-# CHECK: Iterations: 1
-# CHECK: Instructions: 71
-# CHECK: Total Cycles: 562
-# CHECK: Total uOps: 77
-
-# CHECK: Resources:
-# CHECK: [0] - HWBranch
-# CHECK: [1] - HWExport
-# CHECK: [2] - HWLGKM
-# CHECK: [3] - HWSALU
-# CHECK: [4] - HWVALU
-# CHECK: [5] - HWVMEM
-# CHECK: [6] - HWXDL
-
-v_pk_fma_f32 v[0:1], v[0:1], v[0:1], v[0:1]
-v_pk_mov_b32 v[0:1], v[2:3], v[4:5]
-v_pk_add_f32 v[0:1], v[0:1], v[0:1]
-v_pk_mul_f32 v[0:1], v[0:1], v[0:1]
-v_add_co_u32 v5, s[0:1], v1, v2
-v_sub_co_u32 v5, s[0:1], v1, v2
-v_subrev_co_u32 v5, s[0:1], v1, v2
-v_addc_co_u32 v5, s[0:1], v1, v2, s[2:3]
-v_subb_co_u32 v5, s[0:1], v1, v2, s[2:3]
-v_subbrev_co_u32 v5, s[0:1], v1, v2, s[2:3]
-v_add_u32 v5, v1, v2
-v_sub_u32 v5, v1, v2
-v_subrev_u32 v5, v1, v2
-
-v_mfma_f32_16x16x4_f32 a[0:3], v0, v1, a[2:5]
-v_mfma_f32_16x16x4_f32 v[0:3], v0, v1, v[2:5]
-
-v_mfma_f32_32x32x2_f32 a[0:15], v0, v1, a[18:33]
-v_mfma_f32_32x32x2_f32 v[0:15], v0, v1, v[18:33]
-
-v_mfma_f64_4x4x4_4b_f64 a[0:1], v[0:1], a[2:3], a[2:3]
-v_mfma_f64_4x4x4_4b_f64 v[0:1], v[0:1], v[2:3], v[2:3]
-
-v_mfma_f64_16x16x4_f64 a[0:7], v[0:1], v[2:3], a[0:7]
-v_mfma_f64_16x16x4_f64 v[0:7], v[0:1], v[2:3], v[0:7]
-
-v_mfma_f32_16x16x16_f16 v[0:3], v[4:5], v[6:7], v[0:3]
-v_mfma_f32_16x16x16_f16 a[0:3], v[4:5], v[6:7], a[0:3]
-
-v_mfma_f32_32x32x8_f16 v[0:15], v[4:5], v[6:7], v[0:15]
-v_mfma_f32_32x32x8_f16 a[0:15], v[4:5], v[6:7], a[0:15]
-
-v_mfma_f32_16x16x16_bf16 v[0:3], v[4:5], v[6:7], v[0:3]
-v_mfma_f32_16x16x16_bf16 a[0:3], v[4:5], v[6:7], a[0:3]
-
-v_mfma_f32_32x32x8_bf16 v[0:15], v[4:5], v[6:7], v[0:15]
-v_mfma_f32_32x32x8_bf16 a[0:15], v[4:5], v[6:7], a[0:15]
-
-v_mfma_i32_16x16x32_i8 v[0:3], v[4:5], v[6:7], v[0:3]
-v_mfma_i32_16x16x32_i8 a[0:3], v[4:5], v[6:7], a[0:3]
-
-v_mfma_i32_32x32x16_i8 v[0:15], v[2:3], v[4:5], v[0:15]
-v_mfma_i32_32x32x16_i8 a[0:15], v[2:3], v[4:5], a[0:15]
-
-v_mfma_f32_4x4x4_16b_f16 v[0:3], v[0:1], v[2:3], v[2:5]
-v_mfma_f32_4x4x4_16b_f16 a[0:3], v[0:1], v[2:3], a[2:5]
-
-v_mfma_f32_16x16x4_4b_f16 v[0:15], v[2:3], v[4:5], v[18:33]
-v_mfma_f32_16x16x4_4b_f16 a[0:15], v[2:3], v[4:5], a[18:33]
-
-v_mfma_f32_32x32x4_2b_f16 v[0:31], v[0:1], v[2:3], v[34:65]
-v_mfma_f32_32x32x4_2b_f16 a[0:31], v[0:1], v[2:3], a[34:65]
-
-v_mfma_f32_4x4x4_16b_bf16 v[0:3], v[0:1], v[2:3], v[2:5]
-v_mfma_f32_4x4x4_16b_bf16 a[0:3], v[0:1], v[2:3], a[2:5]
-
-v_mfma_f32_16x16x4_4b_bf16 v[0:15], v[2:3], v[4:5], v[18:33]
-v_mfma_f32_16x16x4_4b_bf16 a[0:15], v[2:3], v[4:5], a[18:33]
-
-v_mfma_f32_32x32x4_2b_bf16 v[0:31], v[0:1], v[2:3], v[34:65]
-v_mfma_f32_32x32x4_2b_bf16 a[0:31], v[0:1], v[2:3], a[34:65]
-
-v_mfma_f32_4x4x1_16b_f32 v[0:3], v0, v1, v[2:5]
-v_mfma_f32_4x4x1_16b_f32 a[0:3], v0, v1, a[2:5]
-
-v_mfma_f32_16x16x1_4b_f32 v[0:15], v0, v1, v[18:33]
-v_mfma_f32_16x16x1_4b_f32 a[0:15], v0, v1, a[18:33]
-
-v_mfma_f32_16x16x4_f32 v[0:3], v0, v1, v[2:5]
-v_mfma_f32_16x16x4_f32 a[0:3], v0, v1, a[2:5]
-
-v_mfma_f32_32x32x1_2b_f32 v[0:31], v0, v1, v[34:65] blgp:7
-v_mfma_f32_32x32x1_2b_f32 a[0:31], v0, v1, a[34:65] blgp:7
-
-v_mfma_f32_32x32x2_f32 v[0:15], v0, v1, v[18:33]
-v_mfma_f32_32x32x2_f32 a[0:15], v0, v1, a[18:33]
-
-v_mfma_i32_4x4x4_16b_i8 v[0:3], v0, v1, v[2:5]
-v_mfma_i32_4x4x4_16b_i8 a[0:3], v0, v1, a[2:5]
-
-v_mfma_i32_16x16x4_4b_i8 v[0:15], v0, v1, v[18:33]
-v_mfma_i32_16x16x4_4b_i8 a[0:15], v0, v1, a[18:33]
-
-v_mfma_i32_32x32x4_2b_i8 v[0:31], v0, v1, v[34:65]
-v_mfma_i32_32x32x4_2b_i8 a[0:31], v0, v1, a[34:65]
-
-v_smfmac_f32_16x16x32_f16 v[10:13], a[2:3], v[4:7], v0 cbsz:3 abid:1
-v_smfmac_f32_16x16x32_f16 a[10:13], v[2:3], a[4:7], v1
-
-v_smfmac_f32_32x32x16_f16 v[10:25], a[2:3], v[4:7], v2 cbsz:3 abid:1
-v_smfmac_f32_32x32x16_f16 a[10:25], v[2:3], a[4:7], v3
-
-v_smfmac_f32_16x16x32_bf16 v[10:13], a[2:3], v[4:7], v4 cbsz:3 abid:1
-v_smfmac_f32_16x16x32_bf16 a[10:13], v[2:3], a[4:7], v5
-
-v_smfmac_i32_16x16x64_i8 v[10:13], a[2:3], v[4:7], v8 cbsz:3 abid:1
-v_smfmac_i32_16x16x64_i8 a[10:13], v[2:3], a[4:7], v9
-
-v_smfmac_i32_32x32x32_i8 v[10:25], a[2:3], v[4:7], v10 cbsz:3 abid:1
-v_smfmac_i32_32x32x32_i8 a[10:25], v[2:3], a[4:7], v11
-
-# CHECK: [0] [1] [2] [3] [4] [5] [6] Instructions:
-# CHECK-NEXT: - - - - 1.00 - - v_pk_fma_f32 v[0:1], v[0:1], v[0:1], v[0:1]
-# CHECK-NEXT: - - - - 1.00 - - v_pk_mov_b32 v[0:1], v[2:3], v[4:5]
-# CHECK-NEXT: - - - - 1.00 - - v_pk_add_f32 v[0:1], v[0:1], v[0:1]
-# CHECK-NEXT: - - - - 1.00 - - v_pk_mul_f32 v[0:1], v[0:1], v[0:1]
-# CHECK-NEXT: - - - 1.00 1.00 - - v_add_co_u32_e64 v5, s[0:1], v1, v2
-# CHECK-NEXT: - - - 1.00 1.00 - - v_sub_co_u32_e64 v5, s[0:1], v1, v2
-# CHECK-NEXT: - - - 1.00 1.00 - - v_subrev_co_u32_e64 v5, s[0:1], v1, v2
-# CHECK-NEXT: - - - 1.00 1.00 - - v_addc_co_u32_e64 v5, s[0:1], v1, v2, s[2:3]
-# CHECK-NEXT: - - - 1.00 1.00 - - v_subb_co_u32_e64 v5, s[0:1], v1, v2, s[2:3]
-# CHECK-NEXT: - - - 1.00 1.00 - - v_subbrev_co_u32_e64 v5, s[0:1], v1, v2, s[2:3]
-# CHECK-NEXT: - - - - 1.00 - - v_add_u32_e32 v5, v1, v2
-# CHECK-NEXT: - - - - 1.00 - - v_sub_u32_e32 v5, v1, v2
-# CHECK-NEXT: - - - - 1.00 - - v_subrev_u32_e32 v5, v1, v2
-# CHECK-NEXT: - - - - - - 8.00 v_mfma_f32_16x16x4_f32 a[0:3], v0, v1, a[2:5]
-# CHECK-NEXT: - - - - - - 8.00 v_mfma_f32_16x16x4_f32 v[0:3], v0, v1, v[2:5]
-# CHECK-NEXT: - - - - - - 16.00 v_mfma_f32_32x32x2_f32 a[0:15], v0, v1, a[18:33]
-# CHECK-NEXT: - - - - - - 16.00 v_mfma_f32_32x32x2_f32 v[0:15], v0, v1, v[18:33]
-# CHECK-NEXT: - - - - 1.00 - - v_mfma_f64_4x4x4_4b_f64 a[0:1], v[0:1], a[2:3], a[2:3]
-# CHECK-NEXT: - - - - 1.00 - - v_mfma_f64_4x4x4_4b_f64 v[0:1], v[0:1], v[2:3], v[2:3]
-# CHECK-NEXT: - - - - 1.00 - - v_mfma_f64_16x16x4_f64 a[0:7], v[0:1], v[2:3], a[0:7]
-# CHECK-NEXT: - - - - 1.00 - - v_mfma_f64_16x16x4_f64 v[0:7], v[0:1], v[2:3], v[0:7]
-# CHECK-NEXT: - - - - - - 4.00 v_mfma_f32_16x16x16_f16 v[0:3], v[4:5], v[6:7], v[0:3]
-# CHECK-NEXT: - - - - - - 4.00 v_mfma_f32_16x16x16_f16 a[0:3], v[4:5], v[6:7], a[0:3]
-# CHECK-NEXT: - - - - - - 8.00 v_mfma_f32_32x32x8_f16 v[0:15], v[4:5], v[6:7], v[0:15]
-# CHECK-NEXT: - - - - - - 8.00 v_mfma_f32_32x32x8_f16 a[0:15], v[4:5], v[6:7], a[0:15]
-# CHECK-NEXT: - - - - - - 4.00 v_mfma_f32_16x16x16_bf16 v[0:3], v[4:5], v[6:7], v[0:3]
-# CHECK-NEXT: - - - - - - 4.00 v_mfma_f32_16x16x16_bf16 a[0:3], v[4:5], v[6:7], a[0:3]
-# CHECK-NEXT: - - - - - - 8.00 v_mfma_f32_32x32x8_bf16 v[0:15], v[4:5], v[6:7], v[0:15]
-# CHECK-NEXT: - - - - - - 8.00 v_mfma_f32_32x32x8_bf16 a[0:15], v[4:5], v[6:7], a[0:15]
-# CHECK-NEXT: - - - - - - 4.00 v_mfma_i32_16x16x32_i8 v[0:3], v[4:5], v[6:7], v[0:3]
-# CHECK-NEXT: - - - - - - 4.00 v_mfma_i32_16x16x32_i8 a[0:3], v[4:5], v[6:7], a[0:3]
-# CHECK-NEXT: - - - - - - 8.00 v_mfma_i32_32x32x16_i8 v[0:15], v[2:3], v[4:5], v[0:15]
-# CHECK-NEXT: - - - - - - 8.00 v_mfma_i32_32x32x16_i8 a[0:15], v[2:3], v[4:5], a[0:15]
-# CHECK-NEXT: - - - - - - 2.00 v_mfma_f32_4x4x4_16b_f16 v[0:3], v[0:1], v[2:3], v[2:5]
-# CHECK-NEXT: - - - - - - 2.00 v_mfma_f32_4x4x4_16b_f16 a[0:3], v[0:1], v[2:3], a[2:5]
-# CHECK-NEXT: - - - - - - 8.00 v_mfma_f32_16x16x4_4b_f16 v[0:15], v[2:3], v[4:5], v[18:33]
-# CHECK-NEXT: - - - - - - 8.00 v_mfma_f32_16x16x4_4b_f16 a[0:15], v[2:3], v[4:5], a[18:33]
-# CHECK-NEXT: - - - - - - 16.00 v_mfma_f32_32x32x4_2b_f16 v[0:31], v[0:1], v[2:3], v[34:65]
-# CHECK-NEXT: - - - - - - 16.00 v_mfma_f32_32x32x4_2b_f16 a[0:31], v[0:1], v[2:3], a[34:65]
-# CHECK-NEXT: - - - - - - 2.00 v_mfma_f32_4x4x4_16b_bf16 v[0:3], v[0:1], v[2:3], v[2:5]
-# CHECK-NEXT: - - - - - - 2.00 v_mfma_f32_4x4x4_16b_bf16 a[0:3], v[0:1], v[2:3], a[2:5]
-# CHECK-NEXT: - - - - - - 8.00 v_mfma_f32_16x16x4_4b_bf16 v[0:15], v[2:3], v[4:5], v[18:33]
-# CHECK-NEXT: - - - - - - 8.00 v_mfma_f32_16x16x4_4b_bf16 a[0:15], v[2:3], v[4:5], a[18:33]
-# CHECK-NEXT: - - - - - - 16.00 v_mfma_f32_32x32x4_2b_bf16 v[0:31], v[0:1], v[2:3], v[34:65]
-# CHECK-NEXT: - - - - - - 16.00 v_mfma_f32_32x32x4_2b_bf16 a[0:31], v[0:1], v[2:3], a[34:65]
-# CHECK-NEXT: - - - - - - 2.00 v_mfma_f32_4x4x1_16b_f32 v[0:3], v0, v1, v[2:5]
-# CHECK-NEXT: - - - - - - 2.00 v_mfma_f32_4x4x1_16b_f32 a[0:3], v0, v1, a[2:5]
-# CHECK-NEXT: - - - - - - 8.00 v_mfma_f32_16x16x1_4b_f32 v[0:15], v0, v1, v[18:33]
-# CHECK-NEXT: - - - - - - 8.00 v_mfma_f32_16x16x1_4b_f32 a[0:15], v0, v1, a[18:33]
-# CHECK-NEXT: - - - - - - 8.00 v_mfma_f32_16x16x4_f32 v[0:3], v0, v1, v[2:5]
-# CHECK-NEXT: - - - - - - 8.00 v_mfma_f32_16x16x4_f32 a[0:3], v0, v1, a[2:5]
-# CHECK-NEXT: - - - - - - 16.00 v_mfma_f32_32x32x1_2b_f32 v[0:31], v0, v1, v[34:65] blgp:7
-# CHECK-NEXT: - - - - - - 16.00 v_mfma_f32_32x32x1_2b_f32 a[0:31], v0, v1, a[34:65] blgp:7
-# CHECK-NEXT: - - - - - - 16.00 v_mfma_f32_32x32x2_f32 v[0:15], v0, v1, v[18:33]
-# CHECK-NEXT: - - - - - - 16.00 v_mfma_f32_32x32x2_f32 a[0:15], v0, v1, a[18:33]
-# CHECK-NEXT: - - - - - - 2.00 v_mfma_i32_4x4x4_16b_i8 v[0:3], v0, v1, v[2:5]
-# CHECK-NEXT: - - - - - - 2.00 v_mfma_i32_4x4x4_16b_i8 a[0:3], v0, v1, a[2:5]
-# CHECK-NEXT: - - - - - - 8.00 v_mfma_i32_16x16x4_4b_i8 v[0:15], v0, v1, v[18:33]
-# CHECK-NEXT: - - - - - - 8.00 v_mfma_i32_16x16x4_4b_i8 a[0:15], v0, v1, a[18:33]
-# CHECK-NEXT: - - - - - - 16.00 v_mfma_i32_32x32x4_2b_i8 v[0:31], v0, v1, v[34:65]
-# CHECK-NEXT: - - - - - - 16.00 v_mfma_i32_32x32x4_2b_i8 a[0:31], v0, v1, a[34:65]
-# CHECK-NEXT: - - - - - - 4.00 v_smfmac_f32_16x16x32_f16 v[10:13], a[2:3], v[4:7], v0 cbsz:3 abid:1
-# CHECK-NEXT: - - - - - - 4.00 v_smfmac_f32_16x16x32_f16 a[10:13], v[2:3], a[4:7], v1
-# CHECK-NEXT: - - - - - - 8.00 v_smfmac_f32_32x32x16_f16 v[10:25], a[2:3], v[4:7], v2 cbsz:3 abid:1
-# CHECK-NEXT: - - - - - - 8.00 v_smfmac_f32_32x32x16_f16 a[10:25], v[2:3], a[4:7], v3
-# CHECK-NEXT: - - - - - - 4.00 v_smfmac_f32_16x16x32_bf16 v[10:13], a[2:3], v[4:7], v4 cbsz:3 abid:1
-# CHECK-NEXT: - - - - - - 4.00 v_smfmac_f32_16x16x32_bf16 a[10:13], v[2:3], a[4:7], v5
-# CHECK-NEXT: - - - - - - 4.00 v_smfmac_i32_16x16x64_i8 v[10:13], a[2:3], v[4:7], v8 cbsz:3 abid:1
-# CHECK-NEXT: - - - - - - 4.00 v_smfmac_i32_16x16x64_i8 a[10:13], v[2:3], a[4:7], v9
-# CHECK-NEXT: - - - - - - 8.00 v_smfmac_i32_32x32x32_i8 v[10:25], a[2:3], v[4:7], v10 cbsz:3 abid:1
-# CHECK-NEXT: - - - - - - 8.00 v_smfmac_i32_32x32x32_i8 a[10:25], v[2:3], a[4:7], v11
>From 20fe83bc852e15b2928a168635972a5d29689a49 Mon Sep 17 00:00:00 2001
From: Jay Foad <jay.foad at amd.com>
Date: Thu, 29 Feb 2024 12:02:06 +0000
Subject: [PATCH 114/406] [AMDGPU] Add new aliases ds_subrev_rtn_u32/u64 for
ds_rsub_rtn_u32/u64 (#83408)
Following on from #83118, this adds aliases for the "rtn" forms of these
instructions. The fact that they were missing from SP3 was an oversight
which has been fixed now.
---
llvm/lib/Target/AMDGPU/DSInstructions.td | 2 ++
llvm/test/MC/AMDGPU/gfx11_unsupported.s | 12 ++++++++++++
llvm/test/MC/AMDGPU/gfx12_asm_ds_alias.s | 6 ++++++
3 files changed, 20 insertions(+)
diff --git a/llvm/lib/Target/AMDGPU/DSInstructions.td b/llvm/lib/Target/AMDGPU/DSInstructions.td
index e6d27c2e64690d..7d79b9bba243cf 100644
--- a/llvm/lib/Target/AMDGPU/DSInstructions.td
+++ b/llvm/lib/Target/AMDGPU/DSInstructions.td
@@ -1262,7 +1262,9 @@ defm DS_PK_ADD_RTN_BF16 : DS_Real_gfx12<0x0ab>;
// New aliases added in GFX12 without renaming the instructions.
def : MnemonicAlias<"ds_subrev_u32", "ds_rsub_u32">, Requires<[isGFX12Plus]>;
+def : MnemonicAlias<"ds_subrev_rtn_u32", "ds_rsub_rtn_u32">, Requires<[isGFX12Plus]>;
def : MnemonicAlias<"ds_subrev_u64", "ds_rsub_u64">, Requires<[isGFX12Plus]>;
+def : MnemonicAlias<"ds_subrev_rtn_u64", "ds_rsub_rtn_u64">, Requires<[isGFX12Plus]>;
//===----------------------------------------------------------------------===//
// GFX11.
diff --git a/llvm/test/MC/AMDGPU/gfx11_unsupported.s b/llvm/test/MC/AMDGPU/gfx11_unsupported.s
index bfca71ae3a01ef..f447263c30223d 100644
--- a/llvm/test/MC/AMDGPU/gfx11_unsupported.s
+++ b/llvm/test/MC/AMDGPU/gfx11_unsupported.s
@@ -2052,3 +2052,15 @@ global_atomic_cond_sub_u32 v0, v2, s[0:1] offset:64
global_atomic_ordered_add_b64 v0, v[2:3], s[0:1] offset:64
// CHECK: :[[@LINE-1]]:{{[0-9]+}}: error: instruction not supported on this GPU
+
+ds_subrev_u32 v1, v2
+// CHECK: :[[@LINE-1]]:{{[0-9]+}}: error: instruction not supported on this GPU
+
+ds_subrev_rtn_u32 v5, v1, v2
+// CHECK: :[[@LINE-1]]:{{[0-9]+}}: error: instruction not supported on this GPU
+
+ds_subrev_u64 v1, v[2:3]
+// CHECK: :[[@LINE-1]]:{{[0-9]+}}: error: instruction not supported on this GPU
+
+ds_subrev_rtn_u64 v[5:6], v1, v[2:3]
+// CHECK: :[[@LINE-1]]:{{[0-9]+}}: error: instruction not supported on this GPU
diff --git a/llvm/test/MC/AMDGPU/gfx12_asm_ds_alias.s b/llvm/test/MC/AMDGPU/gfx12_asm_ds_alias.s
index aa063c8800aa41..057e99330bcaef 100644
--- a/llvm/test/MC/AMDGPU/gfx12_asm_ds_alias.s
+++ b/llvm/test/MC/AMDGPU/gfx12_asm_ds_alias.s
@@ -27,5 +27,11 @@ ds_min_rtn_f64 v[5:6], v1, v[2:3]
ds_subrev_u32 v1, v2
// GFX12: ds_rsub_u32 v1, v2 ; encoding: [0x00,0x00,0x08,0xd8,0x01,0x02,0x00,0x00]
+ds_subrev_rtn_u32 v5, v1, v2
+// GFX12: ds_rsub_rtn_u32 v5, v1, v2 ; encoding: [0x00,0x00,0x88,0xd8,0x01,0x02,0x00,0x05]
+
ds_subrev_u64 v1, v[2:3]
// GFX12: ds_rsub_u64 v1, v[2:3] ; encoding: [0x00,0x00,0x08,0xd9,0x01,0x02,0x00,0x00]
+
+ds_subrev_rtn_u64 v[5:6], v1, v[2:3]
+// GFX12: ds_rsub_rtn_u64 v[5:6], v1, v[2:3] ; encoding: [0x00,0x00,0x88,0xd9,0x01,0x02,0x00,0x05]
>From c57002db6afcd2474247d066fae71f696ce31947 Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?Nicolai=20H=C3=A4hnle?= <nicolai.haehnle at amd.com>
Date: Thu, 29 Feb 2024 13:15:41 +0100
Subject: [PATCH 115/406] Verifier: More helpful error message for
cross-function references (#82906)
This came up on Discourse.
See:
https://discourse.llvm.org/t/module-verification-failed-instruction-does-not-dominate-all-uses/77207/
---
llvm/lib/IR/Verifier.cpp | 4 +++-
llvm/unittests/IR/VerifierTest.cpp | 28 ++++++++++++++++++++++++++++
2 files changed, 31 insertions(+), 1 deletion(-)
diff --git a/llvm/lib/IR/Verifier.cpp b/llvm/lib/IR/Verifier.cpp
index 3741e5deaa4cd1..e0de179e57146f 100644
--- a/llvm/lib/IR/Verifier.cpp
+++ b/llvm/lib/IR/Verifier.cpp
@@ -5002,7 +5002,9 @@ void Verifier::visitInstruction(Instruction &I) {
} else if (GlobalValue *GV = dyn_cast<GlobalValue>(I.getOperand(i))) {
Check(GV->getParent() == &M, "Referencing global in another module!", &I,
&M, GV, GV->getParent());
- } else if (isa<Instruction>(I.getOperand(i))) {
+ } else if (Instruction *OpInst = dyn_cast<Instruction>(I.getOperand(i))) {
+ Check(OpInst->getFunction() == BB->getParent(),
+ "Referring to an instruction in another function!", &I);
verifyDominatesUse(I, i);
} else if (isa<InlineAsm>(I.getOperand(i))) {
Check(CBI && &CBI->getCalledOperandUse() == &I.getOperandUse(i),
diff --git a/llvm/unittests/IR/VerifierTest.cpp b/llvm/unittests/IR/VerifierTest.cpp
index 31e3b9dfab4bfd..b2cd71e6a38568 100644
--- a/llvm/unittests/IR/VerifierTest.cpp
+++ b/llvm/unittests/IR/VerifierTest.cpp
@@ -339,5 +339,33 @@ TEST(VerifierTest, SwitchInst) {
EXPECT_TRUE(verifyFunction(*F));
}
+TEST(VerifierTest, CrossFunctionRef) {
+ LLVMContext C;
+ Module M("M", C);
+ FunctionType *FTy = FunctionType::get(Type::getVoidTy(C), /*isVarArg=*/false);
+ Function *F1 = Function::Create(FTy, Function::ExternalLinkage, "foo1", M);
+ Function *F2 = Function::Create(FTy, Function::ExternalLinkage, "foo2", M);
+ BasicBlock *Entry1 = BasicBlock::Create(C, "entry", F1);
+ BasicBlock *Entry2 = BasicBlock::Create(C, "entry", F2);
+ Type *I32 = Type::getInt32Ty(C);
+
+ Value *Alloca = new AllocaInst(I32, 0, "alloca", Entry1);
+ ReturnInst::Create(C, Entry1);
+
+ Instruction *Store = new StoreInst(ConstantInt::get(I32, 0), Alloca, Entry2);
+ ReturnInst::Create(C, Entry2);
+
+ std::string Error;
+ raw_string_ostream ErrorOS(Error);
+ EXPECT_TRUE(verifyModule(M, &ErrorOS));
+ EXPECT_TRUE(
+ StringRef(ErrorOS.str())
+ .starts_with("Referring to an instruction in another function!"));
+
+ // Explicitly erase the store to avoid a use-after-free when the module is
+ // destroyed.
+ Store->eraseFromParent();
+}
+
} // end anonymous namespace
} // end namespace llvm
>From b50b50bfbf55b883dcd290027cfd6ca5904b0495 Mon Sep 17 00:00:00 2001
From: Simon Pilgrim <llvm-dev at redking.me.uk>
Date: Thu, 29 Feb 2024 10:39:32 +0000
Subject: [PATCH 116/406] [X86] cmov-fp.ll - regenerate with common 'NOSSE'
prefix to reduce duplication
---
llvm/test/CodeGen/X86/cmov-fp.ll | 548 ++++++++++---------------------
1 file changed, 178 insertions(+), 370 deletions(-)
diff --git a/llvm/test/CodeGen/X86/cmov-fp.ll b/llvm/test/CodeGen/X86/cmov-fp.ll
index 26e720ffcebccd..77665d083b7e3e 100644
--- a/llvm/test/CodeGen/X86/cmov-fp.ll
+++ b/llvm/test/CodeGen/X86/cmov-fp.ll
@@ -1,7 +1,7 @@
; NOTE: Assertions have been autogenerated by utils/update_llc_test_checks.py
; RUN: llc -mtriple=i686-- -mcpu pentium4 < %s | FileCheck %s -check-prefix=SSE
-; RUN: llc -mtriple=i686-- -mcpu pentium3 < %s | FileCheck %s -check-prefix=NOSSE2
-; RUN: llc -mtriple=i686-- -mcpu pentium2 < %s | FileCheck %s -check-prefix=NOSSE1
+; RUN: llc -mtriple=i686-- -mcpu pentium3 < %s | FileCheck %s -check-prefixes=NOSSE,NOSSE2
+; RUN: llc -mtriple=i686-- -mcpu pentium2 < %s | FileCheck %s -check-prefixes=NOSSE,NOSSE1
; RUN: llc -mtriple=i686-- -mcpu pentium < %s | FileCheck %s -check-prefix=NOCMOV
; PR14035
@@ -27,27 +27,16 @@ define double @test1(i32 %a, i32 %b, double %x) nounwind {
; SSE-NEXT: popl %ebp
; SSE-NEXT: retl
;
-; NOSSE2-LABEL: test1:
-; NOSSE2: # %bb.0:
-; NOSSE2-NEXT: fldl {{[0-9]+}}(%esp)
-; NOSSE2-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE2-NEXT: fxch %st(1)
-; NOSSE2-NEXT: fcmovnbe %st(1), %st
-; NOSSE2-NEXT: fstp %st(1)
-; NOSSE2-NEXT: retl
-;
-; NOSSE1-LABEL: test1:
-; NOSSE1: # %bb.0:
-; NOSSE1-NEXT: fldl {{[0-9]+}}(%esp)
-; NOSSE1-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE1-NEXT: fxch %st(1)
-; NOSSE1-NEXT: fcmovnbe %st(1), %st
-; NOSSE1-NEXT: fstp %st(1)
-; NOSSE1-NEXT: retl
+; NOSSE-LABEL: test1:
+; NOSSE: # %bb.0:
+; NOSSE-NEXT: fldl {{[0-9]+}}(%esp)
+; NOSSE-NEXT: movl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: cmpl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
+; NOSSE-NEXT: fxch %st(1)
+; NOSSE-NEXT: fcmovnbe %st(1), %st
+; NOSSE-NEXT: fstp %st(1)
+; NOSSE-NEXT: retl
;
; NOCMOV-LABEL: test1:
; NOCMOV: # %bb.0:
@@ -90,27 +79,16 @@ define double @test2(i32 %a, i32 %b, double %x) nounwind {
; SSE-NEXT: popl %ebp
; SSE-NEXT: retl
;
-; NOSSE2-LABEL: test2:
-; NOSSE2: # %bb.0:
-; NOSSE2-NEXT: fldl {{[0-9]+}}(%esp)
-; NOSSE2-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE2-NEXT: fxch %st(1)
-; NOSSE2-NEXT: fcmovnb %st(1), %st
-; NOSSE2-NEXT: fstp %st(1)
-; NOSSE2-NEXT: retl
-;
-; NOSSE1-LABEL: test2:
-; NOSSE1: # %bb.0:
-; NOSSE1-NEXT: fldl {{[0-9]+}}(%esp)
-; NOSSE1-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE1-NEXT: fxch %st(1)
-; NOSSE1-NEXT: fcmovnb %st(1), %st
-; NOSSE1-NEXT: fstp %st(1)
-; NOSSE1-NEXT: retl
+; NOSSE-LABEL: test2:
+; NOSSE: # %bb.0:
+; NOSSE-NEXT: fldl {{[0-9]+}}(%esp)
+; NOSSE-NEXT: movl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: cmpl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
+; NOSSE-NEXT: fxch %st(1)
+; NOSSE-NEXT: fcmovnb %st(1), %st
+; NOSSE-NEXT: fstp %st(1)
+; NOSSE-NEXT: retl
;
; NOCMOV-LABEL: test2:
; NOCMOV: # %bb.0:
@@ -153,27 +131,16 @@ define double @test3(i32 %a, i32 %b, double %x) nounwind {
; SSE-NEXT: popl %ebp
; SSE-NEXT: retl
;
-; NOSSE2-LABEL: test3:
-; NOSSE2: # %bb.0:
-; NOSSE2-NEXT: fldl {{[0-9]+}}(%esp)
-; NOSSE2-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE2-NEXT: fxch %st(1)
-; NOSSE2-NEXT: fcmovb %st(1), %st
-; NOSSE2-NEXT: fstp %st(1)
-; NOSSE2-NEXT: retl
-;
-; NOSSE1-LABEL: test3:
-; NOSSE1: # %bb.0:
-; NOSSE1-NEXT: fldl {{[0-9]+}}(%esp)
-; NOSSE1-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE1-NEXT: fxch %st(1)
-; NOSSE1-NEXT: fcmovb %st(1), %st
-; NOSSE1-NEXT: fstp %st(1)
-; NOSSE1-NEXT: retl
+; NOSSE-LABEL: test3:
+; NOSSE: # %bb.0:
+; NOSSE-NEXT: fldl {{[0-9]+}}(%esp)
+; NOSSE-NEXT: movl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: cmpl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
+; NOSSE-NEXT: fxch %st(1)
+; NOSSE-NEXT: fcmovb %st(1), %st
+; NOSSE-NEXT: fstp %st(1)
+; NOSSE-NEXT: retl
;
; NOCMOV-LABEL: test3:
; NOCMOV: # %bb.0:
@@ -216,27 +183,16 @@ define double @test4(i32 %a, i32 %b, double %x) nounwind {
; SSE-NEXT: popl %ebp
; SSE-NEXT: retl
;
-; NOSSE2-LABEL: test4:
-; NOSSE2: # %bb.0:
-; NOSSE2-NEXT: fldl {{[0-9]+}}(%esp)
-; NOSSE2-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE2-NEXT: fxch %st(1)
-; NOSSE2-NEXT: fcmovbe %st(1), %st
-; NOSSE2-NEXT: fstp %st(1)
-; NOSSE2-NEXT: retl
-;
-; NOSSE1-LABEL: test4:
-; NOSSE1: # %bb.0:
-; NOSSE1-NEXT: fldl {{[0-9]+}}(%esp)
-; NOSSE1-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE1-NEXT: fxch %st(1)
-; NOSSE1-NEXT: fcmovbe %st(1), %st
-; NOSSE1-NEXT: fstp %st(1)
-; NOSSE1-NEXT: retl
+; NOSSE-LABEL: test4:
+; NOSSE: # %bb.0:
+; NOSSE-NEXT: fldl {{[0-9]+}}(%esp)
+; NOSSE-NEXT: movl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: cmpl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
+; NOSSE-NEXT: fxch %st(1)
+; NOSSE-NEXT: fcmovbe %st(1), %st
+; NOSSE-NEXT: fstp %st(1)
+; NOSSE-NEXT: retl
;
; NOCMOV-LABEL: test4:
; NOCMOV: # %bb.0:
@@ -279,31 +235,18 @@ define double @test5(i32 %a, i32 %b, double %x) nounwind {
; SSE-NEXT: popl %ebp
; SSE-NEXT: retl
;
-; NOSSE2-LABEL: test5:
-; NOSSE2: # %bb.0:
-; NOSSE2-NEXT: fldl {{[0-9]+}}(%esp)
-; NOSSE2-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: setg %al
-; NOSSE2-NEXT: testb %al, %al
-; NOSSE2-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE2-NEXT: fxch %st(1)
-; NOSSE2-NEXT: fcmovne %st(1), %st
-; NOSSE2-NEXT: fstp %st(1)
-; NOSSE2-NEXT: retl
-;
-; NOSSE1-LABEL: test5:
-; NOSSE1: # %bb.0:
-; NOSSE1-NEXT: fldl {{[0-9]+}}(%esp)
-; NOSSE1-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: setg %al
-; NOSSE1-NEXT: testb %al, %al
-; NOSSE1-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE1-NEXT: fxch %st(1)
-; NOSSE1-NEXT: fcmovne %st(1), %st
-; NOSSE1-NEXT: fstp %st(1)
-; NOSSE1-NEXT: retl
+; NOSSE-LABEL: test5:
+; NOSSE: # %bb.0:
+; NOSSE-NEXT: fldl {{[0-9]+}}(%esp)
+; NOSSE-NEXT: movl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: cmpl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: setg %al
+; NOSSE-NEXT: testb %al, %al
+; NOSSE-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
+; NOSSE-NEXT: fxch %st(1)
+; NOSSE-NEXT: fcmovne %st(1), %st
+; NOSSE-NEXT: fstp %st(1)
+; NOSSE-NEXT: retl
;
; NOCMOV-LABEL: test5:
; NOCMOV: # %bb.0:
@@ -346,31 +289,18 @@ define double @test6(i32 %a, i32 %b, double %x) nounwind {
; SSE-NEXT: popl %ebp
; SSE-NEXT: retl
;
-; NOSSE2-LABEL: test6:
-; NOSSE2: # %bb.0:
-; NOSSE2-NEXT: fldl {{[0-9]+}}(%esp)
-; NOSSE2-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: setge %al
-; NOSSE2-NEXT: testb %al, %al
-; NOSSE2-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE2-NEXT: fxch %st(1)
-; NOSSE2-NEXT: fcmovne %st(1), %st
-; NOSSE2-NEXT: fstp %st(1)
-; NOSSE2-NEXT: retl
-;
-; NOSSE1-LABEL: test6:
-; NOSSE1: # %bb.0:
-; NOSSE1-NEXT: fldl {{[0-9]+}}(%esp)
-; NOSSE1-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: setge %al
-; NOSSE1-NEXT: testb %al, %al
-; NOSSE1-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE1-NEXT: fxch %st(1)
-; NOSSE1-NEXT: fcmovne %st(1), %st
-; NOSSE1-NEXT: fstp %st(1)
-; NOSSE1-NEXT: retl
+; NOSSE-LABEL: test6:
+; NOSSE: # %bb.0:
+; NOSSE-NEXT: fldl {{[0-9]+}}(%esp)
+; NOSSE-NEXT: movl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: cmpl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: setge %al
+; NOSSE-NEXT: testb %al, %al
+; NOSSE-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
+; NOSSE-NEXT: fxch %st(1)
+; NOSSE-NEXT: fcmovne %st(1), %st
+; NOSSE-NEXT: fstp %st(1)
+; NOSSE-NEXT: retl
;
; NOCMOV-LABEL: test6:
; NOCMOV: # %bb.0:
@@ -413,31 +343,18 @@ define double @test7(i32 %a, i32 %b, double %x) nounwind {
; SSE-NEXT: popl %ebp
; SSE-NEXT: retl
;
-; NOSSE2-LABEL: test7:
-; NOSSE2: # %bb.0:
-; NOSSE2-NEXT: fldl {{[0-9]+}}(%esp)
-; NOSSE2-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: setl %al
-; NOSSE2-NEXT: testb %al, %al
-; NOSSE2-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE2-NEXT: fxch %st(1)
-; NOSSE2-NEXT: fcmovne %st(1), %st
-; NOSSE2-NEXT: fstp %st(1)
-; NOSSE2-NEXT: retl
-;
-; NOSSE1-LABEL: test7:
-; NOSSE1: # %bb.0:
-; NOSSE1-NEXT: fldl {{[0-9]+}}(%esp)
-; NOSSE1-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: setl %al
-; NOSSE1-NEXT: testb %al, %al
-; NOSSE1-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE1-NEXT: fxch %st(1)
-; NOSSE1-NEXT: fcmovne %st(1), %st
-; NOSSE1-NEXT: fstp %st(1)
-; NOSSE1-NEXT: retl
+; NOSSE-LABEL: test7:
+; NOSSE: # %bb.0:
+; NOSSE-NEXT: fldl {{[0-9]+}}(%esp)
+; NOSSE-NEXT: movl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: cmpl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: setl %al
+; NOSSE-NEXT: testb %al, %al
+; NOSSE-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
+; NOSSE-NEXT: fxch %st(1)
+; NOSSE-NEXT: fcmovne %st(1), %st
+; NOSSE-NEXT: fstp %st(1)
+; NOSSE-NEXT: retl
;
; NOCMOV-LABEL: test7:
; NOCMOV: # %bb.0:
@@ -480,31 +397,18 @@ define double @test8(i32 %a, i32 %b, double %x) nounwind {
; SSE-NEXT: popl %ebp
; SSE-NEXT: retl
;
-; NOSSE2-LABEL: test8:
-; NOSSE2: # %bb.0:
-; NOSSE2-NEXT: fldl {{[0-9]+}}(%esp)
-; NOSSE2-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: setle %al
-; NOSSE2-NEXT: testb %al, %al
-; NOSSE2-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE2-NEXT: fxch %st(1)
-; NOSSE2-NEXT: fcmovne %st(1), %st
-; NOSSE2-NEXT: fstp %st(1)
-; NOSSE2-NEXT: retl
-;
-; NOSSE1-LABEL: test8:
-; NOSSE1: # %bb.0:
-; NOSSE1-NEXT: fldl {{[0-9]+}}(%esp)
-; NOSSE1-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: setle %al
-; NOSSE1-NEXT: testb %al, %al
-; NOSSE1-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE1-NEXT: fxch %st(1)
-; NOSSE1-NEXT: fcmovne %st(1), %st
-; NOSSE1-NEXT: fstp %st(1)
-; NOSSE1-NEXT: retl
+; NOSSE-LABEL: test8:
+; NOSSE: # %bb.0:
+; NOSSE-NEXT: fldl {{[0-9]+}}(%esp)
+; NOSSE-NEXT: movl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: cmpl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: setle %al
+; NOSSE-NEXT: testb %al, %al
+; NOSSE-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
+; NOSSE-NEXT: fxch %st(1)
+; NOSSE-NEXT: fcmovne %st(1), %st
+; NOSSE-NEXT: fstp %st(1)
+; NOSSE-NEXT: retl
;
; NOCMOV-LABEL: test8:
; NOCMOV: # %bb.0:
@@ -1065,27 +969,16 @@ define x86_fp80 @test17(i32 %a, i32 %b, x86_fp80 %x) nounwind {
; SSE-NEXT: fstp %st(1)
; SSE-NEXT: retl
;
-; NOSSE2-LABEL: test17:
-; NOSSE2: # %bb.0:
-; NOSSE2-NEXT: fldt {{[0-9]+}}(%esp)
-; NOSSE2-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE2-NEXT: fxch %st(1)
-; NOSSE2-NEXT: fcmovnbe %st(1), %st
-; NOSSE2-NEXT: fstp %st(1)
-; NOSSE2-NEXT: retl
-;
-; NOSSE1-LABEL: test17:
-; NOSSE1: # %bb.0:
-; NOSSE1-NEXT: fldt {{[0-9]+}}(%esp)
-; NOSSE1-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE1-NEXT: fxch %st(1)
-; NOSSE1-NEXT: fcmovnbe %st(1), %st
-; NOSSE1-NEXT: fstp %st(1)
-; NOSSE1-NEXT: retl
+; NOSSE-LABEL: test17:
+; NOSSE: # %bb.0:
+; NOSSE-NEXT: fldt {{[0-9]+}}(%esp)
+; NOSSE-NEXT: movl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: cmpl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
+; NOSSE-NEXT: fxch %st(1)
+; NOSSE-NEXT: fcmovnbe %st(1), %st
+; NOSSE-NEXT: fstp %st(1)
+; NOSSE-NEXT: retl
;
; NOCMOV-LABEL: test17:
; NOCMOV: # %bb.0:
@@ -1118,27 +1011,16 @@ define x86_fp80 @test18(i32 %a, i32 %b, x86_fp80 %x) nounwind {
; SSE-NEXT: fstp %st(1)
; SSE-NEXT: retl
;
-; NOSSE2-LABEL: test18:
-; NOSSE2: # %bb.0:
-; NOSSE2-NEXT: fldt {{[0-9]+}}(%esp)
-; NOSSE2-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE2-NEXT: fxch %st(1)
-; NOSSE2-NEXT: fcmovnb %st(1), %st
-; NOSSE2-NEXT: fstp %st(1)
-; NOSSE2-NEXT: retl
-;
-; NOSSE1-LABEL: test18:
-; NOSSE1: # %bb.0:
-; NOSSE1-NEXT: fldt {{[0-9]+}}(%esp)
-; NOSSE1-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE1-NEXT: fxch %st(1)
-; NOSSE1-NEXT: fcmovnb %st(1), %st
-; NOSSE1-NEXT: fstp %st(1)
-; NOSSE1-NEXT: retl
+; NOSSE-LABEL: test18:
+; NOSSE: # %bb.0:
+; NOSSE-NEXT: fldt {{[0-9]+}}(%esp)
+; NOSSE-NEXT: movl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: cmpl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
+; NOSSE-NEXT: fxch %st(1)
+; NOSSE-NEXT: fcmovnb %st(1), %st
+; NOSSE-NEXT: fstp %st(1)
+; NOSSE-NEXT: retl
;
; NOCMOV-LABEL: test18:
; NOCMOV: # %bb.0:
@@ -1171,27 +1053,16 @@ define x86_fp80 @test19(i32 %a, i32 %b, x86_fp80 %x) nounwind {
; SSE-NEXT: fstp %st(1)
; SSE-NEXT: retl
;
-; NOSSE2-LABEL: test19:
-; NOSSE2: # %bb.0:
-; NOSSE2-NEXT: fldt {{[0-9]+}}(%esp)
-; NOSSE2-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE2-NEXT: fxch %st(1)
-; NOSSE2-NEXT: fcmovb %st(1), %st
-; NOSSE2-NEXT: fstp %st(1)
-; NOSSE2-NEXT: retl
-;
-; NOSSE1-LABEL: test19:
-; NOSSE1: # %bb.0:
-; NOSSE1-NEXT: fldt {{[0-9]+}}(%esp)
-; NOSSE1-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE1-NEXT: fxch %st(1)
-; NOSSE1-NEXT: fcmovb %st(1), %st
-; NOSSE1-NEXT: fstp %st(1)
-; NOSSE1-NEXT: retl
+; NOSSE-LABEL: test19:
+; NOSSE: # %bb.0:
+; NOSSE-NEXT: fldt {{[0-9]+}}(%esp)
+; NOSSE-NEXT: movl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: cmpl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
+; NOSSE-NEXT: fxch %st(1)
+; NOSSE-NEXT: fcmovb %st(1), %st
+; NOSSE-NEXT: fstp %st(1)
+; NOSSE-NEXT: retl
;
; NOCMOV-LABEL: test19:
; NOCMOV: # %bb.0:
@@ -1224,27 +1095,16 @@ define x86_fp80 @test20(i32 %a, i32 %b, x86_fp80 %x) nounwind {
; SSE-NEXT: fstp %st(1)
; SSE-NEXT: retl
;
-; NOSSE2-LABEL: test20:
-; NOSSE2: # %bb.0:
-; NOSSE2-NEXT: fldt {{[0-9]+}}(%esp)
-; NOSSE2-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE2-NEXT: fxch %st(1)
-; NOSSE2-NEXT: fcmovbe %st(1), %st
-; NOSSE2-NEXT: fstp %st(1)
-; NOSSE2-NEXT: retl
-;
-; NOSSE1-LABEL: test20:
-; NOSSE1: # %bb.0:
-; NOSSE1-NEXT: fldt {{[0-9]+}}(%esp)
-; NOSSE1-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE1-NEXT: fxch %st(1)
-; NOSSE1-NEXT: fcmovbe %st(1), %st
-; NOSSE1-NEXT: fstp %st(1)
-; NOSSE1-NEXT: retl
+; NOSSE-LABEL: test20:
+; NOSSE: # %bb.0:
+; NOSSE-NEXT: fldt {{[0-9]+}}(%esp)
+; NOSSE-NEXT: movl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: cmpl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
+; NOSSE-NEXT: fxch %st(1)
+; NOSSE-NEXT: fcmovbe %st(1), %st
+; NOSSE-NEXT: fstp %st(1)
+; NOSSE-NEXT: retl
;
; NOCMOV-LABEL: test20:
; NOCMOV: # %bb.0:
@@ -1279,31 +1139,18 @@ define x86_fp80 @test21(i32 %a, i32 %b, x86_fp80 %x) nounwind {
; SSE-NEXT: fstp %st(1)
; SSE-NEXT: retl
;
-; NOSSE2-LABEL: test21:
-; NOSSE2: # %bb.0:
-; NOSSE2-NEXT: fldt {{[0-9]+}}(%esp)
-; NOSSE2-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: setg %al
-; NOSSE2-NEXT: testb %al, %al
-; NOSSE2-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE2-NEXT: fxch %st(1)
-; NOSSE2-NEXT: fcmovne %st(1), %st
-; NOSSE2-NEXT: fstp %st(1)
-; NOSSE2-NEXT: retl
-;
-; NOSSE1-LABEL: test21:
-; NOSSE1: # %bb.0:
-; NOSSE1-NEXT: fldt {{[0-9]+}}(%esp)
-; NOSSE1-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: setg %al
-; NOSSE1-NEXT: testb %al, %al
-; NOSSE1-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE1-NEXT: fxch %st(1)
-; NOSSE1-NEXT: fcmovne %st(1), %st
-; NOSSE1-NEXT: fstp %st(1)
-; NOSSE1-NEXT: retl
+; NOSSE-LABEL: test21:
+; NOSSE: # %bb.0:
+; NOSSE-NEXT: fldt {{[0-9]+}}(%esp)
+; NOSSE-NEXT: movl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: cmpl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: setg %al
+; NOSSE-NEXT: testb %al, %al
+; NOSSE-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
+; NOSSE-NEXT: fxch %st(1)
+; NOSSE-NEXT: fcmovne %st(1), %st
+; NOSSE-NEXT: fstp %st(1)
+; NOSSE-NEXT: retl
;
; NOCMOV-LABEL: test21:
; NOCMOV: # %bb.0:
@@ -1339,31 +1186,18 @@ define x86_fp80 @test22(i32 %a, i32 %b, x86_fp80 %x) nounwind {
; SSE-NEXT: fstp %st(1)
; SSE-NEXT: retl
;
-; NOSSE2-LABEL: test22:
-; NOSSE2: # %bb.0:
-; NOSSE2-NEXT: fldt {{[0-9]+}}(%esp)
-; NOSSE2-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: setge %al
-; NOSSE2-NEXT: testb %al, %al
-; NOSSE2-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE2-NEXT: fxch %st(1)
-; NOSSE2-NEXT: fcmovne %st(1), %st
-; NOSSE2-NEXT: fstp %st(1)
-; NOSSE2-NEXT: retl
-;
-; NOSSE1-LABEL: test22:
-; NOSSE1: # %bb.0:
-; NOSSE1-NEXT: fldt {{[0-9]+}}(%esp)
-; NOSSE1-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: setge %al
-; NOSSE1-NEXT: testb %al, %al
-; NOSSE1-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE1-NEXT: fxch %st(1)
-; NOSSE1-NEXT: fcmovne %st(1), %st
-; NOSSE1-NEXT: fstp %st(1)
-; NOSSE1-NEXT: retl
+; NOSSE-LABEL: test22:
+; NOSSE: # %bb.0:
+; NOSSE-NEXT: fldt {{[0-9]+}}(%esp)
+; NOSSE-NEXT: movl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: cmpl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: setge %al
+; NOSSE-NEXT: testb %al, %al
+; NOSSE-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
+; NOSSE-NEXT: fxch %st(1)
+; NOSSE-NEXT: fcmovne %st(1), %st
+; NOSSE-NEXT: fstp %st(1)
+; NOSSE-NEXT: retl
;
; NOCMOV-LABEL: test22:
; NOCMOV: # %bb.0:
@@ -1398,31 +1232,18 @@ define x86_fp80 @test23(i32 %a, i32 %b, x86_fp80 %x) nounwind {
; SSE-NEXT: fstp %st(1)
; SSE-NEXT: retl
;
-; NOSSE2-LABEL: test23:
-; NOSSE2: # %bb.0:
-; NOSSE2-NEXT: fldt {{[0-9]+}}(%esp)
-; NOSSE2-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: setl %al
-; NOSSE2-NEXT: testb %al, %al
-; NOSSE2-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE2-NEXT: fxch %st(1)
-; NOSSE2-NEXT: fcmovne %st(1), %st
-; NOSSE2-NEXT: fstp %st(1)
-; NOSSE2-NEXT: retl
-;
-; NOSSE1-LABEL: test23:
-; NOSSE1: # %bb.0:
-; NOSSE1-NEXT: fldt {{[0-9]+}}(%esp)
-; NOSSE1-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: setl %al
-; NOSSE1-NEXT: testb %al, %al
-; NOSSE1-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE1-NEXT: fxch %st(1)
-; NOSSE1-NEXT: fcmovne %st(1), %st
-; NOSSE1-NEXT: fstp %st(1)
-; NOSSE1-NEXT: retl
+; NOSSE-LABEL: test23:
+; NOSSE: # %bb.0:
+; NOSSE-NEXT: fldt {{[0-9]+}}(%esp)
+; NOSSE-NEXT: movl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: cmpl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: setl %al
+; NOSSE-NEXT: testb %al, %al
+; NOSSE-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
+; NOSSE-NEXT: fxch %st(1)
+; NOSSE-NEXT: fcmovne %st(1), %st
+; NOSSE-NEXT: fstp %st(1)
+; NOSSE-NEXT: retl
;
; NOCMOV-LABEL: test23:
; NOCMOV: # %bb.0:
@@ -1457,31 +1278,18 @@ define x86_fp80 @test24(i32 %a, i32 %b, x86_fp80 %x) nounwind {
; SSE-NEXT: fstp %st(1)
; SSE-NEXT: retl
;
-; NOSSE2-LABEL: test24:
-; NOSSE2: # %bb.0:
-; NOSSE2-NEXT: fldt {{[0-9]+}}(%esp)
-; NOSSE2-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE2-NEXT: setle %al
-; NOSSE2-NEXT: testb %al, %al
-; NOSSE2-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE2-NEXT: fxch %st(1)
-; NOSSE2-NEXT: fcmovne %st(1), %st
-; NOSSE2-NEXT: fstp %st(1)
-; NOSSE2-NEXT: retl
-;
-; NOSSE1-LABEL: test24:
-; NOSSE1: # %bb.0:
-; NOSSE1-NEXT: fldt {{[0-9]+}}(%esp)
-; NOSSE1-NEXT: movl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: cmpl {{[0-9]+}}(%esp), %eax
-; NOSSE1-NEXT: setle %al
-; NOSSE1-NEXT: testb %al, %al
-; NOSSE1-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
-; NOSSE1-NEXT: fxch %st(1)
-; NOSSE1-NEXT: fcmovne %st(1), %st
-; NOSSE1-NEXT: fstp %st(1)
-; NOSSE1-NEXT: retl
+; NOSSE-LABEL: test24:
+; NOSSE: # %bb.0:
+; NOSSE-NEXT: fldt {{[0-9]+}}(%esp)
+; NOSSE-NEXT: movl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: cmpl {{[0-9]+}}(%esp), %eax
+; NOSSE-NEXT: setle %al
+; NOSSE-NEXT: testb %al, %al
+; NOSSE-NEXT: flds {{\.?LCPI[0-9]+_[0-9]+}}
+; NOSSE-NEXT: fxch %st(1)
+; NOSSE-NEXT: fcmovne %st(1), %st
+; NOSSE-NEXT: fstp %st(1)
+; NOSSE-NEXT: retl
;
; NOCMOV-LABEL: test24:
; NOCMOV: # %bb.0:
>From 139bcda542514b7a064fe9225014ec4268bb2b65 Mon Sep 17 00:00:00 2001
From: Simon Pilgrim <llvm-dev at redking.me.uk>
Date: Thu, 29 Feb 2024 12:33:49 +0000
Subject: [PATCH 117/406] [X86] SimplifyDemandedVectorEltsForTargetNode - add
basic CVTPH2PS/CVTPS2PH handling
Allows us to peek through the F16 conversion nodes, mainly to simplify shuffles
An easy part of #83414
---
llvm/lib/Target/X86/X86ISelLowering.cpp | 4 +-
.../test/CodeGen/X86/avx512-insert-extract.ll | 8 +-
llvm/test/CodeGen/X86/avx512-vec-cmp.ll | 21 +--
llvm/test/CodeGen/X86/cvt16.ll | 1 -
.../CodeGen/X86/f16c-intrinsics-fast-isel.ll | 7 +-
.../X86/fold-int-pow2-with-fmul-or-fdiv.ll | 4 -
llvm/test/CodeGen/X86/fp-roundeven.ll | 1 -
llvm/test/CodeGen/X86/fpclamptosat_vec.ll | 86 ++++++------
llvm/test/CodeGen/X86/half.ll | 62 ++++-----
llvm/test/CodeGen/X86/pr31088.ll | 12 +-
llvm/test/CodeGen/X86/pr57340.ll | 125 +++++++++---------
llvm/test/CodeGen/X86/prefer-fpext-splat.ll | 2 -
.../CodeGen/X86/vector-half-conversions.ll | 30 ++---
.../CodeGen/X86/vector-reduce-fmax-nnan.ll | 12 +-
.../CodeGen/X86/vector-reduce-fmin-nnan.ll | 12 +-
15 files changed, 160 insertions(+), 227 deletions(-)
diff --git a/llvm/lib/Target/X86/X86ISelLowering.cpp b/llvm/lib/Target/X86/X86ISelLowering.cpp
index 93088c7cde938b..d98d914894a3f8 100644
--- a/llvm/lib/Target/X86/X86ISelLowering.cpp
+++ b/llvm/lib/Target/X86/X86ISelLowering.cpp
@@ -41402,7 +41402,9 @@ bool X86TargetLowering::SimplifyDemandedVectorEltsForTargetNode(
break;
}
case X86ISD::CVTSI2P:
- case X86ISD::CVTUI2P: {
+ case X86ISD::CVTUI2P:
+ case X86ISD::CVTPH2PS:
+ case X86ISD::CVTPS2PH: {
SDValue Src = Op.getOperand(0);
MVT SrcVT = Src.getSimpleValueType();
APInt SrcUndef, SrcZero;
diff --git a/llvm/test/CodeGen/X86/avx512-insert-extract.ll b/llvm/test/CodeGen/X86/avx512-insert-extract.ll
index 22aae4de4db9d2..3e40bfa1e791d0 100644
--- a/llvm/test/CodeGen/X86/avx512-insert-extract.ll
+++ b/llvm/test/CodeGen/X86/avx512-insert-extract.ll
@@ -2171,14 +2171,13 @@ define void @test_concat_v2i1(ptr %arg, ptr %arg1, ptr %arg2) nounwind {
; KNL-LABEL: test_concat_v2i1:
; KNL: ## %bb.0:
; KNL-NEXT: vmovq {{.*#+}} xmm0 = mem[0],zero
-; KNL-NEXT: vpmovzxwq {{.*#+}} xmm1 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
-; KNL-NEXT: vcvtph2ps %xmm1, %xmm1
+; KNL-NEXT: vcvtph2ps %xmm0, %xmm1
; KNL-NEXT: vmovss {{.*#+}} xmm2 = [6.0E+0,0.0E+0,0.0E+0,0.0E+0]
; KNL-NEXT: vucomiss %xmm2, %xmm1
; KNL-NEXT: setb %al
; KNL-NEXT: andl $1, %eax
; KNL-NEXT: kmovw %eax, %k0
-; KNL-NEXT: vpshufb {{.*#+}} xmm0 = xmm0[2,3],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
+; KNL-NEXT: vpshuflw {{.*#+}} xmm0 = xmm0[1,1,1,1,4,5,6,7]
; KNL-NEXT: vcvtph2ps %xmm0, %xmm0
; KNL-NEXT: vucomiss %xmm2, %xmm0
; KNL-NEXT: setb %al
@@ -2207,14 +2206,13 @@ define void @test_concat_v2i1(ptr %arg, ptr %arg1, ptr %arg2) nounwind {
; SKX-LABEL: test_concat_v2i1:
; SKX: ## %bb.0:
; SKX-NEXT: vmovq {{.*#+}} xmm0 = mem[0],zero
-; SKX-NEXT: vpshufb {{.*#+}} xmm1 = xmm0[2,3],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
+; SKX-NEXT: vpshuflw {{.*#+}} xmm1 = xmm0[1,1,1,1,4,5,6,7]
; SKX-NEXT: vcvtph2ps %xmm1, %xmm1
; SKX-NEXT: vmovss {{.*#+}} xmm2 = [6.0E+0,0.0E+0,0.0E+0,0.0E+0]
; SKX-NEXT: vucomiss %xmm2, %xmm1
; SKX-NEXT: setb %al
; SKX-NEXT: kmovd %eax, %k0
; SKX-NEXT: kshiftlb $1, %k0, %k0
-; SKX-NEXT: vpmovzxwq {{.*#+}} xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
; SKX-NEXT: vcvtph2ps %xmm0, %xmm0
; SKX-NEXT: vucomiss %xmm2, %xmm0
; SKX-NEXT: setb %al
diff --git a/llvm/test/CodeGen/X86/avx512-vec-cmp.ll b/llvm/test/CodeGen/X86/avx512-vec-cmp.ll
index f3c728a990f514..86ebb1e40870f8 100644
--- a/llvm/test/CodeGen/X86/avx512-vec-cmp.ll
+++ b/llvm/test/CodeGen/X86/avx512-vec-cmp.ll
@@ -1436,9 +1436,8 @@ define void @half_vec_compare(ptr %x, ptr %y) {
; KNL: ## %bb.0: ## %entry
; KNL-NEXT: vmovd {{.*#+}} xmm0 = mem[0],zero,zero,zero
; KNL-NEXT: ## EVEX TO VEX Compression encoding: [0xc5,0xf9,0x6e,0x07]
-; KNL-NEXT: vpshufb {{.*#+}} xmm1 = xmm0[2,3],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
-; KNL-NEXT: ## encoding: [0xc4,0xe2,0x79,0x00,0x0d,A,A,A,A]
-; KNL-NEXT: ## fixup A - offset: 5, value: {{\.?LCPI[0-9]+_[0-9]+}}-4, kind: reloc_riprel_4byte
+; KNL-NEXT: vpshuflw $85, %xmm0, %xmm1 ## encoding: [0xc5,0xfb,0x70,0xc8,0x55]
+; KNL-NEXT: ## xmm1 = xmm0[1,1,1,1,4,5,6,7]
; KNL-NEXT: vcvtph2ps %xmm1, %xmm1 ## encoding: [0xc4,0xe2,0x79,0x13,0xc9]
; KNL-NEXT: xorl %eax, %eax ## encoding: [0x31,0xc0]
; KNL-NEXT: vxorps %xmm2, %xmm2, %xmm2 ## encoding: [0xc5,0xe8,0x57,0xd2]
@@ -1448,8 +1447,6 @@ define void @half_vec_compare(ptr %x, ptr %y) {
; KNL-NEXT: movl $0, %edx ## encoding: [0xba,0x00,0x00,0x00,0x00]
; KNL-NEXT: cmovnel %ecx, %edx ## encoding: [0x0f,0x45,0xd1]
; KNL-NEXT: cmovpl %ecx, %edx ## encoding: [0x0f,0x4a,0xd1]
-; KNL-NEXT: vpmovzxwq %xmm0, %xmm0 ## encoding: [0xc4,0xe2,0x79,0x34,0xc0]
-; KNL-NEXT: ## xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
; KNL-NEXT: vcvtph2ps %xmm0, %xmm0 ## encoding: [0xc4,0xe2,0x79,0x13,0xc0]
; KNL-NEXT: vucomiss %xmm2, %xmm0 ## EVEX TO VEX Compression encoding: [0xc5,0xf8,0x2e,0xc2]
; KNL-NEXT: cmovnel %ecx, %eax ## encoding: [0x0f,0x45,0xc1]
@@ -1466,9 +1463,8 @@ define void @half_vec_compare(ptr %x, ptr %y) {
; AVX512BW: ## %bb.0: ## %entry
; AVX512BW-NEXT: vmovd {{.*#+}} xmm0 = mem[0],zero,zero,zero
; AVX512BW-NEXT: ## EVEX TO VEX Compression encoding: [0xc5,0xf9,0x6e,0x07]
-; AVX512BW-NEXT: vpshufb {{.*#+}} xmm1 = xmm0[2,3],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
-; AVX512BW-NEXT: ## encoding: [0xc4,0xe2,0x79,0x00,0x0d,A,A,A,A]
-; AVX512BW-NEXT: ## fixup A - offset: 5, value: {{\.?LCPI[0-9]+_[0-9]+}}-4, kind: reloc_riprel_4byte
+; AVX512BW-NEXT: vpshuflw $85, %xmm0, %xmm1 ## encoding: [0xc5,0xfb,0x70,0xc8,0x55]
+; AVX512BW-NEXT: ## xmm1 = xmm0[1,1,1,1,4,5,6,7]
; AVX512BW-NEXT: vcvtph2ps %xmm1, %xmm1 ## encoding: [0xc4,0xe2,0x79,0x13,0xc9]
; AVX512BW-NEXT: xorl %eax, %eax ## encoding: [0x31,0xc0]
; AVX512BW-NEXT: vxorps %xmm2, %xmm2, %xmm2 ## encoding: [0xc5,0xe8,0x57,0xd2]
@@ -1478,8 +1474,6 @@ define void @half_vec_compare(ptr %x, ptr %y) {
; AVX512BW-NEXT: movl $0, %edx ## encoding: [0xba,0x00,0x00,0x00,0x00]
; AVX512BW-NEXT: cmovnel %ecx, %edx ## encoding: [0x0f,0x45,0xd1]
; AVX512BW-NEXT: cmovpl %ecx, %edx ## encoding: [0x0f,0x4a,0xd1]
-; AVX512BW-NEXT: vpmovzxwq %xmm0, %xmm0 ## encoding: [0xc4,0xe2,0x79,0x34,0xc0]
-; AVX512BW-NEXT: ## xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
; AVX512BW-NEXT: vcvtph2ps %xmm0, %xmm0 ## encoding: [0xc4,0xe2,0x79,0x13,0xc0]
; AVX512BW-NEXT: vucomiss %xmm2, %xmm0 ## EVEX TO VEX Compression encoding: [0xc5,0xf8,0x2e,0xc2]
; AVX512BW-NEXT: cmovnel %ecx, %eax ## encoding: [0x0f,0x45,0xc1]
@@ -1496,9 +1490,8 @@ define void @half_vec_compare(ptr %x, ptr %y) {
; SKX: ## %bb.0: ## %entry
; SKX-NEXT: vmovd {{.*#+}} xmm0 = mem[0],zero,zero,zero
; SKX-NEXT: ## EVEX TO VEX Compression encoding: [0xc5,0xf9,0x6e,0x07]
-; SKX-NEXT: vpshufb {{.*#+}} xmm1 = xmm0[2,3],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
-; SKX-NEXT: ## EVEX TO VEX Compression encoding: [0xc4,0xe2,0x79,0x00,0x0d,A,A,A,A]
-; SKX-NEXT: ## fixup A - offset: 5, value: {{\.?LCPI[0-9]+_[0-9]+}}-4, kind: reloc_riprel_4byte
+; SKX-NEXT: vpshuflw $85, %xmm0, %xmm1 ## EVEX TO VEX Compression encoding: [0xc5,0xfb,0x70,0xc8,0x55]
+; SKX-NEXT: ## xmm1 = xmm0[1,1,1,1,4,5,6,7]
; SKX-NEXT: vcvtph2ps %xmm1, %xmm1 ## EVEX TO VEX Compression encoding: [0xc4,0xe2,0x79,0x13,0xc9]
; SKX-NEXT: vxorps %xmm2, %xmm2, %xmm2 ## EVEX TO VEX Compression encoding: [0xc5,0xe8,0x57,0xd2]
; SKX-NEXT: vucomiss %xmm2, %xmm1 ## EVEX TO VEX Compression encoding: [0xc5,0xf8,0x2e,0xca]
@@ -1507,8 +1500,6 @@ define void @half_vec_compare(ptr %x, ptr %y) {
; SKX-NEXT: orb %al, %cl ## encoding: [0x08,0xc1]
; SKX-NEXT: testb %cl, %cl ## encoding: [0x84,0xc9]
; SKX-NEXT: setne %al ## encoding: [0x0f,0x95,0xc0]
-; SKX-NEXT: vpmovzxwq %xmm0, %xmm0 ## EVEX TO VEX Compression encoding: [0xc4,0xe2,0x79,0x34,0xc0]
-; SKX-NEXT: ## xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
; SKX-NEXT: vcvtph2ps %xmm0, %xmm0 ## EVEX TO VEX Compression encoding: [0xc4,0xe2,0x79,0x13,0xc0]
; SKX-NEXT: vucomiss %xmm2, %xmm0 ## EVEX TO VEX Compression encoding: [0xc5,0xf8,0x2e,0xc2]
; SKX-NEXT: setp %cl ## encoding: [0x0f,0x9a,0xc1]
diff --git a/llvm/test/CodeGen/X86/cvt16.ll b/llvm/test/CodeGen/X86/cvt16.ll
index 59097f8fb5d247..c7ef353f7f6038 100644
--- a/llvm/test/CodeGen/X86/cvt16.ll
+++ b/llvm/test/CodeGen/X86/cvt16.ll
@@ -89,7 +89,6 @@ define float @test3(float %src) nounwind uwtable readnone {
; F16C-LABEL: test3:
; F16C: # %bb.0:
; F16C-NEXT: vcvtps2ph $4, %xmm0, %xmm0
-; F16C-NEXT: vpmovzxwq {{.*#+}} xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
; F16C-NEXT: vcvtph2ps %xmm0, %xmm0
; F16C-NEXT: retq
;
diff --git a/llvm/test/CodeGen/X86/f16c-intrinsics-fast-isel.ll b/llvm/test/CodeGen/X86/f16c-intrinsics-fast-isel.ll
index e114c205d7972b..1886e2911ede80 100644
--- a/llvm/test/CodeGen/X86/f16c-intrinsics-fast-isel.ll
+++ b/llvm/test/CodeGen/X86/f16c-intrinsics-fast-isel.ll
@@ -18,8 +18,7 @@ define float @test_cvtsh_ss(i16 %a0) nounwind {
;
; X64-LABEL: test_cvtsh_ss:
; X64: # %bb.0:
-; X64-NEXT: movzwl %di, %eax
-; X64-NEXT: vmovd %eax, %xmm0
+; X64-NEXT: vmovd %edi, %xmm0
; X64-NEXT: vcvtph2ps %xmm0, %xmm0
; X64-NEXT: retq
%ins0 = insertelement <8 x i16> undef, i16 %a0, i32 0
@@ -41,8 +40,6 @@ define i16 @test_cvtss_sh(float %a0) nounwind {
; X86-LABEL: test_cvtss_sh:
; X86: # %bb.0:
; X86-NEXT: vmovss {{.*#+}} xmm0 = mem[0],zero,zero,zero
-; X86-NEXT: vxorps %xmm1, %xmm1, %xmm1
-; X86-NEXT: vblendps {{.*#+}} xmm0 = xmm0[0],xmm1[1,2,3]
; X86-NEXT: vcvtps2ph $0, %xmm0, %xmm0
; X86-NEXT: vmovd %xmm0, %eax
; X86-NEXT: # kill: def $ax killed $ax killed $eax
@@ -50,8 +47,6 @@ define i16 @test_cvtss_sh(float %a0) nounwind {
;
; X64-LABEL: test_cvtss_sh:
; X64: # %bb.0:
-; X64-NEXT: vxorps %xmm1, %xmm1, %xmm1
-; X64-NEXT: vblendps {{.*#+}} xmm0 = xmm0[0],xmm1[1,2,3]
; X64-NEXT: vcvtps2ph $0, %xmm0, %xmm0
; X64-NEXT: vmovd %xmm0, %eax
; X64-NEXT: # kill: def $ax killed $ax killed $eax
diff --git a/llvm/test/CodeGen/X86/fold-int-pow2-with-fmul-or-fdiv.ll b/llvm/test/CodeGen/X86/fold-int-pow2-with-fmul-or-fdiv.ll
index 5f326b6d6998fb..8f875c70a25f6d 100644
--- a/llvm/test/CodeGen/X86/fold-int-pow2-with-fmul-or-fdiv.ll
+++ b/llvm/test/CodeGen/X86/fold-int-pow2-with-fmul-or-fdiv.ll
@@ -1432,7 +1432,6 @@ define half @fdiv_pow_shl_cnt_fail_out_of_bounds(i32 %cnt) nounwind {
; CHECK-NO-FASTFMA-NEXT: shll %cl, %eax
; CHECK-NO-FASTFMA-NEXT: vcvtusi2ss %eax, %xmm0, %xmm0
; CHECK-NO-FASTFMA-NEXT: vcvtps2ph $4, %xmm0, %xmm0
-; CHECK-NO-FASTFMA-NEXT: vpmovzxwq {{.*#+}} xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
; CHECK-NO-FASTFMA-NEXT: vcvtph2ps %xmm0, %xmm0
; CHECK-NO-FASTFMA-NEXT: vmovss {{.*#+}} xmm1 = [8.192E+3,0.0E+0,0.0E+0,0.0E+0]
; CHECK-NO-FASTFMA-NEXT: vdivss %xmm0, %xmm1, %xmm0
@@ -1447,7 +1446,6 @@ define half @fdiv_pow_shl_cnt_fail_out_of_bounds(i32 %cnt) nounwind {
; CHECK-FMA-NEXT: shlxl %edi, %eax, %eax
; CHECK-FMA-NEXT: vcvtusi2ss %eax, %xmm0, %xmm0
; CHECK-FMA-NEXT: vcvtps2ph $4, %xmm0, %xmm0
-; CHECK-FMA-NEXT: vpmovzxwq {{.*#+}} xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
; CHECK-FMA-NEXT: vcvtph2ps %xmm0, %xmm0
; CHECK-FMA-NEXT: vmovss {{.*#+}} xmm1 = [8.192E+3,0.0E+0,0.0E+0,0.0E+0]
; CHECK-FMA-NEXT: vdivss %xmm0, %xmm1, %xmm0
@@ -1550,7 +1548,6 @@ define half @fdiv_pow_shl_cnt_fail_out_of_bound2(i16 %cnt) nounwind {
; CHECK-NO-FASTFMA-NEXT: movzwl %ax, %eax
; CHECK-NO-FASTFMA-NEXT: vcvtsi2ss %eax, %xmm0, %xmm0
; CHECK-NO-FASTFMA-NEXT: vcvtps2ph $4, %xmm0, %xmm0
-; CHECK-NO-FASTFMA-NEXT: vpmovzxwq {{.*#+}} xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
; CHECK-NO-FASTFMA-NEXT: vcvtph2ps %xmm0, %xmm0
; CHECK-NO-FASTFMA-NEXT: vmovss {{.*#+}} xmm1 = [2.0E+0,0.0E+0,0.0E+0,0.0E+0]
; CHECK-NO-FASTFMA-NEXT: vdivss %xmm0, %xmm1, %xmm0
@@ -1566,7 +1563,6 @@ define half @fdiv_pow_shl_cnt_fail_out_of_bound2(i16 %cnt) nounwind {
; CHECK-FMA-NEXT: movzwl %ax, %eax
; CHECK-FMA-NEXT: vcvtsi2ss %eax, %xmm0, %xmm0
; CHECK-FMA-NEXT: vcvtps2ph $4, %xmm0, %xmm0
-; CHECK-FMA-NEXT: vpmovzxwq {{.*#+}} xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
; CHECK-FMA-NEXT: vcvtph2ps %xmm0, %xmm0
; CHECK-FMA-NEXT: vmovss {{.*#+}} xmm1 = [2.0E+0,0.0E+0,0.0E+0,0.0E+0]
; CHECK-FMA-NEXT: vdivss %xmm0, %xmm1, %xmm0
diff --git a/llvm/test/CodeGen/X86/fp-roundeven.ll b/llvm/test/CodeGen/X86/fp-roundeven.ll
index fed2060dabd3af..8037c783dd8e67 100644
--- a/llvm/test/CodeGen/X86/fp-roundeven.ll
+++ b/llvm/test/CodeGen/X86/fp-roundeven.ll
@@ -51,7 +51,6 @@ define half @roundeven_f16(half %h) {
; AVX512F-LABEL: roundeven_f16:
; AVX512F: ## %bb.0: ## %entry
; AVX512F-NEXT: vpextrw $0, %xmm0, %eax
-; AVX512F-NEXT: movzwl %ax, %eax
; AVX512F-NEXT: vmovd %eax, %xmm0
; AVX512F-NEXT: vcvtph2ps %xmm0, %xmm0
; AVX512F-NEXT: vroundss $8, %xmm0, %xmm0, %xmm0
diff --git a/llvm/test/CodeGen/X86/fpclamptosat_vec.ll b/llvm/test/CodeGen/X86/fpclamptosat_vec.ll
index a3fb71f817ce47..6aad4c2ebba1d8 100644
--- a/llvm/test/CodeGen/X86/fpclamptosat_vec.ll
+++ b/llvm/test/CodeGen/X86/fpclamptosat_vec.ll
@@ -698,24 +698,23 @@ define <4 x i32> @stest_f16i32(<4 x half> %x) nounwind {
;
; AVX2-LABEL: stest_f16i32:
; AVX2: # %bb.0: # %entry
-; AVX2-NEXT: vpsrlq $48, %xmm0, %xmm1
+; AVX2-NEXT: vpshuflw {{.*#+}} xmm1 = xmm0[3,3,3,3,4,5,6,7]
; AVX2-NEXT: vcvtph2ps %xmm1, %xmm1
; AVX2-NEXT: vcvttss2si %xmm1, %rax
-; AVX2-NEXT: vpshufb {{.*#+}} xmm1 = xmm0[4,5],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
+; AVX2-NEXT: vmovshdup {{.*#+}} xmm1 = xmm0[1,1,3,3]
; AVX2-NEXT: vcvtph2ps %xmm1, %xmm1
; AVX2-NEXT: vcvttss2si %xmm1, %rcx
-; AVX2-NEXT: vpshufb {{.*#+}} xmm1 = xmm0[2,3],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
-; AVX2-NEXT: vcvtph2ps %xmm1, %xmm1
+; AVX2-NEXT: vcvtph2ps %xmm0, %xmm1
; AVX2-NEXT: vmovq %rax, %xmm2
; AVX2-NEXT: vcvttss2si %xmm1, %rax
; AVX2-NEXT: vmovq %rcx, %xmm1
; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm1 = xmm1[0],xmm2[0]
-; AVX2-NEXT: vpmovzxwq {{.*#+}} xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
+; AVX2-NEXT: vpshuflw {{.*#+}} xmm0 = xmm0[1,1,1,1,4,5,6,7]
; AVX2-NEXT: vcvtph2ps %xmm0, %xmm0
; AVX2-NEXT: vmovq %rax, %xmm2
; AVX2-NEXT: vcvttss2si %xmm0, %rax
; AVX2-NEXT: vmovq %rax, %xmm0
-; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm0 = xmm0[0],xmm2[0]
+; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm0 = xmm2[0],xmm0[0]
; AVX2-NEXT: vinserti128 $1, %xmm1, %ymm0, %ymm0
; AVX2-NEXT: vpbroadcastq {{.*#+}} ymm1 = [2147483647,2147483647,2147483647,2147483647]
; AVX2-NEXT: vpcmpgtq %ymm0, %ymm1, %ymm2
@@ -837,7 +836,7 @@ define <4 x i32> @utesth_f16i32(<4 x half> %x) nounwind {
;
; AVX2-LABEL: utesth_f16i32:
; AVX2: # %bb.0: # %entry
-; AVX2-NEXT: vpsrlq $48, %xmm0, %xmm1
+; AVX2-NEXT: vpshuflw {{.*#+}} xmm1 = xmm0[3,3,3,3,4,5,6,7]
; AVX2-NEXT: vcvtph2ps %xmm1, %xmm2
; AVX2-NEXT: vmovss {{.*#+}} xmm1 = [9.22337203E+18,0.0E+0,0.0E+0,0.0E+0]
; AVX2-NEXT: vsubss %xmm1, %xmm2, %xmm3
@@ -846,29 +845,28 @@ define <4 x i32> @utesth_f16i32(<4 x half> %x) nounwind {
; AVX2-NEXT: movq %rcx, %rdx
; AVX2-NEXT: sarq $63, %rdx
; AVX2-NEXT: andq %rax, %rdx
-; AVX2-NEXT: vpshufb {{.*#+}} xmm2 = xmm0[4,5],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
-; AVX2-NEXT: vcvtph2ps %xmm2, %xmm2
; AVX2-NEXT: orq %rcx, %rdx
+; AVX2-NEXT: vmovshdup {{.*#+}} xmm2 = xmm0[1,1,3,3]
+; AVX2-NEXT: vcvtph2ps %xmm2, %xmm2
; AVX2-NEXT: vsubss %xmm1, %xmm2, %xmm3
; AVX2-NEXT: vcvttss2si %xmm3, %rax
-; AVX2-NEXT: vmovq %rdx, %xmm3
; AVX2-NEXT: vcvttss2si %xmm2, %rcx
+; AVX2-NEXT: vmovq %rdx, %xmm2
; AVX2-NEXT: movq %rcx, %rdx
; AVX2-NEXT: sarq $63, %rdx
-; AVX2-NEXT: vpshufb {{.*#+}} xmm2 = xmm0[2,3],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
-; AVX2-NEXT: vcvtph2ps %xmm2, %xmm2
+; AVX2-NEXT: vcvtph2ps %xmm0, %xmm3
; AVX2-NEXT: andq %rax, %rdx
-; AVX2-NEXT: vsubss %xmm1, %xmm2, %xmm4
+; AVX2-NEXT: vsubss %xmm1, %xmm3, %xmm4
; AVX2-NEXT: vcvttss2si %xmm4, %rax
; AVX2-NEXT: orq %rcx, %rdx
; AVX2-NEXT: vmovq %rdx, %xmm4
-; AVX2-NEXT: vcvttss2si %xmm2, %rcx
-; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm2 = xmm4[0],xmm3[0]
+; AVX2-NEXT: vcvttss2si %xmm3, %rcx
+; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm2 = xmm4[0],xmm2[0]
; AVX2-NEXT: movq %rcx, %rdx
; AVX2-NEXT: sarq $63, %rdx
; AVX2-NEXT: andq %rax, %rdx
; AVX2-NEXT: orq %rcx, %rdx
-; AVX2-NEXT: vpmovzxwq {{.*#+}} xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
+; AVX2-NEXT: vpshuflw {{.*#+}} xmm0 = xmm0[1,1,1,1,4,5,6,7]
; AVX2-NEXT: vcvtph2ps %xmm0, %xmm0
; AVX2-NEXT: vsubss %xmm1, %xmm0, %xmm1
; AVX2-NEXT: vcvttss2si %xmm1, %rax
@@ -879,7 +877,7 @@ define <4 x i32> @utesth_f16i32(<4 x half> %x) nounwind {
; AVX2-NEXT: andq %rax, %rdx
; AVX2-NEXT: orq %rcx, %rdx
; AVX2-NEXT: vmovq %rdx, %xmm1
-; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm0 = xmm1[0],xmm0[0]
+; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm0 = xmm0[0],xmm1[0]
; AVX2-NEXT: vinserti128 $1, %xmm2, %ymm0, %ymm0
; AVX2-NEXT: vbroadcastsd {{.*#+}} ymm1 = [4294967295,4294967295,4294967295,4294967295]
; AVX2-NEXT: vpbroadcastq {{.*#+}} ymm2 = [9223372036854775808,9223372036854775808,9223372036854775808,9223372036854775808]
@@ -1001,24 +999,23 @@ define <4 x i32> @ustest_f16i32(<4 x half> %x) nounwind {
;
; AVX2-LABEL: ustest_f16i32:
; AVX2: # %bb.0: # %entry
-; AVX2-NEXT: vpsrlq $48, %xmm0, %xmm1
+; AVX2-NEXT: vpshuflw {{.*#+}} xmm1 = xmm0[3,3,3,3,4,5,6,7]
; AVX2-NEXT: vcvtph2ps %xmm1, %xmm1
; AVX2-NEXT: vcvttss2si %xmm1, %rax
; AVX2-NEXT: vmovq %rax, %xmm1
-; AVX2-NEXT: vpshufb {{.*#+}} xmm2 = xmm0[4,5],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
+; AVX2-NEXT: vmovshdup {{.*#+}} xmm2 = xmm0[1,1,3,3]
; AVX2-NEXT: vcvtph2ps %xmm2, %xmm2
; AVX2-NEXT: vcvttss2si %xmm2, %rax
; AVX2-NEXT: vmovq %rax, %xmm2
; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm1 = xmm2[0],xmm1[0]
-; AVX2-NEXT: vpshufb {{.*#+}} xmm2 = xmm0[2,3],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
-; AVX2-NEXT: vcvtph2ps %xmm2, %xmm2
+; AVX2-NEXT: vcvtph2ps %xmm0, %xmm2
; AVX2-NEXT: vcvttss2si %xmm2, %rax
; AVX2-NEXT: vmovq %rax, %xmm2
-; AVX2-NEXT: vpmovzxwq {{.*#+}} xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
+; AVX2-NEXT: vpshuflw {{.*#+}} xmm0 = xmm0[1,1,1,1,4,5,6,7]
; AVX2-NEXT: vcvtph2ps %xmm0, %xmm0
; AVX2-NEXT: vcvttss2si %xmm0, %rax
; AVX2-NEXT: vmovq %rax, %xmm0
-; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm0 = xmm0[0],xmm2[0]
+; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm0 = xmm2[0],xmm0[0]
; AVX2-NEXT: vinserti128 $1, %xmm1, %ymm0, %ymm0
; AVX2-NEXT: vpbroadcastq {{.*#+}} ymm1 = [4294967295,4294967295,4294967295,4294967295]
; AVX2-NEXT: vpcmpgtq %ymm0, %ymm1, %ymm2
@@ -3313,24 +3310,23 @@ define <4 x i32> @stest_f16i32_mm(<4 x half> %x) nounwind {
;
; AVX2-LABEL: stest_f16i32_mm:
; AVX2: # %bb.0: # %entry
-; AVX2-NEXT: vpsrlq $48, %xmm0, %xmm1
+; AVX2-NEXT: vpshuflw {{.*#+}} xmm1 = xmm0[3,3,3,3,4,5,6,7]
; AVX2-NEXT: vcvtph2ps %xmm1, %xmm1
; AVX2-NEXT: vcvttss2si %xmm1, %rax
-; AVX2-NEXT: vpshufb {{.*#+}} xmm1 = xmm0[4,5],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
+; AVX2-NEXT: vmovshdup {{.*#+}} xmm1 = xmm0[1,1,3,3]
; AVX2-NEXT: vcvtph2ps %xmm1, %xmm1
; AVX2-NEXT: vcvttss2si %xmm1, %rcx
-; AVX2-NEXT: vpshufb {{.*#+}} xmm1 = xmm0[2,3],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
-; AVX2-NEXT: vcvtph2ps %xmm1, %xmm1
+; AVX2-NEXT: vcvtph2ps %xmm0, %xmm1
; AVX2-NEXT: vmovq %rax, %xmm2
; AVX2-NEXT: vcvttss2si %xmm1, %rax
; AVX2-NEXT: vmovq %rcx, %xmm1
; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm1 = xmm1[0],xmm2[0]
-; AVX2-NEXT: vpmovzxwq {{.*#+}} xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
+; AVX2-NEXT: vpshuflw {{.*#+}} xmm0 = xmm0[1,1,1,1,4,5,6,7]
; AVX2-NEXT: vcvtph2ps %xmm0, %xmm0
; AVX2-NEXT: vmovq %rax, %xmm2
; AVX2-NEXT: vcvttss2si %xmm0, %rax
; AVX2-NEXT: vmovq %rax, %xmm0
-; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm0 = xmm0[0],xmm2[0]
+; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm0 = xmm2[0],xmm0[0]
; AVX2-NEXT: vinserti128 $1, %xmm1, %ymm0, %ymm0
; AVX2-NEXT: vpbroadcastq {{.*#+}} ymm1 = [2147483647,2147483647,2147483647,2147483647]
; AVX2-NEXT: vpcmpgtq %ymm0, %ymm1, %ymm2
@@ -3450,7 +3446,7 @@ define <4 x i32> @utesth_f16i32_mm(<4 x half> %x) nounwind {
;
; AVX2-LABEL: utesth_f16i32_mm:
; AVX2: # %bb.0: # %entry
-; AVX2-NEXT: vpsrlq $48, %xmm0, %xmm1
+; AVX2-NEXT: vpshuflw {{.*#+}} xmm1 = xmm0[3,3,3,3,4,5,6,7]
; AVX2-NEXT: vcvtph2ps %xmm1, %xmm2
; AVX2-NEXT: vmovss {{.*#+}} xmm1 = [9.22337203E+18,0.0E+0,0.0E+0,0.0E+0]
; AVX2-NEXT: vsubss %xmm1, %xmm2, %xmm3
@@ -3459,29 +3455,28 @@ define <4 x i32> @utesth_f16i32_mm(<4 x half> %x) nounwind {
; AVX2-NEXT: movq %rcx, %rdx
; AVX2-NEXT: sarq $63, %rdx
; AVX2-NEXT: andq %rax, %rdx
-; AVX2-NEXT: vpshufb {{.*#+}} xmm2 = xmm0[4,5],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
-; AVX2-NEXT: vcvtph2ps %xmm2, %xmm2
; AVX2-NEXT: orq %rcx, %rdx
+; AVX2-NEXT: vmovshdup {{.*#+}} xmm2 = xmm0[1,1,3,3]
+; AVX2-NEXT: vcvtph2ps %xmm2, %xmm2
; AVX2-NEXT: vsubss %xmm1, %xmm2, %xmm3
; AVX2-NEXT: vcvttss2si %xmm3, %rax
-; AVX2-NEXT: vmovq %rdx, %xmm3
; AVX2-NEXT: vcvttss2si %xmm2, %rcx
+; AVX2-NEXT: vmovq %rdx, %xmm2
; AVX2-NEXT: movq %rcx, %rdx
; AVX2-NEXT: sarq $63, %rdx
-; AVX2-NEXT: vpshufb {{.*#+}} xmm2 = xmm0[2,3],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
-; AVX2-NEXT: vcvtph2ps %xmm2, %xmm2
+; AVX2-NEXT: vcvtph2ps %xmm0, %xmm3
; AVX2-NEXT: andq %rax, %rdx
-; AVX2-NEXT: vsubss %xmm1, %xmm2, %xmm4
+; AVX2-NEXT: vsubss %xmm1, %xmm3, %xmm4
; AVX2-NEXT: vcvttss2si %xmm4, %rax
; AVX2-NEXT: orq %rcx, %rdx
; AVX2-NEXT: vmovq %rdx, %xmm4
-; AVX2-NEXT: vcvttss2si %xmm2, %rcx
-; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm2 = xmm4[0],xmm3[0]
+; AVX2-NEXT: vcvttss2si %xmm3, %rcx
+; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm2 = xmm4[0],xmm2[0]
; AVX2-NEXT: movq %rcx, %rdx
; AVX2-NEXT: sarq $63, %rdx
; AVX2-NEXT: andq %rax, %rdx
; AVX2-NEXT: orq %rcx, %rdx
-; AVX2-NEXT: vpmovzxwq {{.*#+}} xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
+; AVX2-NEXT: vpshuflw {{.*#+}} xmm0 = xmm0[1,1,1,1,4,5,6,7]
; AVX2-NEXT: vcvtph2ps %xmm0, %xmm0
; AVX2-NEXT: vsubss %xmm1, %xmm0, %xmm1
; AVX2-NEXT: vcvttss2si %xmm1, %rax
@@ -3492,7 +3487,7 @@ define <4 x i32> @utesth_f16i32_mm(<4 x half> %x) nounwind {
; AVX2-NEXT: andq %rax, %rdx
; AVX2-NEXT: orq %rcx, %rdx
; AVX2-NEXT: vmovq %rdx, %xmm1
-; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm0 = xmm1[0],xmm0[0]
+; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm0 = xmm0[0],xmm1[0]
; AVX2-NEXT: vinserti128 $1, %xmm2, %ymm0, %ymm0
; AVX2-NEXT: vpbroadcastq {{.*#+}} ymm1 = [9223372036854775808,9223372036854775808,9223372036854775808,9223372036854775808]
; AVX2-NEXT: vpxor %ymm1, %ymm0, %ymm1
@@ -3613,24 +3608,23 @@ define <4 x i32> @ustest_f16i32_mm(<4 x half> %x) nounwind {
;
; AVX2-LABEL: ustest_f16i32_mm:
; AVX2: # %bb.0: # %entry
-; AVX2-NEXT: vpsrlq $48, %xmm0, %xmm1
+; AVX2-NEXT: vpshuflw {{.*#+}} xmm1 = xmm0[3,3,3,3,4,5,6,7]
; AVX2-NEXT: vcvtph2ps %xmm1, %xmm1
; AVX2-NEXT: vcvttss2si %xmm1, %rax
; AVX2-NEXT: vmovq %rax, %xmm1
-; AVX2-NEXT: vpshufb {{.*#+}} xmm2 = xmm0[4,5],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
+; AVX2-NEXT: vmovshdup {{.*#+}} xmm2 = xmm0[1,1,3,3]
; AVX2-NEXT: vcvtph2ps %xmm2, %xmm2
; AVX2-NEXT: vcvttss2si %xmm2, %rax
; AVX2-NEXT: vmovq %rax, %xmm2
; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm1 = xmm2[0],xmm1[0]
-; AVX2-NEXT: vpshufb {{.*#+}} xmm2 = xmm0[2,3],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
-; AVX2-NEXT: vcvtph2ps %xmm2, %xmm2
+; AVX2-NEXT: vcvtph2ps %xmm0, %xmm2
; AVX2-NEXT: vcvttss2si %xmm2, %rax
; AVX2-NEXT: vmovq %rax, %xmm2
-; AVX2-NEXT: vpmovzxwq {{.*#+}} xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
+; AVX2-NEXT: vpshuflw {{.*#+}} xmm0 = xmm0[1,1,1,1,4,5,6,7]
; AVX2-NEXT: vcvtph2ps %xmm0, %xmm0
; AVX2-NEXT: vcvttss2si %xmm0, %rax
; AVX2-NEXT: vmovq %rax, %xmm0
-; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm0 = xmm0[0],xmm2[0]
+; AVX2-NEXT: vpunpcklqdq {{.*#+}} xmm0 = xmm2[0],xmm0[0]
; AVX2-NEXT: vinserti128 $1, %xmm1, %ymm0, %ymm0
; AVX2-NEXT: vpbroadcastq {{.*#+}} ymm1 = [4294967295,4294967295,4294967295,4294967295]
; AVX2-NEXT: vpcmpgtq %ymm0, %ymm1, %ymm2
diff --git a/llvm/test/CodeGen/X86/half.ll b/llvm/test/CodeGen/X86/half.ll
index 2e1322446032ff..9f01d07e6a6705 100644
--- a/llvm/test/CodeGen/X86/half.ll
+++ b/llvm/test/CodeGen/X86/half.ll
@@ -851,16 +851,14 @@ define float @test_sitofp_fadd_i32(i32 %a, ptr %b) #0 {
;
; BWON-F16C-LABEL: test_sitofp_fadd_i32:
; BWON-F16C: # %bb.0:
-; BWON-F16C-NEXT: movzwl (%rsi), %eax
; BWON-F16C-NEXT: vcvtsi2ss %edi, %xmm0, %xmm0
; BWON-F16C-NEXT: vcvtps2ph $4, %xmm0, %xmm0
-; BWON-F16C-NEXT: vpmovzxwq {{.*#+}} xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
; BWON-F16C-NEXT: vcvtph2ps %xmm0, %xmm0
+; BWON-F16C-NEXT: movzwl (%rsi), %eax
; BWON-F16C-NEXT: vmovd %eax, %xmm1
; BWON-F16C-NEXT: vcvtph2ps %xmm1, %xmm1
; BWON-F16C-NEXT: vaddss %xmm0, %xmm1, %xmm0
; BWON-F16C-NEXT: vcvtps2ph $4, %xmm0, %xmm0
-; BWON-F16C-NEXT: vpmovzxwq {{.*#+}} xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
; BWON-F16C-NEXT: vcvtph2ps %xmm0, %xmm0
; BWON-F16C-NEXT: retq
;
@@ -919,7 +917,6 @@ define half @PR40273(half) #0 {
; BWON-F16C-LABEL: PR40273:
; BWON-F16C: # %bb.0:
; BWON-F16C-NEXT: vpextrw $0, %xmm0, %eax
-; BWON-F16C-NEXT: movzwl %ax, %eax
; BWON-F16C-NEXT: vmovd %eax, %xmm0
; BWON-F16C-NEXT: vcvtph2ps %xmm0, %xmm0
; BWON-F16C-NEXT: xorl %eax, %eax
@@ -973,7 +970,6 @@ define void @brcond(half %0) #0 {
; BWON-F16C-LABEL: brcond:
; BWON-F16C: # %bb.0: # %entry
; BWON-F16C-NEXT: vpextrw $0, %xmm0, %eax
-; BWON-F16C-NEXT: movzwl %ax, %eax
; BWON-F16C-NEXT: vmovd %eax, %xmm0
; BWON-F16C-NEXT: vcvtph2ps %xmm0, %xmm0
; BWON-F16C-NEXT: vxorps %xmm1, %xmm1, %xmm1
@@ -1029,7 +1025,6 @@ define half @test_sqrt(half %0) #0 {
; BWON-F16C-LABEL: test_sqrt:
; BWON-F16C: # %bb.0: # %entry
; BWON-F16C-NEXT: vpextrw $0, %xmm0, %eax
-; BWON-F16C-NEXT: movzwl %ax, %eax
; BWON-F16C-NEXT: vmovd %eax, %xmm0
; BWON-F16C-NEXT: vcvtph2ps %xmm0, %xmm0
; BWON-F16C-NEXT: vsqrtss %xmm0, %xmm0, %xmm0
@@ -1083,7 +1078,6 @@ define void @main.158() #0 {
; BWON-F16C: # %bb.0: # %entry
; BWON-F16C-NEXT: vxorps %xmm0, %xmm0, %xmm0
; BWON-F16C-NEXT: vcvtps2ph $4, %xmm0, %xmm1
-; BWON-F16C-NEXT: vpmovzxwq {{.*#+}} xmm1 = xmm1[0],zero,zero,zero,xmm1[1],zero,zero,zero
; BWON-F16C-NEXT: vcvtph2ps %xmm1, %xmm1
; BWON-F16C-NEXT: vmovss {{.*#+}} xmm2 = [8.0E+0,0.0E+0,0.0E+0,0.0E+0]
; BWON-F16C-NEXT: vucomiss %xmm1, %xmm2
@@ -1172,8 +1166,7 @@ define void @main.45() #0 {
;
; BWON-F16C-LABEL: main.45:
; BWON-F16C: # %bb.0: # %entry
-; BWON-F16C-NEXT: movzwl (%rax), %eax
-; BWON-F16C-NEXT: vmovd %eax, %xmm0
+; BWON-F16C-NEXT: vmovd {{.*#+}} xmm0 = mem[0],zero,zero,zero
; BWON-F16C-NEXT: vpshuflw {{.*#+}} xmm1 = xmm0[0,0,0,0,4,5,6,7]
; BWON-F16C-NEXT: vcvtph2ps %xmm0, %xmm0
; BWON-F16C-NEXT: xorl %eax, %eax
@@ -1345,10 +1338,8 @@ define half @pr61271(half %0, half %1) #0 {
; BWON-F16C: # %bb.0:
; BWON-F16C-NEXT: vpextrw $0, %xmm0, %eax
; BWON-F16C-NEXT: vpextrw $0, %xmm1, %ecx
-; BWON-F16C-NEXT: movzwl %cx, %ecx
; BWON-F16C-NEXT: vmovd %ecx, %xmm0
; BWON-F16C-NEXT: vcvtph2ps %xmm0, %xmm0
-; BWON-F16C-NEXT: movzwl %ax, %eax
; BWON-F16C-NEXT: vmovd %eax, %xmm1
; BWON-F16C-NEXT: vcvtph2ps %xmm1, %xmm1
; BWON-F16C-NEXT: vminss %xmm0, %xmm1, %xmm0
@@ -1614,10 +1605,9 @@ define <8 x half> @maxnum_v8f16(<8 x half> %0, <8 x half> %1) #0 {
;
; BWON-F16C-LABEL: maxnum_v8f16:
; BWON-F16C: # %bb.0:
-; BWON-F16C-NEXT: vmovdqa {{.*#+}} xmm3 = [10,11,128,128,128,128,128,128,128,128,128,128,128,128,128,128]
-; BWON-F16C-NEXT: vpshufb %xmm3, %xmm1, %xmm2
+; BWON-F16C-NEXT: vpsrldq {{.*#+}} xmm2 = xmm1[14,15],zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero
; BWON-F16C-NEXT: vcvtph2ps %xmm2, %xmm2
-; BWON-F16C-NEXT: vpshufb %xmm3, %xmm0, %xmm3
+; BWON-F16C-NEXT: vpsrldq {{.*#+}} xmm3 = xmm0[14,15],zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero
; BWON-F16C-NEXT: vcvtph2ps %xmm3, %xmm3
; BWON-F16C-NEXT: vucomiss %xmm2, %xmm3
; BWON-F16C-NEXT: ja .LBB26_2
@@ -1625,10 +1615,9 @@ define <8 x half> @maxnum_v8f16(<8 x half> %0, <8 x half> %1) #0 {
; BWON-F16C-NEXT: vmovaps %xmm2, %xmm3
; BWON-F16C-NEXT: .LBB26_2:
; BWON-F16C-NEXT: vcvtps2ph $4, %xmm3, %xmm2
-; BWON-F16C-NEXT: vmovdqa {{.*#+}} xmm4 = [8,9,128,128,128,128,128,128,128,128,128,128,128,128,128,128]
-; BWON-F16C-NEXT: vpshufb %xmm4, %xmm1, %xmm3
+; BWON-F16C-NEXT: vpshufd {{.*#+}} xmm3 = xmm1[3,3,3,3]
; BWON-F16C-NEXT: vcvtph2ps %xmm3, %xmm3
-; BWON-F16C-NEXT: vpshufb %xmm4, %xmm0, %xmm4
+; BWON-F16C-NEXT: vpshufd {{.*#+}} xmm4 = xmm0[3,3,3,3]
; BWON-F16C-NEXT: vcvtph2ps %xmm4, %xmm4
; BWON-F16C-NEXT: vucomiss %xmm3, %xmm4
; BWON-F16C-NEXT: ja .LBB26_4
@@ -1638,10 +1627,9 @@ define <8 x half> @maxnum_v8f16(<8 x half> %0, <8 x half> %1) #0 {
; BWON-F16C-NEXT: vmovd %xmm2, %eax
; BWON-F16C-NEXT: vcvtps2ph $4, %xmm4, %xmm2
; BWON-F16C-NEXT: vmovd %xmm2, %ecx
-; BWON-F16C-NEXT: vmovdqa {{.*#+}} xmm2 = [12,13,128,128,128,128,128,128,128,128,128,128,128,128,128,128]
-; BWON-F16C-NEXT: vpshufb %xmm2, %xmm1, %xmm3
-; BWON-F16C-NEXT: vcvtph2ps %xmm3, %xmm3
-; BWON-F16C-NEXT: vpshufb %xmm2, %xmm0, %xmm2
+; BWON-F16C-NEXT: vpsrldq {{.*#+}} xmm2 = xmm1[10,11,12,13,14,15],zero,zero,zero,zero,zero,zero,zero,zero,zero,zero
+; BWON-F16C-NEXT: vcvtph2ps %xmm2, %xmm3
+; BWON-F16C-NEXT: vpsrldq {{.*#+}} xmm2 = xmm0[10,11,12,13,14,15],zero,zero,zero,zero,zero,zero,zero,zero,zero,zero
; BWON-F16C-NEXT: vcvtph2ps %xmm2, %xmm2
; BWON-F16C-NEXT: vucomiss %xmm3, %xmm2
; BWON-F16C-NEXT: ja .LBB26_6
@@ -1650,9 +1638,9 @@ define <8 x half> @maxnum_v8f16(<8 x half> %0, <8 x half> %1) #0 {
; BWON-F16C-NEXT: .LBB26_6:
; BWON-F16C-NEXT: vcvtps2ph $4, %xmm2, %xmm2
; BWON-F16C-NEXT: vmovd %xmm2, %edx
-; BWON-F16C-NEXT: vpsrldq {{.*#+}} xmm2 = xmm1[14,15],zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero
+; BWON-F16C-NEXT: vshufpd {{.*#+}} xmm2 = xmm1[1,0]
; BWON-F16C-NEXT: vcvtph2ps %xmm2, %xmm3
-; BWON-F16C-NEXT: vpsrldq {{.*#+}} xmm2 = xmm0[14,15],zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero
+; BWON-F16C-NEXT: vshufpd {{.*#+}} xmm2 = xmm0[1,0]
; BWON-F16C-NEXT: vcvtph2ps %xmm2, %xmm2
; BWON-F16C-NEXT: vucomiss %xmm3, %xmm2
; BWON-F16C-NEXT: ja .LBB26_8
@@ -1661,10 +1649,9 @@ define <8 x half> @maxnum_v8f16(<8 x half> %0, <8 x half> %1) #0 {
; BWON-F16C-NEXT: .LBB26_8:
; BWON-F16C-NEXT: vcvtps2ph $4, %xmm2, %xmm2
; BWON-F16C-NEXT: vmovd %xmm2, %esi
-; BWON-F16C-NEXT: vmovdqa {{.*#+}} xmm3 = [4,5,128,128,128,128,128,128,128,128,128,128,128,128,128,128]
-; BWON-F16C-NEXT: vpshufb %xmm3, %xmm1, %xmm2
+; BWON-F16C-NEXT: vpshuflw {{.*#+}} xmm2 = xmm1[3,3,3,3,4,5,6,7]
; BWON-F16C-NEXT: vcvtph2ps %xmm2, %xmm2
-; BWON-F16C-NEXT: vpshufb %xmm3, %xmm0, %xmm3
+; BWON-F16C-NEXT: vpshuflw {{.*#+}} xmm3 = xmm0[3,3,3,3,4,5,6,7]
; BWON-F16C-NEXT: vcvtph2ps %xmm3, %xmm6
; BWON-F16C-NEXT: vucomiss %xmm2, %xmm6
; BWON-F16C-NEXT: ja .LBB26_10
@@ -1677,9 +1664,9 @@ define <8 x half> @maxnum_v8f16(<8 x half> %0, <8 x half> %1) #0 {
; BWON-F16C-NEXT: vpinsrw $0, %esi, %xmm0, %xmm5
; BWON-F16C-NEXT: vcvtps2ph $4, %xmm6, %xmm6
; BWON-F16C-NEXT: vmovd %xmm6, %eax
-; BWON-F16C-NEXT: vpsrlq $48, %xmm1, %xmm6
+; BWON-F16C-NEXT: vmovshdup {{.*#+}} xmm6 = xmm1[1,1,3,3]
; BWON-F16C-NEXT: vcvtph2ps %xmm6, %xmm7
-; BWON-F16C-NEXT: vpsrlq $48, %xmm0, %xmm6
+; BWON-F16C-NEXT: vmovshdup {{.*#+}} xmm6 = xmm0[1,1,3,3]
; BWON-F16C-NEXT: vcvtph2ps %xmm6, %xmm6
; BWON-F16C-NEXT: vucomiss %xmm7, %xmm6
; BWON-F16C-NEXT: ja .LBB26_12
@@ -1687,29 +1674,26 @@ define <8 x half> @maxnum_v8f16(<8 x half> %0, <8 x half> %1) #0 {
; BWON-F16C-NEXT: vmovaps %xmm7, %xmm6
; BWON-F16C-NEXT: .LBB26_12:
; BWON-F16C-NEXT: vpunpcklwd {{.*#+}} xmm2 = xmm3[0],xmm2[0],xmm3[1],xmm2[1],xmm3[2],xmm2[2],xmm3[3],xmm2[3]
-; BWON-F16C-NEXT: vpunpcklwd {{.*#+}} xmm3 = xmm4[0],xmm5[0],xmm4[1],xmm5[1],xmm4[2],xmm5[2],xmm4[3],xmm5[3]
+; BWON-F16C-NEXT: vpunpcklwd {{.*#+}} xmm3 = xmm5[0],xmm4[0],xmm5[1],xmm4[1],xmm5[2],xmm4[2],xmm5[3],xmm4[3]
; BWON-F16C-NEXT: vpinsrw $0, %eax, %xmm0, %xmm4
; BWON-F16C-NEXT: vcvtps2ph $4, %xmm6, %xmm5
; BWON-F16C-NEXT: vmovd %xmm5, %eax
; BWON-F16C-NEXT: vpinsrw $0, %eax, %xmm0, %xmm5
-; BWON-F16C-NEXT: vmovdqa {{.*#+}} xmm6 = [2,3,128,128,128,128,128,128,128,128,128,128,128,128,128,128]
-; BWON-F16C-NEXT: vpshufb %xmm6, %xmm1, %xmm7
-; BWON-F16C-NEXT: vcvtph2ps %xmm7, %xmm7
-; BWON-F16C-NEXT: vpshufb %xmm6, %xmm0, %xmm6
-; BWON-F16C-NEXT: vcvtph2ps %xmm6, %xmm6
+; BWON-F16C-NEXT: vcvtph2ps %xmm1, %xmm7
+; BWON-F16C-NEXT: vcvtph2ps %xmm0, %xmm6
; BWON-F16C-NEXT: vucomiss %xmm7, %xmm6
; BWON-F16C-NEXT: ja .LBB26_14
; BWON-F16C-NEXT: # %bb.13:
; BWON-F16C-NEXT: vmovaps %xmm7, %xmm6
; BWON-F16C-NEXT: .LBB26_14:
-; BWON-F16C-NEXT: vpunpckldq {{.*#+}} xmm2 = xmm2[0],xmm3[0],xmm2[1],xmm3[1]
-; BWON-F16C-NEXT: vpunpcklwd {{.*#+}} xmm3 = xmm4[0],xmm5[0],xmm4[1],xmm5[1],xmm4[2],xmm5[2],xmm4[3],xmm5[3]
+; BWON-F16C-NEXT: vpunpckldq {{.*#+}} xmm2 = xmm3[0],xmm2[0],xmm3[1],xmm2[1]
+; BWON-F16C-NEXT: vpunpcklwd {{.*#+}} xmm3 = xmm5[0],xmm4[0],xmm5[1],xmm4[1],xmm5[2],xmm4[2],xmm5[3],xmm4[3]
; BWON-F16C-NEXT: vcvtps2ph $4, %xmm6, %xmm4
; BWON-F16C-NEXT: vmovd %xmm4, %eax
; BWON-F16C-NEXT: vpinsrw $0, %eax, %xmm0, %xmm4
-; BWON-F16C-NEXT: vpmovzxwq {{.*#+}} xmm1 = xmm1[0],zero,zero,zero,xmm1[1],zero,zero,zero
+; BWON-F16C-NEXT: vpshuflw {{.*#+}} xmm1 = xmm1[1,1,1,1,4,5,6,7]
; BWON-F16C-NEXT: vcvtph2ps %xmm1, %xmm1
-; BWON-F16C-NEXT: vpmovzxwq {{.*#+}} xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
+; BWON-F16C-NEXT: vpshuflw {{.*#+}} xmm0 = xmm0[1,1,1,1,4,5,6,7]
; BWON-F16C-NEXT: vcvtph2ps %xmm0, %xmm0
; BWON-F16C-NEXT: vucomiss %xmm1, %xmm0
; BWON-F16C-NEXT: ja .LBB26_16
@@ -1719,7 +1703,7 @@ define <8 x half> @maxnum_v8f16(<8 x half> %0, <8 x half> %1) #0 {
; BWON-F16C-NEXT: vcvtps2ph $4, %xmm0, %xmm0
; BWON-F16C-NEXT: vmovd %xmm0, %eax
; BWON-F16C-NEXT: vpinsrw $0, %eax, %xmm0, %xmm0
-; BWON-F16C-NEXT: vpunpcklwd {{.*#+}} xmm0 = xmm0[0],xmm4[0],xmm0[1],xmm4[1],xmm0[2],xmm4[2],xmm0[3],xmm4[3]
+; BWON-F16C-NEXT: vpunpcklwd {{.*#+}} xmm0 = xmm4[0],xmm0[0],xmm4[1],xmm0[1],xmm4[2],xmm0[2],xmm4[3],xmm0[3]
; BWON-F16C-NEXT: vpunpckldq {{.*#+}} xmm0 = xmm0[0],xmm3[0],xmm0[1],xmm3[1]
; BWON-F16C-NEXT: vpunpcklqdq {{.*#+}} xmm0 = xmm0[0],xmm2[0]
; BWON-F16C-NEXT: retq
diff --git a/llvm/test/CodeGen/X86/pr31088.ll b/llvm/test/CodeGen/X86/pr31088.ll
index a21653bc7330c9..ce37622c476db4 100644
--- a/llvm/test/CodeGen/X86/pr31088.ll
+++ b/llvm/test/CodeGen/X86/pr31088.ll
@@ -41,9 +41,7 @@ define <1 x half> @ir_fadd_v1f16(<1 x half> %arg0, <1 x half> %arg1) nounwind {
;
; F16C-LABEL: ir_fadd_v1f16:
; F16C: # %bb.0:
-; F16C-NEXT: vpmovzxwq {{.*#+}} xmm1 = xmm1[0],zero,zero,zero,xmm1[1],zero,zero,zero
; F16C-NEXT: vcvtph2ps %xmm1, %xmm1
-; F16C-NEXT: vpmovzxwq {{.*#+}} xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
; F16C-NEXT: vcvtph2ps %xmm0, %xmm0
; F16C-NEXT: vaddss %xmm1, %xmm0, %xmm0
; F16C-NEXT: vcvtps2ph $4, %xmm0, %xmm0
@@ -54,13 +52,15 @@ define <1 x half> @ir_fadd_v1f16(<1 x half> %arg0, <1 x half> %arg1) nounwind {
; F16C-O0-LABEL: ir_fadd_v1f16:
; F16C-O0: # %bb.0:
; F16C-O0-NEXT: vpextrw $0, %xmm1, %eax
-; F16C-O0-NEXT: # kill: def $ax killed $ax killed $eax
-; F16C-O0-NEXT: movzwl %ax, %eax
+; F16C-O0-NEXT: movw %ax, %cx
+; F16C-O0-NEXT: # implicit-def: $eax
+; F16C-O0-NEXT: movw %cx, %ax
; F16C-O0-NEXT: vmovd %eax, %xmm1
; F16C-O0-NEXT: vcvtph2ps %xmm1, %xmm1
; F16C-O0-NEXT: vpextrw $0, %xmm0, %eax
-; F16C-O0-NEXT: # kill: def $ax killed $ax killed $eax
-; F16C-O0-NEXT: movzwl %ax, %eax
+; F16C-O0-NEXT: movw %ax, %cx
+; F16C-O0-NEXT: # implicit-def: $eax
+; F16C-O0-NEXT: movw %cx, %ax
; F16C-O0-NEXT: vmovd %eax, %xmm0
; F16C-O0-NEXT: vcvtph2ps %xmm0, %xmm0
; F16C-O0-NEXT: vaddss %xmm1, %xmm0, %xmm0
diff --git a/llvm/test/CodeGen/X86/pr57340.ll b/llvm/test/CodeGen/X86/pr57340.ll
index 95f839c338e701..00a52c639e43c6 100644
--- a/llvm/test/CodeGen/X86/pr57340.ll
+++ b/llvm/test/CodeGen/X86/pr57340.ll
@@ -5,29 +5,28 @@ define void @main.41() local_unnamed_addr #1 {
; CHECK-LABEL: main.41:
; CHECK: # %bb.0: # %entry
; CHECK-NEXT: vpbroadcastw (%rax), %xmm0
-; CHECK-NEXT: vmovdqu (%rax), %ymm1
-; CHECK-NEXT: vinserti128 $1, %xmm0, %ymm0, %ymm2
-; CHECK-NEXT: vpmovsxbw {{.*#+}} ymm3 = [31,0,1,2,3,4,5,6,7,8,9,10,11,12,13,14]
-; CHECK-NEXT: vpermi2w %ymm2, %ymm1, %ymm3
-; CHECK-NEXT: vmovdqu (%rax), %xmm10
-; CHECK-NEXT: vmovdqa {{.*#+}} xmm1 = [2,3,128,128,128,128,128,128,128,128,128,128,128,128,128,128]
-; CHECK-NEXT: vpshufb %xmm1, %xmm10, %xmm2
-; CHECK-NEXT: vcvtph2ps %xmm2, %xmm2
-; CHECK-NEXT: vpshufb %xmm1, %xmm3, %xmm4
-; CHECK-NEXT: vcvtph2ps %xmm4, %xmm4
-; CHECK-NEXT: vucomiss %xmm4, %xmm2
-; CHECK-NEXT: setnp %al
-; CHECK-NEXT: sete %cl
-; CHECK-NEXT: testb %al, %cl
-; CHECK-NEXT: setne %al
-; CHECK-NEXT: kmovd %eax, %k0
+; CHECK-NEXT: vpextrw $0, %xmm0, %eax
+; CHECK-NEXT: vinserti128 $1, %xmm0, %ymm0, %ymm1
+; CHECK-NEXT: vmovdqu (%rax), %ymm3
+; CHECK-NEXT: vpmovsxbw {{.*#+}} ymm2 = [31,0,1,2,3,4,5,6,7,8,9,10,11,12,13,14]
+; CHECK-NEXT: vpermi2w %ymm1, %ymm3, %ymm2
+; CHECK-NEXT: vprold $16, %xmm2, %xmm1
+; CHECK-NEXT: vcvtph2ps %xmm1, %xmm3
+; CHECK-NEXT: vmovdqu (%rax), %xmm5
+; CHECK-NEXT: vprold $16, %xmm5, %xmm1
+; CHECK-NEXT: vcvtph2ps %xmm1, %xmm1
+; CHECK-NEXT: vucomiss %xmm3, %xmm1
+; CHECK-NEXT: setnp %cl
+; CHECK-NEXT: sete %dl
+; CHECK-NEXT: testb %cl, %dl
+; CHECK-NEXT: setne %cl
+; CHECK-NEXT: kmovd %ecx, %k0
; CHECK-NEXT: kshiftlw $15, %k0, %k0
+; CHECK-NEXT: vmovd %eax, %xmm3
+; CHECK-NEXT: vcvtph2ps %xmm3, %xmm3
+; CHECK-NEXT: vcvtph2ps %xmm5, %xmm6
; CHECK-NEXT: kshiftrw $14, %k0, %k0
-; CHECK-NEXT: vpmovzxwq {{.*#+}} xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
-; CHECK-NEXT: vcvtph2ps %xmm0, %xmm0
-; CHECK-NEXT: vpmovzxwq {{.*#+}} xmm4 = xmm10[0],zero,zero,zero,xmm10[1],zero,zero,zero
-; CHECK-NEXT: vcvtph2ps %xmm4, %xmm11
-; CHECK-NEXT: vucomiss %xmm0, %xmm11
+; CHECK-NEXT: vucomiss %xmm3, %xmm6
; CHECK-NEXT: setnp %al
; CHECK-NEXT: sete %cl
; CHECK-NEXT: testb %al, %cl
@@ -38,10 +37,10 @@ define void @main.41() local_unnamed_addr #1 {
; CHECK-NEXT: movw $-5, %ax
; CHECK-NEXT: kmovd %eax, %k1
; CHECK-NEXT: kandw %k1, %k0, %k0
-; CHECK-NEXT: vmovdqa {{.*#+}} xmm4 = [4,5,128,128,128,128,128,128,128,128,128,128,128,128,128,128]
-; CHECK-NEXT: vpshufb %xmm4, %xmm3, %xmm5
-; CHECK-NEXT: vcvtph2ps %xmm5, %xmm5
-; CHECK-NEXT: vucomiss %xmm5, %xmm0
+; CHECK-NEXT: vpshufd {{.*#+}} xmm3 = xmm2[1,1,3,3]
+; CHECK-NEXT: vcvtph2ps %xmm3, %xmm3
+; CHECK-NEXT: vcvtph2ps %xmm0, %xmm0
+; CHECK-NEXT: vucomiss %xmm3, %xmm0
; CHECK-NEXT: setnp %al
; CHECK-NEXT: sete %cl
; CHECK-NEXT: testb %al, %cl
@@ -52,12 +51,12 @@ define void @main.41() local_unnamed_addr #1 {
; CHECK-NEXT: korw %k1, %k0, %k0
; CHECK-NEXT: movw $-9, %ax
; CHECK-NEXT: kmovd %eax, %k1
-; CHECK-NEXT: vpsrlq $48, %xmm3, %xmm5
-; CHECK-NEXT: vcvtph2ps %xmm5, %xmm6
-; CHECK-NEXT: vpsrlq $48, %xmm10, %xmm5
-; CHECK-NEXT: vcvtph2ps %xmm5, %xmm5
; CHECK-NEXT: kandw %k1, %k0, %k0
-; CHECK-NEXT: vucomiss %xmm6, %xmm5
+; CHECK-NEXT: vprolq $16, %xmm2, %xmm3
+; CHECK-NEXT: vcvtph2ps %xmm3, %xmm4
+; CHECK-NEXT: vprolq $16, %xmm5, %xmm3
+; CHECK-NEXT: vcvtph2ps %xmm3, %xmm3
+; CHECK-NEXT: vucomiss %xmm4, %xmm3
; CHECK-NEXT: setnp %al
; CHECK-NEXT: sete %cl
; CHECK-NEXT: testb %al, %cl
@@ -68,11 +67,10 @@ define void @main.41() local_unnamed_addr #1 {
; CHECK-NEXT: korw %k1, %k0, %k0
; CHECK-NEXT: movw $-17, %ax
; CHECK-NEXT: kmovd %eax, %k1
-; CHECK-NEXT: vmovdqa {{.*#+}} xmm6 = [8,9,128,128,128,128,128,128,128,128,128,128,128,128,128,128]
; CHECK-NEXT: kandw %k1, %k0, %k0
-; CHECK-NEXT: vpshufb %xmm6, %xmm3, %xmm7
-; CHECK-NEXT: vcvtph2ps %xmm7, %xmm7
-; CHECK-NEXT: vucomiss %xmm7, %xmm0
+; CHECK-NEXT: vpshufd {{.*#+}} xmm4 = xmm2[2,3,0,1]
+; CHECK-NEXT: vcvtph2ps %xmm4, %xmm4
+; CHECK-NEXT: vucomiss %xmm4, %xmm0
; CHECK-NEXT: setnp %al
; CHECK-NEXT: sete %cl
; CHECK-NEXT: testb %al, %cl
@@ -83,13 +81,12 @@ define void @main.41() local_unnamed_addr #1 {
; CHECK-NEXT: korw %k1, %k0, %k0
; CHECK-NEXT: movw $-33, %ax
; CHECK-NEXT: kmovd %eax, %k1
-; CHECK-NEXT: vmovdqa {{.*#+}} xmm7 = [10,11,128,128,128,128,128,128,128,128,128,128,128,128,128,128]
-; CHECK-NEXT: vpshufb %xmm7, %xmm10, %xmm8
-; CHECK-NEXT: vcvtph2ps %xmm8, %xmm8
+; CHECK-NEXT: vpsrldq {{.*#+}} xmm4 = xmm2[10,11,12,13,14,15],zero,zero,zero,zero,zero,zero,zero,zero,zero,zero
+; CHECK-NEXT: vcvtph2ps %xmm4, %xmm7
+; CHECK-NEXT: vpsrldq {{.*#+}} xmm4 = xmm5[10,11,12,13,14,15],zero,zero,zero,zero,zero,zero,zero,zero,zero,zero
+; CHECK-NEXT: vcvtph2ps %xmm4, %xmm4
; CHECK-NEXT: kandw %k1, %k0, %k0
-; CHECK-NEXT: vpshufb %xmm7, %xmm3, %xmm9
-; CHECK-NEXT: vcvtph2ps %xmm9, %xmm9
-; CHECK-NEXT: vucomiss %xmm9, %xmm8
+; CHECK-NEXT: vucomiss %xmm7, %xmm4
; CHECK-NEXT: setnp %al
; CHECK-NEXT: sete %cl
; CHECK-NEXT: testb %al, %cl
@@ -100,11 +97,10 @@ define void @main.41() local_unnamed_addr #1 {
; CHECK-NEXT: korw %k1, %k0, %k0
; CHECK-NEXT: movw $-65, %ax
; CHECK-NEXT: kmovd %eax, %k1
-; CHECK-NEXT: vmovdqa {{.*#+}} xmm9 = [12,13,128,128,128,128,128,128,128,128,128,128,128,128,128,128]
-; CHECK-NEXT: vpshufb %xmm9, %xmm3, %xmm12
-; CHECK-NEXT: vcvtph2ps %xmm12, %xmm12
; CHECK-NEXT: kandw %k1, %k0, %k0
-; CHECK-NEXT: vucomiss %xmm12, %xmm0
+; CHECK-NEXT: vshufps {{.*#+}} xmm7 = xmm2[3,3,3,3]
+; CHECK-NEXT: vcvtph2ps %xmm7, %xmm7
+; CHECK-NEXT: vucomiss %xmm7, %xmm0
; CHECK-NEXT: setnp %al
; CHECK-NEXT: sete %cl
; CHECK-NEXT: testb %al, %cl
@@ -116,11 +112,11 @@ define void @main.41() local_unnamed_addr #1 {
; CHECK-NEXT: movw $-129, %ax
; CHECK-NEXT: kmovd %eax, %k1
; CHECK-NEXT: kandw %k1, %k0, %k0
-; CHECK-NEXT: vpsrldq {{.*#+}} xmm12 = xmm3[14,15],zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero
-; CHECK-NEXT: vcvtph2ps %xmm12, %xmm12
-; CHECK-NEXT: vpsrldq {{.*#+}} xmm10 = xmm10[14,15],zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero
-; CHECK-NEXT: vcvtph2ps %xmm10, %xmm10
-; CHECK-NEXT: vucomiss %xmm12, %xmm10
+; CHECK-NEXT: vpsrldq {{.*#+}} xmm7 = xmm2[14,15],zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero
+; CHECK-NEXT: vcvtph2ps %xmm7, %xmm7
+; CHECK-NEXT: vpsrldq {{.*#+}} xmm5 = xmm5[14,15],zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero
+; CHECK-NEXT: vcvtph2ps %xmm5, %xmm5
+; CHECK-NEXT: vucomiss %xmm7, %xmm5
; CHECK-NEXT: setnp %al
; CHECK-NEXT: sete %cl
; CHECK-NEXT: testb %al, %cl
@@ -131,11 +127,10 @@ define void @main.41() local_unnamed_addr #1 {
; CHECK-NEXT: korw %k1, %k0, %k0
; CHECK-NEXT: movw $-257, %ax # imm = 0xFEFF
; CHECK-NEXT: kmovd %eax, %k1
-; CHECK-NEXT: vextracti128 $1, %ymm3, %xmm3
-; CHECK-NEXT: vpmovzxwq {{.*#+}} xmm12 = xmm3[0],zero,zero,zero,xmm3[1],zero,zero,zero
-; CHECK-NEXT: vcvtph2ps %xmm12, %xmm12
+; CHECK-NEXT: vextracti128 $1, %ymm2, %xmm2
+; CHECK-NEXT: vcvtph2ps %xmm2, %xmm7
; CHECK-NEXT: kandw %k1, %k0, %k0
-; CHECK-NEXT: vucomiss %xmm12, %xmm11
+; CHECK-NEXT: vucomiss %xmm7, %xmm6
; CHECK-NEXT: setnp %al
; CHECK-NEXT: sete %cl
; CHECK-NEXT: testb %al, %cl
@@ -147,9 +142,9 @@ define void @main.41() local_unnamed_addr #1 {
; CHECK-NEXT: movw $-513, %ax # imm = 0xFDFF
; CHECK-NEXT: kmovd %eax, %k1
; CHECK-NEXT: kandw %k1, %k0, %k0
-; CHECK-NEXT: vpshufb %xmm1, %xmm3, %xmm1
-; CHECK-NEXT: vcvtph2ps %xmm1, %xmm1
-; CHECK-NEXT: vucomiss %xmm1, %xmm2
+; CHECK-NEXT: vprold $16, %xmm2, %xmm6
+; CHECK-NEXT: vcvtph2ps %xmm6, %xmm6
+; CHECK-NEXT: vucomiss %xmm6, %xmm1
; CHECK-NEXT: setnp %al
; CHECK-NEXT: sete %cl
; CHECK-NEXT: testb %al, %cl
@@ -161,7 +156,7 @@ define void @main.41() local_unnamed_addr #1 {
; CHECK-NEXT: movw $-1025, %ax # imm = 0xFBFF
; CHECK-NEXT: kmovd %eax, %k1
; CHECK-NEXT: kandw %k1, %k0, %k0
-; CHECK-NEXT: vpshufb %xmm4, %xmm3, %xmm1
+; CHECK-NEXT: vpshufd {{.*#+}} xmm1 = xmm2[1,1,3,3]
; CHECK-NEXT: vcvtph2ps %xmm1, %xmm1
; CHECK-NEXT: vucomiss %xmm1, %xmm0
; CHECK-NEXT: setnp %al
@@ -175,9 +170,9 @@ define void @main.41() local_unnamed_addr #1 {
; CHECK-NEXT: movw $-2049, %ax # imm = 0xF7FF
; CHECK-NEXT: kmovd %eax, %k1
; CHECK-NEXT: kandw %k1, %k0, %k0
-; CHECK-NEXT: vpsrlq $48, %xmm3, %xmm1
+; CHECK-NEXT: vprolq $16, %xmm2, %xmm1
; CHECK-NEXT: vcvtph2ps %xmm1, %xmm1
-; CHECK-NEXT: vucomiss %xmm1, %xmm5
+; CHECK-NEXT: vucomiss %xmm1, %xmm3
; CHECK-NEXT: setnp %al
; CHECK-NEXT: sete %cl
; CHECK-NEXT: testb %al, %cl
@@ -189,7 +184,7 @@ define void @main.41() local_unnamed_addr #1 {
; CHECK-NEXT: movw $-4097, %ax # imm = 0xEFFF
; CHECK-NEXT: kmovd %eax, %k1
; CHECK-NEXT: kandw %k1, %k0, %k0
-; CHECK-NEXT: vpshufb %xmm6, %xmm3, %xmm1
+; CHECK-NEXT: vpshufd {{.*#+}} xmm1 = xmm2[2,3,0,1]
; CHECK-NEXT: vcvtph2ps %xmm1, %xmm1
; CHECK-NEXT: vucomiss %xmm1, %xmm0
; CHECK-NEXT: setnp %al
@@ -203,9 +198,9 @@ define void @main.41() local_unnamed_addr #1 {
; CHECK-NEXT: movw $-8193, %ax # imm = 0xDFFF
; CHECK-NEXT: kmovd %eax, %k1
; CHECK-NEXT: kandw %k1, %k0, %k0
-; CHECK-NEXT: vpshufb %xmm7, %xmm3, %xmm1
+; CHECK-NEXT: vpsrldq {{.*#+}} xmm1 = xmm2[10,11,12,13,14,15],zero,zero,zero,zero,zero,zero,zero,zero,zero,zero
; CHECK-NEXT: vcvtph2ps %xmm1, %xmm1
-; CHECK-NEXT: vucomiss %xmm1, %xmm8
+; CHECK-NEXT: vucomiss %xmm1, %xmm4
; CHECK-NEXT: setnp %al
; CHECK-NEXT: sete %cl
; CHECK-NEXT: testb %al, %cl
@@ -216,7 +211,7 @@ define void @main.41() local_unnamed_addr #1 {
; CHECK-NEXT: korw %k1, %k0, %k0
; CHECK-NEXT: movw $-16385, %ax # imm = 0xBFFF
; CHECK-NEXT: kmovd %eax, %k1
-; CHECK-NEXT: vpshufb %xmm9, %xmm3, %xmm1
+; CHECK-NEXT: vshufps {{.*#+}} xmm1 = xmm2[3,3,3,3]
; CHECK-NEXT: vcvtph2ps %xmm1, %xmm1
; CHECK-NEXT: kandw %k1, %k0, %k0
; CHECK-NEXT: vucomiss %xmm1, %xmm0
@@ -228,10 +223,10 @@ define void @main.41() local_unnamed_addr #1 {
; CHECK-NEXT: kshiftlw $14, %k1, %k1
; CHECK-NEXT: korw %k1, %k0, %k0
; CHECK-NEXT: kshiftlw $1, %k0, %k0
-; CHECK-NEXT: vpsrldq {{.*#+}} xmm0 = xmm3[14,15],zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero
+; CHECK-NEXT: vpsrldq {{.*#+}} xmm0 = xmm2[14,15],zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero,zero
; CHECK-NEXT: vcvtph2ps %xmm0, %xmm0
; CHECK-NEXT: kshiftrw $1, %k0, %k0
-; CHECK-NEXT: vucomiss %xmm0, %xmm10
+; CHECK-NEXT: vucomiss %xmm0, %xmm5
; CHECK-NEXT: setnp %al
; CHECK-NEXT: sete %cl
; CHECK-NEXT: testb %al, %cl
diff --git a/llvm/test/CodeGen/X86/prefer-fpext-splat.ll b/llvm/test/CodeGen/X86/prefer-fpext-splat.ll
index 1d8b8b3f9a96ec..c3d7b2e15d0170 100644
--- a/llvm/test/CodeGen/X86/prefer-fpext-splat.ll
+++ b/llvm/test/CodeGen/X86/prefer-fpext-splat.ll
@@ -176,8 +176,6 @@ define <2 x double> @prefer_f16_v2f64(ptr %p) nounwind {
; AVX512F-LABEL: prefer_f16_v2f64:
; AVX512F: # %bb.0: # %entry
; AVX512F-NEXT: vpbroadcastw (%rdi), %xmm0
-; AVX512F-NEXT: vpxor %xmm1, %xmm1, %xmm1
-; AVX512F-NEXT: vpblendd {{.*#+}} xmm0 = xmm0[0],xmm1[1,2,3]
; AVX512F-NEXT: vcvtph2ps %xmm0, %xmm0
; AVX512F-NEXT: vcvtps2pd %xmm0, %xmm0
; AVX512F-NEXT: retq
diff --git a/llvm/test/CodeGen/X86/vector-half-conversions.ll b/llvm/test/CodeGen/X86/vector-half-conversions.ll
index 3b82df5d5b74d2..ba21af231985a1 100644
--- a/llvm/test/CodeGen/X86/vector-half-conversions.ll
+++ b/llvm/test/CodeGen/X86/vector-half-conversions.ll
@@ -21,15 +21,13 @@ define float @cvt_i16_to_f32(i16 %a0) nounwind {
;
; F16C-LABEL: cvt_i16_to_f32:
; F16C: # %bb.0:
-; F16C-NEXT: movzwl %di, %eax
-; F16C-NEXT: vmovd %eax, %xmm0
+; F16C-NEXT: vmovd %edi, %xmm0
; F16C-NEXT: vcvtph2ps %xmm0, %xmm0
; F16C-NEXT: retq
;
; AVX512-LABEL: cvt_i16_to_f32:
; AVX512: # %bb.0:
-; AVX512-NEXT: movzwl %di, %eax
-; AVX512-NEXT: vmovd %eax, %xmm0
+; AVX512-NEXT: vmovd %edi, %xmm0
; AVX512-NEXT: vcvtph2ps %xmm0, %xmm0
; AVX512-NEXT: retq
%1 = bitcast i16 %a0 to half
@@ -1370,16 +1368,14 @@ define double @cvt_i16_to_f64(i16 %a0) nounwind {
;
; F16C-LABEL: cvt_i16_to_f64:
; F16C: # %bb.0:
-; F16C-NEXT: movzwl %di, %eax
-; F16C-NEXT: vmovd %eax, %xmm0
+; F16C-NEXT: vmovd %edi, %xmm0
; F16C-NEXT: vcvtph2ps %xmm0, %xmm0
; F16C-NEXT: vcvtss2sd %xmm0, %xmm0, %xmm0
; F16C-NEXT: retq
;
; AVX512-LABEL: cvt_i16_to_f64:
; AVX512: # %bb.0:
-; AVX512-NEXT: movzwl %di, %eax
-; AVX512-NEXT: vmovd %eax, %xmm0
+; AVX512-NEXT: vmovd %edi, %xmm0
; AVX512-NEXT: vcvtph2ps %xmm0, %xmm0
; AVX512-NEXT: vcvtss2sd %xmm0, %xmm0, %xmm0
; AVX512-NEXT: retq
@@ -1410,14 +1406,12 @@ define <2 x double> @cvt_2i16_to_2f64(<2 x i16> %a0) nounwind {
;
; F16C-LABEL: cvt_2i16_to_2f64:
; F16C: # %bb.0:
-; F16C-NEXT: vpmovzxdq {{.*#+}} xmm0 = xmm0[0],zero,xmm0[1],zero
; F16C-NEXT: vcvtph2ps %xmm0, %xmm0
; F16C-NEXT: vcvtps2pd %xmm0, %xmm0
; F16C-NEXT: retq
;
; AVX512-LABEL: cvt_2i16_to_2f64:
; AVX512: # %bb.0:
-; AVX512-NEXT: vpmovzxdq {{.*#+}} xmm0 = xmm0[0],zero,xmm0[1],zero
; AVX512-NEXT: vcvtph2ps %xmm0, %xmm0
; AVX512-NEXT: vcvtps2pd %xmm0, %xmm0
; AVX512-NEXT: retq
@@ -1503,14 +1497,12 @@ define <2 x double> @cvt_8i16_to_2f64(<8 x i16> %a0) nounwind {
;
; F16C-LABEL: cvt_8i16_to_2f64:
; F16C: # %bb.0:
-; F16C-NEXT: vpmovzxdq {{.*#+}} xmm0 = xmm0[0],zero,xmm0[1],zero
; F16C-NEXT: vcvtph2ps %xmm0, %xmm0
; F16C-NEXT: vcvtps2pd %xmm0, %xmm0
; F16C-NEXT: retq
;
; AVX512-LABEL: cvt_8i16_to_2f64:
; AVX512: # %bb.0:
-; AVX512-NEXT: vpmovzxdq {{.*#+}} xmm0 = xmm0[0],zero,xmm0[1],zero
; AVX512-NEXT: vcvtph2ps %xmm0, %xmm0
; AVX512-NEXT: vcvtps2pd %xmm0, %xmm0
; AVX512-NEXT: retq
@@ -1877,16 +1869,14 @@ define <2 x double> @load_cvt_2i16_to_2f64(ptr %a0) nounwind {
;
; F16C-LABEL: load_cvt_2i16_to_2f64:
; F16C: # %bb.0:
-; F16C-NEXT: vmovd {{.*#+}} xmm0 = mem[0],zero,zero,zero
-; F16C-NEXT: vpmovzxdq {{.*#+}} xmm0 = xmm0[0],zero,xmm0[1],zero
+; F16C-NEXT: vmovss {{.*#+}} xmm0 = mem[0],zero,zero,zero
; F16C-NEXT: vcvtph2ps %xmm0, %xmm0
; F16C-NEXT: vcvtps2pd %xmm0, %xmm0
; F16C-NEXT: retq
;
; AVX512-LABEL: load_cvt_2i16_to_2f64:
; AVX512: # %bb.0:
-; AVX512-NEXT: vmovd {{.*#+}} xmm0 = mem[0],zero,zero,zero
-; AVX512-NEXT: vpmovzxdq {{.*#+}} xmm0 = xmm0[0],zero,xmm0[1],zero
+; AVX512-NEXT: vmovss {{.*#+}} xmm0 = mem[0],zero,zero,zero
; AVX512-NEXT: vcvtph2ps %xmm0, %xmm0
; AVX512-NEXT: vcvtps2pd %xmm0, %xmm0
; AVX512-NEXT: retq
@@ -4976,9 +4966,9 @@ define <4 x i32> @fptosi_2f16_to_4i32(<2 x half> %a) nounwind {
;
; F16C-LABEL: fptosi_2f16_to_4i32:
; F16C: # %bb.0:
-; F16C-NEXT: vpshufb {{.*#+}} xmm1 = xmm0[2,3],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
+; F16C-NEXT: vpsrld $16, %xmm0, %xmm1
; F16C-NEXT: vcvtph2ps %xmm1, %xmm1
-; F16C-NEXT: vpmovzxwq {{.*#+}} xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
+; F16C-NEXT: vpmovzxwd {{.*#+}} xmm0 = xmm0[0],zero,xmm0[1],zero,xmm0[2],zero,xmm0[3],zero
; F16C-NEXT: vcvtph2ps %xmm0, %xmm0
; F16C-NEXT: vunpcklps {{.*#+}} xmm0 = xmm0[0],xmm1[0],xmm0[1],xmm1[1]
; F16C-NEXT: vcvttps2dq %xmm0, %xmm0
@@ -4987,9 +4977,9 @@ define <4 x i32> @fptosi_2f16_to_4i32(<2 x half> %a) nounwind {
;
; AVX512-LABEL: fptosi_2f16_to_4i32:
; AVX512: # %bb.0:
-; AVX512-NEXT: vpshufb {{.*#+}} xmm1 = xmm0[2,3],zero,zero,zero,zero,zero,zero,xmm0[u,u,u,u,u,u,u,u]
+; AVX512-NEXT: vpsrld $16, %xmm0, %xmm1
; AVX512-NEXT: vcvtph2ps %xmm1, %xmm1
-; AVX512-NEXT: vpmovzxwq {{.*#+}} xmm0 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
+; AVX512-NEXT: vpmovzxwd {{.*#+}} xmm0 = xmm0[0],zero,xmm0[1],zero,xmm0[2],zero,xmm0[3],zero
; AVX512-NEXT: vcvtph2ps %xmm0, %xmm0
; AVX512-NEXT: vunpcklps {{.*#+}} xmm0 = xmm0[0],xmm1[0],xmm0[1],xmm1[1]
; AVX512-NEXT: vcvttps2dq %xmm0, %xmm0
diff --git a/llvm/test/CodeGen/X86/vector-reduce-fmax-nnan.ll b/llvm/test/CodeGen/X86/vector-reduce-fmax-nnan.ll
index 6e8eefc607ee11..24113441a4e25a 100644
--- a/llvm/test/CodeGen/X86/vector-reduce-fmax-nnan.ll
+++ b/llvm/test/CodeGen/X86/vector-reduce-fmax-nnan.ll
@@ -413,10 +413,8 @@ define half @test_v2f16(<2 x half> %a0) nounwind {
; AVX512F: # %bb.0:
; AVX512F-NEXT: # kill: def $xmm0 killed $xmm0 def $zmm0
; AVX512F-NEXT: vpsrld $16, %xmm0, %xmm1
-; AVX512F-NEXT: vpmovzxwq {{.*#+}} xmm2 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
-; AVX512F-NEXT: vcvtph2ps %xmm2, %xmm2
-; AVX512F-NEXT: vpmovzxwq {{.*#+}} xmm3 = xmm1[0],zero,zero,zero,xmm1[1],zero,zero,zero
-; AVX512F-NEXT: vcvtph2ps %xmm3, %xmm3
+; AVX512F-NEXT: vcvtph2ps %xmm0, %xmm2
+; AVX512F-NEXT: vcvtph2ps %xmm1, %xmm3
; AVX512F-NEXT: xorl %eax, %eax
; AVX512F-NEXT: vucomiss %xmm3, %xmm2
; AVX512F-NEXT: movl $255, %ecx
@@ -430,10 +428,8 @@ define half @test_v2f16(<2 x half> %a0) nounwind {
; AVX512VL-LABEL: test_v2f16:
; AVX512VL: # %bb.0:
; AVX512VL-NEXT: vpsrld $16, %xmm0, %xmm1
-; AVX512VL-NEXT: vpmovzxwq {{.*#+}} xmm2 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
-; AVX512VL-NEXT: vcvtph2ps %xmm2, %xmm2
-; AVX512VL-NEXT: vpmovzxwq {{.*#+}} xmm3 = xmm1[0],zero,zero,zero,xmm1[1],zero,zero,zero
-; AVX512VL-NEXT: vcvtph2ps %xmm3, %xmm3
+; AVX512VL-NEXT: vcvtph2ps %xmm0, %xmm2
+; AVX512VL-NEXT: vcvtph2ps %xmm1, %xmm3
; AVX512VL-NEXT: xorl %eax, %eax
; AVX512VL-NEXT: vucomiss %xmm3, %xmm2
; AVX512VL-NEXT: movl $255, %ecx
diff --git a/llvm/test/CodeGen/X86/vector-reduce-fmin-nnan.ll b/llvm/test/CodeGen/X86/vector-reduce-fmin-nnan.ll
index 804ca183ad4c9d..edefb16d40e6ed 100644
--- a/llvm/test/CodeGen/X86/vector-reduce-fmin-nnan.ll
+++ b/llvm/test/CodeGen/X86/vector-reduce-fmin-nnan.ll
@@ -412,10 +412,8 @@ define half @test_v2f16(<2 x half> %a0) nounwind {
; AVX512F: # %bb.0:
; AVX512F-NEXT: # kill: def $xmm0 killed $xmm0 def $zmm0
; AVX512F-NEXT: vpsrld $16, %xmm0, %xmm1
-; AVX512F-NEXT: vpmovzxwq {{.*#+}} xmm2 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
-; AVX512F-NEXT: vcvtph2ps %xmm2, %xmm2
-; AVX512F-NEXT: vpmovzxwq {{.*#+}} xmm3 = xmm1[0],zero,zero,zero,xmm1[1],zero,zero,zero
-; AVX512F-NEXT: vcvtph2ps %xmm3, %xmm3
+; AVX512F-NEXT: vcvtph2ps %xmm0, %xmm2
+; AVX512F-NEXT: vcvtph2ps %xmm1, %xmm3
; AVX512F-NEXT: xorl %eax, %eax
; AVX512F-NEXT: vucomiss %xmm3, %xmm2
; AVX512F-NEXT: movl $255, %ecx
@@ -429,10 +427,8 @@ define half @test_v2f16(<2 x half> %a0) nounwind {
; AVX512VL-LABEL: test_v2f16:
; AVX512VL: # %bb.0:
; AVX512VL-NEXT: vpsrld $16, %xmm0, %xmm1
-; AVX512VL-NEXT: vpmovzxwq {{.*#+}} xmm2 = xmm0[0],zero,zero,zero,xmm0[1],zero,zero,zero
-; AVX512VL-NEXT: vcvtph2ps %xmm2, %xmm2
-; AVX512VL-NEXT: vpmovzxwq {{.*#+}} xmm3 = xmm1[0],zero,zero,zero,xmm1[1],zero,zero,zero
-; AVX512VL-NEXT: vcvtph2ps %xmm3, %xmm3
+; AVX512VL-NEXT: vcvtph2ps %xmm0, %xmm2
+; AVX512VL-NEXT: vcvtph2ps %xmm1, %xmm3
; AVX512VL-NEXT: xorl %eax, %eax
; AVX512VL-NEXT: vucomiss %xmm3, %xmm2
; AVX512VL-NEXT: movl $255, %ecx
>From 4d525f2b9a42fee4bd3a3c45873fc38b35dd8004 Mon Sep 17 00:00:00 2001
From: Florian Hahn <flo at fhahn.com>
Date: Thu, 29 Feb 2024 12:37:12 +0000
Subject: [PATCH 118/406] [VPlan] Remove unneeded InsertPointGuard (NFCI).
getBlockInMask now simply returns an already computed mask, hence
there's no need to adjust the builder insert point.
---
llvm/lib/Transforms/Vectorize/LoopVectorize.cpp | 5 +----
1 file changed, 1 insertion(+), 4 deletions(-)
diff --git a/llvm/lib/Transforms/Vectorize/LoopVectorize.cpp b/llvm/lib/Transforms/Vectorize/LoopVectorize.cpp
index b81cd508663c32..50a073e890626e 100644
--- a/llvm/lib/Transforms/Vectorize/LoopVectorize.cpp
+++ b/llvm/lib/Transforms/Vectorize/LoopVectorize.cpp
@@ -9003,11 +9003,8 @@ void LoopVectorizationPlanner::adjustRecipesForReductions(
BasicBlock *BB = CurrentLinkI->getParent();
VPValue *CondOp = nullptr;
- if (CM.blockNeedsPredicationForAnyReason(BB)) {
- VPBuilder::InsertPointGuard Guard(Builder);
- Builder.setInsertPoint(CurrentLink);
+ if (CM.blockNeedsPredicationForAnyReason(BB))
CondOp = RecipeBuilder.getBlockInMask(BB);
- }
VPReductionRecipe *RedRecipe = new VPReductionRecipe(
RdxDesc, CurrentLinkI, PreviousLink, VecOp, CondOp);
>From 23f3651c7c5653781249ca0f87809dde76ceeac7 Mon Sep 17 00:00:00 2001
From: Joseph Huber <huberjn at outlook.com>
Date: Thu, 29 Feb 2024 06:51:01 -0600
Subject: [PATCH 119/406] [libc] Remove workaround for fmin / fmax after being
fixed in LLVM (#83421)
Summary:
These hacks can be removed now that
https://github.com/llvm/llvm-project/pull/83376 fixed the underlying
problem.
---
libc/src/math/amdgpu/fmax.cpp | 4 ----
libc/src/math/amdgpu/fmaxf.cpp | 6 ------
libc/src/math/amdgpu/fmin.cpp | 6 ------
libc/src/math/amdgpu/fminf.cpp | 6 ------
libc/src/math/nvptx/fmax.cpp | 6 ------
libc/src/math/nvptx/fmaxf.cpp | 4 ----
libc/src/math/nvptx/fmin.cpp | 6 ------
libc/src/math/nvptx/fminf.cpp | 6 ------
8 files changed, 44 deletions(-)
diff --git a/libc/src/math/amdgpu/fmax.cpp b/libc/src/math/amdgpu/fmax.cpp
index 09624cc6f092af..09f0f942a042a4 100644
--- a/libc/src/math/amdgpu/fmax.cpp
+++ b/libc/src/math/amdgpu/fmax.cpp
@@ -15,10 +15,6 @@
namespace LIBC_NAMESPACE {
LLVM_LIBC_FUNCTION(double, fmax, (double x, double y)) {
- // FIXME: The builtin function does not correctly handle the +/-0.0 case.
- if (LIBC_UNLIKELY(x == y))
- return cpp::bit_cast<double>(cpp::bit_cast<uint64_t>(x) &
- cpp::bit_cast<uint64_t>(y));
return __builtin_fmax(x, y);
}
diff --git a/libc/src/math/amdgpu/fmaxf.cpp b/libc/src/math/amdgpu/fmaxf.cpp
index f6ed46699a049f..5913a85df63703 100644
--- a/libc/src/math/amdgpu/fmaxf.cpp
+++ b/libc/src/math/amdgpu/fmaxf.cpp
@@ -8,17 +8,11 @@
#include "src/math/fmaxf.h"
-#include "src/__support/CPP/bit.h"
#include "src/__support/common.h"
-#include "src/__support/macros/optimization.h"
namespace LIBC_NAMESPACE {
LLVM_LIBC_FUNCTION(float, fmaxf, (float x, float y)) {
- // FIXME: The builtin function does not correctly handle the +/-0.0 case.
- if (LIBC_UNLIKELY(x == y))
- return cpp::bit_cast<float>(cpp::bit_cast<uint32_t>(x) &
- cpp::bit_cast<uint32_t>(y));
return __builtin_fmaxf(x, y);
}
diff --git a/libc/src/math/amdgpu/fmin.cpp b/libc/src/math/amdgpu/fmin.cpp
index 8977ff7a066c6b..0d6f3521dcb705 100644
--- a/libc/src/math/amdgpu/fmin.cpp
+++ b/libc/src/math/amdgpu/fmin.cpp
@@ -8,17 +8,11 @@
#include "src/math/fmin.h"
-#include "src/__support/CPP/bit.h"
#include "src/__support/common.h"
-#include "src/__support/macros/optimization.h"
namespace LIBC_NAMESPACE {
LLVM_LIBC_FUNCTION(double, fmin, (double x, double y)) {
- // FIXME: The builtin function does not correctly handle the +/-0.0 case.
- if (LIBC_UNLIKELY(x == y))
- return cpp::bit_cast<double>(cpp::bit_cast<uint64_t>(x) |
- cpp::bit_cast<uint64_t>(y));
return __builtin_fmin(x, y);
}
diff --git a/libc/src/math/amdgpu/fminf.cpp b/libc/src/math/amdgpu/fminf.cpp
index 3be55257f61649..42744abfb3b02f 100644
--- a/libc/src/math/amdgpu/fminf.cpp
+++ b/libc/src/math/amdgpu/fminf.cpp
@@ -8,17 +8,11 @@
#include "src/math/fminf.h"
-#include "src/__support/CPP/bit.h"
#include "src/__support/common.h"
-#include "src/__support/macros/optimization.h"
namespace LIBC_NAMESPACE {
LLVM_LIBC_FUNCTION(float, fminf, (float x, float y)) {
- // FIXME: The builtin function does not correctly handle the +/-0.0 case.
- if (LIBC_UNLIKELY(x == y))
- return cpp::bit_cast<float>(cpp::bit_cast<uint32_t>(x) |
- cpp::bit_cast<uint32_t>(y));
return __builtin_fminf(x, y);
}
diff --git a/libc/src/math/nvptx/fmax.cpp b/libc/src/math/nvptx/fmax.cpp
index 09624cc6f092af..3ba65d7eccd369 100644
--- a/libc/src/math/nvptx/fmax.cpp
+++ b/libc/src/math/nvptx/fmax.cpp
@@ -8,17 +8,11 @@
#include "src/math/fmax.h"
-#include "src/__support/CPP/bit.h"
#include "src/__support/common.h"
-#include "src/__support/macros/optimization.h"
namespace LIBC_NAMESPACE {
LLVM_LIBC_FUNCTION(double, fmax, (double x, double y)) {
- // FIXME: The builtin function does not correctly handle the +/-0.0 case.
- if (LIBC_UNLIKELY(x == y))
- return cpp::bit_cast<double>(cpp::bit_cast<uint64_t>(x) &
- cpp::bit_cast<uint64_t>(y));
return __builtin_fmax(x, y);
}
diff --git a/libc/src/math/nvptx/fmaxf.cpp b/libc/src/math/nvptx/fmaxf.cpp
index f6ed46699a049f..e977082b39f403 100644
--- a/libc/src/math/nvptx/fmaxf.cpp
+++ b/libc/src/math/nvptx/fmaxf.cpp
@@ -15,10 +15,6 @@
namespace LIBC_NAMESPACE {
LLVM_LIBC_FUNCTION(float, fmaxf, (float x, float y)) {
- // FIXME: The builtin function does not correctly handle the +/-0.0 case.
- if (LIBC_UNLIKELY(x == y))
- return cpp::bit_cast<float>(cpp::bit_cast<uint32_t>(x) &
- cpp::bit_cast<uint32_t>(y));
return __builtin_fmaxf(x, y);
}
diff --git a/libc/src/math/nvptx/fmin.cpp b/libc/src/math/nvptx/fmin.cpp
index 8977ff7a066c6b..0d6f3521dcb705 100644
--- a/libc/src/math/nvptx/fmin.cpp
+++ b/libc/src/math/nvptx/fmin.cpp
@@ -8,17 +8,11 @@
#include "src/math/fmin.h"
-#include "src/__support/CPP/bit.h"
#include "src/__support/common.h"
-#include "src/__support/macros/optimization.h"
namespace LIBC_NAMESPACE {
LLVM_LIBC_FUNCTION(double, fmin, (double x, double y)) {
- // FIXME: The builtin function does not correctly handle the +/-0.0 case.
- if (LIBC_UNLIKELY(x == y))
- return cpp::bit_cast<double>(cpp::bit_cast<uint64_t>(x) |
- cpp::bit_cast<uint64_t>(y));
return __builtin_fmin(x, y);
}
diff --git a/libc/src/math/nvptx/fminf.cpp b/libc/src/math/nvptx/fminf.cpp
index 3be55257f61649..42744abfb3b02f 100644
--- a/libc/src/math/nvptx/fminf.cpp
+++ b/libc/src/math/nvptx/fminf.cpp
@@ -8,17 +8,11 @@
#include "src/math/fminf.h"
-#include "src/__support/CPP/bit.h"
#include "src/__support/common.h"
-#include "src/__support/macros/optimization.h"
namespace LIBC_NAMESPACE {
LLVM_LIBC_FUNCTION(float, fminf, (float x, float y)) {
- // FIXME: The builtin function does not correctly handle the +/-0.0 case.
- if (LIBC_UNLIKELY(x == y))
- return cpp::bit_cast<float>(cpp::bit_cast<uint32_t>(x) |
- cpp::bit_cast<uint32_t>(y));
return __builtin_fminf(x, y);
}
>From dbca8a49b6dbbb79913d6a1bc1d59f4947353e96 Mon Sep 17 00:00:00 2001
From: David Green <david.green at arm.com>
Date: Thu, 29 Feb 2024 12:53:13 +0000
Subject: [PATCH 120/406] [DAG] Improve known bits of Zext/Sext loads with
range metadata (#80829)
This extends the known bits for extending loads which have range
metadata, handling the range metadata on the original memory type,
extending that to the correct BitWidth.
---
.../lib/CodeGen/SelectionDAG/SelectionDAG.cpp | 48 +++++++------
llvm/test/CodeGen/AArch64/setcc_knownbits.ll | 4 +-
.../CodeGen/AArch64SelectionDAGTest.cpp | 68 +++++++++++++++++++
3 files changed, 98 insertions(+), 22 deletions(-)
diff --git a/llvm/lib/CodeGen/SelectionDAG/SelectionDAG.cpp b/llvm/lib/CodeGen/SelectionDAG/SelectionDAG.cpp
index e3e7de1573c818..5b1b7c7c627723 100644
--- a/llvm/lib/CodeGen/SelectionDAG/SelectionDAG.cpp
+++ b/llvm/lib/CodeGen/SelectionDAG/SelectionDAG.cpp
@@ -3645,32 +3645,42 @@ KnownBits SelectionDAG::computeKnownBits(SDValue Op, const APInt &DemandedElts,
}
}
}
- } else if (ISD::isZEXTLoad(Op.getNode()) && Op.getResNo() == 0) {
- // If this is a ZEXTLoad and we are looking at the loaded value.
- EVT VT = LD->getMemoryVT();
- unsigned MemBits = VT.getScalarSizeInBits();
- Known.Zero.setBitsFrom(MemBits);
- } else if (const MDNode *Ranges = LD->getRanges()) {
- EVT VT = LD->getValueType(0);
-
- // TODO: Handle for extending loads
- if (LD->getExtensionType() == ISD::NON_EXTLOAD) {
+ } else if (Op.getResNo() == 0) {
+ KnownBits Known0(!LD->getMemoryVT().isScalableVT()
+ ? LD->getMemoryVT().getFixedSizeInBits()
+ : BitWidth);
+ EVT VT = Op.getValueType();
+ // Fill in any known bits from range information. There are 3 types being
+ // used. The results VT (same vector elt size as BitWidth), the loaded
+ // MemoryVT (which may or may not be vector) and the range VTs original
+ // type. The range matadata needs the full range (i.e
+ // MemoryVT().getSizeInBits()), which is truncated to the correct elt size
+ // if it is know. These are then extended to the original VT sizes below.
+ if (const MDNode *MD = LD->getRanges()) {
+ computeKnownBitsFromRangeMetadata(*MD, Known0);
if (VT.isVector()) {
// Handle truncation to the first demanded element.
// TODO: Figure out which demanded elements are covered
if (DemandedElts != 1 || !getDataLayout().isLittleEndian())
break;
+ Known0 = Known0.trunc(BitWidth);
+ }
+ }
- // Handle the case where a load has a vector type, but scalar memory
- // with an attached range.
- EVT MemVT = LD->getMemoryVT();
- KnownBits KnownFull(MemVT.getSizeInBits());
+ if (LD->getMemoryVT().isVector())
+ Known0 = Known0.trunc(LD->getMemoryVT().getScalarSizeInBits());
- computeKnownBitsFromRangeMetadata(*Ranges, KnownFull);
- Known = KnownFull.trunc(BitWidth);
- } else
- computeKnownBitsFromRangeMetadata(*Ranges, Known);
- }
+ // Extend the Known bits from memory to the size of the result.
+ if (ISD::isZEXTLoad(Op.getNode()))
+ Known = Known0.zext(BitWidth);
+ else if (ISD::isSEXTLoad(Op.getNode()))
+ Known = Known0.sext(BitWidth);
+ else if (ISD::isEXTLoad(Op.getNode()))
+ Known = Known0.anyext(BitWidth);
+ else
+ Known = Known0;
+ assert(Known.getBitWidth() == BitWidth);
+ return Known;
}
break;
}
diff --git a/llvm/test/CodeGen/AArch64/setcc_knownbits.ll b/llvm/test/CodeGen/AArch64/setcc_knownbits.ll
index 46b714d8e5fbbe..bb9546af8bb7b6 100644
--- a/llvm/test/CodeGen/AArch64/setcc_knownbits.ll
+++ b/llvm/test/CodeGen/AArch64/setcc_knownbits.ll
@@ -21,9 +21,7 @@ define noundef i1 @logger(i32 noundef %logLevel, ptr %ea, ptr %pll) {
; CHECK-NEXT: ret
; CHECK-NEXT: .LBB1_2: // %land.rhs
; CHECK-NEXT: ldr x8, [x1]
-; CHECK-NEXT: ldrb w8, [x8]
-; CHECK-NEXT: cmp w8, #0
-; CHECK-NEXT: cset w0, ne
+; CHECK-NEXT: ldrb w0, [x8]
; CHECK-NEXT: ret
entry:
%0 = load i32, ptr %pll, align 4
diff --git a/llvm/unittests/CodeGen/AArch64SelectionDAGTest.cpp b/llvm/unittests/CodeGen/AArch64SelectionDAGTest.cpp
index bb8e76a2eeb8be..e0772684e3a954 100644
--- a/llvm/unittests/CodeGen/AArch64SelectionDAGTest.cpp
+++ b/llvm/unittests/CodeGen/AArch64SelectionDAGTest.cpp
@@ -6,11 +6,13 @@
//
//===----------------------------------------------------------------------===//
+#include "llvm/Analysis/MemoryLocation.h"
#include "llvm/Analysis/OptimizationRemarkEmitter.h"
#include "llvm/AsmParser/Parser.h"
#include "llvm/CodeGen/MachineModuleInfo.h"
#include "llvm/CodeGen/SelectionDAG.h"
#include "llvm/CodeGen/TargetLowering.h"
+#include "llvm/IR/MDBuilder.h"
#include "llvm/MC/TargetRegistry.h"
#include "llvm/Support/KnownBits.h"
#include "llvm/Support/SourceMgr.h"
@@ -728,4 +730,70 @@ TEST_F(AArch64SelectionDAGTest, ReplaceAllUsesWith) {
EXPECT_EQ(DAG->getPCSections(New.getNode()), MD);
}
+TEST_F(AArch64SelectionDAGTest, computeKnownBits_extload_known01) {
+ SDLoc Loc;
+ auto Int8VT = EVT::getIntegerVT(Context, 8);
+ auto Int32VT = EVT::getIntegerVT(Context, 32);
+ auto Int64VT = EVT::getIntegerVT(Context, 64);
+ auto Ptr = DAG->getConstant(0, Loc, Int64VT);
+ auto PtrInfo =
+ MachinePointerInfo::getFixedStack(DAG->getMachineFunction(), 0);
+ AAMDNodes AA;
+ MDBuilder MDHelper(*DAG->getContext());
+ MDNode *Range = MDHelper.createRange(APInt(8, 0), APInt(8, 2));
+ MachineMemOperand *MMO = DAG->getMachineFunction().getMachineMemOperand(
+ PtrInfo, MachineMemOperand::MOLoad, 8, Align(8), AA, Range);
+
+ auto ALoad = DAG->getExtLoad(ISD::EXTLOAD, Loc, Int32VT, DAG->getEntryNode(),
+ Ptr, Int8VT, MMO);
+ KnownBits Known = DAG->computeKnownBits(ALoad);
+ EXPECT_EQ(Known.Zero, APInt(32, 0xfe));
+ EXPECT_EQ(Known.One, APInt(32, 0));
+
+ auto ZLoad = DAG->getExtLoad(ISD::ZEXTLOAD, Loc, Int32VT, DAG->getEntryNode(),
+ Ptr, Int8VT, MMO);
+ Known = DAG->computeKnownBits(ZLoad);
+ EXPECT_EQ(Known.Zero, APInt(32, 0xfffffffe));
+ EXPECT_EQ(Known.One, APInt(32, 0));
+
+ auto SLoad = DAG->getExtLoad(ISD::SEXTLOAD, Loc, Int32VT, DAG->getEntryNode(),
+ Ptr, Int8VT, MMO);
+ Known = DAG->computeKnownBits(SLoad);
+ EXPECT_EQ(Known.Zero, APInt(32, 0xfffffffe));
+ EXPECT_EQ(Known.One, APInt(32, 0));
+}
+
+TEST_F(AArch64SelectionDAGTest, computeKnownBits_extload_knownnegative) {
+ SDLoc Loc;
+ auto Int8VT = EVT::getIntegerVT(Context, 8);
+ auto Int32VT = EVT::getIntegerVT(Context, 32);
+ auto Int64VT = EVT::getIntegerVT(Context, 64);
+ auto Ptr = DAG->getConstant(0, Loc, Int64VT);
+ auto PtrInfo =
+ MachinePointerInfo::getFixedStack(DAG->getMachineFunction(), 0);
+ AAMDNodes AA;
+ MDBuilder MDHelper(*DAG->getContext());
+ MDNode *Range = MDHelper.createRange(APInt(8, 0xf0), APInt(8, 0xff));
+ MachineMemOperand *MMO = DAG->getMachineFunction().getMachineMemOperand(
+ PtrInfo, MachineMemOperand::MOLoad, 8, Align(8), AA, Range);
+
+ auto ALoad = DAG->getExtLoad(ISD::EXTLOAD, Loc, Int32VT, DAG->getEntryNode(),
+ Ptr, Int8VT, MMO);
+ KnownBits Known = DAG->computeKnownBits(ALoad);
+ EXPECT_EQ(Known.Zero, APInt(32, 0));
+ EXPECT_EQ(Known.One, APInt(32, 0xf0));
+
+ auto ZLoad = DAG->getExtLoad(ISD::ZEXTLOAD, Loc, Int32VT, DAG->getEntryNode(),
+ Ptr, Int8VT, MMO);
+ Known = DAG->computeKnownBits(ZLoad);
+ EXPECT_EQ(Known.Zero, APInt(32, 0xffffff00));
+ EXPECT_EQ(Known.One, APInt(32, 0x000000f0));
+
+ auto SLoad = DAG->getExtLoad(ISD::SEXTLOAD, Loc, Int32VT, DAG->getEntryNode(),
+ Ptr, Int8VT, MMO);
+ Known = DAG->computeKnownBits(SLoad);
+ EXPECT_EQ(Known.Zero, APInt(32, 0));
+ EXPECT_EQ(Known.One, APInt(32, 0xfffffff0));
+}
+
} // end namespace llvm
>From 6c2eec5ceadf26ce8d732d718a8906d075a7d6c7 Mon Sep 17 00:00:00 2001
From: Petar Avramovic <Petar.Avramovic at amd.com>
Date: Thu, 29 Feb 2024 13:57:59 +0100
Subject: [PATCH 121/406] AMDGPU/GlobalISel: lane masks merging (#73337)
Basic implementation of lane mask merging for GlobalISel.
Lane masks on GlobalISel are registers with sgpr register class
and S1 LLT - required by machine uniformity analysis.
Implements equivalent of lowerPhis from SILowerI1Copies.cpp in:
patch 1: https://github.com/llvm/llvm-project/pull/75340
patch 2: https://github.com/llvm/llvm-project/pull/75349
patch 3: https://github.com/llvm/llvm-project/pull/80003
patch 4: https://github.com/llvm/llvm-project/pull/78431
patch 5: is in this commit:
AMDGPU/GlobalISelDivergenceLowering: constrain incoming registers
Previously, in PHIs that represent lane masks, incoming registers
taken as-is were not selected as lane masks. Such registers are not
being merged with another lane mask and most often only have S1 LLT.
Implement constrainAsLaneMask by constraining incoming registers
taken as-is with lane mask attributes, essentially transforming them
to lane masks. This is final step in having PHI instructions created
in this pass to be fully instruction-selected.
---
.../AMDGPUGlobalISelDivergenceLowering.cpp | 11 +-
...-divergent-i1-phis-no-lane-mask-merging.ll | 24 +--
...divergent-i1-phis-no-lane-mask-merging.mir | 66 ++++---
...vergence-divergent-i1-used-outside-loop.ll | 36 ++--
...ergence-divergent-i1-used-outside-loop.mir | 177 +++++++++---------
.../GlobalISel/divergence-structurizer.ll | 13 +-
.../GlobalISel/divergence-structurizer.mir | 161 ++++++++--------
7 files changed, 256 insertions(+), 232 deletions(-)
diff --git a/llvm/lib/Target/AMDGPU/AMDGPUGlobalISelDivergenceLowering.cpp b/llvm/lib/Target/AMDGPU/AMDGPUGlobalISelDivergenceLowering.cpp
index 4f65a95de82ac8..a0c6bf7cc31c0a 100644
--- a/llvm/lib/Target/AMDGPU/AMDGPUGlobalISelDivergenceLowering.cpp
+++ b/llvm/lib/Target/AMDGPU/AMDGPUGlobalISelDivergenceLowering.cpp
@@ -177,7 +177,16 @@ void DivergenceLoweringHelper::buildMergeLaneMasks(
B.buildInstr(OrOp, {DstReg}, {PrevMaskedReg, CurMaskedReg});
}
-void DivergenceLoweringHelper::constrainAsLaneMask(Incoming &In) { return; }
+// GlobalISel has to constrain S1 incoming taken as-is with lane mask register
+// class. Insert a copy of Incoming.Reg to new lane mask inside Incoming.Block,
+// Incoming.Reg becomes that new lane mask.
+void DivergenceLoweringHelper::constrainAsLaneMask(Incoming &In) {
+ B.setInsertPt(*In.Block, In.Block->getFirstTerminator());
+
+ auto Copy = B.buildCopy(LLT::scalar(1), In.Reg);
+ MRI->setRegClass(Copy.getReg(0), ST->getBoolRC());
+ In.Reg = Copy.getReg(0);
+}
} // End anonymous namespace.
diff --git a/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-divergent-i1-phis-no-lane-mask-merging.ll b/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-divergent-i1-phis-no-lane-mask-merging.ll
index 0f70c1996d6e02..d4d5cb18bbd30e 100644
--- a/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-divergent-i1-phis-no-lane-mask-merging.ll
+++ b/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-divergent-i1-phis-no-lane-mask-merging.ll
@@ -1,5 +1,5 @@
; NOTE: Assertions have been autogenerated by utils/update_llc_test_checks.py UTC_ARGS: --version 3
-; RUN: llc -global-isel -amdgpu-global-isel-risky-select -mtriple=amdgcn-amd-amdpal -mcpu=gfx1010 -verify-machineinstrs < %s | FileCheck -check-prefix=GFX10 %s
+; RUN: llc -global-isel -mtriple=amdgcn-amd-amdpal -mcpu=gfx1010 -verify-machineinstrs < %s | FileCheck -check-prefix=GFX10 %s
; Divergent phis that don't require lowering using lane mask merging
@@ -147,32 +147,28 @@ define void @divergent_i1_phi_used_inside_loop_bigger_loop_body(float %val, floa
; GFX10-LABEL: divergent_i1_phi_used_inside_loop_bigger_loop_body:
; GFX10: ; %bb.0: ; %entry
; GFX10-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
-; GFX10-NEXT: v_cmp_lt_f32_e32 vcc_lo, 1.0, v1
-; GFX10-NEXT: s_mov_b32 s5, 0
+; GFX10-NEXT: s_mov_b32 s4, 0
+; GFX10-NEXT: v_cmp_lt_f32_e64 s5, 1.0, v1
; GFX10-NEXT: v_mov_b32_e32 v1, 0x3e8
-; GFX10-NEXT: v_mov_b32_e32 v8, s5
+; GFX10-NEXT: v_mov_b32_e32 v8, s4
; GFX10-NEXT: ; implicit-def: $sgpr6
-; GFX10-NEXT: v_cndmask_b32_e64 v9, 0, 1, vcc_lo
; GFX10-NEXT: s_branch .LBB3_2
; GFX10-NEXT: .LBB3_1: ; %loop_body
; GFX10-NEXT: ; in Loop: Header=BB3_2 Depth=1
; GFX10-NEXT: v_cvt_f32_u32_e32 v9, v8
-; GFX10-NEXT: s_xor_b32 s4, s4, -1
+; GFX10-NEXT: s_xor_b32 s5, s5, -1
; GFX10-NEXT: v_add_nc_u32_e32 v8, 1, v8
; GFX10-NEXT: v_cmp_gt_f32_e32 vcc_lo, v9, v0
-; GFX10-NEXT: v_cndmask_b32_e64 v9, 0, 1, s4
-; GFX10-NEXT: s_or_b32 s5, vcc_lo, s5
+; GFX10-NEXT: s_or_b32 s4, vcc_lo, s4
; GFX10-NEXT: s_andn2_b32 s6, s6, exec_lo
-; GFX10-NEXT: s_and_b32 s4, exec_lo, s4
-; GFX10-NEXT: s_or_b32 s6, s6, s4
-; GFX10-NEXT: s_andn2_b32 exec_lo, exec_lo, s5
+; GFX10-NEXT: s_and_b32 s7, exec_lo, s5
+; GFX10-NEXT: s_or_b32 s6, s6, s7
+; GFX10-NEXT: s_andn2_b32 exec_lo, exec_lo, s4
; GFX10-NEXT: s_cbranch_execz .LBB3_6
; GFX10-NEXT: .LBB3_2: ; %loop_start
; GFX10-NEXT: ; =>This Inner Loop Header: Depth=1
-; GFX10-NEXT: v_and_b32_e32 v9, 1, v9
; GFX10-NEXT: v_cmp_ge_i32_e32 vcc_lo, 0x3e8, v8
; GFX10-NEXT: s_mov_b32 s7, 1
-; GFX10-NEXT: v_cmp_ne_u32_e64 s4, 0, v9
; GFX10-NEXT: s_cbranch_vccz .LBB3_4
; GFX10-NEXT: ; %bb.3: ; %else
; GFX10-NEXT: ; in Loop: Header=BB3_2 Depth=1
@@ -189,7 +185,7 @@ define void @divergent_i1_phi_used_inside_loop_bigger_loop_body(float %val, floa
; GFX10-NEXT: flat_store_dword v[4:5], v1
; GFX10-NEXT: s_branch .LBB3_1
; GFX10-NEXT: .LBB3_6: ; %exit
-; GFX10-NEXT: s_or_b32 exec_lo, exec_lo, s5
+; GFX10-NEXT: s_or_b32 exec_lo, exec_lo, s4
; GFX10-NEXT: v_cndmask_b32_e64 v0, 0, 1.0, s6
; GFX10-NEXT: flat_store_dword v[2:3], v0
; GFX10-NEXT: s_waitcnt lgkmcnt(0)
diff --git a/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-divergent-i1-phis-no-lane-mask-merging.mir b/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-divergent-i1-phis-no-lane-mask-merging.mir
index 5549c89dc402f8..9b0bd2752b8231 100644
--- a/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-divergent-i1-phis-no-lane-mask-merging.mir
+++ b/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-divergent-i1-phis-no-lane-mask-merging.mir
@@ -33,6 +33,7 @@ body: |
; GFX10-NEXT: [[ICMP:%[0-9]+]]:_(s1) = G_ICMP intpred(uge), [[COPY2]](s32), [[C]]
; GFX10-NEXT: [[C1:%[0-9]+]]:_(s32) = G_CONSTANT i32 0
; GFX10-NEXT: [[ICMP1:%[0-9]+]]:_(s1) = G_ICMP intpred(ne), [[COPY3]](s32), [[C1]]
+ ; GFX10-NEXT: [[COPY6:%[0-9]+]]:sreg_32(s1) = COPY [[ICMP]](s1)
; GFX10-NEXT: G_BRCOND [[ICMP1]](s1), %bb.2
; GFX10-NEXT: G_BR %bb.1
; GFX10-NEXT: {{ $}}
@@ -46,7 +47,8 @@ body: |
; GFX10-NEXT: bb.2:
; GFX10-NEXT: successors: %bb.4(0x80000000)
; GFX10-NEXT: {{ $}}
- ; GFX10-NEXT: [[PHI:%[0-9]+]]:sreg_32(s1) = G_PHI %14(s1), %bb.3, [[ICMP]](s1), %bb.0
+ ; GFX10-NEXT: [[PHI:%[0-9]+]]:sreg_32(s1) = PHI [[COPY6]](s1), %bb.0, %20(s1), %bb.3
+ ; GFX10-NEXT: [[COPY7:%[0-9]+]]:sreg_32(s1) = COPY [[PHI]](s1)
; GFX10-NEXT: G_BR %bb.4
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: bb.3:
@@ -54,12 +56,13 @@ body: |
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: [[C3:%[0-9]+]]:_(s32) = G_CONSTANT i32 1
; GFX10-NEXT: [[ICMP2:%[0-9]+]]:_(s1) = G_ICMP intpred(ult), [[COPY2]](s32), [[C3]]
+ ; GFX10-NEXT: [[COPY8:%[0-9]+]]:sreg_32(s1) = COPY [[ICMP2]](s1)
; GFX10-NEXT: G_BR %bb.2
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: bb.4:
; GFX10-NEXT: [[C4:%[0-9]+]]:_(s32) = G_CONSTANT i32 2
; GFX10-NEXT: [[C5:%[0-9]+]]:_(s32) = G_CONSTANT i32 1
- ; GFX10-NEXT: [[SELECT:%[0-9]+]]:_(s32) = G_SELECT [[PHI]](s1), [[C5]], [[C4]]
+ ; GFX10-NEXT: [[SELECT:%[0-9]+]]:_(s32) = G_SELECT [[COPY7]](s1), [[C5]], [[C4]]
; GFX10-NEXT: G_STORE [[SELECT]](s32), [[MV]](p1) :: (store (s32), addrspace 1)
; GFX10-NEXT: S_ENDPGM 0
bb.0:
@@ -126,9 +129,10 @@ body: |
; GFX10-NEXT: [[COPY3:%[0-9]+]]:_(s32) = COPY $sgpr0
; GFX10-NEXT: [[C:%[0-9]+]]:_(s32) = G_CONSTANT i32 6
; GFX10-NEXT: [[ICMP:%[0-9]+]]:_(s1) = G_ICMP intpred(uge), [[COPY2]](s32), [[C]]
- ; GFX10-NEXT: [[COPY4:%[0-9]+]]:sreg_32(s1) = COPY [[ICMP]](s1)
; GFX10-NEXT: [[C1:%[0-9]+]]:_(s32) = G_CONSTANT i32 0
; GFX10-NEXT: [[ICMP1:%[0-9]+]]:_(s1) = G_ICMP intpred(ne), [[COPY3]](s32), [[C1]]
+ ; GFX10-NEXT: [[COPY4:%[0-9]+]]:sreg_32(s1) = COPY [[ICMP]](s1)
+ ; GFX10-NEXT: [[COPY5:%[0-9]+]]:sreg_32(s1) = COPY [[COPY4]](s1)
; GFX10-NEXT: G_BRCOND [[ICMP1]](s1), %bb.2
; GFX10-NEXT: G_BR %bb.1
; GFX10-NEXT: {{ $}}
@@ -137,17 +141,17 @@ body: |
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: [[C2:%[0-9]+]]:_(s32) = G_CONSTANT i32 1
; GFX10-NEXT: [[ICMP2:%[0-9]+]]:_(s1) = G_ICMP intpred(ult), [[COPY2]](s32), [[C2]]
- ; GFX10-NEXT: [[COPY5:%[0-9]+]]:sreg_32(s1) = COPY [[ICMP2]](s1)
- ; GFX10-NEXT: [[S_ANDN2_B32_:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY4]](s1), $exec_lo, implicit-def $scc
- ; GFX10-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY5]](s1), implicit-def $scc
+ ; GFX10-NEXT: [[COPY6:%[0-9]+]]:sreg_32(s1) = COPY [[ICMP2]](s1)
+ ; GFX10-NEXT: [[S_ANDN2_B32_:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY5]](s1), $exec_lo, implicit-def $scc
+ ; GFX10-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY6]](s1), implicit-def $scc
; GFX10-NEXT: [[S_OR_B32_:%[0-9]+]]:sreg_32(s1) = S_OR_B32 [[S_ANDN2_B32_]](s1), [[S_AND_B32_]](s1), implicit-def $scc
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: bb.2:
- ; GFX10-NEXT: [[PHI:%[0-9]+]]:sreg_32(s1) = PHI [[ICMP]](s1), %bb.0, [[S_OR_B32_]](s1), %bb.1
- ; GFX10-NEXT: [[COPY6:%[0-9]+]]:sreg_32(s1) = COPY [[PHI]](s1)
+ ; GFX10-NEXT: [[PHI:%[0-9]+]]:sreg_32(s1) = PHI [[COPY4]](s1), %bb.0, [[S_OR_B32_]](s1), %bb.1
+ ; GFX10-NEXT: [[COPY7:%[0-9]+]]:sreg_32(s1) = COPY [[PHI]](s1)
; GFX10-NEXT: [[C3:%[0-9]+]]:_(s32) = G_CONSTANT i32 2
; GFX10-NEXT: [[C4:%[0-9]+]]:_(s32) = G_CONSTANT i32 1
- ; GFX10-NEXT: [[SELECT:%[0-9]+]]:_(s32) = G_SELECT [[COPY6]](s1), [[C4]], [[C3]]
+ ; GFX10-NEXT: [[SELECT:%[0-9]+]]:_(s32) = G_SELECT [[COPY7]](s1), [[C4]], [[C3]]
; GFX10-NEXT: G_STORE [[SELECT]](s32), [[MV]](p1) :: (store (s32), addrspace 1)
; GFX10-NEXT: S_ENDPGM 0
bb.0:
@@ -292,19 +296,21 @@ body: |
; GFX10-NEXT: [[C:%[0-9]+]]:_(s32) = G_CONSTANT i32 0
; GFX10-NEXT: [[C1:%[0-9]+]]:_(s32) = G_FCONSTANT float 1.000000e+00
; GFX10-NEXT: [[FCMP:%[0-9]+]]:_(s1) = G_FCMP floatpred(ogt), [[COPY1]](s32), [[C1]]
+ ; GFX10-NEXT: [[COPY8:%[0-9]+]]:sreg_32(s1) = COPY [[FCMP]](s1)
; GFX10-NEXT: [[DEF:%[0-9]+]]:sreg_32(s1) = IMPLICIT_DEF
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: bb.1:
; GFX10-NEXT: successors: %bb.4(0x40000000), %bb.2(0x40000000)
; GFX10-NEXT: {{ $}}
- ; GFX10-NEXT: [[PHI:%[0-9]+]]:sreg_32(s1) = PHI [[DEF]](s1), %bb.0, %39(s1), %bb.5
- ; GFX10-NEXT: [[PHI1:%[0-9]+]]:_(s32) = G_PHI %15(s32), %bb.5, [[C]](s32), %bb.0
- ; GFX10-NEXT: [[PHI2:%[0-9]+]]:_(s32) = G_PHI [[C]](s32), %bb.0, %17(s32), %bb.5
- ; GFX10-NEXT: [[PHI3:%[0-9]+]]:sreg_32(s1) = G_PHI [[FCMP]](s1), %bb.0, %19(s1), %bb.5
- ; GFX10-NEXT: [[COPY8:%[0-9]+]]:sreg_32(s1) = COPY [[PHI]](s1)
+ ; GFX10-NEXT: [[PHI:%[0-9]+]]:sreg_32(s1) = PHI [[DEF]](s1), %bb.0, %42(s1), %bb.5
+ ; GFX10-NEXT: [[PHI1:%[0-9]+]]:sreg_32(s1) = PHI [[COPY8]](s1), %bb.0, %39(s1), %bb.5
+ ; GFX10-NEXT: [[PHI2:%[0-9]+]]:_(s32) = G_PHI %15(s32), %bb.5, [[C]](s32), %bb.0
+ ; GFX10-NEXT: [[PHI3:%[0-9]+]]:_(s32) = G_PHI [[C]](s32), %bb.0, %17(s32), %bb.5
+ ; GFX10-NEXT: [[COPY9:%[0-9]+]]:sreg_32(s1) = COPY [[PHI]](s1)
+ ; GFX10-NEXT: [[COPY10:%[0-9]+]]:sreg_32(s1) = COPY [[PHI1]](s1)
; GFX10-NEXT: [[C2:%[0-9]+]]:_(s1) = G_CONSTANT i1 true
; GFX10-NEXT: [[C3:%[0-9]+]]:_(s32) = G_CONSTANT i32 1000
- ; GFX10-NEXT: [[ICMP:%[0-9]+]]:_(s1) = G_ICMP intpred(sle), [[PHI2]](s32), [[C3]]
+ ; GFX10-NEXT: [[ICMP:%[0-9]+]]:_(s1) = G_ICMP intpred(sle), [[PHI3]](s32), [[C3]]
; GFX10-NEXT: G_BRCOND [[ICMP]](s1), %bb.4
; GFX10-NEXT: G_BR %bb.2
; GFX10-NEXT: {{ $}}
@@ -336,26 +342,27 @@ body: |
; GFX10-NEXT: successors: %bb.6(0x04000000), %bb.1(0x7c000000)
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: [[C8:%[0-9]+]]:_(s1) = G_CONSTANT i1 true
- ; GFX10-NEXT: [[XOR1:%[0-9]+]]:_(s1) = G_XOR [[PHI3]], [[C8]]
- ; GFX10-NEXT: [[COPY9:%[0-9]+]]:sreg_32(s1) = COPY [[XOR1]](s1)
- ; GFX10-NEXT: [[UITOFP:%[0-9]+]]:_(s32) = G_UITOFP [[PHI2]](s32)
+ ; GFX10-NEXT: [[XOR1:%[0-9]+]]:_(s1) = G_XOR [[COPY10]], [[C8]]
+ ; GFX10-NEXT: [[COPY11:%[0-9]+]]:sreg_32(s1) = COPY [[XOR1]](s1)
+ ; GFX10-NEXT: [[UITOFP:%[0-9]+]]:_(s32) = G_UITOFP [[PHI3]](s32)
; GFX10-NEXT: [[FCMP1:%[0-9]+]]:_(s1) = G_FCMP floatpred(ogt), [[UITOFP]](s32), [[COPY]]
; GFX10-NEXT: [[C9:%[0-9]+]]:_(s32) = G_CONSTANT i32 1
- ; GFX10-NEXT: [[ADD:%[0-9]+]]:_(s32) = G_ADD [[PHI2]], [[C9]]
- ; GFX10-NEXT: [[INTRINSIC_CONVERGENT:%[0-9]+]]:sreg_32_xm0_xexec(s32) = G_INTRINSIC_CONVERGENT intrinsic(@llvm.amdgcn.if.break), [[FCMP1]](s1), [[PHI1]](s32)
- ; GFX10-NEXT: [[S_ANDN2_B32_:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY8]](s1), $exec_lo, implicit-def $scc
- ; GFX10-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY9]](s1), implicit-def $scc
+ ; GFX10-NEXT: [[ADD:%[0-9]+]]:_(s32) = G_ADD [[PHI3]], [[C9]]
+ ; GFX10-NEXT: [[INTRINSIC_CONVERGENT:%[0-9]+]]:sreg_32_xm0_xexec(s32) = G_INTRINSIC_CONVERGENT intrinsic(@llvm.amdgcn.if.break), [[FCMP1]](s1), [[PHI2]](s32)
+ ; GFX10-NEXT: [[COPY12:%[0-9]+]]:sreg_32(s1) = COPY [[XOR1]](s1)
+ ; GFX10-NEXT: [[S_ANDN2_B32_:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY9]](s1), $exec_lo, implicit-def $scc
+ ; GFX10-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY11]](s1), implicit-def $scc
; GFX10-NEXT: [[S_OR_B32_:%[0-9]+]]:sreg_32(s1) = S_OR_B32 [[S_ANDN2_B32_]](s1), [[S_AND_B32_]](s1), implicit-def $scc
; GFX10-NEXT: SI_LOOP [[INTRINSIC_CONVERGENT]](s32), %bb.1, implicit-def $exec, implicit-def $scc, implicit $exec
; GFX10-NEXT: G_BR %bb.6
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: bb.6:
; GFX10-NEXT: [[PHI5:%[0-9]+]]:_(s32) = G_PHI [[INTRINSIC_CONVERGENT]](s32), %bb.5
- ; GFX10-NEXT: [[COPY10:%[0-9]+]]:sreg_32(s1) = COPY [[S_OR_B32_]](s1)
+ ; GFX10-NEXT: [[COPY13:%[0-9]+]]:sreg_32(s1) = COPY [[S_OR_B32_]](s1)
; GFX10-NEXT: G_INTRINSIC_CONVERGENT_W_SIDE_EFFECTS intrinsic(@llvm.amdgcn.end.cf), [[PHI5]](s32)
; GFX10-NEXT: [[C10:%[0-9]+]]:_(s32) = G_FCONSTANT float 0.000000e+00
; GFX10-NEXT: [[C11:%[0-9]+]]:_(s32) = G_FCONSTANT float 1.000000e+00
- ; GFX10-NEXT: [[SELECT:%[0-9]+]]:_(s32) = G_SELECT [[COPY10]](s1), [[C11]], [[C10]]
+ ; GFX10-NEXT: [[SELECT:%[0-9]+]]:_(s32) = G_SELECT [[COPY13]](s1), [[C11]], [[C10]]
; GFX10-NEXT: G_STORE [[SELECT]](s32), [[MV]](p0) :: (store (s32))
; GFX10-NEXT: SI_RETURN
bb.0:
@@ -475,6 +482,7 @@ body: |
; GFX10-NEXT: [[TRUNC1:%[0-9]+]]:_(s1) = G_TRUNC [[AND1]](s32)
; GFX10-NEXT: [[C5:%[0-9]+]]:_(s1) = G_CONSTANT i1 true
; GFX10-NEXT: [[XOR:%[0-9]+]]:_(s1) = G_XOR [[TRUNC1]], [[C5]]
+ ; GFX10-NEXT: [[COPY3:%[0-9]+]]:sreg_32(s1) = COPY [[C5]](s1)
; GFX10-NEXT: G_BRCOND [[XOR]](s1), %bb.2
; GFX10-NEXT: G_BR %bb.1
; GFX10-NEXT: {{ $}}
@@ -487,9 +495,10 @@ body: |
; GFX10-NEXT: bb.2:
; GFX10-NEXT: successors: %bb.5(0x40000000), %bb.6(0x40000000)
; GFX10-NEXT: {{ $}}
- ; GFX10-NEXT: [[PHI:%[0-9]+]]:_(s32) = G_PHI %30(s32), %bb.4, [[DEF]](s32), %bb.0
- ; GFX10-NEXT: [[PHI1:%[0-9]+]]:sreg_32(s1) = G_PHI %32(s1), %bb.4, [[C5]](s1), %bb.0
- ; GFX10-NEXT: G_BRCOND [[PHI1]](s1), %bb.5
+ ; GFX10-NEXT: [[PHI:%[0-9]+]]:sreg_32(s1) = PHI [[COPY3]](s1), %bb.0, %58(s1), %bb.4
+ ; GFX10-NEXT: [[PHI1:%[0-9]+]]:_(s32) = G_PHI %30(s32), %bb.4, [[DEF]](s32), %bb.0
+ ; GFX10-NEXT: [[COPY4:%[0-9]+]]:sreg_32(s1) = COPY [[PHI]](s1)
+ ; GFX10-NEXT: G_BRCOND [[COPY4]](s1), %bb.5
; GFX10-NEXT: G_BR %bb.6
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: bb.3:
@@ -517,6 +526,7 @@ body: |
; GFX10-NEXT: [[ICMP2:%[0-9]+]]:_(s1) = G_ICMP intpred(eq), [[PHI5]](s32), [[AMDGPU_BUFFER_LOAD]]
; GFX10-NEXT: [[OR1:%[0-9]+]]:_(s1) = G_OR [[ICMP]], [[ICMP2]]
; GFX10-NEXT: [[ZEXT1:%[0-9]+]]:_(s32) = G_ZEXT [[OR1]](s1)
+ ; GFX10-NEXT: [[COPY5:%[0-9]+]]:sreg_32(s1) = COPY [[C10]](s1)
; GFX10-NEXT: G_BR %bb.2
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: bb.5:
@@ -527,7 +537,7 @@ body: |
; GFX10-NEXT: [[OR2:%[0-9]+]]:_(s32) = G_OR [[ZEXT2]], [[C11]]
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: bb.6:
- ; GFX10-NEXT: [[PHI6:%[0-9]+]]:_(s32) = G_PHI [[PHI]](s32), %bb.2, [[OR2]](s32), %bb.5
+ ; GFX10-NEXT: [[PHI6:%[0-9]+]]:_(s32) = G_PHI [[PHI1]](s32), %bb.2, [[OR2]](s32), %bb.5
; GFX10-NEXT: [[UV:%[0-9]+]]:_(<4 x s32>), [[UV1:%[0-9]+]]:_(<4 x s32>) = G_UNMERGE_VALUES [[LOAD]](<8 x s32>)
; GFX10-NEXT: [[ADD3:%[0-9]+]]:_(s32) = G_ADD [[COPY2]], [[COPY1]]
; GFX10-NEXT: [[C12:%[0-9]+]]:_(s32) = G_CONSTANT i32 2
diff --git a/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-divergent-i1-used-outside-loop.ll b/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-divergent-i1-used-outside-loop.ll
index e9df20f9688e6d..49c232661c6dc1 100644
--- a/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-divergent-i1-used-outside-loop.ll
+++ b/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-divergent-i1-used-outside-loop.ll
@@ -1,5 +1,5 @@
; NOTE: Assertions have been autogenerated by utils/update_llc_test_checks.py UTC_ARGS: --version 3
-; RUN: llc -global-isel -mtriple=amdgcn-amd-amdpal -amdgpu-global-isel-risky-select -mcpu=gfx1010 -verify-machineinstrs < %s | FileCheck -check-prefix=GFX10 %s
+; RUN: llc -global-isel -mtriple=amdgcn-amd-amdpal -mcpu=gfx1010 -verify-machineinstrs < %s | FileCheck -check-prefix=GFX10 %s
; This file contains various tests that have divergent i1s used outside of
; the loop. These are lane masks is sgpr and need to have correct value in
@@ -137,28 +137,24 @@ define void @divergent_i1_xor_used_outside_loop(float %val, float %pre.cond.val,
; GFX10-LABEL: divergent_i1_xor_used_outside_loop:
; GFX10: ; %bb.0: ; %entry
; GFX10-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
-; GFX10-NEXT: v_cmp_lt_f32_e32 vcc_lo, 1.0, v1
-; GFX10-NEXT: s_mov_b32 s5, 0
+; GFX10-NEXT: s_mov_b32 s4, 0
+; GFX10-NEXT: v_cmp_lt_f32_e64 s5, 1.0, v1
+; GFX10-NEXT: v_mov_b32_e32 v1, s4
; GFX10-NEXT: ; implicit-def: $sgpr6
-; GFX10-NEXT: v_mov_b32_e32 v1, s5
-; GFX10-NEXT: v_cndmask_b32_e64 v4, 0, 1, vcc_lo
; GFX10-NEXT: .LBB2_1: ; %loop
; GFX10-NEXT: ; =>This Inner Loop Header: Depth=1
-; GFX10-NEXT: v_and_b32_e32 v4, 1, v4
-; GFX10-NEXT: v_cvt_f32_u32_e32 v5, v1
+; GFX10-NEXT: v_cvt_f32_u32_e32 v4, v1
+; GFX10-NEXT: s_xor_b32 s5, s5, -1
; GFX10-NEXT: v_add_nc_u32_e32 v1, 1, v1
-; GFX10-NEXT: v_cmp_ne_u32_e32 vcc_lo, 0, v4
-; GFX10-NEXT: v_cmp_gt_f32_e64 s4, v5, v0
-; GFX10-NEXT: s_xor_b32 s7, vcc_lo, -1
-; GFX10-NEXT: s_or_b32 s5, s4, s5
-; GFX10-NEXT: v_mov_b32_e32 v4, s7
-; GFX10-NEXT: s_andn2_b32 s4, s6, exec_lo
-; GFX10-NEXT: s_and_b32 s6, exec_lo, s7
-; GFX10-NEXT: s_or_b32 s6, s4, s6
-; GFX10-NEXT: s_andn2_b32 exec_lo, exec_lo, s5
+; GFX10-NEXT: v_cmp_gt_f32_e32 vcc_lo, v4, v0
+; GFX10-NEXT: s_or_b32 s4, vcc_lo, s4
+; GFX10-NEXT: s_andn2_b32 s6, s6, exec_lo
+; GFX10-NEXT: s_and_b32 s7, exec_lo, s5
+; GFX10-NEXT: s_or_b32 s6, s6, s7
+; GFX10-NEXT: s_andn2_b32 exec_lo, exec_lo, s4
; GFX10-NEXT: s_cbranch_execnz .LBB2_1
; GFX10-NEXT: ; %bb.2: ; %exit
-; GFX10-NEXT: s_or_b32 exec_lo, exec_lo, s5
+; GFX10-NEXT: s_or_b32 exec_lo, exec_lo, s4
; GFX10-NEXT: v_cndmask_b32_e64 v0, 0, 1.0, s6
; GFX10-NEXT: flat_store_dword v[2:3], v0
; GFX10-NEXT: s_waitcnt lgkmcnt(0)
@@ -197,7 +193,7 @@ define void @divergent_i1_xor_used_outside_loop_larger_loop_body(i32 %num.elts,
; GFX10-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
; GFX10-NEXT: v_cmp_eq_u32_e32 vcc_lo, 0, v0
; GFX10-NEXT: s_mov_b32 s5, 0
-; GFX10-NEXT: s_mov_b32 s6, 1
+; GFX10-NEXT: s_mov_b32 s6, -1
; GFX10-NEXT: s_and_saveexec_b32 s4, vcc_lo
; GFX10-NEXT: s_cbranch_execz .LBB3_6
; GFX10-NEXT: ; %bb.1: ; %loop.start.preheader
@@ -332,7 +328,7 @@ define void @divergent_i1_icmp_used_outside_loop(i32 %v0, i32 %v1, ptr addrspace
; GFX10-NEXT: s_waitcnt_depctr 0xffe3
; GFX10-NEXT: s_or_b32 exec_lo, exec_lo, s7
; GFX10-NEXT: v_cmp_ne_u32_e64 s4, v1, v4
-; GFX10-NEXT: s_mov_b32 s7, 1
+; GFX10-NEXT: s_mov_b32 s7, -1
; GFX10-NEXT: ; implicit-def: $vgpr5
; GFX10-NEXT: s_and_saveexec_b32 s8, s4
; GFX10-NEXT: s_cbranch_execz .LBB4_1
@@ -410,7 +406,7 @@ define amdgpu_ps void @divergent_i1_freeze_used_outside_loop(i32 %n, ptr addrspa
; GFX10-LABEL: divergent_i1_freeze_used_outside_loop:
; GFX10: ; %bb.0: ; %entry
; GFX10-NEXT: s_mov_b32 s0, 0
-; GFX10-NEXT: s_mov_b32 s3, 1
+; GFX10-NEXT: s_mov_b32 s3, -1
; GFX10-NEXT: v_mov_b32_e32 v5, s0
; GFX10-NEXT: ; implicit-def: $sgpr1
; GFX10-NEXT: ; implicit-def: $sgpr2
diff --git a/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-divergent-i1-used-outside-loop.mir b/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-divergent-i1-used-outside-loop.mir
index ace9bec6e1c2c8..206c0adb6c0c1f 100644
--- a/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-divergent-i1-used-outside-loop.mir
+++ b/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-divergent-i1-used-outside-loop.mir
@@ -175,14 +175,15 @@ body: |
; GFX10-NEXT: [[S_ANDN2_B32_3:%[0-9]+]]:sreg_32_xm0_xexec(s1) = S_ANDN2_B32 [[COPY9]](s1), $exec_lo, implicit-def $scc
; GFX10-NEXT: [[S_AND_B32_3:%[0-9]+]]:sreg_32_xm0_xexec(s1) = S_AND_B32 $exec_lo, [[COPY13]](s1), implicit-def $scc
; GFX10-NEXT: [[S_OR_B32_3:%[0-9]+]]:sreg_32_xm0_xexec(s1) = S_OR_B32 [[S_ANDN2_B32_3]](s1), [[S_AND_B32_3]](s1), implicit-def $scc
+ ; GFX10-NEXT: [[COPY14:%[0-9]+]]:sreg_32(s1) = COPY [[COPY7]](s1)
; GFX10-NEXT: G_BRCOND [[ICMP1]](s1), %bb.1
; GFX10-NEXT: G_BR %bb.4
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: bb.4:
- ; GFX10-NEXT: [[COPY14:%[0-9]+]]:sreg_32(s1) = COPY [[COPY7]](s1)
+ ; GFX10-NEXT: [[COPY15:%[0-9]+]]:sreg_32(s1) = COPY [[COPY14]](s1)
; GFX10-NEXT: [[C6:%[0-9]+]]:_(s32) = G_FCONSTANT float 0.000000e+00
; GFX10-NEXT: [[C7:%[0-9]+]]:_(s32) = G_FCONSTANT float 1.000000e+00
- ; GFX10-NEXT: [[SELECT:%[0-9]+]]:_(s32) = G_SELECT [[COPY14]](s1), [[C7]], [[C6]]
+ ; GFX10-NEXT: [[SELECT:%[0-9]+]]:_(s32) = G_SELECT [[COPY15]](s1), [[C7]], [[C6]]
; GFX10-NEXT: G_STORE [[SELECT]](s32), [[MV1]](p0) :: (store (s32))
; GFX10-NEXT: SI_RETURN
bb.0:
@@ -255,37 +256,40 @@ body: |
; GFX10-NEXT: [[C:%[0-9]+]]:_(s32) = G_CONSTANT i32 0
; GFX10-NEXT: [[C1:%[0-9]+]]:_(s32) = G_FCONSTANT float 1.000000e+00
; GFX10-NEXT: [[FCMP:%[0-9]+]]:_(s1) = G_FCMP floatpred(ogt), [[COPY1]](s32), [[C1]]
+ ; GFX10-NEXT: [[COPY4:%[0-9]+]]:sreg_32(s1) = COPY [[FCMP]](s1)
; GFX10-NEXT: [[DEF:%[0-9]+]]:sreg_32(s1) = IMPLICIT_DEF
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: bb.1:
; GFX10-NEXT: successors: %bb.2(0x04000000), %bb.1(0x7c000000)
; GFX10-NEXT: {{ $}}
- ; GFX10-NEXT: [[PHI:%[0-9]+]]:sreg_32(s1) = PHI [[DEF]](s1), %bb.0, %24(s1), %bb.1
- ; GFX10-NEXT: [[PHI1:%[0-9]+]]:_(s32) = G_PHI %9(s32), %bb.1, [[C]](s32), %bb.0
- ; GFX10-NEXT: [[PHI2:%[0-9]+]]:_(s32) = G_PHI [[C]](s32), %bb.0, %11(s32), %bb.1
- ; GFX10-NEXT: [[PHI3:%[0-9]+]]:sreg_32(s1) = G_PHI [[FCMP]](s1), %bb.0, %13(s1), %bb.1
- ; GFX10-NEXT: [[COPY4:%[0-9]+]]:sreg_32(s1) = COPY [[PHI]](s1)
+ ; GFX10-NEXT: [[PHI:%[0-9]+]]:sreg_32(s1) = PHI [[DEF]](s1), %bb.0, %27(s1), %bb.1
+ ; GFX10-NEXT: [[PHI1:%[0-9]+]]:sreg_32(s1) = PHI [[COPY4]](s1), %bb.0, %24(s1), %bb.1
+ ; GFX10-NEXT: [[PHI2:%[0-9]+]]:_(s32) = G_PHI %9(s32), %bb.1, [[C]](s32), %bb.0
+ ; GFX10-NEXT: [[PHI3:%[0-9]+]]:_(s32) = G_PHI [[C]](s32), %bb.0, %11(s32), %bb.1
+ ; GFX10-NEXT: [[COPY5:%[0-9]+]]:sreg_32(s1) = COPY [[PHI]](s1)
+ ; GFX10-NEXT: [[COPY6:%[0-9]+]]:sreg_32(s1) = COPY [[PHI1]](s1)
; GFX10-NEXT: [[C2:%[0-9]+]]:_(s1) = G_CONSTANT i1 true
- ; GFX10-NEXT: [[XOR:%[0-9]+]]:_(s1) = G_XOR [[PHI3]], [[C2]]
- ; GFX10-NEXT: [[COPY5:%[0-9]+]]:sreg_32(s1) = COPY [[XOR]](s1)
- ; GFX10-NEXT: [[UITOFP:%[0-9]+]]:_(s32) = G_UITOFP [[PHI2]](s32)
+ ; GFX10-NEXT: [[XOR:%[0-9]+]]:_(s1) = G_XOR [[COPY6]], [[C2]]
+ ; GFX10-NEXT: [[COPY7:%[0-9]+]]:sreg_32(s1) = COPY [[XOR]](s1)
+ ; GFX10-NEXT: [[UITOFP:%[0-9]+]]:_(s32) = G_UITOFP [[PHI3]](s32)
; GFX10-NEXT: [[FCMP1:%[0-9]+]]:_(s1) = G_FCMP floatpred(ogt), [[UITOFP]](s32), [[COPY]]
; GFX10-NEXT: [[C3:%[0-9]+]]:_(s32) = G_CONSTANT i32 1
- ; GFX10-NEXT: [[ADD:%[0-9]+]]:_(s32) = G_ADD [[PHI2]], [[C3]]
- ; GFX10-NEXT: [[INTRINSIC_CONVERGENT:%[0-9]+]]:sreg_32_xm0_xexec(s32) = G_INTRINSIC_CONVERGENT intrinsic(@llvm.amdgcn.if.break), [[FCMP1]](s1), [[PHI1]](s32)
- ; GFX10-NEXT: [[S_ANDN2_B32_:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY4]](s1), $exec_lo, implicit-def $scc
- ; GFX10-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY5]](s1), implicit-def $scc
+ ; GFX10-NEXT: [[ADD:%[0-9]+]]:_(s32) = G_ADD [[PHI3]], [[C3]]
+ ; GFX10-NEXT: [[INTRINSIC_CONVERGENT:%[0-9]+]]:sreg_32_xm0_xexec(s32) = G_INTRINSIC_CONVERGENT intrinsic(@llvm.amdgcn.if.break), [[FCMP1]](s1), [[PHI2]](s32)
+ ; GFX10-NEXT: [[COPY8:%[0-9]+]]:sreg_32(s1) = COPY [[XOR]](s1)
+ ; GFX10-NEXT: [[S_ANDN2_B32_:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY5]](s1), $exec_lo, implicit-def $scc
+ ; GFX10-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY7]](s1), implicit-def $scc
; GFX10-NEXT: [[S_OR_B32_:%[0-9]+]]:sreg_32(s1) = S_OR_B32 [[S_ANDN2_B32_]](s1), [[S_AND_B32_]](s1), implicit-def $scc
; GFX10-NEXT: SI_LOOP [[INTRINSIC_CONVERGENT]](s32), %bb.1, implicit-def $exec, implicit-def $scc, implicit $exec
; GFX10-NEXT: G_BR %bb.2
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: bb.2:
; GFX10-NEXT: [[PHI4:%[0-9]+]]:_(s32) = G_PHI [[INTRINSIC_CONVERGENT]](s32), %bb.1
- ; GFX10-NEXT: [[COPY6:%[0-9]+]]:sreg_32(s1) = COPY [[S_OR_B32_]](s1)
+ ; GFX10-NEXT: [[COPY9:%[0-9]+]]:sreg_32(s1) = COPY [[S_OR_B32_]](s1)
; GFX10-NEXT: G_INTRINSIC_CONVERGENT_W_SIDE_EFFECTS intrinsic(@llvm.amdgcn.end.cf), [[PHI4]](s32)
; GFX10-NEXT: [[C4:%[0-9]+]]:_(s32) = G_FCONSTANT float 0.000000e+00
; GFX10-NEXT: [[C5:%[0-9]+]]:_(s32) = G_FCONSTANT float 1.000000e+00
- ; GFX10-NEXT: [[SELECT:%[0-9]+]]:_(s32) = G_SELECT [[COPY6]](s1), [[C5]], [[C4]]
+ ; GFX10-NEXT: [[SELECT:%[0-9]+]]:_(s32) = G_SELECT [[COPY9]](s1), [[C5]], [[C4]]
; GFX10-NEXT: G_STORE [[SELECT]](s32), [[MV]](p0) :: (store (s32))
; GFX10-NEXT: SI_RETURN
bb.0:
@@ -349,7 +353,8 @@ body: |
; GFX10-NEXT: [[C:%[0-9]+]]:_(s32) = G_CONSTANT i32 0
; GFX10-NEXT: [[ICMP:%[0-9]+]]:sreg_32_xm0_xexec(s1) = G_ICMP intpred(eq), [[COPY]](s32), [[C]]
; GFX10-NEXT: [[C1:%[0-9]+]]:_(s1) = G_CONSTANT i1 true
- ; GFX10-NEXT: [[COPY5:%[0-9]+]]:sreg_32_xm0_xexec(s1) = COPY [[C1]](s1)
+ ; GFX10-NEXT: [[COPY5:%[0-9]+]]:sreg_32(s1) = COPY [[C1]](s1)
+ ; GFX10-NEXT: [[COPY6:%[0-9]+]]:sreg_32_xm0_xexec(s1) = COPY [[COPY5]](s1)
; GFX10-NEXT: [[SI_IF:%[0-9]+]]:sreg_32_xm0_xexec(s32) = SI_IF [[ICMP]](s1), %bb.2, implicit-def $exec, implicit-def $scc, implicit $exec
; GFX10-NEXT: G_BR %bb.1
; GFX10-NEXT: {{ $}}
@@ -365,26 +370,26 @@ body: |
; GFX10-NEXT: bb.2:
; GFX10-NEXT: successors: %bb.5(0x40000000), %bb.6(0x40000000)
; GFX10-NEXT: {{ $}}
- ; GFX10-NEXT: [[PHI:%[0-9]+]]:sreg_32_xm0_xexec(s1) = PHI [[C1]](s1), %bb.0, %39(s1), %bb.8
- ; GFX10-NEXT: [[COPY6:%[0-9]+]]:sreg_32_xm0_xexec(s1) = COPY [[PHI]](s1)
+ ; GFX10-NEXT: [[PHI:%[0-9]+]]:sreg_32_xm0_xexec(s1) = PHI [[COPY5]](s1), %bb.0, %40(s1), %bb.8
+ ; GFX10-NEXT: [[COPY7:%[0-9]+]]:sreg_32_xm0_xexec(s1) = COPY [[PHI]](s1)
; GFX10-NEXT: G_INTRINSIC_CONVERGENT_W_SIDE_EFFECTS intrinsic(@llvm.amdgcn.end.cf), [[SI_IF]](s32)
- ; GFX10-NEXT: [[SI_IF1:%[0-9]+]]:sreg_32_xm0_xexec(s32) = SI_IF [[COPY6]](s1), %bb.6, implicit-def $exec, implicit-def $scc, implicit $exec
+ ; GFX10-NEXT: [[SI_IF1:%[0-9]+]]:sreg_32_xm0_xexec(s32) = SI_IF [[COPY7]](s1), %bb.6, implicit-def $exec, implicit-def $scc, implicit $exec
; GFX10-NEXT: G_BR %bb.5
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: bb.3:
; GFX10-NEXT: successors: %bb.4(0x40000000), %bb.7(0x40000000)
; GFX10-NEXT: {{ $}}
- ; GFX10-NEXT: [[PHI1:%[0-9]+]]:sreg_32(s1) = PHI [[DEF3]](s1), %bb.1, %72(s1), %bb.7
- ; GFX10-NEXT: [[PHI2:%[0-9]+]]:sreg_32(s1) = PHI [[DEF2]](s1), %bb.1, %61(s1), %bb.7
- ; GFX10-NEXT: [[PHI3:%[0-9]+]]:sreg_32(s1) = PHI [[DEF1]](s1), %bb.1, %48(s1), %bb.7
+ ; GFX10-NEXT: [[PHI1:%[0-9]+]]:sreg_32(s1) = PHI [[DEF3]](s1), %bb.1, %73(s1), %bb.7
+ ; GFX10-NEXT: [[PHI2:%[0-9]+]]:sreg_32(s1) = PHI [[DEF2]](s1), %bb.1, %62(s1), %bb.7
+ ; GFX10-NEXT: [[PHI3:%[0-9]+]]:sreg_32(s1) = PHI [[DEF1]](s1), %bb.1, %49(s1), %bb.7
; GFX10-NEXT: [[PHI4:%[0-9]+]]:_(s32) = G_PHI [[C2]](s32), %bb.1, %17(s32), %bb.7
; GFX10-NEXT: [[PHI5:%[0-9]+]]:_(s32) = G_PHI %19(s32), %bb.7, [[C2]](s32), %bb.1
- ; GFX10-NEXT: [[COPY7:%[0-9]+]]:sreg_32(s1) = COPY [[PHI1]](s1)
- ; GFX10-NEXT: [[COPY8:%[0-9]+]]:sreg_32(s1) = COPY [[PHI2]](s1)
- ; GFX10-NEXT: [[COPY9:%[0-9]+]]:sreg_32(s1) = COPY [[PHI3]](s1)
+ ; GFX10-NEXT: [[COPY8:%[0-9]+]]:sreg_32(s1) = COPY [[PHI1]](s1)
+ ; GFX10-NEXT: [[COPY9:%[0-9]+]]:sreg_32(s1) = COPY [[PHI2]](s1)
+ ; GFX10-NEXT: [[COPY10:%[0-9]+]]:sreg_32(s1) = COPY [[PHI3]](s1)
; GFX10-NEXT: [[C3:%[0-9]+]]:_(s1) = G_CONSTANT i1 true
- ; GFX10-NEXT: [[COPY10:%[0-9]+]]:sreg_32(s1) = COPY [[C3]](s1)
; GFX10-NEXT: [[COPY11:%[0-9]+]]:sreg_32(s1) = COPY [[C3]](s1)
+ ; GFX10-NEXT: [[COPY12:%[0-9]+]]:sreg_32(s1) = COPY [[C3]](s1)
; GFX10-NEXT: [[SEXT:%[0-9]+]]:_(s64) = G_SEXT [[PHI5]](s32)
; GFX10-NEXT: [[C4:%[0-9]+]]:_(s32) = G_CONSTANT i32 2
; GFX10-NEXT: [[SHL:%[0-9]+]]:_(s64) = G_SHL [[SEXT]], [[C4]](s32)
@@ -392,14 +397,14 @@ body: |
; GFX10-NEXT: [[LOAD:%[0-9]+]]:_(s32) = G_LOAD [[PTR_ADD]](p1) :: (load (s32), addrspace 1)
; GFX10-NEXT: [[C5:%[0-9]+]]:_(s32) = G_CONSTANT i32 0
; GFX10-NEXT: [[ICMP1:%[0-9]+]]:sreg_32_xm0_xexec(s1) = G_ICMP intpred(ne), [[LOAD]](s32), [[C5]]
- ; GFX10-NEXT: [[S_ANDN2_B32_:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY9]](s1), $exec_lo, implicit-def $scc
- ; GFX10-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY11]](s1), implicit-def $scc
+ ; GFX10-NEXT: [[S_ANDN2_B32_:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY10]](s1), $exec_lo, implicit-def $scc
+ ; GFX10-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY12]](s1), implicit-def $scc
; GFX10-NEXT: [[S_OR_B32_:%[0-9]+]]:sreg_32(s1) = S_OR_B32 [[S_ANDN2_B32_]](s1), [[S_AND_B32_]](s1), implicit-def $scc
- ; GFX10-NEXT: [[COPY12:%[0-9]+]]:sreg_32(s1) = COPY [[S_OR_B32_]](s1)
- ; GFX10-NEXT: [[S_ANDN2_B32_1:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY8]](s1), $exec_lo, implicit-def $scc
- ; GFX10-NEXT: [[S_AND_B32_1:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY10]](s1), implicit-def $scc
+ ; GFX10-NEXT: [[COPY13:%[0-9]+]]:sreg_32(s1) = COPY [[S_OR_B32_]](s1)
+ ; GFX10-NEXT: [[S_ANDN2_B32_1:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY9]](s1), $exec_lo, implicit-def $scc
+ ; GFX10-NEXT: [[S_AND_B32_1:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY11]](s1), implicit-def $scc
; GFX10-NEXT: [[S_OR_B32_1:%[0-9]+]]:sreg_32(s1) = S_OR_B32 [[S_ANDN2_B32_1]](s1), [[S_AND_B32_1]](s1), implicit-def $scc
- ; GFX10-NEXT: [[COPY13:%[0-9]+]]:sreg_32(s1) = COPY [[S_OR_B32_1]](s1)
+ ; GFX10-NEXT: [[COPY14:%[0-9]+]]:sreg_32(s1) = COPY [[S_OR_B32_1]](s1)
; GFX10-NEXT: [[SI_IF2:%[0-9]+]]:sreg_32_xm0_xexec(s32) = SI_IF [[ICMP1]](s1), %bb.7, implicit-def $exec, implicit-def $scc, implicit $exec
; GFX10-NEXT: G_BR %bb.4
; GFX10-NEXT: {{ $}}
@@ -407,16 +412,16 @@ body: |
; GFX10-NEXT: successors: %bb.7(0x80000000)
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: [[C6:%[0-9]+]]:_(s1) = G_CONSTANT i1 false
- ; GFX10-NEXT: [[COPY14:%[0-9]+]]:sreg_32(s1) = COPY [[C6]](s1)
+ ; GFX10-NEXT: [[COPY15:%[0-9]+]]:sreg_32(s1) = COPY [[C6]](s1)
; GFX10-NEXT: [[C7:%[0-9]+]]:_(s32) = G_CONSTANT i32 1
; GFX10-NEXT: [[ADD:%[0-9]+]]:_(s32) = G_ADD [[PHI5]], [[C7]]
; GFX10-NEXT: [[ICMP2:%[0-9]+]]:_(s1) = G_ICMP intpred(slt), [[PHI5]](s32), [[COPY]]
- ; GFX10-NEXT: [[COPY15:%[0-9]+]]:sreg_32(s1) = COPY [[ICMP2]](s1)
- ; GFX10-NEXT: [[S_ANDN2_B32_2:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY12]](s1), $exec_lo, implicit-def $scc
- ; GFX10-NEXT: [[S_AND_B32_2:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY14]](s1), implicit-def $scc
+ ; GFX10-NEXT: [[COPY16:%[0-9]+]]:sreg_32(s1) = COPY [[ICMP2]](s1)
+ ; GFX10-NEXT: [[S_ANDN2_B32_2:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY13]](s1), $exec_lo, implicit-def $scc
+ ; GFX10-NEXT: [[S_AND_B32_2:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY15]](s1), implicit-def $scc
; GFX10-NEXT: [[S_OR_B32_2:%[0-9]+]]:sreg_32(s1) = S_OR_B32 [[S_ANDN2_B32_2]](s1), [[S_AND_B32_2]](s1), implicit-def $scc
- ; GFX10-NEXT: [[S_ANDN2_B32_3:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY13]](s1), $exec_lo, implicit-def $scc
- ; GFX10-NEXT: [[S_AND_B32_3:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY15]](s1), implicit-def $scc
+ ; GFX10-NEXT: [[S_ANDN2_B32_3:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY14]](s1), $exec_lo, implicit-def $scc
+ ; GFX10-NEXT: [[S_AND_B32_3:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY16]](s1), implicit-def $scc
; GFX10-NEXT: [[S_OR_B32_3:%[0-9]+]]:sreg_32(s1) = S_OR_B32 [[S_ANDN2_B32_3]](s1), [[S_AND_B32_3]](s1), implicit-def $scc
; GFX10-NEXT: G_BR %bb.7
; GFX10-NEXT: {{ $}}
@@ -436,15 +441,15 @@ body: |
; GFX10-NEXT: [[PHI6:%[0-9]+]]:sreg_32(s1) = PHI [[S_OR_B32_1]](s1), %bb.3, [[S_OR_B32_3]](s1), %bb.4
; GFX10-NEXT: [[PHI7:%[0-9]+]]:sreg_32(s1) = PHI [[S_OR_B32_]](s1), %bb.3, [[S_OR_B32_2]](s1), %bb.4
; GFX10-NEXT: [[PHI8:%[0-9]+]]:_(s32) = G_PHI [[ADD]](s32), %bb.4, [[DEF]](s32), %bb.3
- ; GFX10-NEXT: [[COPY16:%[0-9]+]]:sreg_32(s1) = COPY [[PHI6]](s1)
- ; GFX10-NEXT: [[COPY17:%[0-9]+]]:sreg_32(s1) = COPY [[PHI7]](s1)
+ ; GFX10-NEXT: [[COPY17:%[0-9]+]]:sreg_32(s1) = COPY [[PHI6]](s1)
+ ; GFX10-NEXT: [[COPY18:%[0-9]+]]:sreg_32(s1) = COPY [[PHI7]](s1)
; GFX10-NEXT: G_INTRINSIC_CONVERGENT_W_SIDE_EFFECTS intrinsic(@llvm.amdgcn.end.cf), [[SI_IF2]](s32)
; GFX10-NEXT: [[C9:%[0-9]+]]:_(s1) = G_CONSTANT i1 true
- ; GFX10-NEXT: [[XOR:%[0-9]+]]:_(s1) = G_XOR [[COPY17]], [[C9]]
- ; GFX10-NEXT: [[COPY18:%[0-9]+]]:sreg_32(s1) = COPY [[XOR]](s1)
- ; GFX10-NEXT: [[INTRINSIC_CONVERGENT:%[0-9]+]]:sreg_32_xm0_xexec(s32) = G_INTRINSIC_CONVERGENT intrinsic(@llvm.amdgcn.if.break), [[COPY16]](s1), [[PHI4]](s32)
- ; GFX10-NEXT: [[S_ANDN2_B32_4:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY7]](s1), $exec_lo, implicit-def $scc
- ; GFX10-NEXT: [[S_AND_B32_4:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY18]](s1), implicit-def $scc
+ ; GFX10-NEXT: [[XOR:%[0-9]+]]:_(s1) = G_XOR [[COPY18]], [[C9]]
+ ; GFX10-NEXT: [[COPY19:%[0-9]+]]:sreg_32(s1) = COPY [[XOR]](s1)
+ ; GFX10-NEXT: [[INTRINSIC_CONVERGENT:%[0-9]+]]:sreg_32_xm0_xexec(s32) = G_INTRINSIC_CONVERGENT intrinsic(@llvm.amdgcn.if.break), [[COPY17]](s1), [[PHI4]](s32)
+ ; GFX10-NEXT: [[S_ANDN2_B32_4:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY8]](s1), $exec_lo, implicit-def $scc
+ ; GFX10-NEXT: [[S_AND_B32_4:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY19]](s1), implicit-def $scc
; GFX10-NEXT: [[S_OR_B32_4:%[0-9]+]]:sreg_32(s1) = S_OR_B32 [[S_ANDN2_B32_4]](s1), [[S_AND_B32_4]](s1), implicit-def $scc
; GFX10-NEXT: SI_LOOP [[INTRINSIC_CONVERGENT]](s32), %bb.3, implicit-def $exec, implicit-def $scc, implicit $exec
; GFX10-NEXT: G_BR %bb.8
@@ -453,11 +458,11 @@ body: |
; GFX10-NEXT: successors: %bb.2(0x80000000)
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: [[PHI9:%[0-9]+]]:_(s32) = G_PHI [[INTRINSIC_CONVERGENT]](s32), %bb.7
- ; GFX10-NEXT: [[COPY19:%[0-9]+]]:sreg_32(s1) = COPY [[S_OR_B32_4]](s1)
- ; GFX10-NEXT: [[COPY20:%[0-9]+]]:sreg_32_xm0_xexec(s1) = COPY [[COPY19]](s1)
+ ; GFX10-NEXT: [[COPY20:%[0-9]+]]:sreg_32(s1) = COPY [[S_OR_B32_4]](s1)
+ ; GFX10-NEXT: [[COPY21:%[0-9]+]]:sreg_32_xm0_xexec(s1) = COPY [[COPY20]](s1)
; GFX10-NEXT: G_INTRINSIC_CONVERGENT_W_SIDE_EFFECTS intrinsic(@llvm.amdgcn.end.cf), [[PHI9]](s32)
- ; GFX10-NEXT: [[S_ANDN2_B32_5:%[0-9]+]]:sreg_32_xm0_xexec(s1) = S_ANDN2_B32 [[COPY5]](s1), $exec_lo, implicit-def $scc
- ; GFX10-NEXT: [[S_AND_B32_5:%[0-9]+]]:sreg_32_xm0_xexec(s1) = S_AND_B32 $exec_lo, [[COPY20]](s1), implicit-def $scc
+ ; GFX10-NEXT: [[S_ANDN2_B32_5:%[0-9]+]]:sreg_32_xm0_xexec(s1) = S_ANDN2_B32 [[COPY6]](s1), $exec_lo, implicit-def $scc
+ ; GFX10-NEXT: [[S_AND_B32_5:%[0-9]+]]:sreg_32_xm0_xexec(s1) = S_AND_B32 $exec_lo, [[COPY21]](s1), implicit-def $scc
; GFX10-NEXT: [[S_OR_B32_5:%[0-9]+]]:sreg_32_xm0_xexec(s1) = S_OR_B32 [[S_ANDN2_B32_5]](s1), [[S_AND_B32_5]](s1), implicit-def $scc
; GFX10-NEXT: G_BR %bb.2
bb.0:
@@ -574,7 +579,7 @@ body: |
; GFX10-NEXT: bb.1:
; GFX10-NEXT: successors: %bb.2(0x80000000)
; GFX10-NEXT: {{ $}}
- ; GFX10-NEXT: [[PHI:%[0-9]+]]:sreg_32_xm0_xexec(s1) = PHI [[DEF1]](s1), %bb.0, %38(s1), %bb.6
+ ; GFX10-NEXT: [[PHI:%[0-9]+]]:sreg_32_xm0_xexec(s1) = PHI [[DEF1]](s1), %bb.0, %39(s1), %bb.6
; GFX10-NEXT: [[PHI1:%[0-9]+]]:_(s32) = G_PHI %11(s32), %bb.6, [[C]](s32), %bb.0
; GFX10-NEXT: [[PHI2:%[0-9]+]]:_(s32) = G_PHI [[C]](s32), %bb.0, %13(s32), %bb.6
; GFX10-NEXT: [[COPY6:%[0-9]+]]:sreg_32_xm0_xexec(s1) = COPY [[PHI]](s1)
@@ -600,9 +605,10 @@ body: |
; GFX10-NEXT: successors: %bb.5(0x40000000), %bb.6(0x40000000)
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: [[C2:%[0-9]+]]:_(s1) = G_CONSTANT i1 true
- ; GFX10-NEXT: [[COPY8:%[0-9]+]]:sreg_32(s1) = COPY [[C2]](s1)
; GFX10-NEXT: G_INTRINSIC_CONVERGENT_W_SIDE_EFFECTS intrinsic(@llvm.amdgcn.end.cf), [[SI_IF]](s32)
; GFX10-NEXT: [[ICMP1:%[0-9]+]]:sreg_32_xm0_xexec(s1) = G_ICMP intpred(ne), [[COPY1]](s32), [[PHI2]]
+ ; GFX10-NEXT: [[COPY8:%[0-9]+]]:sreg_32(s1) = COPY [[C2]](s1)
+ ; GFX10-NEXT: [[COPY9:%[0-9]+]]:sreg_32(s1) = COPY [[COPY8]](s1)
; GFX10-NEXT: [[SI_IF1:%[0-9]+]]:sreg_32_xm0_xexec(s32) = SI_IF [[ICMP1]](s1), %bb.6, implicit-def $exec, implicit-def $scc, implicit $exec
; GFX10-NEXT: G_BR %bb.5
; GFX10-NEXT: {{ $}}
@@ -610,21 +616,21 @@ body: |
; GFX10-NEXT: successors: %bb.6(0x80000000)
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: [[C3:%[0-9]+]]:_(s1) = G_CONSTANT i1 false
- ; GFX10-NEXT: [[COPY9:%[0-9]+]]:sreg_32(s1) = COPY [[C3]](s1)
+ ; GFX10-NEXT: [[COPY10:%[0-9]+]]:sreg_32(s1) = COPY [[C3]](s1)
; GFX10-NEXT: [[C4:%[0-9]+]]:_(s32) = G_CONSTANT i32 1
; GFX10-NEXT: [[ADD:%[0-9]+]]:_(s32) = G_ADD [[PHI2]], [[C4]]
- ; GFX10-NEXT: [[S_ANDN2_B32_:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY8]](s1), $exec_lo, implicit-def $scc
- ; GFX10-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY9]](s1), implicit-def $scc
+ ; GFX10-NEXT: [[S_ANDN2_B32_:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY9]](s1), $exec_lo, implicit-def $scc
+ ; GFX10-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY10]](s1), implicit-def $scc
; GFX10-NEXT: [[S_OR_B32_:%[0-9]+]]:sreg_32(s1) = S_OR_B32 [[S_ANDN2_B32_]](s1), [[S_AND_B32_]](s1), implicit-def $scc
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: bb.6:
; GFX10-NEXT: successors: %bb.7(0x04000000), %bb.1(0x7c000000)
; GFX10-NEXT: {{ $}}
- ; GFX10-NEXT: [[PHI3:%[0-9]+]]:sreg_32(s1) = PHI [[C2]](s1), %bb.4, [[S_OR_B32_]](s1), %bb.5
+ ; GFX10-NEXT: [[PHI3:%[0-9]+]]:sreg_32(s1) = PHI [[COPY8]](s1), %bb.4, [[S_OR_B32_]](s1), %bb.5
; GFX10-NEXT: [[PHI4:%[0-9]+]]:_(s32) = G_PHI [[ADD]](s32), %bb.5, [[DEF]](s32), %bb.4
- ; GFX10-NEXT: [[COPY10:%[0-9]+]]:sreg_32(s1) = COPY [[PHI3]](s1)
+ ; GFX10-NEXT: [[COPY11:%[0-9]+]]:sreg_32(s1) = COPY [[PHI3]](s1)
; GFX10-NEXT: G_INTRINSIC_CONVERGENT_W_SIDE_EFFECTS intrinsic(@llvm.amdgcn.end.cf), [[SI_IF1]](s32)
- ; GFX10-NEXT: [[INTRINSIC_CONVERGENT:%[0-9]+]]:sreg_32_xm0_xexec(s32) = G_INTRINSIC_CONVERGENT intrinsic(@llvm.amdgcn.if.break), [[COPY10]](s1), [[PHI1]](s32)
+ ; GFX10-NEXT: [[INTRINSIC_CONVERGENT:%[0-9]+]]:sreg_32_xm0_xexec(s32) = G_INTRINSIC_CONVERGENT intrinsic(@llvm.amdgcn.if.break), [[COPY11]](s1), [[PHI1]](s32)
; GFX10-NEXT: [[S_ANDN2_B32_1:%[0-9]+]]:sreg_32_xm0_xexec(s1) = S_ANDN2_B32 [[COPY6]](s1), $exec_lo, implicit-def $scc
; GFX10-NEXT: [[S_AND_B32_1:%[0-9]+]]:sreg_32_xm0_xexec(s1) = S_AND_B32 $exec_lo, [[COPY7]](s1), implicit-def $scc
; GFX10-NEXT: [[S_OR_B32_1:%[0-9]+]]:sreg_32_xm0_xexec(s1) = S_OR_B32 [[S_ANDN2_B32_1]](s1), [[S_AND_B32_1]](s1), implicit-def $scc
@@ -636,9 +642,9 @@ body: |
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: [[PHI5:%[0-9]+]]:_(s32) = G_PHI [[INTRINSIC_CONVERGENT]](s32), %bb.6
; GFX10-NEXT: [[PHI6:%[0-9]+]]:_(s32) = G_PHI [[PHI2]](s32), %bb.6
- ; GFX10-NEXT: [[COPY11:%[0-9]+]]:sreg_32_xm0_xexec(s1) = COPY [[S_OR_B32_1]](s1)
+ ; GFX10-NEXT: [[COPY12:%[0-9]+]]:sreg_32_xm0_xexec(s1) = COPY [[S_OR_B32_1]](s1)
; GFX10-NEXT: G_INTRINSIC_CONVERGENT_W_SIDE_EFFECTS intrinsic(@llvm.amdgcn.end.cf), [[PHI5]](s32)
- ; GFX10-NEXT: [[SI_IF2:%[0-9]+]]:sreg_32_xm0_xexec(s32) = SI_IF [[COPY11]](s1), %bb.9, implicit-def $exec, implicit-def $scc, implicit $exec
+ ; GFX10-NEXT: [[SI_IF2:%[0-9]+]]:sreg_32_xm0_xexec(s32) = SI_IF [[COPY12]](s1), %bb.9, implicit-def $exec, implicit-def $scc, implicit $exec
; GFX10-NEXT: G_BR %bb.8
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: bb.8:
@@ -751,26 +757,27 @@ body: |
; GFX10-NEXT: [[MV1:%[0-9]+]]:_(p0) = G_MERGE_VALUES [[COPY3]](s32), [[COPY4]](s32)
; GFX10-NEXT: [[C:%[0-9]+]]:_(s32) = G_CONSTANT i32 0
; GFX10-NEXT: [[C1:%[0-9]+]]:_(s1) = G_CONSTANT i1 true
+ ; GFX10-NEXT: [[COPY5:%[0-9]+]]:sreg_32(s1) = COPY [[C1]](s1)
; GFX10-NEXT: [[DEF:%[0-9]+]]:sreg_32(s1) = IMPLICIT_DEF
; GFX10-NEXT: [[DEF1:%[0-9]+]]:sreg_32(s1) = IMPLICIT_DEF
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: bb.1:
; GFX10-NEXT: successors: %bb.2(0x40000000), %bb.3(0x40000000)
; GFX10-NEXT: {{ $}}
- ; GFX10-NEXT: [[PHI:%[0-9]+]]:sreg_32(s1) = PHI [[DEF1]](s1), %bb.0, %53(s1), %bb.3
- ; GFX10-NEXT: [[PHI1:%[0-9]+]]:sreg_32(s1) = PHI [[DEF]](s1), %bb.0, %42(s1), %bb.3
- ; GFX10-NEXT: [[PHI2:%[0-9]+]]:sreg_32_xm0_xexec(s1) = PHI [[C1]](s1), %bb.0, %32(s1), %bb.3
+ ; GFX10-NEXT: [[PHI:%[0-9]+]]:sreg_32(s1) = PHI [[DEF1]](s1), %bb.0, %54(s1), %bb.3
+ ; GFX10-NEXT: [[PHI1:%[0-9]+]]:sreg_32(s1) = PHI [[DEF]](s1), %bb.0, %43(s1), %bb.3
+ ; GFX10-NEXT: [[PHI2:%[0-9]+]]:sreg_32_xm0_xexec(s1) = PHI [[COPY5]](s1), %bb.0, %33(s1), %bb.3
; GFX10-NEXT: [[PHI3:%[0-9]+]]:_(s32) = G_PHI %10(s32), %bb.3, [[C]](s32), %bb.0
; GFX10-NEXT: [[PHI4:%[0-9]+]]:_(s32) = G_PHI [[C]](s32), %bb.0, %12(s32), %bb.3
- ; GFX10-NEXT: [[COPY5:%[0-9]+]]:sreg_32(s1) = COPY [[PHI]](s1)
- ; GFX10-NEXT: [[COPY6:%[0-9]+]]:sreg_32(s1) = COPY [[PHI1]](s1)
- ; GFX10-NEXT: [[COPY7:%[0-9]+]]:sreg_32_xm0_xexec(s1) = COPY [[PHI2]](s1)
- ; GFX10-NEXT: [[COPY8:%[0-9]+]]:sreg_32(s1) = COPY [[COPY7]](s1)
- ; GFX10-NEXT: [[S_ANDN2_B32_:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY6]](s1), $exec_lo, implicit-def $scc
- ; GFX10-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY8]](s1), implicit-def $scc
+ ; GFX10-NEXT: [[COPY6:%[0-9]+]]:sreg_32(s1) = COPY [[PHI]](s1)
+ ; GFX10-NEXT: [[COPY7:%[0-9]+]]:sreg_32(s1) = COPY [[PHI1]](s1)
+ ; GFX10-NEXT: [[COPY8:%[0-9]+]]:sreg_32_xm0_xexec(s1) = COPY [[PHI2]](s1)
+ ; GFX10-NEXT: [[COPY9:%[0-9]+]]:sreg_32(s1) = COPY [[COPY8]](s1)
+ ; GFX10-NEXT: [[S_ANDN2_B32_:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY7]](s1), $exec_lo, implicit-def $scc
+ ; GFX10-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY9]](s1), implicit-def $scc
; GFX10-NEXT: [[S_OR_B32_:%[0-9]+]]:sreg_32(s1) = S_OR_B32 [[S_ANDN2_B32_]](s1), [[S_AND_B32_]](s1), implicit-def $scc
- ; GFX10-NEXT: [[COPY9:%[0-9]+]]:sreg_32(s1) = COPY [[S_OR_B32_]](s1)
- ; GFX10-NEXT: [[SI_IF:%[0-9]+]]:sreg_32_xm0_xexec(s32) = SI_IF [[COPY7]](s1), %bb.3, implicit-def $exec, implicit-def $scc, implicit $exec
+ ; GFX10-NEXT: [[COPY10:%[0-9]+]]:sreg_32(s1) = COPY [[S_OR_B32_]](s1)
+ ; GFX10-NEXT: [[SI_IF:%[0-9]+]]:sreg_32_xm0_xexec(s32) = SI_IF [[COPY8]](s1), %bb.3, implicit-def $exec, implicit-def $scc, implicit $exec
; GFX10-NEXT: G_BR %bb.2
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: bb.2:
@@ -783,10 +790,10 @@ body: |
; GFX10-NEXT: [[LOAD:%[0-9]+]]:_(s32) = G_LOAD [[PTR_ADD]](p1) :: (load (s32), addrspace 1)
; GFX10-NEXT: [[C3:%[0-9]+]]:_(s32) = G_CONSTANT i32 0
; GFX10-NEXT: [[ICMP:%[0-9]+]]:_(s1) = G_ICMP intpred(eq), [[LOAD]](s32), [[C3]]
- ; GFX10-NEXT: [[COPY10:%[0-9]+]]:sreg_32(s1) = COPY [[ICMP]](s1)
+ ; GFX10-NEXT: [[COPY11:%[0-9]+]]:sreg_32(s1) = COPY [[ICMP]](s1)
; GFX10-NEXT: [[DEF2:%[0-9]+]]:sreg_32_xm0_xexec(s1) = IMPLICIT_DEF
- ; GFX10-NEXT: [[S_ANDN2_B32_1:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY9]](s1), $exec_lo, implicit-def $scc
- ; GFX10-NEXT: [[S_AND_B32_1:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY10]](s1), implicit-def $scc
+ ; GFX10-NEXT: [[S_ANDN2_B32_1:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY10]](s1), $exec_lo, implicit-def $scc
+ ; GFX10-NEXT: [[S_AND_B32_1:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY11]](s1), implicit-def $scc
; GFX10-NEXT: [[S_OR_B32_1:%[0-9]+]]:sreg_32(s1) = S_OR_B32 [[S_ANDN2_B32_1]](s1), [[S_AND_B32_1]](s1), implicit-def $scc
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: bb.3:
@@ -794,32 +801,32 @@ body: |
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: [[PHI5:%[0-9]+]]:sreg_32(s1) = PHI [[S_OR_B32_]](s1), %bb.1, [[S_OR_B32_1]](s1), %bb.2
; GFX10-NEXT: [[PHI6:%[0-9]+]]:sreg_32_xm0_xexec(s1) = PHI [[PHI2]](s1), %bb.1, [[DEF2]](s1), %bb.2
- ; GFX10-NEXT: [[COPY11:%[0-9]+]]:sreg_32(s1) = COPY [[PHI5]](s1)
- ; GFX10-NEXT: [[COPY12:%[0-9]+]]:sreg_32_xm0_xexec(s1) = COPY [[PHI6]](s1)
+ ; GFX10-NEXT: [[COPY12:%[0-9]+]]:sreg_32(s1) = COPY [[PHI5]](s1)
+ ; GFX10-NEXT: [[COPY13:%[0-9]+]]:sreg_32_xm0_xexec(s1) = COPY [[PHI6]](s1)
; GFX10-NEXT: G_INTRINSIC_CONVERGENT_W_SIDE_EFFECTS intrinsic(@llvm.amdgcn.end.cf), [[SI_IF]](s32)
- ; GFX10-NEXT: [[FREEZE:%[0-9]+]]:_(s1) = G_FREEZE [[COPY11]]
- ; GFX10-NEXT: [[COPY13:%[0-9]+]]:sreg_32(s1) = COPY [[FREEZE]](s1)
- ; GFX10-NEXT: [[COPY14:%[0-9]+]]:sreg_32_xm0_xexec(s1) = COPY [[FREEZE]](s1)
+ ; GFX10-NEXT: [[FREEZE:%[0-9]+]]:_(s1) = G_FREEZE [[COPY12]]
+ ; GFX10-NEXT: [[COPY14:%[0-9]+]]:sreg_32(s1) = COPY [[FREEZE]](s1)
+ ; GFX10-NEXT: [[COPY15:%[0-9]+]]:sreg_32_xm0_xexec(s1) = COPY [[FREEZE]](s1)
; GFX10-NEXT: [[C4:%[0-9]+]]:_(s32) = G_CONSTANT i32 1
; GFX10-NEXT: [[ADD:%[0-9]+]]:_(s32) = G_ADD [[PHI4]], [[C4]]
; GFX10-NEXT: [[ICMP1:%[0-9]+]]:_(s1) = G_ICMP intpred(slt), [[PHI4]](s32), [[COPY]]
; GFX10-NEXT: [[INTRINSIC_CONVERGENT:%[0-9]+]]:sreg_32_xm0_xexec(s32) = G_INTRINSIC_CONVERGENT intrinsic(@llvm.amdgcn.if.break), [[ICMP1]](s1), [[PHI3]](s32)
- ; GFX10-NEXT: [[S_ANDN2_B32_2:%[0-9]+]]:sreg_32_xm0_xexec(s1) = S_ANDN2_B32 [[COPY12]](s1), $exec_lo, implicit-def $scc
- ; GFX10-NEXT: [[S_AND_B32_2:%[0-9]+]]:sreg_32_xm0_xexec(s1) = S_AND_B32 $exec_lo, [[COPY14]](s1), implicit-def $scc
+ ; GFX10-NEXT: [[S_ANDN2_B32_2:%[0-9]+]]:sreg_32_xm0_xexec(s1) = S_ANDN2_B32 [[COPY13]](s1), $exec_lo, implicit-def $scc
+ ; GFX10-NEXT: [[S_AND_B32_2:%[0-9]+]]:sreg_32_xm0_xexec(s1) = S_AND_B32 $exec_lo, [[COPY15]](s1), implicit-def $scc
; GFX10-NEXT: [[S_OR_B32_2:%[0-9]+]]:sreg_32_xm0_xexec(s1) = S_OR_B32 [[S_ANDN2_B32_2]](s1), [[S_AND_B32_2]](s1), implicit-def $scc
- ; GFX10-NEXT: [[S_ANDN2_B32_3:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY5]](s1), $exec_lo, implicit-def $scc
- ; GFX10-NEXT: [[S_AND_B32_3:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY13]](s1), implicit-def $scc
+ ; GFX10-NEXT: [[S_ANDN2_B32_3:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY6]](s1), $exec_lo, implicit-def $scc
+ ; GFX10-NEXT: [[S_AND_B32_3:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY14]](s1), implicit-def $scc
; GFX10-NEXT: [[S_OR_B32_3:%[0-9]+]]:sreg_32(s1) = S_OR_B32 [[S_ANDN2_B32_3]](s1), [[S_AND_B32_3]](s1), implicit-def $scc
; GFX10-NEXT: SI_LOOP [[INTRINSIC_CONVERGENT]](s32), %bb.1, implicit-def $exec, implicit-def $scc, implicit $exec
; GFX10-NEXT: G_BR %bb.4
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: bb.4:
; GFX10-NEXT: [[PHI7:%[0-9]+]]:_(s32) = G_PHI [[INTRINSIC_CONVERGENT]](s32), %bb.3
- ; GFX10-NEXT: [[COPY15:%[0-9]+]]:sreg_32(s1) = COPY [[S_OR_B32_3]](s1)
+ ; GFX10-NEXT: [[COPY16:%[0-9]+]]:sreg_32(s1) = COPY [[S_OR_B32_3]](s1)
; GFX10-NEXT: G_INTRINSIC_CONVERGENT_W_SIDE_EFFECTS intrinsic(@llvm.amdgcn.end.cf), [[PHI7]](s32)
; GFX10-NEXT: [[C5:%[0-9]+]]:_(s32) = G_FCONSTANT float 0.000000e+00
; GFX10-NEXT: [[C6:%[0-9]+]]:_(s32) = G_FCONSTANT float 1.000000e+00
- ; GFX10-NEXT: [[SELECT:%[0-9]+]]:_(s32) = G_SELECT [[COPY15]](s1), [[C6]], [[C5]]
+ ; GFX10-NEXT: [[SELECT:%[0-9]+]]:_(s32) = G_SELECT [[COPY16]](s1), [[C6]], [[C5]]
; GFX10-NEXT: G_STORE [[SELECT]](s32), [[MV1]](p0) :: (store (s32))
; GFX10-NEXT: S_ENDPGM 0
bb.0:
diff --git a/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-structurizer.ll b/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-structurizer.ll
index 609fff51863a03..1698f84eea5185 100644
--- a/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-structurizer.ll
+++ b/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-structurizer.ll
@@ -1,5 +1,5 @@
; NOTE: Assertions have been autogenerated by utils/update_llc_test_checks.py UTC_ARGS: --version 3
-; RUN: llc -global-isel -mtriple=amdgcn-amd-amdpal -amdgpu-global-isel-risky-select -mcpu=gfx1010 -verify-machineinstrs < %s | FileCheck -check-prefix=GFX10 %s
+; RUN: llc -global-isel -mtriple=amdgcn-amd-amdpal -mcpu=gfx1010 -verify-machineinstrs < %s | FileCheck -check-prefix=GFX10 %s
; Simples case, if - then, that requires lane mask merging,
; %phi lane mask will hold %val_A at %A. Lanes that are active in %B
@@ -43,13 +43,12 @@ define amdgpu_ps void @divergent_i1_phi_if_else(ptr addrspace(1) %out, i32 %tid,
; GFX10: ; %bb.0: ; %entry
; GFX10-NEXT: s_and_b32 s0, 1, s0
; GFX10-NEXT: v_cmp_ne_u32_e32 vcc_lo, 0, v3
-; GFX10-NEXT: v_cmp_ne_u32_e64 s2, 0, s0
-; GFX10-NEXT: ; implicit-def: $sgpr0
+; GFX10-NEXT: v_cmp_ne_u32_e64 s0, 0, s0
; GFX10-NEXT: s_and_saveexec_b32 s1, vcc_lo
; GFX10-NEXT: s_xor_b32 s1, exec_lo, s1
; GFX10-NEXT: ; %bb.1: ; %B
; GFX10-NEXT: v_cmp_gt_u32_e32 vcc_lo, 2, v2
-; GFX10-NEXT: s_andn2_b32 s0, s2, exec_lo
+; GFX10-NEXT: s_andn2_b32 s0, s0, exec_lo
; GFX10-NEXT: ; implicit-def: $vgpr2
; GFX10-NEXT: s_and_b32 s2, exec_lo, vcc_lo
; GFX10-NEXT: s_or_b32 s0, s0, s2
@@ -211,7 +210,7 @@ define amdgpu_cs void @loop_with_2breaks(ptr addrspace(1) %x, ptr addrspace(1) %
; GFX10-NEXT: ; in Loop: Header=BB3_3 Depth=1
; GFX10-NEXT: v_add_co_u32 v9, vcc_lo, v4, v7
; GFX10-NEXT: v_add_co_ci_u32_e32 v10, vcc_lo, v5, v8, vcc_lo
-; GFX10-NEXT: s_mov_b32 s4, 1
+; GFX10-NEXT: s_mov_b32 s4, -1
; GFX10-NEXT: global_load_dword v9, v[9:10], off
; GFX10-NEXT: s_waitcnt vmcnt(0)
; GFX10-NEXT: v_cmp_ne_u32_e32 vcc_lo, 0, v9
@@ -308,7 +307,7 @@ define amdgpu_cs void @loop_with_3breaks(ptr addrspace(1) %x, ptr addrspace(1) %
; GFX10-NEXT: ; in Loop: Header=BB4_4 Depth=1
; GFX10-NEXT: v_add_co_u32 v11, vcc_lo, v4, v9
; GFX10-NEXT: v_add_co_ci_u32_e32 v12, vcc_lo, v5, v10, vcc_lo
-; GFX10-NEXT: s_mov_b32 s4, 1
+; GFX10-NEXT: s_mov_b32 s4, -1
; GFX10-NEXT: global_load_dword v11, v[11:12], off
; GFX10-NEXT: s_waitcnt vmcnt(0)
; GFX10-NEXT: v_cmp_ne_u32_e32 vcc_lo, 0, v11
@@ -318,7 +317,7 @@ define amdgpu_cs void @loop_with_3breaks(ptr addrspace(1) %x, ptr addrspace(1) %
; GFX10-NEXT: ; in Loop: Header=BB4_4 Depth=1
; GFX10-NEXT: v_add_co_u32 v11, vcc_lo, v6, v9
; GFX10-NEXT: v_add_co_ci_u32_e32 v12, vcc_lo, v7, v10, vcc_lo
-; GFX10-NEXT: s_mov_b32 s5, 1
+; GFX10-NEXT: s_mov_b32 s5, -1
; GFX10-NEXT: global_load_dword v11, v[11:12], off
; GFX10-NEXT: s_waitcnt vmcnt(0)
; GFX10-NEXT: v_cmp_ne_u32_e32 vcc_lo, 0, v11
diff --git a/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-structurizer.mir b/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-structurizer.mir
index df5505e1b28bbc..8197b072c740b6 100644
--- a/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-structurizer.mir
+++ b/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-structurizer.mir
@@ -18,9 +18,10 @@ body: |
; GFX10-NEXT: [[COPY3:%[0-9]+]]:_(s32) = COPY $vgpr3
; GFX10-NEXT: [[C:%[0-9]+]]:_(s32) = G_CONSTANT i32 6
; GFX10-NEXT: [[ICMP:%[0-9]+]]:_(s1) = G_ICMP intpred(uge), [[COPY2]](s32), [[C]]
- ; GFX10-NEXT: [[COPY4:%[0-9]+]]:sreg_32(s1) = COPY [[ICMP]](s1)
; GFX10-NEXT: [[C1:%[0-9]+]]:_(s32) = G_CONSTANT i32 0
; GFX10-NEXT: [[ICMP1:%[0-9]+]]:sreg_32_xm0_xexec(s1) = G_ICMP intpred(eq), [[COPY3]](s32), [[C1]]
+ ; GFX10-NEXT: [[COPY4:%[0-9]+]]:sreg_32(s1) = COPY [[ICMP]](s1)
+ ; GFX10-NEXT: [[COPY5:%[0-9]+]]:sreg_32(s1) = COPY [[COPY4]](s1)
; GFX10-NEXT: [[SI_IF:%[0-9]+]]:sreg_32_xm0_xexec(s32) = SI_IF [[ICMP1]](s1), %bb.2, implicit-def $exec, implicit-def $scc, implicit $exec
; GFX10-NEXT: G_BR %bb.1
; GFX10-NEXT: {{ $}}
@@ -29,18 +30,18 @@ body: |
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: [[C2:%[0-9]+]]:_(s32) = G_CONSTANT i32 1
; GFX10-NEXT: [[ICMP2:%[0-9]+]]:_(s1) = G_ICMP intpred(ult), [[COPY2]](s32), [[C2]]
- ; GFX10-NEXT: [[COPY5:%[0-9]+]]:sreg_32(s1) = COPY [[ICMP2]](s1)
- ; GFX10-NEXT: [[S_ANDN2_B32_:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY4]](s1), $exec_lo, implicit-def $scc
- ; GFX10-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY5]](s1), implicit-def $scc
+ ; GFX10-NEXT: [[COPY6:%[0-9]+]]:sreg_32(s1) = COPY [[ICMP2]](s1)
+ ; GFX10-NEXT: [[S_ANDN2_B32_:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY5]](s1), $exec_lo, implicit-def $scc
+ ; GFX10-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY6]](s1), implicit-def $scc
; GFX10-NEXT: [[S_OR_B32_:%[0-9]+]]:sreg_32(s1) = S_OR_B32 [[S_ANDN2_B32_]](s1), [[S_AND_B32_]](s1), implicit-def $scc
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: bb.2:
- ; GFX10-NEXT: [[PHI:%[0-9]+]]:sreg_32(s1) = PHI [[ICMP]](s1), %bb.0, [[S_OR_B32_]](s1), %bb.1
- ; GFX10-NEXT: [[COPY6:%[0-9]+]]:sreg_32(s1) = COPY [[PHI]](s1)
+ ; GFX10-NEXT: [[PHI:%[0-9]+]]:sreg_32(s1) = PHI [[COPY4]](s1), %bb.0, [[S_OR_B32_]](s1), %bb.1
+ ; GFX10-NEXT: [[COPY7:%[0-9]+]]:sreg_32(s1) = COPY [[PHI]](s1)
; GFX10-NEXT: G_INTRINSIC_CONVERGENT_W_SIDE_EFFECTS intrinsic(@llvm.amdgcn.end.cf), [[SI_IF]](s32)
; GFX10-NEXT: [[C3:%[0-9]+]]:_(s32) = G_CONSTANT i32 2
; GFX10-NEXT: [[C4:%[0-9]+]]:_(s32) = G_CONSTANT i32 1
- ; GFX10-NEXT: [[SELECT:%[0-9]+]]:_(s32) = G_SELECT [[COPY6]](s1), [[C4]], [[C3]]
+ ; GFX10-NEXT: [[SELECT:%[0-9]+]]:_(s32) = G_SELECT [[COPY7]](s1), [[C4]], [[C3]]
; GFX10-NEXT: G_STORE [[SELECT]](s32), [[MV]](p1) :: (store (s32), addrspace 1)
; GFX10-NEXT: S_ENDPGM 0
bb.0:
@@ -91,18 +92,20 @@ body: |
; GFX10-NEXT: [[COPY2:%[0-9]+]]:_(s32) = COPY $vgpr2
; GFX10-NEXT: [[COPY3:%[0-9]+]]:_(s32) = COPY $vgpr3
; GFX10-NEXT: [[DEF:%[0-9]+]]:_(s1) = G_IMPLICIT_DEF
- ; GFX10-NEXT: [[COPY4:%[0-9]+]]:sreg_32(s1) = COPY [[DEF]](s1)
; GFX10-NEXT: [[C:%[0-9]+]]:_(s32) = G_CONSTANT i32 0
; GFX10-NEXT: [[ICMP:%[0-9]+]]:sreg_32_xm0_xexec(s1) = G_ICMP intpred(ne), [[COPY3]](s32), [[C]]
+ ; GFX10-NEXT: [[COPY4:%[0-9]+]]:sreg_32(s1) = COPY [[DEF]](s1)
+ ; GFX10-NEXT: [[COPY5:%[0-9]+]]:sreg_32(s1) = COPY [[COPY4]](s1)
; GFX10-NEXT: [[SI_IF:%[0-9]+]]:sreg_32_xm0_xexec(s32) = SI_IF [[ICMP]](s1), %bb.1, implicit-def $exec, implicit-def $scc, implicit $exec
; GFX10-NEXT: G_BR %bb.3
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: bb.1:
; GFX10-NEXT: successors: %bb.2(0x40000000), %bb.4(0x40000000)
; GFX10-NEXT: {{ $}}
- ; GFX10-NEXT: [[PHI:%[0-9]+]]:sreg_32(s1) = PHI [[DEF]](s1), %bb.0, %19(s1), %bb.3
- ; GFX10-NEXT: [[COPY5:%[0-9]+]]:sreg_32(s1) = COPY [[PHI]](s1)
- ; GFX10-NEXT: [[COPY6:%[0-9]+]]:sreg_32(s1) = COPY [[COPY5]](s1)
+ ; GFX10-NEXT: [[PHI:%[0-9]+]]:sreg_32(s1) = PHI [[COPY4]](s1), %bb.0, %20(s1), %bb.3
+ ; GFX10-NEXT: [[COPY6:%[0-9]+]]:sreg_32(s1) = COPY [[PHI]](s1)
+ ; GFX10-NEXT: [[COPY7:%[0-9]+]]:sreg_32(s1) = COPY [[COPY6]](s1)
+ ; GFX10-NEXT: [[COPY8:%[0-9]+]]:sreg_32(s1) = COPY [[COPY7]](s1)
; GFX10-NEXT: [[SI_ELSE:%[0-9]+]]:sreg_32_xm0_xexec(s32) = SI_ELSE [[SI_IF]](s32), %bb.4, implicit-def $exec, implicit-def $scc, implicit $exec
; GFX10-NEXT: G_BR %bb.2
; GFX10-NEXT: {{ $}}
@@ -111,9 +114,9 @@ body: |
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: [[C1:%[0-9]+]]:_(s32) = G_CONSTANT i32 1
; GFX10-NEXT: [[ICMP1:%[0-9]+]]:_(s1) = G_ICMP intpred(uge), [[COPY2]](s32), [[C1]]
- ; GFX10-NEXT: [[COPY7:%[0-9]+]]:sreg_32(s1) = COPY [[ICMP1]](s1)
- ; GFX10-NEXT: [[S_ANDN2_B32_:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY6]](s1), $exec_lo, implicit-def $scc
- ; GFX10-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY7]](s1), implicit-def $scc
+ ; GFX10-NEXT: [[COPY9:%[0-9]+]]:sreg_32(s1) = COPY [[ICMP1]](s1)
+ ; GFX10-NEXT: [[S_ANDN2_B32_:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY8]](s1), $exec_lo, implicit-def $scc
+ ; GFX10-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY9]](s1), implicit-def $scc
; GFX10-NEXT: [[S_OR_B32_:%[0-9]+]]:sreg_32(s1) = S_OR_B32 [[S_ANDN2_B32_]](s1), [[S_AND_B32_]](s1), implicit-def $scc
; GFX10-NEXT: G_BR %bb.4
; GFX10-NEXT: {{ $}}
@@ -122,19 +125,19 @@ body: |
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: [[C2:%[0-9]+]]:_(s32) = G_CONSTANT i32 2
; GFX10-NEXT: [[ICMP2:%[0-9]+]]:_(s1) = G_ICMP intpred(ult), [[COPY2]](s32), [[C2]]
- ; GFX10-NEXT: [[COPY8:%[0-9]+]]:sreg_32(s1) = COPY [[ICMP2]](s1)
- ; GFX10-NEXT: [[S_ANDN2_B32_1:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY4]](s1), $exec_lo, implicit-def $scc
- ; GFX10-NEXT: [[S_AND_B32_1:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY8]](s1), implicit-def $scc
+ ; GFX10-NEXT: [[COPY10:%[0-9]+]]:sreg_32(s1) = COPY [[ICMP2]](s1)
+ ; GFX10-NEXT: [[S_ANDN2_B32_1:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY5]](s1), $exec_lo, implicit-def $scc
+ ; GFX10-NEXT: [[S_AND_B32_1:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY10]](s1), implicit-def $scc
; GFX10-NEXT: [[S_OR_B32_1:%[0-9]+]]:sreg_32(s1) = S_OR_B32 [[S_ANDN2_B32_1]](s1), [[S_AND_B32_1]](s1), implicit-def $scc
; GFX10-NEXT: G_BR %bb.1
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: bb.4:
- ; GFX10-NEXT: [[PHI1:%[0-9]+]]:sreg_32(s1) = PHI [[COPY5]](s1), %bb.1, [[S_OR_B32_]](s1), %bb.2
- ; GFX10-NEXT: [[COPY9:%[0-9]+]]:sreg_32(s1) = COPY [[PHI1]](s1)
+ ; GFX10-NEXT: [[PHI1:%[0-9]+]]:sreg_32(s1) = PHI [[COPY7]](s1), %bb.1, [[S_OR_B32_]](s1), %bb.2
+ ; GFX10-NEXT: [[COPY11:%[0-9]+]]:sreg_32(s1) = COPY [[PHI1]](s1)
; GFX10-NEXT: G_INTRINSIC_CONVERGENT_W_SIDE_EFFECTS intrinsic(@llvm.amdgcn.end.cf), [[SI_ELSE]](s32)
; GFX10-NEXT: [[C3:%[0-9]+]]:_(s32) = G_CONSTANT i32 1
; GFX10-NEXT: [[C4:%[0-9]+]]:_(s32) = G_CONSTANT i32 2
- ; GFX10-NEXT: [[SELECT:%[0-9]+]]:_(s32) = G_SELECT [[COPY9]](s1), [[C3]], [[C4]]
+ ; GFX10-NEXT: [[SELECT:%[0-9]+]]:_(s32) = G_SELECT [[COPY11]](s1), [[C3]], [[C4]]
; GFX10-NEXT: G_STORE [[SELECT]](s32), [[MV]](p1) :: (store (s32), addrspace 1)
; GFX10-NEXT: S_ENDPGM 0
bb.0:
@@ -368,13 +371,14 @@ body: |
; GFX10-NEXT: successors: %bb.4(0x40000000), %bb.5(0x40000000)
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: [[C4:%[0-9]+]]:_(s1) = G_CONSTANT i1 true
- ; GFX10-NEXT: [[COPY9:%[0-9]+]]:sreg_32(s1) = COPY [[C4]](s1)
; GFX10-NEXT: [[C5:%[0-9]+]]:_(s32) = G_CONSTANT i32 2
; GFX10-NEXT: [[SHL1:%[0-9]+]]:_(s64) = G_SHL [[SEXT]], [[C5]](s32)
; GFX10-NEXT: [[PTR_ADD1:%[0-9]+]]:_(p1) = G_PTR_ADD [[MV2]], [[SHL1]](s64)
; GFX10-NEXT: [[LOAD1:%[0-9]+]]:_(s32) = G_LOAD [[PTR_ADD1]](p1) :: (load (s32), addrspace 1)
; GFX10-NEXT: [[C6:%[0-9]+]]:_(s32) = G_CONSTANT i32 0
; GFX10-NEXT: [[ICMP1:%[0-9]+]]:sreg_32_xm0_xexec(s1) = G_ICMP intpred(ne), [[LOAD1]](s32), [[C6]]
+ ; GFX10-NEXT: [[COPY9:%[0-9]+]]:sreg_32(s1) = COPY [[C4]](s1)
+ ; GFX10-NEXT: [[COPY10:%[0-9]+]]:sreg_32(s1) = COPY [[COPY9]](s1)
; GFX10-NEXT: [[SI_IF1:%[0-9]+]]:sreg_32_xm0_xexec(s32) = SI_IF [[ICMP1]](s1), %bb.5, implicit-def $exec, implicit-def $scc, implicit $exec
; GFX10-NEXT: G_BR %bb.4
; GFX10-NEXT: {{ $}}
@@ -383,9 +387,9 @@ body: |
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: [[PHI3:%[0-9]+]]:sreg_32(s1) = PHI [[S_OR_B32_]](s1), %bb.1, %47(s1), %bb.5
; GFX10-NEXT: [[PHI4:%[0-9]+]]:_(s32) = G_PHI %32(s32), %bb.5, [[DEF]](s32), %bb.1
- ; GFX10-NEXT: [[COPY10:%[0-9]+]]:sreg_32(s1) = COPY [[PHI3]](s1)
+ ; GFX10-NEXT: [[COPY11:%[0-9]+]]:sreg_32(s1) = COPY [[PHI3]](s1)
; GFX10-NEXT: G_INTRINSIC_CONVERGENT_W_SIDE_EFFECTS intrinsic(@llvm.amdgcn.end.cf), [[SI_IF]](s32)
- ; GFX10-NEXT: [[INTRINSIC_CONVERGENT:%[0-9]+]]:sreg_32_xm0_xexec(s32) = G_INTRINSIC_CONVERGENT intrinsic(@llvm.amdgcn.if.break), [[COPY10]](s1), [[PHI1]](s32)
+ ; GFX10-NEXT: [[INTRINSIC_CONVERGENT:%[0-9]+]]:sreg_32_xm0_xexec(s32) = G_INTRINSIC_CONVERGENT intrinsic(@llvm.amdgcn.if.break), [[COPY11]](s1), [[PHI1]](s32)
; GFX10-NEXT: SI_LOOP [[INTRINSIC_CONVERGENT]](s32), %bb.1, implicit-def $exec, implicit-def $scc, implicit $exec
; GFX10-NEXT: G_BR %bb.6
; GFX10-NEXT: {{ $}}
@@ -402,21 +406,21 @@ body: |
; GFX10-NEXT: [[ADD1:%[0-9]+]]:_(s32) = G_ADD [[PHI2]], [[C8]]
; GFX10-NEXT: [[C9:%[0-9]+]]:_(s32) = G_CONSTANT i32 100
; GFX10-NEXT: [[ICMP2:%[0-9]+]]:_(s1) = G_ICMP intpred(ult), [[PHI2]](s32), [[C9]]
- ; GFX10-NEXT: [[COPY11:%[0-9]+]]:sreg_32(s1) = COPY [[ICMP2]](s1)
- ; GFX10-NEXT: [[S_ANDN2_B32_1:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY9]](s1), $exec_lo, implicit-def $scc
- ; GFX10-NEXT: [[S_AND_B32_1:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY11]](s1), implicit-def $scc
+ ; GFX10-NEXT: [[COPY12:%[0-9]+]]:sreg_32(s1) = COPY [[ICMP2]](s1)
+ ; GFX10-NEXT: [[S_ANDN2_B32_1:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY10]](s1), $exec_lo, implicit-def $scc
+ ; GFX10-NEXT: [[S_AND_B32_1:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY12]](s1), implicit-def $scc
; GFX10-NEXT: [[S_OR_B32_1:%[0-9]+]]:sreg_32(s1) = S_OR_B32 [[S_ANDN2_B32_1]](s1), [[S_AND_B32_1]](s1), implicit-def $scc
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: bb.5:
; GFX10-NEXT: successors: %bb.3(0x80000000)
; GFX10-NEXT: {{ $}}
- ; GFX10-NEXT: [[PHI5:%[0-9]+]]:sreg_32(s1) = PHI [[C4]](s1), %bb.2, [[S_OR_B32_1]](s1), %bb.4
+ ; GFX10-NEXT: [[PHI5:%[0-9]+]]:sreg_32(s1) = PHI [[COPY9]](s1), %bb.2, [[S_OR_B32_1]](s1), %bb.4
; GFX10-NEXT: [[PHI6:%[0-9]+]]:_(s32) = G_PHI [[ADD1]](s32), %bb.4, [[DEF]](s32), %bb.2
- ; GFX10-NEXT: [[COPY12:%[0-9]+]]:sreg_32(s1) = COPY [[PHI5]](s1)
- ; GFX10-NEXT: [[COPY13:%[0-9]+]]:sreg_32(s1) = COPY [[COPY12]](s1)
+ ; GFX10-NEXT: [[COPY13:%[0-9]+]]:sreg_32(s1) = COPY [[PHI5]](s1)
+ ; GFX10-NEXT: [[COPY14:%[0-9]+]]:sreg_32(s1) = COPY [[COPY13]](s1)
; GFX10-NEXT: G_INTRINSIC_CONVERGENT_W_SIDE_EFFECTS intrinsic(@llvm.amdgcn.end.cf), [[SI_IF1]](s32)
; GFX10-NEXT: [[S_ANDN2_B32_2:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY8]](s1), $exec_lo, implicit-def $scc
- ; GFX10-NEXT: [[S_AND_B32_2:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY13]](s1), implicit-def $scc
+ ; GFX10-NEXT: [[S_AND_B32_2:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY14]](s1), implicit-def $scc
; GFX10-NEXT: [[S_OR_B32_2:%[0-9]+]]:sreg_32(s1) = S_OR_B32 [[S_ANDN2_B32_2]](s1), [[S_AND_B32_2]](s1), implicit-def $scc
; GFX10-NEXT: G_BR %bb.3
; GFX10-NEXT: {{ $}}
@@ -560,13 +564,14 @@ body: |
; GFX10-NEXT: successors: %bb.4(0x40000000), %bb.5(0x40000000)
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: [[C4:%[0-9]+]]:_(s1) = G_CONSTANT i1 true
- ; GFX10-NEXT: [[COPY11:%[0-9]+]]:sreg_32(s1) = COPY [[C4]](s1)
; GFX10-NEXT: [[C5:%[0-9]+]]:_(s32) = G_CONSTANT i32 2
; GFX10-NEXT: [[SHL1:%[0-9]+]]:_(s64) = G_SHL [[SEXT]], [[C5]](s32)
; GFX10-NEXT: [[PTR_ADD1:%[0-9]+]]:_(p1) = G_PTR_ADD [[MV2]], [[SHL1]](s64)
; GFX10-NEXT: [[LOAD1:%[0-9]+]]:_(s32) = G_LOAD [[PTR_ADD1]](p1) :: (load (s32), addrspace 1)
; GFX10-NEXT: [[C6:%[0-9]+]]:_(s32) = G_CONSTANT i32 0
; GFX10-NEXT: [[ICMP1:%[0-9]+]]:sreg_32_xm0_xexec(s1) = G_ICMP intpred(ne), [[LOAD1]](s32), [[C6]]
+ ; GFX10-NEXT: [[COPY11:%[0-9]+]]:sreg_32(s1) = COPY [[C4]](s1)
+ ; GFX10-NEXT: [[COPY12:%[0-9]+]]:sreg_32(s1) = COPY [[COPY11]](s1)
; GFX10-NEXT: [[SI_IF1:%[0-9]+]]:sreg_32_xm0_xexec(s32) = SI_IF [[ICMP1]](s1), %bb.5, implicit-def $exec, implicit-def $scc, implicit $exec
; GFX10-NEXT: G_BR %bb.4
; GFX10-NEXT: {{ $}}
@@ -575,9 +580,9 @@ body: |
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: [[PHI3:%[0-9]+]]:sreg_32(s1) = PHI [[S_OR_B32_]](s1), %bb.1, %60(s1), %bb.5
; GFX10-NEXT: [[PHI4:%[0-9]+]]:_(s32) = G_PHI %35(s32), %bb.5, [[DEF]](s32), %bb.1
- ; GFX10-NEXT: [[COPY12:%[0-9]+]]:sreg_32(s1) = COPY [[PHI3]](s1)
+ ; GFX10-NEXT: [[COPY13:%[0-9]+]]:sreg_32(s1) = COPY [[PHI3]](s1)
; GFX10-NEXT: G_INTRINSIC_CONVERGENT_W_SIDE_EFFECTS intrinsic(@llvm.amdgcn.end.cf), [[SI_IF]](s32)
- ; GFX10-NEXT: [[INTRINSIC_CONVERGENT:%[0-9]+]]:sreg_32_xm0_xexec(s32) = G_INTRINSIC_CONVERGENT intrinsic(@llvm.amdgcn.if.break), [[COPY12]](s1), [[PHI1]](s32)
+ ; GFX10-NEXT: [[INTRINSIC_CONVERGENT:%[0-9]+]]:sreg_32_xm0_xexec(s32) = G_INTRINSIC_CONVERGENT intrinsic(@llvm.amdgcn.if.break), [[COPY13]](s1), [[PHI1]](s32)
; GFX10-NEXT: SI_LOOP [[INTRINSIC_CONVERGENT]](s32), %bb.1, implicit-def $exec, implicit-def $scc, implicit $exec
; GFX10-NEXT: G_BR %bb.8
; GFX10-NEXT: {{ $}}
@@ -585,26 +590,27 @@ body: |
; GFX10-NEXT: successors: %bb.6(0x40000000), %bb.7(0x40000000)
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: [[C7:%[0-9]+]]:_(s1) = G_CONSTANT i1 true
- ; GFX10-NEXT: [[COPY13:%[0-9]+]]:sreg_32(s1) = COPY [[C7]](s1)
; GFX10-NEXT: [[C8:%[0-9]+]]:_(s32) = G_CONSTANT i32 2
; GFX10-NEXT: [[SHL2:%[0-9]+]]:_(s64) = G_SHL [[SEXT]], [[C8]](s32)
; GFX10-NEXT: [[PTR_ADD2:%[0-9]+]]:_(p1) = G_PTR_ADD [[MV3]], [[SHL2]](s64)
; GFX10-NEXT: [[LOAD2:%[0-9]+]]:_(s32) = G_LOAD [[PTR_ADD2]](p1) :: (load (s32), addrspace 1)
; GFX10-NEXT: [[C9:%[0-9]+]]:_(s32) = G_CONSTANT i32 0
; GFX10-NEXT: [[ICMP2:%[0-9]+]]:sreg_32_xm0_xexec(s1) = G_ICMP intpred(ne), [[LOAD2]](s32), [[C9]]
+ ; GFX10-NEXT: [[COPY14:%[0-9]+]]:sreg_32(s1) = COPY [[C7]](s1)
+ ; GFX10-NEXT: [[COPY15:%[0-9]+]]:sreg_32(s1) = COPY [[COPY14]](s1)
; GFX10-NEXT: [[SI_IF2:%[0-9]+]]:sreg_32_xm0_xexec(s32) = SI_IF [[ICMP2]](s1), %bb.7, implicit-def $exec, implicit-def $scc, implicit $exec
; GFX10-NEXT: G_BR %bb.6
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: bb.5:
; GFX10-NEXT: successors: %bb.3(0x80000000)
; GFX10-NEXT: {{ $}}
- ; GFX10-NEXT: [[PHI5:%[0-9]+]]:sreg_32(s1) = PHI [[C4]](s1), %bb.2, %71(s1), %bb.7
+ ; GFX10-NEXT: [[PHI5:%[0-9]+]]:sreg_32(s1) = PHI [[COPY11]](s1), %bb.2, %72(s1), %bb.7
; GFX10-NEXT: [[PHI6:%[0-9]+]]:_(s32) = G_PHI %46(s32), %bb.7, [[DEF]](s32), %bb.2
- ; GFX10-NEXT: [[COPY14:%[0-9]+]]:sreg_32(s1) = COPY [[PHI5]](s1)
- ; GFX10-NEXT: [[COPY15:%[0-9]+]]:sreg_32(s1) = COPY [[COPY14]](s1)
+ ; GFX10-NEXT: [[COPY16:%[0-9]+]]:sreg_32(s1) = COPY [[PHI5]](s1)
+ ; GFX10-NEXT: [[COPY17:%[0-9]+]]:sreg_32(s1) = COPY [[COPY16]](s1)
; GFX10-NEXT: G_INTRINSIC_CONVERGENT_W_SIDE_EFFECTS intrinsic(@llvm.amdgcn.end.cf), [[SI_IF1]](s32)
; GFX10-NEXT: [[S_ANDN2_B32_1:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY10]](s1), $exec_lo, implicit-def $scc
- ; GFX10-NEXT: [[S_AND_B32_1:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY15]](s1), implicit-def $scc
+ ; GFX10-NEXT: [[S_AND_B32_1:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY17]](s1), implicit-def $scc
; GFX10-NEXT: [[S_OR_B32_1:%[0-9]+]]:sreg_32(s1) = S_OR_B32 [[S_ANDN2_B32_1]](s1), [[S_AND_B32_1]](s1), implicit-def $scc
; GFX10-NEXT: G_BR %bb.3
; GFX10-NEXT: {{ $}}
@@ -621,21 +627,21 @@ body: |
; GFX10-NEXT: [[ADD1:%[0-9]+]]:_(s32) = G_ADD [[PHI2]], [[C11]]
; GFX10-NEXT: [[C12:%[0-9]+]]:_(s32) = G_CONSTANT i32 100
; GFX10-NEXT: [[ICMP3:%[0-9]+]]:_(s1) = G_ICMP intpred(ult), [[PHI2]](s32), [[C12]]
- ; GFX10-NEXT: [[COPY16:%[0-9]+]]:sreg_32(s1) = COPY [[ICMP3]](s1)
- ; GFX10-NEXT: [[S_ANDN2_B32_2:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY13]](s1), $exec_lo, implicit-def $scc
- ; GFX10-NEXT: [[S_AND_B32_2:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY16]](s1), implicit-def $scc
+ ; GFX10-NEXT: [[COPY18:%[0-9]+]]:sreg_32(s1) = COPY [[ICMP3]](s1)
+ ; GFX10-NEXT: [[S_ANDN2_B32_2:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY15]](s1), $exec_lo, implicit-def $scc
+ ; GFX10-NEXT: [[S_AND_B32_2:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY18]](s1), implicit-def $scc
; GFX10-NEXT: [[S_OR_B32_2:%[0-9]+]]:sreg_32(s1) = S_OR_B32 [[S_ANDN2_B32_2]](s1), [[S_AND_B32_2]](s1), implicit-def $scc
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: bb.7:
; GFX10-NEXT: successors: %bb.5(0x80000000)
; GFX10-NEXT: {{ $}}
- ; GFX10-NEXT: [[PHI7:%[0-9]+]]:sreg_32(s1) = PHI [[C7]](s1), %bb.4, [[S_OR_B32_2]](s1), %bb.6
+ ; GFX10-NEXT: [[PHI7:%[0-9]+]]:sreg_32(s1) = PHI [[COPY14]](s1), %bb.4, [[S_OR_B32_2]](s1), %bb.6
; GFX10-NEXT: [[PHI8:%[0-9]+]]:_(s32) = G_PHI [[ADD1]](s32), %bb.6, [[DEF]](s32), %bb.4
- ; GFX10-NEXT: [[COPY17:%[0-9]+]]:sreg_32(s1) = COPY [[PHI7]](s1)
- ; GFX10-NEXT: [[COPY18:%[0-9]+]]:sreg_32(s1) = COPY [[COPY17]](s1)
+ ; GFX10-NEXT: [[COPY19:%[0-9]+]]:sreg_32(s1) = COPY [[PHI7]](s1)
+ ; GFX10-NEXT: [[COPY20:%[0-9]+]]:sreg_32(s1) = COPY [[COPY19]](s1)
; GFX10-NEXT: G_INTRINSIC_CONVERGENT_W_SIDE_EFFECTS intrinsic(@llvm.amdgcn.end.cf), [[SI_IF2]](s32)
- ; GFX10-NEXT: [[S_ANDN2_B32_3:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY11]](s1), $exec_lo, implicit-def $scc
- ; GFX10-NEXT: [[S_AND_B32_3:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY18]](s1), implicit-def $scc
+ ; GFX10-NEXT: [[S_ANDN2_B32_3:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY12]](s1), $exec_lo, implicit-def $scc
+ ; GFX10-NEXT: [[S_AND_B32_3:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY20]](s1), implicit-def $scc
; GFX10-NEXT: [[S_OR_B32_3:%[0-9]+]]:sreg_32(s1) = S_OR_B32 [[S_ANDN2_B32_3]](s1), [[S_AND_B32_3]](s1), implicit-def $scc
; GFX10-NEXT: G_BR %bb.5
; GFX10-NEXT: {{ $}}
@@ -970,6 +976,7 @@ body: |
; GFX10-NEXT: [[DEF1:%[0-9]+]]:sreg_32(s1) = IMPLICIT_DEF
; GFX10-NEXT: [[DEF2:%[0-9]+]]:sreg_32(s1) = IMPLICIT_DEF
; GFX10-NEXT: [[DEF3:%[0-9]+]]:sreg_32(s1) = IMPLICIT_DEF
+ ; GFX10-NEXT: [[COPY7:%[0-9]+]]:sreg_32(s1) = COPY [[ICMP]](s1)
; GFX10-NEXT: G_BR %bb.7
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: bb.1:
@@ -982,19 +989,19 @@ body: |
; GFX10-NEXT: bb.2:
; GFX10-NEXT: successors: %bb.4(0x40000000), %bb.7(0x40000000)
; GFX10-NEXT: {{ $}}
- ; GFX10-NEXT: [[PHI:%[0-9]+]]:sreg_32_xm0_xexec(s1) = PHI %67(s1), %bb.6, %70(s1), %bb.7
+ ; GFX10-NEXT: [[PHI:%[0-9]+]]:sreg_32_xm0_xexec(s1) = PHI %67(s1), %bb.6, %71(s1), %bb.7
; GFX10-NEXT: [[PHI1:%[0-9]+]]:sreg_32(s1) = PHI %49(s1), %bb.6, %48(s1), %bb.7
; GFX10-NEXT: [[PHI2:%[0-9]+]]:sreg_32(s1) = PHI %35(s1), %bb.6, %34(s1), %bb.7
- ; GFX10-NEXT: [[COPY7:%[0-9]+]]:sreg_32_xm0_xexec(s1) = COPY [[PHI]](s1)
- ; GFX10-NEXT: [[COPY8:%[0-9]+]]:sreg_32(s1) = COPY [[PHI1]](s1)
- ; GFX10-NEXT: [[COPY9:%[0-9]+]]:sreg_32(s1) = COPY [[PHI2]](s1)
- ; GFX10-NEXT: [[COPY10:%[0-9]+]]:sreg_32_xm0_xexec(s1) = COPY [[COPY9]](s1)
+ ; GFX10-NEXT: [[COPY8:%[0-9]+]]:sreg_32_xm0_xexec(s1) = COPY [[PHI]](s1)
+ ; GFX10-NEXT: [[COPY9:%[0-9]+]]:sreg_32(s1) = COPY [[PHI1]](s1)
+ ; GFX10-NEXT: [[COPY10:%[0-9]+]]:sreg_32(s1) = COPY [[PHI2]](s1)
+ ; GFX10-NEXT: [[COPY11:%[0-9]+]]:sreg_32_xm0_xexec(s1) = COPY [[COPY10]](s1)
; GFX10-NEXT: G_INTRINSIC_CONVERGENT_W_SIDE_EFFECTS intrinsic(@llvm.amdgcn.end.cf), %15(s32)
- ; GFX10-NEXT: [[INTRINSIC_CONVERGENT:%[0-9]+]]:sreg_32_xm0_xexec(s32) = G_INTRINSIC_CONVERGENT intrinsic(@llvm.amdgcn.if.break), [[COPY8]](s1), %17(s32)
- ; GFX10-NEXT: [[S_ANDN2_B32_:%[0-9]+]]:sreg_32_xm0_xexec(s1) = S_ANDN2_B32 [[COPY7]](s1), $exec_lo, implicit-def $scc
- ; GFX10-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32_xm0_xexec(s1) = S_AND_B32 $exec_lo, [[COPY10]](s1), implicit-def $scc
+ ; GFX10-NEXT: [[INTRINSIC_CONVERGENT:%[0-9]+]]:sreg_32_xm0_xexec(s32) = G_INTRINSIC_CONVERGENT intrinsic(@llvm.amdgcn.if.break), [[COPY9]](s1), %17(s32)
+ ; GFX10-NEXT: [[S_ANDN2_B32_:%[0-9]+]]:sreg_32_xm0_xexec(s1) = S_ANDN2_B32 [[COPY8]](s1), $exec_lo, implicit-def $scc
+ ; GFX10-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32_xm0_xexec(s1) = S_AND_B32 $exec_lo, [[COPY11]](s1), implicit-def $scc
; GFX10-NEXT: [[S_OR_B32_:%[0-9]+]]:sreg_32_xm0_xexec(s1) = S_OR_B32 [[S_ANDN2_B32_]](s1), [[S_AND_B32_]](s1), implicit-def $scc
- ; GFX10-NEXT: [[COPY11:%[0-9]+]]:sreg_32_xm0_xexec(s1) = COPY [[S_OR_B32_]](s1)
+ ; GFX10-NEXT: [[COPY12:%[0-9]+]]:sreg_32_xm0_xexec(s1) = COPY [[S_OR_B32_]](s1)
; GFX10-NEXT: SI_LOOP [[INTRINSIC_CONVERGENT]](s32), %bb.7, implicit-def $exec, implicit-def $scc, implicit $exec
; GFX10-NEXT: G_BR %bb.4
; GFX10-NEXT: {{ $}}
@@ -1011,28 +1018,28 @@ body: |
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: G_INTRINSIC_CONVERGENT_W_SIDE_EFFECTS intrinsic(@llvm.amdgcn.end.cf), [[INTRINSIC_CONVERGENT]](s32)
; GFX10-NEXT: [[ICMP2:%[0-9]+]]:_(s1) = G_ICMP intpred(sgt), [[COPY5]](s32), [[COPY]]
- ; GFX10-NEXT: [[COPY12:%[0-9]+]]:sreg_32(s1) = COPY [[ICMP2]](s1)
+ ; GFX10-NEXT: [[COPY13:%[0-9]+]]:sreg_32(s1) = COPY [[ICMP2]](s1)
; GFX10-NEXT: [[C2:%[0-9]+]]:_(s1) = G_CONSTANT i1 true
- ; GFX10-NEXT: [[COPY13:%[0-9]+]]:sreg_32_xm0_xexec(s1) = COPY [[C2]](s1)
+ ; GFX10-NEXT: [[COPY14:%[0-9]+]]:sreg_32_xm0_xexec(s1) = COPY [[C2]](s1)
; GFX10-NEXT: [[XOR:%[0-9]+]]:_(s1) = G_XOR [[ICMP]], [[C2]]
; GFX10-NEXT: [[OR:%[0-9]+]]:_(s1) = G_OR [[ICMP2]], [[XOR]]
; GFX10-NEXT: [[INTRINSIC_CONVERGENT2:%[0-9]+]]:sreg_32_xm0_xexec(s32) = G_INTRINSIC_CONVERGENT intrinsic(@llvm.amdgcn.if.break), [[OR]](s1), %25(s32)
; GFX10-NEXT: [[DEF4:%[0-9]+]]:sreg_32(s1) = IMPLICIT_DEF
; GFX10-NEXT: [[DEF5:%[0-9]+]]:sreg_32(s1) = IMPLICIT_DEF
; GFX10-NEXT: [[S_ANDN2_B32_1:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 %63(s1), $exec_lo, implicit-def $scc
- ; GFX10-NEXT: [[S_AND_B32_1:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY12]](s1), implicit-def $scc
+ ; GFX10-NEXT: [[S_AND_B32_1:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY13]](s1), implicit-def $scc
; GFX10-NEXT: [[S_OR_B32_1:%[0-9]+]]:sreg_32(s1) = S_OR_B32 [[S_ANDN2_B32_1]](s1), [[S_AND_B32_1]](s1), implicit-def $scc
- ; GFX10-NEXT: [[S_ANDN2_B32_2:%[0-9]+]]:sreg_32_xm0_xexec(s1) = S_ANDN2_B32 [[COPY11]](s1), $exec_lo, implicit-def $scc
- ; GFX10-NEXT: [[S_AND_B32_2:%[0-9]+]]:sreg_32_xm0_xexec(s1) = S_AND_B32 $exec_lo, [[COPY13]](s1), implicit-def $scc
+ ; GFX10-NEXT: [[S_ANDN2_B32_2:%[0-9]+]]:sreg_32_xm0_xexec(s1) = S_ANDN2_B32 [[COPY12]](s1), $exec_lo, implicit-def $scc
+ ; GFX10-NEXT: [[S_AND_B32_2:%[0-9]+]]:sreg_32_xm0_xexec(s1) = S_AND_B32 $exec_lo, [[COPY14]](s1), implicit-def $scc
; GFX10-NEXT: [[S_OR_B32_2:%[0-9]+]]:sreg_32_xm0_xexec(s1) = S_OR_B32 [[S_ANDN2_B32_2]](s1), [[S_AND_B32_2]](s1), implicit-def $scc
; GFX10-NEXT: SI_LOOP [[INTRINSIC_CONVERGENT2]](s32), %bb.7, implicit-def $exec, implicit-def $scc, implicit $exec
; GFX10-NEXT: G_BR %bb.5
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: bb.5:
; GFX10-NEXT: [[PHI4:%[0-9]+]]:_(s32) = G_PHI [[INTRINSIC_CONVERGENT2]](s32), %bb.4
- ; GFX10-NEXT: [[COPY14:%[0-9]+]]:sreg_32(s1) = COPY [[S_OR_B32_1]](s1)
+ ; GFX10-NEXT: [[COPY15:%[0-9]+]]:sreg_32(s1) = COPY [[S_OR_B32_1]](s1)
; GFX10-NEXT: G_INTRINSIC_CONVERGENT_W_SIDE_EFFECTS intrinsic(@llvm.amdgcn.end.cf), [[PHI4]](s32)
- ; GFX10-NEXT: [[SELECT:%[0-9]+]]:_(s32) = G_SELECT [[COPY14]](s1), [[COPY3]], [[COPY2]]
+ ; GFX10-NEXT: [[SELECT:%[0-9]+]]:_(s32) = G_SELECT [[COPY15]](s1), [[COPY3]], [[COPY2]]
; GFX10-NEXT: [[INTRINSIC_CONVERGENT3:%[0-9]+]]:_(s32) = G_INTRINSIC_CONVERGENT intrinsic(@llvm.amdgcn.readfirstlane), [[SELECT]](s32)
; GFX10-NEXT: $sgpr0 = COPY [[INTRINSIC_CONVERGENT3]](s32)
; GFX10-NEXT: SI_RETURN_TO_EPILOG implicit $sgpr0
@@ -1042,14 +1049,14 @@ body: |
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: [[PHI5:%[0-9]+]]:_(s32) = G_PHI [[INTRINSIC_CONVERGENT1]](s32), %bb.3
; GFX10-NEXT: [[C3:%[0-9]+]]:_(s1) = G_CONSTANT i1 false
- ; GFX10-NEXT: [[COPY15:%[0-9]+]]:sreg_32(s1) = COPY [[C3]](s1)
; GFX10-NEXT: [[COPY16:%[0-9]+]]:sreg_32(s1) = COPY [[C3]](s1)
+ ; GFX10-NEXT: [[COPY17:%[0-9]+]]:sreg_32(s1) = COPY [[C3]](s1)
; GFX10-NEXT: G_INTRINSIC_CONVERGENT_W_SIDE_EFFECTS intrinsic(@llvm.amdgcn.end.cf), [[PHI5]](s32)
; GFX10-NEXT: [[S_ANDN2_B32_3:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 %42(s1), $exec_lo, implicit-def $scc
- ; GFX10-NEXT: [[S_AND_B32_3:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY16]](s1), implicit-def $scc
+ ; GFX10-NEXT: [[S_AND_B32_3:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY17]](s1), implicit-def $scc
; GFX10-NEXT: [[S_OR_B32_3:%[0-9]+]]:sreg_32(s1) = S_OR_B32 [[S_ANDN2_B32_3]](s1), [[S_AND_B32_3]](s1), implicit-def $scc
; GFX10-NEXT: [[S_ANDN2_B32_4:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 %56(s1), $exec_lo, implicit-def $scc
- ; GFX10-NEXT: [[S_AND_B32_4:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY15]](s1), implicit-def $scc
+ ; GFX10-NEXT: [[S_AND_B32_4:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY16]](s1), implicit-def $scc
; GFX10-NEXT: [[S_OR_B32_4:%[0-9]+]]:sreg_32(s1) = S_OR_B32 [[S_ANDN2_B32_4]](s1), [[S_AND_B32_4]](s1), implicit-def $scc
; GFX10-NEXT: [[DEF6:%[0-9]+]]:sreg_32_xm0_xexec(s1) = IMPLICIT_DEF
; GFX10-NEXT: G_BR %bb.2
@@ -1057,27 +1064,27 @@ body: |
; GFX10-NEXT: bb.7:
; GFX10-NEXT: successors: %bb.1(0x40000000), %bb.2(0x40000000)
; GFX10-NEXT: {{ $}}
- ; GFX10-NEXT: [[PHI6:%[0-9]+]]:sreg_32_xm0_xexec(s1) = PHI [[ICMP]](s1), %bb.0, [[S_OR_B32_]](s1), %bb.2, [[S_OR_B32_2]](s1), %bb.4
+ ; GFX10-NEXT: [[PHI6:%[0-9]+]]:sreg_32_xm0_xexec(s1) = PHI [[COPY7]](s1), %bb.0, [[S_OR_B32_]](s1), %bb.2, [[S_OR_B32_2]](s1), %bb.4
; GFX10-NEXT: [[PHI7:%[0-9]+]]:sreg_32(s1) = PHI [[DEF3]](s1), %bb.0, [[PHI7]](s1), %bb.2, [[S_OR_B32_1]](s1), %bb.4
; GFX10-NEXT: [[PHI8:%[0-9]+]]:sreg_32(s1) = PHI [[DEF2]](s1), %bb.0, [[PHI1]](s1), %bb.2, [[DEF5]](s1), %bb.4
; GFX10-NEXT: [[PHI9:%[0-9]+]]:sreg_32(s1) = PHI [[DEF1]](s1), %bb.0, [[PHI2]](s1), %bb.2, [[DEF4]](s1), %bb.4
; GFX10-NEXT: [[PHI10:%[0-9]+]]:_(s32) = G_PHI [[INTRINSIC_CONVERGENT2]](s32), %bb.4, [[PHI10]](s32), %bb.2, [[C]](s32), %bb.0
; GFX10-NEXT: [[PHI11:%[0-9]+]]:_(s32) = G_PHI [[C]](s32), %bb.4, [[INTRINSIC_CONVERGENT]](s32), %bb.2, [[C]](s32), %bb.0
- ; GFX10-NEXT: [[COPY17:%[0-9]+]]:sreg_32_xm0_xexec(s1) = COPY [[PHI6]](s1)
- ; GFX10-NEXT: [[COPY18:%[0-9]+]]:sreg_32(s1) = COPY [[PHI7]](s1)
- ; GFX10-NEXT: [[COPY19:%[0-9]+]]:sreg_32(s1) = COPY [[PHI8]](s1)
- ; GFX10-NEXT: [[COPY20:%[0-9]+]]:sreg_32(s1) = COPY [[PHI9]](s1)
+ ; GFX10-NEXT: [[COPY18:%[0-9]+]]:sreg_32_xm0_xexec(s1) = COPY [[PHI6]](s1)
+ ; GFX10-NEXT: [[COPY19:%[0-9]+]]:sreg_32(s1) = COPY [[PHI7]](s1)
+ ; GFX10-NEXT: [[COPY20:%[0-9]+]]:sreg_32(s1) = COPY [[PHI8]](s1)
+ ; GFX10-NEXT: [[COPY21:%[0-9]+]]:sreg_32(s1) = COPY [[PHI9]](s1)
; GFX10-NEXT: [[C4:%[0-9]+]]:_(s1) = G_CONSTANT i1 true
- ; GFX10-NEXT: [[COPY21:%[0-9]+]]:sreg_32(s1) = COPY [[C4]](s1)
- ; GFX10-NEXT: [[S_ANDN2_B32_5:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY20]](s1), $exec_lo, implicit-def $scc
+ ; GFX10-NEXT: [[COPY22:%[0-9]+]]:sreg_32(s1) = COPY [[C4]](s1)
+ ; GFX10-NEXT: [[S_ANDN2_B32_5:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY21]](s1), $exec_lo, implicit-def $scc
; GFX10-NEXT: [[S_AND_B32_5:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY6]](s1), implicit-def $scc
; GFX10-NEXT: [[S_OR_B32_5:%[0-9]+]]:sreg_32(s1) = S_OR_B32 [[S_ANDN2_B32_5]](s1), [[S_AND_B32_5]](s1), implicit-def $scc
- ; GFX10-NEXT: [[COPY22:%[0-9]+]]:sreg_32(s1) = COPY [[S_OR_B32_5]](s1)
- ; GFX10-NEXT: [[S_ANDN2_B32_6:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY19]](s1), $exec_lo, implicit-def $scc
- ; GFX10-NEXT: [[S_AND_B32_6:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY21]](s1), implicit-def $scc
+ ; GFX10-NEXT: [[COPY23:%[0-9]+]]:sreg_32(s1) = COPY [[S_OR_B32_5]](s1)
+ ; GFX10-NEXT: [[S_ANDN2_B32_6:%[0-9]+]]:sreg_32(s1) = S_ANDN2_B32 [[COPY20]](s1), $exec_lo, implicit-def $scc
+ ; GFX10-NEXT: [[S_AND_B32_6:%[0-9]+]]:sreg_32(s1) = S_AND_B32 $exec_lo, [[COPY22]](s1), implicit-def $scc
; GFX10-NEXT: [[S_OR_B32_6:%[0-9]+]]:sreg_32(s1) = S_OR_B32 [[S_ANDN2_B32_6]](s1), [[S_AND_B32_6]](s1), implicit-def $scc
- ; GFX10-NEXT: [[COPY23:%[0-9]+]]:sreg_32(s1) = COPY [[S_OR_B32_6]](s1)
- ; GFX10-NEXT: [[SI_IF:%[0-9]+]]:sreg_32_xm0_xexec(s32) = SI_IF [[COPY17]](s1), %bb.2, implicit-def $exec, implicit-def $scc, implicit $exec
+ ; GFX10-NEXT: [[COPY24:%[0-9]+]]:sreg_32(s1) = COPY [[S_OR_B32_6]](s1)
+ ; GFX10-NEXT: [[SI_IF:%[0-9]+]]:sreg_32_xm0_xexec(s32) = SI_IF [[COPY18]](s1), %bb.2, implicit-def $exec, implicit-def $scc, implicit $exec
; GFX10-NEXT: G_BR %bb.1
bb.0:
successors: %bb.7(0x80000000)
>From 7e88d5176060fa4d86376460db8310083b7c0e2d Mon Sep 17 00:00:00 2001
From: Jeremy Morse <jeremy.morse at sony.com>
Date: Thu, 29 Feb 2024 13:00:29 +0000
Subject: [PATCH 122/406] [NFC][RemoveDIs] Have CreateNeg only accept iterators
(#82999)
Removing debug-intrinsics requires that we always insert with an
iterator, not with an instruction position. To enforce that, we need to
eliminate the `Instruction *` taking functions. It's safe to leave the
insert-at-end-of-block functions as the intention is clear for debug
info purposes (i.e., insert after both instructions and debug-info at
the end of the function).
This patch demonstrates how that needs to happen. At a variety of
call-sites to the `CreateNeg` constructor we need to consider:
* Has this instruction been selected because of the operation it
performs? In that case, just call `getIterator` and pass an iterator in.
* Has this instruction been selected because of it's position? If so, we
need to keep the iterator identifying that position (see the 3rd hunk
changing Reassociate.cpp, although it's coincidentally not debug-info
significant).
This also demonstrates what we'll try and do with the constructor
methods going forwards: have one fully explicit set of parameters
including iterator, and another with default-arguments where the
block-to-insert-into argument defaults to nullptr / no-position,
creating an instruction that hasn't been inserted yet.
---
llvm/include/llvm/IR/InstrTypes.h | 4 +---
llvm/lib/IR/Instruction.cpp | 9 ++++-----
llvm/lib/IR/Instructions.cpp | 8 --------
.../Scalar/CorrelatedValuePropagation.cpp | 14 ++++++++------
llvm/lib/Transforms/Scalar/Reassociate.cpp | 8 +++++---
5 files changed, 18 insertions(+), 25 deletions(-)
diff --git a/llvm/include/llvm/IR/InstrTypes.h b/llvm/include/llvm/IR/InstrTypes.h
index 4ee51cd192ed7c..a124fbb88e3bcd 100644
--- a/llvm/include/llvm/IR/InstrTypes.h
+++ b/llvm/include/llvm/IR/InstrTypes.h
@@ -468,9 +468,7 @@ class BinaryOperator : public Instruction {
static BinaryOperator *CreateNeg(Value *Op, const Twine &Name,
BasicBlock::iterator InsertBefore);
static BinaryOperator *CreateNeg(Value *Op, const Twine &Name = "",
- Instruction *InsertBefore = nullptr);
- static BinaryOperator *CreateNeg(Value *Op, const Twine &Name,
- BasicBlock *InsertAtEnd);
+ BasicBlock *InsertAtEnd = nullptr);
static BinaryOperator *CreateNSWNeg(Value *Op, const Twine &Name,
BasicBlock::iterator InsertBefore);
static BinaryOperator *CreateNSWNeg(Value *Op, const Twine &Name = "",
diff --git a/llvm/lib/IR/Instruction.cpp b/llvm/lib/IR/Instruction.cpp
index c54f8d7aca4a96..ce221758ef798b 100644
--- a/llvm/lib/IR/Instruction.cpp
+++ b/llvm/lib/IR/Instruction.cpp
@@ -46,11 +46,11 @@ Instruction::Instruction(Type *ty, unsigned it, Use *Ops, unsigned NumOps,
Instruction::Instruction(Type *ty, unsigned it, Use *Ops, unsigned NumOps,
BasicBlock *InsertAtEnd)
- : User(ty, Value::InstructionVal + it, Ops, NumOps), Parent(nullptr) {
+ : User(ty, Value::InstructionVal + it, Ops, NumOps), Parent(nullptr) {
- // append this instruction into the basic block
- assert(InsertAtEnd && "Basic block to append to may not be NULL!");
- insertInto(InsertAtEnd, InsertAtEnd->end());
+ // If requested, append this instruction into the basic block.
+ if (InsertAtEnd)
+ insertInto(InsertAtEnd, InsertAtEnd->end());
}
Instruction::~Instruction() {
@@ -73,7 +73,6 @@ Instruction::~Instruction() {
setMetadata(LLVMContext::MD_DIAssignID, nullptr);
}
-
void Instruction::setParent(BasicBlock *P) {
Parent = P;
}
diff --git a/llvm/lib/IR/Instructions.cpp b/llvm/lib/IR/Instructions.cpp
index 25778570ebf34a..976015656a5f96 100644
--- a/llvm/lib/IR/Instructions.cpp
+++ b/llvm/lib/IR/Instructions.cpp
@@ -3245,14 +3245,6 @@ BinaryOperator *BinaryOperator::CreateNeg(Value *Op, const Twine &Name,
InsertBefore);
}
-BinaryOperator *BinaryOperator::CreateNeg(Value *Op, const Twine &Name,
- Instruction *InsertBefore) {
- Value *Zero = ConstantInt::get(Op->getType(), 0);
- return new BinaryOperator(Instruction::Sub,
- Zero, Op,
- Op->getType(), Name, InsertBefore);
-}
-
BinaryOperator *BinaryOperator::CreateNeg(Value *Op, const Twine &Name,
BasicBlock *InsertAtEnd) {
Value *Zero = ConstantInt::get(Op->getType(), 0);
diff --git a/llvm/lib/Transforms/Scalar/CorrelatedValuePropagation.cpp b/llvm/lib/Transforms/Scalar/CorrelatedValuePropagation.cpp
index 6ce9eb3656c93a..490cb7e528eb6f 100644
--- a/llvm/lib/Transforms/Scalar/CorrelatedValuePropagation.cpp
+++ b/llvm/lib/Transforms/Scalar/CorrelatedValuePropagation.cpp
@@ -905,8 +905,8 @@ static bool processSRem(BinaryOperator *SDI, const ConstantRange &LCR,
for (Operand &Op : Ops) {
if (Op.D == Domain::NonNegative)
continue;
- auto *BO =
- BinaryOperator::CreateNeg(Op.V, Op.V->getName() + ".nonneg", SDI);
+ auto *BO = BinaryOperator::CreateNeg(Op.V, Op.V->getName() + ".nonneg",
+ SDI->getIterator());
BO->setDebugLoc(SDI->getDebugLoc());
Op.V = BO;
}
@@ -919,7 +919,8 @@ static bool processSRem(BinaryOperator *SDI, const ConstantRange &LCR,
// If the divident was non-positive, we need to negate the result.
if (Ops[0].D == Domain::NonPositive) {
- Res = BinaryOperator::CreateNeg(Res, Res->getName() + ".neg", SDI);
+ Res = BinaryOperator::CreateNeg(Res, Res->getName() + ".neg",
+ SDI->getIterator());
Res->setDebugLoc(SDI->getDebugLoc());
}
@@ -966,8 +967,8 @@ static bool processSDiv(BinaryOperator *SDI, const ConstantRange &LCR,
for (Operand &Op : Ops) {
if (Op.D == Domain::NonNegative)
continue;
- auto *BO =
- BinaryOperator::CreateNeg(Op.V, Op.V->getName() + ".nonneg", SDI);
+ auto *BO = BinaryOperator::CreateNeg(Op.V, Op.V->getName() + ".nonneg",
+ SDI->getIterator());
BO->setDebugLoc(SDI->getDebugLoc());
Op.V = BO;
}
@@ -981,7 +982,8 @@ static bool processSDiv(BinaryOperator *SDI, const ConstantRange &LCR,
// If the operands had two different domains, we need to negate the result.
if (Ops[0].D != Ops[1].D) {
- Res = BinaryOperator::CreateNeg(Res, Res->getName() + ".neg", SDI);
+ Res = BinaryOperator::CreateNeg(Res, Res->getName() + ".neg",
+ SDI->getIterator());
Res->setDebugLoc(SDI->getDebugLoc());
}
diff --git a/llvm/lib/Transforms/Scalar/Reassociate.cpp b/llvm/lib/Transforms/Scalar/Reassociate.cpp
index 818c7b40d489ef..61109ed3765987 100644
--- a/llvm/lib/Transforms/Scalar/Reassociate.cpp
+++ b/llvm/lib/Transforms/Scalar/Reassociate.cpp
@@ -270,7 +270,8 @@ static BinaryOperator *CreateMul(Value *S1, Value *S2, const Twine &Name,
}
static Instruction *CreateNeg(Value *S1, const Twine &Name,
- Instruction *InsertBefore, Value *FlagsOp) {
+ BasicBlock::iterator InsertBefore,
+ Value *FlagsOp) {
if (S1->getType()->isIntOrIntVectorTy())
return BinaryOperator::CreateNeg(S1, Name, InsertBefore);
@@ -958,7 +959,8 @@ static Value *NegateValue(Value *V, Instruction *BI,
// Insert a 'neg' instruction that subtracts the value from zero to get the
// negation.
- Instruction *NewNeg = CreateNeg(V, V->getName() + ".neg", BI, BI);
+ Instruction *NewNeg =
+ CreateNeg(V, V->getName() + ".neg", BI->getIterator(), BI);
ToRedo.insert(NewNeg);
return NewNeg;
}
@@ -1246,7 +1248,7 @@ Value *ReassociatePass::RemoveFactorFromExpression(Value *V, Value *Factor) {
}
if (NeedsNegate)
- V = CreateNeg(V, "neg", &*InsertPt, BO);
+ V = CreateNeg(V, "neg", InsertPt, BO);
return V;
}
>From 780d55690ec5d8cd5c0e5fa4af799155d5d00534 Mon Sep 17 00:00:00 2001
From: Benjamin Maxwell <benjamin.maxwell at arm.com>
Date: Thu, 29 Feb 2024 13:00:37 +0000
Subject: [PATCH 123/406] [mlir][ArmSVE] Fix test-setArmVLBits.mlir after
#83213
---
.../CPU/ArmSVE/Emulated/test-setArmVLBits.mlir | 17 ++++++-----------
1 file changed, 6 insertions(+), 11 deletions(-)
diff --git a/mlir/test/Integration/Dialect/Vector/CPU/ArmSVE/Emulated/test-setArmVLBits.mlir b/mlir/test/Integration/Dialect/Vector/CPU/ArmSVE/Emulated/test-setArmVLBits.mlir
index 4f46c6e1ebf6a8..aa8d0e4d5104ab 100644
--- a/mlir/test/Integration/Dialect/Vector/CPU/ArmSVE/Emulated/test-setArmVLBits.mlir
+++ b/mlir/test/Integration/Dialect/Vector/CPU/ArmSVE/Emulated/test-setArmVLBits.mlir
@@ -8,7 +8,7 @@
func.func @checkVScale() {
%vscale = vector.vscale
- vector.print str "vscale"
+ vector.print str "vscale = "
vector.print %vscale : index
return
}
@@ -20,28 +20,23 @@ func.func @setAndCheckVL(%bits: i32) {
}
func.func @main() {
- // CHECK: vscale
- // CHECK-NEXT: 1
+ // CHECK: vscale = 1
%c128 = arith.constant 128 : i32
func.call @setAndCheckVL(%c128) : (i32) -> ()
- // CHECK: vscale
- // CHECK-NEXT: 2
+ // CHECK: vscale = 2
%c256 = arith.constant 256 : i32
func.call @setAndCheckVL(%c256) : (i32) -> ()
- // CHECK: vscale
- // CHECK-NEXT: 4
+ // CHECK: vscale = 4
%c512 = arith.constant 512 : i32
func.call @setAndCheckVL(%c512) : (i32) -> ()
- // CHECK: vscale
- // CHECK-NEXT: 8
+ // CHECK: vscale = 8
%c1024 = arith.constant 1024 : i32
func.call @setAndCheckVL(%c1024) : (i32) -> ()
- // CHECK: vscale
- // CHECK-NEXT: 16
+ // CHECK: vscale = 16
%c2048 = arith.constant 2048 : i32
func.call @setAndCheckVL(%c2048) : (i32) -> ()
>From e08fe575d5953b6ca0d7a578c1afa00247f0a12f Mon Sep 17 00:00:00 2001
From: Dani <daniel.kiss at arm.com>
Date: Thu, 29 Feb 2024 14:05:37 +0100
Subject: [PATCH 124/406] [NFC][ARM][AArch64] Deduplicated code. (#82785)
Add the SignReturnAddressScopeKind to the BranchProtectionInfo class.
---
clang/include/clang/Basic/TargetInfo.h | 36 +++++++++++++++++++++-----
clang/lib/CodeGen/Targets/AArch64.cpp | 3 +--
clang/lib/CodeGen/Targets/ARM.cpp | 8 +-----
3 files changed, 31 insertions(+), 16 deletions(-)
diff --git a/clang/include/clang/Basic/TargetInfo.h b/clang/include/clang/Basic/TargetInfo.h
index 48e9cec482755c..b94d13609c3dd2 100644
--- a/clang/include/clang/Basic/TargetInfo.h
+++ b/clang/include/clang/Basic/TargetInfo.h
@@ -1369,13 +1369,35 @@ class TargetInfo : public TransferrableTargetInfo,
}
struct BranchProtectionInfo {
- LangOptions::SignReturnAddressScopeKind SignReturnAddr =
- LangOptions::SignReturnAddressScopeKind::None;
- LangOptions::SignReturnAddressKeyKind SignKey =
- LangOptions::SignReturnAddressKeyKind::AKey;
- bool BranchTargetEnforcement = false;
- bool BranchProtectionPAuthLR = false;
- bool GuardedControlStack = false;
+ LangOptions::SignReturnAddressScopeKind SignReturnAddr;
+ LangOptions::SignReturnAddressKeyKind SignKey;
+ bool BranchTargetEnforcement;
+ bool BranchProtectionPAuthLR;
+ bool GuardedControlStack;
+
+ BranchProtectionInfo() = default;
+
+ const char *getSignReturnAddrStr() const {
+ switch (SignReturnAddr) {
+ case LangOptions::SignReturnAddressScopeKind::None:
+ return "none";
+ case LangOptions::SignReturnAddressScopeKind::NonLeaf:
+ return "non-leaf";
+ case LangOptions::SignReturnAddressScopeKind::All:
+ return "all";
+ }
+ assert(false && "Unexpected SignReturnAddressScopeKind");
+ }
+
+ const char *getSignKeyStr() const {
+ switch (SignKey) {
+ case LangOptions::SignReturnAddressKeyKind::AKey:
+ return "a_key";
+ case LangOptions::SignReturnAddressKeyKind::BKey:
+ return "b_key";
+ }
+ assert(false && "Unexpected SignReturnAddressKeyKind");
+ }
};
/// Determine if the Architecture in this TargetInfo supports branch
diff --git a/clang/lib/CodeGen/Targets/AArch64.cpp b/clang/lib/CodeGen/Targets/AArch64.cpp
index adfdd516351901..2b8e2aeb4265f3 100644
--- a/clang/lib/CodeGen/Targets/AArch64.cpp
+++ b/clang/lib/CodeGen/Targets/AArch64.cpp
@@ -132,8 +132,7 @@ class AArch64TargetCodeGenInfo : public TargetCodeGenInfo {
assert(Error.empty());
auto *Fn = cast<llvm::Function>(GV);
- static const char *SignReturnAddrStr[] = {"none", "non-leaf", "all"};
- Fn->addFnAttr("sign-return-address", SignReturnAddrStr[static_cast<int>(BPI.SignReturnAddr)]);
+ Fn->addFnAttr("sign-return-address", BPI.getSignReturnAddrStr());
if (BPI.SignReturnAddr != LangOptions::SignReturnAddressScopeKind::None) {
Fn->addFnAttr("sign-return-address-key",
diff --git a/clang/lib/CodeGen/Targets/ARM.cpp b/clang/lib/CodeGen/Targets/ARM.cpp
index d7d175ff1724f7..5d42e6286e525b 100644
--- a/clang/lib/CodeGen/Targets/ARM.cpp
+++ b/clang/lib/CodeGen/Targets/ARM.cpp
@@ -152,13 +152,7 @@ class ARMTargetCodeGenInfo : public TargetCodeGenInfo {
diag::warn_target_unsupported_branch_protection_attribute)
<< Arch;
} else {
- static const char *SignReturnAddrStr[] = {"none", "non-leaf", "all"};
- assert(static_cast<unsigned>(BPI.SignReturnAddr) <= 2 &&
- "Unexpected SignReturnAddressScopeKind");
- Fn->addFnAttr(
- "sign-return-address",
- SignReturnAddrStr[static_cast<int>(BPI.SignReturnAddr)]);
-
+ Fn->addFnAttr("sign-return-address", BPI.getSignReturnAddrStr());
Fn->addFnAttr("branch-target-enforcement",
BPI.BranchTargetEnforcement ? "true" : "false");
}
>From 86f4b4dfde543287c1b29ecae27cc1bee470eebb Mon Sep 17 00:00:00 2001
From: Erich Keane <ekeane at nvidia.com>
Date: Thu, 29 Feb 2024 06:06:57 -0800
Subject: [PATCH 125/406] [OpenACC] Implement Compute Construct 'goto' in/out
logic (#83326)
Compute Constructs do not permit jumping in/out of them, so this patch
implements this for 'goto' as a followup to the other patches that have
done the same thing.
It does this by modifying the JumpDiagnostics to work with this, plus
setting the function to needing jump diagnostics if we discover a goto
or label inside of a Compute Construct.
---
.../clang/Basic/DiagnosticSemaKinds.td | 4 +
clang/lib/Sema/JumpDiagnostics.cpp | 19 +-
clang/lib/Sema/SemaStmt.cpp | 16 ++
clang/test/SemaOpenACC/no-branch-in-out.c | 197 ++++++++++++++++++
4 files changed, 234 insertions(+), 2 deletions(-)
diff --git a/clang/include/clang/Basic/DiagnosticSemaKinds.td b/clang/include/clang/Basic/DiagnosticSemaKinds.td
index f726805dc02bd9..378b537e029710 100644
--- a/clang/include/clang/Basic/DiagnosticSemaKinds.td
+++ b/clang/include/clang/Basic/DiagnosticSemaKinds.td
@@ -12214,4 +12214,8 @@ def err_acc_construct_appertainment
def err_acc_branch_in_out_compute_construct
: Error<"invalid %select{branch|return}0 %select{out of|into}1 OpenACC "
"Compute Construct">;
+def note_acc_branch_into_compute_construct
+ : Note<"invalid branch into OpenACC Compute Construct">;
+def note_acc_branch_out_of_compute_construct
+ : Note<"invalid branch out of OpenACC Compute Construct">;
} // end of sema component.
diff --git a/clang/lib/Sema/JumpDiagnostics.cpp b/clang/lib/Sema/JumpDiagnostics.cpp
index ec3892e92f3c3b..6722878883be8e 100644
--- a/clang/lib/Sema/JumpDiagnostics.cpp
+++ b/clang/lib/Sema/JumpDiagnostics.cpp
@@ -604,6 +604,16 @@ void JumpScopeChecker::BuildScopeInformation(Stmt *S,
break;
}
+ case Stmt::OpenACCComputeConstructClass: {
+ unsigned NewParentScope = Scopes.size();
+ OpenACCComputeConstruct *CC = cast<OpenACCComputeConstruct>(S);
+ Scopes.push_back(GotoScope(
+ ParentScope, diag::note_acc_branch_into_compute_construct,
+ diag::note_acc_branch_out_of_compute_construct, CC->getBeginLoc()));
+ BuildScopeInformation(CC->getStructuredBlock(), NewParentScope);
+ return;
+ }
+
default:
if (auto *ED = dyn_cast<OMPExecutableDirective>(S)) {
if (!ED->isStandaloneDirective()) {
@@ -936,11 +946,16 @@ void JumpScopeChecker::CheckJump(Stmt *From, Stmt *To, SourceLocation DiagLoc,
if (Scopes[I].InDiag == diag::note_protected_by_seh_finally) {
S.Diag(From->getBeginLoc(), diag::warn_jump_out_of_seh_finally);
break;
- }
- if (Scopes[I].InDiag == diag::note_omp_protected_structured_block) {
+ } else if (Scopes[I].InDiag ==
+ diag::note_omp_protected_structured_block) {
S.Diag(From->getBeginLoc(), diag::err_goto_into_protected_scope);
S.Diag(To->getBeginLoc(), diag::note_omp_exits_structured_block);
break;
+ } else if (Scopes[I].InDiag ==
+ diag::note_acc_branch_into_compute_construct) {
+ S.Diag(From->getBeginLoc(), diag::err_goto_into_protected_scope);
+ S.Diag(Scopes[I].Loc, diag::note_acc_branch_out_of_compute_construct);
+ return;
}
}
}
diff --git a/clang/lib/Sema/SemaStmt.cpp b/clang/lib/Sema/SemaStmt.cpp
index 0a5c2b23a90c8e..ca2d206752744c 100644
--- a/clang/lib/Sema/SemaStmt.cpp
+++ b/clang/lib/Sema/SemaStmt.cpp
@@ -567,6 +567,11 @@ Sema::ActOnLabelStmt(SourceLocation IdentLoc, LabelDecl *TheDecl,
Diag(IdentLoc, diag::warn_reserved_extern_symbol)
<< TheDecl << static_cast<int>(Status);
+ // If this label is in a compute construct scope, we need to make sure we
+ // check gotos in/out.
+ if (getCurScope()->isInOpenACCComputeConstructScope())
+ setFunctionHasBranchProtectedScope();
+
// Otherwise, things are good. Fill in the declaration and return it.
LabelStmt *LS = new (Context) LabelStmt(IdentLoc, TheDecl, SubStmt);
TheDecl->setStmt(LS);
@@ -3304,6 +3309,12 @@ StmtResult Sema::ActOnGotoStmt(SourceLocation GotoLoc,
SourceLocation LabelLoc,
LabelDecl *TheDecl) {
setFunctionHasBranchIntoScope();
+
+ // If this goto is in a compute construct scope, we need to make sure we check
+ // gotos in/out.
+ if (getCurScope()->isInOpenACCComputeConstructScope())
+ setFunctionHasBranchProtectedScope();
+
TheDecl->markUsed(Context);
return new (Context) GotoStmt(TheDecl, GotoLoc, LabelLoc);
}
@@ -3332,6 +3343,11 @@ Sema::ActOnIndirectGotoStmt(SourceLocation GotoLoc, SourceLocation StarLoc,
setFunctionHasIndirectGoto();
+ // If this goto is in a compute construct scope, we need to make sure we
+ // check gotos in/out.
+ if (getCurScope()->isInOpenACCComputeConstructScope())
+ setFunctionHasBranchProtectedScope();
+
return new (Context) IndirectGotoStmt(GotoLoc, StarLoc, E);
}
diff --git a/clang/test/SemaOpenACC/no-branch-in-out.c b/clang/test/SemaOpenACC/no-branch-in-out.c
index f8fb40a1ca8f72..d070247fa65b86 100644
--- a/clang/test/SemaOpenACC/no-branch-in-out.c
+++ b/clang/test/SemaOpenACC/no-branch-in-out.c
@@ -113,3 +113,200 @@ void Return() {
}
}
}
+
+void Goto() {
+ int j;
+#pragma acc parallel // expected-note{{invalid branch out of OpenACC Compute Construct}}
+ while(j) {
+ if (j <3)
+ goto LABEL; // expected-error{{cannot jump from this goto statement to its label}}
+ }
+
+LABEL:
+ {}
+
+ goto LABEL_IN; // expected-error{{cannot jump from this goto statement to its label}}
+
+#pragma acc parallel // expected-note{{invalid branch into OpenACC Compute Construct}}
+ for(int i = 0; i < 5; ++i) {
+LABEL_IN:
+ {}
+ }
+
+#pragma acc parallel
+ for(int i = 0; i < 5; ++i) {
+LABEL_NOT_CALLED:
+ {}
+ }
+
+#pragma acc parallel
+ {
+ goto ANOTHER_LOOP; // expected-error{{cannot jump from this goto statement to its label}}
+
+ }
+#pragma acc parallel// expected-note{{invalid branch into OpenACC Compute Construct}}
+
+ {
+ANOTHER_LOOP:
+ {}
+ }
+
+#pragma acc parallel
+ {
+ while (j) {
+ --j;
+ if (j < 3)
+ goto LABEL2;
+
+ if (j > 4)
+ break;
+ }
+LABEL2:
+ {}
+ }
+
+#pragma acc parallel
+ do {
+ if (j < 3)
+ goto LABEL3;
+
+ if (j > 4)
+ break; // expected-error{{invalid branch out of OpenACC Compute Construct}}
+
+LABEL3:
+ {}
+ } while (j);
+
+LABEL4:
+ {}
+#pragma acc parallel// expected-note{{invalid branch out of OpenACC Compute Construct}}
+ {
+ goto LABEL4;// expected-error{{cannot jump from this goto statement to its label}}
+ }
+
+#pragma acc parallel// expected-note{{invalid branch into OpenACC Compute Construct}}
+
+ {
+LABEL5:
+ {}
+ }
+
+ {
+ goto LABEL5;// expected-error{{cannot jump from this goto statement to its label}}
+ }
+
+#pragma acc parallel
+ {
+LABEL6:
+ {}
+ goto LABEL6;
+
+ }
+
+#pragma acc parallel
+ goto LABEL7; // expected-error{{cannot jump from this goto statement to its label}}
+#pragma acc parallel// expected-note{{invalid branch into OpenACC Compute Construct}}
+ {
+LABEL7:{}
+ }
+
+#pragma acc parallel
+ LABEL8:{}
+#pragma acc parallel// expected-note{{invalid branch out of OpenACC Compute Construct}}
+ {
+ goto LABEL8;// expected-error{{cannot jump from this goto statement to its label}}
+ }
+
+
+#pragma acc parallel// expected-note{{invalid branch into OpenACC Compute Construct}}
+ {
+LABEL9:{}
+ }
+
+ ({goto LABEL9;});// expected-error{{cannot jump from this goto statement to its label}}
+
+#pragma acc parallel// expected-note{{invalid branch out of OpenACC Compute Construct}}
+ {
+ ({goto LABEL10;});// expected-error{{cannot jump from this goto statement to its label}}
+ }
+
+LABEL10:{}
+
+ ({goto LABEL11;});// expected-error{{cannot jump from this goto statement to its label}}
+#pragma acc parallel// expected-note{{invalid branch into OpenACC Compute Construct}}
+ {
+LABEL11:{}
+ }
+
+LABEL12:{}
+#pragma acc parallel// expected-note{{invalid branch out of OpenACC Compute Construct}}
+ {
+ ({goto LABEL12;});// expected-error{{cannot jump from this goto statement to its label}}
+ }
+
+#pragma acc parallel
+ {
+ ({goto LABEL13;});
+LABEL13:{}
+ }
+
+#pragma acc parallel
+ {
+ LABEL14:{}
+ ({goto LABEL14;});
+ }
+}
+
+void IndirectGoto1() {
+ void* ptr;
+#pragma acc parallel
+ {
+LABEL1:{}
+ ptr = &&LABEL1;
+
+ goto *ptr;
+
+ }
+}
+
+void IndirectGoto2() {
+ void* ptr;
+LABEL2:{} // #GOTOLBL2
+ ptr = &&LABEL2;
+#pragma acc parallel // #GOTOPAR2
+ {
+// expected-error at +3{{cannot jump from this indirect goto statement to one of its possible targets}}
+// expected-note@#GOTOLBL2{{possible target of indirect goto statement}}
+// expected-note@#GOTOPAR2{{invalid branch out of OpenACC Compute Construct}}
+ goto *ptr;
+ }
+}
+
+void IndirectGoto3() {
+ void* ptr;
+#pragma acc parallel // #GOTOPAR3
+ {
+LABEL3:{} // #GOTOLBL3
+ ptr = &&LABEL3;
+ }
+// expected-error at +3{{cannot jump from this indirect goto statement to one of its possible targets}}
+// expected-note@#GOTOLBL3{{possible target of indirect goto statement}}
+// expected-note@#GOTOPAR3{{invalid branch into OpenACC Compute Construct}}
+ goto *ptr;
+}
+
+void IndirectGoto4() {
+ void* ptr;
+#pragma acc parallel // #GOTOPAR4
+ {
+LABEL4:{}
+ ptr = &&LABEL4;
+// expected-error at +3{{cannot jump from this indirect goto statement to one of its possible targets}}
+// expected-note@#GOTOLBL5{{possible target of indirect goto statement}}
+// expected-note@#GOTOPAR4{{invalid branch out of OpenACC Compute Construct}}
+ goto *ptr;
+ }
+LABEL5:// #GOTOLBL5
+
+ ptr=&&LABEL5;
+}
>From 6f7d824b804b272335d55f5b899295db833f3829 Mon Sep 17 00:00:00 2001
From: Vinayak Dev <104419489+vinayakdsci at users.noreply.github.com>
Date: Thu, 29 Feb 2024 19:39:39 +0530
Subject: [PATCH 126/406] [Clang][Sema]: Diagnose lambda to bool implicit casts
(#83152)
Adds diagnostics for lambda expressions being cast to boolean values,
which results in the expression always evaluating to true.
Earlier, Clang allowed compilation of such erroneous programs, but now
emits a warning through `-Wpointer-bool-conversion`.
Fixes #82512
---
clang/docs/ReleaseNotes.rst | 3 +++
clang/include/clang/Basic/DiagnosticSemaKinds.td | 4 ++--
clang/lib/Sema/SemaChecking.cpp | 11 +++++++++++
clang/test/CXX/drs/dr18xx.cpp | 1 +
.../CXX/expr/expr.prim/expr.prim.lambda/blocks.mm | 9 +++++----
clang/test/SemaCXX/warn-bool-conversion.cpp | 12 ++++++++++++
6 files changed, 34 insertions(+), 6 deletions(-)
diff --git a/clang/docs/ReleaseNotes.rst b/clang/docs/ReleaseNotes.rst
index 7e16b9f0c67dbd..a5c6b80c4e99e1 100644
--- a/clang/docs/ReleaseNotes.rst
+++ b/clang/docs/ReleaseNotes.rst
@@ -192,6 +192,9 @@ Improvements to Clang's diagnostics
- Clang now diagnoses declarative nested name specifiers that name alias templates.
+- Clang now diagnoses lambda function expressions being implicitly cast to boolean values, under ``-Wpointer-bool-conversion``.
+ Fixes `#82512 <https://github.com/llvm/llvm-project/issues/82512>`_.
+
Improvements to Clang's time-trace
----------------------------------
diff --git a/clang/include/clang/Basic/DiagnosticSemaKinds.td b/clang/include/clang/Basic/DiagnosticSemaKinds.td
index 378b537e029710..ff88c4f293abfd 100644
--- a/clang/include/clang/Basic/DiagnosticSemaKinds.td
+++ b/clang/include/clang/Basic/DiagnosticSemaKinds.td
@@ -4127,8 +4127,8 @@ def ext_ms_impcast_fn_obj : ExtWarn<
"Microsoft extension">, InGroup<MicrosoftCast>;
def warn_impcast_pointer_to_bool : Warning<
- "address of%select{| function| array}0 '%1' will always evaluate to "
- "'true'">,
+ "address of %select{'%1'|function '%1'|array '%1'|lambda function pointer "
+ "conversion operator}0 will always evaluate to 'true'">,
InGroup<PointerBoolConversion>;
def warn_cast_nonnull_to_bool : Warning<
"nonnull %select{function call|parameter}0 '%1' will evaluate to "
diff --git a/clang/lib/Sema/SemaChecking.cpp b/clang/lib/Sema/SemaChecking.cpp
index 979b63884359fc..35d453e013e84b 100644
--- a/clang/lib/Sema/SemaChecking.cpp
+++ b/clang/lib/Sema/SemaChecking.cpp
@@ -16544,6 +16544,17 @@ void Sema::DiagnoseAlwaysNonNullPointer(Expr *E,
}
}
+ // Complain if we are converting a lambda expression to a boolean value
+ if (const auto *MCallExpr = dyn_cast<CXXMemberCallExpr>(E)) {
+ if (const auto *MRecordDecl = MCallExpr->getRecordDecl();
+ MRecordDecl && MRecordDecl->isLambda()) {
+ Diag(E->getExprLoc(), diag::warn_impcast_pointer_to_bool)
+ << /*LambdaPointerConversionOperatorType=*/3
+ << MRecordDecl->getSourceRange() << Range << IsEqual;
+ return;
+ }
+ }
+
// Expect to find a single Decl. Skip anything more complicated.
ValueDecl *D = nullptr;
if (DeclRefExpr *R = dyn_cast<DeclRefExpr>(E)) {
diff --git a/clang/test/CXX/drs/dr18xx.cpp b/clang/test/CXX/drs/dr18xx.cpp
index a7cee4ef8902f9..e78730e8992cf8 100644
--- a/clang/test/CXX/drs/dr18xx.cpp
+++ b/clang/test/CXX/drs/dr18xx.cpp
@@ -282,6 +282,7 @@ namespace dr1837 { // dr1837: 3.3
struct A {
int f();
bool b = [] {
+ // since-cxx11-warning at -1 {{address of lambda function pointer conversion operator will always evaluate to 'true'}}
struct Local {
static_assert(sizeof(this->f()) == sizeof(int), "");
};
diff --git a/clang/test/CXX/expr/expr.prim/expr.prim.lambda/blocks.mm b/clang/test/CXX/expr/expr.prim/expr.prim.lambda/blocks.mm
index cb56f6816ad036..e93c37f3b9ae12 100644
--- a/clang/test/CXX/expr/expr.prim/expr.prim.lambda/blocks.mm
+++ b/clang/test/CXX/expr/expr.prim/expr.prim.lambda/blocks.mm
@@ -65,10 +65,10 @@ void nesting() {
namespace overloading {
void bool_conversion() {
- if ([](){}) {
+ if ([](){}) { // expected-warning{{address of lambda function pointer conversion operator will always evaluate to 'true'}}
}
- bool b = []{};
+ bool b = []{}; // expected-warning{{address of lambda function pointer conversion operator will always evaluate to 'true'}}
b = (bool)[]{};
}
@@ -108,8 +108,9 @@ void call_with_lambda() {
using decltype(a)::operator id<void(*)()>; // expected-note {{here}}
} extern d;
- bool r1 = c;
- bool r2 = d; // expected-error {{private}}
+ bool r1 = c; // expected-warning{{address of lambda function pointer conversion operator will always evaluate to 'true'}}
+ bool r2 = d; // expected-error {{private}} \
+ expected-warning{{address of lambda function pointer conversion operator will always evaluate to 'true'}}
}
namespace PR13117 {
diff --git a/clang/test/SemaCXX/warn-bool-conversion.cpp b/clang/test/SemaCXX/warn-bool-conversion.cpp
index c81d52d864f2d2..9e8cf0e4f8944a 100644
--- a/clang/test/SemaCXX/warn-bool-conversion.cpp
+++ b/clang/test/SemaCXX/warn-bool-conversion.cpp
@@ -81,6 +81,18 @@ struct S2 {
bool f5();
bool f6(int);
+#if __cplusplus >= 201103L
+auto f7 = []{};
+auto f8 = [](){};
+
+void foo() {
+ bool b;
+ b = f7; // expected-warning {{address of lambda function pointer conversion operator will always evaluate to 'true'}}
+ b = f8; // expected-warning {{address of lambda function pointer conversion operator will always evaluate to 'true'}}
+ bool is_true = [](){ return true; };
+ // expected-warning at -1{{address of lambda function pointer conversion operator will always evaluate to 'true'}}
+}
+#endif
void bar() {
bool b;
>From b1c8b9f89cac91db857b9123838ac6b6aeb0ae74 Mon Sep 17 00:00:00 2001
From: "S. Bharadwaj Yadavalli" <Bharadwaj.Yadavalli at microsoft.com>
Date: Thu, 29 Feb 2024 09:21:44 -0500
Subject: [PATCH 127/406] [DirectX][NFC] Leverage LLVM and DirectX intrinsic
description in DXIL Op records (#83193)
* Leverage TableGen record descriptions of LLVM or DirectX intrinsics
that can be directly mapped in DXIL Ops TableGen description. As a
result, such DXIL Ops can be succinctly described without duplication.
DXILEmitter backend can derive the properties of DXIL Ops accordingly.
* Ensured that corresponding lit tests pass.
---
llvm/lib/Target/DirectX/DXIL.td | 347 +++++++++++-------
llvm/lib/Target/DirectX/DXILOpBuilder.cpp | 25 +-
llvm/lib/Target/DirectX/DXILOpBuilder.h | 3 +-
llvm/lib/Target/DirectX/DXILOpLowering.cpp | 3 +-
llvm/utils/TableGen/DXILEmitter.cpp | 408 +++++++++------------
5 files changed, 413 insertions(+), 373 deletions(-)
diff --git a/llvm/lib/Target/DirectX/DXIL.td b/llvm/lib/Target/DirectX/DXIL.td
index 8a3454c89542ce..67ef7986622092 100644
--- a/llvm/lib/Target/DirectX/DXIL.td
+++ b/llvm/lib/Target/DirectX/DXIL.td
@@ -12,139 +12,224 @@
//===----------------------------------------------------------------------===//
include "llvm/IR/Intrinsics.td"
-include "llvm/IR/Attributes.td"
-// Abstract representation of the class a DXIL Operation belongs to.
-class DXILOpClass<string name> {
- string Name = name;
+class DXILOpClass;
+
+// Following is a set of DXIL Operation classes whose names appear to be
+// arbitrary, yet need to be a substring of the function name used during
+// lowering to DXIL Operation calls. These class name strings are specified
+// as the third argument of add_dixil_op in utils/hct/hctdb.py and case converted
+// in utils/hct/hctdb_instrhelp.py of DirectXShaderCompiler repo. The function
+// name has the format "dx.op.<class-name>.<return-type>".
+
+defset list<DXILOpClass> OpClasses = {
+ def acceptHitAndEndSearch : DXILOpClass;
+ def allocateNodeOutputRecords : DXILOpClass;
+ def allocateRayQuery : DXILOpClass;
+ def annotateHandle : DXILOpClass;
+ def annotateNodeHandle : DXILOpClass;
+ def annotateNodeRecordHandle : DXILOpClass;
+ def atomicBinOp : DXILOpClass;
+ def atomicCompareExchange : DXILOpClass;
+ def attributeAtVertex : DXILOpClass;
+ def barrier : DXILOpClass;
+ def barrierByMemoryHandle : DXILOpClass;
+ def barrierByMemoryType : DXILOpClass;
+ def barrierByNodeRecordHandle : DXILOpClass;
+ def binary : DXILOpClass;
+ def binaryWithCarryOrBorrow : DXILOpClass;
+ def binaryWithTwoOuts : DXILOpClass;
+ def bitcastF16toI16 : DXILOpClass;
+ def bitcastF32toI32 : DXILOpClass;
+ def bitcastF64toI64 : DXILOpClass;
+ def bitcastI16toF16 : DXILOpClass;
+ def bitcastI32toF32 : DXILOpClass;
+ def bitcastI64toF64 : DXILOpClass;
+ def bufferLoad : DXILOpClass;
+ def bufferStore : DXILOpClass;
+ def bufferUpdateCounter : DXILOpClass;
+ def calculateLOD : DXILOpClass;
+ def callShader : DXILOpClass;
+ def cbufferLoad : DXILOpClass;
+ def cbufferLoadLegacy : DXILOpClass;
+ def checkAccessFullyMapped : DXILOpClass;
+ def coverage : DXILOpClass;
+ def createHandle : DXILOpClass;
+ def createHandleForLib : DXILOpClass;
+ def createHandleFromBinding : DXILOpClass;
+ def createHandleFromHeap : DXILOpClass;
+ def createNodeInputRecordHandle : DXILOpClass;
+ def createNodeOutputHandle : DXILOpClass;
+ def cutStream : DXILOpClass;
+ def cycleCounterLegacy : DXILOpClass;
+ def discard : DXILOpClass;
+ def dispatchMesh : DXILOpClass;
+ def dispatchRaysDimensions : DXILOpClass;
+ def dispatchRaysIndex : DXILOpClass;
+ def domainLocation : DXILOpClass;
+ def dot2 : DXILOpClass;
+ def dot2AddHalf : DXILOpClass;
+ def dot3 : DXILOpClass;
+ def dot4 : DXILOpClass;
+ def dot4AddPacked : DXILOpClass;
+ def emitIndices : DXILOpClass;
+ def emitStream : DXILOpClass;
+ def emitThenCutStream : DXILOpClass;
+ def evalCentroid : DXILOpClass;
+ def evalSampleIndex : DXILOpClass;
+ def evalSnapped : DXILOpClass;
+ def finishedCrossGroupSharing : DXILOpClass;
+ def flattenedThreadIdInGroup : DXILOpClass;
+ def geometryIndex : DXILOpClass;
+ def getDimensions : DXILOpClass;
+ def getInputRecordCount : DXILOpClass;
+ def getMeshPayload : DXILOpClass;
+ def getNodeRecordPtr : DXILOpClass;
+ def getRemainingRecursionLevels : DXILOpClass;
+ def groupId : DXILOpClass;
+ def gsInstanceID : DXILOpClass;
+ def hitKind : DXILOpClass;
+ def ignoreHit : DXILOpClass;
+ def incrementOutputCount : DXILOpClass;
+ def indexNodeHandle : DXILOpClass;
+ def innerCoverage : DXILOpClass;
+ def instanceID : DXILOpClass;
+ def instanceIndex : DXILOpClass;
+ def isHelperLane : DXILOpClass;
+ def isSpecialFloat : DXILOpClass;
+ def legacyDoubleToFloat : DXILOpClass;
+ def legacyDoubleToSInt32 : DXILOpClass;
+ def legacyDoubleToUInt32 : DXILOpClass;
+ def legacyF16ToF32 : DXILOpClass;
+ def legacyF32ToF16 : DXILOpClass;
+ def loadInput : DXILOpClass;
+ def loadOutputControlPoint : DXILOpClass;
+ def loadPatchConstant : DXILOpClass;
+ def makeDouble : DXILOpClass;
+ def minPrecXRegLoad : DXILOpClass;
+ def minPrecXRegStore : DXILOpClass;
+ def nodeOutputIsValid : DXILOpClass;
+ def objectRayDirection : DXILOpClass;
+ def objectRayOrigin : DXILOpClass;
+ def objectToWorld : DXILOpClass;
+ def outputComplete : DXILOpClass;
+ def outputControlPointID : DXILOpClass;
+ def pack4x8 : DXILOpClass;
+ def primitiveID : DXILOpClass;
+ def primitiveIndex : DXILOpClass;
+ def quadOp : DXILOpClass;
+ def quadReadLaneAt : DXILOpClass;
+ def quadVote : DXILOpClass;
+ def quaternary : DXILOpClass;
+ def rawBufferLoad : DXILOpClass;
+ def rawBufferStore : DXILOpClass;
+ def rayFlags : DXILOpClass;
+ def rayQuery_Abort : DXILOpClass;
+ def rayQuery_CommitNonOpaqueTriangleHit : DXILOpClass;
+ def rayQuery_CommitProceduralPrimitiveHit : DXILOpClass;
+ def rayQuery_Proceed : DXILOpClass;
+ def rayQuery_StateMatrix : DXILOpClass;
+ def rayQuery_StateScalar : DXILOpClass;
+ def rayQuery_StateVector : DXILOpClass;
+ def rayQuery_TraceRayInline : DXILOpClass;
+ def rayTCurrent : DXILOpClass;
+ def rayTMin : DXILOpClass;
+ def renderTargetGetSampleCount : DXILOpClass;
+ def renderTargetGetSamplePosition : DXILOpClass;
+ def reportHit : DXILOpClass;
+ def sample : DXILOpClass;
+ def sampleBias : DXILOpClass;
+ def sampleCmp : DXILOpClass;
+ def sampleCmpBias : DXILOpClass;
+ def sampleCmpGrad : DXILOpClass;
+ def sampleCmpLevel : DXILOpClass;
+ def sampleCmpLevelZero : DXILOpClass;
+ def sampleGrad : DXILOpClass;
+ def sampleIndex : DXILOpClass;
+ def sampleLevel : DXILOpClass;
+ def setMeshOutputCounts : DXILOpClass;
+ def splitDouble : DXILOpClass;
+ def startInstanceLocation : DXILOpClass;
+ def startVertexLocation : DXILOpClass;
+ def storeOutput : DXILOpClass;
+ def storePatchConstant : DXILOpClass;
+ def storePrimitiveOutput : DXILOpClass;
+ def storeVertexOutput : DXILOpClass;
+ def tempRegLoad : DXILOpClass;
+ def tempRegStore : DXILOpClass;
+ def tertiary : DXILOpClass;
+ def texture2DMSGetSamplePosition : DXILOpClass;
+ def textureGather : DXILOpClass;
+ def textureGatherCmp : DXILOpClass;
+ def textureGatherRaw : DXILOpClass;
+ def textureLoad : DXILOpClass;
+ def textureStore : DXILOpClass;
+ def textureStoreSample : DXILOpClass;
+ def threadId : DXILOpClass;
+ def threadIdInGroup : DXILOpClass;
+ def traceRay : DXILOpClass;
+ def unary : DXILOpClass;
+ def unaryBits : DXILOpClass;
+ def unpack4x8 : DXILOpClass;
+ def viewID : DXILOpClass;
+ def waveActiveAllEqual : DXILOpClass;
+ def waveActiveBallot : DXILOpClass;
+ def waveActiveBit : DXILOpClass;
+ def waveActiveOp : DXILOpClass;
+ def waveAllOp : DXILOpClass;
+ def waveAllTrue : DXILOpClass;
+ def waveAnyTrue : DXILOpClass;
+ def waveGetLaneCount : DXILOpClass;
+ def waveGetLaneIndex : DXILOpClass;
+ def waveIsFirstLane : DXILOpClass;
+ def waveMatch : DXILOpClass;
+ def waveMatrix_Accumulate : DXILOpClass;
+ def waveMatrix_Annotate : DXILOpClass;
+ def waveMatrix_Depth : DXILOpClass;
+ def waveMatrix_Fill : DXILOpClass;
+ def waveMatrix_LoadGroupShared : DXILOpClass;
+ def waveMatrix_LoadRawBuf : DXILOpClass;
+ def waveMatrix_Multiply : DXILOpClass;
+ def waveMatrix_ScalarOp : DXILOpClass;
+ def waveMatrix_StoreGroupShared : DXILOpClass;
+ def waveMatrix_StoreRawBuf : DXILOpClass;
+ def waveMultiPrefixBitCount : DXILOpClass;
+ def waveMultiPrefixOp : DXILOpClass;
+ def wavePrefixOp : DXILOpClass;
+ def waveReadLaneAt : DXILOpClass;
+ def waveReadLaneFirst : DXILOpClass;
+ def worldRayDirection : DXILOpClass;
+ def worldRayOrigin : DXILOpClass;
+ def worldToObject : DXILOpClass;
+ def writeSamplerFeedback : DXILOpClass;
+ def writeSamplerFeedbackBias : DXILOpClass;
+ def writeSamplerFeedbackGrad : DXILOpClass;
+ def writeSamplerFeedbackLevel: DXILOpClass;
}
-// Abstract representation of the category a DXIL Operation belongs to
-class DXILOpCategory<string name> {
- string Name = name;
+// Abstraction DXIL Operation to LLVM intrinsic
+class DXILOpMapping<int opCode, DXILOpClass opClass, Intrinsic intrinsic, string doc> {
+ int OpCode = opCode; // Opcode corresponding to DXIL Operation
+ DXILOpClass OpClass = opClass; // Class of DXIL Operation.
+ Intrinsic LLVMIntrinsic = intrinsic; // LLVM Intrinsic the DXIL Operation maps
+ string Doc = doc; // to a short description of the operation
}
-def UnaryClass : DXILOpClass<"Unary">;
-def BinaryClass : DXILOpClass<"Binary">;
-def FlattenedThreadIdInGroupClass : DXILOpClass<"FlattenedThreadIdInGroup">;
-def ThreadIdInGroupClass : DXILOpClass<"ThreadIdInGroup">;
-def ThreadIdClass : DXILOpClass<"ThreadId">;
-def GroupIdClass : DXILOpClass<"GroupId">;
-
-def BinaryUintCategory : DXILOpCategory<"Binary uint">;
-def UnaryFloatCategory : DXILOpCategory<"Unary float">;
-def ComputeIDCategory : DXILOpCategory<"Compute/Mesh/Amplification shader">;
-
-// Represent as any pointer type with an option to change to a qualified pointer
-// type with address space specified.
-def dxil_handle_ty : LLVMAnyPointerType;
-def dxil_cbuffer_ty : LLVMAnyPointerType;
-def dxil_resource_ty : LLVMAnyPointerType;
-
-// The parameter description for a DXIL operation
-class DXILOpParameter<int pos, LLVMType type, string name, string doc,
- bit isConstant = 0, string enumName = "",
- int maxValue = 0> {
- int Pos = pos; // Position in parameter list
- LLVMType ParamType = type; // Parameter type
- string Name = name; // Short, unique parameter name
- string Doc = doc; // Description of this parameter
- bit IsConstant = isConstant; // Whether this parameter requires a constant value in the IR
- string EnumName = enumName; // Name of the enum type, if applicable
- int MaxValue = maxValue; // Maximum value for this parameter, if applicable
-}
-
-// A representation for a DXIL operation
-class DXILOperationDesc {
- string OpName = ""; // Name of DXIL operation
- int OpCode = 0; // Unique non-negative integer associated with the operation
- DXILOpClass OpClass; // Class of the operation
- DXILOpCategory OpCategory; // Category of the operation
- string Doc = ""; // Description of the operation
- list<DXILOpParameter> Params = []; // Parameter list of the operation
- list<LLVMType> OverloadTypes = []; // Overload types, if applicable
- EnumAttr Attribute; // Operation Attribute. Leverage attributes defined in Attributes.td
- // ReadNone - operation does not access memory.
- // ReadOnly - only reads from memory.
- // "ReadMemory" - reads memory
- bit IsDerivative = 0; // Whether this is some kind of derivative
- bit IsGradient = 0; // Whether this requires a gradient calculation
- bit IsFeedback = 0; // Whether this is a sampler feedback operation
- bit IsWave = 0; // Whether this requires in-wave, cross-lane functionality
- bit NeedsUniformInputs = 0; // Whether this operation requires that all
- // of its inputs are uniform across the wave
- // Group DXIL operation for stats - e.g., to accumulate the number of atomic/float/uint/int/...
- // operations used in the program.
- list<string> StatsGroup = [];
-}
-
-class DXILOperation<string name, int opCode, DXILOpClass opClass, DXILOpCategory opCategory, string doc,
- list<LLVMType> oloadTypes, EnumAttr attrs, list<DXILOpParameter> params,
- list<string> statsGroup = []> : DXILOperationDesc {
- let OpName = name;
- let OpCode = opCode;
- let Doc = doc;
- let Params = params;
- let OpClass = opClass;
- let OpCategory = opCategory;
- let OverloadTypes = oloadTypes;
- let Attribute = attrs;
- let StatsGroup = statsGroup;
-}
-
-// LLVM intrinsic that DXIL operation maps to.
-class LLVMIntrinsic<Intrinsic llvm_intrinsic_> { Intrinsic llvm_intrinsic = llvm_intrinsic_; }
-
-def Sin : DXILOperation<"Sin", 13, UnaryClass, UnaryFloatCategory, "returns sine(theta) for theta in radians.",
- [llvm_half_ty, llvm_float_ty], ReadNone,
- [
- DXILOpParameter<0, llvm_anyfloat_ty, "", "operation result">,
- DXILOpParameter<1, llvm_i32_ty, "opcode", "DXIL opcode">,
- DXILOpParameter<2, llvm_anyfloat_ty, "value", "input value">
- ],
- ["floats"]>,
- LLVMIntrinsic<int_sin>;
-
-def UMax : DXILOperation< "UMax", 39, BinaryClass, BinaryUintCategory, "unsigned integer maximum. UMax(a,b) = a > b ? a : b",
- [llvm_i16_ty, llvm_i32_ty, llvm_i64_ty], ReadNone,
- [
- DXILOpParameter<0, llvm_anyint_ty, "", "operation result">,
- DXILOpParameter<1, llvm_i32_ty, "opcode", "DXIL opcode">,
- DXILOpParameter<2, llvm_anyint_ty, "a", "input value">,
- DXILOpParameter<3, llvm_anyint_ty, "b", "input value">
- ],
- ["uints"]>,
- LLVMIntrinsic<int_umax>;
-
-def ThreadId : DXILOperation< "ThreadId", 93, ThreadIdClass, ComputeIDCategory, "reads the thread ID", [llvm_i32_ty], ReadNone,
- [
- DXILOpParameter<0, llvm_i32_ty, "", "thread ID component">,
- DXILOpParameter<1, llvm_i32_ty, "opcode", "DXIL opcode">,
- DXILOpParameter<2, llvm_i32_ty, "component", "component to read (x,y,z)">
- ]>,
- LLVMIntrinsic<int_dx_thread_id>;
-
-def GroupId : DXILOperation< "GroupId", 94, GroupIdClass, ComputeIDCategory, "reads the group ID (SV_GroupID)", [llvm_i32_ty], ReadNone,
- [
- DXILOpParameter<0, llvm_i32_ty, "", "group ID component">,
- DXILOpParameter<1, llvm_i32_ty, "opcode", "DXIL opcode">,
- DXILOpParameter<2, llvm_i32_ty, "component", "component to read">
- ]>,
- LLVMIntrinsic<int_dx_group_id>;
-
-def ThreadIdInGroup : DXILOperation< "ThreadIdInGroup", 95, ThreadIdInGroupClass, ComputeIDCategory,
- "reads the thread ID within the group (SV_GroupThreadID)", [llvm_i32_ty], ReadNone,
- [
- DXILOpParameter<0, llvm_i32_ty, "", "thread ID in group component">,
- DXILOpParameter<1, llvm_i32_ty, "opcode", "DXIL opcode">,
- DXILOpParameter<2, llvm_i32_ty, "component", "component to read (x,y,z)">
- ]>,
- LLVMIntrinsic<int_dx_thread_id_in_group>;
-
-def FlattenedThreadIdInGroup : DXILOperation< "FlattenedThreadIdInGroup", 96, FlattenedThreadIdInGroupClass, ComputeIDCategory,
- "provides a flattened index for a given thread within a given group (SV_GroupIndex)", [llvm_i32_ty], ReadNone,
- [
- DXILOpParameter<0, llvm_i32_ty, "", "result">,
- DXILOpParameter<1, llvm_i32_ty, "opcode", "DXIL opcode">
- ]>,
- LLVMIntrinsic<int_dx_flattened_thread_id_in_group>;
+// Concrete definition of DXIL Operation mapping to corresponding LLVM intrinsic
+def Sin : DXILOpMapping<13, unary, int_sin,
+ "Returns sine(theta) for theta in radians.">;
+def UMax : DXILOpMapping<39, binary, int_umax,
+ "Unsigned integer maximum. UMax(a,b) = a > b ? a : b">;
+def ThreadId : DXILOpMapping<93, threadId, int_dx_thread_id,
+ "Reads the thread ID">;
+def GroupId : DXILOpMapping<94, groupId, int_dx_group_id,
+ "Reads the group ID (SV_GroupID)">;
+def ThreadIdInGroup : DXILOpMapping<95, threadIdInGroup,
+ int_dx_thread_id_in_group,
+ "Reads the thread ID within the group "
+ "(SV_GroupThreadID)">;
+def FlattenedThreadIdInGroup : DXILOpMapping<96, flattenedThreadIdInGroup,
+ int_dx_flattened_thread_id_in_group,
+ "Provides a flattened index for a "
+ "given thread within a given "
+ "group (SV_GroupIndex)">;
diff --git a/llvm/lib/Target/DirectX/DXILOpBuilder.cpp b/llvm/lib/Target/DirectX/DXILOpBuilder.cpp
index 42180a865b72e3..21a20d45b922d9 100644
--- a/llvm/lib/Target/DirectX/DXILOpBuilder.cpp
+++ b/llvm/lib/Target/DirectX/DXILOpBuilder.cpp
@@ -221,12 +221,26 @@ static Type *getTypeFromParameterKind(ParameterKind Kind, Type *OverloadTy) {
return nullptr;
}
+/// Construct DXIL function type. This is the type of a function with
+/// the following prototype
+/// OverloadType dx.op.<opclass>.<return-type>(int opcode, <param types>)
+/// <param-types> are constructed from types in Prop.
+/// \param Prop Structure containing DXIL Operation properties based on
+/// its specification in DXIL.td.
+/// \param OverloadTy Return type to be used to construct DXIL function type.
static FunctionType *getDXILOpFunctionType(const OpCodeProperty *Prop,
Type *OverloadTy) {
SmallVector<Type *> ArgTys;
auto ParamKinds = getOpCodeParameterKind(*Prop);
+ // Add OverloadTy as return type of the function
+ ArgTys.emplace_back(OverloadTy);
+
+ // Add DXIL Opcode value type viz., Int32 as first argument
+ ArgTys.emplace_back(Type::getInt32Ty(OverloadTy->getContext()));
+
+ // Add DXIL Operation parameter types as specified in DXIL properties
for (unsigned I = 0; I < Prop->NumOfParameters; ++I) {
ParameterKind Kind = ParamKinds[I];
ArgTys.emplace_back(getTypeFromParameterKind(Kind, OverloadTy));
@@ -267,13 +281,13 @@ CallInst *DXILOpBuilder::createDXILOpCall(dxil::OpCode OpCode, Type *OverloadTy,
return B.CreateCall(Fn, FullArgs);
}
-Type *DXILOpBuilder::getOverloadTy(dxil::OpCode OpCode, FunctionType *FT,
- bool NoOpCodeParam) {
+Type *DXILOpBuilder::getOverloadTy(dxil::OpCode OpCode, FunctionType *FT) {
const OpCodeProperty *Prop = getOpCodeProperty(OpCode);
+ // If DXIL Op has no overload parameter, just return the
+ // precise return type specified.
if (Prop->OverloadParamIndex < 0) {
auto &Ctx = FT->getContext();
- // When only has 1 overload type, just return it.
switch (Prop->OverloadTys) {
case OverloadKind::VOID:
return Type::getVoidTy(Ctx);
@@ -302,9 +316,8 @@ Type *DXILOpBuilder::getOverloadTy(dxil::OpCode OpCode, FunctionType *FT,
// Prop->OverloadParamIndex is 0, overload type is FT->getReturnType().
Type *OverloadType = FT->getReturnType();
if (Prop->OverloadParamIndex != 0) {
- // Skip Return Type and Type for DXIL opcode.
- const unsigned SkipedParam = NoOpCodeParam ? 2 : 1;
- OverloadType = FT->getParamType(Prop->OverloadParamIndex - SkipedParam);
+ // Skip Return Type.
+ OverloadType = FT->getParamType(Prop->OverloadParamIndex - 1);
}
auto ParamKinds = getOpCodeParameterKind(*Prop);
diff --git a/llvm/lib/Target/DirectX/DXILOpBuilder.h b/llvm/lib/Target/DirectX/DXILOpBuilder.h
index 940ed538c7ce15..1c15f109184adf 100644
--- a/llvm/lib/Target/DirectX/DXILOpBuilder.h
+++ b/llvm/lib/Target/DirectX/DXILOpBuilder.h
@@ -31,8 +31,7 @@ class DXILOpBuilder {
DXILOpBuilder(Module &M, IRBuilderBase &B) : M(M), B(B) {}
CallInst *createDXILOpCall(dxil::OpCode OpCode, Type *OverloadTy,
llvm::iterator_range<Use *> Args);
- Type *getOverloadTy(dxil::OpCode OpCode, FunctionType *FT,
- bool NoOpCodeParam);
+ Type *getOverloadTy(dxil::OpCode OpCode, FunctionType *FT);
static const char *getOpCodeName(dxil::OpCode DXILOp);
private:
diff --git a/llvm/lib/Target/DirectX/DXILOpLowering.cpp b/llvm/lib/Target/DirectX/DXILOpLowering.cpp
index f6e2297e9af41f..6b649b76beecdf 100644
--- a/llvm/lib/Target/DirectX/DXILOpLowering.cpp
+++ b/llvm/lib/Target/DirectX/DXILOpLowering.cpp
@@ -33,8 +33,7 @@ static void lowerIntrinsic(dxil::OpCode DXILOp, Function &F, Module &M) {
IRBuilder<> B(M.getContext());
Value *DXILOpArg = B.getInt32(static_cast<unsigned>(DXILOp));
DXILOpBuilder DXILB(M, B);
- Type *OverloadTy =
- DXILB.getOverloadTy(DXILOp, F.getFunctionType(), /*NoOpCodeParam*/ true);
+ Type *OverloadTy = DXILB.getOverloadTy(DXILOp, F.getFunctionType());
for (User *U : make_early_inc_range(F.users())) {
CallInst *CI = dyn_cast<CallInst>(U);
if (!CI)
diff --git a/llvm/utils/TableGen/DXILEmitter.cpp b/llvm/utils/TableGen/DXILEmitter.cpp
index d47df597d53a35..fc958f5328736c 100644
--- a/llvm/utils/TableGen/DXILEmitter.cpp
+++ b/llvm/utils/TableGen/DXILEmitter.cpp
@@ -11,11 +11,14 @@
//
//===----------------------------------------------------------------------===//
+#include "CodeGenTarget.h"
#include "SequenceToOffsetTable.h"
#include "llvm/ADT/STLExtras.h"
+#include "llvm/ADT/SmallSet.h"
#include "llvm/ADT/SmallVector.h"
#include "llvm/ADT/StringSet.h"
#include "llvm/ADT/StringSwitch.h"
+#include "llvm/CodeGenTypes/MachineValueType.h"
#include "llvm/Support/DXILABI.h"
#include "llvm/TableGen/Record.h"
#include "llvm/TableGen/TableGenBackend.h"
@@ -30,28 +33,15 @@ struct DXILShaderModel {
int Minor = 0;
};
-struct DXILParameter {
- int Pos; // position in parameter list
- ParameterKind Kind;
- StringRef Name; // short, unique name
- StringRef Doc; // the documentation description of this parameter
- bool IsConst; // whether this argument requires a constant value in the IR
- StringRef EnumName; // the name of the enum type if applicable
- int MaxValue; // the maximum value for this parameter if applicable
- DXILParameter(const Record *R);
-};
-
struct DXILOperationDesc {
- StringRef OpName; // name of DXIL operation
+ std::string OpName; // name of DXIL operation
int OpCode; // ID of DXIL operation
StringRef OpClass; // name of the opcode class
- StringRef Category; // classification for this instruction
StringRef Doc; // the documentation description of this instruction
-
- SmallVector<DXILParameter> Params; // the operands that this instruction takes
- SmallVector<ParameterKind> OverloadTypes; // overload types if applicable
- StringRef Attr; // operation attribute; reference to string representation
- // of llvm::Attribute::AttrKind
+ SmallVector<MVT::SimpleValueType> OpTypes; // Vector of operand types -
+ // return type is at index 0
+ SmallVector<std::string>
+ OpAttributes; // operation attribute represented as strings
StringRef Intrinsic; // The llvm intrinsic map to OpName. Default is "" which
// means no map exists
bool IsDeriv = false; // whether this is some kind of derivative
@@ -74,81 +64,99 @@ struct DXILOperationDesc {
};
} // end anonymous namespace
-/*!
- Convert DXIL type name string to dxil::ParameterKind
-
- @param typeNameStr Type name string
- @return ParameterKind As defined in llvm/Support/DXILABI.h
-*/
-static ParameterKind lookupParameterKind(StringRef typeNameStr) {
- auto paramKind = StringSwitch<ParameterKind>(typeNameStr)
- .Case("llvm_void_ty", ParameterKind::VOID)
- .Case("llvm_half_ty", ParameterKind::HALF)
- .Case("llvm_float_ty", ParameterKind::FLOAT)
- .Case("llvm_double_ty", ParameterKind::DOUBLE)
- .Case("llvm_i1_ty", ParameterKind::I1)
- .Case("llvm_i8_ty", ParameterKind::I8)
- .Case("llvm_i16_ty", ParameterKind::I16)
- .Case("llvm_i32_ty", ParameterKind::I32)
- .Case("llvm_i64_ty", ParameterKind::I64)
- .Case("llvm_anyfloat_ty", ParameterKind::OVERLOAD)
- .Case("llvm_anyint_ty", ParameterKind::OVERLOAD)
- .Case("dxil_handle_ty", ParameterKind::DXIL_HANDLE)
- .Case("dxil_cbuffer_ty", ParameterKind::CBUFFER_RET)
- .Case("dxil_resource_ty", ParameterKind::RESOURCE_RET)
- .Default(ParameterKind::INVALID);
- assert(paramKind != ParameterKind::INVALID &&
- "Unsupported DXIL Type specified");
- return paramKind;
+/// Convert DXIL type name string to dxil::ParameterKind
+///
+/// \param VT Simple Value Type
+/// \return ParameterKind As defined in llvm/Support/DXILABI.h
+
+static ParameterKind getParameterKind(MVT::SimpleValueType VT) {
+ switch (VT) {
+ case MVT::isVoid:
+ return ParameterKind::VOID;
+ case MVT::f16:
+ return ParameterKind::HALF;
+ case MVT::f32:
+ return ParameterKind::FLOAT;
+ case MVT::f64:
+ return ParameterKind::DOUBLE;
+ case MVT::i1:
+ return ParameterKind::I1;
+ case MVT::i8:
+ return ParameterKind::I8;
+ case MVT::i16:
+ return ParameterKind::I16;
+ case MVT::i32:
+ return ParameterKind::I32;
+ case MVT::fAny:
+ case MVT::iAny:
+ return ParameterKind::OVERLOAD;
+ default:
+ llvm_unreachable("Support for specified DXIL Type not yet implemented");
+ }
}
+/// Construct an object using the DXIL Operation records specified
+/// in DXIL.td. This serves as the single source of reference of
+/// the information extracted from the specified Record R, for
+/// C++ code generated by this TableGen backend.
+// \param R Object representing TableGen record of a DXIL Operation
DXILOperationDesc::DXILOperationDesc(const Record *R) {
- OpName = R->getValueAsString("OpName");
+ OpName = R->getNameInitAsString();
OpCode = R->getValueAsInt("OpCode");
- OpClass = R->getValueAsDef("OpClass")->getValueAsString("Name");
- Category = R->getValueAsDef("OpCategory")->getValueAsString("Name");
- if (R->getValue("llvm_intrinsic")) {
- auto *IntrinsicDef = R->getValueAsDef("llvm_intrinsic");
+ Doc = R->getValueAsString("Doc");
+
+ if (R->getValue("LLVMIntrinsic")) {
+ auto *IntrinsicDef = R->getValueAsDef("LLVMIntrinsic");
auto DefName = IntrinsicDef->getName();
assert(DefName.starts_with("int_") && "invalid intrinsic name");
// Remove the int_ from intrinsic name.
Intrinsic = DefName.substr(4);
+ // TODO: It is expected that return type and parameter types of
+ // DXIL Operation are the same as that of the intrinsic. Deviations
+ // are expected to be encoded in TableGen record specification and
+ // handled accordingly here. Support to be added later, as needed.
+ // Get parameter type list of the intrinsic. Types attribute contains
+ // the list of as [returnType, param1Type,, param2Type, ...]
+
+ OverloadParamIndex = -1;
+ auto TypeRecs = IntrinsicDef->getValueAsListOfDefs("Types");
+ unsigned TypeRecsSize = TypeRecs.size();
+ // Populate return type and parameter type names
+ for (unsigned i = 0; i < TypeRecsSize; i++) {
+ auto TR = TypeRecs[i];
+ OpTypes.emplace_back(getValueType(TR->getValueAsDef("VT")));
+ // Get the overload parameter index.
+ // TODO : Seems hacky. Is it possible that more than one parameter can
+ // be of overload kind??
+ // TODO: Check for any additional constraints specified for DXIL operation
+ // restricting return type.
+ if (i > 0) {
+ auto &CurParam = OpTypes.back();
+ if (getParameterKind(CurParam) >= ParameterKind::OVERLOAD) {
+ OverloadParamIndex = i;
+ }
+ }
+ }
+ // Get the operation class
+ OpClass = R->getValueAsDef("OpClass")->getName();
+
+ // NOTE: For now, assume that attributes of DXIL Operation are the same as
+ // that of the intrinsic. Deviations are expected to be encoded in TableGen
+ // record specification and handled accordingly here. Support to be added
+ // later.
+ auto IntrPropList = IntrinsicDef->getValueAsListInit("IntrProperties");
+ auto IntrPropListSize = IntrPropList->size();
+ for (unsigned i = 0; i < IntrPropListSize; i++) {
+ OpAttributes.emplace_back(IntrPropList->getElement(i)->getAsString());
+ }
}
-
- Doc = R->getValueAsString("Doc");
-
- ListInit *ParamList = R->getValueAsListInit("Params");
- OverloadParamIndex = -1;
- for (unsigned I = 0; I < ParamList->size(); ++I) {
- Record *Param = ParamList->getElementAsRecord(I);
- Params.emplace_back(DXILParameter(Param));
- auto &CurParam = Params.back();
- if (CurParam.Kind >= ParameterKind::OVERLOAD)
- OverloadParamIndex = I;
- }
- ListInit *OverloadTypeList = R->getValueAsListInit("OverloadTypes");
-
- for (unsigned I = 0; I < OverloadTypeList->size(); ++I) {
- Record *R = OverloadTypeList->getElementAsRecord(I);
- OverloadTypes.emplace_back(lookupParameterKind(R->getNameInitAsString()));
- }
- Attr = StringRef(R->getValue("Attribute")->getNameInitAsString());
}
-DXILParameter::DXILParameter(const Record *R) {
- Name = R->getValueAsString("Name");
- Pos = R->getValueAsInt("Pos");
- Kind =
- lookupParameterKind(R->getValue("ParamType")->getValue()->getAsString());
- if (R->getValue("Doc"))
- Doc = R->getValueAsString("Doc");
- IsConst = R->getValueAsBit("IsConstant");
- EnumName = R->getValueAsString("EnumName");
- MaxValue = R->getValueAsInt("MaxValue");
-}
-
-static std::string parameterKindToString(ParameterKind Kind) {
+/// Return a string representation of ParameterKind enum
+/// \param Kind Parameter Kind enum value
+/// \return std::string string representation of input Kind
+static std::string getParameterKindStr(ParameterKind Kind) {
switch (Kind) {
case ParameterKind::INVALID:
return "INVALID";
@@ -182,92 +190,77 @@ static std::string parameterKindToString(ParameterKind Kind) {
llvm_unreachable("Unknown llvm::dxil::ParameterKind enum");
}
-static void emitDXILOpEnum(DXILOperationDesc &Op, raw_ostream &OS) {
- // Name = ID, // Doc
- OS << Op.OpName << " = " << Op.OpCode << ", // " << Op.Doc << "\n";
-}
+/// Return a string representation of OverloadKind enum that maps to
+/// input Simple Value Type enum
+/// \param VT Simple Value Type enum
+/// \return std::string string representation of OverloadKind
-static std::string buildCategoryStr(StringSet<> &Cetegorys) {
- std::string Str;
- raw_string_ostream OS(Str);
- for (auto &It : Cetegorys) {
- OS << " " << It.getKey();
+static std::string getOverloadKindStr(MVT::SimpleValueType VT) {
+ switch (VT) {
+ case MVT::isVoid:
+ return "OverloadKind::VOID";
+ case MVT::f16:
+ return "OverloadKind::HALF";
+ case MVT::f32:
+ return "OverloadKind::FLOAT";
+ case MVT::f64:
+ return "OverloadKind::DOUBLE";
+ case MVT::i1:
+ return "OverloadKind::I1";
+ case MVT::i8:
+ return "OverloadKind::I8";
+ case MVT::i16:
+ return "OverloadKind::I16";
+ case MVT::i32:
+ return "OverloadKind::I32";
+ case MVT::i64:
+ return "OverloadKind::I64";
+ case MVT::iAny:
+ return "OverloadKind::I16 | OverloadKind::I32 | OverloadKind::I64";
+ case MVT::fAny:
+ return "OverloadKind::HALF | OverloadKind::FLOAT | OverloadKind::DOUBLE";
+ default:
+ llvm_unreachable(
+ "Support for specified parameter OverloadKind not yet implemented");
}
- return OS.str();
}
-// Emit enum declaration for DXIL.
+/// Emit Enums of DXIL Ops
+/// \param A vector of DXIL Ops
+/// \param Output stream
static void emitDXILEnums(std::vector<DXILOperationDesc> &Ops,
raw_ostream &OS) {
- // Sort by Category + OpName.
+ // Sort by OpCode
llvm::sort(Ops, [](DXILOperationDesc &A, DXILOperationDesc &B) {
- // Group by Category first.
- if (A.Category == B.Category)
- // Inside same Category, order by OpName.
- return A.OpName < B.OpName;
- else
- return A.Category < B.Category;
+ return A.OpCode < B.OpCode;
});
OS << "// Enumeration for operations specified by DXIL\n";
OS << "enum class OpCode : unsigned {\n";
- StringMap<StringSet<>> ClassMap;
- StringRef PrevCategory = "";
for (auto &Op : Ops) {
- StringRef Category = Op.Category;
- if (Category != PrevCategory) {
- OS << "\n// " << Category << "\n";
- PrevCategory = Category;
- }
- emitDXILOpEnum(Op, OS);
- auto It = ClassMap.find(Op.OpClass);
- if (It != ClassMap.end()) {
- It->second.insert(Op.Category);
- } else {
- ClassMap[Op.OpClass].insert(Op.Category);
- }
+ // Name = ID, // Doc
+ OS << Op.OpName << " = " << Op.OpCode << ", // " << Op.Doc << "\n";
}
OS << "\n};\n\n";
- std::vector<std::pair<std::string, std::string>> ClassVec;
- for (auto &It : ClassMap) {
- ClassVec.emplace_back(
- std::pair(It.getKey().str(), buildCategoryStr(It.second)));
- }
- // Sort by Category + ClassName.
- llvm::sort(ClassVec, [](std::pair<std::string, std::string> &A,
- std::pair<std::string, std::string> &B) {
- StringRef ClassA = A.first;
- StringRef CategoryA = A.second;
- StringRef ClassB = B.first;
- StringRef CategoryB = B.second;
- // Group by Category first.
- if (CategoryA == CategoryB)
- // Inside same Category, order by ClassName.
- return ClassA < ClassB;
- else
- return CategoryA < CategoryB;
- });
-
OS << "// Groups for DXIL operations with equivalent function templates\n";
OS << "enum class OpCodeClass : unsigned {\n";
- PrevCategory = "";
- for (auto &It : ClassVec) {
-
- StringRef Category = It.second;
- if (Category != PrevCategory) {
- OS << "\n// " << Category << "\n";
- PrevCategory = Category;
- }
- StringRef Name = It.first;
- OS << Name << ",\n";
+ // Build an OpClass set to print
+ SmallSet<StringRef, 2> OpClassSet;
+ for (auto &Op : Ops) {
+ OpClassSet.insert(Op.OpClass);
+ }
+ for (auto &C : OpClassSet) {
+ OS << C << ",\n";
}
OS << "\n};\n\n";
}
-// Emit map from llvm intrinsic to DXIL operation.
+/// Emit map of DXIL operation to LLVM or DirectX intrinsic
+/// \param A vector of DXIL Ops
+/// \param Output stream
static void emitDXILIntrinsicMap(std::vector<DXILOperationDesc> &Ops,
raw_ostream &OS) {
OS << "\n";
@@ -285,75 +278,27 @@ static void emitDXILIntrinsicMap(std::vector<DXILOperationDesc> &Ops,
OS << "\n";
}
-/*!
- Convert operation attribute string to Attribute enum
-
- @param Attr string reference
- @return std::string Attribute enum string
- */
-static std::string emitDXILOperationAttr(StringRef Attr) {
- return StringSwitch<std::string>(Attr)
- .Case("ReadNone", "Attribute::ReadNone")
- .Case("ReadOnly", "Attribute::ReadOnly")
- .Default("Attribute::None");
-}
-
-static std::string overloadKindStr(ParameterKind Overload) {
- switch (Overload) {
- case ParameterKind::HALF:
- return "OverloadKind::HALF";
- case ParameterKind::FLOAT:
- return "OverloadKind::FLOAT";
- case ParameterKind::DOUBLE:
- return "OverloadKind::DOUBLE";
- case ParameterKind::I1:
- return "OverloadKind::I1";
- case ParameterKind::I8:
- return "OverloadKind::I8";
- case ParameterKind::I16:
- return "OverloadKind::I16";
- case ParameterKind::I32:
- return "OverloadKind::I32";
- case ParameterKind::I64:
- return "OverloadKind::I64";
- case ParameterKind::VOID:
- return "OverloadKind::VOID";
- default:
- return "OverloadKind::UNKNOWN";
- }
-}
-
-static std::string
-getDXILOperationOverloads(SmallVector<ParameterKind> Overloads) {
- // Format is: OverloadKind::FLOAT | OverloadKind::HALF
- auto It = Overloads.begin();
- std::string Result;
- raw_string_ostream OS(Result);
- OS << overloadKindStr(*It);
- for (++It; It != Overloads.end(); ++It) {
- OS << " | " << overloadKindStr(*It);
+/// Convert operation attribute string to Attribute enum
+///
+/// \param Attr string reference
+/// \return std::string Attribute enum string
+
+static std::string emitDXILOperationAttr(SmallVector<std::string> Attrs) {
+ for (auto Attr : Attrs) {
+ // TODO: For now just recognize IntrNoMem and IntrReadMem as valid and
+ // ignore others.
+ if (Attr == "IntrNoMem") {
+ return "Attribute::ReadNone";
+ } else if (Attr == "IntrReadMem") {
+ return "Attribute::ReadOnly";
+ }
}
- return OS.str();
-}
-
-static std::string lowerFirstLetter(StringRef Name) {
- if (Name.empty())
- return "";
-
- std::string LowerName = Name.str();
- LowerName[0] = llvm::toLower(Name[0]);
- return LowerName;
-}
-
-static std::string getDXILOpClassName(StringRef OpClass) {
- // Lower first letter expect for special case.
- return StringSwitch<std::string>(OpClass)
- .Case("CBufferLoad", "cbufferLoad")
- .Case("CBufferLoadLegacy", "cbufferLoadLegacy")
- .Case("GSInstanceID", "gsInstanceID")
- .Default(lowerFirstLetter(OpClass));
+ return "Attribute::None";
}
+/// Emit DXIL operation table
+/// \param A vector of DXIL Ops
+/// \param Output stream
static void emitDXILOperationTable(std::vector<DXILOperationDesc> &Ops,
raw_ostream &OS) {
// Sort by OpCode.
@@ -369,15 +314,16 @@ static void emitDXILOperationTable(std::vector<DXILOperationDesc> &Ops,
StringMap<SmallVector<ParameterKind>> ParameterMap;
StringSet<> ClassSet;
for (auto &Op : Ops) {
- OpStrings.add(Op.OpName.str());
+ OpStrings.add(Op.OpName);
if (ClassSet.contains(Op.OpClass))
continue;
ClassSet.insert(Op.OpClass);
- OpClassStrings.add(getDXILOpClassName(Op.OpClass));
+ OpClassStrings.add(Op.OpClass.data());
SmallVector<ParameterKind> ParamKindVec;
- for (auto &Param : Op.Params) {
- ParamKindVec.emplace_back(Param.Kind);
+ // ParamKindVec is a vector of parameters. Skip return type at index 0
+ for (unsigned i = 1; i < Op.OpTypes.size(); i++) {
+ ParamKindVec.emplace_back(getParameterKind(Op.OpTypes[i]));
}
ParameterMap[Op.OpClass] = ParamKindVec;
Parameters.add(ParamKindVec);
@@ -389,7 +335,7 @@ static void emitDXILOperationTable(std::vector<DXILOperationDesc> &Ops,
Parameters.layout();
// Emit the DXIL operation table.
- //{dxil::OpCode::Sin, OpCodeNameIndex, OpCodeClass::Unary,
+ //{dxil::OpCode::Sin, OpCodeNameIndex, OpCodeClass::unary,
// OpCodeClassNameIndex,
// OverloadKind::FLOAT | OverloadKind::HALF, Attribute::AttrKind::ReadNone, 0,
// 3, ParameterTableOffset},
@@ -398,12 +344,12 @@ static void emitDXILOperationTable(std::vector<DXILOperationDesc> &Ops,
OS << " static const OpCodeProperty OpCodeProps[] = {\n";
for (auto &Op : Ops) {
- OS << " { dxil::OpCode::" << Op.OpName << ", "
- << OpStrings.get(Op.OpName.str()) << ", OpCodeClass::" << Op.OpClass
- << ", " << OpClassStrings.get(getDXILOpClassName(Op.OpClass)) << ", "
- << getDXILOperationOverloads(Op.OverloadTypes) << ", "
- << emitDXILOperationAttr(Op.Attr) << ", " << Op.OverloadParamIndex
- << ", " << Op.Params.size() << ", "
+ OS << " { dxil::OpCode::" << Op.OpName << ", " << OpStrings.get(Op.OpName)
+ << ", OpCodeClass::" << Op.OpClass << ", "
+ << OpClassStrings.get(Op.OpClass.data()) << ", "
+ << getOverloadKindStr(Op.OpTypes[0]) << ", "
+ << emitDXILOperationAttr(Op.OpAttributes) << ", "
+ << Op.OverloadParamIndex << ", " << Op.OpTypes.size() - 1 << ", "
<< Parameters.get(ParameterMap[Op.OpClass]) << " },\n";
}
OS << " };\n";
@@ -418,7 +364,7 @@ static void emitDXILOperationTable(std::vector<DXILOperationDesc> &Ops,
"OpCodeProperty &B) {\n";
OS << " return A.OpCode < B.OpCode;\n";
OS << " });\n";
- OS << " assert(Prop && \"fail to find OpCodeProperty\");\n";
+ OS << " assert(Prop && \"failed to find OpCodeProperty\");\n";
OS << " return Prop;\n";
OS << "}\n\n";
@@ -450,7 +396,7 @@ static void emitDXILOperationTable(std::vector<DXILOperationDesc> &Ops,
Parameters.emit(
OS,
[](raw_ostream &ParamOS, ParameterKind Kind) {
- ParamOS << "ParameterKind::" << parameterKindToString(Kind);
+ ParamOS << "ParameterKind::" << getParameterKindStr(Kind);
},
"ParameterKind::INVALID");
OS << " };\n\n";
@@ -459,30 +405,28 @@ static void emitDXILOperationTable(std::vector<DXILOperationDesc> &Ops,
OS << "}\n ";
}
+/// Entry function call that invokes the functionality of this TableGen backend
+/// \param Records TableGen records of DXIL Operations defined in DXIL.td
+/// \param OS output stream
static void EmitDXILOperation(RecordKeeper &Records, raw_ostream &OS) {
- std::vector<Record *> Ops = Records.getAllDerivedDefinitions("DXILOperation");
OS << "// Generated code, do not edit.\n";
OS << "\n";
-
+ // Get all DXIL Ops to intrinsic mapping records
+ std::vector<Record *> OpIntrMaps =
+ Records.getAllDerivedDefinitions("DXILOpMapping");
std::vector<DXILOperationDesc> DXILOps;
- DXILOps.reserve(Ops.size());
- for (auto *Record : Ops) {
+ for (auto *Record : OpIntrMaps) {
DXILOps.emplace_back(DXILOperationDesc(Record));
}
-
OS << "#ifdef DXIL_OP_ENUM\n";
emitDXILEnums(DXILOps, OS);
OS << "#endif\n\n";
-
OS << "#ifdef DXIL_OP_INTRINSIC_MAP\n";
emitDXILIntrinsicMap(DXILOps, OS);
OS << "#endif\n\n";
-
OS << "#ifdef DXIL_OP_OPERATION_TABLE\n";
emitDXILOperationTable(DXILOps, OS);
OS << "#endif\n\n";
-
- OS << "\n";
}
static TableGen::Emitter::Opt X("gen-dxil-operation", EmitDXILOperation,
>From ec95379df363253ffcbbda21297417e703d5ccca Mon Sep 17 00:00:00 2001
From: David Spickett <david.spickett at linaro.org>
Date: Thu, 29 Feb 2024 14:19:23 +0000
Subject: [PATCH 128/406] [lldb][test] Clear pexpect found var before checking
again
If you run cmake without pexpect installed it errors as expected.
However, if you just `pip install pexpect` and cmake again it still
doesn't find it because it cached the result of the search.
Unset the result before looking for pexpect. So that this works
as expected:
cmake ...
pip3 install pexpect
cmake ...
---
lldb/test/CMakeLists.txt | 1 +
1 file changed, 1 insertion(+)
diff --git a/lldb/test/CMakeLists.txt b/lldb/test/CMakeLists.txt
index d8cbb24b6c9b81..7c31fd487f6ff8 100644
--- a/lldb/test/CMakeLists.txt
+++ b/lldb/test/CMakeLists.txt
@@ -30,6 +30,7 @@ endif()
# LLDB tree. However, we delay the deletion of it from the tree in case
# users/buildbots don't have the package yet and need some time to install it.
if (NOT LLDB_TEST_USE_VENDOR_PACKAGES)
+ unset(PY_pexpect_FOUND CACHE)
lldb_find_python_module(pexpect)
if (NOT PY_pexpect_FOUND)
message(FATAL_ERROR
>From aadd7650447b301f8d08fe94a886df05971adecb Mon Sep 17 00:00:00 2001
From: Stephen Tozer <stephen.tozer at sony.com>
Date: Thu, 29 Feb 2024 14:37:06 +0000
Subject: [PATCH 129/406] [DebugInfo][RemoveDIs] Prevent duplicate DPValues
from being returned by findDbgIntrinsics (#82764)
Fixes the error described here:
https://github.com/llvm/llvm-project/commit/a93a4ec7dd205b965ee5597314bb376520cd736c#commitcomment-138965199
The function `findDbgIntrinsics` is used to return a list of debug
intrinsics and DPValues that use a given value, with the intent that no
duplicates are returned in either list. For DPValues, we've guarded
against DPValues that use a value multiple times as part of a DIArgList,
but we have not guarded against DPValues that use a value multiple times
as separate operands (currently only possible for `dbg_assign`s,
something I missed in my implementation of that type!). This patch adds
a guard, and also updates a test to cover this case.
---
llvm/lib/IR/DebugInfo.cpp | 7 ++++---
llvm/test/Transforms/Coroutines/coro-debug-dbg.values.ll | 7 +++++++
2 files changed, 11 insertions(+), 3 deletions(-)
diff --git a/llvm/lib/IR/DebugInfo.cpp b/llvm/lib/IR/DebugInfo.cpp
index e044ab3230c5f9..1f3ff2246a4453 100644
--- a/llvm/lib/IR/DebugInfo.cpp
+++ b/llvm/lib/IR/DebugInfo.cpp
@@ -99,8 +99,8 @@ static void findDbgIntrinsics(SmallVectorImpl<IntrinsicT *> &Result, Value *V,
SmallPtrSet<DPValue *, 4> EncounteredDPValues;
/// Append IntrinsicT users of MetadataAsValue(MD).
- auto AppendUsers = [&Ctx, &EncounteredIntrinsics, &Result,
- DPValues](Metadata *MD) {
+ auto AppendUsers = [&Ctx, &EncounteredIntrinsics, &EncounteredDPValues,
+ &Result, DPValues](Metadata *MD) {
if (auto *MDV = MetadataAsValue::getIfExists(Ctx, MD)) {
for (User *U : MDV->users())
if (IntrinsicT *DVI = dyn_cast<IntrinsicT>(U))
@@ -113,7 +113,8 @@ static void findDbgIntrinsics(SmallVectorImpl<IntrinsicT *> &Result, Value *V,
if (LocalAsMetadata *L = dyn_cast<LocalAsMetadata>(MD)) {
for (DPValue *DPV : L->getAllDPValueUsers()) {
if (Type == DPValue::LocationType::Any || DPV->getType() == Type)
- DPValues->push_back(DPV);
+ if (EncounteredDPValues.insert(DPV).second)
+ DPValues->push_back(DPV);
}
}
};
diff --git a/llvm/test/Transforms/Coroutines/coro-debug-dbg.values.ll b/llvm/test/Transforms/Coroutines/coro-debug-dbg.values.ll
index 47b2ddafcfc650..9417859480e58a 100644
--- a/llvm/test/Transforms/Coroutines/coro-debug-dbg.values.ll
+++ b/llvm/test/Transforms/Coroutines/coro-debug-dbg.values.ll
@@ -9,6 +9,11 @@
; CHECK-SAME: !DIExpression(DW_OP_plus_uconst, [[OffsetX:[0-9]*]]))
; ^ No deref at the end, as this variable ("x") is an array;
; its value is its address. The entire array is in the frame.
+; CHECK: call void @llvm.dbg.assign(metadata ptr %[[frame]]
+; CHECK-SAME: !DIExpression(DW_OP_plus_uconst, [[OffsetX]])
+;; FIXME: Should we be updating the addresses on assigns here as well?
+; CHECK-SAME: , metadata ptr %[[frame]], !DIExpression())
+
; CHECK: call void @llvm.dbg.value(metadata ptr %[[frame]]
; CHECK-SAME: !DIExpression(DW_OP_plus_uconst, [[OffsetSpill:[0-9]*]], DW_OP_deref))
; CHECK: call void @llvm.dbg.value(metadata ptr %[[frame]]
@@ -78,6 +83,7 @@ init.ready: ; preds = %init.suspend, %coro
%i.init.ready.inc = add nsw i32 0, 1
call void @llvm.dbg.value(metadata i32 %i.init.ready.inc, metadata !6, metadata !DIExpression()), !dbg !11
call void @llvm.dbg.value(metadata ptr %x, metadata !12, metadata !DIExpression()), !dbg !17
+ call void @llvm.dbg.assign(metadata ptr %x, metadata !12, metadata !DIExpression(), metadata !30, metadata ptr %x, metadata !DIExpression()), !dbg !17
call void @llvm.memset.p0.i64(ptr align 16 %x, i8 0, i64 40, i1 false), !dbg !17
call void @print(i32 %i.init.ready.inc)
%ready.again = call zeroext i1 @await_ready()
@@ -250,3 +256,4 @@ attributes #4 = { argmemonly nofree nosync nounwind willreturn writeonly }
!21 = !DILocation(line: 43, column: 3, scope: !7)
!22 = !DILocation(line: 43, column: 8, scope: !7)
!23 = !DILocalVariable(name: "produced", scope: !7, file: !1, line:24, type: !10)
+!30 = distinct !DIAssignID()
\ No newline at end of file
>From 0d572c41f941a4c9b3744a3b849ec35cd26bae2b Mon Sep 17 00:00:00 2001
From: Petar Avramovic <Petar.Avramovic at amd.com>
Date: Thu, 29 Feb 2024 15:38:54 +0100
Subject: [PATCH 130/406] AMDGPU\GlobalISel: remove
amdgpu-global-isel-risky-select flag (#83426)
AMDGPUInstructionSelector should no longer attempt to select S1 G_PHIs.
Remove MIR test that attempts to inst-select divergent vcc(S1) G_PHI.
Lane mask merging algorithm for GlobalISel is now responsible for
selecting divergent S1 G_PHIs in AMDGPUGlobalISelDivergenceLowering.
Uniform S1 G_PHIs should be lowered to S32 G_PHIs in reg bank select
pass. In summary S1 G_PHIs should not reach AMDGPUInstructionSelector.
---
.../AMDGPU/AMDGPUInstructionSelector.cpp | 20 ++-----
.../divergence-temporal-divergent-i1.ll | 2 +-
.../divergence-temporal-divergent-reg.ll | 2 +-
.../AMDGPU/GlobalISel/inst-select-phi.mir | 56 +------------------
4 files changed, 9 insertions(+), 71 deletions(-)
diff --git a/llvm/lib/Target/AMDGPU/AMDGPUInstructionSelector.cpp b/llvm/lib/Target/AMDGPU/AMDGPUInstructionSelector.cpp
index aacc3590a5dbf9..b2c65e61b0097c 100644
--- a/llvm/lib/Target/AMDGPU/AMDGPUInstructionSelector.cpp
+++ b/llvm/lib/Target/AMDGPU/AMDGPUInstructionSelector.cpp
@@ -34,12 +34,6 @@
using namespace llvm;
using namespace MIPatternMatch;
-static cl::opt<bool> AllowRiskySelect(
- "amdgpu-global-isel-risky-select",
- cl::desc("Allow GlobalISel to select cases that are likely to not work yet"),
- cl::init(false),
- cl::ReallyHidden);
-
#define GET_GLOBALISEL_IMPL
#define AMDGPUSubtarget GCNSubtarget
#include "AMDGPUGenGlobalISel.inc"
@@ -211,14 +205,12 @@ bool AMDGPUInstructionSelector::selectPHI(MachineInstr &I) const {
const Register DefReg = I.getOperand(0).getReg();
const LLT DefTy = MRI->getType(DefReg);
- if (DefTy == LLT::scalar(1)) {
- if (!AllowRiskySelect) {
- LLVM_DEBUG(dbgs() << "Skipping risky boolean phi\n");
- return false;
- }
-
- LLVM_DEBUG(dbgs() << "Selecting risky boolean phi\n");
- }
+ // S1 G_PHIs should not be selected in instruction-select, instead:
+ // - divergent S1 G_PHI should go through lane mask merging algorithm
+ // and be fully inst-selected in AMDGPUGlobalISelDivergenceLowering
+ // - uniform S1 G_PHI should be lowered into S32 G_PHI in AMDGPURegBankSelect
+ if (DefTy == LLT::scalar(1))
+ return false;
// TODO: Verify this doesn't have insane operands (i.e. VGPR to SGPR copy)
diff --git a/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-temporal-divergent-i1.ll b/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-temporal-divergent-i1.ll
index 312c6a3822ce4f..1855ede0483def 100644
--- a/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-temporal-divergent-i1.ll
+++ b/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-temporal-divergent-i1.ll
@@ -1,5 +1,5 @@
; NOTE: Assertions have been autogenerated by utils/update_llc_test_checks.py UTC_ARGS: --version 3
-; RUN: llc -global-isel -amdgpu-global-isel-risky-select -mtriple=amdgcn-amd-amdpal -mcpu=gfx1010 -verify-machineinstrs < %s | FileCheck -check-prefix=GFX10 %s
+; RUN: llc -global-isel -mtriple=amdgcn-amd-amdpal -mcpu=gfx1010 -verify-machineinstrs < %s | FileCheck -check-prefix=GFX10 %s
define void @temporal_divergent_i1_phi(float %val, ptr %addr) {
; GFX10-LABEL: temporal_divergent_i1_phi:
diff --git a/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-temporal-divergent-reg.ll b/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-temporal-divergent-reg.ll
index b21e6a729dbc22..1934958ea8f37c 100644
--- a/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-temporal-divergent-reg.ll
+++ b/llvm/test/CodeGen/AMDGPU/GlobalISel/divergence-temporal-divergent-reg.ll
@@ -1,5 +1,5 @@
; NOTE: Assertions have been autogenerated by utils/update_llc_test_checks.py UTC_ARGS: --version 3
-; RUN: llc -global-isel -amdgpu-global-isel-risky-select -mtriple=amdgcn-amd-amdpal -mcpu=gfx1010 -verify-machineinstrs < %s | FileCheck -check-prefix=GFX10 %s
+; RUN: llc -global-isel -mtriple=amdgcn-amd-amdpal -mcpu=gfx1010 -verify-machineinstrs < %s | FileCheck -check-prefix=GFX10 %s
define void @temporal_divergent_i32(float %val, ptr %addr) {
; GFX10-LABEL: temporal_divergent_i32:
diff --git a/llvm/test/CodeGen/AMDGPU/GlobalISel/inst-select-phi.mir b/llvm/test/CodeGen/AMDGPU/GlobalISel/inst-select-phi.mir
index c7d45f062d0d20..4bb9eb807e1568 100644
--- a/llvm/test/CodeGen/AMDGPU/GlobalISel/inst-select-phi.mir
+++ b/llvm/test/CodeGen/AMDGPU/GlobalISel/inst-select-phi.mir
@@ -1,5 +1,5 @@
# NOTE: Assertions have been autogenerated by utils/update_mir_test_checks.py
-# RUN: llc -mtriple=amdgcn -amdgpu-global-isel-risky-select -run-pass=instruction-select -verify-machineinstrs %s -o - | FileCheck %s -check-prefix=GCN
+# RUN: llc -mtriple=amdgcn -run-pass=instruction-select -verify-machineinstrs %s -o - | FileCheck %s -check-prefix=GCN
---
name: g_phi_s32_ss_sbranch
@@ -321,60 +321,6 @@ body: |
...
----
-name: g_phi_vcc_s1_sbranch
-legalized: true
-regBankSelected: true
-tracksRegLiveness: true
-machineFunctionInfo: {}
-body: |
- ; GCN-LABEL: name: g_phi_vcc_s1_sbranch
- ; GCN: bb.0:
- ; GCN-NEXT: successors: %bb.1(0x40000000), %bb.2(0x40000000)
- ; GCN-NEXT: liveins: $vgpr0, $vgpr1, $sgpr2
- ; GCN-NEXT: {{ $}}
- ; GCN-NEXT: [[COPY:%[0-9]+]]:vgpr_32 = COPY $vgpr0
- ; GCN-NEXT: [[COPY1:%[0-9]+]]:vgpr_32 = COPY $vgpr1
- ; GCN-NEXT: [[COPY2:%[0-9]+]]:sreg_32 = COPY $sgpr2
- ; GCN-NEXT: [[S_MOV_B32_:%[0-9]+]]:sreg_32 = S_MOV_B32 0
- ; GCN-NEXT: [[V_CMP_EQ_U32_e64_:%[0-9]+]]:sreg_64 = V_CMP_EQ_U32_e64 [[COPY]], [[S_MOV_B32_]], implicit $exec
- ; GCN-NEXT: S_CMP_EQ_U32 [[COPY2]], [[S_MOV_B32_]], implicit-def $scc
- ; GCN-NEXT: [[COPY3:%[0-9]+]]:sreg_32 = COPY $scc
- ; GCN-NEXT: $scc = COPY [[COPY3]]
- ; GCN-NEXT: S_CBRANCH_SCC1 %bb.1, implicit $scc
- ; GCN-NEXT: S_BRANCH %bb.2
- ; GCN-NEXT: {{ $}}
- ; GCN-NEXT: bb.1:
- ; GCN-NEXT: successors: %bb.2(0x80000000)
- ; GCN-NEXT: {{ $}}
- ; GCN-NEXT: [[V_CMP_EQ_U32_e64_1:%[0-9]+]]:sreg_64 = V_CMP_EQ_U32_e64 [[COPY1]], [[S_MOV_B32_]], implicit $exec
- ; GCN-NEXT: S_BRANCH %bb.2
- ; GCN-NEXT: {{ $}}
- ; GCN-NEXT: bb.2:
- ; GCN-NEXT: [[PHI:%[0-9]+]]:sreg_64_xexec = PHI [[V_CMP_EQ_U32_e64_]], %bb.0, [[V_CMP_EQ_U32_e64_1]], %bb.1
- ; GCN-NEXT: S_SETPC_B64 undef $sgpr30_sgpr31, implicit [[PHI]]
- bb.0:
- liveins: $vgpr0, $vgpr1, $sgpr2
-
- %0:vgpr(s32) = COPY $vgpr0
- %1:vgpr(s32) = COPY $vgpr1
- %2:sgpr(s32) = COPY $sgpr2
- %3:sgpr(s32) = G_CONSTANT i32 0
- %4:vcc(s1) = G_ICMP intpred(eq), %0, %3
- %5:sgpr(s32) = G_ICMP intpred(eq), %2(s32), %3
- G_BRCOND %5, %bb.1
- G_BR %bb.2
-
- bb.1:
- %6:vcc(s1) = G_ICMP intpred(eq), %1, %3
- G_BR %bb.2
-
- bb.2:
- %7:vcc(s1) = G_PHI %4, %bb.0, %6, %bb.1
- S_SETPC_B64 undef $sgpr30_sgpr31, implicit %7
-
-...
-
---
name: phi_s32_ss_sbranch
legalized: true
>From 85dc3dfb1fa2c6720bdfbaaab012ebd96cbe3a58 Mon Sep 17 00:00:00 2001
From: Stephen Tozer <stephen.tozer at sony.com>
Date: Thu, 29 Feb 2024 14:46:52 +0000
Subject: [PATCH 131/406] [DebugInfo][RemoveDIs] Fix incorrect test expect
Fixes: aadd7650447b
The above commit landed with an incorrect test expect, missing a `metadata`
prefix. This patch adds the expected prefix to the test.
---
llvm/test/Transforms/Coroutines/coro-debug-dbg.values.ll | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/llvm/test/Transforms/Coroutines/coro-debug-dbg.values.ll b/llvm/test/Transforms/Coroutines/coro-debug-dbg.values.ll
index 9417859480e58a..dd9310fe34f341 100644
--- a/llvm/test/Transforms/Coroutines/coro-debug-dbg.values.ll
+++ b/llvm/test/Transforms/Coroutines/coro-debug-dbg.values.ll
@@ -12,7 +12,7 @@
; CHECK: call void @llvm.dbg.assign(metadata ptr %[[frame]]
; CHECK-SAME: !DIExpression(DW_OP_plus_uconst, [[OffsetX]])
;; FIXME: Should we be updating the addresses on assigns here as well?
-; CHECK-SAME: , metadata ptr %[[frame]], !DIExpression())
+; CHECK-SAME: , metadata ptr %[[frame]], metadata !DIExpression())
; CHECK: call void @llvm.dbg.value(metadata ptr %[[frame]]
; CHECK-SAME: !DIExpression(DW_OP_plus_uconst, [[OffsetSpill:[0-9]*]], DW_OP_deref))
>From a872a35251b833aaddec2172710ff234236afbd8 Mon Sep 17 00:00:00 2001
From: Jeremy Morse <jeremy.morse at sony.com>
Date: Thu, 29 Feb 2024 14:31:58 +0000
Subject: [PATCH 132/406] [NFC][RemoveDIs] Add bodies for inst-constructors
taking iterators
In a previous commit I added declarations for all these functions, but
forgot to add bodies for them (as nothing uses them yet). These
iterator-taking constructors are necessary for the future where we only
use iterators for insertion, preserving some debug-info properties.
Also adds two extra declarations I missed in 76dd4bc036f
---
llvm/include/llvm/IR/InstrTypes.h | 9 +++
llvm/lib/IR/Instructions.cpp | 129 ++++++++++++++++++++++++++++++
2 files changed, 138 insertions(+)
diff --git a/llvm/include/llvm/IR/InstrTypes.h b/llvm/include/llvm/IR/InstrTypes.h
index a124fbb88e3bcd..0e81d3b391a083 100644
--- a/llvm/include/llvm/IR/InstrTypes.h
+++ b/llvm/include/llvm/IR/InstrTypes.h
@@ -1536,10 +1536,19 @@ class CallBase : public Instruction {
OperandBundleDef OB,
Instruction *InsertPt = nullptr);
+ /// Create a clone of \p CB with operand bundle \p OB added.
+ static CallBase *addOperandBundle(CallBase *CB, uint32_t ID,
+ OperandBundleDef OB,
+ BasicBlock::iterator InsertPt);
+
/// Create a clone of \p CB with operand bundle \p ID removed.
static CallBase *removeOperandBundle(CallBase *CB, uint32_t ID,
Instruction *InsertPt = nullptr);
+ /// Create a clone of \p CB with operand bundle \p ID removed.
+ static CallBase *removeOperandBundle(CallBase *CB, uint32_t ID,
+ BasicBlock::iterator InsertPt);
+
static bool classof(const Instruction *I) {
return I->getOpcode() == Instruction::Call ||
I->getOpcode() == Instruction::Invoke ||
diff --git a/llvm/lib/IR/Instructions.cpp b/llvm/lib/IR/Instructions.cpp
index 976015656a5f96..42cdcad78228f6 100644
--- a/llvm/lib/IR/Instructions.cpp
+++ b/llvm/lib/IR/Instructions.cpp
@@ -303,6 +303,20 @@ void LandingPadInst::addClause(Constant *Val) {
// CallBase Implementation
//===----------------------------------------------------------------------===//
+CallBase *CallBase::Create(CallBase *CB, ArrayRef<OperandBundleDef> Bundles,
+ BasicBlock::iterator InsertPt) {
+ switch (CB->getOpcode()) {
+ case Instruction::Call:
+ return CallInst::Create(cast<CallInst>(CB), Bundles, InsertPt);
+ case Instruction::Invoke:
+ return InvokeInst::Create(cast<InvokeInst>(CB), Bundles, InsertPt);
+ case Instruction::CallBr:
+ return CallBrInst::Create(cast<CallBrInst>(CB), Bundles, InsertPt);
+ default:
+ llvm_unreachable("Unknown CallBase sub-class!");
+ }
+}
+
CallBase *CallBase::Create(CallBase *CB, ArrayRef<OperandBundleDef> Bundles,
Instruction *InsertPt) {
switch (CB->getOpcode()) {
@@ -557,6 +571,18 @@ CallBase::BundleOpInfo &CallBase::getBundleOpInfoForOperand(unsigned OpIdx) {
return *Current;
}
+CallBase *CallBase::addOperandBundle(CallBase *CB, uint32_t ID,
+ OperandBundleDef OB,
+ BasicBlock::iterator InsertPt) {
+ if (CB->getOperandBundle(ID))
+ return CB;
+
+ SmallVector<OperandBundleDef, 1> Bundles;
+ CB->getOperandBundlesAsDefs(Bundles);
+ Bundles.push_back(OB);
+ return Create(CB, Bundles, InsertPt);
+}
+
CallBase *CallBase::addOperandBundle(CallBase *CB, uint32_t ID,
OperandBundleDef OB,
Instruction *InsertPt) {
@@ -569,6 +595,23 @@ CallBase *CallBase::addOperandBundle(CallBase *CB, uint32_t ID,
return Create(CB, Bundles, InsertPt);
}
+CallBase *CallBase::removeOperandBundle(CallBase *CB, uint32_t ID,
+ BasicBlock::iterator InsertPt) {
+ SmallVector<OperandBundleDef, 1> Bundles;
+ bool CreateNew = false;
+
+ for (unsigned I = 0, E = CB->getNumOperandBundles(); I != E; ++I) {
+ auto Bundle = CB->getOperandBundleAt(I);
+ if (Bundle.getTagID() == ID) {
+ CreateNew = true;
+ continue;
+ }
+ Bundles.emplace_back(Bundle);
+ }
+
+ return CreateNew ? Create(CB, Bundles, InsertPt) : CB;
+}
+
CallBase *CallBase::removeOperandBundle(CallBase *CB, uint32_t ID,
Instruction *InsertPt) {
SmallVector<OperandBundleDef, 1> Bundles;
@@ -716,6 +759,13 @@ void CallInst::init(FunctionType *FTy, Value *Func, const Twine &NameStr) {
setName(NameStr);
}
+CallInst::CallInst(FunctionType *Ty, Value *Func, const Twine &Name,
+ BasicBlock::iterator InsertBefore)
+ : CallBase(Ty->getReturnType(), Instruction::Call,
+ OperandTraits<CallBase>::op_end(this) - 1, 1, InsertBefore) {
+ init(Ty, Func, Name);
+}
+
CallInst::CallInst(FunctionType *Ty, Value *Func, const Twine &Name,
Instruction *InsertBefore)
: CallBase(Ty->getReturnType(), Instruction::Call,
@@ -880,6 +930,20 @@ InvokeInst::InvokeInst(const InvokeInst &II)
SubclassOptionalData = II.SubclassOptionalData;
}
+InvokeInst *InvokeInst::Create(InvokeInst *II, ArrayRef<OperandBundleDef> OpB,
+ BasicBlock::iterator InsertPt) {
+ std::vector<Value *> Args(II->arg_begin(), II->arg_end());
+
+ auto *NewII = InvokeInst::Create(
+ II->getFunctionType(), II->getCalledOperand(), II->getNormalDest(),
+ II->getUnwindDest(), Args, OpB, II->getName(), InsertPt);
+ NewII->setCallingConv(II->getCallingConv());
+ NewII->SubclassOptionalData = II->SubclassOptionalData;
+ NewII->setAttributes(II->getAttributes());
+ NewII->setDebugLoc(II->getDebugLoc());
+ return NewII;
+}
+
InvokeInst *InvokeInst::Create(InvokeInst *II, ArrayRef<OperandBundleDef> OpB,
Instruction *InsertPt) {
std::vector<Value *> Args(II->arg_begin(), II->arg_end());
@@ -953,6 +1017,21 @@ CallBrInst::CallBrInst(const CallBrInst &CBI)
NumIndirectDests = CBI.NumIndirectDests;
}
+CallBrInst *CallBrInst::Create(CallBrInst *CBI, ArrayRef<OperandBundleDef> OpB,
+ BasicBlock::iterator InsertPt) {
+ std::vector<Value *> Args(CBI->arg_begin(), CBI->arg_end());
+
+ auto *NewCBI = CallBrInst::Create(
+ CBI->getFunctionType(), CBI->getCalledOperand(), CBI->getDefaultDest(),
+ CBI->getIndirectDests(), Args, OpB, CBI->getName(), InsertPt);
+ NewCBI->setCallingConv(CBI->getCallingConv());
+ NewCBI->SubclassOptionalData = CBI->SubclassOptionalData;
+ NewCBI->setAttributes(CBI->getAttributes());
+ NewCBI->setDebugLoc(CBI->getDebugLoc());
+ NewCBI->NumIndirectDests = CBI->NumIndirectDests;
+ return NewCBI;
+}
+
CallBrInst *CallBrInst::Create(CallBrInst *CBI, ArrayRef<OperandBundleDef> OpB,
Instruction *InsertPt) {
std::vector<Value *> Args(CBI->arg_begin(), CBI->arg_end());
@@ -1135,6 +1214,18 @@ CatchReturnInst::CatchReturnInst(Value *CatchPad, BasicBlock *BB,
// CatchSwitchInst Implementation
//===----------------------------------------------------------------------===//
+CatchSwitchInst::CatchSwitchInst(Value *ParentPad, BasicBlock *UnwindDest,
+ unsigned NumReservedValues,
+ const Twine &NameStr,
+ BasicBlock::iterator InsertBefore)
+ : Instruction(ParentPad->getType(), Instruction::CatchSwitch, nullptr, 0,
+ InsertBefore) {
+ if (UnwindDest)
+ ++NumReservedValues;
+ init(ParentPad, UnwindDest, NumReservedValues + 1);
+ setName(NameStr);
+}
+
CatchSwitchInst::CatchSwitchInst(Value *ParentPad, BasicBlock *UnwindDest,
unsigned NumReservedValues,
const Twine &NameStr,
@@ -3222,6 +3313,14 @@ void BinaryOperator::AssertOK() {
#endif
}
+BinaryOperator *BinaryOperator::Create(BinaryOps Op, Value *S1, Value *S2,
+ const Twine &Name,
+ BasicBlock::iterator InsertBefore) {
+ assert(S1->getType() == S2->getType() &&
+ "Cannot create binary operator with two operands of differing type!");
+ return new BinaryOperator(Op, S1, S2, S1->getType(), Name, InsertBefore);
+}
+
BinaryOperator *BinaryOperator::Create(BinaryOps Op, Value *S1, Value *S2,
const Twine &Name,
Instruction *InsertBefore) {
@@ -3277,6 +3376,13 @@ BinaryOperator *BinaryOperator::CreateNUWNeg(Value *Op, const Twine &Name,
return BinaryOperator::CreateNUWSub(Zero, Op, Name, InsertAtEnd);
}
+BinaryOperator *BinaryOperator::CreateNot(Value *Op, const Twine &Name,
+ BasicBlock::iterator InsertBefore) {
+ Constant *C = Constant::getAllOnesValue(Op->getType());
+ return new BinaryOperator(Instruction::Xor, Op, C,
+ Op->getType(), Name, InsertBefore);
+}
+
BinaryOperator *BinaryOperator::CreateNot(Value *Op, const Twine &Name,
Instruction *InsertBefore) {
Constant *C = Constant::getAllOnesValue(Op->getType());
@@ -3821,6 +3927,17 @@ CastInst *CastInst::CreatePointerBitCastOrAddrSpaceCast(
return Create(Instruction::BitCast, S, Ty, Name, InsertBefore);
}
+CastInst *CastInst::CreateBitOrPointerCast(Value *S, Type *Ty,
+ const Twine &Name,
+ BasicBlock::iterator InsertBefore) {
+ if (S->getType()->isPointerTy() && Ty->isIntegerTy())
+ return Create(Instruction::PtrToInt, S, Ty, Name, InsertBefore);
+ if (S->getType()->isIntegerTy() && Ty->isPointerTy())
+ return Create(Instruction::IntToPtr, S, Ty, Name, InsertBefore);
+
+ return Create(Instruction::BitCast, S, Ty, Name, InsertBefore);
+}
+
CastInst *CastInst::CreateBitOrPointerCast(Value *S, Type *Ty,
const Twine &Name,
Instruction *InsertBefore) {
@@ -4455,6 +4572,18 @@ CmpInst::CmpInst(Type *ty, OtherOps op, Predicate predicate, Value *LHS,
setName(Name);
}
+CmpInst *
+CmpInst::Create(OtherOps Op, Predicate predicate, Value *S1, Value *S2,
+ const Twine &Name, BasicBlock::iterator InsertBefore) {
+ if (Op == Instruction::ICmp) {
+ return new ICmpInst(InsertBefore, CmpInst::Predicate(predicate),
+ S1, S2, Name);
+ }
+
+ return new FCmpInst(InsertBefore, CmpInst::Predicate(predicate),
+ S1, S2, Name);
+}
+
CmpInst *
CmpInst::Create(OtherOps Op, Predicate predicate, Value *S1, Value *S2,
const Twine &Name, Instruction *InsertBefore) {
>From 1e6627ecef42fa8e36dae71589fc17d3adbd18aa Mon Sep 17 00:00:00 2001
From: RicoAfoat <51285519+RicoAfoat at users.noreply.github.com>
Date: Thu, 29 Feb 2024 22:55:51 +0800
Subject: [PATCH 133/406] [X86] matchAddressRecursively - ensure dead nodes are
replaced before matching the index register (#82881)
Fixes #82431 - see #82431 for more information.
---
llvm/lib/Target/X86/X86ISelDAGToDAG.cpp | 10 +++++----
llvm/test/CodeGen/X86/inline-asm-memop.ll | 27 +++++++++++++++++++++++
2 files changed, 33 insertions(+), 4 deletions(-)
create mode 100644 llvm/test/CodeGen/X86/inline-asm-memop.ll
diff --git a/llvm/lib/Target/X86/X86ISelDAGToDAG.cpp b/llvm/lib/Target/X86/X86ISelDAGToDAG.cpp
index c8f80ced354538..5cbd9ab4dc2d6c 100644
--- a/llvm/lib/Target/X86/X86ISelDAGToDAG.cpp
+++ b/llvm/lib/Target/X86/X86ISelDAGToDAG.cpp
@@ -2732,13 +2732,15 @@ bool X86DAGToDAGISel::matchAddressRecursively(SDValue N, X86ISelAddressMode &AM,
insertDAGNode(*CurDAG, N, Zext);
SDValue NewShl = CurDAG->getNode(ISD::SHL, DL, VT, Zext, ShlAmt);
insertDAGNode(*CurDAG, N, NewShl);
+ CurDAG->ReplaceAllUsesWith(N, NewShl);
+ CurDAG->RemoveDeadNode(N.getNode());
// Convert the shift to scale factor.
AM.Scale = 1 << ShAmtV;
- AM.IndexReg = Zext;
-
- CurDAG->ReplaceAllUsesWith(N, NewShl);
- CurDAG->RemoveDeadNode(N.getNode());
+ // If matchIndexRecursively is not called here,
+ // Zext may be replaced by other nodes but later used to call a builder
+ // method
+ AM.IndexReg = matchIndexRecursively(Zext, AM, Depth + 1);
return false;
}
diff --git a/llvm/test/CodeGen/X86/inline-asm-memop.ll b/llvm/test/CodeGen/X86/inline-asm-memop.ll
new file mode 100644
index 00000000000000..83442498076102
--- /dev/null
+++ b/llvm/test/CodeGen/X86/inline-asm-memop.ll
@@ -0,0 +1,27 @@
+; NOTE: Assertions have been autogenerated by utils/update_llc_test_checks.py UTC_ARGS: --version 4
+; RUN: llc -mtriple=x86_64-unknown-linux-gnu -O0 < %s | FileCheck %s
+
+; A bug in X86DAGToDAGISel::matchAddressRecursively create a zext SDValue which
+; is quickly replaced by other SDValue but already pushed into vector for later
+; calling for SelectionDAGISel::Select_INLINEASM getNode builder, see issue
+; 82431 for more infomation.
+
+define void @PR82431(i8 %call, ptr %b) {
+; CHECK-LABEL: PR82431:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: movb %dil, %al
+; CHECK-NEXT: addb $1, %al
+; CHECK-NEXT: movzbl %al, %eax
+; CHECK-NEXT: # kill: def $rax killed $eax
+; CHECK-NEXT: shlq $3, %rax
+; CHECK-NEXT: addq %rax, %rsi
+; CHECK-NEXT: #APP
+; CHECK-NEXT: #NO_APP
+; CHECK-NEXT: retq
+entry:
+ %narrow = add nuw i8 %call, 1
+ %idxprom = zext i8 %narrow to i64
+ %arrayidx = getelementptr [1 x i64], ptr %b, i64 0, i64 %idxprom
+ tail call void asm "", "=*m,*m,~{dirflag},~{fpsr},~{flags}"(ptr elementtype(i64) %arrayidx, ptr elementtype(i64) %arrayidx)
+ ret void
+}
>From 4f132dca711f4b425f9d370f5d59efb766b8bffa Mon Sep 17 00:00:00 2001
From: Michael Maitland <michaeltmaitland at gmail.com>
Date: Thu, 29 Feb 2024 09:57:15 -0500
Subject: [PATCH 134/406] [RISCV] Enable PostRAScheduler for SiFive7 (#83166)
Based on numbers collected in our downstream toolchain.
---
llvm/lib/Target/RISCV/RISCVSchedSiFive7.td | 1 +
llvm/test/CodeGen/RISCV/machine-combiner.ll | 8 +--
.../CodeGen/RISCV/short-forward-branch-opt.ll | 64 +++++++++----------
3 files changed, 37 insertions(+), 36 deletions(-)
diff --git a/llvm/lib/Target/RISCV/RISCVSchedSiFive7.td b/llvm/lib/Target/RISCV/RISCVSchedSiFive7.td
index 040cec42674000..0430d603620b6a 100644
--- a/llvm/lib/Target/RISCV/RISCVSchedSiFive7.td
+++ b/llvm/lib/Target/RISCV/RISCVSchedSiFive7.td
@@ -198,6 +198,7 @@ def SiFive7Model : SchedMachineModel {
let LoadLatency = 3;
let MispredictPenalty = 3;
let CompleteModel = 0;
+ let PostRAScheduler = true;
let EnableIntervals = true;
let UnsupportedFeatures = [HasStdExtZbkb, HasStdExtZbkc, HasStdExtZbkx,
HasStdExtZcmt, HasStdExtZknd, HasStdExtZkne,
diff --git a/llvm/test/CodeGen/RISCV/machine-combiner.ll b/llvm/test/CodeGen/RISCV/machine-combiner.ll
index 7c1792e2f101f5..cfdefec04600c8 100644
--- a/llvm/test/CodeGen/RISCV/machine-combiner.ll
+++ b/llvm/test/CodeGen/RISCV/machine-combiner.ll
@@ -1096,10 +1096,10 @@ declare double @llvm.maxnum.f64(double, double)
define double @test_fmadd_strategy(double %a0, double %a1, double %a2, double %a3, i64 %flag) {
; CHECK_LOCAL-LABEL: test_fmadd_strategy:
; CHECK_LOCAL: # %bb.0: # %entry
-; CHECK_LOCAL-NEXT: fmv.d fa5, fa0
; CHECK_LOCAL-NEXT: fsub.d fa4, fa0, fa1
-; CHECK_LOCAL-NEXT: fmul.d fa0, fa4, fa2
; CHECK_LOCAL-NEXT: andi a0, a0, 1
+; CHECK_LOCAL-NEXT: fmv.d fa5, fa0
+; CHECK_LOCAL-NEXT: fmul.d fa0, fa4, fa2
; CHECK_LOCAL-NEXT: beqz a0, .LBB76_2
; CHECK_LOCAL-NEXT: # %bb.1: # %entry
; CHECK_LOCAL-NEXT: fmul.d fa4, fa5, fa1
@@ -1110,10 +1110,10 @@ define double @test_fmadd_strategy(double %a0, double %a1, double %a2, double %a
;
; CHECK_GLOBAL-LABEL: test_fmadd_strategy:
; CHECK_GLOBAL: # %bb.0: # %entry
-; CHECK_GLOBAL-NEXT: fmv.d fa5, fa0
; CHECK_GLOBAL-NEXT: fsub.d fa4, fa0, fa1
-; CHECK_GLOBAL-NEXT: fmul.d fa0, fa4, fa2
; CHECK_GLOBAL-NEXT: andi a0, a0, 1
+; CHECK_GLOBAL-NEXT: fmv.d fa5, fa0
+; CHECK_GLOBAL-NEXT: fmul.d fa0, fa4, fa2
; CHECK_GLOBAL-NEXT: beqz a0, .LBB76_2
; CHECK_GLOBAL-NEXT: # %bb.1: # %entry
; CHECK_GLOBAL-NEXT: fmul.d fa5, fa5, fa1
diff --git a/llvm/test/CodeGen/RISCV/short-forward-branch-opt.ll b/llvm/test/CodeGen/RISCV/short-forward-branch-opt.ll
index 87406f22d169d1..c0c11fefafb555 100644
--- a/llvm/test/CodeGen/RISCV/short-forward-branch-opt.ll
+++ b/llvm/test/CodeGen/RISCV/short-forward-branch-opt.ll
@@ -813,24 +813,24 @@ define i64 @select_sll(i64 %A, i64 %B, i64 %C, i1 zeroext %cond) {
; RV32SFB-NEXT: not a7, a2
; RV32SFB-NEXT: srli a0, a0, 1
; RV32SFB-NEXT: sll t0, a1, a2
-; RV32SFB-NEXT: srl a0, a0, a7
; RV32SFB-NEXT: addi a2, a2, -32
+; RV32SFB-NEXT: srl a0, a0, a7
; RV32SFB-NEXT: mv a1, a3
-; RV32SFB-NEXT: bgez a2, .LBB20_2
+; RV32SFB-NEXT: bltz a2, .LBB20_2
; RV32SFB-NEXT: # %bb.1: # %entry
-; RV32SFB-NEXT: or a1, t0, a0
+; RV32SFB-NEXT: li a3, 0
; RV32SFB-NEXT: .LBB20_2: # %entry
-; RV32SFB-NEXT: bltz a2, .LBB20_4
+; RV32SFB-NEXT: bgez a2, .LBB20_4
; RV32SFB-NEXT: # %bb.3: # %entry
-; RV32SFB-NEXT: li a3, 0
+; RV32SFB-NEXT: or a1, t0, a0
; RV32SFB-NEXT: .LBB20_4: # %entry
; RV32SFB-NEXT: beqz a6, .LBB20_6
; RV32SFB-NEXT: # %bb.5: # %entry
-; RV32SFB-NEXT: mv a1, a5
+; RV32SFB-NEXT: mv a3, a4
; RV32SFB-NEXT: .LBB20_6: # %entry
; RV32SFB-NEXT: beqz a6, .LBB20_8
; RV32SFB-NEXT: # %bb.7: # %entry
-; RV32SFB-NEXT: mv a3, a4
+; RV32SFB-NEXT: mv a1, a5
; RV32SFB-NEXT: .LBB20_8: # %entry
; RV32SFB-NEXT: mv a0, a3
; RV32SFB-NEXT: ret
@@ -874,24 +874,24 @@ define i64 @select_srl(i64 %A, i64 %B, i64 %C, i1 zeroext %cond) {
; RV32SFB-NEXT: not a7, a2
; RV32SFB-NEXT: slli a1, a1, 1
; RV32SFB-NEXT: srl t0, a0, a2
-; RV32SFB-NEXT: sll a1, a1, a7
; RV32SFB-NEXT: addi a2, a2, -32
+; RV32SFB-NEXT: sll a1, a1, a7
; RV32SFB-NEXT: mv a0, a3
-; RV32SFB-NEXT: bgez a2, .LBB21_2
+; RV32SFB-NEXT: bltz a2, .LBB21_2
; RV32SFB-NEXT: # %bb.1: # %entry
-; RV32SFB-NEXT: or a0, t0, a1
+; RV32SFB-NEXT: li a3, 0
; RV32SFB-NEXT: .LBB21_2: # %entry
-; RV32SFB-NEXT: bltz a2, .LBB21_4
+; RV32SFB-NEXT: bgez a2, .LBB21_4
; RV32SFB-NEXT: # %bb.3: # %entry
-; RV32SFB-NEXT: li a3, 0
+; RV32SFB-NEXT: or a0, t0, a1
; RV32SFB-NEXT: .LBB21_4: # %entry
; RV32SFB-NEXT: beqz a6, .LBB21_6
; RV32SFB-NEXT: # %bb.5: # %entry
-; RV32SFB-NEXT: mv a0, a4
+; RV32SFB-NEXT: mv a3, a5
; RV32SFB-NEXT: .LBB21_6: # %entry
; RV32SFB-NEXT: beqz a6, .LBB21_8
; RV32SFB-NEXT: # %bb.7: # %entry
-; RV32SFB-NEXT: mv a3, a5
+; RV32SFB-NEXT: mv a0, a4
; RV32SFB-NEXT: .LBB21_8: # %entry
; RV32SFB-NEXT: mv a1, a3
; RV32SFB-NEXT: ret
@@ -935,24 +935,24 @@ define i64 @select_sra(i64 %A, i64 %B, i64 %C, i1 zeroext %cond) {
; RV32SFB-NEXT: not a7, a2
; RV32SFB-NEXT: slli t0, a1, 1
; RV32SFB-NEXT: srl t1, a0, a2
-; RV32SFB-NEXT: sll a7, t0, a7
; RV32SFB-NEXT: addi a2, a2, -32
+; RV32SFB-NEXT: sll a7, t0, a7
; RV32SFB-NEXT: mv a0, a3
-; RV32SFB-NEXT: bgez a2, .LBB22_2
+; RV32SFB-NEXT: bltz a2, .LBB22_2
; RV32SFB-NEXT: # %bb.1: # %entry
-; RV32SFB-NEXT: or a0, t1, a7
+; RV32SFB-NEXT: srai a3, a1, 31
; RV32SFB-NEXT: .LBB22_2: # %entry
-; RV32SFB-NEXT: bltz a2, .LBB22_4
+; RV32SFB-NEXT: bgez a2, .LBB22_4
; RV32SFB-NEXT: # %bb.3: # %entry
-; RV32SFB-NEXT: srai a3, a1, 31
+; RV32SFB-NEXT: or a0, t1, a7
; RV32SFB-NEXT: .LBB22_4: # %entry
; RV32SFB-NEXT: beqz a6, .LBB22_6
; RV32SFB-NEXT: # %bb.5: # %entry
-; RV32SFB-NEXT: mv a0, a4
+; RV32SFB-NEXT: mv a3, a5
; RV32SFB-NEXT: .LBB22_6: # %entry
; RV32SFB-NEXT: beqz a6, .LBB22_8
; RV32SFB-NEXT: # %bb.7: # %entry
-; RV32SFB-NEXT: mv a3, a5
+; RV32SFB-NEXT: mv a0, a4
; RV32SFB-NEXT: .LBB22_8: # %entry
; RV32SFB-NEXT: mv a1, a3
; RV32SFB-NEXT: ret
@@ -1088,11 +1088,11 @@ define i64 @select_andi(i64 %A, i64 %C, i1 zeroext %cond) {
; RV32SFB-NEXT: # %bb.1: # %entry
; RV32SFB-NEXT: andi a2, a0, 567
; RV32SFB-NEXT: .LBB25_2: # %entry
+; RV32SFB-NEXT: mv a0, a2
; RV32SFB-NEXT: bnez a4, .LBB25_4
; RV32SFB-NEXT: # %bb.3: # %entry
; RV32SFB-NEXT: li a1, 0
; RV32SFB-NEXT: .LBB25_4: # %entry
-; RV32SFB-NEXT: mv a0, a2
; RV32SFB-NEXT: ret
entry:
%0 = and i64 %A, 567
@@ -1130,13 +1130,13 @@ define i64 @select_ori(i64 %A, i64 %C, i1 zeroext %cond) {
;
; RV32SFB-LABEL: select_ori:
; RV32SFB: # %bb.0: # %entry
-; RV32SFB-NEXT: beqz a4, .LBB26_2
+; RV32SFB-NEXT: bnez a4, .LBB26_2
; RV32SFB-NEXT: # %bb.1: # %entry
-; RV32SFB-NEXT: mv a1, a3
+; RV32SFB-NEXT: ori a2, a0, 890
; RV32SFB-NEXT: .LBB26_2: # %entry
-; RV32SFB-NEXT: bnez a4, .LBB26_4
+; RV32SFB-NEXT: beqz a4, .LBB26_4
; RV32SFB-NEXT: # %bb.3: # %entry
-; RV32SFB-NEXT: ori a2, a0, 890
+; RV32SFB-NEXT: mv a1, a3
; RV32SFB-NEXT: .LBB26_4: # %entry
; RV32SFB-NEXT: mv a0, a2
; RV32SFB-NEXT: ret
@@ -1176,13 +1176,13 @@ define i64 @select_xori(i64 %A, i64 %C, i1 zeroext %cond) {
;
; RV32SFB-LABEL: select_xori:
; RV32SFB: # %bb.0: # %entry
-; RV32SFB-NEXT: beqz a4, .LBB27_2
+; RV32SFB-NEXT: bnez a4, .LBB27_2
; RV32SFB-NEXT: # %bb.1: # %entry
-; RV32SFB-NEXT: mv a1, a3
+; RV32SFB-NEXT: xori a2, a0, 321
; RV32SFB-NEXT: .LBB27_2: # %entry
-; RV32SFB-NEXT: bnez a4, .LBB27_4
+; RV32SFB-NEXT: beqz a4, .LBB27_4
; RV32SFB-NEXT: # %bb.3: # %entry
-; RV32SFB-NEXT: xori a2, a0, 321
+; RV32SFB-NEXT: mv a1, a3
; RV32SFB-NEXT: .LBB27_4: # %entry
; RV32SFB-NEXT: mv a0, a2
; RV32SFB-NEXT: ret
@@ -1272,11 +1272,11 @@ define i64 @select_srli(i64 %A, i64 %C, i1 zeroext %cond) {
; RV32SFB-NEXT: mv a0, a2
; RV32SFB-NEXT: bnez a4, .LBB29_2
; RV32SFB-NEXT: # %bb.1: # %entry
-; RV32SFB-NEXT: srli a0, a1, 3
+; RV32SFB-NEXT: li a3, 0
; RV32SFB-NEXT: .LBB29_2: # %entry
; RV32SFB-NEXT: bnez a4, .LBB29_4
; RV32SFB-NEXT: # %bb.3: # %entry
-; RV32SFB-NEXT: li a3, 0
+; RV32SFB-NEXT: srli a0, a1, 3
; RV32SFB-NEXT: .LBB29_4: # %entry
; RV32SFB-NEXT: mv a1, a3
; RV32SFB-NEXT: ret
>From 99824cf7967922bdd9ac895c949f330bb8d6b85a Mon Sep 17 00:00:00 2001
From: David Spickett <david.spickett at linaro.org>
Date: Thu, 29 Feb 2024 14:32:42 +0000
Subject: [PATCH 135/406] [lldb][test] Use pexpect spawn instead of spawnu
This is marked deprecated from at least 4.6 onward:
Deprecated: pass encoding to spawn() instead.
---
lldb/test/API/macosx/nslog/TestDarwinNSLogOutput.py | 5 +++--
lldb/test/API/terminal/TestSTTYBeforeAndAfter.py | 2 +-
2 files changed, 4 insertions(+), 3 deletions(-)
diff --git a/lldb/test/API/macosx/nslog/TestDarwinNSLogOutput.py b/lldb/test/API/macosx/nslog/TestDarwinNSLogOutput.py
index d7560156e0571a..15d9feb543895a 100644
--- a/lldb/test/API/macosx/nslog/TestDarwinNSLogOutput.py
+++ b/lldb/test/API/macosx/nslog/TestDarwinNSLogOutput.py
@@ -56,8 +56,9 @@ def run_lldb_to_breakpoint(self, exe, source_file, line, settings_commands=None)
# So that the child gets torn down after the test.
import pexpect
- self.child = pexpect.spawnu(
- "%s %s %s" % (lldbtest_config.lldbExec, self.lldbOption, exe)
+ self.child = pexpect.spawn(
+ "%s %s %s" % (lldbtest_config.lldbExec, self.lldbOption, exe),
+ encoding="utf-8",
)
child = self.child
diff --git a/lldb/test/API/terminal/TestSTTYBeforeAndAfter.py b/lldb/test/API/terminal/TestSTTYBeforeAndAfter.py
index e9b5940ff1adaf..31b960859fa2e5 100644
--- a/lldb/test/API/terminal/TestSTTYBeforeAndAfter.py
+++ b/lldb/test/API/terminal/TestSTTYBeforeAndAfter.py
@@ -37,7 +37,7 @@ def test_stty_dash_a_before_and_afetr_invoking_lldb_command(self):
lldb_prompt = "(lldb) "
# So that the child gets torn down after the test.
- self.child = pexpect.spawnu("expect")
+ self.child = pexpect.spawn("expect", encoding="utf-8")
child = self.child
child.expect(expect_prompt)
>From e60ebbd0001f2e66cb9f76874ddd69290e2086c1 Mon Sep 17 00:00:00 2001
From: Farzon Lotfi <1802579+farzonl at users.noreply.github.com>
Date: Thu, 29 Feb 2024 10:01:36 -0500
Subject: [PATCH 136/406] [HLSL] implementation of lerp intrinsic (#83077)
This is the start of implementing the lerp intrinsic
https://learn.microsoft.com/en-us/windows/win32/direct3dhlsl/dx-graphics-hlsl-lerp
Builtins.td - defines the builtin
hlsl_intrinsics.h - defines the lerp api
DiagnosticSemaKinds.td - needed a new error to be inclusive for more
than two operands.
CGBuiltin.cpp - add the lerp intrinsic lowering
SemaChecking.cpp - type checks for lerp builtin
IntrinsicsDirectX.td - define the lerp intrinsic
this change implements the first half of #70102
Co-authored-by: Xiang Li <python3kgae at outlook.com>
---
clang/include/clang/Basic/Builtins.td | 6 +
.../clang/Basic/DiagnosticSemaKinds.td | 5 +
clang/lib/CodeGen/CGBuiltin.cpp | 40 +++++++
clang/lib/Headers/hlsl/hlsl_intrinsics.h | 36 ++++++
clang/lib/Sema/SemaChecking.cpp | 69 +++++++-----
.../CodeGenHLSL/builtins/lerp-builtin.hlsl | 37 ++++++
clang/test/CodeGenHLSL/builtins/lerp.hlsl | 105 ++++++++++++++++++
clang/test/SemaHLSL/BuiltIns/dot-errors.hlsl | 28 ++---
clang/test/SemaHLSL/BuiltIns/lerp-errors.hlsl | 91 +++++++++++++++
llvm/include/llvm/IR/IntrinsicsDirectX.td | 5 +
10 files changed, 381 insertions(+), 41 deletions(-)
create mode 100644 clang/test/CodeGenHLSL/builtins/lerp-builtin.hlsl
create mode 100644 clang/test/CodeGenHLSL/builtins/lerp.hlsl
create mode 100644 clang/test/SemaHLSL/BuiltIns/lerp-errors.hlsl
diff --git a/clang/include/clang/Basic/Builtins.td b/clang/include/clang/Basic/Builtins.td
index 2fbc56d49a59a1..36151b49d9363d 100644
--- a/clang/include/clang/Basic/Builtins.td
+++ b/clang/include/clang/Basic/Builtins.td
@@ -4536,6 +4536,12 @@ def HLSLDotProduct : LangBuiltin<"HLSL_LANG"> {
let Prototype = "void(...)";
}
+def HLSLLerp : LangBuiltin<"HLSL_LANG"> {
+ let Spellings = ["__builtin_hlsl_lerp"];
+ let Attributes = [NoThrow, Const];
+ let Prototype = "void(...)";
+}
+
// Builtins for XRay.
def XRayCustomEvent : Builtin {
let Spellings = ["__xray_customevent"];
diff --git a/clang/include/clang/Basic/DiagnosticSemaKinds.td b/clang/include/clang/Basic/DiagnosticSemaKinds.td
index ff88c4f293abfd..4ef3ac8c96cd26 100644
--- a/clang/include/clang/Basic/DiagnosticSemaKinds.td
+++ b/clang/include/clang/Basic/DiagnosticSemaKinds.td
@@ -10266,6 +10266,11 @@ def err_block_on_vm : Error<
def err_sizeless_nonlocal : Error<
"non-local variable with sizeless type %0">;
+def err_vec_builtin_non_vector_all : Error<
+ "all arguments to %0 must be vectors">;
+def err_vec_builtin_incompatible_vector_all : Error<
+ "all arguments to %0 must have vectors of the same type">;
+
def err_vec_builtin_non_vector : Error<
"first two arguments to %0 must be vectors">;
def err_vec_builtin_incompatible_vector : Error<
diff --git a/clang/lib/CodeGen/CGBuiltin.cpp b/clang/lib/CodeGen/CGBuiltin.cpp
index 2d16e7cdc06053..74ca96117793c4 100644
--- a/clang/lib/CodeGen/CGBuiltin.cpp
+++ b/clang/lib/CodeGen/CGBuiltin.cpp
@@ -18007,6 +18007,46 @@ Value *CodeGenFunction::EmitHLSLBuiltinExpr(unsigned BuiltinID,
/*ReturnType*/ T0->getScalarType(), Intrinsic::dx_dot,
ArrayRef<Value *>{Op0, Op1}, nullptr, "dx.dot");
} break;
+ case Builtin::BI__builtin_hlsl_lerp: {
+ Value *X = EmitScalarExpr(E->getArg(0));
+ Value *Y = EmitScalarExpr(E->getArg(1));
+ Value *S = EmitScalarExpr(E->getArg(2));
+ llvm::Type *Xty = X->getType();
+ llvm::Type *Yty = Y->getType();
+ llvm::Type *Sty = S->getType();
+ if (!Xty->isVectorTy() && !Yty->isVectorTy() && !Sty->isVectorTy()) {
+ if (Xty->isFloatingPointTy()) {
+ auto V = Builder.CreateFSub(Y, X);
+ V = Builder.CreateFMul(S, V);
+ return Builder.CreateFAdd(X, V, "dx.lerp");
+ }
+ // DXC does this via casting to float should we do the same thing?
+ if (Xty->isIntegerTy()) {
+ auto V = Builder.CreateSub(Y, X);
+ V = Builder.CreateMul(S, V);
+ return Builder.CreateAdd(X, V, "dx.lerp");
+ }
+ // Bools should have been promoted
+ llvm_unreachable("Scalar Lerp is only supported on ints and floats.");
+ }
+ // A VectorSplat should have happened
+ assert(Xty->isVectorTy() && Yty->isVectorTy() && Sty->isVectorTy() &&
+ "Lerp of vector and scalar is not supported.");
+
+ [[maybe_unused]] auto *XVecTy =
+ E->getArg(0)->getType()->getAs<VectorType>();
+ [[maybe_unused]] auto *YVecTy =
+ E->getArg(1)->getType()->getAs<VectorType>();
+ [[maybe_unused]] auto *SVecTy =
+ E->getArg(2)->getType()->getAs<VectorType>();
+ // A HLSLVectorTruncation should have happend
+ assert(XVecTy->getNumElements() == YVecTy->getNumElements() &&
+ SVecTy->getNumElements() &&
+ "Lerp requires vectors to be of the same size.");
+ return Builder.CreateIntrinsic(
+ /*ReturnType*/ Xty, Intrinsic::dx_lerp, ArrayRef<Value *>{X, Y, S},
+ nullptr, "dx.lerp");
+ }
}
return nullptr;
}
diff --git a/clang/lib/Headers/hlsl/hlsl_intrinsics.h b/clang/lib/Headers/hlsl/hlsl_intrinsics.h
index 08e5d981a4a4ca..1314bdefa37e7b 100644
--- a/clang/lib/Headers/hlsl/hlsl_intrinsics.h
+++ b/clang/lib/Headers/hlsl/hlsl_intrinsics.h
@@ -317,6 +317,42 @@ double3 floor(double3);
_HLSL_BUILTIN_ALIAS(__builtin_elementwise_floor)
double4 floor(double4);
+//===----------------------------------------------------------------------===//
+// lerp builtins
+//===----------------------------------------------------------------------===//
+
+/// \fn T lerp(T x, T y, T s)
+/// \brief Returns the linear interpolation of x to y by s.
+/// \param x [in] The first-floating point value.
+/// \param y [in] The second-floating point value.
+/// \param s [in] A value that linearly interpolates between the x parameter and
+/// the y parameter.
+///
+/// Linear interpolation is based on the following formula: x*(1-s) + y*s which
+/// can equivalently be written as x + s(y-x).
+
+_HLSL_16BIT_AVAILABILITY(shadermodel, 6.2)
+_HLSL_BUILTIN_ALIAS(__builtin_hlsl_lerp)
+half lerp(half, half, half);
+_HLSL_16BIT_AVAILABILITY(shadermodel, 6.2)
+_HLSL_BUILTIN_ALIAS(__builtin_hlsl_lerp)
+half2 lerp(half2, half2, half2);
+_HLSL_16BIT_AVAILABILITY(shadermodel, 6.2)
+_HLSL_BUILTIN_ALIAS(__builtin_hlsl_lerp)
+half3 lerp(half3, half3, half3);
+_HLSL_16BIT_AVAILABILITY(shadermodel, 6.2)
+_HLSL_BUILTIN_ALIAS(__builtin_hlsl_lerp)
+half4 lerp(half4, half4, half4);
+
+_HLSL_BUILTIN_ALIAS(__builtin_hlsl_lerp)
+float lerp(float, float, float);
+_HLSL_BUILTIN_ALIAS(__builtin_hlsl_lerp)
+float2 lerp(float2, float2, float2);
+_HLSL_BUILTIN_ALIAS(__builtin_hlsl_lerp)
+float3 lerp(float3, float3, float3);
+_HLSL_BUILTIN_ALIAS(__builtin_hlsl_lerp)
+float4 lerp(float4, float4, float4);
+
//===----------------------------------------------------------------------===//
// log builtins
//===----------------------------------------------------------------------===//
diff --git a/clang/lib/Sema/SemaChecking.cpp b/clang/lib/Sema/SemaChecking.cpp
index 35d453e013e84b..016e9830662042 100644
--- a/clang/lib/Sema/SemaChecking.cpp
+++ b/clang/lib/Sema/SemaChecking.cpp
@@ -5197,43 +5197,49 @@ bool Sema::CheckPPCMMAType(QualType Type, SourceLocation TypeLoc) {
bool CheckVectorElementCallArgs(Sema *S, CallExpr *TheCall) {
assert(TheCall->getNumArgs() > 1);
ExprResult A = TheCall->getArg(0);
- ExprResult B = TheCall->getArg(1);
+
QualType ArgTyA = A.get()->getType();
- QualType ArgTyB = B.get()->getType();
+
auto *VecTyA = ArgTyA->getAs<VectorType>();
- auto *VecTyB = ArgTyB->getAs<VectorType>();
SourceLocation BuiltinLoc = TheCall->getBeginLoc();
- if (VecTyA == nullptr && VecTyB == nullptr)
- return false;
- if (VecTyA && VecTyB) {
- bool retValue = false;
- if (VecTyA->getElementType() != VecTyB->getElementType()) {
- // Note: type promotion is intended to be handeled via the intrinsics
- // and not the builtin itself.
- S->Diag(TheCall->getBeginLoc(), diag::err_vec_builtin_incompatible_vector)
- << TheCall->getDirectCallee()
- << SourceRange(A.get()->getBeginLoc(), B.get()->getEndLoc());
- retValue = true;
- }
- if (VecTyA->getNumElements() != VecTyB->getNumElements()) {
- // if we get here a HLSLVectorTruncation is needed.
- S->Diag(BuiltinLoc, diag::err_vec_builtin_incompatible_vector)
- << TheCall->getDirectCallee()
- << SourceRange(TheCall->getArg(0)->getBeginLoc(),
- TheCall->getArg(1)->getEndLoc());
- retValue = true;
- }
+ for (unsigned i = 1; i < TheCall->getNumArgs(); ++i) {
+ ExprResult B = TheCall->getArg(i);
+ QualType ArgTyB = B.get()->getType();
+ auto *VecTyB = ArgTyB->getAs<VectorType>();
+ if (VecTyA == nullptr && VecTyB == nullptr)
+ return false;
+
+ if (VecTyA && VecTyB) {
+ bool retValue = false;
+ if (VecTyA->getElementType() != VecTyB->getElementType()) {
+ // Note: type promotion is intended to be handeled via the intrinsics
+ // and not the builtin itself.
+ S->Diag(TheCall->getBeginLoc(),
+ diag::err_vec_builtin_incompatible_vector_all)
+ << TheCall->getDirectCallee()
+ << SourceRange(A.get()->getBeginLoc(), B.get()->getEndLoc());
+ retValue = true;
+ }
+ if (VecTyA->getNumElements() != VecTyB->getNumElements()) {
+ // if we get here a HLSLVectorTruncation is needed.
+ S->Diag(BuiltinLoc, diag::err_vec_builtin_incompatible_vector_all)
+ << TheCall->getDirectCallee()
+ << SourceRange(TheCall->getArg(0)->getBeginLoc(),
+ TheCall->getArg(1)->getEndLoc());
+ retValue = true;
+ }
- if (retValue)
- TheCall->setType(VecTyA->getElementType());
+ if (!retValue)
+ TheCall->setType(VecTyA->getElementType());
- return retValue;
+ return retValue;
+ }
}
// Note: if we get here one of the args is a scalar which
// requires a VectorSplat on Arg0 or Arg1
- S->Diag(BuiltinLoc, diag::err_vec_builtin_non_vector)
+ S->Diag(BuiltinLoc, diag::err_vec_builtin_non_vector_all)
<< TheCall->getDirectCallee()
<< SourceRange(TheCall->getArg(0)->getBeginLoc(),
TheCall->getArg(1)->getEndLoc());
@@ -5253,6 +5259,15 @@ bool Sema::CheckHLSLBuiltinFunctionCall(unsigned BuiltinID, CallExpr *TheCall) {
return true;
break;
}
+ case Builtin::BI__builtin_hlsl_lerp: {
+ if (checkArgCount(*this, TheCall, 3))
+ return true;
+ if (CheckVectorElementCallArgs(this, TheCall))
+ return true;
+ if (SemaBuiltinElementwiseTernaryMath(TheCall))
+ return true;
+ break;
+ }
}
return false;
}
diff --git a/clang/test/CodeGenHLSL/builtins/lerp-builtin.hlsl b/clang/test/CodeGenHLSL/builtins/lerp-builtin.hlsl
new file mode 100644
index 00000000000000..1f16dec68212e4
--- /dev/null
+++ b/clang/test/CodeGenHLSL/builtins/lerp-builtin.hlsl
@@ -0,0 +1,37 @@
+// RUN: %clang_cc1 -finclude-default-header -x hlsl -triple dxil-pc-shadermodel6.3-library %s -fnative-half-type -emit-llvm -disable-llvm-passes -o - | FileCheck %s
+
+
+
+// CHECK-LABEL: builtin_lerp_half_scalar
+// CHECK: %3 = fsub double %conv1, %conv
+// CHECK: %4 = fmul double %conv2, %3
+// CHECK: %dx.lerp = fadd double %conv, %4
+// CHECK: %conv3 = fptrunc double %dx.lerp to half
+// CHECK: ret half %conv3
+half builtin_lerp_half_scalar (half p0) {
+ return __builtin_hlsl_lerp ( p0, p0, p0 );
+}
+
+// CHECK-LABEL: builtin_lerp_float_scalar
+// CHECK: %3 = fsub double %conv1, %conv
+// CHECK: %4 = fmul double %conv2, %3
+// CHECK: %dx.lerp = fadd double %conv, %4
+// CHECK: %conv3 = fptrunc double %dx.lerp to float
+// CHECK: ret float %conv3
+float builtin_lerp_float_scalar ( float p0) {
+ return __builtin_hlsl_lerp ( p0, p0, p0 );
+}
+
+// CHECK-LABEL: builtin_lerp_half_vector
+// CHECK: %dx.lerp = call <3 x half> @llvm.dx.lerp.v3f16(<3 x half> %0, <3 x half> %1, <3 x half> %2)
+// CHECK: ret <3 x half> %dx.lerp
+half3 builtin_lerp_half_vector (half3 p0) {
+ return __builtin_hlsl_lerp ( p0, p0, p0 );
+}
+
+// CHECK-LABEL: builtin_lerp_floar_vector
+// CHECK: %dx.lerp = call <2 x float> @llvm.dx.lerp.v2f32(<2 x float> %0, <2 x float> %1, <2 x float> %2)
+// CHECK: ret <2 x float> %dx.lerp
+float2 builtin_lerp_floar_vector ( float2 p0) {
+ return __builtin_hlsl_lerp ( p0, p0, p0 );
+}
diff --git a/clang/test/CodeGenHLSL/builtins/lerp.hlsl b/clang/test/CodeGenHLSL/builtins/lerp.hlsl
new file mode 100644
index 00000000000000..1297f6b85bbd48
--- /dev/null
+++ b/clang/test/CodeGenHLSL/builtins/lerp.hlsl
@@ -0,0 +1,105 @@
+// RUN: %clang_cc1 -finclude-default-header -x hlsl -triple \
+// RUN: dxil-pc-shadermodel6.3-library %s -fnative-half-type \
+// RUN: -emit-llvm -disable-llvm-passes -o - | FileCheck %s \
+// RUN: --check-prefixes=CHECK,NATIVE_HALF
+// RUN: %clang_cc1 -finclude-default-header -x hlsl -triple \
+// RUN: dxil-pc-shadermodel6.3-library %s -emit-llvm -disable-llvm-passes \
+// RUN: -o - | FileCheck %s --check-prefixes=CHECK,NO_HALF
+
+// NATIVE_HALF: %3 = fsub half %1, %0
+// NATIVE_HALF: %4 = fmul half %2, %3
+// NATIVE_HALF: %dx.lerp = fadd half %0, %4
+// NATIVE_HALF: ret half %dx.lerp
+// NO_HALF: %3 = fsub float %1, %0
+// NO_HALF: %4 = fmul float %2, %3
+// NO_HALF: %dx.lerp = fadd float %0, %4
+// NO_HALF: ret float %dx.lerp
+half test_lerp_half ( half p0) {
+ return lerp ( p0, p0, p0 );
+}
+
+// NATIVE_HALF: %dx.lerp = call <2 x half> @llvm.dx.lerp.v2f16(<2 x half> %0, <2 x half> %1, <2 x half> %2)
+// NATIVE_HALF: ret <2 x half> %dx.lerp
+// NO_HALF: %dx.lerp = call <2 x float> @llvm.dx.lerp.v2f32(<2 x float> %0, <2 x float> %1, <2 x float> %2)
+// NO_HALF: ret <2 x float> %dx.lerp
+half2 test_lerp_half2 ( half2 p0, half2 p1 ) {
+ return lerp ( p0, p0, p0 );
+}
+
+// NATIVE_HALF: %dx.lerp = call <3 x half> @llvm.dx.lerp.v3f16(<3 x half> %0, <3 x half> %1, <3 x half> %2)
+// NATIVE_HALF: ret <3 x half> %dx.lerp
+// NO_HALF: %dx.lerp = call <3 x float> @llvm.dx.lerp.v3f32(<3 x float> %0, <3 x float> %1, <3 x float> %2)
+// NO_HALF: ret <3 x float> %dx.lerp
+half3 test_lerp_half3 ( half3 p0, half3 p1 ) {
+ return lerp ( p0, p0, p0 );
+}
+
+// NATIVE_HALF: %dx.lerp = call <4 x half> @llvm.dx.lerp.v4f16(<4 x half> %0, <4 x half> %1, <4 x half> %2)
+// NATIVE_HALF: ret <4 x half> %dx.lerp
+// NO_HALF: %dx.lerp = call <4 x float> @llvm.dx.lerp.v4f32(<4 x float> %0, <4 x float> %1, <4 x float> %2)
+// NO_HALF: ret <4 x float> %dx.lerp
+half4 test_lerp_half4 ( half4 p0, half4 p1 ) {
+ return lerp ( p0, p0, p0 );
+}
+
+// CHECK: %3 = fsub float %1, %0
+// CHECK: %4 = fmul float %2, %3
+// CHECK: %dx.lerp = fadd float %0, %4
+// CHECK: ret float %dx.lerp
+float test_lerp_float ( float p0, float p1 ) {
+ return lerp ( p0, p0, p0 );
+}
+
+// CHECK: %dx.lerp = call <2 x float> @llvm.dx.lerp.v2f32(<2 x float> %0, <2 x float> %1, <2 x float> %2)
+// CHECK: ret <2 x float> %dx.lerp
+float2 test_lerp_float2 ( float2 p0, float2 p1 ) {
+ return lerp ( p0, p0, p0 );
+}
+
+// CHECK: %dx.lerp = call <3 x float> @llvm.dx.lerp.v3f32(<3 x float> %0, <3 x float> %1, <3 x float> %2)
+// CHECK: ret <3 x float> %dx.lerp
+float3 test_lerp_float3 ( float3 p0, float3 p1 ) {
+ return lerp ( p0, p0, p0 );
+}
+
+// CHECK: %dx.lerp = call <4 x float> @llvm.dx.lerp.v4f32(<4 x float> %0, <4 x float> %1, <4 x float> %2)
+// CHECK: ret <4 x float> %dx.lerp
+float4 test_lerp_float4 ( float4 p0, float4 p1) {
+ return lerp ( p0, p0, p0 );
+}
+
+// CHECK: %dx.lerp = call <2 x float> @llvm.dx.lerp.v2f32(<2 x float> %splat.splat, <2 x float> %1, <2 x float> %2)
+// CHECK: ret <2 x float> %dx.lerp
+float2 test_lerp_float2_splat ( float p0, float2 p1 ) {
+ return lerp( p0, p1, p1 );
+}
+
+// CHECK: %dx.lerp = call <3 x float> @llvm.dx.lerp.v3f32(<3 x float> %splat.splat, <3 x float> %1, <3 x float> %2)
+// CHECK: ret <3 x float> %dx.lerp
+float3 test_lerp_float3_splat ( float p0, float3 p1 ) {
+ return lerp( p0, p1, p1 );
+}
+
+// CHECK: %dx.lerp = call <4 x float> @llvm.dx.lerp.v4f32(<4 x float> %splat.splat, <4 x float> %1, <4 x float> %2)
+// CHECK: ret <4 x float> %dx.lerp
+float4 test_lerp_float4_splat ( float p0, float4 p1 ) {
+ return lerp( p0, p1, p1 );
+}
+
+// CHECK: %conv = sitofp i32 %2 to float
+// CHECK: %splat.splatinsert = insertelement <2 x float> poison, float %conv, i64 0
+// CHECK: %splat.splat = shufflevector <2 x float> %splat.splatinsert, <2 x float> poison, <2 x i32> zeroinitializer
+// CHECK: %dx.lerp = call <2 x float> @llvm.dx.lerp.v2f32(<2 x float> %0, <2 x float> %1, <2 x float> %splat.splat)
+// CHECK: ret <2 x float> %dx.lerp
+float2 test_lerp_float2_int_splat ( float2 p0, int p1 ) {
+ return lerp ( p0, p0, p1 );
+}
+
+// CHECK: %conv = sitofp i32 %2 to float
+// CHECK: %splat.splatinsert = insertelement <3 x float> poison, float %conv, i64 0
+// CHECK: %splat.splat = shufflevector <3 x float> %splat.splatinsert, <3 x float> poison, <3 x i32> zeroinitializer
+// CHECK: %dx.lerp = call <3 x float> @llvm.dx.lerp.v3f32(<3 x float> %0, <3 x float> %1, <3 x float> %splat.splat)
+// CHECK: ret <3 x float> %dx.lerp
+float3 test_lerp_float3_int_splat ( float3 p0, int p1 ) {
+ return lerp ( p0, p0, p1 );
+}
diff --git a/clang/test/SemaHLSL/BuiltIns/dot-errors.hlsl b/clang/test/SemaHLSL/BuiltIns/dot-errors.hlsl
index 54d093aa7ce3a4..5dbb52a80c6bd0 100644
--- a/clang/test/SemaHLSL/BuiltIns/dot-errors.hlsl
+++ b/clang/test/SemaHLSL/BuiltIns/dot-errors.hlsl
@@ -22,7 +22,7 @@ float test_dot_vector_size_mismatch ( float3 p0, float2 p1 ) {
float test_dot_builtin_vector_size_mismatch ( float3 p0, float2 p1 ) {
return __builtin_hlsl_dot ( p0, p1 );
- // expected-error at -1 {{first two arguments to '__builtin_hlsl_dot' must have the same type}}
+ // expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have vectors of the same type}}
}
float test_dot_scalar_mismatch ( float p0, int p1 ) {
@@ -38,69 +38,69 @@ float test_dot_element_type_mismatch ( int2 p0, float2 p1 ) {
//NOTE: for all the *_promotion we are intentionally not handling type promotion in builtins
float test_builtin_dot_vec_int_to_float_promotion ( int2 p0, float2 p1 ) {
return __builtin_hlsl_dot ( p0, p1 );
- // expected-error at -1 {{first two arguments to '__builtin_hlsl_dot' must have the same type}}
+ // expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have vectors of the same type}}
}
int64_t test_builtin_dot_vec_int_to_int64_promotion( int64_t2 p0, int2 p1 ) {
return __builtin_hlsl_dot( p0, p1 );
- // expected-error at -1 {{first two arguments to '__builtin_hlsl_dot' must have the same type}}
+ // expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have vectors of the same type}}
}
float test_builtin_dot_vec_half_to_float_promotion( float2 p0, half2 p1 ) {
return __builtin_hlsl_dot( p0, p1 );
- // expected-error at -1 {{first two arguments to '__builtin_hlsl_dot' must have the same type}}
+ // expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have vectors of the same type}}
}
#ifdef __HLSL_ENABLE_16_BIT
float test_builtin_dot_vec_int16_to_float_promotion( float2 p0, int16_t2 p1 ) {
return __builtin_hlsl_dot( p0, p1 );
- // expected-error at -1 {{first two arguments to '__builtin_hlsl_dot' must have the same type}}
+ // expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have vectors of the same type}}
}
half test_builtin_dot_vec_int16_to_half_promotion( half2 p0, int16_t2 p1 ) {
return __builtin_hlsl_dot( p0, p1 );
- // expected-error at -1 {{first two arguments to '__builtin_hlsl_dot' must have the same type}}
+ // expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have vectors of the same type}}
}
int test_builtin_dot_vec_int16_to_int_promotion( int2 p0, int16_t2 p1 ) {
return __builtin_hlsl_dot( p0, p1 );
- // expected-error at -1 {{first two arguments to '__builtin_hlsl_dot' must have the same type}}
+ // expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have vectors of the same type}}
}
int64_t test_builtin_dot_vec_int16_to_int64_promotion( int64_t2 p0, int16_t2 p1 ) {
return __builtin_hlsl_dot( p0, p1 );
- // expected-error at -1 {{first two arguments to '__builtin_hlsl_dot' must have the same type}}
+ // expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have vectors of the same type}}
}
#endif
float test_builtin_dot_float2_splat ( float p0, float2 p1 ) {
return __builtin_hlsl_dot( p0, p1 );
- // expected-error at -1 {{first two arguments to '__builtin_hlsl_dot' must be vectors}}
+ // expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must be vectors}}
}
float test_builtin_dot_float3_splat ( float p0, float3 p1 ) {
return __builtin_hlsl_dot( p0, p1 );
- // expected-error at -1 {{first two arguments to '__builtin_hlsl_dot' must be vectors}}
+ // expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must be vectors}}
}
float test_builtin_dot_float4_splat ( float p0, float4 p1 ) {
return __builtin_hlsl_dot( p0, p1 );
- // expected-error at -1 {{first two arguments to '__builtin_hlsl_dot' must be vectors}}
+ // expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must be vectors}}
}
float test_dot_float2_int_splat ( float2 p0, int p1 ) {
return __builtin_hlsl_dot ( p0, p1 );
- // expected-error at -1 {{first two arguments to '__builtin_hlsl_dot' must be vectors}}
+ // expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must be vectors}}
}
float test_dot_float3_int_splat ( float3 p0, int p1 ) {
return __builtin_hlsl_dot ( p0, p1 );
- // expected-error at -1 {{first two arguments to '__builtin_hlsl_dot' must be vectors}}
+ // expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must be vectors}}
}
float test_builtin_dot_int_vect_to_float_vec_promotion ( int2 p0, float p1 ) {
return __builtin_hlsl_dot ( p0, p1 );
- // expected-error at -1 {{first two arguments to '__builtin_hlsl_dot' must be vectors}}
+ // expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must be vectors}}
}
int test_builtin_dot_bool_type_promotion ( bool p0, bool p1 ) {
diff --git a/clang/test/SemaHLSL/BuiltIns/lerp-errors.hlsl b/clang/test/SemaHLSL/BuiltIns/lerp-errors.hlsl
new file mode 100644
index 00000000000000..c062aa60a8df45
--- /dev/null
+++ b/clang/test/SemaHLSL/BuiltIns/lerp-errors.hlsl
@@ -0,0 +1,91 @@
+// RUN: %clang_cc1 -finclude-default-header -triple dxil-pc-shadermodel6.6-library %s -fnative-half-type -emit-llvm -disable-llvm-passes -verify -verify-ignore-unexpected
+
+float2 test_no_second_arg ( float2 p0) {
+ return __builtin_hlsl_lerp ( p0 );
+ // expected-error at -1 {{too few arguments to function call, expected 3, have 1}}
+}
+
+float2 test_no_third_arg ( float2 p0) {
+ return __builtin_hlsl_lerp ( p0, p0 );
+ // expected-error at -1 {{too few arguments to function call, expected 3, have 2}}
+}
+
+float2 test_too_many_arg ( float2 p0) {
+ return __builtin_hlsl_lerp ( p0, p0, p0, p0 );
+ // expected-error at -1 {{too many arguments to function call, expected 3, have 4}}
+}
+
+float2 test_lerp_no_second_arg ( float2 p0) {
+ return lerp ( p0 );
+ // expected-error at -1 {{no matching function for call to 'lerp'}}
+}
+
+float2 test_lerp_vector_size_mismatch ( float3 p0, float2 p1 ) {
+ return lerp ( p0, p0, p1 );
+ // expected-warning at -1 {{implicit conversion truncates vector: 'float3' (aka 'vector<float, 3>') to 'float __attribute__((ext_vector_type(2)))' (vector of 2 'float' values)}}
+}
+
+float test_lerp_builtin_vector_size_mismatch ( float3 p0, float2 p1 ) {
+ return __builtin_hlsl_lerp ( p0, p1, p1 );
+ // expected-error at -1 {{all arguments to '__builtin_hlsl_lerp' must have vectors of the same type}}
+}
+
+float test_lerp_scalar_mismatch ( float p0, half p1 ) {
+ return lerp ( p1, p0, p1 );
+ // expected-error at -1 {{call to 'lerp' is ambiguous}}
+}
+
+float test_lerp_element_type_mismatch ( half2 p0, float2 p1 ) {
+ return lerp ( p1, p0, p1 );
+ // expected-error at -1 {{call to 'lerp' is ambiguous}}
+}
+
+float test_builtin_lerp_float2_splat ( float p0, float2 p1 ) {
+ return __builtin_hlsl_lerp( p0, p1, p1 );
+ // expected-error at -1 {{all arguments to '__builtin_hlsl_lerp' must be vectors}}
+}
+
+float test_builtin_lerp_float3_splat ( float p0, float3 p1 ) {
+ return __builtin_hlsl_lerp( p0, p1, p1 );
+ // expected-error at -1 {{all arguments to '__builtin_hlsl_lerp' must be vectors}}
+}
+
+float test_builtin_lerp_float4_splat ( float p0, float4 p1 ) {
+ return __builtin_hlsl_lerp( p0, p1, p1 );
+ // expected-error at -1 {{all arguments to '__builtin_hlsl_lerp' must be vectors}}
+}
+
+float test_lerp_float2_int_splat ( float2 p0, int p1 ) {
+ return __builtin_hlsl_lerp( p0, p1, p1 );
+ // expected-error at -1 {{all arguments to '__builtin_hlsl_lerp' must be vectors}}
+}
+
+float test_lerp_float3_int_splat ( float3 p0, int p1 ) {
+ return __builtin_hlsl_lerp( p0, p1, p1 );
+ // expected-error at -1 {{all arguments to '__builtin_hlsl_lerp' must be vectors}}
+}
+
+float test_builtin_lerp_int_vect_to_float_vec_promotion ( int2 p0, float p1 ) {
+ return __builtin_hlsl_lerp( p0, p1, p1 );
+ // expected-error at -1 {{all arguments to '__builtin_hlsl_lerp' must be vectors}}
+}
+
+int test_builtin_lerp_bool_type_promotion (bool p0) {
+ return __builtin_hlsl_lerp( p0, p0, p0 );
+ // expected-error at -1 {{1st argument must be a floating point type (was 'bool')}}
+}
+
+float builtin_bool_to_float_type_promotion ( float p0, bool p1 ) {
+ return __builtin_hlsl_lerp ( p0, p0, p1 );
+ // expected-error at -1 {{3rd argument must be a floating point type (was 'bool')}}
+}
+
+float builtin_bool_to_float_type_promotion2 ( bool p0, float p1 ) {
+ return __builtin_hlsl_lerp ( p1, p0, p1 );
+ // expected-error at -1 {{2nd argument must be a floating point type (was 'bool')}}
+}
+
+float builtin_lerp_int_to_float_promotion ( float p0, int p1 ) {
+ return __builtin_hlsl_lerp ( p0, p0, p1 );
+ // expected-error at -1 {{3rd argument must be a floating point type (was 'int')}}
+}
\ No newline at end of file
diff --git a/llvm/include/llvm/IR/IntrinsicsDirectX.td b/llvm/include/llvm/IR/IntrinsicsDirectX.td
index c192d4b84417c9..48332b917693a0 100644
--- a/llvm/include/llvm/IR/IntrinsicsDirectX.td
+++ b/llvm/include/llvm/IR/IntrinsicsDirectX.td
@@ -24,4 +24,9 @@ def int_dx_dot :
Intrinsic<[LLVMVectorElementType<0>],
[llvm_anyvector_ty, LLVMScalarOrSameVectorWidth<0, LLVMVectorElementType<0>>],
[IntrNoMem, IntrWillReturn, Commutative] >;
+
+def int_dx_lerp :
+ Intrinsic<[LLVMMatchType<0>],
+ [llvm_anyvector_ty, LLVMMatchType<0>, LLVMMatchType<0>],
+ [IntrNoMem, IntrWillReturn, Commutative] >;
}
>From 37dca605c9bd41732da010ee97ed15ad9585a37d Mon Sep 17 00:00:00 2001
From: Louis Dionne <ldionne.2 at gmail.com>
Date: Thu, 29 Feb 2024 10:12:22 -0500
Subject: [PATCH 137/406] [libc++] Clean up includes of <__assert> (#80091)
Originally, we used __libcpp_verbose_abort to handle assertion failures.
That function was declared from all public headers. Since we don't use
that mechanism anymore, we don't need to declare __libcpp_verbose_abort
from all public headers, and we can clean up a lot of unnecessary
includes.
This patch also moves the definition of the various assertion categories
to the <__assert> header, since we now rely on regular IWYU for these
assertion macros.
rdar://105510916
---
libcxx/include/__assert | 81 +++++++++++++++++++
libcxx/include/__atomic/atomic_flag.h | 1 +
.../include/__charconv/from_chars_integral.h | 1 +
libcxx/include/__charconv/to_chars_base_10.h | 1 +
libcxx/include/__charconv/to_chars_integral.h | 1 +
libcxx/include/__charconv/traits.h | 1 +
libcxx/include/__config | 81 -------------------
.../__format/formatter_floating_point.h | 1 +
.../include/__numeric/saturation_arithmetic.h | 1 +
.../__random/negative_binomial_distribution.h | 1 +
libcxx/include/__ranges/repeat_view.h | 1 +
libcxx/include/__stop_token/stop_state.h | 1 +
libcxx/include/__string/char_traits.h | 1 +
libcxx/include/algorithm | 1 -
libcxx/include/any | 1 -
libcxx/include/array | 2 +-
libcxx/include/atomic | 1 -
libcxx/include/barrier | 2 +-
libcxx/include/bit | 1 -
libcxx/include/bitset | 1 -
libcxx/include/cassert | 1 -
libcxx/include/ccomplex | 1 -
libcxx/include/cctype | 1 -
libcxx/include/cerrno | 1 -
libcxx/include/cfenv | 1 -
libcxx/include/cfloat | 1 -
libcxx/include/charconv | 1 -
libcxx/include/chrono | 1 -
libcxx/include/cinttypes | 1 -
libcxx/include/ciso646 | 1 -
libcxx/include/climits | 1 -
libcxx/include/clocale | 1 -
libcxx/include/cmath | 1 -
libcxx/include/codecvt | 1 -
libcxx/include/compare | 1 -
libcxx/include/complex | 1 -
libcxx/include/concepts | 1 -
libcxx/include/condition_variable | 1 -
libcxx/include/coroutine | 1 -
libcxx/include/csetjmp | 1 -
libcxx/include/csignal | 1 -
libcxx/include/cstdarg | 1 -
libcxx/include/cstdbool | 1 -
libcxx/include/cstddef | 1 -
libcxx/include/cstdint | 1 -
libcxx/include/cstdio | 1 -
libcxx/include/cstdlib | 1 -
libcxx/include/cstring | 1 -
libcxx/include/ctgmath | 1 -
libcxx/include/ctime | 1 -
libcxx/include/cuchar | 1 -
libcxx/include/cwchar | 1 -
libcxx/include/cwctype | 1 -
libcxx/include/deque | 2 +-
libcxx/include/exception | 1 -
libcxx/include/execution | 1 -
libcxx/include/expected | 1 -
libcxx/include/experimental/__simd/scalar.h | 1 +
libcxx/include/experimental/__simd/vec_ext.h | 1 +
libcxx/include/experimental/iterator | 1 -
libcxx/include/experimental/propagate_const | 1 -
libcxx/include/experimental/simd | 2 -
libcxx/include/experimental/type_traits | 1 -
libcxx/include/experimental/utility | 1 -
libcxx/include/ext/hash_map | 1 -
libcxx/include/ext/hash_set | 1 -
libcxx/include/filesystem | 1 -
libcxx/include/format | 1 -
libcxx/include/forward_list | 1 -
libcxx/include/fstream | 2 +-
libcxx/include/functional | 1 -
libcxx/include/future | 2 +-
libcxx/include/initializer_list | 1 -
libcxx/include/iomanip | 1 -
libcxx/include/ios | 1 -
libcxx/include/iosfwd | 1 -
libcxx/include/iostream | 1 -
libcxx/include/istream | 1 -
libcxx/include/iterator | 1 -
libcxx/include/latch | 2 +-
libcxx/include/limits | 1 -
libcxx/include/list | 2 +-
libcxx/include/locale | 2 +-
libcxx/include/map | 2 +-
libcxx/include/memory | 1 -
libcxx/include/mutex | 1 -
libcxx/include/new | 2 +-
libcxx/include/numbers | 1 -
libcxx/include/numeric | 1 -
libcxx/include/optional | 2 +-
libcxx/include/ostream | 1 -
libcxx/include/print | 2 +-
libcxx/include/queue | 1 -
libcxx/include/random | 1 -
libcxx/include/ranges | 1 -
libcxx/include/ratio | 1 -
libcxx/include/regex | 2 +-
libcxx/include/scoped_allocator | 1 -
libcxx/include/semaphore | 2 +-
libcxx/include/set | 2 +-
libcxx/include/shared_mutex | 1 -
libcxx/include/span | 2 +-
libcxx/include/sstream | 1 -
libcxx/include/stack | 1 -
libcxx/include/stdexcept | 1 -
libcxx/include/stop_token | 1 -
libcxx/include/streambuf | 1 -
libcxx/include/string | 2 +-
libcxx/include/string_view | 2 +-
libcxx/include/strstream | 1 -
libcxx/include/system_error | 1 -
libcxx/include/thread | 1 -
libcxx/include/tuple | 1 -
libcxx/include/type_traits | 2 +-
libcxx/include/typeindex | 1 -
libcxx/include/typeinfo | 1 -
libcxx/include/unordered_map | 2 +-
libcxx/include/unordered_set | 2 +-
libcxx/include/utility | 1 -
libcxx/include/valarray | 2 +-
libcxx/include/variant | 1 -
libcxx/include/vector | 2 +-
libcxx/include/version | 1 -
...customize_verbose_abort.link-time.pass.cpp | 1 +
.../headers_declare_verbose_abort.gen.py | 33 --------
.../libcxx/assertions/modes/none.pass.cpp | 1 +
.../generate_feature_test_macro_components.py | 1 -
127 files changed, 119 insertions(+), 224 deletions(-)
delete mode 100644 libcxx/test/libcxx/assertions/headers_declare_verbose_abort.gen.py
diff --git a/libcxx/include/__assert b/libcxx/include/__assert
index eb862b5369b258..49769fb4d44978 100644
--- a/libcxx/include/__assert
+++ b/libcxx/include/__assert
@@ -34,4 +34,85 @@
# define _LIBCPP_ASSUME(expression) ((void)0)
#endif
+// clang-format off
+// Fast hardening mode checks.
+
+#if _LIBCPP_HARDENING_MODE == _LIBCPP_HARDENING_MODE_FAST
+
+// Enabled checks.
+# define _LIBCPP_ASSERT_VALID_INPUT_RANGE(expression, message) _LIBCPP_ASSERT(expression, message)
+# define _LIBCPP_ASSERT_VALID_ELEMENT_ACCESS(expression, message) _LIBCPP_ASSERT(expression, message)
+// Disabled checks.
+// On most modern platforms, dereferencing a null pointer does not lead to an actual memory access.
+# define _LIBCPP_ASSERT_NON_NULL(expression, message) _LIBCPP_ASSUME(expression)
+// Overlapping ranges will make algorithms produce incorrect results but don't directly lead to a security
+// vulnerability.
+# define _LIBCPP_ASSERT_NON_OVERLAPPING_RANGES(expression, message) _LIBCPP_ASSUME(expression)
+# define _LIBCPP_ASSERT_VALID_DEALLOCATION(expression, message) _LIBCPP_ASSUME(expression)
+# define _LIBCPP_ASSERT_VALID_EXTERNAL_API_CALL(expression, message) _LIBCPP_ASSUME(expression)
+# define _LIBCPP_ASSERT_COMPATIBLE_ALLOCATOR(expression, message) _LIBCPP_ASSUME(expression)
+# define _LIBCPP_ASSERT_ARGUMENT_WITHIN_DOMAIN(expression, message) _LIBCPP_ASSUME(expression)
+# define _LIBCPP_ASSERT_PEDANTIC(expression, message) _LIBCPP_ASSUME(expression)
+# define _LIBCPP_ASSERT_SEMANTIC_REQUIREMENT(expression, message) _LIBCPP_ASSUME(expression)
+# define _LIBCPP_ASSERT_INTERNAL(expression, message) _LIBCPP_ASSUME(expression)
+# define _LIBCPP_ASSERT_UNCATEGORIZED(expression, message) _LIBCPP_ASSUME(expression)
+
+// Extensive hardening mode checks.
+
+#elif _LIBCPP_HARDENING_MODE == _LIBCPP_HARDENING_MODE_EXTENSIVE
+
+// Enabled checks.
+# define _LIBCPP_ASSERT_VALID_INPUT_RANGE(expression, message) _LIBCPP_ASSERT(expression, message)
+# define _LIBCPP_ASSERT_VALID_ELEMENT_ACCESS(expression, message) _LIBCPP_ASSERT(expression, message)
+# define _LIBCPP_ASSERT_NON_NULL(expression, message) _LIBCPP_ASSERT(expression, message)
+# define _LIBCPP_ASSERT_NON_OVERLAPPING_RANGES(expression, message) _LIBCPP_ASSERT(expression, message)
+# define _LIBCPP_ASSERT_VALID_DEALLOCATION(expression, message) _LIBCPP_ASSERT(expression, message)
+# define _LIBCPP_ASSERT_VALID_EXTERNAL_API_CALL(expression, message) _LIBCPP_ASSERT(expression, message)
+# define _LIBCPP_ASSERT_COMPATIBLE_ALLOCATOR(expression, message) _LIBCPP_ASSERT(expression, message)
+# define _LIBCPP_ASSERT_ARGUMENT_WITHIN_DOMAIN(expression, message) _LIBCPP_ASSERT(expression, message)
+# define _LIBCPP_ASSERT_PEDANTIC(expression, message) _LIBCPP_ASSERT(expression, message)
+# define _LIBCPP_ASSERT_UNCATEGORIZED(expression, message) _LIBCPP_ASSERT(expression, message)
+// Disabled checks.
+# define _LIBCPP_ASSERT_SEMANTIC_REQUIREMENT(expression, message) _LIBCPP_ASSUME(expression)
+# define _LIBCPP_ASSERT_INTERNAL(expression, message) _LIBCPP_ASSUME(expression)
+
+// Debug hardening mode checks.
+
+#elif _LIBCPP_HARDENING_MODE == _LIBCPP_HARDENING_MODE_DEBUG
+
+// All checks enabled.
+# define _LIBCPP_ASSERT_VALID_INPUT_RANGE(expression, message) _LIBCPP_ASSERT(expression, message)
+# define _LIBCPP_ASSERT_VALID_ELEMENT_ACCESS(expression, message) _LIBCPP_ASSERT(expression, message)
+# define _LIBCPP_ASSERT_NON_NULL(expression, message) _LIBCPP_ASSERT(expression, message)
+# define _LIBCPP_ASSERT_NON_OVERLAPPING_RANGES(expression, message) _LIBCPP_ASSERT(expression, message)
+# define _LIBCPP_ASSERT_VALID_DEALLOCATION(expression, message) _LIBCPP_ASSERT(expression, message)
+# define _LIBCPP_ASSERT_VALID_EXTERNAL_API_CALL(expression, message) _LIBCPP_ASSERT(expression, message)
+# define _LIBCPP_ASSERT_COMPATIBLE_ALLOCATOR(expression, message) _LIBCPP_ASSERT(expression, message)
+# define _LIBCPP_ASSERT_ARGUMENT_WITHIN_DOMAIN(expression, message) _LIBCPP_ASSERT(expression, message)
+# define _LIBCPP_ASSERT_PEDANTIC(expression, message) _LIBCPP_ASSERT(expression, message)
+# define _LIBCPP_ASSERT_SEMANTIC_REQUIREMENT(expression, message) _LIBCPP_ASSERT(expression, message)
+# define _LIBCPP_ASSERT_INTERNAL(expression, message) _LIBCPP_ASSERT(expression, message)
+# define _LIBCPP_ASSERT_UNCATEGORIZED(expression, message) _LIBCPP_ASSERT(expression, message)
+
+// Disable all checks if hardening is not enabled.
+
+#else
+
+// All checks disabled.
+# define _LIBCPP_ASSERT_VALID_INPUT_RANGE(expression, message) _LIBCPP_ASSUME(expression)
+# define _LIBCPP_ASSERT_VALID_ELEMENT_ACCESS(expression, message) _LIBCPP_ASSUME(expression)
+# define _LIBCPP_ASSERT_NON_NULL(expression, message) _LIBCPP_ASSUME(expression)
+# define _LIBCPP_ASSERT_NON_OVERLAPPING_RANGES(expression, message) _LIBCPP_ASSUME(expression)
+# define _LIBCPP_ASSERT_VALID_DEALLOCATION(expression, message) _LIBCPP_ASSUME(expression)
+# define _LIBCPP_ASSERT_VALID_EXTERNAL_API_CALL(expression, message) _LIBCPP_ASSUME(expression)
+# define _LIBCPP_ASSERT_COMPATIBLE_ALLOCATOR(expression, message) _LIBCPP_ASSUME(expression)
+# define _LIBCPP_ASSERT_ARGUMENT_WITHIN_DOMAIN(expression, message) _LIBCPP_ASSUME(expression)
+# define _LIBCPP_ASSERT_PEDANTIC(expression, message) _LIBCPP_ASSUME(expression)
+# define _LIBCPP_ASSERT_SEMANTIC_REQUIREMENT(expression, message) _LIBCPP_ASSUME(expression)
+# define _LIBCPP_ASSERT_INTERNAL(expression, message) _LIBCPP_ASSUME(expression)
+# define _LIBCPP_ASSERT_UNCATEGORIZED(expression, message) _LIBCPP_ASSUME(expression)
+
+#endif // _LIBCPP_HARDENING_MODE == _LIBCPP_HARDENING_MODE_FAST
+// clang-format on
+
#endif // _LIBCPP___ASSERT
diff --git a/libcxx/include/__atomic/atomic_flag.h b/libcxx/include/__atomic/atomic_flag.h
index a45a7183547726..18a864523de06f 100644
--- a/libcxx/include/__atomic/atomic_flag.h
+++ b/libcxx/include/__atomic/atomic_flag.h
@@ -13,6 +13,7 @@
#include <__atomic/contention_t.h>
#include <__atomic/cxx_atomic_impl.h>
#include <__atomic/memory_order.h>
+#include <__availability>
#include <__chrono/duration.h>
#include <__config>
#include <__thread/support.h>
diff --git a/libcxx/include/__charconv/from_chars_integral.h b/libcxx/include/__charconv/from_chars_integral.h
index e969cedb33cbe4..c1f033b37b913e 100644
--- a/libcxx/include/__charconv/from_chars_integral.h
+++ b/libcxx/include/__charconv/from_chars_integral.h
@@ -11,6 +11,7 @@
#define _LIBCPP___CHARCONV_FROM_CHARS_INTEGRAL_H
#include <__algorithm/copy_n.h>
+#include <__assert>
#include <__charconv/from_chars_result.h>
#include <__charconv/traits.h>
#include <__config>
diff --git a/libcxx/include/__charconv/to_chars_base_10.h b/libcxx/include/__charconv/to_chars_base_10.h
index 0dee351521f9c6..c49f4f6797aa43 100644
--- a/libcxx/include/__charconv/to_chars_base_10.h
+++ b/libcxx/include/__charconv/to_chars_base_10.h
@@ -11,6 +11,7 @@
#define _LIBCPP___CHARCONV_TO_CHARS_BASE_10_H
#include <__algorithm/copy_n.h>
+#include <__assert>
#include <__charconv/tables.h>
#include <__config>
#include <cstdint>
diff --git a/libcxx/include/__charconv/to_chars_integral.h b/libcxx/include/__charconv/to_chars_integral.h
index 40fbe334d8d54c..0369f4dfb9bda6 100644
--- a/libcxx/include/__charconv/to_chars_integral.h
+++ b/libcxx/include/__charconv/to_chars_integral.h
@@ -11,6 +11,7 @@
#define _LIBCPP___CHARCONV_TO_CHARS_INTEGRAL_H
#include <__algorithm/copy_n.h>
+#include <__assert>
#include <__bit/countl.h>
#include <__charconv/tables.h>
#include <__charconv/to_chars_base_10.h>
diff --git a/libcxx/include/__charconv/traits.h b/libcxx/include/__charconv/traits.h
index b4907c3f775715..c91c6da3247978 100644
--- a/libcxx/include/__charconv/traits.h
+++ b/libcxx/include/__charconv/traits.h
@@ -10,6 +10,7 @@
#ifndef _LIBCPP___CHARCONV_TRAITS
#define _LIBCPP___CHARCONV_TRAITS
+#include <__assert>
#include <__bit/countl.h>
#include <__charconv/tables.h>
#include <__charconv/to_chars_base_10.h>
diff --git a/libcxx/include/__config b/libcxx/include/__config
index 53ff113a16b2a8..8d4d17378b2973 100644
--- a/libcxx/include/__config
+++ b/libcxx/include/__config
@@ -345,87 +345,6 @@ _LIBCPP_HARDENING_MODE_EXTENSIVE, \
_LIBCPP_HARDENING_MODE_DEBUG
# endif
-// clang-format off
-// Fast hardening mode checks.
-
-# if _LIBCPP_HARDENING_MODE == _LIBCPP_HARDENING_MODE_FAST
-
-// Enabled checks.
-# define _LIBCPP_ASSERT_VALID_INPUT_RANGE(expression, message) _LIBCPP_ASSERT(expression, message)
-# define _LIBCPP_ASSERT_VALID_ELEMENT_ACCESS(expression, message) _LIBCPP_ASSERT(expression, message)
-// Disabled checks.
-// On most modern platforms, dereferencing a null pointer does not lead to an actual memory access.
-# define _LIBCPP_ASSERT_NON_NULL(expression, message) _LIBCPP_ASSUME(expression)
-// Overlapping ranges will make algorithms produce incorrect results but don't directly lead to a security
-// vulnerability.
-# define _LIBCPP_ASSERT_NON_OVERLAPPING_RANGES(expression, message) _LIBCPP_ASSUME(expression)
-# define _LIBCPP_ASSERT_VALID_DEALLOCATION(expression, message) _LIBCPP_ASSUME(expression)
-# define _LIBCPP_ASSERT_VALID_EXTERNAL_API_CALL(expression, message) _LIBCPP_ASSUME(expression)
-# define _LIBCPP_ASSERT_COMPATIBLE_ALLOCATOR(expression, message) _LIBCPP_ASSUME(expression)
-# define _LIBCPP_ASSERT_ARGUMENT_WITHIN_DOMAIN(expression, message) _LIBCPP_ASSUME(expression)
-# define _LIBCPP_ASSERT_PEDANTIC(expression, message) _LIBCPP_ASSUME(expression)
-# define _LIBCPP_ASSERT_SEMANTIC_REQUIREMENT(expression, message) _LIBCPP_ASSUME(expression)
-# define _LIBCPP_ASSERT_INTERNAL(expression, message) _LIBCPP_ASSUME(expression)
-# define _LIBCPP_ASSERT_UNCATEGORIZED(expression, message) _LIBCPP_ASSUME(expression)
-
-// Extensive hardening mode checks.
-
-# elif _LIBCPP_HARDENING_MODE == _LIBCPP_HARDENING_MODE_EXTENSIVE
-
-// Enabled checks.
-# define _LIBCPP_ASSERT_VALID_INPUT_RANGE(expression, message) _LIBCPP_ASSERT(expression, message)
-# define _LIBCPP_ASSERT_VALID_ELEMENT_ACCESS(expression, message) _LIBCPP_ASSERT(expression, message)
-# define _LIBCPP_ASSERT_NON_NULL(expression, message) _LIBCPP_ASSERT(expression, message)
-# define _LIBCPP_ASSERT_NON_OVERLAPPING_RANGES(expression, message) _LIBCPP_ASSERT(expression, message)
-# define _LIBCPP_ASSERT_VALID_DEALLOCATION(expression, message) _LIBCPP_ASSERT(expression, message)
-# define _LIBCPP_ASSERT_VALID_EXTERNAL_API_CALL(expression, message) _LIBCPP_ASSERT(expression, message)
-# define _LIBCPP_ASSERT_COMPATIBLE_ALLOCATOR(expression, message) _LIBCPP_ASSERT(expression, message)
-# define _LIBCPP_ASSERT_ARGUMENT_WITHIN_DOMAIN(expression, message) _LIBCPP_ASSERT(expression, message)
-# define _LIBCPP_ASSERT_PEDANTIC(expression, message) _LIBCPP_ASSERT(expression, message)
-# define _LIBCPP_ASSERT_UNCATEGORIZED(expression, message) _LIBCPP_ASSERT(expression, message)
-// Disabled checks.
-# define _LIBCPP_ASSERT_SEMANTIC_REQUIREMENT(expression, message) _LIBCPP_ASSUME(expression)
-# define _LIBCPP_ASSERT_INTERNAL(expression, message) _LIBCPP_ASSUME(expression)
-
-// Debug hardening mode checks.
-
-# elif _LIBCPP_HARDENING_MODE == _LIBCPP_HARDENING_MODE_DEBUG
-
-// All checks enabled.
-# define _LIBCPP_ASSERT_VALID_INPUT_RANGE(expression, message) _LIBCPP_ASSERT(expression, message)
-# define _LIBCPP_ASSERT_VALID_ELEMENT_ACCESS(expression, message) _LIBCPP_ASSERT(expression, message)
-# define _LIBCPP_ASSERT_NON_NULL(expression, message) _LIBCPP_ASSERT(expression, message)
-# define _LIBCPP_ASSERT_NON_OVERLAPPING_RANGES(expression, message) _LIBCPP_ASSERT(expression, message)
-# define _LIBCPP_ASSERT_VALID_DEALLOCATION(expression, message) _LIBCPP_ASSERT(expression, message)
-# define _LIBCPP_ASSERT_VALID_EXTERNAL_API_CALL(expression, message) _LIBCPP_ASSERT(expression, message)
-# define _LIBCPP_ASSERT_COMPATIBLE_ALLOCATOR(expression, message) _LIBCPP_ASSERT(expression, message)
-# define _LIBCPP_ASSERT_ARGUMENT_WITHIN_DOMAIN(expression, message) _LIBCPP_ASSERT(expression, message)
-# define _LIBCPP_ASSERT_PEDANTIC(expression, message) _LIBCPP_ASSERT(expression, message)
-# define _LIBCPP_ASSERT_SEMANTIC_REQUIREMENT(expression, message) _LIBCPP_ASSERT(expression, message)
-# define _LIBCPP_ASSERT_INTERNAL(expression, message) _LIBCPP_ASSERT(expression, message)
-# define _LIBCPP_ASSERT_UNCATEGORIZED(expression, message) _LIBCPP_ASSERT(expression, message)
-
-// Disable all checks if hardening is not enabled.
-
-# else
-
-// All checks disabled.
-# define _LIBCPP_ASSERT_VALID_INPUT_RANGE(expression, message) _LIBCPP_ASSUME(expression)
-# define _LIBCPP_ASSERT_VALID_ELEMENT_ACCESS(expression, message) _LIBCPP_ASSUME(expression)
-# define _LIBCPP_ASSERT_NON_NULL(expression, message) _LIBCPP_ASSUME(expression)
-# define _LIBCPP_ASSERT_NON_OVERLAPPING_RANGES(expression, message) _LIBCPP_ASSUME(expression)
-# define _LIBCPP_ASSERT_VALID_DEALLOCATION(expression, message) _LIBCPP_ASSUME(expression)
-# define _LIBCPP_ASSERT_VALID_EXTERNAL_API_CALL(expression, message) _LIBCPP_ASSUME(expression)
-# define _LIBCPP_ASSERT_COMPATIBLE_ALLOCATOR(expression, message) _LIBCPP_ASSUME(expression)
-# define _LIBCPP_ASSERT_ARGUMENT_WITHIN_DOMAIN(expression, message) _LIBCPP_ASSUME(expression)
-# define _LIBCPP_ASSERT_PEDANTIC(expression, message) _LIBCPP_ASSUME(expression)
-# define _LIBCPP_ASSERT_SEMANTIC_REQUIREMENT(expression, message) _LIBCPP_ASSUME(expression)
-# define _LIBCPP_ASSERT_INTERNAL(expression, message) _LIBCPP_ASSUME(expression)
-# define _LIBCPP_ASSERT_UNCATEGORIZED(expression, message) _LIBCPP_ASSUME(expression)
-
-# endif // _LIBCPP_HARDENING_MODE == _LIBCPP_HARDENING_MODE_FAST
-// clang-format on
-
// } HARDENING
# define _LIBCPP_TOSTRING2(x) #x
diff --git a/libcxx/include/__format/formatter_floating_point.h b/libcxx/include/__format/formatter_floating_point.h
index 6802a8b7bd4ca3..f01d323efff5fc 100644
--- a/libcxx/include/__format/formatter_floating_point.h
+++ b/libcxx/include/__format/formatter_floating_point.h
@@ -16,6 +16,7 @@
#include <__algorithm/min.h>
#include <__algorithm/rotate.h>
#include <__algorithm/transform.h>
+#include <__assert>
#include <__charconv/chars_format.h>
#include <__charconv/to_chars_floating_point.h>
#include <__charconv/to_chars_result.h>
diff --git a/libcxx/include/__numeric/saturation_arithmetic.h b/libcxx/include/__numeric/saturation_arithmetic.h
index 0e6f455cf22825..41596a0c58e27d 100644
--- a/libcxx/include/__numeric/saturation_arithmetic.h
+++ b/libcxx/include/__numeric/saturation_arithmetic.h
@@ -10,6 +10,7 @@
#ifndef _LIBCPP___NUMERIC_SATURATION_ARITHMETIC_H
#define _LIBCPP___NUMERIC_SATURATION_ARITHMETIC_H
+#include <__assert>
#include <__concepts/arithmetic.h>
#include <__config>
#include <__utility/cmp.h>
diff --git a/libcxx/include/__random/negative_binomial_distribution.h b/libcxx/include/__random/negative_binomial_distribution.h
index eed4f511e87190..6d0055d01ed432 100644
--- a/libcxx/include/__random/negative_binomial_distribution.h
+++ b/libcxx/include/__random/negative_binomial_distribution.h
@@ -9,6 +9,7 @@
#ifndef _LIBCPP___RANDOM_NEGATIVE_BINOMIAL_DISTRIBUTION_H
#define _LIBCPP___RANDOM_NEGATIVE_BINOMIAL_DISTRIBUTION_H
+#include <__assert>
#include <__config>
#include <__random/bernoulli_distribution.h>
#include <__random/gamma_distribution.h>
diff --git a/libcxx/include/__ranges/repeat_view.h b/libcxx/include/__ranges/repeat_view.h
index d08f0e0d4e9f74..620a2645497285 100644
--- a/libcxx/include/__ranges/repeat_view.h
+++ b/libcxx/include/__ranges/repeat_view.h
@@ -10,6 +10,7 @@
#ifndef _LIBCPP___RANGES_REPEAT_VIEW_H
#define _LIBCPP___RANGES_REPEAT_VIEW_H
+#include <__assert>
#include <__concepts/constructible.h>
#include <__concepts/same_as.h>
#include <__concepts/semiregular.h>
diff --git a/libcxx/include/__stop_token/stop_state.h b/libcxx/include/__stop_token/stop_state.h
index 462aa73952b84f..df07573f878628 100644
--- a/libcxx/include/__stop_token/stop_state.h
+++ b/libcxx/include/__stop_token/stop_state.h
@@ -10,6 +10,7 @@
#ifndef _LIBCPP___STOP_TOKEN_STOP_STATE_H
#define _LIBCPP___STOP_TOKEN_STOP_STATE_H
+#include <__assert>
#include <__availability>
#include <__config>
#include <__stop_token/atomic_unique_lock.h>
diff --git a/libcxx/include/__string/char_traits.h b/libcxx/include/__string/char_traits.h
index 8ea9625d071834..5880d3a22db2e7 100644
--- a/libcxx/include/__string/char_traits.h
+++ b/libcxx/include/__string/char_traits.h
@@ -14,6 +14,7 @@
#include <__algorithm/find_end.h>
#include <__algorithm/find_first_of.h>
#include <__algorithm/min.h>
+#include <__assert>
#include <__compare/ordering.h>
#include <__config>
#include <__functional/hash.h>
diff --git a/libcxx/include/algorithm b/libcxx/include/algorithm
index 70e30bc87e8128..0f62de7fa83f98 100644
--- a/libcxx/include/algorithm
+++ b/libcxx/include/algorithm
@@ -1793,7 +1793,6 @@ template <class BidirectionalIterator, class Compare>
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <version>
diff --git a/libcxx/include/any b/libcxx/include/any
index 378dfb6e21b536..ce54803cd91b5b 100644
--- a/libcxx/include/any
+++ b/libcxx/include/any
@@ -80,7 +80,6 @@ namespace std {
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__availability>
#include <__config>
#include <__memory/allocator.h>
diff --git a/libcxx/include/array b/libcxx/include/array
index 41f016a4859a32..961b620efb9357 100644
--- a/libcxx/include/array
+++ b/libcxx/include/array
@@ -116,7 +116,7 @@ template <size_t I, class T, size_t N> const T&& get(const array<T, N>&&) noexce
#include <__algorithm/lexicographical_compare.h>
#include <__algorithm/lexicographical_compare_three_way.h>
#include <__algorithm/swap_ranges.h>
-#include <__assert> // all public C++ headers provide the assertion handler
+#include <__assert>
#include <__config>
#include <__fwd/array.h>
#include <__iterator/reverse_iterator.h>
diff --git a/libcxx/include/atomic b/libcxx/include/atomic
index 2dac69377b77f0..61ff61d415dd84 100644
--- a/libcxx/include/atomic
+++ b/libcxx/include/atomic
@@ -587,7 +587,6 @@ template <class T>
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__atomic/aliases.h>
#include <__atomic/atomic.h>
#include <__atomic/atomic_base.h>
diff --git a/libcxx/include/barrier b/libcxx/include/barrier
index f91452c8d0064c..c5fd84b91925b1 100644
--- a/libcxx/include/barrier
+++ b/libcxx/include/barrier
@@ -51,7 +51,7 @@ namespace std
# error "<barrier> is not supported since libc++ has been configured without support for threads."
#endif
-#include <__assert> // all public C++ headers provide the assertion handler
+#include <__assert>
#include <__atomic/atomic_base.h>
#include <__atomic/memory_order.h>
#include <__availability>
diff --git a/libcxx/include/bit b/libcxx/include/bit
index 84e2080377e4fa..b8e4bdc2dfe202 100644
--- a/libcxx/include/bit
+++ b/libcxx/include/bit
@@ -61,7 +61,6 @@ namespace std {
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__bit/bit_cast.h>
#include <__bit/bit_ceil.h>
#include <__bit/bit_floor.h>
diff --git a/libcxx/include/bitset b/libcxx/include/bitset
index 95f7a63b23179c..8818ab6563b570 100644
--- a/libcxx/include/bitset
+++ b/libcxx/include/bitset
@@ -129,7 +129,6 @@ template <size_t N> struct hash<std::bitset<N>>;
#include <__algorithm/count.h>
#include <__algorithm/fill.h>
#include <__algorithm/find.h>
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__bit_reference>
#include <__config>
#include <__functional/hash.h>
diff --git a/libcxx/include/cassert b/libcxx/include/cassert
index 761f57dee1db57..6fec37dc637610 100644
--- a/libcxx/include/cassert
+++ b/libcxx/include/cassert
@@ -16,7 +16,6 @@ Macros:
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
// <assert.h> is not provided by libc++
diff --git a/libcxx/include/ccomplex b/libcxx/include/ccomplex
index cf05c7a9108141..94d2c8d7d003d4 100644
--- a/libcxx/include/ccomplex
+++ b/libcxx/include/ccomplex
@@ -17,7 +17,6 @@
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <complex>
#if !defined(_LIBCPP_HAS_NO_PRAGMA_SYSTEM_HEADER)
diff --git a/libcxx/include/cctype b/libcxx/include/cctype
index 32be6f38e5f898..d7af7e084aa23a 100644
--- a/libcxx/include/cctype
+++ b/libcxx/include/cctype
@@ -34,7 +34,6 @@ int toupper(int c);
} // std
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <ctype.h>
diff --git a/libcxx/include/cerrno b/libcxx/include/cerrno
index 937ec23c6971ad..d488fa72a54b7a 100644
--- a/libcxx/include/cerrno
+++ b/libcxx/include/cerrno
@@ -22,7 +22,6 @@ Macros:
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <errno.h>
diff --git a/libcxx/include/cfenv b/libcxx/include/cfenv
index 16b3761ee27b16..f8cacd562f76bd 100644
--- a/libcxx/include/cfenv
+++ b/libcxx/include/cfenv
@@ -52,7 +52,6 @@ int feupdateenv(const fenv_t* envp);
} // std
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <fenv.h>
diff --git a/libcxx/include/cfloat b/libcxx/include/cfloat
index 4f991dd49ff4f8..5d1b38c557dcad 100644
--- a/libcxx/include/cfloat
+++ b/libcxx/include/cfloat
@@ -69,7 +69,6 @@ Macros:
LDBL_TRUE_MIN // C11
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <float.h>
diff --git a/libcxx/include/charconv b/libcxx/include/charconv
index 5a2869acba8715..5bc7b9011be024 100644
--- a/libcxx/include/charconv
+++ b/libcxx/include/charconv
@@ -69,7 +69,6 @@ namespace std {
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__charconv/chars_format.h>
#include <__charconv/from_chars_integral.h>
#include <__charconv/from_chars_result.h>
diff --git a/libcxx/include/chrono b/libcxx/include/chrono
index fe73f7c772b996..b3b260c2a998e6 100644
--- a/libcxx/include/chrono
+++ b/libcxx/include/chrono
@@ -825,7 +825,6 @@ constexpr chrono::year operator ""y(unsigned lo
// clang-format on
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__chrono/calendar.h>
#include <__chrono/convert_to_timespec.h>
#include <__chrono/convert_to_tm.h>
diff --git a/libcxx/include/cinttypes b/libcxx/include/cinttypes
index a5b9558abde12d..52663a4f35fad5 100644
--- a/libcxx/include/cinttypes
+++ b/libcxx/include/cinttypes
@@ -234,7 +234,6 @@ uintmax_t wcstoumax(const wchar_t* restrict nptr, wchar_t** restrict endptr, int
} // std
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
// standard-mandated includes
diff --git a/libcxx/include/ciso646 b/libcxx/include/ciso646
index e0cd722495ed0d..1d859f08fac572 100644
--- a/libcxx/include/ciso646
+++ b/libcxx/include/ciso646
@@ -15,7 +15,6 @@
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#if !defined(_LIBCPP_HAS_NO_PRAGMA_SYSTEM_HEADER)
diff --git a/libcxx/include/climits b/libcxx/include/climits
index 2e8993e4d6a519..bcd8b4a56a073c 100644
--- a/libcxx/include/climits
+++ b/libcxx/include/climits
@@ -37,7 +37,6 @@ Macros:
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <limits.h>
diff --git a/libcxx/include/clocale b/libcxx/include/clocale
index e2ace355d7b648..c689a64be288a3 100644
--- a/libcxx/include/clocale
+++ b/libcxx/include/clocale
@@ -34,7 +34,6 @@ lconv* localeconv();
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <locale.h>
diff --git a/libcxx/include/cmath b/libcxx/include/cmath
index 798ddb4963b0ec..dd194bbb558969 100644
--- a/libcxx/include/cmath
+++ b/libcxx/include/cmath
@@ -304,7 +304,6 @@ constexpr long double lerp(long double a, long double b, long double t) noexcept
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <__type_traits/enable_if.h>
#include <__type_traits/is_arithmetic.h>
diff --git a/libcxx/include/codecvt b/libcxx/include/codecvt
index 504dd71f300405..b7182ff471559d 100644
--- a/libcxx/include/codecvt
+++ b/libcxx/include/codecvt
@@ -54,7 +54,6 @@ class codecvt_utf8_utf16
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <__locale>
#include <version>
diff --git a/libcxx/include/compare b/libcxx/include/compare
index cc0cae8a544d62..93953254b78436 100644
--- a/libcxx/include/compare
+++ b/libcxx/include/compare
@@ -140,7 +140,6 @@ namespace std {
}
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__compare/common_comparison_category.h>
#include <__compare/compare_partial_order_fallback.h>
#include <__compare/compare_strong_order_fallback.h>
diff --git a/libcxx/include/complex b/libcxx/include/complex
index 0aba60e514ba22..e996485a38ae67 100644
--- a/libcxx/include/complex
+++ b/libcxx/include/complex
@@ -256,7 +256,6 @@ template<class T> complex<T> tanh (const complex<T>&);
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <__fwd/complex.h>
#include <__tuple/tuple_element.h>
diff --git a/libcxx/include/concepts b/libcxx/include/concepts
index 5fdf30ecfbd3fb..e10f5ab5ad8a18 100644
--- a/libcxx/include/concepts
+++ b/libcxx/include/concepts
@@ -129,7 +129,6 @@ namespace std {
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__concepts/arithmetic.h>
#include <__concepts/assignable.h>
#include <__concepts/boolean_testable.h>
diff --git a/libcxx/include/condition_variable b/libcxx/include/condition_variable
index 6aac3c13ef4a74..4ded1140d46b1b 100644
--- a/libcxx/include/condition_variable
+++ b/libcxx/include/condition_variable
@@ -118,7 +118,6 @@ public:
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__availability>
#include <__chrono/duration.h>
#include <__chrono/steady_clock.h>
diff --git a/libcxx/include/coroutine b/libcxx/include/coroutine
index f264570128bb80..4bd1d4e9c3103a 100644
--- a/libcxx/include/coroutine
+++ b/libcxx/include/coroutine
@@ -38,7 +38,6 @@ struct suspend_always;
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <__coroutine/coroutine_handle.h>
#include <__coroutine/coroutine_traits.h>
diff --git a/libcxx/include/csetjmp b/libcxx/include/csetjmp
index 9012cad22ebe74..7ba90068710aea 100644
--- a/libcxx/include/csetjmp
+++ b/libcxx/include/csetjmp
@@ -30,7 +30,6 @@ void longjmp(jmp_buf env, int val);
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
// <setjmp.h> is not provided by libc++
diff --git a/libcxx/include/csignal b/libcxx/include/csignal
index cf45f507535e1d..804a7f95ae9682 100644
--- a/libcxx/include/csignal
+++ b/libcxx/include/csignal
@@ -39,7 +39,6 @@ int raise(int sig);
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
// <signal.h> is not provided by libc++
diff --git a/libcxx/include/cstdarg b/libcxx/include/cstdarg
index 3a4291f4584aa1..4642eb7b5258ca 100644
--- a/libcxx/include/cstdarg
+++ b/libcxx/include/cstdarg
@@ -31,7 +31,6 @@ Types:
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
// <stdarg.h> is not provided by libc++
diff --git a/libcxx/include/cstdbool b/libcxx/include/cstdbool
index ce608033a22ce1..ef731c021a4ab8 100644
--- a/libcxx/include/cstdbool
+++ b/libcxx/include/cstdbool
@@ -19,7 +19,6 @@ Macros:
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#if !defined(_LIBCPP_HAS_NO_PRAGMA_SYSTEM_HEADER)
diff --git a/libcxx/include/cstddef b/libcxx/include/cstddef
index 1d7bac24c81eaa..ed16ae44fb2bf8 100644
--- a/libcxx/include/cstddef
+++ b/libcxx/include/cstddef
@@ -33,7 +33,6 @@ Types:
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <__type_traits/enable_if.h>
#include <__type_traits/integral_constant.h>
diff --git a/libcxx/include/cstdint b/libcxx/include/cstdint
index 829d9398f387a8..8c4782859426dd 100644
--- a/libcxx/include/cstdint
+++ b/libcxx/include/cstdint
@@ -140,7 +140,6 @@ Types:
} // std
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <stdint.h>
diff --git a/libcxx/include/cstdio b/libcxx/include/cstdio
index 0a867cec1a388b..7f94371081f8b1 100644
--- a/libcxx/include/cstdio
+++ b/libcxx/include/cstdio
@@ -95,7 +95,6 @@ void perror(const char* s);
} // std
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <stdio.h>
diff --git a/libcxx/include/cstdlib b/libcxx/include/cstdlib
index 9bf0ea3f73b169..c817fd8f4accda 100644
--- a/libcxx/include/cstdlib
+++ b/libcxx/include/cstdlib
@@ -81,7 +81,6 @@ void *aligned_alloc(size_t alignment, size_t size); // C11
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <stdlib.h>
diff --git a/libcxx/include/cstring b/libcxx/include/cstring
index a9bdf4ff2dfca7..c2c92b02e73cc1 100644
--- a/libcxx/include/cstring
+++ b/libcxx/include/cstring
@@ -56,7 +56,6 @@ size_t strlen(const char* s);
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <__type_traits/is_constant_evaluated.h>
diff --git a/libcxx/include/ctgmath b/libcxx/include/ctgmath
index bfcf2f98d470c8..6237979be4906c 100644
--- a/libcxx/include/ctgmath
+++ b/libcxx/include/ctgmath
@@ -18,7 +18,6 @@
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <ccomplex>
#include <cmath>
diff --git a/libcxx/include/ctime b/libcxx/include/ctime
index b61e19d6446ddc..f47b49a43e23ef 100644
--- a/libcxx/include/ctime
+++ b/libcxx/include/ctime
@@ -45,7 +45,6 @@ int timespec_get( struct timespec *ts, int base); // C++17
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
// <time.h> is not provided by libc++
diff --git a/libcxx/include/cuchar b/libcxx/include/cuchar
index 03b8c7d2a88bcf..f0015be275367d 100644
--- a/libcxx/include/cuchar
+++ b/libcxx/include/cuchar
@@ -36,7 +36,6 @@ size_t c32rtomb(char* s, char32_t c32, mbstate_t* ps);
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <uchar.h>
diff --git a/libcxx/include/cwchar b/libcxx/include/cwchar
index 122af242880e04..7442438d8f447f 100644
--- a/libcxx/include/cwchar
+++ b/libcxx/include/cwchar
@@ -102,7 +102,6 @@ size_t wcsrtombs(char* restrict dst, const wchar_t** restrict src, size_t len,
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <__type_traits/apply_cv.h>
#include <__type_traits/is_constant_evaluated.h>
diff --git a/libcxx/include/cwctype b/libcxx/include/cwctype
index 5a2d2427d8471f..04abfabef57933 100644
--- a/libcxx/include/cwctype
+++ b/libcxx/include/cwctype
@@ -49,7 +49,6 @@ wctrans_t wctrans(const char* property);
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <cctype>
diff --git a/libcxx/include/deque b/libcxx/include/deque
index c539a06bdd95c0..85ea9c6f661ed6 100644
--- a/libcxx/include/deque
+++ b/libcxx/include/deque
@@ -188,7 +188,7 @@ template <class T, class Allocator, class Predicate>
#include <__algorithm/remove.h>
#include <__algorithm/remove_if.h>
#include <__algorithm/unwrap_iter.h>
-#include <__assert> // all public C++ headers provide the assertion handler
+#include <__assert>
#include <__availability>
#include <__config>
#include <__format/enable_insertable.h>
diff --git a/libcxx/include/exception b/libcxx/include/exception
index 97fee977690d0a..5eff8e3f8a4bfa 100644
--- a/libcxx/include/exception
+++ b/libcxx/include/exception
@@ -76,7 +76,6 @@ template <class E> void rethrow_if_nested(const E& e);
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <__exception/exception.h>
#include <__exception/exception_ptr.h>
diff --git a/libcxx/include/execution b/libcxx/include/execution
index 56facc87379ef1..822ffa1fd3ebc4 100644
--- a/libcxx/include/execution
+++ b/libcxx/include/execution
@@ -32,7 +32,6 @@ namespace std {
}
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <__type_traits/is_execution_policy.h>
#include <__type_traits/is_same.h>
diff --git a/libcxx/include/expected b/libcxx/include/expected
index 44d0ce6b00c81e..f455ab7d5d61c6 100644
--- a/libcxx/include/expected
+++ b/libcxx/include/expected
@@ -38,7 +38,6 @@ namespace std {
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <__expected/bad_expected_access.h>
#include <__expected/expected.h>
diff --git a/libcxx/include/experimental/__simd/scalar.h b/libcxx/include/experimental/__simd/scalar.h
index 717fd6cd92d710..aff2cd11cfcfaa 100644
--- a/libcxx/include/experimental/__simd/scalar.h
+++ b/libcxx/include/experimental/__simd/scalar.h
@@ -10,6 +10,7 @@
#ifndef _LIBCPP_EXPERIMENTAL___SIMD_SCALAR_H
#define _LIBCPP_EXPERIMENTAL___SIMD_SCALAR_H
+#include <__assert>
#include <cstddef>
#include <experimental/__config>
#include <experimental/__simd/declaration.h>
diff --git a/libcxx/include/experimental/__simd/vec_ext.h b/libcxx/include/experimental/__simd/vec_ext.h
index 7883132ba6c0db..c9423df93cfacc 100644
--- a/libcxx/include/experimental/__simd/vec_ext.h
+++ b/libcxx/include/experimental/__simd/vec_ext.h
@@ -10,6 +10,7 @@
#ifndef _LIBCPP_EXPERIMENTAL___SIMD_VEC_EXT_H
#define _LIBCPP_EXPERIMENTAL___SIMD_VEC_EXT_H
+#include <__assert>
#include <__bit/bit_ceil.h>
#include <__utility/forward.h>
#include <__utility/integer_sequence.h>
diff --git a/libcxx/include/experimental/iterator b/libcxx/include/experimental/iterator
index e9c1fb6924eced..de82da2d3d72bd 100644
--- a/libcxx/include/experimental/iterator
+++ b/libcxx/include/experimental/iterator
@@ -52,7 +52,6 @@ namespace std {
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__memory/addressof.h>
#include <__type_traits/decay.h>
#include <__utility/forward.h>
diff --git a/libcxx/include/experimental/propagate_const b/libcxx/include/experimental/propagate_const
index 06d7ba43daf1ca..8c2ceb9def3357 100644
--- a/libcxx/include/experimental/propagate_const
+++ b/libcxx/include/experimental/propagate_const
@@ -107,7 +107,6 @@
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__functional/operations.h>
#include <__fwd/hash.h>
#include <__type_traits/conditional.h>
diff --git a/libcxx/include/experimental/simd b/libcxx/include/experimental/simd
index adca9faa47bb06..fad6431d13a193 100644
--- a/libcxx/include/experimental/simd
+++ b/libcxx/include/experimental/simd
@@ -71,8 +71,6 @@ inline namespace parallelism_v2 {
*/
-#include <__assert> // all public C++ headers provide the assertion handler
-
#if !defined(_LIBCPP_HAS_NO_PRAGMA_SYSTEM_HEADER)
# pragma GCC system_header
#endif
diff --git a/libcxx/include/experimental/type_traits b/libcxx/include/experimental/type_traits
index 62f9574ec58f4f..37be434f8edd56 100644
--- a/libcxx/include/experimental/type_traits
+++ b/libcxx/include/experimental/type_traits
@@ -68,7 +68,6 @@ inline namespace fundamentals_v1 {
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <experimental/__config>
#if _LIBCPP_STD_VER >= 14
diff --git a/libcxx/include/experimental/utility b/libcxx/include/experimental/utility
index c1bd9364fd51e4..8bd0a055b7783f 100644
--- a/libcxx/include/experimental/utility
+++ b/libcxx/include/experimental/utility
@@ -30,7 +30,6 @@ inline namespace fundamentals_v1 {
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <experimental/__config>
#include <utility>
diff --git a/libcxx/include/ext/hash_map b/libcxx/include/ext/hash_map
index 7ac268d5dcbdec..7b5b31c4081788 100644
--- a/libcxx/include/ext/hash_map
+++ b/libcxx/include/ext/hash_map
@@ -201,7 +201,6 @@ template <class Key, class T, class Hash, class Pred, class Alloc>
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <__hash_table>
#include <algorithm>
diff --git a/libcxx/include/ext/hash_set b/libcxx/include/ext/hash_set
index 79f0925f6f4c67..1ab259b59979f3 100644
--- a/libcxx/include/ext/hash_set
+++ b/libcxx/include/ext/hash_set
@@ -192,7 +192,6 @@ template <class Value, class Hash, class Pred, class Alloc>
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <__hash_table>
#include <algorithm>
diff --git a/libcxx/include/filesystem b/libcxx/include/filesystem
index ec68354a9fc933..b344ed468082e8 100644
--- a/libcxx/include/filesystem
+++ b/libcxx/include/filesystem
@@ -533,7 +533,6 @@ inline constexpr bool std::ranges::enable_view<std::filesystem::recursive_direct
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <__filesystem/copy_options.h>
#include <__filesystem/directory_entry.h>
diff --git a/libcxx/include/format b/libcxx/include/format
index 64f6ba1d25284a..b2fe0053b974bb 100644
--- a/libcxx/include/format
+++ b/libcxx/include/format
@@ -188,7 +188,6 @@ namespace std {
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <__format/buffer.h>
#include <__format/concepts.h>
diff --git a/libcxx/include/forward_list b/libcxx/include/forward_list
index ffa390f42a1072..a62b171a46783b 100644
--- a/libcxx/include/forward_list
+++ b/libcxx/include/forward_list
@@ -199,7 +199,6 @@ template <class T, class Allocator, class Predicate>
#include <__algorithm/lexicographical_compare.h>
#include <__algorithm/lexicographical_compare_three_way.h>
#include <__algorithm/min.h>
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__availability>
#include <__config>
#include <__iterator/distance.h>
diff --git a/libcxx/include/fstream b/libcxx/include/fstream
index 203cc6dfb4b134..513c8dc2b127a4 100644
--- a/libcxx/include/fstream
+++ b/libcxx/include/fstream
@@ -187,7 +187,7 @@ typedef basic_fstream<wchar_t> wfstream;
*/
#include <__algorithm/max.h>
-#include <__assert> // all public C++ headers provide the assertion handler
+#include <__assert>
#include <__availability>
#include <__config>
#include <__fwd/fstream.h>
diff --git a/libcxx/include/functional b/libcxx/include/functional
index fd99e11fb18180..a2774a48bda0ee 100644
--- a/libcxx/include/functional
+++ b/libcxx/include/functional
@@ -513,7 +513,6 @@ POLICY: For non-variadic implementations, the number of arguments is limited
*/
#include <__algorithm/search.h>
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__compare/compare_three_way.h>
#include <__config>
#include <__functional/binary_function.h>
diff --git a/libcxx/include/future b/libcxx/include/future
index 13828680f03335..fda1591818a667 100644
--- a/libcxx/include/future
+++ b/libcxx/include/future
@@ -368,7 +368,7 @@ template <class R, class Alloc> struct uses_allocator<packaged_task<R>, Alloc>;
# error "<future> is not supported since libc++ has been configured without support for threads."
#endif
-#include <__assert> // all public C++ headers provide the assertion handler
+#include <__assert>
#include <__availability>
#include <__chrono/duration.h>
#include <__chrono/time_point.h>
diff --git a/libcxx/include/initializer_list b/libcxx/include/initializer_list
index 4c2a7925a57bbf..680ca1cd20d550 100644
--- a/libcxx/include/initializer_list
+++ b/libcxx/include/initializer_list
@@ -42,7 +42,6 @@ template<class E> const E* end(initializer_list<E> il) noexcept; // constexpr in
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <cstddef>
diff --git a/libcxx/include/iomanip b/libcxx/include/iomanip
index 867408affd22b6..fb4f15b9a58533 100644
--- a/libcxx/include/iomanip
+++ b/libcxx/include/iomanip
@@ -42,7 +42,6 @@ template <class charT, class traits, class Allocator>
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <istream>
#include <version>
diff --git a/libcxx/include/ios b/libcxx/include/ios
index 8465860d08dc14..4b1306fc2ad830 100644
--- a/libcxx/include/ios
+++ b/libcxx/include/ios
@@ -217,7 +217,6 @@ storage-class-specifier const error_category& iostream_category() noexcept;
# error "The iostreams library is not supported since libc++ has been configured without support for localization."
#endif
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__fwd/ios.h>
#include <__ios/fpos.h>
#include <__locale>
diff --git a/libcxx/include/iosfwd b/libcxx/include/iosfwd
index e28998d004156d..1579fa12754daf 100644
--- a/libcxx/include/iosfwd
+++ b/libcxx/include/iosfwd
@@ -106,7 +106,6 @@ using wosyncstream = basic_osyncstream<wchar_t>; // C++20
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <__fwd/fstream.h>
#include <__fwd/ios.h>
diff --git a/libcxx/include/iostream b/libcxx/include/iostream
index 568ce8caed6ef1..5df45c6d3f78e7 100644
--- a/libcxx/include/iostream
+++ b/libcxx/include/iostream
@@ -33,7 +33,6 @@ extern wostream wclog;
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <version>
diff --git a/libcxx/include/istream b/libcxx/include/istream
index 7975a9e599a5b6..3f20c355046cea 100644
--- a/libcxx/include/istream
+++ b/libcxx/include/istream
@@ -158,7 +158,6 @@ template <class Stream, class T>
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <__fwd/istream.h>
#include <__iterator/istreambuf_iterator.h>
diff --git a/libcxx/include/iterator b/libcxx/include/iterator
index 2f9280742370a2..5779bf828711b8 100644
--- a/libcxx/include/iterator
+++ b/libcxx/include/iterator
@@ -674,7 +674,6 @@ template <class E> constexpr const E* data(initializer_list<E> il) noexcept;
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <__iterator/access.h>
#include <__iterator/advance.h>
diff --git a/libcxx/include/latch b/libcxx/include/latch
index dd389d296f5c11..3fe201b63d1385 100644
--- a/libcxx/include/latch
+++ b/libcxx/include/latch
@@ -46,7 +46,7 @@ namespace std
# error "<latch> is not supported since libc++ has been configured without support for threads."
#endif
-#include <__assert> // all public C++ headers provide the assertion handler
+#include <__assert>
#include <__atomic/atomic_base.h>
#include <__atomic/atomic_sync.h>
#include <__atomic/memory_order.h>
diff --git a/libcxx/include/limits b/libcxx/include/limits
index c704b4dddaf8e2..f15b5b1ab1d52f 100644
--- a/libcxx/include/limits
+++ b/libcxx/include/limits
@@ -102,7 +102,6 @@ template<> class numeric_limits<cv long double>;
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <__type_traits/is_arithmetic.h>
#include <__type_traits/is_signed.h>
diff --git a/libcxx/include/list b/libcxx/include/list
index 2705d4c9914d80..8f0689268e2a5a 100644
--- a/libcxx/include/list
+++ b/libcxx/include/list
@@ -202,7 +202,7 @@ template <class T, class Allocator, class Predicate>
#include <__algorithm/lexicographical_compare.h>
#include <__algorithm/lexicographical_compare_three_way.h>
#include <__algorithm/min.h>
-#include <__assert> // all public C++ headers provide the assertion handler
+#include <__assert>
#include <__availability>
#include <__config>
#include <__format/enable_insertable.h>
diff --git a/libcxx/include/locale b/libcxx/include/locale
index 9e97eb9f339533..e3c63e3abe130e 100644
--- a/libcxx/include/locale
+++ b/libcxx/include/locale
@@ -193,7 +193,7 @@ template <class charT> class messages_byname;
#include <__algorithm/max.h>
#include <__algorithm/reverse.h>
#include <__algorithm/unwrap_iter.h>
-#include <__assert> // all public C++ headers provide the assertion handler
+#include <__assert>
#include <__config>
#include <__iterator/access.h>
#include <__iterator/back_insert_iterator.h>
diff --git a/libcxx/include/map b/libcxx/include/map
index a56584589f5c85..5b6ec9d3a21936 100644
--- a/libcxx/include/map
+++ b/libcxx/include/map
@@ -574,7 +574,7 @@ erase_if(multimap<Key, T, Compare, Allocator>& c, Predicate pred); // C++20
#include <__algorithm/equal.h>
#include <__algorithm/lexicographical_compare.h>
#include <__algorithm/lexicographical_compare_three_way.h>
-#include <__assert> // all public C++ headers provide the assertion handler
+#include <__assert>
#include <__availability>
#include <__config>
#include <__functional/binary_function.h>
diff --git a/libcxx/include/memory b/libcxx/include/memory
index 0ada7cdfa20690..a8c0264eb9eb78 100644
--- a/libcxx/include/memory
+++ b/libcxx/include/memory
@@ -917,7 +917,6 @@ template<size_t N, class T>
// clang-format on
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <__memory/addressof.h>
#include <__memory/align.h>
diff --git a/libcxx/include/mutex b/libcxx/include/mutex
index e67135fc0ec04e..ea56e3051908a7 100644
--- a/libcxx/include/mutex
+++ b/libcxx/include/mutex
@@ -186,7 +186,6 @@ template<class Callable, class ...Args>
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__chrono/steady_clock.h>
#include <__chrono/time_point.h>
#include <__condition_variable/condition_variable.h>
diff --git a/libcxx/include/new b/libcxx/include/new
index 86fbcb524b66d8..988f7a84422c84 100644
--- a/libcxx/include/new
+++ b/libcxx/include/new
@@ -86,13 +86,13 @@ void operator delete[](void* ptr, void*) noexcept;
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__availability>
#include <__config>
#include <__exception/exception.h>
#include <__type_traits/is_function.h>
#include <__type_traits/is_same.h>
#include <__type_traits/remove_cv.h>
+#include <__verbose_abort>
#include <cstddef>
#include <version>
diff --git a/libcxx/include/numbers b/libcxx/include/numbers
index 0d834c6b863f66..f48ba4baf38ffd 100644
--- a/libcxx/include/numbers
+++ b/libcxx/include/numbers
@@ -58,7 +58,6 @@ namespace std::numbers {
}
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__concepts/arithmetic.h>
#include <__config>
#include <version>
diff --git a/libcxx/include/numeric b/libcxx/include/numeric
index 0fe7115f1c666e..8b429fa2f7e7d5 100644
--- a/libcxx/include/numeric
+++ b/libcxx/include/numeric
@@ -156,7 +156,6 @@ constexpr T saturate_cast(U x) noexcept; // freestanding, Sin
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <version>
diff --git a/libcxx/include/optional b/libcxx/include/optional
index 73da0a8a5a7c19..9e4f0fff2f4a7a 100644
--- a/libcxx/include/optional
+++ b/libcxx/include/optional
@@ -177,7 +177,7 @@ namespace std {
*/
-#include <__assert> // all public C++ headers provide the assertion handler
+#include <__assert>
#include <__availability>
#include <__compare/compare_three_way_result.h>
#include <__compare/three_way_comparable.h>
diff --git a/libcxx/include/ostream b/libcxx/include/ostream
index 2e2607340a5de1..42819ceb252c65 100644
--- a/libcxx/include/ostream
+++ b/libcxx/include/ostream
@@ -171,7 +171,6 @@ void vprint_nonunicode(ostream& os, string_view fmt, format_args args);
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__availability>
#include <__config>
#include <__exception/operations.h>
diff --git a/libcxx/include/print b/libcxx/include/print
index 543a540ee4f27d..a9f10433a7dc61 100644
--- a/libcxx/include/print
+++ b/libcxx/include/print
@@ -31,7 +31,7 @@ namespace std {
}
*/
-#include <__assert> // all public C++ headers provide the assertion handler
+#include <__assert>
#include <__availability>
#include <__concepts/same_as.h>
#include <__config>
diff --git a/libcxx/include/queue b/libcxx/include/queue
index 2263f71fde9073..521a465713cd22 100644
--- a/libcxx/include/queue
+++ b/libcxx/include/queue
@@ -258,7 +258,6 @@ template <class T, class Container, class Compare>
#include <__algorithm/pop_heap.h>
#include <__algorithm/push_heap.h>
#include <__algorithm/ranges_copy.h>
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <__functional/operations.h>
#include <__iterator/back_insert_iterator.h>
diff --git a/libcxx/include/random b/libcxx/include/random
index 02d71ad6dd25c8..9edd6c4608ec26 100644
--- a/libcxx/include/random
+++ b/libcxx/include/random
@@ -1677,7 +1677,6 @@ class piecewise_linear_distribution
} // std
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <__random/bernoulli_distribution.h>
#include <__random/binomial_distribution.h>
diff --git a/libcxx/include/ranges b/libcxx/include/ranges
index 660d533b2a7830..167d2137eaf454 100644
--- a/libcxx/include/ranges
+++ b/libcxx/include/ranges
@@ -375,7 +375,6 @@ namespace std {
}
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <__ranges/access.h>
#include <__ranges/all.h>
diff --git a/libcxx/include/ratio b/libcxx/include/ratio
index de656f38e01de6..b989c272aaee6a 100644
--- a/libcxx/include/ratio
+++ b/libcxx/include/ratio
@@ -81,7 +81,6 @@ using quetta = ratio <1'000'000'000'000'000'000'000'000'000'000, 1>; // Since C+
}
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <__type_traits/integral_constant.h>
#include <climits>
diff --git a/libcxx/include/regex b/libcxx/include/regex
index 48af5b8b57fd64..dc3db93744b489 100644
--- a/libcxx/include/regex
+++ b/libcxx/include/regex
@@ -791,7 +791,7 @@ typedef regex_token_iterator<wstring::const_iterator> wsregex_token_iterator;
#include <__algorithm/find.h>
#include <__algorithm/search.h>
-#include <__assert> // all public C++ headers provide the assertion handler
+#include <__assert>
#include <__availability>
#include <__config>
#include <__iterator/back_insert_iterator.h>
diff --git a/libcxx/include/scoped_allocator b/libcxx/include/scoped_allocator
index fa6c6c5d20d864..c53261025be9d7 100644
--- a/libcxx/include/scoped_allocator
+++ b/libcxx/include/scoped_allocator
@@ -109,7 +109,6 @@ template <class OuterA1, class OuterA2, class... InnerAllocs>
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <__memory/allocator_traits.h>
#include <__memory/uses_allocator_construction.h>
diff --git a/libcxx/include/semaphore b/libcxx/include/semaphore
index 448b5fbd8c58cf..2dfdae9aa148c1 100644
--- a/libcxx/include/semaphore
+++ b/libcxx/include/semaphore
@@ -51,7 +51,7 @@ using binary_semaphore = counting_semaphore<1>;
# error "<semaphore> is not supported since libc++ has been configured without support for threads."
#endif
-#include <__assert> // all public C++ headers provide the assertion handler
+#include <__assert>
#include <__atomic/atomic_base.h>
#include <__atomic/atomic_sync.h>
#include <__atomic/memory_order.h>
diff --git a/libcxx/include/set b/libcxx/include/set
index 7f8245f8b605ab..e2e87e4cdcfe3b 100644
--- a/libcxx/include/set
+++ b/libcxx/include/set
@@ -515,7 +515,7 @@ erase_if(multiset<Key, Compare, Allocator>& c, Predicate pred); // C++20
#include <__algorithm/equal.h>
#include <__algorithm/lexicographical_compare.h>
#include <__algorithm/lexicographical_compare_three_way.h>
-#include <__assert> // all public C++ headers provide the assertion handler
+#include <__assert>
#include <__availability>
#include <__config>
#include <__functional/is_transparent.h>
diff --git a/libcxx/include/shared_mutex b/libcxx/include/shared_mutex
index 57f385b5435eb2..38b559e8930fc5 100644
--- a/libcxx/include/shared_mutex
+++ b/libcxx/include/shared_mutex
@@ -128,7 +128,6 @@ template <class Mutex>
# error "<shared_mutex> is not supported since libc++ has been configured without support for threads."
#endif
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__availability>
#include <__chrono/duration.h>
#include <__chrono/steady_clock.h>
diff --git a/libcxx/include/span b/libcxx/include/span
index 32364b4270be9e..9efaac517fc8f6 100644
--- a/libcxx/include/span
+++ b/libcxx/include/span
@@ -128,7 +128,7 @@ template<class R>
*/
-#include <__assert> // all public C++ headers provide the assertion handler
+#include <__assert>
#include <__config>
#include <__fwd/span.h>
#include <__iterator/bounded_iter.h>
diff --git a/libcxx/include/sstream b/libcxx/include/sstream
index 8862e2ef99f8da..60bec52209d75e 100644
--- a/libcxx/include/sstream
+++ b/libcxx/include/sstream
@@ -278,7 +278,6 @@ typedef basic_stringstream<wchar_t> wstringstream;
// clang-format on
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__availability>
#include <__config>
#include <__fwd/sstream.h>
diff --git a/libcxx/include/stack b/libcxx/include/stack
index 77f1a4e11b732d..4003792600a004 100644
--- a/libcxx/include/stack
+++ b/libcxx/include/stack
@@ -114,7 +114,6 @@ template <class T, class Container>
*/
#include <__algorithm/ranges_copy.h>
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <__iterator/back_insert_iterator.h>
#include <__iterator/iterator_traits.h>
diff --git a/libcxx/include/stdexcept b/libcxx/include/stdexcept
index 3016c130a91b8f..4e4cd22a6a64d2 100644
--- a/libcxx/include/stdexcept
+++ b/libcxx/include/stdexcept
@@ -41,7 +41,6 @@ public:
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <__exception/exception.h>
#include <__fwd/string.h>
diff --git a/libcxx/include/stop_token b/libcxx/include/stop_token
index 66c7a6ab5996c1..fee195f9d63d4b 100644
--- a/libcxx/include/stop_token
+++ b/libcxx/include/stop_token
@@ -37,7 +37,6 @@ namespace std {
# error "<stop_token> is not supported since libc++ has been configured without support for threads."
#endif
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__stop_token/stop_callback.h>
#include <__stop_token/stop_source.h>
#include <__stop_token/stop_token.h>
diff --git a/libcxx/include/streambuf b/libcxx/include/streambuf
index aad7686a435cbc..aec537866c2031 100644
--- a/libcxx/include/streambuf
+++ b/libcxx/include/streambuf
@@ -107,7 +107,6 @@ protected:
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <__fwd/streambuf.h>
#include <__type_traits/is_same.h>
diff --git a/libcxx/include/string b/libcxx/include/string
index 530a2233860434..ca5b3fa6a01472 100644
--- a/libcxx/include/string
+++ b/libcxx/include/string
@@ -572,7 +572,7 @@ basic_string<char32_t> operator""s( const char32_t *str, size_t len );
#include <__algorithm/min.h>
#include <__algorithm/remove.h>
#include <__algorithm/remove_if.h>
-#include <__assert> // all public C++ headers provide the assertion handler
+#include <__assert>
#include <__config>
#include <__format/enable_insertable.h>
#include <__functional/hash.h>
diff --git a/libcxx/include/string_view b/libcxx/include/string_view
index e414507a7933b6..48bbcd80021670 100644
--- a/libcxx/include/string_view
+++ b/libcxx/include/string_view
@@ -206,7 +206,7 @@ namespace std {
// clang-format on
#include <__algorithm/min.h>
-#include <__assert> // all public C++ headers provide the assertion handler
+#include <__assert>
#include <__config>
#include <__functional/hash.h>
#include <__functional/unary_function.h>
diff --git a/libcxx/include/strstream b/libcxx/include/strstream
index e20c86baa6dfc5..e9f533644f78cf 100644
--- a/libcxx/include/strstream
+++ b/libcxx/include/strstream
@@ -129,7 +129,6 @@ private:
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <istream>
#include <ostream>
diff --git a/libcxx/include/system_error b/libcxx/include/system_error
index a60c98492aaced..eeab347788a9a5 100644
--- a/libcxx/include/system_error
+++ b/libcxx/include/system_error
@@ -144,7 +144,6 @@ template <> struct hash<std::error_condition>;
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <__system_error/errc.h>
#include <__system_error/error_category.h>
diff --git a/libcxx/include/thread b/libcxx/include/thread
index 29c7e86785cde4..ed70bde76094ae 100644
--- a/libcxx/include/thread
+++ b/libcxx/include/thread
@@ -92,7 +92,6 @@ void sleep_for(const chrono::duration<Rep, Period>& rel_time);
# error "<thread> is not supported since libc++ has been configured without support for threads."
#endif
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__availability>
#include <__thread/formatter.h>
#include <__thread/jthread.h>
diff --git a/libcxx/include/tuple b/libcxx/include/tuple
index 96cf3be85b76f2..0101d64aea4a72 100644
--- a/libcxx/include/tuple
+++ b/libcxx/include/tuple
@@ -205,7 +205,6 @@ template <class... Types>
// clang-format on
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__compare/common_comparison_category.h>
#include <__compare/synth_three_way.h>
#include <__config>
diff --git a/libcxx/include/type_traits b/libcxx/include/type_traits
index 466aeb6e0ddd71..0037c426560e6f 100644
--- a/libcxx/include/type_traits
+++ b/libcxx/include/type_traits
@@ -416,7 +416,7 @@ namespace std
}
*/
-#include <__assert> // all public C++ headers provide the assertion handler
+
#include <__config>
#include <__fwd/hash.h> // This is https://llvm.org/PR56938
#include <__type_traits/add_const.h>
diff --git a/libcxx/include/typeindex b/libcxx/include/typeindex
index e6ea12afd52450..6398aa40d616a7 100644
--- a/libcxx/include/typeindex
+++ b/libcxx/include/typeindex
@@ -45,7 +45,6 @@ struct hash<type_index>
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <__functional/unary_function.h>
#include <typeinfo>
diff --git a/libcxx/include/typeinfo b/libcxx/include/typeinfo
index 1144b5b12913e1..dafc7b89248eca 100644
--- a/libcxx/include/typeinfo
+++ b/libcxx/include/typeinfo
@@ -56,7 +56,6 @@ public:
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__availability>
#include <__config>
#include <__exception/exception.h>
diff --git a/libcxx/include/unordered_map b/libcxx/include/unordered_map
index d2a3b769821d84..ca3d1a80bd578d 100644
--- a/libcxx/include/unordered_map
+++ b/libcxx/include/unordered_map
@@ -584,7 +584,7 @@ template <class Key, class T, class Hash, class Pred, class Alloc>
*/
#include <__algorithm/is_permutation.h>
-#include <__assert> // all public C++ headers provide the assertion handler
+#include <__assert>
#include <__availability>
#include <__config>
#include <__functional/is_transparent.h>
diff --git a/libcxx/include/unordered_set b/libcxx/include/unordered_set
index 50b616907f0052..64a02de3cf55d4 100644
--- a/libcxx/include/unordered_set
+++ b/libcxx/include/unordered_set
@@ -532,7 +532,7 @@ template <class Value, class Hash, class Pred, class Alloc>
// clang-format on
#include <__algorithm/is_permutation.h>
-#include <__assert> // all public C++ headers provide the assertion handler
+#include <__assert>
#include <__availability>
#include <__config>
#include <__functional/is_transparent.h>
diff --git a/libcxx/include/utility b/libcxx/include/utility
index 1deef3db204107..90713da621c5da 100644
--- a/libcxx/include/utility
+++ b/libcxx/include/utility
@@ -246,7 +246,6 @@ template <class T>
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__config>
#include <__utility/as_const.h>
#include <__utility/as_lvalue.h>
diff --git a/libcxx/include/valarray b/libcxx/include/valarray
index 88b161eccd332f..3d45925a25bef8 100644
--- a/libcxx/include/valarray
+++ b/libcxx/include/valarray
@@ -350,7 +350,7 @@ template <class T> unspecified2 end(const valarray<T>& v);
#include <__algorithm/min.h>
#include <__algorithm/min_element.h>
#include <__algorithm/unwrap_iter.h>
-#include <__assert> // all public C++ headers provide the assertion handler
+#include <__assert>
#include <__config>
#include <__functional/operations.h>
#include <__memory/addressof.h>
diff --git a/libcxx/include/variant b/libcxx/include/variant
index 6063739e52c86b..5ce99250a8b4f4 100644
--- a/libcxx/include/variant
+++ b/libcxx/include/variant
@@ -210,7 +210,6 @@ namespace std {
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__availability>
#include <__compare/common_comparison_category.h>
#include <__compare/compare_three_way_result.h>
diff --git a/libcxx/include/vector b/libcxx/include/vector
index 579fadfb404c19..89cbdf0b3ff747 100644
--- a/libcxx/include/vector
+++ b/libcxx/include/vector
@@ -315,7 +315,7 @@ template<class T, class charT> requires is-vector-bool-reference<T> // Since C++
#include <__algorithm/remove_if.h>
#include <__algorithm/rotate.h>
#include <__algorithm/unwrap_iter.h>
-#include <__assert> // all public C++ headers provide the assertion handler
+#include <__assert>
#include <__availability>
#include <__bit_reference>
#include <__concepts/same_as.h>
diff --git a/libcxx/include/version b/libcxx/include/version
index b18927a2bc38c2..cd180441c5b9e1 100644
--- a/libcxx/include/version
+++ b/libcxx/include/version
@@ -244,7 +244,6 @@ __cpp_lib_within_lifetime 202306L <type_traits>
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__availability>
#include <__config>
diff --git a/libcxx/test/libcxx/assertions/customize_verbose_abort.link-time.pass.cpp b/libcxx/test/libcxx/assertions/customize_verbose_abort.link-time.pass.cpp
index 585ab73f2cb261..9298a1e365fca4 100644
--- a/libcxx/test/libcxx/assertions/customize_verbose_abort.link-time.pass.cpp
+++ b/libcxx/test/libcxx/assertions/customize_verbose_abort.link-time.pass.cpp
@@ -12,6 +12,7 @@
// failures when back-deploying.
// XFAIL: availability-verbose_abort-missing
+#include <__verbose_abort>
#include <cstdlib>
void std::__libcpp_verbose_abort(char const*, ...) {
diff --git a/libcxx/test/libcxx/assertions/headers_declare_verbose_abort.gen.py b/libcxx/test/libcxx/assertions/headers_declare_verbose_abort.gen.py
deleted file mode 100644
index bd883aa0c14502..00000000000000
--- a/libcxx/test/libcxx/assertions/headers_declare_verbose_abort.gen.py
+++ /dev/null
@@ -1,33 +0,0 @@
-#===----------------------------------------------------------------------===##
-#
-# Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
-# See https://llvm.org/LICENSE.txt for license information.
-# SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
-#
-#===----------------------------------------------------------------------===##
-
-# Test that all public C++ headers define the verbose termination function, which
-# is required for users to be able to include any public header and then override
-# the function using a strong definition.
-
-# RUN: %{python} %s %{libcxx-dir}/utils
-
-import sys
-sys.path.append(sys.argv[1])
-from libcxx.header_information import lit_header_restrictions, public_headers
-
-for header in public_headers:
- # Skip C compatibility headers.
- if header.endswith('.h'):
- continue
-
- BLOCKLIT = '' # block Lit from interpreting a RUN/XFAIL/etc inside the generation script
- print(f"""\
-//--- {header}.compile.pass.cpp
-{lit_header_restrictions.get(header, '')}
-
-// XFAIL{BLOCKLIT}: availability-verbose_abort-missing
-
-#include <{header}>
-using HandlerType = decltype(std::__libcpp_verbose_abort);
-""")
diff --git a/libcxx/test/libcxx/assertions/modes/none.pass.cpp b/libcxx/test/libcxx/assertions/modes/none.pass.cpp
index 4644c5692e70be..8332848c1a8e03 100644
--- a/libcxx/test/libcxx/assertions/modes/none.pass.cpp
+++ b/libcxx/test/libcxx/assertions/modes/none.pass.cpp
@@ -11,6 +11,7 @@
// REQUIRES: libcpp-hardening-mode=none
+#include <__assert>
#include <cassert>
bool executed_condition = false;
diff --git a/libcxx/utils/generate_feature_test_macro_components.py b/libcxx/utils/generate_feature_test_macro_components.py
index b688a30cdb792d..7b6d35d9a7fc53 100755
--- a/libcxx/utils/generate_feature_test_macro_components.py
+++ b/libcxx/utils/generate_feature_test_macro_components.py
@@ -1514,7 +1514,6 @@ def produce_version_header():
*/
-#include <__assert> // all public C++ headers provide the assertion handler
#include <__availability>
#include <__config>
>From 92e5f13ad19ace968309e31146e00e76b87c5a2d Mon Sep 17 00:00:00 2001
From: Tuan Chuong Goh <chuong.goh at arm.com>
Date: Thu, 29 Feb 2024 13:29:35 +0000
Subject: [PATCH 138/406] [AArch64][GlobalISel] Legalize G_SHUFFLE_VECTOR for
Odd-Sized Vectors (#83038)
---
llvm/test/CodeGen/AArch64/shufflevector.ll | 565 +++++++++++++++++++++
1 file changed, 565 insertions(+)
create mode 100644 llvm/test/CodeGen/AArch64/shufflevector.ll
diff --git a/llvm/test/CodeGen/AArch64/shufflevector.ll b/llvm/test/CodeGen/AArch64/shufflevector.ll
new file mode 100644
index 00000000000000..df59eb8e629f44
--- /dev/null
+++ b/llvm/test/CodeGen/AArch64/shufflevector.ll
@@ -0,0 +1,565 @@
+; NOTE: Assertions have been autogenerated by utils/update_llc_test_checks.py UTC_ARGS: --version 4
+; RUN: llc -mtriple=aarch64-none-linux-gnu %s -o - | FileCheck %s --check-prefixes=CHECK,CHECK-SD
+; RUN: llc -mtriple=aarch64-none-linux-gnu -global-isel -global-isel-abort=2 %s -o - 2>&1 | FileCheck %s --check-prefixes=CHECK,CHECK-GI
+
+; CHECK-GI: warning: Instruction selection used fallback path for shufflevector_v2i1
+; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v4i8
+; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v32i8
+; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v2i16
+; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v16i16
+; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v2i1_zeroes
+; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v4i8_zeroes
+; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v32i8_zeroes
+; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v2i16_zeroes
+; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v16i16_zeroes
+; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v3i8
+; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v3i8_zeroes
+
+; ===== Legal Vector Types =====
+
+define <8 x i8> @shufflevector_v8i8(<8 x i8> %a, <8 x i8> %b) {
+; CHECK-SD-LABEL: shufflevector_v8i8:
+; CHECK-SD: // %bb.0:
+; CHECK-SD-NEXT: // kill: def $d0 killed $d0 def $q0
+; CHECK-SD-NEXT: // kill: def $d1 killed $d1 def $q1
+; CHECK-SD-NEXT: adrp x8, .LCPI0_0
+; CHECK-SD-NEXT: mov v0.d[1], v1.d[0]
+; CHECK-SD-NEXT: ldr d1, [x8, :lo12:.LCPI0_0]
+; CHECK-SD-NEXT: tbl v0.8b, { v0.16b }, v1.8b
+; CHECK-SD-NEXT: ret
+;
+; CHECK-GI-LABEL: shufflevector_v8i8:
+; CHECK-GI: // %bb.0:
+; CHECK-GI-NEXT: // kill: def $d0 killed $d0 def $q0
+; CHECK-GI-NEXT: // kill: def $d1 killed $d1 def $q1
+; CHECK-GI-NEXT: adrp x8, .LCPI0_0
+; CHECK-GI-NEXT: mov v0.d[1], v1.d[0]
+; CHECK-GI-NEXT: ldr d1, [x8, :lo12:.LCPI0_0]
+; CHECK-GI-NEXT: tbl v0.16b, { v0.16b }, v1.16b
+; CHECK-GI-NEXT: // kill: def $d0 killed $d0 killed $q0
+; CHECK-GI-NEXT: ret
+ %c = shufflevector <8 x i8> %a, <8 x i8> %b, <8 x i32> <i32 1, i32 3, i32 5, i32 7, i32 8, i32 10, i32 12, i32 15>
+ ret <8 x i8> %c
+}
+
+define <16 x i8> @shufflevector_v16i8(<16 x i8> %a, <16 x i8> %b) {
+; CHECK-SD-LABEL: shufflevector_v16i8:
+; CHECK-SD: // %bb.0:
+; CHECK-SD-NEXT: adrp x8, .LCPI1_0
+; CHECK-SD-NEXT: // kill: def $q1 killed $q1 killed $q0_q1 def $q0_q1
+; CHECK-SD-NEXT: ldr q2, [x8, :lo12:.LCPI1_0]
+; CHECK-SD-NEXT: // kill: def $q0 killed $q0 killed $q0_q1 def $q0_q1
+; CHECK-SD-NEXT: tbl v0.16b, { v0.16b, v1.16b }, v2.16b
+; CHECK-SD-NEXT: ret
+;
+; CHECK-GI-LABEL: shufflevector_v16i8:
+; CHECK-GI: // %bb.0:
+; CHECK-GI-NEXT: adrp x8, .LCPI1_0
+; CHECK-GI-NEXT: // kill: def $q0 killed $q0 killed $q0_q1 def $q0_q1
+; CHECK-GI-NEXT: ldr q2, [x8, :lo12:.LCPI1_0]
+; CHECK-GI-NEXT: // kill: def $q1 killed $q1 killed $q0_q1 def $q0_q1
+; CHECK-GI-NEXT: tbl v0.16b, { v0.16b, v1.16b }, v2.16b
+; CHECK-GI-NEXT: ret
+ %c = shufflevector <16 x i8> %a, <16 x i8> %b, <16 x i32> <i32 1, i32 3, i32 5, i32 7, i32 8, i32 10, i32 12, i32 15, i32 2, i32 4, i32 6, i32 8, i32 25, i32 30, i32 31, i32 31>
+ ret <16 x i8> %c
+}
+
+define <4 x i16> @shufflevector_v4i16(<4 x i16> %a, <4 x i16> %b) {
+; CHECK-LABEL: shufflevector_v4i16:
+; CHECK: // %bb.0:
+; CHECK-NEXT: uzp2 v0.4h, v0.4h, v1.4h
+; CHECK-NEXT: ret
+ %c = shufflevector <4 x i16> %a, <4 x i16> %b, <4 x i32> <i32 1, i32 3, i32 5, i32 7>
+ ret <4 x i16> %c
+}
+
+define <8 x i16> @shufflevector_v8i16(<8 x i16> %a, <8 x i16> %b) {
+; CHECK-SD-LABEL: shufflevector_v8i16:
+; CHECK-SD: // %bb.0:
+; CHECK-SD-NEXT: adrp x8, .LCPI3_0
+; CHECK-SD-NEXT: // kill: def $q1 killed $q1 killed $q0_q1 def $q0_q1
+; CHECK-SD-NEXT: ldr q2, [x8, :lo12:.LCPI3_0]
+; CHECK-SD-NEXT: // kill: def $q0 killed $q0 killed $q0_q1 def $q0_q1
+; CHECK-SD-NEXT: tbl v0.16b, { v0.16b, v1.16b }, v2.16b
+; CHECK-SD-NEXT: ret
+;
+; CHECK-GI-LABEL: shufflevector_v8i16:
+; CHECK-GI: // %bb.0:
+; CHECK-GI-NEXT: adrp x8, .LCPI3_0
+; CHECK-GI-NEXT: // kill: def $q0 killed $q0 killed $q0_q1 def $q0_q1
+; CHECK-GI-NEXT: ldr q2, [x8, :lo12:.LCPI3_0]
+; CHECK-GI-NEXT: // kill: def $q1 killed $q1 killed $q0_q1 def $q0_q1
+; CHECK-GI-NEXT: tbl v0.16b, { v0.16b, v1.16b }, v2.16b
+; CHECK-GI-NEXT: ret
+ %c = shufflevector <8 x i16> %a, <8 x i16> %b, <8 x i32> <i32 1, i32 3, i32 5, i32 7, i32 8, i32 10, i32 12, i32 15>
+ ret <8 x i16> %c
+}
+
+define <2 x i32> @shufflevector_v2i32(<2 x i32> %a, <2 x i32> %b) {
+; CHECK-LABEL: shufflevector_v2i32:
+; CHECK: // %bb.0:
+; CHECK-NEXT: zip2 v0.2s, v0.2s, v1.2s
+; CHECK-NEXT: ret
+ %c = shufflevector <2 x i32> %a, <2 x i32> %b, <2 x i32> <i32 1, i32 3>
+ ret <2 x i32> %c
+}
+
+define <4 x i32> @shufflevector_v4i32(<4 x i32> %a, <4 x i32> %b) {
+; CHECK-LABEL: shufflevector_v4i32:
+; CHECK: // %bb.0:
+; CHECK-NEXT: uzp2 v0.4s, v0.4s, v1.4s
+; CHECK-NEXT: ret
+ %c = shufflevector <4 x i32> %a, <4 x i32> %b, <4 x i32> <i32 1, i32 3, i32 5, i32 7>
+ ret <4 x i32> %c
+}
+
+define <2 x i64> @shufflevector_v2i64(<2 x i64> %a, <2 x i64> %b) {
+; CHECK-LABEL: shufflevector_v2i64:
+; CHECK: // %bb.0:
+; CHECK-NEXT: zip2 v0.2d, v0.2d, v1.2d
+; CHECK-NEXT: ret
+ %c = shufflevector <2 x i64> %a, <2 x i64> %b, <2 x i32> <i32 1, i32 3>
+ ret <2 x i64> %c
+}
+
+; ===== Legal Vector Types with Zero Masks =====
+
+define <8 x i8> @shufflevector_v8i8_zeroes(<8 x i8> %a, <8 x i8> %b) {
+; CHECK-LABEL: shufflevector_v8i8_zeroes:
+; CHECK: // %bb.0:
+; CHECK-NEXT: // kill: def $d0 killed $d0 def $q0
+; CHECK-NEXT: dup v0.8b, v0.b[0]
+; CHECK-NEXT: ret
+ %c = shufflevector <8 x i8> %a, <8 x i8> %b, <8 x i32> <i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0>
+ ret <8 x i8> %c
+}
+
+define <16 x i8> @shufflevector_v16i8_zeroes(<16 x i8> %a, <16 x i8> %b) {
+; CHECK-LABEL: shufflevector_v16i8_zeroes:
+; CHECK: // %bb.0:
+; CHECK-NEXT: dup v0.16b, v0.b[0]
+; CHECK-NEXT: ret
+ %c = shufflevector <16 x i8> %a, <16 x i8> %b, <16 x i32> <i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0>
+ ret <16 x i8> %c
+}
+
+define <4 x i16> @shufflevector_v4i16_zeroes(<4 x i16> %a, <4 x i16> %b) {
+; CHECK-LABEL: shufflevector_v4i16_zeroes:
+; CHECK: // %bb.0:
+; CHECK-NEXT: // kill: def $d0 killed $d0 def $q0
+; CHECK-NEXT: dup v0.4h, v0.h[0]
+; CHECK-NEXT: ret
+ %c = shufflevector <4 x i16> %a, <4 x i16> %b, <4 x i32> <i32 0, i32 0, i32 0, i32 0>
+ ret <4 x i16> %c
+}
+
+define <8 x i16> @shufflevector_v8i16_zeroes(<8 x i16> %a, <8 x i16> %b) {
+; CHECK-LABEL: shufflevector_v8i16_zeroes:
+; CHECK: // %bb.0:
+; CHECK-NEXT: dup v0.8h, v0.h[0]
+; CHECK-NEXT: ret
+ %c = shufflevector <8 x i16> %a, <8 x i16> %b, <8 x i32> <i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0>
+ ret <8 x i16> %c
+}
+
+define <2 x i32> @shufflevector_v2i32_zeroes(<2 x i32> %a, <2 x i32> %b) {
+; CHECK-LABEL: shufflevector_v2i32_zeroes:
+; CHECK: // %bb.0:
+; CHECK-NEXT: // kill: def $d0 killed $d0 def $q0
+; CHECK-NEXT: dup v0.2s, v0.s[0]
+; CHECK-NEXT: ret
+ %c = shufflevector <2 x i32> %a, <2 x i32> %b, <2 x i32> <i32 0, i32 0>
+ ret <2 x i32> %c
+}
+
+define <4 x i32> @shufflevector_v4i32_zeroes(<4 x i32> %a, <4 x i32> %b) {
+; CHECK-LABEL: shufflevector_v4i32_zeroes:
+; CHECK: // %bb.0:
+; CHECK-NEXT: dup v0.4s, v0.s[0]
+; CHECK-NEXT: ret
+ %c = shufflevector <4 x i32> %a, <4 x i32> %b, <4 x i32> <i32 0, i32 0, i32 0, i32 0>
+ ret <4 x i32> %c
+}
+
+define <2 x i64> @shufflevector_v2i64_zeroes(<2 x i64> %a, <2 x i64> %b) {
+; CHECK-LABEL: shufflevector_v2i64_zeroes:
+; CHECK: // %bb.0:
+; CHECK-NEXT: dup v0.2d, v0.d[0]
+; CHECK-NEXT: ret
+ %c = shufflevector <2 x i64> %a, <2 x i64> %b, <2 x i32> <i32 0, i32 0>
+ ret <2 x i64> %c
+}
+
+; ===== Smaller/Larger Width Vectors with Legal Element Sizes =====
+
+define <2 x i1> @shufflevector_v2i1(<2 x i1> %a, <2 x i1> %b){
+; CHECK-LABEL: shufflevector_v2i1:
+; CHECK: // %bb.0:
+; CHECK-NEXT: // kill: def $d0 killed $d0 def $q0
+; CHECK-NEXT: // kill: def $d1 killed $d1 def $q1
+; CHECK-NEXT: mov v0.s[1], v1.s[1]
+; CHECK-NEXT: // kill: def $d0 killed $d0 killed $q0
+; CHECK-NEXT: ret
+ %c = shufflevector <2 x i1> %a, <2 x i1> %b, <2 x i32> <i32 0, i32 3>
+ ret <2 x i1> %c
+}
+
+define i32 @shufflevector_v4i8(<4 x i8> %a, <4 x i8> %b){
+; CHECK-LABEL: shufflevector_v4i8:
+; CHECK: // %bb.0:
+; CHECK-NEXT: sub sp, sp, #16
+; CHECK-NEXT: .cfi_def_cfa_offset 16
+; CHECK-NEXT: ext v0.8b, v1.8b, v0.8b, #6
+; CHECK-NEXT: zip1 v1.4h, v1.4h, v0.4h
+; CHECK-NEXT: ext v0.8b, v0.8b, v1.8b, #4
+; CHECK-NEXT: xtn v0.8b, v0.8h
+; CHECK-NEXT: fmov w0, s0
+; CHECK-NEXT: add sp, sp, #16
+; CHECK-NEXT: ret
+ %c = shufflevector <4 x i8> %a, <4 x i8> %b, <4 x i32> <i32 1, i32 2, i32 4, i32 7>
+ %d = bitcast <4 x i8> %c to i32
+ ret i32 %d
+}
+
+define <32 x i8> @shufflevector_v32i8(<32 x i8> %a, <32 x i8> %b){
+; CHECK-LABEL: shufflevector_v32i8:
+; CHECK: // %bb.0:
+; CHECK-NEXT: // kill: def $q2 killed $q2 def $q1_q2
+; CHECK-NEXT: adrp x8, .LCPI16_0
+; CHECK-NEXT: adrp x9, .LCPI16_1
+; CHECK-NEXT: mov v1.16b, v0.16b
+; CHECK-NEXT: ldr q3, [x8, :lo12:.LCPI16_0]
+; CHECK-NEXT: ldr q4, [x9, :lo12:.LCPI16_1]
+; CHECK-NEXT: tbl v0.16b, { v1.16b, v2.16b }, v3.16b
+; CHECK-NEXT: tbl v1.16b, { v1.16b, v2.16b }, v4.16b
+; CHECK-NEXT: ret
+ %c = shufflevector <32 x i8> %a, <32 x i8> %b, <32 x i32> <i32 0, i32 32, i32 32, i32 32, i32 1, i32 32, i32 32, i32 32, i32 2, i32 32, i32 32, i32 32, i32 3, i32 32, i32 32, i32 32, i32 4, i32 32, i32 32, i32 32, i32 5, i32 32, i32 32, i32 32, i32 6, i32 32, i32 32, i32 32, i32 7, i32 32, i32 32, i32 32>
+ ret <32 x i8> %c
+}
+
+define i32 @shufflevector_v2i16(<2 x i16> %a, <2 x i16> %b){
+; CHECK-LABEL: shufflevector_v2i16:
+; CHECK: // %bb.0:
+; CHECK-NEXT: sub sp, sp, #16
+; CHECK-NEXT: .cfi_def_cfa_offset 16
+; CHECK-NEXT: ext v0.8b, v0.8b, v1.8b, #4
+; CHECK-NEXT: mov w8, v0.s[1]
+; CHECK-NEXT: fmov w9, s0
+; CHECK-NEXT: strh w9, [sp, #12]
+; CHECK-NEXT: strh w8, [sp, #14]
+; CHECK-NEXT: ldr w0, [sp, #12]
+; CHECK-NEXT: add sp, sp, #16
+; CHECK-NEXT: ret
+ %c = shufflevector <2 x i16> %a, <2 x i16> %b, <2 x i32> <i32 1, i32 2>
+ %d = bitcast <2 x i16> %c to i32
+ ret i32 %d
+}
+
+define <16 x i16> @shufflevector_v16i16(<16 x i16> %a, <16 x i16> %b){
+; CHECK-LABEL: shufflevector_v16i16:
+; CHECK: // %bb.0:
+; CHECK-NEXT: // kill: def $q2 killed $q2 def $q1_q2
+; CHECK-NEXT: adrp x8, .LCPI18_0
+; CHECK-NEXT: adrp x9, .LCPI18_1
+; CHECK-NEXT: mov v1.16b, v0.16b
+; CHECK-NEXT: ldr q3, [x8, :lo12:.LCPI18_0]
+; CHECK-NEXT: ldr q4, [x9, :lo12:.LCPI18_1]
+; CHECK-NEXT: tbl v0.16b, { v1.16b, v2.16b }, v3.16b
+; CHECK-NEXT: tbl v1.16b, { v1.16b, v2.16b }, v4.16b
+; CHECK-NEXT: ret
+ %c = shufflevector <16 x i16> %a, <16 x i16> %b, <16 x i32> <i32 0, i32 16, i32 16, i32 16, i32 1, i32 16, i32 16, i32 16, i32 1, i32 16, i32 16, i32 16, i32 3, i32 16, i32 16, i32 16>
+ ret <16 x i16> %c
+}
+
+define <1 x i32> @shufflevector_v1i32(<1 x i32> %a, <1 x i32> %b) {
+; CHECK-LABEL: shufflevector_v1i32:
+; CHECK: // %bb.0:
+; CHECK-NEXT: fmov d0, d1
+; CHECK-NEXT: ret
+ %c = shufflevector <1 x i32> %a, <1 x i32> %b, <1 x i32> <i32 1>
+ ret <1 x i32> %c
+}
+
+define <8 x i32> @shufflevector_v8i32(<8 x i32> %a, <8 x i32> %b) {
+; CHECK-SD-LABEL: shufflevector_v8i32:
+; CHECK-SD: // %bb.0:
+; CHECK-SD-NEXT: uzp1 v2.4s, v2.4s, v3.4s
+; CHECK-SD-NEXT: uzp2 v0.4s, v0.4s, v1.4s
+; CHECK-SD-NEXT: mov v2.s[3], v3.s[3]
+; CHECK-SD-NEXT: mov v1.16b, v2.16b
+; CHECK-SD-NEXT: ret
+;
+; CHECK-GI-LABEL: shufflevector_v8i32:
+; CHECK-GI: // %bb.0:
+; CHECK-GI-NEXT: adrp x8, .LCPI20_0
+; CHECK-GI-NEXT: // kill: def $q2 killed $q2 killed $q2_q3 def $q2_q3
+; CHECK-GI-NEXT: uzp2 v0.4s, v0.4s, v1.4s
+; CHECK-GI-NEXT: ldr q4, [x8, :lo12:.LCPI20_0]
+; CHECK-GI-NEXT: // kill: def $q3 killed $q3 killed $q2_q3 def $q2_q3
+; CHECK-GI-NEXT: tbl v1.16b, { v2.16b, v3.16b }, v4.16b
+; CHECK-GI-NEXT: ret
+ %c = shufflevector <8 x i32> %a, <8 x i32> %b, <8 x i32> <i32 1, i32 3, i32 5, i32 7, i32 8, i32 10, i32 12, i32 15>
+ ret <8 x i32> %c
+}
+
+define <4 x i64> @shufflevector_v4i64(<4 x i64> %a, <4 x i64> %b) {
+; CHECK-SD-LABEL: shufflevector_v4i64:
+; CHECK-SD: // %bb.0:
+; CHECK-SD-NEXT: zip2 v2.2d, v2.2d, v3.2d
+; CHECK-SD-NEXT: zip2 v0.2d, v0.2d, v1.2d
+; CHECK-SD-NEXT: mov v1.16b, v2.16b
+; CHECK-SD-NEXT: ret
+;
+; CHECK-GI-LABEL: shufflevector_v4i64:
+; CHECK-GI: // %bb.0:
+; CHECK-GI-NEXT: zip2 v0.2d, v0.2d, v1.2d
+; CHECK-GI-NEXT: zip2 v1.2d, v2.2d, v3.2d
+; CHECK-GI-NEXT: ret
+ %c = shufflevector <4 x i64> %a, <4 x i64> %b, <4 x i32> <i32 1, i32 3, i32 5, i32 7>
+ ret <4 x i64> %c
+}
+
+; ===== Smaller/Larger Width Vectors with Zero Masks =====
+
+define <2 x i1> @shufflevector_v2i1_zeroes(<2 x i1> %a, <2 x i1> %b){
+; CHECK-LABEL: shufflevector_v2i1_zeroes:
+; CHECK: // %bb.0:
+; CHECK-NEXT: // kill: def $d0 killed $d0 def $q0
+; CHECK-NEXT: dup v0.2s, v0.s[0]
+; CHECK-NEXT: ret
+ %c = shufflevector <2 x i1> %a, <2 x i1> %b, <2 x i32> <i32 0, i32 0>
+ ret <2 x i1> %c
+}
+
+define i32 @shufflevector_v4i8_zeroes(<4 x i8> %a, <4 x i8> %b){
+; CHECK-LABEL: shufflevector_v4i8_zeroes:
+; CHECK: // %bb.0:
+; CHECK-NEXT: sub sp, sp, #16
+; CHECK-NEXT: .cfi_def_cfa_offset 16
+; CHECK-NEXT: // kill: def $d0 killed $d0 def $q0
+; CHECK-NEXT: dup v0.4h, v0.h[0]
+; CHECK-NEXT: xtn v0.8b, v0.8h
+; CHECK-NEXT: fmov w0, s0
+; CHECK-NEXT: add sp, sp, #16
+; CHECK-NEXT: ret
+ %c = shufflevector <4 x i8> %a, <4 x i8> %b, <4 x i32> <i32 0, i32 0, i32 0, i32 0>
+ %d = bitcast <4 x i8> %c to i32
+ ret i32 %d
+}
+
+define <32 x i8> @shufflevector_v32i8_zeroes(<32 x i8> %a, <32 x i8> %b){
+; CHECK-LABEL: shufflevector_v32i8_zeroes:
+; CHECK: // %bb.0:
+; CHECK-NEXT: dup v0.16b, v0.b[0]
+; CHECK-NEXT: mov v1.16b, v0.16b
+; CHECK-NEXT: ret
+ %c = shufflevector <32 x i8> %a, <32 x i8> %b, <32 x i32> <i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0>
+ ret <32 x i8> %c
+}
+
+define i32 @shufflevector_v2i16_zeroes(<2 x i16> %a, <2 x i16> %b){
+; CHECK-LABEL: shufflevector_v2i16_zeroes:
+; CHECK: // %bb.0:
+; CHECK-NEXT: sub sp, sp, #16
+; CHECK-NEXT: .cfi_def_cfa_offset 16
+; CHECK-NEXT: // kill: def $d0 killed $d0 def $q0
+; CHECK-NEXT: dup v1.2s, v0.s[0]
+; CHECK-NEXT: fmov w9, s0
+; CHECK-NEXT: strh w9, [sp, #12]
+; CHECK-NEXT: mov w8, v1.s[1]
+; CHECK-NEXT: strh w8, [sp, #14]
+; CHECK-NEXT: ldr w0, [sp, #12]
+; CHECK-NEXT: add sp, sp, #16
+; CHECK-NEXT: ret
+ %c = shufflevector <2 x i16> %a, <2 x i16> %b, <2 x i32> <i32 0, i32 0>
+ %d = bitcast <2 x i16> %c to i32
+ ret i32 %d
+}
+
+define <16 x i16> @shufflevector_v16i16_zeroes(<16 x i16> %a, <16 x i16> %b){
+; CHECK-LABEL: shufflevector_v16i16_zeroes:
+; CHECK: // %bb.0:
+; CHECK-NEXT: dup v0.8h, v0.h[0]
+; CHECK-NEXT: mov v1.16b, v0.16b
+; CHECK-NEXT: ret
+ %c = shufflevector <16 x i16> %a, <16 x i16> %b, <16 x i32> <i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0>
+ ret <16 x i16> %c
+}
+
+define <1 x i32> @shufflevector_v1i32_zeroes(<1 x i32> %a, <1 x i32> %b) {
+; CHECK-LABEL: shufflevector_v1i32_zeroes:
+; CHECK: // %bb.0:
+; CHECK-NEXT: ret
+ %c = shufflevector <1 x i32> %a, <1 x i32> %b, <1 x i32> <i32 0>
+ ret <1 x i32> %c
+}
+
+define <8 x i32> @shufflevector_v8i32_zeroes(<8 x i32> %a, <8 x i32> %b) {
+; CHECK-LABEL: shufflevector_v8i32_zeroes:
+; CHECK: // %bb.0:
+; CHECK-NEXT: dup v0.4s, v0.s[0]
+; CHECK-NEXT: mov v1.16b, v0.16b
+; CHECK-NEXT: ret
+ %c = shufflevector <8 x i32> %a, <8 x i32> %b, <8 x i32> <i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0>
+ ret <8 x i32> %c
+}
+
+define <4 x i64> @shufflevector_v4i64_zeroes(<4 x i64> %a, <4 x i64> %b) {
+; CHECK-LABEL: shufflevector_v4i64_zeroes:
+; CHECK: // %bb.0:
+; CHECK-NEXT: dup v0.2d, v0.d[0]
+; CHECK-NEXT: mov v1.16b, v0.16b
+; CHECK-NEXT: ret
+ %c = shufflevector <4 x i64> %a, <4 x i64> %b, <4 x i32> <i32 0, i32 0, i32 0, i32 0>
+ ret <4 x i64> %c
+}
+
+; ===== Vectors with Non-Pow 2 Widths =====
+
+define <3 x i8> @shufflevector_v3i8(<3 x i8> %a, <3 x i8> %b) {
+; CHECK-LABEL: shufflevector_v3i8:
+; CHECK: // %bb.0:
+; CHECK-NEXT: mov w0, w1
+; CHECK-NEXT: mov w1, w2
+; CHECK-NEXT: mov w2, w4
+; CHECK-NEXT: ret
+ %c = shufflevector <3 x i8> %a, <3 x i8> %b, <3 x i32> <i32 1, i32 2, i32 4>
+ ret <3 x i8> %c
+}
+
+define <7 x i8> @shufflevector_v7i8(<7 x i8> %a, <7 x i8> %b) {
+; CHECK-SD-LABEL: shufflevector_v7i8:
+; CHECK-SD: // %bb.0:
+; CHECK-SD-NEXT: // kill: def $d0 killed $d0 def $q0
+; CHECK-SD-NEXT: // kill: def $d1 killed $d1 def $q1
+; CHECK-SD-NEXT: adrp x8, .LCPI31_0
+; CHECK-SD-NEXT: mov v0.d[1], v1.d[0]
+; CHECK-SD-NEXT: ldr d1, [x8, :lo12:.LCPI31_0]
+; CHECK-SD-NEXT: tbl v0.8b, { v0.16b }, v1.8b
+; CHECK-SD-NEXT: ret
+;
+; CHECK-GI-LABEL: shufflevector_v7i8:
+; CHECK-GI: // %bb.0:
+; CHECK-GI-NEXT: // kill: def $d0 killed $d0 def $q0
+; CHECK-GI-NEXT: // kill: def $d1 killed $d1 def $q1
+; CHECK-GI-NEXT: adrp x8, .LCPI31_0
+; CHECK-GI-NEXT: mov v0.d[1], v1.d[0]
+; CHECK-GI-NEXT: ldr d1, [x8, :lo12:.LCPI31_0]
+; CHECK-GI-NEXT: tbl v0.16b, { v0.16b }, v1.16b
+; CHECK-GI-NEXT: // kill: def $d0 killed $d0 killed $q0
+; CHECK-GI-NEXT: ret
+ %c = shufflevector <7 x i8> %a, <7 x i8> %b, <7 x i32> <i32 1, i32 3, i32 5, i32 7, i32 8, i32 10, i32 12>
+ ret <7 x i8> %c
+}
+
+define <3 x i16> @shufflevector_v3i16(<3 x i16> %a, <3 x i16> %b) {
+; CHECK-SD-LABEL: shufflevector_v3i16:
+; CHECK-SD: // %bb.0:
+; CHECK-SD-NEXT: zip1 v1.4h, v0.4h, v1.4h
+; CHECK-SD-NEXT: zip2 v0.4h, v1.4h, v0.4h
+; CHECK-SD-NEXT: ret
+;
+; CHECK-GI-LABEL: shufflevector_v3i16:
+; CHECK-GI: // %bb.0:
+; CHECK-GI-NEXT: // kill: def $d0 killed $d0 def $q0
+; CHECK-GI-NEXT: // kill: def $d1 killed $d1 def $q1
+; CHECK-GI-NEXT: adrp x8, .LCPI32_0
+; CHECK-GI-NEXT: mov v0.d[1], v1.d[0]
+; CHECK-GI-NEXT: ldr d1, [x8, :lo12:.LCPI32_0]
+; CHECK-GI-NEXT: tbl v0.16b, { v0.16b }, v1.16b
+; CHECK-GI-NEXT: // kill: def $d0 killed $d0 killed $q0
+; CHECK-GI-NEXT: ret
+ %c = shufflevector <3 x i16> %a, <3 x i16> %b, <3 x i32> <i32 1, i32 2, i32 4>
+ ret <3 x i16> %c
+}
+
+define <7 x i16> @shufflevector_v7i16(<7 x i16> %a, <7 x i16> %b) {
+; CHECK-SD-LABEL: shufflevector_v7i16:
+; CHECK-SD: // %bb.0:
+; CHECK-SD-NEXT: adrp x8, .LCPI33_0
+; CHECK-SD-NEXT: // kill: def $q1 killed $q1 killed $q0_q1 def $q0_q1
+; CHECK-SD-NEXT: ldr q2, [x8, :lo12:.LCPI33_0]
+; CHECK-SD-NEXT: // kill: def $q0 killed $q0 killed $q0_q1 def $q0_q1
+; CHECK-SD-NEXT: tbl v0.16b, { v0.16b, v1.16b }, v2.16b
+; CHECK-SD-NEXT: ret
+;
+; CHECK-GI-LABEL: shufflevector_v7i16:
+; CHECK-GI: // %bb.0:
+; CHECK-GI-NEXT: adrp x8, .LCPI33_0
+; CHECK-GI-NEXT: // kill: def $q0 killed $q0 killed $q0_q1 def $q0_q1
+; CHECK-GI-NEXT: ldr q2, [x8, :lo12:.LCPI33_0]
+; CHECK-GI-NEXT: // kill: def $q1 killed $q1 killed $q0_q1 def $q0_q1
+; CHECK-GI-NEXT: tbl v0.16b, { v0.16b, v1.16b }, v2.16b
+; CHECK-GI-NEXT: ret
+ %c = shufflevector <7 x i16> %a, <7 x i16> %b, <7 x i32> <i32 1, i32 3, i32 5, i32 7, i32 8, i32 10, i32 12>
+ ret <7 x i16> %c
+}
+
+define <3 x i32> @shufflevector_v3i32(<3 x i32> %a, <3 x i32> %b) {
+; CHECK-SD-LABEL: shufflevector_v3i32:
+; CHECK-SD: // %bb.0:
+; CHECK-SD-NEXT: zip1 v1.4s, v0.4s, v1.4s
+; CHECK-SD-NEXT: zip2 v0.4s, v1.4s, v0.4s
+; CHECK-SD-NEXT: ret
+;
+; CHECK-GI-LABEL: shufflevector_v3i32:
+; CHECK-GI: // %bb.0:
+; CHECK-GI-NEXT: adrp x8, .LCPI34_0
+; CHECK-GI-NEXT: // kill: def $q0 killed $q0 killed $q0_q1 def $q0_q1
+; CHECK-GI-NEXT: ldr q2, [x8, :lo12:.LCPI34_0]
+; CHECK-GI-NEXT: // kill: def $q1 killed $q1 killed $q0_q1 def $q0_q1
+; CHECK-GI-NEXT: tbl v0.16b, { v0.16b, v1.16b }, v2.16b
+; CHECK-GI-NEXT: ret
+ %c = shufflevector <3 x i32> %a, <3 x i32> %b, <3 x i32> <i32 1, i32 2, i32 4>
+ ret <3 x i32> %c
+}
+
+; ===== Vectors with Non-Pow 2 Widths with Zero Masks =====
+
+define <3 x i8> @shufflevector_v3i8_zeroes(<3 x i8> %a, <3 x i8> %b) {
+; CHECK-LABEL: shufflevector_v3i8_zeroes:
+; CHECK: // %bb.0:
+; CHECK-NEXT: mov w1, w0
+; CHECK-NEXT: mov w2, w0
+; CHECK-NEXT: ret
+ %c = shufflevector <3 x i8> %a, <3 x i8> %b, <3 x i32> <i32 0, i32 0, i32 0>
+ ret <3 x i8> %c
+}
+
+define <7 x i8> @shufflevector_v7i8_zeroes(<7 x i8> %a, <7 x i8> %b) {
+; CHECK-LABEL: shufflevector_v7i8_zeroes:
+; CHECK: // %bb.0:
+; CHECK-NEXT: // kill: def $d0 killed $d0 def $q0
+; CHECK-NEXT: dup v0.8b, v0.b[0]
+; CHECK-NEXT: ret
+ %c = shufflevector <7 x i8> %a, <7 x i8> %b, <7 x i32> <i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0>
+ ret <7 x i8> %c
+}
+
+define <3 x i16> @shufflevector_v3i16_zeroes(<3 x i16> %a, <3 x i16> %b) {
+; CHECK-LABEL: shufflevector_v3i16_zeroes:
+; CHECK: // %bb.0:
+; CHECK-NEXT: // kill: def $d0 killed $d0 def $q0
+; CHECK-NEXT: dup v0.4h, v0.h[0]
+; CHECK-NEXT: ret
+ %c = shufflevector <3 x i16> %a, <3 x i16> %b, <3 x i32> <i32 0, i32 0, i32 0>
+ ret <3 x i16> %c
+}
+
+define <7 x i16> @shufflevector_v7i16_zeroes(<7 x i16> %a, <7 x i16> %b) {
+; CHECK-LABEL: shufflevector_v7i16_zeroes:
+; CHECK: // %bb.0:
+; CHECK-NEXT: dup v0.8h, v0.h[0]
+; CHECK-NEXT: ret
+ %c = shufflevector <7 x i16> %a, <7 x i16> %b, <7 x i32> <i32 0, i32 0, i32 0, i32 0, i32 0, i32 0, i32 0>
+ ret <7 x i16> %c
+}
+
+define <3 x i32> @shufflevector_v3i32_zeroes(<3 x i32> %a, <3 x i32> %b) {
+; CHECK-LABEL: shufflevector_v3i32_zeroes:
+; CHECK: // %bb.0:
+; CHECK-NEXT: dup v0.4s, v0.s[0]
+; CHECK-NEXT: ret
+ %c = shufflevector <3 x i32> %a, <3 x i32> %b, <3 x i32> <i32 0, i32 0, i32 0>
+ ret <3 x i32> %c
+}
>From 80a328b0118faa691137d6325b0eed4199060adc Mon Sep 17 00:00:00 2001
From: Simon Pilgrim <llvm-dev at redking.me.uk>
Date: Thu, 29 Feb 2024 15:05:46 +0000
Subject: [PATCH 139/406] [X86] SimplifyDemandedVectorEltsForTargetNode - add
basic PCMPEQ/PCMPGT handling
---
llvm/lib/Target/X86/X86ISelLowering.cpp | 14 ++++++++++
.../CodeGen/X86/horizontal-reduce-umax.ll | 2 +-
.../CodeGen/X86/horizontal-reduce-umin.ll | 2 +-
.../CodeGen/X86/srem-seteq-illegal-types.ll | 12 ++++++---
llvm/test/CodeGen/X86/test-shrink-bug.ll | 2 +-
.../CodeGen/X86/urem-seteq-vec-nonzero.ll | 1 -
.../X86/urem-seteq-vec-tautological.ll | 24 ++++++-----------
llvm/test/CodeGen/X86/vector-reduce-umax.ll | 2 +-
llvm/test/CodeGen/X86/vector-reduce-umin.ll | 2 +-
llvm/test/CodeGen/X86/vselect.ll | 26 +++++++++++++------
10 files changed, 53 insertions(+), 34 deletions(-)
diff --git a/llvm/lib/Target/X86/X86ISelLowering.cpp b/llvm/lib/Target/X86/X86ISelLowering.cpp
index d98d914894a3f8..b807a97d6e4851 100644
--- a/llvm/lib/Target/X86/X86ISelLowering.cpp
+++ b/llvm/lib/Target/X86/X86ISelLowering.cpp
@@ -41262,6 +41262,20 @@ bool X86TargetLowering::SimplifyDemandedVectorEltsForTargetNode(
KnownZero = LHSZero;
break;
}
+ case X86ISD::PCMPEQ:
+ case X86ISD::PCMPGT: {
+ APInt LHSUndef, LHSZero;
+ APInt RHSUndef, RHSZero;
+ SDValue LHS = Op.getOperand(0);
+ SDValue RHS = Op.getOperand(1);
+ if (SimplifyDemandedVectorElts(LHS, DemandedElts, LHSUndef, LHSZero, TLO,
+ Depth + 1))
+ return true;
+ if (SimplifyDemandedVectorElts(RHS, DemandedElts, RHSUndef, RHSZero, TLO,
+ Depth + 1))
+ return true;
+ break;
+ }
case X86ISD::KSHIFTL: {
SDValue Src = Op.getOperand(0);
auto *Amt = cast<ConstantSDNode>(Op.getOperand(1));
diff --git a/llvm/test/CodeGen/X86/horizontal-reduce-umax.ll b/llvm/test/CodeGen/X86/horizontal-reduce-umax.ll
index 5fde9bd5566b40..9946267b48e7ff 100644
--- a/llvm/test/CodeGen/X86/horizontal-reduce-umax.ll
+++ b/llvm/test/CodeGen/X86/horizontal-reduce-umax.ll
@@ -635,7 +635,7 @@ define i64 @test_reduce_v4i64(<4 x i64> %a0) {
; X64-AVX2-LABEL: test_reduce_v4i64:
; X64-AVX2: ## %bb.0:
; X64-AVX2-NEXT: vextracti128 $1, %ymm0, %xmm1
-; X64-AVX2-NEXT: vpbroadcastq {{.*#+}} ymm2 = [9223372036854775808,9223372036854775808,9223372036854775808,9223372036854775808]
+; X64-AVX2-NEXT: vpbroadcastq {{.*#+}} xmm2 = [9223372036854775808,9223372036854775808]
; X64-AVX2-NEXT: vpxor %xmm2, %xmm1, %xmm3
; X64-AVX2-NEXT: vpxor %xmm2, %xmm0, %xmm4
; X64-AVX2-NEXT: vpcmpgtq %xmm3, %xmm4, %xmm3
diff --git a/llvm/test/CodeGen/X86/horizontal-reduce-umin.ll b/llvm/test/CodeGen/X86/horizontal-reduce-umin.ll
index 699dce75e505c7..0bbf94f1817f51 100644
--- a/llvm/test/CodeGen/X86/horizontal-reduce-umin.ll
+++ b/llvm/test/CodeGen/X86/horizontal-reduce-umin.ll
@@ -581,7 +581,7 @@ define i64 @test_reduce_v4i64(<4 x i64> %a0) {
; X64-AVX2-LABEL: test_reduce_v4i64:
; X64-AVX2: ## %bb.0:
; X64-AVX2-NEXT: vextracti128 $1, %ymm0, %xmm1
-; X64-AVX2-NEXT: vpbroadcastq {{.*#+}} ymm2 = [9223372036854775808,9223372036854775808,9223372036854775808,9223372036854775808]
+; X64-AVX2-NEXT: vpbroadcastq {{.*#+}} xmm2 = [9223372036854775808,9223372036854775808]
; X64-AVX2-NEXT: vpxor %xmm2, %xmm0, %xmm3
; X64-AVX2-NEXT: vpxor %xmm2, %xmm1, %xmm4
; X64-AVX2-NEXT: vpcmpgtq %xmm3, %xmm4, %xmm3
diff --git a/llvm/test/CodeGen/X86/srem-seteq-illegal-types.ll b/llvm/test/CodeGen/X86/srem-seteq-illegal-types.ll
index fdb2f41ec0e498..d644ed87c3c108 100644
--- a/llvm/test/CodeGen/X86/srem-seteq-illegal-types.ll
+++ b/llvm/test/CodeGen/X86/srem-seteq-illegal-types.ll
@@ -267,11 +267,13 @@ define <3 x i1> @test_srem_vec(<3 x i33> %X) nounwind {
; SSE41-NEXT: pcmpeqq {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpeqd %xmm1, %xmm1
; SSE41-NEXT: pxor %xmm1, %xmm0
-; SSE41-NEXT: pcmpeqq {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm2
-; SSE41-NEXT: pxor %xmm1, %xmm2
+; SSE41-NEXT: movl $3, %eax
+; SSE41-NEXT: movq %rax, %xmm3
+; SSE41-NEXT: pcmpeqq %xmm2, %xmm3
+; SSE41-NEXT: pxor %xmm1, %xmm3
; SSE41-NEXT: movd %xmm0, %eax
; SSE41-NEXT: pextrb $8, %xmm0, %edx
-; SSE41-NEXT: pextrb $0, %xmm2, %ecx
+; SSE41-NEXT: pextrb $0, %xmm3, %ecx
; SSE41-NEXT: # kill: def $al killed $al killed $eax
; SSE41-NEXT: # kill: def $dl killed $dl killed $edx
; SSE41-NEXT: # kill: def $cl killed $cl killed $ecx
@@ -318,7 +320,9 @@ define <3 x i1> @test_srem_vec(<3 x i33> %X) nounwind {
; AVX1-NEXT: vinsertf128 $1, %xmm1, %ymm0, %ymm0
; AVX1-NEXT: vandps {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %ymm0, %ymm0
; AVX1-NEXT: vextractf128 $1, %ymm0, %xmm1
-; AVX1-NEXT: vpcmpeqq {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1, %xmm1
+; AVX1-NEXT: movl $3, %eax
+; AVX1-NEXT: vmovq %rax, %xmm2
+; AVX1-NEXT: vpcmpeqq %xmm2, %xmm1, %xmm1
; AVX1-NEXT: vpcmpeqq {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0, %xmm0
; AVX1-NEXT: vpackssdw %xmm1, %xmm0, %xmm0
; AVX1-NEXT: vpcmpeqd %xmm1, %xmm1, %xmm1
diff --git a/llvm/test/CodeGen/X86/test-shrink-bug.ll b/llvm/test/CodeGen/X86/test-shrink-bug.ll
index 74c5179b187896..ed43cabbdaee11 100644
--- a/llvm/test/CodeGen/X86/test-shrink-bug.ll
+++ b/llvm/test/CodeGen/X86/test-shrink-bug.ll
@@ -67,7 +67,7 @@ define dso_local void @fail(i16 %a, <2 x i8> %b) {
; CHECK-X64-NEXT: testl $263, %edi # imm = 0x107
; CHECK-X64-NEXT: je .LBB1_3
; CHECK-X64-NEXT: # %bb.1:
-; CHECK-X64-NEXT: punpcklbw {{.*#+}} xmm0 = xmm0[0,0,1,1,2,2,3,3,4,4,5,5,6,6,7,7]
+; CHECK-X64-NEXT: pslld $8, %xmm0
; CHECK-X64-NEXT: pcmpeqb {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; CHECK-X64-NEXT: pextrw $1, %xmm0, %eax
; CHECK-X64-NEXT: testb $1, %al
diff --git a/llvm/test/CodeGen/X86/urem-seteq-vec-nonzero.ll b/llvm/test/CodeGen/X86/urem-seteq-vec-nonzero.ll
index a15de8b8e0f6ad..6a36cd2a86d5cd 100644
--- a/llvm/test/CodeGen/X86/urem-seteq-vec-nonzero.ll
+++ b/llvm/test/CodeGen/X86/urem-seteq-vec-nonzero.ll
@@ -264,7 +264,6 @@ define <4 x i1> @t32_tautological(<4 x i32> %X) nounwind {
; CHECK-SSE2-NEXT: movdqa {{.*#+}} xmm1 = [2863311531,2863311531,2863311531,2863311531]
; CHECK-SSE2-NEXT: pshufd {{.*#+}} xmm2 = xmm0[1,1,3,3]
; CHECK-SSE2-NEXT: pmuludq %xmm1, %xmm0
-; CHECK-SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,2,2,3]
; CHECK-SSE2-NEXT: pmuludq %xmm1, %xmm2
; CHECK-SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm2[0,2,2,3]
; CHECK-SSE2-NEXT: punpckldq {{.*#+}} xmm0 = xmm0[0],xmm1[0],xmm0[1],xmm1[1]
diff --git a/llvm/test/CodeGen/X86/urem-seteq-vec-tautological.ll b/llvm/test/CodeGen/X86/urem-seteq-vec-tautological.ll
index 6d99bedd40b91c..cdeca96732dc31 100644
--- a/llvm/test/CodeGen/X86/urem-seteq-vec-tautological.ll
+++ b/llvm/test/CodeGen/X86/urem-seteq-vec-tautological.ll
@@ -25,13 +25,7 @@ define <4 x i1> @t0_all_tautological(<4 x i32> %X) nounwind {
define <4 x i1> @t1_all_odd_eq(<4 x i32> %X) nounwind {
; CHECK-SSE2-LABEL: t1_all_odd_eq:
; CHECK-SSE2: # %bb.0:
-; CHECK-SSE2-NEXT: movdqa {{.*#+}} xmm1 = [2863311531,2863311531,2863311531,2863311531]
-; CHECK-SSE2-NEXT: pshufd {{.*#+}} xmm2 = xmm0[1,1,3,3]
-; CHECK-SSE2-NEXT: pmuludq %xmm1, %xmm0
-; CHECK-SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,2,2,3]
-; CHECK-SSE2-NEXT: pmuludq %xmm1, %xmm2
-; CHECK-SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm2[0,2,2,3]
-; CHECK-SSE2-NEXT: punpckldq {{.*#+}} xmm0 = xmm0[0],xmm1[0],xmm0[1],xmm1[1]
+; CHECK-SSE2-NEXT: pmuludq {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; CHECK-SSE2-NEXT: pxor {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; CHECK-SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; CHECK-SSE2-NEXT: pandn {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
@@ -82,13 +76,7 @@ define <4 x i1> @t1_all_odd_eq(<4 x i32> %X) nounwind {
define <4 x i1> @t1_all_odd_ne(<4 x i32> %X) nounwind {
; CHECK-SSE2-LABEL: t1_all_odd_ne:
; CHECK-SSE2: # %bb.0:
-; CHECK-SSE2-NEXT: movdqa {{.*#+}} xmm1 = [2863311531,2863311531,2863311531,2863311531]
-; CHECK-SSE2-NEXT: pshufd {{.*#+}} xmm2 = xmm0[1,1,3,3]
-; CHECK-SSE2-NEXT: pmuludq %xmm1, %xmm0
-; CHECK-SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,2,2,3]
-; CHECK-SSE2-NEXT: pmuludq %xmm1, %xmm2
-; CHECK-SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm2[0,2,2,3]
-; CHECK-SSE2-NEXT: punpckldq {{.*#+}} xmm0 = xmm0[0],xmm1[0],xmm0[1],xmm1[1]
+; CHECK-SSE2-NEXT: pmuludq {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; CHECK-SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,2,2,3]
; CHECK-SSE2-NEXT: pxor {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; CHECK-SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
@@ -256,7 +244,9 @@ define <2 x i1> @t3_wide(<2 x i64> %X) nounwind {
; CHECK-AVX1-NEXT: vpsllq $32, %xmm0, %xmm0
; CHECK-AVX1-NEXT: vpaddq %xmm0, %xmm2, %xmm0
; CHECK-AVX1-NEXT: vpxor {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0, %xmm0
-; CHECK-AVX1-NEXT: vpcmpgtq {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0, %xmm0
+; CHECK-AVX1-NEXT: movabsq $-3074457345618258603, %rax # imm = 0xD555555555555555
+; CHECK-AVX1-NEXT: vmovq %rax, %xmm1
+; CHECK-AVX1-NEXT: vpcmpgtq %xmm1, %xmm0, %xmm0
; CHECK-AVX1-NEXT: vpcmpeqd %xmm1, %xmm1, %xmm1
; CHECK-AVX1-NEXT: vpxor %xmm1, %xmm0, %xmm0
; CHECK-AVX1-NEXT: vmovq {{.*#+}} xmm0 = xmm0[0],zero
@@ -273,7 +263,9 @@ define <2 x i1> @t3_wide(<2 x i64> %X) nounwind {
; CHECK-AVX2-NEXT: vpsllq $32, %xmm0, %xmm0
; CHECK-AVX2-NEXT: vpaddq %xmm0, %xmm2, %xmm0
; CHECK-AVX2-NEXT: vpxor {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0, %xmm0
-; CHECK-AVX2-NEXT: vpcmpgtq {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0, %xmm0
+; CHECK-AVX2-NEXT: movabsq $-3074457345618258603, %rax # imm = 0xD555555555555555
+; CHECK-AVX2-NEXT: vmovq %rax, %xmm1
+; CHECK-AVX2-NEXT: vpcmpgtq %xmm1, %xmm0, %xmm0
; CHECK-AVX2-NEXT: vpcmpeqd %xmm1, %xmm1, %xmm1
; CHECK-AVX2-NEXT: vpxor %xmm1, %xmm0, %xmm0
; CHECK-AVX2-NEXT: vmovq {{.*#+}} xmm0 = xmm0[0],zero
diff --git a/llvm/test/CodeGen/X86/vector-reduce-umax.ll b/llvm/test/CodeGen/X86/vector-reduce-umax.ll
index 4799b8e7e5857b..3b25a6e033f2fd 100644
--- a/llvm/test/CodeGen/X86/vector-reduce-umax.ll
+++ b/llvm/test/CodeGen/X86/vector-reduce-umax.ll
@@ -210,7 +210,7 @@ define i64 @test_v4i64(<4 x i64> %a0) {
; AVX2-LABEL: test_v4i64:
; AVX2: # %bb.0:
; AVX2-NEXT: vextracti128 $1, %ymm0, %xmm1
-; AVX2-NEXT: vpbroadcastq {{.*#+}} ymm2 = [9223372036854775808,9223372036854775808,9223372036854775808,9223372036854775808]
+; AVX2-NEXT: vpbroadcastq {{.*#+}} xmm2 = [9223372036854775808,9223372036854775808]
; AVX2-NEXT: vpxor %xmm2, %xmm1, %xmm3
; AVX2-NEXT: vpxor %xmm2, %xmm0, %xmm4
; AVX2-NEXT: vpcmpgtq %xmm3, %xmm4, %xmm3
diff --git a/llvm/test/CodeGen/X86/vector-reduce-umin.ll b/llvm/test/CodeGen/X86/vector-reduce-umin.ll
index 75eeec456c9ac3..2d68cf9d6374d7 100644
--- a/llvm/test/CodeGen/X86/vector-reduce-umin.ll
+++ b/llvm/test/CodeGen/X86/vector-reduce-umin.ll
@@ -211,7 +211,7 @@ define i64 @test_v4i64(<4 x i64> %a0) {
; AVX2-LABEL: test_v4i64:
; AVX2: # %bb.0:
; AVX2-NEXT: vextracti128 $1, %ymm0, %xmm1
-; AVX2-NEXT: vpbroadcastq {{.*#+}} ymm2 = [9223372036854775808,9223372036854775808,9223372036854775808,9223372036854775808]
+; AVX2-NEXT: vpbroadcastq {{.*#+}} xmm2 = [9223372036854775808,9223372036854775808]
; AVX2-NEXT: vpxor %xmm2, %xmm0, %xmm3
; AVX2-NEXT: vpxor %xmm2, %xmm1, %xmm4
; AVX2-NEXT: vpcmpgtq %xmm3, %xmm4, %xmm3
diff --git a/llvm/test/CodeGen/X86/vselect.ll b/llvm/test/CodeGen/X86/vselect.ll
index ce3dc8cc873cc7..cc4eb0c8f7343b 100644
--- a/llvm/test/CodeGen/X86/vselect.ll
+++ b/llvm/test/CodeGen/X86/vselect.ll
@@ -741,14 +741,24 @@ define i64 @vselect_any_extend_vector_inreg_crash(ptr %x) {
; SSE-NEXT: shll $15, %eax
; SSE-NEXT: retq
;
-; AVX-LABEL: vselect_any_extend_vector_inreg_crash:
-; AVX: # %bb.0:
-; AVX-NEXT: vmovq {{.*#+}} xmm0 = mem[0],zero
-; AVX-NEXT: vpcmpeqb {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0, %xmm0
-; AVX-NEXT: vmovd %xmm0, %eax
-; AVX-NEXT: andl $1, %eax
-; AVX-NEXT: shll $15, %eax
-; AVX-NEXT: retq
+; AVX1-LABEL: vselect_any_extend_vector_inreg_crash:
+; AVX1: # %bb.0:
+; AVX1-NEXT: vmovq {{.*#+}} xmm0 = mem[0],zero
+; AVX1-NEXT: vpcmpeqb {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0, %xmm0
+; AVX1-NEXT: vmovd %xmm0, %eax
+; AVX1-NEXT: andl $1, %eax
+; AVX1-NEXT: shll $15, %eax
+; AVX1-NEXT: retq
+;
+; AVX2-LABEL: vselect_any_extend_vector_inreg_crash:
+; AVX2: # %bb.0:
+; AVX2-NEXT: vmovq {{.*#+}} xmm0 = mem[0],zero
+; AVX2-NEXT: vpbroadcastd {{.*#+}} xmm1 = [49,49,49,49]
+; AVX2-NEXT: vpcmpeqb %xmm1, %xmm0, %xmm0
+; AVX2-NEXT: vmovd %xmm0, %eax
+; AVX2-NEXT: andl $1, %eax
+; AVX2-NEXT: shll $15, %eax
+; AVX2-NEXT: retq
0:
%1 = load <8 x i8>, ptr %x
%2 = icmp eq <8 x i8> %1, <i8 49, i8 49, i8 49, i8 49, i8 49, i8 49, i8 49, i8 49>
>From 5bd01ac822d1d700623790ef146fb78216576616 Mon Sep 17 00:00:00 2001
From: Sander de Smalen <sander.desmalen at arm.com>
Date: Thu, 29 Feb 2024 15:35:46 +0000
Subject: [PATCH 140/406] [AArch64] Re-enable rematerialization for
streaming-mode-changing functions. (#83235)
We can add implicit defs/uses of the 'VG' register to the instructions
to prevent the register allocator from rematerializing values in between
streaming-mode changes, as the def/use of VG will further nail down the
ordering that comes out of ISel. This avoids the heavy-handed approach
to prevent any kind of rematerialization.
While we could add 'VG' as a Use to all SVE instructions, we only really
need to do this for instructions that are rematerializable, as the
smstart/smstop instructions and pseudos act as scheduling barriers which
is sufficient to prevent other instructions from being scheduled in
between the streaming-mode-changing call sequence. However, we may
revisit this in the future.
---
.../Target/AArch64/AArch64ISelLowering.cpp | 16 ++++++
.../lib/Target/AArch64/AArch64InstrFormats.td | 1 +
llvm/lib/Target/AArch64/AArch64InstrInfo.cpp | 52 -------------------
llvm/lib/Target/AArch64/AArch64InstrInfo.h | 2 -
.../Target/AArch64/AArch64RegisterInfo.cpp | 3 ++
.../lib/Target/AArch64/AArch64SMEInstrInfo.td | 2 +
llvm/lib/Target/AArch64/SMEInstrFormats.td | 2 +
llvm/lib/Target/AArch64/SVEInstrFormats.td | 10 ++++
.../AArch64/debug-info-sve-dbg-declare.mir | 2 +-
.../AArch64/debug-info-sve-dbg-value.mir | 2 +-
.../CodeGen/AArch64/live-debugvalues-sve.mir | 4 +-
.../CodeGen/AArch64/sve-localstackalloc.mir | 2 +-
.../AArch64/sve-pfalse-machine-cse.mir | 6 +--
.../AArch64/sve-pseudos-expand-undef.mir | 4 +-
.../AArch64/sve-ptest-removal-cmpeq.mir | 10 ++--
.../AArch64/sve-ptest-removal-whilege.mir | 24 ++++-----
.../AArch64/sve-ptest-removal-whilegt.mir | 24 ++++-----
.../AArch64/sve-ptest-removal-whilehi.mir | 24 ++++-----
.../AArch64/sve-ptest-removal-whilehs.mir | 24 ++++-----
.../AArch64/sve-ptest-removal-whilele.mir | 24 ++++-----
.../AArch64/sve-ptest-removal-whilelo.mir | 24 ++++-----
.../AArch64/sve-ptest-removal-whilels.mir | 24 ++++-----
.../AArch64/sve-ptest-removal-whilelt.mir | 24 ++++-----
.../AArch64/sve-ptest-removal-whilerw.mir | 16 +++---
.../AArch64/sve-ptest-removal-whilewr.mir | 16 +++---
llvm/test/CodeGen/AArch64/sve2p1_copy_pnr.mir | 12 ++---
26 files changed, 167 insertions(+), 187 deletions(-)
diff --git a/llvm/lib/Target/AArch64/AArch64ISelLowering.cpp b/llvm/lib/Target/AArch64/AArch64ISelLowering.cpp
index c21bc3a4abbc00..b1677df56e1bea 100644
--- a/llvm/lib/Target/AArch64/AArch64ISelLowering.cpp
+++ b/llvm/lib/Target/AArch64/AArch64ISelLowering.cpp
@@ -7518,6 +7518,22 @@ void AArch64TargetLowering::AdjustInstrPostInstrSelection(MachineInstr &MI,
(AArch64::GPR32RegClass.contains(MO.getReg()) ||
AArch64::GPR64RegClass.contains(MO.getReg())))
MI.removeOperand(I);
+
+ // Add an implicit use of 'VG' for ADDXri/SUBXri, which are instructions that
+ // have nothing to do with VG, were it not that they are used to materialise a
+ // frame-address. If they contain a frame-index to a scalable vector, this
+ // will likely require an ADDVL instruction to materialise the address, thus
+ // reading VG.
+ const MachineFunction &MF = *MI.getMF();
+ if (MF.getInfo<AArch64FunctionInfo>()->hasStreamingModeChanges() &&
+ (MI.getOpcode() == AArch64::ADDXri ||
+ MI.getOpcode() == AArch64::SUBXri)) {
+ const MachineOperand &MO = MI.getOperand(1);
+ if (MO.isFI() && MF.getFrameInfo().getStackID(MO.getIndex()) ==
+ TargetStackID::ScalableVector)
+ MI.addOperand(MachineOperand::CreateReg(AArch64::VG, /*IsDef=*/false,
+ /*IsImplicit=*/true));
+ }
}
SDValue AArch64TargetLowering::changeStreamingMode(
diff --git a/llvm/lib/Target/AArch64/AArch64InstrFormats.td b/llvm/lib/Target/AArch64/AArch64InstrFormats.td
index 10ad5b1f8f2580..7f8856db6c6e61 100644
--- a/llvm/lib/Target/AArch64/AArch64InstrFormats.td
+++ b/llvm/lib/Target/AArch64/AArch64InstrFormats.td
@@ -2809,6 +2809,7 @@ class AddSubImmShift<bit isSub, bit setFlags, RegisterClass dstRegtype,
let Inst{23-22} = imm{13-12}; // '00' => lsl #0, '01' => lsl #12
let Inst{21-10} = imm{11-0};
let DecoderMethod = "DecodeAddSubImmShift";
+ let hasPostISelHook = 1;
}
class BaseAddSubRegPseudo<RegisterClass regtype,
diff --git a/llvm/lib/Target/AArch64/AArch64InstrInfo.cpp b/llvm/lib/Target/AArch64/AArch64InstrInfo.cpp
index 39c96092f10319..17e0e36ee6821e 100644
--- a/llvm/lib/Target/AArch64/AArch64InstrInfo.cpp
+++ b/llvm/lib/Target/AArch64/AArch64InstrInfo.cpp
@@ -9481,58 +9481,6 @@ unsigned llvm::getBLRCallOpcode(const MachineFunction &MF) {
return AArch64::BLR;
}
-bool AArch64InstrInfo::isReallyTriviallyReMaterializable(
- const MachineInstr &MI) const {
- const MachineFunction &MF = *MI.getMF();
- const AArch64FunctionInfo &AFI = *MF.getInfo<AArch64FunctionInfo>();
-
- // If the function contains changes to streaming mode, then there
- // is a danger that rematerialised instructions end up between
- // instruction sequences (e.g. call sequences, or prolog/epilogue)
- // where the streaming-SVE mode is temporarily changed.
- if (AFI.hasStreamingModeChanges()) {
- // Avoid rematerializing rematerializable instructions that use/define
- // scalable values, such as 'pfalse' or 'ptrue', which result in different
- // results when the runtime vector length is different.
- const MachineRegisterInfo &MRI = MF.getRegInfo();
- const MachineFrameInfo &MFI = MF.getFrameInfo();
- if (any_of(MI.operands(), [&MRI, &MFI](const MachineOperand &MO) {
- if (MO.isFI() &&
- MFI.getStackID(MO.getIndex()) == TargetStackID::ScalableVector)
- return true;
- if (!MO.isReg())
- return false;
-
- if (MO.getReg().isVirtual()) {
- const TargetRegisterClass *RC = MRI.getRegClass(MO.getReg());
- return AArch64::ZPRRegClass.hasSubClassEq(RC) ||
- AArch64::PPRRegClass.hasSubClassEq(RC);
- }
- return AArch64::ZPRRegClass.contains(MO.getReg()) ||
- AArch64::PPRRegClass.contains(MO.getReg());
- }))
- return false;
-
- // Avoid rematerializing instructions that return a value that is
- // different depending on vector length, even when it is not returned
- // in a scalable vector/predicate register.
- switch (MI.getOpcode()) {
- default:
- break;
- case AArch64::RDVLI_XI:
- case AArch64::ADDVL_XXI:
- case AArch64::ADDPL_XXI:
- case AArch64::CNTB_XPiI:
- case AArch64::CNTH_XPiI:
- case AArch64::CNTW_XPiI:
- case AArch64::CNTD_XPiI:
- return false;
- }
- }
-
- return TargetInstrInfo::isReallyTriviallyReMaterializable(MI);
-}
-
MachineBasicBlock::iterator
AArch64InstrInfo::probedStackAlloc(MachineBasicBlock::iterator MBBI,
Register TargetReg, bool FrameSetup) const {
diff --git a/llvm/lib/Target/AArch64/AArch64InstrInfo.h b/llvm/lib/Target/AArch64/AArch64InstrInfo.h
index 63e0cb80d8586f..6c6689091ead4d 100644
--- a/llvm/lib/Target/AArch64/AArch64InstrInfo.h
+++ b/llvm/lib/Target/AArch64/AArch64InstrInfo.h
@@ -381,8 +381,6 @@ class AArch64InstrInfo final : public AArch64GenInstrInfo {
int64_t &ByteSized,
int64_t &VGSized);
- bool isReallyTriviallyReMaterializable(const MachineInstr &MI) const override;
-
// Return true if address of the form BaseReg + Scale * ScaledReg + Offset can
// be used for a load/store of NumBytes. BaseReg is always present and
// implicit.
diff --git a/llvm/lib/Target/AArch64/AArch64RegisterInfo.cpp b/llvm/lib/Target/AArch64/AArch64RegisterInfo.cpp
index b919c116445c8b..531f21f9c043a2 100644
--- a/llvm/lib/Target/AArch64/AArch64RegisterInfo.cpp
+++ b/llvm/lib/Target/AArch64/AArch64RegisterInfo.cpp
@@ -443,6 +443,9 @@ AArch64RegisterInfo::getStrictlyReservedRegs(const MachineFunction &MF) const {
Reserved.set(SubReg);
}
+ // VG cannot be allocated
+ Reserved.set(AArch64::VG);
+
if (MF.getSubtarget<AArch64Subtarget>().hasSME2()) {
for (MCSubRegIterator SubReg(AArch64::ZT0, this, /*self=*/true);
SubReg.isValid(); ++SubReg)
diff --git a/llvm/lib/Target/AArch64/AArch64SMEInstrInfo.td b/llvm/lib/Target/AArch64/AArch64SMEInstrInfo.td
index acf067f2cc5a9d..2907ba74ff8108 100644
--- a/llvm/lib/Target/AArch64/AArch64SMEInstrInfo.td
+++ b/llvm/lib/Target/AArch64/AArch64SMEInstrInfo.td
@@ -233,6 +233,8 @@ def MSRpstatePseudo :
(ins svcr_op:$pstatefield, timm0_1:$imm, GPR64:$rtpstate, timm0_1:$expected_pstate, variable_ops), []>,
Sched<[WriteSys]> {
let hasPostISelHook = 1;
+ let Uses = [VG];
+ let Defs = [VG];
}
def : Pat<(AArch64_smstart (i32 svcr_op:$pstate), (i64 GPR64:$rtpstate), (i64 timm0_1:$expected_pstate)),
diff --git a/llvm/lib/Target/AArch64/SMEInstrFormats.td b/llvm/lib/Target/AArch64/SMEInstrFormats.td
index 44d9a8ac7cb677..33cb5f9734b819 100644
--- a/llvm/lib/Target/AArch64/SMEInstrFormats.td
+++ b/llvm/lib/Target/AArch64/SMEInstrFormats.td
@@ -223,6 +223,8 @@ def MSRpstatesvcrImm1
let Inst{8} = imm;
let Inst{7-5} = 0b011; // op2
let hasPostISelHook = 1;
+ let Uses = [VG];
+ let Defs = [VG];
}
def : InstAlias<"smstart", (MSRpstatesvcrImm1 0b011, 0b1)>;
diff --git a/llvm/lib/Target/AArch64/SVEInstrFormats.td b/llvm/lib/Target/AArch64/SVEInstrFormats.td
index 789ec817d3d8b8..c8ca1832ec18dd 100644
--- a/llvm/lib/Target/AArch64/SVEInstrFormats.td
+++ b/llvm/lib/Target/AArch64/SVEInstrFormats.td
@@ -365,6 +365,7 @@ class sve_int_ptrue<bits<2> sz8_64, bits<3> opc, string asm, PPRRegOp pprty,
let ElementSize = pprty.ElementSize;
let hasSideEffects = 0;
let isReMaterializable = 1;
+ let Uses = [VG];
}
multiclass sve_int_ptrue<bits<3> opc, string asm, SDPatternOperator op> {
@@ -755,6 +756,7 @@ class sve_int_pfalse<bits<6> opc, string asm>
let hasSideEffects = 0;
let isReMaterializable = 1;
+ let Uses = [VG];
}
multiclass sve_int_pfalse<bits<6> opc, string asm> {
@@ -1090,6 +1092,7 @@ class sve_int_count<bits<3> opc, string asm>
let hasSideEffects = 0;
let isReMaterializable = 1;
+ let Uses = [VG];
}
multiclass sve_int_count<bits<3> opc, string asm, SDPatternOperator op> {
@@ -1982,6 +1985,7 @@ class sve_int_dup_mask_imm<string asm>
let DecoderMethod = "DecodeSVELogicalImmInstruction";
let hasSideEffects = 0;
let isReMaterializable = 1;
+ let Uses = [VG];
}
multiclass sve_int_dup_mask_imm<string asm> {
@@ -2862,6 +2866,7 @@ class sve_int_arith_vl<bit opc, string asm, bit streaming_sve = 0b0>
let Inst{4-0} = Rd;
let hasSideEffects = 0;
+ let Uses = [VG];
}
class sve_int_read_vl_a<bit op, bits<5> opc2, string asm, bit streaming_sve = 0b0>
@@ -2882,6 +2887,7 @@ class sve_int_read_vl_a<bit op, bits<5> opc2, string asm, bit streaming_sve = 0b
let hasSideEffects = 0;
let isReMaterializable = 1;
+ let Uses = [VG];
}
//===----------------------------------------------------------------------===//
@@ -4699,6 +4705,7 @@ class sve_int_dup_imm<bits<2> sz8_64, string asm,
let hasSideEffects = 0;
let isReMaterializable = 1;
+ let Uses = [VG];
}
multiclass sve_int_dup_imm<string asm> {
@@ -4741,6 +4748,7 @@ class sve_int_dup_fpimm<bits<2> sz8_64, Operand fpimmtype,
let hasSideEffects = 0;
let isReMaterializable = 1;
+ let Uses = [VG];
}
multiclass sve_int_dup_fpimm<string asm> {
@@ -5657,6 +5665,7 @@ class sve_int_index_ii<bits<2> sz8_64, string asm, ZPRRegOp zprty,
let hasSideEffects = 0;
let isReMaterializable = 1;
+ let Uses = [VG];
}
multiclass sve_int_index_ii<string asm> {
@@ -9308,6 +9317,7 @@ class sve2p1_ptrue_pn<string mnemonic, bits<2> sz, PNRP8to15RegOp pnrty, SDPatte
let hasSideEffects = 0;
let isReMaterializable = 1;
+ let Uses = [VG];
}
diff --git a/llvm/test/CodeGen/AArch64/debug-info-sve-dbg-declare.mir b/llvm/test/CodeGen/AArch64/debug-info-sve-dbg-declare.mir
index d44d45ea03b6bc..aca2816225e3ee 100644
--- a/llvm/test/CodeGen/AArch64/debug-info-sve-dbg-declare.mir
+++ b/llvm/test/CodeGen/AArch64/debug-info-sve-dbg-declare.mir
@@ -193,7 +193,7 @@ body: |
liveins: $z0, $z1, $p0, $p1, $w0
renamable $p2 = COPY killed $p0
- renamable $p0 = PTRUE_S 31
+ renamable $p0 = PTRUE_S 31, implicit $vg
ST1W_IMM killed renamable $z0, renamable $p0, %stack.0.z0.addr, 0 :: (store unknown-size into %ir.z0.addr, align 16)
ST1W_IMM killed renamable $z1, renamable $p0, %stack.1.z1.addr, 0 :: (store unknown-size into %ir.z1.addr, align 16)
STR_PXI killed renamable $p2, %stack.2.p0.addr, 0 :: (store unknown-size into %ir.p0.addr, align 2)
diff --git a/llvm/test/CodeGen/AArch64/debug-info-sve-dbg-value.mir b/llvm/test/CodeGen/AArch64/debug-info-sve-dbg-value.mir
index 75917ef32ae2ad..0ea180b20730f2 100644
--- a/llvm/test/CodeGen/AArch64/debug-info-sve-dbg-value.mir
+++ b/llvm/test/CodeGen/AArch64/debug-info-sve-dbg-value.mir
@@ -111,7 +111,7 @@ body: |
STRXui killed renamable $x1, %stack.1, 0, debug-location !8
DBG_VALUE %stack.1, $noreg, !11, !DIExpression(DW_OP_constu, 16, DW_OP_plus, DW_OP_deref), debug-location !8
- renamable $p2 = PTRUE_S 31, debug-location !DILocation(line: 4, column: 1, scope: !5)
+ renamable $p2 = PTRUE_S 31, implicit $vg, debug-location !DILocation(line: 4, column: 1, scope: !5)
ST1W_IMM renamable $z0, renamable $p2, %stack.2, 0, debug-location !DILocation(line: 5, column: 1, scope: !5)
DBG_VALUE %stack.2, $noreg, !12, !DIExpression(DW_OP_deref), debug-location !DILocation(line: 5, column: 1, scope: !5)
ST1W_IMM renamable $z1, killed renamable $p2, %stack.3, 0, debug-location !DILocation(line: 6, column: 1, scope: !5)
diff --git a/llvm/test/CodeGen/AArch64/live-debugvalues-sve.mir b/llvm/test/CodeGen/AArch64/live-debugvalues-sve.mir
index 8903ca2b865b98..612453ab53f438 100644
--- a/llvm/test/CodeGen/AArch64/live-debugvalues-sve.mir
+++ b/llvm/test/CodeGen/AArch64/live-debugvalues-sve.mir
@@ -145,7 +145,7 @@ body: |
liveins: $z1
ADJCALLSTACKDOWN 0, 0, implicit-def dead $sp, implicit $sp, debug-location !34
- renamable $p0 = PTRUE_S 31, debug-location !34
+ renamable $p0 = PTRUE_S 31, implicit $vg, debug-location !34
$x0 = ADDXri %stack.0, 0, 0, debug-location !34
ST1W_IMM renamable $z1, killed renamable $p0, %stack.0, 0, debug-location !34 :: (store unknown-size into %stack.0, align 16)
$z0 = COPY renamable $z1, debug-location !34
@@ -157,7 +157,7 @@ body: |
$z7 = COPY renamable $z1, debug-location !34
BL @bar, csr_aarch64_sve_aapcs, implicit-def dead $lr, implicit $sp, implicit $z0, implicit $z1, implicit $z2, implicit $z3, implicit $z4, implicit $z5, implicit $z6, implicit $z7, implicit $x0, implicit-def $sp, implicit-def $z0, implicit-def $z1, debug-location !34
ADJCALLSTACKUP 0, 0, implicit-def dead $sp, implicit $sp, debug-location !34
- renamable $p0 = PTRUE_S 31, debug-location !34
+ renamable $p0 = PTRUE_S 31, implicit $vg, debug-location !34
$z3 = IMPLICIT_DEF
renamable $z1 = LD1W_IMM renamable $p0, %stack.0, 0, debug-location !34 :: (load unknown-size from %stack.0, align 16)
ST1W_IMM renamable $z3, killed renamable $p0, %stack.0, 0 :: (store unknown-size into %stack.0, align 16)
diff --git a/llvm/test/CodeGen/AArch64/sve-localstackalloc.mir b/llvm/test/CodeGen/AArch64/sve-localstackalloc.mir
index 3fbb7889c8b79b..6063c8dfc792c9 100644
--- a/llvm/test/CodeGen/AArch64/sve-localstackalloc.mir
+++ b/llvm/test/CodeGen/AArch64/sve-localstackalloc.mir
@@ -48,7 +48,7 @@ body: |
%2:gpr32 = COPY $w0
%1:zpr = COPY $z1
%0:zpr = COPY $z0
- %5:ppr_3b = PTRUE_B 31
+ %5:ppr_3b = PTRUE_B 31, implicit $vg
%6:gpr64sp = ADDXri %stack.0, 0, 0
ST1B_IMM %1, %5, %6, 1 :: (store unknown-size, align 16)
ST1B_IMM %0, %5, %stack.0, 0 :: (store unknown-size into %stack.0, align 16)
diff --git a/llvm/test/CodeGen/AArch64/sve-pfalse-machine-cse.mir b/llvm/test/CodeGen/AArch64/sve-pfalse-machine-cse.mir
index b76fe7821b6c69..8395a7619fbb46 100644
--- a/llvm/test/CodeGen/AArch64/sve-pfalse-machine-cse.mir
+++ b/llvm/test/CodeGen/AArch64/sve-pfalse-machine-cse.mir
@@ -11,15 +11,15 @@ body: |
; CHECK: liveins: $p0
; CHECK-NEXT: {{ $}}
; CHECK-NEXT: [[COPY:%[0-9]+]]:ppr = COPY $p0
- ; CHECK-NEXT: [[PFALSE:%[0-9]+]]:ppr = PFALSE
+ ; CHECK-NEXT: [[PFALSE:%[0-9]+]]:ppr = PFALSE implicit $vg
; CHECK-NEXT: [[UZP1_PPP_B:%[0-9]+]]:ppr = UZP1_PPP_B [[COPY]], [[PFALSE]]
; CHECK-NEXT: [[UZP1_PPP_B1:%[0-9]+]]:ppr = UZP1_PPP_B killed [[UZP1_PPP_B]], [[PFALSE]]
; CHECK-NEXT: $p0 = COPY [[UZP1_PPP_B1]]
; CHECK-NEXT: RET_ReallyLR implicit $p0
%0:ppr = COPY $p0
- %2:ppr = PFALSE
+ %2:ppr = PFALSE implicit $vg
%3:ppr = UZP1_PPP_B %0, %2
- %4:ppr = PFALSE
+ %4:ppr = PFALSE implicit $vg
%5:ppr = UZP1_PPP_B killed %3, %4
$p0 = COPY %5
RET_ReallyLR implicit $p0
diff --git a/llvm/test/CodeGen/AArch64/sve-pseudos-expand-undef.mir b/llvm/test/CodeGen/AArch64/sve-pseudos-expand-undef.mir
index df0e50de4d1a7a..ae70f91a4ec641 100644
--- a/llvm/test/CodeGen/AArch64/sve-pseudos-expand-undef.mir
+++ b/llvm/test/CodeGen/AArch64/sve-pseudos-expand-undef.mir
@@ -26,7 +26,7 @@ body: |
name: expand_mls_to_msb
body: |
bb.0:
- renamable $p0 = PTRUE_B 31
+ renamable $p0 = PTRUE_B 31, implicit $vg
renamable $z0 = MLS_ZPZZZ_B_UNDEF killed renamable $p0, killed renamable $z2, killed renamable $z0, killed renamable $z1
RET_ReallyLR implicit $z0
...
@@ -36,7 +36,7 @@ body: |
name: expand_mla_to_mad
body: |
bb.0:
- renamable $p0 = PTRUE_B 31
+ renamable $p0 = PTRUE_B 31, implicit $vg
renamable $z0 = MLA_ZPZZZ_B_UNDEF killed renamable $p0, killed renamable $z2, killed renamable $z0, killed renamable $z1
RET_ReallyLR implicit $z0
...
diff --git a/llvm/test/CodeGen/AArch64/sve-ptest-removal-cmpeq.mir b/llvm/test/CodeGen/AArch64/sve-ptest-removal-cmpeq.mir
index 81318aa5c2a58d..5169113697dc60 100644
--- a/llvm/test/CodeGen/AArch64/sve-ptest-removal-cmpeq.mir
+++ b/llvm/test/CodeGen/AArch64/sve-ptest-removal-cmpeq.mir
@@ -174,7 +174,7 @@ body: |
%1:zpr = COPY $z0
%0:ppr_3b = COPY $p0
%2:ppr = CMPEQ_PPzZI_B %0, %1, 0, implicit-def dead $nzcv
- %3:ppr = PTRUE_B 31
+ %3:ppr = PTRUE_B 31, implicit $vg
PTEST_PP killed %3, killed %2, implicit-def $nzcv
%4:gpr32 = COPY $wzr
%5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
@@ -409,14 +409,14 @@ body: |
; CHECK-LABEL: name: cmpeq_imm_nxv16i8_ptest_not_all_active
; CHECK: %2:ppr = CMPEQ_PPzZI_B %0, %1, 0, implicit-def dead $nzcv
- ; CHECK-NEXT: %3:ppr = PTRUE_B 0
+ ; CHECK-NEXT: %3:ppr = PTRUE_B 0, implicit $vg
; CHECK-NEXT: PTEST_PP killed %3, killed %2, implicit-def $nzcv
; CHECK-NEXT: %4:gpr32 = COPY $wzr
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:zpr = COPY $z0
%0:ppr_3b = COPY $p0
%2:ppr = CMPEQ_PPzZI_B %0, %1, 0, implicit-def dead $nzcv
- %3:ppr = PTRUE_B 0
+ %3:ppr = PTRUE_B 0, implicit $vg
PTEST_PP killed %3, killed %2, implicit-def $nzcv
%4:gpr32 = COPY $wzr
%5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
@@ -446,14 +446,14 @@ body: |
; CHECK-LABEL: name: cmpeq_imm_nxv16i8_ptest_of_halfs
; CHECK: %2:ppr = CMPEQ_PPzZI_B %0, %1, 0, implicit-def dead $nzcv
- ; CHECK-NEXT: %3:ppr = PTRUE_H 31
+ ; CHECK-NEXT: %3:ppr = PTRUE_H 31, implicit $vg
; CHECK-NEXT: PTEST_PP killed %3, killed %2, implicit-def $nzcv
; CHECK-NEXT: %4:gpr32 = COPY $wzr
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:zpr = COPY $z0
%0:ppr_3b = COPY $p0
%2:ppr = CMPEQ_PPzZI_B %0, %1, 0, implicit-def dead $nzcv
- %3:ppr = PTRUE_H 31
+ %3:ppr = PTRUE_H 31, implicit $vg
PTEST_PP killed %3, killed %2, implicit-def $nzcv
%4:gpr32 = COPY $wzr
%5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
diff --git a/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilege.mir b/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilege.mir
index 8f7467d99154e3..c1d9dfff73447c 100644
--- a/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilege.mir
+++ b/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilege.mir
@@ -30,7 +30,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_B 31
+ %2:ppr = PTRUE_B 31, implicit $vg
%3:ppr = WHILEGE_PWW_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -63,7 +63,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_B 31
+ %2:ppr = PTRUE_B 31, implicit $vg, implicit $vg
%3:ppr = WHILEGE_PXX_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -98,7 +98,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_H 31
+ %2:ppr = PTRUE_H 31, implicit $vg
%4:ppr = WHILEGE_PWW_H %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -133,7 +133,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_H 31
+ %2:ppr = PTRUE_H 31, implicit $vg
%4:ppr = WHILEGE_PXX_H %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -168,7 +168,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_S 31
+ %2:ppr = PTRUE_S 31, implicit $vg
%4:ppr = WHILEGE_PWW_S %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -203,7 +203,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_S 31
+ %2:ppr = PTRUE_S 31, implicit $vg
%4:ppr = WHILEGE_PXX_S %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -238,7 +238,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_D 31
+ %2:ppr = PTRUE_D 31, implicit $vg
%4:ppr = WHILEGE_PWW_D %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -273,7 +273,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_D 31
+ %2:ppr = PTRUE_D 31, implicit $vg
%4:ppr = WHILEGE_PXX_D %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -313,7 +313,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_B 0
+ %2:ppr = PTRUE_B 0, implicit $vg
%3:ppr = WHILEGE_PXX_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -353,7 +353,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_H 31
+ %2:ppr = PTRUE_H 31, implicit $vg
%3:ppr = WHILEGE_PXX_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -393,7 +393,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_S 31
+ %2:ppr = PTRUE_S 31, implicit $vg
%3:ppr = WHILEGE_PXX_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -433,7 +433,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_D 31
+ %2:ppr = PTRUE_D 31, implicit $vg
%3:ppr = WHILEGE_PXX_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
diff --git a/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilegt.mir b/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilegt.mir
index 217d984560e36c..c6df21f85db773 100644
--- a/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilegt.mir
+++ b/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilegt.mir
@@ -30,7 +30,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_B 31
+ %2:ppr = PTRUE_B 31, implicit $vg
%3:ppr = WHILEGT_PWW_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -63,7 +63,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_B 31
+ %2:ppr = PTRUE_B 31, implicit $vg, implicit $vg
%3:ppr = WHILEGT_PXX_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -98,7 +98,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_H 31
+ %2:ppr = PTRUE_H 31, implicit $vg, implicit $vg
%4:ppr = WHILEGT_PWW_H %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -133,7 +133,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_H 31
+ %2:ppr = PTRUE_H 31, implicit $vg, implicit $vg
%4:ppr = WHILEGT_PXX_H %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -168,7 +168,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_S 31
+ %2:ppr = PTRUE_S 31, implicit $vg, implicit $vg
%4:ppr = WHILEGT_PWW_S %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -203,7 +203,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_S 31
+ %2:ppr = PTRUE_S 31, implicit $vg, implicit $vg
%4:ppr = WHILEGT_PXX_S %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -238,7 +238,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_D 31
+ %2:ppr = PTRUE_D 31, implicit $vg, implicit $vg
%4:ppr = WHILEGT_PWW_D %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -273,7 +273,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_D 31
+ %2:ppr = PTRUE_D 31, implicit $vg, implicit $vg
%4:ppr = WHILEGT_PXX_D %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -313,7 +313,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_H 1
+ %2:ppr = PTRUE_H 1, implicit $vg, implicit $vg
%3:ppr = WHILEGT_PXX_H %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -353,7 +353,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_B 31
+ %2:ppr = PTRUE_B 31, implicit $vg
%3:ppr = WHILEGT_PXX_H %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -393,7 +393,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_S 31
+ %2:ppr = PTRUE_S 31, implicit $vg
%3:ppr = WHILEGT_PXX_H %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -433,7 +433,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_D 31
+ %2:ppr = PTRUE_D 31, implicit $vg
%3:ppr = WHILEGT_PXX_H %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
diff --git a/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilehi.mir b/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilehi.mir
index 8d6f466c6b735d..7d8aed3c325a01 100644
--- a/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilehi.mir
+++ b/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilehi.mir
@@ -30,7 +30,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_B 31
+ %2:ppr = PTRUE_B 31, implicit $vg
%3:ppr = WHILEHI_PWW_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -63,7 +63,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_B 31
+ %2:ppr = PTRUE_B 31, implicit $vg
%3:ppr = WHILEHI_PXX_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -98,7 +98,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_H 31
+ %2:ppr = PTRUE_H 31, implicit $vg
%4:ppr = WHILEHI_PWW_H %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -133,7 +133,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_H 31
+ %2:ppr = PTRUE_H 31, implicit $vg
%4:ppr = WHILEHI_PXX_H %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -168,7 +168,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_S 31
+ %2:ppr = PTRUE_S 31, implicit $vg
%4:ppr = WHILEHI_PWW_S %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -203,7 +203,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_S 31
+ %2:ppr = PTRUE_S 31, implicit $vg
%4:ppr = WHILEHI_PXX_S %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -238,7 +238,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_D 31
+ %2:ppr = PTRUE_D 31, implicit $vg
%4:ppr = WHILEHI_PWW_D %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -273,7 +273,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_D 31
+ %2:ppr = PTRUE_D 31, implicit $vg
%4:ppr = WHILEHI_PXX_D %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -313,7 +313,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_S 29
+ %2:ppr = PTRUE_S 29, implicit $vg
%3:ppr = WHILEHI_PXX_S %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -353,7 +353,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_B 31
+ %2:ppr = PTRUE_B 31, implicit $vg
%3:ppr = WHILEHI_PXX_S %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -393,7 +393,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_H 31
+ %2:ppr = PTRUE_H 31, implicit $vg
%3:ppr = WHILEHI_PXX_S %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -433,7 +433,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_D 31
+ %2:ppr = PTRUE_D 31, implicit $vg
%3:ppr = WHILEHI_PXX_S %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
diff --git a/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilehs.mir b/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilehs.mir
index da76a30f843b7a..f4dbfbc3db1cab 100644
--- a/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilehs.mir
+++ b/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilehs.mir
@@ -30,7 +30,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_B 31
+ %2:ppr = PTRUE_B 31, implicit $vg
%3:ppr = WHILEHS_PWW_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -63,7 +63,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_B 31
+ %2:ppr = PTRUE_B 31, implicit $vg
%3:ppr = WHILEHS_PXX_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -98,7 +98,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_H 31
+ %2:ppr = PTRUE_H 31, implicit $vg
%4:ppr = WHILEHS_PWW_H %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -133,7 +133,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_H 31
+ %2:ppr = PTRUE_H 31, implicit $vg
%4:ppr = WHILEHS_PXX_H %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -168,7 +168,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_S 31
+ %2:ppr = PTRUE_S 31, implicit $vg
%4:ppr = WHILEHS_PWW_S %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -203,7 +203,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_S 31
+ %2:ppr = PTRUE_S 31, implicit $vg
%4:ppr = WHILEHS_PXX_S %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -238,7 +238,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_D 31
+ %2:ppr = PTRUE_D 31, implicit $vg
%4:ppr = WHILEHS_PWW_D %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -273,7 +273,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_D 31
+ %2:ppr = PTRUE_D 31, implicit $vg
%4:ppr = WHILEHS_PXX_D %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -313,7 +313,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_D 30
+ %2:ppr = PTRUE_D 30, implicit $vg
%3:ppr = WHILEHS_PXX_D %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -353,7 +353,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_B 31
+ %2:ppr = PTRUE_B 31, implicit $vg
%3:ppr = WHILEHS_PXX_D %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -393,7 +393,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_H 31
+ %2:ppr = PTRUE_H 31, implicit $vg
%3:ppr = WHILEHS_PXX_D %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -433,7 +433,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_S 31
+ %2:ppr = PTRUE_S 31, implicit $vg
%3:ppr = WHILEHS_PXX_D %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
diff --git a/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilele.mir b/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilele.mir
index 32954d593c1ddd..dc2265490cb55e 100644
--- a/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilele.mir
+++ b/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilele.mir
@@ -30,7 +30,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_B 31
+ %2:ppr = PTRUE_B 31, implicit $vg
%3:ppr = WHILELE_PWW_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -63,7 +63,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_B 31
+ %2:ppr = PTRUE_B 31, implicit $vg
%3:ppr = WHILELE_PXX_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -98,7 +98,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_H 31
+ %2:ppr = PTRUE_H 31, implicit $vg
%4:ppr = WHILELE_PWW_H %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -133,7 +133,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_H 31
+ %2:ppr = PTRUE_H 31, implicit $vg
%4:ppr = WHILELE_PXX_H %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -168,7 +168,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_S 31
+ %2:ppr = PTRUE_S 31, implicit $vg
%4:ppr = WHILELE_PWW_S %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -203,7 +203,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_S 31
+ %2:ppr = PTRUE_S 31, implicit $vg
%4:ppr = WHILELE_PXX_S %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -238,7 +238,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_D 31
+ %2:ppr = PTRUE_D 31, implicit $vg
%4:ppr = WHILELE_PWW_D %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -273,7 +273,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_D 31
+ %2:ppr = PTRUE_D 31, implicit $vg
%4:ppr = WHILELE_PXX_D %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -313,7 +313,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_B 7
+ %2:ppr = PTRUE_B 7, implicit $vg
%3:ppr = WHILELE_PWW_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -353,7 +353,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_H 31
+ %2:ppr = PTRUE_H 31, implicit $vg
%3:ppr = WHILELE_PWW_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -393,7 +393,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_S 31
+ %2:ppr = PTRUE_S 31, implicit $vg
%3:ppr = WHILELE_PWW_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -433,7 +433,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_D 31
+ %2:ppr = PTRUE_D 31, implicit $vg
%3:ppr = WHILELE_PWW_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
diff --git a/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilelo.mir b/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilelo.mir
index cca0ab8ef210b9..4d66e3e57da8b3 100644
--- a/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilelo.mir
+++ b/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilelo.mir
@@ -30,7 +30,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_B 31
+ %2:ppr = PTRUE_B 31, implicit $vg
%3:ppr = WHILELO_PWW_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -63,7 +63,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_B 31
+ %2:ppr = PTRUE_B 31, implicit $vg
%3:ppr = WHILELO_PXX_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -98,7 +98,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_H 31
+ %2:ppr = PTRUE_H 31, implicit $vg
%4:ppr = WHILELO_PWW_H %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -133,7 +133,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_H 31
+ %2:ppr = PTRUE_H 31, implicit $vg
%4:ppr = WHILELO_PXX_H %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -168,7 +168,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_S 31
+ %2:ppr = PTRUE_S 31, implicit $vg
%4:ppr = WHILELO_PWW_S %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -203,7 +203,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_S 31
+ %2:ppr = PTRUE_S 31, implicit $vg
%4:ppr = WHILELO_PXX_S %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -238,7 +238,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_D 31
+ %2:ppr = PTRUE_D 31, implicit $vg
%4:ppr = WHILELO_PWW_D %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -273,7 +273,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_D 31
+ %2:ppr = PTRUE_D 31, implicit $vg
%4:ppr = WHILELO_PXX_D %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -313,7 +313,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_H 6
+ %2:ppr = PTRUE_H 6, implicit $vg
%3:ppr = WHILELO_PWW_H %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -353,7 +353,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_B 31
+ %2:ppr = PTRUE_B 31, implicit $vg
%3:ppr = WHILELO_PWW_H %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -393,7 +393,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_S 31
+ %2:ppr = PTRUE_S 31, implicit $vg
%3:ppr = WHILELO_PWW_H %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -433,7 +433,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_D 31
+ %2:ppr = PTRUE_D 31, implicit $vg
%3:ppr = WHILELO_PWW_H %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
diff --git a/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilels.mir b/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilels.mir
index 4bae3a1986f451..ea02f8c70ef86c 100644
--- a/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilels.mir
+++ b/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilels.mir
@@ -30,7 +30,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_B 31
+ %2:ppr = PTRUE_B 31, implicit $vg
%3:ppr = WHILELS_PWW_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -63,7 +63,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_B 31
+ %2:ppr = PTRUE_B 31, implicit $vg
%3:ppr = WHILELS_PXX_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -98,7 +98,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_H 31
+ %2:ppr = PTRUE_H 31, implicit $vg
%4:ppr = WHILELS_PWW_H %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -133,7 +133,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_H 31
+ %2:ppr = PTRUE_H 31, implicit $vg
%4:ppr = WHILELS_PXX_H %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -168,7 +168,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_S 31
+ %2:ppr = PTRUE_S 31, implicit $vg
%4:ppr = WHILELS_PWW_S %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -203,7 +203,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_S 31
+ %2:ppr = PTRUE_S 31, implicit $vg
%4:ppr = WHILELS_PXX_S %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -238,7 +238,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_D 31
+ %2:ppr = PTRUE_D 31, implicit $vg
%4:ppr = WHILELS_PWW_D %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -273,7 +273,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_D 31
+ %2:ppr = PTRUE_D 31, implicit $vg
%4:ppr = WHILELS_PXX_D %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -313,7 +313,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_S 5
+ %2:ppr = PTRUE_S 5, implicit $vg
%3:ppr = WHILELS_PWW_S %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -353,7 +353,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_B 31
+ %2:ppr = PTRUE_B 31, implicit $vg
%3:ppr = WHILELS_PWW_S %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -393,7 +393,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_H 31
+ %2:ppr = PTRUE_H 31, implicit $vg
%3:ppr = WHILELS_PWW_S %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -433,7 +433,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_D 31
+ %2:ppr = PTRUE_D 31, implicit $vg
%3:ppr = WHILELS_PWW_S %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
diff --git a/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilelt.mir b/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilelt.mir
index 3c6a9e21b4c6c1..d08781f203e328 100644
--- a/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilelt.mir
+++ b/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilelt.mir
@@ -30,7 +30,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_B 31
+ %2:ppr = PTRUE_B 31, implicit $vg
%3:ppr = WHILELT_PWW_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -63,7 +63,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_B 31
+ %2:ppr = PTRUE_B 31, implicit $vg
%3:ppr = WHILELT_PXX_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -98,7 +98,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_H 31
+ %2:ppr = PTRUE_H 31, implicit $vg
%4:ppr = WHILELT_PWW_H %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -133,7 +133,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_H 31
+ %2:ppr = PTRUE_H 31, implicit $vg
%4:ppr = WHILELT_PXX_H %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -168,7 +168,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_S 31
+ %2:ppr = PTRUE_S 31, implicit $vg
%4:ppr = WHILELT_PWW_S %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -203,7 +203,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_S 31
+ %2:ppr = PTRUE_S 31, implicit $vg
%4:ppr = WHILELT_PXX_S %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -238,7 +238,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_D 31
+ %2:ppr = PTRUE_D 31, implicit $vg
%4:ppr = WHILELT_PWW_D %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -273,7 +273,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_D 31
+ %2:ppr = PTRUE_D 31, implicit $vg
%4:ppr = WHILELT_PXX_D %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -313,7 +313,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_D 4
+ %2:ppr = PTRUE_D 4, implicit $vg
%3:ppr = WHILELT_PWW_D %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -353,7 +353,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_B 31
+ %2:ppr = PTRUE_B 31, implicit $vg
%3:ppr = WHILELT_PWW_D %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -393,7 +393,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_H 31
+ %2:ppr = PTRUE_H 31, implicit $vg
%3:ppr = WHILELT_PWW_D %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -433,7 +433,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr32 = COPY $w1
%0:gpr32 = COPY $w0
- %2:ppr = PTRUE_S 31
+ %2:ppr = PTRUE_S 31, implicit $vg
%3:ppr = WHILELT_PWW_D %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
diff --git a/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilerw.mir b/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilerw.mir
index 27cdf593df776f..d800009b9537f3 100644
--- a/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilerw.mir
+++ b/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilerw.mir
@@ -30,7 +30,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_B 31
+ %2:ppr = PTRUE_B 31, implicit $vg
%3:ppr = WHILERW_PXX_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -65,7 +65,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_H 31
+ %2:ppr = PTRUE_H 31, implicit $vg
%4:ppr = WHILERW_PXX_H %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -100,7 +100,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_S 31
+ %2:ppr = PTRUE_S 31, implicit $vg
%4:ppr = WHILERW_PXX_S %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -135,7 +135,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_D 31
+ %2:ppr = PTRUE_D 31, implicit $vg
%4:ppr = WHILERW_PXX_D %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -175,7 +175,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_B 0
+ %2:ppr = PTRUE_B 0, implicit $vg
%3:ppr = WHILERW_PXX_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -215,7 +215,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_H 31
+ %2:ppr = PTRUE_H 31, implicit $vg
%3:ppr = WHILERW_PXX_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -255,7 +255,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_S 31
+ %2:ppr = PTRUE_S 31, implicit $vg
%3:ppr = WHILERW_PXX_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -295,7 +295,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_D 31
+ %2:ppr = PTRUE_D 31, implicit $vg
%3:ppr = WHILERW_PXX_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
diff --git a/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilewr.mir b/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilewr.mir
index 3b49b1ec2c8045..9f8b7c3197ecf2 100644
--- a/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilewr.mir
+++ b/llvm/test/CodeGen/AArch64/sve-ptest-removal-whilewr.mir
@@ -30,7 +30,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_B 31
+ %2:ppr = PTRUE_B 31, implicit $vg
%3:ppr = WHILEWR_PXX_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -65,7 +65,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_H 31
+ %2:ppr = PTRUE_H 31, implicit $vg
%4:ppr = WHILEWR_PXX_H %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -100,7 +100,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_S 31
+ %2:ppr = PTRUE_S 31, implicit $vg
%4:ppr = WHILEWR_PXX_S %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -135,7 +135,7 @@ body: |
; CHECK-NOT: PTEST
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_D 31
+ %2:ppr = PTRUE_D 31, implicit $vg
%4:ppr = WHILEWR_PXX_D %0, %1, implicit-def dead $nzcv
PTEST_PP %2, %4, implicit-def $nzcv
%6:gpr32 = COPY $wzr
@@ -175,7 +175,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_B 0
+ %2:ppr = PTRUE_B 0, implicit $vg
%3:ppr = WHILEWR_PXX_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -215,7 +215,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_H 31
+ %2:ppr = PTRUE_H 31, implicit $vg
%3:ppr = WHILEWR_PXX_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -255,7 +255,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_S 31
+ %2:ppr = PTRUE_S 31, implicit $vg
%3:ppr = WHILEWR_PXX_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
@@ -295,7 +295,7 @@ body: |
; CHECK-NEXT: %5:gpr32 = CSINCWr %4, $wzr, 0, implicit $nzcv
%1:gpr64 = COPY $x1
%0:gpr64 = COPY $x0
- %2:ppr = PTRUE_D 31
+ %2:ppr = PTRUE_D 31, implicit $vg
%3:ppr = WHILEWR_PXX_B %0, %1, implicit-def dead $nzcv
PTEST_PP killed %2, killed %3, implicit-def $nzcv
%4:gpr32 = COPY $wzr
diff --git a/llvm/test/CodeGen/AArch64/sve2p1_copy_pnr.mir b/llvm/test/CodeGen/AArch64/sve2p1_copy_pnr.mir
index d6a87a42a79e00..5e5db2ac4e2079 100644
--- a/llvm/test/CodeGen/AArch64/sve2p1_copy_pnr.mir
+++ b/llvm/test/CodeGen/AArch64/sve2p1_copy_pnr.mir
@@ -13,10 +13,10 @@ machineFunctionInfo:
body: |
bb.0:
; CHECK-LABEL: name: pnr_to_ppr
- ; CHECK: renamable $pn8 = PTRUE_C_D
+ ; CHECK: renamable $pn8 = PTRUE_C_D implicit $vg
; CHECK-NEXT: $p0 = ORR_PPzPP $p8, $p8, killed $p8
; CHECK-NEXT: RET_ReallyLR implicit killed $p0
- renamable $pn8 = PTRUE_C_D
+ renamable $pn8 = PTRUE_C_D implicit $vg
$p0 = COPY killed renamable $pn8
RET_ReallyLR implicit killed $p0
@@ -34,10 +34,10 @@ machineFunctionInfo:
body: |
bb.0:
; CHECK-LABEL: name: ppr_to_pnr
- ; CHECK: renamable $p8 = PTRUE_H 31
+ ; CHECK: renamable $p8 = PTRUE_H 31, implicit $vg
; CHECK-NEXT: $p0 = ORR_PPzPP $p8, $p8, killed $p8, implicit-def $pn0
; CHECK-NEXT: RET_ReallyLR implicit killed $pn0
- renamable $p8 = PTRUE_H 31
+ renamable $p8 = PTRUE_H 31, implicit $vg
$pn0 = COPY killed renamable $p8
RET_ReallyLR implicit killed $pn0
@@ -55,10 +55,10 @@ machineFunctionInfo:
body: |
bb.0:
; CHECK-LABEL: name: pnr_to_pnr
- ; CHECK: renamable $pn8 = PTRUE_C_H
+ ; CHECK: renamable $pn8 = PTRUE_C_H implicit $vg
; CHECK-NEXT: $p0 = ORR_PPzPP $p8, $p8, killed $p8, implicit-def $pn0
; CHECK-NEXT: RET_ReallyLR implicit killed $pn0
- renamable $pn8 = PTRUE_C_H
+ renamable $pn8 = PTRUE_C_H implicit $vg
$pn0 = COPY killed renamable $pn8
RET_ReallyLR implicit killed $pn0
>From c66f2d0c4a46ba66fb98a2cab4e63ad90888a261 Mon Sep 17 00:00:00 2001
From: Devajith Valaparambil Sreeramaswamy <devajithvs at gmail.com>
Date: Thu, 29 Feb 2024 07:46:48 -0800
Subject: [PATCH 141/406] [mlir-query] Add function extraction feature to
mlir-query
This enables specifying the extract modifier to extract all matches into
a function. This currently does this very directly by converting all
operands to function arguments (ones due to results of other matched ops
are dropped) and all results as return values.
Differential Revision: https://reviews.llvm.org/D158693
---
.../include/mlir/Query/Matcher/ErrorBuilder.h | 7 +-
.../mlir/Query/Matcher/MatchersInternal.h | 7 ++
mlir/lib/Query/Matcher/Diagnostics.cpp | 10 +++
mlir/lib/Query/Matcher/Parser.cpp | 67 ++++++++++++++--
mlir/lib/Query/Matcher/Parser.h | 18 +++--
mlir/lib/Query/Matcher/RegistryManager.cpp | 15 +++-
mlir/lib/Query/Matcher/RegistryManager.h | 1 +
mlir/lib/Query/Query.cpp | 80 ++++++++++++++++++-
mlir/test/mlir-query/function-extraction.mlir | 19 +++++
9 files changed, 207 insertions(+), 17 deletions(-)
create mode 100644 mlir/test/mlir-query/function-extraction.mlir
diff --git a/mlir/include/mlir/Query/Matcher/ErrorBuilder.h b/mlir/include/mlir/Query/Matcher/ErrorBuilder.h
index 1073daed8703f5..08f1f415cbd3e5 100644
--- a/mlir/include/mlir/Query/Matcher/ErrorBuilder.h
+++ b/mlir/include/mlir/Query/Matcher/ErrorBuilder.h
@@ -37,8 +37,12 @@ enum class ErrorType {
None,
// Parser Errors
+ ParserChainedExprInvalidArg,
+ ParserChainedExprNoCloseParen,
+ ParserChainedExprNoOpenParen,
ParserFailedToBuildMatcher,
ParserInvalidToken,
+ ParserMalformedChainedExpr,
ParserNoCloseParen,
ParserNoCode,
ParserNoComma,
@@ -50,9 +54,10 @@ enum class ErrorType {
// Registry Errors
RegistryMatcherNotFound,
+ RegistryNotBindable,
RegistryValueNotFound,
RegistryWrongArgCount,
- RegistryWrongArgType
+ RegistryWrongArgType,
};
void addError(Diagnostics *error, SourceRange range, ErrorType errorType,
diff --git a/mlir/include/mlir/Query/Matcher/MatchersInternal.h b/mlir/include/mlir/Query/Matcher/MatchersInternal.h
index 67455be592393b..117f7d4edef9e3 100644
--- a/mlir/include/mlir/Query/Matcher/MatchersInternal.h
+++ b/mlir/include/mlir/Query/Matcher/MatchersInternal.h
@@ -63,8 +63,15 @@ class DynMatcher {
bool match(Operation *op) const { return implementation->match(op); }
+ void setFunctionName(StringRef name) { functionName = name.str(); };
+
+ bool hasFunctionName() const { return !functionName.empty(); };
+
+ StringRef getFunctionName() const { return functionName; };
+
private:
llvm::IntrusiveRefCntPtr<MatcherInterface> implementation;
+ std::string functionName;
};
} // namespace mlir::query::matcher
diff --git a/mlir/lib/Query/Matcher/Diagnostics.cpp b/mlir/lib/Query/Matcher/Diagnostics.cpp
index 10468dbcc53067..2a137e8fdfab0d 100644
--- a/mlir/lib/Query/Matcher/Diagnostics.cpp
+++ b/mlir/lib/Query/Matcher/Diagnostics.cpp
@@ -38,6 +38,8 @@ static llvm::StringRef errorTypeToFormatString(ErrorType type) {
return "Incorrect type for arg $0. (Expected = $1) != (Actual = $2)";
case ErrorType::RegistryValueNotFound:
return "Value not found: $0";
+ case ErrorType::RegistryNotBindable:
+ return "Matcher does not support binding.";
case ErrorType::ParserStringError:
return "Error parsing string token: <$0>";
@@ -57,6 +59,14 @@ static llvm::StringRef errorTypeToFormatString(ErrorType type) {
return "Unexpected end of code.";
case ErrorType::ParserOverloadedType:
return "Input value has unresolved overloaded type: $0";
+ case ErrorType::ParserMalformedChainedExpr:
+ return "Period not followed by valid chained call.";
+ case ErrorType::ParserChainedExprInvalidArg:
+ return "Missing/Invalid argument for the chained call.";
+ case ErrorType::ParserChainedExprNoCloseParen:
+ return "Missing ')' for the chained call.";
+ case ErrorType::ParserChainedExprNoOpenParen:
+ return "Missing '(' for the chained call.";
case ErrorType::ParserFailedToBuildMatcher:
return "Failed to build matcher: $0.";
diff --git a/mlir/lib/Query/Matcher/Parser.cpp b/mlir/lib/Query/Matcher/Parser.cpp
index 30eb4801fc03c1..3609e24f9939f7 100644
--- a/mlir/lib/Query/Matcher/Parser.cpp
+++ b/mlir/lib/Query/Matcher/Parser.cpp
@@ -26,12 +26,17 @@ struct Parser::TokenInfo {
text = newText;
}
+ // Known identifiers.
+ static const char *const ID_Extract;
+
llvm::StringRef text;
TokenKind kind = TokenKind::Eof;
SourceRange range;
VariantValue value;
};
+const char *const Parser::TokenInfo::ID_Extract = "extract";
+
class Parser::CodeTokenizer {
public:
// Constructor with matcherCode and error
@@ -298,6 +303,36 @@ bool Parser::parseIdentifierPrefixImpl(VariantValue *value) {
return parseMatcherExpressionImpl(nameToken, openToken, ctor, value);
}
+bool Parser::parseChainedExpression(std::string &argument) {
+ // Parse the parenthesized argument to .extract("foo")
+ // Note: EOF is handled inside the consume functions and would fail below when
+ // checking token kind.
+ const TokenInfo openToken = tokenizer->consumeNextToken();
+ const TokenInfo argumentToken = tokenizer->consumeNextTokenIgnoreNewlines();
+ const TokenInfo closeToken = tokenizer->consumeNextTokenIgnoreNewlines();
+
+ if (openToken.kind != TokenKind::OpenParen) {
+ error->addError(openToken.range, ErrorType::ParserChainedExprNoOpenParen);
+ return false;
+ }
+
+ if (argumentToken.kind != TokenKind::Literal ||
+ !argumentToken.value.isString()) {
+ error->addError(argumentToken.range,
+ ErrorType::ParserChainedExprInvalidArg);
+ return false;
+ }
+
+ if (closeToken.kind != TokenKind::CloseParen) {
+ error->addError(closeToken.range, ErrorType::ParserChainedExprNoCloseParen);
+ return false;
+ }
+
+ // If all checks passed, extract the argument and return true.
+ argument = argumentToken.value.getString();
+ return true;
+}
+
// Parse the arguments of a matcher
bool Parser::parseMatcherArgs(std::vector<ParserValue> &args, MatcherCtor ctor,
const TokenInfo &nameToken, TokenInfo &endToken) {
@@ -364,13 +399,34 @@ bool Parser::parseMatcherExpressionImpl(const TokenInfo &nameToken,
return false;
}
+ std::string functionName;
+ if (tokenizer->peekNextToken().kind == TokenKind::Period) {
+ tokenizer->consumeNextToken();
+ TokenInfo chainCallToken = tokenizer->consumeNextToken();
+ if (chainCallToken.kind == TokenKind::CodeCompletion) {
+ addCompletion(chainCallToken, MatcherCompletion("extract(\"", "extract"));
+ return false;
+ }
+
+ if (chainCallToken.kind != TokenKind::Ident ||
+ chainCallToken.text != TokenInfo::ID_Extract) {
+ error->addError(chainCallToken.range,
+ ErrorType::ParserMalformedChainedExpr);
+ return false;
+ }
+
+ if (chainCallToken.text == TokenInfo::ID_Extract &&
+ !parseChainedExpression(functionName))
+ return false;
+ }
+
if (!ctor)
return false;
// Merge the start and end infos.
SourceRange matcherRange = nameToken.range;
matcherRange.end = endToken.range.end;
- VariantMatcher result =
- sema->actOnMatcherExpression(*ctor, matcherRange, args, error);
+ VariantMatcher result = sema->actOnMatcherExpression(
+ *ctor, matcherRange, functionName, args, error);
if (result.isNull())
return false;
*value = result;
@@ -470,9 +526,10 @@ Parser::RegistrySema::lookupMatcherCtor(llvm::StringRef matcherName) {
}
VariantMatcher Parser::RegistrySema::actOnMatcherExpression(
- MatcherCtor ctor, SourceRange nameRange, llvm::ArrayRef<ParserValue> args,
- Diagnostics *error) {
- return RegistryManager::constructMatcher(ctor, nameRange, args, error);
+ MatcherCtor ctor, SourceRange nameRange, llvm::StringRef functionName,
+ llvm::ArrayRef<ParserValue> args, Diagnostics *error) {
+ return RegistryManager::constructMatcher(ctor, nameRange, functionName, args,
+ error);
}
std::vector<ArgKind> Parser::RegistrySema::getAcceptedCompletionTypes(
diff --git a/mlir/lib/Query/Matcher/Parser.h b/mlir/lib/Query/Matcher/Parser.h
index f049af34e9c907..58968023022d56 100644
--- a/mlir/lib/Query/Matcher/Parser.h
+++ b/mlir/lib/Query/Matcher/Parser.h
@@ -64,10 +64,9 @@ class Parser {
// Process a matcher expression. The caller takes ownership of the Matcher
// object returned.
- virtual VariantMatcher
- actOnMatcherExpression(MatcherCtor ctor, SourceRange nameRange,
- llvm::ArrayRef<ParserValue> args,
- Diagnostics *error) = 0;
+ virtual VariantMatcher actOnMatcherExpression(
+ MatcherCtor ctor, SourceRange nameRange, llvm::StringRef functionName,
+ llvm::ArrayRef<ParserValue> args, Diagnostics *error) = 0;
// Look up a matcher by name in the matcher name found by the parser.
virtual std::optional<MatcherCtor>
@@ -93,10 +92,11 @@ class Parser {
std::optional<MatcherCtor>
lookupMatcherCtor(llvm::StringRef matcherName) override;
- VariantMatcher actOnMatcherExpression(MatcherCtor ctor,
- SourceRange nameRange,
- llvm::ArrayRef<ParserValue> args,
- Diagnostics *error) override;
+ VariantMatcher actOnMatcherExpression(MatcherCtor Ctor,
+ SourceRange NameRange,
+ StringRef functionName,
+ ArrayRef<ParserValue> Args,
+ Diagnostics *Error) override;
std::vector<ArgKind> getAcceptedCompletionTypes(
llvm::ArrayRef<std::pair<MatcherCtor, unsigned>> context) override;
@@ -153,6 +153,8 @@ class Parser {
Parser(CodeTokenizer *tokenizer, const Registry &matcherRegistry,
const NamedValueMap *namedValues, Diagnostics *error);
+ bool parseChainedExpression(std::string &argument);
+
bool parseExpressionImpl(VariantValue *value);
bool parseMatcherArgs(std::vector<ParserValue> &args, MatcherCtor ctor,
diff --git a/mlir/lib/Query/Matcher/RegistryManager.cpp b/mlir/lib/Query/Matcher/RegistryManager.cpp
index 01856aa8ffa67f..8c9197f4d00981 100644
--- a/mlir/lib/Query/Matcher/RegistryManager.cpp
+++ b/mlir/lib/Query/Matcher/RegistryManager.cpp
@@ -132,8 +132,19 @@ RegistryManager::getMatcherCompletions(llvm::ArrayRef<ArgKind> acceptedTypes,
VariantMatcher RegistryManager::constructMatcher(
MatcherCtor ctor, internal::SourceRange nameRange,
- llvm::ArrayRef<ParserValue> args, internal::Diagnostics *error) {
- return ctor->create(nameRange, args, error);
+ llvm::StringRef functionName, llvm::ArrayRef<ParserValue> args,
+ internal::Diagnostics *error) {
+ VariantMatcher out = ctor->create(nameRange, args, error);
+ if (functionName.empty() || out.isNull())
+ return out;
+
+ if (std::optional<DynMatcher> result = out.getDynMatcher()) {
+ result->setFunctionName(functionName);
+ return VariantMatcher::SingleMatcher(*result);
+ }
+
+ error->addError(nameRange, internal::ErrorType::RegistryNotBindable);
+ return {};
}
} // namespace mlir::query::matcher
diff --git a/mlir/lib/Query/Matcher/RegistryManager.h b/mlir/lib/Query/Matcher/RegistryManager.h
index 5f2867261225e7..e2026e97f83dcb 100644
--- a/mlir/lib/Query/Matcher/RegistryManager.h
+++ b/mlir/lib/Query/Matcher/RegistryManager.h
@@ -61,6 +61,7 @@ class RegistryManager {
static VariantMatcher constructMatcher(MatcherCtor ctor,
internal::SourceRange nameRange,
+ llvm::StringRef functionName,
ArrayRef<ParserValue> args,
internal::Diagnostics *error);
};
diff --git a/mlir/lib/Query/Query.cpp b/mlir/lib/Query/Query.cpp
index 5c42e5a5f0a116..27db52b37dade0 100644
--- a/mlir/lib/Query/Query.cpp
+++ b/mlir/lib/Query/Query.cpp
@@ -8,6 +8,8 @@
#include "mlir/Query/Query.h"
#include "QueryParser.h"
+#include "mlir/Dialect/Func/IR/FuncOps.h"
+#include "mlir/IR/IRMapping.h"
#include "mlir/Query/Matcher/MatchFinder.h"
#include "mlir/Query/QuerySession.h"
#include "mlir/Support/LogicalResult.h"
@@ -34,6 +36,70 @@ static void printMatch(llvm::raw_ostream &os, QuerySession &qs, Operation *op,
"\"" + binding + "\" binds here");
}
+// TODO: Extract into a helper function that can be reused outside query
+// context.
+static Operation *extractFunction(std::vector<Operation *> &ops,
+ MLIRContext *context,
+ llvm::StringRef functionName) {
+ context->loadDialect<func::FuncDialect>();
+ OpBuilder builder(context);
+
+ // Collect data for function creation
+ std::vector<Operation *> slice;
+ std::vector<Value> values;
+ std::vector<Type> outputTypes;
+
+ for (auto *op : ops) {
+ // Return op's operands are propagated, but the op itself isn't needed.
+ if (!isa<func::ReturnOp>(op))
+ slice.push_back(op);
+
+ // All results are returned by the extracted function.
+ outputTypes.insert(outputTypes.end(), op->getResults().getTypes().begin(),
+ op->getResults().getTypes().end());
+
+ // Track all values that need to be taken as input to function.
+ values.insert(values.end(), op->getOperands().begin(),
+ op->getOperands().end());
+ }
+
+ // Create the function
+ FunctionType funcType =
+ builder.getFunctionType(ValueRange(values), outputTypes);
+ auto loc = builder.getUnknownLoc();
+ func::FuncOp funcOp = func::FuncOp::create(loc, functionName, funcType);
+
+ builder.setInsertionPointToEnd(funcOp.addEntryBlock());
+
+ // Map original values to function arguments
+ IRMapping mapper;
+ for (const auto &arg : llvm::enumerate(values))
+ mapper.map(arg.value(), funcOp.getArgument(arg.index()));
+
+ // Clone operations and build function body
+ std::vector<Operation *> clonedOps;
+ std::vector<Value> clonedVals;
+ for (Operation *slicedOp : slice) {
+ Operation *clonedOp =
+ clonedOps.emplace_back(builder.clone(*slicedOp, mapper));
+ clonedVals.insert(clonedVals.end(), clonedOp->result_begin(),
+ clonedOp->result_end());
+ }
+ // Add return operation
+ builder.create<func::ReturnOp>(loc, clonedVals);
+
+ // Remove unused function arguments
+ size_t currentIndex = 0;
+ while (currentIndex < funcOp.getNumArguments()) {
+ if (funcOp.getArgument(currentIndex).use_empty())
+ funcOp.eraseArgument(currentIndex);
+ else
+ ++currentIndex;
+ }
+
+ return funcOp;
+}
+
Query::~Query() = default;
mlir::LogicalResult InvalidQuery::run(llvm::raw_ostream &os,
@@ -65,9 +131,21 @@ mlir::LogicalResult QuitQuery::run(llvm::raw_ostream &os,
mlir::LogicalResult MatchQuery::run(llvm::raw_ostream &os,
QuerySession &qs) const {
+ Operation *rootOp = qs.getRootOp();
int matchCount = 0;
std::vector<Operation *> matches =
- matcher::MatchFinder().getMatches(qs.getRootOp(), matcher);
+ matcher::MatchFinder().getMatches(rootOp, matcher);
+
+ // An extract call is recognized by considering if the matcher has a name.
+ // TODO: Consider making the extract more explicit.
+ if (matcher.hasFunctionName()) {
+ auto functionName = matcher.getFunctionName();
+ Operation *function =
+ extractFunction(matches, rootOp->getContext(), functionName);
+ os << "\n" << *function << "\n\n";
+ return mlir::success();
+ }
+
os << "\n";
for (Operation *op : matches) {
os << "Match #" << ++matchCount << ":\n\n";
diff --git a/mlir/test/mlir-query/function-extraction.mlir b/mlir/test/mlir-query/function-extraction.mlir
new file mode 100644
index 00000000000000..a783f65c6761bc
--- /dev/null
+++ b/mlir/test/mlir-query/function-extraction.mlir
@@ -0,0 +1,19 @@
+// RUN: mlir-query %s -c "m hasOpName(\"arith.mulf\").extract(\"testmul\")" | FileCheck %s
+
+// CHECK: func.func @testmul({{.*}}) -> (f32, f32, f32) {
+// CHECK: %[[MUL0:.*]] = arith.mulf {{.*}} : f32
+// CHECK: %[[MUL1:.*]] = arith.mulf {{.*}}, %[[MUL0]] : f32
+// CHECK: %[[MUL2:.*]] = arith.mulf {{.*}} : f32
+// CHECK-NEXT: return %[[MUL0]], %[[MUL1]], %[[MUL2]] : f32, f32, f32
+
+func.func @mixedOperations(%a: f32, %b: f32, %c: f32) -> f32 {
+ %sum0 = arith.addf %a, %b : f32
+ %sub0 = arith.subf %sum0, %c : f32
+ %mul0 = arith.mulf %a, %sub0 : f32
+ %sum1 = arith.addf %b, %c : f32
+ %mul1 = arith.mulf %sum1, %mul0 : f32
+ %sub2 = arith.subf %mul1, %a : f32
+ %sum2 = arith.addf %mul1, %b : f32
+ %mul2 = arith.mulf %sub2, %sum2 : f32
+ return %mul2 : f32
+}
>From 58e476f757775313d8b2649dedb9a7c5d30d8e19 Mon Sep 17 00:00:00 2001
From: Louis Dionne <ldionne.2 at gmail.com>
Date: Thu, 29 Feb 2024 10:48:23 -0500
Subject: [PATCH 142/406] [libc++] Map forward declaration headers for
iostreams to <iosfwd> (#83327)
This seems more appropriate than mapping them to the headers that
contain actual definitions.
---
libcxx/include/libcxx.imp | 12 ++++++------
libcxx/utils/generate_iwyu_mapping.py | 2 ++
2 files changed, 8 insertions(+), 6 deletions(-)
diff --git a/libcxx/include/libcxx.imp b/libcxx/include/libcxx.imp
index 22fbea99b848bb..eeeae39ca101d9 100644
--- a/libcxx/include/libcxx.imp
+++ b/libcxx/include/libcxx.imp
@@ -425,17 +425,17 @@
{ include: [ "<__fwd/bit_reference.h>", "private", "<bitset>", "public" ] },
{ include: [ "<__fwd/bit_reference.h>", "private", "<vector>", "public" ] },
{ include: [ "<__fwd/complex.h>", "private", "<complex>", "public" ] },
- { include: [ "<__fwd/fstream.h>", "private", "<fstream>", "public" ] },
+ { include: [ "<__fwd/fstream.h>", "private", "<iosfwd>", "public" ] },
{ include: [ "<__fwd/hash.h>", "private", "<functional>", "public" ] },
- { include: [ "<__fwd/ios.h>", "private", "<ios>", "public" ] },
- { include: [ "<__fwd/istream.h>", "private", "<istream>", "public" ] },
+ { include: [ "<__fwd/ios.h>", "private", "<iosfwd>", "public" ] },
+ { include: [ "<__fwd/istream.h>", "private", "<iosfwd>", "public" ] },
{ include: [ "<__fwd/mdspan.h>", "private", "<mdspan>", "public" ] },
{ include: [ "<__fwd/memory_resource.h>", "private", "<memory_resource>", "public" ] },
- { include: [ "<__fwd/ostream.h>", "private", "<ostream>", "public" ] },
+ { include: [ "<__fwd/ostream.h>", "private", "<iosfwd>", "public" ] },
{ include: [ "<__fwd/pair.h>", "private", "<utility>", "public" ] },
{ include: [ "<__fwd/span.h>", "private", "<span>", "public" ] },
- { include: [ "<__fwd/sstream.h>", "private", "<sstream>", "public" ] },
- { include: [ "<__fwd/streambuf.h>", "private", "<streambuf>", "public" ] },
+ { include: [ "<__fwd/sstream.h>", "private", "<iosfwd>", "public" ] },
+ { include: [ "<__fwd/streambuf.h>", "private", "<iosfwd>", "public" ] },
{ include: [ "<__fwd/string.h>", "private", "<string>", "public" ] },
{ include: [ "<__fwd/string_view.h>", "private", "<string_view>", "public" ] },
{ include: [ "<__fwd/subrange.h>", "private", "<ranges>", "public" ] },
diff --git a/libcxx/utils/generate_iwyu_mapping.py b/libcxx/utils/generate_iwyu_mapping.py
index 0a650250e747f6..6eb2c6095bf1e7 100644
--- a/libcxx/utils/generate_iwyu_mapping.py
+++ b/libcxx/utils/generate_iwyu_mapping.py
@@ -40,6 +40,8 @@ def IWYU_mapping(header: str) -> typing.Optional[typing.List[str]]:
return ["utility"]
elif header == "__fwd/subrange.h":
return ["ranges"]
+ elif re.match("__fwd/(fstream|ios|istream|ostream|sstream|streambuf)[.]h", header):
+ return ["iosfwd"]
# Handle remaining forward declaration headers
elif re.match("__fwd/(.+)[.]h", header):
return [re.match("__fwd/(.+)[.]h", header).group(1)]
>From 962f3e4e5bbdbfacb8c857a15013dae09bc49956 Mon Sep 17 00:00:00 2001
From: Sumanth Gundapaneni <sgundapa at quicinc.com>
Date: Thu, 29 Feb 2024 09:51:52 -0600
Subject: [PATCH 143/406] [Hexagon] Use the correct call to detect debug
instructions (#83373)
---
llvm/lib/Target/Hexagon/HexagonBitSimplify.cpp | 2 +-
llvm/lib/Target/Hexagon/HexagonVLIWPacketizer.cpp | 2 +-
2 files changed, 2 insertions(+), 2 deletions(-)
diff --git a/llvm/lib/Target/Hexagon/HexagonBitSimplify.cpp b/llvm/lib/Target/Hexagon/HexagonBitSimplify.cpp
index 3b8234c0118435..4c18e076c43936 100644
--- a/llvm/lib/Target/Hexagon/HexagonBitSimplify.cpp
+++ b/llvm/lib/Target/Hexagon/HexagonBitSimplify.cpp
@@ -1002,7 +1002,7 @@ namespace {
bool DeadCodeElimination::isDead(unsigned R) const {
for (const MachineOperand &MO : MRI.use_operands(R)) {
const MachineInstr *UseI = MO.getParent();
- if (UseI->isDebugValue())
+ if (UseI->isDebugInstr())
continue;
if (UseI->isPHI()) {
assert(!UseI->getOperand(0).getSubReg());
diff --git a/llvm/lib/Target/Hexagon/HexagonVLIWPacketizer.cpp b/llvm/lib/Target/Hexagon/HexagonVLIWPacketizer.cpp
index e38c8bacaf2bab..56472d633694ae 100644
--- a/llvm/lib/Target/Hexagon/HexagonVLIWPacketizer.cpp
+++ b/llvm/lib/Target/Hexagon/HexagonVLIWPacketizer.cpp
@@ -1180,7 +1180,7 @@ void HexagonPacketizerList::unpacketizeSoloInstrs(MachineFunction &MF) {
bool InsertBeforeBundle;
if (MI.isInlineAsm())
InsertBeforeBundle = !hasWriteToReadDep(MI, *BundleIt, HRI);
- else if (MI.isDebugValue())
+ else if (MI.isDebugInstr())
InsertBeforeBundle = true;
else
continue;
>From 147dc81c1d220a54e9e7d0d4dba7f4b69708ffb7 Mon Sep 17 00:00:00 2001
From: Jonathan Thackray <jonathan.thackray at arm.com>
Date: Thu, 29 Feb 2024 15:57:50 +0000
Subject: [PATCH 144/406] [ARM][AArch64] Enable FEAT_FHM for Arm Neoverse N2
(#82613)
Correct an issue with Arm Neoverse N2 after it was
changed to a v9a core in change
f576cbe44eabb8a5ac0af817424a0d1e7c8fbf85:
* FEAT_FHM should be enabled for this core.
---
llvm/include/llvm/TargetParser/AArch64TargetParser.h | 4 ++--
llvm/include/llvm/TargetParser/ARMTargetParser.def | 4 ++--
llvm/lib/Target/AArch64/AArch64.td | 2 +-
llvm/lib/Target/ARM/ARM.td | 1 +
llvm/unittests/TargetParser/TargetParserTest.cpp | 7 ++++---
5 files changed, 10 insertions(+), 8 deletions(-)
diff --git a/llvm/include/llvm/TargetParser/AArch64TargetParser.h b/llvm/include/llvm/TargetParser/AArch64TargetParser.h
index 93e9ed46642dfc..404424beb01931 100644
--- a/llvm/include/llvm/TargetParser/AArch64TargetParser.h
+++ b/llvm/include/llvm/TargetParser/AArch64TargetParser.h
@@ -658,8 +658,8 @@ inline constexpr CpuInfo CpuInfos[] = {
AArch64::AEK_SSBS}))},
{"neoverse-n2", ARMV9A,
(AArch64::ExtensionBitset(
- {AArch64::AEK_BF16, AArch64::AEK_DOTPROD,
- AArch64::AEK_FP16, AArch64::AEK_I8MM, AArch64::AEK_MTE,
+ {AArch64::AEK_BF16, AArch64::AEK_DOTPROD, AArch64::AEK_FP16,
+ AArch64::AEK_FP16FML, AArch64::AEK_I8MM, AArch64::AEK_MTE,
AArch64::AEK_SB, AArch64::AEK_SSBS, AArch64::AEK_SVE,
AArch64::AEK_SVE2, AArch64::AEK_SVE2BITPERM}))},
{"neoverse-512tvb", ARMV8_4A,
diff --git a/llvm/include/llvm/TargetParser/ARMTargetParser.def b/llvm/include/llvm/TargetParser/ARMTargetParser.def
index 1797a1b238d349..f0ddaa1459e567 100644
--- a/llvm/include/llvm/TargetParser/ARMTargetParser.def
+++ b/llvm/include/llvm/TargetParser/ARMTargetParser.def
@@ -346,8 +346,8 @@ ARM_CPU_NAME("cortex-x1c", ARMV8_2A, FK_CRYPTO_NEON_FP_ARMV8, false,
ARM_CPU_NAME("neoverse-n1", ARMV8_2A, FK_CRYPTO_NEON_FP_ARMV8, false,
(ARM::AEK_FP16 | ARM::AEK_DOTPROD))
ARM_CPU_NAME("neoverse-n2", ARMV9A, FK_NEON_FP_ARMV8, false,
- (ARM::AEK_BF16 | ARM::AEK_DOTPROD | ARM::AEK_I8MM | ARM::AEK_RAS |
- ARM::AEK_SB))
+ (ARM::AEK_BF16 | ARM::AEK_DOTPROD | ARM::AEK_FP16FML |
+ ARM::AEK_I8MM | ARM::AEK_RAS | ARM::AEK_SB ))
ARM_CPU_NAME("neoverse-v1", ARMV8_4A, FK_CRYPTO_NEON_FP_ARMV8, false,
(ARM::AEK_RAS | ARM::AEK_FP16 | ARM::AEK_BF16 | ARM::AEK_DOTPROD))
ARM_CPU_NAME("cyclone", ARMV8A, FK_CRYPTO_NEON_FP_ARMV8, false, ARM::AEK_CRC)
diff --git a/llvm/lib/Target/AArch64/AArch64.td b/llvm/lib/Target/AArch64/AArch64.td
index 169b00e5ebc989..b837066554f3c6 100644
--- a/llvm/lib/Target/AArch64/AArch64.td
+++ b/llvm/lib/Target/AArch64/AArch64.td
@@ -1514,7 +1514,7 @@ def ProcessorFeatures {
FeatureFPARMv8, FeatureFullFP16, FeatureNEON,
FeatureRCPC, FeatureSPE, FeatureSSBS,
FeaturePerfMon];
- list<SubtargetFeature> NeoverseN2 = [HasV9_0aOps, FeatureBF16, FeatureETE,
+ list<SubtargetFeature> NeoverseN2 = [HasV9_0aOps, FeatureBF16, FeatureETE, FeatureFP16FML,
FeatureMatMulInt8, FeatureMTE, FeatureSVE2,
FeatureSVE2BitPerm, FeatureTRBE,
FeaturePerfMon];
diff --git a/llvm/lib/Target/ARM/ARM.td b/llvm/lib/Target/ARM/ARM.td
index 877781568307dc..b62e1a032631fd 100644
--- a/llvm/lib/Target/ARM/ARM.td
+++ b/llvm/lib/Target/ARM/ARM.td
@@ -1682,6 +1682,7 @@ def : ProcNoItin<"neoverse-n1", [ARMv82a,
def : ProcNoItin<"neoverse-n2", [ARMv9a,
FeatureBF16,
+ FeatureFP16FML,
FeatureMatMulInt8]>;
def : ProcessorModel<"cyclone", SwiftModel, [ARMv8a, ProcSwift,
diff --git a/llvm/unittests/TargetParser/TargetParserTest.cpp b/llvm/unittests/TargetParser/TargetParserTest.cpp
index e89fc687451cd7..297100441113a6 100644
--- a/llvm/unittests/TargetParser/TargetParserTest.cpp
+++ b/llvm/unittests/TargetParser/TargetParserTest.cpp
@@ -439,7 +439,7 @@ INSTANTIATE_TEST_SUITE_P(
ARM::AEK_HWDIVARM | ARM::AEK_MP | ARM::AEK_SEC |
ARM::AEK_VIRT | ARM::AEK_DSP | ARM::AEK_BF16 |
ARM::AEK_DOTPROD | ARM::AEK_RAS | ARM::AEK_I8MM |
- ARM::AEK_SB,
+ ARM::AEK_FP16FML | ARM::AEK_SB,
"9-A"),
ARMCPUTestParams<uint64_t>("neoverse-v1", "armv8.4-a", "crypto-neon-fp-armv8",
ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT |
@@ -1575,8 +1575,9 @@ INSTANTIATE_TEST_SUITE_P(
AArch64::AEK_SB, AArch64::AEK_SVE2,
AArch64::AEK_SVE2BITPERM, AArch64::AEK_BF16,
AArch64::AEK_I8MM, AArch64::AEK_JSCVT,
- AArch64::AEK_FCMA, AArch64::AEK_PAUTH})),
- "8.5-A"),
+ AArch64::AEK_FCMA, AArch64::AEK_PAUTH,
+ AArch64::AEK_FP16FML})),
+ "9-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"ampere1", "armv8.6-a", "crypto-neon-fp-armv8",
(AArch64::ExtensionBitset(
>From 310ed337092d6afc78594e1d8e32e6f44fff5568 Mon Sep 17 00:00:00 2001
From: Jonas Devlieghere <jonas at devlieghere.com>
Date: Thu, 29 Feb 2024 08:05:38 -0800
Subject: [PATCH 145/406] [Support] Use all_read | all_write for
createTemporaryFile (#83360)
In a04879ce7dd6, dsymutil switched from using TempFile to
createTemporaryFile. This caused a regression because the two use
different permissions:
- TempFile opens the file as all_read | all_write
- createTemporaryFile opens the file as owner_read | owner_write
The latter turns out to be problematic for dsymutil because it either
promotes the temporary to a proper output file, or it would pass it to
`lipo` to create a universal binary and `lipo` preserves the permissions
of the input files. Either way, this caused issues when the build system
was run as a different user than the one ingesting the resulting
binaries.
I did some version control archeology and I couldn't find evidence that
these permissions were chosen purposely. Both could be considered
reasonable default.
This patch changes the permissions to `all read | all write` to make the
two consistent and match the one currently used by the higher level
abstraction (TempFile).
rdar://123722848
---
llvm/lib/Support/Path.cpp | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/llvm/lib/Support/Path.cpp b/llvm/lib/Support/Path.cpp
index c8de2c0625aa26..acee228a0d0462 100644
--- a/llvm/lib/Support/Path.cpp
+++ b/llvm/lib/Support/Path.cpp
@@ -850,7 +850,7 @@ createTemporaryFile(const Twine &Model, int &ResultFD,
"Model must be a simple filename.");
// Use P.begin() so that createUniqueEntity doesn't need to recreate Storage.
return createUniqueEntity(P.begin(), ResultFD, ResultPath, true, Type, Flags,
- owner_read | owner_write);
+ all_read | all_write);
}
static std::error_code
>From 5a0bd2a36591fe48c24de220a5f8ddef9ce6f0b1 Mon Sep 17 00:00:00 2001
From: Jonas Devlieghere <jonas at devlieghere.com>
Date: Wed, 28 Feb 2024 21:19:02 -0800
Subject: [PATCH 146/406] [lldb] Add pexpect to
LLDB_ENFORCE_STRICT_TEST_REQUIREMENTS
This executed Alex' idea [1] of adding pexpect to the list of "strict
test requirements" as we're planning to stop vendoring it. This will
ensure all the bots have the package before we toggle the default.
[1] https://github.com/llvm/llvm-project/pull/83191
---
lldb/test/CMakeLists.txt | 3 ++-
1 file changed, 2 insertions(+), 1 deletion(-)
diff --git a/lldb/test/CMakeLists.txt b/lldb/test/CMakeLists.txt
index 7c31fd487f6ff8..2a9877c721e3b4 100644
--- a/lldb/test/CMakeLists.txt
+++ b/lldb/test/CMakeLists.txt
@@ -12,7 +12,8 @@ endif()
if(LLDB_ENFORCE_STRICT_TEST_REQUIREMENTS)
message(STATUS "Enforcing strict test requirements for LLDB")
set(useful_python_modules
- psutil # Lit uses psutil to do per-test timeouts.
+ psutil # Lit uses psutil to do per-test timeouts.
+ pexpect # We no longer vendor pexpect.
)
foreach(module ${useful_python_modules})
lldb_find_python_module(${module})
>From a344db793aca6881379c7c83f5112d2870dbf958 Mon Sep 17 00:00:00 2001
From: chuongg3 <chuong.goh at arm.com>
Date: Thu, 29 Feb 2024 16:31:05 +0000
Subject: [PATCH 147/406] [AArch64][GlobalISel] Legalize G_SHUFFLE_VECTOR for
Odd-Sized Vectors (#83038)
Legalize Smaller/Larger than legal vectors with i8 and i16 element
sizes.
Vectors with elements smaller than i8 will get widened to i8 elements.
---
.../llvm/CodeGen/GlobalISel/LegalizerInfo.h | 12 +
.../CodeGen/GlobalISel/LegalizerHelper.cpp | 1 +
.../AArch64/GISel/AArch64LegalizerInfo.cpp | 3 +
.../AArch64/GlobalISel/legalize-select.mir | 72 +++---
llvm/test/CodeGen/AArch64/shufflevector.ll | 232 ++++++++++++------
5 files changed, 212 insertions(+), 108 deletions(-)
diff --git a/llvm/include/llvm/CodeGen/GlobalISel/LegalizerInfo.h b/llvm/include/llvm/CodeGen/GlobalISel/LegalizerInfo.h
index 637c2c71b02411..6afaea3f3fc5c6 100644
--- a/llvm/include/llvm/CodeGen/GlobalISel/LegalizerInfo.h
+++ b/llvm/include/llvm/CodeGen/GlobalISel/LegalizerInfo.h
@@ -908,6 +908,18 @@ class LegalizeRuleSet {
LegalizeMutations::widenScalarOrEltToNextPow2(TypeIdx, MinSize));
}
+ /// Widen the scalar or vector element type to the next power of two that is
+ /// at least MinSize. No effect if the scalar size is a power of two.
+ LegalizeRuleSet &widenScalarOrEltToNextPow2OrMinSize(unsigned TypeIdx,
+ unsigned MinSize = 0) {
+ using namespace LegalityPredicates;
+ return actionIf(
+ LegalizeAction::WidenScalar,
+ any(scalarOrEltNarrowerThan(TypeIdx, MinSize),
+ scalarOrEltSizeNotPow2(typeIdx(TypeIdx))),
+ LegalizeMutations::widenScalarOrEltToNextPow2(TypeIdx, MinSize));
+ }
+
LegalizeRuleSet &narrowScalar(unsigned TypeIdx, LegalizeMutation Mutation) {
using namespace LegalityPredicates;
return actionIf(LegalizeAction::NarrowScalar, isScalar(typeIdx(TypeIdx)),
diff --git a/llvm/lib/CodeGen/GlobalISel/LegalizerHelper.cpp b/llvm/lib/CodeGen/GlobalISel/LegalizerHelper.cpp
index 8079f853aef855..1d016e684c48f6 100644
--- a/llvm/lib/CodeGen/GlobalISel/LegalizerHelper.cpp
+++ b/llvm/lib/CodeGen/GlobalISel/LegalizerHelper.cpp
@@ -2495,6 +2495,7 @@ LegalizerHelper::widenScalar(MachineInstr &MI, unsigned TypeIdx, LLT WideTy) {
case TargetOpcode::G_OR:
case TargetOpcode::G_XOR:
case TargetOpcode::G_SUB:
+ case TargetOpcode::G_SHUFFLE_VECTOR:
// Perform operation at larger width (any extension is fines here, high bits
// don't affect the result) and then truncate the result back to the
// original type.
diff --git a/llvm/lib/Target/AArch64/GISel/AArch64LegalizerInfo.cpp b/llvm/lib/Target/AArch64/GISel/AArch64LegalizerInfo.cpp
index 91323e456a5ef8..84b4ecb7d2700a 100644
--- a/llvm/lib/Target/AArch64/GISel/AArch64LegalizerInfo.cpp
+++ b/llvm/lib/Target/AArch64/GISel/AArch64LegalizerInfo.cpp
@@ -956,6 +956,9 @@ AArch64LegalizerInfo::AArch64LegalizerInfo(const AArch64Subtarget &ST)
},
changeTo(1, 0))
.moreElementsToNextPow2(0)
+ .widenScalarOrEltToNextPow2OrMinSize(0, 8)
+ .clampNumElements(0, v8s8, v16s8)
+ .clampNumElements(0, v4s16, v8s16)
.clampNumElements(0, v4s32, v4s32)
.clampNumElements(0, v2s64, v2s64)
.moreElementsIf(
diff --git a/llvm/test/CodeGen/AArch64/GlobalISel/legalize-select.mir b/llvm/test/CodeGen/AArch64/GlobalISel/legalize-select.mir
index 4879ffd28784c1..63a26dcfea4762 100644
--- a/llvm/test/CodeGen/AArch64/GlobalISel/legalize-select.mir
+++ b/llvm/test/CodeGen/AArch64/GlobalISel/legalize-select.mir
@@ -287,39 +287,47 @@ body: |
; CHECK-NEXT: %q0:_(<4 x s32>) = COPY $q0
; CHECK-NEXT: %q1:_(<4 x s32>) = COPY $q1
; CHECK-NEXT: %q2:_(<4 x s32>) = COPY $q2
- ; CHECK-NEXT: %vec_cond0:_(<4 x s1>) = G_ICMP intpred(eq), %q0(<4 x s32>), %q1
- ; CHECK-NEXT: %vec_cond1:_(<4 x s1>) = G_ICMP intpred(eq), %q0(<4 x s32>), %q2
+ ; CHECK-NEXT: [[ICMP:%[0-9]+]]:_(<4 x s32>) = G_ICMP intpred(eq), %q0(<4 x s32>), %q1
+ ; CHECK-NEXT: [[ICMP1:%[0-9]+]]:_(<4 x s32>) = G_ICMP intpred(eq), %q0(<4 x s32>), %q2
; CHECK-NEXT: [[C:%[0-9]+]]:_(s32) = G_CONSTANT i32 4100
- ; CHECK-NEXT: [[C1:%[0-9]+]]:_(s32) = G_FCONSTANT float 0.000000e+00
- ; CHECK-NEXT: [[BUILD_VECTOR:%[0-9]+]]:_(<4 x s32>) = G_BUILD_VECTOR [[C1]](s32), [[C1]](s32), [[C1]](s32), [[C1]](s32)
- ; CHECK-NEXT: %cmp:_(s1) = G_ICMP intpred(eq), %w0(s32), [[C]]
- ; CHECK-NEXT: [[ZEXT:%[0-9]+]]:_(s32) = G_ZEXT %cmp(s1)
- ; CHECK-NEXT: [[SEXT_INREG:%[0-9]+]]:_(s32) = G_SEXT_INREG [[ZEXT]], 1
- ; CHECK-NEXT: [[TRUNC:%[0-9]+]]:_(s1) = G_TRUNC [[SEXT_INREG]](s32)
- ; CHECK-NEXT: [[DEF:%[0-9]+]]:_(<4 x s1>) = G_IMPLICIT_DEF
- ; CHECK-NEXT: [[C2:%[0-9]+]]:_(s64) = G_CONSTANT i64 0
- ; CHECK-NEXT: [[IVEC:%[0-9]+]]:_(<4 x s1>) = G_INSERT_VECTOR_ELT [[DEF]], [[TRUNC]](s1), [[C2]](s64)
- ; CHECK-NEXT: [[SHUF:%[0-9]+]]:_(<4 x s1>) = G_SHUFFLE_VECTOR [[IVEC]](<4 x s1>), [[DEF]], shufflemask(0, 0, 0, 0)
- ; CHECK-NEXT: [[C3:%[0-9]+]]:_(s8) = G_CONSTANT i8 1
- ; CHECK-NEXT: [[TRUNC1:%[0-9]+]]:_(s1) = G_TRUNC [[C3]](s8)
- ; CHECK-NEXT: [[BUILD_VECTOR1:%[0-9]+]]:_(<4 x s1>) = G_BUILD_VECTOR [[TRUNC1]](s1), [[TRUNC1]](s1), [[TRUNC1]](s1), [[TRUNC1]](s1)
- ; CHECK-NEXT: [[ANYEXT:%[0-9]+]]:_(<4 x s16>) = G_ANYEXT [[SHUF]](<4 x s1>)
- ; CHECK-NEXT: [[ANYEXT1:%[0-9]+]]:_(<4 x s16>) = G_ANYEXT [[BUILD_VECTOR1]](<4 x s1>)
- ; CHECK-NEXT: [[XOR:%[0-9]+]]:_(<4 x s16>) = G_XOR [[ANYEXT]], [[ANYEXT1]]
- ; CHECK-NEXT: [[TRUNC2:%[0-9]+]]:_(<4 x s1>) = G_TRUNC [[XOR]](<4 x s16>)
- ; CHECK-NEXT: [[ANYEXT2:%[0-9]+]]:_(<4 x s16>) = G_ANYEXT %vec_cond0(<4 x s1>)
- ; CHECK-NEXT: [[ANYEXT3:%[0-9]+]]:_(<4 x s16>) = G_ANYEXT [[SHUF]](<4 x s1>)
- ; CHECK-NEXT: [[AND:%[0-9]+]]:_(<4 x s16>) = G_AND [[ANYEXT2]], [[ANYEXT3]]
- ; CHECK-NEXT: [[TRUNC3:%[0-9]+]]:_(<4 x s1>) = G_TRUNC [[AND]](<4 x s16>)
- ; CHECK-NEXT: [[ANYEXT4:%[0-9]+]]:_(<4 x s16>) = G_ANYEXT %vec_cond1(<4 x s1>)
- ; CHECK-NEXT: [[ANYEXT5:%[0-9]+]]:_(<4 x s16>) = G_ANYEXT [[TRUNC2]](<4 x s1>)
- ; CHECK-NEXT: [[AND1:%[0-9]+]]:_(<4 x s16>) = G_AND [[ANYEXT4]], [[ANYEXT5]]
- ; CHECK-NEXT: [[TRUNC4:%[0-9]+]]:_(<4 x s1>) = G_TRUNC [[AND1]](<4 x s16>)
- ; CHECK-NEXT: [[ANYEXT6:%[0-9]+]]:_(<4 x s16>) = G_ANYEXT [[TRUNC3]](<4 x s1>)
- ; CHECK-NEXT: [[ANYEXT7:%[0-9]+]]:_(<4 x s16>) = G_ANYEXT [[TRUNC4]](<4 x s1>)
- ; CHECK-NEXT: [[OR:%[0-9]+]]:_(<4 x s16>) = G_OR [[ANYEXT6]], [[ANYEXT7]]
- ; CHECK-NEXT: %select:_(<4 x s1>) = G_TRUNC [[OR]](<4 x s16>)
- ; CHECK-NEXT: %zext_select:_(<4 x s32>) = G_ZEXT %select(<4 x s1>)
+ ; CHECK-NEXT: [[ICMP2:%[0-9]+]]:_(s32) = G_ICMP intpred(eq), %w0(s32), [[C]]
+ ; CHECK-NEXT: [[SEXT_INREG:%[0-9]+]]:_(s32) = G_SEXT_INREG [[ICMP2]], 1
+ ; CHECK-NEXT: [[DEF:%[0-9]+]]:_(s8) = G_IMPLICIT_DEF
+ ; CHECK-NEXT: [[DEF1:%[0-9]+]]:_(s16) = G_IMPLICIT_DEF
+ ; CHECK-NEXT: [[COPY:%[0-9]+]]:_(s16) = COPY [[DEF1]](s16)
+ ; CHECK-NEXT: [[COPY1:%[0-9]+]]:_(s16) = COPY [[DEF1]](s16)
+ ; CHECK-NEXT: [[COPY2:%[0-9]+]]:_(s16) = COPY [[DEF1]](s16)
+ ; CHECK-NEXT: [[BUILD_VECTOR:%[0-9]+]]:_(<4 x s16>) = G_BUILD_VECTOR [[COPY]](s16), [[COPY1]](s16), [[COPY2]](s16), [[DEF1]](s16)
+ ; CHECK-NEXT: [[C1:%[0-9]+]]:_(s64) = G_CONSTANT i64 0
+ ; CHECK-NEXT: [[TRUNC:%[0-9]+]]:_(s16) = G_TRUNC [[SEXT_INREG]](s32)
+ ; CHECK-NEXT: [[IVEC:%[0-9]+]]:_(<4 x s16>) = G_INSERT_VECTOR_ELT [[BUILD_VECTOR]], [[TRUNC]](s16), [[C1]](s64)
+ ; CHECK-NEXT: [[UV:%[0-9]+]]:_(s16), [[UV1:%[0-9]+]]:_(s16), [[UV2:%[0-9]+]]:_(s16), [[UV3:%[0-9]+]]:_(s16) = G_UNMERGE_VALUES [[IVEC]](<4 x s16>)
+ ; CHECK-NEXT: [[TRUNC1:%[0-9]+]]:_(s8) = G_TRUNC [[UV]](s16)
+ ; CHECK-NEXT: [[TRUNC2:%[0-9]+]]:_(s8) = G_TRUNC [[UV1]](s16)
+ ; CHECK-NEXT: [[TRUNC3:%[0-9]+]]:_(s8) = G_TRUNC [[UV2]](s16)
+ ; CHECK-NEXT: [[TRUNC4:%[0-9]+]]:_(s8) = G_TRUNC [[UV3]](s16)
+ ; CHECK-NEXT: [[DEF2:%[0-9]+]]:_(s8) = G_IMPLICIT_DEF
+ ; CHECK-NEXT: [[BUILD_VECTOR1:%[0-9]+]]:_(<8 x s8>) = G_BUILD_VECTOR [[TRUNC1]](s8), [[TRUNC2]](s8), [[TRUNC3]](s8), [[TRUNC4]](s8), [[DEF2]](s8), [[DEF2]](s8), [[DEF2]](s8), [[DEF2]](s8)
+ ; CHECK-NEXT: [[BUILD_VECTOR2:%[0-9]+]]:_(<8 x s8>) = G_BUILD_VECTOR [[DEF]](s8), [[DEF]](s8), [[DEF]](s8), [[DEF]](s8), [[DEF2]](s8), [[DEF2]](s8), [[DEF2]](s8), [[DEF2]](s8)
+ ; CHECK-NEXT: [[SHUF:%[0-9]+]]:_(<8 x s8>) = G_SHUFFLE_VECTOR [[BUILD_VECTOR1]](<8 x s8>), [[BUILD_VECTOR2]], shufflemask(0, 0, 0, 0, undef, undef, undef, undef)
+ ; CHECK-NEXT: [[UV4:%[0-9]+]]:_(<4 x s8>), [[UV5:%[0-9]+]]:_(<4 x s8>) = G_UNMERGE_VALUES [[SHUF]](<8 x s8>)
+ ; CHECK-NEXT: [[C2:%[0-9]+]]:_(s16) = G_CONSTANT i16 1
+ ; CHECK-NEXT: [[COPY3:%[0-9]+]]:_(s16) = COPY [[C2]](s16)
+ ; CHECK-NEXT: [[COPY4:%[0-9]+]]:_(s16) = COPY [[C2]](s16)
+ ; CHECK-NEXT: [[COPY5:%[0-9]+]]:_(s16) = COPY [[C2]](s16)
+ ; CHECK-NEXT: [[BUILD_VECTOR3:%[0-9]+]]:_(<4 x s16>) = G_BUILD_VECTOR [[COPY3]](s16), [[COPY4]](s16), [[COPY5]](s16), [[C2]](s16)
+ ; CHECK-NEXT: [[ANYEXT:%[0-9]+]]:_(<4 x s16>) = G_ANYEXT [[UV4]](<4 x s8>)
+ ; CHECK-NEXT: [[XOR:%[0-9]+]]:_(<4 x s16>) = G_XOR [[ANYEXT]], [[BUILD_VECTOR3]]
+ ; CHECK-NEXT: [[TRUNC5:%[0-9]+]]:_(<4 x s16>) = G_TRUNC [[ICMP]](<4 x s32>)
+ ; CHECK-NEXT: [[ANYEXT1:%[0-9]+]]:_(<4 x s16>) = G_ANYEXT [[UV4]](<4 x s8>)
+ ; CHECK-NEXT: [[AND:%[0-9]+]]:_(<4 x s16>) = G_AND [[TRUNC5]], [[ANYEXT1]]
+ ; CHECK-NEXT: [[TRUNC6:%[0-9]+]]:_(<4 x s16>) = G_TRUNC [[ICMP1]](<4 x s32>)
+ ; CHECK-NEXT: [[AND1:%[0-9]+]]:_(<4 x s16>) = G_AND [[TRUNC6]], [[XOR]]
+ ; CHECK-NEXT: [[OR:%[0-9]+]]:_(<4 x s16>) = G_OR [[AND]], [[AND1]]
+ ; CHECK-NEXT: [[ANYEXT2:%[0-9]+]]:_(<4 x s32>) = G_ANYEXT [[OR]](<4 x s16>)
+ ; CHECK-NEXT: [[C3:%[0-9]+]]:_(s32) = G_CONSTANT i32 1
+ ; CHECK-NEXT: [[BUILD_VECTOR4:%[0-9]+]]:_(<4 x s32>) = G_BUILD_VECTOR [[C3]](s32), [[C3]](s32), [[C3]](s32), [[C3]](s32)
+ ; CHECK-NEXT: %zext_select:_(<4 x s32>) = G_AND [[ANYEXT2]], [[BUILD_VECTOR4]]
; CHECK-NEXT: $q0 = COPY %zext_select(<4 x s32>)
; CHECK-NEXT: RET_ReallyLR implicit $q0
%w0:_(s32) = COPY $w0
diff --git a/llvm/test/CodeGen/AArch64/shufflevector.ll b/llvm/test/CodeGen/AArch64/shufflevector.ll
index df59eb8e629f44..5638347ee63340 100644
--- a/llvm/test/CodeGen/AArch64/shufflevector.ll
+++ b/llvm/test/CodeGen/AArch64/shufflevector.ll
@@ -3,15 +3,7 @@
; RUN: llc -mtriple=aarch64-none-linux-gnu -global-isel -global-isel-abort=2 %s -o - 2>&1 | FileCheck %s --check-prefixes=CHECK,CHECK-GI
; CHECK-GI: warning: Instruction selection used fallback path for shufflevector_v2i1
-; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v4i8
-; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v32i8
-; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v2i16
-; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v16i16
; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v2i1_zeroes
-; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v4i8_zeroes
-; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v32i8_zeroes
-; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v2i16_zeroes
-; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v16i16_zeroes
; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v3i8
; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v3i8_zeroes
@@ -205,68 +197,142 @@ define <2 x i1> @shufflevector_v2i1(<2 x i1> %a, <2 x i1> %b){
}
define i32 @shufflevector_v4i8(<4 x i8> %a, <4 x i8> %b){
-; CHECK-LABEL: shufflevector_v4i8:
-; CHECK: // %bb.0:
-; CHECK-NEXT: sub sp, sp, #16
-; CHECK-NEXT: .cfi_def_cfa_offset 16
-; CHECK-NEXT: ext v0.8b, v1.8b, v0.8b, #6
-; CHECK-NEXT: zip1 v1.4h, v1.4h, v0.4h
-; CHECK-NEXT: ext v0.8b, v0.8b, v1.8b, #4
-; CHECK-NEXT: xtn v0.8b, v0.8h
-; CHECK-NEXT: fmov w0, s0
-; CHECK-NEXT: add sp, sp, #16
-; CHECK-NEXT: ret
+; CHECK-SD-LABEL: shufflevector_v4i8:
+; CHECK-SD: // %bb.0:
+; CHECK-SD-NEXT: sub sp, sp, #16
+; CHECK-SD-NEXT: .cfi_def_cfa_offset 16
+; CHECK-SD-NEXT: ext v0.8b, v1.8b, v0.8b, #6
+; CHECK-SD-NEXT: zip1 v1.4h, v1.4h, v0.4h
+; CHECK-SD-NEXT: ext v0.8b, v0.8b, v1.8b, #4
+; CHECK-SD-NEXT: xtn v0.8b, v0.8h
+; CHECK-SD-NEXT: fmov w0, s0
+; CHECK-SD-NEXT: add sp, sp, #16
+; CHECK-SD-NEXT: ret
+;
+; CHECK-GI-LABEL: shufflevector_v4i8:
+; CHECK-GI: // %bb.0:
+; CHECK-GI-NEXT: // kill: def $d0 killed $d0 def $q0
+; CHECK-GI-NEXT: mov h2, v0.h[1]
+; CHECK-GI-NEXT: // kill: def $d1 killed $d1 def $q1
+; CHECK-GI-NEXT: mov h3, v1.h[1]
+; CHECK-GI-NEXT: adrp x8, .LCPI15_0
+; CHECK-GI-NEXT: mov h4, v0.h[2]
+; CHECK-GI-NEXT: mov h5, v0.h[3]
+; CHECK-GI-NEXT: mov h6, v1.h[3]
+; CHECK-GI-NEXT: mov v0.b[1], v2.b[0]
+; CHECK-GI-NEXT: mov h2, v1.h[2]
+; CHECK-GI-NEXT: mov v1.b[1], v3.b[0]
+; CHECK-GI-NEXT: mov v0.b[2], v4.b[0]
+; CHECK-GI-NEXT: mov v1.b[2], v2.b[0]
+; CHECK-GI-NEXT: mov v0.b[3], v5.b[0]
+; CHECK-GI-NEXT: mov v1.b[3], v6.b[0]
+; CHECK-GI-NEXT: mov v0.b[4], v0.b[0]
+; CHECK-GI-NEXT: mov v1.b[4], v0.b[0]
+; CHECK-GI-NEXT: mov v0.b[5], v0.b[0]
+; CHECK-GI-NEXT: mov v1.b[5], v0.b[0]
+; CHECK-GI-NEXT: mov v0.b[6], v0.b[0]
+; CHECK-GI-NEXT: mov v1.b[6], v0.b[0]
+; CHECK-GI-NEXT: mov v0.b[7], v0.b[0]
+; CHECK-GI-NEXT: mov v1.b[7], v0.b[0]
+; CHECK-GI-NEXT: mov v0.d[1], v1.d[0]
+; CHECK-GI-NEXT: ldr d1, [x8, :lo12:.LCPI15_0]
+; CHECK-GI-NEXT: tbl v0.16b, { v0.16b }, v1.16b
+; CHECK-GI-NEXT: fmov w0, s0
+; CHECK-GI-NEXT: ret
%c = shufflevector <4 x i8> %a, <4 x i8> %b, <4 x i32> <i32 1, i32 2, i32 4, i32 7>
%d = bitcast <4 x i8> %c to i32
ret i32 %d
}
define <32 x i8> @shufflevector_v32i8(<32 x i8> %a, <32 x i8> %b){
-; CHECK-LABEL: shufflevector_v32i8:
-; CHECK: // %bb.0:
-; CHECK-NEXT: // kill: def $q2 killed $q2 def $q1_q2
-; CHECK-NEXT: adrp x8, .LCPI16_0
-; CHECK-NEXT: adrp x9, .LCPI16_1
-; CHECK-NEXT: mov v1.16b, v0.16b
-; CHECK-NEXT: ldr q3, [x8, :lo12:.LCPI16_0]
-; CHECK-NEXT: ldr q4, [x9, :lo12:.LCPI16_1]
-; CHECK-NEXT: tbl v0.16b, { v1.16b, v2.16b }, v3.16b
-; CHECK-NEXT: tbl v1.16b, { v1.16b, v2.16b }, v4.16b
-; CHECK-NEXT: ret
+; CHECK-SD-LABEL: shufflevector_v32i8:
+; CHECK-SD: // %bb.0:
+; CHECK-SD-NEXT: // kill: def $q2 killed $q2 def $q1_q2
+; CHECK-SD-NEXT: adrp x8, .LCPI16_0
+; CHECK-SD-NEXT: adrp x9, .LCPI16_1
+; CHECK-SD-NEXT: mov v1.16b, v0.16b
+; CHECK-SD-NEXT: ldr q3, [x8, :lo12:.LCPI16_0]
+; CHECK-SD-NEXT: ldr q4, [x9, :lo12:.LCPI16_1]
+; CHECK-SD-NEXT: tbl v0.16b, { v1.16b, v2.16b }, v3.16b
+; CHECK-SD-NEXT: tbl v1.16b, { v1.16b, v2.16b }, v4.16b
+; CHECK-SD-NEXT: ret
+;
+; CHECK-GI-LABEL: shufflevector_v32i8:
+; CHECK-GI: // %bb.0:
+; CHECK-GI-NEXT: mov v3.16b, v0.16b
+; CHECK-GI-NEXT: adrp x8, .LCPI16_1
+; CHECK-GI-NEXT: adrp x9, .LCPI16_0
+; CHECK-GI-NEXT: mov v4.16b, v2.16b
+; CHECK-GI-NEXT: ldr q0, [x8, :lo12:.LCPI16_1]
+; CHECK-GI-NEXT: ldr q1, [x9, :lo12:.LCPI16_0]
+; CHECK-GI-NEXT: tbl v0.16b, { v3.16b, v4.16b }, v0.16b
+; CHECK-GI-NEXT: tbl v1.16b, { v3.16b, v4.16b }, v1.16b
+; CHECK-GI-NEXT: ret
%c = shufflevector <32 x i8> %a, <32 x i8> %b, <32 x i32> <i32 0, i32 32, i32 32, i32 32, i32 1, i32 32, i32 32, i32 32, i32 2, i32 32, i32 32, i32 32, i32 3, i32 32, i32 32, i32 32, i32 4, i32 32, i32 32, i32 32, i32 5, i32 32, i32 32, i32 32, i32 6, i32 32, i32 32, i32 32, i32 7, i32 32, i32 32, i32 32>
ret <32 x i8> %c
}
define i32 @shufflevector_v2i16(<2 x i16> %a, <2 x i16> %b){
-; CHECK-LABEL: shufflevector_v2i16:
-; CHECK: // %bb.0:
-; CHECK-NEXT: sub sp, sp, #16
-; CHECK-NEXT: .cfi_def_cfa_offset 16
-; CHECK-NEXT: ext v0.8b, v0.8b, v1.8b, #4
-; CHECK-NEXT: mov w8, v0.s[1]
-; CHECK-NEXT: fmov w9, s0
-; CHECK-NEXT: strh w9, [sp, #12]
-; CHECK-NEXT: strh w8, [sp, #14]
-; CHECK-NEXT: ldr w0, [sp, #12]
-; CHECK-NEXT: add sp, sp, #16
-; CHECK-NEXT: ret
+; CHECK-SD-LABEL: shufflevector_v2i16:
+; CHECK-SD: // %bb.0:
+; CHECK-SD-NEXT: sub sp, sp, #16
+; CHECK-SD-NEXT: .cfi_def_cfa_offset 16
+; CHECK-SD-NEXT: ext v0.8b, v0.8b, v1.8b, #4
+; CHECK-SD-NEXT: mov w8, v0.s[1]
+; CHECK-SD-NEXT: fmov w9, s0
+; CHECK-SD-NEXT: strh w9, [sp, #12]
+; CHECK-SD-NEXT: strh w8, [sp, #14]
+; CHECK-SD-NEXT: ldr w0, [sp, #12]
+; CHECK-SD-NEXT: add sp, sp, #16
+; CHECK-SD-NEXT: ret
+;
+; CHECK-GI-LABEL: shufflevector_v2i16:
+; CHECK-GI: // %bb.0:
+; CHECK-GI-NEXT: // kill: def $d0 killed $d0 def $q0
+; CHECK-GI-NEXT: mov s2, v0.s[1]
+; CHECK-GI-NEXT: // kill: def $d1 killed $d1 def $q1
+; CHECK-GI-NEXT: mov s3, v1.s[1]
+; CHECK-GI-NEXT: adrp x8, .LCPI17_0
+; CHECK-GI-NEXT: mov v0.h[1], v2.h[0]
+; CHECK-GI-NEXT: mov v1.h[1], v3.h[0]
+; CHECK-GI-NEXT: mov v0.h[2], v0.h[0]
+; CHECK-GI-NEXT: mov v1.h[2], v0.h[0]
+; CHECK-GI-NEXT: mov v0.h[3], v0.h[0]
+; CHECK-GI-NEXT: mov v1.h[3], v0.h[0]
+; CHECK-GI-NEXT: mov v0.d[1], v1.d[0]
+; CHECK-GI-NEXT: ldr d1, [x8, :lo12:.LCPI17_0]
+; CHECK-GI-NEXT: tbl v0.16b, { v0.16b }, v1.16b
+; CHECK-GI-NEXT: fmov w0, s0
+; CHECK-GI-NEXT: ret
%c = shufflevector <2 x i16> %a, <2 x i16> %b, <2 x i32> <i32 1, i32 2>
%d = bitcast <2 x i16> %c to i32
ret i32 %d
}
define <16 x i16> @shufflevector_v16i16(<16 x i16> %a, <16 x i16> %b){
-; CHECK-LABEL: shufflevector_v16i16:
-; CHECK: // %bb.0:
-; CHECK-NEXT: // kill: def $q2 killed $q2 def $q1_q2
-; CHECK-NEXT: adrp x8, .LCPI18_0
-; CHECK-NEXT: adrp x9, .LCPI18_1
-; CHECK-NEXT: mov v1.16b, v0.16b
-; CHECK-NEXT: ldr q3, [x8, :lo12:.LCPI18_0]
-; CHECK-NEXT: ldr q4, [x9, :lo12:.LCPI18_1]
-; CHECK-NEXT: tbl v0.16b, { v1.16b, v2.16b }, v3.16b
-; CHECK-NEXT: tbl v1.16b, { v1.16b, v2.16b }, v4.16b
-; CHECK-NEXT: ret
+; CHECK-SD-LABEL: shufflevector_v16i16:
+; CHECK-SD: // %bb.0:
+; CHECK-SD-NEXT: // kill: def $q2 killed $q2 def $q1_q2
+; CHECK-SD-NEXT: adrp x8, .LCPI18_0
+; CHECK-SD-NEXT: adrp x9, .LCPI18_1
+; CHECK-SD-NEXT: mov v1.16b, v0.16b
+; CHECK-SD-NEXT: ldr q3, [x8, :lo12:.LCPI18_0]
+; CHECK-SD-NEXT: ldr q4, [x9, :lo12:.LCPI18_1]
+; CHECK-SD-NEXT: tbl v0.16b, { v1.16b, v2.16b }, v3.16b
+; CHECK-SD-NEXT: tbl v1.16b, { v1.16b, v2.16b }, v4.16b
+; CHECK-SD-NEXT: ret
+;
+; CHECK-GI-LABEL: shufflevector_v16i16:
+; CHECK-GI: // %bb.0:
+; CHECK-GI-NEXT: mov v3.16b, v0.16b
+; CHECK-GI-NEXT: adrp x8, .LCPI18_1
+; CHECK-GI-NEXT: adrp x9, .LCPI18_0
+; CHECK-GI-NEXT: mov v4.16b, v2.16b
+; CHECK-GI-NEXT: ldr q0, [x8, :lo12:.LCPI18_1]
+; CHECK-GI-NEXT: ldr q1, [x9, :lo12:.LCPI18_0]
+; CHECK-GI-NEXT: tbl v0.16b, { v3.16b, v4.16b }, v0.16b
+; CHECK-GI-NEXT: tbl v1.16b, { v3.16b, v4.16b }, v1.16b
+; CHECK-GI-NEXT: ret
%c = shufflevector <16 x i16> %a, <16 x i16> %b, <16 x i32> <i32 0, i32 16, i32 16, i32 16, i32 1, i32 16, i32 16, i32 16, i32 1, i32 16, i32 16, i32 16, i32 3, i32 16, i32 16, i32 16>
ret <16 x i16> %c
}
@@ -332,16 +398,23 @@ define <2 x i1> @shufflevector_v2i1_zeroes(<2 x i1> %a, <2 x i1> %b){
}
define i32 @shufflevector_v4i8_zeroes(<4 x i8> %a, <4 x i8> %b){
-; CHECK-LABEL: shufflevector_v4i8_zeroes:
-; CHECK: // %bb.0:
-; CHECK-NEXT: sub sp, sp, #16
-; CHECK-NEXT: .cfi_def_cfa_offset 16
-; CHECK-NEXT: // kill: def $d0 killed $d0 def $q0
-; CHECK-NEXT: dup v0.4h, v0.h[0]
-; CHECK-NEXT: xtn v0.8b, v0.8h
-; CHECK-NEXT: fmov w0, s0
-; CHECK-NEXT: add sp, sp, #16
-; CHECK-NEXT: ret
+; CHECK-SD-LABEL: shufflevector_v4i8_zeroes:
+; CHECK-SD: // %bb.0:
+; CHECK-SD-NEXT: sub sp, sp, #16
+; CHECK-SD-NEXT: .cfi_def_cfa_offset 16
+; CHECK-SD-NEXT: // kill: def $d0 killed $d0 def $q0
+; CHECK-SD-NEXT: dup v0.4h, v0.h[0]
+; CHECK-SD-NEXT: xtn v0.8b, v0.8h
+; CHECK-SD-NEXT: fmov w0, s0
+; CHECK-SD-NEXT: add sp, sp, #16
+; CHECK-SD-NEXT: ret
+;
+; CHECK-GI-LABEL: shufflevector_v4i8_zeroes:
+; CHECK-GI: // %bb.0:
+; CHECK-GI-NEXT: fmov w8, s0
+; CHECK-GI-NEXT: dup v0.8b, w8
+; CHECK-GI-NEXT: fmov w0, s0
+; CHECK-GI-NEXT: ret
%c = shufflevector <4 x i8> %a, <4 x i8> %b, <4 x i32> <i32 0, i32 0, i32 0, i32 0>
%d = bitcast <4 x i8> %c to i32
ret i32 %d
@@ -358,19 +431,26 @@ define <32 x i8> @shufflevector_v32i8_zeroes(<32 x i8> %a, <32 x i8> %b){
}
define i32 @shufflevector_v2i16_zeroes(<2 x i16> %a, <2 x i16> %b){
-; CHECK-LABEL: shufflevector_v2i16_zeroes:
-; CHECK: // %bb.0:
-; CHECK-NEXT: sub sp, sp, #16
-; CHECK-NEXT: .cfi_def_cfa_offset 16
-; CHECK-NEXT: // kill: def $d0 killed $d0 def $q0
-; CHECK-NEXT: dup v1.2s, v0.s[0]
-; CHECK-NEXT: fmov w9, s0
-; CHECK-NEXT: strh w9, [sp, #12]
-; CHECK-NEXT: mov w8, v1.s[1]
-; CHECK-NEXT: strh w8, [sp, #14]
-; CHECK-NEXT: ldr w0, [sp, #12]
-; CHECK-NEXT: add sp, sp, #16
-; CHECK-NEXT: ret
+; CHECK-SD-LABEL: shufflevector_v2i16_zeroes:
+; CHECK-SD: // %bb.0:
+; CHECK-SD-NEXT: sub sp, sp, #16
+; CHECK-SD-NEXT: .cfi_def_cfa_offset 16
+; CHECK-SD-NEXT: // kill: def $d0 killed $d0 def $q0
+; CHECK-SD-NEXT: dup v1.2s, v0.s[0]
+; CHECK-SD-NEXT: fmov w9, s0
+; CHECK-SD-NEXT: strh w9, [sp, #12]
+; CHECK-SD-NEXT: mov w8, v1.s[1]
+; CHECK-SD-NEXT: strh w8, [sp, #14]
+; CHECK-SD-NEXT: ldr w0, [sp, #12]
+; CHECK-SD-NEXT: add sp, sp, #16
+; CHECK-SD-NEXT: ret
+;
+; CHECK-GI-LABEL: shufflevector_v2i16_zeroes:
+; CHECK-GI: // %bb.0:
+; CHECK-GI-NEXT: fmov w8, s0
+; CHECK-GI-NEXT: dup v0.4h, w8
+; CHECK-GI-NEXT: fmov w0, s0
+; CHECK-GI-NEXT: ret
%c = shufflevector <2 x i16> %a, <2 x i16> %b, <2 x i32> <i32 0, i32 0>
%d = bitcast <2 x i16> %c to i32
ret i32 %d
>From 9491aecd235da9674150fe56bd0f29c3a22472c4 Mon Sep 17 00:00:00 2001
From: Francesco Petrogalli <francesco.petrogalli at apple.com>
Date: Thu, 29 Feb 2024 17:35:34 +0100
Subject: [PATCH 148/406] [TableGen][CodeGenTarget] Add support for v3i8 and
v3i1 MVTs. [NFCI] (#83140)
---
llvm/utils/TableGen/CodeGenTarget.cpp | 2 ++
1 file changed, 2 insertions(+)
diff --git a/llvm/utils/TableGen/CodeGenTarget.cpp b/llvm/utils/TableGen/CodeGenTarget.cpp
index f26815c2f184fa..980c9bdb6367f7 100644
--- a/llvm/utils/TableGen/CodeGenTarget.cpp
+++ b/llvm/utils/TableGen/CodeGenTarget.cpp
@@ -91,6 +91,7 @@ StringRef llvm::getEnumName(MVT::SimpleValueType T) {
case MVT::isVoid: return "MVT::isVoid";
case MVT::v1i1: return "MVT::v1i1";
case MVT::v2i1: return "MVT::v2i1";
+ case MVT::v3i1: return "MVT::v3i1";
case MVT::v4i1: return "MVT::v4i1";
case MVT::v8i1: return "MVT::v8i1";
case MVT::v16i1: return "MVT::v16i1";
@@ -107,6 +108,7 @@ StringRef llvm::getEnumName(MVT::SimpleValueType T) {
case MVT::v128i4: return "MVT::v128i4";
case MVT::v1i8: return "MVT::v1i8";
case MVT::v2i8: return "MVT::v2i8";
+ case MVT::v3i8: return "MVT::v3i8";
case MVT::v4i8: return "MVT::v4i8";
case MVT::v8i8: return "MVT::v8i8";
case MVT::v16i8: return "MVT::v16i8";
>From 3fda50d3915b2163a54a37b602be7783a89dd808 Mon Sep 17 00:00:00 2001
From: Jeremy Morse <jeremy.morse at sony.com>
Date: Thu, 29 Feb 2024 15:27:32 +0000
Subject: [PATCH 149/406] [NFC][RemoveDIs] Bulk update utilities to insert with
iterators
As part of the RemoveDIs project we need LLVM to insert instructions using
iterators wherever possible, so that the iterators can carry a bit of
debug-info. This commit implements some of that by updating the contents of
llvm/lib/Transforms/Utils to always use iterator-versions of instruction
constructors.
There are two general flavours of update:
* Almost all call-sites just call getIterator on an instruction
* Several make use of an existing iterator (scenarios where the code is
actually significant for debug-info)
The underlying logic is that any call to getFirstInsertionPt or similar
APIs that identify the start of a block need to have that iterator passed
directly to the insertion function, without being converted to a bare
Instruction pointer along the way.
I've also switched DemotePHIToStack to take an optional iterator: it needs
to take an iterator, and having a no-insert-location behaviour appears to
be important. The constructors for ICmpInst and FCmpInst have been updated
too. They're the only instructions that take block _references_ rather than
pointers for certain calls, and a future patch is going to make use of
default-null block insertion locations.
All of this should be NFC.
---
llvm/include/llvm/IR/Instructions.h | 8 ++---
llvm/include/llvm/Transforms/Utils/Local.h | 4 +--
llvm/lib/IR/Instructions.cpp | 4 +--
llvm/lib/Transforms/CFGuard/CFGuard.cpp | 2 +-
llvm/lib/Transforms/Scalar/Reg2Mem.cpp | 6 ++--
llvm/lib/Transforms/Utils/BasicBlockUtils.cpp | 8 ++---
.../Transforms/Utils/BreakCriticalEdges.cpp | 5 +--
.../Transforms/Utils/CallPromotionUtils.cpp | 8 ++---
.../Utils/CanonicalizeFreezeInLoops.cpp | 2 +-
llvm/lib/Transforms/Utils/CodeExtractor.cpp | 31 +++++++++----------
.../lib/Transforms/Utils/DemoteRegToStack.cpp | 26 ++++++++--------
.../Utils/EntryExitInstrumenter.cpp | 6 ++--
llvm/lib/Transforms/Utils/InlineFunction.cpp | 18 +++++------
llvm/lib/Transforms/Utils/Local.cpp | 18 +++++------
llvm/lib/Transforms/Utils/LoopConstrainer.cpp | 4 +--
.../Transforms/Utils/LoopRotationUtils.cpp | 2 +-
llvm/lib/Transforms/Utils/LoopSimplify.cpp | 2 +-
llvm/lib/Transforms/Utils/LoopUnroll.cpp | 2 +-
.../lib/Transforms/Utils/LoopUnrollAndJam.cpp | 6 ++--
.../lib/Transforms/Utils/LowerGlobalDtors.cpp | 2 +-
llvm/lib/Transforms/Utils/LowerInvoke.cpp | 4 +--
.../Transforms/Utils/LowerMemIntrinsics.cpp | 10 +++---
llvm/lib/Transforms/Utils/LowerSwitch.cpp | 10 +++---
llvm/lib/Transforms/Utils/MatrixUtils.cpp | 2 +-
.../Transforms/Utils/MemoryTaggingSupport.cpp | 4 +--
llvm/lib/Transforms/Utils/SCCPSolver.cpp | 6 ++--
.../Utils/ScalarEvolutionExpander.cpp | 4 +--
llvm/lib/Transforms/Utils/SimplifyCFG.cpp | 16 +++++-----
llvm/lib/Transforms/Utils/SimplifyIndVar.cpp | 14 ++++-----
.../lib/Transforms/Utils/StripGCRelocates.cpp | 2 +-
llvm/lib/Transforms/Utils/UnifyLoopExits.cpp | 2 +-
llvm/tools/bugpoint/Miscompilation.cpp | 2 +-
32 files changed, 120 insertions(+), 120 deletions(-)
diff --git a/llvm/include/llvm/IR/Instructions.h b/llvm/include/llvm/IR/Instructions.h
index bc357074e5cb21..4e4cf71a349d74 100644
--- a/llvm/include/llvm/IR/Instructions.h
+++ b/llvm/include/llvm/IR/Instructions.h
@@ -1298,14 +1298,14 @@ class ICmpInst: public CmpInst {
/// Constructor with insert-at-end semantics.
ICmpInst(
- BasicBlock &InsertAtEnd, ///< Block to insert into.
+ BasicBlock *InsertAtEnd, ///< Block to insert into.
Predicate pred, ///< The predicate to use for the comparison
Value *LHS, ///< The left-hand-side of the expression
Value *RHS, ///< The right-hand-side of the expression
const Twine &NameStr = "" ///< Name of the instruction
) : CmpInst(makeCmpResultType(LHS->getType()),
Instruction::ICmp, pred, LHS, RHS, NameStr,
- &InsertAtEnd) {
+ InsertAtEnd) {
#ifndef NDEBUG
AssertOK();
#endif
@@ -1481,14 +1481,14 @@ class FCmpInst: public CmpInst {
/// Constructor with insert-at-end semantics.
FCmpInst(
- BasicBlock &InsertAtEnd, ///< Block to insert into.
+ BasicBlock *InsertAtEnd, ///< Block to insert into.
Predicate pred, ///< The predicate to use for the comparison
Value *LHS, ///< The left-hand-side of the expression
Value *RHS, ///< The right-hand-side of the expression
const Twine &NameStr = "" ///< Name of the instruction
) : CmpInst(makeCmpResultType(LHS->getType()),
Instruction::FCmp, pred, LHS, RHS, NameStr,
- &InsertAtEnd) {
+ InsertAtEnd) {
AssertOK();
}
diff --git a/llvm/include/llvm/Transforms/Utils/Local.h b/llvm/include/llvm/Transforms/Utils/Local.h
index 2df3c9049c7d62..8dc843d2eaf604 100644
--- a/llvm/include/llvm/Transforms/Utils/Local.h
+++ b/llvm/include/llvm/Transforms/Utils/Local.h
@@ -206,12 +206,12 @@ bool FoldBranchToCommonDest(BranchInst *BI, llvm::DomTreeUpdater *DTU = nullptr,
/// to create a stack slot for X.
AllocaInst *DemoteRegToStack(Instruction &X,
bool VolatileLoads = false,
- Instruction *AllocaPoint = nullptr);
+ std::optional<BasicBlock::iterator> AllocaPoint = std::nullopt);
/// This function takes a virtual register computed by a phi node and replaces
/// it with a slot in the stack frame, allocated via alloca. The phi node is
/// deleted and it returns the pointer to the alloca inserted.
-AllocaInst *DemotePHIToStack(PHINode *P, Instruction *AllocaPoint = nullptr);
+AllocaInst *DemotePHIToStack(PHINode *P, std::optional<BasicBlock::iterator> AllocaPoint = std::nullopt);
/// If the specified pointer points to an object that we control, try to modify
/// the object's alignment to PrefAlign. Returns a minimum known alignment of
diff --git a/llvm/lib/IR/Instructions.cpp b/llvm/lib/IR/Instructions.cpp
index 42cdcad78228f6..c55d6cff84ed55 100644
--- a/llvm/lib/IR/Instructions.cpp
+++ b/llvm/lib/IR/Instructions.cpp
@@ -4608,10 +4608,10 @@ CmpInst *
CmpInst::Create(OtherOps Op, Predicate predicate, Value *S1, Value *S2,
const Twine &Name, BasicBlock *InsertAtEnd) {
if (Op == Instruction::ICmp) {
- return new ICmpInst(*InsertAtEnd, CmpInst::Predicate(predicate),
+ return new ICmpInst(InsertAtEnd, CmpInst::Predicate(predicate),
S1, S2, Name);
}
- return new FCmpInst(*InsertAtEnd, CmpInst::Predicate(predicate),
+ return new FCmpInst(InsertAtEnd, CmpInst::Predicate(predicate),
S1, S2, Name);
}
diff --git a/llvm/lib/Transforms/CFGuard/CFGuard.cpp b/llvm/lib/Transforms/CFGuard/CFGuard.cpp
index 4d4306576017be..32326b5801031f 100644
--- a/llvm/lib/Transforms/CFGuard/CFGuard.cpp
+++ b/llvm/lib/Transforms/CFGuard/CFGuard.cpp
@@ -219,7 +219,7 @@ void CFGuardImpl::insertCFGuardDispatch(CallBase *CB) {
// Create a copy of the call/invoke instruction and add the new bundle.
assert((isa<CallInst>(CB) || isa<InvokeInst>(CB)) &&
"Unknown indirect call type");
- CallBase *NewCB = CallBase::Create(CB, Bundles, CB);
+ CallBase *NewCB = CallBase::Create(CB, Bundles, CB->getIterator());
// Change the target of the call to be the guard dispatch function.
NewCB->setCalledOperand(GuardDispatchLoad);
diff --git a/llvm/lib/Transforms/Scalar/Reg2Mem.cpp b/llvm/lib/Transforms/Scalar/Reg2Mem.cpp
index 6c2b3e9bd4a721..ebc5075aa36fe8 100644
--- a/llvm/lib/Transforms/Scalar/Reg2Mem.cpp
+++ b/llvm/lib/Transforms/Scalar/Reg2Mem.cpp
@@ -64,7 +64,7 @@ static bool runPass(Function &F) {
CastInst *AllocaInsertionPoint = new BitCastInst(
Constant::getNullValue(Type::getInt32Ty(F.getContext())),
- Type::getInt32Ty(F.getContext()), "reg2mem alloca point", &*I);
+ Type::getInt32Ty(F.getContext()), "reg2mem alloca point", I);
// Find the escaped instructions. But don't create stack slots for
// allocas in entry block.
@@ -76,7 +76,7 @@ static bool runPass(Function &F) {
// Demote escaped instructions
NumRegsDemoted += WorkList.size();
for (Instruction *I : WorkList)
- DemoteRegToStack(*I, false, AllocaInsertionPoint);
+ DemoteRegToStack(*I, false, AllocaInsertionPoint->getIterator());
WorkList.clear();
@@ -88,7 +88,7 @@ static bool runPass(Function &F) {
// Demote phi nodes
NumPhisDemoted += WorkList.size();
for (Instruction *I : WorkList)
- DemotePHIToStack(cast<PHINode>(I), AllocaInsertionPoint);
+ DemotePHIToStack(cast<PHINode>(I), AllocaInsertionPoint->getIterator());
return true;
}
diff --git a/llvm/lib/Transforms/Utils/BasicBlockUtils.cpp b/llvm/lib/Transforms/Utils/BasicBlockUtils.cpp
index 5bb109a04ff178..5aa59acfa6df99 100644
--- a/llvm/lib/Transforms/Utils/BasicBlockUtils.cpp
+++ b/llvm/lib/Transforms/Utils/BasicBlockUtils.cpp
@@ -1297,7 +1297,7 @@ static void UpdatePHINodes(BasicBlock *OrigBB, BasicBlock *NewBB,
// PHI.
// Create the new PHI node, insert it into NewBB at the end of the block
PHINode *NewPHI =
- PHINode::Create(PN->getType(), Preds.size(), PN->getName() + ".ph", BI);
+ PHINode::Create(PN->getType(), Preds.size(), PN->getName() + ".ph", BI->getIterator());
// NOTE! This loop walks backwards for a reason! First off, this minimizes
// the cost of removal if we end up removing a large number of values, and
@@ -1517,7 +1517,7 @@ static void SplitLandingPadPredecessorsImpl(
assert(!LPad->getType()->isTokenTy() &&
"Split cannot be applied if LPad is token type. Otherwise an "
"invalid PHINode of token type would be created.");
- PHINode *PN = PHINode::Create(LPad->getType(), 2, "lpad.phi", LPad);
+ PHINode *PN = PHINode::Create(LPad->getType(), 2, "lpad.phi", LPad->getIterator());
PN->addIncoming(Clone1, NewBB1);
PN->addIncoming(Clone2, NewBB2);
LPad->replaceAllUsesWith(PN);
@@ -1904,7 +1904,7 @@ static void reconnectPhis(BasicBlock *Out, BasicBlock *GuardBlock,
auto Phi = cast<PHINode>(I);
auto NewPhi =
PHINode::Create(Phi->getType(), Incoming.size(),
- Phi->getName() + ".moved", &FirstGuardBlock->front());
+ Phi->getName() + ".moved", FirstGuardBlock->begin());
for (auto *In : Incoming) {
Value *V = UndefValue::get(Phi->getType());
if (In == Out) {
@@ -2023,7 +2023,7 @@ static void calcPredicateUsingInteger(
Value *Id1 = ConstantInt::get(Type::getInt32Ty(Context),
std::distance(Outgoing.begin(), Succ1Iter));
IncomingId = SelectInst::Create(Condition, Id0, Id1, "target.bb.idx",
- In->getTerminator());
+ In->getTerminator()->getIterator());
} else {
// Get the index of the non-null successor.
auto SuccIter = Succ0 ? find(Outgoing, Succ0) : find(Outgoing, Succ1);
diff --git a/llvm/lib/Transforms/Utils/BreakCriticalEdges.cpp b/llvm/lib/Transforms/Utils/BreakCriticalEdges.cpp
index 4a784c11c611d9..4606514cbc7175 100644
--- a/llvm/lib/Transforms/Utils/BreakCriticalEdges.cpp
+++ b/llvm/lib/Transforms/Utils/BreakCriticalEdges.cpp
@@ -420,7 +420,7 @@ bool llvm::SplitIndirectBrCriticalEdges(Function &F,
// (b) Leave that as the only edge in the "Indirect" PHI.
// (c) Merge the two in the body block.
BasicBlock::iterator Indirect = Target->begin(),
- End = Target->getFirstNonPHI()->getIterator();
+ End = Target->getFirstNonPHIIt();
BasicBlock::iterator Direct = DirectSucc->begin();
BasicBlock::iterator MergeInsert = BodyBlock->getFirstInsertionPt();
@@ -430,6 +430,7 @@ bool llvm::SplitIndirectBrCriticalEdges(Function &F,
while (Indirect != End) {
PHINode *DirPHI = cast<PHINode>(Direct);
PHINode *IndPHI = cast<PHINode>(Indirect);
+ BasicBlock::iterator InsertPt = Indirect;
// Now, clean up - the direct block shouldn't get the indirect value,
// and vice versa.
@@ -440,7 +441,7 @@ bool llvm::SplitIndirectBrCriticalEdges(Function &F,
// PHI is erased.
Indirect++;
- PHINode *NewIndPHI = PHINode::Create(IndPHI->getType(), 1, "ind", IndPHI);
+ PHINode *NewIndPHI = PHINode::Create(IndPHI->getType(), 1, "ind", InsertPt);
NewIndPHI->addIncoming(IndPHI->getIncomingValueForBlock(IBRPred),
IBRPred);
diff --git a/llvm/lib/Transforms/Utils/CallPromotionUtils.cpp b/llvm/lib/Transforms/Utils/CallPromotionUtils.cpp
index 4e84927f1cfc90..48c33d6c0c8e0e 100644
--- a/llvm/lib/Transforms/Utils/CallPromotionUtils.cpp
+++ b/llvm/lib/Transforms/Utils/CallPromotionUtils.cpp
@@ -168,12 +168,12 @@ static void createRetBitCast(CallBase &CB, Type *RetTy, CastInst **RetBitCast) {
// Determine an appropriate location to create the bitcast for the return
// value. The location depends on if we have a call or invoke instruction.
- Instruction *InsertBefore = nullptr;
+ BasicBlock::iterator InsertBefore;
if (auto *Invoke = dyn_cast<InvokeInst>(&CB))
InsertBefore =
- &SplitEdge(Invoke->getParent(), Invoke->getNormalDest())->front();
+ SplitEdge(Invoke->getParent(), Invoke->getNormalDest())->begin();
else
- InsertBefore = &*std::next(CB.getIterator());
+ InsertBefore = std::next(CB.getIterator());
// Bitcast the return value to the correct type.
auto *Cast = CastInst::CreateBitOrPointerCast(&CB, RetTy, "", InsertBefore);
@@ -509,7 +509,7 @@ CallBase &llvm::promoteCall(CallBase &CB, Function *Callee,
Type *FormalTy = CalleeType->getParamType(ArgNo);
Type *ActualTy = Arg->getType();
if (FormalTy != ActualTy) {
- auto *Cast = CastInst::CreateBitOrPointerCast(Arg, FormalTy, "", &CB);
+ auto *Cast = CastInst::CreateBitOrPointerCast(Arg, FormalTy, "", CB.getIterator());
CB.setArgOperand(ArgNo, Cast);
// Remove any incompatible attributes for the argument.
diff --git a/llvm/lib/Transforms/Utils/CanonicalizeFreezeInLoops.cpp b/llvm/lib/Transforms/Utils/CanonicalizeFreezeInLoops.cpp
index 282c4456346678..40010aee9c1114 100644
--- a/llvm/lib/Transforms/Utils/CanonicalizeFreezeInLoops.cpp
+++ b/llvm/lib/Transforms/Utils/CanonicalizeFreezeInLoops.cpp
@@ -144,7 +144,7 @@ void CanonicalizeFreezeInLoopsImpl::InsertFreezeAndForgetFromSCEV(Use &U) {
LLVM_DEBUG(dbgs() << "\tOperand: " << *U.get() << "\n");
U.set(new FreezeInst(ValueToFr, ValueToFr->getName() + ".frozen",
- PH->getTerminator()));
+ PH->getTerminator()->getIterator()));
SE.forgetValue(UserI);
}
diff --git a/llvm/lib/Transforms/Utils/CodeExtractor.cpp b/llvm/lib/Transforms/Utils/CodeExtractor.cpp
index bab065153f3efa..3071ec0c911321 100644
--- a/llvm/lib/Transforms/Utils/CodeExtractor.cpp
+++ b/llvm/lib/Transforms/Utils/CodeExtractor.cpp
@@ -570,7 +570,7 @@ void CodeExtractor::findAllocas(const CodeExtractorAnalysisCache &CEAC,
LLVMContext &Ctx = M->getContext();
auto *Int8PtrTy = PointerType::getUnqual(Ctx);
CastInst *CastI =
- CastInst::CreatePointerCast(AI, Int8PtrTy, "lt.cast", I);
+ CastInst::CreatePointerCast(AI, Int8PtrTy, "lt.cast", I->getIterator());
I->replaceUsesOfWith(I->getOperand(1), CastI);
}
@@ -1024,7 +1024,7 @@ Function *CodeExtractor::constructFunction(const ValueSet &inputs,
Value *Idx[2];
Idx[0] = Constant::getNullValue(Type::getInt32Ty(header->getContext()));
Idx[1] = ConstantInt::get(Type::getInt32Ty(header->getContext()), aggIdx);
- Instruction *TI = newFunction->begin()->getTerminator();
+ BasicBlock::iterator TI = newFunction->begin()->getTerminator()->getIterator();
GetElementPtrInst *GEP = GetElementPtrInst::Create(
StructTy, &*AggAI, Idx, "gep_" + inputs[i]->getName(), TI);
RewriteVal = new LoadInst(StructTy->getElementType(aggIdx), GEP,
@@ -1173,7 +1173,7 @@ CallInst *CodeExtractor::emitCallAndSwitchStatement(Function *newFunction,
AllocaInst *alloca =
new AllocaInst(output->getType(), DL.getAllocaAddrSpace(),
nullptr, output->getName() + ".loc",
- &codeReplacer->getParent()->front().front());
+ codeReplacer->getParent()->front().begin());
ReloadOutputs.push_back(alloca);
params.push_back(alloca);
++ScalarOutputArgNo;
@@ -1192,8 +1192,8 @@ CallInst *CodeExtractor::emitCallAndSwitchStatement(Function *newFunction,
StructArgTy = StructType::get(newFunction->getContext(), ArgTypes);
Struct = new AllocaInst(
StructArgTy, DL.getAllocaAddrSpace(), nullptr, "structArg",
- AllocationBlock ? &*AllocationBlock->getFirstInsertionPt()
- : &codeReplacer->getParent()->front().front());
+ AllocationBlock ? AllocationBlock->getFirstInsertionPt()
+ : codeReplacer->getParent()->front().begin());
if (ArgsInZeroAddressSpace && DL.getAllocaAddrSpace() != 0) {
auto *StructSpaceCast = new AddrSpaceCastInst(
@@ -1358,9 +1358,8 @@ CallInst *CodeExtractor::emitCallAndSwitchStatement(Function *newFunction,
else
InsertPt = std::next(OutI->getIterator());
- Instruction *InsertBefore = &*InsertPt;
- assert((InsertBefore->getFunction() == newFunction ||
- Blocks.count(InsertBefore->getParent())) &&
+ assert((InsertPt->getFunction() == newFunction ||
+ Blocks.count(InsertPt->getParent())) &&
"InsertPt should be in new function");
if (AggregateArgs && StructValues.contains(outputs[i])) {
assert(AggOutputArgBegin != newFunction->arg_end() &&
@@ -1371,8 +1370,8 @@ CallInst *CodeExtractor::emitCallAndSwitchStatement(Function *newFunction,
Idx[1] = ConstantInt::get(Type::getInt32Ty(Context), aggIdx);
GetElementPtrInst *GEP = GetElementPtrInst::Create(
StructArgTy, &*AggOutputArgBegin, Idx, "gep_" + outputs[i]->getName(),
- InsertBefore);
- new StoreInst(outputs[i], GEP, InsertBefore);
+ InsertPt);
+ new StoreInst(outputs[i], GEP, InsertPt);
++aggIdx;
// Since there should be only one struct argument aggregating
// all the output values, we shouldn't increment AggOutputArgBegin, which
@@ -1381,7 +1380,7 @@ CallInst *CodeExtractor::emitCallAndSwitchStatement(Function *newFunction,
assert(ScalarOutputArgBegin != newFunction->arg_end() &&
"Number of scalar output arguments should match "
"the number of defined values");
- new StoreInst(outputs[i], &*ScalarOutputArgBegin, InsertBefore);
+ new StoreInst(outputs[i], &*ScalarOutputArgBegin, InsertPt);
++ScalarOutputArgBegin;
}
}
@@ -1396,15 +1395,15 @@ CallInst *CodeExtractor::emitCallAndSwitchStatement(Function *newFunction,
// Check if the function should return a value
if (OldFnRetTy->isVoidTy()) {
- ReturnInst::Create(Context, nullptr, TheSwitch); // Return void
+ ReturnInst::Create(Context, nullptr, TheSwitch->getIterator()); // Return void
} else if (OldFnRetTy == TheSwitch->getCondition()->getType()) {
// return what we have
- ReturnInst::Create(Context, TheSwitch->getCondition(), TheSwitch);
+ ReturnInst::Create(Context, TheSwitch->getCondition(), TheSwitch->getIterator());
} else {
// Otherwise we must have code extracted an unwind or something, just
// return whatever we want.
ReturnInst::Create(Context,
- Constant::getNullValue(OldFnRetTy), TheSwitch);
+ Constant::getNullValue(OldFnRetTy), TheSwitch->getIterator());
}
TheSwitch->eraseFromParent();
@@ -1412,12 +1411,12 @@ CallInst *CodeExtractor::emitCallAndSwitchStatement(Function *newFunction,
case 1:
// Only a single destination, change the switch into an unconditional
// branch.
- BranchInst::Create(TheSwitch->getSuccessor(1), TheSwitch);
+ BranchInst::Create(TheSwitch->getSuccessor(1), TheSwitch->getIterator());
TheSwitch->eraseFromParent();
break;
case 2:
BranchInst::Create(TheSwitch->getSuccessor(1), TheSwitch->getSuccessor(2),
- call, TheSwitch);
+ call, TheSwitch->getIterator());
TheSwitch->eraseFromParent();
break;
default:
diff --git a/llvm/lib/Transforms/Utils/DemoteRegToStack.cpp b/llvm/lib/Transforms/Utils/DemoteRegToStack.cpp
index c894afee68a27a..b2a88eadd3dee8 100644
--- a/llvm/lib/Transforms/Utils/DemoteRegToStack.cpp
+++ b/llvm/lib/Transforms/Utils/DemoteRegToStack.cpp
@@ -20,7 +20,7 @@ using namespace llvm;
/// invalidating the SSA information for the value. It returns the pointer to
/// the alloca inserted to create a stack slot for I.
AllocaInst *llvm::DemoteRegToStack(Instruction &I, bool VolatileLoads,
- Instruction *AllocaPoint) {
+ std::optional<BasicBlock::iterator> AllocaPoint) {
if (I.use_empty()) {
I.eraseFromParent();
return nullptr;
@@ -33,10 +33,10 @@ AllocaInst *llvm::DemoteRegToStack(Instruction &I, bool VolatileLoads,
AllocaInst *Slot;
if (AllocaPoint) {
Slot = new AllocaInst(I.getType(), DL.getAllocaAddrSpace(), nullptr,
- I.getName()+".reg2mem", AllocaPoint);
+ I.getName()+".reg2mem", *AllocaPoint);
} else {
Slot = new AllocaInst(I.getType(), DL.getAllocaAddrSpace(), nullptr,
- I.getName() + ".reg2mem", &F->getEntryBlock().front());
+ I.getName() + ".reg2mem", F->getEntryBlock().begin());
}
// We cannot demote invoke instructions to the stack if their normal edge
@@ -73,7 +73,7 @@ AllocaInst *llvm::DemoteRegToStack(Instruction &I, bool VolatileLoads,
// Insert the load into the predecessor block
V = new LoadInst(I.getType(), Slot, I.getName() + ".reload",
VolatileLoads,
- PN->getIncomingBlock(i)->getTerminator());
+ PN->getIncomingBlock(i)->getTerminator()->getIterator());
Loads[PN->getIncomingBlock(i)] = V;
}
PN->setIncomingValue(i, V);
@@ -82,7 +82,7 @@ AllocaInst *llvm::DemoteRegToStack(Instruction &I, bool VolatileLoads,
} else {
// If this is a normal instruction, just insert a load.
Value *V = new LoadInst(I.getType(), Slot, I.getName() + ".reload",
- VolatileLoads, U);
+ VolatileLoads, U->getIterator());
U->replaceUsesOfWith(&I, V);
}
}
@@ -99,7 +99,7 @@ AllocaInst *llvm::DemoteRegToStack(Instruction &I, bool VolatileLoads,
break;
if (isa<CatchSwitchInst>(InsertPt)) {
for (BasicBlock *Handler : successors(&*InsertPt))
- new StoreInst(&I, Slot, &*Handler->getFirstInsertionPt());
+ new StoreInst(&I, Slot, Handler->getFirstInsertionPt());
return Slot;
}
} else {
@@ -107,14 +107,14 @@ AllocaInst *llvm::DemoteRegToStack(Instruction &I, bool VolatileLoads,
InsertPt = II.getNormalDest()->getFirstInsertionPt();
}
- new StoreInst(&I, Slot, &*InsertPt);
+ new StoreInst(&I, Slot, InsertPt);
return Slot;
}
/// DemotePHIToStack - This function takes a virtual register computed by a PHI
/// node and replaces it with a slot in the stack frame allocated via alloca.
/// The PHI node is deleted. It returns the pointer to the alloca inserted.
-AllocaInst *llvm::DemotePHIToStack(PHINode *P, Instruction *AllocaPoint) {
+AllocaInst *llvm::DemotePHIToStack(PHINode *P, std::optional<BasicBlock::iterator> AllocaPoint) {
if (P->use_empty()) {
P->eraseFromParent();
return nullptr;
@@ -126,12 +126,12 @@ AllocaInst *llvm::DemotePHIToStack(PHINode *P, Instruction *AllocaPoint) {
AllocaInst *Slot;
if (AllocaPoint) {
Slot = new AllocaInst(P->getType(), DL.getAllocaAddrSpace(), nullptr,
- P->getName()+".reg2mem", AllocaPoint);
+ P->getName()+".reg2mem", *AllocaPoint);
} else {
Function *F = P->getParent()->getParent();
Slot = new AllocaInst(P->getType(), DL.getAllocaAddrSpace(), nullptr,
P->getName() + ".reg2mem",
- &F->getEntryBlock().front());
+ F->getEntryBlock().begin());
}
// Iterate over each operand inserting a store in each predecessor.
@@ -141,7 +141,7 @@ AllocaInst *llvm::DemotePHIToStack(PHINode *P, Instruction *AllocaPoint) {
"Invoke edge not supported yet"); (void)II;
}
new StoreInst(P->getIncomingValue(i), Slot,
- P->getIncomingBlock(i)->getTerminator());
+ P->getIncomingBlock(i)->getTerminator()->getIterator());
}
// Insert a load in place of the PHI and replace all uses.
@@ -159,12 +159,12 @@ AllocaInst *llvm::DemotePHIToStack(PHINode *P, Instruction *AllocaPoint) {
}
for (Instruction *User : Users) {
Value *V =
- new LoadInst(P->getType(), Slot, P->getName() + ".reload", User);
+ new LoadInst(P->getType(), Slot, P->getName() + ".reload", User->getIterator());
User->replaceUsesOfWith(P, V);
}
} else {
Value *V =
- new LoadInst(P->getType(), Slot, P->getName() + ".reload", &*InsertPt);
+ new LoadInst(P->getType(), Slot, P->getName() + ".reload", InsertPt);
P->replaceAllUsesWith(V);
}
// Delete PHI.
diff --git a/llvm/lib/Transforms/Utils/EntryExitInstrumenter.cpp b/llvm/lib/Transforms/Utils/EntryExitInstrumenter.cpp
index 092f1799755d17..f4207474e9a68a 100644
--- a/llvm/lib/Transforms/Utils/EntryExitInstrumenter.cpp
+++ b/llvm/lib/Transforms/Utils/EntryExitInstrumenter.cpp
@@ -20,7 +20,7 @@
using namespace llvm;
static void insertCall(Function &CurFn, StringRef Func,
- Instruction *InsertionPt, DebugLoc DL) {
+ BasicBlock::iterator InsertionPt, DebugLoc DL) {
Module &M = *InsertionPt->getParent()->getParent()->getParent();
LLVMContext &C = InsertionPt->getParent()->getContext();
@@ -105,7 +105,7 @@ static bool runOnFunction(Function &F, bool PostInlining) {
if (auto SP = F.getSubprogram())
DL = DILocation::get(SP->getContext(), SP->getScopeLine(), 0, SP);
- insertCall(F, EntryFunc, &*F.begin()->getFirstInsertionPt(), DL);
+ insertCall(F, EntryFunc, F.begin()->getFirstInsertionPt(), DL);
Changed = true;
F.removeFnAttr(EntryAttr);
}
@@ -126,7 +126,7 @@ static bool runOnFunction(Function &F, bool PostInlining) {
else if (auto SP = F.getSubprogram())
DL = DILocation::get(SP->getContext(), 0, 0, SP);
- insertCall(F, ExitFunc, T, DL);
+ insertCall(F, ExitFunc, T->getIterator(), DL);
Changed = true;
}
F.removeFnAttr(ExitAttr);
diff --git a/llvm/lib/Transforms/Utils/InlineFunction.cpp b/llvm/lib/Transforms/Utils/InlineFunction.cpp
index f68fdb26f28173..0e8e72678de613 100644
--- a/llvm/lib/Transforms/Utils/InlineFunction.cpp
+++ b/llvm/lib/Transforms/Utils/InlineFunction.cpp
@@ -689,7 +689,7 @@ static void HandleInlinedEHPad(InvokeInst *II, BasicBlock *FirstNewBlock,
if (auto *CRI = dyn_cast<CleanupReturnInst>(BB->getTerminator())) {
if (CRI->unwindsToCaller()) {
auto *CleanupPad = CRI->getCleanupPad();
- CleanupReturnInst::Create(CleanupPad, UnwindDest, CRI);
+ CleanupReturnInst::Create(CleanupPad, UnwindDest, CRI->getIterator());
CRI->eraseFromParent();
UpdatePHINodes(&*BB);
// Finding a cleanupret with an unwind destination would confuse
@@ -737,7 +737,7 @@ static void HandleInlinedEHPad(InvokeInst *II, BasicBlock *FirstNewBlock,
auto *NewCatchSwitch = CatchSwitchInst::Create(
CatchSwitch->getParentPad(), UnwindDest,
CatchSwitch->getNumHandlers(), CatchSwitch->getName(),
- CatchSwitch);
+ CatchSwitch->getIterator());
for (BasicBlock *PadBB : CatchSwitch->handlers())
NewCatchSwitch->addHandler(PadBB);
// Propagate info for the old catchswitch over to the new one in
@@ -972,7 +972,7 @@ static void PropagateOperandBundles(Function::iterator InlinedBB,
I->getOperandBundlesAsDefs(OpBundles);
OpBundles.emplace_back("funclet", CallSiteEHPad);
- Instruction *NewInst = CallBase::Create(I, OpBundles, I);
+ Instruction *NewInst = CallBase::Create(I, OpBundles, I->getIterator());
NewInst->takeName(I);
I->replaceAllUsesWith(NewInst);
I->eraseFromParent();
@@ -2002,7 +2002,7 @@ inlineRetainOrClaimRVCalls(CallBase &CB, objcarc::ARCInstKind RVCallKind,
Value *BundleArgs[] = {*objcarc::getAttachedARCFunction(&CB)};
OperandBundleDef OB("clang.arc.attachedcall", BundleArgs);
auto *NewCall = CallBase::addOperandBundle(
- CI, LLVMContext::OB_clang_arc_attachedcall, OB, CI);
+ CI, LLVMContext::OB_clang_arc_attachedcall, OB, CI->getIterator());
NewCall->copyMetadata(*CI);
CI->replaceAllUsesWith(NewCall);
CI->eraseFromParent();
@@ -2326,7 +2326,7 @@ llvm::InlineResult llvm::InlineFunction(CallBase &CB, InlineFunctionInfo &IFI,
OpDefs.emplace_back("deopt", std::move(MergedDeoptArgs));
}
- Instruction *NewI = CallBase::Create(ICS, OpDefs, ICS);
+ Instruction *NewI = CallBase::Create(ICS, OpDefs, ICS->getIterator());
// Note: the RAUW does the appropriate fixup in VMap, so we need to do
// this even if the call returns void.
@@ -2479,7 +2479,7 @@ llvm::InlineResult llvm::InlineFunction(CallBase &CB, InlineFunctionInfo &IFI,
SmallVector<Value *, 6> Params(CI->args());
Params.append(VarArgsToForward.begin(), VarArgsToForward.end());
CallInst *NewCI = CallInst::Create(
- CI->getFunctionType(), CI->getCalledOperand(), Params, "", CI);
+ CI->getFunctionType(), CI->getCalledOperand(), Params, "", CI->getIterator());
NewCI->setDebugLoc(CI->getDebugLoc());
NewCI->setAttributes(Attrs);
NewCI->setCallingConv(CI->getCallingConv());
@@ -2776,7 +2776,7 @@ llvm::InlineResult llvm::InlineFunction(CallBase &CB, InlineFunctionInfo &IFI,
// If the call site was an invoke instruction, add a branch to the normal
// destination.
if (InvokeInst *II = dyn_cast<InvokeInst>(&CB)) {
- BranchInst *NewBr = BranchInst::Create(II->getNormalDest(), &CB);
+ BranchInst *NewBr = BranchInst::Create(II->getNormalDest(), CB.getIterator());
NewBr->setDebugLoc(Returns[0]->getDebugLoc());
}
@@ -2813,7 +2813,7 @@ llvm::InlineResult llvm::InlineFunction(CallBase &CB, InlineFunctionInfo &IFI,
if (InvokeInst *II = dyn_cast<InvokeInst>(&CB)) {
// Add an unconditional branch to make this look like the CallInst case...
- CreatedBranchToNormalDest = BranchInst::Create(II->getNormalDest(), &CB);
+ CreatedBranchToNormalDest = BranchInst::Create(II->getNormalDest(), CB.getIterator());
// Split the basic block. This guarantees that no PHI nodes will have to be
// updated due to new incoming edges, and make the invoke case more
@@ -2881,7 +2881,7 @@ llvm::InlineResult llvm::InlineFunction(CallBase &CB, InlineFunctionInfo &IFI,
DebugLoc Loc;
for (unsigned i = 0, e = Returns.size(); i != e; ++i) {
ReturnInst *RI = Returns[i];
- BranchInst* BI = BranchInst::Create(AfterCallBB, RI);
+ BranchInst* BI = BranchInst::Create(AfterCallBB, RI->getIterator());
Loc = RI->getDebugLoc();
BI->setDebugLoc(Loc);
RI->eraseFromParent();
diff --git a/llvm/lib/Transforms/Utils/Local.cpp b/llvm/lib/Transforms/Utils/Local.cpp
index 075eeb5b19fd2b..c4a8843f2840b3 100644
--- a/llvm/lib/Transforms/Utils/Local.cpp
+++ b/llvm/lib/Transforms/Utils/Local.cpp
@@ -2811,7 +2811,7 @@ unsigned llvm::changeToUnreachable(Instruction *I, bool PreserveLCSSA,
if (DTU)
UniqueSuccessors.insert(Successor);
}
- auto *UI = new UnreachableInst(I->getContext(), I);
+ auto *UI = new UnreachableInst(I->getContext(), I->getIterator());
UI->setDebugLoc(I->getDebugLoc());
// All instructions after this are dead.
@@ -2868,7 +2868,7 @@ CallInst *llvm::changeToCall(InvokeInst *II, DomTreeUpdater *DTU) {
// Follow the call by a branch to the normal destination.
BasicBlock *NormalDestBB = II->getNormalDest();
- BranchInst::Create(NormalDestBB, II);
+ BranchInst::Create(NormalDestBB, II->getIterator());
// Update PHI nodes in the unwind destination
BasicBlock *BB = II->getParent();
@@ -3048,7 +3048,7 @@ static bool markAliveBlocks(Function &F,
// jump to the normal destination branch.
BasicBlock *NormalDestBB = II->getNormalDest();
BasicBlock *UnwindDestBB = II->getUnwindDest();
- BranchInst::Create(NormalDestBB, II);
+ BranchInst::Create(NormalDestBB, II->getIterator());
UnwindDestBB->removePredecessor(II->getParent());
II->eraseFromParent();
if (DTU)
@@ -3131,12 +3131,12 @@ Instruction *llvm::removeUnwindEdge(BasicBlock *BB, DomTreeUpdater *DTU) {
BasicBlock *UnwindDest;
if (auto *CRI = dyn_cast<CleanupReturnInst>(TI)) {
- NewTI = CleanupReturnInst::Create(CRI->getCleanupPad(), nullptr, CRI);
+ NewTI = CleanupReturnInst::Create(CRI->getCleanupPad(), nullptr, CRI->getIterator());
UnwindDest = CRI->getUnwindDest();
} else if (auto *CatchSwitch = dyn_cast<CatchSwitchInst>(TI)) {
auto *NewCatchSwitch = CatchSwitchInst::Create(
CatchSwitch->getParentPad(), nullptr, CatchSwitch->getNumHandlers(),
- CatchSwitch->getName(), CatchSwitch);
+ CatchSwitch->getName(), CatchSwitch->getIterator());
for (BasicBlock *PadBB : CatchSwitch->handlers())
NewCatchSwitch->addHandler(PadBB);
@@ -3972,23 +3972,23 @@ bool llvm::recognizeBSwapOrBitReverseIdiom(
// We may need to truncate the provider.
if (DemandedTy != Provider->getType()) {
auto *Trunc =
- CastInst::CreateIntegerCast(Provider, DemandedTy, false, "trunc", I);
+ CastInst::CreateIntegerCast(Provider, DemandedTy, false, "trunc", I->getIterator());
InsertedInsts.push_back(Trunc);
Provider = Trunc;
}
- Instruction *Result = CallInst::Create(F, Provider, "rev", I);
+ Instruction *Result = CallInst::Create(F, Provider, "rev", I->getIterator());
InsertedInsts.push_back(Result);
if (!DemandedMask.isAllOnes()) {
auto *Mask = ConstantInt::get(DemandedTy, DemandedMask);
- Result = BinaryOperator::Create(Instruction::And, Result, Mask, "mask", I);
+ Result = BinaryOperator::Create(Instruction::And, Result, Mask, "mask", I->getIterator());
InsertedInsts.push_back(Result);
}
// We may need to zeroextend back to the result type.
if (ITy != Result->getType()) {
- auto *ExtInst = CastInst::CreateIntegerCast(Result, ITy, false, "zext", I);
+ auto *ExtInst = CastInst::CreateIntegerCast(Result, ITy, false, "zext", I->getIterator());
InsertedInsts.push_back(ExtInst);
}
diff --git a/llvm/lib/Transforms/Utils/LoopConstrainer.cpp b/llvm/lib/Transforms/Utils/LoopConstrainer.cpp
index ea6d952cfa7d4f..81545ef375219c 100644
--- a/llvm/lib/Transforms/Utils/LoopConstrainer.cpp
+++ b/llvm/lib/Transforms/Utils/LoopConstrainer.cpp
@@ -644,7 +644,7 @@ LoopConstrainer::RewrittenRangeInfo LoopConstrainer::changeIterationSpaceEnd(
// value of the same PHI nodes if/when we continue execution.
for (PHINode &PN : LS.Header->phis()) {
PHINode *NewPHI = PHINode::Create(PN.getType(), 2, PN.getName() + ".copy",
- BranchToContinuation);
+ BranchToContinuation->getIterator());
NewPHI->addIncoming(PN.getIncomingValueForBlock(Preheader), Preheader);
NewPHI->addIncoming(PN.getIncomingValueForBlock(LS.Latch),
@@ -653,7 +653,7 @@ LoopConstrainer::RewrittenRangeInfo LoopConstrainer::changeIterationSpaceEnd(
}
RRI.IndVarEnd = PHINode::Create(IndVarBase->getType(), 2, "indvar.end",
- BranchToContinuation);
+ BranchToContinuation->getIterator());
RRI.IndVarEnd->addIncoming(IndVarStart, Preheader);
RRI.IndVarEnd->addIncoming(IndVarBase, RRI.ExitSelector);
diff --git a/llvm/lib/Transforms/Utils/LoopRotationUtils.cpp b/llvm/lib/Transforms/Utils/LoopRotationUtils.cpp
index adae796ee02997..cec47810e04447 100644
--- a/llvm/lib/Transforms/Utils/LoopRotationUtils.cpp
+++ b/llvm/lib/Transforms/Utils/LoopRotationUtils.cpp
@@ -874,7 +874,7 @@ bool LoopRotate::rotateLoop(Loop *L, bool SimplifiedLatch) {
// We can fold the conditional branch in the preheader, this makes things
// simpler. The first step is to remove the extra edge to the Exit block.
Exit->removePredecessor(OrigPreheader, true /*preserve LCSSA*/);
- BranchInst *NewBI = BranchInst::Create(NewHeader, PHBI);
+ BranchInst *NewBI = BranchInst::Create(NewHeader, PHBI->getIterator());
NewBI->setDebugLoc(PHBI->getDebugLoc());
PHBI->eraseFromParent();
diff --git a/llvm/lib/Transforms/Utils/LoopSimplify.cpp b/llvm/lib/Transforms/Utils/LoopSimplify.cpp
index 07e622b1577fe1..b38fecd6d8b416 100644
--- a/llvm/lib/Transforms/Utils/LoopSimplify.cpp
+++ b/llvm/lib/Transforms/Utils/LoopSimplify.cpp
@@ -399,7 +399,7 @@ static BasicBlock *insertUniqueBackedgeBlock(Loop *L, BasicBlock *Preheader,
for (BasicBlock::iterator I = Header->begin(); isa<PHINode>(I); ++I) {
PHINode *PN = cast<PHINode>(I);
PHINode *NewPN = PHINode::Create(PN->getType(), BackedgeBlocks.size(),
- PN->getName()+".be", BETerminator);
+ PN->getName()+".be", BETerminator->getIterator());
// Loop over the PHI node, moving all entries except the one for the
// preheader over to the new PHI node.
diff --git a/llvm/lib/Transforms/Utils/LoopUnroll.cpp b/llvm/lib/Transforms/Utils/LoopUnroll.cpp
index ee6f7b35750af0..6f0d000815726e 100644
--- a/llvm/lib/Transforms/Utils/LoopUnroll.cpp
+++ b/llvm/lib/Transforms/Utils/LoopUnroll.cpp
@@ -721,7 +721,7 @@ LoopUnrollResult llvm::UnrollLoop(Loop *L, UnrollLoopOptions ULO, LoopInfo *LI,
DeadSucc->removePredecessor(Src, /* KeepOneInputPHIs */ true);
// Replace the conditional branch with an unconditional one.
- BranchInst::Create(Dest, Term);
+ BranchInst::Create(Dest, Term->getIterator());
Term->eraseFromParent();
DTUpdates.emplace_back(DominatorTree::Delete, Src, DeadSucc);
diff --git a/llvm/lib/Transforms/Utils/LoopUnrollAndJam.cpp b/llvm/lib/Transforms/Utils/LoopUnrollAndJam.cpp
index 26b8c790f2a062..c7b88d3c48a69f 100644
--- a/llvm/lib/Transforms/Utils/LoopUnrollAndJam.cpp
+++ b/llvm/lib/Transforms/Utils/LoopUnrollAndJam.cpp
@@ -522,7 +522,7 @@ llvm::UnrollAndJamLoop(Loop *L, unsigned Count, unsigned TripCount,
// unconditional one to this one
BranchInst *SubTerm =
cast<BranchInst>(SubLoopBlocksLast[It - 1]->getTerminator());
- BranchInst::Create(SubLoopBlocksFirst[It], SubTerm);
+ BranchInst::Create(SubLoopBlocksFirst[It], SubTerm->getIterator());
SubTerm->eraseFromParent();
SubLoopBlocksFirst[It]->replacePhiUsesWith(ForeBlocksLast[It],
@@ -535,7 +535,7 @@ llvm::UnrollAndJamLoop(Loop *L, unsigned Count, unsigned TripCount,
// Aft blocks successors and phis
BranchInst *AftTerm = cast<BranchInst>(AftBlocksLast.back()->getTerminator());
if (CompletelyUnroll) {
- BranchInst::Create(LoopExit, AftTerm);
+ BranchInst::Create(LoopExit, AftTerm->getIterator());
AftTerm->eraseFromParent();
} else {
AftTerm->setSuccessor(!ContinueOnTrue, ForeBlocksFirst[0]);
@@ -550,7 +550,7 @@ llvm::UnrollAndJamLoop(Loop *L, unsigned Count, unsigned TripCount,
// unconditional one to this one
BranchInst *AftTerm =
cast<BranchInst>(AftBlocksLast[It - 1]->getTerminator());
- BranchInst::Create(AftBlocksFirst[It], AftTerm);
+ BranchInst::Create(AftBlocksFirst[It], AftTerm->getIterator());
AftTerm->eraseFromParent();
AftBlocksFirst[It]->replacePhiUsesWith(SubLoopBlocksLast[It],
diff --git a/llvm/lib/Transforms/Utils/LowerGlobalDtors.cpp b/llvm/lib/Transforms/Utils/LowerGlobalDtors.cpp
index 4908535cba5411..791eeed9cb62cd 100644
--- a/llvm/lib/Transforms/Utils/LowerGlobalDtors.cpp
+++ b/llvm/lib/Transforms/Utils/LowerGlobalDtors.cpp
@@ -207,7 +207,7 @@ static bool runImpl(Module &M) {
Value *Null = ConstantPointerNull::get(VoidStar);
Value *Args[] = {CallDtors, Null, DsoHandle};
Value *Res = CallInst::Create(AtExit, Args, "call", EntryBB);
- Value *Cmp = new ICmpInst(*EntryBB, ICmpInst::ICMP_NE, Res,
+ Value *Cmp = new ICmpInst(EntryBB, ICmpInst::ICMP_NE, Res,
Constant::getNullValue(Res->getType()));
BranchInst::Create(FailBB, RetBB, Cmp, EntryBB);
diff --git a/llvm/lib/Transforms/Utils/LowerInvoke.cpp b/llvm/lib/Transforms/Utils/LowerInvoke.cpp
index 22ff3c2e5848fc..ff2ab3c6dce9c8 100644
--- a/llvm/lib/Transforms/Utils/LowerInvoke.cpp
+++ b/llvm/lib/Transforms/Utils/LowerInvoke.cpp
@@ -52,7 +52,7 @@ static bool runImpl(Function &F) {
// Insert a normal call instruction...
CallInst *NewCall =
CallInst::Create(II->getFunctionType(), II->getCalledOperand(),
- CallArgs, OpBundles, "", II);
+ CallArgs, OpBundles, "", II->getIterator());
NewCall->takeName(II);
NewCall->setCallingConv(II->getCallingConv());
NewCall->setAttributes(II->getAttributes());
@@ -60,7 +60,7 @@ static bool runImpl(Function &F) {
II->replaceAllUsesWith(NewCall);
// Insert an unconditional branch to the normal destination.
- BranchInst::Create(II->getNormalDest(), II);
+ BranchInst::Create(II->getNormalDest(), II->getIterator());
// Remove any PHI node entries from the exception destination.
II->getUnwindDest()->removePredecessor(&BB);
diff --git a/llvm/lib/Transforms/Utils/LowerMemIntrinsics.cpp b/llvm/lib/Transforms/Utils/LowerMemIntrinsics.cpp
index 88934a34d2e2a0..acd3f2802031ea 100644
--- a/llvm/lib/Transforms/Utils/LowerMemIntrinsics.cpp
+++ b/llvm/lib/Transforms/Utils/LowerMemIntrinsics.cpp
@@ -384,10 +384,10 @@ static void createMemMoveLoop(Instruction *InsertBefore, Value *SrcAddr,
// SplitBlockAndInsertIfThenElse conveniently creates the basic if-then-else
// structure. Its block terminators (unconditional branches) are replaced by
// the appropriate conditional branches when the loop is built.
- ICmpInst *PtrCompare = new ICmpInst(InsertBefore, ICmpInst::ICMP_ULT,
+ ICmpInst *PtrCompare = new ICmpInst(InsertBefore->getIterator(), ICmpInst::ICMP_ULT,
SrcAddr, DstAddr, "compare_src_dst");
Instruction *ThenTerm, *ElseTerm;
- SplitBlockAndInsertIfThenElse(PtrCompare, InsertBefore, &ThenTerm,
+ SplitBlockAndInsertIfThenElse(PtrCompare, InsertBefore->getIterator(), &ThenTerm,
&ElseTerm);
// Each part of the function consists of two blocks:
@@ -409,7 +409,7 @@ static void createMemMoveLoop(Instruction *InsertBefore, Value *SrcAddr,
// Initial comparison of n == 0 that lets us skip the loops altogether. Shared
// between both backwards and forward copy clauses.
ICmpInst *CompareN =
- new ICmpInst(OrigBB->getTerminator(), ICmpInst::ICMP_EQ, CopyLen,
+ new ICmpInst(OrigBB->getTerminator()->getIterator(), ICmpInst::ICMP_EQ, CopyLen,
ConstantInt::get(TypeOfCopyLen, 0), "compare_n_to_0");
// Copying backwards.
@@ -431,7 +431,7 @@ static void createMemMoveLoop(Instruction *InsertBefore, Value *SrcAddr,
ExitBB, LoopBB);
LoopPhi->addIncoming(IndexPtr, LoopBB);
LoopPhi->addIncoming(CopyLen, CopyBackwardsBB);
- BranchInst::Create(ExitBB, LoopBB, CompareN, ThenTerm);
+ BranchInst::Create(ExitBB, LoopBB, CompareN, ThenTerm->getIterator());
ThenTerm->eraseFromParent();
// Copying forward.
@@ -451,7 +451,7 @@ static void createMemMoveLoop(Instruction *InsertBefore, Value *SrcAddr,
FwdCopyPhi->addIncoming(FwdIndexPtr, FwdLoopBB);
FwdCopyPhi->addIncoming(ConstantInt::get(TypeOfCopyLen, 0), CopyForwardBB);
- BranchInst::Create(ExitBB, FwdLoopBB, CompareN, ElseTerm);
+ BranchInst::Create(ExitBB, FwdLoopBB, CompareN, ElseTerm->getIterator());
ElseTerm->eraseFromParent();
}
diff --git a/llvm/lib/Transforms/Utils/LowerSwitch.cpp b/llvm/lib/Transforms/Utils/LowerSwitch.cpp
index 4131d36b572d74..f5921e5ccb0914 100644
--- a/llvm/lib/Transforms/Utils/LowerSwitch.cpp
+++ b/llvm/lib/Transforms/Utils/LowerSwitch.cpp
@@ -165,20 +165,20 @@ BasicBlock *NewLeafBlock(CaseRange &Leaf, Value *Val, ConstantInt *LowerBound,
if (Leaf.Low == Leaf.High) {
// Make the seteq instruction...
Comp =
- new ICmpInst(*NewLeaf, ICmpInst::ICMP_EQ, Val, Leaf.Low, "SwitchLeaf");
+ new ICmpInst(NewLeaf, ICmpInst::ICMP_EQ, Val, Leaf.Low, "SwitchLeaf");
} else {
// Make range comparison
if (Leaf.Low == LowerBound) {
// Val >= Min && Val <= Hi --> Val <= Hi
- Comp = new ICmpInst(*NewLeaf, ICmpInst::ICMP_SLE, Val, Leaf.High,
+ Comp = new ICmpInst(NewLeaf, ICmpInst::ICMP_SLE, Val, Leaf.High,
"SwitchLeaf");
} else if (Leaf.High == UpperBound) {
// Val <= Max && Val >= Lo --> Val >= Lo
- Comp = new ICmpInst(*NewLeaf, ICmpInst::ICMP_SGE, Val, Leaf.Low,
+ Comp = new ICmpInst(NewLeaf, ICmpInst::ICMP_SGE, Val, Leaf.Low,
"SwitchLeaf");
} else if (Leaf.Low->isZero()) {
// Val >= 0 && Val <= Hi --> Val <=u Hi
- Comp = new ICmpInst(*NewLeaf, ICmpInst::ICMP_ULE, Val, Leaf.High,
+ Comp = new ICmpInst(NewLeaf, ICmpInst::ICMP_ULE, Val, Leaf.High,
"SwitchLeaf");
} else {
// Emit V-Lo <=u Hi-Lo
@@ -186,7 +186,7 @@ BasicBlock *NewLeafBlock(CaseRange &Leaf, Value *Val, ConstantInt *LowerBound,
Instruction *Add = BinaryOperator::CreateAdd(
Val, NegLo, Val->getName() + ".off", NewLeaf);
Constant *UpperBound = ConstantExpr::getAdd(NegLo, Leaf.High);
- Comp = new ICmpInst(*NewLeaf, ICmpInst::ICMP_ULE, Add, UpperBound,
+ Comp = new ICmpInst(NewLeaf, ICmpInst::ICMP_ULE, Add, UpperBound,
"SwitchLeaf");
}
}
diff --git a/llvm/lib/Transforms/Utils/MatrixUtils.cpp b/llvm/lib/Transforms/Utils/MatrixUtils.cpp
index e218773cf5da15..7866d6434c1156 100644
--- a/llvm/lib/Transforms/Utils/MatrixUtils.cpp
+++ b/llvm/lib/Transforms/Utils/MatrixUtils.cpp
@@ -36,7 +36,7 @@ BasicBlock *TileInfo::CreateLoop(BasicBlock *Preheader, BasicBlock *Exit,
BranchInst::Create(Body, Header);
BranchInst::Create(Latch, Body);
PHINode *IV =
- PHINode::Create(I32Ty, 2, Name + ".iv", Header->getTerminator());
+ PHINode::Create(I32Ty, 2, Name + ".iv", Header->getTerminator()->getIterator());
IV->addIncoming(ConstantInt::get(I32Ty, 0), Preheader);
B.SetInsertPoint(Latch);
diff --git a/llvm/lib/Transforms/Utils/MemoryTaggingSupport.cpp b/llvm/lib/Transforms/Utils/MemoryTaggingSupport.cpp
index 2ff7c015107677..2ffe89a2458405 100644
--- a/llvm/lib/Transforms/Utils/MemoryTaggingSupport.cpp
+++ b/llvm/lib/Transforms/Utils/MemoryTaggingSupport.cpp
@@ -219,7 +219,7 @@ void alignAndPadAlloca(memtag::AllocaInfo &Info, llvm::Align Alignment) {
Type *PaddingType = ArrayType::get(Type::getInt8Ty(Ctx), AlignedSize - Size);
Type *TypeWithPadding = StructType::get(AllocatedType, PaddingType);
auto *NewAI = new AllocaInst(TypeWithPadding, Info.AI->getAddressSpace(),
- nullptr, "", Info.AI);
+ nullptr, "", Info.AI->getIterator());
NewAI->takeName(Info.AI);
NewAI->setAlignment(Info.AI->getAlign());
NewAI->setUsedWithInAlloca(Info.AI->isUsedWithInAlloca());
@@ -230,7 +230,7 @@ void alignAndPadAlloca(memtag::AllocaInfo &Info, llvm::Align Alignment) {
// TODO: Remove when typed pointers dropped
if (Info.AI->getType() != NewAI->getType())
- NewPtr = new BitCastInst(NewAI, Info.AI->getType(), "", Info.AI);
+ NewPtr = new BitCastInst(NewAI, Info.AI->getType(), "", Info.AI->getIterator());
Info.AI->replaceAllUsesWith(NewPtr);
Info.AI->eraseFromParent();
diff --git a/llvm/lib/Transforms/Utils/SCCPSolver.cpp b/llvm/lib/Transforms/Utils/SCCPSolver.cpp
index 3dc6016a0a373f..a185e8cd371c60 100644
--- a/llvm/lib/Transforms/Utils/SCCPSolver.cpp
+++ b/llvm/lib/Transforms/Utils/SCCPSolver.cpp
@@ -177,7 +177,7 @@ static bool replaceSignedInst(SCCPSolver &Solver,
Value *Op0 = Inst.getOperand(0);
if (InsertedValues.count(Op0) || !isNonNegative(Op0))
return false;
- NewInst = new ZExtInst(Op0, Inst.getType(), "", &Inst);
+ NewInst = new ZExtInst(Op0, Inst.getType(), "", Inst.getIterator());
NewInst->setNonNeg();
break;
}
@@ -186,7 +186,7 @@ static bool replaceSignedInst(SCCPSolver &Solver,
Value *Op0 = Inst.getOperand(0);
if (InsertedValues.count(Op0) || !isNonNegative(Op0))
return false;
- NewInst = BinaryOperator::CreateLShr(Op0, Inst.getOperand(1), "", &Inst);
+ NewInst = BinaryOperator::CreateLShr(Op0, Inst.getOperand(1), "", Inst.getIterator());
NewInst->setIsExact(Inst.isExact());
break;
}
@@ -199,7 +199,7 @@ static bool replaceSignedInst(SCCPSolver &Solver,
return false;
auto NewOpcode = Inst.getOpcode() == Instruction::SDiv ? Instruction::UDiv
: Instruction::URem;
- NewInst = BinaryOperator::Create(NewOpcode, Op0, Op1, "", &Inst);
+ NewInst = BinaryOperator::Create(NewOpcode, Op0, Op1, "", Inst.getIterator());
if (Inst.getOpcode() == Instruction::SDiv)
NewInst->setIsExact(Inst.isExact());
break;
diff --git a/llvm/lib/Transforms/Utils/ScalarEvolutionExpander.cpp b/llvm/lib/Transforms/Utils/ScalarEvolutionExpander.cpp
index 0f67cc3ff4faca..3a3bcde7c3dcdd 100644
--- a/llvm/lib/Transforms/Utils/ScalarEvolutionExpander.cpp
+++ b/llvm/lib/Transforms/Utils/ScalarEvolutionExpander.cpp
@@ -1267,7 +1267,7 @@ Value *SCEVExpander::visitAddRecExpr(const SCEVAddRecExpr *S) {
// corresponding to the back-edge.
Instruction *Add = BinaryOperator::CreateAdd(CanonicalIV, One,
"indvar.next",
- HP->getTerminator());
+ HP->getTerminator()->getIterator());
Add->setDebugLoc(HP->getTerminator()->getDebugLoc());
rememberInstruction(Add);
CanonicalIV->addIncoming(Add, HP);
@@ -2232,7 +2232,7 @@ Value *SCEVExpander::fixupLCSSAFormFor(Value *V) {
if (!PreserveLCSSA || !DefI)
return V;
- Instruction *InsertPt = &*Builder.GetInsertPoint();
+ BasicBlock::iterator InsertPt = Builder.GetInsertPoint();
Loop *DefLoop = SE.LI.getLoopFor(DefI->getParent());
Loop *UseLoop = SE.LI.getLoopFor(InsertPt->getParent());
if (!DefLoop || UseLoop == DefLoop || DefLoop->contains(UseLoop))
diff --git a/llvm/lib/Transforms/Utils/SimplifyCFG.cpp b/llvm/lib/Transforms/Utils/SimplifyCFG.cpp
index bbdbfbbf776f32..fe65e52110f97a 100644
--- a/llvm/lib/Transforms/Utils/SimplifyCFG.cpp
+++ b/llvm/lib/Transforms/Utils/SimplifyCFG.cpp
@@ -2710,7 +2710,7 @@ static void MergeCompatibleInvokesImpl(ArrayRef<InvokeInst *> Invokes,
// Form a PHI out of all the data ops under this index.
PHINode *PN = PHINode::Create(
- U->getType(), /*NumReservedValues=*/Invokes.size(), "", MergedInvoke);
+ U->getType(), /*NumReservedValues=*/Invokes.size(), "", MergedInvoke->getIterator());
for (InvokeInst *II : Invokes)
PN->addIncoming(II->getOperand(U.getOperandNo()), II->getParent());
@@ -4663,7 +4663,7 @@ bool SimplifyCFGOpt::SimplifyTerminatorOnSelect(Instruction *OldTerm,
} else if (KeepEdge1 && (KeepEdge2 || TrueBB == FalseBB)) {
// Neither of the selected blocks were successors, so this
// terminator must be unreachable.
- new UnreachableInst(OldTerm->getContext(), OldTerm);
+ new UnreachableInst(OldTerm->getContext(), OldTerm->getIterator());
} else {
// One of the selected values was a successor, but the other wasn't.
// Insert an unconditional branch to the one that was found;
@@ -5353,7 +5353,7 @@ bool SimplifyCFGOpt::simplifyUnreachable(UnreachableInst *UI) {
// or a degenerate conditional branch with matching destinations.
if (all_of(BI->successors(),
[BB](auto *Successor) { return Successor == BB; })) {
- new UnreachableInst(TI->getContext(), TI);
+ new UnreachableInst(TI->getContext(), TI->getIterator());
TI->eraseFromParent();
Changed = true;
} else {
@@ -5452,7 +5452,7 @@ bool SimplifyCFGOpt::simplifyUnreachable(UnreachableInst *UI) {
removeUnwindEdge(EHPred, DTU);
}
// The catchswitch is no longer reachable.
- new UnreachableInst(CSI->getContext(), CSI);
+ new UnreachableInst(CSI->getContext(), CSI->getIterator());
CSI->eraseFromParent();
Changed = true;
}
@@ -5462,7 +5462,7 @@ bool SimplifyCFGOpt::simplifyUnreachable(UnreachableInst *UI) {
"Expected to always have an unwind to BB.");
if (DTU)
Updates.push_back({DominatorTree::Delete, Predecessor, BB});
- new UnreachableInst(TI->getContext(), TI);
+ new UnreachableInst(TI->getContext(), TI->getIterator());
TI->eraseFromParent();
Changed = true;
}
@@ -6604,7 +6604,7 @@ static void reuseTableCompare(
// The compare yields the same result, just inverted. We can replace it.
Value *InvertedTableCmp = BinaryOperator::CreateXor(
RangeCmp, ConstantInt::get(RangeCmp->getType(), 1), "inverted.cmp",
- RangeCheckBranch);
+ RangeCheckBranch->getIterator());
CmpInst->replaceAllUsesWith(InvertedTableCmp);
++NumTableCmpReuses;
}
@@ -7155,14 +7155,14 @@ bool SimplifyCFGOpt::simplifyIndirectBr(IndirectBrInst *IBI) {
if (IBI->getNumDestinations() == 0) {
// If the indirectbr has no successors, change it to unreachable.
- new UnreachableInst(IBI->getContext(), IBI);
+ new UnreachableInst(IBI->getContext(), IBI->getIterator());
EraseTerminatorAndDCECond(IBI);
return true;
}
if (IBI->getNumDestinations() == 1) {
// If the indirectbr has one successor, change it to a direct branch.
- BranchInst::Create(IBI->getDestination(0), IBI);
+ BranchInst::Create(IBI->getDestination(0), IBI->getIterator());
EraseTerminatorAndDCECond(IBI);
return true;
}
diff --git a/llvm/lib/Transforms/Utils/SimplifyIndVar.cpp b/llvm/lib/Transforms/Utils/SimplifyIndVar.cpp
index 297cfe5124d85d..b8fa985fa3462e 100644
--- a/llvm/lib/Transforms/Utils/SimplifyIndVar.cpp
+++ b/llvm/lib/Transforms/Utils/SimplifyIndVar.cpp
@@ -301,7 +301,7 @@ bool SimplifyIndvar::eliminateSDiv(BinaryOperator *SDiv) {
if (SE->isKnownNonNegative(N) && SE->isKnownNonNegative(D)) {
auto *UDiv = BinaryOperator::Create(
BinaryOperator::UDiv, SDiv->getOperand(0), SDiv->getOperand(1),
- SDiv->getName() + ".udiv", SDiv);
+ SDiv->getName() + ".udiv", SDiv->getIterator());
UDiv->setIsExact(SDiv->isExact());
SDiv->replaceAllUsesWith(UDiv);
LLVM_DEBUG(dbgs() << "INDVARS: Simplified sdiv: " << *SDiv << '\n');
@@ -318,7 +318,7 @@ bool SimplifyIndvar::eliminateSDiv(BinaryOperator *SDiv) {
void SimplifyIndvar::replaceSRemWithURem(BinaryOperator *Rem) {
auto *N = Rem->getOperand(0), *D = Rem->getOperand(1);
auto *URem = BinaryOperator::Create(BinaryOperator::URem, N, D,
- Rem->getName() + ".urem", Rem);
+ Rem->getName() + ".urem", Rem->getIterator());
Rem->replaceAllUsesWith(URem);
LLVM_DEBUG(dbgs() << "INDVARS: Simplified srem: " << *Rem << '\n');
++NumSimplifiedSRem;
@@ -339,9 +339,9 @@ void SimplifyIndvar::replaceRemWithNumerator(BinaryOperator *Rem) {
void SimplifyIndvar::replaceRemWithNumeratorOrZero(BinaryOperator *Rem) {
auto *T = Rem->getType();
auto *N = Rem->getOperand(0), *D = Rem->getOperand(1);
- ICmpInst *ICmp = new ICmpInst(Rem, ICmpInst::ICMP_EQ, N, D);
+ ICmpInst *ICmp = new ICmpInst(Rem->getIterator(), ICmpInst::ICMP_EQ, N, D);
SelectInst *Sel =
- SelectInst::Create(ICmp, ConstantInt::get(T, 0), N, "iv.rem", Rem);
+ SelectInst::Create(ICmp, ConstantInt::get(T, 0), N, "iv.rem", Rem->getIterator());
Rem->replaceAllUsesWith(Sel);
LLVM_DEBUG(dbgs() << "INDVARS: Simplified rem: " << *Rem << '\n');
++NumElimRem;
@@ -411,7 +411,7 @@ bool SimplifyIndvar::eliminateOverflowIntrinsic(WithOverflowInst *WO) {
// intrinsic as well.
BinaryOperator *NewResult = BinaryOperator::Create(
- WO->getBinaryOp(), WO->getLHS(), WO->getRHS(), "", WO);
+ WO->getBinaryOp(), WO->getLHS(), WO->getRHS(), "", WO->getIterator());
if (WO->isSigned())
NewResult->setHasNoSignedWrap(true);
@@ -449,7 +449,7 @@ bool SimplifyIndvar::eliminateSaturatingIntrinsic(SaturatingInst *SI) {
return false;
BinaryOperator *BO = BinaryOperator::Create(
- SI->getBinaryOp(), SI->getLHS(), SI->getRHS(), SI->getName(), SI);
+ SI->getBinaryOp(), SI->getLHS(), SI->getRHS(), SI->getName(), SI->getIterator());
if (SI->isSigned())
BO->setHasNoSignedWrap();
else
@@ -1767,7 +1767,7 @@ Instruction *WidenIV::widenIVUse(WidenIV::NarrowIVDefUse DU,
PHINode *WidePhi =
PHINode::Create(DU.WideDef->getType(), 1, UsePhi->getName() + ".wide",
- UsePhi);
+ UsePhi->getIterator());
WidePhi->addIncoming(DU.WideDef, UsePhi->getIncomingBlock(0));
BasicBlock *WidePhiBB = WidePhi->getParent();
IRBuilder<> Builder(WidePhiBB, WidePhiBB->getFirstInsertionPt());
diff --git a/llvm/lib/Transforms/Utils/StripGCRelocates.cpp b/llvm/lib/Transforms/Utils/StripGCRelocates.cpp
index 6094f36a77f45c..3ae76ffd5ecab4 100644
--- a/llvm/lib/Transforms/Utils/StripGCRelocates.cpp
+++ b/llvm/lib/Transforms/Utils/StripGCRelocates.cpp
@@ -42,7 +42,7 @@ static bool stripGCRelocates(Function &F) {
// All gc_relocates are i8 addrspace(1)* typed, we need a bitcast from i8
// addrspace(1)* to the type of the OrigPtr, if the are not the same.
if (GCRel->getType() != OrigPtr->getType())
- ReplaceGCRel = new BitCastInst(OrigPtr, GCRel->getType(), "cast", GCRel);
+ ReplaceGCRel = new BitCastInst(OrigPtr, GCRel->getType(), "cast", GCRel->getIterator());
// Replace all uses of gc.relocate and delete the gc.relocate
// There maybe unncessary bitcasts back to the OrigPtr type, an instcombine
diff --git a/llvm/lib/Transforms/Utils/UnifyLoopExits.cpp b/llvm/lib/Transforms/Utils/UnifyLoopExits.cpp
index 2f37f7f972cbbf..1d51f61351fe27 100644
--- a/llvm/lib/Transforms/Utils/UnifyLoopExits.cpp
+++ b/llvm/lib/Transforms/Utils/UnifyLoopExits.cpp
@@ -119,7 +119,7 @@ static void restoreSSA(const DominatorTree &DT, const Loop *L,
LLVM_DEBUG(dbgs() << "externally used: " << Def->getName() << "\n");
auto NewPhi =
PHINode::Create(Def->getType(), Incoming.size(),
- Def->getName() + ".moved", &LoopExitBlock->front());
+ Def->getName() + ".moved", LoopExitBlock->begin());
for (auto *In : Incoming) {
LLVM_DEBUG(dbgs() << "predecessor " << In->getName() << ": ");
if (Def->getParent() == In || DT.dominates(Def, In)) {
diff --git a/llvm/tools/bugpoint/Miscompilation.cpp b/llvm/tools/bugpoint/Miscompilation.cpp
index 22806bab83eecf..b165b8220c20bd 100644
--- a/llvm/tools/bugpoint/Miscompilation.cpp
+++ b/llvm/tools/bugpoint/Miscompilation.cpp
@@ -884,7 +884,7 @@ CleanupAndPrepareModules(BugDriver &BD, std::unique_ptr<Module> Test,
// Check to see if we already looked up the value.
Value *CachedVal =
new LoadInst(F->getType(), Cache, "fpcache", EntryBB);
- Value *IsNull = new ICmpInst(*EntryBB, ICmpInst::ICMP_EQ, CachedVal,
+ Value *IsNull = new ICmpInst(EntryBB, ICmpInst::ICMP_EQ, CachedVal,
NullPtr, "isNull");
BranchInst::Create(LookupBB, DoCallBB, IsNull, EntryBB);
>From c4c35d9522d19a0a511ee2cc011a21661e69f3c0 Mon Sep 17 00:00:00 2001
From: Sirraide <aeternalmail at gmail.com>
Date: Thu, 29 Feb 2024 17:43:01 +0100
Subject: [PATCH 150/406] [Clang] [Sema] Handle `this` in
`__restrict`-qualified member functions properly (#83187)
When resolving the type of `this` inside a member function, we were
attaching all qualifiers present on the member function to the class
type and then making it a pointer; however, `__restrict`, unlike `const`
and `volatile`, needs to be attached to the pointer type rather than the
pointee type.
This fixes #82941, #42411, and #18121.
---
clang/docs/ReleaseNotes.rst | 5 ++
clang/lib/AST/DeclCXX.cpp | 15 +++++-
clang/lib/Sema/SemaExprCXX.cpp | 2 +-
clang/test/SemaCXX/restrict-this.cpp | 69 ++++++++++++++++++++++++++++
4 files changed, 88 insertions(+), 3 deletions(-)
create mode 100644 clang/test/SemaCXX/restrict-this.cpp
diff --git a/clang/docs/ReleaseNotes.rst b/clang/docs/ReleaseNotes.rst
index a5c6b80c4e99e1..f44fef28b9f17f 100644
--- a/clang/docs/ReleaseNotes.rst
+++ b/clang/docs/ReleaseNotes.rst
@@ -293,6 +293,11 @@ Bug Fixes to C++ Support
lookup searches the bases of an incomplete class.
- Fix a crash when an unresolved overload set is encountered on the RHS of a ``.*`` operator.
(`#53815 <https://github.com/llvm/llvm-project/issues/53815>`_)
+- In ``__restrict``-qualified member functions, attach ``__restrict`` to the pointer type of
+ ``this`` rather than the pointee type.
+ Fixes (`#82941 <https://github.com/llvm/llvm-project/issues/82941>`_),
+ (`#42411 <https://github.com/llvm/llvm-project/issues/42411>`_), and
+ (`#18121 <https://github.com/llvm/llvm-project/issues/18121>`_).
Bug Fixes to AST Handling
^^^^^^^^^^^^^^^^^^^^^^^^^
diff --git a/clang/lib/AST/DeclCXX.cpp b/clang/lib/AST/DeclCXX.cpp
index 117e802dae2d9d..b4f2327d9c560a 100644
--- a/clang/lib/AST/DeclCXX.cpp
+++ b/clang/lib/AST/DeclCXX.cpp
@@ -2543,8 +2543,19 @@ QualType CXXMethodDecl::getThisType(const FunctionProtoType *FPT,
const CXXRecordDecl *Decl) {
ASTContext &C = Decl->getASTContext();
QualType ObjectTy = ::getThisObjectType(C, FPT, Decl);
- return C.getLangOpts().HLSL ? C.getLValueReferenceType(ObjectTy)
- : C.getPointerType(ObjectTy);
+
+ // Unlike 'const' and 'volatile', a '__restrict' qualifier must be
+ // attached to the pointer type, not the pointee.
+ bool Restrict = FPT->getMethodQuals().hasRestrict();
+ if (Restrict)
+ ObjectTy.removeLocalRestrict();
+
+ ObjectTy = C.getLangOpts().HLSL ? C.getLValueReferenceType(ObjectTy)
+ : C.getPointerType(ObjectTy);
+
+ if (Restrict)
+ ObjectTy.addRestrict();
+ return ObjectTy;
}
QualType CXXMethodDecl::getThisType() const {
diff --git a/clang/lib/Sema/SemaExprCXX.cpp b/clang/lib/Sema/SemaExprCXX.cpp
index 59758d3bd6d1a3..c4750ce78fa9c1 100644
--- a/clang/lib/Sema/SemaExprCXX.cpp
+++ b/clang/lib/Sema/SemaExprCXX.cpp
@@ -1220,7 +1220,7 @@ static QualType adjustCVQualifiersForCXXThisWithinLambda(
: nullptr;
}
}
- return ASTCtx.getPointerType(ClassType);
+ return ThisTy;
}
QualType Sema::getCurrentThisType() {
diff --git a/clang/test/SemaCXX/restrict-this.cpp b/clang/test/SemaCXX/restrict-this.cpp
new file mode 100644
index 00000000000000..e78c8e0d56e2f8
--- /dev/null
+++ b/clang/test/SemaCXX/restrict-this.cpp
@@ -0,0 +1,69 @@
+// RUN: %clang_cc1 -verify -fsyntax-only %s
+// expected-no-diagnostics
+
+struct C {
+ void f() __restrict {
+ static_assert(__is_same(decltype(this), C *__restrict));
+ (void) [this]() {
+ static_assert(__is_same(decltype(this), C *__restrict));
+ (void) [this]() { static_assert(__is_same(decltype(this), C *__restrict)); };
+
+ // By-value capture means 'this' is now a different object; do not
+ // make it __restrict.
+ (void) [*this]() { static_assert(__is_same(decltype(this), const C *)); };
+ (void) [*this]() mutable { static_assert(__is_same(decltype(this), C *)); };
+ };
+ }
+};
+
+template <typename T> struct TC {
+ void f() __restrict {
+ static_assert(__is_same(decltype(this), TC<int> *__restrict));
+ (void) [this]() {
+ static_assert(__is_same(decltype(this), TC<int> *__restrict));
+ (void) [this]() { static_assert(__is_same(decltype(this), TC<int> *__restrict)); };
+
+ // By-value capture means 'this' is now a different object; do not
+ // make it __restrict.
+ (void) [*this]() { static_assert(__is_same(decltype(this), const TC<int> *)); };
+ (void) [*this]() mutable { static_assert(__is_same(decltype(this), TC<int> *)); };
+ };
+ }
+};
+
+void f() {
+ TC<int>{}.f();
+}
+
+namespace gh18121 {
+struct Foo {
+ void member() __restrict {
+ Foo *__restrict This = this;
+ }
+};
+}
+
+namespace gh42411 {
+struct foo {
+ int v;
+ void f() const __restrict {
+ static_assert(__is_same(decltype((v)), const int&));
+ (void) [this]() { static_assert(__is_same(decltype((v)), const int&)); };
+ }
+};
+}
+
+namespace gh82941 {
+void f(int& x) {
+ (void)x;
+}
+
+class C {
+ int x;
+ void g() __restrict;
+};
+
+void C::g() __restrict {
+ f(this->x);
+}
+}
>From 6c7805d5d186a6d1263f90b8033ad85e2d2633d7 Mon Sep 17 00:00:00 2001
From: Jeremy Morse <jeremy.morse at sony.com>
Date: Thu, 29 Feb 2024 16:49:40 +0000
Subject: [PATCH 151/406] Revert "[NFC][RemoveDIs] Bulk update utilities to
insert with iterators"
This reverts commit 3fda50d3915b2163a54a37b602be7783a89dd808.
Apparently I've missed a hunk while staging this; will back out for now.
Picked up here: https://lab.llvm.org/buildbot/#/builders/139/builds/60429/steps/6/logs/stdio
---
llvm/include/llvm/IR/Instructions.h | 8 ++---
llvm/include/llvm/Transforms/Utils/Local.h | 4 +--
llvm/lib/IR/Instructions.cpp | 4 +--
llvm/lib/Transforms/CFGuard/CFGuard.cpp | 2 +-
llvm/lib/Transforms/Scalar/Reg2Mem.cpp | 6 ++--
llvm/lib/Transforms/Utils/BasicBlockUtils.cpp | 8 ++---
.../Transforms/Utils/BreakCriticalEdges.cpp | 5 ++-
.../Transforms/Utils/CallPromotionUtils.cpp | 8 ++---
.../Utils/CanonicalizeFreezeInLoops.cpp | 2 +-
llvm/lib/Transforms/Utils/CodeExtractor.cpp | 31 ++++++++++---------
.../lib/Transforms/Utils/DemoteRegToStack.cpp | 26 ++++++++--------
.../Utils/EntryExitInstrumenter.cpp | 6 ++--
llvm/lib/Transforms/Utils/InlineFunction.cpp | 18 +++++------
llvm/lib/Transforms/Utils/Local.cpp | 18 +++++------
llvm/lib/Transforms/Utils/LoopConstrainer.cpp | 4 +--
.../Transforms/Utils/LoopRotationUtils.cpp | 2 +-
llvm/lib/Transforms/Utils/LoopSimplify.cpp | 2 +-
llvm/lib/Transforms/Utils/LoopUnroll.cpp | 2 +-
.../lib/Transforms/Utils/LoopUnrollAndJam.cpp | 6 ++--
.../lib/Transforms/Utils/LowerGlobalDtors.cpp | 2 +-
llvm/lib/Transforms/Utils/LowerInvoke.cpp | 4 +--
.../Transforms/Utils/LowerMemIntrinsics.cpp | 10 +++---
llvm/lib/Transforms/Utils/LowerSwitch.cpp | 10 +++---
llvm/lib/Transforms/Utils/MatrixUtils.cpp | 2 +-
.../Transforms/Utils/MemoryTaggingSupport.cpp | 4 +--
llvm/lib/Transforms/Utils/SCCPSolver.cpp | 6 ++--
.../Utils/ScalarEvolutionExpander.cpp | 4 +--
llvm/lib/Transforms/Utils/SimplifyCFG.cpp | 16 +++++-----
llvm/lib/Transforms/Utils/SimplifyIndVar.cpp | 14 ++++-----
.../lib/Transforms/Utils/StripGCRelocates.cpp | 2 +-
llvm/lib/Transforms/Utils/UnifyLoopExits.cpp | 2 +-
llvm/tools/bugpoint/Miscompilation.cpp | 2 +-
32 files changed, 120 insertions(+), 120 deletions(-)
diff --git a/llvm/include/llvm/IR/Instructions.h b/llvm/include/llvm/IR/Instructions.h
index 4e4cf71a349d74..bc357074e5cb21 100644
--- a/llvm/include/llvm/IR/Instructions.h
+++ b/llvm/include/llvm/IR/Instructions.h
@@ -1298,14 +1298,14 @@ class ICmpInst: public CmpInst {
/// Constructor with insert-at-end semantics.
ICmpInst(
- BasicBlock *InsertAtEnd, ///< Block to insert into.
+ BasicBlock &InsertAtEnd, ///< Block to insert into.
Predicate pred, ///< The predicate to use for the comparison
Value *LHS, ///< The left-hand-side of the expression
Value *RHS, ///< The right-hand-side of the expression
const Twine &NameStr = "" ///< Name of the instruction
) : CmpInst(makeCmpResultType(LHS->getType()),
Instruction::ICmp, pred, LHS, RHS, NameStr,
- InsertAtEnd) {
+ &InsertAtEnd) {
#ifndef NDEBUG
AssertOK();
#endif
@@ -1481,14 +1481,14 @@ class FCmpInst: public CmpInst {
/// Constructor with insert-at-end semantics.
FCmpInst(
- BasicBlock *InsertAtEnd, ///< Block to insert into.
+ BasicBlock &InsertAtEnd, ///< Block to insert into.
Predicate pred, ///< The predicate to use for the comparison
Value *LHS, ///< The left-hand-side of the expression
Value *RHS, ///< The right-hand-side of the expression
const Twine &NameStr = "" ///< Name of the instruction
) : CmpInst(makeCmpResultType(LHS->getType()),
Instruction::FCmp, pred, LHS, RHS, NameStr,
- InsertAtEnd) {
+ &InsertAtEnd) {
AssertOK();
}
diff --git a/llvm/include/llvm/Transforms/Utils/Local.h b/llvm/include/llvm/Transforms/Utils/Local.h
index 8dc843d2eaf604..2df3c9049c7d62 100644
--- a/llvm/include/llvm/Transforms/Utils/Local.h
+++ b/llvm/include/llvm/Transforms/Utils/Local.h
@@ -206,12 +206,12 @@ bool FoldBranchToCommonDest(BranchInst *BI, llvm::DomTreeUpdater *DTU = nullptr,
/// to create a stack slot for X.
AllocaInst *DemoteRegToStack(Instruction &X,
bool VolatileLoads = false,
- std::optional<BasicBlock::iterator> AllocaPoint = std::nullopt);
+ Instruction *AllocaPoint = nullptr);
/// This function takes a virtual register computed by a phi node and replaces
/// it with a slot in the stack frame, allocated via alloca. The phi node is
/// deleted and it returns the pointer to the alloca inserted.
-AllocaInst *DemotePHIToStack(PHINode *P, std::optional<BasicBlock::iterator> AllocaPoint = std::nullopt);
+AllocaInst *DemotePHIToStack(PHINode *P, Instruction *AllocaPoint = nullptr);
/// If the specified pointer points to an object that we control, try to modify
/// the object's alignment to PrefAlign. Returns a minimum known alignment of
diff --git a/llvm/lib/IR/Instructions.cpp b/llvm/lib/IR/Instructions.cpp
index c55d6cff84ed55..42cdcad78228f6 100644
--- a/llvm/lib/IR/Instructions.cpp
+++ b/llvm/lib/IR/Instructions.cpp
@@ -4608,10 +4608,10 @@ CmpInst *
CmpInst::Create(OtherOps Op, Predicate predicate, Value *S1, Value *S2,
const Twine &Name, BasicBlock *InsertAtEnd) {
if (Op == Instruction::ICmp) {
- return new ICmpInst(InsertAtEnd, CmpInst::Predicate(predicate),
+ return new ICmpInst(*InsertAtEnd, CmpInst::Predicate(predicate),
S1, S2, Name);
}
- return new FCmpInst(InsertAtEnd, CmpInst::Predicate(predicate),
+ return new FCmpInst(*InsertAtEnd, CmpInst::Predicate(predicate),
S1, S2, Name);
}
diff --git a/llvm/lib/Transforms/CFGuard/CFGuard.cpp b/llvm/lib/Transforms/CFGuard/CFGuard.cpp
index 32326b5801031f..4d4306576017be 100644
--- a/llvm/lib/Transforms/CFGuard/CFGuard.cpp
+++ b/llvm/lib/Transforms/CFGuard/CFGuard.cpp
@@ -219,7 +219,7 @@ void CFGuardImpl::insertCFGuardDispatch(CallBase *CB) {
// Create a copy of the call/invoke instruction and add the new bundle.
assert((isa<CallInst>(CB) || isa<InvokeInst>(CB)) &&
"Unknown indirect call type");
- CallBase *NewCB = CallBase::Create(CB, Bundles, CB->getIterator());
+ CallBase *NewCB = CallBase::Create(CB, Bundles, CB);
// Change the target of the call to be the guard dispatch function.
NewCB->setCalledOperand(GuardDispatchLoad);
diff --git a/llvm/lib/Transforms/Scalar/Reg2Mem.cpp b/llvm/lib/Transforms/Scalar/Reg2Mem.cpp
index ebc5075aa36fe8..6c2b3e9bd4a721 100644
--- a/llvm/lib/Transforms/Scalar/Reg2Mem.cpp
+++ b/llvm/lib/Transforms/Scalar/Reg2Mem.cpp
@@ -64,7 +64,7 @@ static bool runPass(Function &F) {
CastInst *AllocaInsertionPoint = new BitCastInst(
Constant::getNullValue(Type::getInt32Ty(F.getContext())),
- Type::getInt32Ty(F.getContext()), "reg2mem alloca point", I);
+ Type::getInt32Ty(F.getContext()), "reg2mem alloca point", &*I);
// Find the escaped instructions. But don't create stack slots for
// allocas in entry block.
@@ -76,7 +76,7 @@ static bool runPass(Function &F) {
// Demote escaped instructions
NumRegsDemoted += WorkList.size();
for (Instruction *I : WorkList)
- DemoteRegToStack(*I, false, AllocaInsertionPoint->getIterator());
+ DemoteRegToStack(*I, false, AllocaInsertionPoint);
WorkList.clear();
@@ -88,7 +88,7 @@ static bool runPass(Function &F) {
// Demote phi nodes
NumPhisDemoted += WorkList.size();
for (Instruction *I : WorkList)
- DemotePHIToStack(cast<PHINode>(I), AllocaInsertionPoint->getIterator());
+ DemotePHIToStack(cast<PHINode>(I), AllocaInsertionPoint);
return true;
}
diff --git a/llvm/lib/Transforms/Utils/BasicBlockUtils.cpp b/llvm/lib/Transforms/Utils/BasicBlockUtils.cpp
index 5aa59acfa6df99..5bb109a04ff178 100644
--- a/llvm/lib/Transforms/Utils/BasicBlockUtils.cpp
+++ b/llvm/lib/Transforms/Utils/BasicBlockUtils.cpp
@@ -1297,7 +1297,7 @@ static void UpdatePHINodes(BasicBlock *OrigBB, BasicBlock *NewBB,
// PHI.
// Create the new PHI node, insert it into NewBB at the end of the block
PHINode *NewPHI =
- PHINode::Create(PN->getType(), Preds.size(), PN->getName() + ".ph", BI->getIterator());
+ PHINode::Create(PN->getType(), Preds.size(), PN->getName() + ".ph", BI);
// NOTE! This loop walks backwards for a reason! First off, this minimizes
// the cost of removal if we end up removing a large number of values, and
@@ -1517,7 +1517,7 @@ static void SplitLandingPadPredecessorsImpl(
assert(!LPad->getType()->isTokenTy() &&
"Split cannot be applied if LPad is token type. Otherwise an "
"invalid PHINode of token type would be created.");
- PHINode *PN = PHINode::Create(LPad->getType(), 2, "lpad.phi", LPad->getIterator());
+ PHINode *PN = PHINode::Create(LPad->getType(), 2, "lpad.phi", LPad);
PN->addIncoming(Clone1, NewBB1);
PN->addIncoming(Clone2, NewBB2);
LPad->replaceAllUsesWith(PN);
@@ -1904,7 +1904,7 @@ static void reconnectPhis(BasicBlock *Out, BasicBlock *GuardBlock,
auto Phi = cast<PHINode>(I);
auto NewPhi =
PHINode::Create(Phi->getType(), Incoming.size(),
- Phi->getName() + ".moved", FirstGuardBlock->begin());
+ Phi->getName() + ".moved", &FirstGuardBlock->front());
for (auto *In : Incoming) {
Value *V = UndefValue::get(Phi->getType());
if (In == Out) {
@@ -2023,7 +2023,7 @@ static void calcPredicateUsingInteger(
Value *Id1 = ConstantInt::get(Type::getInt32Ty(Context),
std::distance(Outgoing.begin(), Succ1Iter));
IncomingId = SelectInst::Create(Condition, Id0, Id1, "target.bb.idx",
- In->getTerminator()->getIterator());
+ In->getTerminator());
} else {
// Get the index of the non-null successor.
auto SuccIter = Succ0 ? find(Outgoing, Succ0) : find(Outgoing, Succ1);
diff --git a/llvm/lib/Transforms/Utils/BreakCriticalEdges.cpp b/llvm/lib/Transforms/Utils/BreakCriticalEdges.cpp
index 4606514cbc7175..4a784c11c611d9 100644
--- a/llvm/lib/Transforms/Utils/BreakCriticalEdges.cpp
+++ b/llvm/lib/Transforms/Utils/BreakCriticalEdges.cpp
@@ -420,7 +420,7 @@ bool llvm::SplitIndirectBrCriticalEdges(Function &F,
// (b) Leave that as the only edge in the "Indirect" PHI.
// (c) Merge the two in the body block.
BasicBlock::iterator Indirect = Target->begin(),
- End = Target->getFirstNonPHIIt();
+ End = Target->getFirstNonPHI()->getIterator();
BasicBlock::iterator Direct = DirectSucc->begin();
BasicBlock::iterator MergeInsert = BodyBlock->getFirstInsertionPt();
@@ -430,7 +430,6 @@ bool llvm::SplitIndirectBrCriticalEdges(Function &F,
while (Indirect != End) {
PHINode *DirPHI = cast<PHINode>(Direct);
PHINode *IndPHI = cast<PHINode>(Indirect);
- BasicBlock::iterator InsertPt = Indirect;
// Now, clean up - the direct block shouldn't get the indirect value,
// and vice versa.
@@ -441,7 +440,7 @@ bool llvm::SplitIndirectBrCriticalEdges(Function &F,
// PHI is erased.
Indirect++;
- PHINode *NewIndPHI = PHINode::Create(IndPHI->getType(), 1, "ind", InsertPt);
+ PHINode *NewIndPHI = PHINode::Create(IndPHI->getType(), 1, "ind", IndPHI);
NewIndPHI->addIncoming(IndPHI->getIncomingValueForBlock(IBRPred),
IBRPred);
diff --git a/llvm/lib/Transforms/Utils/CallPromotionUtils.cpp b/llvm/lib/Transforms/Utils/CallPromotionUtils.cpp
index 48c33d6c0c8e0e..4e84927f1cfc90 100644
--- a/llvm/lib/Transforms/Utils/CallPromotionUtils.cpp
+++ b/llvm/lib/Transforms/Utils/CallPromotionUtils.cpp
@@ -168,12 +168,12 @@ static void createRetBitCast(CallBase &CB, Type *RetTy, CastInst **RetBitCast) {
// Determine an appropriate location to create the bitcast for the return
// value. The location depends on if we have a call or invoke instruction.
- BasicBlock::iterator InsertBefore;
+ Instruction *InsertBefore = nullptr;
if (auto *Invoke = dyn_cast<InvokeInst>(&CB))
InsertBefore =
- SplitEdge(Invoke->getParent(), Invoke->getNormalDest())->begin();
+ &SplitEdge(Invoke->getParent(), Invoke->getNormalDest())->front();
else
- InsertBefore = std::next(CB.getIterator());
+ InsertBefore = &*std::next(CB.getIterator());
// Bitcast the return value to the correct type.
auto *Cast = CastInst::CreateBitOrPointerCast(&CB, RetTy, "", InsertBefore);
@@ -509,7 +509,7 @@ CallBase &llvm::promoteCall(CallBase &CB, Function *Callee,
Type *FormalTy = CalleeType->getParamType(ArgNo);
Type *ActualTy = Arg->getType();
if (FormalTy != ActualTy) {
- auto *Cast = CastInst::CreateBitOrPointerCast(Arg, FormalTy, "", CB.getIterator());
+ auto *Cast = CastInst::CreateBitOrPointerCast(Arg, FormalTy, "", &CB);
CB.setArgOperand(ArgNo, Cast);
// Remove any incompatible attributes for the argument.
diff --git a/llvm/lib/Transforms/Utils/CanonicalizeFreezeInLoops.cpp b/llvm/lib/Transforms/Utils/CanonicalizeFreezeInLoops.cpp
index 40010aee9c1114..282c4456346678 100644
--- a/llvm/lib/Transforms/Utils/CanonicalizeFreezeInLoops.cpp
+++ b/llvm/lib/Transforms/Utils/CanonicalizeFreezeInLoops.cpp
@@ -144,7 +144,7 @@ void CanonicalizeFreezeInLoopsImpl::InsertFreezeAndForgetFromSCEV(Use &U) {
LLVM_DEBUG(dbgs() << "\tOperand: " << *U.get() << "\n");
U.set(new FreezeInst(ValueToFr, ValueToFr->getName() + ".frozen",
- PH->getTerminator()->getIterator()));
+ PH->getTerminator()));
SE.forgetValue(UserI);
}
diff --git a/llvm/lib/Transforms/Utils/CodeExtractor.cpp b/llvm/lib/Transforms/Utils/CodeExtractor.cpp
index 3071ec0c911321..bab065153f3efa 100644
--- a/llvm/lib/Transforms/Utils/CodeExtractor.cpp
+++ b/llvm/lib/Transforms/Utils/CodeExtractor.cpp
@@ -570,7 +570,7 @@ void CodeExtractor::findAllocas(const CodeExtractorAnalysisCache &CEAC,
LLVMContext &Ctx = M->getContext();
auto *Int8PtrTy = PointerType::getUnqual(Ctx);
CastInst *CastI =
- CastInst::CreatePointerCast(AI, Int8PtrTy, "lt.cast", I->getIterator());
+ CastInst::CreatePointerCast(AI, Int8PtrTy, "lt.cast", I);
I->replaceUsesOfWith(I->getOperand(1), CastI);
}
@@ -1024,7 +1024,7 @@ Function *CodeExtractor::constructFunction(const ValueSet &inputs,
Value *Idx[2];
Idx[0] = Constant::getNullValue(Type::getInt32Ty(header->getContext()));
Idx[1] = ConstantInt::get(Type::getInt32Ty(header->getContext()), aggIdx);
- BasicBlock::iterator TI = newFunction->begin()->getTerminator()->getIterator();
+ Instruction *TI = newFunction->begin()->getTerminator();
GetElementPtrInst *GEP = GetElementPtrInst::Create(
StructTy, &*AggAI, Idx, "gep_" + inputs[i]->getName(), TI);
RewriteVal = new LoadInst(StructTy->getElementType(aggIdx), GEP,
@@ -1173,7 +1173,7 @@ CallInst *CodeExtractor::emitCallAndSwitchStatement(Function *newFunction,
AllocaInst *alloca =
new AllocaInst(output->getType(), DL.getAllocaAddrSpace(),
nullptr, output->getName() + ".loc",
- codeReplacer->getParent()->front().begin());
+ &codeReplacer->getParent()->front().front());
ReloadOutputs.push_back(alloca);
params.push_back(alloca);
++ScalarOutputArgNo;
@@ -1192,8 +1192,8 @@ CallInst *CodeExtractor::emitCallAndSwitchStatement(Function *newFunction,
StructArgTy = StructType::get(newFunction->getContext(), ArgTypes);
Struct = new AllocaInst(
StructArgTy, DL.getAllocaAddrSpace(), nullptr, "structArg",
- AllocationBlock ? AllocationBlock->getFirstInsertionPt()
- : codeReplacer->getParent()->front().begin());
+ AllocationBlock ? &*AllocationBlock->getFirstInsertionPt()
+ : &codeReplacer->getParent()->front().front());
if (ArgsInZeroAddressSpace && DL.getAllocaAddrSpace() != 0) {
auto *StructSpaceCast = new AddrSpaceCastInst(
@@ -1358,8 +1358,9 @@ CallInst *CodeExtractor::emitCallAndSwitchStatement(Function *newFunction,
else
InsertPt = std::next(OutI->getIterator());
- assert((InsertPt->getFunction() == newFunction ||
- Blocks.count(InsertPt->getParent())) &&
+ Instruction *InsertBefore = &*InsertPt;
+ assert((InsertBefore->getFunction() == newFunction ||
+ Blocks.count(InsertBefore->getParent())) &&
"InsertPt should be in new function");
if (AggregateArgs && StructValues.contains(outputs[i])) {
assert(AggOutputArgBegin != newFunction->arg_end() &&
@@ -1370,8 +1371,8 @@ CallInst *CodeExtractor::emitCallAndSwitchStatement(Function *newFunction,
Idx[1] = ConstantInt::get(Type::getInt32Ty(Context), aggIdx);
GetElementPtrInst *GEP = GetElementPtrInst::Create(
StructArgTy, &*AggOutputArgBegin, Idx, "gep_" + outputs[i]->getName(),
- InsertPt);
- new StoreInst(outputs[i], GEP, InsertPt);
+ InsertBefore);
+ new StoreInst(outputs[i], GEP, InsertBefore);
++aggIdx;
// Since there should be only one struct argument aggregating
// all the output values, we shouldn't increment AggOutputArgBegin, which
@@ -1380,7 +1381,7 @@ CallInst *CodeExtractor::emitCallAndSwitchStatement(Function *newFunction,
assert(ScalarOutputArgBegin != newFunction->arg_end() &&
"Number of scalar output arguments should match "
"the number of defined values");
- new StoreInst(outputs[i], &*ScalarOutputArgBegin, InsertPt);
+ new StoreInst(outputs[i], &*ScalarOutputArgBegin, InsertBefore);
++ScalarOutputArgBegin;
}
}
@@ -1395,15 +1396,15 @@ CallInst *CodeExtractor::emitCallAndSwitchStatement(Function *newFunction,
// Check if the function should return a value
if (OldFnRetTy->isVoidTy()) {
- ReturnInst::Create(Context, nullptr, TheSwitch->getIterator()); // Return void
+ ReturnInst::Create(Context, nullptr, TheSwitch); // Return void
} else if (OldFnRetTy == TheSwitch->getCondition()->getType()) {
// return what we have
- ReturnInst::Create(Context, TheSwitch->getCondition(), TheSwitch->getIterator());
+ ReturnInst::Create(Context, TheSwitch->getCondition(), TheSwitch);
} else {
// Otherwise we must have code extracted an unwind or something, just
// return whatever we want.
ReturnInst::Create(Context,
- Constant::getNullValue(OldFnRetTy), TheSwitch->getIterator());
+ Constant::getNullValue(OldFnRetTy), TheSwitch);
}
TheSwitch->eraseFromParent();
@@ -1411,12 +1412,12 @@ CallInst *CodeExtractor::emitCallAndSwitchStatement(Function *newFunction,
case 1:
// Only a single destination, change the switch into an unconditional
// branch.
- BranchInst::Create(TheSwitch->getSuccessor(1), TheSwitch->getIterator());
+ BranchInst::Create(TheSwitch->getSuccessor(1), TheSwitch);
TheSwitch->eraseFromParent();
break;
case 2:
BranchInst::Create(TheSwitch->getSuccessor(1), TheSwitch->getSuccessor(2),
- call, TheSwitch->getIterator());
+ call, TheSwitch);
TheSwitch->eraseFromParent();
break;
default:
diff --git a/llvm/lib/Transforms/Utils/DemoteRegToStack.cpp b/llvm/lib/Transforms/Utils/DemoteRegToStack.cpp
index b2a88eadd3dee8..c894afee68a27a 100644
--- a/llvm/lib/Transforms/Utils/DemoteRegToStack.cpp
+++ b/llvm/lib/Transforms/Utils/DemoteRegToStack.cpp
@@ -20,7 +20,7 @@ using namespace llvm;
/// invalidating the SSA information for the value. It returns the pointer to
/// the alloca inserted to create a stack slot for I.
AllocaInst *llvm::DemoteRegToStack(Instruction &I, bool VolatileLoads,
- std::optional<BasicBlock::iterator> AllocaPoint) {
+ Instruction *AllocaPoint) {
if (I.use_empty()) {
I.eraseFromParent();
return nullptr;
@@ -33,10 +33,10 @@ AllocaInst *llvm::DemoteRegToStack(Instruction &I, bool VolatileLoads,
AllocaInst *Slot;
if (AllocaPoint) {
Slot = new AllocaInst(I.getType(), DL.getAllocaAddrSpace(), nullptr,
- I.getName()+".reg2mem", *AllocaPoint);
+ I.getName()+".reg2mem", AllocaPoint);
} else {
Slot = new AllocaInst(I.getType(), DL.getAllocaAddrSpace(), nullptr,
- I.getName() + ".reg2mem", F->getEntryBlock().begin());
+ I.getName() + ".reg2mem", &F->getEntryBlock().front());
}
// We cannot demote invoke instructions to the stack if their normal edge
@@ -73,7 +73,7 @@ AllocaInst *llvm::DemoteRegToStack(Instruction &I, bool VolatileLoads,
// Insert the load into the predecessor block
V = new LoadInst(I.getType(), Slot, I.getName() + ".reload",
VolatileLoads,
- PN->getIncomingBlock(i)->getTerminator()->getIterator());
+ PN->getIncomingBlock(i)->getTerminator());
Loads[PN->getIncomingBlock(i)] = V;
}
PN->setIncomingValue(i, V);
@@ -82,7 +82,7 @@ AllocaInst *llvm::DemoteRegToStack(Instruction &I, bool VolatileLoads,
} else {
// If this is a normal instruction, just insert a load.
Value *V = new LoadInst(I.getType(), Slot, I.getName() + ".reload",
- VolatileLoads, U->getIterator());
+ VolatileLoads, U);
U->replaceUsesOfWith(&I, V);
}
}
@@ -99,7 +99,7 @@ AllocaInst *llvm::DemoteRegToStack(Instruction &I, bool VolatileLoads,
break;
if (isa<CatchSwitchInst>(InsertPt)) {
for (BasicBlock *Handler : successors(&*InsertPt))
- new StoreInst(&I, Slot, Handler->getFirstInsertionPt());
+ new StoreInst(&I, Slot, &*Handler->getFirstInsertionPt());
return Slot;
}
} else {
@@ -107,14 +107,14 @@ AllocaInst *llvm::DemoteRegToStack(Instruction &I, bool VolatileLoads,
InsertPt = II.getNormalDest()->getFirstInsertionPt();
}
- new StoreInst(&I, Slot, InsertPt);
+ new StoreInst(&I, Slot, &*InsertPt);
return Slot;
}
/// DemotePHIToStack - This function takes a virtual register computed by a PHI
/// node and replaces it with a slot in the stack frame allocated via alloca.
/// The PHI node is deleted. It returns the pointer to the alloca inserted.
-AllocaInst *llvm::DemotePHIToStack(PHINode *P, std::optional<BasicBlock::iterator> AllocaPoint) {
+AllocaInst *llvm::DemotePHIToStack(PHINode *P, Instruction *AllocaPoint) {
if (P->use_empty()) {
P->eraseFromParent();
return nullptr;
@@ -126,12 +126,12 @@ AllocaInst *llvm::DemotePHIToStack(PHINode *P, std::optional<BasicBlock::iterato
AllocaInst *Slot;
if (AllocaPoint) {
Slot = new AllocaInst(P->getType(), DL.getAllocaAddrSpace(), nullptr,
- P->getName()+".reg2mem", *AllocaPoint);
+ P->getName()+".reg2mem", AllocaPoint);
} else {
Function *F = P->getParent()->getParent();
Slot = new AllocaInst(P->getType(), DL.getAllocaAddrSpace(), nullptr,
P->getName() + ".reg2mem",
- F->getEntryBlock().begin());
+ &F->getEntryBlock().front());
}
// Iterate over each operand inserting a store in each predecessor.
@@ -141,7 +141,7 @@ AllocaInst *llvm::DemotePHIToStack(PHINode *P, std::optional<BasicBlock::iterato
"Invoke edge not supported yet"); (void)II;
}
new StoreInst(P->getIncomingValue(i), Slot,
- P->getIncomingBlock(i)->getTerminator()->getIterator());
+ P->getIncomingBlock(i)->getTerminator());
}
// Insert a load in place of the PHI and replace all uses.
@@ -159,12 +159,12 @@ AllocaInst *llvm::DemotePHIToStack(PHINode *P, std::optional<BasicBlock::iterato
}
for (Instruction *User : Users) {
Value *V =
- new LoadInst(P->getType(), Slot, P->getName() + ".reload", User->getIterator());
+ new LoadInst(P->getType(), Slot, P->getName() + ".reload", User);
User->replaceUsesOfWith(P, V);
}
} else {
Value *V =
- new LoadInst(P->getType(), Slot, P->getName() + ".reload", InsertPt);
+ new LoadInst(P->getType(), Slot, P->getName() + ".reload", &*InsertPt);
P->replaceAllUsesWith(V);
}
// Delete PHI.
diff --git a/llvm/lib/Transforms/Utils/EntryExitInstrumenter.cpp b/llvm/lib/Transforms/Utils/EntryExitInstrumenter.cpp
index f4207474e9a68a..092f1799755d17 100644
--- a/llvm/lib/Transforms/Utils/EntryExitInstrumenter.cpp
+++ b/llvm/lib/Transforms/Utils/EntryExitInstrumenter.cpp
@@ -20,7 +20,7 @@
using namespace llvm;
static void insertCall(Function &CurFn, StringRef Func,
- BasicBlock::iterator InsertionPt, DebugLoc DL) {
+ Instruction *InsertionPt, DebugLoc DL) {
Module &M = *InsertionPt->getParent()->getParent()->getParent();
LLVMContext &C = InsertionPt->getParent()->getContext();
@@ -105,7 +105,7 @@ static bool runOnFunction(Function &F, bool PostInlining) {
if (auto SP = F.getSubprogram())
DL = DILocation::get(SP->getContext(), SP->getScopeLine(), 0, SP);
- insertCall(F, EntryFunc, F.begin()->getFirstInsertionPt(), DL);
+ insertCall(F, EntryFunc, &*F.begin()->getFirstInsertionPt(), DL);
Changed = true;
F.removeFnAttr(EntryAttr);
}
@@ -126,7 +126,7 @@ static bool runOnFunction(Function &F, bool PostInlining) {
else if (auto SP = F.getSubprogram())
DL = DILocation::get(SP->getContext(), 0, 0, SP);
- insertCall(F, ExitFunc, T->getIterator(), DL);
+ insertCall(F, ExitFunc, T, DL);
Changed = true;
}
F.removeFnAttr(ExitAttr);
diff --git a/llvm/lib/Transforms/Utils/InlineFunction.cpp b/llvm/lib/Transforms/Utils/InlineFunction.cpp
index 0e8e72678de613..f68fdb26f28173 100644
--- a/llvm/lib/Transforms/Utils/InlineFunction.cpp
+++ b/llvm/lib/Transforms/Utils/InlineFunction.cpp
@@ -689,7 +689,7 @@ static void HandleInlinedEHPad(InvokeInst *II, BasicBlock *FirstNewBlock,
if (auto *CRI = dyn_cast<CleanupReturnInst>(BB->getTerminator())) {
if (CRI->unwindsToCaller()) {
auto *CleanupPad = CRI->getCleanupPad();
- CleanupReturnInst::Create(CleanupPad, UnwindDest, CRI->getIterator());
+ CleanupReturnInst::Create(CleanupPad, UnwindDest, CRI);
CRI->eraseFromParent();
UpdatePHINodes(&*BB);
// Finding a cleanupret with an unwind destination would confuse
@@ -737,7 +737,7 @@ static void HandleInlinedEHPad(InvokeInst *II, BasicBlock *FirstNewBlock,
auto *NewCatchSwitch = CatchSwitchInst::Create(
CatchSwitch->getParentPad(), UnwindDest,
CatchSwitch->getNumHandlers(), CatchSwitch->getName(),
- CatchSwitch->getIterator());
+ CatchSwitch);
for (BasicBlock *PadBB : CatchSwitch->handlers())
NewCatchSwitch->addHandler(PadBB);
// Propagate info for the old catchswitch over to the new one in
@@ -972,7 +972,7 @@ static void PropagateOperandBundles(Function::iterator InlinedBB,
I->getOperandBundlesAsDefs(OpBundles);
OpBundles.emplace_back("funclet", CallSiteEHPad);
- Instruction *NewInst = CallBase::Create(I, OpBundles, I->getIterator());
+ Instruction *NewInst = CallBase::Create(I, OpBundles, I);
NewInst->takeName(I);
I->replaceAllUsesWith(NewInst);
I->eraseFromParent();
@@ -2002,7 +2002,7 @@ inlineRetainOrClaimRVCalls(CallBase &CB, objcarc::ARCInstKind RVCallKind,
Value *BundleArgs[] = {*objcarc::getAttachedARCFunction(&CB)};
OperandBundleDef OB("clang.arc.attachedcall", BundleArgs);
auto *NewCall = CallBase::addOperandBundle(
- CI, LLVMContext::OB_clang_arc_attachedcall, OB, CI->getIterator());
+ CI, LLVMContext::OB_clang_arc_attachedcall, OB, CI);
NewCall->copyMetadata(*CI);
CI->replaceAllUsesWith(NewCall);
CI->eraseFromParent();
@@ -2326,7 +2326,7 @@ llvm::InlineResult llvm::InlineFunction(CallBase &CB, InlineFunctionInfo &IFI,
OpDefs.emplace_back("deopt", std::move(MergedDeoptArgs));
}
- Instruction *NewI = CallBase::Create(ICS, OpDefs, ICS->getIterator());
+ Instruction *NewI = CallBase::Create(ICS, OpDefs, ICS);
// Note: the RAUW does the appropriate fixup in VMap, so we need to do
// this even if the call returns void.
@@ -2479,7 +2479,7 @@ llvm::InlineResult llvm::InlineFunction(CallBase &CB, InlineFunctionInfo &IFI,
SmallVector<Value *, 6> Params(CI->args());
Params.append(VarArgsToForward.begin(), VarArgsToForward.end());
CallInst *NewCI = CallInst::Create(
- CI->getFunctionType(), CI->getCalledOperand(), Params, "", CI->getIterator());
+ CI->getFunctionType(), CI->getCalledOperand(), Params, "", CI);
NewCI->setDebugLoc(CI->getDebugLoc());
NewCI->setAttributes(Attrs);
NewCI->setCallingConv(CI->getCallingConv());
@@ -2776,7 +2776,7 @@ llvm::InlineResult llvm::InlineFunction(CallBase &CB, InlineFunctionInfo &IFI,
// If the call site was an invoke instruction, add a branch to the normal
// destination.
if (InvokeInst *II = dyn_cast<InvokeInst>(&CB)) {
- BranchInst *NewBr = BranchInst::Create(II->getNormalDest(), CB.getIterator());
+ BranchInst *NewBr = BranchInst::Create(II->getNormalDest(), &CB);
NewBr->setDebugLoc(Returns[0]->getDebugLoc());
}
@@ -2813,7 +2813,7 @@ llvm::InlineResult llvm::InlineFunction(CallBase &CB, InlineFunctionInfo &IFI,
if (InvokeInst *II = dyn_cast<InvokeInst>(&CB)) {
// Add an unconditional branch to make this look like the CallInst case...
- CreatedBranchToNormalDest = BranchInst::Create(II->getNormalDest(), CB.getIterator());
+ CreatedBranchToNormalDest = BranchInst::Create(II->getNormalDest(), &CB);
// Split the basic block. This guarantees that no PHI nodes will have to be
// updated due to new incoming edges, and make the invoke case more
@@ -2881,7 +2881,7 @@ llvm::InlineResult llvm::InlineFunction(CallBase &CB, InlineFunctionInfo &IFI,
DebugLoc Loc;
for (unsigned i = 0, e = Returns.size(); i != e; ++i) {
ReturnInst *RI = Returns[i];
- BranchInst* BI = BranchInst::Create(AfterCallBB, RI->getIterator());
+ BranchInst* BI = BranchInst::Create(AfterCallBB, RI);
Loc = RI->getDebugLoc();
BI->setDebugLoc(Loc);
RI->eraseFromParent();
diff --git a/llvm/lib/Transforms/Utils/Local.cpp b/llvm/lib/Transforms/Utils/Local.cpp
index c4a8843f2840b3..075eeb5b19fd2b 100644
--- a/llvm/lib/Transforms/Utils/Local.cpp
+++ b/llvm/lib/Transforms/Utils/Local.cpp
@@ -2811,7 +2811,7 @@ unsigned llvm::changeToUnreachable(Instruction *I, bool PreserveLCSSA,
if (DTU)
UniqueSuccessors.insert(Successor);
}
- auto *UI = new UnreachableInst(I->getContext(), I->getIterator());
+ auto *UI = new UnreachableInst(I->getContext(), I);
UI->setDebugLoc(I->getDebugLoc());
// All instructions after this are dead.
@@ -2868,7 +2868,7 @@ CallInst *llvm::changeToCall(InvokeInst *II, DomTreeUpdater *DTU) {
// Follow the call by a branch to the normal destination.
BasicBlock *NormalDestBB = II->getNormalDest();
- BranchInst::Create(NormalDestBB, II->getIterator());
+ BranchInst::Create(NormalDestBB, II);
// Update PHI nodes in the unwind destination
BasicBlock *BB = II->getParent();
@@ -3048,7 +3048,7 @@ static bool markAliveBlocks(Function &F,
// jump to the normal destination branch.
BasicBlock *NormalDestBB = II->getNormalDest();
BasicBlock *UnwindDestBB = II->getUnwindDest();
- BranchInst::Create(NormalDestBB, II->getIterator());
+ BranchInst::Create(NormalDestBB, II);
UnwindDestBB->removePredecessor(II->getParent());
II->eraseFromParent();
if (DTU)
@@ -3131,12 +3131,12 @@ Instruction *llvm::removeUnwindEdge(BasicBlock *BB, DomTreeUpdater *DTU) {
BasicBlock *UnwindDest;
if (auto *CRI = dyn_cast<CleanupReturnInst>(TI)) {
- NewTI = CleanupReturnInst::Create(CRI->getCleanupPad(), nullptr, CRI->getIterator());
+ NewTI = CleanupReturnInst::Create(CRI->getCleanupPad(), nullptr, CRI);
UnwindDest = CRI->getUnwindDest();
} else if (auto *CatchSwitch = dyn_cast<CatchSwitchInst>(TI)) {
auto *NewCatchSwitch = CatchSwitchInst::Create(
CatchSwitch->getParentPad(), nullptr, CatchSwitch->getNumHandlers(),
- CatchSwitch->getName(), CatchSwitch->getIterator());
+ CatchSwitch->getName(), CatchSwitch);
for (BasicBlock *PadBB : CatchSwitch->handlers())
NewCatchSwitch->addHandler(PadBB);
@@ -3972,23 +3972,23 @@ bool llvm::recognizeBSwapOrBitReverseIdiom(
// We may need to truncate the provider.
if (DemandedTy != Provider->getType()) {
auto *Trunc =
- CastInst::CreateIntegerCast(Provider, DemandedTy, false, "trunc", I->getIterator());
+ CastInst::CreateIntegerCast(Provider, DemandedTy, false, "trunc", I);
InsertedInsts.push_back(Trunc);
Provider = Trunc;
}
- Instruction *Result = CallInst::Create(F, Provider, "rev", I->getIterator());
+ Instruction *Result = CallInst::Create(F, Provider, "rev", I);
InsertedInsts.push_back(Result);
if (!DemandedMask.isAllOnes()) {
auto *Mask = ConstantInt::get(DemandedTy, DemandedMask);
- Result = BinaryOperator::Create(Instruction::And, Result, Mask, "mask", I->getIterator());
+ Result = BinaryOperator::Create(Instruction::And, Result, Mask, "mask", I);
InsertedInsts.push_back(Result);
}
// We may need to zeroextend back to the result type.
if (ITy != Result->getType()) {
- auto *ExtInst = CastInst::CreateIntegerCast(Result, ITy, false, "zext", I->getIterator());
+ auto *ExtInst = CastInst::CreateIntegerCast(Result, ITy, false, "zext", I);
InsertedInsts.push_back(ExtInst);
}
diff --git a/llvm/lib/Transforms/Utils/LoopConstrainer.cpp b/llvm/lib/Transforms/Utils/LoopConstrainer.cpp
index 81545ef375219c..ea6d952cfa7d4f 100644
--- a/llvm/lib/Transforms/Utils/LoopConstrainer.cpp
+++ b/llvm/lib/Transforms/Utils/LoopConstrainer.cpp
@@ -644,7 +644,7 @@ LoopConstrainer::RewrittenRangeInfo LoopConstrainer::changeIterationSpaceEnd(
// value of the same PHI nodes if/when we continue execution.
for (PHINode &PN : LS.Header->phis()) {
PHINode *NewPHI = PHINode::Create(PN.getType(), 2, PN.getName() + ".copy",
- BranchToContinuation->getIterator());
+ BranchToContinuation);
NewPHI->addIncoming(PN.getIncomingValueForBlock(Preheader), Preheader);
NewPHI->addIncoming(PN.getIncomingValueForBlock(LS.Latch),
@@ -653,7 +653,7 @@ LoopConstrainer::RewrittenRangeInfo LoopConstrainer::changeIterationSpaceEnd(
}
RRI.IndVarEnd = PHINode::Create(IndVarBase->getType(), 2, "indvar.end",
- BranchToContinuation->getIterator());
+ BranchToContinuation);
RRI.IndVarEnd->addIncoming(IndVarStart, Preheader);
RRI.IndVarEnd->addIncoming(IndVarBase, RRI.ExitSelector);
diff --git a/llvm/lib/Transforms/Utils/LoopRotationUtils.cpp b/llvm/lib/Transforms/Utils/LoopRotationUtils.cpp
index cec47810e04447..adae796ee02997 100644
--- a/llvm/lib/Transforms/Utils/LoopRotationUtils.cpp
+++ b/llvm/lib/Transforms/Utils/LoopRotationUtils.cpp
@@ -874,7 +874,7 @@ bool LoopRotate::rotateLoop(Loop *L, bool SimplifiedLatch) {
// We can fold the conditional branch in the preheader, this makes things
// simpler. The first step is to remove the extra edge to the Exit block.
Exit->removePredecessor(OrigPreheader, true /*preserve LCSSA*/);
- BranchInst *NewBI = BranchInst::Create(NewHeader, PHBI->getIterator());
+ BranchInst *NewBI = BranchInst::Create(NewHeader, PHBI);
NewBI->setDebugLoc(PHBI->getDebugLoc());
PHBI->eraseFromParent();
diff --git a/llvm/lib/Transforms/Utils/LoopSimplify.cpp b/llvm/lib/Transforms/Utils/LoopSimplify.cpp
index b38fecd6d8b416..07e622b1577fe1 100644
--- a/llvm/lib/Transforms/Utils/LoopSimplify.cpp
+++ b/llvm/lib/Transforms/Utils/LoopSimplify.cpp
@@ -399,7 +399,7 @@ static BasicBlock *insertUniqueBackedgeBlock(Loop *L, BasicBlock *Preheader,
for (BasicBlock::iterator I = Header->begin(); isa<PHINode>(I); ++I) {
PHINode *PN = cast<PHINode>(I);
PHINode *NewPN = PHINode::Create(PN->getType(), BackedgeBlocks.size(),
- PN->getName()+".be", BETerminator->getIterator());
+ PN->getName()+".be", BETerminator);
// Loop over the PHI node, moving all entries except the one for the
// preheader over to the new PHI node.
diff --git a/llvm/lib/Transforms/Utils/LoopUnroll.cpp b/llvm/lib/Transforms/Utils/LoopUnroll.cpp
index 6f0d000815726e..ee6f7b35750af0 100644
--- a/llvm/lib/Transforms/Utils/LoopUnroll.cpp
+++ b/llvm/lib/Transforms/Utils/LoopUnroll.cpp
@@ -721,7 +721,7 @@ LoopUnrollResult llvm::UnrollLoop(Loop *L, UnrollLoopOptions ULO, LoopInfo *LI,
DeadSucc->removePredecessor(Src, /* KeepOneInputPHIs */ true);
// Replace the conditional branch with an unconditional one.
- BranchInst::Create(Dest, Term->getIterator());
+ BranchInst::Create(Dest, Term);
Term->eraseFromParent();
DTUpdates.emplace_back(DominatorTree::Delete, Src, DeadSucc);
diff --git a/llvm/lib/Transforms/Utils/LoopUnrollAndJam.cpp b/llvm/lib/Transforms/Utils/LoopUnrollAndJam.cpp
index c7b88d3c48a69f..26b8c790f2a062 100644
--- a/llvm/lib/Transforms/Utils/LoopUnrollAndJam.cpp
+++ b/llvm/lib/Transforms/Utils/LoopUnrollAndJam.cpp
@@ -522,7 +522,7 @@ llvm::UnrollAndJamLoop(Loop *L, unsigned Count, unsigned TripCount,
// unconditional one to this one
BranchInst *SubTerm =
cast<BranchInst>(SubLoopBlocksLast[It - 1]->getTerminator());
- BranchInst::Create(SubLoopBlocksFirst[It], SubTerm->getIterator());
+ BranchInst::Create(SubLoopBlocksFirst[It], SubTerm);
SubTerm->eraseFromParent();
SubLoopBlocksFirst[It]->replacePhiUsesWith(ForeBlocksLast[It],
@@ -535,7 +535,7 @@ llvm::UnrollAndJamLoop(Loop *L, unsigned Count, unsigned TripCount,
// Aft blocks successors and phis
BranchInst *AftTerm = cast<BranchInst>(AftBlocksLast.back()->getTerminator());
if (CompletelyUnroll) {
- BranchInst::Create(LoopExit, AftTerm->getIterator());
+ BranchInst::Create(LoopExit, AftTerm);
AftTerm->eraseFromParent();
} else {
AftTerm->setSuccessor(!ContinueOnTrue, ForeBlocksFirst[0]);
@@ -550,7 +550,7 @@ llvm::UnrollAndJamLoop(Loop *L, unsigned Count, unsigned TripCount,
// unconditional one to this one
BranchInst *AftTerm =
cast<BranchInst>(AftBlocksLast[It - 1]->getTerminator());
- BranchInst::Create(AftBlocksFirst[It], AftTerm->getIterator());
+ BranchInst::Create(AftBlocksFirst[It], AftTerm);
AftTerm->eraseFromParent();
AftBlocksFirst[It]->replacePhiUsesWith(SubLoopBlocksLast[It],
diff --git a/llvm/lib/Transforms/Utils/LowerGlobalDtors.cpp b/llvm/lib/Transforms/Utils/LowerGlobalDtors.cpp
index 791eeed9cb62cd..4908535cba5411 100644
--- a/llvm/lib/Transforms/Utils/LowerGlobalDtors.cpp
+++ b/llvm/lib/Transforms/Utils/LowerGlobalDtors.cpp
@@ -207,7 +207,7 @@ static bool runImpl(Module &M) {
Value *Null = ConstantPointerNull::get(VoidStar);
Value *Args[] = {CallDtors, Null, DsoHandle};
Value *Res = CallInst::Create(AtExit, Args, "call", EntryBB);
- Value *Cmp = new ICmpInst(EntryBB, ICmpInst::ICMP_NE, Res,
+ Value *Cmp = new ICmpInst(*EntryBB, ICmpInst::ICMP_NE, Res,
Constant::getNullValue(Res->getType()));
BranchInst::Create(FailBB, RetBB, Cmp, EntryBB);
diff --git a/llvm/lib/Transforms/Utils/LowerInvoke.cpp b/llvm/lib/Transforms/Utils/LowerInvoke.cpp
index ff2ab3c6dce9c8..22ff3c2e5848fc 100644
--- a/llvm/lib/Transforms/Utils/LowerInvoke.cpp
+++ b/llvm/lib/Transforms/Utils/LowerInvoke.cpp
@@ -52,7 +52,7 @@ static bool runImpl(Function &F) {
// Insert a normal call instruction...
CallInst *NewCall =
CallInst::Create(II->getFunctionType(), II->getCalledOperand(),
- CallArgs, OpBundles, "", II->getIterator());
+ CallArgs, OpBundles, "", II);
NewCall->takeName(II);
NewCall->setCallingConv(II->getCallingConv());
NewCall->setAttributes(II->getAttributes());
@@ -60,7 +60,7 @@ static bool runImpl(Function &F) {
II->replaceAllUsesWith(NewCall);
// Insert an unconditional branch to the normal destination.
- BranchInst::Create(II->getNormalDest(), II->getIterator());
+ BranchInst::Create(II->getNormalDest(), II);
// Remove any PHI node entries from the exception destination.
II->getUnwindDest()->removePredecessor(&BB);
diff --git a/llvm/lib/Transforms/Utils/LowerMemIntrinsics.cpp b/llvm/lib/Transforms/Utils/LowerMemIntrinsics.cpp
index acd3f2802031ea..88934a34d2e2a0 100644
--- a/llvm/lib/Transforms/Utils/LowerMemIntrinsics.cpp
+++ b/llvm/lib/Transforms/Utils/LowerMemIntrinsics.cpp
@@ -384,10 +384,10 @@ static void createMemMoveLoop(Instruction *InsertBefore, Value *SrcAddr,
// SplitBlockAndInsertIfThenElse conveniently creates the basic if-then-else
// structure. Its block terminators (unconditional branches) are replaced by
// the appropriate conditional branches when the loop is built.
- ICmpInst *PtrCompare = new ICmpInst(InsertBefore->getIterator(), ICmpInst::ICMP_ULT,
+ ICmpInst *PtrCompare = new ICmpInst(InsertBefore, ICmpInst::ICMP_ULT,
SrcAddr, DstAddr, "compare_src_dst");
Instruction *ThenTerm, *ElseTerm;
- SplitBlockAndInsertIfThenElse(PtrCompare, InsertBefore->getIterator(), &ThenTerm,
+ SplitBlockAndInsertIfThenElse(PtrCompare, InsertBefore, &ThenTerm,
&ElseTerm);
// Each part of the function consists of two blocks:
@@ -409,7 +409,7 @@ static void createMemMoveLoop(Instruction *InsertBefore, Value *SrcAddr,
// Initial comparison of n == 0 that lets us skip the loops altogether. Shared
// between both backwards and forward copy clauses.
ICmpInst *CompareN =
- new ICmpInst(OrigBB->getTerminator()->getIterator(), ICmpInst::ICMP_EQ, CopyLen,
+ new ICmpInst(OrigBB->getTerminator(), ICmpInst::ICMP_EQ, CopyLen,
ConstantInt::get(TypeOfCopyLen, 0), "compare_n_to_0");
// Copying backwards.
@@ -431,7 +431,7 @@ static void createMemMoveLoop(Instruction *InsertBefore, Value *SrcAddr,
ExitBB, LoopBB);
LoopPhi->addIncoming(IndexPtr, LoopBB);
LoopPhi->addIncoming(CopyLen, CopyBackwardsBB);
- BranchInst::Create(ExitBB, LoopBB, CompareN, ThenTerm->getIterator());
+ BranchInst::Create(ExitBB, LoopBB, CompareN, ThenTerm);
ThenTerm->eraseFromParent();
// Copying forward.
@@ -451,7 +451,7 @@ static void createMemMoveLoop(Instruction *InsertBefore, Value *SrcAddr,
FwdCopyPhi->addIncoming(FwdIndexPtr, FwdLoopBB);
FwdCopyPhi->addIncoming(ConstantInt::get(TypeOfCopyLen, 0), CopyForwardBB);
- BranchInst::Create(ExitBB, FwdLoopBB, CompareN, ElseTerm->getIterator());
+ BranchInst::Create(ExitBB, FwdLoopBB, CompareN, ElseTerm);
ElseTerm->eraseFromParent();
}
diff --git a/llvm/lib/Transforms/Utils/LowerSwitch.cpp b/llvm/lib/Transforms/Utils/LowerSwitch.cpp
index f5921e5ccb0914..4131d36b572d74 100644
--- a/llvm/lib/Transforms/Utils/LowerSwitch.cpp
+++ b/llvm/lib/Transforms/Utils/LowerSwitch.cpp
@@ -165,20 +165,20 @@ BasicBlock *NewLeafBlock(CaseRange &Leaf, Value *Val, ConstantInt *LowerBound,
if (Leaf.Low == Leaf.High) {
// Make the seteq instruction...
Comp =
- new ICmpInst(NewLeaf, ICmpInst::ICMP_EQ, Val, Leaf.Low, "SwitchLeaf");
+ new ICmpInst(*NewLeaf, ICmpInst::ICMP_EQ, Val, Leaf.Low, "SwitchLeaf");
} else {
// Make range comparison
if (Leaf.Low == LowerBound) {
// Val >= Min && Val <= Hi --> Val <= Hi
- Comp = new ICmpInst(NewLeaf, ICmpInst::ICMP_SLE, Val, Leaf.High,
+ Comp = new ICmpInst(*NewLeaf, ICmpInst::ICMP_SLE, Val, Leaf.High,
"SwitchLeaf");
} else if (Leaf.High == UpperBound) {
// Val <= Max && Val >= Lo --> Val >= Lo
- Comp = new ICmpInst(NewLeaf, ICmpInst::ICMP_SGE, Val, Leaf.Low,
+ Comp = new ICmpInst(*NewLeaf, ICmpInst::ICMP_SGE, Val, Leaf.Low,
"SwitchLeaf");
} else if (Leaf.Low->isZero()) {
// Val >= 0 && Val <= Hi --> Val <=u Hi
- Comp = new ICmpInst(NewLeaf, ICmpInst::ICMP_ULE, Val, Leaf.High,
+ Comp = new ICmpInst(*NewLeaf, ICmpInst::ICMP_ULE, Val, Leaf.High,
"SwitchLeaf");
} else {
// Emit V-Lo <=u Hi-Lo
@@ -186,7 +186,7 @@ BasicBlock *NewLeafBlock(CaseRange &Leaf, Value *Val, ConstantInt *LowerBound,
Instruction *Add = BinaryOperator::CreateAdd(
Val, NegLo, Val->getName() + ".off", NewLeaf);
Constant *UpperBound = ConstantExpr::getAdd(NegLo, Leaf.High);
- Comp = new ICmpInst(NewLeaf, ICmpInst::ICMP_ULE, Add, UpperBound,
+ Comp = new ICmpInst(*NewLeaf, ICmpInst::ICMP_ULE, Add, UpperBound,
"SwitchLeaf");
}
}
diff --git a/llvm/lib/Transforms/Utils/MatrixUtils.cpp b/llvm/lib/Transforms/Utils/MatrixUtils.cpp
index 7866d6434c1156..e218773cf5da15 100644
--- a/llvm/lib/Transforms/Utils/MatrixUtils.cpp
+++ b/llvm/lib/Transforms/Utils/MatrixUtils.cpp
@@ -36,7 +36,7 @@ BasicBlock *TileInfo::CreateLoop(BasicBlock *Preheader, BasicBlock *Exit,
BranchInst::Create(Body, Header);
BranchInst::Create(Latch, Body);
PHINode *IV =
- PHINode::Create(I32Ty, 2, Name + ".iv", Header->getTerminator()->getIterator());
+ PHINode::Create(I32Ty, 2, Name + ".iv", Header->getTerminator());
IV->addIncoming(ConstantInt::get(I32Ty, 0), Preheader);
B.SetInsertPoint(Latch);
diff --git a/llvm/lib/Transforms/Utils/MemoryTaggingSupport.cpp b/llvm/lib/Transforms/Utils/MemoryTaggingSupport.cpp
index 2ffe89a2458405..2ff7c015107677 100644
--- a/llvm/lib/Transforms/Utils/MemoryTaggingSupport.cpp
+++ b/llvm/lib/Transforms/Utils/MemoryTaggingSupport.cpp
@@ -219,7 +219,7 @@ void alignAndPadAlloca(memtag::AllocaInfo &Info, llvm::Align Alignment) {
Type *PaddingType = ArrayType::get(Type::getInt8Ty(Ctx), AlignedSize - Size);
Type *TypeWithPadding = StructType::get(AllocatedType, PaddingType);
auto *NewAI = new AllocaInst(TypeWithPadding, Info.AI->getAddressSpace(),
- nullptr, "", Info.AI->getIterator());
+ nullptr, "", Info.AI);
NewAI->takeName(Info.AI);
NewAI->setAlignment(Info.AI->getAlign());
NewAI->setUsedWithInAlloca(Info.AI->isUsedWithInAlloca());
@@ -230,7 +230,7 @@ void alignAndPadAlloca(memtag::AllocaInfo &Info, llvm::Align Alignment) {
// TODO: Remove when typed pointers dropped
if (Info.AI->getType() != NewAI->getType())
- NewPtr = new BitCastInst(NewAI, Info.AI->getType(), "", Info.AI->getIterator());
+ NewPtr = new BitCastInst(NewAI, Info.AI->getType(), "", Info.AI);
Info.AI->replaceAllUsesWith(NewPtr);
Info.AI->eraseFromParent();
diff --git a/llvm/lib/Transforms/Utils/SCCPSolver.cpp b/llvm/lib/Transforms/Utils/SCCPSolver.cpp
index a185e8cd371c60..3dc6016a0a373f 100644
--- a/llvm/lib/Transforms/Utils/SCCPSolver.cpp
+++ b/llvm/lib/Transforms/Utils/SCCPSolver.cpp
@@ -177,7 +177,7 @@ static bool replaceSignedInst(SCCPSolver &Solver,
Value *Op0 = Inst.getOperand(0);
if (InsertedValues.count(Op0) || !isNonNegative(Op0))
return false;
- NewInst = new ZExtInst(Op0, Inst.getType(), "", Inst.getIterator());
+ NewInst = new ZExtInst(Op0, Inst.getType(), "", &Inst);
NewInst->setNonNeg();
break;
}
@@ -186,7 +186,7 @@ static bool replaceSignedInst(SCCPSolver &Solver,
Value *Op0 = Inst.getOperand(0);
if (InsertedValues.count(Op0) || !isNonNegative(Op0))
return false;
- NewInst = BinaryOperator::CreateLShr(Op0, Inst.getOperand(1), "", Inst.getIterator());
+ NewInst = BinaryOperator::CreateLShr(Op0, Inst.getOperand(1), "", &Inst);
NewInst->setIsExact(Inst.isExact());
break;
}
@@ -199,7 +199,7 @@ static bool replaceSignedInst(SCCPSolver &Solver,
return false;
auto NewOpcode = Inst.getOpcode() == Instruction::SDiv ? Instruction::UDiv
: Instruction::URem;
- NewInst = BinaryOperator::Create(NewOpcode, Op0, Op1, "", Inst.getIterator());
+ NewInst = BinaryOperator::Create(NewOpcode, Op0, Op1, "", &Inst);
if (Inst.getOpcode() == Instruction::SDiv)
NewInst->setIsExact(Inst.isExact());
break;
diff --git a/llvm/lib/Transforms/Utils/ScalarEvolutionExpander.cpp b/llvm/lib/Transforms/Utils/ScalarEvolutionExpander.cpp
index 3a3bcde7c3dcdd..0f67cc3ff4faca 100644
--- a/llvm/lib/Transforms/Utils/ScalarEvolutionExpander.cpp
+++ b/llvm/lib/Transforms/Utils/ScalarEvolutionExpander.cpp
@@ -1267,7 +1267,7 @@ Value *SCEVExpander::visitAddRecExpr(const SCEVAddRecExpr *S) {
// corresponding to the back-edge.
Instruction *Add = BinaryOperator::CreateAdd(CanonicalIV, One,
"indvar.next",
- HP->getTerminator()->getIterator());
+ HP->getTerminator());
Add->setDebugLoc(HP->getTerminator()->getDebugLoc());
rememberInstruction(Add);
CanonicalIV->addIncoming(Add, HP);
@@ -2232,7 +2232,7 @@ Value *SCEVExpander::fixupLCSSAFormFor(Value *V) {
if (!PreserveLCSSA || !DefI)
return V;
- BasicBlock::iterator InsertPt = Builder.GetInsertPoint();
+ Instruction *InsertPt = &*Builder.GetInsertPoint();
Loop *DefLoop = SE.LI.getLoopFor(DefI->getParent());
Loop *UseLoop = SE.LI.getLoopFor(InsertPt->getParent());
if (!DefLoop || UseLoop == DefLoop || DefLoop->contains(UseLoop))
diff --git a/llvm/lib/Transforms/Utils/SimplifyCFG.cpp b/llvm/lib/Transforms/Utils/SimplifyCFG.cpp
index fe65e52110f97a..bbdbfbbf776f32 100644
--- a/llvm/lib/Transforms/Utils/SimplifyCFG.cpp
+++ b/llvm/lib/Transforms/Utils/SimplifyCFG.cpp
@@ -2710,7 +2710,7 @@ static void MergeCompatibleInvokesImpl(ArrayRef<InvokeInst *> Invokes,
// Form a PHI out of all the data ops under this index.
PHINode *PN = PHINode::Create(
- U->getType(), /*NumReservedValues=*/Invokes.size(), "", MergedInvoke->getIterator());
+ U->getType(), /*NumReservedValues=*/Invokes.size(), "", MergedInvoke);
for (InvokeInst *II : Invokes)
PN->addIncoming(II->getOperand(U.getOperandNo()), II->getParent());
@@ -4663,7 +4663,7 @@ bool SimplifyCFGOpt::SimplifyTerminatorOnSelect(Instruction *OldTerm,
} else if (KeepEdge1 && (KeepEdge2 || TrueBB == FalseBB)) {
// Neither of the selected blocks were successors, so this
// terminator must be unreachable.
- new UnreachableInst(OldTerm->getContext(), OldTerm->getIterator());
+ new UnreachableInst(OldTerm->getContext(), OldTerm);
} else {
// One of the selected values was a successor, but the other wasn't.
// Insert an unconditional branch to the one that was found;
@@ -5353,7 +5353,7 @@ bool SimplifyCFGOpt::simplifyUnreachable(UnreachableInst *UI) {
// or a degenerate conditional branch with matching destinations.
if (all_of(BI->successors(),
[BB](auto *Successor) { return Successor == BB; })) {
- new UnreachableInst(TI->getContext(), TI->getIterator());
+ new UnreachableInst(TI->getContext(), TI);
TI->eraseFromParent();
Changed = true;
} else {
@@ -5452,7 +5452,7 @@ bool SimplifyCFGOpt::simplifyUnreachable(UnreachableInst *UI) {
removeUnwindEdge(EHPred, DTU);
}
// The catchswitch is no longer reachable.
- new UnreachableInst(CSI->getContext(), CSI->getIterator());
+ new UnreachableInst(CSI->getContext(), CSI);
CSI->eraseFromParent();
Changed = true;
}
@@ -5462,7 +5462,7 @@ bool SimplifyCFGOpt::simplifyUnreachable(UnreachableInst *UI) {
"Expected to always have an unwind to BB.");
if (DTU)
Updates.push_back({DominatorTree::Delete, Predecessor, BB});
- new UnreachableInst(TI->getContext(), TI->getIterator());
+ new UnreachableInst(TI->getContext(), TI);
TI->eraseFromParent();
Changed = true;
}
@@ -6604,7 +6604,7 @@ static void reuseTableCompare(
// The compare yields the same result, just inverted. We can replace it.
Value *InvertedTableCmp = BinaryOperator::CreateXor(
RangeCmp, ConstantInt::get(RangeCmp->getType(), 1), "inverted.cmp",
- RangeCheckBranch->getIterator());
+ RangeCheckBranch);
CmpInst->replaceAllUsesWith(InvertedTableCmp);
++NumTableCmpReuses;
}
@@ -7155,14 +7155,14 @@ bool SimplifyCFGOpt::simplifyIndirectBr(IndirectBrInst *IBI) {
if (IBI->getNumDestinations() == 0) {
// If the indirectbr has no successors, change it to unreachable.
- new UnreachableInst(IBI->getContext(), IBI->getIterator());
+ new UnreachableInst(IBI->getContext(), IBI);
EraseTerminatorAndDCECond(IBI);
return true;
}
if (IBI->getNumDestinations() == 1) {
// If the indirectbr has one successor, change it to a direct branch.
- BranchInst::Create(IBI->getDestination(0), IBI->getIterator());
+ BranchInst::Create(IBI->getDestination(0), IBI);
EraseTerminatorAndDCECond(IBI);
return true;
}
diff --git a/llvm/lib/Transforms/Utils/SimplifyIndVar.cpp b/llvm/lib/Transforms/Utils/SimplifyIndVar.cpp
index b8fa985fa3462e..297cfe5124d85d 100644
--- a/llvm/lib/Transforms/Utils/SimplifyIndVar.cpp
+++ b/llvm/lib/Transforms/Utils/SimplifyIndVar.cpp
@@ -301,7 +301,7 @@ bool SimplifyIndvar::eliminateSDiv(BinaryOperator *SDiv) {
if (SE->isKnownNonNegative(N) && SE->isKnownNonNegative(D)) {
auto *UDiv = BinaryOperator::Create(
BinaryOperator::UDiv, SDiv->getOperand(0), SDiv->getOperand(1),
- SDiv->getName() + ".udiv", SDiv->getIterator());
+ SDiv->getName() + ".udiv", SDiv);
UDiv->setIsExact(SDiv->isExact());
SDiv->replaceAllUsesWith(UDiv);
LLVM_DEBUG(dbgs() << "INDVARS: Simplified sdiv: " << *SDiv << '\n');
@@ -318,7 +318,7 @@ bool SimplifyIndvar::eliminateSDiv(BinaryOperator *SDiv) {
void SimplifyIndvar::replaceSRemWithURem(BinaryOperator *Rem) {
auto *N = Rem->getOperand(0), *D = Rem->getOperand(1);
auto *URem = BinaryOperator::Create(BinaryOperator::URem, N, D,
- Rem->getName() + ".urem", Rem->getIterator());
+ Rem->getName() + ".urem", Rem);
Rem->replaceAllUsesWith(URem);
LLVM_DEBUG(dbgs() << "INDVARS: Simplified srem: " << *Rem << '\n');
++NumSimplifiedSRem;
@@ -339,9 +339,9 @@ void SimplifyIndvar::replaceRemWithNumerator(BinaryOperator *Rem) {
void SimplifyIndvar::replaceRemWithNumeratorOrZero(BinaryOperator *Rem) {
auto *T = Rem->getType();
auto *N = Rem->getOperand(0), *D = Rem->getOperand(1);
- ICmpInst *ICmp = new ICmpInst(Rem->getIterator(), ICmpInst::ICMP_EQ, N, D);
+ ICmpInst *ICmp = new ICmpInst(Rem, ICmpInst::ICMP_EQ, N, D);
SelectInst *Sel =
- SelectInst::Create(ICmp, ConstantInt::get(T, 0), N, "iv.rem", Rem->getIterator());
+ SelectInst::Create(ICmp, ConstantInt::get(T, 0), N, "iv.rem", Rem);
Rem->replaceAllUsesWith(Sel);
LLVM_DEBUG(dbgs() << "INDVARS: Simplified rem: " << *Rem << '\n');
++NumElimRem;
@@ -411,7 +411,7 @@ bool SimplifyIndvar::eliminateOverflowIntrinsic(WithOverflowInst *WO) {
// intrinsic as well.
BinaryOperator *NewResult = BinaryOperator::Create(
- WO->getBinaryOp(), WO->getLHS(), WO->getRHS(), "", WO->getIterator());
+ WO->getBinaryOp(), WO->getLHS(), WO->getRHS(), "", WO);
if (WO->isSigned())
NewResult->setHasNoSignedWrap(true);
@@ -449,7 +449,7 @@ bool SimplifyIndvar::eliminateSaturatingIntrinsic(SaturatingInst *SI) {
return false;
BinaryOperator *BO = BinaryOperator::Create(
- SI->getBinaryOp(), SI->getLHS(), SI->getRHS(), SI->getName(), SI->getIterator());
+ SI->getBinaryOp(), SI->getLHS(), SI->getRHS(), SI->getName(), SI);
if (SI->isSigned())
BO->setHasNoSignedWrap();
else
@@ -1767,7 +1767,7 @@ Instruction *WidenIV::widenIVUse(WidenIV::NarrowIVDefUse DU,
PHINode *WidePhi =
PHINode::Create(DU.WideDef->getType(), 1, UsePhi->getName() + ".wide",
- UsePhi->getIterator());
+ UsePhi);
WidePhi->addIncoming(DU.WideDef, UsePhi->getIncomingBlock(0));
BasicBlock *WidePhiBB = WidePhi->getParent();
IRBuilder<> Builder(WidePhiBB, WidePhiBB->getFirstInsertionPt());
diff --git a/llvm/lib/Transforms/Utils/StripGCRelocates.cpp b/llvm/lib/Transforms/Utils/StripGCRelocates.cpp
index 3ae76ffd5ecab4..6094f36a77f45c 100644
--- a/llvm/lib/Transforms/Utils/StripGCRelocates.cpp
+++ b/llvm/lib/Transforms/Utils/StripGCRelocates.cpp
@@ -42,7 +42,7 @@ static bool stripGCRelocates(Function &F) {
// All gc_relocates are i8 addrspace(1)* typed, we need a bitcast from i8
// addrspace(1)* to the type of the OrigPtr, if the are not the same.
if (GCRel->getType() != OrigPtr->getType())
- ReplaceGCRel = new BitCastInst(OrigPtr, GCRel->getType(), "cast", GCRel->getIterator());
+ ReplaceGCRel = new BitCastInst(OrigPtr, GCRel->getType(), "cast", GCRel);
// Replace all uses of gc.relocate and delete the gc.relocate
// There maybe unncessary bitcasts back to the OrigPtr type, an instcombine
diff --git a/llvm/lib/Transforms/Utils/UnifyLoopExits.cpp b/llvm/lib/Transforms/Utils/UnifyLoopExits.cpp
index 1d51f61351fe27..2f37f7f972cbbf 100644
--- a/llvm/lib/Transforms/Utils/UnifyLoopExits.cpp
+++ b/llvm/lib/Transforms/Utils/UnifyLoopExits.cpp
@@ -119,7 +119,7 @@ static void restoreSSA(const DominatorTree &DT, const Loop *L,
LLVM_DEBUG(dbgs() << "externally used: " << Def->getName() << "\n");
auto NewPhi =
PHINode::Create(Def->getType(), Incoming.size(),
- Def->getName() + ".moved", LoopExitBlock->begin());
+ Def->getName() + ".moved", &LoopExitBlock->front());
for (auto *In : Incoming) {
LLVM_DEBUG(dbgs() << "predecessor " << In->getName() << ": ");
if (Def->getParent() == In || DT.dominates(Def, In)) {
diff --git a/llvm/tools/bugpoint/Miscompilation.cpp b/llvm/tools/bugpoint/Miscompilation.cpp
index b165b8220c20bd..22806bab83eecf 100644
--- a/llvm/tools/bugpoint/Miscompilation.cpp
+++ b/llvm/tools/bugpoint/Miscompilation.cpp
@@ -884,7 +884,7 @@ CleanupAndPrepareModules(BugDriver &BD, std::unique_ptr<Module> Test,
// Check to see if we already looked up the value.
Value *CachedVal =
new LoadInst(F->getType(), Cache, "fpcache", EntryBB);
- Value *IsNull = new ICmpInst(EntryBB, ICmpInst::ICMP_EQ, CachedVal,
+ Value *IsNull = new ICmpInst(*EntryBB, ICmpInst::ICMP_EQ, CachedVal,
NullPtr, "isNull");
BranchInst::Create(LookupBB, DoCallBB, IsNull, EntryBB);
>From 6afda56faa6260cff4e6e9264226737d96d952c1 Mon Sep 17 00:00:00 2001
From: Craig Topper <craig.topper at sifive.com>
Date: Thu, 29 Feb 2024 08:55:52 -0800
Subject: [PATCH 152/406] [RISCV] Store RVC and TSO ELF flags explicitly in
RISCVTargetStreamer. NFCI (#83344)
Instead of caching STI in the RISCVELFTargetStreamer, store the two
flags we need from it.
My goal is to allow RISCVAsmPrinter to override these flags using IR
module metadata for LTO. So they need to be separated from the STI used
to construct the TargetStreamer.
This patch should be NFC as long as no one is changing the contents of
the STI that was used to construct the TargetStreamer between the
constructor and the use of the flags.
---
llvm/lib/Target/RISCV/MCTargetDesc/RISCVELFStreamer.cpp | 8 ++++----
llvm/lib/Target/RISCV/MCTargetDesc/RISCVELFStreamer.h | 1 -
.../lib/Target/RISCV/MCTargetDesc/RISCVTargetStreamer.cpp | 6 ++++++
llvm/lib/Target/RISCV/MCTargetDesc/RISCVTargetStreamer.h | 5 +++++
4 files changed, 15 insertions(+), 5 deletions(-)
diff --git a/llvm/lib/Target/RISCV/MCTargetDesc/RISCVELFStreamer.cpp b/llvm/lib/Target/RISCV/MCTargetDesc/RISCVELFStreamer.cpp
index b375e8bb4b8fac..cdf7c048a4bf11 100644
--- a/llvm/lib/Target/RISCV/MCTargetDesc/RISCVELFStreamer.cpp
+++ b/llvm/lib/Target/RISCV/MCTargetDesc/RISCVELFStreamer.cpp
@@ -31,12 +31,13 @@ using namespace llvm;
// This part is for ELF object output.
RISCVTargetELFStreamer::RISCVTargetELFStreamer(MCStreamer &S,
const MCSubtargetInfo &STI)
- : RISCVTargetStreamer(S), CurrentVendor("riscv"), STI(STI) {
+ : RISCVTargetStreamer(S), CurrentVendor("riscv") {
MCAssembler &MCA = getStreamer().getAssembler();
const FeatureBitset &Features = STI.getFeatureBits();
auto &MAB = static_cast<RISCVAsmBackend &>(MCA.getBackend());
setTargetABI(RISCVABI::computeTargetABI(STI.getTargetTriple(), Features,
MAB.getTargetOptions().getABIName()));
+ setFlagsFromFeatures(STI);
// `j label` in `.option norelax; j label; .option relax; ...; label:` needs a
// relocation to ensure the jump target is correct after linking. This is due
// to a limitation that shouldForceRelocation has to make the decision upfront
@@ -91,10 +92,9 @@ void RISCVTargetELFStreamer::finish() {
unsigned EFlags = MCA.getELFHeaderEFlags();
- if (STI.hasFeature(RISCV::FeatureStdExtC) ||
- STI.hasFeature(RISCV::FeatureStdExtZca))
+ if (hasRVC())
EFlags |= ELF::EF_RISCV_RVC;
- if (STI.hasFeature(RISCV::FeatureStdExtZtso))
+ if (hasTSO())
EFlags |= ELF::EF_RISCV_TSO;
switch (ABI) {
diff --git a/llvm/lib/Target/RISCV/MCTargetDesc/RISCVELFStreamer.h b/llvm/lib/Target/RISCV/MCTargetDesc/RISCVELFStreamer.h
index a6f54bf67b5d2b..e8f29cd8449ba0 100644
--- a/llvm/lib/Target/RISCV/MCTargetDesc/RISCVELFStreamer.h
+++ b/llvm/lib/Target/RISCV/MCTargetDesc/RISCVELFStreamer.h
@@ -46,7 +46,6 @@ class RISCVTargetELFStreamer : public RISCVTargetStreamer {
StringRef CurrentVendor;
MCSection *AttributeSection = nullptr;
- const MCSubtargetInfo &STI;
void emitAttribute(unsigned Attribute, unsigned Value) override;
void emitTextAttribute(unsigned Attribute, StringRef String) override;
diff --git a/llvm/lib/Target/RISCV/MCTargetDesc/RISCVTargetStreamer.cpp b/llvm/lib/Target/RISCV/MCTargetDesc/RISCVTargetStreamer.cpp
index 071a3a5aa5d6e7..4a4b1e13c2b9ec 100644
--- a/llvm/lib/Target/RISCV/MCTargetDesc/RISCVTargetStreamer.cpp
+++ b/llvm/lib/Target/RISCV/MCTargetDesc/RISCVTargetStreamer.cpp
@@ -48,6 +48,12 @@ void RISCVTargetStreamer::setTargetABI(RISCVABI::ABI ABI) {
TargetABI = ABI;
}
+void RISCVTargetStreamer::setFlagsFromFeatures(const MCSubtargetInfo &STI) {
+ HasRVC = STI.hasFeature(RISCV::FeatureStdExtC) ||
+ STI.hasFeature(RISCV::FeatureStdExtZca);
+ HasTSO = STI.hasFeature(RISCV::FeatureStdExtZtso);
+}
+
void RISCVTargetStreamer::emitTargetAttributes(const MCSubtargetInfo &STI,
bool EmitStackAlign) {
if (EmitStackAlign) {
diff --git a/llvm/lib/Target/RISCV/MCTargetDesc/RISCVTargetStreamer.h b/llvm/lib/Target/RISCV/MCTargetDesc/RISCVTargetStreamer.h
index 070e72fb157ae9..cb8bc21cb63557 100644
--- a/llvm/lib/Target/RISCV/MCTargetDesc/RISCVTargetStreamer.h
+++ b/llvm/lib/Target/RISCV/MCTargetDesc/RISCVTargetStreamer.h
@@ -33,6 +33,8 @@ struct RISCVOptionArchArg {
class RISCVTargetStreamer : public MCTargetStreamer {
RISCVABI::ABI TargetABI = RISCVABI::ABI_Unknown;
+ bool HasRVC = false;
+ bool HasTSO = false;
public:
RISCVTargetStreamer(MCStreamer &S);
@@ -58,6 +60,9 @@ class RISCVTargetStreamer : public MCTargetStreamer {
void emitTargetAttributes(const MCSubtargetInfo &STI, bool EmitStackAlign);
void setTargetABI(RISCVABI::ABI ABI);
RISCVABI::ABI getTargetABI() const { return TargetABI; }
+ void setFlagsFromFeatures(const MCSubtargetInfo &STI);
+ bool hasRVC() const { return HasRVC; }
+ bool hasTSO() const { return HasTSO; }
};
// This part is for ascii assembly output
>From 2d61979137cfea8f016e618dd17f5be8e7d865bf Mon Sep 17 00:00:00 2001
From: erichkeane <ekeane at nvidia.com>
Date: Thu, 29 Feb 2024 08:54:00 -0800
Subject: [PATCH 153/406] [OpenACC] Add dependent test for break/continue
compute construct diag
I discovered while debugging something else that this could possibly
cause an assert if I'm not careful with followup patches, so add the
tests.
---
clang/test/SemaOpenACC/no-branch-in-out.cpp | 97 +++++++++++++++++++++
1 file changed, 97 insertions(+)
diff --git a/clang/test/SemaOpenACC/no-branch-in-out.cpp b/clang/test/SemaOpenACC/no-branch-in-out.cpp
index 232e372cedd357..9affdf733ace8d 100644
--- a/clang/test/SemaOpenACC/no-branch-in-out.cpp
+++ b/clang/test/SemaOpenACC/no-branch-in-out.cpp
@@ -15,3 +15,100 @@ void ReturnTest() {
}
}
}
+
+template<typename T>
+void BreakContinue() {
+
+#pragma acc parallel
+ for(int i =0; i < 5; ++i) {
+ switch(i) {
+ case 0:
+ break; // leaves switch, not 'for'.
+ default:
+ i +=2;
+ break;
+ }
+ if (i == 2)
+ continue;
+
+ break; // expected-error{{invalid branch out of OpenACC Compute Construct}}
+ }
+
+ int j;
+ switch(j) {
+ case 0:
+#pragma acc parallel
+ {
+ break; // expected-error{{invalid branch out of OpenACC Compute Construct}}
+ }
+ case 1:
+#pragma acc parallel
+ {
+ }
+ break;
+ }
+
+#pragma acc parallel
+ for(int i = 0; i < 5; ++i) {
+ if (i > 1)
+ break; // expected-error{{invalid branch out of OpenACC Compute Construct}}
+ }
+
+#pragma acc parallel
+ switch(j) {
+ case 1:
+ break;
+ }
+
+#pragma acc parallel
+ {
+ for(int i = 1; i < 100; i++) {
+ if (i > 4)
+ break;
+ }
+ }
+
+ for (int i =0; i < 5; ++i) {
+#pragma acc parallel
+ {
+ continue; // expected-error{{invalid branch out of OpenACC Compute Construct}}
+ }
+ }
+
+#pragma acc parallel
+ for (int i =0; i < 5; ++i) {
+ continue;
+ }
+
+#pragma acc parallel
+ for (int i =0; i < 5; ++i) {
+ {
+ continue;
+ }
+ }
+
+ for (int i =0; i < 5; ++i) {
+#pragma acc parallel
+ {
+ break; // expected-error{{invalid branch out of OpenACC Compute Construct}}
+ }
+ }
+
+#pragma acc parallel
+ while (j) {
+ --j;
+ if (j > 4)
+ break; // expected-error{{invalid branch out of OpenACC Compute Construct}}
+ }
+
+#pragma acc parallel
+ do {
+ --j;
+ if (j > 4)
+ break; // expected-error{{invalid branch out of OpenACC Compute Construct}}
+ } while (j );
+}
+
+void Instantiate() {
+ BreakContinue<int>();
+}
>From 0699749cb45db77e8393f198b1837945a958aebf Mon Sep 17 00:00:00 2001
From: Slava Zakharin <szakharin at nvidia.com>
Date: Thu, 29 Feb 2024 09:05:43 -0800
Subject: [PATCH 154/406] [flang][runtime] Moved support for some REAL(16)
intrinsics to Float128Math. (#83383)
This adds support for 128-bit float versions of SCALE, NEAREST, MOD,
MODULO, SET_EXPONENT, EXPONENT, FRACTION, SPACING and RRSPACING.
---
flang/runtime/Float128Math/CMakeLists.txt | 9 +
flang/runtime/Float128Math/acos.cpp | 2 +-
flang/runtime/Float128Math/acosh.cpp | 2 +-
flang/runtime/Float128Math/asin.cpp | 2 +-
flang/runtime/Float128Math/asinh.cpp | 2 +-
flang/runtime/Float128Math/atan.cpp | 2 +-
flang/runtime/Float128Math/atan2.cpp | 2 +-
flang/runtime/Float128Math/atanh.cpp | 2 +-
flang/runtime/Float128Math/cabs.cpp | 2 +-
flang/runtime/Float128Math/ceil.cpp | 2 +-
flang/runtime/Float128Math/cos.cpp | 2 +-
flang/runtime/Float128Math/cosh.cpp | 2 +-
flang/runtime/Float128Math/erf.cpp | 2 +-
flang/runtime/Float128Math/erfc.cpp | 2 +-
flang/runtime/Float128Math/exp.cpp | 2 +-
flang/runtime/Float128Math/exponent.cpp | 26 ++
flang/runtime/Float128Math/floor.cpp | 2 +-
flang/runtime/Float128Math/fraction.cpp | 21 ++
flang/runtime/Float128Math/hypot.cpp | 2 +-
flang/runtime/Float128Math/j0.cpp | 2 +-
flang/runtime/Float128Math/j1.cpp | 2 +-
flang/runtime/Float128Math/jn.cpp | 2 +-
flang/runtime/Float128Math/lgamma.cpp | 2 +-
flang/runtime/Float128Math/llround.cpp | 2 +-
flang/runtime/Float128Math/log.cpp | 2 +-
flang/runtime/Float128Math/log10.cpp | 2 +-
flang/runtime/Float128Math/lround.cpp | 2 +-
flang/runtime/Float128Math/math-entries.h | 150 ++++----
flang/runtime/Float128Math/mod-real.cpp | 24 ++
flang/runtime/Float128Math/modulo-real.cpp | 24 ++
flang/runtime/Float128Math/nearest.cpp | 23 ++
flang/runtime/Float128Math/norm2.cpp | 34 +-
.../Float128Math/numeric-template-specs.h | 55 +++
flang/runtime/Float128Math/pow.cpp | 2 +-
flang/runtime/Float128Math/round.cpp | 2 +-
flang/runtime/Float128Math/rrspacing.cpp | 21 ++
flang/runtime/Float128Math/scale.cpp | 28 ++
flang/runtime/Float128Math/set-exponent.cpp | 23 ++
flang/runtime/Float128Math/sin.cpp | 2 +-
flang/runtime/Float128Math/sinh.cpp | 2 +-
flang/runtime/Float128Math/spacing.cpp | 21 ++
flang/runtime/Float128Math/sqrt.cpp | 6 +-
flang/runtime/Float128Math/tan.cpp | 2 +-
flang/runtime/Float128Math/tanh.cpp | 2 +-
flang/runtime/Float128Math/tgamma.cpp | 2 +-
flang/runtime/Float128Math/trunc.cpp | 2 +-
flang/runtime/Float128Math/y0.cpp | 2 +-
flang/runtime/Float128Math/y1.cpp | 2 +-
flang/runtime/Float128Math/yn.cpp | 2 +-
flang/runtime/extrema.cpp | 85 +----
flang/runtime/numeric-templates.h | 339 ++++++++++++++++++
flang/runtime/numeric.cpp | 211 +----------
flang/runtime/reduction-templates.h | 36 +-
53 files changed, 762 insertions(+), 444 deletions(-)
create mode 100644 flang/runtime/Float128Math/exponent.cpp
create mode 100644 flang/runtime/Float128Math/fraction.cpp
create mode 100644 flang/runtime/Float128Math/mod-real.cpp
create mode 100644 flang/runtime/Float128Math/modulo-real.cpp
create mode 100644 flang/runtime/Float128Math/nearest.cpp
create mode 100644 flang/runtime/Float128Math/numeric-template-specs.h
create mode 100644 flang/runtime/Float128Math/rrspacing.cpp
create mode 100644 flang/runtime/Float128Math/scale.cpp
create mode 100644 flang/runtime/Float128Math/set-exponent.cpp
create mode 100644 flang/runtime/Float128Math/spacing.cpp
create mode 100644 flang/runtime/numeric-templates.h
diff --git a/flang/runtime/Float128Math/CMakeLists.txt b/flang/runtime/Float128Math/CMakeLists.txt
index f11678cd70b769..60d44c78be0faf 100644
--- a/flang/runtime/Float128Math/CMakeLists.txt
+++ b/flang/runtime/Float128Math/CMakeLists.txt
@@ -59,7 +59,9 @@ set(sources
erf.cpp
erfc.cpp
exp.cpp
+ exponent.cpp
floor.cpp
+ fraction.cpp
hypot.cpp
j0.cpp
j1.cpp
@@ -69,11 +71,18 @@ set(sources
log.cpp
log10.cpp
lround.cpp
+ mod-real.cpp
+ modulo-real.cpp
+ nearest.cpp
norm2.cpp
pow.cpp
round.cpp
+ rrspacing.cpp
+ scale.cpp
+ set-exponent.cpp
sin.cpp
sinh.cpp
+ spacing.cpp
sqrt.cpp
tan.cpp
tanh.cpp
diff --git a/flang/runtime/Float128Math/acos.cpp b/flang/runtime/Float128Math/acos.cpp
index 531c79c7444bd3..14ff6944856844 100644
--- a/flang/runtime/Float128Math/acos.cpp
+++ b/flang/runtime/Float128Math/acos.cpp
@@ -14,7 +14,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Real, 16> RTDEF(AcosF128)(
CppTypeFor<TypeCategory::Real, 16> x) {
- return Acos<RTNAME(AcosF128)>::invoke(x);
+ return Acos<true>::invoke(x);
}
#endif
diff --git a/flang/runtime/Float128Math/acosh.cpp b/flang/runtime/Float128Math/acosh.cpp
index 1495120edd1a07..9d70804e44a470 100644
--- a/flang/runtime/Float128Math/acosh.cpp
+++ b/flang/runtime/Float128Math/acosh.cpp
@@ -14,7 +14,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Real, 16> RTDEF(AcoshF128)(
CppTypeFor<TypeCategory::Real, 16> x) {
- return Acosh<RTNAME(AcoshF128)>::invoke(x);
+ return Acosh<true>::invoke(x);
}
#endif
diff --git a/flang/runtime/Float128Math/asin.cpp b/flang/runtime/Float128Math/asin.cpp
index 2fb8c6c5e97d71..6781b23f0363db 100644
--- a/flang/runtime/Float128Math/asin.cpp
+++ b/flang/runtime/Float128Math/asin.cpp
@@ -14,7 +14,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Real, 16> RTDEF(AsinF128)(
CppTypeFor<TypeCategory::Real, 16> x) {
- return Asin<RTNAME(AsinF128)>::invoke(x);
+ return Asin<true>::invoke(x);
}
#endif
diff --git a/flang/runtime/Float128Math/asinh.cpp b/flang/runtime/Float128Math/asinh.cpp
index 3630a77be42b2c..1310bc61c1de0f 100644
--- a/flang/runtime/Float128Math/asinh.cpp
+++ b/flang/runtime/Float128Math/asinh.cpp
@@ -14,7 +14,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Real, 16> RTDEF(AsinhF128)(
CppTypeFor<TypeCategory::Real, 16> x) {
- return Asinh<RTNAME(AsinhF128)>::invoke(x);
+ return Asinh<true>::invoke(x);
}
#endif
diff --git a/flang/runtime/Float128Math/atan.cpp b/flang/runtime/Float128Math/atan.cpp
index 4609343e9d1273..f01382df90c0ee 100644
--- a/flang/runtime/Float128Math/atan.cpp
+++ b/flang/runtime/Float128Math/atan.cpp
@@ -14,7 +14,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Real, 16> RTDEF(AtanF128)(
CppTypeFor<TypeCategory::Real, 16> x) {
- return Atan<RTNAME(AtanF128)>::invoke(x);
+ return Atan<true>::invoke(x);
}
#endif
diff --git a/flang/runtime/Float128Math/atan2.cpp b/flang/runtime/Float128Math/atan2.cpp
index c0175e67ec71bd..dd646b0452b115 100644
--- a/flang/runtime/Float128Math/atan2.cpp
+++ b/flang/runtime/Float128Math/atan2.cpp
@@ -15,7 +15,7 @@ extern "C" {
CppTypeFor<TypeCategory::Real, 16> RTDEF(Atan2F128)(
CppTypeFor<TypeCategory::Real, 16> x,
CppTypeFor<TypeCategory::Real, 16> y) {
- return Atan2<RTNAME(Atan2F128)>::invoke(x, y);
+ return Atan2<true>::invoke(x, y);
}
#endif
diff --git a/flang/runtime/Float128Math/atanh.cpp b/flang/runtime/Float128Math/atanh.cpp
index bfacb967117d70..5fc5ba5debc81a 100644
--- a/flang/runtime/Float128Math/atanh.cpp
+++ b/flang/runtime/Float128Math/atanh.cpp
@@ -14,7 +14,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Real, 16> RTDEF(AtanhF128)(
CppTypeFor<TypeCategory::Real, 16> x) {
- return Atanh<RTNAME(AtanhF128)>::invoke(x);
+ return Atanh<true>::invoke(x);
}
#endif
diff --git a/flang/runtime/Float128Math/cabs.cpp b/flang/runtime/Float128Math/cabs.cpp
index 827b197a6a81ae..3b8c9d17003c6e 100644
--- a/flang/runtime/Float128Math/cabs.cpp
+++ b/flang/runtime/Float128Math/cabs.cpp
@@ -16,7 +16,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
// NOTE: Flang calls the runtime APIs using C _Complex ABI
CppTypeFor<TypeCategory::Real, 16> RTDEF(CAbsF128)(CFloat128ComplexType x) {
- return CAbs<RTNAME(CAbsF128)>::invoke(x);
+ return CAbs<true>::invoke(x);
}
#endif
#endif
diff --git a/flang/runtime/Float128Math/ceil.cpp b/flang/runtime/Float128Math/ceil.cpp
index a53a2c27c616b5..ed4d164a62bedc 100644
--- a/flang/runtime/Float128Math/ceil.cpp
+++ b/flang/runtime/Float128Math/ceil.cpp
@@ -14,7 +14,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Real, 16> RTDEF(CeilF128)(
CppTypeFor<TypeCategory::Real, 16> x) {
- return Ceil<RTNAME(CeilF128)>::invoke(x);
+ return Ceil<true>::invoke(x);
}
#endif
diff --git a/flang/runtime/Float128Math/cos.cpp b/flang/runtime/Float128Math/cos.cpp
index 845c970bd8e639..b93c92f275f791 100644
--- a/flang/runtime/Float128Math/cos.cpp
+++ b/flang/runtime/Float128Math/cos.cpp
@@ -14,7 +14,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Real, 16> RTDEF(CosF128)(
CppTypeFor<TypeCategory::Real, 16> x) {
- return Cos<RTNAME(CosF128)>::invoke(x);
+ return Cos<true>::invoke(x);
}
#endif
diff --git a/flang/runtime/Float128Math/cosh.cpp b/flang/runtime/Float128Math/cosh.cpp
index acf6ff4130ee3c..a3662a826dcb1c 100644
--- a/flang/runtime/Float128Math/cosh.cpp
+++ b/flang/runtime/Float128Math/cosh.cpp
@@ -14,7 +14,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Real, 16> RTDEF(CoshF128)(
CppTypeFor<TypeCategory::Real, 16> x) {
- return Cosh<RTNAME(CoshF128)>::invoke(x);
+ return Cosh<true>::invoke(x);
}
#endif
diff --git a/flang/runtime/Float128Math/erf.cpp b/flang/runtime/Float128Math/erf.cpp
index 862f3b97411873..631f71c76effe7 100644
--- a/flang/runtime/Float128Math/erf.cpp
+++ b/flang/runtime/Float128Math/erf.cpp
@@ -14,7 +14,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Real, 16> RTDEF(ErfF128)(
CppTypeFor<TypeCategory::Real, 16> x) {
- return Erf<RTNAME(ErfF128)>::invoke(x);
+ return Erf<true>::invoke(x);
}
#endif
diff --git a/flang/runtime/Float128Math/erfc.cpp b/flang/runtime/Float128Math/erfc.cpp
index 0ac0b945563747..ea3cd646d8c4ba 100644
--- a/flang/runtime/Float128Math/erfc.cpp
+++ b/flang/runtime/Float128Math/erfc.cpp
@@ -14,7 +14,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Real, 16> RTDEF(ErfcF128)(
CppTypeFor<TypeCategory::Real, 16> x) {
- return Erfc<RTNAME(ErfcF128)>::invoke(x);
+ return Erfc<true>::invoke(x);
}
#endif
diff --git a/flang/runtime/Float128Math/exp.cpp b/flang/runtime/Float128Math/exp.cpp
index 50386fdbfb6449..b1161b0f29294c 100644
--- a/flang/runtime/Float128Math/exp.cpp
+++ b/flang/runtime/Float128Math/exp.cpp
@@ -14,7 +14,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Real, 16> RTDEF(ExpF128)(
CppTypeFor<TypeCategory::Real, 16> x) {
- return Exp<RTNAME(ExpF128)>::invoke(x);
+ return Exp<true>::invoke(x);
}
#endif
diff --git a/flang/runtime/Float128Math/exponent.cpp b/flang/runtime/Float128Math/exponent.cpp
new file mode 100644
index 00000000000000..1be1dd0d0ac8b8
--- /dev/null
+++ b/flang/runtime/Float128Math/exponent.cpp
@@ -0,0 +1,26 @@
+//===-- runtime/Float128Math/exponent.cpp ---------------------------------===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+
+#include "math-entries.h"
+#include "numeric-template-specs.h"
+
+namespace Fortran::runtime {
+extern "C" {
+
+#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
+// EXPONENT (16.9.75)
+CppTypeFor<TypeCategory::Integer, 4> RTDEF(Exponent16_4)(F128Type x) {
+ return Exponent<CppTypeFor<TypeCategory::Integer, 4>>(x);
+}
+CppTypeFor<TypeCategory::Integer, 8> RTDEF(Exponent16_8)(F128Type x) {
+ return Exponent<CppTypeFor<TypeCategory::Integer, 8>>(x);
+}
+#endif
+
+} // extern "C"
+} // namespace Fortran::runtime
diff --git a/flang/runtime/Float128Math/floor.cpp b/flang/runtime/Float128Math/floor.cpp
index 48cf4e01448070..78a94984cac8a3 100644
--- a/flang/runtime/Float128Math/floor.cpp
+++ b/flang/runtime/Float128Math/floor.cpp
@@ -14,7 +14,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Real, 16> RTDEF(FloorF128)(
CppTypeFor<TypeCategory::Real, 16> x) {
- return Floor<RTNAME(FloorF128)>::invoke(x);
+ return Floor<true>::invoke(x);
}
#endif
diff --git a/flang/runtime/Float128Math/fraction.cpp b/flang/runtime/Float128Math/fraction.cpp
new file mode 100644
index 00000000000000..8c9889b7f6871e
--- /dev/null
+++ b/flang/runtime/Float128Math/fraction.cpp
@@ -0,0 +1,21 @@
+//===-- runtime/Float128Math/fraction.cpp ---------------------------------===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+
+#include "math-entries.h"
+#include "numeric-template-specs.h"
+
+namespace Fortran::runtime {
+extern "C" {
+
+#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
+// FRACTION (16.9.80)
+F128Type RTDEF(Fraction16)(F128Type x) { return Fraction(x); }
+#endif
+
+} // extern "C"
+} // namespace Fortran::runtime
diff --git a/flang/runtime/Float128Math/hypot.cpp b/flang/runtime/Float128Math/hypot.cpp
index 33c83a1654993e..b4fa1d66bcfa6a 100644
--- a/flang/runtime/Float128Math/hypot.cpp
+++ b/flang/runtime/Float128Math/hypot.cpp
@@ -15,7 +15,7 @@ extern "C" {
CppTypeFor<TypeCategory::Real, 16> RTDEF(HypotF128)(
CppTypeFor<TypeCategory::Real, 16> x,
CppTypeFor<TypeCategory::Real, 16> y) {
- return Hypot<RTNAME(HypotF128)>::invoke(x, y);
+ return Hypot<true>::invoke(x, y);
}
#endif
diff --git a/flang/runtime/Float128Math/j0.cpp b/flang/runtime/Float128Math/j0.cpp
index f8f3fe71d8a616..9390a7eeb3c605 100644
--- a/flang/runtime/Float128Math/j0.cpp
+++ b/flang/runtime/Float128Math/j0.cpp
@@ -14,7 +14,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Real, 16> RTDEF(J0F128)(
CppTypeFor<TypeCategory::Real, 16> x) {
- return J0<RTNAME(J0F128)>::invoke(x);
+ return J0<true>::invoke(x);
}
#endif
diff --git a/flang/runtime/Float128Math/j1.cpp b/flang/runtime/Float128Math/j1.cpp
index 9a51b973e1cf88..c54927123388c6 100644
--- a/flang/runtime/Float128Math/j1.cpp
+++ b/flang/runtime/Float128Math/j1.cpp
@@ -14,7 +14,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Real, 16> RTDEF(J1F128)(
CppTypeFor<TypeCategory::Real, 16> x) {
- return J1<RTNAME(J1F128)>::invoke(x);
+ return J1<true>::invoke(x);
}
#endif
diff --git a/flang/runtime/Float128Math/jn.cpp b/flang/runtime/Float128Math/jn.cpp
index 644a66863c0d23..15afd83400c320 100644
--- a/flang/runtime/Float128Math/jn.cpp
+++ b/flang/runtime/Float128Math/jn.cpp
@@ -14,7 +14,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Real, 16> RTDEF(JnF128)(
int n, CppTypeFor<TypeCategory::Real, 16> x) {
- return Jn<RTNAME(JnF128)>::invoke(n, x);
+ return Jn<true>::invoke(n, x);
}
#endif
diff --git a/flang/runtime/Float128Math/lgamma.cpp b/flang/runtime/Float128Math/lgamma.cpp
index fff7dfcb9c15db..ac31c89a912b32 100644
--- a/flang/runtime/Float128Math/lgamma.cpp
+++ b/flang/runtime/Float128Math/lgamma.cpp
@@ -14,7 +14,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Real, 16> RTDEF(LgammaF128)(
CppTypeFor<TypeCategory::Real, 16> x) {
- return Lgamma<RTNAME(LgammaF128)>::invoke(x);
+ return Lgamma<true>::invoke(x);
}
#endif
diff --git a/flang/runtime/Float128Math/llround.cpp b/flang/runtime/Float128Math/llround.cpp
index 00c62818af19db..b77281c507fe7c 100644
--- a/flang/runtime/Float128Math/llround.cpp
+++ b/flang/runtime/Float128Math/llround.cpp
@@ -14,7 +14,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Integer, 8> RTDEF(LlroundF128)(
CppTypeFor<TypeCategory::Real, 16> x) {
- return Llround<RTNAME(LlroundF128)>::invoke(x);
+ return Llround<true>::invoke(x);
}
#endif
diff --git a/flang/runtime/Float128Math/log.cpp b/flang/runtime/Float128Math/log.cpp
index 0cfe329c6f7f59..38e6b581fd849c 100644
--- a/flang/runtime/Float128Math/log.cpp
+++ b/flang/runtime/Float128Math/log.cpp
@@ -14,7 +14,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Real, 16> RTDEF(LogF128)(
CppTypeFor<TypeCategory::Real, 16> x) {
- return Log<RTNAME(LogF128)>::invoke(x);
+ return Log<true>::invoke(x);
}
#endif
diff --git a/flang/runtime/Float128Math/log10.cpp b/flang/runtime/Float128Math/log10.cpp
index cd8bf27fcb121b..3c89c0e707774f 100644
--- a/flang/runtime/Float128Math/log10.cpp
+++ b/flang/runtime/Float128Math/log10.cpp
@@ -14,7 +14,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Real, 16> RTDEF(Log10F128)(
CppTypeFor<TypeCategory::Real, 16> x) {
- return Log10<RTNAME(Log10F128)>::invoke(x);
+ return Log10<true>::invoke(x);
}
#endif
diff --git a/flang/runtime/Float128Math/lround.cpp b/flang/runtime/Float128Math/lround.cpp
index 6ced66a1b2d3af..ce7a228038a1d3 100644
--- a/flang/runtime/Float128Math/lround.cpp
+++ b/flang/runtime/Float128Math/lround.cpp
@@ -14,7 +14,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Integer, 4> RTDEF(LroundF128)(
CppTypeFor<TypeCategory::Real, 16> x) {
- return Lround<RTNAME(LroundF128)>::invoke(x);
+ return Lround<true>::invoke(x);
}
#endif
diff --git a/flang/runtime/Float128Math/math-entries.h b/flang/runtime/Float128Math/math-entries.h
index a0d81d0cbb5407..ad3f6aa18aa9a1 100644
--- a/flang/runtime/Float128Math/math-entries.h
+++ b/flang/runtime/Float128Math/math-entries.h
@@ -13,36 +13,40 @@
#include "flang/Common/float128.h"
#include "flang/Runtime/entry-names.h"
#include <cfloat>
+#include <cmath>
#include <type_traits>
+namespace {
+using namespace Fortran::runtime;
+using F128RetType = CppTypeFor<TypeCategory::Real, 16>;
+using I32RetType = CppTypeFor<TypeCategory::Integer, 4>;
+using I64RetType = CppTypeFor<TypeCategory::Integer, 8>;
+} // namespace
+
namespace Fortran::runtime {
// Define a class template to gracefully fail, when
// there is no specialized template that implements
// the required function via using the third-party
// implementation.
-#define DEFINE_FALLBACK(caller) \
- template <auto F> struct caller { \
- template <typename... ATs> \
- [[noreturn]] static std::invoke_result_t<decltype(F), ATs...> invoke( \
- ATs... args) { \
+#define DEFINE_FALLBACK(caller, ret_type) \
+ template <bool = false, typename RT = ret_type> struct caller { \
+ template <typename... ATs> [[noreturn]] static RT invoke(ATs... args) { \
Terminator terminator{__FILE__, __LINE__}; \
terminator.Crash("Float128 variant of '%s' is unsupported", #caller); \
} \
};
// Define template specialization that is calling the third-party
-// implementation. The template is specialized by a function pointer
-// that is the FortranFloat128Math entry point. The signatures
-// of the caller and the callee must match.
+// implementation.
//
// Defining the specialization for any target library requires
// adding the generic template via DEFINE_FALLBACK, so that
// a build with another target library that does not define
// the same alias can gracefully fail in runtime.
#define DEFINE_SIMPLE_ALIAS(caller, callee) \
- template <typename RT, typename... ATs, RT (*p)(ATs...)> struct caller<p> { \
- static RT invoke(ATs... args) { \
+ template <typename RT> struct caller<true, RT> { \
+ template <typename... ATs> static RT invoke(ATs... args) { \
static_assert(std::is_invocable_r_v<RT, \
decltype(callee(std::declval<ATs>()...))(ATs...), ATs...>); \
if constexpr (std::is_same_v<RT, void>) { \
@@ -54,48 +58,58 @@ namespace Fortran::runtime {
};
// Define fallback callers.
-DEFINE_FALLBACK(Abs)
-DEFINE_FALLBACK(Acos)
-DEFINE_FALLBACK(Acosh)
-DEFINE_FALLBACK(Asin)
-DEFINE_FALLBACK(Asinh)
-DEFINE_FALLBACK(Atan)
-DEFINE_FALLBACK(Atan2)
-DEFINE_FALLBACK(Atanh)
-DEFINE_FALLBACK(Ceil)
-DEFINE_FALLBACK(Cos)
-DEFINE_FALLBACK(Cosh)
-DEFINE_FALLBACK(Erf)
-DEFINE_FALLBACK(Erfc)
-DEFINE_FALLBACK(Exp)
-DEFINE_FALLBACK(Floor)
-DEFINE_FALLBACK(Hypot)
-DEFINE_FALLBACK(J0)
-DEFINE_FALLBACK(J1)
-DEFINE_FALLBACK(Jn)
-DEFINE_FALLBACK(Lgamma)
-DEFINE_FALLBACK(Llround)
-DEFINE_FALLBACK(Lround)
-DEFINE_FALLBACK(Log)
-DEFINE_FALLBACK(Log10)
-DEFINE_FALLBACK(Pow)
-DEFINE_FALLBACK(Round)
-DEFINE_FALLBACK(Sin)
-DEFINE_FALLBACK(Sinh)
-DEFINE_FALLBACK(Sqrt)
-DEFINE_FALLBACK(Tan)
-DEFINE_FALLBACK(Tanh)
-DEFINE_FALLBACK(Tgamma)
-DEFINE_FALLBACK(Trunc)
-DEFINE_FALLBACK(Y0)
-DEFINE_FALLBACK(Y1)
-DEFINE_FALLBACK(Yn)
+#define DEFINE_FALLBACK_F128(caller) DEFINE_FALLBACK(caller, ::F128RetType)
+#define DEFINE_FALLBACK_I32(caller) DEFINE_FALLBACK(caller, ::I32RetType)
+#define DEFINE_FALLBACK_I64(caller) DEFINE_FALLBACK(caller, ::I64RetType)
+
+DEFINE_FALLBACK_F128(Abs)
+DEFINE_FALLBACK_F128(Acos)
+DEFINE_FALLBACK_F128(Acosh)
+DEFINE_FALLBACK_F128(Asin)
+DEFINE_FALLBACK_F128(Asinh)
+DEFINE_FALLBACK_F128(Atan)
+DEFINE_FALLBACK_F128(Atan2)
+DEFINE_FALLBACK_F128(Atanh)
+DEFINE_FALLBACK_F128(Ceil)
+DEFINE_FALLBACK_F128(Cos)
+DEFINE_FALLBACK_F128(Cosh)
+DEFINE_FALLBACK_F128(Erf)
+DEFINE_FALLBACK_F128(Erfc)
+DEFINE_FALLBACK_F128(Exp)
+DEFINE_FALLBACK_F128(Floor)
+DEFINE_FALLBACK_F128(Frexp)
+DEFINE_FALLBACK_F128(Hypot)
+DEFINE_FALLBACK_I32(Ilogb)
+DEFINE_FALLBACK_I32(Isinf)
+DEFINE_FALLBACK_I32(Isnan)
+DEFINE_FALLBACK_F128(J0)
+DEFINE_FALLBACK_F128(J1)
+DEFINE_FALLBACK_F128(Jn)
+DEFINE_FALLBACK_F128(Ldexp)
+DEFINE_FALLBACK_F128(Lgamma)
+DEFINE_FALLBACK_I64(Llround)
+DEFINE_FALLBACK_F128(Log)
+DEFINE_FALLBACK_F128(Log10)
+DEFINE_FALLBACK_I32(Lround)
+DEFINE_FALLBACK_F128(Nextafter)
+DEFINE_FALLBACK_F128(Pow)
+DEFINE_FALLBACK_F128(Qnan)
+DEFINE_FALLBACK_F128(Round)
+DEFINE_FALLBACK_F128(Sin)
+DEFINE_FALLBACK_F128(Sinh)
+DEFINE_FALLBACK_F128(Sqrt)
+DEFINE_FALLBACK_F128(Tan)
+DEFINE_FALLBACK_F128(Tanh)
+DEFINE_FALLBACK_F128(Tgamma)
+DEFINE_FALLBACK_F128(Trunc)
+DEFINE_FALLBACK_F128(Y0)
+DEFINE_FALLBACK_F128(Y1)
+DEFINE_FALLBACK_F128(Yn)
#if HAS_LIBM
-// Define wrapper callers for libm.
-#include <ccomplex>
-#include <cmath>
+#include <limits>
+// Define wrapper callers for libm.
#if LDBL_MANT_DIG == 113
// Use STD math functions. They provide IEEE-754 128-bit float
// support either via 'long double' or __float128.
@@ -118,15 +132,21 @@ DEFINE_SIMPLE_ALIAS(Erf, std::erf)
DEFINE_SIMPLE_ALIAS(Erfc, std::erfc)
DEFINE_SIMPLE_ALIAS(Exp, std::exp)
DEFINE_SIMPLE_ALIAS(Floor, std::floor)
+DEFINE_SIMPLE_ALIAS(Frexp, std::frexp)
DEFINE_SIMPLE_ALIAS(Hypot, std::hypot)
+DEFINE_SIMPLE_ALIAS(Ilogb, std::ilogb)
+DEFINE_SIMPLE_ALIAS(Isinf, std::isinf)
+DEFINE_SIMPLE_ALIAS(Isnan, std::isnan)
DEFINE_SIMPLE_ALIAS(J0, j0l)
DEFINE_SIMPLE_ALIAS(J1, j1l)
DEFINE_SIMPLE_ALIAS(Jn, jnl)
+DEFINE_SIMPLE_ALIAS(Ldexp, std::ldexp)
DEFINE_SIMPLE_ALIAS(Lgamma, std::lgamma)
DEFINE_SIMPLE_ALIAS(Llround, std::llround)
-DEFINE_SIMPLE_ALIAS(Lround, std::lround)
DEFINE_SIMPLE_ALIAS(Log, std::log)
DEFINE_SIMPLE_ALIAS(Log10, std::log10)
+DEFINE_SIMPLE_ALIAS(Lround, std::lround)
+DEFINE_SIMPLE_ALIAS(Nextafter, std::nextafter)
DEFINE_SIMPLE_ALIAS(Pow, std::pow)
DEFINE_SIMPLE_ALIAS(Round, std::round)
DEFINE_SIMPLE_ALIAS(Sin, std::sin)
@@ -139,6 +159,12 @@ DEFINE_SIMPLE_ALIAS(Trunc, std::trunc)
DEFINE_SIMPLE_ALIAS(Y0, y0l)
DEFINE_SIMPLE_ALIAS(Y1, y1l)
DEFINE_SIMPLE_ALIAS(Yn, ynl)
+
+// Use numeric_limits to produce infinity of the right type.
+#define F128_RT_INFINITY \
+ (std::numeric_limits<CppTypeFor<TypeCategory::Real, 16>>::infinity())
+#define F128_RT_QNAN \
+ (std::numeric_limits<CppTypeFor<TypeCategory::Real, 16>>::quiet_NaN())
#else // LDBL_MANT_DIG != 113
#if !HAS_LIBMF128
// glibc >=2.26 seems to have complete support for __float128
@@ -172,15 +198,21 @@ DEFINE_SIMPLE_ALIAS(Erf, erfq)
DEFINE_SIMPLE_ALIAS(Erfc, erfcq)
DEFINE_SIMPLE_ALIAS(Exp, expq)
DEFINE_SIMPLE_ALIAS(Floor, floorq)
+DEFINE_SIMPLE_ALIAS(Frexp, frexpq)
DEFINE_SIMPLE_ALIAS(Hypot, hypotq)
+DEFINE_SIMPLE_ALIAS(Ilogb, ilogbq)
+DEFINE_SIMPLE_ALIAS(Isinf, isinfq)
+DEFINE_SIMPLE_ALIAS(Isnan, isnanq)
DEFINE_SIMPLE_ALIAS(J0, j0q)
DEFINE_SIMPLE_ALIAS(J1, j1q)
DEFINE_SIMPLE_ALIAS(Jn, jnq)
+DEFINE_SIMPLE_ALIAS(Ldexp, ldexpq)
DEFINE_SIMPLE_ALIAS(Lgamma, lgammaq)
DEFINE_SIMPLE_ALIAS(Llround, llroundq)
-DEFINE_SIMPLE_ALIAS(Lround, lroundq)
DEFINE_SIMPLE_ALIAS(Log, logq)
DEFINE_SIMPLE_ALIAS(Log10, log10q)
+DEFINE_SIMPLE_ALIAS(Lround, lroundq)
+DEFINE_SIMPLE_ALIAS(Nextafter, nextafterq)
DEFINE_SIMPLE_ALIAS(Pow, powq)
DEFINE_SIMPLE_ALIAS(Round, roundq)
DEFINE_SIMPLE_ALIAS(Sin, sinq)
@@ -193,19 +225,11 @@ DEFINE_SIMPLE_ALIAS(Trunc, truncq)
DEFINE_SIMPLE_ALIAS(Y0, y0q)
DEFINE_SIMPLE_ALIAS(Y1, y1q)
DEFINE_SIMPLE_ALIAS(Yn, ynq)
-#endif
-extern "C" {
-// Declarations of the entry points that might be referenced
-// within the Float128Math library itself.
-// Note that not all of these entry points are actually
-// defined in this library. Some of them are used just
-// as template parameters to call the corresponding callee directly.
-CppTypeFor<TypeCategory::Real, 16> RTDECL(AbsF128)(
- CppTypeFor<TypeCategory::Real, 16> x);
-CppTypeFor<TypeCategory::Real, 16> RTDECL(SqrtF128)(
- CppTypeFor<TypeCategory::Real, 16> x);
-} // extern "C"
+// Use cmath INFINITY/NAN definition. Rely on C implicit conversions.
+#define F128_RT_INFINITY (INFINITY)
+#define F128_RT_QNAN (NAN)
+#endif
} // namespace Fortran::runtime
diff --git a/flang/runtime/Float128Math/mod-real.cpp b/flang/runtime/Float128Math/mod-real.cpp
new file mode 100644
index 00000000000000..42e6ce76e2fa1b
--- /dev/null
+++ b/flang/runtime/Float128Math/mod-real.cpp
@@ -0,0 +1,24 @@
+//===-- runtime/Float128Math/mod-real.cpp ---------------------------------===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+
+#include "math-entries.h"
+#include "numeric-template-specs.h"
+
+namespace Fortran::runtime {
+extern "C" {
+
+#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
+// MOD (16.9.135)
+F128Type RTDEF(ModReal16)(
+ F128Type x, F128Type p, const char *sourceFile, int sourceLine) {
+ return RealMod<false>(x, p, sourceFile, sourceLine);
+}
+#endif
+
+} // extern "C"
+} // namespace Fortran::runtime
diff --git a/flang/runtime/Float128Math/modulo-real.cpp b/flang/runtime/Float128Math/modulo-real.cpp
new file mode 100644
index 00000000000000..13000aba8c8323
--- /dev/null
+++ b/flang/runtime/Float128Math/modulo-real.cpp
@@ -0,0 +1,24 @@
+//===-- runtime/Float128Math/modulo-real.cpp ------------------------------===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+
+#include "math-entries.h"
+#include "numeric-template-specs.h"
+
+namespace Fortran::runtime {
+extern "C" {
+
+#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
+// MODULO (16.9.136)
+F128Type RTDEF(ModuloReal16)(
+ F128Type x, F128Type p, const char *sourceFile, int sourceLine) {
+ return RealMod<true>(x, p, sourceFile, sourceLine);
+}
+#endif
+
+} // extern "C"
+} // namespace Fortran::runtime
diff --git a/flang/runtime/Float128Math/nearest.cpp b/flang/runtime/Float128Math/nearest.cpp
new file mode 100644
index 00000000000000..148ac4ef839160
--- /dev/null
+++ b/flang/runtime/Float128Math/nearest.cpp
@@ -0,0 +1,23 @@
+//===-- runtime/Float128Math/nearest.cpp ----------------------------------===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+
+#include "math-entries.h"
+
+namespace Fortran::runtime {
+extern "C" {
+
+#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
+CppTypeFor<TypeCategory::Real, 16> RTDEF(Nearest16)(
+ CppTypeFor<TypeCategory::Real, 16> x, bool positive) {
+ return Nextafter<true>::invoke(
+ x, positive ? F128_RT_INFINITY : -F128_RT_INFINITY);
+}
+#endif
+
+} // extern "C"
+} // namespace Fortran::runtime
diff --git a/flang/runtime/Float128Math/norm2.cpp b/flang/runtime/Float128Math/norm2.cpp
index 17453bd2d6cbd7..15c482f7f007ce 100644
--- a/flang/runtime/Float128Math/norm2.cpp
+++ b/flang/runtime/Float128Math/norm2.cpp
@@ -7,39 +7,17 @@
//===----------------------------------------------------------------------===//
#include "math-entries.h"
+#include "numeric-template-specs.h"
#include "reduction-templates.h"
-#include <cmath>
-
-#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
-
-namespace {
-using namespace Fortran::runtime;
-
-using AccumType = Norm2AccumType<16>;
-
-struct ABSTy {
- static AccumType compute(AccumType x) {
- return Sqrt<RTNAME(AbsF128)>::invoke(x);
- }
-};
-
-struct SQRTTy {
- static AccumType compute(AccumType x) {
- return Sqrt<RTNAME(SqrtF128)>::invoke(x);
- }
-};
-
-using Float128Norm2Accumulator = Norm2Accumulator<16, ABSTy, SQRTTy>;
-} // namespace
namespace Fortran::runtime {
extern "C" {
+#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Real, 16> RTDEF(Norm2_16)(
const Descriptor &x, const char *source, int line, int dim) {
- auto accumulator{::Float128Norm2Accumulator(x)};
return GetTotalReduction<TypeCategory::Real, 16>(
- x, source, line, dim, nullptr, accumulator, "NORM2");
+ x, source, line, dim, nullptr, Norm2Accumulator<16>{x}, "NORM2");
}
void RTDEF(Norm2DimReal16)(Descriptor &result, const Descriptor &x, int dim,
@@ -49,11 +27,9 @@ void RTDEF(Norm2DimReal16)(Descriptor &result, const Descriptor &x, int dim,
RUNTIME_CHECK(terminator, type);
RUNTIME_CHECK(
terminator, type->first == TypeCategory::Real && type->second == 16);
- DoMaxMinNorm2<TypeCategory::Real, 16, ::Float128Norm2Accumulator>(
- result, x, dim, nullptr, "NORM2", terminator);
+ Norm2Helper<16>{}(result, x, dim, nullptr, terminator);
}
+#endif
} // extern "C"
} // namespace Fortran::runtime
-
-#endif
diff --git a/flang/runtime/Float128Math/numeric-template-specs.h b/flang/runtime/Float128Math/numeric-template-specs.h
new file mode 100644
index 00000000000000..a0a77230c3e9eb
--- /dev/null
+++ b/flang/runtime/Float128Math/numeric-template-specs.h
@@ -0,0 +1,55 @@
+//===-- runtime/Float128Math/numeric-template-specs.h -----------*- C++ -*-===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+
+#ifndef FORTRAN_RUNTIME_FLOAT128MATH_NUMERIC_TEMPLATE_SPECS_H_
+#define FORTRAN_RUNTIME_FLOAT128MATH_NUMERIC_TEMPLATE_SPECS_H_
+
+#include "math-entries.h"
+#include "numeric-templates.h"
+
+namespace Fortran::runtime {
+using F128Type = CppTypeFor<TypeCategory::Real, 16>;
+
+template <> struct ABSTy<F128Type> {
+ static F128Type compute(F128Type x) { return Abs<true>::invoke(x); }
+};
+
+template <> struct FREXPTy<F128Type> {
+ static F128Type compute(F128Type x, int *e) {
+ return Frexp<true>::invoke(x, e);
+ }
+};
+
+template <> struct ILOGBTy<F128Type> {
+ static int compute(F128Type x) { return Ilogb<true>::invoke(x); }
+};
+
+template <> struct ISINFTy<F128Type> {
+ static bool compute(F128Type x) { return Isinf<true>::invoke(x); }
+};
+
+template <> struct ISNANTy<F128Type> {
+ static bool compute(F128Type x) { return Isnan<true>::invoke(x); }
+};
+
+template <> struct LDEXPTy<F128Type> {
+ template <typename ET> static F128Type compute(F128Type x, ET p) {
+ return Ldexp<true>::invoke(x, p);
+ }
+};
+
+template <> struct QNANTy<F128Type> {
+ static F128Type compute() { return F128_RT_QNAN; }
+};
+
+template <> struct SQRTTy<F128Type> {
+ static F128Type compute(F128Type x) { return Sqrt<true>::invoke(x); }
+};
+
+} // namespace Fortran::runtime
+#endif // FORTRAN_RUNTIME_FLOAT128MATH_NUMERIC_TEMPLATE_SPECS_H_
diff --git a/flang/runtime/Float128Math/pow.cpp b/flang/runtime/Float128Math/pow.cpp
index 02958a890e5221..7a48828ee3e765 100644
--- a/flang/runtime/Float128Math/pow.cpp
+++ b/flang/runtime/Float128Math/pow.cpp
@@ -15,7 +15,7 @@ extern "C" {
CppTypeFor<TypeCategory::Real, 16> RTDEF(PowF128)(
CppTypeFor<TypeCategory::Real, 16> x,
CppTypeFor<TypeCategory::Real, 16> y) {
- return Pow<RTNAME(PowF128)>::invoke(x, y);
+ return Pow<true>::invoke(x, y);
}
#endif
diff --git a/flang/runtime/Float128Math/round.cpp b/flang/runtime/Float128Math/round.cpp
index 43ab57768cb77a..6420c1bc9cd25d 100644
--- a/flang/runtime/Float128Math/round.cpp
+++ b/flang/runtime/Float128Math/round.cpp
@@ -18,7 +18,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Real, 16> RTDEF(RoundF128)(
CppTypeFor<TypeCategory::Real, 16> x) {
- return Round<RTNAME(RoundF128)>::invoke(x);
+ return Round<true>::invoke(x);
}
#endif
diff --git a/flang/runtime/Float128Math/rrspacing.cpp b/flang/runtime/Float128Math/rrspacing.cpp
new file mode 100644
index 00000000000000..feddac418eec39
--- /dev/null
+++ b/flang/runtime/Float128Math/rrspacing.cpp
@@ -0,0 +1,21 @@
+//===-- runtime/Float128Math/rrspacing.cpp --------------------------------===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+
+#include "math-entries.h"
+#include "numeric-template-specs.h"
+
+namespace Fortran::runtime {
+extern "C" {
+
+#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
+// FRACTION (16.9.80)
+F128Type RTDEF(RRSpacing16)(F128Type x) { return RRSpacing<113>(x); }
+#endif
+
+} // extern "C"
+} // namespace Fortran::runtime
diff --git a/flang/runtime/Float128Math/scale.cpp b/flang/runtime/Float128Math/scale.cpp
new file mode 100644
index 00000000000000..0be958bd9f2a72
--- /dev/null
+++ b/flang/runtime/Float128Math/scale.cpp
@@ -0,0 +1,28 @@
+//===-- runtime/Float128Math/scale.cpp ------------------------------------===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+
+#include "math-entries.h"
+#include "numeric-template-specs.h"
+#include <limits>
+
+namespace Fortran::runtime {
+extern "C" {
+
+#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
+F128Type RTDEF(Scale16)(F128Type x, std::int64_t p) {
+ auto ip{static_cast<int>(p)};
+ if (ip != p) {
+ ip = p < 0 ? std::numeric_limits<int>::min()
+ : std::numeric_limits<int>::max();
+ }
+ return LDEXPTy<F128Type>::compute(x, ip);
+}
+#endif
+
+} // extern "C"
+} // namespace Fortran::runtime
diff --git a/flang/runtime/Float128Math/set-exponent.cpp b/flang/runtime/Float128Math/set-exponent.cpp
new file mode 100644
index 00000000000000..99c34af7962b9a
--- /dev/null
+++ b/flang/runtime/Float128Math/set-exponent.cpp
@@ -0,0 +1,23 @@
+//===-- runtime/Float128Math/set-exponent.cpp -----------------------------===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+
+#include "math-entries.h"
+#include "numeric-template-specs.h"
+
+namespace Fortran::runtime {
+extern "C" {
+
+#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
+// SET_EXPONENT (16.9.171)
+F128Type RTDEF(SetExponent16)(F128Type x, std::int64_t p) {
+ return SetExponent(x, p);
+}
+#endif
+
+} // extern "C"
+} // namespace Fortran::runtime
diff --git a/flang/runtime/Float128Math/sin.cpp b/flang/runtime/Float128Math/sin.cpp
index 013eb9d119a6a3..8ebc3f9881586e 100644
--- a/flang/runtime/Float128Math/sin.cpp
+++ b/flang/runtime/Float128Math/sin.cpp
@@ -14,7 +14,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Real, 16> RTDEF(SinF128)(
CppTypeFor<TypeCategory::Real, 16> x) {
- return Sin<RTNAME(SinF128)>::invoke(x);
+ return Sin<true>::invoke(x);
}
#endif
diff --git a/flang/runtime/Float128Math/sinh.cpp b/flang/runtime/Float128Math/sinh.cpp
index 9c907041fd7eb4..aa716a3e51ef5a 100644
--- a/flang/runtime/Float128Math/sinh.cpp
+++ b/flang/runtime/Float128Math/sinh.cpp
@@ -14,7 +14,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Real, 16> RTDEF(SinhF128)(
CppTypeFor<TypeCategory::Real, 16> x) {
- return Sinh<RTNAME(SinhF128)>::invoke(x);
+ return Sinh<true>::invoke(x);
}
#endif
diff --git a/flang/runtime/Float128Math/spacing.cpp b/flang/runtime/Float128Math/spacing.cpp
new file mode 100644
index 00000000000000..a86c0b30e567ab
--- /dev/null
+++ b/flang/runtime/Float128Math/spacing.cpp
@@ -0,0 +1,21 @@
+//===-- runtime/Float128Math/spacing.cpp ----------------------------------===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+
+#include "math-entries.h"
+#include "numeric-template-specs.h"
+
+namespace Fortran::runtime {
+extern "C" {
+
+#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
+// SPACING (16.9.180)
+F128Type RTDEF(Spacing16)(F128Type x) { return Spacing<113>(x); }
+#endif
+
+} // extern "C"
+} // namespace Fortran::runtime
diff --git a/flang/runtime/Float128Math/sqrt.cpp b/flang/runtime/Float128Math/sqrt.cpp
index aafbd850ca973a..83165a4c623191 100644
--- a/flang/runtime/Float128Math/sqrt.cpp
+++ b/flang/runtime/Float128Math/sqrt.cpp
@@ -7,15 +7,13 @@
//===----------------------------------------------------------------------===//
#include "math-entries.h"
+#include "numeric-template-specs.h"
namespace Fortran::runtime {
extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
-CppTypeFor<TypeCategory::Real, 16> RTDEF(SqrtF128)(
- CppTypeFor<TypeCategory::Real, 16> x) {
- return Sqrt<RTNAME(SqrtF128)>::invoke(x);
-}
+F128Type RTDEF(SqrtF128)(F128Type x) { return SQRTTy<F128Type>::compute(x); }
#endif
} // extern "C"
diff --git a/flang/runtime/Float128Math/tan.cpp b/flang/runtime/Float128Math/tan.cpp
index 01d3c7bdd2e85d..8f4b723ca977bd 100644
--- a/flang/runtime/Float128Math/tan.cpp
+++ b/flang/runtime/Float128Math/tan.cpp
@@ -14,7 +14,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Real, 16> RTDEF(TanF128)(
CppTypeFor<TypeCategory::Real, 16> x) {
- return Tan<RTNAME(TanF128)>::invoke(x);
+ return Tan<true>::invoke(x);
}
#endif
diff --git a/flang/runtime/Float128Math/tanh.cpp b/flang/runtime/Float128Math/tanh.cpp
index fedc1a4120caf5..b43a89520b6797 100644
--- a/flang/runtime/Float128Math/tanh.cpp
+++ b/flang/runtime/Float128Math/tanh.cpp
@@ -14,7 +14,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Real, 16> RTDEF(TanhF128)(
CppTypeFor<TypeCategory::Real, 16> x) {
- return Tanh<RTNAME(TanhF128)>::invoke(x);
+ return Tanh<true>::invoke(x);
}
#endif
diff --git a/flang/runtime/Float128Math/tgamma.cpp b/flang/runtime/Float128Math/tgamma.cpp
index 329defff38cf91..93f97800bdc966 100644
--- a/flang/runtime/Float128Math/tgamma.cpp
+++ b/flang/runtime/Float128Math/tgamma.cpp
@@ -14,7 +14,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Real, 16> RTDEF(TgammaF128)(
CppTypeFor<TypeCategory::Real, 16> x) {
- return Tgamma<RTNAME(TgammaF128)>::invoke(x);
+ return Tgamma<true>::invoke(x);
}
#endif
diff --git a/flang/runtime/Float128Math/trunc.cpp b/flang/runtime/Float128Math/trunc.cpp
index 3cab219ce31c2d..ca15a739c030e8 100644
--- a/flang/runtime/Float128Math/trunc.cpp
+++ b/flang/runtime/Float128Math/trunc.cpp
@@ -18,7 +18,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Real, 16> RTDEF(TruncF128)(
CppTypeFor<TypeCategory::Real, 16> x) {
- return Trunc<RTNAME(TruncF128)>::invoke(x);
+ return Trunc<true>::invoke(x);
}
#endif
diff --git a/flang/runtime/Float128Math/y0.cpp b/flang/runtime/Float128Math/y0.cpp
index f3e2ee454aeab5..d6f39aac1053a8 100644
--- a/flang/runtime/Float128Math/y0.cpp
+++ b/flang/runtime/Float128Math/y0.cpp
@@ -14,7 +14,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Real, 16> RTDEF(Y0F128)(
CppTypeFor<TypeCategory::Real, 16> x) {
- return Y0<RTNAME(Y0F128)>::invoke(x);
+ return Y0<true>::invoke(x);
}
#endif
diff --git a/flang/runtime/Float128Math/y1.cpp b/flang/runtime/Float128Math/y1.cpp
index c117bbcb2b5a86..477d36a9ea3c66 100644
--- a/flang/runtime/Float128Math/y1.cpp
+++ b/flang/runtime/Float128Math/y1.cpp
@@ -14,7 +14,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Real, 16> RTDEF(Y1F128)(
CppTypeFor<TypeCategory::Real, 16> x) {
- return Y1<RTNAME(Y1F128)>::invoke(x);
+ return Y1<true>::invoke(x);
}
#endif
diff --git a/flang/runtime/Float128Math/yn.cpp b/flang/runtime/Float128Math/yn.cpp
index 237bc2866a0d5b..3a040cc8858970 100644
--- a/flang/runtime/Float128Math/yn.cpp
+++ b/flang/runtime/Float128Math/yn.cpp
@@ -14,7 +14,7 @@ extern "C" {
#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
CppTypeFor<TypeCategory::Real, 16> RTDEF(YnF128)(
int n, CppTypeFor<TypeCategory::Real, 16> x) {
- return Yn<RTNAME(YnF128)>::invoke(n, x);
+ return Yn<true>::invoke(n, x);
}
#endif
diff --git a/flang/runtime/extrema.cpp b/flang/runtime/extrema.cpp
index fc2b4e165cb269..61afb0458430db 100644
--- a/flang/runtime/extrema.cpp
+++ b/flang/runtime/extrema.cpp
@@ -424,62 +424,6 @@ RT_EXT_API_GROUP_END
// MAXVAL and MINVAL
-template <TypeCategory CAT, int KIND, bool IS_MAXVAL, typename Enable = void>
-struct MaxOrMinIdentity {
- using Type = CppTypeFor<CAT, KIND>;
- static constexpr RT_API_ATTRS Type Value() {
- return IS_MAXVAL ? std::numeric_limits<Type>::lowest()
- : std::numeric_limits<Type>::max();
- }
-};
-
-// std::numeric_limits<> may not know int128_t
-template <bool IS_MAXVAL>
-struct MaxOrMinIdentity<TypeCategory::Integer, 16, IS_MAXVAL> {
- using Type = CppTypeFor<TypeCategory::Integer, 16>;
- static constexpr RT_API_ATTRS Type Value() {
- return IS_MAXVAL ? Type{1} << 127 : ~Type{0} >> 1;
- }
-};
-
-#if HAS_FLOAT128
-// std::numeric_limits<> may not support __float128.
-//
-// Usage of GCC quadmath.h's FLT128_MAX is complicated by the fact that
-// even GCC complains about 'Q' literal suffix under -Wpedantic.
-// We just recreate FLT128_MAX ourselves.
-//
-// This specialization must engage only when
-// CppTypeFor<TypeCategory::Real, 16> is __float128.
-template <bool IS_MAXVAL>
-struct MaxOrMinIdentity<TypeCategory::Real, 16, IS_MAXVAL,
- typename std::enable_if_t<
- std::is_same_v<CppTypeFor<TypeCategory::Real, 16>, __float128>>> {
- using Type = __float128;
- static RT_API_ATTRS Type Value() {
- // Create a buffer to store binary representation of __float128 constant.
- constexpr std::size_t alignment =
- std::max(alignof(Type), alignof(std::uint64_t));
- alignas(alignment) char data[sizeof(Type)];
-
- // First, verify that our interpretation of __float128 format is correct,
- // e.g. by checking at least one known constant.
- *reinterpret_cast<Type *>(data) = Type(1.0);
- if (*reinterpret_cast<std::uint64_t *>(data) != 0 ||
- *(reinterpret_cast<std::uint64_t *>(data) + 1) != 0x3FFF000000000000) {
- Terminator terminator{__FILE__, __LINE__};
- terminator.Crash("not yet implemented: no full support for __float128");
- }
-
- // Recreate FLT128_MAX.
- *reinterpret_cast<std::uint64_t *>(data) = 0xFFFFFFFFFFFFFFFF;
- *(reinterpret_cast<std::uint64_t *>(data) + 1) = 0x7FFEFFFFFFFFFFFF;
- Type max = *reinterpret_cast<Type *>(data);
- return IS_MAXVAL ? -max : max;
- }
-};
-#endif // HAS_FLOAT128
-
template <TypeCategory CAT, int KIND, bool IS_MAXVAL>
class NumericExtremumAccumulator {
public:
@@ -773,42 +717,25 @@ RT_EXT_API_GROUP_END
// NORM2
-template <int KIND> struct Norm2Helper {
- RT_API_ATTRS void operator()(Descriptor &result, const Descriptor &x, int dim,
- const Descriptor *mask, Terminator &terminator) const {
- DoMaxMinNorm2<TypeCategory::Real, KIND,
- typename Norm2AccumulatorGetter<KIND>::Type>(
- result, x, dim, mask, "NORM2", terminator);
- }
-};
-
extern "C" {
RT_EXT_API_GROUP_BEGIN
// TODO: REAL(2 & 3)
CppTypeFor<TypeCategory::Real, 4> RTDEF(Norm2_4)(
const Descriptor &x, const char *source, int line, int dim) {
- return GetTotalReduction<TypeCategory::Real, 4>(x, source, line, dim, nullptr,
- Norm2AccumulatorGetter<4>::create(x), "NORM2");
+ return GetTotalReduction<TypeCategory::Real, 4>(
+ x, source, line, dim, nullptr, Norm2Accumulator<4>{x}, "NORM2");
}
CppTypeFor<TypeCategory::Real, 8> RTDEF(Norm2_8)(
const Descriptor &x, const char *source, int line, int dim) {
- return GetTotalReduction<TypeCategory::Real, 8>(x, source, line, dim, nullptr,
- Norm2AccumulatorGetter<8>::create(x), "NORM2");
+ return GetTotalReduction<TypeCategory::Real, 8>(
+ x, source, line, dim, nullptr, Norm2Accumulator<8>{x}, "NORM2");
}
#if LDBL_MANT_DIG == 64
CppTypeFor<TypeCategory::Real, 10> RTDEF(Norm2_10)(
const Descriptor &x, const char *source, int line, int dim) {
- return GetTotalReduction<TypeCategory::Real, 10>(x, source, line, dim,
- nullptr, Norm2AccumulatorGetter<10>::create(x), "NORM2");
-}
-#endif
-#if LDBL_MANT_DIG == 113
-// The __float128 implementation resides in FortranFloat128Math library.
-CppTypeFor<TypeCategory::Real, 16> RTDEF(Norm2_16)(
- const Descriptor &x, const char *source, int line, int dim) {
- return GetTotalReduction<TypeCategory::Real, 16>(x, source, line, dim,
- nullptr, Norm2AccumulatorGetter<16>::create(x), "NORM2");
+ return GetTotalReduction<TypeCategory::Real, 10>(
+ x, source, line, dim, nullptr, Norm2Accumulator<10>{x}, "NORM2");
}
#endif
diff --git a/flang/runtime/numeric-templates.h b/flang/runtime/numeric-templates.h
new file mode 100644
index 00000000000000..b16440dbc2241a
--- /dev/null
+++ b/flang/runtime/numeric-templates.h
@@ -0,0 +1,339 @@
+//===-- runtime/numeric-templates.h -----------------------------*- C++ -*-===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+
+// Generic class and function templates used for implementing
+// various numeric intrinsics (EXPONENT, FRACTION, etc.).
+//
+// This header file also defines generic templates for "basic"
+// math operations like abs, isnan, etc. The Float128Math
+// library provides specializations for these templates
+// for the data type corresponding to CppTypeFor<TypeCategory::Real, 16>
+// on the target.
+
+#ifndef FORTRAN_RUNTIME_NUMERIC_TEMPLATES_H_
+#define FORTRAN_RUNTIME_NUMERIC_TEMPLATES_H_
+
+#include "terminator.h"
+#include "tools.h"
+#include "flang/Common/float128.h"
+#include <cstdint>
+#include <limits>
+
+namespace Fortran::runtime {
+
+// MAX/MIN/LOWEST values for different data types.
+
+// MaxOrMinIdentity returns MAX or LOWEST value of the given type.
+template <TypeCategory CAT, int KIND, bool IS_MAXVAL, typename Enable = void>
+struct MaxOrMinIdentity {
+ using Type = CppTypeFor<CAT, KIND>;
+ static constexpr RT_API_ATTRS Type Value() {
+ return IS_MAXVAL ? std::numeric_limits<Type>::lowest()
+ : std::numeric_limits<Type>::max();
+ }
+};
+
+// std::numeric_limits<> may not know int128_t
+template <bool IS_MAXVAL>
+struct MaxOrMinIdentity<TypeCategory::Integer, 16, IS_MAXVAL> {
+ using Type = CppTypeFor<TypeCategory::Integer, 16>;
+ static constexpr RT_API_ATTRS Type Value() {
+ return IS_MAXVAL ? Type{1} << 127 : ~Type{0} >> 1;
+ }
+};
+
+#if HAS_FLOAT128
+// std::numeric_limits<> may not support __float128.
+//
+// Usage of GCC quadmath.h's FLT128_MAX is complicated by the fact that
+// even GCC complains about 'Q' literal suffix under -Wpedantic.
+// We just recreate FLT128_MAX ourselves.
+//
+// This specialization must engage only when
+// CppTypeFor<TypeCategory::Real, 16> is __float128.
+template <bool IS_MAXVAL>
+struct MaxOrMinIdentity<TypeCategory::Real, 16, IS_MAXVAL,
+ typename std::enable_if_t<
+ std::is_same_v<CppTypeFor<TypeCategory::Real, 16>, __float128>>> {
+ using Type = __float128;
+ static RT_API_ATTRS Type Value() {
+ // Create a buffer to store binary representation of __float128 constant.
+ constexpr std::size_t alignment =
+ std::max(alignof(Type), alignof(std::uint64_t));
+ alignas(alignment) char data[sizeof(Type)];
+
+ // First, verify that our interpretation of __float128 format is correct,
+ // e.g. by checking at least one known constant.
+ *reinterpret_cast<Type *>(data) = Type(1.0);
+ if (*reinterpret_cast<std::uint64_t *>(data) != 0 ||
+ *(reinterpret_cast<std::uint64_t *>(data) + 1) != 0x3FFF000000000000) {
+ Terminator terminator{__FILE__, __LINE__};
+ terminator.Crash("not yet implemented: no full support for __float128");
+ }
+
+ // Recreate FLT128_MAX.
+ *reinterpret_cast<std::uint64_t *>(data) = 0xFFFFFFFFFFFFFFFF;
+ *(reinterpret_cast<std::uint64_t *>(data) + 1) = 0x7FFEFFFFFFFFFFFF;
+ Type max = *reinterpret_cast<Type *>(data);
+ return IS_MAXVAL ? -max : max;
+ }
+};
+#endif // HAS_FLOAT128
+
+// Minimum finite representable value.
+// For floating-point types, returns minimum positive normalized value.
+template <typename T> struct MinValue {
+ static RT_API_ATTRS T get() { return std::numeric_limits<T>::min(); }
+};
+
+#if HAS_FLOAT128
+template <> struct MinValue<CppTypeFor<TypeCategory::Real, 16>> {
+ using Type = CppTypeFor<TypeCategory::Real, 16>;
+ static RT_API_ATTRS Type get() {
+ // Create a buffer to store binary representation of __float128 constant.
+ constexpr std::size_t alignment =
+ std::max(alignof(Type), alignof(std::uint64_t));
+ alignas(alignment) char data[sizeof(Type)];
+
+ // First, verify that our interpretation of __float128 format is correct,
+ // e.g. by checking at least one known constant.
+ *reinterpret_cast<Type *>(data) = Type(1.0);
+ if (*reinterpret_cast<std::uint64_t *>(data) != 0 ||
+ *(reinterpret_cast<std::uint64_t *>(data) + 1) != 0x3FFF000000000000) {
+ Terminator terminator{__FILE__, __LINE__};
+ terminator.Crash("not yet implemented: no full support for __float128");
+ }
+
+ // Recreate FLT128_MIN.
+ *reinterpret_cast<std::uint64_t *>(data) = 0;
+ *(reinterpret_cast<std::uint64_t *>(data) + 1) = 0x1000000000000;
+ return *reinterpret_cast<Type *>(data);
+ }
+};
+#endif // HAS_FLOAT128
+
+template <typename T> struct ABSTy {
+ static constexpr RT_API_ATTRS T compute(T x) { return std::abs(x); }
+};
+
+template <typename T> struct FREXPTy {
+ static constexpr RT_API_ATTRS T compute(T x, int *e) {
+ return std::frexp(x, e);
+ }
+};
+
+template <typename T> struct ILOGBTy {
+ static constexpr RT_API_ATTRS int compute(T x) { return std::ilogb(x); }
+};
+
+template <typename T> struct ISINFTy {
+ static constexpr RT_API_ATTRS bool compute(T x) { return std::isinf(x); }
+};
+
+template <typename T> struct ISNANTy {
+ static constexpr RT_API_ATTRS bool compute(T x) { return std::isnan(x); }
+};
+
+template <typename T> struct LDEXPTy {
+ template <typename ET> static constexpr RT_API_ATTRS T compute(T x, ET e) {
+ return std::ldexp(x, e);
+ }
+};
+
+template <typename T> struct MAXTy {
+ static constexpr RT_API_ATTRS T compute() {
+ return std::numeric_limits<T>::max();
+ }
+};
+
+#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
+template <> struct MAXTy<CppTypeFor<TypeCategory::Real, 16>> {
+ static CppTypeFor<TypeCategory::Real, 16> compute() {
+ return MaxOrMinIdentity<TypeCategory::Real, 16, true>::Value();
+ }
+};
+#endif
+
+template <typename T> struct MINTy {
+ static constexpr RT_API_ATTRS T compute() { return MinValue<T>::get(); }
+};
+
+template <typename T> struct QNANTy {
+ static constexpr RT_API_ATTRS T compute() {
+ return std::numeric_limits<T>::quiet_NaN();
+ }
+};
+
+template <typename T> struct SQRTTy {
+ static constexpr RT_API_ATTRS T compute(T x) { return std::sqrt(x); }
+};
+
+// EXPONENT (16.9.75)
+template <typename RESULT, typename ARG>
+inline RT_API_ATTRS RESULT Exponent(ARG x) {
+ if (ISINFTy<ARG>::compute(x) || ISNANTy<ARG>::compute(x)) {
+ return MAXTy<RESULT>::compute(); // +/-Inf, NaN -> HUGE(0)
+ } else if (x == 0) {
+ return 0; // 0 -> 0
+ } else {
+ return ILOGBTy<ARG>::compute(x) + 1;
+ }
+}
+
+// Suppress the warnings about calling __host__-only std::frexp,
+// defined in C++ STD header files, from __device__ code.
+RT_DIAG_PUSH
+RT_DIAG_DISABLE_CALL_HOST_FROM_DEVICE_WARN
+
+// FRACTION (16.9.80)
+template <typename T> inline RT_API_ATTRS T Fraction(T x) {
+ if (ISNANTy<T>::compute(x)) {
+ return x; // NaN -> same NaN
+ } else if (ISINFTy<T>::compute(x)) {
+ return QNANTy<T>::compute(); // +/-Inf -> NaN
+ } else if (x == 0) {
+ return x; // 0 -> same 0
+ } else {
+ int ignoredExp;
+ return FREXPTy<T>::compute(x, &ignoredExp);
+ }
+}
+
+RT_DIAG_POP
+
+// SET_EXPONENT (16.9.171)
+template <typename T> inline RT_API_ATTRS T SetExponent(T x, std::int64_t p) {
+ if (ISNANTy<T>::compute(x)) {
+ return x; // NaN -> same NaN
+ } else if (ISINFTy<T>::compute(x)) {
+ return QNANTy<T>::compute(); // +/-Inf -> NaN
+ } else if (x == 0) {
+ return x; // return negative zero if x is negative zero
+ } else {
+ int expo{ILOGBTy<T>::compute(x) + 1};
+ auto ip{static_cast<int>(p - expo)};
+ if (ip != p - expo) {
+ ip = p < 0 ? std::numeric_limits<int>::min()
+ : std::numeric_limits<int>::max();
+ }
+ return LDEXPTy<T>::compute(x, ip); // x*2**(p-e)
+ }
+}
+
+// MOD & MODULO (16.9.135, .136)
+template <bool IS_MODULO, typename T>
+inline RT_API_ATTRS T RealMod(
+ T a, T p, const char *sourceFile, int sourceLine) {
+ if (p == 0) {
+ Terminator{sourceFile, sourceLine}.Crash(
+ IS_MODULO ? "MODULO with P==0" : "MOD with P==0");
+ }
+ if (ISNANTy<T>::compute(a) || ISNANTy<T>::compute(p) ||
+ ISINFTy<T>::compute(a)) {
+ return QNANTy<T>::compute();
+ } else if (ISINFTy<T>::compute(p)) {
+ return a;
+ }
+ T aAbs{ABSTy<T>::compute(a)};
+ T pAbs{ABSTy<T>::compute(p)};
+ if (aAbs <= static_cast<T>(std::numeric_limits<std::int64_t>::max()) &&
+ pAbs <= static_cast<T>(std::numeric_limits<std::int64_t>::max())) {
+ if (auto aInt{static_cast<std::int64_t>(a)}; a == aInt) {
+ if (auto pInt{static_cast<std::int64_t>(p)}; p == pInt) {
+ // Fast exact case for integer operands
+ auto mod{aInt - (aInt / pInt) * pInt};
+ if (IS_MODULO && (aInt > 0) != (pInt > 0)) {
+ mod += pInt;
+ }
+ return static_cast<T>(mod);
+ }
+ }
+ }
+ if constexpr (std::is_same_v<T, float> || std::is_same_v<T, double> ||
+ std::is_same_v<T, long double>) {
+ // std::fmod() semantics on signed operands seems to match
+ // the requirements of MOD(). MODULO() needs adjustment.
+ T result{std::fmod(a, p)};
+ if constexpr (IS_MODULO) {
+ if ((a < 0) != (p < 0)) {
+ if (result == 0.) {
+ result = -result;
+ } else {
+ result += p;
+ }
+ }
+ }
+ return result;
+ } else {
+ // The standard defines MOD(a,p)=a-AINT(a/p)*p and
+ // MODULO(a,p)=a-FLOOR(a/p)*p, but those definitions lose
+ // precision badly due to cancellation when ABS(a) is
+ // much larger than ABS(p).
+ // Insights:
+ // - MOD(a,p)=MOD(a-n*p,p) when a>0, p>0, integer n>0, and a>=n*p
+ // - when n is a power of two, n*p is exact
+ // - as a>=n*p, a-n*p does not round.
+ // So repeatedly reduce a by all n*p in decreasing order of n;
+ // what's left is the desired remainder. This is basically
+ // the same algorithm as arbitrary precision binary long division,
+ // discarding the quotient.
+ T tmp{aAbs};
+ for (T adj{SetExponent(pAbs, Exponent<int>(aAbs))}; tmp >= pAbs; adj /= 2) {
+ if (tmp >= adj) {
+ tmp -= adj;
+ if (tmp == 0) {
+ break;
+ }
+ }
+ }
+ if (a < 0) {
+ tmp = -tmp;
+ }
+ if constexpr (IS_MODULO) {
+ if ((a < 0) != (p < 0)) {
+ tmp += p;
+ }
+ }
+ return tmp;
+ }
+}
+
+// RRSPACING (16.9.164)
+template <int PREC, typename T> inline RT_API_ATTRS T RRSpacing(T x) {
+ if (ISNANTy<T>::compute(x)) {
+ return x; // NaN -> same NaN
+ } else if (ISINFTy<T>::compute(x)) {
+ return QNANTy<T>::compute(); // +/-Inf -> NaN
+ } else if (x == 0) {
+ return 0; // 0 -> 0
+ } else {
+ return LDEXPTy<T>::compute(
+ ABSTy<T>::compute(x), PREC - (ILOGBTy<T>::compute(x) + 1));
+ }
+}
+
+// SPACING (16.9.180)
+template <int PREC, typename T> inline RT_API_ATTRS T Spacing(T x) {
+ if (ISNANTy<T>::compute(x)) {
+ return x; // NaN -> same NaN
+ } else if (ISINFTy<T>::compute(x)) {
+ return QNANTy<T>::compute(); // +/-Inf -> NaN
+ } else if (x == 0) {
+ // The standard-mandated behavior seems broken, since TINY() can't be
+ // subnormal.
+ return MINTy<T>::compute(); // 0 -> TINY(x)
+ } else {
+ T result{LDEXPTy<T>::compute(
+ static_cast<T>(1.0), ILOGBTy<T>::compute(x) + 1 - PREC)}; // 2**(e-p)
+ return result == 0 ? /*TINY(x)*/ MINTy<T>::compute() : result;
+ }
+}
+
+} // namespace Fortran::runtime
+
+#endif // FORTRAN_RUNTIME_NUMERIC_TEMPLATES_H_
diff --git a/flang/runtime/numeric.cpp b/flang/runtime/numeric.cpp
index ede00d69f20e25..abd3e500029fe4 100644
--- a/flang/runtime/numeric.cpp
+++ b/flang/runtime/numeric.cpp
@@ -7,6 +7,7 @@
//===----------------------------------------------------------------------===//
#include "flang/Runtime/numeric.h"
+#include "numeric-templates.h"
#include "terminator.h"
#include "flang/Common/float128.h"
#include <cfloat>
@@ -68,58 +69,6 @@ inline RT_API_ATTRS RESULT Floor(ARG x) {
return std::floor(x);
}
-// EXPONENT (16.9.75)
-template <typename RESULT, typename ARG>
-inline RT_API_ATTRS RESULT Exponent(ARG x) {
- if (std::isinf(x) || std::isnan(x)) {
- return std::numeric_limits<RESULT>::max(); // +/-Inf, NaN -> HUGE(0)
- } else if (x == 0) {
- return 0; // 0 -> 0
- } else {
- return std::ilogb(x) + 1;
- }
-}
-
-// Suppress the warnings about calling __host__-only std::frexp,
-// defined in C++ STD header files, from __device__ code.
-RT_DIAG_PUSH
-RT_DIAG_DISABLE_CALL_HOST_FROM_DEVICE_WARN
-
-// FRACTION (16.9.80)
-template <typename T> inline RT_API_ATTRS T Fraction(T x) {
- if (std::isnan(x)) {
- return x; // NaN -> same NaN
- } else if (std::isinf(x)) {
- return std::numeric_limits<T>::quiet_NaN(); // +/-Inf -> NaN
- } else if (x == 0) {
- return x; // 0 -> same 0
- } else {
- int ignoredExp;
- return std::frexp(x, &ignoredExp);
- }
-}
-
-RT_DIAG_POP
-
-// SET_EXPONENT (16.9.171)
-template <typename T> inline RT_API_ATTRS T SetExponent(T x, std::int64_t p) {
- if (std::isnan(x)) {
- return x; // NaN -> same NaN
- } else if (std::isinf(x)) {
- return std::numeric_limits<T>::quiet_NaN(); // +/-Inf -> NaN
- } else if (x == 0) {
- return x; // return negative zero if x is negative zero
- } else {
- int expo{std::ilogb(x) + 1};
- auto ip{static_cast<int>(p - expo)};
- if (ip != p - expo) {
- ip = p < 0 ? std::numeric_limits<int>::min()
- : std::numeric_limits<int>::max();
- }
- return std::ldexp(x, ip); // x*2**(p-e)
- }
-}
-
// MOD & MODULO (16.9.135, .136)
template <bool IS_MODULO, typename T>
inline RT_API_ATTRS T IntMod(T x, T p, const char *sourceFile, int sourceLine) {
@@ -133,94 +82,6 @@ inline RT_API_ATTRS T IntMod(T x, T p, const char *sourceFile, int sourceLine) {
}
return mod;
}
-template <bool IS_MODULO, typename T>
-inline RT_API_ATTRS T RealMod(
- T a, T p, const char *sourceFile, int sourceLine) {
- if (p == 0) {
- Terminator{sourceFile, sourceLine}.Crash(
- IS_MODULO ? "MODULO with P==0" : "MOD with P==0");
- }
- if (std::isnan(a) || std::isnan(p) || std::isinf(a)) {
- return std::numeric_limits<T>::quiet_NaN();
- } else if (std::isinf(p)) {
- return a;
- }
- T aAbs{std::abs(a)};
- T pAbs{std::abs(p)};
- if (aAbs <= static_cast<T>(std::numeric_limits<std::int64_t>::max()) &&
- pAbs <= static_cast<T>(std::numeric_limits<std::int64_t>::max())) {
- if (auto aInt{static_cast<std::int64_t>(a)}; a == aInt) {
- if (auto pInt{static_cast<std::int64_t>(p)}; p == pInt) {
- // Fast exact case for integer operands
- auto mod{aInt - (aInt / pInt) * pInt};
- if (IS_MODULO && (aInt > 0) != (pInt > 0)) {
- mod += pInt;
- }
- return static_cast<T>(mod);
- }
- }
- }
- if constexpr (std::is_same_v<T, float> || std::is_same_v<T, double> ||
- std::is_same_v<T, long double>) {
- // std::fmod() semantics on signed operands seems to match
- // the requirements of MOD(). MODULO() needs adjustment.
- T result{std::fmod(a, p)};
- if constexpr (IS_MODULO) {
- if ((a < 0) != (p < 0)) {
- if (result == 0.) {
- result = -result;
- } else {
- result += p;
- }
- }
- }
- return result;
- } else {
- // The standard defines MOD(a,p)=a-AINT(a/p)*p and
- // MODULO(a,p)=a-FLOOR(a/p)*p, but those definitions lose
- // precision badly due to cancellation when ABS(a) is
- // much larger than ABS(p).
- // Insights:
- // - MOD(a,p)=MOD(a-n*p,p) when a>0, p>0, integer n>0, and a>=n*p
- // - when n is a power of two, n*p is exact
- // - as a>=n*p, a-n*p does not round.
- // So repeatedly reduce a by all n*p in decreasing order of n;
- // what's left is the desired remainder. This is basically
- // the same algorithm as arbitrary precision binary long division,
- // discarding the quotient.
- T tmp{aAbs};
- for (T adj{SetExponent(pAbs, Exponent<int>(aAbs))}; tmp >= pAbs; adj /= 2) {
- if (tmp >= adj) {
- tmp -= adj;
- if (tmp == 0) {
- break;
- }
- }
- }
- if (a < 0) {
- tmp = -tmp;
- }
- if constexpr (IS_MODULO) {
- if ((a < 0) != (p < 0)) {
- tmp += p;
- }
- }
- return tmp;
- }
-}
-
-// RRSPACING (16.9.164)
-template <int PREC, typename T> inline RT_API_ATTRS T RRSpacing(T x) {
- if (std::isnan(x)) {
- return x; // NaN -> same NaN
- } else if (std::isinf(x)) {
- return std::numeric_limits<T>::quiet_NaN(); // +/-Inf -> NaN
- } else if (x == 0) {
- return 0; // 0 -> 0
- } else {
- return std::ldexp(std::abs(x), PREC - (std::ilogb(x) + 1));
- }
-}
// SCALE (16.9.166)
template <typename T> inline RT_API_ATTRS T Scale(T x, std::int64_t p) {
@@ -229,7 +90,7 @@ template <typename T> inline RT_API_ATTRS T Scale(T x, std::int64_t p) {
ip = p < 0 ? std::numeric_limits<int>::min()
: std::numeric_limits<int>::max();
}
- return std::ldexp(x, p); // x*2**p
+ return std::ldexp(x, ip); // x*2**p
}
// SELECTED_INT_KIND (16.9.169)
@@ -300,23 +161,6 @@ inline RT_API_ATTRS CppTypeFor<TypeCategory::Integer, 4> SelectedRealKind(
return error ? error : kind;
}
-// SPACING (16.9.180)
-template <int PREC, typename T> inline RT_API_ATTRS T Spacing(T x) {
- if (std::isnan(x)) {
- return x; // NaN -> same NaN
- } else if (std::isinf(x)) {
- return std::numeric_limits<T>::quiet_NaN(); // +/-Inf -> NaN
- } else if (x == 0) {
- // The standard-mandated behavior seems broken, since TINY() can't be
- // subnormal.
- return std::numeric_limits<T>::min(); // 0 -> TINY(x)
- } else {
- T result{
- std::ldexp(static_cast<T>(1.0), std::ilogb(x) + 1 - PREC)}; // 2**(e-p)
- return result == 0 ? /*TINY(x)*/ std::numeric_limits<T>::min() : result;
- }
-}
-
// NEAREST (16.9.139)
template <int PREC, typename T>
inline RT_API_ATTRS T Nearest(T x, bool positive) {
@@ -480,15 +324,6 @@ CppTypeFor<TypeCategory::Integer, 8> RTDEF(Exponent10_8)(
CppTypeFor<TypeCategory::Real, 10> x) {
return Exponent<CppTypeFor<TypeCategory::Integer, 8>>(x);
}
-#elif LDBL_MANT_DIG == 113
-CppTypeFor<TypeCategory::Integer, 4> RTDEF(Exponent16_4)(
- CppTypeFor<TypeCategory::Real, 16> x) {
- return Exponent<CppTypeFor<TypeCategory::Integer, 4>>(x);
-}
-CppTypeFor<TypeCategory::Integer, 8> RTDEF(Exponent16_8)(
- CppTypeFor<TypeCategory::Real, 16> x) {
- return Exponent<CppTypeFor<TypeCategory::Integer, 8>>(x);
-}
#endif
CppTypeFor<TypeCategory::Integer, 1> RTDEF(Floor4_1)(
@@ -596,11 +431,6 @@ CppTypeFor<TypeCategory::Real, 10> RTDEF(Fraction10)(
CppTypeFor<TypeCategory::Real, 10> x) {
return Fraction(x);
}
-#elif LDBL_MANT_DIG == 113
-CppTypeFor<TypeCategory::Real, 16> RTDEF(Fraction16)(
- CppTypeFor<TypeCategory::Real, 16> x) {
- return Fraction(x);
-}
#endif
bool RTDEF(IsFinite4)(CppTypeFor<TypeCategory::Real, 4> x) {
@@ -683,12 +513,6 @@ CppTypeFor<TypeCategory::Real, 10> RTDEF(ModReal10)(
const char *sourceFile, int sourceLine) {
return RealMod<false>(x, p, sourceFile, sourceLine);
}
-#elif LDBL_MANT_DIG == 113
-CppTypeFor<TypeCategory::Real, 16> RTDEF(ModReal16)(
- CppTypeFor<TypeCategory::Real, 16> x, CppTypeFor<TypeCategory::Real, 16> p,
- const char *sourceFile, int sourceLine) {
- return RealMod<false>(x, p, sourceFile, sourceLine);
-}
#endif
CppTypeFor<TypeCategory::Integer, 1> RTDEF(ModuloInteger1)(
@@ -739,12 +563,6 @@ CppTypeFor<TypeCategory::Real, 10> RTDEF(ModuloReal10)(
const char *sourceFile, int sourceLine) {
return RealMod<true>(x, p, sourceFile, sourceLine);
}
-#elif LDBL_MANT_DIG == 113
-CppTypeFor<TypeCategory::Real, 16> RTDEF(ModuloReal16)(
- CppTypeFor<TypeCategory::Real, 16> x, CppTypeFor<TypeCategory::Real, 16> p,
- const char *sourceFile, int sourceLine) {
- return RealMod<true>(x, p, sourceFile, sourceLine);
-}
#endif
CppTypeFor<TypeCategory::Real, 4> RTDEF(Nearest4)(
@@ -760,11 +578,6 @@ CppTypeFor<TypeCategory::Real, 10> RTDEF(Nearest10)(
CppTypeFor<TypeCategory::Real, 10> x, bool positive) {
return Nearest<64>(x, positive);
}
-#elif LDBL_MANT_DIG == 113
-CppTypeFor<TypeCategory::Real, 16> RTDEF(Nearest16)(
- CppTypeFor<TypeCategory::Real, 16> x, bool positive) {
- return Nearest<113>(x, positive);
-}
#endif
CppTypeFor<TypeCategory::Integer, 1> RTDEF(Nint4_1)(
@@ -872,11 +685,6 @@ CppTypeFor<TypeCategory::Real, 10> RTDEF(RRSpacing10)(
CppTypeFor<TypeCategory::Real, 10> x) {
return RRSpacing<64>(x);
}
-#elif LDBL_MANT_DIG == 113
-CppTypeFor<TypeCategory::Real, 16> RTDEF(RRSpacing16)(
- CppTypeFor<TypeCategory::Real, 16> x) {
- return RRSpacing<113>(x);
-}
#endif
CppTypeFor<TypeCategory::Real, 4> RTDEF(SetExponent4)(
@@ -892,11 +700,6 @@ CppTypeFor<TypeCategory::Real, 10> RTDEF(SetExponent10)(
CppTypeFor<TypeCategory::Real, 10> x, std::int64_t p) {
return SetExponent(x, p);
}
-#elif LDBL_MANT_DIG == 113
-CppTypeFor<TypeCategory::Real, 16> RTDEF(SetExponent16)(
- CppTypeFor<TypeCategory::Real, 16> x, std::int64_t p) {
- return SetExponent(x, p);
-}
#endif
CppTypeFor<TypeCategory::Real, 4> RTDEF(Scale4)(
@@ -912,11 +715,6 @@ CppTypeFor<TypeCategory::Real, 10> RTDEF(Scale10)(
CppTypeFor<TypeCategory::Real, 10> x, std::int64_t p) {
return Scale(x, p);
}
-#elif LDBL_MANT_DIG == 113
-CppTypeFor<TypeCategory::Real, 16> RTDEF(Scale16)(
- CppTypeFor<TypeCategory::Real, 16> x, std::int64_t p) {
- return Scale(x, p);
-}
#endif
// SELECTED_INT_KIND
@@ -971,11 +769,6 @@ CppTypeFor<TypeCategory::Real, 10> RTDEF(Spacing10)(
CppTypeFor<TypeCategory::Real, 10> x) {
return Spacing<64>(x);
}
-#elif LDBL_MANT_DIG == 113
-CppTypeFor<TypeCategory::Real, 16> RTDEF(Spacing16)(
- CppTypeFor<TypeCategory::Real, 16> x) {
- return Spacing<113>(x);
-}
#endif
CppTypeFor<TypeCategory::Real, 4> RTDEF(FPow4i)(
diff --git a/flang/runtime/reduction-templates.h b/flang/runtime/reduction-templates.h
index 0891bc021ff753..5b793deb2a123d 100644
--- a/flang/runtime/reduction-templates.h
+++ b/flang/runtime/reduction-templates.h
@@ -1,4 +1,4 @@
-//===-- runtime/reduction-templates.h -------------------------------------===//
+//===-- runtime/reduction-templates.h ---------------------------*- C++ -*-===//
//
// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
// See https://llvm.org/LICENSE.txt for license information.
@@ -21,6 +21,7 @@
#ifndef FORTRAN_RUNTIME_REDUCTION_TEMPLATES_H_
#define FORTRAN_RUNTIME_REDUCTION_TEMPLATES_H_
+#include "numeric-templates.h"
#include "terminator.h"
#include "tools.h"
#include "flang/Runtime/cpp-type.h"
@@ -385,7 +386,7 @@ template <int KIND>
using Norm2AccumType =
CppTypeFor<TypeCategory::Real, std::clamp(KIND, 8, Norm2LargestLDKind)>;
-template <int KIND, typename ABS, typename SQRT> class Norm2Accumulator {
+template <int KIND> class Norm2Accumulator {
public:
using Type = CppTypeFor<TypeCategory::Real, KIND>;
using AccumType = Norm2AccumType<KIND>;
@@ -395,10 +396,10 @@ template <int KIND, typename ABS, typename SQRT> class Norm2Accumulator {
template <typename A>
RT_API_ATTRS void GetResult(A *p, int /*zeroBasedDim*/ = -1) const {
// m * sqrt(1 + sum((others(:)/m)**2))
- *p = static_cast<Type>(max_ * SQRT::compute(1 + sum_));
+ *p = static_cast<Type>(max_ * SQRTTy<AccumType>::compute(1 + sum_));
}
RT_API_ATTRS bool Accumulate(Type x) {
- auto absX{ABS::compute(static_cast<AccumType>(x))};
+ auto absX{ABSTy<AccumType>::compute(static_cast<AccumType>(x))};
if (!max_) {
max_ = absX;
} else if (absX > max_) {
@@ -424,27 +425,12 @@ template <int KIND, typename ABS, typename SQRT> class Norm2Accumulator {
AccumType sum_{0}; // sum((others(:)/m)**2)
};
-// Helper class for creating Norm2Accumulator instance
-// based on the given KIND. This helper returns and instance
-// that uses std::abs and std::sqrt for the computations.
-template <int KIND> class Norm2AccumulatorGetter {
- using AccumType = Norm2AccumType<KIND>;
-
-public:
- struct ABSTy {
- static constexpr RT_API_ATTRS AccumType compute(AccumType &&x) {
- return std::abs(std::forward<AccumType>(x));
- }
- };
- struct SQRTTy {
- static constexpr RT_API_ATTRS AccumType compute(AccumType &&x) {
- return std::sqrt(std::forward<AccumType>(x));
- }
- };
-
- using Type = Norm2Accumulator<KIND, ABSTy, SQRTTy>;
-
- static RT_API_ATTRS Type create(const Descriptor &x) { return Type(x); }
+template <int KIND> struct Norm2Helper {
+ RT_API_ATTRS void operator()(Descriptor &result, const Descriptor &x, int dim,
+ const Descriptor *mask, Terminator &terminator) const {
+ DoMaxMinNorm2<TypeCategory::Real, KIND, Norm2Accumulator<KIND>>(
+ result, x, dim, mask, "NORM2", terminator);
+ }
};
} // namespace Fortran::runtime
>From 0869ffa6bd6e9562b35bc93e48207d11261d67df Mon Sep 17 00:00:00 2001
From: SunilKuravinakop <98882378+SunilKuravinakop at users.noreply.github.com>
Date: Thu, 29 Feb 2024 22:41:29 +0530
Subject: [PATCH 155/406] [OpenMP] Clang Codegen Interop : Accept multiple use
& destroy clauses (#83398)
Modified clang/lib/CodeGen/CGStmtOpenMP.cpp to accept multiple use &
destroy clauses with interop directive.
Modified clang/test/OpenMP/interop_codegen.cpp to check for the changes.
Co-authored-by: Sunil Kuravinakop <kuravina at pe28vega.us.cray.com>
---
clang/lib/CodeGen/CGStmtOpenMP.cpp | 34 +++++++++++++++++----------
clang/test/OpenMP/interop_codegen.cpp | 22 ++++++++++++-----
2 files changed, 38 insertions(+), 18 deletions(-)
diff --git a/clang/lib/CodeGen/CGStmtOpenMP.cpp b/clang/lib/CodeGen/CGStmtOpenMP.cpp
index ffcd3ae2711e34..3fbd2e03eb61df 100644
--- a/clang/lib/CodeGen/CGStmtOpenMP.cpp
+++ b/clang/lib/CodeGen/CGStmtOpenMP.cpp
@@ -7042,18 +7042,28 @@ void CodeGenFunction::EmitOMPInteropDirective(const OMPInteropDirective &S) {
Device, NumDependences, DependenceList,
Data.HasNowaitClause);
}
- } else if (const auto *C = S.getSingleClause<OMPDestroyClause>()) {
- llvm::Value *InteropvarPtr =
- EmitLValue(C->getInteropVar()).getPointer(*this);
- OMPBuilder.createOMPInteropDestroy(Builder, InteropvarPtr, Device,
- NumDependences, DependenceList,
- Data.HasNowaitClause);
- } else if (const auto *C = S.getSingleClause<OMPUseClause>()) {
- llvm::Value *InteropvarPtr =
- EmitLValue(C->getInteropVar()).getPointer(*this);
- OMPBuilder.createOMPInteropUse(Builder, InteropvarPtr, Device,
- NumDependences, DependenceList,
- Data.HasNowaitClause);
+ }
+ auto ItOMPDestroyClause = S.getClausesOfKind<OMPDestroyClause>();
+ if (!ItOMPDestroyClause.empty()) {
+ // Look at the multiple destroy clauses
+ for (const OMPDestroyClause *C : ItOMPDestroyClause) {
+ llvm::Value *InteropvarPtr =
+ EmitLValue(C->getInteropVar()).getPointer(*this);
+ OMPBuilder.createOMPInteropDestroy(Builder, InteropvarPtr, Device,
+ NumDependences, DependenceList,
+ Data.HasNowaitClause);
+ }
+ }
+ auto ItOMPUseClause = S.getClausesOfKind<OMPUseClause>();
+ if (!ItOMPUseClause.empty()) {
+ // Look at the multiple use clauses
+ for (const OMPUseClause *C : ItOMPUseClause) {
+ llvm::Value *InteropvarPtr =
+ EmitLValue(C->getInteropVar()).getPointer(*this);
+ OMPBuilder.createOMPInteropUse(Builder, InteropvarPtr, Device,
+ NumDependences, DependenceList,
+ Data.HasNowaitClause);
+ }
}
}
diff --git a/clang/test/OpenMP/interop_codegen.cpp b/clang/test/OpenMP/interop_codegen.cpp
index ea83ef8ed4909f..31df2f1ba58c5f 100644
--- a/clang/test/OpenMP/interop_codegen.cpp
+++ b/clang/test/OpenMP/interop_codegen.cpp
@@ -15,21 +15,31 @@ typedef long omp_intptr_t;
extern omp_intptr_t omp_get_interop_int(const omp_interop_t, int, int *);
int main() {
- omp_interop_t obj = omp_interop_none;
+ omp_interop_t obj1 = omp_interop_none;
+ omp_interop_t obj2 = omp_interop_none;
omp_interop_t i1 = omp_interop_none;
omp_interop_t i2 = omp_interop_none;
omp_interop_t i3 = omp_interop_none;
omp_interop_t i4 = omp_interop_none;
omp_interop_t i5 = omp_interop_none;
- #pragma omp interop init(targetsync: i1) init(targetsync: obj)
- int id = (int )omp_get_interop_int(obj, omp_ipr_fr_id, NULL);
- int id1 = (int )omp_get_interop_int(i1, omp_ipr_fr_id, NULL);
+ #pragma omp interop init(targetsync: obj1) init(targetsync: obj2)
+ int id = (int )omp_get_interop_int(obj1, omp_ipr_fr_id, NULL);
+ int id1 = (int )omp_get_interop_int(obj2, omp_ipr_fr_id, NULL);
+
+ #pragma omp interop init(target,targetsync: i1) use(i2) use(i3) destroy(i4) destroy(i5)
+ int id2 = (int )omp_get_interop_int(i1, omp_ipr_fr_id, NULL);
+ int id3 = (int )omp_get_interop_int(i2, omp_ipr_fr_id, NULL);
}
#endif
-// CHECK-LABEL: define {{.+}}main{{.+}}
+// CHECK-LABEL: define {{.+}}main{{.+}}
+// CHECK: call {{.+}}__tgt_interop_init({{.+}}obj1{{.*}})
+// CHECK: call {{.+}}__tgt_interop_init({{.+}}obj2{{.*}})
// CHECK: call {{.+}}__tgt_interop_init({{.+}}i1{{.*}})
-// CHECK: call {{.+}}__tgt_interop_init({{.+}}obj{{.*}})
+// CHECK: call {{.+}}__tgt_interop_destroy({{.+}}i4{{.*}})
+// CHECK: call {{.+}}__tgt_interop_destroy({{.+}}i5{{.*}})
+// CHECK: call {{.+}}__tgt_interop_use({{.+}}i2{{.*}})
+// CHECK: call {{.+}}__tgt_interop_use({{.+}}i3{{.*}})
>From a6d9b7ba2722953960b83fbacda1757349f00156 Mon Sep 17 00:00:00 2001
From: Jonas Devlieghere <jonas at devlieghere.com>
Date: Thu, 29 Feb 2024 09:11:29 -0800
Subject: [PATCH 156/406] [lldb] Don't cache lldb_find_python_module result
Don't cache lldb_find_python_module result as that requires you to do a
clean build after installing the dependency.
---
lldb/cmake/modules/AddLLDB.cmake | 6 +++---
1 file changed, 3 insertions(+), 3 deletions(-)
diff --git a/lldb/cmake/modules/AddLLDB.cmake b/lldb/cmake/modules/AddLLDB.cmake
index 328e883ddbe5a6..fdc4ee0c05d755 100644
--- a/lldb/cmake/modules/AddLLDB.cmake
+++ b/lldb/cmake/modules/AddLLDB.cmake
@@ -383,7 +383,7 @@ endfunction()
function(lldb_find_python_module module)
set(MODULE_FOUND PY_${module}_FOUND)
- if (DEFINED ${MODULE_FOUND})
+ if (${MODULE_FOUND})
return()
endif()
@@ -392,10 +392,10 @@ function(lldb_find_python_module module)
ERROR_QUIET)
if (status)
- set(${MODULE_FOUND} OFF CACHE BOOL "Failed to find python module '${module}'")
+ set(${MODULE_FOUND} OFF PARENT_SCOPE)
message(STATUS "Could NOT find Python module '${module}'")
else()
- set(${MODULE_FOUND} ON CACHE BOOL "Found python module '${module}'")
+ set(${MODULE_FOUND} ON PARENT_SCOPE)
message(STATUS "Found Python module '${module}'")
endif()
endfunction()
>From 3e0425c76c894c2ed538978140f59bd4a14acabd Mon Sep 17 00:00:00 2001
From: Alexey Bataev <a.bataev at outlook.com>
Date: Thu, 29 Feb 2024 09:06:38 -0800
Subject: [PATCH 157/406] [SLP][NFC]Add a test showing incorrect
transformation, NFC.
---
.../SLPVectorizer/X86/reorder-node.ll | 48 +++++++++++++++++++
1 file changed, 48 insertions(+)
create mode 100644 llvm/test/Transforms/SLPVectorizer/X86/reorder-node.ll
diff --git a/llvm/test/Transforms/SLPVectorizer/X86/reorder-node.ll b/llvm/test/Transforms/SLPVectorizer/X86/reorder-node.ll
new file mode 100644
index 00000000000000..c45e1e8b17bf8c
--- /dev/null
+++ b/llvm/test/Transforms/SLPVectorizer/X86/reorder-node.ll
@@ -0,0 +1,48 @@
+; NOTE: Assertions have been autogenerated by utils/update_test_checks.py UTC_ARGS: --version 4
+; RUN: opt -S --passes=slp-vectorizer -mtriple=x86_64-linux-gnu < %s | FileCheck %s
+
+define void @test(ptr noalias %arg, ptr noalias %arg1, ptr %arg2) {
+; CHECK-LABEL: define void @test(
+; CHECK-SAME: ptr noalias [[ARG:%.*]], ptr noalias [[ARG1:%.*]], ptr [[ARG2:%.*]]) {
+; CHECK-NEXT: bb:
+; CHECK-NEXT: [[TMP_I_I:%.*]] = getelementptr i8, ptr [[ARG1]], i64 24
+; CHECK-NEXT: [[TMP_I_I4:%.*]] = getelementptr i8, ptr [[ARG]], i64 24
+; CHECK-NEXT: [[TMP0:%.*]] = load <4 x float>, ptr [[TMP_I_I]], align 8
+; CHECK-NEXT: [[TMP1:%.*]] = extractelement <4 x float> [[TMP0]], i32 1
+; CHECK-NEXT: store float [[TMP1]], ptr [[ARG2]], align 4
+; CHECK-NEXT: [[TMP2:%.*]] = fcmp olt <4 x float> [[TMP0]], zeroinitializer
+; CHECK-NEXT: [[TMP3:%.*]] = shufflevector <4 x float> [[TMP0]], <4 x float> poison, <4 x i32> <i32 2, i32 3, i32 2, i32 3>
+; CHECK-NEXT: [[TMP4:%.*]] = shufflevector <4 x float> [[TMP0]], <4 x float> poison, <4 x i32> <i32 0, i32 1, i32 0, i32 1>
+; CHECK-NEXT: [[TMP5:%.*]] = select <4 x i1> [[TMP2]], <4 x float> [[TMP3]], <4 x float> [[TMP4]]
+; CHECK-NEXT: [[TMP6:%.*]] = shufflevector <4 x float> [[TMP5]], <4 x float> poison, <4 x i32> <i32 1, i32 2, i32 3, i32 0>
+; CHECK-NEXT: store <4 x float> [[TMP6]], ptr [[TMP_I_I4]], align 8
+; CHECK-NEXT: ret void
+;
+bb:
+ %tmp.i.i = getelementptr i8, ptr %arg1, i64 24
+ %tmp1.i.i = load float, ptr %tmp.i.i, align 8
+ %tmp.i.i2 = getelementptr i8, ptr %arg1, i64 32
+ %tmp1.i.i3 = load float, ptr %tmp.i.i2, align 8
+ %tmp1.i.i.i = fcmp olt float %tmp1.i.i3, 0.000000e+00
+ %tmp9 = select i1 %tmp1.i.i.i, float %tmp1.i.i3, float %tmp1.i.i
+ %tmp.i.i4 = getelementptr i8, ptr %arg, i64 24
+ store float %tmp9, ptr %tmp.i.i4, align 8
+ %tmp1.i.i.i10 = fcmp olt float %tmp1.i.i, 0.000000e+00
+ %tmp13 = select i1 %tmp1.i.i.i10, float %tmp1.i.i3, float %tmp1.i.i
+ %tmp.i.i12 = getelementptr i8, ptr %arg, i64 28
+ store float %tmp13, ptr %tmp.i.i12, align 4
+ %tmp.i.i13 = getelementptr i8, ptr %arg1, i64 28
+ %tmp1.i.i14 = load float, ptr %tmp.i.i13, align 4
+ %tmp.i.i15 = getelementptr i8, ptr %arg1, i64 36
+ %tmp1.i.i16 = load float, ptr %tmp.i.i15, align 4
+ %tmp1.i.i.i18 = fcmp olt float %tmp1.i.i16, 0.000000e+00
+ %tmp17 = select i1 %tmp1.i.i.i18, float %tmp1.i.i16, float %tmp1.i.i14
+ %tmp.i.i20 = getelementptr i8, ptr %arg, i64 32
+ store float %tmp17, ptr %tmp.i.i20, align 8
+ store float %tmp1.i.i14, ptr %arg2, align 4
+ %tmp1.i.i.i24 = fcmp olt float %tmp1.i.i14, 0.000000e+00
+ %tmp20 = select i1 %tmp1.i.i.i24, float %tmp1.i.i16, float %tmp1.i.i14
+ %tmp.i.i26 = getelementptr i8, ptr %arg, i64 36
+ store float %tmp20, ptr %tmp.i.i26, align 4
+ ret void
+}
>From be8f987d8cddd2d1df5ed1afff64fd9a730ec97a Mon Sep 17 00:00:00 2001
From: Jason Eckhardt <jeckhardt at nvidia.com>
Date: Thu, 29 Feb 2024 11:57:06 -0600
Subject: [PATCH 158/406] [TableGen] Use consistent field kind checking in
getNumericKey. (#83284)
Fields GenericField::IsInstruction and GenericField::Enum can be
simultaneously active for a given field. Methods compareBy and
primaryRepresentation both order the checking of IsInstruction before
GenericField::Enum. Do the same in getNumericKey for consistency.
---
llvm/utils/TableGen/SearchableTableEmitter.cpp | 9 ++++++---
1 file changed, 6 insertions(+), 3 deletions(-)
diff --git a/llvm/utils/TableGen/SearchableTableEmitter.cpp b/llvm/utils/TableGen/SearchableTableEmitter.cpp
index 5bab4ff188e8ed..51f18f360ed311 100644
--- a/llvm/utils/TableGen/SearchableTableEmitter.cpp
+++ b/llvm/utils/TableGen/SearchableTableEmitter.cpp
@@ -215,12 +215,15 @@ int64_t SearchableTableEmitter::getNumericKey(const SearchIndex &Index,
Record *Rec) {
assert(Index.Fields.size() == 1);
+ // To be consistent with compareBy and primaryRepresentation elsewhere,
+ // we check for IsInstruction before Enum-- these fields are not exclusive.
+ if (Index.Fields[0].IsInstruction) {
+ Record *TheDef = Rec->getValueAsDef(Index.Fields[0].Name);
+ return Target->getInstrIntValue(TheDef);
+ }
if (Index.Fields[0].Enum) {
Record *EnumEntry = Rec->getValueAsDef(Index.Fields[0].Name);
return Index.Fields[0].Enum->EntryMap[EnumEntry]->second;
- } else if (Index.Fields[0].IsInstruction) {
- Record *TheDef = Rec->getValueAsDef(Index.Fields[0].Name);
- return Target->getInstrIntValue(TheDef);
}
return getInt(Rec, Index.Fields[0].Name);
>From 856ce495e52b8ea8855d7f34d84346c82b1fddc2 Mon Sep 17 00:00:00 2001
From: Kalesh Singh <kaleshsingh96 at gmail.com>
Date: Thu, 29 Feb 2024 10:06:25 -0800
Subject: [PATCH 159/406] ANDROID: AArch64: Change default max-page-size from
4k to 16k (#70251)
File size increase were found negligible from sparseness and zero
block compression in f2fs and ext4 (supported filesystems for
Android's userdata partition).
Signed-off-by: Kalesh Singh <kaleshsingh at google.com>
Co-authored-by: Kalesh Singh <kaleshsingh at google.com>
---
clang/lib/Driver/ToolChains/Linux.cpp | 17 ++++++++++++-----
clang/test/Driver/android-link.cpp | 3 ++-
2 files changed, 14 insertions(+), 6 deletions(-)
diff --git a/clang/lib/Driver/ToolChains/Linux.cpp b/clang/lib/Driver/ToolChains/Linux.cpp
index 4300a2bdff1791..dc09b13351f46f 100644
--- a/clang/lib/Driver/ToolChains/Linux.cpp
+++ b/clang/lib/Driver/ToolChains/Linux.cpp
@@ -237,11 +237,18 @@ Linux::Linux(const Driver &D, const llvm::Triple &Triple, const ArgList &Args)
ExtraOpts.push_back("relro");
}
- // Android ARM/AArch64 use max-page-size=4096 to reduce VMA usage. Note, lld
- // from 11 onwards default max-page-size to 65536 for both ARM and AArch64.
- if ((Triple.isARM() || Triple.isAArch64()) && Triple.isAndroid()) {
- ExtraOpts.push_back("-z");
- ExtraOpts.push_back("max-page-size=4096");
+ // Note, lld from 11 onwards default max-page-size to 65536 for both ARM and
+ // AArch64.
+ if (Triple.isAndroid()) {
+ if (Triple.isARM()) {
+ // Android ARM uses max-page-size=4096 to reduce VMA usage.
+ ExtraOpts.push_back("-z");
+ ExtraOpts.push_back("max-page-size=4096");
+ } else if (Triple.isAArch64()) {
+ // Android AArch64 uses max-page-size=16384 to support 4k/16k page sizes.
+ ExtraOpts.push_back("-z");
+ ExtraOpts.push_back("max-page-size=16384");
+ }
}
if (GCCInstallation.getParentLibPath().contains("opt/rh/"))
diff --git a/clang/test/Driver/android-link.cpp b/clang/test/Driver/android-link.cpp
index fa9cbc5d0c7a55..f9bdd00507d7bc 100644
--- a/clang/test/Driver/android-link.cpp
+++ b/clang/test/Driver/android-link.cpp
@@ -17,9 +17,10 @@
//
// RUN: %clang -target aarch64-none-linux-android \
// RUN: -### -v %s 2> %t
-// RUN: FileCheck -check-prefix=MAX-PAGE-SIZE < %t %s
+// RUN: FileCheck -check-prefix=MAX-PAGE-SIZE-AARCH64 < %t %s
//
// GENERIC-ARM: --fix-cortex-a53-843419
// CORTEX-A53: --fix-cortex-a53-843419
// CORTEX-A57-NOT: --fix-cortex-a53-843419
// MAX-PAGE-SIZE: "-z" "max-page-size=4096"
+// MAX-PAGE-SIZE-AARCH64: "-z" "max-page-size=16384"
>From 489eadd142e858dc28e375320da774eba53d21bb Mon Sep 17 00:00:00 2001
From: Farzon Lotfi <1802579+farzonl at users.noreply.github.com>
Date: Thu, 29 Feb 2024 13:40:38 -0500
Subject: [PATCH 160/406] [HLSL] Implementation of the frac intrinsic (#83315)
This change implements the frontend for #70099
Builtins.td - add the frac builtin
CGBuiltin.cpp - add the builtin to DirectX intrinsic mapping
hlsl_intrinsics.h - add the frac api
SemaChecking.cpp - add type checks for builtin
IntrinsicsDirectX.td - add the frac intrinsic
The backend changes for this are going to be very simple:
https://github.com/llvm/llvm-project/commit/f309a0eb558b65dfaff0d1d23b7d07fb07e27121
They were not included because llvm/lib/Target/DirectX/DXIL.td is going
through a major refactor.
---
clang/include/clang/Basic/Builtins.td | 6 +
.../clang/Basic/DiagnosticSemaKinds.td | 2 +-
clang/lib/CodeGen/CGBuiltin.cpp | 23 ++-
clang/lib/Headers/hlsl/hlsl_intrinsics.h | 32 ++++
clang/lib/Sema/SemaChecking.cpp | 26 +++
clang/test/CodeGenHLSL/builtins/dot.hlsl | 160 +++++-------------
clang/test/CodeGenHLSL/builtins/frac.hlsl | 53 ++++++
clang/test/CodeGenHLSL/builtins/lerp.hlsl | 52 ++----
clang/test/SemaHLSL/BuiltIns/dot-errors.hlsl | 85 +++++-----
clang/test/SemaHLSL/BuiltIns/frac-errors.hlsl | 27 +++
clang/test/SemaHLSL/BuiltIns/lerp-errors.hlsl | 79 +++++----
.../test/SemaHLSL/OverloadResolutionBugs.hlsl | 64 ++++---
llvm/include/llvm/IR/IntrinsicsDirectX.td | 8 +-
13 files changed, 337 insertions(+), 280 deletions(-)
create mode 100644 clang/test/CodeGenHLSL/builtins/frac.hlsl
create mode 100644 clang/test/SemaHLSL/BuiltIns/frac-errors.hlsl
diff --git a/clang/include/clang/Basic/Builtins.td b/clang/include/clang/Basic/Builtins.td
index 36151b49d9363d..2c83dca248fb7d 100644
--- a/clang/include/clang/Basic/Builtins.td
+++ b/clang/include/clang/Basic/Builtins.td
@@ -4536,6 +4536,12 @@ def HLSLDotProduct : LangBuiltin<"HLSL_LANG"> {
let Prototype = "void(...)";
}
+def HLSLFrac : LangBuiltin<"HLSL_LANG"> {
+ let Spellings = ["__builtin_hlsl_elementwise_frac"];
+ let Attributes = [NoThrow, Const];
+ let Prototype = "void(...)";
+}
+
def HLSLLerp : LangBuiltin<"HLSL_LANG"> {
let Spellings = ["__builtin_hlsl_lerp"];
let Attributes = [NoThrow, Const];
diff --git a/clang/include/clang/Basic/DiagnosticSemaKinds.td b/clang/include/clang/Basic/DiagnosticSemaKinds.td
index 4ef3ac8c96cd26..4f8902e37bd3bb 100644
--- a/clang/include/clang/Basic/DiagnosticSemaKinds.td
+++ b/clang/include/clang/Basic/DiagnosticSemaKinds.td
@@ -10270,7 +10270,7 @@ def err_vec_builtin_non_vector_all : Error<
"all arguments to %0 must be vectors">;
def err_vec_builtin_incompatible_vector_all : Error<
"all arguments to %0 must have vectors of the same type">;
-
+
def err_vec_builtin_non_vector : Error<
"first two arguments to %0 must be vectors">;
def err_vec_builtin_incompatible_vector : Error<
diff --git a/clang/lib/CodeGen/CGBuiltin.cpp b/clang/lib/CodeGen/CGBuiltin.cpp
index 74ca96117793c4..98684448f4ff5c 100644
--- a/clang/lib/CodeGen/CGBuiltin.cpp
+++ b/clang/lib/CodeGen/CGBuiltin.cpp
@@ -18020,14 +18020,7 @@ Value *CodeGenFunction::EmitHLSLBuiltinExpr(unsigned BuiltinID,
V = Builder.CreateFMul(S, V);
return Builder.CreateFAdd(X, V, "dx.lerp");
}
- // DXC does this via casting to float should we do the same thing?
- if (Xty->isIntegerTy()) {
- auto V = Builder.CreateSub(Y, X);
- V = Builder.CreateMul(S, V);
- return Builder.CreateAdd(X, V, "dx.lerp");
- }
- // Bools should have been promoted
- llvm_unreachable("Scalar Lerp is only supported on ints and floats.");
+ llvm_unreachable("Scalar Lerp is only supported on floats.");
}
// A VectorSplat should have happened
assert(Xty->isVectorTy() && Yty->isVectorTy() && Sty->isVectorTy() &&
@@ -18041,12 +18034,24 @@ Value *CodeGenFunction::EmitHLSLBuiltinExpr(unsigned BuiltinID,
E->getArg(2)->getType()->getAs<VectorType>();
// A HLSLVectorTruncation should have happend
assert(XVecTy->getNumElements() == YVecTy->getNumElements() &&
- SVecTy->getNumElements() &&
+ XVecTy->getNumElements() == SVecTy->getNumElements() &&
"Lerp requires vectors to be of the same size.");
+ assert(XVecTy->getElementType()->isRealFloatingType() &&
+ XVecTy->getElementType() == YVecTy->getElementType() &&
+ XVecTy->getElementType() == SVecTy->getElementType() &&
+ "Lerp requires float vectors to be of the same type.");
return Builder.CreateIntrinsic(
/*ReturnType*/ Xty, Intrinsic::dx_lerp, ArrayRef<Value *>{X, Y, S},
nullptr, "dx.lerp");
}
+ case Builtin::BI__builtin_hlsl_elementwise_frac: {
+ Value *Op0 = EmitScalarExpr(E->getArg(0));
+ if (!E->getArg(0)->getType()->hasFloatingRepresentation())
+ llvm_unreachable("frac operand must have a float representation");
+ return Builder.CreateIntrinsic(
+ /*ReturnType*/ Op0->getType(), Intrinsic::dx_frac,
+ ArrayRef<Value *>{Op0}, nullptr, "dx.frac");
+ }
}
return nullptr;
}
diff --git a/clang/lib/Headers/hlsl/hlsl_intrinsics.h b/clang/lib/Headers/hlsl/hlsl_intrinsics.h
index 1314bdefa37e7b..0aa8651ba80dc4 100644
--- a/clang/lib/Headers/hlsl/hlsl_intrinsics.h
+++ b/clang/lib/Headers/hlsl/hlsl_intrinsics.h
@@ -317,6 +317,38 @@ double3 floor(double3);
_HLSL_BUILTIN_ALIAS(__builtin_elementwise_floor)
double4 floor(double4);
+//===----------------------------------------------------------------------===//
+// frac builtins
+//===----------------------------------------------------------------------===//
+
+/// \fn T frac(T x)
+/// \brief Returns the fractional (or decimal) part of x. \a x parameter.
+/// \param x The specified input value.
+///
+/// If \a the return value is greater than or equal to 0 and less than 1.
+
+_HLSL_16BIT_AVAILABILITY(shadermodel, 6.2)
+_HLSL_BUILTIN_ALIAS(__builtin_hlsl_elementwise_frac)
+half frac(half);
+_HLSL_16BIT_AVAILABILITY(shadermodel, 6.2)
+_HLSL_BUILTIN_ALIAS(__builtin_hlsl_elementwise_frac)
+half2 frac(half2);
+_HLSL_16BIT_AVAILABILITY(shadermodel, 6.2)
+_HLSL_BUILTIN_ALIAS(__builtin_hlsl_elementwise_frac)
+half3 frac(half3);
+_HLSL_16BIT_AVAILABILITY(shadermodel, 6.2)
+_HLSL_BUILTIN_ALIAS(__builtin_hlsl_elementwise_frac)
+half4 frac(half4);
+
+_HLSL_BUILTIN_ALIAS(__builtin_hlsl_elementwise_frac)
+float frac(float);
+_HLSL_BUILTIN_ALIAS(__builtin_hlsl_elementwise_frac)
+float2 frac(float2);
+_HLSL_BUILTIN_ALIAS(__builtin_hlsl_elementwise_frac)
+float3 frac(float3);
+_HLSL_BUILTIN_ALIAS(__builtin_hlsl_elementwise_frac)
+float4 frac(float4);
+
//===----------------------------------------------------------------------===//
// lerp builtins
//===----------------------------------------------------------------------===//
diff --git a/clang/lib/Sema/SemaChecking.cpp b/clang/lib/Sema/SemaChecking.cpp
index 016e9830662042..690bdaa63d058b 100644
--- a/clang/lib/Sema/SemaChecking.cpp
+++ b/clang/lib/Sema/SemaChecking.cpp
@@ -5246,6 +5246,23 @@ bool CheckVectorElementCallArgs(Sema *S, CallExpr *TheCall) {
return true;
}
+bool CheckAllArgsHaveFloatRepresentation(Sema *S, CallExpr *TheCall) {
+ QualType ExpectedType = S->Context.FloatTy;
+ for (unsigned i = 0; i < TheCall->getNumArgs(); ++i) {
+ QualType PassedType = TheCall->getArg(i)->getType();
+ if (!PassedType->hasFloatingRepresentation()) {
+ if (auto *VecTyA = PassedType->getAs<VectorType>())
+ ExpectedType = S->Context.getVectorType(
+ ExpectedType, VecTyA->getNumElements(), VecTyA->getVectorKind());
+ S->Diag(TheCall->getArg(0)->getBeginLoc(),
+ diag::err_typecheck_convert_incompatible)
+ << PassedType << ExpectedType << 1 << 0 << 0;
+ return true;
+ }
+ }
+ return false;
+}
+
// Note: returning true in this case results in CheckBuiltinFunctionCall
// returning an ExprError
bool Sema::CheckHLSLBuiltinFunctionCall(unsigned BuiltinID, CallExpr *TheCall) {
@@ -5259,6 +5276,13 @@ bool Sema::CheckHLSLBuiltinFunctionCall(unsigned BuiltinID, CallExpr *TheCall) {
return true;
break;
}
+ case Builtin::BI__builtin_hlsl_elementwise_frac: {
+ if (PrepareBuiltinElementwiseMathOneArgCall(TheCall))
+ return true;
+ if (CheckAllArgsHaveFloatRepresentation(this, TheCall))
+ return true;
+ break;
+ }
case Builtin::BI__builtin_hlsl_lerp: {
if (checkArgCount(*this, TheCall, 3))
return true;
@@ -5266,6 +5290,8 @@ bool Sema::CheckHLSLBuiltinFunctionCall(unsigned BuiltinID, CallExpr *TheCall) {
return true;
if (SemaBuiltinElementwiseTernaryMath(TheCall))
return true;
+ if (CheckAllArgsHaveFloatRepresentation(this, TheCall))
+ return true;
break;
}
}
diff --git a/clang/test/CodeGenHLSL/builtins/dot.hlsl b/clang/test/CodeGenHLSL/builtins/dot.hlsl
index b2c1bae31d13b1..c064d118caf3e7 100644
--- a/clang/test/CodeGenHLSL/builtins/dot.hlsl
+++ b/clang/test/CodeGenHLSL/builtins/dot.hlsl
@@ -9,230 +9,160 @@
#ifdef __HLSL_ENABLE_16_BIT
// NATIVE_HALF: %dx.dot = mul i16 %0, %1
// NATIVE_HALF: ret i16 %dx.dot
-int16_t test_dot_short ( int16_t p0, int16_t p1 ) {
- return dot ( p0, p1 );
-}
+int16_t test_dot_short(int16_t p0, int16_t p1) { return dot(p0, p1); }
// NATIVE_HALF: %dx.dot = call i16 @llvm.dx.dot.v2i16(<2 x i16> %0, <2 x i16> %1)
// NATIVE_HALF: ret i16 %dx.dot
-int16_t test_dot_short2 ( int16_t2 p0, int16_t2 p1 ) {
- return dot ( p0, p1 );
-}
+int16_t test_dot_short2(int16_t2 p0, int16_t2 p1) { return dot(p0, p1); }
// NATIVE_HALF: %dx.dot = call i16 @llvm.dx.dot.v3i16(<3 x i16> %0, <3 x i16> %1)
// NATIVE_HALF: ret i16 %dx.dot
-int16_t test_dot_short3 ( int16_t3 p0, int16_t3 p1 ) {
- return dot ( p0, p1 );
-}
+int16_t test_dot_short3(int16_t3 p0, int16_t3 p1) { return dot(p0, p1); }
// NATIVE_HALF: %dx.dot = call i16 @llvm.dx.dot.v4i16(<4 x i16> %0, <4 x i16> %1)
// NATIVE_HALF: ret i16 %dx.dot
-int16_t test_dot_short4 ( int16_t4 p0, int16_t4 p1 ) {
- return dot ( p0, p1 );
-}
+int16_t test_dot_short4(int16_t4 p0, int16_t4 p1) { return dot(p0, p1); }
// NATIVE_HALF: %dx.dot = mul i16 %0, %1
// NATIVE_HALF: ret i16 %dx.dot
-uint16_t test_dot_ushort ( uint16_t p0, uint16_t p1 ) {
- return dot ( p0, p1 );
-}
+uint16_t test_dot_ushort(uint16_t p0, uint16_t p1) { return dot(p0, p1); }
// NATIVE_HALF: %dx.dot = call i16 @llvm.dx.dot.v2i16(<2 x i16> %0, <2 x i16> %1)
// NATIVE_HALF: ret i16 %dx.dot
-uint16_t test_dot_ushort2 ( uint16_t2 p0, uint16_t2 p1 ) {
- return dot ( p0, p1 );
-}
+uint16_t test_dot_ushort2(uint16_t2 p0, uint16_t2 p1) { return dot(p0, p1); }
// NATIVE_HALF: %dx.dot = call i16 @llvm.dx.dot.v3i16(<3 x i16> %0, <3 x i16> %1)
// NATIVE_HALF: ret i16 %dx.dot
-uint16_t test_dot_ushort3 ( uint16_t3 p0, uint16_t3 p1 ) {
- return dot ( p0, p1 );
-}
+uint16_t test_dot_ushort3(uint16_t3 p0, uint16_t3 p1) { return dot(p0, p1); }
// NATIVE_HALF: %dx.dot = call i16 @llvm.dx.dot.v4i16(<4 x i16> %0, <4 x i16> %1)
// NATIVE_HALF: ret i16 %dx.dot
-uint16_t test_dot_ushort4 ( uint16_t4 p0, uint16_t4 p1 ) {
- return dot ( p0, p1 );
-}
+uint16_t test_dot_ushort4(uint16_t4 p0, uint16_t4 p1) { return dot(p0, p1); }
#endif
// CHECK: %dx.dot = mul i32 %0, %1
// CHECK: ret i32 %dx.dot
-int test_dot_int ( int p0, int p1 ) {
- return dot ( p0, p1 );
-}
+int test_dot_int(int p0, int p1) { return dot(p0, p1); }
// CHECK: %dx.dot = call i32 @llvm.dx.dot.v2i32(<2 x i32> %0, <2 x i32> %1)
// CHECK: ret i32 %dx.dot
-int test_dot_int2 ( int2 p0, int2 p1 ) {
- return dot ( p0, p1 );
-}
+int test_dot_int2(int2 p0, int2 p1) { return dot(p0, p1); }
// CHECK: %dx.dot = call i32 @llvm.dx.dot.v3i32(<3 x i32> %0, <3 x i32> %1)
// CHECK: ret i32 %dx.dot
-int test_dot_int3 ( int3 p0, int3 p1 ) {
- return dot ( p0, p1 );
-}
+int test_dot_int3(int3 p0, int3 p1) { return dot(p0, p1); }
// CHECK: %dx.dot = call i32 @llvm.dx.dot.v4i32(<4 x i32> %0, <4 x i32> %1)
// CHECK: ret i32 %dx.dot
-int test_dot_int4 ( int4 p0, int4 p1 ) {
- return dot ( p0, p1 );
-}
+int test_dot_int4(int4 p0, int4 p1) { return dot(p0, p1); }
// CHECK: %dx.dot = mul i32 %0, %1
// CHECK: ret i32 %dx.dot
-uint test_dot_uint ( uint p0, uint p1 ) {
- return dot ( p0, p1 );
-}
+uint test_dot_uint(uint p0, uint p1) { return dot(p0, p1); }
// CHECK: %dx.dot = call i32 @llvm.dx.dot.v2i32(<2 x i32> %0, <2 x i32> %1)
// CHECK: ret i32 %dx.dot
-uint test_dot_uint2 ( uint2 p0, uint2 p1 ) {
- return dot ( p0, p1 );
-}
+uint test_dot_uint2(uint2 p0, uint2 p1) { return dot(p0, p1); }
// CHECK: %dx.dot = call i32 @llvm.dx.dot.v3i32(<3 x i32> %0, <3 x i32> %1)
// CHECK: ret i32 %dx.dot
-uint test_dot_uint3 ( uint3 p0, uint3 p1 ) {
- return dot ( p0, p1 );
-}
+uint test_dot_uint3(uint3 p0, uint3 p1) { return dot(p0, p1); }
// CHECK: %dx.dot = call i32 @llvm.dx.dot.v4i32(<4 x i32> %0, <4 x i32> %1)
// CHECK: ret i32 %dx.dot
-uint test_dot_uint4 ( uint4 p0, uint4 p1 ) {
- return dot ( p0, p1 );
-}
+uint test_dot_uint4(uint4 p0, uint4 p1) { return dot(p0, p1); }
// CHECK: %dx.dot = mul i64 %0, %1
// CHECK: ret i64 %dx.dot
-int64_t test_dot_long ( int64_t p0, int64_t p1 ) {
- return dot ( p0, p1 );
-}
+int64_t test_dot_long(int64_t p0, int64_t p1) { return dot(p0, p1); }
// CHECK: %dx.dot = call i64 @llvm.dx.dot.v2i64(<2 x i64> %0, <2 x i64> %1)
// CHECK: ret i64 %dx.dot
-int64_t test_dot_long2 ( int64_t2 p0, int64_t2 p1 ) {
- return dot ( p0, p1 );
-}
+int64_t test_dot_long2(int64_t2 p0, int64_t2 p1) { return dot(p0, p1); }
// CHECK: %dx.dot = call i64 @llvm.dx.dot.v3i64(<3 x i64> %0, <3 x i64> %1)
// CHECK: ret i64 %dx.dot
-int64_t test_dot_long3 ( int64_t3 p0, int64_t3 p1 ) {
- return dot ( p0, p1 );
-}
+int64_t test_dot_long3(int64_t3 p0, int64_t3 p1) { return dot(p0, p1); }
// CHECK: %dx.dot = call i64 @llvm.dx.dot.v4i64(<4 x i64> %0, <4 x i64> %1)
// CHECK: ret i64 %dx.dot
-int64_t test_dot_long4 ( int64_t4 p0, int64_t4 p1 ) {
- return dot ( p0, p1 );
-}
+int64_t test_dot_long4(int64_t4 p0, int64_t4 p1) { return dot(p0, p1); }
// CHECK: %dx.dot = mul i64 %0, %1
// CHECK: ret i64 %dx.dot
-uint64_t test_dot_ulong ( uint64_t p0, uint64_t p1 ) {
- return dot ( p0, p1 );
-}
+uint64_t test_dot_ulong(uint64_t p0, uint64_t p1) { return dot(p0, p1); }
// CHECK: %dx.dot = call i64 @llvm.dx.dot.v2i64(<2 x i64> %0, <2 x i64> %1)
// CHECK: ret i64 %dx.dot
-uint64_t test_dot_ulong2 ( uint64_t2 p0, uint64_t2 p1 ) {
- return dot ( p0, p1 );
-}
+uint64_t test_dot_ulong2(uint64_t2 p0, uint64_t2 p1) { return dot(p0, p1); }
// CHECK: %dx.dot = call i64 @llvm.dx.dot.v3i64(<3 x i64> %0, <3 x i64> %1)
// CHECK: ret i64 %dx.dot
-uint64_t test_dot_ulong3 ( uint64_t3 p0, uint64_t3 p1 ) {
- return dot ( p0, p1 );
-}
+uint64_t test_dot_ulong3(uint64_t3 p0, uint64_t3 p1) { return dot(p0, p1); }
// CHECK: %dx.dot = call i64 @llvm.dx.dot.v4i64(<4 x i64> %0, <4 x i64> %1)
// CHECK: ret i64 %dx.dot
-uint64_t test_dot_ulong4 ( uint64_t4 p0, uint64_t4 p1 ) {
- return dot ( p0, p1 );
-}
+uint64_t test_dot_ulong4(uint64_t4 p0, uint64_t4 p1) { return dot(p0, p1); }
// NATIVE_HALF: %dx.dot = fmul half %0, %1
// NATIVE_HALF: ret half %dx.dot
// NO_HALF: %dx.dot = fmul float %0, %1
// NO_HALF: ret float %dx.dot
-half test_dot_half ( half p0, half p1 ) {
- return dot ( p0, p1 );
-}
+half test_dot_half(half p0, half p1) { return dot(p0, p1); }
// NATIVE_HALF: %dx.dot = call half @llvm.dx.dot.v2f16(<2 x half> %0, <2 x half> %1)
// NATIVE_HALF: ret half %dx.dot
// NO_HALF: %dx.dot = call float @llvm.dx.dot.v2f32(<2 x float> %0, <2 x float> %1)
// NO_HALF: ret float %dx.dot
-half test_dot_half2 ( half2 p0, half2 p1 ) {
- return dot ( p0, p1 );
-}
+half test_dot_half2(half2 p0, half2 p1) { return dot(p0, p1); }
// NATIVE_HALF: %dx.dot = call half @llvm.dx.dot.v3f16(<3 x half> %0, <3 x half> %1)
// NATIVE_HALF: ret half %dx.dot
// NO_HALF: %dx.dot = call float @llvm.dx.dot.v3f32(<3 x float> %0, <3 x float> %1)
// NO_HALF: ret float %dx.dot
-half test_dot_half3 ( half3 p0, half3 p1 ) {
- return dot ( p0, p1 );
-}
+half test_dot_half3(half3 p0, half3 p1) { return dot(p0, p1); }
// NATIVE_HALF: %dx.dot = call half @llvm.dx.dot.v4f16(<4 x half> %0, <4 x half> %1)
// NATIVE_HALF: ret half %dx.dot
// NO_HALF: %dx.dot = call float @llvm.dx.dot.v4f32(<4 x float> %0, <4 x float> %1)
// NO_HALF: ret float %dx.dot
-half test_dot_half4 ( half4 p0, half4 p1 ) {
- return dot ( p0, p1 );
-}
+half test_dot_half4(half4 p0, half4 p1) { return dot(p0, p1); }
// CHECK: %dx.dot = fmul float %0, %1
// CHECK: ret float %dx.dot
-float test_dot_float ( float p0, float p1 ) {
- return dot ( p0, p1 );
-}
+float test_dot_float(float p0, float p1) { return dot(p0, p1); }
// CHECK: %dx.dot = call float @llvm.dx.dot.v2f32(<2 x float> %0, <2 x float> %1)
// CHECK: ret float %dx.dot
-float test_dot_float2 ( float2 p0, float2 p1 ) {
- return dot ( p0, p1 );
-}
+float test_dot_float2(float2 p0, float2 p1) { return dot(p0, p1); }
// CHECK: %dx.dot = call float @llvm.dx.dot.v3f32(<3 x float> %0, <3 x float> %1)
// CHECK: ret float %dx.dot
-float test_dot_float3 ( float3 p0, float3 p1 ) {
- return dot ( p0, p1 );
-}
+float test_dot_float3(float3 p0, float3 p1) { return dot(p0, p1); }
// CHECK: %dx.dot = call float @llvm.dx.dot.v4f32(<4 x float> %0, <4 x float> %1)
// CHECK: ret float %dx.dot
-float test_dot_float4 ( float4 p0, float4 p1) {
- return dot ( p0, p1 );
-}
+float test_dot_float4(float4 p0, float4 p1) { return dot(p0, p1); }
// CHECK: %dx.dot = call float @llvm.dx.dot.v2f32(<2 x float> %splat.splat, <2 x float> %1)
// CHECK: ret float %dx.dot
-float test_dot_float2_splat ( float p0, float2 p1 ) {
- return dot( p0, p1 );
-}
+float test_dot_float2_splat(float p0, float2 p1) { return dot(p0, p1); }
// CHECK: %dx.dot = call float @llvm.dx.dot.v3f32(<3 x float> %splat.splat, <3 x float> %1)
// CHECK: ret float %dx.dot
-float test_dot_float3_splat ( float p0, float3 p1 ) {
- return dot( p0, p1 );
-}
+float test_dot_float3_splat(float p0, float3 p1) { return dot(p0, p1); }
// CHECK: %dx.dot = call float @llvm.dx.dot.v4f32(<4 x float> %splat.splat, <4 x float> %1)
// CHECK: ret float %dx.dot
-float test_dot_float4_splat ( float p0, float4 p1 ) {
- return dot( p0, p1 );
-}
+float test_dot_float4_splat(float p0, float4 p1) { return dot(p0, p1); }
// CHECK: %conv = sitofp i32 %1 to float
// CHECK: %splat.splatinsert = insertelement <2 x float> poison, float %conv, i64 0
// CHECK: %splat.splat = shufflevector <2 x float> %splat.splatinsert, <2 x float> poison, <2 x i32> zeroinitializer
// CHECK: %dx.dot = call float @llvm.dx.dot.v2f32(<2 x float> %0, <2 x float> %splat.splat)
// CHECK: ret float %dx.dot
-float test_builtin_dot_float2_int_splat ( float2 p0, int p1 ) {
- return dot ( p0, p1 );
+float test_builtin_dot_float2_int_splat(float2 p0, int p1) {
+ return dot(p0, p1);
}
// CHECK: %conv = sitofp i32 %1 to float
@@ -240,26 +170,24 @@ float test_builtin_dot_float2_int_splat ( float2 p0, int p1 ) {
// CHECK: %splat.splat = shufflevector <3 x float> %splat.splatinsert, <3 x float> poison, <3 x i32> zeroinitializer
// CHECK: %dx.dot = call float @llvm.dx.dot.v3f32(<3 x float> %0, <3 x float> %splat.splat)
// CHECK: ret float %dx.dot
-float test_builtin_dot_float3_int_splat ( float3 p0, int p1 ) {
- return dot ( p0, p1 );
+float test_builtin_dot_float3_int_splat(float3 p0, int p1) {
+ return dot(p0, p1);
}
// CHECK: %dx.dot = fmul double %0, %1
// CHECK: ret double %dx.dot
-double test_dot_double ( double p0, double p1 ) {
- return dot ( p0, p1 );
-}
+double test_dot_double(double p0, double p1) { return dot(p0, p1); }
// CHECK: %conv = zext i1 %tobool to i32
// CHECK: %dx.dot = mul i32 %conv, %1
// CHECK: ret i32 %dx.dot
-int test_dot_bool_scalar_arg0_type_promotion ( bool p0, int p1 ) {
- return dot ( p0, p1 );
+int test_dot_bool_scalar_arg0_type_promotion(bool p0, int p1) {
+ return dot(p0, p1);
}
// CHECK: %conv = zext i1 %tobool to i32
// CHECK: %dx.dot = mul i32 %0, %conv
// CHECK: ret i32 %dx.dot
-int test_dot_bool_scalar_arg1_type_promotion ( int p0, bool p1 ) {
- return dot ( p0, p1 );
+int test_dot_bool_scalar_arg1_type_promotion(int p0, bool p1) {
+ return dot(p0, p1);
}
diff --git a/clang/test/CodeGenHLSL/builtins/frac.hlsl b/clang/test/CodeGenHLSL/builtins/frac.hlsl
new file mode 100644
index 00000000000000..7c4d1468e96d27
--- /dev/null
+++ b/clang/test/CodeGenHLSL/builtins/frac.hlsl
@@ -0,0 +1,53 @@
+// RUN: %clang_cc1 -finclude-default-header -x hlsl -triple \
+// RUN: dxil-pc-shadermodel6.3-library %s -fnative-half-type \
+// RUN: -emit-llvm -disable-llvm-passes -o - | FileCheck %s \
+// RUN: --check-prefixes=CHECK,NATIVE_HALF
+// RUN: %clang_cc1 -finclude-default-header -x hlsl -triple \
+// RUN: dxil-pc-shadermodel6.3-library %s -emit-llvm -disable-llvm-passes \
+// RUN: -o - | FileCheck %s --check-prefixes=CHECK,NO_HALF
+
+// NATIVE_HALF: define noundef half @
+// NATIVE_HALF: %dx.frac = call half @llvm.dx.frac.f16(
+// NATIVE_HALF: ret half %dx.frac
+// NO_HALF: define noundef float @"?test_frac_half@@YA$halff@$halff@@Z"(
+// NO_HALF: %dx.frac = call float @llvm.dx.frac.f32(
+// NO_HALF: ret float %dx.frac
+half test_frac_half(half p0) { return frac(p0); }
+// NATIVE_HALF: define noundef <2 x half> @
+// NATIVE_HALF: %dx.frac = call <2 x half> @llvm.dx.frac.v2f16
+// NATIVE_HALF: ret <2 x half> %dx.frac
+// NO_HALF: define noundef <2 x float> @
+// NO_HALF: %dx.frac = call <2 x float> @llvm.dx.frac.v2f32(
+// NO_HALF: ret <2 x float> %dx.frac
+half2 test_frac_half2(half2 p0) { return frac(p0); }
+// NATIVE_HALF: define noundef <3 x half> @
+// NATIVE_HALF: %dx.frac = call <3 x half> @llvm.dx.frac.v3f16
+// NATIVE_HALF: ret <3 x half> %dx.frac
+// NO_HALF: define noundef <3 x float> @
+// NO_HALF: %dx.frac = call <3 x float> @llvm.dx.frac.v3f32(
+// NO_HALF: ret <3 x float> %dx.frac
+half3 test_frac_half3(half3 p0) { return frac(p0); }
+// NATIVE_HALF: define noundef <4 x half> @
+// NATIVE_HALF: %dx.frac = call <4 x half> @llvm.dx.frac.v4f16
+// NATIVE_HALF: ret <4 x half> %dx.frac
+// NO_HALF: define noundef <4 x float> @
+// NO_HALF: %dx.frac = call <4 x float> @llvm.dx.frac.v4f32(
+// NO_HALF: ret <4 x float> %dx.frac
+half4 test_frac_half4(half4 p0) { return frac(p0); }
+
+// CHECK: define noundef float @
+// CHECK: %dx.frac = call float @llvm.dx.frac.f32(
+// CHECK: ret float %dx.frac
+float test_frac_float(float p0) { return frac(p0); }
+// CHECK: define noundef <2 x float> @
+// CHECK: %dx.frac = call <2 x float> @llvm.dx.frac.v2f32
+// CHECK: ret <2 x float> %dx.frac
+float2 test_frac_float2(float2 p0) { return frac(p0); }
+// CHECK: define noundef <3 x float> @
+// CHECK: %dx.frac = call <3 x float> @llvm.dx.frac.v3f32
+// CHECK: ret <3 x float> %dx.frac
+float3 test_frac_float3(float3 p0) { return frac(p0); }
+// CHECK: define noundef <4 x float> @
+// CHECK: %dx.frac = call <4 x float> @llvm.dx.frac.v4f32
+// CHECK: ret <4 x float> %dx.frac
+float4 test_frac_float4(float4 p0) { return frac(p0); }
diff --git a/clang/test/CodeGenHLSL/builtins/lerp.hlsl b/clang/test/CodeGenHLSL/builtins/lerp.hlsl
index 1297f6b85bbd48..a6b3d9643d674c 100644
--- a/clang/test/CodeGenHLSL/builtins/lerp.hlsl
+++ b/clang/test/CodeGenHLSL/builtins/lerp.hlsl
@@ -14,85 +14,63 @@
// NO_HALF: %4 = fmul float %2, %3
// NO_HALF: %dx.lerp = fadd float %0, %4
// NO_HALF: ret float %dx.lerp
-half test_lerp_half ( half p0) {
- return lerp ( p0, p0, p0 );
-}
+half test_lerp_half(half p0) { return lerp(p0, p0, p0); }
// NATIVE_HALF: %dx.lerp = call <2 x half> @llvm.dx.lerp.v2f16(<2 x half> %0, <2 x half> %1, <2 x half> %2)
// NATIVE_HALF: ret <2 x half> %dx.lerp
// NO_HALF: %dx.lerp = call <2 x float> @llvm.dx.lerp.v2f32(<2 x float> %0, <2 x float> %1, <2 x float> %2)
// NO_HALF: ret <2 x float> %dx.lerp
-half2 test_lerp_half2 ( half2 p0, half2 p1 ) {
- return lerp ( p0, p0, p0 );
-}
+half2 test_lerp_half2(half2 p0, half2 p1) { return lerp(p0, p0, p0); }
// NATIVE_HALF: %dx.lerp = call <3 x half> @llvm.dx.lerp.v3f16(<3 x half> %0, <3 x half> %1, <3 x half> %2)
// NATIVE_HALF: ret <3 x half> %dx.lerp
// NO_HALF: %dx.lerp = call <3 x float> @llvm.dx.lerp.v3f32(<3 x float> %0, <3 x float> %1, <3 x float> %2)
// NO_HALF: ret <3 x float> %dx.lerp
-half3 test_lerp_half3 ( half3 p0, half3 p1 ) {
- return lerp ( p0, p0, p0 );
-}
+half3 test_lerp_half3(half3 p0, half3 p1) { return lerp(p0, p0, p0); }
// NATIVE_HALF: %dx.lerp = call <4 x half> @llvm.dx.lerp.v4f16(<4 x half> %0, <4 x half> %1, <4 x half> %2)
// NATIVE_HALF: ret <4 x half> %dx.lerp
// NO_HALF: %dx.lerp = call <4 x float> @llvm.dx.lerp.v4f32(<4 x float> %0, <4 x float> %1, <4 x float> %2)
// NO_HALF: ret <4 x float> %dx.lerp
-half4 test_lerp_half4 ( half4 p0, half4 p1 ) {
- return lerp ( p0, p0, p0 );
-}
+half4 test_lerp_half4(half4 p0, half4 p1) { return lerp(p0, p0, p0); }
// CHECK: %3 = fsub float %1, %0
// CHECK: %4 = fmul float %2, %3
// CHECK: %dx.lerp = fadd float %0, %4
// CHECK: ret float %dx.lerp
-float test_lerp_float ( float p0, float p1 ) {
- return lerp ( p0, p0, p0 );
-}
+float test_lerp_float(float p0, float p1) { return lerp(p0, p0, p0); }
// CHECK: %dx.lerp = call <2 x float> @llvm.dx.lerp.v2f32(<2 x float> %0, <2 x float> %1, <2 x float> %2)
// CHECK: ret <2 x float> %dx.lerp
-float2 test_lerp_float2 ( float2 p0, float2 p1 ) {
- return lerp ( p0, p0, p0 );
-}
+float2 test_lerp_float2(float2 p0, float2 p1) { return lerp(p0, p0, p0); }
// CHECK: %dx.lerp = call <3 x float> @llvm.dx.lerp.v3f32(<3 x float> %0, <3 x float> %1, <3 x float> %2)
// CHECK: ret <3 x float> %dx.lerp
-float3 test_lerp_float3 ( float3 p0, float3 p1 ) {
- return lerp ( p0, p0, p0 );
-}
+float3 test_lerp_float3(float3 p0, float3 p1) { return lerp(p0, p0, p0); }
// CHECK: %dx.lerp = call <4 x float> @llvm.dx.lerp.v4f32(<4 x float> %0, <4 x float> %1, <4 x float> %2)
// CHECK: ret <4 x float> %dx.lerp
-float4 test_lerp_float4 ( float4 p0, float4 p1) {
- return lerp ( p0, p0, p0 );
-}
+float4 test_lerp_float4(float4 p0, float4 p1) { return lerp(p0, p0, p0); }
// CHECK: %dx.lerp = call <2 x float> @llvm.dx.lerp.v2f32(<2 x float> %splat.splat, <2 x float> %1, <2 x float> %2)
// CHECK: ret <2 x float> %dx.lerp
-float2 test_lerp_float2_splat ( float p0, float2 p1 ) {
- return lerp( p0, p1, p1 );
-}
+float2 test_lerp_float2_splat(float p0, float2 p1) { return lerp(p0, p1, p1); }
// CHECK: %dx.lerp = call <3 x float> @llvm.dx.lerp.v3f32(<3 x float> %splat.splat, <3 x float> %1, <3 x float> %2)
// CHECK: ret <3 x float> %dx.lerp
-float3 test_lerp_float3_splat ( float p0, float3 p1 ) {
- return lerp( p0, p1, p1 );
-}
+float3 test_lerp_float3_splat(float p0, float3 p1) { return lerp(p0, p1, p1); }
// CHECK: %dx.lerp = call <4 x float> @llvm.dx.lerp.v4f32(<4 x float> %splat.splat, <4 x float> %1, <4 x float> %2)
// CHECK: ret <4 x float> %dx.lerp
-float4 test_lerp_float4_splat ( float p0, float4 p1 ) {
- return lerp( p0, p1, p1 );
-}
+float4 test_lerp_float4_splat(float p0, float4 p1) { return lerp(p0, p1, p1); }
// CHECK: %conv = sitofp i32 %2 to float
// CHECK: %splat.splatinsert = insertelement <2 x float> poison, float %conv, i64 0
// CHECK: %splat.splat = shufflevector <2 x float> %splat.splatinsert, <2 x float> poison, <2 x i32> zeroinitializer
// CHECK: %dx.lerp = call <2 x float> @llvm.dx.lerp.v2f32(<2 x float> %0, <2 x float> %1, <2 x float> %splat.splat)
// CHECK: ret <2 x float> %dx.lerp
-float2 test_lerp_float2_int_splat ( float2 p0, int p1 ) {
- return lerp ( p0, p0, p1 );
+float2 test_lerp_float2_int_splat(float2 p0, int p1) {
+ return lerp(p0, p0, p1);
}
// CHECK: %conv = sitofp i32 %2 to float
@@ -100,6 +78,6 @@ float2 test_lerp_float2_int_splat ( float2 p0, int p1 ) {
// CHECK: %splat.splat = shufflevector <3 x float> %splat.splatinsert, <3 x float> poison, <3 x i32> zeroinitializer
// CHECK: %dx.lerp = call <3 x float> @llvm.dx.lerp.v3f32(<3 x float> %0, <3 x float> %1, <3 x float> %splat.splat)
// CHECK: ret <3 x float> %dx.lerp
-float3 test_lerp_float3_int_splat ( float3 p0, int p1 ) {
- return lerp ( p0, p0, p1 );
+float3 test_lerp_float3_int_splat(float3 p0, int p1) {
+ return lerp(p0, p0, p1);
}
diff --git a/clang/test/SemaHLSL/BuiltIns/dot-errors.hlsl b/clang/test/SemaHLSL/BuiltIns/dot-errors.hlsl
index 5dbb52a80c6bd0..8de8f86d7eb260 100644
--- a/clang/test/SemaHLSL/BuiltIns/dot-errors.hlsl
+++ b/clang/test/SemaHLSL/BuiltIns/dot-errors.hlsl
@@ -1,109 +1,110 @@
// RUN: %clang_cc1 -finclude-default-header -triple dxil-pc-shadermodel6.6-library %s -fnative-half-type -emit-llvm -disable-llvm-passes -verify -verify-ignore-unexpected
-float test_no_second_arg ( float2 p0) {
- return __builtin_hlsl_dot ( p0 );
+float test_no_second_arg(float2 p0) {
+ return __builtin_hlsl_dot(p0);
// expected-error at -1 {{too few arguments to function call, expected 2, have 1}}
}
-float test_too_many_arg ( float2 p0) {
- return __builtin_hlsl_dot ( p0, p0, p0 );
+float test_too_many_arg(float2 p0) {
+ return __builtin_hlsl_dot(p0, p0, p0);
// expected-error at -1 {{too many arguments to function call, expected 2, have 3}}
}
-float test_dot_no_second_arg ( float2 p0) {
- return dot ( p0 );
+float test_dot_no_second_arg(float2 p0) {
+ return dot(p0);
// expected-error at -1 {{no matching function for call to 'dot'}}
}
-float test_dot_vector_size_mismatch ( float3 p0, float2 p1 ) {
- return dot ( p0, p1 );
+float test_dot_vector_size_mismatch(float3 p0, float2 p1) {
+ return dot(p0, p1);
// expected-warning at -1 {{implicit conversion truncates vector: 'float3' (aka 'vector<float, 3>') to 'float __attribute__((ext_vector_type(2)))' (vector of 2 'float' values)}}
}
-float test_dot_builtin_vector_size_mismatch ( float3 p0, float2 p1 ) {
- return __builtin_hlsl_dot ( p0, p1 );
+float test_dot_builtin_vector_size_mismatch(float3 p0, float2 p1) {
+ return __builtin_hlsl_dot(p0, p1);
// expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have vectors of the same type}}
}
-float test_dot_scalar_mismatch ( float p0, int p1 ) {
- return dot ( p0, p1 );
+float test_dot_scalar_mismatch(float p0, int p1) {
+ return dot(p0, p1);
// expected-error at -1 {{call to 'dot' is ambiguous}}
}
-float test_dot_element_type_mismatch ( int2 p0, float2 p1 ) {
- return dot ( p0, p1 );
+float test_dot_element_type_mismatch(int2 p0, float2 p1) {
+ return dot(p0, p1);
// expected-error at -1 {{call to 'dot' is ambiguous}}
}
//NOTE: for all the *_promotion we are intentionally not handling type promotion in builtins
-float test_builtin_dot_vec_int_to_float_promotion ( int2 p0, float2 p1 ) {
- return __builtin_hlsl_dot ( p0, p1 );
+float test_builtin_dot_vec_int_to_float_promotion(int2 p0, float2 p1) {
+ return __builtin_hlsl_dot(p0, p1);
// expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have vectors of the same type}}
}
-int64_t test_builtin_dot_vec_int_to_int64_promotion( int64_t2 p0, int2 p1 ) {
- return __builtin_hlsl_dot( p0, p1 );
+int64_t test_builtin_dot_vec_int_to_int64_promotion(int64_t2 p0, int2 p1) {
+ return __builtin_hlsl_dot(p0, p1);
// expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have vectors of the same type}}
}
-float test_builtin_dot_vec_half_to_float_promotion( float2 p0, half2 p1 ) {
- return __builtin_hlsl_dot( p0, p1 );
+float test_builtin_dot_vec_half_to_float_promotion(float2 p0, half2 p1) {
+ return __builtin_hlsl_dot(p0, p1);
// expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have vectors of the same type}}
}
#ifdef __HLSL_ENABLE_16_BIT
-float test_builtin_dot_vec_int16_to_float_promotion( float2 p0, int16_t2 p1 ) {
- return __builtin_hlsl_dot( p0, p1 );
+float test_builtin_dot_vec_int16_to_float_promotion(float2 p0, int16_t2 p1) {
+ return __builtin_hlsl_dot(p0, p1);
// expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have vectors of the same type}}
}
-half test_builtin_dot_vec_int16_to_half_promotion( half2 p0, int16_t2 p1 ) {
- return __builtin_hlsl_dot( p0, p1 );
+half test_builtin_dot_vec_int16_to_half_promotion(half2 p0, int16_t2 p1) {
+ return __builtin_hlsl_dot(p0, p1);
// expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have vectors of the same type}}
}
-int test_builtin_dot_vec_int16_to_int_promotion( int2 p0, int16_t2 p1 ) {
- return __builtin_hlsl_dot( p0, p1 );
+int test_builtin_dot_vec_int16_to_int_promotion(int2 p0, int16_t2 p1) {
+ return __builtin_hlsl_dot(p0, p1);
// expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have vectors of the same type}}
}
-int64_t test_builtin_dot_vec_int16_to_int64_promotion( int64_t2 p0, int16_t2 p1 ) {
- return __builtin_hlsl_dot( p0, p1 );
+int64_t test_builtin_dot_vec_int16_to_int64_promotion(int64_t2 p0,
+ int16_t2 p1) {
+ return __builtin_hlsl_dot(p0, p1);
// expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have vectors of the same type}}
}
#endif
-float test_builtin_dot_float2_splat ( float p0, float2 p1 ) {
- return __builtin_hlsl_dot( p0, p1 );
+float test_builtin_dot_float2_splat(float p0, float2 p1) {
+ return __builtin_hlsl_dot(p0, p1);
// expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must be vectors}}
}
-float test_builtin_dot_float3_splat ( float p0, float3 p1 ) {
- return __builtin_hlsl_dot( p0, p1 );
+float test_builtin_dot_float3_splat(float p0, float3 p1) {
+ return __builtin_hlsl_dot(p0, p1);
// expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must be vectors}}
}
-float test_builtin_dot_float4_splat ( float p0, float4 p1 ) {
- return __builtin_hlsl_dot( p0, p1 );
+float test_builtin_dot_float4_splat(float p0, float4 p1) {
+ return __builtin_hlsl_dot(p0, p1);
// expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must be vectors}}
}
-float test_dot_float2_int_splat ( float2 p0, int p1 ) {
- return __builtin_hlsl_dot ( p0, p1 );
+float test_dot_float2_int_splat(float2 p0, int p1) {
+ return __builtin_hlsl_dot(p0, p1);
// expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must be vectors}}
}
-float test_dot_float3_int_splat ( float3 p0, int p1 ) {
- return __builtin_hlsl_dot ( p0, p1 );
+float test_dot_float3_int_splat(float3 p0, int p1) {
+ return __builtin_hlsl_dot(p0, p1);
// expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must be vectors}}
}
-float test_builtin_dot_int_vect_to_float_vec_promotion ( int2 p0, float p1 ) {
- return __builtin_hlsl_dot ( p0, p1 );
+float test_builtin_dot_int_vect_to_float_vec_promotion(int2 p0, float p1) {
+ return __builtin_hlsl_dot(p0, p1);
// expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must be vectors}}
}
-int test_builtin_dot_bool_type_promotion ( bool p0, bool p1 ) {
- return __builtin_hlsl_dot ( p0, p1 );
+int test_builtin_dot_bool_type_promotion(bool p0, bool p1) {
+ return __builtin_hlsl_dot(p0, p1);
// expected-error at -1 {{1st argument must be a vector, integer or floating point type (was 'bool')}}
}
diff --git a/clang/test/SemaHLSL/BuiltIns/frac-errors.hlsl b/clang/test/SemaHLSL/BuiltIns/frac-errors.hlsl
new file mode 100644
index 00000000000000..06dbdf0a68dfc1
--- /dev/null
+++ b/clang/test/SemaHLSL/BuiltIns/frac-errors.hlsl
@@ -0,0 +1,27 @@
+
+// RUN: %clang_cc1 -finclude-default-header -triple dxil-pc-shadermodel6.6-library %s -fnative-half-type -emit-llvm -disable-llvm-passes -verify -verify-ignore-unexpected
+
+float test_too_few_arg() {
+ return __builtin_hlsl_elementwise_frac();
+ // expected-error at -1 {{too few arguments to function call, expected 1, have 0}}
+}
+
+float2 test_too_many_arg(float2 p0) {
+ return __builtin_hlsl_elementwise_frac(p0, p0);
+ // expected-error at -1 {{too many arguments to function call, expected 1, have 2}}
+}
+
+float builtin_bool_to_float_type_promotion(bool p1) {
+ return __builtin_hlsl_elementwise_frac(p1);
+ // expected-error at -1 {{1st argument must be a vector, integer or floating point type (was 'bool')}}
+}
+
+float builtin_frac_int_to_float_promotion(int p1) {
+ return __builtin_hlsl_elementwise_frac(p1);
+ // expected-error at -1 {{passing 'int' to parameter of incompatible type 'float'}}
+}
+
+float2 builtin_frac_int2_to_float2_promotion(int2 p1) {
+ return __builtin_hlsl_elementwise_frac(p1);
+ // expected-error at -1 {{passing 'int2' (aka 'vector<int, 2>') to parameter of incompatible type '__attribute__((__vector_size__(2 * sizeof(float)))) float' (vector of 2 'float' values)}}
+}
diff --git a/clang/test/SemaHLSL/BuiltIns/lerp-errors.hlsl b/clang/test/SemaHLSL/BuiltIns/lerp-errors.hlsl
index c062aa60a8df45..4ec5a4cdd26a30 100644
--- a/clang/test/SemaHLSL/BuiltIns/lerp-errors.hlsl
+++ b/clang/test/SemaHLSL/BuiltIns/lerp-errors.hlsl
@@ -1,91 +1,96 @@
// RUN: %clang_cc1 -finclude-default-header -triple dxil-pc-shadermodel6.6-library %s -fnative-half-type -emit-llvm -disable-llvm-passes -verify -verify-ignore-unexpected
-float2 test_no_second_arg ( float2 p0) {
- return __builtin_hlsl_lerp ( p0 );
+float2 test_no_second_arg(float2 p0) {
+ return __builtin_hlsl_lerp(p0);
// expected-error at -1 {{too few arguments to function call, expected 3, have 1}}
}
-float2 test_no_third_arg ( float2 p0) {
- return __builtin_hlsl_lerp ( p0, p0 );
+float2 test_no_third_arg(float2 p0) {
+ return __builtin_hlsl_lerp(p0, p0);
// expected-error at -1 {{too few arguments to function call, expected 3, have 2}}
}
-float2 test_too_many_arg ( float2 p0) {
- return __builtin_hlsl_lerp ( p0, p0, p0, p0 );
+float2 test_too_many_arg(float2 p0) {
+ return __builtin_hlsl_lerp(p0, p0, p0, p0);
// expected-error at -1 {{too many arguments to function call, expected 3, have 4}}
}
-float2 test_lerp_no_second_arg ( float2 p0) {
- return lerp ( p0 );
+float2 test_lerp_no_second_arg(float2 p0) {
+ return lerp(p0);
// expected-error at -1 {{no matching function for call to 'lerp'}}
}
-float2 test_lerp_vector_size_mismatch ( float3 p0, float2 p1 ) {
- return lerp ( p0, p0, p1 );
+float2 test_lerp_vector_size_mismatch(float3 p0, float2 p1) {
+ return lerp(p0, p0, p1);
// expected-warning at -1 {{implicit conversion truncates vector: 'float3' (aka 'vector<float, 3>') to 'float __attribute__((ext_vector_type(2)))' (vector of 2 'float' values)}}
}
-float test_lerp_builtin_vector_size_mismatch ( float3 p0, float2 p1 ) {
- return __builtin_hlsl_lerp ( p0, p1, p1 );
+float2 test_lerp_builtin_vector_size_mismatch(float3 p0, float2 p1) {
+ return __builtin_hlsl_lerp(p0, p1, p1);
// expected-error at -1 {{all arguments to '__builtin_hlsl_lerp' must have vectors of the same type}}
}
-float test_lerp_scalar_mismatch ( float p0, half p1 ) {
- return lerp ( p1, p0, p1 );
+float test_lerp_scalar_mismatch(float p0, half p1) {
+ return lerp(p1, p0, p1);
// expected-error at -1 {{call to 'lerp' is ambiguous}}
}
-float test_lerp_element_type_mismatch ( half2 p0, float2 p1 ) {
- return lerp ( p1, p0, p1 );
+float2 test_lerp_element_type_mismatch(half2 p0, float2 p1) {
+ return lerp(p1, p0, p1);
// expected-error at -1 {{call to 'lerp' is ambiguous}}
}
-float test_builtin_lerp_float2_splat ( float p0, float2 p1 ) {
- return __builtin_hlsl_lerp( p0, p1, p1 );
+float2 test_builtin_lerp_float2_splat(float p0, float2 p1) {
+ return __builtin_hlsl_lerp(p0, p1, p1);
// expected-error at -1 {{all arguments to '__builtin_hlsl_lerp' must be vectors}}
}
-float test_builtin_lerp_float3_splat ( float p0, float3 p1 ) {
- return __builtin_hlsl_lerp( p0, p1, p1 );
+float3 test_builtin_lerp_float3_splat(float p0, float3 p1) {
+ return __builtin_hlsl_lerp(p0, p1, p1);
// expected-error at -1 {{all arguments to '__builtin_hlsl_lerp' must be vectors}}
}
-float test_builtin_lerp_float4_splat ( float p0, float4 p1 ) {
- return __builtin_hlsl_lerp( p0, p1, p1 );
+float4 test_builtin_lerp_float4_splat(float p0, float4 p1) {
+ return __builtin_hlsl_lerp(p0, p1, p1);
// expected-error at -1 {{all arguments to '__builtin_hlsl_lerp' must be vectors}}
}
-float test_lerp_float2_int_splat ( float2 p0, int p1 ) {
- return __builtin_hlsl_lerp( p0, p1, p1 );
+float2 test_lerp_float2_int_splat(float2 p0, int p1) {
+ return __builtin_hlsl_lerp(p0, p1, p1);
// expected-error at -1 {{all arguments to '__builtin_hlsl_lerp' must be vectors}}
}
-float test_lerp_float3_int_splat ( float3 p0, int p1 ) {
- return __builtin_hlsl_lerp( p0, p1, p1 );
+float3 test_lerp_float3_int_splat(float3 p0, int p1) {
+ return __builtin_hlsl_lerp(p0, p1, p1);
// expected-error at -1 {{all arguments to '__builtin_hlsl_lerp' must be vectors}}
}
-float test_builtin_lerp_int_vect_to_float_vec_promotion ( int2 p0, float p1 ) {
- return __builtin_hlsl_lerp( p0, p1, p1 );
+float2 test_builtin_lerp_int_vect_to_float_vec_promotion(int2 p0, float p1) {
+ return __builtin_hlsl_lerp(p0, p1, p1);
// expected-error at -1 {{all arguments to '__builtin_hlsl_lerp' must be vectors}}
}
-int test_builtin_lerp_bool_type_promotion (bool p0) {
- return __builtin_hlsl_lerp( p0, p0, p0 );
+float test_builtin_lerp_bool_type_promotion(bool p0) {
+ return __builtin_hlsl_lerp(p0, p0, p0);
// expected-error at -1 {{1st argument must be a floating point type (was 'bool')}}
}
-float builtin_bool_to_float_type_promotion ( float p0, bool p1 ) {
- return __builtin_hlsl_lerp ( p0, p0, p1 );
- // expected-error at -1 {{3rd argument must be a floating point type (was 'bool')}}
+float builtin_bool_to_float_type_promotion(float p0, bool p1) {
+ return __builtin_hlsl_lerp(p0, p0, p1);
+ // expected-error at -1 {{3rd argument must be a floating point type (was 'bool')}}
}
-float builtin_bool_to_float_type_promotion2 ( bool p0, float p1 ) {
- return __builtin_hlsl_lerp ( p1, p0, p1 );
+float builtin_bool_to_float_type_promotion2(bool p0, float p1) {
+ return __builtin_hlsl_lerp(p1, p0, p1);
// expected-error at -1 {{2nd argument must be a floating point type (was 'bool')}}
}
-float builtin_lerp_int_to_float_promotion ( float p0, int p1 ) {
- return __builtin_hlsl_lerp ( p0, p0, p1 );
+float builtin_lerp_int_to_float_promotion(float p0, int p1) {
+ return __builtin_hlsl_lerp(p0, p0, p1);
// expected-error at -1 {{3rd argument must be a floating point type (was 'int')}}
+}
+
+float4 test_lerp_int4(int4 p0, int4 p1, int4 p2) {
+ return __builtin_hlsl_lerp(p0, p1, p2);
+ // expected-error at -1 {{1st argument must be a floating point type (was 'int4' (aka 'vector<int, 4>'))}}
}
\ No newline at end of file
diff --git a/clang/test/SemaHLSL/OverloadResolutionBugs.hlsl b/clang/test/SemaHLSL/OverloadResolutionBugs.hlsl
index 8464f1c1a7c2cd..c13cb299127aac 100644
--- a/clang/test/SemaHLSL/OverloadResolutionBugs.hlsl
+++ b/clang/test/SemaHLSL/OverloadResolutionBugs.hlsl
@@ -7,73 +7,67 @@
void Fn3(double2 D);
void Fn3(float2 F);
-void Call3(half2 H) {
- Fn3(H);
-}
+void Call3(half2 H) { Fn3(H); }
void Fn5(double2 D);
-void Call5(half2 H) {
- Fn5(H);
-}
+void Call5(half2 H) { Fn5(H); }
void Fn4(int64_t2 L);
void Fn4(int2 I);
-void Call4(int16_t H) {
- Fn4(H);
-}
+void Call4(int16_t H) { Fn4(H); }
-int test_builtin_dot_bool_type_promotion ( bool p0, bool p1 ) {
- return dot ( p0, p1 );
+int test_builtin_dot_bool_type_promotion(bool p0, bool p1) {
+ return dot(p0, p1);
}
-float test_dot_scalar_mismatch ( float p0, int p1 ) {
- return dot ( p0, p1 );
-}
+float test_dot_scalar_mismatch(float p0, int p1) { return dot(p0, p1); }
-float test_dot_element_type_mismatch ( int2 p0, float2 p1 ) {
- return dot ( p0, p1 );
-}
+float test_dot_element_type_mismatch(int2 p0, float2 p1) { return dot(p0, p1); }
-float test_builtin_dot_vec_int_to_float_promotion ( int2 p0, float2 p1 ) {
- return dot ( p0, p1 );
+float test_builtin_dot_vec_int_to_float_promotion(int2 p0, float2 p1) {
+ return dot(p0, p1);
}
-int64_t test_builtin_dot_vec_int_to_int64_promotion( int64_t2 p0, int2 p1 ) {
- return dot ( p0, p1 );
+int64_t test_builtin_dot_vec_int_to_int64_promotion(int64_t2 p0, int2 p1) {
+ return dot(p0, p1);
}
-float test_builtin_dot_vec_half_to_float_promotion( float2 p0, half2 p1 ) {
- return dot( p0, p1 );
+float test_builtin_dot_vec_half_to_float_promotion(float2 p0, half2 p1) {
+ return dot(p0, p1);
}
-float test_builtin_dot_vec_int16_to_float_promotion( float2 p0, int16_t2 p1 ) {
- return dot( p0, p1 );
+float test_builtin_dot_vec_int16_to_float_promotion(float2 p0, int16_t2 p1) {
+ return dot(p0, p1);
}
-half test_builtin_dot_vec_int16_to_half_promotion( half2 p0, int16_t2 p1 ) {
- return dot( p0, p1 );
+half test_builtin_dot_vec_int16_to_half_promotion(half2 p0, int16_t2 p1) {
+ return dot(p0, p1);
}
-int test_builtin_dot_vec_int16_to_int_promotion( int2 p0, int16_t2 p1 ) {
- return dot( p0, p1 );
+int test_builtin_dot_vec_int16_to_int_promotion(int2 p0, int16_t2 p1) {
+ return dot(p0, p1);
}
-int64_t test_builtin_dot_vec_int16_to_int64_promotion( int64_t2 p0, int16_t2 p1 ) {
- return dot( p0, p1 );
+int64_t test_builtin_dot_vec_int16_to_int64_promotion(int64_t2 p0,
+ int16_t2 p1) {
+ return dot(p0, p1);
}
+float4 test_frac_int4(int4 p0) { return frac(p0); }
+
+float test_frac_int(int p0) { return frac(p0); }
+
+float test_frac_bool(bool p0) { return frac(p0); }
+
// https://github.com/llvm/llvm-project/issues/81049
// RUN: %clang_cc1 -std=hlsl2021 -finclude-default-header -x hlsl -triple \
// RUN: dxil-pc-shadermodel6.2-library %s -emit-llvm -disable-llvm-passes \
// RUN: -o - | FileCheck %s --check-prefix=NO_HALF
-half sqrt_h(half x)
-{
- return sqrt(x);
-}
+half sqrt_h(half x) { return sqrt(x); }
// NO_HALF: define noundef float @"?sqrt_h@@YA$halff@$halff@@Z"(
// NO_HALF: call float @llvm.sqrt.f32(float %0)
diff --git a/llvm/include/llvm/IR/IntrinsicsDirectX.td b/llvm/include/llvm/IR/IntrinsicsDirectX.td
index 48332b917693a0..b44d1c6d3d2f06 100644
--- a/llvm/include/llvm/IR/IntrinsicsDirectX.td
+++ b/llvm/include/llvm/IR/IntrinsicsDirectX.td
@@ -25,8 +25,10 @@ def int_dx_dot :
[llvm_anyvector_ty, LLVMScalarOrSameVectorWidth<0, LLVMVectorElementType<0>>],
[IntrNoMem, IntrWillReturn, Commutative] >;
+def int_dx_frac : DefaultAttrsIntrinsic<[llvm_anyfloat_ty], [LLVMMatchType<0>]>;
+
def int_dx_lerp :
- Intrinsic<[LLVMMatchType<0>],
- [llvm_anyvector_ty, LLVMMatchType<0>, LLVMMatchType<0>],
- [IntrNoMem, IntrWillReturn, Commutative] >;
+ Intrinsic<[LLVMScalarOrSameVectorWidth<0, LLVMVectorElementType<0>>],
+ [llvm_anyvector_ty, LLVMScalarOrSameVectorWidth<0, LLVMVectorElementType<0>>,LLVMScalarOrSameVectorWidth<0, LLVMVectorElementType<0>>],
+ [IntrNoMem, IntrWillReturn] >;
}
>From c9b1f1c337ce7c12664b670c0ba1022e5d5b8001 Mon Sep 17 00:00:00 2001
From: Farzon Lotfi <1802579+farzonl at users.noreply.github.com>
Date: Thu, 29 Feb 2024 13:41:40 -0500
Subject: [PATCH 161/406] [HLSL] standardize builtin unit tests (#83340)
This PR brings best practices mentioned to me on other prs and adds them
to the existing builtin tests.
Note to reviewers: I put this up in two commits because the clang-format
changes is making it hard to tell what actually changed.
use the first commit to check for correctness.
---
clang/test/CodeGenHLSL/builtins/abs.hlsl | 134 ++++-------
clang/test/CodeGenHLSL/builtins/ceil.hlsl | 69 ++----
clang/test/CodeGenHLSL/builtins/cos.hlsl | 69 +++---
clang/test/CodeGenHLSL/builtins/floor.hlsl | 69 ++----
clang/test/CodeGenHLSL/builtins/log.hlsl | 67 +++---
clang/test/CodeGenHLSL/builtins/log10.hlsl | 69 +++---
clang/test/CodeGenHLSL/builtins/log2.hlsl | 69 +++---
clang/test/CodeGenHLSL/builtins/max.hlsl | 214 ++++++------------
clang/test/CodeGenHLSL/builtins/min.hlsl | 207 ++++++-----------
clang/test/CodeGenHLSL/builtins/pow.hlsl | 97 +++-----
clang/test/CodeGenHLSL/builtins/sin.hlsl | 59 ++---
clang/test/CodeGenHLSL/builtins/trunc.hlsl | 75 +++---
.../SemaHLSL/VectorOverloadResolution.hlsl | 2 +-
13 files changed, 421 insertions(+), 779 deletions(-)
diff --git a/clang/test/CodeGenHLSL/builtins/abs.hlsl b/clang/test/CodeGenHLSL/builtins/abs.hlsl
index 54c9d1a9dded45..ad65cab2721a2b 100644
--- a/clang/test/CodeGenHLSL/builtins/abs.hlsl
+++ b/clang/test/CodeGenHLSL/builtins/abs.hlsl
@@ -1,141 +1,93 @@
// RUN: %clang_cc1 -std=hlsl2021 -finclude-default-header -x hlsl -triple \
// RUN: dxil-pc-shadermodel6.3-library %s -fnative-half-type \
-// RUN: -emit-llvm -disable-llvm-passes -O3 -o - | FileCheck %s
+// RUN: -emit-llvm -disable-llvm-passes -o - | FileCheck %s \
+// RUN: --check-prefixes=CHECK,NATIVE_HALF
// RUN: %clang_cc1 -std=hlsl2021 -finclude-default-header -x hlsl -triple \
// RUN: dxil-pc-shadermodel6.3-library %s -emit-llvm -disable-llvm-passes \
-// RUN: -o - | FileCheck %s --check-prefix=NO_HALF
+// RUN: -o - | FileCheck %s --check-prefixes=CHECK,NO_HALF
using hlsl::abs;
#ifdef __HLSL_ENABLE_16_BIT
-// CHECK: define noundef i16 @
-// CHECK: call i16 @llvm.abs.i16(
-int16_t test_abs_int16_t ( int16_t p0 ) {
- return abs ( p0 );
-}
-// CHECK: define noundef <2 x i16> @
-// CHECK: call <2 x i16> @llvm.abs.v2i16(
-int16_t2 test_abs_int16_t2 ( int16_t2 p0 ) {
- return abs ( p0 );
-}
-// CHECK: define noundef <3 x i16> @
-// CHECK: call <3 x i16> @llvm.abs.v3i16(
-int16_t3 test_abs_int16_t3 ( int16_t3 p0 ) {
- return abs ( p0 );
-}
-// CHECK: define noundef <4 x i16> @
-// CHECK: call <4 x i16> @llvm.abs.v4i16(
-int16_t4 test_abs_int16_t4 ( int16_t4 p0 ) {
- return abs ( p0 );
-}
+// NATIVE_HALF: define noundef i16 @
+// NATIVE_HALF: call i16 @llvm.abs.i16(
+int16_t test_abs_int16_t(int16_t p0) { return abs(p0); }
+// NATIVE_HALF: define noundef <2 x i16> @
+// NATIVE_HALF: call <2 x i16> @llvm.abs.v2i16(
+int16_t2 test_abs_int16_t2(int16_t2 p0) { return abs(p0); }
+// NATIVE_HALF: define noundef <3 x i16> @
+// NATIVE_HALF: call <3 x i16> @llvm.abs.v3i16(
+int16_t3 test_abs_int16_t3(int16_t3 p0) { return abs(p0); }
+// NATIVE_HALF: define noundef <4 x i16> @
+// NATIVE_HALF: call <4 x i16> @llvm.abs.v4i16(
+int16_t4 test_abs_int16_t4(int16_t4 p0) { return abs(p0); }
#endif // __HLSL_ENABLE_16_BIT
-// CHECK: define noundef half @
-// CHECK: call half @llvm.fabs.f16(
+// NATIVE_HALF: define noundef half @
+// NATIVE_HALF: call half @llvm.fabs.f16(
// NO_HALF: define noundef float @"?test_abs_half@@YA$halff@$halff@@Z"(
// NO_HALF: call float @llvm.fabs.f32(float %0)
-half test_abs_half ( half p0 ) {
- return abs ( p0 );
-}
-// CHECK: define noundef <2 x half> @
-// CHECK: call <2 x half> @llvm.fabs.v2f16(
+half test_abs_half(half p0) { return abs(p0); }
+// NATIVE_HALF: define noundef <2 x half> @
+// NATIVE_HALF: call <2 x half> @llvm.fabs.v2f16(
// NO_HALF: define noundef <2 x float> @"?test_abs_half2@@YAT?$__vector@$halff@$01 at __clang@@T12@@Z"(
// NO_HALF: call <2 x float> @llvm.fabs.v2f32(
-half2 test_abs_half2 ( half2 p0 ) {
- return abs ( p0 );
-}
-// CHECK: define noundef <3 x half> @
-// CHECK: call <3 x half> @llvm.fabs.v3f16(
+half2 test_abs_half2(half2 p0) { return abs(p0); }
+// NATIVE_HALF: define noundef <3 x half> @
+// NATIVE_HALF: call <3 x half> @llvm.fabs.v3f16(
// NO_HALF: define noundef <3 x float> @"?test_abs_half3@@YAT?$__vector@$halff@$02 at __clang@@T12@@Z"(
// NO_HALF: call <3 x float> @llvm.fabs.v3f32(
-half3 test_abs_half3 ( half3 p0 ) {
- return abs ( p0 );
-}
-// CHECK: define noundef <4 x half> @
-// CHECK: call <4 x half> @llvm.fabs.v4f16(
+half3 test_abs_half3(half3 p0) { return abs(p0); }
+// NATIVE_HALF: define noundef <4 x half> @
+// NATIVE_HALF: call <4 x half> @llvm.fabs.v4f16(
// NO_HALF: define noundef <4 x float> @"?test_abs_half4@@YAT?$__vector@$halff@$03 at __clang@@T12@@Z"(
// NO_HALF: call <4 x float> @llvm.fabs.v4f32(
-half4 test_abs_half4 ( half4 p0 ) {
- return abs ( p0 );
-}
+half4 test_abs_half4(half4 p0) { return abs(p0); }
// CHECK: define noundef i32 @
// CHECK: call i32 @llvm.abs.i32(
-// NO_HALF: define noundef i32 @"?test_abs_int@@YAHH at Z"
-int test_abs_int ( int p0 ) {
- return abs ( p0 );
-}
+int test_abs_int(int p0) { return abs(p0); }
// CHECK: define noundef <2 x i32> @
// CHECK: call <2 x i32> @llvm.abs.v2i32(
-int2 test_abs_int2 ( int2 p0 ) {
- return abs ( p0 );
-}
+int2 test_abs_int2(int2 p0) { return abs(p0); }
// CHECK: define noundef <3 x i32> @
// CHECK: call <3 x i32> @llvm.abs.v3i32(
-int3 test_abs_int3 ( int3 p0 ) {
- return abs ( p0 );
-}
+int3 test_abs_int3(int3 p0) { return abs(p0); }
// CHECK: define noundef <4 x i32> @
// CHECK: call <4 x i32> @llvm.abs.v4i32(
-int4 test_abs_int4 ( int4 p0 ) {
- return abs ( p0 );
-}
+int4 test_abs_int4(int4 p0) { return abs(p0); }
// CHECK: define noundef float @
// CHECK: call float @llvm.fabs.f32(
-float test_abs_float ( float p0 ) {
- return abs ( p0 );
-}
+float test_abs_float(float p0) { return abs(p0); }
// CHECK: define noundef <2 x float> @
// CHECK: call <2 x float> @llvm.fabs.v2f32(
-float2 test_abs_float2 ( float2 p0 ) {
- return abs ( p0 );
-}
+float2 test_abs_float2(float2 p0) { return abs(p0); }
// CHECK: define noundef <3 x float> @
// CHECK: call <3 x float> @llvm.fabs.v3f32(
-float3 test_abs_float3 ( float3 p0 ) {
- return abs ( p0 );
-}
+float3 test_abs_float3(float3 p0) { return abs(p0); }
// CHECK: define noundef <4 x float> @
// CHECK: call <4 x float> @llvm.fabs.v4f32(
-float4 test_abs_float4 ( float4 p0 ) {
- return abs ( p0 );
-}
+float4 test_abs_float4(float4 p0) { return abs(p0); }
// CHECK: define noundef i64 @
// CHECK: call i64 @llvm.abs.i64(
-int64_t test_abs_int64_t ( int64_t p0 ) {
- return abs ( p0 );
-}
+int64_t test_abs_int64_t(int64_t p0) { return abs(p0); }
// CHECK: define noundef <2 x i64> @
// CHECK: call <2 x i64> @llvm.abs.v2i64(
-int64_t2 test_abs_int64_t2 ( int64_t2 p0 ) {
- return abs ( p0 );
-}
+int64_t2 test_abs_int64_t2(int64_t2 p0) { return abs(p0); }
// CHECK: define noundef <3 x i64> @
// CHECK: call <3 x i64> @llvm.abs.v3i64(
-int64_t3 test_abs_int64_t3 ( int64_t3 p0 ) {
- return abs ( p0 );
-}
+int64_t3 test_abs_int64_t3(int64_t3 p0) { return abs(p0); }
// CHECK: define noundef <4 x i64> @
// CHECK: call <4 x i64> @llvm.abs.v4i64(
-int64_t4 test_abs_int64_t4 ( int64_t4 p0 ) {
- return abs ( p0 );
-}
+int64_t4 test_abs_int64_t4(int64_t4 p0) { return abs(p0); }
// CHECK: define noundef double @
// CHECK: call double @llvm.fabs.f64(
-double test_abs_double ( double p0 ) {
- return abs ( p0 );
-}
+double test_abs_double(double p0) { return abs(p0); }
// CHECK: define noundef <2 x double> @
// CHECK: call <2 x double> @llvm.fabs.v2f64(
-double2 test_abs_double2 ( double2 p0 ) {
- return abs ( p0 );
-}
+double2 test_abs_double2(double2 p0) { return abs(p0); }
// CHECK: define noundef <3 x double> @
// CHECK: call <3 x double> @llvm.fabs.v3f64(
-double3 test_abs_double3 ( double3 p0 ) {
- return abs ( p0 );
-}
+double3 test_abs_double3(double3 p0) { return abs(p0); }
// CHECK: define noundef <4 x double> @
// CHECK: call <4 x double> @llvm.fabs.v4f64(
-double4 test_abs_double4 ( double4 p0 ) {
- return abs ( p0 );
-}
+double4 test_abs_double4(double4 p0) { return abs(p0); }
diff --git a/clang/test/CodeGenHLSL/builtins/ceil.hlsl b/clang/test/CodeGenHLSL/builtins/ceil.hlsl
index f1672816e72bc2..06d0d4c2cf546d 100644
--- a/clang/test/CodeGenHLSL/builtins/ceil.hlsl
+++ b/clang/test/CodeGenHLSL/builtins/ceil.hlsl
@@ -1,79 +1,56 @@
// RUN: %clang_cc1 -std=hlsl2021 -finclude-default-header -x hlsl -triple \
// RUN: dxil-pc-shadermodel6.3-library %s -fnative-half-type \
-// RUN: -emit-llvm -disable-llvm-passes -O3 -o - | FileCheck %s
+// RUN: -emit-llvm -disable-llvm-passes -o - | FileCheck %s \
+// RUN: --check-prefixes=CHECK,NATIVE_HALF
// RUN: %clang_cc1 -std=hlsl2021 -finclude-default-header -x hlsl -triple \
// RUN: dxil-pc-shadermodel6.3-library %s -emit-llvm -disable-llvm-passes \
-// RUN: -o - | FileCheck %s --check-prefix=NO_HALF
+// RUN: -o - | FileCheck %s --check-prefixes=CHECK,NO_HALF
using hlsl::ceil;
-// CHECK: define noundef half @
-// CHECK: call half @llvm.ceil.f16(
+// NATIVE_HALF: define noundef half @
+// NATIVE_HALF: call half @llvm.ceil.f16(
// NO_HALF: define noundef float @"?test_ceil_half@@YA$halff@$halff@@Z"(
// NO_HALF: call float @llvm.ceil.f32(float %0)
-half test_ceil_half ( half p0 ) {
- return ceil ( p0 );
-}
-// CHECK: define noundef <2 x half> @
-// CHECK: call <2 x half> @llvm.ceil.v2f16(
+half test_ceil_half(half p0) { return ceil(p0); }
+// NATIVE_HALF: define noundef <2 x half> @
+// NATIVE_HALF: call <2 x half> @llvm.ceil.v2f16(
// NO_HALF: define noundef <2 x float> @"?test_ceil_half2@@YAT?$__vector@$halff@$01 at __clang@@T12@@Z"(
// NO_HALF: call <2 x float> @llvm.ceil.v2f32(
-half2 test_ceil_half2 ( half2 p0 ) {
- return ceil ( p0 );
-}
-// CHECK: define noundef <3 x half> @
-// CHECK: call <3 x half> @llvm.ceil.v3f16(
+half2 test_ceil_half2(half2 p0) { return ceil(p0); }
+// NATIVE_HALF: define noundef <3 x half> @
+// NATIVE_HALF: call <3 x half> @llvm.ceil.v3f16(
// NO_HALF: define noundef <3 x float> @"?test_ceil_half3@@YAT?$__vector@$halff@$02 at __clang@@T12@@Z"(
// NO_HALF: call <3 x float> @llvm.ceil.v3f32(
-half3 test_ceil_half3 ( half3 p0 ) {
- return ceil ( p0 );
-}
-// CHECK: define noundef <4 x half> @
-// CHECK: call <4 x half> @llvm.ceil.v4f16(
+half3 test_ceil_half3(half3 p0) { return ceil(p0); }
+// NATIVE_HALF: define noundef <4 x half> @
+// NATIVE_HALF: call <4 x half> @llvm.ceil.v4f16(
// NO_HALF: define noundef <4 x float> @"?test_ceil_half4@@YAT?$__vector@$halff@$03 at __clang@@T12@@Z"(
// NO_HALF: call <4 x float> @llvm.ceil.v4f32(
-half4 test_ceil_half4 ( half4 p0 ) {
- return ceil ( p0 );
-}
+half4 test_ceil_half4(half4 p0) { return ceil(p0); }
// CHECK: define noundef float @
// CHECK: call float @llvm.ceil.f32(
-float test_ceil_float ( float p0 ) {
- return ceil ( p0 );
-}
+float test_ceil_float(float p0) { return ceil(p0); }
// CHECK: define noundef <2 x float> @
// CHECK: call <2 x float> @llvm.ceil.v2f32(
-float2 test_ceil_float2 ( float2 p0 ) {
- return ceil ( p0 );
-}
+float2 test_ceil_float2(float2 p0) { return ceil(p0); }
// CHECK: define noundef <3 x float> @
// CHECK: call <3 x float> @llvm.ceil.v3f32(
-float3 test_ceil_float3 ( float3 p0 ) {
- return ceil ( p0 );
-}
+float3 test_ceil_float3(float3 p0) { return ceil(p0); }
// CHECK: define noundef <4 x float> @
// CHECK: call <4 x float> @llvm.ceil.v4f32(
-float4 test_ceil_float4 ( float4 p0 ) {
- return ceil ( p0 );
-}
+float4 test_ceil_float4(float4 p0) { return ceil(p0); }
// CHECK: define noundef double @
// CHECK: call double @llvm.ceil.f64(
-double test_ceil_double ( double p0 ) {
- return ceil ( p0 );
-}
+double test_ceil_double(double p0) { return ceil(p0); }
// CHECK: define noundef <2 x double> @
// CHECK: call <2 x double> @llvm.ceil.v2f64(
-double2 test_ceil_double2 ( double2 p0 ) {
- return ceil ( p0 );
-}
+double2 test_ceil_double2(double2 p0) { return ceil(p0); }
// CHECK: define noundef <3 x double> @
// CHECK: call <3 x double> @llvm.ceil.v3f64(
-double3 test_ceil_double3 ( double3 p0 ) {
- return ceil ( p0 );
-}
+double3 test_ceil_double3(double3 p0) { return ceil(p0); }
// CHECK: define noundef <4 x double> @
// CHECK: call <4 x double> @llvm.ceil.v4f64(
-double4 test_ceil_double4 ( double4 p0 ) {
- return ceil ( p0 );
-}
+double4 test_ceil_double4(double4 p0) { return ceil(p0); }
diff --git a/clang/test/CodeGenHLSL/builtins/cos.hlsl b/clang/test/CodeGenHLSL/builtins/cos.hlsl
index 2fc1571949b2c5..fb416fcaa49d76 100644
--- a/clang/test/CodeGenHLSL/builtins/cos.hlsl
+++ b/clang/test/CodeGenHLSL/builtins/cos.hlsl
@@ -1,56 +1,41 @@
// RUN: %clang_cc1 -std=hlsl2021 -finclude-default-header -x hlsl -triple \
// RUN: dxil-pc-shadermodel6.3-library %s -fnative-half-type \
-// RUN: -emit-llvm -disable-llvm-passes -O3 -o - | FileCheck %s
+// RUN: -emit-llvm -disable-llvm-passes -o - | FileCheck %s \
+// RUN: --check-prefixes=CHECK,NATIVE_HALF
// RUN: %clang_cc1 -std=hlsl2021 -finclude-default-header -x hlsl -triple \
// RUN: dxil-pc-shadermodel6.3-library %s -emit-llvm -disable-llvm-passes \
-// RUN: -o - | FileCheck %s --check-prefix=NO_HALF
+// RUN: -o - | FileCheck %s --check-prefixes=CHECK,NO_HALF
-// CHECK: define noundef half @
-// CHECK: call half @llvm.cos.f16(
-// NO_HALF: define noundef float @"?test_cos_half@@YA$halff@$halff@@Z"(
+// NATIVE_HALF: define noundef half @
+// NATIVE_HALF: call half @llvm.cos.f16(
+// NO_HALF: define noundef float @"?test_cos_half
// NO_HALF: call float @llvm.cos.f32(
-half test_cos_half ( half p0 ) {
- return cos ( p0 );
-}
-// CHECK: define noundef <2 x half> @
-// CHECK: call <2 x half> @llvm.cos.v2f16
-// NO_HALF: define noundef <2 x float> @"?test_cos_float2@@YAT?$__vector at M$01 at __clang@@T12@@Z"(
+half test_cos_half(half p0) { return cos(p0); }
+// NATIVE_HALF: define noundef <2 x half> @
+// NATIVE_HALF: call <2 x half> @llvm.cos.v2f16
+// NO_HALF: define noundef <2 x float> @"?test_cos_half2
// NO_HALF: call <2 x float> @llvm.cos.v2f32(
-half2 test_cos_half2 ( half2 p0 ) {
- return cos ( p0 );
-}
-// CHECK: define noundef <3 x half> @
-// CHECK: call <3 x half> @llvm.cos.v3f16
-// NO_HALF: define noundef <3 x float> @"?test_cos_float3@@YAT?$__vector at M$02 at __clang@@T12@@Z"(
+half2 test_cos_half2(half2 p0) { return cos(p0); }
+// NATIVE_HALF: define noundef <3 x half> @
+// NATIVE_HALF: call <3 x half> @llvm.cos.v3f16
+// NO_HALF: define noundef <3 x float> @"?test_cos_half3
// NO_HALF: call <3 x float> @llvm.cos.v3f32(
-half3 test_cos_half3 ( half3 p0 ) {
- return cos ( p0 );
-}
-// CHECK: define noundef <4 x half> @
-// CHECK: call <4 x half> @llvm.cos.v4f16
-// NO_HALF: define noundef <4 x float> @"?test_cos_float4@@YAT?$__vector at M$03 at __clang@@T12@@Z"(
+half3 test_cos_half3(half3 p0) { return cos(p0); }
+// NATIVE_HALF: define noundef <4 x half> @
+// NATIVE_HALF: call <4 x half> @llvm.cos.v4f16
+// NO_HALF: define noundef <4 x float> @"?test_cos_half4
// NO_HALF: call <4 x float> @llvm.cos.v4f32(
-half4 test_cos_half4 ( half4 p0 ) {
- return cos ( p0 );
-}
+half4 test_cos_half4(half4 p0) { return cos(p0); }
-// CHECK: define noundef float @
+// CHECK: define noundef float @"?test_cos_float
// CHECK: call float @llvm.cos.f32(
-float test_cos_float ( float p0 ) {
- return cos ( p0 );
-}
-// CHECK: define noundef <2 x float> @
+float test_cos_float(float p0) { return cos(p0); }
+// CHECK: define noundef <2 x float> @"?test_cos_float2
// CHECK: call <2 x float> @llvm.cos.v2f32
-float2 test_cos_float2 ( float2 p0 ) {
- return cos ( p0 );
-}
-// CHECK: define noundef <3 x float> @
+float2 test_cos_float2(float2 p0) { return cos(p0); }
+// CHECK: define noundef <3 x float> @"?test_cos_float3
// CHECK: call <3 x float> @llvm.cos.v3f32
-float3 test_cos_float3 ( float3 p0 ) {
- return cos ( p0 );
-}
-// CHECK: define noundef <4 x float> @
+float3 test_cos_float3(float3 p0) { return cos(p0); }
+// CHECK: define noundef <4 x float> @"?test_cos_float4
// CHECK: call <4 x float> @llvm.cos.v4f32
-float4 test_cos_float4 ( float4 p0 ) {
- return cos ( p0 );
-}
+float4 test_cos_float4(float4 p0) { return cos(p0); }
diff --git a/clang/test/CodeGenHLSL/builtins/floor.hlsl b/clang/test/CodeGenHLSL/builtins/floor.hlsl
index 357661761b762a..d2a2f6e52f1ec3 100644
--- a/clang/test/CodeGenHLSL/builtins/floor.hlsl
+++ b/clang/test/CodeGenHLSL/builtins/floor.hlsl
@@ -1,79 +1,56 @@
// RUN: %clang_cc1 -std=hlsl2021 -finclude-default-header -x hlsl -triple \
// RUN: dxil-pc-shadermodel6.3-library %s -fnative-half-type \
-// RUN: -emit-llvm -disable-llvm-passes -O3 -o - | FileCheck %s
+// RUN: -emit-llvm -disable-llvm-passes -o - | FileCheck %s \
+// RUN: --check-prefixes=CHECK,NATIVE_HALF
// RUN: %clang_cc1 -std=hlsl2021 -finclude-default-header -x hlsl -triple \
// RUN: dxil-pc-shadermodel6.3-library %s -emit-llvm -disable-llvm-passes \
-// RUN: -o - | FileCheck %s --check-prefix=NO_HALF
+// RUN: -o - | FileCheck %s --check-prefixes=CHECK,NO_HALF
using hlsl::floor;
-// CHECK: define noundef half @
-// CHECK: call half @llvm.floor.f16(
+// NATIVE_HALF: define noundef half @
+// NATIVE_HALF: call half @llvm.floor.f16(
// NO_HALF: define noundef float @"?test_floor_half@@YA$halff@$halff@@Z"(
// NO_HALF: call float @llvm.floor.f32(float %0)
-half test_floor_half ( half p0 ) {
- return floor ( p0 );
-}
-// CHECK: define noundef <2 x half> @
-// CHECK: call <2 x half> @llvm.floor.v2f16(
+half test_floor_half(half p0) { return floor(p0); }
+// NATIVE_HALF: define noundef <2 x half> @
+// NATIVE_HALF: call <2 x half> @llvm.floor.v2f16(
// NO_HALF: define noundef <2 x float> @"?test_floor_half2@@YAT?$__vector@$halff@$01 at __clang@@T12@@Z"(
// NO_HALF: call <2 x float> @llvm.floor.v2f32(
-half2 test_floor_half2 ( half2 p0 ) {
- return floor ( p0 );
-}
-// CHECK: define noundef <3 x half> @
-// CHECK: call <3 x half> @llvm.floor.v3f16(
+half2 test_floor_half2(half2 p0) { return floor(p0); }
+// NATIVE_HALF: define noundef <3 x half> @
+// NATIVE_HALF: call <3 x half> @llvm.floor.v3f16(
// NO_HALF: define noundef <3 x float> @"?test_floor_half3@@YAT?$__vector@$halff@$02 at __clang@@T12@@Z"(
// NO_HALF: call <3 x float> @llvm.floor.v3f32(
-half3 test_floor_half3 ( half3 p0 ) {
- return floor ( p0 );
-}
-// CHECK: define noundef <4 x half> @
-// CHECK: call <4 x half> @llvm.floor.v4f16(
+half3 test_floor_half3(half3 p0) { return floor(p0); }
+// NATIVE_HALF: define noundef <4 x half> @
+// NATIVE_HALF: call <4 x half> @llvm.floor.v4f16(
// NO_HALF: define noundef <4 x float> @"?test_floor_half4@@YAT?$__vector@$halff@$03 at __clang@@T12@@Z"(
// NO_HALF: call <4 x float> @llvm.floor.v4f32(
-half4 test_floor_half4 ( half4 p0 ) {
- return floor ( p0 );
-}
+half4 test_floor_half4(half4 p0) { return floor(p0); }
// CHECK: define noundef float @
// CHECK: call float @llvm.floor.f32(
-float test_floor_float ( float p0 ) {
- return floor ( p0 );
-}
+float test_floor_float(float p0) { return floor(p0); }
// CHECK: define noundef <2 x float> @
// CHECK: call <2 x float> @llvm.floor.v2f32(
-float2 test_floor_float2 ( float2 p0 ) {
- return floor ( p0 );
-}
+float2 test_floor_float2(float2 p0) { return floor(p0); }
// CHECK: define noundef <3 x float> @
// CHECK: call <3 x float> @llvm.floor.v3f32(
-float3 test_floor_float3 ( float3 p0 ) {
- return floor ( p0 );
-}
+float3 test_floor_float3(float3 p0) { return floor(p0); }
// CHECK: define noundef <4 x float> @
// CHECK: call <4 x float> @llvm.floor.v4f32(
-float4 test_floor_float4 ( float4 p0 ) {
- return floor ( p0 );
-}
+float4 test_floor_float4(float4 p0) { return floor(p0); }
// CHECK: define noundef double @
// CHECK: call double @llvm.floor.f64(
-double test_floor_double ( double p0 ) {
- return floor ( p0 );
-}
+double test_floor_double(double p0) { return floor(p0); }
// CHECK: define noundef <2 x double> @
// CHECK: call <2 x double> @llvm.floor.v2f64(
-double2 test_floor_double2 ( double2 p0 ) {
- return floor ( p0 );
-}
+double2 test_floor_double2(double2 p0) { return floor(p0); }
// CHECK: define noundef <3 x double> @
// CHECK: call <3 x double> @llvm.floor.v3f64(
-double3 test_floor_double3 ( double3 p0 ) {
- return floor ( p0 );
-}
+double3 test_floor_double3(double3 p0) { return floor(p0); }
// CHECK: define noundef <4 x double> @
// CHECK: call <4 x double> @llvm.floor.v4f64(
-double4 test_floor_double4 ( double4 p0 ) {
- return floor ( p0 );
-}
+double4 test_floor_double4(double4 p0) { return floor(p0); }
diff --git a/clang/test/CodeGenHLSL/builtins/log.hlsl b/clang/test/CodeGenHLSL/builtins/log.hlsl
index 6a8e4ac2e5f294..ecbdf1e98ac346 100644
--- a/clang/test/CodeGenHLSL/builtins/log.hlsl
+++ b/clang/test/CodeGenHLSL/builtins/log.hlsl
@@ -1,56 +1,41 @@
// RUN: %clang_cc1 -std=hlsl2021 -finclude-default-header -x hlsl -triple \
// RUN: dxil-pc-shadermodel6.3-library %s -fnative-half-type \
-// RUN: -emit-llvm -disable-llvm-passes -O3 -o - | FileCheck %s
+// RUN: -emit-llvm -disable-llvm-passes -o - | FileCheck %s \
+// RUN: --check-prefixes=CHECK,NATIVE_HALF
// RUN: %clang_cc1 -std=hlsl2021 -finclude-default-header -x hlsl -triple \
// RUN: dxil-pc-shadermodel6.3-library %s -emit-llvm -disable-llvm-passes \
-// RUN: -o - | FileCheck %s --check-prefix=NO_HALF
+// RUN: -o - | FileCheck %s --check-prefixes=CHECK,NO_HALF
-// CHECK: define noundef half @
-// CHECK: call half @llvm.log.f16(
+// NATIVE_HALF: define noundef half @
+// NATIVE_HALF: call half @llvm.log.f16(
// NO_HALF: define noundef float @"?test_log_half@@YA$halff@$halff@@Z"(
// NO_HALF: call float @llvm.log.f32(
-half test_log_half ( half p0 ) {
- return log ( p0 );
-}
-// CHECK: define noundef <2 x half> @
-// CHECK: call <2 x half> @llvm.log.v2f16
-// NO_HALF: define noundef <2 x float> @"?test_log_float2@@YAT?$__vector at M$01 at __clang@@T12@@Z"(
+half test_log_half(half p0) { return log(p0); }
+// NATIVE_HALF: define noundef <2 x half> @
+// NATIVE_HALF: call <2 x half> @llvm.log.v2f16
+// NO_HALF: define noundef <2 x float> @"?test_log_half2
// NO_HALF: call <2 x float> @llvm.log.v2f32(
-half2 test_log_half2 ( half2 p0 ) {
- return log ( p0 );
-}
-// CHECK: define noundef <3 x half> @
-// CHECK: call <3 x half> @llvm.log.v3f16
-// NO_HALF: define noundef <3 x float> @"?test_log_float3@@YAT?$__vector at M$02 at __clang@@T12@@Z"(
+half2 test_log_half2(half2 p0) { return log(p0); }
+// NATIVE_HALF: define noundef <3 x half> @
+// NATIVE_HALF: call <3 x half> @llvm.log.v3f16
+// NO_HALF: define noundef <3 x float> @"?test_log_half3
// NO_HALF: call <3 x float> @llvm.log.v3f32(
-half3 test_log_half3 ( half3 p0 ) {
- return log ( p0 );
-}
-// CHECK: define noundef <4 x half> @
-// CHECK: call <4 x half> @llvm.log.v4f16
-// NO_HALF: define noundef <4 x float> @"?test_log_float4@@YAT?$__vector at M$03 at __clang@@T12@@Z"(
+half3 test_log_half3(half3 p0) { return log(p0); }
+// NATIVE_HALF: define noundef <4 x half> @
+// NATIVE_HALF: call <4 x half> @llvm.log.v4f16
+// NO_HALF: define noundef <4 x float> @"?test_log_half4
// NO_HALF: call <4 x float> @llvm.log.v4f32(
-half4 test_log_half4 ( half4 p0 ) {
- return log ( p0 );
-}
+half4 test_log_half4(half4 p0) { return log(p0); }
-// CHECK: define noundef float @
+// CHECK: define noundef float @"?test_log_float
// CHECK: call float @llvm.log.f32(
-float test_log_float ( float p0 ) {
- return log ( p0 );
-}
-// CHECK: define noundef <2 x float> @
+float test_log_float(float p0) { return log(p0); }
+// CHECK: define noundef <2 x float> @"?test_log_float2
// CHECK: call <2 x float> @llvm.log.v2f32
-float2 test_log_float2 ( float2 p0 ) {
- return log ( p0 );
-}
-// CHECK: define noundef <3 x float> @
+float2 test_log_float2(float2 p0) { return log(p0); }
+// CHECK: define noundef <3 x float> @"?test_log_float3
// CHECK: call <3 x float> @llvm.log.v3f32
-float3 test_log_float3 ( float3 p0 ) {
- return log ( p0 );
-}
-// CHECK: define noundef <4 x float> @
+float3 test_log_float3(float3 p0) { return log(p0); }
+// CHECK: define noundef <4 x float> @"?test_log_float4
// CHECK: call <4 x float> @llvm.log.v4f32
-float4 test_log_float4 ( float4 p0 ) {
- return log ( p0 );
-}
+float4 test_log_float4(float4 p0) { return log(p0); }
diff --git a/clang/test/CodeGenHLSL/builtins/log10.hlsl b/clang/test/CodeGenHLSL/builtins/log10.hlsl
index 8ce24fd530dd3c..638b86e8d5eaf7 100644
--- a/clang/test/CodeGenHLSL/builtins/log10.hlsl
+++ b/clang/test/CodeGenHLSL/builtins/log10.hlsl
@@ -1,56 +1,41 @@
// RUN: %clang_cc1 -std=hlsl2021 -finclude-default-header -x hlsl -triple \
// RUN: dxil-pc-shadermodel6.3-library %s -fnative-half-type \
-// RUN: -emit-llvm -disable-llvm-passes -O3 -o - | FileCheck %s
+// RUN: -emit-llvm -disable-llvm-passes -o - | FileCheck %s \
+// RUN: --check-prefixes=CHECK,NATIVE_HALF
// RUN: %clang_cc1 -std=hlsl2021 -finclude-default-header -x hlsl -triple \
// RUN: dxil-pc-shadermodel6.3-library %s -emit-llvm -disable-llvm-passes \
-// RUN: -o - | FileCheck %s --check-prefix=NO_HALF
+// RUN: -o - | FileCheck %s --check-prefixes=CHECK,NO_HALF
-// CHECK: define noundef half @
-// CHECK: call half @llvm.log10.f16(
-// NO_HALF: define noundef float @"?test_log10_half@@YA$halff@$halff@@Z"(
+// NATIVE_HALF: define noundef half @
+// NATIVE_HALF: call half @llvm.log10.f16(
+// NO_HALF: define noundef float @"?test_log10_half
// NO_HALF: call float @llvm.log10.f32(
-half test_log10_half ( half p0 ) {
- return log10 ( p0 );
-}
-// CHECK: define noundef <2 x half> @
-// CHECK: call <2 x half> @llvm.log10.v2f16
-// NO_HALF: define noundef <2 x float> @"?test_log10_float2@@YAT?$__vector at M$01 at __clang@@T12@@Z"(
+half test_log10_half(half p0) { return log10(p0); }
+// NATIVE_HALF: define noundef <2 x half> @
+// NATIVE_HALF: call <2 x half> @llvm.log10.v2f16
+// NO_HALF: define noundef <2 x float> @"?test_log10_half2
// NO_HALF: call <2 x float> @llvm.log10.v2f32(
-half2 test_log10_half2 ( half2 p0 ) {
- return log10 ( p0 );
-}
-// CHECK: define noundef <3 x half> @
-// CHECK: call <3 x half> @llvm.log10.v3f16
-// NO_HALF: define noundef <3 x float> @"?test_log10_float3@@YAT?$__vector at M$02 at __clang@@T12@@Z"(
+half2 test_log10_half2(half2 p0) { return log10(p0); }
+// NATIVE_HALF: define noundef <3 x half> @
+// NATIVE_HALF: call <3 x half> @llvm.log10.v3f16
+// NO_HALF: define noundef <3 x float> @"?test_log10_half3
// NO_HALF: call <3 x float> @llvm.log10.v3f32(
-half3 test_log10_half3 ( half3 p0 ) {
- return log10 ( p0 );
-}
-// CHECK: define noundef <4 x half> @
-// CHECK: call <4 x half> @llvm.log10.v4f16
-// NO_HALF: define noundef <4 x float> @"?test_log10_float4@@YAT?$__vector at M$03 at __clang@@T12@@Z"(
+half3 test_log10_half3(half3 p0) { return log10(p0); }
+// NATIVE_HALF: define noundef <4 x half> @
+// NATIVE_HALF: call <4 x half> @llvm.log10.v4f16
+// NO_HALF: define noundef <4 x float> @"?test_log10_half4
// NO_HALF: call <4 x float> @llvm.log10.v4f32(
-half4 test_log10_half4 ( half4 p0 ) {
- return log10 ( p0 );
-}
+half4 test_log10_half4(half4 p0) { return log10(p0); }
-// CHECK: define noundef float @
+// CHECK: define noundef float @"?test_log10_float
// CHECK: call float @llvm.log10.f32(
-float test_log10_float ( float p0 ) {
- return log10 ( p0 );
-}
-// CHECK: define noundef <2 x float> @
+float test_log10_float(float p0) { return log10(p0); }
+// CHECK: define noundef <2 x float> @"?test_log10_float2
// CHECK: call <2 x float> @llvm.log10.v2f32
-float2 test_log10_float2 ( float2 p0 ) {
- return log10 ( p0 );
-}
-// CHECK: define noundef <3 x float> @
+float2 test_log10_float2(float2 p0) { return log10(p0); }
+// CHECK: define noundef <3 x float> @"?test_log10_float3
// CHECK: call <3 x float> @llvm.log10.v3f32
-float3 test_log10_float3 ( float3 p0 ) {
- return log10 ( p0 );
-}
-// CHECK: define noundef <4 x float> @
+float3 test_log10_float3(float3 p0) { return log10(p0); }
+// CHECK: define noundef <4 x float> @"?test_log10_float4
// CHECK: call <4 x float> @llvm.log10.v4f32
-float4 test_log10_float4 ( float4 p0 ) {
- return log10 ( p0 );
-}
+float4 test_log10_float4(float4 p0) { return log10(p0); }
diff --git a/clang/test/CodeGenHLSL/builtins/log2.hlsl b/clang/test/CodeGenHLSL/builtins/log2.hlsl
index f0f0a6c7c50e81..9ed8185a06b04f 100644
--- a/clang/test/CodeGenHLSL/builtins/log2.hlsl
+++ b/clang/test/CodeGenHLSL/builtins/log2.hlsl
@@ -1,56 +1,41 @@
// RUN: %clang_cc1 -std=hlsl2021 -finclude-default-header -x hlsl -triple \
// RUN: dxil-pc-shadermodel6.3-library %s -fnative-half-type \
-// RUN: -emit-llvm -disable-llvm-passes -O3 -o - | FileCheck %s
+// RUN: -emit-llvm -disable-llvm-passes -o - | FileCheck %s \
+// RUN: --check-prefixes=CHECK,NATIVE_HALF
// RUN: %clang_cc1 -std=hlsl2021 -finclude-default-header -x hlsl -triple \
// RUN: dxil-pc-shadermodel6.3-library %s -emit-llvm -disable-llvm-passes \
-// RUN: -o - | FileCheck %s --check-prefix=NO_HALF
+// RUN: -o - | FileCheck %s --check-prefixes=CHECK,NO_HALF
-// CHECK: define noundef half @
-// CHECK: call half @llvm.log2.f16(
-// NO_HALF: define noundef float @"?test_log2_half@@YA$halff@$halff@@Z"(
+// NATIVE_HALF: define noundef half @
+// NATIVE_HALF: call half @llvm.log2.f16(
+// NO_HALF: define noundef float @"?test_log2_half
// NO_HALF: call float @llvm.log2.f32(
-half test_log2_half ( half p0 ) {
- return log2 ( p0 );
-}
-// CHECK: define noundef <2 x half> @
-// CHECK: call <2 x half> @llvm.log2.v2f16
-// NO_HALF: define noundef <2 x float> @"?test_log2_float2@@YAT?$__vector at M$01 at __clang@@T12@@Z"(
+half test_log2_half(half p0) { return log2(p0); }
+// NATIVE_HALF: define noundef <2 x half> @
+// NATIVE_HALF: call <2 x half> @llvm.log2.v2f16
+// NO_HALF: define noundef <2 x float> @"?test_log2_half2
// NO_HALF: call <2 x float> @llvm.log2.v2f32(
-half2 test_log2_half2 ( half2 p0 ) {
- return log2 ( p0 );
-}
-// CHECK: define noundef <3 x half> @
-// CHECK: call <3 x half> @llvm.log2.v3f16
-// NO_HALF: define noundef <3 x float> @"?test_log2_float3@@YAT?$__vector at M$02 at __clang@@T12@@Z"(
+half2 test_log2_half2(half2 p0) { return log2(p0); }
+// NATIVE_HALF: define noundef <3 x half> @
+// NATIVE_HALF: call <3 x half> @llvm.log2.v3f16
+// NO_HALF: define noundef <3 x float> @"?test_log2_half3
// NO_HALF: call <3 x float> @llvm.log2.v3f32(
-half3 test_log2_half3 ( half3 p0 ) {
- return log2 ( p0 );
-}
-// CHECK: define noundef <4 x half> @
-// CHECK: call <4 x half> @llvm.log2.v4f16
-// NO_HALF: define noundef <4 x float> @"?test_log2_float4@@YAT?$__vector at M$03 at __clang@@T12@@Z"(
+half3 test_log2_half3(half3 p0) { return log2(p0); }
+// NATIVE_HALF: define noundef <4 x half> @
+// NATIVE_HALF: call <4 x half> @llvm.log2.v4f16
+// NO_HALF: define noundef <4 x float> @"?test_log2_half4
// NO_HALF: call <4 x float> @llvm.log2.v4f32(
-half4 test_log2_half4 ( half4 p0 ) {
- return log2 ( p0 );
-}
+half4 test_log2_half4(half4 p0) { return log2(p0); }
-// CHECK: define noundef float @
+// CHECK: define noundef float @"?test_log2_float
// CHECK: call float @llvm.log2.f32(
-float test_log2_float ( float p0 ) {
- return log2 ( p0 );
-}
-// CHECK: define noundef <2 x float> @
+float test_log2_float(float p0) { return log2(p0); }
+// CHECK: define noundef <2 x float> @"?test_log2_float2
// CHECK: call <2 x float> @llvm.log2.v2f32
-float2 test_log2_float2 ( float2 p0 ) {
- return log2 ( p0 );
-}
-// CHECK: define noundef <3 x float> @
+float2 test_log2_float2(float2 p0) { return log2(p0); }
+// CHECK: define noundef <3 x float> @"?test_log2_float3
// CHECK: call <3 x float> @llvm.log2.v3f32
-float3 test_log2_float3 ( float3 p0 ) {
- return log2 ( p0 );
-}
-// CHECK: define noundef <4 x float> @
+float3 test_log2_float3(float3 p0) { return log2(p0); }
+// CHECK: define noundef <4 x float> @"?test_log2_float4
// CHECK: call <4 x float> @llvm.log2.v4f32
-float4 test_log2_float4 ( float4 p0 ) {
- return log2 ( p0 );
-}
+float4 test_log2_float4(float4 p0) { return log2(p0); }
diff --git a/clang/test/CodeGenHLSL/builtins/max.hlsl b/clang/test/CodeGenHLSL/builtins/max.hlsl
index d8879c3332fb88..272d1e8a10bd7c 100644
--- a/clang/test/CodeGenHLSL/builtins/max.hlsl
+++ b/clang/test/CodeGenHLSL/builtins/max.hlsl
@@ -1,206 +1,134 @@
// RUN: %clang_cc1 -std=hlsl2021 -finclude-default-header -x hlsl -triple \
// RUN: dxil-pc-shadermodel6.3-library %s -fnative-half-type \
-// RUN: -emit-llvm -disable-llvm-passes -O3 -o - | FileCheck %s
+// RUN: -emit-llvm -disable-llvm-passes -o - | FileCheck %s \
+// RUN: --check-prefixes=CHECK,NATIVE_HALF
// RUN: %clang_cc1 -std=hlsl2021 -finclude-default-header -x hlsl -triple \
// RUN: dxil-pc-shadermodel6.3-library %s -emit-llvm -disable-llvm-passes \
-// RUN: -o - | FileCheck %s --check-prefix=NO_HALF
+// RUN: -o - | FileCheck %s --check-prefixes=CHECK,NO_HALF
#ifdef __HLSL_ENABLE_16_BIT
-// CHECK: define noundef i16 @
-// CHECK: call i16 @llvm.smax.i16(
-int16_t test_max_short ( int16_t p0, int16_t p1 ) {
- return max ( p0, p1 );
-}
-// CHECK: define noundef <2 x i16> @
-// CHECK: call <2 x i16> @llvm.smax.v2i16(
-int16_t2 test_max_short2 ( int16_t2 p0, int16_t2 p1 ) {
- return max ( p0, p1 );
-}
-// CHECK: define noundef <3 x i16> @
-// CHECK: call <3 x i16> @llvm.smax.v3i16
-int16_t3 test_max_short3 ( int16_t3 p0, int16_t3 p1 ) {
- return max ( p0, p1 );
-}
-// CHECK: define noundef <4 x i16> @
-// CHECK: call <4 x i16> @llvm.smax.v4i16
-int16_t4 test_max_short4 ( int16_t4 p0, int16_t4 p1 ) {
- return max ( p0, p1 );
-}
+// NATIVE_HALF: define noundef i16 @
+// NATIVE_HALF: call i16 @llvm.smax.i16(
+int16_t test_max_short(int16_t p0, int16_t p1) { return max(p0, p1); }
+// NATIVE_HALF: define noundef <2 x i16> @
+// NATIVE_HALF: call <2 x i16> @llvm.smax.v2i16(
+int16_t2 test_max_short2(int16_t2 p0, int16_t2 p1) { return max(p0, p1); }
+// NATIVE_HALF: define noundef <3 x i16> @
+// NATIVE_HALF: call <3 x i16> @llvm.smax.v3i16
+int16_t3 test_max_short3(int16_t3 p0, int16_t3 p1) { return max(p0, p1); }
+// NATIVE_HALF: define noundef <4 x i16> @
+// NATIVE_HALF: call <4 x i16> @llvm.smax.v4i16
+int16_t4 test_max_short4(int16_t4 p0, int16_t4 p1) { return max(p0, p1); }
-// CHECK: define noundef i16 @
-// CHECK: call i16 @llvm.umax.i16(
-uint16_t test_max_ushort ( uint16_t p0, uint16_t p1 ) {
- return max ( p0, p1 );
-}
-// CHECK: define noundef <2 x i16> @
-// CHECK: call <2 x i16> @llvm.umax.v2i16
-uint16_t2 test_max_ushort2 ( uint16_t2 p0, uint16_t2 p1 ) {
- return max ( p0, p1 );
-}
-// CHECK: define noundef <3 x i16> @
-// CHECK: call <3 x i16> @llvm.umax.v3i16
-uint16_t3 test_max_ushort3 ( uint16_t3 p0, uint16_t3 p1 ) {
- return max ( p0, p1 );
-}
-// CHECK: define noundef <4 x i16> @
-// CHECK: call <4 x i16> @llvm.umax.v4i16
-uint16_t4 test_max_ushort4 ( uint16_t4 p0, uint16_t4 p1 ) {
- return max ( p0, p1 );
-}
+// NATIVE_HALF: define noundef i16 @
+// NATIVE_HALF: call i16 @llvm.umax.i16(
+uint16_t test_max_ushort(uint16_t p0, uint16_t p1) { return max(p0, p1); }
+// NATIVE_HALF: define noundef <2 x i16> @
+// NATIVE_HALF: call <2 x i16> @llvm.umax.v2i16
+uint16_t2 test_max_ushort2(uint16_t2 p0, uint16_t2 p1) { return max(p0, p1); }
+// NATIVE_HALF: define noundef <3 x i16> @
+// NATIVE_HALF: call <3 x i16> @llvm.umax.v3i16
+uint16_t3 test_max_ushort3(uint16_t3 p0, uint16_t3 p1) { return max(p0, p1); }
+// NATIVE_HALF: define noundef <4 x i16> @
+// NATIVE_HALF: call <4 x i16> @llvm.umax.v4i16
+uint16_t4 test_max_ushort4(uint16_t4 p0, uint16_t4 p1) { return max(p0, p1); }
#endif
// CHECK: define noundef i32 @
// CHECK: call i32 @llvm.smax.i32(
-int test_max_int ( int p0, int p1 ) {
- return max ( p0, p1 );
-}
+int test_max_int(int p0, int p1) { return max(p0, p1); }
// CHECK: define noundef <2 x i32> @
// CHECK: call <2 x i32> @llvm.smax.v2i32
-int2 test_max_int2 ( int2 p0, int2 p1 ) {
- return max ( p0, p1 );
-}
+int2 test_max_int2(int2 p0, int2 p1) { return max(p0, p1); }
// CHECK: define noundef <3 x i32> @
// CHECK: call <3 x i32> @llvm.smax.v3i32
-int3 test_max_int3 ( int3 p0, int3 p1 ) {
- return max ( p0, p1 );
-}
+int3 test_max_int3(int3 p0, int3 p1) { return max(p0, p1); }
// CHECK: define noundef <4 x i32> @
// CHECK: call <4 x i32> @llvm.smax.v4i32
-int4 test_max_int4 ( int4 p0, int4 p1) {
- return max ( p0, p1 );
-}
+int4 test_max_int4(int4 p0, int4 p1) { return max(p0, p1); }
// CHECK: define noundef i32 @
// CHECK: call i32 @llvm.umax.i32(
-int test_max_uint ( uint p0, uint p1 ) {
- return max ( p0, p1 );
-}
+int test_max_uint(uint p0, uint p1) { return max(p0, p1); }
// CHECK: define noundef <2 x i32> @
// CHECK: call <2 x i32> @llvm.umax.v2i32
-uint2 test_max_uint2 ( uint2 p0, uint2 p1 ) {
- return max ( p0, p1 );
-}
+uint2 test_max_uint2(uint2 p0, uint2 p1) { return max(p0, p1); }
// CHECK: define noundef <3 x i32> @
// CHECK: call <3 x i32> @llvm.umax.v3i32
-uint3 test_max_uint3 ( uint3 p0, uint3 p1 ) {
- return max ( p0, p1 );
-}
+uint3 test_max_uint3(uint3 p0, uint3 p1) { return max(p0, p1); }
// CHECK: define noundef <4 x i32> @
// CHECK: call <4 x i32> @llvm.umax.v4i32
-uint4 test_max_uint4 ( uint4 p0, uint4 p1) {
- return max ( p0, p1 );
-}
+uint4 test_max_uint4(uint4 p0, uint4 p1) { return max(p0, p1); }
// CHECK: define noundef i64 @
// CHECK: call i64 @llvm.smax.i64(
-int64_t test_max_long ( int64_t p0, int64_t p1 ) {
- return max ( p0, p1 );
-}
+int64_t test_max_long(int64_t p0, int64_t p1) { return max(p0, p1); }
// CHECK: define noundef <2 x i64> @
// CHECK: call <2 x i64> @llvm.smax.v2i64
-int64_t2 test_max_long2 ( int64_t2 p0, int64_t2 p1 ) {
- return max ( p0, p1 );
-}
+int64_t2 test_max_long2(int64_t2 p0, int64_t2 p1) { return max(p0, p1); }
// CHECK: define noundef <3 x i64> @
// CHECK: call <3 x i64> @llvm.smax.v3i64
-int64_t3 test_max_long3 ( int64_t3 p0, int64_t3 p1 ) {
- return max ( p0, p1 );
-}
+int64_t3 test_max_long3(int64_t3 p0, int64_t3 p1) { return max(p0, p1); }
// CHECK: define noundef <4 x i64> @
// CHECK: call <4 x i64> @llvm.smax.v4i64
-int64_t4 test_max_long4 ( int64_t4 p0, int64_t4 p1) {
- return max ( p0, p1 );
-}
+int64_t4 test_max_long4(int64_t4 p0, int64_t4 p1) { return max(p0, p1); }
// CHECK: define noundef i64 @
// CHECK: call i64 @llvm.umax.i64(
-uint64_t test_max_long ( uint64_t p0, uint64_t p1 ) {
- return max ( p0, p1 );
-}
+uint64_t test_max_long(uint64_t p0, uint64_t p1) { return max(p0, p1); }
// CHECK: define noundef <2 x i64> @
// CHECK: call <2 x i64> @llvm.umax.v2i64
-uint64_t2 test_max_long2 ( uint64_t2 p0, uint64_t2 p1 ) {
- return max ( p0, p1 );
-}
+uint64_t2 test_max_long2(uint64_t2 p0, uint64_t2 p1) { return max(p0, p1); }
// CHECK: define noundef <3 x i64> @
// CHECK: call <3 x i64> @llvm.umax.v3i64
-uint64_t3 test_max_long3 ( uint64_t3 p0, uint64_t3 p1 ) {
- return max ( p0, p1 );
-}
+uint64_t3 test_max_long3(uint64_t3 p0, uint64_t3 p1) { return max(p0, p1); }
// CHECK: define noundef <4 x i64> @
// CHECK: call <4 x i64> @llvm.umax.v4i64
-uint64_t4 test_max_long4 ( uint64_t4 p0, uint64_t4 p1) {
- return max ( p0, p1 );
-}
+uint64_t4 test_max_long4(uint64_t4 p0, uint64_t4 p1) { return max(p0, p1); }
-
-// CHECK: define noundef half @
-// CHECK: call half @llvm.maxnum.f16(
-// NO_HALF: define noundef float @"?test_max_half@@YA$halff@$halff at 0@Z"(
+// NATIVE_HALF: define noundef half @
+// NATIVE_HALF: call half @llvm.maxnum.f16(
+// NO_HALF: define noundef float @"?test_max_half
// NO_HALF: call float @llvm.maxnum.f32(
-half test_max_half ( half p0, half p1 ) {
- return max ( p0, p1 );
-}
-// CHECK: define noundef <2 x half> @
-// CHECK: call <2 x half> @llvm.maxnum.v2f16
-// NO_HALF: define noundef <2 x float> @"?test_max_float2@@YAT?$__vector at M$01 at __clang@@T12 at 0@Z"(
+half test_max_half(half p0, half p1) { return max(p0, p1); }
+// NATIVE_HALF: define noundef <2 x half> @
+// NATIVE_HALF: call <2 x half> @llvm.maxnum.v2f16
+// NO_HALF: define noundef <2 x float> @"?test_max_half2
// NO_HALF: call <2 x float> @llvm.maxnum.v2f32(
-half2 test_max_half2 ( half2 p0, half2 p1 ) {
- return max ( p0, p1 );
-}
-// CHECK: define noundef <3 x half> @
-// CHECK: call <3 x half> @llvm.maxnum.v3f16
-// NO_HALF: define noundef <3 x float> @"?test_max_float3@@YAT?$__vector at M$02 at __clang@@T12 at 0@Z"(
+half2 test_max_half2(half2 p0, half2 p1) { return max(p0, p1); }
+// NATIVE_HALF: define noundef <3 x half> @
+// NATIVE_HALF: call <3 x half> @llvm.maxnum.v3f16
+// NO_HALF: define noundef <3 x float> @"?test_max_half3
// NO_HALF: call <3 x float> @llvm.maxnum.v3f32(
-half3 test_max_half3 ( half3 p0, half3 p1 ) {
- return max ( p0, p1 );
-}
-// CHECK: define noundef <4 x half> @
-// CHECK: call <4 x half> @llvm.maxnum.v4f16
-// NO_HALF: define noundef <4 x float> @"?test_max_float4@@YAT?$__vector at M$03 at __clang@@T12 at 0@Z"(
+half3 test_max_half3(half3 p0, half3 p1) { return max(p0, p1); }
+// NATIVE_HALF: define noundef <4 x half> @
+// NATIVE_HALF: call <4 x half> @llvm.maxnum.v4f16
+// NO_HALF: define noundef <4 x float> @"?test_max_half4
// NO_HALF: call <4 x float> @llvm.maxnum.v4f32(
-half4 test_max_half4 ( half4 p0, half4 p1 ) {
- return max ( p0, p1 );
-}
+half4 test_max_half4(half4 p0, half4 p1) { return max(p0, p1); }
-// CHECK: define noundef float @
+// CHECK: define noundef float @"?test_max_float
// CHECK: call float @llvm.maxnum.f32(
-float test_max_float ( float p0, float p1 ) {
- return max ( p0, p1 );
-}
-// CHECK: define noundef <2 x float> @
+float test_max_float(float p0, float p1) { return max(p0, p1); }
+// CHECK: define noundef <2 x float> @"?test_max_float2
// CHECK: call <2 x float> @llvm.maxnum.v2f32
-float2 test_max_float2 ( float2 p0, float2 p1 ) {
- return max ( p0, p1 );
-}
-// CHECK: define noundef <3 x float> @
+float2 test_max_float2(float2 p0, float2 p1) { return max(p0, p1); }
+// CHECK: define noundef <3 x float> @"?test_max_float3
// CHECK: call <3 x float> @llvm.maxnum.v3f32
-float3 test_max_float3 ( float3 p0, float3 p1 ) {
- return max ( p0, p1 );
-}
-// CHECK: define noundef <4 x float> @
+float3 test_max_float3(float3 p0, float3 p1) { return max(p0, p1); }
+// CHECK: define noundef <4 x float> @"?test_max_float4
// CHECK: call <4 x float> @llvm.maxnum.v4f32
-float4 test_max_float4 ( float4 p0, float4 p1) {
- return max ( p0, p1 );
-}
+float4 test_max_float4(float4 p0, float4 p1) { return max(p0, p1); }
// CHECK: define noundef double @
// CHECK: call double @llvm.maxnum.f64(
-double test_max_double ( double p0, double p1 ) {
- return max ( p0, p1 );
-}
+double test_max_double(double p0, double p1) { return max(p0, p1); }
// CHECK: define noundef <2 x double> @
// CHECK: call <2 x double> @llvm.maxnum.v2f64
-double2 test_max_double2 ( double2 p0, double2 p1 ) {
- return max ( p0, p1 );
-}
+double2 test_max_double2(double2 p0, double2 p1) { return max(p0, p1); }
// CHECK: define noundef <3 x double> @
// CHECK: call <3 x double> @llvm.maxnum.v3f64
-double3 test_max_double3 ( double3 p0, double3 p1 ) {
- return max ( p0, p1 );
-}
+double3 test_max_double3(double3 p0, double3 p1) { return max(p0, p1); }
// CHECK: define noundef <4 x double> @
// CHECK: call <4 x double> @llvm.maxnum.v4f64
-double4 test_max_double4 ( double4 p0, double4 p1) {
- return max ( p0, p1 );
-}
+double4 test_max_double4(double4 p0, double4 p1) { return max(p0, p1); }
diff --git a/clang/test/CodeGenHLSL/builtins/min.hlsl b/clang/test/CodeGenHLSL/builtins/min.hlsl
index 743053cbdd2620..a0c233dac4d5fc 100644
--- a/clang/test/CodeGenHLSL/builtins/min.hlsl
+++ b/clang/test/CodeGenHLSL/builtins/min.hlsl
@@ -1,207 +1,134 @@
// RUN: %clang_cc1 -std=hlsl2021 -finclude-default-header -x hlsl -triple \
// RUN: dxil-pc-shadermodel6.3-library %s -fnative-half-type \
-// RUN: -emit-llvm -disable-llvm-passes -O3 -o - | FileCheck %s
+// RUN: -emit-llvm -disable-llvm-passes -o - | FileCheck %s \
+// RUN: --check-prefixes=CHECK,NATIVE_HALF
// RUN: %clang_cc1 -std=hlsl2021 -finclude-default-header -x hlsl -triple \
// RUN: dxil-pc-shadermodel6.3-library %s -emit-llvm -disable-llvm-passes \
-// RUN: -o - | FileCheck %s --check-prefix=NO_HALF
+// RUN: -o - | FileCheck %s --check-prefixes=CHECK,NO_HALF
#ifdef __HLSL_ENABLE_16_BIT
-// CHECK: define noundef i16 @
-// CHECK: call i16 @llvm.smin.i16(
-int16_t test_min_short ( int16_t p0, int16_t p1 ) {
- return min ( p0, p1 );
-}
-// CHECK: define noundef <2 x i16> @
-// CHECK: call <2 x i16> @llvm.smin.v2i16(
-int16_t2 test_min_short2 ( int16_t2 p0, int16_t2 p1 ) {
- return min ( p0, p1 );
-}
-// CHECK: define noundef <3 x i16> @
-// CHECK: call <3 x i16> @llvm.smin.v3i16
-int16_t3 test_min_short3 ( int16_t3 p0, int16_t3 p1 ) {
- return min ( p0, p1 );
-}
-// CHECK: define noundef <4 x i16> @
-// CHECK: call <4 x i16> @llvm.smin.v4i16
-int16_t4 test_min_short4 ( int16_t4 p0, int16_t4 p1 ) {
- return min ( p0, p1 );
-}
+// NATIVE_HALF: define noundef i16 @
+// NATIVE_HALF: call i16 @llvm.smin.i16(
+int16_t test_min_short(int16_t p0, int16_t p1) { return min(p0, p1); }
+// NATIVE_HALF: define noundef <2 x i16> @
+// NATIVE_HALF: call <2 x i16> @llvm.smin.v2i16(
+int16_t2 test_min_short2(int16_t2 p0, int16_t2 p1) { return min(p0, p1); }
+// NATIVE_HALF: define noundef <3 x i16> @
+// NATIVE_HALF: call <3 x i16> @llvm.smin.v3i16
+int16_t3 test_min_short3(int16_t3 p0, int16_t3 p1) { return min(p0, p1); }
+// NATIVE_HALF: define noundef <4 x i16> @
+// NATIVE_HALF: call <4 x i16> @llvm.smin.v4i16
+int16_t4 test_min_short4(int16_t4 p0, int16_t4 p1) { return min(p0, p1); }
-
-// CHECK: define noundef i16 @
-// CHECK: call i16 @llvm.umin.i16(
-uint16_t test_min_ushort ( uint16_t p0, uint16_t p1 ) {
- return min ( p0, p1 );
-}
-// CHECK: define noundef <2 x i16> @
-// CHECK: call <2 x i16> @llvm.umin.v2i16
-uint16_t2 test_min_ushort2 ( uint16_t2 p0, uint16_t2 p1 ) {
- return min ( p0, p1 );
-}
-// CHECK: define noundef <3 x i16> @
-// CHECK: call <3 x i16> @llvm.umin.v3i16
-uint16_t3 test_min_ushort3 ( uint16_t3 p0, uint16_t3 p1 ) {
- return min ( p0, p1 );
-}
-// CHECK: define noundef <4 x i16> @
-// CHECK: call <4 x i16> @llvm.umin.v4i16
-uint16_t4 test_min_ushort4 ( uint16_t4 p0, uint16_t4 p1 ) {
- return min ( p0, p1 );
-}
+// NATIVE_HALF: define noundef i16 @
+// NATIVE_HALF: call i16 @llvm.umin.i16(
+uint16_t test_min_ushort(uint16_t p0, uint16_t p1) { return min(p0, p1); }
+// NATIVE_HALF: define noundef <2 x i16> @
+// NATIVE_HALF: call <2 x i16> @llvm.umin.v2i16
+uint16_t2 test_min_ushort2(uint16_t2 p0, uint16_t2 p1) { return min(p0, p1); }
+// NATIVE_HALF: define noundef <3 x i16> @
+// NATIVE_HALF: call <3 x i16> @llvm.umin.v3i16
+uint16_t3 test_min_ushort3(uint16_t3 p0, uint16_t3 p1) { return min(p0, p1); }
+// NATIVE_HALF: define noundef <4 x i16> @
+// NATIVE_HALF: call <4 x i16> @llvm.umin.v4i16
+uint16_t4 test_min_ushort4(uint16_t4 p0, uint16_t4 p1) { return min(p0, p1); }
#endif
// CHECK: define noundef i32 @
// CHECK: call i32 @llvm.smin.i32(
-int test_min_int ( int p0, int p1 ) {
- return min ( p0, p1 );
-}
+int test_min_int(int p0, int p1) { return min(p0, p1); }
// CHECK: define noundef <2 x i32> @
// CHECK: call <2 x i32> @llvm.smin.v2i32
-int2 test_min_int2 ( int2 p0, int2 p1 ) {
- return min ( p0, p1 );
-}
+int2 test_min_int2(int2 p0, int2 p1) { return min(p0, p1); }
// CHECK: define noundef <3 x i32> @
// CHECK: call <3 x i32> @llvm.smin.v3i32
-int3 test_min_int3 ( int3 p0, int3 p1 ) {
- return min ( p0, p1 );
-}
+int3 test_min_int3(int3 p0, int3 p1) { return min(p0, p1); }
// CHECK: define noundef <4 x i32> @
// CHECK: call <4 x i32> @llvm.smin.v4i32
-int4 test_min_int4 ( int4 p0, int4 p1) {
- return min ( p0, p1 );
-}
+int4 test_min_int4(int4 p0, int4 p1) { return min(p0, p1); }
// CHECK: define noundef i32 @
// CHECK: call i32 @llvm.umin.i32(
-int test_min_uint ( uint p0, uint p1 ) {
- return min ( p0, p1 );
-}
+int test_min_uint(uint p0, uint p1) { return min(p0, p1); }
// CHECK: define noundef <2 x i32> @
// CHECK: call <2 x i32> @llvm.umin.v2i32
-uint2 test_min_uint2 ( uint2 p0, uint2 p1 ) {
- return min ( p0, p1 );
-}
+uint2 test_min_uint2(uint2 p0, uint2 p1) { return min(p0, p1); }
// CHECK: define noundef <3 x i32> @
// CHECK: call <3 x i32> @llvm.umin.v3i32
-uint3 test_min_uint3 ( uint3 p0, uint3 p1 ) {
- return min ( p0, p1 );
-}
+uint3 test_min_uint3(uint3 p0, uint3 p1) { return min(p0, p1); }
// CHECK: define noundef <4 x i32> @
// CHECK: call <4 x i32> @llvm.umin.v4i32
-uint4 test_min_uint4 ( uint4 p0, uint4 p1) {
- return min ( p0, p1 );
-}
+uint4 test_min_uint4(uint4 p0, uint4 p1) { return min(p0, p1); }
// CHECK: define noundef i64 @
// CHECK: call i64 @llvm.smin.i64(
-int64_t test_min_long ( int64_t p0, int64_t p1 ) {
- return min ( p0, p1 );
-}
+int64_t test_min_long(int64_t p0, int64_t p1) { return min(p0, p1); }
// CHECK: define noundef <2 x i64> @
// CHECK: call <2 x i64> @llvm.smin.v2i64
-int64_t2 test_min_long2 ( int64_t2 p0, int64_t2 p1 ) {
- return min ( p0, p1 );
-}
+int64_t2 test_min_long2(int64_t2 p0, int64_t2 p1) { return min(p0, p1); }
// CHECK: define noundef <3 x i64> @
// CHECK: call <3 x i64> @llvm.smin.v3i64
-int64_t3 test_min_long3 ( int64_t3 p0, int64_t3 p1 ) {
- return min ( p0, p1 );
-}
+int64_t3 test_min_long3(int64_t3 p0, int64_t3 p1) { return min(p0, p1); }
// CHECK: define noundef <4 x i64> @
// CHECK: call <4 x i64> @llvm.smin.v4i64
-int64_t4 test_min_long4 ( int64_t4 p0, int64_t4 p1) {
- return min ( p0, p1 );
-}
+int64_t4 test_min_long4(int64_t4 p0, int64_t4 p1) { return min(p0, p1); }
// CHECK: define noundef i64 @
// CHECK: call i64 @llvm.umin.i64(
-uint64_t test_min_long ( uint64_t p0, uint64_t p1 ) {
- return min ( p0, p1 );
-}
+uint64_t test_min_long(uint64_t p0, uint64_t p1) { return min(p0, p1); }
// CHECK: define noundef <2 x i64> @
// CHECK: call <2 x i64> @llvm.umin.v2i64
-uint64_t2 test_min_long2 ( uint64_t2 p0, uint64_t2 p1 ) {
- return min ( p0, p1 );
-}
+uint64_t2 test_min_long2(uint64_t2 p0, uint64_t2 p1) { return min(p0, p1); }
// CHECK: define noundef <3 x i64> @
// CHECK: call <3 x i64> @llvm.umin.v3i64
-uint64_t3 test_min_long3 ( uint64_t3 p0, uint64_t3 p1 ) {
- return min ( p0, p1 );
-}
+uint64_t3 test_min_long3(uint64_t3 p0, uint64_t3 p1) { return min(p0, p1); }
// CHECK: define noundef <4 x i64> @
// CHECK: call <4 x i64> @llvm.umin.v4i64
-uint64_t4 test_min_long4 ( uint64_t4 p0, uint64_t4 p1) {
- return min ( p0, p1 );
-}
-
+uint64_t4 test_min_long4(uint64_t4 p0, uint64_t4 p1) { return min(p0, p1); }
-// CHECK: define noundef half @
-// CHECK: call half @llvm.minnum.f16(
-// NO_HALF: define noundef float @"?test_min_half@@YA$halff@$halff at 0@Z"(
+// NATIVE_HALF: define noundef half @
+// NATIVE_HALF: call half @llvm.minnum.f16(
+// NO_HALF: define noundef float @"?test_min_half
// NO_HALF: call float @llvm.minnum.f32(
-half test_min_half ( half p0, half p1 ) {
- return min ( p0, p1 );
-}
-// CHECK: define noundef <2 x half> @
-// CHECK: call <2 x half> @llvm.minnum.v2f16
-// NO_HALF: define noundef <2 x float> @"?test_min_float2@@YAT?$__vector at M$01 at __clang@@T12 at 0@Z"(
+half test_min_half(half p0, half p1) { return min(p0, p1); }
+// NATIVE_HALF: define noundef <2 x half> @
+// NATIVE_HALF: call <2 x half> @llvm.minnum.v2f16
+// NO_HALF: define noundef <2 x float> @"?test_min_half2
// NO_HALF: call <2 x float> @llvm.minnum.v2f32(
-half2 test_min_half2 ( half2 p0, half2 p1 ) {
- return min ( p0, p1 );
-}
-// CHECK: define noundef <3 x half> @
-// CHECK: call <3 x half> @llvm.minnum.v3f16
-// NO_HALF: define noundef <3 x float> @"?test_min_float3@@YAT?$__vector at M$02 at __clang@@T12 at 0@Z"(
+half2 test_min_half2(half2 p0, half2 p1) { return min(p0, p1); }
+// NATIVE_HALF: define noundef <3 x half> @
+// NATIVE_HALF: call <3 x half> @llvm.minnum.v3f16
+// NO_HALF: define noundef <3 x float> @"?test_min_half3
// NO_HALF: call <3 x float> @llvm.minnum.v3f32(
-half3 test_min_half3 ( half3 p0, half3 p1 ) {
- return min ( p0, p1 );
-}
-// CHECK: define noundef <4 x half> @
-// CHECK: call <4 x half> @llvm.minnum.v4f16
-// NO_HALF: define noundef <4 x float> @"?test_min_float4@@YAT?$__vector at M$03 at __clang@@T12 at 0@Z"(
+half3 test_min_half3(half3 p0, half3 p1) { return min(p0, p1); }
+// NATIVE_HALF: define noundef <4 x half> @
+// NATIVE_HALF: call <4 x half> @llvm.minnum.v4f16
+// NO_HALF: define noundef <4 x float> @"?test_min_half4
// NO_HALF: call <4 x float> @llvm.minnum.v4f32(
-half4 test_min_half4 ( half4 p0, half4 p1 ) {
- return min ( p0, p1 );
-}
+half4 test_min_half4(half4 p0, half4 p1) { return min(p0, p1); }
// CHECK: define noundef float @
// CHECK: call float @llvm.minnum.f32(
-float test_min_float ( float p0, float p1 ) {
- return min ( p0, p1 );
-}
+float test_min_float(float p0, float p1) { return min(p0, p1); }
// CHECK: define noundef <2 x float> @
// CHECK: call <2 x float> @llvm.minnum.v2f32
-float2 test_min_float2 ( float2 p0, float2 p1 ) {
- return min ( p0, p1 );
-}
+float2 test_min_float2(float2 p0, float2 p1) { return min(p0, p1); }
// CHECK: define noundef <3 x float> @
// CHECK: call <3 x float> @llvm.minnum.v3f32
-float3 test_min_float3 ( float3 p0, float3 p1 ) {
- return min ( p0, p1 );
-}
+float3 test_min_float3(float3 p0, float3 p1) { return min(p0, p1); }
// CHECK: define noundef <4 x float> @
// CHECK: call <4 x float> @llvm.minnum.v4f32
-float4 test_min_float4 ( float4 p0, float4 p1) {
- return min ( p0, p1 );
-}
+float4 test_min_float4(float4 p0, float4 p1) { return min(p0, p1); }
// CHECK: define noundef double @
// CHECK: call double @llvm.minnum.f64(
-double test_min_double ( double p0, double p1 ) {
- return min ( p0, p1 );
-}
+double test_min_double(double p0, double p1) { return min(p0, p1); }
// CHECK: define noundef <2 x double> @
// CHECK: call <2 x double> @llvm.minnum.v2f64
-double2 test_min_double2 ( double2 p0, double2 p1 ) {
- return min ( p0, p1 );
-}
+double2 test_min_double2(double2 p0, double2 p1) { return min(p0, p1); }
// CHECK: define noundef <3 x double> @
// CHECK: call <3 x double> @llvm.minnum.v3f64
-double3 test_min_double3 ( double3 p0, double3 p1 ) {
- return min ( p0, p1 );
-}
+double3 test_min_double3(double3 p0, double3 p1) { return min(p0, p1); }
// CHECK: define noundef <4 x double> @
// CHECK: call <4 x double> @llvm.minnum.v4f64
-double4 test_min_double4 ( double4 p0, double4 p1) {
- return min ( p0, p1 );
-}
+double4 test_min_double4(double4 p0, double4 p1) { return min(p0, p1); }
diff --git a/clang/test/CodeGenHLSL/builtins/pow.hlsl b/clang/test/CodeGenHLSL/builtins/pow.hlsl
index 86bfe98058a6eb..e996ca2f336410 100644
--- a/clang/test/CodeGenHLSL/builtins/pow.hlsl
+++ b/clang/test/CodeGenHLSL/builtins/pow.hlsl
@@ -1,89 +1,54 @@
// RUN: %clang_cc1 -std=hlsl2021 -finclude-default-header -x hlsl -triple \
// RUN: dxil-pc-shadermodel6.3-library %s -fnative-half-type \
-// RUN: -emit-llvm -disable-llvm-passes -O3 -o - | FileCheck %s
+// RUN: -emit-llvm -disable-llvm-passes -o - | FileCheck %s \
+// RUN: --check-prefixes=CHECK,NATIVE_HALF
// RUN: %clang_cc1 -std=hlsl2021 -finclude-default-header -x hlsl -triple \
// RUN: dxil-pc-shadermodel6.3-library %s -emit-llvm -disable-llvm-passes \
-// RUN: -o - | FileCheck %s --check-prefix=NO_HALF
+// RUN: -o - | FileCheck %s --check-prefixes=CHECK,NO_HALF
-// CHECK: define noundef half @
-// CHECK: call half @llvm.pow.f16(
-// NO_HALF: define noundef float @"?test_pow_half@@YA$halff@$halff at 0@Z"(
+// NATIVE_HALF: define noundef half @
+// NATIVE_HALF: call half @llvm.pow.f16(
+// NO_HALF: define noundef float @"?test_pow_half
// NO_HALF: call float @llvm.pow.f32(
-half test_pow_half(half p0, half p1)
-{
- return pow(p0, p1);
-}
-// CHECK: define noundef <2 x half> @"?test_pow_half2@@YAT?$__vector@$f16@$01 at __clang@@T12 at 0@Z"(
-// CHECK: call <2 x half> @llvm.pow.v2f16
-// NO_HALF: define noundef <2 x float> @"?test_pow_float2@@YAT?$__vector at M$01 at __clang@@T12 at 0@Z"(
+half test_pow_half(half p0, half p1) { return pow(p0, p1); }
+// NATIVE_HALF: define noundef <2 x half> @"?test_pow_half2
+// NATIVE_HALF: call <2 x half> @llvm.pow.v2f16
+// NO_HALF: define noundef <2 x float> @"?test_pow_half2
// NO_HALF: call <2 x float> @llvm.pow.v2f32(
-half2 test_pow_half2(half2 p0, half2 p1)
-{
- return pow(p0, p1);
-}
-// CHECK: define noundef <3 x half> @"?test_pow_half3@@YAT?$__vector@$f16@$02 at __clang@@T12 at 0@Z"(
-// CHECK: call <3 x half> @llvm.pow.v3f16
-// NO_HALF: define noundef <3 x float> @"?test_pow_float3@@YAT?$__vector at M$02 at __clang@@T12 at 0@Z"(
+half2 test_pow_half2(half2 p0, half2 p1) { return pow(p0, p1); }
+// NATIVE_HALF: define noundef <3 x half> @"?test_pow_half3
+// NATIVE_HALF: call <3 x half> @llvm.pow.v3f16
+// NO_HALF: define noundef <3 x float> @"?test_pow_half3
// NO_HALF: call <3 x float> @llvm.pow.v3f32(
-half3 test_pow_half3(half3 p0, half3 p1)
-{
- return pow(p0, p1);
-}
-// CHECK: define noundef <4 x half> @"?test_pow_half4@@YAT?$__vector@$f16@$03 at __clang@@T12 at 0@Z"(
-// CHECK: call <4 x half> @llvm.pow.v4f16
-// NO_HALF: define noundef <4 x float> @"?test_pow_float4@@YAT?$__vector at M$03 at __clang@@T12 at 0@Z"(
+half3 test_pow_half3(half3 p0, half3 p1) { return pow(p0, p1); }
+// NATIVE_HALF: define noundef <4 x half> @"?test_pow_half4
+// NATIVE_HALF: call <4 x half> @llvm.pow.v4f16
+// NO_HALF: define noundef <4 x float> @"?test_pow_half4
// NO_HALF: call <4 x float> @llvm.pow.v4f32(
-half4 test_pow_half4(half4 p0, half4 p1)
-{
- return pow(p0, p1);
-}
+half4 test_pow_half4(half4 p0, half4 p1) { return pow(p0, p1); }
-// CHECK: define noundef float @"?test_pow_float@@YAMMM at Z"(
+// CHECK: define noundef float @"?test_pow_float
// CHECK: call float @llvm.pow.f32(
-float test_pow_float(float p0, float p1)
-{
- return pow(p0, p1);
-}
-// CHECK: define noundef <2 x float> @"?test_pow_float2@@YAT?$__vector at M$01 at __clang@@T12 at 0@Z"(
+float test_pow_float(float p0, float p1) { return pow(p0, p1); }
+// CHECK: define noundef <2 x float> @"?test_pow_float2
// CHECK: call <2 x float> @llvm.pow.v2f32
-float2 test_pow_float2(float2 p0, float2 p1)
-{
- return pow(p0, p1);
-}
-// CHECK: define noundef <3 x float> @"?test_pow_float3@@YAT?$__vector at M$02 at __clang@@T12 at 0@Z"(
+float2 test_pow_float2(float2 p0, float2 p1) { return pow(p0, p1); }
+// CHECK: define noundef <3 x float> @"?test_pow_float3
// CHECK: call <3 x float> @llvm.pow.v3f32
-float3 test_pow_float3(float3 p0, float3 p1)
-{
- return pow(p0, p1);
-}
-// CHECK: define noundef <4 x float> @"?test_pow_float4@@YAT?$__vector at M$03 at __clang@@T12 at 0@Z"(
+float3 test_pow_float3(float3 p0, float3 p1) { return pow(p0, p1); }
+// CHECK: define noundef <4 x float> @"?test_pow_float4
// CHECK: call <4 x float> @llvm.pow.v4f32
-float4 test_pow_float4(float4 p0, float4 p1)
-{
- return pow(p0, p1);
-}
+float4 test_pow_float4(float4 p0, float4 p1) { return pow(p0, p1); }
// CHECK: define noundef double @"?test_pow_double@@YANNN at Z"(
// CHECK: call double @llvm.pow.f64(
-double test_pow_double(double p0, double p1)
-{
- return pow(p0, p1);
-}
+double test_pow_double(double p0, double p1) { return pow(p0, p1); }
// CHECK: define noundef <2 x double> @"?test_pow_double2@@YAT?$__vector at N$01 at __clang@@T12 at 0@Z"(
// CHECK: call <2 x double> @llvm.pow.v2f64
-double2 test_pow_double2(double2 p0, double2 p1)
-{
- return pow(p0, p1);
-}
+double2 test_pow_double2(double2 p0, double2 p1) { return pow(p0, p1); }
// CHECK: define noundef <3 x double> @"?test_pow_double3@@YAT?$__vector at N$02 at __clang@@T12 at 0@Z"(
// CHECK: call <3 x double> @llvm.pow.v3f64
-double3 test_pow_double3(double3 p0, double3 p1)
-{
- return pow(p0, p1);
-}
+double3 test_pow_double3(double3 p0, double3 p1) { return pow(p0, p1); }
// CHECK: define noundef <4 x double> @"?test_pow_double4@@YAT?$__vector at N$03 at __clang@@T12 at 0@Z"(
// CHECK: call <4 x double> @llvm.pow.v4f64
-double4 test_pow_double4(double4 p0, double4 p1)
-{
- return pow(p0, p1);
-}
+double4 test_pow_double4(double4 p0, double4 p1) { return pow(p0, p1); }
diff --git a/clang/test/CodeGenHLSL/builtins/sin.hlsl b/clang/test/CodeGenHLSL/builtins/sin.hlsl
index 2445e6063a7052..ffb52214913886 100644
--- a/clang/test/CodeGenHLSL/builtins/sin.hlsl
+++ b/clang/test/CodeGenHLSL/builtins/sin.hlsl
@@ -1,56 +1,41 @@
// RUN: %clang_cc1 -std=hlsl2021 -finclude-default-header -x hlsl -triple \
// RUN: dxil-pc-shadermodel6.3-library %s -fnative-half-type \
-// RUN: -emit-llvm -disable-llvm-passes -O3 -o - | FileCheck %s
+// RUN: -emit-llvm -disable-llvm-passes -o - | FileCheck %s \
+// RUN: --check-prefixes=CHECK,NATIVE_HALF
// RUN: %clang_cc1 -std=hlsl2021 -finclude-default-header -x hlsl -triple \
// RUN: dxil-pc-shadermodel6.3-library %s -emit-llvm -disable-llvm-passes \
-// RUN: -o - | FileCheck %s --check-prefix=NO_HALF
+// RUN: -o - | FileCheck %s --check-prefixes=CHECK,NO_HALF
-// CHECK: define noundef half @
-// CHECK: call half @llvm.sin.f16(
+// NATIVE_HALF: define noundef half @
+// NATIVE_HALF: call half @llvm.sin.f16(
// NO_HALF: define noundef float @"?test_sin_half@@YA$halff@$halff@@Z"(
// NO_HALF: call float @llvm.sin.f32(
-half test_sin_half ( half p0 ) {
- return sin ( p0 );
-}
-// CHECK: define noundef <2 x half> @
-// CHECK: call <2 x half> @llvm.sin.v2f16
-// NO_HALF: define noundef <2 x float> @"?test_sin_float2@@YAT?$__vector at M$01 at __clang@@T12@@Z"(
+half test_sin_half(half p0) { return sin(p0); }
+// NATIVE_HALF: define noundef <2 x half> @
+// NATIVE_HALF: call <2 x half> @llvm.sin.v2f16
+// NO_HALF: define noundef <2 x float> @"?test_sin_half2
// NO_HALF: call <2 x float> @llvm.sin.v2f32(
-half2 test_sin_half2 ( half2 p0 ) {
- return sin ( p0 );
-}
-// CHECK: define noundef <3 x half> @
-// CHECK: call <3 x half> @llvm.sin.v3f16
-// NO_HALF: define noundef <3 x float> @"?test_sin_float3@@YAT?$__vector at M$02 at __clang@@T12@@Z"(
+half2 test_sin_half2(half2 p0) { return sin(p0); }
+// NATIVE_HALF: define noundef <3 x half> @
+// NATIVE_HALF: call <3 x half> @llvm.sin.v3f16
+// NO_HALF: define noundef <3 x float> @"?test_sin_half3
// NO_HALF: call <3 x float> @llvm.sin.v3f32(
-half3 test_sin_half3 ( half3 p0 ) {
- return sin ( p0 );
-}
-// CHECK: define noundef <4 x half> @
-// CHECK: call <4 x half> @llvm.sin.v4f16
-// NO_HALF: define noundef <4 x float> @"?test_sin_float4@@YAT?$__vector at M$03 at __clang@@T12@@Z"(
+half3 test_sin_half3(half3 p0) { return sin(p0); }
+// NATIVE_HALF: define noundef <4 x half> @
+// NATIVE_HALF: call <4 x half> @llvm.sin.v4f16
+// NO_HALF: define noundef <4 x float> @"?test_sin_half4
// NO_HALF: call <4 x float> @llvm.sin.v4f32(
-half4 test_sin_half4 ( half4 p0 ) {
- return sin ( p0 );
-}
+half4 test_sin_half4(half4 p0) { return sin(p0); }
// CHECK: define noundef float @
// CHECK: call float @llvm.sin.f32(
-float test_sin_float ( float p0 ) {
- return sin ( p0 );
-}
+float test_sin_float(float p0) { return sin(p0); }
// CHECK: define noundef <2 x float> @
// CHECK: call <2 x float> @llvm.sin.v2f32
-float2 test_sin_float2 ( float2 p0 ) {
- return sin ( p0 );
-}
+float2 test_sin_float2(float2 p0) { return sin(p0); }
// CHECK: define noundef <3 x float> @
// CHECK: call <3 x float> @llvm.sin.v3f32
-float3 test_sin_float3 ( float3 p0 ) {
- return sin ( p0 );
-}
+float3 test_sin_float3(float3 p0) { return sin(p0); }
// CHECK: define noundef <4 x float> @
// CHECK: call <4 x float> @llvm.sin.v4f32
-float4 test_sin_float4 ( float4 p0 ) {
- return sin ( p0 );
-}
+float4 test_sin_float4(float4 p0) { return sin(p0); }
diff --git a/clang/test/CodeGenHLSL/builtins/trunc.hlsl b/clang/test/CodeGenHLSL/builtins/trunc.hlsl
index 4ae3cd20257ec0..6078aae5f873fe 100644
--- a/clang/test/CodeGenHLSL/builtins/trunc.hlsl
+++ b/clang/test/CodeGenHLSL/builtins/trunc.hlsl
@@ -1,56 +1,47 @@
// RUN: %clang_cc1 -std=hlsl2021 -finclude-default-header -x hlsl -triple \
// RUN: dxil-pc-shadermodel6.3-library %s -fnative-half-type \
-// RUN: -emit-llvm -disable-llvm-passes -O3 -o - | FileCheck %s
+// RUN: -emit-llvm -disable-llvm-passes -o - | FileCheck %s \
+// RUN: --check-prefixes=CHECK,NATIVE_HALF
// RUN: %clang_cc1 -std=hlsl2021 -finclude-default-header -x hlsl -triple \
// RUN: dxil-pc-shadermodel6.3-library %s -emit-llvm -disable-llvm-passes \
-// RUN: -o - | FileCheck %s --check-prefix=NO_HALF
+// RUN: -o - | FileCheck %s --check-prefixes=CHECK,NO_HALF
-// CHECK: define noundef half @
-// CHECK: call half @llvm.trunc.f16(
-// NO_HALF: define noundef float @"?test_trunc_half@@YA$halff@$halff@@Z"(
+// NATIVE_HALF: define noundef half @"?test_trunc_half
+// NATIVE_HALF: call half @llvm.trunc.f16(
+// NO_HALF: define noundef float @"?test_trunc_half
// NO_HALF: call float @llvm.trunc.f32(
-half test_trunc_half ( half p0 ) {
- return trunc ( p0 );
-}
-// CHECK: define noundef <2 x half> @
-// CHECK: call <2 x half> @llvm.trunc.v2f16
-// NO_HALF: define noundef <2 x float> @"?test_trunc_float2@@YAT?$__vector at M$01 at __clang@@T12@@Z"(
+half test_trunc_half(half p0) { return trunc(p0); }
+
+// NATIVE_HALF: define noundef <2 x half> @"?test_trunc_half2
+// NATIVE_HALF: call <2 x half> @llvm.trunc.v2f16
+// NO_HALF: define noundef <2 x float> @"?test_trunc_half2
// NO_HALF: call <2 x float> @llvm.trunc.v2f32(
-half2 test_trunc_half2 ( half2 p0 ) {
- return trunc ( p0 );
-}
-// CHECK: define noundef <3 x half> @
-// CHECK: call <3 x half> @llvm.trunc.v3f16
-// NO_HALF: define noundef <3 x float> @"?test_trunc_float3@@YAT?$__vector at M$02 at __clang@@T12@@Z"(
+half2 test_trunc_half2(half2 p0) { return trunc(p0); }
+
+// NATIVE_HALF: define noundef <3 x half> @"?test_trunc_half3
+// NATIVE_HALF: call <3 x half> @llvm.trunc.v3f16
+// NO_HALF: define noundef <3 x float> @"?test_trunc_half3
// NO_HALF: call <3 x float> @llvm.trunc.v3f32(
-half3 test_trunc_half3 ( half3 p0 ) {
- return trunc ( p0 );
-}
-// CHECK: define noundef <4 x half> @
-// CHECK: call <4 x half> @llvm.trunc.v4f16
-// NO_HALF: define noundef <4 x float> @"?test_trunc_float4@@YAT?$__vector at M$03 at __clang@@T12@@Z"(
+half3 test_trunc_half3(half3 p0) { return trunc(p0); }
+
+// NATIVE_HALF: define noundef <4 x half> @"?test_trunc_half4
+// NATIVE_HALF: call <4 x half> @llvm.trunc.v4f16
+// NO_HALF: define noundef <4 x float> @"?test_trunc_half4
// NO_HALF: call <4 x float> @llvm.trunc.v4f32(
-half4 test_trunc_half4 ( half4 p0 ) {
- return trunc ( p0 );
-}
+half4 test_trunc_half4(half4 p0) { return trunc(p0); }
-// CHECK: define noundef float @
+// CHECK: define noundef float @"?test_trunc_float
// CHECK: call float @llvm.trunc.f32(
-float test_trunc_float ( float p0 ) {
- return trunc ( p0 );
-}
-// CHECK: define noundef <2 x float> @
+float test_trunc_float(float p0) { return trunc(p0); }
+
+// CHECK: define noundef <2 x float> @"?test_trunc_float2
// CHECK: call <2 x float> @llvm.trunc.v2f32
-float2 test_trunc_float2 ( float2 p0 ) {
- return trunc ( p0 );
-}
-// CHECK: define noundef <3 x float> @
+float2 test_trunc_float2(float2 p0) { return trunc(p0); }
+
+// CHECK: define noundef <3 x float> @"?test_trunc_float3
// CHECK: call <3 x float> @llvm.trunc.v3f32
-float3 test_trunc_float3 ( float3 p0 ) {
- return trunc ( p0 );
-}
-// CHECK: define noundef <4 x float> @
+float3 test_trunc_float3(float3 p0) { return trunc(p0); }
+
+// CHECK: define noundef <4 x float> @"?test_trunc_float4
// CHECK: call <4 x float> @llvm.trunc.v4f32
-float4 test_trunc_float4 ( float4 p0 ) {
- return trunc ( p0 );
-}
+float4 test_trunc_float4(float4 p0) { return trunc(p0); }
diff --git a/clang/test/SemaHLSL/VectorOverloadResolution.hlsl b/clang/test/SemaHLSL/VectorOverloadResolution.hlsl
index 81fedc2de31570..2ea7d14e80eebf 100644
--- a/clang/test/SemaHLSL/VectorOverloadResolution.hlsl
+++ b/clang/test/SemaHLSL/VectorOverloadResolution.hlsl
@@ -40,7 +40,7 @@ void Fn3( int64_t2 p0);
// CHECK-NEXT: ImplicitCastExpr {{.*}} 'half2':'half __attribute__((ext_vector_type(2)))' <LValueToRValue>
// CHECK-NEXT: DeclRefExpr {{.*}} 'half2':'half __attribute__((ext_vector_type(2)))' lvalue ParmVar {{.*}} 'p0' 'half2':'half __attribute__((ext_vector_type(2)))'
// CHECKIR-LABEL: Call3
-// CHECKIR: %conv = fptosi <2 x half> {{.*}} to <2 x i64>
+// CHECKIR: {{.*}} = fptosi <2 x half> {{.*}} to <2 x i64>
void Call3(half2 p0) {
Fn3(p0);
}
>From de8e2b7b8649ffa516d357a646eacbce8e69e39e Mon Sep 17 00:00:00 2001
From: Arthur Eubanks <aeubanks at google.com>
Date: Thu, 29 Feb 2024 18:53:02 +0000
Subject: [PATCH 162/406] [test][SROA] Regenerate vector-promotion.ll
---
llvm/test/Transforms/SROA/vector-promotion.ll | 364 +++++++++---------
1 file changed, 182 insertions(+), 182 deletions(-)
diff --git a/llvm/test/Transforms/SROA/vector-promotion.ll b/llvm/test/Transforms/SROA/vector-promotion.ll
index e48dd5bb392082..1691f7733acea5 100644
--- a/llvm/test/Transforms/SROA/vector-promotion.ll
+++ b/llvm/test/Transforms/SROA/vector-promotion.ll
@@ -22,21 +22,21 @@ define i32 @test1(<4 x i32> %x, <4 x i32> %y) {
;
; DEBUG-LABEL: @test1(
; DEBUG-NEXT: entry:
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META9:![0-9]+]], metadata !DIExpression()), !dbg [[DBG21:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META11:![0-9]+]], metadata !DIExpression()), !dbg [[DBG22:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META12:![0-9]+]], metadata !DIExpression()), !dbg [[DBG23:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META9:![0-9]+]], metadata !DIExpression()), !dbg [[DBG21:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META11:![0-9]+]], metadata !DIExpression()), !dbg [[DBG22:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META12:![0-9]+]], metadata !DIExpression()), !dbg [[DBG23:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_0_8_VEC_EXTRACT:%.*]] = extractelement <4 x i32> [[X:%.*]], i32 2, !dbg [[DBG24:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[A_SROA_0_8_VEC_EXTRACT]], metadata [[META13:![0-9]+]], metadata !DIExpression()), !dbg [[DBG24]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META15:![0-9]+]], metadata !DIExpression()), !dbg [[DBG25:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[A_SROA_0_8_VEC_EXTRACT]], metadata [[META13:![0-9]+]], metadata !DIExpression()), !dbg [[DBG24]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META15:![0-9]+]], metadata !DIExpression()), !dbg [[DBG25:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_2_28_VEC_EXTRACT:%.*]] = extractelement <4 x i32> [[Y:%.*]], i32 3, !dbg [[DBG26:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[A_SROA_2_28_VEC_EXTRACT]], metadata [[META16:![0-9]+]], metadata !DIExpression()), !dbg [[DBG26]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META17:![0-9]+]], metadata !DIExpression()), !dbg [[DBG27:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[A_SROA_2_28_VEC_EXTRACT]], metadata [[META16:![0-9]+]], metadata !DIExpression()), !dbg [[DBG26]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META17:![0-9]+]], metadata !DIExpression()), !dbg [[DBG27:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_2_16_VEC_EXTRACT:%.*]] = extractelement <4 x i32> [[Y]], i32 0, !dbg [[DBG28:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[A_SROA_2_16_VEC_EXTRACT]], metadata [[META18:![0-9]+]], metadata !DIExpression()), !dbg [[DBG28]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[A_SROA_2_16_VEC_EXTRACT]], metadata [[META18:![0-9]+]], metadata !DIExpression()), !dbg [[DBG28]]
; DEBUG-NEXT: [[TMP4:%.*]] = add i32 [[A_SROA_0_8_VEC_EXTRACT]], [[A_SROA_2_28_VEC_EXTRACT]], !dbg [[DBG29:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[TMP4]], metadata [[META19:![0-9]+]], metadata !DIExpression()), !dbg [[DBG29]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[TMP4]], metadata [[META19:![0-9]+]], metadata !DIExpression()), !dbg [[DBG29]]
; DEBUG-NEXT: [[TMP5:%.*]] = add i32 [[A_SROA_2_16_VEC_EXTRACT]], [[TMP4]], !dbg [[DBG30:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[TMP5]], metadata [[META20:![0-9]+]], metadata !DIExpression()), !dbg [[DBG30]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[TMP5]], metadata [[META20:![0-9]+]], metadata !DIExpression()), !dbg [[DBG30]]
; DEBUG-NEXT: ret i32 [[TMP5]], !dbg [[DBG31:![0-9]+]]
;
entry:
@@ -71,23 +71,23 @@ define i32 @test2(<4 x i32> %x, <4 x i32> %y) {
;
; DEBUG-LABEL: @test2(
; DEBUG-NEXT: entry:
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META34:![0-9]+]], metadata !DIExpression()), !dbg [[DBG45:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META35:![0-9]+]], metadata !DIExpression()), !dbg [[DBG46:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META36:![0-9]+]], metadata !DIExpression()), !dbg [[DBG47:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META34:![0-9]+]], metadata !DIExpression()), !dbg [[DBG45:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META35:![0-9]+]], metadata !DIExpression()), !dbg [[DBG46:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META36:![0-9]+]], metadata !DIExpression()), !dbg [[DBG47:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_0_8_VEC_EXTRACT:%.*]] = extractelement <4 x i32> [[X:%.*]], i32 2, !dbg [[DBG48:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[A_SROA_0_8_VEC_EXTRACT]], metadata [[META37:![0-9]+]], metadata !DIExpression()), !dbg [[DBG48]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META38:![0-9]+]], metadata !DIExpression()), !dbg [[DBG49:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[A_SROA_0_8_VEC_EXTRACT]], metadata [[META37:![0-9]+]], metadata !DIExpression()), !dbg [[DBG48]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META38:![0-9]+]], metadata !DIExpression()), !dbg [[DBG49:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_2_28_VEC_EXTRACT:%.*]] = extractelement <4 x i32> [[Y:%.*]], i32 3, !dbg [[DBG50:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[A_SROA_2_28_VEC_EXTRACT]], metadata [[META39:![0-9]+]], metadata !DIExpression()), !dbg [[DBG50]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META40:![0-9]+]], metadata !DIExpression()), !dbg [[DBG51:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[A_SROA_2_28_VEC_EXTRACT]], metadata [[META39:![0-9]+]], metadata !DIExpression()), !dbg [[DBG50]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META40:![0-9]+]], metadata !DIExpression()), !dbg [[DBG51:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_2_16_VEC_EXTRACT:%.*]] = shufflevector <4 x i32> [[Y]], <4 x i32> poison, <2 x i32> <i32 0, i32 1>, !dbg [[DBG52:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata <2 x i32> [[A_SROA_2_16_VEC_EXTRACT]], metadata [[META41:![0-9]+]], metadata !DIExpression()), !dbg [[DBG52]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata <2 x i32> [[A_SROA_2_16_VEC_EXTRACT]], metadata [[META41:![0-9]+]], metadata !DIExpression()), !dbg [[DBG52]]
; DEBUG-NEXT: [[TMP3:%.*]] = extractelement <2 x i32> [[A_SROA_2_16_VEC_EXTRACT]], i32 0, !dbg [[DBG53:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[TMP3]], metadata [[META42:![0-9]+]], metadata !DIExpression()), !dbg [[DBG53]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[TMP3]], metadata [[META42:![0-9]+]], metadata !DIExpression()), !dbg [[DBG53]]
; DEBUG-NEXT: [[TMP4:%.*]] = add i32 [[A_SROA_0_8_VEC_EXTRACT]], [[A_SROA_2_28_VEC_EXTRACT]], !dbg [[DBG54:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[TMP4]], metadata [[META43:![0-9]+]], metadata !DIExpression()), !dbg [[DBG54]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[TMP4]], metadata [[META43:![0-9]+]], metadata !DIExpression()), !dbg [[DBG54]]
; DEBUG-NEXT: [[TMP5:%.*]] = add i32 [[TMP3]], [[TMP4]], !dbg [[DBG55:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[TMP5]], metadata [[META44:![0-9]+]], metadata !DIExpression()), !dbg [[DBG55]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[TMP5]], metadata [[META44:![0-9]+]], metadata !DIExpression()), !dbg [[DBG55]]
; DEBUG-NEXT: ret i32 [[TMP5]], !dbg [[DBG56:![0-9]+]]
;
entry:
@@ -123,22 +123,22 @@ define i32 @test3(<4 x i32> %x, <4 x i32> %y) {
;
; DEBUG-LABEL: @test3(
; DEBUG-NEXT: entry:
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META59:![0-9]+]], metadata !DIExpression()), !dbg [[DBG69:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META60:![0-9]+]], metadata !DIExpression()), !dbg [[DBG70:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META61:![0-9]+]], metadata !DIExpression()), !dbg [[DBG71:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META59:![0-9]+]], metadata !DIExpression()), !dbg [[DBG69:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META60:![0-9]+]], metadata !DIExpression()), !dbg [[DBG70:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META61:![0-9]+]], metadata !DIExpression()), !dbg [[DBG71:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_0_8_VEC_INSERT:%.*]] = insertelement <4 x i32> [[X:%.*]], i32 -1, i32 2, !dbg [[DBG72:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_0_8_VEC_EXTRACT:%.*]] = extractelement <4 x i32> [[A_SROA_0_8_VEC_INSERT]], i32 2, !dbg [[DBG73:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[A_SROA_0_8_VEC_EXTRACT]], metadata [[META62:![0-9]+]], metadata !DIExpression()), !dbg [[DBG73]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META63:![0-9]+]], metadata !DIExpression()), !dbg [[DBG74:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[A_SROA_0_8_VEC_EXTRACT]], metadata [[META62:![0-9]+]], metadata !DIExpression()), !dbg [[DBG73]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META63:![0-9]+]], metadata !DIExpression()), !dbg [[DBG74:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_3_28_VEC_EXTRACT:%.*]] = extractelement <4 x i32> zeroinitializer, i32 3, !dbg [[DBG75:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[A_SROA_3_28_VEC_EXTRACT]], metadata [[META64:![0-9]+]], metadata !DIExpression()), !dbg [[DBG75]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META65:![0-9]+]], metadata !DIExpression()), !dbg [[DBG76:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[A_SROA_3_28_VEC_EXTRACT]], metadata [[META64:![0-9]+]], metadata !DIExpression()), !dbg [[DBG75]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META65:![0-9]+]], metadata !DIExpression()), !dbg [[DBG76:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_3_16_VEC_EXTRACT:%.*]] = extractelement <4 x i32> zeroinitializer, i32 0, !dbg [[DBG77:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[A_SROA_3_16_VEC_EXTRACT]], metadata [[META66:![0-9]+]], metadata !DIExpression()), !dbg [[DBG77]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[A_SROA_3_16_VEC_EXTRACT]], metadata [[META66:![0-9]+]], metadata !DIExpression()), !dbg [[DBG77]]
; DEBUG-NEXT: [[TMP4:%.*]] = add i32 [[A_SROA_0_8_VEC_EXTRACT]], [[A_SROA_3_28_VEC_EXTRACT]], !dbg [[DBG78:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[TMP4]], metadata [[META67:![0-9]+]], metadata !DIExpression()), !dbg [[DBG78]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[TMP4]], metadata [[META67:![0-9]+]], metadata !DIExpression()), !dbg [[DBG78]]
; DEBUG-NEXT: [[TMP5:%.*]] = add i32 [[A_SROA_3_16_VEC_EXTRACT]], [[TMP4]], !dbg [[DBG79:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[TMP5]], metadata [[META68:![0-9]+]], metadata !DIExpression()), !dbg [[DBG79]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[TMP5]], metadata [[META68:![0-9]+]], metadata !DIExpression()), !dbg [[DBG79]]
; DEBUG-NEXT: ret i32 [[TMP5]], !dbg [[DBG80:![0-9]+]]
;
entry:
@@ -179,26 +179,26 @@ define i32 @test4(<4 x i32> %x, <4 x i32> %y, ptr %z) {
;
; DEBUG-LABEL: @test4(
; DEBUG-NEXT: entry:
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META83:![0-9]+]], metadata !DIExpression()), !dbg [[DBG94:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META84:![0-9]+]], metadata !DIExpression()), !dbg [[DBG95:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META83:![0-9]+]], metadata !DIExpression()), !dbg [[DBG94:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META84:![0-9]+]], metadata !DIExpression()), !dbg [[DBG95:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_3_16_COPYLOAD:%.*]] = load <4 x i32>, ptr [[Z:%.*]], align 1, !dbg [[DBG96:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META85:![0-9]+]], metadata !DIExpression()), !dbg [[DBG97:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META85:![0-9]+]], metadata !DIExpression()), !dbg [[DBG97:![0-9]+]]
; DEBUG-NEXT: [[Z_TMP1:%.*]] = getelementptr inbounds <4 x i32>, ptr [[Z]], i64 0, i64 2, !dbg [[DBG98:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr [[Z_TMP1]], metadata [[META86:![0-9]+]], metadata !DIExpression()), !dbg [[DBG98]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr [[Z_TMP1]], metadata [[META86:![0-9]+]], metadata !DIExpression()), !dbg [[DBG98]]
; DEBUG-NEXT: [[A_SROA_0_8_COPYLOAD:%.*]] = load i32, ptr [[Z_TMP1]], align 1, !dbg [[DBG99:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_0_8_VEC_INSERT:%.*]] = insertelement <4 x i32> [[X:%.*]], i32 [[A_SROA_0_8_COPYLOAD]], i32 2, !dbg [[DBG99]]
; DEBUG-NEXT: [[A_SROA_0_8_VEC_EXTRACT:%.*]] = extractelement <4 x i32> [[A_SROA_0_8_VEC_INSERT]], i32 2, !dbg [[DBG100:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[A_SROA_0_8_VEC_EXTRACT]], metadata [[META87:![0-9]+]], metadata !DIExpression()), !dbg [[DBG100]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META88:![0-9]+]], metadata !DIExpression()), !dbg [[DBG101:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[A_SROA_0_8_VEC_EXTRACT]], metadata [[META87:![0-9]+]], metadata !DIExpression()), !dbg [[DBG100]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META88:![0-9]+]], metadata !DIExpression()), !dbg [[DBG101:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_3_28_VEC_EXTRACT:%.*]] = extractelement <4 x i32> [[A_SROA_3_16_COPYLOAD]], i32 3, !dbg [[DBG102:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[A_SROA_3_28_VEC_EXTRACT]], metadata [[META89:![0-9]+]], metadata !DIExpression()), !dbg [[DBG102]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META90:![0-9]+]], metadata !DIExpression()), !dbg [[DBG103:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[A_SROA_3_28_VEC_EXTRACT]], metadata [[META89:![0-9]+]], metadata !DIExpression()), !dbg [[DBG102]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META90:![0-9]+]], metadata !DIExpression()), !dbg [[DBG103:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_3_16_VEC_EXTRACT:%.*]] = extractelement <4 x i32> [[A_SROA_3_16_COPYLOAD]], i32 0, !dbg [[DBG104:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[A_SROA_3_16_VEC_EXTRACT]], metadata [[META91:![0-9]+]], metadata !DIExpression()), !dbg [[DBG104]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[A_SROA_3_16_VEC_EXTRACT]], metadata [[META91:![0-9]+]], metadata !DIExpression()), !dbg [[DBG104]]
; DEBUG-NEXT: [[TMP4:%.*]] = add i32 [[A_SROA_0_8_VEC_EXTRACT]], [[A_SROA_3_28_VEC_EXTRACT]], !dbg [[DBG105:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[TMP4]], metadata [[META92:![0-9]+]], metadata !DIExpression()), !dbg [[DBG105]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[TMP4]], metadata [[META92:![0-9]+]], metadata !DIExpression()), !dbg [[DBG105]]
; DEBUG-NEXT: [[TMP5:%.*]] = add i32 [[A_SROA_3_16_VEC_EXTRACT]], [[TMP4]], !dbg [[DBG106:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[TMP5]], metadata [[META93:![0-9]+]], metadata !DIExpression()), !dbg [[DBG106]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[TMP5]], metadata [[META93:![0-9]+]], metadata !DIExpression()), !dbg [[DBG106]]
; DEBUG-NEXT: ret i32 [[TMP5]], !dbg [[DBG107:![0-9]+]]
;
entry:
@@ -243,26 +243,26 @@ define i32 @test4_as1(<4 x i32> %x, <4 x i32> %y, ptr addrspace(1) %z) {
;
; DEBUG-LABEL: @test4_as1(
; DEBUG-NEXT: entry:
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META110:![0-9]+]], metadata !DIExpression()), !dbg [[DBG121:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META111:![0-9]+]], metadata !DIExpression()), !dbg [[DBG122:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META110:![0-9]+]], metadata !DIExpression()), !dbg [[DBG121:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META111:![0-9]+]], metadata !DIExpression()), !dbg [[DBG122:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_3_16_COPYLOAD:%.*]] = load <4 x i32>, ptr addrspace(1) [[Z:%.*]], align 1, !dbg [[DBG123:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META112:![0-9]+]], metadata !DIExpression()), !dbg [[DBG124:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META112:![0-9]+]], metadata !DIExpression()), !dbg [[DBG124:![0-9]+]]
; DEBUG-NEXT: [[Z_TMP1:%.*]] = getelementptr inbounds <4 x i32>, ptr addrspace(1) [[Z]], i16 0, i16 2, !dbg [[DBG125:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr addrspace(1) [[Z_TMP1]], metadata [[META113:![0-9]+]], metadata !DIExpression()), !dbg [[DBG125]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr addrspace(1) [[Z_TMP1]], metadata [[META113:![0-9]+]], metadata !DIExpression()), !dbg [[DBG125]]
; DEBUG-NEXT: [[A_SROA_0_8_COPYLOAD:%.*]] = load i32, ptr addrspace(1) [[Z_TMP1]], align 1, !dbg [[DBG126:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_0_8_VEC_INSERT:%.*]] = insertelement <4 x i32> [[X:%.*]], i32 [[A_SROA_0_8_COPYLOAD]], i32 2, !dbg [[DBG126]]
; DEBUG-NEXT: [[A_SROA_0_8_VEC_EXTRACT:%.*]] = extractelement <4 x i32> [[A_SROA_0_8_VEC_INSERT]], i32 2, !dbg [[DBG127:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[A_SROA_0_8_VEC_EXTRACT]], metadata [[META114:![0-9]+]], metadata !DIExpression()), !dbg [[DBG127]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META115:![0-9]+]], metadata !DIExpression()), !dbg [[DBG128:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[A_SROA_0_8_VEC_EXTRACT]], metadata [[META114:![0-9]+]], metadata !DIExpression()), !dbg [[DBG127]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META115:![0-9]+]], metadata !DIExpression()), !dbg [[DBG128:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_3_28_VEC_EXTRACT:%.*]] = extractelement <4 x i32> [[A_SROA_3_16_COPYLOAD]], i32 3, !dbg [[DBG129:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[A_SROA_3_28_VEC_EXTRACT]], metadata [[META116:![0-9]+]], metadata !DIExpression()), !dbg [[DBG129]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META117:![0-9]+]], metadata !DIExpression()), !dbg [[DBG130:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[A_SROA_3_28_VEC_EXTRACT]], metadata [[META116:![0-9]+]], metadata !DIExpression()), !dbg [[DBG129]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META117:![0-9]+]], metadata !DIExpression()), !dbg [[DBG130:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_3_16_VEC_EXTRACT:%.*]] = extractelement <4 x i32> [[A_SROA_3_16_COPYLOAD]], i32 0, !dbg [[DBG131:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[A_SROA_3_16_VEC_EXTRACT]], metadata [[META118:![0-9]+]], metadata !DIExpression()), !dbg [[DBG131]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[A_SROA_3_16_VEC_EXTRACT]], metadata [[META118:![0-9]+]], metadata !DIExpression()), !dbg [[DBG131]]
; DEBUG-NEXT: [[TMP4:%.*]] = add i32 [[A_SROA_0_8_VEC_EXTRACT]], [[A_SROA_3_28_VEC_EXTRACT]], !dbg [[DBG132:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[TMP4]], metadata [[META119:![0-9]+]], metadata !DIExpression()), !dbg [[DBG132]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[TMP4]], metadata [[META119:![0-9]+]], metadata !DIExpression()), !dbg [[DBG132]]
; DEBUG-NEXT: [[TMP5:%.*]] = add i32 [[A_SROA_3_16_VEC_EXTRACT]], [[TMP4]], !dbg [[DBG133:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[TMP5]], metadata [[META120:![0-9]+]], metadata !DIExpression()), !dbg [[DBG133]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[TMP5]], metadata [[META120:![0-9]+]], metadata !DIExpression()), !dbg [[DBG133]]
; DEBUG-NEXT: ret i32 [[TMP5]], !dbg [[DBG134:![0-9]+]]
;
entry:
@@ -305,25 +305,25 @@ define i32 @test5(<4 x i32> %x, <4 x i32> %y, ptr %z) {
;
; DEBUG-LABEL: @test5(
; DEBUG-NEXT: entry:
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META137:![0-9]+]], metadata !DIExpression()), !dbg [[DBG148:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META138:![0-9]+]], metadata !DIExpression()), !dbg [[DBG149:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META139:![0-9]+]], metadata !DIExpression()), !dbg [[DBG150:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META137:![0-9]+]], metadata !DIExpression()), !dbg [[DBG148:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META138:![0-9]+]], metadata !DIExpression()), !dbg [[DBG149:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META139:![0-9]+]], metadata !DIExpression()), !dbg [[DBG150:![0-9]+]]
; DEBUG-NEXT: [[Z_TMP1:%.*]] = getelementptr inbounds <4 x i32>, ptr [[Z:%.*]], i64 0, i64 2, !dbg [[DBG151:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr [[Z_TMP1]], metadata [[META140:![0-9]+]], metadata !DIExpression()), !dbg [[DBG151]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr [[Z_TMP1]], metadata [[META140:![0-9]+]], metadata !DIExpression()), !dbg [[DBG151]]
; DEBUG-NEXT: [[A_SROA_0_8_VEC_EXTRACT3:%.*]] = extractelement <4 x i32> [[Y:%.*]], i32 2, !dbg [[DBG152:![0-9]+]]
; DEBUG-NEXT: store i32 [[A_SROA_0_8_VEC_EXTRACT3]], ptr [[Z_TMP1]], align 1, !dbg [[DBG152]]
; DEBUG-NEXT: [[A_SROA_0_8_VEC_EXTRACT:%.*]] = extractelement <4 x i32> [[Y]], i32 2, !dbg [[DBG153:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[A_SROA_0_8_VEC_EXTRACT]], metadata [[META141:![0-9]+]], metadata !DIExpression()), !dbg [[DBG153]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META142:![0-9]+]], metadata !DIExpression()), !dbg [[DBG154:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[A_SROA_0_8_VEC_EXTRACT]], metadata [[META141:![0-9]+]], metadata !DIExpression()), !dbg [[DBG153]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META142:![0-9]+]], metadata !DIExpression()), !dbg [[DBG154:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_4_12_VEC_EXTRACT:%.*]] = extractelement <4 x i32> [[Y]], i32 3, !dbg [[DBG155:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[A_SROA_4_12_VEC_EXTRACT]], metadata [[META143:![0-9]+]], metadata !DIExpression()), !dbg [[DBG155]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META144:![0-9]+]], metadata !DIExpression()), !dbg [[DBG156:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[A_SROA_4_12_VEC_EXTRACT]], metadata [[META143:![0-9]+]], metadata !DIExpression()), !dbg [[DBG155]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META144:![0-9]+]], metadata !DIExpression()), !dbg [[DBG156:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_4_0_VEC_EXTRACT:%.*]] = extractelement <4 x i32> [[Y]], i32 0, !dbg [[DBG157:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[A_SROA_4_0_VEC_EXTRACT]], metadata [[META145:![0-9]+]], metadata !DIExpression()), !dbg [[DBG157]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[A_SROA_4_0_VEC_EXTRACT]], metadata [[META145:![0-9]+]], metadata !DIExpression()), !dbg [[DBG157]]
; DEBUG-NEXT: [[TMP4:%.*]] = add i32 [[A_SROA_0_8_VEC_EXTRACT]], [[A_SROA_4_12_VEC_EXTRACT]], !dbg [[DBG158:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[TMP4]], metadata [[META146:![0-9]+]], metadata !DIExpression()), !dbg [[DBG158]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[TMP4]], metadata [[META146:![0-9]+]], metadata !DIExpression()), !dbg [[DBG158]]
; DEBUG-NEXT: [[TMP5:%.*]] = add i32 [[A_SROA_4_0_VEC_EXTRACT]], [[TMP4]], !dbg [[DBG159:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[TMP5]], metadata [[META147:![0-9]+]], metadata !DIExpression()), !dbg [[DBG159]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[TMP5]], metadata [[META147:![0-9]+]], metadata !DIExpression()), !dbg [[DBG159]]
; DEBUG-NEXT: ret i32 [[TMP5]], !dbg [[DBG160:![0-9]+]]
;
entry:
@@ -367,17 +367,17 @@ define i64 @test6(<4 x i64> %x, <4 x i64> %y, i64 %n) {
;
; DEBUG-LABEL: @test6(
; DEBUG-NEXT: [[TMP:%.*]] = alloca { <4 x i64>, <4 x i64> }, align 32, !dbg [[DBG168:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr [[TMP]], metadata [[META163:![0-9]+]], metadata !DIExpression()), !dbg [[DBG168]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr [[TMP]], metadata [[META163:![0-9]+]], metadata !DIExpression()), !dbg [[DBG168]]
; DEBUG-NEXT: [[P0:%.*]] = getelementptr inbounds { <4 x i64>, <4 x i64> }, ptr [[TMP]], i32 0, i32 0, !dbg [[DBG169:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr [[P0]], metadata [[META164:![0-9]+]], metadata !DIExpression()), !dbg [[DBG169]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr [[P0]], metadata [[META164:![0-9]+]], metadata !DIExpression()), !dbg [[DBG169]]
; DEBUG-NEXT: store <4 x i64> [[X:%.*]], ptr [[P0]], align 32, !dbg [[DBG170:![0-9]+]]
; DEBUG-NEXT: [[P1:%.*]] = getelementptr inbounds { <4 x i64>, <4 x i64> }, ptr [[TMP]], i32 0, i32 1, !dbg [[DBG171:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr [[P1]], metadata [[META165:![0-9]+]], metadata !DIExpression()), !dbg [[DBG171]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr [[P1]], metadata [[META165:![0-9]+]], metadata !DIExpression()), !dbg [[DBG171]]
; DEBUG-NEXT: store <4 x i64> [[Y:%.*]], ptr [[P1]], align 32, !dbg [[DBG172:![0-9]+]]
; DEBUG-NEXT: [[ADDR:%.*]] = getelementptr inbounds { <4 x i64>, <4 x i64> }, ptr [[TMP]], i32 0, i32 0, i64 [[N:%.*]], !dbg [[DBG173:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr [[ADDR]], metadata [[META166:![0-9]+]], metadata !DIExpression()), !dbg [[DBG173]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr [[ADDR]], metadata [[META166:![0-9]+]], metadata !DIExpression()), !dbg [[DBG173]]
; DEBUG-NEXT: [[RES:%.*]] = load i64, ptr [[ADDR]], align 4, !dbg [[DBG174:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i64 [[RES]], metadata [[META167:![0-9]+]], metadata !DIExpression()), !dbg [[DBG174]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i64 [[RES]], metadata [[META167:![0-9]+]], metadata !DIExpression()), !dbg [[DBG174]]
; DEBUG-NEXT: ret i64 [[RES]], !dbg [[DBG175:![0-9]+]]
;
%tmp = alloca { <4 x i64>, <4 x i64> }
@@ -401,15 +401,15 @@ define <4 x i32> @test_subvec_store() {
;
; DEBUG-LABEL: @test_subvec_store(
; DEBUG-NEXT: entry:
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META178:![0-9]+]], metadata !DIExpression()), !dbg [[DBG184:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META178:![0-9]+]], metadata !DIExpression()), !dbg [[DBG184:![0-9]+]]
; DEBUG-NEXT: [[A_0_VECBLEND:%.*]] = select <4 x i1> <i1 true, i1 true, i1 false, i1 false>, <4 x i32> <i32 0, i32 0, i32 undef, i32 undef>, <4 x i32> undef, !dbg [[DBG185:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META179:![0-9]+]], metadata !DIExpression()), !dbg [[DBG186:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META179:![0-9]+]], metadata !DIExpression()), !dbg [[DBG186:![0-9]+]]
; DEBUG-NEXT: [[A_4_VECBLEND:%.*]] = select <4 x i1> <i1 false, i1 true, i1 true, i1 false>, <4 x i32> <i32 undef, i32 1, i32 1, i32 undef>, <4 x i32> [[A_0_VECBLEND]], !dbg [[DBG187:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META180:![0-9]+]], metadata !DIExpression()), !dbg [[DBG188:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META180:![0-9]+]], metadata !DIExpression()), !dbg [[DBG188:![0-9]+]]
; DEBUG-NEXT: [[A_8_VECBLEND:%.*]] = select <4 x i1> <i1 false, i1 false, i1 true, i1 true>, <4 x i32> <i32 undef, i32 undef, i32 2, i32 2>, <4 x i32> [[A_4_VECBLEND]], !dbg [[DBG189:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META181:![0-9]+]], metadata !DIExpression()), !dbg [[DBG190:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META181:![0-9]+]], metadata !DIExpression()), !dbg [[DBG190:![0-9]+]]
; DEBUG-NEXT: [[A_12_VEC_INSERT:%.*]] = insertelement <4 x i32> [[A_8_VECBLEND]], i32 3, i32 3, !dbg [[DBG191:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata <4 x i32> [[A_12_VEC_INSERT]], metadata [[META182:![0-9]+]], metadata !DIExpression()), !dbg [[DBG192:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata <4 x i32> [[A_12_VEC_INSERT]], metadata [[META182:![0-9]+]], metadata !DIExpression()), !dbg [[DBG192:![0-9]+]]
; DEBUG-NEXT: ret <4 x i32> [[A_12_VEC_INSERT]], !dbg [[DBG193:![0-9]+]]
;
entry:
@@ -443,19 +443,19 @@ define <4 x i32> @test_subvec_load() {
;
; DEBUG-LABEL: @test_subvec_load(
; DEBUG-NEXT: entry:
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META196:![0-9]+]], metadata !DIExpression()), !dbg [[DBG204:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META196:![0-9]+]], metadata !DIExpression()), !dbg [[DBG204:![0-9]+]]
; DEBUG-NEXT: [[A_0_VEC_EXTRACT:%.*]] = shufflevector <4 x i32> <i32 0, i32 1, i32 2, i32 3>, <4 x i32> poison, <2 x i32> <i32 0, i32 1>, !dbg [[DBG205:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata <2 x i32> [[A_0_VEC_EXTRACT]], metadata [[META197:![0-9]+]], metadata !DIExpression()), !dbg [[DBG205]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META198:![0-9]+]], metadata !DIExpression()), !dbg [[DBG206:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata <2 x i32> [[A_0_VEC_EXTRACT]], metadata [[META197:![0-9]+]], metadata !DIExpression()), !dbg [[DBG205]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META198:![0-9]+]], metadata !DIExpression()), !dbg [[DBG206:![0-9]+]]
; DEBUG-NEXT: [[A_4_VEC_EXTRACT:%.*]] = shufflevector <4 x i32> <i32 0, i32 1, i32 2, i32 3>, <4 x i32> poison, <2 x i32> <i32 1, i32 2>, !dbg [[DBG207:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata <2 x i32> [[A_4_VEC_EXTRACT]], metadata [[META199:![0-9]+]], metadata !DIExpression()), !dbg [[DBG207]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META200:![0-9]+]], metadata !DIExpression()), !dbg [[DBG208:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata <2 x i32> [[A_4_VEC_EXTRACT]], metadata [[META199:![0-9]+]], metadata !DIExpression()), !dbg [[DBG207]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META200:![0-9]+]], metadata !DIExpression()), !dbg [[DBG208:![0-9]+]]
; DEBUG-NEXT: [[A_8_VEC_EXTRACT:%.*]] = shufflevector <4 x i32> <i32 0, i32 1, i32 2, i32 3>, <4 x i32> poison, <2 x i32> <i32 2, i32 3>, !dbg [[DBG209:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata <2 x i32> [[A_8_VEC_EXTRACT]], metadata [[META201:![0-9]+]], metadata !DIExpression()), !dbg [[DBG209]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata <2 x i32> [[A_8_VEC_EXTRACT]], metadata [[META201:![0-9]+]], metadata !DIExpression()), !dbg [[DBG209]]
; DEBUG-NEXT: [[TMP:%.*]] = shufflevector <2 x i32> [[A_0_VEC_EXTRACT]], <2 x i32> [[A_4_VEC_EXTRACT]], <2 x i32> <i32 0, i32 2>, !dbg [[DBG210:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata <2 x i32> [[TMP]], metadata [[META202:![0-9]+]], metadata !DIExpression()), !dbg [[DBG210]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata <2 x i32> [[TMP]], metadata [[META202:![0-9]+]], metadata !DIExpression()), !dbg [[DBG210]]
; DEBUG-NEXT: [[RET:%.*]] = shufflevector <2 x i32> [[TMP]], <2 x i32> [[A_8_VEC_EXTRACT]], <4 x i32> <i32 0, i32 1, i32 2, i32 3>, !dbg [[DBG211:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata <4 x i32> [[RET]], metadata [[META203:![0-9]+]], metadata !DIExpression()), !dbg [[DBG211]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata <4 x i32> [[RET]], metadata [[META203:![0-9]+]], metadata !DIExpression()), !dbg [[DBG211]]
; DEBUG-NEXT: ret <4 x i32> [[RET]], !dbg [[DBG212:![0-9]+]]
;
entry:
@@ -488,15 +488,15 @@ define <4 x float> @test_subvec_memset() {
;
; DEBUG-LABEL: @test_subvec_memset(
; DEBUG-NEXT: entry:
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META215:![0-9]+]], metadata !DIExpression()), !dbg [[DBG220:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META215:![0-9]+]], metadata !DIExpression()), !dbg [[DBG220:![0-9]+]]
; DEBUG-NEXT: [[A_0_VECBLEND:%.*]] = select <4 x i1> <i1 true, i1 true, i1 false, i1 false>, <4 x float> <float 0.000000e+00, float 0.000000e+00, float undef, float undef>, <4 x float> undef, !dbg [[DBG221:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META216:![0-9]+]], metadata !DIExpression()), !dbg [[DBG222:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META216:![0-9]+]], metadata !DIExpression()), !dbg [[DBG222:![0-9]+]]
; DEBUG-NEXT: [[A_4_VECBLEND:%.*]] = select <4 x i1> <i1 false, i1 true, i1 true, i1 false>, <4 x float> <float undef, float 0x3820202020000000, float 0x3820202020000000, float undef>, <4 x float> [[A_0_VECBLEND]], !dbg [[DBG223:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META217:![0-9]+]], metadata !DIExpression()), !dbg [[DBG224:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META217:![0-9]+]], metadata !DIExpression()), !dbg [[DBG224:![0-9]+]]
; DEBUG-NEXT: [[A_8_VECBLEND:%.*]] = select <4 x i1> <i1 false, i1 false, i1 true, i1 true>, <4 x float> <float undef, float undef, float 0x3860606060000000, float 0x3860606060000000>, <4 x float> [[A_4_VECBLEND]], !dbg [[DBG225:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META218:![0-9]+]], metadata !DIExpression()), !dbg [[DBG226:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META218:![0-9]+]], metadata !DIExpression()), !dbg [[DBG226:![0-9]+]]
; DEBUG-NEXT: [[A_12_VEC_INSERT:%.*]] = insertelement <4 x float> [[A_8_VECBLEND]], float 0x38E0E0E0E0000000, i32 3, !dbg [[DBG227:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata <4 x float> [[A_12_VEC_INSERT]], metadata [[META219:![0-9]+]], metadata !DIExpression()), !dbg [[DBG228:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata <4 x float> [[A_12_VEC_INSERT]], metadata [[META219:![0-9]+]], metadata !DIExpression()), !dbg [[DBG228:![0-9]+]]
; DEBUG-NEXT: ret <4 x float> [[A_12_VEC_INSERT]], !dbg [[DBG229:![0-9]+]]
;
entry:
@@ -538,24 +538,24 @@ define <4 x float> @test_subvec_memcpy(ptr %x, ptr %y, ptr %z, ptr %f, ptr %out)
;
; DEBUG-LABEL: @test_subvec_memcpy(
; DEBUG-NEXT: entry:
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META232:![0-9]+]], metadata !DIExpression()), !dbg [[DBG237:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META232:![0-9]+]], metadata !DIExpression()), !dbg [[DBG237:![0-9]+]]
; DEBUG-NEXT: [[A_0_COPYLOAD:%.*]] = load <2 x float>, ptr [[X:%.*]], align 1, !dbg [[DBG238:![0-9]+]]
; DEBUG-NEXT: [[A_0_VEC_EXPAND:%.*]] = shufflevector <2 x float> [[A_0_COPYLOAD]], <2 x float> poison, <4 x i32> <i32 0, i32 1, i32 poison, i32 poison>, !dbg [[DBG238]]
; DEBUG-NEXT: [[A_0_VECBLEND:%.*]] = select <4 x i1> <i1 true, i1 true, i1 false, i1 false>, <4 x float> [[A_0_VEC_EXPAND]], <4 x float> undef, !dbg [[DBG238]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META233:![0-9]+]], metadata !DIExpression()), !dbg [[DBG239:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META233:![0-9]+]], metadata !DIExpression()), !dbg [[DBG239:![0-9]+]]
; DEBUG-NEXT: [[A_4_COPYLOAD:%.*]] = load <2 x float>, ptr [[Y:%.*]], align 1, !dbg [[DBG240:![0-9]+]]
; DEBUG-NEXT: [[A_4_VEC_EXPAND:%.*]] = shufflevector <2 x float> [[A_4_COPYLOAD]], <2 x float> poison, <4 x i32> <i32 poison, i32 0, i32 1, i32 poison>, !dbg [[DBG240]]
; DEBUG-NEXT: [[A_4_VECBLEND:%.*]] = select <4 x i1> <i1 false, i1 true, i1 true, i1 false>, <4 x float> [[A_4_VEC_EXPAND]], <4 x float> [[A_0_VECBLEND]], !dbg [[DBG240]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META234:![0-9]+]], metadata !DIExpression()), !dbg [[DBG241:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META234:![0-9]+]], metadata !DIExpression()), !dbg [[DBG241:![0-9]+]]
; DEBUG-NEXT: [[A_8_COPYLOAD:%.*]] = load <2 x float>, ptr [[Z:%.*]], align 1, !dbg [[DBG242:![0-9]+]]
; DEBUG-NEXT: [[A_8_VEC_EXPAND:%.*]] = shufflevector <2 x float> [[A_8_COPYLOAD]], <2 x float> poison, <4 x i32> <i32 poison, i32 poison, i32 0, i32 1>, !dbg [[DBG242]]
; DEBUG-NEXT: [[A_8_VECBLEND:%.*]] = select <4 x i1> <i1 false, i1 false, i1 true, i1 true>, <4 x float> [[A_8_VEC_EXPAND]], <4 x float> [[A_4_VECBLEND]], !dbg [[DBG242]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META235:![0-9]+]], metadata !DIExpression()), !dbg [[DBG243:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META235:![0-9]+]], metadata !DIExpression()), !dbg [[DBG243:![0-9]+]]
; DEBUG-NEXT: [[A_12_COPYLOAD:%.*]] = load float, ptr [[F:%.*]], align 1, !dbg [[DBG244:![0-9]+]]
; DEBUG-NEXT: [[A_12_VEC_INSERT:%.*]] = insertelement <4 x float> [[A_8_VECBLEND]], float [[A_12_COPYLOAD]], i32 3, !dbg [[DBG244]]
; DEBUG-NEXT: [[A_8_VEC_EXTRACT:%.*]] = shufflevector <4 x float> [[A_12_VEC_INSERT]], <4 x float> poison, <2 x i32> <i32 2, i32 3>, !dbg [[DBG245:![0-9]+]]
; DEBUG-NEXT: store <2 x float> [[A_8_VEC_EXTRACT]], ptr [[OUT:%.*]], align 1, !dbg [[DBG245]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata <4 x float> [[A_12_VEC_INSERT]], metadata [[META236:![0-9]+]], metadata !DIExpression()), !dbg [[DBG246:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata <4 x float> [[A_12_VEC_INSERT]], metadata [[META236:![0-9]+]], metadata !DIExpression()), !dbg [[DBG246:![0-9]+]]
; DEBUG-NEXT: ret <4 x float> [[A_12_VEC_INSERT]], !dbg [[DBG247:![0-9]+]]
;
entry:
@@ -596,7 +596,7 @@ define i32 @PR14212(<3 x i8> %val) {
;
; DEBUG-LABEL: @PR14212(
; DEBUG-NEXT: entry:
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META250:![0-9]+]], metadata !DIExpression()), !dbg [[DBG252:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META250:![0-9]+]], metadata !DIExpression()), !dbg [[DBG252:![0-9]+]]
; DEBUG-NEXT: [[TMP0:%.*]] = bitcast <3 x i8> [[VAL:%.*]] to i24, !dbg [[DBG253:![0-9]+]]
; DEBUG-NEXT: [[RETVAL_SROA_2_0_INSERT_EXT:%.*]] = zext i8 undef to i32, !dbg [[DBG254:![0-9]+]]
; DEBUG-NEXT: [[RETVAL_SROA_2_0_INSERT_SHIFT:%.*]] = shl i32 [[RETVAL_SROA_2_0_INSERT_EXT]], 24, !dbg [[DBG254]]
@@ -605,7 +605,7 @@ define i32 @PR14212(<3 x i8> %val) {
; DEBUG-NEXT: [[RETVAL_0_INSERT_EXT:%.*]] = zext i24 [[TMP0]] to i32, !dbg [[DBG254]]
; DEBUG-NEXT: [[RETVAL_0_INSERT_MASK:%.*]] = and i32 [[RETVAL_SROA_2_0_INSERT_INSERT]], -16777216, !dbg [[DBG254]]
; DEBUG-NEXT: [[RETVAL_0_INSERT_INSERT:%.*]] = or i32 [[RETVAL_0_INSERT_MASK]], [[RETVAL_0_INSERT_EXT]], !dbg [[DBG254]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[RETVAL_0_INSERT_INSERT]], metadata [[META251:![0-9]+]], metadata !DIExpression()), !dbg [[DBG253]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[RETVAL_0_INSERT_INSERT]], metadata [[META251:![0-9]+]], metadata !DIExpression()), !dbg [[DBG253]]
; DEBUG-NEXT: ret i32 [[RETVAL_0_INSERT_INSERT]], !dbg [[DBG254]]
;
entry:
@@ -630,12 +630,12 @@ define <2 x i8> @PR14349.1(i32 %x) {
;
; DEBUG-LABEL: @PR14349.1(
; DEBUG-NEXT: entry:
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META257:![0-9]+]], metadata !DIExpression()), !dbg [[DBG260:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META257:![0-9]+]], metadata !DIExpression()), !dbg [[DBG260:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_0_0_EXTRACT_TRUNC:%.*]] = trunc i32 [[X:%.*]] to i16, !dbg [[DBG261:![0-9]+]]
; DEBUG-NEXT: [[TMP0:%.*]] = bitcast i16 [[A_SROA_0_0_EXTRACT_TRUNC]] to <2 x i8>, !dbg [[DBG261]]
; DEBUG-NEXT: [[A_SROA_2_0_EXTRACT_SHIFT:%.*]] = lshr i32 [[X]], 16, !dbg [[DBG261]]
; DEBUG-NEXT: [[A_SROA_2_0_EXTRACT_TRUNC:%.*]] = trunc i32 [[A_SROA_2_0_EXTRACT_SHIFT]] to i16, !dbg [[DBG261]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata <2 x i8> [[TMP0]], metadata [[META258:![0-9]+]], metadata !DIExpression()), !dbg [[DBG262:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata <2 x i8> [[TMP0]], metadata [[META258:![0-9]+]], metadata !DIExpression()), !dbg [[DBG262:![0-9]+]]
; DEBUG-NEXT: ret <2 x i8> [[TMP0]], !dbg [[DBG263:![0-9]+]]
;
entry:
@@ -666,7 +666,7 @@ define i32 @PR14349.2(<2 x i8> %x) {
;
; DEBUG-LABEL: @PR14349.2(
; DEBUG-NEXT: entry:
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META266:![0-9]+]], metadata !DIExpression()), !dbg [[DBG268:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META266:![0-9]+]], metadata !DIExpression()), !dbg [[DBG268:![0-9]+]]
; DEBUG-NEXT: [[TMP0:%.*]] = bitcast <2 x i8> [[X:%.*]] to i16, !dbg [[DBG269:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_2_0_INSERT_EXT:%.*]] = zext i16 undef to i32, !dbg [[DBG270:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_2_0_INSERT_SHIFT:%.*]] = shl i32 [[A_SROA_2_0_INSERT_EXT]], 16, !dbg [[DBG270]]
@@ -675,7 +675,7 @@ define i32 @PR14349.2(<2 x i8> %x) {
; DEBUG-NEXT: [[A_SROA_0_0_INSERT_EXT:%.*]] = zext i16 [[TMP0]] to i32, !dbg [[DBG270]]
; DEBUG-NEXT: [[A_SROA_0_0_INSERT_MASK:%.*]] = and i32 [[A_SROA_2_0_INSERT_INSERT]], -65536, !dbg [[DBG270]]
; DEBUG-NEXT: [[A_SROA_0_0_INSERT_INSERT:%.*]] = or i32 [[A_SROA_0_0_INSERT_MASK]], [[A_SROA_0_0_INSERT_EXT]], !dbg [[DBG270]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[A_SROA_0_0_INSERT_INSERT]], metadata [[META267:![0-9]+]], metadata !DIExpression()), !dbg [[DBG269]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[A_SROA_0_0_INSERT_INSERT]], metadata [[META267:![0-9]+]], metadata !DIExpression()), !dbg [[DBG269]]
; DEBUG-NEXT: ret i32 [[A_SROA_0_0_INSERT_INSERT]], !dbg [[DBG270]]
;
entry:
@@ -702,21 +702,21 @@ define i32 @test7(<2 x i32> %x, <2 x i32> %y) {
;
; DEBUG-LABEL: @test7(
; DEBUG-NEXT: entry:
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META273:![0-9]+]], metadata !DIExpression()), !dbg [[DBG283:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META274:![0-9]+]], metadata !DIExpression()), !dbg [[DBG284:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META275:![0-9]+]], metadata !DIExpression()), !dbg [[DBG285:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META273:![0-9]+]], metadata !DIExpression()), !dbg [[DBG283:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META274:![0-9]+]], metadata !DIExpression()), !dbg [[DBG284:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META275:![0-9]+]], metadata !DIExpression()), !dbg [[DBG285:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_0_4_VEC_EXTRACT:%.*]] = extractelement <2 x i32> [[X:%.*]], i32 1, !dbg [[DBG286:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[A_SROA_0_4_VEC_EXTRACT]], metadata [[META276:![0-9]+]], metadata !DIExpression()), !dbg [[DBG286]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META277:![0-9]+]], metadata !DIExpression()), !dbg [[DBG287:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[A_SROA_0_4_VEC_EXTRACT]], metadata [[META276:![0-9]+]], metadata !DIExpression()), !dbg [[DBG286]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META277:![0-9]+]], metadata !DIExpression()), !dbg [[DBG287:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_2_12_VEC_EXTRACT:%.*]] = extractelement <2 x i32> [[Y:%.*]], i32 1, !dbg [[DBG288:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[A_SROA_2_12_VEC_EXTRACT]], metadata [[META278:![0-9]+]], metadata !DIExpression()), !dbg [[DBG288]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META279:![0-9]+]], metadata !DIExpression()), !dbg [[DBG289:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[A_SROA_2_12_VEC_EXTRACT]], metadata [[META278:![0-9]+]], metadata !DIExpression()), !dbg [[DBG288]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META279:![0-9]+]], metadata !DIExpression()), !dbg [[DBG289:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_2_8_VEC_EXTRACT:%.*]] = extractelement <2 x i32> [[Y]], i32 0, !dbg [[DBG290:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[A_SROA_2_8_VEC_EXTRACT]], metadata [[META280:![0-9]+]], metadata !DIExpression()), !dbg [[DBG290]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[A_SROA_2_8_VEC_EXTRACT]], metadata [[META280:![0-9]+]], metadata !DIExpression()), !dbg [[DBG290]]
; DEBUG-NEXT: [[TMP4:%.*]] = add i32 [[A_SROA_0_4_VEC_EXTRACT]], [[A_SROA_2_12_VEC_EXTRACT]], !dbg [[DBG291:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[TMP4]], metadata [[META281:![0-9]+]], metadata !DIExpression()), !dbg [[DBG291]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[TMP4]], metadata [[META281:![0-9]+]], metadata !DIExpression()), !dbg [[DBG291]]
; DEBUG-NEXT: [[TMP5:%.*]] = add i32 [[A_SROA_2_8_VEC_EXTRACT]], [[TMP4]], !dbg [[DBG292:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[TMP5]], metadata [[META282:![0-9]+]], metadata !DIExpression()), !dbg [[DBG292]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[TMP5]], metadata [[META282:![0-9]+]], metadata !DIExpression()), !dbg [[DBG292]]
; DEBUG-NEXT: ret i32 [[TMP5]], !dbg [[DBG293:![0-9]+]]
;
entry:
@@ -751,14 +751,14 @@ define i32 @test8(<2 x i32> %x) {
;
; DEBUG-LABEL: @test8(
; DEBUG-NEXT: entry:
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META296:![0-9]+]], metadata !DIExpression()), !dbg [[DBG301:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META296:![0-9]+]], metadata !DIExpression()), !dbg [[DBG301:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_0_0_VEC_EXTRACT:%.*]] = extractelement <2 x i32> [[X:%.*]], i32 0, !dbg [[DBG302:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[A_SROA_0_0_VEC_EXTRACT]], metadata [[META297:![0-9]+]], metadata !DIExpression()), !dbg [[DBG302]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META298:![0-9]+]], metadata !DIExpression()), !dbg [[DBG303:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[A_SROA_0_0_VEC_EXTRACT]], metadata [[META297:![0-9]+]], metadata !DIExpression()), !dbg [[DBG302]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META298:![0-9]+]], metadata !DIExpression()), !dbg [[DBG303:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_0_4_VEC_EXTRACT:%.*]] = extractelement <2 x i32> [[X]], i32 1, !dbg [[DBG304:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[A_SROA_0_4_VEC_EXTRACT]], metadata [[META299:![0-9]+]], metadata !DIExpression()), !dbg [[DBG304]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[A_SROA_0_4_VEC_EXTRACT]], metadata [[META299:![0-9]+]], metadata !DIExpression()), !dbg [[DBG304]]
; DEBUG-NEXT: [[TMP4:%.*]] = add i32 [[A_SROA_0_0_VEC_EXTRACT]], [[A_SROA_0_4_VEC_EXTRACT]], !dbg [[DBG305:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[TMP4]], metadata [[META300:![0-9]+]], metadata !DIExpression()), !dbg [[DBG305]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[TMP4]], metadata [[META300:![0-9]+]], metadata !DIExpression()), !dbg [[DBG305]]
; DEBUG-NEXT: ret i32 [[TMP4]], !dbg [[DBG306:![0-9]+]]
;
entry:
@@ -786,11 +786,11 @@ define <2 x i32> @test9(i32 %x, i32 %y) {
;
; DEBUG-LABEL: @test9(
; DEBUG-NEXT: entry:
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META309:![0-9]+]], metadata !DIExpression()), !dbg [[DBG312:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META309:![0-9]+]], metadata !DIExpression()), !dbg [[DBG312:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_0_0_VEC_INSERT:%.*]] = insertelement <2 x i32> undef, i32 [[X:%.*]], i32 0, !dbg [[DBG313:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META310:![0-9]+]], metadata !DIExpression()), !dbg [[DBG314:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META310:![0-9]+]], metadata !DIExpression()), !dbg [[DBG314:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_0_4_VEC_INSERT:%.*]] = insertelement <2 x i32> [[A_SROA_0_0_VEC_INSERT]], i32 [[Y:%.*]], i32 1, !dbg [[DBG315:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata <2 x i32> [[A_SROA_0_4_VEC_INSERT]], metadata [[META311:![0-9]+]], metadata !DIExpression()), !dbg [[DBG316:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata <2 x i32> [[A_SROA_0_4_VEC_INSERT]], metadata [[META311:![0-9]+]], metadata !DIExpression()), !dbg [[DBG316:![0-9]+]]
; DEBUG-NEXT: ret <2 x i32> [[A_SROA_0_4_VEC_INSERT]], !dbg [[DBG317:![0-9]+]]
;
entry:
@@ -817,11 +817,11 @@ define <2 x i32> @test10(<4 x i16> %x, i32 %y) {
;
; DEBUG-LABEL: @test10(
; DEBUG-NEXT: entry:
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META320:![0-9]+]], metadata !DIExpression()), !dbg [[DBG323:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META320:![0-9]+]], metadata !DIExpression()), !dbg [[DBG323:![0-9]+]]
; DEBUG-NEXT: [[TMP0:%.*]] = bitcast <4 x i16> [[X:%.*]] to <2 x i32>, !dbg [[DBG324:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META321:![0-9]+]], metadata !DIExpression()), !dbg [[DBG325:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META321:![0-9]+]], metadata !DIExpression()), !dbg [[DBG325:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_0_4_VEC_INSERT:%.*]] = insertelement <2 x i32> [[TMP0]], i32 [[Y:%.*]], i32 1, !dbg [[DBG326:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata <2 x i32> [[A_SROA_0_4_VEC_INSERT]], metadata [[META322:![0-9]+]], metadata !DIExpression()), !dbg [[DBG327:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata <2 x i32> [[A_SROA_0_4_VEC_INSERT]], metadata [[META322:![0-9]+]], metadata !DIExpression()), !dbg [[DBG327:![0-9]+]]
; DEBUG-NEXT: ret <2 x i32> [[A_SROA_0_4_VEC_INSERT]], !dbg [[DBG328:![0-9]+]]
;
entry:
@@ -850,12 +850,12 @@ define <2 x float> @test11(<4 x i16> %x, i32 %y) {
;
; DEBUG-LABEL: @test11(
; DEBUG-NEXT: entry:
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META331:![0-9]+]], metadata !DIExpression()), !dbg [[DBG334:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META331:![0-9]+]], metadata !DIExpression()), !dbg [[DBG334:![0-9]+]]
; DEBUG-NEXT: [[TMP0:%.*]] = bitcast <4 x i16> [[X:%.*]] to <2 x i32>, !dbg [[DBG335:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META332:![0-9]+]], metadata !DIExpression()), !dbg [[DBG336:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META332:![0-9]+]], metadata !DIExpression()), !dbg [[DBG336:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_0_4_VEC_INSERT:%.*]] = insertelement <2 x i32> [[TMP0]], i32 [[Y:%.*]], i32 1, !dbg [[DBG337:![0-9]+]]
; DEBUG-NEXT: [[TMP1:%.*]] = bitcast <2 x i32> [[A_SROA_0_4_VEC_INSERT]] to <2 x float>, !dbg [[DBG338:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata <2 x float> [[TMP1]], metadata [[META333:![0-9]+]], metadata !DIExpression()), !dbg [[DBG338]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata <2 x float> [[TMP1]], metadata [[META333:![0-9]+]], metadata !DIExpression()), !dbg [[DBG338]]
; DEBUG-NEXT: ret <2 x float> [[TMP1]], !dbg [[DBG339:![0-9]+]]
;
entry:
@@ -876,9 +876,9 @@ define <4 x float> @test12(<4 x i32> %val) {
; CHECK-NEXT: ret <4 x float> [[TMP1]]
;
; DEBUG-LABEL: @test12(
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META342:![0-9]+]], metadata !DIExpression()), !dbg [[DBG344:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META342:![0-9]+]], metadata !DIExpression()), !dbg [[DBG344:![0-9]+]]
; DEBUG-NEXT: [[TMP1:%.*]] = bitcast <4 x i32> [[VAL:%.*]] to <4 x float>, !dbg [[DBG345:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata <4 x float> [[TMP1]], metadata [[META343:![0-9]+]], metadata !DIExpression()), !dbg [[DBG345]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata <4 x float> [[TMP1]], metadata [[META343:![0-9]+]], metadata !DIExpression()), !dbg [[DBG345]]
; DEBUG-NEXT: ret <4 x float> [[TMP1]], !dbg [[DBG346:![0-9]+]]
;
%a = alloca <3 x i32>, align 16
@@ -904,16 +904,16 @@ define <2 x i64> @test13(i32 %a, i32 %b, i32 %c, i32 %d) {
;
; DEBUG-LABEL: @test13(
; DEBUG-NEXT: entry:
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META349:![0-9]+]], metadata !DIExpression()), !dbg [[DBG354:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META349:![0-9]+]], metadata !DIExpression()), !dbg [[DBG354:![0-9]+]]
; DEBUG-NEXT: [[X_SROA_0_0_VEC_INSERT:%.*]] = insertelement <4 x i32> undef, i32 [[A:%.*]], i32 0, !dbg [[DBG355:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META350:![0-9]+]], metadata !DIExpression()), !dbg [[DBG356:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META350:![0-9]+]], metadata !DIExpression()), !dbg [[DBG356:![0-9]+]]
; DEBUG-NEXT: [[X_SROA_0_4_VEC_INSERT:%.*]] = insertelement <4 x i32> [[X_SROA_0_0_VEC_INSERT]], i32 [[B:%.*]], i32 1, !dbg [[DBG357:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META351:![0-9]+]], metadata !DIExpression()), !dbg [[DBG358:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META351:![0-9]+]], metadata !DIExpression()), !dbg [[DBG358:![0-9]+]]
; DEBUG-NEXT: [[X_SROA_0_8_VEC_INSERT:%.*]] = insertelement <4 x i32> [[X_SROA_0_4_VEC_INSERT]], i32 [[C:%.*]], i32 2, !dbg [[DBG359:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META352:![0-9]+]], metadata !DIExpression()), !dbg [[DBG360:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META352:![0-9]+]], metadata !DIExpression()), !dbg [[DBG360:![0-9]+]]
; DEBUG-NEXT: [[X_SROA_0_12_VEC_INSERT:%.*]] = insertelement <4 x i32> [[X_SROA_0_8_VEC_INSERT]], i32 [[D:%.*]], i32 3, !dbg [[DBG361:![0-9]+]]
; DEBUG-NEXT: [[TMP0:%.*]] = bitcast <4 x i32> [[X_SROA_0_12_VEC_INSERT]] to <2 x i64>, !dbg [[DBG362:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata <2 x i64> [[TMP0]], metadata [[META353:![0-9]+]], metadata !DIExpression()), !dbg [[DBG362]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata <2 x i64> [[TMP0]], metadata [[META353:![0-9]+]], metadata !DIExpression()), !dbg [[DBG362]]
; DEBUG-NEXT: ret <2 x i64> [[TMP0]], !dbg [[DBG363:![0-9]+]]
;
entry:
@@ -946,26 +946,26 @@ define i32 @test14(<2 x i64> %x) {
;
; DEBUG-LABEL: @test14(
; DEBUG-NEXT: entry:
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META366:![0-9]+]], metadata !DIExpression()), !dbg [[DBG378:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META366:![0-9]+]], metadata !DIExpression()), !dbg [[DBG378:![0-9]+]]
; DEBUG-NEXT: [[TMP0:%.*]] = bitcast <2 x i64> [[X:%.*]] to <4 x i32>, !dbg [[DBG379:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META367:![0-9]+]], metadata !DIExpression()), !dbg [[DBG380:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META367:![0-9]+]], metadata !DIExpression()), !dbg [[DBG380:![0-9]+]]
; DEBUG-NEXT: [[X_ADDR_SROA_0_0_VEC_EXTRACT:%.*]] = extractelement <4 x i32> [[TMP0]], i32 0, !dbg [[DBG381:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[X_ADDR_SROA_0_0_VEC_EXTRACT]], metadata [[META368:![0-9]+]], metadata !DIExpression()), !dbg [[DBG381]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META369:![0-9]+]], metadata !DIExpression()), !dbg [[DBG382:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[X_ADDR_SROA_0_0_VEC_EXTRACT]], metadata [[META368:![0-9]+]], metadata !DIExpression()), !dbg [[DBG381]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META369:![0-9]+]], metadata !DIExpression()), !dbg [[DBG382:![0-9]+]]
; DEBUG-NEXT: [[X_ADDR_SROA_0_4_VEC_EXTRACT:%.*]] = extractelement <4 x i32> [[TMP0]], i32 1, !dbg [[DBG383:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[X_ADDR_SROA_0_4_VEC_EXTRACT]], metadata [[META370:![0-9]+]], metadata !DIExpression()), !dbg [[DBG383]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META371:![0-9]+]], metadata !DIExpression()), !dbg [[DBG384:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[X_ADDR_SROA_0_4_VEC_EXTRACT]], metadata [[META370:![0-9]+]], metadata !DIExpression()), !dbg [[DBG383]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META371:![0-9]+]], metadata !DIExpression()), !dbg [[DBG384:![0-9]+]]
; DEBUG-NEXT: [[X_ADDR_SROA_0_8_VEC_EXTRACT:%.*]] = extractelement <4 x i32> [[TMP0]], i32 2, !dbg [[DBG385:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[X_ADDR_SROA_0_8_VEC_EXTRACT]], metadata [[META372:![0-9]+]], metadata !DIExpression()), !dbg [[DBG385]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META373:![0-9]+]], metadata !DIExpression()), !dbg [[DBG386:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[X_ADDR_SROA_0_8_VEC_EXTRACT]], metadata [[META372:![0-9]+]], metadata !DIExpression()), !dbg [[DBG385]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META373:![0-9]+]], metadata !DIExpression()), !dbg [[DBG386:![0-9]+]]
; DEBUG-NEXT: [[X_ADDR_SROA_0_12_VEC_EXTRACT:%.*]] = extractelement <4 x i32> [[TMP0]], i32 3, !dbg [[DBG387:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[X_ADDR_SROA_0_12_VEC_EXTRACT]], metadata [[META374:![0-9]+]], metadata !DIExpression()), !dbg [[DBG387]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[X_ADDR_SROA_0_12_VEC_EXTRACT]], metadata [[META374:![0-9]+]], metadata !DIExpression()), !dbg [[DBG387]]
; DEBUG-NEXT: [[ADD:%.*]] = add i32 [[X_ADDR_SROA_0_0_VEC_EXTRACT]], [[X_ADDR_SROA_0_4_VEC_EXTRACT]], !dbg [[DBG388:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[ADD]], metadata [[META375:![0-9]+]], metadata !DIExpression()), !dbg [[DBG388]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[ADD]], metadata [[META375:![0-9]+]], metadata !DIExpression()), !dbg [[DBG388]]
; DEBUG-NEXT: [[ADD1:%.*]] = add i32 [[X_ADDR_SROA_0_8_VEC_EXTRACT]], [[X_ADDR_SROA_0_12_VEC_EXTRACT]], !dbg [[DBG389:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[ADD1]], metadata [[META376:![0-9]+]], metadata !DIExpression()), !dbg [[DBG389]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[ADD1]], metadata [[META376:![0-9]+]], metadata !DIExpression()), !dbg [[DBG389]]
; DEBUG-NEXT: [[ADD2:%.*]] = add i32 [[ADD]], [[ADD1]], !dbg [[DBG390:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i32 [[ADD2]], metadata [[META377:![0-9]+]], metadata !DIExpression()), !dbg [[DBG390]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i32 [[ADD2]], metadata [[META377:![0-9]+]], metadata !DIExpression()), !dbg [[DBG390]]
; DEBUG-NEXT: ret i32 [[ADD2]], !dbg [[DBG391:![0-9]+]]
;
entry:
@@ -1002,19 +1002,19 @@ define <4 x ptr> @test15(i32 %a, i32 %b, i32 %c, i32 %d) {
; DEBUG-LABEL: @test15(
; DEBUG-NEXT: entry:
; DEBUG-NEXT: [[X_SROA_0:%.*]] = alloca <4 x ptr>, align 32, !dbg [[DBG400:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META394:![0-9]+]], metadata !DIExpression()), !dbg [[DBG400]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META394:![0-9]+]], metadata !DIExpression()), !dbg [[DBG400]]
; DEBUG-NEXT: store i32 [[A:%.*]], ptr [[X_SROA_0]], align 32, !dbg [[DBG401:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META395:![0-9]+]], metadata !DIExpression()), !dbg [[DBG402:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META395:![0-9]+]], metadata !DIExpression()), !dbg [[DBG402:![0-9]+]]
; DEBUG-NEXT: [[X_SROA_0_4_X_TMP2_SROA_IDX1:%.*]] = getelementptr inbounds i8, ptr [[X_SROA_0]], i64 4, !dbg [[DBG403:![0-9]+]]
; DEBUG-NEXT: store i32 [[B:%.*]], ptr [[X_SROA_0_4_X_TMP2_SROA_IDX1]], align 4, !dbg [[DBG403]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META396:![0-9]+]], metadata !DIExpression()), !dbg [[DBG404:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META396:![0-9]+]], metadata !DIExpression()), !dbg [[DBG404:![0-9]+]]
; DEBUG-NEXT: [[X_SROA_0_8_X_TMP3_SROA_IDX2:%.*]] = getelementptr inbounds i8, ptr [[X_SROA_0]], i64 8, !dbg [[DBG405:![0-9]+]]
; DEBUG-NEXT: store i32 [[C:%.*]], ptr [[X_SROA_0_8_X_TMP3_SROA_IDX2]], align 8, !dbg [[DBG405]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META397:![0-9]+]], metadata !DIExpression()), !dbg [[DBG406:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META397:![0-9]+]], metadata !DIExpression()), !dbg [[DBG406:![0-9]+]]
; DEBUG-NEXT: [[X_SROA_0_12_X_TMP4_SROA_IDX3:%.*]] = getelementptr inbounds i8, ptr [[X_SROA_0]], i64 12, !dbg [[DBG407:![0-9]+]]
; DEBUG-NEXT: store i32 [[D:%.*]], ptr [[X_SROA_0_12_X_TMP4_SROA_IDX3]], align 4, !dbg [[DBG407]]
; DEBUG-NEXT: [[X_SROA_0_0_X_SROA_0_0_RESULT:%.*]] = load <4 x ptr>, ptr [[X_SROA_0]], align 32, !dbg [[DBG408:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata <4 x ptr> [[X_SROA_0_0_X_SROA_0_0_RESULT]], metadata [[META398:![0-9]+]], metadata !DIExpression()), !dbg [[DBG408]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata <4 x ptr> [[X_SROA_0_0_X_SROA_0_0_RESULT]], metadata [[META398:![0-9]+]], metadata !DIExpression()), !dbg [[DBG408]]
; DEBUG-NEXT: ret <4 x ptr> [[X_SROA_0_0_X_SROA_0_0_RESULT]], !dbg [[DBG409:![0-9]+]]
;
entry:
@@ -1045,19 +1045,19 @@ define <4 x ptr> @test16(i64 %a, i64 %b, i64 %c, i64 %d) {
;
; DEBUG-LABEL: @test16(
; DEBUG-NEXT: entry:
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META412:![0-9]+]], metadata !DIExpression()), !dbg [[DBG417:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META412:![0-9]+]], metadata !DIExpression()), !dbg [[DBG417:![0-9]+]]
; DEBUG-NEXT: [[TMP0:%.*]] = inttoptr i64 [[A:%.*]] to ptr, !dbg [[DBG418:![0-9]+]]
; DEBUG-NEXT: [[X_SROA_0_0_VEC_INSERT:%.*]] = insertelement <4 x ptr> undef, ptr [[TMP0]], i32 0, !dbg [[DBG418]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META413:![0-9]+]], metadata !DIExpression()), !dbg [[DBG419:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META413:![0-9]+]], metadata !DIExpression()), !dbg [[DBG419:![0-9]+]]
; DEBUG-NEXT: [[TMP1:%.*]] = inttoptr i64 [[B:%.*]] to ptr, !dbg [[DBG420:![0-9]+]]
; DEBUG-NEXT: [[X_SROA_0_8_VEC_INSERT:%.*]] = insertelement <4 x ptr> [[X_SROA_0_0_VEC_INSERT]], ptr [[TMP1]], i32 1, !dbg [[DBG420]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META414:![0-9]+]], metadata !DIExpression()), !dbg [[DBG421:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META414:![0-9]+]], metadata !DIExpression()), !dbg [[DBG421:![0-9]+]]
; DEBUG-NEXT: [[TMP2:%.*]] = inttoptr i64 [[C:%.*]] to ptr, !dbg [[DBG422:![0-9]+]]
; DEBUG-NEXT: [[X_SROA_0_16_VEC_INSERT:%.*]] = insertelement <4 x ptr> [[X_SROA_0_8_VEC_INSERT]], ptr [[TMP2]], i32 2, !dbg [[DBG422]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META415:![0-9]+]], metadata !DIExpression()), !dbg [[DBG423:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META415:![0-9]+]], metadata !DIExpression()), !dbg [[DBG423:![0-9]+]]
; DEBUG-NEXT: [[TMP3:%.*]] = inttoptr i64 [[D:%.*]] to ptr, !dbg [[DBG424:![0-9]+]]
; DEBUG-NEXT: [[X_SROA_0_24_VEC_INSERT:%.*]] = insertelement <4 x ptr> [[X_SROA_0_16_VEC_INSERT]], ptr [[TMP3]], i32 3, !dbg [[DBG424]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata <4 x ptr> [[X_SROA_0_24_VEC_INSERT]], metadata [[META416:![0-9]+]], metadata !DIExpression()), !dbg [[DBG425:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata <4 x ptr> [[X_SROA_0_24_VEC_INSERT]], metadata [[META416:![0-9]+]], metadata !DIExpression()), !dbg [[DBG425:![0-9]+]]
; DEBUG-NEXT: ret <4 x ptr> [[X_SROA_0_24_VEC_INSERT]], !dbg [[DBG426:![0-9]+]]
;
entry:
@@ -1090,19 +1090,19 @@ define <4 x ptr> @test17(i32 %a, i32 %b, i64 %c, i64 %d) {
; DEBUG-LABEL: @test17(
; DEBUG-NEXT: entry:
; DEBUG-NEXT: [[X_SROA_0:%.*]] = alloca <4 x ptr>, align 32, !dbg [[DBG434:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META429:![0-9]+]], metadata !DIExpression()), !dbg [[DBG434]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META429:![0-9]+]], metadata !DIExpression()), !dbg [[DBG434]]
; DEBUG-NEXT: store i32 [[A:%.*]], ptr [[X_SROA_0]], align 32, !dbg [[DBG435:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META430:![0-9]+]], metadata !DIExpression()), !dbg [[DBG436:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META430:![0-9]+]], metadata !DIExpression()), !dbg [[DBG436:![0-9]+]]
; DEBUG-NEXT: [[X_SROA_0_4_X_TMP2_SROA_IDX1:%.*]] = getelementptr inbounds i8, ptr [[X_SROA_0]], i64 4, !dbg [[DBG437:![0-9]+]]
; DEBUG-NEXT: store i32 [[B:%.*]], ptr [[X_SROA_0_4_X_TMP2_SROA_IDX1]], align 4, !dbg [[DBG437]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META431:![0-9]+]], metadata !DIExpression()), !dbg [[DBG438:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META431:![0-9]+]], metadata !DIExpression()), !dbg [[DBG438:![0-9]+]]
; DEBUG-NEXT: [[X_SROA_0_16_X_TMP3_SROA_IDX2:%.*]] = getelementptr inbounds i8, ptr [[X_SROA_0]], i64 16, !dbg [[DBG439:![0-9]+]]
; DEBUG-NEXT: store i64 [[C:%.*]], ptr [[X_SROA_0_16_X_TMP3_SROA_IDX2]], align 16, !dbg [[DBG439]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META432:![0-9]+]], metadata !DIExpression()), !dbg [[DBG440:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META432:![0-9]+]], metadata !DIExpression()), !dbg [[DBG440:![0-9]+]]
; DEBUG-NEXT: [[X_SROA_0_24_X_TMP4_SROA_IDX3:%.*]] = getelementptr inbounds i8, ptr [[X_SROA_0]], i64 24, !dbg [[DBG441:![0-9]+]]
; DEBUG-NEXT: store i64 [[D:%.*]], ptr [[X_SROA_0_24_X_TMP4_SROA_IDX3]], align 8, !dbg [[DBG441]]
; DEBUG-NEXT: [[X_SROA_0_0_X_SROA_0_0_RESULT:%.*]] = load <4 x ptr>, ptr [[X_SROA_0]], align 32, !dbg [[DBG442:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata <4 x ptr> [[X_SROA_0_0_X_SROA_0_0_RESULT]], metadata [[META433:![0-9]+]], metadata !DIExpression()), !dbg [[DBG442]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata <4 x ptr> [[X_SROA_0_0_X_SROA_0_0_RESULT]], metadata [[META433:![0-9]+]], metadata !DIExpression()), !dbg [[DBG442]]
; DEBUG-NEXT: ret <4 x ptr> [[X_SROA_0_0_X_SROA_0_0_RESULT]], !dbg [[DBG443:![0-9]+]]
;
entry:
@@ -1129,10 +1129,10 @@ define i1 @test18() {
;
; DEBUG-LABEL: @test18(
; DEBUG-NEXT: [[A_SROA_0:%.*]] = alloca <2 x i64>, align 32, !dbg [[DBG449:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META446:![0-9]+]], metadata !DIExpression()), !dbg [[DBG449]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META446:![0-9]+]], metadata !DIExpression()), !dbg [[DBG449]]
; DEBUG-NEXT: store <2 x i64> <i64 0, i64 -1>, ptr [[A_SROA_0]], align 32, !dbg [[DBG450:![0-9]+]]
; DEBUG-NEXT: [[A_SROA_0_0_A_SROA_0_0_L:%.*]] = load i1, ptr [[A_SROA_0]], align 32, !dbg [[DBG451:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata i1 [[A_SROA_0_0_A_SROA_0_0_L]], metadata [[META447:![0-9]+]], metadata !DIExpression()), !dbg [[DBG451]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata i1 [[A_SROA_0_0_A_SROA_0_0_L]], metadata [[META447:![0-9]+]], metadata !DIExpression()), !dbg [[DBG451]]
; DEBUG-NEXT: ret i1 [[A_SROA_0_0_A_SROA_0_0_L]], !dbg [[DBG452:![0-9]+]]
;
%a = alloca <8 x i32>
@@ -1149,7 +1149,7 @@ define void @swap-8bytes(ptr %x, ptr %y) {
; CHECK-NEXT: ret void
;
; DEBUG-LABEL: @swap-8bytes(
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META455:![0-9]+]], metadata !DIExpression()), !dbg [[DBG456:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META455:![0-9]+]], metadata !DIExpression()), !dbg [[DBG456:![0-9]+]]
; DEBUG-NEXT: [[TMP_SROA_0_0_COPYLOAD:%.*]] = load i64, ptr [[X:%.*]], align 1, !dbg [[DBG457:![0-9]+]]
; DEBUG-NEXT: tail call void @llvm.memcpy.p0.p0.i64(ptr [[X]], ptr [[Y:%.*]], i64 8, i1 false), !dbg [[DBG458:![0-9]+]]
; DEBUG-NEXT: store i64 [[TMP_SROA_0_0_COPYLOAD]], ptr [[Y]], align 1, !dbg [[DBG459:![0-9]+]]
@@ -1172,7 +1172,7 @@ define void @swap-7bytes(ptr %x, ptr %y) {
;
; DEBUG-LABEL: @swap-7bytes(
; DEBUG-NEXT: [[TMP:%.*]] = alloca [7 x i8], align 1, !dbg [[DBG464:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr [[TMP]], metadata [[META463:![0-9]+]], metadata !DIExpression()), !dbg [[DBG464]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr [[TMP]], metadata [[META463:![0-9]+]], metadata !DIExpression()), !dbg [[DBG464]]
; DEBUG-NEXT: call void @llvm.memcpy.p0.p0.i64(ptr [[TMP]], ptr [[X:%.*]], i64 7, i1 false), !dbg [[DBG465:![0-9]+]]
; DEBUG-NEXT: tail call void @llvm.memcpy.p0.p0.i64(ptr [[X]], ptr [[Y:%.*]], i64 7, i1 false), !dbg [[DBG466:![0-9]+]]
; DEBUG-NEXT: call void @llvm.memcpy.p0.p0.i64(ptr [[Y]], ptr [[TMP]], i64 7, i1 false), !dbg [[DBG467:![0-9]+]]
@@ -1195,7 +1195,7 @@ define void @swap-16bytes(ptr %x, ptr %y) {
;
; DEBUG-LABEL: @swap-16bytes(
; DEBUG-NEXT: [[TMP:%.*]] = alloca [2 x i64], align 8, !dbg [[DBG472:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr [[TMP]], metadata [[META471:![0-9]+]], metadata !DIExpression()), !dbg [[DBG472]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr [[TMP]], metadata [[META471:![0-9]+]], metadata !DIExpression()), !dbg [[DBG472]]
; DEBUG-NEXT: call void @llvm.memcpy.p0.p0.i64(ptr [[TMP]], ptr [[X:%.*]], i64 16, i1 false), !dbg [[DBG473:![0-9]+]]
; DEBUG-NEXT: tail call void @llvm.memcpy.p0.p0.i64(ptr [[X]], ptr [[Y:%.*]], i64 16, i1 false), !dbg [[DBG474:![0-9]+]]
; DEBUG-NEXT: call void @llvm.memcpy.p0.p0.i64(ptr [[Y]], ptr [[TMP]], i64 16, i1 false), !dbg [[DBG475:![0-9]+]]
@@ -1218,7 +1218,7 @@ define void @swap-15bytes(ptr %x, ptr %y) {
;
; DEBUG-LABEL: @swap-15bytes(
; DEBUG-NEXT: [[TMP:%.*]] = alloca [15 x i8], align 1, !dbg [[DBG480:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr [[TMP]], metadata [[META479:![0-9]+]], metadata !DIExpression()), !dbg [[DBG480]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr [[TMP]], metadata [[META479:![0-9]+]], metadata !DIExpression()), !dbg [[DBG480]]
; DEBUG-NEXT: call void @llvm.memcpy.p0.p0.i64(ptr [[TMP]], ptr [[X:%.*]], i64 15, i1 false), !dbg [[DBG481:![0-9]+]]
; DEBUG-NEXT: tail call void @llvm.memcpy.p0.p0.i64(ptr [[X]], ptr [[Y:%.*]], i64 15, i1 false), !dbg [[DBG482:![0-9]+]]
; DEBUG-NEXT: call void @llvm.memcpy.p0.p0.i64(ptr [[Y]], ptr [[TMP]], i64 15, i1 false), !dbg [[DBG483:![0-9]+]]
@@ -1245,17 +1245,17 @@ define <4 x i32> @ptrLoadStoreTys(ptr %init, i32 %val2) {
;
; DEBUG-LABEL: @ptrLoadStoreTys(
; DEBUG-NEXT: [[VAL0:%.*]] = load ptr, ptr [[INIT:%.*]], align 8, !dbg [[DBG492:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr [[VAL0]], metadata [[META487:![0-9]+]], metadata !DIExpression()), !dbg [[DBG492]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META488:![0-9]+]], metadata !DIExpression()), !dbg [[DBG493:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr [[VAL0]], metadata [[META487:![0-9]+]], metadata !DIExpression()), !dbg [[DBG492]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META488:![0-9]+]], metadata !DIExpression()), !dbg [[DBG493:![0-9]+]]
; DEBUG-NEXT: [[TMP1:%.*]] = ptrtoint ptr [[VAL0]] to i64, !dbg [[DBG494:![0-9]+]]
; DEBUG-NEXT: [[TMP2:%.*]] = bitcast i64 [[TMP1]] to <2 x i32>, !dbg [[DBG494]]
; DEBUG-NEXT: [[OBJ_0_VEC_EXPAND:%.*]] = shufflevector <2 x i32> [[TMP2]], <2 x i32> poison, <4 x i32> <i32 0, i32 1, i32 poison, i32 poison>, !dbg [[DBG494]]
; DEBUG-NEXT: [[OBJ_0_VECBLEND:%.*]] = select <4 x i1> <i1 true, i1 true, i1 false, i1 false>, <4 x i32> [[OBJ_0_VEC_EXPAND]], <4 x i32> zeroinitializer, !dbg [[DBG494]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META489:![0-9]+]], metadata !DIExpression()), !dbg [[DBG495:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META489:![0-9]+]], metadata !DIExpression()), !dbg [[DBG495:![0-9]+]]
; DEBUG-NEXT: [[OBJ_8_VEC_INSERT:%.*]] = insertelement <4 x i32> [[OBJ_0_VECBLEND]], i32 [[VAL2:%.*]], i32 2, !dbg [[DBG496:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META490:![0-9]+]], metadata !DIExpression()), !dbg [[DBG497:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META490:![0-9]+]], metadata !DIExpression()), !dbg [[DBG497:![0-9]+]]
; DEBUG-NEXT: [[OBJ_12_VEC_INSERT:%.*]] = insertelement <4 x i32> [[OBJ_8_VEC_INSERT]], i32 131072, i32 3, !dbg [[DBG498:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata <4 x i32> [[OBJ_12_VEC_INSERT]], metadata [[META491:![0-9]+]], metadata !DIExpression()), !dbg [[DBG499:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata <4 x i32> [[OBJ_12_VEC_INSERT]], metadata [[META491:![0-9]+]], metadata !DIExpression()), !dbg [[DBG499:![0-9]+]]
; DEBUG-NEXT: ret <4 x i32> [[OBJ_12_VEC_INSERT]], !dbg [[DBG500:![0-9]+]]
;
%val0 = load ptr, ptr %init, align 8
@@ -1285,19 +1285,19 @@ define <4 x float> @ptrLoadStoreTysFloat(ptr %init, float %val2) {
;
; DEBUG-LABEL: @ptrLoadStoreTysFloat(
; DEBUG-NEXT: [[VAL0:%.*]] = load ptr, ptr [[INIT:%.*]], align 8, !dbg [[DBG508:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr [[VAL0]], metadata [[META503:![0-9]+]], metadata !DIExpression()), !dbg [[DBG508]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr [[VAL0]], metadata [[META503:![0-9]+]], metadata !DIExpression()), !dbg [[DBG508]]
; DEBUG-NEXT: [[OBJ:%.*]] = alloca <4 x float>, align 16, !dbg [[DBG509:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr [[OBJ]], metadata [[META504:![0-9]+]], metadata !DIExpression()), !dbg [[DBG509]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr [[OBJ]], metadata [[META504:![0-9]+]], metadata !DIExpression()), !dbg [[DBG509]]
; DEBUG-NEXT: store <4 x float> zeroinitializer, ptr [[OBJ]], align 16, !dbg [[DBG510:![0-9]+]]
; DEBUG-NEXT: store ptr [[VAL0]], ptr [[OBJ]], align 16, !dbg [[DBG511:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META505:![0-9]+]], metadata !DIExpression()), !dbg [[DBG512:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META505:![0-9]+]], metadata !DIExpression()), !dbg [[DBG512:![0-9]+]]
; DEBUG-NEXT: [[OBJ_8_PTR2_SROA_IDX:%.*]] = getelementptr inbounds i8, ptr [[OBJ]], i64 8, !dbg [[DBG513:![0-9]+]]
; DEBUG-NEXT: store float [[VAL2:%.*]], ptr [[OBJ_8_PTR2_SROA_IDX]], align 8, !dbg [[DBG513]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META506:![0-9]+]], metadata !DIExpression()), !dbg [[DBG514:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META506:![0-9]+]], metadata !DIExpression()), !dbg [[DBG514:![0-9]+]]
; DEBUG-NEXT: [[OBJ_12_PTR3_SROA_IDX:%.*]] = getelementptr inbounds i8, ptr [[OBJ]], i64 12, !dbg [[DBG515:![0-9]+]]
; DEBUG-NEXT: store float 1.310720e+05, ptr [[OBJ_12_PTR3_SROA_IDX]], align 4, !dbg [[DBG515]]
; DEBUG-NEXT: [[OBJ_0_SROAVAL:%.*]] = load <4 x float>, ptr [[OBJ]], align 16, !dbg [[DBG516:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata <4 x float> [[OBJ_0_SROAVAL]], metadata [[META507:![0-9]+]], metadata !DIExpression()), !dbg [[DBG516]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata <4 x float> [[OBJ_0_SROAVAL]], metadata [[META507:![0-9]+]], metadata !DIExpression()), !dbg [[DBG516]]
; DEBUG-NEXT: ret <4 x float> [[OBJ_0_SROAVAL]], !dbg [[DBG517:![0-9]+]]
;
%val0 = load ptr, ptr %init, align 8
@@ -1325,17 +1325,17 @@ define <4 x i32> @ptrLoadStoreTysAS3(ptr %init, i32 %val2) {
;
; DEBUG-LABEL: @ptrLoadStoreTysAS3(
; DEBUG-NEXT: [[VAL0:%.*]] = load ptr addrspace(3), ptr [[INIT:%.*]], align 8, !dbg [[DBG525:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr addrspace(3) [[VAL0]], metadata [[META520:![0-9]+]], metadata !DIExpression()), !dbg [[DBG525]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META521:![0-9]+]], metadata !DIExpression()), !dbg [[DBG526:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr addrspace(3) [[VAL0]], metadata [[META520:![0-9]+]], metadata !DIExpression()), !dbg [[DBG525]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META521:![0-9]+]], metadata !DIExpression()), !dbg [[DBG526:![0-9]+]]
; DEBUG-NEXT: [[TMP1:%.*]] = ptrtoint ptr addrspace(3) [[VAL0]] to i64, !dbg [[DBG527:![0-9]+]]
; DEBUG-NEXT: [[TMP2:%.*]] = bitcast i64 [[TMP1]] to <2 x i32>, !dbg [[DBG527]]
; DEBUG-NEXT: [[OBJ_0_VEC_EXPAND:%.*]] = shufflevector <2 x i32> [[TMP2]], <2 x i32> poison, <4 x i32> <i32 0, i32 1, i32 poison, i32 poison>, !dbg [[DBG527]]
; DEBUG-NEXT: [[OBJ_0_VECBLEND:%.*]] = select <4 x i1> <i1 true, i1 true, i1 false, i1 false>, <4 x i32> [[OBJ_0_VEC_EXPAND]], <4 x i32> zeroinitializer, !dbg [[DBG527]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META522:![0-9]+]], metadata !DIExpression()), !dbg [[DBG528:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META522:![0-9]+]], metadata !DIExpression()), !dbg [[DBG528:![0-9]+]]
; DEBUG-NEXT: [[OBJ_8_VEC_INSERT:%.*]] = insertelement <4 x i32> [[OBJ_0_VECBLEND]], i32 [[VAL2:%.*]], i32 2, !dbg [[DBG529:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META523:![0-9]+]], metadata !DIExpression()), !dbg [[DBG530:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META523:![0-9]+]], metadata !DIExpression()), !dbg [[DBG530:![0-9]+]]
; DEBUG-NEXT: [[OBJ_12_VEC_INSERT:%.*]] = insertelement <4 x i32> [[OBJ_8_VEC_INSERT]], i32 131072, i32 3, !dbg [[DBG531:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata <4 x i32> [[OBJ_12_VEC_INSERT]], metadata [[META524:![0-9]+]], metadata !DIExpression()), !dbg [[DBG532:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata <4 x i32> [[OBJ_12_VEC_INSERT]], metadata [[META524:![0-9]+]], metadata !DIExpression()), !dbg [[DBG532:![0-9]+]]
; DEBUG-NEXT: ret <4 x i32> [[OBJ_12_VEC_INSERT]], !dbg [[DBG533:![0-9]+]]
;
%val0 = load ptr addrspace(3), ptr %init, align 8
@@ -1365,19 +1365,19 @@ define <4 x ptr> @ptrLoadStoreTysPtr(ptr %init, i64 %val2) {
;
; DEBUG-LABEL: @ptrLoadStoreTysPtr(
; DEBUG-NEXT: [[VAL0:%.*]] = load ptr, ptr [[INIT:%.*]], align 8, !dbg [[DBG541:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr [[VAL0]], metadata [[META536:![0-9]+]], metadata !DIExpression()), !dbg [[DBG541]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr [[VAL0]], metadata [[META536:![0-9]+]], metadata !DIExpression()), !dbg [[DBG541]]
; DEBUG-NEXT: [[OBJ:%.*]] = alloca <4 x ptr>, align 16, !dbg [[DBG542:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr [[OBJ]], metadata [[META537:![0-9]+]], metadata !DIExpression()), !dbg [[DBG542]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr [[OBJ]], metadata [[META537:![0-9]+]], metadata !DIExpression()), !dbg [[DBG542]]
; DEBUG-NEXT: store <4 x ptr> zeroinitializer, ptr [[OBJ]], align 16, !dbg [[DBG543:![0-9]+]]
; DEBUG-NEXT: store ptr [[VAL0]], ptr [[OBJ]], align 16, !dbg [[DBG544:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META538:![0-9]+]], metadata !DIExpression()), !dbg [[DBG545:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META538:![0-9]+]], metadata !DIExpression()), !dbg [[DBG545:![0-9]+]]
; DEBUG-NEXT: [[OBJ_8_PTR2_SROA_IDX:%.*]] = getelementptr inbounds i8, ptr [[OBJ]], i64 8, !dbg [[DBG546:![0-9]+]]
; DEBUG-NEXT: store i64 [[VAL2:%.*]], ptr [[OBJ_8_PTR2_SROA_IDX]], align 8, !dbg [[DBG546]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata ptr undef, metadata [[META539:![0-9]+]], metadata !DIExpression()), !dbg [[DBG547:![0-9]+]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata ptr undef, metadata [[META539:![0-9]+]], metadata !DIExpression()), !dbg [[DBG547:![0-9]+]]
; DEBUG-NEXT: [[OBJ_12_PTR3_SROA_IDX:%.*]] = getelementptr inbounds i8, ptr [[OBJ]], i64 12, !dbg [[DBG548:![0-9]+]]
; DEBUG-NEXT: store i64 131072, ptr [[OBJ_12_PTR3_SROA_IDX]], align 4, !dbg [[DBG548]]
; DEBUG-NEXT: [[OBJ_0_SROAVAL:%.*]] = load <4 x ptr>, ptr [[OBJ]], align 16, !dbg [[DBG549:![0-9]+]]
-; DEBUG-NEXT: call void @llvm.dbg.value(metadata <4 x ptr> [[OBJ_0_SROAVAL]], metadata [[META540:![0-9]+]], metadata !DIExpression()), !dbg [[DBG549]]
+; DEBUG-NEXT: tail call void @llvm.dbg.value(metadata <4 x ptr> [[OBJ_0_SROAVAL]], metadata [[META540:![0-9]+]], metadata !DIExpression()), !dbg [[DBG549]]
; DEBUG-NEXT: ret <4 x ptr> [[OBJ_0_SROAVAL]], !dbg [[DBG550:![0-9]+]]
;
%val0 = load ptr, ptr %init, align 8
>From 1ca65dd74a4370e5788c69e939106b53da13dbf6 Mon Sep 17 00:00:00 2001
From: Yinying Li <107574043+yinying-lisa-li at users.noreply.github.com>
Date: Thu, 29 Feb 2024 14:14:31 -0500
Subject: [PATCH 163/406] [mlir][sparse] Migration to sparse_tensor.print
(#83377)
Continuous efforts following #83357.
---
.../SparseTensor/CPU/sparse_loose.mlir | 23 +-
.../SparseTensor/CPU/sparse_matmul.mlir | 237 ++++++++++--------
.../SparseTensor/CPU/sparse_matmul_slice.mlir | 84 +++----
.../SparseTensor/CPU/sparse_matrix_ops.mlir | 114 +++++----
4 files changed, 259 insertions(+), 199 deletions(-)
diff --git a/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_loose.mlir b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_loose.mlir
index 228d4e5f6f8a1a..e1f062121b12f9 100644
--- a/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_loose.mlir
+++ b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_loose.mlir
@@ -10,7 +10,7 @@
// DEFINE: %{compile} = mlir-opt %s --sparsifier="%{sparsifier_opts}"
// DEFINE: %{compile_sve} = mlir-opt %s --sparsifier="%{sparsifier_opts_sve}"
// DEFINE: %{run_libs} = -shared-libs=%mlir_c_runner_utils,%mlir_runner_utils
-// DEFINE: %{run_opts} = -e entry -entry-point-result=void
+// DEFINE: %{run_opts} = -e main -entry-point-result=void
// DEFINE: %{run} = mlir-cpu-runner %{run_opts} %{run_libs}
// DEFINE: %{run_sve} = %mcr_aarch64_cmd --march=aarch64 --mattr="+sve" %{run_opts} %{run_libs}
//
@@ -28,7 +28,7 @@
}>
module {
- func.func @entry() {
+ func.func @main() {
%c0 = arith.constant 0 : index
%f0 = arith.constant 0.0 : f64
%d = arith.constant dense<[[ 1.0, 2.0, 3.0, 4.0 ],
@@ -39,19 +39,14 @@ module {
%s = sparse_tensor.convert %d : tensor<5x4xf64> to tensor<5x4xf64, #CSR_hi>
//
- // CHECK: ( 0, 4, 4, 8, 8, 9, 9, 13 )
- // CHECK-NEXT: ( 0, 1, 2, 3, 0, 1, 2, 3, 2, 0, 1, 2, 3, 0, 1, 2, 3 )
- // CHECK-NEXT: ( 1, 2, 3, 4, 5, 6, 7, 8, 5.5, 9, 10, 11, 12, 13, 14, 15, 16 )
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 17
+ // CHECK-NEXT: pos[1] : ( 0, 4, 4, 8, 8, 9, 9, 13
+ // CHECK-NEXT: crd[1] : ( 0, 1, 2, 3, 0, 1, 2, 3, 2, 0, 1, 2, 3, 0, 1, 2, 3
+ // CHECK-NEXT: values : ( 1, 2, 3, 4, 5, 6, 7, 8, 5.5, 9, 10, 11, 12, 13, 14, 15, 16
+ // CHECK-NEXT: ----
//
- %pos = sparse_tensor.positions %s {level = 1 : index } : tensor<5x4xf64, #CSR_hi> to memref<?xindex>
- %vecp = vector.transfer_read %pos[%c0], %c0 : memref<?xindex>, vector<8xindex>
- vector.print %vecp : vector<8xindex>
- %crd = sparse_tensor.coordinates %s {level = 1 : index } : tensor<5x4xf64, #CSR_hi> to memref<?xindex>
- %vecc = vector.transfer_read %crd[%c0], %c0 : memref<?xindex>, vector<17xindex>
- vector.print %vecc : vector<17xindex>
- %val = sparse_tensor.values %s : tensor<5x4xf64, #CSR_hi> to memref<?xf64>
- %vecv = vector.transfer_read %val[%c0], %f0 : memref<?xf64>, vector<17xf64>
- vector.print %vecv : vector<17xf64>
+ sparse_tensor.print %s : tensor<5x4xf64, #CSR_hi>
// Release the resources.
bufferization.dealloc_tensor %s: tensor<5x4xf64, #CSR_hi>
diff --git a/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matmul.mlir b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matmul.mlir
index fa0dbac269b926..863e1c62370e32 100644
--- a/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matmul.mlir
+++ b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matmul.mlir
@@ -10,7 +10,7 @@
// DEFINE: %{compile} = mlir-opt %s --sparsifier="%{sparsifier_opts}"
// DEFINE: %{compile_sve} = mlir-opt %s --sparsifier="%{sparsifier_opts_sve}"
// DEFINE: %{run_libs} = -shared-libs=%mlir_c_runner_utils,%mlir_runner_utils
-// DEFINE: %{run_opts} = -e entry -entry-point-result=void
+// DEFINE: %{run_opts} = -e main -entry-point-result=void
// DEFINE: %{run} = mlir-cpu-runner %{run_opts} %{run_libs}
// DEFINE: %{run_sve} = %mcr_aarch64_cmd --march=aarch64 --mattr="+sve" %{run_opts} %{run_libs}
//
@@ -90,7 +90,7 @@ module {
//
// Main driver.
//
- func.func @entry() {
+ func.func @main() {
%c0 = arith.constant 0 : index
// Initialize various matrices, dense for stress testing,
@@ -140,33 +140,94 @@ module {
%b4 = sparse_tensor.convert %sb : tensor<8x4xf64> to tensor<8x4xf64, #DCSR>
//
- // Sanity check on stored entries before going into the computations.
- //
- // CHECK: 32
- // CHECK-NEXT: 32
- // CHECK-NEXT: 4
- // CHECK-NEXT: 4
- // CHECK-NEXT: 32
- // CHECK-NEXT: 32
- // CHECK-NEXT: 8
- // CHECK-NEXT: 8
- //
- %noea1 = sparse_tensor.number_of_entries %a1 : tensor<4x8xf64, #CSR>
- %noea2 = sparse_tensor.number_of_entries %a2 : tensor<4x8xf64, #DCSR>
- %noea3 = sparse_tensor.number_of_entries %a3 : tensor<4x8xf64, #CSR>
- %noea4 = sparse_tensor.number_of_entries %a4 : tensor<4x8xf64, #DCSR>
- %noeb1 = sparse_tensor.number_of_entries %b1 : tensor<8x4xf64, #CSR>
- %noeb2 = sparse_tensor.number_of_entries %b2 : tensor<8x4xf64, #DCSR>
- %noeb3 = sparse_tensor.number_of_entries %b3 : tensor<8x4xf64, #CSR>
- %noeb4 = sparse_tensor.number_of_entries %b4 : tensor<8x4xf64, #DCSR>
- vector.print %noea1 : index
- vector.print %noea2 : index
- vector.print %noea3 : index
- vector.print %noea4 : index
- vector.print %noeb1 : index
- vector.print %noeb2 : index
- vector.print %noeb3 : index
- vector.print %noeb4 : index
+ // Sanity check before going into the computations.
+ //
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 32
+ // CHECK-NEXT: pos[1] : ( 0, 8, 16, 24, 32
+ // CHECK-NEXT: crd[1] : ( 0, 1, 2, 3, 4, 5, 6, 7, 0, 1, 2, 3, 4, 5, 6, 7, 0, 1, 2, 3, 4, 5, 6, 7, 0, 1, 2, 3, 4, 5, 6, 7
+ // CHECK-NEXT: values : ( 1.1, 2.1, 3.1, 4.1, 5.1, 6.1, 7.1, 8.1, 1.2, 2.2, 3.2, 4.2, 5.2, 6.2, 7.2, 8.2, 1.3, 2.3, 3.3, 4.3, 5.3, 6.3, 7.3, 8.3, 1.4, 2.4, 3.4, 4.4, 5.4, 6.4, 7.4, 8.4
+ // CHECK-NEXT: ----
+ //
+ sparse_tensor.print %a1 : tensor<4x8xf64, #CSR>
+
+ //
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 32
+ // CHECK-NEXT: pos[0] : ( 0, 4
+ // CHECK-NEXT: crd[0] : ( 0, 1, 2, 3
+ // CHECK-NEXT: pos[1] : ( 0, 8, 16, 24, 32
+ // CHECK-NEXT: crd[1] : ( 0, 1, 2, 3, 4, 5, 6, 7, 0, 1, 2, 3, 4, 5, 6, 7, 0, 1, 2, 3, 4, 5, 6, 7, 0, 1, 2, 3, 4, 5, 6, 7
+ // CHECK-NEXT: values : ( 1.1, 2.1, 3.1, 4.1, 5.1, 6.1, 7.1, 8.1, 1.2, 2.2, 3.2, 4.2, 5.2, 6.2, 7.2, 8.2, 1.3, 2.3, 3.3, 4.3, 5.3, 6.3, 7.3, 8.3, 1.4, 2.4, 3.4, 4.4, 5.4, 6.4, 7.4, 8.4
+ // CHECK-NEXT: ----
+ //
+ sparse_tensor.print %a2 : tensor<4x8xf64, #DCSR>
+
+ //
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 4
+ // CHECK-NEXT: pos[1] : ( 0, 2, 2, 3, 4
+ // CHECK-NEXT: crd[1] : ( 1, 5, 1, 7
+ // CHECK-NEXT: values : ( 2.1, 6.1, 2.3, 1
+ // CHECK-NEXT: ----
+ //
+ sparse_tensor.print %a3 : tensor<4x8xf64, #CSR>
+
+ //
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 4
+ // CHECK-NEXT: pos[0] : ( 0, 3
+ // CHECK-NEXT: crd[0] : ( 0, 2, 3
+ // CHECK-NEXT: pos[1] : ( 0, 2, 3, 4
+ // CHECK-NEXT: crd[1] : ( 1, 5, 1, 7
+ // CHECK-NEXT: values : ( 2.1, 6.1, 2.3, 1
+ // CHECK-NEXT: ----
+ //
+ sparse_tensor.print %a4 : tensor<4x8xf64, #DCSR>
+
+ //
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 32
+ // CHECK-NEXT: pos[1] : ( 0, 4, 8, 12, 16, 20, 24, 28, 32
+ // CHECK-NEXT: crd[1] : ( 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3
+ // CHECK-NEXT: values : ( 10.1, 11.1, 12.1, 13.1, 10.2, 11.2, 12.2, 13.2, 10.3, 11.3, 12.3, 13.3, 10.4, 11.4, 12.4, 13.4, 10.5, 11.5, 12.5, 13.5, 10.6, 11.6, 12.6, 13.6, 10.7, 11.7, 12.7, 13.7, 10.8, 11.8, 12.8, 13.8
+ // CHECK-NEXT: ----
+ //
+ sparse_tensor.print %b1 : tensor<8x4xf64, #CSR>
+
+ //
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 32
+ // CHECK-NEXT: pos[0] : ( 0, 8
+ // CHECK-NEXT: crd[0] : ( 0, 1, 2, 3, 4, 5, 6, 7
+ // CHECK-NEXT: pos[1] : ( 0, 4, 8, 12, 16, 20, 24, 28, 32
+ // CHECK-NEXT: crd[1] : ( 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3
+ // CHECK-NEXT: values : ( 10.1, 11.1, 12.1, 13.1, 10.2, 11.2, 12.2, 13.2, 10.3, 11.3, 12.3, 13.3, 10.4, 11.4, 12.4, 13.4, 10.5, 11.5, 12.5, 13.5, 10.6, 11.6, 12.6, 13.6, 10.7, 11.7, 12.7, 13.7, 10.8, 11.8, 12.8, 13.8
+ // CHECK-NEXT: ----
+ //
+ sparse_tensor.print %b2 : tensor<8x4xf64, #DCSR>
+
+ //
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 8
+ // CHECK-NEXT: pos[1] : ( 0, 1, 2, 3, 4, 4, 5, 6, 8
+ // CHECK-NEXT: crd[1] : ( 3, 2, 1, 0, 1, 2, 2, 3
+ // CHECK-NEXT: values : ( 1, 2, 3, 4, 5, 6, 7, 8
+ // CHECK-NEXT: ----
+ //
+ sparse_tensor.print %b3 : tensor<8x4xf64, #CSR>
+
+ //
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 8
+ // CHECK-NEXT: pos[0] : ( 0, 7
+ // CHECK-NEXT: crd[0] : ( 0, 1, 2, 3, 5, 6, 7
+ // CHECK-NEXT: pos[1] : ( 0, 1, 2, 3, 4, 5, 6, 8
+ // CHECK-NEXT: crd[1] : ( 3, 2, 1, 0, 1, 2, 2, 3
+ // CHECK-NEXT: values : ( 1, 2, 3, 4, 5, 6, 7, 8
+ // CHECK-NEXT: ----
+ //
+ sparse_tensor.print %b4 : tensor<8x4xf64, #DCSR>
// Call kernels with dense.
%0 = call @matmul1(%da, %db, %zero)
@@ -208,24 +269,26 @@ module {
call @printMemrefF64(%u0) : (tensor<*xf64>) -> ()
//
- // CHECK: {{\[}}[388.76, 425.56, 462.36, 499.16],
- // CHECK-NEXT: [397.12, 434.72, 472.32, 509.92],
- // CHECK-NEXT: [405.48, 443.88, 482.28, 520.68],
- // CHECK-NEXT: [413.84, 453.04, 492.24, 531.44]]
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 16
+ // CHECK-NEXT: pos[1] : ( 0, 4, 8, 12, 16
+ // CHECK-NEXT: crd[1] : ( 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3
+ // CHECK-NEXT: values : ( 388.76, 425.56, 462.36, 499.16, 397.12, 434.72, 472.32, 509.92, 405.48, 443.88, 482.28, 520.68, 413.84, 453.04, 492.24, 531.44
+ // CHECK-NEXT: ----
//
- %c1 = sparse_tensor.convert %1 : tensor<4x4xf64, #CSR> to tensor<4x4xf64>
- %c1u = tensor.cast %c1 : tensor<4x4xf64> to tensor<*xf64>
- call @printMemrefF64(%c1u) : (tensor<*xf64>) -> ()
+ sparse_tensor.print %1 : tensor<4x4xf64, #CSR>
//
- // CHECK: {{\[}}[388.76, 425.56, 462.36, 499.16],
- // CHECK-NEXT: [397.12, 434.72, 472.32, 509.92],
- // CHECK-NEXT: [405.48, 443.88, 482.28, 520.68],
- // CHECK-NEXT: [413.84, 453.04, 492.24, 531.44]]
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 16
+ // CHECK-NEXT: pos[0] : ( 0, 4
+ // CHECK-NEXT: crd[0] : ( 0, 1, 2, 3
+ // CHECK-NEXT: pos[1] : ( 0, 4, 8, 12, 16
+ // CHECK-NEXT: crd[1] : ( 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3
+ // CHECK-NEXT: values : ( 388.76, 425.56, 462.36, 499.16, 397.12, 434.72, 472.32, 509.92, 405.48, 443.88, 482.28, 520.68, 413.84, 453.04, 492.24, 531.44
+ // CHECK-NEXT: ----
//
- %c2 = sparse_tensor.convert %2 : tensor<4x4xf64, #DCSR> to tensor<4x4xf64>
- %c2u = tensor.cast %c2 : tensor<4x4xf64> to tensor<*xf64>
- call @printMemrefF64(%c2u) : (tensor<*xf64>) -> ()
+ sparse_tensor.print %2 : tensor<4x4xf64, #DCSR>
//
// CHECK: {{\[}}[86.08, 94.28, 102.48, 110.68],
@@ -237,24 +300,26 @@ module {
call @printMemrefF64(%u3) : (tensor<*xf64>) -> ()
//
- // CHECK: {{\[}}[86.08, 94.28, 102.48, 110.68],
- // CHECK-NEXT: [0, 0, 0, 0],
- // CHECK-NEXT: [23.46, 25.76, 28.06, 30.36],
- // CHECK-NEXT: [10.8, 11.8, 12.8, 13.8]]
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 12
+ // CHECK-NEXT: pos[1] : ( 0, 4, 4, 8, 12
+ // CHECK-NEXT: crd[1] : ( 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3
+ // CHECK-NEXT: values : ( 86.08, 94.28, 102.48, 110.68, 23.46, 25.76, 28.06, 30.36, 10.8, 11.8, 12.8, 13.8
+ // CHECK-NEXT: ----
//
- %c4 = sparse_tensor.convert %4 : tensor<4x4xf64, #CSR> to tensor<4x4xf64>
- %c4u = tensor.cast %c4 : tensor<4x4xf64> to tensor<*xf64>
- call @printMemrefF64(%c4u) : (tensor<*xf64>) -> ()
+ sparse_tensor.print %4 : tensor<4x4xf64, #CSR>
//
- // CHECK: {{\[}}[86.08, 94.28, 102.48, 110.68],
- // CHECK-NEXT: [0, 0, 0, 0],
- // CHECK-NEXT: [23.46, 25.76, 28.06, 30.36],
- // CHECK-NEXT: [10.8, 11.8, 12.8, 13.8]]
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 12
+ // CHECK-NEXT: pos[0] : ( 0, 3
+ // CHECK-NEXT: crd[0] : ( 0, 2, 3
+ // CHECK-NEXT: pos[1] : ( 0, 4, 8, 12
+ // CHECK-NEXT: crd[1] : ( 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3
+ // CHECK-NEXT: values : ( 86.08, 94.28, 102.48, 110.68, 23.46, 25.76, 28.06, 30.36, 10.8, 11.8, 12.8, 13.8
+ // CHECK-NEXT: ----
//
- %c5 = sparse_tensor.convert %5 : tensor<4x4xf64, #DCSR> to tensor<4x4xf64>
- %c5u = tensor.cast %c5 : tensor<4x4xf64> to tensor<*xf64>
- call @printMemrefF64(%c5u) : (tensor<*xf64>) -> ()
+ sparse_tensor.print %5 : tensor<4x4xf64, #DCSR>
//
// CHECK: {{\[}}[0, 30.5, 4.2, 0],
@@ -266,46 +331,26 @@ module {
call @printMemrefF64(%u6) : (tensor<*xf64>) -> ()
//
- // CHECK: {{\[}}[0, 30.5, 4.2, 0],
- // CHECK-NEXT: [0, 0, 0, 0],
- // CHECK-NEXT: [0, 0, 4.6, 0],
- // CHECK-NEXT: [0, 0, 7, 8]]
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 5
+ // CHECK-NEXT: pos[1] : ( 0, 2, 2, 3, 5
+ // CHECK-NEXT: crd[1] : ( 1, 2, 2, 2, 3
+ // CHECK-NEXT: values : ( 30.5, 4.2, 4.6, 7, 8
+ // CHECK-NEXT: ----
//
- %c7 = sparse_tensor.convert %7 : tensor<4x4xf64, #CSR> to tensor<4x4xf64>
- %c7u = tensor.cast %c7 : tensor<4x4xf64> to tensor<*xf64>
- call @printMemrefF64(%c7u) : (tensor<*xf64>) -> ()
+ sparse_tensor.print %7 : tensor<4x4xf64, #CSR>
//
- // CHECK: {{\[}}[0, 30.5, 4.2, 0],
- // CHECK-NEXT: [0, 0, 0, 0],
- // CHECK-NEXT: [0, 0, 4.6, 0],
- // CHECK-NEXT: [0, 0, 7, 8]]
- //
- %c8 = sparse_tensor.convert %8 : tensor<4x4xf64, #DCSR> to tensor<4x4xf64>
- %c8u = tensor.cast %c8 : tensor<4x4xf64> to tensor<*xf64>
- call @printMemrefF64(%c8u) : (tensor<*xf64>) -> ()
-
- //
- // Sanity check on nonzeros.
- //
- // CHECK: [30.5, 4.2, 4.6, 7, 8{{.*}}]
- // CHECK: [30.5, 4.2, 4.6, 7, 8{{.*}}]
- //
- %val7 = sparse_tensor.values %7 : tensor<4x4xf64, #CSR> to memref<?xf64>
- %val8 = sparse_tensor.values %8 : tensor<4x4xf64, #DCSR> to memref<?xf64>
- call @printMemref1dF64(%val7) : (memref<?xf64>) -> ()
- call @printMemref1dF64(%val8) : (memref<?xf64>) -> ()
-
- //
- // Sanity check on stored entries after the computations.
- //
- // CHECK-NEXT: 5
- // CHECK-NEXT: 5
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 5
+ // CHECK-NEXT: pos[0] : ( 0, 3
+ // CHECK-NEXT: crd[0] : ( 0, 2, 3
+ // CHECK-NEXT: pos[1] : ( 0, 2, 3, 5
+ // CHECK-NEXT: crd[1] : ( 1, 2, 2, 2, 3
+ // CHECK-NEXT: values : ( 30.5, 4.2, 4.6, 7, 8
+ // CHECK-NEXT: ----
//
- %noe7 = sparse_tensor.number_of_entries %7 : tensor<4x4xf64, #CSR>
- %noe8 = sparse_tensor.number_of_entries %8 : tensor<4x4xf64, #DCSR>
- vector.print %noe7 : index
- vector.print %noe8 : index
+ sparse_tensor.print %8 : tensor<4x4xf64, #DCSR>
// Release the resources.
bufferization.dealloc_tensor %a1 : tensor<4x8xf64, #CSR>
@@ -316,12 +361,6 @@ module {
bufferization.dealloc_tensor %b2 : tensor<8x4xf64, #DCSR>
bufferization.dealloc_tensor %b3 : tensor<8x4xf64, #CSR>
bufferization.dealloc_tensor %b4 : tensor<8x4xf64, #DCSR>
- bufferization.dealloc_tensor %c1 : tensor<4x4xf64>
- bufferization.dealloc_tensor %c2 : tensor<4x4xf64>
- bufferization.dealloc_tensor %c4 : tensor<4x4xf64>
- bufferization.dealloc_tensor %c5 : tensor<4x4xf64>
- bufferization.dealloc_tensor %c7 : tensor<4x4xf64>
- bufferization.dealloc_tensor %c8 : tensor<4x4xf64>
bufferization.dealloc_tensor %0 : tensor<4x4xf64>
bufferization.dealloc_tensor %1 : tensor<4x4xf64, #CSR>
bufferization.dealloc_tensor %2 : tensor<4x4xf64, #DCSR>
diff --git a/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matmul_slice.mlir b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matmul_slice.mlir
index 96c8a30ade8e42..a7184c044569ca 100644
--- a/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matmul_slice.mlir
+++ b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matmul_slice.mlir
@@ -10,7 +10,7 @@
// DEFINE: %{compile} = mlir-opt %s --sparsifier="%{sparsifier_opts}"
// DEFINE: %{compile_sve} = mlir-opt %s --sparsifier="%{sparsifier_opts_sve}"
// DEFINE: %{run_libs} = -shared-libs=%mlir_c_runner_utils,%mlir_runner_utils
-// DEFINE: %{run_opts} = -e entry -entry-point-result=void
+// DEFINE: %{run_opts} = -e main -entry-point-result=void
// DEFINE: %{run} = mlir-cpu-runner %{run_opts} %{run_libs}
// DEFINE: %{run_sve} = %mcr_aarch64_cmd --march=aarch64 --mattr="+sve" %{run_opts} %{run_libs}
//
@@ -132,7 +132,7 @@ module {
//
// Main driver.
//
- func.func @entry() {
+ func.func @main() {
%c_0 = arith.constant 0 : index
%c_1 = arith.constant 1 : index
%c_2 = arith.constant 2 : index
@@ -170,14 +170,16 @@ module {
// DCSR test
//
- // CHECK: [0, 30.5, 4.2, 0],
- // CHECK-NEXT: [0, 0, 0, 0],
- // CHECK-NEXT: [0, 0, 4.6, 0],
- // CHECK-NEXT: [0, 0, 7, 8]
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 5
+ // CHECK-NEXT: pos[0] : ( 0, 3
+ // CHECK-NEXT: crd[0] : ( 0, 2, 3
+ // CHECK-NEXT: pos[1] : ( 0, 2, 3, 5
+ // CHECK-NEXT: crd[1] : ( 1, 2, 2, 2, 3
+ // CHECK-NEXT: values : ( 30.5, 4.2, 4.6, 7, 8
+ // CHECK-NEXT: ----
//
- %c2 = sparse_tensor.convert %2 : tensor<4x4xf64, #DCSR> to tensor<4x4xf64>
- %c2u = tensor.cast %c2 : tensor<4x4xf64> to tensor<*xf64>
- call @printMemrefF64(%c2u) : (tensor<*xf64>) -> ()
+ sparse_tensor.print %2 : tensor<4x4xf64, #DCSR>
%t1 = sparse_tensor.convert %sa : tensor<8x8xf64> to tensor<8x8xf64, #CSR>
%a1 = tensor.extract_slice %t1[0, 0][4, 8][1, 1] : tensor<8x8xf64, #CSR> to tensor<4x8xf64, #CSR_SLICE>
@@ -188,63 +190,64 @@ module {
// CSR test
//
- // CHECK: [0, 30.5, 4.2, 0],
- // CHECK-NEXT: [0, 0, 0, 0],
- // CHECK-NEXT: [0, 0, 4.6, 0],
- // CHECK-NEXT: [0, 0, 7, 8]
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 5
+ // CHECK-NEXT: pos[1] : ( 0, 2, 2, 3, 5
+ // CHECK-NEXT: crd[1] : ( 1, 2, 2, 2, 3
+ // CHECK-NEXT: values : ( 30.5, 4.2, 4.6, 7, 8
+ // CHECK-NEXT: ----
//
- %c3 = sparse_tensor.convert %3 : tensor<4x4xf64, #CSR> to tensor<4x4xf64>
- %c3u = tensor.cast %c3 : tensor<4x4xf64> to tensor<*xf64>
- call @printMemrefF64(%c3u) : (tensor<*xf64>) -> ()
+ sparse_tensor.print %3 : tensor<4x4xf64, #CSR>
+
// slice x slice
//
- // CHECK: [2.3, 0, 0, 0],
- // CHECK-NEXT: [6.9, 0, 0, 0],
- // CHECK-NEXT: [0, 0, 0, 0],
- // CHECK-NEXT: [12.6, 0, 0, 0]]
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 3
+ // CHECK-NEXT: pos[1] : ( 0, 1, 2, 2, 3
+ // CHECK-NEXT: crd[1] : ( 0, 0, 0
+ // CHECK-NEXT: values : ( 2.3, 6.9, 12.6
+ // CHECK-NEXT: ----
//
+ sparse_tensor.print %4 : tensor<4x4xf64, #CSR>
+
%s1 = tensor.extract_slice %tmp[0, 1][4, 4][2, 1] : tensor<8x8xf64, #DCSR> to tensor<4x4xf64, #DCSR_SLICE_1>
%s2 = tensor.extract_slice %b1[0, 0][4, 4][2, 1] : tensor<8x4xf64, #CSR> to tensor<4x4xf64, #CSR_SLICE_1>
%4 = call @matmul1(%s2, %s1)
: (tensor<4x4xf64, #CSR_SLICE_1>,
tensor<4x4xf64, #DCSR_SLICE_1>) -> tensor<4x4xf64, #CSR>
- %c4 = sparse_tensor.convert %4 : tensor<4x4xf64, #CSR> to tensor<4x4xf64>
- %c4u = tensor.cast %c4 : tensor<4x4xf64> to tensor<*xf64>
- call @printMemrefF64(%c4u) : (tensor<*xf64>) -> ()
// slice coo x slice coo
//
- // CHECK: [2.3, 0, 0, 0],
- // CHECK-NEXT: [6.9, 0, 0, 0],
- // CHECK-NEXT: [0, 0, 0, 0],
- // CHECK-NEXT: [12.6, 0, 0, 0]]
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 3
+ // CHECK-NEXT: pos[0] : ( 0, 3
+ // CHECK-NEXT: crd[0] : ( 0, 0, 1, 0, 3, 0
+ // CHECK-NEXT: values : ( 2.3, 6.9, 12.6
+ // CHECK-NEXT: ----
//
+ sparse_tensor.print %o_coo : tensor<4x4xf64, #COO>
%t1_coo = sparse_tensor.convert %sa : tensor<8x8xf64> to tensor<8x8xf64, #COO>
%b1_coo = sparse_tensor.convert %sb : tensor<8x4xf64> to tensor<8x4xf64, #COO>
%s2_coo = tensor.extract_slice %b1_coo[0, 0][4, 4][2, 1] : tensor<8x4xf64, #COO> to tensor<4x4xf64, #COO_SLICE_1>
%s1_coo = tensor.extract_slice %t1_coo[0, 1][4, 4][2, 1] : tensor<8x8xf64, #COO> to tensor<4x4xf64, #COO_SLICE_2>
%o_coo = call @matmul5(%s2_coo, %s1_coo) : (tensor<4x4xf64, #COO_SLICE_1>, tensor<4x4xf64, #COO_SLICE_2>) -> tensor<4x4xf64, #COO>
- %c4_coo = sparse_tensor.convert %o_coo : tensor<4x4xf64, #COO> to tensor<4x4xf64>
- %c4u_coo = tensor.cast %c4_coo : tensor<4x4xf64> to tensor<*xf64>
- call @printMemrefF64(%c4u_coo) : (tensor<*xf64>) -> ()
-
// slice x slice (same as above, but with dynamic stride information)
//
- // CHECK: [2.3, 0, 0, 0],
- // CHECK-NEXT: [6.9, 0, 0, 0],
- // CHECK-NEXT: [0, 0, 0, 0],
- // CHECK-NEXT: [12.6, 0, 0, 0]]
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 3
+ // CHECK-NEXT: pos[1] : ( 0, 1, 2, 2, 3
+ // CHECK-NEXT: crd[1] : ( 0, 0, 0
+ // CHECK-NEXT: values : ( 2.3, 6.9, 12.6
+ // CHECK-NEXT: ----
//
+ sparse_tensor.print %dyn_4 : tensor<4x4xf64, #CSR>
%s1_dyn = tensor.extract_slice %tmp[%c_0, %c_1][4, 4][%c_2, %c_1] : tensor<8x8xf64, #DCSR> to tensor<4x4xf64, #DCSR_SLICE_dyn>
%s2_dyn = tensor.extract_slice %b1[%c_0, %c_0][4, 4][%c_2, %c_1] : tensor<8x4xf64, #CSR> to tensor<4x4xf64, #CSR_SLICE_dyn>
%dyn_4 = call @matmul_dyn(%s2_dyn, %s1_dyn)
: (tensor<4x4xf64, #CSR_SLICE_dyn>,
tensor<4x4xf64, #DCSR_SLICE_dyn>) -> tensor<4x4xf64, #CSR>
- %c4_dyn = sparse_tensor.convert %dyn_4 : tensor<4x4xf64, #CSR> to tensor<4x4xf64>
- %c4u_dyn = tensor.cast %c4_dyn : tensor<4x4xf64> to tensor<*xf64>
- call @printMemrefF64(%c4u_dyn) : (tensor<*xf64>) -> ()
// sparse slices should generate the same result as dense slices
//
@@ -265,11 +268,6 @@ module {
call @printMemrefF64(%du) : (tensor<*xf64>) -> ()
// Releases resources.
- bufferization.dealloc_tensor %c2 : tensor<4x4xf64>
- bufferization.dealloc_tensor %c3 : tensor<4x4xf64>
- bufferization.dealloc_tensor %c4 : tensor<4x4xf64>
- bufferization.dealloc_tensor %c4_coo : tensor<4x4xf64>
- bufferization.dealloc_tensor %c4_dyn : tensor<4x4xf64>
bufferization.dealloc_tensor %d : tensor<4x4xf64>
bufferization.dealloc_tensor %b1 : tensor<8x4xf64, #CSR>
bufferization.dealloc_tensor %t1 : tensor<8x8xf64, #CSR>
diff --git a/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matrix_ops.mlir b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matrix_ops.mlir
index 2cecc242034389..2cef46f4cb1546 100644
--- a/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matrix_ops.mlir
+++ b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matrix_ops.mlir
@@ -10,7 +10,7 @@
// DEFINE: %{compile} = mlir-opt %s --sparsifier="%{sparsifier_opts}"
// DEFINE: %{compile_sve} = mlir-opt %s --sparsifier="%{sparsifier_opts_sve}"
// DEFINE: %{run_libs} = -shared-libs=%mlir_c_runner_utils,%mlir_runner_utils
-// DEFINE: %{run_opts} = -e entry -entry-point-result=void
+// DEFINE: %{run_opts} = -e main -entry-point-result=void
// DEFINE: %{run} = mlir-cpu-runner %{run_opts} %{run_libs}
// DEFINE: %{run_sve} = %mcr_aarch64_cmd --march=aarch64 --mattr="+sve" %{run_opts} %{run_libs}
//
@@ -61,8 +61,6 @@
}
module {
- func.func private @printMemrefF64(%ptr : tensor<*xf64>)
-
// Scales a sparse matrix into a new sparse matrix.
func.func @matrix_scale(%arga: tensor<?x?xf64, #DCSR>) -> tensor<?x?xf64, #DCSR> {
%s = arith.constant 2.0 : f64
@@ -129,17 +127,8 @@ module {
return %0 : tensor<?x?xf64, #DCSR>
}
- // Dump a sparse matrix.
- func.func @dump(%arg0: tensor<?x?xf64, #DCSR>) {
- %dm = sparse_tensor.convert %arg0 : tensor<?x?xf64, #DCSR> to tensor<?x?xf64>
- %u = tensor.cast %dm : tensor<?x?xf64> to tensor<*xf64>
- call @printMemrefF64(%u) : (tensor<*xf64>) -> ()
- bufferization.dealloc_tensor %dm : tensor<?x?xf64>
- return
- }
-
// Driver method to call and verify matrix kernels.
- func.func @entry() {
+ func.func @main() {
%c0 = arith.constant 0 : index
%d1 = arith.constant 1.1 : f64
@@ -170,37 +159,76 @@ module {
//
// Verify the results.
//
- // CHECK: {{\[}}[1, 2, 0, 0, 0, 0, 0, 0],
- // CHECK-NEXT: [0, 0, 0, 0, 0, 0, 0, 3],
- // CHECK-NEXT: [0, 0, 4, 0, 5, 0, 0, 6],
- // CHECK-NEXT: [7, 0, 8, 9, 0, 0, 0, 0]]
- // CHECK: {{\[}}[6, 0, 0, 0, 0, 0, 0, 5],
- // CHECK-NEXT: [4, 0, 0, 0, 0, 0, 3, 0],
- // CHECK-NEXT: [0, 2, 0, 0, 0, 0, 0, 1],
- // CHECK-NEXT: [0, 0, 0, 0, 0, 0, 0, 0]]
- // CHECK: {{\[}}[2, 4, 0, 0, 0, 0, 0, 0],
- // CHECK-NEXT: [0, 0, 0, 0, 0, 0, 0, 6],
- // CHECK-NEXT: [0, 0, 8, 0, 10, 0, 0, 12],
- // CHECK-NEXT: [14, 0, 16, 18, 0, 0, 0, 0]]
- // CHECK: {{\[}}[2, 4, 0, 0, 0, 0, 0, 0],
- // CHECK-NEXT: [0, 0, 0, 0, 0, 0, 0, 6],
- // CHECK-NEXT: [0, 0, 8, 0, 10, 0, 0, 12],
- // CHECK-NEXT: [14, 0, 16, 18, 0, 0, 0, 0]]
- // CHECK: {{\[}}[8, 4, 0, 0, 0, 0, 0, 5],
- // CHECK-NEXT: [4, 0, 0, 0, 0, 0, 3, 6],
- // CHECK-NEXT: [0, 2, 8, 0, 10, 0, 0, 13],
- // CHECK-NEXT: [14, 0, 16, 18, 0, 0, 0, 0]]
- // CHECK: {{\[}}[12, 0, 0, 0, 0, 0, 0, 0],
- // CHECK-NEXT: [0, 0, 0, 0, 0, 0, 0, 0],
- // CHECK-NEXT: [0, 0, 0, 0, 0, 0, 0, 12],
- // CHECK-NEXT: [0, 0, 0, 0, 0, 0, 0, 0]]
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 9
+ // CHECK-NEXT: pos[0] : ( 0, 4
+ // CHECK-NEXT: crd[0] : ( 0, 1, 2, 3
+ // CHECK-NEXT: pos[1] : ( 0, 2, 3, 6, 9
+ // CHECK-NEXT: crd[1] : ( 0, 1, 7, 2, 4, 7, 0, 2, 3
+ // CHECK-NEXT: values : ( 1, 2, 3, 4, 5, 6, 7, 8, 9
+ // CHECK-NEXT: ----
+ //
+ sparse_tensor.print %sm1 : tensor<?x?xf64, #DCSR>
+
+ //
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 6
+ // CHECK-NEXT: pos[0] : ( 0, 3
+ // CHECK-NEXT: crd[0] : ( 0, 1, 2
+ // CHECK-NEXT: pos[1] : ( 0, 2, 4, 6
+ // CHECK-NEXT: crd[1] : ( 0, 7, 0, 6, 1, 7
+ // CHECK-NEXT: values : ( 6, 5, 4, 3, 2, 1
+ // CHECK-NEXT: ----
+ //
+ sparse_tensor.print %sm2 : tensor<?x?xf64, #DCSR>
+
+ //
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 9
+ // CHECK-NEXT: pos[0] : ( 0, 4
+ // CHECK-NEXT: crd[0] : ( 0, 1, 2, 3
+ // CHECK-NEXT: pos[1] : ( 0, 2, 3, 6, 9
+ // CHECK-NEXT: crd[1] : ( 0, 1, 7, 2, 4, 7, 0, 2, 3
+ // CHECK-NEXT: values : ( 2, 4, 6, 8, 10, 12, 14, 16, 18
+ // CHECK-NEXT: ----
+ //
+ sparse_tensor.print %0 : tensor<?x?xf64, #DCSR>
+
+ //
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 9
+ // CHECK-NEXT: pos[0] : ( 0, 4
+ // CHECK-NEXT: crd[0] : ( 0, 1, 2, 3
+ // CHECK-NEXT: pos[1] : ( 0, 2, 3, 6, 9
+ // CHECK-NEXT: crd[1] : ( 0, 1, 7, 2, 4, 7, 0, 2, 3
+ // CHECK-NEXT: values : ( 2, 4, 6, 8, 10, 12, 14, 16, 18
+ // CHECK-NEXT: ----
+ //
+ sparse_tensor.print %1 : tensor<?x?xf64, #DCSR>
+
+ //
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 13
+ // CHECK-NEXT: pos[0] : ( 0, 4
+ // CHECK-NEXT: crd[0] : ( 0, 1, 2, 3
+ // CHECK-NEXT: pos[1] : ( 0, 3, 6, 10, 13
+ // CHECK-NEXT: crd[1] : ( 0, 1, 7, 0, 6, 7, 1, 2, 4, 7, 0, 2, 3
+ // CHECK-NEXT: values : ( 8, 4, 5, 4, 3, 6, 2, 8, 10, 13, 14, 16, 18
+ // CHECK-NEXT: ----
+ //
+ sparse_tensor.print %2 : tensor<?x?xf64, #DCSR>
+
+ //
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 2
+ // CHECK-NEXT: pos[0] : ( 0, 2
+ // CHECK-NEXT: crd[0] : ( 0, 2
+ // CHECK-NEXT: pos[1] : ( 0, 1, 2
+ // CHECK-NEXT: crd[1] : ( 0, 7
+ // CHECK-NEXT: values : ( 12, 12
+ // CHECK-NEXT: ----
//
- call @dump(%sm1) : (tensor<?x?xf64, #DCSR>) -> ()
- call @dump(%sm2) : (tensor<?x?xf64, #DCSR>) -> ()
- call @dump(%0) : (tensor<?x?xf64, #DCSR>) -> ()
- call @dump(%1) : (tensor<?x?xf64, #DCSR>) -> ()
- call @dump(%2) : (tensor<?x?xf64, #DCSR>) -> ()
- call @dump(%3) : (tensor<?x?xf64, #DCSR>) -> ()
+ sparse_tensor.print %3 : tensor<?x?xf64, #DCSR>
// Release the resources.
bufferization.dealloc_tensor %sm1 : tensor<?x?xf64, #DCSR>
>From 45d82f33af9334907dde39cc69921c679299114e Mon Sep 17 00:00:00 2001
From: Alexey Bataev <a.bataev at outlook.com>
Date: Thu, 29 Feb 2024 11:02:30 -0800
Subject: [PATCH 164/406] [SLP]Fix miscompilation, cause by incorrect final
node reordering.
Need to use the regular reordering from the correct node for the final
store/insertelement node to avoid miscommilation.
---
llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp | 4 ++--
llvm/test/Transforms/SLPVectorizer/X86/reorder-node.ll | 2 +-
2 files changed, 3 insertions(+), 3 deletions(-)
diff --git a/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp b/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
index 2b7d518c1c1a78..94b7c4952f055e 100644
--- a/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
+++ b/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
@@ -5158,7 +5158,7 @@ void BoUpSLP::reorderBottomToTop(bool IgnoreReorder) {
OrderedEntries.insert(Data.first);
}
} else {
- reorderOrder(Data.first->ReorderIndices, Mask, /*BottomOrder=*/true);
+ reorderOrder(Data.first->ReorderIndices, Mask);
}
}
}
@@ -8102,7 +8102,7 @@ const BoUpSLP::TreeEntry *BoUpSLP::getOperandEntry(const TreeEntry *E,
unsigned Idx) const {
Value *Op = E->getOperand(Idx).front();
if (const TreeEntry *TE = getTreeEntry(Op)) {
- if (find_if(E->UserTreeIndices, [&](const EdgeInfo &EI) {
+ if (find_if(TE->UserTreeIndices, [&](const EdgeInfo &EI) {
return EI.EdgeIdx == Idx && EI.UserTE == E;
}) != TE->UserTreeIndices.end())
return TE;
diff --git a/llvm/test/Transforms/SLPVectorizer/X86/reorder-node.ll b/llvm/test/Transforms/SLPVectorizer/X86/reorder-node.ll
index c45e1e8b17bf8c..1940e1bc8d18ac 100644
--- a/llvm/test/Transforms/SLPVectorizer/X86/reorder-node.ll
+++ b/llvm/test/Transforms/SLPVectorizer/X86/reorder-node.ll
@@ -14,7 +14,7 @@ define void @test(ptr noalias %arg, ptr noalias %arg1, ptr %arg2) {
; CHECK-NEXT: [[TMP3:%.*]] = shufflevector <4 x float> [[TMP0]], <4 x float> poison, <4 x i32> <i32 2, i32 3, i32 2, i32 3>
; CHECK-NEXT: [[TMP4:%.*]] = shufflevector <4 x float> [[TMP0]], <4 x float> poison, <4 x i32> <i32 0, i32 1, i32 0, i32 1>
; CHECK-NEXT: [[TMP5:%.*]] = select <4 x i1> [[TMP2]], <4 x float> [[TMP3]], <4 x float> [[TMP4]]
-; CHECK-NEXT: [[TMP6:%.*]] = shufflevector <4 x float> [[TMP5]], <4 x float> poison, <4 x i32> <i32 1, i32 2, i32 3, i32 0>
+; CHECK-NEXT: [[TMP6:%.*]] = shufflevector <4 x float> [[TMP5]], <4 x float> poison, <4 x i32> <i32 2, i32 0, i32 3, i32 1>
; CHECK-NEXT: store <4 x float> [[TMP6]], ptr [[TMP_I_I4]], align 8
; CHECK-NEXT: ret void
;
>From 73aab2f69773324ef0250f093bd4d782beee921a Mon Sep 17 00:00:00 2001
From: lntue <35648136+lntue at users.noreply.github.com>
Date: Thu, 29 Feb 2024 14:43:53 -0500
Subject: [PATCH 165/406] [libc] Revert
https://github.com/llvm/llvm-project/pull/83199 since it broke Fuchsia.
(#83374)
With some header fix forward for GPU builds.
---
libc/benchmarks/automemcpy/lib/CMakeLists.txt | 2 +-
libc/cmake/modules/LLVMLibCObjectRules.cmake | 4 ----
libc/cmake/modules/LLVMLibCTestRules.cmake | 4 ----
libc/cmake/modules/compiler_features/check_fixed_point.cpp | 2 +-
libc/fuzzing/stdio/printf_fixed_conv_fuzz.cpp | 2 +-
libc/include/llvm-libc-types/float128.h | 2 +-
libc/src/__support/CPP/limits.h | 2 +-
libc/src/__support/CPP/type_traits/is_fixed_point.h | 2 +-
libc/src/__support/HashTable/table.h | 2 +-
libc/src/__support/RPC/rpc_client.h | 2 +-
libc/src/__support/fixed_point/fx_bits.h | 2 +-
libc/src/__support/fixed_point/fx_rep.h | 2 +-
libc/src/__support/fixed_point/sqrt.h | 2 +-
libc/src/__support/macros/properties/types.h | 4 ++--
libc/src/stdfix/abshk.h | 2 +-
libc/src/stdfix/abshr.h | 2 +-
libc/src/stdfix/absk.h | 2 +-
libc/src/stdfix/abslk.h | 2 +-
libc/src/stdfix/abslr.h | 2 +-
libc/src/stdfix/absr.h | 2 +-
libc/src/stdfix/roundhk.h | 2 +-
libc/src/stdfix/roundhr.h | 2 +-
libc/src/stdfix/roundk.h | 2 +-
libc/src/stdfix/roundlk.h | 2 +-
libc/src/stdfix/roundlr.h | 2 +-
libc/src/stdfix/roundr.h | 2 +-
libc/src/stdfix/rounduhk.h | 2 +-
libc/src/stdfix/rounduhr.h | 2 +-
libc/src/stdfix/rounduk.h | 2 +-
libc/src/stdfix/roundulk.h | 2 +-
libc/src/stdfix/roundulr.h | 2 +-
libc/src/stdfix/roundur.h | 2 +-
libc/src/stdfix/sqrtuhk.h | 2 +-
libc/src/stdfix/sqrtuhr.h | 2 +-
libc/src/stdfix/sqrtuk.h | 2 +-
libc/src/stdfix/sqrtulr.h | 2 +-
libc/src/stdfix/sqrtur.h | 2 +-
libc/src/stdio/printf_core/fixed_converter.h | 2 +-
libc/src/stdio/printf_core/parser.h | 2 +-
libc/src/sys/epoll/epoll_pwait.h | 4 ++--
libc/src/sys/epoll/epoll_pwait2.h | 6 +++---
libc/src/sys/epoll/epoll_wait.h | 2 +-
libc/src/sys/epoll/linux/epoll_pwait.cpp | 4 ++--
libc/src/sys/epoll/linux/epoll_pwait2.cpp | 6 +++---
libc/src/sys/epoll/linux/epoll_wait.cpp | 4 ++--
libc/test/UnitTest/CMakeLists.txt | 3 +--
libc/test/UnitTest/LibcTest.cpp | 2 +-
libc/test/include/stdbit_test.cpp | 2 +-
libc/test/include/stdckdint_test.cpp | 2 +-
libc/test/include/sys/queue_test.cpp | 2 +-
libc/test/integration/startup/CMakeLists.txt | 1 -
libc/test/integration/startup/gpu/rpc_interface_test.cpp | 2 +-
libc/test/integration/startup/gpu/rpc_stream_test.cpp | 2 +-
libc/test/integration/startup/gpu/rpc_test.cpp | 2 +-
libc/test/src/__support/fixed_point/fx_bits_test.cpp | 2 +-
libc/test/src/compiler/stack_chk_guard_test.cpp | 2 +-
libc/test/src/math/differential_testing/CMakeLists.txt | 1 -
libc/utils/LibcTableGenUtil/CMakeLists.txt | 2 +-
libc/utils/gpu/loader/Loader.h | 2 +-
59 files changed, 63 insertions(+), 74 deletions(-)
diff --git a/libc/benchmarks/automemcpy/lib/CMakeLists.txt b/libc/benchmarks/automemcpy/lib/CMakeLists.txt
index bb6a5631f2c3f6..e66b9045b6074a 100644
--- a/libc/benchmarks/automemcpy/lib/CMakeLists.txt
+++ b/libc/benchmarks/automemcpy/lib/CMakeLists.txt
@@ -19,7 +19,7 @@ add_custom_command(
add_library(automemcpy_implementations "${Implementations}")
target_link_libraries(automemcpy_implementations PUBLIC LLVMSupport libc-memory-benchmark)
target_include_directories(automemcpy_implementations PRIVATE
- ${LIBC_SOURCE_DIR} ${LIBC_SOURCE_DIR}/include ${LIBC_AUTOMEMCPY_INCLUDE_DIR})
+ ${LIBC_SOURCE_DIR} ${LIBC_AUTOMEMCPY_INCLUDE_DIR})
target_compile_options(automemcpy_implementations PRIVATE ${LIBC_COMPILE_OPTIONS_NATIVE} "SHELL:-mllvm -combiner-global-alias-analysis" -fno-builtin)
llvm_update_compile_flags(automemcpy_implementations)
diff --git a/libc/cmake/modules/LLVMLibCObjectRules.cmake b/libc/cmake/modules/LLVMLibCObjectRules.cmake
index 5469799f023983..0649e9f7a76709 100644
--- a/libc/cmake/modules/LLVMLibCObjectRules.cmake
+++ b/libc/cmake/modules/LLVMLibCObjectRules.cmake
@@ -59,7 +59,6 @@ function(create_object_library fq_target_name)
)
target_include_directories(${fq_target_name} SYSTEM PRIVATE ${LIBC_INCLUDE_DIR})
target_include_directories(${fq_target_name} PRIVATE ${LIBC_SOURCE_DIR})
- target_include_directories(${fq_target_name} PRIVATE ${LIBC_SOURCE_DIR}/include)
target_compile_options(${fq_target_name} PRIVATE ${compile_options})
# The NVPTX target is installed as LLVM-IR but the internal testing toolchain
@@ -74,7 +73,6 @@ function(create_object_library fq_target_name)
)
target_include_directories(${internal_target_name} SYSTEM PRIVATE ${LIBC_INCLUDE_DIR})
target_include_directories(${internal_target_name} PRIVATE ${LIBC_SOURCE_DIR})
- target_include_directories(${internal_target_name} PRIVATE ${LIBC_SOURCE_DIR}/include)
target_compile_options(${internal_target_name} PRIVATE ${compile_options}
-fno-lto -march=${LIBC_GPU_TARGET_ARCHITECTURE})
endif()
@@ -281,7 +279,6 @@ function(create_entrypoint_object fq_target_name)
target_compile_options(${internal_target_name} BEFORE PRIVATE ${common_compile_options})
target_include_directories(${internal_target_name} SYSTEM PRIVATE ${LIBC_INCLUDE_DIR})
target_include_directories(${internal_target_name} PRIVATE ${LIBC_SOURCE_DIR})
- target_include_directories(${internal_target_name} PRIVATE ${LIBC_SOURCE_DIR}/include)
add_dependencies(${internal_target_name} ${full_deps_list})
target_link_libraries(${internal_target_name} ${full_deps_list})
@@ -303,7 +300,6 @@ function(create_entrypoint_object fq_target_name)
target_compile_options(${fq_target_name} BEFORE PRIVATE ${common_compile_options} -DLIBC_COPT_PUBLIC_PACKAGING)
target_include_directories(${fq_target_name} SYSTEM PRIVATE ${LIBC_INCLUDE_DIR})
target_include_directories(${fq_target_name} PRIVATE ${LIBC_SOURCE_DIR})
- target_include_directories(${fq_target_name} PRIVATE ${LIBC_SOURCE_DIR}/include)
add_dependencies(${fq_target_name} ${full_deps_list})
target_link_libraries(${fq_target_name} ${full_deps_list})
diff --git a/libc/cmake/modules/LLVMLibCTestRules.cmake b/libc/cmake/modules/LLVMLibCTestRules.cmake
index 5981d427b71f8d..836e15d34741b2 100644
--- a/libc/cmake/modules/LLVMLibCTestRules.cmake
+++ b/libc/cmake/modules/LLVMLibCTestRules.cmake
@@ -184,7 +184,6 @@ function(create_libc_unittest fq_target_name)
)
target_include_directories(${fq_build_target_name} SYSTEM PRIVATE ${LIBC_INCLUDE_DIR})
target_include_directories(${fq_build_target_name} PRIVATE ${LIBC_SOURCE_DIR})
- target_include_directories(${fq_build_target_name} PRIVATE ${LIBC_SOURCE_DIR}/include)
target_compile_options(${fq_build_target_name} PRIVATE ${compile_options})
if(NOT LIBC_UNITTEST_CXX_STANDARD)
@@ -318,7 +317,6 @@ function(add_libc_fuzzer target_name)
)
target_include_directories(${fq_target_name} SYSTEM PRIVATE ${LIBC_INCLUDE_DIR})
target_include_directories(${fq_target_name} PRIVATE ${LIBC_SOURCE_DIR})
- target_include_directories(${fq_target_name} PRIVATE ${LIBC_SOURCE_DIR}/include)
target_link_libraries(${fq_target_name} PRIVATE
${link_object_files}
@@ -459,7 +457,6 @@ function(add_integration_test test_name)
PROPERTIES RUNTIME_OUTPUT_DIRECTORY ${CMAKE_CURRENT_BINARY_DIR})
target_include_directories(${fq_build_target_name} SYSTEM PRIVATE ${LIBC_INCLUDE_DIR})
target_include_directories(${fq_build_target_name} PRIVATE ${LIBC_SOURCE_DIR})
- target_include_directories(${fq_build_target_name} PRIVATE ${LIBC_SOURCE_DIR}/include)
_get_hermetic_test_compile_options(compile_options "${INTEGRATION_TEST_COMPILE_OPTIONS}")
target_compile_options(${fq_build_target_name} PRIVATE ${compile_options})
@@ -635,7 +632,6 @@ function(add_libc_hermetic_test test_name)
_get_hermetic_test_compile_options(compile_options "${HERMETIC_TEST_COMPILE_OPTIONS}")
target_include_directories(${fq_build_target_name} SYSTEM PRIVATE ${LIBC_INCLUDE_DIR})
target_include_directories(${fq_build_target_name} PRIVATE ${LIBC_SOURCE_DIR})
- target_include_directories(${fq_build_target_name} PRIVATE ${LIBC_SOURCE_DIR}/include)
_get_hermetic_test_compile_options(compile_options "${HERMETIC_TEST_COMPILE_OPTIONS}")
target_compile_options(${fq_build_target_name} PRIVATE ${compile_options})
diff --git a/libc/cmake/modules/compiler_features/check_fixed_point.cpp b/libc/cmake/modules/compiler_features/check_fixed_point.cpp
index 9199340fe652ea..a5192697d43f77 100644
--- a/libc/cmake/modules/compiler_features/check_fixed_point.cpp
+++ b/libc/cmake/modules/compiler_features/check_fixed_point.cpp
@@ -1,4 +1,4 @@
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
#ifndef LIBC_COMPILER_HAS_FIXED_POINT
#error unsupported
diff --git a/libc/fuzzing/stdio/printf_fixed_conv_fuzz.cpp b/libc/fuzzing/stdio/printf_fixed_conv_fuzz.cpp
index c385c3a8f3e44a..b4a8621891203d 100644
--- a/libc/fuzzing/stdio/printf_fixed_conv_fuzz.cpp
+++ b/libc/fuzzing/stdio/printf_fixed_conv_fuzz.cpp
@@ -11,7 +11,7 @@
//===----------------------------------------------------------------------===//
#include "src/stdio/snprintf.h"
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
#include "src/__support/fixed_point/fx_bits.h"
#include "src/__support/fixed_point/fx_rep.h"
diff --git a/libc/include/llvm-libc-types/float128.h b/libc/include/llvm-libc-types/float128.h
index e2dc18c040d99e..0b290c676ecc02 100644
--- a/libc/include/llvm-libc-types/float128.h
+++ b/libc/include/llvm-libc-types/float128.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_TYPES_FLOAT128_H
#define LLVM_LIBC_TYPES_FLOAT128_H
-#include "llvm-libc-macros/float-macros.h" // LDBL_MANT_DIG
+#include "../llvm-libc-macros/float-macros.h" // LDBL_MANT_DIG
// Currently, C23 `_Float128` type is only defined as a built-in type in GCC 7
// or later, and only for C. For C++, or for clang, `__float128` is defined
diff --git a/libc/src/__support/CPP/limits.h b/libc/src/__support/CPP/limits.h
index 6440e8cb358fa7..1ffde5f9556f87 100644
--- a/libc/src/__support/CPP/limits.h
+++ b/libc/src/__support/CPP/limits.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC___SUPPORT_CPP_LIMITS_H
#define LLVM_LIBC_SRC___SUPPORT_CPP_LIMITS_H
-#include "llvm-libc-macros/limits-macros.h" // CHAR_BIT
+#include "include/llvm-libc-macros/limits-macros.h" // CHAR_BIT
#include "src/__support/CPP/type_traits/is_integral.h"
#include "src/__support/CPP/type_traits/is_signed.h"
#include "src/__support/macros/attributes.h" // LIBC_INLINE
diff --git a/libc/src/__support/CPP/type_traits/is_fixed_point.h b/libc/src/__support/CPP/type_traits/is_fixed_point.h
index 09dba8b7ecbcd4..025268bc2979d3 100644
--- a/libc/src/__support/CPP/type_traits/is_fixed_point.h
+++ b/libc/src/__support/CPP/type_traits/is_fixed_point.h
@@ -12,7 +12,7 @@
#include "src/__support/CPP/type_traits/remove_cv.h"
#include "src/__support/macros/attributes.h"
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
namespace LIBC_NAMESPACE::cpp {
diff --git a/libc/src/__support/HashTable/table.h b/libc/src/__support/HashTable/table.h
index 07fcd42c97f3e7..8f6c5887c189e8 100644
--- a/libc/src/__support/HashTable/table.h
+++ b/libc/src/__support/HashTable/table.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC___SUPPORT_HASHTABLE_TABLE_H
#define LLVM_LIBC_SRC___SUPPORT_HASHTABLE_TABLE_H
-#include "llvm-libc-types/ENTRY.h"
+#include "include/llvm-libc-types/ENTRY.h"
#include "src/__support/CPP/bit.h" // bit_ceil
#include "src/__support/CPP/new.h"
#include "src/__support/HashTable/bitmask.h"
diff --git a/libc/src/__support/RPC/rpc_client.h b/libc/src/__support/RPC/rpc_client.h
index 571d7cce2a8039..6e1827dbfeea92 100644
--- a/libc/src/__support/RPC/rpc_client.h
+++ b/libc/src/__support/RPC/rpc_client.h
@@ -11,7 +11,7 @@
#include "rpc.h"
-#include "llvm-libc-types/rpc_opcodes_t.h"
+#include "include/llvm-libc-types/rpc_opcodes_t.h"
namespace LIBC_NAMESPACE {
namespace rpc {
diff --git a/libc/src/__support/fixed_point/fx_bits.h b/libc/src/__support/fixed_point/fx_bits.h
index 6fdbc6f6ece63f..41da45c01e4e19 100644
--- a/libc/src/__support/fixed_point/fx_bits.h
+++ b/libc/src/__support/fixed_point/fx_bits.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC___SUPPORT_FIXED_POINT_FX_BITS_H
#define LLVM_LIBC_SRC___SUPPORT_FIXED_POINT_FX_BITS_H
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
#include "src/__support/CPP/bit.h"
#include "src/__support/CPP/type_traits.h"
#include "src/__support/macros/attributes.h" // LIBC_INLINE
diff --git a/libc/src/__support/fixed_point/fx_rep.h b/libc/src/__support/fixed_point/fx_rep.h
index e1fee62f335eb9..f8593a93684cbc 100644
--- a/libc/src/__support/fixed_point/fx_rep.h
+++ b/libc/src/__support/fixed_point/fx_rep.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC___SUPPORT_FIXED_POINT_FX_REP_H
#define LLVM_LIBC_SRC___SUPPORT_FIXED_POINT_FX_REP_H
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
#include "src/__support/CPP/type_traits.h"
#include "src/__support/macros/attributes.h" // LIBC_INLINE, LIBC_INLINE_VAR
diff --git a/libc/src/__support/fixed_point/sqrt.h b/libc/src/__support/fixed_point/sqrt.h
index 236ebb2857030b..d8df294b18a1a8 100644
--- a/libc/src/__support/fixed_point/sqrt.h
+++ b/libc/src/__support/fixed_point/sqrt.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC___SUPPORT_FIXEDPOINT_SQRT_H
#define LLVM_LIBC_SRC___SUPPORT_FIXEDPOINT_SQRT_H
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
#include "src/__support/CPP/bit.h"
#include "src/__support/CPP/type_traits.h"
#include "src/__support/macros/attributes.h" // LIBC_INLINE
diff --git a/libc/src/__support/macros/properties/types.h b/libc/src/__support/macros/properties/types.h
index e812a9dfcfd8ab..0a3c834663cc92 100644
--- a/libc/src/__support/macros/properties/types.h
+++ b/libc/src/__support/macros/properties/types.h
@@ -10,8 +10,8 @@
#ifndef LLVM_LIBC_SRC___SUPPORT_MACROS_PROPERTIES_TYPES_H
#define LLVM_LIBC_SRC___SUPPORT_MACROS_PROPERTIES_TYPES_H
-#include "llvm-libc-macros/float-macros.h" // LDBL_MANT_DIG
-#include "llvm-libc-types/float128.h" // float128
+#include "include/llvm-libc-macros/float-macros.h" // LDBL_MANT_DIG
+#include "include/llvm-libc-types/float128.h" // float128
#include "src/__support/macros/properties/architectures.h"
#include "src/__support/macros/properties/compiler.h"
#include "src/__support/macros/properties/cpu_features.h"
diff --git a/libc/src/stdfix/abshk.h b/libc/src/stdfix/abshk.h
index 80dc73053dfb45..13c9300caab883 100644
--- a/libc/src/stdfix/abshk.h
+++ b/libc/src/stdfix/abshk.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_STDFIX_ABSHK_H
#define LLVM_LIBC_SRC_STDFIX_ABSHK_H
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/stdfix/abshr.h b/libc/src/stdfix/abshr.h
index 035f9a6de222e8..5acd0cfc4a60db 100644
--- a/libc/src/stdfix/abshr.h
+++ b/libc/src/stdfix/abshr.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_STDFIX_ABSHR_H
#define LLVM_LIBC_SRC_STDFIX_ABSHR_H
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/stdfix/absk.h b/libc/src/stdfix/absk.h
index 426415de28e6ae..73dfcac0ac8e7f 100644
--- a/libc/src/stdfix/absk.h
+++ b/libc/src/stdfix/absk.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_STDFIX_ABSK_H
#define LLVM_LIBC_SRC_STDFIX_ABSK_H
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/stdfix/abslk.h b/libc/src/stdfix/abslk.h
index 21e33f856bfc65..7de116fa227932 100644
--- a/libc/src/stdfix/abslk.h
+++ b/libc/src/stdfix/abslk.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_STDFIX_ABSLK_H
#define LLVM_LIBC_SRC_STDFIX_ABSLK_H
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/stdfix/abslr.h b/libc/src/stdfix/abslr.h
index ebca35e58aa510..bf5b585bbbb669 100644
--- a/libc/src/stdfix/abslr.h
+++ b/libc/src/stdfix/abslr.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_STDFIX_ABSLR_H
#define LLVM_LIBC_SRC_STDFIX_ABSLR_H
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/stdfix/absr.h b/libc/src/stdfix/absr.h
index 2744fcb5a7eccc..b5ead7ce14e2a0 100644
--- a/libc/src/stdfix/absr.h
+++ b/libc/src/stdfix/absr.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_STDFIX_ABSR_H
#define LLVM_LIBC_SRC_STDFIX_ABSR_H
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/stdfix/roundhk.h b/libc/src/stdfix/roundhk.h
index 06de5cc05cdbe4..9a5c874cc030db 100644
--- a/libc/src/stdfix/roundhk.h
+++ b/libc/src/stdfix/roundhk.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_STDFIX_ROUNDHK_H
#define LLVM_LIBC_SRC_STDFIX_ROUNDHK_H
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/stdfix/roundhr.h b/libc/src/stdfix/roundhr.h
index 6729bf5b139973..ba5a67945d6c3b 100644
--- a/libc/src/stdfix/roundhr.h
+++ b/libc/src/stdfix/roundhr.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_STDFIX_ROUNDHR_H
#define LLVM_LIBC_SRC_STDFIX_ROUNDHR_H
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/stdfix/roundk.h b/libc/src/stdfix/roundk.h
index 02fb9a8c9b1a86..e9fa6d8f9c3b8c 100644
--- a/libc/src/stdfix/roundk.h
+++ b/libc/src/stdfix/roundk.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_STDFIX_ROUNDK_H
#define LLVM_LIBC_SRC_STDFIX_ROUNDK_H
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/stdfix/roundlk.h b/libc/src/stdfix/roundlk.h
index 28be9c00549498..5fa0e90e855a64 100644
--- a/libc/src/stdfix/roundlk.h
+++ b/libc/src/stdfix/roundlk.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_STDFIX_ROUNDLK_H
#define LLVM_LIBC_SRC_STDFIX_ROUNDLK_H
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/stdfix/roundlr.h b/libc/src/stdfix/roundlr.h
index be97a35a64204d..c015292e8f3f28 100644
--- a/libc/src/stdfix/roundlr.h
+++ b/libc/src/stdfix/roundlr.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_STDFIX_ROUNDLR_H
#define LLVM_LIBC_SRC_STDFIX_ROUNDLR_H
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/stdfix/roundr.h b/libc/src/stdfix/roundr.h
index 15523f8b6c9a38..b5b1375c882e03 100644
--- a/libc/src/stdfix/roundr.h
+++ b/libc/src/stdfix/roundr.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_STDFIX_ROUNDR_H
#define LLVM_LIBC_SRC_STDFIX_ROUNDR_H
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/stdfix/rounduhk.h b/libc/src/stdfix/rounduhk.h
index d1c4a4416d7636..85ebf2903ec7e9 100644
--- a/libc/src/stdfix/rounduhk.h
+++ b/libc/src/stdfix/rounduhk.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_STDFIX_ROUNDUHK_H
#define LLVM_LIBC_SRC_STDFIX_ROUNDUHK_H
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/stdfix/rounduhr.h b/libc/src/stdfix/rounduhr.h
index 6cecb733dd3b18..1be0aab1f5a79d 100644
--- a/libc/src/stdfix/rounduhr.h
+++ b/libc/src/stdfix/rounduhr.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_STDFIX_ROUNDUHR_H
#define LLVM_LIBC_SRC_STDFIX_ROUNDUHR_H
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/stdfix/rounduk.h b/libc/src/stdfix/rounduk.h
index 4511d69525c5d5..8dae89586c4901 100644
--- a/libc/src/stdfix/rounduk.h
+++ b/libc/src/stdfix/rounduk.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_STDFIX_ROUNDUK_H
#define LLVM_LIBC_SRC_STDFIX_ROUNDUK_H
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/stdfix/roundulk.h b/libc/src/stdfix/roundulk.h
index 8bd90beeb830c5..81dfd1dceb6001 100644
--- a/libc/src/stdfix/roundulk.h
+++ b/libc/src/stdfix/roundulk.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_STDFIX_ROUNDULK_H
#define LLVM_LIBC_SRC_STDFIX_ROUNDULK_H
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/stdfix/roundulr.h b/libc/src/stdfix/roundulr.h
index 65e5c27b1c8531..002fc94907c613 100644
--- a/libc/src/stdfix/roundulr.h
+++ b/libc/src/stdfix/roundulr.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_STDFIX_ROUNDULR_H
#define LLVM_LIBC_SRC_STDFIX_ROUNDULR_H
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/stdfix/roundur.h b/libc/src/stdfix/roundur.h
index 110e578da79319..72de44b1e0c4e5 100644
--- a/libc/src/stdfix/roundur.h
+++ b/libc/src/stdfix/roundur.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_STDFIX_ROUNDUR_H
#define LLVM_LIBC_SRC_STDFIX_ROUNDUR_H
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/stdfix/sqrtuhk.h b/libc/src/stdfix/sqrtuhk.h
index b57340003fa03c..80000a0079696d 100644
--- a/libc/src/stdfix/sqrtuhk.h
+++ b/libc/src/stdfix/sqrtuhk.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_STDFIX_SQRTUHK_H
#define LLVM_LIBC_SRC_STDFIX_SQRTUHK_H
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/stdfix/sqrtuhr.h b/libc/src/stdfix/sqrtuhr.h
index 6b629a29de3c88..fd95f0924e8d48 100644
--- a/libc/src/stdfix/sqrtuhr.h
+++ b/libc/src/stdfix/sqrtuhr.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_STDFIX_SQRTUHR_H
#define LLVM_LIBC_SRC_STDFIX_SQRTUHR_H
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/stdfix/sqrtuk.h b/libc/src/stdfix/sqrtuk.h
index 6bd7a2608716cd..04d0adadde9ad2 100644
--- a/libc/src/stdfix/sqrtuk.h
+++ b/libc/src/stdfix/sqrtuk.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_STDFIX_SQRTUK_H
#define LLVM_LIBC_SRC_STDFIX_SQRTUK_H
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/stdfix/sqrtulr.h b/libc/src/stdfix/sqrtulr.h
index d1982a6b1c0518..284adaaf35bf59 100644
--- a/libc/src/stdfix/sqrtulr.h
+++ b/libc/src/stdfix/sqrtulr.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_STDFIX_SQRTULR_H
#define LLVM_LIBC_SRC_STDFIX_SQRTULR_H
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/stdfix/sqrtur.h b/libc/src/stdfix/sqrtur.h
index 13f7d1e5e466ec..df9dfe5a0bf39e 100644
--- a/libc/src/stdfix/sqrtur.h
+++ b/libc/src/stdfix/sqrtur.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_STDFIX_SQRTUR_H
#define LLVM_LIBC_SRC_STDFIX_SQRTUR_H
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
namespace LIBC_NAMESPACE {
diff --git a/libc/src/stdio/printf_core/fixed_converter.h b/libc/src/stdio/printf_core/fixed_converter.h
index c89971e20686e4..de69c603be6b63 100644
--- a/libc/src/stdio/printf_core/fixed_converter.h
+++ b/libc/src/stdio/printf_core/fixed_converter.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_STDIO_PRINTF_CORE_FIXED_CONVERTER_H
#define LLVM_LIBC_SRC_STDIO_PRINTF_CORE_FIXED_CONVERTER_H
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
#include "src/__support/CPP/string_view.h"
#include "src/__support/fixed_point/fx_bits.h"
#include "src/__support/fixed_point/fx_rep.h"
diff --git a/libc/src/stdio/printf_core/parser.h b/libc/src/stdio/printf_core/parser.h
index 13fdbf243a22e8..0876116a0bac86 100644
--- a/libc/src/stdio/printf_core/parser.h
+++ b/libc/src/stdio/printf_core/parser.h
@@ -9,7 +9,7 @@
#ifndef LLVM_LIBC_SRC_STDIO_PRINTF_CORE_PARSER_H
#define LLVM_LIBC_SRC_STDIO_PRINTF_CORE_PARSER_H
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
#include "src/__support/CPP/optional.h"
#include "src/__support/CPP/type_traits.h"
#include "src/__support/str_to_integer.h"
diff --git a/libc/src/sys/epoll/epoll_pwait.h b/libc/src/sys/epoll/epoll_pwait.h
index 16105850d6942e..9dcb55533009f9 100644
--- a/libc/src/sys/epoll/epoll_pwait.h
+++ b/libc/src/sys/epoll/epoll_pwait.h
@@ -10,8 +10,8 @@
#define LLVM_LIBC_SRC_SYS_EPOLL_EPOLL_PWAIT_H
// TODO: Use this include once the include headers are also using quotes.
-// #include "llvm-libc-types/sigset_t.h"
-// #include "llvm-libc-types/struct_epoll_event.h"
+// #include "include/llvm-libc-types/sigset_t.h"
+// #include "include/llvm-libc-types/struct_epoll_event.h"
#include <sys/epoll.h>
diff --git a/libc/src/sys/epoll/epoll_pwait2.h b/libc/src/sys/epoll/epoll_pwait2.h
index f7b28d4fbc51d9..622ede6a0f9f9a 100644
--- a/libc/src/sys/epoll/epoll_pwait2.h
+++ b/libc/src/sys/epoll/epoll_pwait2.h
@@ -10,9 +10,9 @@
#define LLVM_LIBC_SRC_SYS_EPOLL_EPOLL_PWAIT2_H
// TODO: Use this include once the include headers are also using quotes.
-// #include "llvm-libc-types/sigset_t.h"
-// #include "llvm-libc-types/struct_epoll_event.h"
-// #include "llvm-libc-types/struct_timespec.h"
+// #include "include/llvm-libc-types/sigset_t.h"
+// #include "include/llvm-libc-types/struct_epoll_event.h"
+// #include "include/llvm-libc-types/struct_timespec.h"
#include <sys/epoll.h>
diff --git a/libc/src/sys/epoll/epoll_wait.h b/libc/src/sys/epoll/epoll_wait.h
index 0dc487bba5bdf4..d51c9100846ce0 100644
--- a/libc/src/sys/epoll/epoll_wait.h
+++ b/libc/src/sys/epoll/epoll_wait.h
@@ -10,7 +10,7 @@
#define LLVM_LIBC_SRC_SYS_EPOLL_EPOLL_WAIT_H
// TODO: Use this include once the include headers are also using quotes.
-// #include "llvm-libc-types/struct_epoll_event.h"
+// #include "include/llvm-libc-types/struct_epoll_event.h"
#include <sys/epoll.h>
diff --git a/libc/src/sys/epoll/linux/epoll_pwait.cpp b/libc/src/sys/epoll/linux/epoll_pwait.cpp
index e0c13a7a79602f..ee1b4e66e98444 100644
--- a/libc/src/sys/epoll/linux/epoll_pwait.cpp
+++ b/libc/src/sys/epoll/linux/epoll_pwait.cpp
@@ -15,8 +15,8 @@
#include <sys/syscall.h> // For syscall numbers.
// TODO: Use this include once the include headers are also using quotes.
-// #include "llvm-libc-types/sigset_t.h"
-// #include "llvm-libc-types/struct_epoll_event.h"
+// #include "include/llvm-libc-types/sigset_t.h"
+// #include "include/llvm-libc-types/struct_epoll_event.h"
#include <sys/epoll.h>
diff --git a/libc/src/sys/epoll/linux/epoll_pwait2.cpp b/libc/src/sys/epoll/linux/epoll_pwait2.cpp
index a44b0c2a9f70f0..671dede2a1058d 100644
--- a/libc/src/sys/epoll/linux/epoll_pwait2.cpp
+++ b/libc/src/sys/epoll/linux/epoll_pwait2.cpp
@@ -15,9 +15,9 @@
#include <sys/syscall.h> // For syscall numbers.
// TODO: Use this include once the include headers are also using quotes.
-// #include "llvm-libc-types/sigset_t.h"
-// #include "llvm-libc-types/struct_epoll_event.h"
-// #include "llvm-libc-types/struct_timespec.h"
+// #include "include/llvm-libc-types/sigset_t.h"
+// #include "include/llvm-libc-types/struct_epoll_event.h"
+// #include "include/llvm-libc-types/struct_timespec.h"
#include <sys/epoll.h>
diff --git a/libc/src/sys/epoll/linux/epoll_wait.cpp b/libc/src/sys/epoll/linux/epoll_wait.cpp
index b643e2dd720cb6..0c43edf7645454 100644
--- a/libc/src/sys/epoll/linux/epoll_wait.cpp
+++ b/libc/src/sys/epoll/linux/epoll_wait.cpp
@@ -14,8 +14,8 @@
#include <sys/syscall.h> // For syscall numbers.
// TODO: Use this include once the include headers are also using quotes.
-// #include "llvm-libc-types/sigset_t.h"
-// #include "llvm-libc-types/struct_epoll_event.h"
+// #include "include/llvm-libc-types/sigset_t.h"
+// #include "include/llvm-libc-types/struct_epoll_event.h"
#include <sys/epoll.h>
diff --git a/libc/test/UnitTest/CMakeLists.txt b/libc/test/UnitTest/CMakeLists.txt
index 466494f038f4e3..4668f0061975f8 100644
--- a/libc/test/UnitTest/CMakeLists.txt
+++ b/libc/test/UnitTest/CMakeLists.txt
@@ -26,8 +26,7 @@ function(add_unittest_framework_library name)
${TEST_LIB_SRCS}
${TEST_LIB_HDRS}
)
- target_include_directories(${lib} PUBLIC
- ${LIBC_SOURCE_DIR} ${LIBC_SOURCE_DIR}/include)
+ target_include_directories(${lib} PUBLIC ${LIBC_SOURCE_DIR})
list(APPEND compile_options -fno-exceptions -fno-rtti)
if(TARGET libc.src.time.clock)
target_compile_definitions(${lib} PRIVATE TARGET_SUPPORTS_CLOCK)
diff --git a/libc/test/UnitTest/LibcTest.cpp b/libc/test/UnitTest/LibcTest.cpp
index babd44f9b20630..7b0e4fca83683b 100644
--- a/libc/test/UnitTest/LibcTest.cpp
+++ b/libc/test/UnitTest/LibcTest.cpp
@@ -8,7 +8,7 @@
#include "LibcTest.h"
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
#include "src/__support/CPP/string.h"
#include "src/__support/CPP/string_view.h"
#include "src/__support/UInt128.h"
diff --git a/libc/test/include/stdbit_test.cpp b/libc/test/include/stdbit_test.cpp
index 84a4cde18b9f40..acb79ca0f3ff11 100644
--- a/libc/test/include/stdbit_test.cpp
+++ b/libc/test/include/stdbit_test.cpp
@@ -88,7 +88,7 @@ bool stdc_has_single_bit_ul(unsigned long) noexcept { return false; }
bool stdc_has_single_bit_ull(unsigned long long) noexcept { return false; }
}
-#include "llvm-libc-macros/stdbit-macros.h"
+#include "include/llvm-libc-macros/stdbit-macros.h"
TEST(LlvmLibcStdbitTest, TypeGenericMacroLeadingZeros) {
EXPECT_EQ(stdc_leading_zeros(static_cast<unsigned char>(0U)), 0xAAU);
diff --git a/libc/test/include/stdckdint_test.cpp b/libc/test/include/stdckdint_test.cpp
index 5ac8c95f4ef26f..1180a6de9efe2e 100644
--- a/libc/test/include/stdckdint_test.cpp
+++ b/libc/test/include/stdckdint_test.cpp
@@ -8,7 +8,7 @@
#include "test/UnitTest/Test.h"
-#include "llvm-libc-macros/stdckdint-macros.h"
+#include "include/llvm-libc-macros/stdckdint-macros.h"
TEST(LlvmLibcStdCkdIntTest, Add) {
int result;
diff --git a/libc/test/include/sys/queue_test.cpp b/libc/test/include/sys/queue_test.cpp
index 48c0e811c61542..c10e48d627caa2 100644
--- a/libc/test/include/sys/queue_test.cpp
+++ b/libc/test/include/sys/queue_test.cpp
@@ -10,7 +10,7 @@
#include "src/__support/char_vector.h"
#include "test/UnitTest/Test.h"
-#include "llvm-libc-macros/sys-queue-macros.h"
+#include "include/llvm-libc-macros/sys-queue-macros.h"
using LIBC_NAMESPACE::CharVector;
using LIBC_NAMESPACE::cpp::string;
diff --git a/libc/test/integration/startup/CMakeLists.txt b/libc/test/integration/startup/CMakeLists.txt
index 08c0d978602b80..fb5d6bc787cc26 100644
--- a/libc/test/integration/startup/CMakeLists.txt
+++ b/libc/test/integration/startup/CMakeLists.txt
@@ -31,7 +31,6 @@ function(add_startup_test target_name)
${fq_target_name}
PRIVATE
${LIBC_SOURCE_DIR}
- ${LIBC_SOURCE_DIR}/include
${LIBC_BUILD_DIR}
${LIBC_BUILD_DIR}/include
)
diff --git a/libc/test/integration/startup/gpu/rpc_interface_test.cpp b/libc/test/integration/startup/gpu/rpc_interface_test.cpp
index 7bbd7085fc2f45..674e2cc1ed7499 100644
--- a/libc/test/integration/startup/gpu/rpc_interface_test.cpp
+++ b/libc/test/integration/startup/gpu/rpc_interface_test.cpp
@@ -6,7 +6,7 @@
//
//===----------------------------------------------------------------------===//
-#include "llvm-libc-types/test_rpc_opcodes_t.h"
+#include "include/llvm-libc-types/test_rpc_opcodes_t.h"
#include "src/__support/GPU/utils.h"
#include "src/__support/RPC/rpc_client.h"
#include "test/IntegrationTest/test.h"
diff --git a/libc/test/integration/startup/gpu/rpc_stream_test.cpp b/libc/test/integration/startup/gpu/rpc_stream_test.cpp
index 9401f822904d04..09a4ae67256e3a 100644
--- a/libc/test/integration/startup/gpu/rpc_stream_test.cpp
+++ b/libc/test/integration/startup/gpu/rpc_stream_test.cpp
@@ -6,7 +6,7 @@
//
//===----------------------------------------------------------------------===//
-#include "llvm-libc-types/test_rpc_opcodes_t.h"
+#include "include/llvm-libc-types/test_rpc_opcodes_t.h"
#include "src/__support/GPU/utils.h"
#include "src/__support/RPC/rpc_client.h"
#include "src/__support/integer_to_string.h"
diff --git a/libc/test/integration/startup/gpu/rpc_test.cpp b/libc/test/integration/startup/gpu/rpc_test.cpp
index bb36b6cedb63cb..4032d890c53ec8 100644
--- a/libc/test/integration/startup/gpu/rpc_test.cpp
+++ b/libc/test/integration/startup/gpu/rpc_test.cpp
@@ -6,7 +6,7 @@
//
//===----------------------------------------------------------------------===//
-#include "llvm-libc-types/test_rpc_opcodes_t.h"
+#include "include/llvm-libc-types/test_rpc_opcodes_t.h"
#include "src/__support/GPU/utils.h"
#include "src/__support/RPC/rpc_client.h"
#include "test/IntegrationTest/test.h"
diff --git a/libc/test/src/__support/fixed_point/fx_bits_test.cpp b/libc/test/src/__support/fixed_point/fx_bits_test.cpp
index 5670687273d5ba..58627816eb8d97 100644
--- a/libc/test/src/__support/fixed_point/fx_bits_test.cpp
+++ b/libc/test/src/__support/fixed_point/fx_bits_test.cpp
@@ -6,7 +6,7 @@
//
//===----------------------------------------------------------------------===//
-#include "llvm-libc-macros/stdfix-macros.h"
+#include "include/llvm-libc-macros/stdfix-macros.h"
#include "src/__support/fixed_point/fx_bits.h"
#include "src/__support/integer_literals.h"
diff --git a/libc/test/src/compiler/stack_chk_guard_test.cpp b/libc/test/src/compiler/stack_chk_guard_test.cpp
index 427e20c2ac5046..6b71e155fa3e4d 100644
--- a/libc/test/src/compiler/stack_chk_guard_test.cpp
+++ b/libc/test/src/compiler/stack_chk_guard_test.cpp
@@ -6,7 +6,7 @@
//
//===----------------------------------------------------------------------===//
-#include "llvm-libc-macros/signal-macros.h"
+#include "include/llvm-libc-macros/signal-macros.h"
#include "src/__support/macros/sanitizer.h"
#include "src/compiler/__stack_chk_fail.h"
#include "src/string/memset.h"
diff --git a/libc/test/src/math/differential_testing/CMakeLists.txt b/libc/test/src/math/differential_testing/CMakeLists.txt
index 36bfdca1a442d6..878f81f1d573c8 100644
--- a/libc/test/src/math/differential_testing/CMakeLists.txt
+++ b/libc/test/src/math/differential_testing/CMakeLists.txt
@@ -47,7 +47,6 @@ function(add_diff_binary target_name)
${fq_target_name}
PRIVATE
${LIBC_SOURCE_DIR}
- ${LIBC_SOURCE_DIR}/include
)
if(DIFF_COMPILE_OPTIONS)
target_compile_options(
diff --git a/libc/utils/LibcTableGenUtil/CMakeLists.txt b/libc/utils/LibcTableGenUtil/CMakeLists.txt
index 60208ed790d574..dca6a7bb830655 100644
--- a/libc/utils/LibcTableGenUtil/CMakeLists.txt
+++ b/libc/utils/LibcTableGenUtil/CMakeLists.txt
@@ -5,5 +5,5 @@ add_llvm_library(
DISABLE_LLVM_LINK_LLVM_DYLIB
LINK_COMPONENTS Support TableGen
)
-target_include_directories(LibcTableGenUtil PUBLIC ${LIBC_SOURCE_DIR} ${LIBC_SOURCE_DIR}/include)
+target_include_directories(LibcTableGenUtil PUBLIC ${LIBC_SOURCE_DIR})
target_include_directories(LibcTableGenUtil PRIVATE ${LLVM_INCLUDE_DIR} ${LLVM_MAIN_INCLUDE_DIR})
diff --git a/libc/utils/gpu/loader/Loader.h b/libc/utils/gpu/loader/Loader.h
index d74d65e8993829..e2aabb08c11dac 100644
--- a/libc/utils/gpu/loader/Loader.h
+++ b/libc/utils/gpu/loader/Loader.h
@@ -11,7 +11,7 @@
#include "utils/gpu/server/llvmlibc_rpc_server.h"
-#include "llvm-libc-types/test_rpc_opcodes_t.h"
+#include "include/llvm-libc-types/test_rpc_opcodes_t.h"
#include <cstddef>
#include <cstdint>
>From 525fe4492bbecf357d3580d879f2092bf99c12a2 Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?Danny=20M=C3=B6sch?= <danny.moesch at icloud.com>
Date: Thu, 29 Feb 2024 20:48:05 +0100
Subject: [PATCH 166/406] [clang-tidy] Add new check
`modernize-use-designated-initializers` (#80541)
---
.../clang-tidy/modernize/CMakeLists.txt | 1 +
.../modernize/ModernizeTidyModule.cpp | 3 +
.../UseDesignatedInitializersCheck.cpp | 184 ++++++++++++++++
.../UseDesignatedInitializersCheck.h | 40 ++++
.../clang-tidy/utils/CMakeLists.txt | 1 +
.../utils/DesignatedInitializers.cpp | 195 +++++++++++++++++
.../clang-tidy/utils/DesignatedInitializers.h | 42 ++++
clang-tools-extra/clangd/CMakeLists.txt | 1 +
clang-tools-extra/clangd/InlayHints.cpp | 170 +--------------
clang-tools-extra/clangd/tool/CMakeLists.txt | 1 +
.../clangd/unittests/CMakeLists.txt | 1 +
clang-tools-extra/docs/ReleaseNotes.rst | 6 +
.../docs/clang-tidy/checks/list.rst | 1 +
.../modernize/use-designated-initializers.rst | 62 ++++++
.../modernize/use-designated-initializers.cpp | 203 ++++++++++++++++++
15 files changed, 745 insertions(+), 166 deletions(-)
create mode 100644 clang-tools-extra/clang-tidy/modernize/UseDesignatedInitializersCheck.cpp
create mode 100644 clang-tools-extra/clang-tidy/modernize/UseDesignatedInitializersCheck.h
create mode 100644 clang-tools-extra/clang-tidy/utils/DesignatedInitializers.cpp
create mode 100644 clang-tools-extra/clang-tidy/utils/DesignatedInitializers.h
create mode 100644 clang-tools-extra/docs/clang-tidy/checks/modernize/use-designated-initializers.rst
create mode 100644 clang-tools-extra/test/clang-tidy/checkers/modernize/use-designated-initializers.cpp
diff --git a/clang-tools-extra/clang-tidy/modernize/CMakeLists.txt b/clang-tools-extra/clang-tidy/modernize/CMakeLists.txt
index 28ca52f46943a8..6852db6c2ee311 100644
--- a/clang-tools-extra/clang-tidy/modernize/CMakeLists.txt
+++ b/clang-tools-extra/clang-tidy/modernize/CMakeLists.txt
@@ -31,6 +31,7 @@ add_clang_library(clangTidyModernizeModule
UseBoolLiteralsCheck.cpp
UseConstraintsCheck.cpp
UseDefaultMemberInitCheck.cpp
+ UseDesignatedInitializersCheck.cpp
UseEmplaceCheck.cpp
UseEqualsDefaultCheck.cpp
UseEqualsDeleteCheck.cpp
diff --git a/clang-tools-extra/clang-tidy/modernize/ModernizeTidyModule.cpp b/clang-tools-extra/clang-tidy/modernize/ModernizeTidyModule.cpp
index 654f4bd0c6ba47..e96cf274f58cfe 100644
--- a/clang-tools-extra/clang-tidy/modernize/ModernizeTidyModule.cpp
+++ b/clang-tools-extra/clang-tidy/modernize/ModernizeTidyModule.cpp
@@ -32,6 +32,7 @@
#include "UseBoolLiteralsCheck.h"
#include "UseConstraintsCheck.h"
#include "UseDefaultMemberInitCheck.h"
+#include "UseDesignatedInitializersCheck.h"
#include "UseEmplaceCheck.h"
#include "UseEqualsDefaultCheck.h"
#include "UseEqualsDeleteCheck.h"
@@ -68,6 +69,8 @@ class ModernizeModule : public ClangTidyModule {
CheckFactories.registerCheck<MakeSharedCheck>("modernize-make-shared");
CheckFactories.registerCheck<MakeUniqueCheck>("modernize-make-unique");
CheckFactories.registerCheck<PassByValueCheck>("modernize-pass-by-value");
+ CheckFactories.registerCheck<UseDesignatedInitializersCheck>(
+ "modernize-use-designated-initializers");
CheckFactories.registerCheck<UseStartsEndsWithCheck>(
"modernize-use-starts-ends-with");
CheckFactories.registerCheck<UseStdNumbersCheck>(
diff --git a/clang-tools-extra/clang-tidy/modernize/UseDesignatedInitializersCheck.cpp b/clang-tools-extra/clang-tidy/modernize/UseDesignatedInitializersCheck.cpp
new file mode 100644
index 00000000000000..9ff6bb15043b54
--- /dev/null
+++ b/clang-tools-extra/clang-tidy/modernize/UseDesignatedInitializersCheck.cpp
@@ -0,0 +1,184 @@
+//===--- UseDesignatedInitializersCheck.cpp - clang-tidy ------------------===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+
+#include "UseDesignatedInitializersCheck.h"
+#include "../utils/DesignatedInitializers.h"
+#include "clang/AST/APValue.h"
+#include "clang/AST/Decl.h"
+#include "clang/AST/Expr.h"
+#include "clang/AST/Stmt.h"
+#include "clang/ASTMatchers/ASTMatchFinder.h"
+#include "clang/ASTMatchers/ASTMatchers.h"
+#include "clang/ASTMatchers/ASTMatchersMacros.h"
+#include "clang/Basic/Diagnostic.h"
+#include "clang/Lex/Lexer.h"
+
+using namespace clang::ast_matchers;
+
+namespace clang::tidy::modernize {
+
+static constexpr char IgnoreSingleElementAggregatesName[] =
+ "IgnoreSingleElementAggregates";
+static constexpr bool IgnoreSingleElementAggregatesDefault = true;
+
+static constexpr char RestrictToPODTypesName[] = "RestrictToPODTypes";
+static constexpr bool RestrictToPODTypesDefault = false;
+
+static constexpr char IgnoreMacrosName[] = "IgnoreMacros";
+static constexpr bool IgnoreMacrosDefault = true;
+
+namespace {
+
+struct Designators {
+
+ Designators(const InitListExpr *InitList) : InitList(InitList) {
+ assert(InitList->isSyntacticForm());
+ };
+
+ unsigned size() { return getCached().size(); }
+
+ std::optional<llvm::StringRef> operator[](const SourceLocation &Location) {
+ const auto Designators = getCached();
+ const auto Result = Designators.find(Location);
+ if (Result == Designators.end())
+ return {};
+ const llvm::StringRef Designator = Result->getSecond();
+ return (Designator.front() == '.' ? Designator.substr(1) : Designator)
+ .trim("\0"); // Trim NULL characters appearing on Windows in the
+ // name.
+ }
+
+private:
+ using LocationToNameMap = llvm::DenseMap<clang::SourceLocation, std::string>;
+
+ std::optional<LocationToNameMap> CachedDesignators;
+ const InitListExpr *InitList;
+
+ LocationToNameMap &getCached() {
+ return CachedDesignators ? *CachedDesignators
+ : CachedDesignators.emplace(
+ utils::getUnwrittenDesignators(InitList));
+ }
+};
+
+unsigned getNumberOfDesignated(const InitListExpr *SyntacticInitList) {
+ return llvm::count_if(*SyntacticInitList, [](auto *InitExpr) {
+ return isa<DesignatedInitExpr>(InitExpr);
+ });
+}
+
+AST_MATCHER(CXXRecordDecl, isAggregate) { return Node.isAggregate(); }
+
+AST_MATCHER(CXXRecordDecl, isPOD) { return Node.isPOD(); }
+
+AST_MATCHER(InitListExpr, isFullyDesignated) {
+ if (const InitListExpr *SyntacticForm =
+ Node.isSyntacticForm() ? &Node : Node.getSyntacticForm())
+ return getNumberOfDesignated(SyntacticForm) == SyntacticForm->getNumInits();
+ return true;
+}
+
+AST_MATCHER(InitListExpr, hasMoreThanOneElement) {
+ return Node.getNumInits() > 1;
+}
+
+} // namespace
+
+UseDesignatedInitializersCheck::UseDesignatedInitializersCheck(
+ StringRef Name, ClangTidyContext *Context)
+ : ClangTidyCheck(Name, Context), IgnoreSingleElementAggregates(Options.get(
+ IgnoreSingleElementAggregatesName,
+ IgnoreSingleElementAggregatesDefault)),
+ RestrictToPODTypes(
+ Options.get(RestrictToPODTypesName, RestrictToPODTypesDefault)),
+ IgnoreMacros(
+ Options.getLocalOrGlobal(IgnoreMacrosName, IgnoreMacrosDefault)) {}
+
+void UseDesignatedInitializersCheck::registerMatchers(MatchFinder *Finder) {
+ const auto HasBaseWithFields =
+ hasAnyBase(hasType(cxxRecordDecl(has(fieldDecl()))));
+ Finder->addMatcher(
+ initListExpr(
+ hasType(cxxRecordDecl(RestrictToPODTypes ? isPOD() : isAggregate(),
+ unless(HasBaseWithFields))
+ .bind("type")),
+ IgnoreSingleElementAggregates ? hasMoreThanOneElement() : anything(),
+ unless(isFullyDesignated()))
+ .bind("init"),
+ this);
+}
+
+void UseDesignatedInitializersCheck::check(
+ const MatchFinder::MatchResult &Result) {
+ const auto *InitList = Result.Nodes.getNodeAs<InitListExpr>("init");
+ const auto *Type = Result.Nodes.getNodeAs<CXXRecordDecl>("type");
+ if (!Type || !InitList)
+ return;
+ const auto *SyntacticInitList = InitList->getSyntacticForm();
+ if (!SyntacticInitList)
+ return;
+ Designators Designators{SyntacticInitList};
+ const unsigned NumberOfDesignated = getNumberOfDesignated(SyntacticInitList);
+ if (SyntacticInitList->getNumInits() - NumberOfDesignated >
+ Designators.size())
+ return;
+
+ // If the whole initializer list is un-designated, issue only one warning and
+ // a single fix-it for the whole expression.
+ if (0 == NumberOfDesignated) {
+ if (IgnoreMacros && InitList->getBeginLoc().isMacroID())
+ return;
+ {
+ DiagnosticBuilder Diag =
+ diag(InitList->getLBraceLoc(),
+ "use designated initializer list to initialize %0");
+ Diag << Type << InitList->getSourceRange();
+ for (const Stmt *InitExpr : *SyntacticInitList) {
+ const auto Designator = Designators[InitExpr->getBeginLoc()];
+ if (Designator && !Designator->empty())
+ Diag << FixItHint::CreateInsertion(InitExpr->getBeginLoc(),
+ ("." + *Designator + "=").str());
+ }
+ }
+ diag(Type->getBeginLoc(), "aggregate type is defined here",
+ DiagnosticIDs::Note);
+ return;
+ }
+
+ // In case that only a few elements are un-designated (not all as before), the
+ // check offers dedicated issues and fix-its for each of them.
+ for (const auto *InitExpr : *SyntacticInitList) {
+ if (isa<DesignatedInitExpr>(InitExpr))
+ continue;
+ if (IgnoreMacros && InitExpr->getBeginLoc().isMacroID())
+ continue;
+ const auto Designator = Designators[InitExpr->getBeginLoc()];
+ if (!Designator || Designator->empty()) {
+ // There should always be a designator. If there's unexpectedly none, we
+ // at least report a generic diagnostic.
+ diag(InitExpr->getBeginLoc(), "use designated init expression")
+ << InitExpr->getSourceRange();
+ } else {
+ diag(InitExpr->getBeginLoc(),
+ "use designated init expression to initialize field '%0'")
+ << InitExpr->getSourceRange() << *Designator
+ << FixItHint::CreateInsertion(InitExpr->getBeginLoc(),
+ ("." + *Designator + "=").str());
+ }
+ }
+}
+
+void UseDesignatedInitializersCheck::storeOptions(
+ ClangTidyOptions::OptionMap &Opts) {
+ Options.store(Opts, IgnoreSingleElementAggregatesName,
+ IgnoreSingleElementAggregates);
+ Options.store(Opts, RestrictToPODTypesName, RestrictToPODTypes);
+ Options.store(Opts, IgnoreMacrosName, IgnoreMacros);
+}
+
+} // namespace clang::tidy::modernize
diff --git a/clang-tools-extra/clang-tidy/modernize/UseDesignatedInitializersCheck.h b/clang-tools-extra/clang-tidy/modernize/UseDesignatedInitializersCheck.h
new file mode 100644
index 00000000000000..0a496f51b95762
--- /dev/null
+++ b/clang-tools-extra/clang-tidy/modernize/UseDesignatedInitializersCheck.h
@@ -0,0 +1,40 @@
+//===--- UseDesignatedInitializersCheck.h - clang-tidy ----------*- C++ -*-===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+
+#ifndef LLVM_CLANG_TOOLS_EXTRA_CLANG_TIDY_MODERNIZE_USEDESIGNATEDINITIALIZERSCHECK_H
+#define LLVM_CLANG_TOOLS_EXTRA_CLANG_TIDY_MODERNIZE_USEDESIGNATEDINITIALIZERSCHECK_H
+
+#include "../ClangTidyCheck.h"
+
+namespace clang::tidy::modernize {
+
+/// Finds initializer lists for aggregate type that could be
+/// written as designated initializers instead.
+///
+/// For the user-facing documentation see:
+/// http://clang.llvm.org/extra/clang-tidy/checks/modernize/use-designated-initializers.html
+class UseDesignatedInitializersCheck : public ClangTidyCheck {
+public:
+ UseDesignatedInitializersCheck(StringRef Name, ClangTidyContext *Context);
+ void registerMatchers(ast_matchers::MatchFinder *Finder) override;
+ void check(const ast_matchers::MatchFinder::MatchResult &Result) override;
+ void storeOptions(ClangTidyOptions::OptionMap &Opts) override;
+
+ std::optional<TraversalKind> getCheckTraversalKind() const override {
+ return TK_IgnoreUnlessSpelledInSource;
+ }
+
+private:
+ bool IgnoreSingleElementAggregates;
+ bool RestrictToPODTypes;
+ bool IgnoreMacros;
+};
+
+} // namespace clang::tidy::modernize
+
+#endif // LLVM_CLANG_TOOLS_EXTRA_CLANG_TIDY_MODERNIZE_USEDESIGNATEDINITIALIZERSCHECK_H
diff --git a/clang-tools-extra/clang-tidy/utils/CMakeLists.txt b/clang-tools-extra/clang-tidy/utils/CMakeLists.txt
index 88638d4acd5567..f0160fa9df7487 100644
--- a/clang-tools-extra/clang-tidy/utils/CMakeLists.txt
+++ b/clang-tools-extra/clang-tidy/utils/CMakeLists.txt
@@ -7,6 +7,7 @@ add_clang_library(clangTidyUtils
Aliasing.cpp
ASTUtils.cpp
DeclRefExprUtils.cpp
+ DesignatedInitializers.cpp
ExceptionAnalyzer.cpp
ExceptionSpecAnalyzer.cpp
ExprSequence.cpp
diff --git a/clang-tools-extra/clang-tidy/utils/DesignatedInitializers.cpp b/clang-tools-extra/clang-tidy/utils/DesignatedInitializers.cpp
new file mode 100644
index 00000000000000..6faeb7a0b76e19
--- /dev/null
+++ b/clang-tools-extra/clang-tidy/utils/DesignatedInitializers.cpp
@@ -0,0 +1,195 @@
+//===--- DesignatedInitializers.cpp - clang-tidy --------------------------===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+///
+/// \file
+/// This file provides utilities for designated initializers.
+///
+//===----------------------------------------------------------------------===//
+
+#include "DesignatedInitializers.h"
+#include "clang/AST/DeclCXX.h"
+#include "llvm/ADT/DenseSet.h"
+#include "llvm/ADT/ScopeExit.h"
+
+namespace clang::tidy::utils {
+
+namespace {
+
+/// Returns true if Name is reserved, like _Foo or __Vector_base.
+static inline bool isReservedName(llvm::StringRef Name) {
+ // This doesn't catch all cases, but the most common.
+ return Name.size() >= 2 && Name[0] == '_' &&
+ (isUppercase(Name[1]) || Name[1] == '_');
+}
+
+// Helper class to iterate over the designator names of an aggregate type.
+//
+// For an array type, yields [0], [1], [2]...
+// For aggregate classes, yields null for each base, then .field1, .field2,
+// ...
+class AggregateDesignatorNames {
+public:
+ AggregateDesignatorNames(QualType T) {
+ if (!T.isNull()) {
+ T = T.getCanonicalType();
+ if (T->isArrayType()) {
+ IsArray = true;
+ Valid = true;
+ return;
+ }
+ if (const RecordDecl *RD = T->getAsRecordDecl()) {
+ Valid = true;
+ FieldsIt = RD->field_begin();
+ FieldsEnd = RD->field_end();
+ if (const auto *CRD = llvm::dyn_cast<CXXRecordDecl>(RD)) {
+ BasesIt = CRD->bases_begin();
+ BasesEnd = CRD->bases_end();
+ Valid = CRD->isAggregate();
+ }
+ OneField = Valid && BasesIt == BasesEnd && FieldsIt != FieldsEnd &&
+ std::next(FieldsIt) == FieldsEnd;
+ }
+ }
+ }
+ // Returns false if the type was not an aggregate.
+ operator bool() { return Valid; }
+ // Advance to the next element in the aggregate.
+ void next() {
+ if (IsArray)
+ ++Index;
+ else if (BasesIt != BasesEnd)
+ ++BasesIt;
+ else if (FieldsIt != FieldsEnd)
+ ++FieldsIt;
+ }
+ // Print the designator to Out.
+ // Returns false if we could not produce a designator for this element.
+ bool append(std::string &Out, bool ForSubobject) {
+ if (IsArray) {
+ Out.push_back('[');
+ Out.append(std::to_string(Index));
+ Out.push_back(']');
+ return true;
+ }
+ if (BasesIt != BasesEnd)
+ return false; // Bases can't be designated. Should we make one up?
+ if (FieldsIt != FieldsEnd) {
+ llvm::StringRef FieldName;
+ if (const IdentifierInfo *II = FieldsIt->getIdentifier())
+ FieldName = II->getName();
+
+ // For certain objects, their subobjects may be named directly.
+ if (ForSubobject &&
+ (FieldsIt->isAnonymousStructOrUnion() ||
+ // std::array<int,3> x = {1,2,3}. Designators not strictly valid!
+ (OneField && isReservedName(FieldName))))
+ return true;
+
+ if (!FieldName.empty() && !isReservedName(FieldName)) {
+ Out.push_back('.');
+ Out.append(FieldName.begin(), FieldName.end());
+ return true;
+ }
+ return false;
+ }
+ return false;
+ }
+
+private:
+ bool Valid = false;
+ bool IsArray = false;
+ bool OneField = false; // e.g. std::array { T __elements[N]; }
+ unsigned Index = 0;
+ CXXRecordDecl::base_class_const_iterator BasesIt;
+ CXXRecordDecl::base_class_const_iterator BasesEnd;
+ RecordDecl::field_iterator FieldsIt;
+ RecordDecl::field_iterator FieldsEnd;
+};
+
+// Collect designator labels describing the elements of an init list.
+//
+// This function contributes the designators of some (sub)object, which is
+// represented by the semantic InitListExpr Sem.
+// This includes any nested subobjects, but *only* if they are part of the
+// same original syntactic init list (due to brace elision). In other words,
+// it may descend into subobjects but not written init-lists.
+//
+// For example: struct Outer { Inner a,b; }; struct Inner { int x, y; }
+// Outer o{{1, 2}, 3};
+// This function will be called with Sem = { {1, 2}, {3, ImplicitValue} }
+// It should generate designators '.a:' and '.b.x:'.
+// '.a:' is produced directly without recursing into the written sublist.
+// (The written sublist will have a separate collectDesignators() call later).
+// Recursion with Prefix='.b' and Sem = {3, ImplicitValue} produces '.b.x:'.
+void collectDesignators(const InitListExpr *Sem,
+ llvm::DenseMap<SourceLocation, std::string> &Out,
+ const llvm::DenseSet<SourceLocation> &NestedBraces,
+ std::string &Prefix) {
+ if (!Sem || Sem->isTransparent())
+ return;
+ assert(Sem->isSemanticForm());
+
+ // The elements of the semantic form all correspond to direct subobjects of
+ // the aggregate type. `Fields` iterates over these subobject names.
+ AggregateDesignatorNames Fields(Sem->getType());
+ if (!Fields)
+ return;
+ for (const Expr *Init : Sem->inits()) {
+ auto Next = llvm::make_scope_exit([&, Size(Prefix.size())] {
+ Fields.next(); // Always advance to the next subobject name.
+ Prefix.resize(Size); // Erase any designator we appended.
+ });
+ // Skip for a broken initializer or if it is a "hole" in a subobject that
+ // was not explicitly initialized.
+ if (!Init || llvm::isa<ImplicitValueInitExpr>(Init))
+ continue;
+
+ const auto *BraceElidedSubobject = llvm::dyn_cast<InitListExpr>(Init);
+ if (BraceElidedSubobject &&
+ NestedBraces.contains(BraceElidedSubobject->getLBraceLoc()))
+ BraceElidedSubobject = nullptr; // there were braces!
+
+ if (!Fields.append(Prefix, BraceElidedSubobject != nullptr))
+ continue; // no designator available for this subobject
+ if (BraceElidedSubobject) {
+ // If the braces were elided, this aggregate subobject is initialized
+ // inline in the same syntactic list.
+ // Descend into the semantic list describing the subobject.
+ // (NestedBraces are still correct, they're from the same syntactic
+ // list).
+ collectDesignators(BraceElidedSubobject, Out, NestedBraces, Prefix);
+ continue;
+ }
+ Out.try_emplace(Init->getBeginLoc(), Prefix);
+ }
+}
+
+} // namespace
+
+llvm::DenseMap<SourceLocation, std::string>
+getUnwrittenDesignators(const InitListExpr *Syn) {
+ assert(Syn->isSyntacticForm());
+
+ // collectDesignators needs to know which InitListExprs in the semantic tree
+ // were actually written, but InitListExpr::isExplicit() lies.
+ // Instead, record where braces of sub-init-lists occur in the syntactic form.
+ llvm::DenseSet<SourceLocation> NestedBraces;
+ for (const Expr *Init : Syn->inits())
+ if (auto *Nested = llvm::dyn_cast<InitListExpr>(Init))
+ NestedBraces.insert(Nested->getLBraceLoc());
+
+ // Traverse the semantic form to find the designators.
+ // We use their SourceLocation to correlate with the syntactic form later.
+ llvm::DenseMap<SourceLocation, std::string> Designators;
+ std::string EmptyPrefix;
+ collectDesignators(Syn->isSemanticForm() ? Syn : Syn->getSemanticForm(),
+ Designators, NestedBraces, EmptyPrefix);
+ return Designators;
+}
+
+} // namespace clang::tidy::utils
diff --git a/clang-tools-extra/clang-tidy/utils/DesignatedInitializers.h b/clang-tools-extra/clang-tidy/utils/DesignatedInitializers.h
new file mode 100644
index 00000000000000..a6cb2963faf72f
--- /dev/null
+++ b/clang-tools-extra/clang-tidy/utils/DesignatedInitializers.h
@@ -0,0 +1,42 @@
+//===--- DesignatedInitializers.h - clang-tidy ------------------*- C++ -*-===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+///
+/// \file
+/// This file provides utilities for designated initializers.
+///
+//===----------------------------------------------------------------------===//
+
+#include "clang/AST/Expr.h"
+#include "clang/Basic/SourceLocation.h"
+#include "llvm/ADT/DenseMap.h"
+
+namespace clang::tidy::utils {
+
+/// Get designators describing the elements of a (syntactic) init list.
+///
+/// Given for example the type
+/// \code
+/// struct S { int i, j; };
+/// \endcode
+/// and the definition
+/// \code
+/// S s{1, 2};
+/// \endcode
+/// calling `getUnwrittenDesignators` for the initializer list expression
+/// `{1, 2}` would produce the map `{loc(1): ".i", loc(2): ".j"}`.
+///
+/// It does not produce designators for any explicitly-written nested lists,
+/// e.g. `{1, .j=2}` would only return `{loc(1): ".i"}`.
+///
+/// It also considers structs with fields of record types like
+/// `struct T { S s; };`. In this case, there would be designators of the
+/// form `.s.i` and `.s.j` in the returned map.
+llvm::DenseMap<clang::SourceLocation, std::string>
+getUnwrittenDesignators(const clang::InitListExpr *Syn);
+
+} // namespace clang::tidy::utils
diff --git a/clang-tools-extra/clangd/CMakeLists.txt b/clang-tools-extra/clangd/CMakeLists.txt
index 3911fb6c6c746a..f49704157880d3 100644
--- a/clang-tools-extra/clangd/CMakeLists.txt
+++ b/clang-tools-extra/clangd/CMakeLists.txt
@@ -182,6 +182,7 @@ target_link_libraries(clangDaemon
clangIncludeCleaner
clangPseudo
clangTidy
+ clangTidyUtils
clangdSupport
)
diff --git a/clang-tools-extra/clangd/InlayHints.cpp b/clang-tools-extra/clangd/InlayHints.cpp
index 671a9c30ffa959..a0ebc631ef8285 100644
--- a/clang-tools-extra/clangd/InlayHints.cpp
+++ b/clang-tools-extra/clangd/InlayHints.cpp
@@ -6,6 +6,7 @@
//
//===----------------------------------------------------------------------===//
#include "InlayHints.h"
+#include "../clang-tidy/utils/DesignatedInitializers.h"
#include "AST.h"
#include "Config.h"
#include "HeuristicResolver.h"
@@ -24,7 +25,6 @@
#include "clang/Basic/OperatorKinds.h"
#include "clang/Basic/SourceManager.h"
#include "llvm/ADT/DenseSet.h"
-#include "llvm/ADT/ScopeExit.h"
#include "llvm/ADT/StringExtras.h"
#include "llvm/ADT/StringRef.h"
#include "llvm/ADT/Twine.h"
@@ -42,169 +42,6 @@ namespace {
// For now, inlay hints are always anchored at the left or right of their range.
enum class HintSide { Left, Right };
-// Helper class to iterate over the designator names of an aggregate type.
-//
-// For an array type, yields [0], [1], [2]...
-// For aggregate classes, yields null for each base, then .field1, .field2, ...
-class AggregateDesignatorNames {
-public:
- AggregateDesignatorNames(QualType T) {
- if (!T.isNull()) {
- T = T.getCanonicalType();
- if (T->isArrayType()) {
- IsArray = true;
- Valid = true;
- return;
- }
- if (const RecordDecl *RD = T->getAsRecordDecl()) {
- Valid = true;
- FieldsIt = RD->field_begin();
- FieldsEnd = RD->field_end();
- if (const auto *CRD = llvm::dyn_cast<CXXRecordDecl>(RD)) {
- BasesIt = CRD->bases_begin();
- BasesEnd = CRD->bases_end();
- Valid = CRD->isAggregate();
- }
- OneField = Valid && BasesIt == BasesEnd && FieldsIt != FieldsEnd &&
- std::next(FieldsIt) == FieldsEnd;
- }
- }
- }
- // Returns false if the type was not an aggregate.
- operator bool() { return Valid; }
- // Advance to the next element in the aggregate.
- void next() {
- if (IsArray)
- ++Index;
- else if (BasesIt != BasesEnd)
- ++BasesIt;
- else if (FieldsIt != FieldsEnd)
- ++FieldsIt;
- }
- // Print the designator to Out.
- // Returns false if we could not produce a designator for this element.
- bool append(std::string &Out, bool ForSubobject) {
- if (IsArray) {
- Out.push_back('[');
- Out.append(std::to_string(Index));
- Out.push_back(']');
- return true;
- }
- if (BasesIt != BasesEnd)
- return false; // Bases can't be designated. Should we make one up?
- if (FieldsIt != FieldsEnd) {
- llvm::StringRef FieldName;
- if (const IdentifierInfo *II = FieldsIt->getIdentifier())
- FieldName = II->getName();
-
- // For certain objects, their subobjects may be named directly.
- if (ForSubobject &&
- (FieldsIt->isAnonymousStructOrUnion() ||
- // std::array<int,3> x = {1,2,3}. Designators not strictly valid!
- (OneField && isReservedName(FieldName))))
- return true;
-
- if (!FieldName.empty() && !isReservedName(FieldName)) {
- Out.push_back('.');
- Out.append(FieldName.begin(), FieldName.end());
- return true;
- }
- return false;
- }
- return false;
- }
-
-private:
- bool Valid = false;
- bool IsArray = false;
- bool OneField = false; // e.g. std::array { T __elements[N]; }
- unsigned Index = 0;
- CXXRecordDecl::base_class_const_iterator BasesIt;
- CXXRecordDecl::base_class_const_iterator BasesEnd;
- RecordDecl::field_iterator FieldsIt;
- RecordDecl::field_iterator FieldsEnd;
-};
-
-// Collect designator labels describing the elements of an init list.
-//
-// This function contributes the designators of some (sub)object, which is
-// represented by the semantic InitListExpr Sem.
-// This includes any nested subobjects, but *only* if they are part of the same
-// original syntactic init list (due to brace elision).
-// In other words, it may descend into subobjects but not written init-lists.
-//
-// For example: struct Outer { Inner a,b; }; struct Inner { int x, y; }
-// Outer o{{1, 2}, 3};
-// This function will be called with Sem = { {1, 2}, {3, ImplicitValue} }
-// It should generate designators '.a:' and '.b.x:'.
-// '.a:' is produced directly without recursing into the written sublist.
-// (The written sublist will have a separate collectDesignators() call later).
-// Recursion with Prefix='.b' and Sem = {3, ImplicitValue} produces '.b.x:'.
-void collectDesignators(const InitListExpr *Sem,
- llvm::DenseMap<SourceLocation, std::string> &Out,
- const llvm::DenseSet<SourceLocation> &NestedBraces,
- std::string &Prefix) {
- if (!Sem || Sem->isTransparent())
- return;
- assert(Sem->isSemanticForm());
-
- // The elements of the semantic form all correspond to direct subobjects of
- // the aggregate type. `Fields` iterates over these subobject names.
- AggregateDesignatorNames Fields(Sem->getType());
- if (!Fields)
- return;
- for (const Expr *Init : Sem->inits()) {
- auto Next = llvm::make_scope_exit([&, Size(Prefix.size())] {
- Fields.next(); // Always advance to the next subobject name.
- Prefix.resize(Size); // Erase any designator we appended.
- });
- // Skip for a broken initializer or if it is a "hole" in a subobject that
- // was not explicitly initialized.
- if (!Init || llvm::isa<ImplicitValueInitExpr>(Init))
- continue;
-
- const auto *BraceElidedSubobject = llvm::dyn_cast<InitListExpr>(Init);
- if (BraceElidedSubobject &&
- NestedBraces.contains(BraceElidedSubobject->getLBraceLoc()))
- BraceElidedSubobject = nullptr; // there were braces!
-
- if (!Fields.append(Prefix, BraceElidedSubobject != nullptr))
- continue; // no designator available for this subobject
- if (BraceElidedSubobject) {
- // If the braces were elided, this aggregate subobject is initialized
- // inline in the same syntactic list.
- // Descend into the semantic list describing the subobject.
- // (NestedBraces are still correct, they're from the same syntactic list).
- collectDesignators(BraceElidedSubobject, Out, NestedBraces, Prefix);
- continue;
- }
- Out.try_emplace(Init->getBeginLoc(), Prefix);
- }
-}
-
-// Get designators describing the elements of a (syntactic) init list.
-// This does not produce designators for any explicitly-written nested lists.
-llvm::DenseMap<SourceLocation, std::string>
-getDesignators(const InitListExpr *Syn) {
- assert(Syn->isSyntacticForm());
-
- // collectDesignators needs to know which InitListExprs in the semantic tree
- // were actually written, but InitListExpr::isExplicit() lies.
- // Instead, record where braces of sub-init-lists occur in the syntactic form.
- llvm::DenseSet<SourceLocation> NestedBraces;
- for (const Expr *Init : Syn->inits())
- if (auto *Nested = llvm::dyn_cast<InitListExpr>(Init))
- NestedBraces.insert(Nested->getLBraceLoc());
-
- // Traverse the semantic form to find the designators.
- // We use their SourceLocation to correlate with the syntactic form later.
- llvm::DenseMap<SourceLocation, std::string> Designators;
- std::string EmptyPrefix;
- collectDesignators(Syn->isSemanticForm() ? Syn : Syn->getSemanticForm(),
- Designators, NestedBraces, EmptyPrefix);
- return Designators;
-}
-
void stripLeadingUnderscores(StringRef &Name) { Name = Name.ltrim('_'); }
// getDeclForType() returns the decl responsible for Type's spelling.
@@ -847,14 +684,15 @@ class InlayHintVisitor : public RecursiveASTVisitor<InlayHintVisitor> {
// This is the one we will ultimately attach designators to.
// It may have subobject initializers inlined without braces. The *semantic*
// form of the init-list has nested init-lists for these.
- // getDesignators will look at the semantic form to determine the labels.
+ // getUnwrittenDesignators will look at the semantic form to determine the
+ // labels.
assert(Syn->isSyntacticForm() && "RAV should not visit implicit code!");
if (!Cfg.InlayHints.Designators)
return true;
if (Syn->isIdiomaticZeroInitializer(AST.getLangOpts()))
return true;
llvm::DenseMap<SourceLocation, std::string> Designators =
- getDesignators(Syn);
+ tidy::utils::getUnwrittenDesignators(Syn);
for (const Expr *Init : Syn->inits()) {
if (llvm::isa<DesignatedInitExpr>(Init))
continue;
diff --git a/clang-tools-extra/clangd/tool/CMakeLists.txt b/clang-tools-extra/clangd/tool/CMakeLists.txt
index 6c21175d7687c3..4012b6401c0080 100644
--- a/clang-tools-extra/clangd/tool/CMakeLists.txt
+++ b/clang-tools-extra/clangd/tool/CMakeLists.txt
@@ -33,6 +33,7 @@ clang_target_link_libraries(clangdMain
target_link_libraries(clangdMain
PRIVATE
clangTidy
+ clangTidyUtils
clangDaemon
clangdRemoteIndex
diff --git a/clang-tools-extra/clangd/unittests/CMakeLists.txt b/clang-tools-extra/clangd/unittests/CMakeLists.txt
index 9cd195eaf164fb..e432db8d0912e7 100644
--- a/clang-tools-extra/clangd/unittests/CMakeLists.txt
+++ b/clang-tools-extra/clangd/unittests/CMakeLists.txt
@@ -175,6 +175,7 @@ target_link_libraries(ClangdTests
clangIncludeCleaner
clangTesting
clangTidy
+ clangTidyUtils
clangdSupport
)
diff --git a/clang-tools-extra/docs/ReleaseNotes.rst b/clang-tools-extra/docs/ReleaseNotes.rst
index 3f90e7d63d6b23..5bae530e942384 100644
--- a/clang-tools-extra/docs/ReleaseNotes.rst
+++ b/clang-tools-extra/docs/ReleaseNotes.rst
@@ -104,6 +104,12 @@ Improvements to clang-tidy
New checks
^^^^^^^^^^
+- New :doc:`modernize-use-designated-initializers
+ <clang-tidy/checks/modernize/use-designated-initializers>` check.
+
+ Finds initializer lists for aggregate types that could be
+ written as designated initializers instead.
+
- New :doc:`readability-use-std-min-max
<clang-tidy/checks/readability/use-std-min-max>` check.
diff --git a/clang-tools-extra/docs/clang-tidy/checks/list.rst b/clang-tools-extra/docs/clang-tidy/checks/list.rst
index 59ef69f390ee91..5e57bc0ee483fe 100644
--- a/clang-tools-extra/docs/clang-tidy/checks/list.rst
+++ b/clang-tools-extra/docs/clang-tidy/checks/list.rst
@@ -287,6 +287,7 @@ Clang-Tidy Checks
:doc:`modernize-use-bool-literals <modernize/use-bool-literals>`, "Yes"
:doc:`modernize-use-constraints <modernize/use-constraints>`, "Yes"
:doc:`modernize-use-default-member-init <modernize/use-default-member-init>`, "Yes"
+ :doc:`modernize-use-designated-initializers <modernize/use-designated-initializers>`, "Yes"
:doc:`modernize-use-emplace <modernize/use-emplace>`, "Yes"
:doc:`modernize-use-equals-default <modernize/use-equals-default>`, "Yes"
:doc:`modernize-use-equals-delete <modernize/use-equals-delete>`, "Yes"
diff --git a/clang-tools-extra/docs/clang-tidy/checks/modernize/use-designated-initializers.rst b/clang-tools-extra/docs/clang-tidy/checks/modernize/use-designated-initializers.rst
new file mode 100644
index 00000000000000..22f50980baade6
--- /dev/null
+++ b/clang-tools-extra/docs/clang-tidy/checks/modernize/use-designated-initializers.rst
@@ -0,0 +1,62 @@
+.. title:: clang-tidy - modernize-use-designated-initializers
+
+modernize-use-designated-initializers
+=====================================
+
+Finds initializer lists for aggregate types which could be written as designated
+initializers instead.
+
+With plain initializer lists, it is very easy to introduce bugs when adding new
+fields in the middle of a struct or class type. The same confusion might arise
+when changing the order of fields.
+
+C++20 supports the designated initializer syntax for aggregate types. By
+applying it, we can always be sure that aggregates are constructed correctly,
+because every variable being initialized is referenced by its name.
+
+Example:
+
+.. code-block::
+
+ struct S { int i, j; };
+
+is an aggregate type that should be initialized as
+
+.. code-block::
+
+ S s{.i = 1, .j = 2};
+
+instead of
+
+.. code-block::
+
+ S s{1, 2};
+
+which could easily become an issue when ``i`` and ``j`` are swapped in the
+declaration of ``S``.
+
+Even when compiling in a language version older than C++20, depending on your
+compiler, designated initializers are potentially supported. Therefore, the
+check is not restricted to C++20 and newer versions. Check out the options
+``-Wc99-designator`` to get support for mixed designators in initializer list in
+C and ``-Wc++20-designator`` for support of designated initializers in older C++
+language modes.
+
+Options
+-------
+
+.. option:: IgnoreMacros
+
+ The value `false` specifies that components of initializer lists expanded from
+ macros are not checked. The default value is `true`.
+
+.. option:: IgnoreSingleElementAggregates
+
+ The value `false` specifies that even initializers for aggregate types with
+ only a single element should be checked. The default value is `true`.
+
+.. option:: RestrictToPODTypes
+
+ The value `true` specifies that only Plain Old Data (POD) types shall be
+ checked. This makes the check applicable to even older C++ standards. The
+ default value is `false`.
diff --git a/clang-tools-extra/test/clang-tidy/checkers/modernize/use-designated-initializers.cpp b/clang-tools-extra/test/clang-tidy/checkers/modernize/use-designated-initializers.cpp
new file mode 100644
index 00000000000000..7e5c26e3f4404a
--- /dev/null
+++ b/clang-tools-extra/test/clang-tidy/checkers/modernize/use-designated-initializers.cpp
@@ -0,0 +1,203 @@
+// RUN: %check_clang_tidy -std=c++17 %s modernize-use-designated-initializers %t \
+// RUN: -- \
+// RUN: -- -fno-delayed-template-parsing
+// RUN: %check_clang_tidy -check-suffixes=,SINGLE-ELEMENT -std=c++17 %s modernize-use-designated-initializers %t \
+// RUN: -- -config="{CheckOptions: {modernize-use-designated-initializers.IgnoreSingleElementAggregates: false}}" \
+// RUN: -- -fno-delayed-template-parsing
+// RUN: %check_clang_tidy -check-suffixes=POD -std=c++17 %s modernize-use-designated-initializers %t \
+// RUN: -- -config="{CheckOptions: {modernize-use-designated-initializers.RestrictToPODTypes: true}}" \
+// RUN: -- -fno-delayed-template-parsing
+// RUN: %check_clang_tidy -check-suffixes=,MACROS -std=c++17 %s modernize-use-designated-initializers %t \
+// RUN: -- -config="{CheckOptions: {modernize-use-designated-initializers.IgnoreMacros: false}}" \
+// RUN: -- -fno-delayed-template-parsing
+
+struct S1 {};
+
+S1 s11{};
+S1 s12 = {};
+S1 s13();
+S1 s14;
+
+struct S2 { int i, j; };
+
+S2 s21{.i=1, .j =2};
+
+S2 s22 = {1, 2};
+// CHECK-MESSAGES: :[[@LINE-1]]:10: warning: use designated initializer list to initialize 'S2' [modernize-use-designated-initializers]
+// CHECK-MESSAGES: :[[@LINE-6]]:1: note: aggregate type is defined here
+// CHECK-MESSAGES-POD: :[[@LINE-3]]:10: warning: use designated initializer list to initialize 'S2' [modernize-use-designated-initializers]
+// CHECK-MESSAGES-POD: :[[@LINE-8]]:1: note: aggregate type is defined here
+// CHECK-FIXES: S2 s22 = {.i=1, .j=2};
+
+S2 s23{1};
+// CHECK-MESSAGES: :[[@LINE-1]]:7: warning: use designated initializer list to initialize 'S2' [modernize-use-designated-initializers]
+// CHECK-MESSAGES: :[[@LINE-13]]:1: note: aggregate type is defined here
+// CHECK-MESSAGES-POD: :[[@LINE-3]]:7: warning: use designated initializer list to initialize 'S2' [modernize-use-designated-initializers]
+// CHECK-MESSAGES-POD: :[[@LINE-15]]:1: note: aggregate type is defined here
+// CHECK-FIXES: S2 s23{.i=1};
+
+S2 s24{.i = 1};
+
+S2 s25 = {.i=1, 2};
+// CHECK-MESSAGES: :[[@LINE-1]]:17: warning: use designated init expression to initialize field 'j' [modernize-use-designated-initializers]
+// CHECK-MESSAGES-POD: :[[@LINE-2]]:17: warning: use designated init expression to initialize field 'j' [modernize-use-designated-initializers]
+// CHECK-FIXES: S2 s25 = {.i=1, .j=2};
+
+class S3 {
+ public:
+ S2 s2;
+ double d;
+};
+
+S3 s31 = {.s2 = 1, 2, 3.1};
+// CHECK-MESSAGES: :[[@LINE-1]]:20: warning: use designated init expression to initialize field 's2.j' [modernize-use-designated-initializers]
+// CHECK-MESSAGES: :[[@LINE-2]]:23: warning: use designated init expression to initialize field 'd' [modernize-use-designated-initializers]
+// CHECK-MESSAGES-POD: :[[@LINE-3]]:20: warning: use designated init expression to initialize field 's2.j' [modernize-use-designated-initializers]
+// CHECK-MESSAGES-POD: :[[@LINE-4]]:23: warning: use designated init expression to initialize field 'd' [modernize-use-designated-initializers]
+// CHECK-FIXES: S3 s31 = {.s2 = 1, .s2.j=2, .d=3.1};
+
+S3 s32 = {{.i = 1, 2}};
+// CHECK-MESSAGES: :[[@LINE-1]]:10: warning: use designated initializer list to initialize 'S3' [modernize-use-designated-initializers]
+// CHECK-MESSAGES: :[[@LINE-15]]:1: note: aggregate type is defined here
+// CHECK-MESSAGES: :[[@LINE-3]]:20: warning: use designated init expression to initialize field 'j' [modernize-use-designated-initializers]
+// CHECK-MESSAGES-POD: :[[@LINE-4]]:10: warning: use designated initializer list to initialize 'S3' [modernize-use-designated-initializers]
+// CHECK-MESSAGES-POD: :[[@LINE-18]]:1: note: aggregate type is defined here
+// CHECK-MESSAGES-POD: :[[@LINE-6]]:20: warning: use designated init expression to initialize field 'j' [modernize-use-designated-initializers]
+// CHECK-FIXES: S3 s32 = {.s2={.i = 1, .j=2}};
+
+S3 s33 = {{2}, .d=3.1};
+// CHECK-MESSAGES: :[[@LINE-1]]:11: warning: use designated init expression to initialize field 's2' [modernize-use-designated-initializers]
+// CHECK-MESSAGES: :[[@LINE-2]]:11: warning: use designated initializer list to initialize 'S2' [modernize-use-designated-initializers]
+// CHECK-MESSAGES: :[[@LINE-50]]:1: note: aggregate type is defined here
+// CHECK-MESSAGES-POD: :[[@LINE-4]]:11: warning: use designated init expression to initialize field 's2' [modernize-use-designated-initializers]
+// CHECK-MESSAGES-POD: :[[@LINE-5]]:11: warning: use designated initializer list to initialize 'S2' [modernize-use-designated-initializers]
+// CHECK-MESSAGES-POD: :[[@LINE-53]]:1: note: aggregate type is defined here
+// CHECK-FIXES: S3 s33 = {.s2={.i=2}, .d=3.1};
+
+struct S4 {
+ double d;
+ private: static int i;
+};
+
+S4 s41 {2.2};
+// CHECK-MESSAGES-SINGLE-ELEMENT: :[[@LINE-1]]:8: warning: use designated initializer list to initialize 'S4' [modernize-use-designated-initializers]
+// CHECK-MESSAGES-SINGLE-ELEMENT: :[[@LINE-7]]:1: note: aggregate type is defined here
+// CHECK-FIXES-SINGLE-ELEMENT: S4 s41 {.d=2.2};
+
+S4 s42 = {{}};
+// CHECK-MESSAGES-SINGLE-ELEMENT: :[[@LINE-1]]:10: warning: use designated initializer list to initialize 'S4' [modernize-use-designated-initializers]
+// CHECK-MESSAGES-SINGLE-ELEMENT: :[[@LINE-12]]:1: note: aggregate type is defined here
+// CHECK-FIXES-SINGLE-ELEMENT: S4 s42 = {.d={}};
+
+template<typename S> S template1() { return {10, 11}; }
+
+S2 s26 = template1<S2>();
+
+template<typename S> S template2() { return {}; }
+
+S2 s27 = template2<S2>();
+
+struct S5: S2 { int x, y; };
+
+S5 s51 {1, 2, .x = 3, .y = 4};
+
+struct S6 {
+ int i;
+ struct { int j; } s;
+};
+
+S6 s61 {1, 2};
+// CHECK-MESSAGES: :[[@LINE-1]]:8: warning: use designated initializer list to initialize 'S6' [modernize-use-designated-initializers]
+// CHECK-MESSAGES: :[[@LINE-7]]:1: note: aggregate type is defined here
+// CHECK-MESSAGES-POD: :[[@LINE-3]]:8: warning: use designated initializer list to initialize 'S6' [modernize-use-designated-initializers]
+// CHECK-MESSAGES-POD: :[[@LINE-9]]:1: note: aggregate type is defined here
+// CHECK-FIXES: S6 s61 {.i=1, .s.j=2};
+
+struct S7 {
+ union {
+ int k;
+ double d;
+ } u;
+};
+
+S7 s71 {1};
+// CHECK-MESSAGES-SINGLE-ELEMENT: :[[@LINE-1]]:8: warning: use designated initializer list to initialize 'S7' [modernize-use-designated-initializers]
+// CHECK-MESSAGES-SINGLE-ELEMENT: :[[@LINE-9]]:1: note: aggregate type is defined here
+// CHECK-FIXES-SINGLE-ELEMENT: S7 s71 {.u.k=1};
+
+struct S8: S7 { int i; };
+
+S8 s81{1, 2};
+
+struct S9 {
+ int i, j;
+ S9 &operator=(S9);
+};
+
+S9 s91{1, 2};
+// CHECK-MESSAGES: :[[@LINE-1]]:7: warning: use designated initializer list to initialize 'S9' [modernize-use-designated-initializers]
+// CHECK-MESSAGES: :[[@LINE-7]]:1: note: aggregate type is defined here
+// CHECK-FIXES: S9 s91{.i=1, .j=2};
+
+struct S10 { int i = 1, j = 2; };
+
+S10 s101 {1, .j=2};
+// CHECK-MESSAGES: :[[@LINE-1]]:11: warning: use designated init expression to initialize field 'i' [modernize-use-designated-initializers]
+// CHECK-FIXES: S10 s101 {.i=1, .j=2};
+
+struct S11 { int i; S10 s10; };
+
+S11 s111 { .i = 1 };
+S11 s112 { 1 };
+// CHECK-MESSAGES: :[[@LINE-1]]:10: warning: use designated initializer list to initialize 'S11' [modernize-use-designated-initializers]
+// CHECK-MESSAGES: :[[@LINE-5]]:1: note: aggregate type is defined here
+// CHECK-FIXES: S11 s112 { .i=1 };
+
+S11 s113 { .i=1, {}};
+// CHECK-MESSAGES: :[[@LINE-1]]:18: warning: use designated init expression to initialize field 's10' [modernize-use-designated-initializers]
+// CHECK-FIXES: S11 s113 { .i=1, .s10={}};
+
+S11 s114 { .i=1, .s10={1, .j=2}};
+// CHECK-MESSAGES: :[[@LINE-1]]:24: warning: use designated init expression to initialize field 'i' [modernize-use-designated-initializers]
+// CHECK-FIXES: S11 s114 { .i=1, .s10={.i=1, .j=2}};
+
+struct S12 {
+ int i;
+ struct { int j; };
+};
+
+S12 s121 {1, 2};
+// CHECK-MESSAGES: :[[@LINE-1]]:10: warning: use designated initializer list to initialize 'S12' [modernize-use-designated-initializers]
+// CHECK-MESSAGES: :[[@LINE-7]]:1: note: aggregate type is defined here
+// CHECK-MESSAGES-POD: :[[@LINE-3]]:10: warning: use designated initializer list to initialize 'S12' [modernize-use-designated-initializers]
+// CHECK-MESSAGES-POD: :[[@LINE-9]]:1: note: aggregate type is defined here
+// CHECK-FIXES: S12 s121 {.i=1, .j=2};
+
+struct S13 {
+ union {
+ int k;
+ double d;
+ };
+ int i;
+};
+
+S13 s131 {1, 2};
+// CHECK-MESSAGES: :[[@LINE-1]]:10: warning: use designated initializer list to initialize 'S13' [modernize-use-designated-initializers]
+// CHECK-MESSAGES: :[[@LINE-10]]:1: note: aggregate type is defined here
+// CHECK-MESSAGES-POD: :[[@LINE-3]]:10: warning: use designated initializer list to initialize 'S13' [modernize-use-designated-initializers]
+// CHECK-MESSAGES-POD: :[[@LINE-12]]:1: note: aggregate type is defined here
+// CHECK-FIXES: S13 s131 {.k=1, .i=2};
+
+#define A (3+2)
+#define B .j=1
+
+S9 s92 {A, B};
+// CHECK-MESSAGES-MACROS: :[[@LINE-1]]:9: warning: use designated init expression to initialize field 'i' [modernize-use-designated-initializers]
+// CHECK-MESSAGES-MACROS: :[[@LINE-5]]:11: note: expanded from macro 'A'
+
+#define DECLARE_S93 S9 s93 {1, 2}
+
+DECLARE_S93;
+// CHECK-MESSAGES-MACROS: :[[@LINE-1]]:1: warning: use designated initializer list to initialize 'S9' [modernize-use-designated-initializers]
+// CHECK-MESSAGES-MACROS: :[[@LINE-4]]:28: note: expanded from macro 'DECLARE_S93'
+// CHECK-MESSAGES-MACROS: :[[@LINE-71]]:1: note: aggregate type is defined here
>From 920094ea3b84a9f99f3e4d014c3eac062a617efe Mon Sep 17 00:00:00 2001
From: LLVM GN Syncbot <llvmgnsyncbot at gmail.com>
Date: Thu, 29 Feb 2024 19:49:37 +0000
Subject: [PATCH 167/406] [gn build] Port 525fe4492bbe
---
.../gn/secondary/clang-tools-extra/clang-tidy/modernize/BUILD.gn | 1 +
.../gn/secondary/clang-tools-extra/clang-tidy/utils/BUILD.gn | 1 +
2 files changed, 2 insertions(+)
diff --git a/llvm/utils/gn/secondary/clang-tools-extra/clang-tidy/modernize/BUILD.gn b/llvm/utils/gn/secondary/clang-tools-extra/clang-tidy/modernize/BUILD.gn
index 551c790e3c4d68..c9e081383fa026 100644
--- a/llvm/utils/gn/secondary/clang-tools-extra/clang-tidy/modernize/BUILD.gn
+++ b/llvm/utils/gn/secondary/clang-tools-extra/clang-tidy/modernize/BUILD.gn
@@ -40,6 +40,7 @@ static_library("modernize") {
"UseBoolLiteralsCheck.cpp",
"UseConstraintsCheck.cpp",
"UseDefaultMemberInitCheck.cpp",
+ "UseDesignatedInitializersCheck.cpp",
"UseEmplaceCheck.cpp",
"UseEqualsDefaultCheck.cpp",
"UseEqualsDeleteCheck.cpp",
diff --git a/llvm/utils/gn/secondary/clang-tools-extra/clang-tidy/utils/BUILD.gn b/llvm/utils/gn/secondary/clang-tools-extra/clang-tidy/utils/BUILD.gn
index c5bb21ba966971..da3a37d4615307 100644
--- a/llvm/utils/gn/secondary/clang-tools-extra/clang-tidy/utils/BUILD.gn
+++ b/llvm/utils/gn/secondary/clang-tools-extra/clang-tidy/utils/BUILD.gn
@@ -14,6 +14,7 @@ static_library("utils") {
"ASTUtils.cpp",
"Aliasing.cpp",
"DeclRefExprUtils.cpp",
+ "DesignatedInitializers.cpp",
"ExceptionAnalyzer.cpp",
"ExceptionSpecAnalyzer.cpp",
"ExprSequence.cpp",
>From 22f5e30c1798280c7476c0374280342b48880bb5 Mon Sep 17 00:00:00 2001
From: Guillaume Chatelet <gchatelet at google.com>
Date: Thu, 29 Feb 2024 21:19:42 +0100
Subject: [PATCH 168/406] [libc][NFC] Rename `LIBC_COMPILER_HAS_C23_FLOAT16` to
`LIBC_TYPES_HAS_FLOAT16` (#83396)
Umbrella bug #83182
---
libc/src/__support/FPUtil/FPBits.h | 4 ++--
libc/src/__support/macros/properties/types.h | 15 +++++++--------
2 files changed, 9 insertions(+), 10 deletions(-)
diff --git a/libc/src/__support/FPUtil/FPBits.h b/libc/src/__support/FPUtil/FPBits.h
index 1703e9a2bb3317..64bf2d0ac43825 100644
--- a/libc/src/__support/FPUtil/FPBits.h
+++ b/libc/src/__support/FPUtil/FPBits.h
@@ -804,8 +804,8 @@ template <typename T> LIBC_INLINE static constexpr FPType get_fp_type() {
else if constexpr (__LDBL_MANT_DIG__ == 113)
return FPType::IEEE754_Binary128;
}
-#if defined(LIBC_COMPILER_HAS_C23_FLOAT16)
- else if constexpr (cpp::is_same_v<UnqualT, _Float16>)
+#if defined(LIBC_TYPES_HAS_FLOAT16)
+ else if constexpr (cpp::is_same_v<UnqualT, float16>)
return FPType::IEEE754_Binary16;
#endif
#if defined(LIBC_COMPILER_HAS_C23_FLOAT128)
diff --git a/libc/src/__support/macros/properties/types.h b/libc/src/__support/macros/properties/types.h
index 0a3c834663cc92..f1108aef33ba6c 100644
--- a/libc/src/__support/macros/properties/types.h
+++ b/libc/src/__support/macros/properties/types.h
@@ -27,28 +27,27 @@
#endif
// float16 support.
+// TODO: move this logic to "llvm-libc-types/float16.h"
#if defined(LIBC_TARGET_ARCH_IS_X86_64) && defined(LIBC_TARGET_CPU_HAS_SSE2)
#if (defined(LIBC_COMPILER_CLANG_VER) && (LIBC_COMPILER_CLANG_VER >= 1500)) || \
(defined(LIBC_COMPILER_GCC_VER) && (LIBC_COMPILER_GCC_VER >= 1201))
-#define LIBC_COMPILER_HAS_C23_FLOAT16
+#define LIBC_TYPES_HAS_FLOAT16
+using float16 = _Float16;
#endif
#endif
#if defined(LIBC_TARGET_ARCH_IS_AARCH64)
#if (defined(LIBC_COMPILER_CLANG_VER) && (LIBC_COMPILER_CLANG_VER >= 900)) || \
(defined(LIBC_COMPILER_GCC_VER) && (LIBC_COMPILER_GCC_VER >= 1301))
-#define LIBC_COMPILER_HAS_C23_FLOAT16
+#define LIBC_TYPES_HAS_FLOAT16
+using float16 = _Float16;
#endif
#endif
#if defined(LIBC_TARGET_ARCH_IS_ANY_RISCV)
#if (defined(LIBC_COMPILER_CLANG_VER) && (LIBC_COMPILER_CLANG_VER >= 1300)) || \
(defined(LIBC_COMPILER_GCC_VER) && (LIBC_COMPILER_GCC_VER >= 1301))
-#define LIBC_COMPILER_HAS_C23_FLOAT16
-#endif
-#endif
-
-#if defined(LIBC_COMPILER_HAS_C23_FLOAT16)
+#define LIBC_TYPES_HAS_FLOAT16
using float16 = _Float16;
-#define LIBC_HAS_FLOAT16
+#endif
#endif
// float128 support.
>From cff36bb198759c4fe557adc594eabc097cf7d565 Mon Sep 17 00:00:00 2001
From: Aiden Grossman <agrossman154 at yahoo.com>
Date: Thu, 29 Feb 2024 12:27:52 -0800
Subject: [PATCH 169/406] [ADT] Add std::string_view conversion to SmallString
(#83397)
This patch adds a std::string_view conversion to SmallString which we've
recently found a use for downstream in a project that is using c++
standard library IO.
---
llvm/include/llvm/ADT/SmallString.h | 5 +++++
llvm/unittests/ADT/SmallStringTest.cpp | 6 ++++++
2 files changed, 11 insertions(+)
diff --git a/llvm/include/llvm/ADT/SmallString.h b/llvm/include/llvm/ADT/SmallString.h
index a5b9eec50c8257..ab5d483558cac8 100644
--- a/llvm/include/llvm/ADT/SmallString.h
+++ b/llvm/include/llvm/ADT/SmallString.h
@@ -265,6 +265,11 @@ class SmallString : public SmallVector<char, InternalLen> {
/// Implicit conversion to StringRef.
operator StringRef() const { return str(); }
+ /// Implicit conversion to std::string_view.
+ operator std::string_view() const {
+ return std::string_view(this->data(), this->size());
+ }
+
explicit operator std::string() const {
return std::string(this->data(), this->size());
}
diff --git a/llvm/unittests/ADT/SmallStringTest.cpp b/llvm/unittests/ADT/SmallStringTest.cpp
index 2f4df8afeafa59..d68d73157988ab 100644
--- a/llvm/unittests/ADT/SmallStringTest.cpp
+++ b/llvm/unittests/ADT/SmallStringTest.cpp
@@ -244,4 +244,10 @@ TEST_F(SmallStringTest, GTestPrinter) {
EXPECT_EQ(R"("foo")", ::testing::PrintToString(ErasedSmallString));
}
+TEST_F(SmallStringTest, StringView) {
+ theString = "hello from std::string_view";
+ EXPECT_EQ("hello from std::string_view",
+ static_cast<std::string_view>(theString));
+}
+
} // namespace
>From 21be2fbd17f9ff6f3f04e0ababc91c9cdd5aed85 Mon Sep 17 00:00:00 2001
From: Piotr Zegar <me at piotrzegar.pl>
Date: Thu, 29 Feb 2024 20:52:32 +0000
Subject: [PATCH 170/406] [clang-tidy][NFC] Fix buffer overflow in
modernize-use-designated-initializers
Instance of DenseMap were copied into local variable,
and as a result reference to string stored in that local
variable were returned from function. At the end fix-it
were applied with already destroyed string causing some
non utf-8 characters to be printed.
Related to #80541
---
.../clang-tidy/modernize/UseDesignatedInitializersCheck.cpp | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/clang-tools-extra/clang-tidy/modernize/UseDesignatedInitializersCheck.cpp b/clang-tools-extra/clang-tidy/modernize/UseDesignatedInitializersCheck.cpp
index 9ff6bb15043b54..ebc5338d0a7bfa 100644
--- a/clang-tools-extra/clang-tidy/modernize/UseDesignatedInitializersCheck.cpp
+++ b/clang-tools-extra/clang-tidy/modernize/UseDesignatedInitializersCheck.cpp
@@ -43,7 +43,7 @@ struct Designators {
unsigned size() { return getCached().size(); }
std::optional<llvm::StringRef> operator[](const SourceLocation &Location) {
- const auto Designators = getCached();
+ const auto &Designators = getCached();
const auto Result = Designators.find(Location);
if (Result == Designators.end())
return {};
>From 75fb825bccaa1e0f1ca9f76f9c72434a26d9966a Mon Sep 17 00:00:00 2001
From: Guillaume Chatelet <gchatelet at google.com>
Date: Thu, 29 Feb 2024 21:59:58 +0100
Subject: [PATCH 171/406] [libc][NFC] Rename `LIBC_COMPILER_HAS_FLOAT128` to
`LIBC_TYPES_HAS_FLOAT128` (#83395)
Umbrella bug #83182
---
.../cmake/modules/CheckCompilerFeatures.cmake | 2 +-
.../compiler_features/check_float128.cpp | 2 +-
libc/config/linux/aarch64/entrypoints.txt | 2 +-
libc/config/linux/riscv/entrypoints.txt | 2 +-
libc/config/linux/x86_64/entrypoints.txt | 2 +-
libc/docs/dev/code_style.rst | 2 +-
libc/spec/stdc.td | 30 +++++++++----------
.../CPP/type_traits/is_floating_point.h | 6 ++--
libc/src/__support/FPUtil/FPBits.h | 10 ++-----
libc/src/__support/macros/properties/types.h | 3 +-
.../test/src/__support/FPUtil/fpbits_test.cpp | 4 +--
libc/test/src/__support/uint_test.cpp | 4 +--
12 files changed, 32 insertions(+), 37 deletions(-)
diff --git a/libc/cmake/modules/CheckCompilerFeatures.cmake b/libc/cmake/modules/CheckCompilerFeatures.cmake
index c3f50df1dda53c..3a9e1e3b1cf8b4 100644
--- a/libc/cmake/modules/CheckCompilerFeatures.cmake
+++ b/libc/cmake/modules/CheckCompilerFeatures.cmake
@@ -55,7 +55,7 @@ foreach(feature IN LISTS ALL_COMPILER_FEATURES)
if(has_feature)
list(APPEND AVAILABLE_COMPILER_FEATURES ${feature})
if(${feature} STREQUAL "float128")
- set(LIBC_COMPILER_HAS_FLOAT128 TRUE)
+ set(LIBC_TYPES_HAS_FLOAT128 TRUE)
elseif(${feature} STREQUAL "fixed_point")
set(LIBC_COMPILER_HAS_FIXED_POINT TRUE)
endif()
diff --git a/libc/cmake/modules/compiler_features/check_float128.cpp b/libc/cmake/modules/compiler_features/check_float128.cpp
index 20f889c14f997b..64fa9f97dff3ad 100644
--- a/libc/cmake/modules/compiler_features/check_float128.cpp
+++ b/libc/cmake/modules/compiler_features/check_float128.cpp
@@ -1,5 +1,5 @@
#include "src/__support/macros/properties/types.h"
-#ifndef LIBC_COMPILER_HAS_FLOAT128
+#ifndef LIBC_TYPES_HAS_FLOAT128
#error unsupported
#endif
diff --git a/libc/config/linux/aarch64/entrypoints.txt b/libc/config/linux/aarch64/entrypoints.txt
index a6dc74101dbccb..06832a41221dd8 100644
--- a/libc/config/linux/aarch64/entrypoints.txt
+++ b/libc/config/linux/aarch64/entrypoints.txt
@@ -414,7 +414,7 @@ set(TARGET_LIBM_ENTRYPOINTS
libc.src.math.truncl
)
-if(LIBC_COMPILER_HAS_FLOAT128)
+if(LIBC_TYPES_HAS_FLOAT128)
list(APPEND TARGET_LIBM_ENTRYPOINTS
# math.h C23 _Float128 entrypoints
libc.src.math.ceilf128
diff --git a/libc/config/linux/riscv/entrypoints.txt b/libc/config/linux/riscv/entrypoints.txt
index fc4d8828f4c68d..bf518083b51f55 100644
--- a/libc/config/linux/riscv/entrypoints.txt
+++ b/libc/config/linux/riscv/entrypoints.txt
@@ -423,7 +423,7 @@ set(TARGET_LIBM_ENTRYPOINTS
libc.src.math.truncl
)
-if(LIBC_COMPILER_HAS_FLOAT128)
+if(LIBC_TYPES_HAS_FLOAT128)
list(APPEND TARGET_LIBM_ENTRYPOINTS
# math.h C23 _Float128 entrypoints
libc.src.math.ceilf128
diff --git a/libc/config/linux/x86_64/entrypoints.txt b/libc/config/linux/x86_64/entrypoints.txt
index 27c9a42934c240..bc10512d942fa7 100644
--- a/libc/config/linux/x86_64/entrypoints.txt
+++ b/libc/config/linux/x86_64/entrypoints.txt
@@ -442,7 +442,7 @@ set(TARGET_LIBM_ENTRYPOINTS
libc.src.math.truncl
)
-if(LIBC_COMPILER_HAS_FLOAT128)
+if(LIBC_TYPES_HAS_FLOAT128)
list(APPEND TARGET_LIBM_ENTRYPOINTS
# math.h C23 _Float128 entrypoints
libc.src.math.ceilf128
diff --git a/libc/docs/dev/code_style.rst b/libc/docs/dev/code_style.rst
index c76f8874f3aef6..e6fc6df5a0f6b3 100644
--- a/libc/docs/dev/code_style.rst
+++ b/libc/docs/dev/code_style.rst
@@ -48,7 +48,7 @@ We define two kinds of macros:
* ``cpu_features.h`` - Target cpu feature availability.
e.g., ``LIBC_TARGET_CPU_HAS_AVX2``.
* ``types.h`` - Type properties and availability.
- e.g., ``LIBC_COMPILER_HAS_FLOAT128``.
+ e.g., ``LIBC_TYPES_HAS_FLOAT128``.
* ``os.h`` - Target os properties.
e.g., ``LIBC_TARGET_OS_IS_LINUX``.
diff --git a/libc/spec/stdc.td b/libc/spec/stdc.td
index 5b97255b899746..94ac62966f3ba5 100644
--- a/libc/spec/stdc.td
+++ b/libc/spec/stdc.td
@@ -364,37 +364,37 @@ def StdC : StandardSpec<"stdc"> {
FunctionSpec<"copysign", RetValSpec<DoubleType>, [ArgSpec<DoubleType>, ArgSpec<DoubleType>]>,
FunctionSpec<"copysignf", RetValSpec<FloatType>, [ArgSpec<FloatType>, ArgSpec<FloatType>]>,
FunctionSpec<"copysignl", RetValSpec<LongDoubleType>, [ArgSpec<LongDoubleType>, ArgSpec<LongDoubleType>]>,
- GuardedFunctionSpec<"copysignf128", RetValSpec<Float128Type>, [ArgSpec<Float128Type>, ArgSpec<Float128Type>], "LIBC_COMPILER_HAS_FLOAT128">,
+ GuardedFunctionSpec<"copysignf128", RetValSpec<Float128Type>, [ArgSpec<Float128Type>, ArgSpec<Float128Type>], "LIBC_TYPES_HAS_FLOAT128">,
FunctionSpec<"ceil", RetValSpec<DoubleType>, [ArgSpec<DoubleType>]>,
FunctionSpec<"ceilf", RetValSpec<FloatType>, [ArgSpec<FloatType>]>,
FunctionSpec<"ceill", RetValSpec<LongDoubleType>, [ArgSpec<LongDoubleType>]>,
- GuardedFunctionSpec<"ceilf128", RetValSpec<Float128Type>, [ArgSpec<Float128Type>], "LIBC_COMPILER_HAS_FLOAT128">,
+ GuardedFunctionSpec<"ceilf128", RetValSpec<Float128Type>, [ArgSpec<Float128Type>], "LIBC_TYPES_HAS_FLOAT128">,
FunctionSpec<"fabs", RetValSpec<DoubleType>, [ArgSpec<DoubleType>], [ConstAttr]>,
FunctionSpec<"fabsf", RetValSpec<FloatType>, [ArgSpec<FloatType>]>,
FunctionSpec<"fabsl", RetValSpec<LongDoubleType>, [ArgSpec<LongDoubleType>]>,
- GuardedFunctionSpec<"fabsf128", RetValSpec<Float128Type>, [ArgSpec<Float128Type>], "LIBC_COMPILER_HAS_FLOAT128">,
+ GuardedFunctionSpec<"fabsf128", RetValSpec<Float128Type>, [ArgSpec<Float128Type>], "LIBC_TYPES_HAS_FLOAT128">,
FunctionSpec<"fdim", RetValSpec<DoubleType>, [ArgSpec<DoubleType>, ArgSpec<DoubleType>]>,
FunctionSpec<"fdimf", RetValSpec<FloatType>, [ArgSpec<FloatType>, ArgSpec<FloatType>]>,
FunctionSpec<"fdiml", RetValSpec<LongDoubleType>, [ArgSpec<LongDoubleType>, ArgSpec<LongDoubleType>]>,
- GuardedFunctionSpec<"fdimf128", RetValSpec<Float128Type>, [ArgSpec<Float128Type>, ArgSpec<Float128Type>], "LIBC_COMPILER_HAS_FLOAT128">,
+ GuardedFunctionSpec<"fdimf128", RetValSpec<Float128Type>, [ArgSpec<Float128Type>, ArgSpec<Float128Type>], "LIBC_TYPES_HAS_FLOAT128">,
FunctionSpec<"floor", RetValSpec<DoubleType>, [ArgSpec<DoubleType>]>,
FunctionSpec<"floorf", RetValSpec<FloatType>, [ArgSpec<FloatType>]>,
FunctionSpec<"floorl", RetValSpec<LongDoubleType>, [ArgSpec<LongDoubleType>]>,
- GuardedFunctionSpec<"floorf128", RetValSpec<Float128Type>, [ArgSpec<Float128Type>], "LIBC_COMPILER_HAS_FLOAT128">,
+ GuardedFunctionSpec<"floorf128", RetValSpec<Float128Type>, [ArgSpec<Float128Type>], "LIBC_TYPES_HAS_FLOAT128">,
FunctionSpec<"fmin", RetValSpec<DoubleType>, [ArgSpec<DoubleType>, ArgSpec<DoubleType>]>,
FunctionSpec<"fminf", RetValSpec<FloatType>, [ArgSpec<FloatType>, ArgSpec<FloatType>]>,
FunctionSpec<"fminl", RetValSpec<LongDoubleType>, [ArgSpec<LongDoubleType>, ArgSpec<LongDoubleType>]>,
- GuardedFunctionSpec<"fminf128", RetValSpec<Float128Type>, [ArgSpec<Float128Type>, ArgSpec<Float128Type>], "LIBC_COMPILER_HAS_FLOAT128">,
+ GuardedFunctionSpec<"fminf128", RetValSpec<Float128Type>, [ArgSpec<Float128Type>, ArgSpec<Float128Type>], "LIBC_TYPES_HAS_FLOAT128">,
FunctionSpec<"fmax", RetValSpec<DoubleType>, [ArgSpec<DoubleType>, ArgSpec<DoubleType>]>,
FunctionSpec<"fmaxf", RetValSpec<FloatType>, [ArgSpec<FloatType>, ArgSpec<FloatType>]>,
FunctionSpec<"fmaxl", RetValSpec<LongDoubleType>, [ArgSpec<LongDoubleType>, ArgSpec<LongDoubleType>]>,
- GuardedFunctionSpec<"fmaxf128", RetValSpec<Float128Type>, [ArgSpec<Float128Type>, ArgSpec<Float128Type>], "LIBC_COMPILER_HAS_FLOAT128">,
+ GuardedFunctionSpec<"fmaxf128", RetValSpec<Float128Type>, [ArgSpec<Float128Type>, ArgSpec<Float128Type>], "LIBC_TYPES_HAS_FLOAT128">,
FunctionSpec<"fma", RetValSpec<DoubleType>, [ArgSpec<DoubleType>, ArgSpec<DoubleType>, ArgSpec<DoubleType>]>,
FunctionSpec<"fmaf", RetValSpec<FloatType>, [ArgSpec<FloatType>, ArgSpec<FloatType>, ArgSpec<FloatType>]>,
@@ -406,7 +406,7 @@ def StdC : StandardSpec<"stdc"> {
FunctionSpec<"frexp", RetValSpec<DoubleType>, [ArgSpec<DoubleType>, ArgSpec<IntPtr>]>,
FunctionSpec<"frexpf", RetValSpec<FloatType>, [ArgSpec<FloatType>, ArgSpec<IntPtr>]>,
FunctionSpec<"frexpl", RetValSpec<LongDoubleType>, [ArgSpec<LongDoubleType>, ArgSpec<IntPtr>]>,
- GuardedFunctionSpec<"frexpf128", RetValSpec<Float128Type>, [ArgSpec<Float128Type>, ArgSpec<IntPtr>], "LIBC_COMPILER_HAS_FLOAT128">,
+ GuardedFunctionSpec<"frexpf128", RetValSpec<Float128Type>, [ArgSpec<Float128Type>, ArgSpec<IntPtr>], "LIBC_TYPES_HAS_FLOAT128">,
FunctionSpec<"hypot", RetValSpec<DoubleType>, [ArgSpec<DoubleType>, ArgSpec<DoubleType>]>,
FunctionSpec<"hypotf", RetValSpec<FloatType>, [ArgSpec<FloatType>, ArgSpec<FloatType>]>,
@@ -414,17 +414,17 @@ def StdC : StandardSpec<"stdc"> {
FunctionSpec<"ilogb", RetValSpec<IntType>, [ArgSpec<DoubleType>]>,
FunctionSpec<"ilogbf", RetValSpec<IntType>, [ArgSpec<FloatType>]>,
FunctionSpec<"ilogbl", RetValSpec<IntType>, [ArgSpec<LongDoubleType>]>,
- GuardedFunctionSpec<"ilogbf128", RetValSpec<IntType>, [ArgSpec<Float128Type>], "LIBC_COMPILER_HAS_FLOAT128">,
+ GuardedFunctionSpec<"ilogbf128", RetValSpec<IntType>, [ArgSpec<Float128Type>], "LIBC_TYPES_HAS_FLOAT128">,
FunctionSpec<"llogb", RetValSpec<LongType>, [ArgSpec<DoubleType>]>,
FunctionSpec<"llogbf", RetValSpec<LongType>, [ArgSpec<FloatType>]>,
FunctionSpec<"llogbl", RetValSpec<LongType>, [ArgSpec<LongDoubleType>]>,
- GuardedFunctionSpec<"llogbf128", RetValSpec<LongType>, [ArgSpec<Float128Type>], "LIBC_COMPILER_HAS_FLOAT128">,
+ GuardedFunctionSpec<"llogbf128", RetValSpec<LongType>, [ArgSpec<Float128Type>], "LIBC_TYPES_HAS_FLOAT128">,
FunctionSpec<"ldexp", RetValSpec<DoubleType>, [ArgSpec<DoubleType>, ArgSpec<IntType>]>,
FunctionSpec<"ldexpf", RetValSpec<FloatType>, [ArgSpec<FloatType>, ArgSpec<IntType>]>,
FunctionSpec<"ldexpl", RetValSpec<LongDoubleType>, [ArgSpec<LongDoubleType>, ArgSpec<IntType>]>,
- GuardedFunctionSpec<"ldexpf128", RetValSpec<Float128Type>, [ArgSpec<Float128Type>, ArgSpec<IntType>], "LIBC_COMPILER_HAS_FLOAT128">,
+ GuardedFunctionSpec<"ldexpf128", RetValSpec<Float128Type>, [ArgSpec<Float128Type>, ArgSpec<IntType>], "LIBC_TYPES_HAS_FLOAT128">,
FunctionSpec<"log10", RetValSpec<DoubleType>, [ArgSpec<DoubleType>]>,
FunctionSpec<"log10f", RetValSpec<FloatType>, [ArgSpec<FloatType>]>,
@@ -441,7 +441,7 @@ def StdC : StandardSpec<"stdc"> {
FunctionSpec<"logb", RetValSpec<DoubleType>, [ArgSpec<DoubleType>]>,
FunctionSpec<"logbf", RetValSpec<FloatType>, [ArgSpec<FloatType>]>,
FunctionSpec<"logbl", RetValSpec<LongDoubleType>, [ArgSpec<LongDoubleType>]>,
- GuardedFunctionSpec<"logbf128", RetValSpec<Float128Type>, [ArgSpec<Float128Type>], "LIBC_COMPILER_HAS_FLOAT128">,
+ GuardedFunctionSpec<"logbf128", RetValSpec<Float128Type>, [ArgSpec<Float128Type>], "LIBC_TYPES_HAS_FLOAT128">,
FunctionSpec<"modf", RetValSpec<DoubleType>, [ArgSpec<DoubleType>, ArgSpec<DoublePtr>]>,
FunctionSpec<"modff", RetValSpec<FloatType>, [ArgSpec<FloatType>, ArgSpec<FloatPtr>]>,
@@ -476,7 +476,7 @@ def StdC : StandardSpec<"stdc"> {
FunctionSpec<"round", RetValSpec<DoubleType>, [ArgSpec<DoubleType>]>,
FunctionSpec<"roundf", RetValSpec<FloatType>, [ArgSpec<FloatType>]>,
FunctionSpec<"roundl", RetValSpec<LongDoubleType>, [ArgSpec<LongDoubleType>]>,
- GuardedFunctionSpec<"roundf128", RetValSpec<Float128Type>, [ArgSpec<Float128Type>], "LIBC_COMPILER_HAS_FLOAT128">,
+ GuardedFunctionSpec<"roundf128", RetValSpec<Float128Type>, [ArgSpec<Float128Type>], "LIBC_TYPES_HAS_FLOAT128">,
FunctionSpec<"lround", RetValSpec<LongType>, [ArgSpec<DoubleType>]>,
FunctionSpec<"lroundf", RetValSpec<LongType>, [ArgSpec<FloatType>]>,
@@ -501,12 +501,12 @@ def StdC : StandardSpec<"stdc"> {
FunctionSpec<"sqrt", RetValSpec<DoubleType>, [ArgSpec<DoubleType>]>,
FunctionSpec<"sqrtf", RetValSpec<FloatType>, [ArgSpec<FloatType>]>,
FunctionSpec<"sqrtl", RetValSpec<LongDoubleType>, [ArgSpec<LongDoubleType>]>,
- GuardedFunctionSpec<"sqrtf128", RetValSpec<Float128Type>, [ArgSpec<Float128Type>], "LIBC_COMPILER_HAS_FLOAT128">,
+ GuardedFunctionSpec<"sqrtf128", RetValSpec<Float128Type>, [ArgSpec<Float128Type>], "LIBC_TYPES_HAS_FLOAT128">,
FunctionSpec<"trunc", RetValSpec<DoubleType>, [ArgSpec<DoubleType>]>,
FunctionSpec<"truncf", RetValSpec<FloatType>, [ArgSpec<FloatType>]>,
FunctionSpec<"truncl", RetValSpec<LongDoubleType>, [ArgSpec<LongDoubleType>]>,
- GuardedFunctionSpec<"truncf128", RetValSpec<Float128Type>, [ArgSpec<Float128Type>], "LIBC_COMPILER_HAS_FLOAT128">,
+ GuardedFunctionSpec<"truncf128", RetValSpec<Float128Type>, [ArgSpec<Float128Type>], "LIBC_TYPES_HAS_FLOAT128">,
FunctionSpec<"nearbyint", RetValSpec<DoubleType>, [ArgSpec<DoubleType>]>,
FunctionSpec<"nearbyintf", RetValSpec<FloatType>, [ArgSpec<FloatType>]>,
diff --git a/libc/src/__support/CPP/type_traits/is_floating_point.h b/libc/src/__support/CPP/type_traits/is_floating_point.h
index 7f01cc41cae8fe..4c8f50f4e91f97 100644
--- a/libc/src/__support/CPP/type_traits/is_floating_point.h
+++ b/libc/src/__support/CPP/type_traits/is_floating_point.h
@@ -11,7 +11,7 @@
#include "src/__support/CPP/type_traits/is_same.h"
#include "src/__support/CPP/type_traits/remove_cv.h"
#include "src/__support/macros/attributes.h"
-#include "src/__support/macros/properties/types.h"
+#include "src/__support/macros/properties/types.h" // LIBC_TYPES_HAS_FLOAT128
namespace LIBC_NAMESPACE::cpp {
@@ -24,13 +24,13 @@ template <typename T> struct is_floating_point {
}
public:
-#if defined(LIBC_COMPILER_HAS_FLOAT128)
+#if defined(LIBC_TYPES_HAS_FLOAT128)
LIBC_INLINE_VAR static constexpr bool value =
__is_unqualified_any_of<T, float, double, long double, float128>();
#else
LIBC_INLINE_VAR static constexpr bool value =
__is_unqualified_any_of<T, float, double, long double>();
-#endif // LIBC_COMPILER_HAS_FLOAT128
+#endif // LIBC_TYPES_HAS_FLOAT128
};
template <typename T>
LIBC_INLINE_VAR constexpr bool is_floating_point_v =
diff --git a/libc/src/__support/FPUtil/FPBits.h b/libc/src/__support/FPUtil/FPBits.h
index 64bf2d0ac43825..7b3882dde1b72b 100644
--- a/libc/src/__support/FPUtil/FPBits.h
+++ b/libc/src/__support/FPUtil/FPBits.h
@@ -15,7 +15,7 @@
#include "src/__support/common.h"
#include "src/__support/libc_assert.h" // LIBC_ASSERT
#include "src/__support/macros/attributes.h" // LIBC_INLINE, LIBC_INLINE_VAR
-#include "src/__support/macros/properties/types.h" // LIBC_COMPILER_HAS_FLOAT128
+#include "src/__support/macros/properties/types.h" // LIBC_TYPES_HAS_FLOAT128
#include "src/__support/math_extras.h" // mask_trailing_ones
#include <stdint.h>
@@ -808,12 +808,8 @@ template <typename T> LIBC_INLINE static constexpr FPType get_fp_type() {
else if constexpr (cpp::is_same_v<UnqualT, float16>)
return FPType::IEEE754_Binary16;
#endif
-#if defined(LIBC_COMPILER_HAS_C23_FLOAT128)
- else if constexpr (cpp::is_same_v<UnqualT, _Float128>)
- return FPType::IEEE754_Binary128;
-#endif
-#if defined(LIBC_COMPILER_HAS_FLOAT128_EXTENSION)
- else if constexpr (cpp::is_same_v<UnqualT, __float128>)
+#if defined(LIBC_TYPES_HAS_FLOAT128)
+ else if constexpr (cpp::is_same_v<UnqualT, float128>)
return FPType::IEEE754_Binary128;
#endif
else
diff --git a/libc/src/__support/macros/properties/types.h b/libc/src/__support/macros/properties/types.h
index f1108aef33ba6c..595871e73b8fcc 100644
--- a/libc/src/__support/macros/properties/types.h
+++ b/libc/src/__support/macros/properties/types.h
@@ -54,8 +54,7 @@ using float16 = _Float16;
#if defined(LIBC_COMPILER_HAS_C23_FLOAT128) || \
defined(LIBC_COMPILER_HAS_FLOAT128_EXTENSION) || \
defined(LIBC_LONG_DOUBLE_IS_FLOAT128)
-// TODO: Replace with LIBC_HAS_FLOAT128
-#define LIBC_COMPILER_HAS_FLOAT128
+#define LIBC_TYPES_HAS_FLOAT128
#endif
#endif // LLVM_LIBC_SRC___SUPPORT_MACROS_PROPERTIES_TYPES_H
diff --git a/libc/test/src/__support/FPUtil/fpbits_test.cpp b/libc/test/src/__support/FPUtil/fpbits_test.cpp
index 4f9f53afe54785..852ab6e31b65bd 100644
--- a/libc/test/src/__support/FPUtil/fpbits_test.cpp
+++ b/libc/test/src/__support/FPUtil/fpbits_test.cpp
@@ -575,7 +575,7 @@ TEST(LlvmLibcFPBitsTest, LongDoubleType) {
}
#endif
-#if defined(LIBC_COMPILER_HAS_FLOAT128)
+#if defined(LIBC_TYPES_HAS_FLOAT128)
TEST(LlvmLibcFPBitsTest, Float128Type) {
using Float128Bits = FPBits<float128>;
@@ -643,4 +643,4 @@ TEST(LlvmLibcFPBitsTest, Float128Type) {
Float128Bits quiet_nan = Float128Bits::quiet_nan();
EXPECT_EQ(quiet_nan.is_quiet_nan(), true);
}
-#endif // LIBC_COMPILER_HAS_FLOAT128
+#endif // LIBC_TYPES_HAS_FLOAT128
diff --git a/libc/test/src/__support/uint_test.cpp b/libc/test/src/__support/uint_test.cpp
index 1a1171b46781e8..963c553b10d01d 100644
--- a/libc/test/src/__support/uint_test.cpp
+++ b/libc/test/src/__support/uint_test.cpp
@@ -54,7 +54,7 @@ TEST(LlvmLibcUIntClassTest, BitCastToFromNativeUint128) {
}
#endif
-#ifdef LIBC_COMPILER_HAS_FLOAT128
+#ifdef LIBC_TYPES_HAS_FLOAT128
TEST(LlvmLibcUIntClassTest, BitCastToFromNativeFloat128) {
static_assert(cpp::is_trivially_copyable<LL_UInt128>::value);
static_assert(sizeof(LL_UInt128) == sizeof(float128));
@@ -65,7 +65,7 @@ TEST(LlvmLibcUIntClassTest, BitCastToFromNativeFloat128) {
EXPECT_TRUE(value == forth);
}
}
-#endif
+#endif // LIBC_TYPES_HAS_FLOAT128
TEST(LlvmLibcUIntClassTest, BasicInit) {
LL_UInt128 half_val(12345);
>From 5225901ecd53ba1e3f1519f3edea7d1aec15502d Mon Sep 17 00:00:00 2001
From: Peter Klausler <35819229+klausler at users.noreply.github.com>
Date: Thu, 29 Feb 2024 13:02:39 -0800
Subject: [PATCH 172/406] [flang] Add [[maybe_unused]] to fix -Werror build
(#83456)
Add the [[maybe_unused]] attribute to a variable in
lib/Lower/OpenMP/OpenMP.cpp to avoid a (possibly bogus) unused variable
warning when building with GCC 9.3.0.
---
flang/lib/Lower/OpenMP/OpenMP.cpp | 3 ++-
1 file changed, 2 insertions(+), 1 deletion(-)
diff --git a/flang/lib/Lower/OpenMP/OpenMP.cpp b/flang/lib/Lower/OpenMP/OpenMP.cpp
index 21ad51c53d8742..90fc1f80f57ab7 100644
--- a/flang/lib/Lower/OpenMP/OpenMP.cpp
+++ b/flang/lib/Lower/OpenMP/OpenMP.cpp
@@ -840,7 +840,8 @@ genEnterExitUpdateDataOp(Fortran::lower::AbstractConverter &converter,
llvm::SmallVector<mlir::Attribute> dependTypeOperands;
Fortran::parser::OmpIfClause::DirectiveNameModifier directiveName;
- llvm::omp::Directive directive;
+ // GCC 9.3.0 emits a (probably) bogus warning about an unused variable.
+ [[maybe_unused]] llvm::omp::Directive directive;
if constexpr (std::is_same_v<OpTy, mlir::omp::EnterDataOp>) {
directiveName =
Fortran::parser::OmpIfClause::DirectiveNameModifier::TargetEnterData;
>From 81578477645b7f2e97744d53a4cea962872925b0 Mon Sep 17 00:00:00 2001
From: Fangrui Song <i at maskray.me>
Date: Thu, 29 Feb 2024 13:05:59 -0800
Subject: [PATCH 173/406] [libc++] Include missing <__assert> after #80091
(#83480)
_LIBCPP_ASSERT_SHIM used by the -fno-exceptions and
LIBCXX_ENABLE_NEW_DELETE_DEFINITIONS=on configuration
needs _LIBCPP_ASSERT from <__assert>.
---
libcxx/src/new.cpp | 1 +
1 file changed, 1 insertion(+)
diff --git a/libcxx/src/new.cpp b/libcxx/src/new.cpp
index 0869d90661dd51..b0c731678cac30 100644
--- a/libcxx/src/new.cpp
+++ b/libcxx/src/new.cpp
@@ -7,6 +7,7 @@
//===----------------------------------------------------------------------===//
#include "include/overridable_function.h"
+#include <__assert>
#include <__memory/aligned_alloc.h>
#include <cstddef>
#include <cstdlib>
>From 82c1bfc44ecee97425582f345d04e787f066b899 Mon Sep 17 00:00:00 2001
From: Shubham Sandeep Rastogi <srastogi22 at apple.com>
Date: Thu, 29 Feb 2024 13:12:03 -0800
Subject: [PATCH 174/406] Increase timeout to reduce test failure rate.
(#83312)
The timeout for this test was set to 1.0s which is very low, it should
be a default of 10s and be increased by a factor of 10 if ASAN is
enabled. This will help reduce the falkiness of the test, especially in
ASAN builds.
---
.../test/tools/lldb-dap/lldbdap_testcase.py | 3 +++
.../test/API/tools/lldb-dap/launch/TestDAP_launch.py | 12 ++++++------
2 files changed, 9 insertions(+), 6 deletions(-)
diff --git a/lldb/packages/Python/lldbsuite/test/tools/lldb-dap/lldbdap_testcase.py b/lldb/packages/Python/lldbsuite/test/tools/lldb-dap/lldbdap_testcase.py
index 288cc8cf9a48c8..23f650d2d36fdd 100644
--- a/lldb/packages/Python/lldbsuite/test/tools/lldb-dap/lldbdap_testcase.py
+++ b/lldb/packages/Python/lldbsuite/test/tools/lldb-dap/lldbdap_testcase.py
@@ -6,6 +6,9 @@
class DAPTestCaseBase(TestBase):
+ # set timeout based on whether ASAN was enabled or not. Increase
+ # timeout by a factor of 10 if ASAN is enabled.
+ timeoutval = 10 * (10 if ('ASAN_OPTIONS' in os.environ) else 1)
NO_DEBUG_INFO_TESTCASE = True
def create_debug_adaptor(self, lldbDAPEnv=None):
diff --git a/lldb/test/API/tools/lldb-dap/launch/TestDAP_launch.py b/lldb/test/API/tools/lldb-dap/launch/TestDAP_launch.py
index 04d741c1d47201..0760d358d9c0b3 100644
--- a/lldb/test/API/tools/lldb-dap/launch/TestDAP_launch.py
+++ b/lldb/test/API/tools/lldb-dap/launch/TestDAP_launch.py
@@ -44,7 +44,7 @@ def test_termination(self):
self.dap_server.request_disconnect()
# Wait until the underlying lldb-dap process dies.
- self.dap_server.process.wait(timeout=10)
+ self.dap_server.process.wait(timeout=lldbdap_testcase.DAPTestCaseBase.timeoutval)
# Check the return code
self.assertEqual(self.dap_server.process.poll(), 0)
@@ -334,14 +334,14 @@ def test_commands(self):
# Get output from the console. This should contain both the
# "stopCommands" that were run after the first breakpoint was hit
self.continue_to_breakpoints(breakpoint_ids)
- output = self.get_console(timeout=1.0)
+ output = self.get_console(timeout=lldbdap_testcase.DAPTestCaseBase.timeoutval)
self.verify_commands("stopCommands", output, stopCommands)
# Continue again and hit the second breakpoint.
# Get output from the console. This should contain both the
# "stopCommands" that were run after the second breakpoint was hit
self.continue_to_breakpoints(breakpoint_ids)
- output = self.get_console(timeout=1.0)
+ output = self.get_console(timeout=lldbdap_testcase.DAPTestCaseBase.timeoutval)
self.verify_commands("stopCommands", output, stopCommands)
# Continue until the program exits
@@ -402,21 +402,21 @@ def test_extra_launch_commands(self):
self.verify_commands("launchCommands", output, launchCommands)
# Verify the "stopCommands" here
self.continue_to_next_stop()
- output = self.get_console(timeout=1.0)
+ output = self.get_console(timeout=lldbdap_testcase.DAPTestCaseBase.timeoutval)
self.verify_commands("stopCommands", output, stopCommands)
# Continue and hit the second breakpoint.
# Get output from the console. This should contain both the
# "stopCommands" that were run after the first breakpoint was hit
self.continue_to_next_stop()
- output = self.get_console(timeout=1.0)
+ output = self.get_console(timeout=lldbdap_testcase.DAPTestCaseBase.timeoutval)
self.verify_commands("stopCommands", output, stopCommands)
# Continue until the program exits
self.continue_to_exit()
# Get output from the console. This should contain both the
# "exitCommands" that were run after the second breakpoint was hit
- output = self.get_console(timeout=1.0)
+ output = self.get_console(timeout=lldbdap_testcase.DAPTestCaseBase.timeoutval)
self.verify_commands("exitCommands", output, exitCommands)
@skipIfWindows
>From de55c2f869925a3ed7f26e168424021c6bc46799 Mon Sep 17 00:00:00 2001
From: Mehdi Amini <joker.eph at gmail.com>
Date: Thu, 29 Feb 2024 13:14:00 -0800
Subject: [PATCH 175/406] Revert "[mlir-query] Add function extraction feature
to mlir-query"
This reverts commit c66f2d0c4a46ba66fb98a2cab4e63ad90888a261.
The bot is broken.
---
.../include/mlir/Query/Matcher/ErrorBuilder.h | 7 +-
.../mlir/Query/Matcher/MatchersInternal.h | 7 --
mlir/lib/Query/Matcher/Diagnostics.cpp | 10 ---
mlir/lib/Query/Matcher/Parser.cpp | 67 ++--------------
mlir/lib/Query/Matcher/Parser.h | 18 ++---
mlir/lib/Query/Matcher/RegistryManager.cpp | 15 +---
mlir/lib/Query/Matcher/RegistryManager.h | 1 -
mlir/lib/Query/Query.cpp | 80 +------------------
mlir/test/mlir-query/function-extraction.mlir | 19 -----
9 files changed, 17 insertions(+), 207 deletions(-)
delete mode 100644 mlir/test/mlir-query/function-extraction.mlir
diff --git a/mlir/include/mlir/Query/Matcher/ErrorBuilder.h b/mlir/include/mlir/Query/Matcher/ErrorBuilder.h
index 08f1f415cbd3e5..1073daed8703f5 100644
--- a/mlir/include/mlir/Query/Matcher/ErrorBuilder.h
+++ b/mlir/include/mlir/Query/Matcher/ErrorBuilder.h
@@ -37,12 +37,8 @@ enum class ErrorType {
None,
// Parser Errors
- ParserChainedExprInvalidArg,
- ParserChainedExprNoCloseParen,
- ParserChainedExprNoOpenParen,
ParserFailedToBuildMatcher,
ParserInvalidToken,
- ParserMalformedChainedExpr,
ParserNoCloseParen,
ParserNoCode,
ParserNoComma,
@@ -54,10 +50,9 @@ enum class ErrorType {
// Registry Errors
RegistryMatcherNotFound,
- RegistryNotBindable,
RegistryValueNotFound,
RegistryWrongArgCount,
- RegistryWrongArgType,
+ RegistryWrongArgType
};
void addError(Diagnostics *error, SourceRange range, ErrorType errorType,
diff --git a/mlir/include/mlir/Query/Matcher/MatchersInternal.h b/mlir/include/mlir/Query/Matcher/MatchersInternal.h
index 117f7d4edef9e3..67455be592393b 100644
--- a/mlir/include/mlir/Query/Matcher/MatchersInternal.h
+++ b/mlir/include/mlir/Query/Matcher/MatchersInternal.h
@@ -63,15 +63,8 @@ class DynMatcher {
bool match(Operation *op) const { return implementation->match(op); }
- void setFunctionName(StringRef name) { functionName = name.str(); };
-
- bool hasFunctionName() const { return !functionName.empty(); };
-
- StringRef getFunctionName() const { return functionName; };
-
private:
llvm::IntrusiveRefCntPtr<MatcherInterface> implementation;
- std::string functionName;
};
} // namespace mlir::query::matcher
diff --git a/mlir/lib/Query/Matcher/Diagnostics.cpp b/mlir/lib/Query/Matcher/Diagnostics.cpp
index 2a137e8fdfab0d..10468dbcc53067 100644
--- a/mlir/lib/Query/Matcher/Diagnostics.cpp
+++ b/mlir/lib/Query/Matcher/Diagnostics.cpp
@@ -38,8 +38,6 @@ static llvm::StringRef errorTypeToFormatString(ErrorType type) {
return "Incorrect type for arg $0. (Expected = $1) != (Actual = $2)";
case ErrorType::RegistryValueNotFound:
return "Value not found: $0";
- case ErrorType::RegistryNotBindable:
- return "Matcher does not support binding.";
case ErrorType::ParserStringError:
return "Error parsing string token: <$0>";
@@ -59,14 +57,6 @@ static llvm::StringRef errorTypeToFormatString(ErrorType type) {
return "Unexpected end of code.";
case ErrorType::ParserOverloadedType:
return "Input value has unresolved overloaded type: $0";
- case ErrorType::ParserMalformedChainedExpr:
- return "Period not followed by valid chained call.";
- case ErrorType::ParserChainedExprInvalidArg:
- return "Missing/Invalid argument for the chained call.";
- case ErrorType::ParserChainedExprNoCloseParen:
- return "Missing ')' for the chained call.";
- case ErrorType::ParserChainedExprNoOpenParen:
- return "Missing '(' for the chained call.";
case ErrorType::ParserFailedToBuildMatcher:
return "Failed to build matcher: $0.";
diff --git a/mlir/lib/Query/Matcher/Parser.cpp b/mlir/lib/Query/Matcher/Parser.cpp
index 3609e24f9939f7..30eb4801fc03c1 100644
--- a/mlir/lib/Query/Matcher/Parser.cpp
+++ b/mlir/lib/Query/Matcher/Parser.cpp
@@ -26,17 +26,12 @@ struct Parser::TokenInfo {
text = newText;
}
- // Known identifiers.
- static const char *const ID_Extract;
-
llvm::StringRef text;
TokenKind kind = TokenKind::Eof;
SourceRange range;
VariantValue value;
};
-const char *const Parser::TokenInfo::ID_Extract = "extract";
-
class Parser::CodeTokenizer {
public:
// Constructor with matcherCode and error
@@ -303,36 +298,6 @@ bool Parser::parseIdentifierPrefixImpl(VariantValue *value) {
return parseMatcherExpressionImpl(nameToken, openToken, ctor, value);
}
-bool Parser::parseChainedExpression(std::string &argument) {
- // Parse the parenthesized argument to .extract("foo")
- // Note: EOF is handled inside the consume functions and would fail below when
- // checking token kind.
- const TokenInfo openToken = tokenizer->consumeNextToken();
- const TokenInfo argumentToken = tokenizer->consumeNextTokenIgnoreNewlines();
- const TokenInfo closeToken = tokenizer->consumeNextTokenIgnoreNewlines();
-
- if (openToken.kind != TokenKind::OpenParen) {
- error->addError(openToken.range, ErrorType::ParserChainedExprNoOpenParen);
- return false;
- }
-
- if (argumentToken.kind != TokenKind::Literal ||
- !argumentToken.value.isString()) {
- error->addError(argumentToken.range,
- ErrorType::ParserChainedExprInvalidArg);
- return false;
- }
-
- if (closeToken.kind != TokenKind::CloseParen) {
- error->addError(closeToken.range, ErrorType::ParserChainedExprNoCloseParen);
- return false;
- }
-
- // If all checks passed, extract the argument and return true.
- argument = argumentToken.value.getString();
- return true;
-}
-
// Parse the arguments of a matcher
bool Parser::parseMatcherArgs(std::vector<ParserValue> &args, MatcherCtor ctor,
const TokenInfo &nameToken, TokenInfo &endToken) {
@@ -399,34 +364,13 @@ bool Parser::parseMatcherExpressionImpl(const TokenInfo &nameToken,
return false;
}
- std::string functionName;
- if (tokenizer->peekNextToken().kind == TokenKind::Period) {
- tokenizer->consumeNextToken();
- TokenInfo chainCallToken = tokenizer->consumeNextToken();
- if (chainCallToken.kind == TokenKind::CodeCompletion) {
- addCompletion(chainCallToken, MatcherCompletion("extract(\"", "extract"));
- return false;
- }
-
- if (chainCallToken.kind != TokenKind::Ident ||
- chainCallToken.text != TokenInfo::ID_Extract) {
- error->addError(chainCallToken.range,
- ErrorType::ParserMalformedChainedExpr);
- return false;
- }
-
- if (chainCallToken.text == TokenInfo::ID_Extract &&
- !parseChainedExpression(functionName))
- return false;
- }
-
if (!ctor)
return false;
// Merge the start and end infos.
SourceRange matcherRange = nameToken.range;
matcherRange.end = endToken.range.end;
- VariantMatcher result = sema->actOnMatcherExpression(
- *ctor, matcherRange, functionName, args, error);
+ VariantMatcher result =
+ sema->actOnMatcherExpression(*ctor, matcherRange, args, error);
if (result.isNull())
return false;
*value = result;
@@ -526,10 +470,9 @@ Parser::RegistrySema::lookupMatcherCtor(llvm::StringRef matcherName) {
}
VariantMatcher Parser::RegistrySema::actOnMatcherExpression(
- MatcherCtor ctor, SourceRange nameRange, llvm::StringRef functionName,
- llvm::ArrayRef<ParserValue> args, Diagnostics *error) {
- return RegistryManager::constructMatcher(ctor, nameRange, functionName, args,
- error);
+ MatcherCtor ctor, SourceRange nameRange, llvm::ArrayRef<ParserValue> args,
+ Diagnostics *error) {
+ return RegistryManager::constructMatcher(ctor, nameRange, args, error);
}
std::vector<ArgKind> Parser::RegistrySema::getAcceptedCompletionTypes(
diff --git a/mlir/lib/Query/Matcher/Parser.h b/mlir/lib/Query/Matcher/Parser.h
index 58968023022d56..f049af34e9c907 100644
--- a/mlir/lib/Query/Matcher/Parser.h
+++ b/mlir/lib/Query/Matcher/Parser.h
@@ -64,9 +64,10 @@ class Parser {
// Process a matcher expression. The caller takes ownership of the Matcher
// object returned.
- virtual VariantMatcher actOnMatcherExpression(
- MatcherCtor ctor, SourceRange nameRange, llvm::StringRef functionName,
- llvm::ArrayRef<ParserValue> args, Diagnostics *error) = 0;
+ virtual VariantMatcher
+ actOnMatcherExpression(MatcherCtor ctor, SourceRange nameRange,
+ llvm::ArrayRef<ParserValue> args,
+ Diagnostics *error) = 0;
// Look up a matcher by name in the matcher name found by the parser.
virtual std::optional<MatcherCtor>
@@ -92,11 +93,10 @@ class Parser {
std::optional<MatcherCtor>
lookupMatcherCtor(llvm::StringRef matcherName) override;
- VariantMatcher actOnMatcherExpression(MatcherCtor Ctor,
- SourceRange NameRange,
- StringRef functionName,
- ArrayRef<ParserValue> Args,
- Diagnostics *Error) override;
+ VariantMatcher actOnMatcherExpression(MatcherCtor ctor,
+ SourceRange nameRange,
+ llvm::ArrayRef<ParserValue> args,
+ Diagnostics *error) override;
std::vector<ArgKind> getAcceptedCompletionTypes(
llvm::ArrayRef<std::pair<MatcherCtor, unsigned>> context) override;
@@ -153,8 +153,6 @@ class Parser {
Parser(CodeTokenizer *tokenizer, const Registry &matcherRegistry,
const NamedValueMap *namedValues, Diagnostics *error);
- bool parseChainedExpression(std::string &argument);
-
bool parseExpressionImpl(VariantValue *value);
bool parseMatcherArgs(std::vector<ParserValue> &args, MatcherCtor ctor,
diff --git a/mlir/lib/Query/Matcher/RegistryManager.cpp b/mlir/lib/Query/Matcher/RegistryManager.cpp
index 8c9197f4d00981..01856aa8ffa67f 100644
--- a/mlir/lib/Query/Matcher/RegistryManager.cpp
+++ b/mlir/lib/Query/Matcher/RegistryManager.cpp
@@ -132,19 +132,8 @@ RegistryManager::getMatcherCompletions(llvm::ArrayRef<ArgKind> acceptedTypes,
VariantMatcher RegistryManager::constructMatcher(
MatcherCtor ctor, internal::SourceRange nameRange,
- llvm::StringRef functionName, llvm::ArrayRef<ParserValue> args,
- internal::Diagnostics *error) {
- VariantMatcher out = ctor->create(nameRange, args, error);
- if (functionName.empty() || out.isNull())
- return out;
-
- if (std::optional<DynMatcher> result = out.getDynMatcher()) {
- result->setFunctionName(functionName);
- return VariantMatcher::SingleMatcher(*result);
- }
-
- error->addError(nameRange, internal::ErrorType::RegistryNotBindable);
- return {};
+ llvm::ArrayRef<ParserValue> args, internal::Diagnostics *error) {
+ return ctor->create(nameRange, args, error);
}
} // namespace mlir::query::matcher
diff --git a/mlir/lib/Query/Matcher/RegistryManager.h b/mlir/lib/Query/Matcher/RegistryManager.h
index e2026e97f83dcb..5f2867261225e7 100644
--- a/mlir/lib/Query/Matcher/RegistryManager.h
+++ b/mlir/lib/Query/Matcher/RegistryManager.h
@@ -61,7 +61,6 @@ class RegistryManager {
static VariantMatcher constructMatcher(MatcherCtor ctor,
internal::SourceRange nameRange,
- llvm::StringRef functionName,
ArrayRef<ParserValue> args,
internal::Diagnostics *error);
};
diff --git a/mlir/lib/Query/Query.cpp b/mlir/lib/Query/Query.cpp
index 27db52b37dade0..5c42e5a5f0a116 100644
--- a/mlir/lib/Query/Query.cpp
+++ b/mlir/lib/Query/Query.cpp
@@ -8,8 +8,6 @@
#include "mlir/Query/Query.h"
#include "QueryParser.h"
-#include "mlir/Dialect/Func/IR/FuncOps.h"
-#include "mlir/IR/IRMapping.h"
#include "mlir/Query/Matcher/MatchFinder.h"
#include "mlir/Query/QuerySession.h"
#include "mlir/Support/LogicalResult.h"
@@ -36,70 +34,6 @@ static void printMatch(llvm::raw_ostream &os, QuerySession &qs, Operation *op,
"\"" + binding + "\" binds here");
}
-// TODO: Extract into a helper function that can be reused outside query
-// context.
-static Operation *extractFunction(std::vector<Operation *> &ops,
- MLIRContext *context,
- llvm::StringRef functionName) {
- context->loadDialect<func::FuncDialect>();
- OpBuilder builder(context);
-
- // Collect data for function creation
- std::vector<Operation *> slice;
- std::vector<Value> values;
- std::vector<Type> outputTypes;
-
- for (auto *op : ops) {
- // Return op's operands are propagated, but the op itself isn't needed.
- if (!isa<func::ReturnOp>(op))
- slice.push_back(op);
-
- // All results are returned by the extracted function.
- outputTypes.insert(outputTypes.end(), op->getResults().getTypes().begin(),
- op->getResults().getTypes().end());
-
- // Track all values that need to be taken as input to function.
- values.insert(values.end(), op->getOperands().begin(),
- op->getOperands().end());
- }
-
- // Create the function
- FunctionType funcType =
- builder.getFunctionType(ValueRange(values), outputTypes);
- auto loc = builder.getUnknownLoc();
- func::FuncOp funcOp = func::FuncOp::create(loc, functionName, funcType);
-
- builder.setInsertionPointToEnd(funcOp.addEntryBlock());
-
- // Map original values to function arguments
- IRMapping mapper;
- for (const auto &arg : llvm::enumerate(values))
- mapper.map(arg.value(), funcOp.getArgument(arg.index()));
-
- // Clone operations and build function body
- std::vector<Operation *> clonedOps;
- std::vector<Value> clonedVals;
- for (Operation *slicedOp : slice) {
- Operation *clonedOp =
- clonedOps.emplace_back(builder.clone(*slicedOp, mapper));
- clonedVals.insert(clonedVals.end(), clonedOp->result_begin(),
- clonedOp->result_end());
- }
- // Add return operation
- builder.create<func::ReturnOp>(loc, clonedVals);
-
- // Remove unused function arguments
- size_t currentIndex = 0;
- while (currentIndex < funcOp.getNumArguments()) {
- if (funcOp.getArgument(currentIndex).use_empty())
- funcOp.eraseArgument(currentIndex);
- else
- ++currentIndex;
- }
-
- return funcOp;
-}
-
Query::~Query() = default;
mlir::LogicalResult InvalidQuery::run(llvm::raw_ostream &os,
@@ -131,21 +65,9 @@ mlir::LogicalResult QuitQuery::run(llvm::raw_ostream &os,
mlir::LogicalResult MatchQuery::run(llvm::raw_ostream &os,
QuerySession &qs) const {
- Operation *rootOp = qs.getRootOp();
int matchCount = 0;
std::vector<Operation *> matches =
- matcher::MatchFinder().getMatches(rootOp, matcher);
-
- // An extract call is recognized by considering if the matcher has a name.
- // TODO: Consider making the extract more explicit.
- if (matcher.hasFunctionName()) {
- auto functionName = matcher.getFunctionName();
- Operation *function =
- extractFunction(matches, rootOp->getContext(), functionName);
- os << "\n" << *function << "\n\n";
- return mlir::success();
- }
-
+ matcher::MatchFinder().getMatches(qs.getRootOp(), matcher);
os << "\n";
for (Operation *op : matches) {
os << "Match #" << ++matchCount << ":\n\n";
diff --git a/mlir/test/mlir-query/function-extraction.mlir b/mlir/test/mlir-query/function-extraction.mlir
deleted file mode 100644
index a783f65c6761bc..00000000000000
--- a/mlir/test/mlir-query/function-extraction.mlir
+++ /dev/null
@@ -1,19 +0,0 @@
-// RUN: mlir-query %s -c "m hasOpName(\"arith.mulf\").extract(\"testmul\")" | FileCheck %s
-
-// CHECK: func.func @testmul({{.*}}) -> (f32, f32, f32) {
-// CHECK: %[[MUL0:.*]] = arith.mulf {{.*}} : f32
-// CHECK: %[[MUL1:.*]] = arith.mulf {{.*}}, %[[MUL0]] : f32
-// CHECK: %[[MUL2:.*]] = arith.mulf {{.*}} : f32
-// CHECK-NEXT: return %[[MUL0]], %[[MUL1]], %[[MUL2]] : f32, f32, f32
-
-func.func @mixedOperations(%a: f32, %b: f32, %c: f32) -> f32 {
- %sum0 = arith.addf %a, %b : f32
- %sub0 = arith.subf %sum0, %c : f32
- %mul0 = arith.mulf %a, %sub0 : f32
- %sum1 = arith.addf %b, %c : f32
- %mul1 = arith.mulf %sum1, %mul0 : f32
- %sub2 = arith.subf %mul1, %a : f32
- %sum2 = arith.addf %mul1, %b : f32
- %mul2 = arith.mulf %sub2, %sum2 : f32
- return %mul2 : f32
-}
>From 5abbe8ec9edcc034fad383ab69046e8c0d13c97d Mon Sep 17 00:00:00 2001
From: Aiden Grossman <agrossman154 at yahoo.com>
Date: Thu, 29 Feb 2024 13:13:58 -0800
Subject: [PATCH 176/406] Revert "[ADT] Add std::string_view conversion to
SmallString (#83397)"
This reverts commit cff36bb198759c4fe557adc594eabc097cf7d565.
This patch was causing build failures in certain configurations.
---
llvm/include/llvm/ADT/SmallString.h | 5 -----
llvm/unittests/ADT/SmallStringTest.cpp | 6 ------
2 files changed, 11 deletions(-)
diff --git a/llvm/include/llvm/ADT/SmallString.h b/llvm/include/llvm/ADT/SmallString.h
index ab5d483558cac8..a5b9eec50c8257 100644
--- a/llvm/include/llvm/ADT/SmallString.h
+++ b/llvm/include/llvm/ADT/SmallString.h
@@ -265,11 +265,6 @@ class SmallString : public SmallVector<char, InternalLen> {
/// Implicit conversion to StringRef.
operator StringRef() const { return str(); }
- /// Implicit conversion to std::string_view.
- operator std::string_view() const {
- return std::string_view(this->data(), this->size());
- }
-
explicit operator std::string() const {
return std::string(this->data(), this->size());
}
diff --git a/llvm/unittests/ADT/SmallStringTest.cpp b/llvm/unittests/ADT/SmallStringTest.cpp
index d68d73157988ab..2f4df8afeafa59 100644
--- a/llvm/unittests/ADT/SmallStringTest.cpp
+++ b/llvm/unittests/ADT/SmallStringTest.cpp
@@ -244,10 +244,4 @@ TEST_F(SmallStringTest, GTestPrinter) {
EXPECT_EQ(R"("foo")", ::testing::PrintToString(ErasedSmallString));
}
-TEST_F(SmallStringTest, StringView) {
- theString = "hello from std::string_view";
- EXPECT_EQ("hello from std::string_view",
- static_cast<std::string_view>(theString));
-}
-
} // namespace
>From ac267081a387a53d83ec9e3bfccedb27c21a050f Mon Sep 17 00:00:00 2001
From: Teresa Johnson <tejohnson at google.com>
Date: Thu, 29 Feb 2024 13:14:29 -0800
Subject: [PATCH 177/406] [MemProf][NFC] Make new test actually check cold
attributes
The test added by PR81322 didn't actually check the coldness of the
attributes being matched on the IR. Add that checking.
---
llvm/test/Transforms/MemProfContextDisambiguation/inlined3.ll | 3 +++
1 file changed, 3 insertions(+)
diff --git a/llvm/test/Transforms/MemProfContextDisambiguation/inlined3.ll b/llvm/test/Transforms/MemProfContextDisambiguation/inlined3.ll
index 39a595897c370c..a2e01187108d7f 100644
--- a/llvm/test/Transforms/MemProfContextDisambiguation/inlined3.ll
+++ b/llvm/test/Transforms/MemProfContextDisambiguation/inlined3.ll
@@ -188,6 +188,9 @@ attributes #7 = { builtin }
; IR: define {{.*}} @_Z1Mv.memprof.1()
; IR: call {{.*}} @_Z2XZv.memprof.1()
+; IR: attributes #[[NOTCOLD]] = { builtin "memprof"="notcold" }
+; IR: attributes #[[COLD]] = { builtin "memprof"="cold" }
+
; STATS: 2 memprof-context-disambiguation - Number of cold static allocations (possibly cloned)
; STATS: 2 memprof-context-disambiguation - Number of not cold static allocations (possibly cloned)
; STATS: 3 memprof-context-disambiguation - Number of function clones created during whole program analysis
>From 8c1003266520ac396ce2a9e799f318af30efdd19 Mon Sep 17 00:00:00 2001
From: Michael Buch <michaelbuch12 at gmail.com>
Date: Thu, 29 Feb 2024 21:32:28 +0000
Subject: [PATCH 178/406] [lldb][NFC] Move helpers to import record layout into
ClangASTImporter (#83291)
This patch moves the logic for copying the layout info of a
`RecordDecl`s origin into a target AST.
A follow-up patch re-uses the logic from within the `ClangASTImporter`,
so the natural choice was to move it there.
---
.../Clang/ClangASTImporter.cpp | 233 +++++++++++++++
.../ExpressionParser/Clang/ClangASTImporter.h | 74 +++++
.../ExpressionParser/Clang/ClangASTSource.cpp | 278 ++----------------
.../ExpressionParser/Clang/ClangASTSource.h | 5 +
4 files changed, 331 insertions(+), 259 deletions(-)
diff --git a/lldb/source/Plugins/ExpressionParser/Clang/ClangASTImporter.cpp b/lldb/source/Plugins/ExpressionParser/Clang/ClangASTImporter.cpp
index 62a30c14912bc9..99d210c347a21d 100644
--- a/lldb/source/Plugins/ExpressionParser/Clang/ClangASTImporter.cpp
+++ b/lldb/source/Plugins/ExpressionParser/Clang/ClangASTImporter.cpp
@@ -10,9 +10,11 @@
#include "lldb/Utility/LLDBAssert.h"
#include "lldb/Utility/LLDBLog.h"
#include "lldb/Utility/Log.h"
+#include "clang/AST/ASTContext.h"
#include "clang/AST/Decl.h"
#include "clang/AST/DeclCXX.h"
#include "clang/AST/DeclObjC.h"
+#include "clang/AST/RecordLayout.h"
#include "clang/Sema/Lookup.h"
#include "clang/Sema/Sema.h"
#include "llvm/Support/raw_ostream.h"
@@ -26,6 +28,7 @@
#include <memory>
#include <optional>
+#include <type_traits>
using namespace lldb_private;
using namespace clang;
@@ -517,6 +520,236 @@ bool ClangASTImporter::CompleteType(const CompilerType &compiler_type) {
return false;
}
+/// Copy layout information from \ref source_map to the \ref destination_map.
+///
+/// In the process of copying over layout info, we may need to import
+/// decls from the \ref source_map. This function will use the supplied
+/// \ref importer to import the necessary decls into \ref dest_ctx.
+///
+/// \param[in,out] dest_ctx Destination ASTContext into which we import
+/// decls from the \ref source_map.
+/// \param[out] destination_map A map from decls in \ref dest_ctx to an
+/// integral offest, which will be copies
+/// of the decl/offest pairs in \ref source_map
+/// if successful.
+/// \param[in] source_map A map from decls to integral offests. These will
+/// be copied into \ref destination_map.
+/// \param[in,out] importer Used to import decls into \ref dest_ctx.
+///
+/// \returns On success, will return 'true' and the offsets in \ref
+/// destination_map
+/// are usable copies of \ref source_map.
+template <class D, class O>
+static bool ImportOffsetMap(clang::ASTContext *dest_ctx,
+ llvm::DenseMap<const D *, O> &destination_map,
+ llvm::DenseMap<const D *, O> &source_map,
+ ClangASTImporter &importer) {
+ // When importing fields into a new record, clang has a hard requirement that
+ // fields be imported in field offset order. Since they are stored in a
+ // DenseMap with a pointer as the key type, this means we cannot simply
+ // iterate over the map, as the order will be non-deterministic. Instead we
+ // have to sort by the offset and then insert in sorted order.
+ typedef llvm::DenseMap<const D *, O> MapType;
+ typedef typename MapType::value_type PairType;
+ std::vector<PairType> sorted_items;
+ sorted_items.reserve(source_map.size());
+ sorted_items.assign(source_map.begin(), source_map.end());
+ llvm::sort(sorted_items, llvm::less_second());
+
+ for (const auto &item : sorted_items) {
+ DeclFromUser<D> user_decl(const_cast<D *>(item.first));
+ DeclFromParser<D> parser_decl(user_decl.Import(dest_ctx, importer));
+ if (parser_decl.IsInvalid())
+ return false;
+ destination_map.insert(
+ std::pair<const D *, O>(parser_decl.decl, item.second));
+ }
+
+ return true;
+}
+
+/// Given a CXXRecordDecl, will calculate and populate \ref base_offsets
+/// with the integral offsets of any of its (possibly virtual) base classes.
+///
+/// \param[in] record_layout ASTRecordLayout of \ref record.
+/// \param[in] record The record that we're calculating the base layouts of.
+/// \param[out] base_offsets Map of base-class decl to integral offset which
+/// this function will fill in.
+///
+/// \returns On success, will return 'true' and the offsets in \ref base_offsets
+/// are usable.
+template <bool IsVirtual>
+bool ExtractBaseOffsets(const ASTRecordLayout &record_layout,
+ DeclFromUser<const CXXRecordDecl> &record,
+ llvm::DenseMap<const clang::CXXRecordDecl *,
+ clang::CharUnits> &base_offsets) {
+ for (CXXRecordDecl::base_class_const_iterator
+ bi = (IsVirtual ? record->vbases_begin() : record->bases_begin()),
+ be = (IsVirtual ? record->vbases_end() : record->bases_end());
+ bi != be; ++bi) {
+ if (!IsVirtual && bi->isVirtual())
+ continue;
+
+ const clang::Type *origin_base_type = bi->getType().getTypePtr();
+ const clang::RecordType *origin_base_record_type =
+ origin_base_type->getAs<RecordType>();
+
+ if (!origin_base_record_type)
+ return false;
+
+ DeclFromUser<RecordDecl> origin_base_record(
+ origin_base_record_type->getDecl());
+
+ if (origin_base_record.IsInvalid())
+ return false;
+
+ DeclFromUser<CXXRecordDecl> origin_base_cxx_record(
+ DynCast<CXXRecordDecl>(origin_base_record));
+
+ if (origin_base_cxx_record.IsInvalid())
+ return false;
+
+ CharUnits base_offset;
+
+ if (IsVirtual)
+ base_offset =
+ record_layout.getVBaseClassOffset(origin_base_cxx_record.decl);
+ else
+ base_offset =
+ record_layout.getBaseClassOffset(origin_base_cxx_record.decl);
+
+ base_offsets.insert(std::pair<const CXXRecordDecl *, CharUnits>(
+ origin_base_cxx_record.decl, base_offset));
+ }
+
+ return true;
+}
+
+bool ClangASTImporter::importRecordLayoutFromOrigin(
+ const RecordDecl *record, uint64_t &size, uint64_t &alignment,
+ llvm::DenseMap<const clang::FieldDecl *, uint64_t> &field_offsets,
+ llvm::DenseMap<const clang::CXXRecordDecl *, clang::CharUnits>
+ &base_offsets,
+ llvm::DenseMap<const clang::CXXRecordDecl *, clang::CharUnits>
+ &vbase_offsets) {
+
+ Log *log = GetLog(LLDBLog::Expressions);
+
+ clang::ASTContext &dest_ctx = record->getASTContext();
+ LLDB_LOG(log,
+ "LayoutRecordType on (ASTContext*){0} '{1}' for (RecordDecl*)"
+ "{2} [name = '{3}']",
+ &dest_ctx,
+ TypeSystemClang::GetASTContext(&dest_ctx)->getDisplayName(), record,
+ record->getName());
+
+ DeclFromParser<const RecordDecl> parser_record(record);
+ DeclFromUser<const RecordDecl> origin_record(parser_record.GetOrigin(*this));
+
+ if (origin_record.IsInvalid())
+ return false;
+
+ std::remove_reference_t<decltype(field_offsets)> origin_field_offsets;
+ std::remove_reference_t<decltype(base_offsets)> origin_base_offsets;
+ std::remove_reference_t<decltype(vbase_offsets)> origin_virtual_base_offsets;
+
+ TypeSystemClang::GetCompleteDecl(
+ &origin_record->getASTContext(),
+ const_cast<RecordDecl *>(origin_record.decl));
+
+ clang::RecordDecl *definition = origin_record.decl->getDefinition();
+ if (!definition || !definition->isCompleteDefinition())
+ return false;
+
+ const ASTRecordLayout &record_layout(
+ origin_record->getASTContext().getASTRecordLayout(origin_record.decl));
+
+ int field_idx = 0, field_count = record_layout.getFieldCount();
+
+ for (RecordDecl::field_iterator fi = origin_record->field_begin(),
+ fe = origin_record->field_end();
+ fi != fe; ++fi) {
+ if (field_idx >= field_count)
+ return false; // Layout didn't go well. Bail out.
+
+ uint64_t field_offset = record_layout.getFieldOffset(field_idx);
+
+ origin_field_offsets.insert(
+ std::pair<const FieldDecl *, uint64_t>(*fi, field_offset));
+
+ field_idx++;
+ }
+
+ DeclFromUser<const CXXRecordDecl> origin_cxx_record(
+ DynCast<const CXXRecordDecl>(origin_record));
+
+ if (origin_cxx_record.IsValid()) {
+ if (!ExtractBaseOffsets<false>(record_layout, origin_cxx_record,
+ origin_base_offsets) ||
+ !ExtractBaseOffsets<true>(record_layout, origin_cxx_record,
+ origin_virtual_base_offsets))
+ return false;
+ }
+
+ if (!ImportOffsetMap(&dest_ctx, field_offsets, origin_field_offsets, *this) ||
+ !ImportOffsetMap(&dest_ctx, base_offsets, origin_base_offsets, *this) ||
+ !ImportOffsetMap(&dest_ctx, vbase_offsets, origin_virtual_base_offsets,
+ *this))
+ return false;
+
+ size = record_layout.getSize().getQuantity() * dest_ctx.getCharWidth();
+ alignment =
+ record_layout.getAlignment().getQuantity() * dest_ctx.getCharWidth();
+
+ if (log) {
+ LLDB_LOG(log, "LRT returned:");
+ LLDB_LOG(log, "LRT Original = (RecordDecl*){0}",
+ static_cast<const void *>(origin_record.decl));
+ LLDB_LOG(log, "LRT Size = {0}", size);
+ LLDB_LOG(log, "LRT Alignment = {0}", alignment);
+ LLDB_LOG(log, "LRT Fields:");
+ for (RecordDecl::field_iterator fi = record->field_begin(),
+ fe = record->field_end();
+ fi != fe; ++fi) {
+ LLDB_LOG(log,
+ "LRT (FieldDecl*){0}, Name = '{1}', Type = '{2}', Offset = "
+ "{3} bits",
+ *fi, fi->getName(), fi->getType().getAsString(),
+ field_offsets[*fi]);
+ }
+ DeclFromParser<const CXXRecordDecl> parser_cxx_record =
+ DynCast<const CXXRecordDecl>(parser_record);
+ if (parser_cxx_record.IsValid()) {
+ LLDB_LOG(log, "LRT Bases:");
+ for (CXXRecordDecl::base_class_const_iterator
+ bi = parser_cxx_record->bases_begin(),
+ be = parser_cxx_record->bases_end();
+ bi != be; ++bi) {
+ bool is_virtual = bi->isVirtual();
+
+ QualType base_type = bi->getType();
+ const RecordType *base_record_type = base_type->getAs<RecordType>();
+ DeclFromParser<RecordDecl> base_record(base_record_type->getDecl());
+ DeclFromParser<CXXRecordDecl> base_cxx_record =
+ DynCast<CXXRecordDecl>(base_record);
+
+ LLDB_LOG(log,
+ "LRT {0}(CXXRecordDecl*){1}, Name = '{2}', Offset = "
+ "{3} chars",
+ (is_virtual ? "Virtual " : ""), base_cxx_record.decl,
+ base_cxx_record.decl->getName(),
+ (is_virtual
+ ? vbase_offsets[base_cxx_record.decl].getQuantity()
+ : base_offsets[base_cxx_record.decl].getQuantity()));
+ }
+ } else {
+ LLDB_LOG(log, "LRD Not a CXXRecord, so no bases");
+ }
+ }
+
+ return true;
+}
+
bool ClangASTImporter::LayoutRecordType(
const clang::RecordDecl *record_decl, uint64_t &bit_size,
uint64_t &alignment,
diff --git a/lldb/source/Plugins/ExpressionParser/Clang/ClangASTImporter.h b/lldb/source/Plugins/ExpressionParser/Clang/ClangASTImporter.h
index e565a96b217ff4..bc962e544d2f1a 100644
--- a/lldb/source/Plugins/ExpressionParser/Clang/ClangASTImporter.h
+++ b/lldb/source/Plugins/ExpressionParser/Clang/ClangASTImporter.h
@@ -14,6 +14,7 @@
#include <set>
#include <vector>
+#include "clang/AST/ASTContext.h"
#include "clang/AST/ASTImporter.h"
#include "clang/AST/CharUnits.h"
#include "clang/AST/Decl.h"
@@ -127,6 +128,27 @@ class ClangASTImporter {
llvm::DenseMap<const clang::CXXRecordDecl *, clang::CharUnits>
&vbase_offsets);
+ /// If \ref record has a valid origin, this function copies that
+ /// origin's layout into this ClangASTImporter instance.
+ ///
+ /// \param[in] record The decl whose layout we're calculating.
+ /// \param[out] size Size of \ref record in bytes.
+ /// \param[out] alignment Alignment of \ref record in bytes.
+ /// \param[out] field_offsets Offsets of fields of \ref record.
+ /// \param[out] base_offsets Offsets of base classes of \ref record.
+ /// \param[out] vbase_offsets Offsets of virtual base classes of \ref record.
+ ///
+ /// \returns Returns 'false' if no valid origin was found for \ref record or
+ /// this function failed to import the layout from the origin. Otherwise,
+ /// returns 'true' and the offsets/size/alignment are valid for use.
+ bool importRecordLayoutFromOrigin(
+ const clang::RecordDecl *record, uint64_t &size, uint64_t &alignment,
+ llvm::DenseMap<const clang::FieldDecl *, uint64_t> &field_offsets,
+ llvm::DenseMap<const clang::CXXRecordDecl *, clang::CharUnits>
+ &base_offsets,
+ llvm::DenseMap<const clang::CXXRecordDecl *, clang::CharUnits>
+ &vbase_offsets);
+
/// Returns true iff the given type was copied from another TypeSystemClang
/// and the original type in this other TypeSystemClang might contain
/// additional information (e.g., the definition of a 'class' type) that could
@@ -456,6 +478,58 @@ class ClangASTImporter {
RecordDeclToLayoutMap m_record_decl_to_layout_map;
};
+template <class D> class TaggedASTDecl {
+public:
+ TaggedASTDecl() : decl(nullptr) {}
+ TaggedASTDecl(D *_decl) : decl(_decl) {}
+ bool IsValid() const { return (decl != nullptr); }
+ bool IsInvalid() const { return !IsValid(); }
+ D *operator->() const { return decl; }
+ D *decl;
+};
+
+template <class D2, template <class D> class TD, class D1>
+TD<D2> DynCast(TD<D1> source) {
+ return TD<D2>(llvm::dyn_cast<D2>(source.decl));
+}
+
+template <class D = clang::Decl> class DeclFromParser;
+template <class D = clang::Decl> class DeclFromUser;
+
+template <class D> class DeclFromParser : public TaggedASTDecl<D> {
+public:
+ DeclFromParser() : TaggedASTDecl<D>() {}
+ DeclFromParser(D *_decl) : TaggedASTDecl<D>(_decl) {}
+
+ DeclFromUser<D> GetOrigin(ClangASTImporter &importer);
+};
+
+template <class D> class DeclFromUser : public TaggedASTDecl<D> {
+public:
+ DeclFromUser() : TaggedASTDecl<D>() {}
+ DeclFromUser(D *_decl) : TaggedASTDecl<D>(_decl) {}
+
+ DeclFromParser<D> Import(clang::ASTContext *dest_ctx,
+ ClangASTImporter &importer);
+};
+
+template <class D>
+DeclFromUser<D> DeclFromParser<D>::GetOrigin(ClangASTImporter &importer) {
+ ClangASTImporter::DeclOrigin origin = importer.GetDeclOrigin(this->decl);
+ if (!origin.Valid())
+ return DeclFromUser<D>();
+ return DeclFromUser<D>(llvm::dyn_cast<D>(origin.decl));
+}
+
+template <class D>
+DeclFromParser<D> DeclFromUser<D>::Import(clang::ASTContext *dest_ctx,
+ ClangASTImporter &importer) {
+ DeclFromParser<> parser_generic_decl(importer.CopyDecl(dest_ctx, this->decl));
+ if (parser_generic_decl.IsInvalid())
+ return DeclFromParser<D>();
+ return DeclFromParser<D>(llvm::dyn_cast<D>(parser_generic_decl.decl));
+}
+
} // namespace lldb_private
#endif // LLDB_SOURCE_PLUGINS_EXPRESSIONPARSER_CLANG_CLANGASTIMPORTER_H
diff --git a/lldb/source/Plugins/ExpressionParser/Clang/ClangASTSource.cpp b/lldb/source/Plugins/ExpressionParser/Clang/ClangASTSource.cpp
index 79dd306f7627fd..a95a9e9f01e3fc 100644
--- a/lldb/source/Plugins/ExpressionParser/Clang/ClangASTSource.cpp
+++ b/lldb/source/Plugins/ExpressionParser/Clang/ClangASTSource.cpp
@@ -21,7 +21,6 @@
#include "lldb/Utility/LLDBLog.h"
#include "lldb/Utility/Log.h"
#include "clang/AST/ASTContext.h"
-#include "clang/AST/RecordLayout.h"
#include "clang/Basic/SourceManager.h"
#include "Plugins/ExpressionParser/Clang/ClangUtil.h"
@@ -705,56 +704,6 @@ void ClangASTSource::FillNamespaceMap(
}
}
-template <class D> class TaggedASTDecl {
-public:
- TaggedASTDecl() : decl(nullptr) {}
- TaggedASTDecl(D *_decl) : decl(_decl) {}
- bool IsValid() const { return (decl != nullptr); }
- bool IsInvalid() const { return !IsValid(); }
- D *operator->() const { return decl; }
- D *decl;
-};
-
-template <class D2, template <class D> class TD, class D1>
-TD<D2> DynCast(TD<D1> source) {
- return TD<D2>(dyn_cast<D2>(source.decl));
-}
-
-template <class D = Decl> class DeclFromParser;
-template <class D = Decl> class DeclFromUser;
-
-template <class D> class DeclFromParser : public TaggedASTDecl<D> {
-public:
- DeclFromParser() : TaggedASTDecl<D>() {}
- DeclFromParser(D *_decl) : TaggedASTDecl<D>(_decl) {}
-
- DeclFromUser<D> GetOrigin(ClangASTSource &source);
-};
-
-template <class D> class DeclFromUser : public TaggedASTDecl<D> {
-public:
- DeclFromUser() : TaggedASTDecl<D>() {}
- DeclFromUser(D *_decl) : TaggedASTDecl<D>(_decl) {}
-
- DeclFromParser<D> Import(ClangASTSource &source);
-};
-
-template <class D>
-DeclFromUser<D> DeclFromParser<D>::GetOrigin(ClangASTSource &source) {
- ClangASTImporter::DeclOrigin origin = source.GetDeclOrigin(this->decl);
- if (!origin.Valid())
- return DeclFromUser<D>();
- return DeclFromUser<D>(dyn_cast<D>(origin.decl));
-}
-
-template <class D>
-DeclFromParser<D> DeclFromUser<D>::Import(ClangASTSource &source) {
- DeclFromParser<> parser_generic_decl(source.CopyDecl(this->decl));
- if (parser_generic_decl.IsInvalid())
- return DeclFromParser<D>();
- return DeclFromParser<D>(dyn_cast<D>(parser_generic_decl.decl));
-}
-
bool ClangASTSource::FindObjCMethodDeclsWithOrigin(
NameSearchContext &context, ObjCInterfaceDecl *original_interface_decl,
const char *log_info) {
@@ -1188,8 +1137,8 @@ void ClangASTSource::FindObjCMethodDecls(NameSearchContext &context) {
} while (false);
}
-static bool FindObjCPropertyAndIvarDeclsWithOrigin(
- NameSearchContext &context, ClangASTSource &source,
+bool ClangASTSource::FindObjCPropertyAndIvarDeclsWithOrigin(
+ NameSearchContext &context,
DeclFromUser<const ObjCInterfaceDecl> &origin_iface_decl) {
Log *log = GetLog(LLDBLog::Expressions);
@@ -1209,7 +1158,7 @@ static bool FindObjCPropertyAndIvarDeclsWithOrigin(
if (origin_property_decl.IsValid()) {
DeclFromParser<ObjCPropertyDecl> parser_property_decl(
- origin_property_decl.Import(source));
+ origin_property_decl.Import(m_ast_context, *m_ast_importer_sp));
if (parser_property_decl.IsValid()) {
LLDB_LOG(log, " CAS::FOPD found\n{0}",
ClangUtil::DumpDecl(parser_property_decl.decl));
@@ -1224,7 +1173,7 @@ static bool FindObjCPropertyAndIvarDeclsWithOrigin(
if (origin_ivar_decl.IsValid()) {
DeclFromParser<ObjCIvarDecl> parser_ivar_decl(
- origin_ivar_decl.Import(source));
+ origin_ivar_decl.Import(m_ast_context, *m_ast_importer_sp));
if (parser_ivar_decl.IsValid()) {
LLDB_LOG(log, " CAS::FOPD found\n{0}",
ClangUtil::DumpDecl(parser_ivar_decl.decl));
@@ -1243,7 +1192,7 @@ void ClangASTSource::FindObjCPropertyAndIvarDecls(NameSearchContext &context) {
DeclFromParser<const ObjCInterfaceDecl> parser_iface_decl(
cast<ObjCInterfaceDecl>(context.m_decl_context));
DeclFromUser<const ObjCInterfaceDecl> origin_iface_decl(
- parser_iface_decl.GetOrigin(*this));
+ parser_iface_decl.GetOrigin(*m_ast_importer_sp));
ConstString class_name(parser_iface_decl->getNameAsString().c_str());
@@ -1253,7 +1202,7 @@ void ClangASTSource::FindObjCPropertyAndIvarDecls(NameSearchContext &context) {
m_ast_context, m_clang_ast_context->getDisplayName(),
parser_iface_decl->getName(), context.m_decl_name.getAsString());
- if (FindObjCPropertyAndIvarDeclsWithOrigin(context, *this, origin_iface_decl))
+ if (FindObjCPropertyAndIvarDeclsWithOrigin(context, origin_iface_decl))
return;
LLDB_LOG(log,
@@ -1286,7 +1235,7 @@ void ClangASTSource::FindObjCPropertyAndIvarDecls(NameSearchContext &context) {
"(ObjCInterfaceDecl*){0}/(ASTContext*){1}...",
complete_iface_decl.decl, &complete_iface_decl->getASTContext());
- FindObjCPropertyAndIvarDeclsWithOrigin(context, *this, complete_iface_decl);
+ FindObjCPropertyAndIvarDeclsWithOrigin(context, complete_iface_decl);
return;
} while (false);
@@ -1320,7 +1269,7 @@ void ClangASTSource::FindObjCPropertyAndIvarDecls(NameSearchContext &context) {
interface_decl_from_modules.decl,
&interface_decl_from_modules->getASTContext());
- if (FindObjCPropertyAndIvarDeclsWithOrigin(context, *this,
+ if (FindObjCPropertyAndIvarDeclsWithOrigin(context,
interface_decl_from_modules))
return;
} while (false);
@@ -1364,7 +1313,7 @@ void ClangASTSource::FindObjCPropertyAndIvarDecls(NameSearchContext &context) {
interface_decl_from_runtime.decl,
&interface_decl_from_runtime->getASTContext());
- if (FindObjCPropertyAndIvarDeclsWithOrigin(context, *this,
+ if (FindObjCPropertyAndIvarDeclsWithOrigin(context,
interface_decl_from_runtime))
return;
} while (false);
@@ -1395,205 +1344,16 @@ void ClangASTSource::LookupInNamespace(NameSearchContext &context) {
}
}
-typedef llvm::DenseMap<const FieldDecl *, uint64_t> FieldOffsetMap;
-typedef llvm::DenseMap<const CXXRecordDecl *, CharUnits> BaseOffsetMap;
-
-template <class D, class O>
-static bool ImportOffsetMap(llvm::DenseMap<const D *, O> &destination_map,
- llvm::DenseMap<const D *, O> &source_map,
- ClangASTSource &source) {
- // When importing fields into a new record, clang has a hard requirement that
- // fields be imported in field offset order. Since they are stored in a
- // DenseMap with a pointer as the key type, this means we cannot simply
- // iterate over the map, as the order will be non-deterministic. Instead we
- // have to sort by the offset and then insert in sorted order.
- typedef llvm::DenseMap<const D *, O> MapType;
- typedef typename MapType::value_type PairType;
- std::vector<PairType> sorted_items;
- sorted_items.reserve(source_map.size());
- sorted_items.assign(source_map.begin(), source_map.end());
- llvm::sort(sorted_items, llvm::less_second());
-
- for (const auto &item : sorted_items) {
- DeclFromUser<D> user_decl(const_cast<D *>(item.first));
- DeclFromParser<D> parser_decl(user_decl.Import(source));
- if (parser_decl.IsInvalid())
- return false;
- destination_map.insert(
- std::pair<const D *, O>(parser_decl.decl, item.second));
- }
-
- return true;
-}
-
-template <bool IsVirtual>
-bool ExtractBaseOffsets(const ASTRecordLayout &record_layout,
- DeclFromUser<const CXXRecordDecl> &record,
- BaseOffsetMap &base_offsets) {
- for (CXXRecordDecl::base_class_const_iterator
- bi = (IsVirtual ? record->vbases_begin() : record->bases_begin()),
- be = (IsVirtual ? record->vbases_end() : record->bases_end());
- bi != be; ++bi) {
- if (!IsVirtual && bi->isVirtual())
- continue;
-
- const clang::Type *origin_base_type = bi->getType().getTypePtr();
- const clang::RecordType *origin_base_record_type =
- origin_base_type->getAs<RecordType>();
-
- if (!origin_base_record_type)
- return false;
-
- DeclFromUser<RecordDecl> origin_base_record(
- origin_base_record_type->getDecl());
-
- if (origin_base_record.IsInvalid())
- return false;
-
- DeclFromUser<CXXRecordDecl> origin_base_cxx_record(
- DynCast<CXXRecordDecl>(origin_base_record));
-
- if (origin_base_cxx_record.IsInvalid())
- return false;
-
- CharUnits base_offset;
-
- if (IsVirtual)
- base_offset =
- record_layout.getVBaseClassOffset(origin_base_cxx_record.decl);
- else
- base_offset =
- record_layout.getBaseClassOffset(origin_base_cxx_record.decl);
-
- base_offsets.insert(std::pair<const CXXRecordDecl *, CharUnits>(
- origin_base_cxx_record.decl, base_offset));
- }
-
- return true;
-}
-
-bool ClangASTSource::layoutRecordType(const RecordDecl *record, uint64_t &size,
- uint64_t &alignment,
- FieldOffsetMap &field_offsets,
- BaseOffsetMap &base_offsets,
- BaseOffsetMap &virtual_base_offsets) {
-
- Log *log = GetLog(LLDBLog::Expressions);
-
- LLDB_LOG(log,
- "LayoutRecordType on (ASTContext*){0} '{1}' for (RecordDecl*)"
- "{2} [name = '{3}']",
- m_ast_context, m_clang_ast_context->getDisplayName(), record,
- record->getName());
-
- DeclFromParser<const RecordDecl> parser_record(record);
- DeclFromUser<const RecordDecl> origin_record(
- parser_record.GetOrigin(*this));
-
- if (origin_record.IsInvalid())
- return false;
-
- FieldOffsetMap origin_field_offsets;
- BaseOffsetMap origin_base_offsets;
- BaseOffsetMap origin_virtual_base_offsets;
-
- TypeSystemClang::GetCompleteDecl(
- &origin_record->getASTContext(),
- const_cast<RecordDecl *>(origin_record.decl));
-
- clang::RecordDecl *definition = origin_record.decl->getDefinition();
- if (!definition || !definition->isCompleteDefinition())
- return false;
-
- const ASTRecordLayout &record_layout(
- origin_record->getASTContext().getASTRecordLayout(origin_record.decl));
-
- int field_idx = 0, field_count = record_layout.getFieldCount();
-
- for (RecordDecl::field_iterator fi = origin_record->field_begin(),
- fe = origin_record->field_end();
- fi != fe; ++fi) {
- if (field_idx >= field_count)
- return false; // Layout didn't go well. Bail out.
-
- uint64_t field_offset = record_layout.getFieldOffset(field_idx);
-
- origin_field_offsets.insert(
- std::pair<const FieldDecl *, uint64_t>(*fi, field_offset));
-
- field_idx++;
- }
-
- lldbassert(&record->getASTContext() == m_ast_context);
-
- DeclFromUser<const CXXRecordDecl> origin_cxx_record(
- DynCast<const CXXRecordDecl>(origin_record));
-
- if (origin_cxx_record.IsValid()) {
- if (!ExtractBaseOffsets<false>(record_layout, origin_cxx_record,
- origin_base_offsets) ||
- !ExtractBaseOffsets<true>(record_layout, origin_cxx_record,
- origin_virtual_base_offsets))
- return false;
- }
-
- if (!ImportOffsetMap(field_offsets, origin_field_offsets, *this) ||
- !ImportOffsetMap(base_offsets, origin_base_offsets, *this) ||
- !ImportOffsetMap(virtual_base_offsets, origin_virtual_base_offsets,
- *this))
- return false;
-
- size = record_layout.getSize().getQuantity() * m_ast_context->getCharWidth();
- alignment = record_layout.getAlignment().getQuantity() *
- m_ast_context->getCharWidth();
-
- if (log) {
- LLDB_LOG(log, "LRT returned:");
- LLDB_LOG(log, "LRT Original = (RecordDecl*){0}",
- static_cast<const void *>(origin_record.decl));
- LLDB_LOG(log, "LRT Size = {0}", size);
- LLDB_LOG(log, "LRT Alignment = {0}", alignment);
- LLDB_LOG(log, "LRT Fields:");
- for (RecordDecl::field_iterator fi = record->field_begin(),
- fe = record->field_end();
- fi != fe; ++fi) {
- LLDB_LOG(log,
- "LRT (FieldDecl*){0}, Name = '{1}', Type = '{2}', Offset = "
- "{3} bits",
- *fi, fi->getName(), fi->getType().getAsString(),
- field_offsets[*fi]);
- }
- DeclFromParser<const CXXRecordDecl> parser_cxx_record =
- DynCast<const CXXRecordDecl>(parser_record);
- if (parser_cxx_record.IsValid()) {
- LLDB_LOG(log, "LRT Bases:");
- for (CXXRecordDecl::base_class_const_iterator
- bi = parser_cxx_record->bases_begin(),
- be = parser_cxx_record->bases_end();
- bi != be; ++bi) {
- bool is_virtual = bi->isVirtual();
-
- QualType base_type = bi->getType();
- const RecordType *base_record_type = base_type->getAs<RecordType>();
- DeclFromParser<RecordDecl> base_record(base_record_type->getDecl());
- DeclFromParser<CXXRecordDecl> base_cxx_record =
- DynCast<CXXRecordDecl>(base_record);
-
- LLDB_LOG(log,
- "LRT {0}(CXXRecordDecl*){1}, Name = '{2}', Offset = "
- "{3} chars",
- (is_virtual ? "Virtual " : ""), base_cxx_record.decl,
- base_cxx_record.decl->getName(),
- (is_virtual
- ? virtual_base_offsets[base_cxx_record.decl].getQuantity()
- : base_offsets[base_cxx_record.decl].getQuantity()));
- }
- } else {
- LLDB_LOG(log, "LRD Not a CXXRecord, so no bases");
- }
- }
-
- return true;
+bool ClangASTSource::layoutRecordType(
+ const RecordDecl *record, uint64_t &size, uint64_t &alignment,
+ llvm::DenseMap<const clang::FieldDecl *, uint64_t> &field_offsets,
+ llvm::DenseMap<const clang::CXXRecordDecl *, clang::CharUnits>
+ &base_offsets,
+ llvm::DenseMap<const clang::CXXRecordDecl *, clang::CharUnits>
+ &virtual_base_offsets) {
+ return m_ast_importer_sp->importRecordLayoutFromOrigin(
+ record, size, alignment, field_offsets, base_offsets,
+ virtual_base_offsets);
}
void ClangASTSource::CompleteNamespaceMap(
diff --git a/lldb/source/Plugins/ExpressionParser/Clang/ClangASTSource.h b/lldb/source/Plugins/ExpressionParser/Clang/ClangASTSource.h
index f3fec3f944a146..f34e4661a81ca3 100644
--- a/lldb/source/Plugins/ExpressionParser/Clang/ClangASTSource.h
+++ b/lldb/source/Plugins/ExpressionParser/Clang/ClangASTSource.h
@@ -352,6 +352,11 @@ class ClangASTSource : public clang::ExternalASTSource,
/// ExternalASTSource.
TypeSystemClang *GetTypeSystem() const { return m_clang_ast_context; }
+private:
+ bool FindObjCPropertyAndIvarDeclsWithOrigin(
+ NameSearchContext &context,
+ DeclFromUser<const clang::ObjCInterfaceDecl> &origin_iface_decl);
+
protected:
bool FindObjCMethodDeclsWithOrigin(
NameSearchContext &context,
>From 4d12f708967f932b584be5fc4efd17ad3272f87c Mon Sep 17 00:00:00 2001
From: Reid Kleckner <rnk at google.com>
Date: Thu, 29 Feb 2024 13:34:11 -0800
Subject: [PATCH 179/406] Add guidance on bans to the CoC section and link to
the developer policy (#82551)
This seemed like relevant information to include in the code of conduct.
---
llvm/docs/CodeOfConduct.rst | 11 +++++++++++
1 file changed, 11 insertions(+)
diff --git a/llvm/docs/CodeOfConduct.rst b/llvm/docs/CodeOfConduct.rst
index 0e986b25df3c86..08fe7b3bcf65f2 100644
--- a/llvm/docs/CodeOfConduct.rst
+++ b/llvm/docs/CodeOfConduct.rst
@@ -135,6 +135,17 @@ events as part of each events' information. In person reports will still be
kept confidential exactly as above, but also feel free to (anonymously if
needed) email conduct at llvm.org.
+Bans
+====
+
+The code of conduct committee may decide to ban an individual from the
+community for violating the code of conduct. The goal of a ban is to protect
+community members from having to interact with people who are consistently not
+respecting the code of conduct. Please refer to the
+:doc:`Developer Policy<DeveloperPolicy>` section on Bans for how to handle
+interactions with former community members. If you need further guidance,
+please contact conduct at llvm.org.
+
Code of Conduct Committee
=========================
>From 07ffb7e294767b74e43f90e9ab3d713da929b907 Mon Sep 17 00:00:00 2001
From: Michael Buch <michaelbuch12 at gmail.com>
Date: Thu, 29 Feb 2024 21:40:02 +0000
Subject: [PATCH 180/406] [lldb][ClangASTImporter] Import record layouts from
origin if available (#83295)
Layout information for a record gets stored in the `ClangASTImporter`
associated with the `DWARFASTParserClang` that originally parsed the
record. LLDB sometimes moves clang types from one AST to another (in the
reproducer the origin AST was a precompiled-header and the destination
was the AST backing the executable). When clang then asks LLDB to
`layoutRecordType`, it will do so with the help of the
`ClangASTImporter` the type is associated with. If the type's origin is
actually in a different LLDB module (and thus a different
`DWARFASTParserClang` was used to set its layout info), we won't find
the layout info in our local `ClangASTImporter`.
In the reproducer this meant we would drop the alignment info of the
origin type and misread a variable's contents with `frame var` and
`expr`.
There is logic in `ClangASTSource::layoutRecordType` to import an
origin's layout info. This patch re-uses that infrastructure to import
an origin's layout from one `ClangASTImporter` instance to another.
rdar://123274144
---
.../Clang/ClangASTImporter.cpp | 23 ++++---
.../API/lang/cpp/gmodules/alignment/Makefile | 4 ++
.../gmodules/alignment/TestPchAlignment.py | 60 +++++++++++++++++++
.../API/lang/cpp/gmodules/alignment/main.cpp | 10 ++++
.../API/lang/cpp/gmodules/alignment/pch.h | 21 +++++++
5 files changed, 111 insertions(+), 7 deletions(-)
create mode 100644 lldb/test/API/lang/cpp/gmodules/alignment/Makefile
create mode 100644 lldb/test/API/lang/cpp/gmodules/alignment/TestPchAlignment.py
create mode 100644 lldb/test/API/lang/cpp/gmodules/alignment/main.cpp
create mode 100644 lldb/test/API/lang/cpp/gmodules/alignment/pch.h
diff --git a/lldb/source/Plugins/ExpressionParser/Clang/ClangASTImporter.cpp b/lldb/source/Plugins/ExpressionParser/Clang/ClangASTImporter.cpp
index 99d210c347a21d..30b50df79da90f 100644
--- a/lldb/source/Plugins/ExpressionParser/Clang/ClangASTImporter.cpp
+++ b/lldb/source/Plugins/ExpressionParser/Clang/ClangASTImporter.cpp
@@ -760,7 +760,6 @@ bool ClangASTImporter::LayoutRecordType(
&vbase_offsets) {
RecordDeclToLayoutMap::iterator pos =
m_record_decl_to_layout_map.find(record_decl);
- bool success = false;
base_offsets.clear();
vbase_offsets.clear();
if (pos != m_record_decl_to_layout_map.end()) {
@@ -770,13 +769,23 @@ bool ClangASTImporter::LayoutRecordType(
base_offsets.swap(pos->second.base_offsets);
vbase_offsets.swap(pos->second.vbase_offsets);
m_record_decl_to_layout_map.erase(pos);
- success = true;
- } else {
- bit_size = 0;
- alignment = 0;
- field_offsets.clear();
+ return true;
}
- return success;
+
+ // It's possible that we calculated the layout in a different
+ // ClangASTImporter instance. Try to import such layout if
+ // our decl has an origin.
+ if (auto origin = GetDeclOrigin(record_decl); origin.Valid())
+ if (importRecordLayoutFromOrigin(record_decl, bit_size, alignment,
+ field_offsets, base_offsets,
+ vbase_offsets))
+ return true;
+
+ bit_size = 0;
+ alignment = 0;
+ field_offsets.clear();
+
+ return false;
}
void ClangASTImporter::SetRecordLayout(clang::RecordDecl *decl,
diff --git a/lldb/test/API/lang/cpp/gmodules/alignment/Makefile b/lldb/test/API/lang/cpp/gmodules/alignment/Makefile
new file mode 100644
index 00000000000000..a6c3e8ca84a3e4
--- /dev/null
+++ b/lldb/test/API/lang/cpp/gmodules/alignment/Makefile
@@ -0,0 +1,4 @@
+PCH_CXX_SOURCE = pch.h
+CXX_SOURCES = main.cpp
+
+include Makefile.rules
diff --git a/lldb/test/API/lang/cpp/gmodules/alignment/TestPchAlignment.py b/lldb/test/API/lang/cpp/gmodules/alignment/TestPchAlignment.py
new file mode 100644
index 00000000000000..535dd13d0ada48
--- /dev/null
+++ b/lldb/test/API/lang/cpp/gmodules/alignment/TestPchAlignment.py
@@ -0,0 +1,60 @@
+"""
+Tests that we correctly track AST layout info
+(specifically alignment) when moving AST nodes
+between ClangASTImporter instances (in this case,
+from pch to executable to expression AST).
+"""
+
+import lldb
+import os
+from lldbsuite.test.decorators import *
+from lldbsuite.test.lldbtest import *
+from lldbsuite.test import lldbutil
+
+
+class TestPchAlignment(TestBase):
+ @add_test_categories(["gmodules"])
+ def test_expr(self):
+ self.build()
+ lldbutil.run_to_source_breakpoint(
+ self, "return data", lldb.SBFileSpec("main.cpp")
+ )
+
+ self.expect(
+ "frame variable data",
+ substrs=["row = 1", "col = 2", "row = 3", "col = 4", "stride = 5"],
+ )
+
+ @add_test_categories(["gmodules"])
+ def test_frame_var(self):
+ self.build()
+ lldbutil.run_to_source_breakpoint(
+ self, "return data", lldb.SBFileSpec("main.cpp")
+ )
+
+ self.expect_expr(
+ "data",
+ result_type="MatrixData",
+ result_children=[
+ ValueCheck(
+ name="section",
+ children=[
+ ValueCheck(
+ name="origin",
+ children=[
+ ValueCheck(name="row", value="1"),
+ ValueCheck(name="col", value="2"),
+ ],
+ ),
+ ValueCheck(
+ name="size",
+ children=[
+ ValueCheck(name="row", value="3"),
+ ValueCheck(name="col", value="4"),
+ ],
+ ),
+ ],
+ ),
+ ValueCheck(name="stride", value="5"),
+ ],
+ )
diff --git a/lldb/test/API/lang/cpp/gmodules/alignment/main.cpp b/lldb/test/API/lang/cpp/gmodules/alignment/main.cpp
new file mode 100644
index 00000000000000..5481f3fad1ff76
--- /dev/null
+++ b/lldb/test/API/lang/cpp/gmodules/alignment/main.cpp
@@ -0,0 +1,10 @@
+int main(int argc, const char *argv[]) {
+ struct MatrixData data = {0};
+ data.section.origin.row = 1;
+ data.section.origin.col = 2;
+ data.section.size.row = 3;
+ data.section.size.col = 4;
+ data.stride = 5;
+
+ return data.section.size.row;
+}
diff --git a/lldb/test/API/lang/cpp/gmodules/alignment/pch.h b/lldb/test/API/lang/cpp/gmodules/alignment/pch.h
new file mode 100644
index 00000000000000..f0be272aa601aa
--- /dev/null
+++ b/lldb/test/API/lang/cpp/gmodules/alignment/pch.h
@@ -0,0 +1,21 @@
+#ifndef PCH_H_IN
+#define PCH_H_IN
+
+static const int kAlignment = 64;
+
+struct [[gnu::aligned(kAlignment)]] RowCol {
+ unsigned row;
+ unsigned col;
+};
+
+struct [[gnu::aligned(kAlignment)]] Submatrix {
+ struct RowCol origin;
+ struct RowCol size;
+};
+
+struct [[gnu::aligned(kAlignment)]] MatrixData {
+ struct Submatrix section;
+ unsigned stride;
+};
+
+#endif // _H_IN
>From 91895f59f43217b120506bf98327a13adfc4c598 Mon Sep 17 00:00:00 2001
From: Mircea Trofin <mtrofin at google.com>
Date: Thu, 29 Feb 2024 13:41:00 -0800
Subject: [PATCH 181/406] [pr-subscribers] added `third-party:benchmark` to
`new-prs-labeler` (#83486)
---
.github/new-prs-labeler.yml | 3 +++
1 file changed, 3 insertions(+)
diff --git a/.github/new-prs-labeler.yml b/.github/new-prs-labeler.yml
index 8ed976fbdddc64..9a580c6d6984e1 100644
--- a/.github/new-prs-labeler.yml
+++ b/.github/new-prs-labeler.yml
@@ -869,6 +869,9 @@ backend:SystemZ:
third-party:unittests:
- third-party/unittests/**
+third-party:benchmark:
+ - third-party/benchmark/**
+
llvm:binary-utilities:
- llvm/docs/CommandGuide/llvm-*
- llvm/include/llvm/BinaryFormat/**
>From 2fef685363e13e0640b624cc3d07b1006f12113c Mon Sep 17 00:00:00 2001
From: Paul Kirth <paulkirth at google.com>
Date: Thu, 29 Feb 2024 13:46:13 -0800
Subject: [PATCH 182/406] [llvm][loop-rotate] Allow forcing loop-rotation
(#82828)
Many profitable optimizations cannot be performed at -Oz, due to
unrotated loops. While this is worse for size (minimally), many of the
optimizations significantly reduce code size, such as memcpy
optimizations and other patterns found by loop idiom recognition.
Related discussion can be found in issue #50308.
This patch adds an experimental, backend-only flag to allow loop header
duplication, regardless of the optimization level. Downstream consumers
can experiment with this flag, and if it is profitable, we can adjust
the compiler's defaults accordingly, and expose any useful frontend
flags to opt into the new behavior.
---
llvm/lib/Passes/PassBuilderPipelines.cpp | 21 +++++--
llvm/test/Transforms/LoopRotate/oz-disable.ll | 3 +
.../enable-loop-header-duplication-oz.ll | 57 +++++++++++++++++++
3 files changed, 77 insertions(+), 4 deletions(-)
create mode 100644 llvm/test/Transforms/PhaseOrdering/enable-loop-header-duplication-oz.ll
diff --git a/llvm/lib/Passes/PassBuilderPipelines.cpp b/llvm/lib/Passes/PassBuilderPipelines.cpp
index 991c3ac8f7446c..cbbbec0ccc8c4d 100644
--- a/llvm/lib/Passes/PassBuilderPipelines.cpp
+++ b/llvm/lib/Passes/PassBuilderPipelines.cpp
@@ -209,6 +209,15 @@ static cl::opt<bool> EnableLoopFlatten("enable-loop-flatten", cl::init(false),
cl::Hidden,
cl::desc("Enable the LoopFlatten Pass"));
+// Experimentally allow loop header duplication. This should allow for better
+// optimization at Oz, since loop-idiom recognition can then recognize things
+// like memcpy. If this ends up being useful for many targets, we should drop
+// this flag and make a code generation option that can be controlled
+// independent of the opt level and exposed through the frontend.
+static cl::opt<bool> EnableLoopHeaderDuplication(
+ "enable-loop-header-duplication", cl::init(false), cl::Hidden,
+ cl::desc("Enable loop header duplication at any optimization level"));
+
static cl::opt<bool>
EnableDFAJumpThreading("enable-dfa-jump-thread",
cl::desc("Enable DFA jump threading"),
@@ -630,8 +639,9 @@ PassBuilder::buildFunctionSimplificationPipeline(OptimizationLevel Level,
/*AllowSpeculation=*/false));
// Disable header duplication in loop rotation at -Oz.
- LPM1.addPass(
- LoopRotatePass(Level != OptimizationLevel::Oz, isLTOPreLink(Phase)));
+ LPM1.addPass(LoopRotatePass(EnableLoopHeaderDuplication ||
+ Level != OptimizationLevel::Oz,
+ isLTOPreLink(Phase)));
// TODO: Investigate promotion cap for O1.
LPM1.addPass(LICMPass(PTO.LicmMssaOptCap, PTO.LicmMssaNoAccForPromotionCap,
/*AllowSpeculation=*/true));
@@ -812,7 +822,8 @@ void PassBuilder::addPGOInstrPasses(ModulePassManager &MPM,
// Disable header duplication in loop rotation at -Oz.
MPM.addPass(createModuleToFunctionPassAdaptor(
createFunctionToLoopPassAdaptor(
- LoopRotatePass(Level != OptimizationLevel::Oz),
+ LoopRotatePass(EnableLoopHeaderDuplication ||
+ Level != OptimizationLevel::Oz),
/*UseMemorySSA=*/false,
/*UseBlockFrequencyInfo=*/false),
PTO.EagerlyInvalidateAnalyses));
@@ -1422,7 +1433,9 @@ PassBuilder::buildModuleOptimizationPipeline(OptimizationLevel Level,
LoopPassManager LPM;
// First rotate loops that may have been un-rotated by prior passes.
// Disable header duplication at -Oz.
- LPM.addPass(LoopRotatePass(Level != OptimizationLevel::Oz, LTOPreLink));
+ LPM.addPass(LoopRotatePass(EnableLoopHeaderDuplication ||
+ Level != OptimizationLevel::Oz,
+ LTOPreLink));
// Some loops may have become dead by now. Try to delete them.
// FIXME: see discussion in https://reviews.llvm.org/D112851,
// this may need to be revisited once we run GVN before loop deletion
diff --git a/llvm/test/Transforms/LoopRotate/oz-disable.ll b/llvm/test/Transforms/LoopRotate/oz-disable.ll
index 6a7847ac0ff215..c45603878ee65c 100644
--- a/llvm/test/Transforms/LoopRotate/oz-disable.ll
+++ b/llvm/test/Transforms/LoopRotate/oz-disable.ll
@@ -4,6 +4,9 @@
; RUN: opt < %s -S -passes='default<Os>' -debug -debug-only=loop-rotate 2>&1 | FileCheck %s -check-prefix=OS
; RUN: opt < %s -S -passes='default<Oz>' -debug -debug-only=loop-rotate 2>&1 | FileCheck %s -check-prefix=OZ
+;; Make sure -allow-loop-header-duplication overrides the default behavior at Oz
+; RUN: opt < %s -S -passes='default<Oz>' -enable-loop-header-duplication -debug -debug-only=loop-rotate 2>&1 | FileCheck %s -check-prefix=OS
+
; Loop should be rotated for -Os but not for -Oz.
; OS: rotating Loop at depth 1
; OZ-NOT: rotating Loop at depth 1
diff --git a/llvm/test/Transforms/PhaseOrdering/enable-loop-header-duplication-oz.ll b/llvm/test/Transforms/PhaseOrdering/enable-loop-header-duplication-oz.ll
new file mode 100644
index 00000000000000..98b11578b49fbf
--- /dev/null
+++ b/llvm/test/Transforms/PhaseOrdering/enable-loop-header-duplication-oz.ll
@@ -0,0 +1,57 @@
+; NOTE: Assertions have been autogenerated by utils/update_test_checks.py UTC_ARGS: --version 3
+
+;; Check that -enable-loop-header-duplication at Oz enables certain types of
+;; optimizations, for example replacing the loop body w/ a call to memset. If
+;; loop idiom recognition begins to recognize unrotated loops, this test will
+;; need to be updated.
+
+; RUN: opt -passes='default<Oz>' -S < %s | FileCheck %s --check-prefix=NOROTATION
+; RUN: opt -passes='default<Oz>' -S -enable-loop-header-duplication < %s | FileCheck %s --check-prefix=ROTATION
+; RUN: opt -passes='default<O2>' -S < %s | FileCheck %s --check-prefix=ROTATION
+
+define void @test(i8* noalias nonnull align 1 %start, i8* %end) unnamed_addr {
+; NOROTATION-LABEL: define void @test(
+; NOROTATION-SAME: ptr noalias nonnull writeonly align 1 [[START:%.*]], ptr readnone [[END:%.*]]) unnamed_addr #[[ATTR0:[0-9]+]] {
+; NOROTATION-NEXT: entry:
+; NOROTATION-NEXT: br label [[LOOP_HEADER:%.*]]
+; NOROTATION: loop.header:
+; NOROTATION-NEXT: [[PTR_IV:%.*]] = phi ptr [ [[START]], [[ENTRY:%.*]] ], [ [[PTR_IV_NEXT:%.*]], [[LOOP_LATCH:%.*]] ]
+; NOROTATION-NEXT: [[_12_I:%.*]] = icmp eq ptr [[PTR_IV]], [[END]]
+; NOROTATION-NEXT: br i1 [[_12_I]], label [[EXIT:%.*]], label [[LOOP_LATCH]]
+; NOROTATION: loop.latch:
+; NOROTATION-NEXT: [[PTR_IV_NEXT]] = getelementptr inbounds i8, ptr [[PTR_IV]], i64 1
+; NOROTATION-NEXT: store i8 1, ptr [[PTR_IV]], align 1
+; NOROTATION-NEXT: br label [[LOOP_HEADER]]
+; NOROTATION: exit:
+; NOROTATION-NEXT: ret void
+;
+; ROTATION-LABEL: define void @test(
+; ROTATION-SAME: ptr noalias nonnull writeonly align 1 [[START:%.*]], ptr readnone [[END:%.*]]) unnamed_addr #[[ATTR0:[0-9]+]] {
+; ROTATION-NEXT: entry:
+; ROTATION-NEXT: [[_12_I1:%.*]] = icmp eq ptr [[START]], [[END]]
+; ROTATION-NEXT: br i1 [[_12_I1]], label [[EXIT:%.*]], label [[LOOP_LATCH_PREHEADER:%.*]]
+; ROTATION: loop.latch.preheader:
+; ROTATION-NEXT: [[END3:%.*]] = ptrtoint ptr [[END]] to i64
+; ROTATION-NEXT: [[START4:%.*]] = ptrtoint ptr [[START]] to i64
+; ROTATION-NEXT: [[TMP0:%.*]] = sub i64 [[END3]], [[START4]]
+; ROTATION-NEXT: tail call void @llvm.memset.p0.i64(ptr nonnull align 1 [[START]], i8 1, i64 [[TMP0]], i1 false)
+; ROTATION-NEXT: br label [[EXIT]]
+; ROTATION: exit:
+; ROTATION-NEXT: ret void
+;
+entry:
+ br label %loop.header
+
+loop.header:
+ %ptr.iv = phi i8* [ %start, %entry ], [ %ptr.iv.next, %loop.latch ]
+ %_12.i = icmp eq i8* %ptr.iv, %end
+ br i1 %_12.i, label %exit, label %loop.latch
+
+loop.latch:
+ %ptr.iv.next = getelementptr inbounds i8, i8* %ptr.iv, i64 1
+ store i8 1, i8* %ptr.iv, align 1
+ br label %loop.header
+
+exit:
+ ret void
+}
>From 5b07fd479902b485cdc6f9fb61738fb05ed65095 Mon Sep 17 00:00:00 2001
From: Leon Clark <PeddleSpam at users.noreply.github.com>
Date: Thu, 29 Feb 2024 22:28:13 +0000
Subject: [PATCH 183/406] [AMDGPU] Fix OpenCL conformance test failures for
ctlz. (#83170)
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
Remove LSH transform and restore previous lowering.
Fixes conformance issue in
[77615](https://github.com/llvm/llvm-project/pull/77615) where OpenCL
integer_ops tests fail for integer_clz.
Co-authored-by: Leon Clark <leoclark at amd.com>
---
llvm/lib/Target/AMDGPU/AMDGPUISelLowering.cpp | 4 +-
llvm/test/CodeGen/AMDGPU/ctlz.ll | 27 ++++---
llvm/test/CodeGen/AMDGPU/ctlz_zero_undef.ll | 77 ++++++++++---------
3 files changed, 54 insertions(+), 54 deletions(-)
diff --git a/llvm/lib/Target/AMDGPU/AMDGPUISelLowering.cpp b/llvm/lib/Target/AMDGPU/AMDGPUISelLowering.cpp
index e8cc87e52e65a3..8a71550e5532cd 100644
--- a/llvm/lib/Target/AMDGPU/AMDGPUISelLowering.cpp
+++ b/llvm/lib/Target/AMDGPU/AMDGPUISelLowering.cpp
@@ -3089,10 +3089,10 @@ SDValue AMDGPUTargetLowering::lowerCTLZResults(SDValue Op,
assert(ResultVT == Arg.getValueType());
auto const LeadingZeroes = 32u - ResultVT.getFixedSizeInBits();
+ auto SubVal = DAG.getConstant(LeadingZeroes, SL, MVT::i32);
auto NewOp = DAG.getNode(ISD::ZERO_EXTEND, SL, MVT::i32, Arg);
- auto ShiftVal = DAG.getConstant(LeadingZeroes, SL, MVT::i32);
- NewOp = DAG.getNode(ISD::SHL, SL, MVT::i32, NewOp, ShiftVal);
NewOp = DAG.getNode(Op.getOpcode(), SL, MVT::i32, NewOp);
+ NewOp = DAG.getNode(ISD::SUB, SL, MVT::i32, NewOp, SubVal);
return DAG.getNode(ISD::TRUNCATE, SL, ResultVT, NewOp);
}
diff --git a/llvm/test/CodeGen/AMDGPU/ctlz.ll b/llvm/test/CodeGen/AMDGPU/ctlz.ll
index 9307d8952293b1..4decf39d040134 100644
--- a/llvm/test/CodeGen/AMDGPU/ctlz.ll
+++ b/llvm/test/CodeGen/AMDGPU/ctlz.ll
@@ -492,9 +492,9 @@ define amdgpu_kernel void @v_ctlz_i8(ptr addrspace(1) noalias %out, ptr addrspac
; SI-NEXT: s_mov_b32 s4, s0
; SI-NEXT: s_mov_b32 s5, s1
; SI-NEXT: s_waitcnt vmcnt(0)
-; SI-NEXT: v_lshlrev_b32_e32 v0, 24, v0
; SI-NEXT: v_ffbh_u32_e32 v0, v0
; SI-NEXT: v_min_u32_e32 v0, 32, v0
+; SI-NEXT: v_subrev_i32_e32 v0, vcc, 24, v0
; SI-NEXT: buffer_store_byte v0, off, s[4:7], 0
; SI-NEXT: s_endpgm
;
@@ -512,9 +512,9 @@ define amdgpu_kernel void @v_ctlz_i8(ptr addrspace(1) noalias %out, ptr addrspac
; VI-NEXT: s_mov_b32 s4, s0
; VI-NEXT: s_mov_b32 s5, s1
; VI-NEXT: s_waitcnt vmcnt(0)
-; VI-NEXT: v_lshlrev_b32_e32 v0, 24, v0
; VI-NEXT: v_ffbh_u32_e32 v0, v0
; VI-NEXT: v_min_u32_e32 v0, 32, v0
+; VI-NEXT: v_subrev_u32_e32 v0, vcc, 24, v0
; VI-NEXT: buffer_store_byte v0, off, s[4:7], 0
; VI-NEXT: s_endpgm
;
@@ -522,7 +522,7 @@ define amdgpu_kernel void @v_ctlz_i8(ptr addrspace(1) noalias %out, ptr addrspac
; EG: ; %bb.0:
; EG-NEXT: ALU 0, @8, KC0[CB0:0-32], KC1[]
; EG-NEXT: TEX 0 @6
-; EG-NEXT: ALU 16, @9, KC0[CB0:0-32], KC1[]
+; EG-NEXT: ALU 15, @9, KC0[CB0:0-32], KC1[]
; EG-NEXT: MEM_RAT MSKOR T0.XW, T1.X
; EG-NEXT: CF_END
; EG-NEXT: PAD
@@ -531,15 +531,14 @@ define amdgpu_kernel void @v_ctlz_i8(ptr addrspace(1) noalias %out, ptr addrspac
; EG-NEXT: ALU clause starting at 8:
; EG-NEXT: MOV * T0.X, KC0[2].Z,
; EG-NEXT: ALU clause starting at 9:
-; EG-NEXT: LSHL * T0.W, T0.X, literal.x,
-; EG-NEXT: 24(3.363116e-44), 0(0.000000e+00)
-; EG-NEXT: FFBH_UINT T1.W, PV.W,
-; EG-NEXT: AND_INT * T2.W, KC0[2].Y, literal.x,
-; EG-NEXT: 3(4.203895e-45), 0(0.000000e+00)
-; EG-NEXT: CNDE_INT * T0.W, T0.W, literal.x, PV.W,
-; EG-NEXT: 32(4.484155e-44), 0(0.000000e+00)
+; EG-NEXT: FFBH_UINT * T0.W, T0.X,
+; EG-NEXT: CNDE_INT T0.W, T0.X, literal.x, PV.W,
+; EG-NEXT: AND_INT * T1.W, KC0[2].Y, literal.y,
+; EG-NEXT: 32(4.484155e-44), 3(4.203895e-45)
+; EG-NEXT: ADD_INT * T0.W, PV.W, literal.x,
+; EG-NEXT: -24(nan), 0(0.000000e+00)
; EG-NEXT: AND_INT T0.W, PV.W, literal.x,
-; EG-NEXT: LSHL * T1.W, T2.W, literal.y,
+; EG-NEXT: LSHL * T1.W, T1.W, literal.y,
; EG-NEXT: 255(3.573311e-43), 3(4.203895e-45)
; EG-NEXT: LSHL T0.X, PV.W, PS,
; EG-NEXT: LSHL * T0.W, literal.x, PS,
@@ -556,9 +555,9 @@ define amdgpu_kernel void @v_ctlz_i8(ptr addrspace(1) noalias %out, ptr addrspac
; GFX10-NEXT: s_waitcnt lgkmcnt(0)
; GFX10-NEXT: global_load_ubyte v1, v0, s[2:3]
; GFX10-NEXT: s_waitcnt vmcnt(0)
-; GFX10-NEXT: v_lshlrev_b32_e32 v1, 24, v1
; GFX10-NEXT: v_ffbh_u32_e32 v1, v1
; GFX10-NEXT: v_min_u32_e32 v1, 32, v1
+; GFX10-NEXT: v_subrev_nc_u32_e32 v1, 24, v1
; GFX10-NEXT: global_store_byte v0, v1, s[0:1]
; GFX10-NEXT: s_endpgm
;
@@ -582,10 +581,10 @@ define amdgpu_kernel void @v_ctlz_i8(ptr addrspace(1) noalias %out, ptr addrspac
; GFX11-NEXT: s_waitcnt lgkmcnt(0)
; GFX11-NEXT: global_load_u8 v1, v0, s[2:3]
; GFX11-NEXT: s_waitcnt vmcnt(0)
-; GFX11-NEXT: v_lshlrev_b32_e32 v1, 24, v1
-; GFX11-NEXT: s_delay_alu instid0(VALU_DEP_1) | instskip(NEXT) | instid1(VALU_DEP_1)
; GFX11-NEXT: v_clz_i32_u32_e32 v1, v1
+; GFX11-NEXT: s_delay_alu instid0(VALU_DEP_1) | instskip(NEXT) | instid1(VALU_DEP_1)
; GFX11-NEXT: v_min_u32_e32 v1, 32, v1
+; GFX11-NEXT: v_subrev_nc_u32_e32 v1, 24, v1
; GFX11-NEXT: global_store_b8 v0, v1, s[0:1]
; GFX11-NEXT: s_nop 0
; GFX11-NEXT: s_sendmsg sendmsg(MSG_DEALLOC_VGPRS)
diff --git a/llvm/test/CodeGen/AMDGPU/ctlz_zero_undef.ll b/llvm/test/CodeGen/AMDGPU/ctlz_zero_undef.ll
index 2830e5258e92b2..21aff62b9226d0 100644
--- a/llvm/test/CodeGen/AMDGPU/ctlz_zero_undef.ll
+++ b/llvm/test/CodeGen/AMDGPU/ctlz_zero_undef.ll
@@ -314,8 +314,9 @@ define amdgpu_kernel void @s_ctlz_zero_undef_i8_with_select(ptr addrspace(1) noa
; SI-NEXT: s_load_dwordx2 s[0:1], s[0:1], 0x9
; SI-NEXT: s_mov_b32 s3, 0xf000
; SI-NEXT: s_waitcnt lgkmcnt(0)
-; SI-NEXT: s_lshl_b32 s2, s2, 24
-; SI-NEXT: s_flbit_i32_b32 s4, s2
+; SI-NEXT: s_and_b32 s2, s2, 0xff
+; SI-NEXT: s_flbit_i32_b32 s2, s2
+; SI-NEXT: s_sub_i32 s4, s2, 24
; SI-NEXT: s_mov_b32 s2, -1
; SI-NEXT: v_mov_b32_e32 v0, s4
; SI-NEXT: buffer_store_byte v0, off, s[0:3], 0
@@ -326,8 +327,9 @@ define amdgpu_kernel void @s_ctlz_zero_undef_i8_with_select(ptr addrspace(1) noa
; VI-NEXT: s_load_dword s2, s[0:1], 0x2c
; VI-NEXT: s_load_dwordx2 s[0:1], s[0:1], 0x24
; VI-NEXT: s_waitcnt lgkmcnt(0)
-; VI-NEXT: s_lshl_b32 s2, s2, 24
+; VI-NEXT: s_and_b32 s2, s2, 0xff
; VI-NEXT: s_flbit_i32_b32 s2, s2
+; VI-NEXT: s_sub_i32 s2, s2, 24
; VI-NEXT: v_mov_b32_e32 v0, s0
; VI-NEXT: v_mov_b32_e32 v1, s1
; VI-NEXT: v_mov_b32_e32 v2, s2
@@ -347,13 +349,13 @@ define amdgpu_kernel void @s_ctlz_zero_undef_i8_with_select(ptr addrspace(1) noa
; EG-NEXT: ALU clause starting at 8:
; EG-NEXT: MOV * T0.X, 0.0,
; EG-NEXT: ALU clause starting at 9:
-; EG-NEXT: LSHL * T0.W, T0.X, literal.x,
-; EG-NEXT: 24(3.363116e-44), 0(0.000000e+00)
-; EG-NEXT: FFBH_UINT T0.W, PV.W,
+; EG-NEXT: FFBH_UINT T0.W, T0.X,
; EG-NEXT: AND_INT * T1.W, KC0[2].Y, literal.x,
; EG-NEXT: 3(4.203895e-45), 0(0.000000e+00)
+; EG-NEXT: ADD_INT * T0.W, PV.W, literal.x,
+; EG-NEXT: -24(nan), 0(0.000000e+00)
; EG-NEXT: AND_INT T0.W, PV.W, literal.x,
-; EG-NEXT: LSHL * T1.W, PS, literal.y,
+; EG-NEXT: LSHL * T1.W, T1.W, literal.y,
; EG-NEXT: 255(3.573311e-43), 3(4.203895e-45)
; EG-NEXT: LSHL T0.X, PV.W, PS,
; EG-NEXT: LSHL * T0.W, literal.x, PS,
@@ -389,8 +391,9 @@ define amdgpu_kernel void @s_ctlz_zero_undef_i16_with_select(ptr addrspace(1) no
; SI-NEXT: s_load_dwordx2 s[0:1], s[0:1], 0x9
; SI-NEXT: s_mov_b32 s3, 0xf000
; SI-NEXT: s_waitcnt lgkmcnt(0)
-; SI-NEXT: s_lshl_b32 s2, s2, 16
-; SI-NEXT: s_flbit_i32_b32 s4, s2
+; SI-NEXT: s_and_b32 s2, s2, 0xffff
+; SI-NEXT: s_flbit_i32_b32 s2, s2
+; SI-NEXT: s_add_i32 s4, s2, -16
; SI-NEXT: s_mov_b32 s2, -1
; SI-NEXT: v_mov_b32_e32 v0, s4
; SI-NEXT: buffer_store_short v0, off, s[0:3], 0
@@ -423,13 +426,13 @@ define amdgpu_kernel void @s_ctlz_zero_undef_i16_with_select(ptr addrspace(1) no
; EG-NEXT: ALU clause starting at 8:
; EG-NEXT: MOV * T0.X, 0.0,
; EG-NEXT: ALU clause starting at 9:
-; EG-NEXT: LSHL * T0.W, T0.X, literal.x,
-; EG-NEXT: 16(2.242078e-44), 0(0.000000e+00)
-; EG-NEXT: FFBH_UINT T0.W, PV.W,
+; EG-NEXT: FFBH_UINT T0.W, T0.X,
; EG-NEXT: AND_INT * T1.W, KC0[2].Y, literal.x,
; EG-NEXT: 3(4.203895e-45), 0(0.000000e+00)
+; EG-NEXT: ADD_INT * T0.W, PV.W, literal.x,
+; EG-NEXT: -16(nan), 0(0.000000e+00)
; EG-NEXT: AND_INT T0.W, PV.W, literal.x,
-; EG-NEXT: LSHL * T1.W, PS, literal.y,
+; EG-NEXT: LSHL * T1.W, T1.W, literal.y,
; EG-NEXT: 65535(9.183409e-41), 3(4.203895e-45)
; EG-NEXT: LSHL T0.X, PV.W, PS,
; EG-NEXT: LSHL * T0.W, literal.x, PS,
@@ -587,8 +590,8 @@ define amdgpu_kernel void @v_ctlz_zero_undef_i8_with_select(ptr addrspace(1) noa
; SI-NEXT: s_mov_b32 s4, s0
; SI-NEXT: s_mov_b32 s5, s1
; SI-NEXT: s_waitcnt vmcnt(0)
-; SI-NEXT: v_lshlrev_b32_e32 v1, 24, v0
-; SI-NEXT: v_ffbh_u32_e32 v1, v1
+; SI-NEXT: v_ffbh_u32_e32 v1, v0
+; SI-NEXT: v_subrev_i32_e32 v1, vcc, 24, v1
; SI-NEXT: v_cmp_ne_u32_e32 vcc, 0, v0
; SI-NEXT: v_cndmask_b32_e32 v0, 32, v1, vcc
; SI-NEXT: buffer_store_byte v0, off, s[4:7], 0
@@ -602,8 +605,8 @@ define amdgpu_kernel void @v_ctlz_zero_undef_i8_with_select(ptr addrspace(1) noa
; VI-NEXT: v_mov_b32_e32 v1, s3
; VI-NEXT: flat_load_ubyte v0, v[0:1]
; VI-NEXT: s_waitcnt vmcnt(0)
-; VI-NEXT: v_lshlrev_b32_e32 v1, 24, v0
-; VI-NEXT: v_ffbh_u32_e32 v1, v1
+; VI-NEXT: v_ffbh_u32_sdwa v1, v0 dst_sel:DWORD dst_unused:UNUSED_PAD src0_sel:WORD_0
+; VI-NEXT: v_subrev_u32_e32 v1, vcc, 24, v1
; VI-NEXT: v_cmp_ne_u16_e32 vcc, 0, v0
; VI-NEXT: v_cndmask_b32_e32 v2, 32, v1, vcc
; VI-NEXT: v_mov_b32_e32 v0, s0
@@ -615,7 +618,7 @@ define amdgpu_kernel void @v_ctlz_zero_undef_i8_with_select(ptr addrspace(1) noa
; EG: ; %bb.0:
; EG-NEXT: ALU 0, @8, KC0[CB0:0-32], KC1[]
; EG-NEXT: TEX 0 @6
-; EG-NEXT: ALU 16, @9, KC0[CB0:0-32], KC1[]
+; EG-NEXT: ALU 15, @9, KC0[CB0:0-32], KC1[]
; EG-NEXT: MEM_RAT MSKOR T0.XW, T1.X
; EG-NEXT: CF_END
; EG-NEXT: PAD
@@ -624,11 +627,10 @@ define amdgpu_kernel void @v_ctlz_zero_undef_i8_with_select(ptr addrspace(1) noa
; EG-NEXT: ALU clause starting at 8:
; EG-NEXT: MOV * T0.X, KC0[2].Z,
; EG-NEXT: ALU clause starting at 9:
-; EG-NEXT: LSHL * T0.W, T0.X, literal.x,
-; EG-NEXT: 24(3.363116e-44), 0(0.000000e+00)
-; EG-NEXT: FFBH_UINT T0.W, PV.W,
-; EG-NEXT: AND_INT * T1.W, KC0[2].Y, literal.x,
-; EG-NEXT: 3(4.203895e-45), 0(0.000000e+00)
+; EG-NEXT: FFBH_UINT * T0.W, T0.X,
+; EG-NEXT: ADD_INT T0.W, PV.W, literal.x,
+; EG-NEXT: AND_INT * T1.W, KC0[2].Y, literal.y,
+; EG-NEXT: -24(nan), 3(4.203895e-45)
; EG-NEXT: CNDE_INT * T0.W, T0.X, literal.x, PV.W,
; EG-NEXT: 32(4.484155e-44), 0(0.000000e+00)
; EG-NEXT: AND_INT T0.W, PV.W, literal.x,
@@ -683,8 +685,8 @@ define amdgpu_kernel void @v_ctlz_zero_undef_i16_with_select(ptr addrspace(1) no
; SI-NEXT: v_lshlrev_b32_e32 v0, 8, v0
; SI-NEXT: s_waitcnt vmcnt(0)
; SI-NEXT: v_or_b32_e32 v0, v0, v1
-; SI-NEXT: v_lshlrev_b32_e32 v1, 16, v0
-; SI-NEXT: v_ffbh_u32_e32 v1, v1
+; SI-NEXT: v_ffbh_u32_e32 v1, v0
+; SI-NEXT: v_add_i32_e32 v1, vcc, -16, v1
; SI-NEXT: v_cmp_ne_u32_e32 vcc, 0, v0
; SI-NEXT: v_cndmask_b32_e32 v0, 32, v1, vcc
; SI-NEXT: buffer_store_short v0, off, s[4:7], 0
@@ -719,7 +721,7 @@ define amdgpu_kernel void @v_ctlz_zero_undef_i16_with_select(ptr addrspace(1) no
; EG: ; %bb.0:
; EG-NEXT: ALU 0, @8, KC0[CB0:0-32], KC1[]
; EG-NEXT: TEX 0 @6
-; EG-NEXT: ALU 16, @9, KC0[CB0:0-32], KC1[]
+; EG-NEXT: ALU 15, @9, KC0[CB0:0-32], KC1[]
; EG-NEXT: MEM_RAT MSKOR T0.XW, T1.X
; EG-NEXT: CF_END
; EG-NEXT: PAD
@@ -728,11 +730,10 @@ define amdgpu_kernel void @v_ctlz_zero_undef_i16_with_select(ptr addrspace(1) no
; EG-NEXT: ALU clause starting at 8:
; EG-NEXT: MOV * T0.X, KC0[2].Z,
; EG-NEXT: ALU clause starting at 9:
-; EG-NEXT: LSHL * T0.W, T0.X, literal.x,
-; EG-NEXT: 16(2.242078e-44), 0(0.000000e+00)
-; EG-NEXT: FFBH_UINT T0.W, PV.W,
-; EG-NEXT: AND_INT * T1.W, KC0[2].Y, literal.x,
-; EG-NEXT: 3(4.203895e-45), 0(0.000000e+00)
+; EG-NEXT: FFBH_UINT * T0.W, T0.X,
+; EG-NEXT: ADD_INT T0.W, PV.W, literal.x,
+; EG-NEXT: AND_INT * T1.W, KC0[2].Y, literal.y,
+; EG-NEXT: -16(nan), 3(4.203895e-45)
; EG-NEXT: CNDE_INT * T0.W, T0.X, literal.x, PV.W,
; EG-NEXT: 32(4.484155e-44), 0(0.000000e+00)
; EG-NEXT: AND_INT T0.W, PV.W, literal.x,
@@ -1101,8 +1102,8 @@ define amdgpu_kernel void @v_ctlz_zero_undef_i8(ptr addrspace(1) noalias %out, p
; SI-NEXT: s_mov_b32 s4, s0
; SI-NEXT: s_mov_b32 s5, s1
; SI-NEXT: s_waitcnt vmcnt(0)
-; SI-NEXT: v_lshlrev_b32_e32 v0, 24, v0
; SI-NEXT: v_ffbh_u32_e32 v0, v0
+; SI-NEXT: v_subrev_i32_e32 v0, vcc, 24, v0
; SI-NEXT: buffer_store_byte v0, off, s[4:7], 0
; SI-NEXT: s_endpgm
;
@@ -1115,8 +1116,8 @@ define amdgpu_kernel void @v_ctlz_zero_undef_i8(ptr addrspace(1) noalias %out, p
; VI-NEXT: v_addc_u32_e32 v1, vcc, 0, v1, vcc
; VI-NEXT: flat_load_ubyte v0, v[0:1]
; VI-NEXT: s_waitcnt vmcnt(0)
-; VI-NEXT: v_lshlrev_b32_e32 v0, 24, v0
-; VI-NEXT: v_ffbh_u32_e32 v2, v0
+; VI-NEXT: v_ffbh_u32_e32 v0, v0
+; VI-NEXT: v_subrev_u32_e32 v2, vcc, 24, v0
; VI-NEXT: v_mov_b32_e32 v0, s0
; VI-NEXT: v_mov_b32_e32 v1, s1
; VI-NEXT: flat_store_byte v[0:1], v2
@@ -1135,13 +1136,13 @@ define amdgpu_kernel void @v_ctlz_zero_undef_i8(ptr addrspace(1) noalias %out, p
; EG-NEXT: ALU clause starting at 8:
; EG-NEXT: ADD_INT * T0.X, KC0[2].Z, T0.X,
; EG-NEXT: ALU clause starting at 9:
-; EG-NEXT: LSHL * T0.W, T0.X, literal.x,
-; EG-NEXT: 24(3.363116e-44), 0(0.000000e+00)
-; EG-NEXT: FFBH_UINT T0.W, PV.W,
+; EG-NEXT: FFBH_UINT T0.W, T0.X,
; EG-NEXT: AND_INT * T1.W, KC0[2].Y, literal.x,
; EG-NEXT: 3(4.203895e-45), 0(0.000000e+00)
+; EG-NEXT: ADD_INT * T0.W, PV.W, literal.x,
+; EG-NEXT: -24(nan), 0(0.000000e+00)
; EG-NEXT: AND_INT T0.W, PV.W, literal.x,
-; EG-NEXT: LSHL * T1.W, PS, literal.y,
+; EG-NEXT: LSHL * T1.W, T1.W, literal.y,
; EG-NEXT: 255(3.573311e-43), 3(4.203895e-45)
; EG-NEXT: LSHL T0.X, PV.W, PS,
; EG-NEXT: LSHL * T0.W, literal.x, PS,
>From c5cdf3432a3928de8f111a7483962f0e5103546f Mon Sep 17 00:00:00 2001
From: Slava Zakharin <szakharin at nvidia.com>
Date: Thu, 29 Feb 2024 14:47:28 -0800
Subject: [PATCH 184/406] [flang][runtime] Partial revert of #83383. (#83478)
For `LDBL_MANT_DIG == 113` targets the REAL(16) versions of F18
runtime APIs can stay and should better stay in FortranRuntime.
This way, no additional linking actions are required, because
glibc provides all that is needed.
I thought I would isolate all REAL(16) implementations (both
via `__float128` and `long double`) into Float128Math library,
but that was a bad idea.
This should fix aarch64 buildbots failing gfortran tests.
---
flang/runtime/Float128Math/exponent.cpp | 2 +-
flang/runtime/Float128Math/fraction.cpp | 2 +-
flang/runtime/Float128Math/mod-real.cpp | 2 +-
flang/runtime/Float128Math/modulo-real.cpp | 2 +-
flang/runtime/Float128Math/nearest.cpp | 2 +-
flang/runtime/Float128Math/rrspacing.cpp | 2 +-
flang/runtime/Float128Math/scale.cpp | 2 +-
flang/runtime/Float128Math/set-exponent.cpp | 2 +-
flang/runtime/Float128Math/spacing.cpp | 2 +-
flang/runtime/numeric-templates.h | 1 +
flang/runtime/numeric.cpp | 60 +++++++++++++++++++++
11 files changed, 70 insertions(+), 9 deletions(-)
diff --git a/flang/runtime/Float128Math/exponent.cpp b/flang/runtime/Float128Math/exponent.cpp
index 1be1dd0d0ac8b8..c0e43c0ee8d36e 100644
--- a/flang/runtime/Float128Math/exponent.cpp
+++ b/flang/runtime/Float128Math/exponent.cpp
@@ -12,7 +12,7 @@
namespace Fortran::runtime {
extern "C" {
-#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
+#if LDBL_MANT_DIG != 113 && HAS_FLOAT128
// EXPONENT (16.9.75)
CppTypeFor<TypeCategory::Integer, 4> RTDEF(Exponent16_4)(F128Type x) {
return Exponent<CppTypeFor<TypeCategory::Integer, 4>>(x);
diff --git a/flang/runtime/Float128Math/fraction.cpp b/flang/runtime/Float128Math/fraction.cpp
index 8c9889b7f6871e..8de6d3c7ff6c07 100644
--- a/flang/runtime/Float128Math/fraction.cpp
+++ b/flang/runtime/Float128Math/fraction.cpp
@@ -12,7 +12,7 @@
namespace Fortran::runtime {
extern "C" {
-#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
+#if LDBL_MANT_DIG != 113 && HAS_FLOAT128
// FRACTION (16.9.80)
F128Type RTDEF(Fraction16)(F128Type x) { return Fraction(x); }
#endif
diff --git a/flang/runtime/Float128Math/mod-real.cpp b/flang/runtime/Float128Math/mod-real.cpp
index 42e6ce76e2fa1b..9cc2926e45d51a 100644
--- a/flang/runtime/Float128Math/mod-real.cpp
+++ b/flang/runtime/Float128Math/mod-real.cpp
@@ -12,7 +12,7 @@
namespace Fortran::runtime {
extern "C" {
-#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
+#if LDBL_MANT_DIG != 113 && HAS_FLOAT128
// MOD (16.9.135)
F128Type RTDEF(ModReal16)(
F128Type x, F128Type p, const char *sourceFile, int sourceLine) {
diff --git a/flang/runtime/Float128Math/modulo-real.cpp b/flang/runtime/Float128Math/modulo-real.cpp
index 13000aba8c8323..b25797fd8f4128 100644
--- a/flang/runtime/Float128Math/modulo-real.cpp
+++ b/flang/runtime/Float128Math/modulo-real.cpp
@@ -12,7 +12,7 @@
namespace Fortran::runtime {
extern "C" {
-#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
+#if LDBL_MANT_DIG != 113 && HAS_FLOAT128
// MODULO (16.9.136)
F128Type RTDEF(ModuloReal16)(
F128Type x, F128Type p, const char *sourceFile, int sourceLine) {
diff --git a/flang/runtime/Float128Math/nearest.cpp b/flang/runtime/Float128Math/nearest.cpp
index 148ac4ef839160..fd990532e52293 100644
--- a/flang/runtime/Float128Math/nearest.cpp
+++ b/flang/runtime/Float128Math/nearest.cpp
@@ -11,7 +11,7 @@
namespace Fortran::runtime {
extern "C" {
-#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
+#if LDBL_MANT_DIG != 113 && HAS_FLOAT128
CppTypeFor<TypeCategory::Real, 16> RTDEF(Nearest16)(
CppTypeFor<TypeCategory::Real, 16> x, bool positive) {
return Nextafter<true>::invoke(
diff --git a/flang/runtime/Float128Math/rrspacing.cpp b/flang/runtime/Float128Math/rrspacing.cpp
index feddac418eec39..f2187f42313ae5 100644
--- a/flang/runtime/Float128Math/rrspacing.cpp
+++ b/flang/runtime/Float128Math/rrspacing.cpp
@@ -12,7 +12,7 @@
namespace Fortran::runtime {
extern "C" {
-#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
+#if LDBL_MANT_DIG != 113 && HAS_FLOAT128
// FRACTION (16.9.80)
F128Type RTDEF(RRSpacing16)(F128Type x) { return RRSpacing<113>(x); }
#endif
diff --git a/flang/runtime/Float128Math/scale.cpp b/flang/runtime/Float128Math/scale.cpp
index 0be958bd9f2a72..d6b843150e726f 100644
--- a/flang/runtime/Float128Math/scale.cpp
+++ b/flang/runtime/Float128Math/scale.cpp
@@ -13,7 +13,7 @@
namespace Fortran::runtime {
extern "C" {
-#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
+#if LDBL_MANT_DIG != 113 && HAS_FLOAT128
F128Type RTDEF(Scale16)(F128Type x, std::int64_t p) {
auto ip{static_cast<int>(p)};
if (ip != p) {
diff --git a/flang/runtime/Float128Math/set-exponent.cpp b/flang/runtime/Float128Math/set-exponent.cpp
index 99c34af7962b9a..0f942d238b8f35 100644
--- a/flang/runtime/Float128Math/set-exponent.cpp
+++ b/flang/runtime/Float128Math/set-exponent.cpp
@@ -12,7 +12,7 @@
namespace Fortran::runtime {
extern "C" {
-#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
+#if LDBL_MANT_DIG != 113 && HAS_FLOAT128
// SET_EXPONENT (16.9.171)
F128Type RTDEF(SetExponent16)(F128Type x, std::int64_t p) {
return SetExponent(x, p);
diff --git a/flang/runtime/Float128Math/spacing.cpp b/flang/runtime/Float128Math/spacing.cpp
index a86c0b30e567ab..d00e74644f8a86 100644
--- a/flang/runtime/Float128Math/spacing.cpp
+++ b/flang/runtime/Float128Math/spacing.cpp
@@ -12,7 +12,7 @@
namespace Fortran::runtime {
extern "C" {
-#if LDBL_MANT_DIG == 113 || HAS_FLOAT128
+#if LDBL_MANT_DIG != 113 && HAS_FLOAT128
// SPACING (16.9.180)
F128Type RTDEF(Spacing16)(F128Type x) { return Spacing<113>(x); }
#endif
diff --git a/flang/runtime/numeric-templates.h b/flang/runtime/numeric-templates.h
index b16440dbc2241a..ecc3b2654d9652 100644
--- a/flang/runtime/numeric-templates.h
+++ b/flang/runtime/numeric-templates.h
@@ -21,6 +21,7 @@
#include "terminator.h"
#include "tools.h"
#include "flang/Common/float128.h"
+#include "flang/Runtime/api-attrs.h"
#include <cstdint>
#include <limits>
diff --git a/flang/runtime/numeric.cpp b/flang/runtime/numeric.cpp
index abd3e500029fe4..d61f32e1d5b866 100644
--- a/flang/runtime/numeric.cpp
+++ b/flang/runtime/numeric.cpp
@@ -324,6 +324,16 @@ CppTypeFor<TypeCategory::Integer, 8> RTDEF(Exponent10_8)(
CppTypeFor<TypeCategory::Real, 10> x) {
return Exponent<CppTypeFor<TypeCategory::Integer, 8>>(x);
}
+#elif LDBL_MANT_DIG == 113
+// The __float128 implementation resides in FortranFloat128Math library.
+CppTypeFor<TypeCategory::Integer, 4> RTDEF(Exponent16_4)(
+ CppTypeFor<TypeCategory::Real, 16> x) {
+ return Exponent<CppTypeFor<TypeCategory::Integer, 4>>(x);
+}
+CppTypeFor<TypeCategory::Integer, 8> RTDEF(Exponent16_8)(
+ CppTypeFor<TypeCategory::Real, 16> x) {
+ return Exponent<CppTypeFor<TypeCategory::Integer, 8>>(x);
+}
#endif
CppTypeFor<TypeCategory::Integer, 1> RTDEF(Floor4_1)(
@@ -431,6 +441,12 @@ CppTypeFor<TypeCategory::Real, 10> RTDEF(Fraction10)(
CppTypeFor<TypeCategory::Real, 10> x) {
return Fraction(x);
}
+#elif LDBL_MANT_DIG == 113
+// The __float128 implementation resides in FortranFloat128Math library.
+CppTypeFor<TypeCategory::Real, 16> RTDEF(Fraction16)(
+ CppTypeFor<TypeCategory::Real, 16> x) {
+ return Fraction(x);
+}
#endif
bool RTDEF(IsFinite4)(CppTypeFor<TypeCategory::Real, 4> x) {
@@ -513,6 +529,13 @@ CppTypeFor<TypeCategory::Real, 10> RTDEF(ModReal10)(
const char *sourceFile, int sourceLine) {
return RealMod<false>(x, p, sourceFile, sourceLine);
}
+#elif LDBL_MANT_DIG == 113
+// The __float128 implementation resides in FortranFloat128Math library.
+CppTypeFor<TypeCategory::Real, 16> RTDEF(ModReal16)(
+ CppTypeFor<TypeCategory::Real, 16> x, CppTypeFor<TypeCategory::Real, 16> p,
+ const char *sourceFile, int sourceLine) {
+ return RealMod<false>(x, p, sourceFile, sourceLine);
+}
#endif
CppTypeFor<TypeCategory::Integer, 1> RTDEF(ModuloInteger1)(
@@ -563,6 +586,13 @@ CppTypeFor<TypeCategory::Real, 10> RTDEF(ModuloReal10)(
const char *sourceFile, int sourceLine) {
return RealMod<true>(x, p, sourceFile, sourceLine);
}
+#elif LDBL_MANT_DIG == 113
+// The __float128 implementation resides in FortranFloat128Math library.
+CppTypeFor<TypeCategory::Real, 16> RTDEF(ModuloReal16)(
+ CppTypeFor<TypeCategory::Real, 16> x, CppTypeFor<TypeCategory::Real, 16> p,
+ const char *sourceFile, int sourceLine) {
+ return RealMod<true>(x, p, sourceFile, sourceLine);
+}
#endif
CppTypeFor<TypeCategory::Real, 4> RTDEF(Nearest4)(
@@ -578,6 +608,12 @@ CppTypeFor<TypeCategory::Real, 10> RTDEF(Nearest10)(
CppTypeFor<TypeCategory::Real, 10> x, bool positive) {
return Nearest<64>(x, positive);
}
+#elif LDBL_MANT_DIG == 113
+// The __float128 implementation resides in FortranFloat128Math library.
+CppTypeFor<TypeCategory::Real, 16> RTDEF(Nearest16)(
+ CppTypeFor<TypeCategory::Real, 16> x, bool positive) {
+ return Nearest<113>(x, positive);
+}
#endif
CppTypeFor<TypeCategory::Integer, 1> RTDEF(Nint4_1)(
@@ -685,6 +721,12 @@ CppTypeFor<TypeCategory::Real, 10> RTDEF(RRSpacing10)(
CppTypeFor<TypeCategory::Real, 10> x) {
return RRSpacing<64>(x);
}
+#elif LDBL_MANT_DIG == 113
+// The __float128 implementation resides in FortranFloat128Math library.
+CppTypeFor<TypeCategory::Real, 16> RTDEF(RRSpacing16)(
+ CppTypeFor<TypeCategory::Real, 16> x) {
+ return RRSpacing<113>(x);
+}
#endif
CppTypeFor<TypeCategory::Real, 4> RTDEF(SetExponent4)(
@@ -700,6 +742,12 @@ CppTypeFor<TypeCategory::Real, 10> RTDEF(SetExponent10)(
CppTypeFor<TypeCategory::Real, 10> x, std::int64_t p) {
return SetExponent(x, p);
}
+#elif LDBL_MANT_DIG == 113
+// The __float128 implementation resides in FortranFloat128Math library.
+CppTypeFor<TypeCategory::Real, 16> RTDEF(SetExponent16)(
+ CppTypeFor<TypeCategory::Real, 16> x, std::int64_t p) {
+ return SetExponent(x, p);
+}
#endif
CppTypeFor<TypeCategory::Real, 4> RTDEF(Scale4)(
@@ -715,6 +763,12 @@ CppTypeFor<TypeCategory::Real, 10> RTDEF(Scale10)(
CppTypeFor<TypeCategory::Real, 10> x, std::int64_t p) {
return Scale(x, p);
}
+#elif LDBL_MANT_DIG == 113
+// The __float128 implementation resides in FortranFloat128Math library.
+CppTypeFor<TypeCategory::Real, 16> RTDEF(Scale16)(
+ CppTypeFor<TypeCategory::Real, 16> x, std::int64_t p) {
+ return Scale(x, p);
+}
#endif
// SELECTED_INT_KIND
@@ -769,6 +823,12 @@ CppTypeFor<TypeCategory::Real, 10> RTDEF(Spacing10)(
CppTypeFor<TypeCategory::Real, 10> x) {
return Spacing<64>(x);
}
+#elif LDBL_MANT_DIG == 113
+// The __float128 implementation resides in FortranFloat128Math library.
+CppTypeFor<TypeCategory::Real, 16> RTDEF(Spacing16)(
+ CppTypeFor<TypeCategory::Real, 16> x) {
+ return Spacing<113>(x);
+}
#endif
CppTypeFor<TypeCategory::Real, 4> RTDEF(FPow4i)(
>From 8466ab98ca5353e22eab0ae6d9885a65091786fb Mon Sep 17 00:00:00 2001
From: Matthias Braun <matze at braunis.de>
Date: Thu, 29 Feb 2024 14:53:11 -0800
Subject: [PATCH 185/406] llvm-profgen: Fix race condition (#83489)
Fix race condition when multiple instances of `llvm-progen` read from
the same inputs.
---
llvm/tools/llvm-profgen/PerfReader.cpp | 11 ++++++++---
1 file changed, 8 insertions(+), 3 deletions(-)
diff --git a/llvm/tools/llvm-profgen/PerfReader.cpp b/llvm/tools/llvm-profgen/PerfReader.cpp
index 313d40483a2591..c6fcf7e1196ec8 100644
--- a/llvm/tools/llvm-profgen/PerfReader.cpp
+++ b/llvm/tools/llvm-profgen/PerfReader.cpp
@@ -7,6 +7,7 @@
//===----------------------------------------------------------------------===//
#include "PerfReader.h"
#include "ProfileGenerator.h"
+#include "llvm/ADT/SmallString.h"
#include "llvm/DebugInfo/Symbolize/SymbolizableModule.h"
#include "llvm/Support/FileSystem.h"
#include "llvm/Support/Process.h"
@@ -361,8 +362,11 @@ PerfScriptReader::convertPerfDataToTrace(ProfiledBinary *Binary,
exitWithError("Perf not found.");
}
std::string PerfPath = *PerfExecutable;
- std::string PerfTraceFile = PerfData.str() + ".script.tmp";
- std::string ErrorFile = PerfData.str() + ".script.err.tmp";
+
+ SmallString<128> PerfTraceFile;
+ sys::fs::createUniquePath("perf-script-%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%.tmp",
+ PerfTraceFile, /*MakeAbsolute=*/true);
+ std::string ErrorFile = std::string(PerfTraceFile) + ".err";
StringRef ScriptMMapArgs[] = {PerfPath, "script", "--show-mmap-events",
"-F", "comm,pid", "-i",
PerfData};
@@ -400,7 +404,8 @@ PerfScriptReader::convertPerfDataToTrace(ProfiledBinary *Binary,
PIDs, "-i", PerfData};
sys::ExecuteAndWait(PerfPath, ScriptSampleArgs, std::nullopt, Redirects);
- return {PerfTraceFile, PerfFormat::PerfScript, PerfContent::UnknownContent};
+ return {std::string(PerfTraceFile), PerfFormat::PerfScript,
+ PerfContent::UnknownContent};
}
void PerfScriptReader::updateBinaryAddress(const MMapEvent &Event) {
>From ca9d2e923b28adec9ae1754f0bb61b2e8ada025e Mon Sep 17 00:00:00 2001
From: Sumanth Gundapaneni <sgundapa at quicinc.com>
Date: Thu, 29 Feb 2024 16:57:33 -0600
Subject: [PATCH 186/406] [Hexagon] Add Loop Alignment pass. (#83379)
Inspect a basic block and if its single basic block loop with a small
number of instructions, set the Loop Alignment to 32 bytes. This will
avoid the cache line break in the first packet of loop which will cause
a stall per each execution of loop.
---
clang/test/CodeGen/builtins-hexagon.c | 2 +-
llvm/lib/Target/Hexagon/CMakeLists.txt | 1 +
llvm/lib/Target/Hexagon/HexagonLoopAlign.cpp | 216 ++++++++++++++++++
.../Target/Hexagon/HexagonTargetMachine.cpp | 9 +-
.../lib/Target/Hexagon/HexagonTargetMachine.h | 1 +
llvm/test/CodeGen/Hexagon/loop-balign.ll | 91 ++++++++
llvm/test/CodeGen/Hexagon/loop_align_count.ll | 115 ++++++++++
.../test/CodeGen/Hexagon/loop_align_count.mir | 130 +++++++++++
llvm/test/CodeGen/Hexagon/v6-haar-balign32.ll | 117 ++++++++++
9 files changed, 680 insertions(+), 2 deletions(-)
create mode 100644 llvm/lib/Target/Hexagon/HexagonLoopAlign.cpp
create mode 100644 llvm/test/CodeGen/Hexagon/loop-balign.ll
create mode 100644 llvm/test/CodeGen/Hexagon/loop_align_count.ll
create mode 100644 llvm/test/CodeGen/Hexagon/loop_align_count.mir
create mode 100644 llvm/test/CodeGen/Hexagon/v6-haar-balign32.ll
diff --git a/clang/test/CodeGen/builtins-hexagon.c b/clang/test/CodeGen/builtins-hexagon.c
index 9a1b733da5cdb8..52073f27ae70f5 100644
--- a/clang/test/CodeGen/builtins-hexagon.c
+++ b/clang/test/CodeGen/builtins-hexagon.c
@@ -1,5 +1,5 @@
// REQUIRES: hexagon-registered-target
-// RUN: %clang_cc1 -triple hexagon-unknown-elf -target-cpu hexagonv65 -target-feature +hvxv65 -emit-llvm %s -o - | FileCheck %s
+// RUN: %clang_cc1 -triple hexagon-unknown-elf -target-cpu hexagonv65 -target-feature +hvxv65 -target-feature +hvx-length128b -emit-llvm %s -o - | FileCheck %s
void test() {
int v64 __attribute__((__vector_size__(64)));
diff --git a/llvm/lib/Target/Hexagon/CMakeLists.txt b/llvm/lib/Target/Hexagon/CMakeLists.txt
index a22a5c11e6ab3a..cdc062eee72b1e 100644
--- a/llvm/lib/Target/Hexagon/CMakeLists.txt
+++ b/llvm/lib/Target/Hexagon/CMakeLists.txt
@@ -43,6 +43,7 @@ add_llvm_target(HexagonCodeGen
HexagonISelDAGToDAGHVX.cpp
HexagonISelLowering.cpp
HexagonISelLoweringHVX.cpp
+ HexagonLoopAlign.cpp
HexagonLoopIdiomRecognition.cpp
HexagonMachineFunctionInfo.cpp
HexagonMachineScheduler.cpp
diff --git a/llvm/lib/Target/Hexagon/HexagonLoopAlign.cpp b/llvm/lib/Target/Hexagon/HexagonLoopAlign.cpp
new file mode 100644
index 00000000000000..c79b528ff2f3f9
--- /dev/null
+++ b/llvm/lib/Target/Hexagon/HexagonLoopAlign.cpp
@@ -0,0 +1,216 @@
+//===----- HexagonLoopAlign.cpp - Generate loop alignment directives -----===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+// Inspect a basic block and if its single basic block loop with a small
+// number of instructions, set the prefLoopAlignment to 32 bytes (5).
+//===----------------------------------------------------------------------===//
+
+#define DEBUG_TYPE "hexagon-loop-align"
+
+#include "HexagonTargetMachine.h"
+#include "llvm/CodeGen/MachineBlockFrequencyInfo.h"
+#include "llvm/CodeGen/MachineBranchProbabilityInfo.h"
+#include "llvm/CodeGen/SchedulerRegistry.h"
+#include "llvm/Support/Debug.h"
+
+using namespace llvm;
+
+static cl::opt<bool>
+ DisableLoopAlign("disable-hexagon-loop-align", cl::Hidden,
+ cl::desc("Disable Hexagon loop alignment pass"));
+
+static cl::opt<uint32_t> HVXLoopAlignLimitUB(
+ "hexagon-hvx-loop-align-limit-ub", cl::Hidden, cl::init(16),
+ cl::desc("Set hexagon hvx loop upper bound align limit"));
+
+static cl::opt<uint32_t> TinyLoopAlignLimitUB(
+ "hexagon-tiny-loop-align-limit-ub", cl::Hidden, cl::init(16),
+ cl::desc("Set hexagon tiny-core loop upper bound align limit"));
+
+static cl::opt<uint32_t>
+ LoopAlignLimitUB("hexagon-loop-align-limit-ub", cl::Hidden, cl::init(8),
+ cl::desc("Set hexagon loop upper bound align limit"));
+
+static cl::opt<uint32_t>
+ LoopAlignLimitLB("hexagon-loop-align-limit-lb", cl::Hidden, cl::init(4),
+ cl::desc("Set hexagon loop lower bound align limit"));
+
+static cl::opt<uint32_t>
+ LoopBndlAlignLimit("hexagon-loop-bundle-align-limit", cl::Hidden,
+ cl::init(4),
+ cl::desc("Set hexagon loop align bundle limit"));
+
+static cl::opt<uint32_t> TinyLoopBndlAlignLimit(
+ "hexagon-tiny-loop-bundle-align-limit", cl::Hidden, cl::init(8),
+ cl::desc("Set hexagon tiny-core loop align bundle limit"));
+
+static cl::opt<uint32_t>
+ LoopEdgeThreshold("hexagon-loop-edge-threshold", cl::Hidden, cl::init(7500),
+ cl::desc("Set hexagon loop align edge theshold"));
+
+namespace llvm {
+FunctionPass *createHexagonLoopAlign();
+void initializeHexagonLoopAlignPass(PassRegistry &);
+} // namespace llvm
+
+namespace {
+
+class HexagonLoopAlign : public MachineFunctionPass {
+ const HexagonSubtarget *HST = nullptr;
+ const TargetMachine *HTM = nullptr;
+ const HexagonInstrInfo *HII = nullptr;
+
+public:
+ static char ID;
+ HexagonLoopAlign() : MachineFunctionPass(ID) {
+ initializeHexagonLoopAlignPass(*PassRegistry::getPassRegistry());
+ }
+ bool shouldBalignLoop(MachineBasicBlock &BB, bool AboveThres);
+ bool isSingleLoop(MachineBasicBlock &MBB);
+ bool attemptToBalignSmallLoop(MachineFunction &MF, MachineBasicBlock &MBB);
+
+ void getAnalysisUsage(AnalysisUsage &AU) const override {
+ AU.addRequired<MachineBranchProbabilityInfo>();
+ AU.addRequired<MachineBlockFrequencyInfo>();
+ MachineFunctionPass::getAnalysisUsage(AU);
+ }
+
+ StringRef getPassName() const override { return "Hexagon LoopAlign pass"; }
+ bool runOnMachineFunction(MachineFunction &MF) override;
+};
+
+char HexagonLoopAlign::ID = 0;
+
+bool HexagonLoopAlign::shouldBalignLoop(MachineBasicBlock &BB,
+ bool AboveThres) {
+ bool isVec = false;
+ unsigned InstCnt = 0;
+ unsigned BndlCnt = 0;
+
+ for (MachineBasicBlock::instr_iterator II = BB.instr_begin(),
+ IE = BB.instr_end();
+ II != IE; ++II) {
+
+ // End if the instruction is endloop.
+ if (HII->isEndLoopN(II->getOpcode()))
+ break;
+ // Count the number of bundles.
+ if (II->isBundle()) {
+ BndlCnt++;
+ continue;
+ }
+ // Skip over debug instructions.
+ if (II->isDebugInstr())
+ continue;
+ // Check if there are any HVX instructions in loop.
+ isVec |= HII->isHVXVec(*II);
+ // Count the number of instructions.
+ InstCnt++;
+ }
+
+ LLVM_DEBUG({
+ dbgs() << "Bundle Count : " << BndlCnt << "\n";
+ dbgs() << "Instruction Count : " << InstCnt << "\n";
+ });
+
+ unsigned LimitUB = 0;
+ unsigned LimitBndl = LoopBndlAlignLimit;
+ // The conditions in the order of priority.
+ if (HST->isTinyCore()) {
+ LimitUB = TinyLoopAlignLimitUB;
+ LimitBndl = TinyLoopBndlAlignLimit;
+ } else if (isVec)
+ LimitUB = HVXLoopAlignLimitUB;
+ else if (AboveThres)
+ LimitUB = LoopAlignLimitUB;
+
+ // if the upper bound is not set to a value, implies we didn't meet
+ // the criteria.
+ if (LimitUB == 0)
+ return false;
+
+ return InstCnt >= LoopAlignLimitLB && InstCnt <= LimitUB &&
+ BndlCnt <= LimitBndl;
+}
+
+bool HexagonLoopAlign::isSingleLoop(MachineBasicBlock &MBB) {
+ int Succs = MBB.succ_size();
+ return (MBB.isSuccessor(&MBB) && (Succs == 2));
+}
+
+bool HexagonLoopAlign::attemptToBalignSmallLoop(MachineFunction &MF,
+ MachineBasicBlock &MBB) {
+ if (!isSingleLoop(MBB))
+ return false;
+
+ const MachineBranchProbabilityInfo *MBPI =
+ &getAnalysis<MachineBranchProbabilityInfo>();
+ const MachineBlockFrequencyInfo *MBFI =
+ &getAnalysis<MachineBlockFrequencyInfo>();
+
+ // Compute frequency of back edge,
+ BlockFrequency BlockFreq = MBFI->getBlockFreq(&MBB);
+ BranchProbability BrProb = MBPI->getEdgeProbability(&MBB, &MBB);
+ BlockFrequency EdgeFreq = BlockFreq * BrProb;
+ LLVM_DEBUG({
+ dbgs() << "Loop Align Pass:\n";
+ dbgs() << "\tedge with freq(" << EdgeFreq.getFrequency() << ")\n";
+ });
+
+ bool AboveThres = EdgeFreq.getFrequency() > LoopEdgeThreshold;
+ if (shouldBalignLoop(MBB, AboveThres)) {
+ // We found a loop, change its alignment to be 32 (5).
+ MBB.setAlignment(llvm::Align(1 << 5));
+ return true;
+ }
+ return false;
+}
+
+// Inspect each basic block, and if its a single BB loop, see if it
+// meets the criteria for increasing alignment to 32.
+
+bool HexagonLoopAlign::runOnMachineFunction(MachineFunction &MF) {
+
+ HST = &MF.getSubtarget<HexagonSubtarget>();
+ HII = HST->getInstrInfo();
+ HTM = &MF.getTarget();
+
+ if (skipFunction(MF.getFunction()))
+ return false;
+ if (DisableLoopAlign)
+ return false;
+
+ // This optimization is performed at
+ // i) -O2 and above, and when the loop has a HVX instruction.
+ // ii) -O3
+ if (HST->useHVXOps()) {
+ if (HTM->getOptLevel() < CodeGenOptLevel::Default)
+ return false;
+ } else {
+ if (HTM->getOptLevel() < CodeGenOptLevel::Aggressive)
+ return false;
+ }
+
+ bool Changed = false;
+ for (MachineFunction::iterator MBBi = MF.begin(), MBBe = MF.end();
+ MBBi != MBBe; ++MBBi) {
+ MachineBasicBlock &MBB = *MBBi;
+ Changed |= attemptToBalignSmallLoop(MF, MBB);
+ }
+ return Changed;
+}
+
+} // namespace
+
+INITIALIZE_PASS(HexagonLoopAlign, "hexagon-loop-align",
+ "Hexagon LoopAlign pass", false, false)
+
+//===----------------------------------------------------------------------===//
+// Public Constructor Functions
+//===----------------------------------------------------------------------===//
+
+FunctionPass *llvm::createHexagonLoopAlign() { return new HexagonLoopAlign(); }
diff --git a/llvm/lib/Target/Hexagon/HexagonTargetMachine.cpp b/llvm/lib/Target/Hexagon/HexagonTargetMachine.cpp
index 7d77286339399d..3c346c334d6d30 100644
--- a/llvm/lib/Target/Hexagon/HexagonTargetMachine.cpp
+++ b/llvm/lib/Target/Hexagon/HexagonTargetMachine.cpp
@@ -164,6 +164,7 @@ namespace llvm {
void initializeHexagonGenMuxPass(PassRegistry&);
void initializeHexagonHardwareLoopsPass(PassRegistry&);
void initializeHexagonLoopIdiomRecognizeLegacyPassPass(PassRegistry &);
+ void initializeHexagonLoopAlignPass(PassRegistry &);
void initializeHexagonNewValueJumpPass(PassRegistry&);
void initializeHexagonOptAddrModePass(PassRegistry&);
void initializeHexagonPacketizerPass(PassRegistry&);
@@ -194,6 +195,7 @@ namespace llvm {
FunctionPass *createHexagonHardwareLoops();
FunctionPass *createHexagonISelDag(HexagonTargetMachine &TM,
CodeGenOptLevel OptLevel);
+ FunctionPass *createHexagonLoopAlign();
FunctionPass *createHexagonLoopRescheduling();
FunctionPass *createHexagonNewValueJump();
FunctionPass *createHexagonOptAddrMode();
@@ -256,8 +258,10 @@ HexagonTargetMachine::HexagonTargetMachine(const Target &T, const Triple &TT,
TT, CPU, FS, Options, getEffectiveRelocModel(RM),
getEffectiveCodeModel(CM, CodeModel::Small),
(HexagonNoOpt ? CodeGenOptLevel::None : OL)),
- TLOF(std::make_unique<HexagonTargetObjectFile>()) {
+ TLOF(std::make_unique<HexagonTargetObjectFile>()),
+ Subtarget(Triple(TT), CPU, FS, *this) {
initializeHexagonExpandCondsetsPass(*PassRegistry::getPassRegistry());
+ initializeHexagonLoopAlignPass(*PassRegistry::getPassRegistry());
initializeHexagonTfrCleanupPass(*PassRegistry::getPassRegistry());
initAsmInfo();
}
@@ -476,6 +480,9 @@ void HexagonPassConfig::addPreEmitPass() {
// Packetization is mandatory: it handles gather/scatter at all opt levels.
addPass(createHexagonPacketizer(NoOpt));
+ if (!NoOpt)
+ addPass(createHexagonLoopAlign());
+
if (EnableVectorPrint)
addPass(createHexagonVectorPrint());
diff --git a/llvm/lib/Target/Hexagon/HexagonTargetMachine.h b/llvm/lib/Target/Hexagon/HexagonTargetMachine.h
index c5fed0cd65a814..34ff45b6acf345 100644
--- a/llvm/lib/Target/Hexagon/HexagonTargetMachine.h
+++ b/llvm/lib/Target/Hexagon/HexagonTargetMachine.h
@@ -23,6 +23,7 @@ namespace llvm {
class HexagonTargetMachine : public LLVMTargetMachine {
std::unique_ptr<TargetLoweringObjectFile> TLOF;
+ HexagonSubtarget Subtarget;
mutable StringMap<std::unique_ptr<HexagonSubtarget>> SubtargetMap;
public:
diff --git a/llvm/test/CodeGen/Hexagon/loop-balign.ll b/llvm/test/CodeGen/Hexagon/loop-balign.ll
new file mode 100644
index 00000000000000..9d1f42a4b14b18
--- /dev/null
+++ b/llvm/test/CodeGen/Hexagon/loop-balign.ll
@@ -0,0 +1,91 @@
+; RUN: llc -march=hexagon -O3 < %s | FileCheck %s -check-prefix=BALIGN
+; BALIGN: .p2align{{.*}}5
+
+; The test for checking the alignment of 'for.body4.for.body4_crit_edge' basic block
+
+define dso_local void @foo(i32 %nCol, i32 %nRow, ptr nocapture %resMat) local_unnamed_addr {
+entry:
+ %shl = shl i32 %nRow, 2
+ %cmp36 = icmp sgt i32 %nRow, 0
+ %0 = add i32 %nCol, -1
+ %.inv = icmp slt i32 %0, 1
+ %1 = select i1 %.inv, i32 1, i32 %nCol
+ br label %Outerloop
+
+Outerloop: ; preds = %for.end7, %entry
+ %r12.0 = phi i32 [ 0, %entry ], [ %inc8, %for.end7 ]
+ %r7_6.0 = phi i64 [ undef, %entry ], [ %r7_6.1.lcssa, %for.end7 ]
+ %r0i.0 = phi i32 [ undef, %entry ], [ %r0i.1.lcssa, %for.end7 ]
+ %r5.0 = phi ptr [ %resMat, %entry ], [ %r5.1.lcssa, %for.end7 ]
+ %r8.0 = phi i32 [ %shl, %entry ], [ %r8.1.lcssa, %for.end7 ]
+ br i1 %cmp36, label %for.body.lr.ph, label %for.end7
+
+for.body.lr.ph: ; preds = %Outerloop
+ %cmp332 = icmp eq i32 %r12.0, 0
+ %exitcond.peel = icmp eq i32 %r12.0, 1
+ br label %for.body
+
+for.body: ; preds = %for.end, %for.body.lr.ph
+ %r8.141 = phi i32 [ %r8.0, %for.body.lr.ph ], [ %add, %for.end ]
+ %r5.140 = phi ptr [ %r5.0, %for.body.lr.ph ], [ %add.ptr, %for.end ]
+ %i.039 = phi i32 [ 0, %for.body.lr.ph ], [ %inc6, %for.end ]
+ %r0i.138 = phi i32 [ %r0i.0, %for.body.lr.ph ], [ %4, %for.end ]
+ %r7_6.137 = phi i64 [ %r7_6.0, %for.body.lr.ph ], [ %r7_6.2.lcssa, %for.end ]
+ %add = add nsw i32 %r8.141, %shl
+ br i1 %cmp332, label %for.end, label %for.body4.peel
+
+for.body4.peel: ; preds = %for.body
+ %r1i.0.in.peel = inttoptr i32 %r8.141 to ptr
+ %r1i.0.peel = load i32, ptr %r1i.0.in.peel, align 4
+ %2 = tail call i64 @llvm.hexagon.M2.dpmpyss.nac.s0(i64 %r7_6.137, i32 %r1i.0.peel, i32 %r0i.138)
+ br i1 %exitcond.peel, label %for.end, label %for.body4.preheader.peel.newph
+
+for.body4.preheader.peel.newph: ; preds = %for.body4.peel
+ %r1i.0.in = inttoptr i32 %add to ptr
+ %r1i.0 = load i32, ptr %r1i.0.in, align 4
+ br label %for.body4
+
+for.body4: ; preds = %for.body4.for.body4_crit_edge, %for.body4.preheader.peel.newph
+ %inc.phi = phi i32 [ %inc.0, %for.body4.for.body4_crit_edge ], [ 2, %for.body4.preheader.peel.newph ]
+ %r7_6.233 = phi i64 [ %3, %for.body4.for.body4_crit_edge ], [ %2, %for.body4.preheader.peel.newph ]
+ %3 = tail call i64 @llvm.hexagon.M2.dpmpyss.nac.s0(i64 %r7_6.233, i32 %r1i.0, i32 %r0i.138)
+ %exitcond = icmp eq i32 %inc.phi, %r12.0
+ br i1 %exitcond, label %for.end.loopexit, label %for.body4.for.body4_crit_edge
+
+for.body4.for.body4_crit_edge: ; preds = %for.body4
+ %inc.0 = add nuw nsw i32 %inc.phi, 1
+ br label %for.body4
+
+for.end.loopexit: ; preds = %for.body4
+ br label %for.end
+
+for.end: ; preds = %for.end.loopexit, %for.body4.peel, %for.body
+ %r7_6.2.lcssa = phi i64 [ %r7_6.137, %for.body ], [ %2, %for.body4.peel ], [ %3, %for.end.loopexit ]
+ %4 = tail call i32 @llvm.hexagon.S2.clbp(i64 %r7_6.2.lcssa)
+ store i32 %4, ptr %r5.140, align 4
+ %add.ptr = getelementptr inbounds i8, ptr %r5.140, i32 undef
+ %inc6 = add nuw nsw i32 %i.039, 1
+ %exitcond47 = icmp eq i32 %inc6, %nRow
+ br i1 %exitcond47, label %for.end7.loopexit, label %for.body
+
+for.end7.loopexit: ; preds = %for.end
+ br label %for.end7
+
+for.end7: ; preds = %for.end7.loopexit, %Outerloop
+ %r7_6.1.lcssa = phi i64 [ %r7_6.0, %Outerloop ], [ %r7_6.2.lcssa, %for.end7.loopexit ]
+ %r0i.1.lcssa = phi i32 [ %r0i.0, %Outerloop ], [ %4, %for.end7.loopexit ]
+ %r5.1.lcssa = phi ptr [ %r5.0, %Outerloop ], [ %add.ptr, %for.end7.loopexit ]
+ %r8.1.lcssa = phi i32 [ %r8.0, %Outerloop ], [ %add, %for.end7.loopexit ]
+ %inc8 = add nuw i32 %r12.0, 1
+ %exitcond48 = icmp eq i32 %inc8, %1
+ br i1 %exitcond48, label %if.end, label %Outerloop
+
+if.end: ; preds = %for.end7
+ ret void
+}
+
+; Function Attrs: nounwind readnone
+declare i64 @llvm.hexagon.M2.dpmpyss.nac.s0(i64, i32, i32)
+
+; Function Attrs: nounwind readnone
+declare i32 @llvm.hexagon.S2.clbp(i64)
diff --git a/llvm/test/CodeGen/Hexagon/loop_align_count.ll b/llvm/test/CodeGen/Hexagon/loop_align_count.ll
new file mode 100644
index 00000000000000..07d7e4a8d61176
--- /dev/null
+++ b/llvm/test/CodeGen/Hexagon/loop_align_count.ll
@@ -0,0 +1,115 @@
+; RUN: llc -march=hexagon -mcpu=hexagonv73 -O2 -mattr=+hvxv73,hvx-length64b \
+; RUN: -debug-only=hexagon-loop-align 2>&1 < %s | FileCheck %s
+; Validate that there are 4 bundles in the loop.
+
+; CHECK: Loop Align Pass:
+; CHECK: Bundle Count : 4
+; CHECK: .p2align{{.*}}5
+
+; Function Attrs: nounwind
+define void @ham(ptr noalias nocapture readonly %arg, i32 %arg1, i32 %arg2, i32 %arg3, ptr noalias nocapture %arg4, i32 %arg5) #0 {
+bb:
+ %ashr = ashr i32 %arg3, 2
+ %ashr6 = ashr i32 %arg3, 1
+ %add = add nsw i32 %ashr6, %ashr
+ %icmp = icmp sgt i32 %arg2, 0
+ br i1 %icmp, label %bb7, label %bb61
+
+bb7: ; preds = %bb
+ %sdiv = sdiv i32 %arg1, 64
+ %icmp8 = icmp sgt i32 %arg1, 63
+ br label %bb9
+
+bb9: ; preds = %bb57, %bb7
+ %phi = phi i32 [ 0, %bb7 ], [ %add58, %bb57 ]
+ %ashr10 = ashr exact i32 %phi, 1
+ %mul = mul nsw i32 %ashr10, %arg3
+ br i1 %icmp8, label %bb11, label %bb57
+
+bb11: ; preds = %bb9
+ %add12 = add nsw i32 %phi, 1
+ %mul13 = mul nsw i32 %add12, %arg5
+ %mul14 = mul nsw i32 %phi, %arg5
+ %add15 = add i32 %add, %mul
+ %add16 = add i32 %mul, %ashr
+ %add17 = add i32 %mul, %ashr6
+ %getelementptr = getelementptr inbounds i8, ptr %arg4, i32 %mul13
+ %getelementptr18 = getelementptr inbounds i8, ptr %arg4, i32 %mul14
+ %getelementptr19 = getelementptr inbounds i16, ptr %arg, i32 %add15
+ %getelementptr20 = getelementptr inbounds i16, ptr %arg, i32 %add16
+ %getelementptr21 = getelementptr inbounds i16, ptr %arg, i32 %add17
+ %getelementptr22 = getelementptr inbounds i16, ptr %arg, i32 %mul
+ %bitcast = bitcast ptr %getelementptr to ptr
+ %bitcast23 = bitcast ptr %getelementptr18 to ptr
+ %bitcast24 = bitcast ptr %getelementptr19 to ptr
+ %bitcast25 = bitcast ptr %getelementptr20 to ptr
+ %bitcast26 = bitcast ptr %getelementptr21 to ptr
+ %bitcast27 = bitcast ptr %getelementptr22 to ptr
+ br label %bb28
+
+bb28: ; preds = %bb28, %bb11
+ %phi29 = phi i32 [ 0, %bb11 ], [ %add54, %bb28 ]
+ %phi30 = phi ptr [ %bitcast27, %bb11 ], [ %getelementptr36, %bb28 ]
+ %phi31 = phi ptr [ %bitcast26, %bb11 ], [ %getelementptr37, %bb28 ]
+ %phi32 = phi ptr [ %bitcast25, %bb11 ], [ %getelementptr39, %bb28 ]
+ %phi33 = phi ptr [ %bitcast24, %bb11 ], [ %getelementptr41, %bb28 ]
+ %phi34 = phi ptr [ %bitcast, %bb11 ], [ %getelementptr53, %bb28 ]
+ %phi35 = phi ptr [ %bitcast23, %bb11 ], [ %getelementptr52, %bb28 ]
+ %getelementptr36 = getelementptr inbounds <16 x i32>, ptr %phi30, i32 1
+ %load = load <16 x i32>, ptr %phi30, align 64
+ %getelementptr37 = getelementptr inbounds <16 x i32>, ptr %phi31, i32 1
+ %load38 = load <16 x i32>, ptr %phi31, align 64
+ %getelementptr39 = getelementptr inbounds <16 x i32>, ptr %phi32, i32 1
+ %load40 = load <16 x i32>, ptr %phi32, align 64
+ %getelementptr41 = getelementptr inbounds <16 x i32>, ptr %phi33, i32 1
+ %load42 = load <16 x i32>, ptr %phi33, align 64
+ %call = tail call <16 x i32> @llvm.hexagon.V6.vaddh(<16 x i32> %load, <16 x i32> %load38)
+ %call43 = tail call <16 x i32> @llvm.hexagon.V6.vsubh(<16 x i32> %load, <16 x i32> %load38)
+ %call44 = tail call <16 x i32> @llvm.hexagon.V6.vaddh(<16 x i32> %load40, <16 x i32> %load42)
+ %call45 = tail call <16 x i32> @llvm.hexagon.V6.vsubh(<16 x i32> %load40, <16 x i32> %load42)
+ %call46 = tail call <16 x i32> @llvm.hexagon.V6.vavgh(<16 x i32> %call, <16 x i32> %call44)
+ %call47 = tail call <16 x i32> @llvm.hexagon.V6.vnavgh(<16 x i32> %call, <16 x i32> %call44)
+ %call48 = tail call <16 x i32> @llvm.hexagon.V6.vavgh(<16 x i32> %call43, <16 x i32> %call45)
+ %call49 = tail call <16 x i32> @llvm.hexagon.V6.vnavgh(<16 x i32> %call43, <16 x i32> %call45)
+ %call50 = tail call <16 x i32> @llvm.hexagon.V6.vsathub(<16 x i32> %call47, <16 x i32> %call46)
+ %call51 = tail call <16 x i32> @llvm.hexagon.V6.vsathub(<16 x i32> %call49, <16 x i32> %call48)
+ %getelementptr52 = getelementptr inbounds <16 x i32>, ptr %phi35, i32 1
+ store <16 x i32> %call50, ptr %phi35, align 64
+ %getelementptr53 = getelementptr inbounds <16 x i32>, ptr %phi34, i32 1
+ store <16 x i32> %call51, ptr %phi34, align 64
+ %add54 = add nsw i32 %phi29, 1
+ %icmp55 = icmp slt i32 %add54, %sdiv
+ br i1 %icmp55, label %bb28, label %bb56
+
+bb56: ; preds = %bb28
+ br label %bb57
+
+bb57: ; preds = %bb56, %bb9
+ %add58 = add nsw i32 %phi, 2
+ %icmp59 = icmp slt i32 %add58, %arg2
+ br i1 %icmp59, label %bb9, label %bb60
+
+bb60: ; preds = %bb57
+ br label %bb61
+
+bb61: ; preds = %bb60, %bb
+ ret void
+}
+
+; Function Attrs: nocallback nofree nosync nounwind willreturn memory(none)
+declare <16 x i32> @llvm.hexagon.V6.vaddh(<16 x i32>, <16 x i32>) #1
+
+; Function Attrs: nocallback nofree nosync nounwind willreturn memory(none)
+declare <16 x i32> @llvm.hexagon.V6.vsubh(<16 x i32>, <16 x i32>) #1
+
+; Function Attrs: nocallback nofree nosync nounwind willreturn memory(none)
+declare <16 x i32> @llvm.hexagon.V6.vavgh(<16 x i32>, <16 x i32>) #1
+
+; Function Attrs: nocallback nofree nosync nounwind willreturn memory(none)
+declare <16 x i32> @llvm.hexagon.V6.vnavgh(<16 x i32>, <16 x i32>) #1
+
+; Function Attrs: nocallback nofree nosync nounwind willreturn memory(none)
+declare <16 x i32> @llvm.hexagon.V6.vsathub(<16 x i32>, <16 x i32>) #1
+
+attributes #0 = { nounwind "less-precise-fpmad"="false" "no-frame-pointer-elim"="true" "no-frame-pointer-elim-non-leaf" "no-infs-fp-math"="false" "no-nans-fp-math"="false" "stack-protector-buffer-size"="8" "unsafe-fp-math"="false" "use-soft-float"="false" }
+attributes #1 = { nocallback nofree nosync nounwind willreturn memory(none) }
diff --git a/llvm/test/CodeGen/Hexagon/loop_align_count.mir b/llvm/test/CodeGen/Hexagon/loop_align_count.mir
new file mode 100644
index 00000000000000..afbd917f4f0db3
--- /dev/null
+++ b/llvm/test/CodeGen/Hexagon/loop_align_count.mir
@@ -0,0 +1,130 @@
+# RUN: llc -march=hexagon -O3 -run-pass hexagon-loop-align -o - %s\
+# RUN: -debug-only=hexagon-loop-align -verify-machineinstrs 2>&1 | FileCheck %s
+
+# Test that we only count til endloop instruction and we align this
+# loop to 32.
+# CHECK: Loop Align Pass:
+# CHECK: Instruction Count : 16
+# CHECK: bb.5 (align 32)
+---
+name: fred
+tracksRegLiveness: true
+
+body: |
+ bb.0:
+ successors: %bb.1(0x50000000), %bb.8(0x30000000)
+ liveins: $r0, $r1, $r2, $r3, $r4, $r5
+
+ renamable $p0 = C2_cmpgti renamable $r2, 0
+ J2_jumpf killed renamable $p0, %bb.8, implicit-def dead $pc
+ J2_jump %bb.1, implicit-def dead $pc
+
+ bb.1:
+ successors: %bb.2(0x80000000)
+ liveins: $r0, $r1, $r2, $r3, $r4, $r5
+
+ renamable $r7 = A2_addi killed renamable $r2, 1
+ renamable $r8 = S2_asr_i_r renamable $r1, 31
+ renamable $p0 = C2_cmpgti renamable $r1, 63
+ renamable $r2 = S2_asr_i_r renamable $r3, 2
+ renamable $r6 = S2_asr_i_r renamable $r3, 1
+ renamable $r9 = S2_lsr_i_r killed renamable $r7, 1
+ renamable $r1 = S2_lsr_i_r_acc killed renamable $r1, killed renamable $r8, 26
+ renamable $r7 = A2_tfrsi 0
+ renamable $r1 = S2_asr_i_r killed renamable $r1, 6
+ J2_loop1r %bb.2, killed renamable $r9, implicit-def $lc1, implicit-def $sa1
+ renamable $r8 = nsw A2_add renamable $r6, renamable $r2
+
+ bb.2:
+ successors: %bb.3(0x40000000), %bb.7(0x40000000)
+ liveins: $p0, $r0, $r1, $r2, $r3, $r4, $r5, $r6, $r7, $r8
+
+ J2_jumpf renamable $p0, %bb.7, implicit-def dead $pc
+ J2_jump %bb.3, implicit-def dead $pc
+
+ bb.3:
+ successors: %bb.4(0x80000000)
+ liveins: $p0, $r0, $r1, $r2, $r3, $r4, $r5, $r6, $r7, $r8
+
+ renamable $r13 = exact S2_asr_i_r renamable $r7, 1
+ renamable $r12 = COPY renamable $r4
+ renamable $r9 = COPY renamable $r4
+ renamable $r14 = nsw A2_addi renamable $r7, 1
+ renamable $r15 = nsw M2_mpyi killed renamable $r13, renamable $r3
+ renamable $r9 = M2_maci killed renamable $r9, killed renamable $r14, renamable $r5
+ renamable $r13 = A2_add renamable $r8, renamable $r15
+ renamable $r28 = A2_add renamable $r15, renamable $r2
+ renamable $r10 = A2_add renamable $r15, renamable $r6
+ renamable $r12 = M2_maci killed renamable $r12, renamable $r7, renamable $r5
+ renamable $r13 = S2_addasl_rrri renamable $r0, killed renamable $r13, 1
+ renamable $r14 = S2_addasl_rrri renamable $r0, killed renamable $r15, 1
+ renamable $r15 = S2_addasl_rrri renamable $r0, killed renamable $r28, 1
+ renamable $r28 = S2_addasl_rrri renamable $r0, killed renamable $r10, 1
+
+ bb.4:
+ successors: %bb.5(0x40000000), %bb.6(0x40000000)
+ liveins: $p0, $r0, $r1, $r2, $r3, $r4, $r5, $r6, $r7, $r8, $r9, $r12, $r13, $r14, $r15, $r28
+
+ renamable $v0, renamable $r14 = V6_vL32b_pi killed renamable $r14, 64
+ renamable $p1 = C2_cmpgtui renamable $r1, 1
+ renamable $r10 = A2_addi renamable $r1, -1
+ renamable $v2, renamable $r28 = V6_vL32b_pi killed renamable $r28, 64
+ renamable $v1 = V6_vaddh renamable $v0, renamable $v2
+ renamable $v3, renamable $r15 = V6_vL32b_pi killed renamable $r15, 64
+ renamable $v0 = V6_vsubh killed renamable $v0, killed renamable $v2
+ J2_loop0r %bb.5, killed renamable $r10, implicit-def $lc0, implicit-def $sa0, implicit-def $usr
+ renamable $v4, renamable $r13 = V6_vL32b_pi killed renamable $r13, 64
+ renamable $v2 = V6_vaddh renamable $v3, renamable $v4
+ J2_jumpf killed renamable $p1, %bb.6, implicit-def $pc
+ J2_jump %bb.5, implicit-def $pc
+
+ bb.5:
+ successors: %bb.5(0x7c000000), %bb.6(0x04000000)
+ liveins: $p0, $r0, $r1, $r2, $r3, $r4, $r5, $r6, $r7, $r8, $r9, $r12, $r13, $r14, $r15, $r28, $v0, $v1, $v2, $v3, $v4
+
+ renamable $v3 = V6_vsubh killed renamable $v3, killed renamable $v4
+ renamable $v4, renamable $r14 = V6_vL32b_pi killed renamable $r14, 64
+ renamable $v5 = V6_vnavgh renamable $v1, renamable $v2
+ renamable $v1 = V6_vavgh killed renamable $v1, killed renamable $v2
+ renamable $v2, renamable $r28 = V6_vL32b_pi killed renamable $r28, 64
+ renamable $v1 = V6_vsathub killed renamable $v5, killed renamable $v1
+ renamable $v5 = V6_vnavgh renamable $v0, renamable $v3
+ renamable $v6 = V6_vavgh killed renamable $v0, killed renamable $v3
+ renamable $r12 = V6_vS32b_pi killed renamable $r12, 64, killed renamable $v1
+ renamable $v1 = V6_vaddh renamable $v4, renamable $v2
+ renamable $v3, renamable $r15 = V6_vL32b_pi killed renamable $r15, 64
+ renamable $v0 = V6_vsubh killed renamable $v4, killed renamable $v2
+ renamable $v4, renamable $r13 = V6_vL32b_pi killed renamable $r13, 64
+ renamable $v2 = V6_vaddh renamable $v3, renamable $v4
+ renamable $v5 = V6_vsathub killed renamable $v5, killed renamable $v6
+ renamable $r9 = V6_vS32b_pi killed renamable $r9, 64, killed renamable $v5
+ ENDLOOP0 %bb.5, implicit-def $pc, implicit-def $lc0, implicit $sa0, implicit $lc0
+ J2_jump %bb.6, implicit-def $pc
+
+ bb.6:
+ successors: %bb.7(0x80000000)
+ liveins: $p0, $r0, $r1, $r2, $r3, $r4, $r5, $r6, $r7, $r8, $r9, $r12, $v0, $v1, $v2, $v3, $v4
+
+ renamable $v3 = V6_vsubh killed renamable $v3, killed renamable $v4
+ renamable $v4 = V6_vavgh renamable $v1, renamable $v2
+ renamable $v1 = V6_vnavgh killed renamable $v1, killed renamable $v2
+ renamable $v2 = V6_vavgh renamable $v0, renamable $v3
+ renamable $v0 = V6_vnavgh killed renamable $v0, killed renamable $v3
+ renamable $v1 = V6_vsathub killed renamable $v1, killed renamable $v4
+ dead renamable $r12 = V6_vS32b_pi killed renamable $r12, 64, killed renamable $v1
+ renamable $v0 = V6_vsathub killed renamable $v0, killed renamable $v2
+ dead renamable $r9 = V6_vS32b_pi killed renamable $r9, 64, killed renamable $v0
+ J2_jump %bb.7, implicit-def $pc
+
+ bb.7:
+ successors: %bb.2(0x7c000000), %bb.8(0x04000000)
+ liveins: $p0, $r0, $r1, $r2, $r3, $r4, $r5, $r6, $r7, $r8
+
+ renamable $r7 = nsw A2_addi killed renamable $r7, 2
+ ENDLOOP1 %bb.2, implicit-def $pc, implicit-def $lc1, implicit $sa1, implicit $lc1
+ J2_jump %bb.8, implicit-def dead $pc
+
+ bb.8:
+ PS_jmpret $r31, implicit-def dead $pc
+
+...
diff --git a/llvm/test/CodeGen/Hexagon/v6-haar-balign32.ll b/llvm/test/CodeGen/Hexagon/v6-haar-balign32.ll
new file mode 100644
index 00000000000000..6b3c0a94a494dc
--- /dev/null
+++ b/llvm/test/CodeGen/Hexagon/v6-haar-balign32.ll
@@ -0,0 +1,117 @@
+; RUN: llc -march=hexagon -mcpu=hexagonv73 -O2 -mattr=+hvxv73,hvx-length64b < %s | FileCheck %s
+; CHECK: .p2align{{.*}}5
+
+; Function Attrs: nounwind
+define void @wobble(ptr noalias nocapture readonly %arg, i32 %arg1, i32 %arg2, i32 %arg3, ptr noalias nocapture %arg4, i32 %arg5) #0 {
+bb:
+ %ashr = ashr i32 %arg3, 2
+ %ashr6 = ashr i32 %arg3, 1
+ %add = add nsw i32 %ashr6, %ashr
+ %icmp = icmp sgt i32 %arg2, 0
+ br i1 %icmp, label %bb7, label %bb61
+
+bb7: ; preds = %bb
+ %sdiv = sdiv i32 %arg1, 64
+ %icmp8 = icmp sgt i32 %arg1, 63
+ br label %bb9
+
+bb9: ; preds = %bb57, %bb7
+ %phi = phi i32 [ 0, %bb7 ], [ %add58, %bb57 ]
+ %ashr10 = ashr exact i32 %phi, 1
+ %mul = mul nsw i32 %ashr10, %arg3
+ br i1 %icmp8, label %bb11, label %bb57
+
+bb11: ; preds = %bb9
+ %add12 = add nsw i32 %phi, 1
+ %mul13 = mul nsw i32 %add12, %arg5
+ %mul14 = mul nsw i32 %phi, %arg5
+ %add15 = add i32 %add, %mul
+ %add16 = add i32 %mul, %ashr
+ %add17 = add i32 %mul, %ashr6
+ %getelementptr = getelementptr inbounds i8, ptr %arg4, i32 %mul13
+ %getelementptr18 = getelementptr inbounds i8, ptr %arg4, i32 %mul14
+ %getelementptr19 = getelementptr inbounds i16, ptr %arg, i32 %add15
+ %getelementptr20 = getelementptr inbounds i16, ptr %arg, i32 %add16
+ %getelementptr21 = getelementptr inbounds i16, ptr %arg, i32 %add17
+ %getelementptr22 = getelementptr inbounds i16, ptr %arg, i32 %mul
+ %bitcast = bitcast ptr %getelementptr to ptr
+ %bitcast23 = bitcast ptr %getelementptr18 to ptr
+ %bitcast24 = bitcast ptr %getelementptr19 to ptr
+ %bitcast25 = bitcast ptr %getelementptr20 to ptr
+ %bitcast26 = bitcast ptr %getelementptr21 to ptr
+ %bitcast27 = bitcast ptr %getelementptr22 to ptr
+ br label %bb28
+
+bb28: ; preds = %bb28, %bb11
+ %phi29 = phi i32 [ 0, %bb11 ], [ %add54, %bb28 ]
+ %phi30 = phi ptr [ %bitcast27, %bb11 ], [ %getelementptr36, %bb28 ]
+ %phi31 = phi ptr [ %bitcast26, %bb11 ], [ %getelementptr37, %bb28 ]
+ %phi32 = phi ptr [ %bitcast25, %bb11 ], [ %getelementptr39, %bb28 ]
+ %phi33 = phi ptr [ %bitcast24, %bb11 ], [ %getelementptr41, %bb28 ]
+ %phi34 = phi ptr [ %bitcast, %bb11 ], [ %getelementptr53, %bb28 ]
+ %phi35 = phi ptr [ %bitcast23, %bb11 ], [ %getelementptr52, %bb28 ]
+ %getelementptr36 = getelementptr inbounds <16 x i32>, ptr %phi30, i32 1
+ %load = load <16 x i32>, ptr %phi30, align 64, !tbaa !1
+ %getelementptr37 = getelementptr inbounds <16 x i32>, ptr %phi31, i32 1
+ %load38 = load <16 x i32>, ptr %phi31, align 64, !tbaa !1
+ %getelementptr39 = getelementptr inbounds <16 x i32>, ptr %phi32, i32 1
+ %load40 = load <16 x i32>, ptr %phi32, align 64, !tbaa !1
+ %getelementptr41 = getelementptr inbounds <16 x i32>, ptr %phi33, i32 1
+ %load42 = load <16 x i32>, ptr %phi33, align 64, !tbaa !1
+ %call = tail call <16 x i32> @llvm.hexagon.V6.vaddh(<16 x i32> %load, <16 x i32> %load38)
+ %call43 = tail call <16 x i32> @llvm.hexagon.V6.vsubh(<16 x i32> %load, <16 x i32> %load38)
+ %call44 = tail call <16 x i32> @llvm.hexagon.V6.vaddh(<16 x i32> %load40, <16 x i32> %load42)
+ %call45 = tail call <16 x i32> @llvm.hexagon.V6.vsubh(<16 x i32> %load40, <16 x i32> %load42)
+ %call46 = tail call <16 x i32> @llvm.hexagon.V6.vavgh(<16 x i32> %call, <16 x i32> %call44)
+ %call47 = tail call <16 x i32> @llvm.hexagon.V6.vnavgh(<16 x i32> %call, <16 x i32> %call44)
+ %call48 = tail call <16 x i32> @llvm.hexagon.V6.vavgh(<16 x i32> %call43, <16 x i32> %call45)
+ %call49 = tail call <16 x i32> @llvm.hexagon.V6.vnavgh(<16 x i32> %call43, <16 x i32> %call45)
+ %call50 = tail call <16 x i32> @llvm.hexagon.V6.vsathub(<16 x i32> %call47, <16 x i32> %call46)
+ %call51 = tail call <16 x i32> @llvm.hexagon.V6.vsathub(<16 x i32> %call49, <16 x i32> %call48)
+ %getelementptr52 = getelementptr inbounds <16 x i32>, ptr %phi35, i32 1
+ store <16 x i32> %call50, ptr %phi35, align 64, !tbaa !1
+ %getelementptr53 = getelementptr inbounds <16 x i32>, ptr %phi34, i32 1
+ store <16 x i32> %call51, ptr %phi34, align 64, !tbaa !1
+ %add54 = add nsw i32 %phi29, 1
+ %icmp55 = icmp slt i32 %add54, %sdiv
+ br i1 %icmp55, label %bb28, label %bb56
+
+bb56: ; preds = %bb28
+ br label %bb57
+
+bb57: ; preds = %bb56, %bb9
+ %add58 = add nsw i32 %phi, 2
+ %icmp59 = icmp slt i32 %add58, %arg2
+ br i1 %icmp59, label %bb9, label %bb60
+
+bb60: ; preds = %bb57
+ br label %bb61
+
+bb61: ; preds = %bb60, %bb
+ ret void
+}
+
+; Function Attrs: nocallback nofree nosync nounwind willreturn memory(none)
+declare <16 x i32> @llvm.hexagon.V6.vaddh(<16 x i32>, <16 x i32>) #1
+
+; Function Attrs: nocallback nofree nosync nounwind willreturn memory(none)
+declare <16 x i32> @llvm.hexagon.V6.vsubh(<16 x i32>, <16 x i32>) #1
+
+; Function Attrs: nocallback nofree nosync nounwind willreturn memory(none)
+declare <16 x i32> @llvm.hexagon.V6.vavgh(<16 x i32>, <16 x i32>) #1
+
+; Function Attrs: nocallback nofree nosync nounwind willreturn memory(none)
+declare <16 x i32> @llvm.hexagon.V6.vnavgh(<16 x i32>, <16 x i32>) #1
+
+; Function Attrs: nocallback nofree nosync nounwind willreturn memory(none)
+declare <16 x i32> @llvm.hexagon.V6.vsathub(<16 x i32>, <16 x i32>) #1
+
+attributes #0 = { nounwind "less-precise-fpmad"="false" "no-frame-pointer-elim"="true" "no-frame-pointer-elim-non-leaf" "no-infs-fp-math"="false" "no-nans-fp-math"="false" "stack-protector-buffer-size"="8" "unsafe-fp-math"="false" "use-soft-float"="false" }
+attributes #1 = { nocallback nofree nosync nounwind willreturn memory(none) }
+
+!llvm.ident = !{!0}
+
+!0 = !{!"Clang 3.1"}
+!1 = !{!2, !2, i64 0}
+!2 = !{!"omnipotent char", !3, i64 0}
+!3 = !{!"Simple C/C++ TBAA"}
>From 6137f482fca8b57d9c075b41cc4959b4e63a74f1 Mon Sep 17 00:00:00 2001
From: LLVM GN Syncbot <llvmgnsyncbot at gmail.com>
Date: Thu, 29 Feb 2024 22:58:02 +0000
Subject: [PATCH 187/406] [gn build] Port ca9d2e923b28
---
llvm/utils/gn/secondary/llvm/lib/Target/Hexagon/BUILD.gn | 1 +
1 file changed, 1 insertion(+)
diff --git a/llvm/utils/gn/secondary/llvm/lib/Target/Hexagon/BUILD.gn b/llvm/utils/gn/secondary/llvm/lib/Target/Hexagon/BUILD.gn
index b966b74842670a..cae491a343311a 100644
--- a/llvm/utils/gn/secondary/llvm/lib/Target/Hexagon/BUILD.gn
+++ b/llvm/utils/gn/secondary/llvm/lib/Target/Hexagon/BUILD.gn
@@ -67,6 +67,7 @@ static_library("LLVMHexagonCodeGen") {
"HexagonISelLowering.cpp",
"HexagonISelLoweringHVX.cpp",
"HexagonInstrInfo.cpp",
+ "HexagonLoopAlign.cpp",
"HexagonLoopIdiomRecognition.cpp",
"HexagonMCInstLower.cpp",
"HexagonMachineFunctionInfo.cpp",
>From 71eead512eb1e3c19d940678a82712ef05cdd994 Mon Sep 17 00:00:00 2001
From: Mehdi Amini <joker.eph at gmail.com>
Date: Thu, 29 Feb 2024 15:04:58 -0800
Subject: [PATCH 188/406] Revert "[mlir][sparse] Migration to
sparse_tensor.print" (#83499)
Reverts llvm/llvm-project#83377
The test does not pass on the bot.
---
.../SparseTensor/CPU/sparse_loose.mlir | 23 +-
.../SparseTensor/CPU/sparse_matmul.mlir | 237 ++++++++----------
.../SparseTensor/CPU/sparse_matmul_slice.mlir | 84 ++++---
.../SparseTensor/CPU/sparse_matrix_ops.mlir | 114 ++++-----
4 files changed, 199 insertions(+), 259 deletions(-)
diff --git a/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_loose.mlir b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_loose.mlir
index e1f062121b12f9..228d4e5f6f8a1a 100644
--- a/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_loose.mlir
+++ b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_loose.mlir
@@ -10,7 +10,7 @@
// DEFINE: %{compile} = mlir-opt %s --sparsifier="%{sparsifier_opts}"
// DEFINE: %{compile_sve} = mlir-opt %s --sparsifier="%{sparsifier_opts_sve}"
// DEFINE: %{run_libs} = -shared-libs=%mlir_c_runner_utils,%mlir_runner_utils
-// DEFINE: %{run_opts} = -e main -entry-point-result=void
+// DEFINE: %{run_opts} = -e entry -entry-point-result=void
// DEFINE: %{run} = mlir-cpu-runner %{run_opts} %{run_libs}
// DEFINE: %{run_sve} = %mcr_aarch64_cmd --march=aarch64 --mattr="+sve" %{run_opts} %{run_libs}
//
@@ -28,7 +28,7 @@
}>
module {
- func.func @main() {
+ func.func @entry() {
%c0 = arith.constant 0 : index
%f0 = arith.constant 0.0 : f64
%d = arith.constant dense<[[ 1.0, 2.0, 3.0, 4.0 ],
@@ -39,14 +39,19 @@ module {
%s = sparse_tensor.convert %d : tensor<5x4xf64> to tensor<5x4xf64, #CSR_hi>
//
- // CHECK: ---- Sparse Tensor ----
- // CHECK-NEXT: nse = 17
- // CHECK-NEXT: pos[1] : ( 0, 4, 4, 8, 8, 9, 9, 13
- // CHECK-NEXT: crd[1] : ( 0, 1, 2, 3, 0, 1, 2, 3, 2, 0, 1, 2, 3, 0, 1, 2, 3
- // CHECK-NEXT: values : ( 1, 2, 3, 4, 5, 6, 7, 8, 5.5, 9, 10, 11, 12, 13, 14, 15, 16
- // CHECK-NEXT: ----
+ // CHECK: ( 0, 4, 4, 8, 8, 9, 9, 13 )
+ // CHECK-NEXT: ( 0, 1, 2, 3, 0, 1, 2, 3, 2, 0, 1, 2, 3, 0, 1, 2, 3 )
+ // CHECK-NEXT: ( 1, 2, 3, 4, 5, 6, 7, 8, 5.5, 9, 10, 11, 12, 13, 14, 15, 16 )
//
- sparse_tensor.print %s : tensor<5x4xf64, #CSR_hi>
+ %pos = sparse_tensor.positions %s {level = 1 : index } : tensor<5x4xf64, #CSR_hi> to memref<?xindex>
+ %vecp = vector.transfer_read %pos[%c0], %c0 : memref<?xindex>, vector<8xindex>
+ vector.print %vecp : vector<8xindex>
+ %crd = sparse_tensor.coordinates %s {level = 1 : index } : tensor<5x4xf64, #CSR_hi> to memref<?xindex>
+ %vecc = vector.transfer_read %crd[%c0], %c0 : memref<?xindex>, vector<17xindex>
+ vector.print %vecc : vector<17xindex>
+ %val = sparse_tensor.values %s : tensor<5x4xf64, #CSR_hi> to memref<?xf64>
+ %vecv = vector.transfer_read %val[%c0], %f0 : memref<?xf64>, vector<17xf64>
+ vector.print %vecv : vector<17xf64>
// Release the resources.
bufferization.dealloc_tensor %s: tensor<5x4xf64, #CSR_hi>
diff --git a/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matmul.mlir b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matmul.mlir
index 863e1c62370e32..fa0dbac269b926 100644
--- a/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matmul.mlir
+++ b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matmul.mlir
@@ -10,7 +10,7 @@
// DEFINE: %{compile} = mlir-opt %s --sparsifier="%{sparsifier_opts}"
// DEFINE: %{compile_sve} = mlir-opt %s --sparsifier="%{sparsifier_opts_sve}"
// DEFINE: %{run_libs} = -shared-libs=%mlir_c_runner_utils,%mlir_runner_utils
-// DEFINE: %{run_opts} = -e main -entry-point-result=void
+// DEFINE: %{run_opts} = -e entry -entry-point-result=void
// DEFINE: %{run} = mlir-cpu-runner %{run_opts} %{run_libs}
// DEFINE: %{run_sve} = %mcr_aarch64_cmd --march=aarch64 --mattr="+sve" %{run_opts} %{run_libs}
//
@@ -90,7 +90,7 @@ module {
//
// Main driver.
//
- func.func @main() {
+ func.func @entry() {
%c0 = arith.constant 0 : index
// Initialize various matrices, dense for stress testing,
@@ -140,94 +140,33 @@ module {
%b4 = sparse_tensor.convert %sb : tensor<8x4xf64> to tensor<8x4xf64, #DCSR>
//
- // Sanity check before going into the computations.
- //
- // CHECK: ---- Sparse Tensor ----
- // CHECK-NEXT: nse = 32
- // CHECK-NEXT: pos[1] : ( 0, 8, 16, 24, 32
- // CHECK-NEXT: crd[1] : ( 0, 1, 2, 3, 4, 5, 6, 7, 0, 1, 2, 3, 4, 5, 6, 7, 0, 1, 2, 3, 4, 5, 6, 7, 0, 1, 2, 3, 4, 5, 6, 7
- // CHECK-NEXT: values : ( 1.1, 2.1, 3.1, 4.1, 5.1, 6.1, 7.1, 8.1, 1.2, 2.2, 3.2, 4.2, 5.2, 6.2, 7.2, 8.2, 1.3, 2.3, 3.3, 4.3, 5.3, 6.3, 7.3, 8.3, 1.4, 2.4, 3.4, 4.4, 5.4, 6.4, 7.4, 8.4
- // CHECK-NEXT: ----
- //
- sparse_tensor.print %a1 : tensor<4x8xf64, #CSR>
-
- //
- // CHECK: ---- Sparse Tensor ----
- // CHECK-NEXT: nse = 32
- // CHECK-NEXT: pos[0] : ( 0, 4
- // CHECK-NEXT: crd[0] : ( 0, 1, 2, 3
- // CHECK-NEXT: pos[1] : ( 0, 8, 16, 24, 32
- // CHECK-NEXT: crd[1] : ( 0, 1, 2, 3, 4, 5, 6, 7, 0, 1, 2, 3, 4, 5, 6, 7, 0, 1, 2, 3, 4, 5, 6, 7, 0, 1, 2, 3, 4, 5, 6, 7
- // CHECK-NEXT: values : ( 1.1, 2.1, 3.1, 4.1, 5.1, 6.1, 7.1, 8.1, 1.2, 2.2, 3.2, 4.2, 5.2, 6.2, 7.2, 8.2, 1.3, 2.3, 3.3, 4.3, 5.3, 6.3, 7.3, 8.3, 1.4, 2.4, 3.4, 4.4, 5.4, 6.4, 7.4, 8.4
- // CHECK-NEXT: ----
- //
- sparse_tensor.print %a2 : tensor<4x8xf64, #DCSR>
-
- //
- // CHECK: ---- Sparse Tensor ----
- // CHECK-NEXT: nse = 4
- // CHECK-NEXT: pos[1] : ( 0, 2, 2, 3, 4
- // CHECK-NEXT: crd[1] : ( 1, 5, 1, 7
- // CHECK-NEXT: values : ( 2.1, 6.1, 2.3, 1
- // CHECK-NEXT: ----
- //
- sparse_tensor.print %a3 : tensor<4x8xf64, #CSR>
-
- //
- // CHECK: ---- Sparse Tensor ----
- // CHECK-NEXT: nse = 4
- // CHECK-NEXT: pos[0] : ( 0, 3
- // CHECK-NEXT: crd[0] : ( 0, 2, 3
- // CHECK-NEXT: pos[1] : ( 0, 2, 3, 4
- // CHECK-NEXT: crd[1] : ( 1, 5, 1, 7
- // CHECK-NEXT: values : ( 2.1, 6.1, 2.3, 1
- // CHECK-NEXT: ----
- //
- sparse_tensor.print %a4 : tensor<4x8xf64, #DCSR>
-
- //
- // CHECK: ---- Sparse Tensor ----
- // CHECK-NEXT: nse = 32
- // CHECK-NEXT: pos[1] : ( 0, 4, 8, 12, 16, 20, 24, 28, 32
- // CHECK-NEXT: crd[1] : ( 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3
- // CHECK-NEXT: values : ( 10.1, 11.1, 12.1, 13.1, 10.2, 11.2, 12.2, 13.2, 10.3, 11.3, 12.3, 13.3, 10.4, 11.4, 12.4, 13.4, 10.5, 11.5, 12.5, 13.5, 10.6, 11.6, 12.6, 13.6, 10.7, 11.7, 12.7, 13.7, 10.8, 11.8, 12.8, 13.8
- // CHECK-NEXT: ----
- //
- sparse_tensor.print %b1 : tensor<8x4xf64, #CSR>
-
- //
- // CHECK: ---- Sparse Tensor ----
- // CHECK-NEXT: nse = 32
- // CHECK-NEXT: pos[0] : ( 0, 8
- // CHECK-NEXT: crd[0] : ( 0, 1, 2, 3, 4, 5, 6, 7
- // CHECK-NEXT: pos[1] : ( 0, 4, 8, 12, 16, 20, 24, 28, 32
- // CHECK-NEXT: crd[1] : ( 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3
- // CHECK-NEXT: values : ( 10.1, 11.1, 12.1, 13.1, 10.2, 11.2, 12.2, 13.2, 10.3, 11.3, 12.3, 13.3, 10.4, 11.4, 12.4, 13.4, 10.5, 11.5, 12.5, 13.5, 10.6, 11.6, 12.6, 13.6, 10.7, 11.7, 12.7, 13.7, 10.8, 11.8, 12.8, 13.8
- // CHECK-NEXT: ----
- //
- sparse_tensor.print %b2 : tensor<8x4xf64, #DCSR>
-
- //
- // CHECK: ---- Sparse Tensor ----
- // CHECK-NEXT: nse = 8
- // CHECK-NEXT: pos[1] : ( 0, 1, 2, 3, 4, 4, 5, 6, 8
- // CHECK-NEXT: crd[1] : ( 3, 2, 1, 0, 1, 2, 2, 3
- // CHECK-NEXT: values : ( 1, 2, 3, 4, 5, 6, 7, 8
- // CHECK-NEXT: ----
- //
- sparse_tensor.print %b3 : tensor<8x4xf64, #CSR>
-
- //
- // CHECK: ---- Sparse Tensor ----
- // CHECK-NEXT: nse = 8
- // CHECK-NEXT: pos[0] : ( 0, 7
- // CHECK-NEXT: crd[0] : ( 0, 1, 2, 3, 5, 6, 7
- // CHECK-NEXT: pos[1] : ( 0, 1, 2, 3, 4, 5, 6, 8
- // CHECK-NEXT: crd[1] : ( 3, 2, 1, 0, 1, 2, 2, 3
- // CHECK-NEXT: values : ( 1, 2, 3, 4, 5, 6, 7, 8
- // CHECK-NEXT: ----
- //
- sparse_tensor.print %b4 : tensor<8x4xf64, #DCSR>
+ // Sanity check on stored entries before going into the computations.
+ //
+ // CHECK: 32
+ // CHECK-NEXT: 32
+ // CHECK-NEXT: 4
+ // CHECK-NEXT: 4
+ // CHECK-NEXT: 32
+ // CHECK-NEXT: 32
+ // CHECK-NEXT: 8
+ // CHECK-NEXT: 8
+ //
+ %noea1 = sparse_tensor.number_of_entries %a1 : tensor<4x8xf64, #CSR>
+ %noea2 = sparse_tensor.number_of_entries %a2 : tensor<4x8xf64, #DCSR>
+ %noea3 = sparse_tensor.number_of_entries %a3 : tensor<4x8xf64, #CSR>
+ %noea4 = sparse_tensor.number_of_entries %a4 : tensor<4x8xf64, #DCSR>
+ %noeb1 = sparse_tensor.number_of_entries %b1 : tensor<8x4xf64, #CSR>
+ %noeb2 = sparse_tensor.number_of_entries %b2 : tensor<8x4xf64, #DCSR>
+ %noeb3 = sparse_tensor.number_of_entries %b3 : tensor<8x4xf64, #CSR>
+ %noeb4 = sparse_tensor.number_of_entries %b4 : tensor<8x4xf64, #DCSR>
+ vector.print %noea1 : index
+ vector.print %noea2 : index
+ vector.print %noea3 : index
+ vector.print %noea4 : index
+ vector.print %noeb1 : index
+ vector.print %noeb2 : index
+ vector.print %noeb3 : index
+ vector.print %noeb4 : index
// Call kernels with dense.
%0 = call @matmul1(%da, %db, %zero)
@@ -269,26 +208,24 @@ module {
call @printMemrefF64(%u0) : (tensor<*xf64>) -> ()
//
- // CHECK: ---- Sparse Tensor ----
- // CHECK-NEXT: nse = 16
- // CHECK-NEXT: pos[1] : ( 0, 4, 8, 12, 16
- // CHECK-NEXT: crd[1] : ( 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3
- // CHECK-NEXT: values : ( 388.76, 425.56, 462.36, 499.16, 397.12, 434.72, 472.32, 509.92, 405.48, 443.88, 482.28, 520.68, 413.84, 453.04, 492.24, 531.44
- // CHECK-NEXT: ----
+ // CHECK: {{\[}}[388.76, 425.56, 462.36, 499.16],
+ // CHECK-NEXT: [397.12, 434.72, 472.32, 509.92],
+ // CHECK-NEXT: [405.48, 443.88, 482.28, 520.68],
+ // CHECK-NEXT: [413.84, 453.04, 492.24, 531.44]]
//
- sparse_tensor.print %1 : tensor<4x4xf64, #CSR>
+ %c1 = sparse_tensor.convert %1 : tensor<4x4xf64, #CSR> to tensor<4x4xf64>
+ %c1u = tensor.cast %c1 : tensor<4x4xf64> to tensor<*xf64>
+ call @printMemrefF64(%c1u) : (tensor<*xf64>) -> ()
//
- // CHECK: ---- Sparse Tensor ----
- // CHECK-NEXT: nse = 16
- // CHECK-NEXT: pos[0] : ( 0, 4
- // CHECK-NEXT: crd[0] : ( 0, 1, 2, 3
- // CHECK-NEXT: pos[1] : ( 0, 4, 8, 12, 16
- // CHECK-NEXT: crd[1] : ( 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3
- // CHECK-NEXT: values : ( 388.76, 425.56, 462.36, 499.16, 397.12, 434.72, 472.32, 509.92, 405.48, 443.88, 482.28, 520.68, 413.84, 453.04, 492.24, 531.44
- // CHECK-NEXT: ----
+ // CHECK: {{\[}}[388.76, 425.56, 462.36, 499.16],
+ // CHECK-NEXT: [397.12, 434.72, 472.32, 509.92],
+ // CHECK-NEXT: [405.48, 443.88, 482.28, 520.68],
+ // CHECK-NEXT: [413.84, 453.04, 492.24, 531.44]]
//
- sparse_tensor.print %2 : tensor<4x4xf64, #DCSR>
+ %c2 = sparse_tensor.convert %2 : tensor<4x4xf64, #DCSR> to tensor<4x4xf64>
+ %c2u = tensor.cast %c2 : tensor<4x4xf64> to tensor<*xf64>
+ call @printMemrefF64(%c2u) : (tensor<*xf64>) -> ()
//
// CHECK: {{\[}}[86.08, 94.28, 102.48, 110.68],
@@ -300,26 +237,24 @@ module {
call @printMemrefF64(%u3) : (tensor<*xf64>) -> ()
//
- // CHECK: ---- Sparse Tensor ----
- // CHECK-NEXT: nse = 12
- // CHECK-NEXT: pos[1] : ( 0, 4, 4, 8, 12
- // CHECK-NEXT: crd[1] : ( 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3
- // CHECK-NEXT: values : ( 86.08, 94.28, 102.48, 110.68, 23.46, 25.76, 28.06, 30.36, 10.8, 11.8, 12.8, 13.8
- // CHECK-NEXT: ----
+ // CHECK: {{\[}}[86.08, 94.28, 102.48, 110.68],
+ // CHECK-NEXT: [0, 0, 0, 0],
+ // CHECK-NEXT: [23.46, 25.76, 28.06, 30.36],
+ // CHECK-NEXT: [10.8, 11.8, 12.8, 13.8]]
//
- sparse_tensor.print %4 : tensor<4x4xf64, #CSR>
+ %c4 = sparse_tensor.convert %4 : tensor<4x4xf64, #CSR> to tensor<4x4xf64>
+ %c4u = tensor.cast %c4 : tensor<4x4xf64> to tensor<*xf64>
+ call @printMemrefF64(%c4u) : (tensor<*xf64>) -> ()
//
- // CHECK: ---- Sparse Tensor ----
- // CHECK-NEXT: nse = 12
- // CHECK-NEXT: pos[0] : ( 0, 3
- // CHECK-NEXT: crd[0] : ( 0, 2, 3
- // CHECK-NEXT: pos[1] : ( 0, 4, 8, 12
- // CHECK-NEXT: crd[1] : ( 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3
- // CHECK-NEXT: values : ( 86.08, 94.28, 102.48, 110.68, 23.46, 25.76, 28.06, 30.36, 10.8, 11.8, 12.8, 13.8
- // CHECK-NEXT: ----
+ // CHECK: {{\[}}[86.08, 94.28, 102.48, 110.68],
+ // CHECK-NEXT: [0, 0, 0, 0],
+ // CHECK-NEXT: [23.46, 25.76, 28.06, 30.36],
+ // CHECK-NEXT: [10.8, 11.8, 12.8, 13.8]]
//
- sparse_tensor.print %5 : tensor<4x4xf64, #DCSR>
+ %c5 = sparse_tensor.convert %5 : tensor<4x4xf64, #DCSR> to tensor<4x4xf64>
+ %c5u = tensor.cast %c5 : tensor<4x4xf64> to tensor<*xf64>
+ call @printMemrefF64(%c5u) : (tensor<*xf64>) -> ()
//
// CHECK: {{\[}}[0, 30.5, 4.2, 0],
@@ -331,26 +266,46 @@ module {
call @printMemrefF64(%u6) : (tensor<*xf64>) -> ()
//
- // CHECK: ---- Sparse Tensor ----
- // CHECK-NEXT: nse = 5
- // CHECK-NEXT: pos[1] : ( 0, 2, 2, 3, 5
- // CHECK-NEXT: crd[1] : ( 1, 2, 2, 2, 3
- // CHECK-NEXT: values : ( 30.5, 4.2, 4.6, 7, 8
- // CHECK-NEXT: ----
+ // CHECK: {{\[}}[0, 30.5, 4.2, 0],
+ // CHECK-NEXT: [0, 0, 0, 0],
+ // CHECK-NEXT: [0, 0, 4.6, 0],
+ // CHECK-NEXT: [0, 0, 7, 8]]
//
- sparse_tensor.print %7 : tensor<4x4xf64, #CSR>
+ %c7 = sparse_tensor.convert %7 : tensor<4x4xf64, #CSR> to tensor<4x4xf64>
+ %c7u = tensor.cast %c7 : tensor<4x4xf64> to tensor<*xf64>
+ call @printMemrefF64(%c7u) : (tensor<*xf64>) -> ()
//
- // CHECK: ---- Sparse Tensor ----
- // CHECK-NEXT: nse = 5
- // CHECK-NEXT: pos[0] : ( 0, 3
- // CHECK-NEXT: crd[0] : ( 0, 2, 3
- // CHECK-NEXT: pos[1] : ( 0, 2, 3, 5
- // CHECK-NEXT: crd[1] : ( 1, 2, 2, 2, 3
- // CHECK-NEXT: values : ( 30.5, 4.2, 4.6, 7, 8
- // CHECK-NEXT: ----
+ // CHECK: {{\[}}[0, 30.5, 4.2, 0],
+ // CHECK-NEXT: [0, 0, 0, 0],
+ // CHECK-NEXT: [0, 0, 4.6, 0],
+ // CHECK-NEXT: [0, 0, 7, 8]]
+ //
+ %c8 = sparse_tensor.convert %8 : tensor<4x4xf64, #DCSR> to tensor<4x4xf64>
+ %c8u = tensor.cast %c8 : tensor<4x4xf64> to tensor<*xf64>
+ call @printMemrefF64(%c8u) : (tensor<*xf64>) -> ()
+
+ //
+ // Sanity check on nonzeros.
+ //
+ // CHECK: [30.5, 4.2, 4.6, 7, 8{{.*}}]
+ // CHECK: [30.5, 4.2, 4.6, 7, 8{{.*}}]
+ //
+ %val7 = sparse_tensor.values %7 : tensor<4x4xf64, #CSR> to memref<?xf64>
+ %val8 = sparse_tensor.values %8 : tensor<4x4xf64, #DCSR> to memref<?xf64>
+ call @printMemref1dF64(%val7) : (memref<?xf64>) -> ()
+ call @printMemref1dF64(%val8) : (memref<?xf64>) -> ()
+
+ //
+ // Sanity check on stored entries after the computations.
+ //
+ // CHECK-NEXT: 5
+ // CHECK-NEXT: 5
//
- sparse_tensor.print %8 : tensor<4x4xf64, #DCSR>
+ %noe7 = sparse_tensor.number_of_entries %7 : tensor<4x4xf64, #CSR>
+ %noe8 = sparse_tensor.number_of_entries %8 : tensor<4x4xf64, #DCSR>
+ vector.print %noe7 : index
+ vector.print %noe8 : index
// Release the resources.
bufferization.dealloc_tensor %a1 : tensor<4x8xf64, #CSR>
@@ -361,6 +316,12 @@ module {
bufferization.dealloc_tensor %b2 : tensor<8x4xf64, #DCSR>
bufferization.dealloc_tensor %b3 : tensor<8x4xf64, #CSR>
bufferization.dealloc_tensor %b4 : tensor<8x4xf64, #DCSR>
+ bufferization.dealloc_tensor %c1 : tensor<4x4xf64>
+ bufferization.dealloc_tensor %c2 : tensor<4x4xf64>
+ bufferization.dealloc_tensor %c4 : tensor<4x4xf64>
+ bufferization.dealloc_tensor %c5 : tensor<4x4xf64>
+ bufferization.dealloc_tensor %c7 : tensor<4x4xf64>
+ bufferization.dealloc_tensor %c8 : tensor<4x4xf64>
bufferization.dealloc_tensor %0 : tensor<4x4xf64>
bufferization.dealloc_tensor %1 : tensor<4x4xf64, #CSR>
bufferization.dealloc_tensor %2 : tensor<4x4xf64, #DCSR>
diff --git a/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matmul_slice.mlir b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matmul_slice.mlir
index a7184c044569ca..96c8a30ade8e42 100644
--- a/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matmul_slice.mlir
+++ b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matmul_slice.mlir
@@ -10,7 +10,7 @@
// DEFINE: %{compile} = mlir-opt %s --sparsifier="%{sparsifier_opts}"
// DEFINE: %{compile_sve} = mlir-opt %s --sparsifier="%{sparsifier_opts_sve}"
// DEFINE: %{run_libs} = -shared-libs=%mlir_c_runner_utils,%mlir_runner_utils
-// DEFINE: %{run_opts} = -e main -entry-point-result=void
+// DEFINE: %{run_opts} = -e entry -entry-point-result=void
// DEFINE: %{run} = mlir-cpu-runner %{run_opts} %{run_libs}
// DEFINE: %{run_sve} = %mcr_aarch64_cmd --march=aarch64 --mattr="+sve" %{run_opts} %{run_libs}
//
@@ -132,7 +132,7 @@ module {
//
// Main driver.
//
- func.func @main() {
+ func.func @entry() {
%c_0 = arith.constant 0 : index
%c_1 = arith.constant 1 : index
%c_2 = arith.constant 2 : index
@@ -170,16 +170,14 @@ module {
// DCSR test
//
- // CHECK: ---- Sparse Tensor ----
- // CHECK-NEXT: nse = 5
- // CHECK-NEXT: pos[0] : ( 0, 3
- // CHECK-NEXT: crd[0] : ( 0, 2, 3
- // CHECK-NEXT: pos[1] : ( 0, 2, 3, 5
- // CHECK-NEXT: crd[1] : ( 1, 2, 2, 2, 3
- // CHECK-NEXT: values : ( 30.5, 4.2, 4.6, 7, 8
- // CHECK-NEXT: ----
+ // CHECK: [0, 30.5, 4.2, 0],
+ // CHECK-NEXT: [0, 0, 0, 0],
+ // CHECK-NEXT: [0, 0, 4.6, 0],
+ // CHECK-NEXT: [0, 0, 7, 8]
//
- sparse_tensor.print %2 : tensor<4x4xf64, #DCSR>
+ %c2 = sparse_tensor.convert %2 : tensor<4x4xf64, #DCSR> to tensor<4x4xf64>
+ %c2u = tensor.cast %c2 : tensor<4x4xf64> to tensor<*xf64>
+ call @printMemrefF64(%c2u) : (tensor<*xf64>) -> ()
%t1 = sparse_tensor.convert %sa : tensor<8x8xf64> to tensor<8x8xf64, #CSR>
%a1 = tensor.extract_slice %t1[0, 0][4, 8][1, 1] : tensor<8x8xf64, #CSR> to tensor<4x8xf64, #CSR_SLICE>
@@ -190,64 +188,63 @@ module {
// CSR test
//
- // CHECK: ---- Sparse Tensor ----
- // CHECK-NEXT: nse = 5
- // CHECK-NEXT: pos[1] : ( 0, 2, 2, 3, 5
- // CHECK-NEXT: crd[1] : ( 1, 2, 2, 2, 3
- // CHECK-NEXT: values : ( 30.5, 4.2, 4.6, 7, 8
- // CHECK-NEXT: ----
+ // CHECK: [0, 30.5, 4.2, 0],
+ // CHECK-NEXT: [0, 0, 0, 0],
+ // CHECK-NEXT: [0, 0, 4.6, 0],
+ // CHECK-NEXT: [0, 0, 7, 8]
//
- sparse_tensor.print %3 : tensor<4x4xf64, #CSR>
-
+ %c3 = sparse_tensor.convert %3 : tensor<4x4xf64, #CSR> to tensor<4x4xf64>
+ %c3u = tensor.cast %c3 : tensor<4x4xf64> to tensor<*xf64>
+ call @printMemrefF64(%c3u) : (tensor<*xf64>) -> ()
// slice x slice
//
- // CHECK: ---- Sparse Tensor ----
- // CHECK-NEXT: nse = 3
- // CHECK-NEXT: pos[1] : ( 0, 1, 2, 2, 3
- // CHECK-NEXT: crd[1] : ( 0, 0, 0
- // CHECK-NEXT: values : ( 2.3, 6.9, 12.6
- // CHECK-NEXT: ----
+ // CHECK: [2.3, 0, 0, 0],
+ // CHECK-NEXT: [6.9, 0, 0, 0],
+ // CHECK-NEXT: [0, 0, 0, 0],
+ // CHECK-NEXT: [12.6, 0, 0, 0]]
//
- sparse_tensor.print %4 : tensor<4x4xf64, #CSR>
-
%s1 = tensor.extract_slice %tmp[0, 1][4, 4][2, 1] : tensor<8x8xf64, #DCSR> to tensor<4x4xf64, #DCSR_SLICE_1>
%s2 = tensor.extract_slice %b1[0, 0][4, 4][2, 1] : tensor<8x4xf64, #CSR> to tensor<4x4xf64, #CSR_SLICE_1>
%4 = call @matmul1(%s2, %s1)
: (tensor<4x4xf64, #CSR_SLICE_1>,
tensor<4x4xf64, #DCSR_SLICE_1>) -> tensor<4x4xf64, #CSR>
+ %c4 = sparse_tensor.convert %4 : tensor<4x4xf64, #CSR> to tensor<4x4xf64>
+ %c4u = tensor.cast %c4 : tensor<4x4xf64> to tensor<*xf64>
+ call @printMemrefF64(%c4u) : (tensor<*xf64>) -> ()
// slice coo x slice coo
//
- // CHECK: ---- Sparse Tensor ----
- // CHECK-NEXT: nse = 3
- // CHECK-NEXT: pos[0] : ( 0, 3
- // CHECK-NEXT: crd[0] : ( 0, 0, 1, 0, 3, 0
- // CHECK-NEXT: values : ( 2.3, 6.9, 12.6
- // CHECK-NEXT: ----
+ // CHECK: [2.3, 0, 0, 0],
+ // CHECK-NEXT: [6.9, 0, 0, 0],
+ // CHECK-NEXT: [0, 0, 0, 0],
+ // CHECK-NEXT: [12.6, 0, 0, 0]]
//
- sparse_tensor.print %o_coo : tensor<4x4xf64, #COO>
%t1_coo = sparse_tensor.convert %sa : tensor<8x8xf64> to tensor<8x8xf64, #COO>
%b1_coo = sparse_tensor.convert %sb : tensor<8x4xf64> to tensor<8x4xf64, #COO>
%s2_coo = tensor.extract_slice %b1_coo[0, 0][4, 4][2, 1] : tensor<8x4xf64, #COO> to tensor<4x4xf64, #COO_SLICE_1>
%s1_coo = tensor.extract_slice %t1_coo[0, 1][4, 4][2, 1] : tensor<8x8xf64, #COO> to tensor<4x4xf64, #COO_SLICE_2>
%o_coo = call @matmul5(%s2_coo, %s1_coo) : (tensor<4x4xf64, #COO_SLICE_1>, tensor<4x4xf64, #COO_SLICE_2>) -> tensor<4x4xf64, #COO>
+ %c4_coo = sparse_tensor.convert %o_coo : tensor<4x4xf64, #COO> to tensor<4x4xf64>
+ %c4u_coo = tensor.cast %c4_coo : tensor<4x4xf64> to tensor<*xf64>
+ call @printMemrefF64(%c4u_coo) : (tensor<*xf64>) -> ()
+
// slice x slice (same as above, but with dynamic stride information)
//
- // CHECK: ---- Sparse Tensor ----
- // CHECK-NEXT: nse = 3
- // CHECK-NEXT: pos[1] : ( 0, 1, 2, 2, 3
- // CHECK-NEXT: crd[1] : ( 0, 0, 0
- // CHECK-NEXT: values : ( 2.3, 6.9, 12.6
- // CHECK-NEXT: ----
+ // CHECK: [2.3, 0, 0, 0],
+ // CHECK-NEXT: [6.9, 0, 0, 0],
+ // CHECK-NEXT: [0, 0, 0, 0],
+ // CHECK-NEXT: [12.6, 0, 0, 0]]
//
- sparse_tensor.print %dyn_4 : tensor<4x4xf64, #CSR>
%s1_dyn = tensor.extract_slice %tmp[%c_0, %c_1][4, 4][%c_2, %c_1] : tensor<8x8xf64, #DCSR> to tensor<4x4xf64, #DCSR_SLICE_dyn>
%s2_dyn = tensor.extract_slice %b1[%c_0, %c_0][4, 4][%c_2, %c_1] : tensor<8x4xf64, #CSR> to tensor<4x4xf64, #CSR_SLICE_dyn>
%dyn_4 = call @matmul_dyn(%s2_dyn, %s1_dyn)
: (tensor<4x4xf64, #CSR_SLICE_dyn>,
tensor<4x4xf64, #DCSR_SLICE_dyn>) -> tensor<4x4xf64, #CSR>
+ %c4_dyn = sparse_tensor.convert %dyn_4 : tensor<4x4xf64, #CSR> to tensor<4x4xf64>
+ %c4u_dyn = tensor.cast %c4_dyn : tensor<4x4xf64> to tensor<*xf64>
+ call @printMemrefF64(%c4u_dyn) : (tensor<*xf64>) -> ()
// sparse slices should generate the same result as dense slices
//
@@ -268,6 +265,11 @@ module {
call @printMemrefF64(%du) : (tensor<*xf64>) -> ()
// Releases resources.
+ bufferization.dealloc_tensor %c2 : tensor<4x4xf64>
+ bufferization.dealloc_tensor %c3 : tensor<4x4xf64>
+ bufferization.dealloc_tensor %c4 : tensor<4x4xf64>
+ bufferization.dealloc_tensor %c4_coo : tensor<4x4xf64>
+ bufferization.dealloc_tensor %c4_dyn : tensor<4x4xf64>
bufferization.dealloc_tensor %d : tensor<4x4xf64>
bufferization.dealloc_tensor %b1 : tensor<8x4xf64, #CSR>
bufferization.dealloc_tensor %t1 : tensor<8x8xf64, #CSR>
diff --git a/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matrix_ops.mlir b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matrix_ops.mlir
index 2cef46f4cb1546..2cecc242034389 100644
--- a/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matrix_ops.mlir
+++ b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matrix_ops.mlir
@@ -10,7 +10,7 @@
// DEFINE: %{compile} = mlir-opt %s --sparsifier="%{sparsifier_opts}"
// DEFINE: %{compile_sve} = mlir-opt %s --sparsifier="%{sparsifier_opts_sve}"
// DEFINE: %{run_libs} = -shared-libs=%mlir_c_runner_utils,%mlir_runner_utils
-// DEFINE: %{run_opts} = -e main -entry-point-result=void
+// DEFINE: %{run_opts} = -e entry -entry-point-result=void
// DEFINE: %{run} = mlir-cpu-runner %{run_opts} %{run_libs}
// DEFINE: %{run_sve} = %mcr_aarch64_cmd --march=aarch64 --mattr="+sve" %{run_opts} %{run_libs}
//
@@ -61,6 +61,8 @@
}
module {
+ func.func private @printMemrefF64(%ptr : tensor<*xf64>)
+
// Scales a sparse matrix into a new sparse matrix.
func.func @matrix_scale(%arga: tensor<?x?xf64, #DCSR>) -> tensor<?x?xf64, #DCSR> {
%s = arith.constant 2.0 : f64
@@ -127,8 +129,17 @@ module {
return %0 : tensor<?x?xf64, #DCSR>
}
+ // Dump a sparse matrix.
+ func.func @dump(%arg0: tensor<?x?xf64, #DCSR>) {
+ %dm = sparse_tensor.convert %arg0 : tensor<?x?xf64, #DCSR> to tensor<?x?xf64>
+ %u = tensor.cast %dm : tensor<?x?xf64> to tensor<*xf64>
+ call @printMemrefF64(%u) : (tensor<*xf64>) -> ()
+ bufferization.dealloc_tensor %dm : tensor<?x?xf64>
+ return
+ }
+
// Driver method to call and verify matrix kernels.
- func.func @main() {
+ func.func @entry() {
%c0 = arith.constant 0 : index
%d1 = arith.constant 1.1 : f64
@@ -159,76 +170,37 @@ module {
//
// Verify the results.
//
- // CHECK: ---- Sparse Tensor ----
- // CHECK-NEXT: nse = 9
- // CHECK-NEXT: pos[0] : ( 0, 4
- // CHECK-NEXT: crd[0] : ( 0, 1, 2, 3
- // CHECK-NEXT: pos[1] : ( 0, 2, 3, 6, 9
- // CHECK-NEXT: crd[1] : ( 0, 1, 7, 2, 4, 7, 0, 2, 3
- // CHECK-NEXT: values : ( 1, 2, 3, 4, 5, 6, 7, 8, 9
- // CHECK-NEXT: ----
- //
- sparse_tensor.print %sm1 : tensor<?x?xf64, #DCSR>
-
- //
- // CHECK: ---- Sparse Tensor ----
- // CHECK-NEXT: nse = 6
- // CHECK-NEXT: pos[0] : ( 0, 3
- // CHECK-NEXT: crd[0] : ( 0, 1, 2
- // CHECK-NEXT: pos[1] : ( 0, 2, 4, 6
- // CHECK-NEXT: crd[1] : ( 0, 7, 0, 6, 1, 7
- // CHECK-NEXT: values : ( 6, 5, 4, 3, 2, 1
- // CHECK-NEXT: ----
- //
- sparse_tensor.print %sm2 : tensor<?x?xf64, #DCSR>
-
- //
- // CHECK: ---- Sparse Tensor ----
- // CHECK-NEXT: nse = 9
- // CHECK-NEXT: pos[0] : ( 0, 4
- // CHECK-NEXT: crd[0] : ( 0, 1, 2, 3
- // CHECK-NEXT: pos[1] : ( 0, 2, 3, 6, 9
- // CHECK-NEXT: crd[1] : ( 0, 1, 7, 2, 4, 7, 0, 2, 3
- // CHECK-NEXT: values : ( 2, 4, 6, 8, 10, 12, 14, 16, 18
- // CHECK-NEXT: ----
- //
- sparse_tensor.print %0 : tensor<?x?xf64, #DCSR>
-
- //
- // CHECK: ---- Sparse Tensor ----
- // CHECK-NEXT: nse = 9
- // CHECK-NEXT: pos[0] : ( 0, 4
- // CHECK-NEXT: crd[0] : ( 0, 1, 2, 3
- // CHECK-NEXT: pos[1] : ( 0, 2, 3, 6, 9
- // CHECK-NEXT: crd[1] : ( 0, 1, 7, 2, 4, 7, 0, 2, 3
- // CHECK-NEXT: values : ( 2, 4, 6, 8, 10, 12, 14, 16, 18
- // CHECK-NEXT: ----
- //
- sparse_tensor.print %1 : tensor<?x?xf64, #DCSR>
-
- //
- // CHECK: ---- Sparse Tensor ----
- // CHECK-NEXT: nse = 13
- // CHECK-NEXT: pos[0] : ( 0, 4
- // CHECK-NEXT: crd[0] : ( 0, 1, 2, 3
- // CHECK-NEXT: pos[1] : ( 0, 3, 6, 10, 13
- // CHECK-NEXT: crd[1] : ( 0, 1, 7, 0, 6, 7, 1, 2, 4, 7, 0, 2, 3
- // CHECK-NEXT: values : ( 8, 4, 5, 4, 3, 6, 2, 8, 10, 13, 14, 16, 18
- // CHECK-NEXT: ----
- //
- sparse_tensor.print %2 : tensor<?x?xf64, #DCSR>
-
- //
- // CHECK: ---- Sparse Tensor ----
- // CHECK-NEXT: nse = 2
- // CHECK-NEXT: pos[0] : ( 0, 2
- // CHECK-NEXT: crd[0] : ( 0, 2
- // CHECK-NEXT: pos[1] : ( 0, 1, 2
- // CHECK-NEXT: crd[1] : ( 0, 7
- // CHECK-NEXT: values : ( 12, 12
- // CHECK-NEXT: ----
+ // CHECK: {{\[}}[1, 2, 0, 0, 0, 0, 0, 0],
+ // CHECK-NEXT: [0, 0, 0, 0, 0, 0, 0, 3],
+ // CHECK-NEXT: [0, 0, 4, 0, 5, 0, 0, 6],
+ // CHECK-NEXT: [7, 0, 8, 9, 0, 0, 0, 0]]
+ // CHECK: {{\[}}[6, 0, 0, 0, 0, 0, 0, 5],
+ // CHECK-NEXT: [4, 0, 0, 0, 0, 0, 3, 0],
+ // CHECK-NEXT: [0, 2, 0, 0, 0, 0, 0, 1],
+ // CHECK-NEXT: [0, 0, 0, 0, 0, 0, 0, 0]]
+ // CHECK: {{\[}}[2, 4, 0, 0, 0, 0, 0, 0],
+ // CHECK-NEXT: [0, 0, 0, 0, 0, 0, 0, 6],
+ // CHECK-NEXT: [0, 0, 8, 0, 10, 0, 0, 12],
+ // CHECK-NEXT: [14, 0, 16, 18, 0, 0, 0, 0]]
+ // CHECK: {{\[}}[2, 4, 0, 0, 0, 0, 0, 0],
+ // CHECK-NEXT: [0, 0, 0, 0, 0, 0, 0, 6],
+ // CHECK-NEXT: [0, 0, 8, 0, 10, 0, 0, 12],
+ // CHECK-NEXT: [14, 0, 16, 18, 0, 0, 0, 0]]
+ // CHECK: {{\[}}[8, 4, 0, 0, 0, 0, 0, 5],
+ // CHECK-NEXT: [4, 0, 0, 0, 0, 0, 3, 6],
+ // CHECK-NEXT: [0, 2, 8, 0, 10, 0, 0, 13],
+ // CHECK-NEXT: [14, 0, 16, 18, 0, 0, 0, 0]]
+ // CHECK: {{\[}}[12, 0, 0, 0, 0, 0, 0, 0],
+ // CHECK-NEXT: [0, 0, 0, 0, 0, 0, 0, 0],
+ // CHECK-NEXT: [0, 0, 0, 0, 0, 0, 0, 12],
+ // CHECK-NEXT: [0, 0, 0, 0, 0, 0, 0, 0]]
//
- sparse_tensor.print %3 : tensor<?x?xf64, #DCSR>
+ call @dump(%sm1) : (tensor<?x?xf64, #DCSR>) -> ()
+ call @dump(%sm2) : (tensor<?x?xf64, #DCSR>) -> ()
+ call @dump(%0) : (tensor<?x?xf64, #DCSR>) -> ()
+ call @dump(%1) : (tensor<?x?xf64, #DCSR>) -> ()
+ call @dump(%2) : (tensor<?x?xf64, #DCSR>) -> ()
+ call @dump(%3) : (tensor<?x?xf64, #DCSR>) -> ()
// Release the resources.
bufferization.dealloc_tensor %sm1 : tensor<?x?xf64, #DCSR>
>From bf0f874e4883a98ab69cff3da323713a5fe80dfd Mon Sep 17 00:00:00 2001
From: Andrei Homescu <ahomescu at google.com>
Date: Thu, 29 Feb 2024 15:05:47 -0800
Subject: [PATCH 189/406] [scudo] Avoid splitting aligned allocations on Trusty
(#69281)
Don't use multiple tagged pages at the beginning of an allocation, since
it prevents using such allocations for memrefs, and mappings aren't
reused anyway since Trusty uses MapAllocatorNoCache.
Upstreamed from https://r.android.com/2537251.
Co-authored-by: Marco Nelissen <marcone at google.com>
---
compiler-rt/lib/scudo/standalone/secondary.h | 24 +++++++++++++++++++-
1 file changed, 23 insertions(+), 1 deletion(-)
diff --git a/compiler-rt/lib/scudo/standalone/secondary.h b/compiler-rt/lib/scudo/standalone/secondary.h
index f52a4188bcf3a6..732fd307ed2f43 100644
--- a/compiler-rt/lib/scudo/standalone/secondary.h
+++ b/compiler-rt/lib/scudo/standalone/secondary.h
@@ -122,7 +122,29 @@ bool mapSecondary(const Options &Options, uptr CommitBase, uptr CommitSize,
Flags |= MAP_RESIZABLE;
Flags |= MAP_ALLOWNOMEM;
- const uptr MaxUnusedCacheBytes = MaxUnusedCachePages * getPageSizeCached();
+ const uptr PageSize = getPageSizeCached();
+ if (SCUDO_TRUSTY) {
+ /*
+ * On Trusty we need AllocPos to be usable for shared memory, which cannot
+ * cross multiple mappings. This means we need to split around AllocPos
+ * and not over it. We can only do this if the address is page-aligned.
+ */
+ const uptr TaggedSize = AllocPos - CommitBase;
+ if (useMemoryTagging<Config>(Options) && isAligned(TaggedSize, PageSize)) {
+ DCHECK_GT(TaggedSize, 0);
+ return MemMap.remap(CommitBase, TaggedSize, "scudo:secondary",
+ MAP_MEMTAG | Flags) &&
+ MemMap.remap(AllocPos, CommitSize - TaggedSize, "scudo:secondary",
+ Flags);
+ } else {
+ const uptr RemapFlags =
+ (useMemoryTagging<Config>(Options) ? MAP_MEMTAG : 0) | Flags;
+ return MemMap.remap(CommitBase, CommitSize, "scudo:secondary",
+ RemapFlags);
+ }
+ }
+
+ const uptr MaxUnusedCacheBytes = MaxUnusedCachePages * PageSize;
if (useMemoryTagging<Config>(Options) && CommitSize > MaxUnusedCacheBytes) {
const uptr UntaggedPos = Max(AllocPos, CommitBase + MaxUnusedCacheBytes);
return MemMap.remap(CommitBase, UntaggedPos - CommitBase, "scudo:secondary",
>From b9b8333ed51b67ab73f8bc4cf25ce400d91e7008 Mon Sep 17 00:00:00 2001
From: Florian Mayer <fmayer at google.com>
Date: Thu, 29 Feb 2024 15:06:58 -0800
Subject: [PATCH 190/406] [HWASan] add test for hwasan_handle_longjmp ignore
logic (#83359)
---
.../hwasan/TestCases/longjmp-out-of-range.c | 20 +++++++++++++++++++
1 file changed, 20 insertions(+)
create mode 100644 compiler-rt/test/hwasan/TestCases/longjmp-out-of-range.c
diff --git a/compiler-rt/test/hwasan/TestCases/longjmp-out-of-range.c b/compiler-rt/test/hwasan/TestCases/longjmp-out-of-range.c
new file mode 100644
index 00000000000000..2d7ed2ab5ee242
--- /dev/null
+++ b/compiler-rt/test/hwasan/TestCases/longjmp-out-of-range.c
@@ -0,0 +1,20 @@
+// RUN: %clang_hwasan -O0 %s -o %t && %run %t 2>&1 | FileCheck %s
+
+// REQUIRES: pointer-tagging
+#include <assert.h>
+#include <sanitizer/hwasan_interface.h>
+#include <stdlib.h>
+
+__attribute__((noinline)) int f(void *caller_frame) {
+ int z = 0;
+ int *volatile p = &z;
+ // Tag of local is never zero.
+ assert(__hwasan_tag_pointer(p, 0) != p);
+ __hwasan_handle_longjmp(NULL);
+ return p[0];
+}
+
+int main() {
+ return f(__builtin_frame_address(0));
+ // CHECK: HWASan is ignoring requested __hwasan_handle_longjmp:
+}
>From 3be05d898ffd1e687bd67dcd5fe0c8c16ff2d4d7 Mon Sep 17 00:00:00 2001
From: Mehdi Amini <joker.eph at gmail.com>
Date: Thu, 29 Feb 2024 15:08:31 -0800
Subject: [PATCH 191/406] [MLIR] Fix test on Windows
Windows folds to 1.01563 and linux to 1.01562, let's just check the prefix here.
---
mlir/test/mlir-cpu-runner/expand-arith-ops.mlir | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/mlir/test/mlir-cpu-runner/expand-arith-ops.mlir b/mlir/test/mlir-cpu-runner/expand-arith-ops.mlir
index 0bf6523c5e5d5c..2b62b8c0bb140f 100644
--- a/mlir/test/mlir-cpu-runner/expand-arith-ops.mlir
+++ b/mlir/test/mlir-cpu-runner/expand-arith-ops.mlir
@@ -24,7 +24,7 @@ func.func @main() {
// Note: this is a tie (low 16 bits are 0x8000). We expect the rounding behavior
// to break ties "to nearest-even", which in this case means upwards,
// since bit 16 is set.
- // CHECK-NEXT: 1.01562
+ // CHECK-NEXT: 1.0156
%value_1_01172_I = arith.constant 0x3f818000 : i32
%value_1_01172_F = arith.bitcast %value_1_01172_I : i32 to f32
call @trunc_bf16(%value_1_01172_F): (f32) -> ()
>From 1a2960bab6381f2b288328e2371829b460ac020c Mon Sep 17 00:00:00 2001
From: Mircea Trofin <mtrofin at google.com>
Date: Thu, 29 Feb 2024 15:12:07 -0800
Subject: [PATCH 192/406] [pgo][nfc] Model `Count` as a `std::optional` in
`PGOUseBBInfo` (#83364)
Simpler code, compared to tracking state of 2 variables and the ambiguity of "0" CountValue (is it 0 or is it invalid?)
---
.../Instrumentation/PGOInstrumentation.cpp | 86 +++++++++----------
1 file changed, 39 insertions(+), 47 deletions(-)
diff --git a/llvm/lib/Transforms/Instrumentation/PGOInstrumentation.cpp b/llvm/lib/Transforms/Instrumentation/PGOInstrumentation.cpp
index c20fc942eaf0d5..0c042e73ba0836 100644
--- a/llvm/lib/Transforms/Instrumentation/PGOInstrumentation.cpp
+++ b/llvm/lib/Transforms/Instrumentation/PGOInstrumentation.cpp
@@ -983,27 +983,22 @@ using DirectEdges = SmallVector<PGOUseEdge *, 2>;
// This class stores the auxiliary information for each BB.
struct PGOUseBBInfo : public PGOBBInfo {
- uint64_t CountValue = 0;
- bool CountValid;
+ std::optional<uint64_t> Count;
int32_t UnknownCountInEdge = 0;
int32_t UnknownCountOutEdge = 0;
DirectEdges InEdges;
DirectEdges OutEdges;
- PGOUseBBInfo(unsigned IX) : PGOBBInfo(IX), CountValid(false) {}
+ PGOUseBBInfo(unsigned IX) : PGOBBInfo(IX) {}
// Set the profile count value for this BB.
- void setBBInfoCount(uint64_t Value) {
- CountValue = Value;
- CountValid = true;
- }
+ void setBBInfoCount(uint64_t Value) { Count = Value; }
// Return the information string of this object.
std::string infoString() const {
- if (!CountValid)
+ if (!Count)
return PGOBBInfo::infoString();
- return (Twine(PGOBBInfo::infoString()) + " Count=" + Twine(CountValue))
- .str();
+ return (Twine(PGOBBInfo::infoString()) + " Count=" + Twine(*Count)).str();
}
// Add an OutEdge and update the edge count.
@@ -1216,15 +1211,15 @@ bool PGOUseFunc::setInstrumentedCounts(
// If only one out-edge, the edge profile count should be the same as BB
// profile count.
- if (SrcInfo.CountValid && SrcInfo.OutEdges.size() == 1)
- setEdgeCount(E.get(), SrcInfo.CountValue);
+ if (SrcInfo.Count && SrcInfo.OutEdges.size() == 1)
+ setEdgeCount(E.get(), *SrcInfo.Count);
else {
const BasicBlock *DestBB = E->DestBB;
PGOUseBBInfo &DestInfo = getBBInfo(DestBB);
// If only one in-edge, the edge profile count should be the same as BB
// profile count.
- if (DestInfo.CountValid && DestInfo.InEdges.size() == 1)
- setEdgeCount(E.get(), DestInfo.CountValue);
+ if (DestInfo.Count && DestInfo.InEdges.size() == 1)
+ setEdgeCount(E.get(), *DestInfo.Count);
}
if (E->CountValid)
continue;
@@ -1481,38 +1476,36 @@ void PGOUseFunc::populateCounters() {
// For efficient traversal, it's better to start from the end as most
// of the instrumented edges are at the end.
for (auto &BB : reverse(F)) {
- PGOUseBBInfo *Count = findBBInfo(&BB);
- if (Count == nullptr)
+ PGOUseBBInfo *UseBBInfo = findBBInfo(&BB);
+ if (UseBBInfo == nullptr)
continue;
- if (!Count->CountValid) {
- if (Count->UnknownCountOutEdge == 0) {
- Count->CountValue = sumEdgeCount(Count->OutEdges);
- Count->CountValid = true;
+ if (!UseBBInfo->Count) {
+ if (UseBBInfo->UnknownCountOutEdge == 0) {
+ UseBBInfo->Count = sumEdgeCount(UseBBInfo->OutEdges);
Changes = true;
- } else if (Count->UnknownCountInEdge == 0) {
- Count->CountValue = sumEdgeCount(Count->InEdges);
- Count->CountValid = true;
+ } else if (UseBBInfo->UnknownCountInEdge == 0) {
+ UseBBInfo->Count = sumEdgeCount(UseBBInfo->InEdges);
Changes = true;
}
}
- if (Count->CountValid) {
- if (Count->UnknownCountOutEdge == 1) {
+ if (UseBBInfo->Count) {
+ if (UseBBInfo->UnknownCountOutEdge == 1) {
uint64_t Total = 0;
- uint64_t OutSum = sumEdgeCount(Count->OutEdges);
+ uint64_t OutSum = sumEdgeCount(UseBBInfo->OutEdges);
// If the one of the successor block can early terminate (no-return),
// we can end up with situation where out edge sum count is larger as
// the source BB's count is collected by a post-dominated block.
- if (Count->CountValue > OutSum)
- Total = Count->CountValue - OutSum;
- setEdgeCount(Count->OutEdges, Total);
+ if (*UseBBInfo->Count > OutSum)
+ Total = *UseBBInfo->Count - OutSum;
+ setEdgeCount(UseBBInfo->OutEdges, Total);
Changes = true;
}
- if (Count->UnknownCountInEdge == 1) {
+ if (UseBBInfo->UnknownCountInEdge == 1) {
uint64_t Total = 0;
- uint64_t InSum = sumEdgeCount(Count->InEdges);
- if (Count->CountValue > InSum)
- Total = Count->CountValue - InSum;
- setEdgeCount(Count->InEdges, Total);
+ uint64_t InSum = sumEdgeCount(UseBBInfo->InEdges);
+ if (*UseBBInfo->Count > InSum)
+ Total = *UseBBInfo->Count - InSum;
+ setEdgeCount(UseBBInfo->InEdges, Total);
Changes = true;
}
}
@@ -1527,16 +1520,16 @@ void PGOUseFunc::populateCounters() {
auto BI = findBBInfo(&BB);
if (BI == nullptr)
continue;
- assert(BI->CountValid && "BB count is not valid");
+ assert(BI->Count && "BB count is not valid");
}
#endif
- uint64_t FuncEntryCount = getBBInfo(&*F.begin()).CountValue;
+ uint64_t FuncEntryCount = *getBBInfo(&*F.begin()).Count;
uint64_t FuncMaxCount = FuncEntryCount;
for (auto &BB : F) {
auto BI = findBBInfo(&BB);
if (BI == nullptr)
continue;
- FuncMaxCount = std::max(FuncMaxCount, BI->CountValue);
+ FuncMaxCount = std::max(FuncMaxCount, *BI->Count);
}
// Fix the obviously inconsistent entry count.
@@ -1566,11 +1559,11 @@ void PGOUseFunc::setBranchWeights() {
isa<CallBrInst>(TI)))
continue;
- if (getBBInfo(&BB).CountValue == 0)
+ const PGOUseBBInfo &BBCountInfo = getBBInfo(&BB);
+ if (!*BBCountInfo.Count)
continue;
// We have a non-zero Branch BB.
- const PGOUseBBInfo &BBCountInfo = getBBInfo(&BB);
unsigned Size = BBCountInfo.OutEdges.size();
SmallVector<uint64_t, 2> EdgeCounts(Size, 0);
uint64_t MaxCount = 0;
@@ -1622,7 +1615,7 @@ void PGOUseFunc::annotateIrrLoopHeaderWeights() {
if (BFI->isIrrLoopHeader(&BB) || isIndirectBrTarget(&BB)) {
Instruction *TI = BB.getTerminator();
const PGOUseBBInfo &BBCountInfo = getBBInfo(&BB);
- setIrrLoopHeaderMetadata(M, TI, BBCountInfo.CountValue);
+ setIrrLoopHeaderMetadata(M, TI, *BBCountInfo.Count);
}
}
}
@@ -1649,7 +1642,7 @@ void SelectInstVisitor::annotateOneSelectInst(SelectInst &SI) {
uint64_t TotalCount = 0;
auto BI = UseFunc->findBBInfo(SI.getParent());
if (BI != nullptr)
- TotalCount = BI->CountValue;
+ TotalCount = *BI->Count;
// False Count
SCounts[1] = (TotalCount > SCounts[0] ? TotalCount - SCounts[0] : 0);
uint64_t MaxCount = std::max(SCounts[0], SCounts[1]);
@@ -1850,7 +1843,7 @@ static void fixFuncEntryCount(PGOUseFunc &Func, LoopInfo &LI,
if (!Func.findBBInfo(&BBI))
continue;
auto BFICount = NBFI.getBlockProfileCount(&BBI);
- CountValue = Func.getBBInfo(&BBI).CountValue;
+ CountValue = *Func.getBBInfo(&BBI).Count;
BFICountValue = *BFICount;
SumCount.add(APFloat(CountValue * 1.0), APFloat::rmNearestTiesToEven);
SumBFICount.add(APFloat(BFICountValue * 1.0), APFloat::rmNearestTiesToEven);
@@ -1866,7 +1859,7 @@ static void fixFuncEntryCount(PGOUseFunc &Func, LoopInfo &LI,
if (Scale < 1.001 && Scale > 0.999)
return;
- uint64_t FuncEntryCount = Func.getBBInfo(&*F.begin()).CountValue;
+ uint64_t FuncEntryCount = *Func.getBBInfo(&*F.begin()).Count;
uint64_t NewEntryCount = 0.5 + FuncEntryCount * Scale;
if (NewEntryCount == 0)
NewEntryCount = 1;
@@ -1896,8 +1889,7 @@ static void verifyFuncBFI(PGOUseFunc &Func, LoopInfo &LI,
uint64_t CountValue = 0;
uint64_t BFICountValue = 0;
- if (Func.getBBInfo(&BBI).CountValid)
- CountValue = Func.getBBInfo(&BBI).CountValue;
+ CountValue = Func.getBBInfo(&BBI).Count.value_or(CountValue);
BBNum++;
if (CountValue)
@@ -2279,8 +2271,8 @@ template <> struct DOTGraphTraits<PGOUseFunc *> : DefaultDOTGraphTraits {
OS << getSimpleNodeName(Node) << ":\\l";
PGOUseBBInfo *BI = Graph->findBBInfo(Node);
OS << "Count : ";
- if (BI && BI->CountValid)
- OS << BI->CountValue << "\\l";
+ if (BI && BI->Count)
+ OS << *BI->Count << "\\l";
else
OS << "Unknown\\l";
>From d1924f0474b65fe3189ffd658a12f452e4696c28 Mon Sep 17 00:00:00 2001
From: Kai Luo <lkail at cn.ibm.com>
Date: Fri, 1 Mar 2024 08:03:06 +0800
Subject: [PATCH 193/406] [PowerPC] Do not generate `isel` instruction if
target doesn't have this instruction (#72845)
When expand `select_cc` in finalize-isel, we should not generate `isel`
for targets not feature it.
---
llvm/lib/Target/PowerPC/PPCISelLowering.cpp | 82 ++-
.../CodeGen/PowerPC/2008-10-28-f128-i32.ll | 64 +-
.../PowerPC/atomicrmw-uinc-udec-wrap.ll | 272 ++++----
llvm/test/CodeGen/PowerPC/ctrloops-pseudo.ll | 40 +-
.../CodeGen/PowerPC/expand-isel-to-branch.ll | 12 +-
.../CodeGen/PowerPC/fp-strict-fcmp-spe.ll | 260 ++++----
llvm/test/CodeGen/PowerPC/fp-to-int-to-fp.ll | 103 ++-
llvm/test/CodeGen/PowerPC/fptoui-be-crash.ll | 78 ++-
llvm/test/CodeGen/PowerPC/funnel-shift-rot.ll | 124 ++--
llvm/test/CodeGen/PowerPC/funnel-shift.ll | 605 +++++++++---------
llvm/test/CodeGen/PowerPC/i1-to-double.ll | 52 +-
.../ppcf128-constrained-fp-intrinsics.ll | 15 +-
llvm/test/CodeGen/PowerPC/pr43976.ll | 18 +-
llvm/test/CodeGen/PowerPC/pr49509.ll | 35 +-
.../CodeGen/PowerPC/save-crbp-ppc32svr4.ll | 2 +-
.../test/CodeGen/PowerPC/select-cc-no-isel.ll | 20 +-
llvm/test/CodeGen/PowerPC/select.ll | 99 +--
llvm/test/CodeGen/PowerPC/select_const.ll | 225 +++----
llvm/test/CodeGen/PowerPC/smulfixsat.ll | 36 +-
llvm/test/CodeGen/PowerPC/spe.ll | 176 +++--
.../PowerPC/srem-seteq-illegal-types.ll | 29 +-
llvm/test/CodeGen/PowerPC/umulfixsat.ll | 20 +-
.../umulo-128-legalisation-lowering.ll | 180 +++---
.../PowerPC/urem-seteq-illegal-types.ll | 74 +--
llvm/test/CodeGen/PowerPC/varargs.ll | 39 +-
...lar-shift-by-byte-multiple-legalization.ll | 58 +-
.../PowerPC/wide-scalar-shift-legalization.ll | 58 +-
27 files changed, 1375 insertions(+), 1401 deletions(-)
diff --git a/llvm/lib/Target/PowerPC/PPCISelLowering.cpp b/llvm/lib/Target/PowerPC/PPCISelLowering.cpp
index 51becf1d5b8584..19cf1a8394b069 100644
--- a/llvm/lib/Target/PowerPC/PPCISelLowering.cpp
+++ b/llvm/lib/Target/PowerPC/PPCISelLowering.cpp
@@ -12661,6 +12661,44 @@ PPCTargetLowering::emitProbedAlloca(MachineInstr &MI,
return TailMBB;
}
+static bool IsSelectCC(MachineInstr &MI) {
+ switch (MI.getOpcode()) {
+ case PPC::SELECT_CC_I4:
+ case PPC::SELECT_CC_I8:
+ case PPC::SELECT_CC_F4:
+ case PPC::SELECT_CC_F8:
+ case PPC::SELECT_CC_F16:
+ case PPC::SELECT_CC_VRRC:
+ case PPC::SELECT_CC_VSFRC:
+ case PPC::SELECT_CC_VSSRC:
+ case PPC::SELECT_CC_VSRC:
+ case PPC::SELECT_CC_SPE4:
+ case PPC::SELECT_CC_SPE:
+ return true;
+ default:
+ return false;
+ }
+}
+
+static bool IsSelect(MachineInstr &MI) {
+ switch (MI.getOpcode()) {
+ case PPC::SELECT_I4:
+ case PPC::SELECT_I8:
+ case PPC::SELECT_F4:
+ case PPC::SELECT_F8:
+ case PPC::SELECT_F16:
+ case PPC::SELECT_SPE:
+ case PPC::SELECT_SPE4:
+ case PPC::SELECT_VRRC:
+ case PPC::SELECT_VSFRC:
+ case PPC::SELECT_VSSRC:
+ case PPC::SELECT_VSRC:
+ return true;
+ default:
+ return false;
+ }
+}
+
MachineBasicBlock *
PPCTargetLowering::EmitInstrWithCustomInserter(MachineInstr &MI,
MachineBasicBlock *BB) const {
@@ -12698,9 +12736,10 @@ PPCTargetLowering::EmitInstrWithCustomInserter(MachineInstr &MI,
MachineFunction *F = BB->getParent();
MachineRegisterInfo &MRI = F->getRegInfo();
- if (MI.getOpcode() == PPC::SELECT_CC_I4 ||
- MI.getOpcode() == PPC::SELECT_CC_I8 || MI.getOpcode() == PPC::SELECT_I4 ||
- MI.getOpcode() == PPC::SELECT_I8) {
+ if (Subtarget.hasISEL() &&
+ (MI.getOpcode() == PPC::SELECT_CC_I4 ||
+ MI.getOpcode() == PPC::SELECT_CC_I8 ||
+ MI.getOpcode() == PPC::SELECT_I4 || MI.getOpcode() == PPC::SELECT_I8)) {
SmallVector<MachineOperand, 2> Cond;
if (MI.getOpcode() == PPC::SELECT_CC_I4 ||
MI.getOpcode() == PPC::SELECT_CC_I8)
@@ -12712,24 +12751,7 @@ PPCTargetLowering::EmitInstrWithCustomInserter(MachineInstr &MI,
DebugLoc dl = MI.getDebugLoc();
TII->insertSelect(*BB, MI, dl, MI.getOperand(0).getReg(), Cond,
MI.getOperand(2).getReg(), MI.getOperand(3).getReg());
- } else if (MI.getOpcode() == PPC::SELECT_CC_F4 ||
- MI.getOpcode() == PPC::SELECT_CC_F8 ||
- MI.getOpcode() == PPC::SELECT_CC_F16 ||
- MI.getOpcode() == PPC::SELECT_CC_VRRC ||
- MI.getOpcode() == PPC::SELECT_CC_VSFRC ||
- MI.getOpcode() == PPC::SELECT_CC_VSSRC ||
- MI.getOpcode() == PPC::SELECT_CC_VSRC ||
- MI.getOpcode() == PPC::SELECT_CC_SPE4 ||
- MI.getOpcode() == PPC::SELECT_CC_SPE ||
- MI.getOpcode() == PPC::SELECT_F4 ||
- MI.getOpcode() == PPC::SELECT_F8 ||
- MI.getOpcode() == PPC::SELECT_F16 ||
- MI.getOpcode() == PPC::SELECT_SPE ||
- MI.getOpcode() == PPC::SELECT_SPE4 ||
- MI.getOpcode() == PPC::SELECT_VRRC ||
- MI.getOpcode() == PPC::SELECT_VSFRC ||
- MI.getOpcode() == PPC::SELECT_VSSRC ||
- MI.getOpcode() == PPC::SELECT_VSRC) {
+ } else if (IsSelectCC(MI) || IsSelect(MI)) {
// The incoming instruction knows the destination vreg to set, the
// condition code register to branch on, the true/false values to
// select between, and a branch opcode to use.
@@ -12738,7 +12760,7 @@ PPCTargetLowering::EmitInstrWithCustomInserter(MachineInstr &MI,
// ...
// TrueVal = ...
// cmpTY ccX, r1, r2
- // bCC copy1MBB
+ // bCC sinkMBB
// fallthrough --> copy0MBB
MachineBasicBlock *thisMBB = BB;
MachineBasicBlock *copy0MBB = F->CreateMachineBasicBlock(LLVM_BB);
@@ -12747,6 +12769,12 @@ PPCTargetLowering::EmitInstrWithCustomInserter(MachineInstr &MI,
F->insert(It, copy0MBB);
F->insert(It, sinkMBB);
+ // Set the call frame size on entry to the new basic blocks.
+ // See https://reviews.llvm.org/D156113.
+ unsigned CallFrameSize = TII->getCallFrameSizeAt(MI);
+ copy0MBB->setCallFrameSize(CallFrameSize);
+ sinkMBB->setCallFrameSize(CallFrameSize);
+
// Transfer the remainder of BB and its successor edges to sinkMBB.
sinkMBB->splice(sinkMBB->begin(), BB,
std::next(MachineBasicBlock::iterator(MI)), BB->end());
@@ -12756,15 +12784,7 @@ PPCTargetLowering::EmitInstrWithCustomInserter(MachineInstr &MI,
BB->addSuccessor(copy0MBB);
BB->addSuccessor(sinkMBB);
- if (MI.getOpcode() == PPC::SELECT_I4 || MI.getOpcode() == PPC::SELECT_I8 ||
- MI.getOpcode() == PPC::SELECT_F4 || MI.getOpcode() == PPC::SELECT_F8 ||
- MI.getOpcode() == PPC::SELECT_F16 ||
- MI.getOpcode() == PPC::SELECT_SPE4 ||
- MI.getOpcode() == PPC::SELECT_SPE ||
- MI.getOpcode() == PPC::SELECT_VRRC ||
- MI.getOpcode() == PPC::SELECT_VSFRC ||
- MI.getOpcode() == PPC::SELECT_VSSRC ||
- MI.getOpcode() == PPC::SELECT_VSRC) {
+ if (IsSelect(MI)) {
BuildMI(BB, dl, TII->get(PPC::BC))
.addReg(MI.getOperand(1).getReg())
.addMBB(sinkMBB);
diff --git a/llvm/test/CodeGen/PowerPC/2008-10-28-f128-i32.ll b/llvm/test/CodeGen/PowerPC/2008-10-28-f128-i32.ll
index 0405b25e7fb032..e20fc400f80f8f 100644
--- a/llvm/test/CodeGen/PowerPC/2008-10-28-f128-i32.ll
+++ b/llvm/test/CodeGen/PowerPC/2008-10-28-f128-i32.ll
@@ -36,7 +36,7 @@ define i64 @__fixunstfdi(ppc_fp128 %a) nounwind readnone {
; CHECK-NEXT: # %bb.1: # %bb5
; CHECK-NEXT: li 3, 0
; CHECK-NEXT: li 4, 0
-; CHECK-NEXT: b .LBB0_17
+; CHECK-NEXT: b .LBB0_19
; CHECK-NEXT: .LBB0_2: # %bb1
; CHECK-NEXT: lfd 0, 400(1)
; CHECK-NEXT: lis 3, 15856
@@ -99,24 +99,22 @@ define i64 @__fixunstfdi(ppc_fp128 %a) nounwind readnone {
; CHECK-NEXT: fadd 1, 28, 29
; CHECK-NEXT: mtfsf 1, 0
; CHECK-NEXT: lfs 0, .LCPI0_1 at l(3)
-; CHECK-NEXT: fctiwz 1, 1
-; CHECK-NEXT: stfd 1, 152(1)
; CHECK-NEXT: fcmpu 0, 28, 27
-; CHECK-NEXT: lwz 3, 164(1)
+; CHECK-NEXT: fctiwz 1, 1
; CHECK-NEXT: fcmpu 1, 29, 0
-; CHECK-NEXT: lwz 4, 156(1)
; CHECK-NEXT: crandc 20, 6, 0
; CHECK-NEXT: cror 20, 5, 20
-; CHECK-NEXT: addis 3, 3, -32768
+; CHECK-NEXT: stfd 1, 152(1)
; CHECK-NEXT: bc 12, 20, .LBB0_4
; CHECK-NEXT: # %bb.3: # %bb1
-; CHECK-NEXT: ori 30, 4, 0
+; CHECK-NEXT: lwz 30, 156(1)
; CHECK-NEXT: b .LBB0_5
-; CHECK-NEXT: .LBB0_4: # %bb1
-; CHECK-NEXT: addi 30, 3, 0
+; CHECK-NEXT: .LBB0_4:
+; CHECK-NEXT: lwz 3, 164(1)
+; CHECK-NEXT: addis 30, 3, -32768
; CHECK-NEXT: .LBB0_5: # %bb1
-; CHECK-NEXT: li 4, 0
; CHECK-NEXT: mr 3, 30
+; CHECK-NEXT: li 4, 0
; CHECK-NEXT: bl __floatditf
; CHECK-NEXT: lis 3, 17392
; CHECK-NEXT: stfd 1, 208(1)
@@ -179,10 +177,10 @@ define i64 @__fixunstfdi(ppc_fp128 %a) nounwind readnone {
; CHECK-NEXT: lwz 3, 168(1)
; CHECK-NEXT: stw 3, 272(1)
; CHECK-NEXT: lfd 31, 272(1)
-; CHECK-NEXT: bc 12, 20, .LBB0_14
+; CHECK-NEXT: bc 12, 20, .LBB0_13
; CHECK-NEXT: # %bb.10: # %bb1
; CHECK-NEXT: cror 20, 1, 3
-; CHECK-NEXT: bc 12, 20, .LBB0_14
+; CHECK-NEXT: bc 12, 20, .LBB0_13
; CHECK-NEXT: # %bb.11: # %bb2
; CHECK-NEXT: fneg 29, 31
; CHECK-NEXT: stfd 29, 48(1)
@@ -223,24 +221,17 @@ define i64 @__fixunstfdi(ppc_fp128 %a) nounwind readnone {
; CHECK-NEXT: fadd 1, 28, 29
; CHECK-NEXT: mtfsf 1, 0
; CHECK-NEXT: lfs 0, .LCPI0_3 at l(3)
-; CHECK-NEXT: fctiwz 1, 1
-; CHECK-NEXT: stfd 1, 24(1)
; CHECK-NEXT: fcmpu 0, 30, 2
-; CHECK-NEXT: lwz 3, 36(1)
+; CHECK-NEXT: fctiwz 1, 1
; CHECK-NEXT: fcmpu 1, 31, 0
-; CHECK-NEXT: lwz 4, 28(1)
; CHECK-NEXT: crandc 20, 6, 1
; CHECK-NEXT: cror 20, 4, 20
-; CHECK-NEXT: addis 3, 3, -32768
-; CHECK-NEXT: bc 12, 20, .LBB0_13
+; CHECK-NEXT: stfd 1, 24(1)
+; CHECK-NEXT: bc 12, 20, .LBB0_17
; CHECK-NEXT: # %bb.12: # %bb2
-; CHECK-NEXT: ori 3, 4, 0
-; CHECK-NEXT: b .LBB0_13
-; CHECK-NEXT: .LBB0_13: # %bb2
-; CHECK-NEXT: subfic 4, 3, 0
-; CHECK-NEXT: subfe 3, 29, 30
-; CHECK-NEXT: b .LBB0_17
-; CHECK-NEXT: .LBB0_14: # %bb3
+; CHECK-NEXT: lwz 3, 28(1)
+; CHECK-NEXT: b .LBB0_18
+; CHECK-NEXT: .LBB0_13: # %bb3
; CHECK-NEXT: stfd 31, 112(1)
; CHECK-NEXT: li 3, 0
; CHECK-NEXT: stw 3, 148(1)
@@ -278,22 +269,29 @@ define i64 @__fixunstfdi(ppc_fp128 %a) nounwind readnone {
; CHECK-NEXT: fadd 2, 30, 31
; CHECK-NEXT: mtfsf 1, 0
; CHECK-NEXT: lfs 0, .LCPI0_1 at l(3)
-; CHECK-NEXT: fctiwz 2, 2
-; CHECK-NEXT: stfd 2, 88(1)
; CHECK-NEXT: fcmpu 0, 30, 1
-; CHECK-NEXT: lwz 3, 100(1)
+; CHECK-NEXT: fctiwz 1, 2
; CHECK-NEXT: fcmpu 1, 31, 0
-; CHECK-NEXT: lwz 4, 92(1)
; CHECK-NEXT: crandc 20, 6, 0
; CHECK-NEXT: cror 20, 5, 20
-; CHECK-NEXT: addis 3, 3, -32768
+; CHECK-NEXT: stfd 1, 88(1)
; CHECK-NEXT: bc 12, 20, .LBB0_15
+; CHECK-NEXT: # %bb.14: # %bb3
+; CHECK-NEXT: lwz 4, 92(1)
; CHECK-NEXT: b .LBB0_16
-; CHECK-NEXT: .LBB0_15: # %bb3
-; CHECK-NEXT: addi 4, 3, 0
+; CHECK-NEXT: .LBB0_15:
+; CHECK-NEXT: lwz 3, 100(1)
+; CHECK-NEXT: addis 4, 3, -32768
; CHECK-NEXT: .LBB0_16: # %bb3
; CHECK-NEXT: mr 3, 30
-; CHECK-NEXT: .LBB0_17: # %bb5
+; CHECK-NEXT: b .LBB0_19
+; CHECK-NEXT: .LBB0_17:
+; CHECK-NEXT: lwz 3, 36(1)
+; CHECK-NEXT: addis 3, 3, -32768
+; CHECK-NEXT: .LBB0_18: # %bb2
+; CHECK-NEXT: subfic 4, 3, 0
+; CHECK-NEXT: subfe 3, 29, 30
+; CHECK-NEXT: .LBB0_19: # %bb3
; CHECK-NEXT: lfd 31, 456(1) # 8-byte Folded Reload
; CHECK-NEXT: lfd 30, 448(1) # 8-byte Folded Reload
; CHECK-NEXT: lfd 29, 440(1) # 8-byte Folded Reload
diff --git a/llvm/test/CodeGen/PowerPC/atomicrmw-uinc-udec-wrap.ll b/llvm/test/CodeGen/PowerPC/atomicrmw-uinc-udec-wrap.ll
index adbb956ba32ad9..505ac8639595fd 100644
--- a/llvm/test/CodeGen/PowerPC/atomicrmw-uinc-udec-wrap.ll
+++ b/llvm/test/CodeGen/PowerPC/atomicrmw-uinc-udec-wrap.ll
@@ -6,55 +6,50 @@ define i8 @atomicrmw_uinc_wrap_i8(ptr %ptr, i8 %val) {
; CHECK: # %bb.0:
; CHECK-NEXT: sync
; CHECK-NEXT: mr 5, 3
-; CHECK-NEXT: rlwinm 7, 5, 3, 27, 28
+; CHECK-NEXT: rlwinm 6, 5, 3, 27, 28
; CHECK-NEXT: lbz 3, 0(3)
-; CHECK-NEXT: xori 7, 7, 24
-; CHECK-NEXT: li 8, 255
-; CHECK-NEXT: li 6, 0
+; CHECK-NEXT: xori 6, 6, 24
+; CHECK-NEXT: li 7, 255
; CHECK-NEXT: clrlwi 4, 4, 24
; CHECK-NEXT: rldicr 5, 5, 0, 61
-; CHECK-NEXT: slw 8, 8, 7
+; CHECK-NEXT: slw 7, 7, 6
; CHECK-NEXT: b .LBB0_2
; CHECK-NEXT: .LBB0_1: # %atomicrmw.start
; CHECK-NEXT: #
-; CHECK-NEXT: srw 3, 11, 7
-; CHECK-NEXT: cmplw 3, 9
-; CHECK-NEXT: beq 0, .LBB0_8
+; CHECK-NEXT: srw 3, 10, 6
+; CHECK-NEXT: cmplw 3, 8
+; CHECK-NEXT: beq 0, .LBB0_7
; CHECK-NEXT: .LBB0_2: # %atomicrmw.start
; CHECK-NEXT: # =>This Loop Header: Depth=1
-; CHECK-NEXT: # Child Loop BB0_6 Depth 2
-; CHECK-NEXT: clrlwi 9, 3, 24
-; CHECK-NEXT: addi 10, 3, 1
-; CHECK-NEXT: cmplw 9, 4
-; CHECK-NEXT: bc 12, 0, .LBB0_4
+; CHECK-NEXT: # Child Loop BB0_5 Depth 2
+; CHECK-NEXT: clrlwi 8, 3, 24
+; CHECK-NEXT: cmplw 8, 4
+; CHECK-NEXT: li 9, 0
+; CHECK-NEXT: bge 0, .LBB0_4
; CHECK-NEXT: # %bb.3: # %atomicrmw.start
; CHECK-NEXT: #
-; CHECK-NEXT: ori 3, 6, 0
-; CHECK-NEXT: b .LBB0_5
+; CHECK-NEXT: addi 9, 3, 1
; CHECK-NEXT: .LBB0_4: # %atomicrmw.start
; CHECK-NEXT: #
-; CHECK-NEXT: addi 3, 10, 0
+; CHECK-NEXT: slw 3, 9, 6
+; CHECK-NEXT: slw 9, 8, 6
+; CHECK-NEXT: and 3, 3, 7
+; CHECK-NEXT: and 9, 9, 7
; CHECK-NEXT: .LBB0_5: # %atomicrmw.start
-; CHECK-NEXT: #
-; CHECK-NEXT: slw 11, 9, 7
-; CHECK-NEXT: slw 3, 3, 7
-; CHECK-NEXT: and 3, 3, 8
-; CHECK-NEXT: and 10, 11, 8
-; CHECK-NEXT: .LBB0_6: # %atomicrmw.start
; CHECK-NEXT: # Parent Loop BB0_2 Depth=1
; CHECK-NEXT: # => This Inner Loop Header: Depth=2
-; CHECK-NEXT: lwarx 12, 0, 5
-; CHECK-NEXT: and 11, 12, 8
-; CHECK-NEXT: cmpw 11, 10
+; CHECK-NEXT: lwarx 11, 0, 5
+; CHECK-NEXT: and 10, 11, 7
+; CHECK-NEXT: cmpw 10, 9
; CHECK-NEXT: bne 0, .LBB0_1
-; CHECK-NEXT: # %bb.7: # %atomicrmw.start
+; CHECK-NEXT: # %bb.6: # %atomicrmw.start
; CHECK-NEXT: #
-; CHECK-NEXT: andc 12, 12, 8
-; CHECK-NEXT: or 12, 12, 3
-; CHECK-NEXT: stwcx. 12, 0, 5
-; CHECK-NEXT: bne 0, .LBB0_6
+; CHECK-NEXT: andc 11, 11, 7
+; CHECK-NEXT: or 11, 11, 3
+; CHECK-NEXT: stwcx. 11, 0, 5
+; CHECK-NEXT: bne 0, .LBB0_5
; CHECK-NEXT: b .LBB0_1
-; CHECK-NEXT: .LBB0_8: # %atomicrmw.end
+; CHECK-NEXT: .LBB0_7: # %atomicrmw.end
; CHECK-NEXT: lwsync
; CHECK-NEXT: blr
%result = atomicrmw uinc_wrap ptr %ptr, i8 %val seq_cst
@@ -66,55 +61,51 @@ define i16 @atomicrmw_uinc_wrap_i16(ptr %ptr, i16 %val) {
; CHECK: # %bb.0:
; CHECK-NEXT: sync
; CHECK-NEXT: mr 5, 3
-; CHECK-NEXT: li 6, 0
+; CHECK-NEXT: li 7, 0
; CHECK-NEXT: lhz 3, 0(3)
-; CHECK-NEXT: rlwinm 7, 5, 3, 27, 27
-; CHECK-NEXT: xori 7, 7, 16
-; CHECK-NEXT: ori 8, 6, 65535
+; CHECK-NEXT: rlwinm 6, 5, 3, 27, 27
+; CHECK-NEXT: xori 6, 6, 16
+; CHECK-NEXT: ori 7, 7, 65535
; CHECK-NEXT: clrlwi 4, 4, 16
; CHECK-NEXT: rldicr 5, 5, 0, 61
-; CHECK-NEXT: slw 8, 8, 7
+; CHECK-NEXT: slw 7, 7, 6
; CHECK-NEXT: b .LBB1_2
; CHECK-NEXT: .LBB1_1: # %atomicrmw.start
; CHECK-NEXT: #
-; CHECK-NEXT: srw 3, 11, 7
-; CHECK-NEXT: cmplw 3, 9
-; CHECK-NEXT: beq 0, .LBB1_8
+; CHECK-NEXT: srw 3, 10, 6
+; CHECK-NEXT: cmplw 3, 8
+; CHECK-NEXT: beq 0, .LBB1_7
; CHECK-NEXT: .LBB1_2: # %atomicrmw.start
; CHECK-NEXT: # =>This Loop Header: Depth=1
-; CHECK-NEXT: # Child Loop BB1_6 Depth 2
-; CHECK-NEXT: clrlwi 9, 3, 16
-; CHECK-NEXT: addi 10, 3, 1
-; CHECK-NEXT: cmplw 9, 4
-; CHECK-NEXT: bc 12, 0, .LBB1_4
+; CHECK-NEXT: # Child Loop BB1_5 Depth 2
+; CHECK-NEXT: clrlwi 8, 3, 16
+; CHECK-NEXT: cmplw 8, 4
+; CHECK-NEXT: li 9, 0
+; CHECK-NEXT: bge 0, .LBB1_4
; CHECK-NEXT: # %bb.3: # %atomicrmw.start
; CHECK-NEXT: #
-; CHECK-NEXT: ori 3, 6, 0
-; CHECK-NEXT: b .LBB1_5
+; CHECK-NEXT: addi 9, 3, 1
; CHECK-NEXT: .LBB1_4: # %atomicrmw.start
; CHECK-NEXT: #
-; CHECK-NEXT: addi 3, 10, 0
+; CHECK-NEXT: slw 3, 9, 6
+; CHECK-NEXT: slw 9, 8, 6
+; CHECK-NEXT: and 3, 3, 7
+; CHECK-NEXT: and 9, 9, 7
; CHECK-NEXT: .LBB1_5: # %atomicrmw.start
-; CHECK-NEXT: #
-; CHECK-NEXT: slw 11, 9, 7
-; CHECK-NEXT: slw 3, 3, 7
-; CHECK-NEXT: and 3, 3, 8
-; CHECK-NEXT: and 10, 11, 8
-; CHECK-NEXT: .LBB1_6: # %atomicrmw.start
; CHECK-NEXT: # Parent Loop BB1_2 Depth=1
; CHECK-NEXT: # => This Inner Loop Header: Depth=2
-; CHECK-NEXT: lwarx 12, 0, 5
-; CHECK-NEXT: and 11, 12, 8
-; CHECK-NEXT: cmpw 11, 10
+; CHECK-NEXT: lwarx 11, 0, 5
+; CHECK-NEXT: and 10, 11, 7
+; CHECK-NEXT: cmpw 10, 9
; CHECK-NEXT: bne 0, .LBB1_1
-; CHECK-NEXT: # %bb.7: # %atomicrmw.start
+; CHECK-NEXT: # %bb.6: # %atomicrmw.start
; CHECK-NEXT: #
-; CHECK-NEXT: andc 12, 12, 8
-; CHECK-NEXT: or 12, 12, 3
-; CHECK-NEXT: stwcx. 12, 0, 5
-; CHECK-NEXT: bne 0, .LBB1_6
+; CHECK-NEXT: andc 11, 11, 7
+; CHECK-NEXT: or 11, 11, 3
+; CHECK-NEXT: stwcx. 11, 0, 5
+; CHECK-NEXT: bne 0, .LBB1_5
; CHECK-NEXT: b .LBB1_1
-; CHECK-NEXT: .LBB1_8: # %atomicrmw.end
+; CHECK-NEXT: .LBB1_7: # %atomicrmw.end
; CHECK-NEXT: lwsync
; CHECK-NEXT: blr
%result = atomicrmw uinc_wrap ptr %ptr, i16 %val seq_cst
@@ -125,39 +116,34 @@ define i32 @atomicrmw_uinc_wrap_i32(ptr %ptr, i32 %val) {
; CHECK-LABEL: atomicrmw_uinc_wrap_i32:
; CHECK: # %bb.0:
; CHECK-NEXT: sync
-; CHECK-NEXT: li 6, 0
-; CHECK-NEXT: lwz 5, 0(3)
+; CHECK-NEXT: lwz 6, 0(3)
; CHECK-NEXT: b .LBB2_2
; CHECK-NEXT: .LBB2_1: # %atomicrmw.start
; CHECK-NEXT: #
-; CHECK-NEXT: cmplw 5, 7
-; CHECK-NEXT: beq 0, .LBB2_7
+; CHECK-NEXT: cmplw 5, 6
+; CHECK-NEXT: mr 6, 5
+; CHECK-NEXT: beq 0, .LBB2_6
; CHECK-NEXT: .LBB2_2: # %atomicrmw.start
; CHECK-NEXT: # =>This Loop Header: Depth=1
-; CHECK-NEXT: # Child Loop BB2_5 Depth 2
-; CHECK-NEXT: mr 7, 5
-; CHECK-NEXT: addi 5, 5, 1
-; CHECK-NEXT: cmplw 7, 4
-; CHECK-NEXT: bc 12, 0, .LBB2_4
+; CHECK-NEXT: # Child Loop BB2_4 Depth 2
+; CHECK-NEXT: cmplw 6, 4
+; CHECK-NEXT: li 7, 0
+; CHECK-NEXT: bge 0, .LBB2_4
; CHECK-NEXT: # %bb.3: # %atomicrmw.start
; CHECK-NEXT: #
-; CHECK-NEXT: ori 8, 6, 0
-; CHECK-NEXT: b .LBB2_5
+; CHECK-NEXT: addi 7, 6, 1
; CHECK-NEXT: .LBB2_4: # %atomicrmw.start
-; CHECK-NEXT: #
-; CHECK-NEXT: addi 8, 5, 0
-; CHECK-NEXT: .LBB2_5: # %atomicrmw.start
; CHECK-NEXT: # Parent Loop BB2_2 Depth=1
; CHECK-NEXT: # => This Inner Loop Header: Depth=2
; CHECK-NEXT: lwarx 5, 0, 3
-; CHECK-NEXT: cmpw 5, 7
+; CHECK-NEXT: cmpw 5, 6
; CHECK-NEXT: bne 0, .LBB2_1
-; CHECK-NEXT: # %bb.6: # %atomicrmw.start
+; CHECK-NEXT: # %bb.5: # %atomicrmw.start
; CHECK-NEXT: #
-; CHECK-NEXT: stwcx. 8, 0, 3
-; CHECK-NEXT: bne 0, .LBB2_5
+; CHECK-NEXT: stwcx. 7, 0, 3
+; CHECK-NEXT: bne 0, .LBB2_4
; CHECK-NEXT: b .LBB2_1
-; CHECK-NEXT: .LBB2_7: # %atomicrmw.end
+; CHECK-NEXT: .LBB2_6: # %atomicrmw.end
; CHECK-NEXT: mr 3, 5
; CHECK-NEXT: lwsync
; CHECK-NEXT: blr
@@ -169,39 +155,34 @@ define i64 @atomicrmw_uinc_wrap_i64(ptr %ptr, i64 %val) {
; CHECK-LABEL: atomicrmw_uinc_wrap_i64:
; CHECK: # %bb.0:
; CHECK-NEXT: sync
-; CHECK-NEXT: ld 5, 0(3)
-; CHECK-NEXT: li 6, 0
+; CHECK-NEXT: ld 6, 0(3)
; CHECK-NEXT: b .LBB3_2
; CHECK-NEXT: .LBB3_1: # %atomicrmw.start
; CHECK-NEXT: #
-; CHECK-NEXT: cmpld 5, 7
-; CHECK-NEXT: beq 0, .LBB3_7
+; CHECK-NEXT: cmpld 5, 6
+; CHECK-NEXT: mr 6, 5
+; CHECK-NEXT: beq 0, .LBB3_6
; CHECK-NEXT: .LBB3_2: # %atomicrmw.start
; CHECK-NEXT: # =>This Loop Header: Depth=1
-; CHECK-NEXT: # Child Loop BB3_5 Depth 2
-; CHECK-NEXT: mr 7, 5
-; CHECK-NEXT: addi 5, 5, 1
-; CHECK-NEXT: cmpld 7, 4
-; CHECK-NEXT: bc 12, 0, .LBB3_4
+; CHECK-NEXT: # Child Loop BB3_4 Depth 2
+; CHECK-NEXT: cmpld 6, 4
+; CHECK-NEXT: li 7, 0
+; CHECK-NEXT: bge 0, .LBB3_4
; CHECK-NEXT: # %bb.3: # %atomicrmw.start
; CHECK-NEXT: #
-; CHECK-NEXT: ori 8, 6, 0
-; CHECK-NEXT: b .LBB3_5
+; CHECK-NEXT: addi 7, 6, 1
; CHECK-NEXT: .LBB3_4: # %atomicrmw.start
-; CHECK-NEXT: #
-; CHECK-NEXT: addi 8, 5, 0
-; CHECK-NEXT: .LBB3_5: # %atomicrmw.start
; CHECK-NEXT: # Parent Loop BB3_2 Depth=1
; CHECK-NEXT: # => This Inner Loop Header: Depth=2
; CHECK-NEXT: ldarx 5, 0, 3
-; CHECK-NEXT: cmpd 5, 7
+; CHECK-NEXT: cmpd 5, 6
; CHECK-NEXT: bne 0, .LBB3_1
-; CHECK-NEXT: # %bb.6: # %atomicrmw.start
+; CHECK-NEXT: # %bb.5: # %atomicrmw.start
; CHECK-NEXT: #
-; CHECK-NEXT: stdcx. 8, 0, 3
-; CHECK-NEXT: bne 0, .LBB3_5
+; CHECK-NEXT: stdcx. 7, 0, 3
+; CHECK-NEXT: bne 0, .LBB3_4
; CHECK-NEXT: b .LBB3_1
-; CHECK-NEXT: .LBB3_7: # %atomicrmw.end
+; CHECK-NEXT: .LBB3_6: # %atomicrmw.end
; CHECK-NEXT: mr 3, 5
; CHECK-NEXT: lwsync
; CHECK-NEXT: blr
@@ -226,43 +207,39 @@ define i8 @atomicrmw_udec_wrap_i8(ptr %ptr, i8 %val) {
; CHECK-NEXT: #
; CHECK-NEXT: srw 3, 11, 7
; CHECK-NEXT: cmplw 3, 9
-; CHECK-NEXT: beq 0, .LBB4_8
+; CHECK-NEXT: beq 0, .LBB4_7
; CHECK-NEXT: .LBB4_2: # %atomicrmw.start
; CHECK-NEXT: # =>This Loop Header: Depth=1
-; CHECK-NEXT: # Child Loop BB4_6 Depth 2
+; CHECK-NEXT: # Child Loop BB4_5 Depth 2
; CHECK-NEXT: andi. 9, 3, 255
; CHECK-NEXT: cmplw 1, 9, 6
-; CHECK-NEXT: addi 10, 3, -1
; CHECK-NEXT: cror 20, 2, 5
+; CHECK-NEXT: mr 10, 4
; CHECK-NEXT: bc 12, 20, .LBB4_4
; CHECK-NEXT: # %bb.3: # %atomicrmw.start
; CHECK-NEXT: #
-; CHECK-NEXT: ori 3, 10, 0
-; CHECK-NEXT: b .LBB4_5
+; CHECK-NEXT: addi 10, 3, -1
; CHECK-NEXT: .LBB4_4: # %atomicrmw.start
; CHECK-NEXT: #
-; CHECK-NEXT: addi 3, 4, 0
-; CHECK-NEXT: .LBB4_5: # %atomicrmw.start
-; CHECK-NEXT: #
-; CHECK-NEXT: slw 11, 9, 7
-; CHECK-NEXT: slw 3, 3, 7
+; CHECK-NEXT: slw 3, 10, 7
+; CHECK-NEXT: slw 10, 9, 7
; CHECK-NEXT: and 3, 3, 8
-; CHECK-NEXT: and 10, 11, 8
-; CHECK-NEXT: .LBB4_6: # %atomicrmw.start
+; CHECK-NEXT: and 10, 10, 8
+; CHECK-NEXT: .LBB4_5: # %atomicrmw.start
; CHECK-NEXT: # Parent Loop BB4_2 Depth=1
; CHECK-NEXT: # => This Inner Loop Header: Depth=2
; CHECK-NEXT: lwarx 12, 0, 5
; CHECK-NEXT: and 11, 12, 8
; CHECK-NEXT: cmpw 11, 10
; CHECK-NEXT: bne 0, .LBB4_1
-; CHECK-NEXT: # %bb.7: # %atomicrmw.start
+; CHECK-NEXT: # %bb.6: # %atomicrmw.start
; CHECK-NEXT: #
; CHECK-NEXT: andc 12, 12, 8
; CHECK-NEXT: or 12, 12, 3
; CHECK-NEXT: stwcx. 12, 0, 5
-; CHECK-NEXT: bne 0, .LBB4_6
+; CHECK-NEXT: bne 0, .LBB4_5
; CHECK-NEXT: b .LBB4_1
-; CHECK-NEXT: .LBB4_8: # %atomicrmw.end
+; CHECK-NEXT: .LBB4_7: # %atomicrmw.end
; CHECK-NEXT: lwsync
; CHECK-NEXT: blr
%result = atomicrmw udec_wrap ptr %ptr, i8 %val seq_cst
@@ -287,43 +264,39 @@ define i16 @atomicrmw_udec_wrap_i16(ptr %ptr, i16 %val) {
; CHECK-NEXT: #
; CHECK-NEXT: srw 3, 11, 7
; CHECK-NEXT: cmplw 3, 9
-; CHECK-NEXT: beq 0, .LBB5_8
+; CHECK-NEXT: beq 0, .LBB5_7
; CHECK-NEXT: .LBB5_2: # %atomicrmw.start
; CHECK-NEXT: # =>This Loop Header: Depth=1
-; CHECK-NEXT: # Child Loop BB5_6 Depth 2
+; CHECK-NEXT: # Child Loop BB5_5 Depth 2
; CHECK-NEXT: andi. 9, 3, 65535
; CHECK-NEXT: cmplw 1, 9, 6
-; CHECK-NEXT: addi 10, 3, -1
; CHECK-NEXT: cror 20, 2, 5
+; CHECK-NEXT: mr 10, 4
; CHECK-NEXT: bc 12, 20, .LBB5_4
; CHECK-NEXT: # %bb.3: # %atomicrmw.start
; CHECK-NEXT: #
-; CHECK-NEXT: ori 3, 10, 0
-; CHECK-NEXT: b .LBB5_5
+; CHECK-NEXT: addi 10, 3, -1
; CHECK-NEXT: .LBB5_4: # %atomicrmw.start
; CHECK-NEXT: #
-; CHECK-NEXT: addi 3, 4, 0
-; CHECK-NEXT: .LBB5_5: # %atomicrmw.start
-; CHECK-NEXT: #
-; CHECK-NEXT: slw 11, 9, 7
-; CHECK-NEXT: slw 3, 3, 7
+; CHECK-NEXT: slw 3, 10, 7
+; CHECK-NEXT: slw 10, 9, 7
; CHECK-NEXT: and 3, 3, 8
-; CHECK-NEXT: and 10, 11, 8
-; CHECK-NEXT: .LBB5_6: # %atomicrmw.start
+; CHECK-NEXT: and 10, 10, 8
+; CHECK-NEXT: .LBB5_5: # %atomicrmw.start
; CHECK-NEXT: # Parent Loop BB5_2 Depth=1
; CHECK-NEXT: # => This Inner Loop Header: Depth=2
; CHECK-NEXT: lwarx 12, 0, 5
; CHECK-NEXT: and 11, 12, 8
; CHECK-NEXT: cmpw 11, 10
; CHECK-NEXT: bne 0, .LBB5_1
-; CHECK-NEXT: # %bb.7: # %atomicrmw.start
+; CHECK-NEXT: # %bb.6: # %atomicrmw.start
; CHECK-NEXT: #
; CHECK-NEXT: andc 12, 12, 8
; CHECK-NEXT: or 12, 12, 3
; CHECK-NEXT: stwcx. 12, 0, 5
-; CHECK-NEXT: bne 0, .LBB5_6
+; CHECK-NEXT: bne 0, .LBB5_5
; CHECK-NEXT: b .LBB5_1
-; CHECK-NEXT: .LBB5_8: # %atomicrmw.end
+; CHECK-NEXT: .LBB5_7: # %atomicrmw.end
; CHECK-NEXT: lwsync
; CHECK-NEXT: blr
%result = atomicrmw udec_wrap ptr %ptr, i16 %val seq_cst
@@ -334,28 +307,27 @@ define i32 @atomicrmw_udec_wrap_i32(ptr %ptr, i32 %val) {
; CHECK-LABEL: atomicrmw_udec_wrap_i32:
; CHECK: # %bb.0:
; CHECK-NEXT: sync
-; CHECK-NEXT: lwz 5, 0(3)
+; CHECK-NEXT: lwz 6, 0(3)
; CHECK-NEXT: b .LBB6_2
; CHECK-NEXT: .LBB6_1: # %atomicrmw.start
; CHECK-NEXT: #
; CHECK-NEXT: cmplw 5, 6
+; CHECK-NEXT: mr 6, 5
; CHECK-NEXT: beq 0, .LBB6_7
; CHECK-NEXT: .LBB6_2: # %atomicrmw.start
; CHECK-NEXT: # =>This Loop Header: Depth=1
; CHECK-NEXT: # Child Loop BB6_5 Depth 2
-; CHECK-NEXT: mr 6, 5
; CHECK-NEXT: cmpwi 6, 0
-; CHECK-NEXT: cmplw 1, 6, 4
-; CHECK-NEXT: addi 5, 5, -1
-; CHECK-NEXT: cror 20, 2, 5
-; CHECK-NEXT: bc 12, 20, .LBB6_4
+; CHECK-NEXT: mr 7, 4
+; CHECK-NEXT: bc 12, 2, .LBB6_5
; CHECK-NEXT: # %bb.3: # %atomicrmw.start
; CHECK-NEXT: #
-; CHECK-NEXT: ori 7, 5, 0
-; CHECK-NEXT: b .LBB6_5
-; CHECK-NEXT: .LBB6_4: # %atomicrmw.start
+; CHECK-NEXT: cmplw 6, 4
+; CHECK-NEXT: mr 7, 4
+; CHECK-NEXT: bc 12, 1, .LBB6_5
+; CHECK-NEXT: # %bb.4: # %atomicrmw.start
; CHECK-NEXT: #
-; CHECK-NEXT: addi 7, 4, 0
+; CHECK-NEXT: addi 7, 6, -1
; CHECK-NEXT: .LBB6_5: # %atomicrmw.start
; CHECK-NEXT: # Parent Loop BB6_2 Depth=1
; CHECK-NEXT: # => This Inner Loop Header: Depth=2
@@ -379,27 +351,27 @@ define i64 @atomicrmw_udec_wrap_i64(ptr %ptr, i64 %val) {
; CHECK-LABEL: atomicrmw_udec_wrap_i64:
; CHECK: # %bb.0:
; CHECK-NEXT: sync
-; CHECK-NEXT: ld 5, 0(3)
+; CHECK-NEXT: ld 6, 0(3)
; CHECK-NEXT: b .LBB7_2
; CHECK-NEXT: .LBB7_1: # %atomicrmw.start
; CHECK-NEXT: #
; CHECK-NEXT: cmpld 5, 6
+; CHECK-NEXT: mr 6, 5
; CHECK-NEXT: beq 0, .LBB7_7
; CHECK-NEXT: .LBB7_2: # %atomicrmw.start
; CHECK-NEXT: # =>This Loop Header: Depth=1
; CHECK-NEXT: # Child Loop BB7_5 Depth 2
-; CHECK-NEXT: mr. 6, 5
-; CHECK-NEXT: cmpld 1, 6, 4
-; CHECK-NEXT: addi 5, 5, -1
-; CHECK-NEXT: cror 20, 2, 5
-; CHECK-NEXT: bc 12, 20, .LBB7_4
+; CHECK-NEXT: cmpdi 6, 0
+; CHECK-NEXT: mr 7, 4
+; CHECK-NEXT: bc 12, 2, .LBB7_5
; CHECK-NEXT: # %bb.3: # %atomicrmw.start
; CHECK-NEXT: #
-; CHECK-NEXT: ori 7, 5, 0
-; CHECK-NEXT: b .LBB7_5
-; CHECK-NEXT: .LBB7_4: # %atomicrmw.start
+; CHECK-NEXT: cmpld 6, 4
+; CHECK-NEXT: mr 7, 4
+; CHECK-NEXT: bc 12, 1, .LBB7_5
+; CHECK-NEXT: # %bb.4: # %atomicrmw.start
; CHECK-NEXT: #
-; CHECK-NEXT: addi 7, 4, 0
+; CHECK-NEXT: addi 7, 6, -1
; CHECK-NEXT: .LBB7_5: # %atomicrmw.start
; CHECK-NEXT: # Parent Loop BB7_2 Depth=1
; CHECK-NEXT: # => This Inner Loop Header: Depth=2
diff --git a/llvm/test/CodeGen/PowerPC/ctrloops-pseudo.ll b/llvm/test/CodeGen/PowerPC/ctrloops-pseudo.ll
index e7c49c9dcc7d99..9d2d70d5a4b92f 100644
--- a/llvm/test/CodeGen/PowerPC/ctrloops-pseudo.ll
+++ b/llvm/test/CodeGen/PowerPC/ctrloops-pseudo.ll
@@ -35,6 +35,7 @@ define void @test1(i32 %c) nounwind {
; AIX64-NEXT: {{ $}}
; AIX64-NEXT: bb.2.for.end:
; AIX64-NEXT: BLR8 implicit $lr8, implicit $rm
+ ;
; AIX32-LABEL: name: test1
; AIX32: bb.0.entry:
; AIX32-NEXT: successors: %bb.1(0x80000000)
@@ -57,6 +58,7 @@ define void @test1(i32 %c) nounwind {
; AIX32-NEXT: {{ $}}
; AIX32-NEXT: bb.2.for.end:
; AIX32-NEXT: BLR implicit $lr, implicit $rm
+ ;
; LE64-LABEL: name: test1
; LE64: bb.0.entry:
; LE64-NEXT: successors: %bb.1(0x80000000)
@@ -134,6 +136,7 @@ define void @test2(i32 %c, i32 %d) nounwind {
; AIX64-NEXT: {{ $}}
; AIX64-NEXT: bb.3.for.end:
; AIX64-NEXT: BLR8 implicit $lr8, implicit $rm
+ ;
; AIX32-LABEL: name: test2
; AIX32: bb.0.entry:
; AIX32-NEXT: successors: %bb.1(0x50000000), %bb.3(0x30000000)
@@ -163,6 +166,7 @@ define void @test2(i32 %c, i32 %d) nounwind {
; AIX32-NEXT: {{ $}}
; AIX32-NEXT: bb.3.for.end:
; AIX32-NEXT: BLR implicit $lr, implicit $rm
+ ;
; LE64-LABEL: name: test2
; LE64: bb.0.entry:
; LE64-NEXT: successors: %bb.1(0x50000000), %bb.3(0x30000000)
@@ -257,6 +261,7 @@ define void @test3(i32 %c, i32 %d) nounwind {
; AIX64-NEXT: {{ $}}
; AIX64-NEXT: bb.3.for.end:
; AIX64-NEXT: BLR8 implicit $lr8, implicit $rm
+ ;
; AIX32-LABEL: name: test3
; AIX32: bb.0.entry:
; AIX32-NEXT: successors: %bb.1(0x50000000), %bb.3(0x30000000)
@@ -289,6 +294,7 @@ define void @test3(i32 %c, i32 %d) nounwind {
; AIX32-NEXT: {{ $}}
; AIX32-NEXT: bb.3.for.end:
; AIX32-NEXT: BLR implicit $lr, implicit $rm
+ ;
; LE64-LABEL: name: test3
; LE64: bb.0.entry:
; LE64-NEXT: successors: %bb.1(0x50000000), %bb.3(0x30000000)
@@ -352,15 +358,23 @@ for.end: ; preds = %for.body, %entry
define i32 @test4(i32 %inp) {
; AIX64-LABEL: name: test4
; AIX64: bb.0.entry:
- ; AIX64-NEXT: successors: %bb.1(0x80000000)
+ ; AIX64-NEXT: successors: %bb.3(0x40000000), %bb.4(0x40000000)
; AIX64-NEXT: liveins: $x3
; AIX64-NEXT: {{ $}}
; AIX64-NEXT: [[COPY:%[0-9]+]]:g8rc = COPY $x3
; AIX64-NEXT: [[COPY1:%[0-9]+]]:gprc_and_gprc_nor0 = COPY [[COPY]].sub_32
; AIX64-NEXT: [[CMPWI:%[0-9]+]]:crrc = CMPWI [[COPY1]], 1
; AIX64-NEXT: [[LI:%[0-9]+]]:gprc_and_gprc_nor0 = LI 1
- ; AIX64-NEXT: [[ISEL:%[0-9]+]]:gprc = ISEL [[COPY1]], [[LI]], [[CMPWI]].sub_lt
- ; AIX64-NEXT: [[SUBF:%[0-9]+]]:gprc = SUBF [[ISEL]], [[COPY1]]
+ ; AIX64-NEXT: BCC 12, [[CMPWI]], %bb.4
+ ; AIX64-NEXT: {{ $}}
+ ; AIX64-NEXT: bb.3.entry:
+ ; AIX64-NEXT: successors: %bb.4(0x80000000)
+ ; AIX64-NEXT: {{ $}}
+ ; AIX64-NEXT: bb.4.entry:
+ ; AIX64-NEXT: successors: %bb.1(0x80000000)
+ ; AIX64-NEXT: {{ $}}
+ ; AIX64-NEXT: [[PHI:%[0-9]+]]:gprc = PHI [[LI]], %bb.3, [[COPY1]], %bb.0
+ ; AIX64-NEXT: [[SUBF:%[0-9]+]]:gprc = SUBF [[PHI]], [[COPY1]]
; AIX64-NEXT: [[DEF:%[0-9]+]]:g8rc = IMPLICIT_DEF
; AIX64-NEXT: [[INSERT_SUBREG:%[0-9]+]]:g8rc = INSERT_SUBREG [[DEF]], killed [[SUBF]], %subreg.sub_32
; AIX64-NEXT: [[RLDICL:%[0-9]+]]:g8rc_and_g8rc_nox0 = RLDICL killed [[INSERT_SUBREG]], 0, 32
@@ -379,21 +393,30 @@ define i32 @test4(i32 %inp) {
; AIX64-NEXT: [[LDtoc1:%[0-9]+]]:g8rc = LDtoc target-flags(ppc-tlsgd) @tls_var, $x2 :: (load (s64) from got)
; AIX64-NEXT: [[TLSGDAIX8_:%[0-9]+]]:g8rc = TLSGDAIX8 killed [[LDtoc1]], killed [[LDtoc]]
; AIX64-NEXT: [[COPY2:%[0-9]+]]:gprc = COPY [[TLSGDAIX8_]].sub_32
- ; AIX64-NEXT: [[ADD4_:%[0-9]+]]:gprc = ADD4 killed [[COPY2]], [[ISEL]]
+ ; AIX64-NEXT: [[ADD4_:%[0-9]+]]:gprc = ADD4 killed [[COPY2]], [[PHI]]
; AIX64-NEXT: [[DEF1:%[0-9]+]]:g8rc = IMPLICIT_DEF
; AIX64-NEXT: [[INSERT_SUBREG1:%[0-9]+]]:g8rc = INSERT_SUBREG [[DEF1]], killed [[ADD4_]], %subreg.sub_32
; AIX64-NEXT: $x3 = COPY [[INSERT_SUBREG1]]
; AIX64-NEXT: BLR8 implicit $lr8, implicit $rm, implicit $x3
+ ;
; AIX32-LABEL: name: test4
; AIX32: bb.0.entry:
- ; AIX32-NEXT: successors: %bb.1(0x80000000)
+ ; AIX32-NEXT: successors: %bb.3(0x40000000), %bb.4(0x40000000)
; AIX32-NEXT: liveins: $r3
; AIX32-NEXT: {{ $}}
; AIX32-NEXT: [[COPY:%[0-9]+]]:gprc_and_gprc_nor0 = COPY $r3
; AIX32-NEXT: [[CMPWI:%[0-9]+]]:crrc = CMPWI [[COPY]], 1
; AIX32-NEXT: [[LI:%[0-9]+]]:gprc_and_gprc_nor0 = LI 1
- ; AIX32-NEXT: [[ISEL:%[0-9]+]]:gprc = ISEL [[COPY]], [[LI]], [[CMPWI]].sub_lt
- ; AIX32-NEXT: [[SUBF:%[0-9]+]]:gprc_and_gprc_nor0 = SUBF [[ISEL]], [[COPY]]
+ ; AIX32-NEXT: BCC 12, [[CMPWI]], %bb.4
+ ; AIX32-NEXT: {{ $}}
+ ; AIX32-NEXT: bb.3.entry:
+ ; AIX32-NEXT: successors: %bb.4(0x80000000)
+ ; AIX32-NEXT: {{ $}}
+ ; AIX32-NEXT: bb.4.entry:
+ ; AIX32-NEXT: successors: %bb.1(0x80000000)
+ ; AIX32-NEXT: {{ $}}
+ ; AIX32-NEXT: [[PHI:%[0-9]+]]:gprc = PHI [[LI]], %bb.3, [[COPY]], %bb.0
+ ; AIX32-NEXT: [[SUBF:%[0-9]+]]:gprc_and_gprc_nor0 = SUBF [[PHI]], [[COPY]]
; AIX32-NEXT: [[ADDI:%[0-9]+]]:gprc = ADDI killed [[SUBF]], 1
; AIX32-NEXT: MTCTRloop killed [[ADDI]], implicit-def dead $ctr
; AIX32-NEXT: {{ $}}
@@ -408,9 +431,10 @@ define i32 @test4(i32 %inp) {
; AIX32-NEXT: [[LWZtoc:%[0-9]+]]:gprc = LWZtoc target-flags(ppc-tlsgdm) @tls_var, $r2 :: (load (s32) from got)
; AIX32-NEXT: [[LWZtoc1:%[0-9]+]]:gprc = LWZtoc target-flags(ppc-tlsgd) @tls_var, $r2 :: (load (s32) from got)
; AIX32-NEXT: [[TLSGDAIX:%[0-9]+]]:gprc = TLSGDAIX killed [[LWZtoc1]], killed [[LWZtoc]]
- ; AIX32-NEXT: [[ADD4_:%[0-9]+]]:gprc = ADD4 killed [[TLSGDAIX]], [[ISEL]]
+ ; AIX32-NEXT: [[ADD4_:%[0-9]+]]:gprc = ADD4 killed [[TLSGDAIX]], [[PHI]]
; AIX32-NEXT: $r3 = COPY [[ADD4_]]
; AIX32-NEXT: BLR implicit $lr, implicit $rm, implicit $r3
+ ;
; LE64-LABEL: name: test4
; LE64: bb.0.entry:
; LE64-NEXT: successors: %bb.1(0x80000000)
diff --git a/llvm/test/CodeGen/PowerPC/expand-isel-to-branch.ll b/llvm/test/CodeGen/PowerPC/expand-isel-to-branch.ll
index 6f3e9f78b31756..f46225c6137f59 100644
--- a/llvm/test/CodeGen/PowerPC/expand-isel-to-branch.ll
+++ b/llvm/test/CodeGen/PowerPC/expand-isel-to-branch.ll
@@ -6,13 +6,13 @@ define noundef signext i32 @ham(ptr nocapture noundef %arg) #0 {
; CHECK: # %bb.0: # %bb
; CHECK-NEXT: lwz 4, 0(3)
; CHECK-NEXT: cmpwi 4, 750
-; CHECK-NEXT: addi 5, 4, 1
+; CHECK-NEXT: blt 0, L..BB0_2
+; CHECK-NEXT: # %bb.1: # %bb
; CHECK-NEXT: li 4, 1
-; CHECK-NEXT: bc 12, 0, L..BB0_1
-; CHECK-NEXT: b L..BB0_2
-; CHECK-NEXT: L..BB0_1: # %bb
-; CHECK-NEXT: addi 4, 5, 0
-; CHECK-NEXT: L..BB0_2: # %bb
+; CHECK-NEXT: b L..BB0_3
+; CHECK-NEXT: L..BB0_2:
+; CHECK-NEXT: addi 4, 4, 1
+; CHECK-NEXT: L..BB0_3: # %bb
; CHECK-NEXT: stw 4, 0(3)
; CHECK-NEXT: li 3, 0
; CHECK-NEXT: blr
diff --git a/llvm/test/CodeGen/PowerPC/fp-strict-fcmp-spe.ll b/llvm/test/CodeGen/PowerPC/fp-strict-fcmp-spe.ll
index 6aae299786cc7e..c20d319f2ac795 100644
--- a/llvm/test/CodeGen/PowerPC/fp-strict-fcmp-spe.ll
+++ b/llvm/test/CodeGen/PowerPC/fp-strict-fcmp-spe.ll
@@ -7,7 +7,7 @@ define i32 @test_f32_oeq_s(i32 %a, i32 %b, float %f1, float %f2) #0 {
; SPE-NEXT: efscmpeq cr0, r5, r6
; SPE-NEXT: bclr 12, gt, 0
; SPE-NEXT: # %bb.1:
-; SPE-NEXT: ori r3, r4, 0
+; SPE-NEXT: mr r3, r4
; SPE-NEXT: blr
%cond = call i1 @llvm.experimental.constrained.fcmps.f32(float %f1, float %f2, metadata !"oeq", metadata !"fpexcept.strict") #0
%res = select i1 %cond, i32 %a, i32 %b
@@ -20,7 +20,7 @@ define i32 @test_f32_ogt_s(i32 %a, i32 %b, float %f1, float %f2) #0 {
; SPE-NEXT: efscmpgt cr0, r5, r6
; SPE-NEXT: bclr 12, gt, 0
; SPE-NEXT: # %bb.1:
-; SPE-NEXT: ori r3, r4, 0
+; SPE-NEXT: mr r3, r4
; SPE-NEXT: blr
%cond = call i1 @llvm.experimental.constrained.fcmps.f32(float %f1, float %f2, metadata !"ogt", metadata !"fpexcept.strict") #0
%res = select i1 %cond, i32 %a, i32 %b
@@ -31,13 +31,15 @@ define i32 @test_f32_oge_s(i32 %a, i32 %b, float %f1, float %f2) #0 {
; SPE-LABEL: test_f32_oge_s:
; SPE: # %bb.0:
; SPE-NEXT: efscmpeq cr0, r6, r6
-; SPE-NEXT: efscmpeq cr1, r5, r5
-; SPE-NEXT: crand 4*cr5+lt, 4*cr1+gt, gt
-; SPE-NEXT: efscmplt cr0, r5, r6
-; SPE-NEXT: crandc 4*cr5+lt, 4*cr5+lt, gt
-; SPE-NEXT: bclr 12, 4*cr5+lt, 0
+; SPE-NEXT: bc 4, gt, .LBB2_3
; SPE-NEXT: # %bb.1:
-; SPE-NEXT: ori r3, r4, 0
+; SPE-NEXT: efscmpeq cr0, r5, r5
+; SPE-NEXT: bc 4, gt, .LBB2_3
+; SPE-NEXT: # %bb.2:
+; SPE-NEXT: efscmplt cr0, r5, r6
+; SPE-NEXT: bclr 4, gt, 0
+; SPE-NEXT: .LBB2_3:
+; SPE-NEXT: mr r3, r4
; SPE-NEXT: blr
%cond = call i1 @llvm.experimental.constrained.fcmps.f32(float %f1, float %f2, metadata !"oge", metadata !"fpexcept.strict") #0
%res = select i1 %cond, i32 %a, i32 %b
@@ -50,7 +52,7 @@ define i32 @test_f32_olt_s(i32 %a, i32 %b, float %f1, float %f2) #0 {
; SPE-NEXT: efscmplt cr0, r5, r6
; SPE-NEXT: bclr 12, gt, 0
; SPE-NEXT: # %bb.1:
-; SPE-NEXT: ori r3, r4, 0
+; SPE-NEXT: mr r3, r4
; SPE-NEXT: blr
%cond = call i1 @llvm.experimental.constrained.fcmps.f32(float %f1, float %f2, metadata !"olt", metadata !"fpexcept.strict") #0
%res = select i1 %cond, i32 %a, i32 %b
@@ -61,13 +63,15 @@ define i32 @test_f32_ole_s(i32 %a, i32 %b, float %f1, float %f2) #0 {
; SPE-LABEL: test_f32_ole_s:
; SPE: # %bb.0:
; SPE-NEXT: efscmpeq cr0, r6, r6
-; SPE-NEXT: efscmpeq cr1, r5, r5
-; SPE-NEXT: crand 4*cr5+lt, 4*cr1+gt, gt
-; SPE-NEXT: efscmpgt cr0, r5, r6
-; SPE-NEXT: crandc 4*cr5+lt, 4*cr5+lt, gt
-; SPE-NEXT: bclr 12, 4*cr5+lt, 0
+; SPE-NEXT: bc 4, gt, .LBB4_3
; SPE-NEXT: # %bb.1:
-; SPE-NEXT: ori r3, r4, 0
+; SPE-NEXT: efscmpeq cr0, r5, r5
+; SPE-NEXT: bc 4, gt, .LBB4_3
+; SPE-NEXT: # %bb.2:
+; SPE-NEXT: efscmpgt cr0, r5, r6
+; SPE-NEXT: bclr 4, gt, 0
+; SPE-NEXT: .LBB4_3:
+; SPE-NEXT: mr r3, r4
; SPE-NEXT: blr
%cond = call i1 @llvm.experimental.constrained.fcmps.f32(float %f1, float %f2, metadata !"ole", metadata !"fpexcept.strict") #0
%res = select i1 %cond, i32 %a, i32 %b
@@ -78,11 +82,12 @@ define i32 @test_f32_one_s(i32 %a, i32 %b, float %f1, float %f2) #0 {
; SPE-LABEL: test_f32_one_s:
; SPE: # %bb.0:
; SPE-NEXT: efscmplt cr0, r5, r6
-; SPE-NEXT: efscmpgt cr1, r5, r6
-; SPE-NEXT: cror 4*cr5+lt, 4*cr1+gt, gt
-; SPE-NEXT: bclr 12, 4*cr5+lt, 0
+; SPE-NEXT: bclr 12, gt, 0
; SPE-NEXT: # %bb.1:
-; SPE-NEXT: ori r3, r4, 0
+; SPE-NEXT: efscmpgt cr0, r5, r6
+; SPE-NEXT: bclr 12, gt, 0
+; SPE-NEXT: # %bb.2:
+; SPE-NEXT: mr r3, r4
; SPE-NEXT: blr
%cond = call i1 @llvm.experimental.constrained.fcmps.f32(float %f1, float %f2, metadata !"one", metadata !"fpexcept.strict") #0
%res = select i1 %cond, i32 %a, i32 %b
@@ -93,11 +98,12 @@ define i32 @test_f32_ord_s(i32 %a, i32 %b, float %f1, float %f2) #0 {
; SPE-LABEL: test_f32_ord_s:
; SPE: # %bb.0:
; SPE-NEXT: efscmpeq cr0, r6, r6
-; SPE-NEXT: efscmpeq cr1, r5, r5
-; SPE-NEXT: crand 4*cr5+lt, 4*cr1+gt, gt
-; SPE-NEXT: bclr 12, 4*cr5+lt, 0
+; SPE-NEXT: bc 4, gt, .LBB6_2
; SPE-NEXT: # %bb.1:
-; SPE-NEXT: ori r3, r4, 0
+; SPE-NEXT: efscmpeq cr0, r5, r5
+; SPE-NEXT: bclr 12, gt, 0
+; SPE-NEXT: .LBB6_2:
+; SPE-NEXT: mr r3, r4
; SPE-NEXT: blr
%cond = call i1 @llvm.experimental.constrained.fcmps.f32(float %f1, float %f2, metadata !"ord", metadata !"fpexcept.strict") #0
%res = select i1 %cond, i32 %a, i32 %b
@@ -108,12 +114,14 @@ define i32 @test_f32_ueq_s(i32 %a, i32 %b, float %f1, float %f2) #0 {
; SPE-LABEL: test_f32_ueq_s:
; SPE: # %bb.0:
; SPE-NEXT: efscmplt cr0, r5, r6
-; SPE-NEXT: efscmpgt cr1, r5, r6
-; SPE-NEXT: cror 4*cr5+lt, 4*cr1+gt, gt
-; SPE-NEXT: bc 12, 4*cr5+lt, .LBB7_1
-; SPE-NEXT: blr
-; SPE-NEXT: .LBB7_1:
-; SPE-NEXT: addi r3, r4, 0
+; SPE-NEXT: bc 12, gt, .LBB7_3
+; SPE-NEXT: # %bb.1:
+; SPE-NEXT: efscmpgt cr0, r5, r6
+; SPE-NEXT: bc 12, gt, .LBB7_3
+; SPE-NEXT: # %bb.2:
+; SPE-NEXT: mr r4, r3
+; SPE-NEXT: .LBB7_3:
+; SPE-NEXT: mr r3, r4
; SPE-NEXT: blr
%cond = call i1 @llvm.experimental.constrained.fcmps.f32(float %f1, float %f2, metadata !"ueq", metadata !"fpexcept.strict") #0
%res = select i1 %cond, i32 %a, i32 %b
@@ -124,13 +132,15 @@ define i32 @test_f32_ugt_s(i32 %a, i32 %b, float %f1, float %f2) #0 {
; SPE-LABEL: test_f32_ugt_s:
; SPE: # %bb.0:
; SPE-NEXT: efscmpeq cr0, r5, r5
-; SPE-NEXT: efscmpeq cr1, r6, r6
-; SPE-NEXT: crnand 4*cr5+lt, 4*cr1+gt, gt
-; SPE-NEXT: efscmpgt cr0, r5, r6
-; SPE-NEXT: cror 4*cr5+lt, gt, 4*cr5+lt
-; SPE-NEXT: bclr 12, 4*cr5+lt, 0
+; SPE-NEXT: bclr 4, gt, 0
; SPE-NEXT: # %bb.1:
-; SPE-NEXT: ori r3, r4, 0
+; SPE-NEXT: efscmpeq cr0, r6, r6
+; SPE-NEXT: bclr 4, gt, 0
+; SPE-NEXT: # %bb.2:
+; SPE-NEXT: efscmpgt cr0, r5, r6
+; SPE-NEXT: bclr 12, gt, 0
+; SPE-NEXT: # %bb.3:
+; SPE-NEXT: mr r3, r4
; SPE-NEXT: blr
%cond = call i1 @llvm.experimental.constrained.fcmps.f32(float %f1, float %f2, metadata !"ugt", metadata !"fpexcept.strict") #0
%res = select i1 %cond, i32 %a, i32 %b
@@ -141,10 +151,11 @@ define i32 @test_f32_uge_s(i32 %a, i32 %b, float %f1, float %f2) #0 {
; SPE-LABEL: test_f32_uge_s:
; SPE: # %bb.0:
; SPE-NEXT: efscmplt cr0, r5, r6
-; SPE-NEXT: bc 12, gt, .LBB9_1
-; SPE-NEXT: blr
-; SPE-NEXT: .LBB9_1:
-; SPE-NEXT: addi r3, r4, 0
+; SPE-NEXT: bc 12, gt, .LBB9_2
+; SPE-NEXT: # %bb.1:
+; SPE-NEXT: mr r4, r3
+; SPE-NEXT: .LBB9_2:
+; SPE-NEXT: mr r3, r4
; SPE-NEXT: blr
%cond = call i1 @llvm.experimental.constrained.fcmps.f32(float %f1, float %f2, metadata !"uge", metadata !"fpexcept.strict") #0
%res = select i1 %cond, i32 %a, i32 %b
@@ -155,13 +166,15 @@ define i32 @test_f32_ult_s(i32 %a, i32 %b, float %f1, float %f2) #0 {
; SPE-LABEL: test_f32_ult_s:
; SPE: # %bb.0:
; SPE-NEXT: efscmpeq cr0, r5, r5
-; SPE-NEXT: efscmpeq cr1, r6, r6
-; SPE-NEXT: crnand 4*cr5+lt, 4*cr1+gt, gt
-; SPE-NEXT: efscmplt cr0, r5, r6
-; SPE-NEXT: cror 4*cr5+lt, gt, 4*cr5+lt
-; SPE-NEXT: bclr 12, 4*cr5+lt, 0
+; SPE-NEXT: bclr 4, gt, 0
; SPE-NEXT: # %bb.1:
-; SPE-NEXT: ori r3, r4, 0
+; SPE-NEXT: efscmpeq cr0, r6, r6
+; SPE-NEXT: bclr 4, gt, 0
+; SPE-NEXT: # %bb.2:
+; SPE-NEXT: efscmplt cr0, r5, r6
+; SPE-NEXT: bclr 12, gt, 0
+; SPE-NEXT: # %bb.3:
+; SPE-NEXT: mr r3, r4
; SPE-NEXT: blr
%cond = call i1 @llvm.experimental.constrained.fcmps.f32(float %f1, float %f2, metadata !"ult", metadata !"fpexcept.strict") #0
%res = select i1 %cond, i32 %a, i32 %b
@@ -172,10 +185,11 @@ define i32 @test_f32_ule_s(i32 %a, i32 %b, float %f1, float %f2) #0 {
; SPE-LABEL: test_f32_ule_s:
; SPE: # %bb.0:
; SPE-NEXT: efscmpgt cr0, r5, r6
-; SPE-NEXT: bc 12, gt, .LBB11_1
-; SPE-NEXT: blr
-; SPE-NEXT: .LBB11_1:
-; SPE-NEXT: addi r3, r4, 0
+; SPE-NEXT: bc 12, gt, .LBB11_2
+; SPE-NEXT: # %bb.1:
+; SPE-NEXT: mr r4, r3
+; SPE-NEXT: .LBB11_2:
+; SPE-NEXT: mr r3, r4
; SPE-NEXT: blr
%cond = call i1 @llvm.experimental.constrained.fcmps.f32(float %f1, float %f2, metadata !"ule", metadata !"fpexcept.strict") #0
%res = select i1 %cond, i32 %a, i32 %b
@@ -186,10 +200,11 @@ define i32 @test_f32_une_s(i32 %a, i32 %b, float %f1, float %f2) #0 {
; SPE-LABEL: test_f32_une_s:
; SPE: # %bb.0:
; SPE-NEXT: efscmpeq cr0, r5, r6
-; SPE-NEXT: bc 12, gt, .LBB12_1
-; SPE-NEXT: blr
-; SPE-NEXT: .LBB12_1:
-; SPE-NEXT: addi r3, r4, 0
+; SPE-NEXT: bc 12, gt, .LBB12_2
+; SPE-NEXT: # %bb.1:
+; SPE-NEXT: mr r4, r3
+; SPE-NEXT: .LBB12_2:
+; SPE-NEXT: mr r3, r4
; SPE-NEXT: blr
%cond = call i1 @llvm.experimental.constrained.fcmps.f32(float %f1, float %f2, metadata !"une", metadata !"fpexcept.strict") #0
%res = select i1 %cond, i32 %a, i32 %b
@@ -200,11 +215,12 @@ define i32 @test_f32_uno_s(i32 %a, i32 %b, float %f1, float %f2) #0 {
; SPE-LABEL: test_f32_uno_s:
; SPE: # %bb.0:
; SPE-NEXT: efscmpeq cr0, r5, r5
-; SPE-NEXT: efscmpeq cr1, r6, r6
-; SPE-NEXT: crnand 4*cr5+lt, 4*cr1+gt, gt
-; SPE-NEXT: bclr 12, 4*cr5+lt, 0
+; SPE-NEXT: bclr 4, gt, 0
; SPE-NEXT: # %bb.1:
-; SPE-NEXT: ori r3, r4, 0
+; SPE-NEXT: efscmpeq cr0, r6, r6
+; SPE-NEXT: bclr 4, gt, 0
+; SPE-NEXT: # %bb.2:
+; SPE-NEXT: mr r3, r4
; SPE-NEXT: blr
%cond = call i1 @llvm.experimental.constrained.fcmps.f32(float %f1, float %f2, metadata !"uno", metadata !"fpexcept.strict") #0
%res = select i1 %cond, i32 %a, i32 %b
@@ -219,7 +235,7 @@ define i32 @test_f64_oeq_s(i32 %a, i32 %b, double %f1, double %f2) #0 {
; SPE-NEXT: efdcmpeq cr0, r5, r7
; SPE-NEXT: bclr 12, gt, 0
; SPE-NEXT: # %bb.1:
-; SPE-NEXT: ori r3, r4, 0
+; SPE-NEXT: mr r3, r4
; SPE-NEXT: blr
%cond = call i1 @llvm.experimental.constrained.fcmps.f64(double %f1, double %f2, metadata !"oeq", metadata !"fpexcept.strict") #0
%res = select i1 %cond, i32 %a, i32 %b
@@ -234,7 +250,7 @@ define i32 @test_f64_ogt_s(i32 %a, i32 %b, double %f1, double %f2) #0 {
; SPE-NEXT: efdcmpgt cr0, r5, r7
; SPE-NEXT: bclr 12, gt, 0
; SPE-NEXT: # %bb.1:
-; SPE-NEXT: ori r3, r4, 0
+; SPE-NEXT: mr r3, r4
; SPE-NEXT: blr
%cond = call i1 @llvm.experimental.constrained.fcmps.f64(double %f1, double %f2, metadata !"ogt", metadata !"fpexcept.strict") #0
%res = select i1 %cond, i32 %a, i32 %b
@@ -247,13 +263,15 @@ define i32 @test_f64_oge_s(i32 %a, i32 %b, double %f1, double %f2) #0 {
; SPE-NEXT: evmergelo r5, r5, r6
; SPE-NEXT: evmergelo r6, r7, r8
; SPE-NEXT: efdcmpeq cr0, r6, r6
-; SPE-NEXT: efdcmpeq cr1, r5, r5
-; SPE-NEXT: efdcmplt cr5, r5, r6
-; SPE-NEXT: crand 4*cr5+lt, 4*cr1+gt, gt
-; SPE-NEXT: crandc 4*cr5+lt, 4*cr5+lt, 4*cr5+gt
-; SPE-NEXT: bclr 12, 4*cr5+lt, 0
+; SPE-NEXT: bc 4, gt, .LBB16_3
; SPE-NEXT: # %bb.1:
-; SPE-NEXT: ori r3, r4, 0
+; SPE-NEXT: efdcmpeq cr0, r5, r5
+; SPE-NEXT: bc 4, gt, .LBB16_3
+; SPE-NEXT: # %bb.2:
+; SPE-NEXT: efdcmplt cr0, r5, r6
+; SPE-NEXT: bclr 4, gt, 0
+; SPE-NEXT: .LBB16_3:
+; SPE-NEXT: mr r3, r4
; SPE-NEXT: blr
%cond = call i1 @llvm.experimental.constrained.fcmps.f64(double %f1, double %f2, metadata !"oge", metadata !"fpexcept.strict") #0
%res = select i1 %cond, i32 %a, i32 %b
@@ -268,7 +286,7 @@ define i32 @test_f64_olt_s(i32 %a, i32 %b, double %f1, double %f2) #0 {
; SPE-NEXT: efdcmplt cr0, r5, r7
; SPE-NEXT: bclr 12, gt, 0
; SPE-NEXT: # %bb.1:
-; SPE-NEXT: ori r3, r4, 0
+; SPE-NEXT: mr r3, r4
; SPE-NEXT: blr
%cond = call i1 @llvm.experimental.constrained.fcmps.f64(double %f1, double %f2, metadata !"olt", metadata !"fpexcept.strict") #0
%res = select i1 %cond, i32 %a, i32 %b
@@ -281,13 +299,15 @@ define i32 @test_f64_ole_s(i32 %a, i32 %b, double %f1, double %f2) #0 {
; SPE-NEXT: evmergelo r5, r5, r6
; SPE-NEXT: evmergelo r6, r7, r8
; SPE-NEXT: efdcmpeq cr0, r6, r6
-; SPE-NEXT: efdcmpeq cr1, r5, r5
-; SPE-NEXT: efdcmpgt cr5, r5, r6
-; SPE-NEXT: crand 4*cr5+lt, 4*cr1+gt, gt
-; SPE-NEXT: crandc 4*cr5+lt, 4*cr5+lt, 4*cr5+gt
-; SPE-NEXT: bclr 12, 4*cr5+lt, 0
+; SPE-NEXT: bc 4, gt, .LBB18_3
; SPE-NEXT: # %bb.1:
-; SPE-NEXT: ori r3, r4, 0
+; SPE-NEXT: efdcmpeq cr0, r5, r5
+; SPE-NEXT: bc 4, gt, .LBB18_3
+; SPE-NEXT: # %bb.2:
+; SPE-NEXT: efdcmpgt cr0, r5, r6
+; SPE-NEXT: bclr 4, gt, 0
+; SPE-NEXT: .LBB18_3:
+; SPE-NEXT: mr r3, r4
; SPE-NEXT: blr
%cond = call i1 @llvm.experimental.constrained.fcmps.f64(double %f1, double %f2, metadata !"ole", metadata !"fpexcept.strict") #0
%res = select i1 %cond, i32 %a, i32 %b
@@ -300,11 +320,12 @@ define i32 @test_f64_one_s(i32 %a, i32 %b, double %f1, double %f2) #0 {
; SPE-NEXT: evmergelo r7, r7, r8
; SPE-NEXT: evmergelo r5, r5, r6
; SPE-NEXT: efdcmplt cr0, r5, r7
-; SPE-NEXT: efdcmpgt cr1, r5, r7
-; SPE-NEXT: cror 4*cr5+lt, 4*cr1+gt, gt
-; SPE-NEXT: bclr 12, 4*cr5+lt, 0
+; SPE-NEXT: bclr 12, gt, 0
; SPE-NEXT: # %bb.1:
-; SPE-NEXT: ori r3, r4, 0
+; SPE-NEXT: efdcmpgt cr0, r5, r7
+; SPE-NEXT: bclr 12, gt, 0
+; SPE-NEXT: # %bb.2:
+; SPE-NEXT: mr r3, r4
; SPE-NEXT: blr
%cond = call i1 @llvm.experimental.constrained.fcmps.f64(double %f1, double %f2, metadata !"one", metadata !"fpexcept.strict") #0
%res = select i1 %cond, i32 %a, i32 %b
@@ -317,11 +338,12 @@ define i32 @test_f64_ord_s(i32 %a, i32 %b, double %f1, double %f2) #0 {
; SPE-NEXT: evmergelo r5, r5, r6
; SPE-NEXT: evmergelo r6, r7, r8
; SPE-NEXT: efdcmpeq cr0, r6, r6
-; SPE-NEXT: efdcmpeq cr1, r5, r5
-; SPE-NEXT: crand 4*cr5+lt, 4*cr1+gt, gt
-; SPE-NEXT: bclr 12, 4*cr5+lt, 0
+; SPE-NEXT: bc 4, gt, .LBB20_2
; SPE-NEXT: # %bb.1:
-; SPE-NEXT: ori r3, r4, 0
+; SPE-NEXT: efdcmpeq cr0, r5, r5
+; SPE-NEXT: bclr 12, gt, 0
+; SPE-NEXT: .LBB20_2:
+; SPE-NEXT: mr r3, r4
; SPE-NEXT: blr
%cond = call i1 @llvm.experimental.constrained.fcmps.f64(double %f1, double %f2, metadata !"ord", metadata !"fpexcept.strict") #0
%res = select i1 %cond, i32 %a, i32 %b
@@ -334,12 +356,14 @@ define i32 @test_f64_ueq_s(i32 %a, i32 %b, double %f1, double %f2) #0 {
; SPE-NEXT: evmergelo r7, r7, r8
; SPE-NEXT: evmergelo r5, r5, r6
; SPE-NEXT: efdcmplt cr0, r5, r7
-; SPE-NEXT: efdcmpgt cr1, r5, r7
-; SPE-NEXT: cror 4*cr5+lt, 4*cr1+gt, gt
-; SPE-NEXT: bc 12, 4*cr5+lt, .LBB21_1
-; SPE-NEXT: blr
-; SPE-NEXT: .LBB21_1:
-; SPE-NEXT: addi r3, r4, 0
+; SPE-NEXT: bc 12, gt, .LBB21_3
+; SPE-NEXT: # %bb.1:
+; SPE-NEXT: efdcmpgt cr0, r5, r7
+; SPE-NEXT: bc 12, gt, .LBB21_3
+; SPE-NEXT: # %bb.2:
+; SPE-NEXT: mr r4, r3
+; SPE-NEXT: .LBB21_3:
+; SPE-NEXT: mr r3, r4
; SPE-NEXT: blr
%cond = call i1 @llvm.experimental.constrained.fcmps.f64(double %f1, double %f2, metadata !"ueq", metadata !"fpexcept.strict") #0
%res = select i1 %cond, i32 %a, i32 %b
@@ -352,13 +376,15 @@ define i32 @test_f64_ugt_s(i32 %a, i32 %b, double %f1, double %f2) #0 {
; SPE-NEXT: evmergelo r7, r7, r8
; SPE-NEXT: evmergelo r5, r5, r6
; SPE-NEXT: efdcmpeq cr0, r5, r5
-; SPE-NEXT: efdcmpeq cr1, r7, r7
-; SPE-NEXT: efdcmpgt cr5, r5, r7
-; SPE-NEXT: crnand 4*cr5+lt, 4*cr1+gt, gt
-; SPE-NEXT: cror 4*cr5+lt, 4*cr5+gt, 4*cr5+lt
-; SPE-NEXT: bclr 12, 4*cr5+lt, 0
+; SPE-NEXT: bclr 4, gt, 0
; SPE-NEXT: # %bb.1:
-; SPE-NEXT: ori r3, r4, 0
+; SPE-NEXT: efdcmpeq cr0, r7, r7
+; SPE-NEXT: bclr 4, gt, 0
+; SPE-NEXT: # %bb.2:
+; SPE-NEXT: efdcmpgt cr0, r5, r7
+; SPE-NEXT: bclr 12, gt, 0
+; SPE-NEXT: # %bb.3:
+; SPE-NEXT: mr r3, r4
; SPE-NEXT: blr
%cond = call i1 @llvm.experimental.constrained.fcmps.f64(double %f1, double %f2, metadata !"ugt", metadata !"fpexcept.strict") #0
%res = select i1 %cond, i32 %a, i32 %b
@@ -371,10 +397,11 @@ define i32 @test_f64_uge_s(i32 %a, i32 %b, double %f1, double %f2) #0 {
; SPE-NEXT: evmergelo r7, r7, r8
; SPE-NEXT: evmergelo r5, r5, r6
; SPE-NEXT: efdcmplt cr0, r5, r7
-; SPE-NEXT: bc 12, gt, .LBB23_1
-; SPE-NEXT: blr
-; SPE-NEXT: .LBB23_1:
-; SPE-NEXT: addi r3, r4, 0
+; SPE-NEXT: bc 12, gt, .LBB23_2
+; SPE-NEXT: # %bb.1:
+; SPE-NEXT: mr r4, r3
+; SPE-NEXT: .LBB23_2:
+; SPE-NEXT: mr r3, r4
; SPE-NEXT: blr
%cond = call i1 @llvm.experimental.constrained.fcmps.f64(double %f1, double %f2, metadata !"uge", metadata !"fpexcept.strict") #0
%res = select i1 %cond, i32 %a, i32 %b
@@ -387,13 +414,15 @@ define i32 @test_f64_ult_s(i32 %a, i32 %b, double %f1, double %f2) #0 {
; SPE-NEXT: evmergelo r7, r7, r8
; SPE-NEXT: evmergelo r5, r5, r6
; SPE-NEXT: efdcmpeq cr0, r5, r5
-; SPE-NEXT: efdcmpeq cr1, r7, r7
-; SPE-NEXT: efdcmplt cr5, r5, r7
-; SPE-NEXT: crnand 4*cr5+lt, 4*cr1+gt, gt
-; SPE-NEXT: cror 4*cr5+lt, 4*cr5+gt, 4*cr5+lt
-; SPE-NEXT: bclr 12, 4*cr5+lt, 0
+; SPE-NEXT: bclr 4, gt, 0
; SPE-NEXT: # %bb.1:
-; SPE-NEXT: ori r3, r4, 0
+; SPE-NEXT: efdcmpeq cr0, r7, r7
+; SPE-NEXT: bclr 4, gt, 0
+; SPE-NEXT: # %bb.2:
+; SPE-NEXT: efdcmplt cr0, r5, r7
+; SPE-NEXT: bclr 12, gt, 0
+; SPE-NEXT: # %bb.3:
+; SPE-NEXT: mr r3, r4
; SPE-NEXT: blr
%cond = call i1 @llvm.experimental.constrained.fcmps.f64(double %f1, double %f2, metadata !"ult", metadata !"fpexcept.strict") #0
%res = select i1 %cond, i32 %a, i32 %b
@@ -406,10 +435,11 @@ define i32 @test_f64_ule_s(i32 %a, i32 %b, double %f1, double %f2) #0 {
; SPE-NEXT: evmergelo r7, r7, r8
; SPE-NEXT: evmergelo r5, r5, r6
; SPE-NEXT: efdcmpgt cr0, r5, r7
-; SPE-NEXT: bc 12, gt, .LBB25_1
-; SPE-NEXT: blr
-; SPE-NEXT: .LBB25_1:
-; SPE-NEXT: addi r3, r4, 0
+; SPE-NEXT: bc 12, gt, .LBB25_2
+; SPE-NEXT: # %bb.1:
+; SPE-NEXT: mr r4, r3
+; SPE-NEXT: .LBB25_2:
+; SPE-NEXT: mr r3, r4
; SPE-NEXT: blr
%cond = call i1 @llvm.experimental.constrained.fcmps.f64(double %f1, double %f2, metadata !"ule", metadata !"fpexcept.strict") #0
%res = select i1 %cond, i32 %a, i32 %b
@@ -422,10 +452,11 @@ define i32 @test_f64_une_s(i32 %a, i32 %b, double %f1, double %f2) #0 {
; SPE-NEXT: evmergelo r7, r7, r8
; SPE-NEXT: evmergelo r5, r5, r6
; SPE-NEXT: efdcmpeq cr0, r5, r7
-; SPE-NEXT: bc 12, gt, .LBB26_1
-; SPE-NEXT: blr
-; SPE-NEXT: .LBB26_1:
-; SPE-NEXT: addi r3, r4, 0
+; SPE-NEXT: bc 12, gt, .LBB26_2
+; SPE-NEXT: # %bb.1:
+; SPE-NEXT: mr r4, r3
+; SPE-NEXT: .LBB26_2:
+; SPE-NEXT: mr r3, r4
; SPE-NEXT: blr
%cond = call i1 @llvm.experimental.constrained.fcmps.f64(double %f1, double %f2, metadata !"une", metadata !"fpexcept.strict") #0
%res = select i1 %cond, i32 %a, i32 %b
@@ -438,11 +469,12 @@ define i32 @test_f64_uno_s(i32 %a, i32 %b, double %f1, double %f2) #0 {
; SPE-NEXT: evmergelo r7, r7, r8
; SPE-NEXT: evmergelo r5, r5, r6
; SPE-NEXT: efdcmpeq cr0, r5, r5
-; SPE-NEXT: efdcmpeq cr1, r7, r7
-; SPE-NEXT: crnand 4*cr5+lt, 4*cr1+gt, gt
-; SPE-NEXT: bclr 12, 4*cr5+lt, 0
+; SPE-NEXT: bclr 4, gt, 0
; SPE-NEXT: # %bb.1:
-; SPE-NEXT: ori r3, r4, 0
+; SPE-NEXT: efdcmpeq cr0, r7, r7
+; SPE-NEXT: bclr 4, gt, 0
+; SPE-NEXT: # %bb.2:
+; SPE-NEXT: mr r3, r4
; SPE-NEXT: blr
%cond = call i1 @llvm.experimental.constrained.fcmps.f64(double %f1, double %f2, metadata !"uno", metadata !"fpexcept.strict") #0
%res = select i1 %cond, i32 %a, i32 %b
diff --git a/llvm/test/CodeGen/PowerPC/fp-to-int-to-fp.ll b/llvm/test/CodeGen/PowerPC/fp-to-int-to-fp.ll
index 9cc42cf74b7f94..11460349c90fbd 100644
--- a/llvm/test/CodeGen/PowerPC/fp-to-int-to-fp.ll
+++ b/llvm/test/CodeGen/PowerPC/fp-to-int-to-fp.ll
@@ -66,61 +66,60 @@ define float @fooul(float %X) #0 {
; PPC64-LABEL: fooul:
; PPC64: # %bb.0: # %entry
; PPC64-NEXT: addis 3, 2, .LCPI2_0 at toc@ha
-; PPC64-NEXT: li 4, 1
; PPC64-NEXT: lfs 0, .LCPI2_0 at toc@l(3)
-; PPC64-NEXT: rldic 4, 4, 63, 0
; PPC64-NEXT: fsubs 2, 1, 0
; PPC64-NEXT: fcmpu 0, 1, 0
; PPC64-NEXT: fctidz 2, 2
; PPC64-NEXT: stfd 2, -8(1)
; PPC64-NEXT: fctidz 2, 1
; PPC64-NEXT: stfd 2, -16(1)
+; PPC64-NEXT: blt 0, .LBB2_2
+; PPC64-NEXT: # %bb.1: # %entry
; PPC64-NEXT: ld 3, -8(1)
-; PPC64-NEXT: ld 5, -16(1)
+; PPC64-NEXT: li 4, 1
+; PPC64-NEXT: rldic 4, 4, 63, 0
; PPC64-NEXT: xor 3, 3, 4
-; PPC64-NEXT: bc 12, 0, .LBB2_1
-; PPC64-NEXT: b .LBB2_2
-; PPC64-NEXT: .LBB2_1: # %entry
-; PPC64-NEXT: addi 3, 5, 0
-; PPC64-NEXT: .LBB2_2: # %entry
+; PPC64-NEXT: b .LBB2_3
+; PPC64-NEXT: .LBB2_2:
+; PPC64-NEXT: ld 3, -16(1)
+; PPC64-NEXT: .LBB2_3: # %entry
; PPC64-NEXT: sradi 4, 3, 53
-; PPC64-NEXT: rldicl 5, 3, 63, 1
; PPC64-NEXT: addi 4, 4, 1
-; PPC64-NEXT: clrldi 6, 3, 63
; PPC64-NEXT: cmpldi 4, 1
+; PPC64-NEXT: bgt 0, .LBB2_5
+; PPC64-NEXT: # %bb.4: # %entry
+; PPC64-NEXT: mr 4, 3
+; PPC64-NEXT: b .LBB2_6
+; PPC64-NEXT: .LBB2_5:
; PPC64-NEXT: clrldi 4, 3, 53
-; PPC64-NEXT: or 6, 6, 5
-; PPC64-NEXT: clrldi 7, 6, 53
; PPC64-NEXT: addi 4, 4, 2047
-; PPC64-NEXT: addi 7, 7, 2047
; PPC64-NEXT: or 4, 4, 3
-; PPC64-NEXT: or 5, 7, 5
-; PPC64-NEXT: rldicl 7, 3, 10, 54
; PPC64-NEXT: rldicr 4, 4, 0, 52
-; PPC64-NEXT: addi 7, 7, 1
-; PPC64-NEXT: bc 12, 1, .LBB2_4
-; PPC64-NEXT: # %bb.3: # %entry
-; PPC64-NEXT: ori 4, 3, 0
-; PPC64-NEXT: b .LBB2_4
-; PPC64-NEXT: .LBB2_4: # %entry
-; PPC64-NEXT: rldicl 5, 5, 53, 11
-; PPC64-NEXT: std 4, -32(1)
-; PPC64-NEXT: rldicl 4, 5, 11, 1
-; PPC64-NEXT: cmpldi 7, 1
-; PPC64-NEXT: bc 12, 1, .LBB2_6
-; PPC64-NEXT: # %bb.5: # %entry
-; PPC64-NEXT: ori 4, 6, 0
-; PPC64-NEXT: b .LBB2_6
; PPC64-NEXT: .LBB2_6: # %entry
+; PPC64-NEXT: rldicl 5, 3, 10, 54
+; PPC64-NEXT: clrldi 6, 3, 63
+; PPC64-NEXT: std 4, -32(1)
+; PPC64-NEXT: addi 5, 5, 1
+; PPC64-NEXT: cmpldi 5, 1
+; PPC64-NEXT: rldicl 5, 3, 63, 1
+; PPC64-NEXT: or 4, 6, 5
+; PPC64-NEXT: ble 0, .LBB2_8
+; PPC64-NEXT: # %bb.7:
+; PPC64-NEXT: clrldi 4, 4, 53
+; PPC64-NEXT: addi 4, 4, 2047
+; PPC64-NEXT: or 4, 4, 5
+; PPC64-NEXT: rldicl 4, 4, 53, 11
+; PPC64-NEXT: rldicl 4, 4, 11, 1
+; PPC64-NEXT: .LBB2_8: # %entry
; PPC64-NEXT: cmpdi 3, 0
; PPC64-NEXT: std 4, -24(1)
-; PPC64-NEXT: bc 12, 0, .LBB2_8
-; PPC64-NEXT: # %bb.7: # %entry
+; PPC64-NEXT: bc 12, 0, .LBB2_10
+; PPC64-NEXT: # %bb.9: # %entry
; PPC64-NEXT: lfd 0, -32(1)
; PPC64-NEXT: fcfid 0, 0
; PPC64-NEXT: frsp 1, 0
; PPC64-NEXT: blr
-; PPC64-NEXT: .LBB2_8:
+; PPC64-NEXT: .LBB2_10:
; PPC64-NEXT: lfd 0, -24(1)
; PPC64-NEXT: fcfid 0, 0
; PPC64-NEXT: frsp 0, 0
@@ -148,34 +147,34 @@ define double @fooudl(double %X) #0 {
; PPC64-LABEL: fooudl:
; PPC64: # %bb.0: # %entry
; PPC64-NEXT: addis 3, 2, .LCPI3_0 at toc@ha
-; PPC64-NEXT: li 4, 1
; PPC64-NEXT: lfs 0, .LCPI3_0 at toc@l(3)
-; PPC64-NEXT: rldic 4, 4, 63, 0
; PPC64-NEXT: fsub 2, 1, 0
; PPC64-NEXT: fcmpu 0, 1, 0
; PPC64-NEXT: fctidz 2, 2
; PPC64-NEXT: stfd 2, -8(1)
; PPC64-NEXT: fctidz 2, 1
; PPC64-NEXT: stfd 2, -16(1)
+; PPC64-NEXT: blt 0, .LBB3_2
+; PPC64-NEXT: # %bb.1: # %entry
; PPC64-NEXT: ld 3, -8(1)
-; PPC64-NEXT: ld 5, -16(1)
+; PPC64-NEXT: li 4, 1
+; PPC64-NEXT: rldic 4, 4, 63, 0
; PPC64-NEXT: xor 3, 3, 4
-; PPC64-NEXT: li 4, 1107
-; PPC64-NEXT: rldic 4, 4, 52, 1
-; PPC64-NEXT: bc 12, 0, .LBB3_1
-; PPC64-NEXT: b .LBB3_2
-; PPC64-NEXT: .LBB3_1: # %entry
-; PPC64-NEXT: addi 3, 5, 0
-; PPC64-NEXT: .LBB3_2: # %entry
-; PPC64-NEXT: rldicl 5, 3, 32, 32
+; PPC64-NEXT: b .LBB3_3
+; PPC64-NEXT: .LBB3_2:
+; PPC64-NEXT: ld 3, -16(1)
+; PPC64-NEXT: .LBB3_3: # %entry
+; PPC64-NEXT: li 5, 1107
+; PPC64-NEXT: rldicl 4, 3, 32, 32
+; PPC64-NEXT: rldic 5, 5, 52, 1
; PPC64-NEXT: clrldi 3, 3, 32
-; PPC64-NEXT: or 4, 5, 4
-; PPC64-NEXT: addis 5, 2, .LCPI3_1 at toc@ha
+; PPC64-NEXT: or 4, 4, 5
+; PPC64-NEXT: li 5, 1075
; PPC64-NEXT: std 4, -24(1)
-; PPC64-NEXT: li 4, 1075
-; PPC64-NEXT: rldic 4, 4, 52, 1
+; PPC64-NEXT: addis 4, 2, .LCPI3_1 at toc@ha
+; PPC64-NEXT: lfd 0, .LCPI3_1 at toc@l(4)
+; PPC64-NEXT: rldic 4, 5, 52, 1
; PPC64-NEXT: or 3, 3, 4
-; PPC64-NEXT: lfd 0, .LCPI3_1 at toc@l(5)
; PPC64-NEXT: std 3, -32(1)
; PPC64-NEXT: lfd 1, -24(1)
; PPC64-NEXT: lfd 2, -32(1)
@@ -269,12 +268,10 @@ define double @si1_to_f64(i1 %X) #0 {
; PPC64-LABEL: si1_to_f64:
; PPC64: # %bb.0: # %entry
; PPC64-NEXT: andi. 3, 3, 1
-; PPC64-NEXT: li 4, -1
+; PPC64-NEXT: li 3, -1
+; PPC64-NEXT: bc 12, 1, .LBB6_2
+; PPC64-NEXT: # %bb.1: # %entry
; PPC64-NEXT: li 3, 0
-; PPC64-NEXT: bc 12, 1, .LBB6_1
-; PPC64-NEXT: b .LBB6_2
-; PPC64-NEXT: .LBB6_1: # %entry
-; PPC64-NEXT: addi 3, 4, 0
; PPC64-NEXT: .LBB6_2: # %entry
; PPC64-NEXT: std 3, -8(1)
; PPC64-NEXT: lfd 0, -8(1)
diff --git a/llvm/test/CodeGen/PowerPC/fptoui-be-crash.ll b/llvm/test/CodeGen/PowerPC/fptoui-be-crash.ll
index fc93f893b1d5d6..004d77eb33933a 100644
--- a/llvm/test/CodeGen/PowerPC/fptoui-be-crash.ll
+++ b/llvm/test/CodeGen/PowerPC/fptoui-be-crash.ll
@@ -5,67 +5,65 @@ define dso_local void @calc_buffer() local_unnamed_addr #0 {
; CHECK-LABEL: calc_buffer:
; CHECK: # %bb.0:
; CHECK-NEXT: ld r3, 0(r3)
-; CHECK-NEXT: sradi r5, r3, 53
-; CHECK-NEXT: rldicl r6, r3, 63, 1
-; CHECK-NEXT: clrldi r7, r3, 63
+; CHECK-NEXT: sradi r4, r3, 53
+; CHECK-NEXT: addi r4, r4, 1
+; CHECK-NEXT: cmpldi r4, 1
+; CHECK-NEXT: bgt cr0, .LBB0_2
+; CHECK-NEXT: # %bb.1:
+; CHECK-NEXT: mr r4, r3
+; CHECK-NEXT: b .LBB0_3
+; CHECK-NEXT: .LBB0_2:
; CHECK-NEXT: clrldi r4, r3, 53
-; CHECK-NEXT: addi r5, r5, 1
-; CHECK-NEXT: or r7, r7, r6
-; CHECK-NEXT: cmpldi r5, 1
-; CHECK-NEXT: clrldi r5, r7, 53
; CHECK-NEXT: addi r4, r4, 2047
-; CHECK-NEXT: addi r5, r5, 2047
-; CHECK-NEXT: or r5, r5, r6
-; CHECK-NEXT: rldicl r6, r3, 10, 54
; CHECK-NEXT: or r4, r4, r3
-; CHECK-NEXT: addi r6, r6, 1
-; CHECK-NEXT: rldicl r5, r5, 53, 11
-; CHECK-NEXT: cmpldi cr1, r6, 1
; CHECK-NEXT: rldicr r4, r4, 0, 52
-; CHECK-NEXT: rldicl r5, r5, 11, 1
-; CHECK-NEXT: bc 12, gt, .LBB0_2
-; CHECK-NEXT: # %bb.1:
-; CHECK-NEXT: ori r4, r3, 0
-; CHECK-NEXT: b .LBB0_2
-; CHECK-NEXT: .LBB0_2:
-; CHECK-NEXT: bc 12, 4*cr1+gt, .LBB0_4
-; CHECK-NEXT: # %bb.3:
-; CHECK-NEXT: ori r5, r7, 0
-; CHECK-NEXT: b .LBB0_4
-; CHECK-NEXT: .LBB0_4:
-; CHECK-NEXT: cmpdi r3, 0
+; CHECK-NEXT: .LBB0_3:
+; CHECK-NEXT: rldicl r6, r3, 10, 54
; CHECK-NEXT: std r4, -32(r1)
-; CHECK-NEXT: std r5, -24(r1)
-; CHECK-NEXT: bc 12, lt, .LBB0_6
-; CHECK-NEXT: # %bb.5:
+; CHECK-NEXT: rldicl r5, r3, 63, 1
+; CHECK-NEXT: clrldi r4, r3, 63
+; CHECK-NEXT: addi r6, r6, 1
+; CHECK-NEXT: cmpldi r6, 1
+; CHECK-NEXT: or r4, r4, r5
+; CHECK-NEXT: ble cr0, .LBB0_5
+; CHECK-NEXT: # %bb.4:
+; CHECK-NEXT: clrldi r4, r4, 53
+; CHECK-NEXT: addi r4, r4, 2047
+; CHECK-NEXT: or r4, r4, r5
+; CHECK-NEXT: rldicl r4, r4, 53, 11
+; CHECK-NEXT: rldicl r4, r4, 11, 1
+; CHECK-NEXT: .LBB0_5:
+; CHECK-NEXT: cmpdi r3, 0
+; CHECK-NEXT: std r4, -24(r1)
+; CHECK-NEXT: bc 12, lt, .LBB0_7
+; CHECK-NEXT: # %bb.6:
; CHECK-NEXT: lfd f0, -32(r1)
; CHECK-NEXT: fcfid f0, f0
; CHECK-NEXT: frsp f0, f0
-; CHECK-NEXT: b .LBB0_7
-; CHECK-NEXT: .LBB0_6:
+; CHECK-NEXT: b .LBB0_8
+; CHECK-NEXT: .LBB0_7:
; CHECK-NEXT: lfd f0, -24(r1)
; CHECK-NEXT: fcfid f0, f0
; CHECK-NEXT: frsp f0, f0
; CHECK-NEXT: fadds f0, f0, f0
-; CHECK-NEXT: .LBB0_7:
+; CHECK-NEXT: .LBB0_8:
; CHECK-NEXT: addis r3, r2, .LCPI0_0 at toc@ha
-; CHECK-NEXT: li r4, 1
; CHECK-NEXT: lfs f1, .LCPI0_0 at toc@l(r3)
-; CHECK-NEXT: rldic r4, r4, 63, 0
; CHECK-NEXT: fsubs f2, f0, f1
; CHECK-NEXT: fctidz f2, f2
; CHECK-NEXT: stfd f2, -8(r1)
; CHECK-NEXT: fctidz f2, f0
+; CHECK-NEXT: fcmpu cr0, f0, f1
; CHECK-NEXT: stfd f2, -16(r1)
+; CHECK-NEXT: blt cr0, .LBB0_10
+; CHECK-NEXT: # %bb.9:
; CHECK-NEXT: ld r3, -8(r1)
-; CHECK-NEXT: ld r5, -16(r1)
-; CHECK-NEXT: fcmpu cr0, f0, f1
+; CHECK-NEXT: li r4, 1
+; CHECK-NEXT: rldic r4, r4, 63, 0
; CHECK-NEXT: xor r3, r3, r4
-; CHECK-NEXT: bc 12, lt, .LBB0_8
-; CHECK-NEXT: b .LBB0_9
-; CHECK-NEXT: .LBB0_8:
-; CHECK-NEXT: addi r3, r5, 0
-; CHECK-NEXT: .LBB0_9:
+; CHECK-NEXT: std r3, 0(r3)
+; CHECK-NEXT: .LBB0_10:
+; CHECK-NEXT: ld r3, -16(r1)
; CHECK-NEXT: std r3, 0(r3)
%load_initial = load i64, ptr poison, align 8
%conv39 = uitofp i64 %load_initial to float
diff --git a/llvm/test/CodeGen/PowerPC/funnel-shift-rot.ll b/llvm/test/CodeGen/PowerPC/funnel-shift-rot.ll
index 72f8af9dfed5d4..12078adbbc2f39 100644
--- a/llvm/test/CodeGen/PowerPC/funnel-shift-rot.ll
+++ b/llvm/test/CodeGen/PowerPC/funnel-shift-rot.ll
@@ -74,47 +74,27 @@ define i32 @rotl_i32(i32 %x, i32 %z) {
}
define i64 @rotl_i64(i64 %x, i64 %z) {
-; CHECK32_32-LABEL: rotl_i64:
-; CHECK32_32: # %bb.0:
-; CHECK32_32-NEXT: andi. 5, 6, 32
-; CHECK32_32-NEXT: clrlwi 5, 6, 27
-; CHECK32_32-NEXT: subfic 6, 5, 32
-; CHECK32_32-NEXT: bc 12, 2, .LBB4_2
-; CHECK32_32-NEXT: # %bb.1:
-; CHECK32_32-NEXT: ori 7, 3, 0
-; CHECK32_32-NEXT: ori 3, 4, 0
-; CHECK32_32-NEXT: b .LBB4_3
-; CHECK32_32-NEXT: .LBB4_2:
-; CHECK32_32-NEXT: addi 7, 4, 0
-; CHECK32_32-NEXT: .LBB4_3:
-; CHECK32_32-NEXT: srw 4, 7, 6
-; CHECK32_32-NEXT: slw 8, 3, 5
-; CHECK32_32-NEXT: srw 6, 3, 6
-; CHECK32_32-NEXT: slw 5, 7, 5
-; CHECK32_32-NEXT: or 3, 8, 4
-; CHECK32_32-NEXT: or 4, 5, 6
-; CHECK32_32-NEXT: blr
-;
-; CHECK32_64-LABEL: rotl_i64:
-; CHECK32_64: # %bb.0:
-; CHECK32_64-NEXT: andi. 5, 6, 32
-; CHECK32_64-NEXT: clrlwi 5, 6, 27
-; CHECK32_64-NEXT: bc 12, 2, .LBB4_2
-; CHECK32_64-NEXT: # %bb.1:
-; CHECK32_64-NEXT: ori 7, 3, 0
-; CHECK32_64-NEXT: ori 3, 4, 0
-; CHECK32_64-NEXT: b .LBB4_3
-; CHECK32_64-NEXT: .LBB4_2:
-; CHECK32_64-NEXT: addi 7, 4, 0
-; CHECK32_64-NEXT: .LBB4_3:
-; CHECK32_64-NEXT: subfic 6, 5, 32
-; CHECK32_64-NEXT: srw 4, 7, 6
-; CHECK32_64-NEXT: slw 8, 3, 5
-; CHECK32_64-NEXT: srw 6, 3, 6
-; CHECK32_64-NEXT: slw 5, 7, 5
-; CHECK32_64-NEXT: or 3, 8, 4
-; CHECK32_64-NEXT: or 4, 5, 6
-; CHECK32_64-NEXT: blr
+; CHECK32-LABEL: rotl_i64:
+; CHECK32: # %bb.0:
+; CHECK32-NEXT: andi. 5, 6, 32
+; CHECK32-NEXT: mr 5, 3
+; CHECK32-NEXT: bne 0, .LBB4_2
+; CHECK32-NEXT: # %bb.1:
+; CHECK32-NEXT: mr 5, 4
+; CHECK32-NEXT: .LBB4_2:
+; CHECK32-NEXT: clrlwi 6, 6, 27
+; CHECK32-NEXT: subfic 8, 6, 32
+; CHECK32-NEXT: srw 7, 5, 8
+; CHECK32-NEXT: bne 0, .LBB4_4
+; CHECK32-NEXT: # %bb.3:
+; CHECK32-NEXT: mr 4, 3
+; CHECK32-NEXT: .LBB4_4:
+; CHECK32-NEXT: slw 3, 4, 6
+; CHECK32-NEXT: srw 4, 4, 8
+; CHECK32-NEXT: slw 5, 5, 6
+; CHECK32-NEXT: or 3, 3, 7
+; CHECK32-NEXT: or 4, 5, 4
+; CHECK32-NEXT: blr
;
; CHECK64-LABEL: rotl_i64:
; CHECK64: # %bb.0:
@@ -224,47 +204,27 @@ define i32 @rotr_i32(i32 %x, i32 %z) {
}
define i64 @rotr_i64(i64 %x, i64 %z) {
-; CHECK32_32-LABEL: rotr_i64:
-; CHECK32_32: # %bb.0:
-; CHECK32_32-NEXT: andi. 5, 6, 32
-; CHECK32_32-NEXT: clrlwi 5, 6, 27
-; CHECK32_32-NEXT: subfic 6, 5, 32
-; CHECK32_32-NEXT: bc 12, 2, .LBB11_2
-; CHECK32_32-NEXT: # %bb.1:
-; CHECK32_32-NEXT: ori 7, 4, 0
-; CHECK32_32-NEXT: b .LBB11_3
-; CHECK32_32-NEXT: .LBB11_2:
-; CHECK32_32-NEXT: addi 7, 3, 0
-; CHECK32_32-NEXT: addi 3, 4, 0
-; CHECK32_32-NEXT: .LBB11_3:
-; CHECK32_32-NEXT: srw 4, 7, 5
-; CHECK32_32-NEXT: slw 8, 3, 6
-; CHECK32_32-NEXT: srw 5, 3, 5
-; CHECK32_32-NEXT: slw 6, 7, 6
-; CHECK32_32-NEXT: or 3, 8, 4
-; CHECK32_32-NEXT: or 4, 6, 5
-; CHECK32_32-NEXT: blr
-;
-; CHECK32_64-LABEL: rotr_i64:
-; CHECK32_64: # %bb.0:
-; CHECK32_64-NEXT: andi. 5, 6, 32
-; CHECK32_64-NEXT: clrlwi 5, 6, 27
-; CHECK32_64-NEXT: bc 12, 2, .LBB11_2
-; CHECK32_64-NEXT: # %bb.1:
-; CHECK32_64-NEXT: ori 7, 4, 0
-; CHECK32_64-NEXT: b .LBB11_3
-; CHECK32_64-NEXT: .LBB11_2:
-; CHECK32_64-NEXT: addi 7, 3, 0
-; CHECK32_64-NEXT: addi 3, 4, 0
-; CHECK32_64-NEXT: .LBB11_3:
-; CHECK32_64-NEXT: subfic 6, 5, 32
-; CHECK32_64-NEXT: srw 4, 7, 5
-; CHECK32_64-NEXT: slw 8, 3, 6
-; CHECK32_64-NEXT: srw 5, 3, 5
-; CHECK32_64-NEXT: slw 6, 7, 6
-; CHECK32_64-NEXT: or 3, 8, 4
-; CHECK32_64-NEXT: or 4, 6, 5
-; CHECK32_64-NEXT: blr
+; CHECK32-LABEL: rotr_i64:
+; CHECK32: # %bb.0:
+; CHECK32-NEXT: andi. 5, 6, 32
+; CHECK32-NEXT: mr 5, 3
+; CHECK32-NEXT: beq 0, .LBB11_2
+; CHECK32-NEXT: # %bb.1:
+; CHECK32-NEXT: mr 5, 4
+; CHECK32-NEXT: .LBB11_2:
+; CHECK32-NEXT: clrlwi 7, 6, 27
+; CHECK32-NEXT: srw 6, 5, 7
+; CHECK32-NEXT: beq 0, .LBB11_4
+; CHECK32-NEXT: # %bb.3:
+; CHECK32-NEXT: mr 4, 3
+; CHECK32-NEXT: .LBB11_4:
+; CHECK32-NEXT: subfic 3, 7, 32
+; CHECK32-NEXT: srw 7, 4, 7
+; CHECK32-NEXT: slw 4, 4, 3
+; CHECK32-NEXT: slw 5, 5, 3
+; CHECK32-NEXT: or 3, 4, 6
+; CHECK32-NEXT: or 4, 5, 7
+; CHECK32-NEXT: blr
;
; CHECK64-LABEL: rotr_i64:
; CHECK64: # %bb.0:
diff --git a/llvm/test/CodeGen/PowerPC/funnel-shift.ll b/llvm/test/CodeGen/PowerPC/funnel-shift.ll
index c766c950f0a551..be95233656f47f 100644
--- a/llvm/test/CodeGen/PowerPC/funnel-shift.ll
+++ b/llvm/test/CodeGen/PowerPC/funnel-shift.ll
@@ -32,50 +32,31 @@ define i32 @fshl_i32(i32 %x, i32 %y, i32 %z) {
}
define i64 @fshl_i64(i64 %x, i64 %y, i64 %z) {
-; CHECK32_32-LABEL: fshl_i64:
-; CHECK32_32: # %bb.0:
-; CHECK32_32-NEXT: andi. 7, 8, 32
-; CHECK32_32-NEXT: clrlwi 7, 8, 27
-; CHECK32_32-NEXT: subfic 8, 7, 32
-; CHECK32_32-NEXT: bc 12, 2, .LBB1_2
-; CHECK32_32-NEXT: # %bb.1:
-; CHECK32_32-NEXT: ori 9, 5, 0
-; CHECK32_32-NEXT: ori 3, 4, 0
-; CHECK32_32-NEXT: ori 4, 6, 0
-; CHECK32_32-NEXT: b .LBB1_3
-; CHECK32_32-NEXT: .LBB1_2:
-; CHECK32_32-NEXT: addi 9, 4, 0
-; CHECK32_32-NEXT: addi 4, 5, 0
-; CHECK32_32-NEXT: .LBB1_3:
-; CHECK32_32-NEXT: srw 5, 9, 8
-; CHECK32_32-NEXT: slw 3, 3, 7
-; CHECK32_32-NEXT: srw 4, 4, 8
-; CHECK32_32-NEXT: slw 6, 9, 7
-; CHECK32_32-NEXT: or 3, 3, 5
-; CHECK32_32-NEXT: or 4, 6, 4
-; CHECK32_32-NEXT: blr
-;
-; CHECK32_64-LABEL: fshl_i64:
-; CHECK32_64: # %bb.0:
-; CHECK32_64-NEXT: andi. 7, 8, 32
-; CHECK32_64-NEXT: clrlwi 7, 8, 27
-; CHECK32_64-NEXT: bc 12, 2, .LBB1_2
-; CHECK32_64-NEXT: # %bb.1:
-; CHECK32_64-NEXT: ori 9, 5, 0
-; CHECK32_64-NEXT: ori 3, 4, 0
-; CHECK32_64-NEXT: ori 5, 6, 0
-; CHECK32_64-NEXT: b .LBB1_3
-; CHECK32_64-NEXT: .LBB1_2:
-; CHECK32_64-NEXT: addi 9, 4, 0
-; CHECK32_64-NEXT: .LBB1_3:
-; CHECK32_64-NEXT: subfic 8, 7, 32
-; CHECK32_64-NEXT: srw 4, 9, 8
-; CHECK32_64-NEXT: slw 3, 3, 7
-; CHECK32_64-NEXT: srw 5, 5, 8
-; CHECK32_64-NEXT: slw 6, 9, 7
-; CHECK32_64-NEXT: or 3, 3, 4
-; CHECK32_64-NEXT: or 4, 6, 5
-; CHECK32_64-NEXT: blr
+; CHECK32-LABEL: fshl_i64:
+; CHECK32: # %bb.0:
+; CHECK32-NEXT: andi. 7, 8, 32
+; CHECK32-NEXT: mr 7, 5
+; CHECK32-NEXT: bne 0, .LBB1_2
+; CHECK32-NEXT: # %bb.1:
+; CHECK32-NEXT: mr 7, 4
+; CHECK32-NEXT: .LBB1_2:
+; CHECK32-NEXT: clrlwi 8, 8, 27
+; CHECK32-NEXT: subfic 9, 8, 32
+; CHECK32-NEXT: srw 10, 7, 9
+; CHECK32-NEXT: bne 0, .LBB1_4
+; CHECK32-NEXT: # %bb.3:
+; CHECK32-NEXT: mr 4, 3
+; CHECK32-NEXT: .LBB1_4:
+; CHECK32-NEXT: slw 3, 4, 8
+; CHECK32-NEXT: or 3, 3, 10
+; CHECK32-NEXT: bne 0, .LBB1_6
+; CHECK32-NEXT: # %bb.5:
+; CHECK32-NEXT: mr 6, 5
+; CHECK32-NEXT: .LBB1_6:
+; CHECK32-NEXT: srw 4, 6, 9
+; CHECK32-NEXT: slw 5, 7, 8
+; CHECK32-NEXT: or 4, 5, 4
+; CHECK32-NEXT: blr
;
; CHECK64-LABEL: fshl_i64:
; CHECK64: # %bb.0:
@@ -92,113 +73,177 @@ define i64 @fshl_i64(i64 %x, i64 %y, i64 %z) {
define i128 @fshl_i128(i128 %x, i128 %y, i128 %z) nounwind {
; CHECK32_32-LABEL: fshl_i128:
; CHECK32_32: # %bb.0:
-; CHECK32_32-NEXT: lwz 11, 20(1)
-; CHECK32_32-NEXT: andi. 12, 11, 64
+; CHECK32_32-NEXT: stwu 1, -32(1)
+; CHECK32_32-NEXT: lwz 12, 52(1)
+; CHECK32_32-NEXT: stw 29, 20(1) # 4-byte Folded Spill
+; CHECK32_32-NEXT: andi. 11, 12, 64
; CHECK32_32-NEXT: mcrf 1, 0
-; CHECK32_32-NEXT: andi. 12, 11, 32
-; CHECK32_32-NEXT: clrlwi 11, 11, 27
-; CHECK32_32-NEXT: bc 12, 6, .LBB2_2
+; CHECK32_32-NEXT: mr 11, 6
+; CHECK32_32-NEXT: stw 30, 24(1) # 4-byte Folded Spill
+; CHECK32_32-NEXT: bne 0, .LBB2_2
; CHECK32_32-NEXT: # %bb.1:
-; CHECK32_32-NEXT: ori 4, 6, 0
-; CHECK32_32-NEXT: ori 12, 7, 0
-; CHECK32_32-NEXT: ori 3, 5, 0
-; CHECK32_32-NEXT: ori 5, 8, 0
-; CHECK32_32-NEXT: ori 6, 9, 0
-; CHECK32_32-NEXT: ori 7, 10, 0
-; CHECK32_32-NEXT: b .LBB2_3
+; CHECK32_32-NEXT: mr 11, 4
; CHECK32_32-NEXT: .LBB2_2:
-; CHECK32_32-NEXT: addi 12, 5, 0
-; CHECK32_32-NEXT: addi 5, 6, 0
-; CHECK32_32-NEXT: addi 6, 7, 0
-; CHECK32_32-NEXT: addi 7, 8, 0
-; CHECK32_32-NEXT: .LBB2_3:
-; CHECK32_32-NEXT: subfic 8, 11, 32
-; CHECK32_32-NEXT: bc 12, 2, .LBB2_5
-; CHECK32_32-NEXT: # %bb.4:
-; CHECK32_32-NEXT: ori 9, 12, 0
-; CHECK32_32-NEXT: ori 3, 4, 0
-; CHECK32_32-NEXT: ori 4, 5, 0
-; CHECK32_32-NEXT: ori 5, 6, 0
-; CHECK32_32-NEXT: ori 6, 7, 0
-; CHECK32_32-NEXT: b .LBB2_6
-; CHECK32_32-NEXT: .LBB2_5:
-; CHECK32_32-NEXT: addi 9, 4, 0
-; CHECK32_32-NEXT: addi 4, 12, 0
+; CHECK32_32-NEXT: mr 30, 7
+; CHECK32_32-NEXT: bne 1, .LBB2_4
+; CHECK32_32-NEXT: # %bb.3:
+; CHECK32_32-NEXT: mr 30, 5
+; CHECK32_32-NEXT: .LBB2_4:
+; CHECK32_32-NEXT: andi. 4, 12, 32
+; CHECK32_32-NEXT: mr 4, 30
+; CHECK32_32-NEXT: beq 0, .LBB2_18
+; CHECK32_32-NEXT: # %bb.5:
+; CHECK32_32-NEXT: beq 1, .LBB2_19
; CHECK32_32-NEXT: .LBB2_6:
-; CHECK32_32-NEXT: srw 7, 9, 8
-; CHECK32_32-NEXT: slw 3, 3, 11
-; CHECK32_32-NEXT: srw 10, 4, 8
-; CHECK32_32-NEXT: slw 9, 9, 11
-; CHECK32_32-NEXT: srw 12, 5, 8
-; CHECK32_32-NEXT: slw 0, 4, 11
-; CHECK32_32-NEXT: srw 6, 6, 8
-; CHECK32_32-NEXT: slw 8, 5, 11
-; CHECK32_32-NEXT: or 3, 3, 7
-; CHECK32_32-NEXT: or 4, 9, 10
-; CHECK32_32-NEXT: or 5, 0, 12
-; CHECK32_32-NEXT: or 6, 8, 6
+; CHECK32_32-NEXT: beq 0, .LBB2_20
+; CHECK32_32-NEXT: .LBB2_7:
+; CHECK32_32-NEXT: mr 5, 8
+; CHECK32_32-NEXT: beq 1, .LBB2_21
+; CHECK32_32-NEXT: .LBB2_8:
+; CHECK32_32-NEXT: mr 3, 5
+; CHECK32_32-NEXT: beq 0, .LBB2_22
+; CHECK32_32-NEXT: .LBB2_9:
+; CHECK32_32-NEXT: clrlwi 6, 12, 27
+; CHECK32_32-NEXT: bne 1, .LBB2_11
+; CHECK32_32-NEXT: .LBB2_10:
+; CHECK32_32-NEXT: mr 9, 7
+; CHECK32_32-NEXT: .LBB2_11:
+; CHECK32_32-NEXT: subfic 7, 6, 32
+; CHECK32_32-NEXT: mr 12, 9
+; CHECK32_32-NEXT: bne 0, .LBB2_13
+; CHECK32_32-NEXT: # %bb.12:
+; CHECK32_32-NEXT: mr 12, 5
+; CHECK32_32-NEXT: .LBB2_13:
+; CHECK32_32-NEXT: srw 5, 4, 7
+; CHECK32_32-NEXT: slw 11, 11, 6
+; CHECK32_32-NEXT: srw 0, 3, 7
+; CHECK32_32-NEXT: slw 4, 4, 6
+; CHECK32_32-NEXT: srw 30, 12, 7
+; CHECK32_32-NEXT: slw 29, 3, 6
+; CHECK32_32-NEXT: bne 1, .LBB2_15
+; CHECK32_32-NEXT: # %bb.14:
+; CHECK32_32-NEXT: mr 10, 8
+; CHECK32_32-NEXT: .LBB2_15:
+; CHECK32_32-NEXT: or 3, 11, 5
+; CHECK32_32-NEXT: or 4, 4, 0
+; CHECK32_32-NEXT: or 5, 29, 30
+; CHECK32_32-NEXT: bne 0, .LBB2_17
+; CHECK32_32-NEXT: # %bb.16:
+; CHECK32_32-NEXT: mr 10, 9
+; CHECK32_32-NEXT: .LBB2_17:
+; CHECK32_32-NEXT: srw 7, 10, 7
+; CHECK32_32-NEXT: slw 6, 12, 6
+; CHECK32_32-NEXT: or 6, 6, 7
+; CHECK32_32-NEXT: lwz 30, 24(1) # 4-byte Folded Reload
+; CHECK32_32-NEXT: lwz 29, 20(1) # 4-byte Folded Reload
+; CHECK32_32-NEXT: addi 1, 1, 32
; CHECK32_32-NEXT: blr
+; CHECK32_32-NEXT: .LBB2_18:
+; CHECK32_32-NEXT: mr 4, 11
+; CHECK32_32-NEXT: bne 1, .LBB2_6
+; CHECK32_32-NEXT: .LBB2_19:
+; CHECK32_32-NEXT: mr 5, 3
+; CHECK32_32-NEXT: bne 0, .LBB2_7
+; CHECK32_32-NEXT: .LBB2_20:
+; CHECK32_32-NEXT: mr 11, 5
+; CHECK32_32-NEXT: mr 5, 8
+; CHECK32_32-NEXT: bne 1, .LBB2_8
+; CHECK32_32-NEXT: .LBB2_21:
+; CHECK32_32-NEXT: mr 5, 6
+; CHECK32_32-NEXT: mr 3, 5
+; CHECK32_32-NEXT: bne 0, .LBB2_9
+; CHECK32_32-NEXT: .LBB2_22:
+; CHECK32_32-NEXT: mr 3, 30
+; CHECK32_32-NEXT: clrlwi 6, 12, 27
+; CHECK32_32-NEXT: beq 1, .LBB2_10
+; CHECK32_32-NEXT: b .LBB2_11
;
; CHECK32_64-LABEL: fshl_i128:
; CHECK32_64: # %bb.0:
-; CHECK32_64-NEXT: stwu 1, -16(1)
-; CHECK32_64-NEXT: lwz 11, 36(1)
-; CHECK32_64-NEXT: andi. 12, 11, 64
-; CHECK32_64-NEXT: stw 30, 8(1) # 4-byte Folded Spill
+; CHECK32_64-NEXT: stwu 1, -32(1)
+; CHECK32_64-NEXT: lwz 12, 52(1)
+; CHECK32_64-NEXT: andi. 11, 12, 64
+; CHECK32_64-NEXT: stw 29, 20(1) # 4-byte Folded Spill
; CHECK32_64-NEXT: mcrf 1, 0
-; CHECK32_64-NEXT: clrlwi 12, 11, 27
-; CHECK32_64-NEXT: andi. 11, 11, 32
-; CHECK32_64-NEXT: bc 12, 6, .LBB2_2
+; CHECK32_64-NEXT: mr 11, 6
+; CHECK32_64-NEXT: stw 30, 24(1) # 4-byte Folded Spill
+; CHECK32_64-NEXT: bne 0, .LBB2_2
; CHECK32_64-NEXT: # %bb.1:
-; CHECK32_64-NEXT: ori 4, 6, 0
-; CHECK32_64-NEXT: ori 30, 7, 0
-; CHECK32_64-NEXT: ori 3, 5, 0
-; CHECK32_64-NEXT: ori 7, 9, 0
-; CHECK32_64-NEXT: b .LBB2_3
+; CHECK32_64-NEXT: mr 11, 4
; CHECK32_64-NEXT: .LBB2_2:
-; CHECK32_64-NEXT: addi 30, 5, 0
-; CHECK32_64-NEXT: .LBB2_3:
-; CHECK32_64-NEXT: bc 12, 2, .LBB2_5
-; CHECK32_64-NEXT: # %bb.4:
-; CHECK32_64-NEXT: ori 5, 30, 0
-; CHECK32_64-NEXT: ori 3, 4, 0
-; CHECK32_64-NEXT: b .LBB2_6
-; CHECK32_64-NEXT: .LBB2_5:
-; CHECK32_64-NEXT: addi 5, 4, 0
+; CHECK32_64-NEXT: mr 30, 7
+; CHECK32_64-NEXT: bne 1, .LBB2_4
+; CHECK32_64-NEXT: # %bb.3:
+; CHECK32_64-NEXT: mr 30, 5
+; CHECK32_64-NEXT: .LBB2_4:
+; CHECK32_64-NEXT: andi. 4, 12, 32
+; CHECK32_64-NEXT: mr 4, 30
+; CHECK32_64-NEXT: beq 0, .LBB2_18
+; CHECK32_64-NEXT: # %bb.5:
+; CHECK32_64-NEXT: beq 1, .LBB2_19
; CHECK32_64-NEXT: .LBB2_6:
-; CHECK32_64-NEXT: bc 12, 6, .LBB2_8
-; CHECK32_64-NEXT: # %bb.7:
-; CHECK32_64-NEXT: ori 4, 8, 0
-; CHECK32_64-NEXT: ori 8, 10, 0
-; CHECK32_64-NEXT: b .LBB2_9
+; CHECK32_64-NEXT: beq 0, .LBB2_20
+; CHECK32_64-NEXT: .LBB2_7:
+; CHECK32_64-NEXT: mr 5, 8
+; CHECK32_64-NEXT: beq 1, .LBB2_21
; CHECK32_64-NEXT: .LBB2_8:
-; CHECK32_64-NEXT: addi 4, 6, 0
+; CHECK32_64-NEXT: mr 3, 5
+; CHECK32_64-NEXT: beq 0, .LBB2_22
; CHECK32_64-NEXT: .LBB2_9:
-; CHECK32_64-NEXT: subfic 11, 12, 32
-; CHECK32_64-NEXT: bc 12, 2, .LBB2_11
-; CHECK32_64-NEXT: # %bb.10:
-; CHECK32_64-NEXT: ori 0, 4, 0
-; CHECK32_64-NEXT: ori 4, 7, 0
-; CHECK32_64-NEXT: ori 7, 8, 0
-; CHECK32_64-NEXT: b .LBB2_12
+; CHECK32_64-NEXT: clrlwi 6, 12, 27
+; CHECK32_64-NEXT: bne 1, .LBB2_11
+; CHECK32_64-NEXT: .LBB2_10:
+; CHECK32_64-NEXT: mr 9, 7
; CHECK32_64-NEXT: .LBB2_11:
-; CHECK32_64-NEXT: addi 0, 30, 0
-; CHECK32_64-NEXT: .LBB2_12:
-; CHECK32_64-NEXT: srw 6, 5, 11
-; CHECK32_64-NEXT: lwz 30, 8(1) # 4-byte Folded Reload
-; CHECK32_64-NEXT: slw 3, 3, 12
-; CHECK32_64-NEXT: srw 9, 0, 11
-; CHECK32_64-NEXT: slw 5, 5, 12
-; CHECK32_64-NEXT: srw 10, 4, 11
-; CHECK32_64-NEXT: slw 0, 0, 12
-; CHECK32_64-NEXT: srw 7, 7, 11
-; CHECK32_64-NEXT: slw 8, 4, 12
-; CHECK32_64-NEXT: or 3, 3, 6
-; CHECK32_64-NEXT: or 4, 5, 9
-; CHECK32_64-NEXT: or 5, 0, 10
-; CHECK32_64-NEXT: or 6, 8, 7
-; CHECK32_64-NEXT: addi 1, 1, 16
+; CHECK32_64-NEXT: subfic 7, 6, 32
+; CHECK32_64-NEXT: mr 12, 9
+; CHECK32_64-NEXT: bne 0, .LBB2_13
+; CHECK32_64-NEXT: # %bb.12:
+; CHECK32_64-NEXT: mr 12, 5
+; CHECK32_64-NEXT: .LBB2_13:
+; CHECK32_64-NEXT: srw 5, 4, 7
+; CHECK32_64-NEXT: slw 11, 11, 6
+; CHECK32_64-NEXT: srw 0, 3, 7
+; CHECK32_64-NEXT: slw 4, 4, 6
+; CHECK32_64-NEXT: srw 30, 12, 7
+; CHECK32_64-NEXT: slw 29, 3, 6
+; CHECK32_64-NEXT: bne 1, .LBB2_15
+; CHECK32_64-NEXT: # %bb.14:
+; CHECK32_64-NEXT: mr 10, 8
+; CHECK32_64-NEXT: .LBB2_15:
+; CHECK32_64-NEXT: or 3, 11, 5
+; CHECK32_64-NEXT: or 4, 4, 0
+; CHECK32_64-NEXT: or 5, 29, 30
+; CHECK32_64-NEXT: bne 0, .LBB2_17
+; CHECK32_64-NEXT: # %bb.16:
+; CHECK32_64-NEXT: mr 10, 9
+; CHECK32_64-NEXT: .LBB2_17:
+; CHECK32_64-NEXT: srw 7, 10, 7
+; CHECK32_64-NEXT: slw 6, 12, 6
+; CHECK32_64-NEXT: lwz 30, 24(1) # 4-byte Folded Reload
+; CHECK32_64-NEXT: or 6, 6, 7
+; CHECK32_64-NEXT: lwz 29, 20(1) # 4-byte Folded Reload
+; CHECK32_64-NEXT: addi 1, 1, 32
; CHECK32_64-NEXT: blr
+; CHECK32_64-NEXT: .LBB2_18:
+; CHECK32_64-NEXT: mr 4, 11
+; CHECK32_64-NEXT: bne 1, .LBB2_6
+; CHECK32_64-NEXT: .LBB2_19:
+; CHECK32_64-NEXT: mr 5, 3
+; CHECK32_64-NEXT: bne 0, .LBB2_7
+; CHECK32_64-NEXT: .LBB2_20:
+; CHECK32_64-NEXT: mr 11, 5
+; CHECK32_64-NEXT: mr 5, 8
+; CHECK32_64-NEXT: bne 1, .LBB2_8
+; CHECK32_64-NEXT: .LBB2_21:
+; CHECK32_64-NEXT: mr 5, 6
+; CHECK32_64-NEXT: mr 3, 5
+; CHECK32_64-NEXT: bne 0, .LBB2_9
+; CHECK32_64-NEXT: .LBB2_22:
+; CHECK32_64-NEXT: mr 3, 30
+; CHECK32_64-NEXT: clrlwi 6, 12, 27
+; CHECK32_64-NEXT: beq 1, .LBB2_10
+; CHECK32_64-NEXT: b .LBB2_11
;
; CHECK64-LABEL: fshl_i128:
; CHECK64: # %bb.0:
@@ -235,11 +280,11 @@ define i37 @fshl_i37(i37 %x, i37 %y, i37 %z) {
; CHECK32_32-NEXT: .cfi_offset r29, -12
; CHECK32_32-NEXT: .cfi_offset r30, -8
; CHECK32_32-NEXT: stw 27, 12(1) # 4-byte Folded Spill
-; CHECK32_32-NEXT: mr 27, 3
+; CHECK32_32-NEXT: mr 27, 5
; CHECK32_32-NEXT: stw 28, 16(1) # 4-byte Folded Spill
-; CHECK32_32-NEXT: mr 28, 4
+; CHECK32_32-NEXT: mr 28, 3
; CHECK32_32-NEXT: stw 29, 20(1) # 4-byte Folded Spill
-; CHECK32_32-NEXT: mr 29, 5
+; CHECK32_32-NEXT: mr 29, 4
; CHECK32_32-NEXT: stw 30, 24(1) # 4-byte Folded Spill
; CHECK32_32-NEXT: mr 30, 6
; CHECK32_32-NEXT: clrlwi 3, 7, 27
@@ -247,29 +292,31 @@ define i37 @fshl_i37(i37 %x, i37 %y, i37 %z) {
; CHECK32_32-NEXT: li 5, 0
; CHECK32_32-NEXT: li 6, 37
; CHECK32_32-NEXT: bl __umoddi3
-; CHECK32_32-NEXT: rotlwi 3, 30, 27
-; CHECK32_32-NEXT: slwi 5, 30, 27
-; CHECK32_32-NEXT: andi. 6, 4, 32
-; CHECK32_32-NEXT: rlwimi 3, 29, 27, 0, 4
-; CHECK32_32-NEXT: clrlwi 4, 4, 27
-; CHECK32_32-NEXT: subfic 6, 4, 32
-; CHECK32_32-NEXT: bc 12, 2, .LBB3_2
+; CHECK32_32-NEXT: rotlwi 5, 30, 27
+; CHECK32_32-NEXT: rlwimi 5, 27, 27, 0, 4
+; CHECK32_32-NEXT: andi. 3, 4, 32
+; CHECK32_32-NEXT: mr 6, 5
+; CHECK32_32-NEXT: bne 0, .LBB3_2
; CHECK32_32-NEXT: # %bb.1:
-; CHECK32_32-NEXT: ori 7, 3, 0
-; CHECK32_32-NEXT: ori 8, 28, 0
-; CHECK32_32-NEXT: ori 3, 5, 0
-; CHECK32_32-NEXT: b .LBB3_3
+; CHECK32_32-NEXT: mr 6, 29
; CHECK32_32-NEXT: .LBB3_2:
-; CHECK32_32-NEXT: addi 7, 28, 0
-; CHECK32_32-NEXT: addi 8, 27, 0
-; CHECK32_32-NEXT: .LBB3_3:
+; CHECK32_32-NEXT: clrlwi 4, 4, 27
+; CHECK32_32-NEXT: subfic 7, 4, 32
+; CHECK32_32-NEXT: srw 3, 6, 7
+; CHECK32_32-NEXT: bne 0, .LBB3_4
+; CHECK32_32-NEXT: # %bb.3:
+; CHECK32_32-NEXT: mr 29, 28
+; CHECK32_32-NEXT: .LBB3_4:
+; CHECK32_32-NEXT: slw 8, 29, 4
+; CHECK32_32-NEXT: or 3, 8, 3
+; CHECK32_32-NEXT: beq 0, .LBB3_6
+; CHECK32_32-NEXT: # %bb.5:
+; CHECK32_32-NEXT: slwi 5, 30, 27
+; CHECK32_32-NEXT: .LBB3_6:
+; CHECK32_32-NEXT: srw 5, 5, 7
+; CHECK32_32-NEXT: slw 4, 6, 4
+; CHECK32_32-NEXT: or 4, 4, 5
; CHECK32_32-NEXT: lwz 30, 24(1) # 4-byte Folded Reload
-; CHECK32_32-NEXT: srw 5, 7, 6
-; CHECK32_32-NEXT: slw 8, 8, 4
-; CHECK32_32-NEXT: srw 6, 3, 6
-; CHECK32_32-NEXT: slw 4, 7, 4
-; CHECK32_32-NEXT: or 3, 8, 5
-; CHECK32_32-NEXT: or 4, 4, 6
; CHECK32_32-NEXT: lwz 29, 20(1) # 4-byte Folded Reload
; CHECK32_32-NEXT: lwz 28, 16(1) # 4-byte Folded Reload
; CHECK32_32-NEXT: lwz 27, 12(1) # 4-byte Folded Reload
@@ -290,53 +337,46 @@ define i37 @fshl_i37(i37 %x, i37 %y, i37 %z) {
; CHECK32_64-NEXT: .cfi_offset r29, -12
; CHECK32_64-NEXT: .cfi_offset r30, -8
; CHECK32_64-NEXT: stw 27, 12(1) # 4-byte Folded Spill
-; CHECK32_64-NEXT: mr 27, 3
-; CHECK32_64-NEXT: clrlwi 3, 7, 27
+; CHECK32_64-NEXT: mr 27, 5
+; CHECK32_64-NEXT: li 5, 0
; CHECK32_64-NEXT: stw 28, 16(1) # 4-byte Folded Spill
-; CHECK32_64-NEXT: mr 28, 4
-; CHECK32_64-NEXT: mr 4, 8
+; CHECK32_64-NEXT: mr 28, 3
+; CHECK32_64-NEXT: clrlwi 3, 7, 27
; CHECK32_64-NEXT: stw 29, 20(1) # 4-byte Folded Spill
-; CHECK32_64-NEXT: mr 29, 5
-; CHECK32_64-NEXT: li 5, 0
+; CHECK32_64-NEXT: mr 29, 4
+; CHECK32_64-NEXT: mr 4, 8
; CHECK32_64-NEXT: stw 30, 24(1) # 4-byte Folded Spill
; CHECK32_64-NEXT: mr 30, 6
; CHECK32_64-NEXT: li 6, 37
; CHECK32_64-NEXT: bl __umoddi3
-; CHECK32_64-NEXT: rotlwi 3, 30, 27
-; CHECK32_64-NEXT: andi. 5, 4, 32
-; CHECK32_64-NEXT: bc 12, 2, .LBB3_2
+; CHECK32_64-NEXT: rotlwi 5, 30, 27
+; CHECK32_64-NEXT: andi. 3, 4, 32
+; CHECK32_64-NEXT: rlwimi 5, 27, 27, 0, 4
+; CHECK32_64-NEXT: mr 6, 5
+; CHECK32_64-NEXT: bne 0, .LBB3_2
; CHECK32_64-NEXT: # %bb.1:
-; CHECK32_64-NEXT: ori 8, 28, 0
-; CHECK32_64-NEXT: b .LBB3_3
+; CHECK32_64-NEXT: mr 6, 29
; CHECK32_64-NEXT: .LBB3_2:
-; CHECK32_64-NEXT: addi 8, 27, 0
-; CHECK32_64-NEXT: .LBB3_3:
-; CHECK32_64-NEXT: lwz 27, 12(1) # 4-byte Folded Reload
-; CHECK32_64-NEXT: rlwimi 3, 29, 27, 0, 4
; CHECK32_64-NEXT: clrlwi 4, 4, 27
-; CHECK32_64-NEXT: bc 12, 2, .LBB3_5
-; CHECK32_64-NEXT: # %bb.4:
-; CHECK32_64-NEXT: ori 7, 3, 0
-; CHECK32_64-NEXT: b .LBB3_6
-; CHECK32_64-NEXT: .LBB3_5:
-; CHECK32_64-NEXT: addi 7, 28, 0
-; CHECK32_64-NEXT: .LBB3_6:
+; CHECK32_64-NEXT: subfic 7, 4, 32
+; CHECK32_64-NEXT: srw 3, 6, 7
+; CHECK32_64-NEXT: bne 0, .LBB3_4
+; CHECK32_64-NEXT: # %bb.3:
+; CHECK32_64-NEXT: mr 29, 28
+; CHECK32_64-NEXT: .LBB3_4:
+; CHECK32_64-NEXT: slw 8, 29, 4
+; CHECK32_64-NEXT: or 3, 8, 3
+; CHECK32_64-NEXT: beq 0, .LBB3_6
+; CHECK32_64-NEXT: # %bb.5:
; CHECK32_64-NEXT: slwi 5, 30, 27
+; CHECK32_64-NEXT: .LBB3_6:
+; CHECK32_64-NEXT: srw 5, 5, 7
+; CHECK32_64-NEXT: slw 4, 6, 4
; CHECK32_64-NEXT: lwz 30, 24(1) # 4-byte Folded Reload
-; CHECK32_64-NEXT: bc 12, 2, .LBB3_8
-; CHECK32_64-NEXT: # %bb.7:
-; CHECK32_64-NEXT: ori 3, 5, 0
-; CHECK32_64-NEXT: b .LBB3_8
-; CHECK32_64-NEXT: .LBB3_8:
-; CHECK32_64-NEXT: subfic 6, 4, 32
-; CHECK32_64-NEXT: slw 8, 8, 4
+; CHECK32_64-NEXT: or 4, 4, 5
; CHECK32_64-NEXT: lwz 29, 20(1) # 4-byte Folded Reload
-; CHECK32_64-NEXT: srw 9, 7, 6
-; CHECK32_64-NEXT: srw 5, 3, 6
-; CHECK32_64-NEXT: slw 4, 7, 4
-; CHECK32_64-NEXT: or 3, 8, 9
; CHECK32_64-NEXT: lwz 28, 16(1) # 4-byte Folded Reload
-; CHECK32_64-NEXT: or 4, 4, 5
+; CHECK32_64-NEXT: lwz 27, 12(1) # 4-byte Folded Reload
; CHECK32_64-NEXT: lwz 0, 36(1)
; CHECK32_64-NEXT: addi 1, 1, 32
; CHECK32_64-NEXT: mtlr 0
@@ -453,50 +493,31 @@ define i32 @fshr_i32(i32 %x, i32 %y, i32 %z) {
}
define i64 @fshr_i64(i64 %x, i64 %y, i64 %z) {
-; CHECK32_32-LABEL: fshr_i64:
-; CHECK32_32: # %bb.0:
-; CHECK32_32-NEXT: andi. 7, 8, 32
-; CHECK32_32-NEXT: clrlwi 7, 8, 27
-; CHECK32_32-NEXT: subfic 8, 7, 32
-; CHECK32_32-NEXT: bc 12, 2, .LBB10_2
-; CHECK32_32-NEXT: # %bb.1:
-; CHECK32_32-NEXT: ori 9, 4, 0
-; CHECK32_32-NEXT: ori 4, 5, 0
-; CHECK32_32-NEXT: b .LBB10_3
-; CHECK32_32-NEXT: .LBB10_2:
-; CHECK32_32-NEXT: addi 9, 5, 0
-; CHECK32_32-NEXT: addi 3, 4, 0
-; CHECK32_32-NEXT: addi 4, 6, 0
-; CHECK32_32-NEXT: .LBB10_3:
-; CHECK32_32-NEXT: srw 5, 9, 7
-; CHECK32_32-NEXT: slw 3, 3, 8
-; CHECK32_32-NEXT: srw 4, 4, 7
-; CHECK32_32-NEXT: slw 6, 9, 8
-; CHECK32_32-NEXT: or 3, 3, 5
-; CHECK32_32-NEXT: or 4, 6, 4
-; CHECK32_32-NEXT: blr
-;
-; CHECK32_64-LABEL: fshr_i64:
-; CHECK32_64: # %bb.0:
-; CHECK32_64-NEXT: andi. 7, 8, 32
-; CHECK32_64-NEXT: clrlwi 7, 8, 27
-; CHECK32_64-NEXT: bc 12, 2, .LBB10_2
-; CHECK32_64-NEXT: # %bb.1:
-; CHECK32_64-NEXT: ori 9, 4, 0
-; CHECK32_64-NEXT: b .LBB10_3
-; CHECK32_64-NEXT: .LBB10_2:
-; CHECK32_64-NEXT: addi 9, 5, 0
-; CHECK32_64-NEXT: addi 3, 4, 0
-; CHECK32_64-NEXT: addi 5, 6, 0
-; CHECK32_64-NEXT: .LBB10_3:
-; CHECK32_64-NEXT: subfic 8, 7, 32
-; CHECK32_64-NEXT: srw 4, 9, 7
-; CHECK32_64-NEXT: slw 3, 3, 8
-; CHECK32_64-NEXT: srw 5, 5, 7
-; CHECK32_64-NEXT: slw 6, 9, 8
-; CHECK32_64-NEXT: or 3, 3, 4
-; CHECK32_64-NEXT: or 4, 6, 5
-; CHECK32_64-NEXT: blr
+; CHECK32-LABEL: fshr_i64:
+; CHECK32: # %bb.0:
+; CHECK32-NEXT: andi. 7, 8, 32
+; CHECK32-NEXT: mr 7, 5
+; CHECK32-NEXT: beq 0, .LBB10_2
+; CHECK32-NEXT: # %bb.1:
+; CHECK32-NEXT: mr 7, 4
+; CHECK32-NEXT: .LBB10_2:
+; CHECK32-NEXT: clrlwi 8, 8, 27
+; CHECK32-NEXT: srw 10, 7, 8
+; CHECK32-NEXT: beq 0, .LBB10_4
+; CHECK32-NEXT: # %bb.3:
+; CHECK32-NEXT: mr 4, 3
+; CHECK32-NEXT: .LBB10_4:
+; CHECK32-NEXT: subfic 9, 8, 32
+; CHECK32-NEXT: slw 3, 4, 9
+; CHECK32-NEXT: or 3, 3, 10
+; CHECK32-NEXT: beq 0, .LBB10_6
+; CHECK32-NEXT: # %bb.5:
+; CHECK32-NEXT: mr 6, 5
+; CHECK32-NEXT: .LBB10_6:
+; CHECK32-NEXT: srw 4, 6, 8
+; CHECK32-NEXT: slw 5, 7, 9
+; CHECK32-NEXT: or 4, 5, 4
+; CHECK32-NEXT: blr
;
; CHECK64-LABEL: fshr_i64:
; CHECK64: # %bb.0:
@@ -525,11 +546,11 @@ define i37 @fshr_i37(i37 %x, i37 %y, i37 %z) {
; CHECK32_32-NEXT: .cfi_offset r29, -12
; CHECK32_32-NEXT: .cfi_offset r30, -8
; CHECK32_32-NEXT: stw 27, 12(1) # 4-byte Folded Spill
-; CHECK32_32-NEXT: mr 27, 3
+; CHECK32_32-NEXT: mr 27, 5
; CHECK32_32-NEXT: stw 28, 16(1) # 4-byte Folded Spill
-; CHECK32_32-NEXT: mr 28, 4
+; CHECK32_32-NEXT: mr 28, 3
; CHECK32_32-NEXT: stw 29, 20(1) # 4-byte Folded Spill
-; CHECK32_32-NEXT: mr 29, 5
+; CHECK32_32-NEXT: mr 29, 4
; CHECK32_32-NEXT: stw 30, 24(1) # 4-byte Folded Spill
; CHECK32_32-NEXT: mr 30, 6
; CHECK32_32-NEXT: clrlwi 3, 7, 27
@@ -537,30 +558,32 @@ define i37 @fshr_i37(i37 %x, i37 %y, i37 %z) {
; CHECK32_32-NEXT: li 5, 0
; CHECK32_32-NEXT: li 6, 37
; CHECK32_32-NEXT: bl __umoddi3
-; CHECK32_32-NEXT: rotlwi 3, 30, 27
-; CHECK32_32-NEXT: addi 4, 4, 27
-; CHECK32_32-NEXT: slwi 5, 30, 27
-; CHECK32_32-NEXT: rlwimi 3, 29, 27, 0, 4
-; CHECK32_32-NEXT: andi. 6, 4, 32
-; CHECK32_32-NEXT: clrlwi 4, 4, 27
-; CHECK32_32-NEXT: subfic 6, 4, 32
-; CHECK32_32-NEXT: bc 12, 2, .LBB11_2
+; CHECK32_32-NEXT: rotlwi 5, 30, 27
+; CHECK32_32-NEXT: addi 3, 4, 27
+; CHECK32_32-NEXT: andi. 4, 3, 32
+; CHECK32_32-NEXT: rlwimi 5, 27, 27, 0, 4
+; CHECK32_32-NEXT: mr 4, 5
+; CHECK32_32-NEXT: beq 0, .LBB11_2
; CHECK32_32-NEXT: # %bb.1:
-; CHECK32_32-NEXT: ori 7, 28, 0
-; CHECK32_32-NEXT: ori 8, 27, 0
-; CHECK32_32-NEXT: b .LBB11_3
+; CHECK32_32-NEXT: mr 4, 29
; CHECK32_32-NEXT: .LBB11_2:
-; CHECK32_32-NEXT: addi 7, 3, 0
-; CHECK32_32-NEXT: addi 8, 28, 0
-; CHECK32_32-NEXT: addi 3, 5, 0
-; CHECK32_32-NEXT: .LBB11_3:
+; CHECK32_32-NEXT: clrlwi 6, 3, 27
+; CHECK32_32-NEXT: srw 3, 4, 6
+; CHECK32_32-NEXT: beq 0, .LBB11_4
+; CHECK32_32-NEXT: # %bb.3:
+; CHECK32_32-NEXT: mr 29, 28
+; CHECK32_32-NEXT: .LBB11_4:
+; CHECK32_32-NEXT: subfic 7, 6, 32
+; CHECK32_32-NEXT: slw 8, 29, 7
+; CHECK32_32-NEXT: or 3, 8, 3
+; CHECK32_32-NEXT: bne 0, .LBB11_6
+; CHECK32_32-NEXT: # %bb.5:
+; CHECK32_32-NEXT: slwi 5, 30, 27
+; CHECK32_32-NEXT: .LBB11_6:
+; CHECK32_32-NEXT: srw 5, 5, 6
+; CHECK32_32-NEXT: slw 4, 4, 7
+; CHECK32_32-NEXT: or 4, 4, 5
; CHECK32_32-NEXT: lwz 30, 24(1) # 4-byte Folded Reload
-; CHECK32_32-NEXT: srw 5, 7, 4
-; CHECK32_32-NEXT: slw 8, 8, 6
-; CHECK32_32-NEXT: srw 4, 3, 4
-; CHECK32_32-NEXT: slw 6, 7, 6
-; CHECK32_32-NEXT: or 3, 8, 5
-; CHECK32_32-NEXT: or 4, 6, 4
; CHECK32_32-NEXT: lwz 29, 20(1) # 4-byte Folded Reload
; CHECK32_32-NEXT: lwz 28, 16(1) # 4-byte Folded Reload
; CHECK32_32-NEXT: lwz 27, 12(1) # 4-byte Folded Reload
@@ -581,49 +604,47 @@ define i37 @fshr_i37(i37 %x, i37 %y, i37 %z) {
; CHECK32_64-NEXT: .cfi_offset r29, -12
; CHECK32_64-NEXT: .cfi_offset r30, -8
; CHECK32_64-NEXT: stw 27, 12(1) # 4-byte Folded Spill
-; CHECK32_64-NEXT: mr 27, 3
-; CHECK32_64-NEXT: clrlwi 3, 7, 27
+; CHECK32_64-NEXT: mr 27, 5
+; CHECK32_64-NEXT: li 5, 0
; CHECK32_64-NEXT: stw 28, 16(1) # 4-byte Folded Spill
-; CHECK32_64-NEXT: mr 28, 4
-; CHECK32_64-NEXT: mr 4, 8
+; CHECK32_64-NEXT: mr 28, 3
+; CHECK32_64-NEXT: clrlwi 3, 7, 27
; CHECK32_64-NEXT: stw 29, 20(1) # 4-byte Folded Spill
-; CHECK32_64-NEXT: mr 29, 5
-; CHECK32_64-NEXT: li 5, 0
+; CHECK32_64-NEXT: mr 29, 4
+; CHECK32_64-NEXT: mr 4, 8
; CHECK32_64-NEXT: stw 30, 24(1) # 4-byte Folded Spill
; CHECK32_64-NEXT: mr 30, 6
; CHECK32_64-NEXT: li 6, 37
; CHECK32_64-NEXT: bl __umoddi3
-; CHECK32_64-NEXT: addi 4, 4, 27
-; CHECK32_64-NEXT: rotlwi 3, 30, 27
-; CHECK32_64-NEXT: andi. 5, 4, 32
-; CHECK32_64-NEXT: rlwimi 3, 29, 27, 0, 4
-; CHECK32_64-NEXT: lwz 29, 20(1) # 4-byte Folded Reload
-; CHECK32_64-NEXT: bc 12, 2, .LBB11_2
+; CHECK32_64-NEXT: rotlwi 5, 30, 27
+; CHECK32_64-NEXT: addi 3, 4, 27
+; CHECK32_64-NEXT: andi. 4, 3, 32
+; CHECK32_64-NEXT: rlwimi 5, 27, 27, 0, 4
+; CHECK32_64-NEXT: mr 4, 5
+; CHECK32_64-NEXT: beq 0, .LBB11_2
; CHECK32_64-NEXT: # %bb.1:
-; CHECK32_64-NEXT: ori 7, 28, 0
-; CHECK32_64-NEXT: ori 8, 27, 0
-; CHECK32_64-NEXT: b .LBB11_3
+; CHECK32_64-NEXT: mr 4, 29
; CHECK32_64-NEXT: .LBB11_2:
-; CHECK32_64-NEXT: addi 7, 3, 0
-; CHECK32_64-NEXT: addi 8, 28, 0
-; CHECK32_64-NEXT: .LBB11_3:
-; CHECK32_64-NEXT: clrlwi 4, 4, 27
-; CHECK32_64-NEXT: lwz 28, 16(1) # 4-byte Folded Reload
-; CHECK32_64-NEXT: slwi 5, 30, 27
-; CHECK32_64-NEXT: subfic 6, 4, 32
-; CHECK32_64-NEXT: bc 12, 2, .LBB11_4
-; CHECK32_64-NEXT: b .LBB11_5
+; CHECK32_64-NEXT: clrlwi 6, 3, 27
+; CHECK32_64-NEXT: srw 3, 4, 6
+; CHECK32_64-NEXT: beq 0, .LBB11_4
+; CHECK32_64-NEXT: # %bb.3:
+; CHECK32_64-NEXT: mr 29, 28
; CHECK32_64-NEXT: .LBB11_4:
-; CHECK32_64-NEXT: addi 3, 5, 0
-; CHECK32_64-NEXT: .LBB11_5:
-; CHECK32_64-NEXT: srw 9, 7, 4
-; CHECK32_64-NEXT: slw 8, 8, 6
+; CHECK32_64-NEXT: subfic 7, 6, 32
+; CHECK32_64-NEXT: slw 8, 29, 7
+; CHECK32_64-NEXT: or 3, 8, 3
+; CHECK32_64-NEXT: bne 0, .LBB11_6
+; CHECK32_64-NEXT: # %bb.5:
+; CHECK32_64-NEXT: slwi 5, 30, 27
+; CHECK32_64-NEXT: .LBB11_6:
+; CHECK32_64-NEXT: srw 5, 5, 6
+; CHECK32_64-NEXT: slw 4, 4, 7
; CHECK32_64-NEXT: lwz 30, 24(1) # 4-byte Folded Reload
-; CHECK32_64-NEXT: srw 4, 3, 4
-; CHECK32_64-NEXT: slw 5, 7, 6
+; CHECK32_64-NEXT: or 4, 4, 5
+; CHECK32_64-NEXT: lwz 29, 20(1) # 4-byte Folded Reload
+; CHECK32_64-NEXT: lwz 28, 16(1) # 4-byte Folded Reload
; CHECK32_64-NEXT: lwz 27, 12(1) # 4-byte Folded Reload
-; CHECK32_64-NEXT: or 3, 8, 9
-; CHECK32_64-NEXT: or 4, 5, 4
; CHECK32_64-NEXT: lwz 0, 36(1)
; CHECK32_64-NEXT: addi 1, 1, 32
; CHECK32_64-NEXT: mtlr 0
diff --git a/llvm/test/CodeGen/PowerPC/i1-to-double.ll b/llvm/test/CodeGen/PowerPC/i1-to-double.ll
index 0b8cdef87053d7..df5ed27056be8d 100644
--- a/llvm/test/CodeGen/PowerPC/i1-to-double.ll
+++ b/llvm/test/CodeGen/PowerPC/i1-to-double.ll
@@ -4,16 +4,16 @@
define double @test(i1 %X) {
; CHECK-LABEL: test:
; CHECK: # %bb.0:
-; CHECK-NEXT: li 4, .LCPI0_0 at l
; CHECK-NEXT: andi. 3, 3, 1
-; CHECK-NEXT: addis 3, 4, .LCPI0_0 at ha
-; CHECK-NEXT: li 4, .LCPI0_1 at l
-; CHECK-NEXT: addis 4, 4, .LCPI0_1 at ha
-; CHECK-NEXT: bc 12, 1, .LBB0_1
-; CHECK-NEXT: b .LBB0_2
-; CHECK-NEXT: .LBB0_1:
-; CHECK-NEXT: addi 3, 4, 0
+; CHECK-NEXT: bc 12, 1, .LBB0_2
+; CHECK-NEXT: # %bb.1:
+; CHECK-NEXT: li 3, .LCPI0_0 at l
+; CHECK-NEXT: addis 3, 3, .LCPI0_0 at ha
+; CHECK-NEXT: lfs 1, 0(3)
+; CHECK-NEXT: blr
; CHECK-NEXT: .LBB0_2:
+; CHECK-NEXT: li 3, .LCPI0_1 at l
+; CHECK-NEXT: addis 3, 3, .LCPI0_1 at ha
; CHECK-NEXT: lfs 1, 0(3)
; CHECK-NEXT: blr
%Y = uitofp i1 %X to double
@@ -27,17 +27,17 @@ define double @test(i1 %X) {
define double @u1tofp(i1 %i, double %d) #0 {
; CHECK-LABEL: u1tofp:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: li 4, .LCPI1_0 at l
; CHECK-NEXT: andi. 3, 3, 1
-; CHECK-NEXT: addis 3, 4, .LCPI1_0 at ha
-; CHECK-NEXT: li 4, .LCPI1_1 at l
-; CHECK-NEXT: addis 4, 4, .LCPI1_1 at ha
-; CHECK-NEXT: bc 12, 1, .LBB1_1
-; CHECK-NEXT: b .LBB1_2
-; CHECK-NEXT: .LBB1_1: # %entry
-; CHECK-NEXT: addi 3, 4, 0
-; CHECK-NEXT: .LBB1_2: # %entry
; CHECK-NEXT: fmr 0, 1
+; CHECK-NEXT: bc 12, 1, .LBB1_2
+; CHECK-NEXT: # %bb.1: # %entry
+; CHECK-NEXT: li 3, .LCPI1_0 at l
+; CHECK-NEXT: addis 3, 3, .LCPI1_0 at ha
+; CHECK-NEXT: b .LBB1_3
+; CHECK-NEXT: .LBB1_2:
+; CHECK-NEXT: li 3, .LCPI1_1 at l
+; CHECK-NEXT: addis 3, 3, .LCPI1_1 at ha
+; CHECK-NEXT: .LBB1_3: # %entry
; CHECK-NEXT: lfs 1, 0(3)
; CHECK-NEXT: lis 3, foo at ha
; CHECK-NEXT: stfd 0, foo at l(3)
@@ -51,17 +51,17 @@ entry:
define double @s1tofp(i1 %i, double %d) #0 {
; CHECK-LABEL: s1tofp:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: li 4, .LCPI2_0 at l
; CHECK-NEXT: andi. 3, 3, 1
-; CHECK-NEXT: addis 3, 4, .LCPI2_0 at ha
-; CHECK-NEXT: li 4, .LCPI2_1 at l
-; CHECK-NEXT: addis 4, 4, .LCPI2_1 at ha
-; CHECK-NEXT: bc 12, 1, .LBB2_1
-; CHECK-NEXT: b .LBB2_2
-; CHECK-NEXT: .LBB2_1: # %entry
-; CHECK-NEXT: addi 3, 4, 0
-; CHECK-NEXT: .LBB2_2: # %entry
; CHECK-NEXT: fmr 0, 1
+; CHECK-NEXT: bc 12, 1, .LBB2_2
+; CHECK-NEXT: # %bb.1: # %entry
+; CHECK-NEXT: li 3, .LCPI2_0 at l
+; CHECK-NEXT: addis 3, 3, .LCPI2_0 at ha
+; CHECK-NEXT: b .LBB2_3
+; CHECK-NEXT: .LBB2_2:
+; CHECK-NEXT: li 3, .LCPI2_1 at l
+; CHECK-NEXT: addis 3, 3, .LCPI2_1 at ha
+; CHECK-NEXT: .LBB2_3: # %entry
; CHECK-NEXT: lfs 1, 0(3)
; CHECK-NEXT: lis 3, foo at ha
; CHECK-NEXT: stfd 0, foo at l(3)
diff --git a/llvm/test/CodeGen/PowerPC/ppcf128-constrained-fp-intrinsics.ll b/llvm/test/CodeGen/PowerPC/ppcf128-constrained-fp-intrinsics.ll
index 033728500abc8c..42972fe069df6a 100644
--- a/llvm/test/CodeGen/PowerPC/ppcf128-constrained-fp-intrinsics.ll
+++ b/llvm/test/CodeGen/PowerPC/ppcf128-constrained-fp-intrinsics.ll
@@ -1383,19 +1383,18 @@ define i32 @test_fptoui_ppc_i32_ppc_fp128(ppc_fp128 %first) #0 {
; PC64-NEXT: nop
; PC64-NEXT: mffs 0
; PC64-NEXT: mtfsb1 31
-; PC64-NEXT: lis 4, -32768
-; PC64-NEXT: bc 12, 8, .LBB31_3
-; PC64-NEXT: b .LBB31_4
-; PC64-NEXT: .LBB31_3: # %entry
-; PC64-NEXT: li 4, 0
-; PC64-NEXT: .LBB31_4: # %entry
+; PC64-NEXT: li 3, 0
; PC64-NEXT: mtfsb0 30
; PC64-NEXT: fadd 1, 2, 1
; PC64-NEXT: mtfsf 1, 0
; PC64-NEXT: fctiwz 0, 1
; PC64-NEXT: stfd 0, 120(1)
-; PC64-NEXT: lwz 3, 124(1)
-; PC64-NEXT: xor 3, 3, 4
+; PC64-NEXT: bc 12, 8, .LBB31_4
+; PC64-NEXT: # %bb.3: # %entry
+; PC64-NEXT: lis 3, -32768
+; PC64-NEXT: .LBB31_4: # %entry
+; PC64-NEXT: lwz 4, 124(1)
+; PC64-NEXT: xor 3, 4, 3
; PC64-NEXT: addi 1, 1, 128
; PC64-NEXT: ld 0, 16(1)
; PC64-NEXT: lwz 12, 8(1)
diff --git a/llvm/test/CodeGen/PowerPC/pr43976.ll b/llvm/test/CodeGen/PowerPC/pr43976.ll
index 5c29a15083158c..9cc49efd78eb6e 100644
--- a/llvm/test/CodeGen/PowerPC/pr43976.ll
+++ b/llvm/test/CodeGen/PowerPC/pr43976.ll
@@ -10,25 +10,25 @@ define dso_local signext i32 @b() local_unnamed_addr #0 {
; CHECK-NEXT: stdu r1, -144(r1)
; CHECK-NEXT: std r0, 160(r1)
; CHECK-NEXT: addis r3, r2, a at toc@ha
-; CHECK-NEXT: li r4, 1
; CHECK-NEXT: lfd f0, a at toc@l(r3)
; CHECK-NEXT: addis r3, r2, .LCPI0_0 at toc@ha
-; CHECK-NEXT: rldic r4, r4, 63, 0
; CHECK-NEXT: lfs f1, .LCPI0_0 at toc@l(r3)
; CHECK-NEXT: fsub f2, f0, f1
; CHECK-NEXT: fctidz f2, f2
; CHECK-NEXT: stfd f2, 128(r1)
; CHECK-NEXT: fctidz f2, f0
+; CHECK-NEXT: fcmpu cr0, f0, f1
; CHECK-NEXT: stfd f2, 120(r1)
+; CHECK-NEXT: blt cr0, .LBB0_2
+; CHECK-NEXT: # %bb.1: # %entry
; CHECK-NEXT: ld r3, 128(r1)
-; CHECK-NEXT: ld r5, 120(r1)
-; CHECK-NEXT: fcmpu cr0, f0, f1
+; CHECK-NEXT: li r4, 1
+; CHECK-NEXT: rldic r4, r4, 63, 0
; CHECK-NEXT: xor r3, r3, r4
-; CHECK-NEXT: bc 12, lt, .LBB0_1
-; CHECK-NEXT: b .LBB0_2
-; CHECK-NEXT: .LBB0_1: # %entry
-; CHECK-NEXT: addi r3, r5, 0
-; CHECK-NEXT: .LBB0_2: # %entry
+; CHECK-NEXT: b .LBB0_3
+; CHECK-NEXT: .LBB0_2:
+; CHECK-NEXT: ld r3, 120(r1)
+; CHECK-NEXT: .LBB0_3: # %entry
; CHECK-NEXT: std r3, 112(r1)
; CHECK-NEXT: addis r3, r2, .LCPI0_1 at toc@ha
; CHECK-NEXT: lfd f0, 112(r1)
diff --git a/llvm/test/CodeGen/PowerPC/pr49509.ll b/llvm/test/CodeGen/PowerPC/pr49509.ll
index 7b6248c60ab421..48fe65e48e1ff6 100644
--- a/llvm/test/CodeGen/PowerPC/pr49509.ll
+++ b/llvm/test/CodeGen/PowerPC/pr49509.ll
@@ -23,32 +23,23 @@ define void @test() {
; CHECK-NEXT: lbz 3, 0(3)
; CHECK-NEXT: and 5, 5, 6
; CHECK-NEXT: and 4, 4, 7
-; CHECK-NEXT: and 4, 4, 5
+; CHECK-NEXT: and 5, 4, 5
; CHECK-NEXT: cmpwi 3, 0
-; CHECK-NEXT: lis 3, 256
-; CHECK-NEXT: lis 7, 512
-; CHECK-NEXT: bc 12, 2, .LBB0_4
-; CHECK-NEXT: b .LBB0_5
-; CHECK-NEXT: .LBB0_4: # %bb66
; CHECK-NEXT: li 3, 0
+; CHECK-NEXT: cmpwi 1, 5, -1
+; CHECK-NEXT: li 4, 0
+; CHECK-NEXT: bc 12, 2, .LBB0_5
+; CHECK-NEXT: # %bb.4: # %bb66
+; CHECK-NEXT: lis 4, 256
; CHECK-NEXT: .LBB0_5: # %bb66
-; CHECK-NEXT: cmpwi 1, 4, -1
-; CHECK-NEXT: cmpwi 5, 4, -1
-; CHECK-NEXT: li 6, 0
-; CHECK-NEXT: bc 12, 6, .LBB0_6
-; CHECK-NEXT: b .LBB0_7
-; CHECK-NEXT: .LBB0_6: # %bb66
-; CHECK-NEXT: addi 3, 7, 0
+; CHECK-NEXT: cmpwi 5, 5, -1
+; CHECK-NEXT: lis 5, 512
+; CHECK-NEXT: beq 5, .LBB0_7
+; CHECK-NEXT: # %bb.6: # %bb66
+; CHECK-NEXT: mr 5, 4
; CHECK-NEXT: .LBB0_7: # %bb66
-; CHECK-NEXT: cror 20, 22, 2
-; CHECK-NEXT: stw 3, 0(3)
-; CHECK-NEXT: bc 12, 20, .LBB0_9
-; CHECK-NEXT: # %bb.8: # %bb66
-; CHECK-NEXT: ori 3, 6, 0
-; CHECK-NEXT: b .LBB0_10
-; CHECK-NEXT: .LBB0_9: # %bb66
-; CHECK-NEXT: li 3, 0
-; CHECK-NEXT: .LBB0_10: # %bb66
+; CHECK-NEXT: cror 20, 6, 2
+; CHECK-NEXT: stw 5, 0(3)
; CHECK-NEXT: stw 3, 0(3)
; CHECK-NEXT: blr
bb:
diff --git a/llvm/test/CodeGen/PowerPC/save-crbp-ppc32svr4.ll b/llvm/test/CodeGen/PowerPC/save-crbp-ppc32svr4.ll
index 514f96b2203524..9e29c6fc982198 100644
--- a/llvm/test/CodeGen/PowerPC/save-crbp-ppc32svr4.ll
+++ b/llvm/test/CodeGen/PowerPC/save-crbp-ppc32svr4.ll
@@ -13,7 +13,7 @@
; CHECK: addic 29, 0, 20
; Save CR through R12 using R29 as the stack pointer (aligned base pointer).
; CHECK: mfcr 12
-; CHECK: stw 12, -24(29)
+; CHECK: stw 12, -28(29)
target datalayout = "E-m:e-p:32:32-i64:64-n32"
target triple = "powerpc-unknown-freebsd"
diff --git a/llvm/test/CodeGen/PowerPC/select-cc-no-isel.ll b/llvm/test/CodeGen/PowerPC/select-cc-no-isel.ll
index 345f3804c0c493..1e9dd0caf0adb8 100644
--- a/llvm/test/CodeGen/PowerPC/select-cc-no-isel.ll
+++ b/llvm/test/CodeGen/PowerPC/select-cc-no-isel.ll
@@ -7,6 +7,7 @@
define signext i32 @foo(ptr nocapture noundef %dummy) #0 {
; CHECK-LABEL: name: foo
; CHECK: bb.0.entry:
+ ; CHECK-NEXT: successors: %bb.1, %bb.2
; CHECK-NEXT: liveins: $x3
; CHECK-NEXT: {{ $}}
; CHECK-NEXT: [[COPY:%[0-9]+]]:g8rc_and_g8rc_nox0 = COPY $x3
@@ -14,14 +15,20 @@ define signext i32 @foo(ptr nocapture noundef %dummy) #0 {
; CHECK-NEXT: [[ADDI:%[0-9]+]]:gprc_and_gprc_nor0 = nsw ADDI [[LWZ]], 1
; CHECK-NEXT: [[CMPWI:%[0-9]+]]:crrc = CMPWI [[LWZ]], 750
; CHECK-NEXT: [[LI:%[0-9]+]]:gprc_and_gprc_nor0 = LI 1
- ; CHECK-NEXT: [[ISEL:%[0-9]+]]:gprc = ISEL [[ADDI]], [[LI]], [[CMPWI]].sub_lt
- ; CHECK-NEXT: STW killed [[ISEL]], 0, [[COPY]] :: (store (s32) into %ir.dummy)
+ ; CHECK-NEXT: BCC 12, [[CMPWI]], %bb.2
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: bb.1.entry:
+ ; CHECK-NEXT: {{ $}}
+ ; CHECK-NEXT: bb.2.entry:
+ ; CHECK-NEXT: [[PHI:%[0-9]+]]:gprc = PHI [[LI]], %bb.1, [[ADDI]], %bb.0
+ ; CHECK-NEXT: STW killed [[PHI]], 0, [[COPY]] :: (store (s32) into %ir.dummy)
; CHECK-NEXT: [[LI8_:%[0-9]+]]:g8rc = LI8 0
; CHECK-NEXT: $x3 = COPY [[LI8_]]
; CHECK-NEXT: BLR8 implicit $lr8, implicit $rm, implicit $x3
;
; CHECK-32-LABEL: name: foo
; CHECK-32: bb.0.entry:
+ ; CHECK-32-NEXT: successors: %bb.1, %bb.2
; CHECK-32-NEXT: liveins: $r3
; CHECK-32-NEXT: {{ $}}
; CHECK-32-NEXT: [[COPY:%[0-9]+]]:gprc_and_gprc_nor0 = COPY $r3
@@ -29,8 +36,13 @@ define signext i32 @foo(ptr nocapture noundef %dummy) #0 {
; CHECK-32-NEXT: [[ADDI:%[0-9]+]]:gprc_and_gprc_nor0 = nsw ADDI [[LWZ]], 1
; CHECK-32-NEXT: [[CMPWI:%[0-9]+]]:crrc = CMPWI [[LWZ]], 750
; CHECK-32-NEXT: [[LI:%[0-9]+]]:gprc_and_gprc_nor0 = LI 1
- ; CHECK-32-NEXT: [[ISEL:%[0-9]+]]:gprc = ISEL [[ADDI]], [[LI]], [[CMPWI]].sub_lt
- ; CHECK-32-NEXT: STW killed [[ISEL]], 0, [[COPY]] :: (store (s32) into %ir.dummy)
+ ; CHECK-32-NEXT: BCC 12, [[CMPWI]], %bb.2
+ ; CHECK-32-NEXT: {{ $}}
+ ; CHECK-32-NEXT: bb.1.entry:
+ ; CHECK-32-NEXT: {{ $}}
+ ; CHECK-32-NEXT: bb.2.entry:
+ ; CHECK-32-NEXT: [[PHI:%[0-9]+]]:gprc = PHI [[LI]], %bb.1, [[ADDI]], %bb.0
+ ; CHECK-32-NEXT: STW killed [[PHI]], 0, [[COPY]] :: (store (s32) into %ir.dummy)
; CHECK-32-NEXT: [[LI1:%[0-9]+]]:gprc = LI 0
; CHECK-32-NEXT: $r3 = COPY [[LI1]]
; CHECK-32-NEXT: BLR implicit $lr, implicit $rm, implicit $r3
diff --git a/llvm/test/CodeGen/PowerPC/select.ll b/llvm/test/CodeGen/PowerPC/select.ll
index 49d55c7df524af..289f83c475ff3c 100644
--- a/llvm/test/CodeGen/PowerPC/select.ll
+++ b/llvm/test/CodeGen/PowerPC/select.ll
@@ -17,13 +17,11 @@ define i64 @f0(i64 %x) {
;
; CHECK-32-LABEL: f0:
; CHECK-32: # %bb.0:
-; CHECK-32-NEXT: li r4, 125
-; CHECK-32-NEXT: li r5, -3
; CHECK-32-NEXT: cmpwi r3, 0
-; CHECK-32-NEXT: bc 12, lt, .LBB0_1
-; CHECK-32-NEXT: b .LBB0_2
-; CHECK-32-NEXT: .LBB0_1:
-; CHECK-32-NEXT: addi r4, r5, 0
+; CHECK-32-NEXT: li r4, -3
+; CHECK-32-NEXT: blt cr0, .LBB0_2
+; CHECK-32-NEXT: # %bb.1:
+; CHECK-32-NEXT: li r4, 125
; CHECK-32-NEXT: .LBB0_2:
; CHECK-32-NEXT: srawi r3, r3, 31
; CHECK-32-NEXT: blr
@@ -43,13 +41,11 @@ define i64 @f1(i64 %x) {
;
; CHECK-32-LABEL: f1:
; CHECK-32: # %bb.0:
-; CHECK-32-NEXT: li r4, 512
; CHECK-32-NEXT: cmpwi r3, 0
-; CHECK-32-NEXT: li r3, 64
-; CHECK-32-NEXT: bc 12, lt, .LBB1_1
-; CHECK-32-NEXT: b .LBB1_2
-; CHECK-32-NEXT: .LBB1_1:
-; CHECK-32-NEXT: addi r4, r3, 0
+; CHECK-32-NEXT: li r4, 64
+; CHECK-32-NEXT: blt cr0, .LBB1_2
+; CHECK-32-NEXT: # %bb.1:
+; CHECK-32-NEXT: li r4, 512
; CHECK-32-NEXT: .LBB1_2:
; CHECK-32-NEXT: li r3, 0
; CHECK-32-NEXT: blr
@@ -69,14 +65,11 @@ define i64 @f2(i64 %x) {
; CHECK-32-LABEL: f2:
; CHECK-32: # %bb.0:
; CHECK-32-NEXT: or. r3, r4, r3
-; CHECK-32-NEXT: li r3, 1024
+; CHECK-32-NEXT: li r4, 0
; CHECK-32-NEXT: bc 12, eq, .LBB2_2
; CHECK-32-NEXT: # %bb.1:
-; CHECK-32-NEXT: ori r4, r3, 0
-; CHECK-32-NEXT: b .LBB2_3
+; CHECK-32-NEXT: li r4, 1024
; CHECK-32-NEXT: .LBB2_2:
-; CHECK-32-NEXT: li r4, 0
-; CHECK-32-NEXT: .LBB2_3:
; CHECK-32-NEXT: li r3, 0
; CHECK-32-NEXT: blr
%c = icmp eq i64 %x, 0
@@ -93,15 +86,17 @@ define i64 @f3(i64 %x, i64 %y) {
;
; CHECK-32-LABEL: f3:
; CHECK-32: # %bb.0:
-; CHECK-32-NEXT: or. r3, r4, r3
-; CHECK-32-NEXT: bc 12, eq, .LBB3_2
+; CHECK-32-NEXT: mr r7, r4
+; CHECK-32-NEXT: or. r3, r7, r3
+; CHECK-32-NEXT: li r4, 0
+; CHECK-32-NEXT: li r3, 0
+; CHECK-32-NEXT: beq cr0, .LBB3_2
; CHECK-32-NEXT: # %bb.1:
-; CHECK-32-NEXT: ori r3, r5, 0
-; CHECK-32-NEXT: ori r4, r6, 0
-; CHECK-32-NEXT: blr
+; CHECK-32-NEXT: mr r3, r5
; CHECK-32-NEXT: .LBB3_2:
-; CHECK-32-NEXT: li r3, 0
-; CHECK-32-NEXT: li r4, 0
+; CHECK-32-NEXT: beqlr cr0
+; CHECK-32-NEXT: # %bb.3:
+; CHECK-32-NEXT: mr r4, r6
; CHECK-32-NEXT: blr
%c = icmp eq i64 %x, 0
%r = select i1 %c, i64 0, i64 %y
@@ -140,14 +135,18 @@ define i64 @f4_sge_0(i64 %x) {
;
; CHECK-32-LABEL: f4_sge_0:
; CHECK-32: # %bb.0:
-; CHECK-32-NEXT: subfic r5, r4, 0
-; CHECK-32-NEXT: subfze r6, r3
+; CHECK-32-NEXT: mr r5, r4
+; CHECK-32-NEXT: subfic r4, r4, 0
+; CHECK-32-NEXT: mr r6, r3
; CHECK-32-NEXT: cmpwi r3, -1
-; CHECK-32-NEXT: bc 12, gt, .LBB5_1
-; CHECK-32-NEXT: blr
-; CHECK-32-NEXT: .LBB5_1:
-; CHECK-32-NEXT: addi r3, r6, 0
-; CHECK-32-NEXT: addi r4, r5, 0
+; CHECK-32-NEXT: subfze r3, r3
+; CHECK-32-NEXT: bgt cr0, .LBB5_2
+; CHECK-32-NEXT: # %bb.1:
+; CHECK-32-NEXT: mr r3, r6
+; CHECK-32-NEXT: .LBB5_2:
+; CHECK-32-NEXT: bgtlr cr0
+; CHECK-32-NEXT: # %bb.3:
+; CHECK-32-NEXT: mr r4, r5
; CHECK-32-NEXT: blr
%c = icmp sge i64 %x, 0
%x.neg = sub i64 0, %x
@@ -191,14 +190,17 @@ define i64 @f4_sle_0(i64 %x) {
; CHECK-32-NEXT: cmpwi cr1, r3, 0
; CHECK-32-NEXT: crandc 4*cr5+lt, 4*cr1+lt, eq
; CHECK-32-NEXT: cmpwi cr1, r4, 0
-; CHECK-32-NEXT: subfic r5, r4, 0
; CHECK-32-NEXT: crand 4*cr5+gt, eq, 4*cr1+eq
+; CHECK-32-NEXT: subfic r5, r4, 0
; CHECK-32-NEXT: cror 4*cr5+lt, 4*cr5+gt, 4*cr5+lt
; CHECK-32-NEXT: subfze r6, r3
-; CHECK-32-NEXT: bclr 12, 4*cr5+lt, 0
+; CHECK-32-NEXT: bc 12, 4*cr5+lt, .LBB7_2
; CHECK-32-NEXT: # %bb.1:
-; CHECK-32-NEXT: ori r3, r6, 0
-; CHECK-32-NEXT: ori r4, r5, 0
+; CHECK-32-NEXT: mr r3, r6
+; CHECK-32-NEXT: .LBB7_2:
+; CHECK-32-NEXT: bclr 12, 4*cr5+lt, 0
+; CHECK-32-NEXT: # %bb.3:
+; CHECK-32-NEXT: mr r4, r5
; CHECK-32-NEXT: blr
%c = icmp sle i64 %x, 0
%x.neg = sub i64 0, %x
@@ -238,16 +240,20 @@ define i64 @f5(i64 %x, i64 %y) {
;
; CHECK-32-LABEL: f5:
; CHECK-32: # %bb.0:
-; CHECK-32-NEXT: li r7, 0
; CHECK-32-NEXT: or. r3, r4, r3
-; CHECK-32-NEXT: bc 12, eq, .LBB9_2
+; CHECK-32-NEXT: mr r3, r5
+; CHECK-32-NEXT: bne cr0, .LBB9_3
; CHECK-32-NEXT: # %bb.1:
-; CHECK-32-NEXT: ori r3, r7, 0
-; CHECK-32-NEXT: ori r4, r7, 0
-; CHECK-32-NEXT: blr
+; CHECK-32-NEXT: bne cr0, .LBB9_4
; CHECK-32-NEXT: .LBB9_2:
-; CHECK-32-NEXT: addi r3, r5, 0
-; CHECK-32-NEXT: addi r4, r6, 0
+; CHECK-32-NEXT: mr r4, r6
+; CHECK-32-NEXT: blr
+; CHECK-32-NEXT: .LBB9_3:
+; CHECK-32-NEXT: li r3, 0
+; CHECK-32-NEXT: beq cr0, .LBB9_2
+; CHECK-32-NEXT: .LBB9_4:
+; CHECK-32-NEXT: li r6, 0
+; CHECK-32-NEXT: mr r4, r6
; CHECK-32-NEXT: blr
%c = icmp eq i64 %x, 0
%r = select i1 %c, i64 %y, i64 0
@@ -264,14 +270,11 @@ define i32 @f5_i32(i32 %x, i32 %y) {
;
; CHECK-32-LABEL: f5_i32:
; CHECK-32: # %bb.0:
-; CHECK-32-NEXT: li r5, 0
; CHECK-32-NEXT: cmplwi r3, 0
-; CHECK-32-NEXT: bc 12, eq, .LBB10_2
+; CHECK-32-NEXT: mr r3, r4
+; CHECK-32-NEXT: beqlr cr0
; CHECK-32-NEXT: # %bb.1:
-; CHECK-32-NEXT: ori r3, r5, 0
-; CHECK-32-NEXT: blr
-; CHECK-32-NEXT: .LBB10_2:
-; CHECK-32-NEXT: addi r3, r4, 0
+; CHECK-32-NEXT: li r3, 0
; CHECK-32-NEXT: blr
%c = icmp eq i32 %x, 0
%r = select i1 %c, i32 %y, i32 0
diff --git a/llvm/test/CodeGen/PowerPC/select_const.ll b/llvm/test/CodeGen/PowerPC/select_const.ll
index 606cfe22887802..ca4be83cc16ac7 100644
--- a/llvm/test/CodeGen/PowerPC/select_const.ll
+++ b/llvm/test/CodeGen/PowerPC/select_const.ll
@@ -198,12 +198,10 @@ define i32 @select_C1_C2(i1 %cond) {
; NO_ISEL-LABEL: select_C1_C2:
; NO_ISEL: # %bb.0:
; NO_ISEL-NEXT: andi. 3, 3, 1
+; NO_ISEL-NEXT: li 3, 421
+; NO_ISEL-NEXT: bclr 12, 1, 0
+; NO_ISEL-NEXT: # %bb.1:
; NO_ISEL-NEXT: li 3, 42
-; NO_ISEL-NEXT: li 4, 421
-; NO_ISEL-NEXT: bc 12, 1, .LBB18_1
-; NO_ISEL-NEXT: blr
-; NO_ISEL-NEXT: .LBB18_1:
-; NO_ISEL-NEXT: addi 3, 4, 0
; NO_ISEL-NEXT: blr
%sel = select i1 %cond, i32 421, i32 42
ret i32 %sel
@@ -221,12 +219,10 @@ define i32 @select_C1_C2_zeroext(i1 zeroext %cond) {
; NO_ISEL-LABEL: select_C1_C2_zeroext:
; NO_ISEL: # %bb.0:
; NO_ISEL-NEXT: andi. 3, 3, 1
+; NO_ISEL-NEXT: li 3, 421
+; NO_ISEL-NEXT: bclr 12, 1, 0
+; NO_ISEL-NEXT: # %bb.1:
; NO_ISEL-NEXT: li 3, 42
-; NO_ISEL-NEXT: li 4, 421
-; NO_ISEL-NEXT: bc 12, 1, .LBB19_1
-; NO_ISEL-NEXT: blr
-; NO_ISEL-NEXT: .LBB19_1:
-; NO_ISEL-NEXT: addi 3, 4, 0
; NO_ISEL-NEXT: blr
%sel = select i1 %cond, i32 421, i32 42
ret i32 %sel
@@ -244,12 +240,10 @@ define i32 @select_C1_C2_signext(i1 signext %cond) {
; NO_ISEL-LABEL: select_C1_C2_signext:
; NO_ISEL: # %bb.0:
; NO_ISEL-NEXT: andi. 3, 3, 1
+; NO_ISEL-NEXT: li 3, 421
+; NO_ISEL-NEXT: bclr 12, 1, 0
+; NO_ISEL-NEXT: # %bb.1:
; NO_ISEL-NEXT: li 3, 42
-; NO_ISEL-NEXT: li 4, 421
-; NO_ISEL-NEXT: bc 12, 1, .LBB20_1
-; NO_ISEL-NEXT: blr
-; NO_ISEL-NEXT: .LBB20_1:
-; NO_ISEL-NEXT: addi 3, 4, 0
; NO_ISEL-NEXT: blr
%sel = select i1 %cond, i32 421, i32 42
ret i32 %sel
@@ -269,12 +263,10 @@ define i8 @sel_constants_add_constant(i1 %cond) {
; NO_ISEL-LABEL: sel_constants_add_constant:
; NO_ISEL: # %bb.0:
; NO_ISEL-NEXT: andi. 3, 3, 1
+; NO_ISEL-NEXT: li 3, 1
+; NO_ISEL-NEXT: bclr 12, 1, 0
+; NO_ISEL-NEXT: # %bb.1:
; NO_ISEL-NEXT: li 3, 28
-; NO_ISEL-NEXT: li 4, 1
-; NO_ISEL-NEXT: bc 12, 1, .LBB21_1
-; NO_ISEL-NEXT: blr
-; NO_ISEL-NEXT: .LBB21_1:
-; NO_ISEL-NEXT: addi 3, 4, 0
; NO_ISEL-NEXT: blr
%sel = select i1 %cond, i8 -4, i8 23
%bo = add i8 %sel, 5
@@ -293,12 +285,10 @@ define i8 @sel_constants_sub_constant(i1 %cond) {
; NO_ISEL-LABEL: sel_constants_sub_constant:
; NO_ISEL: # %bb.0:
; NO_ISEL-NEXT: andi. 3, 3, 1
+; NO_ISEL-NEXT: li 3, -9
+; NO_ISEL-NEXT: bclr 12, 1, 0
+; NO_ISEL-NEXT: # %bb.1:
; NO_ISEL-NEXT: li 3, 18
-; NO_ISEL-NEXT: li 4, -9
-; NO_ISEL-NEXT: bc 12, 1, .LBB22_1
-; NO_ISEL-NEXT: blr
-; NO_ISEL-NEXT: .LBB22_1:
-; NO_ISEL-NEXT: addi 3, 4, 0
; NO_ISEL-NEXT: blr
%sel = select i1 %cond, i8 -4, i8 23
%bo = sub i8 %sel, 5
@@ -317,12 +307,10 @@ define i8 @sel_constants_sub_constant_sel_constants(i1 %cond) {
; NO_ISEL-LABEL: sel_constants_sub_constant_sel_constants:
; NO_ISEL: # %bb.0:
; NO_ISEL-NEXT: andi. 3, 3, 1
+; NO_ISEL-NEXT: li 3, 9
+; NO_ISEL-NEXT: bclr 12, 1, 0
+; NO_ISEL-NEXT: # %bb.1:
; NO_ISEL-NEXT: li 3, 2
-; NO_ISEL-NEXT: li 4, 9
-; NO_ISEL-NEXT: bc 12, 1, .LBB23_1
-; NO_ISEL-NEXT: blr
-; NO_ISEL-NEXT: .LBB23_1:
-; NO_ISEL-NEXT: addi 3, 4, 0
; NO_ISEL-NEXT: blr
%sel = select i1 %cond, i8 -4, i8 3
%bo = sub i8 5, %sel
@@ -341,12 +329,10 @@ define i8 @sel_constants_mul_constant(i1 %cond) {
; NO_ISEL-LABEL: sel_constants_mul_constant:
; NO_ISEL: # %bb.0:
; NO_ISEL-NEXT: andi. 3, 3, 1
+; NO_ISEL-NEXT: li 3, -20
+; NO_ISEL-NEXT: bclr 12, 1, 0
+; NO_ISEL-NEXT: # %bb.1:
; NO_ISEL-NEXT: li 3, 115
-; NO_ISEL-NEXT: li 4, -20
-; NO_ISEL-NEXT: bc 12, 1, .LBB24_1
-; NO_ISEL-NEXT: blr
-; NO_ISEL-NEXT: .LBB24_1:
-; NO_ISEL-NEXT: addi 3, 4, 0
; NO_ISEL-NEXT: blr
%sel = select i1 %cond, i8 -4, i8 23
%bo = mul i8 %sel, 5
@@ -364,11 +350,10 @@ define i8 @sel_constants_sdiv_constant(i1 %cond) {
; NO_ISEL-LABEL: sel_constants_sdiv_constant:
; NO_ISEL: # %bb.0:
; NO_ISEL-NEXT: andi. 3, 3, 1
-; NO_ISEL-NEXT: li 3, 4
-; NO_ISEL-NEXT: bc 12, 1, .LBB25_1
-; NO_ISEL-NEXT: blr
-; NO_ISEL-NEXT: .LBB25_1:
; NO_ISEL-NEXT: li 3, 0
+; NO_ISEL-NEXT: bclr 12, 1, 0
+; NO_ISEL-NEXT: # %bb.1:
+; NO_ISEL-NEXT: li 3, 4
; NO_ISEL-NEXT: blr
%sel = select i1 %cond, i8 -4, i8 23
%bo = sdiv i8 %sel, 5
@@ -386,11 +371,10 @@ define i8 @sdiv_constant_sel_constants(i1 %cond) {
; NO_ISEL-LABEL: sdiv_constant_sel_constants:
; NO_ISEL: # %bb.0:
; NO_ISEL-NEXT: andi. 3, 3, 1
-; NO_ISEL-NEXT: li 3, 5
-; NO_ISEL-NEXT: bc 12, 1, .LBB26_1
-; NO_ISEL-NEXT: blr
-; NO_ISEL-NEXT: .LBB26_1:
; NO_ISEL-NEXT: li 3, 0
+; NO_ISEL-NEXT: bclr 12, 1, 0
+; NO_ISEL-NEXT: # %bb.1:
+; NO_ISEL-NEXT: li 3, 5
; NO_ISEL-NEXT: blr
%sel = select i1 %cond, i8 121, i8 23
%bo = sdiv i8 120, %sel
@@ -409,12 +393,10 @@ define i8 @sel_constants_udiv_constant(i1 %cond) {
; NO_ISEL-LABEL: sel_constants_udiv_constant:
; NO_ISEL: # %bb.0:
; NO_ISEL-NEXT: andi. 3, 3, 1
+; NO_ISEL-NEXT: li 3, 50
+; NO_ISEL-NEXT: bclr 12, 1, 0
+; NO_ISEL-NEXT: # %bb.1:
; NO_ISEL-NEXT: li 3, 4
-; NO_ISEL-NEXT: li 4, 50
-; NO_ISEL-NEXT: bc 12, 1, .LBB27_1
-; NO_ISEL-NEXT: blr
-; NO_ISEL-NEXT: .LBB27_1:
-; NO_ISEL-NEXT: addi 3, 4, 0
; NO_ISEL-NEXT: blr
%sel = select i1 %cond, i8 -4, i8 23
%bo = udiv i8 %sel, 5
@@ -432,11 +414,10 @@ define i8 @udiv_constant_sel_constants(i1 %cond) {
; NO_ISEL-LABEL: udiv_constant_sel_constants:
; NO_ISEL: # %bb.0:
; NO_ISEL-NEXT: andi. 3, 3, 1
-; NO_ISEL-NEXT: li 3, 5
-; NO_ISEL-NEXT: bc 12, 1, .LBB28_1
-; NO_ISEL-NEXT: blr
-; NO_ISEL-NEXT: .LBB28_1:
; NO_ISEL-NEXT: li 3, 0
+; NO_ISEL-NEXT: bclr 12, 1, 0
+; NO_ISEL-NEXT: # %bb.1:
+; NO_ISEL-NEXT: li 3, 5
; NO_ISEL-NEXT: blr
%sel = select i1 %cond, i8 -4, i8 23
%bo = udiv i8 120, %sel
@@ -455,12 +436,10 @@ define i8 @sel_constants_srem_constant(i1 %cond) {
; NO_ISEL-LABEL: sel_constants_srem_constant:
; NO_ISEL: # %bb.0:
; NO_ISEL-NEXT: andi. 3, 3, 1
+; NO_ISEL-NEXT: li 3, -4
+; NO_ISEL-NEXT: bclr 12, 1, 0
+; NO_ISEL-NEXT: # %bb.1:
; NO_ISEL-NEXT: li 3, 3
-; NO_ISEL-NEXT: li 4, -4
-; NO_ISEL-NEXT: bc 12, 1, .LBB29_1
-; NO_ISEL-NEXT: blr
-; NO_ISEL-NEXT: .LBB29_1:
-; NO_ISEL-NEXT: addi 3, 4, 0
; NO_ISEL-NEXT: blr
%sel = select i1 %cond, i8 -4, i8 23
%bo = srem i8 %sel, 5
@@ -479,12 +458,10 @@ define i8 @srem_constant_sel_constants(i1 %cond) {
; NO_ISEL-LABEL: srem_constant_sel_constants:
; NO_ISEL: # %bb.0:
; NO_ISEL-NEXT: andi. 3, 3, 1
+; NO_ISEL-NEXT: li 3, 120
+; NO_ISEL-NEXT: bclr 12, 1, 0
+; NO_ISEL-NEXT: # %bb.1:
; NO_ISEL-NEXT: li 3, 5
-; NO_ISEL-NEXT: li 4, 120
-; NO_ISEL-NEXT: bc 12, 1, .LBB30_1
-; NO_ISEL-NEXT: blr
-; NO_ISEL-NEXT: .LBB30_1:
-; NO_ISEL-NEXT: addi 3, 4, 0
; NO_ISEL-NEXT: blr
%sel = select i1 %cond, i8 121, i8 23
%bo = srem i8 120, %sel
@@ -514,12 +491,10 @@ define i8 @urem_constant_sel_constants(i1 %cond) {
; NO_ISEL-LABEL: urem_constant_sel_constants:
; NO_ISEL: # %bb.0:
; NO_ISEL-NEXT: andi. 3, 3, 1
+; NO_ISEL-NEXT: li 3, 120
+; NO_ISEL-NEXT: bclr 12, 1, 0
+; NO_ISEL-NEXT: # %bb.1:
; NO_ISEL-NEXT: li 3, 5
-; NO_ISEL-NEXT: li 4, 120
-; NO_ISEL-NEXT: bc 12, 1, .LBB32_1
-; NO_ISEL-NEXT: blr
-; NO_ISEL-NEXT: .LBB32_1:
-; NO_ISEL-NEXT: addi 3, 4, 0
; NO_ISEL-NEXT: blr
%sel = select i1 %cond, i8 -4, i8 23
%bo = urem i8 120, %sel
@@ -549,12 +524,10 @@ define i8 @sel_constants_or_constant(i1 %cond) {
; NO_ISEL-LABEL: sel_constants_or_constant:
; NO_ISEL: # %bb.0:
; NO_ISEL-NEXT: andi. 3, 3, 1
+; NO_ISEL-NEXT: li 3, -3
+; NO_ISEL-NEXT: bclr 12, 1, 0
+; NO_ISEL-NEXT: # %bb.1:
; NO_ISEL-NEXT: li 3, 23
-; NO_ISEL-NEXT: li 4, -3
-; NO_ISEL-NEXT: bc 12, 1, .LBB34_1
-; NO_ISEL-NEXT: blr
-; NO_ISEL-NEXT: .LBB34_1:
-; NO_ISEL-NEXT: addi 3, 4, 0
; NO_ISEL-NEXT: blr
%sel = select i1 %cond, i8 -4, i8 23
%bo = or i8 %sel, 5
@@ -573,12 +546,10 @@ define i8 @sel_constants_xor_constant(i1 %cond) {
; NO_ISEL-LABEL: sel_constants_xor_constant:
; NO_ISEL: # %bb.0:
; NO_ISEL-NEXT: andi. 3, 3, 1
+; NO_ISEL-NEXT: li 3, -7
+; NO_ISEL-NEXT: bclr 12, 1, 0
+; NO_ISEL-NEXT: # %bb.1:
; NO_ISEL-NEXT: li 3, 18
-; NO_ISEL-NEXT: li 4, -7
-; NO_ISEL-NEXT: bc 12, 1, .LBB35_1
-; NO_ISEL-NEXT: blr
-; NO_ISEL-NEXT: .LBB35_1:
-; NO_ISEL-NEXT: addi 3, 4, 0
; NO_ISEL-NEXT: blr
%sel = select i1 %cond, i8 -4, i8 23
%bo = xor i8 %sel, 5
@@ -597,12 +568,10 @@ define i8 @sel_constants_shl_constant(i1 %cond) {
; NO_ISEL-LABEL: sel_constants_shl_constant:
; NO_ISEL: # %bb.0:
; NO_ISEL-NEXT: andi. 3, 3, 1
+; NO_ISEL-NEXT: li 3, -128
+; NO_ISEL-NEXT: bclr 12, 1, 0
+; NO_ISEL-NEXT: # %bb.1:
; NO_ISEL-NEXT: li 3, -32
-; NO_ISEL-NEXT: li 4, -128
-; NO_ISEL-NEXT: bc 12, 1, .LBB36_1
-; NO_ISEL-NEXT: blr
-; NO_ISEL-NEXT: .LBB36_1:
-; NO_ISEL-NEXT: addi 3, 4, 0
; NO_ISEL-NEXT: blr
%sel = select i1 %cond, i8 -4, i8 23
%bo = shl i8 %sel, 5
@@ -634,12 +603,10 @@ define i8 @sel_constants_lshr_constant(i1 %cond) {
; NO_ISEL-LABEL: sel_constants_lshr_constant:
; NO_ISEL: # %bb.0:
; NO_ISEL-NEXT: andi. 3, 3, 1
+; NO_ISEL-NEXT: li 3, 7
+; NO_ISEL-NEXT: bclr 12, 1, 0
+; NO_ISEL-NEXT: # %bb.1:
; NO_ISEL-NEXT: li 3, 0
-; NO_ISEL-NEXT: li 4, 7
-; NO_ISEL-NEXT: bc 12, 1, .LBB38_1
-; NO_ISEL-NEXT: blr
-; NO_ISEL-NEXT: .LBB38_1:
-; NO_ISEL-NEXT: addi 3, 4, 0
; NO_ISEL-NEXT: blr
%sel = select i1 %cond, i8 -4, i8 23
%bo = lshr i8 %sel, 5
@@ -699,15 +666,15 @@ define double @sel_constants_fadd_constant(i1 %cond) {
; NO_ISEL-LABEL: sel_constants_fadd_constant:
; NO_ISEL: # %bb.0:
; NO_ISEL-NEXT: andi. 3, 3, 1
+; NO_ISEL-NEXT: bc 12, 1, .LBB42_2
+; NO_ISEL-NEXT: # %bb.1:
; NO_ISEL-NEXT: addis 3, 2, .LCPI42_0 at toc@ha
-; NO_ISEL-NEXT: addis 4, 2, .LCPI42_1 at toc@ha
; NO_ISEL-NEXT: addi 3, 3, .LCPI42_0 at toc@l
-; NO_ISEL-NEXT: addi 4, 4, .LCPI42_1 at toc@l
-; NO_ISEL-NEXT: bc 12, 1, .LBB42_1
-; NO_ISEL-NEXT: b .LBB42_2
-; NO_ISEL-NEXT: .LBB42_1:
-; NO_ISEL-NEXT: addi 3, 4, 0
+; NO_ISEL-NEXT: lfd 1, 0(3)
+; NO_ISEL-NEXT: blr
; NO_ISEL-NEXT: .LBB42_2:
+; NO_ISEL-NEXT: addis 3, 2, .LCPI42_1 at toc@ha
+; NO_ISEL-NEXT: addi 3, 3, .LCPI42_1 at toc@l
; NO_ISEL-NEXT: lfd 1, 0(3)
; NO_ISEL-NEXT: blr
%sel = select i1 %cond, double -4.0, double 23.3
@@ -730,15 +697,15 @@ define double @sel_constants_fsub_constant(i1 %cond) {
; NO_ISEL-LABEL: sel_constants_fsub_constant:
; NO_ISEL: # %bb.0:
; NO_ISEL-NEXT: andi. 3, 3, 1
+; NO_ISEL-NEXT: bc 12, 1, .LBB43_2
+; NO_ISEL-NEXT: # %bb.1:
; NO_ISEL-NEXT: addis 3, 2, .LCPI43_0 at toc@ha
-; NO_ISEL-NEXT: addis 4, 2, .LCPI43_1 at toc@ha
; NO_ISEL-NEXT: addi 3, 3, .LCPI43_0 at toc@l
-; NO_ISEL-NEXT: addi 4, 4, .LCPI43_1 at toc@l
-; NO_ISEL-NEXT: bc 12, 1, .LBB43_1
-; NO_ISEL-NEXT: b .LBB43_2
-; NO_ISEL-NEXT: .LBB43_1:
-; NO_ISEL-NEXT: addi 3, 4, 0
+; NO_ISEL-NEXT: lfd 1, 0(3)
+; NO_ISEL-NEXT: blr
; NO_ISEL-NEXT: .LBB43_2:
+; NO_ISEL-NEXT: addis 3, 2, .LCPI43_1 at toc@ha
+; NO_ISEL-NEXT: addi 3, 3, .LCPI43_1 at toc@l
; NO_ISEL-NEXT: lfd 1, 0(3)
; NO_ISEL-NEXT: blr
%sel = select i1 %cond, double -4.0, double 23.3
@@ -761,15 +728,15 @@ define double @fsub_constant_sel_constants(i1 %cond) {
; NO_ISEL-LABEL: fsub_constant_sel_constants:
; NO_ISEL: # %bb.0:
; NO_ISEL-NEXT: andi. 3, 3, 1
+; NO_ISEL-NEXT: bc 12, 1, .LBB44_2
+; NO_ISEL-NEXT: # %bb.1:
; NO_ISEL-NEXT: addis 3, 2, .LCPI44_0 at toc@ha
-; NO_ISEL-NEXT: addis 4, 2, .LCPI44_1 at toc@ha
; NO_ISEL-NEXT: addi 3, 3, .LCPI44_0 at toc@l
-; NO_ISEL-NEXT: addi 4, 4, .LCPI44_1 at toc@l
-; NO_ISEL-NEXT: bc 12, 1, .LBB44_1
-; NO_ISEL-NEXT: b .LBB44_2
-; NO_ISEL-NEXT: .LBB44_1:
-; NO_ISEL-NEXT: addi 3, 4, 0
+; NO_ISEL-NEXT: lfd 1, 0(3)
+; NO_ISEL-NEXT: blr
; NO_ISEL-NEXT: .LBB44_2:
+; NO_ISEL-NEXT: addis 3, 2, .LCPI44_1 at toc@ha
+; NO_ISEL-NEXT: addi 3, 3, .LCPI44_1 at toc@l
; NO_ISEL-NEXT: lfd 1, 0(3)
; NO_ISEL-NEXT: blr
%sel = select i1 %cond, double -4.0, double 23.3
@@ -792,15 +759,15 @@ define double @sel_constants_fmul_constant(i1 %cond) {
; NO_ISEL-LABEL: sel_constants_fmul_constant:
; NO_ISEL: # %bb.0:
; NO_ISEL-NEXT: andi. 3, 3, 1
+; NO_ISEL-NEXT: bc 12, 1, .LBB45_2
+; NO_ISEL-NEXT: # %bb.1:
; NO_ISEL-NEXT: addis 3, 2, .LCPI45_0 at toc@ha
-; NO_ISEL-NEXT: addis 4, 2, .LCPI45_1 at toc@ha
; NO_ISEL-NEXT: addi 3, 3, .LCPI45_0 at toc@l
-; NO_ISEL-NEXT: addi 4, 4, .LCPI45_1 at toc@l
-; NO_ISEL-NEXT: bc 12, 1, .LBB45_1
-; NO_ISEL-NEXT: b .LBB45_2
-; NO_ISEL-NEXT: .LBB45_1:
-; NO_ISEL-NEXT: addi 3, 4, 0
+; NO_ISEL-NEXT: lfd 1, 0(3)
+; NO_ISEL-NEXT: blr
; NO_ISEL-NEXT: .LBB45_2:
+; NO_ISEL-NEXT: addis 3, 2, .LCPI45_1 at toc@ha
+; NO_ISEL-NEXT: addi 3, 3, .LCPI45_1 at toc@l
; NO_ISEL-NEXT: lfd 1, 0(3)
; NO_ISEL-NEXT: blr
%sel = select i1 %cond, double -4.0, double 23.3
@@ -823,15 +790,15 @@ define double @sel_constants_fdiv_constant(i1 %cond) {
; NO_ISEL-LABEL: sel_constants_fdiv_constant:
; NO_ISEL: # %bb.0:
; NO_ISEL-NEXT: andi. 3, 3, 1
+; NO_ISEL-NEXT: bc 12, 1, .LBB46_2
+; NO_ISEL-NEXT: # %bb.1:
; NO_ISEL-NEXT: addis 3, 2, .LCPI46_0 at toc@ha
-; NO_ISEL-NEXT: addis 4, 2, .LCPI46_1 at toc@ha
; NO_ISEL-NEXT: addi 3, 3, .LCPI46_0 at toc@l
-; NO_ISEL-NEXT: addi 4, 4, .LCPI46_1 at toc@l
-; NO_ISEL-NEXT: bc 12, 1, .LBB46_1
-; NO_ISEL-NEXT: b .LBB46_2
-; NO_ISEL-NEXT: .LBB46_1:
-; NO_ISEL-NEXT: addi 3, 4, 0
+; NO_ISEL-NEXT: lfd 1, 0(3)
+; NO_ISEL-NEXT: blr
; NO_ISEL-NEXT: .LBB46_2:
+; NO_ISEL-NEXT: addis 3, 2, .LCPI46_1 at toc@ha
+; NO_ISEL-NEXT: addi 3, 3, .LCPI46_1 at toc@l
; NO_ISEL-NEXT: lfd 1, 0(3)
; NO_ISEL-NEXT: blr
%sel = select i1 %cond, double -4.0, double 23.3
@@ -854,15 +821,15 @@ define double @fdiv_constant_sel_constants(i1 %cond) {
; NO_ISEL-LABEL: fdiv_constant_sel_constants:
; NO_ISEL: # %bb.0:
; NO_ISEL-NEXT: andi. 3, 3, 1
+; NO_ISEL-NEXT: bc 12, 1, .LBB47_2
+; NO_ISEL-NEXT: # %bb.1:
; NO_ISEL-NEXT: addis 3, 2, .LCPI47_0 at toc@ha
-; NO_ISEL-NEXT: addis 4, 2, .LCPI47_1 at toc@ha
; NO_ISEL-NEXT: addi 3, 3, .LCPI47_0 at toc@l
-; NO_ISEL-NEXT: addi 4, 4, .LCPI47_1 at toc@l
-; NO_ISEL-NEXT: bc 12, 1, .LBB47_1
-; NO_ISEL-NEXT: b .LBB47_2
-; NO_ISEL-NEXT: .LBB47_1:
-; NO_ISEL-NEXT: addi 3, 4, 0
+; NO_ISEL-NEXT: lfd 1, 0(3)
+; NO_ISEL-NEXT: blr
; NO_ISEL-NEXT: .LBB47_2:
+; NO_ISEL-NEXT: addis 3, 2, .LCPI47_1 at toc@ha
+; NO_ISEL-NEXT: addi 3, 3, .LCPI47_1 at toc@l
; NO_ISEL-NEXT: lfd 1, 0(3)
; NO_ISEL-NEXT: blr
%sel = select i1 %cond, double -4.0, double 23.3
@@ -905,15 +872,15 @@ define double @frem_constant_sel_constants(i1 %cond) {
; NO_ISEL-LABEL: frem_constant_sel_constants:
; NO_ISEL: # %bb.0:
; NO_ISEL-NEXT: andi. 3, 3, 1
+; NO_ISEL-NEXT: bc 12, 1, .LBB49_2
+; NO_ISEL-NEXT: # %bb.1:
; NO_ISEL-NEXT: addis 3, 2, .LCPI49_0 at toc@ha
-; NO_ISEL-NEXT: addis 4, 2, .LCPI49_1 at toc@ha
; NO_ISEL-NEXT: addi 3, 3, .LCPI49_0 at toc@l
-; NO_ISEL-NEXT: addi 4, 4, .LCPI49_1 at toc@l
-; NO_ISEL-NEXT: bc 12, 1, .LBB49_1
-; NO_ISEL-NEXT: b .LBB49_2
-; NO_ISEL-NEXT: .LBB49_1:
-; NO_ISEL-NEXT: addi 3, 4, 0
+; NO_ISEL-NEXT: lfd 1, 0(3)
+; NO_ISEL-NEXT: blr
; NO_ISEL-NEXT: .LBB49_2:
+; NO_ISEL-NEXT: addis 3, 2, .LCPI49_1 at toc@ha
+; NO_ISEL-NEXT: addi 3, 3, .LCPI49_1 at toc@l
; NO_ISEL-NEXT: lfd 1, 0(3)
; NO_ISEL-NEXT: blr
%sel = select i1 %cond, double -4.0, double 23.3
diff --git a/llvm/test/CodeGen/PowerPC/smulfixsat.ll b/llvm/test/CodeGen/PowerPC/smulfixsat.ll
index 9e371d499da35a..b65c99d680908e 100644
--- a/llvm/test/CodeGen/PowerPC/smulfixsat.ll
+++ b/llvm/test/CodeGen/PowerPC/smulfixsat.ll
@@ -10,12 +10,11 @@ define i32 @func1(i32 %x, i32 %y) nounwind {
; CHECK-NEXT: mullw 3, 3, 4
; CHECK-NEXT: srawi 4, 3, 31
; CHECK-NEXT: cmplw 5, 4
-; CHECK-NEXT: srawi 4, 5, 31
-; CHECK-NEXT: xori 4, 4, 65535
-; CHECK-NEXT: xoris 4, 4, 32767
-; CHECK-NEXT: bclr 12, 2, 0
+; CHECK-NEXT: beqlr 0
; CHECK-NEXT: # %bb.1:
-; CHECK-NEXT: ori 3, 4, 0
+; CHECK-NEXT: srawi 3, 5, 31
+; CHECK-NEXT: xori 3, 3, 65535
+; CHECK-NEXT: xoris 3, 3, 32767
; CHECK-NEXT: blr
%tmp = call i32 @llvm.smul.fix.sat.i32(i32 %x, i32 %y, i32 0)
ret i32 %tmp
@@ -24,23 +23,22 @@ define i32 @func1(i32 %x, i32 %y) nounwind {
define i32 @func2(i32 %x, i32 %y) nounwind {
; CHECK-LABEL: func2:
; CHECK: # %bb.0:
-; CHECK-NEXT: mulhw. 6, 3, 4
-; CHECK-NEXT: lis 5, 32767
+; CHECK-NEXT: mulhw. 5, 3, 4
+; CHECK-NEXT: bgt 0, .LBB1_2
+; CHECK-NEXT: # %bb.1:
; CHECK-NEXT: mullw 3, 3, 4
-; CHECK-NEXT: rotlwi 3, 3, 31
-; CHECK-NEXT: ori 4, 5, 65535
-; CHECK-NEXT: rlwimi 3, 6, 31, 0, 0
-; CHECK-NEXT: bc 12, 1, .LBB1_1
-; CHECK-NEXT: b .LBB1_2
-; CHECK-NEXT: .LBB1_1:
-; CHECK-NEXT: addi 3, 4, 0
+; CHECK-NEXT: rotlwi 4, 3, 31
+; CHECK-NEXT: rlwimi 4, 5, 31, 0, 0
+; CHECK-NEXT: b .LBB1_3
; CHECK-NEXT: .LBB1_2:
-; CHECK-NEXT: cmpwi 6, -1
-; CHECK-NEXT: lis 4, -32768
-; CHECK-NEXT: bc 12, 0, .LBB1_3
-; CHECK-NEXT: blr
+; CHECK-NEXT: lis 3, 32767
+; CHECK-NEXT: ori 4, 3, 65535
; CHECK-NEXT: .LBB1_3:
-; CHECK-NEXT: addi 3, 4, 0
+; CHECK-NEXT: cmpwi 5, -1
+; CHECK-NEXT: lis 3, -32768
+; CHECK-NEXT: bltlr 0
+; CHECK-NEXT: # %bb.4:
+; CHECK-NEXT: mr 3, 4
; CHECK-NEXT: blr
%tmp = call i32 @llvm.smul.fix.sat.i32(i32 %x, i32 %y, i32 1)
ret i32 %tmp
diff --git a/llvm/test/CodeGen/PowerPC/spe.ll b/llvm/test/CodeGen/PowerPC/spe.ll
index 4bfc413a5a2aa2..b9df47d6d64529 100644
--- a/llvm/test/CodeGen/PowerPC/spe.ll
+++ b/llvm/test/CodeGen/PowerPC/spe.ll
@@ -252,15 +252,13 @@ define i1 @test_fcmpuno(float %a, float %b) #0 {
; CHECK-LABEL: test_fcmpuno:
; CHECK: # %bb.0: # %entry
; CHECK-NEXT: efscmpeq 0, 3, 3
-; CHECK-NEXT: efscmpeq 1, 4, 4
-; CHECK-NEXT: li 5, 1
-; CHECK-NEXT: crand 20, 5, 1
-; CHECK-NEXT: bc 12, 20, .LBB12_2
+; CHECK-NEXT: li 3, 0
+; CHECK-NEXT: bc 4, 1, .LBB12_2
; CHECK-NEXT: # %bb.1: # %entry
-; CHECK-NEXT: ori 3, 5, 0
-; CHECK-NEXT: blr
+; CHECK-NEXT: efscmpeq 0, 4, 4
+; CHECK-NEXT: bclr 12, 1, 0
; CHECK-NEXT: .LBB12_2: # %entry
-; CHECK-NEXT: li 3, 0
+; CHECK-NEXT: li 3, 1
; CHECK-NEXT: blr
entry:
%r = fcmp uno float %a, %b
@@ -270,16 +268,15 @@ define i1 @test_fcmpuno(float %a, float %b) #0 {
define i1 @test_fcmpord(float %a, float %b) #0 {
; CHECK-LABEL: test_fcmpord:
; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: mr 5, 3
; CHECK-NEXT: efscmpeq 0, 4, 4
-; CHECK-NEXT: efscmpeq 1, 3, 3
-; CHECK-NEXT: li 5, 1
-; CHECK-NEXT: crnand 20, 5, 1
-; CHECK-NEXT: bc 12, 20, .LBB13_2
-; CHECK-NEXT: # %bb.1: # %entry
-; CHECK-NEXT: ori 3, 5, 0
-; CHECK-NEXT: blr
-; CHECK-NEXT: .LBB13_2: # %entry
; CHECK-NEXT: li 3, 0
+; CHECK-NEXT: bclr 4, 1, 0
+; CHECK-NEXT: # %bb.1: # %entry
+; CHECK-NEXT: efscmpeq 0, 5, 5
+; CHECK-NEXT: bclr 4, 1, 0
+; CHECK-NEXT: # %bb.2: # %entry
+; CHECK-NEXT: li 3, 1
; CHECK-NEXT: blr
entry:
%r = fcmp ord float %a, %b
@@ -289,16 +286,15 @@ define i1 @test_fcmpord(float %a, float %b) #0 {
define i1 @test_fcmpueq(float %a, float %b) #0 {
; CHECK-LABEL: test_fcmpueq:
; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: mr 5, 3
; CHECK-NEXT: efscmpgt 0, 3, 4
-; CHECK-NEXT: efscmplt 1, 3, 4
-; CHECK-NEXT: li 5, 1
-; CHECK-NEXT: cror 20, 5, 1
-; CHECK-NEXT: bc 12, 20, .LBB14_2
-; CHECK-NEXT: # %bb.1: # %entry
-; CHECK-NEXT: ori 3, 5, 0
-; CHECK-NEXT: blr
-; CHECK-NEXT: .LBB14_2: # %entry
; CHECK-NEXT: li 3, 0
+; CHECK-NEXT: bclr 12, 1, 0
+; CHECK-NEXT: # %bb.1: # %entry
+; CHECK-NEXT: efscmplt 0, 5, 4
+; CHECK-NEXT: bclr 12, 1, 0
+; CHECK-NEXT: # %bb.2: # %entry
+; CHECK-NEXT: li 3, 1
; CHECK-NEXT: blr
entry:
%r = fcmp ueq float %a, %b
@@ -308,16 +304,15 @@ define i1 @test_fcmpueq(float %a, float %b) #0 {
define i1 @test_fcmpne(float %a, float %b) #0 {
; CHECK-LABEL: test_fcmpne:
; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: mr 5, 3
; CHECK-NEXT: efscmplt 0, 3, 4
-; CHECK-NEXT: efscmpgt 1, 3, 4
-; CHECK-NEXT: li 5, 1
-; CHECK-NEXT: crnor 20, 5, 1
-; CHECK-NEXT: bc 12, 20, .LBB15_2
+; CHECK-NEXT: li 3, 0
+; CHECK-NEXT: bc 12, 1, .LBB15_2
; CHECK-NEXT: # %bb.1: # %entry
-; CHECK-NEXT: ori 3, 5, 0
-; CHECK-NEXT: blr
+; CHECK-NEXT: efscmpgt 0, 5, 4
+; CHECK-NEXT: bclr 4, 1, 0
; CHECK-NEXT: .LBB15_2: # %entry
-; CHECK-NEXT: li 3, 0
+; CHECK-NEXT: li 3, 1
; CHECK-NEXT: blr
entry:
%r = fcmp one float %a, %b
@@ -389,18 +384,18 @@ ret:
define i1 @test_fcmpult(float %a, float %b) #0 {
; CHECK-LABEL: test_fcmpult:
; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: mr 5, 3
; CHECK-NEXT: efscmpeq 0, 3, 3
-; CHECK-NEXT: efscmpeq 1, 4, 4
-; CHECK-NEXT: crnand 20, 5, 1
-; CHECK-NEXT: efscmplt 0, 3, 4
-; CHECK-NEXT: li 5, 1
-; CHECK-NEXT: crnor 20, 1, 20
-; CHECK-NEXT: bc 12, 20, .LBB18_2
-; CHECK-NEXT: # %bb.1: # %entry
-; CHECK-NEXT: ori 3, 5, 0
-; CHECK-NEXT: blr
-; CHECK-NEXT: .LBB18_2: # %entry
; CHECK-NEXT: li 3, 0
+; CHECK-NEXT: bc 4, 1, .LBB18_3
+; CHECK-NEXT: # %bb.1: # %entry
+; CHECK-NEXT: efscmpeq 0, 4, 4
+; CHECK-NEXT: bc 4, 1, .LBB18_3
+; CHECK-NEXT: # %bb.2: # %entry
+; CHECK-NEXT: efscmplt 0, 5, 4
+; CHECK-NEXT: bclr 4, 1, 0
+; CHECK-NEXT: .LBB18_3: # %entry
+; CHECK-NEXT: li 3, 1
; CHECK-NEXT: blr
entry:
%r = fcmp ult float %a, %b
@@ -747,16 +742,14 @@ define i1 @test_dcmpuno(double %a, double %b) #0 {
; SPE: # %bb.0: # %entry
; SPE-NEXT: evmergelo 5, 5, 6
; SPE-NEXT: evmergelo 3, 3, 4
-; SPE-NEXT: li 7, 1
; SPE-NEXT: efdcmpeq 0, 3, 3
-; SPE-NEXT: efdcmpeq 1, 5, 5
-; SPE-NEXT: crand 20, 5, 1
-; SPE-NEXT: bc 12, 20, .LBB35_2
+; SPE-NEXT: li 3, 0
+; SPE-NEXT: bc 4, 1, .LBB35_2
; SPE-NEXT: # %bb.1: # %entry
-; SPE-NEXT: ori 3, 7, 0
-; SPE-NEXT: blr
+; SPE-NEXT: efdcmpeq 0, 5, 5
+; SPE-NEXT: bclr 12, 1, 0
; SPE-NEXT: .LBB35_2: # %entry
-; SPE-NEXT: li 3, 0
+; SPE-NEXT: li 3, 1
; SPE-NEXT: blr
;
; EFPU2-LABEL: test_dcmpuno:
@@ -780,18 +773,16 @@ define i1 @test_dcmpuno(double %a, double %b) #0 {
define i1 @test_dcmpord(double %a, double %b) #0 {
; SPE-LABEL: test_dcmpord:
; SPE: # %bb.0: # %entry
-; SPE-NEXT: evmergelo 3, 3, 4
-; SPE-NEXT: evmergelo 4, 5, 6
-; SPE-NEXT: li 7, 1
-; SPE-NEXT: efdcmpeq 0, 4, 4
-; SPE-NEXT: efdcmpeq 1, 3, 3
-; SPE-NEXT: crnand 20, 5, 1
-; SPE-NEXT: bc 12, 20, .LBB36_2
-; SPE-NEXT: # %bb.1: # %entry
-; SPE-NEXT: ori 3, 7, 0
-; SPE-NEXT: blr
-; SPE-NEXT: .LBB36_2: # %entry
+; SPE-NEXT: evmergelo 4, 3, 4
+; SPE-NEXT: evmergelo 3, 5, 6
+; SPE-NEXT: efdcmpeq 0, 3, 3
; SPE-NEXT: li 3, 0
+; SPE-NEXT: bclr 4, 1, 0
+; SPE-NEXT: # %bb.1: # %entry
+; SPE-NEXT: efdcmpeq 0, 4, 4
+; SPE-NEXT: bclr 4, 1, 0
+; SPE-NEXT: # %bb.2: # %entry
+; SPE-NEXT: li 3, 1
; SPE-NEXT: blr
;
; EFPU2-LABEL: test_dcmpord:
@@ -1173,17 +1164,15 @@ define i1 @test_dcmpne(double %a, double %b) #0 {
; SPE-LABEL: test_dcmpne:
; SPE: # %bb.0: # %entry
; SPE-NEXT: evmergelo 5, 5, 6
-; SPE-NEXT: evmergelo 3, 3, 4
-; SPE-NEXT: li 7, 1
-; SPE-NEXT: efdcmplt 0, 3, 5
-; SPE-NEXT: efdcmpgt 1, 3, 5
-; SPE-NEXT: crnor 20, 5, 1
-; SPE-NEXT: bc 12, 20, .LBB43_2
+; SPE-NEXT: evmergelo 4, 3, 4
+; SPE-NEXT: li 3, 0
+; SPE-NEXT: efdcmplt 0, 4, 5
+; SPE-NEXT: bc 12, 1, .LBB43_2
; SPE-NEXT: # %bb.1: # %entry
-; SPE-NEXT: ori 3, 7, 0
-; SPE-NEXT: blr
+; SPE-NEXT: efdcmpgt 0, 4, 5
+; SPE-NEXT: bclr 4, 1, 0
; SPE-NEXT: .LBB43_2: # %entry
-; SPE-NEXT: li 3, 0
+; SPE-NEXT: li 3, 1
; SPE-NEXT: blr
;
; EFPU2-LABEL: test_dcmpne:
@@ -1208,20 +1197,19 @@ define i1 @test_dcmpne(double %a, double %b) #0 {
; EFPU2-NEXT: mr 5, 29
; EFPU2-NEXT: mr 6, 30
; EFPU2-NEXT: bl __eqdf2
+; EFPU2-NEXT: mr 4, 3
+; EFPU2-NEXT: li 3, 0
+; EFPU2-NEXT: bc 4, 10, .LBB43_3
+; EFPU2-NEXT: # %bb.1: # %entry
+; EFPU2-NEXT: cmpwi 4, 0
+; EFPU2-NEXT: bc 12, 2, .LBB43_3
+; EFPU2-NEXT: # %bb.2: # %entry
+; EFPU2-NEXT: li 3, 1
+; EFPU2-NEXT: .LBB43_3: # %entry
; EFPU2-NEXT: lwz 30, 40(1) # 4-byte Folded Reload
-; EFPU2-NEXT: cmpwi 3, 0
; EFPU2-NEXT: lwz 29, 36(1) # 4-byte Folded Reload
-; EFPU2-NEXT: li 4, 1
; EFPU2-NEXT: lwz 28, 32(1) # 4-byte Folded Reload
-; EFPU2-NEXT: crorc 20, 2, 10
; EFPU2-NEXT: lwz 12, 24(1)
-; EFPU2-NEXT: bc 12, 20, .LBB43_2
-; EFPU2-NEXT: # %bb.1: # %entry
-; EFPU2-NEXT: ori 3, 4, 0
-; EFPU2-NEXT: b .LBB43_3
-; EFPU2-NEXT: .LBB43_2: # %entry
-; EFPU2-NEXT: li 3, 0
-; EFPU2-NEXT: .LBB43_3: # %entry
; EFPU2-NEXT: lwz 27, 28(1) # 4-byte Folded Reload
; EFPU2-NEXT: mtcrf 32, 12 # cr2
; EFPU2-NEXT: lwz 0, 52(1)
@@ -1404,20 +1392,19 @@ ret:
define i1 @test_dcmpge(double %a, double %b) #0 {
; SPE-LABEL: test_dcmpge:
; SPE: # %bb.0: # %entry
-; SPE-NEXT: evmergelo 3, 3, 4
-; SPE-NEXT: evmergelo 4, 5, 6
-; SPE-NEXT: li 7, 1
-; SPE-NEXT: efdcmpeq 0, 4, 4
-; SPE-NEXT: efdcmpeq 1, 3, 3
-; SPE-NEXT: efdcmplt 5, 3, 4
-; SPE-NEXT: crand 20, 5, 1
-; SPE-NEXT: crorc 20, 21, 20
-; SPE-NEXT: bc 12, 20, .LBB47_2
-; SPE-NEXT: # %bb.1: # %entry
-; SPE-NEXT: ori 3, 7, 0
-; SPE-NEXT: blr
-; SPE-NEXT: .LBB47_2: # %entry
+; SPE-NEXT: evmergelo 4, 3, 4
+; SPE-NEXT: evmergelo 5, 5, 6
; SPE-NEXT: li 3, 0
+; SPE-NEXT: efdcmpeq 0, 5, 5
+; SPE-NEXT: bclr 4, 1, 0
+; SPE-NEXT: # %bb.1: # %entry
+; SPE-NEXT: efdcmpeq 0, 4, 4
+; SPE-NEXT: bclr 4, 1, 0
+; SPE-NEXT: # %bb.2: # %entry
+; SPE-NEXT: efdcmplt 0, 4, 5
+; SPE-NEXT: bclr 12, 1, 0
+; SPE-NEXT: # %bb.3: # %entry
+; SPE-NEXT: li 3, 1
; SPE-NEXT: blr
;
; EFPU2-LABEL: test_dcmpge:
@@ -1507,10 +1494,13 @@ define double @test_dselect(double %a, double %b, i1 %c) #0 {
; EFPU2-LABEL: test_dselect:
; EFPU2: # %bb.0: # %entry
; EFPU2-NEXT: andi. 7, 7, 1
-; EFPU2-NEXT: bclr 12, 1, 0
+; EFPU2-NEXT: bc 12, 1, .LBB49_2
; EFPU2-NEXT: # %bb.1: # %entry
-; EFPU2-NEXT: ori 3, 5, 0
-; EFPU2-NEXT: ori 4, 6, 0
+; EFPU2-NEXT: mr 3, 5
+; EFPU2-NEXT: .LBB49_2: # %entry
+; EFPU2-NEXT: bclr 12, 1, 0
+; EFPU2-NEXT: # %bb.3: # %entry
+; EFPU2-NEXT: mr 4, 6
; EFPU2-NEXT: blr
entry:
%r = select i1 %c, double %a, double %b
diff --git a/llvm/test/CodeGen/PowerPC/srem-seteq-illegal-types.ll b/llvm/test/CodeGen/PowerPC/srem-seteq-illegal-types.ll
index 65068d14e16005..b0cc89d1828eda 100644
--- a/llvm/test/CodeGen/PowerPC/srem-seteq-illegal-types.ll
+++ b/llvm/test/CodeGen/PowerPC/srem-seteq-illegal-types.ll
@@ -11,15 +11,13 @@ define i1 @test_srem_odd(i29 %X) nounwind {
; PPC-NEXT: addi 3, 3, 24493
; PPC-NEXT: lis 4, 82
; PPC-NEXT: addis 3, 3, 41
-; PPC-NEXT: ori 4, 4, 48987
; PPC-NEXT: clrlwi 3, 3, 3
+; PPC-NEXT: ori 4, 4, 48987
; PPC-NEXT: cmplw 3, 4
+; PPC-NEXT: li 3, 1
+; PPC-NEXT: bclr 12, 0, 0
+; PPC-NEXT: # %bb.1:
; PPC-NEXT: li 3, 0
-; PPC-NEXT: li 4, 1
-; PPC-NEXT: bc 12, 0, .LBB0_1
-; PPC-NEXT: blr
-; PPC-NEXT: .LBB0_1:
-; PPC-NEXT: addi 3, 4, 0
; PPC-NEXT: blr
;
; PPC64LE-LABEL: test_srem_odd:
@@ -45,21 +43,20 @@ define i1 @test_srem_odd(i29 %X) nounwind {
define i1 @test_srem_even(i4 %X) nounwind {
; PPC-LABEL: test_srem_even:
; PPC: # %bb.0:
-; PPC-NEXT: slwi 5, 3, 28
-; PPC-NEXT: srawi 5, 5, 28
-; PPC-NEXT: mulli 5, 5, 3
-; PPC-NEXT: rlwinm 6, 5, 25, 31, 31
-; PPC-NEXT: srwi 5, 5, 4
-; PPC-NEXT: add 5, 5, 6
-; PPC-NEXT: mulli 5, 5, 6
-; PPC-NEXT: sub 3, 3, 5
+; PPC-NEXT: slwi 4, 3, 28
+; PPC-NEXT: srawi 4, 4, 28
+; PPC-NEXT: mulli 4, 4, 3
+; PPC-NEXT: rlwinm 5, 4, 25, 31, 31
+; PPC-NEXT: srwi 4, 4, 4
+; PPC-NEXT: add 4, 4, 5
+; PPC-NEXT: mulli 4, 4, 6
+; PPC-NEXT: sub 3, 3, 4
; PPC-NEXT: clrlwi 3, 3, 28
-; PPC-NEXT: li 4, 0
; PPC-NEXT: cmpwi 3, 1
; PPC-NEXT: li 3, 1
; PPC-NEXT: bclr 12, 2, 0
; PPC-NEXT: # %bb.1:
-; PPC-NEXT: ori 3, 4, 0
+; PPC-NEXT: li 3, 0
; PPC-NEXT: blr
;
; PPC64LE-LABEL: test_srem_even:
diff --git a/llvm/test/CodeGen/PowerPC/umulfixsat.ll b/llvm/test/CodeGen/PowerPC/umulfixsat.ll
index bc41da99e3db0e..081c461c7b6374 100644
--- a/llvm/test/CodeGen/PowerPC/umulfixsat.ll
+++ b/llvm/test/CodeGen/PowerPC/umulfixsat.ll
@@ -6,12 +6,13 @@ declare i32 @llvm.umul.fix.sat.i32(i32, i32, i32)
define i32 @func1(i32 %x, i32 %y) nounwind {
; CHECK-LABEL: func1:
; CHECK: # %bb.0:
+; CHECK-NEXT: mulhwu. 5, 3, 4
; CHECK-NEXT: li 5, -1
-; CHECK-NEXT: mulhwu. 6, 3, 4
-; CHECK-NEXT: mullw 3, 3, 4
-; CHECK-NEXT: bclr 12, 2, 0
+; CHECK-NEXT: bne 0, .LBB0_2
; CHECK-NEXT: # %bb.1:
-; CHECK-NEXT: ori 3, 5, 0
+; CHECK-NEXT: mullw 5, 3, 4
+; CHECK-NEXT: .LBB0_2:
+; CHECK-NEXT: mr 3, 5
; CHECK-NEXT: blr
%tmp = call i32 @llvm.umul.fix.sat.i32(i32 %x, i32 %y, i32 0)
ret i32 %tmp
@@ -21,15 +22,14 @@ define i32 @func2(i32 %x, i32 %y) nounwind {
; CHECK-LABEL: func2:
; CHECK: # %bb.0:
; CHECK-NEXT: mulhwu 6, 3, 4
-; CHECK-NEXT: li 5, -1
+; CHECK-NEXT: mr 5, 3
; CHECK-NEXT: cmplwi 6, 1
-; CHECK-NEXT: mullw 3, 3, 4
+; CHECK-NEXT: li 3, -1
+; CHECK-NEXT: bgtlr 0
+; CHECK-NEXT: # %bb.1:
+; CHECK-NEXT: mullw 3, 5, 4
; CHECK-NEXT: rotlwi 3, 3, 31
; CHECK-NEXT: rlwimi 3, 6, 31, 0, 0
-; CHECK-NEXT: bc 12, 1, .LBB1_1
-; CHECK-NEXT: blr
-; CHECK-NEXT: .LBB1_1:
-; CHECK-NEXT: addi 3, 5, 0
; CHECK-NEXT: blr
%tmp = call i32 @llvm.umul.fix.sat.i32(i32 %x, i32 %y, i32 1)
ret i32 %tmp
diff --git a/llvm/test/CodeGen/PowerPC/umulo-128-legalisation-lowering.ll b/llvm/test/CodeGen/PowerPC/umulo-128-legalisation-lowering.ll
index 48098e3a277c18..120b5383bd5e18 100644
--- a/llvm/test/CodeGen/PowerPC/umulo-128-legalisation-lowering.ll
+++ b/llvm/test/CodeGen/PowerPC/umulo-128-legalisation-lowering.ll
@@ -32,102 +32,110 @@ define { i128, i8 } @muloti_test(i128 %l, i128 %r) unnamed_addr #0 {
;
; PPC32-LABEL: muloti_test:
; PPC32: # %bb.0: # %start
-; PPC32-NEXT: stwu 1, -64(1)
-; PPC32-NEXT: stw 26, 40(1) # 4-byte Folded Spill
-; PPC32-NEXT: mulhwu. 26, 7, 6
-; PPC32-NEXT: mcrf 1, 0
-; PPC32-NEXT: stw 30, 56(1) # 4-byte Folded Spill
+; PPC32-NEXT: stwu 1, -80(1)
+; PPC32-NEXT: mr 11, 7
+; PPC32-NEXT: stw 26, 56(1) # 4-byte Folded Spill
+; PPC32-NEXT: mulhwu. 26, 11, 6
+; PPC32-NEXT: stw 24, 48(1) # 4-byte Folded Spill
; PPC32-NEXT: mfcr 12
-; PPC32-NEXT: cmpwi 7, 5, 0
-; PPC32-NEXT: cmpwi 2, 7, 0
+; PPC32-NEXT: stw 27, 60(1) # 4-byte Folded Spill
+; PPC32-NEXT: mcrf 1, 0
+; PPC32-NEXT: stw 19, 28(1) # 4-byte Folded Spill
+; PPC32-NEXT: mulhwu 27, 6, 10
+; PPC32-NEXT: stw 20, 32(1) # 4-byte Folded Spill
+; PPC32-NEXT: cmpwi 6, 11, 0
+; PPC32-NEXT: stw 21, 36(1) # 4-byte Folded Spill
+; PPC32-NEXT: li 7, 0
+; PPC32-NEXT: stw 22, 40(1) # 4-byte Folded Spill
; PPC32-NEXT: mulhwu. 26, 5, 8
+; PPC32-NEXT: stw 23, 44(1) # 4-byte Folded Spill
; PPC32-NEXT: mcrf 5, 0
-; PPC32-NEXT: stw 22, 24(1) # 4-byte Folded Spill
-; PPC32-NEXT: crnor 20, 30, 10
-; PPC32-NEXT: stw 23, 28(1) # 4-byte Folded Spill
-; PPC32-NEXT: cmpwi 7, 9, 0
-; PPC32-NEXT: mulhwu. 26, 3, 10
-; PPC32-NEXT: mcrf 6, 0
-; PPC32-NEXT: stw 29, 52(1) # 4-byte Folded Spill
-; PPC32-NEXT: cmpwi 2, 3, 0
-; PPC32-NEXT: stw 24, 32(1) # 4-byte Folded Spill
-; PPC32-NEXT: crnor 21, 30, 10
-; PPC32-NEXT: mulhwu. 26, 9, 4
-; PPC32-NEXT: stw 25, 36(1) # 4-byte Folded Spill
+; PPC32-NEXT: stw 25, 52(1) # 4-byte Folded Spill
+; PPC32-NEXT: cmpwi 5, 0
+; PPC32-NEXT: stw 28, 64(1) # 4-byte Folded Spill
+; PPC32-NEXT: mullw 24, 5, 10
+; PPC32-NEXT: stw 29, 68(1) # 4-byte Folded Spill
+; PPC32-NEXT: crnor 20, 2, 26
+; PPC32-NEXT: stw 30, 72(1) # 4-byte Folded Spill
+; PPC32-NEXT: cmpwi 3, 0
+; PPC32-NEXT: stw 12, 24(1)
+; PPC32-NEXT: mulhwu 30, 5, 10
+; PPC32-NEXT: cmpwi 6, 9, 0
+; PPC32-NEXT: crnor 21, 26, 2
; PPC32-NEXT: crorc 20, 20, 6
-; PPC32-NEXT: stw 27, 44(1) # 4-byte Folded Spill
-; PPC32-NEXT: crorc 21, 21, 26
-; PPC32-NEXT: stw 28, 48(1) # 4-byte Folded Spill
-; PPC32-NEXT: mulhwu 30, 6, 10
-; PPC32-NEXT: stw 12, 20(1)
; PPC32-NEXT: crorc 20, 20, 22
-; PPC32-NEXT: crorc 21, 21, 2
-; PPC32-NEXT: li 11, 0
-; PPC32-NEXT: mullw 26, 5, 10
-; PPC32-NEXT: addc 30, 26, 30
-; PPC32-NEXT: mulhwu 29, 5, 10
-; PPC32-NEXT: addze 29, 29
-; PPC32-NEXT: mullw 23, 5, 8
-; PPC32-NEXT: mullw 22, 7, 6
-; PPC32-NEXT: mulhwu 0, 6, 9
; PPC32-NEXT: mulhwu 12, 5, 9
-; PPC32-NEXT: mulhwu 27, 8, 6
-; PPC32-NEXT: mullw 25, 6, 9
-; PPC32-NEXT: mullw 24, 5, 9
-; PPC32-NEXT: mullw 5, 9, 4
-; PPC32-NEXT: add 9, 22, 23
-; PPC32-NEXT: add 9, 27, 9
-; PPC32-NEXT: cmplw 1, 9, 27
-; PPC32-NEXT: cror 20, 20, 4
-; PPC32-NEXT: mullw 23, 3, 10
-; PPC32-NEXT: add 26, 23, 5
-; PPC32-NEXT: addc 5, 25, 30
-; PPC32-NEXT: addze 0, 0
-; PPC32-NEXT: or. 3, 4, 3
-; PPC32-NEXT: mulhwu 28, 4, 10
+; PPC32-NEXT: mullw 26, 5, 9
+; PPC32-NEXT: mullw 22, 5, 8
+; PPC32-NEXT: addc 5, 24, 27
+; PPC32-NEXT: addze 30, 30
+; PPC32-NEXT: mullw 23, 6, 9
+; PPC32-NEXT: addc 5, 23, 5
+; PPC32-NEXT: mullw 21, 11, 6
+; PPC32-NEXT: add 27, 21, 22
+; PPC32-NEXT: mulhwu 28, 8, 6
+; PPC32-NEXT: add 27, 28, 27
+; PPC32-NEXT: cmplw 7, 27, 28
+; PPC32-NEXT: mulhwu. 23, 3, 10
+; PPC32-NEXT: mcrf 6, 0
+; PPC32-NEXT: cror 24, 20, 28
+; PPC32-NEXT: crorc 25, 21, 26
+; PPC32-NEXT: mulhwu 0, 6, 9
+; PPC32-NEXT: mullw 20, 9, 4
+; PPC32-NEXT: mulhwu. 9, 9, 4
; PPC32-NEXT: mcrf 1, 0
-; PPC32-NEXT: addc 3, 29, 0
-; PPC32-NEXT: add 26, 28, 26
-; PPC32-NEXT: cmplw 6, 26, 28
-; PPC32-NEXT: cror 21, 21, 24
-; PPC32-NEXT: mullw 30, 4, 10
-; PPC32-NEXT: or. 4, 8, 7
-; PPC32-NEXT: addze 4, 11
-; PPC32-NEXT: addc 7, 24, 3
-; PPC32-NEXT: crnor 22, 2, 6
-; PPC32-NEXT: mullw 27, 8, 6
-; PPC32-NEXT: adde 8, 12, 4
-; PPC32-NEXT: addc 3, 30, 27
-; PPC32-NEXT: adde 9, 26, 9
-; PPC32-NEXT: addc 4, 7, 3
-; PPC32-NEXT: adde 3, 8, 9
-; PPC32-NEXT: cror 21, 22, 21
-; PPC32-NEXT: cmplw 4, 7
-; PPC32-NEXT: cmplw 1, 3, 8
-; PPC32-NEXT: lwz 12, 20(1)
+; PPC32-NEXT: addze 9, 0
+; PPC32-NEXT: mullw 19, 3, 10
+; PPC32-NEXT: or. 3, 4, 3
+; PPC32-NEXT: mcrf 5, 0
+; PPC32-NEXT: addc 3, 30, 9
+; PPC32-NEXT: add 24, 19, 20
+; PPC32-NEXT: mulhwu 29, 4, 10
+; PPC32-NEXT: add 28, 29, 24
+; PPC32-NEXT: cmplw 2, 28, 29
+; PPC32-NEXT: crorc 20, 25, 6
+; PPC32-NEXT: cror 20, 20, 8
+; PPC32-NEXT: mullw 22, 4, 10
+; PPC32-NEXT: or. 4, 8, 11
+; PPC32-NEXT: addze 4, 7
+; PPC32-NEXT: crnor 21, 2, 22
; PPC32-NEXT: cror 20, 21, 20
-; PPC32-NEXT: crandc 21, 4, 6
-; PPC32-NEXT: crand 22, 6, 0
-; PPC32-NEXT: cror 21, 22, 21
-; PPC32-NEXT: crnor 20, 20, 21
-; PPC32-NEXT: li 7, 1
+; PPC32-NEXT: mullw 25, 8, 6
+; PPC32-NEXT: addc 8, 26, 3
+; PPC32-NEXT: adde 9, 12, 4
+; PPC32-NEXT: addc 3, 22, 25
+; PPC32-NEXT: adde 11, 28, 27
+; PPC32-NEXT: addc 4, 8, 3
+; PPC32-NEXT: adde 3, 9, 11
+; PPC32-NEXT: cmplw 1, 3, 9
+; PPC32-NEXT: cmplw 4, 8
+; PPC32-NEXT: crandc 22, 4, 6
; PPC32-NEXT: mullw 6, 6, 10
-; PPC32-NEXT: bc 12, 20, .LBB0_1
-; PPC32-NEXT: b .LBB0_2
-; PPC32-NEXT: .LBB0_1: # %start
-; PPC32-NEXT: li 7, 0
-; PPC32-NEXT: .LBB0_2: # %start
+; PPC32-NEXT: bc 12, 22, .LBB0_3
+; PPC32-NEXT: # %bb.1: # %start
+; PPC32-NEXT: crand 21, 6, 0
+; PPC32-NEXT: bc 12, 21, .LBB0_3
+; PPC32-NEXT: # %bb.2: # %start
+; PPC32-NEXT: cror 20, 20, 24
+; PPC32-NEXT: bc 4, 20, .LBB0_4
+; PPC32-NEXT: .LBB0_3: # %start
+; PPC32-NEXT: li 7, 1
+; PPC32-NEXT: .LBB0_4: # %start
+; PPC32-NEXT: lwz 12, 24(1)
+; PPC32-NEXT: lwz 30, 72(1) # 4-byte Folded Reload
; PPC32-NEXT: mtcrf 32, 12 # cr2
-; PPC32-NEXT: lwz 30, 56(1) # 4-byte Folded Reload
-; PPC32-NEXT: lwz 29, 52(1) # 4-byte Folded Reload
-; PPC32-NEXT: lwz 28, 48(1) # 4-byte Folded Reload
-; PPC32-NEXT: lwz 27, 44(1) # 4-byte Folded Reload
-; PPC32-NEXT: lwz 26, 40(1) # 4-byte Folded Reload
-; PPC32-NEXT: lwz 25, 36(1) # 4-byte Folded Reload
-; PPC32-NEXT: lwz 24, 32(1) # 4-byte Folded Reload
-; PPC32-NEXT: lwz 23, 28(1) # 4-byte Folded Reload
-; PPC32-NEXT: lwz 22, 24(1) # 4-byte Folded Reload
-; PPC32-NEXT: addi 1, 1, 64
+; PPC32-NEXT: lwz 29, 68(1) # 4-byte Folded Reload
+; PPC32-NEXT: lwz 28, 64(1) # 4-byte Folded Reload
+; PPC32-NEXT: lwz 27, 60(1) # 4-byte Folded Reload
+; PPC32-NEXT: lwz 26, 56(1) # 4-byte Folded Reload
+; PPC32-NEXT: lwz 25, 52(1) # 4-byte Folded Reload
+; PPC32-NEXT: lwz 24, 48(1) # 4-byte Folded Reload
+; PPC32-NEXT: lwz 23, 44(1) # 4-byte Folded Reload
+; PPC32-NEXT: lwz 22, 40(1) # 4-byte Folded Reload
+; PPC32-NEXT: lwz 21, 36(1) # 4-byte Folded Reload
+; PPC32-NEXT: lwz 20, 32(1) # 4-byte Folded Reload
+; PPC32-NEXT: lwz 19, 28(1) # 4-byte Folded Reload
+; PPC32-NEXT: addi 1, 1, 80
; PPC32-NEXT: blr
start:
%0 = tail call { i128, i1 } @llvm.umul.with.overflow.i128(i128 %l, i128 %r) #2
diff --git a/llvm/test/CodeGen/PowerPC/urem-seteq-illegal-types.ll b/llvm/test/CodeGen/PowerPC/urem-seteq-illegal-types.ll
index f708da86444b2b..e5c5356ce50a40 100644
--- a/llvm/test/CodeGen/PowerPC/urem-seteq-illegal-types.ll
+++ b/llvm/test/CodeGen/PowerPC/urem-seteq-illegal-types.ll
@@ -7,12 +7,11 @@ define i1 @test_urem_odd(i13 %X) nounwind {
; PPC: # %bb.0:
; PPC-NEXT: mulli 3, 3, 3277
; PPC-NEXT: clrlwi 3, 3, 19
-; PPC-NEXT: li 4, 0
; PPC-NEXT: cmplwi 3, 1639
; PPC-NEXT: li 3, 1
; PPC-NEXT: bclr 12, 0, 0
; PPC-NEXT: # %bb.1:
-; PPC-NEXT: ori 3, 4, 0
+; PPC-NEXT: li 3, 0
; PPC-NEXT: blr
;
; PPC64LE-LABEL: test_urem_odd:
@@ -40,12 +39,10 @@ define i1 @test_urem_even(i27 %X) nounwind {
; PPC-NEXT: lis 3, 146
; PPC-NEXT: ori 3, 3, 18725
; PPC-NEXT: cmplw 4, 3
+; PPC-NEXT: li 3, 1
+; PPC-NEXT: bclr 12, 0, 0
+; PPC-NEXT: # %bb.1:
; PPC-NEXT: li 3, 0
-; PPC-NEXT: li 4, 1
-; PPC-NEXT: bc 12, 0, .LBB1_1
-; PPC-NEXT: blr
-; PPC-NEXT: .LBB1_1:
-; PPC-NEXT: addi 3, 4, 0
; PPC-NEXT: blr
;
; PPC64LE-LABEL: test_urem_even:
@@ -72,12 +69,11 @@ define i1 @test_urem_odd_setne(i4 %X) nounwind {
; PPC: # %bb.0:
; PPC-NEXT: mulli 3, 3, 13
; PPC-NEXT: clrlwi 3, 3, 28
-; PPC-NEXT: li 4, 0
; PPC-NEXT: cmplwi 3, 3
; PPC-NEXT: li 3, 1
; PPC-NEXT: bclr 12, 1, 0
; PPC-NEXT: # %bb.1:
-; PPC-NEXT: ori 3, 4, 0
+; PPC-NEXT: li 3, 0
; PPC-NEXT: blr
;
; PPC64LE-LABEL: test_urem_odd_setne:
@@ -101,12 +97,11 @@ define i1 @test_urem_negative_odd(i9 %X) nounwind {
; PPC: # %bb.0:
; PPC-NEXT: mulli 3, 3, 307
; PPC-NEXT: clrlwi 3, 3, 23
-; PPC-NEXT: li 4, 0
; PPC-NEXT: cmplwi 3, 1
; PPC-NEXT: li 3, 1
; PPC-NEXT: bclr 12, 1, 0
; PPC-NEXT: # %bb.1:
-; PPC-NEXT: ori 3, 4, 0
+; PPC-NEXT: li 3, 0
; PPC-NEXT: blr
;
; PPC64LE-LABEL: test_urem_negative_odd:
@@ -126,37 +121,33 @@ define i1 @test_urem_negative_odd(i9 %X) nounwind {
define <3 x i1> @test_urem_vec(<3 x i11> %X) nounwind {
; PPC-LABEL: test_urem_vec:
; PPC: # %bb.0:
-; PPC-NEXT: mulli 3, 3, 683
-; PPC-NEXT: rlwinm 7, 3, 31, 22, 31
-; PPC-NEXT: rlwimi 7, 3, 10, 21, 21
+; PPC-NEXT: mr 6, 3
+; PPC-NEXT: mulli 6, 6, 683
+; PPC-NEXT: rlwinm 7, 6, 31, 22, 31
+; PPC-NEXT: rlwimi 7, 6, 10, 21, 21
; PPC-NEXT: mulli 5, 5, 819
-; PPC-NEXT: li 6, 0
-; PPC-NEXT: cmplwi 7, 341
-; PPC-NEXT: mulli 3, 4, 1463
-; PPC-NEXT: addi 4, 5, -1638
-; PPC-NEXT: addi 3, 3, -1463
+; PPC-NEXT: addi 5, 5, -1638
+; PPC-NEXT: clrlwi 5, 5, 21
+; PPC-NEXT: mulli 4, 4, 1463
+; PPC-NEXT: addi 4, 4, -1463
; PPC-NEXT: clrlwi 4, 4, 21
-; PPC-NEXT: clrlwi 3, 3, 21
-; PPC-NEXT: cmplwi 1, 4, 1
-; PPC-NEXT: cmplwi 5, 3, 292
; PPC-NEXT: li 3, 1
+; PPC-NEXT: cmplwi 7, 341
+; PPC-NEXT: cmplwi 1, 5, 1
+; PPC-NEXT: cmplwi 5, 4, 292
+; PPC-NEXT: li 4, 1
; PPC-NEXT: bc 12, 21, .LBB4_2
; PPC-NEXT: # %bb.1:
-; PPC-NEXT: ori 4, 6, 0
-; PPC-NEXT: b .LBB4_3
+; PPC-NEXT: li 4, 0
; PPC-NEXT: .LBB4_2:
-; PPC-NEXT: addi 4, 3, 0
-; PPC-NEXT: .LBB4_3:
-; PPC-NEXT: bc 12, 5, .LBB4_5
-; PPC-NEXT: # %bb.4:
-; PPC-NEXT: ori 5, 6, 0
-; PPC-NEXT: b .LBB4_6
-; PPC-NEXT: .LBB4_5:
-; PPC-NEXT: addi 5, 3, 0
-; PPC-NEXT: .LBB4_6:
+; PPC-NEXT: li 5, 1
+; PPC-NEXT: bc 12, 5, .LBB4_4
+; PPC-NEXT: # %bb.3:
+; PPC-NEXT: li 5, 0
+; PPC-NEXT: .LBB4_4:
; PPC-NEXT: bclr 12, 1, 0
-; PPC-NEXT: # %bb.7:
-; PPC-NEXT: ori 3, 6, 0
+; PPC-NEXT: # %bb.5:
+; PPC-NEXT: li 3, 0
; PPC-NEXT: blr
;
; PPC64LE-LABEL: test_urem_vec:
@@ -244,16 +235,15 @@ define i1 @test_urem_oversized(i66 %X) nounwind {
; PPC-NEXT: cmplw 5, 11
; PPC-NEXT: cmplwi 1, 10, 13
; PPC-NEXT: rlwinm 3, 3, 31, 31, 31
-; PPC-NEXT: crand 20, 6, 0
-; PPC-NEXT: crandc 21, 4, 6
+; PPC-NEXT: crandc 20, 4, 6
+; PPC-NEXT: crand 21, 6, 0
; PPC-NEXT: rlwimi. 3, 6, 1, 30, 30
-; PPC-NEXT: cror 20, 20, 21
+; PPC-NEXT: cror 20, 21, 20
; PPC-NEXT: crnand 20, 2, 20
-; PPC-NEXT: li 3, 1
-; PPC-NEXT: bc 12, 20, .LBB5_1
-; PPC-NEXT: blr
-; PPC-NEXT: .LBB5_1:
; PPC-NEXT: li 3, 0
+; PPC-NEXT: bclr 12, 20, 0
+; PPC-NEXT: # %bb.1:
+; PPC-NEXT: li 3, 1
; PPC-NEXT: blr
;
; PPC64LE-LABEL: test_urem_oversized:
diff --git a/llvm/test/CodeGen/PowerPC/varargs.ll b/llvm/test/CodeGen/PowerPC/varargs.ll
index 2b686bf0d38d52..d4aafac5c56e26 100644
--- a/llvm/test/CodeGen/PowerPC/varargs.ll
+++ b/llvm/test/CodeGen/PowerPC/varargs.ll
@@ -7,31 +7,28 @@
define ptr @test1(ptr %foo) nounwind {
; P32-LABEL: test1:
; P32: # %bb.0:
-; P32-NEXT: lbz r4, 0(r3)
-; P32-NEXT: lwz r5, 4(r3)
-; P32-NEXT: lwz r6, 8(r3)
-; P32-NEXT: addi r7, r4, 1
-; P32-NEXT: stb r7, 0(r3)
-; P32-NEXT: addi r7, r5, 4
-; P32-NEXT: cmpwi r4, 8
-; P32-NEXT: slwi r4, r4, 2
-; P32-NEXT: add r4, r6, r4
-; P32-NEXT: bc 12, lt, .LBB0_2
+; P32-NEXT: lbz r5, 0(r3)
+; P32-NEXT: lwz r4, 4(r3)
+; P32-NEXT: addi r6, r5, 1
+; P32-NEXT: cmpwi r5, 8
+; P32-NEXT: stb r6, 0(r3)
+; P32-NEXT: mr r6, r4
+; P32-NEXT: bge cr0, .LBB0_3
; P32-NEXT: # %bb.1:
-; P32-NEXT: ori r6, r7, 0
-; P32-NEXT: b .LBB0_3
+; P32-NEXT: stw r6, 4(r3)
+; P32-NEXT: blt cr0, .LBB0_4
; P32-NEXT: .LBB0_2:
-; P32-NEXT: addi r6, r5, 0
+; P32-NEXT: lwz r3, 0(r4)
+; P32-NEXT: blr
; P32-NEXT: .LBB0_3:
+; P32-NEXT: addi r6, r4, 4
; P32-NEXT: stw r6, 4(r3)
-; P32-NEXT: bc 12, lt, .LBB0_5
-; P32-NEXT: # %bb.4:
-; P32-NEXT: ori r3, r5, 0
-; P32-NEXT: b .LBB0_6
-; P32-NEXT: .LBB0_5:
-; P32-NEXT: addi r3, r4, 0
-; P32-NEXT: .LBB0_6:
-; P32-NEXT: lwz r3, 0(r3)
+; P32-NEXT: bge cr0, .LBB0_2
+; P32-NEXT: .LBB0_4:
+; P32-NEXT: lwz r3, 8(r3)
+; P32-NEXT: slwi r4, r5, 2
+; P32-NEXT: add r4, r3, r4
+; P32-NEXT: lwz r3, 0(r4)
; P32-NEXT: blr
;
; P64-LABEL: test1:
diff --git a/llvm/test/CodeGen/PowerPC/wide-scalar-shift-by-byte-multiple-legalization.ll b/llvm/test/CodeGen/PowerPC/wide-scalar-shift-by-byte-multiple-legalization.ll
index 16aa63cac0ab71..f6fdb4ae207947 100644
--- a/llvm/test/CodeGen/PowerPC/wide-scalar-shift-by-byte-multiple-legalization.ll
+++ b/llvm/test/CodeGen/PowerPC/wide-scalar-shift-by-byte-multiple-legalization.ll
@@ -160,22 +160,22 @@ define void @ashr_8bytes(ptr %src.ptr, ptr %byteOff.ptr, ptr %dst) nounwind {
; LE-32BIT-LABEL: ashr_8bytes:
; LE-32BIT: # %bb.0:
; LE-32BIT-NEXT: lwz 4, 4(4)
-; LE-32BIT-NEXT: lwz 6, 4(3)
-; LE-32BIT-NEXT: lwz 3, 0(3)
+; LE-32BIT-NEXT: lwz 6, 0(3)
; LE-32BIT-NEXT: slwi 4, 4, 3
-; LE-32BIT-NEXT: subfic 7, 4, 32
-; LE-32BIT-NEXT: srw 6, 6, 4
-; LE-32BIT-NEXT: addi 8, 4, -32
-; LE-32BIT-NEXT: slw 7, 3, 7
-; LE-32BIT-NEXT: sraw 4, 3, 4
-; LE-32BIT-NEXT: sraw 3, 3, 8
-; LE-32BIT-NEXT: cmpwi 8, 1
-; LE-32BIT-NEXT: or 6, 6, 7
-; LE-32BIT-NEXT: bc 12, 0, .LBB5_1
-; LE-32BIT-NEXT: b .LBB5_2
-; LE-32BIT-NEXT: .LBB5_1:
-; LE-32BIT-NEXT: addi 3, 6, 0
+; LE-32BIT-NEXT: addi 7, 4, -32
+; LE-32BIT-NEXT: cmpwi 7, 0
+; LE-32BIT-NEXT: ble 0, .LBB5_2
+; LE-32BIT-NEXT: # %bb.1:
+; LE-32BIT-NEXT: sraw 3, 6, 7
+; LE-32BIT-NEXT: b .LBB5_3
; LE-32BIT-NEXT: .LBB5_2:
+; LE-32BIT-NEXT: lwz 3, 4(3)
+; LE-32BIT-NEXT: subfic 7, 4, 32
+; LE-32BIT-NEXT: slw 7, 6, 7
+; LE-32BIT-NEXT: srw 3, 3, 4
+; LE-32BIT-NEXT: or 3, 3, 7
+; LE-32BIT-NEXT: .LBB5_3:
+; LE-32BIT-NEXT: sraw 4, 6, 4
; LE-32BIT-NEXT: stw 4, 0(5)
; LE-32BIT-NEXT: stw 3, 4(5)
; LE-32BIT-NEXT: blr
@@ -357,24 +357,24 @@ define void @ashr_16bytes(ptr %src.ptr, ptr %byteOff.ptr, ptr %dst) nounwind {
; BE-LABEL: ashr_16bytes:
; BE: # %bb.0:
; BE-NEXT: lwz 4, 12(4)
-; BE-NEXT: ld 6, 8(3)
-; BE-NEXT: ld 3, 0(3)
+; BE-NEXT: ld 6, 0(3)
; BE-NEXT: slwi 4, 4, 3
-; BE-NEXT: subfic 7, 4, 64
-; BE-NEXT: srd 6, 6, 4
-; BE-NEXT: addi 8, 4, -64
-; BE-NEXT: sld 7, 3, 7
-; BE-NEXT: cmpwi 8, 1
-; BE-NEXT: or 6, 6, 7
-; BE-NEXT: srad 7, 3, 8
-; BE-NEXT: srad 3, 3, 4
-; BE-NEXT: bc 12, 0, .LBB8_2
+; BE-NEXT: addi 7, 4, -64
+; BE-NEXT: cmpwi 7, 1
+; BE-NEXT: blt 0, .LBB8_2
; BE-NEXT: # %bb.1:
-; BE-NEXT: ori 6, 7, 0
-; BE-NEXT: b .LBB8_2
+; BE-NEXT: srad 3, 6, 7
+; BE-NEXT: b .LBB8_3
; BE-NEXT: .LBB8_2:
-; BE-NEXT: std 3, 0(5)
-; BE-NEXT: std 6, 8(5)
+; BE-NEXT: ld 3, 8(3)
+; BE-NEXT: subfic 7, 4, 64
+; BE-NEXT: sld 7, 6, 7
+; BE-NEXT: srd 3, 3, 4
+; BE-NEXT: or 3, 3, 7
+; BE-NEXT: .LBB8_3:
+; BE-NEXT: srad 4, 6, 4
+; BE-NEXT: std 3, 8(5)
+; BE-NEXT: std 4, 0(5)
; BE-NEXT: blr
;
; LE-32BIT-LABEL: ashr_16bytes:
diff --git a/llvm/test/CodeGen/PowerPC/wide-scalar-shift-legalization.ll b/llvm/test/CodeGen/PowerPC/wide-scalar-shift-legalization.ll
index abfe6a953dd6c8..044ddf562294c8 100644
--- a/llvm/test/CodeGen/PowerPC/wide-scalar-shift-legalization.ll
+++ b/llvm/test/CodeGen/PowerPC/wide-scalar-shift-legalization.ll
@@ -144,21 +144,21 @@ define void @ashr_8bytes(ptr %src.ptr, ptr %bitOff.ptr, ptr %dst) nounwind {
; LE-32BIT-LABEL: ashr_8bytes:
; LE-32BIT: # %bb.0:
; LE-32BIT-NEXT: lwz 4, 4(4)
-; LE-32BIT-NEXT: lwz 6, 4(3)
-; LE-32BIT-NEXT: lwz 3, 0(3)
-; LE-32BIT-NEXT: subfic 7, 4, 32
-; LE-32BIT-NEXT: srw 6, 6, 4
-; LE-32BIT-NEXT: addi 8, 4, -32
-; LE-32BIT-NEXT: slw 7, 3, 7
-; LE-32BIT-NEXT: sraw 4, 3, 4
-; LE-32BIT-NEXT: sraw 3, 3, 8
-; LE-32BIT-NEXT: cmpwi 8, 1
-; LE-32BIT-NEXT: or 6, 6, 7
-; LE-32BIT-NEXT: bc 12, 0, .LBB5_1
-; LE-32BIT-NEXT: b .LBB5_2
-; LE-32BIT-NEXT: .LBB5_1:
-; LE-32BIT-NEXT: addi 3, 6, 0
+; LE-32BIT-NEXT: lwz 6, 0(3)
+; LE-32BIT-NEXT: addi 7, 4, -32
+; LE-32BIT-NEXT: cmpwi 7, 0
+; LE-32BIT-NEXT: ble 0, .LBB5_2
+; LE-32BIT-NEXT: # %bb.1:
+; LE-32BIT-NEXT: sraw 3, 6, 7
+; LE-32BIT-NEXT: b .LBB5_3
; LE-32BIT-NEXT: .LBB5_2:
+; LE-32BIT-NEXT: lwz 3, 4(3)
+; LE-32BIT-NEXT: subfic 7, 4, 32
+; LE-32BIT-NEXT: slw 7, 6, 7
+; LE-32BIT-NEXT: srw 3, 3, 4
+; LE-32BIT-NEXT: or 3, 3, 7
+; LE-32BIT-NEXT: .LBB5_3:
+; LE-32BIT-NEXT: sraw 4, 6, 4
; LE-32BIT-NEXT: stw 4, 0(5)
; LE-32BIT-NEXT: stw 3, 4(5)
; LE-32BIT-NEXT: blr
@@ -364,23 +364,23 @@ define void @ashr_16bytes(ptr %src.ptr, ptr %bitOff.ptr, ptr %dst) nounwind {
; BE-LABEL: ashr_16bytes:
; BE: # %bb.0:
; BE-NEXT: lwz 4, 12(4)
-; BE-NEXT: ld 6, 8(3)
-; BE-NEXT: ld 3, 0(3)
-; BE-NEXT: subfic 7, 4, 64
-; BE-NEXT: srd 6, 6, 4
-; BE-NEXT: addi 8, 4, -64
-; BE-NEXT: sld 7, 3, 7
-; BE-NEXT: cmpwi 8, 1
-; BE-NEXT: or 6, 6, 7
-; BE-NEXT: srad 7, 3, 8
-; BE-NEXT: srad 3, 3, 4
-; BE-NEXT: bc 12, 0, .LBB8_2
+; BE-NEXT: ld 6, 0(3)
+; BE-NEXT: addi 7, 4, -64
+; BE-NEXT: cmpwi 7, 1
+; BE-NEXT: blt 0, .LBB8_2
; BE-NEXT: # %bb.1:
-; BE-NEXT: ori 6, 7, 0
-; BE-NEXT: b .LBB8_2
+; BE-NEXT: srad 3, 6, 7
+; BE-NEXT: b .LBB8_3
; BE-NEXT: .LBB8_2:
-; BE-NEXT: std 3, 0(5)
-; BE-NEXT: std 6, 8(5)
+; BE-NEXT: ld 3, 8(3)
+; BE-NEXT: subfic 7, 4, 64
+; BE-NEXT: sld 7, 6, 7
+; BE-NEXT: srd 3, 3, 4
+; BE-NEXT: or 3, 3, 7
+; BE-NEXT: .LBB8_3:
+; BE-NEXT: srad 4, 6, 4
+; BE-NEXT: std 3, 8(5)
+; BE-NEXT: std 4, 0(5)
; BE-NEXT: blr
;
; LE-32BIT-LABEL: ashr_16bytes:
>From 7d7d4752a8f3d7b83586c10a882f974d821c0c53 Mon Sep 17 00:00:00 2001
From: ZijunZhaoCCK <88353225+ZijunZhaoCCK at users.noreply.github.com>
Date: Thu, 29 Feb 2024 16:06:32 -0800
Subject: [PATCH 194/406] [libc++] Set feature test macros
__cpp_lib_ranges_contains and__cpp_lib_ranges_starts_ends_with (#81816)
ranges::contains: fdd089b50063
ranges::starts_with: 205175578e0d
ranges::ends_with: 0218ea4aaa54
Co-authored-by: Louis Dionne <ldionne.2 at gmail.com>
---
libcxx/docs/FeatureTestMacroTable.rst | 4 +-
libcxx/docs/ReleaseNotes/19.rst | 3 +-
libcxx/docs/Status/Cxx23Papers.csv | 4 +-
libcxx/include/version | 4 +-
.../algorithm.version.compile.pass.cpp | 63 ++++++++++++-------
.../version.version.compile.pass.cpp | 63 ++++++++++++-------
.../generate_feature_test_macro_components.py | 6 +-
7 files changed, 97 insertions(+), 50 deletions(-)
diff --git a/libcxx/docs/FeatureTestMacroTable.rst b/libcxx/docs/FeatureTestMacroTable.rst
index 468226c0c2dddf..60e0aea9768b4f 100644
--- a/libcxx/docs/FeatureTestMacroTable.rst
+++ b/libcxx/docs/FeatureTestMacroTable.rst
@@ -354,6 +354,8 @@ Status
--------------------------------------------------- -----------------
``__cpp_lib_ranges_chunk_by`` ``202202L``
--------------------------------------------------- -----------------
+ ``__cpp_lib_ranges_contains`` ``202207L``
+ --------------------------------------------------- -----------------
``__cpp_lib_ranges_iota`` *unimplemented*
--------------------------------------------------- -----------------
``__cpp_lib_ranges_join_with`` *unimplemented*
@@ -362,7 +364,7 @@ Status
--------------------------------------------------- -----------------
``__cpp_lib_ranges_slide`` *unimplemented*
--------------------------------------------------- -----------------
- ``__cpp_lib_ranges_starts_ends_with`` *unimplemented*
+ ``__cpp_lib_ranges_starts_ends_with`` ``202106L``
--------------------------------------------------- -----------------
``__cpp_lib_ranges_to_container`` ``202202L``
--------------------------------------------------- -----------------
diff --git a/libcxx/docs/ReleaseNotes/19.rst b/libcxx/docs/ReleaseNotes/19.rst
index 78c6bb87a5a402..0d381df5f0442c 100644
--- a/libcxx/docs/ReleaseNotes/19.rst
+++ b/libcxx/docs/ReleaseNotes/19.rst
@@ -41,7 +41,8 @@ Implemented Papers
- P2637R3 - Member ``visit``
- P2652R2 - Disallow User Specialization of ``allocator_traits``
- P2819R2 - Add ``tuple`` protocol to ``complex``
-
+- P2302R4 - ``std::ranges::contains``
+- P1659R3 - ``std::ranges::starts_with`` and ``std::ranges::ends_with``
Improvements and New Features
-----------------------------
diff --git a/libcxx/docs/Status/Cxx23Papers.csv b/libcxx/docs/Status/Cxx23Papers.csv
index eb415ed8c031fa..56e1468b4ca1a3 100644
--- a/libcxx/docs/Status/Cxx23Papers.csv
+++ b/libcxx/docs/Status/Cxx23Papers.csv
@@ -17,7 +17,7 @@
"`P1328R1 <https://wg21.link/P1328R1>`__","LWG","Making std::type_info::operator== constexpr","June 2021","|Complete|","17.0"
"`P1425R4 <https://wg21.link/P1425R4>`__","LWG","Iterators pair constructors for stack and queue","June 2021","|Complete|","14.0","|ranges|"
"`P1518R2 <https://wg21.link/P1518R2>`__","LWG","Stop overconstraining allocators in container deduction guides","June 2021","|Complete|","13.0"
-"`P1659R3 <https://wg21.link/P1659R3>`__","LWG","starts_with and ends_with","June 2021","","","|ranges|"
+"`P1659R3 <https://wg21.link/P1659R3>`__","LWG","starts_with and ends_with","June 2021","|Complete|","19.0","|ranges|"
"`P1951R1 <https://wg21.link/P1951R1>`__","LWG","Default Arguments for pair Forwarding Constructor","June 2021","|Complete|","14.0"
"`P1989R2 <https://wg21.link/P1989R2>`__","LWG","Range constructor for std::string_view","June 2021","|Complete|","14.0","|ranges|"
"`P2136R3 <https://wg21.link/P2136R3>`__","LWG","invoke_r","June 2021","|Complete|","17.0"
@@ -64,7 +64,7 @@
"`P2278R4 <https://wg21.link/P2278R4>`__","LWG","``cbegin`` should always return a constant iterator","July 2022","","","|ranges|"
"`P2286R8 <https://wg21.link/P2286R8>`__","LWG","Formatting Ranges","July 2022","|Complete|","16.0","|format| |ranges|"
"`P2291R3 <https://wg21.link/P2291R3>`__","LWG","Add Constexpr Modifiers to Functions ``to_chars`` and ``from_chars`` for Integral Types in ``<charconv>`` Header","July 2022","|Complete|","16.0"
-"`P2302R4 <https://wg21.link/P2302R4>`__","LWG","``std::ranges::contains``","July 2022","","","|ranges|"
+"`P2302R4 <https://wg21.link/P2302R4>`__","LWG","``std::ranges::contains``","July 2022","|Complete|","19.0","|ranges|"
"`P2322R6 <https://wg21.link/P2322R6>`__","LWG","``ranges::fold``","July 2022","","","|ranges|"
"`P2374R4 <https://wg21.link/P2374R4>`__","LWG","``views::cartesian_product``","July 2022","","","|ranges|"
"`P2404R3 <https://wg21.link/P2404R3>`__","LWG","Move-only types for ``equality_comparable_with``, ``totally_ordered_with``, and ``three_way_comparable_with``","July 2022","",""
diff --git a/libcxx/include/version b/libcxx/include/version
index cd180441c5b9e1..055d0f30f9c438 100644
--- a/libcxx/include/version
+++ b/libcxx/include/version
@@ -170,6 +170,7 @@ __cpp_lib_ranges_as_const 202207L <ranges>
__cpp_lib_ranges_as_rvalue 202207L <ranges>
__cpp_lib_ranges_chunk 202202L <ranges>
__cpp_lib_ranges_chunk_by 202202L <ranges>
+__cpp_lib_ranges_contains 202207L <algorithm>
__cpp_lib_ranges_iota 202202L <numeric>
__cpp_lib_ranges_join_with 202202L <ranges>
__cpp_lib_ranges_repeat 202207L <ranges>
@@ -463,11 +464,12 @@ __cpp_lib_within_lifetime 202306L <type_traits>
# define __cpp_lib_ranges_as_rvalue 202207L
// # define __cpp_lib_ranges_chunk 202202L
# define __cpp_lib_ranges_chunk_by 202202L
+# define __cpp_lib_ranges_contains 202207L
// # define __cpp_lib_ranges_iota 202202L
// # define __cpp_lib_ranges_join_with 202202L
# define __cpp_lib_ranges_repeat 202207L
// # define __cpp_lib_ranges_slide 202202L
-// # define __cpp_lib_ranges_starts_ends_with 202106L
+# define __cpp_lib_ranges_starts_ends_with 202106L
# define __cpp_lib_ranges_to_container 202202L
// # define __cpp_lib_ranges_zip 202110L
// # define __cpp_lib_reference_from_temporary 202202L
diff --git a/libcxx/test/std/language.support/support.limits/support.limits.general/algorithm.version.compile.pass.cpp b/libcxx/test/std/language.support/support.limits/support.limits.general/algorithm.version.compile.pass.cpp
index ec6503ec237554..ece13b0a232cee 100644
--- a/libcxx/test/std/language.support/support.limits/support.limits.general/algorithm.version.compile.pass.cpp
+++ b/libcxx/test/std/language.support/support.limits/support.limits.general/algorithm.version.compile.pass.cpp
@@ -21,6 +21,7 @@
__cpp_lib_freestanding_algorithm 202311L [C++26]
__cpp_lib_parallel_algorithm 201603L [C++17]
__cpp_lib_ranges 202207L [C++20]
+ __cpp_lib_ranges_contains 202207L [C++23]
__cpp_lib_ranges_starts_ends_with 202106L [C++23]
__cpp_lib_robust_nonmodifying_seq_ops 201304L [C++14]
__cpp_lib_sample 201603L [C++17]
@@ -52,6 +53,10 @@
# error "__cpp_lib_ranges should not be defined before c++20"
# endif
+# ifdef __cpp_lib_ranges_contains
+# error "__cpp_lib_ranges_contains should not be defined before c++23"
+# endif
+
# ifdef __cpp_lib_ranges_starts_ends_with
# error "__cpp_lib_ranges_starts_ends_with should not be defined before c++23"
# endif
@@ -90,6 +95,10 @@
# error "__cpp_lib_ranges should not be defined before c++20"
# endif
+# ifdef __cpp_lib_ranges_contains
+# error "__cpp_lib_ranges_contains should not be defined before c++23"
+# endif
+
# ifdef __cpp_lib_ranges_starts_ends_with
# error "__cpp_lib_ranges_starts_ends_with should not be defined before c++23"
# endif
@@ -143,6 +152,10 @@
# error "__cpp_lib_ranges should not be defined before c++20"
# endif
+# ifdef __cpp_lib_ranges_contains
+# error "__cpp_lib_ranges_contains should not be defined before c++23"
+# endif
+
# ifdef __cpp_lib_ranges_starts_ends_with
# error "__cpp_lib_ranges_starts_ends_with should not be defined before c++23"
# endif
@@ -205,6 +218,10 @@
# error "__cpp_lib_ranges should have the value 202207L in c++20"
# endif
+# ifdef __cpp_lib_ranges_contains
+# error "__cpp_lib_ranges_contains should not be defined before c++23"
+# endif
+
# ifdef __cpp_lib_ranges_starts_ends_with
# error "__cpp_lib_ranges_starts_ends_with should not be defined before c++23"
# endif
@@ -270,17 +287,18 @@
# error "__cpp_lib_ranges should have the value 202207L in c++23"
# endif
-# if !defined(_LIBCPP_VERSION)
-# ifndef __cpp_lib_ranges_starts_ends_with
-# error "__cpp_lib_ranges_starts_ends_with should be defined in c++23"
-# endif
-# if __cpp_lib_ranges_starts_ends_with != 202106L
-# error "__cpp_lib_ranges_starts_ends_with should have the value 202106L in c++23"
-# endif
-# else // _LIBCPP_VERSION
-# ifdef __cpp_lib_ranges_starts_ends_with
-# error "__cpp_lib_ranges_starts_ends_with should not be defined because it is unimplemented in libc++!"
-# endif
+# ifndef __cpp_lib_ranges_contains
+# error "__cpp_lib_ranges_contains should be defined in c++23"
+# endif
+# if __cpp_lib_ranges_contains != 202207L
+# error "__cpp_lib_ranges_contains should have the value 202207L in c++23"
+# endif
+
+# ifndef __cpp_lib_ranges_starts_ends_with
+# error "__cpp_lib_ranges_starts_ends_with should be defined in c++23"
+# endif
+# if __cpp_lib_ranges_starts_ends_with != 202106L
+# error "__cpp_lib_ranges_starts_ends_with should have the value 202106L in c++23"
# endif
# ifndef __cpp_lib_robust_nonmodifying_seq_ops
@@ -353,17 +371,18 @@
# error "__cpp_lib_ranges should have the value 202207L in c++26"
# endif
-# if !defined(_LIBCPP_VERSION)
-# ifndef __cpp_lib_ranges_starts_ends_with
-# error "__cpp_lib_ranges_starts_ends_with should be defined in c++26"
-# endif
-# if __cpp_lib_ranges_starts_ends_with != 202106L
-# error "__cpp_lib_ranges_starts_ends_with should have the value 202106L in c++26"
-# endif
-# else // _LIBCPP_VERSION
-# ifdef __cpp_lib_ranges_starts_ends_with
-# error "__cpp_lib_ranges_starts_ends_with should not be defined because it is unimplemented in libc++!"
-# endif
+# ifndef __cpp_lib_ranges_contains
+# error "__cpp_lib_ranges_contains should be defined in c++26"
+# endif
+# if __cpp_lib_ranges_contains != 202207L
+# error "__cpp_lib_ranges_contains should have the value 202207L in c++26"
+# endif
+
+# ifndef __cpp_lib_ranges_starts_ends_with
+# error "__cpp_lib_ranges_starts_ends_with should be defined in c++26"
+# endif
+# if __cpp_lib_ranges_starts_ends_with != 202106L
+# error "__cpp_lib_ranges_starts_ends_with should have the value 202106L in c++26"
# endif
# ifndef __cpp_lib_robust_nonmodifying_seq_ops
diff --git a/libcxx/test/std/language.support/support.limits/support.limits.general/version.version.compile.pass.cpp b/libcxx/test/std/language.support/support.limits/support.limits.general/version.version.compile.pass.cpp
index 14271308624e65..20804d835015e2 100644
--- a/libcxx/test/std/language.support/support.limits/support.limits.general/version.version.compile.pass.cpp
+++ b/libcxx/test/std/language.support/support.limits/support.limits.general/version.version.compile.pass.cpp
@@ -158,6 +158,7 @@
__cpp_lib_ranges_as_rvalue 202207L [C++23]
__cpp_lib_ranges_chunk 202202L [C++23]
__cpp_lib_ranges_chunk_by 202202L [C++23]
+ __cpp_lib_ranges_contains 202207L [C++23]
__cpp_lib_ranges_iota 202202L [C++23]
__cpp_lib_ranges_join_with 202202L [C++23]
__cpp_lib_ranges_repeat 202207L [C++23]
@@ -772,6 +773,10 @@
# error "__cpp_lib_ranges_chunk_by should not be defined before c++23"
# endif
+# ifdef __cpp_lib_ranges_contains
+# error "__cpp_lib_ranges_contains should not be defined before c++23"
+# endif
+
# ifdef __cpp_lib_ranges_iota
# error "__cpp_lib_ranges_iota should not be defined before c++23"
# endif
@@ -1604,6 +1609,10 @@
# error "__cpp_lib_ranges_chunk_by should not be defined before c++23"
# endif
+# ifdef __cpp_lib_ranges_contains
+# error "__cpp_lib_ranges_contains should not be defined before c++23"
+# endif
+
# ifdef __cpp_lib_ranges_iota
# error "__cpp_lib_ranges_iota should not be defined before c++23"
# endif
@@ -2607,6 +2616,10 @@
# error "__cpp_lib_ranges_chunk_by should not be defined before c++23"
# endif
+# ifdef __cpp_lib_ranges_contains
+# error "__cpp_lib_ranges_contains should not be defined before c++23"
+# endif
+
# ifdef __cpp_lib_ranges_iota
# error "__cpp_lib_ranges_iota should not be defined before c++23"
# endif
@@ -3889,6 +3902,10 @@
# error "__cpp_lib_ranges_chunk_by should not be defined before c++23"
# endif
+# ifdef __cpp_lib_ranges_contains
+# error "__cpp_lib_ranges_contains should not be defined before c++23"
+# endif
+
# ifdef __cpp_lib_ranges_iota
# error "__cpp_lib_ranges_iota should not be defined before c++23"
# endif
@@ -5357,6 +5374,13 @@
# error "__cpp_lib_ranges_chunk_by should have the value 202202L in c++23"
# endif
+# ifndef __cpp_lib_ranges_contains
+# error "__cpp_lib_ranges_contains should be defined in c++23"
+# endif
+# if __cpp_lib_ranges_contains != 202207L
+# error "__cpp_lib_ranges_contains should have the value 202207L in c++23"
+# endif
+
# if !defined(_LIBCPP_VERSION)
# ifndef __cpp_lib_ranges_iota
# error "__cpp_lib_ranges_iota should be defined in c++23"
@@ -5403,17 +5427,11 @@
# endif
# endif
-# if !defined(_LIBCPP_VERSION)
-# ifndef __cpp_lib_ranges_starts_ends_with
-# error "__cpp_lib_ranges_starts_ends_with should be defined in c++23"
-# endif
-# if __cpp_lib_ranges_starts_ends_with != 202106L
-# error "__cpp_lib_ranges_starts_ends_with should have the value 202106L in c++23"
-# endif
-# else // _LIBCPP_VERSION
-# ifdef __cpp_lib_ranges_starts_ends_with
-# error "__cpp_lib_ranges_starts_ends_with should not be defined because it is unimplemented in libc++!"
-# endif
+# ifndef __cpp_lib_ranges_starts_ends_with
+# error "__cpp_lib_ranges_starts_ends_with should be defined in c++23"
+# endif
+# if __cpp_lib_ranges_starts_ends_with != 202106L
+# error "__cpp_lib_ranges_starts_ends_with should have the value 202106L in c++23"
# endif
# ifndef __cpp_lib_ranges_to_container
@@ -7074,6 +7092,13 @@
# error "__cpp_lib_ranges_chunk_by should have the value 202202L in c++26"
# endif
+# ifndef __cpp_lib_ranges_contains
+# error "__cpp_lib_ranges_contains should be defined in c++26"
+# endif
+# if __cpp_lib_ranges_contains != 202207L
+# error "__cpp_lib_ranges_contains should have the value 202207L in c++26"
+# endif
+
# if !defined(_LIBCPP_VERSION)
# ifndef __cpp_lib_ranges_iota
# error "__cpp_lib_ranges_iota should be defined in c++26"
@@ -7120,17 +7145,11 @@
# endif
# endif
-# if !defined(_LIBCPP_VERSION)
-# ifndef __cpp_lib_ranges_starts_ends_with
-# error "__cpp_lib_ranges_starts_ends_with should be defined in c++26"
-# endif
-# if __cpp_lib_ranges_starts_ends_with != 202106L
-# error "__cpp_lib_ranges_starts_ends_with should have the value 202106L in c++26"
-# endif
-# else // _LIBCPP_VERSION
-# ifdef __cpp_lib_ranges_starts_ends_with
-# error "__cpp_lib_ranges_starts_ends_with should not be defined because it is unimplemented in libc++!"
-# endif
+# ifndef __cpp_lib_ranges_starts_ends_with
+# error "__cpp_lib_ranges_starts_ends_with should be defined in c++26"
+# endif
+# if __cpp_lib_ranges_starts_ends_with != 202106L
+# error "__cpp_lib_ranges_starts_ends_with should have the value 202106L in c++26"
# endif
# ifndef __cpp_lib_ranges_to_container
diff --git a/libcxx/utils/generate_feature_test_macro_components.py b/libcxx/utils/generate_feature_test_macro_components.py
index 7b6d35d9a7fc53..16d2fc6a532dbc 100755
--- a/libcxx/utils/generate_feature_test_macro_components.py
+++ b/libcxx/utils/generate_feature_test_macro_components.py
@@ -914,6 +914,11 @@ def add_version_header(tc):
"values": {"c++23": 202202},
"headers": ["ranges"],
},
+ {
+ "name": "__cpp_lib_ranges_contains",
+ "values": {"c++23": 202207},
+ "headers": ["algorithm"],
+ },
{
"name": "__cpp_lib_ranges_iota",
"values": {"c++23": 202202},
@@ -941,7 +946,6 @@ def add_version_header(tc):
"name": "__cpp_lib_ranges_starts_ends_with",
"values": {"c++23": 202106},
"headers": ["algorithm"],
- "unimplemented": True,
},
{
"name": "__cpp_lib_ranges_to_container",
>From 5b058709536dd883980722ee000bb7b8c7b2cd8b Mon Sep 17 00:00:00 2001
From: "Felix (Ting Wang)" <Ting.Wang.SH at ibm.com>
Date: Fri, 1 Mar 2024 08:09:40 +0800
Subject: [PATCH 195/406] [PowerPC] Support local-dynamic TLS relocation on AIX
(#66316)
Supports TLS local-dynamic on AIX, generates below sequence of code:
```
.tc foo[TC],foo[TL]@ld # Variable offset, ld relocation specifier
.tc mh[TC],mh[TC]@ml # Module handle for the caller
lwz 3,mh[TC]\(2\) $$ For 64-bit: ld 3,mh[TC]\(2\)
bla .__tls_get_mod # Modifies r0,r3,r4,r5,r11,lr,cr0
#r3 = &TLS for module
lwz 4,foo[TC]\(2\) $$ For 64-bit: ld 4,foo[TC]\(2\)
add 5,3,4 # Compute &foo
.rename mh[TC], "\_$TLSML" # Symbol for the module handle must have the name "_$TLSML"
```
---------
Co-authored-by: tingwang <tingwang at tingwangs-MBP.lan>
Co-authored-by: tingwang <tingwang at tingwangs-MacBook-Pro.local>
---
.../clang/Basic/DiagnosticDriverKinds.td | 1 -
clang/lib/Frontend/CompilerInvocation.cpp | 8 -
clang/lib/Sema/SemaDeclAttr.cpp | 6 -
clang/test/CodeGen/PowerPC/aix-tls-model.cpp | 9 +-
clang/test/Sema/aix-attr-tls_model.c | 2 +-
llvm/include/llvm/MC/MCExpr.h | 2 +
.../CodeGen/TargetLoweringObjectFileImpl.cpp | 23 +-
llvm/lib/MC/MCExpr.cpp | 4 +
llvm/lib/MC/XCOFFObjectWriter.cpp | 3 +-
.../PowerPC/MCTargetDesc/PPCMCTargetDesc.cpp | 13 +-
.../MCTargetDesc/PPCXCOFFObjectWriter.cpp | 4 +
llvm/lib/Target/PowerPC/PPC.h | 6 +
llvm/lib/Target/PowerPC/PPCAsmPrinter.cpp | 58 ++-
llvm/lib/Target/PowerPC/PPCISelLowering.cpp | 39 +-
llvm/lib/Target/PowerPC/PPCISelLowering.h | 13 +-
llvm/lib/Target/PowerPC/PPCInstr64Bit.td | 12 +-
llvm/lib/Target/PowerPC/PPCInstrInfo.cpp | 1 +
llvm/lib/Target/PowerPC/PPCInstrInfo.td | 12 +-
llvm/lib/Target/PowerPC/PPCTLSDynamicCall.cpp | 119 +++++-
.../test/CodeGen/PowerPC/aix-tls-gd-double.ll | 110 ++---
llvm/test/CodeGen/PowerPC/aix-tls-gd-int.ll | 94 +++--
.../CodeGen/PowerPC/aix-tls-gd-longlong.ll | 346 +++++++--------
.../PowerPC/aix-tls-ld-xcoff-reloc-large.ll | 349 +++++++++++++++
.../CodeGen/PowerPC/aix-tls-local-dynamic.ll | 396 ++++++++++++++++++
.../PowerPC/aix-tls-xcoff-reloc-large.ll | 217 +++++-----
.../CodeGen/PowerPC/aix-tls-xcoff-reloc.ll | 219 +++++-----
26 files changed, 1545 insertions(+), 521 deletions(-)
create mode 100644 llvm/test/CodeGen/PowerPC/aix-tls-ld-xcoff-reloc-large.ll
create mode 100644 llvm/test/CodeGen/PowerPC/aix-tls-local-dynamic.ll
diff --git a/clang/include/clang/Basic/DiagnosticDriverKinds.td b/clang/include/clang/Basic/DiagnosticDriverKinds.td
index b13181f6e70894..1bc9885849d54b 100644
--- a/clang/include/clang/Basic/DiagnosticDriverKinds.td
+++ b/clang/include/clang/Basic/DiagnosticDriverKinds.td
@@ -693,7 +693,6 @@ def err_drv_cannot_mix_options : Error<"cannot specify '%1' along with '%0'">;
def err_drv_invalid_object_mode : Error<
"OBJECT_MODE setting %0 is not recognized and is not a valid setting">;
-def err_aix_unsupported_tls_model : Error<"TLS model '%0' is not yet supported on AIX">;
def err_roptr_requires_data_sections: Error<"-mxcoff-roptr is supported only with -fdata-sections">;
def err_roptr_cannot_build_shared: Error<"-mxcoff-roptr is not supported with -shared">;
diff --git a/clang/lib/Frontend/CompilerInvocation.cpp b/clang/lib/Frontend/CompilerInvocation.cpp
index 8d7b75b56d6129..9555dbf663d334 100644
--- a/clang/lib/Frontend/CompilerInvocation.cpp
+++ b/clang/lib/Frontend/CompilerInvocation.cpp
@@ -1975,14 +1975,6 @@ bool CompilerInvocation::ParseCodeGenArgs(CodeGenOptions &Opts, ArgList &Args,
Opts.LinkBitcodeFiles.push_back(F);
}
- if (Arg *A = Args.getLastArg(OPT_ftlsmodel_EQ)) {
- if (T.isOSAIX()) {
- StringRef Name = A->getValue();
- if (Name == "local-dynamic")
- Diags.Report(diag::err_aix_unsupported_tls_model) << Name;
- }
- }
-
if (Arg *A = Args.getLastArg(OPT_fdenormal_fp_math_EQ)) {
StringRef Val = A->getValue();
Opts.FPDenormalMode = llvm::parseDenormalFPAttribute(Val);
diff --git a/clang/lib/Sema/SemaDeclAttr.cpp b/clang/lib/Sema/SemaDeclAttr.cpp
index c1c28a73fd79ce..397b5db0dc0669 100644
--- a/clang/lib/Sema/SemaDeclAttr.cpp
+++ b/clang/lib/Sema/SemaDeclAttr.cpp
@@ -2053,12 +2053,6 @@ static void handleTLSModelAttr(Sema &S, Decl *D, const ParsedAttr &AL) {
return;
}
- if (S.Context.getTargetInfo().getTriple().isOSAIX() &&
- Model == "local-dynamic") {
- S.Diag(LiteralLoc, diag::err_aix_attr_unsupported_tls_model) << Model;
- return;
- }
-
D->addAttr(::new (S.Context) TLSModelAttr(S.Context, AL, Model));
}
diff --git a/clang/test/CodeGen/PowerPC/aix-tls-model.cpp b/clang/test/CodeGen/PowerPC/aix-tls-model.cpp
index 9fdd6855a89ee9..cd0a08aa9a3b77 100644
--- a/clang/test/CodeGen/PowerPC/aix-tls-model.cpp
+++ b/clang/test/CodeGen/PowerPC/aix-tls-model.cpp
@@ -1,11 +1,11 @@
// RUN: %clang_cc1 %s -triple powerpc-unknown-aix -target-cpu pwr8 -emit-llvm -o - | FileCheck %s -check-prefix=CHECK-GD
// RUN: %clang_cc1 %s -triple powerpc-unknown-aix -target-cpu pwr8 -ftls-model=global-dynamic -emit-llvm -o - | FileCheck %s -check-prefix=CHECK-GD
-// RUN: not %clang_cc1 %s -triple powerpc-unknown-aix -target-cpu pwr8 -ftls-model=local-dynamic -emit-llvm 2>&1 | FileCheck %s -check-prefix=CHECK-LD-ERROR
+// RUN: %clang_cc1 %s -triple powerpc-unknown-aix -target-cpu pwr8 -ftls-model=local-dynamic -emit-llvm -o - | FileCheck %s -check-prefix=CHECK-LD
// RUN: %clang_cc1 %s -triple powerpc-unknown-aix -target-cpu pwr8 -ftls-model=initial-exec -emit-llvm -o - | FileCheck %s -check-prefix=CHECK-IE
// RUN: %clang_cc1 %s -triple powerpc-unknown-aix -target-cpu pwr8 -ftls-model=local-exec -emit-llvm -o - | FileCheck %s -check-prefix=CHECK-LE
// RUN: %clang_cc1 %s -triple powerpc64-unknown-aix -target-cpu pwr8 -emit-llvm -o - | FileCheck %s -check-prefix=CHECK-GD
// RUN: %clang_cc1 %s -triple powerpc64-unknown-aix -target-cpu pwr8 -ftls-model=global-dynamic -emit-llvm -o - | FileCheck %s -check-prefix=CHECK-GD
-// RUN: not %clang_cc1 %s -triple powerpc64-unknown-aix -target-cpu pwr8 -ftls-model=local-dynamic -emit-llvm 2>&1 | FileCheck %s -check-prefix=CHECK-LD-ERROR
+// RUN: %clang_cc1 %s -triple powerpc64-unknown-aix -target-cpu pwr8 -ftls-model=local-dynamic -emit-llvm -o - | FileCheck %s -check-prefix=CHECK-LD
// RUN: %clang_cc1 %s -triple powerpc64-unknown-aix -target-cpu pwr8 -ftls-model=initial-exec -emit-llvm -o - | FileCheck %s -check-prefix=CHECK-IE
// RUN: %clang_cc1 %s -triple powerpc64-unknown-aix -target-cpu pwr8 -ftls-model=local-exec -emit-llvm -o - | FileCheck %s -check-prefix=CHECK-LE
@@ -21,7 +21,10 @@ int f() {
// CHECK-GD: @z2 ={{.*}} global i32 0
// CHECK-GD: @x ={{.*}} thread_local global i32 0
// CHECK-GD: @_ZZ1fvE1y = internal thread_local global i32 0
-// CHECK-LD-ERROR: error: TLS model 'local-dynamic' is not yet supported on AIX
+// CHECK-LD: @z1 ={{.*}} global i32 0
+// CHECK-LD: @z2 ={{.*}} global i32 0
+// CHECK-LD: @x ={{.*}} thread_local(localdynamic) global i32 0
+// CHECK-LD: @_ZZ1fvE1y = internal thread_local(localdynamic) global i32 0
// CHECK-IE: @z1 ={{.*}} global i32 0
// CHECK-IE: @z2 ={{.*}} global i32 0
// CHECK-IE: @x ={{.*}} thread_local(initialexec) global i32 0
diff --git a/clang/test/Sema/aix-attr-tls_model.c b/clang/test/Sema/aix-attr-tls_model.c
index 9c22d6cceed81c..7c2047bced9391 100644
--- a/clang/test/Sema/aix-attr-tls_model.c
+++ b/clang/test/Sema/aix-attr-tls_model.c
@@ -6,6 +6,6 @@
#endif
static __thread int y __attribute((tls_model("global-dynamic"))); // no-warning
-static __thread int y __attribute((tls_model("local-dynamic"))); // expected-error {{TLS model 'local-dynamic' is not yet supported on AIX}}
+static __thread int y __attribute((tls_model("local-dynamic"))); // expected-no-diagnostics
static __thread int y __attribute((tls_model("initial-exec"))); // no-warning
static __thread int y __attribute((tls_model("local-exec"))); // no-warning
diff --git a/llvm/include/llvm/MC/MCExpr.h b/llvm/include/llvm/MC/MCExpr.h
index b3119609372049..42d240254be6aa 100644
--- a/llvm/include/llvm/MC/MCExpr.h
+++ b/llvm/include/llvm/MC/MCExpr.h
@@ -307,6 +307,8 @@ class MCSymbolRefExpr : public MCExpr {
VK_PPC_AIX_TLSGDM, // symbol at m
VK_PPC_AIX_TLSIE, // symbol at ie
VK_PPC_AIX_TLSLE, // symbol at le
+ VK_PPC_AIX_TLSLD, // symbol at ld
+ VK_PPC_AIX_TLSML, // symbol at ml
VK_PPC_GOT_TLSLD, // symbol at got@tlsld
VK_PPC_GOT_TLSLD_LO, // symbol at got@tlsld at l
VK_PPC_GOT_TLSLD_HI, // symbol at got@tlsld at h
diff --git a/llvm/lib/CodeGen/TargetLoweringObjectFileImpl.cpp b/llvm/lib/CodeGen/TargetLoweringObjectFileImpl.cpp
index 654a6157270861..6943ce261d9d9c 100644
--- a/llvm/lib/CodeGen/TargetLoweringObjectFileImpl.cpp
+++ b/llvm/lib/CodeGen/TargetLoweringObjectFileImpl.cpp
@@ -2418,6 +2418,15 @@ MCSection *TargetLoweringObjectFileXCOFF::getSectionForExternalReference(
SmallString<128> Name;
getNameWithPrefix(Name, GO, TM);
+ // AIX TLS local-dynamic does not need the external reference for the
+ // "_$TLSML" symbol.
+ if (GO->getThreadLocalMode() == GlobalVariable::LocalDynamicTLSModel &&
+ GO->hasName() && GO->getName() == "_$TLSML") {
+ return getContext().getXCOFFSection(
+ Name, SectionKind::getData(),
+ XCOFF::CsectProperties(XCOFF::XMC_TC, XCOFF::XTY_SD));
+ }
+
XCOFF::StorageMappingClass SMC =
isa<Function>(GO) ? XCOFF::XMC_DS : XCOFF::XMC_UA;
if (GO->isThreadLocal())
@@ -2675,13 +2684,17 @@ MCSection *TargetLoweringObjectFileXCOFF::getSectionForTOCEntry(
// the chance of needing -bbigtoc is decreased. Also, the toc-entry for
// EH info is never referenced directly using instructions so it can be
// allocated with TE storage-mapping class.
+ // The "_$TLSML" symbol for TLS local-dynamic mode requires XMC_TC, otherwise
+ // the AIX assembler will complain.
return getContext().getXCOFFSection(
cast<MCSymbolXCOFF>(Sym)->getSymbolTableName(), SectionKind::getData(),
- XCOFF::CsectProperties((TM.getCodeModel() == CodeModel::Large ||
- cast<MCSymbolXCOFF>(Sym)->isEHInfo())
- ? XCOFF::XMC_TE
- : XCOFF::XMC_TC,
- XCOFF::XTY_SD));
+ XCOFF::CsectProperties(
+ ((TM.getCodeModel() == CodeModel::Large &&
+ cast<MCSymbolXCOFF>(Sym)->getSymbolTableName() != "_$TLSML") ||
+ cast<MCSymbolXCOFF>(Sym)->isEHInfo())
+ ? XCOFF::XMC_TE
+ : XCOFF::XMC_TC,
+ XCOFF::XTY_SD));
}
MCSection *TargetLoweringObjectFileXCOFF::getSectionForLSDA(
diff --git a/llvm/lib/MC/MCExpr.cpp b/llvm/lib/MC/MCExpr.cpp
index 485fd1885ddb52..28b2cbb0e8b04b 100644
--- a/llvm/lib/MC/MCExpr.cpp
+++ b/llvm/lib/MC/MCExpr.cpp
@@ -338,6 +338,10 @@ StringRef MCSymbolRefExpr::getVariantKindName(VariantKind Kind) {
return "ie";
case VK_PPC_AIX_TLSLE:
return "le";
+ case VK_PPC_AIX_TLSLD:
+ return "ld";
+ case VK_PPC_AIX_TLSML:
+ return "ml";
case VK_PPC_GOT_TLSLD: return "got at tlsld";
case VK_PPC_GOT_TLSLD_LO: return "got at tlsld@l";
case VK_PPC_GOT_TLSLD_HI: return "got at tlsld@h";
diff --git a/llvm/lib/MC/XCOFFObjectWriter.cpp b/llvm/lib/MC/XCOFFObjectWriter.cpp
index 8809af2e5e0c18..d46bbaf7576571 100644
--- a/llvm/lib/MC/XCOFFObjectWriter.cpp
+++ b/llvm/lib/MC/XCOFFObjectWriter.cpp
@@ -715,7 +715,8 @@ void XCOFFObjectWriter::recordRelocation(MCAssembler &Asm,
if (Type == XCOFF::RelocationType::R_POS ||
Type == XCOFF::RelocationType::R_TLS ||
Type == XCOFF::RelocationType::R_TLS_LE ||
- Type == XCOFF::RelocationType::R_TLS_IE)
+ Type == XCOFF::RelocationType::R_TLS_IE ||
+ Type == XCOFF::RelocationType::R_TLS_LD)
// The FixedValue should be symbol's virtual address in this object file
// plus any constant value that we might get.
FixedValue = getVirtualAddress(SymA, SymASec) + Target.getConstant();
diff --git a/llvm/lib/Target/PowerPC/MCTargetDesc/PPCMCTargetDesc.cpp b/llvm/lib/Target/PowerPC/MCTargetDesc/PPCMCTargetDesc.cpp
index a804dd823daa4d..b849b7be7b7be8 100644
--- a/llvm/lib/Target/PowerPC/MCTargetDesc/PPCMCTargetDesc.cpp
+++ b/llvm/lib/Target/PowerPC/MCTargetDesc/PPCMCTargetDesc.cpp
@@ -231,12 +231,19 @@ class PPCTargetAsmStreamer : public PPCTargetStreamer {
MCSymbolXCOFF *TCSym =
cast<MCSectionXCOFF>(Streamer.getCurrentSectionOnly())
->getQualNameSymbol();
- // On AIX, we have a region handle (symbol at m) and the variable offset
- // (symbol@{gd|ie|le}) for TLS variables, depending on the TLS model.
+ // On AIX, we have TLS variable offsets (symbol@({gd|ie|le|ld}) depending
+ // on the TLS access method (or model). For the general-dynamic access
+ // method, we also have region handle (symbol at m) for each variable. For
+ // local-dynamic, there is a module handle (_$TLSML[TC]@ml) for all
+ // variables. Finally for local-exec and initial-exec, we have a thread
+ // pointer, in r13 for 64-bit mode and returned by .__get_tpointer for
+ // 32-bit mode.
if (Kind == MCSymbolRefExpr::VariantKind::VK_PPC_AIX_TLSGD ||
Kind == MCSymbolRefExpr::VariantKind::VK_PPC_AIX_TLSGDM ||
Kind == MCSymbolRefExpr::VariantKind::VK_PPC_AIX_TLSIE ||
- Kind == MCSymbolRefExpr::VariantKind::VK_PPC_AIX_TLSLE)
+ Kind == MCSymbolRefExpr::VariantKind::VK_PPC_AIX_TLSLE ||
+ Kind == MCSymbolRefExpr::VariantKind::VK_PPC_AIX_TLSLD ||
+ Kind == MCSymbolRefExpr::VariantKind::VK_PPC_AIX_TLSML)
OS << "\t.tc " << TCSym->getName() << "," << XSym->getName() << "@"
<< MCSymbolRefExpr::getVariantKindName(Kind) << '\n';
else
diff --git a/llvm/lib/Target/PowerPC/MCTargetDesc/PPCXCOFFObjectWriter.cpp b/llvm/lib/Target/PowerPC/MCTargetDesc/PPCXCOFFObjectWriter.cpp
index 065daf42fe6eb0..f4998e9b9dcba8 100644
--- a/llvm/lib/Target/PowerPC/MCTargetDesc/PPCXCOFFObjectWriter.cpp
+++ b/llvm/lib/Target/PowerPC/MCTargetDesc/PPCXCOFFObjectWriter.cpp
@@ -116,6 +116,10 @@ std::pair<uint8_t, uint8_t> PPCXCOFFObjectWriter::getRelocTypeAndSignSize(
return {XCOFF::RelocationType::R_TLS_IE, SignAndSizeForFKData};
case MCSymbolRefExpr::VK_PPC_AIX_TLSLE:
return {XCOFF::RelocationType::R_TLS_LE, SignAndSizeForFKData};
+ case MCSymbolRefExpr::VK_PPC_AIX_TLSLD:
+ return {XCOFF::RelocationType::R_TLS_LD, SignAndSizeForFKData};
+ case MCSymbolRefExpr::VK_PPC_AIX_TLSML:
+ return {XCOFF::RelocationType::R_TLSML, SignAndSizeForFKData};
case MCSymbolRefExpr::VK_None:
return {XCOFF::RelocationType::R_POS, SignAndSizeForFKData};
}
diff --git a/llvm/lib/Target/PowerPC/PPC.h b/llvm/lib/Target/PowerPC/PPC.h
index 3d9ea560819385..eb8886dcc9075c 100644
--- a/llvm/lib/Target/PowerPC/PPC.h
+++ b/llvm/lib/Target/PowerPC/PPC.h
@@ -139,6 +139,12 @@ class ModulePass;
/// and Local Exec models.
MO_TPREL_FLAG,
+ /// MO_TLSLDM_FLAG - on AIX the ML relocation type is only valid for a
+ /// reference to a TOC symbol from the symbol itself, and right now its only
+ /// user is the symbol "_$TLSML". The symbol name is used to decide that
+ /// the R_TLSML relocation is expected.
+ MO_TLSLDM_FLAG,
+
/// MO_TLSLD_FLAG - If this bit is set the symbol reference is relative to
/// TLS Local Dynamic model.
MO_TLSLD_FLAG,
diff --git a/llvm/lib/Target/PowerPC/PPCAsmPrinter.cpp b/llvm/lib/Target/PowerPC/PPCAsmPrinter.cpp
index 483cd788ebfe0c..9396ca22dacf86 100644
--- a/llvm/lib/Target/PowerPC/PPCAsmPrinter.cpp
+++ b/llvm/lib/Target/PowerPC/PPCAsmPrinter.cpp
@@ -621,12 +621,23 @@ void PPCAsmPrinter::LowerPATCHPOINT(StackMaps &SM, const MachineInstr &MI) {
EmitToStreamer(*OutStreamer, MCInstBuilder(PPC::NOP));
}
-/// This helper function creates the TlsGetAddr MCSymbol for AIX. We will
-/// create the csect and use the qual-name symbol instead of creating just the
-/// external symbol.
+/// This helper function creates the TlsGetAddr/TlsGetMod MCSymbol for AIX. We
+/// will create the csect and use the qual-name symbol instead of creating just
+/// the external symbol.
static MCSymbol *createMCSymbolForTlsGetAddr(MCContext &Ctx, unsigned MIOpc) {
- StringRef SymName =
- MIOpc == PPC::GETtlsTpointer32AIX ? ".__get_tpointer" : ".__tls_get_addr";
+ StringRef SymName;
+ switch (MIOpc) {
+ default:
+ SymName = ".__tls_get_addr";
+ break;
+ case PPC::GETtlsTpointer32AIX:
+ SymName = ".__get_tpointer";
+ break;
+ case PPC::GETtlsMOD32AIX:
+ case PPC::GETtlsMOD64AIX:
+ SymName = ".__tls_get_mod";
+ break;
+ }
return Ctx
.getXCOFFSection(SymName, SectionKind::getText(),
XCOFF::CsectProperties(XCOFF::XMC_PR, XCOFF::XTY_ER))
@@ -668,14 +679,16 @@ void PPCAsmPrinter::EmitTlsCall(const MachineInstr *MI,
"GETtls[ld]ADDR[32] must read GPR3");
if (Subtarget->isAIXABI()) {
- // On AIX, the variable offset should already be in R4 and the region handle
- // should already be in R3.
- // For TLSGD, which currently is the only supported access model, we only
- // need to generate an absolute branch to .__tls_get_addr.
+ // For TLSGD, the variable offset should already be in R4 and the region
+ // handle should already be in R3. We generate an absolute branch to
+ // .__tls_get_addr. For TLSLD, the module handle should already be in R3.
+ // We generate an absolute branch to .__tls_get_mod.
Register VarOffsetReg = Subtarget->isPPC64() ? PPC::X4 : PPC::R4;
(void)VarOffsetReg;
- assert(MI->getOperand(2).isReg() &&
- MI->getOperand(2).getReg() == VarOffsetReg &&
+ assert((MI->getOpcode() == PPC::GETtlsMOD32AIX ||
+ MI->getOpcode() == PPC::GETtlsMOD64AIX ||
+ (MI->getOperand(2).isReg() &&
+ MI->getOperand(2).getReg() == VarOffsetReg)) &&
"GETtls[ld]ADDR[32] must read GPR4");
EmitAIXTlsCallHelper(MI);
return;
@@ -844,6 +857,13 @@ void PPCAsmPrinter::emitInstruction(const MachineInstr *MI) {
return MCSymbolRefExpr::VariantKind::VK_PPC_AIX_TLSGDM;
if (Flag == PPCII::MO_TLSGD_FLAG || Flag == PPCII::MO_GOT_TLSGD_PCREL_FLAG)
return MCSymbolRefExpr::VariantKind::VK_PPC_AIX_TLSGD;
+ // For local-dynamic TLS access on AIX, we have one TOC entry for the symbol
+ // (the variable offset) and one shared TOC entry for the module handle.
+ // They are differentiated by MO_TLSLD_FLAG and MO_TLSLDM_FLAG.
+ if (Flag == PPCII::MO_TLSLD_FLAG && IsAIX)
+ return MCSymbolRefExpr::VariantKind::VK_PPC_AIX_TLSLD;
+ if (Flag == PPCII::MO_TLSLDM_FLAG && IsAIX)
+ return MCSymbolRefExpr::VariantKind::VK_PPC_AIX_TLSML;
return MCSymbolRefExpr::VariantKind::VK_None;
};
@@ -1354,6 +1374,11 @@ void PPCAsmPrinter::emitInstruction(const MachineInstr *MI) {
.addExpr(SymGotTlsGD));
return;
}
+ case PPC::GETtlsMOD32AIX:
+ case PPC::GETtlsMOD64AIX:
+ // Transform: %r3 = GETtlsMODNNAIX %r3 (for NN == 32/64).
+ // Into: BLA .__tls_get_mod()
+ // Input parameter is a module handle (_$TLSML[TC]@ml) for all variables.
case PPC::GETtlsADDR:
// Transform: %x3 = GETtlsADDR %x3, @sym
// Into: BL8_NOP_TLS __tls_get_addr(sym at tlsgd)
@@ -2167,6 +2192,11 @@ void PPCAIXAsmPrinter::emitLinkage(const GlobalValue *GV,
}
}
+ // Do not emit the _$TLSML symbol.
+ if (GV->getThreadLocalMode() == GlobalVariable::LocalDynamicTLSModel &&
+ GV->hasName() && GV->getName() == "_$TLSML")
+ return;
+
OutStreamer->emitXCOFFSymbolLinkageWithVisibility(GVSym, LinkageAttr,
VisibilityAttr);
}
@@ -2981,11 +3011,13 @@ void PPCAIXAsmPrinter::emitInstruction(const MachineInstr *MI) {
MMI->hasDebugInfo());
break;
}
+ case PPC::GETtlsMOD32AIX:
+ case PPC::GETtlsMOD64AIX:
case PPC::GETtlsTpointer32AIX:
case PPC::GETtlsADDR64AIX:
case PPC::GETtlsADDR32AIX: {
- // A reference to .__tls_get_addr/.__get_tpointer is unknown to the
- // assembler so we need to emit an external symbol reference.
+ // A reference to .__tls_get_mod/.__tls_get_addr/.__get_tpointer is unknown
+ // to the assembler so we need to emit an external symbol reference.
MCSymbol *TlsGetAddr =
createMCSymbolForTlsGetAddr(OutContext, MI->getOpcode());
ExtSymSDNodeSymbols.insert(TlsGetAddr);
diff --git a/llvm/lib/Target/PowerPC/PPCISelLowering.cpp b/llvm/lib/Target/PowerPC/PPCISelLowering.cpp
index 19cf1a8394b069..9fa17bac55450d 100644
--- a/llvm/lib/Target/PowerPC/PPCISelLowering.cpp
+++ b/llvm/lib/Target/PowerPC/PPCISelLowering.cpp
@@ -1774,9 +1774,11 @@ const char *PPCTargetLowering::getTargetNodeName(unsigned Opcode) const {
case PPCISD::ADDIS_TLSGD_HA: return "PPCISD::ADDIS_TLSGD_HA";
case PPCISD::ADDI_TLSGD_L: return "PPCISD::ADDI_TLSGD_L";
case PPCISD::GET_TLS_ADDR: return "PPCISD::GET_TLS_ADDR";
+ case PPCISD::GET_TLS_MOD_AIX: return "PPCISD::GET_TLS_MOD_AIX";
case PPCISD::GET_TPOINTER: return "PPCISD::GET_TPOINTER";
case PPCISD::ADDI_TLSGD_L_ADDR: return "PPCISD::ADDI_TLSGD_L_ADDR";
case PPCISD::TLSGD_AIX: return "PPCISD::TLSGD_AIX";
+ case PPCISD::TLSLD_AIX: return "PPCISD::TLSLD_AIX";
case PPCISD::ADDIS_TLSLD_HA: return "PPCISD::ADDIS_TLSLD_HA";
case PPCISD::ADDI_TLSLD_L: return "PPCISD::ADDI_TLSLD_L";
case PPCISD::GET_TLSLD_ADDR: return "PPCISD::GET_TLSLD_ADDR";
@@ -3415,13 +3417,36 @@ SDValue PPCTargetLowering::LowerGlobalTLSAddressAIX(SDValue Op,
return DAG.getNode(PPCISD::ADD_TLS, dl, PtrVT, TLSReg, VariableOffset);
}
- // Only Local-Exec, Initial-Exec and General-Dynamic TLS models are currently
- // supported models. If Local- or Initial-exec are not possible or specified,
- // all GlobalTLSAddress nodes are lowered using the general-dynamic model.
- // We need to generate two TOC entries, one for the variable offset, one for
- // the region handle. The global address for the TOC entry of the region
- // handle is created with the MO_TLSGDM_FLAG flag and the global address
- // for the TOC entry of the variable offset is created with MO_TLSGD_FLAG.
+ if (Model == TLSModel::LocalDynamic) {
+ // For local-dynamic on AIX, we need to generate one TOC entry for each
+ // variable offset, and a single module-handle TOC entry for the entire
+ // file.
+
+ SDValue VariableOffsetTGA =
+ DAG.getTargetGlobalAddress(GV, dl, PtrVT, 0, PPCII::MO_TLSLD_FLAG);
+ SDValue VariableOffset = getTOCEntry(DAG, dl, VariableOffsetTGA);
+
+ Module *M = DAG.getMachineFunction().getFunction().getParent();
+ GlobalVariable *TLSGV =
+ dyn_cast_or_null<GlobalVariable>(M->getOrInsertGlobal(
+ StringRef("_$TLSML"), PointerType::getUnqual(*DAG.getContext())));
+ TLSGV->setThreadLocalMode(GlobalVariable::LocalDynamicTLSModel);
+ assert(TLSGV && "Not able to create GV for _$TLSML.");
+ SDValue ModuleHandleTGA =
+ DAG.getTargetGlobalAddress(TLSGV, dl, PtrVT, 0, PPCII::MO_TLSLDM_FLAG);
+ SDValue ModuleHandleTOC = getTOCEntry(DAG, dl, ModuleHandleTGA);
+ SDValue ModuleHandle =
+ DAG.getNode(PPCISD::TLSLD_AIX, dl, PtrVT, ModuleHandleTOC);
+
+ return DAG.getNode(ISD::ADD, dl, PtrVT, ModuleHandle, VariableOffset);
+ }
+
+ // If Local- or Initial-exec or Local-dynamic is not possible or specified,
+ // all GlobalTLSAddress nodes are lowered using the general-dynamic model. We
+ // need to generate two TOC entries, one for the variable offset, one for the
+ // region handle. The global address for the TOC entry of the region handle is
+ // created with the MO_TLSGDM_FLAG flag and the global address for the TOC
+ // entry of the variable offset is created with MO_TLSGD_FLAG.
SDValue VariableOffsetTGA =
DAG.getTargetGlobalAddress(GV, dl, PtrVT, 0, PPCII::MO_TLSGD_FLAG);
SDValue RegionHandleTGA =
diff --git a/llvm/lib/Target/PowerPC/PPCISelLowering.h b/llvm/lib/Target/PowerPC/PPCISelLowering.h
index 509a22b0bbf413..0bdfdcd15441f4 100644
--- a/llvm/lib/Target/PowerPC/PPCISelLowering.h
+++ b/llvm/lib/Target/PowerPC/PPCISelLowering.h
@@ -370,11 +370,22 @@ namespace llvm {
/// G8RC = TLSGD_AIX, TOC_ENTRY, TOC_ENTRY
/// Op that combines two register copies of TOC entries
/// (region handle into R3 and variable offset into R4) followed by a
- /// GET_TLS_ADDR node which will be expanded to a call to __get_tls_addr.
+ /// GET_TLS_ADDR node which will be expanded to a call to .__tls_get_addr.
/// This node is used in 64-bit mode as well (in which case the result is
/// G8RC and inputs are X3/X4).
TLSGD_AIX,
+ /// %x3 = GET_TLS_MOD_AIX _$TLSML - For the AIX local-dynamic TLS model,
+ /// produces a call to .__tls_get_mod(_$TLSML\@ml).
+ GET_TLS_MOD_AIX,
+
+ /// [GP|G8]RC = TLSLD_AIX, TOC_ENTRY(module handle)
+ /// Op that requires a single input of the module handle TOC entry in R3,
+ /// and generates a GET_TLS_MOD_AIX node which will be expanded into a call
+ /// to .__tls_get_mod. This node is used in both 32-bit and 64-bit modes.
+ /// The only difference is the register class.
+ TLSLD_AIX,
+
/// G8RC = ADDIS_TLSLD_HA %x2, Symbol - For the local-dynamic TLS
/// model, produces an ADDIS8 instruction that adds the GOT base
/// register to sym\@got\@tlsld\@ha.
diff --git a/llvm/lib/Target/PowerPC/PPCInstr64Bit.td b/llvm/lib/Target/PowerPC/PPCInstr64Bit.td
index 0322bb37b1fdf8..2949d58ab66479 100644
--- a/llvm/lib/Target/PowerPC/PPCInstr64Bit.td
+++ b/llvm/lib/Target/PowerPC/PPCInstr64Bit.td
@@ -1557,12 +1557,19 @@ def GETtlsldADDRPCREL : GETtlsldADDRPseudo <"#GETtlsldADDRPCREL">;
// so we don't need to mark it with a size of 8 bytes. Finally, the assembly
// manual mentions this exact set of registers as the clobbered set, others
// are guaranteed not to be clobbered.
-let Defs = [X0,X4,X5,X11,LR8,CR0] in
+let Defs = [X0,X4,X5,X11,LR8,CR0] in {
def GETtlsADDR64AIX :
PPCEmitTimePseudo<(outs g8rc:$rD),(ins g8rc:$offset, g8rc:$handle),
"GETtlsADDR64AIX",
[(set i64:$rD,
(PPCgetTlsAddr i64:$offset, i64:$handle))]>, isPPC64;
+// On AIX, the call to .__tls_get_mod needs one input in X3 for the module handle.
+def GETtlsMOD64AIX :
+ PPCEmitTimePseudo<(outs g8rc:$rD),(ins g8rc:$handle),
+ "GETtlsMOD64AIX",
+ [(set i64:$rD,
+ (PPCgetTlsMod i64:$handle))]>, isPPC64;
+}
}
// Combined op for ADDItlsgdL and GETtlsADDR, late expanded. X3 and LR8
@@ -1595,6 +1602,9 @@ def TLSGDAIX8 :
"#TLSGDAIX8",
[(set i64:$rD,
(PPCTlsgdAIX i64:$offset, i64:$handle))]>;
+// This pseudo is expanded to the call to GETtlsMOD64AIX.
+def TLSLDAIX8 : PPCEmitTimePseudo<(outs g8rc:$rD), (ins g8rc:$handle),
+ "#TLSLDAIX8", [(set i64:$rD, (PPCTlsldAIX i64:$handle))]>;
// Combined op for ADDItlsldL and GETtlsADDR, late expanded. X3 and LR8
// are true defines, while the rest of the Defs are clobbers.
let hasExtraSrcRegAllocReq = 1, hasExtraDefRegAllocReq = 1,
diff --git a/llvm/lib/Target/PowerPC/PPCInstrInfo.cpp b/llvm/lib/Target/PowerPC/PPCInstrInfo.cpp
index 68cc76a98ff839..1c610b269d32d8 100644
--- a/llvm/lib/Target/PowerPC/PPCInstrInfo.cpp
+++ b/llvm/lib/Target/PowerPC/PPCInstrInfo.cpp
@@ -2965,6 +2965,7 @@ PPCInstrInfo::getSerializableDirectMachineOperandTargetFlags() const {
{MO_PCREL_OPT_FLAG, "ppc-opt-pcrel"},
{MO_TLSGD_FLAG, "ppc-tlsgd"},
{MO_TPREL_FLAG, "ppc-tprel"},
+ {MO_TLSLDM_FLAG, "ppc-tlsldm"},
{MO_TLSLD_FLAG, "ppc-tlsld"},
{MO_TLSGDM_FLAG, "ppc-tlsgdm"},
{MO_GOT_TLSGD_PCREL_FLAG, "ppc-got-tlsgd-pcrel"},
diff --git a/llvm/lib/Target/PowerPC/PPCInstrInfo.td b/llvm/lib/Target/PowerPC/PPCInstrInfo.td
index 3abd97f2c38c09..82da1a3c305983 100644
--- a/llvm/lib/Target/PowerPC/PPCInstrInfo.td
+++ b/llvm/lib/Target/PowerPC/PPCInstrInfo.td
@@ -213,12 +213,14 @@ def PPCaddTls : SDNode<"PPCISD::ADD_TLS", SDTIntBinOp, []>;
def PPCaddisTlsgdHA : SDNode<"PPCISD::ADDIS_TLSGD_HA", SDTIntBinOp>;
def PPCaddiTlsgdL : SDNode<"PPCISD::ADDI_TLSGD_L", SDTIntBinOp>;
def PPCgetTlsAddr : SDNode<"PPCISD::GET_TLS_ADDR", SDTIntBinOp>;
+def PPCgetTlsMod : SDNode<"PPCISD::GET_TLS_MOD_AIX", SDTIntUnaryOp>;
def PPCgetTpointer : SDNode<"PPCISD::GET_TPOINTER", SDTIntLeaf, []>;
def PPCaddiTlsgdLAddr : SDNode<"PPCISD::ADDI_TLSGD_L_ADDR",
SDTypeProfile<1, 3, [
SDTCisSameAs<0, 1>, SDTCisSameAs<0, 2>,
SDTCisSameAs<0, 3>, SDTCisInt<0> ]>>;
def PPCTlsgdAIX : SDNode<"PPCISD::TLSGD_AIX", SDTIntBinOp>;
+def PPCTlsldAIX : SDNode<"PPCISD::TLSLD_AIX", SDTIntUnaryOp>;
def PPCaddisTlsldHA : SDNode<"PPCISD::ADDIS_TLSLD_HA", SDTIntBinOp>;
def PPCaddiTlsldL : SDNode<"PPCISD::ADDI_TLSLD_L", SDTIntBinOp>;
def PPCgetTlsldAddr : SDNode<"PPCISD::GET_TLSLD_ADDR", SDTIntBinOp>;
@@ -3249,11 +3251,16 @@ def GETtlsADDR32 : PPCEmitTimePseudo<(outs gprc:$rD), (ins gprc:$reg, tlsgd32:$s
// The rest of the Defs are the exact set of registers that will be clobbered by
// the call.
let hasExtraSrcRegAllocReq = 1, hasExtraDefRegAllocReq = 1,
- Defs = [R0,R4,R5,R11,LR,CR0] in
+ Defs = [R0,R4,R5,R11,LR,CR0] in {
def GETtlsADDR32AIX : PPCEmitTimePseudo<(outs gprc:$rD), (ins gprc:$offset, gprc:$handle),
"GETtlsADDR32AIX",
[(set i32:$rD,
(PPCgetTlsAddr i32:$offset, i32:$handle))]>;
+def GETtlsMOD32AIX : PPCEmitTimePseudo<(outs gprc:$rD), (ins gprc:$handle),
+ "GETtlsMOD32AIX",
+ [(set i32:$rD,
+ (PPCgetTlsMod i32:$handle))]>;
+}
// For local-exec accesses on 32-bit AIX, a call to .__get_tpointer is
// generated to retrieve the thread pointer. GETtlsTpointer32AIX clobbers both
@@ -3293,6 +3300,9 @@ def TLSGDAIX : PPCEmitTimePseudo<(outs gprc:$rD), (ins gprc:$offset, gprc:$handl
"#TLSGDAIX",
[(set i32:$rD,
(PPCTlsgdAIX i32:$offset, i32:$handle))]>;
+// This pseudo is expanded to the call to GETtlsMOD32AIX.
+def TLSLDAIX : PPCEmitTimePseudo<(outs gprc:$rD), (ins gprc:$handle),
+ "#TLSLDAIX", [(set i32:$rD, (PPCTlsldAIX i32:$handle))]>;
// LR is a true define, while the rest of the Defs are clobbers. R3 is
// explicitly defined when this op is created, so not mentioned here.
let hasExtraSrcRegAllocReq = 1, hasExtraDefRegAllocReq = 1,
diff --git a/llvm/lib/Target/PowerPC/PPCTLSDynamicCall.cpp b/llvm/lib/Target/PowerPC/PPCTLSDynamicCall.cpp
index 9518d5347065cc..147438dfedd87d 100644
--- a/llvm/lib/Target/PowerPC/PPCTLSDynamicCall.cpp
+++ b/llvm/lib/Target/PowerPC/PPCTLSDynamicCall.cpp
@@ -48,9 +48,15 @@ namespace {
bool processBlock(MachineBasicBlock &MBB) {
bool Changed = false;
bool NeedFence = true;
- bool Is64Bit = MBB.getParent()->getSubtarget<PPCSubtarget>().isPPC64();
- bool IsAIX = MBB.getParent()->getSubtarget<PPCSubtarget>().isAIXABI();
+ const PPCSubtarget &Subtarget =
+ MBB.getParent()->getSubtarget<PPCSubtarget>();
+ bool Is64Bit = Subtarget.isPPC64();
+ bool IsAIX = Subtarget.isAIXABI();
+ bool IsLargeModel =
+ Subtarget.getTargetMachine().getCodeModel() == CodeModel::Large;
bool IsPCREL = false;
+ MachineFunction *MF = MBB.getParent();
+ MachineRegisterInfo &RegInfo = MF->getRegInfo();
for (MachineBasicBlock::iterator I = MBB.begin(), IE = MBB.end();
I != IE;) {
@@ -59,13 +65,16 @@ namespace {
// There are a number of slight differences in code generation
// when we call .__get_tpointer (32-bit AIX TLS).
bool IsTLSTPRelMI = MI.getOpcode() == PPC::GETtlsTpointer32AIX;
+ bool IsTLSLDAIXMI = (MI.getOpcode() == PPC::TLSLDAIX8 ||
+ MI.getOpcode() == PPC::TLSLDAIX);
if (MI.getOpcode() != PPC::ADDItlsgdLADDR &&
MI.getOpcode() != PPC::ADDItlsldLADDR &&
MI.getOpcode() != PPC::ADDItlsgdLADDR32 &&
MI.getOpcode() != PPC::ADDItlsldLADDR32 &&
MI.getOpcode() != PPC::TLSGDAIX &&
- MI.getOpcode() != PPC::TLSGDAIX8 && !IsTLSTPRelMI && !IsPCREL) {
+ MI.getOpcode() != PPC::TLSGDAIX8 && !IsTLSTPRelMI && !IsPCREL &&
+ !IsTLSLDAIXMI) {
// Although we create ADJCALLSTACKDOWN and ADJCALLSTACKUP
// as scheduling fences, we skip creating fences if we already
// have existing ADJCALLSTACKDOWN/UP to avoid nesting,
@@ -109,6 +118,16 @@ namespace {
Opc1 = PPC::ADDItlsldL32;
Opc2 = PPC::GETtlsldADDR32;
break;
+ case PPC::TLSLDAIX:
+ // TLSLDAIX is expanded to one copy and GET_TLS_MOD, so we only set
+ // Opc2 here.
+ Opc2 = PPC::GETtlsMOD32AIX;
+ break;
+ case PPC::TLSLDAIX8:
+ // TLSLDAIX8 is expanded to one copy and GET_TLS_MOD, so we only set
+ // Opc2 here.
+ Opc2 = PPC::GETtlsMOD64AIX;
+ break;
case PPC::TLSGDAIX8:
// TLSGDAIX8 is expanded to two copies and GET_TLS_ADDR, so we only
// set Opc2 here.
@@ -145,9 +164,97 @@ namespace {
.addImm(0);
if (IsAIX) {
- // The variable offset and region handle are copied in r4 and r3. The
- // copies are followed by GETtlsADDR32AIX/GETtlsADDR64AIX.
- if (!IsTLSTPRelMI) {
+ if (IsTLSLDAIXMI) {
+ // The relative order between the node that loads the variable
+ // offset from the TOC, and the .__tls_get_mod node is being tuned
+ // here. It is better to put the variable offset TOC load after the
+ // call, since this node can use clobbers r4/r5.
+ // Search for the pattern of the two nodes that load from the TOC
+ // (either for the variable offset or for the module handle), and
+ // then move the variable offset TOC load right before the node that
+ // uses the OutReg of the .__tls_get_mod node.
+ unsigned LDTocOp =
+ Is64Bit ? (IsLargeModel ? PPC::LDtocL : PPC::LDtoc)
+ : (IsLargeModel ? PPC::LWZtocL : PPC::LWZtoc);
+ if (!RegInfo.use_empty(OutReg)) {
+ std::set<MachineInstr *> Uses;
+ // Collect all instructions that use the OutReg.
+ for (MachineOperand &MO : RegInfo.use_operands(OutReg))
+ Uses.insert(MO.getParent());
+ // Find the first user (e.g.: lwax/stfdx) of the OutReg within the
+ // current BB.
+ MachineBasicBlock::iterator UseIter = MBB.begin();
+ for (MachineBasicBlock::iterator IE = MBB.end(); UseIter != IE;
+ ++UseIter)
+ if (Uses.count(&*UseIter))
+ break;
+
+ // Additional handling is required when UserIter (the first user
+ // of OutReg) is pointing to a valid node that loads from the TOC.
+ // Check the pattern and do the movement if the pattern matches.
+ if (UseIter != MBB.end()) {
+ // Collect all associated nodes that load from the TOC. Use
+ // hasOneDef() to guard against unexpected scenarios.
+ std::set<MachineInstr *> LoadFromTocs;
+ for (MachineOperand &MO : UseIter->operands())
+ if (MO.isReg() && MO.isUse()) {
+ Register MOReg = MO.getReg();
+ if (RegInfo.hasOneDef(MOReg)) {
+ MachineInstr *Temp =
+ RegInfo.getOneDef(MOReg)->getParent();
+ // For the current TLSLDAIX node, get the corresponding
+ // node that loads from the TOC for the InReg. Otherwise,
+ // Temp probably pointed to the variable offset TOC load
+ // we would like to move.
+ if (Temp == &MI && RegInfo.hasOneDef(InReg))
+ Temp = RegInfo.getOneDef(InReg)->getParent();
+ if (Temp->getOpcode() == LDTocOp)
+ LoadFromTocs.insert(Temp);
+ } else {
+ // FIXME: analyze this scenario if there is one.
+ LoadFromTocs.clear();
+ break;
+ }
+ }
+
+ // Check the two nodes that loaded from the TOC: one should be
+ // "_$TLSML", and the other will be moved before the node that
+ // uses the OutReg of the .__tls_get_mod node.
+ if (LoadFromTocs.size() == 2) {
+ MachineBasicBlock::iterator TLSMLIter = MBB.end();
+ MachineBasicBlock::iterator OffsetIter = MBB.end();
+ // Make sure the two nodes that loaded from the TOC are within
+ // the current BB, and that one of them is from the "_$TLSML"
+ // pseudo symbol, while the other is from the variable.
+ for (MachineBasicBlock::iterator I = MBB.begin(),
+ IE = MBB.end();
+ I != IE; ++I)
+ if (LoadFromTocs.count(&*I)) {
+ MachineOperand MO = I->getOperand(1);
+ if (MO.isGlobal() && MO.getGlobal()->hasName() &&
+ MO.getGlobal()->getName() == "_$TLSML")
+ TLSMLIter = I;
+ else
+ OffsetIter = I;
+ }
+ // Perform the movement when the desired scenario has been
+ // identified, which should be when both of the iterators are
+ // valid.
+ if (TLSMLIter != MBB.end() && OffsetIter != MBB.end())
+ OffsetIter->moveBefore(&*UseIter);
+ }
+ }
+ }
+ // The module-handle is copied into r3. The copy is followed by
+ // GETtlsMOD32AIX/GETtlsMOD64AIX.
+ BuildMI(MBB, I, DL, TII->get(TargetOpcode::COPY), GPR3)
+ .addReg(InReg);
+ // The call to .__tls_get_mod.
+ BuildMI(MBB, I, DL, TII->get(Opc2), GPR3).addReg(GPR3);
+ } else if (!IsTLSTPRelMI) {
+ // The variable offset and region handle (for TLSGD) are copied in
+ // r4 and r3. The copies are followed by
+ // GETtlsADDR32AIX/GETtlsADDR64AIX.
BuildMI(MBB, I, DL, TII->get(TargetOpcode::COPY), GPR4)
.addReg(MI.getOperand(1).getReg());
BuildMI(MBB, I, DL, TII->get(TargetOpcode::COPY), GPR3)
diff --git a/llvm/test/CodeGen/PowerPC/aix-tls-gd-double.ll b/llvm/test/CodeGen/PowerPC/aix-tls-gd-double.ll
index c0ffb8154c6917..ae41b6b1301064 100644
--- a/llvm/test/CodeGen/PowerPC/aix-tls-gd-double.ll
+++ b/llvm/test/CodeGen/PowerPC/aix-tls-gd-double.ll
@@ -156,11 +156,11 @@ define void @storesTIInit(double %Val) #0 {
; SMALL32: # %bb.0: # %entry
; SMALL32-NEXT: mflr 0
; SMALL32-NEXT: stwu 1, -32(1)
-; SMALL32-NEXT: lwz 3, L..C4(2) # target-flags(ppc-tlsgdm) @TIInit
-; SMALL32-NEXT: lwz 4, L..C5(2) # target-flags(ppc-tlsgd) @TIInit
+; SMALL32-NEXT: lwz 3, L..C4(2) # target-flags(ppc-tlsldm) @"_$TLSML"
; SMALL32-NEXT: stw 0, 40(1)
-; SMALL32-NEXT: bla .__tls_get_addr[PR]
-; SMALL32-NEXT: stfd 1, 0(3)
+; SMALL32-NEXT: bla .__tls_get_mod[PR]
+; SMALL32-NEXT: lwz 4, L..C5(2) # target-flags(ppc-tlsld) @TIInit
+; SMALL32-NEXT: stfdx 1, 3, 4
; SMALL32-NEXT: addi 1, 1, 32
; SMALL32-NEXT: lwz 0, 8(1)
; SMALL32-NEXT: mtlr 0
@@ -171,12 +171,12 @@ define void @storesTIInit(double %Val) #0 {
; LARGE32-NEXT: mflr 0
; LARGE32-NEXT: stwu 1, -32(1)
; LARGE32-NEXT: stw 0, 40(1)
-; LARGE32-NEXT: addis 3, L..C4 at u(2)
-; LARGE32-NEXT: addis 4, L..C5 at u(2)
-; LARGE32-NEXT: lwz 3, L..C4 at l(3)
-; LARGE32-NEXT: lwz 4, L..C5 at l(4)
-; LARGE32-NEXT: bla .__tls_get_addr[PR]
-; LARGE32-NEXT: stfd 1, 0(3)
+; LARGE32-NEXT: addis 6, L..C4 at u(2)
+; LARGE32-NEXT: addis 3, L..C5 at u(2)
+; LARGE32-NEXT: lwz 3, L..C5 at l(3)
+; LARGE32-NEXT: bla .__tls_get_mod[PR]
+; LARGE32-NEXT: lwz 4, L..C4 at l(6)
+; LARGE32-NEXT: stfdx 1, 3, 4
; LARGE32-NEXT: addi 1, 1, 32
; LARGE32-NEXT: lwz 0, 8(1)
; LARGE32-NEXT: mtlr 0
@@ -186,11 +186,11 @@ define void @storesTIInit(double %Val) #0 {
; SMALL64: # %bb.0: # %entry
; SMALL64-NEXT: mflr 0
; SMALL64-NEXT: stdu 1, -48(1)
-; SMALL64-NEXT: ld 3, L..C4(2) # target-flags(ppc-tlsgdm) @TIInit
-; SMALL64-NEXT: ld 4, L..C5(2) # target-flags(ppc-tlsgd) @TIInit
+; SMALL64-NEXT: ld 3, L..C4(2) # target-flags(ppc-tlsldm) @"_$TLSML"
; SMALL64-NEXT: std 0, 64(1)
-; SMALL64-NEXT: bla .__tls_get_addr[PR]
-; SMALL64-NEXT: stfd 1, 0(3)
+; SMALL64-NEXT: bla .__tls_get_mod[PR]
+; SMALL64-NEXT: ld 4, L..C5(2) # target-flags(ppc-tlsld) @TIInit
+; SMALL64-NEXT: stfdx 1, 3, 4
; SMALL64-NEXT: addi 1, 1, 48
; SMALL64-NEXT: ld 0, 16(1)
; SMALL64-NEXT: mtlr 0
@@ -201,12 +201,12 @@ define void @storesTIInit(double %Val) #0 {
; LARGE64-NEXT: mflr 0
; LARGE64-NEXT: stdu 1, -48(1)
; LARGE64-NEXT: addis 3, L..C4 at u(2)
-; LARGE64-NEXT: addis 4, L..C5 at u(2)
; LARGE64-NEXT: std 0, 64(1)
+; LARGE64-NEXT: addis 6, L..C5 at u(2)
; LARGE64-NEXT: ld 3, L..C4 at l(3)
-; LARGE64-NEXT: ld 4, L..C5 at l(4)
-; LARGE64-NEXT: bla .__tls_get_addr[PR]
-; LARGE64-NEXT: stfd 1, 0(3)
+; LARGE64-NEXT: bla .__tls_get_mod[PR]
+; LARGE64-NEXT: ld 4, L..C5 at l(6)
+; LARGE64-NEXT: stfdx 1, 3, 4
; LARGE64-NEXT: addi 1, 1, 48
; LARGE64-NEXT: ld 0, 16(1)
; LARGE64-NEXT: mtlr 0
@@ -452,13 +452,13 @@ define double @loadsTIInit() #1 {
; SMALL32: # %bb.0: # %entry
; SMALL32-NEXT: mflr 0
; SMALL32-NEXT: stwu 1, -32(1)
-; SMALL32-NEXT: lwz 3, L..C4(2) # target-flags(ppc-tlsgdm) @TIInit
-; SMALL32-NEXT: lwz 4, L..C5(2) # target-flags(ppc-tlsgd) @TIInit
+; SMALL32-NEXT: lwz 3, L..C4(2) # target-flags(ppc-tlsldm) @"_$TLSML"
; SMALL32-NEXT: stw 0, 40(1)
-; SMALL32-NEXT: bla .__tls_get_addr[PR]
-; SMALL32-NEXT: lwz 4, L..C8(2) # @GInit
-; SMALL32-NEXT: lfd 0, 0(3)
-; SMALL32-NEXT: lfd 1, 0(4)
+; SMALL32-NEXT: bla .__tls_get_mod[PR]
+; SMALL32-NEXT: lwz 4, L..C5(2) # target-flags(ppc-tlsld) @TIInit
+; SMALL32-NEXT: lfdx 0, 3, 4
+; SMALL32-NEXT: lwz 3, L..C8(2) # @GInit
+; SMALL32-NEXT: lfd 1, 0(3)
; SMALL32-NEXT: fadd 1, 0, 1
; SMALL32-NEXT: addi 1, 1, 32
; SMALL32-NEXT: lwz 0, 8(1)
@@ -470,12 +470,12 @@ define double @loadsTIInit() #1 {
; LARGE32-NEXT: mflr 0
; LARGE32-NEXT: stwu 1, -32(1)
; LARGE32-NEXT: stw 0, 40(1)
-; LARGE32-NEXT: addis 3, L..C4 at u(2)
-; LARGE32-NEXT: addis 4, L..C5 at u(2)
-; LARGE32-NEXT: lwz 3, L..C4 at l(3)
-; LARGE32-NEXT: lwz 4, L..C5 at l(4)
-; LARGE32-NEXT: bla .__tls_get_addr[PR]
-; LARGE32-NEXT: lfd 0, 0(3)
+; LARGE32-NEXT: addis 6, L..C4 at u(2)
+; LARGE32-NEXT: addis 3, L..C5 at u(2)
+; LARGE32-NEXT: lwz 3, L..C5 at l(3)
+; LARGE32-NEXT: bla .__tls_get_mod[PR]
+; LARGE32-NEXT: lwz 4, L..C4 at l(6)
+; LARGE32-NEXT: lfdx 0, 3, 4
; LARGE32-NEXT: addis 3, L..C8 at u(2)
; LARGE32-NEXT: lwz 3, L..C8 at l(3)
; LARGE32-NEXT: lfd 1, 0(3)
@@ -489,13 +489,13 @@ define double @loadsTIInit() #1 {
; SMALL64: # %bb.0: # %entry
; SMALL64-NEXT: mflr 0
; SMALL64-NEXT: stdu 1, -48(1)
-; SMALL64-NEXT: ld 3, L..C4(2) # target-flags(ppc-tlsgdm) @TIInit
-; SMALL64-NEXT: ld 4, L..C5(2) # target-flags(ppc-tlsgd) @TIInit
+; SMALL64-NEXT: ld 3, L..C4(2) # target-flags(ppc-tlsldm) @"_$TLSML"
; SMALL64-NEXT: std 0, 64(1)
-; SMALL64-NEXT: bla .__tls_get_addr[PR]
-; SMALL64-NEXT: ld 4, L..C8(2) # @GInit
-; SMALL64-NEXT: lfd 0, 0(3)
-; SMALL64-NEXT: lfd 1, 0(4)
+; SMALL64-NEXT: bla .__tls_get_mod[PR]
+; SMALL64-NEXT: ld 4, L..C5(2) # target-flags(ppc-tlsld) @TIInit
+; SMALL64-NEXT: lfdx 0, 3, 4
+; SMALL64-NEXT: ld 3, L..C8(2) # @GInit
+; SMALL64-NEXT: lfd 1, 0(3)
; SMALL64-NEXT: fadd 1, 0, 1
; SMALL64-NEXT: addi 1, 1, 48
; SMALL64-NEXT: ld 0, 16(1)
@@ -507,14 +507,14 @@ define double @loadsTIInit() #1 {
; LARGE64-NEXT: mflr 0
; LARGE64-NEXT: stdu 1, -48(1)
; LARGE64-NEXT: addis 3, L..C4 at u(2)
-; LARGE64-NEXT: addis 4, L..C5 at u(2)
; LARGE64-NEXT: std 0, 64(1)
+; LARGE64-NEXT: addis 6, L..C5 at u(2)
; LARGE64-NEXT: ld 3, L..C4 at l(3)
-; LARGE64-NEXT: ld 4, L..C5 at l(4)
-; LARGE64-NEXT: bla .__tls_get_addr[PR]
-; LARGE64-NEXT: addis 4, L..C8 at u(2)
-; LARGE64-NEXT: lfd 0, 0(3)
-; LARGE64-NEXT: ld 3, L..C8 at l(4)
+; LARGE64-NEXT: bla .__tls_get_mod[PR]
+; LARGE64-NEXT: ld 4, L..C5 at l(6)
+; LARGE64-NEXT: addis 5, L..C8 at u(2)
+; LARGE64-NEXT: lfdx 0, 3, 4
+; LARGE64-NEXT: ld 3, L..C8 at l(5)
; LARGE64-NEXT: lfd 1, 0(3)
; LARGE64-NEXT: fadd 1, 0, 1
; LARGE64-NEXT: addi 1, 1, 48
@@ -610,12 +610,16 @@ entry:
ret double %add
}
-; External symbol reference checks for .__tls_get_addr
+; External symbol reference checks for .__tls_get_addr/.__tls_get_mod
; SMALL32: .extern .__tls_get_addr[PR]
+; SMALL32: .extern .__tls_get_mod[PR]
; SMALL64: .extern .__tls_get_addr[PR]
+; SMALL64: .extern .__tls_get_mod[PR]
; LARGE32: .extern .__tls_get_addr[PR]
+; LARGE32: .extern .__tls_get_mod[PR]
; LARGE64: .extern .__tls_get_addr[PR]
+; LARGE64: .extern .__tls_get_mod[PR]
; TOC entry checks
@@ -629,9 +633,10 @@ entry:
; SMALL32-LABEL: L..C3:
; SMALL32-NEXT: .tc TGInit[TC],TGInit[TL]@gd
; SMALL32-LABEL: L..C4:
-; SMALL32-NEXT: .tc .TIInit[TC],TIInit[TL]@m
+; SMALL32-NEXT: .tc _Renamed..5f24__TLSML[TC],_Renamed..5f24__TLSML[TC]@ml
+; SMALL32-NEXT: .rename _Renamed..5f24__TLSML[TC],"_$TLSML"
; SMALL32-LABEL: L..C5:
-; SMALL32-NEXT: .tc TIInit[TC],TIInit[TL]@gd
+; SMALL32-NEXT: .tc TIInit[TC],TIInit[TL]@ld
; SMALL32-LABEL: L..C6:
; SMALL32-NEXT: .tc .TWInit[TC],TWInit[TL]@m
; SMALL32-LABEL: L..C7:
@@ -649,9 +654,10 @@ entry:
; LARGE32-LABEL: L..C3:
; LARGE32-NEXT: .tc TGInit[TE],TGInit[TL]@gd
; LARGE32-LABEL: L..C4:
-; LARGE32-NEXT: .tc .TIInit[TE],TIInit[TL]@m
+; LARGE32-NEXT: .tc TIInit[TE],TIInit[TL]@ld
; LARGE32-LABEL: L..C5:
-; LARGE32-NEXT: .tc TIInit[TE],TIInit[TL]@gd
+; LARGE32-NEXT: .tc _Renamed..5f24__TLSML[TC],_Renamed..5f24__TLSML[TC]@ml
+; LARGE32-NEXT: .rename _Renamed..5f24__TLSML[TC],"_$TLSML"
; LARGE32-LABEL: L..C6:
; LARGE32-NEXT: .tc .TWInit[TE],TWInit[TL]@m
; LARGE32-LABEL: L..C7:
@@ -669,9 +675,10 @@ entry:
; SMALL64-LABEL: L..C3:
; SMALL64-NEXT: .tc TGInit[TC],TGInit[TL]@gd
; SMALL64-LABEL: L..C4:
-; SMALL64-NEXT: .tc .TIInit[TC],TIInit[TL]@m
+; SMALL64-NEXT: .tc _Renamed..5f24__TLSML[TC],_Renamed..5f24__TLSML[TC]@ml
+; SMALL64-NEXT: .rename _Renamed..5f24__TLSML[TC],"_$TLSML"
; SMALL64-LABEL: L..C5:
-; SMALL64-NEXT: .tc TIInit[TC],TIInit[TL]@gd
+; SMALL64-NEXT: .tc TIInit[TC],TIInit[TL]@ld
; SMALL64-LABEL: L..C6:
; SMALL64-NEXT: .tc .TWInit[TC],TWInit[TL]@m
; SMALL64-LABEL: L..C7:
@@ -689,9 +696,10 @@ entry:
; LARGE64-LABEL: L..C3:
; LARGE64-NEXT: .tc TGInit[TE],TGInit[TL]@gd
; LARGE64-LABEL: L..C4:
-; LARGE64-NEXT: .tc .TIInit[TE],TIInit[TL]@m
+; LARGE64-NEXT: .tc _Renamed..5f24__TLSML[TC],_Renamed..5f24__TLSML[TC]@ml
+; LARGE64-NEXT: .rename _Renamed..5f24__TLSML[TC],"_$TLSML"
; LARGE64-LABEL: L..C5:
-; LARGE64-NEXT: .tc TIInit[TE],TIInit[TL]@gd
+; LARGE64-NEXT: .tc TIInit[TE],TIInit[TL]@ld
; LARGE64-LABEL: L..C6:
; LARGE64-NEXT: .tc .TWInit[TE],TWInit[TL]@m
; LARGE64-LABEL: L..C7:
diff --git a/llvm/test/CodeGen/PowerPC/aix-tls-gd-int.ll b/llvm/test/CodeGen/PowerPC/aix-tls-gd-int.ll
index 887c4521a4c90a..bbb8e04b67b95e 100644
--- a/llvm/test/CodeGen/PowerPC/aix-tls-gd-int.ll
+++ b/llvm/test/CodeGen/PowerPC/aix-tls-gd-int.ll
@@ -165,10 +165,10 @@ define void @storesTIUninit(i32 %Val) #0 {
; SMALL32-NEXT: stwu 1, -32(1)
; SMALL32-NEXT: mr 6, 3
; SMALL32-NEXT: lwz 3, L..C4(2)
-; SMALL32-NEXT: lwz 4, L..C5(2)
; SMALL32-NEXT: stw 0, 40(1)
-; SMALL32-NEXT: bla .__tls_get_addr[PR]
-; SMALL32-NEXT: stw 6, 0(3)
+; SMALL32-NEXT: bla .__tls_get_mod[PR]
+; SMALL32-NEXT: lwz 4, L..C5(2)
+; SMALL32-NEXT: stwx 6, 3, 4
; SMALL32-NEXT: addi 1, 1, 32
; SMALL32-NEXT: lwz 0, 8(1)
; SMALL32-NEXT: mtlr 0
@@ -180,12 +180,12 @@ define void @storesTIUninit(i32 %Val) #0 {
; LARGE32-NEXT: stwu 1, -32(1)
; LARGE32-NEXT: stw 0, 40(1)
; LARGE32-NEXT: mr 6, 3
-; LARGE32-NEXT: addis 3, L..C4 at u(2)
-; LARGE32-NEXT: addis 4, L..C5 at u(2)
-; LARGE32-NEXT: lwz 3, L..C4 at l(3)
-; LARGE32-NEXT: lwz 4, L..C5 at l(4)
-; LARGE32-NEXT: bla .__tls_get_addr[PR]
-; LARGE32-NEXT: stw 6, 0(3)
+; LARGE32-NEXT: addis 7, L..C4 at u(2)
+; LARGE32-NEXT: addis 3, L..C5 at u(2)
+; LARGE32-NEXT: lwz 3, L..C5 at l(3)
+; LARGE32-NEXT: bla .__tls_get_mod[PR]
+; LARGE32-NEXT: lwz 4, L..C4 at l(7)
+; LARGE32-NEXT: stwx 6, 3, 4
; LARGE32-NEXT: addi 1, 1, 32
; LARGE32-NEXT: lwz 0, 8(1)
; LARGE32-NEXT: mtlr 0
@@ -197,10 +197,10 @@ define void @storesTIUninit(i32 %Val) #0 {
; SMALL64-NEXT: stdu 1, -48(1)
; SMALL64-NEXT: mr 6, 3
; SMALL64-NEXT: ld 3, L..C4(2)
-; SMALL64-NEXT: ld 4, L..C5(2)
; SMALL64-NEXT: std 0, 64(1)
-; SMALL64-NEXT: bla .__tls_get_addr[PR]
-; SMALL64-NEXT: stw 6, 0(3)
+; SMALL64-NEXT: bla .__tls_get_mod[PR]
+; SMALL64-NEXT: ld 4, L..C5(2)
+; SMALL64-NEXT: stwx 6, 3, 4
; SMALL64-NEXT: addi 1, 1, 48
; SMALL64-NEXT: ld 0, 16(1)
; SMALL64-NEXT: mtlr 0
@@ -212,12 +212,12 @@ define void @storesTIUninit(i32 %Val) #0 {
; LARGE64-NEXT: stdu 1, -48(1)
; LARGE64-NEXT: mr 6, 3
; LARGE64-NEXT: addis 3, L..C4 at u(2)
-; LARGE64-NEXT: addis 4, L..C5 at u(2)
; LARGE64-NEXT: std 0, 64(1)
+; LARGE64-NEXT: addis 7, L..C5 at u(2)
; LARGE64-NEXT: ld 3, L..C4 at l(3)
-; LARGE64-NEXT: ld 4, L..C5 at l(4)
-; LARGE64-NEXT: bla .__tls_get_addr[PR]
-; LARGE64-NEXT: stw 6, 0(3)
+; LARGE64-NEXT: bla .__tls_get_mod[PR]
+; LARGE64-NEXT: ld 4, L..C5 at l(7)
+; LARGE64-NEXT: stwx 6, 3, 4
; LARGE64-NEXT: addi 1, 1, 48
; LARGE64-NEXT: ld 0, 16(1)
; LARGE64-NEXT: mtlr 0
@@ -468,11 +468,11 @@ define i32 @loadsTIUninit() #1 {
; SMALL32-NEXT: mflr 0
; SMALL32-NEXT: stwu 1, -32(1)
; SMALL32-NEXT: lwz 3, L..C4(2)
-; SMALL32-NEXT: lwz 4, L..C5(2)
; SMALL32-NEXT: stw 0, 40(1)
-; SMALL32-NEXT: bla .__tls_get_addr[PR]
+; SMALL32-NEXT: bla .__tls_get_mod[PR]
+; SMALL32-NEXT: lwz 4, L..C5(2)
+; SMALL32-NEXT: lwzx 3, 3, 4
; SMALL32-NEXT: lwz 4, L..C8(2)
-; SMALL32-NEXT: lwz 3, 0(3)
; SMALL32-NEXT: lwz 4, 0(4)
; SMALL32-NEXT: add 3, 4, 3
; SMALL32-NEXT: addi 1, 1, 32
@@ -485,12 +485,12 @@ define i32 @loadsTIUninit() #1 {
; LARGE32-NEXT: mflr 0
; LARGE32-NEXT: stwu 1, -32(1)
; LARGE32-NEXT: stw 0, 40(1)
-; LARGE32-NEXT: addis 3, L..C4 at u(2)
-; LARGE32-NEXT: addis 4, L..C5 at u(2)
-; LARGE32-NEXT: lwz 3, L..C4 at l(3)
-; LARGE32-NEXT: lwz 4, L..C5 at l(4)
-; LARGE32-NEXT: bla .__tls_get_addr[PR]
-; LARGE32-NEXT: lwz 3, 0(3)
+; LARGE32-NEXT: addis 6, L..C4 at u(2)
+; LARGE32-NEXT: addis 3, L..C5 at u(2)
+; LARGE32-NEXT: lwz 3, L..C5 at l(3)
+; LARGE32-NEXT: bla .__tls_get_mod[PR]
+; LARGE32-NEXT: lwz 4, L..C4 at l(6)
+; LARGE32-NEXT: lwzx 3, 3, 4
; LARGE32-NEXT: addis 4, L..C8 at u(2)
; LARGE32-NEXT: lwz 4, L..C8 at l(4)
; LARGE32-NEXT: lwz 4, 0(4)
@@ -505,11 +505,11 @@ define i32 @loadsTIUninit() #1 {
; SMALL64-NEXT: mflr 0
; SMALL64-NEXT: stdu 1, -48(1)
; SMALL64-NEXT: ld 3, L..C4(2)
-; SMALL64-NEXT: ld 4, L..C5(2)
; SMALL64-NEXT: std 0, 64(1)
-; SMALL64-NEXT: bla .__tls_get_addr[PR]
+; SMALL64-NEXT: bla .__tls_get_mod[PR]
+; SMALL64-NEXT: ld 4, L..C5(2)
+; SMALL64-NEXT: lwzx 3, 3, 4
; SMALL64-NEXT: ld 4, L..C8(2)
-; SMALL64-NEXT: lwz 3, 0(3)
; SMALL64-NEXT: lwz 4, 0(4)
; SMALL64-NEXT: add 3, 4, 3
; SMALL64-NEXT: addi 1, 1, 48
@@ -522,14 +522,14 @@ define i32 @loadsTIUninit() #1 {
; LARGE64-NEXT: mflr 0
; LARGE64-NEXT: stdu 1, -48(1)
; LARGE64-NEXT: addis 3, L..C4 at u(2)
-; LARGE64-NEXT: addis 4, L..C5 at u(2)
; LARGE64-NEXT: std 0, 64(1)
+; LARGE64-NEXT: addis 6, L..C5 at u(2)
; LARGE64-NEXT: ld 3, L..C4 at l(3)
-; LARGE64-NEXT: ld 4, L..C5 at l(4)
-; LARGE64-NEXT: bla .__tls_get_addr[PR]
-; LARGE64-NEXT: addis 4, L..C8 at u(2)
-; LARGE64-NEXT: lwz 3, 0(3)
-; LARGE64-NEXT: ld 4, L..C8 at l(4)
+; LARGE64-NEXT: bla .__tls_get_mod[PR]
+; LARGE64-NEXT: ld 4, L..C5 at l(6)
+; LARGE64-NEXT: addis 5, L..C8 at u(2)
+; LARGE64-NEXT: lwzx 3, 3, 4
+; LARGE64-NEXT: ld 4, L..C8 at l(5)
; LARGE64-NEXT: lwz 4, 0(4)
; LARGE64-NEXT: add 3, 4, 3
; LARGE64-NEXT: addi 1, 1, 48
@@ -625,12 +625,16 @@ entry:
ret i32 %add
}
-; External symbol reference checks for .__tls_get_addr
+; External symbol reference checks for .__tls_get_addr/.__tls_get_mod
; SMALL32: .extern .__tls_get_addr[PR]
+; SMALL32: .extern .__tls_get_mod[PR]
; SMALL64: .extern .__tls_get_addr[PR]
+; SMALL64: .extern .__tls_get_mod[PR]
; LARGE32: .extern .__tls_get_addr[PR]
+; LARGE32: .extern .__tls_get_mod[PR]
; LARGE64: .extern .__tls_get_addr[PR]
+; LARGE64: .extern .__tls_get_mod[PR]
; TOC entry checks
@@ -644,9 +648,10 @@ entry:
; SMALL32-LABEL: L..C3:
; SMALL32-NEXT: .tc TGInit[TC],TGInit[TL]@gd
; SMALL32-LABEL: L..C4:
-; SMALL32-NEXT: .tc .TIUninit[TC],TIUninit[UL]@m
+; SMALL32-NEXT: .tc _Renamed..5f24__TLSML[TC],_Renamed..5f24__TLSML[TC]@ml
+; SMALL32-NEXT: .rename _Renamed..5f24__TLSML[TC],"_$TLSML"
; SMALL32-LABEL: L..C5:
-; SMALL32-NEXT: .tc TIUninit[TC],TIUninit[UL]@gd
+; SMALL32-NEXT: .tc TIUninit[TC],TIUninit[UL]@ld
; SMALL32-LABEL: L..C6:
; SMALL32-NEXT: .tc .TWUninit[TC],TWUninit[TL]@m
; SMALL32-LABEL: L..C7:
@@ -664,9 +669,10 @@ entry:
; LARGE32-LABEL: L..C3:
; LARGE32-NEXT: .tc TGInit[TE],TGInit[TL]@gd
; LARGE32-LABEL: L..C4:
-; LARGE32-NEXT: .tc .TIUninit[TE],TIUninit[UL]@m
+; LARGE32-NEXT: .tc TIUninit[TE],TIUninit[UL]@ld
; LARGE32-LABEL: L..C5:
-; LARGE32-NEXT: .tc TIUninit[TE],TIUninit[UL]@gd
+; LARGE32-NEXT: .tc _Renamed..5f24__TLSML[TC],_Renamed..5f24__TLSML[TC]@ml
+; LARGE32-NEXT: .rename _Renamed..5f24__TLSML[TC],"_$TLSML"
; LARGE32-LABEL: L..C6:
; LARGE32-NEXT: .tc .TWUninit[TE],TWUninit[TL]@m
; LARGE32-LABEL: L..C7:
@@ -684,9 +690,10 @@ entry:
; SMALL64-LABEL: L..C3:
; SMALL64-NEXT: .tc TGInit[TC],TGInit[TL]@gd
; SMALL64-LABEL: L..C4:
-; SMALL64-NEXT: .tc .TIUninit[TC],TIUninit[UL]@m
+; SMALL64-NEXT: .tc _Renamed..5f24__TLSML[TC],_Renamed..5f24__TLSML[TC]@ml
+; SMALL64-NEXT: .rename _Renamed..5f24__TLSML[TC],"_$TLSML"
; SMALL64-LABEL: L..C5:
-; SMALL64-NEXT: .tc TIUninit[TC],TIUninit[UL]@gd
+; SMALL64-NEXT: .tc TIUninit[TC],TIUninit[UL]@ld
; SMALL64-LABEL: L..C6:
; SMALL64-NEXT: .tc .TWUninit[TC],TWUninit[TL]@m
; SMALL64-LABEL: L..C7:
@@ -704,9 +711,10 @@ entry:
; LARGE64-LABEL: L..C3:
; LARGE64-NEXT: .tc TGInit[TE],TGInit[TL]@gd
; LARGE64-LABEL: L..C4:
-; LARGE64-NEXT: .tc .TIUninit[TE],TIUninit[UL]@m
+; LARGE64-NEXT: .tc _Renamed..5f24__TLSML[TC],_Renamed..5f24__TLSML[TC]@ml
+; LARGE64-NEXT: .rename _Renamed..5f24__TLSML[TC],"_$TLSML"
; LARGE64-LABEL: L..C5:
-; LARGE64-NEXT: .tc TIUninit[TE],TIUninit[UL]@gd
+; LARGE64-NEXT: .tc TIUninit[TE],TIUninit[UL]@ld
; LARGE64-LABEL: L..C6:
; LARGE64-NEXT: .tc .TWUninit[TE],TWUninit[TL]@m
; LARGE64-LABEL: L..C7:
diff --git a/llvm/test/CodeGen/PowerPC/aix-tls-gd-longlong.ll b/llvm/test/CodeGen/PowerPC/aix-tls-gd-longlong.ll
index 47813b59ba804c..ff087a2144488c 100644
--- a/llvm/test/CodeGen/PowerPC/aix-tls-gd-longlong.ll
+++ b/llvm/test/CodeGen/PowerPC/aix-tls-gd-longlong.ll
@@ -97,14 +97,14 @@ define void @storesTIUninit(i64 %Val) #0 {
; SMALL32: # %bb.0: # %entry
; SMALL32-NEXT: mflr 0
; SMALL32-NEXT: stwu 1, -32(1)
-; SMALL32-NEXT: mr 6, 4
; SMALL32-NEXT: mr 7, 3
; SMALL32-NEXT: lwz 3, L..C2(2)
-; SMALL32-NEXT: lwz 4, L..C3(2)
; SMALL32-NEXT: stw 0, 40(1)
-; SMALL32-NEXT: bla .__tls_get_addr[PR]
+; SMALL32-NEXT: mr 6, 4
+; SMALL32-NEXT: bla .__tls_get_mod[PR]
+; SMALL32-NEXT: lwz 4, L..C3(2)
+; SMALL32-NEXT: stwux 7, 3, 4
; SMALL32-NEXT: stw 6, 4(3)
-; SMALL32-NEXT: stw 7, 0(3)
; SMALL32-NEXT: addi 1, 1, 32
; SMALL32-NEXT: lwz 0, 8(1)
; SMALL32-NEXT: mtlr 0
@@ -115,15 +115,15 @@ define void @storesTIUninit(i64 %Val) #0 {
; LARGE32-NEXT: mflr 0
; LARGE32-NEXT: stwu 1, -32(1)
; LARGE32-NEXT: stw 0, 40(1)
-; LARGE32-NEXT: mr 6, 4
; LARGE32-NEXT: mr 7, 3
-; LARGE32-NEXT: addis 3, L..C2 at u(2)
-; LARGE32-NEXT: addis 4, L..C3 at u(2)
-; LARGE32-NEXT: lwz 3, L..C2 at l(3)
-; LARGE32-NEXT: lwz 4, L..C3 at l(4)
-; LARGE32-NEXT: bla .__tls_get_addr[PR]
+; LARGE32-NEXT: mr 6, 4
+; LARGE32-NEXT: addis 8, L..C2 at u(2)
+; LARGE32-NEXT: addis 3, L..C3 at u(2)
+; LARGE32-NEXT: lwz 3, L..C3 at l(3)
+; LARGE32-NEXT: bla .__tls_get_mod[PR]
+; LARGE32-NEXT: lwz 4, L..C2 at l(8)
+; LARGE32-NEXT: stwux 7, 3, 4
; LARGE32-NEXT: stw 6, 4(3)
-; LARGE32-NEXT: stw 7, 0(3)
; LARGE32-NEXT: addi 1, 1, 32
; LARGE32-NEXT: lwz 0, 8(1)
; LARGE32-NEXT: mtlr 0
@@ -135,10 +135,10 @@ define void @storesTIUninit(i64 %Val) #0 {
; SMALL64-NEXT: stdu 1, -48(1)
; SMALL64-NEXT: mr 6, 3
; SMALL64-NEXT: ld 3, L..C2(2)
-; SMALL64-NEXT: ld 4, L..C3(2)
; SMALL64-NEXT: std 0, 64(1)
-; SMALL64-NEXT: bla .__tls_get_addr[PR]
-; SMALL64-NEXT: std 6, 0(3)
+; SMALL64-NEXT: bla .__tls_get_mod[PR]
+; SMALL64-NEXT: ld 4, L..C3(2)
+; SMALL64-NEXT: stdx 6, 3, 4
; SMALL64-NEXT: addi 1, 1, 48
; SMALL64-NEXT: ld 0, 16(1)
; SMALL64-NEXT: mtlr 0
@@ -150,12 +150,12 @@ define void @storesTIUninit(i64 %Val) #0 {
; LARGE64-NEXT: stdu 1, -48(1)
; LARGE64-NEXT: mr 6, 3
; LARGE64-NEXT: addis 3, L..C2 at u(2)
-; LARGE64-NEXT: addis 4, L..C3 at u(2)
; LARGE64-NEXT: std 0, 64(1)
+; LARGE64-NEXT: addis 7, L..C3 at u(2)
; LARGE64-NEXT: ld 3, L..C2 at l(3)
-; LARGE64-NEXT: ld 4, L..C3 at l(4)
-; LARGE64-NEXT: bla .__tls_get_addr[PR]
-; LARGE64-NEXT: std 6, 0(3)
+; LARGE64-NEXT: bla .__tls_get_mod[PR]
+; LARGE64-NEXT: ld 4, L..C3 at l(7)
+; LARGE64-NEXT: stdx 6, 3, 4
; LARGE64-NEXT: addi 1, 1, 48
; LARGE64-NEXT: ld 0, 16(1)
; LARGE64-NEXT: mtlr 0
@@ -171,14 +171,14 @@ define void @storesTIInit(i64 %Val) #0 {
; SMALL32: # %bb.0: # %entry
; SMALL32-NEXT: mflr 0
; SMALL32-NEXT: stwu 1, -32(1)
-; SMALL32-NEXT: mr 6, 4
; SMALL32-NEXT: mr 7, 3
-; SMALL32-NEXT: lwz 3, L..C4(2)
-; SMALL32-NEXT: lwz 4, L..C5(2)
+; SMALL32-NEXT: lwz 3, L..C2(2)
; SMALL32-NEXT: stw 0, 40(1)
-; SMALL32-NEXT: bla .__tls_get_addr[PR]
+; SMALL32-NEXT: mr 6, 4
+; SMALL32-NEXT: bla .__tls_get_mod[PR]
+; SMALL32-NEXT: lwz 4, L..C4(2)
+; SMALL32-NEXT: stwux 7, 3, 4
; SMALL32-NEXT: stw 6, 4(3)
-; SMALL32-NEXT: stw 7, 0(3)
; SMALL32-NEXT: addi 1, 1, 32
; SMALL32-NEXT: lwz 0, 8(1)
; SMALL32-NEXT: mtlr 0
@@ -189,15 +189,15 @@ define void @storesTIInit(i64 %Val) #0 {
; LARGE32-NEXT: mflr 0
; LARGE32-NEXT: stwu 1, -32(1)
; LARGE32-NEXT: stw 0, 40(1)
-; LARGE32-NEXT: mr 6, 4
; LARGE32-NEXT: mr 7, 3
-; LARGE32-NEXT: addis 3, L..C4 at u(2)
-; LARGE32-NEXT: addis 4, L..C5 at u(2)
-; LARGE32-NEXT: lwz 3, L..C4 at l(3)
-; LARGE32-NEXT: lwz 4, L..C5 at l(4)
-; LARGE32-NEXT: bla .__tls_get_addr[PR]
+; LARGE32-NEXT: mr 6, 4
+; LARGE32-NEXT: addis 8, L..C4 at u(2)
+; LARGE32-NEXT: addis 3, L..C3 at u(2)
+; LARGE32-NEXT: lwz 3, L..C3 at l(3)
+; LARGE32-NEXT: bla .__tls_get_mod[PR]
+; LARGE32-NEXT: lwz 4, L..C4 at l(8)
+; LARGE32-NEXT: stwux 7, 3, 4
; LARGE32-NEXT: stw 6, 4(3)
-; LARGE32-NEXT: stw 7, 0(3)
; LARGE32-NEXT: addi 1, 1, 32
; LARGE32-NEXT: lwz 0, 8(1)
; LARGE32-NEXT: mtlr 0
@@ -208,11 +208,11 @@ define void @storesTIInit(i64 %Val) #0 {
; SMALL64-NEXT: mflr 0
; SMALL64-NEXT: stdu 1, -48(1)
; SMALL64-NEXT: mr 6, 3
-; SMALL64-NEXT: ld 3, L..C4(2)
-; SMALL64-NEXT: ld 4, L..C5(2)
+; SMALL64-NEXT: ld 3, L..C2(2)
; SMALL64-NEXT: std 0, 64(1)
-; SMALL64-NEXT: bla .__tls_get_addr[PR]
-; SMALL64-NEXT: std 6, 0(3)
+; SMALL64-NEXT: bla .__tls_get_mod[PR]
+; SMALL64-NEXT: ld 4, L..C4(2)
+; SMALL64-NEXT: stdx 6, 3, 4
; SMALL64-NEXT: addi 1, 1, 48
; SMALL64-NEXT: ld 0, 16(1)
; SMALL64-NEXT: mtlr 0
@@ -223,13 +223,13 @@ define void @storesTIInit(i64 %Val) #0 {
; LARGE64-NEXT: mflr 0
; LARGE64-NEXT: stdu 1, -48(1)
; LARGE64-NEXT: mr 6, 3
-; LARGE64-NEXT: addis 3, L..C4 at u(2)
-; LARGE64-NEXT: addis 4, L..C5 at u(2)
+; LARGE64-NEXT: addis 3, L..C2 at u(2)
; LARGE64-NEXT: std 0, 64(1)
-; LARGE64-NEXT: ld 3, L..C4 at l(3)
-; LARGE64-NEXT: ld 4, L..C5 at l(4)
-; LARGE64-NEXT: bla .__tls_get_addr[PR]
-; LARGE64-NEXT: std 6, 0(3)
+; LARGE64-NEXT: addis 7, L..C4 at u(2)
+; LARGE64-NEXT: ld 3, L..C2 at l(3)
+; LARGE64-NEXT: bla .__tls_get_mod[PR]
+; LARGE64-NEXT: ld 4, L..C4 at l(7)
+; LARGE64-NEXT: stdx 6, 3, 4
; LARGE64-NEXT: addi 1, 1, 48
; LARGE64-NEXT: ld 0, 16(1)
; LARGE64-NEXT: mtlr 0
@@ -247,8 +247,8 @@ define void @storesTWInit(i64 %Val) #0 {
; SMALL32-NEXT: stwu 1, -32(1)
; SMALL32-NEXT: mr 6, 4
; SMALL32-NEXT: mr 7, 3
-; SMALL32-NEXT: lwz 3, L..C6(2)
-; SMALL32-NEXT: lwz 4, L..C7(2)
+; SMALL32-NEXT: lwz 3, L..C5(2)
+; SMALL32-NEXT: lwz 4, L..C6(2)
; SMALL32-NEXT: stw 0, 40(1)
; SMALL32-NEXT: bla .__tls_get_addr[PR]
; SMALL32-NEXT: stw 6, 4(3)
@@ -265,10 +265,10 @@ define void @storesTWInit(i64 %Val) #0 {
; LARGE32-NEXT: stw 0, 40(1)
; LARGE32-NEXT: mr 6, 4
; LARGE32-NEXT: mr 7, 3
-; LARGE32-NEXT: addis 3, L..C6 at u(2)
-; LARGE32-NEXT: addis 4, L..C7 at u(2)
-; LARGE32-NEXT: lwz 3, L..C6 at l(3)
-; LARGE32-NEXT: lwz 4, L..C7 at l(4)
+; LARGE32-NEXT: addis 3, L..C5 at u(2)
+; LARGE32-NEXT: addis 4, L..C6 at u(2)
+; LARGE32-NEXT: lwz 3, L..C5 at l(3)
+; LARGE32-NEXT: lwz 4, L..C6 at l(4)
; LARGE32-NEXT: bla .__tls_get_addr[PR]
; LARGE32-NEXT: stw 6, 4(3)
; LARGE32-NEXT: stw 7, 0(3)
@@ -282,8 +282,8 @@ define void @storesTWInit(i64 %Val) #0 {
; SMALL64-NEXT: mflr 0
; SMALL64-NEXT: stdu 1, -48(1)
; SMALL64-NEXT: mr 6, 3
-; SMALL64-NEXT: ld 3, L..C6(2)
-; SMALL64-NEXT: ld 4, L..C7(2)
+; SMALL64-NEXT: ld 3, L..C5(2)
+; SMALL64-NEXT: ld 4, L..C6(2)
; SMALL64-NEXT: std 0, 64(1)
; SMALL64-NEXT: bla .__tls_get_addr[PR]
; SMALL64-NEXT: std 6, 0(3)
@@ -297,11 +297,11 @@ define void @storesTWInit(i64 %Val) #0 {
; LARGE64-NEXT: mflr 0
; LARGE64-NEXT: stdu 1, -48(1)
; LARGE64-NEXT: mr 6, 3
-; LARGE64-NEXT: addis 3, L..C6 at u(2)
-; LARGE64-NEXT: addis 4, L..C7 at u(2)
+; LARGE64-NEXT: addis 3, L..C5 at u(2)
+; LARGE64-NEXT: addis 4, L..C6 at u(2)
; LARGE64-NEXT: std 0, 64(1)
-; LARGE64-NEXT: ld 3, L..C6 at l(3)
-; LARGE64-NEXT: ld 4, L..C7 at l(4)
+; LARGE64-NEXT: ld 3, L..C5 at l(3)
+; LARGE64-NEXT: ld 4, L..C6 at l(4)
; LARGE64-NEXT: bla .__tls_get_addr[PR]
; LARGE64-NEXT: std 6, 0(3)
; LARGE64-NEXT: addi 1, 1, 48
@@ -323,7 +323,7 @@ define i64 @loadsTGInit() #1 {
; SMALL32-NEXT: lwz 4, L..C1(2)
; SMALL32-NEXT: stw 0, 40(1)
; SMALL32-NEXT: bla .__tls_get_addr[PR]
-; SMALL32-NEXT: lwz 4, L..C8(2)
+; SMALL32-NEXT: lwz 4, L..C7(2)
; SMALL32-NEXT: lwz 5, 4(3)
; SMALL32-NEXT: lwz 6, 4(4)
; SMALL32-NEXT: lwz 3, 0(3)
@@ -347,8 +347,8 @@ define i64 @loadsTGInit() #1 {
; LARGE32-NEXT: bla .__tls_get_addr[PR]
; LARGE32-NEXT: lwz 4, 4(3)
; LARGE32-NEXT: lwz 3, 0(3)
-; LARGE32-NEXT: addis 5, L..C8 at u(2)
-; LARGE32-NEXT: lwz 5, L..C8 at l(5)
+; LARGE32-NEXT: addis 5, L..C7 at u(2)
+; LARGE32-NEXT: lwz 5, L..C7 at l(5)
; LARGE32-NEXT: lwz 6, 4(5)
; LARGE32-NEXT: lwz 5, 0(5)
; LARGE32-NEXT: addc 4, 6, 4
@@ -366,7 +366,7 @@ define i64 @loadsTGInit() #1 {
; SMALL64-NEXT: ld 4, L..C1(2)
; SMALL64-NEXT: std 0, 64(1)
; SMALL64-NEXT: bla .__tls_get_addr[PR]
-; SMALL64-NEXT: ld 4, L..C8(2)
+; SMALL64-NEXT: ld 4, L..C7(2)
; SMALL64-NEXT: ld 3, 0(3)
; SMALL64-NEXT: ld 4, 0(4)
; SMALL64-NEXT: add 3, 4, 3
@@ -385,9 +385,9 @@ define i64 @loadsTGInit() #1 {
; LARGE64-NEXT: ld 3, L..C0 at l(3)
; LARGE64-NEXT: ld 4, L..C1 at l(4)
; LARGE64-NEXT: bla .__tls_get_addr[PR]
-; LARGE64-NEXT: addis 4, L..C8 at u(2)
+; LARGE64-NEXT: addis 4, L..C7 at u(2)
; LARGE64-NEXT: ld 3, 0(3)
-; LARGE64-NEXT: ld 4, L..C8 at l(4)
+; LARGE64-NEXT: ld 4, L..C7 at l(4)
; LARGE64-NEXT: ld 4, 0(4)
; LARGE64-NEXT: add 3, 4, 3
; LARGE64-NEXT: addi 1, 1, 48
@@ -408,16 +408,16 @@ define i64 @loadsTIUninit() #1 {
; SMALL32-NEXT: mflr 0
; SMALL32-NEXT: stwu 1, -32(1)
; SMALL32-NEXT: lwz 3, L..C2(2)
-; SMALL32-NEXT: lwz 4, L..C3(2)
; SMALL32-NEXT: stw 0, 40(1)
-; SMALL32-NEXT: bla .__tls_get_addr[PR]
-; SMALL32-NEXT: lwz 4, L..C8(2)
-; SMALL32-NEXT: lwz 5, 4(3)
-; SMALL32-NEXT: lwz 6, 4(4)
-; SMALL32-NEXT: lwz 3, 0(3)
-; SMALL32-NEXT: lwz 7, 0(4)
-; SMALL32-NEXT: addc 4, 6, 5
-; SMALL32-NEXT: adde 3, 7, 3
+; SMALL32-NEXT: bla .__tls_get_mod[PR]
+; SMALL32-NEXT: lwz 4, L..C3(2)
+; SMALL32-NEXT: lwz 5, L..C7(2)
+; SMALL32-NEXT: lwzux 6, 3, 4
+; SMALL32-NEXT: lwz 4, 4(5)
+; SMALL32-NEXT: lwz 3, 4(3)
+; SMALL32-NEXT: lwz 5, 0(5)
+; SMALL32-NEXT: addc 4, 4, 3
+; SMALL32-NEXT: adde 3, 5, 6
; SMALL32-NEXT: addi 1, 1, 32
; SMALL32-NEXT: lwz 0, 8(1)
; SMALL32-NEXT: mtlr 0
@@ -428,19 +428,19 @@ define i64 @loadsTIUninit() #1 {
; LARGE32-NEXT: mflr 0
; LARGE32-NEXT: stwu 1, -32(1)
; LARGE32-NEXT: stw 0, 40(1)
-; LARGE32-NEXT: addis 3, L..C2 at u(2)
-; LARGE32-NEXT: addis 4, L..C3 at u(2)
-; LARGE32-NEXT: lwz 3, L..C2 at l(3)
-; LARGE32-NEXT: lwz 4, L..C3 at l(4)
-; LARGE32-NEXT: bla .__tls_get_addr[PR]
-; LARGE32-NEXT: lwz 4, 4(3)
-; LARGE32-NEXT: lwz 3, 0(3)
-; LARGE32-NEXT: addis 5, L..C8 at u(2)
-; LARGE32-NEXT: lwz 5, L..C8 at l(5)
-; LARGE32-NEXT: lwz 6, 4(5)
-; LARGE32-NEXT: lwz 5, 0(5)
-; LARGE32-NEXT: addc 4, 6, 4
-; LARGE32-NEXT: adde 3, 5, 3
+; LARGE32-NEXT: addis 6, L..C2 at u(2)
+; LARGE32-NEXT: addis 3, L..C3 at u(2)
+; LARGE32-NEXT: lwz 3, L..C3 at l(3)
+; LARGE32-NEXT: bla .__tls_get_mod[PR]
+; LARGE32-NEXT: lwz 4, L..C2 at l(6)
+; LARGE32-NEXT: lwzux 5, 3, 4
+; LARGE32-NEXT: lwz 3, 4(3)
+; LARGE32-NEXT: addis 4, L..C7 at u(2)
+; LARGE32-NEXT: lwz 4, L..C7 at l(4)
+; LARGE32-NEXT: lwz 6, 4(4)
+; LARGE32-NEXT: lwz 7, 0(4)
+; LARGE32-NEXT: addc 4, 6, 3
+; LARGE32-NEXT: adde 3, 7, 5
; LARGE32-NEXT: addi 1, 1, 32
; LARGE32-NEXT: lwz 0, 8(1)
; LARGE32-NEXT: mtlr 0
@@ -451,11 +451,11 @@ define i64 @loadsTIUninit() #1 {
; SMALL64-NEXT: mflr 0
; SMALL64-NEXT: stdu 1, -48(1)
; SMALL64-NEXT: ld 3, L..C2(2)
-; SMALL64-NEXT: ld 4, L..C3(2)
; SMALL64-NEXT: std 0, 64(1)
-; SMALL64-NEXT: bla .__tls_get_addr[PR]
-; SMALL64-NEXT: ld 4, L..C8(2)
-; SMALL64-NEXT: ld 3, 0(3)
+; SMALL64-NEXT: bla .__tls_get_mod[PR]
+; SMALL64-NEXT: ld 4, L..C3(2)
+; SMALL64-NEXT: ldx 3, 3, 4
+; SMALL64-NEXT: ld 4, L..C7(2)
; SMALL64-NEXT: ld 4, 0(4)
; SMALL64-NEXT: add 3, 4, 3
; SMALL64-NEXT: addi 1, 1, 48
@@ -468,14 +468,14 @@ define i64 @loadsTIUninit() #1 {
; LARGE64-NEXT: mflr 0
; LARGE64-NEXT: stdu 1, -48(1)
; LARGE64-NEXT: addis 3, L..C2 at u(2)
-; LARGE64-NEXT: addis 4, L..C3 at u(2)
; LARGE64-NEXT: std 0, 64(1)
+; LARGE64-NEXT: addis 6, L..C3 at u(2)
; LARGE64-NEXT: ld 3, L..C2 at l(3)
-; LARGE64-NEXT: ld 4, L..C3 at l(4)
-; LARGE64-NEXT: bla .__tls_get_addr[PR]
-; LARGE64-NEXT: addis 4, L..C8 at u(2)
-; LARGE64-NEXT: ld 3, 0(3)
-; LARGE64-NEXT: ld 4, L..C8 at l(4)
+; LARGE64-NEXT: bla .__tls_get_mod[PR]
+; LARGE64-NEXT: ld 4, L..C3 at l(6)
+; LARGE64-NEXT: addis 5, L..C7 at u(2)
+; LARGE64-NEXT: ldx 3, 3, 4
+; LARGE64-NEXT: ld 4, L..C7 at l(5)
; LARGE64-NEXT: ld 4, 0(4)
; LARGE64-NEXT: add 3, 4, 3
; LARGE64-NEXT: addi 1, 1, 48
@@ -495,17 +495,17 @@ define i64 @loadsTIInit() #1 {
; SMALL32: # %bb.0: # %entry
; SMALL32-NEXT: mflr 0
; SMALL32-NEXT: stwu 1, -32(1)
-; SMALL32-NEXT: lwz 3, L..C4(2)
-; SMALL32-NEXT: lwz 4, L..C5(2)
+; SMALL32-NEXT: lwz 3, L..C2(2)
; SMALL32-NEXT: stw 0, 40(1)
-; SMALL32-NEXT: bla .__tls_get_addr[PR]
-; SMALL32-NEXT: lwz 4, L..C8(2)
-; SMALL32-NEXT: lwz 5, 4(3)
-; SMALL32-NEXT: lwz 6, 4(4)
-; SMALL32-NEXT: lwz 3, 0(3)
-; SMALL32-NEXT: lwz 7, 0(4)
-; SMALL32-NEXT: addc 4, 6, 5
-; SMALL32-NEXT: adde 3, 7, 3
+; SMALL32-NEXT: bla .__tls_get_mod[PR]
+; SMALL32-NEXT: lwz 4, L..C4(2)
+; SMALL32-NEXT: lwz 5, L..C7(2)
+; SMALL32-NEXT: lwzux 6, 3, 4
+; SMALL32-NEXT: lwz 4, 4(5)
+; SMALL32-NEXT: lwz 3, 4(3)
+; SMALL32-NEXT: lwz 5, 0(5)
+; SMALL32-NEXT: addc 4, 4, 3
+; SMALL32-NEXT: adde 3, 5, 6
; SMALL32-NEXT: addi 1, 1, 32
; SMALL32-NEXT: lwz 0, 8(1)
; SMALL32-NEXT: mtlr 0
@@ -516,19 +516,19 @@ define i64 @loadsTIInit() #1 {
; LARGE32-NEXT: mflr 0
; LARGE32-NEXT: stwu 1, -32(1)
; LARGE32-NEXT: stw 0, 40(1)
-; LARGE32-NEXT: addis 3, L..C4 at u(2)
-; LARGE32-NEXT: addis 4, L..C5 at u(2)
-; LARGE32-NEXT: lwz 3, L..C4 at l(3)
-; LARGE32-NEXT: lwz 4, L..C5 at l(4)
-; LARGE32-NEXT: bla .__tls_get_addr[PR]
-; LARGE32-NEXT: lwz 4, 4(3)
-; LARGE32-NEXT: lwz 3, 0(3)
-; LARGE32-NEXT: addis 5, L..C8 at u(2)
-; LARGE32-NEXT: lwz 5, L..C8 at l(5)
-; LARGE32-NEXT: lwz 6, 4(5)
-; LARGE32-NEXT: lwz 5, 0(5)
-; LARGE32-NEXT: addc 4, 6, 4
-; LARGE32-NEXT: adde 3, 5, 3
+; LARGE32-NEXT: addis 6, L..C4 at u(2)
+; LARGE32-NEXT: addis 3, L..C3 at u(2)
+; LARGE32-NEXT: lwz 3, L..C3 at l(3)
+; LARGE32-NEXT: bla .__tls_get_mod[PR]
+; LARGE32-NEXT: lwz 4, L..C4 at l(6)
+; LARGE32-NEXT: lwzux 5, 3, 4
+; LARGE32-NEXT: lwz 3, 4(3)
+; LARGE32-NEXT: addis 4, L..C7 at u(2)
+; LARGE32-NEXT: lwz 4, L..C7 at l(4)
+; LARGE32-NEXT: lwz 6, 4(4)
+; LARGE32-NEXT: lwz 7, 0(4)
+; LARGE32-NEXT: addc 4, 6, 3
+; LARGE32-NEXT: adde 3, 7, 5
; LARGE32-NEXT: addi 1, 1, 32
; LARGE32-NEXT: lwz 0, 8(1)
; LARGE32-NEXT: mtlr 0
@@ -538,12 +538,12 @@ define i64 @loadsTIInit() #1 {
; SMALL64: # %bb.0: # %entry
; SMALL64-NEXT: mflr 0
; SMALL64-NEXT: stdu 1, -48(1)
-; SMALL64-NEXT: ld 3, L..C4(2)
-; SMALL64-NEXT: ld 4, L..C5(2)
+; SMALL64-NEXT: ld 3, L..C2(2)
; SMALL64-NEXT: std 0, 64(1)
-; SMALL64-NEXT: bla .__tls_get_addr[PR]
-; SMALL64-NEXT: ld 4, L..C8(2)
-; SMALL64-NEXT: ld 3, 0(3)
+; SMALL64-NEXT: bla .__tls_get_mod[PR]
+; SMALL64-NEXT: ld 4, L..C4(2)
+; SMALL64-NEXT: ldx 3, 3, 4
+; SMALL64-NEXT: ld 4, L..C7(2)
; SMALL64-NEXT: ld 4, 0(4)
; SMALL64-NEXT: add 3, 4, 3
; SMALL64-NEXT: addi 1, 1, 48
@@ -555,15 +555,15 @@ define i64 @loadsTIInit() #1 {
; LARGE64: # %bb.0: # %entry
; LARGE64-NEXT: mflr 0
; LARGE64-NEXT: stdu 1, -48(1)
-; LARGE64-NEXT: addis 3, L..C4 at u(2)
-; LARGE64-NEXT: addis 4, L..C5 at u(2)
+; LARGE64-NEXT: addis 3, L..C2 at u(2)
; LARGE64-NEXT: std 0, 64(1)
-; LARGE64-NEXT: ld 3, L..C4 at l(3)
-; LARGE64-NEXT: ld 4, L..C5 at l(4)
-; LARGE64-NEXT: bla .__tls_get_addr[PR]
-; LARGE64-NEXT: addis 4, L..C8 at u(2)
-; LARGE64-NEXT: ld 3, 0(3)
-; LARGE64-NEXT: ld 4, L..C8 at l(4)
+; LARGE64-NEXT: addis 6, L..C4 at u(2)
+; LARGE64-NEXT: ld 3, L..C2 at l(3)
+; LARGE64-NEXT: bla .__tls_get_mod[PR]
+; LARGE64-NEXT: ld 4, L..C4 at l(6)
+; LARGE64-NEXT: addis 5, L..C7 at u(2)
+; LARGE64-NEXT: ldx 3, 3, 4
+; LARGE64-NEXT: ld 4, L..C7 at l(5)
; LARGE64-NEXT: ld 4, 0(4)
; LARGE64-NEXT: add 3, 4, 3
; LARGE64-NEXT: addi 1, 1, 48
@@ -583,11 +583,11 @@ define i64 @loadsTWInit() #1 {
; SMALL32: # %bb.0: # %entry
; SMALL32-NEXT: mflr 0
; SMALL32-NEXT: stwu 1, -32(1)
-; SMALL32-NEXT: lwz 3, L..C6(2)
-; SMALL32-NEXT: lwz 4, L..C7(2)
+; SMALL32-NEXT: lwz 3, L..C5(2)
+; SMALL32-NEXT: lwz 4, L..C6(2)
; SMALL32-NEXT: stw 0, 40(1)
; SMALL32-NEXT: bla .__tls_get_addr[PR]
-; SMALL32-NEXT: lwz 4, L..C8(2)
+; SMALL32-NEXT: lwz 4, L..C7(2)
; SMALL32-NEXT: lwz 5, 4(3)
; SMALL32-NEXT: lwz 6, 4(4)
; SMALL32-NEXT: lwz 3, 0(3)
@@ -604,15 +604,15 @@ define i64 @loadsTWInit() #1 {
; LARGE32-NEXT: mflr 0
; LARGE32-NEXT: stwu 1, -32(1)
; LARGE32-NEXT: stw 0, 40(1)
-; LARGE32-NEXT: addis 3, L..C6 at u(2)
-; LARGE32-NEXT: addis 4, L..C7 at u(2)
-; LARGE32-NEXT: lwz 3, L..C6 at l(3)
-; LARGE32-NEXT: lwz 4, L..C7 at l(4)
+; LARGE32-NEXT: addis 3, L..C5 at u(2)
+; LARGE32-NEXT: addis 4, L..C6 at u(2)
+; LARGE32-NEXT: lwz 3, L..C5 at l(3)
+; LARGE32-NEXT: lwz 4, L..C6 at l(4)
; LARGE32-NEXT: bla .__tls_get_addr[PR]
; LARGE32-NEXT: lwz 4, 4(3)
; LARGE32-NEXT: lwz 3, 0(3)
-; LARGE32-NEXT: addis 5, L..C8 at u(2)
-; LARGE32-NEXT: lwz 5, L..C8 at l(5)
+; LARGE32-NEXT: addis 5, L..C7 at u(2)
+; LARGE32-NEXT: lwz 5, L..C7 at l(5)
; LARGE32-NEXT: lwz 6, 4(5)
; LARGE32-NEXT: lwz 5, 0(5)
; LARGE32-NEXT: addc 4, 6, 4
@@ -626,11 +626,11 @@ define i64 @loadsTWInit() #1 {
; SMALL64: # %bb.0: # %entry
; SMALL64-NEXT: mflr 0
; SMALL64-NEXT: stdu 1, -48(1)
-; SMALL64-NEXT: ld 3, L..C6(2)
-; SMALL64-NEXT: ld 4, L..C7(2)
+; SMALL64-NEXT: ld 3, L..C5(2)
+; SMALL64-NEXT: ld 4, L..C6(2)
; SMALL64-NEXT: std 0, 64(1)
; SMALL64-NEXT: bla .__tls_get_addr[PR]
-; SMALL64-NEXT: ld 4, L..C8(2)
+; SMALL64-NEXT: ld 4, L..C7(2)
; SMALL64-NEXT: ld 3, 0(3)
; SMALL64-NEXT: ld 4, 0(4)
; SMALL64-NEXT: add 3, 4, 3
@@ -643,15 +643,15 @@ define i64 @loadsTWInit() #1 {
; LARGE64: # %bb.0: # %entry
; LARGE64-NEXT: mflr 0
; LARGE64-NEXT: stdu 1, -48(1)
-; LARGE64-NEXT: addis 3, L..C6 at u(2)
-; LARGE64-NEXT: addis 4, L..C7 at u(2)
+; LARGE64-NEXT: addis 3, L..C5 at u(2)
+; LARGE64-NEXT: addis 4, L..C6 at u(2)
; LARGE64-NEXT: std 0, 64(1)
-; LARGE64-NEXT: ld 3, L..C6 at l(3)
-; LARGE64-NEXT: ld 4, L..C7 at l(4)
+; LARGE64-NEXT: ld 3, L..C5 at l(3)
+; LARGE64-NEXT: ld 4, L..C6 at l(4)
; LARGE64-NEXT: bla .__tls_get_addr[PR]
-; LARGE64-NEXT: addis 4, L..C8 at u(2)
+; LARGE64-NEXT: addis 4, L..C7 at u(2)
; LARGE64-NEXT: ld 3, 0(3)
-; LARGE64-NEXT: ld 4, L..C8 at l(4)
+; LARGE64-NEXT: ld 4, L..C7 at l(4)
; LARGE64-NEXT: ld 4, 0(4)
; LARGE64-NEXT: add 3, 4, 3
; LARGE64-NEXT: addi 1, 1, 48
@@ -665,12 +665,16 @@ entry:
ret i64 %add
}
-; External symbol reference checks for .__tls_get_addr
+; External symbol reference checks for .__tls_get_addr/.__tls_get_mod
; SMALL32: .extern .__tls_get_addr[PR]
+; SMALL32: .extern .__tls_get_mod[PR]
; SMALL64: .extern .__tls_get_addr[PR]
+; SMALL64: .extern .__tls_get_mod[PR]
; LARGE32: .extern .__tls_get_addr[PR]
+; LARGE32: .extern .__tls_get_mod[PR]
; LARGE64: .extern .__tls_get_addr[PR]
+; LARGE64: .extern .__tls_get_mod[PR]
; TOC entry checks
@@ -680,18 +684,17 @@ entry:
; SMALL32-LABEL: L..C1:
; SMALL32-NEXT: .tc TGInit[TC],TGInit[TL]@gd
; SMALL32-LABEL: L..C2:
-; SMALL32-NEXT: .tc .TIUninit[TC],TIUninit[UL]@m
+; SMALL32-NEXT: .tc _Renamed..5f24__TLSML[TC],_Renamed..5f24__TLSML[TC]@ml
+; SMALL32-NEXT: .rename _Renamed..5f24__TLSML[TC],"_$TLSML"
; SMALL32-LABEL: L..C3:
-; SMALL32-NEXT: .tc TIUninit[TC],TIUninit[UL]@gd
+; SMALL32-NEXT: .tc TIUninit[TC],TIUninit[UL]@ld
; SMALL32-LABEL: L..C4:
-; SMALL32-NEXT: .tc .TIInit[TC],TIInit[TL]@m
+; SMALL32-NEXT: .tc TIInit[TC],TIInit[TL]@ld
; SMALL32-LABEL: L..C5:
-; SMALL32-NEXT: .tc TIInit[TC],TIInit[TL]@gd
-; SMALL32-LABEL: L..C6:
; SMALL32-NEXT: .tc .TWInit[TC],TWInit[TL]@m
-; SMALL32-LABEL: L..C7:
+; SMALL32-LABEL: L..C6:
; SMALL32-NEXT: .tc TWInit[TC],TWInit[TL]@gd
-; SMALL32-LABEL: L..C8:
+; SMALL32-LABEL: L..C7:
; SMALL32-NEXT: .tc GInit[TC],GInit[RW]
; LARGE32-LABEL: .toc
@@ -700,18 +703,17 @@ entry:
; LARGE32-LABEL: L..C1:
; LARGE32-NEXT: .tc TGInit[TE],TGInit[TL]@gd
; LARGE32-LABEL: L..C2:
-; LARGE32-NEXT: .tc .TIUninit[TE],TIUninit[UL]@m
+; LARGE32-NEXT: .tc TIUninit[TE],TIUninit[UL]@ld
; LARGE32-LABEL: L..C3:
-; LARGE32-NEXT: .tc TIUninit[TE],TIUninit[UL]@gd
+; LARGE32-NEXT: .tc _Renamed..5f24__TLSML[TC],_Renamed..5f24__TLSML[TC]@ml
+; LARGE32-NEXT: .rename _Renamed..5f24__TLSML[TC],"_$TLSML"
; LARGE32-LABEL: L..C4:
-; LARGE32-NEXT: .tc .TIInit[TE],TIInit[TL]@m
+; LARGE32-NEXT: .tc TIInit[TE],TIInit[TL]@ld
; LARGE32-LABEL: L..C5:
-; LARGE32-NEXT: .tc TIInit[TE],TIInit[TL]@gd
-; LARGE32-LABEL: L..C6:
; LARGE32-NEXT: .tc .TWInit[TE],TWInit[TL]@m
-; LARGE32-LABEL: L..C7:
+; LARGE32-LABEL: L..C6:
; LARGE32-NEXT: .tc TWInit[TE],TWInit[TL]@gd
-; LARGE32-LABEL: L..C8:
+; LARGE32-LABEL: L..C7:
; LARGE32-NEXT: .tc GInit[TE],GInit[RW]
; SMALL64-LABEL: .toc
@@ -720,18 +722,17 @@ entry:
; SMALL64-LABEL: L..C1:
; SMALL64-NEXT: .tc TGInit[TC],TGInit[TL]@gd
; SMALL64-LABEL: L..C2:
-; SMALL64-NEXT: .tc .TIUninit[TC],TIUninit[UL]@m
+; SMALL64-NEXT: .tc _Renamed..5f24__TLSML[TC],_Renamed..5f24__TLSML[TC]@ml
+; SMALL64-NEXT: .rename _Renamed..5f24__TLSML[TC],"_$TLSML"
; SMALL64-LABEL: L..C3:
-; SMALL64-NEXT: .tc TIUninit[TC],TIUninit[UL]@gd
+; SMALL64-NEXT: .tc TIUninit[TC],TIUninit[UL]@ld
; SMALL64-LABEL: L..C4:
-; SMALL64-NEXT: .tc .TIInit[TC],TIInit[TL]@m
+; SMALL64-NEXT: .tc TIInit[TC],TIInit[TL]@ld
; SMALL64-LABEL: L..C5:
-; SMALL64-NEXT: .tc TIInit[TC],TIInit[TL]@gd
-; SMALL64-LABEL: L..C6:
; SMALL64-NEXT: .tc .TWInit[TC],TWInit[TL]@m
-; SMALL64-LABEL: L..C7:
+; SMALL64-LABEL: L..C6:
; SMALL64-NEXT: .tc TWInit[TC],TWInit[TL]@gd
-; SMALL64-LABEL: L..C8:
+; SMALL64-LABEL: L..C7:
; SMALL64-NEXT: .tc GInit[TC],GInit[RW]
; LARGE64-LABEL: .toc
@@ -740,18 +741,17 @@ entry:
; LARGE64-LABEL: L..C1:
; LARGE64-NEXT: .tc TGInit[TE],TGInit[TL]@gd
; LARGE64-LABEL: L..C2:
-; LARGE64-NEXT: .tc .TIUninit[TE],TIUninit[UL]@m
+; LARGE64-NEXT: .tc _Renamed..5f24__TLSML[TC],_Renamed..5f24__TLSML[TC]@ml
+; LARGE64-NEXT: .rename _Renamed..5f24__TLSML[TC],"_$TLSML"
; LARGE64-LABEL: L..C3:
-; LARGE64-NEXT: .tc TIUninit[TE],TIUninit[UL]@gd
+; LARGE64-NEXT: .tc TIUninit[TE],TIUninit[UL]@ld
; LARGE64-LABEL: L..C4:
-; LARGE64-NEXT: .tc .TIInit[TE],TIInit[TL]@m
+; LARGE64-NEXT: .tc TIInit[TE],TIInit[TL]@ld
; LARGE64-LABEL: L..C5:
-; LARGE64-NEXT: .tc TIInit[TE],TIInit[TL]@gd
-; LARGE64-LABEL: L..C6:
; LARGE64-NEXT: .tc .TWInit[TE],TWInit[TL]@m
-; LARGE64-LABEL: L..C7:
+; LARGE64-LABEL: L..C6:
; LARGE64-NEXT: .tc TWInit[TE],TWInit[TL]@gd
-; LARGE64-LABEL: L..C8:
+; LARGE64-LABEL: L..C7:
; LARGE64-NEXT: .tc GInit[TE],GInit[RW]
attributes #0 = { nofree norecurse nounwind willreturn writeonly "frame-pointer"="none" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="pwr4" "target-features"="-altivec,-bpermd,-crypto,-direct-move,-extdiv,-float128,-htm,-mma,-paired-vector-memops,-power10-vector,-power8-vector,-power9-vector,-spe,-vsx" }
diff --git a/llvm/test/CodeGen/PowerPC/aix-tls-ld-xcoff-reloc-large.ll b/llvm/test/CodeGen/PowerPC/aix-tls-ld-xcoff-reloc-large.ll
new file mode 100644
index 00000000000000..73741a210ed298
--- /dev/null
+++ b/llvm/test/CodeGen/PowerPC/aix-tls-ld-xcoff-reloc-large.ll
@@ -0,0 +1,349 @@
+; RUN: llc -verify-machineinstrs -mcpu=pwr7 -mattr=-altivec -mtriple powerpc64-ibm-aix-xcoff \
+; RUN: -xcoff-traceback-table=false --code-model=large -filetype=obj -o %t.o < %s
+; RUN: llvm-readobj --relocs --expand-relocs %t.o | FileCheck -D#NFA=2 --check-prefix=RELOC %s
+; RUN: llvm-readobj --syms %t.o | FileCheck -D#NFA=2 --check-prefix=SYM %s
+; RUN: llvm-objdump -D -r --symbol-description %t.o | FileCheck -D#NFA=2 --check-prefix=DIS %s
+
+ at ThreadLocalVarInit = thread_local(localdynamic) global i64 1, align 8
+ at IThreadLocalVarUninit = internal thread_local(localdynamic) global i64 0, align 8
+ at IThreadLocalVarUninit2 = internal thread_local(localdynamic) global i64 0, align 8
+declare nonnull ptr @llvm.threadlocal.address.p0(ptr nonnull)
+
+define void @storeITLUninit(i64 noundef %x) {
+entry:
+ %0 = tail call align 8 ptr @llvm.threadlocal.address.p0(ptr align 8 @IThreadLocalVarUninit)
+ store i64 %x, ptr %0, align 8
+ ret void
+}
+
+define i64 @loadTLInit() {
+entry:
+ %0 = tail call align 8 ptr @llvm.threadlocal.address.p0(ptr align 8 @ThreadLocalVarInit)
+ %1 = load i64, ptr %0, align 8
+ ret i64 %1
+}
+
+define signext i64 @loadTLUninit() {
+entry:
+ %0 = tail call align 8 ptr @llvm.threadlocal.address.p0(ptr align 8 @IThreadLocalVarUninit)
+ store i64 1, ptr %0, align 8
+ %1 = tail call align 8 ptr @llvm.threadlocal.address.p0(ptr align 8 @IThreadLocalVarUninit2)
+ %2 = load i64, ptr %1, align 8
+ %add = add nsw i64 %2, 1
+ ret i64 %add
+}
+
+; RELOC: File: {{.*}}aix-tls-ld-xcoff-reloc-large.ll.tmp.o
+; RELOC-NEXT: Format: aix5coff64-rs6000
+; RELOC-NEXT: Arch: powerpc64
+; RELOC-NEXT: AddressSize: 64bit
+; RELOC-NEXT: Relocations [
+; RELOC: Virtual Address: 0xE
+; RELOC-NEXT: Symbol: _$TLSML ([[#NFA+19]])
+; RELOC-NEXT: IsSigned: No
+; RELOC-NEXT: FixupBitValue: 0
+; RELOC-NEXT: Length: 16
+; RELOC-NEXT: Type: R_TOCU (0x30)
+; RELOC-NEXT: }
+; RELOC: Virtual Address: 0x12
+; RELOC-NEXT: Symbol: IThreadLocalVarUninit ([[#NFA+21]])
+; RELOC-NEXT: IsSigned: No
+; RELOC-NEXT: FixupBitValue: 0
+; RELOC-NEXT: Length: 16
+; RELOC-NEXT: Type: R_TOCU (0x30)
+; RELOC-NEXT: }
+; RELOC: Virtual Address: 0x1A
+; RELOC-NEXT: Symbol: _$TLSML ([[#NFA+19]])
+; RELOC-NEXT: IsSigned: No
+; RELOC-NEXT: FixupBitValue: 0
+; RELOC-NEXT: Length: 16
+; RELOC-NEXT: Type: R_TOCL (0x31)
+; RELOC-NEXT: }
+; RELOC: Virtual Address: 0x1C
+; RELOC-NEXT: Symbol: .__tls_get_mod ([[#NFA+1]])
+; RELOC-NEXT: IsSigned: No
+; RELOC-NEXT: FixupBitValue: 0
+; RELOC-NEXT: Length: 26
+; RELOC-NEXT: Type: R_RBA (0x18)
+; RELOC-NEXT: }
+; RELOC: Virtual Address: 0x22
+; RELOC-NEXT: Symbol: IThreadLocalVarUninit ([[#NFA+21]])
+; RELOC-NEXT: IsSigned: No
+; RELOC-NEXT: FixupBitValue: 0
+; RELOC-NEXT: Length: 16
+; RELOC-NEXT: Type: R_TOCL (0x31)
+; RELOC-NEXT: }
+; RELOC: Virtual Address: 0x4A
+; RELOC-NEXT: Symbol: _$TLSML ([[#NFA+19]])
+; RELOC-NEXT: IsSigned: No
+; RELOC-NEXT: FixupBitValue: 0
+; RELOC-NEXT: Length: 16
+; RELOC-NEXT: Type: R_TOCU (0x30)
+; RELOC-NEXT: }
+; RELOC: Virtual Address: 0x4E
+; RELOC-NEXT: Symbol: ThreadLocalVarInit ([[#NFA+23]])
+; RELOC-NEXT: IsSigned: No
+; RELOC-NEXT: FixupBitValue: 0
+; RELOC-NEXT: Length: 16
+; RELOC-NEXT: Type: R_TOCU (0x30)
+; RELOC-NEXT: }
+; RELOC: Virtual Address: 0x56
+; RELOC-NEXT: Symbol: _$TLSML ([[#NFA+19]])
+; RELOC-NEXT: IsSigned: No
+; RELOC-NEXT: FixupBitValue: 0
+; RELOC-NEXT: Length: 16
+; RELOC-NEXT: Type: R_TOCL (0x31)
+; RELOC-NEXT: }
+; RELOC: Virtual Address: 0x58
+; RELOC-NEXT: Symbol: .__tls_get_mod ([[#NFA+1]])
+; RELOC-NEXT: IsSigned: No
+; RELOC-NEXT: FixupBitValue: 0
+; RELOC-NEXT: Length: 26
+; RELOC-NEXT: Type: R_RBA (0x18)
+; RELOC-NEXT: }
+; RELOC: Virtual Address: 0x5E
+; RELOC-NEXT: Symbol: ThreadLocalVarInit ([[#NFA+23]])
+; RELOC-NEXT: IsSigned: No
+; RELOC-NEXT: FixupBitValue: 0
+; RELOC-NEXT: Length: 16
+; RELOC-NEXT: Type: R_TOCL (0x31)
+; RELOC-NEXT: }
+; RELOC: Virtual Address: 0x8A
+; RELOC-NEXT: Symbol: _$TLSML ([[#NFA+19]])
+; RELOC-NEXT: IsSigned: No
+; RELOC-NEXT: FixupBitValue: 0
+; RELOC-NEXT: Length: 16
+; RELOC-NEXT: Type: R_TOCU (0x30)
+; RELOC-NEXT: }
+; RELOC: Virtual Address: 0x8E
+; RELOC-NEXT: Symbol: IThreadLocalVarUninit ([[#NFA+21]])
+; RELOC-NEXT: IsSigned: No
+; RELOC-NEXT: FixupBitValue: 0
+; RELOC-NEXT: Length: 16
+; RELOC-NEXT: Type: R_TOCU (0x30)
+; RELOC-NEXT: }
+; RELOC: Virtual Address: 0x96
+; RELOC-NEXT: Symbol: _$TLSML ([[#NFA+19]])
+; RELOC-NEXT: IsSigned: No
+; RELOC-NEXT: FixupBitValue: 0
+; RELOC-NEXT: Length: 16
+; RELOC-NEXT: Type: R_TOCL (0x31)
+; RELOC-NEXT: }
+; RELOC: Virtual Address: 0x98
+; RELOC-NEXT: Symbol: .__tls_get_mod (3)
+; RELOC-NEXT: IsSigned: No
+; RELOC-NEXT: FixupBitValue: 0
+; RELOC-NEXT: Length: 26
+; RELOC-NEXT: Type: R_RBA (0x18)
+; RELOC-NEXT: }
+; RELOC: Virtual Address: 0x9E
+; RELOC-NEXT: Symbol: IThreadLocalVarUninit ([[#NFA+21]])
+; RELOC-NEXT: IsSigned: No
+; RELOC-NEXT: FixupBitValue: 0
+; RELOC-NEXT: Length: 16
+; RELOC-NEXT: Type: R_TOCL (0x31)
+; RELOC-NEXT: }
+; RELOC: Virtual Address: 0xAA
+; RELOC-NEXT: Symbol: IThreadLocalVarUninit2 ([[#NFA+25]])
+; RELOC-NEXT: IsSigned: No
+; RELOC-NEXT: FixupBitValue: 0
+; RELOC-NEXT: Length: 16
+; RELOC-NEXT: Type: R_TOCU (0x30)
+; RELOC-NEXT: }
+; RELOC: Virtual Address: 0xAE
+; RELOC-NEXT: Symbol: IThreadLocalVarUninit2 ([[#NFA+25]])
+; RELOC-NEXT: IsSigned: No
+; RELOC-NEXT: FixupBitValue: 0
+; RELOC-NEXT: Length: 16
+; RELOC-NEXT: Type: R_TOCL (0x31)
+; RELOC-NEXT: }
+; RELOC: Virtual Address: 0x110
+; RELOC-NEXT: Symbol: _$TLSML ([[#NFA+19]])
+; RELOC-NEXT: IsSigned: No
+; RELOC-NEXT: FixupBitValue: 0
+; RELOC-NEXT: Length: 64
+; RELOC-NEXT: Type: R_TLSML (0x25)
+; RELOC-NEXT: }
+; RELOC: Virtual Address: 0x118
+; RELOC-NEXT: Symbol: IThreadLocalVarUninit ([[#NFA+29]])
+; RELOC-NEXT: IsSigned: No
+; RELOC-NEXT: FixupBitValue: 0
+; RELOC-NEXT: Length: 64
+; RELOC-NEXT: Type: R_TLS_LD (0x22)
+; RELOC-NEXT: }
+; RELOC: Virtual Address: 0x120
+; RELOC-NEXT: Symbol: ThreadLocalVarInit ([[#NFA+27]])
+; RELOC-NEXT: IsSigned: No
+; RELOC-NEXT: FixupBitValue: 0
+; RELOC-NEXT: Length: 64
+; RELOC-NEXT: Type: R_TLS_LD (0x22)
+; RELOC-NEXT: }
+; RELOC: Virtual Address: 0x128
+; RELOC-NEXT: Symbol: IThreadLocalVarUninit2 ([[#NFA+31]])
+; RELOC-NEXT: IsSigned: No
+; RELOC-NEXT: FixupBitValue: 0
+; RELOC-NEXT: Length: 64
+; RELOC-NEXT: Type: R_TLS_LD (0x22)
+; RELOC-NEXT: }
+
+; SYM: File: {{.*}}aix-tls-ld-xcoff-reloc-large.ll.tmp.o
+; SYM-NEXT: Format: aix5coff64-rs6000
+; SYM-NEXT: Arch: powerpc64
+; SYM-NEXT: AddressSize: 64bit
+; SYM-NEXT: Symbols [
+; SYM: Index: [[#NFA+19]]
+; SYM-NEXT: Name: _$TLSML
+; SYM-NEXT: Value (RelocatableAddress): 0x110
+; SYM-NEXT: Section: .data
+; SYM-NEXT: Type: 0x0
+; SYM-NEXT: StorageClass: C_HIDEXT (0x6B)
+; SYM-NEXT: NumberOfAuxEntries: 1
+; SYM-NEXT: CSECT Auxiliary Entry {
+; SYM-NEXT: Index: [[#NFA+20]]
+; SYM-NEXT: SectionLen: 8
+; SYM-NEXT: ParameterHashIndex: 0x0
+; SYM-NEXT: TypeChkSectNum: 0x0
+; SYM-NEXT: SymbolAlignmentLog2: 3
+; SYM-NEXT: SymbolType: XTY_SD (0x1)
+; SYM-NEXT: StorageMappingClass: XMC_TC (0x3)
+; SYM-NEXT: Auxiliary Type: AUX_CSECT (0xFB)
+; SYM-NEXT: }
+; SYM-NEXT: }
+; SYM: Index: [[#NFA+21]]
+; SYM-NEXT: Name: IThreadLocalVarUninit
+; SYM-NEXT: Value (RelocatableAddress): 0x118
+; SYM-NEXT: Section: .data
+; SYM-NEXT: Type: 0x0
+; SYM-NEXT: StorageClass: C_HIDEXT (0x6B)
+; SYM-NEXT: NumberOfAuxEntries: 1
+; SYM-NEXT: CSECT Auxiliary Entry {
+; SYM-NEXT: Index: [[#NFA+22]]
+; SYM-NEXT: SectionLen: 8
+; SYM-NEXT: ParameterHashIndex: 0x0
+; SYM-NEXT: TypeChkSectNum: 0x0
+; SYM-NEXT: SymbolAlignmentLog2: 3
+; SYM-NEXT: SymbolType: XTY_SD (0x1)
+; SYM-NEXT: StorageMappingClass: XMC_TE (0x16)
+; SYM-NEXT: Auxiliary Type: AUX_CSECT (0xFB)
+; SYM-NEXT: }
+; SYM-NEXT: }
+; SYM: Index: [[#NFA+23]]
+; SYM-NEXT: Name: ThreadLocalVarInit
+; SYM-NEXT: Value (RelocatableAddress): 0x120
+; SYM-NEXT: Section: .data
+; SYM-NEXT: Type: 0x0
+; SYM-NEXT: StorageClass: C_HIDEXT (0x6B)
+; SYM-NEXT: NumberOfAuxEntries: 1
+; SYM-NEXT: CSECT Auxiliary Entry {
+; SYM-NEXT: Index: [[#NFA+24]]
+; SYM-NEXT: SectionLen: 8
+; SYM-NEXT: ParameterHashIndex: 0x0
+; SYM-NEXT: TypeChkSectNum: 0x0
+; SYM-NEXT: SymbolAlignmentLog2: 3
+; SYM-NEXT: SymbolType: XTY_SD (0x1)
+; SYM-NEXT: StorageMappingClass: XMC_TE (0x16)
+; SYM-NEXT: Auxiliary Type: AUX_CSECT (0xFB)
+; SYM-NEXT: }
+; SYM-NEXT: }
+; SYM: Index: [[#NFA+25]]
+; SYM-NEXT: Name: IThreadLocalVarUninit2
+; SYM-NEXT: Value (RelocatableAddress): 0x128
+; SYM-NEXT: Section: .data
+; SYM-NEXT: Type: 0x0
+; SYM-NEXT: StorageClass: C_HIDEXT (0x6B)
+; SYM-NEXT: NumberOfAuxEntries: 1
+; SYM-NEXT: CSECT Auxiliary Entry {
+; SYM-NEXT: Index: [[#NFA+26]]
+; SYM-NEXT: SectionLen: 8
+; SYM-NEXT: ParameterHashIndex: 0x0
+; SYM-NEXT: TypeChkSectNum: 0x0
+; SYM-NEXT: SymbolAlignmentLog2: 3
+; SYM-NEXT: SymbolType: XTY_SD (0x1)
+; SYM-NEXT: StorageMappingClass: XMC_TE (0x16)
+; SYM-NEXT: Auxiliary Type: AUX_CSECT (0xFB)
+; SYM-NEXT: }
+; SYM-NEXT: }
+; SYM: Index: [[#NFA+27]]
+; SYM-NEXT: Name: ThreadLocalVarInit
+; SYM-NEXT: Value (RelocatableAddress): 0x0
+; SYM-NEXT: Section: .tdata
+; SYM-NEXT: Type: 0x0
+; SYM-NEXT: StorageClass: C_EXT (0x2)
+; SYM-NEXT: NumberOfAuxEntries: 1
+; SYM-NEXT: CSECT Auxiliary Entry {
+; SYM-NEXT: Index: [[#NFA+28]]
+; SYM-NEXT: SectionLen: 8
+; SYM-NEXT: ParameterHashIndex: 0x0
+; SYM-NEXT: TypeChkSectNum: 0x0
+; SYM-NEXT: SymbolAlignmentLog2: 3
+; SYM-NEXT: SymbolType: XTY_SD (0x1)
+; SYM-NEXT: StorageMappingClass: XMC_TL (0x14)
+; SYM-NEXT: Auxiliary Type: AUX_CSECT (0xFB)
+; SYM-NEXT: }
+; SYM-NEXT: }
+; SYM: Index: [[#NFA+29]]
+; SYM-NEXT: Name: IThreadLocalVarUninit
+; SYM-NEXT: Value (RelocatableAddress): 0x8
+; SYM-NEXT: Section: .tbss
+; SYM-NEXT: Type: 0x0
+; SYM-NEXT: StorageClass: C_HIDEXT (0x6B)
+; SYM-NEXT: NumberOfAuxEntries: 1
+; SYM-NEXT: CSECT Auxiliary Entry {
+; SYM-NEXT: Index: [[#NFA+30]]
+; SYM-NEXT: SectionLen: 8
+; SYM-NEXT: ParameterHashIndex: 0x0
+; SYM-NEXT: TypeChkSectNum: 0x0
+; SYM-NEXT: SymbolAlignmentLog2: 3
+; SYM-NEXT: SymbolType: XTY_CM (0x3)
+; SYM-NEXT: StorageMappingClass: XMC_UL (0x15)
+; SYM-NEXT: Auxiliary Type: AUX_CSECT (0xFB)
+; SYM-NEXT: }
+; SYM-NEXT: }
+; SYM: Index: [[#NFA+31]]
+; SYM-NEXT: Name: IThreadLocalVarUninit2
+; SYM-NEXT: Value (RelocatableAddress): 0x10
+; SYM-NEXT: Section: .tbss
+; SYM-NEXT: Type: 0x0
+; SYM-NEXT: StorageClass: C_HIDEXT (0x6B)
+; SYM-NEXT: NumberOfAuxEntries: 1
+; SYM-NEXT: CSECT Auxiliary Entry {
+; SYM-NEXT: Index: [[#NFA+32]]
+; SYM-NEXT: SectionLen: 8
+; SYM-NEXT: ParameterHashIndex: 0x0
+; SYM-NEXT: TypeChkSectNum: 0x0
+; SYM-NEXT: SymbolAlignmentLog2: 3
+; SYM-NEXT: SymbolType: XTY_CM (0x3)
+; SYM-NEXT: StorageMappingClass: XMC_UL (0x15)
+; SYM-NEXT: Auxiliary Type: AUX_CSECT (0xFB)
+; SYM-NEXT: }
+; SYM-NEXT: }
+
+; DIS: {{.*}}aix-tls-ld-xcoff-reloc-large.ll.tmp.o: file format aix5coff64-rs6000
+; DIS: Disassembly of section .data:
+; DIS: 0000000000000110 (idx: [[#NFA+19]]) _$TLSML[TC]:
+; DIS-NEXT: 110: 00 00 00 00
+; DIS-NEXT: 0000000000000110: R_TLSML (idx: [[#NFA+19]]) _$TLSML[TC]
+; DIS-NEXT: 114: 00 00 00 00
+; DIS: 0000000000000118 (idx: [[#NFA+21]]) IThreadLocalVarUninit[TE]:
+; DIS-NEXT: 118: 00 00 00 00
+; DIS-NEXT: 0000000000000118: R_TLS_LD (idx: [[#NFA+29]]) IThreadLocalVarUninit[UL]
+; DIS-NEXT: 11c: 00 00 00 08
+; DIS: 0000000000000120 (idx: [[#NFA+23]]) ThreadLocalVarInit[TE]:
+; DIS-NEXT: 120: 00 00 00 00
+; DIS-NEXT: 0000000000000120: R_TLS_LD (idx: [[#NFA+27]]) ThreadLocalVarInit[TL]
+; DIS-NEXT: 124: 00 00 00 00
+; DIS: 0000000000000128 (idx: [[#NFA+25]]) IThreadLocalVarUninit2[TE]:
+; DIS-NEXT: 128: 00 00 00 00
+; DIS-NEXT: 0000000000000128: R_TLS_LD (idx: [[#NFA+31]]) IThreadLocalVarUninit2[UL]
+; DIS-NEXT: 12c: 00 00 00 10
+
+; DIS: Disassembly of section .tdata:
+; DIS: 0000000000000000 (idx: [[#NFA+27]]) ThreadLocalVarInit[TL]:
+; DIS-NEXT: 0: 00 00 00 00
+; DIS-NEXT: 4: 00 00 00 01
+
+; DIS: Disassembly of section .tbss:
+; DIS: 0000000000000008 (idx: [[#NFA+29]]) IThreadLocalVarUninit[UL]:
+; DIS-NEXT: ...
+; DIS: 0000000000000010 (idx: [[#NFA+31]]) IThreadLocalVarUninit2[UL]:
+; DIS-NEXT: ...
diff --git a/llvm/test/CodeGen/PowerPC/aix-tls-local-dynamic.ll b/llvm/test/CodeGen/PowerPC/aix-tls-local-dynamic.ll
new file mode 100644
index 00000000000000..22349337f18908
--- /dev/null
+++ b/llvm/test/CodeGen/PowerPC/aix-tls-local-dynamic.ll
@@ -0,0 +1,396 @@
+; RUN: llc -verify-machineinstrs -mcpu=pwr7 -mattr=-altivec -mtriple powerpc64-ibm-aix-xcoff \
+; RUN: --code-model=small < %s | FileCheck %s --check-prefixes=SMALL64,SMALL
+; RUN: llc -verify-machineinstrs -mcpu=pwr7 -mattr=-altivec -mtriple powerpc64-ibm-aix-xcoff \
+; RUN: --code-model=large < %s | FileCheck %s --check-prefixes=LARGE64,LARGE
+; RUN: llc -verify-machineinstrs -mcpu=pwr7 -mattr=-altivec -mtriple powerpc-ibm-aix-xcoff \
+; RUN: --code-model=small < %s | FileCheck %s --check-prefixes=SMALL32,SMALL
+; RUN: llc -verify-machineinstrs -mcpu=pwr7 -mattr=-altivec -mtriple powerpc-ibm-aix-xcoff \
+; RUN: --code-model=large < %s | FileCheck %s --check-prefixes=LARGE32,LARGE
+; RUN: llc -verify-machineinstrs -mcpu=pwr7 -mattr=-altivec -mtriple powerpc64-ibm-aix-xcoff \
+; RUN: --code-model=small -O0 < %s | FileCheck %s --check-prefixes=WITHDUP
+; RUN: llc -verify-machineinstrs -mcpu=pwr7 -mattr=-altivec -mtriple powerpc64-ibm-aix-xcoff \
+; RUN: --code-model=small -O1 < %s | FileCheck %s --check-prefixes=NODUP
+
+ at TGInit = thread_local(localdynamic) global i32 42, align 4
+ at TGUninit = thread_local(localdynamic) global i32 0, align 4
+ at TIInit = internal thread_local(localdynamic) global i32 42, align 4
+ at TIUninit = internal thread_local(localdynamic) global i32 0, align 4
+ at TWInit = weak thread_local(localdynamic) global i32 42, align 4
+ at TWUninit = weak thread_local(localdynamic) global i32 0, align 4
+ at x = thread_local(localdynamic) global i32 42, align 4
+ at y = thread_local(localdynamic) global i32 42, align 4
+
+define i32 @loadTGInit() {
+; SMALL-LABEL: loadTGInit:
+; SMALL64: ld [[ModuleHandleR:3]], [[ModuleHandleL:L..C[0-9]+]](2)
+; SMALL32: lwz [[ModuleHandleR:3]], [[ModuleHandleL:L..C[0-9]+]](2)
+; SMALL: bla .__tls_get_mod[PR]
+; SMALL64: ld [[OffsetR:[0-9]+]], [[TGInitL:L..C[0-9]+]](2)
+; SMALL32: lwz [[OffsetR:[0-9]+]], [[TGInitL:L..C[0-9]+]](2)
+; SMALL: lwzx [[TGInitValR:[0-9]+]], [[ModuleHandleR]], [[OffsetR]]
+;
+; LARGE-LABEL: loadTGInit:
+; LARGE64: addis [[ModuleHandleHR:[0-9]+]], [[ModuleHandleL:L..C[0-9]+]]@u(2)
+; LARGE: addis [[OffsetHR:[0-9]+]], [[TGInitL:L..C[0-9]+]]@u(2)
+; LARGE32: addis [[ModuleHandleHR:[0-9]+]], [[ModuleHandleL:L..C[0-9]+]]@u(2)
+; LARGE64: ld [[ModuleHandleR:3]], [[ModuleHandleL]]@l([[ModuleHandleHR]])
+; LARGE32: lwz [[ModuleHandleR:3]], [[ModuleHandleL]]@l([[ModuleHandleHR]])
+; LARGE: bla .__tls_get_mod[PR]
+; LARGE64: ld [[OffsetR:[0-9]+]], [[TGInitL:L..C[0-9]+]]@l([[OffsetHR]])
+; LARGE32: lwz [[OffsetR:[0-9]+]], [[TGInitL:L..C[0-9]+]]@l([[OffsetHR]])
+; LARGE: lwzx [[TGInitValR:[0-9]+]], [[ModuleHandleR]], [[OffsetR]]
+entry:
+ %0 = tail call align 4 ptr @llvm.threadlocal.address.p0(ptr align 4 @TGInit)
+ %1 = load i32, ptr %0, align 4
+ ret i32 %1
+}
+
+define void @storeTGInit(i32 noundef signext %i) {
+; SMALL-LABEL: storeTGInit:
+; SMALL64: ld [[ModuleHandleR:3]], [[ModuleHandleL:L..C[0-9]+]](2)
+; SMALL32: lwz [[ModuleHandleR:3]], [[ModuleHandleL:L..C[0-9]+]](2)
+; SMALL: bla .__tls_get_mod[PR]
+; SMALL64: ld [[OffsetR:[0-9]+]], [[TGInitL:L..C[0-9]+]](2)
+; SMALL32: lwz [[OffsetR:[0-9]+]], [[TGInitL:L..C[0-9]+]](2)
+; SMALL: stwx [[TGInitValR:[0-9]+]], [[ModuleHandleR]], [[OffsetR]]
+;
+; LARGE-LABEL: storeTGInit:
+; LARGE64: addis [[ModuleHandleHR:[0-9]+]], [[ModuleHandleL:L..C[0-9]+]]@u(2)
+; LARGE: addis [[OffsetHR:[0-9]+]], [[TGInitL:L..C[0-9]+]]@u(2)
+; LARGE32: addis [[ModuleHandleHR:[0-9]+]], [[ModuleHandleL:L..C[0-9]+]]@u(2)
+; LARGE64: ld [[ModuleHandleR:3]], [[ModuleHandleL]]@l([[ModuleHandleHR]])
+; LARGE32: lwz [[ModuleHandleR:3]], [[ModuleHandleL]]@l([[ModuleHandleHR]])
+; LARGE: bla .__tls_get_mod[PR]
+; LARGE64: ld [[OffsetR:[0-9]+]], [[TGInitL:L..C[0-9]+]]@l([[OffsetHR]])
+; LARGE32: lwz [[OffsetR:[0-9]+]], [[TGInitL:L..C[0-9]+]]@l([[OffsetHR]])
+; LARGE: stwx [[TGInitValR:[0-9]+]], [[ModuleHandleR]], [[OffsetR]]
+entry:
+ %0 = tail call align 4 ptr @llvm.threadlocal.address.p0(ptr align 4 @TGInit)
+ store i32 %i, ptr %0, align 4
+ ret void
+}
+
+define i32 @loadTGUninit() {
+; SMALL-LABEL: loadTGUninit:
+; SMALL64: ld [[ModuleHandleR:3]], [[ModuleHandleL:L..C[0-9]+]](2)
+; SMALL32: lwz [[ModuleHandleR:3]], [[ModuleHandleL:L..C[0-9]+]](2)
+; SMALL: bla .__tls_get_mod[PR]
+; SMALL64: ld [[OffsetR:[0-9]+]], [[TGUninitL:L..C[0-9]+]](2)
+; SMALL32: lwz [[OffsetR:[0-9]+]], [[TGUninitL:L..C[0-9]+]](2)
+; SMALL: lwzx [[TGInitValR:[0-9]+]], [[ModuleHandleR]], [[OffsetR]]
+;
+; LARGE-LABEL: loadTGUninit:
+; LARGE64: addis [[ModuleHandleHR:[0-9]+]], [[ModuleHandleL:L..C[0-9]+]]@u(2)
+; LARGE: addis [[OffsetHR:[0-9]+]], [[TGUninitL:L..C[0-9]+]]@u(2)
+; LARGE32: addis [[ModuleHandleHR:[0-9]+]], [[ModuleHandleL:L..C[0-9]+]]@u(2)
+; LARGE64: ld [[ModuleHandleR:3]], [[ModuleHandleL]]@l([[ModuleHandleHR]])
+; LARGE32: lwz [[ModuleHandleR:3]], [[ModuleHandleL]]@l([[ModuleHandleHR]])
+; LARGE: bla .__tls_get_mod[PR]
+; LARGE64: ld [[OffsetR:[0-9]+]], [[TGUninitL:L..C[0-9]+]]@l([[OffsetHR]])
+; LARGE32: lwz [[OffsetR:[0-9]+]], [[TGUninitL:L..C[0-9]+]]@l([[OffsetHR]])
+; LARGE: lwzx [[TGUninitValR:[0-9]+]], [[ModuleHandleR]], [[OffsetR]]
+entry:
+ %0 = tail call align 4 ptr @llvm.threadlocal.address.p0(ptr align 4 @TGUninit)
+ %1 = load i32, ptr %0, align 4
+ ret i32 %1
+}
+
+define void @storeTGUninit(i32 noundef signext %i) {
+; SMALL-LABEL: storeTGUninit:
+; SMALL64: ld [[ModuleHandleR:3]], [[ModuleHandleL:L..C[0-9]+]](2)
+; SMALL32: lwz [[ModuleHandleR:3]], [[ModuleHandleL:L..C[0-9]+]](2)
+; SMALL: bla .__tls_get_mod[PR]
+; SMALL64: ld [[OffsetR:[0-9]+]], [[TGUninitL:L..C[0-9]+]](2)
+; SMALL32: lwz [[OffsetR:[0-9]+]], [[TGUninitL:L..C[0-9]+]](2)
+; SMALL: stwx [[TGUninitValR:[0-9]+]], [[ModuleHandleR]], [[OffsetR]]
+;
+; LARGE-LABEL: storeTGUninit:
+; LARGE64: addis [[ModuleHandleHR:[0-9]+]], [[ModuleHandleL:L..C[0-9]+]]@u(2)
+; LARGE: addis [[OffsetHR:[0-9]+]], [[TGUninitL:L..C[0-9]+]]@u(2)
+; LARGE32: addis [[ModuleHandleHR:[0-9]+]], [[ModuleHandleL:L..C[0-9]+]]@u(2)
+; LARGE64: ld [[ModuleHandleR:3]], [[ModuleHandleL]]@l([[ModuleHandleHR]])
+; LARGE32: lwz [[ModuleHandleR:3]], [[ModuleHandleL]]@l([[ModuleHandleHR]])
+; LARGE: bla .__tls_get_mod[PR]
+; LARGE64: ld [[OffsetR:[0-9]+]], [[TGUninitL:L..C[0-9]+]]@l([[OffsetHR]])
+; LARGE32: lwz [[OffsetR:[0-9]+]], [[TGUninitL:L..C[0-9]+]]@l([[OffsetHR]])
+; LARGE: stwx [[TGUninitValR:[0-9]+]], [[ModuleHandleR]], [[OffsetR]]
+entry:
+ %0 = tail call align 4 ptr @llvm.threadlocal.address.p0(ptr align 4 @TGUninit)
+ store i32 %i, ptr %0, align 4
+ ret void
+}
+
+define i32 @loadTIInit() {
+; SMALL-LABEL: loadTIInit:
+; SMALL64: ld [[ModuleHandleR:3]], [[ModuleHandleL:L..C[0-9]+]](2)
+; SMALL32: lwz [[ModuleHandleR:3]], [[ModuleHandleL:L..C[0-9]+]](2)
+; SMALL: bla .__tls_get_mod[PR]
+; SMALL64: ld [[OffsetR:[0-9]+]], [[TIInitL:L..C[0-9]+]](2)
+; SMALL32: lwz [[OffsetR:[0-9]+]], [[TIInitL:L..C[0-9]+]](2)
+; SMALL: lwzx [[TIInitValR:[0-9]+]], [[ModuleHandleR]], [[OffsetR]]
+;
+; LARGE-LABEL: loadTIInit:
+; LARGE64: addis [[ModuleHandleHR:[0-9]+]], [[ModuleHandleL:L..C[0-9]+]]@u(2)
+; LARGE: addis [[OffsetHR:[0-9]+]], [[TIInitL:L..C[0-9]+]]@u(2)
+; LARGE32: addis [[ModuleHandleHR:[0-9]+]], [[ModuleHandleL:L..C[0-9]+]]@u(2)
+; LARGE64: ld [[ModuleHandleR:3]], [[ModuleHandleL]]@l([[ModuleHandleHR]])
+; LARGE32: lwz [[ModuleHandleR:3]], [[ModuleHandleL]]@l([[ModuleHandleHR]])
+; LARGE: bla .__tls_get_mod[PR]
+; LARGE64: ld [[OffsetR:[0-9]+]], [[TIInitL:L..C[0-9]+]]@l([[OffsetHR]])
+; LARGE32: lwz [[OffsetR:[0-9]+]], [[TIInitL:L..C[0-9]+]]@l([[OffsetHR]])
+; LARGE: lwzx [[TIInitValR:[0-9]+]], [[ModuleHandleR]], [[OffsetR]]
+entry:
+ %0 = tail call align 4 ptr @llvm.threadlocal.address.p0(ptr align 4 @TIInit)
+ %1 = load i32, ptr %0, align 4
+ ret i32 %1
+}
+
+define void @storeTIInit(i32 noundef signext %i) {
+; SMALL-LABEL: storeTIInit:
+; SMALL64: ld [[ModuleHandleR:3]], [[ModuleHandleL:L..C[0-9]+]](2)
+; SMALL32: lwz [[ModuleHandleR:3]], [[ModuleHandleL:L..C[0-9]+]](2)
+; SMALL: bla .__tls_get_mod[PR]
+; SMALL64: ld [[OffsetR:[0-9]+]], [[TIInitL:L..C[0-9]+]](2)
+; SMALL32: lwz [[OffsetR:[0-9]+]], [[TIInitL:L..C[0-9]+]](2)
+; SMALL: stwx [[TIInitValR:[0-9]+]], [[ModuleHandleR]], [[OffsetR]]
+;
+; LARGE-LABEL: storeTIInit:
+; LARGE64: addis [[ModuleHandleHR:[0-9]+]], [[ModuleHandleL:L..C[0-9]+]]@u(2)
+; LARGE: addis [[OffsetHR:[0-9]+]], [[TIInitL:L..C[0-9]+]]@u(2)
+; LARGE32: addis [[ModuleHandleHR:[0-9]+]], [[ModuleHandleL:L..C[0-9]+]]@u(2)
+; LARGE64: ld [[ModuleHandleR:3]], [[ModuleHandleL]]@l([[ModuleHandleHR]])
+; LARGE32: lwz [[ModuleHandleR:3]], [[ModuleHandleL]]@l([[ModuleHandleHR]])
+; LARGE: bla .__tls_get_mod[PR]
+; LARGE64: ld [[OffsetR:[0-9]+]], [[TIInitL:L..C[0-9]+]]@l([[OffsetHR]])
+; LARGE32: lwz [[OffsetR:[0-9]+]], [[TIInitL:L..C[0-9]+]]@l([[OffsetHR]])
+; LARGE: stwx [[TIInitValR:[0-9]+]], [[ModuleHandleR]], [[OffsetR]]
+entry:
+ %0 = tail call align 4 ptr @llvm.threadlocal.address.p0(ptr align 4 @TIInit)
+ store i32 %i, ptr %0, align 4
+ ret void
+}
+
+define i32 @loadTIUninit() {
+; SMALL-LABEL: loadTIUninit:
+; SMALL64: ld [[ModuleHandleR:3]], [[ModuleHandleL:L..C[0-9]+]](2)
+; SMALL32: lwz [[ModuleHandleR:3]], [[ModuleHandleL:L..C[0-9]+]](2)
+; SMALL: bla .__tls_get_mod[PR]
+; SMALL64: ld [[OffsetR:[0-9]+]], [[TIUninitL:L..C[0-9]+]](2)
+; SMALL32: lwz [[OffsetR:[0-9]+]], [[TIUninitL:L..C[0-9]+]](2)
+; SMALL: lwzx [[TIUninitValR:[0-9]+]], [[ModuleHandleR]], [[OffsetR]]
+;
+; LARGE-LABEL: loadTIUninit:
+; LARGE64: addis [[ModuleHandleHR:[0-9]+]], [[ModuleHandleL:L..C[0-9]+]]@u(2)
+; LARGE: addis [[OffsetHR:[0-9]+]], [[TIUninitL:L..C[0-9]+]]@u(2)
+; LARGE32: addis [[ModuleHandleHR:[0-9]+]], [[ModuleHandleL:L..C[0-9]+]]@u(2)
+; LARGE64: ld [[ModuleHandleR:3]], [[ModuleHandleL]]@l([[ModuleHandleHR]])
+; LARGE32: lwz [[ModuleHandleR:3]], [[ModuleHandleL]]@l([[ModuleHandleHR]])
+; LARGE: bla .__tls_get_mod[PR]
+; LARGE64: ld [[OffsetR:[0-9]+]], [[TIUninitL:L..C[0-9]+]]@l([[OffsetHR]])
+; LARGE32: lwz [[OffsetR:[0-9]+]], [[TIUninitL:L..C[0-9]+]]@l([[OffsetHR]])
+; LARGE: lwzx [[TIUninitValR:[0-9]+]], [[ModuleHandleR]], [[OffsetR]]
+entry:
+ %0 = tail call align 4 ptr @llvm.threadlocal.address.p0(ptr align 4 @TIUninit)
+ %1 = load i32, ptr %0, align 4
+ ret i32 %1
+}
+
+define void @storeTIUninit(i32 noundef signext %i) {
+; SMALL-LABEL: storeTIUninit:
+; SMALL64: ld [[ModuleHandleR:3]], [[ModuleHandleL:L..C[0-9]+]](2)
+; SMALL32: lwz [[ModuleHandleR:3]], [[ModuleHandleL:L..C[0-9]+]](2)
+; SMALL: bla .__tls_get_mod[PR]
+; SMALL64: ld [[OffsetR:[0-9]+]], [[TIUninitL:L..C[0-9]+]](2)
+; SMALL32: lwz [[OffsetR:[0-9]+]], [[TIUninitL:L..C[0-9]+]](2)
+; SMALL: stwx [[TIUninitValR:[0-9]+]], [[ModuleHandleR]], [[OffsetR]]
+;
+; LARGE-LABEL: storeTIUninit:
+; LARGE64: addis [[ModuleHandleHR:[0-9]+]], [[ModuleHandleL:L..C[0-9]+]]@u(2)
+; LARGE: addis [[OffsetHR:[0-9]+]], [[TIUninitL:L..C[0-9]+]]@u(2)
+; LARGE32: addis [[ModuleHandleHR:[0-9]+]], [[ModuleHandleL:L..C[0-9]+]]@u(2)
+; LARGE64: ld [[ModuleHandleR:3]], [[ModuleHandleL]]@l([[ModuleHandleHR]])
+; LARGE32: lwz [[ModuleHandleR:3]], [[ModuleHandleL]]@l([[ModuleHandleHR]])
+; LARGE: bla .__tls_get_mod[PR]
+; LARGE64: ld [[OffsetR:[0-9]+]], [[TIUninitL:L..C[0-9]+]]@l([[OffsetHR]])
+; LARGE32: lwz [[OffsetR:[0-9]+]], [[TIUninitL:L..C[0-9]+]]@l([[OffsetHR]])
+; LARGE: stwx [[TIUninitValR:[0-9]+]], [[ModuleHandleR]], [[OffsetR]]
+entry:
+ %0 = tail call align 4 ptr @llvm.threadlocal.address.p0(ptr align 4 @TIUninit)
+ store i32 %i, ptr %0, align 4
+ ret void
+}
+
+define i32 @loadTWInit() {
+; SMALL-LABEL: loadTWInit:
+; SMALL64: ld [[ModuleHandleR:3]], [[ModuleHandleL:L..C[0-9]+]](2)
+; SMALL32: lwz [[ModuleHandleR:3]], [[ModuleHandleL:L..C[0-9]+]](2)
+; SMALL: bla .__tls_get_mod[PR]
+; SMALL64: ld [[OffsetR:[0-9]+]], [[TWInitL:L..C[0-9]+]](2)
+; SMALL32: lwz [[OffsetR:[0-9]+]], [[TWInitL:L..C[0-9]+]](2)
+; SMALL: lwzx [[TWInitValR:[0-9]+]], [[ModuleHandleR]], [[OffsetR]]
+;
+; LARGE-LABEL: loadTWInit:
+; LARGE64: addis [[ModuleHandleHR:[0-9]+]], [[ModuleHandleL:L..C[0-9]+]]@u(2)
+; LARGE: addis [[OffsetHR:[0-9]+]], [[TWInitL:L..C[0-9]+]]@u(2)
+; LARGE32: addis [[ModuleHandleHR:[0-9]+]], [[ModuleHandleL:L..C[0-9]+]]@u(2)
+; LARGE64: ld [[ModuleHandleR:3]], [[ModuleHandleL]]@l([[ModuleHandleHR]])
+; LARGE32: lwz [[ModuleHandleR:3]], [[ModuleHandleL]]@l([[ModuleHandleHR]])
+; LARGE: bla .__tls_get_mod[PR]
+; LARGE64: ld [[OffsetR:[0-9]+]], [[TWInitL:L..C[0-9]+]]@l([[OffsetHR]])
+; LARGE32: lwz [[OffsetR:[0-9]+]], [[TWInitL:L..C[0-9]+]]@l([[OffsetHR]])
+; LARGE: lwzx [[TWInitValR:[0-9]+]], [[ModuleHandleR]], [[OffsetR]]
+entry:
+ %0 = tail call align 4 ptr @llvm.threadlocal.address.p0(ptr align 4 @TWInit)
+ %1 = load i32, ptr %0, align 4
+ ret i32 %1
+}
+
+define void @storeTWInit(i32 noundef signext %i) {
+; SMALL-LABEL: storeTWInit:
+; SMALL64: ld [[ModuleHandleR:3]], [[ModuleHandleL:L..C[0-9]+]](2)
+; SMALL32: lwz [[ModuleHandleR:3]], [[ModuleHandleL:L..C[0-9]+]](2)
+; SMALL: bla .__tls_get_mod[PR]
+; SMALL64: ld [[OffsetR:[0-9]+]], [[TWInitL:L..C[0-9]+]](2)
+; SMALL32: lwz [[OffsetR:[0-9]+]], [[TWInitL:L..C[0-9]+]](2)
+; SMALL: stwx [[TWInitValR:[0-9]+]], [[ModuleHandleR]], [[OffsetR]]
+;
+; LARGE-LABEL: storeTWInit:
+; LARGE64: addis [[ModuleHandleHR:[0-9]+]], [[ModuleHandleL:L..C[0-9]+]]@u(2)
+; LARGE: addis [[OffsetHR:[0-9]+]], [[TWInitL:L..C[0-9]+]]@u(2)
+; LARGE32: addis [[ModuleHandleHR:[0-9]+]], [[ModuleHandleL:L..C[0-9]+]]@u(2)
+; LARGE64: ld [[ModuleHandleR:3]], [[ModuleHandleL]]@l([[ModuleHandleHR]])
+; LARGE32: lwz [[ModuleHandleR:3]], [[ModuleHandleL]]@l([[ModuleHandleHR]])
+; LARGE: bla .__tls_get_mod[PR]
+; LARGE64: ld [[OffsetR:[0-9]+]], [[TWInitL:L..C[0-9]+]]@l([[OffsetHR]])
+; LARGE32: lwz [[OffsetR:[0-9]+]], [[TWInitL:L..C[0-9]+]]@l([[OffsetHR]])
+; LARGE: stwx [[TWInitValR:[0-9]+]], [[ModuleHandleR]], [[OffsetR]]
+entry:
+ %0 = tail call align 4 ptr @llvm.threadlocal.address.p0(ptr align 4 @TWInit)
+ store i32 %i, ptr %0, align 4
+ ret void
+}
+
+define i32 @loadTWUninit() {
+; SMALL-LABEL: loadTWUninit:
+; SMALL64: ld [[ModuleHandleR:3]], [[ModuleHandleL:L..C[0-9]+]](2)
+; SMALL32: lwz [[ModuleHandleR:3]], [[ModuleHandleL:L..C[0-9]+]](2)
+; SMALL: bla .__tls_get_mod[PR]
+; SMALL64: ld [[OffsetR:[0-9]+]], [[TWUninitL:L..C[0-9]+]](2)
+; SMALL32: lwz [[OffsetR:[0-9]+]], [[TWUninitL:L..C[0-9]+]](2)
+; SMALL: lwzx [[TWUninitValR:[0-9]+]], [[ModuleHandleR]], [[OffsetR]]
+;
+; LARGE-LABEL: loadTWUninit:
+; LARGE64: addis [[ModuleHandleHR:[0-9]+]], [[ModuleHandleL:L..C[0-9]+]]@u(2)
+; LARGE: addis [[OffsetHR:[0-9]+]], [[TWUninitL:L..C[0-9]+]]@u(2)
+; LARGE32: addis [[ModuleHandleHR:[0-9]+]], [[ModuleHandleL:L..C[0-9]+]]@u(2)
+; LARGE64: ld [[ModuleHandleR:3]], [[ModuleHandleL]]@l([[ModuleHandleHR]])
+; LARGE32: lwz [[ModuleHandleR:3]], [[ModuleHandleL]]@l([[ModuleHandleHR]])
+; LARGE: bla .__tls_get_mod[PR]
+; LARGE64: ld [[OffsetR:[0-9]+]], [[TWUninitL:L..C[0-9]+]]@l([[OffsetHR]])
+; LARGE32: lwz [[OffsetR:[0-9]+]], [[TWUninitL:L..C[0-9]+]]@l([[OffsetHR]])
+; LARGE: lwzx [[TWUninitValR:[0-9]+]], [[ModuleHandleR]], [[OffsetR]]
+entry:
+ %0 = tail call align 4 ptr @llvm.threadlocal.address.p0(ptr align 4 @TWUninit)
+ %1 = load i32, ptr %0, align 4
+ ret i32 %1
+}
+
+define void @storeTWUninit(i32 noundef signext %i) {
+; SMALL-LABEL: storeTWUninit:
+; SMALL64: ld [[ModuleHandleR:3]], [[ModuleHandleL:L..C[0-9]+]](2)
+; SMALL32: lwz [[ModuleHandleR:3]], [[ModuleHandleL:L..C[0-9]+]](2)
+; SMALL: bla .__tls_get_mod[PR]
+; SMALL64: ld [[OffsetR:[0-9]+]], [[TWUninitL:L..C[0-9]+]](2)
+; SMALL32: lwz [[OffsetR:[0-9]+]], [[TWUninitL:L..C[0-9]+]](2)
+; SMALL: stwx [[TWUninitValR:[0-9]+]], [[ModuleHandleR]], [[OffsetR]]
+;
+; LARGE-LABEL: storeTWUninit:
+; LARGE64: addis [[ModuleHandleHR:[0-9]+]], [[ModuleHandleL:L..C[0-9]+]]@u(2)
+; LARGE: addis [[OffsetHR:[0-9]+]], [[TWUninitL:L..C[0-9]+]]@u(2)
+; LARGE32: addis [[ModuleHandleHR:[0-9]+]], [[ModuleHandleL:L..C[0-9]+]]@u(2)
+; LARGE64: ld [[ModuleHandleR:3]], [[ModuleHandleL]]@l([[ModuleHandleHR]])
+; LARGE32: lwz [[ModuleHandleR:3]], [[ModuleHandleL]]@l([[ModuleHandleHR]])
+; LARGE: bla .__tls_get_mod[PR]
+; LARGE64: ld [[OffsetR:[0-9]+]], [[TWUninitL:L..C[0-9]+]]@l([[OffsetHR]])
+; LARGE32: lwz [[OffsetR:[0-9]+]], [[TWUninitL:L..C[0-9]+]]@l([[OffsetHR]])
+; LARGE: stwx [[TWUninitValR:[0-9]+]], [[ModuleHandleR]], [[OffsetR]]
+entry:
+ %0 = tail call align 4 ptr @llvm.threadlocal.address.p0(ptr align 4 @TWUninit)
+ store i32 %i, ptr %0, align 4
+ ret void
+}
+
+define i32 @DedupTlsGetMod() #0 {
+; WITHDUP-LABEL: DedupTlsGetMod:
+; WITHDUP: ld [[ModuleHandleR:3]], [[ModuleHandleL:L..C[0-9]+]](2)
+; WITHDUP-NEXT: bla .__tls_get_mod[PR]
+; WITHDUP-NEXT: ld [[OffsetXR:[0-9]+]], [[X:L..C[0-9]+]](2)
+; WITHDUP: ld [[ModuleHandleR:3]], [[ModuleHandleL:L..C[0-9]+]](2)
+; WITHDUP-NEXT: bla .__tls_get_mod[PR]
+; WITHDUP: ld [[OffsetYR:[0-9]+]], [[Y:L..C[0-9]+]](2)
+; WITHDUP-LABEL: L..DedupTlsGetMod0:
+;
+; NODUP-LABEL: DedupTlsGetMod:
+; NODUP: ld [[ModuleHandleR:3]], [[ModuleHandleL:L..C[0-9]+]](2)
+; NODUP-NEXT: bla .__tls_get_mod[PR]
+; NODUP-NEXT: ld [[OffsetXR:[0-9]+]], [[X:L..C[0-9]+]](2)
+; NODUP-NEXT: ld [[OffsetYR:[0-9]+]], [[Y:L..C[0-9]+]](2)
+; NODUP-NEXT: lwzx [[XValR:[0-9]+]], [[ModuleHandleR]], [[OffsetXR]]
+; NODUP-NEXT: lwzx [[YValR:[0-9]+]], [[ModuleHandleR]], [[OffsetYR]]
+; NODUP-LABEL: L..DedupTlsGetMod0:
+entry:
+ %retval = alloca i32, align 4
+ store i32 0, ptr %retval, align 4
+ %0 = call align 4 ptr @llvm.threadlocal.address.p0(ptr align 4 @x)
+ %1 = load i32, ptr %0, align 4
+ %2 = call align 4 ptr @llvm.threadlocal.address.p0(ptr align 4 @y)
+ %3 = load i32, ptr %2, align 4
+ %add = add nsw i32 %1, %3
+ ret i32 %add
+}
+
+; SMALL: .extern .__tls_get_mod[PR]
+; LARGE: .extern .__tls_get_mod[PR]
+; SMALL-NOT: .extern _Renamed..5f24__TLSML[TC]
+; LARGE-NOT: .extern _Renamed..5f24__TLSML[TC]
+
+; SMALL: [[ModuleHandleL]]:
+; SMALL-NEXT: .tc _Renamed..5f24__TLSML[TC],_Renamed..5f24__TLSML[TC]@ml
+; SMALL-NEXT: .rename _Renamed..5f24__TLSML[TC],"_$TLSML"
+; SMALL: [[TGInitL]]:
+; SMALL-NEXT: .tc TGInit[TC],TGInit[TL]@ld
+; SMALL: [[TGUninitL]]:
+; SMALL-NEXT: .tc TGUninit[TC],TGUninit[TL]@ld
+; SMALL: [[TIInitL]]:
+; SMALL-NEXT: .tc TIInit[TC],TIInit[TL]@ld
+; SMALL: [[TIUninitL]]:
+; SMALL-NEXT: .tc TIUninit[TC],TIUninit[UL]@ld
+; SMALL: [[TWInitL]]:
+; SMALL-NEXT: .tc TWInit[TC],TWInit[TL]@ld
+; SMALL: [[TWUninitL]]:
+; SMALL-NEXT: .tc TWUninit[TC],TWUninit[TL]@ld
+
+; LARGE64: [[ModuleHandleL]]:
+; LARGE64-NEXT: .tc _Renamed..5f24__TLSML[TC],_Renamed..5f24__TLSML[TC]@ml
+; LARGE64-NEXT: .rename _Renamed..5f24__TLSML[TC],"_$TLSML"
+; LARGE64: [[TGInitL]]:
+; LARGE64-NEXT: .tc TGInit[TE],TGInit[TL]@ld
+;
+; LARGE32: [[TGInitL]]:
+; LARGE32-NEXT: .tc TGInit[TE],TGInit[TL]@ld
+; LARGE32: [[ModuleHandleL]]:
+; LARGE32-NEXT: .tc _Renamed..5f24__TLSML[TC],_Renamed..5f24__TLSML[TC]@ml
+; LARGE32-NEXT: .rename _Renamed..5f24__TLSML[TC],"_$TLSML"
+;
+; LARGE: [[TGUninitL]]:
+; LARGE-NEXT: .tc TGUninit[TE],TGUninit[TL]@ld
+; LARGE: [[TIInitL]]:
+; LARGE-NEXT: .tc TIInit[TE],TIInit[TL]@ld
+; LARGE: [[TIUninitL]]:
+; LARGE-NEXT: .tc TIUninit[TE],TIUninit[UL]@ld
+; LARGE: [[TWInitL]]:
+; LARGE-NEXT: .tc TWInit[TE],TWInit[TL]@ld
+; LARGE: [[TWUninitL]]:
+; LARGE-NEXT: .tc TWUninit[TE],TWUninit[TL]@ld
+
+declare nonnull ptr @llvm.threadlocal.address.p0(ptr nonnull)
diff --git a/llvm/test/CodeGen/PowerPC/aix-tls-xcoff-reloc-large.ll b/llvm/test/CodeGen/PowerPC/aix-tls-xcoff-reloc-large.ll
index 059924f392f6b7..1f7b497bb6c612 100644
--- a/llvm/test/CodeGen/PowerPC/aix-tls-xcoff-reloc-large.ll
+++ b/llvm/test/CodeGen/PowerPC/aix-tls-xcoff-reloc-large.ll
@@ -5,6 +5,7 @@
; RUN: llvm-objdump -D -r --symbol-description %t.o | FileCheck -D#NFA=2 --check-prefix=DIS %s
@GInit = global double 1.000000e+00, align 8
+; @TIInit is local-dynamic indeed
@TIInit = internal thread_local global i64 1, align 8
@TWInit = weak thread_local global double 1.000000e+00, align 8
@@ -32,7 +33,7 @@ entry:
; RELOC-NEXT: Section (index: 1) .text {
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0x16
-; RELOC-NEXT: Symbol: .TIInit ([[#NFA+17]])
+; RELOC-NEXT: Symbol: TIInit ([[#NFA+19]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 16
@@ -40,7 +41,7 @@ entry:
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0x1A
-; RELOC-NEXT: Symbol: TIInit ([[#NFA+19]])
+; RELOC-NEXT: Symbol: _$TLSML ([[#NFA+21]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 16
@@ -48,31 +49,31 @@ entry:
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0x1E
-; RELOC-NEXT: Symbol: .TIInit ([[#NFA+17]])
+; RELOC-NEXT: Symbol: _$TLSML ([[#NFA+21]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 16
; RELOC-NEXT: Type: R_TOCL (0x31)
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
-; RELOC-NEXT: Virtual Address: 0x22
-; RELOC-NEXT: Symbol: TIInit ([[#NFA+19]])
+; RELOC-NEXT: Virtual Address: 0x20
+; RELOC-NEXT: Symbol: .__tls_get_mod ([[#NFA+1]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
-; RELOC-NEXT: Length: 16
-; RELOC-NEXT: Type: R_TOCL (0x31)
+; RELOC-NEXT: Length: 26
+; RELOC-NEXT: Type: R_RBA (0x18)
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
-; RELOC-NEXT: Virtual Address: 0x24
-; RELOC-NEXT: Symbol: .__tls_get_addr ([[#NFA+1]])
+; RELOC-NEXT: Virtual Address: 0x26
+; RELOC-NEXT: Symbol: TIInit ([[#NFA+19]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
-; RELOC-NEXT: Length: 26
-; RELOC-NEXT: Type: R_RBA (0x18)
+; RELOC-NEXT: Length: 16
+; RELOC-NEXT: Type: R_TOCL (0x31)
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0x4E
-; RELOC-NEXT: Symbol: .TWInit ([[#NFA+21]])
+; RELOC-NEXT: Symbol: .TWInit ([[#NFA+23]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 16
@@ -80,7 +81,7 @@ entry:
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0x52
-; RELOC-NEXT: Symbol: TWInit ([[#NFA+23]])
+; RELOC-NEXT: Symbol: TWInit ([[#NFA+25]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 16
@@ -88,7 +89,7 @@ entry:
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0x56
-; RELOC-NEXT: Symbol: .TWInit ([[#NFA+21]])
+; RELOC-NEXT: Symbol: .TWInit ([[#NFA+23]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 16
@@ -96,7 +97,7 @@ entry:
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0x5A
-; RELOC-NEXT: Symbol: TWInit ([[#NFA+23]])
+; RELOC-NEXT: Symbol: TWInit ([[#NFA+25]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 16
@@ -104,7 +105,7 @@ entry:
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0x5C
-; RELOC-NEXT: Symbol: .__tls_get_addr ([[#NFA+1]])
+; RELOC-NEXT: Symbol: .__tls_get_addr ([[#NFA+3]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 26
@@ -112,7 +113,7 @@ entry:
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0x66
-; RELOC-NEXT: Symbol: GInit ([[#NFA+25]])
+; RELOC-NEXT: Symbol: GInit ([[#NFA+27]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 16
@@ -120,7 +121,7 @@ entry:
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0x6A
-; RELOC-NEXT: Symbol: GInit ([[#NFA+25]])
+; RELOC-NEXT: Symbol: GInit ([[#NFA+27]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 16
@@ -130,7 +131,7 @@ entry:
; RELOC-NEXT: Section (index: 2) .data {
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0x90
-; RELOC-NEXT: Symbol: .storesTIInit ([[#NFA+5]])
+; RELOC-NEXT: Symbol: .storesTIInit ([[#NFA+7]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 32
@@ -138,7 +139,7 @@ entry:
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0x94
-; RELOC-NEXT: Symbol: TOC ([[#NFA+15]])
+; RELOC-NEXT: Symbol: TOC ([[#NFA+17]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 32
@@ -146,7 +147,7 @@ entry:
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0x9C
-; RELOC-NEXT: Symbol: .loadsTWInit ([[#NFA+7]])
+; RELOC-NEXT: Symbol: .loadsTWInit ([[#NFA+9]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 32
@@ -154,7 +155,7 @@ entry:
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0xA0
-; RELOC-NEXT: Symbol: TOC ([[#NFA+15]])
+; RELOC-NEXT: Symbol: TOC ([[#NFA+17]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 32
@@ -162,23 +163,23 @@ entry:
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0xA8
-; RELOC-NEXT: Symbol: TIInit ([[#NFA+27]])
+; RELOC-NEXT: Symbol: TIInit ([[#NFA+29]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 32
-; RELOC-NEXT: Type: R_TLSM (0x24)
+; RELOC-NEXT: Type: R_TLS_LD (0x22)
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0xAC
-; RELOC-NEXT: Symbol: TIInit ([[#NFA+27]])
+; RELOC-NEXT: Symbol: _$TLSML ([[#NFA+21]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 32
-; RELOC-NEXT: Type: R_TLS (0x20)
+; RELOC-NEXT: Type: R_TLSML (0x25)
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0xB0
-; RELOC-NEXT: Symbol: TWInit ([[#NFA+29]])
+; RELOC-NEXT: Symbol: TWInit ([[#NFA+31]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 32
@@ -186,7 +187,7 @@ entry:
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0xB4
-; RELOC-NEXT: Symbol: TWInit ([[#NFA+29]])
+; RELOC-NEXT: Symbol: TWInit ([[#NFA+31]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 32
@@ -194,7 +195,7 @@ entry:
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0xB8
-; RELOC-NEXT: Symbol: GInit ([[#NFA+9]])
+; RELOC-NEXT: Symbol: GInit ([[#NFA+11]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 32
@@ -230,7 +231,7 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: Symbol {
; SYM-NEXT: Index: [[#NFA+1]]
-; SYM-NEXT: Name: .__tls_get_addr
+; SYM-NEXT: Name: .__tls_get_mod
; SYM-NEXT: Value (RelocatableAddress): 0x0
; SYM-NEXT: Section: N_UNDEF
; SYM-NEXT: Type: 0x0
@@ -250,6 +251,26 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: Symbol {
; SYM-NEXT: Index: [[#NFA+3]]
+; SYM-NEXT: Name: .__tls_get_addr
+; SYM-NEXT: Value (RelocatableAddress): 0x0
+; SYM-NEXT: Section: N_UNDEF
+; SYM-NEXT: Type: 0x0
+; SYM-NEXT: StorageClass: C_EXT (0x2)
+; SYM-NEXT: NumberOfAuxEntries: 1
+; SYM-NEXT: CSECT Auxiliary Entry {
+; SYM-NEXT: Index: [[#NFA+4]]
+; SYM-NEXT: SectionLen: 0
+; SYM-NEXT: ParameterHashIndex: 0x0
+; SYM-NEXT: TypeChkSectNum: 0x0
+; SYM-NEXT: SymbolAlignmentLog2: 0
+; SYM-NEXT: SymbolType: XTY_ER (0x0)
+; SYM-NEXT: StorageMappingClass: XMC_PR (0x0)
+; SYM-NEXT: StabInfoIndex: 0x0
+; SYM-NEXT: StabSectNum: 0x0
+; SYM-NEXT: }
+; SYM-NEXT: }
+; SYM-NEXT: Symbol {
+; SYM-NEXT: Index: [[#NFA+5]]
; SYM-NEXT: Name:
; SYM-NEXT: Value (RelocatableAddress): 0x0
; SYM-NEXT: Section: .text
@@ -257,7 +278,7 @@ entry:
; SYM-NEXT: StorageClass: C_HIDEXT (0x6B)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+4]]
+; SYM-NEXT: Index: [[#NFA+6]]
; SYM-NEXT: SectionLen: 132
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
@@ -269,7 +290,7 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: }
; SYM-NEXT: Symbol {
-; SYM-NEXT: Index: [[#NFA+5]]
+; SYM-NEXT: Index: [[#NFA+7]]
; SYM-NEXT: Name: .storesTIInit
; SYM-NEXT: Value (RelocatableAddress): 0x0
; SYM-NEXT: Section: .text
@@ -277,8 +298,8 @@ entry:
; SYM-NEXT: StorageClass: C_EXT (0x2)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+6]]
-; SYM-NEXT: ContainingCsectSymbolIndex: [[#NFA+3]]
+; SYM-NEXT: Index: [[#NFA+8]]
+; SYM-NEXT: ContainingCsectSymbolIndex: [[#NFA+5]]
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
; SYM-NEXT: SymbolAlignmentLog2: 0
@@ -289,7 +310,7 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: }
; SYM-NEXT: Symbol {
-; SYM-NEXT: Index: [[#NFA+7]]
+; SYM-NEXT: Index: [[#NFA+9]]
; SYM-NEXT: Name: .loadsTWInit
; SYM-NEXT: Value (RelocatableAddress): 0x40
; SYM-NEXT: Section: .text
@@ -297,8 +318,8 @@ entry:
; SYM-NEXT: StorageClass: C_EXT (0x2)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+8]]
-; SYM-NEXT: ContainingCsectSymbolIndex: [[#NFA+3]]
+; SYM-NEXT: Index: [[#NFA+10]]
+; SYM-NEXT: ContainingCsectSymbolIndex: [[#NFA+5]]
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
; SYM-NEXT: SymbolAlignmentLog2: 0
@@ -309,7 +330,7 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: }
; SYM-NEXT: Symbol {
-; SYM-NEXT: Index: [[#NFA+9]]
+; SYM-NEXT: Index: [[#NFA+11]]
; SYM-NEXT: Name: GInit
; SYM-NEXT: Value (RelocatableAddress): 0x88
; SYM-NEXT: Section: .data
@@ -317,7 +338,7 @@ entry:
; SYM-NEXT: StorageClass: C_EXT (0x2)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+10]]
+; SYM-NEXT: Index: [[#NFA+12]]
; SYM-NEXT: SectionLen: 8
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
@@ -329,7 +350,7 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: }
; SYM-NEXT: Symbol {
-; SYM-NEXT: Index: [[#NFA+11]]
+; SYM-NEXT: Index: [[#NFA+13]]
; SYM-NEXT: Name: storesTIInit
; SYM-NEXT: Value (RelocatableAddress): 0x90
; SYM-NEXT: Section: .data
@@ -337,7 +358,7 @@ entry:
; SYM-NEXT: StorageClass: C_EXT (0x2)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+12]]
+; SYM-NEXT: Index: [[#NFA+14]]
; SYM-NEXT: SectionLen: 12
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
@@ -349,7 +370,7 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: }
; SYM-NEXT: Symbol {
-; SYM-NEXT: Index: [[#NFA+13]]
+; SYM-NEXT: Index: [[#NFA+15]]
; SYM-NEXT: Name: loadsTWInit
; SYM-NEXT: Value (RelocatableAddress): 0x9C
; SYM-NEXT: Section: .data
@@ -357,7 +378,7 @@ entry:
; SYM-NEXT: StorageClass: C_EXT (0x2)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+14]]
+; SYM-NEXT: Index: [[#NFA+16]]
; SYM-NEXT: SectionLen: 12
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
@@ -369,7 +390,7 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: }
; SYM-NEXT: Symbol {
-; SYM-NEXT: Index: [[#NFA+15]]
+; SYM-NEXT: Index: [[#NFA+17]]
; SYM-NEXT: Name: TOC
; SYM-NEXT: Value (RelocatableAddress): 0xA8
; SYM-NEXT: Section: .data
@@ -377,7 +398,7 @@ entry:
; SYM-NEXT: StorageClass: C_HIDEXT (0x6B)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+16]]
+; SYM-NEXT: Index: [[#NFA+18]]
; SYM-NEXT: SectionLen: 0
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
@@ -389,15 +410,15 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: }
; SYM-NEXT: Symbol {
-; SYM-NEXT: Index: [[#NFA+17]]
-; SYM-NEXT: Name: .TIInit
+; SYM-NEXT: Index: [[#NFA+19]]
+; SYM-NEXT: Name: TIInit
; SYM-NEXT: Value (RelocatableAddress): 0xA8
; SYM-NEXT: Section: .data
; SYM-NEXT: Type: 0x0
; SYM-NEXT: StorageClass: C_HIDEXT (0x6B)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+18]]
+; SYM-NEXT: Index: [[#NFA+20]]
; SYM-NEXT: SectionLen: 4
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
@@ -409,27 +430,27 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: }
; SYM-NEXT: Symbol {
-; SYM-NEXT: Index: [[#NFA+19]]
-; SYM-NEXT: Name: TIInit
+; SYM-NEXT: Index: [[#NFA+21]]
+; SYM-NEXT: Name: _$TLSML
; SYM-NEXT: Value (RelocatableAddress): 0xAC
; SYM-NEXT: Section: .data
; SYM-NEXT: Type: 0x0
; SYM-NEXT: StorageClass: C_HIDEXT (0x6B)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+20]]
+; SYM-NEXT: Index: [[#NFA+22]]
; SYM-NEXT: SectionLen: 4
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
; SYM-NEXT: SymbolAlignmentLog2: 2
; SYM-NEXT: SymbolType: XTY_SD (0x1)
-; SYM-NEXT: StorageMappingClass: XMC_TE (0x16)
+; SYM-NEXT: StorageMappingClass: XMC_TC (0x3)
; SYM-NEXT: StabInfoIndex: 0x0
; SYM-NEXT: StabSectNum: 0x0
; SYM-NEXT: }
; SYM-NEXT: }
; SYM-NEXT: Symbol {
-; SYM-NEXT: Index: [[#NFA+21]]
+; SYM-NEXT: Index: [[#NFA+23]]
; SYM-NEXT: Name: .TWInit
; SYM-NEXT: Value (RelocatableAddress): 0xB0
; SYM-NEXT: Section: .data
@@ -437,7 +458,7 @@ entry:
; SYM-NEXT: StorageClass: C_HIDEXT (0x6B)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+22]]
+; SYM-NEXT: Index: [[#NFA+24]]
; SYM-NEXT: SectionLen: 4
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
@@ -449,7 +470,7 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: }
; SYM-NEXT: Symbol {
-; SYM-NEXT: Index: [[#NFA+23]]
+; SYM-NEXT: Index: [[#NFA+25]]
; SYM-NEXT: Name: TWInit
; SYM-NEXT: Value (RelocatableAddress): 0xB4
; SYM-NEXT: Section: .data
@@ -457,7 +478,7 @@ entry:
; SYM-NEXT: StorageClass: C_HIDEXT (0x6B)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+24]]
+; SYM-NEXT: Index: [[#NFA+26]]
; SYM-NEXT: SectionLen: 4
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
@@ -469,7 +490,7 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: }
; SYM-NEXT: Symbol {
-; SYM-NEXT: Index: [[#NFA+25]]
+; SYM-NEXT: Index: [[#NFA+27]]
; SYM-NEXT: Name: GInit
; SYM-NEXT: Value (RelocatableAddress): 0xB8
; SYM-NEXT: Section: .data
@@ -477,7 +498,7 @@ entry:
; SYM-NEXT: StorageClass: C_HIDEXT (0x6B)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+26]]
+; SYM-NEXT: Index: [[#NFA+28]]
; SYM-NEXT: SectionLen: 4
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
@@ -489,7 +510,7 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: }
; SYM-NEXT: Symbol {
-; SYM-NEXT: Index: [[#NFA+27]]
+; SYM-NEXT: Index: [[#NFA+29]]
; SYM-NEXT: Name: TIInit
; SYM-NEXT: Value (RelocatableAddress): 0x0
; SYM-NEXT: Section: .tdata
@@ -497,7 +518,7 @@ entry:
; SYM-NEXT: StorageClass: C_HIDEXT (0x6B)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+28]]
+; SYM-NEXT: Index: [[#NFA+30]]
; SYM-NEXT: SectionLen: 8
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
@@ -509,7 +530,7 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: }
; SYM-NEXT: Symbol {
-; SYM-NEXT: Index: [[#NFA+29]]
+; SYM-NEXT: Index: [[#NFA+31]]
; SYM-NEXT: Name: TWInit
; SYM-NEXT: Value (RelocatableAddress): 0x8
; SYM-NEXT: Section: .tdata
@@ -517,7 +538,7 @@ entry:
; SYM-NEXT: StorageClass: C_WEAKEXT (0x6F)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+30]]
+; SYM-NEXT: Index: [[#NFA+32]]
; SYM-NEXT: SectionLen: 8
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
@@ -536,20 +557,20 @@ entry:
; DIS-NEXT: mflr 0
; DIS-NEXT: stwu 1, -32(1)
; DIS-NEXT: stw 0, 40(1)
-; DIS-NEXT: mr 6, 4
; DIS-NEXT: mr 7, 3
-; DIS-NEXT: [[#%x, ADDR:]]: {{.*}} addis 3, 2, 0
-; DIS-NEXT: {{0*}}[[#ADDR + 2]]: R_TOCU (idx: [[#NFA+17]]) .TIInit[TE]
-; DIS-NEXT: [[#%x, ADDR:]]: {{.*}} addis 4, 2, 0
+; DIS-NEXT: mr 6, 4
+; DIS-NEXT: [[#%x, ADDR:]]: {{.*}} addis 8, 2, 0
; DIS-NEXT: {{0*}}[[#ADDR + 2]]: R_TOCU (idx: [[#NFA+19]]) TIInit[TE]
-; DIS-NEXT: [[#%x, ADDR:]]: {{.*}} lwz 3, 0(3)
-; DIS-NEXT: {{0*}}[[#ADDR + 2]]: R_TOCL (idx: [[#NFA+17]]) .TIInit[TE]
-; DIS-NEXT: [[#%x, ADDR:]]: {{.*}} lwz 4, 4(4)
+; DIS-NEXT: [[#%x, ADDR:]]: {{.*}} addis 3, 2, 0
+; DIS-NEXT: {{0*}}[[#ADDR + 2]]: R_TOCU (idx: [[#NFA+21]]) _$TLSML[TC]
+; DIS-NEXT: [[#%x, ADDR:]]: {{.*}} lwz 3, 4(3)
+; DIS-NEXT: {{0*}}[[#ADDR + 2]]: R_TOCL (idx: [[#NFA+21]]) _$TLSML[TC]
+; DIS-NEXT: [[#%x, ADDR:]]: {{.*}} bla 0x0
+; DIS-NEXT: {{0*}}[[#ADDR]]: R_RBA (idx: [[#NFA+1]]) .__tls_get_mod[PR]
+; DIS-NEXT: [[#%x, ADDR:]]: {{.*}} lwz 4, 0(8)
; DIS-NEXT: {{0*}}[[#ADDR + 2]]: R_TOCL (idx: [[#NFA+19]]) TIInit[TE]
-; DIS-NEXT: [[#%x, ADDR:]]: {{.*}} bla 0
-; DIS-NEXT: {{0*}}[[#ADDR]]: R_RBA (idx: [[#NFA+1]]) .__tls_get_addr[PR]
+; DIS-NEXT: stwux 7, 3, 4
; DIS-NEXT: stw 6, 4(3)
-; DIS-NEXT: stw 7, 0(3)
; DIS-NEXT: addi 1, 1, 32
; DIS-NEXT: lwz 0, 8(1)
; DIS-NEXT: mtlr 0
@@ -559,20 +580,20 @@ entry:
; DIS-NEXT: stwu 1, -32(1)
; DIS-NEXT: stw 0, 40(1)
; DIS-NEXT: [[#%x, ADDR:]]: {{.*}} addis 3, 2, 0
-; DIS-NEXT: {{0*}}[[#ADDR + 2]]: R_TOCU (idx: [[#NFA+21]]) .TWInit[TE]
+; DIS-NEXT: {{0*}}[[#ADDR + 2]]: R_TOCU (idx: [[#NFA+23]]) .TWInit[TE]
; DIS-NEXT: [[#%x, ADDR:]]: {{.*}} addis 4, 2, 0
-; DIS-NEXT: {{0*}}[[#ADDR + 2]]: R_TOCU (idx: [[#NFA+23]]) TWInit[TE]
+; DIS-NEXT: {{0*}}[[#ADDR + 2]]: R_TOCU (idx: [[#NFA+25]]) TWInit[TE]
; DIS-NEXT: [[#%x, ADDR:]]: {{.*}} lwz 3, 8(3)
-; DIS-NEXT: {{0*}}[[#ADDR + 2]]: R_TOCL (idx: [[#NFA+21]]) .TWInit[TE]
+; DIS-NEXT: {{0*}}[[#ADDR + 2]]: R_TOCL (idx: [[#NFA+23]]) .TWInit[TE]
; DIS-NEXT: [[#%x, ADDR:]]: {{.*}} lwz 4, 12(4)
-; DIS-NEXT: {{0*}}[[#ADDR + 2]]: R_TOCL (idx: [[#NFA+23]]) TWInit[TE]
+; DIS-NEXT: {{0*}}[[#ADDR + 2]]: R_TOCL (idx: [[#NFA+25]]) TWInit[TE]
; DIS-NEXT: [[#%x, ADDR:]]: {{.*}} bla 0
-; DIS-NEXT: {{0*}}[[#ADDR]]: R_RBA (idx: [[#NFA+1]]) .__tls_get_addr[PR]
+; DIS-NEXT: {{0*}}[[#ADDR]]: R_RBA (idx: [[#NFA+3]]) .__tls_get_addr[PR]
; DIS-NEXT: lfd 0, 0(3)
; DIS-NEXT: [[#%x, ADDR:]]: {{.*}} addis 3, 2, 0
-; DIS-NEXT: {{0*}}[[#ADDR + 2]]: R_TOCU (idx: [[#NFA+25]]) GInit[TE]
+; DIS-NEXT: {{0*}}[[#ADDR + 2]]: R_TOCU (idx: [[#NFA+27]]) GInit[TE]
; DIS-NEXT: [[#%x, ADDR:]]: {{.*}} lwz 3, 16(3)
-; DIS-NEXT: {{0*}}[[#ADDR + 2]]: R_TOCL (idx: [[#NFA+25]]) GInit[TE]
+; DIS-NEXT: {{0*}}[[#ADDR + 2]]: R_TOCL (idx: [[#NFA+27]]) GInit[TE]
; DIS-NEXT: lfd 1, 0(3)
; DIS-NEXT: fadd 1, 0, 1
; DIS-NEXT: addi 1, 1, 32
@@ -581,42 +602,42 @@ entry:
; DIS-NEXT: blr
; DIS: Disassembly of section .data:
-; DIS: 00000088 (idx: [[#NFA+9]]) GInit[RW]:
+; DIS: 00000088 (idx: [[#NFA+11]]) GInit[RW]:
; DIS-NEXT: 88: 3f f0 00 00
; DIS-NEXT: 8c: 00 00 00 00
-; DIS: 00000090 (idx: [[#NFA+11]]) storesTIInit[DS]:
+; DIS: 00000090 (idx: [[#NFA+13]]) storesTIInit[DS]:
; DIS-NEXT: 90: 00 00 00 00
-; DIS-NEXT: 00000090: R_POS (idx: [[#NFA+5]]) .storesTIInit
+; DIS-NEXT: 00000090: R_POS (idx: [[#NFA+7]]) .storesTIInit
; DIS-NEXT: 94: 00 00 00 a8
-; DIS-NEXT: 00000094: R_POS (idx: [[#NFA+15]]) TOC[TC0]
+; DIS-NEXT: 00000094: R_POS (idx: [[#NFA+17]]) TOC[TC0]
; DIS-NEXT: 98: 00 00 00 00
-; DIS: 0000009c (idx: [[#NFA+13]]) loadsTWInit[DS]:
+; DIS: 0000009c (idx: [[#NFA+15]]) loadsTWInit[DS]:
; DIS-NEXT: 9c: 00 00 00 40
-; DIS-NEXT: 0000009c: R_POS (idx: [[#NFA+7]]) .loadsTWInit
+; DIS-NEXT: 0000009c: R_POS (idx: [[#NFA+9]]) .loadsTWInit
; DIS-NEXT: a0: 00 00 00 a8
-; DIS-NEXT: 000000a0: R_POS (idx: [[#NFA+15]]) TOC[TC0]
+; DIS-NEXT: 000000a0: R_POS (idx: [[#NFA+17]]) TOC[TC0]
; DIS-NEXT: a4: 00 00 00 00
-; DIS: 000000a8 (idx: [[#NFA+17]]) .TIInit[TE]:
+; DIS: 000000a8 (idx: [[#NFA+19]]) TIInit[TE]:
; DIS-NEXT: a8: 00 00 00 00
-; DIS-NEXT: 000000a8: R_TLSM (idx: [[#NFA+27]]) TIInit[TL]
-; DIS: 000000ac (idx: [[#NFA+19]]) TIInit[TE]:
+; DIS-NEXT: 000000a8: R_TLS_LD (idx: [[#NFA+29]]) TIInit[TL]
+; DIS: 000000ac (idx: [[#NFA+21]]) _$TLSML[TC]:
; DIS-NEXT: ac: 00 00 00 00
-; DIS-NEXT: 000000ac: R_TLS (idx: [[#NFA+27]]) TIInit[TL]
-; DIS: 000000b0 (idx: [[#NFA+21]]) .TWInit[TE]:
+; DIS-NEXT: 000000ac: R_TLSML (idx: [[#NFA+21]]) _$TLSML[TC]
+; DIS: 000000b0 (idx: [[#NFA+23]]) .TWInit[TE]:
; DIS-NEXT: b0: 00 00 00 00
-; DIS-NEXT: 000000b0: R_TLSM (idx: [[#NFA+29]]) TWInit[TL]
-; DIS: 000000b4 (idx: [[#NFA+23]]) TWInit[TE]:
+; DIS-NEXT: 000000b0: R_TLSM (idx: [[#NFA+31]]) TWInit[TL]
+; DIS: 000000b4 (idx: [[#NFA+25]]) TWInit[TE]:
; DIS-NEXT: b4: 00 00 00 08
-; DIS-NEXT: 000000b4: R_TLS (idx: [[#NFA+29]]) TWInit[TL]
-; DIS: 000000b8 (idx: [[#NFA+25]]) GInit[TE]:
+; DIS-NEXT: 000000b4: R_TLS (idx: [[#NFA+31]]) TWInit[TL]
+; DIS: 000000b8 (idx: [[#NFA+27]]) GInit[TE]:
; DIS-NEXT: b8: 00 00 00 88
-; DIS-NEXT: 000000b8: R_POS (idx: [[#NFA+9]]) GInit[RW]
+; DIS-NEXT: 000000b8: R_POS (idx: [[#NFA+11]]) GInit[RW]
; DIS: Disassembly of section .tdata:
-; DIS: 00000000 (idx: [[#NFA+27]]) TIInit[TL]:
+; DIS: 00000000 (idx: [[#NFA+29]]) TIInit[TL]:
; DIS-NEXT: 0: 00 00 00 00
; DIS-NEXT: 4: 00 00 00 01
-; DIS: 00000008 (idx: [[#NFA+29]]) TWInit[TL]:
+; DIS: 00000008 (idx: [[#NFA+31]]) TWInit[TL]:
; DIS-NEXT: 8: 3f f0 00 00
; DIS-NEXT: c: 00 00 00 00
diff --git a/llvm/test/CodeGen/PowerPC/aix-tls-xcoff-reloc.ll b/llvm/test/CodeGen/PowerPC/aix-tls-xcoff-reloc.ll
index eb7a0e277a5652..0a3e7637b2e70c 100644
--- a/llvm/test/CodeGen/PowerPC/aix-tls-xcoff-reloc.ll
+++ b/llvm/test/CodeGen/PowerPC/aix-tls-xcoff-reloc.ll
@@ -7,6 +7,7 @@
@const_ivar = constant i32 6, align 4
@GInit = global i32 1, align 4
@TGInit = thread_local global i32 1, align 4
+; @TIUninit is local-dynamic indeed
@TIUninit = internal thread_local global i32 0, align 4
; Function Attrs: nofree norecurse nounwind willreturn writeonly
@@ -33,31 +34,31 @@ entry:
; RELOC-NEXT: Section (index: 1) .text {
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0xE
-; RELOC-NEXT: Symbol: .TIUninit ([[#NFA+23]])
+; RELOC-NEXT: Symbol: _$TLSML ([[#NFA+25]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 16
; RELOC-NEXT: Type: R_TOC (0x3)
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
-; RELOC-NEXT: Virtual Address: 0x12
-; RELOC-NEXT: Symbol: TIUninit ([[#NFA+25]])
+; RELOC-NEXT: Virtual Address: 0x14
+; RELOC-NEXT: Symbol: .__tls_get_mod ([[#NFA+1]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
-; RELOC-NEXT: Length: 16
-; RELOC-NEXT: Type: R_TOC (0x3)
+; RELOC-NEXT: Length: 26
+; RELOC-NEXT: Type: R_RBA (0x18)
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
-; RELOC-NEXT: Virtual Address: 0x18
-; RELOC-NEXT: Symbol: .__tls_get_addr ([[#NFA+1]])
+; RELOC-NEXT: Virtual Address: 0x1A
+; RELOC-NEXT: Symbol: TIUninit ([[#NFA+27]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
-; RELOC-NEXT: Length: 26
-; RELOC-NEXT: Type: R_RBA (0x18)
+; RELOC-NEXT: Length: 16
+; RELOC-NEXT: Type: R_TOC (0x3)
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0x3A
-; RELOC-NEXT: Symbol: .TGInit ([[#NFA+27]])
+; RELOC-NEXT: Symbol: .TGInit ([[#NFA+29]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 16
@@ -65,7 +66,7 @@ entry:
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0x3E
-; RELOC-NEXT: Symbol: TGInit ([[#NFA+29]])
+; RELOC-NEXT: Symbol: TGInit ([[#NFA+31]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 16
@@ -73,7 +74,7 @@ entry:
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0x44
-; RELOC-NEXT: Symbol: .__tls_get_addr ([[#NFA+1]])
+; RELOC-NEXT: Symbol: .__tls_get_addr ([[#NFA+3]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 26
@@ -81,7 +82,7 @@ entry:
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0x4A
-; RELOC-NEXT: Symbol: GInit ([[#NFA+31]])
+; RELOC-NEXT: Symbol: GInit ([[#NFA+33]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 16
@@ -91,7 +92,7 @@ entry:
; RELOC-NEXT: Section (index: 2) .data {
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0x70
-; RELOC-NEXT: Symbol: .storesTIUninit ([[#NFA+5]])
+; RELOC-NEXT: Symbol: .storesTIUninit ([[#NFA+7]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 32
@@ -99,7 +100,7 @@ entry:
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0x74
-; RELOC-NEXT: Symbol: TOC ([[#NFA+21]])
+; RELOC-NEXT: Symbol: TOC ([[#NFA+23]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 32
@@ -107,7 +108,7 @@ entry:
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0x7C
-; RELOC-NEXT: Symbol: .loadsTGInit ([[#NFA+7]])
+; RELOC-NEXT: Symbol: .loadsTGInit ([[#NFA+9]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 32
@@ -115,7 +116,7 @@ entry:
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0x80
-; RELOC-NEXT: Symbol: TOC ([[#NFA+21]])
+; RELOC-NEXT: Symbol: TOC ([[#NFA+23]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 32
@@ -123,23 +124,23 @@ entry:
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0x88
-; RELOC-NEXT: Symbol: TIUninit ([[#NFA+37]])
+; RELOC-NEXT: Symbol: _$TLSML ([[#NFA+25]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 32
-; RELOC-NEXT: Type: R_TLSM (0x24)
+; RELOC-NEXT: Type: R_TLSML (0x25)
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0x8C
-; RELOC-NEXT: Symbol: TIUninit ([[#NFA+37]])
+; RELOC-NEXT: Symbol: TIUninit ([[#NFA+39]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 32
-; RELOC-NEXT: Type: R_TLS (0x20)
+; RELOC-NEXT: Type: R_TLS_LD (0x22)
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0x90
-; RELOC-NEXT: Symbol: TGInit ([[#NFA+35]])
+; RELOC-NEXT: Symbol: TGInit ([[#NFA+37]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 32
@@ -147,7 +148,7 @@ entry:
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0x94
-; RELOC-NEXT: Symbol: TGInit ([[#NFA+35]])
+; RELOC-NEXT: Symbol: TGInit ([[#NFA+37]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 32
@@ -155,7 +156,7 @@ entry:
; RELOC-NEXT: }
; RELOC-NEXT: Relocation {
; RELOC-NEXT: Virtual Address: 0x98
-; RELOC-NEXT: Symbol: GInit ([[#NFA+15]])
+; RELOC-NEXT: Symbol: GInit ([[#NFA+17]])
; RELOC-NEXT: IsSigned: No
; RELOC-NEXT: FixupBitValue: 0
; RELOC-NEXT: Length: 32
@@ -178,9 +179,9 @@ entry:
; SYM-NEXT: CPU Version ID: TCPU_COM (0x3)
; SYM-NEXT: StorageClass: C_FILE (0x67)
; SYM-NEXT: NumberOfAuxEntries: 2
-; SYM: Symbol {
+; SYM: Symbol {
; SYM-NEXT: Index: [[#NFA+1]]
-; SYM-NEXT: Name: .__tls_get_addr
+; SYM-NEXT: Name: .__tls_get_mod
; SYM-NEXT: Value (RelocatableAddress): 0x0
; SYM-NEXT: Section: N_UNDEF
; SYM-NEXT: Type: 0x0
@@ -200,6 +201,26 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: Symbol {
; SYM-NEXT: Index: [[#NFA+3]]
+; SYM-NEXT: Name: .__tls_get_addr
+; SYM-NEXT: Value (RelocatableAddress): 0x0
+; SYM-NEXT: Section: N_UNDEF
+; SYM-NEXT: Type: 0x0
+; SYM-NEXT: StorageClass: C_EXT (0x2)
+; SYM-NEXT: NumberOfAuxEntries: 1
+; SYM-NEXT: CSECT Auxiliary Entry {
+; SYM-NEXT: Index: 6
+; SYM-NEXT: SectionLen: 0
+; SYM-NEXT: ParameterHashIndex: 0x0
+; SYM-NEXT: TypeChkSectNum: 0x0
+; SYM-NEXT: SymbolAlignmentLog2: 0
+; SYM-NEXT: SymbolType: XTY_ER (0x0)
+; SYM-NEXT: StorageMappingClass: XMC_PR (0x0)
+; SYM-NEXT: StabInfoIndex: 0x0
+; SYM-NEXT: StabSectNum: 0x0
+; SYM-NEXT: }
+; SYM-NEXT: }
+; SYM-NEXT: Symbol {
+; SYM-NEXT: Index: [[#NFA+5]]
; SYM-NEXT: Name:
; SYM-NEXT: Value (RelocatableAddress): 0x0
; SYM-NEXT: Section: .text
@@ -207,7 +228,7 @@ entry:
; SYM-NEXT: StorageClass: C_HIDEXT (0x6B)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+4]]
+; SYM-NEXT: Index: [[#NFA+6]]
; SYM-NEXT: SectionLen: 104
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
@@ -219,7 +240,7 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: }
; SYM-NEXT: Symbol {
-; SYM-NEXT: Index: [[#NFA+5]]
+; SYM-NEXT: Index: [[#NFA+7]]
; SYM-NEXT: Name: .storesTIUninit
; SYM-NEXT: Value (RelocatableAddress): 0x0
; SYM-NEXT: Section: .text
@@ -227,8 +248,8 @@ entry:
; SYM-NEXT: StorageClass: C_EXT (0x2)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+6]]
-; SYM-NEXT: ContainingCsectSymbolIndex: [[#NFA+3]]
+; SYM-NEXT: Index: [[#NFA+8]]
+; SYM-NEXT: ContainingCsectSymbolIndex: [[#NFA+5]]
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
; SYM-NEXT: SymbolAlignmentLog2: 0
@@ -239,7 +260,7 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: }
; SYM-NEXT: Symbol {
-; SYM-NEXT: Index: [[#NFA+7]]
+; SYM-NEXT: Index: [[#NFA+9]]
; SYM-NEXT: Name: .loadsTGInit
; SYM-NEXT: Value (RelocatableAddress): 0x30
; SYM-NEXT: Section: .text
@@ -247,8 +268,8 @@ entry:
; SYM-NEXT: StorageClass: C_EXT (0x2)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+8]]
-; SYM-NEXT: ContainingCsectSymbolIndex: [[#NFA+3]]
+; SYM-NEXT: Index: [[#NFA+10]]
+; SYM-NEXT: ContainingCsectSymbolIndex: [[#NFA+5]]
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
; SYM-NEXT: SymbolAlignmentLog2: 0
@@ -259,7 +280,7 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: }
; SYM-NEXT: Symbol {
-; SYM-NEXT: Index: [[#NFA+9]]
+; SYM-NEXT: Index: [[#NFA+11]]
; SYM-NEXT: Name: .rodata
; SYM-NEXT: Value (RelocatableAddress): 0x68
; SYM-NEXT: Section: .text
@@ -267,7 +288,7 @@ entry:
; SYM-NEXT: StorageClass: C_HIDEXT (0x6B)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+10]]
+; SYM-NEXT: Index: [[#NFA+12]]
; SYM-NEXT: SectionLen: 4
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
@@ -279,7 +300,7 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: }
; SYM-NEXT: Symbol {
-; SYM-NEXT: Index: [[#NFA+11]]
+; SYM-NEXT: Index: [[#NFA+13]]
; SYM-NEXT: Name: const_ivar
; SYM-NEXT: Value (RelocatableAddress): 0x68
; SYM-NEXT: Section: .text
@@ -287,8 +308,8 @@ entry:
; SYM-NEXT: StorageClass: C_EXT (0x2)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+12]]
-; SYM-NEXT: ContainingCsectSymbolIndex: [[#NFA+9]]
+; SYM-NEXT: Index: [[#NFA+14]]
+; SYM-NEXT: ContainingCsectSymbolIndex: [[#NFA+11]]
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
; SYM-NEXT: SymbolAlignmentLog2: 0
@@ -299,7 +320,7 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: }
; SYM-NEXT: Symbol {
-; SYM-NEXT: Index: [[#NFA+13]]
+; SYM-NEXT: Index: [[#NFA+15]]
; SYM-NEXT: Name: .data
; SYM-NEXT: Value (RelocatableAddress): 0x6C
; SYM-NEXT: Section: .data
@@ -307,7 +328,7 @@ entry:
; SYM-NEXT: StorageClass: C_HIDEXT (0x6B)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+14]]
+; SYM-NEXT: Index: [[#NFA+16]]
; SYM-NEXT: SectionLen: 4
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
@@ -319,7 +340,7 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: }
; SYM-NEXT: Symbol {
-; SYM-NEXT: Index: [[#NFA+15]]
+; SYM-NEXT: Index: [[#NFA+17]]
; SYM-NEXT: Name: GInit
; SYM-NEXT: Value (RelocatableAddress): 0x6C
; SYM-NEXT: Section: .data
@@ -327,8 +348,8 @@ entry:
; SYM-NEXT: StorageClass: C_EXT (0x2)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+16]]
-; SYM-NEXT: ContainingCsectSymbolIndex: [[#NFA+13]]
+; SYM-NEXT: Index: [[#NFA+18]]
+; SYM-NEXT: ContainingCsectSymbolIndex: [[#NFA+15]]
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
; SYM-NEXT: SymbolAlignmentLog2: 0
@@ -339,7 +360,7 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: }
; SYM-NEXT: Symbol {
-; SYM-NEXT: Index: [[#NFA+17]]
+; SYM-NEXT: Index: [[#NFA+19]]
; SYM-NEXT: Name: storesTIUninit
; SYM-NEXT: Value (RelocatableAddress): 0x70
; SYM-NEXT: Section: .data
@@ -347,7 +368,7 @@ entry:
; SYM-NEXT: StorageClass: C_EXT (0x2)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+18]]
+; SYM-NEXT: Index: [[#NFA+20]]
; SYM-NEXT: SectionLen: 12
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
@@ -359,7 +380,7 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: }
; SYM-NEXT: Symbol {
-; SYM-NEXT: Index: [[#NFA+19]]
+; SYM-NEXT: Index: [[#NFA+21]]
; SYM-NEXT: Name: loadsTGInit
; SYM-NEXT: Value (RelocatableAddress): 0x7C
; SYM-NEXT: Section: .data
@@ -367,7 +388,7 @@ entry:
; SYM-NEXT: StorageClass: C_EXT (0x2)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+20]]
+; SYM-NEXT: Index: [[#NFA+22]]
; SYM-NEXT: SectionLen: 12
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
@@ -379,7 +400,7 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: }
; SYM-NEXT: Symbol {
-; SYM-NEXT: Index: [[#NFA+21]]
+; SYM-NEXT: Index: [[#NFA+23]]
; SYM-NEXT: Name: TOC
; SYM-NEXT: Value (RelocatableAddress): 0x88
; SYM-NEXT: Section: .data
@@ -387,7 +408,7 @@ entry:
; SYM-NEXT: StorageClass: C_HIDEXT (0x6B)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+22]]
+; SYM-NEXT: Index: [[#NFA+24]]
; SYM-NEXT: SectionLen: 0
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
@@ -399,15 +420,15 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: }
; SYM-NEXT: Symbol {
-; SYM-NEXT: Index: [[#NFA+23]]
-; SYM-NEXT: Name: .TIUninit
+; SYM-NEXT: Index: [[#NFA+25]]
+; SYM-NEXT: Name: _$TLSML
; SYM-NEXT: Value (RelocatableAddress): 0x88
; SYM-NEXT: Section: .data
; SYM-NEXT: Type: 0x0
; SYM-NEXT: StorageClass: C_HIDEXT (0x6B)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+24]]
+; SYM-NEXT: Index: [[#NFA+26]]
; SYM-NEXT: SectionLen: 4
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
@@ -419,7 +440,7 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: }
; SYM-NEXT: Symbol {
-; SYM-NEXT: Index: [[#NFA+25]]
+; SYM-NEXT: Index: [[#NFA+27]]
; SYM-NEXT: Name: TIUninit
; SYM-NEXT: Value (RelocatableAddress): 0x8C
; SYM-NEXT: Section: .data
@@ -427,7 +448,7 @@ entry:
; SYM-NEXT: StorageClass: C_HIDEXT (0x6B)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+26]]
+; SYM-NEXT: Index: [[#NFA+28]]
; SYM-NEXT: SectionLen: 4
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
@@ -439,7 +460,7 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: }
; SYM-NEXT: Symbol {
-; SYM-NEXT: Index: [[#NFA+27]]
+; SYM-NEXT: Index: [[#NFA+29]]
; SYM-NEXT: Name: .TGInit
; SYM-NEXT: Value (RelocatableAddress): 0x90
; SYM-NEXT: Section: .data
@@ -447,7 +468,7 @@ entry:
; SYM-NEXT: StorageClass: C_HIDEXT (0x6B)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+28]]
+; SYM-NEXT: Index: [[#NFA+30]]
; SYM-NEXT: SectionLen: 4
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
@@ -459,7 +480,7 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: }
; SYM-NEXT: Symbol {
-; SYM-NEXT: Index: [[#NFA+29]]
+; SYM-NEXT: Index: [[#NFA+31]]
; SYM-NEXT: Name: TGInit
; SYM-NEXT: Value (RelocatableAddress): 0x94
; SYM-NEXT: Section: .data
@@ -467,7 +488,7 @@ entry:
; SYM-NEXT: StorageClass: C_HIDEXT (0x6B)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+30]]
+; SYM-NEXT: Index: [[#NFA+32]]
; SYM-NEXT: SectionLen: 4
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
@@ -479,7 +500,7 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: }
; SYM-NEXT: Symbol {
-; SYM-NEXT: Index: [[#NFA+31]]
+; SYM-NEXT: Index: [[#NFA+33]]
; SYM-NEXT: Name: GInit
; SYM-NEXT: Value (RelocatableAddress): 0x98
; SYM-NEXT: Section: .data
@@ -487,7 +508,7 @@ entry:
; SYM-NEXT: StorageClass: C_HIDEXT (0x6B)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+32]]
+; SYM-NEXT: Index: [[#NFA+34]]
; SYM-NEXT: SectionLen: 4
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
@@ -499,7 +520,7 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: }
; SYM-NEXT: Symbol {
-; SYM-NEXT: Index: [[#NFA+33]]
+; SYM-NEXT: Index: [[#NFA+35]]
; SYM-NEXT: Name: .tdata
; SYM-NEXT: Value (RelocatableAddress): 0x0
; SYM-NEXT: Section: .tdata
@@ -507,7 +528,7 @@ entry:
; SYM-NEXT: StorageClass: C_HIDEXT (0x6B)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+34]]
+; SYM-NEXT: Index: [[#NFA+36]]
; SYM-NEXT: SectionLen: 4
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
@@ -519,7 +540,7 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: }
; SYM-NEXT: Symbol {
-; SYM-NEXT: Index: [[#NFA+35]]
+; SYM-NEXT: Index: [[#NFA+37]]
; SYM-NEXT: Name: TGInit
; SYM-NEXT: Value (RelocatableAddress): 0x0
; SYM-NEXT: Section: .tdata
@@ -527,8 +548,8 @@ entry:
; SYM-NEXT: StorageClass: C_EXT (0x2)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+36]]
-; SYM-NEXT: ContainingCsectSymbolIndex: [[#NFA+33]]
+; SYM-NEXT: Index: [[#NFA+38]]
+; SYM-NEXT: ContainingCsectSymbolIndex: [[#NFA+35]]
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
; SYM-NEXT: SymbolAlignmentLog2: 0
@@ -539,7 +560,7 @@ entry:
; SYM-NEXT: }
; SYM-NEXT: }
; SYM-NEXT: Symbol {
-; SYM-NEXT: Index: [[#NFA+37]]
+; SYM-NEXT: Index: [[#NFA+39]]
; SYM-NEXT: Name: TIUninit
; SYM-NEXT: Value (RelocatableAddress): 0x4
; SYM-NEXT: Section: .tbss
@@ -547,7 +568,7 @@ entry:
; SYM-NEXT: StorageClass: C_HIDEXT (0x6B)
; SYM-NEXT: NumberOfAuxEntries: 1
; SYM-NEXT: CSECT Auxiliary Entry {
-; SYM-NEXT: Index: [[#NFA+38]]
+; SYM-NEXT: Index: [[#NFA+40]]
; SYM-NEXT: SectionLen: 4
; SYM-NEXT: ParameterHashIndex: 0x0
; SYM-NEXT: TypeChkSectNum: 0x0
@@ -562,34 +583,34 @@ entry:
; DIS: {{.*}}aix-tls-xcoff-reloc.ll.tmp.o: file format aixcoff-rs6000
; DIS: Disassembly of section .text:
-; DIS: 00000000 (idx: [[#NFA+5]]) .storesTIUninit:
+; DIS: 00000000 (idx: [[#NFA+7]]) .storesTIUninit:
; DIS-NEXT: mflr 0
; DIS-NEXT: stwu 1, -32(1)
; DIS-NEXT: mr 6, 3
; DIS-NEXT: [[#%x, ADDR:]]: {{.*}} lwz 3, 0(2)
-; DIS-NEXT: {{0*}}[[#ADDR + 2]]: R_TOC (idx: [[#NFA+23]]) .TIUninit[TC]
-; DIS-NEXT: [[#%x, ADDR:]]: {{.*}} lwz 4, 4(2)
-; DIS-NEXT: {{0*}}[[#ADDR + 2]]: R_TOC (idx: [[#NFA+25]]) TIUninit[TC]
+; DIS-NEXT: {{0*}}[[#ADDR + 2]]: R_TOC (idx: [[#NFA+25]]) _$TLSML[TC]
; DIS-NEXT: stw 0, 40(1)
-; DIS-NEXT: [[#%x, ADDR:]]: {{.*}} bla 0
-; DIS-NEXT: {{0*}}[[#ADDR]]: R_RBA (idx: [[#NFA+1]]) .__tls_get_addr[PR]
-; DIS-NEXT: stw 6, 0(3)
+; DIS-NEXT: [[#%x, ADDR:]]: {{.*}} bla 0x0
+; DIS-NEXT: {{0*}}[[#ADDR]]: R_RBA (idx: [[#NFA+1]]) .__tls_get_mod[PR]
+; DIS-NEXT: [[#%x, ADDR:]]: {{.*}} lwz 4, 4(2)
+; DIS-NEXT: {{0*}}[[#ADDR + 2]]: R_TOC (idx: [[#NFA+27]]) TIUninit[TC]
+; DIS-NEXT: stwx 6, 3, 4
; DIS-NEXT: addi 1, 1, 32
; DIS-NEXT: lwz 0, 8(1)
; DIS-NEXT: mtlr 0
; DIS-NEXT: blr
-; DIS: 00000030 (idx: [[#NFA+7]]) .loadsTGInit:
+; DIS: 00000030 (idx: [[#NFA+9]]) .loadsTGInit:
; DIS-NEXT: mflr 0
; DIS-NEXT: stwu 1, -32(1)
; DIS-NEXT: [[#%x, ADDR:]]: {{.*}} lwz 3, 8(2)
-; DIS-NEXT: {{0*}}[[#ADDR + 2]]: R_TOC (idx: [[#NFA+27]]) .TGInit[TC]
+; DIS-NEXT: {{0*}}[[#ADDR + 2]]: R_TOC (idx: [[#NFA+29]]) .TGInit[TC]
; DIS-NEXT: [[#%x, ADDR:]]: {{.*}} lwz 4, 12(2)
-; DIS-NEXT: {{0*}}[[#ADDR + 2]]: R_TOC (idx: [[#NFA+29]]) TGInit[TC]
+; DIS-NEXT: {{0*}}[[#ADDR + 2]]: R_TOC (idx: [[#NFA+31]]) TGInit[TC]
; DIS-NEXT: stw 0, 40(1)
; DIS-NEXT: [[#%x, ADDR:]]: {{.*}} bla 0
-; DIS-NEXT: {{0*}}[[#ADDR]]: R_RBA (idx: [[#NFA+1]]) .__tls_get_addr[PR]
+; DIS-NEXT: {{0*}}[[#ADDR]]: R_RBA (idx: [[#NFA+3]]) .__tls_get_addr[PR]
; DIS-NEXT: [[#%x, ADDR:]]: {{.*}} lwz 4, 16(2)
-; DIS-NEXT: {{0*}}[[#ADDR + 2]]: R_TOC (idx: [[#NFA+31]]) GInit[TC]
+; DIS-NEXT: {{0*}}[[#ADDR + 2]]: R_TOC (idx: [[#NFA+33]]) GInit[TC]
; DIS-NEXT: lwz 3, 0(3)
; DIS-NEXT: lwz 4, 0(4)
; DIS-NEXT: add 3, 4, 3
@@ -597,46 +618,46 @@ entry:
; DIS-NEXT: lwz 0, 8(1)
; DIS-NEXT: mtlr 0
; DIS-NEXT: blr
-; DIS: 00000068 (idx: [[#NFA+11]]) const_ivar:
+; DIS: 00000068 (idx: [[#NFA+13]]) const_ivar:
; DIS-NEXT: 68: 00 00 00 06
; DIS: Disassembly of section .data:
-; DIS: 0000006c (idx: [[#NFA+15]]) GInit:
+; DIS: 0000006c (idx: [[#NFA+17]]) GInit:
; DIS-NEXT: 6c: 00 00 00 01
-; DIS: 00000070 (idx: [[#NFA+17]]) storesTIUninit[DS]:
+; DIS: 00000070 (idx: [[#NFA+19]]) storesTIUninit[DS]:
; DIS-NEXT: 70: 00 00 00 00
-; DIS-NEXT: 00000070: R_POS (idx: [[#NFA+5]]) .storesTIUninit
+; DIS-NEXT: 00000070: R_POS (idx: [[#NFA+7]]) .storesTIUninit
; DIS-NEXT: 74: 00 00 00 88
-; DIS-NEXT: 00000074: R_POS (idx: [[#NFA+21]]) TOC[TC0]
+; DIS-NEXT: 00000074: R_POS (idx: [[#NFA+23]]) TOC[TC0]
; DIS-NEXT: 78: 00 00 00 00
-; DIS: 0000007c (idx: [[#NFA+19]]) loadsTGInit[DS]:
+; DIS: 0000007c (idx: [[#NFA+21]]) loadsTGInit[DS]:
; DIS-NEXT: 7c: 00 00 00 30
-; DIS-NEXT: 0000007c: R_POS (idx: [[#NFA+7]]) .loadsTGInit
+; DIS-NEXT: 0000007c: R_POS (idx: [[#NFA+9]]) .loadsTGInit
; DIS-NEXT: 80: 00 00 00 88
-; DIS-NEXT: 00000080: R_POS (idx: [[#NFA+21]]) TOC[TC0]
+; DIS-NEXT: 00000080: R_POS (idx: [[#NFA+23]]) TOC[TC0]
; DIS-NEXT: 84: 00 00 00 00
-; DIS: 00000088 (idx: [[#NFA+23]]) .TIUninit[TC]:
+; DIS: 00000088 (idx: [[#NFA+25]]) _$TLSML[TC]:
; DIS-NEXT: 88: 00 00 00 00
-; DIS-NEXT: 00000088: R_TLSM (idx: [[#NFA+37]]) TIUninit[UL]
-; DIS: 0000008c (idx: [[#NFA+25]]) TIUninit[TC]:
+; DIS-NEXT: 00000088: R_TLSML (idx: [[#NFA+25]]) _$TLSML[TC]
+; DIS: 0000008c (idx: [[#NFA+27]]) TIUninit[TC]:
; DIS-NEXT: 8c: 00 00 00 04
-; DIS-NEXT: 0000008c: R_TLS (idx: [[#NFA+37]]) TIUninit[UL]
-; DIS: 00000090 (idx: [[#NFA+27]]) .TGInit[TC]:
+; DIS-NEXT: 0000008c: R_TLS_LD (idx: [[#NFA+39]]) TIUninit[UL]
+; DIS: 00000090 (idx: [[#NFA+29]]) .TGInit[TC]:
; DIS-NEXT: 90: 00 00 00 00
-; DIS-NEXT: 00000090: R_TLSM (idx: [[#NFA+35]]) TGInit
-; DIS: 00000094 (idx: [[#NFA+29]]) TGInit[TC]:
+; DIS-NEXT: 00000090: R_TLSM (idx: [[#NFA+37]]) TGInit
+; DIS: 00000094 (idx: [[#NFA+31]]) TGInit[TC]:
; DIS-NEXT: 94: 00 00 00 00
-; DIS-NEXT: 00000094: R_TLS (idx: [[#NFA+35]]) TGInit
-; DIS: 00000098 (idx: [[#NFA+31]]) GInit[TC]:
+; DIS-NEXT: 00000094: R_TLS (idx: [[#NFA+37]]) TGInit
+; DIS: 00000098 (idx: [[#NFA+33]]) GInit[TC]:
; DIS-NEXT: 98: 00 00 00 6c
-; DIS-NEXT: 00000098: R_POS (idx: [[#NFA+15]]) GInit
+; DIS-NEXT: 00000098: R_POS (idx: [[#NFA+17]]) GInit
; DIS: Disassembly of section .tdata:
-; DIS: 00000000 (idx: [[#NFA+35]]) TGInit:
+; DIS: 00000000 (idx: [[#NFA+37]]) TGInit:
; DIS-NEXT: 0: 00 00 00 01
; DIS: Disassembly of section .tbss:
-; DIS: 00000004 (idx: [[#NFA+37]]) TIUninit[UL]:
+; DIS: 00000004 (idx: [[#NFA+39]]) TIUninit[UL]:
; DIS-NEXT: ...
attributes #0 = { nofree norecurse nounwind willreturn writeonly "frame-pointer"="none" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="pwr4" "target-features"="-altivec,-bpermd,-crypto,-direct-move,-extdiv,-float128,-htm,-mma,-paired-vector-memops,-power10-vector,-power8-vector,-power9-vector,-spe,-vsx" }
>From 5899599b01d86545896bd21bd15fb5cb619bd6c7 Mon Sep 17 00:00:00 2001
From: Yinying Li <107574043+yinying-lisa-li at users.noreply.github.com>
Date: Thu, 29 Feb 2024 19:18:35 -0500
Subject: [PATCH 196/406] [mlir][sparse] Migration to sparse_tensor.print
(#83506)
Continuous efforts #83357. Previously reverted #83377.
---
.../SparseTensor/CPU/sparse_loose.mlir | 23 +-
.../SparseTensor/CPU/sparse_matmul.mlir | 237 ++++++++++--------
.../SparseTensor/CPU/sparse_matmul_slice.mlir | 83 +++---
.../SparseTensor/CPU/sparse_matrix_ops.mlir | 114 +++++----
4 files changed, 258 insertions(+), 199 deletions(-)
diff --git a/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_loose.mlir b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_loose.mlir
index 228d4e5f6f8a1a..e1f062121b12f9 100644
--- a/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_loose.mlir
+++ b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_loose.mlir
@@ -10,7 +10,7 @@
// DEFINE: %{compile} = mlir-opt %s --sparsifier="%{sparsifier_opts}"
// DEFINE: %{compile_sve} = mlir-opt %s --sparsifier="%{sparsifier_opts_sve}"
// DEFINE: %{run_libs} = -shared-libs=%mlir_c_runner_utils,%mlir_runner_utils
-// DEFINE: %{run_opts} = -e entry -entry-point-result=void
+// DEFINE: %{run_opts} = -e main -entry-point-result=void
// DEFINE: %{run} = mlir-cpu-runner %{run_opts} %{run_libs}
// DEFINE: %{run_sve} = %mcr_aarch64_cmd --march=aarch64 --mattr="+sve" %{run_opts} %{run_libs}
//
@@ -28,7 +28,7 @@
}>
module {
- func.func @entry() {
+ func.func @main() {
%c0 = arith.constant 0 : index
%f0 = arith.constant 0.0 : f64
%d = arith.constant dense<[[ 1.0, 2.0, 3.0, 4.0 ],
@@ -39,19 +39,14 @@ module {
%s = sparse_tensor.convert %d : tensor<5x4xf64> to tensor<5x4xf64, #CSR_hi>
//
- // CHECK: ( 0, 4, 4, 8, 8, 9, 9, 13 )
- // CHECK-NEXT: ( 0, 1, 2, 3, 0, 1, 2, 3, 2, 0, 1, 2, 3, 0, 1, 2, 3 )
- // CHECK-NEXT: ( 1, 2, 3, 4, 5, 6, 7, 8, 5.5, 9, 10, 11, 12, 13, 14, 15, 16 )
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 17
+ // CHECK-NEXT: pos[1] : ( 0, 4, 4, 8, 8, 9, 9, 13
+ // CHECK-NEXT: crd[1] : ( 0, 1, 2, 3, 0, 1, 2, 3, 2, 0, 1, 2, 3, 0, 1, 2, 3
+ // CHECK-NEXT: values : ( 1, 2, 3, 4, 5, 6, 7, 8, 5.5, 9, 10, 11, 12, 13, 14, 15, 16
+ // CHECK-NEXT: ----
//
- %pos = sparse_tensor.positions %s {level = 1 : index } : tensor<5x4xf64, #CSR_hi> to memref<?xindex>
- %vecp = vector.transfer_read %pos[%c0], %c0 : memref<?xindex>, vector<8xindex>
- vector.print %vecp : vector<8xindex>
- %crd = sparse_tensor.coordinates %s {level = 1 : index } : tensor<5x4xf64, #CSR_hi> to memref<?xindex>
- %vecc = vector.transfer_read %crd[%c0], %c0 : memref<?xindex>, vector<17xindex>
- vector.print %vecc : vector<17xindex>
- %val = sparse_tensor.values %s : tensor<5x4xf64, #CSR_hi> to memref<?xf64>
- %vecv = vector.transfer_read %val[%c0], %f0 : memref<?xf64>, vector<17xf64>
- vector.print %vecv : vector<17xf64>
+ sparse_tensor.print %s : tensor<5x4xf64, #CSR_hi>
// Release the resources.
bufferization.dealloc_tensor %s: tensor<5x4xf64, #CSR_hi>
diff --git a/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matmul.mlir b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matmul.mlir
index fa0dbac269b926..863e1c62370e32 100644
--- a/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matmul.mlir
+++ b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matmul.mlir
@@ -10,7 +10,7 @@
// DEFINE: %{compile} = mlir-opt %s --sparsifier="%{sparsifier_opts}"
// DEFINE: %{compile_sve} = mlir-opt %s --sparsifier="%{sparsifier_opts_sve}"
// DEFINE: %{run_libs} = -shared-libs=%mlir_c_runner_utils,%mlir_runner_utils
-// DEFINE: %{run_opts} = -e entry -entry-point-result=void
+// DEFINE: %{run_opts} = -e main -entry-point-result=void
// DEFINE: %{run} = mlir-cpu-runner %{run_opts} %{run_libs}
// DEFINE: %{run_sve} = %mcr_aarch64_cmd --march=aarch64 --mattr="+sve" %{run_opts} %{run_libs}
//
@@ -90,7 +90,7 @@ module {
//
// Main driver.
//
- func.func @entry() {
+ func.func @main() {
%c0 = arith.constant 0 : index
// Initialize various matrices, dense for stress testing,
@@ -140,33 +140,94 @@ module {
%b4 = sparse_tensor.convert %sb : tensor<8x4xf64> to tensor<8x4xf64, #DCSR>
//
- // Sanity check on stored entries before going into the computations.
- //
- // CHECK: 32
- // CHECK-NEXT: 32
- // CHECK-NEXT: 4
- // CHECK-NEXT: 4
- // CHECK-NEXT: 32
- // CHECK-NEXT: 32
- // CHECK-NEXT: 8
- // CHECK-NEXT: 8
- //
- %noea1 = sparse_tensor.number_of_entries %a1 : tensor<4x8xf64, #CSR>
- %noea2 = sparse_tensor.number_of_entries %a2 : tensor<4x8xf64, #DCSR>
- %noea3 = sparse_tensor.number_of_entries %a3 : tensor<4x8xf64, #CSR>
- %noea4 = sparse_tensor.number_of_entries %a4 : tensor<4x8xf64, #DCSR>
- %noeb1 = sparse_tensor.number_of_entries %b1 : tensor<8x4xf64, #CSR>
- %noeb2 = sparse_tensor.number_of_entries %b2 : tensor<8x4xf64, #DCSR>
- %noeb3 = sparse_tensor.number_of_entries %b3 : tensor<8x4xf64, #CSR>
- %noeb4 = sparse_tensor.number_of_entries %b4 : tensor<8x4xf64, #DCSR>
- vector.print %noea1 : index
- vector.print %noea2 : index
- vector.print %noea3 : index
- vector.print %noea4 : index
- vector.print %noeb1 : index
- vector.print %noeb2 : index
- vector.print %noeb3 : index
- vector.print %noeb4 : index
+ // Sanity check before going into the computations.
+ //
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 32
+ // CHECK-NEXT: pos[1] : ( 0, 8, 16, 24, 32
+ // CHECK-NEXT: crd[1] : ( 0, 1, 2, 3, 4, 5, 6, 7, 0, 1, 2, 3, 4, 5, 6, 7, 0, 1, 2, 3, 4, 5, 6, 7, 0, 1, 2, 3, 4, 5, 6, 7
+ // CHECK-NEXT: values : ( 1.1, 2.1, 3.1, 4.1, 5.1, 6.1, 7.1, 8.1, 1.2, 2.2, 3.2, 4.2, 5.2, 6.2, 7.2, 8.2, 1.3, 2.3, 3.3, 4.3, 5.3, 6.3, 7.3, 8.3, 1.4, 2.4, 3.4, 4.4, 5.4, 6.4, 7.4, 8.4
+ // CHECK-NEXT: ----
+ //
+ sparse_tensor.print %a1 : tensor<4x8xf64, #CSR>
+
+ //
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 32
+ // CHECK-NEXT: pos[0] : ( 0, 4
+ // CHECK-NEXT: crd[0] : ( 0, 1, 2, 3
+ // CHECK-NEXT: pos[1] : ( 0, 8, 16, 24, 32
+ // CHECK-NEXT: crd[1] : ( 0, 1, 2, 3, 4, 5, 6, 7, 0, 1, 2, 3, 4, 5, 6, 7, 0, 1, 2, 3, 4, 5, 6, 7, 0, 1, 2, 3, 4, 5, 6, 7
+ // CHECK-NEXT: values : ( 1.1, 2.1, 3.1, 4.1, 5.1, 6.1, 7.1, 8.1, 1.2, 2.2, 3.2, 4.2, 5.2, 6.2, 7.2, 8.2, 1.3, 2.3, 3.3, 4.3, 5.3, 6.3, 7.3, 8.3, 1.4, 2.4, 3.4, 4.4, 5.4, 6.4, 7.4, 8.4
+ // CHECK-NEXT: ----
+ //
+ sparse_tensor.print %a2 : tensor<4x8xf64, #DCSR>
+
+ //
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 4
+ // CHECK-NEXT: pos[1] : ( 0, 2, 2, 3, 4
+ // CHECK-NEXT: crd[1] : ( 1, 5, 1, 7
+ // CHECK-NEXT: values : ( 2.1, 6.1, 2.3, 1
+ // CHECK-NEXT: ----
+ //
+ sparse_tensor.print %a3 : tensor<4x8xf64, #CSR>
+
+ //
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 4
+ // CHECK-NEXT: pos[0] : ( 0, 3
+ // CHECK-NEXT: crd[0] : ( 0, 2, 3
+ // CHECK-NEXT: pos[1] : ( 0, 2, 3, 4
+ // CHECK-NEXT: crd[1] : ( 1, 5, 1, 7
+ // CHECK-NEXT: values : ( 2.1, 6.1, 2.3, 1
+ // CHECK-NEXT: ----
+ //
+ sparse_tensor.print %a4 : tensor<4x8xf64, #DCSR>
+
+ //
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 32
+ // CHECK-NEXT: pos[1] : ( 0, 4, 8, 12, 16, 20, 24, 28, 32
+ // CHECK-NEXT: crd[1] : ( 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3
+ // CHECK-NEXT: values : ( 10.1, 11.1, 12.1, 13.1, 10.2, 11.2, 12.2, 13.2, 10.3, 11.3, 12.3, 13.3, 10.4, 11.4, 12.4, 13.4, 10.5, 11.5, 12.5, 13.5, 10.6, 11.6, 12.6, 13.6, 10.7, 11.7, 12.7, 13.7, 10.8, 11.8, 12.8, 13.8
+ // CHECK-NEXT: ----
+ //
+ sparse_tensor.print %b1 : tensor<8x4xf64, #CSR>
+
+ //
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 32
+ // CHECK-NEXT: pos[0] : ( 0, 8
+ // CHECK-NEXT: crd[0] : ( 0, 1, 2, 3, 4, 5, 6, 7
+ // CHECK-NEXT: pos[1] : ( 0, 4, 8, 12, 16, 20, 24, 28, 32
+ // CHECK-NEXT: crd[1] : ( 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3
+ // CHECK-NEXT: values : ( 10.1, 11.1, 12.1, 13.1, 10.2, 11.2, 12.2, 13.2, 10.3, 11.3, 12.3, 13.3, 10.4, 11.4, 12.4, 13.4, 10.5, 11.5, 12.5, 13.5, 10.6, 11.6, 12.6, 13.6, 10.7, 11.7, 12.7, 13.7, 10.8, 11.8, 12.8, 13.8
+ // CHECK-NEXT: ----
+ //
+ sparse_tensor.print %b2 : tensor<8x4xf64, #DCSR>
+
+ //
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 8
+ // CHECK-NEXT: pos[1] : ( 0, 1, 2, 3, 4, 4, 5, 6, 8
+ // CHECK-NEXT: crd[1] : ( 3, 2, 1, 0, 1, 2, 2, 3
+ // CHECK-NEXT: values : ( 1, 2, 3, 4, 5, 6, 7, 8
+ // CHECK-NEXT: ----
+ //
+ sparse_tensor.print %b3 : tensor<8x4xf64, #CSR>
+
+ //
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 8
+ // CHECK-NEXT: pos[0] : ( 0, 7
+ // CHECK-NEXT: crd[0] : ( 0, 1, 2, 3, 5, 6, 7
+ // CHECK-NEXT: pos[1] : ( 0, 1, 2, 3, 4, 5, 6, 8
+ // CHECK-NEXT: crd[1] : ( 3, 2, 1, 0, 1, 2, 2, 3
+ // CHECK-NEXT: values : ( 1, 2, 3, 4, 5, 6, 7, 8
+ // CHECK-NEXT: ----
+ //
+ sparse_tensor.print %b4 : tensor<8x4xf64, #DCSR>
// Call kernels with dense.
%0 = call @matmul1(%da, %db, %zero)
@@ -208,24 +269,26 @@ module {
call @printMemrefF64(%u0) : (tensor<*xf64>) -> ()
//
- // CHECK: {{\[}}[388.76, 425.56, 462.36, 499.16],
- // CHECK-NEXT: [397.12, 434.72, 472.32, 509.92],
- // CHECK-NEXT: [405.48, 443.88, 482.28, 520.68],
- // CHECK-NEXT: [413.84, 453.04, 492.24, 531.44]]
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 16
+ // CHECK-NEXT: pos[1] : ( 0, 4, 8, 12, 16
+ // CHECK-NEXT: crd[1] : ( 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3
+ // CHECK-NEXT: values : ( 388.76, 425.56, 462.36, 499.16, 397.12, 434.72, 472.32, 509.92, 405.48, 443.88, 482.28, 520.68, 413.84, 453.04, 492.24, 531.44
+ // CHECK-NEXT: ----
//
- %c1 = sparse_tensor.convert %1 : tensor<4x4xf64, #CSR> to tensor<4x4xf64>
- %c1u = tensor.cast %c1 : tensor<4x4xf64> to tensor<*xf64>
- call @printMemrefF64(%c1u) : (tensor<*xf64>) -> ()
+ sparse_tensor.print %1 : tensor<4x4xf64, #CSR>
//
- // CHECK: {{\[}}[388.76, 425.56, 462.36, 499.16],
- // CHECK-NEXT: [397.12, 434.72, 472.32, 509.92],
- // CHECK-NEXT: [405.48, 443.88, 482.28, 520.68],
- // CHECK-NEXT: [413.84, 453.04, 492.24, 531.44]]
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 16
+ // CHECK-NEXT: pos[0] : ( 0, 4
+ // CHECK-NEXT: crd[0] : ( 0, 1, 2, 3
+ // CHECK-NEXT: pos[1] : ( 0, 4, 8, 12, 16
+ // CHECK-NEXT: crd[1] : ( 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3
+ // CHECK-NEXT: values : ( 388.76, 425.56, 462.36, 499.16, 397.12, 434.72, 472.32, 509.92, 405.48, 443.88, 482.28, 520.68, 413.84, 453.04, 492.24, 531.44
+ // CHECK-NEXT: ----
//
- %c2 = sparse_tensor.convert %2 : tensor<4x4xf64, #DCSR> to tensor<4x4xf64>
- %c2u = tensor.cast %c2 : tensor<4x4xf64> to tensor<*xf64>
- call @printMemrefF64(%c2u) : (tensor<*xf64>) -> ()
+ sparse_tensor.print %2 : tensor<4x4xf64, #DCSR>
//
// CHECK: {{\[}}[86.08, 94.28, 102.48, 110.68],
@@ -237,24 +300,26 @@ module {
call @printMemrefF64(%u3) : (tensor<*xf64>) -> ()
//
- // CHECK: {{\[}}[86.08, 94.28, 102.48, 110.68],
- // CHECK-NEXT: [0, 0, 0, 0],
- // CHECK-NEXT: [23.46, 25.76, 28.06, 30.36],
- // CHECK-NEXT: [10.8, 11.8, 12.8, 13.8]]
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 12
+ // CHECK-NEXT: pos[1] : ( 0, 4, 4, 8, 12
+ // CHECK-NEXT: crd[1] : ( 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3
+ // CHECK-NEXT: values : ( 86.08, 94.28, 102.48, 110.68, 23.46, 25.76, 28.06, 30.36, 10.8, 11.8, 12.8, 13.8
+ // CHECK-NEXT: ----
//
- %c4 = sparse_tensor.convert %4 : tensor<4x4xf64, #CSR> to tensor<4x4xf64>
- %c4u = tensor.cast %c4 : tensor<4x4xf64> to tensor<*xf64>
- call @printMemrefF64(%c4u) : (tensor<*xf64>) -> ()
+ sparse_tensor.print %4 : tensor<4x4xf64, #CSR>
//
- // CHECK: {{\[}}[86.08, 94.28, 102.48, 110.68],
- // CHECK-NEXT: [0, 0, 0, 0],
- // CHECK-NEXT: [23.46, 25.76, 28.06, 30.36],
- // CHECK-NEXT: [10.8, 11.8, 12.8, 13.8]]
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 12
+ // CHECK-NEXT: pos[0] : ( 0, 3
+ // CHECK-NEXT: crd[0] : ( 0, 2, 3
+ // CHECK-NEXT: pos[1] : ( 0, 4, 8, 12
+ // CHECK-NEXT: crd[1] : ( 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3
+ // CHECK-NEXT: values : ( 86.08, 94.28, 102.48, 110.68, 23.46, 25.76, 28.06, 30.36, 10.8, 11.8, 12.8, 13.8
+ // CHECK-NEXT: ----
//
- %c5 = sparse_tensor.convert %5 : tensor<4x4xf64, #DCSR> to tensor<4x4xf64>
- %c5u = tensor.cast %c5 : tensor<4x4xf64> to tensor<*xf64>
- call @printMemrefF64(%c5u) : (tensor<*xf64>) -> ()
+ sparse_tensor.print %5 : tensor<4x4xf64, #DCSR>
//
// CHECK: {{\[}}[0, 30.5, 4.2, 0],
@@ -266,46 +331,26 @@ module {
call @printMemrefF64(%u6) : (tensor<*xf64>) -> ()
//
- // CHECK: {{\[}}[0, 30.5, 4.2, 0],
- // CHECK-NEXT: [0, 0, 0, 0],
- // CHECK-NEXT: [0, 0, 4.6, 0],
- // CHECK-NEXT: [0, 0, 7, 8]]
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 5
+ // CHECK-NEXT: pos[1] : ( 0, 2, 2, 3, 5
+ // CHECK-NEXT: crd[1] : ( 1, 2, 2, 2, 3
+ // CHECK-NEXT: values : ( 30.5, 4.2, 4.6, 7, 8
+ // CHECK-NEXT: ----
//
- %c7 = sparse_tensor.convert %7 : tensor<4x4xf64, #CSR> to tensor<4x4xf64>
- %c7u = tensor.cast %c7 : tensor<4x4xf64> to tensor<*xf64>
- call @printMemrefF64(%c7u) : (tensor<*xf64>) -> ()
+ sparse_tensor.print %7 : tensor<4x4xf64, #CSR>
//
- // CHECK: {{\[}}[0, 30.5, 4.2, 0],
- // CHECK-NEXT: [0, 0, 0, 0],
- // CHECK-NEXT: [0, 0, 4.6, 0],
- // CHECK-NEXT: [0, 0, 7, 8]]
- //
- %c8 = sparse_tensor.convert %8 : tensor<4x4xf64, #DCSR> to tensor<4x4xf64>
- %c8u = tensor.cast %c8 : tensor<4x4xf64> to tensor<*xf64>
- call @printMemrefF64(%c8u) : (tensor<*xf64>) -> ()
-
- //
- // Sanity check on nonzeros.
- //
- // CHECK: [30.5, 4.2, 4.6, 7, 8{{.*}}]
- // CHECK: [30.5, 4.2, 4.6, 7, 8{{.*}}]
- //
- %val7 = sparse_tensor.values %7 : tensor<4x4xf64, #CSR> to memref<?xf64>
- %val8 = sparse_tensor.values %8 : tensor<4x4xf64, #DCSR> to memref<?xf64>
- call @printMemref1dF64(%val7) : (memref<?xf64>) -> ()
- call @printMemref1dF64(%val8) : (memref<?xf64>) -> ()
-
- //
- // Sanity check on stored entries after the computations.
- //
- // CHECK-NEXT: 5
- // CHECK-NEXT: 5
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 5
+ // CHECK-NEXT: pos[0] : ( 0, 3
+ // CHECK-NEXT: crd[0] : ( 0, 2, 3
+ // CHECK-NEXT: pos[1] : ( 0, 2, 3, 5
+ // CHECK-NEXT: crd[1] : ( 1, 2, 2, 2, 3
+ // CHECK-NEXT: values : ( 30.5, 4.2, 4.6, 7, 8
+ // CHECK-NEXT: ----
//
- %noe7 = sparse_tensor.number_of_entries %7 : tensor<4x4xf64, #CSR>
- %noe8 = sparse_tensor.number_of_entries %8 : tensor<4x4xf64, #DCSR>
- vector.print %noe7 : index
- vector.print %noe8 : index
+ sparse_tensor.print %8 : tensor<4x4xf64, #DCSR>
// Release the resources.
bufferization.dealloc_tensor %a1 : tensor<4x8xf64, #CSR>
@@ -316,12 +361,6 @@ module {
bufferization.dealloc_tensor %b2 : tensor<8x4xf64, #DCSR>
bufferization.dealloc_tensor %b3 : tensor<8x4xf64, #CSR>
bufferization.dealloc_tensor %b4 : tensor<8x4xf64, #DCSR>
- bufferization.dealloc_tensor %c1 : tensor<4x4xf64>
- bufferization.dealloc_tensor %c2 : tensor<4x4xf64>
- bufferization.dealloc_tensor %c4 : tensor<4x4xf64>
- bufferization.dealloc_tensor %c5 : tensor<4x4xf64>
- bufferization.dealloc_tensor %c7 : tensor<4x4xf64>
- bufferization.dealloc_tensor %c8 : tensor<4x4xf64>
bufferization.dealloc_tensor %0 : tensor<4x4xf64>
bufferization.dealloc_tensor %1 : tensor<4x4xf64, #CSR>
bufferization.dealloc_tensor %2 : tensor<4x4xf64, #DCSR>
diff --git a/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matmul_slice.mlir b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matmul_slice.mlir
index 96c8a30ade8e42..b95f72e1a4799f 100644
--- a/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matmul_slice.mlir
+++ b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matmul_slice.mlir
@@ -10,7 +10,7 @@
// DEFINE: %{compile} = mlir-opt %s --sparsifier="%{sparsifier_opts}"
// DEFINE: %{compile_sve} = mlir-opt %s --sparsifier="%{sparsifier_opts_sve}"
// DEFINE: %{run_libs} = -shared-libs=%mlir_c_runner_utils,%mlir_runner_utils
-// DEFINE: %{run_opts} = -e entry -entry-point-result=void
+// DEFINE: %{run_opts} = -e main -entry-point-result=void
// DEFINE: %{run} = mlir-cpu-runner %{run_opts} %{run_libs}
// DEFINE: %{run_sve} = %mcr_aarch64_cmd --march=aarch64 --mattr="+sve" %{run_opts} %{run_libs}
//
@@ -132,7 +132,7 @@ module {
//
// Main driver.
//
- func.func @entry() {
+ func.func @main() {
%c_0 = arith.constant 0 : index
%c_1 = arith.constant 1 : index
%c_2 = arith.constant 2 : index
@@ -170,14 +170,16 @@ module {
// DCSR test
//
- // CHECK: [0, 30.5, 4.2, 0],
- // CHECK-NEXT: [0, 0, 0, 0],
- // CHECK-NEXT: [0, 0, 4.6, 0],
- // CHECK-NEXT: [0, 0, 7, 8]
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 5
+ // CHECK-NEXT: pos[0] : ( 0, 3
+ // CHECK-NEXT: crd[0] : ( 0, 2, 3
+ // CHECK-NEXT: pos[1] : ( 0, 2, 3, 5
+ // CHECK-NEXT: crd[1] : ( 1, 2, 2, 2, 3
+ // CHECK-NEXT: values : ( 30.5, 4.2, 4.6, 7, 8
+ // CHECK-NEXT: ----
//
- %c2 = sparse_tensor.convert %2 : tensor<4x4xf64, #DCSR> to tensor<4x4xf64>
- %c2u = tensor.cast %c2 : tensor<4x4xf64> to tensor<*xf64>
- call @printMemrefF64(%c2u) : (tensor<*xf64>) -> ()
+ sparse_tensor.print %2 : tensor<4x4xf64, #DCSR>
%t1 = sparse_tensor.convert %sa : tensor<8x8xf64> to tensor<8x8xf64, #CSR>
%a1 = tensor.extract_slice %t1[0, 0][4, 8][1, 1] : tensor<8x8xf64, #CSR> to tensor<4x8xf64, #CSR_SLICE>
@@ -188,63 +190,63 @@ module {
// CSR test
//
- // CHECK: [0, 30.5, 4.2, 0],
- // CHECK-NEXT: [0, 0, 0, 0],
- // CHECK-NEXT: [0, 0, 4.6, 0],
- // CHECK-NEXT: [0, 0, 7, 8]
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 5
+ // CHECK-NEXT: pos[1] : ( 0, 2, 2, 3, 5
+ // CHECK-NEXT: crd[1] : ( 1, 2, 2, 2, 3
+ // CHECK-NEXT: values : ( 30.5, 4.2, 4.6, 7, 8
+ // CHECK-NEXT: ----
//
- %c3 = sparse_tensor.convert %3 : tensor<4x4xf64, #CSR> to tensor<4x4xf64>
- %c3u = tensor.cast %c3 : tensor<4x4xf64> to tensor<*xf64>
- call @printMemrefF64(%c3u) : (tensor<*xf64>) -> ()
+ sparse_tensor.print %3 : tensor<4x4xf64, #CSR>
+
// slice x slice
//
- // CHECK: [2.3, 0, 0, 0],
- // CHECK-NEXT: [6.9, 0, 0, 0],
- // CHECK-NEXT: [0, 0, 0, 0],
- // CHECK-NEXT: [12.6, 0, 0, 0]]
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 3
+ // CHECK-NEXT: pos[1] : ( 0, 1, 2, 2, 3
+ // CHECK-NEXT: crd[1] : ( 0, 0, 0
+ // CHECK-NEXT: values : ( 2.3, 6.9, 12.6
+ // CHECK-NEXT: ----
//
%s1 = tensor.extract_slice %tmp[0, 1][4, 4][2, 1] : tensor<8x8xf64, #DCSR> to tensor<4x4xf64, #DCSR_SLICE_1>
%s2 = tensor.extract_slice %b1[0, 0][4, 4][2, 1] : tensor<8x4xf64, #CSR> to tensor<4x4xf64, #CSR_SLICE_1>
%4 = call @matmul1(%s2, %s1)
: (tensor<4x4xf64, #CSR_SLICE_1>,
tensor<4x4xf64, #DCSR_SLICE_1>) -> tensor<4x4xf64, #CSR>
- %c4 = sparse_tensor.convert %4 : tensor<4x4xf64, #CSR> to tensor<4x4xf64>
- %c4u = tensor.cast %c4 : tensor<4x4xf64> to tensor<*xf64>
- call @printMemrefF64(%c4u) : (tensor<*xf64>) -> ()
+ sparse_tensor.print %4 : tensor<4x4xf64, #CSR>
// slice coo x slice coo
//
- // CHECK: [2.3, 0, 0, 0],
- // CHECK-NEXT: [6.9, 0, 0, 0],
- // CHECK-NEXT: [0, 0, 0, 0],
- // CHECK-NEXT: [12.6, 0, 0, 0]]
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 3
+ // CHECK-NEXT: pos[0] : ( 0, 3
+ // CHECK-NEXT: crd[0] : ( 0, 0, 1, 0, 3, 0
+ // CHECK-NEXT: values : ( 2.3, 6.9, 12.6
+ // CHECK-NEXT: ----
//
%t1_coo = sparse_tensor.convert %sa : tensor<8x8xf64> to tensor<8x8xf64, #COO>
%b1_coo = sparse_tensor.convert %sb : tensor<8x4xf64> to tensor<8x4xf64, #COO>
%s2_coo = tensor.extract_slice %b1_coo[0, 0][4, 4][2, 1] : tensor<8x4xf64, #COO> to tensor<4x4xf64, #COO_SLICE_1>
%s1_coo = tensor.extract_slice %t1_coo[0, 1][4, 4][2, 1] : tensor<8x8xf64, #COO> to tensor<4x4xf64, #COO_SLICE_2>
%o_coo = call @matmul5(%s2_coo, %s1_coo) : (tensor<4x4xf64, #COO_SLICE_1>, tensor<4x4xf64, #COO_SLICE_2>) -> tensor<4x4xf64, #COO>
-
- %c4_coo = sparse_tensor.convert %o_coo : tensor<4x4xf64, #COO> to tensor<4x4xf64>
- %c4u_coo = tensor.cast %c4_coo : tensor<4x4xf64> to tensor<*xf64>
- call @printMemrefF64(%c4u_coo) : (tensor<*xf64>) -> ()
+ sparse_tensor.print %o_coo : tensor<4x4xf64, #COO>
// slice x slice (same as above, but with dynamic stride information)
//
- // CHECK: [2.3, 0, 0, 0],
- // CHECK-NEXT: [6.9, 0, 0, 0],
- // CHECK-NEXT: [0, 0, 0, 0],
- // CHECK-NEXT: [12.6, 0, 0, 0]]
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 3
+ // CHECK-NEXT: pos[1] : ( 0, 1, 2, 2, 3
+ // CHECK-NEXT: crd[1] : ( 0, 0, 0
+ // CHECK-NEXT: values : ( 2.3, 6.9, 12.6
+ // CHECK-NEXT: ----
//
%s1_dyn = tensor.extract_slice %tmp[%c_0, %c_1][4, 4][%c_2, %c_1] : tensor<8x8xf64, #DCSR> to tensor<4x4xf64, #DCSR_SLICE_dyn>
%s2_dyn = tensor.extract_slice %b1[%c_0, %c_0][4, 4][%c_2, %c_1] : tensor<8x4xf64, #CSR> to tensor<4x4xf64, #CSR_SLICE_dyn>
%dyn_4 = call @matmul_dyn(%s2_dyn, %s1_dyn)
: (tensor<4x4xf64, #CSR_SLICE_dyn>,
tensor<4x4xf64, #DCSR_SLICE_dyn>) -> tensor<4x4xf64, #CSR>
- %c4_dyn = sparse_tensor.convert %dyn_4 : tensor<4x4xf64, #CSR> to tensor<4x4xf64>
- %c4u_dyn = tensor.cast %c4_dyn : tensor<4x4xf64> to tensor<*xf64>
- call @printMemrefF64(%c4u_dyn) : (tensor<*xf64>) -> ()
+ sparse_tensor.print %dyn_4 : tensor<4x4xf64, #CSR>
// sparse slices should generate the same result as dense slices
//
@@ -265,11 +267,6 @@ module {
call @printMemrefF64(%du) : (tensor<*xf64>) -> ()
// Releases resources.
- bufferization.dealloc_tensor %c2 : tensor<4x4xf64>
- bufferization.dealloc_tensor %c3 : tensor<4x4xf64>
- bufferization.dealloc_tensor %c4 : tensor<4x4xf64>
- bufferization.dealloc_tensor %c4_coo : tensor<4x4xf64>
- bufferization.dealloc_tensor %c4_dyn : tensor<4x4xf64>
bufferization.dealloc_tensor %d : tensor<4x4xf64>
bufferization.dealloc_tensor %b1 : tensor<8x4xf64, #CSR>
bufferization.dealloc_tensor %t1 : tensor<8x8xf64, #CSR>
diff --git a/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matrix_ops.mlir b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matrix_ops.mlir
index 2cecc242034389..2cef46f4cb1546 100644
--- a/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matrix_ops.mlir
+++ b/mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_matrix_ops.mlir
@@ -10,7 +10,7 @@
// DEFINE: %{compile} = mlir-opt %s --sparsifier="%{sparsifier_opts}"
// DEFINE: %{compile_sve} = mlir-opt %s --sparsifier="%{sparsifier_opts_sve}"
// DEFINE: %{run_libs} = -shared-libs=%mlir_c_runner_utils,%mlir_runner_utils
-// DEFINE: %{run_opts} = -e entry -entry-point-result=void
+// DEFINE: %{run_opts} = -e main -entry-point-result=void
// DEFINE: %{run} = mlir-cpu-runner %{run_opts} %{run_libs}
// DEFINE: %{run_sve} = %mcr_aarch64_cmd --march=aarch64 --mattr="+sve" %{run_opts} %{run_libs}
//
@@ -61,8 +61,6 @@
}
module {
- func.func private @printMemrefF64(%ptr : tensor<*xf64>)
-
// Scales a sparse matrix into a new sparse matrix.
func.func @matrix_scale(%arga: tensor<?x?xf64, #DCSR>) -> tensor<?x?xf64, #DCSR> {
%s = arith.constant 2.0 : f64
@@ -129,17 +127,8 @@ module {
return %0 : tensor<?x?xf64, #DCSR>
}
- // Dump a sparse matrix.
- func.func @dump(%arg0: tensor<?x?xf64, #DCSR>) {
- %dm = sparse_tensor.convert %arg0 : tensor<?x?xf64, #DCSR> to tensor<?x?xf64>
- %u = tensor.cast %dm : tensor<?x?xf64> to tensor<*xf64>
- call @printMemrefF64(%u) : (tensor<*xf64>) -> ()
- bufferization.dealloc_tensor %dm : tensor<?x?xf64>
- return
- }
-
// Driver method to call and verify matrix kernels.
- func.func @entry() {
+ func.func @main() {
%c0 = arith.constant 0 : index
%d1 = arith.constant 1.1 : f64
@@ -170,37 +159,76 @@ module {
//
// Verify the results.
//
- // CHECK: {{\[}}[1, 2, 0, 0, 0, 0, 0, 0],
- // CHECK-NEXT: [0, 0, 0, 0, 0, 0, 0, 3],
- // CHECK-NEXT: [0, 0, 4, 0, 5, 0, 0, 6],
- // CHECK-NEXT: [7, 0, 8, 9, 0, 0, 0, 0]]
- // CHECK: {{\[}}[6, 0, 0, 0, 0, 0, 0, 5],
- // CHECK-NEXT: [4, 0, 0, 0, 0, 0, 3, 0],
- // CHECK-NEXT: [0, 2, 0, 0, 0, 0, 0, 1],
- // CHECK-NEXT: [0, 0, 0, 0, 0, 0, 0, 0]]
- // CHECK: {{\[}}[2, 4, 0, 0, 0, 0, 0, 0],
- // CHECK-NEXT: [0, 0, 0, 0, 0, 0, 0, 6],
- // CHECK-NEXT: [0, 0, 8, 0, 10, 0, 0, 12],
- // CHECK-NEXT: [14, 0, 16, 18, 0, 0, 0, 0]]
- // CHECK: {{\[}}[2, 4, 0, 0, 0, 0, 0, 0],
- // CHECK-NEXT: [0, 0, 0, 0, 0, 0, 0, 6],
- // CHECK-NEXT: [0, 0, 8, 0, 10, 0, 0, 12],
- // CHECK-NEXT: [14, 0, 16, 18, 0, 0, 0, 0]]
- // CHECK: {{\[}}[8, 4, 0, 0, 0, 0, 0, 5],
- // CHECK-NEXT: [4, 0, 0, 0, 0, 0, 3, 6],
- // CHECK-NEXT: [0, 2, 8, 0, 10, 0, 0, 13],
- // CHECK-NEXT: [14, 0, 16, 18, 0, 0, 0, 0]]
- // CHECK: {{\[}}[12, 0, 0, 0, 0, 0, 0, 0],
- // CHECK-NEXT: [0, 0, 0, 0, 0, 0, 0, 0],
- // CHECK-NEXT: [0, 0, 0, 0, 0, 0, 0, 12],
- // CHECK-NEXT: [0, 0, 0, 0, 0, 0, 0, 0]]
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 9
+ // CHECK-NEXT: pos[0] : ( 0, 4
+ // CHECK-NEXT: crd[0] : ( 0, 1, 2, 3
+ // CHECK-NEXT: pos[1] : ( 0, 2, 3, 6, 9
+ // CHECK-NEXT: crd[1] : ( 0, 1, 7, 2, 4, 7, 0, 2, 3
+ // CHECK-NEXT: values : ( 1, 2, 3, 4, 5, 6, 7, 8, 9
+ // CHECK-NEXT: ----
+ //
+ sparse_tensor.print %sm1 : tensor<?x?xf64, #DCSR>
+
+ //
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 6
+ // CHECK-NEXT: pos[0] : ( 0, 3
+ // CHECK-NEXT: crd[0] : ( 0, 1, 2
+ // CHECK-NEXT: pos[1] : ( 0, 2, 4, 6
+ // CHECK-NEXT: crd[1] : ( 0, 7, 0, 6, 1, 7
+ // CHECK-NEXT: values : ( 6, 5, 4, 3, 2, 1
+ // CHECK-NEXT: ----
+ //
+ sparse_tensor.print %sm2 : tensor<?x?xf64, #DCSR>
+
+ //
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 9
+ // CHECK-NEXT: pos[0] : ( 0, 4
+ // CHECK-NEXT: crd[0] : ( 0, 1, 2, 3
+ // CHECK-NEXT: pos[1] : ( 0, 2, 3, 6, 9
+ // CHECK-NEXT: crd[1] : ( 0, 1, 7, 2, 4, 7, 0, 2, 3
+ // CHECK-NEXT: values : ( 2, 4, 6, 8, 10, 12, 14, 16, 18
+ // CHECK-NEXT: ----
+ //
+ sparse_tensor.print %0 : tensor<?x?xf64, #DCSR>
+
+ //
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 9
+ // CHECK-NEXT: pos[0] : ( 0, 4
+ // CHECK-NEXT: crd[0] : ( 0, 1, 2, 3
+ // CHECK-NEXT: pos[1] : ( 0, 2, 3, 6, 9
+ // CHECK-NEXT: crd[1] : ( 0, 1, 7, 2, 4, 7, 0, 2, 3
+ // CHECK-NEXT: values : ( 2, 4, 6, 8, 10, 12, 14, 16, 18
+ // CHECK-NEXT: ----
+ //
+ sparse_tensor.print %1 : tensor<?x?xf64, #DCSR>
+
+ //
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 13
+ // CHECK-NEXT: pos[0] : ( 0, 4
+ // CHECK-NEXT: crd[0] : ( 0, 1, 2, 3
+ // CHECK-NEXT: pos[1] : ( 0, 3, 6, 10, 13
+ // CHECK-NEXT: crd[1] : ( 0, 1, 7, 0, 6, 7, 1, 2, 4, 7, 0, 2, 3
+ // CHECK-NEXT: values : ( 8, 4, 5, 4, 3, 6, 2, 8, 10, 13, 14, 16, 18
+ // CHECK-NEXT: ----
+ //
+ sparse_tensor.print %2 : tensor<?x?xf64, #DCSR>
+
+ //
+ // CHECK: ---- Sparse Tensor ----
+ // CHECK-NEXT: nse = 2
+ // CHECK-NEXT: pos[0] : ( 0, 2
+ // CHECK-NEXT: crd[0] : ( 0, 2
+ // CHECK-NEXT: pos[1] : ( 0, 1, 2
+ // CHECK-NEXT: crd[1] : ( 0, 7
+ // CHECK-NEXT: values : ( 12, 12
+ // CHECK-NEXT: ----
//
- call @dump(%sm1) : (tensor<?x?xf64, #DCSR>) -> ()
- call @dump(%sm2) : (tensor<?x?xf64, #DCSR>) -> ()
- call @dump(%0) : (tensor<?x?xf64, #DCSR>) -> ()
- call @dump(%1) : (tensor<?x?xf64, #DCSR>) -> ()
- call @dump(%2) : (tensor<?x?xf64, #DCSR>) -> ()
- call @dump(%3) : (tensor<?x?xf64, #DCSR>) -> ()
+ sparse_tensor.print %3 : tensor<?x?xf64, #DCSR>
// Release the resources.
bufferization.dealloc_tensor %sm1 : tensor<?x?xf64, #DCSR>
>From 9a12b0a60084b2b92f728e1bddec884a47458459 Mon Sep 17 00:00:00 2001
From: Jason Molenda <jmolenda at apple.com>
Date: Thu, 29 Feb 2024 17:02:42 -0800
Subject: [PATCH 197/406] [lldb] Add SBProcess methods for get/set/use address
masks (#83095)
I'm reviving a patch from phabracator, https://reviews.llvm.org/D155905
which was approved but I wasn't thrilled with all the API I was adding
to SBProcess for all of the address mask types / memory regions. In this
update, I added enums to control type address mask type (code, data,
any) and address space specifiers (low, high, all) with defaulted
arguments for the most common case.
This patch is also fixing a bug in the "addressable bits to address
mask" calculation I added in AddressableBits::SetProcessMasks. If lldb
were told that 64 bits are valid for addressing, this method would
overflow the calculation and set an invalid mask. Added tests to check
this specific bug while I was adding these APIs.
rdar://123530562
---
lldb/include/lldb/API/SBProcess.h | 114 ++++++++++++++++++
lldb/include/lldb/Utility/AddressableBits.h | 3 +
lldb/include/lldb/lldb-defines.h | 5 +
lldb/include/lldb/lldb-enumerations.h | 16 +++
lldb/source/API/SBProcess.cpp | 92 ++++++++++++++
lldb/source/Target/Process.cpp | 10 +-
lldb/source/Utility/AddressableBits.cpp | 12 +-
.../python_api/process/address-masks/Makefile | 3 +
.../process/address-masks/TestAddressMasks.py | 74 ++++++++++++
.../python_api/process/address-masks/main.c | 5 +
10 files changed, 328 insertions(+), 6 deletions(-)
create mode 100644 lldb/test/API/python_api/process/address-masks/Makefile
create mode 100644 lldb/test/API/python_api/process/address-masks/TestAddressMasks.py
create mode 100644 lldb/test/API/python_api/process/address-masks/main.c
diff --git a/lldb/include/lldb/API/SBProcess.h b/lldb/include/lldb/API/SBProcess.h
index 4f92a41f3028a2..7da3335a7234b7 100644
--- a/lldb/include/lldb/API/SBProcess.h
+++ b/lldb/include/lldb/API/SBProcess.h
@@ -407,6 +407,120 @@ class LLDB_API SBProcess {
/// the process isn't loaded from a core file.
lldb::SBFileSpec GetCoreFile();
+ /// \{
+ /// \group Mask Address Methods
+ ///
+ /// \a type
+ /// All of the methods in this group take \a type argument
+ /// which is an AddressMaskType enum value.
+ /// There can be different address masks for code addresses and
+ /// data addresses, this argument can select which to get/set,
+ /// or to use when clearing non-addressable bits from an address.
+ /// This choice of mask can be important for example on AArch32
+ /// systems. Where instructions where instructions start on even addresses,
+ /// the 0th bit may be used to indicate that a function is thumb code. On
+ /// such a target, the eAddressMaskTypeCode may clear the 0th bit from an
+ /// address to get the actual address Whereas eAddressMaskTypeData would not.
+ ///
+ /// \a addr_range
+ /// Many of the methods in this group take an \a addr_range argument
+ /// which is an AddressMaskRange enum value.
+ /// Needing to specify the address range is highly unusual, and the
+ /// default argument can be used in nearly all circumstances.
+ /// On some architectures (e.g., AArch64), it is possible to have
+ /// different page table setups for low and high memory, so different
+ /// numbers of bits relevant to addressing. It is possible to have
+ /// a program running in one half of memory and accessing the other
+ /// as heap, so we need to maintain two different sets of address masks
+ /// to debug this correctly.
+
+ /// Get the current address mask that will be applied to addresses
+ /// before reading from memory.
+ ///
+ /// \param[in] type
+ /// See \ref Mask Address Methods description of this argument.
+ /// eAddressMaskTypeAny is often a suitable value when code and
+ /// data masks are the same on a given target.
+ ///
+ /// \param[in] addr_range
+ /// See \ref Mask Address Methods description of this argument.
+ /// This will default to eAddressMaskRangeLow which is the
+ /// only set of masks used normally.
+ ///
+ /// \return
+ /// The address mask currently in use. Bits which are not used
+ /// for addressing will be set to 1 in the mask.
+ lldb::addr_t GetAddressMask(
+ lldb::AddressMaskType type,
+ lldb::AddressMaskRange addr_range = lldb::eAddressMaskRangeLow);
+
+ /// Set the current address mask that can be applied to addresses
+ /// before reading from memory.
+ ///
+ /// \param[in] type
+ /// See \ref Mask Address Methods description of this argument.
+ /// eAddressMaskTypeAll is often a suitable value when the
+ /// same mask is being set for both code and data.
+ ///
+ /// \param[in] mask
+ /// The address mask to set. Bits which are not used for addressing
+ /// should be set to 1 in the mask.
+ ///
+ /// \param[in] addr_range
+ /// See \ref Mask Address Methods description of this argument.
+ /// This will default to eAddressMaskRangeLow which is the
+ /// only set of masks used normally.
+ void SetAddressMask(
+ lldb::AddressMaskType type, lldb::addr_t mask,
+ lldb::AddressMaskRange addr_range = lldb::eAddressMaskRangeLow);
+
+ /// Set the number of bits used for addressing in this Process.
+ ///
+ /// On Darwin and similar systems, the addressable bits are expressed
+ /// as the number of low order bits that are relevant to addressing,
+ /// instead of a more general address mask.
+ /// This method calculates the correct mask value for a given number
+ /// of low order addressable bits.
+ ///
+ /// \param[in] type
+ /// See \ref Mask Address Methods description of this argument.
+ /// eAddressMaskTypeAll is often a suitable value when the
+ /// same mask is being set for both code and data.
+ ///
+ /// \param[in] num_bits
+ /// Number of bits that are used for addressing.
+ /// For example, a value of 42 indicates that the low 42 bits
+ /// are relevant for addressing, and that higher-order bits may
+ /// be used for various metadata like pointer authentication,
+ /// Type Byte Ignore, etc.
+ ///
+ /// \param[in] addr_range
+ /// See \ref Mask Address Methods description of this argument.
+ /// This will default to eAddressMaskRangeLow which is the
+ /// only set of masks used normally.
+ void
+ SetAddressableBits(AddressMaskType type, uint32_t num_bits,
+ AddressMaskRange addr_range = lldb::eAddressMaskRangeLow);
+
+ /// Clear the non-address bits of an \a addr value and return a
+ /// virtual address in memory.
+ ///
+ /// Bits that are not used in addressing may be used for other purposes;
+ /// pointer authentication, or metadata in the top byte, or the 0th bit
+ /// of armv7 code addresses to indicate arm/thumb are common examples.
+ ///
+ /// \param[in] addr
+ /// The address that should be cleared of non-address bits.
+ ///
+ /// \param[in] type
+ /// See \ref Mask Address Methods description of this argument.
+ /// eAddressMaskTypeAny is the default value, correct when it
+ /// is unknown if the address is a code or data address.
+ lldb::addr_t
+ FixAddress(lldb::addr_t addr,
+ lldb::AddressMaskType type = lldb::eAddressMaskTypeAny);
+ /// \}
+
/// Allocate memory within the process.
///
/// This function will allocate memory in the process's address space.
diff --git a/lldb/include/lldb/Utility/AddressableBits.h b/lldb/include/lldb/Utility/AddressableBits.h
index 13c21329a8c617..75752fcf840a44 100644
--- a/lldb/include/lldb/Utility/AddressableBits.h
+++ b/lldb/include/lldb/Utility/AddressableBits.h
@@ -10,6 +10,7 @@
#define LLDB_UTILITY_ADDRESSABLEBITS_H
#include "lldb/lldb-forward.h"
+#include "lldb/lldb-public.h"
namespace lldb_private {
@@ -33,6 +34,8 @@ class AddressableBits {
void SetHighmemAddressableBits(uint32_t highmem_addressing_bits);
+ static lldb::addr_t AddressableBitToMask(uint32_t addressable_bits);
+
void SetProcessMasks(lldb_private::Process &process);
private:
diff --git a/lldb/include/lldb/lldb-defines.h b/lldb/include/lldb/lldb-defines.h
index 469be92eabecf3..c7bd019c5c90eb 100644
--- a/lldb/include/lldb/lldb-defines.h
+++ b/lldb/include/lldb/lldb-defines.h
@@ -127,6 +127,11 @@
#define MAX_PATH 260
#endif
+/// Address Mask
+/// Bits not used for addressing are set to 1 in the mask;
+/// all mask bits set is an invalid value.
+#define LLDB_INVALID_ADDRESS_MASK UINT64_MAX
+
// ignore GCC function attributes
#if defined(_MSC_VER) && !defined(__clang__)
#define __attribute__(X)
diff --git a/lldb/include/lldb/lldb-enumerations.h b/lldb/include/lldb/lldb-enumerations.h
index 85769071dae785..646f7bfda98475 100644
--- a/lldb/include/lldb/lldb-enumerations.h
+++ b/lldb/include/lldb/lldb-enumerations.h
@@ -1323,6 +1323,22 @@ enum SymbolDownload {
eSymbolDownloadForeground = 2,
};
+/// Used in the SBProcess AddressMask/FixAddress methods.
+enum AddressMaskType {
+ eAddressMaskTypeCode = 0,
+ eAddressMaskTypeData,
+ eAddressMaskTypeAny,
+ eAddressMaskTypeAll = eAddressMaskTypeAny
+};
+
+/// Used in the SBProcess AddressMask/FixAddress methods.
+enum AddressMaskRange {
+ eAddressMaskRangeLow = 0,
+ eAddressMaskRangeHigh,
+ eAddressMaskRangeAny,
+ eAddressMaskRangeAll = eAddressMaskRangeAny,
+};
+
} // namespace lldb
#endif // LLDB_LLDB_ENUMERATIONS_H
diff --git a/lldb/source/API/SBProcess.cpp b/lldb/source/API/SBProcess.cpp
index a9fe915324683e..b80664882ebcac 100644
--- a/lldb/source/API/SBProcess.cpp
+++ b/lldb/source/API/SBProcess.cpp
@@ -1255,6 +1255,98 @@ lldb::SBFileSpec SBProcess::GetCoreFile() {
return SBFileSpec(core_file);
}
+addr_t SBProcess::GetAddressMask(AddressMaskType type,
+ AddressMaskRange addr_range) {
+ LLDB_INSTRUMENT_VA(this, type, addr_range);
+
+ if (ProcessSP process_sp = GetSP()) {
+ switch (type) {
+ case eAddressMaskTypeCode:
+ if (addr_range == eAddressMaskRangeHigh)
+ return process_sp->GetHighmemCodeAddressMask();
+ else
+ return process_sp->GetCodeAddressMask();
+ case eAddressMaskTypeData:
+ if (addr_range == eAddressMaskRangeHigh)
+ return process_sp->GetHighmemDataAddressMask();
+ else
+ return process_sp->GetDataAddressMask();
+ case eAddressMaskTypeAny:
+ if (addr_range == eAddressMaskRangeHigh)
+ return process_sp->GetHighmemDataAddressMask();
+ else
+ return process_sp->GetDataAddressMask();
+ }
+ }
+ return LLDB_INVALID_ADDRESS_MASK;
+}
+
+void SBProcess::SetAddressMask(AddressMaskType type, addr_t mask,
+ AddressMaskRange addr_range) {
+ LLDB_INSTRUMENT_VA(this, type, mask, addr_range);
+
+ if (ProcessSP process_sp = GetSP()) {
+ switch (type) {
+ case eAddressMaskTypeCode:
+ if (addr_range == eAddressMaskRangeAll) {
+ process_sp->SetCodeAddressMask(mask);
+ process_sp->SetHighmemCodeAddressMask(mask);
+ } else if (addr_range == eAddressMaskRangeHigh) {
+ process_sp->SetHighmemCodeAddressMask(mask);
+ } else {
+ process_sp->SetCodeAddressMask(mask);
+ }
+ break;
+ case eAddressMaskTypeData:
+ if (addr_range == eAddressMaskRangeAll) {
+ process_sp->SetDataAddressMask(mask);
+ process_sp->SetHighmemDataAddressMask(mask);
+ } else if (addr_range == eAddressMaskRangeHigh) {
+ process_sp->SetHighmemDataAddressMask(mask);
+ } else {
+ process_sp->SetDataAddressMask(mask);
+ }
+ break;
+ case eAddressMaskTypeAll:
+ if (addr_range == eAddressMaskRangeAll) {
+ process_sp->SetCodeAddressMask(mask);
+ process_sp->SetDataAddressMask(mask);
+ process_sp->SetHighmemCodeAddressMask(mask);
+ process_sp->SetHighmemDataAddressMask(mask);
+ } else if (addr_range == eAddressMaskRangeHigh) {
+ process_sp->SetHighmemCodeAddressMask(mask);
+ process_sp->SetHighmemDataAddressMask(mask);
+ } else {
+ process_sp->SetCodeAddressMask(mask);
+ process_sp->SetDataAddressMask(mask);
+ }
+ break;
+ }
+ }
+}
+
+void SBProcess::SetAddressableBits(AddressMaskType type, uint32_t num_bits,
+ AddressMaskRange addr_range) {
+ LLDB_INSTRUMENT_VA(this, type, num_bits, addr_range);
+
+ SetAddressMask(type, AddressableBits::AddressableBitToMask(num_bits),
+ addr_range);
+}
+
+addr_t SBProcess::FixAddress(addr_t addr, AddressMaskType type) {
+ LLDB_INSTRUMENT_VA(this, addr, type);
+
+ if (ProcessSP process_sp = GetSP()) {
+ if (type == eAddressMaskTypeAny)
+ return process_sp->FixAnyAddress(addr);
+ else if (type == eAddressMaskTypeData)
+ return process_sp->FixDataAddress(addr);
+ else if (type == eAddressMaskTypeCode)
+ return process_sp->FixCodeAddress(addr);
+ }
+ return addr;
+}
+
lldb::addr_t SBProcess::AllocateMemory(size_t size, uint32_t permissions,
lldb::SBError &sb_error) {
LLDB_INSTRUMENT_VA(this, size, permissions, sb_error);
diff --git a/lldb/source/Target/Process.cpp b/lldb/source/Target/Process.cpp
index 137795cb8cec9e..970bcdf5d69b35 100644
--- a/lldb/source/Target/Process.cpp
+++ b/lldb/source/Target/Process.cpp
@@ -5682,21 +5682,22 @@ void Process::Flush() {
lldb::addr_t Process::GetCodeAddressMask() {
if (uint32_t num_bits_setting = GetVirtualAddressableBits())
- return ~((1ULL << num_bits_setting) - 1);
+ return AddressableBits::AddressableBitToMask(num_bits_setting);
return m_code_address_mask;
}
lldb::addr_t Process::GetDataAddressMask() {
if (uint32_t num_bits_setting = GetVirtualAddressableBits())
- return ~((1ULL << num_bits_setting) - 1);
+ return AddressableBits::AddressableBitToMask(num_bits_setting);
return m_data_address_mask;
}
lldb::addr_t Process::GetHighmemCodeAddressMask() {
if (uint32_t num_bits_setting = GetHighmemVirtualAddressableBits())
- return ~((1ULL << num_bits_setting) - 1);
+ return AddressableBits::AddressableBitToMask(num_bits_setting);
+
if (m_highmem_code_address_mask)
return m_highmem_code_address_mask;
return GetCodeAddressMask();
@@ -5704,7 +5705,8 @@ lldb::addr_t Process::GetHighmemCodeAddressMask() {
lldb::addr_t Process::GetHighmemDataAddressMask() {
if (uint32_t num_bits_setting = GetHighmemVirtualAddressableBits())
- return ~((1ULL << num_bits_setting) - 1);
+ return AddressableBits::AddressableBitToMask(num_bits_setting);
+
if (m_highmem_data_address_mask)
return m_highmem_data_address_mask;
return GetDataAddressMask();
diff --git a/lldb/source/Utility/AddressableBits.cpp b/lldb/source/Utility/AddressableBits.cpp
index c6e25f608da73d..7f9d7ec6c1349c 100644
--- a/lldb/source/Utility/AddressableBits.cpp
+++ b/lldb/source/Utility/AddressableBits.cpp
@@ -33,18 +33,26 @@ void AddressableBits::SetHighmemAddressableBits(
m_high_memory_addr_bits = highmem_addressing_bits;
}
+addr_t AddressableBits::AddressableBitToMask(uint32_t addressable_bits) {
+ assert(addressable_bits <= sizeof(addr_t) * 8);
+ if (addressable_bits == 64)
+ return 0; // all bits used for addressing
+ else
+ return ~((1ULL << addressable_bits) - 1);
+}
+
void AddressableBits::SetProcessMasks(Process &process) {
if (m_low_memory_addr_bits == 0 && m_high_memory_addr_bits == 0)
return;
if (m_low_memory_addr_bits != 0) {
- addr_t low_addr_mask = ~((1ULL << m_low_memory_addr_bits) - 1);
+ addr_t low_addr_mask = AddressableBitToMask(m_low_memory_addr_bits);
process.SetCodeAddressMask(low_addr_mask);
process.SetDataAddressMask(low_addr_mask);
}
if (m_high_memory_addr_bits != 0) {
- addr_t hi_addr_mask = ~((1ULL << m_high_memory_addr_bits) - 1);
+ addr_t hi_addr_mask = AddressableBitToMask(m_high_memory_addr_bits);
process.SetHighmemCodeAddressMask(hi_addr_mask);
process.SetHighmemDataAddressMask(hi_addr_mask);
}
diff --git a/lldb/test/API/python_api/process/address-masks/Makefile b/lldb/test/API/python_api/process/address-masks/Makefile
new file mode 100644
index 00000000000000..10495940055b63
--- /dev/null
+++ b/lldb/test/API/python_api/process/address-masks/Makefile
@@ -0,0 +1,3 @@
+C_SOURCES := main.c
+
+include Makefile.rules
diff --git a/lldb/test/API/python_api/process/address-masks/TestAddressMasks.py b/lldb/test/API/python_api/process/address-masks/TestAddressMasks.py
new file mode 100644
index 00000000000000..5fa6b328ad5229
--- /dev/null
+++ b/lldb/test/API/python_api/process/address-masks/TestAddressMasks.py
@@ -0,0 +1,74 @@
+"""Test Python APIs for setting, getting, and using address masks."""
+
+import os
+import lldb
+from lldbsuite.test.decorators import *
+from lldbsuite.test.lldbtest import *
+from lldbsuite.test import lldbutil
+
+
+class AddressMasksTestCase(TestBase):
+ NO_DEBUG_INFO_TESTCASE = True
+
+ def test_address_masks(self):
+ self.build()
+ (target, process, t, bp) = lldbutil.run_to_source_breakpoint(
+ self, "break here", lldb.SBFileSpec("main.c")
+ )
+
+ process.SetAddressableBits(lldb.eAddressMaskTypeAll, 42)
+ self.assertEqual(0x0000029500003F94, process.FixAddress(0x00265E9500003F94))
+
+ # ~((1ULL<<42)-1) == 0xfffffc0000000000
+ process.SetAddressMask(lldb.eAddressMaskTypeAll, 0xFFFFFC0000000000)
+ self.assertEqual(0x0000029500003F94, process.FixAddress(0x00265E9500003F94))
+
+ # Check that all bits can pass through unmodified
+ process.SetAddressableBits(lldb.eAddressMaskTypeAll, 64)
+ self.assertEqual(0x00265E9500003F94, process.FixAddress(0x00265E9500003F94))
+
+ process.SetAddressableBits(
+ lldb.eAddressMaskTypeAll, 42, lldb.eAddressMaskRangeLow
+ )
+ process.SetAddressableBits(
+ lldb.eAddressMaskTypeAll, 15, lldb.eAddressMaskRangeHigh
+ )
+ self.assertEqual(0x000002950001F694, process.FixAddress(0x00265E950001F694))
+ self.assertEqual(0xFFFFFFFFFFFFF694, process.FixAddress(0xFFA65E950000F694))
+
+ process.SetAddressableBits(
+ lldb.eAddressMaskTypeAll, 42, lldb.eAddressMaskRangeAll
+ )
+ self.assertEqual(0x000002950001F694, process.FixAddress(0x00265E950001F694))
+ self.assertEqual(0xFFFFFE950000F694, process.FixAddress(0xFFA65E950000F694))
+
+ # Set a eAddressMaskTypeCode which has the low 3 bits marked as non-address
+ # bits, confirm that they're cleared by FixAddress.
+ process.SetAddressableBits(
+ lldb.eAddressMaskTypeAll, 42, lldb.eAddressMaskRangeAll
+ )
+ mask = process.GetAddressMask(lldb.eAddressMaskTypeAny)
+ process.SetAddressMask(lldb.eAddressMaskTypeCode, mask | 0x3)
+ process.SetAddressMask(lldb.eAddressMaskTypeCode, 0xFFFFFC0000000003)
+ self.assertEqual(0x000002950001F697, process.FixAddress(0x00265E950001F697))
+ self.assertEqual(0xFFFFFE950000F697, process.FixAddress(0xFFA65E950000F697))
+ self.assertEqual(
+ 0x000002950001F697,
+ process.FixAddress(0x00265E950001F697, lldb.eAddressMaskTypeData),
+ )
+ self.assertEqual(
+ 0x000002950001F694,
+ process.FixAddress(0x00265E950001F697, lldb.eAddressMaskTypeCode),
+ )
+
+ # The user can override whatever settings the Process thinks should be used.
+ process.SetAddressableBits(
+ lldb.eAddressMaskTypeAll, 42, lldb.eAddressMaskRangeAll
+ )
+ self.runCmd("settings set target.process.virtual-addressable-bits 15")
+ self.runCmd("settings set target.process.highmem-virtual-addressable-bits 15")
+ self.assertEqual(0x0000000000007694, process.FixAddress(0x00265E950001F694))
+ self.assertEqual(0xFFFFFFFFFFFFF694, process.FixAddress(0xFFA65E950000F694))
+ self.runCmd("settings set target.process.virtual-addressable-bits 0")
+ self.runCmd("settings set target.process.highmem-virtual-addressable-bits 0")
+ self.assertEqual(0x000002950001F694, process.FixAddress(0x00265E950001F694))
diff --git a/lldb/test/API/python_api/process/address-masks/main.c b/lldb/test/API/python_api/process/address-masks/main.c
new file mode 100644
index 00000000000000..f21a10a16d5a75
--- /dev/null
+++ b/lldb/test/API/python_api/process/address-masks/main.c
@@ -0,0 +1,5 @@
+#include <stdio.h>
+
+int main(int argc, char const *argv[]) {
+ puts("Hello address masking world"); // break here
+}
>From 7ceb74f5b74fa4a0b68ad911afd3cad945f640a3 Mon Sep 17 00:00:00 2001
From: David CARLIER <devnexen at gmail.com>
Date: Fri, 1 Mar 2024 01:25:54 +0000
Subject: [PATCH 198/406] [compiler-rt] fix BSD procmaps stack frame size limit
warning. (#82887)
---
.../sanitizer_procmaps_bsd.cpp | 22 +++++++++----------
1 file changed, 11 insertions(+), 11 deletions(-)
diff --git a/compiler-rt/lib/sanitizer_common/sanitizer_procmaps_bsd.cpp b/compiler-rt/lib/sanitizer_common/sanitizer_procmaps_bsd.cpp
index dcfd94fe3225cd..7c2d8e6f173131 100644
--- a/compiler-rt/lib/sanitizer_common/sanitizer_procmaps_bsd.cpp
+++ b/compiler-rt/lib/sanitizer_common/sanitizer_procmaps_bsd.cpp
@@ -30,17 +30,17 @@ namespace __sanitizer {
#if SANITIZER_FREEBSD
void GetMemoryProfile(fill_profile_f cb, uptr *stats) {
- const int Mib[] = {
- CTL_KERN,
- KERN_PROC,
- KERN_PROC_PID,
- getpid()
- };
-
- struct kinfo_proc InfoProc;
- uptr Len = sizeof(InfoProc);
- CHECK_EQ(internal_sysctl(Mib, ARRAY_SIZE(Mib), nullptr, (uptr *)&InfoProc, &Len, 0), 0);
- cb(0, InfoProc.ki_rssize * GetPageSizeCached(), false, stats);
+ const int Mib[] = {CTL_KERN, KERN_PROC, KERN_PROC_PID, getpid()};
+
+ struct kinfo_proc *InfoProc;
+ uptr Len = sizeof(*InfoProc);
+ uptr Size = Len;
+ InfoProc = (struct kinfo_proc *)MmapOrDie(Size, "GetMemoryProfile()");
+ CHECK_EQ(
+ internal_sysctl(Mib, ARRAY_SIZE(Mib), nullptr, (uptr *)InfoProc, &Len, 0),
+ 0);
+ cb(0, InfoProc->ki_rssize * GetPageSizeCached(), false, stats);
+ UnmapOrDie(InfoProc, Size, true);
}
#endif
>From e8ce864a36ba02ddb63877905d49f1e9ac60b544 Mon Sep 17 00:00:00 2001
From: Jason Molenda <jmolenda at apple.com>
Date: Thu, 29 Feb 2024 17:29:24 -0800
Subject: [PATCH 199/406] Revert "[lldb] Add SBProcess methods for get/set/use
address masks (#83095)"
This reverts commit 9a12b0a60084b2b92f728e1bddec884a47458459.
TestAddressMasks fails its first test on lldb-x86_64-debian,
lldb-arm-ubuntu, lldb-aarch64-ubuntu bots. Reverting while
investigating.
---
lldb/include/lldb/API/SBProcess.h | 114 ------------------
lldb/include/lldb/Utility/AddressableBits.h | 3 -
lldb/include/lldb/lldb-defines.h | 5 -
lldb/include/lldb/lldb-enumerations.h | 16 ---
lldb/source/API/SBProcess.cpp | 92 --------------
lldb/source/Target/Process.cpp | 10 +-
lldb/source/Utility/AddressableBits.cpp | 12 +-
.../python_api/process/address-masks/Makefile | 3 -
.../process/address-masks/TestAddressMasks.py | 74 ------------
.../python_api/process/address-masks/main.c | 5 -
10 files changed, 6 insertions(+), 328 deletions(-)
delete mode 100644 lldb/test/API/python_api/process/address-masks/Makefile
delete mode 100644 lldb/test/API/python_api/process/address-masks/TestAddressMasks.py
delete mode 100644 lldb/test/API/python_api/process/address-masks/main.c
diff --git a/lldb/include/lldb/API/SBProcess.h b/lldb/include/lldb/API/SBProcess.h
index 7da3335a7234b7..4f92a41f3028a2 100644
--- a/lldb/include/lldb/API/SBProcess.h
+++ b/lldb/include/lldb/API/SBProcess.h
@@ -407,120 +407,6 @@ class LLDB_API SBProcess {
/// the process isn't loaded from a core file.
lldb::SBFileSpec GetCoreFile();
- /// \{
- /// \group Mask Address Methods
- ///
- /// \a type
- /// All of the methods in this group take \a type argument
- /// which is an AddressMaskType enum value.
- /// There can be different address masks for code addresses and
- /// data addresses, this argument can select which to get/set,
- /// or to use when clearing non-addressable bits from an address.
- /// This choice of mask can be important for example on AArch32
- /// systems. Where instructions where instructions start on even addresses,
- /// the 0th bit may be used to indicate that a function is thumb code. On
- /// such a target, the eAddressMaskTypeCode may clear the 0th bit from an
- /// address to get the actual address Whereas eAddressMaskTypeData would not.
- ///
- /// \a addr_range
- /// Many of the methods in this group take an \a addr_range argument
- /// which is an AddressMaskRange enum value.
- /// Needing to specify the address range is highly unusual, and the
- /// default argument can be used in nearly all circumstances.
- /// On some architectures (e.g., AArch64), it is possible to have
- /// different page table setups for low and high memory, so different
- /// numbers of bits relevant to addressing. It is possible to have
- /// a program running in one half of memory and accessing the other
- /// as heap, so we need to maintain two different sets of address masks
- /// to debug this correctly.
-
- /// Get the current address mask that will be applied to addresses
- /// before reading from memory.
- ///
- /// \param[in] type
- /// See \ref Mask Address Methods description of this argument.
- /// eAddressMaskTypeAny is often a suitable value when code and
- /// data masks are the same on a given target.
- ///
- /// \param[in] addr_range
- /// See \ref Mask Address Methods description of this argument.
- /// This will default to eAddressMaskRangeLow which is the
- /// only set of masks used normally.
- ///
- /// \return
- /// The address mask currently in use. Bits which are not used
- /// for addressing will be set to 1 in the mask.
- lldb::addr_t GetAddressMask(
- lldb::AddressMaskType type,
- lldb::AddressMaskRange addr_range = lldb::eAddressMaskRangeLow);
-
- /// Set the current address mask that can be applied to addresses
- /// before reading from memory.
- ///
- /// \param[in] type
- /// See \ref Mask Address Methods description of this argument.
- /// eAddressMaskTypeAll is often a suitable value when the
- /// same mask is being set for both code and data.
- ///
- /// \param[in] mask
- /// The address mask to set. Bits which are not used for addressing
- /// should be set to 1 in the mask.
- ///
- /// \param[in] addr_range
- /// See \ref Mask Address Methods description of this argument.
- /// This will default to eAddressMaskRangeLow which is the
- /// only set of masks used normally.
- void SetAddressMask(
- lldb::AddressMaskType type, lldb::addr_t mask,
- lldb::AddressMaskRange addr_range = lldb::eAddressMaskRangeLow);
-
- /// Set the number of bits used for addressing in this Process.
- ///
- /// On Darwin and similar systems, the addressable bits are expressed
- /// as the number of low order bits that are relevant to addressing,
- /// instead of a more general address mask.
- /// This method calculates the correct mask value for a given number
- /// of low order addressable bits.
- ///
- /// \param[in] type
- /// See \ref Mask Address Methods description of this argument.
- /// eAddressMaskTypeAll is often a suitable value when the
- /// same mask is being set for both code and data.
- ///
- /// \param[in] num_bits
- /// Number of bits that are used for addressing.
- /// For example, a value of 42 indicates that the low 42 bits
- /// are relevant for addressing, and that higher-order bits may
- /// be used for various metadata like pointer authentication,
- /// Type Byte Ignore, etc.
- ///
- /// \param[in] addr_range
- /// See \ref Mask Address Methods description of this argument.
- /// This will default to eAddressMaskRangeLow which is the
- /// only set of masks used normally.
- void
- SetAddressableBits(AddressMaskType type, uint32_t num_bits,
- AddressMaskRange addr_range = lldb::eAddressMaskRangeLow);
-
- /// Clear the non-address bits of an \a addr value and return a
- /// virtual address in memory.
- ///
- /// Bits that are not used in addressing may be used for other purposes;
- /// pointer authentication, or metadata in the top byte, or the 0th bit
- /// of armv7 code addresses to indicate arm/thumb are common examples.
- ///
- /// \param[in] addr
- /// The address that should be cleared of non-address bits.
- ///
- /// \param[in] type
- /// See \ref Mask Address Methods description of this argument.
- /// eAddressMaskTypeAny is the default value, correct when it
- /// is unknown if the address is a code or data address.
- lldb::addr_t
- FixAddress(lldb::addr_t addr,
- lldb::AddressMaskType type = lldb::eAddressMaskTypeAny);
- /// \}
-
/// Allocate memory within the process.
///
/// This function will allocate memory in the process's address space.
diff --git a/lldb/include/lldb/Utility/AddressableBits.h b/lldb/include/lldb/Utility/AddressableBits.h
index 75752fcf840a44..13c21329a8c617 100644
--- a/lldb/include/lldb/Utility/AddressableBits.h
+++ b/lldb/include/lldb/Utility/AddressableBits.h
@@ -10,7 +10,6 @@
#define LLDB_UTILITY_ADDRESSABLEBITS_H
#include "lldb/lldb-forward.h"
-#include "lldb/lldb-public.h"
namespace lldb_private {
@@ -34,8 +33,6 @@ class AddressableBits {
void SetHighmemAddressableBits(uint32_t highmem_addressing_bits);
- static lldb::addr_t AddressableBitToMask(uint32_t addressable_bits);
-
void SetProcessMasks(lldb_private::Process &process);
private:
diff --git a/lldb/include/lldb/lldb-defines.h b/lldb/include/lldb/lldb-defines.h
index c7bd019c5c90eb..469be92eabecf3 100644
--- a/lldb/include/lldb/lldb-defines.h
+++ b/lldb/include/lldb/lldb-defines.h
@@ -127,11 +127,6 @@
#define MAX_PATH 260
#endif
-/// Address Mask
-/// Bits not used for addressing are set to 1 in the mask;
-/// all mask bits set is an invalid value.
-#define LLDB_INVALID_ADDRESS_MASK UINT64_MAX
-
// ignore GCC function attributes
#if defined(_MSC_VER) && !defined(__clang__)
#define __attribute__(X)
diff --git a/lldb/include/lldb/lldb-enumerations.h b/lldb/include/lldb/lldb-enumerations.h
index 646f7bfda98475..85769071dae785 100644
--- a/lldb/include/lldb/lldb-enumerations.h
+++ b/lldb/include/lldb/lldb-enumerations.h
@@ -1323,22 +1323,6 @@ enum SymbolDownload {
eSymbolDownloadForeground = 2,
};
-/// Used in the SBProcess AddressMask/FixAddress methods.
-enum AddressMaskType {
- eAddressMaskTypeCode = 0,
- eAddressMaskTypeData,
- eAddressMaskTypeAny,
- eAddressMaskTypeAll = eAddressMaskTypeAny
-};
-
-/// Used in the SBProcess AddressMask/FixAddress methods.
-enum AddressMaskRange {
- eAddressMaskRangeLow = 0,
- eAddressMaskRangeHigh,
- eAddressMaskRangeAny,
- eAddressMaskRangeAll = eAddressMaskRangeAny,
-};
-
} // namespace lldb
#endif // LLDB_LLDB_ENUMERATIONS_H
diff --git a/lldb/source/API/SBProcess.cpp b/lldb/source/API/SBProcess.cpp
index b80664882ebcac..a9fe915324683e 100644
--- a/lldb/source/API/SBProcess.cpp
+++ b/lldb/source/API/SBProcess.cpp
@@ -1255,98 +1255,6 @@ lldb::SBFileSpec SBProcess::GetCoreFile() {
return SBFileSpec(core_file);
}
-addr_t SBProcess::GetAddressMask(AddressMaskType type,
- AddressMaskRange addr_range) {
- LLDB_INSTRUMENT_VA(this, type, addr_range);
-
- if (ProcessSP process_sp = GetSP()) {
- switch (type) {
- case eAddressMaskTypeCode:
- if (addr_range == eAddressMaskRangeHigh)
- return process_sp->GetHighmemCodeAddressMask();
- else
- return process_sp->GetCodeAddressMask();
- case eAddressMaskTypeData:
- if (addr_range == eAddressMaskRangeHigh)
- return process_sp->GetHighmemDataAddressMask();
- else
- return process_sp->GetDataAddressMask();
- case eAddressMaskTypeAny:
- if (addr_range == eAddressMaskRangeHigh)
- return process_sp->GetHighmemDataAddressMask();
- else
- return process_sp->GetDataAddressMask();
- }
- }
- return LLDB_INVALID_ADDRESS_MASK;
-}
-
-void SBProcess::SetAddressMask(AddressMaskType type, addr_t mask,
- AddressMaskRange addr_range) {
- LLDB_INSTRUMENT_VA(this, type, mask, addr_range);
-
- if (ProcessSP process_sp = GetSP()) {
- switch (type) {
- case eAddressMaskTypeCode:
- if (addr_range == eAddressMaskRangeAll) {
- process_sp->SetCodeAddressMask(mask);
- process_sp->SetHighmemCodeAddressMask(mask);
- } else if (addr_range == eAddressMaskRangeHigh) {
- process_sp->SetHighmemCodeAddressMask(mask);
- } else {
- process_sp->SetCodeAddressMask(mask);
- }
- break;
- case eAddressMaskTypeData:
- if (addr_range == eAddressMaskRangeAll) {
- process_sp->SetDataAddressMask(mask);
- process_sp->SetHighmemDataAddressMask(mask);
- } else if (addr_range == eAddressMaskRangeHigh) {
- process_sp->SetHighmemDataAddressMask(mask);
- } else {
- process_sp->SetDataAddressMask(mask);
- }
- break;
- case eAddressMaskTypeAll:
- if (addr_range == eAddressMaskRangeAll) {
- process_sp->SetCodeAddressMask(mask);
- process_sp->SetDataAddressMask(mask);
- process_sp->SetHighmemCodeAddressMask(mask);
- process_sp->SetHighmemDataAddressMask(mask);
- } else if (addr_range == eAddressMaskRangeHigh) {
- process_sp->SetHighmemCodeAddressMask(mask);
- process_sp->SetHighmemDataAddressMask(mask);
- } else {
- process_sp->SetCodeAddressMask(mask);
- process_sp->SetDataAddressMask(mask);
- }
- break;
- }
- }
-}
-
-void SBProcess::SetAddressableBits(AddressMaskType type, uint32_t num_bits,
- AddressMaskRange addr_range) {
- LLDB_INSTRUMENT_VA(this, type, num_bits, addr_range);
-
- SetAddressMask(type, AddressableBits::AddressableBitToMask(num_bits),
- addr_range);
-}
-
-addr_t SBProcess::FixAddress(addr_t addr, AddressMaskType type) {
- LLDB_INSTRUMENT_VA(this, addr, type);
-
- if (ProcessSP process_sp = GetSP()) {
- if (type == eAddressMaskTypeAny)
- return process_sp->FixAnyAddress(addr);
- else if (type == eAddressMaskTypeData)
- return process_sp->FixDataAddress(addr);
- else if (type == eAddressMaskTypeCode)
- return process_sp->FixCodeAddress(addr);
- }
- return addr;
-}
-
lldb::addr_t SBProcess::AllocateMemory(size_t size, uint32_t permissions,
lldb::SBError &sb_error) {
LLDB_INSTRUMENT_VA(this, size, permissions, sb_error);
diff --git a/lldb/source/Target/Process.cpp b/lldb/source/Target/Process.cpp
index 970bcdf5d69b35..137795cb8cec9e 100644
--- a/lldb/source/Target/Process.cpp
+++ b/lldb/source/Target/Process.cpp
@@ -5682,22 +5682,21 @@ void Process::Flush() {
lldb::addr_t Process::GetCodeAddressMask() {
if (uint32_t num_bits_setting = GetVirtualAddressableBits())
- return AddressableBits::AddressableBitToMask(num_bits_setting);
+ return ~((1ULL << num_bits_setting) - 1);
return m_code_address_mask;
}
lldb::addr_t Process::GetDataAddressMask() {
if (uint32_t num_bits_setting = GetVirtualAddressableBits())
- return AddressableBits::AddressableBitToMask(num_bits_setting);
+ return ~((1ULL << num_bits_setting) - 1);
return m_data_address_mask;
}
lldb::addr_t Process::GetHighmemCodeAddressMask() {
if (uint32_t num_bits_setting = GetHighmemVirtualAddressableBits())
- return AddressableBits::AddressableBitToMask(num_bits_setting);
-
+ return ~((1ULL << num_bits_setting) - 1);
if (m_highmem_code_address_mask)
return m_highmem_code_address_mask;
return GetCodeAddressMask();
@@ -5705,8 +5704,7 @@ lldb::addr_t Process::GetHighmemCodeAddressMask() {
lldb::addr_t Process::GetHighmemDataAddressMask() {
if (uint32_t num_bits_setting = GetHighmemVirtualAddressableBits())
- return AddressableBits::AddressableBitToMask(num_bits_setting);
-
+ return ~((1ULL << num_bits_setting) - 1);
if (m_highmem_data_address_mask)
return m_highmem_data_address_mask;
return GetDataAddressMask();
diff --git a/lldb/source/Utility/AddressableBits.cpp b/lldb/source/Utility/AddressableBits.cpp
index 7f9d7ec6c1349c..c6e25f608da73d 100644
--- a/lldb/source/Utility/AddressableBits.cpp
+++ b/lldb/source/Utility/AddressableBits.cpp
@@ -33,26 +33,18 @@ void AddressableBits::SetHighmemAddressableBits(
m_high_memory_addr_bits = highmem_addressing_bits;
}
-addr_t AddressableBits::AddressableBitToMask(uint32_t addressable_bits) {
- assert(addressable_bits <= sizeof(addr_t) * 8);
- if (addressable_bits == 64)
- return 0; // all bits used for addressing
- else
- return ~((1ULL << addressable_bits) - 1);
-}
-
void AddressableBits::SetProcessMasks(Process &process) {
if (m_low_memory_addr_bits == 0 && m_high_memory_addr_bits == 0)
return;
if (m_low_memory_addr_bits != 0) {
- addr_t low_addr_mask = AddressableBitToMask(m_low_memory_addr_bits);
+ addr_t low_addr_mask = ~((1ULL << m_low_memory_addr_bits) - 1);
process.SetCodeAddressMask(low_addr_mask);
process.SetDataAddressMask(low_addr_mask);
}
if (m_high_memory_addr_bits != 0) {
- addr_t hi_addr_mask = AddressableBitToMask(m_high_memory_addr_bits);
+ addr_t hi_addr_mask = ~((1ULL << m_high_memory_addr_bits) - 1);
process.SetHighmemCodeAddressMask(hi_addr_mask);
process.SetHighmemDataAddressMask(hi_addr_mask);
}
diff --git a/lldb/test/API/python_api/process/address-masks/Makefile b/lldb/test/API/python_api/process/address-masks/Makefile
deleted file mode 100644
index 10495940055b63..00000000000000
--- a/lldb/test/API/python_api/process/address-masks/Makefile
+++ /dev/null
@@ -1,3 +0,0 @@
-C_SOURCES := main.c
-
-include Makefile.rules
diff --git a/lldb/test/API/python_api/process/address-masks/TestAddressMasks.py b/lldb/test/API/python_api/process/address-masks/TestAddressMasks.py
deleted file mode 100644
index 5fa6b328ad5229..00000000000000
--- a/lldb/test/API/python_api/process/address-masks/TestAddressMasks.py
+++ /dev/null
@@ -1,74 +0,0 @@
-"""Test Python APIs for setting, getting, and using address masks."""
-
-import os
-import lldb
-from lldbsuite.test.decorators import *
-from lldbsuite.test.lldbtest import *
-from lldbsuite.test import lldbutil
-
-
-class AddressMasksTestCase(TestBase):
- NO_DEBUG_INFO_TESTCASE = True
-
- def test_address_masks(self):
- self.build()
- (target, process, t, bp) = lldbutil.run_to_source_breakpoint(
- self, "break here", lldb.SBFileSpec("main.c")
- )
-
- process.SetAddressableBits(lldb.eAddressMaskTypeAll, 42)
- self.assertEqual(0x0000029500003F94, process.FixAddress(0x00265E9500003F94))
-
- # ~((1ULL<<42)-1) == 0xfffffc0000000000
- process.SetAddressMask(lldb.eAddressMaskTypeAll, 0xFFFFFC0000000000)
- self.assertEqual(0x0000029500003F94, process.FixAddress(0x00265E9500003F94))
-
- # Check that all bits can pass through unmodified
- process.SetAddressableBits(lldb.eAddressMaskTypeAll, 64)
- self.assertEqual(0x00265E9500003F94, process.FixAddress(0x00265E9500003F94))
-
- process.SetAddressableBits(
- lldb.eAddressMaskTypeAll, 42, lldb.eAddressMaskRangeLow
- )
- process.SetAddressableBits(
- lldb.eAddressMaskTypeAll, 15, lldb.eAddressMaskRangeHigh
- )
- self.assertEqual(0x000002950001F694, process.FixAddress(0x00265E950001F694))
- self.assertEqual(0xFFFFFFFFFFFFF694, process.FixAddress(0xFFA65E950000F694))
-
- process.SetAddressableBits(
- lldb.eAddressMaskTypeAll, 42, lldb.eAddressMaskRangeAll
- )
- self.assertEqual(0x000002950001F694, process.FixAddress(0x00265E950001F694))
- self.assertEqual(0xFFFFFE950000F694, process.FixAddress(0xFFA65E950000F694))
-
- # Set a eAddressMaskTypeCode which has the low 3 bits marked as non-address
- # bits, confirm that they're cleared by FixAddress.
- process.SetAddressableBits(
- lldb.eAddressMaskTypeAll, 42, lldb.eAddressMaskRangeAll
- )
- mask = process.GetAddressMask(lldb.eAddressMaskTypeAny)
- process.SetAddressMask(lldb.eAddressMaskTypeCode, mask | 0x3)
- process.SetAddressMask(lldb.eAddressMaskTypeCode, 0xFFFFFC0000000003)
- self.assertEqual(0x000002950001F697, process.FixAddress(0x00265E950001F697))
- self.assertEqual(0xFFFFFE950000F697, process.FixAddress(0xFFA65E950000F697))
- self.assertEqual(
- 0x000002950001F697,
- process.FixAddress(0x00265E950001F697, lldb.eAddressMaskTypeData),
- )
- self.assertEqual(
- 0x000002950001F694,
- process.FixAddress(0x00265E950001F697, lldb.eAddressMaskTypeCode),
- )
-
- # The user can override whatever settings the Process thinks should be used.
- process.SetAddressableBits(
- lldb.eAddressMaskTypeAll, 42, lldb.eAddressMaskRangeAll
- )
- self.runCmd("settings set target.process.virtual-addressable-bits 15")
- self.runCmd("settings set target.process.highmem-virtual-addressable-bits 15")
- self.assertEqual(0x0000000000007694, process.FixAddress(0x00265E950001F694))
- self.assertEqual(0xFFFFFFFFFFFFF694, process.FixAddress(0xFFA65E950000F694))
- self.runCmd("settings set target.process.virtual-addressable-bits 0")
- self.runCmd("settings set target.process.highmem-virtual-addressable-bits 0")
- self.assertEqual(0x000002950001F694, process.FixAddress(0x00265E950001F694))
diff --git a/lldb/test/API/python_api/process/address-masks/main.c b/lldb/test/API/python_api/process/address-masks/main.c
deleted file mode 100644
index f21a10a16d5a75..00000000000000
--- a/lldb/test/API/python_api/process/address-masks/main.c
+++ /dev/null
@@ -1,5 +0,0 @@
-#include <stdio.h>
-
-int main(int argc, char const *argv[]) {
- puts("Hello address masking world"); // break here
-}
>From e7c3cd245665042bbae163f7280aceed35f0fee5 Mon Sep 17 00:00:00 2001
From: Kirill Stoimenov <87100199+kstoimenov at users.noreply.github.com>
Date: Thu, 29 Feb 2024 17:34:32 -0800
Subject: [PATCH 200/406] [HWASAN] Implement selective instrumentation based on
profiling information (#83503)
---
.../Instrumentation/HWAddressSanitizer.cpp | 36 +++++++++++++++++++
.../HWAddressSanitizer/pgo-opt-out-no-ps.ll | 14 ++++++++
.../HWAddressSanitizer/pgo-opt-out.ll | 31 ++++++++++++++++
3 files changed, 81 insertions(+)
create mode 100644 llvm/test/Instrumentation/HWAddressSanitizer/pgo-opt-out-no-ps.ll
create mode 100644 llvm/test/Instrumentation/HWAddressSanitizer/pgo-opt-out.ll
diff --git a/llvm/lib/Transforms/Instrumentation/HWAddressSanitizer.cpp b/llvm/lib/Transforms/Instrumentation/HWAddressSanitizer.cpp
index 33add6d4cd767b..4404382a85b7e3 100644
--- a/llvm/lib/Transforms/Instrumentation/HWAddressSanitizer.cpp
+++ b/llvm/lib/Transforms/Instrumentation/HWAddressSanitizer.cpp
@@ -15,11 +15,14 @@
#include "llvm/ADT/MapVector.h"
#include "llvm/ADT/STLExtras.h"
#include "llvm/ADT/SmallVector.h"
+#include "llvm/ADT/Statistic.h"
#include "llvm/ADT/StringExtras.h"
#include "llvm/ADT/StringRef.h"
+#include "llvm/Analysis/BlockFrequencyInfo.h"
#include "llvm/Analysis/DomTreeUpdater.h"
#include "llvm/Analysis/GlobalsModRef.h"
#include "llvm/Analysis/PostDominators.h"
+#include "llvm/Analysis/ProfileSummaryInfo.h"
#include "llvm/Analysis/StackSafetyAnalysis.h"
#include "llvm/Analysis/TargetLibraryInfo.h"
#include "llvm/Analysis/ValueTracking.h"
@@ -177,6 +180,18 @@ static cl::opt<bool> ClWithTls(
"platforms that support this"),
cl::Hidden, cl::init(true));
+static cl::opt<bool>
+ CSkipHotCode("hwasan-skip-hot-code",
+ cl::desc("Do not instument hot functions based on FDO."),
+ cl::Hidden, cl::init(false));
+
+static cl::opt<int> HotPercentileCutoff("hwasan-percentile-cutoff-hot",
+ cl::init(0));
+
+STATISTIC(NumTotalFuncs, "Number of total funcs HWASAN");
+STATISTIC(NumInstrumentedFuncs, "Number of HWASAN instrumented funcs");
+STATISTIC(NumNoProfileSummaryFuncs, "Number of HWASAN funcs without PS");
+
// Mode for selecting how to insert frame record info into the stack ring
// buffer.
enum RecordStackHistoryMode {
@@ -1507,6 +1522,27 @@ void HWAddressSanitizer::sanitizeFunction(Function &F,
if (!F.hasFnAttribute(Attribute::SanitizeHWAddress))
return;
+ if (F.empty())
+ return;
+
+ NumTotalFuncs++;
+ if (CSkipHotCode) {
+ auto &MAMProxy = FAM.getResult<ModuleAnalysisManagerFunctionProxy>(F);
+ ProfileSummaryInfo *PSI =
+ MAMProxy.getCachedResult<ProfileSummaryAnalysis>(*F.getParent());
+ if (PSI && PSI->hasProfileSummary()) {
+ auto &BFI = FAM.getResult<BlockFrequencyAnalysis>(F);
+ if ((HotPercentileCutoff.getNumOccurrences() && HotPercentileCutoff >= 0)
+ ? PSI->isFunctionHotInCallGraphNthPercentile(HotPercentileCutoff,
+ &F, BFI)
+ : PSI->isFunctionHotInCallGraph(&F, BFI))
+ return;
+ } else {
+ ++NumNoProfileSummaryFuncs;
+ }
+ }
+ NumInstrumentedFuncs++;
+
LLVM_DEBUG(dbgs() << "Function: " << F.getName() << "\n");
SmallVector<InterestingMemoryOperand, 16> OperandsToInstrument;
diff --git a/llvm/test/Instrumentation/HWAddressSanitizer/pgo-opt-out-no-ps.ll b/llvm/test/Instrumentation/HWAddressSanitizer/pgo-opt-out-no-ps.ll
new file mode 100644
index 00000000000000..ebc03668a89142
--- /dev/null
+++ b/llvm/test/Instrumentation/HWAddressSanitizer/pgo-opt-out-no-ps.ll
@@ -0,0 +1,14 @@
+; RUN: opt < %s -passes='require<profile-summary>,hwasan' -S -stats 2>&1 \
+; RUN: -hwasan-skip-hot-code=0 | FileCheck %s --check-prefix=FULL
+; RUN: opt < %s -passes='require<profile-summary>,hwasan' -S -stats 2>&1 \
+; RUN: -hwasan-skip-hot-code=1 | FileCheck %s --check-prefix=SELSAN
+
+; FULL: 1 hwasan - Number of HWASAN instrumented funcs
+; FULL: 1 hwasan - Number of total funcs HWASAN
+
+; SELSAN: 1 hwasan - Number of HWASAN instrumented funcs
+; SELSAN: 1 hwasan - Number of HWASAN funcs without PS
+; SELSAN: 1 hwasan - Number of total funcs HWASAN
+
+define void @not_sanitized() { ret void }
+define void @sanitized_no_ps() sanitize_hwaddress { ret void }
diff --git a/llvm/test/Instrumentation/HWAddressSanitizer/pgo-opt-out.ll b/llvm/test/Instrumentation/HWAddressSanitizer/pgo-opt-out.ll
new file mode 100644
index 00000000000000..ea5366c8759441
--- /dev/null
+++ b/llvm/test/Instrumentation/HWAddressSanitizer/pgo-opt-out.ll
@@ -0,0 +1,31 @@
+; RUN: opt < %s -passes='require<profile-summary>,hwasan' -S -stats 2>&1 \
+; RUN: -hwasan-skip-hot-code=1 | FileCheck %s --check-prefix=DEFAULT
+; RUN: opt < %s -passes='require<profile-summary>,hwasan' -S -stats 2>&1 \
+; RUN: -hwasan-skip-hot-code=1 -hwasan-percentile-cutoff-hot=700000 | FileCheck %s --check-prefix=PERCENT
+
+; DEFAULT: 1 hwasan - Number of total funcs HWASAN
+
+; PERCENT: 1 hwasan - Number of HWASAN instrumented funcs
+; PERCENT: 1 hwasan - Number of total funcs HWASAN
+
+define void @sanitized() sanitize_hwaddress !prof !36 { ret void }
+
+!llvm.module.flags = !{!6}
+!6 = !{i32 1, !"ProfileSummary", !7}
+!7 = !{!8, !9, !10, !11, !12, !13, !14, !17}
+!8 = !{!"ProfileFormat", !"InstrProf"}
+!9 = !{!"TotalCount", i64 30000}
+!10 = !{!"MaxCount", i64 10000}
+!11 = !{!"MaxInternalCount", i64 10000}
+!12 = !{!"MaxFunctionCount", i64 10000}
+!13 = !{!"NumCounts", i64 3}
+!14 = !{!"NumFunctions", i64 5}
+!17 = !{!"DetailedSummary", !18}
+!18 = !{!19, !29, !30, !32, !34}
+!19 = !{i32 10000, i64 10000, i32 3}
+!29 = !{i32 950000, i64 5000, i32 3}
+!30 = !{i32 990000, i64 500, i32 4}
+!32 = !{i32 999900, i64 250, i32 4}
+!34 = !{i32 999999, i64 1, i32 6}
+
+!36 = !{!"function_entry_count", i64 1000}
>From 2cdf611c02392112860e661e8251efa8b1335cc2 Mon Sep 17 00:00:00 2001
From: David CARLIER <devnexen at gmail.com>
Date: Fri, 1 Mar 2024 01:47:05 +0000
Subject: [PATCH 201/406] [compiler-rt][Fuzzer] SetThreadName windows
implementation new try. (#76761)
SetThreadDescription symbol needs to be dynamically loaded before usage.
Then using a wide string buffer, since we re using a null terminated
string, we can use MultiByteToWideChar -1 as 4th argument to finally set
the thread name.
Previously `SetThreadDescription` was called directly causing crash.
It was reverted in dd3aa26fc8e9de37a39611f7a6a602bcb4153784
---
compiler-rt/lib/fuzzer/FuzzerUtilWindows.cpp | 18 ++++++++++++++++--
1 file changed, 16 insertions(+), 2 deletions(-)
diff --git a/compiler-rt/lib/fuzzer/FuzzerUtilWindows.cpp b/compiler-rt/lib/fuzzer/FuzzerUtilWindows.cpp
index 71770166805f78..13f9a67a2f0fe3 100644
--- a/compiler-rt/lib/fuzzer/FuzzerUtilWindows.cpp
+++ b/compiler-rt/lib/fuzzer/FuzzerUtilWindows.cpp
@@ -18,8 +18,10 @@
#include <errno.h>
#include <io.h>
#include <iomanip>
+#include <libloaderapi.h>
#include <signal.h>
#include <stdio.h>
+#include <stringapiset.h>
#include <sys/types.h>
#include <windows.h>
@@ -234,8 +236,20 @@ size_t PageSize() {
}
void SetThreadName(std::thread &thread, const std::string &name) {
- // TODO ?
- // to UTF-8 then SetThreadDescription ?
+ typedef HRESULT(WINAPI * proc)(HANDLE, PCWSTR);
+ HMODULE kbase = GetModuleHandleA("KernelBase.dll");
+ proc ThreadNameProc =
+ reinterpret_cast<proc>(GetProcAddress, "SetThreadDescription");
+ if (proc) {
+ std::wstring buf;
+ auto sz = MultiByteToWideChar(CP_UTF8, 0, name.data(), -1, nullptr, 0);
+ if (sz > 0) {
+ buf.resize(sz);
+ if (MultyByteToWideChar(CP_UTF8, 0, name.data(), -1, &buf[0], sz) > 0) {
+ (void)ThreadNameProc(thread.native_handle(), buf.c_str());
+ }
+ }
+ }
}
} // namespace fuzzer
>From cf68c0427d9d3816eefcfe7d3d648a98146c07cf Mon Sep 17 00:00:00 2001
From: lntue <35648136+lntue at users.noreply.github.com>
Date: Thu, 29 Feb 2024 21:08:17 -0500
Subject: [PATCH 202/406] [libc] Ignore -Winclude-next-absolute-path warning in
float-macros.h (#83513)
---
libc/include/llvm-libc-macros/float-macros.h | 1 +
1 file changed, 1 insertion(+)
diff --git a/libc/include/llvm-libc-macros/float-macros.h b/libc/include/llvm-libc-macros/float-macros.h
index a51eab0c7ed2f3..4fe8590c5f70c8 100644
--- a/libc/include/llvm-libc-macros/float-macros.h
+++ b/libc/include/llvm-libc-macros/float-macros.h
@@ -13,6 +13,7 @@
#ifdef __clang__
#pragma clang diagnostic push
#pragma clang diagnostic ignored "-Wgnu-include-next"
+#pragma clang diagnostic ignored "-Winclude-next-absolute-path"
#else // gcc
#pragma GCC system_header
#endif //__clang__
>From 5b6e58c565cf809e4133a10ff9d9b096754bea1e Mon Sep 17 00:00:00 2001
From: Alexander M <iammorjj at gmail.com>
Date: Fri, 1 Mar 2024 03:23:12 +0100
Subject: [PATCH 203/406] Revert "XFAIL TestLocalVariables.py on Windows"
(#83454)
This reverts commit 3434472ed74141848634b5eb3cd625d651e22562.
Closes #43097.
---
lldb/test/API/lang/c/local_variables/TestLocalVariables.py | 1 -
1 file changed, 1 deletion(-)
diff --git a/lldb/test/API/lang/c/local_variables/TestLocalVariables.py b/lldb/test/API/lang/c/local_variables/TestLocalVariables.py
index cccb8cac013ff2..686636119314ef 100644
--- a/lldb/test/API/lang/c/local_variables/TestLocalVariables.py
+++ b/lldb/test/API/lang/c/local_variables/TestLocalVariables.py
@@ -19,7 +19,6 @@ def setUp(self):
self.source = "main.c"
self.line = line_number(self.source, "// Set break point at this line.")
- @skipIfWindows
def test_c_local_variables(self):
"""Test local variable value."""
self.build()
>From 39c24c52f641849a648e3b01310ed7c3f2c8d91b Mon Sep 17 00:00:00 2001
From: jameshu15869 <55058507+jameshu15869 at users.noreply.github.com>
Date: Thu, 29 Feb 2024 22:04:02 -0500
Subject: [PATCH 204/406] [libc] Allow libc to build on Red Hat (#83517)
Currently, `libc` fails when building on redhat because the triple
format uses `redhat` instead of `linux` (The same problem as openSUSE).
This PR changes `libc` to accept `redhat` as a valid Linux triple.
---------
Co-authored-by: Joseph Huber <huberjn at outlook.com>
---
libc/cmake/modules/LLVMLibCArchitectures.cmake | 9 +++++----
1 file changed, 5 insertions(+), 4 deletions(-)
diff --git a/libc/cmake/modules/LLVMLibCArchitectures.cmake b/libc/cmake/modules/LLVMLibCArchitectures.cmake
index 0dbc59ad643ac4..dacb4db75d3374 100644
--- a/libc/cmake/modules/LLVMLibCArchitectures.cmake
+++ b/libc/cmake/modules/LLVMLibCArchitectures.cmake
@@ -167,13 +167,14 @@ if(LIBC_TARGET_OS STREQUAL "baremetal")
set(LIBC_TARGET_OS_IS_BAREMETAL TRUE)
elseif(LIBC_TARGET_OS STREQUAL "linux")
set(LIBC_TARGET_OS_IS_LINUX TRUE)
-elseif(LIBC_TARGET_OS STREQUAL "poky" OR LIBC_TARGET_OS STREQUAL "suse")
- # poky are ustom Linux-base systems created by yocto. Since these are Linux
+elseif(LIBC_TARGET_OS STREQUAL "poky" OR LIBC_TARGET_OS STREQUAL "suse" OR
+ LIBC_TARGET_OS STREQUAL "redhat")
+ # poky are custom Linux-base systems created by yocto. Since these are Linux
# images, we change the LIBC_TARGET_OS to linux. This define is used to
# include the right directories during compilation.
#
- # openSUSE uses different triple format which causes LIBC_TARGET_OS to be
- # computed as "suse" instead of "linux".
+ # openSUSE and redhat use different triple format which causes LIBC_TARGET_OS
+ # to be computed as "suse" or "redhat" instead of "linux".
set(LIBC_TARGET_OS_IS_LINUX TRUE)
set(LIBC_TARGET_OS "linux")
elseif(LIBC_TARGET_OS STREQUAL "darwin")
>From 8171f6d12eafbd4a67ad263770c142d51504d834 Mon Sep 17 00:00:00 2001
From: Chelsea Cassanova <chelsea_cassanova at apple.com>
Date: Thu, 29 Feb 2024 19:22:23 -0800
Subject: [PATCH 205/406] [lldb][progress][NFC] Fix Doxygen information
(#83502)
---
lldb/include/lldb/Core/Progress.h | 3 +++
1 file changed, 3 insertions(+)
diff --git a/lldb/include/lldb/Core/Progress.h b/lldb/include/lldb/Core/Progress.h
index eb4d9f9d7af08e..9549e3b5aea950 100644
--- a/lldb/include/lldb/Core/Progress.h
+++ b/lldb/include/lldb/Core/Progress.h
@@ -64,6 +64,9 @@ class Progress {
///
/// @param [in] title The title of this progress activity.
///
+ /// @param [in] details Specific information about what the progress report
+ /// is currently working on.
+ ///
/// @param [in] total The total units of work to be done if specified, if
/// set to std::nullopt then an indeterminate progress indicator should be
/// displayed.
>From 2023a230d122d6971c5ff90615c128e7e711b08f Mon Sep 17 00:00:00 2001
From: Wang Pengcheng <wangpengcheng.pp at bytedance.com>
Date: Fri, 1 Mar 2024 12:17:56 +0800
Subject: [PATCH 206/406] [RISCV] Move V0 to the end of register allocation
order (#82967)
According to
https://riscv-optimization-guide-riseproject-c94355ae3e6872252baa952524.gitlab.io/riscv-optimization-guide.html:
> The v0 register defined by the RISC-V vector extension is special in
> that it can be used both as a general purpose vector register and also
> as a mask register. As a preference, use registers other than v0 for
> non-mask values. Otherwise data will have to be moved out of v0 when a
> mask is required in an operation. v0 may be used when all other
> registers are in use, and using v0 would avoid spilling register state
> to memory.
And using V0 register may stall masking pipeline and stop chaining
for some microarchitectures.
So we should try to not use V0 and register groups contained it as
much as possible. We achieve this via moving V0 to the end of RA
order.
---
llvm/lib/Target/RISCV/RISCVRegisterInfo.td | 10 +-
llvm/test/CodeGen/RISCV/pr69586.ll | 170 +++++++++---------
.../rvv/fixed-vector-i8-index-cornercase.ll | 8 +-
.../CodeGen/RISCV/rvv/fixed-vectors-abs-vp.ll | 4 +-
.../RISCV/rvv/fixed-vectors-ctpop-vp.ll | 4 +-
.../RISCV/rvv/fixed-vectors-fmaximum-vp.ll | 34 ++--
.../RISCV/rvv/fixed-vectors-fmaximum.ll | 4 +-
.../RISCV/rvv/fixed-vectors-fminimum-vp.ll | 34 ++--
.../RISCV/rvv/fixed-vectors-fminimum.ll | 4 +-
.../rvv/fixed-vectors-interleaved-access.ll | 144 +++++++--------
.../RISCV/rvv/fixed-vectors-nearbyint-vp.ll | 8 +-
.../RISCV/rvv/fixed-vectors-reduction-fp.ll | 48 ++---
.../RISCV/rvv/fixed-vectors-setcc-fp-vp.ll | 30 ++--
.../RISCV/rvv/fixed-vectors-setcc-int-vp.ll | 28 +--
.../RISCV/rvv/fixed-vectors-shuffle-concat.ll | 8 +-
.../RISCV/rvv/fixed-vectors-trunc-vp.ll | 16 +-
.../RISCV/rvv/fixed-vectors-vadd-vp.ll | 8 +-
.../RISCV/rvv/fixed-vectors-vcopysign-vp.ll | 4 +-
.../RISCV/rvv/fixed-vectors-vfma-vp.ll | 4 +-
.../RISCV/rvv/fixed-vectors-vfmax-vp.ll | 4 +-
.../RISCV/rvv/fixed-vectors-vfmin-vp.ll | 4 +-
.../RISCV/rvv/fixed-vectors-vfmuladd-vp.ll | 4 +-
.../RISCV/rvv/fixed-vectors-vmax-vp.ll | 4 +-
.../RISCV/rvv/fixed-vectors-vmaxu-vp.ll | 4 +-
.../RISCV/rvv/fixed-vectors-vmin-vp.ll | 4 +-
.../RISCV/rvv/fixed-vectors-vminu-vp.ll | 4 +-
.../RISCV/rvv/fixed-vectors-vpgather.ll | 4 +-
.../RISCV/rvv/fixed-vectors-vsadd-vp.ll | 12 +-
.../RISCV/rvv/fixed-vectors-vsaddu-vp.ll | 12 +-
.../RISCV/rvv/fixed-vectors-vssub-vp.ll | 12 +-
.../RISCV/rvv/fixed-vectors-vssubu-vp.ll | 12 +-
.../test/CodeGen/RISCV/rvv/fmaximum-sdnode.ll | 24 +--
llvm/test/CodeGen/RISCV/rvv/fmaximum-vp.ll | 64 +++----
.../test/CodeGen/RISCV/rvv/fminimum-sdnode.ll | 24 +--
llvm/test/CodeGen/RISCV/rvv/fminimum-vp.ll | 64 +++----
.../test/CodeGen/RISCV/rvv/mscatter-sdnode.ll | 10 +-
llvm/test/CodeGen/RISCV/rvv/nearbyint-vp.ll | 8 +-
llvm/test/CodeGen/RISCV/rvv/setcc-fp-vp.ll | 34 ++--
llvm/test/CodeGen/RISCV/rvv/setcc-int-vp.ll | 8 +-
llvm/test/CodeGen/RISCV/rvv/vcopysign-vp.ll | 4 +-
.../RISCV/rvv/vector-interleave-store.ll | 8 +-
llvm/test/CodeGen/RISCV/rvv/vfadd-vp.ll | 8 +-
llvm/test/CodeGen/RISCV/rvv/vfdiv-vp.ll | 8 +-
llvm/test/CodeGen/RISCV/rvv/vfma-vp.ll | 4 +-
llvm/test/CodeGen/RISCV/rvv/vfmadd-sdnode.ll | 4 +-
llvm/test/CodeGen/RISCV/rvv/vfmax-vp.ll | 4 +-
llvm/test/CodeGen/RISCV/rvv/vfmin-vp.ll | 4 +-
llvm/test/CodeGen/RISCV/rvv/vfmul-vp.ll | 8 +-
llvm/test/CodeGen/RISCV/rvv/vfmuladd-vp.ll | 4 +-
.../RISCV/rvv/vfnmadd-constrained-sdnode.ll | 8 +-
.../RISCV/rvv/vfnmsub-constrained-sdnode.ll | 8 +-
llvm/test/CodeGen/RISCV/rvv/vfptrunc-vp.ll | 12 +-
llvm/test/CodeGen/RISCV/rvv/vfsub-vp.ll | 8 +-
llvm/test/CodeGen/RISCV/rvv/vfwmacc-vp.ll | 4 +-
llvm/test/CodeGen/RISCV/rvv/vfwnmacc-vp.ll | 4 +-
llvm/test/CodeGen/RISCV/rvv/vfwnmsac-vp.ll | 4 +-
llvm/test/CodeGen/RISCV/rvv/vpmerge-sdnode.ll | 4 +-
.../CodeGen/RISCV/rvv/vreductions-fp-vp.ll | 20 +--
llvm/test/CodeGen/RISCV/rvv/vselect-fp.ll | 6 +-
llvm/test/CodeGen/RISCV/rvv/vsitofp-vp.ll | 4 +-
llvm/test/CodeGen/RISCV/rvv/vtrunc-vp.ll | 8 +-
llvm/test/CodeGen/RISCV/rvv/vuitofp-vp.ll | 4 +-
62 files changed, 516 insertions(+), 520 deletions(-)
diff --git a/llvm/lib/Target/RISCV/RISCVRegisterInfo.td b/llvm/lib/Target/RISCV/RISCVRegisterInfo.td
index 381e0082c49b0b..53838d6e540123 100644
--- a/llvm/lib/Target/RISCV/RISCVRegisterInfo.td
+++ b/llvm/lib/Target/RISCV/RISCVRegisterInfo.td
@@ -508,19 +508,23 @@ defvar VM8VTs = [vint8m8_t, vint16m8_t, vint32m8_t, vint64m8_t,
vfloat16m8_t, vbfloat16m8_t,
vfloat32m8_t, vfloat64m8_t];
+// We reverse the order of last 8 registers so that we don't needlessly prevent
+// allocation of higher lmul register groups while still putting v0 last in the
+// allocation order.
+
def VR : VReg<!listconcat(VM1VTs, VMaskVTs),
(add (sequence "V%u", 8, 31),
- (sequence "V%u", 0, 7)), 1>;
+ (sequence "V%u", 7, 0)), 1>;
def VRNoV0 : VReg<!listconcat(VM1VTs, VMaskVTs), (sub VR, V0), 1>;
def VRM2 : VReg<VM2VTs, (add (sequence "V%uM2", 8, 31, 2),
- (sequence "V%uM2", 0, 7, 2)), 2>;
+ (sequence "V%uM2", 6, 0, 2)), 2>;
def VRM2NoV0 : VReg<VM2VTs, (sub VRM2, V0M2), 2>;
def VRM4 : VReg<VM4VTs, (add V8M4, V12M4, V16M4, V20M4,
- V24M4, V28M4, V0M4, V4M4), 4>;
+ V24M4, V28M4, V4M4, V0M4), 4>;
def VRM4NoV0 : VReg<VM4VTs, (sub VRM4, V0M4), 4>;
diff --git a/llvm/test/CodeGen/RISCV/pr69586.ll b/llvm/test/CodeGen/RISCV/pr69586.ll
index 2d5fce2ca4970e..15daf2c5779063 100644
--- a/llvm/test/CodeGen/RISCV/pr69586.ll
+++ b/llvm/test/CodeGen/RISCV/pr69586.ll
@@ -146,19 +146,19 @@ define void @test(ptr %0, ptr %1, i64 %2) {
; NOREMAT-NEXT: slli a6, a3, 10
; NOREMAT-NEXT: sd a6, 176(sp) # 8-byte Folded Spill
; NOREMAT-NEXT: add a6, a0, a6
-; NOREMAT-NEXT: vle32.v v0, (a6)
+; NOREMAT-NEXT: vle32.v v6, (a6)
; NOREMAT-NEXT: vle32.v v20, (a6)
; NOREMAT-NEXT: li a6, 19
; NOREMAT-NEXT: slli a6, a6, 9
; NOREMAT-NEXT: sd a6, 168(sp) # 8-byte Folded Spill
; NOREMAT-NEXT: li a7, 19
; NOREMAT-NEXT: add a6, a0, a6
-; NOREMAT-NEXT: vle32.v v2, (a6)
+; NOREMAT-NEXT: vle32.v v4, (a6)
; NOREMAT-NEXT: vle32.v v22, (a6)
; NOREMAT-NEXT: slli a5, a5, 11
; NOREMAT-NEXT: sd a5, 160(sp) # 8-byte Folded Spill
; NOREMAT-NEXT: add a5, a0, a5
-; NOREMAT-NEXT: vle32.v v4, (a5)
+; NOREMAT-NEXT: vle32.v v2, (a5)
; NOREMAT-NEXT: vle32.v v12, (a5)
; NOREMAT-NEXT: li s10, 21
; NOREMAT-NEXT: slli a5, s10, 9
@@ -184,25 +184,25 @@ define void @test(ptr %0, ptr %1, i64 %2) {
; NOREMAT-NEXT: add a5, a0, a5
; NOREMAT-NEXT: vle32.v v30, (a5)
; NOREMAT-NEXT: vle32.v v10, (a5)
-; NOREMAT-NEXT: sf.vc.vv 3, 0, v18, v0
+; NOREMAT-NEXT: sf.vc.vv 3, 0, v18, v6
; NOREMAT-NEXT: li s3, 25
; NOREMAT-NEXT: slli a5, s3, 9
; NOREMAT-NEXT: sd a5, 128(sp) # 8-byte Folded Spill
; NOREMAT-NEXT: add a5, a0, a5
-; NOREMAT-NEXT: vle32.v v0, (a5)
+; NOREMAT-NEXT: vle32.v v6, (a5)
; NOREMAT-NEXT: vle32.v v18, (a5)
-; NOREMAT-NEXT: sf.vc.vv 3, 0, v20, v2
+; NOREMAT-NEXT: sf.vc.vv 3, 0, v20, v4
; NOREMAT-NEXT: slli a5, s2, 10
; NOREMAT-NEXT: sd a5, 120(sp) # 8-byte Folded Spill
; NOREMAT-NEXT: add a5, a0, a5
-; NOREMAT-NEXT: vle32.v v2, (a5)
+; NOREMAT-NEXT: vle32.v v4, (a5)
; NOREMAT-NEXT: vle32.v v20, (a5)
-; NOREMAT-NEXT: sf.vc.vv 3, 0, v22, v4
+; NOREMAT-NEXT: sf.vc.vv 3, 0, v22, v2
; NOREMAT-NEXT: li t5, 27
; NOREMAT-NEXT: slli a5, t5, 9
; NOREMAT-NEXT: sd a5, 112(sp) # 8-byte Folded Spill
; NOREMAT-NEXT: add a5, a0, a5
-; NOREMAT-NEXT: vle32.v v4, (a5)
+; NOREMAT-NEXT: vle32.v v2, (a5)
; NOREMAT-NEXT: vle32.v v22, (a5)
; NOREMAT-NEXT: sf.vc.vv 3, 0, v12, v24
; NOREMAT-NEXT: slli a4, a4, 11
@@ -235,33 +235,33 @@ define void @test(ptr %0, ptr %1, i64 %2) {
; NOREMAT-NEXT: add a4, a0, a4
; NOREMAT-NEXT: vle32.v v30, (a4)
; NOREMAT-NEXT: vle32.v v16, (a4)
-; NOREMAT-NEXT: sf.vc.vv 3, 0, v10, v0
+; NOREMAT-NEXT: sf.vc.vv 3, 0, v10, v6
; NOREMAT-NEXT: lui a6, 4
; NOREMAT-NEXT: add a4, a0, a6
-; NOREMAT-NEXT: vle32.v v0, (a4)
+; NOREMAT-NEXT: vle32.v v6, (a4)
; NOREMAT-NEXT: vle32.v v8, (a4)
; NOREMAT-NEXT: csrr a4, vlenb
; NOREMAT-NEXT: slli a4, a4, 1
; NOREMAT-NEXT: add a4, sp, a4
; NOREMAT-NEXT: addi a4, a4, 288
; NOREMAT-NEXT: vs2r.v v8, (a4) # Unknown-size Folded Spill
-; NOREMAT-NEXT: sf.vc.vv 3, 0, v18, v2
+; NOREMAT-NEXT: sf.vc.vv 3, 0, v18, v4
; NOREMAT-NEXT: addiw a4, a6, 512
; NOREMAT-NEXT: sd a4, 72(sp) # 8-byte Folded Spill
; NOREMAT-NEXT: add a4, a0, a4
-; NOREMAT-NEXT: vle32.v v2, (a4)
+; NOREMAT-NEXT: vle32.v v4, (a4)
; NOREMAT-NEXT: vle32.v v18, (a4)
-; NOREMAT-NEXT: sf.vc.vv 3, 0, v20, v4
+; NOREMAT-NEXT: sf.vc.vv 3, 0, v20, v2
; NOREMAT-NEXT: slli a4, t0, 10
; NOREMAT-NEXT: sd a4, 64(sp) # 8-byte Folded Spill
; NOREMAT-NEXT: add a4, a0, a4
-; NOREMAT-NEXT: vle32.v v4, (a4)
+; NOREMAT-NEXT: vle32.v v2, (a4)
; NOREMAT-NEXT: vle32.v v20, (a4)
; NOREMAT-NEXT: sf.vc.vv 3, 0, v22, v24
; NOREMAT-NEXT: addiw a4, a6, 1536
; NOREMAT-NEXT: sd a4, 56(sp) # 8-byte Folded Spill
; NOREMAT-NEXT: add a4, a0, a4
-; NOREMAT-NEXT: vle32.v v6, (a4)
+; NOREMAT-NEXT: vle32.v v0, (a4)
; NOREMAT-NEXT: vle32.v v22, (a4)
; NOREMAT-NEXT: sf.vc.vv 3, 0, v12, v26
; NOREMAT-NEXT: slli a3, a3, 11
@@ -289,18 +289,18 @@ define void @test(ptr %0, ptr %1, i64 %2) {
; NOREMAT-NEXT: add a3, a0, a3
; NOREMAT-NEXT: vle32.v v10, (a3)
; NOREMAT-NEXT: vle32.v v14, (a3)
-; NOREMAT-NEXT: sf.vc.vv 3, 0, v16, v0
+; NOREMAT-NEXT: sf.vc.vv 3, 0, v16, v6
; NOREMAT-NEXT: addiw a3, s1, -512
; NOREMAT-NEXT: sd a3, 24(sp) # 8-byte Folded Spill
; NOREMAT-NEXT: add a3, a0, a3
-; NOREMAT-NEXT: vle32.v v0, (a3)
+; NOREMAT-NEXT: vle32.v v6, (a3)
; NOREMAT-NEXT: vle32.v v16, (a3)
; NOREMAT-NEXT: csrr a3, vlenb
; NOREMAT-NEXT: slli a3, a3, 1
; NOREMAT-NEXT: add a3, sp, a3
; NOREMAT-NEXT: addi a3, a3, 288
; NOREMAT-NEXT: vl2r.v v26, (a3) # Unknown-size Folded Reload
-; NOREMAT-NEXT: sf.vc.vv 3, 0, v26, v2
+; NOREMAT-NEXT: sf.vc.vv 3, 0, v26, v4
; NOREMAT-NEXT: add a3, a0, s1
; NOREMAT-NEXT: vle32.v v26, (a3)
; NOREMAT-NEXT: vle32.v v28, (a3)
@@ -309,27 +309,27 @@ define void @test(ptr %0, ptr %1, i64 %2) {
; NOREMAT-NEXT: add a3, sp, a3
; NOREMAT-NEXT: addi a3, a3, 288
; NOREMAT-NEXT: vs2r.v v28, (a3) # Unknown-size Folded Spill
-; NOREMAT-NEXT: sf.vc.vv 3, 0, v18, v4
+; NOREMAT-NEXT: sf.vc.vv 3, 0, v18, v2
; NOREMAT-NEXT: addiw ra, s1, 512
; NOREMAT-NEXT: add a3, a0, ra
; NOREMAT-NEXT: vle32.v v28, (a3)
; NOREMAT-NEXT: vle32.v v30, (a3)
-; NOREMAT-NEXT: sf.vc.vv 3, 0, v20, v6
+; NOREMAT-NEXT: sf.vc.vv 3, 0, v20, v0
; NOREMAT-NEXT: slli s11, s10, 10
; NOREMAT-NEXT: add a3, a0, s11
-; NOREMAT-NEXT: vle32.v v2, (a3)
+; NOREMAT-NEXT: vle32.v v4, (a3)
; NOREMAT-NEXT: vle32.v v18, (a3)
; NOREMAT-NEXT: sf.vc.vv 3, 0, v22, v12
; NOREMAT-NEXT: addiw s10, s1, 1536
; NOREMAT-NEXT: add a3, a0, s10
-; NOREMAT-NEXT: vle32.v v4, (a3)
+; NOREMAT-NEXT: vle32.v v2, (a3)
; NOREMAT-NEXT: vle32.v v20, (a3)
; NOREMAT-NEXT: addi a3, sp, 288
; NOREMAT-NEXT: vl2r.v v12, (a3) # Unknown-size Folded Reload
; NOREMAT-NEXT: sf.vc.vv 3, 0, v12, v8
; NOREMAT-NEXT: slli s9, s8, 11
; NOREMAT-NEXT: add a3, a0, s9
-; NOREMAT-NEXT: vle32.v v6, (a3)
+; NOREMAT-NEXT: vle32.v v0, (a3)
; NOREMAT-NEXT: vle32.v v12, (a3)
; NOREMAT-NEXT: sf.vc.vv 3, 0, v24, v10
; NOREMAT-NEXT: lui t0, 6
@@ -337,7 +337,7 @@ define void @test(ptr %0, ptr %1, i64 %2) {
; NOREMAT-NEXT: add a3, a0, s8
; NOREMAT-NEXT: vle32.v v8, (a3)
; NOREMAT-NEXT: vle32.v v22, (a3)
-; NOREMAT-NEXT: sf.vc.vv 3, 0, v14, v0
+; NOREMAT-NEXT: sf.vc.vv 3, 0, v14, v6
; NOREMAT-NEXT: slli s7, s6, 10
; NOREMAT-NEXT: add a3, a0, s7
; NOREMAT-NEXT: vle32.v v10, (a3)
@@ -345,7 +345,7 @@ define void @test(ptr %0, ptr %1, i64 %2) {
; NOREMAT-NEXT: sf.vc.vv 3, 0, v16, v26
; NOREMAT-NEXT: addiw s6, t0, -512
; NOREMAT-NEXT: add a3, a0, s6
-; NOREMAT-NEXT: vle32.v v0, (a3)
+; NOREMAT-NEXT: vle32.v v6, (a3)
; NOREMAT-NEXT: vle32.v v16, (a3)
; NOREMAT-NEXT: csrr a3, vlenb
; NOREMAT-NEXT: slli a3, a3, 2
@@ -361,7 +361,7 @@ define void @test(ptr %0, ptr %1, i64 %2) {
; NOREMAT-NEXT: add a3, sp, a3
; NOREMAT-NEXT: addi a3, a3, 288
; NOREMAT-NEXT: vs2r.v v26, (a3) # Unknown-size Folded Spill
-; NOREMAT-NEXT: sf.vc.vv 3, 0, v30, v2
+; NOREMAT-NEXT: sf.vc.vv 3, 0, v30, v4
; NOREMAT-NEXT: addiw s5, t0, 512
; NOREMAT-NEXT: add a3, a0, s5
; NOREMAT-NEXT: vle32.v v26, (a3)
@@ -371,12 +371,12 @@ define void @test(ptr %0, ptr %1, i64 %2) {
; NOREMAT-NEXT: add a3, sp, a3
; NOREMAT-NEXT: addi a3, a3, 288
; NOREMAT-NEXT: vs2r.v v28, (a3) # Unknown-size Folded Spill
-; NOREMAT-NEXT: sf.vc.vv 3, 0, v18, v4
+; NOREMAT-NEXT: sf.vc.vv 3, 0, v18, v2
; NOREMAT-NEXT: slli s4, s3, 10
; NOREMAT-NEXT: add a3, a0, s4
; NOREMAT-NEXT: vle32.v v28, (a3)
; NOREMAT-NEXT: vle32.v v18, (a3)
-; NOREMAT-NEXT: sf.vc.vv 3, 0, v20, v6
+; NOREMAT-NEXT: sf.vc.vv 3, 0, v20, v0
; NOREMAT-NEXT: addiw s3, t0, 1536
; NOREMAT-NEXT: add a3, a0, s3
; NOREMAT-NEXT: vle32.v v30, (a3)
@@ -384,23 +384,23 @@ define void @test(ptr %0, ptr %1, i64 %2) {
; NOREMAT-NEXT: sf.vc.vv 3, 0, v12, v8
; NOREMAT-NEXT: slli s2, s2, 11
; NOREMAT-NEXT: add a3, a0, s2
-; NOREMAT-NEXT: vle32.v v2, (a3)
+; NOREMAT-NEXT: vle32.v v4, (a3)
; NOREMAT-NEXT: vle32.v v12, (a3)
; NOREMAT-NEXT: sf.vc.vv 3, 0, v22, v10
; NOREMAT-NEXT: lui a3, 7
; NOREMAT-NEXT: addiw s0, a3, -1536
; NOREMAT-NEXT: add a4, a0, s0
-; NOREMAT-NEXT: vle32.v v4, (a4)
+; NOREMAT-NEXT: vle32.v v2, (a4)
; NOREMAT-NEXT: vle32.v v22, (a4)
-; NOREMAT-NEXT: sf.vc.vv 3, 0, v14, v0
+; NOREMAT-NEXT: sf.vc.vv 3, 0, v14, v6
; NOREMAT-NEXT: slli t6, t5, 10
; NOREMAT-NEXT: add a4, a0, t6
-; NOREMAT-NEXT: vle32.v v6, (a4)
+; NOREMAT-NEXT: vle32.v v0, (a4)
; NOREMAT-NEXT: vle32.v v14, (a4)
; NOREMAT-NEXT: sf.vc.vv 3, 0, v16, v24
; NOREMAT-NEXT: addiw t5, a3, -512
; NOREMAT-NEXT: add a4, a0, t5
-; NOREMAT-NEXT: vle32.v v0, (a4)
+; NOREMAT-NEXT: vle32.v v6, (a4)
; NOREMAT-NEXT: vle32.v v16, (a4)
; NOREMAT-NEXT: csrr a4, vlenb
; NOREMAT-NEXT: slli a4, a4, 2
@@ -426,42 +426,42 @@ define void @test(ptr %0, ptr %1, i64 %2) {
; NOREMAT-NEXT: add a4, a0, t3
; NOREMAT-NEXT: vle32.v v18, (a4)
; NOREMAT-NEXT: vle32.v v28, (a4)
-; NOREMAT-NEXT: sf.vc.vv 3, 0, v20, v2
+; NOREMAT-NEXT: sf.vc.vv 3, 0, v20, v4
; NOREMAT-NEXT: addiw t2, a3, 1536
; NOREMAT-NEXT: add a4, a0, t2
; NOREMAT-NEXT: vle32.v v20, (a4)
; NOREMAT-NEXT: vle32.v v30, (a4)
-; NOREMAT-NEXT: sf.vc.vv 3, 0, v12, v4
+; NOREMAT-NEXT: sf.vc.vv 3, 0, v12, v2
; NOREMAT-NEXT: slli t1, a2, 11
; NOREMAT-NEXT: add a2, a0, t1
; NOREMAT-NEXT: vle32.v v12, (a2)
-; NOREMAT-NEXT: vle32.v v2, (a2)
-; NOREMAT-NEXT: sf.vc.vv 3, 0, v22, v6
+; NOREMAT-NEXT: vle32.v v4, (a2)
+; NOREMAT-NEXT: sf.vc.vv 3, 0, v22, v0
; NOREMAT-NEXT: lui a2, 8
; NOREMAT-NEXT: addiw a7, a2, -1536
; NOREMAT-NEXT: add a4, a0, a7
; NOREMAT-NEXT: vle32.v v22, (a4)
-; NOREMAT-NEXT: vle32.v v4, (a4)
-; NOREMAT-NEXT: sf.vc.vv 3, 0, v14, v0
+; NOREMAT-NEXT: vle32.v v2, (a4)
+; NOREMAT-NEXT: sf.vc.vv 3, 0, v14, v6
; NOREMAT-NEXT: slli a6, a5, 10
; NOREMAT-NEXT: add a4, a0, a6
; NOREMAT-NEXT: vle32.v v14, (a4)
-; NOREMAT-NEXT: vle32.v v0, (a4)
+; NOREMAT-NEXT: vle32.v v6, (a4)
; NOREMAT-NEXT: sf.vc.vv 3, 0, v16, v26
; NOREMAT-NEXT: addiw a5, a2, -512
; NOREMAT-NEXT: add a4, a0, a5
; NOREMAT-NEXT: vle32.v v16, (a4)
; NOREMAT-NEXT: vle32.v v26, (a4)
; NOREMAT-NEXT: add a0, a0, a2
-; NOREMAT-NEXT: vle32.v v6, (a0)
+; NOREMAT-NEXT: vle32.v v0, (a0)
; NOREMAT-NEXT: sf.vc.vv 3, 0, v8, v10
; NOREMAT-NEXT: sf.vc.vv 3, 0, v24, v18
; NOREMAT-NEXT: sf.vc.vv 3, 0, v28, v20
; NOREMAT-NEXT: sf.vc.vv 3, 0, v30, v12
-; NOREMAT-NEXT: sf.vc.vv 3, 0, v2, v22
-; NOREMAT-NEXT: sf.vc.vv 3, 0, v4, v14
-; NOREMAT-NEXT: sf.vc.vv 3, 0, v0, v16
-; NOREMAT-NEXT: sf.vc.vv 3, 0, v26, v6
+; NOREMAT-NEXT: sf.vc.vv 3, 0, v4, v22
+; NOREMAT-NEXT: sf.vc.vv 3, 0, v2, v14
+; NOREMAT-NEXT: sf.vc.vv 3, 0, v6, v16
+; NOREMAT-NEXT: sf.vc.vv 3, 0, v26, v0
; NOREMAT-NEXT: sf.vc.v.i 2, 0, v8, 0
; NOREMAT-NEXT: addi a0, a1, 1024
; NOREMAT-NEXT: vse32.v v8, (a0)
@@ -952,17 +952,17 @@ define void @test(ptr %0, ptr %1, i64 %2) {
; REMAT-NEXT: li a2, 13
; REMAT-NEXT: slli a2, a2, 10
; REMAT-NEXT: add a2, a0, a2
-; REMAT-NEXT: vle32.v v0, (a2)
+; REMAT-NEXT: vle32.v v6, (a2)
; REMAT-NEXT: vle32.v v18, (a2)
; REMAT-NEXT: li a2, 27
; REMAT-NEXT: slli a2, a2, 9
; REMAT-NEXT: add a2, a0, a2
-; REMAT-NEXT: vle32.v v2, (a2)
+; REMAT-NEXT: vle32.v v4, (a2)
; REMAT-NEXT: vle32.v v20, (a2)
; REMAT-NEXT: li a2, 7
; REMAT-NEXT: slli a2, a2, 11
; REMAT-NEXT: add a2, a0, a2
-; REMAT-NEXT: vle32.v v4, (a2)
+; REMAT-NEXT: vle32.v v2, (a2)
; REMAT-NEXT: vle32.v v22, (a2)
; REMAT-NEXT: li a2, 29
; REMAT-NEXT: slli a2, a2, 9
@@ -986,23 +986,23 @@ define void @test(ptr %0, ptr %1, i64 %2) {
; REMAT-NEXT: add a2, a0, a2
; REMAT-NEXT: vle32.v v30, (a2)
; REMAT-NEXT: vle32.v v14, (a2)
-; REMAT-NEXT: sf.vc.vv 3, 0, v16, v0
+; REMAT-NEXT: sf.vc.vv 3, 0, v16, v6
; REMAT-NEXT: lui a2, 4
; REMAT-NEXT: addiw a2, a2, 512
; REMAT-NEXT: add a2, a0, a2
-; REMAT-NEXT: vle32.v v0, (a2)
+; REMAT-NEXT: vle32.v v6, (a2)
; REMAT-NEXT: vle32.v v16, (a2)
-; REMAT-NEXT: sf.vc.vv 3, 0, v18, v2
+; REMAT-NEXT: sf.vc.vv 3, 0, v18, v4
; REMAT-NEXT: li a2, 17
; REMAT-NEXT: slli a2, a2, 10
; REMAT-NEXT: add a2, a0, a2
-; REMAT-NEXT: vle32.v v2, (a2)
+; REMAT-NEXT: vle32.v v4, (a2)
; REMAT-NEXT: vle32.v v18, (a2)
-; REMAT-NEXT: sf.vc.vv 3, 0, v20, v4
+; REMAT-NEXT: sf.vc.vv 3, 0, v20, v2
; REMAT-NEXT: lui a2, 4
; REMAT-NEXT: addiw a2, a2, 1536
; REMAT-NEXT: add a2, a0, a2
-; REMAT-NEXT: vle32.v v4, (a2)
+; REMAT-NEXT: vle32.v v2, (a2)
; REMAT-NEXT: vle32.v v20, (a2)
; REMAT-NEXT: sf.vc.vv 3, 0, v22, v24
; REMAT-NEXT: li a2, 9
@@ -1028,22 +1028,22 @@ define void @test(ptr %0, ptr %1, i64 %2) {
; REMAT-NEXT: add a2, a0, ra
; REMAT-NEXT: vle32.v v30, (a2)
; REMAT-NEXT: vle32.v v12, (a2)
-; REMAT-NEXT: sf.vc.vv 3, 0, v14, v0
+; REMAT-NEXT: sf.vc.vv 3, 0, v14, v6
; REMAT-NEXT: lui s11, 5
; REMAT-NEXT: add a2, a0, s11
-; REMAT-NEXT: vle32.v v0, (a2)
+; REMAT-NEXT: vle32.v v6, (a2)
; REMAT-NEXT: vle32.v v14, (a2)
-; REMAT-NEXT: sf.vc.vv 3, 0, v16, v2
+; REMAT-NEXT: sf.vc.vv 3, 0, v16, v4
; REMAT-NEXT: lui s10, 5
; REMAT-NEXT: addiw s10, s10, 512
; REMAT-NEXT: add a2, a0, s10
-; REMAT-NEXT: vle32.v v2, (a2)
+; REMAT-NEXT: vle32.v v4, (a2)
; REMAT-NEXT: vle32.v v16, (a2)
-; REMAT-NEXT: sf.vc.vv 3, 0, v18, v4
+; REMAT-NEXT: sf.vc.vv 3, 0, v18, v2
; REMAT-NEXT: li s9, 21
; REMAT-NEXT: slli s9, s9, 10
; REMAT-NEXT: add a2, a0, s9
-; REMAT-NEXT: vle32.v v4, (a2)
+; REMAT-NEXT: vle32.v v2, (a2)
; REMAT-NEXT: vle32.v v18, (a2)
; REMAT-NEXT: sf.vc.vv 3, 0, v20, v24
; REMAT-NEXT: lui s8, 5
@@ -1069,28 +1069,28 @@ define void @test(ptr %0, ptr %1, i64 %2) {
; REMAT-NEXT: add a2, a0, s5
; REMAT-NEXT: vle32.v v30, (a2)
; REMAT-NEXT: vle32.v v10, (a2)
-; REMAT-NEXT: sf.vc.vv 3, 0, v12, v0
+; REMAT-NEXT: sf.vc.vv 3, 0, v12, v6
; REMAT-NEXT: lui s4, 6
; REMAT-NEXT: addiw s4, s4, -512
; REMAT-NEXT: add a2, a0, s4
-; REMAT-NEXT: vle32.v v0, (a2)
+; REMAT-NEXT: vle32.v v6, (a2)
; REMAT-NEXT: vle32.v v12, (a2)
-; REMAT-NEXT: sf.vc.vv 3, 0, v14, v2
+; REMAT-NEXT: sf.vc.vv 3, 0, v14, v4
; REMAT-NEXT: lui s3, 6
; REMAT-NEXT: add a2, a0, s3
-; REMAT-NEXT: vle32.v v2, (a2)
+; REMAT-NEXT: vle32.v v4, (a2)
; REMAT-NEXT: vle32.v v14, (a2)
-; REMAT-NEXT: sf.vc.vv 3, 0, v16, v4
+; REMAT-NEXT: sf.vc.vv 3, 0, v16, v2
; REMAT-NEXT: lui s2, 6
; REMAT-NEXT: addiw s2, s2, 512
; REMAT-NEXT: add a2, a0, s2
-; REMAT-NEXT: vle32.v v4, (a2)
+; REMAT-NEXT: vle32.v v2, (a2)
; REMAT-NEXT: vle32.v v16, (a2)
; REMAT-NEXT: sf.vc.vv 3, 0, v18, v24
; REMAT-NEXT: li s1, 25
; REMAT-NEXT: slli s1, s1, 10
; REMAT-NEXT: add a2, a0, s1
-; REMAT-NEXT: vle32.v v6, (a2)
+; REMAT-NEXT: vle32.v v0, (a2)
; REMAT-NEXT: vle32.v v18, (a2)
; REMAT-NEXT: sf.vc.vv 3, 0, v20, v26
; REMAT-NEXT: lui s0, 6
@@ -1110,24 +1110,24 @@ define void @test(ptr %0, ptr %1, i64 %2) {
; REMAT-NEXT: add a2, a0, t5
; REMAT-NEXT: vle32.v v30, (a2)
; REMAT-NEXT: vle32.v v24, (a2)
-; REMAT-NEXT: sf.vc.vv 3, 0, v10, v0
+; REMAT-NEXT: sf.vc.vv 3, 0, v10, v6
; REMAT-NEXT: li t4, 27
; REMAT-NEXT: slli t4, t4, 10
; REMAT-NEXT: add a2, a0, t4
-; REMAT-NEXT: vle32.v v0, (a2)
+; REMAT-NEXT: vle32.v v6, (a2)
; REMAT-NEXT: vle32.v v10, (a2)
-; REMAT-NEXT: sf.vc.vv 3, 0, v12, v2
+; REMAT-NEXT: sf.vc.vv 3, 0, v12, v4
; REMAT-NEXT: lui t3, 7
; REMAT-NEXT: addiw t3, t3, -512
; REMAT-NEXT: add a2, a0, t3
-; REMAT-NEXT: vle32.v v2, (a2)
+; REMAT-NEXT: vle32.v v4, (a2)
; REMAT-NEXT: vle32.v v12, (a2)
-; REMAT-NEXT: sf.vc.vv 3, 0, v14, v4
+; REMAT-NEXT: sf.vc.vv 3, 0, v14, v2
; REMAT-NEXT: lui t2, 7
; REMAT-NEXT: add a2, a0, t2
-; REMAT-NEXT: vle32.v v4, (a2)
+; REMAT-NEXT: vle32.v v2, (a2)
; REMAT-NEXT: vle32.v v8, (a2)
-; REMAT-NEXT: sf.vc.vv 3, 0, v16, v6
+; REMAT-NEXT: sf.vc.vv 3, 0, v16, v0
; REMAT-NEXT: lui t1, 7
; REMAT-NEXT: addiw t1, t1, 512
; REMAT-NEXT: add a2, a0, t1
@@ -1151,35 +1151,35 @@ define void @test(ptr %0, ptr %1, i64 %2) {
; REMAT-NEXT: add a2, a0, a6
; REMAT-NEXT: vle32.v v22, (a2)
; REMAT-NEXT: vle32.v v30, (a2)
-; REMAT-NEXT: sf.vc.vv 3, 0, v24, v0
+; REMAT-NEXT: sf.vc.vv 3, 0, v24, v6
; REMAT-NEXT: lui a5, 8
; REMAT-NEXT: addiw a5, a5, -1536
; REMAT-NEXT: add a2, a0, a5
; REMAT-NEXT: vle32.v v24, (a2)
-; REMAT-NEXT: vle32.v v0, (a2)
-; REMAT-NEXT: sf.vc.vv 3, 0, v10, v2
+; REMAT-NEXT: vle32.v v6, (a2)
+; REMAT-NEXT: sf.vc.vv 3, 0, v10, v4
; REMAT-NEXT: li a4, 31
; REMAT-NEXT: slli a4, a4, 10
; REMAT-NEXT: add a2, a0, a4
; REMAT-NEXT: vle32.v v10, (a2)
-; REMAT-NEXT: vle32.v v2, (a2)
-; REMAT-NEXT: sf.vc.vv 3, 0, v12, v4
+; REMAT-NEXT: vle32.v v4, (a2)
+; REMAT-NEXT: sf.vc.vv 3, 0, v12, v2
; REMAT-NEXT: lui a3, 8
; REMAT-NEXT: addiw a3, a3, -512
; REMAT-NEXT: add a2, a0, a3
; REMAT-NEXT: vle32.v v12, (a2)
-; REMAT-NEXT: vle32.v v4, (a2)
+; REMAT-NEXT: vle32.v v2, (a2)
; REMAT-NEXT: lui a2, 8
; REMAT-NEXT: add a0, a0, a2
-; REMAT-NEXT: vle32.v v6, (a0)
+; REMAT-NEXT: vle32.v v0, (a0)
; REMAT-NEXT: sf.vc.vv 3, 0, v8, v14
; REMAT-NEXT: sf.vc.vv 3, 0, v16, v18
; REMAT-NEXT: sf.vc.vv 3, 0, v26, v20
; REMAT-NEXT: sf.vc.vv 3, 0, v28, v22
; REMAT-NEXT: sf.vc.vv 3, 0, v30, v24
-; REMAT-NEXT: sf.vc.vv 3, 0, v0, v10
-; REMAT-NEXT: sf.vc.vv 3, 0, v2, v12
-; REMAT-NEXT: sf.vc.vv 3, 0, v4, v6
+; REMAT-NEXT: sf.vc.vv 3, 0, v6, v10
+; REMAT-NEXT: sf.vc.vv 3, 0, v4, v12
+; REMAT-NEXT: sf.vc.vv 3, 0, v2, v0
; REMAT-NEXT: sf.vc.v.i 2, 0, v8, 0
; REMAT-NEXT: addi a0, a1, 1024
; REMAT-NEXT: vse32.v v8, (a0)
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vector-i8-index-cornercase.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vector-i8-index-cornercase.ll
index be0c68f443af59..2874db6debd740 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vector-i8-index-cornercase.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vector-i8-index-cornercase.ll
@@ -148,17 +148,17 @@ define <512 x i8> @two_source(<512 x i8> %a, <512 x i8> %b) {
; CHECK-NEXT: vsetvli zero, a2, e64, m8, ta, ma
; CHECK-NEXT: vmv.v.x v24, a1
; CHECK-NEXT: vsetivli zero, 8, e64, m1, ta, ma
-; CHECK-NEXT: vmv.v.i v0, 0
+; CHECK-NEXT: vmv.v.i v7, 0
; CHECK-NEXT: lui a1, 1047552
; CHECK-NEXT: addiw a1, a1, 1
; CHECK-NEXT: slli a1, a1, 23
; CHECK-NEXT: addi a1, a1, 1
; CHECK-NEXT: slli a1, a1, 18
-; CHECK-NEXT: vslide1down.vx v0, v0, a1
+; CHECK-NEXT: vslide1down.vx v0, v7, a1
; CHECK-NEXT: lui a1, 4
-; CHECK-NEXT: vmv.s.x v1, a1
+; CHECK-NEXT: vmv.s.x v7, a1
; CHECK-NEXT: vsetivli zero, 7, e64, m1, tu, ma
-; CHECK-NEXT: vslideup.vi v0, v1, 6
+; CHECK-NEXT: vslideup.vi v0, v7, 6
; CHECK-NEXT: vsetvli zero, a0, e8, m8, ta, mu
; CHECK-NEXT: vrgather.vv v8, v16, v24, v0.t
; CHECK-NEXT: addi sp, s0, -1536
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-abs-vp.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-abs-vp.ll
index 2c2301bee468b0..c273dcdfbca17a 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-abs-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-abs-vp.ll
@@ -453,7 +453,7 @@ define <32 x i64> @vp_abs_v32i64(<32 x i64> %va, <32 x i1> %m, i32 zeroext %evl)
; CHECK: # %bb.0:
; CHECK-NEXT: vsetivli zero, 2, e8, mf4, ta, ma
; CHECK-NEXT: li a2, 16
-; CHECK-NEXT: vslidedown.vi v1, v0, 2
+; CHECK-NEXT: vslidedown.vi v7, v0, 2
; CHECK-NEXT: mv a1, a0
; CHECK-NEXT: bltu a0, a2, .LBB34_2
; CHECK-NEXT: # %bb.1:
@@ -467,7 +467,7 @@ define <32 x i64> @vp_abs_v32i64(<32 x i64> %va, <32 x i1> %m, i32 zeroext %evl)
; CHECK-NEXT: addi a0, a0, -1
; CHECK-NEXT: and a0, a0, a1
; CHECK-NEXT: vsetvli zero, a0, e64, m8, ta, ma
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vrsub.vi v24, v16, 0, v0.t
; CHECK-NEXT: vmax.vv v16, v16, v24, v0.t
; CHECK-NEXT: ret
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-ctpop-vp.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-ctpop-vp.ll
index 08f7e2058ad29e..c4162413859921 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-ctpop-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-ctpop-vp.ll
@@ -1535,7 +1535,7 @@ define <32 x i64> @vp_ctpop_v32i64(<32 x i64> %va, <32 x i1> %m, i32 zeroext %ev
; RV32-NEXT: addi a1, a1, 48
; RV32-NEXT: vs8r.v v16, (a1) # Unknown-size Folded Spill
; RV32-NEXT: vsetivli zero, 2, e8, mf4, ta, ma
-; RV32-NEXT: vslidedown.vi v1, v0, 2
+; RV32-NEXT: vslidedown.vi v7, v0, 2
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
; RV32-NEXT: sw a1, 44(sp)
@@ -1638,7 +1638,7 @@ define <32 x i64> @vp_ctpop_v32i64(<32 x i64> %va, <32 x i1> %m, i32 zeroext %ev
; RV32-NEXT: addi a0, a0, -1
; RV32-NEXT: and a0, a0, a2
; RV32-NEXT: vsetvli zero, a0, e64, m8, ta, ma
-; RV32-NEXT: vmv1r.v v0, v1
+; RV32-NEXT: vmv1r.v v0, v7
; RV32-NEXT: csrr a0, vlenb
; RV32-NEXT: li a2, 40
; RV32-NEXT: mul a0, a0, a2
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-fmaximum-vp.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-fmaximum-vp.ll
index 4a5ef21efdb968..3b7480117d375a 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-fmaximum-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-fmaximum-vp.ll
@@ -581,18 +581,18 @@ define <16 x double> @vfmax_vv_v16f64(<16 x double> %va, <16 x double> %vb, <16
; CHECK-NEXT: slli a1, a1, 3
; CHECK-NEXT: sub sp, sp, a1
; CHECK-NEXT: .cfi_escape 0x0f, 0x0d, 0x72, 0x00, 0x11, 0x10, 0x22, 0x11, 0x08, 0x92, 0xa2, 0x38, 0x00, 0x1e, 0x22 # sp + 16 + 8 * vlenb
-; CHECK-NEXT: vmv1r.v v1, v0
+; CHECK-NEXT: vmv1r.v v7, v0
; CHECK-NEXT: vsetvli zero, a0, e64, m8, ta, ma
; CHECK-NEXT: vmfeq.vv v25, v8, v8, v0.t
; CHECK-NEXT: vmv1r.v v0, v25
; CHECK-NEXT: vmerge.vvm v24, v8, v16, v0
; CHECK-NEXT: addi a0, sp, 16
; CHECK-NEXT: vs8r.v v24, (a0) # Unknown-size Folded Spill
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmfeq.vv v25, v16, v16, v0.t
; CHECK-NEXT: vmv1r.v v0, v25
; CHECK-NEXT: vmerge.vvm v8, v16, v8, v0
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vl8r.v v16, (a0) # Unknown-size Folded Reload
; CHECK-NEXT: vfmax.vv v8, v8, v16, v0.t
; CHECK-NEXT: csrr a0, vlenb
@@ -609,9 +609,9 @@ define <16 x double> @vfmax_vv_v16f64_unmasked(<16 x double> %va, <16 x double>
; CHECK: # %bb.0:
; CHECK-NEXT: vsetvli zero, a0, e64, m8, ta, ma
; CHECK-NEXT: vmfeq.vv v0, v8, v8
-; CHECK-NEXT: vmfeq.vv v1, v16, v16
+; CHECK-NEXT: vmfeq.vv v7, v16, v16
; CHECK-NEXT: vmerge.vvm v24, v8, v16, v0
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmerge.vvm v8, v16, v8, v0
; CHECK-NEXT: vfmax.vv v8, v8, v24
; CHECK-NEXT: ret
@@ -632,7 +632,7 @@ define <32 x double> @vfmax_vv_v32f64(<32 x double> %va, <32 x double> %vb, <32
; CHECK-NEXT: slli a1, a1, 5
; CHECK-NEXT: sub sp, sp, a1
; CHECK-NEXT: .cfi_escape 0x0f, 0x0d, 0x72, 0x00, 0x11, 0x10, 0x22, 0x11, 0x20, 0x92, 0xa2, 0x38, 0x00, 0x1e, 0x22 # sp + 16 + 32 * vlenb
-; CHECK-NEXT: vmv1r.v v2, v0
+; CHECK-NEXT: vmv1r.v v6, v0
; CHECK-NEXT: addi a1, a0, 128
; CHECK-NEXT: vsetivli zero, 16, e64, m8, ta, ma
; CHECK-NEXT: vle64.v v24, (a1)
@@ -643,7 +643,7 @@ define <32 x double> @vfmax_vv_v32f64(<32 x double> %va, <32 x double> %vb, <32
; CHECK-NEXT: addi a1, a1, 16
; CHECK-NEXT: vs8r.v v24, (a1) # Unknown-size Folded Spill
; CHECK-NEXT: vsetivli zero, 2, e8, mf4, ta, ma
-; CHECK-NEXT: vslidedown.vi v1, v0, 2
+; CHECK-NEXT: vslidedown.vi v7, v0, 2
; CHECK-NEXT: vsetivli zero, 16, e64, m8, ta, ma
; CHECK-NEXT: vle64.v v24, (a0)
; CHECK-NEXT: csrr a0, vlenb
@@ -663,7 +663,7 @@ define <32 x double> @vfmax_vv_v32f64(<32 x double> %va, <32 x double> %vb, <32
; CHECK-NEXT: li a0, 16
; CHECK-NEXT: .LBB24_2:
; CHECK-NEXT: vsetvli zero, a0, e64, m8, ta, ma
-; CHECK-NEXT: vmv1r.v v0, v2
+; CHECK-NEXT: vmv1r.v v0, v6
; CHECK-NEXT: vmfeq.vv v26, v8, v8, v0.t
; CHECK-NEXT: vmv1r.v v0, v26
; CHECK-NEXT: csrr a0, vlenb
@@ -674,11 +674,11 @@ define <32 x double> @vfmax_vv_v32f64(<32 x double> %va, <32 x double> %vb, <32
; CHECK-NEXT: vmerge.vvm v24, v8, v16, v0
; CHECK-NEXT: addi a0, sp, 16
; CHECK-NEXT: vs8r.v v24, (a0) # Unknown-size Folded Spill
-; CHECK-NEXT: vmv1r.v v0, v2
+; CHECK-NEXT: vmv1r.v v0, v6
; CHECK-NEXT: vmfeq.vv v26, v16, v16, v0.t
; CHECK-NEXT: vmv1r.v v0, v26
; CHECK-NEXT: vmerge.vvm v8, v16, v8, v0
-; CHECK-NEXT: vmv1r.v v0, v2
+; CHECK-NEXT: vmv1r.v v0, v6
; CHECK-NEXT: vl8r.v v16, (a0) # Unknown-size Folded Reload
; CHECK-NEXT: vfmax.vv v8, v8, v16, v0.t
; CHECK-NEXT: csrr a0, vlenb
@@ -691,7 +691,7 @@ define <32 x double> @vfmax_vv_v32f64(<32 x double> %va, <32 x double> %vb, <32
; CHECK-NEXT: addi a1, a1, -1
; CHECK-NEXT: and a0, a1, a0
; CHECK-NEXT: vsetvli zero, a0, e64, m8, ta, ma
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 3
; CHECK-NEXT: add a0, sp, a0
@@ -708,11 +708,11 @@ define <32 x double> @vfmax_vv_v32f64(<32 x double> %va, <32 x double> %vb, <32
; CHECK-NEXT: vmerge.vvm v24, v16, v8, v0
; CHECK-NEXT: addi a0, sp, 16
; CHECK-NEXT: vs8r.v v24, (a0) # Unknown-size Folded Spill
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmfeq.vv v25, v8, v8, v0.t
; CHECK-NEXT: vmv1r.v v0, v25
; CHECK-NEXT: vmerge.vvm v16, v8, v16, v0
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vl8r.v v8, (a0) # Unknown-size Folded Reload
; CHECK-NEXT: vfmax.vv v16, v16, v8, v0.t
; CHECK-NEXT: csrr a0, vlenb
@@ -758,7 +758,7 @@ define <32 x double> @vfmax_vv_v32f64_unmasked(<32 x double> %va, <32 x double>
; CHECK-NEXT: .LBB25_2:
; CHECK-NEXT: vsetvli zero, a0, e64, m8, ta, ma
; CHECK-NEXT: vmfeq.vv v0, v8, v8
-; CHECK-NEXT: vmfeq.vv v1, v24, v24
+; CHECK-NEXT: vmfeq.vv v7, v24, v24
; CHECK-NEXT: vmv8r.v v16, v24
; CHECK-NEXT: vmerge.vvm v24, v8, v24, v0
; CHECK-NEXT: csrr a0, vlenb
@@ -766,7 +766,7 @@ define <32 x double> @vfmax_vv_v32f64_unmasked(<32 x double> %va, <32 x double>
; CHECK-NEXT: add a0, sp, a0
; CHECK-NEXT: addi a0, a0, 16
; CHECK-NEXT: vs8r.v v24, (a0) # Unknown-size Folded Spill
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmerge.vvm v8, v16, v8, v0
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 3
@@ -792,9 +792,9 @@ define <32 x double> @vfmax_vv_v32f64_unmasked(<32 x double> %va, <32 x double>
; CHECK-NEXT: add a0, sp, a0
; CHECK-NEXT: addi a0, a0, 16
; CHECK-NEXT: vl8r.v v8, (a0) # Unknown-size Folded Reload
-; CHECK-NEXT: vmfeq.vv v1, v8, v8
+; CHECK-NEXT: vmfeq.vv v7, v8, v8
; CHECK-NEXT: vmerge.vvm v24, v16, v8, v0
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmerge.vvm v16, v8, v16, v0
; CHECK-NEXT: vfmax.vv v16, v16, v24
; CHECK-NEXT: csrr a0, vlenb
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-fmaximum.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-fmaximum.ll
index d0ba28fc30f4ee..02c2fafc89785f 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-fmaximum.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-fmaximum.ll
@@ -266,9 +266,9 @@ define <16 x double> @vfmax_v16f64_vv(<16 x double> %a, <16 x double> %b) nounwi
; CHECK: # %bb.0:
; CHECK-NEXT: vsetivli zero, 16, e64, m8, ta, ma
; CHECK-NEXT: vmfeq.vv v0, v8, v8
-; CHECK-NEXT: vmfeq.vv v1, v16, v16
+; CHECK-NEXT: vmfeq.vv v7, v16, v16
; CHECK-NEXT: vmerge.vvm v24, v8, v16, v0
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmerge.vvm v8, v16, v8, v0
; CHECK-NEXT: vfmax.vv v8, v8, v24
; CHECK-NEXT: ret
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-fminimum-vp.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-fminimum-vp.ll
index 8ea08bdedd6d34..57275df57a3113 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-fminimum-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-fminimum-vp.ll
@@ -581,18 +581,18 @@ define <16 x double> @vfmin_vv_v16f64(<16 x double> %va, <16 x double> %vb, <16
; CHECK-NEXT: slli a1, a1, 3
; CHECK-NEXT: sub sp, sp, a1
; CHECK-NEXT: .cfi_escape 0x0f, 0x0d, 0x72, 0x00, 0x11, 0x10, 0x22, 0x11, 0x08, 0x92, 0xa2, 0x38, 0x00, 0x1e, 0x22 # sp + 16 + 8 * vlenb
-; CHECK-NEXT: vmv1r.v v1, v0
+; CHECK-NEXT: vmv1r.v v7, v0
; CHECK-NEXT: vsetvli zero, a0, e64, m8, ta, ma
; CHECK-NEXT: vmfeq.vv v25, v8, v8, v0.t
; CHECK-NEXT: vmv1r.v v0, v25
; CHECK-NEXT: vmerge.vvm v24, v8, v16, v0
; CHECK-NEXT: addi a0, sp, 16
; CHECK-NEXT: vs8r.v v24, (a0) # Unknown-size Folded Spill
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmfeq.vv v25, v16, v16, v0.t
; CHECK-NEXT: vmv1r.v v0, v25
; CHECK-NEXT: vmerge.vvm v8, v16, v8, v0
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vl8r.v v16, (a0) # Unknown-size Folded Reload
; CHECK-NEXT: vfmin.vv v8, v8, v16, v0.t
; CHECK-NEXT: csrr a0, vlenb
@@ -609,9 +609,9 @@ define <16 x double> @vfmin_vv_v16f64_unmasked(<16 x double> %va, <16 x double>
; CHECK: # %bb.0:
; CHECK-NEXT: vsetvli zero, a0, e64, m8, ta, ma
; CHECK-NEXT: vmfeq.vv v0, v8, v8
-; CHECK-NEXT: vmfeq.vv v1, v16, v16
+; CHECK-NEXT: vmfeq.vv v7, v16, v16
; CHECK-NEXT: vmerge.vvm v24, v8, v16, v0
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmerge.vvm v8, v16, v8, v0
; CHECK-NEXT: vfmin.vv v8, v8, v24
; CHECK-NEXT: ret
@@ -632,7 +632,7 @@ define <32 x double> @vfmin_vv_v32f64(<32 x double> %va, <32 x double> %vb, <32
; CHECK-NEXT: slli a1, a1, 5
; CHECK-NEXT: sub sp, sp, a1
; CHECK-NEXT: .cfi_escape 0x0f, 0x0d, 0x72, 0x00, 0x11, 0x10, 0x22, 0x11, 0x20, 0x92, 0xa2, 0x38, 0x00, 0x1e, 0x22 # sp + 16 + 32 * vlenb
-; CHECK-NEXT: vmv1r.v v2, v0
+; CHECK-NEXT: vmv1r.v v6, v0
; CHECK-NEXT: addi a1, a0, 128
; CHECK-NEXT: vsetivli zero, 16, e64, m8, ta, ma
; CHECK-NEXT: vle64.v v24, (a1)
@@ -643,7 +643,7 @@ define <32 x double> @vfmin_vv_v32f64(<32 x double> %va, <32 x double> %vb, <32
; CHECK-NEXT: addi a1, a1, 16
; CHECK-NEXT: vs8r.v v24, (a1) # Unknown-size Folded Spill
; CHECK-NEXT: vsetivli zero, 2, e8, mf4, ta, ma
-; CHECK-NEXT: vslidedown.vi v1, v0, 2
+; CHECK-NEXT: vslidedown.vi v7, v0, 2
; CHECK-NEXT: vsetivli zero, 16, e64, m8, ta, ma
; CHECK-NEXT: vle64.v v24, (a0)
; CHECK-NEXT: csrr a0, vlenb
@@ -663,7 +663,7 @@ define <32 x double> @vfmin_vv_v32f64(<32 x double> %va, <32 x double> %vb, <32
; CHECK-NEXT: li a0, 16
; CHECK-NEXT: .LBB24_2:
; CHECK-NEXT: vsetvli zero, a0, e64, m8, ta, ma
-; CHECK-NEXT: vmv1r.v v0, v2
+; CHECK-NEXT: vmv1r.v v0, v6
; CHECK-NEXT: vmfeq.vv v26, v8, v8, v0.t
; CHECK-NEXT: vmv1r.v v0, v26
; CHECK-NEXT: csrr a0, vlenb
@@ -674,11 +674,11 @@ define <32 x double> @vfmin_vv_v32f64(<32 x double> %va, <32 x double> %vb, <32
; CHECK-NEXT: vmerge.vvm v24, v8, v16, v0
; CHECK-NEXT: addi a0, sp, 16
; CHECK-NEXT: vs8r.v v24, (a0) # Unknown-size Folded Spill
-; CHECK-NEXT: vmv1r.v v0, v2
+; CHECK-NEXT: vmv1r.v v0, v6
; CHECK-NEXT: vmfeq.vv v26, v16, v16, v0.t
; CHECK-NEXT: vmv1r.v v0, v26
; CHECK-NEXT: vmerge.vvm v8, v16, v8, v0
-; CHECK-NEXT: vmv1r.v v0, v2
+; CHECK-NEXT: vmv1r.v v0, v6
; CHECK-NEXT: vl8r.v v16, (a0) # Unknown-size Folded Reload
; CHECK-NEXT: vfmin.vv v8, v8, v16, v0.t
; CHECK-NEXT: csrr a0, vlenb
@@ -691,7 +691,7 @@ define <32 x double> @vfmin_vv_v32f64(<32 x double> %va, <32 x double> %vb, <32
; CHECK-NEXT: addi a1, a1, -1
; CHECK-NEXT: and a0, a1, a0
; CHECK-NEXT: vsetvli zero, a0, e64, m8, ta, ma
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 3
; CHECK-NEXT: add a0, sp, a0
@@ -708,11 +708,11 @@ define <32 x double> @vfmin_vv_v32f64(<32 x double> %va, <32 x double> %vb, <32
; CHECK-NEXT: vmerge.vvm v24, v16, v8, v0
; CHECK-NEXT: addi a0, sp, 16
; CHECK-NEXT: vs8r.v v24, (a0) # Unknown-size Folded Spill
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmfeq.vv v25, v8, v8, v0.t
; CHECK-NEXT: vmv1r.v v0, v25
; CHECK-NEXT: vmerge.vvm v16, v8, v16, v0
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vl8r.v v8, (a0) # Unknown-size Folded Reload
; CHECK-NEXT: vfmin.vv v16, v16, v8, v0.t
; CHECK-NEXT: csrr a0, vlenb
@@ -758,7 +758,7 @@ define <32 x double> @vfmin_vv_v32f64_unmasked(<32 x double> %va, <32 x double>
; CHECK-NEXT: .LBB25_2:
; CHECK-NEXT: vsetvli zero, a0, e64, m8, ta, ma
; CHECK-NEXT: vmfeq.vv v0, v8, v8
-; CHECK-NEXT: vmfeq.vv v1, v24, v24
+; CHECK-NEXT: vmfeq.vv v7, v24, v24
; CHECK-NEXT: vmv8r.v v16, v24
; CHECK-NEXT: vmerge.vvm v24, v8, v24, v0
; CHECK-NEXT: csrr a0, vlenb
@@ -766,7 +766,7 @@ define <32 x double> @vfmin_vv_v32f64_unmasked(<32 x double> %va, <32 x double>
; CHECK-NEXT: add a0, sp, a0
; CHECK-NEXT: addi a0, a0, 16
; CHECK-NEXT: vs8r.v v24, (a0) # Unknown-size Folded Spill
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmerge.vvm v8, v16, v8, v0
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 3
@@ -792,9 +792,9 @@ define <32 x double> @vfmin_vv_v32f64_unmasked(<32 x double> %va, <32 x double>
; CHECK-NEXT: add a0, sp, a0
; CHECK-NEXT: addi a0, a0, 16
; CHECK-NEXT: vl8r.v v8, (a0) # Unknown-size Folded Reload
-; CHECK-NEXT: vmfeq.vv v1, v8, v8
+; CHECK-NEXT: vmfeq.vv v7, v8, v8
; CHECK-NEXT: vmerge.vvm v24, v16, v8, v0
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmerge.vvm v16, v8, v16, v0
; CHECK-NEXT: vfmin.vv v16, v16, v24
; CHECK-NEXT: csrr a0, vlenb
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-fminimum.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-fminimum.ll
index 10e972963d4e49..b15d697f0754ed 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-fminimum.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-fminimum.ll
@@ -266,9 +266,9 @@ define <16 x double> @vfmin_v16f64_vv(<16 x double> %a, <16 x double> %b) nounwi
; CHECK: # %bb.0:
; CHECK-NEXT: vsetivli zero, 16, e64, m8, ta, ma
; CHECK-NEXT: vmfeq.vv v0, v8, v8
-; CHECK-NEXT: vmfeq.vv v1, v16, v16
+; CHECK-NEXT: vmfeq.vv v7, v16, v16
; CHECK-NEXT: vmerge.vvm v24, v8, v16, v0
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmerge.vvm v8, v16, v8, v0
; CHECK-NEXT: vfmin.vv v8, v8, v24
; CHECK-NEXT: ret
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-interleaved-access.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-interleaved-access.ll
index e27ff0a573d5f2..f98cb343a2ab42 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-interleaved-access.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-interleaved-access.ll
@@ -181,7 +181,7 @@ define {<8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>} @load_
; RV32-NEXT: addi a4, a4, 16
; RV32-NEXT: vs4r.v v8, (a4) # Unknown-size Folded Spill
; RV32-NEXT: lui a4, 12
-; RV32-NEXT: vmv.s.x v1, a4
+; RV32-NEXT: vmv.s.x v3, a4
; RV32-NEXT: vsetivli zero, 16, e32, m8, ta, ma
; RV32-NEXT: vslidedown.vi v16, v16, 16
; RV32-NEXT: csrr a4, vlenb
@@ -191,12 +191,12 @@ define {<8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>} @load_
; RV32-NEXT: addi a4, a4, 16
; RV32-NEXT: vs8r.v v16, (a4) # Unknown-size Folded Spill
; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, mu
-; RV32-NEXT: vmv1r.v v0, v1
+; RV32-NEXT: vmv1r.v v0, v3
; RV32-NEXT: csrr a4, vlenb
; RV32-NEXT: slli a4, a4, 2
; RV32-NEXT: add a4, sp, a4
; RV32-NEXT: addi a4, a4, 16
-; RV32-NEXT: vs1r.v v1, (a4) # Unknown-size Folded Spill
+; RV32-NEXT: vs1r.v v3, (a4) # Unknown-size Folded Spill
; RV32-NEXT: vslideup.vi v8, v16, 10, v0.t
; RV32-NEXT: csrr a4, vlenb
; RV32-NEXT: li a5, 20
@@ -271,7 +271,7 @@ define {<8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>} @load_
; RV32-NEXT: addi a1, a1, 16
; RV32-NEXT: vl8r.v v16, (a1) # Unknown-size Folded Reload
; RV32-NEXT: vslideup.vi v8, v16, 2
-; RV32-NEXT: vmv1r.v v0, v1
+; RV32-NEXT: vmv1r.v v0, v3
; RV32-NEXT: csrr a1, vlenb
; RV32-NEXT: li a3, 24
; RV32-NEXT: mul a1, a1, a3
@@ -339,8 +339,8 @@ define {<8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>} @load_
; RV32-NEXT: slli a1, a1, 2
; RV32-NEXT: add a1, sp, a1
; RV32-NEXT: addi a1, a1, 16
-; RV32-NEXT: vl1r.v v1, (a1) # Unknown-size Folded Reload
-; RV32-NEXT: vmv1r.v v0, v1
+; RV32-NEXT: vl1r.v v3, (a1) # Unknown-size Folded Reload
+; RV32-NEXT: vmv1r.v v0, v3
; RV32-NEXT: vslideup.vi v12, v16, 6, v0.t
; RV32-NEXT: vmv.v.v v4, v12
; RV32-NEXT: lui a1, %hi(.LCPI6_5)
@@ -394,7 +394,7 @@ define {<8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>} @load_
; RV32-NEXT: addi a1, a1, 16
; RV32-NEXT: vl8r.v v24, (a1) # Unknown-size Folded Reload
; RV32-NEXT: vrgatherei16.vv v28, v24, v8
-; RV32-NEXT: vmv1r.v v0, v1
+; RV32-NEXT: vmv1r.v v0, v3
; RV32-NEXT: csrr a1, vlenb
; RV32-NEXT: li a3, 24
; RV32-NEXT: mul a1, a1, a3
@@ -435,23 +435,23 @@ define {<8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>} @load_
; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, mu
; RV32-NEXT: lui a1, %hi(.LCPI6_10)
; RV32-NEXT: addi a1, a1, %lo(.LCPI6_10)
-; RV32-NEXT: vle16.v v2, (a1)
+; RV32-NEXT: vle16.v v4, (a1)
; RV32-NEXT: lui a1, 15
-; RV32-NEXT: vmv.s.x v5, a1
+; RV32-NEXT: vmv.s.x v6, a1
; RV32-NEXT: csrr a1, vlenb
; RV32-NEXT: slli a1, a1, 5
; RV32-NEXT: add a1, sp, a1
; RV32-NEXT: addi a1, a1, 16
; RV32-NEXT: vl8r.v v24, (a1) # Unknown-size Folded Reload
; RV32-NEXT: vslideup.vi v28, v24, 6
-; RV32-NEXT: vmv1r.v v0, v5
+; RV32-NEXT: vmv1r.v v0, v6
; RV32-NEXT: csrr a1, vlenb
; RV32-NEXT: li a3, 24
; RV32-NEXT: mul a1, a1, a3
; RV32-NEXT: add a1, sp, a1
; RV32-NEXT: addi a1, a1, 16
; RV32-NEXT: vl8r.v v8, (a1) # Unknown-size Folded Reload
-; RV32-NEXT: vrgatherei16.vv v28, v8, v2, v0.t
+; RV32-NEXT: vrgatherei16.vv v28, v8, v4, v0.t
; RV32-NEXT: lui a1, %hi(.LCPI6_11)
; RV32-NEXT: addi a1, a1, %lo(.LCPI6_11)
; RV32-NEXT: vsetvli zero, a2, e32, m8, ta, mu
@@ -460,12 +460,12 @@ define {<8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>} @load_
; RV32-NEXT: vle16.v v0, (a1)
; RV32-NEXT: vle16.v v24, (a3)
; RV32-NEXT: li a1, 1008
-; RV32-NEXT: vmv.s.x v4, a1
+; RV32-NEXT: vmv.s.x v7, a1
; RV32-NEXT: csrr a1, vlenb
; RV32-NEXT: slli a1, a1, 5
; RV32-NEXT: add a1, sp, a1
; RV32-NEXT: addi a1, a1, 16
-; RV32-NEXT: vs1r.v v4, (a1) # Unknown-size Folded Spill
+; RV32-NEXT: vs1r.v v7, (a1) # Unknown-size Folded Spill
; RV32-NEXT: csrr a1, vlenb
; RV32-NEXT: li a3, 40
; RV32-NEXT: mul a1, a1, a3
@@ -473,7 +473,7 @@ define {<8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>} @load_
; RV32-NEXT: addi a1, a1, 16
; RV32-NEXT: vl8r.v v16, (a1) # Unknown-size Folded Reload
; RV32-NEXT: vrgatherei16.vv v8, v16, v0
-; RV32-NEXT: vmv1r.v v0, v4
+; RV32-NEXT: vmv1r.v v0, v7
; RV32-NEXT: csrr a1, vlenb
; RV32-NEXT: li a3, 48
; RV32-NEXT: mul a1, a1, a3
@@ -487,7 +487,7 @@ define {<8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>} @load_
; RV32-NEXT: addi a1, a1, %lo(.LCPI6_13)
; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, mu
; RV32-NEXT: vle16.v v8, (a1)
-; RV32-NEXT: vmv1r.v v0, v5
+; RV32-NEXT: vmv1r.v v0, v6
; RV32-NEXT: csrr a1, vlenb
; RV32-NEXT: slli a1, a1, 4
; RV32-NEXT: add a1, sp, a1
@@ -617,25 +617,25 @@ define {<8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>} @load_
; RV64-NEXT: vsetivli zero, 8, e64, m4, ta, ma
; RV64-NEXT: vrgather.vi v8, v16, 4
; RV64-NEXT: li a1, 128
-; RV64-NEXT: vmv.s.x v4, a1
+; RV64-NEXT: vmv.s.x v0, a1
; RV64-NEXT: vsetivli zero, 8, e64, m8, ta, ma
; RV64-NEXT: vslidedown.vi v24, v16, 8
-; RV64-NEXT: csrr a1, vlenb
-; RV64-NEXT: li a2, 19
-; RV64-NEXT: mul a1, a1, a2
-; RV64-NEXT: add a1, sp, a1
-; RV64-NEXT: addi a1, a1, 16
-; RV64-NEXT: vs8r.v v24, (a1) # Unknown-size Folded Spill
; RV64-NEXT: vsetivli zero, 8, e64, m4, ta, mu
-; RV64-NEXT: vmv1r.v v0, v4
+; RV64-NEXT: vmv1r.v v28, v0
; RV64-NEXT: csrr a1, vlenb
; RV64-NEXT: slli a2, a1, 1
; RV64-NEXT: add a1, a2, a1
; RV64-NEXT: add a1, sp, a1
; RV64-NEXT: addi a1, a1, 16
-; RV64-NEXT: vs1r.v v4, (a1) # Unknown-size Folded Spill
+; RV64-NEXT: vs1r.v v0, (a1) # Unknown-size Folded Spill
; RV64-NEXT: vrgather.vi v8, v24, 2, v0.t
-; RV64-NEXT: vmv.v.v v20, v8
+; RV64-NEXT: csrr a1, vlenb
+; RV64-NEXT: li a2, 19
+; RV64-NEXT: mul a1, a1, a2
+; RV64-NEXT: add a1, sp, a1
+; RV64-NEXT: addi a1, a1, 16
+; RV64-NEXT: vs8r.v v24, (a1) # Unknown-size Folded Spill
+; RV64-NEXT: vmv.v.v v4, v8
; RV64-NEXT: vsetivli zero, 16, e16, m2, ta, ma
; RV64-NEXT: li a1, 6
; RV64-NEXT: vid.v v8
@@ -646,12 +646,12 @@ define {<8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>} @load_
; RV64-NEXT: mul a1, a1, a2
; RV64-NEXT: add a1, sp, a1
; RV64-NEXT: addi a1, a1, 16
-; RV64-NEXT: vl8r.v v24, (a1) # Unknown-size Folded Reload
-; RV64-NEXT: vrgatherei16.vv v8, v24, v2
+; RV64-NEXT: vl8r.v v16, (a1) # Unknown-size Folded Reload
+; RV64-NEXT: vrgatherei16.vv v8, v16, v2
; RV64-NEXT: vsetvli zero, zero, e16, m2, ta, ma
; RV64-NEXT: li a1, 56
; RV64-NEXT: vmv.s.x v1, a1
-; RV64-NEXT: vadd.vi v16, v2, -16
+; RV64-NEXT: vadd.vi v30, v2, -16
; RV64-NEXT: vsetvli zero, zero, e64, m8, ta, mu
; RV64-NEXT: vmv1r.v v0, v1
; RV64-NEXT: csrr a1, vlenb
@@ -659,16 +659,16 @@ define {<8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>} @load_
; RV64-NEXT: mul a1, a1, a2
; RV64-NEXT: add a1, sp, a1
; RV64-NEXT: addi a1, a1, 16
-; RV64-NEXT: vl8r.v v24, (a1) # Unknown-size Folded Reload
-; RV64-NEXT: vrgatherei16.vv v8, v24, v16, v0.t
+; RV64-NEXT: vl8r.v v16, (a1) # Unknown-size Folded Reload
+; RV64-NEXT: vrgatherei16.vv v8, v16, v30, v0.t
; RV64-NEXT: vsetivli zero, 6, e64, m4, tu, ma
-; RV64-NEXT: vmv.v.v v20, v8
+; RV64-NEXT: vmv.v.v v4, v8
; RV64-NEXT: csrr a1, vlenb
; RV64-NEXT: slli a2, a1, 4
; RV64-NEXT: sub a1, a2, a1
; RV64-NEXT: add a1, sp, a1
; RV64-NEXT: addi a1, a1, 16
-; RV64-NEXT: vs4r.v v20, (a1) # Unknown-size Folded Spill
+; RV64-NEXT: vs4r.v v4, (a1) # Unknown-size Folded Spill
; RV64-NEXT: vsetivli zero, 8, e64, m4, ta, mu
; RV64-NEXT: csrr a1, vlenb
; RV64-NEXT: li a2, 27
@@ -676,36 +676,29 @@ define {<8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>} @load_
; RV64-NEXT: add a1, sp, a1
; RV64-NEXT: addi a1, a1, 16
; RV64-NEXT: vl8r.v v16, (a1) # Unknown-size Folded Reload
-; RV64-NEXT: vrgather.vi v8, v16, 5
-; RV64-NEXT: vmv1r.v v0, v4
-; RV64-NEXT: csrr a1, vlenb
-; RV64-NEXT: li a2, 19
-; RV64-NEXT: mul a1, a1, a2
-; RV64-NEXT: add a1, sp, a1
-; RV64-NEXT: addi a1, a1, 16
-; RV64-NEXT: vl8r.v v16, (a1) # Unknown-size Folded Reload
-; RV64-NEXT: vrgather.vi v8, v16, 3, v0.t
-; RV64-NEXT: vmv.v.v v4, v8
+; RV64-NEXT: vrgather.vi v4, v16, 5
+; RV64-NEXT: vmv1r.v v0, v28
+; RV64-NEXT: vrgather.vi v4, v24, 3, v0.t
; RV64-NEXT: vsetivli zero, 16, e16, m2, ta, ma
; RV64-NEXT: addi a1, sp, 16
; RV64-NEXT: vs2r.v v2, (a1) # Unknown-size Folded Spill
-; RV64-NEXT: vadd.vi v24, v2, 1
+; RV64-NEXT: vadd.vi v16, v2, 1
; RV64-NEXT: vsetvli zero, zero, e64, m8, ta, ma
; RV64-NEXT: csrr a1, vlenb
; RV64-NEXT: li a2, 43
; RV64-NEXT: mul a1, a1, a2
; RV64-NEXT: add a1, sp, a1
; RV64-NEXT: addi a1, a1, 16
-; RV64-NEXT: vl8r.v v16, (a1) # Unknown-size Folded Reload
-; RV64-NEXT: vrgatherei16.vv v8, v16, v24
+; RV64-NEXT: vl8r.v v24, (a1) # Unknown-size Folded Reload
+; RV64-NEXT: vrgatherei16.vv v8, v24, v16
; RV64-NEXT: vsetvli zero, zero, e16, m2, ta, ma
-; RV64-NEXT: vadd.vi v24, v2, -15
+; RV64-NEXT: vadd.vi v16, v2, -15
; RV64-NEXT: csrr a1, vlenb
; RV64-NEXT: li a2, 11
; RV64-NEXT: mul a1, a1, a2
; RV64-NEXT: add a1, sp, a1
; RV64-NEXT: addi a1, a1, 16
-; RV64-NEXT: vs2r.v v24, (a1) # Unknown-size Folded Spill
+; RV64-NEXT: vs2r.v v16, (a1) # Unknown-size Folded Spill
; RV64-NEXT: vsetvli zero, zero, e64, m8, ta, mu
; RV64-NEXT: vmv1r.v v0, v1
; RV64-NEXT: csrr a1, vlenb
@@ -713,14 +706,14 @@ define {<8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>} @load_
; RV64-NEXT: mul a1, a1, a2
; RV64-NEXT: add a1, sp, a1
; RV64-NEXT: addi a1, a1, 16
-; RV64-NEXT: vl8r.v v24, (a1) # Unknown-size Folded Reload
+; RV64-NEXT: vl8r.v v16, (a1) # Unknown-size Folded Reload
; RV64-NEXT: csrr a1, vlenb
; RV64-NEXT: li a2, 11
; RV64-NEXT: mul a1, a1, a2
; RV64-NEXT: add a1, sp, a1
; RV64-NEXT: addi a1, a1, 16
; RV64-NEXT: vl2r.v v2, (a1) # Unknown-size Folded Reload
-; RV64-NEXT: vrgatherei16.vv v8, v24, v2, v0.t
+; RV64-NEXT: vrgatherei16.vv v8, v16, v2, v0.t
; RV64-NEXT: vsetivli zero, 6, e64, m4, tu, ma
; RV64-NEXT: vmv.v.v v4, v8
; RV64-NEXT: csrr a1, vlenb
@@ -732,16 +725,16 @@ define {<8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>} @load_
; RV64-NEXT: vsetivli zero, 16, e16, m2, ta, ma
; RV64-NEXT: addi a1, sp, 16
; RV64-NEXT: vl2r.v v2, (a1) # Unknown-size Folded Reload
-; RV64-NEXT: vadd.vi v4, v2, 2
+; RV64-NEXT: vadd.vi v6, v2, 2
; RV64-NEXT: vsetvli zero, zero, e64, m8, ta, ma
-; RV64-NEXT: vrgatherei16.vv v8, v16, v4
+; RV64-NEXT: vrgatherei16.vv v8, v24, v6
; RV64-NEXT: vsetvli zero, zero, e16, m2, ta, ma
; RV64-NEXT: li a1, 24
-; RV64-NEXT: vmv.s.x v4, a1
-; RV64-NEXT: vadd.vi v16, v2, -14
+; RV64-NEXT: vmv.s.x v7, a1
+; RV64-NEXT: vadd.vi v26, v2, -14
; RV64-NEXT: vsetvli zero, zero, e64, m8, ta, mu
-; RV64-NEXT: vmv1r.v v0, v4
-; RV64-NEXT: vrgatherei16.vv v8, v24, v16, v0.t
+; RV64-NEXT: vmv1r.v v0, v7
+; RV64-NEXT: vrgatherei16.vv v8, v16, v26, v0.t
; RV64-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV64-NEXT: vmv.v.i v12, 6
; RV64-NEXT: vsetivli zero, 8, e64, m4, ta, mu
@@ -750,16 +743,15 @@ define {<8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>} @load_
; RV64-NEXT: mul a1, a1, a2
; RV64-NEXT: add a1, sp, a1
; RV64-NEXT: addi a1, a1, 16
-; RV64-NEXT: vl8r.v v16, (a1) # Unknown-size Folded Reload
-; RV64-NEXT: vmv4r.v v24, v16
+; RV64-NEXT: vl8r.v v24, (a1) # Unknown-size Folded Reload
; RV64-NEXT: vrgatherei16.vv v16, v24, v12
; RV64-NEXT: csrr a1, vlenb
; RV64-NEXT: slli a2, a1, 1
; RV64-NEXT: add a1, a2, a1
; RV64-NEXT: add a1, sp, a1
; RV64-NEXT: addi a1, a1, 16
-; RV64-NEXT: vl1r.v v1, (a1) # Unknown-size Folded Reload
-; RV64-NEXT: vmv1r.v v0, v1
+; RV64-NEXT: vl1r.v v6, (a1) # Unknown-size Folded Reload
+; RV64-NEXT: vmv1r.v v0, v6
; RV64-NEXT: csrr a1, vlenb
; RV64-NEXT: li a2, 19
; RV64-NEXT: mul a1, a1, a2
@@ -786,16 +778,16 @@ define {<8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>} @load_
; RV64-NEXT: vl8r.v v16, (a1) # Unknown-size Folded Reload
; RV64-NEXT: vrgatherei16.vv v8, v16, v28
; RV64-NEXT: vsetvli zero, zero, e16, m2, ta, ma
-; RV64-NEXT: vadd.vi v16, v2, -13
+; RV64-NEXT: vadd.vi v28, v2, -13
; RV64-NEXT: vsetvli zero, zero, e64, m8, ta, mu
-; RV64-NEXT: vmv1r.v v0, v4
+; RV64-NEXT: vmv1r.v v0, v7
; RV64-NEXT: csrr a1, vlenb
; RV64-NEXT: li a2, 35
; RV64-NEXT: mul a1, a1, a2
; RV64-NEXT: add a1, sp, a1
; RV64-NEXT: addi a1, a1, 16
-; RV64-NEXT: vl8r.v v24, (a1) # Unknown-size Folded Reload
-; RV64-NEXT: vrgatherei16.vv v8, v24, v16, v0.t
+; RV64-NEXT: vl8r.v v16, (a1) # Unknown-size Folded Reload
+; RV64-NEXT: vrgatherei16.vv v8, v16, v28, v0.t
; RV64-NEXT: lui a1, 16
; RV64-NEXT: addi a1, a1, 7
; RV64-NEXT: vsetivli zero, 4, e32, m1, ta, ma
@@ -806,24 +798,24 @@ define {<8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>} @load_
; RV64-NEXT: mul a1, a1, a2
; RV64-NEXT: add a1, sp, a1
; RV64-NEXT: addi a1, a1, 16
-; RV64-NEXT: vl8r.v v16, (a1) # Unknown-size Folded Reload
-; RV64-NEXT: vrgatherei16.vv v24, v16, v12
-; RV64-NEXT: vmv1r.v v0, v1
+; RV64-NEXT: vl8r.v v24, (a1) # Unknown-size Folded Reload
+; RV64-NEXT: vrgatherei16.vv v16, v24, v12
+; RV64-NEXT: vmv1r.v v0, v6
; RV64-NEXT: csrr a1, vlenb
; RV64-NEXT: li a2, 19
; RV64-NEXT: mul a1, a1, a2
; RV64-NEXT: add a1, sp, a1
; RV64-NEXT: addi a1, a1, 16
-; RV64-NEXT: vl8r.v v16, (a1) # Unknown-size Folded Reload
-; RV64-NEXT: vrgather.vi v24, v16, 5, v0.t
+; RV64-NEXT: vl8r.v v24, (a1) # Unknown-size Folded Reload
+; RV64-NEXT: vrgather.vi v16, v24, 5, v0.t
; RV64-NEXT: vsetivli zero, 5, e64, m4, tu, ma
-; RV64-NEXT: vmv.v.v v24, v8
+; RV64-NEXT: vmv.v.v v16, v8
; RV64-NEXT: csrr a1, vlenb
; RV64-NEXT: slli a2, a1, 1
; RV64-NEXT: add a1, a2, a1
; RV64-NEXT: add a1, sp, a1
; RV64-NEXT: addi a1, a1, 16
-; RV64-NEXT: vs4r.v v24, (a1) # Unknown-size Folded Spill
+; RV64-NEXT: vs4r.v v16, (a1) # Unknown-size Folded Spill
; RV64-NEXT: lui a1, 96
; RV64-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV64-NEXT: vmv.v.x v8, a1
@@ -840,19 +832,19 @@ define {<8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>, <8 x i64>} @load_
; RV64-NEXT: mul a1, a1, a2
; RV64-NEXT: add a1, sp, a1
; RV64-NEXT: addi a1, a1, 16
-; RV64-NEXT: vl8r.v v24, (a1) # Unknown-size Folded Reload
-; RV64-NEXT: vrgather.vi v4, v24, 2
-; RV64-NEXT: vrgatherei16.vv v4, v16, v8, v0.t
+; RV64-NEXT: vl8r.v v16, (a1) # Unknown-size Folded Reload
+; RV64-NEXT: vrgather.vi v4, v16, 2
+; RV64-NEXT: vrgatherei16.vv v4, v24, v8, v0.t
; RV64-NEXT: vsetivli zero, 16, e16, m2, ta, ma
-; RV64-NEXT: vadd.vi v26, v2, 4
+; RV64-NEXT: vadd.vi v16, v2, 4
; RV64-NEXT: vsetvli zero, zero, e64, m8, ta, ma
; RV64-NEXT: csrr a1, vlenb
; RV64-NEXT: li a2, 43
; RV64-NEXT: mul a1, a1, a2
; RV64-NEXT: add a1, sp, a1
; RV64-NEXT: addi a1, a1, 16
-; RV64-NEXT: vl8r.v v16, (a1) # Unknown-size Folded Reload
-; RV64-NEXT: vrgatherei16.vv v8, v16, v26
+; RV64-NEXT: vl8r.v v24, (a1) # Unknown-size Folded Reload
+; RV64-NEXT: vrgatherei16.vv v8, v24, v16
; RV64-NEXT: vsetvli zero, zero, e16, m2, ta, ma
; RV64-NEXT: li a1, 28
; RV64-NEXT: vmv.s.x v1, a1
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-nearbyint-vp.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-nearbyint-vp.ll
index 5407eadb160bde..648fb785cf1512 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-nearbyint-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-nearbyint-vp.ll
@@ -606,7 +606,7 @@ define <32 x double> @vp_nearbyint_v32f64(<32 x double> %va, <32 x i1> %m, i32 z
; CHECK-NEXT: vs8r.v v16, (a1) # Unknown-size Folded Spill
; CHECK-NEXT: vsetivli zero, 2, e8, mf4, ta, ma
; CHECK-NEXT: li a2, 16
-; CHECK-NEXT: vslidedown.vi v1, v0, 2
+; CHECK-NEXT: vslidedown.vi v7, v0, 2
; CHECK-NEXT: mv a1, a0
; CHECK-NEXT: bltu a0, a2, .LBB26_2
; CHECK-NEXT: # %bb.1:
@@ -632,15 +632,15 @@ define <32 x double> @vp_nearbyint_v32f64(<32 x double> %va, <32 x i1> %m, i32 z
; CHECK-NEXT: addi a0, a0, -1
; CHECK-NEXT: and a0, a0, a1
; CHECK-NEXT: vsetvli zero, a0, e64, m8, ta, ma
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: addi a0, sp, 16
; CHECK-NEXT: vl8r.v v24, (a0) # Unknown-size Folded Reload
; CHECK-NEXT: vfabs.v v16, v24, v0.t
; CHECK-NEXT: vsetvli zero, zero, e64, m8, ta, mu
-; CHECK-NEXT: vmflt.vf v1, v16, fa5, v0.t
+; CHECK-NEXT: vmflt.vf v7, v16, fa5, v0.t
; CHECK-NEXT: frflags a0
; CHECK-NEXT: vsetvli zero, zero, e64, m8, ta, ma
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vfcvt.x.f.v v16, v24, v0.t
; CHECK-NEXT: vfcvt.f.x.v v16, v16, v0.t
; CHECK-NEXT: fsflags a0
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-reduction-fp.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-reduction-fp.ll
index d12bd651a10c0a..855e280164a25c 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-reduction-fp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-reduction-fp.ll
@@ -2002,11 +2002,11 @@ define float @vreduce_fminimum_v64f32(ptr %x) {
; CHECK-NEXT: vle32.v v16, (a0)
; CHECK-NEXT: vle32.v v24, (a1)
; CHECK-NEXT: vmfeq.vv v0, v16, v16
-; CHECK-NEXT: vmfeq.vv v1, v24, v24
+; CHECK-NEXT: vmfeq.vv v7, v24, v24
; CHECK-NEXT: vmerge.vvm v8, v16, v24, v0
; CHECK-NEXT: addi a0, sp, 16
; CHECK-NEXT: vs8r.v v8, (a0) # Unknown-size Folded Spill
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmerge.vvm v8, v24, v16, v0
; CHECK-NEXT: vl8r.v v16, (a0) # Unknown-size Folded Reload
; CHECK-NEXT: vfmin.vv v16, v8, v16
@@ -2177,14 +2177,14 @@ define float @vreduce_fminimum_v128f32(ptr %x) {
; CHECK-NEXT: addi a0, a0, 16
; CHECK-NEXT: vl8r.v v8, (a0) # Unknown-size Folded Reload
; CHECK-NEXT: vmfeq.vv v0, v8, v8
-; CHECK-NEXT: vmfeq.vv v1, v24, v24
+; CHECK-NEXT: vmfeq.vv v7, v24, v24
; CHECK-NEXT: vmerge.vvm v16, v8, v24, v0
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 3
; CHECK-NEXT: add a0, sp, a0
; CHECK-NEXT: addi a0, a0, 16
; CHECK-NEXT: vs8r.v v16, (a0) # Unknown-size Folded Spill
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmerge.vvm v24, v24, v8, v0
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 3
@@ -2195,14 +2195,14 @@ define float @vreduce_fminimum_v128f32(ptr %x) {
; CHECK-NEXT: vmfeq.vv v0, v24, v24
; CHECK-NEXT: addi a0, sp, 16
; CHECK-NEXT: vl8r.v v16, (a0) # Unknown-size Folded Reload
-; CHECK-NEXT: vmfeq.vv v1, v16, v16
+; CHECK-NEXT: vmfeq.vv v7, v16, v16
; CHECK-NEXT: vmerge.vvm v8, v24, v16, v0
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 4
; CHECK-NEXT: add a0, sp, a0
; CHECK-NEXT: addi a0, a0, 16
; CHECK-NEXT: vs8r.v v8, (a0) # Unknown-size Folded Spill
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmerge.vvm v8, v16, v24, v0
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 4
@@ -2627,11 +2627,11 @@ define double @vreduce_fminimum_v32f64(ptr %x) {
; CHECK-NEXT: vle64.v v16, (a0)
; CHECK-NEXT: vle64.v v24, (a1)
; CHECK-NEXT: vmfeq.vv v0, v16, v16
-; CHECK-NEXT: vmfeq.vv v1, v24, v24
+; CHECK-NEXT: vmfeq.vv v7, v24, v24
; CHECK-NEXT: vmerge.vvm v8, v16, v24, v0
; CHECK-NEXT: addi a0, sp, 16
; CHECK-NEXT: vs8r.v v8, (a0) # Unknown-size Folded Spill
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmerge.vvm v8, v24, v16, v0
; CHECK-NEXT: vl8r.v v16, (a0) # Unknown-size Folded Reload
; CHECK-NEXT: vfmin.vv v16, v8, v16
@@ -2782,14 +2782,14 @@ define double @vreduce_fminimum_v64f64(ptr %x) {
; CHECK-NEXT: addi a0, a0, 16
; CHECK-NEXT: vl8r.v v8, (a0) # Unknown-size Folded Reload
; CHECK-NEXT: vmfeq.vv v0, v8, v8
-; CHECK-NEXT: vmfeq.vv v1, v24, v24
+; CHECK-NEXT: vmfeq.vv v7, v24, v24
; CHECK-NEXT: vmerge.vvm v16, v8, v24, v0
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 3
; CHECK-NEXT: add a0, sp, a0
; CHECK-NEXT: addi a0, a0, 16
; CHECK-NEXT: vs8r.v v16, (a0) # Unknown-size Folded Spill
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmerge.vvm v24, v24, v8, v0
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 3
@@ -2800,14 +2800,14 @@ define double @vreduce_fminimum_v64f64(ptr %x) {
; CHECK-NEXT: vmfeq.vv v0, v24, v24
; CHECK-NEXT: addi a0, sp, 16
; CHECK-NEXT: vl8r.v v16, (a0) # Unknown-size Folded Reload
-; CHECK-NEXT: vmfeq.vv v1, v16, v16
+; CHECK-NEXT: vmfeq.vv v7, v16, v16
; CHECK-NEXT: vmerge.vvm v8, v24, v16, v0
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 4
; CHECK-NEXT: add a0, sp, a0
; CHECK-NEXT: addi a0, a0, 16
; CHECK-NEXT: vs8r.v v8, (a0) # Unknown-size Folded Spill
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmerge.vvm v8, v16, v24, v0
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 4
@@ -3330,11 +3330,11 @@ define float @vreduce_fmaximum_v64f32(ptr %x) {
; CHECK-NEXT: vle32.v v16, (a0)
; CHECK-NEXT: vle32.v v24, (a1)
; CHECK-NEXT: vmfeq.vv v0, v16, v16
-; CHECK-NEXT: vmfeq.vv v1, v24, v24
+; CHECK-NEXT: vmfeq.vv v7, v24, v24
; CHECK-NEXT: vmerge.vvm v8, v16, v24, v0
; CHECK-NEXT: addi a0, sp, 16
; CHECK-NEXT: vs8r.v v8, (a0) # Unknown-size Folded Spill
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmerge.vvm v8, v24, v16, v0
; CHECK-NEXT: vl8r.v v16, (a0) # Unknown-size Folded Reload
; CHECK-NEXT: vfmax.vv v16, v8, v16
@@ -3505,14 +3505,14 @@ define float @vreduce_fmaximum_v128f32(ptr %x) {
; CHECK-NEXT: addi a0, a0, 16
; CHECK-NEXT: vl8r.v v8, (a0) # Unknown-size Folded Reload
; CHECK-NEXT: vmfeq.vv v0, v8, v8
-; CHECK-NEXT: vmfeq.vv v1, v24, v24
+; CHECK-NEXT: vmfeq.vv v7, v24, v24
; CHECK-NEXT: vmerge.vvm v16, v8, v24, v0
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 3
; CHECK-NEXT: add a0, sp, a0
; CHECK-NEXT: addi a0, a0, 16
; CHECK-NEXT: vs8r.v v16, (a0) # Unknown-size Folded Spill
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmerge.vvm v24, v24, v8, v0
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 3
@@ -3523,14 +3523,14 @@ define float @vreduce_fmaximum_v128f32(ptr %x) {
; CHECK-NEXT: vmfeq.vv v0, v24, v24
; CHECK-NEXT: addi a0, sp, 16
; CHECK-NEXT: vl8r.v v16, (a0) # Unknown-size Folded Reload
-; CHECK-NEXT: vmfeq.vv v1, v16, v16
+; CHECK-NEXT: vmfeq.vv v7, v16, v16
; CHECK-NEXT: vmerge.vvm v8, v24, v16, v0
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 4
; CHECK-NEXT: add a0, sp, a0
; CHECK-NEXT: addi a0, a0, 16
; CHECK-NEXT: vs8r.v v8, (a0) # Unknown-size Folded Spill
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmerge.vvm v8, v16, v24, v0
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 4
@@ -3955,11 +3955,11 @@ define double @vreduce_fmaximum_v32f64(ptr %x) {
; CHECK-NEXT: vle64.v v16, (a0)
; CHECK-NEXT: vle64.v v24, (a1)
; CHECK-NEXT: vmfeq.vv v0, v16, v16
-; CHECK-NEXT: vmfeq.vv v1, v24, v24
+; CHECK-NEXT: vmfeq.vv v7, v24, v24
; CHECK-NEXT: vmerge.vvm v8, v16, v24, v0
; CHECK-NEXT: addi a0, sp, 16
; CHECK-NEXT: vs8r.v v8, (a0) # Unknown-size Folded Spill
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmerge.vvm v8, v24, v16, v0
; CHECK-NEXT: vl8r.v v16, (a0) # Unknown-size Folded Reload
; CHECK-NEXT: vfmax.vv v16, v8, v16
@@ -4110,14 +4110,14 @@ define double @vreduce_fmaximum_v64f64(ptr %x) {
; CHECK-NEXT: addi a0, a0, 16
; CHECK-NEXT: vl8r.v v8, (a0) # Unknown-size Folded Reload
; CHECK-NEXT: vmfeq.vv v0, v8, v8
-; CHECK-NEXT: vmfeq.vv v1, v24, v24
+; CHECK-NEXT: vmfeq.vv v7, v24, v24
; CHECK-NEXT: vmerge.vvm v16, v8, v24, v0
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 3
; CHECK-NEXT: add a0, sp, a0
; CHECK-NEXT: addi a0, a0, 16
; CHECK-NEXT: vs8r.v v16, (a0) # Unknown-size Folded Spill
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmerge.vvm v24, v24, v8, v0
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 3
@@ -4128,14 +4128,14 @@ define double @vreduce_fmaximum_v64f64(ptr %x) {
; CHECK-NEXT: vmfeq.vv v0, v24, v24
; CHECK-NEXT: addi a0, sp, 16
; CHECK-NEXT: vl8r.v v16, (a0) # Unknown-size Folded Reload
-; CHECK-NEXT: vmfeq.vv v1, v16, v16
+; CHECK-NEXT: vmfeq.vv v7, v16, v16
; CHECK-NEXT: vmerge.vvm v8, v24, v16, v0
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 4
; CHECK-NEXT: add a0, sp, a0
; CHECK-NEXT: addi a0, a0, 16
; CHECK-NEXT: vs8r.v v8, (a0) # Unknown-size Folded Spill
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmerge.vvm v8, v16, v24, v0
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 4
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-setcc-fp-vp.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-setcc-fp-vp.ll
index 2ff2529e259a8d..6ba90b00fdba56 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-setcc-fp-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-setcc-fp-vp.ll
@@ -1163,7 +1163,7 @@ define <128 x i1> @fcmp_oeq_vv_v128f16(<128 x half> %va, <128 x half> %vb, <128
; ZVFH32-NEXT: addi a0, sp, 16
; ZVFH32-NEXT: vs8r.v v24, (a0) # Unknown-size Folded Spill
; ZVFH32-NEXT: vsetivli zero, 8, e8, m1, ta, ma
-; ZVFH32-NEXT: vslidedown.vi v1, v0, 8
+; ZVFH32-NEXT: vslidedown.vi v7, v0, 8
; ZVFH32-NEXT: mv a0, a2
; ZVFH32-NEXT: bltu a2, a3, .LBB43_2
; ZVFH32-NEXT: # %bb.1:
@@ -1172,13 +1172,13 @@ define <128 x i1> @fcmp_oeq_vv_v128f16(<128 x half> %va, <128 x half> %vb, <128
; ZVFH32-NEXT: vsetvli zero, a0, e16, m8, ta, ma
; ZVFH32-NEXT: addi a0, sp, 16
; ZVFH32-NEXT: vl8r.v v24, (a0) # Unknown-size Folded Reload
-; ZVFH32-NEXT: vmfeq.vv v2, v8, v24, v0.t
+; ZVFH32-NEXT: vmfeq.vv v6, v8, v24, v0.t
; ZVFH32-NEXT: addi a0, a2, -64
; ZVFH32-NEXT: sltu a1, a2, a0
; ZVFH32-NEXT: addi a1, a1, -1
; ZVFH32-NEXT: and a0, a1, a0
; ZVFH32-NEXT: vsetvli zero, a0, e16, m8, ta, ma
-; ZVFH32-NEXT: vmv1r.v v0, v1
+; ZVFH32-NEXT: vmv1r.v v0, v7
; ZVFH32-NEXT: csrr a0, vlenb
; ZVFH32-NEXT: slli a0, a0, 3
; ZVFH32-NEXT: add a0, sp, a0
@@ -1186,8 +1186,8 @@ define <128 x i1> @fcmp_oeq_vv_v128f16(<128 x half> %va, <128 x half> %vb, <128
; ZVFH32-NEXT: vl8r.v v8, (a0) # Unknown-size Folded Reload
; ZVFH32-NEXT: vmfeq.vv v24, v16, v8, v0.t
; ZVFH32-NEXT: vsetivli zero, 16, e8, m1, ta, ma
-; ZVFH32-NEXT: vslideup.vi v2, v24, 8
-; ZVFH32-NEXT: vmv.v.v v0, v2
+; ZVFH32-NEXT: vslideup.vi v6, v24, 8
+; ZVFH32-NEXT: vmv.v.v v0, v6
; ZVFH32-NEXT: csrr a0, vlenb
; ZVFH32-NEXT: slli a0, a0, 4
; ZVFH32-NEXT: add sp, sp, a0
@@ -1216,7 +1216,7 @@ define <128 x i1> @fcmp_oeq_vv_v128f16(<128 x half> %va, <128 x half> %vb, <128
; ZVFH64-NEXT: vs8r.v v24, (a0) # Unknown-size Folded Spill
; ZVFH64-NEXT: vsetivli zero, 8, e8, m1, ta, ma
; ZVFH64-NEXT: mv a0, a2
-; ZVFH64-NEXT: vslidedown.vi v1, v0, 8
+; ZVFH64-NEXT: vslidedown.vi v7, v0, 8
; ZVFH64-NEXT: bltu a2, a3, .LBB43_2
; ZVFH64-NEXT: # %bb.1:
; ZVFH64-NEXT: li a0, 64
@@ -1224,13 +1224,13 @@ define <128 x i1> @fcmp_oeq_vv_v128f16(<128 x half> %va, <128 x half> %vb, <128
; ZVFH64-NEXT: vsetvli zero, a0, e16, m8, ta, ma
; ZVFH64-NEXT: addi a0, sp, 16
; ZVFH64-NEXT: vl8r.v v24, (a0) # Unknown-size Folded Reload
-; ZVFH64-NEXT: vmfeq.vv v2, v8, v24, v0.t
+; ZVFH64-NEXT: vmfeq.vv v6, v8, v24, v0.t
; ZVFH64-NEXT: addi a0, a2, -64
; ZVFH64-NEXT: sltu a1, a2, a0
; ZVFH64-NEXT: addi a1, a1, -1
; ZVFH64-NEXT: and a0, a1, a0
; ZVFH64-NEXT: vsetvli zero, a0, e16, m8, ta, ma
-; ZVFH64-NEXT: vmv1r.v v0, v1
+; ZVFH64-NEXT: vmv1r.v v0, v7
; ZVFH64-NEXT: csrr a0, vlenb
; ZVFH64-NEXT: slli a0, a0, 3
; ZVFH64-NEXT: add a0, sp, a0
@@ -1238,8 +1238,8 @@ define <128 x i1> @fcmp_oeq_vv_v128f16(<128 x half> %va, <128 x half> %vb, <128
; ZVFH64-NEXT: vl8r.v v8, (a0) # Unknown-size Folded Reload
; ZVFH64-NEXT: vmfeq.vv v24, v16, v8, v0.t
; ZVFH64-NEXT: vsetivli zero, 16, e8, m1, ta, ma
-; ZVFH64-NEXT: vslideup.vi v2, v24, 8
-; ZVFH64-NEXT: vmv.v.v v0, v2
+; ZVFH64-NEXT: vslideup.vi v6, v24, 8
+; ZVFH64-NEXT: vmv.v.v v0, v6
; ZVFH64-NEXT: csrr a0, vlenb
; ZVFH64-NEXT: slli a0, a0, 4
; ZVFH64-NEXT: add sp, sp, a0
@@ -2918,7 +2918,7 @@ define <32 x i1> @fcmp_oeq_vv_v32f64(<32 x double> %va, <32 x double> %vb, <32 x
; CHECK-NEXT: addi a1, a1, 16
; CHECK-NEXT: vs8r.v v24, (a1) # Unknown-size Folded Spill
; CHECK-NEXT: vsetivli zero, 2, e8, mf4, ta, ma
-; CHECK-NEXT: vslidedown.vi v1, v0, 2
+; CHECK-NEXT: vslidedown.vi v7, v0, 2
; CHECK-NEXT: vsetivli zero, 16, e64, m8, ta, ma
; CHECK-NEXT: vle64.v v24, (a0)
; CHECK-NEXT: addi a0, sp, 16
@@ -2932,13 +2932,13 @@ define <32 x i1> @fcmp_oeq_vv_v32f64(<32 x double> %va, <32 x double> %vb, <32 x
; CHECK-NEXT: vsetvli zero, a0, e64, m8, ta, ma
; CHECK-NEXT: addi a0, sp, 16
; CHECK-NEXT: vl8r.v v24, (a0) # Unknown-size Folded Reload
-; CHECK-NEXT: vmfeq.vv v2, v8, v24, v0.t
+; CHECK-NEXT: vmfeq.vv v6, v8, v24, v0.t
; CHECK-NEXT: addi a0, a2, -16
; CHECK-NEXT: sltu a1, a2, a0
; CHECK-NEXT: addi a1, a1, -1
; CHECK-NEXT: and a0, a1, a0
; CHECK-NEXT: vsetvli zero, a0, e64, m8, ta, ma
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 3
; CHECK-NEXT: add a0, sp, a0
@@ -2946,8 +2946,8 @@ define <32 x i1> @fcmp_oeq_vv_v32f64(<32 x double> %va, <32 x double> %vb, <32 x
; CHECK-NEXT: vl8r.v v8, (a0) # Unknown-size Folded Reload
; CHECK-NEXT: vmfeq.vv v24, v16, v8, v0.t
; CHECK-NEXT: vsetivli zero, 4, e8, mf4, ta, ma
-; CHECK-NEXT: vslideup.vi v2, v24, 2
-; CHECK-NEXT: vmv1r.v v0, v2
+; CHECK-NEXT: vslideup.vi v6, v24, 2
+; CHECK-NEXT: vmv1r.v v0, v6
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 4
; CHECK-NEXT: add sp, sp, a0
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-setcc-int-vp.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-setcc-int-vp.ll
index e558d45a3b2d73..8cf069e66e8f22 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-setcc-int-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-setcc-int-vp.ll
@@ -634,7 +634,7 @@ define <256 x i1> @icmp_eq_vv_v256i8(<256 x i8> %va, <256 x i8> %vb, <256 x i1>
; CHECK-NEXT: slli a1, a1, 4
; CHECK-NEXT: sub sp, sp, a1
; CHECK-NEXT: .cfi_escape 0x0f, 0x0d, 0x72, 0x00, 0x11, 0x10, 0x22, 0x11, 0x10, 0x92, 0xa2, 0x38, 0x00, 0x1e, 0x22 # sp + 16 + 16 * vlenb
-; CHECK-NEXT: vmv1r.v v1, v0
+; CHECK-NEXT: vmv1r.v v7, v0
; CHECK-NEXT: csrr a1, vlenb
; CHECK-NEXT: slli a1, a1, 3
; CHECK-NEXT: add a1, sp, a1
@@ -653,13 +653,13 @@ define <256 x i1> @icmp_eq_vv_v256i8(<256 x i8> %va, <256 x i8> %vb, <256 x i1>
; CHECK-NEXT: vs8r.v v24, (a0) # Unknown-size Folded Spill
; CHECK-NEXT: and a2, a4, a2
; CHECK-NEXT: vsetvli zero, a2, e8, m8, ta, ma
-; CHECK-NEXT: vmseq.vv v2, v16, v8, v0.t
+; CHECK-NEXT: vmseq.vv v6, v16, v8, v0.t
; CHECK-NEXT: bltu a3, a1, .LBB51_2
; CHECK-NEXT: # %bb.1:
; CHECK-NEXT: li a3, 128
; CHECK-NEXT: .LBB51_2:
; CHECK-NEXT: vsetvli zero, a3, e8, m8, ta, ma
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 3
; CHECK-NEXT: add a0, sp, a0
@@ -669,7 +669,7 @@ define <256 x i1> @icmp_eq_vv_v256i8(<256 x i8> %va, <256 x i8> %vb, <256 x i1>
; CHECK-NEXT: vl8r.v v24, (a0) # Unknown-size Folded Reload
; CHECK-NEXT: vmseq.vv v16, v8, v24, v0.t
; CHECK-NEXT: vmv1r.v v0, v16
-; CHECK-NEXT: vmv1r.v v8, v2
+; CHECK-NEXT: vmv1r.v v8, v6
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 4
; CHECK-NEXT: add sp, sp, a0
@@ -1336,7 +1336,7 @@ define <64 x i1> @icmp_eq_vv_v64i32(<64 x i32> %va, <64 x i32> %vb, <64 x i1> %m
; RV32-NEXT: addi a0, sp, 16
; RV32-NEXT: vs8r.v v24, (a0) # Unknown-size Folded Spill
; RV32-NEXT: vsetivli zero, 4, e8, mf2, ta, ma
-; RV32-NEXT: vslidedown.vi v1, v0, 4
+; RV32-NEXT: vslidedown.vi v7, v0, 4
; RV32-NEXT: mv a0, a2
; RV32-NEXT: bltu a2, a3, .LBB99_2
; RV32-NEXT: # %bb.1:
@@ -1345,13 +1345,13 @@ define <64 x i1> @icmp_eq_vv_v64i32(<64 x i32> %va, <64 x i32> %vb, <64 x i1> %m
; RV32-NEXT: vsetvli zero, a0, e32, m8, ta, ma
; RV32-NEXT: addi a0, sp, 16
; RV32-NEXT: vl8r.v v24, (a0) # Unknown-size Folded Reload
-; RV32-NEXT: vmseq.vv v2, v8, v24, v0.t
+; RV32-NEXT: vmseq.vv v6, v8, v24, v0.t
; RV32-NEXT: addi a0, a2, -32
; RV32-NEXT: sltu a1, a2, a0
; RV32-NEXT: addi a1, a1, -1
; RV32-NEXT: and a0, a1, a0
; RV32-NEXT: vsetvli zero, a0, e32, m8, ta, ma
-; RV32-NEXT: vmv1r.v v0, v1
+; RV32-NEXT: vmv1r.v v0, v7
; RV32-NEXT: csrr a0, vlenb
; RV32-NEXT: slli a0, a0, 3
; RV32-NEXT: add a0, sp, a0
@@ -1359,8 +1359,8 @@ define <64 x i1> @icmp_eq_vv_v64i32(<64 x i32> %va, <64 x i32> %vb, <64 x i1> %m
; RV32-NEXT: vl8r.v v8, (a0) # Unknown-size Folded Reload
; RV32-NEXT: vmseq.vv v24, v16, v8, v0.t
; RV32-NEXT: vsetivli zero, 8, e8, mf2, ta, ma
-; RV32-NEXT: vslideup.vi v2, v24, 4
-; RV32-NEXT: vmv1r.v v0, v2
+; RV32-NEXT: vslideup.vi v6, v24, 4
+; RV32-NEXT: vmv1r.v v0, v6
; RV32-NEXT: csrr a0, vlenb
; RV32-NEXT: slli a0, a0, 4
; RV32-NEXT: add sp, sp, a0
@@ -1389,7 +1389,7 @@ define <64 x i1> @icmp_eq_vv_v64i32(<64 x i32> %va, <64 x i32> %vb, <64 x i1> %m
; RV64-NEXT: vs8r.v v24, (a0) # Unknown-size Folded Spill
; RV64-NEXT: vsetivli zero, 4, e8, mf2, ta, ma
; RV64-NEXT: mv a0, a2
-; RV64-NEXT: vslidedown.vi v1, v0, 4
+; RV64-NEXT: vslidedown.vi v7, v0, 4
; RV64-NEXT: bltu a2, a3, .LBB99_2
; RV64-NEXT: # %bb.1:
; RV64-NEXT: li a0, 32
@@ -1397,13 +1397,13 @@ define <64 x i1> @icmp_eq_vv_v64i32(<64 x i32> %va, <64 x i32> %vb, <64 x i1> %m
; RV64-NEXT: vsetvli zero, a0, e32, m8, ta, ma
; RV64-NEXT: addi a0, sp, 16
; RV64-NEXT: vl8r.v v24, (a0) # Unknown-size Folded Reload
-; RV64-NEXT: vmseq.vv v2, v8, v24, v0.t
+; RV64-NEXT: vmseq.vv v6, v8, v24, v0.t
; RV64-NEXT: addi a0, a2, -32
; RV64-NEXT: sltu a1, a2, a0
; RV64-NEXT: addi a1, a1, -1
; RV64-NEXT: and a0, a1, a0
; RV64-NEXT: vsetvli zero, a0, e32, m8, ta, ma
-; RV64-NEXT: vmv1r.v v0, v1
+; RV64-NEXT: vmv1r.v v0, v7
; RV64-NEXT: csrr a0, vlenb
; RV64-NEXT: slli a0, a0, 3
; RV64-NEXT: add a0, sp, a0
@@ -1411,8 +1411,8 @@ define <64 x i1> @icmp_eq_vv_v64i32(<64 x i32> %va, <64 x i32> %vb, <64 x i1> %m
; RV64-NEXT: vl8r.v v8, (a0) # Unknown-size Folded Reload
; RV64-NEXT: vmseq.vv v24, v16, v8, v0.t
; RV64-NEXT: vsetivli zero, 8, e8, mf2, ta, ma
-; RV64-NEXT: vslideup.vi v2, v24, 4
-; RV64-NEXT: vmv1r.v v0, v2
+; RV64-NEXT: vslideup.vi v6, v24, 4
+; RV64-NEXT: vmv1r.v v0, v6
; RV64-NEXT: csrr a0, vlenb
; RV64-NEXT: slli a0, a0, 4
; RV64-NEXT: add sp, sp, a0
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-shuffle-concat.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-shuffle-concat.ll
index ce8827fe47536b..6a7ec6dc5bd7df 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-shuffle-concat.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-shuffle-concat.ll
@@ -103,12 +103,12 @@ define <16 x i32> @concat_8xv2i32(<2 x i32> %a, <2 x i32> %b, <2 x i32> %c, <2 x
; CHECK-NEXT: vmv1r.v v20, v14
; CHECK-NEXT: vmv1r.v v24, v13
; CHECK-NEXT: vmv1r.v v28, v11
-; CHECK-NEXT: vmv1r.v v0, v10
-; CHECK-NEXT: vmv1r.v v4, v9
+; CHECK-NEXT: vmv1r.v v4, v10
+; CHECK-NEXT: vmv1r.v v0, v9
; CHECK-NEXT: vsetivli zero, 4, e32, m4, tu, ma
-; CHECK-NEXT: vslideup.vi v8, v4, 2
+; CHECK-NEXT: vslideup.vi v8, v0, 2
; CHECK-NEXT: vsetivli zero, 6, e32, m4, tu, ma
-; CHECK-NEXT: vslideup.vi v8, v0, 4
+; CHECK-NEXT: vslideup.vi v8, v4, 4
; CHECK-NEXT: vsetivli zero, 8, e32, m4, tu, ma
; CHECK-NEXT: vslideup.vi v8, v28, 6
; CHECK-NEXT: vsetivli zero, 10, e32, m4, tu, ma
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-trunc-vp.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-trunc-vp.ll
index 34b0789d801a3c..e7b74737239154 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-trunc-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-trunc-vp.ll
@@ -230,7 +230,7 @@ define <128 x i32> @vtrunc_v128i32_v128i64(<128 x i64> %a, <128 x i1> %m, i32 ze
; CHECK-NEXT: slli a2, a2, 6
; CHECK-NEXT: sub sp, sp, a2
; CHECK-NEXT: .cfi_escape 0x0f, 0x0e, 0x72, 0x00, 0x11, 0x10, 0x22, 0x11, 0xc0, 0x00, 0x92, 0xa2, 0x38, 0x00, 0x1e, 0x22 # sp + 16 + 64 * vlenb
-; CHECK-NEXT: vmv1r.v v4, v0
+; CHECK-NEXT: vmv1r.v v7, v0
; CHECK-NEXT: csrr a2, vlenb
; CHECK-NEXT: slli a2, a2, 5
; CHECK-NEXT: add a2, sp, a2
@@ -243,7 +243,7 @@ define <128 x i32> @vtrunc_v128i32_v128i64(<128 x i64> %a, <128 x i1> %m, i32 ze
; CHECK-NEXT: addi a2, a2, 16
; CHECK-NEXT: vs8r.v v8, (a2) # Unknown-size Folded Spill
; CHECK-NEXT: vsetivli zero, 8, e8, m1, ta, ma
-; CHECK-NEXT: vslidedown.vi v1, v0, 8
+; CHECK-NEXT: vslidedown.vi v5, v0, 8
; CHECK-NEXT: vsetivli zero, 4, e8, mf2, ta, ma
; CHECK-NEXT: vslidedown.vi v26, v0, 4
; CHECK-NEXT: addi a2, a1, 512
@@ -256,7 +256,7 @@ define <128 x i32> @vtrunc_v128i32_v128i64(<128 x i64> %a, <128 x i1> %m, i32 ze
; CHECK-NEXT: addi a2, a2, 16
; CHECK-NEXT: vs8r.v v8, (a2) # Unknown-size Folded Spill
; CHECK-NEXT: vsetivli zero, 4, e8, mf2, ta, ma
-; CHECK-NEXT: vslidedown.vi v27, v1, 4
+; CHECK-NEXT: vslidedown.vi v27, v5, 4
; CHECK-NEXT: addi a2, a1, 640
; CHECK-NEXT: vsetivli zero, 16, e64, m8, ta, ma
; CHECK-NEXT: vle64.v v16, (a2)
@@ -346,7 +346,7 @@ define <128 x i32> @vtrunc_v128i32_v128i64(<128 x i64> %a, <128 x i1> %m, i32 ze
; CHECK-NEXT: li a6, 16
; CHECK-NEXT: .LBB16_6:
; CHECK-NEXT: vsetivli zero, 2, e8, mf4, ta, ma
-; CHECK-NEXT: vslidedown.vi v20, v1, 2
+; CHECK-NEXT: vslidedown.vi v20, v5, 2
; CHECK-NEXT: vsetivli zero, 16, e64, m8, ta, ma
; CHECK-NEXT: vle64.v v8, (a5)
; CHECK-NEXT: addi a1, a1, 256
@@ -382,9 +382,9 @@ define <128 x i32> @vtrunc_v128i32_v128i64(<128 x i64> %a, <128 x i1> %m, i32 ze
; CHECK-NEXT: li a4, 16
; CHECK-NEXT: .LBB16_10:
; CHECK-NEXT: vsetivli zero, 2, e8, mf4, ta, ma
-; CHECK-NEXT: vslidedown.vi v5, v4, 2
+; CHECK-NEXT: vslidedown.vi v6, v7, 2
; CHECK-NEXT: vsetvli zero, a4, e32, m4, ta, ma
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v5
; CHECK-NEXT: vnsrl.wi v8, v24, 0, v0.t
; CHECK-NEXT: vmv.v.v v0, v8
; CHECK-NEXT: bltu a7, a3, .LBB16_12
@@ -444,7 +444,7 @@ define <128 x i32> @vtrunc_v128i32_v128i64(<128 x i64> %a, <128 x i1> %m, i32 ze
; CHECK-NEXT: addi a4, a4, -1
; CHECK-NEXT: and a1, a4, a1
; CHECK-NEXT: vsetvli zero, a1, e32, m4, ta, ma
-; CHECK-NEXT: vmv1r.v v0, v5
+; CHECK-NEXT: vmv1r.v v0, v6
; CHECK-NEXT: csrr a1, vlenb
; CHECK-NEXT: slli a1, a1, 5
; CHECK-NEXT: add a1, sp, a1
@@ -456,7 +456,7 @@ define <128 x i32> @vtrunc_v128i32_v128i64(<128 x i64> %a, <128 x i1> %m, i32 ze
; CHECK-NEXT: li a7, 16
; CHECK-NEXT: .LBB16_14:
; CHECK-NEXT: vsetvli zero, a7, e32, m4, ta, ma
-; CHECK-NEXT: vmv1r.v v0, v4
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: csrr a1, vlenb
; CHECK-NEXT: li a2, 40
; CHECK-NEXT: mul a1, a1, a2
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vadd-vp.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vadd-vp.ll
index 6e8360869ddc64..e15253b67275cc 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vadd-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vadd-vp.ll
@@ -1529,7 +1529,7 @@ define <32 x i64> @vadd_vx_v32i64(<32 x i64> %va, <32 x i1> %m, i32 zeroext %evl
; RV32-LABEL: vadd_vx_v32i64:
; RV32: # %bb.0:
; RV32-NEXT: vsetivli zero, 2, e8, mf4, ta, ma
-; RV32-NEXT: vslidedown.vi v1, v0, 2
+; RV32-NEXT: vslidedown.vi v7, v0, 2
; RV32-NEXT: li a1, 32
; RV32-NEXT: vsetvli zero, a1, e32, m8, ta, ma
; RV32-NEXT: li a2, 16
@@ -1546,7 +1546,7 @@ define <32 x i64> @vadd_vx_v32i64(<32 x i64> %va, <32 x i1> %m, i32 zeroext %evl
; RV32-NEXT: addi a0, a0, -1
; RV32-NEXT: and a0, a0, a1
; RV32-NEXT: vsetvli zero, a0, e64, m8, ta, ma
-; RV32-NEXT: vmv1r.v v0, v1
+; RV32-NEXT: vmv1r.v v0, v7
; RV32-NEXT: vadd.vv v16, v16, v24, v0.t
; RV32-NEXT: ret
;
@@ -1650,14 +1650,14 @@ define <32 x i64> @vadd_vx_v32i64_evl27(<32 x i64> %va, <32 x i1> %m) {
; RV32-LABEL: vadd_vx_v32i64_evl27:
; RV32: # %bb.0:
; RV32-NEXT: vsetivli zero, 2, e8, mf4, ta, ma
-; RV32-NEXT: vslidedown.vi v1, v0, 2
+; RV32-NEXT: vslidedown.vi v7, v0, 2
; RV32-NEXT: li a0, 32
; RV32-NEXT: vsetvli zero, a0, e32, m8, ta, ma
; RV32-NEXT: vmv.v.i v24, -1
; RV32-NEXT: vsetivli zero, 16, e64, m8, ta, ma
; RV32-NEXT: vadd.vv v8, v8, v24, v0.t
; RV32-NEXT: vsetivli zero, 11, e64, m8, ta, ma
-; RV32-NEXT: vmv1r.v v0, v1
+; RV32-NEXT: vmv1r.v v0, v7
; RV32-NEXT: vadd.vv v16, v16, v24, v0.t
; RV32-NEXT: ret
;
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vcopysign-vp.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vcopysign-vp.ll
index f9b67b83f87239..f83968d54b2c98 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vcopysign-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vcopysign-vp.ll
@@ -333,7 +333,7 @@ define <32 x double> @vfsgnj_vv_v32f64(<32 x double> %va, <32 x double> %vb, <32
; CHECK-NEXT: addi a1, sp, 16
; CHECK-NEXT: vs8r.v v24, (a1) # Unknown-size Folded Spill
; CHECK-NEXT: vsetivli zero, 2, e8, mf4, ta, ma
-; CHECK-NEXT: vslidedown.vi v1, v0, 2
+; CHECK-NEXT: vslidedown.vi v7, v0, 2
; CHECK-NEXT: vsetivli zero, 16, e64, m8, ta, ma
; CHECK-NEXT: vle64.v v24, (a0)
; CHECK-NEXT: li a1, 16
@@ -349,7 +349,7 @@ define <32 x double> @vfsgnj_vv_v32f64(<32 x double> %va, <32 x double> %vb, <32
; CHECK-NEXT: addi a1, a1, -1
; CHECK-NEXT: and a0, a1, a0
; CHECK-NEXT: vsetvli zero, a0, e64, m8, ta, ma
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: addi a0, sp, 16
; CHECK-NEXT: vl8r.v v24, (a0) # Unknown-size Folded Reload
; CHECK-NEXT: vfsgnj.vv v16, v16, v24, v0.t
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vfma-vp.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vfma-vp.ll
index 65776339de07a5..d7b89ee054af8c 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vfma-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vfma-vp.ll
@@ -913,7 +913,7 @@ define <32 x double> @vfma_vv_v32f64(<32 x double> %va, <32 x double> %b, <32 x
; CHECK-NEXT: addi a1, a1, 16
; CHECK-NEXT: vs8r.v v24, (a1) # Unknown-size Folded Spill
; CHECK-NEXT: vsetivli zero, 2, e8, mf4, ta, ma
-; CHECK-NEXT: vslidedown.vi v1, v0, 2
+; CHECK-NEXT: vslidedown.vi v7, v0, 2
; CHECK-NEXT: vsetivli zero, 16, e64, m8, ta, ma
; CHECK-NEXT: vle64.v v24, (a2)
; CHECK-NEXT: addi a1, sp, 16
@@ -940,7 +940,7 @@ define <32 x double> @vfma_vv_v32f64(<32 x double> %va, <32 x double> %b, <32 x
; CHECK-NEXT: addi a1, a1, -1
; CHECK-NEXT: and a0, a1, a0
; CHECK-NEXT: vsetvli zero, a0, e64, m8, ta, ma
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: li a1, 24
; CHECK-NEXT: mul a0, a0, a1
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vfmax-vp.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vfmax-vp.ll
index ca033c26dba1f7..86218ddb04bd64 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vfmax-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vfmax-vp.ll
@@ -425,7 +425,7 @@ define <32 x double> @vfmax_vv_v32f64(<32 x double> %va, <32 x double> %vb, <32
; CHECK-NEXT: addi a1, sp, 16
; CHECK-NEXT: vs8r.v v24, (a1) # Unknown-size Folded Spill
; CHECK-NEXT: vsetivli zero, 2, e8, mf4, ta, ma
-; CHECK-NEXT: vslidedown.vi v1, v0, 2
+; CHECK-NEXT: vslidedown.vi v7, v0, 2
; CHECK-NEXT: vsetivli zero, 16, e64, m8, ta, ma
; CHECK-NEXT: vle64.v v24, (a0)
; CHECK-NEXT: li a1, 16
@@ -441,7 +441,7 @@ define <32 x double> @vfmax_vv_v32f64(<32 x double> %va, <32 x double> %vb, <32
; CHECK-NEXT: addi a1, a1, -1
; CHECK-NEXT: and a0, a1, a0
; CHECK-NEXT: vsetvli zero, a0, e64, m8, ta, ma
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: addi a0, sp, 16
; CHECK-NEXT: vl8r.v v24, (a0) # Unknown-size Folded Reload
; CHECK-NEXT: vfmax.vv v16, v16, v24, v0.t
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vfmin-vp.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vfmin-vp.ll
index 1f1efdaf1ee5ac..8b8049ea6c6289 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vfmin-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vfmin-vp.ll
@@ -425,7 +425,7 @@ define <32 x double> @vfmin_vv_v32f64(<32 x double> %va, <32 x double> %vb, <32
; CHECK-NEXT: addi a1, sp, 16
; CHECK-NEXT: vs8r.v v24, (a1) # Unknown-size Folded Spill
; CHECK-NEXT: vsetivli zero, 2, e8, mf4, ta, ma
-; CHECK-NEXT: vslidedown.vi v1, v0, 2
+; CHECK-NEXT: vslidedown.vi v7, v0, 2
; CHECK-NEXT: vsetivli zero, 16, e64, m8, ta, ma
; CHECK-NEXT: vle64.v v24, (a0)
; CHECK-NEXT: li a1, 16
@@ -441,7 +441,7 @@ define <32 x double> @vfmin_vv_v32f64(<32 x double> %va, <32 x double> %vb, <32
; CHECK-NEXT: addi a1, a1, -1
; CHECK-NEXT: and a0, a1, a0
; CHECK-NEXT: vsetvli zero, a0, e64, m8, ta, ma
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: addi a0, sp, 16
; CHECK-NEXT: vl8r.v v24, (a0) # Unknown-size Folded Reload
; CHECK-NEXT: vfmin.vv v16, v16, v24, v0.t
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vfmuladd-vp.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vfmuladd-vp.ll
index 28ab179048ca1b..4af566cb5f55ee 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vfmuladd-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vfmuladd-vp.ll
@@ -677,7 +677,7 @@ define <32 x double> @vfma_vv_v32f64(<32 x double> %va, <32 x double> %b, <32 x
; CHECK-NEXT: addi a1, a1, 16
; CHECK-NEXT: vs8r.v v24, (a1) # Unknown-size Folded Spill
; CHECK-NEXT: vsetivli zero, 2, e8, mf4, ta, ma
-; CHECK-NEXT: vslidedown.vi v1, v0, 2
+; CHECK-NEXT: vslidedown.vi v7, v0, 2
; CHECK-NEXT: vsetivli zero, 16, e64, m8, ta, ma
; CHECK-NEXT: vle64.v v24, (a2)
; CHECK-NEXT: addi a1, sp, 16
@@ -704,7 +704,7 @@ define <32 x double> @vfma_vv_v32f64(<32 x double> %va, <32 x double> %b, <32 x
; CHECK-NEXT: addi a1, a1, -1
; CHECK-NEXT: and a0, a1, a0
; CHECK-NEXT: vsetvli zero, a0, e64, m8, ta, ma
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: li a1, 24
; CHECK-NEXT: mul a0, a0, a1
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vmax-vp.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vmax-vp.ll
index e98a988c87678c..6af5ba185b8b8b 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vmax-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vmax-vp.ll
@@ -1092,7 +1092,7 @@ define <32 x i64> @vmax_vx_v32i64(<32 x i64> %va, <32 x i1> %m, i32 zeroext %evl
; RV32-LABEL: vmax_vx_v32i64:
; RV32: # %bb.0:
; RV32-NEXT: vsetivli zero, 2, e8, mf4, ta, ma
-; RV32-NEXT: vslidedown.vi v1, v0, 2
+; RV32-NEXT: vslidedown.vi v7, v0, 2
; RV32-NEXT: li a1, 32
; RV32-NEXT: vsetvli zero, a1, e32, m8, ta, ma
; RV32-NEXT: li a2, 16
@@ -1109,7 +1109,7 @@ define <32 x i64> @vmax_vx_v32i64(<32 x i64> %va, <32 x i1> %m, i32 zeroext %evl
; RV32-NEXT: addi a0, a0, -1
; RV32-NEXT: and a0, a0, a1
; RV32-NEXT: vsetvli zero, a0, e64, m8, ta, ma
-; RV32-NEXT: vmv1r.v v0, v1
+; RV32-NEXT: vmv1r.v v0, v7
; RV32-NEXT: vmax.vv v16, v16, v24, v0.t
; RV32-NEXT: ret
;
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vmaxu-vp.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vmaxu-vp.ll
index cc33b40c43a85e..12c6410068c693 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vmaxu-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vmaxu-vp.ll
@@ -1091,7 +1091,7 @@ define <32 x i64> @vmaxu_vx_v32i64(<32 x i64> %va, <32 x i1> %m, i32 zeroext %ev
; RV32-LABEL: vmaxu_vx_v32i64:
; RV32: # %bb.0:
; RV32-NEXT: vsetivli zero, 2, e8, mf4, ta, ma
-; RV32-NEXT: vslidedown.vi v1, v0, 2
+; RV32-NEXT: vslidedown.vi v7, v0, 2
; RV32-NEXT: li a1, 32
; RV32-NEXT: vsetvli zero, a1, e32, m8, ta, ma
; RV32-NEXT: li a2, 16
@@ -1108,7 +1108,7 @@ define <32 x i64> @vmaxu_vx_v32i64(<32 x i64> %va, <32 x i1> %m, i32 zeroext %ev
; RV32-NEXT: addi a0, a0, -1
; RV32-NEXT: and a0, a0, a1
; RV32-NEXT: vsetvli zero, a0, e64, m8, ta, ma
-; RV32-NEXT: vmv1r.v v0, v1
+; RV32-NEXT: vmv1r.v v0, v7
; RV32-NEXT: vmaxu.vv v16, v16, v24, v0.t
; RV32-NEXT: ret
;
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vmin-vp.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vmin-vp.ll
index 512b7941481fe6..f5b9421d28c349 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vmin-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vmin-vp.ll
@@ -1092,7 +1092,7 @@ define <32 x i64> @vmin_vx_v32i64(<32 x i64> %va, <32 x i1> %m, i32 zeroext %evl
; RV32-LABEL: vmin_vx_v32i64:
; RV32: # %bb.0:
; RV32-NEXT: vsetivli zero, 2, e8, mf4, ta, ma
-; RV32-NEXT: vslidedown.vi v1, v0, 2
+; RV32-NEXT: vslidedown.vi v7, v0, 2
; RV32-NEXT: li a1, 32
; RV32-NEXT: vsetvli zero, a1, e32, m8, ta, ma
; RV32-NEXT: li a2, 16
@@ -1109,7 +1109,7 @@ define <32 x i64> @vmin_vx_v32i64(<32 x i64> %va, <32 x i1> %m, i32 zeroext %evl
; RV32-NEXT: addi a0, a0, -1
; RV32-NEXT: and a0, a0, a1
; RV32-NEXT: vsetvli zero, a0, e64, m8, ta, ma
-; RV32-NEXT: vmv1r.v v0, v1
+; RV32-NEXT: vmv1r.v v0, v7
; RV32-NEXT: vmin.vv v16, v16, v24, v0.t
; RV32-NEXT: ret
;
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vminu-vp.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vminu-vp.ll
index 993b0364b07f4f..d07580efceb50b 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vminu-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vminu-vp.ll
@@ -1091,7 +1091,7 @@ define <32 x i64> @vminu_vx_v32i64(<32 x i64> %va, <32 x i1> %m, i32 zeroext %ev
; RV32-LABEL: vminu_vx_v32i64:
; RV32: # %bb.0:
; RV32-NEXT: vsetivli zero, 2, e8, mf4, ta, ma
-; RV32-NEXT: vslidedown.vi v1, v0, 2
+; RV32-NEXT: vslidedown.vi v7, v0, 2
; RV32-NEXT: li a1, 32
; RV32-NEXT: vsetvli zero, a1, e32, m8, ta, ma
; RV32-NEXT: li a2, 16
@@ -1108,7 +1108,7 @@ define <32 x i64> @vminu_vx_v32i64(<32 x i64> %va, <32 x i1> %m, i32 zeroext %ev
; RV32-NEXT: addi a0, a0, -1
; RV32-NEXT: and a0, a0, a1
; RV32-NEXT: vsetvli zero, a0, e64, m8, ta, ma
-; RV32-NEXT: vmv1r.v v0, v1
+; RV32-NEXT: vmv1r.v v0, v7
; RV32-NEXT: vminu.vv v16, v16, v24, v0.t
; RV32-NEXT: ret
;
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vpgather.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vpgather.ll
index beff4157b14bba..4d2f55b172e48d 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vpgather.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vpgather.ll
@@ -2460,7 +2460,7 @@ define <32 x double> @vpgather_baseidx_zext_v32i32_v32f64(ptr %base, <32 x i32>
define <32 x double> @vpgather_baseidx_v32f64(ptr %base, <32 x i64> %idxs, <32 x i1> %m, i32 zeroext %evl) {
; RV32-LABEL: vpgather_baseidx_v32f64:
; RV32: # %bb.0:
-; RV32-NEXT: vmv1r.v v1, v0
+; RV32-NEXT: vmv1r.v v7, v0
; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vnsrl.wi v24, v16, 0
; RV32-NEXT: vnsrl.wi v16, v8, 0
@@ -2484,7 +2484,7 @@ define <32 x double> @vpgather_baseidx_v32f64(ptr %base, <32 x i64> %idxs, <32 x
; RV32-NEXT: li a1, 16
; RV32-NEXT: .LBB96_2:
; RV32-NEXT: vsetvli zero, a1, e64, m8, ta, ma
-; RV32-NEXT: vmv1r.v v0, v1
+; RV32-NEXT: vmv1r.v v0, v7
; RV32-NEXT: vluxei32.v v8, (a0), v24, v0.t
; RV32-NEXT: ret
;
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vsadd-vp.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vsadd-vp.ll
index 6c5dd0403dff17..d7ed20f4e09868 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vsadd-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vsadd-vp.ll
@@ -1542,7 +1542,7 @@ define <32 x i64> @vsadd_vx_v32i64(<32 x i64> %va, <32 x i1> %m, i32 zeroext %ev
; RV32-LABEL: vsadd_vx_v32i64:
; RV32: # %bb.0:
; RV32-NEXT: vsetivli zero, 2, e8, mf4, ta, ma
-; RV32-NEXT: vslidedown.vi v1, v0, 2
+; RV32-NEXT: vslidedown.vi v7, v0, 2
; RV32-NEXT: li a1, 32
; RV32-NEXT: vsetvli zero, a1, e32, m8, ta, ma
; RV32-NEXT: li a2, 16
@@ -1559,7 +1559,7 @@ define <32 x i64> @vsadd_vx_v32i64(<32 x i64> %va, <32 x i1> %m, i32 zeroext %ev
; RV32-NEXT: addi a0, a0, -1
; RV32-NEXT: and a0, a0, a1
; RV32-NEXT: vsetvli zero, a0, e64, m8, ta, ma
-; RV32-NEXT: vmv1r.v v0, v1
+; RV32-NEXT: vmv1r.v v0, v7
; RV32-NEXT: vsadd.vv v16, v16, v24, v0.t
; RV32-NEXT: ret
;
@@ -1642,14 +1642,14 @@ define <32 x i64> @vsadd_vx_v32i64_evl12(<32 x i64> %va, <32 x i1> %m) {
; RV32-LABEL: vsadd_vx_v32i64_evl12:
; RV32: # %bb.0:
; RV32-NEXT: vsetivli zero, 2, e8, mf4, ta, ma
-; RV32-NEXT: vslidedown.vi v1, v0, 2
+; RV32-NEXT: vslidedown.vi v7, v0, 2
; RV32-NEXT: li a0, 32
; RV32-NEXT: vsetvli zero, a0, e32, m8, ta, ma
; RV32-NEXT: vmv.v.i v24, -1
; RV32-NEXT: vsetivli zero, 12, e64, m8, ta, ma
; RV32-NEXT: vsadd.vv v8, v8, v24, v0.t
; RV32-NEXT: vsetivli zero, 0, e64, m8, ta, ma
-; RV32-NEXT: vmv1r.v v0, v1
+; RV32-NEXT: vmv1r.v v0, v7
; RV32-NEXT: vsadd.vv v16, v16, v24, v0.t
; RV32-NEXT: ret
;
@@ -1673,14 +1673,14 @@ define <32 x i64> @vsadd_vx_v32i64_evl27(<32 x i64> %va, <32 x i1> %m) {
; RV32-LABEL: vsadd_vx_v32i64_evl27:
; RV32: # %bb.0:
; RV32-NEXT: vsetivli zero, 2, e8, mf4, ta, ma
-; RV32-NEXT: vslidedown.vi v1, v0, 2
+; RV32-NEXT: vslidedown.vi v7, v0, 2
; RV32-NEXT: li a0, 32
; RV32-NEXT: vsetvli zero, a0, e32, m8, ta, ma
; RV32-NEXT: vmv.v.i v24, -1
; RV32-NEXT: vsetivli zero, 16, e64, m8, ta, ma
; RV32-NEXT: vsadd.vv v8, v8, v24, v0.t
; RV32-NEXT: vsetivli zero, 11, e64, m8, ta, ma
-; RV32-NEXT: vmv1r.v v0, v1
+; RV32-NEXT: vmv1r.v v0, v7
; RV32-NEXT: vsadd.vv v16, v16, v24, v0.t
; RV32-NEXT: ret
;
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vsaddu-vp.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vsaddu-vp.ll
index 6227f8abe599e4..ea248010ef09a1 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vsaddu-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vsaddu-vp.ll
@@ -1538,7 +1538,7 @@ define <32 x i64> @vsaddu_vx_v32i64(<32 x i64> %va, <32 x i1> %m, i32 zeroext %e
; RV32-LABEL: vsaddu_vx_v32i64:
; RV32: # %bb.0:
; RV32-NEXT: vsetivli zero, 2, e8, mf4, ta, ma
-; RV32-NEXT: vslidedown.vi v1, v0, 2
+; RV32-NEXT: vslidedown.vi v7, v0, 2
; RV32-NEXT: li a1, 32
; RV32-NEXT: vsetvli zero, a1, e32, m8, ta, ma
; RV32-NEXT: li a2, 16
@@ -1555,7 +1555,7 @@ define <32 x i64> @vsaddu_vx_v32i64(<32 x i64> %va, <32 x i1> %m, i32 zeroext %e
; RV32-NEXT: addi a0, a0, -1
; RV32-NEXT: and a0, a0, a1
; RV32-NEXT: vsetvli zero, a0, e64, m8, ta, ma
-; RV32-NEXT: vmv1r.v v0, v1
+; RV32-NEXT: vmv1r.v v0, v7
; RV32-NEXT: vsaddu.vv v16, v16, v24, v0.t
; RV32-NEXT: ret
;
@@ -1638,14 +1638,14 @@ define <32 x i64> @vsaddu_vx_v32i64_evl12(<32 x i64> %va, <32 x i1> %m) {
; RV32-LABEL: vsaddu_vx_v32i64_evl12:
; RV32: # %bb.0:
; RV32-NEXT: vsetivli zero, 2, e8, mf4, ta, ma
-; RV32-NEXT: vslidedown.vi v1, v0, 2
+; RV32-NEXT: vslidedown.vi v7, v0, 2
; RV32-NEXT: li a0, 32
; RV32-NEXT: vsetvli zero, a0, e32, m8, ta, ma
; RV32-NEXT: vmv.v.i v24, -1
; RV32-NEXT: vsetivli zero, 12, e64, m8, ta, ma
; RV32-NEXT: vsaddu.vv v8, v8, v24, v0.t
; RV32-NEXT: vsetivli zero, 0, e64, m8, ta, ma
-; RV32-NEXT: vmv1r.v v0, v1
+; RV32-NEXT: vmv1r.v v0, v7
; RV32-NEXT: vsaddu.vv v16, v16, v24, v0.t
; RV32-NEXT: ret
;
@@ -1669,14 +1669,14 @@ define <32 x i64> @vsaddu_vx_v32i64_evl27(<32 x i64> %va, <32 x i1> %m) {
; RV32-LABEL: vsaddu_vx_v32i64_evl27:
; RV32: # %bb.0:
; RV32-NEXT: vsetivli zero, 2, e8, mf4, ta, ma
-; RV32-NEXT: vslidedown.vi v1, v0, 2
+; RV32-NEXT: vslidedown.vi v7, v0, 2
; RV32-NEXT: li a0, 32
; RV32-NEXT: vsetvli zero, a0, e32, m8, ta, ma
; RV32-NEXT: vmv.v.i v24, -1
; RV32-NEXT: vsetivli zero, 16, e64, m8, ta, ma
; RV32-NEXT: vsaddu.vv v8, v8, v24, v0.t
; RV32-NEXT: vsetivli zero, 11, e64, m8, ta, ma
-; RV32-NEXT: vmv1r.v v0, v1
+; RV32-NEXT: vmv1r.v v0, v7
; RV32-NEXT: vsaddu.vv v16, v16, v24, v0.t
; RV32-NEXT: ret
;
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vssub-vp.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vssub-vp.ll
index 6360cf49d8d478..32b8d10d87173d 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vssub-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vssub-vp.ll
@@ -1582,7 +1582,7 @@ define <32 x i64> @vssub_vx_v32i64(<32 x i64> %va, <32 x i1> %m, i32 zeroext %ev
; RV32-LABEL: vssub_vx_v32i64:
; RV32: # %bb.0:
; RV32-NEXT: vsetivli zero, 2, e8, mf4, ta, ma
-; RV32-NEXT: vslidedown.vi v1, v0, 2
+; RV32-NEXT: vslidedown.vi v7, v0, 2
; RV32-NEXT: li a1, 32
; RV32-NEXT: vsetvli zero, a1, e32, m8, ta, ma
; RV32-NEXT: li a2, 16
@@ -1599,7 +1599,7 @@ define <32 x i64> @vssub_vx_v32i64(<32 x i64> %va, <32 x i1> %m, i32 zeroext %ev
; RV32-NEXT: addi a0, a0, -1
; RV32-NEXT: and a0, a0, a1
; RV32-NEXT: vsetvli zero, a0, e64, m8, ta, ma
-; RV32-NEXT: vmv1r.v v0, v1
+; RV32-NEXT: vmv1r.v v0, v7
; RV32-NEXT: vssub.vv v16, v16, v24, v0.t
; RV32-NEXT: ret
;
@@ -1684,14 +1684,14 @@ define <32 x i64> @vssub_vx_v32i64_evl12(<32 x i64> %va, <32 x i1> %m) {
; RV32-LABEL: vssub_vx_v32i64_evl12:
; RV32: # %bb.0:
; RV32-NEXT: vsetivli zero, 2, e8, mf4, ta, ma
-; RV32-NEXT: vslidedown.vi v1, v0, 2
+; RV32-NEXT: vslidedown.vi v7, v0, 2
; RV32-NEXT: li a0, 32
; RV32-NEXT: vsetvli zero, a0, e32, m8, ta, ma
; RV32-NEXT: vmv.v.i v24, -1
; RV32-NEXT: vsetivli zero, 12, e64, m8, ta, ma
; RV32-NEXT: vssub.vv v8, v8, v24, v0.t
; RV32-NEXT: vsetivli zero, 0, e64, m8, ta, ma
-; RV32-NEXT: vmv1r.v v0, v1
+; RV32-NEXT: vmv1r.v v0, v7
; RV32-NEXT: vssub.vv v16, v16, v24, v0.t
; RV32-NEXT: ret
;
@@ -1716,14 +1716,14 @@ define <32 x i64> @vssub_vx_v32i64_evl27(<32 x i64> %va, <32 x i1> %m) {
; RV32-LABEL: vssub_vx_v32i64_evl27:
; RV32: # %bb.0:
; RV32-NEXT: vsetivli zero, 2, e8, mf4, ta, ma
-; RV32-NEXT: vslidedown.vi v1, v0, 2
+; RV32-NEXT: vslidedown.vi v7, v0, 2
; RV32-NEXT: li a0, 32
; RV32-NEXT: vsetvli zero, a0, e32, m8, ta, ma
; RV32-NEXT: vmv.v.i v24, -1
; RV32-NEXT: vsetivli zero, 16, e64, m8, ta, ma
; RV32-NEXT: vssub.vv v8, v8, v24, v0.t
; RV32-NEXT: vsetivli zero, 11, e64, m8, ta, ma
-; RV32-NEXT: vmv1r.v v0, v1
+; RV32-NEXT: vmv1r.v v0, v7
; RV32-NEXT: vssub.vv v16, v16, v24, v0.t
; RV32-NEXT: ret
;
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vssubu-vp.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vssubu-vp.ll
index 6ea97588712307..60c16ef543a0ff 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vssubu-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-vssubu-vp.ll
@@ -1577,7 +1577,7 @@ define <32 x i64> @vssubu_vx_v32i64(<32 x i64> %va, <32 x i1> %m, i32 zeroext %e
; RV32-LABEL: vssubu_vx_v32i64:
; RV32: # %bb.0:
; RV32-NEXT: vsetivli zero, 2, e8, mf4, ta, ma
-; RV32-NEXT: vslidedown.vi v1, v0, 2
+; RV32-NEXT: vslidedown.vi v7, v0, 2
; RV32-NEXT: li a1, 32
; RV32-NEXT: vsetvli zero, a1, e32, m8, ta, ma
; RV32-NEXT: li a2, 16
@@ -1594,7 +1594,7 @@ define <32 x i64> @vssubu_vx_v32i64(<32 x i64> %va, <32 x i1> %m, i32 zeroext %e
; RV32-NEXT: addi a0, a0, -1
; RV32-NEXT: and a0, a0, a1
; RV32-NEXT: vsetvli zero, a0, e64, m8, ta, ma
-; RV32-NEXT: vmv1r.v v0, v1
+; RV32-NEXT: vmv1r.v v0, v7
; RV32-NEXT: vssubu.vv v16, v16, v24, v0.t
; RV32-NEXT: ret
;
@@ -1679,14 +1679,14 @@ define <32 x i64> @vssubu_vx_v32i64_evl12(<32 x i64> %va, <32 x i1> %m) {
; RV32-LABEL: vssubu_vx_v32i64_evl12:
; RV32: # %bb.0:
; RV32-NEXT: vsetivli zero, 2, e8, mf4, ta, ma
-; RV32-NEXT: vslidedown.vi v1, v0, 2
+; RV32-NEXT: vslidedown.vi v7, v0, 2
; RV32-NEXT: li a0, 32
; RV32-NEXT: vsetvli zero, a0, e32, m8, ta, ma
; RV32-NEXT: vmv.v.i v24, -1
; RV32-NEXT: vsetivli zero, 12, e64, m8, ta, ma
; RV32-NEXT: vssubu.vv v8, v8, v24, v0.t
; RV32-NEXT: vsetivli zero, 0, e64, m8, ta, ma
-; RV32-NEXT: vmv1r.v v0, v1
+; RV32-NEXT: vmv1r.v v0, v7
; RV32-NEXT: vssubu.vv v16, v16, v24, v0.t
; RV32-NEXT: ret
;
@@ -1711,14 +1711,14 @@ define <32 x i64> @vssubu_vx_v32i64_evl27(<32 x i64> %va, <32 x i1> %m) {
; RV32-LABEL: vssubu_vx_v32i64_evl27:
; RV32: # %bb.0:
; RV32-NEXT: vsetivli zero, 2, e8, mf4, ta, ma
-; RV32-NEXT: vslidedown.vi v1, v0, 2
+; RV32-NEXT: vslidedown.vi v7, v0, 2
; RV32-NEXT: li a0, 32
; RV32-NEXT: vsetvli zero, a0, e32, m8, ta, ma
; RV32-NEXT: vmv.v.i v24, -1
; RV32-NEXT: vsetivli zero, 16, e64, m8, ta, ma
; RV32-NEXT: vssubu.vv v8, v8, v24, v0.t
; RV32-NEXT: vsetivli zero, 11, e64, m8, ta, ma
-; RV32-NEXT: vmv1r.v v0, v1
+; RV32-NEXT: vmv1r.v v0, v7
; RV32-NEXT: vssubu.vv v16, v16, v24, v0.t
; RV32-NEXT: ret
;
diff --git a/llvm/test/CodeGen/RISCV/rvv/fmaximum-sdnode.ll b/llvm/test/CodeGen/RISCV/rvv/fmaximum-sdnode.ll
index c954c9a6d0d113..386f23f68c357e 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fmaximum-sdnode.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fmaximum-sdnode.ll
@@ -175,11 +175,11 @@ define <vscale x 16 x half> @vfmax_nxv16f16_vv(<vscale x 16 x half> %a, <vscale
; ZVFHMIN-NEXT: vfwcvt.f.f.v v24, v8
; ZVFHMIN-NEXT: vsetvli zero, zero, e32, m8, ta, ma
; ZVFHMIN-NEXT: vmfeq.vv v0, v24, v24
-; ZVFHMIN-NEXT: vmfeq.vv v1, v16, v16
+; ZVFHMIN-NEXT: vmfeq.vv v7, v16, v16
; ZVFHMIN-NEXT: vmerge.vvm v8, v24, v16, v0
; ZVFHMIN-NEXT: addi a0, sp, 16
; ZVFHMIN-NEXT: vs8r.v v8, (a0) # Unknown-size Folded Spill
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v7
; ZVFHMIN-NEXT: vmerge.vvm v8, v16, v24, v0
; ZVFHMIN-NEXT: vl8r.v v16, (a0) # Unknown-size Folded Reload
; ZVFHMIN-NEXT: vfmax.vv v16, v8, v16
@@ -201,9 +201,9 @@ define <vscale x 32 x half> @vfmax_nxv32f16_vv(<vscale x 32 x half> %a, <vscale
; ZVFH: # %bb.0:
; ZVFH-NEXT: vsetvli a0, zero, e16, m8, ta, ma
; ZVFH-NEXT: vmfeq.vv v0, v8, v8
-; ZVFH-NEXT: vmfeq.vv v1, v16, v16
+; ZVFH-NEXT: vmfeq.vv v7, v16, v16
; ZVFH-NEXT: vmerge.vvm v24, v8, v16, v0
-; ZVFH-NEXT: vmv1r.v v0, v1
+; ZVFH-NEXT: vmv1r.v v0, v7
; ZVFH-NEXT: vmerge.vvm v8, v16, v8, v0
; ZVFH-NEXT: vfmax.vv v8, v8, v24
; ZVFH-NEXT: ret
@@ -225,9 +225,9 @@ define <vscale x 32 x half> @vfmax_nxv32f16_vv(<vscale x 32 x half> %a, <vscale
; ZVFHMIN-NEXT: vfwcvt.f.f.v v8, v0
; ZVFHMIN-NEXT: vsetvli zero, zero, e32, m8, ta, ma
; ZVFHMIN-NEXT: vmfeq.vv v0, v8, v8
-; ZVFHMIN-NEXT: vmfeq.vv v1, v24, v24
+; ZVFHMIN-NEXT: vmfeq.vv v3, v24, v24
; ZVFHMIN-NEXT: vmerge.vvm v16, v8, v24, v0
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v3
; ZVFHMIN-NEXT: vmerge.vvm v8, v24, v8, v0
; ZVFHMIN-NEXT: vfmax.vv v24, v8, v16
; ZVFHMIN-NEXT: vsetvli zero, zero, e16, m4, ta, ma
@@ -243,14 +243,14 @@ define <vscale x 32 x half> @vfmax_nxv32f16_vv(<vscale x 32 x half> %a, <vscale
; ZVFHMIN-NEXT: vfwcvt.f.f.v v16, v4
; ZVFHMIN-NEXT: vsetvli zero, zero, e32, m8, ta, ma
; ZVFHMIN-NEXT: vmfeq.vv v0, v16, v16
-; ZVFHMIN-NEXT: vmfeq.vv v1, v8, v8
+; ZVFHMIN-NEXT: vmfeq.vv v7, v8, v8
; ZVFHMIN-NEXT: vmerge.vvm v24, v16, v8, v0
; ZVFHMIN-NEXT: csrr a0, vlenb
; ZVFHMIN-NEXT: slli a0, a0, 3
; ZVFHMIN-NEXT: add a0, sp, a0
; ZVFHMIN-NEXT: addi a0, a0, 16
; ZVFHMIN-NEXT: vs8r.v v24, (a0) # Unknown-size Folded Spill
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v7
; ZVFHMIN-NEXT: vmerge.vvm v16, v8, v16, v0
; ZVFHMIN-NEXT: csrr a0, vlenb
; ZVFHMIN-NEXT: slli a0, a0, 3
@@ -346,9 +346,9 @@ define <vscale x 16 x float> @vfmax_nxv16f32_vv(<vscale x 16 x float> %a, <vscal
; CHECK: # %bb.0:
; CHECK-NEXT: vsetvli a0, zero, e32, m8, ta, ma
; CHECK-NEXT: vmfeq.vv v0, v8, v8
-; CHECK-NEXT: vmfeq.vv v1, v16, v16
+; CHECK-NEXT: vmfeq.vv v7, v16, v16
; CHECK-NEXT: vmerge.vvm v24, v8, v16, v0
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmerge.vvm v8, v16, v8, v0
; CHECK-NEXT: vfmax.vv v8, v8, v24
; CHECK-NEXT: ret
@@ -414,9 +414,9 @@ define <vscale x 8 x double> @vfmax_nxv8f64_vv(<vscale x 8 x double> %a, <vscale
; CHECK: # %bb.0:
; CHECK-NEXT: vsetvli a0, zero, e64, m8, ta, ma
; CHECK-NEXT: vmfeq.vv v0, v8, v8
-; CHECK-NEXT: vmfeq.vv v1, v16, v16
+; CHECK-NEXT: vmfeq.vv v7, v16, v16
; CHECK-NEXT: vmerge.vvm v24, v8, v16, v0
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmerge.vvm v8, v16, v8, v0
; CHECK-NEXT: vfmax.vv v8, v8, v24
; CHECK-NEXT: ret
diff --git a/llvm/test/CodeGen/RISCV/rvv/fmaximum-vp.ll b/llvm/test/CodeGen/RISCV/rvv/fmaximum-vp.ll
index f4350a1e1ced31..7774e3e4775af8 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fmaximum-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fmaximum-vp.ll
@@ -336,7 +336,7 @@ define <vscale x 16 x half> @vfmax_vv_nxv16f16(<vscale x 16 x half> %va, <vscale
; ZVFHMIN-NEXT: slli a1, a1, 3
; ZVFHMIN-NEXT: sub sp, sp, a1
; ZVFHMIN-NEXT: .cfi_escape 0x0f, 0x0d, 0x72, 0x00, 0x11, 0x10, 0x22, 0x11, 0x08, 0x92, 0xa2, 0x38, 0x00, 0x1e, 0x22 # sp + 16 + 8 * vlenb
-; ZVFHMIN-NEXT: vmv1r.v v1, v0
+; ZVFHMIN-NEXT: vmv1r.v v7, v0
; ZVFHMIN-NEXT: vsetvli a1, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: vfwcvt.f.f.v v24, v8
; ZVFHMIN-NEXT: vsetvli zero, a0, e32, m8, ta, ma
@@ -348,11 +348,11 @@ define <vscale x 16 x half> @vfmax_vv_nxv16f16(<vscale x 16 x half> %va, <vscale
; ZVFHMIN-NEXT: vmerge.vvm v8, v24, v16, v0
; ZVFHMIN-NEXT: addi a0, sp, 16
; ZVFHMIN-NEXT: vs8r.v v8, (a0) # Unknown-size Folded Spill
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v7
; ZVFHMIN-NEXT: vmfeq.vv v8, v16, v16, v0.t
; ZVFHMIN-NEXT: vmv1r.v v0, v8
; ZVFHMIN-NEXT: vmerge.vvm v8, v16, v24, v0
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v7
; ZVFHMIN-NEXT: vl8r.v v16, (a0) # Unknown-size Folded Reload
; ZVFHMIN-NEXT: vfmax.vv v16, v8, v16, v0.t
; ZVFHMIN-NEXT: vsetvli a0, zero, e16, m4, ta, ma
@@ -393,11 +393,11 @@ define <vscale x 16 x half> @vfmax_vv_nxv16f16_unmasked(<vscale x 16 x half> %va
; ZVFHMIN-NEXT: vsetvli a1, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: vfwcvt.f.f.v v24, v12
; ZVFHMIN-NEXT: vsetvli zero, a0, e32, m8, ta, ma
-; ZVFHMIN-NEXT: vmfeq.vv v1, v24, v24
+; ZVFHMIN-NEXT: vmfeq.vv v7, v24, v24
; ZVFHMIN-NEXT: vmerge.vvm v8, v16, v24, v0
; ZVFHMIN-NEXT: addi a0, sp, 16
; ZVFHMIN-NEXT: vs8r.v v8, (a0) # Unknown-size Folded Spill
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v7
; ZVFHMIN-NEXT: vmerge.vvm v8, v24, v16, v0
; ZVFHMIN-NEXT: vl8r.v v16, (a0) # Unknown-size Folded Reload
; ZVFHMIN-NEXT: vfmax.vv v16, v8, v16
@@ -425,18 +425,18 @@ define <vscale x 32 x half> @vfmax_vv_nxv32f16(<vscale x 32 x half> %va, <vscale
; ZVFH-NEXT: slli a1, a1, 3
; ZVFH-NEXT: sub sp, sp, a1
; ZVFH-NEXT: .cfi_escape 0x0f, 0x0d, 0x72, 0x00, 0x11, 0x10, 0x22, 0x11, 0x08, 0x92, 0xa2, 0x38, 0x00, 0x1e, 0x22 # sp + 16 + 8 * vlenb
-; ZVFH-NEXT: vmv1r.v v1, v0
+; ZVFH-NEXT: vmv1r.v v7, v0
; ZVFH-NEXT: vsetvli zero, a0, e16, m8, ta, ma
; ZVFH-NEXT: vmfeq.vv v25, v8, v8, v0.t
; ZVFH-NEXT: vmv1r.v v0, v25
; ZVFH-NEXT: vmerge.vvm v24, v8, v16, v0
; ZVFH-NEXT: addi a0, sp, 16
; ZVFH-NEXT: vs8r.v v24, (a0) # Unknown-size Folded Spill
-; ZVFH-NEXT: vmv1r.v v0, v1
+; ZVFH-NEXT: vmv1r.v v0, v7
; ZVFH-NEXT: vmfeq.vv v25, v16, v16, v0.t
; ZVFH-NEXT: vmv1r.v v0, v25
; ZVFH-NEXT: vmerge.vvm v8, v16, v8, v0
-; ZVFH-NEXT: vmv1r.v v0, v1
+; ZVFH-NEXT: vmv1r.v v0, v7
; ZVFH-NEXT: vl8r.v v16, (a0) # Unknown-size Folded Reload
; ZVFH-NEXT: vfmax.vv v8, v8, v16, v0.t
; ZVFH-NEXT: csrr a0, vlenb
@@ -611,9 +611,9 @@ define <vscale x 32 x half> @vfmax_vv_nxv32f16_unmasked(<vscale x 32 x half> %va
; ZVFH: # %bb.0:
; ZVFH-NEXT: vsetvli zero, a0, e16, m8, ta, ma
; ZVFH-NEXT: vmfeq.vv v0, v8, v8
-; ZVFH-NEXT: vmfeq.vv v1, v16, v16
+; ZVFH-NEXT: vmfeq.vv v7, v16, v16
; ZVFH-NEXT: vmerge.vvm v24, v8, v16, v0
-; ZVFH-NEXT: vmv1r.v v0, v1
+; ZVFH-NEXT: vmv1r.v v0, v7
; ZVFH-NEXT: vmerge.vvm v8, v16, v8, v0
; ZVFH-NEXT: vfmax.vv v8, v8, v24
; ZVFH-NEXT: ret
@@ -636,7 +636,7 @@ define <vscale x 32 x half> @vfmax_vv_nxv32f16_unmasked(<vscale x 32 x half> %va
; ZVFHMIN-NEXT: and a3, a4, a3
; ZVFHMIN-NEXT: srli a2, a2, 2
; ZVFHMIN-NEXT: vsetvli a4, zero, e8, mf2, ta, ma
-; ZVFHMIN-NEXT: vslidedown.vx v1, v24, a2
+; ZVFHMIN-NEXT: vslidedown.vx v7, v24, a2
; ZVFHMIN-NEXT: vsetvli a2, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: csrr a2, vlenb
; ZVFHMIN-NEXT: slli a2, a2, 4
@@ -647,7 +647,7 @@ define <vscale x 32 x half> @vfmax_vv_nxv32f16_unmasked(<vscale x 32 x half> %va
; ZVFHMIN-NEXT: addi a2, sp, 16
; ZVFHMIN-NEXT: vs8r.v v24, (a2) # Unknown-size Folded Spill
; ZVFHMIN-NEXT: vsetvli zero, a3, e32, m8, ta, ma
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v7
; ZVFHMIN-NEXT: vmfeq.vv v12, v24, v24, v0.t
; ZVFHMIN-NEXT: vsetvli a2, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: vmv4r.v v8, v16
@@ -668,11 +668,11 @@ define <vscale x 32 x half> @vfmax_vv_nxv32f16_unmasked(<vscale x 32 x half> %va
; ZVFHMIN-NEXT: add a2, sp, a2
; ZVFHMIN-NEXT: addi a2, a2, 16
; ZVFHMIN-NEXT: vs8r.v v8, (a2) # Unknown-size Folded Spill
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v7
; ZVFHMIN-NEXT: vmfeq.vv v12, v24, v24, v0.t
; ZVFHMIN-NEXT: vmv1r.v v0, v12
; ZVFHMIN-NEXT: vmerge.vvm v16, v24, v16, v0
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v7
; ZVFHMIN-NEXT: csrr a2, vlenb
; ZVFHMIN-NEXT: slli a2, a2, 3
; ZVFHMIN-NEXT: add a2, sp, a2
@@ -702,9 +702,9 @@ define <vscale x 32 x half> @vfmax_vv_nxv32f16_unmasked(<vscale x 32 x half> %va
; ZVFHMIN-NEXT: vl8r.v v24, (a1) # Unknown-size Folded Reload
; ZVFHMIN-NEXT: vfwcvt.f.f.v v16, v24
; ZVFHMIN-NEXT: vsetvli zero, a0, e32, m8, ta, ma
-; ZVFHMIN-NEXT: vmfeq.vv v1, v16, v16
+; ZVFHMIN-NEXT: vmfeq.vv v3, v16, v16
; ZVFHMIN-NEXT: vmerge.vvm v24, v8, v16, v0
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v3
; ZVFHMIN-NEXT: vmerge.vvm v16, v16, v8, v0
; ZVFHMIN-NEXT: vfmax.vv v16, v16, v24
; ZVFHMIN-NEXT: vsetvli a0, zero, e16, m4, ta, ma
@@ -992,18 +992,18 @@ define <vscale x 8 x double> @vfmax_vv_nxv8f64(<vscale x 8 x double> %va, <vscal
; CHECK-NEXT: slli a1, a1, 3
; CHECK-NEXT: sub sp, sp, a1
; CHECK-NEXT: .cfi_escape 0x0f, 0x0d, 0x72, 0x00, 0x11, 0x10, 0x22, 0x11, 0x08, 0x92, 0xa2, 0x38, 0x00, 0x1e, 0x22 # sp + 16 + 8 * vlenb
-; CHECK-NEXT: vmv1r.v v1, v0
+; CHECK-NEXT: vmv1r.v v7, v0
; CHECK-NEXT: vsetvli zero, a0, e64, m8, ta, ma
; CHECK-NEXT: vmfeq.vv v25, v8, v8, v0.t
; CHECK-NEXT: vmv1r.v v0, v25
; CHECK-NEXT: vmerge.vvm v24, v8, v16, v0
; CHECK-NEXT: addi a0, sp, 16
; CHECK-NEXT: vs8r.v v24, (a0) # Unknown-size Folded Spill
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmfeq.vv v25, v16, v16, v0.t
; CHECK-NEXT: vmv1r.v v0, v25
; CHECK-NEXT: vmerge.vvm v8, v16, v8, v0
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vl8r.v v16, (a0) # Unknown-size Folded Reload
; CHECK-NEXT: vfmax.vv v8, v8, v16, v0.t
; CHECK-NEXT: csrr a0, vlenb
@@ -1020,9 +1020,9 @@ define <vscale x 8 x double> @vfmax_vv_nxv8f64_unmasked(<vscale x 8 x double> %v
; CHECK: # %bb.0:
; CHECK-NEXT: vsetvli zero, a0, e64, m8, ta, ma
; CHECK-NEXT: vmfeq.vv v0, v8, v8
-; CHECK-NEXT: vmfeq.vv v1, v16, v16
+; CHECK-NEXT: vmfeq.vv v7, v16, v16
; CHECK-NEXT: vmerge.vvm v24, v8, v16, v0
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmerge.vvm v8, v16, v8, v0
; CHECK-NEXT: vfmax.vv v8, v8, v24
; CHECK-NEXT: ret
@@ -1073,7 +1073,7 @@ define <vscale x 16 x double> @vfmax_vv_nxv16f64(<vscale x 16 x double> %va, <vs
; CHECK-NEXT: addi a0, a0, 16
; CHECK-NEXT: vs8r.v v0, (a0) # Unknown-size Folded Spill
; CHECK-NEXT: vsetvli zero, a3, e64, m8, ta, ma
-; CHECK-NEXT: vmv1r.v v1, v24
+; CHECK-NEXT: vmv1r.v v7, v24
; CHECK-NEXT: vmv1r.v v0, v24
; CHECK-NEXT: vmfeq.vv v26, v16, v16, v0.t
; CHECK-NEXT: vmv1r.v v0, v26
@@ -1090,7 +1090,7 @@ define <vscale x 16 x double> @vfmax_vv_nxv16f64(<vscale x 16 x double> %va, <vs
; CHECK-NEXT: add a0, sp, a0
; CHECK-NEXT: addi a0, a0, 16
; CHECK-NEXT: vs8r.v v16, (a0) # Unknown-size Folded Spill
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmfeq.vv v17, v24, v24, v0.t
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: li a3, 24
@@ -1102,7 +1102,7 @@ define <vscale x 16 x double> @vfmax_vv_nxv16f64(<vscale x 16 x double> %va, <vs
; CHECK-NEXT: addi a0, sp, 16
; CHECK-NEXT: vl8r.v v8, (a0) # Unknown-size Folded Reload
; CHECK-NEXT: vmerge.vvm v8, v24, v8, v0
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 3
; CHECK-NEXT: add a0, sp, a0
@@ -1123,8 +1123,8 @@ define <vscale x 16 x double> @vfmax_vv_nxv16f64(<vscale x 16 x double> %va, <vs
; CHECK-NEXT: slli a0, a0, 5
; CHECK-NEXT: add a0, sp, a0
; CHECK-NEXT: addi a0, a0, 16
-; CHECK-NEXT: vl1r.v v1, (a0) # Unknown-size Folded Reload
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vl1r.v v7, (a0) # Unknown-size Folded Reload
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: li a1, 24
; CHECK-NEXT: mul a0, a0, a1
@@ -1145,11 +1145,11 @@ define <vscale x 16 x double> @vfmax_vv_nxv16f64(<vscale x 16 x double> %va, <vs
; CHECK-NEXT: add a0, sp, a0
; CHECK-NEXT: addi a0, a0, 16
; CHECK-NEXT: vs8r.v v24, (a0) # Unknown-size Folded Spill
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmfeq.vv v25, v8, v8, v0.t
; CHECK-NEXT: vmv1r.v v0, v25
; CHECK-NEXT: vmerge.vvm v8, v8, v16, v0
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 3
; CHECK-NEXT: add a0, sp, a0
@@ -1202,9 +1202,9 @@ define <vscale x 16 x double> @vfmax_vv_nxv16f64_unmasked(<vscale x 16 x double>
; CHECK-NEXT: and a0, a3, a0
; CHECK-NEXT: vsetvli zero, a0, e64, m8, ta, ma
; CHECK-NEXT: vmfeq.vv v0, v16, v16
-; CHECK-NEXT: vmfeq.vv v1, v24, v24
+; CHECK-NEXT: vmfeq.vv v7, v24, v24
; CHECK-NEXT: vmerge.vvm v8, v16, v24, v0
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmerge.vvm v16, v24, v16, v0
; CHECK-NEXT: vfmax.vv v8, v16, v8
; CHECK-NEXT: addi a0, sp, 16
@@ -1225,9 +1225,9 @@ define <vscale x 16 x double> @vfmax_vv_nxv16f64_unmasked(<vscale x 16 x double>
; CHECK-NEXT: add a0, sp, a0
; CHECK-NEXT: addi a0, a0, 16
; CHECK-NEXT: vl8r.v v8, (a0) # Unknown-size Folded Reload
-; CHECK-NEXT: vmfeq.vv v1, v8, v8
+; CHECK-NEXT: vmfeq.vv v7, v8, v8
; CHECK-NEXT: vmerge.vvm v24, v16, v8, v0
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmerge.vvm v8, v8, v16, v0
; CHECK-NEXT: vfmax.vv v8, v8, v24
; CHECK-NEXT: addi a0, sp, 16
diff --git a/llvm/test/CodeGen/RISCV/rvv/fminimum-sdnode.ll b/llvm/test/CodeGen/RISCV/rvv/fminimum-sdnode.ll
index 567068fdfb1c47..48baa12aa2e59b 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fminimum-sdnode.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fminimum-sdnode.ll
@@ -175,11 +175,11 @@ define <vscale x 16 x half> @vfmin_nxv16f16_vv(<vscale x 16 x half> %a, <vscale
; ZVFHMIN-NEXT: vfwcvt.f.f.v v24, v8
; ZVFHMIN-NEXT: vsetvli zero, zero, e32, m8, ta, ma
; ZVFHMIN-NEXT: vmfeq.vv v0, v24, v24
-; ZVFHMIN-NEXT: vmfeq.vv v1, v16, v16
+; ZVFHMIN-NEXT: vmfeq.vv v7, v16, v16
; ZVFHMIN-NEXT: vmerge.vvm v8, v24, v16, v0
; ZVFHMIN-NEXT: addi a0, sp, 16
; ZVFHMIN-NEXT: vs8r.v v8, (a0) # Unknown-size Folded Spill
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v7
; ZVFHMIN-NEXT: vmerge.vvm v8, v16, v24, v0
; ZVFHMIN-NEXT: vl8r.v v16, (a0) # Unknown-size Folded Reload
; ZVFHMIN-NEXT: vfmin.vv v16, v8, v16
@@ -201,9 +201,9 @@ define <vscale x 32 x half> @vfmin_nxv32f16_vv(<vscale x 32 x half> %a, <vscale
; ZVFH: # %bb.0:
; ZVFH-NEXT: vsetvli a0, zero, e16, m8, ta, ma
; ZVFH-NEXT: vmfeq.vv v0, v8, v8
-; ZVFH-NEXT: vmfeq.vv v1, v16, v16
+; ZVFH-NEXT: vmfeq.vv v7, v16, v16
; ZVFH-NEXT: vmerge.vvm v24, v8, v16, v0
-; ZVFH-NEXT: vmv1r.v v0, v1
+; ZVFH-NEXT: vmv1r.v v0, v7
; ZVFH-NEXT: vmerge.vvm v8, v16, v8, v0
; ZVFH-NEXT: vfmin.vv v8, v8, v24
; ZVFH-NEXT: ret
@@ -225,9 +225,9 @@ define <vscale x 32 x half> @vfmin_nxv32f16_vv(<vscale x 32 x half> %a, <vscale
; ZVFHMIN-NEXT: vfwcvt.f.f.v v8, v0
; ZVFHMIN-NEXT: vsetvli zero, zero, e32, m8, ta, ma
; ZVFHMIN-NEXT: vmfeq.vv v0, v8, v8
-; ZVFHMIN-NEXT: vmfeq.vv v1, v24, v24
+; ZVFHMIN-NEXT: vmfeq.vv v3, v24, v24
; ZVFHMIN-NEXT: vmerge.vvm v16, v8, v24, v0
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v3
; ZVFHMIN-NEXT: vmerge.vvm v8, v24, v8, v0
; ZVFHMIN-NEXT: vfmin.vv v24, v8, v16
; ZVFHMIN-NEXT: vsetvli zero, zero, e16, m4, ta, ma
@@ -243,14 +243,14 @@ define <vscale x 32 x half> @vfmin_nxv32f16_vv(<vscale x 32 x half> %a, <vscale
; ZVFHMIN-NEXT: vfwcvt.f.f.v v16, v4
; ZVFHMIN-NEXT: vsetvli zero, zero, e32, m8, ta, ma
; ZVFHMIN-NEXT: vmfeq.vv v0, v16, v16
-; ZVFHMIN-NEXT: vmfeq.vv v1, v8, v8
+; ZVFHMIN-NEXT: vmfeq.vv v7, v8, v8
; ZVFHMIN-NEXT: vmerge.vvm v24, v16, v8, v0
; ZVFHMIN-NEXT: csrr a0, vlenb
; ZVFHMIN-NEXT: slli a0, a0, 3
; ZVFHMIN-NEXT: add a0, sp, a0
; ZVFHMIN-NEXT: addi a0, a0, 16
; ZVFHMIN-NEXT: vs8r.v v24, (a0) # Unknown-size Folded Spill
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v7
; ZVFHMIN-NEXT: vmerge.vvm v16, v8, v16, v0
; ZVFHMIN-NEXT: csrr a0, vlenb
; ZVFHMIN-NEXT: slli a0, a0, 3
@@ -346,9 +346,9 @@ define <vscale x 16 x float> @vfmin_nxv16f32_vv(<vscale x 16 x float> %a, <vscal
; CHECK: # %bb.0:
; CHECK-NEXT: vsetvli a0, zero, e32, m8, ta, ma
; CHECK-NEXT: vmfeq.vv v0, v8, v8
-; CHECK-NEXT: vmfeq.vv v1, v16, v16
+; CHECK-NEXT: vmfeq.vv v7, v16, v16
; CHECK-NEXT: vmerge.vvm v24, v8, v16, v0
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmerge.vvm v8, v16, v8, v0
; CHECK-NEXT: vfmin.vv v8, v8, v24
; CHECK-NEXT: ret
@@ -414,9 +414,9 @@ define <vscale x 8 x double> @vfmin_nxv8f64_vv(<vscale x 8 x double> %a, <vscale
; CHECK: # %bb.0:
; CHECK-NEXT: vsetvli a0, zero, e64, m8, ta, ma
; CHECK-NEXT: vmfeq.vv v0, v8, v8
-; CHECK-NEXT: vmfeq.vv v1, v16, v16
+; CHECK-NEXT: vmfeq.vv v7, v16, v16
; CHECK-NEXT: vmerge.vvm v24, v8, v16, v0
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmerge.vvm v8, v16, v8, v0
; CHECK-NEXT: vfmin.vv v8, v8, v24
; CHECK-NEXT: ret
diff --git a/llvm/test/CodeGen/RISCV/rvv/fminimum-vp.ll b/llvm/test/CodeGen/RISCV/rvv/fminimum-vp.ll
index 1f8af732e3f995..4e98d0581f896d 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fminimum-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fminimum-vp.ll
@@ -336,7 +336,7 @@ define <vscale x 16 x half> @vfmin_vv_nxv16f16(<vscale x 16 x half> %va, <vscale
; ZVFHMIN-NEXT: slli a1, a1, 3
; ZVFHMIN-NEXT: sub sp, sp, a1
; ZVFHMIN-NEXT: .cfi_escape 0x0f, 0x0d, 0x72, 0x00, 0x11, 0x10, 0x22, 0x11, 0x08, 0x92, 0xa2, 0x38, 0x00, 0x1e, 0x22 # sp + 16 + 8 * vlenb
-; ZVFHMIN-NEXT: vmv1r.v v1, v0
+; ZVFHMIN-NEXT: vmv1r.v v7, v0
; ZVFHMIN-NEXT: vsetvli a1, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: vfwcvt.f.f.v v24, v8
; ZVFHMIN-NEXT: vsetvli zero, a0, e32, m8, ta, ma
@@ -348,11 +348,11 @@ define <vscale x 16 x half> @vfmin_vv_nxv16f16(<vscale x 16 x half> %va, <vscale
; ZVFHMIN-NEXT: vmerge.vvm v8, v24, v16, v0
; ZVFHMIN-NEXT: addi a0, sp, 16
; ZVFHMIN-NEXT: vs8r.v v8, (a0) # Unknown-size Folded Spill
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v7
; ZVFHMIN-NEXT: vmfeq.vv v8, v16, v16, v0.t
; ZVFHMIN-NEXT: vmv1r.v v0, v8
; ZVFHMIN-NEXT: vmerge.vvm v8, v16, v24, v0
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v7
; ZVFHMIN-NEXT: vl8r.v v16, (a0) # Unknown-size Folded Reload
; ZVFHMIN-NEXT: vfmin.vv v16, v8, v16, v0.t
; ZVFHMIN-NEXT: vsetvli a0, zero, e16, m4, ta, ma
@@ -393,11 +393,11 @@ define <vscale x 16 x half> @vfmin_vv_nxv16f16_unmasked(<vscale x 16 x half> %va
; ZVFHMIN-NEXT: vsetvli a1, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: vfwcvt.f.f.v v24, v12
; ZVFHMIN-NEXT: vsetvli zero, a0, e32, m8, ta, ma
-; ZVFHMIN-NEXT: vmfeq.vv v1, v24, v24
+; ZVFHMIN-NEXT: vmfeq.vv v7, v24, v24
; ZVFHMIN-NEXT: vmerge.vvm v8, v16, v24, v0
; ZVFHMIN-NEXT: addi a0, sp, 16
; ZVFHMIN-NEXT: vs8r.v v8, (a0) # Unknown-size Folded Spill
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v7
; ZVFHMIN-NEXT: vmerge.vvm v8, v24, v16, v0
; ZVFHMIN-NEXT: vl8r.v v16, (a0) # Unknown-size Folded Reload
; ZVFHMIN-NEXT: vfmin.vv v16, v8, v16
@@ -425,18 +425,18 @@ define <vscale x 32 x half> @vfmin_vv_nxv32f16(<vscale x 32 x half> %va, <vscale
; ZVFH-NEXT: slli a1, a1, 3
; ZVFH-NEXT: sub sp, sp, a1
; ZVFH-NEXT: .cfi_escape 0x0f, 0x0d, 0x72, 0x00, 0x11, 0x10, 0x22, 0x11, 0x08, 0x92, 0xa2, 0x38, 0x00, 0x1e, 0x22 # sp + 16 + 8 * vlenb
-; ZVFH-NEXT: vmv1r.v v1, v0
+; ZVFH-NEXT: vmv1r.v v7, v0
; ZVFH-NEXT: vsetvli zero, a0, e16, m8, ta, ma
; ZVFH-NEXT: vmfeq.vv v25, v8, v8, v0.t
; ZVFH-NEXT: vmv1r.v v0, v25
; ZVFH-NEXT: vmerge.vvm v24, v8, v16, v0
; ZVFH-NEXT: addi a0, sp, 16
; ZVFH-NEXT: vs8r.v v24, (a0) # Unknown-size Folded Spill
-; ZVFH-NEXT: vmv1r.v v0, v1
+; ZVFH-NEXT: vmv1r.v v0, v7
; ZVFH-NEXT: vmfeq.vv v25, v16, v16, v0.t
; ZVFH-NEXT: vmv1r.v v0, v25
; ZVFH-NEXT: vmerge.vvm v8, v16, v8, v0
-; ZVFH-NEXT: vmv1r.v v0, v1
+; ZVFH-NEXT: vmv1r.v v0, v7
; ZVFH-NEXT: vl8r.v v16, (a0) # Unknown-size Folded Reload
; ZVFH-NEXT: vfmin.vv v8, v8, v16, v0.t
; ZVFH-NEXT: csrr a0, vlenb
@@ -611,9 +611,9 @@ define <vscale x 32 x half> @vfmin_vv_nxv32f16_unmasked(<vscale x 32 x half> %va
; ZVFH: # %bb.0:
; ZVFH-NEXT: vsetvli zero, a0, e16, m8, ta, ma
; ZVFH-NEXT: vmfeq.vv v0, v8, v8
-; ZVFH-NEXT: vmfeq.vv v1, v16, v16
+; ZVFH-NEXT: vmfeq.vv v7, v16, v16
; ZVFH-NEXT: vmerge.vvm v24, v8, v16, v0
-; ZVFH-NEXT: vmv1r.v v0, v1
+; ZVFH-NEXT: vmv1r.v v0, v7
; ZVFH-NEXT: vmerge.vvm v8, v16, v8, v0
; ZVFH-NEXT: vfmin.vv v8, v8, v24
; ZVFH-NEXT: ret
@@ -636,7 +636,7 @@ define <vscale x 32 x half> @vfmin_vv_nxv32f16_unmasked(<vscale x 32 x half> %va
; ZVFHMIN-NEXT: and a3, a4, a3
; ZVFHMIN-NEXT: srli a2, a2, 2
; ZVFHMIN-NEXT: vsetvli a4, zero, e8, mf2, ta, ma
-; ZVFHMIN-NEXT: vslidedown.vx v1, v24, a2
+; ZVFHMIN-NEXT: vslidedown.vx v7, v24, a2
; ZVFHMIN-NEXT: vsetvli a2, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: csrr a2, vlenb
; ZVFHMIN-NEXT: slli a2, a2, 4
@@ -647,7 +647,7 @@ define <vscale x 32 x half> @vfmin_vv_nxv32f16_unmasked(<vscale x 32 x half> %va
; ZVFHMIN-NEXT: addi a2, sp, 16
; ZVFHMIN-NEXT: vs8r.v v24, (a2) # Unknown-size Folded Spill
; ZVFHMIN-NEXT: vsetvli zero, a3, e32, m8, ta, ma
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v7
; ZVFHMIN-NEXT: vmfeq.vv v12, v24, v24, v0.t
; ZVFHMIN-NEXT: vsetvli a2, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: vmv4r.v v8, v16
@@ -668,11 +668,11 @@ define <vscale x 32 x half> @vfmin_vv_nxv32f16_unmasked(<vscale x 32 x half> %va
; ZVFHMIN-NEXT: add a2, sp, a2
; ZVFHMIN-NEXT: addi a2, a2, 16
; ZVFHMIN-NEXT: vs8r.v v8, (a2) # Unknown-size Folded Spill
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v7
; ZVFHMIN-NEXT: vmfeq.vv v12, v24, v24, v0.t
; ZVFHMIN-NEXT: vmv1r.v v0, v12
; ZVFHMIN-NEXT: vmerge.vvm v16, v24, v16, v0
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v7
; ZVFHMIN-NEXT: csrr a2, vlenb
; ZVFHMIN-NEXT: slli a2, a2, 3
; ZVFHMIN-NEXT: add a2, sp, a2
@@ -702,9 +702,9 @@ define <vscale x 32 x half> @vfmin_vv_nxv32f16_unmasked(<vscale x 32 x half> %va
; ZVFHMIN-NEXT: vl8r.v v24, (a1) # Unknown-size Folded Reload
; ZVFHMIN-NEXT: vfwcvt.f.f.v v16, v24
; ZVFHMIN-NEXT: vsetvli zero, a0, e32, m8, ta, ma
-; ZVFHMIN-NEXT: vmfeq.vv v1, v16, v16
+; ZVFHMIN-NEXT: vmfeq.vv v3, v16, v16
; ZVFHMIN-NEXT: vmerge.vvm v24, v8, v16, v0
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v3
; ZVFHMIN-NEXT: vmerge.vvm v16, v16, v8, v0
; ZVFHMIN-NEXT: vfmin.vv v16, v16, v24
; ZVFHMIN-NEXT: vsetvli a0, zero, e16, m4, ta, ma
@@ -992,18 +992,18 @@ define <vscale x 8 x double> @vfmin_vv_nxv8f64(<vscale x 8 x double> %va, <vscal
; CHECK-NEXT: slli a1, a1, 3
; CHECK-NEXT: sub sp, sp, a1
; CHECK-NEXT: .cfi_escape 0x0f, 0x0d, 0x72, 0x00, 0x11, 0x10, 0x22, 0x11, 0x08, 0x92, 0xa2, 0x38, 0x00, 0x1e, 0x22 # sp + 16 + 8 * vlenb
-; CHECK-NEXT: vmv1r.v v1, v0
+; CHECK-NEXT: vmv1r.v v7, v0
; CHECK-NEXT: vsetvli zero, a0, e64, m8, ta, ma
; CHECK-NEXT: vmfeq.vv v25, v8, v8, v0.t
; CHECK-NEXT: vmv1r.v v0, v25
; CHECK-NEXT: vmerge.vvm v24, v8, v16, v0
; CHECK-NEXT: addi a0, sp, 16
; CHECK-NEXT: vs8r.v v24, (a0) # Unknown-size Folded Spill
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmfeq.vv v25, v16, v16, v0.t
; CHECK-NEXT: vmv1r.v v0, v25
; CHECK-NEXT: vmerge.vvm v8, v16, v8, v0
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vl8r.v v16, (a0) # Unknown-size Folded Reload
; CHECK-NEXT: vfmin.vv v8, v8, v16, v0.t
; CHECK-NEXT: csrr a0, vlenb
@@ -1020,9 +1020,9 @@ define <vscale x 8 x double> @vfmin_vv_nxv8f64_unmasked(<vscale x 8 x double> %v
; CHECK: # %bb.0:
; CHECK-NEXT: vsetvli zero, a0, e64, m8, ta, ma
; CHECK-NEXT: vmfeq.vv v0, v8, v8
-; CHECK-NEXT: vmfeq.vv v1, v16, v16
+; CHECK-NEXT: vmfeq.vv v7, v16, v16
; CHECK-NEXT: vmerge.vvm v24, v8, v16, v0
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmerge.vvm v8, v16, v8, v0
; CHECK-NEXT: vfmin.vv v8, v8, v24
; CHECK-NEXT: ret
@@ -1073,7 +1073,7 @@ define <vscale x 16 x double> @vfmin_vv_nxv16f64(<vscale x 16 x double> %va, <vs
; CHECK-NEXT: addi a0, a0, 16
; CHECK-NEXT: vs8r.v v0, (a0) # Unknown-size Folded Spill
; CHECK-NEXT: vsetvli zero, a3, e64, m8, ta, ma
-; CHECK-NEXT: vmv1r.v v1, v24
+; CHECK-NEXT: vmv1r.v v7, v24
; CHECK-NEXT: vmv1r.v v0, v24
; CHECK-NEXT: vmfeq.vv v26, v16, v16, v0.t
; CHECK-NEXT: vmv1r.v v0, v26
@@ -1090,7 +1090,7 @@ define <vscale x 16 x double> @vfmin_vv_nxv16f64(<vscale x 16 x double> %va, <vs
; CHECK-NEXT: add a0, sp, a0
; CHECK-NEXT: addi a0, a0, 16
; CHECK-NEXT: vs8r.v v16, (a0) # Unknown-size Folded Spill
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmfeq.vv v17, v24, v24, v0.t
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: li a3, 24
@@ -1102,7 +1102,7 @@ define <vscale x 16 x double> @vfmin_vv_nxv16f64(<vscale x 16 x double> %va, <vs
; CHECK-NEXT: addi a0, sp, 16
; CHECK-NEXT: vl8r.v v8, (a0) # Unknown-size Folded Reload
; CHECK-NEXT: vmerge.vvm v8, v24, v8, v0
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 3
; CHECK-NEXT: add a0, sp, a0
@@ -1123,8 +1123,8 @@ define <vscale x 16 x double> @vfmin_vv_nxv16f64(<vscale x 16 x double> %va, <vs
; CHECK-NEXT: slli a0, a0, 5
; CHECK-NEXT: add a0, sp, a0
; CHECK-NEXT: addi a0, a0, 16
-; CHECK-NEXT: vl1r.v v1, (a0) # Unknown-size Folded Reload
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vl1r.v v7, (a0) # Unknown-size Folded Reload
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: li a1, 24
; CHECK-NEXT: mul a0, a0, a1
@@ -1145,11 +1145,11 @@ define <vscale x 16 x double> @vfmin_vv_nxv16f64(<vscale x 16 x double> %va, <vs
; CHECK-NEXT: add a0, sp, a0
; CHECK-NEXT: addi a0, a0, 16
; CHECK-NEXT: vs8r.v v24, (a0) # Unknown-size Folded Spill
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmfeq.vv v25, v8, v8, v0.t
; CHECK-NEXT: vmv1r.v v0, v25
; CHECK-NEXT: vmerge.vvm v8, v8, v16, v0
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 3
; CHECK-NEXT: add a0, sp, a0
@@ -1202,9 +1202,9 @@ define <vscale x 16 x double> @vfmin_vv_nxv16f64_unmasked(<vscale x 16 x double>
; CHECK-NEXT: and a0, a3, a0
; CHECK-NEXT: vsetvli zero, a0, e64, m8, ta, ma
; CHECK-NEXT: vmfeq.vv v0, v16, v16
-; CHECK-NEXT: vmfeq.vv v1, v24, v24
+; CHECK-NEXT: vmfeq.vv v7, v24, v24
; CHECK-NEXT: vmerge.vvm v8, v16, v24, v0
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmerge.vvm v16, v24, v16, v0
; CHECK-NEXT: vfmin.vv v8, v16, v8
; CHECK-NEXT: addi a0, sp, 16
@@ -1225,9 +1225,9 @@ define <vscale x 16 x double> @vfmin_vv_nxv16f64_unmasked(<vscale x 16 x double>
; CHECK-NEXT: add a0, sp, a0
; CHECK-NEXT: addi a0, a0, 16
; CHECK-NEXT: vl8r.v v8, (a0) # Unknown-size Folded Reload
-; CHECK-NEXT: vmfeq.vv v1, v8, v8
+; CHECK-NEXT: vmfeq.vv v7, v8, v8
; CHECK-NEXT: vmerge.vvm v24, v16, v8, v0
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmerge.vvm v8, v8, v16, v0
; CHECK-NEXT: vfmin.vv v8, v8, v24
; CHECK-NEXT: addi a0, sp, 16
diff --git a/llvm/test/CodeGen/RISCV/rvv/mscatter-sdnode.ll b/llvm/test/CodeGen/RISCV/rvv/mscatter-sdnode.ll
index 139e1ea262b713..dc67c64f3ffda8 100644
--- a/llvm/test/CodeGen/RISCV/rvv/mscatter-sdnode.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/mscatter-sdnode.ll
@@ -1755,9 +1755,9 @@ define void @mscatter_nxv16f64(<vscale x 8 x double> %val0, <vscale x 8 x double
define void @mscatter_baseidx_nxv16i8_nxv16f64(<vscale x 8 x double> %val0, <vscale x 8 x double> %val1, ptr %base, <vscale x 16 x i8> %idxs, <vscale x 16 x i1> %m) {
; RV32-LABEL: mscatter_baseidx_nxv16i8_nxv16f64:
; RV32: # %bb.0:
-; RV32-NEXT: vl2r.v v2, (a1)
+; RV32-NEXT: vl2r.v v6, (a1)
; RV32-NEXT: vsetvli a1, zero, e32, m8, ta, ma
-; RV32-NEXT: vsext.vf4 v24, v2
+; RV32-NEXT: vsext.vf4 v24, v6
; RV32-NEXT: vsll.vi v24, v24, 3
; RV32-NEXT: vsetvli a1, zero, e64, m8, ta, ma
; RV32-NEXT: vsoxei32.v v8, (a0), v24, v0.t
@@ -1771,12 +1771,12 @@ define void @mscatter_baseidx_nxv16i8_nxv16f64(<vscale x 8 x double> %val0, <vsc
;
; RV64-LABEL: mscatter_baseidx_nxv16i8_nxv16f64:
; RV64: # %bb.0:
-; RV64-NEXT: vl2r.v v2, (a1)
+; RV64-NEXT: vl2r.v v6, (a1)
; RV64-NEXT: vsetvli a1, zero, e64, m8, ta, ma
-; RV64-NEXT: vsext.vf8 v24, v2
+; RV64-NEXT: vsext.vf8 v24, v6
; RV64-NEXT: vsll.vi v24, v24, 3
; RV64-NEXT: vsoxei64.v v8, (a0), v24, v0.t
-; RV64-NEXT: vsext.vf8 v8, v3
+; RV64-NEXT: vsext.vf8 v8, v7
; RV64-NEXT: vsll.vi v8, v8, 3
; RV64-NEXT: csrr a1, vlenb
; RV64-NEXT: srli a1, a1, 3
diff --git a/llvm/test/CodeGen/RISCV/rvv/nearbyint-vp.ll b/llvm/test/CodeGen/RISCV/rvv/nearbyint-vp.ll
index 7c354c3714c6f4..126836cd9390b0 100644
--- a/llvm/test/CodeGen/RISCV/rvv/nearbyint-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/nearbyint-vp.ll
@@ -468,7 +468,7 @@ define <vscale x 32 x half> @vp_nearbyint_nxv32f16(<vscale x 32 x half> %va, <vs
; ZVFHMIN-NEXT: slli a1, a1, 3
; ZVFHMIN-NEXT: sub sp, sp, a1
; ZVFHMIN-NEXT: .cfi_escape 0x0f, 0x0d, 0x72, 0x00, 0x11, 0x10, 0x22, 0x11, 0x08, 0x92, 0xa2, 0x38, 0x00, 0x1e, 0x22 # sp + 16 + 8 * vlenb
-; ZVFHMIN-NEXT: vmv1r.v v1, v0
+; ZVFHMIN-NEXT: vmv1r.v v7, v0
; ZVFHMIN-NEXT: csrr a2, vlenb
; ZVFHMIN-NEXT: slli a1, a2, 1
; ZVFHMIN-NEXT: sub a3, a0, a1
@@ -507,13 +507,13 @@ define <vscale x 32 x half> @vp_nearbyint_nxv32f16(<vscale x 32 x half> %va, <vs
; ZVFHMIN-NEXT: vl8r.v v16, (a1) # Unknown-size Folded Reload
; ZVFHMIN-NEXT: vfwcvt.f.f.v v24, v16
; ZVFHMIN-NEXT: vsetvli zero, a0, e32, m8, ta, ma
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v7
; ZVFHMIN-NEXT: vfabs.v v16, v24, v0.t
; ZVFHMIN-NEXT: vsetvli zero, zero, e32, m8, ta, mu
-; ZVFHMIN-NEXT: vmflt.vf v1, v16, fa5, v0.t
+; ZVFHMIN-NEXT: vmflt.vf v7, v16, fa5, v0.t
; ZVFHMIN-NEXT: frflags a0
; ZVFHMIN-NEXT: vsetvli zero, zero, e32, m8, ta, ma
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v7
; ZVFHMIN-NEXT: vfcvt.x.f.v v16, v24, v0.t
; ZVFHMIN-NEXT: vfcvt.f.x.v v16, v16, v0.t
; ZVFHMIN-NEXT: fsflags a0
diff --git a/llvm/test/CodeGen/RISCV/rvv/setcc-fp-vp.ll b/llvm/test/CodeGen/RISCV/rvv/setcc-fp-vp.ll
index 1ef63ffa9ee0c7..897bfdea69f1f4 100644
--- a/llvm/test/CodeGen/RISCV/rvv/setcc-fp-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/setcc-fp-vp.ll
@@ -2219,7 +2219,7 @@ define <vscale x 64 x i1> @fcmp_oeq_vv_nxv64f16(<vscale x 64 x half> %va, <vscal
; ZVFH-NEXT: vs8r.v v0, (a0) # Unknown-size Folded Spill
; ZVFH-NEXT: vslidedown.vx v0, v24, a1
; ZVFH-NEXT: vsetvli zero, a4, e16, m8, ta, ma
-; ZVFH-NEXT: vmfeq.vv v1, v16, v8, v0.t
+; ZVFH-NEXT: vmfeq.vv v7, v16, v8, v0.t
; ZVFH-NEXT: bltu a2, a3, .LBB85_2
; ZVFH-NEXT: # %bb.1:
; ZVFH-NEXT: mv a2, a3
@@ -2236,7 +2236,7 @@ define <vscale x 64 x i1> @fcmp_oeq_vv_nxv64f16(<vscale x 64 x half> %va, <vscal
; ZVFH-NEXT: vmfeq.vv v16, v8, v24, v0.t
; ZVFH-NEXT: add a0, a1, a1
; ZVFH-NEXT: vsetvli zero, a0, e8, m1, ta, ma
-; ZVFH-NEXT: vslideup.vx v16, v1, a1
+; ZVFH-NEXT: vslideup.vx v16, v7, a1
; ZVFH-NEXT: vmv.v.v v0, v16
; ZVFH-NEXT: csrr a0, vlenb
; ZVFH-NEXT: slli a0, a0, 4
@@ -2280,7 +2280,7 @@ define <vscale x 64 x i1> @fcmp_oeq_vv_nxv64f16(<vscale x 64 x half> %va, <vscal
; ZVFHMIN-NEXT: add t0, sp, t0
; ZVFHMIN-NEXT: addi t0, t0, 16
; ZVFHMIN-NEXT: vs1r.v v0, (t0) # Unknown-size Folded Spill
-; ZVFHMIN-NEXT: vslidedown.vx v0, v0, a1
+; ZVFHMIN-NEXT: vslidedown.vx v7, v0, a1
; ZVFHMIN-NEXT: srli a3, a3, 2
; ZVFHMIN-NEXT: vl8re16.v v8, (a0)
; ZVFHMIN-NEXT: csrr a0, vlenb
@@ -2291,8 +2291,8 @@ define <vscale x 64 x i1> @fcmp_oeq_vv_nxv64f16(<vscale x 64 x half> %va, <vscal
; ZVFHMIN-NEXT: vs8r.v v8, (a0) # Unknown-size Folded Spill
; ZVFHMIN-NEXT: vsetvli a0, zero, e8, mf2, ta, ma
; ZVFHMIN-NEXT: addi a0, sp, 16
-; ZVFHMIN-NEXT: vs1r.v v0, (a0) # Unknown-size Folded Spill
-; ZVFHMIN-NEXT: vslidedown.vx v0, v0, a3
+; ZVFHMIN-NEXT: vs1r.v v7, (a0) # Unknown-size Folded Spill
+; ZVFHMIN-NEXT: vslidedown.vx v0, v7, a3
; ZVFHMIN-NEXT: vsetvli a0, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: csrr a0, vlenb
; ZVFHMIN-NEXT: slli a0, a0, 1
@@ -2331,14 +2331,14 @@ define <vscale x 64 x i1> @fcmp_oeq_vv_nxv64f16(<vscale x 64 x half> %va, <vscal
; ZVFHMIN-NEXT: vsetvli zero, a6, e32, m8, ta, ma
; ZVFHMIN-NEXT: addi a0, sp, 16
; ZVFHMIN-NEXT: vl1r.v v0, (a0) # Unknown-size Folded Reload
-; ZVFHMIN-NEXT: vmfeq.vv v2, v16, v8, v0.t
+; ZVFHMIN-NEXT: vmfeq.vv v6, v16, v8, v0.t
; ZVFHMIN-NEXT: add a0, a3, a3
; ZVFHMIN-NEXT: bltu a2, a5, .LBB85_4
; ZVFHMIN-NEXT: # %bb.3:
; ZVFHMIN-NEXT: mv a2, a5
; ZVFHMIN-NEXT: .LBB85_4:
; ZVFHMIN-NEXT: vsetvli zero, a0, e8, mf2, ta, ma
-; ZVFHMIN-NEXT: vslideup.vx v2, v26, a3
+; ZVFHMIN-NEXT: vslideup.vx v6, v26, a3
; ZVFHMIN-NEXT: sub a5, a2, a4
; ZVFHMIN-NEXT: sltu a6, a2, a5
; ZVFHMIN-NEXT: addi a6, a6, -1
@@ -2348,7 +2348,7 @@ define <vscale x 64 x i1> @fcmp_oeq_vv_nxv64f16(<vscale x 64 x half> %va, <vscal
; ZVFHMIN-NEXT: add a6, sp, a6
; ZVFHMIN-NEXT: addi a6, a6, 16
; ZVFHMIN-NEXT: vl1r.v v8, (a6) # Unknown-size Folded Reload
-; ZVFHMIN-NEXT: vmv1r.v v1, v8
+; ZVFHMIN-NEXT: vmv1r.v v7, v8
; ZVFHMIN-NEXT: vslidedown.vx v0, v8, a3
; ZVFHMIN-NEXT: vsetvli a6, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: csrr a6, vlenb
@@ -2378,7 +2378,7 @@ define <vscale x 64 x i1> @fcmp_oeq_vv_nxv64f16(<vscale x 64 x half> %va, <vscal
; ZVFHMIN-NEXT: add a5, sp, a5
; ZVFHMIN-NEXT: addi a5, a5, 16
; ZVFHMIN-NEXT: vl8r.v v16, (a5) # Unknown-size Folded Reload
-; ZVFHMIN-NEXT: vmfeq.vv v3, v16, v8, v0.t
+; ZVFHMIN-NEXT: vmfeq.vv v5, v16, v8, v0.t
; ZVFHMIN-NEXT: bltu a2, a4, .LBB85_6
; ZVFHMIN-NEXT: # %bb.5:
; ZVFHMIN-NEXT: mv a2, a4
@@ -2393,13 +2393,13 @@ define <vscale x 64 x i1> @fcmp_oeq_vv_nxv64f16(<vscale x 64 x half> %va, <vscal
; ZVFHMIN-NEXT: vl8r.v v8, (a4) # Unknown-size Folded Reload
; ZVFHMIN-NEXT: vfwcvt.f.f.v v24, v8
; ZVFHMIN-NEXT: vsetvli zero, a2, e32, m8, ta, ma
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v7
; ZVFHMIN-NEXT: vmfeq.vv v8, v16, v24, v0.t
; ZVFHMIN-NEXT: vsetvli zero, a0, e8, mf2, ta, ma
-; ZVFHMIN-NEXT: vslideup.vx v8, v3, a3
+; ZVFHMIN-NEXT: vslideup.vx v8, v5, a3
; ZVFHMIN-NEXT: add a0, a1, a1
; ZVFHMIN-NEXT: vsetvli zero, a0, e8, m1, ta, ma
-; ZVFHMIN-NEXT: vslideup.vx v8, v2, a1
+; ZVFHMIN-NEXT: vslideup.vx v8, v6, a1
; ZVFHMIN-NEXT: vmv.v.v v0, v8
; ZVFHMIN-NEXT: csrr a0, vlenb
; ZVFHMIN-NEXT: li a1, 34
@@ -3516,7 +3516,7 @@ define <vscale x 32 x i1> @fcmp_oeq_vv_nxv32f64(<vscale x 32 x double> %va, <vsc
; CHECK-NEXT: slli t1, a3, 3
; CHECK-NEXT: srli a4, a3, 2
; CHECK-NEXT: vsetvli a1, zero, e8, mf2, ta, ma
-; CHECK-NEXT: vslidedown.vx v1, v0, a4
+; CHECK-NEXT: vslidedown.vx v7, v0, a4
; CHECK-NEXT: srli a1, a3, 3
; CHECK-NEXT: vsetvli a5, zero, e8, mf4, ta, ma
; CHECK-NEXT: add a5, a2, t1
@@ -3548,7 +3548,7 @@ define <vscale x 32 x i1> @fcmp_oeq_vv_nxv32f64(<vscale x 32 x double> %va, <vsc
; CHECK-NEXT: add a2, sp, a2
; CHECK-NEXT: addi a2, a2, 16
; CHECK-NEXT: vl8r.v v16, (a2) # Unknown-size Folded Reload
-; CHECK-NEXT: vmfeq.vv v2, v16, v8, v0.t
+; CHECK-NEXT: vmfeq.vv v6, v16, v8, v0.t
; CHECK-NEXT: bltu a7, a3, .LBB171_4
; CHECK-NEXT: # %bb.3:
; CHECK-NEXT: mv a7, a3
@@ -3567,7 +3567,7 @@ define <vscale x 32 x i1> @fcmp_oeq_vv_nxv32f64(<vscale x 32 x double> %va, <vsc
; CHECK-NEXT: addi a2, a2, 16
; CHECK-NEXT: vs8r.v v8, (a2) # Unknown-size Folded Spill
; CHECK-NEXT: vsetvli a2, zero, e8, mf4, ta, ma
-; CHECK-NEXT: vslidedown.vx v18, v1, a1
+; CHECK-NEXT: vslidedown.vx v18, v7, a1
; CHECK-NEXT: vl8re64.v v8, (t0)
; CHECK-NEXT: csrr a2, vlenb
; CHECK-NEXT: slli a2, a2, 3
@@ -3597,14 +3597,14 @@ define <vscale x 32 x i1> @fcmp_oeq_vv_nxv32f64(<vscale x 32 x double> %va, <vsc
; CHECK-NEXT: sltu a2, a6, a0
; CHECK-NEXT: addi a2, a2, -1
; CHECK-NEXT: and a0, a2, a0
-; CHECK-NEXT: vslideup.vx v17, v2, a1
+; CHECK-NEXT: vslideup.vx v17, v6, a1
; CHECK-NEXT: mv a2, a0
; CHECK-NEXT: bltu a0, a3, .LBB171_6
; CHECK-NEXT: # %bb.5:
; CHECK-NEXT: mv a2, a3
; CHECK-NEXT: .LBB171_6:
; CHECK-NEXT: vsetvli zero, a2, e64, m8, ta, ma
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: csrr a2, vlenb
; CHECK-NEXT: slli a2, a2, 3
; CHECK-NEXT: add a2, sp, a2
diff --git a/llvm/test/CodeGen/RISCV/rvv/setcc-int-vp.ll b/llvm/test/CodeGen/RISCV/rvv/setcc-int-vp.ll
index a23b7c7b6ae9e4..b1f1a4dceccfb9 100644
--- a/llvm/test/CodeGen/RISCV/rvv/setcc-int-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/setcc-int-vp.ll
@@ -1184,7 +1184,7 @@ define <vscale x 128 x i1> @icmp_eq_vv_nxv128i8(<vscale x 128 x i8> %va, <vscale
; CHECK-NEXT: addi a2, a2, -1
; CHECK-NEXT: and a0, a2, a0
; CHECK-NEXT: vsetvli zero, a0, e8, m8, ta, ma
-; CHECK-NEXT: vmseq.vv v1, v16, v8, v0.t
+; CHECK-NEXT: vmseq.vv v7, v16, v8, v0.t
; CHECK-NEXT: bltu a3, a1, .LBB96_2
; CHECK-NEXT: # %bb.1:
; CHECK-NEXT: mv a3, a1
@@ -1200,7 +1200,7 @@ define <vscale x 128 x i1> @icmp_eq_vv_nxv128i8(<vscale x 128 x i8> %va, <vscale
; CHECK-NEXT: vl8r.v v24, (a0) # Unknown-size Folded Reload
; CHECK-NEXT: vmseq.vv v16, v8, v24, v0.t
; CHECK-NEXT: vmv1r.v v0, v16
-; CHECK-NEXT: vmv1r.v v8, v1
+; CHECK-NEXT: vmv1r.v v8, v7
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 4
; CHECK-NEXT: add sp, sp, a0
@@ -2408,7 +2408,7 @@ define <vscale x 32 x i1> @icmp_eq_vv_nxv32i32(<vscale x 32 x i32> %va, <vscale
; CHECK-NEXT: vs8r.v v0, (a0) # Unknown-size Folded Spill
; CHECK-NEXT: vslidedown.vx v0, v24, a1
; CHECK-NEXT: vsetvli zero, a4, e32, m8, ta, ma
-; CHECK-NEXT: vmseq.vv v1, v16, v8, v0.t
+; CHECK-NEXT: vmseq.vv v7, v16, v8, v0.t
; CHECK-NEXT: bltu a2, a3, .LBB189_2
; CHECK-NEXT: # %bb.1:
; CHECK-NEXT: mv a2, a3
@@ -2425,7 +2425,7 @@ define <vscale x 32 x i1> @icmp_eq_vv_nxv32i32(<vscale x 32 x i32> %va, <vscale
; CHECK-NEXT: vmseq.vv v16, v8, v24, v0.t
; CHECK-NEXT: add a0, a1, a1
; CHECK-NEXT: vsetvli zero, a0, e8, mf2, ta, ma
-; CHECK-NEXT: vslideup.vx v16, v1, a1
+; CHECK-NEXT: vslideup.vx v16, v7, a1
; CHECK-NEXT: vmv1r.v v0, v16
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 4
diff --git a/llvm/test/CodeGen/RISCV/rvv/vcopysign-vp.ll b/llvm/test/CodeGen/RISCV/rvv/vcopysign-vp.ll
index f3574200054fd4..4de71b6ce06fbb 100644
--- a/llvm/test/CodeGen/RISCV/rvv/vcopysign-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/vcopysign-vp.ll
@@ -255,7 +255,7 @@ define <vscale x 32 x half> @vfsgnj_vv_nxv32f16(<vscale x 32 x half> %va, <vscal
; ZVFHMIN-NEXT: slli a1, a1, 3
; ZVFHMIN-NEXT: sub sp, sp, a1
; ZVFHMIN-NEXT: .cfi_escape 0x0f, 0x0d, 0x72, 0x00, 0x11, 0x10, 0x22, 0x11, 0x08, 0x92, 0xa2, 0x38, 0x00, 0x1e, 0x22 # sp + 16 + 8 * vlenb
-; ZVFHMIN-NEXT: vmv1r.v v1, v0
+; ZVFHMIN-NEXT: vmv1r.v v7, v0
; ZVFHMIN-NEXT: csrr a2, vlenb
; ZVFHMIN-NEXT: slli a1, a2, 1
; ZVFHMIN-NEXT: sub a3, a0, a1
@@ -283,7 +283,7 @@ define <vscale x 32 x half> @vfsgnj_vv_nxv32f16(<vscale x 32 x half> %va, <vscal
; ZVFHMIN-NEXT: vfwcvt.f.f.v v16, v24
; ZVFHMIN-NEXT: vfwcvt.f.f.v v24, v8
; ZVFHMIN-NEXT: vsetvli zero, a0, e32, m8, ta, ma
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v7
; ZVFHMIN-NEXT: vfsgnj.vv v16, v24, v16, v0.t
; ZVFHMIN-NEXT: vsetvli a0, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: vfncvt.f.f.w v8, v16
diff --git a/llvm/test/CodeGen/RISCV/rvv/vector-interleave-store.ll b/llvm/test/CodeGen/RISCV/rvv/vector-interleave-store.ll
index 4c64b1677b3626..4aae8b8bd1dc02 100644
--- a/llvm/test/CodeGen/RISCV/rvv/vector-interleave-store.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/vector-interleave-store.ll
@@ -112,16 +112,16 @@ define void @vector_interleave_store_nxv16i64_nxv8i64(<vscale x 8 x i64> %a, <vs
; CHECK-NEXT: vid.v v24
; CHECK-NEXT: vand.vi v26, v24, 1
; CHECK-NEXT: vmsne.vi v0, v26, 0
-; CHECK-NEXT: vsrl.vi v2, v24, 1
+; CHECK-NEXT: vsrl.vi v6, v24, 1
; CHECK-NEXT: csrr a3, vlenb
; CHECK-NEXT: slli a3, a3, 3
; CHECK-NEXT: add a3, sp, a3
; CHECK-NEXT: addi a3, a3, 16
; CHECK-NEXT: vl8r.v v8, (a3) # Unknown-size Folded Reload
-; CHECK-NEXT: vadd.vx v2, v2, a2, v0.t
+; CHECK-NEXT: vadd.vx v6, v6, a2, v0.t
; CHECK-NEXT: vmv4r.v v12, v16
; CHECK-NEXT: vsetvli zero, zero, e64, m8, ta, ma
-; CHECK-NEXT: vrgatherei16.vv v24, v8, v2
+; CHECK-NEXT: vrgatherei16.vv v24, v8, v6
; CHECK-NEXT: addi a2, sp, 16
; CHECK-NEXT: vs8r.v v24, (a2) # Unknown-size Folded Spill
; CHECK-NEXT: csrr a2, vlenb
@@ -130,7 +130,7 @@ define void @vector_interleave_store_nxv16i64_nxv8i64(<vscale x 8 x i64> %a, <vs
; CHECK-NEXT: addi a2, a2, 16
; CHECK-NEXT: vl8r.v v8, (a2) # Unknown-size Folded Reload
; CHECK-NEXT: vmv4r.v v16, v12
-; CHECK-NEXT: vrgatherei16.vv v8, v16, v2
+; CHECK-NEXT: vrgatherei16.vv v8, v16, v6
; CHECK-NEXT: slli a1, a1, 3
; CHECK-NEXT: add a1, a0, a1
; CHECK-NEXT: vs8r.v v8, (a1)
diff --git a/llvm/test/CodeGen/RISCV/rvv/vfadd-vp.ll b/llvm/test/CodeGen/RISCV/rvv/vfadd-vp.ll
index 00cb54c61a7a94..4168f5cd507911 100644
--- a/llvm/test/CodeGen/RISCV/rvv/vfadd-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/vfadd-vp.ll
@@ -591,7 +591,7 @@ define <vscale x 32 x half> @vfadd_vv_nxv32f16(<vscale x 32 x half> %va, <vscale
; ZVFHMIN-NEXT: slli a1, a1, 3
; ZVFHMIN-NEXT: sub sp, sp, a1
; ZVFHMIN-NEXT: .cfi_escape 0x0f, 0x0d, 0x72, 0x00, 0x11, 0x10, 0x22, 0x11, 0x08, 0x92, 0xa2, 0x38, 0x00, 0x1e, 0x22 # sp + 16 + 8 * vlenb
-; ZVFHMIN-NEXT: vmv1r.v v1, v0
+; ZVFHMIN-NEXT: vmv1r.v v7, v0
; ZVFHMIN-NEXT: csrr a2, vlenb
; ZVFHMIN-NEXT: slli a1, a2, 1
; ZVFHMIN-NEXT: sub a3, a0, a1
@@ -619,7 +619,7 @@ define <vscale x 32 x half> @vfadd_vv_nxv32f16(<vscale x 32 x half> %va, <vscale
; ZVFHMIN-NEXT: vfwcvt.f.f.v v16, v24
; ZVFHMIN-NEXT: vfwcvt.f.f.v v24, v8
; ZVFHMIN-NEXT: vsetvli zero, a0, e32, m8, ta, ma
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v7
; ZVFHMIN-NEXT: vfadd.vv v16, v24, v16, v0.t
; ZVFHMIN-NEXT: vsetvli a0, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: vfncvt.f.f.w v8, v16
@@ -699,7 +699,7 @@ define <vscale x 32 x half> @vfadd_vf_nxv32f16(<vscale x 32 x half> %va, half %b
;
; ZVFHMIN-LABEL: vfadd_vf_nxv32f16:
; ZVFHMIN: # %bb.0:
-; ZVFHMIN-NEXT: vmv1r.v v1, v0
+; ZVFHMIN-NEXT: vmv1r.v v3, v0
; ZVFHMIN-NEXT: fcvt.s.h fa5, fa0
; ZVFHMIN-NEXT: vsetvli a1, zero, e32, m8, ta, ma
; ZVFHMIN-NEXT: vfmv.v.f v24, fa5
@@ -727,7 +727,7 @@ define <vscale x 32 x half> @vfadd_vf_nxv32f16(<vscale x 32 x half> %va, half %b
; ZVFHMIN-NEXT: .LBB24_2:
; ZVFHMIN-NEXT: vfwcvt.f.f.v v16, v8
; ZVFHMIN-NEXT: vsetvli zero, a0, e32, m8, ta, ma
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v3
; ZVFHMIN-NEXT: vfadd.vv v16, v16, v24, v0.t
; ZVFHMIN-NEXT: vsetvli a0, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: vfncvt.f.f.w v8, v16
diff --git a/llvm/test/CodeGen/RISCV/rvv/vfdiv-vp.ll b/llvm/test/CodeGen/RISCV/rvv/vfdiv-vp.ll
index a49c0fd08ffe46..396e99bc5e4f5d 100644
--- a/llvm/test/CodeGen/RISCV/rvv/vfdiv-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/vfdiv-vp.ll
@@ -535,7 +535,7 @@ define <vscale x 32 x half> @vfdiv_vv_nxv32f16(<vscale x 32 x half> %va, <vscale
; ZVFHMIN-NEXT: slli a1, a1, 3
; ZVFHMIN-NEXT: sub sp, sp, a1
; ZVFHMIN-NEXT: .cfi_escape 0x0f, 0x0d, 0x72, 0x00, 0x11, 0x10, 0x22, 0x11, 0x08, 0x92, 0xa2, 0x38, 0x00, 0x1e, 0x22 # sp + 16 + 8 * vlenb
-; ZVFHMIN-NEXT: vmv1r.v v1, v0
+; ZVFHMIN-NEXT: vmv1r.v v7, v0
; ZVFHMIN-NEXT: csrr a2, vlenb
; ZVFHMIN-NEXT: slli a1, a2, 1
; ZVFHMIN-NEXT: sub a3, a0, a1
@@ -563,7 +563,7 @@ define <vscale x 32 x half> @vfdiv_vv_nxv32f16(<vscale x 32 x half> %va, <vscale
; ZVFHMIN-NEXT: vfwcvt.f.f.v v16, v24
; ZVFHMIN-NEXT: vfwcvt.f.f.v v24, v8
; ZVFHMIN-NEXT: vsetvli zero, a0, e32, m8, ta, ma
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v7
; ZVFHMIN-NEXT: vfdiv.vv v16, v24, v16, v0.t
; ZVFHMIN-NEXT: vsetvli a0, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: vfncvt.f.f.w v8, v16
@@ -643,7 +643,7 @@ define <vscale x 32 x half> @vfdiv_vf_nxv32f16(<vscale x 32 x half> %va, half %b
;
; ZVFHMIN-LABEL: vfdiv_vf_nxv32f16:
; ZVFHMIN: # %bb.0:
-; ZVFHMIN-NEXT: vmv1r.v v1, v0
+; ZVFHMIN-NEXT: vmv1r.v v3, v0
; ZVFHMIN-NEXT: fcvt.s.h fa5, fa0
; ZVFHMIN-NEXT: vsetvli a1, zero, e32, m8, ta, ma
; ZVFHMIN-NEXT: vfmv.v.f v24, fa5
@@ -671,7 +671,7 @@ define <vscale x 32 x half> @vfdiv_vf_nxv32f16(<vscale x 32 x half> %va, half %b
; ZVFHMIN-NEXT: .LBB22_2:
; ZVFHMIN-NEXT: vfwcvt.f.f.v v16, v8
; ZVFHMIN-NEXT: vsetvli zero, a0, e32, m8, ta, ma
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v3
; ZVFHMIN-NEXT: vfdiv.vv v16, v16, v24, v0.t
; ZVFHMIN-NEXT: vsetvli a0, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: vfncvt.f.f.w v8, v16
diff --git a/llvm/test/CodeGen/RISCV/rvv/vfma-vp.ll b/llvm/test/CodeGen/RISCV/rvv/vfma-vp.ll
index c18602c98e6b87..9ab907bfcca67e 100644
--- a/llvm/test/CodeGen/RISCV/rvv/vfma-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/vfma-vp.ll
@@ -1204,7 +1204,7 @@ define <vscale x 16 x double> @vfma_vv_nxv16f64(<vscale x 16 x double> %va, <vsc
; CHECK-NEXT: mul a1, a1, a3
; CHECK-NEXT: sub sp, sp, a1
; CHECK-NEXT: .cfi_escape 0x0f, 0x0d, 0x72, 0x00, 0x11, 0x10, 0x22, 0x11, 0x28, 0x92, 0xa2, 0x38, 0x00, 0x1e, 0x22 # sp + 16 + 40 * vlenb
-; CHECK-NEXT: vmv1r.v v1, v0
+; CHECK-NEXT: vmv1r.v v7, v0
; CHECK-NEXT: csrr a1, vlenb
; CHECK-NEXT: li a3, 24
; CHECK-NEXT: mul a1, a1, a3
@@ -1267,7 +1267,7 @@ define <vscale x 16 x double> @vfma_vv_nxv16f64(<vscale x 16 x double> %va, <vsc
; CHECK-NEXT: mv a4, a1
; CHECK-NEXT: .LBB92_2:
; CHECK-NEXT: vsetvli zero, a4, e64, m8, ta, ma
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 5
; CHECK-NEXT: add a0, sp, a0
diff --git a/llvm/test/CodeGen/RISCV/rvv/vfmadd-sdnode.ll b/llvm/test/CodeGen/RISCV/rvv/vfmadd-sdnode.ll
index 1f716a9abcc595..6e3ee2a312185d 100644
--- a/llvm/test/CodeGen/RISCV/rvv/vfmadd-sdnode.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/vfmadd-sdnode.ll
@@ -410,14 +410,14 @@ define <vscale x 32 x half> @vfmadd_vf_nxv32f16(<vscale x 32 x half> %va, <vscal
; ZVFHMIN-NEXT: vsetvli a0, zero, e32, m8, ta, ma
; ZVFHMIN-NEXT: vfmv.v.f v24, fa5
; ZVFHMIN-NEXT: vsetvli zero, zero, e16, m4, ta, ma
-; ZVFHMIN-NEXT: vfncvt.f.f.w v0, v24
+; ZVFHMIN-NEXT: vfncvt.f.f.w v4, v24
; ZVFHMIN-NEXT: vfwcvt.f.f.v v24, v8
; ZVFHMIN-NEXT: csrr a0, vlenb
; ZVFHMIN-NEXT: slli a0, a0, 3
; ZVFHMIN-NEXT: add a0, sp, a0
; ZVFHMIN-NEXT: addi a0, a0, 16
; ZVFHMIN-NEXT: vs8r.v v24, (a0) # Unknown-size Folded Spill
-; ZVFHMIN-NEXT: vfwcvt.f.f.v v8, v0
+; ZVFHMIN-NEXT: vfwcvt.f.f.v v8, v4
; ZVFHMIN-NEXT: vfwcvt.f.f.v v0, v16
; ZVFHMIN-NEXT: vsetvli zero, zero, e32, m8, ta, ma
; ZVFHMIN-NEXT: csrr a0, vlenb
diff --git a/llvm/test/CodeGen/RISCV/rvv/vfmax-vp.ll b/llvm/test/CodeGen/RISCV/rvv/vfmax-vp.ll
index c3aaf743af170b..72101d62567b4d 100644
--- a/llvm/test/CodeGen/RISCV/rvv/vfmax-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/vfmax-vp.ll
@@ -255,7 +255,7 @@ define <vscale x 32 x half> @vfmax_vv_nxv32f16(<vscale x 32 x half> %va, <vscale
; ZVFHMIN-NEXT: slli a1, a1, 3
; ZVFHMIN-NEXT: sub sp, sp, a1
; ZVFHMIN-NEXT: .cfi_escape 0x0f, 0x0d, 0x72, 0x00, 0x11, 0x10, 0x22, 0x11, 0x08, 0x92, 0xa2, 0x38, 0x00, 0x1e, 0x22 # sp + 16 + 8 * vlenb
-; ZVFHMIN-NEXT: vmv1r.v v1, v0
+; ZVFHMIN-NEXT: vmv1r.v v7, v0
; ZVFHMIN-NEXT: csrr a2, vlenb
; ZVFHMIN-NEXT: slli a1, a2, 1
; ZVFHMIN-NEXT: sub a3, a0, a1
@@ -283,7 +283,7 @@ define <vscale x 32 x half> @vfmax_vv_nxv32f16(<vscale x 32 x half> %va, <vscale
; ZVFHMIN-NEXT: vfwcvt.f.f.v v16, v24
; ZVFHMIN-NEXT: vfwcvt.f.f.v v24, v8
; ZVFHMIN-NEXT: vsetvli zero, a0, e32, m8, ta, ma
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v7
; ZVFHMIN-NEXT: vfmax.vv v16, v24, v16, v0.t
; ZVFHMIN-NEXT: vsetvli a0, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: vfncvt.f.f.w v8, v16
diff --git a/llvm/test/CodeGen/RISCV/rvv/vfmin-vp.ll b/llvm/test/CodeGen/RISCV/rvv/vfmin-vp.ll
index f18fa85e68d1be..15fa24a35b7d59 100644
--- a/llvm/test/CodeGen/RISCV/rvv/vfmin-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/vfmin-vp.ll
@@ -255,7 +255,7 @@ define <vscale x 32 x half> @vfmin_vv_nxv32f16(<vscale x 32 x half> %va, <vscale
; ZVFHMIN-NEXT: slli a1, a1, 3
; ZVFHMIN-NEXT: sub sp, sp, a1
; ZVFHMIN-NEXT: .cfi_escape 0x0f, 0x0d, 0x72, 0x00, 0x11, 0x10, 0x22, 0x11, 0x08, 0x92, 0xa2, 0x38, 0x00, 0x1e, 0x22 # sp + 16 + 8 * vlenb
-; ZVFHMIN-NEXT: vmv1r.v v1, v0
+; ZVFHMIN-NEXT: vmv1r.v v7, v0
; ZVFHMIN-NEXT: csrr a2, vlenb
; ZVFHMIN-NEXT: slli a1, a2, 1
; ZVFHMIN-NEXT: sub a3, a0, a1
@@ -283,7 +283,7 @@ define <vscale x 32 x half> @vfmin_vv_nxv32f16(<vscale x 32 x half> %va, <vscale
; ZVFHMIN-NEXT: vfwcvt.f.f.v v16, v24
; ZVFHMIN-NEXT: vfwcvt.f.f.v v24, v8
; ZVFHMIN-NEXT: vsetvli zero, a0, e32, m8, ta, ma
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v7
; ZVFHMIN-NEXT: vfmin.vv v16, v24, v16, v0.t
; ZVFHMIN-NEXT: vsetvli a0, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: vfncvt.f.f.w v8, v16
diff --git a/llvm/test/CodeGen/RISCV/rvv/vfmul-vp.ll b/llvm/test/CodeGen/RISCV/rvv/vfmul-vp.ll
index 46b14153447cf7..bb9d3cfed3001a 100644
--- a/llvm/test/CodeGen/RISCV/rvv/vfmul-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/vfmul-vp.ll
@@ -535,7 +535,7 @@ define <vscale x 32 x half> @vfmul_vv_nxv32f16(<vscale x 32 x half> %va, <vscale
; ZVFHMIN-NEXT: slli a1, a1, 3
; ZVFHMIN-NEXT: sub sp, sp, a1
; ZVFHMIN-NEXT: .cfi_escape 0x0f, 0x0d, 0x72, 0x00, 0x11, 0x10, 0x22, 0x11, 0x08, 0x92, 0xa2, 0x38, 0x00, 0x1e, 0x22 # sp + 16 + 8 * vlenb
-; ZVFHMIN-NEXT: vmv1r.v v1, v0
+; ZVFHMIN-NEXT: vmv1r.v v7, v0
; ZVFHMIN-NEXT: csrr a2, vlenb
; ZVFHMIN-NEXT: slli a1, a2, 1
; ZVFHMIN-NEXT: sub a3, a0, a1
@@ -563,7 +563,7 @@ define <vscale x 32 x half> @vfmul_vv_nxv32f16(<vscale x 32 x half> %va, <vscale
; ZVFHMIN-NEXT: vfwcvt.f.f.v v16, v24
; ZVFHMIN-NEXT: vfwcvt.f.f.v v24, v8
; ZVFHMIN-NEXT: vsetvli zero, a0, e32, m8, ta, ma
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v7
; ZVFHMIN-NEXT: vfmul.vv v16, v24, v16, v0.t
; ZVFHMIN-NEXT: vsetvli a0, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: vfncvt.f.f.w v8, v16
@@ -643,7 +643,7 @@ define <vscale x 32 x half> @vfmul_vf_nxv32f16(<vscale x 32 x half> %va, half %b
;
; ZVFHMIN-LABEL: vfmul_vf_nxv32f16:
; ZVFHMIN: # %bb.0:
-; ZVFHMIN-NEXT: vmv1r.v v1, v0
+; ZVFHMIN-NEXT: vmv1r.v v3, v0
; ZVFHMIN-NEXT: fcvt.s.h fa5, fa0
; ZVFHMIN-NEXT: vsetvli a1, zero, e32, m8, ta, ma
; ZVFHMIN-NEXT: vfmv.v.f v24, fa5
@@ -671,7 +671,7 @@ define <vscale x 32 x half> @vfmul_vf_nxv32f16(<vscale x 32 x half> %va, half %b
; ZVFHMIN-NEXT: .LBB22_2:
; ZVFHMIN-NEXT: vfwcvt.f.f.v v16, v8
; ZVFHMIN-NEXT: vsetvli zero, a0, e32, m8, ta, ma
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v3
; ZVFHMIN-NEXT: vfmul.vv v16, v16, v24, v0.t
; ZVFHMIN-NEXT: vsetvli a0, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: vfncvt.f.f.w v8, v16
diff --git a/llvm/test/CodeGen/RISCV/rvv/vfmuladd-vp.ll b/llvm/test/CodeGen/RISCV/rvv/vfmuladd-vp.ll
index 3bbedc109bd087..582043ffb903f6 100644
--- a/llvm/test/CodeGen/RISCV/rvv/vfmuladd-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/vfmuladd-vp.ll
@@ -1204,7 +1204,7 @@ define <vscale x 16 x double> @vfma_vv_nxv16f64(<vscale x 16 x double> %va, <vsc
; CHECK-NEXT: mul a1, a1, a3
; CHECK-NEXT: sub sp, sp, a1
; CHECK-NEXT: .cfi_escape 0x0f, 0x0d, 0x72, 0x00, 0x11, 0x10, 0x22, 0x11, 0x28, 0x92, 0xa2, 0x38, 0x00, 0x1e, 0x22 # sp + 16 + 40 * vlenb
-; CHECK-NEXT: vmv1r.v v1, v0
+; CHECK-NEXT: vmv1r.v v7, v0
; CHECK-NEXT: csrr a1, vlenb
; CHECK-NEXT: li a3, 24
; CHECK-NEXT: mul a1, a1, a3
@@ -1267,7 +1267,7 @@ define <vscale x 16 x double> @vfma_vv_nxv16f64(<vscale x 16 x double> %va, <vsc
; CHECK-NEXT: mv a4, a1
; CHECK-NEXT: .LBB92_2:
; CHECK-NEXT: vsetvli zero, a4, e64, m8, ta, ma
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 5
; CHECK-NEXT: add a0, sp, a0
diff --git a/llvm/test/CodeGen/RISCV/rvv/vfnmadd-constrained-sdnode.ll b/llvm/test/CodeGen/RISCV/rvv/vfnmadd-constrained-sdnode.ll
index db34980f525264..785f60ad1d39c8 100644
--- a/llvm/test/CodeGen/RISCV/rvv/vfnmadd-constrained-sdnode.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/vfnmadd-constrained-sdnode.ll
@@ -326,7 +326,7 @@ define <vscale x 16 x half> @vfnmsub_vv_nxv16f16(<vscale x 16 x half> %va, <vsca
;
; ZVFHMIN-LABEL: vfnmsub_vv_nxv16f16:
; ZVFHMIN: # %bb.0:
-; ZVFHMIN-NEXT: vmv4r.v v0, v8
+; ZVFHMIN-NEXT: vmv4r.v v4, v8
; ZVFHMIN-NEXT: vsetvli a0, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: vfwcvt.f.f.v v24, v16
; ZVFHMIN-NEXT: vsetvli zero, zero, e32, m8, ta, ma
@@ -338,7 +338,7 @@ define <vscale x 16 x half> @vfnmsub_vv_nxv16f16(<vscale x 16 x half> %va, <vsca
; ZVFHMIN-NEXT: vfneg.v v16, v16
; ZVFHMIN-NEXT: vsetvli zero, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: vfncvt.f.f.w v12, v16
-; ZVFHMIN-NEXT: vfwcvt.f.f.v v16, v0
+; ZVFHMIN-NEXT: vfwcvt.f.f.v v16, v4
; ZVFHMIN-NEXT: vfwcvt.f.f.v v0, v12
; ZVFHMIN-NEXT: vfwcvt.f.f.v v24, v8
; ZVFHMIN-NEXT: vsetvli zero, zero, e32, m8, ta, ma
@@ -529,8 +529,8 @@ define <vscale x 32 x half> @vfnmsub_vf_nxv32f16(<vscale x 32 x half> %va, <vsca
; ZVFHMIN-NEXT: vsetvli a0, zero, e32, m8, ta, ma
; ZVFHMIN-NEXT: vfmv.v.f v24, fa5
; ZVFHMIN-NEXT: vsetvli zero, zero, e16, m4, ta, ma
-; ZVFHMIN-NEXT: vfncvt.f.f.w v0, v24
-; ZVFHMIN-NEXT: vfwcvt.f.f.v v24, v0
+; ZVFHMIN-NEXT: vfncvt.f.f.w v4, v24
+; ZVFHMIN-NEXT: vfwcvt.f.f.v v24, v4
; ZVFHMIN-NEXT: vsetvli zero, zero, e32, m8, ta, ma
; ZVFHMIN-NEXT: vfneg.v v0, v24
; ZVFHMIN-NEXT: vsetvli zero, zero, e16, m4, ta, ma
diff --git a/llvm/test/CodeGen/RISCV/rvv/vfnmsub-constrained-sdnode.ll b/llvm/test/CodeGen/RISCV/rvv/vfnmsub-constrained-sdnode.ll
index ccbed4b9590500..1a2da051c962ea 100644
--- a/llvm/test/CodeGen/RISCV/rvv/vfnmsub-constrained-sdnode.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/vfnmsub-constrained-sdnode.ll
@@ -284,7 +284,7 @@ define <vscale x 16 x half> @vfnmsub_vv_nxv16f16(<vscale x 16 x half> %va, <vsca
; ZVFHMIN-NEXT: slli a0, a0, 2
; ZVFHMIN-NEXT: sub sp, sp, a0
; ZVFHMIN-NEXT: .cfi_escape 0x0f, 0x0d, 0x72, 0x00, 0x11, 0x10, 0x22, 0x11, 0x04, 0x92, 0xa2, 0x38, 0x00, 0x1e, 0x22 # sp + 16 + 4 * vlenb
-; ZVFHMIN-NEXT: vmv4r.v v0, v12
+; ZVFHMIN-NEXT: vmv4r.v v4, v12
; ZVFHMIN-NEXT: addi a0, sp, 16
; ZVFHMIN-NEXT: vs4r.v v8, (a0) # Unknown-size Folded Spill
; ZVFHMIN-NEXT: vsetvli a0, zero, e16, m4, ta, ma
@@ -293,7 +293,7 @@ define <vscale x 16 x half> @vfnmsub_vv_nxv16f16(<vscale x 16 x half> %va, <vsca
; ZVFHMIN-NEXT: vfneg.v v16, v24
; ZVFHMIN-NEXT: vsetvli zero, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: vfncvt.f.f.w v24, v16
-; ZVFHMIN-NEXT: vfwcvt.f.f.v v8, v0
+; ZVFHMIN-NEXT: vfwcvt.f.f.v v8, v4
; ZVFHMIN-NEXT: addi a0, sp, 16
; ZVFHMIN-NEXT: vl4r.v v16, (a0) # Unknown-size Folded Reload
; ZVFHMIN-NEXT: vfwcvt.f.f.v v0, v16
@@ -490,8 +490,8 @@ define <vscale x 32 x half> @vfnmsub_vf_nxv32f16(<vscale x 32 x half> %va, <vsca
; ZVFHMIN-NEXT: vsetvli a0, zero, e32, m8, ta, ma
; ZVFHMIN-NEXT: vfmv.v.f v8, fa5
; ZVFHMIN-NEXT: vsetvli zero, zero, e16, m4, ta, ma
-; ZVFHMIN-NEXT: vfncvt.f.f.w v0, v8
-; ZVFHMIN-NEXT: vfwcvt.f.f.v v8, v0
+; ZVFHMIN-NEXT: vfncvt.f.f.w v4, v8
+; ZVFHMIN-NEXT: vfwcvt.f.f.v v8, v4
; ZVFHMIN-NEXT: vsetvli zero, zero, e32, m8, ta, ma
; ZVFHMIN-NEXT: vfneg.v v0, v8
; ZVFHMIN-NEXT: vsetvli zero, zero, e16, m4, ta, ma
diff --git a/llvm/test/CodeGen/RISCV/rvv/vfptrunc-vp.ll b/llvm/test/CodeGen/RISCV/rvv/vfptrunc-vp.ll
index 4e84a31d71b512..dd122f1f251103 100644
--- a/llvm/test/CodeGen/RISCV/rvv/vfptrunc-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/vfptrunc-vp.ll
@@ -102,7 +102,7 @@ define <vscale x 16 x float> @vfptrunc_nxv16f32_nxv16f64(<vscale x 16 x double>
; CHECK-NEXT: slli a1, a1, 3
; CHECK-NEXT: sub sp, sp, a1
; CHECK-NEXT: .cfi_escape 0x0f, 0x0d, 0x72, 0x00, 0x11, 0x10, 0x22, 0x11, 0x08, 0x92, 0xa2, 0x38, 0x00, 0x1e, 0x22 # sp + 16 + 8 * vlenb
-; CHECK-NEXT: vmv1r.v v1, v0
+; CHECK-NEXT: vmv1r.v v7, v0
; CHECK-NEXT: addi a1, sp, 16
; CHECK-NEXT: vs8r.v v16, (a1) # Unknown-size Folded Spill
; CHECK-NEXT: csrr a1, vlenb
@@ -122,7 +122,7 @@ define <vscale x 16 x float> @vfptrunc_nxv16f32_nxv16f64(<vscale x 16 x double>
; CHECK-NEXT: mv a0, a1
; CHECK-NEXT: .LBB7_2:
; CHECK-NEXT: vsetvli zero, a0, e32, m4, ta, ma
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vfncvt.f.f.w v16, v8, v0.t
; CHECK-NEXT: vmv8r.v v8, v16
; CHECK-NEXT: csrr a0, vlenb
@@ -145,7 +145,7 @@ define <vscale x 32 x float> @vfptrunc_nxv32f32_nxv32f64(<vscale x 32 x double>
; CHECK-NEXT: slli a1, a1, 4
; CHECK-NEXT: sub sp, sp, a1
; CHECK-NEXT: .cfi_escape 0x0f, 0x0d, 0x72, 0x00, 0x11, 0x10, 0x22, 0x11, 0x10, 0x92, 0xa2, 0x38, 0x00, 0x1e, 0x22 # sp + 16 + 16 * vlenb
-; CHECK-NEXT: vmv1r.v v1, v0
+; CHECK-NEXT: vmv1r.v v7, v0
; CHECK-NEXT: addi a1, sp, 16
; CHECK-NEXT: vs8r.v v16, (a1) # Unknown-size Folded Spill
; CHECK-NEXT: csrr a1, vlenb
@@ -180,7 +180,7 @@ define <vscale x 32 x float> @vfptrunc_nxv32f32_nxv32f64(<vscale x 32 x double>
; CHECK-NEXT: mv a5, a1
; CHECK-NEXT: .LBB8_2:
; CHECK-NEXT: vsetvli a0, zero, e8, mf4, ta, ma
-; CHECK-NEXT: vslidedown.vx v2, v1, a3
+; CHECK-NEXT: vslidedown.vx v6, v7, a3
; CHECK-NEXT: vsetvli zero, a5, e32, m4, ta, ma
; CHECK-NEXT: vmv1r.v v0, v16
; CHECK-NEXT: vfncvt.f.f.w v16, v24, v0.t
@@ -193,7 +193,7 @@ define <vscale x 32 x float> @vfptrunc_nxv32f32_nxv32f64(<vscale x 32 x double>
; CHECK-NEXT: addi a3, a3, -1
; CHECK-NEXT: and a0, a3, a0
; CHECK-NEXT: vsetvli zero, a0, e32, m4, ta, ma
-; CHECK-NEXT: vmv1r.v v0, v2
+; CHECK-NEXT: vmv1r.v v0, v6
; CHECK-NEXT: addi a0, sp, 16
; CHECK-NEXT: vl8r.v v8, (a0) # Unknown-size Folded Reload
; CHECK-NEXT: vfncvt.f.f.w v28, v8, v0.t
@@ -202,7 +202,7 @@ define <vscale x 32 x float> @vfptrunc_nxv32f32_nxv32f64(<vscale x 32 x double>
; CHECK-NEXT: mv a2, a1
; CHECK-NEXT: .LBB8_6:
; CHECK-NEXT: vsetvli zero, a2, e32, m4, ta, ma
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 3
; CHECK-NEXT: add a0, sp, a0
diff --git a/llvm/test/CodeGen/RISCV/rvv/vfsub-vp.ll b/llvm/test/CodeGen/RISCV/rvv/vfsub-vp.ll
index 0df7b2ce1978da..010b133e51b1f2 100644
--- a/llvm/test/CodeGen/RISCV/rvv/vfsub-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/vfsub-vp.ll
@@ -535,7 +535,7 @@ define <vscale x 32 x half> @vfsub_vv_nxv32f16(<vscale x 32 x half> %va, <vscale
; ZVFHMIN-NEXT: slli a1, a1, 3
; ZVFHMIN-NEXT: sub sp, sp, a1
; ZVFHMIN-NEXT: .cfi_escape 0x0f, 0x0d, 0x72, 0x00, 0x11, 0x10, 0x22, 0x11, 0x08, 0x92, 0xa2, 0x38, 0x00, 0x1e, 0x22 # sp + 16 + 8 * vlenb
-; ZVFHMIN-NEXT: vmv1r.v v1, v0
+; ZVFHMIN-NEXT: vmv1r.v v7, v0
; ZVFHMIN-NEXT: csrr a2, vlenb
; ZVFHMIN-NEXT: slli a1, a2, 1
; ZVFHMIN-NEXT: sub a3, a0, a1
@@ -563,7 +563,7 @@ define <vscale x 32 x half> @vfsub_vv_nxv32f16(<vscale x 32 x half> %va, <vscale
; ZVFHMIN-NEXT: vfwcvt.f.f.v v16, v24
; ZVFHMIN-NEXT: vfwcvt.f.f.v v24, v8
; ZVFHMIN-NEXT: vsetvli zero, a0, e32, m8, ta, ma
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v7
; ZVFHMIN-NEXT: vfsub.vv v16, v24, v16, v0.t
; ZVFHMIN-NEXT: vsetvli a0, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: vfncvt.f.f.w v8, v16
@@ -643,7 +643,7 @@ define <vscale x 32 x half> @vfsub_vf_nxv32f16(<vscale x 32 x half> %va, half %b
;
; ZVFHMIN-LABEL: vfsub_vf_nxv32f16:
; ZVFHMIN: # %bb.0:
-; ZVFHMIN-NEXT: vmv1r.v v1, v0
+; ZVFHMIN-NEXT: vmv1r.v v3, v0
; ZVFHMIN-NEXT: fcvt.s.h fa5, fa0
; ZVFHMIN-NEXT: vsetvli a1, zero, e32, m8, ta, ma
; ZVFHMIN-NEXT: vfmv.v.f v24, fa5
@@ -671,7 +671,7 @@ define <vscale x 32 x half> @vfsub_vf_nxv32f16(<vscale x 32 x half> %va, half %b
; ZVFHMIN-NEXT: .LBB22_2:
; ZVFHMIN-NEXT: vfwcvt.f.f.v v16, v8
; ZVFHMIN-NEXT: vsetvli zero, a0, e32, m8, ta, ma
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v3
; ZVFHMIN-NEXT: vfsub.vv v16, v16, v24, v0.t
; ZVFHMIN-NEXT: vsetvli a0, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: vfncvt.f.f.w v8, v16
diff --git a/llvm/test/CodeGen/RISCV/rvv/vfwmacc-vp.ll b/llvm/test/CodeGen/RISCV/rvv/vfwmacc-vp.ll
index d84df3a06473cb..8a484c7f6b7769 100644
--- a/llvm/test/CodeGen/RISCV/rvv/vfwmacc-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/vfwmacc-vp.ll
@@ -781,10 +781,10 @@ define <vscale x 16 x float> @vfmacc_vf_nxv16f32_unmasked(<vscale x 16 x half> %
; ZVFHMIN-NEXT: vsetvli a1, zero, e32, m8, ta, ma
; ZVFHMIN-NEXT: vfmv.v.f v24, fa5
; ZVFHMIN-NEXT: vsetvli zero, zero, e16, m4, ta, ma
-; ZVFHMIN-NEXT: vfncvt.f.f.w v0, v24
+; ZVFHMIN-NEXT: vfncvt.f.f.w v4, v24
; ZVFHMIN-NEXT: vsetvli zero, a0, e16, m4, ta, ma
; ZVFHMIN-NEXT: vfwcvt.f.f.v v24, v8
-; ZVFHMIN-NEXT: vfwcvt.f.f.v v8, v0
+; ZVFHMIN-NEXT: vfwcvt.f.f.v v8, v4
; ZVFHMIN-NEXT: vsetvli zero, zero, e32, m8, ta, ma
; ZVFHMIN-NEXT: vfmadd.vv v8, v24, v16
; ZVFHMIN-NEXT: ret
diff --git a/llvm/test/CodeGen/RISCV/rvv/vfwnmacc-vp.ll b/llvm/test/CodeGen/RISCV/rvv/vfwnmacc-vp.ll
index 3dc8340600fded..3a03f0d65273ed 100644
--- a/llvm/test/CodeGen/RISCV/rvv/vfwnmacc-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/vfwnmacc-vp.ll
@@ -764,10 +764,10 @@ define <vscale x 16 x float> @vfnmacc_vf_nxv16f32_unmasked(<vscale x 16 x half>
; ZVFHMIN-NEXT: vsetvli a1, zero, e32, m8, ta, ma
; ZVFHMIN-NEXT: vfmv.v.f v24, fa5
; ZVFHMIN-NEXT: vsetvli zero, zero, e16, m4, ta, ma
-; ZVFHMIN-NEXT: vfncvt.f.f.w v0, v24
+; ZVFHMIN-NEXT: vfncvt.f.f.w v4, v24
; ZVFHMIN-NEXT: vsetvli zero, a0, e16, m4, ta, ma
; ZVFHMIN-NEXT: vfwcvt.f.f.v v24, v8
-; ZVFHMIN-NEXT: vfwcvt.f.f.v v8, v0
+; ZVFHMIN-NEXT: vfwcvt.f.f.v v8, v4
; ZVFHMIN-NEXT: vsetvli zero, zero, e32, m8, ta, ma
; ZVFHMIN-NEXT: vfnmadd.vv v8, v24, v16
; ZVFHMIN-NEXT: ret
diff --git a/llvm/test/CodeGen/RISCV/rvv/vfwnmsac-vp.ll b/llvm/test/CodeGen/RISCV/rvv/vfwnmsac-vp.ll
index 6eb1f512f76af7..a8cc0ce92aa16e 100644
--- a/llvm/test/CodeGen/RISCV/rvv/vfwnmsac-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/vfwnmsac-vp.ll
@@ -735,10 +735,10 @@ define <vscale x 16 x float> @vfnmsac_vf_nxv16f32_unmasked(<vscale x 16 x half>
; ZVFHMIN-NEXT: vsetvli a1, zero, e32, m8, ta, ma
; ZVFHMIN-NEXT: vfmv.v.f v24, fa5
; ZVFHMIN-NEXT: vsetvli zero, zero, e16, m4, ta, ma
-; ZVFHMIN-NEXT: vfncvt.f.f.w v0, v24
+; ZVFHMIN-NEXT: vfncvt.f.f.w v4, v24
; ZVFHMIN-NEXT: vsetvli zero, a0, e16, m4, ta, ma
; ZVFHMIN-NEXT: vfwcvt.f.f.v v24, v8
-; ZVFHMIN-NEXT: vfwcvt.f.f.v v8, v0
+; ZVFHMIN-NEXT: vfwcvt.f.f.v v8, v4
; ZVFHMIN-NEXT: vsetvli zero, zero, e32, m8, ta, ma
; ZVFHMIN-NEXT: vfnmsub.vv v8, v24, v16
; ZVFHMIN-NEXT: ret
diff --git a/llvm/test/CodeGen/RISCV/rvv/vpmerge-sdnode.ll b/llvm/test/CodeGen/RISCV/rvv/vpmerge-sdnode.ll
index 2f8454983d0d6e..4f67aac2d2d2ba 100644
--- a/llvm/test/CodeGen/RISCV/rvv/vpmerge-sdnode.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/vpmerge-sdnode.ll
@@ -379,7 +379,7 @@ define <vscale x 128 x i8> @vpmerge_vv_nxv128i8(<vscale x 128 x i8> %va, <vscale
; CHECK-NEXT: slli a1, a1, 3
; CHECK-NEXT: sub sp, sp, a1
; CHECK-NEXT: .cfi_escape 0x0f, 0x0d, 0x72, 0x00, 0x11, 0x10, 0x22, 0x11, 0x08, 0x92, 0xa2, 0x38, 0x00, 0x1e, 0x22 # sp + 16 + 8 * vlenb
-; CHECK-NEXT: vmv1r.v v1, v0
+; CHECK-NEXT: vmv1r.v v7, v0
; CHECK-NEXT: vmv8r.v v24, v16
; CHECK-NEXT: addi a1, sp, 16
; CHECK-NEXT: vs8r.v v8, (a1) # Unknown-size Folded Spill
@@ -401,7 +401,7 @@ define <vscale x 128 x i8> @vpmerge_vv_nxv128i8(<vscale x 128 x i8> %va, <vscale
; CHECK-NEXT: mv a3, a1
; CHECK-NEXT: .LBB28_2:
; CHECK-NEXT: vsetvli zero, a3, e8, m8, tu, ma
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: addi a0, sp, 16
; CHECK-NEXT: vl8r.v v24, (a0) # Unknown-size Folded Reload
; CHECK-NEXT: vmerge.vvm v8, v8, v24, v0
diff --git a/llvm/test/CodeGen/RISCV/rvv/vreductions-fp-vp.ll b/llvm/test/CodeGen/RISCV/rvv/vreductions-fp-vp.ll
index bd510d26279c48..4f7cb84c086443 100644
--- a/llvm/test/CodeGen/RISCV/rvv/vreductions-fp-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/vreductions-fp-vp.ll
@@ -203,7 +203,7 @@ define half @vpreduce_fadd_nxv64f16(half %s, <vscale x 64 x half> %v, <vscale x
; ZVFHMIN-NEXT: csrr a3, vlenb
; ZVFHMIN-NEXT: srli a1, a3, 1
; ZVFHMIN-NEXT: vsetvli a2, zero, e8, m1, ta, ma
-; ZVFHMIN-NEXT: vslidedown.vx v1, v0, a1
+; ZVFHMIN-NEXT: vslidedown.vx v7, v0, a1
; ZVFHMIN-NEXT: slli a5, a3, 2
; ZVFHMIN-NEXT: sub a1, a0, a5
; ZVFHMIN-NEXT: sltu a2, a0, a1
@@ -228,7 +228,7 @@ define half @vpreduce_fadd_nxv64f16(half %s, <vscale x 64 x half> %v, <vscale x
; ZVFHMIN-NEXT: and a5, a6, a5
; ZVFHMIN-NEXT: srli a3, a3, 2
; ZVFHMIN-NEXT: vsetvli a6, zero, e8, mf2, ta, ma
-; ZVFHMIN-NEXT: vslidedown.vx v2, v0, a3
+; ZVFHMIN-NEXT: vslidedown.vx v6, v0, a3
; ZVFHMIN-NEXT: bltu a0, a4, .LBB6_6
; ZVFHMIN-NEXT: # %bb.5:
; ZVFHMIN-NEXT: mv a0, a4
@@ -248,7 +248,7 @@ define half @vpreduce_fadd_nxv64f16(half %s, <vscale x 64 x half> %v, <vscale x
; ZVFHMIN-NEXT: vsetvli a0, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: vfwcvt.f.f.v v24, v12
; ZVFHMIN-NEXT: vsetvli zero, a5, e32, m8, ta, ma
-; ZVFHMIN-NEXT: vmv1r.v v0, v2
+; ZVFHMIN-NEXT: vmv1r.v v0, v6
; ZVFHMIN-NEXT: vfredusum.vs v8, v24, v8, v0.t
; ZVFHMIN-NEXT: vfmv.f.s fa5, v8
; ZVFHMIN-NEXT: fcvt.h.s fa5, fa5
@@ -258,7 +258,7 @@ define half @vpreduce_fadd_nxv64f16(half %s, <vscale x 64 x half> %v, <vscale x
; ZVFHMIN-NEXT: vsetvli a0, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: vfwcvt.f.f.v v24, v16
; ZVFHMIN-NEXT: vsetvli zero, a1, e32, m8, ta, ma
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v7
; ZVFHMIN-NEXT: vfredusum.vs v8, v24, v8, v0.t
; ZVFHMIN-NEXT: vfmv.f.s fa5, v8
; ZVFHMIN-NEXT: fcvt.h.s fa5, fa5
@@ -266,7 +266,7 @@ define half @vpreduce_fadd_nxv64f16(half %s, <vscale x 64 x half> %v, <vscale x
; ZVFHMIN-NEXT: vsetivli zero, 1, e32, m8, ta, ma
; ZVFHMIN-NEXT: vfmv.s.f v8, fa5
; ZVFHMIN-NEXT: vsetvli a0, zero, e8, mf2, ta, ma
-; ZVFHMIN-NEXT: vslidedown.vx v0, v1, a3
+; ZVFHMIN-NEXT: vslidedown.vx v0, v7, a3
; ZVFHMIN-NEXT: vsetvli a0, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: vfwcvt.f.f.v v24, v20
; ZVFHMIN-NEXT: vsetvli zero, a2, e32, m8, ta, ma
@@ -309,7 +309,7 @@ define half @vpreduce_ord_fadd_nxv64f16(half %s, <vscale x 64 x half> %v, <vscal
; ZVFHMIN-NEXT: csrr a3, vlenb
; ZVFHMIN-NEXT: srli a1, a3, 1
; ZVFHMIN-NEXT: vsetvli a2, zero, e8, m1, ta, ma
-; ZVFHMIN-NEXT: vslidedown.vx v1, v0, a1
+; ZVFHMIN-NEXT: vslidedown.vx v7, v0, a1
; ZVFHMIN-NEXT: slli a5, a3, 2
; ZVFHMIN-NEXT: sub a1, a0, a5
; ZVFHMIN-NEXT: sltu a2, a0, a1
@@ -334,7 +334,7 @@ define half @vpreduce_ord_fadd_nxv64f16(half %s, <vscale x 64 x half> %v, <vscal
; ZVFHMIN-NEXT: and a5, a6, a5
; ZVFHMIN-NEXT: srli a3, a3, 2
; ZVFHMIN-NEXT: vsetvli a6, zero, e8, mf2, ta, ma
-; ZVFHMIN-NEXT: vslidedown.vx v2, v0, a3
+; ZVFHMIN-NEXT: vslidedown.vx v6, v0, a3
; ZVFHMIN-NEXT: bltu a0, a4, .LBB7_6
; ZVFHMIN-NEXT: # %bb.5:
; ZVFHMIN-NEXT: mv a0, a4
@@ -354,7 +354,7 @@ define half @vpreduce_ord_fadd_nxv64f16(half %s, <vscale x 64 x half> %v, <vscal
; ZVFHMIN-NEXT: vsetvli a0, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: vfwcvt.f.f.v v24, v12
; ZVFHMIN-NEXT: vsetvli zero, a5, e32, m8, ta, ma
-; ZVFHMIN-NEXT: vmv1r.v v0, v2
+; ZVFHMIN-NEXT: vmv1r.v v0, v6
; ZVFHMIN-NEXT: vfredosum.vs v8, v24, v8, v0.t
; ZVFHMIN-NEXT: vfmv.f.s fa5, v8
; ZVFHMIN-NEXT: fcvt.h.s fa5, fa5
@@ -364,7 +364,7 @@ define half @vpreduce_ord_fadd_nxv64f16(half %s, <vscale x 64 x half> %v, <vscal
; ZVFHMIN-NEXT: vsetvli a0, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: vfwcvt.f.f.v v24, v16
; ZVFHMIN-NEXT: vsetvli zero, a1, e32, m8, ta, ma
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v7
; ZVFHMIN-NEXT: vfredosum.vs v8, v24, v8, v0.t
; ZVFHMIN-NEXT: vfmv.f.s fa5, v8
; ZVFHMIN-NEXT: fcvt.h.s fa5, fa5
@@ -372,7 +372,7 @@ define half @vpreduce_ord_fadd_nxv64f16(half %s, <vscale x 64 x half> %v, <vscal
; ZVFHMIN-NEXT: vsetivli zero, 1, e32, m8, ta, ma
; ZVFHMIN-NEXT: vfmv.s.f v8, fa5
; ZVFHMIN-NEXT: vsetvli a0, zero, e8, mf2, ta, ma
-; ZVFHMIN-NEXT: vslidedown.vx v0, v1, a3
+; ZVFHMIN-NEXT: vslidedown.vx v0, v7, a3
; ZVFHMIN-NEXT: vsetvli a0, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: vfwcvt.f.f.v v24, v20
; ZVFHMIN-NEXT: vsetvli zero, a2, e32, m8, ta, ma
diff --git a/llvm/test/CodeGen/RISCV/rvv/vselect-fp.ll b/llvm/test/CodeGen/RISCV/rvv/vselect-fp.ll
index 3faceb0aa6b614..17c362fc0a1aeb 100644
--- a/llvm/test/CodeGen/RISCV/rvv/vselect-fp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/vselect-fp.ll
@@ -500,15 +500,15 @@ define void @vselect_legalize_regression(<vscale x 16 x double> %a, <vscale x 16
; CHECK: # %bb.0:
; CHECK-NEXT: vsetvli a2, zero, e8, m2, ta, ma
; CHECK-NEXT: vlm.v v24, (a0)
-; CHECK-NEXT: vmand.mm v1, v0, v24
+; CHECK-NEXT: vmand.mm v7, v0, v24
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: srli a2, a0, 3
; CHECK-NEXT: vsetvli a3, zero, e8, mf4, ta, ma
-; CHECK-NEXT: vslidedown.vx v0, v1, a2
+; CHECK-NEXT: vslidedown.vx v0, v7, a2
; CHECK-NEXT: vsetvli a2, zero, e64, m8, ta, ma
; CHECK-NEXT: vmv.v.i v24, 0
; CHECK-NEXT: vmerge.vvm v16, v24, v16, v0
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: vmerge.vvm v8, v24, v8, v0
; CHECK-NEXT: vs8r.v v8, (a1)
; CHECK-NEXT: slli a0, a0, 3
diff --git a/llvm/test/CodeGen/RISCV/rvv/vsitofp-vp.ll b/llvm/test/CodeGen/RISCV/rvv/vsitofp-vp.ll
index 016a43784733d0..706876dc385475 100644
--- a/llvm/test/CodeGen/RISCV/rvv/vsitofp-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/vsitofp-vp.ll
@@ -410,7 +410,7 @@ define <vscale x 32 x half> @vsitofp_nxv32f16_nxv32i32(<vscale x 32 x i32> %va,
;
; ZVFHMIN-LABEL: vsitofp_nxv32f16_nxv32i32:
; ZVFHMIN: # %bb.0:
-; ZVFHMIN-NEXT: vmv1r.v v1, v0
+; ZVFHMIN-NEXT: vmv1r.v v7, v0
; ZVFHMIN-NEXT: csrr a1, vlenb
; ZVFHMIN-NEXT: srli a2, a1, 2
; ZVFHMIN-NEXT: vsetvli a3, zero, e8, mf2, ta, ma
@@ -429,7 +429,7 @@ define <vscale x 32 x half> @vsitofp_nxv32f16_nxv32i32(<vscale x 32 x i32> %va,
; ZVFHMIN-NEXT: mv a0, a1
; ZVFHMIN-NEXT: .LBB25_2:
; ZVFHMIN-NEXT: vsetvli zero, a0, e32, m8, ta, ma
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v7
; ZVFHMIN-NEXT: vfcvt.f.x.v v8, v8, v0.t
; ZVFHMIN-NEXT: vsetvli a0, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: vfncvt.f.f.w v16, v8
diff --git a/llvm/test/CodeGen/RISCV/rvv/vtrunc-vp.ll b/llvm/test/CodeGen/RISCV/rvv/vtrunc-vp.ll
index a7b4d6616b7b5d..4857810e7a1703 100644
--- a/llvm/test/CodeGen/RISCV/rvv/vtrunc-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/vtrunc-vp.ll
@@ -288,7 +288,7 @@ define <vscale x 32 x i32> @vtrunc_nxv32i64_nxv32i32(<vscale x 32 x i64> %a, <vs
; CHECK-NEXT: slli a1, a1, 4
; CHECK-NEXT: sub sp, sp, a1
; CHECK-NEXT: .cfi_escape 0x0f, 0x0d, 0x72, 0x00, 0x11, 0x10, 0x22, 0x11, 0x10, 0x92, 0xa2, 0x38, 0x00, 0x1e, 0x22 # sp + 16 + 16 * vlenb
-; CHECK-NEXT: vmv1r.v v1, v0
+; CHECK-NEXT: vmv1r.v v7, v0
; CHECK-NEXT: addi a1, sp, 16
; CHECK-NEXT: vs8r.v v16, (a1) # Unknown-size Folded Spill
; CHECK-NEXT: csrr a1, vlenb
@@ -323,7 +323,7 @@ define <vscale x 32 x i32> @vtrunc_nxv32i64_nxv32i32(<vscale x 32 x i64> %a, <vs
; CHECK-NEXT: mv a5, a1
; CHECK-NEXT: .LBB17_2:
; CHECK-NEXT: vsetvli a0, zero, e8, mf4, ta, ma
-; CHECK-NEXT: vslidedown.vx v2, v1, a3
+; CHECK-NEXT: vslidedown.vx v6, v7, a3
; CHECK-NEXT: vsetvli zero, a5, e32, m4, ta, ma
; CHECK-NEXT: vmv1r.v v0, v16
; CHECK-NEXT: vnsrl.wi v16, v24, 0, v0.t
@@ -336,7 +336,7 @@ define <vscale x 32 x i32> @vtrunc_nxv32i64_nxv32i32(<vscale x 32 x i64> %a, <vs
; CHECK-NEXT: addi a3, a3, -1
; CHECK-NEXT: and a0, a3, a0
; CHECK-NEXT: vsetvli zero, a0, e32, m4, ta, ma
-; CHECK-NEXT: vmv1r.v v0, v2
+; CHECK-NEXT: vmv1r.v v0, v6
; CHECK-NEXT: addi a0, sp, 16
; CHECK-NEXT: vl8r.v v8, (a0) # Unknown-size Folded Reload
; CHECK-NEXT: vnsrl.wi v28, v8, 0, v0.t
@@ -345,7 +345,7 @@ define <vscale x 32 x i32> @vtrunc_nxv32i64_nxv32i32(<vscale x 32 x i64> %a, <vs
; CHECK-NEXT: mv a2, a1
; CHECK-NEXT: .LBB17_6:
; CHECK-NEXT: vsetvli zero, a2, e32, m4, ta, ma
-; CHECK-NEXT: vmv1r.v v0, v1
+; CHECK-NEXT: vmv1r.v v0, v7
; CHECK-NEXT: csrr a0, vlenb
; CHECK-NEXT: slli a0, a0, 3
; CHECK-NEXT: add a0, sp, a0
diff --git a/llvm/test/CodeGen/RISCV/rvv/vuitofp-vp.ll b/llvm/test/CodeGen/RISCV/rvv/vuitofp-vp.ll
index 668d9373b81d3b..e083d594db25df 100644
--- a/llvm/test/CodeGen/RISCV/rvv/vuitofp-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/vuitofp-vp.ll
@@ -410,7 +410,7 @@ define <vscale x 32 x half> @vuitofp_nxv32f16_nxv32i32(<vscale x 32 x i32> %va,
;
; ZVFHMIN-LABEL: vuitofp_nxv32f16_nxv32i32:
; ZVFHMIN: # %bb.0:
-; ZVFHMIN-NEXT: vmv1r.v v1, v0
+; ZVFHMIN-NEXT: vmv1r.v v7, v0
; ZVFHMIN-NEXT: csrr a1, vlenb
; ZVFHMIN-NEXT: srli a2, a1, 2
; ZVFHMIN-NEXT: vsetvli a3, zero, e8, mf2, ta, ma
@@ -429,7 +429,7 @@ define <vscale x 32 x half> @vuitofp_nxv32f16_nxv32i32(<vscale x 32 x i32> %va,
; ZVFHMIN-NEXT: mv a0, a1
; ZVFHMIN-NEXT: .LBB25_2:
; ZVFHMIN-NEXT: vsetvli zero, a0, e32, m8, ta, ma
-; ZVFHMIN-NEXT: vmv1r.v v0, v1
+; ZVFHMIN-NEXT: vmv1r.v v0, v7
; ZVFHMIN-NEXT: vfcvt.f.xu.v v8, v8, v0.t
; ZVFHMIN-NEXT: vsetvli a0, zero, e16, m4, ta, ma
; ZVFHMIN-NEXT: vfncvt.f.f.w v16, v8
>From 4551f53523074cd4e2f93a6f79313ca2cdcc40d2 Mon Sep 17 00:00:00 2001
From: Jason Molenda <jmolenda at apple.com>
Date: Thu, 29 Feb 2024 20:22:12 -0800
Subject: [PATCH 207/406] [lldb] [debugserver] fix qLaunchSuccess error, add
QErrorStringInPacketSupported (#82593)
Pavel added an extension to lldb's gdb remote serial protocol that
allows the debug stub to append an error message (ascii hex encoded)
after an error response packet Exx. This was added in 2017 in
https://reviews.llvm.org/D34945 . lldb sends the
QErrorStringInPacketSupported packet and then the remote stub may add
these error strings.
debugserver has two bugs in its use of extended error messages: the
vAttach family would send the extended error string without checking if
the mode had been enabled. And qLaunchSuccess would not properly format
its error response packet (missing the hex digits, did not asciihex
encode the string).
There is also a bug in the HandlePacket_D (detach) packet where the
error packets did not include hex digits, but this one does not append
an error string.
I'm adding a new RNBRemote::SendErrorPacket() and routing all error
packet returns though this one method. It takes an optional second
string which is the longer error message; it now handles appending it to
the Exx response or not, depending on the QErrorStringInPacketSupported
state. I updated all packets to send their errors via this method.
---
lldb/tools/debugserver/source/RNBRemote.cpp | 319 ++++++++++----------
lldb/tools/debugserver/source/RNBRemote.h | 9 +
2 files changed, 168 insertions(+), 160 deletions(-)
diff --git a/lldb/tools/debugserver/source/RNBRemote.cpp b/lldb/tools/debugserver/source/RNBRemote.cpp
index 03d427d3fc5954..f22d626c4af2c6 100644
--- a/lldb/tools/debugserver/source/RNBRemote.cpp
+++ b/lldb/tools/debugserver/source/RNBRemote.cpp
@@ -143,6 +143,39 @@ uint64_t decode_uint64(const char *p, int base, char **end = nullptr,
return addr;
}
+void append_hex_value(std::ostream &ostrm, const void *buf, size_t buf_size,
+ bool swap) {
+ int i;
+ const uint8_t *p = (const uint8_t *)buf;
+ if (swap) {
+ for (i = static_cast<int>(buf_size) - 1; i >= 0; i--)
+ ostrm << RAWHEX8(p[i]);
+ } else {
+ for (size_t i = 0; i < buf_size; i++)
+ ostrm << RAWHEX8(p[i]);
+ }
+}
+
+std::string cstring_to_asciihex_string(const char *str) {
+ std::string hex_str;
+ hex_str.reserve(strlen(str) * 2);
+ while (str && *str) {
+ uint8_t c = *str++;
+ char hexbuf[5];
+ snprintf(hexbuf, sizeof(hexbuf), "%02x", c);
+ hex_str += hexbuf;
+ }
+ return hex_str;
+}
+
+void append_hexified_string(std::ostream &ostrm, const std::string &string) {
+ size_t string_size = string.size();
+ const char *string_buf = string.c_str();
+ for (size_t i = 0; i < string_size; i++) {
+ ostrm << RAWHEX8(*(string_buf + i));
+ }
+}
+
extern void ASLLogCallback(void *baton, uint32_t flags, const char *format,
va_list args);
@@ -171,7 +204,8 @@ RNBRemote::RNBRemote()
m_extended_mode(false), m_noack_mode(false),
m_thread_suffix_supported(false), m_list_threads_in_stop_reply(false),
m_compression_minsize(384), m_enable_compression_next_send_packet(false),
- m_compression_mode(compression_types::none) {
+ m_compression_mode(compression_types::none),
+ m_enable_error_strings(false) {
DNBLogThreadedIf(LOG_RNB_REMOTE, "%s", __PRETTY_FUNCTION__);
CreatePacketTable();
}
@@ -365,6 +399,11 @@ void RNBRemote::CreatePacketTable() {
t.push_back(Packet(
query_symbol_lookup, &RNBRemote::HandlePacket_qSymbol, NULL, "qSymbol:",
"Notify that host debugger is ready to do symbol lookups"));
+ t.push_back(Packet(enable_error_strings,
+ &RNBRemote::HandlePacket_QEnableErrorStrings, NULL,
+ "QEnableErrorStrings",
+ "Tell " DEBUGSERVER_PROGRAM_NAME
+ " it can append descriptive error messages in replies."));
t.push_back(Packet(json_query_thread_extended_info,
&RNBRemote::HandlePacket_jThreadExtendedInfo, NULL,
"jThreadExtendedInfo",
@@ -769,6 +808,15 @@ rnb_err_t RNBRemote::SendPacket(const std::string &s) {
return rnb_err;
}
+rnb_err_t RNBRemote::SendErrorPacket(std::string errcode,
+ const std::string &errmsg) {
+ if (m_enable_error_strings && !errmsg.empty()) {
+ errcode += ";";
+ errcode += cstring_to_asciihex_string(errmsg.c_str());
+ }
+ return SendPacket(errcode);
+}
+
/* Get a packet via gdb remote protocol.
Strip off the prefix/suffix, verify the checksum to make sure
a valid packet was received, send an ACK if they match. */
@@ -884,7 +932,7 @@ rnb_err_t RNBRemote::HandlePacket_ILLFORMED(const char *file, int line,
DNBLogThreadedIf(LOG_RNB_PACKETS, "%8u %s:%i ILLFORMED: '%s' (%s)",
(uint32_t)m_comm.Timer().ElapsedMicroSeconds(true), file,
line, __FUNCTION__, p);
- return SendPacket("E03");
+ return SendErrorPacket("E03");
}
rnb_err_t RNBRemote::GetPacket(std::string &packet_payload,
@@ -1565,13 +1613,8 @@ rnb_err_t RNBRemote::HandlePacket_H(const char *p) {
rnb_err_t RNBRemote::HandlePacket_qLaunchSuccess(const char *p) {
if (m_ctx.HasValidProcessID() || m_ctx.LaunchStatus().Status() == 0)
return SendPacket("OK");
- std::ostringstream ret_str;
std::string status_str;
- std::string error_quoted = binary_encode_string
- (m_ctx.LaunchStatusAsString(status_str));
- ret_str << "E" << error_quoted;
-
- return SendPacket(ret_str.str());
+ return SendErrorPacket("E89", m_ctx.LaunchStatusAsString(status_str));
}
rnb_err_t RNBRemote::HandlePacket_qShlibInfoAddr(const char *p) {
@@ -1584,7 +1627,7 @@ rnb_err_t RNBRemote::HandlePacket_qShlibInfoAddr(const char *p) {
return SendPacket(ostrm.str());
}
}
- return SendPacket("E44");
+ return SendErrorPacket("E44");
}
rnb_err_t RNBRemote::HandlePacket_qStepPacketSupported(const char *p) {
@@ -1758,7 +1801,7 @@ rnb_err_t RNBRemote::HandlePacket_qRcmd(const char *p) {
DNBLogSetLogCallback(FileLogCallback, log_file);
return SendPacket("OK");
}
- return SendPacket("E71");
+ return SendErrorPacket("E71");
} else if (variable == "logmask") {
char *end;
errno = 0;
@@ -1776,13 +1819,13 @@ rnb_err_t RNBRemote::HandlePacket_qRcmd(const char *p) {
DNBLogSetLogMask(logmask);
return SendPacket("OK");
}
- return SendPacket("E72");
+ return SendErrorPacket("E72");
}
- return SendPacket("E70");
+ return SendErrorPacket("E70");
}
- return SendPacket("E69");
+ return SendErrorPacket("E69");
}
- return SendPacket("E73");
+ return SendErrorPacket("E73");
}
rnb_err_t RNBRemote::HandlePacket_qC(const char *p) {
@@ -1974,7 +2017,7 @@ rnb_err_t RNBRemote::HandlePacket_qRegisterInfo(const char *p) {
return SendPacket(ostrm.str());
}
- return SendPacket("E45");
+ return SendErrorPacket("E45");
}
/* This expects a packet formatted like
@@ -2222,7 +2265,7 @@ rnb_err_t set_logging(const char *p) {
rnb_err_t RNBRemote::HandlePacket_QSetIgnoredExceptions(const char *p) {
// We can't set the ignored exceptions if we have a running process:
if (m_ctx.HasValidProcessID())
- return SendPacket("E35");
+ return SendErrorPacket("E35");
p += sizeof("QSetIgnoredExceptions:") - 1;
bool success = true;
@@ -2247,7 +2290,7 @@ rnb_err_t RNBRemote::HandlePacket_QSetIgnoredExceptions(const char *p) {
if (success)
return SendPacket("OK");
else
- return SendPacket("E36");
+ return SendErrorPacket("E36");
}
rnb_err_t RNBRemote::HandlePacket_QThreadSuffixSupported(const char *p) {
@@ -2268,7 +2311,7 @@ rnb_err_t RNBRemote::HandlePacket_QSetLogging(const char *p) {
if (result == rnb_success)
return SendPacket("OK");
else
- return SendPacket("E35");
+ return SendErrorPacket("E35");
}
rnb_err_t RNBRemote::HandlePacket_QSetDisableASLR(const char *p) {
@@ -2282,7 +2325,7 @@ rnb_err_t RNBRemote::HandlePacket_QSetDisableASLR(const char *p) {
g_disable_aslr = 1;
break;
default:
- return SendPacket("E56");
+ return SendErrorPacket("E56");
}
return SendPacket("OK");
}
@@ -2322,9 +2365,9 @@ rnb_err_t RNBRemote::HandlePacket_QSetSTDIO(const char *p) {
}
if (success)
return SendPacket("OK");
- return SendPacket("E57");
+ return SendErrorPacket("E57");
}
- return SendPacket("E58");
+ return SendErrorPacket("E58");
}
rnb_err_t RNBRemote::HandlePacket_QSetWorkingDir(const char *p) {
@@ -2335,15 +2378,15 @@ rnb_err_t RNBRemote::HandlePacket_QSetWorkingDir(const char *p) {
struct stat working_dir_stat;
if (::stat(m_ctx.GetWorkingDirPath(), &working_dir_stat) == -1) {
m_ctx.GetWorkingDir().clear();
- return SendPacket("E61"); // Working directory doesn't exist...
+ return SendErrorPacket("E61"); // Working directory doesn't exist...
} else if ((working_dir_stat.st_mode & S_IFMT) == S_IFDIR) {
return SendPacket("OK");
} else {
m_ctx.GetWorkingDir().clear();
- return SendPacket("E62"); // Working directory isn't a directory...
+ return SendErrorPacket("E62"); // Working directory isn't a directory...
}
}
- return SendPacket("E59"); // Invalid path
+ return SendErrorPacket("E59"); // Invalid path
}
return SendPacket(
"E60"); // Already had a process, too late to set working dir
@@ -2368,7 +2411,7 @@ rnb_err_t RNBRemote::HandlePacket_QSyncThreadState(const char *p) {
if (DNBProcessSyncThreadState(m_ctx.ProcessID(), tid))
return SendPacket("OK");
else
- return SendPacket("E61");
+ return SendErrorPacket("E61");
}
rnb_err_t RNBRemote::HandlePacket_QSetDetachOnError(const char *p) {
@@ -2516,7 +2559,7 @@ rnb_err_t RNBRemote::HandlePacket_QLaunchArch(const char *p) {
p += sizeof("QLaunchArch:") - 1;
if (DNBSetArchitecture(p))
return SendPacket("OK");
- return SendPacket("E63");
+ return SendErrorPacket("E63");
}
rnb_err_t RNBRemote::HandlePacket_QSetProcessEvent(const char *p) {
@@ -2527,46 +2570,13 @@ rnb_err_t RNBRemote::HandlePacket_QSetProcessEvent(const char *p) {
if (DNBProcessSendEvent(Context().ProcessID(), p))
return SendPacket("OK");
else
- return SendPacket("E80");
+ return SendErrorPacket("E80");
} else {
Context().PushProcessEvent(p);
}
return SendPacket("OK");
}
-void append_hex_value(std::ostream &ostrm, const void *buf, size_t buf_size,
- bool swap) {
- int i;
- const uint8_t *p = (const uint8_t *)buf;
- if (swap) {
- for (i = static_cast<int>(buf_size) - 1; i >= 0; i--)
- ostrm << RAWHEX8(p[i]);
- } else {
- for (size_t i = 0; i < buf_size; i++)
- ostrm << RAWHEX8(p[i]);
- }
-}
-
-std::string cstring_to_asciihex_string(const char *str) {
- std::string hex_str;
- hex_str.reserve (strlen (str) * 2);
- while (str && *str) {
- uint8_t c = *str++;
- char hexbuf[5];
- snprintf (hexbuf, sizeof(hexbuf), "%02x", c);
- hex_str += hexbuf;
- }
- return hex_str;
-}
-
-void append_hexified_string(std::ostream &ostrm, const std::string &string) {
- size_t string_size = string.size();
- const char *string_buf = string.c_str();
- for (size_t i = 0; i < string_size; i++) {
- ostrm << RAWHEX8(*(string_buf + i));
- }
-}
-
void register_value_in_hex_fixed_width(std::ostream &ostrm, nub_process_t pid,
nub_thread_t tid,
const register_map_entry_t *reg,
@@ -2690,7 +2700,7 @@ static void ReadStackMemory(nub_process_t pid, nub_thread_t tid,
rnb_err_t RNBRemote::SendStopReplyPacketForThread(nub_thread_t tid) {
const nub_process_t pid = m_ctx.ProcessID();
if (pid == INVALID_NUB_PROCESS)
- return SendPacket("E50");
+ return SendErrorPacket("E50");
struct DNBThreadStopInfo tid_stop_info;
@@ -2944,7 +2954,7 @@ rnb_err_t RNBRemote::SendStopReplyPacketForThread(nub_thread_t tid) {
return SendPacket(ostrm.str());
}
- return SendPacket("E51");
+ return SendErrorPacket("E51");
}
/* '?'
@@ -2954,7 +2964,7 @@ rnb_err_t RNBRemote::SendStopReplyPacketForThread(nub_thread_t tid) {
rnb_err_t RNBRemote::HandlePacket_last_signal(const char *unused) {
if (!m_ctx.HasValidProcessID()) {
// Inferior is not yet specified/running
- return SendPacket("E02");
+ return SendErrorPacket("E02");
}
nub_process_t pid = m_ctx.ProcessID();
@@ -3092,7 +3102,7 @@ rnb_err_t RNBRemote::HandlePacket_M(const char *p) {
nub_size_t wrote =
DNBProcessMemoryWrite(m_ctx.ProcessID(), addr, length, buf);
if (wrote != length)
- return SendPacket("E09");
+ return SendErrorPacket("E09");
else
return SendPacket("OK");
}
@@ -3130,12 +3140,12 @@ rnb_err_t RNBRemote::HandlePacket_m(const char *p) {
std::string buf(length, '\0');
if (buf.empty()) {
- return SendPacket("E78");
+ return SendErrorPacket("E78");
}
nub_size_t bytes_read =
DNBProcessMemoryRead(m_ctx.ProcessID(), addr, buf.size(), &buf[0]);
if (bytes_read == 0) {
- return SendPacket("E08");
+ return SendErrorPacket("E08");
}
// "The reply may contain fewer bytes than requested if the server was able
@@ -3196,12 +3206,12 @@ rnb_err_t RNBRemote::HandlePacket_x(const char *p) {
std::vector<uint8_t> buf(length);
if (buf.capacity() != length) {
- return SendPacket("E79");
+ return SendErrorPacket("E79");
}
nub_size_t bytes_read =
DNBProcessMemoryRead(m_ctx.ProcessID(), addr, buf.size(), &buf[0]);
if (bytes_read == 0) {
- return SendPacket("E80");
+ return SendErrorPacket("E80");
}
std::vector<uint8_t> buf_quoted;
@@ -3272,7 +3282,7 @@ rnb_err_t RNBRemote::HandlePacket_X(const char *p) {
nub_size_t wrote =
DNBProcessMemoryWrite(m_ctx.ProcessID(), addr, data.size(), buf);
if (wrote != data.size())
- return SendPacket("E08");
+ return SendErrorPacket("E08");
return SendPacket("OK");
}
@@ -3285,7 +3295,7 @@ rnb_err_t RNBRemote::HandlePacket_X(const char *p) {
rnb_err_t RNBRemote::HandlePacket_g(const char *p) {
std::ostringstream ostrm;
if (!m_ctx.HasValidProcessID()) {
- return SendPacket("E11");
+ return SendErrorPacket("E11");
}
if (g_num_reg_entries == 0)
@@ -3311,7 +3321,7 @@ rnb_err_t RNBRemote::HandlePacket_g(const char *p) {
return SendPacket(ostrm.str());
}
}
- return SendPacket("E74");
+ return SendErrorPacket("E74");
}
/* 'G XXX...' -- write registers
@@ -3320,7 +3330,7 @@ rnb_err_t RNBRemote::HandlePacket_g(const char *p) {
rnb_err_t RNBRemote::HandlePacket_G(const char *p) {
if (!m_ctx.HasValidProcessID()) {
- return SendPacket("E11");
+ return SendErrorPacket("E11");
}
if (g_num_reg_entries == 0)
@@ -3351,15 +3361,15 @@ rnb_err_t RNBRemote::HandlePacket_G(const char *p) {
if (reg_ctx_size == reg_ctx.size())
return SendPacket("OK");
else
- return SendPacket("E55");
+ return SendErrorPacket("E55");
} else {
DNBLogError("RNBRemote::HandlePacket_G(%s): extracted %llu of %llu "
"bytes, size mismatch\n",
p, (uint64_t)bytes_extracted, (uint64_t)reg_ctx_size);
- return SendPacket("E64");
+ return SendErrorPacket("E64");
}
}
- return SendPacket("E65");
+ return SendErrorPacket("E65");
}
static bool RNBRemoteShouldCancelCallback(void *not_used) {
@@ -3422,7 +3432,7 @@ rnb_err_t RNBRemote::HandlePacket_AllocateMemory(const char *p) {
}
}
}
- return SendPacket("E53");
+ return SendErrorPacket("E53");
}
// FORMAT: _mXXXXXX
@@ -3445,7 +3455,7 @@ rnb_err_t RNBRemote::HandlePacket_DeallocateMemory(const char *p) {
if (DNBProcessMemoryDeallocate(m_ctx.ProcessID(), addr))
return SendPacket("OK");
}
- return SendPacket("E54");
+ return SendErrorPacket("E54");
}
// FORMAT: QSaveRegisterState;thread:TTTT; (when thread suffix is supported)
@@ -3483,7 +3493,7 @@ rnb_err_t RNBRemote::HandlePacket_SaveRegisterState(const char *p) {
snprintf(response, sizeof(response), "%u", save_id);
return SendPacket(response);
} else {
- return SendPacket("E75");
+ return SendErrorPacket("E75");
}
}
// FORMAT: QRestoreRegisterState:SAVEID;thread:TTTT; (when thread suffix is
@@ -3527,9 +3537,9 @@ rnb_err_t RNBRemote::HandlePacket_RestoreRegisterState(const char *p) {
if (DNBThreadRestoreRegisterState(pid, tid, save_id))
return SendPacket("OK");
else
- return SendPacket("E77");
+ return SendErrorPacket("E77");
}
- return SendPacket("E76");
+ return SendErrorPacket("E76");
}
static bool GetProcessNameFrom_vAttach(const char *&p,
@@ -3908,12 +3918,8 @@ rnb_err_t RNBRemote::HandlePacket_v(const char *p) {
if (attach_pid == INVALID_NUB_PROCESS_ARCH) {
DNBLogError("debugserver is x86_64 binary running in translation, attach "
"failed.");
- std::string return_message = "E96;";
- return_message +=
- cstring_to_asciihex_string("debugserver is x86_64 binary running in "
- "translation, attach failed.");
- SendPacket(return_message.c_str());
- return rnb_err;
+ return SendErrorPacket("E96", "debugserver is x86_64 binary running in "
+ "translation, attach failed.");
}
if (attach_pid != INVALID_NUB_PROCESS) {
@@ -3944,16 +3950,12 @@ rnb_err_t RNBRemote::HandlePacket_v(const char *p) {
// The order of these checks is important.
if (process_does_not_exist (pid_attaching_to)) {
DNBLogError("Tried to attach to pid that doesn't exist");
- std::string return_message = "E96;";
- return_message += cstring_to_asciihex_string("no such process.");
- return SendPacket(return_message);
+ return SendErrorPacket("E96", "no such process");
}
if (process_is_already_being_debugged (pid_attaching_to)) {
DNBLogError("Tried to attach to process already being debugged");
- std::string return_message = "E96;";
- return_message += cstring_to_asciihex_string("tried to attach to "
- "process already being debugged");
- return SendPacket(return_message);
+ return SendErrorPacket("E96", "tried to attach to "
+ "process already being debugged");
}
uid_t my_uid, process_uid;
if (attach_failed_due_to_uid_mismatch (pid_attaching_to,
@@ -3969,31 +3971,27 @@ rnb_err_t RNBRemote::HandlePacket_v(const char *p) {
process_username = pw->pw_name;
}
DNBLogError("Tried to attach to process with uid mismatch");
- std::string return_message = "E96;";
- std::string msg = "tried to attach to process as user '"
- + my_username + "' and process is running "
- "as user '" + process_username + "'";
- return_message += cstring_to_asciihex_string(msg.c_str());
- return SendPacket(return_message);
+ std::string msg = "tried to attach to process as user '" +
+ my_username +
+ "' and process is running "
+ "as user '" +
+ process_username + "'";
+ return SendErrorPacket("E96", msg);
}
if (!login_session_has_gui_access() && !developer_mode_enabled()) {
DNBLogError("Developer mode is not enabled and this is a "
"non-interactive session");
- std::string return_message = "E96;";
- return_message += cstring_to_asciihex_string("developer mode is "
- "not enabled on this machine "
- "and this is a non-interactive "
- "debug session.");
- return SendPacket(return_message);
+ return SendErrorPacket("E96", "developer mode is "
+ "not enabled on this machine "
+ "and this is a non-interactive "
+ "debug session.");
}
if (!login_session_has_gui_access()) {
DNBLogError("This is a non-interactive session");
- std::string return_message = "E96;";
- return_message += cstring_to_asciihex_string("this is a "
- "non-interactive debug session, "
- "cannot get permission to debug "
- "processes.");
- return SendPacket(return_message);
+ return SendErrorPacket("E96", "this is a "
+ "non-interactive debug session, "
+ "cannot get permission to debug "
+ "processes.");
}
}
@@ -4013,12 +4011,8 @@ rnb_err_t RNBRemote::HandlePacket_v(const char *p) {
error_explainer += err_str;
error_explainer += ")";
}
- std::string default_return_msg = "E96;";
- default_return_msg += cstring_to_asciihex_string
- (error_explainer.c_str());
- SendPacket (default_return_msg);
DNBLogError("Attach failed: \"%s\".", err_str);
- return rnb_err;
+ return SendErrorPacket("E96", error_explainer);
}
}
@@ -4037,7 +4031,7 @@ rnb_err_t RNBRemote::HandlePacket_T(const char *p) {
"No thread specified in T packet");
}
if (!m_ctx.HasValidProcessID()) {
- return SendPacket("E15");
+ return SendErrorPacket("E15");
}
errno = 0;
nub_thread_t tid = strtoul(p, NULL, 16);
@@ -4049,7 +4043,7 @@ rnb_err_t RNBRemote::HandlePacket_T(const char *p) {
nub_state_t state = DNBThreadGetState(m_ctx.ProcessID(), tid);
if (state == eStateInvalid || state == eStateExited ||
state == eStateCrashed) {
- return SendPacket("E16");
+ return SendErrorPacket("E16");
}
return SendPacket("OK");
@@ -4061,7 +4055,7 @@ rnb_err_t RNBRemote::HandlePacket_z(const char *p) {
"No thread specified in z packet");
if (!m_ctx.HasValidProcessID())
- return SendPacket("E15");
+ return SendErrorPacket("E15");
char packet_cmd = *p++;
char break_type = *p++;
@@ -4105,7 +4099,7 @@ rnb_err_t RNBRemote::HandlePacket_z(const char *p) {
return SendPacket("OK");
} else {
// We failed to set the software breakpoint
- return SendPacket("E09");
+ return SendErrorPacket("E09");
}
} break;
@@ -4126,7 +4120,7 @@ rnb_err_t RNBRemote::HandlePacket_z(const char *p) {
return SendPacket("OK");
} else {
// We failed to set the watchpoint
- return SendPacket("E09");
+ return SendErrorPacket("E09");
}
} break;
@@ -4141,7 +4135,7 @@ rnb_err_t RNBRemote::HandlePacket_z(const char *p) {
if (DNBBreakpointClear(pid, addr)) {
return SendPacket("OK");
} else {
- return SendPacket("E08");
+ return SendErrorPacket("E08");
}
break;
@@ -4151,7 +4145,7 @@ rnb_err_t RNBRemote::HandlePacket_z(const char *p) {
if (DNBWatchpointClear(pid, addr)) {
return SendPacket("OK");
} else {
- return SendPacket("E08");
+ return SendErrorPacket("E08");
}
break;
@@ -4193,7 +4187,7 @@ rnb_err_t RNBRemote::HandlePacket_p(const char *p) {
"No thread specified in p packet");
}
if (!m_ctx.HasValidProcessID()) {
- return SendPacket("E15");
+ return SendErrorPacket("E15");
}
nub_process_t pid = m_ctx.ProcessID();
errno = 0;
@@ -4245,7 +4239,7 @@ rnb_err_t RNBRemote::HandlePacket_P(const char *p) {
return HandlePacket_ILLFORMED(__FILE__, __LINE__, p, "Empty P packet");
}
if (!m_ctx.HasValidProcessID()) {
- return SendPacket("E28");
+ return SendErrorPacket("E28");
}
nub_process_t pid = m_ctx.ProcessID();
@@ -4262,15 +4256,15 @@ rnb_err_t RNBRemote::HandlePacket_P(const char *p) {
"Improperly formed P packet");
if (reg == UINT32_MAX)
- return SendPacket("E29");
+ return SendErrorPacket("E29");
if (equal_char != '=')
- return SendPacket("E30");
+ return SendErrorPacket("E30");
const register_map_entry_t *reg_entry;
if (reg >= g_num_reg_entries)
- return SendPacket("E47");
+ return SendErrorPacket("E47");
reg_entry = &g_reg_entries[reg];
@@ -4279,7 +4273,7 @@ rnb_err_t RNBRemote::HandlePacket_P(const char *p) {
DNBLogError(
"RNBRemote::HandlePacket_P(%s): unknown register number %u requested\n",
p, reg);
- return SendPacket("E48");
+ return SendErrorPacket("E48");
}
DNBRegisterValue reg_value;
@@ -4293,7 +4287,7 @@ rnb_err_t RNBRemote::HandlePacket_P(const char *p) {
if (!DNBThreadSetRegisterValueByID(pid, tid, reg_entry->nub_info.set,
reg_entry->nub_info.reg, ®_value)) {
- return SendPacket("E32");
+ return SendErrorPacket("E32");
}
return SendPacket("OK");
}
@@ -4305,7 +4299,7 @@ rnb_err_t RNBRemote::HandlePacket_c(const char *p) {
const nub_process_t pid = m_ctx.ProcessID();
if (pid == INVALID_NUB_PROCESS)
- return SendPacket("E23");
+ return SendErrorPacket("E23");
DNBThreadResumeAction action = {INVALID_NUB_THREAD, eStateRunning, 0,
INVALID_NUB_ADDRESS};
@@ -4324,7 +4318,7 @@ rnb_err_t RNBRemote::HandlePacket_c(const char *p) {
thread_actions.SetDefaultThreadActionIfNeeded(eStateRunning, 0);
if (!DNBProcessResume(pid, thread_actions.GetFirst(),
thread_actions.GetSize()))
- return SendPacket("E25");
+ return SendErrorPacket("E25");
// Don't send an "OK" packet; response is the stopped/exited message.
return rnb_success;
}
@@ -4362,7 +4356,7 @@ rnb_err_t RNBRemote::HandlePacket_MemoryRegionInfo(const char *p) {
if (*p == '\0')
return SendPacket("OK");
if (*p++ != ':')
- return SendPacket("E67");
+ return SendErrorPacket("E67");
if (*p == '0' && (*(p + 1) == 'x' || *(p + 1) == 'X'))
p += 2;
@@ -4502,7 +4496,7 @@ rnb_err_t RNBRemote::HandlePacket_QEnableCompression(const char *p) {
return SendPacket("OK");
}
- return SendPacket("E88");
+ return SendErrorPacket("E88");
}
rnb_err_t RNBRemote::HandlePacket_qSpeedTest(const char *p) {
@@ -4521,7 +4515,7 @@ rnb_err_t RNBRemote::HandlePacket_qSpeedTest(const char *p) {
g_data[response_size + 5] = '\0';
return SendPacket(g_data);
} else {
- return SendPacket("E79");
+ return SendErrorPacket("E79");
}
}
@@ -4540,7 +4534,7 @@ rnb_err_t RNBRemote::HandlePacket_WatchpointSupportInfo(const char *p) {
if (*p == '\0')
return SendPacket("OK");
if (*p++ != ':')
- return SendPacket("E67");
+ return SendErrorPacket("E67");
errno = 0;
uint32_t num = DNBWatchpointGetNumSupportedHWP(m_ctx.ProcessID());
@@ -4558,7 +4552,7 @@ rnb_err_t RNBRemote::HandlePacket_C(const char *p) {
const nub_process_t pid = m_ctx.ProcessID();
if (pid == INVALID_NUB_PROCESS)
- return SendPacket("E36");
+ return SendErrorPacket("E36");
DNBThreadResumeAction action = {INVALID_NUB_THREAD, eStateRunning, 0,
INVALID_NUB_ADDRESS};
@@ -4584,10 +4578,10 @@ rnb_err_t RNBRemote::HandlePacket_C(const char *p) {
thread_actions.Append(action);
thread_actions.SetDefaultThreadActionIfNeeded(eStateRunning, action.signal);
if (!DNBProcessSignal(pid, process_signo))
- return SendPacket("E52");
+ return SendErrorPacket("E52");
if (!DNBProcessResume(pid, thread_actions.GetFirst(),
thread_actions.GetSize()))
- return SendPacket("E38");
+ return SendErrorPacket("E38");
/* Don't send an "OK" packet; response is the stopped/exited message. */
return rnb_success;
}
@@ -4602,10 +4596,10 @@ rnb_err_t RNBRemote::HandlePacket_D(const char *p) {
else {
DNBLog("error while detaching from pid %u due to D packet",
m_ctx.ProcessID());
- SendPacket("E");
+ SendErrorPacket("E01");
}
} else {
- SendPacket("E");
+ SendErrorPacket("E04");
}
return rnb_success;
}
@@ -4647,7 +4641,7 @@ rnb_err_t RNBRemote::HandlePacket_stop_process(const char *p) {
rnb_err_t RNBRemote::HandlePacket_s(const char *p) {
const nub_process_t pid = m_ctx.ProcessID();
if (pid == INVALID_NUB_PROCESS)
- return SendPacket("E32");
+ return SendErrorPacket("E32");
// Hardware supported stepping not supported on arm
nub_thread_t tid = GetContinueThread();
@@ -4655,7 +4649,7 @@ rnb_err_t RNBRemote::HandlePacket_s(const char *p) {
tid = GetCurrentThread();
if (tid == INVALID_NUB_THREAD)
- return SendPacket("E33");
+ return SendErrorPacket("E33");
DNBThreadResumeActions thread_actions;
thread_actions.AppendAction(tid, eStateStepping);
@@ -4664,7 +4658,7 @@ rnb_err_t RNBRemote::HandlePacket_s(const char *p) {
thread_actions.SetDefaultThreadActionIfNeeded(eStateStopped, 0);
if (!DNBProcessResume(pid, thread_actions.GetFirst(),
thread_actions.GetSize()))
- return SendPacket("E49");
+ return SendErrorPacket("E49");
// Don't send an "OK" packet; response is the stopped/exited message.
return rnb_success;
}
@@ -4675,7 +4669,7 @@ rnb_err_t RNBRemote::HandlePacket_s(const char *p) {
rnb_err_t RNBRemote::HandlePacket_S(const char *p) {
const nub_process_t pid = m_ctx.ProcessID();
if (pid == INVALID_NUB_PROCESS)
- return SendPacket("E36");
+ return SendErrorPacket("E36");
DNBThreadResumeAction action = {INVALID_NUB_THREAD, eStateStepping, 0,
INVALID_NUB_ADDRESS};
@@ -4699,11 +4693,11 @@ rnb_err_t RNBRemote::HandlePacket_S(const char *p) {
action.tid = GetContinueThread();
if (action.tid == 0 || action.tid == (nub_thread_t)-1)
- return SendPacket("E40");
+ return SendErrorPacket("E40");
nub_state_t tstate = DNBThreadGetState(pid, action.tid);
if (tstate == eStateInvalid || tstate == eStateExited)
- return SendPacket("E37");
+ return SendErrorPacket("E37");
DNBThreadResumeActions thread_actions;
thread_actions.Append(action);
@@ -4712,7 +4706,7 @@ rnb_err_t RNBRemote::HandlePacket_S(const char *p) {
thread_actions.SetDefaultThreadActionIfNeeded(eStateStopped, 0);
if (!DNBProcessResume(pid, thread_actions.GetFirst(),
thread_actions.GetSize()))
- return SendPacket("E39");
+ return SendErrorPacket("E39");
// Don't send an "OK" packet; response is the stopped/exited message.
return rnb_success;
@@ -5242,7 +5236,7 @@ rnb_err_t RNBRemote::HandlePacket_qXfer(const char *command) {
UpdateTargetXML();
if (g_target_xml.empty())
- return SendPacket("E83");
+ return SendErrorPacket("E83");
if (length > g_target_xml.size()) {
xml_out << 'l'; // No more data
@@ -5273,13 +5267,13 @@ rnb_err_t RNBRemote::HandlePacket_qXfer(const char *command) {
}
}
} else {
- SendPacket("E85");
+ SendErrorPacket("E85");
}
} else {
- SendPacket("E86");
+ SendErrorPacket("E86");
}
}
- return SendPacket("E82");
+ return SendErrorPacket("E82");
}
rnb_err_t RNBRemote::HandlePacket_qGDBServerVersion(const char *p) {
@@ -5298,7 +5292,7 @@ rnb_err_t RNBRemote::HandlePacket_qGDBServerVersion(const char *p) {
rnb_err_t RNBRemote::HandlePacket_jGetDyldProcessState(const char *p) {
const nub_process_t pid = m_ctx.ProcessID();
if (pid == INVALID_NUB_PROCESS)
- return SendPacket("E87");
+ return SendErrorPacket("E87");
JSONGenerator::ObjectSP dyld_state_sp = DNBGetDyldProcessState(pid);
if (dyld_state_sp) {
@@ -5308,7 +5302,7 @@ rnb_err_t RNBRemote::HandlePacket_jGetDyldProcessState(const char *p) {
if (strm.str().size() > 0)
return SendPacket(strm.str());
}
- return SendPacket("E88");
+ return SendErrorPacket("E88");
}
// A helper function that retrieves a single integer value from
@@ -5648,7 +5642,7 @@ rnb_err_t RNBRemote::HandlePacket_jThreadsInfo(const char *p) {
return SendPacket(strm.str());
}
}
- return SendPacket("E85");
+ return SendErrorPacket("E85");
}
rnb_err_t RNBRemote::HandlePacket_jThreadExtendedInfo(const char *p) {
@@ -5656,7 +5650,7 @@ rnb_err_t RNBRemote::HandlePacket_jThreadExtendedInfo(const char *p) {
std::ostringstream json;
// If we haven't run the process yet, return an error.
if (!m_ctx.HasValidProcessID()) {
- return SendPacket("E81");
+ return SendErrorPacket("E81");
}
pid = m_ctx.ProcessID();
@@ -5925,7 +5919,7 @@ RNBRemote::HandlePacket_jGetLoadedDynamicLibrariesInfos(const char *p) {
nub_process_t pid;
// If we haven't run the process yet, return an error.
if (!m_ctx.HasValidProcessID()) {
- return SendPacket("E83");
+ return SendErrorPacket("E83");
}
pid = m_ctx.ProcessID();
@@ -5960,7 +5954,7 @@ RNBRemote::HandlePacket_jGetLoadedDynamicLibrariesInfos(const char *p) {
if (json_str.str().size() > 0) {
return SendPacket(json_str.str());
} else {
- SendPacket("E84");
+ SendErrorPacket("E84");
}
}
}
@@ -5976,7 +5970,7 @@ rnb_err_t RNBRemote::HandlePacket_jGetSharedCacheInfo(const char *p) {
nub_process_t pid;
// If we haven't run the process yet, return an error.
if (!m_ctx.HasValidProcessID()) {
- return SendPacket("E85");
+ return SendErrorPacket("E85");
}
pid = m_ctx.ProcessID();
@@ -5993,7 +5987,7 @@ rnb_err_t RNBRemote::HandlePacket_jGetSharedCacheInfo(const char *p) {
if (json_str.str().size() > 0) {
return SendPacket(json_str.str());
} else {
- SendPacket("E86");
+ SendErrorPacket("E86");
}
}
}
@@ -6195,6 +6189,11 @@ rnb_err_t RNBRemote::HandlePacket_qSymbol(const char *command) {
}
}
+rnb_err_t RNBRemote::HandlePacket_QEnableErrorStrings(const char *p) {
+ m_enable_error_strings = true;
+ return SendPacket("OK");
+}
+
static std::pair<cpu_type_t, cpu_subtype_t>
GetCPUTypesFromHost(nub_process_t pid) {
cpu_type_t cputype = DNBProcessGetCPUType(pid);
diff --git a/lldb/tools/debugserver/source/RNBRemote.h b/lldb/tools/debugserver/source/RNBRemote.h
index dad390ae0b6320..a95bece79b46c3 100644
--- a/lldb/tools/debugserver/source/RNBRemote.h
+++ b/lldb/tools/debugserver/source/RNBRemote.h
@@ -33,6 +33,7 @@ enum class compression_types { zlib_deflate, lz4, lzma, lzfse, none };
class RNBRemote {
public:
+ // clang-format off
enum PacketEnum {
invalid_packet = 0,
ack, // '+'
@@ -137,8 +138,10 @@ class RNBRemote {
set_detach_on_error, // 'QSetDetachOnError:'
query_transfer, // 'qXfer:'
json_query_dyld_process_state, // 'jGetDyldProcessState'
+ enable_error_strings, // 'QEnableErrorStrings'
unknown_type
};
+ // clang-format on
typedef rnb_err_t (RNBRemote::*HandlePacketCallback)(const char *p);
@@ -196,6 +199,7 @@ class RNBRemote {
rnb_err_t HandlePacket_qGDBServerVersion(const char *p);
rnb_err_t HandlePacket_qProcessInfo(const char *p);
rnb_err_t HandlePacket_qSymbol(const char *p);
+ rnb_err_t HandlePacket_QEnableErrorStrings(const char *p);
rnb_err_t HandlePacket_QStartNoAckMode(const char *p);
rnb_err_t HandlePacket_QThreadSuffixSupported(const char *p);
rnb_err_t HandlePacket_QSetLogging(const char *p);
@@ -356,6 +360,8 @@ class RNBRemote {
rnb_err_t GetPacket(std::string &packet_data, RNBRemote::Packet &packet_info,
bool wait);
rnb_err_t SendPacket(const std::string &);
+ rnb_err_t SendErrorPacket(std::string errcode,
+ const std::string &errmsg = "");
std::string CompressString(const std::string &);
void CreatePacketTable();
@@ -405,6 +411,9 @@ class RNBRemote {
bool m_enable_compression_next_send_packet;
compression_types m_compression_mode;
+
+ bool m_enable_error_strings; // Whether we can append asciihex error strings
+ // after Exx error replies
};
/* We translate the /usr/include/mach/exception_types.h exception types
>From 8fd011ecc61fa83b9520a971aba1fa651a011bff Mon Sep 17 00:00:00 2001
From: Brandon Wu <brandon.wu at sifive.com>
Date: Fri, 1 Mar 2024 13:12:09 +0800
Subject: [PATCH 208/406] [RISCV] Add getFeaturesForCPU function support
(#83269)
This function parse the cpu and return it's supported
features placed in EnabledFeatures. It is same as the
one in X86TargetParser and also is used in IREE.
---
.../llvm/TargetParser/RISCVTargetParser.h | 3 +++
llvm/lib/TargetParser/RISCVTargetParser.cpp | 24 +++++++++++++++++++
2 files changed, 27 insertions(+)
diff --git a/llvm/include/llvm/TargetParser/RISCVTargetParser.h b/llvm/include/llvm/TargetParser/RISCVTargetParser.h
index e7da677c7d3ead..553b4efe0e3038 100644
--- a/llvm/include/llvm/TargetParser/RISCVTargetParser.h
+++ b/llvm/include/llvm/TargetParser/RISCVTargetParser.h
@@ -25,6 +25,9 @@ namespace RISCV {
// We use 64 bits as the known part in the scalable vector types.
static constexpr unsigned RVVBitsPerBlock = 64;
+void getFeaturesForCPU(StringRef CPU,
+ SmallVectorImpl<std::string> &EnabledFeatures,
+ bool NeedPlus = false);
bool parseCPU(StringRef CPU, bool IsRV64);
bool parseTuneCPU(StringRef CPU, bool IsRV64);
StringRef getMArchFromMcpu(StringRef CPU);
diff --git a/llvm/lib/TargetParser/RISCVTargetParser.cpp b/llvm/lib/TargetParser/RISCVTargetParser.cpp
index 85cdd1289a9538..8036df46fb47f7 100644
--- a/llvm/lib/TargetParser/RISCVTargetParser.cpp
+++ b/llvm/lib/TargetParser/RISCVTargetParser.cpp
@@ -14,6 +14,7 @@
#include "llvm/TargetParser/RISCVTargetParser.h"
#include "llvm/ADT/SmallVector.h"
#include "llvm/ADT/StringSwitch.h"
+#include "llvm/Support/RISCVISAInfo.h"
#include "llvm/TargetParser/Triple.h"
namespace llvm {
@@ -95,5 +96,28 @@ void fillValidTuneCPUArchList(SmallVectorImpl<StringRef> &Values, bool IsRV64) {
#include "llvm/TargetParser/RISCVTargetParserDef.inc"
}
+// This function is currently used by IREE, so it's not dead code.
+void getFeaturesForCPU(StringRef CPU,
+ SmallVectorImpl<std::string> &EnabledFeatures,
+ bool NeedPlus) {
+ StringRef MarchFromCPU = llvm::RISCV::getMArchFromMcpu(CPU);
+ if (MarchFromCPU == "")
+ return;
+
+ EnabledFeatures.clear();
+ auto RII = RISCVISAInfo::parseArchString(
+ MarchFromCPU, /* EnableExperimentalExtension */ true);
+
+ if (llvm::errorToBool(RII.takeError()))
+ return;
+
+ std::vector<std::string> FeatStrings =
+ (*RII)->toFeatures(/* AddAllExtensions */ false);
+ for (const auto &F : FeatStrings)
+ if (NeedPlus)
+ EnabledFeatures.push_back(F);
+ else
+ EnabledFeatures.push_back(F.substr(1));
+}
} // namespace RISCV
} // namespace llvm
>From 8116dfb8b58a65e78e341f09f5728d345f086b7b Mon Sep 17 00:00:00 2001
From: Cyndy Ishida <cyndy_ishida at apple.com>
Date: Thu, 29 Feb 2024 21:42:43 -0800
Subject: [PATCH 209/406] [InstallAPI] Use unique identifiers for input buffers
(#83523)
---
clang/lib/InstallAPI/Frontend.cpp | 6 ++++--
1 file changed, 4 insertions(+), 2 deletions(-)
diff --git a/clang/lib/InstallAPI/Frontend.cpp b/clang/lib/InstallAPI/Frontend.cpp
index 9f675ef7d1bd22..133e49230ffa9b 100644
--- a/clang/lib/InstallAPI/Frontend.cpp
+++ b/clang/lib/InstallAPI/Frontend.cpp
@@ -51,8 +51,10 @@ std::unique_ptr<MemoryBuffer> createInputBuffer(const InstallAPIContext &Ctx) {
if (Contents.empty())
return nullptr;
- return llvm::MemoryBuffer::getMemBufferCopy(
- Contents, "installapi-includes" + getFileExtension(Ctx.LangMode));
+ SmallString<64> BufferName(
+ {"installapi-includes-", Ctx.Slice->getTriple().str(), "-",
+ getName(Ctx.Type), getFileExtension(Ctx.LangMode)});
+ return llvm::MemoryBuffer::getMemBufferCopy(Contents, BufferName);
}
} // namespace clang::installapi
>From 346766eae8cb8949c2c13b85c0d1e6ff4869a77e Mon Sep 17 00:00:00 2001
From: Cyndy Ishida <cyndy_ishida at apple.com>
Date: Thu, 29 Feb 2024 22:06:04 -0800
Subject: [PATCH 210/406] [TextAPI] Fixup symbol names of ivars from extensions
(#83525)
---
llvm/include/llvm/TextAPI/Record.h | 2 ++
llvm/lib/TextAPI/RecordVisitor.cpp | 2 +-
2 files changed, 3 insertions(+), 1 deletion(-)
diff --git a/llvm/include/llvm/TextAPI/Record.h b/llvm/include/llvm/TextAPI/Record.h
index 02af3098cc5a54..3b30e6c8c26762 100644
--- a/llvm/include/llvm/TextAPI/Record.h
+++ b/llvm/include/llvm/TextAPI/Record.h
@@ -156,6 +156,8 @@ class ObjCCategoryRecord : public ObjCContainerRecord {
: ObjCContainerRecord(Name, RecordLinkage::Unknown),
ClassToExtend(ClassToExtend) {}
+ StringRef getSuperClassName() const { return ClassToExtend; }
+
private:
StringRef ClassToExtend;
};
diff --git a/llvm/lib/TextAPI/RecordVisitor.cpp b/llvm/lib/TextAPI/RecordVisitor.cpp
index 3ff6bbd8bbcb26..d333b330922632 100644
--- a/llvm/lib/TextAPI/RecordVisitor.cpp
+++ b/llvm/lib/TextAPI/RecordVisitor.cpp
@@ -88,5 +88,5 @@ void SymbolConverter::visitObjCInterface(const ObjCInterfaceRecord &ObjCR) {
}
void SymbolConverter::visitObjCCategory(const ObjCCategoryRecord &Cat) {
- addIVars(Cat.getObjCIVars(), Cat.getName());
+ addIVars(Cat.getObjCIVars(), Cat.getSuperClassName());
}
>From edd0ef4f3cb0ebc4eadc7a207edb9c849e894fc3 Mon Sep 17 00:00:00 2001
From: Douglas Yung <douglas.yung at sony.com>
Date: Fri, 1 Mar 2024 01:05:26 -0500
Subject: [PATCH 211/406] Add "REQUIRES: asserts" to 2 tests added in #83379
using "-debug-only" run arguments.
---
llvm/test/CodeGen/Hexagon/loop_align_count.ll | 1 +
llvm/test/CodeGen/Hexagon/loop_align_count.mir | 1 +
2 files changed, 2 insertions(+)
diff --git a/llvm/test/CodeGen/Hexagon/loop_align_count.ll b/llvm/test/CodeGen/Hexagon/loop_align_count.ll
index 07d7e4a8d61176..1f89d8e39495f6 100644
--- a/llvm/test/CodeGen/Hexagon/loop_align_count.ll
+++ b/llvm/test/CodeGen/Hexagon/loop_align_count.ll
@@ -1,6 +1,7 @@
; RUN: llc -march=hexagon -mcpu=hexagonv73 -O2 -mattr=+hvxv73,hvx-length64b \
; RUN: -debug-only=hexagon-loop-align 2>&1 < %s | FileCheck %s
; Validate that there are 4 bundles in the loop.
+; REQUIRES: asserts
; CHECK: Loop Align Pass:
; CHECK: Bundle Count : 4
diff --git a/llvm/test/CodeGen/Hexagon/loop_align_count.mir b/llvm/test/CodeGen/Hexagon/loop_align_count.mir
index afbd917f4f0db3..6955b525e1ad42 100644
--- a/llvm/test/CodeGen/Hexagon/loop_align_count.mir
+++ b/llvm/test/CodeGen/Hexagon/loop_align_count.mir
@@ -1,5 +1,6 @@
# RUN: llc -march=hexagon -O3 -run-pass hexagon-loop-align -o - %s\
# RUN: -debug-only=hexagon-loop-align -verify-machineinstrs 2>&1 | FileCheck %s
+# REQUIRES: asserts
# Test that we only count til endloop instruction and we align this
# loop to 32.
>From dca32a3b594b3c91f9766a9312b5d82534910fa1 Mon Sep 17 00:00:00 2001
From: Matthias Gehre <matthias.gehre at amd.com>
Date: Fri, 1 Mar 2024 07:29:49 +0100
Subject: [PATCH 212/406] [mlir][PDL] Add support for native constraints with
results (#82760)
>From https://reviews.llvm.org/D153245
This adds support for native PDL (and PDLL) C++ constraints to return
results.
This is useful for situations where a pattern checks for certain
constraints of multiple interdependent attributes and computes a new
attribute value based on them. Currently, for such an example it is
required to escape to C++ during matching to perform the check and after
a successful match again escape to native C++ to perform the computation
during the rewriting part of the pattern. With this work we can do the
computation in C++ during matching and use the result in the rewriting
part of the pattern. Effectively this enables a choice in the trade-off
of memory consumption during matching vs recomputation of values.
This is an example of a situation where this is useful: We have two
operations with certain attributes that have interdependent constraints.
For instance `attr_foo: one_of [0, 2, 4, 8], attr_bar: one_of [0, 2, 4,
8]` and `attr_foo == attr_bar`. The pattern should only match if all
conditions are true. The new operation should be created with a new
attribute which is computed from the two matched attributes e.g.
`attr_baz = attr_foo * attr_bar`. For the check we already escape to
native C++ and have all values at hand so it makes sense to directly
compute the new attribute value as well:
```
Constraint checkAndCompute(attr0: Attr, attr1: Attr) -> Attr;
Pattern example with benefit(1) {
let foo = op<test.foo>() {attr = attr_foo : Attr};
let bar = op<test.bar>(foo) {attr = attr_bar : Attr};
let attr_baz = checkAndCompute(attr_foo, attr_bar);
rewrite bar with {
let baz = op<test.baz> {attr=attr_baz};
replace bar with baz;
};
}
```
To achieve this the following notable changes were necessary:
PDLL:
- Remove check in PDLL parser that prevented native constraints from
returning results
PDL:
- Change PDL definition of pdl.apply_native_constraint to allow variadic
results
PDL_interp:
- Change PDL_interp definition of pdl_interp.apply_constraint to allow
variadic results
PDLToPDLInterp Pass:
The input to the pass is an arbitrary number of PDL patterns. The pass
collects the predicates that are required to match all of the pdl
patterns and establishes an ordering that allows creation of a single
efficient matcher function to match all of them. Values that are matched
and possibly used in the rewriting part of a pattern are represented as
positions. This allows fusion and thus reusing a single position for
multiple matching patterns. Accordingly, we introduce
ConstraintPosition, which records the type and index of the result of
the constraint. The problem is for the corresponding value to be used in
the rewriting part of a pattern it has to be an input to the
pdl_interp.record_match operation, which is generated early during the
pass such that its surrounding block can be referred to by branching
operations. In consequence the value has to be materialized after the
original pdl.apply_native_constraint has been deleted but before we get
the chance to generate the corresponding pdl_interp.apply_constraint
operation. We solve this by emitting a placeholder value when a
ConstraintPosition is evaluated. These placeholder values (due to fusion
there may be multiple for one constraint result) are replaced later when
the actual pdl_interp.apply_constraint operation is created.
Changes since the phabricator review:
- Addressed all comments
- In particular, removed registerConstraintFunctionWithResults and
instead changed registerConstraintFunction so that contraint functions
always have results (empty by default)
- Thus we don't need to reuse `rewriteFunctions` to store constraint
functions with results anymore, and can instead use
`constraintFunctions`
- Perform a stable sort of ConstraintQuestion, so that
ConstraintQuestion appear before other ConstraintQuestion that use their
results.
- Don't create placeholders for pdl_interp::ApplyConstraintOp. Instead
generate the `pdl_interp::ApplyConstraintOp` before generating the
successor block.
- Fixed a test failure in the pdl python bindings
Original code by @martin-luecke
Co-authored-by: martin-luecke <martinpaul.luecke at amd.com>
---
mlir/include/mlir/Dialect/PDL/IR/PDLOps.td | 9 +-
.../mlir/Dialect/PDLInterp/IR/PDLInterpOps.td | 8 +-
mlir/include/mlir/IR/PDLPatternMatch.h.inc | 18 ++-
.../PDLToPDLInterp/PDLToPDLInterp.cpp | 41 +++--
.../lib/Conversion/PDLToPDLInterp/Predicate.h | 58 +++++--
.../PDLToPDLInterp/PredicateTree.cpp | 82 +++++++++-
mlir/lib/Dialect/PDL/IR/PDL.cpp | 6 +
mlir/lib/Rewrite/ByteCode.cpp | 144 ++++++++++++------
mlir/lib/Tools/PDLL/Parser/Parser.cpp | 6 -
.../pdl-to-pdl-interp-matcher.mlir | 51 +++++++
.../PDLToPDLInterp/use-constraint-result.mlir | 77 ++++++++++
mlir/test/Dialect/PDL/ops.mlir | 18 +++
mlir/test/Rewrite/pdl-bytecode.mlir | 68 +++++++++
.../TestTransformDialectExtension.cpp | 2 +-
mlir/test/lib/Rewrite/TestPDLByteCode.cpp | 50 ++++++
.../mlir-pdll/Parser/constraint-failure.pdll | 5 -
mlir/test/mlir-pdll/Parser/constraint.pdll | 8 +
mlir/test/python/dialects/pdl_ops.py | 2 +-
18 files changed, 555 insertions(+), 98 deletions(-)
create mode 100644 mlir/test/Conversion/PDLToPDLInterp/use-constraint-result.mlir
diff --git a/mlir/include/mlir/Dialect/PDL/IR/PDLOps.td b/mlir/include/mlir/Dialect/PDL/IR/PDLOps.td
index 4e9ebccba77d88..1e108c3d8ac77a 100644
--- a/mlir/include/mlir/Dialect/PDL/IR/PDLOps.td
+++ b/mlir/include/mlir/Dialect/PDL/IR/PDLOps.td
@@ -35,20 +35,25 @@ def PDL_ApplyNativeConstraintOp
let description = [{
`pdl.apply_native_constraint` operations apply a native C++ constraint, that
has been registered externally with the consumer of PDL, to a given set of
- entities.
+ entities and optionally return a number of values.
Example:
```mlir
// Apply `myConstraint` to the entities defined by `input`, `attr`, and `op`.
pdl.apply_native_constraint "myConstraint"(%input, %attr, %op : !pdl.value, !pdl.attribute, !pdl.operation)
+ // Apply constraint `with_result` to `root`. This constraint returns an attribute.
+ %attr = pdl.apply_native_constraint "with_result"(%root : !pdl.operation) : !pdl.attribute
```
}];
let arguments = (ins StrAttr:$name,
Variadic<PDL_AnyType>:$args,
DefaultValuedAttr<BoolAttr, "false">:$isNegated);
- let assemblyFormat = "$name `(` $args `:` type($args) `)` attr-dict";
+ let results = (outs Variadic<PDL_AnyType>:$results);
+ let assemblyFormat = [{
+ $name `(` $args `:` type($args) `)` (`:` type($results)^ )? attr-dict
+ }];
let hasVerifier = 1;
}
diff --git a/mlir/include/mlir/Dialect/PDLInterp/IR/PDLInterpOps.td b/mlir/include/mlir/Dialect/PDLInterp/IR/PDLInterpOps.td
index 48f625bd1fa3fd..901acc0e6733bb 100644
--- a/mlir/include/mlir/Dialect/PDLInterp/IR/PDLInterpOps.td
+++ b/mlir/include/mlir/Dialect/PDLInterp/IR/PDLInterpOps.td
@@ -88,7 +88,9 @@ def PDLInterp_ApplyConstraintOp : PDLInterp_PredicateOp<"apply_constraint"> {
let description = [{
`pdl_interp.apply_constraint` operations apply a generic constraint, that
has been registered with the interpreter, with a given set of positional
- values. On success, this operation branches to the true destination,
+ values.
+ The constraint function may return any number of results.
+ On success, this operation branches to the true destination,
otherwise the false destination is taken. This behavior can be reversed
by setting the attribute `isNegated` to true.
@@ -104,8 +106,10 @@ def PDLInterp_ApplyConstraintOp : PDLInterp_PredicateOp<"apply_constraint"> {
let arguments = (ins StrAttr:$name,
Variadic<PDL_AnyType>:$args,
DefaultValuedAttr<BoolAttr, "false">:$isNegated);
+ let results = (outs Variadic<PDL_AnyType>:$results);
let assemblyFormat = [{
- $name `(` $args `:` type($args) `)` attr-dict `->` successors
+ $name `(` $args `:` type($args) `)` (`:` type($results)^)? attr-dict
+ `->` successors
}];
}
diff --git a/mlir/include/mlir/IR/PDLPatternMatch.h.inc b/mlir/include/mlir/IR/PDLPatternMatch.h.inc
index a215da8cb6431d..66286ed7a4c898 100644
--- a/mlir/include/mlir/IR/PDLPatternMatch.h.inc
+++ b/mlir/include/mlir/IR/PDLPatternMatch.h.inc
@@ -318,8 +318,9 @@ protected:
/// A generic PDL pattern constraint function. This function applies a
/// constraint to a given set of opaque PDLValue entities. Returns success if
/// the constraint successfully held, failure otherwise.
-using PDLConstraintFunction =
- std::function<LogicalResult(PatternRewriter &, ArrayRef<PDLValue>)>;
+using PDLConstraintFunction = std::function<LogicalResult(
+ PatternRewriter &, PDLResultList &, ArrayRef<PDLValue>)>;
+
/// A native PDL rewrite function. This function performs a rewrite on the
/// given set of values. Any results from this rewrite that should be passed
/// back to PDL should be added to the provided result list. This method is only
@@ -726,7 +727,7 @@ std::enable_if_t<
PDLConstraintFunction>
buildConstraintFn(ConstraintFnT &&constraintFn) {
return [constraintFn = std::forward<ConstraintFnT>(constraintFn)](
- PatternRewriter &rewriter,
+ PatternRewriter &rewriter, PDLResultList &,
ArrayRef<PDLValue> values) -> LogicalResult {
auto argIndices = std::make_index_sequence<
llvm::function_traits<ConstraintFnT>::num_args - 1>();
@@ -842,10 +843,13 @@ public:
/// Register a constraint function with PDL. A constraint function may be
/// specified in one of two ways:
///
- /// * `LogicalResult (PatternRewriter &, ArrayRef<PDLValue>)`
+ /// * `LogicalResult (PatternRewriter &,
+ /// PDLResultList &,
+ /// ArrayRef<PDLValue>)`
///
/// In this overload the arguments of the constraint function are passed via
- /// the low-level PDLValue form.
+ /// the low-level PDLValue form, and the results are manually appended to
+ /// the given result list.
///
/// * `LogicalResult (PatternRewriter &, ValueTs... values)`
///
@@ -960,8 +964,8 @@ public:
}
};
class PDLResultList {};
-using PDLConstraintFunction =
- std::function<LogicalResult(PatternRewriter &, ArrayRef<PDLValue>)>;
+using PDLConstraintFunction = std::function<LogicalResult(
+ PatternRewriter &, PDLResultList &, ArrayRef<PDLValue>)>;
using PDLRewriteFunction = std::function<LogicalResult(
PatternRewriter &, PDLResultList &, ArrayRef<PDLValue>)>;
diff --git a/mlir/lib/Conversion/PDLToPDLInterp/PDLToPDLInterp.cpp b/mlir/lib/Conversion/PDLToPDLInterp/PDLToPDLInterp.cpp
index e911631a4bc52a..b00cd0dee3ae80 100644
--- a/mlir/lib/Conversion/PDLToPDLInterp/PDLToPDLInterp.cpp
+++ b/mlir/lib/Conversion/PDLToPDLInterp/PDLToPDLInterp.cpp
@@ -50,7 +50,8 @@ struct PatternLowering {
/// Generate interpreter operations for the tree rooted at the given matcher
/// node, in the specified region.
- Block *generateMatcher(MatcherNode &node, Region ®ion);
+ Block *generateMatcher(MatcherNode &node, Region ®ion,
+ Block *block = nullptr);
/// Get or create an access to the provided positional value in the current
/// block. This operation may mutate the provided block pointer if nested
@@ -148,6 +149,10 @@ struct PatternLowering {
/// A mapping between pattern operations and the corresponding configuration
/// set.
DenseMap<Operation *, PDLPatternConfigSet *> *configMap;
+
+ /// A mapping from a constraint question to the ApplyConstraintOp
+ /// that implements it.
+ DenseMap<ConstraintQuestion *, pdl_interp::ApplyConstraintOp> constraintOpMap;
};
} // namespace
@@ -182,9 +187,11 @@ void PatternLowering::lower(ModuleOp module) {
firstMatcherBlock->erase();
}
-Block *PatternLowering::generateMatcher(MatcherNode &node, Region ®ion) {
+Block *PatternLowering::generateMatcher(MatcherNode &node, Region ®ion,
+ Block *block) {
// Push a new scope for the values used by this matcher.
- Block *block = ®ion.emplaceBlock();
+ if (!block)
+ block = ®ion.emplaceBlock();
ValueMapScope scope(values);
// If this is the return node, simply insert the corresponding interpreter
@@ -364,6 +371,15 @@ Value PatternLowering::getValueAt(Block *¤tBlock, Position *pos) {
loc, cast<ArrayAttr>(rawTypeAttr));
break;
}
+ case Predicates::ConstraintResultPos: {
+ // Due to the order of traversal, the ApplyConstraintOp has already been
+ // created and we can find it in constraintOpMap.
+ auto *constrResPos = cast<ConstraintPosition>(pos);
+ auto i = constraintOpMap.find(constrResPos->getQuestion());
+ assert(i != constraintOpMap.end());
+ value = i->second->getResult(constrResPos->getIndex());
+ break;
+ }
default:
llvm_unreachable("Generating unknown Position getter");
break;
@@ -390,12 +406,11 @@ void PatternLowering::generate(BoolNode *boolNode, Block *¤tBlock,
args.push_back(getValueAt(currentBlock, position));
}
- // Generate the matcher in the current (potentially nested) region
- // and get the failure successor.
- Block *success = generateMatcher(*boolNode->getSuccessNode(), *region);
+ // Generate a new block as success successor and get the failure successor.
+ Block *success = ®ion->emplaceBlock();
Block *failure = failureBlockStack.back();
- // Finally, create the predicate.
+ // Create the predicate.
builder.setInsertionPointToEnd(currentBlock);
Predicates::Kind kind = question->getKind();
switch (kind) {
@@ -447,14 +462,20 @@ void PatternLowering::generate(BoolNode *boolNode, Block *¤tBlock,
}
case Predicates::ConstraintQuestion: {
auto *cstQuestion = cast<ConstraintQuestion>(question);
- builder.create<pdl_interp::ApplyConstraintOp>(
- loc, cstQuestion->getName(), args, cstQuestion->getIsNegated(), success,
- failure);
+ auto applyConstraintOp = builder.create<pdl_interp::ApplyConstraintOp>(
+ loc, cstQuestion->getResultTypes(), cstQuestion->getName(), args,
+ cstQuestion->getIsNegated(), success, failure);
+
+ constraintOpMap.insert({cstQuestion, applyConstraintOp});
break;
}
default:
llvm_unreachable("Generating unknown Predicate operation");
}
+
+ // Generate the matcher in the current (potentially nested) region.
+ // This might use the results of the current predicate.
+ generateMatcher(*boolNode->getSuccessNode(), *region, success);
}
template <typename OpT, typename PredT, typename ValT = typename PredT::KeyTy>
diff --git a/mlir/lib/Conversion/PDLToPDLInterp/Predicate.h b/mlir/lib/Conversion/PDLToPDLInterp/Predicate.h
index 2c9b63f86d6efa..5ad2c477573a5b 100644
--- a/mlir/lib/Conversion/PDLToPDLInterp/Predicate.h
+++ b/mlir/lib/Conversion/PDLToPDLInterp/Predicate.h
@@ -47,6 +47,7 @@ enum Kind : unsigned {
OperandPos,
OperandGroupPos,
AttributePos,
+ ConstraintResultPos,
ResultPos,
ResultGroupPos,
TypePos,
@@ -279,6 +280,28 @@ struct OperationPosition : public PredicateBase<OperationPosition, Position,
bool isOperandDefiningOp() const;
};
+//===----------------------------------------------------------------------===//
+// ConstraintPosition
+
+struct ConstraintQuestion;
+
+/// A position describing the result of a native constraint. It saves the
+/// corresponding ConstraintQuestion and result index to enable referring
+/// back to them
+struct ConstraintPosition
+ : public PredicateBase<ConstraintPosition, Position,
+ std::pair<ConstraintQuestion *, unsigned>,
+ Predicates::ConstraintResultPos> {
+ using PredicateBase::PredicateBase;
+
+ /// Returns the ConstraintQuestion to enable keeping track of the native
+ /// constraint this position stems from.
+ ConstraintQuestion *getQuestion() const { return key.first; }
+
+ // Returns the result index of this position
+ unsigned getIndex() const { return key.second; }
+};
+
//===----------------------------------------------------------------------===//
// ResultPosition
@@ -447,11 +470,13 @@ struct AttributeQuestion
: public PredicateBase<AttributeQuestion, Qualifier, void,
Predicates::AttributeQuestion> {};
-/// Apply a parameterized constraint to multiple position values.
+/// Apply a parameterized constraint to multiple position values and possibly
+/// produce results.
struct ConstraintQuestion
- : public PredicateBase<ConstraintQuestion, Qualifier,
- std::tuple<StringRef, ArrayRef<Position *>, bool>,
- Predicates::ConstraintQuestion> {
+ : public PredicateBase<
+ ConstraintQuestion, Qualifier,
+ std::tuple<StringRef, ArrayRef<Position *>, ArrayRef<Type>, bool>,
+ Predicates::ConstraintQuestion> {
using Base::Base;
/// Return the name of the constraint.
@@ -460,15 +485,19 @@ struct ConstraintQuestion
/// Return the arguments of the constraint.
ArrayRef<Position *> getArgs() const { return std::get<1>(key); }
+ /// Return the result types of the constraint.
+ ArrayRef<Type> getResultTypes() const { return std::get<2>(key); }
+
/// Return the negation status of the constraint.
- bool getIsNegated() const { return std::get<2>(key); }
+ bool getIsNegated() const { return std::get<3>(key); }
/// Construct an instance with the given storage allocator.
static ConstraintQuestion *construct(StorageUniquer::StorageAllocator &alloc,
KeyTy key) {
return Base::construct(alloc, KeyTy{alloc.copyInto(std::get<0>(key)),
alloc.copyInto(std::get<1>(key)),
- std::get<2>(key)});
+ alloc.copyInto(std::get<2>(key)),
+ std::get<3>(key)});
}
/// Returns a hash suitable for the given keytype.
@@ -526,6 +555,7 @@ class PredicateUniquer : public StorageUniquer {
// Register the types of Positions with the uniquer.
registerParametricStorageType<AttributePosition>();
registerParametricStorageType<AttributeLiteralPosition>();
+ registerParametricStorageType<ConstraintPosition>();
registerParametricStorageType<ForEachPosition>();
registerParametricStorageType<OperandPosition>();
registerParametricStorageType<OperandGroupPosition>();
@@ -588,6 +618,12 @@ class PredicateBuilder {
return OperationPosition::get(uniquer, p);
}
+ // Returns a position for a new value created by a constraint.
+ ConstraintPosition *getConstraintPosition(ConstraintQuestion *q,
+ unsigned index) {
+ return ConstraintPosition::get(uniquer, std::make_pair(q, index));
+ }
+
/// Returns an attribute position for an attribute of the given operation.
Position *getAttribute(OperationPosition *p, StringRef name) {
return AttributePosition::get(uniquer, p, StringAttr::get(ctx, name));
@@ -673,11 +709,11 @@ class PredicateBuilder {
}
/// Create a predicate that applies a generic constraint.
- Predicate getConstraint(StringRef name, ArrayRef<Position *> pos,
- bool isNegated) {
- return {
- ConstraintQuestion::get(uniquer, std::make_tuple(name, pos, isNegated)),
- TrueAnswer::get(uniquer)};
+ Predicate getConstraint(StringRef name, ArrayRef<Position *> args,
+ ArrayRef<Type> resultTypes, bool isNegated) {
+ return {ConstraintQuestion::get(
+ uniquer, std::make_tuple(name, args, resultTypes, isNegated)),
+ TrueAnswer::get(uniquer)};
}
/// Create a predicate comparing a value with null.
diff --git a/mlir/lib/Conversion/PDLToPDLInterp/PredicateTree.cpp b/mlir/lib/Conversion/PDLToPDLInterp/PredicateTree.cpp
index a9c3b0a71ef0d7..f3d0e08ef49b97 100644
--- a/mlir/lib/Conversion/PDLToPDLInterp/PredicateTree.cpp
+++ b/mlir/lib/Conversion/PDLToPDLInterp/PredicateTree.cpp
@@ -15,6 +15,7 @@
#include "mlir/IR/BuiltinOps.h"
#include "mlir/Interfaces/InferTypeOpInterface.h"
#include "llvm/ADT/MapVector.h"
+#include "llvm/ADT/SmallPtrSet.h"
#include "llvm/ADT/TypeSwitch.h"
#include "llvm/Support/Debug.h"
#include <queue>
@@ -49,14 +50,15 @@ static void getTreePredicates(std::vector<PositionalPredicate> &predList,
DenseMap<Value, Position *> &inputs,
AttributePosition *pos) {
assert(isa<pdl::AttributeType>(val.getType()) && "expected attribute type");
- pdl::AttributeOp attr = cast<pdl::AttributeOp>(val.getDefiningOp());
predList.emplace_back(pos, builder.getIsNotNull());
- // If the attribute has a type or value, add a constraint.
- if (Value type = attr.getValueType())
- getTreePredicates(predList, type, builder, inputs, builder.getType(pos));
- else if (Attribute value = attr.getValueAttr())
- predList.emplace_back(pos, builder.getAttributeConstraint(value));
+ if (auto attr = dyn_cast<pdl::AttributeOp>(val.getDefiningOp())) {
+ // If the attribute has a type or value, add a constraint.
+ if (Value type = attr.getValueType())
+ getTreePredicates(predList, type, builder, inputs, builder.getType(pos));
+ else if (Attribute value = attr.getValueAttr())
+ predList.emplace_back(pos, builder.getAttributeConstraint(value));
+ }
}
/// Collect all of the predicates for the given operand position.
@@ -272,8 +274,25 @@ static void getConstraintPredicates(pdl::ApplyNativeConstraintOp op,
// Push the constraint to the furthest position.
Position *pos = *std::max_element(allPositions.begin(), allPositions.end(),
comparePosDepth);
- PredicateBuilder::Predicate pred =
- builder.getConstraint(op.getName(), allPositions, op.getIsNegated());
+ ResultRange results = op.getResults();
+ PredicateBuilder::Predicate pred = builder.getConstraint(
+ op.getName(), allPositions, SmallVector<Type>(results.getTypes()),
+ op.getIsNegated());
+
+ // For each result register a position so it can be used later
+ for (auto [i, result] : llvm::enumerate(results)) {
+ ConstraintQuestion *q = cast<ConstraintQuestion>(pred.first);
+ ConstraintPosition *pos = builder.getConstraintPosition(q, i);
+ auto [it, inserted] = inputs.insert({result, pos});
+ // If this is an input value that has been visited in the tree, add a
+ // constraint to ensure that both instances refer to the same value.
+ if (!inserted) {
+ auto minMaxPositions =
+ std::minmax<Position *>(pos, it->second, comparePosDepth);
+ predList.emplace_back(minMaxPositions.second,
+ builder.getEqualTo(minMaxPositions.first));
+ }
+ }
predList.emplace_back(pos, pred);
}
@@ -875,6 +894,49 @@ static void insertExitNode(std::unique_ptr<MatcherNode> *root) {
*root = std::make_unique<ExitNode>();
}
+/// Sorts the range begin/end with the partial order given by cmp.
+template <typename Iterator, typename Compare>
+static void stableTopologicalSort(Iterator begin, Iterator end, Compare cmp) {
+ while (begin != end) {
+ // Cannot compute sortBeforeOthers in the predicate of stable_partition
+ // because stable_partition will not keep the [begin, end) range intact
+ // while it runs.
+ llvm::SmallPtrSet<typename Iterator::value_type, 16> sortBeforeOthers;
+ for (auto i = begin; i != end; ++i) {
+ if (std::none_of(begin, end, [&](auto const &b) { return cmp(b, *i); }))
+ sortBeforeOthers.insert(*i);
+ }
+
+ auto const next = std::stable_partition(begin, end, [&](auto const &a) {
+ return sortBeforeOthers.contains(a);
+ });
+ assert(next != begin && "not a partial ordering");
+ begin = next;
+ }
+}
+
+/// Returns true if 'b' depends on a result of 'a'.
+static bool dependsOn(OrderedPredicate *a, OrderedPredicate *b) {
+ auto *cqa = dyn_cast<ConstraintQuestion>(a->question);
+ if (!cqa)
+ return false;
+
+ auto positionDependsOnA = [&](Position *p) {
+ auto *cp = dyn_cast<ConstraintPosition>(p);
+ return cp && cp->getQuestion() == cqa;
+ };
+
+ if (auto *cqb = dyn_cast<ConstraintQuestion>(b->question)) {
+ // Does any argument of b use a?
+ return llvm::any_of(cqb->getArgs(), positionDependsOnA);
+ }
+ if (auto *equalTo = dyn_cast<EqualToQuestion>(b->question)) {
+ return positionDependsOnA(b->position) ||
+ positionDependsOnA(equalTo->getValue());
+ }
+ return positionDependsOnA(b->position);
+}
+
/// Given a module containing PDL pattern operations, generate a matcher tree
/// using the patterns within the given module and return the root matcher node.
std::unique_ptr<MatcherNode>
@@ -955,6 +1017,10 @@ MatcherNode::generateMatcherTree(ModuleOp module, PredicateBuilder &builder,
return *lhs < *rhs;
});
+ // Mostly keep the now established order, but also ensure that
+ // ConstraintQuestions come after the results they use.
+ stableTopologicalSort(ordered.begin(), ordered.end(), dependsOn);
+
// Build the matchers for each of the pattern predicate lists.
std::unique_ptr<MatcherNode> root;
for (OrderedPredicateList &list : lists)
diff --git a/mlir/lib/Dialect/PDL/IR/PDL.cpp b/mlir/lib/Dialect/PDL/IR/PDL.cpp
index d5f34679f06c60..428b19f4c74af8 100644
--- a/mlir/lib/Dialect/PDL/IR/PDL.cpp
+++ b/mlir/lib/Dialect/PDL/IR/PDL.cpp
@@ -94,6 +94,12 @@ static void visit(Operation *op, DenseSet<Operation *> &visited) {
LogicalResult ApplyNativeConstraintOp::verify() {
if (getNumOperands() == 0)
return emitOpError("expected at least one argument");
+ if (llvm::any_of(getResults(), [](OpResult result) {
+ return isa<OperationType>(result.getType());
+ })) {
+ return emitOpError(
+ "returning an operation from a constraint is not supported");
+ }
return success();
}
diff --git a/mlir/lib/Rewrite/ByteCode.cpp b/mlir/lib/Rewrite/ByteCode.cpp
index 6e6992dcdeea78..559ce7f466a83d 100644
--- a/mlir/lib/Rewrite/ByteCode.cpp
+++ b/mlir/lib/Rewrite/ByteCode.cpp
@@ -769,11 +769,25 @@ void Generator::generate(Operation *op, ByteCodeWriter &writer) {
void Generator::generate(pdl_interp::ApplyConstraintOp op,
ByteCodeWriter &writer) {
- assert(constraintToMemIndex.count(op.getName()) &&
- "expected index for constraint function");
+ // Constraints that should return a value have to be registered as rewrites.
+ // If a constraint and a rewrite of similar name are registered the
+ // constraint takes precedence
writer.append(OpCode::ApplyConstraint, constraintToMemIndex[op.getName()]);
writer.appendPDLValueList(op.getArgs());
writer.append(ByteCodeField(op.getIsNegated()));
+ ResultRange results = op.getResults();
+ writer.append(ByteCodeField(results.size()));
+ for (Value result : results) {
+ // We record the expected kind of the result, so that we can provide extra
+ // verification of the native rewrite function and handle the failure case
+ // of constraints accordingly.
+ writer.appendPDLValueKind(result);
+
+ // Range results also need to append the range storage index.
+ if (isa<pdl::RangeType>(result.getType()))
+ writer.append(getRangeStorageIndex(result));
+ writer.append(result);
+ }
writer.append(op.getSuccessors());
}
void Generator::generate(pdl_interp::ApplyRewriteOp op,
@@ -786,11 +800,9 @@ void Generator::generate(pdl_interp::ApplyRewriteOp op,
ResultRange results = op.getResults();
writer.append(ByteCodeField(results.size()));
for (Value result : results) {
- // In debug mode we also record the expected kind of the result, so that we
+ // We record the expected kind of the result, so that we
// can provide extra verification of the native rewrite function.
-#ifndef NDEBUG
writer.appendPDLValueKind(result);
-#endif
// Range results also need to append the range storage index.
if (isa<pdl::RangeType>(result.getType()))
@@ -1076,6 +1088,28 @@ void PDLByteCode::initializeMutableState(PDLByteCodeMutableState &state) const {
// ByteCode Execution
namespace {
+/// This class is an instantiation of the PDLResultList that provides access to
+/// the returned results. This API is not on `PDLResultList` to avoid
+/// overexposing access to information specific solely to the ByteCode.
+class ByteCodeRewriteResultList : public PDLResultList {
+public:
+ ByteCodeRewriteResultList(unsigned maxNumResults)
+ : PDLResultList(maxNumResults) {}
+
+ /// Return the list of PDL results.
+ MutableArrayRef<PDLValue> getResults() { return results; }
+
+ /// Return the type ranges allocated by this list.
+ MutableArrayRef<llvm::OwningArrayRef<Type>> getAllocatedTypeRanges() {
+ return allocatedTypeRanges;
+ }
+
+ /// Return the value ranges allocated by this list.
+ MutableArrayRef<llvm::OwningArrayRef<Value>> getAllocatedValueRanges() {
+ return allocatedValueRanges;
+ }
+};
+
/// This class provides support for executing a bytecode stream.
class ByteCodeExecutor {
public:
@@ -1152,6 +1186,9 @@ class ByteCodeExecutor {
void executeSwitchResultCount();
void executeSwitchType();
void executeSwitchTypes();
+ void processNativeFunResults(ByteCodeRewriteResultList &results,
+ unsigned numResults,
+ LogicalResult &rewriteResult);
/// Pushes a code iterator to the stack.
void pushCodeIt(const ByteCodeField *it) { resumeCodeIt.push_back(it); }
@@ -1225,6 +1262,8 @@ class ByteCodeExecutor {
return T::getFromOpaquePointer(pointer);
}
+ void skip(size_t skipN) { curCodeIt += skipN; }
+
/// Jump to a specific successor based on a predicate value.
void selectJump(bool isTrue) { selectJump(size_t(isTrue ? 0 : 1)); }
/// Jump to a specific successor based on a destination index.
@@ -1381,33 +1420,11 @@ class ByteCodeExecutor {
ArrayRef<PDLConstraintFunction> constraintFunctions;
ArrayRef<PDLRewriteFunction> rewriteFunctions;
};
-
-/// This class is an instantiation of the PDLResultList that provides access to
-/// the returned results. This API is not on `PDLResultList` to avoid
-/// overexposing access to information specific solely to the ByteCode.
-class ByteCodeRewriteResultList : public PDLResultList {
-public:
- ByteCodeRewriteResultList(unsigned maxNumResults)
- : PDLResultList(maxNumResults) {}
-
- /// Return the list of PDL results.
- MutableArrayRef<PDLValue> getResults() { return results; }
-
- /// Return the type ranges allocated by this list.
- MutableArrayRef<llvm::OwningArrayRef<Type>> getAllocatedTypeRanges() {
- return allocatedTypeRanges;
- }
-
- /// Return the value ranges allocated by this list.
- MutableArrayRef<llvm::OwningArrayRef<Value>> getAllocatedValueRanges() {
- return allocatedValueRanges;
- }
-};
} // namespace
void ByteCodeExecutor::executeApplyConstraint(PatternRewriter &rewriter) {
LLVM_DEBUG(llvm::dbgs() << "Executing ApplyConstraint:\n");
- const PDLConstraintFunction &constraintFn = constraintFunctions[read()];
+ ByteCodeField fun_idx = read();
SmallVector<PDLValue, 16> args;
readList<PDLValue>(args);
@@ -1422,8 +1439,29 @@ void ByteCodeExecutor::executeApplyConstraint(PatternRewriter &rewriter) {
llvm::dbgs() << " * isNegated: " << isNegated << "\n";
llvm::interleaveComma(args, llvm::dbgs());
});
- // Invoke the constraint and jump to the proper destination.
- selectJump(isNegated != succeeded(constraintFn(rewriter, args)));
+
+ ByteCodeField numResults = read();
+ const PDLRewriteFunction &constraintFn = constraintFunctions[fun_idx];
+ ByteCodeRewriteResultList results(numResults);
+ LogicalResult rewriteResult = constraintFn(rewriter, results, args);
+ ArrayRef<PDLValue> constraintResults = results.getResults();
+ LLVM_DEBUG({
+ if (succeeded(rewriteResult)) {
+ llvm::dbgs() << " * Constraint succeeded\n";
+ llvm::dbgs() << " * Results: ";
+ llvm::interleaveComma(constraintResults, llvm::dbgs());
+ llvm::dbgs() << "\n";
+ } else {
+ llvm::dbgs() << " * Constraint failed\n";
+ }
+ });
+ assert((failed(rewriteResult) || constraintResults.size() == numResults) &&
+ "native PDL rewrite function succeeded but returned "
+ "unexpected number of results");
+ processNativeFunResults(results, numResults, rewriteResult);
+
+ // Depending on the constraint jump to the proper destination.
+ selectJump(isNegated != succeeded(rewriteResult));
}
LogicalResult ByteCodeExecutor::executeApplyRewrite(PatternRewriter &rewriter) {
@@ -1445,16 +1483,39 @@ LogicalResult ByteCodeExecutor::executeApplyRewrite(PatternRewriter &rewriter) {
assert(results.getResults().size() == numResults &&
"native PDL rewrite function returned unexpected number of results");
- // Store the results in the bytecode memory.
- for (PDLValue &result : results.getResults()) {
- LLVM_DEBUG(llvm::dbgs() << " * Result: " << result << "\n");
+ processNativeFunResults(results, numResults, rewriteResult);
-// In debug mode we also verify the expected kind of the result.
-#ifndef NDEBUG
- assert(result.getKind() == read<PDLValue::Kind>() &&
- "native PDL rewrite function returned an unexpected type of result");
-#endif
+ if (failed(rewriteResult)) {
+ LLVM_DEBUG(llvm::dbgs() << " - Failed");
+ return failure();
+ }
+ return success();
+}
+void ByteCodeExecutor::processNativeFunResults(
+ ByteCodeRewriteResultList &results, unsigned numResults,
+ LogicalResult &rewriteResult) {
+ // Store the results in the bytecode memory or handle missing results on
+ // failure.
+ for (unsigned resultIdx = 0; resultIdx < numResults; resultIdx++) {
+ PDLValue::Kind resultKind = read<PDLValue::Kind>();
+
+ // Skip the according number of values on the buffer on failure and exit
+ // early as there are no results to process.
+ if (failed(rewriteResult)) {
+ if (resultKind == PDLValue::Kind::TypeRange ||
+ resultKind == PDLValue::Kind::ValueRange) {
+ skip(2);
+ } else {
+ skip(1);
+ }
+ return;
+ }
+ PDLValue result = results.getResults()[resultIdx];
+ LLVM_DEBUG(llvm::dbgs() << " * Result: " << result << "\n");
+ assert(result.getKind() == resultKind &&
+ "native PDL rewrite function returned an unexpected type of "
+ "result");
// If the result is a range, we need to copy it over to the bytecodes
// range memory.
if (std::optional<TypeRange> typeRange = result.dyn_cast<TypeRange>()) {
@@ -1476,13 +1537,6 @@ LogicalResult ByteCodeExecutor::executeApplyRewrite(PatternRewriter &rewriter) {
allocatedTypeRangeMemory.push_back(std::move(it));
for (auto &it : results.getAllocatedValueRanges())
allocatedValueRangeMemory.push_back(std::move(it));
-
- // Process the result of the rewrite.
- if (failed(rewriteResult)) {
- LLVM_DEBUG(llvm::dbgs() << " - Failed");
- return failure();
- }
- return success();
}
void ByteCodeExecutor::executeAreEqual() {
diff --git a/mlir/lib/Tools/PDLL/Parser/Parser.cpp b/mlir/lib/Tools/PDLL/Parser/Parser.cpp
index 97ff8bd0d8584d..206781ed146692 100644
--- a/mlir/lib/Tools/PDLL/Parser/Parser.cpp
+++ b/mlir/lib/Tools/PDLL/Parser/Parser.cpp
@@ -1362,12 +1362,6 @@ FailureOr<T *> Parser::parseUserNativeConstraintOrRewriteDecl(
if (failed(parseToken(Token::semicolon,
"expected `;` after native declaration")))
return failure();
- // TODO: PDL should be able to support constraint results in certain
- // situations, we should revise this.
- if (std::is_same<ast::UserConstraintDecl, T>::value && !results.empty()) {
- return emitError(
- "native Constraints currently do not support returning results");
- }
return T::createNative(ctx, name, arguments, results, optCodeStr, resultType);
}
diff --git a/mlir/test/Conversion/PDLToPDLInterp/pdl-to-pdl-interp-matcher.mlir b/mlir/test/Conversion/PDLToPDLInterp/pdl-to-pdl-interp-matcher.mlir
index 02bb8316c02db0..92afb765b5ab4e 100644
--- a/mlir/test/Conversion/PDLToPDLInterp/pdl-to-pdl-interp-matcher.mlir
+++ b/mlir/test/Conversion/PDLToPDLInterp/pdl-to-pdl-interp-matcher.mlir
@@ -79,6 +79,57 @@ module @constraints {
// -----
+// CHECK-LABEL: module @constraint_with_result
+module @constraint_with_result {
+ // CHECK: func @matcher(%[[ROOT:.*]]: !pdl.operation)
+ // CHECK: %[[ATTR:.*]] = pdl_interp.apply_constraint "check_op_and_get_attr_constr"(%[[ROOT]]
+ // CHECK: pdl_interp.record_match @rewriters::@pdl_generated_rewriter(%[[ROOT]], %[[ATTR]] : !pdl.operation, !pdl.attribute)
+ pdl.pattern : benefit(1) {
+ %root = operation
+ %attr = pdl.apply_native_constraint "check_op_and_get_attr_constr"(%root : !pdl.operation) : !pdl.attribute
+ rewrite %root with "rewriter"(%attr : !pdl.attribute)
+ }
+}
+
+// -----
+
+// CHECK-LABEL: module @constraint_with_unused_result
+module @constraint_with_unused_result {
+ // CHECK: func @matcher(%[[ROOT:.*]]: !pdl.operation)
+ // CHECK: %[[ATTR:.*]] = pdl_interp.apply_constraint "check_op_and_get_attr_constr"(%[[ROOT]]
+ // CHECK: pdl_interp.record_match @rewriters::@pdl_generated_rewriter(%[[ROOT]] : !pdl.operation)
+ pdl.pattern : benefit(1) {
+ %root = operation
+ %attr = pdl.apply_native_constraint "check_op_and_get_attr_constr"(%root : !pdl.operation) : !pdl.attribute
+ rewrite %root with "rewriter"
+ }
+}
+
+// -----
+
+// CHECK-LABEL: module @constraint_with_result_multiple
+module @constraint_with_result_multiple {
+ // check that native constraints work as expected even when multiple identical constraints are fused
+
+ // CHECK: func @matcher(%[[ROOT:.*]]: !pdl.operation)
+ // CHECK: %[[ATTR:.*]] = pdl_interp.apply_constraint "check_op_and_get_attr_constr"(%[[ROOT]]
+ // CHECK-NOT: pdl_interp.apply_constraint "check_op_and_get_attr_constr"
+ // CHECK: pdl_interp.record_match @rewriters::@pdl_generated_rewriter_0(%[[ROOT]], %[[ATTR]] : !pdl.operation, !pdl.attribute)
+ // CHECK: pdl_interp.record_match @rewriters::@pdl_generated_rewriter(%[[ROOT]], %[[ATTR]] : !pdl.operation, !pdl.attribute)
+ pdl.pattern : benefit(1) {
+ %root = operation
+ %attr = pdl.apply_native_constraint "check_op_and_get_attr_constr"(%root : !pdl.operation) : !pdl.attribute
+ rewrite %root with "rewriter"(%attr : !pdl.attribute)
+ }
+ pdl.pattern : benefit(1) {
+ %root = operation
+ %attr = pdl.apply_native_constraint "check_op_and_get_attr_constr"(%root : !pdl.operation) : !pdl.attribute
+ rewrite %root with "rewriter"(%attr : !pdl.attribute)
+ }
+}
+
+// -----
+
// CHECK-LABEL: module @negated_constraint
module @negated_constraint {
// CHECK: func @matcher(%[[ROOT:.*]]: !pdl.operation)
diff --git a/mlir/test/Conversion/PDLToPDLInterp/use-constraint-result.mlir b/mlir/test/Conversion/PDLToPDLInterp/use-constraint-result.mlir
new file mode 100644
index 00000000000000..4511baff2015a4
--- /dev/null
+++ b/mlir/test/Conversion/PDLToPDLInterp/use-constraint-result.mlir
@@ -0,0 +1,77 @@
+// RUN: mlir-opt -split-input-file -convert-pdl-to-pdl-interp %s | FileCheck %s
+
+// Ensuse that the dependency between add & less
+// causes them to be in the correct order.
+// CHECK-LABEL: matcher
+// CHECK: apply_constraint "return_attr_constraint"
+// CHECK: apply_constraint "use_attr_constraint"
+
+module {
+ pdl.pattern : benefit(1) {
+ %0 = attribute
+ %1 = types
+ %2 = operation "tosa.mul" {"shift" = %0} -> (%1 : !pdl.range<type>)
+ %3 = attribute = 0 : i32
+ %4 = attribute = 1 : i32
+ %5 = apply_native_constraint "return_attr_constraint"(%3, %4 : !pdl.attribute, !pdl.attribute) : !pdl.attribute
+ apply_native_constraint "use_attr_constraint"(%0, %5 : !pdl.attribute, !pdl.attribute)
+ rewrite %2 with "rewriter"
+ }
+}
+
+// -----
+
+// CHECK-LABEL: matcher
+// CHECK: %[[ATTR:.*]] = pdl_interp.get_attribute "attr" of
+// CHECK: %[[CONSTRAINT:.*]] = pdl_interp.apply_constraint "return_attr_constraint"
+// CHECK: pdl_interp.are_equal %[[ATTR:.*]], %[[CONSTRAINT:.*]]
+
+pdl.pattern : benefit(1) {
+ %inputOp = operation
+ %result = result 0 of %inputOp
+ %attr = pdl.apply_native_constraint "return_attr_constraint"(%inputOp : !pdl.operation) : !pdl.attribute
+ %root = operation(%result : !pdl.value) {"attr" = %attr}
+ rewrite %root with "rewriter"(%attr : !pdl.attribute)
+}
+
+// -----
+
+// CHECK-LABEL: matcher
+// CHECK: %[[CONSTRAINT:.*]] = pdl_interp.apply_constraint "return_value_constr"
+// CHECK: %[[VALUE:.*]] = pdl_interp.get_operand 0
+// CHECK: pdl_interp.are_equal %[[VALUE:.*]], %[[CONSTRAINT:.*]]
+
+pdl.pattern : benefit(1) {
+ %attr = attribute = 10
+ %value = pdl.apply_native_constraint "return_value_constr"(%attr: !pdl.attribute) : !pdl.value
+ %root = operation(%value : !pdl.value)
+ rewrite %root with "rewriter"
+}
+
+// -----
+
+// CHECK-LABEL: matcher
+// CHECK: %[[CONSTRAINT:.*]] = pdl_interp.apply_constraint "return_type_constr"
+// CHECK: %[[TYPE:.*]] = pdl_interp.get_value_type of
+// CHECK: pdl_interp.are_equal %[[TYPE:.*]], %[[CONSTRAINT:.*]]
+
+pdl.pattern : benefit(1) {
+ %attr = attribute = 10
+ %type = pdl.apply_native_constraint "return_type_constr"(%attr: !pdl.attribute) : !pdl.type
+ %root = operation -> (%type : !pdl.type)
+ rewrite %root with "rewriter"
+}
+
+// -----
+
+// CHECK-LABEL: matcher
+// CHECK: %[[CONSTRAINT:.*]] = pdl_interp.apply_constraint "return_type_range_constr"
+// CHECK: %[[TYPE:.*]] = pdl_interp.get_value_type of
+// CHECK: pdl_interp.are_equal %[[TYPE:.*]], %[[CONSTRAINT:.*]]
+
+pdl.pattern : benefit(1) {
+ %attr = attribute = 10
+ %types = pdl.apply_native_constraint "return_type_range_constr"(%attr: !pdl.attribute) : !pdl.range<type>
+ %root = operation -> (%types : !pdl.range<type>)
+ rewrite %root with "rewriter"
+}
diff --git a/mlir/test/Dialect/PDL/ops.mlir b/mlir/test/Dialect/PDL/ops.mlir
index 6e6da5cce446ae..20e40deea5f863 100644
--- a/mlir/test/Dialect/PDL/ops.mlir
+++ b/mlir/test/Dialect/PDL/ops.mlir
@@ -134,6 +134,24 @@ pdl.pattern @apply_rewrite_with_no_results : benefit(1) {
// -----
+pdl.pattern @apply_constraint_with_no_results : benefit(1) {
+ %root = operation
+ apply_native_constraint "NativeConstraint"(%root : !pdl.operation)
+ rewrite %root with "rewriter"
+}
+
+// -----
+
+pdl.pattern @apply_constraint_with_results : benefit(1) {
+ %root = operation
+ %attr = apply_native_constraint "NativeConstraint"(%root : !pdl.operation) : !pdl.attribute
+ rewrite %root {
+ apply_native_rewrite "NativeRewrite"(%attr : !pdl.attribute)
+ }
+}
+
+// -----
+
pdl.pattern @attribute_with_dict : benefit(1) {
%root = operation
rewrite %root {
diff --git a/mlir/test/Rewrite/pdl-bytecode.mlir b/mlir/test/Rewrite/pdl-bytecode.mlir
index ae61c1a079548a..f8e4f2e83b296a 100644
--- a/mlir/test/Rewrite/pdl-bytecode.mlir
+++ b/mlir/test/Rewrite/pdl-bytecode.mlir
@@ -109,6 +109,74 @@ module @ir attributes { test.apply_constraint_3 } {
// -----
+// Test returning a type from a native constraint.
+module @patterns {
+ pdl_interp.func @matcher(%root : !pdl.operation) {
+ pdl_interp.check_operation_name of %root is "test.success_op" -> ^pat, ^end
+
+ ^pat:
+ %new_type = pdl_interp.apply_constraint "op_constr_return_type"(%root : !pdl.operation) : !pdl.type -> ^pat2, ^end
+
+ ^pat2:
+ pdl_interp.record_match @rewriters::@success(%root, %new_type : !pdl.operation, !pdl.type) : benefit(1), loc([%root]) -> ^end
+
+ ^end:
+ pdl_interp.finalize
+ }
+
+ module @rewriters {
+ pdl_interp.func @success(%root : !pdl.operation, %new_type : !pdl.type) {
+ %op = pdl_interp.create_operation "test.replaced_by_pattern" -> (%new_type : !pdl.type)
+ pdl_interp.erase %root
+ pdl_interp.finalize
+ }
+ }
+}
+
+// CHECK-LABEL: test.apply_constraint_4
+// CHECK-NOT: "test.replaced_by_pattern"
+// CHECK: "test.replaced_by_pattern"() : () -> f32
+module @ir attributes { test.apply_constraint_4 } {
+ "test.failure_op"() : () -> ()
+ "test.success_op"() : () -> ()
+}
+
+// -----
+
+// Test success and failure cases of native constraints with pdl.range results.
+module @patterns {
+ pdl_interp.func @matcher(%root : !pdl.operation) {
+ pdl_interp.check_operation_name of %root is "test.success_op" -> ^pat, ^end
+
+ ^pat:
+ %num_results = pdl_interp.create_attribute 2 : i32
+ %types = pdl_interp.apply_constraint "op_constr_return_type_range"(%root, %num_results : !pdl.operation, !pdl.attribute) : !pdl.range<type> -> ^pat1, ^end
+
+ ^pat1:
+ pdl_interp.record_match @rewriters::@success(%root, %types : !pdl.operation, !pdl.range<type>) : benefit(1), loc([%root]) -> ^end
+
+ ^end:
+ pdl_interp.finalize
+ }
+
+ module @rewriters {
+ pdl_interp.func @success(%root : !pdl.operation, %types : !pdl.range<type>) {
+ %op = pdl_interp.create_operation "test.replaced_by_pattern" -> (%types : !pdl.range<type>)
+ pdl_interp.erase %root
+ pdl_interp.finalize
+ }
+ }
+}
+
+// CHECK-LABEL: test.apply_constraint_5
+// CHECK-NOT: "test.replaced_by_pattern"
+// CHECK: "test.replaced_by_pattern"() : () -> (f32, f32)
+module @ir attributes { test.apply_constraint_5 } {
+ "test.failure_op"() : () -> ()
+ "test.success_op"() : () -> ()
+}
+
+// -----
//===----------------------------------------------------------------------===//
// pdl_interp::ApplyRewriteOp
diff --git a/mlir/test/lib/Dialect/Transform/TestTransformDialectExtension.cpp b/mlir/test/lib/Dialect/Transform/TestTransformDialectExtension.cpp
index 50caf8f9cfc709..b9424e06bf0318 100644
--- a/mlir/test/lib/Dialect/Transform/TestTransformDialectExtension.cpp
+++ b/mlir/test/lib/Dialect/Transform/TestTransformDialectExtension.cpp
@@ -887,7 +887,7 @@ class TestTransformDialectExtension
#include "TestTransformDialectExtensionTypes.cpp.inc"
>();
- auto verboseConstraint = [](PatternRewriter &rewriter,
+ auto verboseConstraint = [](PatternRewriter &rewriter, PDLResultList &,
ArrayRef<PDLValue> pdlValues) {
for (const PDLValue &pdlValue : pdlValues) {
if (Operation *op = pdlValue.dyn_cast<Operation *>()) {
diff --git a/mlir/test/lib/Rewrite/TestPDLByteCode.cpp b/mlir/test/lib/Rewrite/TestPDLByteCode.cpp
index daa1c371f27c92..56af3c15b905f1 100644
--- a/mlir/test/lib/Rewrite/TestPDLByteCode.cpp
+++ b/mlir/test/lib/Rewrite/TestPDLByteCode.cpp
@@ -30,6 +30,50 @@ static LogicalResult customMultiEntityVariadicConstraint(
return success();
}
+// Custom constraint that returns a value if the op is named test.success_op
+static LogicalResult customValueResultConstraint(PatternRewriter &rewriter,
+ PDLResultList &results,
+ ArrayRef<PDLValue> args) {
+ auto *op = args[0].cast<Operation *>();
+ if (op->getName().getStringRef() == "test.success_op") {
+ StringAttr customAttr = rewriter.getStringAttr("test.success");
+ results.push_back(customAttr);
+ return success();
+ }
+ return failure();
+}
+
+// Custom constraint that returns a type if the op is named test.success_op
+static LogicalResult customTypeResultConstraint(PatternRewriter &rewriter,
+ PDLResultList &results,
+ ArrayRef<PDLValue> args) {
+ auto *op = args[0].cast<Operation *>();
+ if (op->getName().getStringRef() == "test.success_op") {
+ results.push_back(rewriter.getF32Type());
+ return success();
+ }
+ return failure();
+}
+
+// Custom constraint that returns a type range of variable length if the op is
+// named test.success_op
+static LogicalResult customTypeRangeResultConstraint(PatternRewriter &rewriter,
+ PDLResultList &results,
+ ArrayRef<PDLValue> args) {
+ auto *op = args[0].cast<Operation *>();
+ int numTypes = args[1].cast<Attribute>().cast<IntegerAttr>().getInt();
+
+ if (op->getName().getStringRef() == "test.success_op") {
+ SmallVector<Type> types;
+ for (int i = 0; i < numTypes; i++) {
+ types.push_back(rewriter.getF32Type());
+ }
+ results.push_back(TypeRange(types));
+ return success();
+ }
+ return failure();
+}
+
// Custom creator invoked from PDL.
static Operation *customCreate(PatternRewriter &rewriter, Operation *op) {
return rewriter.create(OperationState(op->getLoc(), "test.success"));
@@ -102,6 +146,12 @@ struct TestPDLByteCodePass
customMultiEntityConstraint);
pdlPattern.registerConstraintFunction("multi_entity_var_constraint",
customMultiEntityVariadicConstraint);
+ pdlPattern.registerConstraintFunction("op_constr_return_attr",
+ customValueResultConstraint);
+ pdlPattern.registerConstraintFunction("op_constr_return_type",
+ customTypeResultConstraint);
+ pdlPattern.registerConstraintFunction("op_constr_return_type_range",
+ customTypeRangeResultConstraint);
pdlPattern.registerRewriteFunction("creator", customCreate);
pdlPattern.registerRewriteFunction("var_creator",
customVariadicResultCreate);
diff --git a/mlir/test/mlir-pdll/Parser/constraint-failure.pdll b/mlir/test/mlir-pdll/Parser/constraint-failure.pdll
index 18877b4bcc50ec..48747d3fa2e681 100644
--- a/mlir/test/mlir-pdll/Parser/constraint-failure.pdll
+++ b/mlir/test/mlir-pdll/Parser/constraint-failure.pdll
@@ -158,8 +158,3 @@ Pattern {
// CHECK: expected `;` after native declaration
Constraint Foo() [{}]
-
-// -----
-
-// CHECK: native Constraints currently do not support returning results
-Constraint Foo() -> Op;
diff --git a/mlir/test/mlir-pdll/Parser/constraint.pdll b/mlir/test/mlir-pdll/Parser/constraint.pdll
index 1c0a015ab4a7b4..e2a52ff130cc84 100644
--- a/mlir/test/mlir-pdll/Parser/constraint.pdll
+++ b/mlir/test/mlir-pdll/Parser/constraint.pdll
@@ -12,6 +12,14 @@ Constraint Foo() [{ /* Native Code */ }];
// -----
+// Test that native constraints support returning results.
+
+// CHECK: Module
+// CHECK: `-UserConstraintDecl {{.*}} Name<Foo> ResultType<Attr>
+Constraint Foo() -> Attr;
+
+// -----
+
// CHECK: Module
// CHECK: `-UserConstraintDecl {{.*}} Name<Foo> ResultType<Value>
// CHECK: `Inputs`
diff --git a/mlir/test/python/dialects/pdl_ops.py b/mlir/test/python/dialects/pdl_ops.py
index 0d364f9222a657..95cb25c14873db 100644
--- a/mlir/test/python/dialects/pdl_ops.py
+++ b/mlir/test/python/dialects/pdl_ops.py
@@ -298,6 +298,6 @@ def test_apply_native_constraint():
pattern = PatternOp(1)
with InsertionPoint(pattern.body):
resultType = TypeOp()
- ApplyNativeConstraintOp("typeConstraint", args=[resultType])
+ ApplyNativeConstraintOp([], "typeConstraint", args=[resultType])
root = OperationOp(types=[resultType])
RewriteOp(root, name="rewrite")
>From c80e6edba4a9593f0587e27fa0ac825ebe174afd Mon Sep 17 00:00:00 2001
From: Matthias Gehre <matthias.gehre at amd.com>
Date: Fri, 1 Mar 2024 07:44:30 +0100
Subject: [PATCH 213/406] Revert "[mlir][PDL] Add support for native
constraints with results (#82760)"
Due to buildbot failure https://lab.llvm.org/buildbot/#/builders/88/builds/72130
This reverts commit dca32a3b594b3c91f9766a9312b5d82534910fa1.
---
mlir/include/mlir/Dialect/PDL/IR/PDLOps.td | 9 +-
.../mlir/Dialect/PDLInterp/IR/PDLInterpOps.td | 8 +-
mlir/include/mlir/IR/PDLPatternMatch.h.inc | 18 +--
.../PDLToPDLInterp/PDLToPDLInterp.cpp | 41 ++---
.../lib/Conversion/PDLToPDLInterp/Predicate.h | 58 ++-----
.../PDLToPDLInterp/PredicateTree.cpp | 82 +---------
mlir/lib/Dialect/PDL/IR/PDL.cpp | 6 -
mlir/lib/Rewrite/ByteCode.cpp | 144 ++++++------------
mlir/lib/Tools/PDLL/Parser/Parser.cpp | 6 +
.../pdl-to-pdl-interp-matcher.mlir | 51 -------
.../PDLToPDLInterp/use-constraint-result.mlir | 77 ----------
mlir/test/Dialect/PDL/ops.mlir | 18 ---
mlir/test/Rewrite/pdl-bytecode.mlir | 68 ---------
.../TestTransformDialectExtension.cpp | 2 +-
mlir/test/lib/Rewrite/TestPDLByteCode.cpp | 50 ------
.../mlir-pdll/Parser/constraint-failure.pdll | 5 +
mlir/test/mlir-pdll/Parser/constraint.pdll | 8 -
mlir/test/python/dialects/pdl_ops.py | 2 +-
18 files changed, 98 insertions(+), 555 deletions(-)
delete mode 100644 mlir/test/Conversion/PDLToPDLInterp/use-constraint-result.mlir
diff --git a/mlir/include/mlir/Dialect/PDL/IR/PDLOps.td b/mlir/include/mlir/Dialect/PDL/IR/PDLOps.td
index 1e108c3d8ac77a..4e9ebccba77d88 100644
--- a/mlir/include/mlir/Dialect/PDL/IR/PDLOps.td
+++ b/mlir/include/mlir/Dialect/PDL/IR/PDLOps.td
@@ -35,25 +35,20 @@ def PDL_ApplyNativeConstraintOp
let description = [{
`pdl.apply_native_constraint` operations apply a native C++ constraint, that
has been registered externally with the consumer of PDL, to a given set of
- entities and optionally return a number of values.
+ entities.
Example:
```mlir
// Apply `myConstraint` to the entities defined by `input`, `attr`, and `op`.
pdl.apply_native_constraint "myConstraint"(%input, %attr, %op : !pdl.value, !pdl.attribute, !pdl.operation)
- // Apply constraint `with_result` to `root`. This constraint returns an attribute.
- %attr = pdl.apply_native_constraint "with_result"(%root : !pdl.operation) : !pdl.attribute
```
}];
let arguments = (ins StrAttr:$name,
Variadic<PDL_AnyType>:$args,
DefaultValuedAttr<BoolAttr, "false">:$isNegated);
- let results = (outs Variadic<PDL_AnyType>:$results);
- let assemblyFormat = [{
- $name `(` $args `:` type($args) `)` (`:` type($results)^ )? attr-dict
- }];
+ let assemblyFormat = "$name `(` $args `:` type($args) `)` attr-dict";
let hasVerifier = 1;
}
diff --git a/mlir/include/mlir/Dialect/PDLInterp/IR/PDLInterpOps.td b/mlir/include/mlir/Dialect/PDLInterp/IR/PDLInterpOps.td
index 901acc0e6733bb..48f625bd1fa3fd 100644
--- a/mlir/include/mlir/Dialect/PDLInterp/IR/PDLInterpOps.td
+++ b/mlir/include/mlir/Dialect/PDLInterp/IR/PDLInterpOps.td
@@ -88,9 +88,7 @@ def PDLInterp_ApplyConstraintOp : PDLInterp_PredicateOp<"apply_constraint"> {
let description = [{
`pdl_interp.apply_constraint` operations apply a generic constraint, that
has been registered with the interpreter, with a given set of positional
- values.
- The constraint function may return any number of results.
- On success, this operation branches to the true destination,
+ values. On success, this operation branches to the true destination,
otherwise the false destination is taken. This behavior can be reversed
by setting the attribute `isNegated` to true.
@@ -106,10 +104,8 @@ def PDLInterp_ApplyConstraintOp : PDLInterp_PredicateOp<"apply_constraint"> {
let arguments = (ins StrAttr:$name,
Variadic<PDL_AnyType>:$args,
DefaultValuedAttr<BoolAttr, "false">:$isNegated);
- let results = (outs Variadic<PDL_AnyType>:$results);
let assemblyFormat = [{
- $name `(` $args `:` type($args) `)` (`:` type($results)^)? attr-dict
- `->` successors
+ $name `(` $args `:` type($args) `)` attr-dict `->` successors
}];
}
diff --git a/mlir/include/mlir/IR/PDLPatternMatch.h.inc b/mlir/include/mlir/IR/PDLPatternMatch.h.inc
index 66286ed7a4c898..a215da8cb6431d 100644
--- a/mlir/include/mlir/IR/PDLPatternMatch.h.inc
+++ b/mlir/include/mlir/IR/PDLPatternMatch.h.inc
@@ -318,9 +318,8 @@ protected:
/// A generic PDL pattern constraint function. This function applies a
/// constraint to a given set of opaque PDLValue entities. Returns success if
/// the constraint successfully held, failure otherwise.
-using PDLConstraintFunction = std::function<LogicalResult(
- PatternRewriter &, PDLResultList &, ArrayRef<PDLValue>)>;
-
+using PDLConstraintFunction =
+ std::function<LogicalResult(PatternRewriter &, ArrayRef<PDLValue>)>;
/// A native PDL rewrite function. This function performs a rewrite on the
/// given set of values. Any results from this rewrite that should be passed
/// back to PDL should be added to the provided result list. This method is only
@@ -727,7 +726,7 @@ std::enable_if_t<
PDLConstraintFunction>
buildConstraintFn(ConstraintFnT &&constraintFn) {
return [constraintFn = std::forward<ConstraintFnT>(constraintFn)](
- PatternRewriter &rewriter, PDLResultList &,
+ PatternRewriter &rewriter,
ArrayRef<PDLValue> values) -> LogicalResult {
auto argIndices = std::make_index_sequence<
llvm::function_traits<ConstraintFnT>::num_args - 1>();
@@ -843,13 +842,10 @@ public:
/// Register a constraint function with PDL. A constraint function may be
/// specified in one of two ways:
///
- /// * `LogicalResult (PatternRewriter &,
- /// PDLResultList &,
- /// ArrayRef<PDLValue>)`
+ /// * `LogicalResult (PatternRewriter &, ArrayRef<PDLValue>)`
///
/// In this overload the arguments of the constraint function are passed via
- /// the low-level PDLValue form, and the results are manually appended to
- /// the given result list.
+ /// the low-level PDLValue form.
///
/// * `LogicalResult (PatternRewriter &, ValueTs... values)`
///
@@ -964,8 +960,8 @@ public:
}
};
class PDLResultList {};
-using PDLConstraintFunction = std::function<LogicalResult(
- PatternRewriter &, PDLResultList &, ArrayRef<PDLValue>)>;
+using PDLConstraintFunction =
+ std::function<LogicalResult(PatternRewriter &, ArrayRef<PDLValue>)>;
using PDLRewriteFunction = std::function<LogicalResult(
PatternRewriter &, PDLResultList &, ArrayRef<PDLValue>)>;
diff --git a/mlir/lib/Conversion/PDLToPDLInterp/PDLToPDLInterp.cpp b/mlir/lib/Conversion/PDLToPDLInterp/PDLToPDLInterp.cpp
index b00cd0dee3ae80..e911631a4bc52a 100644
--- a/mlir/lib/Conversion/PDLToPDLInterp/PDLToPDLInterp.cpp
+++ b/mlir/lib/Conversion/PDLToPDLInterp/PDLToPDLInterp.cpp
@@ -50,8 +50,7 @@ struct PatternLowering {
/// Generate interpreter operations for the tree rooted at the given matcher
/// node, in the specified region.
- Block *generateMatcher(MatcherNode &node, Region ®ion,
- Block *block = nullptr);
+ Block *generateMatcher(MatcherNode &node, Region ®ion);
/// Get or create an access to the provided positional value in the current
/// block. This operation may mutate the provided block pointer if nested
@@ -149,10 +148,6 @@ struct PatternLowering {
/// A mapping between pattern operations and the corresponding configuration
/// set.
DenseMap<Operation *, PDLPatternConfigSet *> *configMap;
-
- /// A mapping from a constraint question to the ApplyConstraintOp
- /// that implements it.
- DenseMap<ConstraintQuestion *, pdl_interp::ApplyConstraintOp> constraintOpMap;
};
} // namespace
@@ -187,11 +182,9 @@ void PatternLowering::lower(ModuleOp module) {
firstMatcherBlock->erase();
}
-Block *PatternLowering::generateMatcher(MatcherNode &node, Region ®ion,
- Block *block) {
+Block *PatternLowering::generateMatcher(MatcherNode &node, Region ®ion) {
// Push a new scope for the values used by this matcher.
- if (!block)
- block = ®ion.emplaceBlock();
+ Block *block = ®ion.emplaceBlock();
ValueMapScope scope(values);
// If this is the return node, simply insert the corresponding interpreter
@@ -371,15 +364,6 @@ Value PatternLowering::getValueAt(Block *¤tBlock, Position *pos) {
loc, cast<ArrayAttr>(rawTypeAttr));
break;
}
- case Predicates::ConstraintResultPos: {
- // Due to the order of traversal, the ApplyConstraintOp has already been
- // created and we can find it in constraintOpMap.
- auto *constrResPos = cast<ConstraintPosition>(pos);
- auto i = constraintOpMap.find(constrResPos->getQuestion());
- assert(i != constraintOpMap.end());
- value = i->second->getResult(constrResPos->getIndex());
- break;
- }
default:
llvm_unreachable("Generating unknown Position getter");
break;
@@ -406,11 +390,12 @@ void PatternLowering::generate(BoolNode *boolNode, Block *¤tBlock,
args.push_back(getValueAt(currentBlock, position));
}
- // Generate a new block as success successor and get the failure successor.
- Block *success = ®ion->emplaceBlock();
+ // Generate the matcher in the current (potentially nested) region
+ // and get the failure successor.
+ Block *success = generateMatcher(*boolNode->getSuccessNode(), *region);
Block *failure = failureBlockStack.back();
- // Create the predicate.
+ // Finally, create the predicate.
builder.setInsertionPointToEnd(currentBlock);
Predicates::Kind kind = question->getKind();
switch (kind) {
@@ -462,20 +447,14 @@ void PatternLowering::generate(BoolNode *boolNode, Block *¤tBlock,
}
case Predicates::ConstraintQuestion: {
auto *cstQuestion = cast<ConstraintQuestion>(question);
- auto applyConstraintOp = builder.create<pdl_interp::ApplyConstraintOp>(
- loc, cstQuestion->getResultTypes(), cstQuestion->getName(), args,
- cstQuestion->getIsNegated(), success, failure);
-
- constraintOpMap.insert({cstQuestion, applyConstraintOp});
+ builder.create<pdl_interp::ApplyConstraintOp>(
+ loc, cstQuestion->getName(), args, cstQuestion->getIsNegated(), success,
+ failure);
break;
}
default:
llvm_unreachable("Generating unknown Predicate operation");
}
-
- // Generate the matcher in the current (potentially nested) region.
- // This might use the results of the current predicate.
- generateMatcher(*boolNode->getSuccessNode(), *region, success);
}
template <typename OpT, typename PredT, typename ValT = typename PredT::KeyTy>
diff --git a/mlir/lib/Conversion/PDLToPDLInterp/Predicate.h b/mlir/lib/Conversion/PDLToPDLInterp/Predicate.h
index 5ad2c477573a5b..2c9b63f86d6efa 100644
--- a/mlir/lib/Conversion/PDLToPDLInterp/Predicate.h
+++ b/mlir/lib/Conversion/PDLToPDLInterp/Predicate.h
@@ -47,7 +47,6 @@ enum Kind : unsigned {
OperandPos,
OperandGroupPos,
AttributePos,
- ConstraintResultPos,
ResultPos,
ResultGroupPos,
TypePos,
@@ -280,28 +279,6 @@ struct OperationPosition : public PredicateBase<OperationPosition, Position,
bool isOperandDefiningOp() const;
};
-//===----------------------------------------------------------------------===//
-// ConstraintPosition
-
-struct ConstraintQuestion;
-
-/// A position describing the result of a native constraint. It saves the
-/// corresponding ConstraintQuestion and result index to enable referring
-/// back to them
-struct ConstraintPosition
- : public PredicateBase<ConstraintPosition, Position,
- std::pair<ConstraintQuestion *, unsigned>,
- Predicates::ConstraintResultPos> {
- using PredicateBase::PredicateBase;
-
- /// Returns the ConstraintQuestion to enable keeping track of the native
- /// constraint this position stems from.
- ConstraintQuestion *getQuestion() const { return key.first; }
-
- // Returns the result index of this position
- unsigned getIndex() const { return key.second; }
-};
-
//===----------------------------------------------------------------------===//
// ResultPosition
@@ -470,13 +447,11 @@ struct AttributeQuestion
: public PredicateBase<AttributeQuestion, Qualifier, void,
Predicates::AttributeQuestion> {};
-/// Apply a parameterized constraint to multiple position values and possibly
-/// produce results.
+/// Apply a parameterized constraint to multiple position values.
struct ConstraintQuestion
- : public PredicateBase<
- ConstraintQuestion, Qualifier,
- std::tuple<StringRef, ArrayRef<Position *>, ArrayRef<Type>, bool>,
- Predicates::ConstraintQuestion> {
+ : public PredicateBase<ConstraintQuestion, Qualifier,
+ std::tuple<StringRef, ArrayRef<Position *>, bool>,
+ Predicates::ConstraintQuestion> {
using Base::Base;
/// Return the name of the constraint.
@@ -485,19 +460,15 @@ struct ConstraintQuestion
/// Return the arguments of the constraint.
ArrayRef<Position *> getArgs() const { return std::get<1>(key); }
- /// Return the result types of the constraint.
- ArrayRef<Type> getResultTypes() const { return std::get<2>(key); }
-
/// Return the negation status of the constraint.
- bool getIsNegated() const { return std::get<3>(key); }
+ bool getIsNegated() const { return std::get<2>(key); }
/// Construct an instance with the given storage allocator.
static ConstraintQuestion *construct(StorageUniquer::StorageAllocator &alloc,
KeyTy key) {
return Base::construct(alloc, KeyTy{alloc.copyInto(std::get<0>(key)),
alloc.copyInto(std::get<1>(key)),
- alloc.copyInto(std::get<2>(key)),
- std::get<3>(key)});
+ std::get<2>(key)});
}
/// Returns a hash suitable for the given keytype.
@@ -555,7 +526,6 @@ class PredicateUniquer : public StorageUniquer {
// Register the types of Positions with the uniquer.
registerParametricStorageType<AttributePosition>();
registerParametricStorageType<AttributeLiteralPosition>();
- registerParametricStorageType<ConstraintPosition>();
registerParametricStorageType<ForEachPosition>();
registerParametricStorageType<OperandPosition>();
registerParametricStorageType<OperandGroupPosition>();
@@ -618,12 +588,6 @@ class PredicateBuilder {
return OperationPosition::get(uniquer, p);
}
- // Returns a position for a new value created by a constraint.
- ConstraintPosition *getConstraintPosition(ConstraintQuestion *q,
- unsigned index) {
- return ConstraintPosition::get(uniquer, std::make_pair(q, index));
- }
-
/// Returns an attribute position for an attribute of the given operation.
Position *getAttribute(OperationPosition *p, StringRef name) {
return AttributePosition::get(uniquer, p, StringAttr::get(ctx, name));
@@ -709,11 +673,11 @@ class PredicateBuilder {
}
/// Create a predicate that applies a generic constraint.
- Predicate getConstraint(StringRef name, ArrayRef<Position *> args,
- ArrayRef<Type> resultTypes, bool isNegated) {
- return {ConstraintQuestion::get(
- uniquer, std::make_tuple(name, args, resultTypes, isNegated)),
- TrueAnswer::get(uniquer)};
+ Predicate getConstraint(StringRef name, ArrayRef<Position *> pos,
+ bool isNegated) {
+ return {
+ ConstraintQuestion::get(uniquer, std::make_tuple(name, pos, isNegated)),
+ TrueAnswer::get(uniquer)};
}
/// Create a predicate comparing a value with null.
diff --git a/mlir/lib/Conversion/PDLToPDLInterp/PredicateTree.cpp b/mlir/lib/Conversion/PDLToPDLInterp/PredicateTree.cpp
index f3d0e08ef49b97..a9c3b0a71ef0d7 100644
--- a/mlir/lib/Conversion/PDLToPDLInterp/PredicateTree.cpp
+++ b/mlir/lib/Conversion/PDLToPDLInterp/PredicateTree.cpp
@@ -15,7 +15,6 @@
#include "mlir/IR/BuiltinOps.h"
#include "mlir/Interfaces/InferTypeOpInterface.h"
#include "llvm/ADT/MapVector.h"
-#include "llvm/ADT/SmallPtrSet.h"
#include "llvm/ADT/TypeSwitch.h"
#include "llvm/Support/Debug.h"
#include <queue>
@@ -50,15 +49,14 @@ static void getTreePredicates(std::vector<PositionalPredicate> &predList,
DenseMap<Value, Position *> &inputs,
AttributePosition *pos) {
assert(isa<pdl::AttributeType>(val.getType()) && "expected attribute type");
+ pdl::AttributeOp attr = cast<pdl::AttributeOp>(val.getDefiningOp());
predList.emplace_back(pos, builder.getIsNotNull());
- if (auto attr = dyn_cast<pdl::AttributeOp>(val.getDefiningOp())) {
- // If the attribute has a type or value, add a constraint.
- if (Value type = attr.getValueType())
- getTreePredicates(predList, type, builder, inputs, builder.getType(pos));
- else if (Attribute value = attr.getValueAttr())
- predList.emplace_back(pos, builder.getAttributeConstraint(value));
- }
+ // If the attribute has a type or value, add a constraint.
+ if (Value type = attr.getValueType())
+ getTreePredicates(predList, type, builder, inputs, builder.getType(pos));
+ else if (Attribute value = attr.getValueAttr())
+ predList.emplace_back(pos, builder.getAttributeConstraint(value));
}
/// Collect all of the predicates for the given operand position.
@@ -274,25 +272,8 @@ static void getConstraintPredicates(pdl::ApplyNativeConstraintOp op,
// Push the constraint to the furthest position.
Position *pos = *std::max_element(allPositions.begin(), allPositions.end(),
comparePosDepth);
- ResultRange results = op.getResults();
- PredicateBuilder::Predicate pred = builder.getConstraint(
- op.getName(), allPositions, SmallVector<Type>(results.getTypes()),
- op.getIsNegated());
-
- // For each result register a position so it can be used later
- for (auto [i, result] : llvm::enumerate(results)) {
- ConstraintQuestion *q = cast<ConstraintQuestion>(pred.first);
- ConstraintPosition *pos = builder.getConstraintPosition(q, i);
- auto [it, inserted] = inputs.insert({result, pos});
- // If this is an input value that has been visited in the tree, add a
- // constraint to ensure that both instances refer to the same value.
- if (!inserted) {
- auto minMaxPositions =
- std::minmax<Position *>(pos, it->second, comparePosDepth);
- predList.emplace_back(minMaxPositions.second,
- builder.getEqualTo(minMaxPositions.first));
- }
- }
+ PredicateBuilder::Predicate pred =
+ builder.getConstraint(op.getName(), allPositions, op.getIsNegated());
predList.emplace_back(pos, pred);
}
@@ -894,49 +875,6 @@ static void insertExitNode(std::unique_ptr<MatcherNode> *root) {
*root = std::make_unique<ExitNode>();
}
-/// Sorts the range begin/end with the partial order given by cmp.
-template <typename Iterator, typename Compare>
-static void stableTopologicalSort(Iterator begin, Iterator end, Compare cmp) {
- while (begin != end) {
- // Cannot compute sortBeforeOthers in the predicate of stable_partition
- // because stable_partition will not keep the [begin, end) range intact
- // while it runs.
- llvm::SmallPtrSet<typename Iterator::value_type, 16> sortBeforeOthers;
- for (auto i = begin; i != end; ++i) {
- if (std::none_of(begin, end, [&](auto const &b) { return cmp(b, *i); }))
- sortBeforeOthers.insert(*i);
- }
-
- auto const next = std::stable_partition(begin, end, [&](auto const &a) {
- return sortBeforeOthers.contains(a);
- });
- assert(next != begin && "not a partial ordering");
- begin = next;
- }
-}
-
-/// Returns true if 'b' depends on a result of 'a'.
-static bool dependsOn(OrderedPredicate *a, OrderedPredicate *b) {
- auto *cqa = dyn_cast<ConstraintQuestion>(a->question);
- if (!cqa)
- return false;
-
- auto positionDependsOnA = [&](Position *p) {
- auto *cp = dyn_cast<ConstraintPosition>(p);
- return cp && cp->getQuestion() == cqa;
- };
-
- if (auto *cqb = dyn_cast<ConstraintQuestion>(b->question)) {
- // Does any argument of b use a?
- return llvm::any_of(cqb->getArgs(), positionDependsOnA);
- }
- if (auto *equalTo = dyn_cast<EqualToQuestion>(b->question)) {
- return positionDependsOnA(b->position) ||
- positionDependsOnA(equalTo->getValue());
- }
- return positionDependsOnA(b->position);
-}
-
/// Given a module containing PDL pattern operations, generate a matcher tree
/// using the patterns within the given module and return the root matcher node.
std::unique_ptr<MatcherNode>
@@ -1017,10 +955,6 @@ MatcherNode::generateMatcherTree(ModuleOp module, PredicateBuilder &builder,
return *lhs < *rhs;
});
- // Mostly keep the now established order, but also ensure that
- // ConstraintQuestions come after the results they use.
- stableTopologicalSort(ordered.begin(), ordered.end(), dependsOn);
-
// Build the matchers for each of the pattern predicate lists.
std::unique_ptr<MatcherNode> root;
for (OrderedPredicateList &list : lists)
diff --git a/mlir/lib/Dialect/PDL/IR/PDL.cpp b/mlir/lib/Dialect/PDL/IR/PDL.cpp
index 428b19f4c74af8..d5f34679f06c60 100644
--- a/mlir/lib/Dialect/PDL/IR/PDL.cpp
+++ b/mlir/lib/Dialect/PDL/IR/PDL.cpp
@@ -94,12 +94,6 @@ static void visit(Operation *op, DenseSet<Operation *> &visited) {
LogicalResult ApplyNativeConstraintOp::verify() {
if (getNumOperands() == 0)
return emitOpError("expected at least one argument");
- if (llvm::any_of(getResults(), [](OpResult result) {
- return isa<OperationType>(result.getType());
- })) {
- return emitOpError(
- "returning an operation from a constraint is not supported");
- }
return success();
}
diff --git a/mlir/lib/Rewrite/ByteCode.cpp b/mlir/lib/Rewrite/ByteCode.cpp
index 559ce7f466a83d..6e6992dcdeea78 100644
--- a/mlir/lib/Rewrite/ByteCode.cpp
+++ b/mlir/lib/Rewrite/ByteCode.cpp
@@ -769,25 +769,11 @@ void Generator::generate(Operation *op, ByteCodeWriter &writer) {
void Generator::generate(pdl_interp::ApplyConstraintOp op,
ByteCodeWriter &writer) {
- // Constraints that should return a value have to be registered as rewrites.
- // If a constraint and a rewrite of similar name are registered the
- // constraint takes precedence
+ assert(constraintToMemIndex.count(op.getName()) &&
+ "expected index for constraint function");
writer.append(OpCode::ApplyConstraint, constraintToMemIndex[op.getName()]);
writer.appendPDLValueList(op.getArgs());
writer.append(ByteCodeField(op.getIsNegated()));
- ResultRange results = op.getResults();
- writer.append(ByteCodeField(results.size()));
- for (Value result : results) {
- // We record the expected kind of the result, so that we can provide extra
- // verification of the native rewrite function and handle the failure case
- // of constraints accordingly.
- writer.appendPDLValueKind(result);
-
- // Range results also need to append the range storage index.
- if (isa<pdl::RangeType>(result.getType()))
- writer.append(getRangeStorageIndex(result));
- writer.append(result);
- }
writer.append(op.getSuccessors());
}
void Generator::generate(pdl_interp::ApplyRewriteOp op,
@@ -800,9 +786,11 @@ void Generator::generate(pdl_interp::ApplyRewriteOp op,
ResultRange results = op.getResults();
writer.append(ByteCodeField(results.size()));
for (Value result : results) {
- // We record the expected kind of the result, so that we
+ // In debug mode we also record the expected kind of the result, so that we
// can provide extra verification of the native rewrite function.
+#ifndef NDEBUG
writer.appendPDLValueKind(result);
+#endif
// Range results also need to append the range storage index.
if (isa<pdl::RangeType>(result.getType()))
@@ -1088,28 +1076,6 @@ void PDLByteCode::initializeMutableState(PDLByteCodeMutableState &state) const {
// ByteCode Execution
namespace {
-/// This class is an instantiation of the PDLResultList that provides access to
-/// the returned results. This API is not on `PDLResultList` to avoid
-/// overexposing access to information specific solely to the ByteCode.
-class ByteCodeRewriteResultList : public PDLResultList {
-public:
- ByteCodeRewriteResultList(unsigned maxNumResults)
- : PDLResultList(maxNumResults) {}
-
- /// Return the list of PDL results.
- MutableArrayRef<PDLValue> getResults() { return results; }
-
- /// Return the type ranges allocated by this list.
- MutableArrayRef<llvm::OwningArrayRef<Type>> getAllocatedTypeRanges() {
- return allocatedTypeRanges;
- }
-
- /// Return the value ranges allocated by this list.
- MutableArrayRef<llvm::OwningArrayRef<Value>> getAllocatedValueRanges() {
- return allocatedValueRanges;
- }
-};
-
/// This class provides support for executing a bytecode stream.
class ByteCodeExecutor {
public:
@@ -1186,9 +1152,6 @@ class ByteCodeExecutor {
void executeSwitchResultCount();
void executeSwitchType();
void executeSwitchTypes();
- void processNativeFunResults(ByteCodeRewriteResultList &results,
- unsigned numResults,
- LogicalResult &rewriteResult);
/// Pushes a code iterator to the stack.
void pushCodeIt(const ByteCodeField *it) { resumeCodeIt.push_back(it); }
@@ -1262,8 +1225,6 @@ class ByteCodeExecutor {
return T::getFromOpaquePointer(pointer);
}
- void skip(size_t skipN) { curCodeIt += skipN; }
-
/// Jump to a specific successor based on a predicate value.
void selectJump(bool isTrue) { selectJump(size_t(isTrue ? 0 : 1)); }
/// Jump to a specific successor based on a destination index.
@@ -1420,11 +1381,33 @@ class ByteCodeExecutor {
ArrayRef<PDLConstraintFunction> constraintFunctions;
ArrayRef<PDLRewriteFunction> rewriteFunctions;
};
+
+/// This class is an instantiation of the PDLResultList that provides access to
+/// the returned results. This API is not on `PDLResultList` to avoid
+/// overexposing access to information specific solely to the ByteCode.
+class ByteCodeRewriteResultList : public PDLResultList {
+public:
+ ByteCodeRewriteResultList(unsigned maxNumResults)
+ : PDLResultList(maxNumResults) {}
+
+ /// Return the list of PDL results.
+ MutableArrayRef<PDLValue> getResults() { return results; }
+
+ /// Return the type ranges allocated by this list.
+ MutableArrayRef<llvm::OwningArrayRef<Type>> getAllocatedTypeRanges() {
+ return allocatedTypeRanges;
+ }
+
+ /// Return the value ranges allocated by this list.
+ MutableArrayRef<llvm::OwningArrayRef<Value>> getAllocatedValueRanges() {
+ return allocatedValueRanges;
+ }
+};
} // namespace
void ByteCodeExecutor::executeApplyConstraint(PatternRewriter &rewriter) {
LLVM_DEBUG(llvm::dbgs() << "Executing ApplyConstraint:\n");
- ByteCodeField fun_idx = read();
+ const PDLConstraintFunction &constraintFn = constraintFunctions[read()];
SmallVector<PDLValue, 16> args;
readList<PDLValue>(args);
@@ -1439,29 +1422,8 @@ void ByteCodeExecutor::executeApplyConstraint(PatternRewriter &rewriter) {
llvm::dbgs() << " * isNegated: " << isNegated << "\n";
llvm::interleaveComma(args, llvm::dbgs());
});
-
- ByteCodeField numResults = read();
- const PDLRewriteFunction &constraintFn = constraintFunctions[fun_idx];
- ByteCodeRewriteResultList results(numResults);
- LogicalResult rewriteResult = constraintFn(rewriter, results, args);
- ArrayRef<PDLValue> constraintResults = results.getResults();
- LLVM_DEBUG({
- if (succeeded(rewriteResult)) {
- llvm::dbgs() << " * Constraint succeeded\n";
- llvm::dbgs() << " * Results: ";
- llvm::interleaveComma(constraintResults, llvm::dbgs());
- llvm::dbgs() << "\n";
- } else {
- llvm::dbgs() << " * Constraint failed\n";
- }
- });
- assert((failed(rewriteResult) || constraintResults.size() == numResults) &&
- "native PDL rewrite function succeeded but returned "
- "unexpected number of results");
- processNativeFunResults(results, numResults, rewriteResult);
-
- // Depending on the constraint jump to the proper destination.
- selectJump(isNegated != succeeded(rewriteResult));
+ // Invoke the constraint and jump to the proper destination.
+ selectJump(isNegated != succeeded(constraintFn(rewriter, args)));
}
LogicalResult ByteCodeExecutor::executeApplyRewrite(PatternRewriter &rewriter) {
@@ -1483,39 +1445,16 @@ LogicalResult ByteCodeExecutor::executeApplyRewrite(PatternRewriter &rewriter) {
assert(results.getResults().size() == numResults &&
"native PDL rewrite function returned unexpected number of results");
- processNativeFunResults(results, numResults, rewriteResult);
+ // Store the results in the bytecode memory.
+ for (PDLValue &result : results.getResults()) {
+ LLVM_DEBUG(llvm::dbgs() << " * Result: " << result << "\n");
- if (failed(rewriteResult)) {
- LLVM_DEBUG(llvm::dbgs() << " - Failed");
- return failure();
- }
- return success();
-}
+// In debug mode we also verify the expected kind of the result.
+#ifndef NDEBUG
+ assert(result.getKind() == read<PDLValue::Kind>() &&
+ "native PDL rewrite function returned an unexpected type of result");
+#endif
-void ByteCodeExecutor::processNativeFunResults(
- ByteCodeRewriteResultList &results, unsigned numResults,
- LogicalResult &rewriteResult) {
- // Store the results in the bytecode memory or handle missing results on
- // failure.
- for (unsigned resultIdx = 0; resultIdx < numResults; resultIdx++) {
- PDLValue::Kind resultKind = read<PDLValue::Kind>();
-
- // Skip the according number of values on the buffer on failure and exit
- // early as there are no results to process.
- if (failed(rewriteResult)) {
- if (resultKind == PDLValue::Kind::TypeRange ||
- resultKind == PDLValue::Kind::ValueRange) {
- skip(2);
- } else {
- skip(1);
- }
- return;
- }
- PDLValue result = results.getResults()[resultIdx];
- LLVM_DEBUG(llvm::dbgs() << " * Result: " << result << "\n");
- assert(result.getKind() == resultKind &&
- "native PDL rewrite function returned an unexpected type of "
- "result");
// If the result is a range, we need to copy it over to the bytecodes
// range memory.
if (std::optional<TypeRange> typeRange = result.dyn_cast<TypeRange>()) {
@@ -1537,6 +1476,13 @@ void ByteCodeExecutor::processNativeFunResults(
allocatedTypeRangeMemory.push_back(std::move(it));
for (auto &it : results.getAllocatedValueRanges())
allocatedValueRangeMemory.push_back(std::move(it));
+
+ // Process the result of the rewrite.
+ if (failed(rewriteResult)) {
+ LLVM_DEBUG(llvm::dbgs() << " - Failed");
+ return failure();
+ }
+ return success();
}
void ByteCodeExecutor::executeAreEqual() {
diff --git a/mlir/lib/Tools/PDLL/Parser/Parser.cpp b/mlir/lib/Tools/PDLL/Parser/Parser.cpp
index 206781ed146692..97ff8bd0d8584d 100644
--- a/mlir/lib/Tools/PDLL/Parser/Parser.cpp
+++ b/mlir/lib/Tools/PDLL/Parser/Parser.cpp
@@ -1362,6 +1362,12 @@ FailureOr<T *> Parser::parseUserNativeConstraintOrRewriteDecl(
if (failed(parseToken(Token::semicolon,
"expected `;` after native declaration")))
return failure();
+ // TODO: PDL should be able to support constraint results in certain
+ // situations, we should revise this.
+ if (std::is_same<ast::UserConstraintDecl, T>::value && !results.empty()) {
+ return emitError(
+ "native Constraints currently do not support returning results");
+ }
return T::createNative(ctx, name, arguments, results, optCodeStr, resultType);
}
diff --git a/mlir/test/Conversion/PDLToPDLInterp/pdl-to-pdl-interp-matcher.mlir b/mlir/test/Conversion/PDLToPDLInterp/pdl-to-pdl-interp-matcher.mlir
index 92afb765b5ab4e..02bb8316c02db0 100644
--- a/mlir/test/Conversion/PDLToPDLInterp/pdl-to-pdl-interp-matcher.mlir
+++ b/mlir/test/Conversion/PDLToPDLInterp/pdl-to-pdl-interp-matcher.mlir
@@ -79,57 +79,6 @@ module @constraints {
// -----
-// CHECK-LABEL: module @constraint_with_result
-module @constraint_with_result {
- // CHECK: func @matcher(%[[ROOT:.*]]: !pdl.operation)
- // CHECK: %[[ATTR:.*]] = pdl_interp.apply_constraint "check_op_and_get_attr_constr"(%[[ROOT]]
- // CHECK: pdl_interp.record_match @rewriters::@pdl_generated_rewriter(%[[ROOT]], %[[ATTR]] : !pdl.operation, !pdl.attribute)
- pdl.pattern : benefit(1) {
- %root = operation
- %attr = pdl.apply_native_constraint "check_op_and_get_attr_constr"(%root : !pdl.operation) : !pdl.attribute
- rewrite %root with "rewriter"(%attr : !pdl.attribute)
- }
-}
-
-// -----
-
-// CHECK-LABEL: module @constraint_with_unused_result
-module @constraint_with_unused_result {
- // CHECK: func @matcher(%[[ROOT:.*]]: !pdl.operation)
- // CHECK: %[[ATTR:.*]] = pdl_interp.apply_constraint "check_op_and_get_attr_constr"(%[[ROOT]]
- // CHECK: pdl_interp.record_match @rewriters::@pdl_generated_rewriter(%[[ROOT]] : !pdl.operation)
- pdl.pattern : benefit(1) {
- %root = operation
- %attr = pdl.apply_native_constraint "check_op_and_get_attr_constr"(%root : !pdl.operation) : !pdl.attribute
- rewrite %root with "rewriter"
- }
-}
-
-// -----
-
-// CHECK-LABEL: module @constraint_with_result_multiple
-module @constraint_with_result_multiple {
- // check that native constraints work as expected even when multiple identical constraints are fused
-
- // CHECK: func @matcher(%[[ROOT:.*]]: !pdl.operation)
- // CHECK: %[[ATTR:.*]] = pdl_interp.apply_constraint "check_op_and_get_attr_constr"(%[[ROOT]]
- // CHECK-NOT: pdl_interp.apply_constraint "check_op_and_get_attr_constr"
- // CHECK: pdl_interp.record_match @rewriters::@pdl_generated_rewriter_0(%[[ROOT]], %[[ATTR]] : !pdl.operation, !pdl.attribute)
- // CHECK: pdl_interp.record_match @rewriters::@pdl_generated_rewriter(%[[ROOT]], %[[ATTR]] : !pdl.operation, !pdl.attribute)
- pdl.pattern : benefit(1) {
- %root = operation
- %attr = pdl.apply_native_constraint "check_op_and_get_attr_constr"(%root : !pdl.operation) : !pdl.attribute
- rewrite %root with "rewriter"(%attr : !pdl.attribute)
- }
- pdl.pattern : benefit(1) {
- %root = operation
- %attr = pdl.apply_native_constraint "check_op_and_get_attr_constr"(%root : !pdl.operation) : !pdl.attribute
- rewrite %root with "rewriter"(%attr : !pdl.attribute)
- }
-}
-
-// -----
-
// CHECK-LABEL: module @negated_constraint
module @negated_constraint {
// CHECK: func @matcher(%[[ROOT:.*]]: !pdl.operation)
diff --git a/mlir/test/Conversion/PDLToPDLInterp/use-constraint-result.mlir b/mlir/test/Conversion/PDLToPDLInterp/use-constraint-result.mlir
deleted file mode 100644
index 4511baff2015a4..00000000000000
--- a/mlir/test/Conversion/PDLToPDLInterp/use-constraint-result.mlir
+++ /dev/null
@@ -1,77 +0,0 @@
-// RUN: mlir-opt -split-input-file -convert-pdl-to-pdl-interp %s | FileCheck %s
-
-// Ensuse that the dependency between add & less
-// causes them to be in the correct order.
-// CHECK-LABEL: matcher
-// CHECK: apply_constraint "return_attr_constraint"
-// CHECK: apply_constraint "use_attr_constraint"
-
-module {
- pdl.pattern : benefit(1) {
- %0 = attribute
- %1 = types
- %2 = operation "tosa.mul" {"shift" = %0} -> (%1 : !pdl.range<type>)
- %3 = attribute = 0 : i32
- %4 = attribute = 1 : i32
- %5 = apply_native_constraint "return_attr_constraint"(%3, %4 : !pdl.attribute, !pdl.attribute) : !pdl.attribute
- apply_native_constraint "use_attr_constraint"(%0, %5 : !pdl.attribute, !pdl.attribute)
- rewrite %2 with "rewriter"
- }
-}
-
-// -----
-
-// CHECK-LABEL: matcher
-// CHECK: %[[ATTR:.*]] = pdl_interp.get_attribute "attr" of
-// CHECK: %[[CONSTRAINT:.*]] = pdl_interp.apply_constraint "return_attr_constraint"
-// CHECK: pdl_interp.are_equal %[[ATTR:.*]], %[[CONSTRAINT:.*]]
-
-pdl.pattern : benefit(1) {
- %inputOp = operation
- %result = result 0 of %inputOp
- %attr = pdl.apply_native_constraint "return_attr_constraint"(%inputOp : !pdl.operation) : !pdl.attribute
- %root = operation(%result : !pdl.value) {"attr" = %attr}
- rewrite %root with "rewriter"(%attr : !pdl.attribute)
-}
-
-// -----
-
-// CHECK-LABEL: matcher
-// CHECK: %[[CONSTRAINT:.*]] = pdl_interp.apply_constraint "return_value_constr"
-// CHECK: %[[VALUE:.*]] = pdl_interp.get_operand 0
-// CHECK: pdl_interp.are_equal %[[VALUE:.*]], %[[CONSTRAINT:.*]]
-
-pdl.pattern : benefit(1) {
- %attr = attribute = 10
- %value = pdl.apply_native_constraint "return_value_constr"(%attr: !pdl.attribute) : !pdl.value
- %root = operation(%value : !pdl.value)
- rewrite %root with "rewriter"
-}
-
-// -----
-
-// CHECK-LABEL: matcher
-// CHECK: %[[CONSTRAINT:.*]] = pdl_interp.apply_constraint "return_type_constr"
-// CHECK: %[[TYPE:.*]] = pdl_interp.get_value_type of
-// CHECK: pdl_interp.are_equal %[[TYPE:.*]], %[[CONSTRAINT:.*]]
-
-pdl.pattern : benefit(1) {
- %attr = attribute = 10
- %type = pdl.apply_native_constraint "return_type_constr"(%attr: !pdl.attribute) : !pdl.type
- %root = operation -> (%type : !pdl.type)
- rewrite %root with "rewriter"
-}
-
-// -----
-
-// CHECK-LABEL: matcher
-// CHECK: %[[CONSTRAINT:.*]] = pdl_interp.apply_constraint "return_type_range_constr"
-// CHECK: %[[TYPE:.*]] = pdl_interp.get_value_type of
-// CHECK: pdl_interp.are_equal %[[TYPE:.*]], %[[CONSTRAINT:.*]]
-
-pdl.pattern : benefit(1) {
- %attr = attribute = 10
- %types = pdl.apply_native_constraint "return_type_range_constr"(%attr: !pdl.attribute) : !pdl.range<type>
- %root = operation -> (%types : !pdl.range<type>)
- rewrite %root with "rewriter"
-}
diff --git a/mlir/test/Dialect/PDL/ops.mlir b/mlir/test/Dialect/PDL/ops.mlir
index 20e40deea5f863..6e6da5cce446ae 100644
--- a/mlir/test/Dialect/PDL/ops.mlir
+++ b/mlir/test/Dialect/PDL/ops.mlir
@@ -134,24 +134,6 @@ pdl.pattern @apply_rewrite_with_no_results : benefit(1) {
// -----
-pdl.pattern @apply_constraint_with_no_results : benefit(1) {
- %root = operation
- apply_native_constraint "NativeConstraint"(%root : !pdl.operation)
- rewrite %root with "rewriter"
-}
-
-// -----
-
-pdl.pattern @apply_constraint_with_results : benefit(1) {
- %root = operation
- %attr = apply_native_constraint "NativeConstraint"(%root : !pdl.operation) : !pdl.attribute
- rewrite %root {
- apply_native_rewrite "NativeRewrite"(%attr : !pdl.attribute)
- }
-}
-
-// -----
-
pdl.pattern @attribute_with_dict : benefit(1) {
%root = operation
rewrite %root {
diff --git a/mlir/test/Rewrite/pdl-bytecode.mlir b/mlir/test/Rewrite/pdl-bytecode.mlir
index f8e4f2e83b296a..ae61c1a079548a 100644
--- a/mlir/test/Rewrite/pdl-bytecode.mlir
+++ b/mlir/test/Rewrite/pdl-bytecode.mlir
@@ -109,74 +109,6 @@ module @ir attributes { test.apply_constraint_3 } {
// -----
-// Test returning a type from a native constraint.
-module @patterns {
- pdl_interp.func @matcher(%root : !pdl.operation) {
- pdl_interp.check_operation_name of %root is "test.success_op" -> ^pat, ^end
-
- ^pat:
- %new_type = pdl_interp.apply_constraint "op_constr_return_type"(%root : !pdl.operation) : !pdl.type -> ^pat2, ^end
-
- ^pat2:
- pdl_interp.record_match @rewriters::@success(%root, %new_type : !pdl.operation, !pdl.type) : benefit(1), loc([%root]) -> ^end
-
- ^end:
- pdl_interp.finalize
- }
-
- module @rewriters {
- pdl_interp.func @success(%root : !pdl.operation, %new_type : !pdl.type) {
- %op = pdl_interp.create_operation "test.replaced_by_pattern" -> (%new_type : !pdl.type)
- pdl_interp.erase %root
- pdl_interp.finalize
- }
- }
-}
-
-// CHECK-LABEL: test.apply_constraint_4
-// CHECK-NOT: "test.replaced_by_pattern"
-// CHECK: "test.replaced_by_pattern"() : () -> f32
-module @ir attributes { test.apply_constraint_4 } {
- "test.failure_op"() : () -> ()
- "test.success_op"() : () -> ()
-}
-
-// -----
-
-// Test success and failure cases of native constraints with pdl.range results.
-module @patterns {
- pdl_interp.func @matcher(%root : !pdl.operation) {
- pdl_interp.check_operation_name of %root is "test.success_op" -> ^pat, ^end
-
- ^pat:
- %num_results = pdl_interp.create_attribute 2 : i32
- %types = pdl_interp.apply_constraint "op_constr_return_type_range"(%root, %num_results : !pdl.operation, !pdl.attribute) : !pdl.range<type> -> ^pat1, ^end
-
- ^pat1:
- pdl_interp.record_match @rewriters::@success(%root, %types : !pdl.operation, !pdl.range<type>) : benefit(1), loc([%root]) -> ^end
-
- ^end:
- pdl_interp.finalize
- }
-
- module @rewriters {
- pdl_interp.func @success(%root : !pdl.operation, %types : !pdl.range<type>) {
- %op = pdl_interp.create_operation "test.replaced_by_pattern" -> (%types : !pdl.range<type>)
- pdl_interp.erase %root
- pdl_interp.finalize
- }
- }
-}
-
-// CHECK-LABEL: test.apply_constraint_5
-// CHECK-NOT: "test.replaced_by_pattern"
-// CHECK: "test.replaced_by_pattern"() : () -> (f32, f32)
-module @ir attributes { test.apply_constraint_5 } {
- "test.failure_op"() : () -> ()
- "test.success_op"() : () -> ()
-}
-
-// -----
//===----------------------------------------------------------------------===//
// pdl_interp::ApplyRewriteOp
diff --git a/mlir/test/lib/Dialect/Transform/TestTransformDialectExtension.cpp b/mlir/test/lib/Dialect/Transform/TestTransformDialectExtension.cpp
index b9424e06bf0318..50caf8f9cfc709 100644
--- a/mlir/test/lib/Dialect/Transform/TestTransformDialectExtension.cpp
+++ b/mlir/test/lib/Dialect/Transform/TestTransformDialectExtension.cpp
@@ -887,7 +887,7 @@ class TestTransformDialectExtension
#include "TestTransformDialectExtensionTypes.cpp.inc"
>();
- auto verboseConstraint = [](PatternRewriter &rewriter, PDLResultList &,
+ auto verboseConstraint = [](PatternRewriter &rewriter,
ArrayRef<PDLValue> pdlValues) {
for (const PDLValue &pdlValue : pdlValues) {
if (Operation *op = pdlValue.dyn_cast<Operation *>()) {
diff --git a/mlir/test/lib/Rewrite/TestPDLByteCode.cpp b/mlir/test/lib/Rewrite/TestPDLByteCode.cpp
index 56af3c15b905f1..daa1c371f27c92 100644
--- a/mlir/test/lib/Rewrite/TestPDLByteCode.cpp
+++ b/mlir/test/lib/Rewrite/TestPDLByteCode.cpp
@@ -30,50 +30,6 @@ static LogicalResult customMultiEntityVariadicConstraint(
return success();
}
-// Custom constraint that returns a value if the op is named test.success_op
-static LogicalResult customValueResultConstraint(PatternRewriter &rewriter,
- PDLResultList &results,
- ArrayRef<PDLValue> args) {
- auto *op = args[0].cast<Operation *>();
- if (op->getName().getStringRef() == "test.success_op") {
- StringAttr customAttr = rewriter.getStringAttr("test.success");
- results.push_back(customAttr);
- return success();
- }
- return failure();
-}
-
-// Custom constraint that returns a type if the op is named test.success_op
-static LogicalResult customTypeResultConstraint(PatternRewriter &rewriter,
- PDLResultList &results,
- ArrayRef<PDLValue> args) {
- auto *op = args[0].cast<Operation *>();
- if (op->getName().getStringRef() == "test.success_op") {
- results.push_back(rewriter.getF32Type());
- return success();
- }
- return failure();
-}
-
-// Custom constraint that returns a type range of variable length if the op is
-// named test.success_op
-static LogicalResult customTypeRangeResultConstraint(PatternRewriter &rewriter,
- PDLResultList &results,
- ArrayRef<PDLValue> args) {
- auto *op = args[0].cast<Operation *>();
- int numTypes = args[1].cast<Attribute>().cast<IntegerAttr>().getInt();
-
- if (op->getName().getStringRef() == "test.success_op") {
- SmallVector<Type> types;
- for (int i = 0; i < numTypes; i++) {
- types.push_back(rewriter.getF32Type());
- }
- results.push_back(TypeRange(types));
- return success();
- }
- return failure();
-}
-
// Custom creator invoked from PDL.
static Operation *customCreate(PatternRewriter &rewriter, Operation *op) {
return rewriter.create(OperationState(op->getLoc(), "test.success"));
@@ -146,12 +102,6 @@ struct TestPDLByteCodePass
customMultiEntityConstraint);
pdlPattern.registerConstraintFunction("multi_entity_var_constraint",
customMultiEntityVariadicConstraint);
- pdlPattern.registerConstraintFunction("op_constr_return_attr",
- customValueResultConstraint);
- pdlPattern.registerConstraintFunction("op_constr_return_type",
- customTypeResultConstraint);
- pdlPattern.registerConstraintFunction("op_constr_return_type_range",
- customTypeRangeResultConstraint);
pdlPattern.registerRewriteFunction("creator", customCreate);
pdlPattern.registerRewriteFunction("var_creator",
customVariadicResultCreate);
diff --git a/mlir/test/mlir-pdll/Parser/constraint-failure.pdll b/mlir/test/mlir-pdll/Parser/constraint-failure.pdll
index 48747d3fa2e681..18877b4bcc50ec 100644
--- a/mlir/test/mlir-pdll/Parser/constraint-failure.pdll
+++ b/mlir/test/mlir-pdll/Parser/constraint-failure.pdll
@@ -158,3 +158,8 @@ Pattern {
// CHECK: expected `;` after native declaration
Constraint Foo() [{}]
+
+// -----
+
+// CHECK: native Constraints currently do not support returning results
+Constraint Foo() -> Op;
diff --git a/mlir/test/mlir-pdll/Parser/constraint.pdll b/mlir/test/mlir-pdll/Parser/constraint.pdll
index e2a52ff130cc84..1c0a015ab4a7b4 100644
--- a/mlir/test/mlir-pdll/Parser/constraint.pdll
+++ b/mlir/test/mlir-pdll/Parser/constraint.pdll
@@ -12,14 +12,6 @@ Constraint Foo() [{ /* Native Code */ }];
// -----
-// Test that native constraints support returning results.
-
-// CHECK: Module
-// CHECK: `-UserConstraintDecl {{.*}} Name<Foo> ResultType<Attr>
-Constraint Foo() -> Attr;
-
-// -----
-
// CHECK: Module
// CHECK: `-UserConstraintDecl {{.*}} Name<Foo> ResultType<Value>
// CHECK: `Inputs`
diff --git a/mlir/test/python/dialects/pdl_ops.py b/mlir/test/python/dialects/pdl_ops.py
index 95cb25c14873db..0d364f9222a657 100644
--- a/mlir/test/python/dialects/pdl_ops.py
+++ b/mlir/test/python/dialects/pdl_ops.py
@@ -298,6 +298,6 @@ def test_apply_native_constraint():
pattern = PatternOp(1)
with InsertionPoint(pattern.body):
resultType = TypeOp()
- ApplyNativeConstraintOp([], "typeConstraint", args=[resultType])
+ ApplyNativeConstraintOp("typeConstraint", args=[resultType])
root = OperationOp(types=[resultType])
RewriteOp(root, name="rewrite")
>From 012b697e7c3633ae17639b086414fd6c02127810 Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?Bal=C3=A1zs=20K=C3=A9ri?= <balazs.keri at ericsson.com>
Date: Fri, 1 Mar 2024 08:21:57 +0100
Subject: [PATCH 214/406] [clang][analyzer] Add StreamChecker note tags for
"indeterminate stream position". (#83288)
If a stream operation fails the position can become "indeterminate".
This may cause warning from the checker at a later operation. The new
note tag shows the place where the position becomes "indeterminate",
this is where a failure occurred.
---
.../StaticAnalyzer/Checkers/StreamChecker.cpp | 297 ++++++++++--------
clang/test/Analysis/stream-note.c | 67 ++++
2 files changed, 238 insertions(+), 126 deletions(-)
diff --git a/clang/lib/StaticAnalyzer/Checkers/StreamChecker.cpp b/clang/lib/StaticAnalyzer/Checkers/StreamChecker.cpp
index 65bdc4cac30940..0208f94e1b5a2a 100644
--- a/clang/lib/StaticAnalyzer/Checkers/StreamChecker.cpp
+++ b/clang/lib/StaticAnalyzer/Checkers/StreamChecker.cpp
@@ -174,6 +174,9 @@ using FnCheck = std::function<void(const StreamChecker *, const FnDescription *,
using ArgNoTy = unsigned int;
static const ArgNoTy ArgNone = std::numeric_limits<ArgNoTy>::max();
+const char *FeofNote = "Assuming stream reaches end-of-file here";
+const char *FerrorNote = "Assuming this stream operation fails";
+
struct FnDescription {
FnCheck PreFn;
FnCheck EvalFn;
@@ -218,87 +221,6 @@ inline void assertStreamStateOpened(const StreamState *SS) {
assert(SS->isOpened() && "Stream is expected to be opened");
}
-struct StreamOperationEvaluator {
- SValBuilder &SVB;
- const ASTContext &ACtx;
-
- SymbolRef StreamSym;
- const StreamState *SS = nullptr;
- const CallExpr *CE = nullptr;
-
- StreamOperationEvaluator(CheckerContext &C)
- : SVB(C.getSValBuilder()), ACtx(C.getASTContext()) {
- ;
- }
-
- bool Init(const FnDescription *Desc, const CallEvent &Call, CheckerContext &C,
- ProgramStateRef State) {
- StreamSym = getStreamArg(Desc, Call).getAsSymbol();
- if (!StreamSym)
- return false;
- SS = State->get<StreamMap>(StreamSym);
- if (!SS)
- return false;
- CE = dyn_cast_or_null<CallExpr>(Call.getOriginExpr());
- if (!CE)
- return false;
-
- assertStreamStateOpened(SS);
-
- return true;
- }
-
- bool isStreamEof() const { return SS->ErrorState == ErrorFEof; }
-
- NonLoc getZeroVal(const CallEvent &Call) {
- return *SVB.makeZeroVal(Call.getResultType()).getAs<NonLoc>();
- }
-
- ProgramStateRef setStreamState(ProgramStateRef State,
- const StreamState &NewSS) {
- return State->set<StreamMap>(StreamSym, NewSS);
- }
-
- ProgramStateRef makeAndBindRetVal(ProgramStateRef State, CheckerContext &C) {
- NonLoc RetVal = makeRetVal(C, CE).castAs<NonLoc>();
- return State->BindExpr(CE, C.getLocationContext(), RetVal);
- }
-
- ProgramStateRef bindReturnValue(ProgramStateRef State, CheckerContext &C,
- uint64_t Val) {
- return State->BindExpr(CE, C.getLocationContext(),
- SVB.makeIntVal(Val, CE->getCallReturnType(ACtx)));
- }
-
- ProgramStateRef bindReturnValue(ProgramStateRef State, CheckerContext &C,
- SVal Val) {
- return State->BindExpr(CE, C.getLocationContext(), Val);
- }
-
- ProgramStateRef bindNullReturnValue(ProgramStateRef State,
- CheckerContext &C) {
- return State->BindExpr(CE, C.getLocationContext(),
- C.getSValBuilder().makeNullWithType(CE->getType()));
- }
-
- ProgramStateRef assumeBinOpNN(ProgramStateRef State,
- BinaryOperator::Opcode Op, NonLoc LHS,
- NonLoc RHS) {
- auto Cond = SVB.evalBinOpNN(State, Op, LHS, RHS, SVB.getConditionType())
- .getAs<DefinedOrUnknownSVal>();
- if (!Cond)
- return nullptr;
- return State->assume(*Cond, true);
- }
-
- ConstraintManager::ProgramStatePair
- makeRetValAndAssumeDual(ProgramStateRef State, CheckerContext &C) {
- DefinedSVal RetVal = makeRetVal(C, CE);
- State = State->BindExpr(CE, C.getLocationContext(), RetVal);
- return C.getConstraintManager().assumeDual(State, RetVal);
- }
-};
-
class StreamChecker : public Checker<check::PreCall, eval::Call,
check::DeadSymbols, check::PointerEscape> {
BugType BT_FileNull{this, "NULL stream pointer", "Stream handling error"};
@@ -322,11 +244,59 @@ class StreamChecker : public Checker<check::PreCall, eval::Call,
const CallEvent *Call,
PointerEscapeKind Kind) const;
+ const BugType *getBT_StreamEof() const { return &BT_StreamEof; }
+ const BugType *getBT_IndeterminatePosition() const {
+ return &BT_IndeterminatePosition;
+ }
+
+ const NoteTag *constructSetEofNoteTag(CheckerContext &C,
+ SymbolRef StreamSym) const {
+ return C.getNoteTag([this, StreamSym](PathSensitiveBugReport &BR) {
+ if (!BR.isInteresting(StreamSym) ||
+ &BR.getBugType() != this->getBT_StreamEof())
+ return "";
+
+ BR.markNotInteresting(StreamSym);
+
+ return FeofNote;
+ });
+ }
+
+ const NoteTag *constructSetErrorNoteTag(CheckerContext &C,
+ SymbolRef StreamSym) const {
+ return C.getNoteTag([this, StreamSym](PathSensitiveBugReport &BR) {
+ if (!BR.isInteresting(StreamSym) ||
+ &BR.getBugType() != this->getBT_IndeterminatePosition())
+ return "";
+
+ BR.markNotInteresting(StreamSym);
+
+ return FerrorNote;
+ });
+ }
+
+ const NoteTag *constructSetEofOrErrorNoteTag(CheckerContext &C,
+ SymbolRef StreamSym) const {
+ return C.getNoteTag([this, StreamSym](PathSensitiveBugReport &BR) {
+ if (!BR.isInteresting(StreamSym))
+ return "";
+
+ if (&BR.getBugType() == this->getBT_StreamEof()) {
+ BR.markNotInteresting(StreamSym);
+ return FeofNote;
+ }
+ if (&BR.getBugType() == this->getBT_IndeterminatePosition()) {
+ BR.markNotInteresting(StreamSym);
+ return FerrorNote;
+ }
+
+ return "";
+ });
+ }
+
/// If true, evaluate special testing stream functions.
bool TestMode = false;
- const BugType *getBT_StreamEof() const { return &BT_StreamEof; }
-
private:
CallDescriptionMap<FnDescription> FnDescriptions = {
{{{"fopen"}, 2}, {nullptr, &StreamChecker::evalFopen, ArgNone}},
@@ -557,8 +527,8 @@ class StreamChecker : public Checker<check::PreCall, eval::Call,
/// Generate a message for BugReporterVisitor if the stored symbol is
/// marked as interesting by the actual bug report.
- const NoteTag *constructNoteTag(CheckerContext &C, SymbolRef StreamSym,
- const std::string &Message) const {
+ const NoteTag *constructLeakNoteTag(CheckerContext &C, SymbolRef StreamSym,
+ const std::string &Message) const {
return C.getNoteTag([this, StreamSym,
Message](PathSensitiveBugReport &BR) -> std::string {
if (BR.isInteresting(StreamSym) && &BR.getBugType() == &BT_ResourceLeak)
@@ -567,19 +537,6 @@ class StreamChecker : public Checker<check::PreCall, eval::Call,
});
}
- const NoteTag *constructSetEofNoteTag(CheckerContext &C,
- SymbolRef StreamSym) const {
- return C.getNoteTag([this, StreamSym](PathSensitiveBugReport &BR) {
- if (!BR.isInteresting(StreamSym) ||
- &BR.getBugType() != this->getBT_StreamEof())
- return "";
-
- BR.markNotInteresting(StreamSym);
-
- return "Assuming stream reaches end-of-file here";
- });
- }
-
void initMacroValues(CheckerContext &C) const {
if (EofVal)
return;
@@ -607,6 +564,102 @@ class StreamChecker : public Checker<check::PreCall, eval::Call,
CheckerContext &C);
};
+struct StreamOperationEvaluator {
+ SValBuilder &SVB;
+ const ASTContext &ACtx;
+
+ SymbolRef StreamSym;
+ const StreamState *SS = nullptr;
+ const CallExpr *CE = nullptr;
+ StreamErrorState NewES;
+
+ StreamOperationEvaluator(CheckerContext &C)
+ : SVB(C.getSValBuilder()), ACtx(C.getASTContext()) {
+ ;
+ }
+
+ bool Init(const FnDescription *Desc, const CallEvent &Call, CheckerContext &C,
+ ProgramStateRef State) {
+ StreamSym = getStreamArg(Desc, Call).getAsSymbol();
+ if (!StreamSym)
+ return false;
+ SS = State->get<StreamMap>(StreamSym);
+ if (!SS)
+ return false;
+ NewES = SS->ErrorState;
+ CE = dyn_cast_or_null<CallExpr>(Call.getOriginExpr());
+ if (!CE)
+ return false;
+
+ assertStreamStateOpened(SS);
+
+ return true;
+ }
+
+ bool isStreamEof() const { return SS->ErrorState == ErrorFEof; }
+
+ NonLoc getZeroVal(const CallEvent &Call) {
+ return *SVB.makeZeroVal(Call.getResultType()).getAs<NonLoc>();
+ }
+
+ ProgramStateRef setStreamState(ProgramStateRef State,
+ const StreamState &NewSS) {
+ NewES = NewSS.ErrorState;
+ return State->set<StreamMap>(StreamSym, NewSS);
+ }
+
+ ProgramStateRef makeAndBindRetVal(ProgramStateRef State, CheckerContext &C) {
+ NonLoc RetVal = makeRetVal(C, CE).castAs<NonLoc>();
+ return State->BindExpr(CE, C.getLocationContext(), RetVal);
+ }
+
+ ProgramStateRef bindReturnValue(ProgramStateRef State, CheckerContext &C,
+ uint64_t Val) {
+ return State->BindExpr(CE, C.getLocationContext(),
+ SVB.makeIntVal(Val, CE->getCallReturnType(ACtx)));
+ }
+
+ ProgramStateRef bindReturnValue(ProgramStateRef State, CheckerContext &C,
+ SVal Val) {
+ return State->BindExpr(CE, C.getLocationContext(), Val);
+ }
+
+ ProgramStateRef bindNullReturnValue(ProgramStateRef State,
+ CheckerContext &C) {
+ return State->BindExpr(CE, C.getLocationContext(),
+ C.getSValBuilder().makeNullWithType(CE->getType()));
+ }
+
+ ProgramStateRef assumeBinOpNN(ProgramStateRef State,
+ BinaryOperator::Opcode Op, NonLoc LHS,
+ NonLoc RHS) {
+ auto Cond = SVB.evalBinOpNN(State, Op, LHS, RHS, SVB.getConditionType())
+ .getAs<DefinedOrUnknownSVal>();
+ if (!Cond)
+ return nullptr;
+ return State->assume(*Cond, true);
+ }
+
+ ConstraintManager::ProgramStatePair
+ makeRetValAndAssumeDual(ProgramStateRef State, CheckerContext &C) {
+ DefinedSVal RetVal = makeRetVal(C, CE);
+ State = State->BindExpr(CE, C.getLocationContext(), RetVal);
+ return C.getConstraintManager().assumeDual(State, RetVal);
+ }
+
+ const NoteTag *getFailureNoteTag(const StreamChecker *Ch, CheckerContext &C) {
+ bool SetFeof = NewES.FEof && !SS->ErrorState.FEof;
+ bool SetFerror = NewES.FError && !SS->ErrorState.FError;
+ if (SetFeof && !SetFerror)
+ return Ch->constructSetEofNoteTag(C, StreamSym);
+ if (!SetFeof && SetFerror)
+ return Ch->constructSetErrorNoteTag(C, StreamSym);
+ if (SetFeof && SetFerror)
+ return Ch->constructSetEofOrErrorNoteTag(C, StreamSym);
+ return nullptr;
+ }
+};
+
} // end anonymous namespace
const ExplodedNode *StreamChecker::getAcquisitionSite(const ExplodedNode *N,
@@ -697,7 +750,7 @@ void StreamChecker::evalFopen(const FnDescription *Desc, const CallEvent &Call,
StateNull->set<StreamMap>(RetSym, StreamState::getOpenFailed(Desc));
C.addTransition(StateNotNull,
- constructNoteTag(C, RetSym, "Stream opened here"));
+ constructLeakNoteTag(C, RetSym, "Stream opened here"));
C.addTransition(StateNull);
}
@@ -755,7 +808,7 @@ void StreamChecker::evalFreopen(const FnDescription *Desc,
StateRetNull->set<StreamMap>(StreamSym, StreamState::getOpenFailed(Desc));
C.addTransition(StateRetNotNull,
- constructNoteTag(C, StreamSym, "Stream reopened here"));
+ constructLeakNoteTag(C, StreamSym, "Stream reopened here"));
C.addTransition(StateRetNull);
}
@@ -867,10 +920,7 @@ void StreamChecker::evalFreadFwrite(const FnDescription *Desc,
// indicator for the stream is indeterminate.
StateFailed = E.setStreamState(
StateFailed, StreamState::getOpened(Desc, NewES, !NewES.isFEof()));
- if (IsFread && !E.isStreamEof())
- C.addTransition(StateFailed, constructSetEofNoteTag(C, E.StreamSym));
- else
- C.addTransition(StateFailed);
+ C.addTransition(StateFailed, E.getFailureNoteTag(this, C));
}
void StreamChecker::evalFgetx(const FnDescription *Desc, const CallEvent &Call,
@@ -929,10 +979,7 @@ void StreamChecker::evalFgetx(const FnDescription *Desc, const CallEvent &Call,
E.isStreamEof() ? ErrorFEof : ErrorFEof | ErrorFError;
StateFailed = E.setStreamState(
StateFailed, StreamState::getOpened(Desc, NewES, !NewES.isFEof()));
- if (!E.isStreamEof())
- C.addTransition(StateFailed, constructSetEofNoteTag(C, E.StreamSym));
- else
- C.addTransition(StateFailed);
+ C.addTransition(StateFailed, E.getFailureNoteTag(this, C));
}
void StreamChecker::evalFputx(const FnDescription *Desc, const CallEvent &Call,
@@ -974,7 +1021,7 @@ void StreamChecker::evalFputx(const FnDescription *Desc, const CallEvent &Call,
ProgramStateRef StateFailed = E.bindReturnValue(State, C, *EofVal);
StateFailed = E.setStreamState(
StateFailed, StreamState::getOpened(Desc, ErrorFError, true));
- C.addTransition(StateFailed);
+ C.addTransition(StateFailed, E.getFailureNoteTag(this, C));
}
void StreamChecker::evalFprintf(const FnDescription *Desc,
@@ -1008,7 +1055,7 @@ void StreamChecker::evalFprintf(const FnDescription *Desc,
// position indicator for the stream is indeterminate.
StateFailed = E.setStreamState(
StateFailed, StreamState::getOpened(Desc, ErrorFError, true));
- C.addTransition(StateFailed);
+ C.addTransition(StateFailed, E.getFailureNoteTag(this, C));
}
void StreamChecker::evalFscanf(const FnDescription *Desc, const CallEvent &Call,
@@ -1058,10 +1105,7 @@ void StreamChecker::evalFscanf(const FnDescription *Desc, const CallEvent &Call,
E.isStreamEof() ? ErrorFEof : ErrorNone | ErrorFEof | ErrorFError;
StateFailed = E.setStreamState(
StateFailed, StreamState::getOpened(Desc, NewES, !NewES.isFEof()));
- if (!E.isStreamEof())
- C.addTransition(StateFailed, constructSetEofNoteTag(C, E.StreamSym));
- else
- C.addTransition(StateFailed);
+ C.addTransition(StateFailed, E.getFailureNoteTag(this, C));
}
void StreamChecker::evalUngetc(const FnDescription *Desc, const CallEvent &Call,
@@ -1129,10 +1173,7 @@ void StreamChecker::evalGetdelim(const FnDescription *Desc,
E.isStreamEof() ? ErrorFEof : ErrorFEof | ErrorFError;
StateFailed = E.setStreamState(
StateFailed, StreamState::getOpened(Desc, NewES, !NewES.isFEof()));
- if (E.isStreamEof())
- C.addTransition(StateFailed, constructSetEofNoteTag(C, E.StreamSym));
- else
- C.addTransition(StateFailed);
+ C.addTransition(StateFailed, E.getFailureNoteTag(this, C));
}
void StreamChecker::preFseek(const FnDescription *Desc, const CallEvent &Call,
@@ -1184,7 +1225,7 @@ void StreamChecker::evalFseek(const FnDescription *Desc, const CallEvent &Call,
NewErrS = NewErrS | ErrorFEof;
StateFailed = E.setStreamState(StateFailed,
StreamState::getOpened(Desc, NewErrS, true));
- C.addTransition(StateFailed, constructSetEofNoteTag(C, E.StreamSym));
+ C.addTransition(StateFailed, E.getFailureNoteTag(this, C));
}
void StreamChecker::evalFgetpos(const FnDescription *Desc,
@@ -1228,7 +1269,7 @@ void StreamChecker::evalFsetpos(const FnDescription *Desc,
StateFailed, StreamState::getOpened(Desc, ErrorNone | ErrorFError, true));
C.addTransition(StateNotFailed);
- C.addTransition(StateFailed);
+ C.addTransition(StateFailed, E.getFailureNoteTag(this, C));
}
void StreamChecker::evalFtell(const FnDescription *Desc, const CallEvent &Call,
@@ -1541,18 +1582,22 @@ ProgramStateRef StreamChecker::ensureNoFilePositionIndeterminate(
if (!N)
return nullptr;
- C.emitReport(std::make_unique<PathSensitiveBugReport>(
- BT_IndeterminatePosition, BugMessage, N));
+ auto R = std::make_unique<PathSensitiveBugReport>(
+ BT_IndeterminatePosition, BugMessage, N);
+ R->markInteresting(Sym);
+ C.emitReport(std::move(R));
return State->set<StreamMap>(
Sym, StreamState::getOpened(SS->LastOperation, ErrorFEof, false));
}
// Known or unknown error state without FEOF possible.
// Stop analysis, report error.
- ExplodedNode *N = C.generateErrorNode(State);
- if (N)
- C.emitReport(std::make_unique<PathSensitiveBugReport>(
- BT_IndeterminatePosition, BugMessage, N));
+ if (ExplodedNode *N = C.generateErrorNode(State)) {
+ auto R = std::make_unique<PathSensitiveBugReport>(
+ BT_IndeterminatePosition, BugMessage, N);
+ R->markInteresting(Sym);
+ C.emitReport(std::move(R));
+ }
return nullptr;
}
diff --git a/clang/test/Analysis/stream-note.c b/clang/test/Analysis/stream-note.c
index abb4784c078aa8..f77cd4aa62841d 100644
--- a/clang/test/Analysis/stream-note.c
+++ b/clang/test/Analysis/stream-note.c
@@ -166,3 +166,70 @@ void check_eof_notes_feof_or_no_error(void) {
}
fclose(F);
}
+
+void check_indeterminate_notes(void) {
+ FILE *F;
+ F = fopen("foo1.c", "r");
+ if (F == NULL) // expected-note {{Taking false branch}} \
+ // expected-note {{'F' is not equal to NULL}}
+ return;
+ int R = fgetc(F); // no note
+ if (R >= 0) { // expected-note {{Taking true branch}} \
+ // expected-note {{'R' is >= 0}}
+ fgetc(F); // expected-note {{Assuming this stream operation fails}}
+ if (ferror(F)) // expected-note {{Taking true branch}}
+ fgetc(F); // expected-warning {{File position of the stream might be 'indeterminate' after a failed operation. Can cause undefined behavior}} \
+ // expected-note {{File position of the stream might be 'indeterminate' after a failed operation. Can cause undefined behavior}}
+ }
+ fclose(F);
+}
+
+void check_indeterminate_after_clearerr(void) {
+ FILE *F;
+ char Buf[10];
+ F = fopen("foo1.c", "r");
+ if (F == NULL) // expected-note {{Taking false branch}} \
+ // expected-note {{'F' is not equal to NULL}}
+ return;
+ fread(Buf, 1, 1, F); // expected-note {{Assuming this stream operation fails}}
+ if (ferror(F)) { // expected-note {{Taking true branch}}
+ clearerr(F);
+ fread(Buf, 1, 1, F); // expected-warning {{might be 'indeterminate' after a failed operation}} \
+ // expected-note {{might be 'indeterminate' after a failed operation}}
+ }
+ fclose(F);
+}
+
+void check_indeterminate_eof(void) {
+ FILE *F;
+ char Buf[2];
+ F = fopen("foo1.c", "r");
+ if (F == NULL) // expected-note {{Taking false branch}} \
+ // expected-note {{'F' is not equal to NULL}} \
+ // expected-note {{Taking false branch}} \
+ // expected-note {{'F' is not equal to NULL}}
+ return;
+ fgets(Buf, sizeof(Buf), F); // expected-note {{Assuming this stream operation fails}} \
+ // expected-note {{Assuming stream reaches end-of-file here}}
+
+ fgets(Buf, sizeof(Buf), F); // expected-warning {{might be 'indeterminate'}} \
+ // expected-note {{might be 'indeterminate'}} \
+ // expected-warning {{stream is in EOF state}} \
+ // expected-note {{stream is in EOF state}}
+ fclose(F);
+}
+
+void check_indeterminate_fseek(void) {
+ FILE *F = fopen("file", "r");
+ if (!F) // expected-note {{Taking false branch}} \
+ // expected-note {{'F' is non-null}}
+ return;
+ int Ret = fseek(F, 1, SEEK_SET); // expected-note {{Assuming this stream operation fails}}
+ if (Ret) { // expected-note {{Taking true branch}} \
+ // expected-note {{'Ret' is not equal to 0}}
+ char Buf[2];
+ fwrite(Buf, 1, 2, F); // expected-warning {{might be 'indeterminate'}} \
+ // expected-note {{might be 'indeterminate'}}
+ }
+ fclose(F);
+}
>From 43bcedd1f09134478b7c8582bac86c78e2dbeb28 Mon Sep 17 00:00:00 2001
From: David CARLIER <devnexen at gmail.com>
Date: Fri, 1 Mar 2024 07:26:47 +0000
Subject: [PATCH 215/406] [compiler-rt] fix __sanitizer_siginfo type on
freebsd. (#77379)
mostly interested in the first half of the type, adding also compile
time check.
---
.../sanitizer_platform_limits_freebsd.cpp | 2 ++
.../sanitizer_platform_limits_freebsd.h | 22 +++++++++++++++++--
2 files changed, 22 insertions(+), 2 deletions(-)
diff --git a/compiler-rt/lib/sanitizer_common/sanitizer_platform_limits_freebsd.cpp b/compiler-rt/lib/sanitizer_common/sanitizer_platform_limits_freebsd.cpp
index 38f968d533b147..4940062eeae47f 100644
--- a/compiler-rt/lib/sanitizer_common/sanitizer_platform_limits_freebsd.cpp
+++ b/compiler-rt/lib/sanitizer_common/sanitizer_platform_limits_freebsd.cpp
@@ -475,6 +475,8 @@ CHECK_TYPE_SIZE(nfds_t);
CHECK_TYPE_SIZE(sigset_t);
COMPILER_CHECK(sizeof(__sanitizer_sigaction) == sizeof(struct sigaction));
+COMPILER_CHECK(sizeof(__sanitizer_siginfo) == sizeof(siginfo_t));
+CHECK_SIZE_AND_OFFSET(siginfo_t, si_value);
// Can't write checks for sa_handler and sa_sigaction due to them being
// preprocessor macros.
CHECK_STRUCT_SIZE_AND_OFFSET(sigaction, sa_mask);
diff --git a/compiler-rt/lib/sanitizer_common/sanitizer_platform_limits_freebsd.h b/compiler-rt/lib/sanitizer_common/sanitizer_platform_limits_freebsd.h
index 43b8a38f39be18..8ce73f206fd88d 100644
--- a/compiler-rt/lib/sanitizer_common/sanitizer_platform_limits_freebsd.h
+++ b/compiler-rt/lib/sanitizer_common/sanitizer_platform_limits_freebsd.h
@@ -301,11 +301,29 @@ struct __sanitizer_sigset_t {
typedef __sanitizer_sigset_t __sanitizer_kernel_sigset_t;
+union __sanitizer_sigval {
+ int sival_int;
+ void *sival_ptr;
+};
+
struct __sanitizer_siginfo {
- // The size is determined by looking at sizeof of real siginfo_t on linux.
- u64 opaque[128 / sizeof(u64)];
+ int si_signo;
+ int si_errno;
+ int si_code;
+ pid_t si_pid;
+ u32 si_uid;
+ int si_status;
+ void *si_addr;
+ union __sanitizer_sigval si_value;
+# if SANITIZER_WORDSIZE == 64
+ char data[40];
+# else
+ char data[32];
+# endif
};
+typedef __sanitizer_siginfo __sanitizer_siginfo_t;
+
using __sanitizer_sighandler_ptr = void (*)(int sig);
using __sanitizer_sigactionhandler_ptr = void (*)(int sig,
__sanitizer_siginfo *siginfo,
>From 6c39fa9e9f198498ff7cf9646081437a0fc0882a Mon Sep 17 00:00:00 2001
From: "Dhruv Chawla (work)" <dhruvc at nvidia.com>
Date: Fri, 1 Mar 2024 13:01:55 +0530
Subject: [PATCH 216/406] [AArch64][GlobalISel] Expand abs.v4i8 to v4i16 and
abs.v2s16 to v2s32 (#81231)
GISel was currently falling back to SDAG for these functions, and this
matches the way SDAG currently generates code for these functions.
---
llvm/lib/Target/AArch64/GISel/AArch64LegalizerInfo.cpp | 6 ++++++
llvm/test/CodeGen/AArch64/abs.ll | 3 ---
2 files changed, 6 insertions(+), 3 deletions(-)
diff --git a/llvm/lib/Target/AArch64/GISel/AArch64LegalizerInfo.cpp b/llvm/lib/Target/AArch64/GISel/AArch64LegalizerInfo.cpp
index 84b4ecb7d2700a..33f04e6ad0c763 100644
--- a/llvm/lib/Target/AArch64/GISel/AArch64LegalizerInfo.cpp
+++ b/llvm/lib/Target/AArch64/GISel/AArch64LegalizerInfo.cpp
@@ -1009,6 +1009,12 @@ AArch64LegalizerInfo::AArch64LegalizerInfo(const AArch64Subtarget &ST)
ABSActions
.legalFor({s32, s64});
ABSActions.legalFor(PackedVectorAllTypeList)
+ .widenScalarIf(
+ [=](const LegalityQuery &Query) { return Query.Types[0] == v4s8; },
+ [=](const LegalityQuery &Query) { return std::make_pair(0, v4s16); })
+ .widenScalarIf(
+ [=](const LegalityQuery &Query) { return Query.Types[0] == v2s16; },
+ [=](const LegalityQuery &Query) { return std::make_pair(0, v2s32); })
.clampNumElements(0, v8s8, v16s8)
.clampNumElements(0, v4s16, v8s16)
.clampNumElements(0, v2s32, v4s32)
diff --git a/llvm/test/CodeGen/AArch64/abs.ll b/llvm/test/CodeGen/AArch64/abs.ll
index 40ba2c12fa15f4..f2cad6631dc267 100644
--- a/llvm/test/CodeGen/AArch64/abs.ll
+++ b/llvm/test/CodeGen/AArch64/abs.ll
@@ -2,9 +2,6 @@
; RUN: llc -mtriple=aarch64-none-linux-gnu %s -o - | FileCheck %s --check-prefixes=CHECK,CHECK-SD
; RUN: llc -mtriple=aarch64-none-linux-gnu -global-isel -global-isel-abort=2 %s -o - 2>&1 | FileCheck %s --check-prefixes=CHECK,CHECK-GI
-; CHECK-GI: warning: Instruction selection used fallback path for abs_v4i8
-; CHECK-GI-NEXT: warning: Instruction selection used fallback path for abs_v2i16
-
; ===== Legal Scalars =====
define i8 @abs_i8(i8 %a){
>From 420928b2fa8b00f23f0adcb19328014592455698 Mon Sep 17 00:00:00 2001
From: Shengchen Kan <shengchen.kan at intel.com>
Date: Fri, 1 Mar 2024 15:53:06 +0800
Subject: [PATCH 217/406] [X86][CodeGen] Fix compile crash in EVEX compression
for corner case
The base register of OPmi_ND may be allocated to the same physic
register as the ND operand.
OPmi_ND is not compressible b/c it has different semnatic from OPmi.
In this case, `isRedundantNewDataDest` should return false, otherwise
we would get error
Assertion `!IsNDLike && "Missing entry for ND-like instruction"' failed.
---
llvm/lib/Target/X86/X86CompressEVEX.cpp | 2 +-
llvm/test/CodeGen/X86/apx/compress-evex.mir | 9 +++++++++
2 files changed, 10 insertions(+), 1 deletion(-)
diff --git a/llvm/lib/Target/X86/X86CompressEVEX.cpp b/llvm/lib/Target/X86/X86CompressEVEX.cpp
index b16ee87487efa0..d2aa712772bfb1 100644
--- a/llvm/lib/Target/X86/X86CompressEVEX.cpp
+++ b/llvm/lib/Target/X86/X86CompressEVEX.cpp
@@ -189,7 +189,7 @@ static bool isRedundantNewDataDest(MachineInstr &MI, const X86Subtarget &ST) {
const MCInstrDesc &Desc = MI.getDesc();
Register Reg0 = MI.getOperand(0).getReg();
const MachineOperand &Op1 = MI.getOperand(1);
- if (!Op1.isReg())
+ if (!Op1.isReg() || X86::getFirstAddrOperandIdx(MI) == 1)
return false;
Register Reg1 = Op1.getReg();
if (Reg1 == Reg0)
diff --git a/llvm/test/CodeGen/X86/apx/compress-evex.mir b/llvm/test/CodeGen/X86/apx/compress-evex.mir
index 997a8395aa752f..d8bef886e234f9 100644
--- a/llvm/test/CodeGen/X86/apx/compress-evex.mir
+++ b/llvm/test/CodeGen/X86/apx/compress-evex.mir
@@ -52,6 +52,15 @@ body: |
RET64 $rax
...
---
+name: ndd_2_non_ndd_mem
+body: |
+ bb.0.entry:
+ ; CHECK: addq $123456, (%rax), %rax # encoding: [0x62,0xf4,0xfc,0x18,0x81,0x00,0x40,0xe2,0x01,0x00]
+ renamable $rax = MOV64rm $noreg, 1, $noreg, 0, $fs
+ renamable $rax = nsw ADD64mi32_ND killed renamable $rax, 1, $noreg, 0, $noreg, 123456, implicit-def dead $eflags
+ RET64 $rax
+...
+---
name: ndd_2_non_ndd_egpr
body: |
bb.0.entry:
>From 128780b06f5bd0e586ee81e1e0e75f63c5664cfc Mon Sep 17 00:00:00 2001
From: martinboehme <mboehme at google.com>
Date: Fri, 1 Mar 2024 09:27:59 +0100
Subject: [PATCH 218/406] [clang][dataflow] Correctly treat empty initializer
lists for unions. (#82986)
This fixes a crash introduced by
https://github.com/llvm/llvm-project/pull/82348
but also adds additional handling to make sure that we treat empty
initializer
lists for both unions and structs/classes correctly (see tests added in
this
patch).
---
.../FlowSensitive/DataflowEnvironment.h | 9 +-
.../FlowSensitive/DataflowEnvironment.cpp | 25 ++++--
clang/lib/Analysis/FlowSensitive/Transfer.cpp | 40 ++++++---
.../Analysis/FlowSensitive/TestingSupport.h | 19 +++++
.../Analysis/FlowSensitive/TransferTest.cpp | 82 ++++++++++++++++++-
5 files changed, 153 insertions(+), 22 deletions(-)
diff --git a/clang/include/clang/Analysis/FlowSensitive/DataflowEnvironment.h b/clang/include/clang/Analysis/FlowSensitive/DataflowEnvironment.h
index 7f8c70d169376e..62e7af7ac219bc 100644
--- a/clang/include/clang/Analysis/FlowSensitive/DataflowEnvironment.h
+++ b/clang/include/clang/Analysis/FlowSensitive/DataflowEnvironment.h
@@ -723,9 +723,12 @@ RecordStorageLocation *getImplicitObjectLocation(const CXXMemberCallExpr &MCE,
RecordStorageLocation *getBaseObjectLocation(const MemberExpr &ME,
const Environment &Env);
-/// Returns the fields of `RD` that are initialized by an `InitListExpr`, in the
-/// order in which they appear in `InitListExpr::inits()`.
-std::vector<FieldDecl *> getFieldsForInitListExpr(const RecordDecl *RD);
+/// Returns the fields of a `RecordDecl` that are initialized by an
+/// `InitListExpr`, in the order in which they appear in
+/// `InitListExpr::inits()`.
+/// `Init->getType()` must be a record type.
+std::vector<const FieldDecl *>
+getFieldsForInitListExpr(const InitListExpr *InitList);
/// Associates a new `RecordValue` with `Loc` and returns the new value.
RecordValue &refreshRecordValue(RecordStorageLocation &Loc, Environment &Env);
diff --git a/clang/lib/Analysis/FlowSensitive/DataflowEnvironment.cpp b/clang/lib/Analysis/FlowSensitive/DataflowEnvironment.cpp
index d487944ce92111..fd7b06efcc7861 100644
--- a/clang/lib/Analysis/FlowSensitive/DataflowEnvironment.cpp
+++ b/clang/lib/Analysis/FlowSensitive/DataflowEnvironment.cpp
@@ -361,8 +361,8 @@ getFieldsGlobalsAndFuncs(const Stmt &S, FieldSet &Fields,
if (const auto *FD = dyn_cast<FieldDecl>(VD))
Fields.insert(FD);
} else if (auto *InitList = dyn_cast<InitListExpr>(&S)) {
- if (RecordDecl *RD = InitList->getType()->getAsRecordDecl())
- for (const auto *FD : getFieldsForInitListExpr(RD))
+ if (InitList->getType()->isRecordType())
+ for (const auto *FD : getFieldsForInitListExpr(InitList))
Fields.insert(FD);
}
}
@@ -983,7 +983,7 @@ StorageLocation &Environment::createObjectInternal(const ValueDecl *D,
}
Value *Val = nullptr;
- if (InitExpr)
+ if (InitExpr) {
// In the (few) cases where an expression is intentionally
// "uninterpreted", `InitExpr` is not associated with a value. There are
// two ways to handle this situation: propagate the status, so that
@@ -998,6 +998,11 @@ StorageLocation &Environment::createObjectInternal(const ValueDecl *D,
// default value (assuming we don't update the environment API to return
// references).
Val = getValue(*InitExpr);
+
+ if (!Val && isa<ImplicitValueInitExpr>(InitExpr) &&
+ InitExpr->getType()->isPointerType())
+ Val = &getOrCreateNullPointerValue(InitExpr->getType()->getPointeeType());
+ }
if (!Val)
Val = createValue(Ty);
@@ -1104,12 +1109,22 @@ RecordStorageLocation *getBaseObjectLocation(const MemberExpr &ME,
return Env.get<RecordStorageLocation>(*Base);
}
-std::vector<FieldDecl *> getFieldsForInitListExpr(const RecordDecl *RD) {
+std::vector<const FieldDecl *>
+getFieldsForInitListExpr(const InitListExpr *InitList) {
+ const RecordDecl *RD = InitList->getType()->getAsRecordDecl();
+ assert(RD != nullptr);
+
+ std::vector<const FieldDecl *> Fields;
+
+ if (InitList->getType()->isUnionType()) {
+ Fields.push_back(InitList->getInitializedFieldInUnion());
+ return Fields;
+ }
+
// Unnamed bitfields are only used for padding and do not appear in
// `InitListExpr`'s inits. However, those fields do appear in `RecordDecl`'s
// field list, and we thus need to remove them before mapping inits to
// fields to avoid mapping inits to the wrongs fields.
- std::vector<FieldDecl *> Fields;
llvm::copy_if(
RD->fields(), std::back_inserter(Fields),
[](const FieldDecl *Field) { return !Field->isUnnamedBitfield(); });
diff --git a/clang/lib/Analysis/FlowSensitive/Transfer.cpp b/clang/lib/Analysis/FlowSensitive/Transfer.cpp
index 089854264f483a..04aa2831df0558 100644
--- a/clang/lib/Analysis/FlowSensitive/Transfer.cpp
+++ b/clang/lib/Analysis/FlowSensitive/Transfer.cpp
@@ -663,14 +663,7 @@ class TransferVisitor : public ConstStmtVisitor<TransferVisitor> {
void VisitInitListExpr(const InitListExpr *S) {
QualType Type = S->getType();
- if (Type->isUnionType()) {
- // FIXME: Initialize unions properly.
- if (auto *Val = Env.createValue(Type))
- Env.setValue(*S, *Val);
- return;
- }
-
- if (!Type->isStructureOrClassType()) {
+ if (!Type->isRecordType()) {
// Until array initialization is implemented, we skip arrays and don't
// need to care about cases where `getNumInits() > 1`.
if (!Type->isArrayType() && S->getNumInits() == 1)
@@ -688,14 +681,26 @@ class TransferVisitor : public ConstStmtVisitor<TransferVisitor> {
llvm::DenseMap<const ValueDecl *, StorageLocation *> FieldLocs;
// This only contains the direct fields for the given type.
- std::vector<FieldDecl *> FieldsForInit =
- getFieldsForInitListExpr(Type->getAsRecordDecl());
+ std::vector<const FieldDecl *> FieldsForInit = getFieldsForInitListExpr(S);
- // `S->inits()` contains all the initializer epressions, including the
+ // `S->inits()` contains all the initializer expressions, including the
// ones for direct base classes.
- auto Inits = S->inits();
+ ArrayRef<Expr *> Inits = S->inits();
size_t InitIdx = 0;
+ // Unions initialized with an empty initializer list need special treatment.
+ // For structs/classes initialized with an empty initializer list, Clang
+ // puts `ImplicitValueInitExpr`s in `InitListExpr::inits()`, but for unions,
+ // it doesn't do this -- so we create an `ImplicitValueInitExpr` ourselves.
+ std::optional<ImplicitValueInitExpr> ImplicitValueInitForUnion;
+ SmallVector<Expr *> InitsForUnion;
+ if (S->getType()->isUnionType() && Inits.empty()) {
+ assert(FieldsForInit.size() == 1);
+ ImplicitValueInitForUnion.emplace(FieldsForInit.front()->getType());
+ InitsForUnion.push_back(&*ImplicitValueInitForUnion);
+ Inits = InitsForUnion;
+ }
+
// Initialize base classes.
if (auto* R = S->getType()->getAsCXXRecordDecl()) {
assert(FieldsForInit.size() + R->getNumBases() == Inits.size());
@@ -731,6 +736,17 @@ class TransferVisitor : public ConstStmtVisitor<TransferVisitor> {
FieldLocs.insert({Field, &Loc});
}
+ // In the case of a union, we don't in general have initializers for all
+ // of the fields. Create storage locations for the remaining fields (but
+ // don't associate them with values).
+ if (Type->isUnionType()) {
+ for (const FieldDecl *Field :
+ Env.getDataflowAnalysisContext().getModeledFields(Type)) {
+ if (auto [it, inserted] = FieldLocs.insert({Field, nullptr}); inserted)
+ it->second = &Env.createStorageLocation(Field->getType());
+ }
+ }
+
// Check that we satisfy the invariant that a `RecordStorageLoation`
// contains exactly the set of modeled fields for that type.
// `ModeledFields` includes fields from all the bases, but only the
diff --git a/clang/unittests/Analysis/FlowSensitive/TestingSupport.h b/clang/unittests/Analysis/FlowSensitive/TestingSupport.h
index 0d36d2802897fd..b7cf6cc966edb0 100644
--- a/clang/unittests/Analysis/FlowSensitive/TestingSupport.h
+++ b/clang/unittests/Analysis/FlowSensitive/TestingSupport.h
@@ -432,6 +432,8 @@ llvm::Error checkDataflowWithNoopAnalysis(
{});
/// Returns the `ValueDecl` for the given identifier.
+/// The returned pointer is guaranteed to be non-null; the function asserts if
+/// no `ValueDecl` with the given name is found.
///
/// Requirements:
///
@@ -475,6 +477,15 @@ ValueT &getValueForDecl(ASTContext &ASTCtx, const Environment &Env,
return *cast<ValueT>(Env.getValue(*VD));
}
+/// Returns the storage location for the field called `Name` of `Loc`.
+/// Optionally casts the field storage location to `T`.
+template <typename T = StorageLocation>
+std::enable_if_t<std::is_base_of_v<StorageLocation, T>, T &>
+getFieldLoc(const RecordStorageLocation &Loc, llvm::StringRef Name,
+ ASTContext &ASTCtx) {
+ return *cast<T>(Loc.getChild(*findValueDecl(ASTCtx, Name)));
+}
+
/// Returns the value of a `Field` on the record referenced by `Loc.`
/// Returns null if `Loc` is null.
inline Value *getFieldValue(const RecordStorageLocation *Loc,
@@ -487,6 +498,14 @@ inline Value *getFieldValue(const RecordStorageLocation *Loc,
return Env.getValue(*FieldLoc);
}
+/// Returns the value of a `Field` on the record referenced by `Loc.`
+/// Returns null if `Loc` is null.
+inline Value *getFieldValue(const RecordStorageLocation *Loc,
+ llvm::StringRef Name, ASTContext &ASTCtx,
+ const Environment &Env) {
+ return getFieldValue(Loc, *findValueDecl(ASTCtx, Name), Env);
+}
+
/// Creates and owns constraints which are boolean values.
class ConstraintContext {
unsigned NextAtom = 0;
diff --git a/clang/unittests/Analysis/FlowSensitive/TransferTest.cpp b/clang/unittests/Analysis/FlowSensitive/TransferTest.cpp
index 2be899f5b6da91..f534ccb1254701 100644
--- a/clang/unittests/Analysis/FlowSensitive/TransferTest.cpp
+++ b/clang/unittests/Analysis/FlowSensitive/TransferTest.cpp
@@ -2392,14 +2392,92 @@ TEST(TransferTest, InitListExprAsUnion) {
} F;
public:
- constexpr target() : F{nullptr} {}
+ constexpr target() : F{nullptr} {
+ int *null = nullptr;
+ F.b; // Make sure we reference 'b' so it is modeled.
+ // [[p]]
+ }
};
)cc";
runDataflow(
Code,
[](const llvm::StringMap<DataflowAnalysisState<NoopLattice>> &Results,
ASTContext &ASTCtx) {
- // Just verify that it doesn't crash.
+ const Environment &Env = getEnvironmentAtAnnotation(Results, "p");
+
+ auto &FLoc = getFieldLoc<RecordStorageLocation>(
+ *Env.getThisPointeeStorageLocation(), "F", ASTCtx);
+ auto *AVal = cast<PointerValue>(getFieldValue(&FLoc, "a", ASTCtx, Env));
+ EXPECT_EQ(AVal, &getValueForDecl<PointerValue>(ASTCtx, Env, "null"));
+ EXPECT_EQ(getFieldValue(&FLoc, "b", ASTCtx, Env), nullptr);
+ });
+}
+
+TEST(TransferTest, EmptyInitListExprForUnion) {
+ // This is a crash repro.
+ std::string Code = R"cc(
+ class target {
+ union {
+ int *a;
+ bool *b;
+ } F;
+
+ public:
+ // Empty initializer list means that `F` is aggregate-initialized.
+ // For a union, this has the effect that the first member of the union
+ // is copy-initialized from an empty initializer list; in this specific
+ // case, this has the effect of initializing `a` with null.
+ constexpr target() : F{} {
+ int *null = nullptr;
+ F.b; // Make sure we reference 'b' so it is modeled.
+ // [[p]]
+ }
+ };
+ )cc";
+ runDataflow(
+ Code,
+ [](const llvm::StringMap<DataflowAnalysisState<NoopLattice>> &Results,
+ ASTContext &ASTCtx) {
+ const Environment &Env = getEnvironmentAtAnnotation(Results, "p");
+
+ auto &FLoc = getFieldLoc<RecordStorageLocation>(
+ *Env.getThisPointeeStorageLocation(), "F", ASTCtx);
+ auto *AVal = cast<PointerValue>(getFieldValue(&FLoc, "a", ASTCtx, Env));
+ EXPECT_EQ(AVal, &getValueForDecl<PointerValue>(ASTCtx, Env, "null"));
+ EXPECT_EQ(getFieldValue(&FLoc, "b", ASTCtx, Env), nullptr);
+ });
+}
+
+TEST(TransferTest, EmptyInitListExprForStruct) {
+ std::string Code = R"cc(
+ class target {
+ struct {
+ int *a;
+ bool *b;
+ } F;
+
+ public:
+ constexpr target() : F{} {
+ int *NullIntPtr = nullptr;
+ bool *NullBoolPtr = nullptr;
+ // [[p]]
+ }
+ };
+ )cc";
+ runDataflow(
+ Code,
+ [](const llvm::StringMap<DataflowAnalysisState<NoopLattice>> &Results,
+ ASTContext &ASTCtx) {
+ const Environment &Env = getEnvironmentAtAnnotation(Results, "p");
+
+ auto &FLoc = getFieldLoc<RecordStorageLocation>(
+ *Env.getThisPointeeStorageLocation(), "F", ASTCtx);
+ auto *AVal = cast<PointerValue>(getFieldValue(&FLoc, "a", ASTCtx, Env));
+ EXPECT_EQ(AVal,
+ &getValueForDecl<PointerValue>(ASTCtx, Env, "NullIntPtr"));
+ auto *BVal = cast<PointerValue>(getFieldValue(&FLoc, "b", ASTCtx, Env));
+ EXPECT_EQ(BVal,
+ &getValueForDecl<PointerValue>(ASTCtx, Env, "NullBoolPtr"));
});
}
>From 40c9a01773507e485f35aa76d3e31cf3ea8c3011 Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?Timm=20B=C3=A4der?= <tbaeder at redhat.com>
Date: Wed, 28 Feb 2024 11:35:23 +0100
Subject: [PATCH 219/406] [clang][Interp][NFC] Add an assertion to
classify(Expr*)
NFC but makes the backtrace easier to read in case the expression
somehow ends up being null.
---
clang/lib/AST/Interp/Context.h | 1 +
1 file changed, 1 insertion(+)
diff --git a/clang/lib/AST/Interp/Context.h b/clang/lib/AST/Interp/Context.h
index c7620921e467e7..dbb63e36918161 100644
--- a/clang/lib/AST/Interp/Context.h
+++ b/clang/lib/AST/Interp/Context.h
@@ -75,6 +75,7 @@ class Context final {
/// Classifies an expression.
std::optional<PrimType> classify(const Expr *E) const {
+ assert(E);
if (E->isGLValue()) {
if (E->getType()->isFunctionType())
return PT_FnPtr;
>From ba8e9ace13c3c2dedf5c496455de822cba931862 Mon Sep 17 00:00:00 2001
From: Nick Anderson <nickleus27 at gmail.com>
Date: Fri, 1 Mar 2024 00:55:46 -0800
Subject: [PATCH 220/406] [AMDGPU] promote i1 arg type for amdgpu_cs (#82971)
fixes #68087
Not sure where to put regression tests for this pr? Also, should i1 args
not in reg also be promoted?
---
llvm/lib/Target/AMDGPU/AMDGPUCallingConv.td | 2 +
.../CodeGen/AMDGPU/calling-conventions.ll | 1214 +++++++++++++++++
2 files changed, 1216 insertions(+)
diff --git a/llvm/lib/Target/AMDGPU/AMDGPUCallingConv.td b/llvm/lib/Target/AMDGPU/AMDGPUCallingConv.td
index c5207228dc913f..4be64629ddac82 100644
--- a/llvm/lib/Target/AMDGPU/AMDGPUCallingConv.td
+++ b/llvm/lib/Target/AMDGPU/AMDGPUCallingConv.td
@@ -66,6 +66,8 @@ def RetCC_SI_Gfx : CallingConv<[
def CC_SI_SHADER : CallingConv<[
+ CCIfType<[i1], CCPromoteToType<i32>>,
+
CCIfInReg<CCIfType<[f32, i32, f16, i16, v2i16, v2f16, bf16, v2bf16] , CCAssignToReg<[
SGPR0, SGPR1, SGPR2, SGPR3, SGPR4, SGPR5, SGPR6, SGPR7,
SGPR8, SGPR9, SGPR10, SGPR11, SGPR12, SGPR13, SGPR14, SGPR15,
diff --git a/llvm/test/CodeGen/AMDGPU/calling-conventions.ll b/llvm/test/CodeGen/AMDGPU/calling-conventions.ll
index ce1ce649c227d2..15ebdd70ae8818 100644
--- a/llvm/test/CodeGen/AMDGPU/calling-conventions.ll
+++ b/llvm/test/CodeGen/AMDGPU/calling-conventions.ll
@@ -2078,4 +2078,1218 @@ entry:
ret void
}
+define amdgpu_cs void @amdgpu_cs_i1(i1 %arg0) {
+; SI-LABEL: amdgpu_cs_i1:
+; SI: ; %bb.0:
+; SI-NEXT: v_and_b32_e32 v0, 1, v0
+; SI-NEXT: s_mov_b32 s3, 0xf000
+; SI-NEXT: s_mov_b32 s2, -1
+; SI-NEXT: buffer_store_byte v0, off, s[0:3], 0
+; SI-NEXT: s_endpgm
+;
+; VI-LABEL: amdgpu_cs_i1:
+; VI: ; %bb.0:
+; VI-NEXT: v_and_b32_e32 v0, 1, v0
+; VI-NEXT: flat_store_byte v[0:1], v0
+; VI-NEXT: s_endpgm
+;
+; GFX11-LABEL: amdgpu_cs_i1:
+; GFX11: ; %bb.0:
+; GFX11-NEXT: v_and_b32_e32 v0, 1, v0
+; GFX11-NEXT: global_store_b8 v[0:1], v0, off
+; GFX11-NEXT: s_nop 0
+; GFX11-NEXT: s_sendmsg sendmsg(MSG_DEALLOC_VGPRS)
+; GFX11-NEXT: s_endpgm
+ store i1 %arg0, ptr addrspace(1) undef
+ ret void
+}
+
+define amdgpu_cs void @amdgpu_cs_v8i1(<8 x i1> %arg0) {
+; SI-LABEL: amdgpu_cs_v8i1:
+; SI: ; %bb.0:
+; SI-NEXT: v_lshlrev_b32_e32 v7, 3, v7
+; SI-NEXT: v_and_b32_e32 v6, 1, v6
+; SI-NEXT: v_lshlrev_b32_e32 v5, 1, v5
+; SI-NEXT: v_and_b32_e32 v4, 1, v4
+; SI-NEXT: v_lshlrev_b32_e32 v3, 3, v3
+; SI-NEXT: v_and_b32_e32 v2, 1, v2
+; SI-NEXT: v_lshlrev_b32_e32 v1, 1, v1
+; SI-NEXT: v_and_b32_e32 v0, 1, v0
+; SI-NEXT: s_mov_b32 s3, 0xf000
+; SI-NEXT: v_lshlrev_b32_e32 v6, 2, v6
+; SI-NEXT: v_or_b32_e32 v4, v4, v5
+; SI-NEXT: v_lshlrev_b32_e32 v2, 2, v2
+; SI-NEXT: v_or_b32_e32 v0, v0, v1
+; SI-NEXT: v_or_b32_e32 v1, v7, v6
+; SI-NEXT: v_and_b32_e32 v4, 3, v4
+; SI-NEXT: v_or_b32_e32 v2, v3, v2
+; SI-NEXT: v_and_b32_e32 v0, 3, v0
+; SI-NEXT: v_or_b32_e32 v1, v4, v1
+; SI-NEXT: v_or_b32_e32 v0, v0, v2
+; SI-NEXT: v_lshlrev_b32_e32 v1, 4, v1
+; SI-NEXT: v_and_b32_e32 v0, 15, v0
+; SI-NEXT: v_or_b32_e32 v0, v0, v1
+; SI-NEXT: s_mov_b32 s2, -1
+; SI-NEXT: buffer_store_byte v0, off, s[0:3], 0
+; SI-NEXT: s_endpgm
+;
+; VI-LABEL: amdgpu_cs_v8i1:
+; VI: ; %bb.0:
+; VI-NEXT: v_and_b32_e32 v6, 1, v6
+; VI-NEXT: v_lshlrev_b16_e32 v5, 1, v5
+; VI-NEXT: v_and_b32_e32 v4, 1, v4
+; VI-NEXT: v_and_b32_e32 v2, 1, v2
+; VI-NEXT: v_lshlrev_b16_e32 v1, 1, v1
+; VI-NEXT: v_and_b32_e32 v0, 1, v0
+; VI-NEXT: v_lshlrev_b16_e32 v7, 3, v7
+; VI-NEXT: v_lshlrev_b16_e32 v6, 2, v6
+; VI-NEXT: v_or_b32_e32 v4, v4, v5
+; VI-NEXT: v_lshlrev_b16_e32 v3, 3, v3
+; VI-NEXT: v_lshlrev_b16_e32 v2, 2, v2
+; VI-NEXT: v_or_b32_e32 v0, v0, v1
+; VI-NEXT: v_or_b32_e32 v6, v7, v6
+; VI-NEXT: v_and_b32_e32 v4, 3, v4
+; VI-NEXT: v_or_b32_e32 v2, v3, v2
+; VI-NEXT: v_and_b32_e32 v0, 3, v0
+; VI-NEXT: v_or_b32_e32 v4, v4, v6
+; VI-NEXT: v_or_b32_e32 v0, v0, v2
+; VI-NEXT: v_lshlrev_b16_e32 v4, 4, v4
+; VI-NEXT: v_and_b32_e32 v0, 15, v0
+; VI-NEXT: v_or_b32_e32 v0, v0, v4
+; VI-NEXT: flat_store_byte v[0:1], v0
+; VI-NEXT: s_endpgm
+;
+; GFX11-LABEL: amdgpu_cs_v8i1:
+; GFX11: ; %bb.0:
+; GFX11-NEXT: v_and_b32_e32 v6, 1, v6
+; GFX11-NEXT: v_lshlrev_b16 v5, 1, v5
+; GFX11-NEXT: v_and_b32_e32 v4, 1, v4
+; GFX11-NEXT: v_and_b32_e32 v2, 1, v2
+; GFX11-NEXT: v_lshlrev_b16 v1, 1, v1
+; GFX11-NEXT: v_and_b32_e32 v0, 1, v0
+; GFX11-NEXT: v_lshlrev_b16 v7, 3, v7
+; GFX11-NEXT: v_lshlrev_b16 v6, 2, v6
+; GFX11-NEXT: v_or_b32_e32 v4, v4, v5
+; GFX11-NEXT: v_lshlrev_b16 v3, 3, v3
+; GFX11-NEXT: v_lshlrev_b16 v2, 2, v2
+; GFX11-NEXT: v_or_b32_e32 v0, v0, v1
+; GFX11-NEXT: v_or_b32_e32 v1, v7, v6
+; GFX11-NEXT: v_and_b32_e32 v4, 3, v4
+; GFX11-NEXT: s_delay_alu instid0(VALU_DEP_4) | instskip(NEXT) | instid1(VALU_DEP_4)
+; GFX11-NEXT: v_or_b32_e32 v2, v3, v2
+; GFX11-NEXT: v_and_b32_e32 v0, 3, v0
+; GFX11-NEXT: s_delay_alu instid0(VALU_DEP_3) | instskip(NEXT) | instid1(VALU_DEP_2)
+; GFX11-NEXT: v_or_b32_e32 v1, v4, v1
+; GFX11-NEXT: v_or_b32_e32 v0, v0, v2
+; GFX11-NEXT: s_delay_alu instid0(VALU_DEP_2) | instskip(NEXT) | instid1(VALU_DEP_2)
+; GFX11-NEXT: v_lshlrev_b16 v1, 4, v1
+; GFX11-NEXT: v_and_b32_e32 v0, 15, v0
+; GFX11-NEXT: s_delay_alu instid0(VALU_DEP_1)
+; GFX11-NEXT: v_or_b32_e32 v0, v0, v1
+; GFX11-NEXT: global_store_b8 v[0:1], v0, off
+; GFX11-NEXT: s_nop 0
+; GFX11-NEXT: s_sendmsg sendmsg(MSG_DEALLOC_VGPRS)
+; GFX11-NEXT: s_endpgm
+ store <8 x i1> %arg0, ptr addrspace(1) undef
+ ret void
+}
+
+define amdgpu_cs void @amdgpu_cs_v16i1(<16 x i1> %arg0) {
+; SI-LABEL: amdgpu_cs_v16i1:
+; SI: ; %bb.0:
+; SI-NEXT: v_lshlrev_b32_e32 v15, 3, v15
+; SI-NEXT: v_and_b32_e32 v14, 1, v14
+; SI-NEXT: v_lshlrev_b32_e32 v13, 1, v13
+; SI-NEXT: v_and_b32_e32 v12, 1, v12
+; SI-NEXT: v_lshlrev_b32_e32 v11, 3, v11
+; SI-NEXT: v_and_b32_e32 v10, 1, v10
+; SI-NEXT: v_lshlrev_b32_e32 v9, 1, v9
+; SI-NEXT: v_and_b32_e32 v8, 1, v8
+; SI-NEXT: v_lshlrev_b32_e32 v7, 3, v7
+; SI-NEXT: v_and_b32_e32 v6, 1, v6
+; SI-NEXT: v_lshlrev_b32_e32 v5, 1, v5
+; SI-NEXT: v_and_b32_e32 v4, 1, v4
+; SI-NEXT: v_lshlrev_b32_e32 v3, 3, v3
+; SI-NEXT: v_and_b32_e32 v2, 1, v2
+; SI-NEXT: v_lshlrev_b32_e32 v1, 1, v1
+; SI-NEXT: v_and_b32_e32 v0, 1, v0
+; SI-NEXT: s_mov_b32 s3, 0xf000
+; SI-NEXT: v_lshlrev_b32_e32 v14, 2, v14
+; SI-NEXT: v_or_b32_e32 v12, v12, v13
+; SI-NEXT: v_lshlrev_b32_e32 v10, 2, v10
+; SI-NEXT: v_or_b32_e32 v8, v8, v9
+; SI-NEXT: v_lshlrev_b32_e32 v6, 2, v6
+; SI-NEXT: v_or_b32_e32 v4, v4, v5
+; SI-NEXT: v_lshlrev_b32_e32 v2, 2, v2
+; SI-NEXT: v_or_b32_e32 v0, v0, v1
+; SI-NEXT: v_or_b32_e32 v1, v15, v14
+; SI-NEXT: v_and_b32_e32 v5, 3, v12
+; SI-NEXT: v_or_b32_e32 v9, v11, v10
+; SI-NEXT: v_and_b32_e32 v8, 3, v8
+; SI-NEXT: v_or_b32_e32 v6, v7, v6
+; SI-NEXT: v_and_b32_e32 v4, 3, v4
+; SI-NEXT: v_or_b32_e32 v2, v3, v2
+; SI-NEXT: v_and_b32_e32 v0, 3, v0
+; SI-NEXT: v_or_b32_e32 v1, v5, v1
+; SI-NEXT: v_or_b32_e32 v3, v8, v9
+; SI-NEXT: v_or_b32_e32 v4, v4, v6
+; SI-NEXT: v_or_b32_e32 v0, v0, v2
+; SI-NEXT: v_lshlrev_b32_e32 v1, 12, v1
+; SI-NEXT: v_and_b32_e32 v2, 15, v3
+; SI-NEXT: v_lshlrev_b32_e32 v3, 4, v4
+; SI-NEXT: v_and_b32_e32 v0, 15, v0
+; SI-NEXT: v_lshlrev_b32_e32 v2, 8, v2
+; SI-NEXT: v_or_b32_e32 v0, v0, v3
+; SI-NEXT: v_or_b32_e32 v1, v1, v2
+; SI-NEXT: v_and_b32_e32 v0, 0xff, v0
+; SI-NEXT: v_or_b32_e32 v0, v0, v1
+; SI-NEXT: s_mov_b32 s2, -1
+; SI-NEXT: buffer_store_short v0, off, s[0:3], 0
+; SI-NEXT: s_endpgm
+;
+; VI-LABEL: amdgpu_cs_v16i1:
+; VI: ; %bb.0:
+; VI-NEXT: v_and_b32_e32 v14, 1, v14
+; VI-NEXT: v_lshlrev_b16_e32 v13, 1, v13
+; VI-NEXT: v_and_b32_e32 v12, 1, v12
+; VI-NEXT: v_and_b32_e32 v10, 1, v10
+; VI-NEXT: v_lshlrev_b16_e32 v9, 1, v9
+; VI-NEXT: v_and_b32_e32 v8, 1, v8
+; VI-NEXT: v_and_b32_e32 v6, 1, v6
+; VI-NEXT: v_lshlrev_b16_e32 v5, 1, v5
+; VI-NEXT: v_and_b32_e32 v4, 1, v4
+; VI-NEXT: v_and_b32_e32 v2, 1, v2
+; VI-NEXT: v_lshlrev_b16_e32 v1, 1, v1
+; VI-NEXT: v_and_b32_e32 v0, 1, v0
+; VI-NEXT: v_lshlrev_b16_e32 v15, 3, v15
+; VI-NEXT: v_lshlrev_b16_e32 v14, 2, v14
+; VI-NEXT: v_or_b32_e32 v12, v12, v13
+; VI-NEXT: v_lshlrev_b16_e32 v11, 3, v11
+; VI-NEXT: v_lshlrev_b16_e32 v10, 2, v10
+; VI-NEXT: v_or_b32_e32 v8, v8, v9
+; VI-NEXT: v_lshlrev_b16_e32 v7, 3, v7
+; VI-NEXT: v_lshlrev_b16_e32 v6, 2, v6
+; VI-NEXT: v_or_b32_e32 v4, v4, v5
+; VI-NEXT: v_lshlrev_b16_e32 v3, 3, v3
+; VI-NEXT: v_lshlrev_b16_e32 v2, 2, v2
+; VI-NEXT: v_or_b32_e32 v0, v0, v1
+; VI-NEXT: v_or_b32_e32 v14, v15, v14
+; VI-NEXT: v_and_b32_e32 v12, 3, v12
+; VI-NEXT: v_or_b32_e32 v10, v11, v10
+; VI-NEXT: v_and_b32_e32 v8, 3, v8
+; VI-NEXT: v_or_b32_e32 v6, v7, v6
+; VI-NEXT: v_and_b32_e32 v4, 3, v4
+; VI-NEXT: v_or_b32_e32 v2, v3, v2
+; VI-NEXT: v_and_b32_e32 v0, 3, v0
+; VI-NEXT: v_or_b32_e32 v12, v12, v14
+; VI-NEXT: v_or_b32_e32 v8, v8, v10
+; VI-NEXT: v_mov_b32_e32 v9, 15
+; VI-NEXT: v_or_b32_e32 v4, v4, v6
+; VI-NEXT: v_or_b32_e32 v0, v0, v2
+; VI-NEXT: v_lshlrev_b16_e32 v12, 12, v12
+; VI-NEXT: v_and_b32_sdwa v8, v8, v9 dst_sel:BYTE_1 dst_unused:UNUSED_PAD src0_sel:DWORD src1_sel:DWORD
+; VI-NEXT: v_lshlrev_b16_e32 v4, 4, v4
+; VI-NEXT: v_and_b32_e32 v0, 15, v0
+; VI-NEXT: v_or_b32_e32 v8, v12, v8
+; VI-NEXT: v_or_b32_e32 v0, v0, v4
+; VI-NEXT: v_or_b32_sdwa v0, v0, v8 dst_sel:DWORD dst_unused:UNUSED_PAD src0_sel:BYTE_0 src1_sel:DWORD
+; VI-NEXT: flat_store_short v[0:1], v0
+; VI-NEXT: s_endpgm
+;
+; GFX11-LABEL: amdgpu_cs_v16i1:
+; GFX11: ; %bb.0:
+; GFX11-NEXT: v_and_b32_e32 v10, 1, v10
+; GFX11-NEXT: v_lshlrev_b16 v9, 1, v9
+; GFX11-NEXT: v_and_b32_e32 v8, 1, v8
+; GFX11-NEXT: v_and_b32_e32 v6, 1, v6
+; GFX11-NEXT: v_lshlrev_b16 v5, 1, v5
+; GFX11-NEXT: v_and_b32_e32 v4, 1, v4
+; GFX11-NEXT: v_and_b32_e32 v2, 1, v2
+; GFX11-NEXT: v_lshlrev_b16 v1, 1, v1
+; GFX11-NEXT: v_and_b32_e32 v0, 1, v0
+; GFX11-NEXT: v_and_b32_e32 v14, 1, v14
+; GFX11-NEXT: v_lshlrev_b16 v13, 1, v13
+; GFX11-NEXT: v_and_b32_e32 v12, 1, v12
+; GFX11-NEXT: v_lshlrev_b16 v11, 3, v11
+; GFX11-NEXT: v_lshlrev_b16 v10, 2, v10
+; GFX11-NEXT: v_or_b32_e32 v8, v8, v9
+; GFX11-NEXT: v_lshlrev_b16 v7, 3, v7
+; GFX11-NEXT: v_lshlrev_b16 v6, 2, v6
+; GFX11-NEXT: v_or_b32_e32 v4, v4, v5
+; GFX11-NEXT: v_lshlrev_b16 v3, 3, v3
+; GFX11-NEXT: v_lshlrev_b16 v2, 2, v2
+; GFX11-NEXT: v_or_b32_e32 v0, v0, v1
+; GFX11-NEXT: v_lshlrev_b16 v15, 3, v15
+; GFX11-NEXT: v_lshlrev_b16 v14, 2, v14
+; GFX11-NEXT: v_or_b32_e32 v12, v12, v13
+; GFX11-NEXT: v_or_b32_e32 v10, v11, v10
+; GFX11-NEXT: v_and_b32_e32 v1, 3, v8
+; GFX11-NEXT: v_or_b32_e32 v5, v7, v6
+; GFX11-NEXT: v_and_b32_e32 v4, 3, v4
+; GFX11-NEXT: v_or_b32_e32 v2, v3, v2
+; GFX11-NEXT: v_and_b32_e32 v0, 3, v0
+; GFX11-NEXT: v_or_b32_e32 v3, v15, v14
+; GFX11-NEXT: v_and_b32_e32 v6, 3, v12
+; GFX11-NEXT: v_or_b32_e32 v1, v1, v10
+; GFX11-NEXT: v_or_b32_e32 v4, v4, v5
+; GFX11-NEXT: v_or_b32_e32 v0, v0, v2
+; GFX11-NEXT: s_delay_alu instid0(VALU_DEP_4) | instskip(NEXT) | instid1(VALU_DEP_4)
+; GFX11-NEXT: v_or_b32_e32 v2, v6, v3
+; GFX11-NEXT: v_and_b32_e32 v1, 15, v1
+; GFX11-NEXT: s_delay_alu instid0(VALU_DEP_4) | instskip(NEXT) | instid1(VALU_DEP_4)
+; GFX11-NEXT: v_lshlrev_b16 v3, 4, v4
+; GFX11-NEXT: v_and_b32_e32 v0, 15, v0
+; GFX11-NEXT: s_delay_alu instid0(VALU_DEP_4) | instskip(NEXT) | instid1(VALU_DEP_4)
+; GFX11-NEXT: v_lshlrev_b16 v2, 12, v2
+; GFX11-NEXT: v_lshlrev_b16 v1, 8, v1
+; GFX11-NEXT: s_delay_alu instid0(VALU_DEP_3) | instskip(NEXT) | instid1(VALU_DEP_2)
+; GFX11-NEXT: v_or_b32_e32 v0, v0, v3
+; GFX11-NEXT: v_or_b32_e32 v1, v2, v1
+; GFX11-NEXT: s_delay_alu instid0(VALU_DEP_2) | instskip(NEXT) | instid1(VALU_DEP_1)
+; GFX11-NEXT: v_and_b32_e32 v0, 0xff, v0
+; GFX11-NEXT: v_or_b32_e32 v0, v0, v1
+; GFX11-NEXT: global_store_b16 v[0:1], v0, off
+; GFX11-NEXT: s_nop 0
+; GFX11-NEXT: s_sendmsg sendmsg(MSG_DEALLOC_VGPRS)
+; GFX11-NEXT: s_endpgm
+ store <16 x i1> %arg0, ptr addrspace(1) undef
+ ret void
+}
+
+define amdgpu_cs void @amdgpu_cs_v32i1(<32 x i1> %arg0) {
+; SI-LABEL: amdgpu_cs_v32i1:
+; SI: ; %bb.0:
+; SI-NEXT: v_lshlrev_b32_e32 v29, 1, v29
+; SI-NEXT: v_and_b32_e32 v28, 1, v28
+; SI-NEXT: v_lshlrev_b32_e32 v25, 1, v25
+; SI-NEXT: v_and_b32_e32 v24, 1, v24
+; SI-NEXT: v_lshlrev_b32_e32 v21, 1, v21
+; SI-NEXT: v_and_b32_e32 v20, 1, v20
+; SI-NEXT: v_lshlrev_b32_e32 v17, 1, v17
+; SI-NEXT: v_and_b32_e32 v16, 1, v16
+; SI-NEXT: v_lshlrev_b32_e32 v13, 1, v13
+; SI-NEXT: v_and_b32_e32 v12, 1, v12
+; SI-NEXT: v_lshlrev_b32_e32 v9, 1, v9
+; SI-NEXT: v_and_b32_e32 v8, 1, v8
+; SI-NEXT: v_lshlrev_b32_e32 v5, 1, v5
+; SI-NEXT: v_and_b32_e32 v4, 1, v4
+; SI-NEXT: v_lshlrev_b32_e32 v1, 1, v1
+; SI-NEXT: v_and_b32_e32 v0, 1, v0
+; SI-NEXT: v_lshlrev_b32_e32 v31, 3, v31
+; SI-NEXT: v_and_b32_e32 v30, 1, v30
+; SI-NEXT: v_lshlrev_b32_e32 v27, 3, v27
+; SI-NEXT: v_and_b32_e32 v26, 1, v26
+; SI-NEXT: v_lshlrev_b32_e32 v23, 3, v23
+; SI-NEXT: v_and_b32_e32 v22, 1, v22
+; SI-NEXT: v_lshlrev_b32_e32 v19, 3, v19
+; SI-NEXT: v_and_b32_e32 v18, 1, v18
+; SI-NEXT: v_lshlrev_b32_e32 v15, 3, v15
+; SI-NEXT: v_and_b32_e32 v14, 1, v14
+; SI-NEXT: v_lshlrev_b32_e32 v11, 3, v11
+; SI-NEXT: v_and_b32_e32 v10, 1, v10
+; SI-NEXT: v_lshlrev_b32_e32 v7, 3, v7
+; SI-NEXT: v_and_b32_e32 v6, 1, v6
+; SI-NEXT: v_lshlrev_b32_e32 v3, 3, v3
+; SI-NEXT: v_and_b32_e32 v2, 1, v2
+; SI-NEXT: s_mov_b32 s3, 0xf000
+; SI-NEXT: v_or_b32_e32 v28, v28, v29
+; SI-NEXT: v_or_b32_e32 v24, v24, v25
+; SI-NEXT: v_or_b32_e32 v20, v20, v21
+; SI-NEXT: v_or_b32_e32 v16, v16, v17
+; SI-NEXT: v_or_b32_e32 v12, v12, v13
+; SI-NEXT: v_or_b32_e32 v8, v8, v9
+; SI-NEXT: v_or_b32_e32 v4, v4, v5
+; SI-NEXT: v_or_b32_e32 v0, v0, v1
+; SI-NEXT: v_lshlrev_b32_e32 v1, 2, v30
+; SI-NEXT: v_lshlrev_b32_e32 v5, 2, v26
+; SI-NEXT: v_lshlrev_b32_e32 v9, 2, v22
+; SI-NEXT: v_lshlrev_b32_e32 v13, 2, v18
+; SI-NEXT: v_lshlrev_b32_e32 v14, 2, v14
+; SI-NEXT: v_lshlrev_b32_e32 v10, 2, v10
+; SI-NEXT: v_lshlrev_b32_e32 v6, 2, v6
+; SI-NEXT: v_lshlrev_b32_e32 v2, 2, v2
+; SI-NEXT: v_or_b32_e32 v1, v31, v1
+; SI-NEXT: v_or_b32_e32 v5, v27, v5
+; SI-NEXT: v_or_b32_e32 v9, v23, v9
+; SI-NEXT: v_and_b32_e32 v17, 3, v28
+; SI-NEXT: v_and_b32_e32 v18, 3, v24
+; SI-NEXT: v_and_b32_e32 v20, 3, v20
+; SI-NEXT: v_or_b32_e32 v13, v19, v13
+; SI-NEXT: v_and_b32_e32 v16, 3, v16
+; SI-NEXT: v_or_b32_e32 v14, v15, v14
+; SI-NEXT: v_and_b32_e32 v12, 3, v12
+; SI-NEXT: v_or_b32_e32 v10, v11, v10
+; SI-NEXT: v_and_b32_e32 v8, 3, v8
+; SI-NEXT: v_or_b32_e32 v6, v7, v6
+; SI-NEXT: v_and_b32_e32 v4, 3, v4
+; SI-NEXT: v_or_b32_e32 v2, v3, v2
+; SI-NEXT: v_and_b32_e32 v0, 3, v0
+; SI-NEXT: v_or_b32_e32 v1, v17, v1
+; SI-NEXT: v_or_b32_e32 v3, v18, v5
+; SI-NEXT: v_or_b32_e32 v5, v20, v9
+; SI-NEXT: v_or_b32_e32 v7, v16, v13
+; SI-NEXT: v_or_b32_e32 v9, v12, v14
+; SI-NEXT: v_or_b32_e32 v8, v8, v10
+; SI-NEXT: v_or_b32_e32 v4, v4, v6
+; SI-NEXT: v_or_b32_e32 v0, v0, v2
+; SI-NEXT: v_lshlrev_b32_e32 v1, 12, v1
+; SI-NEXT: v_and_b32_e32 v2, 15, v3
+; SI-NEXT: v_lshlrev_b32_e32 v3, 4, v5
+; SI-NEXT: v_and_b32_e32 v5, 15, v7
+; SI-NEXT: v_lshlrev_b32_e32 v6, 12, v9
+; SI-NEXT: v_and_b32_e32 v7, 15, v8
+; SI-NEXT: v_lshlrev_b32_e32 v4, 4, v4
+; SI-NEXT: v_and_b32_e32 v0, 15, v0
+; SI-NEXT: v_lshlrev_b32_e32 v2, 8, v2
+; SI-NEXT: v_or_b32_e32 v3, v5, v3
+; SI-NEXT: v_lshlrev_b32_e32 v5, 8, v7
+; SI-NEXT: v_or_b32_e32 v0, v0, v4
+; SI-NEXT: v_or_b32_e32 v1, v1, v2
+; SI-NEXT: v_and_b32_e32 v2, 0xff, v3
+; SI-NEXT: v_or_b32_e32 v3, v6, v5
+; SI-NEXT: v_and_b32_e32 v0, 0xff, v0
+; SI-NEXT: v_or_b32_e32 v1, v2, v1
+; SI-NEXT: v_or_b32_e32 v0, v0, v3
+; SI-NEXT: v_lshlrev_b32_e32 v1, 16, v1
+; SI-NEXT: v_and_b32_e32 v0, 0xffff, v0
+; SI-NEXT: v_or_b32_e32 v0, v0, v1
+; SI-NEXT: s_mov_b32 s2, -1
+; SI-NEXT: buffer_store_dword v0, off, s[0:3], 0
+; SI-NEXT: s_endpgm
+;
+; VI-LABEL: amdgpu_cs_v32i1:
+; VI: ; %bb.0:
+; VI-NEXT: v_and_b32_e32 v6, 1, v6
+; VI-NEXT: v_lshlrev_b16_e32 v5, 1, v5
+; VI-NEXT: v_and_b32_e32 v4, 1, v4
+; VI-NEXT: v_and_b32_e32 v2, 1, v2
+; VI-NEXT: v_lshlrev_b16_e32 v1, 1, v1
+; VI-NEXT: v_and_b32_e32 v0, 1, v0
+; VI-NEXT: v_lshlrev_b16_e32 v7, 3, v7
+; VI-NEXT: v_lshlrev_b16_e32 v6, 2, v6
+; VI-NEXT: v_or_b32_e32 v4, v4, v5
+; VI-NEXT: v_lshlrev_b16_e32 v3, 3, v3
+; VI-NEXT: v_lshlrev_b16_e32 v2, 2, v2
+; VI-NEXT: v_or_b32_e32 v0, v0, v1
+; VI-NEXT: v_or_b32_e32 v6, v7, v6
+; VI-NEXT: v_and_b32_e32 v4, 3, v4
+; VI-NEXT: v_or_b32_e32 v2, v3, v2
+; VI-NEXT: v_and_b32_e32 v0, 3, v0
+; VI-NEXT: v_or_b32_e32 v4, v4, v6
+; VI-NEXT: v_or_b32_e32 v0, v0, v2
+; VI-NEXT: v_lshlrev_b16_e32 v1, 4, v4
+; VI-NEXT: v_and_b32_e32 v0, 15, v0
+; VI-NEXT: v_and_b32_e32 v2, 1, v30
+; VI-NEXT: v_or_b32_e32 v0, v0, v1
+; VI-NEXT: v_lshlrev_b16_e32 v1, 3, v31
+; VI-NEXT: v_lshlrev_b16_e32 v2, 2, v2
+; VI-NEXT: v_or_b32_e32 v1, v1, v2
+; VI-NEXT: v_lshlrev_b16_e32 v2, 1, v29
+; VI-NEXT: v_and_b32_e32 v3, 1, v28
+; VI-NEXT: v_or_b32_e32 v2, v3, v2
+; VI-NEXT: v_and_b32_e32 v2, 3, v2
+; VI-NEXT: v_and_b32_e32 v3, 1, v26
+; VI-NEXT: v_or_b32_e32 v1, v2, v1
+; VI-NEXT: v_lshlrev_b16_e32 v2, 3, v27
+; VI-NEXT: v_lshlrev_b16_e32 v3, 2, v3
+; VI-NEXT: v_and_b32_e32 v10, 1, v10
+; VI-NEXT: v_lshlrev_b16_e32 v9, 1, v9
+; VI-NEXT: v_and_b32_e32 v8, 1, v8
+; VI-NEXT: v_or_b32_e32 v2, v2, v3
+; VI-NEXT: v_lshlrev_b16_e32 v3, 1, v25
+; VI-NEXT: v_and_b32_e32 v4, 1, v24
+; VI-NEXT: v_lshlrev_b16_e32 v11, 3, v11
+; VI-NEXT: v_lshlrev_b16_e32 v10, 2, v10
+; VI-NEXT: v_or_b32_e32 v8, v8, v9
+; VI-NEXT: v_or_b32_e32 v3, v4, v3
+; VI-NEXT: v_or_b32_e32 v10, v11, v10
+; VI-NEXT: v_and_b32_e32 v8, 3, v8
+; VI-NEXT: v_and_b32_e32 v3, 3, v3
+; VI-NEXT: v_or_b32_e32 v8, v8, v10
+; VI-NEXT: v_mov_b32_e32 v10, 15
+; VI-NEXT: v_or_b32_e32 v2, v3, v2
+; VI-NEXT: v_lshlrev_b16_e32 v1, 12, v1
+; VI-NEXT: v_and_b32_sdwa v2, v2, v10 dst_sel:BYTE_1 dst_unused:UNUSED_PAD src0_sel:DWORD src1_sel:DWORD
+; VI-NEXT: v_and_b32_e32 v3, 1, v22
+; VI-NEXT: v_or_b32_e32 v1, v1, v2
+; VI-NEXT: v_lshlrev_b16_e32 v2, 3, v23
+; VI-NEXT: v_lshlrev_b16_e32 v3, 2, v3
+; VI-NEXT: v_or_b32_e32 v2, v2, v3
+; VI-NEXT: v_lshlrev_b16_e32 v3, 1, v21
+; VI-NEXT: v_and_b32_e32 v4, 1, v20
+; VI-NEXT: v_or_b32_e32 v3, v4, v3
+; VI-NEXT: v_and_b32_e32 v3, 3, v3
+; VI-NEXT: v_and_b32_e32 v4, 1, v18
+; VI-NEXT: v_or_b32_e32 v2, v3, v2
+; VI-NEXT: v_lshlrev_b16_e32 v3, 3, v19
+; VI-NEXT: v_lshlrev_b16_e32 v4, 2, v4
+; VI-NEXT: v_and_b32_e32 v14, 1, v14
+; VI-NEXT: v_lshlrev_b16_e32 v13, 1, v13
+; VI-NEXT: v_and_b32_e32 v12, 1, v12
+; VI-NEXT: v_or_b32_e32 v3, v3, v4
+; VI-NEXT: v_lshlrev_b16_e32 v4, 1, v17
+; VI-NEXT: v_and_b32_e32 v5, 1, v16
+; VI-NEXT: v_lshlrev_b16_e32 v15, 3, v15
+; VI-NEXT: v_lshlrev_b16_e32 v14, 2, v14
+; VI-NEXT: v_or_b32_e32 v12, v12, v13
+; VI-NEXT: v_or_b32_e32 v4, v5, v4
+; VI-NEXT: v_or_b32_e32 v14, v15, v14
+; VI-NEXT: v_and_b32_e32 v12, 3, v12
+; VI-NEXT: v_and_b32_e32 v4, 3, v4
+; VI-NEXT: v_or_b32_e32 v12, v12, v14
+; VI-NEXT: v_or_b32_e32 v3, v4, v3
+; VI-NEXT: v_lshlrev_b16_e32 v9, 12, v12
+; VI-NEXT: v_and_b32_sdwa v8, v8, v10 dst_sel:BYTE_1 dst_unused:UNUSED_PAD src0_sel:DWORD src1_sel:DWORD
+; VI-NEXT: v_lshlrev_b16_e32 v2, 4, v2
+; VI-NEXT: v_and_b32_e32 v3, 15, v3
+; VI-NEXT: v_or_b32_e32 v8, v9, v8
+; VI-NEXT: v_or_b32_e32 v2, v3, v2
+; VI-NEXT: v_or_b32_sdwa v0, v0, v8 dst_sel:DWORD dst_unused:UNUSED_PAD src0_sel:BYTE_0 src1_sel:DWORD
+; VI-NEXT: v_or_b32_sdwa v1, v2, v1 dst_sel:WORD_1 dst_unused:UNUSED_PAD src0_sel:BYTE_0 src1_sel:DWORD
+; VI-NEXT: v_or_b32_sdwa v0, v0, v1 dst_sel:DWORD dst_unused:UNUSED_PAD src0_sel:WORD_0 src1_sel:DWORD
+; VI-NEXT: flat_store_dword v[0:1], v0
+; VI-NEXT: s_endpgm
+;
+; GFX11-LABEL: amdgpu_cs_v32i1:
+; GFX11: ; %bb.0:
+; GFX11-NEXT: v_and_b32_e32 v10, 1, v10
+; GFX11-NEXT: v_lshlrev_b16 v9, 1, v9
+; GFX11-NEXT: v_and_b32_e32 v8, 1, v8
+; GFX11-NEXT: v_lshlrev_b16 v11, 3, v11
+; GFX11-NEXT: v_and_b32_e32 v6, 1, v6
+; GFX11-NEXT: v_lshlrev_b16 v10, 2, v10
+; GFX11-NEXT: v_and_b32_e32 v2, 1, v2
+; GFX11-NEXT: v_or_b32_e32 v8, v8, v9
+; GFX11-NEXT: v_lshlrev_b16 v1, 1, v1
+; GFX11-NEXT: v_and_b32_e32 v0, 1, v0
+; GFX11-NEXT: v_and_b32_e32 v14, 1, v14
+; GFX11-NEXT: v_lshlrev_b16 v13, 1, v13
+; GFX11-NEXT: v_and_b32_e32 v12, 1, v12
+; GFX11-NEXT: v_lshlrev_b16 v5, 1, v5
+; GFX11-NEXT: v_and_b32_e32 v4, 1, v4
+; GFX11-NEXT: v_or_b32_e32 v9, v11, v10
+; GFX11-NEXT: v_and_b32_e32 v8, 3, v8
+; GFX11-NEXT: v_lshlrev_b16 v7, 3, v7
+; GFX11-NEXT: v_lshlrev_b16 v6, 2, v6
+; GFX11-NEXT: v_lshlrev_b16 v3, 3, v3
+; GFX11-NEXT: v_lshlrev_b16 v2, 2, v2
+; GFX11-NEXT: v_or_b32_e32 v0, v0, v1
+; GFX11-NEXT: v_lshlrev_b16 v15, 3, v15
+; GFX11-NEXT: v_lshlrev_b16 v14, 2, v14
+; GFX11-NEXT: v_or_b32_e32 v12, v12, v13
+; GFX11-NEXT: v_or_b32_e32 v4, v4, v5
+; GFX11-NEXT: v_or_b32_e32 v5, v7, v6
+; GFX11-NEXT: v_or_b32_e32 v6, v8, v9
+; GFX11-NEXT: v_or_b32_e32 v2, v3, v2
+; GFX11-NEXT: v_and_b32_e32 v0, 3, v0
+; GFX11-NEXT: v_or_b32_e32 v13, v15, v14
+; GFX11-NEXT: v_and_b32_e32 v12, 3, v12
+; GFX11-NEXT: v_and_b32_e32 v3, 15, v6
+; GFX11-NEXT: v_lshlrev_b16 v6, 1, v29
+; GFX11-NEXT: v_or_b32_e32 v0, v0, v2
+; GFX11-NEXT: v_and_b32_e32 v2, 1, v26
+; GFX11-NEXT: v_and_b32_e32 v7, 1, v28
+; GFX11-NEXT: v_lshlrev_b16 v9, 1, v25
+; GFX11-NEXT: v_and_b32_e32 v10, 1, v24
+; GFX11-NEXT: v_and_b32_e32 v4, 3, v4
+; GFX11-NEXT: v_or_b32_e32 v1, v12, v13
+; GFX11-NEXT: v_lshlrev_b16 v8, 3, v27
+; GFX11-NEXT: v_lshlrev_b16 v2, 2, v2
+; GFX11-NEXT: v_or_b32_e32 v6, v7, v6
+; GFX11-NEXT: v_or_b32_e32 v7, v10, v9
+; GFX11-NEXT: v_and_b32_e32 v9, 1, v22
+; GFX11-NEXT: v_lshlrev_b16 v10, 1, v21
+; GFX11-NEXT: v_and_b32_e32 v12, 1, v20
+; GFX11-NEXT: v_and_b32_e32 v13, 1, v18
+; GFX11-NEXT: v_lshlrev_b16 v14, 1, v17
+; GFX11-NEXT: v_and_b32_e32 v15, 1, v16
+; GFX11-NEXT: v_or_b32_e32 v4, v4, v5
+; GFX11-NEXT: v_and_b32_e32 v5, 1, v30
+; GFX11-NEXT: v_or_b32_e32 v2, v8, v2
+; GFX11-NEXT: v_lshlrev_b16 v8, 3, v23
+; GFX11-NEXT: v_lshlrev_b16 v9, 2, v9
+; GFX11-NEXT: v_or_b32_e32 v10, v12, v10
+; GFX11-NEXT: v_lshlrev_b16 v12, 3, v19
+; GFX11-NEXT: v_lshlrev_b16 v13, 2, v13
+; GFX11-NEXT: v_or_b32_e32 v14, v15, v14
+; GFX11-NEXT: v_lshlrev_b16 v11, 3, v31
+; GFX11-NEXT: v_lshlrev_b16 v5, 2, v5
+; GFX11-NEXT: v_and_b32_e32 v7, 3, v7
+; GFX11-NEXT: v_or_b32_e32 v8, v8, v9
+; GFX11-NEXT: v_and_b32_e32 v9, 3, v10
+; GFX11-NEXT: v_or_b32_e32 v10, v12, v13
+; GFX11-NEXT: v_and_b32_e32 v12, 3, v14
+; GFX11-NEXT: v_or_b32_e32 v5, v11, v5
+; GFX11-NEXT: v_and_b32_e32 v6, 3, v6
+; GFX11-NEXT: v_or_b32_e32 v2, v7, v2
+; GFX11-NEXT: v_or_b32_e32 v7, v9, v8
+; GFX11-NEXT: v_or_b32_e32 v8, v12, v10
+; GFX11-NEXT: v_lshlrev_b16 v4, 4, v4
+; GFX11-NEXT: v_and_b32_e32 v0, 15, v0
+; GFX11-NEXT: v_or_b32_e32 v5, v6, v5
+; GFX11-NEXT: v_and_b32_e32 v2, 15, v2
+; GFX11-NEXT: v_lshlrev_b16 v6, 4, v7
+; GFX11-NEXT: v_and_b32_e32 v7, 15, v8
+; GFX11-NEXT: v_lshlrev_b16 v1, 12, v1
+; GFX11-NEXT: v_lshlrev_b16 v3, 8, v3
+; GFX11-NEXT: v_or_b32_e32 v0, v0, v4
+; GFX11-NEXT: v_lshlrev_b16 v4, 12, v5
+; GFX11-NEXT: v_lshlrev_b16 v2, 8, v2
+; GFX11-NEXT: v_or_b32_e32 v5, v7, v6
+; GFX11-NEXT: v_or_b32_e32 v1, v1, v3
+; GFX11-NEXT: v_and_b32_e32 v0, 0xff, v0
+; GFX11-NEXT: s_delay_alu instid0(VALU_DEP_4) | instskip(NEXT) | instid1(VALU_DEP_4)
+; GFX11-NEXT: v_or_b32_e32 v2, v4, v2
+; GFX11-NEXT: v_and_b32_e32 v3, 0xff, v5
+; GFX11-NEXT: s_delay_alu instid0(VALU_DEP_3) | instskip(NEXT) | instid1(VALU_DEP_2)
+; GFX11-NEXT: v_or_b32_e32 v0, v0, v1
+; GFX11-NEXT: v_or_b32_e32 v1, v3, v2
+; GFX11-NEXT: s_delay_alu instid0(VALU_DEP_2) | instskip(NEXT) | instid1(VALU_DEP_2)
+; GFX11-NEXT: v_and_b32_e32 v0, 0xffff, v0
+; GFX11-NEXT: v_lshlrev_b32_e32 v1, 16, v1
+; GFX11-NEXT: s_delay_alu instid0(VALU_DEP_1)
+; GFX11-NEXT: v_or_b32_e32 v0, v0, v1
+; GFX11-NEXT: global_store_b32 v[0:1], v0, off
+; GFX11-NEXT: s_nop 0
+; GFX11-NEXT: s_sendmsg sendmsg(MSG_DEALLOC_VGPRS)
+; GFX11-NEXT: s_endpgm
+ store <32 x i1> %arg0, ptr addrspace(1) undef
+ ret void
+}
+
+define amdgpu_cs void @amdgpu_cs_inreg_i1(i1 inreg %arg0) {
+; SI-LABEL: amdgpu_cs_inreg_i1:
+; SI: ; %bb.0:
+; SI-NEXT: s_and_b32 s0, s0, 1
+; SI-NEXT: s_mov_b32 s3, 0xf000
+; SI-NEXT: s_mov_b32 s2, -1
+; SI-NEXT: v_mov_b32_e32 v0, s0
+; SI-NEXT: buffer_store_byte v0, off, s[0:3], 0
+; SI-NEXT: s_endpgm
+;
+; VI-LABEL: amdgpu_cs_inreg_i1:
+; VI: ; %bb.0:
+; VI-NEXT: s_and_b32 s0, s0, 1
+; VI-NEXT: v_mov_b32_e32 v0, s0
+; VI-NEXT: flat_store_byte v[0:1], v0
+; VI-NEXT: s_endpgm
+;
+; GFX11-LABEL: amdgpu_cs_inreg_i1:
+; GFX11: ; %bb.0:
+; GFX11-NEXT: s_and_b32 s0, s0, 1
+; GFX11-NEXT: s_delay_alu instid0(SALU_CYCLE_1)
+; GFX11-NEXT: v_mov_b32_e32 v0, s0
+; GFX11-NEXT: global_store_b8 v[0:1], v0, off
+; GFX11-NEXT: s_nop 0
+; GFX11-NEXT: s_sendmsg sendmsg(MSG_DEALLOC_VGPRS)
+; GFX11-NEXT: s_endpgm
+ store i1 %arg0, ptr addrspace(1) undef
+ ret void
+}
+
+define amdgpu_cs void @amdgpu_cs_inreg_v8i1(<8 x i1> inreg %arg0) {
+; SI-LABEL: amdgpu_cs_inreg_v8i1:
+; SI: ; %bb.0:
+; SI-NEXT: s_lshl_b32 s7, s7, 3
+; SI-NEXT: s_and_b32 s6, s6, 1
+; SI-NEXT: s_lshl_b32 s5, s5, 1
+; SI-NEXT: s_and_b32 s4, s4, 1
+; SI-NEXT: s_lshl_b32 s8, s3, 3
+; SI-NEXT: s_and_b32 s2, s2, 1
+; SI-NEXT: s_lshl_b32 s1, s1, 1
+; SI-NEXT: s_and_b32 s0, s0, 1
+; SI-NEXT: s_mov_b32 s3, 0xf000
+; SI-NEXT: s_lshl_b32 s6, s6, 2
+; SI-NEXT: s_or_b32 s4, s4, s5
+; SI-NEXT: s_lshl_b32 s2, s2, 2
+; SI-NEXT: s_or_b32 s0, s0, s1
+; SI-NEXT: s_or_b32 s1, s7, s6
+; SI-NEXT: s_and_b32 s4, s4, 3
+; SI-NEXT: s_or_b32 s2, s8, s2
+; SI-NEXT: s_and_b32 s0, s0, 3
+; SI-NEXT: s_or_b32 s1, s4, s1
+; SI-NEXT: s_or_b32 s0, s0, s2
+; SI-NEXT: s_lshl_b32 s1, s1, 4
+; SI-NEXT: s_and_b32 s0, s0, 15
+; SI-NEXT: s_or_b32 s0, s0, s1
+; SI-NEXT: s_mov_b32 s2, -1
+; SI-NEXT: v_mov_b32_e32 v0, s0
+; SI-NEXT: buffer_store_byte v0, off, s[0:3], 0
+; SI-NEXT: s_endpgm
+;
+; VI-LABEL: amdgpu_cs_inreg_v8i1:
+; VI: ; %bb.0:
+; VI-NEXT: v_and_b32_e64 v1, s6, 1
+; VI-NEXT: v_lshlrev_b16_e64 v0, 3, s7
+; VI-NEXT: v_lshlrev_b16_e32 v1, 2, v1
+; VI-NEXT: v_or_b32_e32 v0, v0, v1
+; VI-NEXT: v_lshlrev_b16_e64 v1, 1, s5
+; VI-NEXT: v_and_b32_e64 v2, s4, 1
+; VI-NEXT: v_or_b32_e32 v1, v2, v1
+; VI-NEXT: v_and_b32_e32 v1, 3, v1
+; VI-NEXT: v_and_b32_e64 v2, s2, 1
+; VI-NEXT: v_or_b32_e32 v0, v1, v0
+; VI-NEXT: v_lshlrev_b16_e64 v1, 3, s3
+; VI-NEXT: v_lshlrev_b16_e32 v2, 2, v2
+; VI-NEXT: v_or_b32_e32 v1, v1, v2
+; VI-NEXT: v_lshlrev_b16_e64 v2, 1, s1
+; VI-NEXT: v_and_b32_e64 v3, s0, 1
+; VI-NEXT: v_or_b32_e32 v2, v3, v2
+; VI-NEXT: v_and_b32_e32 v2, 3, v2
+; VI-NEXT: v_or_b32_e32 v1, v2, v1
+; VI-NEXT: v_lshlrev_b16_e32 v0, 4, v0
+; VI-NEXT: v_and_b32_e32 v1, 15, v1
+; VI-NEXT: v_or_b32_e32 v0, v1, v0
+; VI-NEXT: flat_store_byte v[0:1], v0
+; VI-NEXT: s_endpgm
+;
+; GFX11-LABEL: amdgpu_cs_inreg_v8i1:
+; GFX11: ; %bb.0:
+; GFX11-NEXT: v_and_b32_e64 v1, s6, 1
+; GFX11-NEXT: v_lshlrev_b16 v2, 1, s5
+; GFX11-NEXT: v_and_b32_e64 v3, s4, 1
+; GFX11-NEXT: v_and_b32_e64 v4, s2, 1
+; GFX11-NEXT: v_lshlrev_b16 v5, 1, s1
+; GFX11-NEXT: v_and_b32_e64 v6, s0, 1
+; GFX11-NEXT: v_lshlrev_b16 v0, 3, s7
+; GFX11-NEXT: v_lshlrev_b16 v1, 2, v1
+; GFX11-NEXT: v_or_b32_e32 v2, v3, v2
+; GFX11-NEXT: v_lshlrev_b16 v3, 3, s3
+; GFX11-NEXT: v_lshlrev_b16 v4, 2, v4
+; GFX11-NEXT: v_or_b32_e32 v5, v6, v5
+; GFX11-NEXT: v_or_b32_e32 v0, v0, v1
+; GFX11-NEXT: v_and_b32_e32 v1, 3, v2
+; GFX11-NEXT: s_delay_alu instid0(VALU_DEP_4) | instskip(NEXT) | instid1(VALU_DEP_4)
+; GFX11-NEXT: v_or_b32_e32 v2, v3, v4
+; GFX11-NEXT: v_and_b32_e32 v3, 3, v5
+; GFX11-NEXT: s_delay_alu instid0(VALU_DEP_3) | instskip(NEXT) | instid1(VALU_DEP_2)
+; GFX11-NEXT: v_or_b32_e32 v0, v1, v0
+; GFX11-NEXT: v_or_b32_e32 v1, v3, v2
+; GFX11-NEXT: s_delay_alu instid0(VALU_DEP_2) | instskip(NEXT) | instid1(VALU_DEP_2)
+; GFX11-NEXT: v_lshlrev_b16 v0, 4, v0
+; GFX11-NEXT: v_and_b32_e32 v1, 15, v1
+; GFX11-NEXT: s_delay_alu instid0(VALU_DEP_1)
+; GFX11-NEXT: v_or_b32_e32 v0, v1, v0
+; GFX11-NEXT: global_store_b8 v[0:1], v0, off
+; GFX11-NEXT: s_nop 0
+; GFX11-NEXT: s_sendmsg sendmsg(MSG_DEALLOC_VGPRS)
+; GFX11-NEXT: s_endpgm
+ store <8 x i1> %arg0, ptr addrspace(1) undef
+ ret void
+}
+
+define amdgpu_cs void @amdgpu_cs_inreg_v16i1(<16 x i1> inreg %arg0) {
+; SI-LABEL: amdgpu_cs_inreg_v16i1:
+; SI: ; %bb.0:
+; SI-NEXT: s_lshl_b32 s15, s15, 3
+; SI-NEXT: s_and_b32 s14, s14, 1
+; SI-NEXT: s_lshl_b32 s13, s13, 1
+; SI-NEXT: s_and_b32 s12, s12, 1
+; SI-NEXT: s_lshl_b32 s11, s11, 3
+; SI-NEXT: s_and_b32 s10, s10, 1
+; SI-NEXT: s_lshl_b32 s9, s9, 1
+; SI-NEXT: s_and_b32 s8, s8, 1
+; SI-NEXT: s_lshl_b32 s7, s7, 3
+; SI-NEXT: s_and_b32 s6, s6, 1
+; SI-NEXT: s_lshl_b32 s5, s5, 1
+; SI-NEXT: s_and_b32 s4, s4, 1
+; SI-NEXT: s_lshl_b32 s16, s3, 3
+; SI-NEXT: s_and_b32 s2, s2, 1
+; SI-NEXT: s_lshl_b32 s1, s1, 1
+; SI-NEXT: s_and_b32 s0, s0, 1
+; SI-NEXT: s_mov_b32 s3, 0xf000
+; SI-NEXT: s_lshl_b32 s14, s14, 2
+; SI-NEXT: s_or_b32 s12, s12, s13
+; SI-NEXT: s_lshl_b32 s10, s10, 2
+; SI-NEXT: s_or_b32 s8, s8, s9
+; SI-NEXT: s_lshl_b32 s6, s6, 2
+; SI-NEXT: s_or_b32 s4, s4, s5
+; SI-NEXT: s_lshl_b32 s2, s2, 2
+; SI-NEXT: s_or_b32 s0, s0, s1
+; SI-NEXT: s_or_b32 s1, s15, s14
+; SI-NEXT: s_and_b32 s5, s12, 3
+; SI-NEXT: s_or_b32 s9, s11, s10
+; SI-NEXT: s_and_b32 s8, s8, 3
+; SI-NEXT: s_or_b32 s6, s7, s6
+; SI-NEXT: s_and_b32 s4, s4, 3
+; SI-NEXT: s_or_b32 s2, s16, s2
+; SI-NEXT: s_and_b32 s0, s0, 3
+; SI-NEXT: s_or_b32 s1, s5, s1
+; SI-NEXT: s_or_b32 s5, s8, s9
+; SI-NEXT: s_or_b32 s4, s4, s6
+; SI-NEXT: s_or_b32 s0, s0, s2
+; SI-NEXT: s_lshl_b32 s1, s1, 12
+; SI-NEXT: s_and_b32 s2, s5, 15
+; SI-NEXT: s_lshl_b32 s4, s4, 4
+; SI-NEXT: s_and_b32 s0, s0, 15
+; SI-NEXT: s_lshl_b32 s2, s2, 8
+; SI-NEXT: s_or_b32 s0, s0, s4
+; SI-NEXT: s_or_b32 s1, s1, s2
+; SI-NEXT: s_and_b32 s0, s0, 0xff
+; SI-NEXT: s_or_b32 s0, s0, s1
+; SI-NEXT: s_mov_b32 s2, -1
+; SI-NEXT: v_mov_b32_e32 v0, s0
+; SI-NEXT: buffer_store_short v0, off, s[0:3], 0
+; SI-NEXT: s_endpgm
+;
+; VI-LABEL: amdgpu_cs_inreg_v16i1:
+; VI: ; %bb.0:
+; VI-NEXT: v_and_b32_e64 v1, s14, 1
+; VI-NEXT: v_lshlrev_b16_e64 v0, 3, s15
+; VI-NEXT: v_lshlrev_b16_e32 v1, 2, v1
+; VI-NEXT: v_or_b32_e32 v0, v0, v1
+; VI-NEXT: v_lshlrev_b16_e64 v1, 1, s13
+; VI-NEXT: v_and_b32_e64 v2, s12, 1
+; VI-NEXT: v_or_b32_e32 v1, v2, v1
+; VI-NEXT: v_and_b32_e32 v1, 3, v1
+; VI-NEXT: v_and_b32_e64 v2, s10, 1
+; VI-NEXT: v_or_b32_e32 v0, v1, v0
+; VI-NEXT: v_lshlrev_b16_e64 v1, 3, s11
+; VI-NEXT: v_lshlrev_b16_e32 v2, 2, v2
+; VI-NEXT: v_or_b32_e32 v1, v1, v2
+; VI-NEXT: v_lshlrev_b16_e64 v2, 1, s9
+; VI-NEXT: v_and_b32_e64 v3, s8, 1
+; VI-NEXT: v_or_b32_e32 v2, v3, v2
+; VI-NEXT: v_and_b32_e32 v2, 3, v2
+; VI-NEXT: v_or_b32_e32 v1, v2, v1
+; VI-NEXT: v_mov_b32_e32 v2, 15
+; VI-NEXT: v_lshlrev_b16_e32 v0, 12, v0
+; VI-NEXT: v_and_b32_sdwa v1, v1, v2 dst_sel:BYTE_1 dst_unused:UNUSED_PAD src0_sel:DWORD src1_sel:DWORD
+; VI-NEXT: v_and_b32_e64 v2, s6, 1
+; VI-NEXT: v_or_b32_e32 v0, v0, v1
+; VI-NEXT: v_lshlrev_b16_e64 v1, 3, s7
+; VI-NEXT: v_lshlrev_b16_e32 v2, 2, v2
+; VI-NEXT: v_or_b32_e32 v1, v1, v2
+; VI-NEXT: v_lshlrev_b16_e64 v2, 1, s5
+; VI-NEXT: v_and_b32_e64 v3, s4, 1
+; VI-NEXT: v_or_b32_e32 v2, v3, v2
+; VI-NEXT: v_and_b32_e32 v2, 3, v2
+; VI-NEXT: v_and_b32_e64 v3, s2, 1
+; VI-NEXT: v_or_b32_e32 v1, v2, v1
+; VI-NEXT: v_lshlrev_b16_e64 v2, 3, s3
+; VI-NEXT: v_lshlrev_b16_e32 v3, 2, v3
+; VI-NEXT: v_or_b32_e32 v2, v2, v3
+; VI-NEXT: v_lshlrev_b16_e64 v3, 1, s1
+; VI-NEXT: v_and_b32_e64 v4, s0, 1
+; VI-NEXT: v_or_b32_e32 v3, v4, v3
+; VI-NEXT: v_and_b32_e32 v3, 3, v3
+; VI-NEXT: v_or_b32_e32 v2, v3, v2
+; VI-NEXT: v_lshlrev_b16_e32 v1, 4, v1
+; VI-NEXT: v_and_b32_e32 v2, 15, v2
+; VI-NEXT: v_or_b32_e32 v1, v2, v1
+; VI-NEXT: v_or_b32_sdwa v0, v1, v0 dst_sel:DWORD dst_unused:UNUSED_PAD src0_sel:BYTE_0 src1_sel:DWORD
+; VI-NEXT: flat_store_short v[0:1], v0
+; VI-NEXT: s_endpgm
+;
+; GFX11-LABEL: amdgpu_cs_inreg_v16i1:
+; GFX11: ; %bb.0:
+; GFX11-NEXT: v_and_b32_e64 v0, s10, 1
+; GFX11-NEXT: v_lshlrev_b16 v2, 1, s13
+; GFX11-NEXT: v_and_b32_e64 v3, s12, 1
+; GFX11-NEXT: v_lshlrev_b16 v5, 1, s9
+; GFX11-NEXT: v_and_b32_e64 v6, s8, 1
+; GFX11-NEXT: v_lshlrev_b16 v4, 3, s11
+; GFX11-NEXT: v_lshlrev_b16 v0, 2, v0
+; GFX11-NEXT: v_or_b32_e32 v2, v3, v2
+; GFX11-NEXT: v_and_b32_e64 v8, s4, 1
+; GFX11-NEXT: v_or_b32_e32 v3, v6, v5
+; GFX11-NEXT: v_and_b32_e64 v5, s6, 1
+; GFX11-NEXT: v_lshlrev_b16 v6, 1, s5
+; GFX11-NEXT: v_and_b32_e64 v9, s2, 1
+; GFX11-NEXT: v_lshlrev_b16 v10, 1, s1
+; GFX11-NEXT: v_and_b32_e64 v11, s0, 1
+; GFX11-NEXT: v_and_b32_e64 v1, s14, 1
+; GFX11-NEXT: v_or_b32_e32 v0, v4, v0
+; GFX11-NEXT: v_lshlrev_b16 v4, 3, s7
+; GFX11-NEXT: v_lshlrev_b16 v5, 2, v5
+; GFX11-NEXT: v_or_b32_e32 v6, v8, v6
+; GFX11-NEXT: v_lshlrev_b16 v8, 3, s3
+; GFX11-NEXT: v_lshlrev_b16 v9, 2, v9
+; GFX11-NEXT: v_or_b32_e32 v10, v11, v10
+; GFX11-NEXT: v_lshlrev_b16 v7, 3, s15
+; GFX11-NEXT: v_lshlrev_b16 v1, 2, v1
+; GFX11-NEXT: v_and_b32_e32 v3, 3, v3
+; GFX11-NEXT: v_or_b32_e32 v4, v4, v5
+; GFX11-NEXT: v_and_b32_e32 v5, 3, v6
+; GFX11-NEXT: v_or_b32_e32 v6, v8, v9
+; GFX11-NEXT: v_and_b32_e32 v8, 3, v10
+; GFX11-NEXT: v_or_b32_e32 v1, v7, v1
+; GFX11-NEXT: v_and_b32_e32 v2, 3, v2
+; GFX11-NEXT: v_or_b32_e32 v0, v3, v0
+; GFX11-NEXT: v_or_b32_e32 v3, v5, v4
+; GFX11-NEXT: v_or_b32_e32 v4, v8, v6
+; GFX11-NEXT: s_delay_alu instid0(VALU_DEP_4) | instskip(NEXT) | instid1(VALU_DEP_4)
+; GFX11-NEXT: v_or_b32_e32 v1, v2, v1
+; GFX11-NEXT: v_and_b32_e32 v0, 15, v0
+; GFX11-NEXT: s_delay_alu instid0(VALU_DEP_4) | instskip(NEXT) | instid1(VALU_DEP_4)
+; GFX11-NEXT: v_lshlrev_b16 v2, 4, v3
+; GFX11-NEXT: v_and_b32_e32 v3, 15, v4
+; GFX11-NEXT: s_delay_alu instid0(VALU_DEP_4) | instskip(NEXT) | instid1(VALU_DEP_4)
+; GFX11-NEXT: v_lshlrev_b16 v1, 12, v1
+; GFX11-NEXT: v_lshlrev_b16 v0, 8, v0
+; GFX11-NEXT: s_delay_alu instid0(VALU_DEP_3) | instskip(NEXT) | instid1(VALU_DEP_2)
+; GFX11-NEXT: v_or_b32_e32 v2, v3, v2
+; GFX11-NEXT: v_or_b32_e32 v0, v1, v0
+; GFX11-NEXT: s_delay_alu instid0(VALU_DEP_2) | instskip(NEXT) | instid1(VALU_DEP_1)
+; GFX11-NEXT: v_and_b32_e32 v1, 0xff, v2
+; GFX11-NEXT: v_or_b32_e32 v0, v1, v0
+; GFX11-NEXT: global_store_b16 v[0:1], v0, off
+; GFX11-NEXT: s_nop 0
+; GFX11-NEXT: s_sendmsg sendmsg(MSG_DEALLOC_VGPRS)
+; GFX11-NEXT: s_endpgm
+ store <16 x i1> %arg0, ptr addrspace(1) undef
+ ret void
+}
+
+define amdgpu_cs void @amdgpu_cs_inreg_v32i1(<32 x i1> inreg %arg0) {
+; SI-LABEL: amdgpu_cs_inreg_v32i1:
+; SI: ; %bb.0:
+; SI-NEXT: s_lshl_b32 s31, s31, 3
+; SI-NEXT: s_and_b32 s30, s30, 1
+; SI-NEXT: s_lshl_b32 s29, s29, 1
+; SI-NEXT: s_and_b32 s28, s28, 1
+; SI-NEXT: s_lshl_b32 s27, s27, 3
+; SI-NEXT: s_and_b32 s26, s26, 1
+; SI-NEXT: s_lshl_b32 s25, s25, 1
+; SI-NEXT: s_and_b32 s24, s24, 1
+; SI-NEXT: s_lshl_b32 s23, s23, 3
+; SI-NEXT: s_and_b32 s22, s22, 1
+; SI-NEXT: s_lshl_b32 s21, s21, 1
+; SI-NEXT: s_and_b32 s20, s20, 1
+; SI-NEXT: s_lshl_b32 s19, s19, 3
+; SI-NEXT: s_and_b32 s18, s18, 1
+; SI-NEXT: s_lshl_b32 s17, s17, 1
+; SI-NEXT: s_and_b32 s16, s16, 1
+; SI-NEXT: s_lshl_b32 s15, s15, 3
+; SI-NEXT: s_and_b32 s14, s14, 1
+; SI-NEXT: s_lshl_b32 s13, s13, 1
+; SI-NEXT: s_and_b32 s12, s12, 1
+; SI-NEXT: s_lshl_b32 s11, s11, 3
+; SI-NEXT: s_and_b32 s10, s10, 1
+; SI-NEXT: s_lshl_b32 s9, s9, 1
+; SI-NEXT: s_and_b32 s8, s8, 1
+; SI-NEXT: s_lshl_b32 s7, s7, 3
+; SI-NEXT: s_and_b32 s6, s6, 1
+; SI-NEXT: s_lshl_b32 s5, s5, 1
+; SI-NEXT: s_and_b32 s4, s4, 1
+; SI-NEXT: s_lshl_b32 s33, s3, 3
+; SI-NEXT: s_and_b32 s2, s2, 1
+; SI-NEXT: s_lshl_b32 s1, s1, 1
+; SI-NEXT: s_and_b32 s0, s0, 1
+; SI-NEXT: s_mov_b32 s3, 0xf000
+; SI-NEXT: s_lshl_b32 s30, s30, 2
+; SI-NEXT: s_or_b32 s28, s28, s29
+; SI-NEXT: s_lshl_b32 s26, s26, 2
+; SI-NEXT: s_or_b32 s24, s24, s25
+; SI-NEXT: s_lshl_b32 s22, s22, 2
+; SI-NEXT: s_or_b32 s20, s20, s21
+; SI-NEXT: s_lshl_b32 s18, s18, 2
+; SI-NEXT: s_or_b32 s16, s16, s17
+; SI-NEXT: s_lshl_b32 s14, s14, 2
+; SI-NEXT: s_or_b32 s12, s12, s13
+; SI-NEXT: s_lshl_b32 s10, s10, 2
+; SI-NEXT: s_or_b32 s8, s8, s9
+; SI-NEXT: s_lshl_b32 s6, s6, 2
+; SI-NEXT: s_or_b32 s4, s4, s5
+; SI-NEXT: s_lshl_b32 s2, s2, 2
+; SI-NEXT: s_or_b32 s0, s0, s1
+; SI-NEXT: s_or_b32 s1, s31, s30
+; SI-NEXT: s_and_b32 s5, s28, 3
+; SI-NEXT: s_or_b32 s9, s27, s26
+; SI-NEXT: s_and_b32 s13, s24, 3
+; SI-NEXT: s_or_b32 s17, s23, s22
+; SI-NEXT: s_and_b32 s20, s20, 3
+; SI-NEXT: s_or_b32 s18, s19, s18
+; SI-NEXT: s_and_b32 s16, s16, 3
+; SI-NEXT: s_or_b32 s14, s15, s14
+; SI-NEXT: s_and_b32 s12, s12, 3
+; SI-NEXT: s_or_b32 s10, s11, s10
+; SI-NEXT: s_and_b32 s8, s8, 3
+; SI-NEXT: s_or_b32 s6, s7, s6
+; SI-NEXT: s_and_b32 s4, s4, 3
+; SI-NEXT: s_or_b32 s2, s33, s2
+; SI-NEXT: s_and_b32 s0, s0, 3
+; SI-NEXT: s_or_b32 s1, s5, s1
+; SI-NEXT: s_or_b32 s5, s13, s9
+; SI-NEXT: s_or_b32 s7, s20, s17
+; SI-NEXT: s_or_b32 s9, s16, s18
+; SI-NEXT: s_or_b32 s11, s12, s14
+; SI-NEXT: s_or_b32 s8, s8, s10
+; SI-NEXT: s_or_b32 s4, s4, s6
+; SI-NEXT: s_or_b32 s0, s0, s2
+; SI-NEXT: s_lshl_b32 s1, s1, 12
+; SI-NEXT: s_and_b32 s2, s5, 15
+; SI-NEXT: s_lshl_b32 s5, s7, 4
+; SI-NEXT: s_and_b32 s6, s9, 15
+; SI-NEXT: s_lshl_b32 s7, s11, 12
+; SI-NEXT: s_and_b32 s8, s8, 15
+; SI-NEXT: s_lshl_b32 s4, s4, 4
+; SI-NEXT: s_and_b32 s0, s0, 15
+; SI-NEXT: s_lshl_b32 s2, s2, 8
+; SI-NEXT: s_or_b32 s5, s6, s5
+; SI-NEXT: s_lshl_b32 s6, s8, 8
+; SI-NEXT: s_or_b32 s0, s0, s4
+; SI-NEXT: s_or_b32 s1, s1, s2
+; SI-NEXT: s_and_b32 s2, s5, 0xff
+; SI-NEXT: s_or_b32 s4, s7, s6
+; SI-NEXT: s_and_b32 s0, s0, 0xff
+; SI-NEXT: s_or_b32 s1, s2, s1
+; SI-NEXT: s_or_b32 s0, s0, s4
+; SI-NEXT: s_lshl_b32 s1, s1, 16
+; SI-NEXT: s_and_b32 s0, s0, 0xffff
+; SI-NEXT: s_or_b32 s0, s0, s1
+; SI-NEXT: s_mov_b32 s2, -1
+; SI-NEXT: v_mov_b32_e32 v0, s0
+; SI-NEXT: buffer_store_dword v0, off, s[0:3], 0
+; SI-NEXT: s_endpgm
+;
+; VI-LABEL: amdgpu_cs_inreg_v32i1:
+; VI: ; %bb.0:
+; VI-NEXT: v_and_b32_e64 v1, s14, 1
+; VI-NEXT: v_lshlrev_b16_e64 v0, 3, s15
+; VI-NEXT: v_lshlrev_b16_e32 v1, 2, v1
+; VI-NEXT: v_or_b32_e32 v0, v0, v1
+; VI-NEXT: v_lshlrev_b16_e64 v1, 1, s13
+; VI-NEXT: v_and_b32_e64 v2, s12, 1
+; VI-NEXT: v_or_b32_e32 v1, v2, v1
+; VI-NEXT: v_and_b32_e32 v1, 3, v1
+; VI-NEXT: v_and_b32_e64 v2, s10, 1
+; VI-NEXT: v_or_b32_e32 v0, v1, v0
+; VI-NEXT: v_lshlrev_b16_e64 v1, 3, s11
+; VI-NEXT: v_lshlrev_b16_e32 v2, 2, v2
+; VI-NEXT: v_or_b32_e32 v1, v1, v2
+; VI-NEXT: v_lshlrev_b16_e64 v2, 1, s9
+; VI-NEXT: v_and_b32_e64 v3, s8, 1
+; VI-NEXT: v_or_b32_e32 v2, v3, v2
+; VI-NEXT: v_and_b32_e32 v2, 3, v2
+; VI-NEXT: v_or_b32_e32 v1, v2, v1
+; VI-NEXT: v_mov_b32_e32 v2, 15
+; VI-NEXT: v_lshlrev_b16_e32 v0, 12, v0
+; VI-NEXT: v_and_b32_sdwa v1, v1, v2 dst_sel:BYTE_1 dst_unused:UNUSED_PAD src0_sel:DWORD src1_sel:DWORD
+; VI-NEXT: v_and_b32_e64 v3, s6, 1
+; VI-NEXT: v_or_b32_e32 v0, v0, v1
+; VI-NEXT: v_lshlrev_b16_e64 v1, 3, s7
+; VI-NEXT: v_lshlrev_b16_e32 v3, 2, v3
+; VI-NEXT: v_or_b32_e32 v1, v1, v3
+; VI-NEXT: v_lshlrev_b16_e64 v3, 1, s5
+; VI-NEXT: v_and_b32_e64 v4, s4, 1
+; VI-NEXT: v_or_b32_e32 v3, v4, v3
+; VI-NEXT: v_and_b32_e32 v3, 3, v3
+; VI-NEXT: v_and_b32_e64 v4, s2, 1
+; VI-NEXT: v_or_b32_e32 v1, v3, v1
+; VI-NEXT: v_lshlrev_b16_e64 v3, 3, s3
+; VI-NEXT: v_lshlrev_b16_e32 v4, 2, v4
+; VI-NEXT: v_or_b32_e32 v3, v3, v4
+; VI-NEXT: v_lshlrev_b16_e64 v4, 1, s1
+; VI-NEXT: v_and_b32_e64 v5, s0, 1
+; VI-NEXT: v_or_b32_e32 v4, v5, v4
+; VI-NEXT: v_and_b32_e32 v4, 3, v4
+; VI-NEXT: v_or_b32_e32 v3, v4, v3
+; VI-NEXT: v_lshlrev_b16_e32 v1, 4, v1
+; VI-NEXT: v_and_b32_e32 v3, 15, v3
+; VI-NEXT: v_or_b32_e32 v1, v3, v1
+; VI-NEXT: v_and_b32_e64 v3, s30, 1
+; VI-NEXT: v_or_b32_sdwa v0, v1, v0 dst_sel:DWORD dst_unused:UNUSED_PAD src0_sel:BYTE_0 src1_sel:DWORD
+; VI-NEXT: v_lshlrev_b16_e64 v1, 3, s31
+; VI-NEXT: v_lshlrev_b16_e32 v3, 2, v3
+; VI-NEXT: v_or_b32_e32 v1, v1, v3
+; VI-NEXT: v_lshlrev_b16_e64 v3, 1, s29
+; VI-NEXT: v_and_b32_e64 v4, s28, 1
+; VI-NEXT: v_or_b32_e32 v3, v4, v3
+; VI-NEXT: v_and_b32_e32 v3, 3, v3
+; VI-NEXT: v_and_b32_e64 v4, s26, 1
+; VI-NEXT: v_or_b32_e32 v1, v3, v1
+; VI-NEXT: v_lshlrev_b16_e64 v3, 3, s27
+; VI-NEXT: v_lshlrev_b16_e32 v4, 2, v4
+; VI-NEXT: v_or_b32_e32 v3, v3, v4
+; VI-NEXT: v_lshlrev_b16_e64 v4, 1, s25
+; VI-NEXT: v_and_b32_e64 v5, s24, 1
+; VI-NEXT: v_or_b32_e32 v4, v5, v4
+; VI-NEXT: v_and_b32_e32 v4, 3, v4
+; VI-NEXT: v_or_b32_e32 v3, v4, v3
+; VI-NEXT: v_lshlrev_b16_e32 v1, 12, v1
+; VI-NEXT: v_and_b32_sdwa v2, v3, v2 dst_sel:BYTE_1 dst_unused:UNUSED_PAD src0_sel:DWORD src1_sel:DWORD
+; VI-NEXT: v_and_b32_e64 v3, s22, 1
+; VI-NEXT: v_or_b32_e32 v1, v1, v2
+; VI-NEXT: v_lshlrev_b16_e64 v2, 3, s23
+; VI-NEXT: v_lshlrev_b16_e32 v3, 2, v3
+; VI-NEXT: v_or_b32_e32 v2, v2, v3
+; VI-NEXT: v_lshlrev_b16_e64 v3, 1, s21
+; VI-NEXT: v_and_b32_e64 v4, s20, 1
+; VI-NEXT: v_or_b32_e32 v3, v4, v3
+; VI-NEXT: v_and_b32_e32 v3, 3, v3
+; VI-NEXT: v_and_b32_e64 v4, s18, 1
+; VI-NEXT: v_or_b32_e32 v2, v3, v2
+; VI-NEXT: v_lshlrev_b16_e64 v3, 3, s19
+; VI-NEXT: v_lshlrev_b16_e32 v4, 2, v4
+; VI-NEXT: v_or_b32_e32 v3, v3, v4
+; VI-NEXT: v_lshlrev_b16_e64 v4, 1, s17
+; VI-NEXT: v_and_b32_e64 v5, s16, 1
+; VI-NEXT: v_or_b32_e32 v4, v5, v4
+; VI-NEXT: v_and_b32_e32 v4, 3, v4
+; VI-NEXT: v_or_b32_e32 v3, v4, v3
+; VI-NEXT: v_lshlrev_b16_e32 v2, 4, v2
+; VI-NEXT: v_and_b32_e32 v3, 15, v3
+; VI-NEXT: v_or_b32_e32 v2, v3, v2
+; VI-NEXT: v_or_b32_sdwa v1, v2, v1 dst_sel:WORD_1 dst_unused:UNUSED_PAD src0_sel:BYTE_0 src1_sel:DWORD
+; VI-NEXT: v_or_b32_sdwa v0, v0, v1 dst_sel:DWORD dst_unused:UNUSED_PAD src0_sel:WORD_0 src1_sel:DWORD
+; VI-NEXT: flat_store_dword v[0:1], v0
+; VI-NEXT: s_endpgm
+;
+; GFX11-LABEL: amdgpu_cs_inreg_v32i1:
+; GFX11: ; %bb.0:
+; GFX11-NEXT: v_and_b32_e64 v0, s14, 1
+; GFX11-NEXT: v_lshlrev_b16 v1, 1, s13
+; GFX11-NEXT: v_and_b32_e64 v2, s12, 1
+; GFX11-NEXT: v_lshlrev_b16 v3, 3, s15
+; GFX11-NEXT: v_lshlrev_b16 v4, 1, s9
+; GFX11-NEXT: v_lshlrev_b16 v0, 2, v0
+; GFX11-NEXT: v_and_b32_e64 v5, s8, 1
+; GFX11-NEXT: v_or_b32_e32 v1, v2, v1
+; GFX11-NEXT: v_and_b32_e64 v2, s10, 1
+; GFX11-NEXT: v_lshlrev_b16 v6, 1, s5
+; GFX11-NEXT: v_or_b32_e32 v0, v3, v0
+; GFX11-NEXT: v_lshlrev_b16 v3, 3, s11
+; GFX11-NEXT: v_or_b32_e32 v4, v5, v4
+; GFX11-NEXT: v_lshlrev_b16 v2, 2, v2
+; GFX11-NEXT: v_and_b32_e64 v5, s6, 1
+; GFX11-NEXT: v_and_b32_e64 v7, s4, 1
+; GFX11-NEXT: v_lshlrev_b16 v8, 1, s1
+; GFX11-NEXT: v_and_b32_e64 v9, s0, 1
+; GFX11-NEXT: v_or_b32_e32 v2, v3, v2
+; GFX11-NEXT: v_and_b32_e32 v3, 3, v4
+; GFX11-NEXT: v_lshlrev_b16 v4, 3, s7
+; GFX11-NEXT: v_lshlrev_b16 v5, 2, v5
+; GFX11-NEXT: v_or_b32_e32 v6, v7, v6
+; GFX11-NEXT: v_and_b32_e64 v7, s2, 1
+; GFX11-NEXT: v_and_b32_e32 v1, 3, v1
+; GFX11-NEXT: v_or_b32_e32 v8, v9, v8
+; GFX11-NEXT: v_or_b32_e32 v4, v4, v5
+; GFX11-NEXT: v_and_b32_e32 v5, 3, v6
+; GFX11-NEXT: v_lshlrev_b16 v6, 3, s3
+; GFX11-NEXT: v_lshlrev_b16 v7, 2, v7
+; GFX11-NEXT: v_or_b32_e32 v0, v1, v0
+; GFX11-NEXT: v_or_b32_e32 v1, v3, v2
+; GFX11-NEXT: v_or_b32_e32 v2, v5, v4
+; GFX11-NEXT: v_and_b32_e32 v4, 3, v8
+; GFX11-NEXT: v_or_b32_e32 v3, v6, v7
+; GFX11-NEXT: v_lshlrev_b16 v6, 1, s29
+; GFX11-NEXT: v_and_b32_e64 v7, s28, 1
+; GFX11-NEXT: v_lshlrev_b16 v9, 1, s25
+; GFX11-NEXT: v_and_b32_e64 v10, s24, 1
+; GFX11-NEXT: v_or_b32_e32 v3, v4, v3
+; GFX11-NEXT: v_and_b32_e64 v4, s26, 1
+; GFX11-NEXT: v_lshlrev_b16 v8, 3, s27
+; GFX11-NEXT: v_or_b32_e32 v6, v7, v6
+; GFX11-NEXT: v_or_b32_e32 v7, v10, v9
+; GFX11-NEXT: v_and_b32_e64 v9, s22, 1
+; GFX11-NEXT: v_lshlrev_b16 v4, 2, v4
+; GFX11-NEXT: v_lshlrev_b16 v10, 1, s21
+; GFX11-NEXT: v_and_b32_e64 v12, s20, 1
+; GFX11-NEXT: v_and_b32_e64 v13, s18, 1
+; GFX11-NEXT: v_lshlrev_b16 v14, 1, s17
+; GFX11-NEXT: v_and_b32_e64 v15, s16, 1
+; GFX11-NEXT: v_and_b32_e64 v5, s30, 1
+; GFX11-NEXT: v_or_b32_e32 v4, v8, v4
+; GFX11-NEXT: v_lshlrev_b16 v8, 3, s23
+; GFX11-NEXT: v_lshlrev_b16 v9, 2, v9
+; GFX11-NEXT: v_or_b32_e32 v10, v12, v10
+; GFX11-NEXT: v_lshlrev_b16 v12, 3, s19
+; GFX11-NEXT: v_lshlrev_b16 v13, 2, v13
+; GFX11-NEXT: v_or_b32_e32 v14, v15, v14
+; GFX11-NEXT: v_lshlrev_b16 v11, 3, s31
+; GFX11-NEXT: v_lshlrev_b16 v5, 2, v5
+; GFX11-NEXT: v_and_b32_e32 v7, 3, v7
+; GFX11-NEXT: v_or_b32_e32 v8, v8, v9
+; GFX11-NEXT: v_and_b32_e32 v9, 3, v10
+; GFX11-NEXT: v_or_b32_e32 v10, v12, v13
+; GFX11-NEXT: v_and_b32_e32 v12, 3, v14
+; GFX11-NEXT: v_or_b32_e32 v5, v11, v5
+; GFX11-NEXT: v_and_b32_e32 v6, 3, v6
+; GFX11-NEXT: v_or_b32_e32 v4, v7, v4
+; GFX11-NEXT: v_or_b32_e32 v7, v9, v8
+; GFX11-NEXT: v_or_b32_e32 v8, v12, v10
+; GFX11-NEXT: v_and_b32_e32 v1, 15, v1
+; GFX11-NEXT: v_lshlrev_b16 v2, 4, v2
+; GFX11-NEXT: v_and_b32_e32 v3, 15, v3
+; GFX11-NEXT: v_or_b32_e32 v5, v6, v5
+; GFX11-NEXT: v_and_b32_e32 v4, 15, v4
+; GFX11-NEXT: v_lshlrev_b16 v6, 4, v7
+; GFX11-NEXT: v_and_b32_e32 v7, 15, v8
+; GFX11-NEXT: v_lshlrev_b16 v0, 12, v0
+; GFX11-NEXT: v_lshlrev_b16 v1, 8, v1
+; GFX11-NEXT: v_or_b32_e32 v2, v3, v2
+; GFX11-NEXT: v_lshlrev_b16 v3, 12, v5
+; GFX11-NEXT: v_lshlrev_b16 v4, 8, v4
+; GFX11-NEXT: v_or_b32_e32 v5, v7, v6
+; GFX11-NEXT: v_or_b32_e32 v0, v0, v1
+; GFX11-NEXT: v_and_b32_e32 v1, 0xff, v2
+; GFX11-NEXT: s_delay_alu instid0(VALU_DEP_4) | instskip(NEXT) | instid1(VALU_DEP_4)
+; GFX11-NEXT: v_or_b32_e32 v2, v3, v4
+; GFX11-NEXT: v_and_b32_e32 v3, 0xff, v5
+; GFX11-NEXT: s_delay_alu instid0(VALU_DEP_3) | instskip(NEXT) | instid1(VALU_DEP_2)
+; GFX11-NEXT: v_or_b32_e32 v0, v1, v0
+; GFX11-NEXT: v_or_b32_e32 v1, v3, v2
+; GFX11-NEXT: s_delay_alu instid0(VALU_DEP_2) | instskip(NEXT) | instid1(VALU_DEP_2)
+; GFX11-NEXT: v_and_b32_e32 v0, 0xffff, v0
+; GFX11-NEXT: v_lshlrev_b32_e32 v1, 16, v1
+; GFX11-NEXT: s_delay_alu instid0(VALU_DEP_1)
+; GFX11-NEXT: v_or_b32_e32 v0, v0, v1
+; GFX11-NEXT: global_store_b32 v[0:1], v0, off
+; GFX11-NEXT: s_nop 0
+; GFX11-NEXT: s_sendmsg sendmsg(MSG_DEALLOC_VGPRS)
+; GFX11-NEXT: s_endpgm
+ store <32 x i1> %arg0, ptr addrspace(1) undef
+ ret void
+}
+
+define amdgpu_cs void @amdgpu_cs_i1_sext(i1 signext %arg0) {
+; SI-LABEL: amdgpu_cs_i1_sext:
+; SI: ; %bb.0:
+; SI-NEXT: v_and_b32_e32 v0, 1, v0
+; SI-NEXT: s_mov_b32 s3, 0xf000
+; SI-NEXT: s_mov_b32 s2, -1
+; SI-NEXT: buffer_store_byte v0, off, s[0:3], 0
+; SI-NEXT: s_endpgm
+;
+; VI-LABEL: amdgpu_cs_i1_sext:
+; VI: ; %bb.0:
+; VI-NEXT: v_and_b32_e32 v0, 1, v0
+; VI-NEXT: flat_store_byte v[0:1], v0
+; VI-NEXT: s_endpgm
+;
+; GFX11-LABEL: amdgpu_cs_i1_sext:
+; GFX11: ; %bb.0:
+; GFX11-NEXT: v_and_b32_e32 v0, 1, v0
+; GFX11-NEXT: global_store_b8 v[0:1], v0, off
+; GFX11-NEXT: s_nop 0
+; GFX11-NEXT: s_sendmsg sendmsg(MSG_DEALLOC_VGPRS)
+; GFX11-NEXT: s_endpgm
+ store i1 %arg0, ptr addrspace(1) undef
+ ret void
+}
+
+define amdgpu_cs void @amdgpu_cs_i1_zext(i1 zeroext %arg0) {
+; SI-LABEL: amdgpu_cs_i1_zext:
+; SI: ; %bb.0:
+; SI-NEXT: s_mov_b32 s3, 0xf000
+; SI-NEXT: s_mov_b32 s2, -1
+; SI-NEXT: buffer_store_byte v0, off, s[0:3], 0
+; SI-NEXT: s_endpgm
+;
+; VI-LABEL: amdgpu_cs_i1_zext:
+; VI: ; %bb.0:
+; VI-NEXT: flat_store_byte v[0:1], v0
+; VI-NEXT: s_endpgm
+;
+; GFX11-LABEL: amdgpu_cs_i1_zext:
+; GFX11: ; %bb.0:
+; GFX11-NEXT: global_store_b8 v[0:1], v0, off
+; GFX11-NEXT: s_nop 0
+; GFX11-NEXT: s_sendmsg sendmsg(MSG_DEALLOC_VGPRS)
+; GFX11-NEXT: s_endpgm
+ store i1 %arg0, ptr addrspace(1) undef
+ ret void
+}
+
attributes #0 = { nounwind noinline }
>From 4a5ec3cec8316234667897d99fa4ef1b1a132c43 Mon Sep 17 00:00:00 2001
From: chuongg3 <chuong.goh at arm.com>
Date: Fri, 1 Mar 2024 08:56:34 +0000
Subject: [PATCH 221/406] Revert "[AArch64][GlobalISel] Legalize
G_SHUFFLE_VECTOR for Odd-Sized Vectors" (#83544)
Reverts llvm/llvm-project#83038 due to failing build in Fuchsia build
https://lab.llvm.org/staging/#/builders/187/builds/1695
---
.../llvm/CodeGen/GlobalISel/LegalizerInfo.h | 12 -
.../CodeGen/GlobalISel/LegalizerHelper.cpp | 1 -
.../AArch64/GISel/AArch64LegalizerInfo.cpp | 3 -
.../AArch64/GlobalISel/legalize-select.mir | 72 +++---
llvm/test/CodeGen/AArch64/shufflevector.ll | 232 ++++++------------
5 files changed, 108 insertions(+), 212 deletions(-)
diff --git a/llvm/include/llvm/CodeGen/GlobalISel/LegalizerInfo.h b/llvm/include/llvm/CodeGen/GlobalISel/LegalizerInfo.h
index 6afaea3f3fc5c6..637c2c71b02411 100644
--- a/llvm/include/llvm/CodeGen/GlobalISel/LegalizerInfo.h
+++ b/llvm/include/llvm/CodeGen/GlobalISel/LegalizerInfo.h
@@ -908,18 +908,6 @@ class LegalizeRuleSet {
LegalizeMutations::widenScalarOrEltToNextPow2(TypeIdx, MinSize));
}
- /// Widen the scalar or vector element type to the next power of two that is
- /// at least MinSize. No effect if the scalar size is a power of two.
- LegalizeRuleSet &widenScalarOrEltToNextPow2OrMinSize(unsigned TypeIdx,
- unsigned MinSize = 0) {
- using namespace LegalityPredicates;
- return actionIf(
- LegalizeAction::WidenScalar,
- any(scalarOrEltNarrowerThan(TypeIdx, MinSize),
- scalarOrEltSizeNotPow2(typeIdx(TypeIdx))),
- LegalizeMutations::widenScalarOrEltToNextPow2(TypeIdx, MinSize));
- }
-
LegalizeRuleSet &narrowScalar(unsigned TypeIdx, LegalizeMutation Mutation) {
using namespace LegalityPredicates;
return actionIf(LegalizeAction::NarrowScalar, isScalar(typeIdx(TypeIdx)),
diff --git a/llvm/lib/CodeGen/GlobalISel/LegalizerHelper.cpp b/llvm/lib/CodeGen/GlobalISel/LegalizerHelper.cpp
index 1d016e684c48f6..8079f853aef855 100644
--- a/llvm/lib/CodeGen/GlobalISel/LegalizerHelper.cpp
+++ b/llvm/lib/CodeGen/GlobalISel/LegalizerHelper.cpp
@@ -2495,7 +2495,6 @@ LegalizerHelper::widenScalar(MachineInstr &MI, unsigned TypeIdx, LLT WideTy) {
case TargetOpcode::G_OR:
case TargetOpcode::G_XOR:
case TargetOpcode::G_SUB:
- case TargetOpcode::G_SHUFFLE_VECTOR:
// Perform operation at larger width (any extension is fines here, high bits
// don't affect the result) and then truncate the result back to the
// original type.
diff --git a/llvm/lib/Target/AArch64/GISel/AArch64LegalizerInfo.cpp b/llvm/lib/Target/AArch64/GISel/AArch64LegalizerInfo.cpp
index 33f04e6ad0c763..117c4004d41df8 100644
--- a/llvm/lib/Target/AArch64/GISel/AArch64LegalizerInfo.cpp
+++ b/llvm/lib/Target/AArch64/GISel/AArch64LegalizerInfo.cpp
@@ -956,9 +956,6 @@ AArch64LegalizerInfo::AArch64LegalizerInfo(const AArch64Subtarget &ST)
},
changeTo(1, 0))
.moreElementsToNextPow2(0)
- .widenScalarOrEltToNextPow2OrMinSize(0, 8)
- .clampNumElements(0, v8s8, v16s8)
- .clampNumElements(0, v4s16, v8s16)
.clampNumElements(0, v4s32, v4s32)
.clampNumElements(0, v2s64, v2s64)
.moreElementsIf(
diff --git a/llvm/test/CodeGen/AArch64/GlobalISel/legalize-select.mir b/llvm/test/CodeGen/AArch64/GlobalISel/legalize-select.mir
index 63a26dcfea4762..4879ffd28784c1 100644
--- a/llvm/test/CodeGen/AArch64/GlobalISel/legalize-select.mir
+++ b/llvm/test/CodeGen/AArch64/GlobalISel/legalize-select.mir
@@ -287,47 +287,39 @@ body: |
; CHECK-NEXT: %q0:_(<4 x s32>) = COPY $q0
; CHECK-NEXT: %q1:_(<4 x s32>) = COPY $q1
; CHECK-NEXT: %q2:_(<4 x s32>) = COPY $q2
- ; CHECK-NEXT: [[ICMP:%[0-9]+]]:_(<4 x s32>) = G_ICMP intpred(eq), %q0(<4 x s32>), %q1
- ; CHECK-NEXT: [[ICMP1:%[0-9]+]]:_(<4 x s32>) = G_ICMP intpred(eq), %q0(<4 x s32>), %q2
+ ; CHECK-NEXT: %vec_cond0:_(<4 x s1>) = G_ICMP intpred(eq), %q0(<4 x s32>), %q1
+ ; CHECK-NEXT: %vec_cond1:_(<4 x s1>) = G_ICMP intpred(eq), %q0(<4 x s32>), %q2
; CHECK-NEXT: [[C:%[0-9]+]]:_(s32) = G_CONSTANT i32 4100
- ; CHECK-NEXT: [[ICMP2:%[0-9]+]]:_(s32) = G_ICMP intpred(eq), %w0(s32), [[C]]
- ; CHECK-NEXT: [[SEXT_INREG:%[0-9]+]]:_(s32) = G_SEXT_INREG [[ICMP2]], 1
- ; CHECK-NEXT: [[DEF:%[0-9]+]]:_(s8) = G_IMPLICIT_DEF
- ; CHECK-NEXT: [[DEF1:%[0-9]+]]:_(s16) = G_IMPLICIT_DEF
- ; CHECK-NEXT: [[COPY:%[0-9]+]]:_(s16) = COPY [[DEF1]](s16)
- ; CHECK-NEXT: [[COPY1:%[0-9]+]]:_(s16) = COPY [[DEF1]](s16)
- ; CHECK-NEXT: [[COPY2:%[0-9]+]]:_(s16) = COPY [[DEF1]](s16)
- ; CHECK-NEXT: [[BUILD_VECTOR:%[0-9]+]]:_(<4 x s16>) = G_BUILD_VECTOR [[COPY]](s16), [[COPY1]](s16), [[COPY2]](s16), [[DEF1]](s16)
- ; CHECK-NEXT: [[C1:%[0-9]+]]:_(s64) = G_CONSTANT i64 0
- ; CHECK-NEXT: [[TRUNC:%[0-9]+]]:_(s16) = G_TRUNC [[SEXT_INREG]](s32)
- ; CHECK-NEXT: [[IVEC:%[0-9]+]]:_(<4 x s16>) = G_INSERT_VECTOR_ELT [[BUILD_VECTOR]], [[TRUNC]](s16), [[C1]](s64)
- ; CHECK-NEXT: [[UV:%[0-9]+]]:_(s16), [[UV1:%[0-9]+]]:_(s16), [[UV2:%[0-9]+]]:_(s16), [[UV3:%[0-9]+]]:_(s16) = G_UNMERGE_VALUES [[IVEC]](<4 x s16>)
- ; CHECK-NEXT: [[TRUNC1:%[0-9]+]]:_(s8) = G_TRUNC [[UV]](s16)
- ; CHECK-NEXT: [[TRUNC2:%[0-9]+]]:_(s8) = G_TRUNC [[UV1]](s16)
- ; CHECK-NEXT: [[TRUNC3:%[0-9]+]]:_(s8) = G_TRUNC [[UV2]](s16)
- ; CHECK-NEXT: [[TRUNC4:%[0-9]+]]:_(s8) = G_TRUNC [[UV3]](s16)
- ; CHECK-NEXT: [[DEF2:%[0-9]+]]:_(s8) = G_IMPLICIT_DEF
- ; CHECK-NEXT: [[BUILD_VECTOR1:%[0-9]+]]:_(<8 x s8>) = G_BUILD_VECTOR [[TRUNC1]](s8), [[TRUNC2]](s8), [[TRUNC3]](s8), [[TRUNC4]](s8), [[DEF2]](s8), [[DEF2]](s8), [[DEF2]](s8), [[DEF2]](s8)
- ; CHECK-NEXT: [[BUILD_VECTOR2:%[0-9]+]]:_(<8 x s8>) = G_BUILD_VECTOR [[DEF]](s8), [[DEF]](s8), [[DEF]](s8), [[DEF]](s8), [[DEF2]](s8), [[DEF2]](s8), [[DEF2]](s8), [[DEF2]](s8)
- ; CHECK-NEXT: [[SHUF:%[0-9]+]]:_(<8 x s8>) = G_SHUFFLE_VECTOR [[BUILD_VECTOR1]](<8 x s8>), [[BUILD_VECTOR2]], shufflemask(0, 0, 0, 0, undef, undef, undef, undef)
- ; CHECK-NEXT: [[UV4:%[0-9]+]]:_(<4 x s8>), [[UV5:%[0-9]+]]:_(<4 x s8>) = G_UNMERGE_VALUES [[SHUF]](<8 x s8>)
- ; CHECK-NEXT: [[C2:%[0-9]+]]:_(s16) = G_CONSTANT i16 1
- ; CHECK-NEXT: [[COPY3:%[0-9]+]]:_(s16) = COPY [[C2]](s16)
- ; CHECK-NEXT: [[COPY4:%[0-9]+]]:_(s16) = COPY [[C2]](s16)
- ; CHECK-NEXT: [[COPY5:%[0-9]+]]:_(s16) = COPY [[C2]](s16)
- ; CHECK-NEXT: [[BUILD_VECTOR3:%[0-9]+]]:_(<4 x s16>) = G_BUILD_VECTOR [[COPY3]](s16), [[COPY4]](s16), [[COPY5]](s16), [[C2]](s16)
- ; CHECK-NEXT: [[ANYEXT:%[0-9]+]]:_(<4 x s16>) = G_ANYEXT [[UV4]](<4 x s8>)
- ; CHECK-NEXT: [[XOR:%[0-9]+]]:_(<4 x s16>) = G_XOR [[ANYEXT]], [[BUILD_VECTOR3]]
- ; CHECK-NEXT: [[TRUNC5:%[0-9]+]]:_(<4 x s16>) = G_TRUNC [[ICMP]](<4 x s32>)
- ; CHECK-NEXT: [[ANYEXT1:%[0-9]+]]:_(<4 x s16>) = G_ANYEXT [[UV4]](<4 x s8>)
- ; CHECK-NEXT: [[AND:%[0-9]+]]:_(<4 x s16>) = G_AND [[TRUNC5]], [[ANYEXT1]]
- ; CHECK-NEXT: [[TRUNC6:%[0-9]+]]:_(<4 x s16>) = G_TRUNC [[ICMP1]](<4 x s32>)
- ; CHECK-NEXT: [[AND1:%[0-9]+]]:_(<4 x s16>) = G_AND [[TRUNC6]], [[XOR]]
- ; CHECK-NEXT: [[OR:%[0-9]+]]:_(<4 x s16>) = G_OR [[AND]], [[AND1]]
- ; CHECK-NEXT: [[ANYEXT2:%[0-9]+]]:_(<4 x s32>) = G_ANYEXT [[OR]](<4 x s16>)
- ; CHECK-NEXT: [[C3:%[0-9]+]]:_(s32) = G_CONSTANT i32 1
- ; CHECK-NEXT: [[BUILD_VECTOR4:%[0-9]+]]:_(<4 x s32>) = G_BUILD_VECTOR [[C3]](s32), [[C3]](s32), [[C3]](s32), [[C3]](s32)
- ; CHECK-NEXT: %zext_select:_(<4 x s32>) = G_AND [[ANYEXT2]], [[BUILD_VECTOR4]]
+ ; CHECK-NEXT: [[C1:%[0-9]+]]:_(s32) = G_FCONSTANT float 0.000000e+00
+ ; CHECK-NEXT: [[BUILD_VECTOR:%[0-9]+]]:_(<4 x s32>) = G_BUILD_VECTOR [[C1]](s32), [[C1]](s32), [[C1]](s32), [[C1]](s32)
+ ; CHECK-NEXT: %cmp:_(s1) = G_ICMP intpred(eq), %w0(s32), [[C]]
+ ; CHECK-NEXT: [[ZEXT:%[0-9]+]]:_(s32) = G_ZEXT %cmp(s1)
+ ; CHECK-NEXT: [[SEXT_INREG:%[0-9]+]]:_(s32) = G_SEXT_INREG [[ZEXT]], 1
+ ; CHECK-NEXT: [[TRUNC:%[0-9]+]]:_(s1) = G_TRUNC [[SEXT_INREG]](s32)
+ ; CHECK-NEXT: [[DEF:%[0-9]+]]:_(<4 x s1>) = G_IMPLICIT_DEF
+ ; CHECK-NEXT: [[C2:%[0-9]+]]:_(s64) = G_CONSTANT i64 0
+ ; CHECK-NEXT: [[IVEC:%[0-9]+]]:_(<4 x s1>) = G_INSERT_VECTOR_ELT [[DEF]], [[TRUNC]](s1), [[C2]](s64)
+ ; CHECK-NEXT: [[SHUF:%[0-9]+]]:_(<4 x s1>) = G_SHUFFLE_VECTOR [[IVEC]](<4 x s1>), [[DEF]], shufflemask(0, 0, 0, 0)
+ ; CHECK-NEXT: [[C3:%[0-9]+]]:_(s8) = G_CONSTANT i8 1
+ ; CHECK-NEXT: [[TRUNC1:%[0-9]+]]:_(s1) = G_TRUNC [[C3]](s8)
+ ; CHECK-NEXT: [[BUILD_VECTOR1:%[0-9]+]]:_(<4 x s1>) = G_BUILD_VECTOR [[TRUNC1]](s1), [[TRUNC1]](s1), [[TRUNC1]](s1), [[TRUNC1]](s1)
+ ; CHECK-NEXT: [[ANYEXT:%[0-9]+]]:_(<4 x s16>) = G_ANYEXT [[SHUF]](<4 x s1>)
+ ; CHECK-NEXT: [[ANYEXT1:%[0-9]+]]:_(<4 x s16>) = G_ANYEXT [[BUILD_VECTOR1]](<4 x s1>)
+ ; CHECK-NEXT: [[XOR:%[0-9]+]]:_(<4 x s16>) = G_XOR [[ANYEXT]], [[ANYEXT1]]
+ ; CHECK-NEXT: [[TRUNC2:%[0-9]+]]:_(<4 x s1>) = G_TRUNC [[XOR]](<4 x s16>)
+ ; CHECK-NEXT: [[ANYEXT2:%[0-9]+]]:_(<4 x s16>) = G_ANYEXT %vec_cond0(<4 x s1>)
+ ; CHECK-NEXT: [[ANYEXT3:%[0-9]+]]:_(<4 x s16>) = G_ANYEXT [[SHUF]](<4 x s1>)
+ ; CHECK-NEXT: [[AND:%[0-9]+]]:_(<4 x s16>) = G_AND [[ANYEXT2]], [[ANYEXT3]]
+ ; CHECK-NEXT: [[TRUNC3:%[0-9]+]]:_(<4 x s1>) = G_TRUNC [[AND]](<4 x s16>)
+ ; CHECK-NEXT: [[ANYEXT4:%[0-9]+]]:_(<4 x s16>) = G_ANYEXT %vec_cond1(<4 x s1>)
+ ; CHECK-NEXT: [[ANYEXT5:%[0-9]+]]:_(<4 x s16>) = G_ANYEXT [[TRUNC2]](<4 x s1>)
+ ; CHECK-NEXT: [[AND1:%[0-9]+]]:_(<4 x s16>) = G_AND [[ANYEXT4]], [[ANYEXT5]]
+ ; CHECK-NEXT: [[TRUNC4:%[0-9]+]]:_(<4 x s1>) = G_TRUNC [[AND1]](<4 x s16>)
+ ; CHECK-NEXT: [[ANYEXT6:%[0-9]+]]:_(<4 x s16>) = G_ANYEXT [[TRUNC3]](<4 x s1>)
+ ; CHECK-NEXT: [[ANYEXT7:%[0-9]+]]:_(<4 x s16>) = G_ANYEXT [[TRUNC4]](<4 x s1>)
+ ; CHECK-NEXT: [[OR:%[0-9]+]]:_(<4 x s16>) = G_OR [[ANYEXT6]], [[ANYEXT7]]
+ ; CHECK-NEXT: %select:_(<4 x s1>) = G_TRUNC [[OR]](<4 x s16>)
+ ; CHECK-NEXT: %zext_select:_(<4 x s32>) = G_ZEXT %select(<4 x s1>)
; CHECK-NEXT: $q0 = COPY %zext_select(<4 x s32>)
; CHECK-NEXT: RET_ReallyLR implicit $q0
%w0:_(s32) = COPY $w0
diff --git a/llvm/test/CodeGen/AArch64/shufflevector.ll b/llvm/test/CodeGen/AArch64/shufflevector.ll
index 5638347ee63340..df59eb8e629f44 100644
--- a/llvm/test/CodeGen/AArch64/shufflevector.ll
+++ b/llvm/test/CodeGen/AArch64/shufflevector.ll
@@ -3,7 +3,15 @@
; RUN: llc -mtriple=aarch64-none-linux-gnu -global-isel -global-isel-abort=2 %s -o - 2>&1 | FileCheck %s --check-prefixes=CHECK,CHECK-GI
; CHECK-GI: warning: Instruction selection used fallback path for shufflevector_v2i1
+; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v4i8
+; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v32i8
+; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v2i16
+; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v16i16
; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v2i1_zeroes
+; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v4i8_zeroes
+; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v32i8_zeroes
+; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v2i16_zeroes
+; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v16i16_zeroes
; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v3i8
; CHECK-GI-NEXT: warning: Instruction selection used fallback path for shufflevector_v3i8_zeroes
@@ -197,142 +205,68 @@ define <2 x i1> @shufflevector_v2i1(<2 x i1> %a, <2 x i1> %b){
}
define i32 @shufflevector_v4i8(<4 x i8> %a, <4 x i8> %b){
-; CHECK-SD-LABEL: shufflevector_v4i8:
-; CHECK-SD: // %bb.0:
-; CHECK-SD-NEXT: sub sp, sp, #16
-; CHECK-SD-NEXT: .cfi_def_cfa_offset 16
-; CHECK-SD-NEXT: ext v0.8b, v1.8b, v0.8b, #6
-; CHECK-SD-NEXT: zip1 v1.4h, v1.4h, v0.4h
-; CHECK-SD-NEXT: ext v0.8b, v0.8b, v1.8b, #4
-; CHECK-SD-NEXT: xtn v0.8b, v0.8h
-; CHECK-SD-NEXT: fmov w0, s0
-; CHECK-SD-NEXT: add sp, sp, #16
-; CHECK-SD-NEXT: ret
-;
-; CHECK-GI-LABEL: shufflevector_v4i8:
-; CHECK-GI: // %bb.0:
-; CHECK-GI-NEXT: // kill: def $d0 killed $d0 def $q0
-; CHECK-GI-NEXT: mov h2, v0.h[1]
-; CHECK-GI-NEXT: // kill: def $d1 killed $d1 def $q1
-; CHECK-GI-NEXT: mov h3, v1.h[1]
-; CHECK-GI-NEXT: adrp x8, .LCPI15_0
-; CHECK-GI-NEXT: mov h4, v0.h[2]
-; CHECK-GI-NEXT: mov h5, v0.h[3]
-; CHECK-GI-NEXT: mov h6, v1.h[3]
-; CHECK-GI-NEXT: mov v0.b[1], v2.b[0]
-; CHECK-GI-NEXT: mov h2, v1.h[2]
-; CHECK-GI-NEXT: mov v1.b[1], v3.b[0]
-; CHECK-GI-NEXT: mov v0.b[2], v4.b[0]
-; CHECK-GI-NEXT: mov v1.b[2], v2.b[0]
-; CHECK-GI-NEXT: mov v0.b[3], v5.b[0]
-; CHECK-GI-NEXT: mov v1.b[3], v6.b[0]
-; CHECK-GI-NEXT: mov v0.b[4], v0.b[0]
-; CHECK-GI-NEXT: mov v1.b[4], v0.b[0]
-; CHECK-GI-NEXT: mov v0.b[5], v0.b[0]
-; CHECK-GI-NEXT: mov v1.b[5], v0.b[0]
-; CHECK-GI-NEXT: mov v0.b[6], v0.b[0]
-; CHECK-GI-NEXT: mov v1.b[6], v0.b[0]
-; CHECK-GI-NEXT: mov v0.b[7], v0.b[0]
-; CHECK-GI-NEXT: mov v1.b[7], v0.b[0]
-; CHECK-GI-NEXT: mov v0.d[1], v1.d[0]
-; CHECK-GI-NEXT: ldr d1, [x8, :lo12:.LCPI15_0]
-; CHECK-GI-NEXT: tbl v0.16b, { v0.16b }, v1.16b
-; CHECK-GI-NEXT: fmov w0, s0
-; CHECK-GI-NEXT: ret
+; CHECK-LABEL: shufflevector_v4i8:
+; CHECK: // %bb.0:
+; CHECK-NEXT: sub sp, sp, #16
+; CHECK-NEXT: .cfi_def_cfa_offset 16
+; CHECK-NEXT: ext v0.8b, v1.8b, v0.8b, #6
+; CHECK-NEXT: zip1 v1.4h, v1.4h, v0.4h
+; CHECK-NEXT: ext v0.8b, v0.8b, v1.8b, #4
+; CHECK-NEXT: xtn v0.8b, v0.8h
+; CHECK-NEXT: fmov w0, s0
+; CHECK-NEXT: add sp, sp, #16
+; CHECK-NEXT: ret
%c = shufflevector <4 x i8> %a, <4 x i8> %b, <4 x i32> <i32 1, i32 2, i32 4, i32 7>
%d = bitcast <4 x i8> %c to i32
ret i32 %d
}
define <32 x i8> @shufflevector_v32i8(<32 x i8> %a, <32 x i8> %b){
-; CHECK-SD-LABEL: shufflevector_v32i8:
-; CHECK-SD: // %bb.0:
-; CHECK-SD-NEXT: // kill: def $q2 killed $q2 def $q1_q2
-; CHECK-SD-NEXT: adrp x8, .LCPI16_0
-; CHECK-SD-NEXT: adrp x9, .LCPI16_1
-; CHECK-SD-NEXT: mov v1.16b, v0.16b
-; CHECK-SD-NEXT: ldr q3, [x8, :lo12:.LCPI16_0]
-; CHECK-SD-NEXT: ldr q4, [x9, :lo12:.LCPI16_1]
-; CHECK-SD-NEXT: tbl v0.16b, { v1.16b, v2.16b }, v3.16b
-; CHECK-SD-NEXT: tbl v1.16b, { v1.16b, v2.16b }, v4.16b
-; CHECK-SD-NEXT: ret
-;
-; CHECK-GI-LABEL: shufflevector_v32i8:
-; CHECK-GI: // %bb.0:
-; CHECK-GI-NEXT: mov v3.16b, v0.16b
-; CHECK-GI-NEXT: adrp x8, .LCPI16_1
-; CHECK-GI-NEXT: adrp x9, .LCPI16_0
-; CHECK-GI-NEXT: mov v4.16b, v2.16b
-; CHECK-GI-NEXT: ldr q0, [x8, :lo12:.LCPI16_1]
-; CHECK-GI-NEXT: ldr q1, [x9, :lo12:.LCPI16_0]
-; CHECK-GI-NEXT: tbl v0.16b, { v3.16b, v4.16b }, v0.16b
-; CHECK-GI-NEXT: tbl v1.16b, { v3.16b, v4.16b }, v1.16b
-; CHECK-GI-NEXT: ret
+; CHECK-LABEL: shufflevector_v32i8:
+; CHECK: // %bb.0:
+; CHECK-NEXT: // kill: def $q2 killed $q2 def $q1_q2
+; CHECK-NEXT: adrp x8, .LCPI16_0
+; CHECK-NEXT: adrp x9, .LCPI16_1
+; CHECK-NEXT: mov v1.16b, v0.16b
+; CHECK-NEXT: ldr q3, [x8, :lo12:.LCPI16_0]
+; CHECK-NEXT: ldr q4, [x9, :lo12:.LCPI16_1]
+; CHECK-NEXT: tbl v0.16b, { v1.16b, v2.16b }, v3.16b
+; CHECK-NEXT: tbl v1.16b, { v1.16b, v2.16b }, v4.16b
+; CHECK-NEXT: ret
%c = shufflevector <32 x i8> %a, <32 x i8> %b, <32 x i32> <i32 0, i32 32, i32 32, i32 32, i32 1, i32 32, i32 32, i32 32, i32 2, i32 32, i32 32, i32 32, i32 3, i32 32, i32 32, i32 32, i32 4, i32 32, i32 32, i32 32, i32 5, i32 32, i32 32, i32 32, i32 6, i32 32, i32 32, i32 32, i32 7, i32 32, i32 32, i32 32>
ret <32 x i8> %c
}
define i32 @shufflevector_v2i16(<2 x i16> %a, <2 x i16> %b){
-; CHECK-SD-LABEL: shufflevector_v2i16:
-; CHECK-SD: // %bb.0:
-; CHECK-SD-NEXT: sub sp, sp, #16
-; CHECK-SD-NEXT: .cfi_def_cfa_offset 16
-; CHECK-SD-NEXT: ext v0.8b, v0.8b, v1.8b, #4
-; CHECK-SD-NEXT: mov w8, v0.s[1]
-; CHECK-SD-NEXT: fmov w9, s0
-; CHECK-SD-NEXT: strh w9, [sp, #12]
-; CHECK-SD-NEXT: strh w8, [sp, #14]
-; CHECK-SD-NEXT: ldr w0, [sp, #12]
-; CHECK-SD-NEXT: add sp, sp, #16
-; CHECK-SD-NEXT: ret
-;
-; CHECK-GI-LABEL: shufflevector_v2i16:
-; CHECK-GI: // %bb.0:
-; CHECK-GI-NEXT: // kill: def $d0 killed $d0 def $q0
-; CHECK-GI-NEXT: mov s2, v0.s[1]
-; CHECK-GI-NEXT: // kill: def $d1 killed $d1 def $q1
-; CHECK-GI-NEXT: mov s3, v1.s[1]
-; CHECK-GI-NEXT: adrp x8, .LCPI17_0
-; CHECK-GI-NEXT: mov v0.h[1], v2.h[0]
-; CHECK-GI-NEXT: mov v1.h[1], v3.h[0]
-; CHECK-GI-NEXT: mov v0.h[2], v0.h[0]
-; CHECK-GI-NEXT: mov v1.h[2], v0.h[0]
-; CHECK-GI-NEXT: mov v0.h[3], v0.h[0]
-; CHECK-GI-NEXT: mov v1.h[3], v0.h[0]
-; CHECK-GI-NEXT: mov v0.d[1], v1.d[0]
-; CHECK-GI-NEXT: ldr d1, [x8, :lo12:.LCPI17_0]
-; CHECK-GI-NEXT: tbl v0.16b, { v0.16b }, v1.16b
-; CHECK-GI-NEXT: fmov w0, s0
-; CHECK-GI-NEXT: ret
+; CHECK-LABEL: shufflevector_v2i16:
+; CHECK: // %bb.0:
+; CHECK-NEXT: sub sp, sp, #16
+; CHECK-NEXT: .cfi_def_cfa_offset 16
+; CHECK-NEXT: ext v0.8b, v0.8b, v1.8b, #4
+; CHECK-NEXT: mov w8, v0.s[1]
+; CHECK-NEXT: fmov w9, s0
+; CHECK-NEXT: strh w9, [sp, #12]
+; CHECK-NEXT: strh w8, [sp, #14]
+; CHECK-NEXT: ldr w0, [sp, #12]
+; CHECK-NEXT: add sp, sp, #16
+; CHECK-NEXT: ret
%c = shufflevector <2 x i16> %a, <2 x i16> %b, <2 x i32> <i32 1, i32 2>
%d = bitcast <2 x i16> %c to i32
ret i32 %d
}
define <16 x i16> @shufflevector_v16i16(<16 x i16> %a, <16 x i16> %b){
-; CHECK-SD-LABEL: shufflevector_v16i16:
-; CHECK-SD: // %bb.0:
-; CHECK-SD-NEXT: // kill: def $q2 killed $q2 def $q1_q2
-; CHECK-SD-NEXT: adrp x8, .LCPI18_0
-; CHECK-SD-NEXT: adrp x9, .LCPI18_1
-; CHECK-SD-NEXT: mov v1.16b, v0.16b
-; CHECK-SD-NEXT: ldr q3, [x8, :lo12:.LCPI18_0]
-; CHECK-SD-NEXT: ldr q4, [x9, :lo12:.LCPI18_1]
-; CHECK-SD-NEXT: tbl v0.16b, { v1.16b, v2.16b }, v3.16b
-; CHECK-SD-NEXT: tbl v1.16b, { v1.16b, v2.16b }, v4.16b
-; CHECK-SD-NEXT: ret
-;
-; CHECK-GI-LABEL: shufflevector_v16i16:
-; CHECK-GI: // %bb.0:
-; CHECK-GI-NEXT: mov v3.16b, v0.16b
-; CHECK-GI-NEXT: adrp x8, .LCPI18_1
-; CHECK-GI-NEXT: adrp x9, .LCPI18_0
-; CHECK-GI-NEXT: mov v4.16b, v2.16b
-; CHECK-GI-NEXT: ldr q0, [x8, :lo12:.LCPI18_1]
-; CHECK-GI-NEXT: ldr q1, [x9, :lo12:.LCPI18_0]
-; CHECK-GI-NEXT: tbl v0.16b, { v3.16b, v4.16b }, v0.16b
-; CHECK-GI-NEXT: tbl v1.16b, { v3.16b, v4.16b }, v1.16b
-; CHECK-GI-NEXT: ret
+; CHECK-LABEL: shufflevector_v16i16:
+; CHECK: // %bb.0:
+; CHECK-NEXT: // kill: def $q2 killed $q2 def $q1_q2
+; CHECK-NEXT: adrp x8, .LCPI18_0
+; CHECK-NEXT: adrp x9, .LCPI18_1
+; CHECK-NEXT: mov v1.16b, v0.16b
+; CHECK-NEXT: ldr q3, [x8, :lo12:.LCPI18_0]
+; CHECK-NEXT: ldr q4, [x9, :lo12:.LCPI18_1]
+; CHECK-NEXT: tbl v0.16b, { v1.16b, v2.16b }, v3.16b
+; CHECK-NEXT: tbl v1.16b, { v1.16b, v2.16b }, v4.16b
+; CHECK-NEXT: ret
%c = shufflevector <16 x i16> %a, <16 x i16> %b, <16 x i32> <i32 0, i32 16, i32 16, i32 16, i32 1, i32 16, i32 16, i32 16, i32 1, i32 16, i32 16, i32 16, i32 3, i32 16, i32 16, i32 16>
ret <16 x i16> %c
}
@@ -398,23 +332,16 @@ define <2 x i1> @shufflevector_v2i1_zeroes(<2 x i1> %a, <2 x i1> %b){
}
define i32 @shufflevector_v4i8_zeroes(<4 x i8> %a, <4 x i8> %b){
-; CHECK-SD-LABEL: shufflevector_v4i8_zeroes:
-; CHECK-SD: // %bb.0:
-; CHECK-SD-NEXT: sub sp, sp, #16
-; CHECK-SD-NEXT: .cfi_def_cfa_offset 16
-; CHECK-SD-NEXT: // kill: def $d0 killed $d0 def $q0
-; CHECK-SD-NEXT: dup v0.4h, v0.h[0]
-; CHECK-SD-NEXT: xtn v0.8b, v0.8h
-; CHECK-SD-NEXT: fmov w0, s0
-; CHECK-SD-NEXT: add sp, sp, #16
-; CHECK-SD-NEXT: ret
-;
-; CHECK-GI-LABEL: shufflevector_v4i8_zeroes:
-; CHECK-GI: // %bb.0:
-; CHECK-GI-NEXT: fmov w8, s0
-; CHECK-GI-NEXT: dup v0.8b, w8
-; CHECK-GI-NEXT: fmov w0, s0
-; CHECK-GI-NEXT: ret
+; CHECK-LABEL: shufflevector_v4i8_zeroes:
+; CHECK: // %bb.0:
+; CHECK-NEXT: sub sp, sp, #16
+; CHECK-NEXT: .cfi_def_cfa_offset 16
+; CHECK-NEXT: // kill: def $d0 killed $d0 def $q0
+; CHECK-NEXT: dup v0.4h, v0.h[0]
+; CHECK-NEXT: xtn v0.8b, v0.8h
+; CHECK-NEXT: fmov w0, s0
+; CHECK-NEXT: add sp, sp, #16
+; CHECK-NEXT: ret
%c = shufflevector <4 x i8> %a, <4 x i8> %b, <4 x i32> <i32 0, i32 0, i32 0, i32 0>
%d = bitcast <4 x i8> %c to i32
ret i32 %d
@@ -431,26 +358,19 @@ define <32 x i8> @shufflevector_v32i8_zeroes(<32 x i8> %a, <32 x i8> %b){
}
define i32 @shufflevector_v2i16_zeroes(<2 x i16> %a, <2 x i16> %b){
-; CHECK-SD-LABEL: shufflevector_v2i16_zeroes:
-; CHECK-SD: // %bb.0:
-; CHECK-SD-NEXT: sub sp, sp, #16
-; CHECK-SD-NEXT: .cfi_def_cfa_offset 16
-; CHECK-SD-NEXT: // kill: def $d0 killed $d0 def $q0
-; CHECK-SD-NEXT: dup v1.2s, v0.s[0]
-; CHECK-SD-NEXT: fmov w9, s0
-; CHECK-SD-NEXT: strh w9, [sp, #12]
-; CHECK-SD-NEXT: mov w8, v1.s[1]
-; CHECK-SD-NEXT: strh w8, [sp, #14]
-; CHECK-SD-NEXT: ldr w0, [sp, #12]
-; CHECK-SD-NEXT: add sp, sp, #16
-; CHECK-SD-NEXT: ret
-;
-; CHECK-GI-LABEL: shufflevector_v2i16_zeroes:
-; CHECK-GI: // %bb.0:
-; CHECK-GI-NEXT: fmov w8, s0
-; CHECK-GI-NEXT: dup v0.4h, w8
-; CHECK-GI-NEXT: fmov w0, s0
-; CHECK-GI-NEXT: ret
+; CHECK-LABEL: shufflevector_v2i16_zeroes:
+; CHECK: // %bb.0:
+; CHECK-NEXT: sub sp, sp, #16
+; CHECK-NEXT: .cfi_def_cfa_offset 16
+; CHECK-NEXT: // kill: def $d0 killed $d0 def $q0
+; CHECK-NEXT: dup v1.2s, v0.s[0]
+; CHECK-NEXT: fmov w9, s0
+; CHECK-NEXT: strh w9, [sp, #12]
+; CHECK-NEXT: mov w8, v1.s[1]
+; CHECK-NEXT: strh w8, [sp, #14]
+; CHECK-NEXT: ldr w0, [sp, #12]
+; CHECK-NEXT: add sp, sp, #16
+; CHECK-NEXT: ret
%c = shufflevector <2 x i16> %a, <2 x i16> %b, <2 x i32> <i32 0, i32 0>
%d = bitcast <2 x i16> %c to i32
ret i32 %d
>From b051277d5ed8b22fce558272bf3bbbafb95245a5 Mon Sep 17 00:00:00 2001
From: Pravin Jagtap <prjagtap at amd.com>
Date: Fri, 1 Mar 2024 14:37:13 +0530
Subject: [PATCH 222/406] Add llvm_v6i32_ty. NFC. (#83522)
Authored-by: Pravin Jagtap <Pravin.Jagtap at amd.com>
---
llvm/include/llvm/IR/Intrinsics.td | 1 +
1 file changed, 1 insertion(+)
diff --git a/llvm/include/llvm/IR/Intrinsics.td b/llvm/include/llvm/IR/Intrinsics.td
index 0f13d25eb30ebf..0d33e374af7896 100644
--- a/llvm/include/llvm/IR/Intrinsics.td
+++ b/llvm/include/llvm/IR/Intrinsics.td
@@ -535,6 +535,7 @@ def llvm_v1i32_ty : LLVMType<v1i32>; // 1 x i32
def llvm_v2i32_ty : LLVMType<v2i32>; // 2 x i32
def llvm_v3i32_ty : LLVMType<v3i32>; // 3 x i32
def llvm_v4i32_ty : LLVMType<v4i32>; // 4 x i32
+def llvm_v6i32_ty : LLVMType<v6i32>; // 6 x i32
def llvm_v8i32_ty : LLVMType<v8i32>; // 8 x i32
def llvm_v16i32_ty : LLVMType<v16i32>; // 16 x i32
def llvm_v32i32_ty : LLVMType<v32i32>; // 32 x i32
>From e81ef463f10851bfbcd56a4f3450821f1e7c862f Mon Sep 17 00:00:00 2001
From: Alexandros Lamprineas <alexandros.lamprineas at arm.com>
Date: Fri, 1 Mar 2024 09:10:06 +0000
Subject: [PATCH 223/406] [FMV] Use lexicographic order of feature names when
mangling. (#83464)
This decouples feature priorities from name mangling. Doing so will
prevent ABI breakages in case we change the feature priorities.
Formalized in ACLE here: https://github.com/ARM-software/acle/pull/303.
---
clang/lib/CodeGen/Targets/AArch64.cpp | 6 +-
.../test/CodeGen/attr-target-clones-aarch64.c | 20 ++---
clang/test/CodeGen/attr-target-version.c | 52 ++++++-------
.../CodeGenCXX/attr-target-clones-aarch64.cpp | 74 +++++++++++++++----
clang/test/CodeGenCXX/attr-target-version.cpp | 4 +-
5 files changed, 99 insertions(+), 57 deletions(-)
diff --git a/clang/lib/CodeGen/Targets/AArch64.cpp b/clang/lib/CodeGen/Targets/AArch64.cpp
index 2b8e2aeb4265f3..79a9c1d5978a14 100644
--- a/clang/lib/CodeGen/Targets/AArch64.cpp
+++ b/clang/lib/CodeGen/Targets/AArch64.cpp
@@ -882,13 +882,9 @@ void AArch64ABIInfo::appendAttributeMangling(StringRef AttrStr,
for (auto &Feat : Features)
Feat = Feat.trim();
- // FIXME: It was brought up in #79316 that sorting the features which are
- // used for mangling based on their multiversion priority is not a good
- // practice. Changing the feature priorities will break the ABI. Perhaps
- // it would be preferable to perform a lexicographical sort instead.
const TargetInfo &TI = CGT.getTarget();
llvm::sort(Features, [&TI](const StringRef LHS, const StringRef RHS) {
- return TI.multiVersionSortPriority(LHS) < TI.multiVersionSortPriority(RHS);
+ return LHS.compare(RHS) < 0;
});
for (auto &Feat : Features)
diff --git a/clang/test/CodeGen/attr-target-clones-aarch64.c b/clang/test/CodeGen/attr-target-clones-aarch64.c
index 5ea3f4a9b0b112..276a7b87b7a1b4 100644
--- a/clang/test/CodeGen/attr-target-clones-aarch64.c
+++ b/clang/test/CodeGen/attr-target-clones-aarch64.c
@@ -43,7 +43,7 @@ inline int __attribute__((target_clones("fp16", "sve2-bitperm+fcma", "default"))
// CHECK: @ftc_inline3 = weak_odr ifunc i32 (), ptr @ftc_inline3.resolver
//.
// CHECK: Function Attrs: noinline nounwind optnone
-// CHECK-LABEL: @ftc._MlseMaes(
+// CHECK-LABEL: @ftc._MaesMlse(
// CHECK-NEXT: entry:
// CHECK-NEXT: ret i32 0
//
@@ -69,7 +69,7 @@ inline int __attribute__((target_clones("fp16", "sve2-bitperm+fcma", "default"))
// CHECK-NEXT: [[TMP3:%.*]] = and i1 true, [[TMP2]]
// CHECK-NEXT: br i1 [[TMP3]], label [[RESOLVER_RETURN:%.*]], label [[RESOLVER_ELSE:%.*]]
// CHECK: resolver_return:
-// CHECK-NEXT: ret ptr @ftc._MlseMaes
+// CHECK-NEXT: ret ptr @ftc._MaesMlse
// CHECK: resolver_else:
// CHECK-NEXT: [[TMP4:%.*]] = load i64, ptr @__aarch64_cpu_features, align 8
// CHECK-NEXT: [[TMP5:%.*]] = and i64 [[TMP4]], 68719476736
@@ -89,7 +89,7 @@ inline int __attribute__((target_clones("fp16", "sve2-bitperm+fcma", "default"))
//
//
// CHECK: Function Attrs: noinline nounwind optnone
-// CHECK-LABEL: @ftc_def._Msha2Mmemtag2(
+// CHECK-LABEL: @ftc_def._Mmemtag2Msha2(
// CHECK-NEXT: entry:
// CHECK-NEXT: ret i32 1
//
@@ -109,7 +109,7 @@ inline int __attribute__((target_clones("fp16", "sve2-bitperm+fcma", "default"))
// CHECK-NEXT: [[TMP3:%.*]] = and i1 true, [[TMP2]]
// CHECK-NEXT: br i1 [[TMP3]], label [[RESOLVER_RETURN:%.*]], label [[RESOLVER_ELSE:%.*]]
// CHECK: resolver_return:
-// CHECK-NEXT: ret ptr @ftc_def._Msha2Mmemtag2
+// CHECK-NEXT: ret ptr @ftc_def._Mmemtag2Msha2
// CHECK: resolver_else:
// CHECK-NEXT: [[TMP4:%.*]] = load i64, ptr @__aarch64_cpu_features, align 8
// CHECK-NEXT: [[TMP5:%.*]] = and i64 [[TMP4]], 4096
@@ -155,7 +155,7 @@ inline int __attribute__((target_clones("fp16", "sve2-bitperm+fcma", "default"))
//
//
// CHECK: Function Attrs: noinline nounwind optnone
-// CHECK-LABEL: @ftc_dup2._MdotprodMcrc(
+// CHECK-LABEL: @ftc_dup2._McrcMdotprod(
// CHECK-NEXT: entry:
// CHECK-NEXT: ret i32 3
//
@@ -175,7 +175,7 @@ inline int __attribute__((target_clones("fp16", "sve2-bitperm+fcma", "default"))
// CHECK-NEXT: [[TMP3:%.*]] = and i1 true, [[TMP2]]
// CHECK-NEXT: br i1 [[TMP3]], label [[RESOLVER_RETURN:%.*]], label [[RESOLVER_ELSE:%.*]]
// CHECK: resolver_return:
-// CHECK-NEXT: ret ptr @ftc_dup2._MdotprodMcrc
+// CHECK-NEXT: ret ptr @ftc_dup2._McrcMdotprod
// CHECK: resolver_else:
// CHECK-NEXT: [[TMP4:%.*]] = load i64, ptr @__aarch64_cpu_features, align 8
// CHECK-NEXT: [[TMP5:%.*]] = and i64 [[TMP4]], 256
@@ -239,7 +239,7 @@ inline int __attribute__((target_clones("fp16", "sve2-bitperm+fcma", "default"))
// CHECK-NEXT: [[TMP7:%.*]] = and i1 true, [[TMP6]]
// CHECK-NEXT: br i1 [[TMP7]], label [[RESOLVER_RETURN1:%.*]], label [[RESOLVER_ELSE2:%.*]]
// CHECK: resolver_return1:
-// CHECK-NEXT: ret ptr @ftc_inline1._MrcpcMpredres
+// CHECK-NEXT: ret ptr @ftc_inline1._MpredresMrcpc
// CHECK: resolver_else2:
// CHECK-NEXT: [[TMP8:%.*]] = load i64, ptr @__aarch64_cpu_features, align 8
// CHECK-NEXT: [[TMP9:%.*]] = and i64 [[TMP8]], 513
@@ -283,7 +283,7 @@ inline int __attribute__((target_clones("fp16", "sve2-bitperm+fcma", "default"))
// CHECK-NEXT: [[TMP3:%.*]] = and i1 true, [[TMP2]]
// CHECK-NEXT: br i1 [[TMP3]], label [[RESOLVER_RETURN:%.*]], label [[RESOLVER_ELSE:%.*]]
// CHECK: resolver_return:
-// CHECK-NEXT: ret ptr @ftc_inline3._MsveMsb
+// CHECK-NEXT: ret ptr @ftc_inline3._MsbMsve
// CHECK: resolver_else:
// CHECK-NEXT: [[TMP4:%.*]] = load i64, ptr @__aarch64_cpu_features, align 8
// CHECK-NEXT: [[TMP5:%.*]] = and i64 [[TMP4]], 1125899906842624
@@ -303,7 +303,7 @@ inline int __attribute__((target_clones("fp16", "sve2-bitperm+fcma", "default"))
//
//
// CHECK: Function Attrs: noinline nounwind optnone
-// CHECK-LABEL: @ftc_inline1._MrcpcMpredres(
+// CHECK-LABEL: @ftc_inline1._MpredresMrcpc(
// CHECK-NEXT: entry:
// CHECK-NEXT: ret i32 1
//
@@ -345,7 +345,7 @@ inline int __attribute__((target_clones("fp16", "sve2-bitperm+fcma", "default"))
//
//
// CHECK: Function Attrs: noinline nounwind optnone
-// CHECK-LABEL: @ftc_inline3._MsveMsb(
+// CHECK-LABEL: @ftc_inline3._MsbMsve(
// CHECK-NEXT: entry:
// CHECK-NEXT: ret i32 3
//
diff --git a/clang/test/CodeGen/attr-target-version.c b/clang/test/CodeGen/attr-target-version.c
index c27d48f3ecf681..ae97977a9144f6 100644
--- a/clang/test/CodeGen/attr-target-version.c
+++ b/clang/test/CodeGen/attr-target-version.c
@@ -106,14 +106,14 @@ int hoo(void) {
// CHECK: @fmv_c = weak_odr ifunc void (), ptr @fmv_c.resolver
//.
// CHECK: Function Attrs: noinline nounwind optnone
-// CHECK-LABEL: define {{[^@]+}}@fmv._MrngMflagmMfp16fml
+// CHECK-LABEL: define {{[^@]+}}@fmv._MflagmMfp16fmlMrng
// CHECK-SAME: () #[[ATTR0:[0-9]+]] {
// CHECK-NEXT: entry:
// CHECK-NEXT: ret i32 1
//
//
// CHECK: Function Attrs: noinline nounwind optnone
-// CHECK-LABEL: define {{[^@]+}}@fmv_one._MsimdMls64
+// CHECK-LABEL: define {{[^@]+}}@fmv_one._Mls64Msimd
// CHECK-SAME: () #[[ATTR1:[0-9]+]] {
// CHECK-NEXT: entry:
// CHECK-NEXT: ret i32 1
@@ -147,7 +147,7 @@ int hoo(void) {
// CHECK-NEXT: [[TMP3:%.*]] = and i1 true, [[TMP2]]
// CHECK-NEXT: br i1 [[TMP3]], label [[RESOLVER_RETURN:%.*]], label [[RESOLVER_ELSE:%.*]]
// CHECK: resolver_return:
-// CHECK-NEXT: ret ptr @fmv._MrngMflagmMfp16fml
+// CHECK-NEXT: ret ptr @fmv._MflagmMfp16fmlMrng
// CHECK: resolver_else:
// CHECK-NEXT: [[TMP4:%.*]] = load i64, ptr @__aarch64_cpu_features, align 8
// CHECK-NEXT: [[TMP5:%.*]] = and i64 [[TMP4]], 72057594037927940
@@ -187,7 +187,7 @@ int hoo(void) {
// CHECK-NEXT: [[TMP23:%.*]] = and i1 true, [[TMP22]]
// CHECK-NEXT: br i1 [[TMP23]], label [[RESOLVER_RETURN9:%.*]], label [[RESOLVER_ELSE10:%.*]]
// CHECK: resolver_return9:
-// CHECK-NEXT: ret ptr @fmv._MfpMaes
+// CHECK-NEXT: ret ptr @fmv._MaesMfp
// CHECK: resolver_else10:
// CHECK-NEXT: [[TMP24:%.*]] = load i64, ptr @__aarch64_cpu_features, align 8
// CHECK-NEXT: [[TMP25:%.*]] = and i64 [[TMP24]], 4224
@@ -218,12 +218,12 @@ int hoo(void) {
//
// CHECK-LABEL: define {{[^@]+}}@fmv_one.resolver() comdat {
// CHECK-NEXT: resolver_entry:
-// CHECK-NEXT: ret ptr @fmv_one._MsimdMls64
+// CHECK-NEXT: ret ptr @fmv_one._Mls64Msimd
//
//
// CHECK-LABEL: define {{[^@]+}}@fmv_two.resolver() comdat {
// CHECK-NEXT: resolver_entry:
-// CHECK-NEXT: ret ptr @fmv_two._MsimdMfp16
+// CHECK-NEXT: ret ptr @fmv_two._Mfp16Msimd
//
//
// CHECK-LABEL: define {{[^@]+}}@fmv_e.resolver() comdat {
@@ -266,7 +266,7 @@ int hoo(void) {
// CHECK-NEXT: [[TMP3:%.*]] = and i1 true, [[TMP2]]
// CHECK-NEXT: br i1 [[TMP3]], label [[RESOLVER_RETURN:%.*]], label [[RESOLVER_ELSE:%.*]]
// CHECK: resolver_return:
-// CHECK-NEXT: ret ptr @fmv_inline._Mfp16Mfp16MfcmaMsme
+// CHECK-NEXT: ret ptr @fmv_inline._MfcmaMfp16Mfp16Msme
// CHECK: resolver_else:
// CHECK-NEXT: [[TMP4:%.*]] = load i64, ptr @__aarch64_cpu_features, align 8
// CHECK-NEXT: [[TMP5:%.*]] = and i64 [[TMP4]], 864726312827224064
@@ -274,7 +274,7 @@ int hoo(void) {
// CHECK-NEXT: [[TMP7:%.*]] = and i1 true, [[TMP6]]
// CHECK-NEXT: br i1 [[TMP7]], label [[RESOLVER_RETURN1:%.*]], label [[RESOLVER_ELSE2:%.*]]
// CHECK: resolver_return1:
-// CHECK-NEXT: ret ptr @fmv_inline._Mrcpc3Mmemtag3Mmops
+// CHECK-NEXT: ret ptr @fmv_inline._Mmemtag3MmopsMrcpc3
// CHECK: resolver_else2:
// CHECK-NEXT: [[TMP8:%.*]] = load i64, ptr @__aarch64_cpu_features, align 8
// CHECK-NEXT: [[TMP9:%.*]] = and i64 [[TMP8]], 893353197568
@@ -282,7 +282,7 @@ int hoo(void) {
// CHECK-NEXT: [[TMP11:%.*]] = and i1 true, [[TMP10]]
// CHECK-NEXT: br i1 [[TMP11]], label [[RESOLVER_RETURN3:%.*]], label [[RESOLVER_ELSE4:%.*]]
// CHECK: resolver_return3:
-// CHECK-NEXT: ret ptr @fmv_inline._Msve2Msve2-pmull128Msve2-bitperm
+// CHECK-NEXT: ret ptr @fmv_inline._Msve2Msve2-bitpermMsve2-pmull128
// CHECK: resolver_else4:
// CHECK-NEXT: [[TMP12:%.*]] = load i64, ptr @__aarch64_cpu_features, align 8
// CHECK-NEXT: [[TMP13:%.*]] = and i64 [[TMP12]], 34359773184
@@ -290,7 +290,7 @@ int hoo(void) {
// CHECK-NEXT: [[TMP15:%.*]] = and i1 true, [[TMP14]]
// CHECK-NEXT: br i1 [[TMP15]], label [[RESOLVER_RETURN5:%.*]], label [[RESOLVER_ELSE6:%.*]]
// CHECK: resolver_return5:
-// CHECK-NEXT: ret ptr @fmv_inline._Msha1MpmullMf64mm
+// CHECK-NEXT: ret ptr @fmv_inline._Mf64mmMpmullMsha1
// CHECK: resolver_else6:
// CHECK-NEXT: [[TMP16:%.*]] = load i64, ptr @__aarch64_cpu_features, align 8
// CHECK-NEXT: [[TMP17:%.*]] = and i64 [[TMP16]], 17246986240
@@ -298,7 +298,7 @@ int hoo(void) {
// CHECK-NEXT: [[TMP19:%.*]] = and i1 true, [[TMP18]]
// CHECK-NEXT: br i1 [[TMP19]], label [[RESOLVER_RETURN7:%.*]], label [[RESOLVER_ELSE8:%.*]]
// CHECK: resolver_return7:
-// CHECK-NEXT: ret ptr @fmv_inline._Msha3Mi8mmMf32mm
+// CHECK-NEXT: ret ptr @fmv_inline._Mf32mmMi8mmMsha3
// CHECK: resolver_else8:
// CHECK-NEXT: [[TMP20:%.*]] = load i64, ptr @__aarch64_cpu_features, align 8
// CHECK-NEXT: [[TMP21:%.*]] = and i64 [[TMP20]], 19791209299968
@@ -306,7 +306,7 @@ int hoo(void) {
// CHECK-NEXT: [[TMP23:%.*]] = and i1 true, [[TMP22]]
// CHECK-NEXT: br i1 [[TMP23]], label [[RESOLVER_RETURN9:%.*]], label [[RESOLVER_ELSE10:%.*]]
// CHECK: resolver_return9:
-// CHECK-NEXT: ret ptr @fmv_inline._Msve2-sm4Mmemtag2
+// CHECK-NEXT: ret ptr @fmv_inline._Mmemtag2Msve2-sm4
// CHECK: resolver_else10:
// CHECK-NEXT: [[TMP24:%.*]] = load i64, ptr @__aarch64_cpu_features, align 8
// CHECK-NEXT: [[TMP25:%.*]] = and i64 [[TMP24]], 1236950581248
@@ -338,7 +338,7 @@ int hoo(void) {
// CHECK-NEXT: [[TMP39:%.*]] = and i1 true, [[TMP38]]
// CHECK-NEXT: br i1 [[TMP39]], label [[RESOLVER_RETURN17:%.*]], label [[RESOLVER_ELSE18:%.*]]
// CHECK: resolver_return17:
-// CHECK-NEXT: ret ptr @fmv_inline._MrcpcMfrintts
+// CHECK-NEXT: ret ptr @fmv_inline._MfrinttsMrcpc
// CHECK: resolver_else18:
// CHECK-NEXT: [[TMP40:%.*]] = load i64, ptr @__aarch64_cpu_features, align 8
// CHECK-NEXT: [[TMP41:%.*]] = and i64 [[TMP40]], 8650752
@@ -362,7 +362,7 @@ int hoo(void) {
// CHECK-NEXT: [[TMP51:%.*]] = and i1 true, [[TMP50]]
// CHECK-NEXT: br i1 [[TMP51]], label [[RESOLVER_RETURN23:%.*]], label [[RESOLVER_ELSE24:%.*]]
// CHECK: resolver_return23:
-// CHECK-NEXT: ret ptr @fmv_inline._MsimdMfp16fml
+// CHECK-NEXT: ret ptr @fmv_inline._Mfp16fmlMsimd
// CHECK: resolver_else24:
// CHECK-NEXT: [[TMP52:%.*]] = load i64, ptr @__aarch64_cpu_features, align 8
// CHECK-NEXT: [[TMP53:%.*]] = and i64 [[TMP52]], 16400
@@ -370,7 +370,7 @@ int hoo(void) {
// CHECK-NEXT: [[TMP55:%.*]] = and i1 true, [[TMP54]]
// CHECK-NEXT: br i1 [[TMP55]], label [[RESOLVER_RETURN25:%.*]], label [[RESOLVER_ELSE26:%.*]]
// CHECK: resolver_return25:
-// CHECK-NEXT: ret ptr @fmv_inline._MdotprodMaes
+// CHECK-NEXT: ret ptr @fmv_inline._MaesMdotprod
// CHECK: resolver_else26:
// CHECK-NEXT: [[TMP56:%.*]] = load i64, ptr @__aarch64_cpu_features, align 8
// CHECK-NEXT: [[TMP57:%.*]] = and i64 [[TMP56]], 192
@@ -484,7 +484,7 @@ int hoo(void) {
//
//
// CHECK: Function Attrs: noinline nounwind optnone
-// CHECK-LABEL: define {{[^@]+}}@fmv._MfpMaes
+// CHECK-LABEL: define {{[^@]+}}@fmv._MaesMfp
// CHECK-SAME: () #[[ATTR1]] {
// CHECK-NEXT: entry:
// CHECK-NEXT: ret i32 6
@@ -547,7 +547,7 @@ int hoo(void) {
//
//
// CHECK: Function Attrs: noinline nounwind optnone
-// CHECK-LABEL: define {{[^@]+}}@fmv_two._MsimdMfp16
+// CHECK-LABEL: define {{[^@]+}}@fmv_two._Mfp16Msimd
// CHECK-SAME: () #[[ATTR1]] {
// CHECK-NEXT: entry:
// CHECK-NEXT: ret i32 4
@@ -568,21 +568,21 @@ int hoo(void) {
//
//
// CHECK: Function Attrs: noinline nounwind optnone
-// CHECK-LABEL: define {{[^@]+}}@fmv_inline._Msha1MpmullMf64mm
+// CHECK-LABEL: define {{[^@]+}}@fmv_inline._Mf64mmMpmullMsha1
// CHECK-SAME: () #[[ATTR12:[0-9]+]] {
// CHECK-NEXT: entry:
// CHECK-NEXT: ret i32 1
//
//
// CHECK: Function Attrs: noinline nounwind optnone
-// CHECK-LABEL: define {{[^@]+}}@fmv_inline._Mfp16Mfp16MfcmaMsme
+// CHECK-LABEL: define {{[^@]+}}@fmv_inline._MfcmaMfp16Mfp16Msme
// CHECK-SAME: () #[[ATTR13:[0-9]+]] {
// CHECK-NEXT: entry:
// CHECK-NEXT: ret i32 2
//
//
// CHECK: Function Attrs: noinline nounwind optnone
-// CHECK-LABEL: define {{[^@]+}}@fmv_inline._Msha3Mi8mmMf32mm
+// CHECK-LABEL: define {{[^@]+}}@fmv_inline._Mf32mmMi8mmMsha3
// CHECK-SAME: () #[[ATTR14:[0-9]+]] {
// CHECK-NEXT: entry:
// CHECK-NEXT: ret i32 12
@@ -610,7 +610,7 @@ int hoo(void) {
//
//
// CHECK: Function Attrs: noinline nounwind optnone
-// CHECK-LABEL: define {{[^@]+}}@fmv_inline._MrcpcMfrintts
+// CHECK-LABEL: define {{[^@]+}}@fmv_inline._MfrinttsMrcpc
// CHECK-SAME: () #[[ATTR18:[0-9]+]] {
// CHECK-NEXT: entry:
// CHECK-NEXT: ret i32 3
@@ -631,35 +631,35 @@ int hoo(void) {
//
//
// CHECK: Function Attrs: noinline nounwind optnone
-// CHECK-LABEL: define {{[^@]+}}@fmv_inline._Msve2Msve2-pmull128Msve2-bitperm
+// CHECK-LABEL: define {{[^@]+}}@fmv_inline._Msve2Msve2-bitpermMsve2-pmull128
// CHECK-SAME: () #[[ATTR21:[0-9]+]] {
// CHECK-NEXT: entry:
// CHECK-NEXT: ret i32 9
//
//
// CHECK: Function Attrs: noinline nounwind optnone
-// CHECK-LABEL: define {{[^@]+}}@fmv_inline._Msve2-sm4Mmemtag2
+// CHECK-LABEL: define {{[^@]+}}@fmv_inline._Mmemtag2Msve2-sm4
// CHECK-SAME: () #[[ATTR22:[0-9]+]] {
// CHECK-NEXT: entry:
// CHECK-NEXT: ret i32 10
//
//
// CHECK: Function Attrs: noinline nounwind optnone
-// CHECK-LABEL: define {{[^@]+}}@fmv_inline._Mrcpc3Mmemtag3Mmops
+// CHECK-LABEL: define {{[^@]+}}@fmv_inline._Mmemtag3MmopsMrcpc3
// CHECK-SAME: () #[[ATTR23:[0-9]+]] {
// CHECK-NEXT: entry:
// CHECK-NEXT: ret i32 11
//
//
// CHECK: Function Attrs: noinline nounwind optnone
-// CHECK-LABEL: define {{[^@]+}}@fmv_inline._MdotprodMaes
+// CHECK-LABEL: define {{[^@]+}}@fmv_inline._MaesMdotprod
// CHECK-SAME: () #[[ATTR6]] {
// CHECK-NEXT: entry:
// CHECK-NEXT: ret i32 13
//
//
// CHECK: Function Attrs: noinline nounwind optnone
-// CHECK-LABEL: define {{[^@]+}}@fmv_inline._MsimdMfp16fml
+// CHECK-LABEL: define {{[^@]+}}@fmv_inline._Mfp16fmlMsimd
// CHECK-SAME: () #[[ATTR7]] {
// CHECK-NEXT: entry:
// CHECK-NEXT: ret i32 14
diff --git a/clang/test/CodeGenCXX/attr-target-clones-aarch64.cpp b/clang/test/CodeGenCXX/attr-target-clones-aarch64.cpp
index 2d3f4489479913..14963867798d34 100644
--- a/clang/test/CodeGenCXX/attr-target-clones-aarch64.cpp
+++ b/clang/test/CodeGenCXX/attr-target-clones-aarch64.cpp
@@ -36,22 +36,33 @@ void run_foo_tml() {
}
+
+
+//.
// CHECK: @__aarch64_cpu_features = external dso_local global { i64 }
+// CHECK: @_Z7foo_ovli.ifunc = weak_odr alias i32 (i32), ptr @_Z7foo_ovli
+// CHECK: @_Z7foo_ovlv.ifunc = weak_odr alias i32 (), ptr @_Z7foo_ovlv
+// CHECK: @_ZN7MyClassIssE7foo_tmlEv.ifunc = weak_odr alias i32 (ptr), ptr @_ZN7MyClassIssE7foo_tmlEv
+// CHECK: @_ZN7MyClassIisE7foo_tmlEv.ifunc = weak_odr alias i32 (ptr), ptr @_ZN7MyClassIisE7foo_tmlEv
// CHECK: @_Z7foo_ovli = weak_odr ifunc i32 (i32), ptr @_Z7foo_ovli.resolver
// CHECK: @_Z7foo_ovlv = weak_odr ifunc i32 (), ptr @_Z7foo_ovlv.resolver
// CHECK: @_ZN7MyClassIssE7foo_tmlEv = weak_odr ifunc i32 (ptr), ptr @_ZN7MyClassIssE7foo_tmlEv.resolver
// CHECK: @_ZN7MyClassIisE7foo_tmlEv = weak_odr ifunc i32 (ptr), ptr @_ZN7MyClassIisE7foo_tmlEv.resolver
-
+//.
// CHECK-LABEL: @_Z7foo_ovli._Mfp16Mls64_v(
// CHECK-NEXT: entry:
// CHECK-NEXT: [[DOTADDR:%.*]] = alloca i32, align 4
// CHECK-NEXT: store i32 [[TMP0:%.*]], ptr [[DOTADDR]], align 4
// CHECK-NEXT: ret i32 1
+//
+//
// CHECK-LABEL: @_Z7foo_ovli.default(
// CHECK-NEXT: entry:
// CHECK-NEXT: [[DOTADDR:%.*]] = alloca i32, align 4
// CHECK-NEXT: store i32 [[TMP0:%.*]], ptr [[DOTADDR]], align 4
// CHECK-NEXT: ret i32 1
+//
+//
// CHECK-LABEL: @_Z7foo_ovli.resolver(
// CHECK-NEXT: resolver_entry:
// CHECK-NEXT: call void @__init_cpu_features_resolver()
@@ -63,13 +74,19 @@ void run_foo_tml() {
// CHECK: resolver_return:
// CHECK-NEXT: ret ptr @_Z7foo_ovli._Mfp16Mls64_v
// CHECK: resolver_else:
-// CHECK-NEXT: ret ptr @_Z7foo_ovli
+// CHECK-NEXT: ret ptr @_Z7foo_ovli.default
+//
+//
// CHECK-LABEL: @_Z7foo_ovlv._Mls64Mls64_accdata(
// CHECK-NEXT: entry:
// CHECK-NEXT: ret i32 2
+//
+//
// CHECK-LABEL: @_Z7foo_ovlv.default(
// CHECK-NEXT: entry:
// CHECK-NEXT: ret i32 2
+//
+//
// CHECK-LABEL: @_Z7foo_ovlv.resolver(
// CHECK-NEXT: resolver_entry:
// CHECK-NEXT: call void @__init_cpu_features_resolver()
@@ -82,12 +99,16 @@ void run_foo_tml() {
// CHECK-NEXT: ret ptr @_Z7foo_ovlv._Mls64Mls64_accdata
// CHECK: resolver_else:
// CHECK-NEXT: ret ptr @_Z7foo_ovlv.default
+//
+//
// CHECK-LABEL: @_Z3barv(
// CHECK-NEXT: entry:
// CHECK-NEXT: [[CALL:%.*]] = call noundef i32 @_Z7foo_ovli(i32 noundef 1)
// CHECK-NEXT: [[CALL1:%.*]] = call noundef i32 @_Z7foo_ovlv()
// CHECK-NEXT: [[ADD:%.*]] = add nsw i32 [[CALL]], [[CALL1]]
// CHECK-NEXT: ret i32 [[ADD]]
+//
+//
// CHECK-LABEL: @_Z11run_foo_tmlv(
// CHECK-NEXT: entry:
// CHECK-NEXT: [[MC1:%.*]] = alloca [[STRUCT_MYCLASS:%.*]], align 1
@@ -99,6 +120,8 @@ void run_foo_tml() {
// CHECK-NEXT: [[CALL2:%.*]] = call noundef i32 @_ZN7MyClassIfsE7foo_tmlEv(ptr noundef nonnull align 1 dereferenceable(1) [[MC3]])
// CHECK-NEXT: [[CALL3:%.*]] = call noundef i32 @_ZN7MyClassIdfE7foo_tmlEv(ptr noundef nonnull align 1 dereferenceable(1) [[MC4]])
// CHECK-NEXT: ret void
+//
+//
// CHECK-LABEL: @_ZN7MyClassIssE7foo_tmlEv.resolver(
// CHECK-NEXT: resolver_entry:
// CHECK-NEXT: call void @__init_cpu_features_resolver()
@@ -108,7 +131,7 @@ void run_foo_tml() {
// CHECK-NEXT: [[TMP3:%.*]] = and i1 true, [[TMP2]]
// CHECK-NEXT: br i1 [[TMP3]], label [[RESOLVER_RETURN:%.*]], label [[RESOLVER_ELSE:%.*]]
// CHECK: resolver_return:
-// CHECK-NEXT: ret ptr @_ZN7MyClassIssE7foo_tmlEv._MssbsMsme-f64f64
+// CHECK-NEXT: ret ptr @_ZN7MyClassIssE7foo_tmlEv._Msme-f64f64Mssbs
// CHECK: resolver_else:
// CHECK-NEXT: [[TMP4:%.*]] = load i64, ptr @__aarch64_cpu_features, align 8
// CHECK-NEXT: [[TMP5:%.*]] = and i64 [[TMP4]], 16777216
@@ -118,7 +141,9 @@ void run_foo_tml() {
// CHECK: resolver_return1:
// CHECK-NEXT: ret ptr @_ZN7MyClassIssE7foo_tmlEv._Mfrintts
// CHECK: resolver_else2:
-// CHECK-NEXT: ret ptr @_ZN7MyClassIssE7foo_tmlEv
+// CHECK-NEXT: ret ptr @_ZN7MyClassIssE7foo_tmlEv.default
+//
+//
// CHECK-LABEL: @_ZN7MyClassIisE7foo_tmlEv.resolver(
// CHECK-NEXT: resolver_entry:
// CHECK-NEXT: call void @__init_cpu_features_resolver()
@@ -128,7 +153,7 @@ void run_foo_tml() {
// CHECK-NEXT: [[TMP3:%.*]] = and i1 true, [[TMP2]]
// CHECK-NEXT: br i1 [[TMP3]], label [[RESOLVER_RETURN:%.*]], label [[RESOLVER_ELSE:%.*]]
// CHECK: resolver_return:
-// CHECK-NEXT: ret ptr @_ZN7MyClassIisE7foo_tmlEv._MssbsMsme-f64f64
+// CHECK-NEXT: ret ptr @_ZN7MyClassIisE7foo_tmlEv._Msme-f64f64Mssbs
// CHECK: resolver_else:
// CHECK-NEXT: [[TMP4:%.*]] = load i64, ptr @__aarch64_cpu_features, align 8
// CHECK-NEXT: [[TMP5:%.*]] = and i64 [[TMP4]], 16777216
@@ -138,58 +163,79 @@ void run_foo_tml() {
// CHECK: resolver_return1:
// CHECK-NEXT: ret ptr @_ZN7MyClassIisE7foo_tmlEv._Mfrintts
// CHECK: resolver_else2:
-// CHECK-NEXT: ret ptr @_ZN7MyClassIisE7foo_tmlEv
+// CHECK-NEXT: ret ptr @_ZN7MyClassIisE7foo_tmlEv.default
+//
+//
// CHECK-LABEL: @_ZN7MyClassIfsE7foo_tmlEv(
// CHECK-NEXT: entry:
// CHECK-NEXT: [[THIS_ADDR:%.*]] = alloca ptr, align 8
// CHECK-NEXT: store ptr [[THIS:%.*]], ptr [[THIS_ADDR]], align 8
// CHECK-NEXT: [[THIS1:%.*]] = load ptr, ptr [[THIS_ADDR]], align 8
// CHECK-NEXT: ret i32 3
+//
+//
// CHECK-LABEL: @_ZN7MyClassIdfE7foo_tmlEv(
// CHECK-NEXT: entry:
// CHECK-NEXT: [[THIS_ADDR:%.*]] = alloca ptr, align 8
// CHECK-NEXT: store ptr [[THIS:%.*]], ptr [[THIS_ADDR]], align 8
// CHECK-NEXT: [[THIS1:%.*]] = load ptr, ptr [[THIS_ADDR]], align 8
// CHECK-NEXT: ret i32 4
+//
+//
// CHECK-LABEL: @_ZN7MyClassIssE7foo_tmlEv._Mfrintts(
// CHECK-NEXT: entry:
// CHECK-NEXT: [[THIS_ADDR:%.*]] = alloca ptr, align 8
// CHECK-NEXT: store ptr [[THIS:%.*]], ptr [[THIS_ADDR]], align 8
// CHECK-NEXT: [[THIS1:%.*]] = load ptr, ptr [[THIS_ADDR]], align 8
// CHECK-NEXT: ret i32 1
-// CHECK-LABEL: @_ZN7MyClassIssE7foo_tmlEv._MssbsMsme-f64f64(
+//
+//
+// CHECK-LABEL: @_ZN7MyClassIssE7foo_tmlEv._Msme-f64f64Mssbs(
// CHECK-NEXT: entry:
// CHECK-NEXT: [[THIS_ADDR:%.*]] = alloca ptr, align 8
// CHECK-NEXT: store ptr [[THIS:%.*]], ptr [[THIS_ADDR]], align 8
// CHECK-NEXT: [[THIS1:%.*]] = load ptr, ptr [[THIS_ADDR]], align 8
// CHECK-NEXT: ret i32 1
+//
+//
// CHECK-LABEL: @_ZN7MyClassIssE7foo_tmlEv.default(
// CHECK-NEXT: entry:
// CHECK-NEXT: [[THIS_ADDR:%.*]] = alloca ptr, align 8
// CHECK-NEXT: store ptr [[THIS:%.*]], ptr [[THIS_ADDR]], align 8
// CHECK-NEXT: [[THIS1:%.*]] = load ptr, ptr [[THIS_ADDR]], align 8
// CHECK-NEXT: ret i32 1
+//
+//
// CHECK-LABEL: @_ZN7MyClassIisE7foo_tmlEv._Mfrintts(
// CHECK-NEXT: entry:
// CHECK-NEXT: [[THIS_ADDR:%.*]] = alloca ptr, align 8
// CHECK-NEXT: store ptr [[THIS:%.*]], ptr [[THIS_ADDR]], align 8
// CHECK-NEXT: [[THIS1:%.*]] = load ptr, ptr [[THIS_ADDR]], align 8
// CHECK-NEXT: ret i32 2
-// CHECK-LABEL: @_ZN7MyClassIisE7foo_tmlEv._MssbsMsme-f64f64(
+//
+//
+// CHECK-LABEL: @_ZN7MyClassIisE7foo_tmlEv._Msme-f64f64Mssbs(
// CHECK-NEXT: entry:
// CHECK-NEXT: [[THIS_ADDR:%.*]] = alloca ptr, align 8
// CHECK-NEXT: store ptr [[THIS:%.*]], ptr [[THIS_ADDR]], align 8
// CHECK-NEXT: [[THIS1:%.*]] = load ptr, ptr [[THIS_ADDR]], align 8
// CHECK-NEXT: ret i32 2
+//
+//
// CHECK-LABEL: @_ZN7MyClassIisE7foo_tmlEv.default(
// CHECK-NEXT: entry:
// CHECK-NEXT: [[THIS_ADDR:%.*]] = alloca ptr, align 8
// CHECK-NEXT: store ptr [[THIS:%.*]], ptr [[THIS_ADDR]], align 8
// CHECK-NEXT: [[THIS1:%.*]] = load ptr, ptr [[THIS_ADDR]], align 8
// CHECK-NEXT: ret i32 2
-
-// CHECK: attributes #0 = { mustprogress noinline nounwind optnone "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-features"="+fp-armv8,+fullfp16,+neon" }
-// CHECK: attributes #1 = { mustprogress noinline nounwind optnone "no-trapping-math"="true" "stack-protector-buffer-size"="8" }
-// CHECK: attributes #2 = { mustprogress noinline nounwind optnone "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-features"="+ls64" }
-// CHECK: attributes #3 = { mustprogress noinline nounwind optnone "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-features"="+fptoint" }
-// CHECK: attributes #4 = { mustprogress noinline nounwind optnone "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-features"="+bf16,+sme,+sme-f64f64" }
+//
+//.
+// CHECK: attributes #[[ATTR0:[0-9]+]] = { mustprogress noinline nounwind optnone "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-features"="+fp-armv8,+fullfp16,+neon" }
+// CHECK: attributes #[[ATTR1:[0-9]+]] = { mustprogress noinline nounwind optnone "no-trapping-math"="true" "stack-protector-buffer-size"="8" }
+// CHECK: attributes #[[ATTR2:[0-9]+]] = { mustprogress noinline nounwind optnone "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-features"="+ls64" }
+// CHECK: attributes #[[ATTR3:[0-9]+]] = { mustprogress noinline nounwind optnone "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-features"="+fptoint" }
+// CHECK: attributes #[[ATTR4:[0-9]+]] = { mustprogress noinline nounwind optnone "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-features"="+bf16,+sme,+sme-f64f64" }
+//.
+// CHECK: [[META0:![0-9]+]] = !{i32 1, !"wchar_size", i32 4}
+// CHECK: [[META1:![0-9]+]] = !{!"{{.*}}clang version {{.*}}"}
+//.
diff --git a/clang/test/CodeGenCXX/attr-target-version.cpp b/clang/test/CodeGenCXX/attr-target-version.cpp
index b63815db7e40fa..82a928a385e16b 100644
--- a/clang/test/CodeGenCXX/attr-target-version.cpp
+++ b/clang/test/CodeGenCXX/attr-target-version.cpp
@@ -40,7 +40,7 @@ int bar() {
// CHECK-NEXT: ret i32 1
//
//
-// CHECK-LABEL: @_Z3foov._Msm4Mebf16(
+// CHECK-LABEL: @_Z3foov._Mebf16Msm4(
// CHECK-NEXT: entry:
// CHECK-NEXT: ret i32 3
//
@@ -101,7 +101,7 @@ int bar() {
// CHECK-NEXT: [[TMP3:%.*]] = and i1 true, [[TMP2]]
// CHECK-NEXT: br i1 [[TMP3]], label [[RESOLVER_RETURN:%.*]], label [[RESOLVER_ELSE:%.*]]
// CHECK: resolver_return:
-// CHECK-NEXT: ret ptr @_Z3foov._Msm4Mebf16
+// CHECK-NEXT: ret ptr @_Z3foov._Mebf16Msm4
// CHECK: resolver_else:
// CHECK-NEXT: ret ptr @_Z3foov.default
//
>From 990dbf2b7ebb1ddf1a53eb0b25061a0ea42f4ae1 Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?Timm=20B=C3=A4der?= <tbaeder at redhat.com>
Date: Fri, 1 Mar 2024 09:41:29 +0100
Subject: [PATCH 224/406] [clang][Interp] OpaqueValueExprs can have null
subexprs
---
clang/lib/AST/Interp/ByteCodeExprGen.cpp | 10 +++++++---
1 file changed, 7 insertions(+), 3 deletions(-)
diff --git a/clang/lib/AST/Interp/ByteCodeExprGen.cpp b/clang/lib/AST/Interp/ByteCodeExprGen.cpp
index 122b9045a75f6e..0185214fb455de 100644
--- a/clang/lib/AST/Interp/ByteCodeExprGen.cpp
+++ b/clang/lib/AST/Interp/ByteCodeExprGen.cpp
@@ -1220,14 +1220,18 @@ bool ByteCodeExprGen<Emitter>::VisitArrayInitLoopExpr(
template <class Emitter>
bool ByteCodeExprGen<Emitter>::VisitOpaqueValueExpr(const OpaqueValueExpr *E) {
+ const Expr *SourceExpr = E->getSourceExpr();
+ if (!SourceExpr)
+ return false;
+
if (Initializing)
- return this->visitInitializer(E->getSourceExpr());
+ return this->visitInitializer(SourceExpr);
- PrimType SubExprT = classify(E->getSourceExpr()).value_or(PT_Ptr);
+ PrimType SubExprT = classify(SourceExpr).value_or(PT_Ptr);
if (auto It = OpaqueExprs.find(E); It != OpaqueExprs.end())
return this->emitGetLocal(SubExprT, It->second, E);
- if (!this->visit(E->getSourceExpr()))
+ if (!this->visit(SourceExpr))
return false;
// At this point we either have the evaluated source expression or a pointer
>From 062d78ef58ac26e1c6f82201151428d0b89cca21 Mon Sep 17 00:00:00 2001
From: David CARLIER <devnexen at gmail.com>
Date: Fri, 1 Mar 2024 09:13:11 +0000
Subject: [PATCH 225/406] [compiler-rt][fuzzer] windows build unbreak proposal.
(#83538)
shuffling the order of its includes.
---
compiler-rt/lib/fuzzer/FuzzerUtilWindows.cpp | 11 +++++++----
1 file changed, 7 insertions(+), 4 deletions(-)
diff --git a/compiler-rt/lib/fuzzer/FuzzerUtilWindows.cpp b/compiler-rt/lib/fuzzer/FuzzerUtilWindows.cpp
index 13f9a67a2f0fe3..39ab9e241b5914 100644
--- a/compiler-rt/lib/fuzzer/FuzzerUtilWindows.cpp
+++ b/compiler-rt/lib/fuzzer/FuzzerUtilWindows.cpp
@@ -18,15 +18,18 @@
#include <errno.h>
#include <io.h>
#include <iomanip>
-#include <libloaderapi.h>
#include <signal.h>
#include <stdio.h>
-#include <stringapiset.h>
#include <sys/types.h>
+// clang-format off
#include <windows.h>
-
-// This must be included after windows.h.
+// These must be included after windows.h.
+// archicture need to be set before including
+// libloaderapi
+#include <libloaderapi.h>
+#include <stringapiset.h>
#include <psapi.h>
+// clang-format on
namespace fuzzer {
>From 2a67c28abe8cfde47c5058abbeb4b5ff9a393192 Mon Sep 17 00:00:00 2001
From: Nikita Popov <npopov at redhat.com>
Date: Fri, 1 Mar 2024 10:04:44 +0100
Subject: [PATCH 226/406] [IR] Update getOrInsertFunction() docs for opaque
pointers (NFC)
This can no longer return a bitcast, but the function type in
FunctionCallee may differ from the function type of the function.
---
llvm/include/llvm/IR/Module.h | 23 ++++++++---------------
1 file changed, 8 insertions(+), 15 deletions(-)
diff --git a/llvm/include/llvm/IR/Module.h b/llvm/include/llvm/IR/Module.h
index e41a5940540b4d..bb2e667ef6f410 100644
--- a/llvm/include/llvm/IR/Module.h
+++ b/llvm/include/llvm/IR/Module.h
@@ -385,17 +385,14 @@ class LLVM_EXTERNAL_VISIBILITY Module {
/// @name Function Accessors
/// @{
- /// Look up the specified function in the module symbol table. Four
- /// possibilities:
- /// 1. If it does not exist, add a prototype for the function and return it.
- /// 2. Otherwise, if the existing function has the correct prototype, return
- /// the existing function.
- /// 3. Finally, the function exists but has the wrong prototype: return the
- /// function with a constantexpr cast to the right prototype.
+ /// Look up the specified function in the module symbol table. If it does not
+ /// exist, add a prototype for the function and return it. Otherwise, return
+ /// the existing function.
///
/// In all cases, the returned value is a FunctionCallee wrapper around the
- /// 'FunctionType *T' passed in, as well as a 'Value*' either of the Function or
- /// the bitcast to the function.
+ /// 'FunctionType *T' passed in, as well as the 'Value*' of the Function. The
+ /// function type of the function may differ from the function type stored in
+ /// FunctionCallee if it was previously created with a different type.
///
/// Note: For library calls getOrInsertLibFunc() should be used instead.
FunctionCallee getOrInsertFunction(StringRef Name, FunctionType *T,
@@ -403,12 +400,8 @@ class LLVM_EXTERNAL_VISIBILITY Module {
FunctionCallee getOrInsertFunction(StringRef Name, FunctionType *T);
- /// Look up the specified function in the module symbol table. If it does not
- /// exist, add a prototype for the function and return it. This function
- /// guarantees to return a constant of pointer to the specified function type
- /// or a ConstantExpr BitCast of that type if the named function has a
- /// different type. This version of the method takes a list of
- /// function arguments, which makes it easier for clients to use.
+ /// Same as above, but takes a list of function arguments, which makes it
+ /// easier for clients to use.
template <typename... ArgsTy>
FunctionCallee getOrInsertFunction(StringRef Name,
AttributeList AttributeList, Type *RetTy,
>From 6ed67ca14cd05596a8253eeceb247d2743e00f6e Mon Sep 17 00:00:00 2001
From: Jie Fu <jiefu at tencent.com>
Date: Fri, 1 Mar 2024 17:37:11 +0800
Subject: [PATCH 227/406] [clang] Remove unused-lambda-capture in AArch64.cpp
(NFC)
llvm-project/clang/lib/CodeGen/Targets/AArch64.cpp:886:26:
error: lambda capture 'TI' is not used [-Werror,-Wunused-lambda-capture]
886 | llvm::sort(Features, [&TI](const StringRef LHS, const StringRef RHS) {
| ~^~
1 error generated.
---
clang/lib/CodeGen/Targets/AArch64.cpp | 3 +--
1 file changed, 1 insertion(+), 2 deletions(-)
diff --git a/clang/lib/CodeGen/Targets/AArch64.cpp b/clang/lib/CodeGen/Targets/AArch64.cpp
index 79a9c1d5978a14..725e8a70fddfe6 100644
--- a/clang/lib/CodeGen/Targets/AArch64.cpp
+++ b/clang/lib/CodeGen/Targets/AArch64.cpp
@@ -882,8 +882,7 @@ void AArch64ABIInfo::appendAttributeMangling(StringRef AttrStr,
for (auto &Feat : Features)
Feat = Feat.trim();
- const TargetInfo &TI = CGT.getTarget();
- llvm::sort(Features, [&TI](const StringRef LHS, const StringRef RHS) {
+ llvm::sort(Features, [](const StringRef LHS, const StringRef RHS) {
return LHS.compare(RHS) < 0;
});
>From ec8df555702d85511290742388d28016b69468de Mon Sep 17 00:00:00 2001
From: David Spickett <david.spickett at linaro.org>
Date: Fri, 1 Mar 2024 09:45:37 +0000
Subject: [PATCH 228/406] [lldb][test][Windows] Don't check for pexpect with
LLDB_ENFORCE_STRICT_TEST_REQUIREMENTS
See https://github.com/llvm/llvm-project/issues/22648 for why we don't use it on
Windows. Any pexpect tests are skipped there.
---
lldb/test/CMakeLists.txt | 12 ++++++++----
1 file changed, 8 insertions(+), 4 deletions(-)
diff --git a/lldb/test/CMakeLists.txt b/lldb/test/CMakeLists.txt
index 2a9877c721e3b4..950643a5b8cc8e 100644
--- a/lldb/test/CMakeLists.txt
+++ b/lldb/test/CMakeLists.txt
@@ -11,10 +11,14 @@ endif()
if(LLDB_ENFORCE_STRICT_TEST_REQUIREMENTS)
message(STATUS "Enforcing strict test requirements for LLDB")
- set(useful_python_modules
- psutil # Lit uses psutil to do per-test timeouts.
- pexpect # We no longer vendor pexpect.
- )
+ # Lit uses psutil to do per-test timeouts.
+ set(useful_python_modules psutil)
+
+ if(NOT WIN32)
+ # We no longer vendor pexpect and it is not used on Windows.
+ list(APPEND pexpect)
+ endif()
+
foreach(module ${useful_python_modules})
lldb_find_python_module(${module})
if (NOT PY_${module}_FOUND)
>From d50dec6f413ce1953bede94bdd11261b6684c7c4 Mon Sep 17 00:00:00 2001
From: Simon Pilgrim <llvm-dev at redking.me.uk>
Date: Fri, 1 Mar 2024 09:56:55 +0000
Subject: [PATCH 229/406] Fix MSVC "not all control paths return a value"
warnings. NFC.
---
clang/include/clang/Basic/TargetInfo.h | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/clang/include/clang/Basic/TargetInfo.h b/clang/include/clang/Basic/TargetInfo.h
index b94d13609c3dd2..7682f84e491c7b 100644
--- a/clang/include/clang/Basic/TargetInfo.h
+++ b/clang/include/clang/Basic/TargetInfo.h
@@ -1386,7 +1386,7 @@ class TargetInfo : public TransferrableTargetInfo,
case LangOptions::SignReturnAddressScopeKind::All:
return "all";
}
- assert(false && "Unexpected SignReturnAddressScopeKind");
+ llvm_unreachable("Unexpected SignReturnAddressScopeKind");
}
const char *getSignKeyStr() const {
@@ -1396,7 +1396,7 @@ class TargetInfo : public TransferrableTargetInfo,
case LangOptions::SignReturnAddressKeyKind::BKey:
return "b_key";
}
- assert(false && "Unexpected SignReturnAddressKeyKind");
+ llvm_unreachable("Unexpected SignReturnAddressKeyKind");
}
};
>From 199bbe2b380b6fa4a23932739ae55f8890af459b Mon Sep 17 00:00:00 2001
From: Sergei Barannikov <barannikov88 at gmail.com>
Date: Fri, 1 Mar 2024 13:00:39 +0300
Subject: [PATCH 230/406] [MC] Teach checkAsmTiedOperandConstraints about
optional operands (#81381)
At some point in the past, optional operands have become allowed in the
middle of an instruction. However, `checkAsmTiedOperandConstrains`
hasn't been modified to support this. This patch adds the support by
pulling operand offsets counting out of `convertToMCInst` and reusing it
in `checkAsmTiedOperandConstrains`.
---
llvm/utils/TableGen/AsmMatcherEmitter.cpp | 89 ++++++++++++++++-------
1 file changed, 62 insertions(+), 27 deletions(-)
diff --git a/llvm/utils/TableGen/AsmMatcherEmitter.cpp b/llvm/utils/TableGen/AsmMatcherEmitter.cpp
index b5bd9bfd21bebc..febd96086df27b 100644
--- a/llvm/utils/TableGen/AsmMatcherEmitter.cpp
+++ b/llvm/utils/TableGen/AsmMatcherEmitter.cpp
@@ -1976,7 +1976,8 @@ emitConvertFuncs(CodeGenTarget &Target, StringRef ClassName,
<< "convertToMCInst(unsigned Kind, MCInst &Inst, "
<< "unsigned Opcode,\n"
<< " const OperandVector &Operands,\n"
- << " const SmallBitVector &OptionalOperandsMask) {\n";
+ << " const SmallBitVector &OptionalOperandsMask,\n"
+ << " ArrayRef<unsigned> DefaultsOffset) {\n";
} else {
CvtOS << "void " << Target.getName() << ClassName << "::\n"
<< "convertToMCInst(unsigned Kind, MCInst &Inst, "
@@ -1985,25 +1986,13 @@ emitConvertFuncs(CodeGenTarget &Target, StringRef ClassName,
}
CvtOS << " assert(Kind < CVT_NUM_SIGNATURES && \"Invalid signature!\");\n";
CvtOS << " const uint8_t *Converter = ConversionTable[Kind];\n";
- if (HasOptionalOperands) {
- size_t MaxNumOperands = 0;
- for (const auto &MI : Infos) {
- MaxNumOperands = std::max(MaxNumOperands, MI->AsmOperands.size());
- }
- CvtOS << " unsigned DefaultsOffset[" << (MaxNumOperands + 1)
- << "] = { 0 };\n";
- CvtOS << " assert(OptionalOperandsMask.size() == " << (MaxNumOperands)
- << ");\n";
- CvtOS << " for (unsigned i = 0, NumDefaults = 0; i < " << (MaxNumOperands)
- << "; ++i) {\n";
- CvtOS << " DefaultsOffset[i + 1] = NumDefaults;\n";
- CvtOS << " NumDefaults += (OptionalOperandsMask[i] ? 1 : 0);\n";
- CvtOS << " }\n";
- }
CvtOS << " unsigned OpIdx;\n";
CvtOS << " Inst.setOpcode(Opcode);\n";
CvtOS << " for (const uint8_t *p = Converter; *p; p += 2) {\n";
if (HasOptionalOperands) {
+ // When optional operands are involved, formal and actual operand indices
+ // may differ. Map the former to the latter by subtracting the number of
+ // absent optional operands.
CvtOS << " OpIdx = *(p + 1) - DefaultsOffset[*(p + 1)];\n";
} else {
CvtOS << " OpIdx = *(p + 1);\n";
@@ -3031,15 +3020,17 @@ emitCustomOperandParsing(raw_ostream &OS, CodeGenTarget &Target,
}
static void emitAsmTiedOperandConstraints(CodeGenTarget &Target,
- AsmMatcherInfo &Info,
- raw_ostream &OS) {
+ AsmMatcherInfo &Info, raw_ostream &OS,
+ bool HasOptionalOperands) {
std::string AsmParserName =
std::string(Info.AsmParser->getValueAsString("AsmParserClassName"));
OS << "static bool ";
OS << "checkAsmTiedOperandConstraints(const " << Target.getName()
<< AsmParserName << "&AsmParser,\n";
- OS << " unsigned Kind,\n";
- OS << " const OperandVector &Operands,\n";
+ OS << " unsigned Kind, const OperandVector "
+ "&Operands,\n";
+ if (HasOptionalOperands)
+ OS << " ArrayRef<unsigned> DefaultsOffset,\n";
OS << " uint64_t &ErrorInfo) {\n";
OS << " assert(Kind < CVT_NUM_SIGNATURES && \"Invalid signature!\");\n";
OS << " const uint8_t *Converter = ConversionTable[Kind];\n";
@@ -3052,6 +3043,13 @@ static void emitAsmTiedOperandConstraints(CodeGenTarget &Target,
OS << " \"Tied operand not found\");\n";
OS << " unsigned OpndNum1 = TiedAsmOperandTable[OpIdx][1];\n";
OS << " unsigned OpndNum2 = TiedAsmOperandTable[OpIdx][2];\n";
+ if (HasOptionalOperands) {
+ // When optional operands are involved, formal and actual operand indices
+ // may differ. Map the former to the latter by subtracting the number of
+ // absent optional operands.
+ OS << " OpndNum1 = OpndNum1 - DefaultsOffset[OpndNum1];\n";
+ OS << " OpndNum2 = OpndNum2 - DefaultsOffset[OpndNum2];\n";
+ }
OS << " if (OpndNum1 != OpndNum2) {\n";
OS << " auto &SrcOp1 = Operands[OpndNum1];\n";
OS << " auto &SrcOp2 = Operands[OpndNum2];\n";
@@ -3291,7 +3289,8 @@ void AsmMatcherEmitter::run(raw_ostream &OS) {
<< "unsigned Opcode,\n"
<< " const OperandVector &Operands,\n"
<< " const SmallBitVector "
- "&OptionalOperandsMask);\n";
+ "&OptionalOperandsMask,\n"
+ << " ArrayRef<unsigned> DefaultsOffset);\n";
} else {
OS << " void convertToMCInst(unsigned Kind, MCInst &Inst, "
<< "unsigned Opcode,\n"
@@ -3405,7 +3404,7 @@ void AsmMatcherEmitter::run(raw_ostream &OS) {
Info.SubtargetFeatures, OS);
if (!ReportMultipleNearMisses)
- emitAsmTiedOperandConstraints(Target, Info, OS);
+ emitAsmTiedOperandConstraints(Target, Info, OS, HasOptionalOperands);
StringToOffsetTable StringTable;
@@ -3928,11 +3927,39 @@ void AsmMatcherEmitter::run(raw_ostream &OS) {
OS << " }\n\n";
}
+ // When converting parsed operands to MCInst we need to know whether optional
+ // operands were parsed or not so that we can choose the correct converter
+ // function. We also need to know this when checking tied operand constraints.
+ // DefaultsOffset is an array of deltas between the formal (MCInst) and the
+ // actual (parsed operand array) operand indices. When all optional operands
+ // are present, all elements of the array are zeros. If some of the optional
+ // operands are absent, the array might look like '0, 0, 1, 1, 1, 2, 2, 3',
+ // where each increment in value reflects the absence of an optional operand.
+ if (HasOptionalOperands) {
+ OS << " unsigned DefaultsOffset[" << (MaxNumOperands + 1)
+ << "] = { 0 };\n";
+ OS << " assert(OptionalOperandsMask.size() == " << (MaxNumOperands)
+ << ");\n";
+ OS << " for (unsigned i = 0, NumDefaults = 0; i < " << (MaxNumOperands)
+ << "; ++i) {\n";
+ OS << " DefaultsOffset[i + 1] = NumDefaults;\n";
+ OS << " NumDefaults += (OptionalOperandsMask[i] ? 1 : 0);\n";
+ OS << " }\n\n";
+ }
+
OS << " if (matchingInlineAsm) {\n";
OS << " convertToMapAndConstraints(it->ConvertFn, Operands);\n";
if (!ReportMultipleNearMisses) {
- OS << " if (!checkAsmTiedOperandConstraints(*this, it->ConvertFn, "
- "Operands, ErrorInfo))\n";
+ if (HasOptionalOperands) {
+ OS << " if (!checkAsmTiedOperandConstraints(*this, it->ConvertFn, "
+ "Operands,\n";
+ OS << " DefaultsOffset, "
+ "ErrorInfo))\n";
+ } else {
+ OS << " if (!checkAsmTiedOperandConstraints(*this, it->ConvertFn, "
+ "Operands,\n";
+ OS << " ErrorInfo))\n";
+ }
OS << " return Match_InvalidTiedOperand;\n";
OS << "\n";
}
@@ -3942,7 +3969,7 @@ void AsmMatcherEmitter::run(raw_ostream &OS) {
<< " // operands into the appropriate MCInst.\n";
if (HasOptionalOperands) {
OS << " convertToMCInst(it->ConvertFn, Inst, it->Opcode, Operands,\n"
- << " OptionalOperandsMask);\n";
+ << " OptionalOperandsMask, DefaultsOffset);\n";
} else {
OS << " convertToMCInst(it->ConvertFn, Inst, it->Opcode, Operands);\n";
}
@@ -4022,8 +4049,16 @@ void AsmMatcherEmitter::run(raw_ostream &OS) {
}
if (!ReportMultipleNearMisses) {
- OS << " if (!checkAsmTiedOperandConstraints(*this, it->ConvertFn, "
- "Operands, ErrorInfo))\n";
+ if (HasOptionalOperands) {
+ OS << " if (!checkAsmTiedOperandConstraints(*this, it->ConvertFn, "
+ "Operands,\n";
+ OS << " DefaultsOffset, "
+ "ErrorInfo))\n";
+ } else {
+ OS << " if (!checkAsmTiedOperandConstraints(*this, it->ConvertFn, "
+ "Operands,\n";
+ OS << " ErrorInfo))\n";
+ }
OS << " return Match_InvalidTiedOperand;\n";
OS << "\n";
}
>From 195744cca7fd7f1b33971e0f2cf07b8ae47f16b5 Mon Sep 17 00:00:00 2001
From: Benjamin Maxwell <benjamin.maxwell at arm.com>
Date: Fri, 1 Mar 2024 10:08:18 +0000
Subject: [PATCH 231/406] [mlir][VectorOps][nfc] Add result pretty printing to
`vector.vscale` (#83439)
This will now print the value of `vector.vscale` as `%vscale` in IR
dumps which makes it easier to spot where things are scalable.
One test that depended on the value names has also been fixed.
---
mlir/include/mlir/Dialect/Vector/IR/VectorOps.td | 10 +++++++++-
.../Linalg/transform-op-peel-and-vectorize.mlir | 2 +-
2 files changed, 10 insertions(+), 2 deletions(-)
diff --git a/mlir/include/mlir/Dialect/Vector/IR/VectorOps.td b/mlir/include/mlir/Dialect/Vector/IR/VectorOps.td
index 6d50b0654bc575..06360bd10e5258 100644
--- a/mlir/include/mlir/Dialect/Vector/IR/VectorOps.td
+++ b/mlir/include/mlir/Dialect/Vector/IR/VectorOps.td
@@ -2809,7 +2809,8 @@ def Vector_SplatOp : Vector_Op<"splat", [
// call to the function. For that, it might be useful to have a
// 'vector.scale.global' and a 'vector.scale.local' operation.
def VectorScaleOp : Vector_Op<"vscale",
- [Pure]> {
+ [Pure, DeclareOpInterfaceMethods<OpAsmOpInterface, ["getAsmResultNames"]>]
+> {
let summary = "Load vector scale size";
let description = [{
The `vscale` op returns the scale of the scalable vectors, a positive
@@ -2825,6 +2826,13 @@ def VectorScaleOp : Vector_Op<"vscale",
}];
let results = (outs Index:$res);
let assemblyFormat = "attr-dict";
+
+ let extraClassDefinition = [{
+ void $cppClass::getAsmResultNames(
+ ::llvm::function_ref<void(mlir::Value, mlir::StringRef)> setNameFn) {
+ setNameFn(getResult(), "vscale");
+ }
+ }];
}
//===----------------------------------------------------------------------===//
diff --git a/mlir/test/Dialect/Linalg/transform-op-peel-and-vectorize.mlir b/mlir/test/Dialect/Linalg/transform-op-peel-and-vectorize.mlir
index d54cace31efb99..b7e316f8925d37 100644
--- a/mlir/test/Dialect/Linalg/transform-op-peel-and-vectorize.mlir
+++ b/mlir/test/Dialect/Linalg/transform-op-peel-and-vectorize.mlir
@@ -19,7 +19,7 @@ func.func @matmul(%A: tensor<1024x512xf32>,
// CHECK-DAG: %[[C16:.*]] = arith.constant 16 : index
// CHECK: %[[VSCALE:.*]] = vector.vscale
// CHECK: %[[STEP:.*]] = arith.muli %[[VSCALE]], %[[C16]] : index
-// CHECK: %2 = scf.for {{.*}} %[[C0]] to %[[C1024]] step %[[C8]] iter_args(%arg4 = %arg2) -> (tensor<1024x2000xf32>) {
+// CHECK: scf.for {{.*}} %[[C0]] to %[[C1024]] step %[[C8]] iter_args(%arg4 = %arg2) -> (tensor<1024x2000xf32>) {
// Main loop after vectorisation (without masking)
>From 185b1df1b1f7bd88ff0159bc51d5ddaeca27106a Mon Sep 17 00:00:00 2001
From: Pavel Iliin <Pavel.Iliin at arm.com>
Date: Fri, 1 Mar 2024 10:12:19 +0000
Subject: [PATCH 232/406] [X86][AArch64][PowerPC] __builtin_cpu_supports
accepts unknown options. (#83515)
The patch fixes https://github.com/llvm/llvm-project/issues/83407
modifing __builtin_cpu_supports behaviour so that it returns false if
unsupported features names provided in parameter and issue a warning.
__builtin_cpu_supports is target independent, but currently supported by
X86, AArch64 and PowerPC only.
---
clang/include/clang/Basic/DiagnosticSemaKinds.td | 2 +-
clang/lib/CodeGen/CGBuiltin.cpp | 7 ++++++-
clang/lib/Sema/SemaChecking.cpp | 8 +++++---
clang/test/CodeGen/aarch64-cpu-supports.c | 8 ++++++++
clang/test/Misc/warning-flags.c | 3 ++-
clang/test/Sema/aarch64-cpu-supports.c | 10 +++++-----
clang/test/Sema/builtin-cpu-supports.c | 6 +++---
7 files changed, 30 insertions(+), 14 deletions(-)
diff --git a/clang/include/clang/Basic/DiagnosticSemaKinds.td b/clang/include/clang/Basic/DiagnosticSemaKinds.td
index 4f8902e37bd3bb..938de5859513f8 100644
--- a/clang/include/clang/Basic/DiagnosticSemaKinds.td
+++ b/clang/include/clang/Basic/DiagnosticSemaKinds.td
@@ -765,7 +765,7 @@ def err_builtin_redeclare : Error<"cannot redeclare builtin function %0">;
def err_arm_invalid_specialreg : Error<"invalid special register for builtin">;
def err_arm_invalid_coproc : Error<"coprocessor %0 must be configured as "
"%select{GCP|CDE}1">;
-def err_invalid_cpu_supports : Error<"invalid cpu feature string for builtin">;
+def warn_invalid_cpu_supports : Warning<"invalid cpu feature string for builtin">;
def err_invalid_cpu_is : Error<"invalid cpu name for builtin">;
def err_invalid_cpu_specific_dispatch_value : Error<
"invalid option '%0' for %select{cpu_specific|cpu_dispatch}1">;
diff --git a/clang/lib/CodeGen/CGBuiltin.cpp b/clang/lib/CodeGen/CGBuiltin.cpp
index 98684448f4ff5c..e90014261217bc 100644
--- a/clang/lib/CodeGen/CGBuiltin.cpp
+++ b/clang/lib/CodeGen/CGBuiltin.cpp
@@ -13952,6 +13952,8 @@ Value *CodeGenFunction::EmitX86CpuIs(StringRef CPUStr) {
Value *CodeGenFunction::EmitX86CpuSupports(const CallExpr *E) {
const Expr *FeatureExpr = E->getArg(0)->IgnoreParenCasts();
StringRef FeatureStr = cast<StringLiteral>(FeatureExpr)->getString();
+ if (!getContext().getTargetInfo().validateCpuSupports(FeatureStr))
+ return Builder.getFalse();
return EmitX86CpuSupports(FeatureStr);
}
@@ -14041,6 +14043,8 @@ Value *CodeGenFunction::EmitAArch64CpuSupports(const CallExpr *E) {
ArgStr.split(Features, "+");
for (auto &Feature : Features) {
Feature = Feature.trim();
+ if (!llvm::AArch64::parseArchExtension(Feature))
+ return Builder.getFalse();
if (Feature != "default")
Features.push_back(Feature);
}
@@ -16639,7 +16643,8 @@ Value *CodeGenFunction::EmitPPCBuiltinExpr(unsigned BuiltinID,
.Case(Name, {FA_WORD, Bitmask})
#include "llvm/TargetParser/PPCTargetParser.def"
.Default({0, 0});
- assert(BitMask && "Invalid target feature string. Missed by SemaChecking?");
+ if (!BitMask)
+ return Builder.getFalse();
Value *Op0 = llvm::ConstantInt::get(Int32Ty, FeatureWord);
llvm::Function *F = CGM.getIntrinsic(Intrinsic::ppc_fixed_addr_ld);
Value *TheCall = Builder.CreateCall(F, {Op0}, "cpu_supports");
diff --git a/clang/lib/Sema/SemaChecking.cpp b/clang/lib/Sema/SemaChecking.cpp
index 690bdaa63d058b..7be2b31df2413f 100644
--- a/clang/lib/Sema/SemaChecking.cpp
+++ b/clang/lib/Sema/SemaChecking.cpp
@@ -2180,9 +2180,11 @@ static bool SemaBuiltinCpu(Sema &S, const TargetInfo &TI, CallExpr *TheCall,
// Check the contents of the string.
StringRef Feature = cast<StringLiteral>(Arg)->getString();
- if (IsCPUSupports && !TheTI->validateCpuSupports(Feature))
- return S.Diag(TheCall->getBeginLoc(), diag::err_invalid_cpu_supports)
- << Arg->getSourceRange();
+ if (IsCPUSupports && !TheTI->validateCpuSupports(Feature)) {
+ S.Diag(TheCall->getBeginLoc(), diag::warn_invalid_cpu_supports)
+ << Arg->getSourceRange();
+ return false;
+ }
if (!IsCPUSupports && !TheTI->validateCpuIs(Feature))
return S.Diag(TheCall->getBeginLoc(), diag::err_invalid_cpu_is)
<< Arg->getSourceRange();
diff --git a/clang/test/CodeGen/aarch64-cpu-supports.c b/clang/test/CodeGen/aarch64-cpu-supports.c
index 872fec6827ef11..c54b7475a3fd5f 100644
--- a/clang/test/CodeGen/aarch64-cpu-supports.c
+++ b/clang/test/CodeGen/aarch64-cpu-supports.c
@@ -34,6 +34,11 @@
// CHECK-NEXT: store i32 3, ptr [[RETVAL]], align 4
// CHECK-NEXT: br label [[RETURN]]
// CHECK: if.end4:
+// CHECK-NEXT: br i1 false, label [[IF_THEN5:%.*]], label [[IF_END6:%.*]]
+// CHECK: if.then5:
+// CHECK-NEXT: store i32 4, ptr [[RETVAL]], align 4
+// CHECK-NEXT: br label [[RETURN]]
+// CHECK: if.end6:
// CHECK-NEXT: store i32 0, ptr [[RETVAL]], align 4
// CHECK-NEXT: br label [[RETURN]]
// CHECK: return:
@@ -50,5 +55,8 @@ int main(void) {
if (__builtin_cpu_supports("sme2+ls64_v+wfxt"))
return 3;
+ if (__builtin_cpu_supports("avx2"))
+ return 4;
+
return 0;
}
diff --git a/clang/test/Misc/warning-flags.c b/clang/test/Misc/warning-flags.c
index 9d4cac9e39b420..bb3c7d816d2f0e 100644
--- a/clang/test/Misc/warning-flags.c
+++ b/clang/test/Misc/warning-flags.c
@@ -18,7 +18,7 @@ This test serves two purposes:
The list of warnings below should NEVER grow. It should gradually shrink to 0.
-CHECK: Warnings without flags (66):
+CHECK: Warnings without flags (67):
CHECK-NEXT: ext_expected_semi_decl_list
CHECK-NEXT: ext_explicit_specialization_storage_class
@@ -58,6 +58,7 @@ CHECK-NEXT: warn_ignoring_ftabstop_value
CHECK-NEXT: warn_implements_nscopying
CHECK-NEXT: warn_incompatible_qualified_id
CHECK-NEXT: warn_invalid_asm_cast_lvalue
+CHECK-NEXT: warn_invalid_cpu_supports
CHECK-NEXT: warn_maynot_respond
CHECK-NEXT: warn_method_param_redefinition
CHECK-NEXT: warn_missing_case_for_condition
diff --git a/clang/test/Sema/aarch64-cpu-supports.c b/clang/test/Sema/aarch64-cpu-supports.c
index 24aae9542dbc42..ddeed7c5bc9e97 100644
--- a/clang/test/Sema/aarch64-cpu-supports.c
+++ b/clang/test/Sema/aarch64-cpu-supports.c
@@ -5,19 +5,19 @@ int test_aarch64_features(void) {
// expected-error at +1 {{expression is not a string literal}}
if (__builtin_cpu_supports(ssbs2))
return 1;
- // expected-error at +1 {{invalid cpu feature string}}
+ // expected-warning at +1 {{invalid cpu feature string}}
if (__builtin_cpu_supports(""))
return 2;
- // expected-error at +1 {{invalid cpu feature string}}
+ // expected-warning at +1 {{invalid cpu feature string}}
if (__builtin_cpu_supports("pmull128"))
return 3;
- // expected-error at +1 {{invalid cpu feature string}}
+ // expected-warning at +1 {{invalid cpu feature string}}
if (__builtin_cpu_supports("sve2,rpres"))
return 4;
- // expected-error at +1 {{invalid cpu feature string}}
+ // expected-warning at +1 {{invalid cpu feature string}}
if (__builtin_cpu_supports("dgh+sve2-pmull"))
return 5;
- // expected-error at +1 {{invalid cpu feature string}}
+ // expected-warning at +1 {{invalid cpu feature string}}
if (__builtin_cpu_supports("default"))
return 6;
if (__builtin_cpu_supports(" ssbs + bti "))
diff --git a/clang/test/Sema/builtin-cpu-supports.c b/clang/test/Sema/builtin-cpu-supports.c
index 733d797f3ff8f8..51ee9661807f8b 100644
--- a/clang/test/Sema/builtin-cpu-supports.c
+++ b/clang/test/Sema/builtin-cpu-supports.c
@@ -7,7 +7,7 @@ extern const char *str;
int main(void) {
#ifdef __x86_64__
- if (__builtin_cpu_supports("ss")) // expected-error {{invalid cpu feature string}}
+ if (__builtin_cpu_supports("ss")) // expected-warning {{invalid cpu feature string}}
a("sse4.2");
if (__builtin_cpu_supports(str)) // expected-error {{expression is not a string literal}}
@@ -25,9 +25,9 @@ int main(void) {
(void)__builtin_cpu_supports("x86-64-v2");
(void)__builtin_cpu_supports("x86-64-v3");
(void)__builtin_cpu_supports("x86-64-v4");
- (void)__builtin_cpu_supports("x86-64-v5"); // expected-error {{invalid cpu feature string for builtin}}
+ (void)__builtin_cpu_supports("x86-64-v5"); // expected-warning {{invalid cpu feature string for builtin}}
#else
- if (__builtin_cpu_supports("neon")) // expected-error {{invalid cpu feature string for builtin}}
+ if (__builtin_cpu_supports("neon")) // expected-warning {{invalid cpu feature string for builtin}}
a("vsx");
if (__builtin_cpu_is("cortex-x3")) // expected-error {{builtin is not supported on this target}}
>From 4c8c335bcdb93e02b1bc08c5dbc7070af9bc91b5 Mon Sep 17 00:00:00 2001
From: Jay Foad <jay.foad at amd.com>
Date: Fri, 1 Mar 2024 10:14:37 +0000
Subject: [PATCH 233/406] [AMDGPU] Rename hasGFX12Enc to hasRestrictedSOffset
in BUF definitions. NFC. (#83434)
This just renames a tablegen argument to match the corresponding
subtarget feature.
---
llvm/lib/Target/AMDGPU/BUFInstructions.td | 152 +++++++++++-----------
1 file changed, 76 insertions(+), 76 deletions(-)
diff --git a/llvm/lib/Target/AMDGPU/BUFInstructions.td b/llvm/lib/Target/AMDGPU/BUFInstructions.td
index 4b74f3b81e5e78..0636a74a61dc5c 100644
--- a/llvm/lib/Target/AMDGPU/BUFInstructions.td
+++ b/llvm/lib/Target/AMDGPU/BUFInstructions.td
@@ -155,12 +155,12 @@ class MTBUF_Real <MTBUF_Pseudo ps, string real_name = ps.Mnemonic> :
}
class getMTBUFInsDA<list<RegisterClass> vdataList,
- list<RegisterClass> vaddrList=[], bit hasGFX12Enc> {
+ list<RegisterClass> vaddrList=[], bit hasRestrictedSOffset> {
RegisterClass vdataClass = !if(!empty(vdataList), ?, !head(vdataList));
RegisterClass vaddrClass = !if(!empty(vaddrList), ?, !head(vaddrList));
RegisterOperand vdata_op = getLdStRegisterOperand<vdataClass>.ret;
- dag SOffset = !if(hasGFX12Enc, (ins SReg_32:$soffset),
+ dag SOffset = !if(hasRestrictedSOffset, (ins SReg_32:$soffset),
(ins SCSrc_b32:$soffset));
dag NonVaddrInputs = !con((ins SReg_128:$srsrc), SOffset,
@@ -174,13 +174,13 @@ class getMTBUFInsDA<list<RegisterClass> vdataList,
!con((ins vdata_op:$vdata), Inputs));
}
-class getMTBUFIns<int addrKind, list<RegisterClass> vdataList=[], bit hasGFX12Enc> {
+class getMTBUFIns<int addrKind, list<RegisterClass> vdataList=[], bit hasRestrictedSOffset> {
dag ret =
- !if(!eq(addrKind, BUFAddrKind.Offset), getMTBUFInsDA<vdataList, [], hasGFX12Enc>.ret,
- !if(!eq(addrKind, BUFAddrKind.OffEn), getMTBUFInsDA<vdataList, [VGPR_32], hasGFX12Enc>.ret,
- !if(!eq(addrKind, BUFAddrKind.IdxEn), getMTBUFInsDA<vdataList, [VGPR_32], hasGFX12Enc>.ret,
- !if(!eq(addrKind, BUFAddrKind.BothEn), getMTBUFInsDA<vdataList, [VReg_64], hasGFX12Enc>.ret,
- !if(!eq(addrKind, BUFAddrKind.Addr64), getMTBUFInsDA<vdataList, [VReg_64], hasGFX12Enc>.ret,
+ !if(!eq(addrKind, BUFAddrKind.Offset), getMTBUFInsDA<vdataList, [], hasRestrictedSOffset>.ret,
+ !if(!eq(addrKind, BUFAddrKind.OffEn), getMTBUFInsDA<vdataList, [VGPR_32], hasRestrictedSOffset>.ret,
+ !if(!eq(addrKind, BUFAddrKind.IdxEn), getMTBUFInsDA<vdataList, [VGPR_32], hasRestrictedSOffset>.ret,
+ !if(!eq(addrKind, BUFAddrKind.BothEn), getMTBUFInsDA<vdataList, [VReg_64], hasRestrictedSOffset>.ret,
+ !if(!eq(addrKind, BUFAddrKind.Addr64), getMTBUFInsDA<vdataList, [VReg_64], hasRestrictedSOffset>.ret,
(ins))))));
}
@@ -215,13 +215,13 @@ class MTBUF_Load_Pseudo <string opName,
int addrKind,
RegisterClass vdataClass,
int elems,
- bit hasGFX12Enc = 0,
+ bit hasRestrictedSOffset = 0,
list<dag> pattern=[],
// Workaround bug bz30254
int addrKindCopy = addrKind>
: MTBUF_Pseudo<opName,
(outs getLdStRegisterOperand<vdataClass>.ret:$vdata),
- getMTBUFIns<addrKindCopy, [], hasGFX12Enc>.ret,
+ getMTBUFIns<addrKindCopy, [], hasRestrictedSOffset>.ret,
getMTBUFAsmOps<addrKindCopy>.ret,
pattern>,
MTBUF_SetupAddr<addrKindCopy> {
@@ -232,23 +232,23 @@ class MTBUF_Load_Pseudo <string opName,
}
multiclass MTBUF_Pseudo_Loads_Helper<string opName, RegisterClass vdataClass,
- int elems, bit hasGFX12Enc> {
+ int elems, bit hasRestrictedSOffset> {
- def _OFFSET : MTBUF_Load_Pseudo <opName, BUFAddrKind.Offset, vdataClass, elems, hasGFX12Enc>,
+ def _OFFSET : MTBUF_Load_Pseudo <opName, BUFAddrKind.Offset, vdataClass, elems, hasRestrictedSOffset>,
MTBUFAddr64Table<0, NAME>;
- def _ADDR64 : MTBUF_Load_Pseudo <opName, BUFAddrKind.Addr64, vdataClass, elems, hasGFX12Enc>,
+ def _ADDR64 : MTBUF_Load_Pseudo <opName, BUFAddrKind.Addr64, vdataClass, elems, hasRestrictedSOffset>,
MTBUFAddr64Table<1, NAME>;
- def _OFFEN : MTBUF_Load_Pseudo <opName, BUFAddrKind.OffEn, vdataClass, elems, hasGFX12Enc>;
- def _IDXEN : MTBUF_Load_Pseudo <opName, BUFAddrKind.IdxEn, vdataClass, elems, hasGFX12Enc>;
- def _BOTHEN : MTBUF_Load_Pseudo <opName, BUFAddrKind.BothEn, vdataClass, elems, hasGFX12Enc>;
+ def _OFFEN : MTBUF_Load_Pseudo <opName, BUFAddrKind.OffEn, vdataClass, elems, hasRestrictedSOffset>;
+ def _IDXEN : MTBUF_Load_Pseudo <opName, BUFAddrKind.IdxEn, vdataClass, elems, hasRestrictedSOffset>;
+ def _BOTHEN : MTBUF_Load_Pseudo <opName, BUFAddrKind.BothEn, vdataClass, elems, hasRestrictedSOffset>;
let DisableWQM = 1 in {
- def _OFFSET_exact : MTBUF_Load_Pseudo <opName, BUFAddrKind.Offset, vdataClass, elems, hasGFX12Enc>;
- def _OFFEN_exact : MTBUF_Load_Pseudo <opName, BUFAddrKind.OffEn, vdataClass, elems, hasGFX12Enc>;
- def _IDXEN_exact : MTBUF_Load_Pseudo <opName, BUFAddrKind.IdxEn, vdataClass, elems, hasGFX12Enc>;
- def _BOTHEN_exact : MTBUF_Load_Pseudo <opName, BUFAddrKind.BothEn, vdataClass, elems, hasGFX12Enc>;
+ def _OFFSET_exact : MTBUF_Load_Pseudo <opName, BUFAddrKind.Offset, vdataClass, elems, hasRestrictedSOffset>;
+ def _OFFEN_exact : MTBUF_Load_Pseudo <opName, BUFAddrKind.OffEn, vdataClass, elems, hasRestrictedSOffset>;
+ def _IDXEN_exact : MTBUF_Load_Pseudo <opName, BUFAddrKind.IdxEn, vdataClass, elems, hasRestrictedSOffset>;
+ def _BOTHEN_exact : MTBUF_Load_Pseudo <opName, BUFAddrKind.BothEn, vdataClass, elems, hasRestrictedSOffset>;
}
}
@@ -262,14 +262,14 @@ class MTBUF_Store_Pseudo <string opName,
int addrKind,
RegisterClass vdataClass,
int elems,
- bit hasGFX12Enc = 0,
+ bit hasRestrictedSOffset = 0,
list<dag> pattern=[],
// Workaround bug bz30254
int addrKindCopy = addrKind,
RegisterClass vdataClassCopy = vdataClass>
: MTBUF_Pseudo<opName,
(outs),
- getMTBUFIns<addrKindCopy, [vdataClassCopy], hasGFX12Enc>.ret,
+ getMTBUFIns<addrKindCopy, [vdataClassCopy], hasRestrictedSOffset>.ret,
getMTBUFAsmOps<addrKindCopy>.ret,
pattern>,
MTBUF_SetupAddr<addrKindCopy> {
@@ -280,23 +280,23 @@ class MTBUF_Store_Pseudo <string opName,
}
multiclass MTBUF_Pseudo_Stores_Helper<string opName, RegisterClass vdataClass,
- int elems, bit hasGFX12Enc> {
+ int elems, bit hasRestrictedSOffset> {
- def _OFFSET : MTBUF_Store_Pseudo <opName, BUFAddrKind.Offset, vdataClass, elems, hasGFX12Enc>,
+ def _OFFSET : MTBUF_Store_Pseudo <opName, BUFAddrKind.Offset, vdataClass, elems, hasRestrictedSOffset>,
MTBUFAddr64Table<0, NAME>;
- def _ADDR64 : MTBUF_Store_Pseudo <opName, BUFAddrKind.Addr64, vdataClass, elems, hasGFX12Enc>,
+ def _ADDR64 : MTBUF_Store_Pseudo <opName, BUFAddrKind.Addr64, vdataClass, elems, hasRestrictedSOffset>,
MTBUFAddr64Table<1, NAME>;
- def _OFFEN : MTBUF_Store_Pseudo <opName, BUFAddrKind.OffEn, vdataClass, elems, hasGFX12Enc>;
- def _IDXEN : MTBUF_Store_Pseudo <opName, BUFAddrKind.IdxEn, vdataClass, elems, hasGFX12Enc>;
- def _BOTHEN : MTBUF_Store_Pseudo <opName, BUFAddrKind.BothEn, vdataClass, elems, hasGFX12Enc>;
+ def _OFFEN : MTBUF_Store_Pseudo <opName, BUFAddrKind.OffEn, vdataClass, elems, hasRestrictedSOffset>;
+ def _IDXEN : MTBUF_Store_Pseudo <opName, BUFAddrKind.IdxEn, vdataClass, elems, hasRestrictedSOffset>;
+ def _BOTHEN : MTBUF_Store_Pseudo <opName, BUFAddrKind.BothEn, vdataClass, elems, hasRestrictedSOffset>;
let DisableWQM = 1 in {
- def _OFFSET_exact : MTBUF_Store_Pseudo <opName, BUFAddrKind.Offset, vdataClass, elems, hasGFX12Enc>;
- def _OFFEN_exact : MTBUF_Store_Pseudo <opName, BUFAddrKind.OffEn, vdataClass, elems, hasGFX12Enc>;
- def _IDXEN_exact : MTBUF_Store_Pseudo <opName, BUFAddrKind.IdxEn, vdataClass, elems, hasGFX12Enc>;
- def _BOTHEN_exact : MTBUF_Store_Pseudo <opName, BUFAddrKind.BothEn, vdataClass, elems, hasGFX12Enc>;
+ def _OFFSET_exact : MTBUF_Store_Pseudo <opName, BUFAddrKind.Offset, vdataClass, elems, hasRestrictedSOffset>;
+ def _OFFEN_exact : MTBUF_Store_Pseudo <opName, BUFAddrKind.OffEn, vdataClass, elems, hasRestrictedSOffset>;
+ def _IDXEN_exact : MTBUF_Store_Pseudo <opName, BUFAddrKind.IdxEn, vdataClass, elems, hasRestrictedSOffset>;
+ def _BOTHEN_exact : MTBUF_Store_Pseudo <opName, BUFAddrKind.BothEn, vdataClass, elems, hasRestrictedSOffset>;
}
}
@@ -405,12 +405,12 @@ class getLdStVDataRegisterOperand<RegisterClass RC, bit isTFE> {
}
class getMUBUFInsDA<list<RegisterClass> vdataList,
- list<RegisterClass> vaddrList, bit isTFE, bit hasGFX12Enc> {
+ list<RegisterClass> vaddrList, bit isTFE, bit hasRestrictedSOffset> {
RegisterClass vdataClass = !if(!empty(vdataList), ?, !head(vdataList));
RegisterClass vaddrClass = !if(!empty(vaddrList), ?, !head(vaddrList));
RegisterOperand vdata_op = getLdStVDataRegisterOperand<vdataClass, isTFE>.ret;
- dag SOffset = !if(hasGFX12Enc, (ins SReg_32:$soffset), (ins SCSrc_b32:$soffset));
+ dag SOffset = !if(hasRestrictedSOffset, (ins SReg_32:$soffset), (ins SCSrc_b32:$soffset));
dag NonVaddrInputs = !con((ins SReg_128:$srsrc), SOffset, (ins Offset:$offset, CPol_0:$cpol, i1imm_0:$swz));
dag Inputs = !if(!empty(vaddrList), NonVaddrInputs, !con((ins vaddrClass:$vaddr), NonVaddrInputs));
@@ -436,13 +436,13 @@ class getMUBUFElements<ValueType vt> {
);
}
-class getMUBUFIns<int addrKind, list<RegisterClass> vdataList, bit isTFE, bit hasGFX12Enc> {
+class getMUBUFIns<int addrKind, list<RegisterClass> vdataList, bit isTFE, bit hasRestrictedSOffset> {
dag ret =
- !if(!eq(addrKind, BUFAddrKind.Offset), getMUBUFInsDA<vdataList, [], isTFE, hasGFX12Enc>.ret,
- !if(!eq(addrKind, BUFAddrKind.OffEn), getMUBUFInsDA<vdataList, [VGPR_32], isTFE, hasGFX12Enc>.ret,
- !if(!eq(addrKind, BUFAddrKind.IdxEn), getMUBUFInsDA<vdataList, [VGPR_32], isTFE, hasGFX12Enc>.ret,
- !if(!eq(addrKind, BUFAddrKind.BothEn), getMUBUFInsDA<vdataList, [VReg_64], isTFE, hasGFX12Enc>.ret,
- !if(!eq(addrKind, BUFAddrKind.Addr64), getMUBUFInsDA<vdataList, [VReg_64], isTFE, hasGFX12Enc>.ret,
+ !if(!eq(addrKind, BUFAddrKind.Offset), getMUBUFInsDA<vdataList, [], isTFE, hasRestrictedSOffset>.ret,
+ !if(!eq(addrKind, BUFAddrKind.OffEn), getMUBUFInsDA<vdataList, [VGPR_32], isTFE, hasRestrictedSOffset>.ret,
+ !if(!eq(addrKind, BUFAddrKind.IdxEn), getMUBUFInsDA<vdataList, [VGPR_32], isTFE, hasRestrictedSOffset>.ret,
+ !if(!eq(addrKind, BUFAddrKind.BothEn), getMUBUFInsDA<vdataList, [VReg_64], isTFE, hasRestrictedSOffset>.ret,
+ !if(!eq(addrKind, BUFAddrKind.Addr64), getMUBUFInsDA<vdataList, [VReg_64], isTFE, hasRestrictedSOffset>.ret,
(ins))))));
}
@@ -482,7 +482,7 @@ class MUBUF_Load_Pseudo <string opName,
bit isLds = 0,
bit isLdsOpc = 0,
bit isTFE = 0,
- bit hasGFX12Enc = 0,
+ bit hasRestrictedSOffset = 0,
list<dag> pattern=[],
// Workaround bug bz30254
int addrKindCopy = addrKind,
@@ -490,7 +490,7 @@ class MUBUF_Load_Pseudo <string opName,
RegisterOperand vdata_op = getLdStVDataRegisterOperand<vdata_rc, isTFE>.ret>
: MUBUF_Pseudo<opName,
!if(!or(isLds, isLdsOpc), (outs), (outs vdata_op:$vdata)),
- !con(getMUBUFIns<addrKindCopy, [], isTFE, hasGFX12Enc>.ret,
+ !con(getMUBUFIns<addrKindCopy, [], isTFE, hasRestrictedSOffset>.ret,
!if(HasTiedDest, (ins vdata_op:$vdata_in), (ins))),
getMUBUFAsmOps<addrKindCopy, !or(isLds, isLdsOpc), isLds, isTFE>.ret,
pattern>,
@@ -536,24 +536,24 @@ multiclass MUBUF_Pseudo_Load_Pats<string BaseInst, ValueType load_vt = i32, SDPa
}
multiclass MUBUF_Pseudo_Loads_Helper<string opName, ValueType load_vt,
- bit TiedDest, bit isLds, bit isTFE, bit hasGFX12Enc> {
+ bit TiedDest, bit isLds, bit isTFE, bit hasRestrictedSOffset> {
defvar legal_load_vt = !if(!eq(load_vt, v3f16), v4f16, load_vt);
- def _OFFSET : MUBUF_Load_Pseudo <opName, BUFAddrKind.Offset, legal_load_vt, TiedDest, isLds, 0, isTFE, hasGFX12Enc>,
+ def _OFFSET : MUBUF_Load_Pseudo <opName, BUFAddrKind.Offset, legal_load_vt, TiedDest, isLds, 0, isTFE, hasRestrictedSOffset>,
MUBUFAddr64Table<0, NAME # !if(isLds, "_LDS", "")>;
- def _ADDR64 : MUBUF_Load_Pseudo <opName, BUFAddrKind.Addr64, legal_load_vt, TiedDest, isLds, 0, isTFE, hasGFX12Enc>,
+ def _ADDR64 : MUBUF_Load_Pseudo <opName, BUFAddrKind.Addr64, legal_load_vt, TiedDest, isLds, 0, isTFE, hasRestrictedSOffset>,
MUBUFAddr64Table<1, NAME # !if(isLds, "_LDS", "")>;
- def _OFFEN : MUBUF_Load_Pseudo <opName, BUFAddrKind.OffEn, legal_load_vt, TiedDest, isLds, 0, isTFE, hasGFX12Enc>;
- def _IDXEN : MUBUF_Load_Pseudo <opName, BUFAddrKind.IdxEn, legal_load_vt, TiedDest, isLds, 0, isTFE, hasGFX12Enc>;
- def _BOTHEN : MUBUF_Load_Pseudo <opName, BUFAddrKind.BothEn, legal_load_vt, TiedDest, isLds, 0, isTFE, hasGFX12Enc>;
+ def _OFFEN : MUBUF_Load_Pseudo <opName, BUFAddrKind.OffEn, legal_load_vt, TiedDest, isLds, 0, isTFE, hasRestrictedSOffset>;
+ def _IDXEN : MUBUF_Load_Pseudo <opName, BUFAddrKind.IdxEn, legal_load_vt, TiedDest, isLds, 0, isTFE, hasRestrictedSOffset>;
+ def _BOTHEN : MUBUF_Load_Pseudo <opName, BUFAddrKind.BothEn, legal_load_vt, TiedDest, isLds, 0, isTFE, hasRestrictedSOffset>;
let DisableWQM = 1 in {
- def _OFFSET_exact : MUBUF_Load_Pseudo <opName, BUFAddrKind.Offset, legal_load_vt, TiedDest, isLds, 0, isTFE, hasGFX12Enc>;
- def _OFFEN_exact : MUBUF_Load_Pseudo <opName, BUFAddrKind.OffEn, legal_load_vt, TiedDest, isLds, 0, isTFE, hasGFX12Enc>;
- def _IDXEN_exact : MUBUF_Load_Pseudo <opName, BUFAddrKind.IdxEn, legal_load_vt, TiedDest, isLds, 0, isTFE, hasGFX12Enc>;
- def _BOTHEN_exact : MUBUF_Load_Pseudo <opName, BUFAddrKind.BothEn, legal_load_vt, TiedDest, isLds, 0, isTFE, hasGFX12Enc>;
+ def _OFFSET_exact : MUBUF_Load_Pseudo <opName, BUFAddrKind.Offset, legal_load_vt, TiedDest, isLds, 0, isTFE, hasRestrictedSOffset>;
+ def _OFFEN_exact : MUBUF_Load_Pseudo <opName, BUFAddrKind.OffEn, legal_load_vt, TiedDest, isLds, 0, isTFE, hasRestrictedSOffset>;
+ def _IDXEN_exact : MUBUF_Load_Pseudo <opName, BUFAddrKind.IdxEn, legal_load_vt, TiedDest, isLds, 0, isTFE, hasRestrictedSOffset>;
+ def _BOTHEN_exact : MUBUF_Load_Pseudo <opName, BUFAddrKind.BothEn, legal_load_vt, TiedDest, isLds, 0, isTFE, hasRestrictedSOffset>;
}
}
@@ -596,13 +596,13 @@ class MUBUF_Store_Pseudo <string opName,
int addrKind,
ValueType store_vt,
bit isTFE = 0,
- bit hasGFX12Enc = 0,
+ bit hasRestrictedSOffset = 0,
list<dag> pattern=[],
// Workaround bug bz30254
int addrKindCopy = addrKind>
: MUBUF_Pseudo<opName,
(outs),
- getMUBUFIns<addrKindCopy, [getVregSrcForVT<store_vt>.ret.RegClass], isTFE, hasGFX12Enc>.ret,
+ getMUBUFIns<addrKindCopy, [getVregSrcForVT<store_vt>.ret.RegClass], isTFE, hasRestrictedSOffset>.ret,
getMUBUFAsmOps<addrKindCopy, 0, 0, isTFE>.ret,
pattern>,
MUBUF_SetupAddr<addrKindCopy> {
@@ -633,24 +633,24 @@ multiclass MUBUF_Pseudo_Store_Pats<string BaseInst, ValueType store_vt = i32, SD
}
multiclass MUBUF_Pseudo_Stores_Helper<string opName, ValueType store_vt,
- bit isTFE, bit hasGFX12Enc> {
+ bit isTFE, bit hasRestrictedSOffset> {
defvar legal_store_vt = !if(!eq(store_vt, v3f16), v4f16, store_vt);
- def _OFFSET : MUBUF_Store_Pseudo <opName, BUFAddrKind.Offset, legal_store_vt, isTFE, hasGFX12Enc>,
+ def _OFFSET : MUBUF_Store_Pseudo <opName, BUFAddrKind.Offset, legal_store_vt, isTFE, hasRestrictedSOffset>,
MUBUFAddr64Table<0, NAME>;
- def _ADDR64 : MUBUF_Store_Pseudo <opName, BUFAddrKind.Addr64, legal_store_vt, isTFE, hasGFX12Enc>,
+ def _ADDR64 : MUBUF_Store_Pseudo <opName, BUFAddrKind.Addr64, legal_store_vt, isTFE, hasRestrictedSOffset>,
MUBUFAddr64Table<1, NAME>;
- def _OFFEN : MUBUF_Store_Pseudo <opName, BUFAddrKind.OffEn, legal_store_vt, isTFE, hasGFX12Enc>;
- def _IDXEN : MUBUF_Store_Pseudo <opName, BUFAddrKind.IdxEn, legal_store_vt, isTFE, hasGFX12Enc>;
- def _BOTHEN : MUBUF_Store_Pseudo <opName, BUFAddrKind.BothEn, legal_store_vt, isTFE, hasGFX12Enc>;
+ def _OFFEN : MUBUF_Store_Pseudo <opName, BUFAddrKind.OffEn, legal_store_vt, isTFE, hasRestrictedSOffset>;
+ def _IDXEN : MUBUF_Store_Pseudo <opName, BUFAddrKind.IdxEn, legal_store_vt, isTFE, hasRestrictedSOffset>;
+ def _BOTHEN : MUBUF_Store_Pseudo <opName, BUFAddrKind.BothEn, legal_store_vt, isTFE, hasRestrictedSOffset>;
let DisableWQM = 1 in {
- def _OFFSET_exact : MUBUF_Store_Pseudo <opName, BUFAddrKind.Offset, legal_store_vt, isTFE, hasGFX12Enc>;
- def _OFFEN_exact : MUBUF_Store_Pseudo <opName, BUFAddrKind.OffEn, legal_store_vt, isTFE, hasGFX12Enc>;
- def _IDXEN_exact : MUBUF_Store_Pseudo <opName, BUFAddrKind.IdxEn, legal_store_vt, isTFE, hasGFX12Enc>;
- def _BOTHEN_exact : MUBUF_Store_Pseudo <opName, BUFAddrKind.BothEn, legal_store_vt, isTFE, hasGFX12Enc>;
+ def _OFFSET_exact : MUBUF_Store_Pseudo <opName, BUFAddrKind.Offset, legal_store_vt, isTFE, hasRestrictedSOffset>;
+ def _OFFEN_exact : MUBUF_Store_Pseudo <opName, BUFAddrKind.OffEn, legal_store_vt, isTFE, hasRestrictedSOffset>;
+ def _IDXEN_exact : MUBUF_Store_Pseudo <opName, BUFAddrKind.IdxEn, legal_store_vt, isTFE, hasRestrictedSOffset>;
+ def _BOTHEN_exact : MUBUF_Store_Pseudo <opName, BUFAddrKind.BothEn, legal_store_vt, isTFE, hasRestrictedSOffset>;
}
}
@@ -680,14 +680,14 @@ class MUBUF_Pseudo_Store_Lds<string opName>
let AsmMatchConverter = "cvtMubuf";
}
-class getMUBUFAtomicInsDA<RegisterClass vdataClass, bit vdata_in, bit hasGFX12Enc,
+class getMUBUFAtomicInsDA<RegisterClass vdataClass, bit vdata_in, bit hasRestrictedSOffset,
list<RegisterClass> vaddrList=[]> {
RegisterClass vaddrClass = !if(!empty(vaddrList), ?, !head(vaddrList));
RegisterOperand vdata_op = getLdStRegisterOperand<vdataClass>.ret;
dag VData = !if(vdata_in, (ins vdata_op:$vdata_in), (ins vdata_op:$vdata));
dag Data = !if(!empty(vaddrList), VData, !con(VData, (ins vaddrClass:$vaddr)));
- dag SOffset = !if(hasGFX12Enc, (ins SReg_32:$soffset), (ins SCSrc_b32:$soffset));
+ dag SOffset = !if(hasRestrictedSOffset, (ins SReg_32:$soffset), (ins SCSrc_b32:$soffset));
dag MainInputs = !con((ins SReg_128:$srsrc), SOffset, (ins Offset:$offset));
dag CPol = !if(vdata_in, (ins CPol_GLC_WithDefault:$cpol),
(ins CPol_NonGLC_WithDefault:$cpol));
@@ -698,20 +698,20 @@ class getMUBUFAtomicInsDA<RegisterClass vdataClass, bit vdata_in, bit hasGFX12En
class getMUBUFAtomicIns<int addrKind,
RegisterClass vdataClass,
bit vdata_in,
- bit hasGFX12Enc,
+ bit hasRestrictedSOffset,
// Workaround bug bz30254
RegisterClass vdataClassCopy=vdataClass> {
dag ret =
!if(!eq(addrKind, BUFAddrKind.Offset),
- getMUBUFAtomicInsDA<vdataClassCopy, vdata_in, hasGFX12Enc>.ret,
+ getMUBUFAtomicInsDA<vdataClassCopy, vdata_in, hasRestrictedSOffset>.ret,
!if(!eq(addrKind, BUFAddrKind.OffEn),
- getMUBUFAtomicInsDA<vdataClassCopy, vdata_in, hasGFX12Enc, [VGPR_32]>.ret,
+ getMUBUFAtomicInsDA<vdataClassCopy, vdata_in, hasRestrictedSOffset, [VGPR_32]>.ret,
!if(!eq(addrKind, BUFAddrKind.IdxEn),
- getMUBUFAtomicInsDA<vdataClassCopy, vdata_in, hasGFX12Enc, [VGPR_32]>.ret,
+ getMUBUFAtomicInsDA<vdataClassCopy, vdata_in, hasRestrictedSOffset, [VGPR_32]>.ret,
!if(!eq(addrKind, BUFAddrKind.BothEn),
- getMUBUFAtomicInsDA<vdataClassCopy, vdata_in, hasGFX12Enc, [VReg_64]>.ret,
+ getMUBUFAtomicInsDA<vdataClassCopy, vdata_in, hasRestrictedSOffset, [VReg_64]>.ret,
!if(!eq(addrKind, BUFAddrKind.Addr64),
- getMUBUFAtomicInsDA<vdataClassCopy, vdata_in, hasGFX12Enc, [VReg_64]>.ret,
+ getMUBUFAtomicInsDA<vdataClassCopy, vdata_in, hasRestrictedSOffset, [VReg_64]>.ret,
(ins))))));
}
@@ -738,14 +738,14 @@ class MUBUF_Atomic_Pseudo<string opName,
class MUBUF_AtomicNoRet_Pseudo<string opName, int addrKind,
RegisterClass vdataClass,
- bit hasGFX12Enc = 0,
+ bit hasRestrictedSOffset = 0,
list<dag> pattern=[],
// Workaround bug bz30254
int addrKindCopy = addrKind,
RegisterClass vdataClassCopy = vdataClass>
: MUBUF_Atomic_Pseudo<opName, addrKindCopy,
(outs),
- getMUBUFAtomicIns<addrKindCopy, vdataClassCopy, 0, hasGFX12Enc>.ret,
+ getMUBUFAtomicIns<addrKindCopy, vdataClassCopy, 0, hasRestrictedSOffset>.ret,
getMUBUFAsmOps<addrKindCopy>.ret,
pattern>,
AtomicNoRet<opName # "_" # getAddrName<addrKindCopy>.ret, 0> {
@@ -758,7 +758,7 @@ class MUBUF_AtomicNoRet_Pseudo<string opName, int addrKind,
class MUBUF_AtomicRet_Pseudo<string opName, int addrKind,
RegisterClass vdataClass,
- bit hasGFX12Enc = 0,
+ bit hasRestrictedSOffset = 0,
list<dag> pattern=[],
// Workaround bug bz30254
int addrKindCopy = addrKind,
@@ -766,7 +766,7 @@ class MUBUF_AtomicRet_Pseudo<string opName, int addrKind,
RegisterOperand vdata_op = getLdStRegisterOperand<vdataClass>.ret>
: MUBUF_Atomic_Pseudo<opName, addrKindCopy,
(outs vdata_op:$vdata),
- getMUBUFAtomicIns<addrKindCopy, vdataClassCopy, 1, hasGFX12Enc>.ret,
+ getMUBUFAtomicIns<addrKindCopy, vdataClassCopy, 1, hasRestrictedSOffset>.ret,
getMUBUFAsmOps<addrKindCopy>.ret,
pattern>,
AtomicNoRet<opName # "_" # getAddrName<addrKindCopy>.ret, 1> {
>From 44c0bdb402271522a17704b4a18c8bf5efb55c4f Mon Sep 17 00:00:00 2001
From: Tom Eccles <tom.eccles at arm.com>
Date: Fri, 1 Mar 2024 10:16:27 +0000
Subject: [PATCH 234/406] [flang][HLFIR] Use GreedyPatternRewriter in
LowerHLFIRIntrinsics (#83438)
In #83253 @matthias-springer pointed out that LowerHLFIRIntrinsics.cpp
should not be using rewrite patterns with the dialect conversion driver.
The intention of this pass is to lower HLFIR intrinsic operations into
FIR so it conceptually fits dialect conversion. However, dialect
conversion is much stricter about changing types when replacing
operations. This pass sometimes looses track of array bounds, resulting
in replacements with operations with different but compatible types
(expressions of the same rank and element types but with or without
compile time known array bounds). This is difficult to accommodate with
the dialect conversion driver and so I have changed to use the greedy
pattern rewriter.
There is a lot of test churn because the greedy pattern rewriter also
performs canonicalization.
---
.../HLFIR/Transforms/LowerHLFIRIntrinsics.cpp | 39 ++---
flang/test/HLFIR/all-lowering.fir | 8 +-
flang/test/HLFIR/any-lowering.fir | 6 +-
.../count-lowering-default-int-kinds.fir | 16 +-
flang/test/HLFIR/count-lowering.fir | 6 +-
flang/test/HLFIR/dot_product-lowering.fir | 1 -
flang/test/HLFIR/extents-of-shape-of.f90 | 11 +-
flang/test/HLFIR/matmul-lowering.fir | 2 +-
flang/test/HLFIR/maxloc-lowering.fir | 137 ++++++++----------
flang/test/HLFIR/maxval-lowering.fir | 4 +-
flang/test/HLFIR/minloc-lowering.fir | 137 ++++++++----------
flang/test/HLFIR/minval-lowering.fir | 6 +-
flang/test/HLFIR/mul_transpose.f90 | 27 ++--
flang/test/HLFIR/product-lowering.fir | 4 +-
flang/test/HLFIR/sum-lowering.fir | 4 +-
flang/test/HLFIR/transpose-lowering.fir | 2 +-
flang/test/Lower/convert.f90 | 2 +-
17 files changed, 190 insertions(+), 222 deletions(-)
diff --git a/flang/lib/Optimizer/HLFIR/Transforms/LowerHLFIRIntrinsics.cpp b/flang/lib/Optimizer/HLFIR/Transforms/LowerHLFIRIntrinsics.cpp
index 377cc44392028f..0142fb0cfb0bb0 100644
--- a/flang/lib/Optimizer/HLFIR/Transforms/LowerHLFIRIntrinsics.cpp
+++ b/flang/lib/Optimizer/HLFIR/Transforms/LowerHLFIRIntrinsics.cpp
@@ -18,12 +18,12 @@
#include "flang/Optimizer/HLFIR/HLFIROps.h"
#include "flang/Optimizer/HLFIR/Passes.h"
#include "mlir/IR/BuiltinDialect.h"
+#include "mlir/IR/MLIRContext.h"
#include "mlir/IR/PatternMatch.h"
#include "mlir/Pass/Pass.h"
#include "mlir/Pass/PassManager.h"
#include "mlir/Support/LogicalResult.h"
-#include "mlir/Transforms/DialectConversion.h"
-#include <mlir/IR/MLIRContext.h>
+#include "mlir/Transforms/GreedyPatternRewriteDriver.h"
#include <optional>
namespace hlfir {
@@ -176,14 +176,7 @@ class HlfirIntrinsicConversion : public mlir::OpRewritePattern<OP> {
rewriter.eraseOp(use);
}
}
- // TODO: This entire pass should be a greedy pattern rewrite or a manual
- // IR traversal. A dialect conversion cannot be used here because
- // `replaceAllUsesWith` is not supported. Similarly, `replaceOp` is not
- // suitable because "op->getResult(0)" and "base" can have different types.
- // In such a case, the dialect conversion will attempt to convert the type,
- // but no type converter is specified in this pass. Also note that all
- // patterns in this pass are actually rewrite patterns.
- op->getResult(0).replaceAllUsesWith(base);
+
rewriter.replaceOp(op, base);
}
};
@@ -491,19 +484,19 @@ class LowerHLFIRIntrinsics
ProductOpConversion, TransposeOpConversion, CountOpConversion,
DotProductOpConversion, MaxvalOpConversion, MinvalOpConversion,
MinlocOpConversion, MaxlocOpConversion>(context);
- mlir::ConversionTarget target(*context);
- target.addLegalDialect<mlir::BuiltinDialect, mlir::arith::ArithDialect,
- mlir::func::FuncDialect, fir::FIROpsDialect,
- hlfir::hlfirDialect>();
- target.addIllegalOp<hlfir::MatmulOp, hlfir::MatmulTransposeOp, hlfir::SumOp,
- hlfir::ProductOp, hlfir::TransposeOp, hlfir::AnyOp,
- hlfir::AllOp, hlfir::DotProductOp, hlfir::CountOp,
- hlfir::MaxvalOp, hlfir::MinvalOp, hlfir::MinlocOp,
- hlfir::MaxlocOp>();
- target.markUnknownOpDynamicallyLegal(
- [](mlir::Operation *) { return true; });
- if (mlir::failed(
- mlir::applyFullConversion(module, target, std::move(patterns)))) {
+
+ // While conceptually this pass is performing dialect conversion, we use
+ // pattern rewrites here instead of dialect conversion because this pass
+ // looses array bounds from some of the expressions e.g.
+ // !hlfir.expr<2xi32> -> !hlfir.expr<?xi32>
+ // MLIR thinks this is a different type so dialect conversion fails.
+ // Pattern rewriting only requires that the resulting IR is still valid
+ mlir::GreedyRewriteConfig config;
+ // Prevent the pattern driver from merging blocks
+ config.enableRegionSimplification = false;
+
+ if (mlir::failed(mlir::applyPatternsAndFoldGreedily(
+ module, std::move(patterns), config))) {
mlir::emitError(mlir::UnknownLoc::get(context),
"failure in HLFIR intrinsic lowering");
signalPassFailure();
diff --git a/flang/test/HLFIR/all-lowering.fir b/flang/test/HLFIR/all-lowering.fir
index dfd1ace947d68d..e83378eacf9c9f 100644
--- a/flang/test/HLFIR/all-lowering.fir
+++ b/flang/test/HLFIR/all-lowering.fir
@@ -34,6 +34,7 @@ func.func @_QPall2(%arg0: !fir.box<!fir.array<?x?x!fir.logical<4>>> {fir.bindc_n
// CHECK: %[[ARG0:.*]]: !fir.box<!fir.array<?x?x!fir.logical<4>>>
// CHECK: %[[ARG1:.*]]: !fir.box<!fir.array<?x!fir.logical<4>>>
// CHECK: %[[ARG2:.*]]: !fir.ref<i32>
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
// CHECK-DAG: %[[MASK:.*]]:2 = hlfir.declare %[[ARG0]]
// CHECK-DAG: %[[DIM_VAR:.*]]:2 = hlfir.declare %[[ARG2]]
// CHECK-DAG: %[[RES:.*]]:2 = hlfir.declare %[[ARG1]]
@@ -55,7 +56,6 @@ func.func @_QPall2(%arg0: !fir.box<!fir.array<?x?x!fir.logical<4>>> {fir.bindc_n
// CHECK-NEXT: %[[ADDR:.*]] = fir.box_addr %[[RET]]
// CHECK-NEXT: %[[SHIFT:.*]] = fir.shape_shift %[[BOX_DIMS]]#0, %[[BOX_DIMS]]#1
// CHECK-NEXT: %[[TMP:.*]]:2 = hlfir.declare %[[ADDR]](%[[SHIFT]]) {uniq_name = ".tmp.intrinsic_result"}
-// CHECK: %[[TRUE:.*]] = arith.constant true
// CHECK: %[[EXPR:.*]] = hlfir.as_expr %[[TMP]]#0 move %[[TRUE]] : (!fir.box<!fir.array<?x!fir.logical<4>>>, i1) -> !hlfir.expr<?x!fir.logical<4>>
// CHECK: hlfir.assign %[[EXPR]] to %[[RES]]#0
// CHECK: hlfir.destroy %[[EXPR]]
@@ -79,6 +79,7 @@ func.func @_QPall3(%arg0: !fir.ref<!fir.array<2x!fir.logical<4>>> {fir.bindc_nam
}
// CHECK-LABEL: func.func @_QPall3(
// CHECK: %[[ARG0:.*]]: !fir.ref<!fir.array<2x!fir.logical<4>>>
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
// CHECK-DAG: %[[RET_BOX:.*]] = fir.alloca !fir.box<!fir.heap<!fir.array<?x!fir.logical<4>>>>
// CHECK-DAG: %[[RET_ADDR:.*]] = fir.zero_bits !fir.heap<!fir.array<?x!fir.logical<4>>>
// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
@@ -101,7 +102,6 @@ func.func @_QPall3(%arg0: !fir.ref<!fir.array<2x!fir.logical<4>>> {fir.bindc_nam
// CHECK-NEXT: %[[ADDR:.*]] = fir.box_addr %[[RET]]
// CHECK-NEXT: %[[SHIFT:.*]] = fir.shape_shift %[[BOX_DIMS]]#0, %[[BOX_DIMS]]#1
// CHECK-NEXT: %[[TMP:.*]]:2 = hlfir.declare %[[ADDR]](%[[SHIFT]]) {uniq_name = ".tmp.intrinsic_result"}
-// CHECK: %[[TRUE:.*]] = arith.constant true
// CHECK: %[[EXPR:.*]] = hlfir.as_expr %[[TMP]]#0 move %[[TRUE]] : (!fir.box<!fir.array<?x!fir.logical<4>>>, i1) -> !hlfir.expr<?x!fir.logical<4>>
// CHECK: hlfir.assign %[[EXPR]] to %[[RES]]
// CHECK: hlfir.destroy %[[EXPR]]
@@ -125,6 +125,7 @@ func.func @_QPall4(%arg0: !fir.box<!fir.array<?x?x!fir.logical<4>>> {fir.bindc_n
// CHECK: %[[ARG0:.*]]: !fir.box<!fir.array<?x?x!fir.logical<4>>>
// CHECK: %[[ARG1:.*]]: !fir.box<!fir.array<?x!fir.logical<4>>>
// CHECK: %[[ARG2:.*]]: !fir.ref<!fir.box<!fir.ptr<i32>>>
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
// CHECK-DAG: %[[MASK:.*]]:2 = hlfir.declare %[[ARG0]]
// CHECK-DAG: %[[DIM_ARG:.*]]:2 = hlfir.declare %[[ARG2]]
// CHECK-DAG: %[[RES:.*]]:2 = hlfir.declare %[[ARG1]]
@@ -149,9 +150,8 @@ func.func @_QPall4(%arg0: !fir.box<!fir.array<?x?x!fir.logical<4>>> {fir.bindc_n
// CHECK-NEXT: %[[ADDR:.*]] = fir.box_addr %[[RET]]
// CHECK-NEXT: %[[SHIFT:.*]] = fir.shape_shift %[[BOX_DIMS]]#0, %[[BOX_DIMS]]#1
// CHECK-NEXT: %[[TMP:.*]]:2 = hlfir.declare %[[ADDR]](%[[SHIFT]]) {uniq_name = ".tmp.intrinsic_result"}
-// CHECK: %[[TRUE:.*]] = arith.constant true
// CHECK: %[[EXPR:.*]] = hlfir.as_expr %[[TMP]]#0 move %[[TRUE]] : (!fir.box<!fir.array<?x!fir.logical<4>>>, i1) -> !hlfir.expr<?x!fir.logical<4>>
// CHECK: hlfir.assign %[[EXPR]] to %[[RES]]
// CHECK: hlfir.destroy %[[EXPR]]
// CHECK-NEXT: return
-// CHECK-NEXT: }
\ No newline at end of file
+// CHECK-NEXT: }
diff --git a/flang/test/HLFIR/any-lowering.fir b/flang/test/HLFIR/any-lowering.fir
index ef8b8950293190..039146727d3f56 100644
--- a/flang/test/HLFIR/any-lowering.fir
+++ b/flang/test/HLFIR/any-lowering.fir
@@ -36,6 +36,7 @@ func.func @_QPany2(%arg0: !fir.box<!fir.array<?x?x!fir.logical<4>>> {fir.bindc_n
// CHECK: %[[ARG0:.*]]: !fir.box<!fir.array<?x?x!fir.logical<4>>>
// CHECK: %[[ARG1:.*]]: !fir.box<!fir.array<?x!fir.logical<4>>>
// CHECK: %[[ARG2:.*]]: !fir.ref<i32>
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
// CHECK-DAG: %[[MASK:.*]]:2 = hlfir.declare %[[ARG0]]
// CHECK-DAG: %[[DIM_VAR:.*]]:2 = hlfir.declare %[[ARG2]]
// CHECK-DAG: %[[RES:.*]]:2 = hlfir.declare %[[ARG1]]
@@ -57,7 +58,6 @@ func.func @_QPany2(%arg0: !fir.box<!fir.array<?x?x!fir.logical<4>>> {fir.bindc_n
// CHECK-NEXT: %[[ADDR:.*]] = fir.box_addr %[[RET]]
// CHECK-NEXT: %[[SHIFT:.*]] = fir.shape_shift %[[BOX_DIMS]]#0, %[[BOX_DIMS]]#1
// CHECK-NEXT: %[[TMP:.*]]:2 = hlfir.declare %[[ADDR]](%[[SHIFT]]) {uniq_name = ".tmp.intrinsic_result"}
-// CHECK: %[[TRUE:.*]] = arith.constant true
// CHECK: %[[EXPR:.*]] = hlfir.as_expr %[[TMP]]#0 move %[[TRUE]] : (!fir.box<!fir.array<?x!fir.logical<4>>>, i1) -> !hlfir.expr<?x!fir.logical<4>>
// CHECK: hlfir.assign %[[EXPR]] to %[[RES]]#0
// CHECK: hlfir.destroy %[[EXPR]]
@@ -82,6 +82,7 @@ func.func @_QPany3(%arg0: !fir.ref<!fir.array<2x!fir.logical<4>>> {fir.bindc_nam
}
// CHECK-LABEL: func.func @_QPany3(
// CHECK: %[[ARG0:.*]]: !fir.ref<!fir.array<2x!fir.logical<4>>>
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
// CHECK-DAG: %[[RET_BOX:.*]] = fir.alloca !fir.box<!fir.heap<!fir.array<?x!fir.logical<4>>>>
// CHECK-DAG: %[[RET_ADDR:.*]] = fir.zero_bits !fir.heap<!fir.array<?x!fir.logical<4>>>
// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
@@ -104,7 +105,6 @@ func.func @_QPany3(%arg0: !fir.ref<!fir.array<2x!fir.logical<4>>> {fir.bindc_nam
// CHECK-NEXT: %[[ADDR:.*]] = fir.box_addr %[[RET]]
// CHECK-NEXT: %[[SHIFT:.*]] = fir.shape_shift %[[BOX_DIMS]]#0, %[[BOX_DIMS]]#1
// CHECK-NEXT: %[[TMP:.*]]:2 = hlfir.declare %[[ADDR]](%[[SHIFT]]) {uniq_name = ".tmp.intrinsic_result"}
-// CHECK: %[[TRUE:.*]] = arith.constant true
// CHECK: %[[EXPR:.*]] = hlfir.as_expr %[[TMP]]#0 move %[[TRUE]] : (!fir.box<!fir.array<?x!fir.logical<4>>>, i1) -> !hlfir.expr<?x!fir.logical<4>>
// CHECK: hlfir.assign %[[EXPR]] to %[[RES]]
// CHECK: hlfir.destroy %[[EXPR]]
@@ -129,6 +129,7 @@ func.func @_QPany4(%arg0: !fir.box<!fir.array<?x?x!fir.logical<4>>> {fir.bindc_n
// CHECK: %[[ARG0:.*]]: !fir.box<!fir.array<?x?x!fir.logical<4>>>
// CHECK: %[[ARG1:.*]]: !fir.box<!fir.array<?x!fir.logical<4>>>
// CHECK: %[[ARG2:.*]]: !fir.ref<!fir.box<!fir.ptr<i32>>>
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
// CHECK-DAG: %[[MASK:.*]]:2 = hlfir.declare %[[ARG0]]
// CHECK-DAG: %[[DIM_ARG:.*]]:2 = hlfir.declare %[[ARG2]]
// CHECK-DAG: %[[RES:.*]]:2 = hlfir.declare %[[ARG1]]
@@ -153,7 +154,6 @@ func.func @_QPany4(%arg0: !fir.box<!fir.array<?x?x!fir.logical<4>>> {fir.bindc_n
// CHECK-NEXT: %[[ADDR:.*]] = fir.box_addr %[[RET]]
// CHECK-NEXT: %[[SHIFT:.*]] = fir.shape_shift %[[BOX_DIMS]]#0, %[[BOX_DIMS]]#1
// CHECK-NEXT: %[[TMP:.*]]:2 = hlfir.declare %[[ADDR]](%[[SHIFT]]) {uniq_name = ".tmp.intrinsic_result"}
-// CHECK: %[[TRUE:.*]] = arith.constant true
// CHECK: %[[EXPR:.*]] = hlfir.as_expr %[[TMP]]#0 move %[[TRUE]] : (!fir.box<!fir.array<?x!fir.logical<4>>>, i1) -> !hlfir.expr<?x!fir.logical<4>>
// CHECK: hlfir.assign %[[EXPR]] to %[[RES]]
// CHECK: hlfir.destroy %[[EXPR]]
diff --git a/flang/test/HLFIR/count-lowering-default-int-kinds.fir b/flang/test/HLFIR/count-lowering-default-int-kinds.fir
index ea66c435e6a8a7..68bc7fdbaad876 100644
--- a/flang/test/HLFIR/count-lowering-default-int-kinds.fir
+++ b/flang/test/HLFIR/count-lowering-default-int-kinds.fir
@@ -2,9 +2,9 @@
// RUN: fir-opt %s -lower-hlfir-intrinsics | FileCheck %s
module attributes {fir.defaultkind = "a1c4d8i8l4r4", fir.kindmap = ""} {
- func.func @test_i8(%arg0: !fir.box<!fir.array<?x?x!fir.logical<4>>> {fir.bindc_name = "x"}, %arg1: i64) {
+ func.func @test_i8(%arg0: !fir.box<!fir.array<?x?x!fir.logical<4>>> {fir.bindc_name = "x"}, %arg1: i64) -> !hlfir.expr<?xi64> {
%4 = hlfir.count %arg0 dim %arg1 : (!fir.box<!fir.array<?x?x!fir.logical<4>>>, i64) -> !hlfir.expr<?xi64>
- return
+ return %4 : !hlfir.expr<?xi64>
}
}
// CHECK-LABEL: func.func @test_i8
@@ -12,9 +12,9 @@ module attributes {fir.defaultkind = "a1c4d8i8l4r4", fir.kindmap = ""} {
// CHECK: fir.call @_FortranACountDim(%{{.*}}, %{{.*}}, %{{.*}}, %[[KIND]], %{{.*}}, %{{.*}}) : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, i32, !fir.ref<i8>, i32) -> none
module attributes {fir.defaultkind = "a1c4d8i4l4r4", fir.kindmap = ""} {
- func.func @test_i4(%arg0: !fir.box<!fir.array<?x?x!fir.logical<4>>> {fir.bindc_name = "x"}, %arg1: i64) {
+ func.func @test_i4(%arg0: !fir.box<!fir.array<?x?x!fir.logical<4>>> {fir.bindc_name = "x"}, %arg1: i64) -> !hlfir.expr<?xi32> {
%4 = hlfir.count %arg0 dim %arg1 : (!fir.box<!fir.array<?x?x!fir.logical<4>>>, i64) -> !hlfir.expr<?xi32>
- return
+ return %4 : !hlfir.expr<?xi32>
}
}
// CHECK-LABEL: func.func @test_i4
@@ -22,9 +22,9 @@ module attributes {fir.defaultkind = "a1c4d8i4l4r4", fir.kindmap = ""} {
// CHECK: fir.call @_FortranACountDim(%{{.*}}, %{{.*}}, %{{.*}}, %[[KIND]], %{{.*}}, %{{.*}}) : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, i32, !fir.ref<i8>, i32) -> none
module attributes {fir.defaultkind = "a1c4d8i2l4r4", fir.kindmap = ""} {
- func.func @test_i2(%arg0: !fir.box<!fir.array<?x?x!fir.logical<4>>> {fir.bindc_name = "x"}, %arg1: i64) {
+ func.func @test_i2(%arg0: !fir.box<!fir.array<?x?x!fir.logical<4>>> {fir.bindc_name = "x"}, %arg1: i64) -> !hlfir.expr<?xi16> {
%4 = hlfir.count %arg0 dim %arg1 : (!fir.box<!fir.array<?x?x!fir.logical<4>>>, i64) -> !hlfir.expr<?xi16>
- return
+ return %4 : !hlfir.expr<?xi16>
}
}
// CHECK-LABEL: func.func @test_i2
@@ -32,9 +32,9 @@ module attributes {fir.defaultkind = "a1c4d8i2l4r4", fir.kindmap = ""} {
// CHECK: fir.call @_FortranACountDim(%{{.*}}, %{{.*}}, %{{.*}}, %[[KIND]], %{{.*}}, %{{.*}}) : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, i32, !fir.ref<i8>, i32) -> none
module attributes {fir.defaultkind = "a1c4d8i1l4r4", fir.kindmap = ""} {
- func.func @test_i1(%arg0: !fir.box<!fir.array<?x?x!fir.logical<4>>> {fir.bindc_name = "x"}, %arg1: i64) {
+ func.func @test_i1(%arg0: !fir.box<!fir.array<?x?x!fir.logical<4>>> {fir.bindc_name = "x"}, %arg1: i64) -> !hlfir.expr<?xi8> {
%4 = hlfir.count %arg0 dim %arg1 : (!fir.box<!fir.array<?x?x!fir.logical<4>>>, i64) -> !hlfir.expr<?xi8>
- return
+ return %4 : !hlfir.expr<?xi8>
}
}
// CHECK-LABEL: func.func @test_i1
diff --git a/flang/test/HLFIR/count-lowering.fir b/flang/test/HLFIR/count-lowering.fir
index da0f250dceef35..c3309724981a3f 100644
--- a/flang/test/HLFIR/count-lowering.fir
+++ b/flang/test/HLFIR/count-lowering.fir
@@ -34,6 +34,7 @@ func.func @_QPcount2(%arg0: !fir.box<!fir.array<?x?x!fir.logical<4>>> {fir.bindc
// CHECK: %[[ARG0:.*]]: !fir.box<!fir.array<?x?x!fir.logical<4>>>
// CHECK: %[[ARG1:.*]]: !fir.box<!fir.array<?xi32>
// CHECK: %[[ARG2:.*]]: !fir.ref<i32>
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
// CHECK-DAG: %[[KIND:.*]] = arith.constant 4 : i32
// CHECK-DAG: %[[MASK:.*]]:2 = hlfir.declare %[[ARG0]]
// CHECK-DAG: %[[DIM_VAR:.*]]:2 = hlfir.declare %[[ARG2]]
@@ -56,7 +57,6 @@ func.func @_QPcount2(%arg0: !fir.box<!fir.array<?x?x!fir.logical<4>>> {fir.bindc
// CHECK-NEXT: %[[ADDR:.*]] = fir.box_addr %[[RET]]
// CHECK-NEXT: %[[SHIFT:.*]] = fir.shape_shift %[[BOX_DIMS]]#0, %[[BOX_DIMS]]#1
// CHECK-NEXT: %[[TMP:.*]]:2 = hlfir.declare %[[ADDR]](%[[SHIFT]]) {uniq_name = ".tmp.intrinsic_result"}
-// CHECK: %[[TRUE:.*]] = arith.constant true
// CHECK: %[[EXPR:.*]] = hlfir.as_expr %[[TMP]]#0 move %[[TRUE]] : (!fir.box<!fir.array<?xi32>>, i1) -> !hlfir.expr<?xi32>
// CHECK: hlfir.assign %[[EXPR]] to %[[RES]]#0
// CHECK: hlfir.destroy %[[EXPR]]
@@ -80,6 +80,7 @@ func.func @_QPcount3(%arg0: !fir.ref<!fir.array<2xi32>> {fir.bindc_name = "s"})
}
// CHECK-LABEL: func.func @_QPcount3(
// CHECK: %[[ARG0:.*]]: !fir.ref<!fir.array<2xi32>>
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
// CHECK-DAG: %[[RET_BOX:.*]] = fir.alloca !fir.box<!fir.heap<!fir.array<?xi32>>>
// CHECK-DAG: %[[KIND:.*]] = arith.constant 4 : i32
// CHECK-DAG: %[[RET_ADDR:.*]] = fir.zero_bits !fir.heap<!fir.array<?xi32>>
@@ -104,7 +105,6 @@ func.func @_QPcount3(%arg0: !fir.ref<!fir.array<2xi32>> {fir.bindc_name = "s"})
// CHECK-NEXT: %[[ADDR:.*]] = fir.box_addr %[[RET]]
// CHECK-NEXT: %[[SHIFT:.*]] = fir.shape_shift %[[BOX_DIMS]]#0, %[[BOX_DIMS]]#1
// CHECK-NEXT: %[[TMP:.*]]:2 = hlfir.declare %[[ADDR]](%[[SHIFT]]) {uniq_name = ".tmp.intrinsic_result"}
-// CHECK: %[[TRUE:.*]] = arith.constant true
// CHECK: %[[EXPR:.*]] = hlfir.as_expr %[[TMP]]#0 move %[[TRUE]] : (!fir.box<!fir.array<?xi32>>, i1) -> !hlfir.expr<?xi32>
// CHECK: hlfir.assign %[[EXPR]] to %[[RES]]
// CHECK: hlfir.destroy %[[EXPR]]
@@ -133,6 +133,7 @@ func.func @_QPcount4(%arg0: !fir.box<!fir.array<?x?x!fir.logical<4>>> {fir.bindc
// CHECK: %[[ARG0:.*]]: !fir.box<!fir.array<?x?x!fir.logical<4>>>
// CHECK: %[[ARG1:.*]]: !fir.box<!fir.array<?xi32>
// CHECK: %[[ARG2:.*]]: !fir.ref<i32>
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
// CHECK-DAG: %[[MASK:.*]]:2 = hlfir.declare %[[ARG0]]
// CHECK-DAG: %[[DIM_VAR:.*]]:2 = hlfir.declare %[[ARG2]]
// CHECK-DAG: %[[RES:.*]]:2 = hlfir.declare %[[ARG1]]
@@ -155,7 +156,6 @@ func.func @_QPcount4(%arg0: !fir.box<!fir.array<?x?x!fir.logical<4>>> {fir.bindc
// CHECK-NEXT: %[[ADDR:.*]] = fir.box_addr %[[RET]]
// CHECK-NEXT: %[[SHIFT:.*]] = fir.shape_shift %[[BOX_DIMS]]#0, %[[BOX_DIMS]]#1
// CHECK-NEXT: %[[TMP:.*]]:2 = hlfir.declare %[[ADDR]](%[[SHIFT]]) {uniq_name = ".tmp.intrinsic_result"}
-// CHECK: %[[TRUE:.*]] = arith.constant true
// CHECK: %[[EXPR:.*]] = hlfir.as_expr %[[TMP]]#0 move %[[TRUE]] : (!fir.box<!fir.array<?xi64>>, i1) -> !hlfir.expr<?xi64>
// CHECK-NEXT: %[[OUT_SHAPE:.*]] = hlfir.shape_of %[[EXPR]]
// CHECK-NEXT: %[[OUT:.*]] = hlfir.elemental %[[OUT_SHAPE]] : (!fir.shape<1>) -> !hlfir.expr<?xi32>
diff --git a/flang/test/HLFIR/dot_product-lowering.fir b/flang/test/HLFIR/dot_product-lowering.fir
index e4f91eabfc0991..64d65665433f15 100644
--- a/flang/test/HLFIR/dot_product-lowering.fir
+++ b/flang/test/HLFIR/dot_product-lowering.fir
@@ -96,7 +96,6 @@ func.func @_QPdot_product4(%arg0: !fir.box<!fir.array<?x!fir.logical<4>>> {fir.b
// CHECK: %[[VAL_2:.*]] = fir.alloca !fir.logical<4>
// CHECK: %[[VAL_3:.*]]:2 = hlfir.declare %[[VAL_0]] {uniq_name = "_QFdot_product2Elhs"} : (!fir.box<!fir.array<?x!fir.logical<4>>>) -> (!fir.box<!fir.array<?x!fir.logical<4>>>, !fir.box<!fir.array<?x!fir.logical<4>>>)
// CHECK: %[[VAL_4:.*]]:2 = hlfir.declare %[[VAL_1]] {uniq_name = "_QFdot_product2Erhs"} : (!fir.box<!fir.array<?x!fir.logical<4>>>) -> (!fir.box<!fir.array<?x!fir.logical<4>>>, !fir.box<!fir.array<?x!fir.logical<4>>>)
-// CHECK: %[[VAL_5:.*]] = fir.absent !fir.box<!fir.logical<4>>
// CHECK: %[[VAL_9:.*]] = fir.convert %[[VAL_3]]#1 : (!fir.box<!fir.array<?x!fir.logical<4>>>) -> !fir.box<none>
// CHECK: %[[VAL_10:.*]] = fir.convert %[[VAL_4]]#1 : (!fir.box<!fir.array<?x!fir.logical<4>>>) -> !fir.box<none>
// CHECK: %[[VAL_12:.*]] = fir.call @_FortranADotProductLogical(%[[VAL_9]], %[[VAL_10]], %{{.*}}, %{{.*}}) fastmath<contract> : (!fir.box<none>, !fir.box<none>, !fir.ref<i8>, i32) -> i1
diff --git a/flang/test/HLFIR/extents-of-shape-of.f90 b/flang/test/HLFIR/extents-of-shape-of.f90
index d807f8b70302b6..1168004597d191 100644
--- a/flang/test/HLFIR/extents-of-shape-of.f90
+++ b/flang/test/HLFIR/extents-of-shape-of.f90
@@ -31,18 +31,17 @@ elemental subroutine elem_sub(x)
! CHECK-HLFIR-NEXT: hlfir.destroy %[[MUL]]
! ...
+! CHECK-FIR-DAG: %[[C0:.*]] = arith.constant 0 : index
+! CHECK-FIR-DAG: %[[C1:.*]] = arith.constant 1 : index
+! CHECK-FIR-DAG: %[[C2:.*]] = arith.constant 2 : index
! CHECK-FIR: fir.call @_FortranAMatmul
! CHECK-FIR-NEXT: %[[MUL:.*]] = fir.load %[[MUL_BOX:.*]] : !fir.ref<!fir.box<!fir.heap<!fir.array<?x?xf32>>>>
-! CHECK-FIR-NEXT: %[[C0:.*]] = arith.constant 0 : index
! CHECK-FIR-NEXT: %[[DIMS0:.*]]:3 = fir.box_dims %[[MUL]], %[[C0]]
-! CHECK-FIR-NEXT: %[[C1:.*]] = arith.constant 1 : index
! CHECK-FIR-NEXT: %[[DIMS1:.*]]:3 = fir.box_dims %[[MUL]], %[[C1]]
! ...
! CHECK-FIR: %[[SHAPE:.*]] = fir.shape %[[DIMS0]]#1, %[[DIMS1]]#1
-! CHECK-FIR-NEXT: %[[C2:.*]] = arith.constant 2 : index
-! CHECK-FIR-NEXT: %[[C1_1:.*]] = arith.constant 1 : index
-! CHECK-FIR-NEXT: fir.do_loop %[[ARG2:.*]] = %[[C1_1]] to %[[DIMS1]]#1 step %[[C1_1]] unordered {
-! CHECK-FIR-NEXT: fir.do_loop %[[ARG3:.*]] = %[[C1_1]] to %[[C2]] step %[[C1_1]] unordered {
+! CHECK-FIR-NEXT: fir.do_loop %[[ARG2:.*]] = %[[C1]] to %[[DIMS1]]#1 step %[[C1]] unordered {
+! CHECK-FIR-NEXT: fir.do_loop %[[ARG3:.*]] = %[[C1]] to %[[C2]] step %[[C1]] unordered {
! ...
! CHECK-ALL: return
diff --git a/flang/test/HLFIR/matmul-lowering.fir b/flang/test/HLFIR/matmul-lowering.fir
index ee921da9a52563..85a73dd45160ff 100644
--- a/flang/test/HLFIR/matmul-lowering.fir
+++ b/flang/test/HLFIR/matmul-lowering.fir
@@ -14,6 +14,7 @@ func.func @_QPmatmul1(%arg0: !fir.box<!fir.array<?x?xi32>> {fir.bindc_name = "lh
// CHECK: %[[ARG0:.*]]: !fir.box<!fir.array<?x?xi32>> {fir.bindc_name = "lhs"}
// CHECK: %[[ARG1:.*]]: !fir.box<!fir.array<?x?xi32>> {fir.bindc_name = "rhs"}
// CHECK: %[[ARG2:.*]]: !fir.box<!fir.array<?x?xi32>> {fir.bindc_name = "res"}
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
// CHECK-DAG: %[[LHS_VAR:.*]]:2 = hlfir.declare %[[ARG0]]
// CHECK-DAG: %[[RHS_VAR:.*]]:2 = hlfir.declare %[[ARG1]]
// CHECK-DAG: %[[RES_VAR:.*]]:2 = hlfir.declare %[[ARG2]]
@@ -37,7 +38,6 @@ func.func @_QPmatmul1(%arg0: !fir.box<!fir.array<?x?xi32>> {fir.bindc_name = "lh
// TODO: fix alias analysis in hlfir.assign bufferization
// CHECK-NEXT: %[[TMP:.*]]:2 = hlfir.declare %[[ADDR]](%[[SHIFT]]) {uniq_name = ".tmp.intrinsic_result"}
// TODO: add shape information from original intrinsic op
-// CHECK: %[[TRUE:.*]] = arith.constant true
// CHECK: %[[ASEXPR:.*]] = hlfir.as_expr %[[TMP]]#0 move %[[TRUE]] : (!fir.box<!fir.array<?x?xi32>>, i1) -> !hlfir.expr<?x?xi32>
// CHECK: hlfir.assign %[[ASEXPR]] to %[[RES_VAR]]#0
// CHECK: hlfir.destroy %[[ASEXPR]]
diff --git a/flang/test/HLFIR/maxloc-lowering.fir b/flang/test/HLFIR/maxloc-lowering.fir
index 9e52a074a6e285..a51c9b483fa055 100644
--- a/flang/test/HLFIR/maxloc-lowering.fir
+++ b/flang/test/HLFIR/maxloc-lowering.fir
@@ -13,29 +13,28 @@ func.func @_QPmaxloc1(%arg0: !fir.box<!fir.array<?xi32>> {fir.bindc_name = "a"},
// CHECK-LABEL: func.func @_QPmaxloc1(
// CHECK: %[[ARG0:.*]]: !fir.box<!fir.array<?xi32>> {fir.bindc_name = "a"}
// CHECK: %[[ARG1:.*]]: !fir.box<!fir.array<?xi32>> {fir.bindc_name = "s"}
-// CHECK-NEXT: %[[V0:.*]] = fir.alloca !fir.box<!fir.heap<!fir.array<?xi32>>>
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
+// CHECK-DAG: %[[FALSE:.*]] = arith.constant false
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C4:.*]] = arith.constant 4 : i32
+// CHECK: %[[V0:.*]] = fir.alloca !fir.box<!fir.heap<!fir.array<?xi32>>>
// CHECK-NEXT: %[[V1:.*]]:2 = hlfir.declare %[[ARG0]] {uniq_name = "_QFmaxloc1Ea"} : (!fir.box<!fir.array<?xi32>>) -> (!fir.box<!fir.array<?xi32>>, !fir.box<!fir.array<?xi32>>)
// CHECK-NEXT: %[[V2:.*]]:2 = hlfir.declare %[[ARG1]] {uniq_name = "_QFmaxloc1Es"} : (!fir.box<!fir.array<?xi32>>) -> (!fir.box<!fir.array<?xi32>>, !fir.box<!fir.array<?xi32>>)
-// CHECK-NEXT: %c4_i32 = arith.constant 4 : i32
// CHECK-NEXT: %[[V3:.*]] = fir.absent !fir.box<i1>
-// CHECK-NEXT: %false = arith.constant false
// CHECK-NEXT: %[[V4:.*]] = fir.zero_bits !fir.heap<!fir.array<?xi32>>
-// CHECK-NEXT: %c0 = arith.constant 0 : index
-// CHECK-NEXT: %[[V5:.*]] = fir.shape %c0 : (index) -> !fir.shape<1>
+// CHECK-NEXT: %[[V5:.*]] = fir.shape %[[C0]] : (index) -> !fir.shape<1>
// CHECK-NEXT: %[[V6:.*]] = fir.embox %[[V4]](%[[V5]]) : (!fir.heap<!fir.array<?xi32>>, !fir.shape<1>) -> !fir.box<!fir.heap<!fir.array<?xi32>>>
// CHECK-NEXT: fir.store %[[V6]] to %[[V0]] : !fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>
// CHECK: %[[V8:.*]] = fir.convert %[[V0]] : (!fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>) -> !fir.ref<!fir.box<none>>
// CHECK-NEXT: %[[V9:.*]] = fir.convert %[[V1]]#1 : (!fir.box<!fir.array<?xi32>>) -> !fir.box<none>
// CHECK: %[[V12:.*]] = fir.convert %[[V3]] : (!fir.box<i1>) -> !fir.box<none>
-// CHECK-NEXT: %[[V13:.*]] = fir.call @_FortranAMaxlocInteger4(%[[V8]], %[[V9]], %c4_i32, {{.*}}, {{.*}}, %[[V12]], %false) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, !fir.ref<i8>, i32, !fir.box<none>, i1) -> none
+// CHECK-NEXT: %[[V13:.*]] = fir.call @_FortranAMaxlocInteger4(%[[V8]], %[[V9]], %[[C4]], {{.*}}, {{.*}}, %[[V12]], %[[FALSE]]) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, !fir.ref<i8>, i32, !fir.box<none>, i1) -> none
// CHECK-NEXT: %[[V14:.*]] = fir.load %[[V0]] : !fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>
-// CHECK-NEXT: %c0_0 = arith.constant 0 : index
-// CHECK-NEXT: %[[V15:.*]]:3 = fir.box_dims %[[V14]], %c0_0 : (!fir.box<!fir.heap<!fir.array<?xi32>>>, index) -> (index, index, index)
+// CHECK-NEXT: %[[V15:.*]]:3 = fir.box_dims %[[V14]], %[[C0]] : (!fir.box<!fir.heap<!fir.array<?xi32>>>, index) -> (index, index, index)
// CHECK-NEXT: %[[V16:.*]] = fir.box_addr %[[V14]] : (!fir.box<!fir.heap<!fir.array<?xi32>>>) -> !fir.heap<!fir.array<?xi32>>
// CHECK-NEXT: %[[V17:.*]] = fir.shape_shift %[[V15]]#0, %[[V15]]#1 : (index, index) -> !fir.shapeshift<1>
// CHECK-NEXT: %[[V18:.*]]:2 = hlfir.declare %[[V16]](%[[V17]]) {uniq_name = ".tmp.intrinsic_result"} : (!fir.heap<!fir.array<?xi32>>, !fir.shapeshift<1>) -> (!fir.box<!fir.array<?xi32>>, !fir.heap<!fir.array<?xi32>>)
-// CHECK-NEXT: %true = arith.constant true
-// CHECK-NEXT: %[[V19:.*]] = hlfir.as_expr %[[V18]]#0 move %true : (!fir.box<!fir.array<?xi32>>, i1) -> !hlfir.expr<?xi32>
+// CHECK-NEXT: %[[V19:.*]] = hlfir.as_expr %[[V18]]#0 move %[[TRUE]] : (!fir.box<!fir.array<?xi32>>, i1) -> !hlfir.expr<?xi32>
// CHECK-NEXT: hlfir.assign %[[V19]] to %[[V2]]#0 : !hlfir.expr<?xi32>, !fir.box<!fir.array<?xi32>>
// CHECK-NEXT: hlfir.destroy %[[V19]] : !hlfir.expr<?xi32>
@@ -55,32 +54,31 @@ func.func @_QPmaxloc2(%arg0: !fir.box<!fir.array<?x?xi32>> {fir.bindc_name = "a"
// CHECK: %[[ARG0:.*]]: !fir.box<!fir.array<?x?xi32>> {fir.bindc_name = "a"}
// CHECK: %[[ARG1:.*]]: !fir.box<!fir.array<?xi32>> {fir.bindc_name = "s"}
// CHECK: %[[ARG2:.*]]: !fir.ref<index>
-// CHECK-NEXT: %[[V0:.*]] = fir.alloca !fir.box<!fir.heap<!fir.array<?xi32>>>
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
+// CHECK-DAG: %[[FALSE:.*]] = arith.constant false
+// CHECK-DAG: %[[C4:.*]] = arith.constant 4 : i32
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK: %[[V0:.*]] = fir.alloca !fir.box<!fir.heap<!fir.array<?xi32>>>
// CHECK-NEXT: %[[V1:.*]]:2 = hlfir.declare %[[ARG0]] {uniq_name = "_QFmaxloc2Ea"} : (!fir.box<!fir.array<?x?xi32>>) -> (!fir.box<!fir.array<?x?xi32>>, !fir.box<!fir.array<?x?xi32>>)
// CHECK-NEXT: %[[V2:.*]]:2 = hlfir.declare %[[ARG2]] {uniq_name = "_QFmaxloc2Ed"} : (!fir.ref<index>) -> (!fir.ref<index>, !fir.ref<index>)
// CHECK-NEXT: %[[V3:.*]]:2 = hlfir.declare %[[ARG1]] {uniq_name = "_QFmaxloc2Es"} : (!fir.box<!fir.array<?xi32>>) -> (!fir.box<!fir.array<?xi32>>, !fir.box<!fir.array<?xi32>>)
// CHECK-NEXT: %[[V4:.*]] = fir.load %[[V2]]#0 : !fir.ref<index>
-// CHECK-NEXT: %c4_i32 = arith.constant 4 : i32
// CHECK-NEXT: %[[V5:.*]] = fir.convert %[[V4]] : (index) -> i32
// CHECK-NEXT: %[[V6:.*]] = fir.absent !fir.box<i1>
-// CHECK-NEXT: %false = arith.constant false
// CHECK-NEXT: %[[V7:.*]] = fir.zero_bits !fir.heap<!fir.array<?xi32>>
-// CHECK-NEXT: %c0 = arith.constant 0 : index
-// CHECK-NEXT: %[[V8:.*]] = fir.shape %c0 : (index) -> !fir.shape<1>
+// CHECK-NEXT: %[[V8:.*]] = fir.shape %[[C0]] : (index) -> !fir.shape<1>
// CHECK-NEXT: %[[V9:.*]] = fir.embox %[[V7]](%[[V8]]) : (!fir.heap<!fir.array<?xi32>>, !fir.shape<1>) -> !fir.box<!fir.heap<!fir.array<?xi32>>>
// CHECK-NEXT: fir.store %[[V9]] to %[[V0]] : !fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>
// CHECK: %[[V11:.*]] = fir.convert %[[V0]] : (!fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>) -> !fir.ref<!fir.box<none>>
// CHECK-NEXT: %[[V12:.*]] = fir.convert %[[V1]]#1 : (!fir.box<!fir.array<?x?xi32>>) -> !fir.box<none>
// CHECK: %[[V15:.*]] = fir.convert %[[V6]] : (!fir.box<i1>) -> !fir.box<none>
-// CHECK-NEXT: %[[V16:.*]] = fir.call @_FortranAMaxlocDim(%[[V11]], %[[V12]], %c4_i32, %[[V5]], {{.*}}, {{.*}}, %[[V15]], %false) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, i32, !fir.ref<i8>, i32, !fir.box<none>, i1) -> none
+// CHECK-NEXT: %[[V16:.*]] = fir.call @_FortranAMaxlocDim(%[[V11]], %[[V12]], %[[C4]], %[[V5]], {{.*}}, {{.*}}, %[[V15]], %[[FALSE]]) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, i32, !fir.ref<i8>, i32, !fir.box<none>, i1) -> none
// CHECK-NEXT: %[[V17:.*]] = fir.load %[[V0]] : !fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>
-// CHECK-NEXT: %c0_0 = arith.constant 0 : index
-// CHECK-NEXT: %[[V18:.*]]:3 = fir.box_dims %[[V17]], %c0_0 : (!fir.box<!fir.heap<!fir.array<?xi32>>>, index) -> (index, index, index)
+// CHECK-NEXT: %[[V18:.*]]:3 = fir.box_dims %[[V17]], %[[C0]] : (!fir.box<!fir.heap<!fir.array<?xi32>>>, index) -> (index, index, index)
// CHECK-NEXT: %[[V19:.*]] = fir.box_addr %[[V17]] : (!fir.box<!fir.heap<!fir.array<?xi32>>>) -> !fir.heap<!fir.array<?xi32>>
// CHECK-NEXT: %[[V20:.*]] = fir.shape_shift %[[V18]]#0, %[[V18]]#1 : (index, index) -> !fir.shapeshift<1>
// CHECK-NEXT: %[[V21:.*]]:2 = hlfir.declare %[[V19]](%[[V20]]) {uniq_name = ".tmp.intrinsic_result"} : (!fir.heap<!fir.array<?xi32>>, !fir.shapeshift<1>) -> (!fir.box<!fir.array<?xi32>>, !fir.heap<!fir.array<?xi32>>)
-// CHECK-NEXT: %true = arith.constant true
-// CHECK-NEXT: %[[V22:.*]] = hlfir.as_expr %[[V21]]#0 move %true : (!fir.box<!fir.array<?xi32>>, i1) -> !hlfir.expr<?xi32>
+// CHECK-NEXT: %[[V22:.*]] = hlfir.as_expr %[[V21]]#0 move %[[TRUE]] : (!fir.box<!fir.array<?xi32>>, i1) -> !hlfir.expr<?xi32>
// CHECK-NEXT: hlfir.assign %[[V22]] to %[[V3]]#0 : !hlfir.expr<?xi32>, !fir.box<!fir.array<?xi32>>
// CHECK-NEXT: hlfir.destroy %[[V22]] : !hlfir.expr<?xi32>
// CHECK-NEXT: return
@@ -100,30 +98,29 @@ func.func @_QPmaxloc3(%arg0: !fir.box<!fir.array<?xi32>> {fir.bindc_name = "a"},
// CHECK: %[[ARG0:.*]]: !fir.box<!fir.array<?xi32>> {fir.bindc_name = "a"}
// CHECK: %[[ARG1:.*]]: !fir.box<!fir.array<?xi32>> {fir.bindc_name = "s"}
// CHECK: %[[ARG2:.*]]: !fir.ref<!fir.logical<4>>
-// CHECK-NEXT: %[[V0:.*]] = fir.alloca !fir.box<!fir.heap<!fir.array<?xi32>>>
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
+// CHECK-DAG: %[[FALSE:.*]] = arith.constant false
+// CHECK-DAG: %[[C4:.*]] = arith.constant 4 : i32
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK: %[[V0:.*]] = fir.alloca !fir.box<!fir.heap<!fir.array<?xi32>>>
// CHECK-NEXT: %[[V1:.*]]:2 = hlfir.declare %[[ARG0]] {uniq_name = "_QFmaxloc3Ea"} : (!fir.box<!fir.array<?xi32>>) -> (!fir.box<!fir.array<?xi32>>, !fir.box<!fir.array<?xi32>>)
// CHECK-NEXT: %[[V2:.*]]:2 = hlfir.declare %[[ARG2]] {uniq_name = "_QFmaxloc3Em"} : (!fir.ref<!fir.logical<4>>) -> (!fir.ref<!fir.logical<4>>, !fir.ref<!fir.logical<4>>)
// CHECK-NEXT: %[[V3:.*]]:2 = hlfir.declare %[[ARG1]] {uniq_name = "_QFmaxloc3Es"} : (!fir.box<!fir.array<?xi32>>) -> (!fir.box<!fir.array<?xi32>>, !fir.box<!fir.array<?xi32>>)
-// CHECK-NEXT: %c4_i32 = arith.constant 4 : i32
// CHECK-NEXT: %[[V4:.*]] = fir.embox %[[V2]]#1 : (!fir.ref<!fir.logical<4>>) -> !fir.box<!fir.logical<4>>
-// CHECK-NEXT: %false = arith.constant false
// CHECK-NEXT: %[[V5:.*]] = fir.zero_bits !fir.heap<!fir.array<?xi32>>
-// CHECK-NEXT: %c0 = arith.constant 0 : index
-// CHECK-NEXT: %[[V6:.*]] = fir.shape %c0 : (index) -> !fir.shape<1>
+// CHECK-NEXT: %[[V6:.*]] = fir.shape %[[C0]] : (index) -> !fir.shape<1>
// CHECK-NEXT: %[[V7:.*]] = fir.embox %[[V5]](%[[V6]]) : (!fir.heap<!fir.array<?xi32>>, !fir.shape<1>) -> !fir.box<!fir.heap<!fir.array<?xi32>>>
// CHECK-NEXT: fir.store %[[V7]] to %[[V0]] : !fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>
// CHECK: %[[V9:.*]] = fir.convert %[[V0]] : (!fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>) -> !fir.ref<!fir.box<none>>
// CHECK-NEXT: %[[V10:.*]] = fir.convert %[[V1]]#1 : (!fir.box<!fir.array<?xi32>>) -> !fir.box<none>
// CHECK: %[[V13:.*]] = fir.convert %[[V4]] : (!fir.box<!fir.logical<4>>) -> !fir.box<none>
-// CHECK-NEXT: %[[V14:.*]] = fir.call @_FortranAMaxlocInteger4(%[[V9]], %[[V10]], %c4_i32, {{.*}}, {{.*}}, %[[V13]], %false) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, !fir.ref<i8>, i32, !fir.box<none>, i1) -> none
+// CHECK-NEXT: %[[V14:.*]] = fir.call @_FortranAMaxlocInteger4(%[[V9]], %[[V10]], %[[C4]], {{.*}}, {{.*}}, %[[V13]], %[[FALSE]]) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, !fir.ref<i8>, i32, !fir.box<none>, i1) -> none
// CHECK-NEXT: %[[V15:.*]] = fir.load %[[V0]] : !fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>
-// CHECK-NEXT: %c0_0 = arith.constant 0 : index
-// CHECK-NEXT: %[[V16:.*]]:3 = fir.box_dims %[[V15]], %c0_0 : (!fir.box<!fir.heap<!fir.array<?xi32>>>, index) -> (index, index, index)
+// CHECK-NEXT: %[[V16:.*]]:3 = fir.box_dims %[[V15]], %[[C0]] : (!fir.box<!fir.heap<!fir.array<?xi32>>>, index) -> (index, index, index)
// CHECK-NEXT: %[[V17:.*]] = fir.box_addr %[[V15]] : (!fir.box<!fir.heap<!fir.array<?xi32>>>) -> !fir.heap<!fir.array<?xi32>>
// CHECK-NEXT: %[[V18:.*]] = fir.shape_shift %[[V16]]#0, %[[V16]]#1 : (index, index) -> !fir.shapeshift<1>
// CHECK-NEXT: %[[V19:.*]]:2 = hlfir.declare %[[V17]](%[[V18]]) {uniq_name = ".tmp.intrinsic_result"} : (!fir.heap<!fir.array<?xi32>>, !fir.shapeshift<1>) -> (!fir.box<!fir.array<?xi32>>, !fir.heap<!fir.array<?xi32>>)
-// CHECK-NEXT: %true = arith.constant true
-// CHECK-NEXT: %[[V20:.*]] = hlfir.as_expr %[[V19]]#0 move %true : (!fir.box<!fir.array<?xi32>>, i1) -> !hlfir.expr<?xi32>
+// CHECK-NEXT: %[[V20:.*]] = hlfir.as_expr %[[V19]]#0 move %[[TRUE]] : (!fir.box<!fir.array<?xi32>>, i1) -> !hlfir.expr<?xi32>
// CHECK-NEXT: hlfir.assign %[[V20]] to %[[V3]]#0 : !hlfir.expr<?xi32>, !fir.box<!fir.array<?xi32>>
// CHECK-NEXT: hlfir.destroy %[[V20]] : !hlfir.expr<?xi32>
// CHECK-NEXT: return
@@ -143,29 +140,28 @@ func.func @_QPmaxloc4(%arg0: !fir.box<!fir.array<?xi32>> {fir.bindc_name = "a"},
// CHECK: %[[ARG0:.*]]: !fir.box<!fir.array<?xi32>> {fir.bindc_name = "a"}
// CHECK: %[[ARG1:.*]]: !fir.box<!fir.array<?xi32>> {fir.bindc_name = "s"}
// CHECK: %[[ARG2:.*]]: !fir.box<!fir.array<?x!fir.logical<4>>>
-// CHECK-NEXT: %[[V0:.*]] = fir.alloca !fir.box<!fir.heap<!fir.array<?xi32>>>
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
+// CHECK-DAG: %[[FALSE:.*]] = arith.constant false
+// CHECK-DAG: %[[C4:.*]] = arith.constant 4 : i32
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK: %[[V0:.*]] = fir.alloca !fir.box<!fir.heap<!fir.array<?xi32>>>
// CHECK-NEXT: %[[V1:.*]]:2 = hlfir.declare %[[ARG0]] {uniq_name = "_QFmaxloc4Ea"} : (!fir.box<!fir.array<?xi32>>) -> (!fir.box<!fir.array<?xi32>>, !fir.box<!fir.array<?xi32>>)
// CHECK-NEXT: %[[V2:.*]]:2 = hlfir.declare %[[ARG2]] {uniq_name = "_QFmaxloc4Em"} : (!fir.box<!fir.array<?x!fir.logical<4>>>) -> (!fir.box<!fir.array<?x!fir.logical<4>>>, !fir.box<!fir.array<?x!fir.logical<4>>>)
// CHECK-NEXT: %[[V3:.*]]:2 = hlfir.declare %[[ARG1]] {uniq_name = "_QFmaxloc4Es"} : (!fir.box<!fir.array<?xi32>>) -> (!fir.box<!fir.array<?xi32>>, !fir.box<!fir.array<?xi32>>)
-// CHECK-NEXT: %c4_i32 = arith.constant 4 : i32
-// CHECK-NEXT: %false = arith.constant false
// CHECK-NEXT: %[[V4:.*]] = fir.zero_bits !fir.heap<!fir.array<?xi32>>
-// CHECK-NEXT: %c0 = arith.constant 0 : index
-// CHECK-NEXT: %[[V5:.*]] = fir.shape %c0 : (index) -> !fir.shape<1>
+// CHECK-NEXT: %[[V5:.*]] = fir.shape %[[C0]] : (index) -> !fir.shape<1>
// CHECK-NEXT: %[[V6:.*]] = fir.embox %[[V4]](%[[V5]]) : (!fir.heap<!fir.array<?xi32>>, !fir.shape<1>) -> !fir.box<!fir.heap<!fir.array<?xi32>>>
// CHECK-NEXT: fir.store %[[V6]] to %[[V0]] : !fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>
// CHECK: %[[V8:.*]] = fir.convert %[[V0]] : (!fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>) -> !fir.ref<!fir.box<none>>
// CHECK-NEXT: %[[V9:.*]] = fir.convert %[[V1]]#1 : (!fir.box<!fir.array<?xi32>>) -> !fir.box<none>
// CHECK: %[[V12:.*]] = fir.convert %[[V2]]#1 : (!fir.box<!fir.array<?x!fir.logical<4>>>) -> !fir.box<none>
-// CHECK-NEXT: %[[V13:.*]] = fir.call @_FortranAMaxlocInteger4(%[[V8]], %[[V9]], %c4_i32, {{.*}}, {{.*}}, %[[V12]], %false) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, !fir.ref<i8>, i32, !fir.box<none>, i1) -> none
+// CHECK-NEXT: %[[V13:.*]] = fir.call @_FortranAMaxlocInteger4(%[[V8]], %[[V9]], %[[C4]], {{.*}}, {{.*}}, %[[V12]], %[[FALSE]]) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, !fir.ref<i8>, i32, !fir.box<none>, i1) -> none
// CHECK-NEXT: %[[V14:.*]] = fir.load %[[V0]] : !fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>
-// CHECK-NEXT: %c0_0 = arith.constant 0 : index
-// CHECK-NEXT: %[[V15:.*]]:3 = fir.box_dims %[[V14]], %c0_0 : (!fir.box<!fir.heap<!fir.array<?xi32>>>, index) -> (index, index, index)
+// CHECK-NEXT: %[[V15:.*]]:3 = fir.box_dims %[[V14]], %[[C0]] : (!fir.box<!fir.heap<!fir.array<?xi32>>>, index) -> (index, index, index)
// CHECK-NEXT: %[[V16:.*]] = fir.box_addr %[[V14]] : (!fir.box<!fir.heap<!fir.array<?xi32>>>) -> !fir.heap<!fir.array<?xi32>>
// CHECK-NEXT: %[[V17:.*]] = fir.shape_shift %[[V15]]#0, %[[V15]]#1 : (index, index) -> !fir.shapeshift<1>
// CHECK-NEXT: %[[V18:.*]]:2 = hlfir.declare %[[V16]](%[[V17]]) {uniq_name = ".tmp.intrinsic_result"} : (!fir.heap<!fir.array<?xi32>>, !fir.shapeshift<1>) -> (!fir.box<!fir.array<?xi32>>, !fir.heap<!fir.array<?xi32>>)
-// CHECK-NEXT: %true = arith.constant true
-// CHECK-NEXT: %[[V19:.*]] = hlfir.as_expr %[[V18]]#0 move %true : (!fir.box<!fir.array<?xi32>>, i1) -> !hlfir.expr<?xi32>
+// CHECK-NEXT: %[[V19:.*]] = hlfir.as_expr %[[V18]]#0 move %[[TRUE]] : (!fir.box<!fir.array<?xi32>>, i1) -> !hlfir.expr<?xi32>
// CHECK-NEXT: hlfir.assign %[[V19]] to %[[V3]]#0 : !hlfir.expr<?xi32>, !fir.box<!fir.array<?xi32>>
// CHECK-NEXT: hlfir.destroy %[[V19]] : !hlfir.expr<?xi32>
// CHECK-NEXT: return
@@ -205,42 +201,38 @@ func.func @_QPmaxloc5(%arg0: !fir.ref<!fir.array<2xi32>> {fir.bindc_name = "s"})
}
// CHECK-LABEL: func.func @_QPmaxloc5(
// CHECK: %[[ARG0:.*]]: !fir.ref<!fir.array<2xi32>> {fir.bindc_name = "s"}
-// CHECK-NEXT: %[[V0:.*]] = fir.alloca !fir.box<!fir.heap<!fir.array<?xi32>>>
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
+// CHECK-DAG: %[[FALSE:.*]] = arith.constant false
+// CHECK-DAG: %[[C4:.*]] = arith.constant 4 : i32
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : i32
+// CHECK: %[[V0:.*]] = fir.alloca !fir.box<!fir.heap<!fir.array<?xi32>>>
// CHECK-NEXT: %[[V1:.*]] = fir.alloca !fir.logical<4>
// CHECK-NEXT: %[[V2:.*]] = fir.address_of(@_QFmaxloc5Ea) : !fir.ref<!fir.array<2x2xi32>>
-// CHECK-NEXT: %c2 = arith.constant 2 : index
-// CHECK-NEXT: %c2_0 = arith.constant 2 : index
-// CHECK-NEXT: %[[V3:.*]] = fir.shape %c2, %c2_0 : (index, index) -> !fir.shape<2>
+// CHECK-NEXT: %[[V3:.*]] = fir.shape %[[C2]], %[[C2]] : (index, index) -> !fir.shape<2>
// CHECK-NEXT: %[[V4:.*]]:2 = hlfir.declare %[[V2]](%[[V3]]) {uniq_name = "_QFmaxloc5Ea"} : (!fir.ref<!fir.array<2x2xi32>>, !fir.shape<2>) -> (!fir.ref<!fir.array<2x2xi32>>, !fir.ref<!fir.array<2x2xi32>>)
-// CHECK-NEXT: %c2_1 = arith.constant 2 : index
-// CHECK-NEXT: %[[V5:.*]] = fir.shape %c2_1 : (index) -> !fir.shape<1>
+// CHECK-NEXT: %[[V5:.*]] = fir.shape %[[C2]] : (index) -> !fir.shape<1>
// CHECK-NEXT: %[[V6:.*]]:2 = hlfir.declare %[[ARG0]](%[[V5]]) {uniq_name = "_QFmaxloc5Es"} : (!fir.ref<!fir.array<2xi32>>, !fir.shape<1>) -> (!fir.ref<!fir.array<2xi32>>, !fir.ref<!fir.array<2xi32>>)
-// CHECK-NEXT: %c1_i32 = arith.constant 1 : i32
-// CHECK-NEXT: %true = arith.constant true
-// CHECK-NEXT: %c4_i32 = arith.constant 4 : i32
-// CHECK-NEXT: %[[V7:.*]] = fir.shape %c2, %c2_0 : (index, index) -> !fir.shape<2>
+// CHECK-NEXT: %[[V7:.*]] = fir.shape %[[C2]], %[[C2]] : (index, index) -> !fir.shape<2>
// CHECK-NEXT: %[[V8:.*]] = fir.embox %[[V4]]#1(%[[V7]]) : (!fir.ref<!fir.array<2x2xi32>>, !fir.shape<2>) -> !fir.box<!fir.array<2x2xi32>>
-// CHECK-NEXT: %[[V9:.*]] = fir.convert %true : (i1) -> !fir.logical<4>
+// CHECK-NEXT: %[[V9:.*]] = fir.convert %[[TRUE]] : (i1) -> !fir.logical<4>
// CHECK-NEXT: fir.store %[[V9]] to %[[V1]] : !fir.ref<!fir.logical<4>>
// CHECK-NEXT: %[[V10:.*]] = fir.embox %[[V1]] : (!fir.ref<!fir.logical<4>>) -> !fir.box<!fir.logical<4>>
-// CHECK-NEXT: %false = arith.constant false
// CHECK-NEXT: %[[V11:.*]] = fir.zero_bits !fir.heap<!fir.array<?xi32>>
-// CHECK-NEXT: %c0 = arith.constant 0 : index
-// CHECK-NEXT: %[[V12:.*]] = fir.shape %c0 : (index) -> !fir.shape<1>
+// CHECK-NEXT: %[[V12:.*]] = fir.shape %[[C0]] : (index) -> !fir.shape<1>
// CHECK-NEXT: %[[V13:.*]] = fir.embox %[[V11]](%[[V12]]) : (!fir.heap<!fir.array<?xi32>>, !fir.shape<1>) -> !fir.box<!fir.heap<!fir.array<?xi32>>>
// CHECK-NEXT: fir.store %[[V13]] to %[[V0]] : !fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>
// CHECK: %[[V15:.*]] = fir.convert %[[V0]] : (!fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>) -> !fir.ref<!fir.box<none>>
// CHECK-NEXT: %[[V16:.*]] = fir.convert %[[V8]] : (!fir.box<!fir.array<2x2xi32>>) -> !fir.box<none>
// CHECK: %[[V19:.*]] = fir.convert %[[V10]] : (!fir.box<!fir.logical<4>>) -> !fir.box<none>
-// CHECK-NEXT: %[[V20:.*]] = fir.call @_FortranAMaxlocDim(%[[V15]], %[[V16]], %c4_i32, %c1_i32, {{.*}}, {{.*}}, %[[V19]], %false) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, i32, !fir.ref<i8>, i32, !fir.box<none>, i1) -> none
+// CHECK-NEXT: %[[V20:.*]] = fir.call @_FortranAMaxlocDim(%[[V15]], %[[V16]], %[[C4]], %[[C1]], {{.*}}, {{.*}}, %[[V19]], %[[FALSE]]) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, i32, !fir.ref<i8>, i32, !fir.box<none>, i1) -> none
// CHECK-NEXT: %[[V21:.*]] = fir.load %[[V0]] : !fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>
-// CHECK-NEXT: %c0_2 = arith.constant 0 : index
-// CHECK-NEXT: %[[V22:.*]]:3 = fir.box_dims %[[V21]], %c0_2 : (!fir.box<!fir.heap<!fir.array<?xi32>>>, index) -> (index, index, index)
+// CHECK-NEXT: %[[V22:.*]]:3 = fir.box_dims %[[V21]], %[[C0]] : (!fir.box<!fir.heap<!fir.array<?xi32>>>, index) -> (index, index, index)
// CHECK-NEXT: %[[V23:.*]] = fir.box_addr %[[V21]] : (!fir.box<!fir.heap<!fir.array<?xi32>>>) -> !fir.heap<!fir.array<?xi32>>
// CHECK-NEXT: %[[V24:.*]] = fir.shape_shift %[[V22]]#0, %[[V22]]#1 : (index, index) -> !fir.shapeshift<1>
// CHECK-NEXT: %[[V25:.*]]:2 = hlfir.declare %[[V23]](%[[V24]]) {uniq_name = ".tmp.intrinsic_result"} : (!fir.heap<!fir.array<?xi32>>, !fir.shapeshift<1>) -> (!fir.box<!fir.array<?xi32>>, !fir.heap<!fir.array<?xi32>>)
-// CHECK-NEXT: %true_3 = arith.constant true
-// CHECK-NEXT: %[[V26:.*]] = hlfir.as_expr %[[V25]]#0 move %true_3 : (!fir.box<!fir.array<?xi32>>, i1) -> !hlfir.expr<?xi32>
+// CHECK-NEXT: %[[V26:.*]] = hlfir.as_expr %[[V25]]#0 move %[[TRUE]] : (!fir.box<!fir.array<?xi32>>, i1) -> !hlfir.expr<?xi32>
// CHECK-NEXT: hlfir.assign %[[V26]] to %[[V6]]#0 : !hlfir.expr<?xi32>, !fir.ref<!fir.array<2xi32>>
// CHECK-NEXT: hlfir.destroy %[[V26]] : !hlfir.expr<?xi32>
// CHECK-NEXT: return
@@ -258,29 +250,28 @@ func.func @_QPmaxloc6(%arg0: !fir.box<!fir.array<?x!fir.char<1,?>>> {fir.bindc_n
// CHECK-LABEL: func.func @_QPmaxloc6(
// CHECK: %[[ARG0:.*]]: !fir.box<!fir.array<?x!fir.char<1,?>>> {fir.bindc_name = "a"}
// CHECK: %[[ARG1:.*]]: !fir.box<!fir.array<?xi32>> {fir.bindc_name = "s"}
-// CHECK-NEXT: %[[V0:.*]] = fir.alloca !fir.box<!fir.heap<!fir.array<?xi32>>>
+// CHECK-DAG: %[[FALSE:.*]] = arith.constant false
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
+// CHECK-DAG: %[[C4:.*]] = arith.constant 4 : i32
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK: %[[V0:.*]] = fir.alloca !fir.box<!fir.heap<!fir.array<?xi32>>>
// CHECK-NEXT: %[[V1:.*]]:2 = hlfir.declare %[[ARG0]] {uniq_name = "_QFmaxloc6Ea"} : (!fir.box<!fir.array<?x!fir.char<1,?>>>) -> (!fir.box<!fir.array<?x!fir.char<1,?>>>, !fir.box<!fir.array<?x!fir.char<1,?>>>)
// CHECK-NEXT: %[[V2:.*]]:2 = hlfir.declare %[[ARG1]] {uniq_name = "_QFmaxloc4Es"} : (!fir.box<!fir.array<?xi32>>) -> (!fir.box<!fir.array<?xi32>>, !fir.box<!fir.array<?xi32>>)
-// CHECK-NEXT: %c4_i32 = arith.constant 4 : i32
// CHECK-NEXT: %[[V3:.*]] = fir.absent !fir.box<i1>
-// CHECK-NEXT: %false = arith.constant false
// CHECK-NEXT: %[[V4:.*]] = fir.zero_bits !fir.heap<!fir.array<?xi32>>
-// CHECK-NEXT: %c0 = arith.constant 0 : index
-// CHECK-NEXT: %[[V5:.*]] = fir.shape %c0 : (index) -> !fir.shape<1>
+// CHECK-NEXT: %[[V5:.*]] = fir.shape %[[C0]] : (index) -> !fir.shape<1>
// CHECK-NEXT: %[[V6:.*]] = fir.embox %[[V4]](%[[V5]]) : (!fir.heap<!fir.array<?xi32>>, !fir.shape<1>) -> !fir.box<!fir.heap<!fir.array<?xi32>>>
// CHECK-NEXT: fir.store %[[V6]] to %[[V0]] : !fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>
// CHECK: %[[V8:.*]] = fir.convert %[[V0]] : (!fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>) -> !fir.ref<!fir.box<none>>
// CHECK-NEXT: %[[V9:.*]] = fir.convert %[[V1]]#1 : (!fir.box<!fir.array<?x!fir.char<1,?>>>) -> !fir.box<none>
// CHECK: %[[V12:.*]] = fir.convert %[[V3]] : (!fir.box<i1>) -> !fir.box<none>
-// CHECK-NEXT: %[[V13:.*]] = fir.call @_FortranAMaxlocCharacter(%[[V8]], %[[V9]], %c4_i32, {{.*}}, {{.*}}, %[[V12]], %false) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, !fir.ref<i8>, i32, !fir.box<none>, i1) -> none
+// CHECK-NEXT: %[[V13:.*]] = fir.call @_FortranAMaxlocCharacter(%[[V8]], %[[V9]], %[[C4]], {{.*}}, {{.*}}, %[[V12]], %[[FALSE]]) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, !fir.ref<i8>, i32, !fir.box<none>, i1) -> none
// CHECK-NEXT: %[[V14:.*]] = fir.load %[[V0]] : !fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>
-// CHECK-NEXT: %c0_0 = arith.constant 0 : index
-// CHECK-NEXT: %[[V15:.*]]:3 = fir.box_dims %[[V14]], %c0_0 : (!fir.box<!fir.heap<!fir.array<?xi32>>>, index) -> (index, index, index)
+// CHECK-NEXT: %[[V15:.*]]:3 = fir.box_dims %[[V14]], %[[C0]] : (!fir.box<!fir.heap<!fir.array<?xi32>>>, index) -> (index, index, index)
// CHECK-NEXT: %[[V16:.*]] = fir.box_addr %[[V14]] : (!fir.box<!fir.heap<!fir.array<?xi32>>>) -> !fir.heap<!fir.array<?xi32>>
// CHECK-NEXT: %[[V17:.*]] = fir.shape_shift %[[V15]]#0, %[[V15]]#1 : (index, index) -> !fir.shapeshift<1>
// CHECK-NEXT: %[[V18:.*]]:2 = hlfir.declare %[[V16]](%[[V17]]) {uniq_name = ".tmp.intrinsic_result"} : (!fir.heap<!fir.array<?xi32>>, !fir.shapeshift<1>) -> (!fir.box<!fir.array<?xi32>>, !fir.heap<!fir.array<?xi32>>)
-// CHECK-NEXT: %true = arith.constant true
-// CHECK-NEXT: %[[V19:.*]] = hlfir.as_expr %[[V18]]#0 move %true : (!fir.box<!fir.array<?xi32>>, i1) -> !hlfir.expr<?xi32>
+// CHECK-NEXT: %[[V19:.*]] = hlfir.as_expr %[[V18]]#0 move %[[TRUE]] : (!fir.box<!fir.array<?xi32>>, i1) -> !hlfir.expr<?xi32>
// CHECK-NEXT: hlfir.assign %[[V19]] to %[[V2]]#0 : !hlfir.expr<?xi32>, !fir.box<!fir.array<?xi32>>
// CHECK-NEXT: hlfir.destroy %[[V19]] : !hlfir.expr<?xi32>
// CHECK-NEXT: return
@@ -304,22 +295,22 @@ func.func @_QPmaxloc7(%arg0: !fir.box<!fir.array<?xi32>> {fir.bindc_name = "a"},
// CHECK: %[[ARG2:.*]]: !fir.box<!fir.array<?x!fir.logical<4>>> {fir.bindc_name = "m"}
// CHECK: %[[ARG3:.*]]: !fir.ref<!fir.logical<4>> {fir.bindc_name = "b"}
// CHECK: %[[ARG4:.*]]: !fir.box<!fir.array<?xi32>> {fir.bindc_name = "s"}
-// CHECK-NEXT: %[[V0:.*]] = fir.alloca !fir.box<!fir.heap<i32>>
+// CHECK-DAG: %[[FALSE:.*]] = arith.constant false
+// CHECK-DAG: %[[C4:.*]] = arith.constant 4 : i32
+// CHECK: %[[V0:.*]] = fir.alloca !fir.box<!fir.heap<i32>>
// CHECK-NEXT: %[[V1:.*]]:2 = hlfir.declare %[[ARG0]] {uniq_name = "_QFFtestEa"} : (!fir.box<!fir.array<?xi32>>) -> (!fir.box<!fir.array<?xi32>>, !fir.box<!fir.array<?xi32>>)
// CHECK-NEXT: %[[V2:.*]]:2 = hlfir.declare %[[ARG3]] {uniq_name = "_QFFtestEb"} : (!fir.ref<!fir.logical<4>>) -> (!fir.ref<!fir.logical<4>>, !fir.ref<!fir.logical<4>>)
// CHECK-NEXT: %[[V3:.*]]:2 = hlfir.declare %[[ARG1]] {uniq_name = "_QFFtestEd"} : (!fir.ref<i32>) -> (!fir.ref<i32>, !fir.ref<i32>)
// CHECK-NEXT: %[[V4:.*]]:2 = hlfir.declare %[[ARG2]] {uniq_name = "_QFFtestEm"} : (!fir.box<!fir.array<?x!fir.logical<4>>>) -> (!fir.box<!fir.array<?x!fir.logical<4>>>, !fir.box<!fir.array<?x!fir.logical<4>>>)
// CHECK-NEXT: %[[V5:.*]]:2 = hlfir.declare %[[ARG4]] {uniq_name = "_QFFtestEs"} : (!fir.box<!fir.array<?xi32>>) -> (!fir.box<!fir.array<?xi32>>, !fir.box<!fir.array<?xi32>>)
// CHECK-NEXT: %[[V6:.*]] = fir.load %[[V3]]#0 : !fir.ref<i32>
-// CHECK-NEXT: %c4_i32 = arith.constant 4 : i32
-// CHECK-NEXT: %false = arith.constant false
// CHECK-NEXT: %[[V7:.*]] = fir.zero_bits !fir.heap<i32>
// CHECK-NEXT: %[[V8:.*]] = fir.embox %[[V7]] : (!fir.heap<i32>) -> !fir.box<!fir.heap<i32>>
// CHECK-NEXT: fir.store %[[V8]] to %[[V0]] : !fir.ref<!fir.box<!fir.heap<i32>>>
// CHECK: %[[V10:.*]] = fir.convert %[[V0]] : (!fir.ref<!fir.box<!fir.heap<i32>>>) -> !fir.ref<!fir.box<none>>
// CHECK-NEXT: %[[V11:.*]] = fir.convert %[[V1]]#1 : (!fir.box<!fir.array<?xi32>>) -> !fir.box<none>
// CHECK: %[[V14:.*]] = fir.convert %[[V4]]#1 : (!fir.box<!fir.array<?x!fir.logical<4>>>) -> !fir.box<none>
-// CHECK-NEXT: %[[V15:.*]] = fir.call @_FortranAMaxlocDim(%[[V10]], %[[V11]], %c4_i32, %[[V6]], {{.*}}, {{.*}}, %[[V14]], %false) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, i32, !fir.ref<i8>, i32, !fir.box<none>, i1) -> none
+// CHECK-NEXT: %[[V15:.*]] = fir.call @_FortranAMaxlocDim(%[[V10]], %[[V11]], %[[C4]], %[[V6]], {{.*}}, {{.*}}, %[[V14]], %[[FALSE]]) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, i32, !fir.ref<i8>, i32, !fir.box<none>, i1) -> none
// CHECK-NEXT: %[[V16:.*]] = fir.load %[[V0]] : !fir.ref<!fir.box<!fir.heap<i32>>>
// CHECK-NEXT: %[[V17:.*]] = fir.box_addr %[[V16]] : (!fir.box<!fir.heap<i32>>) -> !fir.heap<i32>
// CHECK-NEXT: %[[V18:.*]] = fir.load %[[V17]] : !fir.heap<i32>
diff --git a/flang/test/HLFIR/maxval-lowering.fir b/flang/test/HLFIR/maxval-lowering.fir
index 3eb36cdef2cbfa..5a49ed5273ef87 100644
--- a/flang/test/HLFIR/maxval-lowering.fir
+++ b/flang/test/HLFIR/maxval-lowering.fir
@@ -37,6 +37,7 @@ func.func @_QPmaxval2(%arg0: !fir.box<!fir.array<?x?xi32>> {fir.bindc_name = "a"
// CHECK: %[[ARG0:.*]]: !fir.box<!fir.array<?x?xi32>>
// CHECK: %[[ARG1:.*]]: !fir.box<!fir.array<?xi32>>
// CHECK: %[[ARG2:.*]]: !fir.ref<index>
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
// CHECK-DAG: %[[ARRAY:.*]]:2 = hlfir.declare %[[ARG0]]
// CHECK-DAG: %[[RES:.*]]:2 = hlfir.declare %[[ARG1]]
// CHECK-DAG: %[[DIM_VAR:.*]]:2 = hlfir.declare %[[ARG2]]
@@ -63,7 +64,6 @@ func.func @_QPmaxval2(%arg0: !fir.box<!fir.array<?x?xi32>> {fir.bindc_name = "a"
// CHECK-NEXT: %[[SHIFT:.*]] = fir.shape_shift %[[BOX_DIMS]]#0, %[[BOX_DIMS]]#1
// TODO: fix alias analysis in hlfir.assign bufferization
// CHECK-NEXT: %[[TMP:.*]]:2 = hlfir.declare %[[ADDR]](%[[SHIFT]]) {uniq_name = ".tmp.intrinsic_result"}
-// CHECK: %[[TRUE:.*]] = arith.constant true
// CHECK: %[[ASEXPR:.*]] = hlfir.as_expr %[[TMP]]#0 move %[[TRUE]] : (!fir.box<!fir.array<?xi32>>, i1) -> !hlfir.expr<?xi32>
// CHECK: hlfir.assign %[[ASEXPR]] to %[[RES]]#0
// CHECK: hlfir.destroy %[[ASEXPR]]
@@ -190,6 +190,7 @@ func.func @_QPmaxval6(%arg0: !fir.box<!fir.array<?x!fir.char<1,?>>> {fir.bindc_n
// CHECK-LABEL: func.func @_QPmaxval6(
// CHECK: %[[ARG0:.*]]: !fir.box<!fir.array<?x!fir.char<1,?>>>
// CHECK: %[[ARG1:.*]]: !fir.boxchar<1>
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
// CHECK-DAG: %[[ARRAY:.*]]:2 = hlfir.declare %[[ARG0]]
// CHECK-DAG: %[[UNBOXED:.*]]:2 = fir.unboxchar %[[ARG1]]
// CHECK-DAG: %[[RES:.*]]:2 = hlfir.declare %[[UNBOXED]]#0 typeparams %[[UNBOXED]]#1
@@ -210,7 +211,6 @@ func.func @_QPmaxval6(%arg0: !fir.box<!fir.array<?x!fir.char<1,?>>> {fir.bindc_n
// CHECK: %[[BOX_ELESIZE:.*]] = fir.box_elesize %[[RET]]
// CHECK-NEXT: %[[ADDR:.*]] = fir.box_addr %[[RET]]
// CHECK-NEXT: %[[TMP:.*]]:2 = hlfir.declare %[[ADDR]] typeparams %[[BOX_ELESIZE]] {uniq_name = ".tmp.intrinsic_result"}
-// CHECK: %[[TRUE:.*]] = arith.constant true
// CHECK: %[[ASEXPR:.*]] = hlfir.as_expr %[[TMP]]#0 move %[[TRUE]] : (!fir.boxchar<1>, i1) -> !hlfir.expr<!fir.char<1,?>>
// CHECK: hlfir.assign %[[ASEXPR]] to %[[RES]]#0
// CHECK: hlfir.destroy %[[ASEXPR]]
diff --git a/flang/test/HLFIR/minloc-lowering.fir b/flang/test/HLFIR/minloc-lowering.fir
index fede0a1950121b..6f3cbd171445c7 100644
--- a/flang/test/HLFIR/minloc-lowering.fir
+++ b/flang/test/HLFIR/minloc-lowering.fir
@@ -13,29 +13,28 @@ func.func @_QPminloc1(%arg0: !fir.box<!fir.array<?xi32>> {fir.bindc_name = "a"},
// CHECK-LABEL: func.func @_QPminloc1(
// CHECK: %[[ARG0:.*]]: !fir.box<!fir.array<?xi32>> {fir.bindc_name = "a"}
// CHECK: %[[ARG1:.*]]: !fir.box<!fir.array<?xi32>> {fir.bindc_name = "s"}
-// CHECK-NEXT: %[[V0:.*]] = fir.alloca !fir.box<!fir.heap<!fir.array<?xi32>>>
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
+// CHECK-DAG: %[[FALSE:.*]] = arith.constant false
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C4:.*]] = arith.constant 4 : i32
+// CHECK: %[[V0:.*]] = fir.alloca !fir.box<!fir.heap<!fir.array<?xi32>>>
// CHECK-NEXT: %[[V1:.*]]:2 = hlfir.declare %[[ARG0]] {uniq_name = "_QFminloc1Ea"} : (!fir.box<!fir.array<?xi32>>) -> (!fir.box<!fir.array<?xi32>>, !fir.box<!fir.array<?xi32>>)
// CHECK-NEXT: %[[V2:.*]]:2 = hlfir.declare %[[ARG1]] {uniq_name = "_QFminloc1Es"} : (!fir.box<!fir.array<?xi32>>) -> (!fir.box<!fir.array<?xi32>>, !fir.box<!fir.array<?xi32>>)
-// CHECK-NEXT: %c4_i32 = arith.constant 4 : i32
// CHECK-NEXT: %[[V3:.*]] = fir.absent !fir.box<i1>
-// CHECK-NEXT: %false = arith.constant false
// CHECK-NEXT: %[[V4:.*]] = fir.zero_bits !fir.heap<!fir.array<?xi32>>
-// CHECK-NEXT: %c0 = arith.constant 0 : index
-// CHECK-NEXT: %[[V5:.*]] = fir.shape %c0 : (index) -> !fir.shape<1>
+// CHECK-NEXT: %[[V5:.*]] = fir.shape %[[C0]] : (index) -> !fir.shape<1>
// CHECK-NEXT: %[[V6:.*]] = fir.embox %[[V4]](%[[V5]]) : (!fir.heap<!fir.array<?xi32>>, !fir.shape<1>) -> !fir.box<!fir.heap<!fir.array<?xi32>>>
// CHECK-NEXT: fir.store %[[V6]] to %[[V0]] : !fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>
// CHECK: %[[V8:.*]] = fir.convert %[[V0]] : (!fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>) -> !fir.ref<!fir.box<none>>
// CHECK-NEXT: %[[V9:.*]] = fir.convert %[[V1]]#1 : (!fir.box<!fir.array<?xi32>>) -> !fir.box<none>
// CHECK: %[[V12:.*]] = fir.convert %[[V3]] : (!fir.box<i1>) -> !fir.box<none>
-// CHECK-NEXT: %[[V13:.*]] = fir.call @_FortranAMinlocInteger4(%[[V8]], %[[V9]], %c4_i32, {{.*}}, {{.*}}, %[[V12]], %false) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, !fir.ref<i8>, i32, !fir.box<none>, i1) -> none
+// CHECK-NEXT: %[[V13:.*]] = fir.call @_FortranAMinlocInteger4(%[[V8]], %[[V9]], %[[C4]], {{.*}}, {{.*}}, %[[V12]], %[[FALSE]]) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, !fir.ref<i8>, i32, !fir.box<none>, i1) -> none
// CHECK-NEXT: %[[V14:.*]] = fir.load %[[V0]] : !fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>
-// CHECK-NEXT: %c0_0 = arith.constant 0 : index
-// CHECK-NEXT: %[[V15:.*]]:3 = fir.box_dims %[[V14]], %c0_0 : (!fir.box<!fir.heap<!fir.array<?xi32>>>, index) -> (index, index, index)
+// CHECK-NEXT: %[[V15:.*]]:3 = fir.box_dims %[[V14]], %[[C0]] : (!fir.box<!fir.heap<!fir.array<?xi32>>>, index) -> (index, index, index)
// CHECK-NEXT: %[[V16:.*]] = fir.box_addr %[[V14]] : (!fir.box<!fir.heap<!fir.array<?xi32>>>) -> !fir.heap<!fir.array<?xi32>>
// CHECK-NEXT: %[[V17:.*]] = fir.shape_shift %[[V15]]#0, %[[V15]]#1 : (index, index) -> !fir.shapeshift<1>
// CHECK-NEXT: %[[V18:.*]]:2 = hlfir.declare %[[V16]](%[[V17]]) {uniq_name = ".tmp.intrinsic_result"} : (!fir.heap<!fir.array<?xi32>>, !fir.shapeshift<1>) -> (!fir.box<!fir.array<?xi32>>, !fir.heap<!fir.array<?xi32>>)
-// CHECK-NEXT: %true = arith.constant true
-// CHECK-NEXT: %[[V19:.*]] = hlfir.as_expr %[[V18]]#0 move %true : (!fir.box<!fir.array<?xi32>>, i1) -> !hlfir.expr<?xi32>
+// CHECK-NEXT: %[[V19:.*]] = hlfir.as_expr %[[V18]]#0 move %[[TRUE]] : (!fir.box<!fir.array<?xi32>>, i1) -> !hlfir.expr<?xi32>
// CHECK-NEXT: hlfir.assign %[[V19]] to %[[V2]]#0 : !hlfir.expr<?xi32>, !fir.box<!fir.array<?xi32>>
// CHECK-NEXT: hlfir.destroy %[[V19]] : !hlfir.expr<?xi32>
@@ -55,32 +54,31 @@ func.func @_QPminloc2(%arg0: !fir.box<!fir.array<?x?xi32>> {fir.bindc_name = "a"
// CHECK: %[[ARG0:.*]]: !fir.box<!fir.array<?x?xi32>> {fir.bindc_name = "a"}
// CHECK: %[[ARG1:.*]]: !fir.box<!fir.array<?xi32>> {fir.bindc_name = "s"}
// CHECK: %[[ARG2:.*]]: !fir.ref<index>
-// CHECK-NEXT: %[[V0:.*]] = fir.alloca !fir.box<!fir.heap<!fir.array<?xi32>>>
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
+// CHECK-DAG: %[[FALSE:.*]] = arith.constant false
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C4:.*]] = arith.constant 4 : i32
+// CHECK: %[[V0:.*]] = fir.alloca !fir.box<!fir.heap<!fir.array<?xi32>>>
// CHECK-NEXT: %[[V1:.*]]:2 = hlfir.declare %[[ARG0]] {uniq_name = "_QFminloc2Ea"} : (!fir.box<!fir.array<?x?xi32>>) -> (!fir.box<!fir.array<?x?xi32>>, !fir.box<!fir.array<?x?xi32>>)
// CHECK-NEXT: %[[V2:.*]]:2 = hlfir.declare %[[ARG2]] {uniq_name = "_QFminloc2Ed"} : (!fir.ref<index>) -> (!fir.ref<index>, !fir.ref<index>)
// CHECK-NEXT: %[[V3:.*]]:2 = hlfir.declare %[[ARG1]] {uniq_name = "_QFminloc2Es"} : (!fir.box<!fir.array<?xi32>>) -> (!fir.box<!fir.array<?xi32>>, !fir.box<!fir.array<?xi32>>)
// CHECK-NEXT: %[[V4:.*]] = fir.load %[[V2]]#0 : !fir.ref<index>
-// CHECK-NEXT: %c4_i32 = arith.constant 4 : i32
// CHECK-NEXT: %[[V5:.*]] = fir.convert %[[V4]] : (index) -> i32
// CHECK-NEXT: %[[V6:.*]] = fir.absent !fir.box<i1>
-// CHECK-NEXT: %false = arith.constant false
// CHECK-NEXT: %[[V7:.*]] = fir.zero_bits !fir.heap<!fir.array<?xi32>>
-// CHECK-NEXT: %c0 = arith.constant 0 : index
-// CHECK-NEXT: %[[V8:.*]] = fir.shape %c0 : (index) -> !fir.shape<1>
+// CHECK-NEXT: %[[V8:.*]] = fir.shape %[[C0]] : (index) -> !fir.shape<1>
// CHECK-NEXT: %[[V9:.*]] = fir.embox %[[V7]](%[[V8]]) : (!fir.heap<!fir.array<?xi32>>, !fir.shape<1>) -> !fir.box<!fir.heap<!fir.array<?xi32>>>
// CHECK-NEXT: fir.store %[[V9]] to %[[V0]] : !fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>
// CHECK: %[[V11:.*]] = fir.convert %[[V0]] : (!fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>) -> !fir.ref<!fir.box<none>>
// CHECK-NEXT: %[[V12:.*]] = fir.convert %[[V1]]#1 : (!fir.box<!fir.array<?x?xi32>>) -> !fir.box<none>
// CHECK: %[[V15:.*]] = fir.convert %[[V6]] : (!fir.box<i1>) -> !fir.box<none>
-// CHECK-NEXT: %[[V16:.*]] = fir.call @_FortranAMinlocDim(%[[V11]], %[[V12]], %c4_i32, %[[V5]], {{.*}}, {{.*}}, %[[V15]], %false) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, i32, !fir.ref<i8>, i32, !fir.box<none>, i1) -> none
+// CHECK-NEXT: %[[V16:.*]] = fir.call @_FortranAMinlocDim(%[[V11]], %[[V12]], %[[C4]], %[[V5]], {{.*}}, {{.*}}, %[[V15]], %[[FALSE]]) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, i32, !fir.ref<i8>, i32, !fir.box<none>, i1) -> none
// CHECK-NEXT: %[[V17:.*]] = fir.load %[[V0]] : !fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>
-// CHECK-NEXT: %c0_0 = arith.constant 0 : index
-// CHECK-NEXT: %[[V18:.*]]:3 = fir.box_dims %[[V17]], %c0_0 : (!fir.box<!fir.heap<!fir.array<?xi32>>>, index) -> (index, index, index)
+// CHECK-NEXT: %[[V18:.*]]:3 = fir.box_dims %[[V17]], %[[C0]] : (!fir.box<!fir.heap<!fir.array<?xi32>>>, index) -> (index, index, index)
// CHECK-NEXT: %[[V19:.*]] = fir.box_addr %[[V17]] : (!fir.box<!fir.heap<!fir.array<?xi32>>>) -> !fir.heap<!fir.array<?xi32>>
// CHECK-NEXT: %[[V20:.*]] = fir.shape_shift %[[V18]]#0, %[[V18]]#1 : (index, index) -> !fir.shapeshift<1>
// CHECK-NEXT: %[[V21:.*]]:2 = hlfir.declare %[[V19]](%[[V20]]) {uniq_name = ".tmp.intrinsic_result"} : (!fir.heap<!fir.array<?xi32>>, !fir.shapeshift<1>) -> (!fir.box<!fir.array<?xi32>>, !fir.heap<!fir.array<?xi32>>)
-// CHECK-NEXT: %true = arith.constant true
-// CHECK-NEXT: %[[V22:.*]] = hlfir.as_expr %[[V21]]#0 move %true : (!fir.box<!fir.array<?xi32>>, i1) -> !hlfir.expr<?xi32>
+// CHECK-NEXT: %[[V22:.*]] = hlfir.as_expr %[[V21]]#0 move %[[TRUE]] : (!fir.box<!fir.array<?xi32>>, i1) -> !hlfir.expr<?xi32>
// CHECK-NEXT: hlfir.assign %[[V22]] to %[[V3]]#0 : !hlfir.expr<?xi32>, !fir.box<!fir.array<?xi32>>
// CHECK-NEXT: hlfir.destroy %[[V22]] : !hlfir.expr<?xi32>
// CHECK-NEXT: return
@@ -100,30 +98,29 @@ func.func @_QPminloc3(%arg0: !fir.box<!fir.array<?xi32>> {fir.bindc_name = "a"},
// CHECK: %[[ARG0:.*]]: !fir.box<!fir.array<?xi32>> {fir.bindc_name = "a"}
// CHECK: %[[ARG1:.*]]: !fir.box<!fir.array<?xi32>> {fir.bindc_name = "s"}
// CHECK: %[[ARG2:.*]]: !fir.ref<!fir.logical<4>>
-// CHECK-NEXT: %[[V0:.*]] = fir.alloca !fir.box<!fir.heap<!fir.array<?xi32>>>
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
+// CHECK-DAG: %[[FALSE:.*]] = arith.constant false
+// CHECK-DAG: %[[C0]] = arith.constant 0 : index
+// CHECK-DAG: %[[C4:.*]] = arith.constant 4 : i32
+// CHECK: %[[V0:.*]] = fir.alloca !fir.box<!fir.heap<!fir.array<?xi32>>>
// CHECK-NEXT: %[[V1:.*]]:2 = hlfir.declare %[[ARG0]] {uniq_name = "_QFminloc3Ea"} : (!fir.box<!fir.array<?xi32>>) -> (!fir.box<!fir.array<?xi32>>, !fir.box<!fir.array<?xi32>>)
// CHECK-NEXT: %[[V2:.*]]:2 = hlfir.declare %[[ARG2]] {uniq_name = "_QFminloc3Em"} : (!fir.ref<!fir.logical<4>>) -> (!fir.ref<!fir.logical<4>>, !fir.ref<!fir.logical<4>>)
// CHECK-NEXT: %[[V3:.*]]:2 = hlfir.declare %[[ARG1]] {uniq_name = "_QFminloc3Es"} : (!fir.box<!fir.array<?xi32>>) -> (!fir.box<!fir.array<?xi32>>, !fir.box<!fir.array<?xi32>>)
-// CHECK-NEXT: %c4_i32 = arith.constant 4 : i32
// CHECK-NEXT: %[[V4:.*]] = fir.embox %[[V2]]#1 : (!fir.ref<!fir.logical<4>>) -> !fir.box<!fir.logical<4>>
-// CHECK-NEXT: %false = arith.constant false
// CHECK-NEXT: %[[V5:.*]] = fir.zero_bits !fir.heap<!fir.array<?xi32>>
-// CHECK-NEXT: %c0 = arith.constant 0 : index
-// CHECK-NEXT: %[[V6:.*]] = fir.shape %c0 : (index) -> !fir.shape<1>
+// CHECK-NEXT: %[[V6:.*]] = fir.shape %[[C0]] : (index) -> !fir.shape<1>
// CHECK-NEXT: %[[V7:.*]] = fir.embox %[[V5]](%[[V6]]) : (!fir.heap<!fir.array<?xi32>>, !fir.shape<1>) -> !fir.box<!fir.heap<!fir.array<?xi32>>>
// CHECK-NEXT: fir.store %[[V7]] to %[[V0]] : !fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>
// CHECK: %[[V9:.*]] = fir.convert %[[V0]] : (!fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>) -> !fir.ref<!fir.box<none>>
// CHECK-NEXT: %[[V10:.*]] = fir.convert %[[V1]]#1 : (!fir.box<!fir.array<?xi32>>) -> !fir.box<none>
// CHECK: %[[V13:.*]] = fir.convert %[[V4]] : (!fir.box<!fir.logical<4>>) -> !fir.box<none>
-// CHECK-NEXT: %[[V14:.*]] = fir.call @_FortranAMinlocInteger4(%[[V9]], %[[V10]], %c4_i32, {{.*}}, {{.*}}, %[[V13]], %false) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, !fir.ref<i8>, i32, !fir.box<none>, i1) -> none
+// CHECK-NEXT: %[[V14:.*]] = fir.call @_FortranAMinlocInteger4(%[[V9]], %[[V10]], %[[C4]], {{.*}}, {{.*}}, %[[V13]], %[[FALSE]]) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, !fir.ref<i8>, i32, !fir.box<none>, i1) -> none
// CHECK-NEXT: %[[V15:.*]] = fir.load %[[V0]] : !fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>
-// CHECK-NEXT: %c0_0 = arith.constant 0 : index
-// CHECK-NEXT: %[[V16:.*]]:3 = fir.box_dims %[[V15]], %c0_0 : (!fir.box<!fir.heap<!fir.array<?xi32>>>, index) -> (index, index, index)
+// CHECK-NEXT: %[[V16:.*]]:3 = fir.box_dims %[[V15]], %[[C0]] : (!fir.box<!fir.heap<!fir.array<?xi32>>>, index) -> (index, index, index)
// CHECK-NEXT: %[[V17:.*]] = fir.box_addr %[[V15]] : (!fir.box<!fir.heap<!fir.array<?xi32>>>) -> !fir.heap<!fir.array<?xi32>>
// CHECK-NEXT: %[[V18:.*]] = fir.shape_shift %[[V16]]#0, %[[V16]]#1 : (index, index) -> !fir.shapeshift<1>
// CHECK-NEXT: %[[V19:.*]]:2 = hlfir.declare %[[V17]](%[[V18]]) {uniq_name = ".tmp.intrinsic_result"} : (!fir.heap<!fir.array<?xi32>>, !fir.shapeshift<1>) -> (!fir.box<!fir.array<?xi32>>, !fir.heap<!fir.array<?xi32>>)
-// CHECK-NEXT: %true = arith.constant true
-// CHECK-NEXT: %[[V20:.*]] = hlfir.as_expr %[[V19]]#0 move %true : (!fir.box<!fir.array<?xi32>>, i1) -> !hlfir.expr<?xi32>
+// CHECK-NEXT: %[[V20:.*]] = hlfir.as_expr %[[V19]]#0 move %[[TRUE]] : (!fir.box<!fir.array<?xi32>>, i1) -> !hlfir.expr<?xi32>
// CHECK-NEXT: hlfir.assign %[[V20]] to %[[V3]]#0 : !hlfir.expr<?xi32>, !fir.box<!fir.array<?xi32>>
// CHECK-NEXT: hlfir.destroy %[[V20]] : !hlfir.expr<?xi32>
// CHECK-NEXT: return
@@ -143,29 +140,28 @@ func.func @_QPminloc4(%arg0: !fir.box<!fir.array<?xi32>> {fir.bindc_name = "a"},
// CHECK: %[[ARG0:.*]]: !fir.box<!fir.array<?xi32>> {fir.bindc_name = "a"}
// CHECK: %[[ARG1:.*]]: !fir.box<!fir.array<?xi32>> {fir.bindc_name = "s"}
// CHECK: %[[ARG2:.*]]: !fir.box<!fir.array<?x!fir.logical<4>>>
-// CHECK-NEXT: %[[V0:.*]] = fir.alloca !fir.box<!fir.heap<!fir.array<?xi32>>>
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[FALSE:.*]] = arith.constant false
+// CHECK-DAG: %[[C4:.*]] = arith.constant 4 : i32
+// CHECK: %[[V0:.*]] = fir.alloca !fir.box<!fir.heap<!fir.array<?xi32>>>
// CHECK-NEXT: %[[V1:.*]]:2 = hlfir.declare %[[ARG0]] {uniq_name = "_QFminloc4Ea"} : (!fir.box<!fir.array<?xi32>>) -> (!fir.box<!fir.array<?xi32>>, !fir.box<!fir.array<?xi32>>)
// CHECK-NEXT: %[[V2:.*]]:2 = hlfir.declare %[[ARG2]] {uniq_name = "_QFminloc4Em"} : (!fir.box<!fir.array<?x!fir.logical<4>>>) -> (!fir.box<!fir.array<?x!fir.logical<4>>>, !fir.box<!fir.array<?x!fir.logical<4>>>)
// CHECK-NEXT: %[[V3:.*]]:2 = hlfir.declare %[[ARG1]] {uniq_name = "_QFminloc4Es"} : (!fir.box<!fir.array<?xi32>>) -> (!fir.box<!fir.array<?xi32>>, !fir.box<!fir.array<?xi32>>)
-// CHECK-NEXT: %c4_i32 = arith.constant 4 : i32
-// CHECK-NEXT: %false = arith.constant false
// CHECK-NEXT: %[[V4:.*]] = fir.zero_bits !fir.heap<!fir.array<?xi32>>
-// CHECK-NEXT: %c0 = arith.constant 0 : index
-// CHECK-NEXT: %[[V5:.*]] = fir.shape %c0 : (index) -> !fir.shape<1>
+// CHECK-NEXT: %[[V5:.*]] = fir.shape %[[C0]] : (index) -> !fir.shape<1>
// CHECK-NEXT: %[[V6:.*]] = fir.embox %[[V4]](%[[V5]]) : (!fir.heap<!fir.array<?xi32>>, !fir.shape<1>) -> !fir.box<!fir.heap<!fir.array<?xi32>>>
// CHECK-NEXT: fir.store %[[V6]] to %[[V0]] : !fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>
// CHECK: %[[V8:.*]] = fir.convert %[[V0]] : (!fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>) -> !fir.ref<!fir.box<none>>
// CHECK-NEXT: %[[V9:.*]] = fir.convert %[[V1]]#1 : (!fir.box<!fir.array<?xi32>>) -> !fir.box<none>
// CHECK: %[[V12:.*]] = fir.convert %[[V2]]#1 : (!fir.box<!fir.array<?x!fir.logical<4>>>) -> !fir.box<none>
-// CHECK-NEXT: %[[V13:.*]] = fir.call @_FortranAMinlocInteger4(%[[V8]], %[[V9]], %c4_i32, {{.*}}, {{.*}}, %[[V12]], %false) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, !fir.ref<i8>, i32, !fir.box<none>, i1) -> none
+// CHECK-NEXT: %[[V13:.*]] = fir.call @_FortranAMinlocInteger4(%[[V8]], %[[V9]], %[[C4]], {{.*}}, {{.*}}, %[[V12]], %[[FALSE]]) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, !fir.ref<i8>, i32, !fir.box<none>, i1) -> none
// CHECK-NEXT: %[[V14:.*]] = fir.load %[[V0]] : !fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>
-// CHECK-NEXT: %c0_0 = arith.constant 0 : index
-// CHECK-NEXT: %[[V15:.*]]:3 = fir.box_dims %[[V14]], %c0_0 : (!fir.box<!fir.heap<!fir.array<?xi32>>>, index) -> (index, index, index)
+// CHECK-NEXT: %[[V15:.*]]:3 = fir.box_dims %[[V14]], %[[C0]] : (!fir.box<!fir.heap<!fir.array<?xi32>>>, index) -> (index, index, index)
// CHECK-NEXT: %[[V16:.*]] = fir.box_addr %[[V14]] : (!fir.box<!fir.heap<!fir.array<?xi32>>>) -> !fir.heap<!fir.array<?xi32>>
// CHECK-NEXT: %[[V17:.*]] = fir.shape_shift %[[V15]]#0, %[[V15]]#1 : (index, index) -> !fir.shapeshift<1>
// CHECK-NEXT: %[[V18:.*]]:2 = hlfir.declare %[[V16]](%[[V17]]) {uniq_name = ".tmp.intrinsic_result"} : (!fir.heap<!fir.array<?xi32>>, !fir.shapeshift<1>) -> (!fir.box<!fir.array<?xi32>>, !fir.heap<!fir.array<?xi32>>)
-// CHECK-NEXT: %true = arith.constant true
-// CHECK-NEXT: %[[V19:.*]] = hlfir.as_expr %[[V18]]#0 move %true : (!fir.box<!fir.array<?xi32>>, i1) -> !hlfir.expr<?xi32>
+// CHECK-NEXT: %[[V19:.*]] = hlfir.as_expr %[[V18]]#0 move %[[TRUE]] : (!fir.box<!fir.array<?xi32>>, i1) -> !hlfir.expr<?xi32>
// CHECK-NEXT: hlfir.assign %[[V19]] to %[[V3]]#0 : !hlfir.expr<?xi32>, !fir.box<!fir.array<?xi32>>
// CHECK-NEXT: hlfir.destroy %[[V19]] : !hlfir.expr<?xi32>
// CHECK-NEXT: return
@@ -205,42 +201,38 @@ func.func @_QPminloc5(%arg0: !fir.ref<!fir.array<2xi32>> {fir.bindc_name = "s"})
}
// CHECK-LABEL: func.func @_QPminloc5(
// CHECK: %[[ARG0:.*]]: !fir.ref<!fir.array<2xi32>> {fir.bindc_name = "s"}
-// CHECK-NEXT: %[[V0:.*]] = fir.alloca !fir.box<!fir.heap<!fir.array<?xi32>>>
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
+// CHECK-DAG: %[[FALSE:.*]] = arith.constant false
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C1:.*]] = arith.constant 1 : i32
+// CHECK-DAG: %[[C2:.*]] = arith.constant 2 : index
+// CHECK-DAG: %[[C4:.*]] = arith.constant 4 : i32
+// CHECK: %[[V0:.*]] = fir.alloca !fir.box<!fir.heap<!fir.array<?xi32>>>
// CHECK-NEXT: %[[V1:.*]] = fir.alloca !fir.logical<4>
// CHECK-NEXT: %[[V2:.*]] = fir.address_of(@_QFminloc5Ea) : !fir.ref<!fir.array<2x2xi32>>
-// CHECK-NEXT: %c2 = arith.constant 2 : index
-// CHECK-NEXT: %c2_0 = arith.constant 2 : index
-// CHECK-NEXT: %[[V3:.*]] = fir.shape %c2, %c2_0 : (index, index) -> !fir.shape<2>
+// CHECK-NEXT: %[[V3:.*]] = fir.shape %[[C2]], %[[C2]] : (index, index) -> !fir.shape<2>
// CHECK-NEXT: %[[V4:.*]]:2 = hlfir.declare %[[V2]](%[[V3]]) {uniq_name = "_QFminloc5Ea"} : (!fir.ref<!fir.array<2x2xi32>>, !fir.shape<2>) -> (!fir.ref<!fir.array<2x2xi32>>, !fir.ref<!fir.array<2x2xi32>>)
-// CHECK-NEXT: %c2_1 = arith.constant 2 : index
-// CHECK-NEXT: %[[V5:.*]] = fir.shape %c2_1 : (index) -> !fir.shape<1>
+// CHECK-NEXT: %[[V5:.*]] = fir.shape %[[C2]] : (index) -> !fir.shape<1>
// CHECK-NEXT: %[[V6:.*]]:2 = hlfir.declare %[[ARG0]](%[[V5]]) {uniq_name = "_QFminloc5Es"} : (!fir.ref<!fir.array<2xi32>>, !fir.shape<1>) -> (!fir.ref<!fir.array<2xi32>>, !fir.ref<!fir.array<2xi32>>)
-// CHECK-NEXT: %c1_i32 = arith.constant 1 : i32
-// CHECK-NEXT: %true = arith.constant true
-// CHECK-NEXT: %c4_i32 = arith.constant 4 : i32
-// CHECK-NEXT: %[[V7:.*]] = fir.shape %c2, %c2_0 : (index, index) -> !fir.shape<2>
+// CHECK-NEXT: %[[V7:.*]] = fir.shape %[[C2]], %[[C2]] : (index, index) -> !fir.shape<2>
// CHECK-NEXT: %[[V8:.*]] = fir.embox %[[V4]]#1(%[[V7]]) : (!fir.ref<!fir.array<2x2xi32>>, !fir.shape<2>) -> !fir.box<!fir.array<2x2xi32>>
-// CHECK-NEXT: %[[V9:.*]] = fir.convert %true : (i1) -> !fir.logical<4>
+// CHECK-NEXT: %[[V9:.*]] = fir.convert %[[TRUE]] : (i1) -> !fir.logical<4>
// CHECK-NEXT: fir.store %[[V9]] to %[[V1]] : !fir.ref<!fir.logical<4>>
// CHECK-NEXT: %[[V10:.*]] = fir.embox %[[V1]] : (!fir.ref<!fir.logical<4>>) -> !fir.box<!fir.logical<4>>
-// CHECK-NEXT: %false = arith.constant false
// CHECK-NEXT: %[[V11:.*]] = fir.zero_bits !fir.heap<!fir.array<?xi32>>
-// CHECK-NEXT: %c0 = arith.constant 0 : index
-// CHECK-NEXT: %[[V12:.*]] = fir.shape %c0 : (index) -> !fir.shape<1>
+// CHECK-NEXT: %[[V12:.*]] = fir.shape %[[C0]] : (index) -> !fir.shape<1>
// CHECK-NEXT: %[[V13:.*]] = fir.embox %[[V11]](%[[V12]]) : (!fir.heap<!fir.array<?xi32>>, !fir.shape<1>) -> !fir.box<!fir.heap<!fir.array<?xi32>>>
// CHECK-NEXT: fir.store %[[V13]] to %[[V0]] : !fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>
// CHECK: %[[V15:.*]] = fir.convert %[[V0]] : (!fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>) -> !fir.ref<!fir.box<none>>
// CHECK-NEXT: %[[V16:.*]] = fir.convert %[[V8]] : (!fir.box<!fir.array<2x2xi32>>) -> !fir.box<none>
// CHECK: %[[V19:.*]] = fir.convert %[[V10]] : (!fir.box<!fir.logical<4>>) -> !fir.box<none>
-// CHECK-NEXT: %[[V20:.*]] = fir.call @_FortranAMinlocDim(%[[V15]], %[[V16]], %c4_i32, %c1_i32, {{.*}}, {{.*}}, %[[V19]], %false) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, i32, !fir.ref<i8>, i32, !fir.box<none>, i1) -> none
+// CHECK-NEXT: %[[V20:.*]] = fir.call @_FortranAMinlocDim(%[[V15]], %[[V16]], %[[C4]], %[[C1]], {{.*}}, {{.*}}, %[[V19]], %[[FALSE]]) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, i32, !fir.ref<i8>, i32, !fir.box<none>, i1) -> none
// CHECK-NEXT: %[[V21:.*]] = fir.load %[[V0]] : !fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>
-// CHECK-NEXT: %c0_2 = arith.constant 0 : index
-// CHECK-NEXT: %[[V22:.*]]:3 = fir.box_dims %[[V21]], %c0_2 : (!fir.box<!fir.heap<!fir.array<?xi32>>>, index) -> (index, index, index)
+// CHECK-NEXT: %[[V22:.*]]:3 = fir.box_dims %[[V21]], %[[C0]] : (!fir.box<!fir.heap<!fir.array<?xi32>>>, index) -> (index, index, index)
// CHECK-NEXT: %[[V23:.*]] = fir.box_addr %[[V21]] : (!fir.box<!fir.heap<!fir.array<?xi32>>>) -> !fir.heap<!fir.array<?xi32>>
// CHECK-NEXT: %[[V24:.*]] = fir.shape_shift %[[V22]]#0, %[[V22]]#1 : (index, index) -> !fir.shapeshift<1>
// CHECK-NEXT: %[[V25:.*]]:2 = hlfir.declare %[[V23]](%[[V24]]) {uniq_name = ".tmp.intrinsic_result"} : (!fir.heap<!fir.array<?xi32>>, !fir.shapeshift<1>) -> (!fir.box<!fir.array<?xi32>>, !fir.heap<!fir.array<?xi32>>)
-// CHECK-NEXT: %true_3 = arith.constant true
-// CHECK-NEXT: %[[V26:.*]] = hlfir.as_expr %[[V25]]#0 move %true_3 : (!fir.box<!fir.array<?xi32>>, i1) -> !hlfir.expr<?xi32>
+// CHECK-NEXT: %[[V26:.*]] = hlfir.as_expr %[[V25]]#0 move %[[TRUE]] : (!fir.box<!fir.array<?xi32>>, i1) -> !hlfir.expr<?xi32>
// CHECK-NEXT: hlfir.assign %[[V26]] to %[[V6]]#0 : !hlfir.expr<?xi32>, !fir.ref<!fir.array<2xi32>>
// CHECK-NEXT: hlfir.destroy %[[V26]] : !hlfir.expr<?xi32>
// CHECK-NEXT: return
@@ -258,29 +250,28 @@ func.func @_QPminloc6(%arg0: !fir.box<!fir.array<?x!fir.char<1,?>>> {fir.bindc_n
// CHECK-LABEL: func.func @_QPminloc6(
// CHECK: %[[ARG0:.*]]: !fir.box<!fir.array<?x!fir.char<1,?>>> {fir.bindc_name = "a"}
// CHECK: %[[ARG1:.*]]: !fir.box<!fir.array<?xi32>> {fir.bindc_name = "s"}
-// CHECK-NEXT: %[[V0:.*]] = fir.alloca !fir.box<!fir.heap<!fir.array<?xi32>>>
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
+// CHECK-DAG: %[[FALSE:.*]] = arith.constant false
+// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
+// CHECK-DAG: %[[C4:.*]] = arith.constant 4 : i32
+// CHECK: %[[V0:.*]] = fir.alloca !fir.box<!fir.heap<!fir.array<?xi32>>>
// CHECK-NEXT: %[[V1:.*]]:2 = hlfir.declare %[[ARG0]] {uniq_name = "_QFminloc6Ea"} : (!fir.box<!fir.array<?x!fir.char<1,?>>>) -> (!fir.box<!fir.array<?x!fir.char<1,?>>>, !fir.box<!fir.array<?x!fir.char<1,?>>>)
// CHECK-NEXT: %[[V2:.*]]:2 = hlfir.declare %[[ARG1]] {uniq_name = "_QFminloc4Es"} : (!fir.box<!fir.array<?xi32>>) -> (!fir.box<!fir.array<?xi32>>, !fir.box<!fir.array<?xi32>>)
-// CHECK-NEXT: %c4_i32 = arith.constant 4 : i32
// CHECK-NEXT: %[[V3:.*]] = fir.absent !fir.box<i1>
-// CHECK-NEXT: %false = arith.constant false
// CHECK-NEXT: %[[V4:.*]] = fir.zero_bits !fir.heap<!fir.array<?xi32>>
-// CHECK-NEXT: %c0 = arith.constant 0 : index
-// CHECK-NEXT: %[[V5:.*]] = fir.shape %c0 : (index) -> !fir.shape<1>
+// CHECK-NEXT: %[[V5:.*]] = fir.shape %[[C0]] : (index) -> !fir.shape<1>
// CHECK-NEXT: %[[V6:.*]] = fir.embox %[[V4]](%[[V5]]) : (!fir.heap<!fir.array<?xi32>>, !fir.shape<1>) -> !fir.box<!fir.heap<!fir.array<?xi32>>>
// CHECK-NEXT: fir.store %[[V6]] to %[[V0]] : !fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>
// CHECK: %[[V8:.*]] = fir.convert %[[V0]] : (!fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>) -> !fir.ref<!fir.box<none>>
// CHECK-NEXT: %[[V9:.*]] = fir.convert %[[V1]]#1 : (!fir.box<!fir.array<?x!fir.char<1,?>>>) -> !fir.box<none>
// CHECK: %[[V12:.*]] = fir.convert %[[V3]] : (!fir.box<i1>) -> !fir.box<none>
-// CHECK-NEXT: %[[V13:.*]] = fir.call @_FortranAMinlocCharacter(%[[V8]], %[[V9]], %c4_i32, {{.*}}, {{.*}}, %[[V12]], %false) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, !fir.ref<i8>, i32, !fir.box<none>, i1) -> none
+// CHECK-NEXT: %[[V13:.*]] = fir.call @_FortranAMinlocCharacter(%[[V8]], %[[V9]], %[[C4]], {{.*}}, {{.*}}, %[[V12]], %[[FALSE]]) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, !fir.ref<i8>, i32, !fir.box<none>, i1) -> none
// CHECK-NEXT: %[[V14:.*]] = fir.load %[[V0]] : !fir.ref<!fir.box<!fir.heap<!fir.array<?xi32>>>>
-// CHECK-NEXT: %c0_0 = arith.constant 0 : index
-// CHECK-NEXT: %[[V15:.*]]:3 = fir.box_dims %[[V14]], %c0_0 : (!fir.box<!fir.heap<!fir.array<?xi32>>>, index) -> (index, index, index)
+// CHECK-NEXT: %[[V15:.*]]:3 = fir.box_dims %[[V14]], %[[C0]] : (!fir.box<!fir.heap<!fir.array<?xi32>>>, index) -> (index, index, index)
// CHECK-NEXT: %[[V16:.*]] = fir.box_addr %[[V14]] : (!fir.box<!fir.heap<!fir.array<?xi32>>>) -> !fir.heap<!fir.array<?xi32>>
// CHECK-NEXT: %[[V17:.*]] = fir.shape_shift %[[V15]]#0, %[[V15]]#1 : (index, index) -> !fir.shapeshift<1>
// CHECK-NEXT: %[[V18:.*]]:2 = hlfir.declare %[[V16]](%[[V17]]) {uniq_name = ".tmp.intrinsic_result"} : (!fir.heap<!fir.array<?xi32>>, !fir.shapeshift<1>) -> (!fir.box<!fir.array<?xi32>>, !fir.heap<!fir.array<?xi32>>)
-// CHECK-NEXT: %true = arith.constant true
-// CHECK-NEXT: %[[V19:.*]] = hlfir.as_expr %[[V18]]#0 move %true : (!fir.box<!fir.array<?xi32>>, i1) -> !hlfir.expr<?xi32>
+// CHECK-NEXT: %[[V19:.*]] = hlfir.as_expr %[[V18]]#0 move %[[TRUE]] : (!fir.box<!fir.array<?xi32>>, i1) -> !hlfir.expr<?xi32>
// CHECK-NEXT: hlfir.assign %[[V19]] to %[[V2]]#0 : !hlfir.expr<?xi32>, !fir.box<!fir.array<?xi32>>
// CHECK-NEXT: hlfir.destroy %[[V19]] : !hlfir.expr<?xi32>
// CHECK-NEXT: return
@@ -304,22 +295,22 @@ func.func @_QPminloc7(%arg0: !fir.box<!fir.array<?xi32>> {fir.bindc_name = "a"},
// CHECK: %[[ARG2:.*]]: !fir.box<!fir.array<?x!fir.logical<4>>> {fir.bindc_name = "m"}
// CHECK: %[[ARG3:.*]]: !fir.ref<!fir.logical<4>> {fir.bindc_name = "b"}
// CHECK: %[[ARG4:.*]]: !fir.box<!fir.array<?xi32>> {fir.bindc_name = "s"}
-// CHECK-NEXT: %[[V0:.*]] = fir.alloca !fir.box<!fir.heap<i32>>
+// CHECK-DAG: %[[FALSE:.*]] = arith.constant false
+// CHECK-DAG: %[[C4:.*]] = arith.constant 4 : i32
+// CHECK: %[[V0:.*]] = fir.alloca !fir.box<!fir.heap<i32>>
// CHECK-NEXT: %[[V1:.*]]:2 = hlfir.declare %[[ARG0]] {uniq_name = "_QFFtestEa"} : (!fir.box<!fir.array<?xi32>>) -> (!fir.box<!fir.array<?xi32>>, !fir.box<!fir.array<?xi32>>)
// CHECK-NEXT: %[[V2:.*]]:2 = hlfir.declare %[[ARG3]] {uniq_name = "_QFFtestEb"} : (!fir.ref<!fir.logical<4>>) -> (!fir.ref<!fir.logical<4>>, !fir.ref<!fir.logical<4>>)
// CHECK-NEXT: %[[V3:.*]]:2 = hlfir.declare %[[ARG1]] {uniq_name = "_QFFtestEd"} : (!fir.ref<i32>) -> (!fir.ref<i32>, !fir.ref<i32>)
// CHECK-NEXT: %[[V4:.*]]:2 = hlfir.declare %[[ARG2]] {uniq_name = "_QFFtestEm"} : (!fir.box<!fir.array<?x!fir.logical<4>>>) -> (!fir.box<!fir.array<?x!fir.logical<4>>>, !fir.box<!fir.array<?x!fir.logical<4>>>)
// CHECK-NEXT: %[[V5:.*]]:2 = hlfir.declare %[[ARG4]] {uniq_name = "_QFFtestEs"} : (!fir.box<!fir.array<?xi32>>) -> (!fir.box<!fir.array<?xi32>>, !fir.box<!fir.array<?xi32>>)
// CHECK-NEXT: %[[V6:.*]] = fir.load %[[V3]]#0 : !fir.ref<i32>
-// CHECK-NEXT: %c4_i32 = arith.constant 4 : i32
-// CHECK-NEXT: %false = arith.constant false
// CHECK-NEXT: %[[V7:.*]] = fir.zero_bits !fir.heap<i32>
// CHECK-NEXT: %[[V8:.*]] = fir.embox %[[V7]] : (!fir.heap<i32>) -> !fir.box<!fir.heap<i32>>
// CHECK-NEXT: fir.store %[[V8]] to %[[V0]] : !fir.ref<!fir.box<!fir.heap<i32>>>
// CHECK: %[[V10:.*]] = fir.convert %[[V0]] : (!fir.ref<!fir.box<!fir.heap<i32>>>) -> !fir.ref<!fir.box<none>>
// CHECK-NEXT: %[[V11:.*]] = fir.convert %[[V1]]#1 : (!fir.box<!fir.array<?xi32>>) -> !fir.box<none>
// CHECK: %[[V14:.*]] = fir.convert %[[V4]]#1 : (!fir.box<!fir.array<?x!fir.logical<4>>>) -> !fir.box<none>
-// CHECK-NEXT: %[[V15:.*]] = fir.call @_FortranAMinlocDim(%[[V10]], %[[V11]], %c4_i32, %[[V6]], {{.*}}, {{.*}}, %[[V14]], %false) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, i32, !fir.ref<i8>, i32, !fir.box<none>, i1) -> none
+// CHECK-NEXT: %[[V15:.*]] = fir.call @_FortranAMinlocDim(%[[V10]], %[[V11]], %[[C4]], %[[V6]], {{.*}}, {{.*}}, %[[V14]], %[[FALSE]]) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, i32, !fir.ref<i8>, i32, !fir.box<none>, i1) -> none
// CHECK-NEXT: %[[V16:.*]] = fir.load %[[V0]] : !fir.ref<!fir.box<!fir.heap<i32>>>
// CHECK-NEXT: %[[V17:.*]] = fir.box_addr %[[V16]] : (!fir.box<!fir.heap<i32>>) -> !fir.heap<i32>
// CHECK-NEXT: %[[V18:.*]] = fir.load %[[V17]] : !fir.heap<i32>
diff --git a/flang/test/HLFIR/minval-lowering.fir b/flang/test/HLFIR/minval-lowering.fir
index fc8fe92dc08a25..d03dec15523095 100644
--- a/flang/test/HLFIR/minval-lowering.fir
+++ b/flang/test/HLFIR/minval-lowering.fir
@@ -37,6 +37,7 @@ func.func @_QPminval2(%arg0: !fir.box<!fir.array<?x?xi32>> {fir.bindc_name = "a"
// CHECK: %[[ARG0:.*]]: !fir.box<!fir.array<?x?xi32>>
// CHECK: %[[ARG1:.*]]: !fir.box<!fir.array<?xi32>>
// CHECK: %[[ARG2:.*]]: !fir.ref<index>
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
// CHECK-DAG: %[[ARRAY:.*]]:2 = hlfir.declare %[[ARG0]]
// CHECK-DAG: %[[RES:.*]]:2 = hlfir.declare %[[ARG1]]
// CHECK-DAG: %[[DIM_VAR:.*]]:2 = hlfir.declare %[[ARG2]]
@@ -63,7 +64,6 @@ func.func @_QPminval2(%arg0: !fir.box<!fir.array<?x?xi32>> {fir.bindc_name = "a"
// CHECK-NEXT: %[[SHIFT:.*]] = fir.shape_shift %[[BOX_DIMS]]#0, %[[BOX_DIMS]]#1
// TODO: fix alias analysis in hlfir.assign bufferization
// CHECK-NEXT: %[[TMP:.*]]:2 = hlfir.declare %[[ADDR]](%[[SHIFT]]) {uniq_name = ".tmp.intrinsic_result"}
-// CHECK: %[[TRUE:.*]] = arith.constant true
// CHECK: %[[ASEXPR:.*]] = hlfir.as_expr %[[TMP]]#0 move %[[TRUE]] : (!fir.box<!fir.array<?xi32>>, i1) -> !hlfir.expr<?xi32>
// CHECK: hlfir.assign %[[ASEXPR]] to %[[RES]]#0
// CHECK: hlfir.destroy %[[ASEXPR]]
@@ -151,6 +151,7 @@ func.func @_QPminval5(%arg0: !fir.ref<!fir.array<2xi32>> {fir.bindc_name = "s"})
}
// CHECK-LABEL: func.func @_QPminval5(
// CHECK: %[[ARG0:.*]]: !fir.ref<!fir.array<2xi32>>
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
// CHECK-DAG: %[[RET_BOX:.*]] = fir.alloca !fir.box<!fir.heap<!fir.array<?xi32>>>
// CHECK-DAG: %[[RET_ADDR:.*]] = fir.zero_bits !fir.heap<!fir.array<?xi32>>
// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
@@ -161,7 +162,6 @@ func.func @_QPminval5(%arg0: !fir.ref<!fir.array<2xi32>> {fir.bindc_name = "s"})
// CHECK-DAG: %[[RES_VAR:.*]] = hlfir.declare %[[ARG0]](%[[RES_SHAPE:.*]])
// CHECK-DAG: %[[MASK_ALLOC:.*]] = fir.alloca !fir.logical<4>
-// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
// CHECK-DAG: %[[MASK_VAL:.*]] = fir.convert %[[TRUE]] : (i1) -> !fir.logical<4>
// CHECK-DAG: fir.store %[[MASK_VAL]] to %[[MASK_ALLOC]] : !fir.ref<!fir.logical<4>>
// CHECK-DAG: %[[MASK_BOX:.*]] = fir.embox %[[MASK_ALLOC]]
@@ -190,6 +190,7 @@ func.func @_QPminval6(%arg0: !fir.box<!fir.array<?x!fir.char<1,?>>> {fir.bindc_n
// CHECK-LABEL: func.func @_QPminval6(
// CHECK: %[[ARG0:.*]]: !fir.box<!fir.array<?x!fir.char<1,?>>>
// CHECK: %[[ARG1:.*]]: !fir.boxchar<1>
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
// CHECK-DAG: %[[ARRAY:.*]]:2 = hlfir.declare %[[ARG0]]
// CHECK-DAG: %[[UNBOXED:.*]]:2 = fir.unboxchar %[[ARG1]]
// CHECK-DAG: %[[RES:.*]]:2 = hlfir.declare %[[UNBOXED]]#0 typeparams %[[UNBOXED]]#1
@@ -210,7 +211,6 @@ func.func @_QPminval6(%arg0: !fir.box<!fir.array<?x!fir.char<1,?>>> {fir.bindc_n
// CHECK: %[[BOX_ELESIZE:.*]] = fir.box_elesize %[[RET]]
// CHECK-NEXT: %[[ADDR:.*]] = fir.box_addr %[[RET]]
// CHECK-NEXT: %[[TMP:.*]]:2 = hlfir.declare %[[ADDR]] typeparams %[[BOX_ELESIZE]] {uniq_name = ".tmp.intrinsic_result"}
-// CHECK: %[[TRUE:.*]] = arith.constant true
// CHECK: %[[ASEXPR:.*]] = hlfir.as_expr %[[TMP]]#0 move %[[TRUE]] : (!fir.boxchar<1>, i1) -> !hlfir.expr<!fir.char<1,?>>
// CHECK: hlfir.assign %[[ASEXPR]] to %[[RES]]#0
// CHECK: hlfir.destroy %[[ASEXPR]]
diff --git a/flang/test/HLFIR/mul_transpose.f90 b/flang/test/HLFIR/mul_transpose.f90
index a4ec704547b9a7..378ecfe4886aa9 100644
--- a/flang/test/HLFIR/mul_transpose.f90
+++ b/flang/test/HLFIR/mul_transpose.f90
@@ -35,24 +35,22 @@ subroutine mul_transpose(a, b, res)
! CHECK-LOWERING: %[[TRANSPOSE_RES_LD:.*]] = fir.load %[[TRANSPOSE_RES_BOX:.*]]
! CHECK-LOWERING: %[[TRANSPOSE_RES_ADDR:.*]] = fir.box_addr %[[TRANSPOSE_RES_LD]]
! CHECK-LOWERING: %[[TRANSPOSE_RES_VAR:.*]]:2 = hlfir.declare %[[TRANSPOSE_RES_ADDR]]({{.*}}) {uniq_name = ".tmp.intrinsic_result"}
-! CHECK-LOWERING: %[[TRUE:.*]] = arith.constant true
-! CHECK-LOWERING: %[[TRANSPOSE_EXPR:.*]] = hlfir.as_expr %[[TRANSPOSE_RES_VAR]]#0 move %[[TRUE]] : (!fir.box<!fir.array<?x?xf32>>, i1) -> !hlfir.expr<?x?xf32>
+! CHECK-LOWERING: %[[TRANSPOSE_EXPR:.*]] = hlfir.as_expr %[[TRANSPOSE_RES_VAR]]#0 move {{.*}} : (!fir.box<!fir.array<?x?xf32>>, i1) -> !hlfir.expr<?x?xf32>
! CHECK-LOWERING: %[[TRANSPOSE_ASSOC:.*]]:3 = hlfir.associate %[[TRANSPOSE_EXPR]]({{.*}}) {adapt.valuebyref}
-! CHECK-LOWERING: (!hlfir.expr<?x?xf32>, !fir.shape<2>) -> (!fir.box<!fir.array<?x?xf32>>, !fir.ref<!fir.array<?x?xf32>>, i1)
+! CHECK-LOWERING: (!hlfir.expr<?x?xf32>, !fir.shape<2>) -> (!fir.ref<!fir.array<1x2xf32>>, !fir.ref<!fir.array<1x2xf32>>, i1)
! CHECK-LOWERING: %[[LHS_BOX:.*]] = fir.embox %[[TRANSPOSE_ASSOC]]#1
! CHECK-LOWERING: %[[B_BOX:.*]] = fir.embox %[[B_DECL]]#1(%{{.*}})
! CHECK-LOWERING: %[[MUL_CONV_RES:.*]] = fir.convert %[[MUL_RES_BOX:.*]] : (!fir.ref<!fir.box<!fir.heap<!fir.array<?x?xf32>>>>) -> !fir.ref<!fir.box<none>>
-! CHECK-LOWERING: %[[LHS_CONV:.*]] = fir.convert %[[LHS_BOX]] : (!fir.box<!fir.array<?x?xf32>>) -> !fir.box<none>
+! CHECK-LOWERING: %[[LHS_CONV:.*]] = fir.convert %[[LHS_BOX]] : (!fir.box<!fir.array<1x2xf32>>) -> !fir.box<none>
! CHECK-LOWERING: %[[B_BOX_CONV:.*]] = fir.convert %[[B_BOX]] : (!fir.box<!fir.array<2x2xf32>>) -> !fir.box<none>
! CHECK-LOWERING: fir.call @_FortranAMatmul(%[[MUL_CONV_RES]], %[[LHS_CONV]], %[[B_BOX_CONV]], %[[LOC_STR2:.*]], %[[LOC_N2:.*]])
! CHECK-LOWERING: %[[MUL_RES_LD:.*]] = fir.load %[[MUL_RES_BOX:.*]]
! CHECK-LOWERING: %[[MUL_RES_ADDR:.*]] = fir.box_addr %[[MUL_RES_LD]]
! CHECK-LOWERING: %[[MUL_RES_VAR:.*]]:2 = hlfir.declare %[[MUL_RES_ADDR]]({{.*}}) {uniq_name = ".tmp.intrinsic_result"}
-! CHECK-LOWERING: %[[TRUE2:.*]] = arith.constant true
-! CHECK-LOWERING: %[[MUL_EXPR:.*]] = hlfir.as_expr %[[MUL_RES_VAR]]#0 move %[[TRUE2]] : (!fir.box<!fir.array<?x?xf32>>, i1) -> !hlfir.expr<?x?xf32>
+! CHECK-LOWERING: %[[MUL_EXPR:.*]] = hlfir.as_expr %[[MUL_RES_VAR]]#0 move {{.*}} : (!fir.box<!fir.array<?x?xf32>>, i1) -> !hlfir.expr<?x?xf32>
-! CHECK-LOWERING: hlfir.end_associate %[[TRANSPOSE_ASSOC]]#1, %[[TRANSPOSE_ASSOC]]#2 : !fir.ref<!fir.array<?x?xf32>>, i1
+! CHECK-LOWERING: hlfir.end_associate %[[TRANSPOSE_ASSOC]]#1, %[[TRANSPOSE_ASSOC]]#2 : !fir.ref<!fir.array<1x2xf32>>, i1
! CHECK-LOWERING-NEXT: hlfir.assign %[[MUL_EXPR]] to %[[RES_DECL]]#0 : !hlfir.expr<?x?xf32>, !fir.ref<!fir.array<1x2xf32>>
! CHECK-LOWERING-NEXT: hlfir.destroy %[[MUL_EXPR]]
! CHECK-LOWERING-NEXT: hlfir.destroy %[[TRANSPOSE_EXPR]]
@@ -66,8 +64,7 @@ subroutine mul_transpose(a, b, res)
! CHECK-LOWERING-OPT: %[[MUL_RES_LD:.*]] = fir.load %[[MUL_RES_BOX:.*]]
! CHECK-LOWERING-OPT: %[[MUL_RES_ADDR:.*]] = fir.box_addr %[[MUL_RES_LD]]
! CHECK-LOWERING-OPT: %[[MUL_RES_VAR:.*]]:2 = hlfir.declare %[[MUL_RES_ADDR]]({{.*}}) {uniq_name = ".tmp.intrinsic_result"}
-! CHECK-LOWERING-OPT: %[[TRUE2:.*]] = arith.constant true
-! CHECK-LOWERING-OPT: %[[MUL_EXPR:.*]] = hlfir.as_expr %[[MUL_RES_VAR]]#0 move %[[TRUE2]] : (!fir.box<!fir.array<?x?xf32>>, i1) -> !hlfir.expr<?x?xf32>
+! CHECK-LOWERING-OPT: %[[MUL_EXPR:.*]] = hlfir.as_expr %[[MUL_RES_VAR]]#0 move {{.*}} : (!fir.box<!fir.array<?x?xf32>>, i1) -> !hlfir.expr<?x?xf32>
! CHECK-LOWERING-OPT: hlfir.assign %[[MUL_EXPR]] to %[[RES_DECL]]#0 : !hlfir.expr<?x?xf32>, !fir.ref<!fir.array<1x2xf32>>
! CHECK-LOWERING-OPT: hlfir.destroy %[[MUL_EXPR]]
@@ -76,25 +73,23 @@ subroutine mul_transpose(a, b, res)
! CHECK-BUFFERING: %[[TRANSPOSE_RES_LD:.*]] = fir.load %[[TRANSPOSE_RES_BOX:.*]]
! CHECK-BUFFERING: %[[TRANSPOSE_RES_ADDR:.*]] = fir.box_addr %[[TRANSPOSE_RES_LD]]
! CHECK-BUFFERING: %[[TRANSPOSE_RES_VAR:.*]]:2 = hlfir.declare %[[TRANSPOSE_RES_ADDR]]({{.*}}) {uniq_name = ".tmp.intrinsic_result"}
-! CHECK-BUFFERING: %[[TRUE:.*]] = arith.constant true
! CHECK-BUFFERING: %[[TUPLE0:.*]] = fir.undefined tuple<!fir.box<!fir.array<?x?xf32>>, i1>
-! CHECK-BUFFERING: %[[TUPLE1:.*]] = fir.insert_value %[[TUPLE0]], %[[TRUE]], [1 : index]
+! CHECK-BUFFERING: %[[TUPLE1:.*]] = fir.insert_value %[[TUPLE0]], {{.*}}, [1 : index]
! CHECK-BUFFERING: %[[TUPLE2:.*]] = fir.insert_value %[[TUPLE1]], %[[TRANSPOSE_RES_VAR]]#0, [0 : index]
-! CHECK-BUFFERING: %[[TRANSPOSE_RES_REF:.*]] = fir.convert %[[TRANSPOSE_RES_VAR]]#1 : (!fir.heap<!fir.array<?x?xf32>>) -> !fir.ref<!fir.array<?x?xf32>>
+! CHECK-BUFFERING: %[[TRANSPOSE_RES_REF:.*]] = fir.convert %[[TRANSPOSE_RES_VAR]]#1 : (!fir.heap<!fir.array<?x?xf32>>) -> !fir.ref<!fir.array<1x2xf32>>
! CHECK-BUFFERING: %[[TRANSPOSE_RES_BOX:.*]] = fir.embox %[[TRANSPOSE_RES_REF]]({{.*}})
-! CHECK-BUFFERING: %[[LHS_CONV:.*]] = fir.convert %[[TRANSPOSE_RES_BOX]] : (!fir.box<!fir.array<?x?xf32>>) -> !fir.box<none>
+! CHECK-BUFFERING: %[[LHS_CONV:.*]] = fir.convert %[[TRANSPOSE_RES_BOX]] : (!fir.box<!fir.array<1x2xf32>>) -> !fir.box<none>
! [argument handling unchanged]
! CHECK-BUFFERING: fir.call @_FortranAMatmul(
! CHECK-BUFFERING: %[[MUL_RES_LD:.*]] = fir.load %[[MUL_RES_BOX:.*]]
! CHECK-BUFFERING: %[[MUL_RES_ADDR:.*]] = fir.box_addr %[[MUL_RES_LD]]
! CHECK-BUFFERING: %[[MUL_RES_VAR:.*]]:2 = hlfir.declare %[[MUL_RES_ADDR]]({{.*}}) {uniq_name = ".tmp.intrinsic_result"}
-! CHECK-BUFFERING: %[[TRUE2:.*]] = arith.constant true
! CHECK-BUFFERING: %[[TUPLE3:.*]] = fir.undefined tuple<!fir.box<!fir.array<?x?xf32>>, i1>
-! CHECK-BUFFERING: %[[TUPLE4:.*]] = fir.insert_value %[[TUPLE3]], %[[TRUE2]], [1 : index]
+! CHECK-BUFFERING: %[[TUPLE4:.*]] = fir.insert_value %[[TUPLE3]], {{.*}}, [1 : index]
! CHECK-BUFFERING: %[[TUPLE5:.*]] = fir.insert_value %[[TUPLE4]], %[[MUL_RES_VAR]]#0, [0 : index]
-! CHECK-BUFFERING: %[[TRANSPOSE_RES_HEAP:.*]] = fir.convert %[[TRANSPOSE_RES_REF]] : (!fir.ref<!fir.array<?x?xf32>>) -> !fir.heap<!fir.array<?x?xf32>>
+! CHECK-BUFFERING: %[[TRANSPOSE_RES_HEAP:.*]] = fir.convert %[[TRANSPOSE_RES_REF]] : (!fir.ref<!fir.array<1x2xf32>>) -> !fir.heap<!fir.array<1x2xf32>>
! CHECK-BUFFERING-NEXT: fir.freemem %[[TRANSPOSE_RES_HEAP]]
! CHECK-BUFFERING-NEXT: hlfir.assign %[[MUL_RES_VAR]]#0 to %[[RES_DECL]]#0 : !fir.box<!fir.array<?x?xf32>>, !fir.ref<!fir.array<1x2xf32>>
! CHECK-BUFFERING-NEXT: %[[MUL_RES_HEAP:.*]] = fir.box_addr %[[MUL_RES_VAR]]#0 : (!fir.box<!fir.array<?x?xf32>>) -> !fir.heap<!fir.array<?x?xf32>>
diff --git a/flang/test/HLFIR/product-lowering.fir b/flang/test/HLFIR/product-lowering.fir
index 337b5fc3d73d34..dd3506937cacbd 100644
--- a/flang/test/HLFIR/product-lowering.fir
+++ b/flang/test/HLFIR/product-lowering.fir
@@ -39,6 +39,7 @@ func.func @_QPproduct2(%arg0: !fir.box<!fir.array<?x?xi32>> {fir.bindc_name = "a
// CHECK: %[[ARG0:.*]]: !fir.box<!fir.array<?x?xi32>>
// CHECK: %[[ARG1:.*]]: !fir.box<!fir.array<?xi32>>
// CHECK: %[[ARG2:.*]]: !fir.ref<index>
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
// CHECK-DAG: %[[ARRAY:.*]]:2 = hlfir.declare %[[ARG0]]
// CHECK-DAG: %[[DIM_VAR:.*]]:2 = hlfir.declare %[[ARG2]]
// CHECK-DAG: %[[RES:.*]]:2 = hlfir.declare %[[ARG1]]
@@ -64,7 +65,6 @@ func.func @_QPproduct2(%arg0: !fir.box<!fir.array<?x?xi32>> {fir.bindc_name = "a
// CHECK-NEXT: %[[ADDR:.*]] = fir.box_addr %[[RET]]
// CHECK-NEXT: %[[SHIFT:.*]] = fir.shape_shift %[[BOX_DIMS]]#0, %[[BOX_DIMS]]#1
// CHECK-NEXT: %[[TMP:.*]]:2 = hlfir.declare %[[ADDR]](%[[SHIFT]]) {uniq_name = ".tmp.intrinsic_result"}
-// CHECK: %[[TRUE:.*]] = arith.constant true
// CHECK: %[[EXPR:.*]] = hlfir.as_expr %[[TMP]]#0 move %[[TRUE]] : (!fir.box<!fir.array<?xi32>>, i1) -> !hlfir.expr<?xi32>
// CHECK: hlfir.assign %[[EXPR]] to %[[RES]]#0
// CHECK: hlfir.destroy %[[EXPR]]
@@ -141,6 +141,7 @@ func.func @_QPproduct5(%arg0: !fir.ref<!fir.array<2xi32>> {fir.bindc_name = "s"}
// CHECK-LABEL: func.func @_QPproduct5(
// CHECK: %[[ARG0:.*]]: !fir.ref<!fir.array<2xi32>>
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
// CHECK-DAG: %[[RET_BOX:.*]] = fir.alloca !fir.box<!fir.heap<!fir.array<?xi32>>>
// CHECK-DAG: %[[RET_ADDR:.*]] = fir.zero_bits !fir.heap<!fir.array<?xi32>>
// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
@@ -151,7 +152,6 @@ func.func @_QPproduct5(%arg0: !fir.ref<!fir.array<2xi32>> {fir.bindc_name = "s"}
// CHECK-DAG: %[[RES_VAR:.*]] = hlfir.declare %[[ARG0]](%[[RES_SHAPE:.*]])
// CHECK-DAG: %[[MASK_ALLOC:.*]] = fir.alloca !fir.logical<4>
-// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
// CHECK-DAG: %[[MASK_VAL:.*]] = fir.convert %[[TRUE]] : (i1) -> !fir.logical<4>
// CHECK-DAG: fir.store %[[MASK_VAL]] to %[[MASK_ALLOC]] : !fir.ref<!fir.logical<4>>
// CHECK-DAG: %[[MASK_BOX:.*]] = fir.embox %[[MASK_ALLOC]]
diff --git a/flang/test/HLFIR/sum-lowering.fir b/flang/test/HLFIR/sum-lowering.fir
index e33b9bc028aea0..d4a79d278acc48 100644
--- a/flang/test/HLFIR/sum-lowering.fir
+++ b/flang/test/HLFIR/sum-lowering.fir
@@ -37,6 +37,7 @@ func.func @_QPsum2(%arg0: !fir.box<!fir.array<?x?xi32>> {fir.bindc_name = "a"},
// CHECK: %[[ARG0:.*]]: !fir.box<!fir.array<?x?xi32>>
// CHECK: %[[ARG1:.*]]: !fir.box<!fir.array<?xi32>>
// CHECK: %[[ARG2:.*]]: !fir.ref<index>
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
// CHECK-DAG: %[[ARRAY:.*]]:2 = hlfir.declare %[[ARG0]]
// CHECK-DAG: %[[RES:.*]]:2 = hlfir.declare %[[ARG1]]
// CHECK-DAG: %[[DIM_VAR:.*]]:2 = hlfir.declare %[[ARG2]]
@@ -63,7 +64,6 @@ func.func @_QPsum2(%arg0: !fir.box<!fir.array<?x?xi32>> {fir.bindc_name = "a"},
// CHECK-NEXT: %[[SHIFT:.*]] = fir.shape_shift %[[BOX_DIMS]]#0, %[[BOX_DIMS]]#1
// TODO: fix alias analysis in hlfir.assign bufferization
// CHECK-NEXT: %[[TMP:.*]]:2 = hlfir.declare %[[ADDR]](%[[SHIFT]]) {uniq_name = ".tmp.intrinsic_result"}
-// CHECK: %[[TRUE:.*]] = arith.constant true
// CHECK: %[[ASEXPR:.*]] = hlfir.as_expr %[[TMP]]#0 move %[[TRUE]] : (!fir.box<!fir.array<?xi32>>, i1) -> !hlfir.expr<?xi32>
// CHECK: hlfir.assign %[[ASEXPR]] to %[[RES]]#0
// CHECK: hlfir.destroy %[[ASEXPR]]
@@ -151,6 +151,7 @@ func.func @_QPsum5(%arg0: !fir.ref<!fir.array<2xi32>> {fir.bindc_name = "s"}) {
}
// CHECK-LABEL: func.func @_QPsum5(
// CHECK: %[[ARG0:.*]]: !fir.ref<!fir.array<2xi32>>
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
// CHECK-DAG: %[[RET_BOX:.*]] = fir.alloca !fir.box<!fir.heap<!fir.array<?xi32>>>
// CHECK-DAG: %[[RET_ADDR:.*]] = fir.zero_bits !fir.heap<!fir.array<?xi32>>
// CHECK-DAG: %[[C0:.*]] = arith.constant 0 : index
@@ -161,7 +162,6 @@ func.func @_QPsum5(%arg0: !fir.ref<!fir.array<2xi32>> {fir.bindc_name = "s"}) {
// CHECK-DAG: %[[RES_VAR:.*]] = hlfir.declare %[[ARG0]](%[[RES_SHAPE:.*]])
// CHECK-DAG: %[[MASK_ALLOC:.*]] = fir.alloca !fir.logical<4>
-// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
// CHECK-DAG: %[[MASK_VAL:.*]] = fir.convert %[[TRUE]] : (i1) -> !fir.logical<4>
// CHECK-DAG: fir.store %[[MASK_VAL]] to %[[MASK_ALLOC]] : !fir.ref<!fir.logical<4>>
// CHECK-DAG: %[[MASK_BOX:.*]] = fir.embox %[[MASK_ALLOC]]
diff --git a/flang/test/HLFIR/transpose-lowering.fir b/flang/test/HLFIR/transpose-lowering.fir
index 733e6f1a61090e..9afe8a058b8b85 100644
--- a/flang/test/HLFIR/transpose-lowering.fir
+++ b/flang/test/HLFIR/transpose-lowering.fir
@@ -18,6 +18,7 @@ func.func @_QPtranspose1(%arg0: !fir.ref<!fir.array<1x2xi32>> {fir.bindc_name =
// CHECK-LABEL: func.func @_QPtranspose1(
// CHECK: %[[ARG0:.*]]: !fir.ref<!fir.array<1x2xi32>> {fir.bindc_name = "m"}
// CHECK: %[[ARG1:.*]]: !fir.ref<!fir.array<2x1xi32>> {fir.bindc_name = "res"}
+// CHECK-DAG: %[[TRUE:.*]] = arith.constant true
// CHECK-DAG: %[[M_VAR:.*]]:2 = hlfir.declare %[[ARG0]]
// CHECK-DAG: %[[RES_VAR:.*]]:2 = hlfir.declare %[[ARG1]]
@@ -40,7 +41,6 @@ func.func @_QPtranspose1(%arg0: !fir.ref<!fir.array<1x2xi32>> {fir.bindc_name =
// CHECK-NEXT: %[[SHIFT:.*]] = fir.shape_shift %[[BOX_DIMS]]#0, %[[BOX_DIMS]]#1
// TODO: fix alias analysis in hlfir.assign bufferization
// CHECK-NEXT: %[[TMP:.*]]:2 = hlfir.declare %[[ADDR]](%[[SHIFT]]) {uniq_name = ".tmp.intrinsic_result"}
-// CHECK: %[[TRUE:.*]] = arith.constant true
// CHECK: %[[ASEXPR:.*]] = hlfir.as_expr %[[TMP]]#0 move %[[TRUE]] : (!fir.box<!fir.array<?x?xi32>>, i1) -> !hlfir.expr<?x?xi32>
// CHECK: hlfir.assign %[[ASEXPR]] to %[[RES_VAR]]#0
// CHECK: hlfir.destroy %[[ASEXPR]]
diff --git a/flang/test/Lower/convert.f90 b/flang/test/Lower/convert.f90
index 1ab93dcc17320a..b7c8b8dc20cc7b 100755
--- a/flang/test/Lower/convert.f90
+++ b/flang/test/Lower/convert.f90
@@ -34,8 +34,8 @@ program test
! ALL: fir.has_value %[[VAL_0]] : !fir.char<1,[[OPT_STR_LEN]]>
! ALL: fir.global linkonce @_QQEnvironmentDefaults.list constant : tuple<i[[int_size:.*]], !fir.ref<!fir.array<1xtuple<!fir.ref<i8>, !fir.ref<i8>>>>> {
-! ALL: %[[VAL_0:.*]] = fir.undefined tuple<i[[int_size]], !fir.ref<!fir.array<1xtuple<!fir.ref<i8>, !fir.ref<i8>>>>>
! ALL: %[[VAL_1:.*]] = arith.constant 1 : i[[int_size]]
+! ALL: %[[VAL_0:.*]] = fir.undefined tuple<i[[int_size]], !fir.ref<!fir.array<1xtuple<!fir.ref<i8>, !fir.ref<i8>>>>>
! ALL: %[[VAL_2:.*]] = fir.insert_value %[[VAL_0]], %[[VAL_1]], [0 : index] : (tuple<i[[int_size]], !fir.ref<!fir.array<1xtuple<!fir.ref<i8>, !fir.ref<i8>>>>>, i[[int_size]]) -> tuple<i[[int_size]], !fir.ref<!fir.array<1xtuple<!fir.ref<i8>, !fir.ref<i8>>>>>
! ALL: %[[VAL_3:.*]] = fir.address_of(@_QQEnvironmentDefaults.items) : !fir.ref<!fir.array<1xtuple<!fir.ref<i8>, !fir.ref<i8>>>>
! ALL: %[[VAL_4:.*]] = fir.insert_value %[[VAL_2]], %[[VAL_3]], [1 : index] : (tuple<i[[int_size]], !fir.ref<!fir.array<1xtuple<!fir.ref<i8>, !fir.ref<i8>>>>>, !fir.ref<!fir.array<1xtuple<!fir.ref<i8>, !fir.ref<i8>>>>) -> tuple<i[[int_size]], !fir.ref<!fir.array<1xtuple<!fir.ref<i8>, !fir.ref<i8>>>>>
>From 4c642b62b99fa128c180f28278637b32be5e5576 Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?Martin=20Storsj=C3=B6?= <martin at martin.st>
Date: Fri, 23 Feb 2024 00:45:32 +0200
Subject: [PATCH 235/406] [llvm-jitlink] [test] Add an XFAIL for a JITLink test
on MinGW
This testcase fails on MinGW targets, because when compiling the
main() function, it gets an implicit call to __main(), which is
missing in this context.
---
llvm/test/ExecutionEngine/JITLink/Generic/sectcreate.test | 5 +++++
1 file changed, 5 insertions(+)
diff --git a/llvm/test/ExecutionEngine/JITLink/Generic/sectcreate.test b/llvm/test/ExecutionEngine/JITLink/Generic/sectcreate.test
index ec71011d545ebd..c09513a7d3707c 100644
--- a/llvm/test/ExecutionEngine/JITLink/Generic/sectcreate.test
+++ b/llvm/test/ExecutionEngine/JITLink/Generic/sectcreate.test
@@ -8,4 +8,9 @@
# Jitlink does not support ARM64 COFF files.
# UNSUPPORTED: target=aarch64-pc-windows-{{.*}}
+# On MinGW targets, when compiling the main() function, it gets
+# an implicitly generated call to __main(), which is missing in
+# this context.
+# XFAIL: target={{.*}}-windows-gnu
+
# jitlink-check: *{4}foo = 0x2a2a5a5a
\ No newline at end of file
>From d458a1931769aa4bcdb3fcd537c4ee946507ff1a Mon Sep 17 00:00:00 2001
From: David Green <david.green at arm.com>
Date: Fri, 1 Mar 2024 10:24:27 +0000
Subject: [PATCH 236/406] [AArch64] Mark AESD and AESE instructions as
commutative. (#83390)
This come from
https://discourse.llvm.org/t/combining-aes-and-xor-can-be-improved-further/77248.
These instructions start out with:
```
XOR Vd, Vn
<some complicated math>
```
The initial XOR means that they can be treated as commutative, removing
some of the unnecessary mov's introduced during register allocation.
---
llvm/lib/Target/AArch64/AArch64InstrInfo.td | 2 ++
llvm/test/CodeGen/AArch64/aes.ll | 6 ++----
llvm/test/CodeGen/AArch64/misched-fusion-aes.ll | 2 +-
3 files changed, 5 insertions(+), 5 deletions(-)
diff --git a/llvm/lib/Target/AArch64/AArch64InstrInfo.td b/llvm/lib/Target/AArch64/AArch64InstrInfo.td
index b01a8cd00025f8..0fc91be1ad56d2 100644
--- a/llvm/lib/Target/AArch64/AArch64InstrInfo.td
+++ b/llvm/lib/Target/AArch64/AArch64InstrInfo.td
@@ -8216,8 +8216,10 @@ defm ST4 : SIMDLdSt4SingleAliases<"st4">;
//----------------------------------------------------------------------------
let Predicates = [HasAES] in {
+let isCommutable = 1 in {
def AESErr : AESTiedInst<0b0100, "aese", int_aarch64_crypto_aese>;
def AESDrr : AESTiedInst<0b0101, "aesd", int_aarch64_crypto_aesd>;
+}
def AESMCrr : AESInst< 0b0110, "aesmc", int_aarch64_crypto_aesmc>;
def AESIMCrr : AESInst< 0b0111, "aesimc", int_aarch64_crypto_aesimc>;
}
diff --git a/llvm/test/CodeGen/AArch64/aes.ll b/llvm/test/CodeGen/AArch64/aes.ll
index 2bef28de895baf..386114f4a0d79d 100644
--- a/llvm/test/CodeGen/AArch64/aes.ll
+++ b/llvm/test/CodeGen/AArch64/aes.ll
@@ -16,8 +16,7 @@ define <16 x i8> @aese(<16 x i8> %a, <16 x i8> %b) {
define <16 x i8> @aese_c(<16 x i8> %a, <16 x i8> %b) {
; CHECK-LABEL: aese_c:
; CHECK: // %bb.0:
-; CHECK-NEXT: aese v1.16b, v0.16b
-; CHECK-NEXT: mov v0.16b, v1.16b
+; CHECK-NEXT: aese v0.16b, v1.16b
; CHECK-NEXT: ret
%r = call <16 x i8> @llvm.aarch64.crypto.aese(<16 x i8> %b, <16 x i8> %a)
ret <16 x i8> %r
@@ -35,8 +34,7 @@ define <16 x i8> @aesd(<16 x i8> %a, <16 x i8> %b) {
define <16 x i8> @aesd_c(<16 x i8> %a, <16 x i8> %b) {
; CHECK-LABEL: aesd_c:
; CHECK: // %bb.0:
-; CHECK-NEXT: aesd v1.16b, v0.16b
-; CHECK-NEXT: mov v0.16b, v1.16b
+; CHECK-NEXT: aesd v0.16b, v1.16b
; CHECK-NEXT: ret
%r = call <16 x i8> @llvm.aarch64.crypto.aesd(<16 x i8> %b, <16 x i8> %a)
ret <16 x i8> %r
diff --git a/llvm/test/CodeGen/AArch64/misched-fusion-aes.ll b/llvm/test/CodeGen/AArch64/misched-fusion-aes.ll
index bf166954d80c98..dc6fa9128e9336 100644
--- a/llvm/test/CodeGen/AArch64/misched-fusion-aes.ll
+++ b/llvm/test/CodeGen/AArch64/misched-fusion-aes.ll
@@ -206,7 +206,7 @@ entry:
%aese1 = call <16 x i8> @llvm.aarch64.crypto.aese(<16 x i8> %in1, <16 x i8> %in1) #2
%in2 = load <16 x i8>, ptr %p2, align 16
%aesmc1= call <16 x i8> @llvm.aarch64.crypto.aesmc(<16 x i8> %aese1) #2
- %aese2 = call <16 x i8> @llvm.aarch64.crypto.aese(<16 x i8> %in1, <16 x i8> %in2) #2
+ %aese2 = call <16 x i8> @llvm.aarch64.crypto.aese(<16 x i8> %aesmc1, <16 x i8> %in2) #2
store <16 x i8> %aesmc1, ptr %x3, align 16
%in3 = load <16 x i8>, ptr %p3, align 16
%aesmc2= call <16 x i8> @llvm.aarch64.crypto.aesmc(<16 x i8> %aese2) #2
>From d1538c15f9c65a70f4650bd724972536f00f5094 Mon Sep 17 00:00:00 2001
From: David CARLIER <devnexen at gmail.com>
Date: Fri, 1 Mar 2024 10:32:10 +0000
Subject: [PATCH 237/406] Revert fuzzer windows changes (#83551)
---
compiler-rt/lib/fuzzer/FuzzerUtilWindows.cpp | 25 ++++----------------
1 file changed, 4 insertions(+), 21 deletions(-)
diff --git a/compiler-rt/lib/fuzzer/FuzzerUtilWindows.cpp b/compiler-rt/lib/fuzzer/FuzzerUtilWindows.cpp
index 39ab9e241b5914..71770166805f78 100644
--- a/compiler-rt/lib/fuzzer/FuzzerUtilWindows.cpp
+++ b/compiler-rt/lib/fuzzer/FuzzerUtilWindows.cpp
@@ -21,15 +21,10 @@
#include <signal.h>
#include <stdio.h>
#include <sys/types.h>
-// clang-format off
#include <windows.h>
-// These must be included after windows.h.
-// archicture need to be set before including
-// libloaderapi
-#include <libloaderapi.h>
-#include <stringapiset.h>
+
+// This must be included after windows.h.
#include <psapi.h>
-// clang-format on
namespace fuzzer {
@@ -239,20 +234,8 @@ size_t PageSize() {
}
void SetThreadName(std::thread &thread, const std::string &name) {
- typedef HRESULT(WINAPI * proc)(HANDLE, PCWSTR);
- HMODULE kbase = GetModuleHandleA("KernelBase.dll");
- proc ThreadNameProc =
- reinterpret_cast<proc>(GetProcAddress, "SetThreadDescription");
- if (proc) {
- std::wstring buf;
- auto sz = MultiByteToWideChar(CP_UTF8, 0, name.data(), -1, nullptr, 0);
- if (sz > 0) {
- buf.resize(sz);
- if (MultyByteToWideChar(CP_UTF8, 0, name.data(), -1, &buf[0], sz) > 0) {
- (void)ThreadNameProc(thread.native_handle(), buf.c_str());
- }
- }
- }
+ // TODO ?
+ // to UTF-8 then SetThreadDescription ?
}
} // namespace fuzzer
>From 0e9a102129c07d31dccec06cb45f6e2a74c6e590 Mon Sep 17 00:00:00 2001
From: David Green <david.green at arm.com>
Date: Fri, 1 Mar 2024 11:44:58 +0000
Subject: [PATCH 239/406] [AArch64] Remove unused AArch64ISD::BIT. NFC
These were last used in the fcopysign lowering, which now uses AArch64ISD::BSP.
---
llvm/lib/Target/AArch64/AArch64ISelLowering.cpp | 1 -
llvm/lib/Target/AArch64/AArch64ISelLowering.h | 3 ---
llvm/lib/Target/AArch64/AArch64InstrInfo.td | 3 +--
3 files changed, 1 insertion(+), 6 deletions(-)
diff --git a/llvm/lib/Target/AArch64/AArch64ISelLowering.cpp b/llvm/lib/Target/AArch64/AArch64ISelLowering.cpp
index b1677df56e1bea..7f80e877cb2406 100644
--- a/llvm/lib/Target/AArch64/AArch64ISelLowering.cpp
+++ b/llvm/lib/Target/AArch64/AArch64ISelLowering.cpp
@@ -2547,7 +2547,6 @@ const char *AArch64TargetLowering::getTargetNodeName(unsigned Opcode) const {
MAKE_CASE(AArch64ISD::FSUB_PRED)
MAKE_CASE(AArch64ISD::RDSVL)
MAKE_CASE(AArch64ISD::BIC)
- MAKE_CASE(AArch64ISD::BIT)
MAKE_CASE(AArch64ISD::CBZ)
MAKE_CASE(AArch64ISD::CBNZ)
MAKE_CASE(AArch64ISD::TBZ)
diff --git a/llvm/lib/Target/AArch64/AArch64ISelLowering.h b/llvm/lib/Target/AArch64/AArch64ISelLowering.h
index bec13484450d78..c1fe76c07cba87 100644
--- a/llvm/lib/Target/AArch64/AArch64ISelLowering.h
+++ b/llvm/lib/Target/AArch64/AArch64ISelLowering.h
@@ -285,9 +285,6 @@ enum NodeType : unsigned {
EORV_PRED,
ANDV_PRED,
- // Vector bitwise insertion
- BIT,
-
// Compare-and-branch
CBZ,
CBNZ,
diff --git a/llvm/lib/Target/AArch64/AArch64InstrInfo.td b/llvm/lib/Target/AArch64/AArch64InstrInfo.td
index 0fc91be1ad56d2..52137c1f4065bc 100644
--- a/llvm/lib/Target/AArch64/AArch64InstrInfo.td
+++ b/llvm/lib/Target/AArch64/AArch64InstrInfo.td
@@ -730,7 +730,6 @@ def AArch64urshri : SDNode<"AArch64ISD::URSHR_I", SDT_AArch64vshift>;
def AArch64vsli : SDNode<"AArch64ISD::VSLI", SDT_AArch64vshiftinsert>;
def AArch64vsri : SDNode<"AArch64ISD::VSRI", SDT_AArch64vshiftinsert>;
-def AArch64bit: SDNode<"AArch64ISD::BIT", SDT_AArch64trivec>;
def AArch64bsp: SDNode<"AArch64ISD::BSP", SDT_AArch64trivec>;
def AArch64cmeq: SDNode<"AArch64ISD::CMEQ", SDT_AArch64binvec>;
@@ -5333,7 +5332,7 @@ defm ORR : SIMDLogicalThreeVector<0, 0b10, "orr", or>;
defm BSP : SIMDLogicalThreeVectorPseudo<TriOpFrag<(or (and node:$LHS, node:$MHS),
(and (vnot node:$LHS), node:$RHS))>>;
defm BSL : SIMDLogicalThreeVectorTied<1, 0b01, "bsl">;
-defm BIT : SIMDLogicalThreeVectorTied<1, 0b10, "bit", AArch64bit>;
+defm BIT : SIMDLogicalThreeVectorTied<1, 0b10, "bit">;
defm BIF : SIMDLogicalThreeVectorTied<1, 0b11, "bif">;
def : Pat<(AArch64bsp (v8i8 V64:$Rd), V64:$Rn, V64:$Rm),
>From 2d98d763a8e627b2d1a18a9cdd1c62a4b58be3aa Mon Sep 17 00:00:00 2001
From: Alexey Bataev <5361294+alexey-bataev at users.noreply.github.com>
Date: Fri, 1 Mar 2024 07:12:07 -0500
Subject: [PATCH 240/406] [SLP]Fix the cost model for extracts combined with
later shuffle.
If the buildvector node contains extract, which later should be combined
with some other nodes by shuffling, need to estimate the cost of this
shuffle before building the mask after shuffle.
Reviewers: RKSimon
Reviewed By: RKSimon
Pull Request: https://github.com/llvm/llvm-project/pull/83442
---
.../Transforms/Vectorize/SLPVectorizer.cpp | 19 ++++++++++++++++++-
.../SLPVectorizer/X86/crash_clear_undefs.ll | 2 +-
.../X86/multi-nodes-to-shuffle.ll | 2 +-
3 files changed, 20 insertions(+), 3 deletions(-)
diff --git a/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp b/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
index 94b7c4952f055e..df740c07f267eb 100644
--- a/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
+++ b/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
@@ -7606,7 +7606,24 @@ class BoUpSLP::ShuffleCostEstimator : public BaseShuffleAnalysis {
}
SameNodesEstimated = false;
Cost += createShuffle(&E1, E2, Mask);
- transformMaskAfterShuffle(CommonMask, Mask);
+ if (!E2 && InVectors.size() == 1) {
+ unsigned VF = E1.getVectorFactor();
+ if (Value *V1 = InVectors.front().dyn_cast<Value *>()) {
+ VF = std::max(VF,
+ cast<FixedVectorType>(V1->getType())->getNumElements());
+ } else {
+ const auto *E = InVectors.front().get<const TreeEntry *>();
+ VF = std::max(VF, E->getVectorFactor());
+ }
+ for (unsigned Idx = 0, Sz = CommonMask.size(); Idx < Sz; ++Idx)
+ if (Mask[Idx] != PoisonMaskElem && CommonMask[Idx] == PoisonMaskElem)
+ CommonMask[Idx] = Mask[Idx] + VF;
+ Cost += createShuffle(InVectors.front(), &E1, CommonMask);
+ transformMaskAfterShuffle(CommonMask, CommonMask);
+ } else {
+ Cost += createShuffle(&E1, E2, Mask);
+ transformMaskAfterShuffle(CommonMask, Mask);
+ }
}
class ShuffleCostBuilder {
diff --git a/llvm/test/Transforms/SLPVectorizer/X86/crash_clear_undefs.ll b/llvm/test/Transforms/SLPVectorizer/X86/crash_clear_undefs.ll
index c2369a6a89ec1d..de99654d84eb81 100644
--- a/llvm/test/Transforms/SLPVectorizer/X86/crash_clear_undefs.ll
+++ b/llvm/test/Transforms/SLPVectorizer/X86/crash_clear_undefs.ll
@@ -9,7 +9,7 @@ target datalayout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16
; YAML-NEXT: Function: foo
; YAML-NEXT: Args:
; YAML-NEXT: - String: 'SLP vectorized with cost '
-; YAML-NEXT: - Cost: '-4'
+; YAML-NEXT: - Cost: '-3'
; YAML-NEXT: - String: ' and with tree size '
; YAML-NEXT: - TreeSize: '10'
; YAML-NEXT: ...
diff --git a/llvm/test/Transforms/SLPVectorizer/X86/multi-nodes-to-shuffle.ll b/llvm/test/Transforms/SLPVectorizer/X86/multi-nodes-to-shuffle.ll
index e5b5a5c6c4a00c..a48076adc80900 100644
--- a/llvm/test/Transforms/SLPVectorizer/X86/multi-nodes-to-shuffle.ll
+++ b/llvm/test/Transforms/SLPVectorizer/X86/multi-nodes-to-shuffle.ll
@@ -1,5 +1,5 @@
; NOTE: Assertions have been autogenerated by utils/update_test_checks.py
-; RUN: opt -passes=slp-vectorizer -S < %s -mtriple=x86_64-unknown-linux -slp-threshold=-115 | FileCheck %s
+; RUN: opt -passes=slp-vectorizer -S < %s -mtriple=x86_64-unknown-linux -slp-threshold=-127 | FileCheck %s
; RUN: opt -passes=slp-vectorizer -S < %s -mtriple=x86_64-unknown-linux -slp-threshold=-115 -mattr=+avx2 | FileCheck %s --check-prefix=AVX2
define void @test(i64 %p0, i64 %p1, i64 %p2, i64 %p3) {
>From 7ac03e8a369d8ac74a2c4d97a9e2a41221428abd Mon Sep 17 00:00:00 2001
From: Marius Brehler <marius.brehler at iml.fraunhofer.de>
Date: Fri, 1 Mar 2024 13:21:11 +0100
Subject: [PATCH 241/406] [mlir][EmitC] Add bitwise operators (#83387)
This adds operations for bitwise operators. Furthermore, an UnaryOp
class and a helper to print unary operations are introduced.
---
mlir/include/mlir/Dialect/EmitC/IR/EmitC.td | 119 +++++++++++++++++++-
mlir/lib/Target/Cpp/TranslateToCpp.cpp | 72 ++++++++++--
mlir/test/Dialect/EmitC/ops.mlir | 10 ++
mlir/test/Target/Cpp/bitwise_operators.mlir | 20 ++++
4 files changed, 207 insertions(+), 14 deletions(-)
create mode 100644 mlir/test/Target/Cpp/bitwise_operators.mlir
diff --git a/mlir/include/mlir/Dialect/EmitC/IR/EmitC.td b/mlir/include/mlir/Dialect/EmitC/IR/EmitC.td
index 7b9fbb494e895a..5679742bfa16ec 100644
--- a/mlir/include/mlir/Dialect/EmitC/IR/EmitC.td
+++ b/mlir/include/mlir/Dialect/EmitC/IR/EmitC.td
@@ -31,6 +31,14 @@ include "mlir/IR/RegionKindInterface.td"
class EmitC_Op<string mnemonic, list<Trait> traits = []>
: Op<EmitC_Dialect, mnemonic, traits>;
+// Base class for unary operations.
+class EmitC_UnaryOp<string mnemonic, list<Trait> traits = []> :
+ EmitC_Op<mnemonic, traits> {
+ let arguments = (ins AnyType);
+ let results = (outs AnyType);
+ let assemblyFormat = "operands attr-dict `:` functional-type(operands, results)";
+}
+
// Base class for binary operations.
class EmitC_BinaryOp<string mnemonic, list<Trait> traits = []> :
EmitC_Op<mnemonic, traits> {
@@ -95,6 +103,114 @@ def EmitC_ApplyOp : EmitC_Op<"apply", []> {
let hasVerifier = 1;
}
+def EmitC_BitwiseAndOp : EmitC_BinaryOp<"bitwise_and", []> {
+ let summary = "Bitwise and operation";
+ let description = [{
+ With the `bitwise_and` operation the bitwise operator & (and) can
+ be applied.
+
+ Example:
+
+ ```mlir
+ %0 = emitc.bitwise_and %arg0, %arg1 : (i32, i32) -> i32
+ ```
+ ```c++
+ // Code emitted for the operation above.
+ int32_t v3 = v1 & v2;
+ ```
+ }];
+}
+
+def EmitC_BitwiseLeftShiftOp : EmitC_BinaryOp<"bitwise_left_shift", []> {
+ let summary = "Bitwise left shift operation";
+ let description = [{
+ With the `bitwise_left_shift` operation the bitwise operator <<
+ (left shift) can be applied.
+
+ Example:
+
+ ```mlir
+ %0 = emitc.bitwise_left_shift %arg0, %arg1 : (i32, i32) -> i32
+ ```
+ ```c++
+ // Code emitted for the operation above.
+ int32_t v3 = v1 << v2;
+ ```
+ }];
+}
+
+def EmitC_BitwiseNotOp : EmitC_UnaryOp<"bitwise_not", []> {
+ let summary = "Bitwise not operation";
+ let description = [{
+ With the `bitwise_not` operation the bitwise operator ~ (not) can
+ be applied.
+
+ Example:
+
+ ```mlir
+ %0 = emitc.bitwise_not %arg0 : (i32) -> i32
+ ```
+ ```c++
+ // Code emitted for the operation above.
+ int32_t v2 = ~v1;
+ ```
+ }];
+}
+
+def EmitC_BitwiseOrOp : EmitC_BinaryOp<"bitwise_or", []> {
+ let summary = "Bitwise or operation";
+ let description = [{
+ With the `bitwise_or` operation the bitwise operator | (or)
+ can be applied.
+
+ Example:
+
+ ```mlir
+ %0 = emitc.bitwise_or %arg0, %arg1 : (i32, i32) -> i32
+ ```
+ ```c++
+ // Code emitted for the operation above.
+ int32_t v3 = v1 | v2;
+ ```
+ }];
+}
+
+def EmitC_BitwiseRightShiftOp : EmitC_BinaryOp<"bitwise_right_shift", []> {
+ let summary = "Bitwise right shift operation";
+ let description = [{
+ With the `bitwise_right_shift` operation the bitwise operator >>
+ (right shift) can be applied.
+
+ Example:
+
+ ```mlir
+ %0 = emitc.bitwise_right_shift %arg0, %arg1 : (i32, i32) -> i32
+ ```
+ ```c++
+ // Code emitted for the operation above.
+ int32_t v3 = v1 >> v2;
+ ```
+ }];
+}
+
+def EmitC_BitwiseXorOp : EmitC_BinaryOp<"bitwise_xor", []> {
+ let summary = "Bitwise xor operation";
+ let description = [{
+ With the `bitwise_xor` operation the bitwise operator ^ (xor)
+ can be applied.
+
+ Example:
+
+ ```mlir
+ %0 = emitc.bitwise_xor %arg0, %arg1 : (i32, i32) -> i32
+ ```
+ ```c++
+ // Code emitted for the operation above.
+ int32_t v3 = v1 ^ v2;
+ ```
+ }];
+}
+
def EmitC_CallOpaqueOp : EmitC_Op<"call_opaque", []> {
let summary = "Opaque call operation";
let description = [{
@@ -679,7 +795,7 @@ def EmitC_LogicalAndOp : EmitC_BinaryOp<"logical_and", []> {
let assemblyFormat = "operands attr-dict `:` type(operands)";
}
-def EmitC_LogicalNotOp : EmitC_Op<"logical_not", []> {
+def EmitC_LogicalNotOp : EmitC_UnaryOp<"logical_not", []> {
let summary = "Logical not operation";
let description = [{
With the `logical_not` operation the logical operator ! (negation) can
@@ -696,7 +812,6 @@ def EmitC_LogicalNotOp : EmitC_Op<"logical_not", []> {
```
}];
- let arguments = (ins AnyType);
let results = (outs I1);
let assemblyFormat = "operands attr-dict `:` type(operands)";
}
diff --git a/mlir/lib/Target/Cpp/TranslateToCpp.cpp b/mlir/lib/Target/Cpp/TranslateToCpp.cpp
index 16aa136c5a4e28..4bc707c43ad92f 100644
--- a/mlir/lib/Target/Cpp/TranslateToCpp.cpp
+++ b/mlir/lib/Target/Cpp/TranslateToCpp.cpp
@@ -361,6 +361,22 @@ static LogicalResult printBinaryOperation(CppEmitter &emitter,
return success();
}
+static LogicalResult printUnaryOperation(CppEmitter &emitter,
+ Operation *operation,
+ StringRef unaryOperator) {
+ raw_ostream &os = emitter.ostream();
+
+ if (failed(emitter.emitAssignPrefix(*operation)))
+ return failure();
+
+ os << unaryOperator;
+
+ if (failed(emitter.emitOperand(operation->getOperand(0))))
+ return failure();
+
+ return success();
+}
+
static LogicalResult printOperation(CppEmitter &emitter, emitc::AddOp addOp) {
Operation *operation = addOp.getOperation();
@@ -588,6 +604,44 @@ static LogicalResult printOperation(CppEmitter &emitter,
return success();
}
+static LogicalResult printOperation(CppEmitter &emitter,
+ emitc::BitwiseAndOp bitwiseAndOp) {
+ Operation *operation = bitwiseAndOp.getOperation();
+ return printBinaryOperation(emitter, operation, "&");
+}
+
+static LogicalResult
+printOperation(CppEmitter &emitter,
+ emitc::BitwiseLeftShiftOp bitwiseLeftShiftOp) {
+ Operation *operation = bitwiseLeftShiftOp.getOperation();
+ return printBinaryOperation(emitter, operation, "<<");
+}
+
+static LogicalResult printOperation(CppEmitter &emitter,
+ emitc::BitwiseNotOp bitwiseNotOp) {
+ Operation *operation = bitwiseNotOp.getOperation();
+ return printUnaryOperation(emitter, operation, "~");
+}
+
+static LogicalResult printOperation(CppEmitter &emitter,
+ emitc::BitwiseOrOp bitwiseOrOp) {
+ Operation *operation = bitwiseOrOp.getOperation();
+ return printBinaryOperation(emitter, operation, "|");
+}
+
+static LogicalResult
+printOperation(CppEmitter &emitter,
+ emitc::BitwiseRightShiftOp bitwiseRightShiftOp) {
+ Operation *operation = bitwiseRightShiftOp.getOperation();
+ return printBinaryOperation(emitter, operation, ">>");
+}
+
+static LogicalResult printOperation(CppEmitter &emitter,
+ emitc::BitwiseXorOp bitwiseXorOp) {
+ Operation *operation = bitwiseXorOp.getOperation();
+ return printBinaryOperation(emitter, operation, "^");
+}
+
static LogicalResult printOperation(CppEmitter &emitter, emitc::CastOp castOp) {
raw_ostream &os = emitter.ostream();
Operation &op = *castOp.getOperation();
@@ -635,17 +689,8 @@ static LogicalResult printOperation(CppEmitter &emitter,
static LogicalResult printOperation(CppEmitter &emitter,
emitc::LogicalNotOp logicalNotOp) {
- raw_ostream &os = emitter.ostream();
-
- if (failed(emitter.emitAssignPrefix(*logicalNotOp.getOperation())))
- return failure();
-
- os << "!";
-
- if (failed(emitter.emitOperand(logicalNotOp.getOperand())))
- return failure();
-
- return success();
+ Operation *operation = logicalNotOp.getOperation();
+ return printUnaryOperation(emitter, operation, "!");
}
static LogicalResult printOperation(CppEmitter &emitter,
@@ -1307,7 +1352,10 @@ LogicalResult CppEmitter::emitOperation(Operation &op, bool trailingSemicolon) {
.Case<cf::BranchOp, cf::CondBranchOp>(
[&](auto op) { return printOperation(*this, op); })
// EmitC ops.
- .Case<emitc::AddOp, emitc::ApplyOp, emitc::AssignOp, emitc::CallOp,
+ .Case<emitc::AddOp, emitc::ApplyOp, emitc::AssignOp,
+ emitc::BitwiseAndOp, emitc::BitwiseLeftShiftOp,
+ emitc::BitwiseNotOp, emitc::BitwiseOrOp,
+ emitc::BitwiseRightShiftOp, emitc::BitwiseXorOp, emitc::CallOp,
emitc::CallOpaqueOp, emitc::CastOp, emitc::CmpOp,
emitc::ConstantOp, emitc::DeclareFuncOp, emitc::DivOp,
emitc::ExpressionOp, emitc::ForOp, emitc::FuncOp, emitc::IfOp,
diff --git a/mlir/test/Dialect/EmitC/ops.mlir b/mlir/test/Dialect/EmitC/ops.mlir
index 045fb24cb67f8d..f852390f03e298 100644
--- a/mlir/test/Dialect/EmitC/ops.mlir
+++ b/mlir/test/Dialect/EmitC/ops.mlir
@@ -61,6 +61,16 @@ func.func @add_pointer(%arg0: !emitc.ptr<f32>, %arg1: i32, %arg2: !emitc.opaque<
return
}
+func.func @bitwise(%arg0: i32, %arg1: i32) -> () {
+ %0 = emitc.bitwise_and %arg0, %arg1 : (i32, i32) -> i32
+ %1 = emitc.bitwise_left_shift %arg0, %arg1 : (i32, i32) -> i32
+ %2 = emitc.bitwise_not %arg0 : (i32) -> i32
+ %3 = emitc.bitwise_or %arg0, %arg1 : (i32, i32) -> i32
+ %4 = emitc.bitwise_right_shift %arg0, %arg1 : (i32, i32) -> i32
+ %5 = emitc.bitwise_xor %arg0, %arg1 : (i32, i32) -> i32
+ return
+}
+
func.func @div_int(%arg0: i32, %arg1: i32) {
%1 = "emitc.div" (%arg0, %arg1) : (i32, i32) -> i32
return
diff --git a/mlir/test/Target/Cpp/bitwise_operators.mlir b/mlir/test/Target/Cpp/bitwise_operators.mlir
new file mode 100644
index 00000000000000..e666359fc82c91
--- /dev/null
+++ b/mlir/test/Target/Cpp/bitwise_operators.mlir
@@ -0,0 +1,20 @@
+// RUN: mlir-translate -mlir-to-cpp %s | FileCheck %s
+
+func.func @bitwise(%arg0: i32, %arg1: i32) -> () {
+ %0 = emitc.bitwise_and %arg0, %arg1 : (i32, i32) -> i32
+ %1 = emitc.bitwise_left_shift %arg0, %arg1 : (i32, i32) -> i32
+ %2 = emitc.bitwise_not %arg0 : (i32) -> i32
+ %3 = emitc.bitwise_or %arg0, %arg1 : (i32, i32) -> i32
+ %4 = emitc.bitwise_right_shift %arg0, %arg1 : (i32, i32) -> i32
+ %5 = emitc.bitwise_xor %arg0, %arg1 : (i32, i32) -> i32
+
+ return
+}
+
+// CHECK-LABEL: void bitwise
+// CHECK-NEXT: int32_t [[V2:[^ ]*]] = [[V0:[^ ]*]] & [[V1:[^ ]*]];
+// CHECK-NEXT: int32_t [[V3:[^ ]*]] = [[V0]] << [[V1]];
+// CHECK-NEXT: int32_t [[V4:[^ ]*]] = ~[[V0]];
+// CHECK-NEXT: int32_t [[V5:[^ ]*]] = [[V0]] | [[V1]];
+// CHECK-NEXT: int32_t [[V6:[^ ]*]] = [[V0]] >> [[V1]];
+// CHECK-NEXT: int32_t [[V7:[^ ]*]] = [[V0]] ^ [[V1]];
>From f28c4b4bacfc3fdc66b525b9a959c6b91a29d882 Mon Sep 17 00:00:00 2001
From: Alexey Bataev <5361294+alexey-bataev at users.noreply.github.com>
Date: Fri, 1 Mar 2024 07:38:18 -0500
Subject: [PATCH 242/406] [SLP]Fix/improve potential masked gather loads
analysis.
When do the analysis for the (potential) masked gather node, we check
that not greater than half of the pointer operands are loop invariants
or potentially vectorizable.
Need to check actually, that we have a loop at first
and do better check for the potentially vectorizable
pointers.
Reviewers: RKSimon
Reviewed By: RKSimon
Pull Request: https://github.com/llvm/llvm-project/pull/83472
---
.../Transforms/Vectorize/SLPVectorizer.cpp | 10 +-
.../SLPVectorizer/RISCV/complex-loads.ll | 626 +++++++++---------
.../SLPVectorizer/X86/split-load8_2-unord.ll | 65 +-
3 files changed, 355 insertions(+), 346 deletions(-)
diff --git a/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp b/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
index df740c07f267eb..cdb341efcedca3 100644
--- a/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
+++ b/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
@@ -4100,14 +4100,14 @@ static LoadsState canVectorizeLoads(ArrayRef<Value *> VL, const Value *VL0,
// increases the cost.
Loop *L = LI.getLoopFor(cast<LoadInst>(VL0)->getParent());
bool ProfitableGatherPointers =
- static_cast<unsigned>(count_if(
- PointerOps,
- [L](Value *V) { return L && L->isLoopInvariant(V); })) <= Sz / 2 &&
- Sz > 2;
+ L && Sz > 2 && count_if(PointerOps, [L](Value *V) {
+ return L->isLoopInvariant(V);
+ }) <= Sz / 2;
if (ProfitableGatherPointers || all_of(PointerOps, [IsSorted](Value *P) {
auto *GEP = dyn_cast<GetElementPtrInst>(P);
return (IsSorted && !GEP && doesNotNeedToBeScheduled(P)) ||
- (GEP && GEP->getNumOperands() == 2);
+ (GEP && GEP->getNumOperands() == 2 &&
+ isa<Constant, Instruction>(GEP->getOperand(1)));
})) {
Align CommonAlignment = computeCommonAlignment<LoadInst>(VL);
if (TTI.isLegalMaskedGather(VecTy, CommonAlignment) &&
diff --git a/llvm/test/Transforms/SLPVectorizer/RISCV/complex-loads.ll b/llvm/test/Transforms/SLPVectorizer/RISCV/complex-loads.ll
index e167b6a47af592..97008ac6785961 100644
--- a/llvm/test/Transforms/SLPVectorizer/RISCV/complex-loads.ll
+++ b/llvm/test/Transforms/SLPVectorizer/RISCV/complex-loads.ll
@@ -17,353 +17,359 @@ define i32 @test(ptr %pix1, ptr %pix2, i64 %idx.ext, i64 %idx.ext63, ptr %add.pt
; CHECK-NEXT: [[ARRAYIDX20:%.*]] = getelementptr i8, ptr [[PIX1]], i64 2
; CHECK-NEXT: [[ARRAYIDX22:%.*]] = getelementptr i8, ptr [[PIX2]], i64 2
; CHECK-NEXT: [[ADD_PTR3:%.*]] = getelementptr i8, ptr [[PIX1]], i64 [[IDX_EXT]]
+; CHECK-NEXT: [[ADD_PTR644:%.*]] = getelementptr i8, ptr [[PIX2]], i64 [[IDX_EXT63]]
; CHECK-NEXT: [[TMP9:%.*]] = load i8, ptr [[ADD_PTR3]], align 1
; CHECK-NEXT: [[CONV_1:%.*]] = zext i8 [[TMP9]] to i32
+; CHECK-NEXT: [[TMP10:%.*]] = load i8, ptr [[ADD_PTR644]], align 1
; CHECK-NEXT: [[ARRAYIDX8_1:%.*]] = getelementptr i8, ptr [[ADD_PTR3]], i64 1
+; CHECK-NEXT: [[ARRAYIDX22_1:%.*]] = getelementptr i8, ptr [[ADD_PTR644]], i64 2
+; CHECK-NEXT: [[TMP11:%.*]] = load i8, ptr [[ARRAYIDX22_1]], align 1
; CHECK-NEXT: [[ARRAYIDX32_1:%.*]] = getelementptr i8, ptr [[ADD_PTR3]], i64 3
-; CHECK-NEXT: [[TMP10:%.*]] = load i8, ptr [[ARRAYIDX32_1]], align 1
-; CHECK-NEXT: [[CONV33_1:%.*]] = zext i8 [[TMP10]] to i32
+; CHECK-NEXT: [[TMP12:%.*]] = load i8, ptr [[ARRAYIDX32_1]], align 1
+; CHECK-NEXT: [[CONV33_1:%.*]] = zext i8 [[TMP12]] to i32
; CHECK-NEXT: [[ADD_PTR_1:%.*]] = getelementptr i8, ptr [[ADD_PTR]], i64 [[IDX_EXT]]
; CHECK-NEXT: [[ADD_PTR64_1:%.*]] = getelementptr i8, ptr [[ADD_PTR64]], i64 [[IDX_EXT63]]
+; CHECK-NEXT: [[TMP13:%.*]] = load i8, ptr [[ADD_PTR_1]], align 1
+; CHECK-NEXT: [[TMP14:%.*]] = load i8, ptr [[ADD_PTR64_1]], align 1
; CHECK-NEXT: [[ARRAYIDX20_2:%.*]] = getelementptr i8, ptr [[ADD_PTR_1]], i64 2
-; CHECK-NEXT: [[TMP11:%.*]] = insertelement <2 x ptr> poison, ptr [[ADD_PTR_1]], i32 0
-; CHECK-NEXT: [[TMP12:%.*]] = insertelement <2 x ptr> [[TMP11]], ptr [[ARRAYIDX20_2]], i32 1
-; CHECK-NEXT: [[TMP13:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP12]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP14:%.*]] = zext <2 x i8> [[TMP13]] to <2 x i32>
+; CHECK-NEXT: [[TMP15:%.*]] = load i8, ptr [[ARRAYIDX20_2]], align 1
; CHECK-NEXT: [[ARRAYIDX22_2:%.*]] = getelementptr i8, ptr [[ADD_PTR64_1]], i64 2
-; CHECK-NEXT: [[TMP15:%.*]] = insertelement <2 x ptr> poison, ptr [[ADD_PTR64_1]], i32 0
-; CHECK-NEXT: [[TMP16:%.*]] = insertelement <2 x ptr> [[TMP15]], ptr [[ARRAYIDX22_2]], i32 1
-; CHECK-NEXT: [[TMP17:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP16]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP18:%.*]] = zext <2 x i8> [[TMP17]] to <2 x i32>
-; CHECK-NEXT: [[TMP19:%.*]] = sub <2 x i32> [[TMP14]], [[TMP18]]
-; CHECK-NEXT: [[TMP20:%.*]] = shufflevector <2 x ptr> [[TMP12]], <2 x ptr> poison, <2 x i32> zeroinitializer
-; CHECK-NEXT: [[TMP21:%.*]] = getelementptr i8, <2 x ptr> [[TMP20]], <2 x i64> <i64 4, i64 6>
-; CHECK-NEXT: [[TMP22:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP21]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP23:%.*]] = zext <2 x i8> [[TMP22]] to <2 x i32>
-; CHECK-NEXT: [[TMP24:%.*]] = shufflevector <2 x ptr> [[TMP16]], <2 x ptr> poison, <2 x i32> zeroinitializer
-; CHECK-NEXT: [[TMP25:%.*]] = getelementptr i8, <2 x ptr> [[TMP24]], <2 x i64> <i64 4, i64 6>
-; CHECK-NEXT: [[TMP26:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP25]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP27:%.*]] = zext <2 x i8> [[TMP26]] to <2 x i32>
-; CHECK-NEXT: [[TMP28:%.*]] = sub <2 x i32> [[TMP23]], [[TMP27]]
-; CHECK-NEXT: [[TMP29:%.*]] = shl <2 x i32> [[TMP28]], <i32 16, i32 16>
-; CHECK-NEXT: [[TMP30:%.*]] = add <2 x i32> [[TMP29]], [[TMP19]]
-; CHECK-NEXT: [[TMP31:%.*]] = getelementptr i8, <2 x ptr> [[TMP20]], <2 x i64> <i64 1, i64 3>
+; CHECK-NEXT: [[TMP16:%.*]] = load i8, ptr [[ARRAYIDX22_2]], align 1
+; CHECK-NEXT: [[TMP17:%.*]] = insertelement <2 x i8> poison, i8 [[TMP13]], i32 0
+; CHECK-NEXT: [[TMP18:%.*]] = insertelement <2 x i8> [[TMP17]], i8 [[TMP15]], i32 1
+; CHECK-NEXT: [[TMP19:%.*]] = zext <2 x i8> [[TMP18]] to <2 x i32>
+; CHECK-NEXT: [[TMP20:%.*]] = insertelement <2 x i8> poison, i8 [[TMP14]], i32 0
+; CHECK-NEXT: [[TMP21:%.*]] = insertelement <2 x i8> [[TMP20]], i8 [[TMP16]], i32 1
+; CHECK-NEXT: [[TMP22:%.*]] = zext <2 x i8> [[TMP21]] to <2 x i32>
+; CHECK-NEXT: [[TMP23:%.*]] = sub <2 x i32> [[TMP19]], [[TMP22]]
+; CHECK-NEXT: [[TMP24:%.*]] = insertelement <2 x ptr> poison, ptr [[ADD_PTR_1]], i32 0
+; CHECK-NEXT: [[TMP25:%.*]] = shufflevector <2 x ptr> [[TMP24]], <2 x ptr> poison, <2 x i32> zeroinitializer
+; CHECK-NEXT: [[TMP26:%.*]] = getelementptr i8, <2 x ptr> [[TMP25]], <2 x i64> <i64 4, i64 6>
+; CHECK-NEXT: [[TMP27:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP26]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP28:%.*]] = zext <2 x i8> [[TMP27]] to <2 x i32>
+; CHECK-NEXT: [[TMP29:%.*]] = insertelement <2 x ptr> poison, ptr [[ADD_PTR64_1]], i32 0
+; CHECK-NEXT: [[TMP30:%.*]] = shufflevector <2 x ptr> [[TMP29]], <2 x ptr> poison, <2 x i32> zeroinitializer
+; CHECK-NEXT: [[TMP31:%.*]] = getelementptr i8, <2 x ptr> [[TMP30]], <2 x i64> <i64 4, i64 6>
; CHECK-NEXT: [[TMP32:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP31]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
; CHECK-NEXT: [[TMP33:%.*]] = zext <2 x i8> [[TMP32]] to <2 x i32>
-; CHECK-NEXT: [[TMP34:%.*]] = getelementptr i8, <2 x ptr> [[TMP24]], <2 x i64> <i64 1, i64 3>
-; CHECK-NEXT: [[TMP35:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP34]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP36:%.*]] = zext <2 x i8> [[TMP35]] to <2 x i32>
-; CHECK-NEXT: [[TMP37:%.*]] = sub <2 x i32> [[TMP33]], [[TMP36]]
-; CHECK-NEXT: [[TMP38:%.*]] = getelementptr i8, <2 x ptr> [[TMP20]], <2 x i64> <i64 5, i64 7>
-; CHECK-NEXT: [[TMP39:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP38]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP40:%.*]] = zext <2 x i8> [[TMP39]] to <2 x i32>
-; CHECK-NEXT: [[TMP41:%.*]] = getelementptr i8, <2 x ptr> [[TMP24]], <2 x i64> <i64 5, i64 7>
-; CHECK-NEXT: [[TMP42:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP41]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP43:%.*]] = zext <2 x i8> [[TMP42]] to <2 x i32>
-; CHECK-NEXT: [[TMP44:%.*]] = sub <2 x i32> [[TMP40]], [[TMP43]]
-; CHECK-NEXT: [[TMP45:%.*]] = shl <2 x i32> [[TMP44]], <i32 16, i32 16>
-; CHECK-NEXT: [[TMP46:%.*]] = add <2 x i32> [[TMP45]], [[TMP37]]
-; CHECK-NEXT: [[TMP47:%.*]] = sub <2 x i32> [[TMP30]], [[TMP46]]
-; CHECK-NEXT: [[TMP48:%.*]] = extractelement <2 x i32> [[TMP47]], i32 0
-; CHECK-NEXT: [[TMP49:%.*]] = extractelement <2 x i32> [[TMP47]], i32 1
-; CHECK-NEXT: [[SUB59_2:%.*]] = sub i32 [[TMP48]], [[TMP49]]
-; CHECK-NEXT: [[TMP50:%.*]] = load i8, ptr null, align 1
+; CHECK-NEXT: [[TMP34:%.*]] = sub <2 x i32> [[TMP28]], [[TMP33]]
+; CHECK-NEXT: [[TMP35:%.*]] = shl <2 x i32> [[TMP34]], <i32 16, i32 16>
+; CHECK-NEXT: [[TMP36:%.*]] = add <2 x i32> [[TMP35]], [[TMP23]]
+; CHECK-NEXT: [[TMP37:%.*]] = getelementptr i8, <2 x ptr> [[TMP25]], <2 x i64> <i64 1, i64 3>
+; CHECK-NEXT: [[TMP38:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP37]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP39:%.*]] = zext <2 x i8> [[TMP38]] to <2 x i32>
+; CHECK-NEXT: [[TMP40:%.*]] = getelementptr i8, <2 x ptr> [[TMP30]], <2 x i64> <i64 1, i64 3>
+; CHECK-NEXT: [[TMP41:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP40]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP42:%.*]] = zext <2 x i8> [[TMP41]] to <2 x i32>
+; CHECK-NEXT: [[TMP43:%.*]] = sub <2 x i32> [[TMP39]], [[TMP42]]
+; CHECK-NEXT: [[TMP44:%.*]] = getelementptr i8, <2 x ptr> [[TMP25]], <2 x i64> <i64 5, i64 7>
+; CHECK-NEXT: [[TMP45:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP44]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP46:%.*]] = zext <2 x i8> [[TMP45]] to <2 x i32>
+; CHECK-NEXT: [[TMP47:%.*]] = getelementptr i8, <2 x ptr> [[TMP30]], <2 x i64> <i64 5, i64 7>
+; CHECK-NEXT: [[TMP48:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP47]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP49:%.*]] = zext <2 x i8> [[TMP48]] to <2 x i32>
+; CHECK-NEXT: [[TMP50:%.*]] = sub <2 x i32> [[TMP46]], [[TMP49]]
+; CHECK-NEXT: [[TMP51:%.*]] = shl <2 x i32> [[TMP50]], <i32 16, i32 16>
+; CHECK-NEXT: [[TMP52:%.*]] = add <2 x i32> [[TMP51]], [[TMP43]]
+; CHECK-NEXT: [[TMP53:%.*]] = sub <2 x i32> [[TMP36]], [[TMP52]]
+; CHECK-NEXT: [[TMP54:%.*]] = extractelement <2 x i32> [[TMP53]], i32 0
+; CHECK-NEXT: [[TMP55:%.*]] = extractelement <2 x i32> [[TMP53]], i32 1
+; CHECK-NEXT: [[SUB59_2:%.*]] = sub i32 [[TMP54]], [[TMP55]]
+; CHECK-NEXT: [[TMP56:%.*]] = load i8, ptr null, align 1
; CHECK-NEXT: [[ARRAYIDX20_3:%.*]] = getelementptr i8, ptr null, i64 2
; CHECK-NEXT: [[ARRAYIDX22_3:%.*]] = getelementptr i8, ptr null, i64 2
-; CHECK-NEXT: [[TMP51:%.*]] = load i8, ptr null, align 1
-; CHECK-NEXT: [[TMP52:%.*]] = insertelement <2 x ptr> <ptr poison, ptr null>, ptr [[ARRAYIDX20_3]], i32 0
-; CHECK-NEXT: [[TMP53:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP52]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP54:%.*]] = zext <2 x i8> [[TMP53]] to <2 x i32>
-; CHECK-NEXT: [[TMP55:%.*]] = insertelement <2 x ptr> <ptr poison, ptr null>, ptr [[ARRAYIDX22_3]], i32 0
-; CHECK-NEXT: [[TMP56:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP55]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP57:%.*]] = zext <2 x i8> [[TMP56]] to <2 x i32>
-; CHECK-NEXT: [[TMP58:%.*]] = sub <2 x i32> [[TMP54]], [[TMP57]]
-; CHECK-NEXT: [[TMP59:%.*]] = call <2 x i8> @llvm.experimental.vp.strided.load.v2i8.p0.i64(ptr align 1 null, i64 4, <2 x i1> <i1 true, i1 true>, i32 2)
+; CHECK-NEXT: [[TMP57:%.*]] = load i8, ptr null, align 1
+; CHECK-NEXT: [[TMP58:%.*]] = insertelement <2 x ptr> <ptr poison, ptr null>, ptr [[ARRAYIDX20_3]], i32 0
+; CHECK-NEXT: [[TMP59:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP58]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
; CHECK-NEXT: [[TMP60:%.*]] = zext <2 x i8> [[TMP59]] to <2 x i32>
-; CHECK-NEXT: [[TMP61:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> getelementptr (i8, <2 x ptr> zeroinitializer, <2 x i64> <i64 6, i64 4>), i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP62:%.*]] = zext <2 x i8> [[TMP61]] to <2 x i32>
-; CHECK-NEXT: [[TMP63:%.*]] = sub <2 x i32> [[TMP60]], [[TMP62]]
-; CHECK-NEXT: [[TMP64:%.*]] = shl <2 x i32> [[TMP63]], <i32 16, i32 16>
-; CHECK-NEXT: [[TMP65:%.*]] = add <2 x i32> [[TMP64]], [[TMP58]]
-; CHECK-NEXT: [[TMP66:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> getelementptr (i8, <2 x ptr> zeroinitializer, <2 x i64> <i64 3, i64 1>), i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP67:%.*]] = zext <2 x i8> [[TMP66]] to <2 x i32>
-; CHECK-NEXT: [[TMP68:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> getelementptr (i8, <2 x ptr> zeroinitializer, <2 x i64> <i64 3, i64 1>), i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP69:%.*]] = zext <2 x i8> [[TMP68]] to <2 x i32>
-; CHECK-NEXT: [[TMP70:%.*]] = sub <2 x i32> [[TMP67]], [[TMP69]]
-; CHECK-NEXT: [[TMP71:%.*]] = insertelement <2 x i8> poison, i8 [[TMP51]], i32 0
-; CHECK-NEXT: [[TMP72:%.*]] = insertelement <2 x i8> [[TMP71]], i8 [[TMP50]], i32 1
+; CHECK-NEXT: [[TMP61:%.*]] = insertelement <2 x ptr> <ptr poison, ptr null>, ptr [[ARRAYIDX22_3]], i32 0
+; CHECK-NEXT: [[TMP62:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP61]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP63:%.*]] = zext <2 x i8> [[TMP62]] to <2 x i32>
+; CHECK-NEXT: [[TMP64:%.*]] = sub <2 x i32> [[TMP60]], [[TMP63]]
+; CHECK-NEXT: [[TMP65:%.*]] = call <2 x i8> @llvm.experimental.vp.strided.load.v2i8.p0.i64(ptr align 1 null, i64 4, <2 x i1> <i1 true, i1 true>, i32 2)
+; CHECK-NEXT: [[TMP66:%.*]] = zext <2 x i8> [[TMP65]] to <2 x i32>
+; CHECK-NEXT: [[TMP67:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> getelementptr (i8, <2 x ptr> zeroinitializer, <2 x i64> <i64 6, i64 4>), i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP68:%.*]] = zext <2 x i8> [[TMP67]] to <2 x i32>
+; CHECK-NEXT: [[TMP69:%.*]] = sub <2 x i32> [[TMP66]], [[TMP68]]
+; CHECK-NEXT: [[TMP70:%.*]] = shl <2 x i32> [[TMP69]], <i32 16, i32 16>
+; CHECK-NEXT: [[TMP71:%.*]] = add <2 x i32> [[TMP70]], [[TMP64]]
+; CHECK-NEXT: [[TMP72:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> getelementptr (i8, <2 x ptr> zeroinitializer, <2 x i64> <i64 3, i64 1>), i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
; CHECK-NEXT: [[TMP73:%.*]] = zext <2 x i8> [[TMP72]] to <2 x i32>
-; CHECK-NEXT: [[TMP74:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> getelementptr (i8, <2 x ptr> zeroinitializer, <2 x i64> <i64 7, i64 5>), i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP74:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> getelementptr (i8, <2 x ptr> zeroinitializer, <2 x i64> <i64 3, i64 1>), i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
; CHECK-NEXT: [[TMP75:%.*]] = zext <2 x i8> [[TMP74]] to <2 x i32>
; CHECK-NEXT: [[TMP76:%.*]] = sub <2 x i32> [[TMP73]], [[TMP75]]
-; CHECK-NEXT: [[TMP77:%.*]] = shl <2 x i32> [[TMP76]], <i32 16, i32 16>
-; CHECK-NEXT: [[TMP78:%.*]] = add <2 x i32> [[TMP77]], [[TMP70]]
-; CHECK-NEXT: [[TMP79:%.*]] = sub <2 x i32> [[TMP65]], [[TMP78]]
-; CHECK-NEXT: [[TMP80:%.*]] = shufflevector <2 x i32> [[TMP78]], <2 x i32> [[TMP46]], <2 x i32> <i32 1, i32 2>
-; CHECK-NEXT: [[TMP81:%.*]] = shufflevector <2 x i32> [[TMP65]], <2 x i32> [[TMP30]], <2 x i32> <i32 1, i32 2>
-; CHECK-NEXT: [[TMP82:%.*]] = add <2 x i32> [[TMP80]], [[TMP81]]
-; CHECK-NEXT: [[TMP83:%.*]] = shufflevector <2 x i32> [[TMP78]], <2 x i32> [[TMP46]], <2 x i32> <i32 0, i32 3>
-; CHECK-NEXT: [[TMP84:%.*]] = shufflevector <2 x i32> [[TMP65]], <2 x i32> [[TMP30]], <2 x i32> <i32 0, i32 3>
-; CHECK-NEXT: [[TMP85:%.*]] = add <2 x i32> [[TMP83]], [[TMP84]]
-; CHECK-NEXT: [[TMP86:%.*]] = add <2 x i32> [[TMP85]], [[TMP82]]
-; CHECK-NEXT: [[TMP87:%.*]] = sub <2 x i32> [[TMP82]], [[TMP85]]
-; CHECK-NEXT: [[TMP88:%.*]] = extractelement <2 x i32> [[TMP79]], i32 0
-; CHECK-NEXT: [[TMP89:%.*]] = extractelement <2 x i32> [[TMP79]], i32 1
-; CHECK-NEXT: [[SUB59_3:%.*]] = sub i32 [[TMP89]], [[TMP88]]
-; CHECK-NEXT: [[TMP90:%.*]] = extractelement <2 x i32> [[TMP86]], i32 0
-; CHECK-NEXT: [[TMP91:%.*]] = extractelement <2 x i32> [[TMP86]], i32 1
-; CHECK-NEXT: [[ADD94:%.*]] = add i32 [[TMP90]], [[TMP91]]
-; CHECK-NEXT: [[SUB102:%.*]] = sub i32 [[TMP91]], [[TMP90]]
-; CHECK-NEXT: [[TMP92:%.*]] = extractelement <2 x i32> [[TMP54]], i32 1
-; CHECK-NEXT: [[SHR_I:%.*]] = lshr i32 [[TMP92]], 15
+; CHECK-NEXT: [[TMP77:%.*]] = insertelement <2 x i8> poison, i8 [[TMP57]], i32 0
+; CHECK-NEXT: [[TMP78:%.*]] = insertelement <2 x i8> [[TMP77]], i8 [[TMP56]], i32 1
+; CHECK-NEXT: [[TMP79:%.*]] = zext <2 x i8> [[TMP78]] to <2 x i32>
+; CHECK-NEXT: [[TMP80:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> getelementptr (i8, <2 x ptr> zeroinitializer, <2 x i64> <i64 7, i64 5>), i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP81:%.*]] = zext <2 x i8> [[TMP80]] to <2 x i32>
+; CHECK-NEXT: [[TMP82:%.*]] = sub <2 x i32> [[TMP79]], [[TMP81]]
+; CHECK-NEXT: [[TMP83:%.*]] = shl <2 x i32> [[TMP82]], <i32 16, i32 16>
+; CHECK-NEXT: [[TMP84:%.*]] = add <2 x i32> [[TMP83]], [[TMP76]]
+; CHECK-NEXT: [[TMP85:%.*]] = sub <2 x i32> [[TMP71]], [[TMP84]]
+; CHECK-NEXT: [[TMP86:%.*]] = shufflevector <2 x i32> [[TMP84]], <2 x i32> [[TMP52]], <2 x i32> <i32 1, i32 2>
+; CHECK-NEXT: [[TMP87:%.*]] = shufflevector <2 x i32> [[TMP71]], <2 x i32> [[TMP36]], <2 x i32> <i32 1, i32 2>
+; CHECK-NEXT: [[TMP88:%.*]] = add <2 x i32> [[TMP86]], [[TMP87]]
+; CHECK-NEXT: [[TMP89:%.*]] = shufflevector <2 x i32> [[TMP84]], <2 x i32> [[TMP52]], <2 x i32> <i32 0, i32 3>
+; CHECK-NEXT: [[TMP90:%.*]] = shufflevector <2 x i32> [[TMP71]], <2 x i32> [[TMP36]], <2 x i32> <i32 0, i32 3>
+; CHECK-NEXT: [[TMP91:%.*]] = add <2 x i32> [[TMP89]], [[TMP90]]
+; CHECK-NEXT: [[TMP92:%.*]] = add <2 x i32> [[TMP91]], [[TMP88]]
+; CHECK-NEXT: [[TMP93:%.*]] = sub <2 x i32> [[TMP88]], [[TMP91]]
+; CHECK-NEXT: [[TMP94:%.*]] = extractelement <2 x i32> [[TMP85]], i32 0
+; CHECK-NEXT: [[TMP95:%.*]] = extractelement <2 x i32> [[TMP85]], i32 1
+; CHECK-NEXT: [[SUB59_3:%.*]] = sub i32 [[TMP95]], [[TMP94]]
+; CHECK-NEXT: [[TMP96:%.*]] = extractelement <2 x i32> [[TMP92]], i32 0
+; CHECK-NEXT: [[TMP97:%.*]] = extractelement <2 x i32> [[TMP92]], i32 1
+; CHECK-NEXT: [[ADD94:%.*]] = add i32 [[TMP96]], [[TMP97]]
+; CHECK-NEXT: [[SUB102:%.*]] = sub i32 [[TMP97]], [[TMP96]]
+; CHECK-NEXT: [[TMP98:%.*]] = extractelement <2 x i32> [[TMP60]], i32 1
+; CHECK-NEXT: [[SHR_I:%.*]] = lshr i32 [[TMP98]], 15
; CHECK-NEXT: [[AND_I:%.*]] = and i32 [[SHR_I]], 65537
; CHECK-NEXT: [[MUL_I:%.*]] = mul i32 [[AND_I]], 65535
-; CHECK-NEXT: [[TMP93:%.*]] = extractelement <2 x i32> [[TMP85]], i32 1
-; CHECK-NEXT: [[SHR_I49:%.*]] = lshr i32 [[TMP93]], 15
+; CHECK-NEXT: [[TMP99:%.*]] = extractelement <2 x i32> [[TMP91]], i32 1
+; CHECK-NEXT: [[SHR_I49:%.*]] = lshr i32 [[TMP99]], 15
; CHECK-NEXT: [[AND_I50:%.*]] = and i32 [[SHR_I49]], 65537
; CHECK-NEXT: [[MUL_I51:%.*]] = mul i32 [[AND_I50]], 65535
-; CHECK-NEXT: [[TMP94:%.*]] = extractelement <2 x i32> [[TMP87]], i32 0
-; CHECK-NEXT: [[TMP95:%.*]] = extractelement <2 x i32> [[TMP87]], i32 1
-; CHECK-NEXT: [[ADD94_2:%.*]] = add i32 [[TMP94]], [[TMP95]]
-; CHECK-NEXT: [[TMP96:%.*]] = load <2 x i8>, ptr [[ARRAYIDX20]], align 1
-; CHECK-NEXT: [[TMP97:%.*]] = zext <2 x i8> [[TMP96]] to <2 x i32>
-; CHECK-NEXT: [[TMP98:%.*]] = insertelement <2 x i32> poison, i32 [[SUB59_2]], i32 0
-; CHECK-NEXT: [[TMP99:%.*]] = shufflevector <2 x i32> [[TMP98]], <2 x i32> poison, <2 x i32> zeroinitializer
-; CHECK-NEXT: [[TMP100:%.*]] = insertelement <2 x i32> poison, i32 [[SUB59_3]], i32 0
-; CHECK-NEXT: [[TMP101:%.*]] = shufflevector <2 x i32> [[TMP100]], <2 x i32> poison, <2 x i32> zeroinitializer
-; CHECK-NEXT: [[TMP102:%.*]] = add <2 x i32> [[TMP99]], [[TMP101]]
-; CHECK-NEXT: [[TMP103:%.*]] = sub <2 x i32> [[TMP99]], [[TMP101]]
-; CHECK-NEXT: [[TMP104:%.*]] = shufflevector <2 x i32> [[TMP102]], <2 x i32> [[TMP103]], <2 x i32> <i32 0, i32 3>
-; CHECK-NEXT: [[TMP105:%.*]] = load <2 x i8>, ptr [[PIX1]], align 1
-; CHECK-NEXT: [[TMP106:%.*]] = zext <2 x i8> [[TMP105]] to <2 x i32>
-; CHECK-NEXT: [[TMP107:%.*]] = shufflevector <2 x i32> [[TMP106]], <2 x i32> poison, <2 x i32> <i32 1, i32 0>
-; CHECK-NEXT: [[TMP108:%.*]] = insertelement <2 x ptr> [[TMP4]], ptr [[ARRAYIDX22]], i32 1
-; CHECK-NEXT: [[TMP109:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP108]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP110:%.*]] = zext <2 x i8> [[TMP109]] to <2 x i32>
-; CHECK-NEXT: [[TMP111:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP2]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP100:%.*]] = extractelement <2 x i32> [[TMP93]], i32 0
+; CHECK-NEXT: [[TMP101:%.*]] = extractelement <2 x i32> [[TMP93]], i32 1
+; CHECK-NEXT: [[ADD94_2:%.*]] = add i32 [[TMP100]], [[TMP101]]
+; CHECK-NEXT: [[TMP102:%.*]] = load <2 x i8>, ptr [[ARRAYIDX20]], align 1
+; CHECK-NEXT: [[TMP103:%.*]] = zext <2 x i8> [[TMP102]] to <2 x i32>
+; CHECK-NEXT: [[TMP104:%.*]] = insertelement <2 x i32> poison, i32 [[SUB59_2]], i32 0
+; CHECK-NEXT: [[TMP105:%.*]] = shufflevector <2 x i32> [[TMP104]], <2 x i32> poison, <2 x i32> zeroinitializer
+; CHECK-NEXT: [[TMP106:%.*]] = insertelement <2 x i32> poison, i32 [[SUB59_3]], i32 0
+; CHECK-NEXT: [[TMP107:%.*]] = shufflevector <2 x i32> [[TMP106]], <2 x i32> poison, <2 x i32> zeroinitializer
+; CHECK-NEXT: [[TMP108:%.*]] = add <2 x i32> [[TMP105]], [[TMP107]]
+; CHECK-NEXT: [[TMP109:%.*]] = sub <2 x i32> [[TMP105]], [[TMP107]]
+; CHECK-NEXT: [[TMP110:%.*]] = shufflevector <2 x i32> [[TMP108]], <2 x i32> [[TMP109]], <2 x i32> <i32 0, i32 3>
+; CHECK-NEXT: [[TMP111:%.*]] = load <2 x i8>, ptr [[PIX1]], align 1
; CHECK-NEXT: [[TMP112:%.*]] = zext <2 x i8> [[TMP111]] to <2 x i32>
-; CHECK-NEXT: [[TMP113:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP5]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP114:%.*]] = zext <2 x i8> [[TMP113]] to <2 x i32>
-; CHECK-NEXT: [[TMP115:%.*]] = sub <2 x i32> [[TMP112]], [[TMP114]]
-; CHECK-NEXT: [[TMP116:%.*]] = shl <2 x i32> [[TMP115]], <i32 16, i32 16>
-; CHECK-NEXT: [[TMP117:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP6]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP113:%.*]] = shufflevector <2 x i32> [[TMP112]], <2 x i32> poison, <2 x i32> <i32 1, i32 0>
+; CHECK-NEXT: [[TMP114:%.*]] = insertelement <2 x ptr> [[TMP4]], ptr [[ARRAYIDX22]], i32 1
+; CHECK-NEXT: [[TMP115:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP114]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP116:%.*]] = zext <2 x i8> [[TMP115]] to <2 x i32>
+; CHECK-NEXT: [[TMP117:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP2]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
; CHECK-NEXT: [[TMP118:%.*]] = zext <2 x i8> [[TMP117]] to <2 x i32>
-; CHECK-NEXT: [[TMP119:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP7]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP119:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP5]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
; CHECK-NEXT: [[TMP120:%.*]] = zext <2 x i8> [[TMP119]] to <2 x i32>
-; CHECK-NEXT: [[TMP121:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP8]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP122:%.*]] = zext <2 x i8> [[TMP121]] to <2 x i32>
-; CHECK-NEXT: [[TMP123:%.*]] = sub <2 x i32> [[TMP120]], [[TMP122]]
-; CHECK-NEXT: [[TMP124:%.*]] = shl <2 x i32> [[TMP123]], <i32 16, i32 16>
-; CHECK-NEXT: [[TMP125:%.*]] = shufflevector <2 x i32> [[TMP106]], <2 x i32> [[TMP97]], <2 x i32> <i32 0, i32 2>
-; CHECK-NEXT: [[TMP126:%.*]] = sub <2 x i32> [[TMP125]], [[TMP110]]
-; CHECK-NEXT: [[TMP127:%.*]] = add <2 x i32> [[TMP116]], [[TMP126]]
-; CHECK-NEXT: [[TMP128:%.*]] = shufflevector <2 x i32> [[TMP107]], <2 x i32> [[TMP97]], <2 x i32> <i32 0, i32 3>
-; CHECK-NEXT: [[TMP129:%.*]] = sub <2 x i32> [[TMP128]], [[TMP118]]
-; CHECK-NEXT: [[TMP130:%.*]] = add <2 x i32> [[TMP124]], [[TMP129]]
-; CHECK-NEXT: [[TMP131:%.*]] = extractelement <2 x i32> [[TMP127]], i32 1
-; CHECK-NEXT: [[TMP132:%.*]] = extractelement <2 x i32> [[TMP130]], i32 1
-; CHECK-NEXT: [[ADD46:%.*]] = add i32 [[TMP132]], [[TMP131]]
-; CHECK-NEXT: [[TMP133:%.*]] = sub <2 x i32> [[TMP127]], [[TMP130]]
-; CHECK-NEXT: [[TMP134:%.*]] = extractelement <2 x i32> [[TMP127]], i32 0
-; CHECK-NEXT: [[TMP135:%.*]] = extractelement <2 x i32> [[TMP130]], i32 0
-; CHECK-NEXT: [[ADD44:%.*]] = add i32 [[TMP135]], [[TMP134]]
-; CHECK-NEXT: [[TMP136:%.*]] = lshr <2 x i32> [[TMP107]], <i32 15, i32 15>
-; CHECK-NEXT: [[TMP137:%.*]] = and <2 x i32> [[TMP136]], <i32 65537, i32 65537>
-; CHECK-NEXT: [[TMP138:%.*]] = mul <2 x i32> [[TMP137]], <i32 65535, i32 65535>
-; CHECK-NEXT: [[TMP139:%.*]] = extractelement <2 x i32> [[TMP133]], i32 0
-; CHECK-NEXT: [[TMP140:%.*]] = extractelement <2 x i32> [[TMP133]], i32 1
-; CHECK-NEXT: [[SUB59:%.*]] = sub i32 [[TMP139]], [[TMP140]]
-; CHECK-NEXT: [[TMP141:%.*]] = load <2 x i8>, ptr [[ARRAYIDX8_1]], align 1
-; CHECK-NEXT: [[TMP142:%.*]] = zext <2 x i8> [[TMP141]] to <2 x i32>
-; CHECK-NEXT: [[ADD_PTR644:%.*]] = getelementptr i8, ptr [[PIX2]], i64 [[IDX_EXT63]]
-; CHECK-NEXT: [[ARRAYIDX22_1:%.*]] = getelementptr i8, ptr [[ADD_PTR644]], i64 2
-; CHECK-NEXT: [[TMP143:%.*]] = insertelement <2 x ptr> poison, ptr [[ADD_PTR644]], i32 0
-; CHECK-NEXT: [[TMP144:%.*]] = insertelement <2 x ptr> [[TMP143]], ptr [[ARRAYIDX22_1]], i32 1
-; CHECK-NEXT: [[TMP145:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP144]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP146:%.*]] = zext <2 x i8> [[TMP145]] to <2 x i32>
-; CHECK-NEXT: [[TMP147:%.*]] = insertelement <2 x ptr> poison, ptr [[ADD_PTR3]], i32 0
-; CHECK-NEXT: [[TMP148:%.*]] = shufflevector <2 x ptr> [[TMP147]], <2 x ptr> poison, <2 x i32> zeroinitializer
-; CHECK-NEXT: [[TMP149:%.*]] = getelementptr i8, <2 x ptr> [[TMP148]], <2 x i64> <i64 4, i64 6>
-; CHECK-NEXT: [[TMP150:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP149]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP121:%.*]] = sub <2 x i32> [[TMP118]], [[TMP120]]
+; CHECK-NEXT: [[TMP122:%.*]] = shl <2 x i32> [[TMP121]], <i32 16, i32 16>
+; CHECK-NEXT: [[TMP123:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP6]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP124:%.*]] = zext <2 x i8> [[TMP123]] to <2 x i32>
+; CHECK-NEXT: [[TMP125:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP7]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP126:%.*]] = zext <2 x i8> [[TMP125]] to <2 x i32>
+; CHECK-NEXT: [[TMP127:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP8]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP128:%.*]] = zext <2 x i8> [[TMP127]] to <2 x i32>
+; CHECK-NEXT: [[TMP129:%.*]] = sub <2 x i32> [[TMP126]], [[TMP128]]
+; CHECK-NEXT: [[TMP130:%.*]] = shl <2 x i32> [[TMP129]], <i32 16, i32 16>
+; CHECK-NEXT: [[TMP131:%.*]] = shufflevector <2 x i32> [[TMP112]], <2 x i32> [[TMP103]], <2 x i32> <i32 0, i32 2>
+; CHECK-NEXT: [[TMP132:%.*]] = sub <2 x i32> [[TMP131]], [[TMP116]]
+; CHECK-NEXT: [[TMP133:%.*]] = add <2 x i32> [[TMP122]], [[TMP132]]
+; CHECK-NEXT: [[TMP134:%.*]] = shufflevector <2 x i32> [[TMP113]], <2 x i32> [[TMP103]], <2 x i32> <i32 0, i32 3>
+; CHECK-NEXT: [[TMP135:%.*]] = sub <2 x i32> [[TMP134]], [[TMP124]]
+; CHECK-NEXT: [[TMP136:%.*]] = add <2 x i32> [[TMP130]], [[TMP135]]
+; CHECK-NEXT: [[TMP137:%.*]] = extractelement <2 x i32> [[TMP133]], i32 1
+; CHECK-NEXT: [[TMP138:%.*]] = extractelement <2 x i32> [[TMP136]], i32 1
+; CHECK-NEXT: [[ADD46:%.*]] = add i32 [[TMP138]], [[TMP137]]
+; CHECK-NEXT: [[TMP139:%.*]] = sub <2 x i32> [[TMP133]], [[TMP136]]
+; CHECK-NEXT: [[TMP140:%.*]] = extractelement <2 x i32> [[TMP133]], i32 0
+; CHECK-NEXT: [[TMP141:%.*]] = extractelement <2 x i32> [[TMP136]], i32 0
+; CHECK-NEXT: [[ADD44:%.*]] = add i32 [[TMP141]], [[TMP140]]
+; CHECK-NEXT: [[TMP142:%.*]] = lshr <2 x i32> [[TMP113]], <i32 15, i32 15>
+; CHECK-NEXT: [[TMP143:%.*]] = and <2 x i32> [[TMP142]], <i32 65537, i32 65537>
+; CHECK-NEXT: [[TMP144:%.*]] = mul <2 x i32> [[TMP143]], <i32 65535, i32 65535>
+; CHECK-NEXT: [[TMP145:%.*]] = extractelement <2 x i32> [[TMP139]], i32 0
+; CHECK-NEXT: [[TMP146:%.*]] = extractelement <2 x i32> [[TMP139]], i32 1
+; CHECK-NEXT: [[SUB59:%.*]] = sub i32 [[TMP145]], [[TMP146]]
+; CHECK-NEXT: [[TMP147:%.*]] = load <2 x i8>, ptr [[ARRAYIDX8_1]], align 1
+; CHECK-NEXT: [[TMP148:%.*]] = zext <2 x i8> [[TMP147]] to <2 x i32>
+; CHECK-NEXT: [[TMP149:%.*]] = insertelement <2 x i8> poison, i8 [[TMP10]], i32 0
+; CHECK-NEXT: [[TMP150:%.*]] = insertelement <2 x i8> [[TMP149]], i8 [[TMP11]], i32 1
; CHECK-NEXT: [[TMP151:%.*]] = zext <2 x i8> [[TMP150]] to <2 x i32>
-; CHECK-NEXT: [[TMP152:%.*]] = shufflevector <2 x ptr> [[TMP144]], <2 x ptr> poison, <2 x i32> zeroinitializer
-; CHECK-NEXT: [[TMP153:%.*]] = getelementptr i8, <2 x ptr> [[TMP152]], <2 x i64> <i64 4, i64 6>
-; CHECK-NEXT: [[TMP154:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP153]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP155:%.*]] = zext <2 x i8> [[TMP154]] to <2 x i32>
-; CHECK-NEXT: [[TMP156:%.*]] = sub <2 x i32> [[TMP151]], [[TMP155]]
-; CHECK-NEXT: [[TMP157:%.*]] = shl <2 x i32> [[TMP156]], <i32 16, i32 16>
-; CHECK-NEXT: [[TMP158:%.*]] = getelementptr i8, <2 x ptr> [[TMP152]], <2 x i64> <i64 1, i64 3>
-; CHECK-NEXT: [[TMP159:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP158]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP160:%.*]] = zext <2 x i8> [[TMP159]] to <2 x i32>
-; CHECK-NEXT: [[TMP161:%.*]] = getelementptr i8, <2 x ptr> [[TMP148]], <2 x i64> <i64 5, i64 7>
-; CHECK-NEXT: [[TMP162:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP161]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP163:%.*]] = zext <2 x i8> [[TMP162]] to <2 x i32>
-; CHECK-NEXT: [[TMP164:%.*]] = getelementptr i8, <2 x ptr> [[TMP152]], <2 x i64> <i64 5, i64 7>
+; CHECK-NEXT: [[TMP152:%.*]] = insertelement <2 x ptr> poison, ptr [[ADD_PTR3]], i32 0
+; CHECK-NEXT: [[TMP153:%.*]] = shufflevector <2 x ptr> [[TMP152]], <2 x ptr> poison, <2 x i32> zeroinitializer
+; CHECK-NEXT: [[TMP154:%.*]] = getelementptr i8, <2 x ptr> [[TMP153]], <2 x i64> <i64 4, i64 6>
+; CHECK-NEXT: [[TMP155:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP154]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP156:%.*]] = zext <2 x i8> [[TMP155]] to <2 x i32>
+; CHECK-NEXT: [[TMP157:%.*]] = insertelement <2 x ptr> poison, ptr [[ADD_PTR644]], i32 0
+; CHECK-NEXT: [[TMP158:%.*]] = shufflevector <2 x ptr> [[TMP157]], <2 x ptr> poison, <2 x i32> zeroinitializer
+; CHECK-NEXT: [[TMP159:%.*]] = getelementptr i8, <2 x ptr> [[TMP158]], <2 x i64> <i64 4, i64 6>
+; CHECK-NEXT: [[TMP160:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP159]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP161:%.*]] = zext <2 x i8> [[TMP160]] to <2 x i32>
+; CHECK-NEXT: [[TMP162:%.*]] = sub <2 x i32> [[TMP156]], [[TMP161]]
+; CHECK-NEXT: [[TMP163:%.*]] = shl <2 x i32> [[TMP162]], <i32 16, i32 16>
+; CHECK-NEXT: [[TMP164:%.*]] = getelementptr i8, <2 x ptr> [[TMP158]], <2 x i64> <i64 1, i64 3>
; CHECK-NEXT: [[TMP165:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP164]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
; CHECK-NEXT: [[TMP166:%.*]] = zext <2 x i8> [[TMP165]] to <2 x i32>
-; CHECK-NEXT: [[TMP167:%.*]] = sub <2 x i32> [[TMP163]], [[TMP166]]
-; CHECK-NEXT: [[TMP168:%.*]] = shl <2 x i32> [[TMP167]], <i32 16, i32 16>
-; CHECK-NEXT: [[TMP169:%.*]] = insertelement <2 x i32> [[TMP142]], i32 [[CONV33_1]], i32 1
-; CHECK-NEXT: [[TMP170:%.*]] = sub <2 x i32> [[TMP169]], [[TMP160]]
-; CHECK-NEXT: [[TMP171:%.*]] = add <2 x i32> [[TMP168]], [[TMP170]]
-; CHECK-NEXT: [[TMP172:%.*]] = insertelement <2 x i32> [[TMP142]], i32 [[CONV_1]], i32 0
-; CHECK-NEXT: [[TMP173:%.*]] = sub <2 x i32> [[TMP172]], [[TMP146]]
-; CHECK-NEXT: [[TMP174:%.*]] = add <2 x i32> [[TMP157]], [[TMP173]]
-; CHECK-NEXT: [[TMP175:%.*]] = add <2 x i32> [[TMP171]], [[TMP174]]
-; CHECK-NEXT: [[TMP176:%.*]] = sub <2 x i32> [[TMP174]], [[TMP171]]
-; CHECK-NEXT: [[TMP177:%.*]] = extractelement <2 x i32> [[TMP175]], i32 0
-; CHECK-NEXT: [[TMP178:%.*]] = extractelement <2 x i32> [[TMP175]], i32 1
-; CHECK-NEXT: [[SUB51_1:%.*]] = sub i32 [[TMP177]], [[TMP178]]
-; CHECK-NEXT: [[TMP179:%.*]] = shufflevector <2 x i32> [[TMP176]], <2 x i32> [[TMP133]], <2 x i32> <i32 1, i32 3>
-; CHECK-NEXT: [[TMP180:%.*]] = shufflevector <2 x i32> [[TMP176]], <2 x i32> [[TMP133]], <2 x i32> <i32 0, i32 2>
-; CHECK-NEXT: [[TMP181:%.*]] = add <2 x i32> [[TMP179]], [[TMP180]]
-; CHECK-NEXT: [[TMP182:%.*]] = extractelement <2 x i32> [[TMP176]], i32 0
-; CHECK-NEXT: [[TMP183:%.*]] = extractelement <2 x i32> [[TMP176]], i32 1
-; CHECK-NEXT: [[SUB59_1:%.*]] = sub i32 [[TMP182]], [[TMP183]]
-; CHECK-NEXT: [[SHR_I54:%.*]] = lshr i32 [[TMP178]], 15
+; CHECK-NEXT: [[TMP167:%.*]] = getelementptr i8, <2 x ptr> [[TMP153]], <2 x i64> <i64 5, i64 7>
+; CHECK-NEXT: [[TMP168:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP167]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP169:%.*]] = zext <2 x i8> [[TMP168]] to <2 x i32>
+; CHECK-NEXT: [[TMP170:%.*]] = getelementptr i8, <2 x ptr> [[TMP158]], <2 x i64> <i64 5, i64 7>
+; CHECK-NEXT: [[TMP171:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP170]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP172:%.*]] = zext <2 x i8> [[TMP171]] to <2 x i32>
+; CHECK-NEXT: [[TMP173:%.*]] = sub <2 x i32> [[TMP169]], [[TMP172]]
+; CHECK-NEXT: [[TMP174:%.*]] = shl <2 x i32> [[TMP173]], <i32 16, i32 16>
+; CHECK-NEXT: [[TMP175:%.*]] = insertelement <2 x i32> [[TMP148]], i32 [[CONV33_1]], i32 1
+; CHECK-NEXT: [[TMP176:%.*]] = sub <2 x i32> [[TMP175]], [[TMP166]]
+; CHECK-NEXT: [[TMP177:%.*]] = add <2 x i32> [[TMP174]], [[TMP176]]
+; CHECK-NEXT: [[TMP178:%.*]] = insertelement <2 x i32> [[TMP148]], i32 [[CONV_1]], i32 0
+; CHECK-NEXT: [[TMP179:%.*]] = sub <2 x i32> [[TMP178]], [[TMP151]]
+; CHECK-NEXT: [[TMP180:%.*]] = add <2 x i32> [[TMP163]], [[TMP179]]
+; CHECK-NEXT: [[TMP181:%.*]] = add <2 x i32> [[TMP177]], [[TMP180]]
+; CHECK-NEXT: [[TMP182:%.*]] = sub <2 x i32> [[TMP180]], [[TMP177]]
+; CHECK-NEXT: [[TMP183:%.*]] = extractelement <2 x i32> [[TMP181]], i32 0
+; CHECK-NEXT: [[TMP184:%.*]] = extractelement <2 x i32> [[TMP181]], i32 1
+; CHECK-NEXT: [[SUB51_1:%.*]] = sub i32 [[TMP183]], [[TMP184]]
+; CHECK-NEXT: [[TMP185:%.*]] = shufflevector <2 x i32> [[TMP182]], <2 x i32> [[TMP139]], <2 x i32> <i32 1, i32 3>
+; CHECK-NEXT: [[TMP186:%.*]] = shufflevector <2 x i32> [[TMP182]], <2 x i32> [[TMP139]], <2 x i32> <i32 0, i32 2>
+; CHECK-NEXT: [[TMP187:%.*]] = add <2 x i32> [[TMP185]], [[TMP186]]
+; CHECK-NEXT: [[TMP188:%.*]] = extractelement <2 x i32> [[TMP182]], i32 0
+; CHECK-NEXT: [[TMP189:%.*]] = extractelement <2 x i32> [[TMP182]], i32 1
+; CHECK-NEXT: [[SUB59_1:%.*]] = sub i32 [[TMP188]], [[TMP189]]
+; CHECK-NEXT: [[SHR_I54:%.*]] = lshr i32 [[TMP184]], 15
; CHECK-NEXT: [[AND_I55:%.*]] = and i32 [[SHR_I54]], 65537
; CHECK-NEXT: [[MUL_I56:%.*]] = mul i32 [[AND_I55]], 65535
-; CHECK-NEXT: [[TMP184:%.*]] = lshr <2 x i32> [[TMP142]], <i32 15, i32 15>
-; CHECK-NEXT: [[TMP185:%.*]] = and <2 x i32> [[TMP184]], <i32 65537, i32 65537>
-; CHECK-NEXT: [[TMP186:%.*]] = mul <2 x i32> [[TMP185]], <i32 65535, i32 65535>
-; CHECK-NEXT: [[TMP187:%.*]] = insertelement <2 x i32> poison, i32 [[SUB59_1]], i32 0
-; CHECK-NEXT: [[TMP188:%.*]] = shufflevector <2 x i32> [[TMP187]], <2 x i32> poison, <2 x i32> zeroinitializer
-; CHECK-NEXT: [[TMP189:%.*]] = extractelement <2 x i32> [[TMP181]], i32 0
-; CHECK-NEXT: [[TMP190:%.*]] = extractelement <2 x i32> [[TMP181]], i32 1
-; CHECK-NEXT: [[ADD78_1:%.*]] = add i32 [[TMP189]], [[TMP190]]
-; CHECK-NEXT: [[TMP191:%.*]] = shufflevector <2 x i32> [[TMP33]], <2 x i32> [[TMP176]], <2 x i32> <i32 0, i32 3>
-; CHECK-NEXT: [[TMP192:%.*]] = lshr <2 x i32> [[TMP191]], <i32 15, i32 15>
-; CHECK-NEXT: [[TMP193:%.*]] = and <2 x i32> [[TMP192]], <i32 65537, i32 65537>
-; CHECK-NEXT: [[TMP194:%.*]] = mul <2 x i32> [[TMP193]], <i32 65535, i32 65535>
-; CHECK-NEXT: [[TMP195:%.*]] = insertelement <2 x i32> poison, i32 [[ADD78_1]], i32 0
-; CHECK-NEXT: [[TMP196:%.*]] = shufflevector <2 x i32> [[TMP195]], <2 x i32> poison, <2 x i32> zeroinitializer
-; CHECK-NEXT: [[TMP197:%.*]] = insertelement <2 x i32> poison, i32 [[ADD94_2]], i32 0
-; CHECK-NEXT: [[TMP198:%.*]] = shufflevector <2 x i32> [[TMP197]], <2 x i32> poison, <2 x i32> zeroinitializer
-; CHECK-NEXT: [[TMP199:%.*]] = insertelement <2 x i32> poison, i32 [[ADD44]], i32 0
-; CHECK-NEXT: [[TMP200:%.*]] = shufflevector <2 x i32> [[TMP199]], <2 x i32> poison, <2 x i32> zeroinitializer
-; CHECK-NEXT: [[TMP201:%.*]] = insertelement <2 x i32> <i32 15, i32 poison>, i32 [[ADD46]], i32 1
-; CHECK-NEXT: [[TMP202:%.*]] = lshr <2 x i32> [[TMP200]], [[TMP201]]
-; CHECK-NEXT: [[TMP203:%.*]] = sub <2 x i32> [[TMP200]], [[TMP201]]
-; CHECK-NEXT: [[TMP204:%.*]] = shufflevector <2 x i32> [[TMP202]], <2 x i32> [[TMP203]], <2 x i32> <i32 0, i32 3>
-; CHECK-NEXT: [[TMP205:%.*]] = extractelement <2 x i32> [[TMP204]], i32 1
-; CHECK-NEXT: [[ADD78_2:%.*]] = add i32 [[SUB51_1]], [[TMP205]]
-; CHECK-NEXT: [[TMP206:%.*]] = insertelement <2 x i32> <i32 65537, i32 poison>, i32 [[SUB51_1]], i32 1
-; CHECK-NEXT: [[TMP207:%.*]] = and <2 x i32> [[TMP204]], [[TMP206]]
-; CHECK-NEXT: [[TMP208:%.*]] = sub <2 x i32> [[TMP204]], [[TMP206]]
-; CHECK-NEXT: [[TMP209:%.*]] = shufflevector <2 x i32> [[TMP207]], <2 x i32> [[TMP208]], <2 x i32> <i32 0, i32 3>
-; CHECK-NEXT: [[TMP210:%.*]] = insertelement <2 x i32> poison, i32 [[ADD78_2]], i32 0
-; CHECK-NEXT: [[TMP211:%.*]] = shufflevector <2 x i32> [[TMP210]], <2 x i32> poison, <2 x i32> zeroinitializer
-; CHECK-NEXT: [[TMP212:%.*]] = add <2 x i32> [[TMP211]], [[TMP198]]
-; CHECK-NEXT: [[TMP213:%.*]] = sub <2 x i32> [[TMP211]], [[TMP198]]
-; CHECK-NEXT: [[TMP214:%.*]] = shufflevector <2 x i32> [[TMP212]], <2 x i32> [[TMP213]], <2 x i32> <i32 0, i32 3>
-; CHECK-NEXT: [[TMP215:%.*]] = insertelement <2 x i32> [[TMP133]], i32 [[CONV_1]], i32 0
-; CHECK-NEXT: [[TMP216:%.*]] = lshr <2 x i32> [[TMP215]], <i32 15, i32 15>
-; CHECK-NEXT: [[TMP217:%.*]] = and <2 x i32> [[TMP216]], <i32 65537, i32 65537>
-; CHECK-NEXT: [[TMP218:%.*]] = mul <2 x i32> [[TMP217]], <i32 65535, i32 65535>
-; CHECK-NEXT: [[TMP219:%.*]] = shufflevector <2 x i32> [[TMP87]], <2 x i32> poison, <2 x i32> <i32 1, i32 poison>
-; CHECK-NEXT: [[TMP220:%.*]] = shufflevector <2 x i32> [[TMP219]], <2 x i32> [[TMP181]], <2 x i32> <i32 0, i32 3>
-; CHECK-NEXT: [[TMP221:%.*]] = shufflevector <2 x i32> [[TMP87]], <2 x i32> [[TMP181]], <2 x i32> <i32 0, i32 2>
-; CHECK-NEXT: [[TMP222:%.*]] = sub <2 x i32> [[TMP220]], [[TMP221]]
-; CHECK-NEXT: [[TMP223:%.*]] = shufflevector <2 x i32> [[TMP47]], <2 x i32> poison, <2 x i32> <i32 1, i32 poison>
-; CHECK-NEXT: [[TMP224:%.*]] = insertelement <2 x i32> [[TMP223]], i32 [[ADD46]], i32 1
-; CHECK-NEXT: [[TMP225:%.*]] = insertelement <2 x i32> [[TMP47]], i32 [[ADD44]], i32 1
-; CHECK-NEXT: [[TMP226:%.*]] = add <2 x i32> [[TMP224]], [[TMP225]]
-; CHECK-NEXT: [[TMP227:%.*]] = shufflevector <2 x i32> [[TMP79]], <2 x i32> [[TMP175]], <2 x i32> <i32 0, i32 3>
-; CHECK-NEXT: [[TMP228:%.*]] = shufflevector <2 x i32> [[TMP79]], <2 x i32> [[TMP175]], <2 x i32> <i32 1, i32 2>
-; CHECK-NEXT: [[TMP229:%.*]] = add <2 x i32> [[TMP227]], [[TMP228]]
-; CHECK-NEXT: [[TMP230:%.*]] = extractelement <2 x i32> [[TMP226]], i32 0
-; CHECK-NEXT: [[TMP231:%.*]] = extractelement <2 x i32> [[TMP229]], i32 0
-; CHECK-NEXT: [[ADD94_1:%.*]] = add i32 [[TMP231]], [[TMP230]]
-; CHECK-NEXT: [[TMP232:%.*]] = insertelement <2 x i32> [[TMP14]], i32 [[ADD46]], i32 1
-; CHECK-NEXT: [[TMP233:%.*]] = lshr <2 x i32> [[TMP232]], <i32 15, i32 15>
-; CHECK-NEXT: [[TMP234:%.*]] = and <2 x i32> [[TMP233]], <i32 65537, i32 65537>
-; CHECK-NEXT: [[TMP235:%.*]] = mul <2 x i32> [[TMP234]], <i32 65535, i32 65535>
-; CHECK-NEXT: [[TMP236:%.*]] = extractelement <2 x i32> [[TMP226]], i32 1
-; CHECK-NEXT: [[TMP237:%.*]] = extractelement <2 x i32> [[TMP229]], i32 1
-; CHECK-NEXT: [[ADD78:%.*]] = add i32 [[TMP237]], [[TMP236]]
-; CHECK-NEXT: [[TMP238:%.*]] = sub <2 x i32> [[TMP226]], [[TMP229]]
+; CHECK-NEXT: [[TMP190:%.*]] = lshr <2 x i32> [[TMP148]], <i32 15, i32 15>
+; CHECK-NEXT: [[TMP191:%.*]] = and <2 x i32> [[TMP190]], <i32 65537, i32 65537>
+; CHECK-NEXT: [[TMP192:%.*]] = mul <2 x i32> [[TMP191]], <i32 65535, i32 65535>
+; CHECK-NEXT: [[TMP193:%.*]] = insertelement <2 x i32> poison, i32 [[SUB59_1]], i32 0
+; CHECK-NEXT: [[TMP194:%.*]] = shufflevector <2 x i32> [[TMP193]], <2 x i32> poison, <2 x i32> zeroinitializer
+; CHECK-NEXT: [[TMP195:%.*]] = extractelement <2 x i32> [[TMP187]], i32 0
+; CHECK-NEXT: [[TMP196:%.*]] = extractelement <2 x i32> [[TMP187]], i32 1
+; CHECK-NEXT: [[ADD78_1:%.*]] = add i32 [[TMP195]], [[TMP196]]
+; CHECK-NEXT: [[TMP197:%.*]] = shufflevector <2 x i32> [[TMP39]], <2 x i32> [[TMP182]], <2 x i32> <i32 0, i32 3>
+; CHECK-NEXT: [[TMP198:%.*]] = lshr <2 x i32> [[TMP197]], <i32 15, i32 15>
+; CHECK-NEXT: [[TMP199:%.*]] = and <2 x i32> [[TMP198]], <i32 65537, i32 65537>
+; CHECK-NEXT: [[TMP200:%.*]] = mul <2 x i32> [[TMP199]], <i32 65535, i32 65535>
+; CHECK-NEXT: [[TMP201:%.*]] = insertelement <2 x i32> poison, i32 [[ADD78_1]], i32 0
+; CHECK-NEXT: [[TMP202:%.*]] = shufflevector <2 x i32> [[TMP201]], <2 x i32> poison, <2 x i32> zeroinitializer
+; CHECK-NEXT: [[TMP203:%.*]] = insertelement <2 x i32> poison, i32 [[ADD94_2]], i32 0
+; CHECK-NEXT: [[TMP204:%.*]] = shufflevector <2 x i32> [[TMP203]], <2 x i32> poison, <2 x i32> zeroinitializer
+; CHECK-NEXT: [[TMP205:%.*]] = insertelement <2 x i32> poison, i32 [[ADD44]], i32 0
+; CHECK-NEXT: [[TMP206:%.*]] = shufflevector <2 x i32> [[TMP205]], <2 x i32> poison, <2 x i32> zeroinitializer
+; CHECK-NEXT: [[TMP207:%.*]] = insertelement <2 x i32> <i32 15, i32 poison>, i32 [[ADD46]], i32 1
+; CHECK-NEXT: [[TMP208:%.*]] = lshr <2 x i32> [[TMP206]], [[TMP207]]
+; CHECK-NEXT: [[TMP209:%.*]] = sub <2 x i32> [[TMP206]], [[TMP207]]
+; CHECK-NEXT: [[TMP210:%.*]] = shufflevector <2 x i32> [[TMP208]], <2 x i32> [[TMP209]], <2 x i32> <i32 0, i32 3>
+; CHECK-NEXT: [[TMP211:%.*]] = extractelement <2 x i32> [[TMP210]], i32 1
+; CHECK-NEXT: [[ADD78_2:%.*]] = add i32 [[SUB51_1]], [[TMP211]]
+; CHECK-NEXT: [[TMP212:%.*]] = insertelement <2 x i32> <i32 65537, i32 poison>, i32 [[SUB51_1]], i32 1
+; CHECK-NEXT: [[TMP213:%.*]] = and <2 x i32> [[TMP210]], [[TMP212]]
+; CHECK-NEXT: [[TMP214:%.*]] = sub <2 x i32> [[TMP210]], [[TMP212]]
+; CHECK-NEXT: [[TMP215:%.*]] = shufflevector <2 x i32> [[TMP213]], <2 x i32> [[TMP214]], <2 x i32> <i32 0, i32 3>
+; CHECK-NEXT: [[TMP216:%.*]] = insertelement <2 x i32> poison, i32 [[ADD78_2]], i32 0
+; CHECK-NEXT: [[TMP217:%.*]] = shufflevector <2 x i32> [[TMP216]], <2 x i32> poison, <2 x i32> zeroinitializer
+; CHECK-NEXT: [[TMP218:%.*]] = add <2 x i32> [[TMP217]], [[TMP204]]
+; CHECK-NEXT: [[TMP219:%.*]] = sub <2 x i32> [[TMP217]], [[TMP204]]
+; CHECK-NEXT: [[TMP220:%.*]] = shufflevector <2 x i32> [[TMP218]], <2 x i32> [[TMP219]], <2 x i32> <i32 0, i32 3>
+; CHECK-NEXT: [[TMP221:%.*]] = insertelement <2 x i32> [[TMP139]], i32 [[CONV_1]], i32 0
+; CHECK-NEXT: [[TMP222:%.*]] = lshr <2 x i32> [[TMP221]], <i32 15, i32 15>
+; CHECK-NEXT: [[TMP223:%.*]] = and <2 x i32> [[TMP222]], <i32 65537, i32 65537>
+; CHECK-NEXT: [[TMP224:%.*]] = mul <2 x i32> [[TMP223]], <i32 65535, i32 65535>
+; CHECK-NEXT: [[TMP225:%.*]] = shufflevector <2 x i32> [[TMP93]], <2 x i32> poison, <2 x i32> <i32 1, i32 poison>
+; CHECK-NEXT: [[TMP226:%.*]] = shufflevector <2 x i32> [[TMP225]], <2 x i32> [[TMP187]], <2 x i32> <i32 0, i32 3>
+; CHECK-NEXT: [[TMP227:%.*]] = shufflevector <2 x i32> [[TMP93]], <2 x i32> [[TMP187]], <2 x i32> <i32 0, i32 2>
+; CHECK-NEXT: [[TMP228:%.*]] = sub <2 x i32> [[TMP226]], [[TMP227]]
+; CHECK-NEXT: [[TMP229:%.*]] = shufflevector <2 x i32> [[TMP53]], <2 x i32> poison, <2 x i32> <i32 1, i32 poison>
+; CHECK-NEXT: [[TMP230:%.*]] = insertelement <2 x i32> [[TMP229]], i32 [[ADD46]], i32 1
+; CHECK-NEXT: [[TMP231:%.*]] = insertelement <2 x i32> [[TMP53]], i32 [[ADD44]], i32 1
+; CHECK-NEXT: [[TMP232:%.*]] = add <2 x i32> [[TMP230]], [[TMP231]]
+; CHECK-NEXT: [[TMP233:%.*]] = shufflevector <2 x i32> [[TMP85]], <2 x i32> [[TMP181]], <2 x i32> <i32 0, i32 3>
+; CHECK-NEXT: [[TMP234:%.*]] = shufflevector <2 x i32> [[TMP85]], <2 x i32> [[TMP181]], <2 x i32> <i32 1, i32 2>
+; CHECK-NEXT: [[TMP235:%.*]] = add <2 x i32> [[TMP233]], [[TMP234]]
+; CHECK-NEXT: [[TMP236:%.*]] = extractelement <2 x i32> [[TMP232]], i32 0
+; CHECK-NEXT: [[TMP237:%.*]] = extractelement <2 x i32> [[TMP235]], i32 0
+; CHECK-NEXT: [[ADD94_1:%.*]] = add i32 [[TMP237]], [[TMP236]]
+; CHECK-NEXT: [[TMP238:%.*]] = insertelement <2 x i32> [[TMP19]], i32 [[ADD46]], i32 1
+; CHECK-NEXT: [[TMP239:%.*]] = lshr <2 x i32> [[TMP238]], <i32 15, i32 15>
+; CHECK-NEXT: [[TMP240:%.*]] = and <2 x i32> [[TMP239]], <i32 65537, i32 65537>
+; CHECK-NEXT: [[TMP241:%.*]] = mul <2 x i32> [[TMP240]], <i32 65535, i32 65535>
+; CHECK-NEXT: [[TMP242:%.*]] = extractelement <2 x i32> [[TMP232]], i32 1
+; CHECK-NEXT: [[TMP243:%.*]] = extractelement <2 x i32> [[TMP235]], i32 1
+; CHECK-NEXT: [[ADD78:%.*]] = add i32 [[TMP243]], [[TMP242]]
+; CHECK-NEXT: [[TMP244:%.*]] = sub <2 x i32> [[TMP232]], [[TMP235]]
; CHECK-NEXT: [[ADD103:%.*]] = add i32 [[ADD94]], [[ADD78]]
; CHECK-NEXT: [[SUB104:%.*]] = sub i32 [[ADD78]], [[ADD94]]
-; CHECK-NEXT: [[TMP239:%.*]] = extractelement <2 x i32> [[TMP238]], i32 1
-; CHECK-NEXT: [[ADD105:%.*]] = add i32 [[SUB102]], [[TMP239]]
+; CHECK-NEXT: [[TMP245:%.*]] = extractelement <2 x i32> [[TMP244]], i32 1
+; CHECK-NEXT: [[ADD105:%.*]] = add i32 [[SUB102]], [[TMP245]]
; CHECK-NEXT: [[ADD_I:%.*]] = add i32 [[MUL_I]], [[ADD103]]
-; CHECK-NEXT: [[XOR_I:%.*]] = xor i32 [[ADD_I]], [[TMP92]]
+; CHECK-NEXT: [[XOR_I:%.*]] = xor i32 [[ADD_I]], [[TMP98]]
; CHECK-NEXT: [[ADD_I52:%.*]] = add i32 [[MUL_I51]], [[ADD105]]
-; CHECK-NEXT: [[XOR_I53:%.*]] = xor i32 [[ADD_I52]], [[TMP93]]
+; CHECK-NEXT: [[XOR_I53:%.*]] = xor i32 [[ADD_I52]], [[TMP99]]
; CHECK-NEXT: [[ADD_I57:%.*]] = add i32 [[MUL_I56]], [[SUB104]]
-; CHECK-NEXT: [[XOR_I58:%.*]] = xor i32 [[ADD_I57]], [[TMP178]]
+; CHECK-NEXT: [[XOR_I58:%.*]] = xor i32 [[ADD_I57]], [[TMP184]]
; CHECK-NEXT: [[ADD110:%.*]] = add i32 [[XOR_I53]], [[XOR_I]]
; CHECK-NEXT: [[ADD112:%.*]] = add i32 [[ADD110]], [[XOR_I58]]
-; CHECK-NEXT: [[TMP240:%.*]] = shufflevector <2 x i32> [[TMP222]], <2 x i32> poison, <2 x i32> <i32 1, i32 poison>
-; CHECK-NEXT: [[TMP241:%.*]] = insertelement <2 x i32> [[TMP240]], i32 [[SUB102]], i32 1
-; CHECK-NEXT: [[TMP242:%.*]] = add <2 x i32> [[TMP238]], [[TMP241]]
-; CHECK-NEXT: [[TMP243:%.*]] = sub <2 x i32> [[TMP238]], [[TMP241]]
-; CHECK-NEXT: [[TMP244:%.*]] = shufflevector <2 x i32> [[TMP242]], <2 x i32> [[TMP243]], <2 x i32> <i32 0, i32 3>
-; CHECK-NEXT: [[TMP245:%.*]] = add <2 x i32> [[TMP235]], [[TMP244]]
-; CHECK-NEXT: [[TMP246:%.*]] = xor <2 x i32> [[TMP245]], [[TMP232]]
-; CHECK-NEXT: [[TMP247:%.*]] = extractelement <2 x i32> [[TMP246]], i32 1
-; CHECK-NEXT: [[ADD113:%.*]] = add i32 [[ADD112]], [[TMP247]]
-; CHECK-NEXT: [[TMP248:%.*]] = insertelement <2 x i32> poison, i32 [[ADD94_1]], i32 0
-; CHECK-NEXT: [[TMP249:%.*]] = shufflevector <2 x i32> [[TMP248]], <2 x i32> poison, <2 x i32> zeroinitializer
-; CHECK-NEXT: [[TMP250:%.*]] = add <2 x i32> [[TMP196]], [[TMP249]]
-; CHECK-NEXT: [[TMP251:%.*]] = sub <2 x i32> [[TMP196]], [[TMP249]]
-; CHECK-NEXT: [[TMP252:%.*]] = shufflevector <2 x i32> [[TMP250]], <2 x i32> [[TMP251]], <2 x i32> <i32 0, i32 3>
-; CHECK-NEXT: [[TMP253:%.*]] = add <2 x i32> [[TMP194]], [[TMP252]]
-; CHECK-NEXT: [[TMP254:%.*]] = xor <2 x i32> [[TMP253]], [[TMP191]]
-; CHECK-NEXT: [[TMP255:%.*]] = extractelement <2 x i32> [[TMP246]], i32 0
-; CHECK-NEXT: [[ADD108_1:%.*]] = add i32 [[TMP255]], [[ADD113]]
-; CHECK-NEXT: [[TMP256:%.*]] = extractelement <2 x i32> [[TMP254]], i32 0
-; CHECK-NEXT: [[ADD110_1:%.*]] = add i32 [[ADD108_1]], [[TMP256]]
-; CHECK-NEXT: [[TMP257:%.*]] = extractelement <2 x i32> [[TMP254]], i32 1
-; CHECK-NEXT: [[ADD112_1:%.*]] = add i32 [[ADD110_1]], [[TMP257]]
-; CHECK-NEXT: [[TMP258:%.*]] = shufflevector <2 x i32> [[TMP209]], <2 x i32> poison, <2 x i32> <i32 1, i32 poison>
-; CHECK-NEXT: [[TMP259:%.*]] = shufflevector <2 x i32> [[TMP258]], <2 x i32> [[TMP238]], <2 x i32> <i32 0, i32 2>
-; CHECK-NEXT: [[TMP260:%.*]] = add <2 x i32> [[TMP222]], [[TMP259]]
-; CHECK-NEXT: [[TMP261:%.*]] = sub <2 x i32> [[TMP222]], [[TMP259]]
-; CHECK-NEXT: [[TMP262:%.*]] = shufflevector <2 x i32> [[TMP260]], <2 x i32> [[TMP261]], <2 x i32> <i32 0, i32 3>
-; CHECK-NEXT: [[TMP263:%.*]] = add <2 x i32> [[TMP218]], [[TMP262]]
-; CHECK-NEXT: [[TMP264:%.*]] = xor <2 x i32> [[TMP263]], [[TMP215]]
-; CHECK-NEXT: [[TMP265:%.*]] = extractelement <2 x i32> [[TMP264]], i32 1
-; CHECK-NEXT: [[ADD113_1:%.*]] = add i32 [[ADD112_1]], [[TMP265]]
-; CHECK-NEXT: [[TMP266:%.*]] = shufflevector <2 x i32> <i32 65535, i32 poison>, <2 x i32> [[TMP222]], <2 x i32> <i32 0, i32 2>
-; CHECK-NEXT: [[TMP267:%.*]] = mul <2 x i32> [[TMP209]], [[TMP266]]
-; CHECK-NEXT: [[TMP268:%.*]] = sub <2 x i32> [[TMP209]], [[TMP266]]
-; CHECK-NEXT: [[TMP269:%.*]] = shufflevector <2 x i32> [[TMP267]], <2 x i32> [[TMP268]], <2 x i32> <i32 0, i32 3>
-; CHECK-NEXT: [[TMP270:%.*]] = add <2 x i32> [[TMP186]], [[TMP214]]
-; CHECK-NEXT: [[TMP271:%.*]] = xor <2 x i32> [[TMP270]], [[TMP142]]
-; CHECK-NEXT: [[TMP272:%.*]] = extractelement <2 x i32> [[TMP269]], i32 0
-; CHECK-NEXT: [[TMP273:%.*]] = extractelement <2 x i32> [[TMP269]], i32 1
-; CHECK-NEXT: [[ADD_I62_2:%.*]] = add i32 [[TMP272]], [[TMP273]]
+; CHECK-NEXT: [[TMP246:%.*]] = shufflevector <2 x i32> [[TMP228]], <2 x i32> poison, <2 x i32> <i32 1, i32 poison>
+; CHECK-NEXT: [[TMP247:%.*]] = insertelement <2 x i32> [[TMP246]], i32 [[SUB102]], i32 1
+; CHECK-NEXT: [[TMP248:%.*]] = add <2 x i32> [[TMP244]], [[TMP247]]
+; CHECK-NEXT: [[TMP249:%.*]] = sub <2 x i32> [[TMP244]], [[TMP247]]
+; CHECK-NEXT: [[TMP250:%.*]] = shufflevector <2 x i32> [[TMP248]], <2 x i32> [[TMP249]], <2 x i32> <i32 0, i32 3>
+; CHECK-NEXT: [[TMP251:%.*]] = add <2 x i32> [[TMP241]], [[TMP250]]
+; CHECK-NEXT: [[TMP252:%.*]] = xor <2 x i32> [[TMP251]], [[TMP238]]
+; CHECK-NEXT: [[TMP253:%.*]] = extractelement <2 x i32> [[TMP252]], i32 1
+; CHECK-NEXT: [[ADD113:%.*]] = add i32 [[ADD112]], [[TMP253]]
+; CHECK-NEXT: [[TMP254:%.*]] = insertelement <2 x i32> poison, i32 [[ADD94_1]], i32 0
+; CHECK-NEXT: [[TMP255:%.*]] = shufflevector <2 x i32> [[TMP254]], <2 x i32> poison, <2 x i32> zeroinitializer
+; CHECK-NEXT: [[TMP256:%.*]] = add <2 x i32> [[TMP202]], [[TMP255]]
+; CHECK-NEXT: [[TMP257:%.*]] = sub <2 x i32> [[TMP202]], [[TMP255]]
+; CHECK-NEXT: [[TMP258:%.*]] = shufflevector <2 x i32> [[TMP256]], <2 x i32> [[TMP257]], <2 x i32> <i32 0, i32 3>
+; CHECK-NEXT: [[TMP259:%.*]] = add <2 x i32> [[TMP200]], [[TMP258]]
+; CHECK-NEXT: [[TMP260:%.*]] = xor <2 x i32> [[TMP259]], [[TMP197]]
+; CHECK-NEXT: [[TMP261:%.*]] = extractelement <2 x i32> [[TMP252]], i32 0
+; CHECK-NEXT: [[ADD108_1:%.*]] = add i32 [[TMP261]], [[ADD113]]
+; CHECK-NEXT: [[TMP262:%.*]] = extractelement <2 x i32> [[TMP260]], i32 0
+; CHECK-NEXT: [[ADD110_1:%.*]] = add i32 [[ADD108_1]], [[TMP262]]
+; CHECK-NEXT: [[TMP263:%.*]] = extractelement <2 x i32> [[TMP260]], i32 1
+; CHECK-NEXT: [[ADD112_1:%.*]] = add i32 [[ADD110_1]], [[TMP263]]
+; CHECK-NEXT: [[TMP264:%.*]] = shufflevector <2 x i32> [[TMP215]], <2 x i32> poison, <2 x i32> <i32 1, i32 poison>
+; CHECK-NEXT: [[TMP265:%.*]] = shufflevector <2 x i32> [[TMP264]], <2 x i32> [[TMP244]], <2 x i32> <i32 0, i32 2>
+; CHECK-NEXT: [[TMP266:%.*]] = add <2 x i32> [[TMP228]], [[TMP265]]
+; CHECK-NEXT: [[TMP267:%.*]] = sub <2 x i32> [[TMP228]], [[TMP265]]
+; CHECK-NEXT: [[TMP268:%.*]] = shufflevector <2 x i32> [[TMP266]], <2 x i32> [[TMP267]], <2 x i32> <i32 0, i32 3>
+; CHECK-NEXT: [[TMP269:%.*]] = add <2 x i32> [[TMP224]], [[TMP268]]
+; CHECK-NEXT: [[TMP270:%.*]] = xor <2 x i32> [[TMP269]], [[TMP221]]
+; CHECK-NEXT: [[TMP271:%.*]] = extractelement <2 x i32> [[TMP270]], i32 1
+; CHECK-NEXT: [[ADD113_1:%.*]] = add i32 [[ADD112_1]], [[TMP271]]
+; CHECK-NEXT: [[TMP272:%.*]] = shufflevector <2 x i32> <i32 65535, i32 poison>, <2 x i32> [[TMP228]], <2 x i32> <i32 0, i32 2>
+; CHECK-NEXT: [[TMP273:%.*]] = mul <2 x i32> [[TMP215]], [[TMP272]]
+; CHECK-NEXT: [[TMP274:%.*]] = sub <2 x i32> [[TMP215]], [[TMP272]]
+; CHECK-NEXT: [[TMP275:%.*]] = shufflevector <2 x i32> [[TMP273]], <2 x i32> [[TMP274]], <2 x i32> <i32 0, i32 3>
+; CHECK-NEXT: [[TMP276:%.*]] = add <2 x i32> [[TMP192]], [[TMP220]]
+; CHECK-NEXT: [[TMP277:%.*]] = xor <2 x i32> [[TMP276]], [[TMP148]]
+; CHECK-NEXT: [[TMP278:%.*]] = extractelement <2 x i32> [[TMP275]], i32 0
+; CHECK-NEXT: [[TMP279:%.*]] = extractelement <2 x i32> [[TMP275]], i32 1
+; CHECK-NEXT: [[ADD_I62_2:%.*]] = add i32 [[TMP278]], [[TMP279]]
; CHECK-NEXT: [[XOR_I63_2:%.*]] = xor i32 [[ADD_I62_2]], [[ADD44]]
-; CHECK-NEXT: [[TMP274:%.*]] = extractelement <2 x i32> [[TMP264]], i32 0
-; CHECK-NEXT: [[ADD108_2:%.*]] = add i32 [[TMP274]], [[ADD113_1]]
-; CHECK-NEXT: [[TMP275:%.*]] = extractelement <2 x i32> [[TMP271]], i32 0
-; CHECK-NEXT: [[ADD110_2:%.*]] = add i32 [[ADD108_2]], [[TMP275]]
-; CHECK-NEXT: [[TMP276:%.*]] = extractelement <2 x i32> [[TMP271]], i32 1
-; CHECK-NEXT: [[ADD112_2:%.*]] = add i32 [[ADD110_2]], [[TMP276]]
+; CHECK-NEXT: [[TMP280:%.*]] = extractelement <2 x i32> [[TMP270]], i32 0
+; CHECK-NEXT: [[ADD108_2:%.*]] = add i32 [[TMP280]], [[ADD113_1]]
+; CHECK-NEXT: [[TMP281:%.*]] = extractelement <2 x i32> [[TMP277]], i32 0
+; CHECK-NEXT: [[ADD110_2:%.*]] = add i32 [[ADD108_2]], [[TMP281]]
+; CHECK-NEXT: [[TMP282:%.*]] = extractelement <2 x i32> [[TMP277]], i32 1
+; CHECK-NEXT: [[ADD112_2:%.*]] = add i32 [[ADD110_2]], [[TMP282]]
; CHECK-NEXT: [[ADD113_2:%.*]] = add i32 [[ADD112_2]], [[XOR_I63_2]]
-; CHECK-NEXT: [[TMP277:%.*]] = insertelement <2 x i32> poison, i32 [[SUB59]], i32 0
-; CHECK-NEXT: [[TMP278:%.*]] = shufflevector <2 x i32> [[TMP277]], <2 x i32> poison, <2 x i32> zeroinitializer
-; CHECK-NEXT: [[TMP279:%.*]] = add <2 x i32> [[TMP278]], [[TMP188]]
-; CHECK-NEXT: [[TMP280:%.*]] = sub <2 x i32> [[TMP278]], [[TMP188]]
-; CHECK-NEXT: [[TMP281:%.*]] = shufflevector <2 x i32> [[TMP279]], <2 x i32> [[TMP280]], <2 x i32> <i32 0, i32 3>
-; CHECK-NEXT: [[TMP282:%.*]] = add <2 x i32> [[TMP104]], [[TMP281]]
-; CHECK-NEXT: [[TMP283:%.*]] = sub <2 x i32> [[TMP281]], [[TMP104]]
-; CHECK-NEXT: [[TMP284:%.*]] = add <2 x i32> [[TMP138]], [[TMP282]]
-; CHECK-NEXT: [[TMP285:%.*]] = xor <2 x i32> [[TMP284]], [[TMP107]]
-; CHECK-NEXT: [[TMP286:%.*]] = lshr <2 x i32> [[TMP97]], <i32 15, i32 15>
-; CHECK-NEXT: [[TMP287:%.*]] = and <2 x i32> [[TMP286]], <i32 65537, i32 65537>
-; CHECK-NEXT: [[TMP288:%.*]] = mul <2 x i32> [[TMP287]], <i32 65535, i32 65535>
-; CHECK-NEXT: [[TMP289:%.*]] = add <2 x i32> [[TMP288]], [[TMP283]]
-; CHECK-NEXT: [[TMP290:%.*]] = xor <2 x i32> [[TMP289]], [[TMP97]]
-; CHECK-NEXT: [[TMP291:%.*]] = extractelement <2 x i32> [[TMP285]], i32 1
-; CHECK-NEXT: [[ADD108_3:%.*]] = add i32 [[TMP291]], [[ADD113_2]]
-; CHECK-NEXT: [[TMP292:%.*]] = extractelement <2 x i32> [[TMP285]], i32 0
-; CHECK-NEXT: [[ADD110_3:%.*]] = add i32 [[ADD108_3]], [[TMP292]]
-; CHECK-NEXT: [[TMP293:%.*]] = extractelement <2 x i32> [[TMP290]], i32 0
-; CHECK-NEXT: [[ADD112_3:%.*]] = add i32 [[ADD110_3]], [[TMP293]]
-; CHECK-NEXT: [[TMP294:%.*]] = extractelement <2 x i32> [[TMP290]], i32 1
-; CHECK-NEXT: [[ADD113_3:%.*]] = add i32 [[ADD112_3]], [[TMP294]]
+; CHECK-NEXT: [[TMP283:%.*]] = insertelement <2 x i32> poison, i32 [[SUB59]], i32 0
+; CHECK-NEXT: [[TMP284:%.*]] = shufflevector <2 x i32> [[TMP283]], <2 x i32> poison, <2 x i32> zeroinitializer
+; CHECK-NEXT: [[TMP285:%.*]] = add <2 x i32> [[TMP284]], [[TMP194]]
+; CHECK-NEXT: [[TMP286:%.*]] = sub <2 x i32> [[TMP284]], [[TMP194]]
+; CHECK-NEXT: [[TMP287:%.*]] = shufflevector <2 x i32> [[TMP285]], <2 x i32> [[TMP286]], <2 x i32> <i32 0, i32 3>
+; CHECK-NEXT: [[TMP288:%.*]] = add <2 x i32> [[TMP110]], [[TMP287]]
+; CHECK-NEXT: [[TMP289:%.*]] = sub <2 x i32> [[TMP287]], [[TMP110]]
+; CHECK-NEXT: [[TMP290:%.*]] = add <2 x i32> [[TMP144]], [[TMP288]]
+; CHECK-NEXT: [[TMP291:%.*]] = xor <2 x i32> [[TMP290]], [[TMP113]]
+; CHECK-NEXT: [[TMP292:%.*]] = lshr <2 x i32> [[TMP103]], <i32 15, i32 15>
+; CHECK-NEXT: [[TMP293:%.*]] = and <2 x i32> [[TMP292]], <i32 65537, i32 65537>
+; CHECK-NEXT: [[TMP294:%.*]] = mul <2 x i32> [[TMP293]], <i32 65535, i32 65535>
+; CHECK-NEXT: [[TMP295:%.*]] = add <2 x i32> [[TMP294]], [[TMP289]]
+; CHECK-NEXT: [[TMP296:%.*]] = xor <2 x i32> [[TMP295]], [[TMP103]]
+; CHECK-NEXT: [[TMP297:%.*]] = extractelement <2 x i32> [[TMP291]], i32 1
+; CHECK-NEXT: [[ADD108_3:%.*]] = add i32 [[TMP297]], [[ADD113_2]]
+; CHECK-NEXT: [[TMP298:%.*]] = extractelement <2 x i32> [[TMP291]], i32 0
+; CHECK-NEXT: [[ADD110_3:%.*]] = add i32 [[ADD108_3]], [[TMP298]]
+; CHECK-NEXT: [[TMP299:%.*]] = extractelement <2 x i32> [[TMP296]], i32 0
+; CHECK-NEXT: [[ADD112_3:%.*]] = add i32 [[ADD110_3]], [[TMP299]]
+; CHECK-NEXT: [[TMP300:%.*]] = extractelement <2 x i32> [[TMP296]], i32 1
+; CHECK-NEXT: [[ADD113_3:%.*]] = add i32 [[ADD112_3]], [[TMP300]]
; CHECK-NEXT: ret i32 [[ADD113_3]]
;
entry:
diff --git a/llvm/test/Transforms/SLPVectorizer/X86/split-load8_2-unord.ll b/llvm/test/Transforms/SLPVectorizer/X86/split-load8_2-unord.ll
index 63d13452bc96d1..6825f43b5a9eb4 100644
--- a/llvm/test/Transforms/SLPVectorizer/X86/split-load8_2-unord.ll
+++ b/llvm/test/Transforms/SLPVectorizer/X86/split-load8_2-unord.ll
@@ -8,24 +8,27 @@ define dso_local void @_Z4testP1S(ptr %p) local_unnamed_addr {
; CHECK-NEXT: entry:
; CHECK-NEXT: [[ARRAYIDX:%.*]] = getelementptr inbounds [[STRUCT_S:%.*]], ptr [[P:%.*]], i64 0, i32 1, i64 0
; CHECK-NEXT: [[ARRAYIDX1:%.*]] = getelementptr inbounds [[STRUCT_S]], ptr [[P]], i64 0, i32 2, i64 15
-; CHECK-NEXT: [[ARRAYIDX6:%.*]] = getelementptr inbounds [[STRUCT_S]], ptr [[P]], i64 0, i32 2, i64 7
+; CHECK-NEXT: [[I1:%.*]] = load i32, ptr [[ARRAYIDX1]], align 4
; CHECK-NEXT: [[ARRAYIDX13:%.*]] = getelementptr inbounds [[STRUCT_S]], ptr [[P]], i64 0, i32 2, i64 6
+; CHECK-NEXT: [[TMP0:%.*]] = load <2 x i32>, ptr [[ARRAYIDX13]], align 4
; CHECK-NEXT: [[ARRAYIDX20:%.*]] = getelementptr inbounds [[STRUCT_S]], ptr [[P]], i64 0, i32 2, i64 4
+; CHECK-NEXT: [[I7:%.*]] = load i32, ptr [[ARRAYIDX20]], align 4
; CHECK-NEXT: [[ARRAYIDX27:%.*]] = getelementptr inbounds [[STRUCT_S]], ptr [[P]], i64 0, i32 2, i64 12
+; CHECK-NEXT: [[I9:%.*]] = load i32, ptr [[ARRAYIDX27]], align 4
; CHECK-NEXT: [[ARRAYIDX34:%.*]] = getelementptr inbounds [[STRUCT_S]], ptr [[P]], i64 0, i32 2, i64 13
-; CHECK-NEXT: [[ARRAYIDX41:%.*]] = getelementptr inbounds [[STRUCT_S]], ptr [[P]], i64 0, i32 2, i64 14
+; CHECK-NEXT: [[TMP1:%.*]] = load <2 x i32>, ptr [[ARRAYIDX34]], align 4
; CHECK-NEXT: [[ARRAYIDX48:%.*]] = getelementptr inbounds [[STRUCT_S]], ptr [[P]], i64 0, i32 2, i64 5
-; CHECK-NEXT: [[TMP1:%.*]] = load <8 x i32>, ptr [[ARRAYIDX]], align 4
-; CHECK-NEXT: [[TMP2:%.*]] = insertelement <8 x ptr> poison, ptr [[ARRAYIDX1]], i32 0
-; CHECK-NEXT: [[TMP3:%.*]] = insertelement <8 x ptr> [[TMP2]], ptr [[ARRAYIDX6]], i32 1
-; CHECK-NEXT: [[TMP4:%.*]] = insertelement <8 x ptr> [[TMP3]], ptr [[ARRAYIDX13]], i32 2
-; CHECK-NEXT: [[TMP5:%.*]] = insertelement <8 x ptr> [[TMP4]], ptr [[ARRAYIDX20]], i32 3
-; CHECK-NEXT: [[TMP6:%.*]] = insertelement <8 x ptr> [[TMP5]], ptr [[ARRAYIDX27]], i32 4
-; CHECK-NEXT: [[TMP7:%.*]] = insertelement <8 x ptr> [[TMP6]], ptr [[ARRAYIDX34]], i32 5
-; CHECK-NEXT: [[TMP8:%.*]] = insertelement <8 x ptr> [[TMP7]], ptr [[ARRAYIDX41]], i32 6
-; CHECK-NEXT: [[TMP9:%.*]] = insertelement <8 x ptr> [[TMP8]], ptr [[ARRAYIDX48]], i32 7
-; CHECK-NEXT: [[TMP10:%.*]] = call <8 x i32> @llvm.masked.gather.v8i32.v8p0(<8 x ptr> [[TMP9]], i32 4, <8 x i1> <i1 true, i1 true, i1 true, i1 true, i1 true, i1 true, i1 true, i1 true>, <8 x i32> poison)
-; CHECK-NEXT: [[TMP11:%.*]] = add nsw <8 x i32> [[TMP10]], [[TMP1]]
+; CHECK-NEXT: [[I15:%.*]] = load i32, ptr [[ARRAYIDX48]], align 4
+; CHECK-NEXT: [[TMP2:%.*]] = load <8 x i32>, ptr [[ARRAYIDX]], align 4
+; CHECK-NEXT: [[TMP3:%.*]] = insertelement <8 x i32> poison, i32 [[I1]], i32 0
+; CHECK-NEXT: [[TMP4:%.*]] = shufflevector <2 x i32> [[TMP0]], <2 x i32> poison, <8 x i32> <i32 1, i32 0, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison>
+; CHECK-NEXT: [[TMP5:%.*]] = shufflevector <8 x i32> [[TMP3]], <8 x i32> [[TMP4]], <8 x i32> <i32 0, i32 8, i32 9, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison>
+; CHECK-NEXT: [[TMP6:%.*]] = insertelement <8 x i32> [[TMP5]], i32 [[I7]], i32 3
+; CHECK-NEXT: [[TMP7:%.*]] = insertelement <8 x i32> [[TMP6]], i32 [[I9]], i32 4
+; CHECK-NEXT: [[TMP8:%.*]] = shufflevector <2 x i32> [[TMP1]], <2 x i32> poison, <8 x i32> <i32 0, i32 1, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison>
+; CHECK-NEXT: [[TMP9:%.*]] = shufflevector <8 x i32> [[TMP7]], <8 x i32> [[TMP8]], <8 x i32> <i32 0, i32 1, i32 2, i32 3, i32 4, i32 8, i32 9, i32 poison>
+; CHECK-NEXT: [[TMP10:%.*]] = insertelement <8 x i32> [[TMP9]], i32 [[I15]], i32 7
+; CHECK-NEXT: [[TMP11:%.*]] = add nsw <8 x i32> [[TMP10]], [[TMP2]]
; CHECK-NEXT: store <8 x i32> [[TMP11]], ptr [[P]], align 4
; CHECK-NEXT: ret void
;
@@ -101,13 +104,13 @@ define dso_local void @test_unordered_splits(ptr nocapture %p) local_unnamed_add
; CHECK-NEXT: [[P2:%.*]] = alloca [16 x i32], align 16
; CHECK-NEXT: [[G10:%.*]] = getelementptr inbounds [16 x i32], ptr [[P1]], i32 0, i64 4
; CHECK-NEXT: [[G20:%.*]] = getelementptr inbounds [16 x i32], ptr [[P2]], i32 0, i64 12
-; CHECK-NEXT: [[TMP1:%.*]] = load <4 x i32>, ptr [[G10]], align 4
-; CHECK-NEXT: [[TMP3:%.*]] = load <4 x i32>, ptr [[G20]], align 4
-; CHECK-NEXT: [[TMP4:%.*]] = shufflevector <4 x i32> [[TMP1]], <4 x i32> poison, <8 x i32> <i32 0, i32 1, i32 2, i32 3, i32 poison, i32 poison, i32 poison, i32 poison>
-; CHECK-NEXT: [[TMP5:%.*]] = shufflevector <4 x i32> [[TMP3]], <4 x i32> poison, <8 x i32> <i32 0, i32 1, i32 2, i32 3, i32 poison, i32 poison, i32 poison, i32 poison>
-; CHECK-NEXT: [[TMP6:%.*]] = shufflevector <8 x i32> [[TMP4]], <8 x i32> [[TMP5]], <8 x i32> <i32 0, i32 1, i32 2, i32 3, i32 8, i32 9, i32 10, i32 11>
-; CHECK-NEXT: [[SHUFFLE:%.*]] = shufflevector <8 x i32> [[TMP6]], <8 x i32> poison, <8 x i32> <i32 1, i32 0, i32 2, i32 3, i32 7, i32 5, i32 6, i32 4>
-; CHECK-NEXT: store <8 x i32> [[SHUFFLE]], ptr [[P:%.*]], align 4
+; CHECK-NEXT: [[TMP0:%.*]] = load <4 x i32>, ptr [[G10]], align 4
+; CHECK-NEXT: [[TMP1:%.*]] = load <4 x i32>, ptr [[G20]], align 4
+; CHECK-NEXT: [[TMP2:%.*]] = shufflevector <4 x i32> [[TMP0]], <4 x i32> poison, <8 x i32> <i32 0, i32 1, i32 2, i32 3, i32 poison, i32 poison, i32 poison, i32 poison>
+; CHECK-NEXT: [[TMP3:%.*]] = shufflevector <4 x i32> [[TMP1]], <4 x i32> poison, <8 x i32> <i32 0, i32 1, i32 2, i32 3, i32 poison, i32 poison, i32 poison, i32 poison>
+; CHECK-NEXT: [[TMP4:%.*]] = shufflevector <8 x i32> [[TMP2]], <8 x i32> [[TMP3]], <8 x i32> <i32 0, i32 1, i32 2, i32 3, i32 8, i32 9, i32 10, i32 11>
+; CHECK-NEXT: [[TMP5:%.*]] = shufflevector <8 x i32> [[TMP4]], <8 x i32> poison, <8 x i32> <i32 1, i32 0, i32 2, i32 3, i32 7, i32 5, i32 6, i32 4>
+; CHECK-NEXT: store <8 x i32> [[TMP5]], ptr [[P:%.*]], align 4
; CHECK-NEXT: ret void
;
entry:
@@ -158,18 +161,18 @@ define dso_local void @test_cost_splits(ptr nocapture %p) local_unnamed_addr {
; CHECK-NEXT: [[G12:%.*]] = getelementptr inbounds [16 x i32], ptr [[P2]], i32 0, i64 6
; CHECK-NEXT: [[G20:%.*]] = getelementptr inbounds [16 x i32], ptr [[P3]], i32 0, i64 12
; CHECK-NEXT: [[G22:%.*]] = getelementptr inbounds [16 x i32], ptr [[P4]], i32 0, i64 14
-; CHECK-NEXT: [[TMP1:%.*]] = load <2 x i32>, ptr [[G10]], align 4
-; CHECK-NEXT: [[TMP3:%.*]] = load <2 x i32>, ptr [[G12]], align 4
-; CHECK-NEXT: [[TMP5:%.*]] = load <2 x i32>, ptr [[G20]], align 4
-; CHECK-NEXT: [[TMP7:%.*]] = load <2 x i32>, ptr [[G22]], align 4
-; CHECK-NEXT: [[TMP8:%.*]] = shufflevector <2 x i32> [[TMP1]], <2 x i32> poison, <8 x i32> <i32 0, i32 1, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison>
+; CHECK-NEXT: [[TMP0:%.*]] = load <2 x i32>, ptr [[G10]], align 4
+; CHECK-NEXT: [[TMP1:%.*]] = load <2 x i32>, ptr [[G12]], align 4
+; CHECK-NEXT: [[TMP2:%.*]] = load <2 x i32>, ptr [[G20]], align 4
+; CHECK-NEXT: [[TMP3:%.*]] = load <2 x i32>, ptr [[G22]], align 4
+; CHECK-NEXT: [[TMP4:%.*]] = shufflevector <2 x i32> [[TMP0]], <2 x i32> poison, <8 x i32> <i32 0, i32 1, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison>
+; CHECK-NEXT: [[TMP5:%.*]] = shufflevector <2 x i32> [[TMP1]], <2 x i32> poison, <8 x i32> <i32 0, i32 1, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison>
+; CHECK-NEXT: [[TMP6:%.*]] = shufflevector <8 x i32> [[TMP4]], <8 x i32> [[TMP5]], <8 x i32> <i32 0, i32 1, i32 8, i32 9, i32 poison, i32 poison, i32 poison, i32 poison>
+; CHECK-NEXT: [[TMP7:%.*]] = shufflevector <2 x i32> [[TMP2]], <2 x i32> poison, <8 x i32> <i32 0, i32 1, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison>
+; CHECK-NEXT: [[TMP8:%.*]] = shufflevector <8 x i32> [[TMP6]], <8 x i32> [[TMP7]], <8 x i32> <i32 0, i32 1, i32 2, i32 3, i32 8, i32 9, i32 poison, i32 poison>
; CHECK-NEXT: [[TMP9:%.*]] = shufflevector <2 x i32> [[TMP3]], <2 x i32> poison, <8 x i32> <i32 0, i32 1, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison>
-; CHECK-NEXT: [[TMP10:%.*]] = shufflevector <8 x i32> [[TMP8]], <8 x i32> [[TMP9]], <8 x i32> <i32 0, i32 1, i32 8, i32 9, i32 poison, i32 poison, i32 poison, i32 poison>
-; CHECK-NEXT: [[TMP11:%.*]] = shufflevector <2 x i32> [[TMP5]], <2 x i32> poison, <8 x i32> <i32 0, i32 1, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison>
-; CHECK-NEXT: [[TMP12:%.*]] = shufflevector <8 x i32> [[TMP10]], <8 x i32> [[TMP11]], <8 x i32> <i32 0, i32 1, i32 2, i32 3, i32 8, i32 9, i32 poison, i32 poison>
-; CHECK-NEXT: [[TMP13:%.*]] = shufflevector <2 x i32> [[TMP7]], <2 x i32> poison, <8 x i32> <i32 0, i32 1, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison>
-; CHECK-NEXT: [[TMP14:%.*]] = shufflevector <8 x i32> [[TMP12]], <8 x i32> [[TMP13]], <8 x i32> <i32 0, i32 1, i32 2, i32 3, i32 4, i32 5, i32 8, i32 9>
-; CHECK-NEXT: store <8 x i32> [[TMP14]], ptr [[P:%.*]], align 4
+; CHECK-NEXT: [[TMP10:%.*]] = shufflevector <8 x i32> [[TMP8]], <8 x i32> [[TMP9]], <8 x i32> <i32 0, i32 1, i32 2, i32 3, i32 4, i32 5, i32 8, i32 9>
+; CHECK-NEXT: store <8 x i32> [[TMP10]], ptr [[P:%.*]], align 4
; CHECK-NEXT: ret void
;
entry:
>From 756166e342a3692fd8de1ad1c5620df516bac33a Mon Sep 17 00:00:00 2001
From: Pierre van Houtryve <pierre.vanhoutryve at amd.com>
Date: Fri, 1 Mar 2024 14:01:10 +0100
Subject: [PATCH 243/406] [AMDGPU] Improve detection of non-null addrspacecast
operands (#82311)
Use IR analysis to infer when an addrspacecast operand is nonnull, then
lower it to an intrinsic that the DAG can use to skip the null check.
I did this using an intrinsic as it's non-intrusive. An alternative
would have been to allow something like `!nonnull` on `addrspacecast`
then lower that to a custom opcode (or add an operand to the
addrspacecast MIR/DAG opcodes), but it's a lot of boilerplate for just
one target's use case IMO.
I'm hoping that when we switch to GISel that we can move all this logic
to the MIR level without losing info, but currently the DAG doesn't see
enough so we need to act in CGP.
Fixes: SWDEV-316445
---
llvm/include/llvm/IR/IntrinsicsAMDGPU.td | 7 +
.../Target/AMDGPU/AMDGPUCodeGenPrepare.cpp | 73 +++++
.../lib/Target/AMDGPU/AMDGPULegalizerInfo.cpp | 20 +-
llvm/lib/Target/AMDGPU/SIISelLowering.cpp | 57 +++-
llvm/lib/Target/AMDGPU/SIISelLowering.h | 4 +
...n-prepare-addrspacecast-non-null-vector.ll | 13 +
.../codegen-prepare-addrspacecast-non-null.ll | 272 ++++++++++++++++++
.../llvm.amdgcn.addrspacecast.nonnull.ll | 69 +++++
8 files changed, 498 insertions(+), 17 deletions(-)
create mode 100644 llvm/test/CodeGen/AMDGPU/codegen-prepare-addrspacecast-non-null-vector.ll
create mode 100644 llvm/test/CodeGen/AMDGPU/codegen-prepare-addrspacecast-non-null.ll
create mode 100644 llvm/test/CodeGen/AMDGPU/llvm.amdgcn.addrspacecast.nonnull.ll
diff --git a/llvm/include/llvm/IR/IntrinsicsAMDGPU.td b/llvm/include/llvm/IR/IntrinsicsAMDGPU.td
index 0f29653f1f5bec..051e603c0819d2 100644
--- a/llvm/include/llvm/IR/IntrinsicsAMDGPU.td
+++ b/llvm/include/llvm/IR/IntrinsicsAMDGPU.td
@@ -3196,4 +3196,11 @@ def int_amdgcn_fdiv_fast : DefaultAttrsIntrinsic<
[llvm_float_ty], [llvm_float_ty, llvm_float_ty],
[IntrNoMem, IntrSpeculatable]
>;
+
+/// Emit an addrspacecast without null pointer checking.
+/// Should only be inserted by a pass based on analysis of an addrspacecast's src.
+def int_amdgcn_addrspacecast_nonnull : DefaultAttrsIntrinsic<
+ [llvm_anyptr_ty], [llvm_anyptr_ty],
+ [IntrNoMem, IntrSpeculatable]
+>;
}
diff --git a/llvm/lib/Target/AMDGPU/AMDGPUCodeGenPrepare.cpp b/llvm/lib/Target/AMDGPU/AMDGPUCodeGenPrepare.cpp
index 1c75c5a47c9d27..0edbbf7cb0af54 100644
--- a/llvm/lib/Target/AMDGPU/AMDGPUCodeGenPrepare.cpp
+++ b/llvm/lib/Target/AMDGPU/AMDGPUCodeGenPrepare.cpp
@@ -99,6 +99,7 @@ class AMDGPUCodeGenPrepareImpl
: public InstVisitor<AMDGPUCodeGenPrepareImpl, bool> {
public:
const GCNSubtarget *ST = nullptr;
+ const AMDGPUTargetMachine *TM = nullptr;
const TargetLibraryInfo *TLInfo = nullptr;
AssumptionCache *AC = nullptr;
DominatorTree *DT = nullptr;
@@ -310,6 +311,7 @@ class AMDGPUCodeGenPrepareImpl
bool visitICmpInst(ICmpInst &I);
bool visitSelectInst(SelectInst &I);
bool visitPHINode(PHINode &I);
+ bool visitAddrSpaceCastInst(AddrSpaceCastInst &I);
bool visitIntrinsicInst(IntrinsicInst &I);
bool visitBitreverseIntrinsicInst(IntrinsicInst &I);
@@ -2013,6 +2015,75 @@ bool AMDGPUCodeGenPrepareImpl::visitPHINode(PHINode &I) {
return true;
}
+/// \param V Value to check
+/// \param DL DataLayout
+/// \param TM TargetMachine (TODO: remove once DL contains nullptr values)
+/// \param AS Target Address Space
+/// \return true if \p V cannot be the null value of \p AS, false otherwise.
+static bool isPtrKnownNeverNull(const Value *V, const DataLayout &DL,
+ const AMDGPUTargetMachine &TM, unsigned AS) {
+ // Pointer cannot be null if it's a block address, GV or alloca.
+ // NOTE: We don't support extern_weak, but if we did, we'd need to check for
+ // it as the symbol could be null in such cases.
+ if (isa<BlockAddress>(V) || isa<GlobalValue>(V) || isa<AllocaInst>(V))
+ return true;
+
+ // Check nonnull arguments.
+ if (const auto *Arg = dyn_cast<Argument>(V); Arg && Arg->hasNonNullAttr())
+ return true;
+
+ // TODO: Calls that return nonnull?
+
+ // For all other things, use KnownBits.
+ // We either use 0 or all bits set to indicate null, so check whether the
+ // value can be zero or all ones.
+ //
+ // TODO: Use ValueTracking's isKnownNeverNull if it becomes aware that some
+ // address spaces have non-zero null values.
+ auto SrcPtrKB = computeKnownBits(V, DL).trunc(DL.getPointerSizeInBits(AS));
+ const auto NullVal = TM.getNullPointerValue(AS);
+ assert((NullVal == 0 || NullVal == -1) &&
+ "don't know how to check for this null value!");
+ return NullVal ? !SrcPtrKB.getMaxValue().isAllOnes() : SrcPtrKB.isNonZero();
+}
+
+bool AMDGPUCodeGenPrepareImpl::visitAddrSpaceCastInst(AddrSpaceCastInst &I) {
+ // Intrinsic doesn't support vectors, also it seems that it's often difficult
+ // to prove that a vector cannot have any nulls in it so it's unclear if it's
+ // worth supporting.
+ if (I.getType()->isVectorTy())
+ return false;
+
+ // Check if this can be lowered to a amdgcn.addrspacecast.nonnull.
+ // This is only worthwhile for casts from/to priv/local to flat.
+ const unsigned SrcAS = I.getSrcAddressSpace();
+ const unsigned DstAS = I.getDestAddressSpace();
+
+ bool CanLower = false;
+ if (SrcAS == AMDGPUAS::FLAT_ADDRESS)
+ CanLower = (DstAS == AMDGPUAS::LOCAL_ADDRESS ||
+ DstAS == AMDGPUAS::PRIVATE_ADDRESS);
+ else if (DstAS == AMDGPUAS::FLAT_ADDRESS)
+ CanLower = (SrcAS == AMDGPUAS::LOCAL_ADDRESS ||
+ SrcAS == AMDGPUAS::PRIVATE_ADDRESS);
+ if (!CanLower)
+ return false;
+
+ SmallVector<const Value *, 4> WorkList;
+ getUnderlyingObjects(I.getOperand(0), WorkList);
+ if (!all_of(WorkList, [&](const Value *V) {
+ return isPtrKnownNeverNull(V, *DL, *TM, SrcAS);
+ }))
+ return false;
+
+ IRBuilder<> B(&I);
+ auto *Intrin = B.CreateIntrinsic(
+ I.getType(), Intrinsic::amdgcn_addrspacecast_nonnull, {I.getOperand(0)});
+ I.replaceAllUsesWith(Intrin);
+ I.eraseFromParent();
+ return true;
+}
+
bool AMDGPUCodeGenPrepareImpl::visitIntrinsicInst(IntrinsicInst &I) {
switch (I.getIntrinsicID()) {
case Intrinsic::bitreverse:
@@ -2196,6 +2267,7 @@ bool AMDGPUCodeGenPrepare::runOnFunction(Function &F) {
return false;
const AMDGPUTargetMachine &TM = TPC->getTM<AMDGPUTargetMachine>();
+ Impl.TM = &TM;
Impl.TLInfo = &getAnalysis<TargetLibraryInfoWrapperPass>().getTLI(F);
Impl.ST = &TM.getSubtarget<GCNSubtarget>(F);
Impl.AC = &getAnalysis<AssumptionCacheTracker>().getAssumptionCache(F);
@@ -2214,6 +2286,7 @@ PreservedAnalyses AMDGPUCodeGenPreparePass::run(Function &F,
AMDGPUCodeGenPrepareImpl Impl;
Impl.Mod = F.getParent();
Impl.DL = &Impl.Mod->getDataLayout();
+ Impl.TM = static_cast<const AMDGPUTargetMachine *>(&TM);
Impl.TLInfo = &FAM.getResult<TargetLibraryAnalysis>(F);
Impl.ST = &TM.getSubtarget<GCNSubtarget>(F);
Impl.AC = &FAM.getResult<AssumptionAnalysis>(F);
diff --git a/llvm/lib/Target/AMDGPU/AMDGPULegalizerInfo.cpp b/llvm/lib/Target/AMDGPU/AMDGPULegalizerInfo.cpp
index 13d7510729139b..4c3b983f2960df 100644
--- a/llvm/lib/Target/AMDGPU/AMDGPULegalizerInfo.cpp
+++ b/llvm/lib/Target/AMDGPU/AMDGPULegalizerInfo.cpp
@@ -2247,10 +2247,16 @@ bool AMDGPULegalizerInfo::legalizeAddrSpaceCast(
MachineIRBuilder &B) const {
MachineFunction &MF = B.getMF();
+ // MI can either be a G_ADDRSPACE_CAST or a
+ // G_INTRINSIC @llvm.amdgcn.addrspacecast.nonnull
+ assert(MI.getOpcode() == TargetOpcode::G_ADDRSPACE_CAST ||
+ (isa<GIntrinsic>(MI) && cast<GIntrinsic>(MI).getIntrinsicID() ==
+ Intrinsic::amdgcn_addrspacecast_nonnull));
+
const LLT S32 = LLT::scalar(32);
Register Dst = MI.getOperand(0).getReg();
- Register Src = MI.getOperand(1).getReg();
-
+ Register Src = isa<GIntrinsic>(MI) ? MI.getOperand(2).getReg()
+ : MI.getOperand(1).getReg();
LLT DstTy = MRI.getType(Dst);
LLT SrcTy = MRI.getType(Src);
unsigned DestAS = DstTy.getAddressSpace();
@@ -2271,7 +2277,9 @@ bool AMDGPULegalizerInfo::legalizeAddrSpaceCast(
if (SrcAS == AMDGPUAS::FLAT_ADDRESS &&
(DestAS == AMDGPUAS::LOCAL_ADDRESS ||
DestAS == AMDGPUAS::PRIVATE_ADDRESS)) {
- if (isKnownNonNull(Src, MRI, TM, SrcAS)) {
+ // For llvm.amdgcn.addrspacecast.nonnull we can always assume non-null, for
+ // G_ADDRSPACE_CAST we need to guess.
+ if (isa<GIntrinsic>(MI) || isKnownNonNull(Src, MRI, TM, SrcAS)) {
// Extract low 32-bits of the pointer.
B.buildExtract(Dst, Src, 0);
MI.eraseFromParent();
@@ -2308,7 +2316,9 @@ bool AMDGPULegalizerInfo::legalizeAddrSpaceCast(
// avoid the ptrtoint?
auto BuildPtr = B.buildMergeLikeInstr(DstTy, {SrcAsInt, ApertureReg});
- if (isKnownNonNull(Src, MRI, TM, SrcAS)) {
+ // For llvm.amdgcn.addrspacecast.nonnull we can always assume non-null, for
+ // G_ADDRSPACE_CAST we need to guess.
+ if (isa<GIntrinsic>(MI) || isKnownNonNull(Src, MRI, TM, SrcAS)) {
B.buildCopy(Dst, BuildPtr);
MI.eraseFromParent();
return true;
@@ -7020,6 +7030,8 @@ bool AMDGPULegalizerInfo::legalizeIntrinsic(LegalizerHelper &Helper,
return false;
}
+ case Intrinsic::amdgcn_addrspacecast_nonnull:
+ return legalizeAddrSpaceCast(MI, MRI, B);
case Intrinsic::amdgcn_make_buffer_rsrc:
return legalizePointerAsRsrcIntrin(MI, MRI, B);
case Intrinsic::amdgcn_kernarg_segment_ptr:
diff --git a/llvm/lib/Target/AMDGPU/SIISelLowering.cpp b/llvm/lib/Target/AMDGPU/SIISelLowering.cpp
index 84ef9679ab9563..34c6038115329f 100644
--- a/llvm/lib/Target/AMDGPU/SIISelLowering.cpp
+++ b/llvm/lib/Target/AMDGPU/SIISelLowering.cpp
@@ -1415,6 +1415,23 @@ bool SITargetLowering::getTgtMemIntrinsic(IntrinsicInfo &Info,
}
}
+void SITargetLowering::CollectTargetIntrinsicOperands(
+ const CallInst &I, SmallVectorImpl<SDValue> &Ops, SelectionDAG &DAG) const {
+ switch (cast<IntrinsicInst>(I).getIntrinsicID()) {
+ case Intrinsic::amdgcn_addrspacecast_nonnull: {
+ // The DAG's ValueType loses the addrspaces.
+ // Add them as 2 extra Constant operands "from" and "to".
+ unsigned SrcAS = I.getOperand(0)->getType()->getPointerAddressSpace();
+ unsigned DstAS = I.getType()->getPointerAddressSpace();
+ Ops.push_back(DAG.getTargetConstant(SrcAS, SDLoc(), MVT::i32));
+ Ops.push_back(DAG.getTargetConstant(DstAS, SDLoc(), MVT::i32));
+ break;
+ }
+ default:
+ break;
+ }
+}
+
bool SITargetLowering::getAddrModeArguments(IntrinsicInst *II,
SmallVectorImpl<Value*> &Ops,
Type *&AccessTy) const {
@@ -6635,24 +6652,36 @@ static bool isKnownNonNull(SDValue Val, SelectionDAG &DAG,
SDValue SITargetLowering::lowerADDRSPACECAST(SDValue Op,
SelectionDAG &DAG) const {
SDLoc SL(Op);
- const AddrSpaceCastSDNode *ASC = cast<AddrSpaceCastSDNode>(Op);
-
- SDValue Src = ASC->getOperand(0);
- SDValue FlatNullPtr = DAG.getConstant(0, SL, MVT::i64);
- unsigned SrcAS = ASC->getSrcAddressSpace();
const AMDGPUTargetMachine &TM =
static_cast<const AMDGPUTargetMachine &>(getTargetMachine());
+ unsigned DestAS, SrcAS;
+ SDValue Src;
+ bool IsNonNull = false;
+ if (const auto *ASC = dyn_cast<AddrSpaceCastSDNode>(Op)) {
+ SrcAS = ASC->getSrcAddressSpace();
+ Src = ASC->getOperand(0);
+ DestAS = ASC->getDestAddressSpace();
+ } else {
+ assert(Op.getOpcode() == ISD::INTRINSIC_WO_CHAIN &&
+ Op.getConstantOperandVal(0) ==
+ Intrinsic::amdgcn_addrspacecast_nonnull);
+ Src = Op->getOperand(1);
+ SrcAS = Op->getConstantOperandVal(2);
+ DestAS = Op->getConstantOperandVal(3);
+ IsNonNull = true;
+ }
+
+ SDValue FlatNullPtr = DAG.getConstant(0, SL, MVT::i64);
+
// flat -> local/private
if (SrcAS == AMDGPUAS::FLAT_ADDRESS) {
- unsigned DestAS = ASC->getDestAddressSpace();
-
if (DestAS == AMDGPUAS::LOCAL_ADDRESS ||
DestAS == AMDGPUAS::PRIVATE_ADDRESS) {
SDValue Ptr = DAG.getNode(ISD::TRUNCATE, SL, MVT::i32, Src);
- if (isKnownNonNull(Src, DAG, TM, SrcAS))
+ if (IsNonNull || isKnownNonNull(Op, DAG, TM, SrcAS))
return Ptr;
unsigned NullVal = TM.getNullPointerValue(DestAS);
@@ -6665,16 +6694,16 @@ SDValue SITargetLowering::lowerADDRSPACECAST(SDValue Op,
}
// local/private -> flat
- if (ASC->getDestAddressSpace() == AMDGPUAS::FLAT_ADDRESS) {
+ if (DestAS == AMDGPUAS::FLAT_ADDRESS) {
if (SrcAS == AMDGPUAS::LOCAL_ADDRESS ||
SrcAS == AMDGPUAS::PRIVATE_ADDRESS) {
- SDValue Aperture = getSegmentAperture(ASC->getSrcAddressSpace(), SL, DAG);
+ SDValue Aperture = getSegmentAperture(SrcAS, SL, DAG);
SDValue CvtPtr =
DAG.getNode(ISD::BUILD_VECTOR, SL, MVT::v2i32, Src, Aperture);
CvtPtr = DAG.getNode(ISD::BITCAST, SL, MVT::i64, CvtPtr);
- if (isKnownNonNull(Src, DAG, TM, SrcAS))
+ if (IsNonNull || isKnownNonNull(Op, DAG, TM, SrcAS))
return CvtPtr;
unsigned NullVal = TM.getNullPointerValue(SrcAS);
@@ -6697,7 +6726,7 @@ SDValue SITargetLowering::lowerADDRSPACECAST(SDValue Op,
return DAG.getNode(ISD::BITCAST, SL, MVT::i64, Vec);
}
- if (ASC->getDestAddressSpace() == AMDGPUAS::CONSTANT_ADDRESS_32BIT &&
+ if (DestAS == AMDGPUAS::CONSTANT_ADDRESS_32BIT &&
Src.getValueType() == MVT::i64)
return DAG.getNode(ISD::TRUNCATE, SL, MVT::i32, Src);
@@ -6708,7 +6737,7 @@ SDValue SITargetLowering::lowerADDRSPACECAST(SDValue Op,
MF.getFunction(), "invalid addrspacecast", SL.getDebugLoc());
DAG.getContext()->diagnose(InvalidAddrSpaceCast);
- return DAG.getUNDEF(ASC->getValueType(0));
+ return DAG.getUNDEF(Op->getValueType(0));
}
// This lowers an INSERT_SUBVECTOR by extracting the individual elements from
@@ -8325,6 +8354,8 @@ SDValue SITargetLowering::LowerINTRINSIC_WO_CHAIN(SDValue Op,
Op.getOperand(3), Op.getOperand(4), Op.getOperand(5),
IndexKeyi32, Op.getOperand(7)});
}
+ case Intrinsic::amdgcn_addrspacecast_nonnull:
+ return lowerADDRSPACECAST(Op, DAG);
default:
if (const AMDGPU::ImageDimIntrinsicInfo *ImageDimIntr =
AMDGPU::getImageDimIntrinsicInfo(IntrinsicID))
diff --git a/llvm/lib/Target/AMDGPU/SIISelLowering.h b/llvm/lib/Target/AMDGPU/SIISelLowering.h
index f6e1d198f40aec..fc90a208fa0b3a 100644
--- a/llvm/lib/Target/AMDGPU/SIISelLowering.h
+++ b/llvm/lib/Target/AMDGPU/SIISelLowering.h
@@ -305,6 +305,10 @@ class SITargetLowering final : public AMDGPUTargetLowering {
MachineFunction &MF,
unsigned IntrinsicID) const override;
+ void CollectTargetIntrinsicOperands(const CallInst &I,
+ SmallVectorImpl<SDValue> &Ops,
+ SelectionDAG &DAG) const override;
+
bool getAddrModeArguments(IntrinsicInst * /*I*/,
SmallVectorImpl<Value*> &/*Ops*/,
Type *&/*AccessTy*/) const override;
diff --git a/llvm/test/CodeGen/AMDGPU/codegen-prepare-addrspacecast-non-null-vector.ll b/llvm/test/CodeGen/AMDGPU/codegen-prepare-addrspacecast-non-null-vector.ll
new file mode 100644
index 00000000000000..94c571a29f9911
--- /dev/null
+++ b/llvm/test/CodeGen/AMDGPU/codegen-prepare-addrspacecast-non-null-vector.ll
@@ -0,0 +1,13 @@
+; NOTE: Assertions have been autogenerated by utils/update_test_checks.py UTC_ARGS: --version 4
+; RUN: opt -mtriple=amdgcn-- -amdgpu-codegenprepare -S < %s | FileCheck -check-prefix=OPT %s
+
+; Check that CGP doesn't try to create a amdgcn.addrspace.nonnull of vector, as that's not supported.
+
+define <4 x ptr> @vec_of_local_to_flat_nonnull_arg() {
+; OPT-LABEL: define <4 x ptr> @vec_of_local_to_flat_nonnull_arg() {
+; OPT-NEXT: [[X:%.*]] = addrspacecast <4 x ptr addrspace(3)> zeroinitializer to <4 x ptr>
+; OPT-NEXT: ret <4 x ptr> [[X]]
+;
+ %x = addrspacecast <4 x ptr addrspace(3)> zeroinitializer to <4 x ptr>
+ ret <4 x ptr> %x
+}
diff --git a/llvm/test/CodeGen/AMDGPU/codegen-prepare-addrspacecast-non-null.ll b/llvm/test/CodeGen/AMDGPU/codegen-prepare-addrspacecast-non-null.ll
new file mode 100644
index 00000000000000..bcdfb75ab1ef98
--- /dev/null
+++ b/llvm/test/CodeGen/AMDGPU/codegen-prepare-addrspacecast-non-null.ll
@@ -0,0 +1,272 @@
+; NOTE: Assertions have been autogenerated by utils/update_llc_test_checks.py UTC_ARGS: --version 4
+; RUN: opt -mtriple=amdgcn-- -amdgpu-codegenprepare -S < %s | FileCheck -check-prefix=OPT %s
+; RUN: llc -mtriple=amdgcn-amd-amdhsa -mcpu=gfx900 < %s | FileCheck %s --check-prefixes=ASM,DAGISEL-ASM
+; RUN: llc -mtriple=amdgcn-amd-amdhsa -global-isel -mcpu=gfx900 < %s | FileCheck %s --check-prefixes=ASM,GISEL-ASM
+
+; Tests that we can avoid nullptr checks for addrspacecasts from/to priv/local.
+;
+; Whenever a testcase is successful, we should see the addrspacecast replaced with the intrinsic
+; and the resulting code should have no select/cndmask null check for the pointer.
+
+define void @local_to_flat_nonnull_arg(ptr addrspace(3) nonnull %ptr) {
+; OPT-LABEL: define void @local_to_flat_nonnull_arg(
+; OPT-SAME: ptr addrspace(3) nonnull [[PTR:%.*]]) {
+; OPT-NEXT: [[TMP1:%.*]] = call ptr @llvm.amdgcn.addrspacecast.nonnull.p0.p3(ptr addrspace(3) [[PTR]])
+; OPT-NEXT: store volatile i32 7, ptr [[TMP1]], align 4
+; OPT-NEXT: ret void
+;
+; ASM-LABEL: local_to_flat_nonnull_arg:
+; ASM: ; %bb.0:
+; ASM-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
+; ASM-NEXT: s_mov_b64 s[4:5], src_shared_base
+; ASM-NEXT: v_mov_b32_e32 v1, s5
+; ASM-NEXT: v_mov_b32_e32 v2, 7
+; ASM-NEXT: flat_store_dword v[0:1], v2
+; ASM-NEXT: s_waitcnt vmcnt(0) lgkmcnt(0)
+; ASM-NEXT: s_setpc_b64 s[30:31]
+ %x = addrspacecast ptr addrspace(3) %ptr to ptr
+ store volatile i32 7, ptr %x
+ ret void
+}
+
+define void @private_to_flat_nonnull_arg(ptr addrspace(5) nonnull %ptr) {
+; OPT-LABEL: define void @private_to_flat_nonnull_arg(
+; OPT-SAME: ptr addrspace(5) nonnull [[PTR:%.*]]) {
+; OPT-NEXT: [[TMP1:%.*]] = call ptr @llvm.amdgcn.addrspacecast.nonnull.p0.p5(ptr addrspace(5) [[PTR]])
+; OPT-NEXT: store volatile i32 7, ptr [[TMP1]], align 4
+; OPT-NEXT: ret void
+;
+; ASM-LABEL: private_to_flat_nonnull_arg:
+; ASM: ; %bb.0:
+; ASM-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
+; ASM-NEXT: s_mov_b64 s[4:5], src_private_base
+; ASM-NEXT: v_mov_b32_e32 v1, s5
+; ASM-NEXT: v_mov_b32_e32 v2, 7
+; ASM-NEXT: flat_store_dword v[0:1], v2
+; ASM-NEXT: s_waitcnt vmcnt(0) lgkmcnt(0)
+; ASM-NEXT: s_setpc_b64 s[30:31]
+ %x = addrspacecast ptr addrspace(5) %ptr to ptr
+ store volatile i32 7, ptr %x
+ ret void
+}
+
+define void @flat_to_local_nonnull_arg(ptr nonnull %ptr) {
+; OPT-LABEL: define void @flat_to_local_nonnull_arg(
+; OPT-SAME: ptr nonnull [[PTR:%.*]]) {
+; OPT-NEXT: [[TMP1:%.*]] = call ptr addrspace(3) @llvm.amdgcn.addrspacecast.nonnull.p3.p0(ptr [[PTR]])
+; OPT-NEXT: store volatile i32 7, ptr addrspace(3) [[TMP1]], align 4
+; OPT-NEXT: ret void
+;
+; ASM-LABEL: flat_to_local_nonnull_arg:
+; ASM: ; %bb.0:
+; ASM-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
+; ASM-NEXT: v_mov_b32_e32 v1, 7
+; ASM-NEXT: ds_write_b32 v0, v1
+; ASM-NEXT: s_waitcnt lgkmcnt(0)
+; ASM-NEXT: s_setpc_b64 s[30:31]
+ %x = addrspacecast ptr %ptr to ptr addrspace(3)
+ store volatile i32 7, ptr addrspace(3) %x
+ ret void
+}
+
+define void @flat_to_private_nonnull_arg(ptr nonnull %ptr) {
+; OPT-LABEL: define void @flat_to_private_nonnull_arg(
+; OPT-SAME: ptr nonnull [[PTR:%.*]]) {
+; OPT-NEXT: [[TMP1:%.*]] = call ptr addrspace(5) @llvm.amdgcn.addrspacecast.nonnull.p5.p0(ptr [[PTR]])
+; OPT-NEXT: store volatile i32 7, ptr addrspace(5) [[TMP1]], align 4
+; OPT-NEXT: ret void
+;
+; ASM-LABEL: flat_to_private_nonnull_arg:
+; ASM: ; %bb.0:
+; ASM-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
+; ASM-NEXT: v_mov_b32_e32 v1, 7
+; ASM-NEXT: buffer_store_dword v1, v0, s[0:3], 0 offen
+; ASM-NEXT: s_waitcnt vmcnt(0)
+; ASM-NEXT: s_setpc_b64 s[30:31]
+ %x = addrspacecast ptr %ptr to ptr addrspace(5)
+ store volatile i32 7, ptr addrspace(5) %x
+ ret void
+}
+
+define void @private_alloca_to_flat(ptr %ptr) {
+; OPT-LABEL: define void @private_alloca_to_flat(
+; OPT-SAME: ptr [[PTR:%.*]]) {
+; OPT-NEXT: [[ALLOCA:%.*]] = alloca i8, align 1, addrspace(5)
+; OPT-NEXT: [[TMP1:%.*]] = call ptr @llvm.amdgcn.addrspacecast.nonnull.p0.p5(ptr addrspace(5) [[ALLOCA]])
+; OPT-NEXT: store volatile i32 7, ptr [[TMP1]], align 4
+; OPT-NEXT: ret void
+;
+; ASM-LABEL: private_alloca_to_flat:
+; ASM: ; %bb.0:
+; ASM-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
+; ASM-NEXT: s_mov_b64 s[4:5], src_private_base
+; ASM-NEXT: v_lshrrev_b32_e64 v0, 6, s32
+; ASM-NEXT: v_mov_b32_e32 v1, s5
+; ASM-NEXT: v_mov_b32_e32 v2, 7
+; ASM-NEXT: flat_store_dword v[0:1], v2
+; ASM-NEXT: s_waitcnt vmcnt(0) lgkmcnt(0)
+; ASM-NEXT: s_setpc_b64 s[30:31]
+ %alloca = alloca i8, addrspace(5)
+ %x = addrspacecast ptr addrspace(5) %alloca to ptr
+ store volatile i32 7, ptr %x
+ ret void
+}
+
+ at lds = internal unnamed_addr addrspace(3) global i8 poison, align 4
+
+define void @knownbits_on_flat_to_priv(ptr %ptr) {
+; OPT-LABEL: define void @knownbits_on_flat_to_priv(
+; OPT-SAME: ptr [[PTR:%.*]]) {
+; OPT-NEXT: [[PTR_INT:%.*]] = ptrtoint ptr [[PTR]] to i64
+; OPT-NEXT: [[PTR_OR:%.*]] = or i64 [[PTR_INT]], 15
+; OPT-NEXT: [[KB_PTR:%.*]] = inttoptr i64 [[PTR_OR]] to ptr
+; OPT-NEXT: [[TMP1:%.*]] = call ptr addrspace(5) @llvm.amdgcn.addrspacecast.nonnull.p5.p0(ptr [[KB_PTR]])
+; OPT-NEXT: store volatile i32 7, ptr addrspace(5) [[TMP1]], align 4
+; OPT-NEXT: ret void
+;
+; ASM-LABEL: knownbits_on_flat_to_priv:
+; ASM: ; %bb.0:
+; ASM-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
+; ASM-NEXT: v_or_b32_e32 v0, 15, v0
+; ASM-NEXT: v_mov_b32_e32 v1, 7
+; ASM-NEXT: buffer_store_dword v1, v0, s[0:3], 0 offen
+; ASM-NEXT: s_waitcnt vmcnt(0)
+; ASM-NEXT: s_setpc_b64 s[30:31]
+ %ptr.int = ptrtoint ptr %ptr to i64
+ %ptr.or = or i64 %ptr.int, 15 ; set some low bits
+ %kb.ptr = inttoptr i64 %ptr.or to ptr
+ %x = addrspacecast ptr %kb.ptr to ptr addrspace(5)
+ store volatile i32 7, ptr addrspace(5) %x
+ ret void
+}
+
+define void @knownbits_on_priv_to_flat(ptr addrspace(5) %ptr) {
+; OPT-LABEL: define void @knownbits_on_priv_to_flat(
+; OPT-SAME: ptr addrspace(5) [[PTR:%.*]]) {
+; OPT-NEXT: [[PTR_INT:%.*]] = ptrtoint ptr addrspace(5) [[PTR]] to i32
+; OPT-NEXT: [[PTR_OR:%.*]] = and i32 [[PTR_INT]], 65535
+; OPT-NEXT: [[KB_PTR:%.*]] = inttoptr i32 [[PTR_OR]] to ptr addrspace(5)
+; OPT-NEXT: [[TMP1:%.*]] = call ptr @llvm.amdgcn.addrspacecast.nonnull.p0.p5(ptr addrspace(5) [[KB_PTR]])
+; OPT-NEXT: store volatile i32 7, ptr [[TMP1]], align 4
+; OPT-NEXT: ret void
+;
+; ASM-LABEL: knownbits_on_priv_to_flat:
+; ASM: ; %bb.0:
+; ASM-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
+; ASM-NEXT: s_mov_b64 s[4:5], src_private_base
+; ASM-NEXT: v_and_b32_e32 v0, 0xffff, v0
+; ASM-NEXT: v_mov_b32_e32 v1, s5
+; ASM-NEXT: v_mov_b32_e32 v2, 7
+; ASM-NEXT: flat_store_dword v[0:1], v2
+; ASM-NEXT: s_waitcnt vmcnt(0) lgkmcnt(0)
+; ASM-NEXT: s_setpc_b64 s[30:31]
+ %ptr.int = ptrtoint ptr addrspace(5) %ptr to i32
+ %ptr.or = and i32 %ptr.int, 65535 ; ensure only lower 16 bits can be set.
+ %kb.ptr = inttoptr i32 %ptr.or to ptr addrspace(5)
+ %x = addrspacecast ptr addrspace(5) %kb.ptr to ptr
+ store volatile i32 7, ptr %x
+ ret void
+}
+
+define void @recursive_phis(i1 %cond, ptr addrspace(5) %ptr) {
+; OPT-LABEL: define void @recursive_phis(
+; OPT-SAME: i1 [[COND:%.*]], ptr addrspace(5) [[PTR:%.*]]) {
+; OPT-NEXT: entry:
+; OPT-NEXT: [[ALLOCA:%.*]] = alloca i8, align 1, addrspace(5)
+; OPT-NEXT: br i1 [[COND]], label [[THEN:%.*]], label [[ELSE:%.*]]
+; OPT: then:
+; OPT-NEXT: [[PTR_INT:%.*]] = ptrtoint ptr addrspace(5) [[PTR]] to i32
+; OPT-NEXT: [[PTR_OR:%.*]] = and i32 [[PTR_INT]], 65535
+; OPT-NEXT: [[KB_PTR:%.*]] = inttoptr i32 [[PTR_OR]] to ptr addrspace(5)
+; OPT-NEXT: br label [[FINALLY:%.*]]
+; OPT: else:
+; OPT-NEXT: [[OTHER_PHI:%.*]] = phi ptr addrspace(5) [ [[ALLOCA]], [[ENTRY:%.*]] ], [ [[PHI_PTR:%.*]], [[FINALLY]] ]
+; OPT-NEXT: br label [[FINALLY]]
+; OPT: finally:
+; OPT-NEXT: [[PHI_PTR]] = phi ptr addrspace(5) [ [[KB_PTR]], [[THEN]] ], [ [[OTHER_PHI]], [[ELSE]] ]
+; OPT-NEXT: [[TMP0:%.*]] = call ptr @llvm.amdgcn.addrspacecast.nonnull.p0.p5(ptr addrspace(5) [[PHI_PTR]])
+; OPT-NEXT: store volatile i32 7, ptr [[TMP0]], align 4
+; OPT-NEXT: br i1 [[COND]], label [[ELSE]], label [[END:%.*]]
+; OPT: end:
+; OPT-NEXT: ret void
+;
+; DAGISEL-ASM-LABEL: recursive_phis:
+; DAGISEL-ASM: ; %bb.0: ; %entry
+; DAGISEL-ASM-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
+; DAGISEL-ASM-NEXT: v_and_b32_e32 v0, 1, v0
+; DAGISEL-ASM-NEXT: v_cmp_eq_u32_e32 vcc, 1, v0
+; DAGISEL-ASM-NEXT: v_lshrrev_b32_e64 v0, 6, s32
+; DAGISEL-ASM-NEXT: s_and_saveexec_b64 s[4:5], vcc
+; DAGISEL-ASM-NEXT: ; %bb.1: ; %then
+; DAGISEL-ASM-NEXT: v_and_b32_e32 v0, 0xffff, v1
+; DAGISEL-ASM-NEXT: ; %bb.2: ; %finallyendcf.split
+; DAGISEL-ASM-NEXT: s_or_b64 exec, exec, s[4:5]
+; DAGISEL-ASM-NEXT: s_xor_b64 s[6:7], vcc, -1
+; DAGISEL-ASM-NEXT: s_mov_b64 s[4:5], 0
+; DAGISEL-ASM-NEXT: s_mov_b64 s[8:9], src_private_base
+; DAGISEL-ASM-NEXT: v_mov_b32_e32 v2, 7
+; DAGISEL-ASM-NEXT: .LBB7_3: ; %finally
+; DAGISEL-ASM-NEXT: ; =>This Inner Loop Header: Depth=1
+; DAGISEL-ASM-NEXT: s_and_b64 s[10:11], exec, s[6:7]
+; DAGISEL-ASM-NEXT: s_or_b64 s[4:5], s[10:11], s[4:5]
+; DAGISEL-ASM-NEXT: v_mov_b32_e32 v1, s9
+; DAGISEL-ASM-NEXT: flat_store_dword v[0:1], v2
+; DAGISEL-ASM-NEXT: s_waitcnt vmcnt(0)
+; DAGISEL-ASM-NEXT: s_andn2_b64 exec, exec, s[4:5]
+; DAGISEL-ASM-NEXT: s_cbranch_execnz .LBB7_3
+; DAGISEL-ASM-NEXT: ; %bb.4: ; %end
+; DAGISEL-ASM-NEXT: s_or_b64 exec, exec, s[4:5]
+; DAGISEL-ASM-NEXT: s_waitcnt lgkmcnt(0)
+; DAGISEL-ASM-NEXT: s_setpc_b64 s[30:31]
+;
+; GISEL-ASM-LABEL: recursive_phis:
+; GISEL-ASM: ; %bb.0: ; %entry
+; GISEL-ASM-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
+; GISEL-ASM-NEXT: v_and_b32_e32 v0, 1, v0
+; GISEL-ASM-NEXT: v_cmp_ne_u32_e32 vcc, 0, v0
+; GISEL-ASM-NEXT: s_xor_b64 s[4:5], vcc, -1
+; GISEL-ASM-NEXT: v_lshrrev_b32_e64 v0, 6, s32
+; GISEL-ASM-NEXT: s_and_saveexec_b64 s[6:7], vcc
+; GISEL-ASM-NEXT: ; %bb.1: ; %then
+; GISEL-ASM-NEXT: v_and_b32_e32 v0, 0xffff, v1
+; GISEL-ASM-NEXT: ; %bb.2: ; %finallyendcf.split
+; GISEL-ASM-NEXT: s_or_b64 exec, exec, s[6:7]
+; GISEL-ASM-NEXT: s_mov_b64 s[8:9], src_private_base
+; GISEL-ASM-NEXT: s_mov_b64 s[6:7], 0
+; GISEL-ASM-NEXT: v_mov_b32_e32 v1, s9
+; GISEL-ASM-NEXT: v_mov_b32_e32 v2, 7
+; GISEL-ASM-NEXT: .LBB7_3: ; %finally
+; GISEL-ASM-NEXT: ; =>This Inner Loop Header: Depth=1
+; GISEL-ASM-NEXT: s_and_b64 s[8:9], exec, s[4:5]
+; GISEL-ASM-NEXT: s_or_b64 s[6:7], s[8:9], s[6:7]
+; GISEL-ASM-NEXT: flat_store_dword v[0:1], v2
+; GISEL-ASM-NEXT: s_waitcnt vmcnt(0)
+; GISEL-ASM-NEXT: s_andn2_b64 exec, exec, s[6:7]
+; GISEL-ASM-NEXT: s_cbranch_execnz .LBB7_3
+; GISEL-ASM-NEXT: ; %bb.4: ; %end
+; GISEL-ASM-NEXT: s_or_b64 exec, exec, s[6:7]
+; GISEL-ASM-NEXT: s_waitcnt lgkmcnt(0)
+; GISEL-ASM-NEXT: s_setpc_b64 s[30:31]
+entry:
+ %alloca = alloca i8, addrspace(5)
+ br i1 %cond, label %then, label %else
+
+then:
+ %ptr.int = ptrtoint ptr addrspace(5) %ptr to i32
+ %ptr.or = and i32 %ptr.int, 65535 ; ensure low bits are zeroes
+ %kb.ptr = inttoptr i32 %ptr.or to ptr addrspace(5)
+ br label %finally
+
+else:
+ %other.phi = phi ptr addrspace(5) [%alloca, %entry], [%phi.ptr, %finally]
+ br label %finally
+
+finally:
+ %phi.ptr = phi ptr addrspace(5) [%kb.ptr, %then], [%other.phi, %else]
+ %x = addrspacecast ptr addrspace(5) %phi.ptr to ptr
+ store volatile i32 7, ptr %x
+ br i1 %cond, label %else, label %end
+
+end:
+ ret void
+}
diff --git a/llvm/test/CodeGen/AMDGPU/llvm.amdgcn.addrspacecast.nonnull.ll b/llvm/test/CodeGen/AMDGPU/llvm.amdgcn.addrspacecast.nonnull.ll
new file mode 100644
index 00000000000000..265353675b349c
--- /dev/null
+++ b/llvm/test/CodeGen/AMDGPU/llvm.amdgcn.addrspacecast.nonnull.ll
@@ -0,0 +1,69 @@
+; NOTE: Assertions have been autogenerated by utils/update_llc_test_checks.py UTC_ARGS: --version 4
+; RUN: llc -mtriple=amdgcn-amd-amdhsa -mcpu=gfx900 < %s | FileCheck %s --check-prefixes=ASM,DAGISEL-ASM
+; RUN: llc -mtriple=amdgcn-amd-amdhsa -global-isel -mcpu=gfx900 < %s | FileCheck %s --check-prefixes=ASM,GISEL-ASM
+
+define void @local_to_flat(ptr addrspace(3) %ptr) {
+; ASM-LABEL: local_to_flat:
+; ASM: ; %bb.0:
+; ASM-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
+; ASM-NEXT: s_mov_b64 s[4:5], src_shared_base
+; ASM-NEXT: v_mov_b32_e32 v1, s5
+; ASM-NEXT: v_mov_b32_e32 v2, 7
+; ASM-NEXT: flat_store_dword v[0:1], v2
+; ASM-NEXT: s_waitcnt vmcnt(0) lgkmcnt(0)
+; ASM-NEXT: s_setpc_b64 s[30:31]
+ %1 = call ptr @llvm.amdgcn.addrspacecast.nonnull.p0.p3(ptr addrspace(3) %ptr)
+ store volatile i32 7, ptr %1, align 4
+ ret void
+}
+
+define void @private_to_flat(ptr addrspace(5) %ptr) {
+; ASM-LABEL: private_to_flat:
+; ASM: ; %bb.0:
+; ASM-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
+; ASM-NEXT: s_mov_b64 s[4:5], src_private_base
+; ASM-NEXT: v_mov_b32_e32 v1, s5
+; ASM-NEXT: v_mov_b32_e32 v2, 7
+; ASM-NEXT: flat_store_dword v[0:1], v2
+; ASM-NEXT: s_waitcnt vmcnt(0) lgkmcnt(0)
+; ASM-NEXT: s_setpc_b64 s[30:31]
+ %1 = call ptr @llvm.amdgcn.addrspacecast.nonnull.p0.p5(ptr addrspace(5) %ptr)
+ store volatile i32 7, ptr %1, align 4
+ ret void
+}
+
+define void @flat_to_local(ptr %ptr) {
+; ASM-LABEL: flat_to_local:
+; ASM: ; %bb.0:
+; ASM-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
+; ASM-NEXT: v_mov_b32_e32 v1, 7
+; ASM-NEXT: ds_write_b32 v0, v1
+; ASM-NEXT: s_waitcnt lgkmcnt(0)
+; ASM-NEXT: s_setpc_b64 s[30:31]
+ %1 = call ptr addrspace(3) @llvm.amdgcn.addrspacecast.nonnull.p3.p0(ptr %ptr)
+ store volatile i32 7, ptr addrspace(3) %1, align 4
+ ret void
+}
+
+define void @flat_to_private(ptr %ptr) {
+; ASM-LABEL: flat_to_private:
+; ASM: ; %bb.0:
+; ASM-NEXT: s_waitcnt vmcnt(0) expcnt(0) lgkmcnt(0)
+; ASM-NEXT: v_mov_b32_e32 v1, 7
+; ASM-NEXT: buffer_store_dword v1, v0, s[0:3], 0 offen
+; ASM-NEXT: s_waitcnt vmcnt(0)
+; ASM-NEXT: s_setpc_b64 s[30:31]
+ %1 = call ptr addrspace(5) @llvm.amdgcn.addrspacecast.nonnull.p5.p0(ptr %ptr)
+ store volatile i32 7, ptr addrspace(5) %1, align 4
+ ret void
+}
+
+declare ptr @llvm.amdgcn.addrspacecast.nonnull.p0.p3(ptr addrspace(3))
+declare ptr @llvm.amdgcn.addrspacecast.nonnull.p0.p5(ptr addrspace(5))
+declare ptr addrspace(3) @llvm.amdgcn.addrspacecast.nonnull.p3.p0(ptr)
+declare ptr addrspace(5) @llvm.amdgcn.addrspacecast.nonnull.p5.p0(ptr)
+
+declare <4 x ptr> @llvm.amdgcn.addrspacecast.nonnull.v4p0.v4p3(<4 x ptr addrspace(3)>)
+;; NOTE: These prefixes are unused and the list is autogenerated. Do not add tests below this line:
+; DAGISEL-ASM: {{.*}}
+; GISEL-ASM: {{.*}}
>From b8e0f3e81e579ea6db439d39ced3926d6ae4f563 Mon Sep 17 00:00:00 2001
From: Alfie Richards <156316945+AlfieRichardsArm at users.noreply.github.com>
Date: Fri, 1 Mar 2024 13:12:06 +0000
Subject: [PATCH 244/406] [ARM] Change the type of CC and VCC code in
`splitMnemonic`. (#83413)
This changes the type of `PredicationCode` and `VPTPredicationCode` from
`unsigned` to `ARMCC::CondCodes` and `ARMVCC::VPTCodes` resp' for
clarity and correctness.
---
.../lib/Target/ARM/AsmParser/ARMAsmParser.cpp | 27 ++++++++++---------
1 file changed, 14 insertions(+), 13 deletions(-)
diff --git a/llvm/lib/Target/ARM/AsmParser/ARMAsmParser.cpp b/llvm/lib/Target/ARM/AsmParser/ARMAsmParser.cpp
index 37bfb76a494dee..efec163c6ed634 100644
--- a/llvm/lib/Target/ARM/AsmParser/ARMAsmParser.cpp
+++ b/llvm/lib/Target/ARM/AsmParser/ARMAsmParser.cpp
@@ -506,9 +506,10 @@ class ARMAsmParser : public MCTargetAsmParser {
bool isMnemonicVPTPredicable(StringRef Mnemonic, StringRef ExtraToken);
StringRef splitMnemonic(StringRef Mnemonic, StringRef ExtraToken,
- unsigned &PredicationCode,
- unsigned &VPTPredicationCode, bool &CarrySetting,
- unsigned &ProcessorIMod, StringRef &ITMask);
+ ARMCC::CondCodes &PredicationCode,
+ ARMVCC::VPTCodes &VPTPredicationCode,
+ bool &CarrySetting, unsigned &ProcessorIMod,
+ StringRef &ITMask);
void getMnemonicAcceptInfo(StringRef Mnemonic, StringRef ExtraToken,
StringRef FullInst, bool &CanAcceptCarrySet,
bool &CanAcceptPredicationCode,
@@ -6283,10 +6284,9 @@ bool ARMAsmParser::parsePrefix(ARMMCExpr::VariantKind &RefKind) {
//
// FIXME: Would be nice to autogen this.
// FIXME: This is a bit of a maze of special cases.
-StringRef ARMAsmParser::splitMnemonic(StringRef Mnemonic,
- StringRef ExtraToken,
- unsigned &PredicationCode,
- unsigned &VPTPredicationCode,
+StringRef ARMAsmParser::splitMnemonic(StringRef Mnemonic, StringRef ExtraToken,
+ ARMCC::CondCodes &PredicationCode,
+ ARMVCC::VPTCodes &VPTPredicationCode,
bool &CarrySetting,
unsigned &ProcessorIMod,
StringRef &ITMask) {
@@ -6340,7 +6340,7 @@ StringRef ARMAsmParser::splitMnemonic(StringRef Mnemonic,
unsigned CC = ARMCondCodeFromString(Mnemonic.substr(Mnemonic.size()-2));
if (CC != ~0U) {
Mnemonic = Mnemonic.slice(0, Mnemonic.size() - 2);
- PredicationCode = CC;
+ PredicationCode = static_cast<ARMCC::CondCodes>(CC);
}
}
@@ -6384,10 +6384,11 @@ StringRef ARMAsmParser::splitMnemonic(StringRef Mnemonic,
Mnemonic != "vqmovnt" && Mnemonic != "vqmovunt" &&
Mnemonic != "vqmovnt" && Mnemonic != "vmovnt" && Mnemonic != "vqdmullt" &&
Mnemonic != "vpnot" && Mnemonic != "vcvtt" && Mnemonic != "vcvt") {
- unsigned CC = ARMVectorCondCodeFromString(Mnemonic.substr(Mnemonic.size()-1));
- if (CC != ~0U) {
+ unsigned VCC =
+ ARMVectorCondCodeFromString(Mnemonic.substr(Mnemonic.size() - 1));
+ if (VCC != ~0U) {
Mnemonic = Mnemonic.slice(0, Mnemonic.size()-1);
- VPTPredicationCode = CC;
+ VPTPredicationCode = static_cast<ARMVCC::VPTCodes>(VCC);
}
return Mnemonic;
}
@@ -6966,8 +6967,8 @@ bool ARMAsmParser::ParseInstruction(ParseInstructionInfo &Info, StringRef Name,
StringRef ExtraToken = Name.slice(Next, Name.find(' ', Next + 1));
// Split out the predication code and carry setting flag from the mnemonic.
- unsigned PredicationCode;
- unsigned VPTPredicationCode;
+ ARMCC::CondCodes PredicationCode;
+ ARMVCC::VPTCodes VPTPredicationCode;
unsigned ProcessorIMod;
bool CarrySetting;
StringRef ITMask;
>From 924ad198f52508ff19e7944d856ba1a2fca81961 Mon Sep 17 00:00:00 2001
From: Shengchen Kan <shengchen.kan at intel.com>
Date: Fri, 1 Mar 2024 21:22:51 +0800
Subject: [PATCH 245/406] [X86][CodeGen] Add missing patterns for APX NDD
instructions about encoding trick
---
llvm/lib/Target/X86/X86InstrCompiler.td | 81 ++++++++++++++++++-------
llvm/test/CodeGen/X86/apx/sub.ll | 36 +++++------
2 files changed, 76 insertions(+), 41 deletions(-)
diff --git a/llvm/lib/Target/X86/X86InstrCompiler.td b/llvm/lib/Target/X86/X86InstrCompiler.td
index 9f1712274bc304..f393f86e64aadd 100644
--- a/llvm/lib/Target/X86/X86InstrCompiler.td
+++ b/llvm/lib/Target/X86/X86InstrCompiler.td
@@ -1493,27 +1493,71 @@ def : Pat<(xor GR32:$src1, -2147483648),
// Odd encoding trick: -128 fits into an 8-bit immediate field while
// +128 doesn't, so in this special case use a sub instead of an add.
-def : Pat<(add GR16:$src1, 128),
- (SUB16ri GR16:$src1, -128)>;
+let Predicates = [NoNDD] in {
+ def : Pat<(add GR16:$src1, 128),
+ (SUB16ri GR16:$src1, -128)>;
+ def : Pat<(add GR32:$src1, 128),
+ (SUB32ri GR32:$src1, -128)>;
+ def : Pat<(add GR64:$src1, 128),
+ (SUB64ri32 GR64:$src1, -128)>;
+
+ def : Pat<(X86add_flag_nocf GR16:$src1, 128),
+ (SUB16ri GR16:$src1, -128)>;
+ def : Pat<(X86add_flag_nocf GR32:$src1, 128),
+ (SUB32ri GR32:$src1, -128)>;
+ def : Pat<(X86add_flag_nocf GR64:$src1, 128),
+ (SUB64ri32 GR64:$src1, -128)>;
+}
+let Predicates = [HasNDD] in {
+ def : Pat<(add GR16:$src1, 128),
+ (SUB16ri_ND GR16:$src1, -128)>;
+ def : Pat<(add GR32:$src1, 128),
+ (SUB32ri_ND GR32:$src1, -128)>;
+ def : Pat<(add GR64:$src1, 128),
+ (SUB64ri32_ND GR64:$src1, -128)>;
+
+ def : Pat<(X86add_flag_nocf GR16:$src1, 128),
+ (SUB16ri_ND GR16:$src1, -128)>;
+ def : Pat<(X86add_flag_nocf GR32:$src1, 128),
+ (SUB32ri_ND GR32:$src1, -128)>;
+ def : Pat<(X86add_flag_nocf GR64:$src1, 128),
+ (SUB64ri32_ND GR64:$src1, -128)>;
+}
def : Pat<(store (add (loadi16 addr:$dst), 128), addr:$dst),
(SUB16mi addr:$dst, -128)>;
-
-def : Pat<(add GR32:$src1, 128),
- (SUB32ri GR32:$src1, -128)>;
def : Pat<(store (add (loadi32 addr:$dst), 128), addr:$dst),
(SUB32mi addr:$dst, -128)>;
-
-def : Pat<(add GR64:$src1, 128),
- (SUB64ri32 GR64:$src1, -128)>;
def : Pat<(store (add (loadi64 addr:$dst), 128), addr:$dst),
(SUB64mi32 addr:$dst, -128)>;
+let Predicates = [HasNDD] in {
+ def : Pat<(add (loadi16 addr:$src), 128),
+ (SUB16mi_ND addr:$src, -128)>;
+ def : Pat<(add (loadi32 addr:$src), 128),
+ (SUB32mi_ND addr:$src, -128)>;
+ def : Pat<(add (loadi64 addr:$src), 128),
+ (SUB64mi32_ND addr:$src, -128)>;
+}
-def : Pat<(X86add_flag_nocf GR16:$src1, 128),
- (SUB16ri GR16:$src1, -128)>;
-def : Pat<(X86add_flag_nocf GR32:$src1, 128),
- (SUB32ri GR32:$src1, -128)>;
-def : Pat<(X86add_flag_nocf GR64:$src1, 128),
- (SUB64ri32 GR64:$src1, -128)>;
+// The same trick applies for 32-bit immediate fields in 64-bit
+// instructions.
+let Predicates = [NoNDD] in {
+ def : Pat<(add GR64:$src1, 0x0000000080000000),
+ (SUB64ri32 GR64:$src1, 0xffffffff80000000)>;
+ def : Pat<(X86add_flag_nocf GR64:$src1, 0x0000000080000000),
+ (SUB64ri32 GR64:$src1, 0xffffffff80000000)>;
+}
+let Predicates = [HasNDD] in {
+ def : Pat<(add GR64:$src1, 0x0000000080000000),
+ (SUB64ri32_ND GR64:$src1, 0xffffffff80000000)>;
+ def : Pat<(X86add_flag_nocf GR64:$src1, 0x0000000080000000),
+ (SUB64ri32_ND GR64:$src1, 0xffffffff80000000)>;
+}
+def : Pat<(store (add (loadi64 addr:$dst), 0x0000000080000000), addr:$dst),
+ (SUB64mi32 addr:$dst, 0xffffffff80000000)>;
+let Predicates = [HasNDD] in {
+ def : Pat<(add(loadi64 addr:$src), 0x0000000080000000),
+ (SUB64mi32_ND addr:$src, 0xffffffff80000000)>;
+}
// Depositing value to 8/16 bit subreg:
def : Pat<(or (and GR64:$dst, -256),
@@ -1532,15 +1576,6 @@ def : Pat<(or (and GR32:$dst, -65536),
(i32 (zextloadi16 addr:$src))),
(INSERT_SUBREG (i32 (COPY $dst)), (MOV16rm i16mem:$src), sub_16bit)>;
-// The same trick applies for 32-bit immediate fields in 64-bit
-// instructions.
-def : Pat<(add GR64:$src1, 0x0000000080000000),
- (SUB64ri32 GR64:$src1, 0xffffffff80000000)>;
-def : Pat<(store (add (loadi64 addr:$dst), 0x0000000080000000), addr:$dst),
- (SUB64mi32 addr:$dst, 0xffffffff80000000)>;
-def : Pat<(X86add_flag_nocf GR64:$src1, 0x0000000080000000),
- (SUB64ri32 GR64:$src1, 0xffffffff80000000)>;
-
// To avoid needing to materialize an immediate in a register, use a 32-bit and
// with implicit zero-extension instead of a 64-bit and if the immediate has at
// least 32 bits of leading zeros. If in addition the last 32 bits can be
diff --git a/llvm/test/CodeGen/X86/apx/sub.ll b/llvm/test/CodeGen/X86/apx/sub.ll
index 4bcfa2586fbf36..4b0bd14872141b 100644
--- a/llvm/test/CodeGen/X86/apx/sub.ll
+++ b/llvm/test/CodeGen/X86/apx/sub.ll
@@ -89,31 +89,31 @@ entry:
define i16 @sub16ri8(i16 noundef %a) {
; CHECK-LABEL: sub16ri8:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: addl $-123, %edi, %eax # encoding: [0x62,0xf4,0x7c,0x18,0x83,0xc7,0x85]
+; CHECK-NEXT: subl $-128, %edi, %eax # encoding: [0x62,0xf4,0x7c,0x18,0x83,0xef,0x80]
; CHECK-NEXT: # kill: def $ax killed $ax killed $eax
; CHECK-NEXT: retq # encoding: [0xc3]
entry:
- %sub = sub i16 %a, 123
+ %sub = sub i16 %a, -128
ret i16 %sub
}
define i32 @sub32ri8(i32 noundef %a) {
; CHECK-LABEL: sub32ri8:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: addl $-123, %edi, %eax # encoding: [0x62,0xf4,0x7c,0x18,0x83,0xc7,0x85]
+; CHECK-NEXT: subl $-128, %edi, %eax # encoding: [0x62,0xf4,0x7c,0x18,0x83,0xef,0x80]
; CHECK-NEXT: retq # encoding: [0xc3]
entry:
- %sub = sub i32 %a, 123
+ %sub = sub i32 %a, -128
ret i32 %sub
}
define i64 @sub64ri8(i64 noundef %a) {
; CHECK-LABEL: sub64ri8:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: addq $-123, %rdi, %rax # encoding: [0x62,0xf4,0xfc,0x18,0x83,0xc7,0x85]
+; CHECK-NEXT: subq $-128, %rdi, %rax # encoding: [0x62,0xf4,0xfc,0x18,0x83,0xef,0x80]
; CHECK-NEXT: retq # encoding: [0xc3]
entry:
- %sub = sub i64 %a, 123
+ %sub = sub i64 %a, -128
ret i64 %sub
}
@@ -153,11 +153,11 @@ entry:
define i64 @sub64ri(i64 noundef %a) {
; CHECK-LABEL: sub64ri:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: addq $-123456, %rdi, %rax # encoding: [0x62,0xf4,0xfc,0x18,0x81,0xc7,0xc0,0x1d,0xfe,0xff]
-; CHECK-NEXT: # imm = 0xFFFE1DC0
+; CHECK-NEXT: subq $-2147483648, %rdi, %rax # encoding: [0x62,0xf4,0xfc,0x18,0x81,0xef,0x00,0x00,0x00,0x80]
+; CHECK-NEXT: # imm = 0x80000000
; CHECK-NEXT: retq # encoding: [0xc3]
entry:
- %sub = sub i64 %a, 123456
+ %sub = sub i64 %a, -2147483648
ret i64 %sub
}
@@ -211,34 +211,34 @@ define i16 @sub16mi8(ptr %a) {
; CHECK-LABEL: sub16mi8:
; CHECK: # %bb.0: # %entry
; CHECK-NEXT: movzwl (%rdi), %eax # encoding: [0x0f,0xb7,0x07]
-; CHECK-NEXT: addl $-123, %eax # EVEX TO LEGACY Compression encoding: [0x83,0xc0,0x85]
+; CHECK-NEXT: subl $-128, %eax # EVEX TO LEGACY Compression encoding: [0x83,0xe8,0x80]
; CHECK-NEXT: # kill: def $ax killed $ax killed $eax
; CHECK-NEXT: retq # encoding: [0xc3]
entry:
%t= load i16, ptr %a
- %sub = sub nsw i16 %t, 123
+ %sub = sub nsw i16 %t, -128
ret i16 %sub
}
define i32 @sub32mi8(ptr %a) {
; CHECK-LABEL: sub32mi8:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: addl $-123, (%rdi), %eax # encoding: [0x62,0xf4,0x7c,0x18,0x83,0x07,0x85]
+; CHECK-NEXT: subl $-128, (%rdi), %eax # encoding: [0x62,0xf4,0x7c,0x18,0x83,0x2f,0x80]
; CHECK-NEXT: retq # encoding: [0xc3]
entry:
%t= load i32, ptr %a
- %sub = sub nsw i32 %t, 123
+ %sub = sub nsw i32 %t, -128
ret i32 %sub
}
define i64 @sub64mi8(ptr %a) {
; CHECK-LABEL: sub64mi8:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: addq $-123, (%rdi), %rax # encoding: [0x62,0xf4,0xfc,0x18,0x83,0x07,0x85]
+; CHECK-NEXT: subq $-128, (%rdi), %rax # encoding: [0x62,0xf4,0xfc,0x18,0x83,0x2f,0x80]
; CHECK-NEXT: retq # encoding: [0xc3]
entry:
%t= load i64, ptr %a
- %sub = sub nsw i64 %t, 123
+ %sub = sub nsw i64 %t, -128
ret i64 %sub
}
@@ -282,12 +282,12 @@ entry:
define i64 @sub64mi(ptr %a) {
; CHECK-LABEL: sub64mi:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: addq $-123456, (%rdi), %rax # encoding: [0x62,0xf4,0xfc,0x18,0x81,0x07,0xc0,0x1d,0xfe,0xff]
-; CHECK-NEXT: # imm = 0xFFFE1DC0
+; CHECK-NEXT: subq $-2147483648, (%rdi), %rax # encoding: [0x62,0xf4,0xfc,0x18,0x81,0x2f,0x00,0x00,0x00,0x80]
+; CHECK-NEXT: # imm = 0x80000000
; CHECK-NEXT: retq # encoding: [0xc3]
entry:
%t= load i64, ptr %a
- %sub = sub nsw i64 %t, 123456
+ %sub = sub nsw i64 %t, -2147483648
ret i64 %sub
}
>From dfec4ef1a2ff8dc6685594813bcf14c27db9d5bc Mon Sep 17 00:00:00 2001
From: Martin Wehking <martin.wehking at codeplay.com>
Date: Fri, 1 Mar 2024 13:45:42 +0000
Subject: [PATCH 246/406] Use object directly instead of accessing ArrayRef
(#83263)
Use RegOp directly inside debug code to silence a static analyzer that
warns about accessing it through its ArrayRef wrapper.
---
llvm/lib/Target/AMDGPU/AMDGPUMachineCFGStructurizer.cpp | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/llvm/lib/Target/AMDGPU/AMDGPUMachineCFGStructurizer.cpp b/llvm/lib/Target/AMDGPU/AMDGPUMachineCFGStructurizer.cpp
index 9dade7442c3566..e2678e8336c569 100644
--- a/llvm/lib/Target/AMDGPU/AMDGPUMachineCFGStructurizer.cpp
+++ b/llvm/lib/Target/AMDGPU/AMDGPUMachineCFGStructurizer.cpp
@@ -2292,7 +2292,7 @@ MachineBasicBlock *AMDGPUMachineCFGStructurizer::createIfRegion(
MachineOperand::CreateReg(Reg, false, false, true);
ArrayRef<MachineOperand> Cond(RegOp);
LLVM_DEBUG(dbgs() << "RegionExitReg: ");
- LLVM_DEBUG(Cond[0].print(dbgs(), TRI));
+ LLVM_DEBUG(RegOp.print(dbgs(), TRI));
LLVM_DEBUG(dbgs() << "\n");
TII->insertBranch(*RegionExit, CurrentRegion->getEntry(), RegionExit,
Cond, DebugLoc());
>From b873847a53ae638e2146e3657fe33efe30c2afe1 Mon Sep 17 00:00:00 2001
From: Nikolas Klauser <nikolasklauser at berlin.de>
Date: Fri, 1 Mar 2024 15:15:11 +0100
Subject: [PATCH 247/406] [Clang] Fix __has_cpp_attribute and C++11 attributes
with arguments in C++03 (#83065)
The values for `__has_cpp_attribute` don't have to be guarded behind
`LangOpts.CPlusPlus` because `__has_cpp_attribute` isn't available if
Clang isn't in a C++ mode.
Fixes #82995
---
clang/docs/ReleaseNotes.rst | 3 ++
clang/test/Preprocessor/has_attribute.cpp | 4 ++-
clang/test/SemaCXX/attr-declspec-ignored.cpp | 3 +-
clang/test/SemaCXX/attr-gnu.cpp | 29 ++++++++++----------
clang/test/SemaCXX/cxx03-cxx11-attr.cpp | 9 ++++++
clang/utils/TableGen/ClangAttrEmitter.cpp | 12 +-------
6 files changed, 33 insertions(+), 27 deletions(-)
create mode 100644 clang/test/SemaCXX/cxx03-cxx11-attr.cpp
diff --git a/clang/docs/ReleaseNotes.rst b/clang/docs/ReleaseNotes.rst
index f44fef28b9f17f..4e5c870e4177fe 100644
--- a/clang/docs/ReleaseNotes.rst
+++ b/clang/docs/ReleaseNotes.rst
@@ -298,6 +298,9 @@ Bug Fixes to C++ Support
Fixes (`#82941 <https://github.com/llvm/llvm-project/issues/82941>`_),
(`#42411 <https://github.com/llvm/llvm-project/issues/42411>`_), and
(`#18121 <https://github.com/llvm/llvm-project/issues/18121>`_).
+- Clang now properly reports supported C++11 attributes when using
+ ``__has_cpp_attribute`` and parses attributes with arguments in C++03
+ (`#82995 <https://github.com/llvm/llvm-project/issues/82995>`_)
Bug Fixes to AST Handling
^^^^^^^^^^^^^^^^^^^^^^^^^
diff --git a/clang/test/Preprocessor/has_attribute.cpp b/clang/test/Preprocessor/has_attribute.cpp
index 33546dbb175f61..00ec57615c84b8 100644
--- a/clang/test/Preprocessor/has_attribute.cpp
+++ b/clang/test/Preprocessor/has_attribute.cpp
@@ -1,4 +1,6 @@
+// RUN: %clang_cc1 -triple i386-unknown-unknown -fms-compatibility -std=c++03 -E -P %s -o - | FileCheck %s --check-prefixes=CHECK,ITANIUM --implicit-check-not=:
// RUN: %clang_cc1 -triple i386-unknown-unknown -fms-compatibility -std=c++11 -E -P %s -o - | FileCheck %s --check-prefixes=CHECK,ITANIUM --implicit-check-not=:
+// RUN: %clang_cc1 -triple i386-windows -fms-compatibility -std=c++03 -E -P %s -o - | FileCheck %s --check-prefixes=CHECK,WINDOWS --implicit-check-not=:
// RUN: %clang_cc1 -triple i386-windows -fms-compatibility -std=c++11 -E -P %s -o - | FileCheck %s --check-prefixes=CHECK,WINDOWS --implicit-check-not=:
#define CXX11(x) x: __has_cpp_attribute(x)
@@ -65,7 +67,7 @@ CXX11(unlikely)
// CHECK: likely: 201803L
// CHECK: maybe_unused: 201603L
// ITANIUM: no_unique_address: 201803L
-// WINDOWS: no_unique_address: 0
+// WINDOWS: no_unique_address: 0
// ITANIUM: msvc::no_unique_address: 0
// WINDOWS: msvc::no_unique_address: 201803L
// CHECK: nodiscard: 201907L
diff --git a/clang/test/SemaCXX/attr-declspec-ignored.cpp b/clang/test/SemaCXX/attr-declspec-ignored.cpp
index dfea8cc4d47c8d..98e0ffd1a1afdc 100644
--- a/clang/test/SemaCXX/attr-declspec-ignored.cpp
+++ b/clang/test/SemaCXX/attr-declspec-ignored.cpp
@@ -1,4 +1,5 @@
// RUN: %clang_cc1 %s -verify -fsyntax-only
+// RUN: %clang_cc1 %s -std=c++03 -Wno-c++11-extensions -verify -fsyntax-only
namespace test1 {
__attribute__((visibility("hidden"))) __attribute__((aligned)) class A; // expected-warning{{attribute 'visibility' is ignored, place it after "class" to apply attribute to type declaration}} \
@@ -28,7 +29,7 @@ namespace test1 {
// expected-warning{{attribute 'aligned' is ignored, place it after "enum class" to apply attribute to type declaration}}
__attribute__((visibility("hidden"))) __attribute__((aligned)) enum struct ES {}; // expected-warning{{attribute 'visibility' is ignored, place it after "enum struct" to apply attribute to type declaration}} \
// expected-warning{{attribute 'aligned' is ignored, place it after "enum struct" to apply attribute to type declaration}}
-
+
// Also test [[]] attribute syntax. (On a non-nested declaration, these
// generate a hard "misplaced attributes" error, which we test for
// elsewhere.)
diff --git a/clang/test/SemaCXX/attr-gnu.cpp b/clang/test/SemaCXX/attr-gnu.cpp
index c257c2b029127b..941d01a2e611a8 100644
--- a/clang/test/SemaCXX/attr-gnu.cpp
+++ b/clang/test/SemaCXX/attr-gnu.cpp
@@ -1,7 +1,8 @@
-// RUN: %clang_cc1 -std=gnu++17 -fsyntax-only -fms-compatibility -verify %s
-
-void f() {
- // GNU-style attributes are prohibited in this position.
+// RUN: %clang_cc1 -std=gnu++03 -fsyntax-only -fms-compatibility -Wno-c++11-extensions -Wno-c++17-extensions -verify %s
+// RUN: %clang_cc1 -std=gnu++17 -fsyntax-only -fms-compatibility -verify %s
+
+void f() {
+ // GNU-style attributes are prohibited in this position.
auto P = new int * __attribute__((vector_size(8))); // expected-error {{an attribute list cannot appear here}} \
// expected-error {{invalid vector element type 'int *'}}
@@ -47,13 +48,13 @@ void tuTest1(Tu<int> u); // expected-note {{candidate function not viable: no kn
void tuTest2(Tu3 u); // expected-note {{candidate function not viable: no known conversion from 'int' to 'Tu3' for 1st argument}}
void tu() {
int x = 2;
- tuTest1(x); // expected-error {{no matching function for call to 'tuTest1'}}
- tuTest2(x); // expected-error {{no matching function for call to 'tuTest2'}}
-}
-
-[[gnu::__const__]] int f2() { return 12; }
-[[__gnu__::__const__]] int f3() { return 12; }
-[[using __gnu__ : __const__]] int f4() { return 12; }
-
-static_assert(__has_cpp_attribute(gnu::__const__));
-static_assert(__has_cpp_attribute(__gnu__::__const__));
+ tuTest1(x); // expected-error {{no matching function for call to 'tuTest1'}}
+ tuTest2(x); // expected-error {{no matching function for call to 'tuTest2'}}
+}
+
+[[gnu::__const__]] int f2() { return 12; }
+[[__gnu__::__const__]] int f3() { return 12; }
+[[using __gnu__ : __const__]] int f4() { return 12; }
+
+static_assert(__has_cpp_attribute(gnu::__const__));
+static_assert(__has_cpp_attribute(__gnu__::__const__));
diff --git a/clang/test/SemaCXX/cxx03-cxx11-attr.cpp b/clang/test/SemaCXX/cxx03-cxx11-attr.cpp
new file mode 100644
index 00000000000000..5a273c8fe2534a
--- /dev/null
+++ b/clang/test/SemaCXX/cxx03-cxx11-attr.cpp
@@ -0,0 +1,9 @@
+// RUN: %clang_cc1 -std=c++03 -fsyntax-only %s
+
+// Ensure that __has_cpp_attribute and argument parsing work in C++03
+
+#if !__has_cpp_attribute(nodiscard)
+# error
+#endif
+
+[[gnu::assume_aligned(4)]] void* g() { return __nullptr; }
diff --git a/clang/utils/TableGen/ClangAttrEmitter.cpp b/clang/utils/TableGen/ClangAttrEmitter.cpp
index 935b9846990ee5..eb5c34d15693d7 100644
--- a/clang/utils/TableGen/ClangAttrEmitter.cpp
+++ b/clang/utils/TableGen/ClangAttrEmitter.cpp
@@ -3576,10 +3576,6 @@ static void GenerateHasAttrSpellingStringSwitch(
const Record *R = Attr->getValueAsDef("Target");
std::vector<StringRef> Arches = R->getValueAsListOfStrings("Arches");
GenerateTargetSpecificAttrChecks(R, Arches, Test, nullptr);
-
- // If this is the C++11 variety, also add in the LangOpts test.
- if (Variety == "CXX11")
- Test += " && LangOpts.CPlusPlus11";
} else if (!Attr->getValueAsListOfDefs("TargetSpecificSpellings").empty()) {
// Add target checks if this spelling is target-specific.
const std::vector<Record *> TargetSpellings =
@@ -3597,13 +3593,7 @@ static void GenerateHasAttrSpellingStringSwitch(
}
}
}
-
- if (Variety == "CXX11")
- Test += " && LangOpts.CPlusPlus11";
- } else if (Variety == "CXX11")
- // C++11 mode should be checked against LangOpts, which is presumed to be
- // present in the caller.
- Test = "LangOpts.CPlusPlus11";
+ }
std::string TestStr = !Test.empty()
? Test + " ? " + llvm::itostr(Version) + " : 0"
>From 3034632a2708f3b79aa30f895dc42f35569c3647 Mon Sep 17 00:00:00 2001
From: zhijian lin <zhijian at ca.ibm.com>
Date: Fri, 1 Mar 2024 09:21:11 -0500
Subject: [PATCH 248/406] [llvm-readobj] enable demangle option for the xcoff
object file (#78455)
enable `--demangle` option for the xcoff object file for llvm-readobj
---
llvm/docs/CommandGuide/llvm-readobj.rst | 14 +++++---
.../XCOFF/loader-section-relocation.test | 32 +++++++++++++------
.../XCOFF/loader-section-symbol.test | 13 ++++++--
.../tools/llvm-readobj/XCOFF/relocations.test | 22 ++++++++++---
.../tools/llvm-readobj/XCOFF/symbols.test | 9 ++++--
llvm/tools/llvm-readobj/XCOFFDumper.cpp | 22 ++++++++-----
6 files changed, 80 insertions(+), 32 deletions(-)
diff --git a/llvm/docs/CommandGuide/llvm-readobj.rst b/llvm/docs/CommandGuide/llvm-readobj.rst
index 09dabb28cfa71b..ca7fb253f00a0b 100644
--- a/llvm/docs/CommandGuide/llvm-readobj.rst
+++ b/llvm/docs/CommandGuide/llvm-readobj.rst
@@ -61,6 +61,11 @@ file formats.
Dump decompressed section content when used with ``-x`` or ``-p``.
If the section(s) are not compressed, they are displayed as is.
+.. option:: --demangle, -C
+
+ Display demangled symbol names in the output. This option is only for ELF and
+ XCOFF file formats.
+
.. option:: --expand-relocs
When used with :option:`--relocs`, display each relocation in an expanded
@@ -94,6 +99,11 @@ file formats.
Display the needed libraries.
+.. option:: --no-demangle
+
+ Do not demangle symbol names in the output. This option is only for ELF and
+ XCOFF file formats. The option is enabled by default.
+
.. option:: --relocations, --relocs, -r
Display the relocation entries in the file.
@@ -175,10 +185,6 @@ The following options are implemented only for the ELF file format.
Requires :option:`--bb-addr-map` to have an effect.
-.. option:: --demangle, -C
-
- Display demangled symbol names in the output.
-
.. option:: --dependent-libraries
Display the dependent libraries section.
diff --git a/llvm/test/tools/llvm-readobj/XCOFF/loader-section-relocation.test b/llvm/test/tools/llvm-readobj/XCOFF/loader-section-relocation.test
index 42eb897d073939..d03d07bd8b0cbe 100644
--- a/llvm/test/tools/llvm-readobj/XCOFF/loader-section-relocation.test
+++ b/llvm/test/tools/llvm-readobj/XCOFF/loader-section-relocation.test
@@ -2,18 +2,27 @@
# RUN: yaml2obj --docnum=1 %s -o %t_xcoff32.o
# RUN: yaml2obj --docnum=2 %s -o %t_xcoff64.o
-# RUN: llvm-readobj --loader-section-relocations --expand-relocs %t_xcoff32.o | FileCheck --check-prefixes=COMMON,EXPAND %s
-# RUN: llvm-readobj --loader-section-relocations --expand-relocs %t_xcoff64.o | FileCheck --check-prefixes=COMMON,EXPAND %s
-# RUN: llvm-readobj --loader-section-relocations %t_xcoff32.o | FileCheck --check-prefixes=COMMON,NOEXPAND32 %s
-# RUN: llvm-readobj --loader-section-relocations %t_xcoff64.o | FileCheck --check-prefixes=COMMON,NOEXPAND64 %s
+# RUN: llvm-readobj --loader-section-relocations --expand-relocs %t_xcoff32.o | FileCheck --check-prefixes=COMMON,EXPAND,NODEMANEXP %s
+# RUN: llvm-readobj --loader-section-relocations --expand-relocs %t_xcoff64.o | FileCheck --check-prefixes=COMMON,EXPAND,NODEMANEXP %s
+# RUN: llvm-readobj --loader-section-relocations %t_xcoff32.o | FileCheck --check-prefixes=COMMON,NOEXPAND32,NODEMAN32 %s
+# RUN: llvm-readobj --loader-section-relocations %t_xcoff64.o | FileCheck --check-prefixes=COMMON,NOEXPAND64,NODEMAN64 %s
+# RUN: llvm-readobj --loader-section-relocations --expand-relocs --no-demangle %t_xcoff32.o | FileCheck --check-prefixes=COMMON,EXPAND,NODEMANEXP %s
+# RUN: llvm-readobj --loader-section-relocations --expand-relocs --no-demangle %t_xcoff64.o | FileCheck --check-prefixes=COMMON,EXPAND,NODEMANEXP %s
+# RUN: llvm-readobj --loader-section-relocations --no-demangle %t_xcoff32.o | FileCheck --check-prefixes=COMMON,NOEXPAND32,NODEMAN32 %s
+# RUN: llvm-readobj --loader-section-relocations --no-demangle %t_xcoff64.o | FileCheck --check-prefixes=COMMON,NOEXPAND64,NODEMAN64 %s
+
+# RUN: llvm-readobj --loader-section-relocations --expand-relocs --demangle %t_xcoff32.o | FileCheck --check-prefixes=COMMON,EXPAND,DEMANEXP %s
+# RUN: llvm-readobj --loader-section-relocations --expand-relocs --demangle %t_xcoff64.o | FileCheck --check-prefixes=COMMON,EXPAND,DEMANEXP %s
+# RUN: llvm-readobj --loader-section-relocations --demangle %t_xcoff32.o | FileCheck --check-prefixes=COMMON,NOEXPAND32,DEMAN32 %s
+# RUN: llvm-readobj --loader-section-relocations --demangle %t_xcoff64.o | FileCheck --check-prefixes=COMMON,NOEXPAND64,DEMAN64 %s
--- !XCOFF
FileHeader:
MagicNumber: 0x1DF
Sections:
- Name: .loader
Flags: [ STYP_LOADER ]
- SectionData: "0000000100000001000000020000016D00000001000000A400000000000000506d79696e747661722000028000021105000000000000000020000294000000011f0000022000029c000000031f000002"
+ SectionData: "0000000100000001000000020000016D00000001000000A400000000000000505f5a3466756e63762000028000021105000000000000000020000294000000011f0000022000029c000000031f000002"
## ^------- -Version=1
## ^------- -NumberOfSymbolEntries=1
## ^------- -NumberOfRelocationEntries=2
@@ -22,7 +31,7 @@ Sections:
## ^------- -OffsetToImportFileIDs=0xA4
## ^------- -LengthOfStringTable=0
## ^------- -OffsetToStringTable=0
-## ^--------------- SymbolName=myintvar
+## ^--------------- SymbolName=_Z4funcv
## ^------- Value=0x20000280
## ^--- sectionNumber = 2
## ^- SymbolType=0x11
@@ -44,7 +53,7 @@ FileHeader:
Sections:
- Name: .loader
Flags: [ STYP_LOADER ]
- SectionData: "0000000200000001000000020000016D000000010000001200000000000000D000000000000000700000000000000038000000000000005000000001100003000000000200021105000000000000000000000000200002941f00000200000001000000002000029C1f0000020000000300096d79696e747661720000"
+ SectionData: "0000000200000001000000020000016D000000010000001200000000000000D000000000000000700000000000000038000000000000005000000001100003000000000200021105000000000000000000000000200002941f00000200000001000000002000029C1f0000020000000300095f5a3466756e63760000"
## ^------- -Version=2
## ^------- -NumberOfSymbolEntries=1
## ^------- -NumberOfRelocationEntries=2
@@ -76,10 +85,12 @@ Sections:
# COMMON-NEXT: Loader Section Relocations {
# NOEXPAND64-NEXT: Vaddr Type SecNum SymbolName (Index)
# NOEXPAND64-NEXT: 0x0000000020000294 0x1f00 (R_POS) 2 .data (1)
-# NOEXPAND64-NEXT: 0x000000002000029c 0x1f00 (R_POS) 2 myintvar (3)
+# NODEMAN64-NEXT: 0x000000002000029c 0x1f00 (R_POS) 2 _Z4funcv (3)
+# DEMAN64-NEXT: 0x000000002000029c 0x1f00 (R_POS) 2 func() (3)
# NOEXPAND32-NEXT: Vaddr Type SecNum SymbolName (Index)
# NOEXPAND32-NEXT: 0x20000294 0x1f00 (R_POS) 2 .data (1)
-# NOEXPAND32-NEXT: 0x2000029c 0x1f00 (R_POS) 2 myintvar (3)
+# NODEMAN32-NEXT: 0x2000029c 0x1f00 (R_POS) 2 _Z4funcv (3)
+# DEMAN32-NEXT: 0x2000029c 0x1f00 (R_POS) 2 func() (3)
# EXPAND-NEXT: Relocation {
# EXPAND-NEXT: Virtual Address: 0x20000294
# EXPAND-NEXT: Symbol: .data (1)
@@ -91,7 +102,8 @@ Sections:
# EXPAND-NEXT: }
# EXPAND-NEXT: Relocation {
# EXPAND-NEXT: Virtual Address: 0x2000029C
-# EXPAND-NEXT: Symbol: myintvar (3)
+# NODEMANEXP-NEXT: Symbol: _Z4funcv (3)
+# DEMANEXP-NEXT: Symbol: func() (3)
# EXPAND-NEXT: IsSigned: No
# EXPAND-NEXT: FixupBitValue: 0
# EXPAND-NEXT: Length: 32
diff --git a/llvm/test/tools/llvm-readobj/XCOFF/loader-section-symbol.test b/llvm/test/tools/llvm-readobj/XCOFF/loader-section-symbol.test
index 8f2b20ca814963..053c5b496f6217 100644
--- a/llvm/test/tools/llvm-readobj/XCOFF/loader-section-symbol.test
+++ b/llvm/test/tools/llvm-readobj/XCOFF/loader-section-symbol.test
@@ -6,10 +6,18 @@
# RUN: llvm-readobj --loader-section-symbols %t_xcoff32.o |\
# RUN: FileCheck %s --check-prefixes=CHECK32
+# RUN: llvm-readobj --loader-section-symbols --no-demangle %t_xcoff32.o |\
+# RUN: FileCheck %s --check-prefixes=CHECK32
+# RUN: llvm-readobj --loader-section-symbols --demangle %t_xcoff32.o |\
+# RUN: FileCheck %s --check-prefixes=CHECK32
# RUN: llvm-readobj --loader-section-symbols %t_xcoff32_invalid.o 2>&1 |\
# RUN: FileCheck -DFILE=%t_xcoff32_invalid.o %s --check-prefixes=CHECK32,WARN
# RUN: llvm-readobj --loader-section-symbols %t_xcoff64.o |\
-# RUN: FileCheck %s --check-prefixes=CHECK64
+# RUN: FileCheck %s --check-prefixes=CHECK64,NODEMAN64
+# RUN: llvm-readobj --loader-section-symbols --no-demangle %t_xcoff64.o |\
+# RUN: FileCheck %s --check-prefixes=CHECK64,NODEMAN64
+# RUN: llvm-readobj --loader-section-symbols --demangle %t_xcoff64.o |\
+# RUN: FileCheck %s --check-prefixes=CHECK64,DEMAN64
--- !XCOFF
FileHeader:
@@ -112,7 +120,8 @@ Sections:
# CHECK64-NEXT: ParameterTypeCheck: 0
# CHECK64-NEXT: }
# CHECK64-NEXT: Symbol {
-# CHECK64-NEXT: Name: _Z5func0v
+# NODEMAN64-NEXT: Name: _Z5func0v
+# DEMAN64-NEXT: Name: func0()
# CHECK64-NEXT: Virtual Address: 0x110000308
# CHECK64-NEXT: SectionNum: 2
# CHECK64-NEXT: SymbolType: 0x11
diff --git a/llvm/test/tools/llvm-readobj/XCOFF/relocations.test b/llvm/test/tools/llvm-readobj/XCOFF/relocations.test
index 9e327c4fbbdccd..917db8b05e48cd 100644
--- a/llvm/test/tools/llvm-readobj/XCOFF/relocations.test
+++ b/llvm/test/tools/llvm-readobj/XCOFF/relocations.test
@@ -2,9 +2,19 @@
# RUN: yaml2obj %s -o %t
# RUN: llvm-readobj --relocs --expand-relocs %t | \
-# RUN: FileCheck %s --strict-whitespace --match-full-lines --check-prefix=RELOCSEXP
+# RUN: FileCheck %s --strict-whitespace --check-prefixes=RELOCSEXP,NODEMANEXP
# RUN: llvm-readobj --relocs %t | \
-# RUN: FileCheck %s --strict-whitespace --match-full-lines --check-prefix=RELOCS
+# RUN: FileCheck %s --strict-whitespace --check-prefixes=RELOCS,NODEMAN
+
+# RUN: llvm-readobj --relocs --expand-relocs --no-demangle %t | \
+# RUN: FileCheck %s --strict-whitespace --check-prefixes=RELOCSEXP,NODEMANEXP
+# RUN: llvm-readobj --relocs --no-demangle %t | \
+# RUN: FileCheck %s --strict-whitespace --check-prefixes=RELOCS,NODEMAN
+
+# RUN: llvm-readobj --relocs --expand-relocs --demangle %t | \
+# RUN: FileCheck %s --strict-whitespace --check-prefixes=RELOCSEXP,DEMANEXP
+# RUN: llvm-readobj --relocs --demangle %t | \
+# RUN: FileCheck %s --strict-whitespace --check-prefixes=RELOCS,DEMAN
# RELOCSEXP:Relocations [
# RELOCSEXP-NEXT: Section (index: 1) .text {
@@ -28,7 +38,8 @@
# RELOCSEXP-NEXT: Section (index: 2) .data {
# RELOCSEXP-NEXT: Relocation {
# RELOCSEXP-NEXT: Virtual Address: 0x200
-# RELOCSEXP-NEXT: Symbol: bar (1)
+# NODEMANEXP-NEXT: Symbol: _Z3fwpv (1)
+# DEMANEXP-NEXT: Symbol: fwp() (1)
# RELOCSEXP-NEXT: IsSigned: No
# RELOCSEXP-NEXT: FixupBitValue: 0
# RELOCSEXP-NEXT: Length: 20
@@ -43,7 +54,8 @@
# RELOCS-NEXT: 0x100 R_REL foo(0) 0x14
# RELOCS-NEXT: }
# RELOCS-NEXT: Section (index: 2) .data {
-# RELOCS-NEXT: 0x200 R_TOC bar(1) 0x13
+# NODEMAN-NEXT: 0x200 R_TOC _Z3fwpv(1) 0x13
+# DEMAN-NEXT: 0x200 R_TOC fwp()(1) 0x13
# RELOCS-NEXT: }
# RELOCS-NEXT:]
@@ -73,6 +85,6 @@ Symbols:
- Name: foo
Value: 0x0
Section: .text
- - Name: bar
+ - Name: _Z3fwpv
Value: 0x80
Section: .data
diff --git a/llvm/test/tools/llvm-readobj/XCOFF/symbols.test b/llvm/test/tools/llvm-readobj/XCOFF/symbols.test
index 72ec8967cc9576..89439a3d0f02d4 100644
--- a/llvm/test/tools/llvm-readobj/XCOFF/symbols.test
+++ b/llvm/test/tools/llvm-readobj/XCOFF/symbols.test
@@ -2,7 +2,9 @@
## 32-bit XCOFF object file.
# RUN: yaml2obj %s -o %t
-# RUN: llvm-readobj --symbols %t | FileCheck --check-prefix=SYMBOL32 %s
+# RUN: llvm-readobj --symbols %t | FileCheck --check-prefixes=SYMBOL32,NODEMANGLE %s
+# RUN: llvm-readobj --symbols --no-demangle %t | FileCheck --check-prefixes=SYMBOL32,NODEMANGLE %s
+# RUN: llvm-readobj --symbols --demangle %t | FileCheck --check-prefixes=SYMBOL32,DEMANGLE %s
--- !XCOFF
FileHeader:
@@ -56,7 +58,7 @@ Symbols:
StabInfoIndex: 5
StabSectNum: 6
## The C_EXT symbol with a CSECT auxiliary entry.
- - Name: .fun1
+ - Name: ._Z5func1i
Value: 0x0
Section: .text
Type: 0x20
@@ -224,7 +226,8 @@ Symbols:
# SYMBOL32-NEXT: }
# SYMBOL32-NEXT: Symbol {
# SYMBOL32-NEXT: Index: 8
-# SYMBOL32-NEXT: Name: .fun1
+# NODEMANGLE-NEXT: Name: ._Z5func1i
+# DEMANGLE-NEXT: Name: .func1(int)
# SYMBOL32-NEXT: Value (RelocatableAddress): 0x0
# SYMBOL32-NEXT: Section: .text
# SYMBOL32-NEXT: Type: 0x20
diff --git a/llvm/tools/llvm-readobj/XCOFFDumper.cpp b/llvm/tools/llvm-readobj/XCOFFDumper.cpp
index e7f50e8a188416..46b510cfb06a3f 100644
--- a/llvm/tools/llvm-readobj/XCOFFDumper.cpp
+++ b/llvm/tools/llvm-readobj/XCOFFDumper.cpp
@@ -12,6 +12,7 @@
#include "ObjDumper.h"
#include "llvm-readobj.h"
+#include "llvm/Demangle/Demangle.h"
#include "llvm/Object/XCOFFObjectFile.h"
#include "llvm/Support/FormattedStream.h"
#include "llvm/Support/ScopedPrinter.h"
@@ -250,7 +251,8 @@ void XCOFFDumper::printLoaderSectionSymbolsHelper(uintptr_t LoaderSectionAddr) {
}
DictScope DS(W, "Symbol");
- W.printString("Name", SymbolNameOrErr.get());
+ StringRef SymbolName = SymbolNameOrErr.get();
+ W.printString("Name", opts::Demangle ? demangle(SymbolName) : SymbolName);
W.printHex("Virtual Address", LoadSecSymEntPtr->Value);
W.printNumber("SectionNum", LoadSecSymEntPtr->SectionNumber);
W.printHex("SymbolType", LoadSecSymEntPtr->SymbolType);
@@ -326,7 +328,8 @@ void XCOFFDumper::printLoaderSectionRelocationEntry(
uint8_t Info = Type >> 8;
W.printHex("Virtual Address", LoaderSecRelEntPtr->VirtualAddr);
- W.printNumber("Symbol", SymbolName, LoaderSecRelEntPtr->SymbolIndex);
+ W.printNumber("Symbol", opts::Demangle ? demangle(SymbolName) : SymbolName,
+ LoaderSecRelEntPtr->SymbolIndex);
W.printString("IsSigned", IsRelocationSigned(Info) ? "Yes" : "No");
W.printNumber("FixupBitValue", IsFixupIndicated(Info) ? 1 : 0);
W.printNumber("Length", GetRelocatedLength(Info));
@@ -340,8 +343,9 @@ void XCOFFDumper::printLoaderSectionRelocationEntry(
<< XCOFF::getRelocationTypeString(
static_cast<XCOFF::RelocationType>(Type))
<< ")" << format_decimal(LoaderSecRelEntPtr->SectionNum, 8)
- << " " << SymbolName << " ("
- << LoaderSecRelEntPtr->SymbolIndex << ")\n";
+ << " "
+ << (opts::Demangle ? demangle(SymbolName) : SymbolName)
+ << " (" << LoaderSecRelEntPtr->SymbolIndex << ")\n";
}
}
@@ -466,15 +470,17 @@ template <typename RelTy> void XCOFFDumper::printRelocation(RelTy Reloc) {
if (opts::ExpandRelocs) {
DictScope Group(W, "Relocation");
W.printHex("Virtual Address", Reloc.VirtualAddress);
- W.printNumber("Symbol", SymbolName, Reloc.SymbolIndex);
+ W.printNumber("Symbol", opts::Demangle ? demangle(SymbolName) : SymbolName,
+ Reloc.SymbolIndex);
W.printString("IsSigned", Reloc.isRelocationSigned() ? "Yes" : "No");
W.printNumber("FixupBitValue", Reloc.isFixupIndicated() ? 1 : 0);
W.printNumber("Length", Reloc.getRelocatedLength());
W.printEnum("Type", (uint8_t)Reloc.Type, ArrayRef(RelocationTypeNameclass));
} else {
raw_ostream &OS = W.startLine();
- OS << W.hex(Reloc.VirtualAddress) << " " << RelocName << " " << SymbolName
- << "(" << Reloc.SymbolIndex << ") " << W.hex(Reloc.Info) << "\n";
+ OS << W.hex(Reloc.VirtualAddress) << " " << RelocName << " "
+ << (opts::Demangle ? demangle(SymbolName) : SymbolName) << "("
+ << Reloc.SymbolIndex << ") " << W.hex(Reloc.Info) << "\n";
}
}
@@ -752,7 +758,7 @@ void XCOFFDumper::printSymbol(const SymbolRef &S) {
XCOFF::StorageClass SymbolClass = SymbolEntRef.getStorageClass();
W.printNumber("Index", SymbolIdx);
- W.printString("Name", SymbolName);
+ W.printString("Name", opts::Demangle ? demangle(SymbolName) : SymbolName);
W.printHex(GetSymbolValueName(SymbolClass), SymbolEntRef.getValue());
StringRef SectionName =
>From 18d2ff4be7898eaf666564dcca07ad6bd38ababf Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?Timm=20B=C3=A4der?= <tbaeder at redhat.com>
Date: Fri, 1 Mar 2024 11:14:08 +0100
Subject: [PATCH 249/406] [clang][Interp] Allow recursive intepretation
This shouldn't be a problem in general, but we used to have some
sanity checks that prevented it from working. Remove those and
only do them on the non-recursive calls instead.
---
clang/lib/AST/Interp/Context.cpp | 37 +++++++++++++++++++-------------
1 file changed, 22 insertions(+), 15 deletions(-)
diff --git a/clang/lib/AST/Interp/Context.cpp b/clang/lib/AST/Interp/Context.cpp
index b09019f3e65b79..0cec0d78326bd6 100644
--- a/clang/lib/AST/Interp/Context.cpp
+++ b/clang/lib/AST/Interp/Context.cpp
@@ -41,7 +41,7 @@ bool Context::isPotentialConstantExpr(State &Parent, const FunctionDecl *FD) {
}
bool Context::evaluateAsRValue(State &Parent, const Expr *E, APValue &Result) {
- assert(Stk.empty());
+ bool Recursing = !Stk.empty();
ByteCodeExprGen<EvalEmitter> C(*this, *P, Parent, Stk, Result);
auto Res = C.interpretExpr(E, /*ConvertResultToRValue=*/E->isGLValue());
@@ -51,12 +51,14 @@ bool Context::evaluateAsRValue(State &Parent, const Expr *E, APValue &Result) {
return false;
}
- assert(Stk.empty());
+ if (!Recursing) {
+ assert(Stk.empty());
#ifndef NDEBUG
- // Make sure we don't rely on some value being still alive in
- // InterpStack memory.
- Stk.clear();
+ // Make sure we don't rely on some value being still alive in
+ // InterpStack memory.
+ Stk.clear();
#endif
+ }
Result = Res.toAPValue();
@@ -64,7 +66,7 @@ bool Context::evaluateAsRValue(State &Parent, const Expr *E, APValue &Result) {
}
bool Context::evaluate(State &Parent, const Expr *E, APValue &Result) {
- assert(Stk.empty());
+ bool Recursing = !Stk.empty();
ByteCodeExprGen<EvalEmitter> C(*this, *P, Parent, Stk, Result);
auto Res = C.interpretExpr(E);
@@ -73,19 +75,22 @@ bool Context::evaluate(State &Parent, const Expr *E, APValue &Result) {
return false;
}
- assert(Stk.empty());
+ if (!Recursing) {
+ assert(Stk.empty());
#ifndef NDEBUG
- // Make sure we don't rely on some value being still alive in
- // InterpStack memory.
- Stk.clear();
+ // Make sure we don't rely on some value being still alive in
+ // InterpStack memory.
+ Stk.clear();
#endif
+ }
+
Result = Res.toAPValue();
return true;
}
bool Context::evaluateAsInitializer(State &Parent, const VarDecl *VD,
APValue &Result) {
- assert(Stk.empty());
+ bool Recursing = !Stk.empty();
ByteCodeExprGen<EvalEmitter> C(*this, *P, Parent, Stk, Result);
bool CheckGlobalInitialized =
@@ -97,12 +102,14 @@ bool Context::evaluateAsInitializer(State &Parent, const VarDecl *VD,
return false;
}
- assert(Stk.empty());
+ if (!Recursing) {
+ assert(Stk.empty());
#ifndef NDEBUG
- // Make sure we don't rely on some value being still alive in
- // InterpStack memory.
- Stk.clear();
+ // Make sure we don't rely on some value being still alive in
+ // InterpStack memory.
+ Stk.clear();
#endif
+ }
Result = Res.toAPValue();
return true;
>From dbf3d779bdb3cc22652b6ab24ac9827e9f228f4e Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?Timm=20B=C3=A4der?= <tbaeder at redhat.com>
Date: Fri, 1 Mar 2024 15:27:39 +0100
Subject: [PATCH 250/406] [clang][Interp][NFC] Remove unused paramter
We manage the Result through EvaluationResult now.
---
clang/lib/AST/Interp/Context.cpp | 6 +++---
clang/lib/AST/Interp/EvalEmitter.cpp | 2 +-
clang/lib/AST/Interp/EvalEmitter.h | 3 +--
3 files changed, 5 insertions(+), 6 deletions(-)
diff --git a/clang/lib/AST/Interp/Context.cpp b/clang/lib/AST/Interp/Context.cpp
index 0cec0d78326bd6..6121395f5fc4fd 100644
--- a/clang/lib/AST/Interp/Context.cpp
+++ b/clang/lib/AST/Interp/Context.cpp
@@ -42,7 +42,7 @@ bool Context::isPotentialConstantExpr(State &Parent, const FunctionDecl *FD) {
bool Context::evaluateAsRValue(State &Parent, const Expr *E, APValue &Result) {
bool Recursing = !Stk.empty();
- ByteCodeExprGen<EvalEmitter> C(*this, *P, Parent, Stk, Result);
+ ByteCodeExprGen<EvalEmitter> C(*this, *P, Parent, Stk);
auto Res = C.interpretExpr(E, /*ConvertResultToRValue=*/E->isGLValue());
@@ -67,7 +67,7 @@ bool Context::evaluateAsRValue(State &Parent, const Expr *E, APValue &Result) {
bool Context::evaluate(State &Parent, const Expr *E, APValue &Result) {
bool Recursing = !Stk.empty();
- ByteCodeExprGen<EvalEmitter> C(*this, *P, Parent, Stk, Result);
+ ByteCodeExprGen<EvalEmitter> C(*this, *P, Parent, Stk);
auto Res = C.interpretExpr(E);
if (Res.isInvalid()) {
@@ -91,7 +91,7 @@ bool Context::evaluate(State &Parent, const Expr *E, APValue &Result) {
bool Context::evaluateAsInitializer(State &Parent, const VarDecl *VD,
APValue &Result) {
bool Recursing = !Stk.empty();
- ByteCodeExprGen<EvalEmitter> C(*this, *P, Parent, Stk, Result);
+ ByteCodeExprGen<EvalEmitter> C(*this, *P, Parent, Stk);
bool CheckGlobalInitialized =
shouldBeGloballyIndexed(VD) &&
diff --git a/clang/lib/AST/Interp/EvalEmitter.cpp b/clang/lib/AST/Interp/EvalEmitter.cpp
index c9c2bf9b145b22..bfd502d21b4cec 100644
--- a/clang/lib/AST/Interp/EvalEmitter.cpp
+++ b/clang/lib/AST/Interp/EvalEmitter.cpp
@@ -18,7 +18,7 @@ using namespace clang;
using namespace clang::interp;
EvalEmitter::EvalEmitter(Context &Ctx, Program &P, State &Parent,
- InterpStack &Stk, APValue &Result)
+ InterpStack &Stk)
: Ctx(Ctx), P(P), S(Parent, P, Stk, Ctx, this), EvalResult(&Ctx) {
// Create a dummy frame for the interpreter which does not have locals.
S.Current =
diff --git a/clang/lib/AST/Interp/EvalEmitter.h b/clang/lib/AST/Interp/EvalEmitter.h
index 032c8860ee677a..5b02b992fef6f7 100644
--- a/clang/lib/AST/Interp/EvalEmitter.h
+++ b/clang/lib/AST/Interp/EvalEmitter.h
@@ -41,8 +41,7 @@ class EvalEmitter : public SourceMapper {
InterpState &getState() { return S; }
protected:
- EvalEmitter(Context &Ctx, Program &P, State &Parent, InterpStack &Stk,
- APValue &Result);
+ EvalEmitter(Context &Ctx, Program &P, State &Parent, InterpStack &Stk);
virtual ~EvalEmitter();
>From 765a5d62bc59971d267a9effee2bfc0cee036182 Mon Sep 17 00:00:00 2001
From: Simon Pilgrim <RKSimon at users.noreply.github.com>
Date: Fri, 1 Mar 2024 14:29:12 +0000
Subject: [PATCH 251/406] [X86] Pre-SSE42 v2i64 sgt lowering - check if
representable as v2i32 (#83560)
Without PCMPGTQ, if the i64 elements are sign-extended enough to be representable as i32 then we can compare the lower i32 bits with PCMPGTD and splat the results into the upper elements.
Value tracking has meant we already get pretty close with this, but this allows us to remove a lot of unnecessary bit flipping.
---
llvm/lib/Target/X86/X86ISelLowering.cpp | 14 +
.../CodeGen/X86/vector-popcnt-128-ult-ugt.ll | 976 +++++-------------
2 files changed, 258 insertions(+), 732 deletions(-)
diff --git a/llvm/lib/Target/X86/X86ISelLowering.cpp b/llvm/lib/Target/X86/X86ISelLowering.cpp
index b807a97d6e4851..0162bb65afe3b0 100644
--- a/llvm/lib/Target/X86/X86ISelLowering.cpp
+++ b/llvm/lib/Target/X86/X86ISelLowering.cpp
@@ -23422,6 +23422,20 @@ static SDValue LowerVSETCC(SDValue Op, const X86Subtarget &Subtarget,
return DAG.getBitcast(VT, Result);
}
+ // If the i64 elements are sign-extended enough to be representable as i32
+ // then we can compare the lower i32 bits and splat.
+ if (!FlipSigns && !Invert && DAG.ComputeNumSignBits(Op0) > 32 &&
+ DAG.ComputeNumSignBits(Op1) > 32) {
+ Op0 = DAG.getBitcast(MVT::v4i32, Op0);
+ Op1 = DAG.getBitcast(MVT::v4i32, Op1);
+
+ SDValue GT = DAG.getNode(X86ISD::PCMPGT, dl, MVT::v4i32, Op0, Op1);
+ static const int MaskLo[] = {0, 0, 2, 2};
+ SDValue Result = DAG.getVectorShuffle(MVT::v4i32, dl, GT, GT, MaskLo);
+
+ return DAG.getBitcast(VT, Result);
+ }
+
// Since SSE has no unsigned integer comparisons, we need to flip the sign
// bits of the inputs before performing those operations. The lower
// compare is always unsigned.
diff --git a/llvm/test/CodeGen/X86/vector-popcnt-128-ult-ugt.ll b/llvm/test/CodeGen/X86/vector-popcnt-128-ult-ugt.ll
index 8aafec7427b4f3..c3d5a4b32edbc7 100644
--- a/llvm/test/CodeGen/X86/vector-popcnt-128-ult-ugt.ll
+++ b/llvm/test/CodeGen/X86/vector-popcnt-128-ult-ugt.ll
@@ -16972,7 +16972,6 @@ define <2 x i64> @ugt_2_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -16995,7 +16994,6 @@ define <2 x i64> @ugt_2_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -17014,7 +17012,6 @@ define <2 x i64> @ugt_2_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -17033,7 +17030,6 @@ define <2 x i64> @ugt_2_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -17126,8 +17122,7 @@ define <2 x i64> @ult_3_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483651,2147483651,2147483651,2147483651]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [3,3,3,3]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -17150,8 +17145,7 @@ define <2 x i64> @ult_3_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483651,2147483651,2147483651,2147483651]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [3,3,3,3]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -17170,8 +17164,7 @@ define <2 x i64> @ult_3_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483651,2147483651,2147483651,2147483651]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [3,3,3,3]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -17190,8 +17183,7 @@ define <2 x i64> @ult_3_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483651,2147483651,2147483651,2147483651]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [3,3,3,3]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -17288,7 +17280,6 @@ define <2 x i64> @ugt_3_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -17311,7 +17302,6 @@ define <2 x i64> @ugt_3_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -17330,7 +17320,6 @@ define <2 x i64> @ugt_3_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -17349,7 +17338,6 @@ define <2 x i64> @ugt_3_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -17442,8 +17430,7 @@ define <2 x i64> @ult_4_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483652,2147483652,2147483652,2147483652]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [4,4,4,4]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -17466,8 +17453,7 @@ define <2 x i64> @ult_4_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483652,2147483652,2147483652,2147483652]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [4,4,4,4]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -17486,8 +17472,7 @@ define <2 x i64> @ult_4_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483652,2147483652,2147483652,2147483652]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [4,4,4,4]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -17506,8 +17491,7 @@ define <2 x i64> @ult_4_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483652,2147483652,2147483652,2147483652]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [4,4,4,4]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -17604,7 +17588,6 @@ define <2 x i64> @ugt_4_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -17627,7 +17610,6 @@ define <2 x i64> @ugt_4_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -17646,7 +17628,6 @@ define <2 x i64> @ugt_4_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -17665,7 +17646,6 @@ define <2 x i64> @ugt_4_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -17758,8 +17738,7 @@ define <2 x i64> @ult_5_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483653,2147483653,2147483653,2147483653]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [5,5,5,5]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -17782,8 +17761,7 @@ define <2 x i64> @ult_5_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483653,2147483653,2147483653,2147483653]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [5,5,5,5]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -17802,8 +17780,7 @@ define <2 x i64> @ult_5_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483653,2147483653,2147483653,2147483653]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [5,5,5,5]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -17822,8 +17799,7 @@ define <2 x i64> @ult_5_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483653,2147483653,2147483653,2147483653]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [5,5,5,5]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -17920,7 +17896,6 @@ define <2 x i64> @ugt_5_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -17943,7 +17918,6 @@ define <2 x i64> @ugt_5_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -17962,7 +17936,6 @@ define <2 x i64> @ugt_5_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -17981,7 +17954,6 @@ define <2 x i64> @ugt_5_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -18074,8 +18046,7 @@ define <2 x i64> @ult_6_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483654,2147483654,2147483654,2147483654]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [6,6,6,6]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -18098,8 +18069,7 @@ define <2 x i64> @ult_6_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483654,2147483654,2147483654,2147483654]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [6,6,6,6]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -18118,8 +18088,7 @@ define <2 x i64> @ult_6_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483654,2147483654,2147483654,2147483654]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [6,6,6,6]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -18138,8 +18107,7 @@ define <2 x i64> @ult_6_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483654,2147483654,2147483654,2147483654]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [6,6,6,6]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -18236,7 +18204,6 @@ define <2 x i64> @ugt_6_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -18259,7 +18226,6 @@ define <2 x i64> @ugt_6_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -18278,7 +18244,6 @@ define <2 x i64> @ugt_6_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -18297,7 +18262,6 @@ define <2 x i64> @ugt_6_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -18390,8 +18354,7 @@ define <2 x i64> @ult_7_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483655,2147483655,2147483655,2147483655]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [7,7,7,7]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -18414,8 +18377,7 @@ define <2 x i64> @ult_7_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483655,2147483655,2147483655,2147483655]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [7,7,7,7]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -18434,8 +18396,7 @@ define <2 x i64> @ult_7_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483655,2147483655,2147483655,2147483655]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [7,7,7,7]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -18454,8 +18415,7 @@ define <2 x i64> @ult_7_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483655,2147483655,2147483655,2147483655]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [7,7,7,7]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -18552,7 +18512,6 @@ define <2 x i64> @ugt_7_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -18575,7 +18534,6 @@ define <2 x i64> @ugt_7_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -18594,7 +18552,6 @@ define <2 x i64> @ugt_7_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -18613,7 +18570,6 @@ define <2 x i64> @ugt_7_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -18706,8 +18662,7 @@ define <2 x i64> @ult_8_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483656,2147483656,2147483656,2147483656]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [8,8,8,8]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -18730,8 +18685,7 @@ define <2 x i64> @ult_8_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483656,2147483656,2147483656,2147483656]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [8,8,8,8]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -18750,8 +18704,7 @@ define <2 x i64> @ult_8_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483656,2147483656,2147483656,2147483656]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [8,8,8,8]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -18770,8 +18723,7 @@ define <2 x i64> @ult_8_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483656,2147483656,2147483656,2147483656]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [8,8,8,8]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -18868,7 +18820,6 @@ define <2 x i64> @ugt_8_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -18891,7 +18842,6 @@ define <2 x i64> @ugt_8_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -18910,7 +18860,6 @@ define <2 x i64> @ugt_8_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -18929,7 +18878,6 @@ define <2 x i64> @ugt_8_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -19022,8 +18970,7 @@ define <2 x i64> @ult_9_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483657,2147483657,2147483657,2147483657]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [9,9,9,9]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -19046,8 +18993,7 @@ define <2 x i64> @ult_9_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483657,2147483657,2147483657,2147483657]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [9,9,9,9]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -19066,8 +19012,7 @@ define <2 x i64> @ult_9_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483657,2147483657,2147483657,2147483657]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [9,9,9,9]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -19086,8 +19031,7 @@ define <2 x i64> @ult_9_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483657,2147483657,2147483657,2147483657]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [9,9,9,9]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -19184,7 +19128,6 @@ define <2 x i64> @ugt_9_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -19207,7 +19150,6 @@ define <2 x i64> @ugt_9_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -19226,7 +19168,6 @@ define <2 x i64> @ugt_9_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -19245,7 +19186,6 @@ define <2 x i64> @ugt_9_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -19338,8 +19278,7 @@ define <2 x i64> @ult_10_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483658,2147483658,2147483658,2147483658]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [10,10,10,10]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -19362,8 +19301,7 @@ define <2 x i64> @ult_10_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483658,2147483658,2147483658,2147483658]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [10,10,10,10]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -19382,8 +19320,7 @@ define <2 x i64> @ult_10_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483658,2147483658,2147483658,2147483658]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [10,10,10,10]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -19402,8 +19339,7 @@ define <2 x i64> @ult_10_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483658,2147483658,2147483658,2147483658]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [10,10,10,10]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -19500,7 +19436,6 @@ define <2 x i64> @ugt_10_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -19523,7 +19458,6 @@ define <2 x i64> @ugt_10_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -19542,7 +19476,6 @@ define <2 x i64> @ugt_10_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -19561,7 +19494,6 @@ define <2 x i64> @ugt_10_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -19654,8 +19586,7 @@ define <2 x i64> @ult_11_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483659,2147483659,2147483659,2147483659]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [11,11,11,11]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -19678,8 +19609,7 @@ define <2 x i64> @ult_11_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483659,2147483659,2147483659,2147483659]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [11,11,11,11]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -19698,8 +19628,7 @@ define <2 x i64> @ult_11_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483659,2147483659,2147483659,2147483659]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [11,11,11,11]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -19718,8 +19647,7 @@ define <2 x i64> @ult_11_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483659,2147483659,2147483659,2147483659]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [11,11,11,11]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -19816,7 +19744,6 @@ define <2 x i64> @ugt_11_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -19839,7 +19766,6 @@ define <2 x i64> @ugt_11_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -19858,7 +19784,6 @@ define <2 x i64> @ugt_11_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -19877,7 +19802,6 @@ define <2 x i64> @ugt_11_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -19970,8 +19894,7 @@ define <2 x i64> @ult_12_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483660,2147483660,2147483660,2147483660]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [12,12,12,12]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -19994,8 +19917,7 @@ define <2 x i64> @ult_12_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483660,2147483660,2147483660,2147483660]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [12,12,12,12]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -20014,8 +19936,7 @@ define <2 x i64> @ult_12_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483660,2147483660,2147483660,2147483660]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [12,12,12,12]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -20034,8 +19955,7 @@ define <2 x i64> @ult_12_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483660,2147483660,2147483660,2147483660]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [12,12,12,12]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -20132,7 +20052,6 @@ define <2 x i64> @ugt_12_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -20155,7 +20074,6 @@ define <2 x i64> @ugt_12_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -20174,7 +20092,6 @@ define <2 x i64> @ugt_12_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -20193,7 +20110,6 @@ define <2 x i64> @ugt_12_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -20286,8 +20202,7 @@ define <2 x i64> @ult_13_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483661,2147483661,2147483661,2147483661]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [13,13,13,13]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -20310,8 +20225,7 @@ define <2 x i64> @ult_13_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483661,2147483661,2147483661,2147483661]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [13,13,13,13]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -20330,8 +20244,7 @@ define <2 x i64> @ult_13_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483661,2147483661,2147483661,2147483661]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [13,13,13,13]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -20350,8 +20263,7 @@ define <2 x i64> @ult_13_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483661,2147483661,2147483661,2147483661]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [13,13,13,13]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -20448,7 +20360,6 @@ define <2 x i64> @ugt_13_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -20471,7 +20382,6 @@ define <2 x i64> @ugt_13_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -20490,7 +20400,6 @@ define <2 x i64> @ugt_13_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -20509,7 +20418,6 @@ define <2 x i64> @ugt_13_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -20602,8 +20510,7 @@ define <2 x i64> @ult_14_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483662,2147483662,2147483662,2147483662]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [14,14,14,14]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -20626,8 +20533,7 @@ define <2 x i64> @ult_14_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483662,2147483662,2147483662,2147483662]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [14,14,14,14]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -20646,8 +20552,7 @@ define <2 x i64> @ult_14_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483662,2147483662,2147483662,2147483662]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [14,14,14,14]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -20666,8 +20571,7 @@ define <2 x i64> @ult_14_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483662,2147483662,2147483662,2147483662]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [14,14,14,14]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -20764,7 +20668,6 @@ define <2 x i64> @ugt_14_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -20787,7 +20690,6 @@ define <2 x i64> @ugt_14_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -20806,7 +20708,6 @@ define <2 x i64> @ugt_14_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -20825,7 +20726,6 @@ define <2 x i64> @ugt_14_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -20918,8 +20818,7 @@ define <2 x i64> @ult_15_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483663,2147483663,2147483663,2147483663]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [15,15,15,15]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -20942,8 +20841,7 @@ define <2 x i64> @ult_15_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483663,2147483663,2147483663,2147483663]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [15,15,15,15]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -20962,8 +20860,7 @@ define <2 x i64> @ult_15_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483663,2147483663,2147483663,2147483663]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [15,15,15,15]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -20982,8 +20879,7 @@ define <2 x i64> @ult_15_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483663,2147483663,2147483663,2147483663]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [15,15,15,15]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -21080,7 +20976,6 @@ define <2 x i64> @ugt_15_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -21103,7 +20998,6 @@ define <2 x i64> @ugt_15_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -21122,7 +21016,6 @@ define <2 x i64> @ugt_15_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -21141,7 +21034,6 @@ define <2 x i64> @ugt_15_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -21234,8 +21126,7 @@ define <2 x i64> @ult_16_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483664,2147483664,2147483664,2147483664]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [16,16,16,16]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -21258,8 +21149,7 @@ define <2 x i64> @ult_16_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483664,2147483664,2147483664,2147483664]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [16,16,16,16]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -21278,8 +21168,7 @@ define <2 x i64> @ult_16_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483664,2147483664,2147483664,2147483664]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [16,16,16,16]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -21298,8 +21187,7 @@ define <2 x i64> @ult_16_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483664,2147483664,2147483664,2147483664]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [16,16,16,16]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -21396,7 +21284,6 @@ define <2 x i64> @ugt_16_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -21419,7 +21306,6 @@ define <2 x i64> @ugt_16_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -21438,7 +21324,6 @@ define <2 x i64> @ugt_16_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -21457,7 +21342,6 @@ define <2 x i64> @ugt_16_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -21550,8 +21434,7 @@ define <2 x i64> @ult_17_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483665,2147483665,2147483665,2147483665]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [17,17,17,17]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -21574,8 +21457,7 @@ define <2 x i64> @ult_17_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483665,2147483665,2147483665,2147483665]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [17,17,17,17]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -21594,8 +21476,7 @@ define <2 x i64> @ult_17_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483665,2147483665,2147483665,2147483665]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [17,17,17,17]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -21614,8 +21495,7 @@ define <2 x i64> @ult_17_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483665,2147483665,2147483665,2147483665]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [17,17,17,17]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -21712,7 +21592,6 @@ define <2 x i64> @ugt_17_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -21735,7 +21614,6 @@ define <2 x i64> @ugt_17_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -21754,7 +21632,6 @@ define <2 x i64> @ugt_17_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -21773,7 +21650,6 @@ define <2 x i64> @ugt_17_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -21866,8 +21742,7 @@ define <2 x i64> @ult_18_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483666,2147483666,2147483666,2147483666]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [18,18,18,18]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -21890,8 +21765,7 @@ define <2 x i64> @ult_18_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483666,2147483666,2147483666,2147483666]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [18,18,18,18]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -21910,8 +21784,7 @@ define <2 x i64> @ult_18_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483666,2147483666,2147483666,2147483666]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [18,18,18,18]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -21930,8 +21803,7 @@ define <2 x i64> @ult_18_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483666,2147483666,2147483666,2147483666]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [18,18,18,18]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -22028,7 +21900,6 @@ define <2 x i64> @ugt_18_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -22051,7 +21922,6 @@ define <2 x i64> @ugt_18_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -22070,7 +21940,6 @@ define <2 x i64> @ugt_18_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -22089,7 +21958,6 @@ define <2 x i64> @ugt_18_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -22182,8 +22050,7 @@ define <2 x i64> @ult_19_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483667,2147483667,2147483667,2147483667]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [19,19,19,19]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -22206,8 +22073,7 @@ define <2 x i64> @ult_19_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483667,2147483667,2147483667,2147483667]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [19,19,19,19]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -22226,8 +22092,7 @@ define <2 x i64> @ult_19_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483667,2147483667,2147483667,2147483667]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [19,19,19,19]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -22246,8 +22111,7 @@ define <2 x i64> @ult_19_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483667,2147483667,2147483667,2147483667]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [19,19,19,19]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -22344,7 +22208,6 @@ define <2 x i64> @ugt_19_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -22367,7 +22230,6 @@ define <2 x i64> @ugt_19_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -22386,7 +22248,6 @@ define <2 x i64> @ugt_19_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -22405,7 +22266,6 @@ define <2 x i64> @ugt_19_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -22498,8 +22358,7 @@ define <2 x i64> @ult_20_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483668,2147483668,2147483668,2147483668]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [20,20,20,20]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -22522,8 +22381,7 @@ define <2 x i64> @ult_20_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483668,2147483668,2147483668,2147483668]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [20,20,20,20]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -22542,8 +22400,7 @@ define <2 x i64> @ult_20_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483668,2147483668,2147483668,2147483668]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [20,20,20,20]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -22562,8 +22419,7 @@ define <2 x i64> @ult_20_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483668,2147483668,2147483668,2147483668]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [20,20,20,20]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -22660,7 +22516,6 @@ define <2 x i64> @ugt_20_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -22683,7 +22538,6 @@ define <2 x i64> @ugt_20_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -22702,7 +22556,6 @@ define <2 x i64> @ugt_20_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -22721,7 +22574,6 @@ define <2 x i64> @ugt_20_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -22814,8 +22666,7 @@ define <2 x i64> @ult_21_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483669,2147483669,2147483669,2147483669]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [21,21,21,21]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -22838,8 +22689,7 @@ define <2 x i64> @ult_21_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483669,2147483669,2147483669,2147483669]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [21,21,21,21]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -22858,8 +22708,7 @@ define <2 x i64> @ult_21_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483669,2147483669,2147483669,2147483669]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [21,21,21,21]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -22878,8 +22727,7 @@ define <2 x i64> @ult_21_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483669,2147483669,2147483669,2147483669]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [21,21,21,21]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -22976,7 +22824,6 @@ define <2 x i64> @ugt_21_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -22999,7 +22846,6 @@ define <2 x i64> @ugt_21_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -23018,7 +22864,6 @@ define <2 x i64> @ugt_21_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -23037,7 +22882,6 @@ define <2 x i64> @ugt_21_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -23130,8 +22974,7 @@ define <2 x i64> @ult_22_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483670,2147483670,2147483670,2147483670]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [22,22,22,22]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -23154,8 +22997,7 @@ define <2 x i64> @ult_22_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483670,2147483670,2147483670,2147483670]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [22,22,22,22]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -23174,8 +23016,7 @@ define <2 x i64> @ult_22_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483670,2147483670,2147483670,2147483670]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [22,22,22,22]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -23194,8 +23035,7 @@ define <2 x i64> @ult_22_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483670,2147483670,2147483670,2147483670]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [22,22,22,22]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -23292,7 +23132,6 @@ define <2 x i64> @ugt_22_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -23315,7 +23154,6 @@ define <2 x i64> @ugt_22_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -23334,7 +23172,6 @@ define <2 x i64> @ugt_22_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -23353,7 +23190,6 @@ define <2 x i64> @ugt_22_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -23446,8 +23282,7 @@ define <2 x i64> @ult_23_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483671,2147483671,2147483671,2147483671]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [23,23,23,23]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -23470,8 +23305,7 @@ define <2 x i64> @ult_23_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483671,2147483671,2147483671,2147483671]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [23,23,23,23]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -23490,8 +23324,7 @@ define <2 x i64> @ult_23_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483671,2147483671,2147483671,2147483671]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [23,23,23,23]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -23510,8 +23343,7 @@ define <2 x i64> @ult_23_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483671,2147483671,2147483671,2147483671]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [23,23,23,23]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -23608,7 +23440,6 @@ define <2 x i64> @ugt_23_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -23631,7 +23462,6 @@ define <2 x i64> @ugt_23_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -23650,7 +23480,6 @@ define <2 x i64> @ugt_23_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -23669,7 +23498,6 @@ define <2 x i64> @ugt_23_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -23762,8 +23590,7 @@ define <2 x i64> @ult_24_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483672,2147483672,2147483672,2147483672]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [24,24,24,24]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -23786,8 +23613,7 @@ define <2 x i64> @ult_24_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483672,2147483672,2147483672,2147483672]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [24,24,24,24]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -23806,8 +23632,7 @@ define <2 x i64> @ult_24_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483672,2147483672,2147483672,2147483672]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [24,24,24,24]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -23826,8 +23651,7 @@ define <2 x i64> @ult_24_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483672,2147483672,2147483672,2147483672]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [24,24,24,24]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -23924,7 +23748,6 @@ define <2 x i64> @ugt_24_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -23947,7 +23770,6 @@ define <2 x i64> @ugt_24_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -23966,7 +23788,6 @@ define <2 x i64> @ugt_24_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -23985,7 +23806,6 @@ define <2 x i64> @ugt_24_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -24078,8 +23898,7 @@ define <2 x i64> @ult_25_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483673,2147483673,2147483673,2147483673]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [25,25,25,25]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -24102,8 +23921,7 @@ define <2 x i64> @ult_25_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483673,2147483673,2147483673,2147483673]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [25,25,25,25]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -24122,8 +23940,7 @@ define <2 x i64> @ult_25_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483673,2147483673,2147483673,2147483673]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [25,25,25,25]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -24142,8 +23959,7 @@ define <2 x i64> @ult_25_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483673,2147483673,2147483673,2147483673]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [25,25,25,25]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -24240,7 +24056,6 @@ define <2 x i64> @ugt_25_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -24263,7 +24078,6 @@ define <2 x i64> @ugt_25_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -24282,7 +24096,6 @@ define <2 x i64> @ugt_25_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -24301,7 +24114,6 @@ define <2 x i64> @ugt_25_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -24394,8 +24206,7 @@ define <2 x i64> @ult_26_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483674,2147483674,2147483674,2147483674]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [26,26,26,26]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -24418,8 +24229,7 @@ define <2 x i64> @ult_26_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483674,2147483674,2147483674,2147483674]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [26,26,26,26]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -24438,8 +24248,7 @@ define <2 x i64> @ult_26_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483674,2147483674,2147483674,2147483674]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [26,26,26,26]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -24458,8 +24267,7 @@ define <2 x i64> @ult_26_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483674,2147483674,2147483674,2147483674]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [26,26,26,26]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -24556,7 +24364,6 @@ define <2 x i64> @ugt_26_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -24579,7 +24386,6 @@ define <2 x i64> @ugt_26_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -24598,7 +24404,6 @@ define <2 x i64> @ugt_26_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -24617,7 +24422,6 @@ define <2 x i64> @ugt_26_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -24710,8 +24514,7 @@ define <2 x i64> @ult_27_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483675,2147483675,2147483675,2147483675]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [27,27,27,27]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -24734,8 +24537,7 @@ define <2 x i64> @ult_27_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483675,2147483675,2147483675,2147483675]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [27,27,27,27]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -24754,8 +24556,7 @@ define <2 x i64> @ult_27_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483675,2147483675,2147483675,2147483675]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [27,27,27,27]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -24774,8 +24575,7 @@ define <2 x i64> @ult_27_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483675,2147483675,2147483675,2147483675]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [27,27,27,27]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -24872,7 +24672,6 @@ define <2 x i64> @ugt_27_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -24895,7 +24694,6 @@ define <2 x i64> @ugt_27_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -24914,7 +24712,6 @@ define <2 x i64> @ugt_27_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -24933,7 +24730,6 @@ define <2 x i64> @ugt_27_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -25026,8 +24822,7 @@ define <2 x i64> @ult_28_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483676,2147483676,2147483676,2147483676]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [28,28,28,28]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -25050,8 +24845,7 @@ define <2 x i64> @ult_28_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483676,2147483676,2147483676,2147483676]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [28,28,28,28]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -25070,8 +24864,7 @@ define <2 x i64> @ult_28_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483676,2147483676,2147483676,2147483676]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [28,28,28,28]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -25090,8 +24883,7 @@ define <2 x i64> @ult_28_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483676,2147483676,2147483676,2147483676]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [28,28,28,28]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -25188,7 +24980,6 @@ define <2 x i64> @ugt_28_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -25211,7 +25002,6 @@ define <2 x i64> @ugt_28_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -25230,7 +25020,6 @@ define <2 x i64> @ugt_28_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -25249,7 +25038,6 @@ define <2 x i64> @ugt_28_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -25342,8 +25130,7 @@ define <2 x i64> @ult_29_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483677,2147483677,2147483677,2147483677]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [29,29,29,29]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -25366,8 +25153,7 @@ define <2 x i64> @ult_29_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483677,2147483677,2147483677,2147483677]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [29,29,29,29]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -25386,8 +25172,7 @@ define <2 x i64> @ult_29_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483677,2147483677,2147483677,2147483677]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [29,29,29,29]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -25406,8 +25191,7 @@ define <2 x i64> @ult_29_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483677,2147483677,2147483677,2147483677]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [29,29,29,29]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -25504,7 +25288,6 @@ define <2 x i64> @ugt_29_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -25527,7 +25310,6 @@ define <2 x i64> @ugt_29_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -25546,7 +25328,6 @@ define <2 x i64> @ugt_29_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -25565,7 +25346,6 @@ define <2 x i64> @ugt_29_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -25658,8 +25438,7 @@ define <2 x i64> @ult_30_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483678,2147483678,2147483678,2147483678]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [30,30,30,30]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -25682,8 +25461,7 @@ define <2 x i64> @ult_30_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483678,2147483678,2147483678,2147483678]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [30,30,30,30]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -25702,8 +25480,7 @@ define <2 x i64> @ult_30_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483678,2147483678,2147483678,2147483678]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [30,30,30,30]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -25722,8 +25499,7 @@ define <2 x i64> @ult_30_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483678,2147483678,2147483678,2147483678]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [30,30,30,30]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -25820,7 +25596,6 @@ define <2 x i64> @ugt_30_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -25843,7 +25618,6 @@ define <2 x i64> @ugt_30_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -25862,7 +25636,6 @@ define <2 x i64> @ugt_30_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -25881,7 +25654,6 @@ define <2 x i64> @ugt_30_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -25974,8 +25746,7 @@ define <2 x i64> @ult_31_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483679,2147483679,2147483679,2147483679]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [31,31,31,31]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -25998,8 +25769,7 @@ define <2 x i64> @ult_31_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483679,2147483679,2147483679,2147483679]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [31,31,31,31]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -26018,8 +25788,7 @@ define <2 x i64> @ult_31_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483679,2147483679,2147483679,2147483679]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [31,31,31,31]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -26038,8 +25807,7 @@ define <2 x i64> @ult_31_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483679,2147483679,2147483679,2147483679]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [31,31,31,31]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -26136,7 +25904,6 @@ define <2 x i64> @ugt_31_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -26159,7 +25926,6 @@ define <2 x i64> @ugt_31_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -26178,7 +25944,6 @@ define <2 x i64> @ugt_31_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -26197,7 +25962,6 @@ define <2 x i64> @ugt_31_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -26290,8 +26054,7 @@ define <2 x i64> @ult_32_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483680,2147483680,2147483680,2147483680]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [32,32,32,32]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -26314,8 +26077,7 @@ define <2 x i64> @ult_32_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483680,2147483680,2147483680,2147483680]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [32,32,32,32]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -26334,8 +26096,7 @@ define <2 x i64> @ult_32_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483680,2147483680,2147483680,2147483680]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [32,32,32,32]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -26354,8 +26115,7 @@ define <2 x i64> @ult_32_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483680,2147483680,2147483680,2147483680]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [32,32,32,32]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -26452,7 +26212,6 @@ define <2 x i64> @ugt_32_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -26475,7 +26234,6 @@ define <2 x i64> @ugt_32_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -26494,7 +26252,6 @@ define <2 x i64> @ugt_32_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -26513,7 +26270,6 @@ define <2 x i64> @ugt_32_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -26606,8 +26362,7 @@ define <2 x i64> @ult_33_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483681,2147483681,2147483681,2147483681]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [33,33,33,33]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -26630,8 +26385,7 @@ define <2 x i64> @ult_33_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483681,2147483681,2147483681,2147483681]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [33,33,33,33]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -26650,8 +26404,7 @@ define <2 x i64> @ult_33_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483681,2147483681,2147483681,2147483681]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [33,33,33,33]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -26670,8 +26423,7 @@ define <2 x i64> @ult_33_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483681,2147483681,2147483681,2147483681]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [33,33,33,33]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -26768,7 +26520,6 @@ define <2 x i64> @ugt_33_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -26791,7 +26542,6 @@ define <2 x i64> @ugt_33_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -26810,7 +26560,6 @@ define <2 x i64> @ugt_33_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -26829,7 +26578,6 @@ define <2 x i64> @ugt_33_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -26922,8 +26670,7 @@ define <2 x i64> @ult_34_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483682,2147483682,2147483682,2147483682]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [34,34,34,34]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -26946,8 +26693,7 @@ define <2 x i64> @ult_34_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483682,2147483682,2147483682,2147483682]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [34,34,34,34]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -26966,8 +26712,7 @@ define <2 x i64> @ult_34_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483682,2147483682,2147483682,2147483682]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [34,34,34,34]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -26986,8 +26731,7 @@ define <2 x i64> @ult_34_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483682,2147483682,2147483682,2147483682]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [34,34,34,34]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -27084,7 +26828,6 @@ define <2 x i64> @ugt_34_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -27107,7 +26850,6 @@ define <2 x i64> @ugt_34_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -27126,7 +26868,6 @@ define <2 x i64> @ugt_34_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -27145,7 +26886,6 @@ define <2 x i64> @ugt_34_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -27238,8 +26978,7 @@ define <2 x i64> @ult_35_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483683,2147483683,2147483683,2147483683]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [35,35,35,35]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -27262,8 +27001,7 @@ define <2 x i64> @ult_35_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483683,2147483683,2147483683,2147483683]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [35,35,35,35]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -27282,8 +27020,7 @@ define <2 x i64> @ult_35_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483683,2147483683,2147483683,2147483683]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [35,35,35,35]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -27302,8 +27039,7 @@ define <2 x i64> @ult_35_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483683,2147483683,2147483683,2147483683]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [35,35,35,35]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -27400,7 +27136,6 @@ define <2 x i64> @ugt_35_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -27423,7 +27158,6 @@ define <2 x i64> @ugt_35_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -27442,7 +27176,6 @@ define <2 x i64> @ugt_35_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -27461,7 +27194,6 @@ define <2 x i64> @ugt_35_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -27554,8 +27286,7 @@ define <2 x i64> @ult_36_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483684,2147483684,2147483684,2147483684]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [36,36,36,36]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -27578,8 +27309,7 @@ define <2 x i64> @ult_36_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483684,2147483684,2147483684,2147483684]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [36,36,36,36]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -27598,8 +27328,7 @@ define <2 x i64> @ult_36_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483684,2147483684,2147483684,2147483684]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [36,36,36,36]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -27618,8 +27347,7 @@ define <2 x i64> @ult_36_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483684,2147483684,2147483684,2147483684]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [36,36,36,36]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -27716,7 +27444,6 @@ define <2 x i64> @ugt_36_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -27739,7 +27466,6 @@ define <2 x i64> @ugt_36_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -27758,7 +27484,6 @@ define <2 x i64> @ugt_36_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -27777,7 +27502,6 @@ define <2 x i64> @ugt_36_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -27870,8 +27594,7 @@ define <2 x i64> @ult_37_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483685,2147483685,2147483685,2147483685]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [37,37,37,37]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -27894,8 +27617,7 @@ define <2 x i64> @ult_37_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483685,2147483685,2147483685,2147483685]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [37,37,37,37]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -27914,8 +27636,7 @@ define <2 x i64> @ult_37_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483685,2147483685,2147483685,2147483685]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [37,37,37,37]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -27934,8 +27655,7 @@ define <2 x i64> @ult_37_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483685,2147483685,2147483685,2147483685]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [37,37,37,37]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -28032,7 +27752,6 @@ define <2 x i64> @ugt_37_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -28055,7 +27774,6 @@ define <2 x i64> @ugt_37_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -28074,7 +27792,6 @@ define <2 x i64> @ugt_37_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -28093,7 +27810,6 @@ define <2 x i64> @ugt_37_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -28186,8 +27902,7 @@ define <2 x i64> @ult_38_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483686,2147483686,2147483686,2147483686]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [38,38,38,38]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -28210,8 +27925,7 @@ define <2 x i64> @ult_38_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483686,2147483686,2147483686,2147483686]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [38,38,38,38]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -28230,8 +27944,7 @@ define <2 x i64> @ult_38_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483686,2147483686,2147483686,2147483686]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [38,38,38,38]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -28250,8 +27963,7 @@ define <2 x i64> @ult_38_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483686,2147483686,2147483686,2147483686]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [38,38,38,38]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -28348,7 +28060,6 @@ define <2 x i64> @ugt_38_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -28371,7 +28082,6 @@ define <2 x i64> @ugt_38_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -28390,7 +28100,6 @@ define <2 x i64> @ugt_38_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -28409,7 +28118,6 @@ define <2 x i64> @ugt_38_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -28502,8 +28210,7 @@ define <2 x i64> @ult_39_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483687,2147483687,2147483687,2147483687]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [39,39,39,39]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -28526,8 +28233,7 @@ define <2 x i64> @ult_39_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483687,2147483687,2147483687,2147483687]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [39,39,39,39]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -28546,8 +28252,7 @@ define <2 x i64> @ult_39_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483687,2147483687,2147483687,2147483687]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [39,39,39,39]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -28566,8 +28271,7 @@ define <2 x i64> @ult_39_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483687,2147483687,2147483687,2147483687]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [39,39,39,39]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -28664,7 +28368,6 @@ define <2 x i64> @ugt_39_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -28687,7 +28390,6 @@ define <2 x i64> @ugt_39_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -28706,7 +28408,6 @@ define <2 x i64> @ugt_39_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -28725,7 +28426,6 @@ define <2 x i64> @ugt_39_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -28818,8 +28518,7 @@ define <2 x i64> @ult_40_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483688,2147483688,2147483688,2147483688]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [40,40,40,40]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -28842,8 +28541,7 @@ define <2 x i64> @ult_40_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483688,2147483688,2147483688,2147483688]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [40,40,40,40]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -28862,8 +28560,7 @@ define <2 x i64> @ult_40_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483688,2147483688,2147483688,2147483688]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [40,40,40,40]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -28882,8 +28579,7 @@ define <2 x i64> @ult_40_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483688,2147483688,2147483688,2147483688]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [40,40,40,40]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -28980,7 +28676,6 @@ define <2 x i64> @ugt_40_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -29003,7 +28698,6 @@ define <2 x i64> @ugt_40_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -29022,7 +28716,6 @@ define <2 x i64> @ugt_40_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -29041,7 +28734,6 @@ define <2 x i64> @ugt_40_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -29134,8 +28826,7 @@ define <2 x i64> @ult_41_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483689,2147483689,2147483689,2147483689]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [41,41,41,41]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -29158,8 +28849,7 @@ define <2 x i64> @ult_41_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483689,2147483689,2147483689,2147483689]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [41,41,41,41]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -29178,8 +28868,7 @@ define <2 x i64> @ult_41_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483689,2147483689,2147483689,2147483689]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [41,41,41,41]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -29198,8 +28887,7 @@ define <2 x i64> @ult_41_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483689,2147483689,2147483689,2147483689]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [41,41,41,41]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -29296,7 +28984,6 @@ define <2 x i64> @ugt_41_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -29319,7 +29006,6 @@ define <2 x i64> @ugt_41_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -29338,7 +29024,6 @@ define <2 x i64> @ugt_41_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -29357,7 +29042,6 @@ define <2 x i64> @ugt_41_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -29450,8 +29134,7 @@ define <2 x i64> @ult_42_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483690,2147483690,2147483690,2147483690]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [42,42,42,42]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -29474,8 +29157,7 @@ define <2 x i64> @ult_42_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483690,2147483690,2147483690,2147483690]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [42,42,42,42]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -29494,8 +29176,7 @@ define <2 x i64> @ult_42_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483690,2147483690,2147483690,2147483690]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [42,42,42,42]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -29514,8 +29195,7 @@ define <2 x i64> @ult_42_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483690,2147483690,2147483690,2147483690]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [42,42,42,42]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -29612,7 +29292,6 @@ define <2 x i64> @ugt_42_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -29635,7 +29314,6 @@ define <2 x i64> @ugt_42_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -29654,7 +29332,6 @@ define <2 x i64> @ugt_42_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -29673,7 +29350,6 @@ define <2 x i64> @ugt_42_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -29766,8 +29442,7 @@ define <2 x i64> @ult_43_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483691,2147483691,2147483691,2147483691]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [43,43,43,43]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -29790,8 +29465,7 @@ define <2 x i64> @ult_43_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483691,2147483691,2147483691,2147483691]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [43,43,43,43]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -29810,8 +29484,7 @@ define <2 x i64> @ult_43_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483691,2147483691,2147483691,2147483691]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [43,43,43,43]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -29830,8 +29503,7 @@ define <2 x i64> @ult_43_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483691,2147483691,2147483691,2147483691]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [43,43,43,43]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -29928,7 +29600,6 @@ define <2 x i64> @ugt_43_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -29951,7 +29622,6 @@ define <2 x i64> @ugt_43_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -29970,7 +29640,6 @@ define <2 x i64> @ugt_43_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -29989,7 +29658,6 @@ define <2 x i64> @ugt_43_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -30082,8 +29750,7 @@ define <2 x i64> @ult_44_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483692,2147483692,2147483692,2147483692]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [44,44,44,44]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -30106,8 +29773,7 @@ define <2 x i64> @ult_44_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483692,2147483692,2147483692,2147483692]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [44,44,44,44]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -30126,8 +29792,7 @@ define <2 x i64> @ult_44_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483692,2147483692,2147483692,2147483692]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [44,44,44,44]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -30146,8 +29811,7 @@ define <2 x i64> @ult_44_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483692,2147483692,2147483692,2147483692]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [44,44,44,44]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -30244,7 +29908,6 @@ define <2 x i64> @ugt_44_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -30267,7 +29930,6 @@ define <2 x i64> @ugt_44_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -30286,7 +29948,6 @@ define <2 x i64> @ugt_44_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -30305,7 +29966,6 @@ define <2 x i64> @ugt_44_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -30398,8 +30058,7 @@ define <2 x i64> @ult_45_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483693,2147483693,2147483693,2147483693]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [45,45,45,45]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -30422,8 +30081,7 @@ define <2 x i64> @ult_45_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483693,2147483693,2147483693,2147483693]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [45,45,45,45]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -30442,8 +30100,7 @@ define <2 x i64> @ult_45_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483693,2147483693,2147483693,2147483693]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [45,45,45,45]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -30462,8 +30119,7 @@ define <2 x i64> @ult_45_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483693,2147483693,2147483693,2147483693]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [45,45,45,45]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -30560,7 +30216,6 @@ define <2 x i64> @ugt_45_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -30583,7 +30238,6 @@ define <2 x i64> @ugt_45_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -30602,7 +30256,6 @@ define <2 x i64> @ugt_45_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -30621,7 +30274,6 @@ define <2 x i64> @ugt_45_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -30714,8 +30366,7 @@ define <2 x i64> @ult_46_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483694,2147483694,2147483694,2147483694]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [46,46,46,46]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -30738,8 +30389,7 @@ define <2 x i64> @ult_46_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483694,2147483694,2147483694,2147483694]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [46,46,46,46]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -30758,8 +30408,7 @@ define <2 x i64> @ult_46_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483694,2147483694,2147483694,2147483694]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [46,46,46,46]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -30778,8 +30427,7 @@ define <2 x i64> @ult_46_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483694,2147483694,2147483694,2147483694]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [46,46,46,46]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -30876,7 +30524,6 @@ define <2 x i64> @ugt_46_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -30899,7 +30546,6 @@ define <2 x i64> @ugt_46_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -30918,7 +30564,6 @@ define <2 x i64> @ugt_46_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -30937,7 +30582,6 @@ define <2 x i64> @ugt_46_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -31030,8 +30674,7 @@ define <2 x i64> @ult_47_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483695,2147483695,2147483695,2147483695]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [47,47,47,47]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -31054,8 +30697,7 @@ define <2 x i64> @ult_47_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483695,2147483695,2147483695,2147483695]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [47,47,47,47]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -31074,8 +30716,7 @@ define <2 x i64> @ult_47_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483695,2147483695,2147483695,2147483695]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [47,47,47,47]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -31094,8 +30735,7 @@ define <2 x i64> @ult_47_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483695,2147483695,2147483695,2147483695]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [47,47,47,47]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -31192,7 +30832,6 @@ define <2 x i64> @ugt_47_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -31215,7 +30854,6 @@ define <2 x i64> @ugt_47_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -31234,7 +30872,6 @@ define <2 x i64> @ugt_47_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -31253,7 +30890,6 @@ define <2 x i64> @ugt_47_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -31346,8 +30982,7 @@ define <2 x i64> @ult_48_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483696,2147483696,2147483696,2147483696]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [48,48,48,48]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -31370,8 +31005,7 @@ define <2 x i64> @ult_48_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483696,2147483696,2147483696,2147483696]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [48,48,48,48]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -31390,8 +31024,7 @@ define <2 x i64> @ult_48_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483696,2147483696,2147483696,2147483696]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [48,48,48,48]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -31410,8 +31043,7 @@ define <2 x i64> @ult_48_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483696,2147483696,2147483696,2147483696]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [48,48,48,48]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -31508,7 +31140,6 @@ define <2 x i64> @ugt_48_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -31531,7 +31162,6 @@ define <2 x i64> @ugt_48_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -31550,7 +31180,6 @@ define <2 x i64> @ugt_48_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -31569,7 +31198,6 @@ define <2 x i64> @ugt_48_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -31662,8 +31290,7 @@ define <2 x i64> @ult_49_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483697,2147483697,2147483697,2147483697]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [49,49,49,49]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -31686,8 +31313,7 @@ define <2 x i64> @ult_49_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483697,2147483697,2147483697,2147483697]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [49,49,49,49]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -31706,8 +31332,7 @@ define <2 x i64> @ult_49_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483697,2147483697,2147483697,2147483697]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [49,49,49,49]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -31726,8 +31351,7 @@ define <2 x i64> @ult_49_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483697,2147483697,2147483697,2147483697]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [49,49,49,49]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -31824,7 +31448,6 @@ define <2 x i64> @ugt_49_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -31847,7 +31470,6 @@ define <2 x i64> @ugt_49_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -31866,7 +31488,6 @@ define <2 x i64> @ugt_49_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -31885,7 +31506,6 @@ define <2 x i64> @ugt_49_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -31978,8 +31598,7 @@ define <2 x i64> @ult_50_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483698,2147483698,2147483698,2147483698]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [50,50,50,50]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -32002,8 +31621,7 @@ define <2 x i64> @ult_50_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483698,2147483698,2147483698,2147483698]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [50,50,50,50]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -32022,8 +31640,7 @@ define <2 x i64> @ult_50_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483698,2147483698,2147483698,2147483698]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [50,50,50,50]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -32042,8 +31659,7 @@ define <2 x i64> @ult_50_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483698,2147483698,2147483698,2147483698]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [50,50,50,50]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -32140,7 +31756,6 @@ define <2 x i64> @ugt_50_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -32163,7 +31778,6 @@ define <2 x i64> @ugt_50_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -32182,7 +31796,6 @@ define <2 x i64> @ugt_50_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -32201,7 +31814,6 @@ define <2 x i64> @ugt_50_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -32294,8 +31906,7 @@ define <2 x i64> @ult_51_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483699,2147483699,2147483699,2147483699]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [51,51,51,51]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -32318,8 +31929,7 @@ define <2 x i64> @ult_51_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483699,2147483699,2147483699,2147483699]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [51,51,51,51]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -32338,8 +31948,7 @@ define <2 x i64> @ult_51_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483699,2147483699,2147483699,2147483699]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [51,51,51,51]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -32358,8 +31967,7 @@ define <2 x i64> @ult_51_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483699,2147483699,2147483699,2147483699]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [51,51,51,51]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -32456,7 +32064,6 @@ define <2 x i64> @ugt_51_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -32479,7 +32086,6 @@ define <2 x i64> @ugt_51_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -32498,7 +32104,6 @@ define <2 x i64> @ugt_51_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -32517,7 +32122,6 @@ define <2 x i64> @ugt_51_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -32610,8 +32214,7 @@ define <2 x i64> @ult_52_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483700,2147483700,2147483700,2147483700]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [52,52,52,52]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -32634,8 +32237,7 @@ define <2 x i64> @ult_52_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483700,2147483700,2147483700,2147483700]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [52,52,52,52]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -32654,8 +32256,7 @@ define <2 x i64> @ult_52_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483700,2147483700,2147483700,2147483700]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [52,52,52,52]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -32674,8 +32275,7 @@ define <2 x i64> @ult_52_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483700,2147483700,2147483700,2147483700]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [52,52,52,52]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -32772,7 +32372,6 @@ define <2 x i64> @ugt_52_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -32795,7 +32394,6 @@ define <2 x i64> @ugt_52_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -32814,7 +32412,6 @@ define <2 x i64> @ugt_52_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -32833,7 +32430,6 @@ define <2 x i64> @ugt_52_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -32926,8 +32522,7 @@ define <2 x i64> @ult_53_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483701,2147483701,2147483701,2147483701]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [53,53,53,53]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -32950,8 +32545,7 @@ define <2 x i64> @ult_53_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483701,2147483701,2147483701,2147483701]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [53,53,53,53]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -32970,8 +32564,7 @@ define <2 x i64> @ult_53_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483701,2147483701,2147483701,2147483701]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [53,53,53,53]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -32990,8 +32583,7 @@ define <2 x i64> @ult_53_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483701,2147483701,2147483701,2147483701]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [53,53,53,53]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -33088,7 +32680,6 @@ define <2 x i64> @ugt_53_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -33111,7 +32702,6 @@ define <2 x i64> @ugt_53_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -33130,7 +32720,6 @@ define <2 x i64> @ugt_53_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -33149,7 +32738,6 @@ define <2 x i64> @ugt_53_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -33242,8 +32830,7 @@ define <2 x i64> @ult_54_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483702,2147483702,2147483702,2147483702]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [54,54,54,54]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -33266,8 +32853,7 @@ define <2 x i64> @ult_54_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483702,2147483702,2147483702,2147483702]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [54,54,54,54]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -33286,8 +32872,7 @@ define <2 x i64> @ult_54_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483702,2147483702,2147483702,2147483702]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [54,54,54,54]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -33306,8 +32891,7 @@ define <2 x i64> @ult_54_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483702,2147483702,2147483702,2147483702]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [54,54,54,54]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -33404,7 +32988,6 @@ define <2 x i64> @ugt_54_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -33427,7 +33010,6 @@ define <2 x i64> @ugt_54_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -33446,7 +33028,6 @@ define <2 x i64> @ugt_54_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -33465,7 +33046,6 @@ define <2 x i64> @ugt_54_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -33558,8 +33138,7 @@ define <2 x i64> @ult_55_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483703,2147483703,2147483703,2147483703]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [55,55,55,55]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -33582,8 +33161,7 @@ define <2 x i64> @ult_55_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483703,2147483703,2147483703,2147483703]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [55,55,55,55]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -33602,8 +33180,7 @@ define <2 x i64> @ult_55_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483703,2147483703,2147483703,2147483703]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [55,55,55,55]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -33622,8 +33199,7 @@ define <2 x i64> @ult_55_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483703,2147483703,2147483703,2147483703]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [55,55,55,55]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -33720,7 +33296,6 @@ define <2 x i64> @ugt_55_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -33743,7 +33318,6 @@ define <2 x i64> @ugt_55_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -33762,7 +33336,6 @@ define <2 x i64> @ugt_55_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -33781,7 +33354,6 @@ define <2 x i64> @ugt_55_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -33874,8 +33446,7 @@ define <2 x i64> @ult_56_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483704,2147483704,2147483704,2147483704]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [56,56,56,56]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -33898,8 +33469,7 @@ define <2 x i64> @ult_56_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483704,2147483704,2147483704,2147483704]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [56,56,56,56]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -33918,8 +33488,7 @@ define <2 x i64> @ult_56_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483704,2147483704,2147483704,2147483704]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [56,56,56,56]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -33938,8 +33507,7 @@ define <2 x i64> @ult_56_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483704,2147483704,2147483704,2147483704]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [56,56,56,56]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -34036,7 +33604,6 @@ define <2 x i64> @ugt_56_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -34059,7 +33626,6 @@ define <2 x i64> @ugt_56_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -34078,7 +33644,6 @@ define <2 x i64> @ugt_56_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -34097,7 +33662,6 @@ define <2 x i64> @ugt_56_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -34190,8 +33754,7 @@ define <2 x i64> @ult_57_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483705,2147483705,2147483705,2147483705]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [57,57,57,57]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -34214,8 +33777,7 @@ define <2 x i64> @ult_57_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483705,2147483705,2147483705,2147483705]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [57,57,57,57]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -34234,8 +33796,7 @@ define <2 x i64> @ult_57_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483705,2147483705,2147483705,2147483705]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [57,57,57,57]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -34254,8 +33815,7 @@ define <2 x i64> @ult_57_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483705,2147483705,2147483705,2147483705]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [57,57,57,57]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -34352,7 +33912,6 @@ define <2 x i64> @ugt_57_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -34375,7 +33934,6 @@ define <2 x i64> @ugt_57_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -34394,7 +33952,6 @@ define <2 x i64> @ugt_57_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -34413,7 +33970,6 @@ define <2 x i64> @ugt_57_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -34506,8 +34062,7 @@ define <2 x i64> @ult_58_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483706,2147483706,2147483706,2147483706]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [58,58,58,58]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -34530,8 +34085,7 @@ define <2 x i64> @ult_58_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483706,2147483706,2147483706,2147483706]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [58,58,58,58]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -34550,8 +34104,7 @@ define <2 x i64> @ult_58_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483706,2147483706,2147483706,2147483706]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [58,58,58,58]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -34570,8 +34123,7 @@ define <2 x i64> @ult_58_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483706,2147483706,2147483706,2147483706]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [58,58,58,58]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -34668,7 +34220,6 @@ define <2 x i64> @ugt_58_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -34691,7 +34242,6 @@ define <2 x i64> @ugt_58_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -34710,7 +34260,6 @@ define <2 x i64> @ugt_58_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -34729,7 +34278,6 @@ define <2 x i64> @ugt_58_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -34822,8 +34370,7 @@ define <2 x i64> @ult_59_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483707,2147483707,2147483707,2147483707]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [59,59,59,59]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -34846,8 +34393,7 @@ define <2 x i64> @ult_59_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483707,2147483707,2147483707,2147483707]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [59,59,59,59]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -34866,8 +34412,7 @@ define <2 x i64> @ult_59_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483707,2147483707,2147483707,2147483707]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [59,59,59,59]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -34886,8 +34431,7 @@ define <2 x i64> @ult_59_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483707,2147483707,2147483707,2147483707]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [59,59,59,59]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -34984,7 +34528,6 @@ define <2 x i64> @ugt_59_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -35007,7 +34550,6 @@ define <2 x i64> @ugt_59_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -35026,7 +34568,6 @@ define <2 x i64> @ugt_59_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -35045,7 +34586,6 @@ define <2 x i64> @ugt_59_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -35138,8 +34678,7 @@ define <2 x i64> @ult_60_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483708,2147483708,2147483708,2147483708]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [60,60,60,60]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -35162,8 +34701,7 @@ define <2 x i64> @ult_60_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483708,2147483708,2147483708,2147483708]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [60,60,60,60]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -35182,8 +34720,7 @@ define <2 x i64> @ult_60_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483708,2147483708,2147483708,2147483708]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [60,60,60,60]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -35202,8 +34739,7 @@ define <2 x i64> @ult_60_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483708,2147483708,2147483708,2147483708]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [60,60,60,60]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -35300,7 +34836,6 @@ define <2 x i64> @ugt_60_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -35323,7 +34858,6 @@ define <2 x i64> @ugt_60_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -35342,7 +34876,6 @@ define <2 x i64> @ugt_60_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -35361,7 +34894,6 @@ define <2 x i64> @ugt_60_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -35454,8 +34986,7 @@ define <2 x i64> @ult_61_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483709,2147483709,2147483709,2147483709]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [61,61,61,61]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -35478,8 +35009,7 @@ define <2 x i64> @ult_61_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483709,2147483709,2147483709,2147483709]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [61,61,61,61]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -35498,8 +35028,7 @@ define <2 x i64> @ult_61_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483709,2147483709,2147483709,2147483709]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [61,61,61,61]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -35518,8 +35047,7 @@ define <2 x i64> @ult_61_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483709,2147483709,2147483709,2147483709]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [61,61,61,61]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -35616,7 +35144,6 @@ define <2 x i64> @ugt_61_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -35639,7 +35166,6 @@ define <2 x i64> @ugt_61_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -35658,7 +35184,6 @@ define <2 x i64> @ugt_61_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -35677,7 +35202,6 @@ define <2 x i64> @ugt_61_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -35770,8 +35294,7 @@ define <2 x i64> @ult_62_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483710,2147483710,2147483710,2147483710]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [62,62,62,62]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -35794,8 +35317,7 @@ define <2 x i64> @ult_62_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483710,2147483710,2147483710,2147483710]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [62,62,62,62]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -35814,8 +35336,7 @@ define <2 x i64> @ult_62_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483710,2147483710,2147483710,2147483710]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [62,62,62,62]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -35834,8 +35355,7 @@ define <2 x i64> @ult_62_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483710,2147483710,2147483710,2147483710]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [62,62,62,62]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
@@ -35932,7 +35452,6 @@ define <2 x i64> @ugt_62_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -35955,7 +35474,6 @@ define <2 x i64> @ugt_62_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE3-NEXT: retq
;
@@ -35974,7 +35492,6 @@ define <2 x i64> @ugt_62_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -35993,7 +35510,6 @@ define <2 x i64> @ugt_62_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm0 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: pcmpgtd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE41-NEXT: retq
;
@@ -36086,8 +35602,7 @@ define <2 x i64> @ult_63_v2i64(<2 x i64> %0) {
; SSE2-NEXT: pxor %xmm0, %xmm0
; SSE2-NEXT: psadbw %xmm1, %xmm0
; SSE2-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE2-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [2147483711,2147483711,2147483711,2147483711]
+; SSE2-NEXT: movdqa {{.*#+}} xmm0 = [63,63,63,63]
; SSE2-NEXT: pcmpgtd %xmm1, %xmm0
; SSE2-NEXT: retq
;
@@ -36110,8 +35625,7 @@ define <2 x i64> @ult_63_v2i64(<2 x i64> %0) {
; SSE3-NEXT: pxor %xmm0, %xmm0
; SSE3-NEXT: psadbw %xmm1, %xmm0
; SSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483711,2147483711,2147483711,2147483711]
+; SSE3-NEXT: movdqa {{.*#+}} xmm0 = [63,63,63,63]
; SSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSE3-NEXT: retq
;
@@ -36130,8 +35644,7 @@ define <2 x i64> @ult_63_v2i64(<2 x i64> %0) {
; SSSE3-NEXT: pxor %xmm0, %xmm0
; SSSE3-NEXT: psadbw %xmm3, %xmm0
; SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSSE3-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [2147483711,2147483711,2147483711,2147483711]
+; SSSE3-NEXT: movdqa {{.*#+}} xmm0 = [63,63,63,63]
; SSSE3-NEXT: pcmpgtd %xmm1, %xmm0
; SSSE3-NEXT: retq
;
@@ -36150,8 +35663,7 @@ define <2 x i64> @ult_63_v2i64(<2 x i64> %0) {
; SSE41-NEXT: pxor %xmm0, %xmm0
; SSE41-NEXT: psadbw %xmm3, %xmm0
; SSE41-NEXT: pshufd {{.*#+}} xmm1 = xmm0[0,0,2,2]
-; SSE41-NEXT: por {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1
-; SSE41-NEXT: movdqa {{.*#+}} xmm0 = [2147483711,2147483711,2147483711,2147483711]
+; SSE41-NEXT: pmovsxbd {{.*#+}} xmm0 = [63,63,63,63]
; SSE41-NEXT: pcmpgtd %xmm1, %xmm0
; SSE41-NEXT: retq
;
>From 6ecd26132bbb92cceeb92524bf880bd11a2d3033 Mon Sep 17 00:00:00 2001
From: Florian Hahn <flo at fhahn.com>
Date: Fri, 1 Mar 2024 14:30:01 +0000
Subject: [PATCH 252/406] [SLP] Use ScopeExit to update Operands/PrevDist on
all paths. (NFC) (#83490)
Use ScopeExit to make sure Operands/PrevDist are updated on all paths in
the loop. This makes it easier to ensure they are updated correctly if
new early continues are added.
Split off from https://github.com/llvm/llvm-project/pull/83283
PR: https://github.com/llvm/llvm-project/pull/83490
---
llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp | 14 +++++++-------
1 file changed, 7 insertions(+), 7 deletions(-)
diff --git a/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp b/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
index cdb341efcedca3..eb7fe2d0487ff8 100644
--- a/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
+++ b/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
@@ -21,6 +21,7 @@
#include "llvm/ADT/DenseSet.h"
#include "llvm/ADT/PriorityQueue.h"
#include "llvm/ADT/STLExtras.h"
+#include "llvm/ADT/ScopeExit.h"
#include "llvm/ADT/SetOperations.h"
#include "llvm/ADT/SetVector.h"
#include "llvm/ADT/SmallBitVector.h"
@@ -13908,12 +13909,14 @@ bool SLPVectorizerPass::vectorizeStores(ArrayRef<StoreInst *> Stores,
if (Idx != Set.size() - 1)
continue;
}
- if (Operands.size() <= 1) {
+ auto E = make_scope_exit([&, &DataVar = Data]() {
Operands.clear();
- Operands.push_back(Stores[Data.first]);
- PrevDist = Data.second;
+ Operands.push_back(Stores[DataVar.first]);
+ PrevDist = DataVar.second;
+ });
+
+ if (Operands.size() <= 1)
continue;
- }
unsigned MaxVecRegSize = R.getMaxVecRegSize();
unsigned EltSize = R.getVectorElementSize(Operands[0]);
@@ -13972,9 +13975,6 @@ bool SLPVectorizerPass::vectorizeStores(ArrayRef<StoreInst *> Stores,
if (StartIdx >= Operands.size())
break;
}
- Operands.clear();
- Operands.push_back(Stores[Data.first]);
- PrevDist = Data.second;
}
};
>From 5bafb8d95220895ca76742db297cbb75dc0fa162 Mon Sep 17 00:00:00 2001
From: Alexey Bataev <a.bataev at outlook.com>
Date: Fri, 1 Mar 2024 06:36:09 -0800
Subject: [PATCH 253/406] [SLP][NFC]Add/use single UsesLimit constant, NFC.
---
llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp | 11 ++++++-----
1 file changed, 6 insertions(+), 5 deletions(-)
diff --git a/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp b/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
index eb7fe2d0487ff8..7082463bb37870 100644
--- a/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
+++ b/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
@@ -193,6 +193,10 @@ static cl::opt<bool>
// it has no negative effect on the llvm benchmarks.
static const unsigned AliasedCheckLimit = 10;
+// Limit of the number of uses for potentially transformed instructions/values,
+// used in checks to avoid compile-time explode.
+static constexpr int UsesLimit = 8;
+
// Another limit for the alias checks: The maximum distance between load/store
// instructions where alias checks are done.
// This limit is useful for very large basic blocks.
@@ -941,7 +945,6 @@ static bool isUsedOutsideBlock(Value *V) {
if (!I)
return true;
// Limits the number of uses to save compile time.
- constexpr int UsesLimit = 8;
return !I->mayReadOrWriteMemory() && !I->hasNUsesOrMore(UsesLimit) &&
all_of(I->users(), [I](User *U) {
auto *IU = dyn_cast<Instruction>(U);
@@ -1285,8 +1288,7 @@ class BoUpSLP {
// Retruns true if the users of V1 and V2 won't need to be extracted.
auto AllUsersAreInternal = [U1, U2, this](Value *V1, Value *V2) {
// Bail out if we have too many uses to save compilation time.
- static constexpr unsigned Limit = 8;
- if (V1->hasNUsesOrMore(Limit) || V2->hasNUsesOrMore(Limit))
+ if (V1->hasNUsesOrMore(UsesLimit) || V2->hasNUsesOrMore(UsesLimit))
return false;
auto AllUsersVectorized = [U1, U2, this](Value *V) {
@@ -5235,8 +5237,7 @@ BoUpSLP::collectUserStores(const BoUpSLP::TreeEntry *TE) const {
for (unsigned Lane : seq<unsigned>(0, TE->Scalars.size())) {
Value *V = TE->Scalars[Lane];
// To save compilation time we don't visit if we have too many users.
- static constexpr unsigned UsersLimit = 4;
- if (V->hasNUsesOrMore(UsersLimit))
+ if (V->hasNUsesOrMore(UsesLimit))
break;
// Collect stores per pointer object.
>From 3fc277f665f520c351b203faf3273552e77508f8 Mon Sep 17 00:00:00 2001
From: Benjamin Kramer <benny.kra at googlemail.com>
Date: Fri, 1 Mar 2024 15:37:54 +0100
Subject: [PATCH 254/406] [SLPVectorizer] Make the insert/extractvector
PHICompare a strict-weak ordering (#83571)
This was tripping off STL implementations that check for it (like libc++
with debug checking). The goal of this sort is to cluster operations on
the same values so preserve that property but sort everything else based
on the existing numbering.
---
.../lib/Transforms/Vectorize/SLPVectorizer.cpp | 18 +++++-------------
1 file changed, 5 insertions(+), 13 deletions(-)
diff --git a/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp b/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
index 7082463bb37870..3e75b5ed485770 100644
--- a/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
+++ b/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
@@ -4395,24 +4395,16 @@ BoUpSLP::getReorderingData(const TreeEntry &TE, bool TopToBottom) {
if (!areTwoInsertFromSameBuildVector(
IE1, IE2,
[](InsertElementInst *II) { return II->getOperand(0); }))
- return false;
- std::optional<unsigned> Idx1 = getInsertIndex(IE1);
- std::optional<unsigned> Idx2 = getInsertIndex(IE2);
- if (Idx1 == std::nullopt || Idx2 == std::nullopt)
- return false;
- return *Idx1 < *Idx2;
+ return I1 < I2;
+ return getInsertIndex(IE1) < getInsertIndex(IE2);
}
if (auto *EE1 = dyn_cast<ExtractElementInst>(FirstUserOfPhi1))
if (auto *EE2 = dyn_cast<ExtractElementInst>(FirstUserOfPhi2)) {
if (EE1->getOperand(0) != EE2->getOperand(0))
- return false;
- std::optional<unsigned> Idx1 = getExtractIndex(EE1);
- std::optional<unsigned> Idx2 = getExtractIndex(EE2);
- if (Idx1 == std::nullopt || Idx2 == std::nullopt)
- return false;
- return *Idx1 < *Idx2;
+ return I1 < I2;
+ return getInsertIndex(EE1) < getInsertIndex(EE2);
}
- return false;
+ return I1 < I2;
};
auto IsIdentityOrder = [](const OrdersType &Order) {
for (unsigned Idx : seq<unsigned>(0, Order.size()))
>From e59681d96327e2ed1963ec1c0f2bc3d40df26443 Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?Timm=20B=C3=A4der?= <tbaeder at redhat.com>
Date: Fri, 1 Mar 2024 11:35:33 +0100
Subject: [PATCH 255/406] [clang][Interp] Allow inc/dec on boolean values
The warnings or errors are emitted in Sema, but we still need to
do the operation and provide a reasonable result.
---
clang/lib/AST/Interp/Interp.h | 7 ++++++
clang/lib/AST/Interp/Opcodes.td | 8 +++----
clang/test/AST/Interp/literals.cpp | 37 ++++++++++++++++++++++++++++++
clang/test/SemaCXX/bool.cpp | 5 ++++
4 files changed, 53 insertions(+), 4 deletions(-)
diff --git a/clang/lib/AST/Interp/Interp.h b/clang/lib/AST/Interp/Interp.h
index f379c9869d8d8e..677c699efc2ab2 100644
--- a/clang/lib/AST/Interp/Interp.h
+++ b/clang/lib/AST/Interp/Interp.h
@@ -199,6 +199,8 @@ bool InterpretBuiltin(InterpState &S, CodePtr OpPC, const Function *F,
bool InterpretOffsetOf(InterpState &S, CodePtr OpPC, const OffsetOfExpr *E,
llvm::ArrayRef<int64_t> ArrayIndices, int64_t &Result);
+inline bool Invalid(InterpState &S, CodePtr OpPC);
+
enum class ArithOp { Add, Sub };
//===----------------------------------------------------------------------===//
@@ -522,6 +524,11 @@ bool IncDecHelper(InterpState &S, CodePtr OpPC, const Pointer &Ptr) {
if (Ptr.isDummy())
return false;
+ if constexpr (std::is_same_v<T, Boolean>) {
+ if (!S.getLangOpts().CPlusPlus14)
+ return Invalid(S, OpPC);
+ }
+
const T &Value = Ptr.deref<T>();
T Result;
diff --git a/clang/lib/AST/Interp/Opcodes.td b/clang/lib/AST/Interp/Opcodes.td
index 3e3ba1b163e339..ffc54646f0279e 100644
--- a/clang/lib/AST/Interp/Opcodes.td
+++ b/clang/lib/AST/Interp/Opcodes.td
@@ -563,10 +563,10 @@ def Inv: Opcode {
}
// Increment and decrement.
-def Inc: IntegerOpcode;
-def IncPop : IntegerOpcode;
-def Dec: IntegerOpcode;
-def DecPop: IntegerOpcode;
+def Inc: AluOpcode;
+def IncPop : AluOpcode;
+def Dec: AluOpcode;
+def DecPop: AluOpcode;
// Float increment and decrement.
def Incf: FloatOpcode;
diff --git a/clang/test/AST/Interp/literals.cpp b/clang/test/AST/Interp/literals.cpp
index 8ea1c1155143e9..10b687c1408ac3 100644
--- a/clang/test/AST/Interp/literals.cpp
+++ b/clang/test/AST/Interp/literals.cpp
@@ -1131,3 +1131,40 @@ namespace nullptrsub {
f = (char *)((char *)0 - (char *)0);
}
}
+
+namespace incdecbool {
+#if __cplusplus >= 201402L
+ constexpr bool incb(bool c) {
+ if (!c)
+ ++c;
+ else {++c; c++; }
+#if __cplusplus >= 202002L
+ // both-error at -3 {{ISO C++17 does not allow incrementing expression of type bool}}
+ // both-error at -3 2{{ISO C++17 does not allow incrementing expression of type bool}}
+#else
+ // both-warning at -6 {{incrementing expression of type bool is deprecated and incompatible with C++17}}
+#endif
+ return c;
+ }
+ static_assert(incb(false), "");
+ static_assert(incb(true), "");
+ static_assert(incb(true) == 1, "");
+#endif
+
+
+#if __cplusplus == 201103L
+ constexpr bool foo() { // both-error {{never produces a constant expression}}
+ bool b = true; // both-warning {{variable declaration in a constexpr function is a C++14 extension}}
+ b++; // both-warning {{incrementing expression of type bool is deprecated and incompatible with C++17}} \
+ // both-warning {{use of this statement in a constexpr function is a C++14 extension}} \
+ // both-note 2{{subexpression not valid in a constant expression}}
+
+ return b;
+ }
+ static_assert(foo() == 1, ""); // both-error {{not an integral constant expression}} \
+ // both-note {{in call to}}
+#endif
+
+
+
+}
diff --git a/clang/test/SemaCXX/bool.cpp b/clang/test/SemaCXX/bool.cpp
index 33e22c8f6d36f7..57cdba1b1a830d 100644
--- a/clang/test/SemaCXX/bool.cpp
+++ b/clang/test/SemaCXX/bool.cpp
@@ -2,6 +2,11 @@
// RUN: %clang_cc1 %std_cxx98-14 -fsyntax-only -verify=expected,precxx17 -Wno-constant-conversion -Wno-deprecated -Wdeprecated-increment-bool %s
// RUN: %clang_cc1 %std_cxx17- -fsyntax-only -verify=expected,cxx17 -Wno-constant-conversion -Wno-deprecated -Wdeprecated-increment-bool %s
+// RUN: %clang_cc1 %std_cxx98-14 -fsyntax-only -verify=expected,precxx17 -Wno-constant-conversion %s -fexperimental-new-constant-interpreter
+// RUN: %clang_cc1 %std_cxx98-14 -fsyntax-only -verify=expected,precxx17 -Wno-constant-conversion -Wno-deprecated -Wdeprecated-increment-bool %s -fexperimental-new-constant-interpreter
+// RUN: %clang_cc1 %std_cxx17- -fsyntax-only -verify=expected,cxx17 -Wno-constant-conversion -Wno-deprecated -Wdeprecated-increment-bool %s -fexperimental-new-constant-interpreter
+
+
// Bool literals can be enum values.
enum {
ReadWrite = false,
>From f651f134bbaec069968f6b12bdcdb5f7752fd700 Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?Timm=20B=C3=A4der?= <tbaeder at redhat.com>
Date: Fri, 1 Mar 2024 12:30:39 +0100
Subject: [PATCH 256/406] [clang][Interp][NFC] Add precondition assertions
All three of these need to be non-null.
---
clang/lib/AST/Interp/Context.cpp | 3 +++
1 file changed, 3 insertions(+)
diff --git a/clang/lib/AST/Interp/Context.cpp b/clang/lib/AST/Interp/Context.cpp
index 6121395f5fc4fd..017095352dc235 100644
--- a/clang/lib/AST/Interp/Context.cpp
+++ b/clang/lib/AST/Interp/Context.cpp
@@ -224,6 +224,9 @@ const CXXMethodDecl *
Context::getOverridingFunction(const CXXRecordDecl *DynamicDecl,
const CXXRecordDecl *StaticDecl,
const CXXMethodDecl *InitialFunction) const {
+ assert(DynamicDecl);
+ assert(StaticDecl);
+ assert(InitialFunction);
const CXXRecordDecl *CurRecord = DynamicDecl;
const CXXMethodDecl *FoundFunction = InitialFunction;
>From f15d799f16092918b948536775475dfd8675c7d9 Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?Timm=20B=C3=A4der?= <tbaeder at redhat.com>
Date: Fri, 1 Mar 2024 14:13:38 +0100
Subject: [PATCH 257/406] [clang][Interp] Fix variadic operator calls
Operator calls pass their instance member explicitly, so remove
it from NumParams when calling a variadic function
---
clang/lib/AST/Interp/ByteCodeExprGen.cpp | 3 ++-
clang/test/AST/Interp/functions.cpp | 10 ++++++++++
2 files changed, 12 insertions(+), 1 deletion(-)
diff --git a/clang/lib/AST/Interp/ByteCodeExprGen.cpp b/clang/lib/AST/Interp/ByteCodeExprGen.cpp
index 0185214fb455de..388da0e324c732 100644
--- a/clang/lib/AST/Interp/ByteCodeExprGen.cpp
+++ b/clang/lib/AST/Interp/ByteCodeExprGen.cpp
@@ -2842,7 +2842,8 @@ bool ByteCodeExprGen<Emitter>::VisitCallExpr(const CallExpr *E) {
return false;
} else if (Func->isVariadic()) {
uint32_t VarArgSize = 0;
- unsigned NumParams = Func->getNumWrittenParams();
+ unsigned NumParams =
+ Func->getNumWrittenParams() + isa<CXXOperatorCallExpr>(E);
for (unsigned I = NumParams, N = E->getNumArgs(); I != N; ++I)
VarArgSize += align(primSize(classify(E->getArg(I)).value_or(PT_Ptr)));
if (!this->emitCallVar(Func, VarArgSize, E))
diff --git a/clang/test/AST/Interp/functions.cpp b/clang/test/AST/Interp/functions.cpp
index 9daf8722050f07..38f761f563bef7 100644
--- a/clang/test/AST/Interp/functions.cpp
+++ b/clang/test/AST/Interp/functions.cpp
@@ -555,3 +555,13 @@ namespace Local {
return t;
}
}
+
+namespace VariadicOperator {
+ struct Callable {
+ float& operator()(...);
+ };
+
+ void test_callable(Callable c) {
+ float &fr = c(10);
+ }
+}
>From b0181be36cace3460e4ec5d0d11ecbf49484cc55 Mon Sep 17 00:00:00 2001
From: Erich Keane <ekeane at nvidia.com>
Date: Fri, 1 Mar 2024 07:11:17 -0800
Subject: [PATCH 258/406] [OpenACC] Implement Duffs-Device restriction for
Compute Constructs (#83460)
Like the last few patches, branching in/out of a compute construct is
not valid. This patch implements checking to ensure that a 'case' or
'default' statement cannot jump into a Compute Construct (in the style
of a duff's device!).
---
clang/include/clang/Sema/Scope.h | 19 +++++++++++++
clang/lib/Sema/SemaStmt.cpp | 14 ++++++++++
clang/test/SemaOpenACC/no-branch-in-out.c | 27 +++++++++++++++++++
clang/test/SemaOpenACC/no-branch-in-out.cpp | 30 ++++++++++++++++++++-
4 files changed, 89 insertions(+), 1 deletion(-)
diff --git a/clang/include/clang/Sema/Scope.h b/clang/include/clang/Sema/Scope.h
index b6b5a1f3479a25..1cb2fa83e0bb33 100644
--- a/clang/include/clang/Sema/Scope.h
+++ b/clang/include/clang/Sema/Scope.h
@@ -534,6 +534,25 @@ class Scope {
return false;
}
+ /// Determine if this scope (or its parents) are a compute construct inside of
+ /// the nearest 'switch' scope. This is needed to check whether we are inside
+ /// of a 'duffs' device, which is an illegal branch into a compute construct.
+ bool isInOpenACCComputeConstructBeforeSwitch() const {
+ for (const Scope *S = this; S; S = S->getParent()) {
+ if (S->getFlags() & Scope::OpenACCComputeConstructScope)
+ return true;
+ if (S->getFlags() & Scope::SwitchScope)
+ return false;
+
+ if (S->getFlags() &
+ (Scope::FnScope | Scope::ClassScope | Scope::BlockScope |
+ Scope::TemplateParamScope | Scope::FunctionPrototypeScope |
+ Scope::AtCatchScope | Scope::ObjCMethodScope))
+ return false;
+ }
+ return false;
+ }
+
/// Determine whether this scope is a while/do/for statement, which can have
/// continue statements embedded into it.
bool isContinueScope() const {
diff --git a/clang/lib/Sema/SemaStmt.cpp b/clang/lib/Sema/SemaStmt.cpp
index ca2d206752744c..4a15a8f6effd31 100644
--- a/clang/lib/Sema/SemaStmt.cpp
+++ b/clang/lib/Sema/SemaStmt.cpp
@@ -527,6 +527,13 @@ Sema::ActOnCaseStmt(SourceLocation CaseLoc, ExprResult LHSVal,
return StmtError();
}
+ if (LangOpts.OpenACC &&
+ getCurScope()->isInOpenACCComputeConstructBeforeSwitch()) {
+ Diag(CaseLoc, diag::err_acc_branch_in_out_compute_construct)
+ << /*branch*/ 0 << /*into*/ 1;
+ return StmtError();
+ }
+
auto *CS = CaseStmt::Create(Context, LHSVal.get(), RHSVal.get(),
CaseLoc, DotDotDotLoc, ColonLoc);
getCurFunction()->SwitchStack.back().getPointer()->addSwitchCase(CS);
@@ -546,6 +553,13 @@ Sema::ActOnDefaultStmt(SourceLocation DefaultLoc, SourceLocation ColonLoc,
return SubStmt;
}
+ if (LangOpts.OpenACC &&
+ getCurScope()->isInOpenACCComputeConstructBeforeSwitch()) {
+ Diag(DefaultLoc, diag::err_acc_branch_in_out_compute_construct)
+ << /*branch*/ 0 << /*into*/ 1;
+ return StmtError();
+ }
+
DefaultStmt *DS = new (Context) DefaultStmt(DefaultLoc, ColonLoc, SubStmt);
getCurFunction()->SwitchStack.back().getPointer()->addSwitchCase(DS);
return DS;
diff --git a/clang/test/SemaOpenACC/no-branch-in-out.c b/clang/test/SemaOpenACC/no-branch-in-out.c
index d070247fa65b86..eccc6432450045 100644
--- a/clang/test/SemaOpenACC/no-branch-in-out.c
+++ b/clang/test/SemaOpenACC/no-branch-in-out.c
@@ -310,3 +310,30 @@ LABEL4:{}
ptr=&&LABEL5;
}
+
+void DuffsDevice() {
+ int j;
+ switch (j) {
+#pragma acc parallel
+ for(int i =0; i < 5; ++i) {
+ case 0: // expected-error{{invalid branch into OpenACC Compute Construct}}
+ {}
+ }
+ }
+
+ switch (j) {
+#pragma acc parallel
+ for(int i =0; i < 5; ++i) {
+ default: // expected-error{{invalid branch into OpenACC Compute Construct}}
+ {}
+ }
+ }
+
+ switch (j) {
+#pragma acc parallel
+ for(int i =0; i < 5; ++i) {
+ case 'a' ... 'z': // expected-error{{invalid branch into OpenACC Compute Construct}}
+ {}
+ }
+ }
+}
diff --git a/clang/test/SemaOpenACC/no-branch-in-out.cpp b/clang/test/SemaOpenACC/no-branch-in-out.cpp
index 9affdf733ace8d..e7d5683f9bc78b 100644
--- a/clang/test/SemaOpenACC/no-branch-in-out.cpp
+++ b/clang/test/SemaOpenACC/no-branch-in-out.cpp
@@ -18,7 +18,6 @@ void ReturnTest() {
template<typename T>
void BreakContinue() {
-
#pragma acc parallel
for(int i =0; i < 5; ++i) {
switch(i) {
@@ -109,6 +108,35 @@ void BreakContinue() {
} while (j );
}
+template<typename T>
+void DuffsDevice() {
+ int j;
+ switch (j) {
+#pragma acc parallel
+ for(int i =0; i < 5; ++i) {
+ case 0: // expected-error{{invalid branch into OpenACC Compute Construct}}
+ {}
+ }
+ }
+
+ switch (j) {
+#pragma acc parallel
+ for(int i =0; i < 5; ++i) {
+ default: // expected-error{{invalid branch into OpenACC Compute Construct}}
+ {}
+ }
+ }
+
+ switch (j) {
+#pragma acc parallel
+ for(int i =0; i < 5; ++i) {
+ case 'a' ... 'z': // expected-error{{invalid branch into OpenACC Compute Construct}}
+ {}
+ }
+ }
+}
+
void Instantiate() {
BreakContinue<int>();
+ DuffsDevice<int>();
}
>From a038f9758e02812803b7efce10ecf784f9842bbb Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?Timm=20B=C3=A4der?= <tbaeder at redhat.com>
Date: Fri, 1 Mar 2024 14:36:07 +0100
Subject: [PATCH 259/406] [clang][Interp] Fix virtual calls with reference
instance pointers
getCXXRecordType() on those types does not return the type we need.
Use getPointeeCXXRecordType() instead in those cases.
---
clang/lib/AST/Interp/Interp.h | 8 ++++++--
clang/test/SemaCXX/undefined-internal.cpp | 10 ++++++++++
2 files changed, 16 insertions(+), 2 deletions(-)
diff --git a/clang/lib/AST/Interp/Interp.h b/clang/lib/AST/Interp/Interp.h
index 677c699efc2ab2..84f65a33bef361 100644
--- a/clang/lib/AST/Interp/Interp.h
+++ b/clang/lib/AST/Interp/Interp.h
@@ -2074,8 +2074,12 @@ inline bool CallVirt(InterpState &S, CodePtr OpPC, const Function *Func,
size_t ThisOffset = ArgSize - (Func->hasRVO() ? primSize(PT_Ptr) : 0);
Pointer &ThisPtr = S.Stk.peek<Pointer>(ThisOffset);
- const CXXRecordDecl *DynamicDecl =
- ThisPtr.getDeclDesc()->getType()->getAsCXXRecordDecl();
+ QualType DynamicType = ThisPtr.getDeclDesc()->getType();
+ const CXXRecordDecl *DynamicDecl;
+ if (DynamicType->isPointerType() || DynamicType->isReferenceType())
+ DynamicDecl = DynamicType->getPointeeCXXRecordDecl();
+ else
+ DynamicDecl = ThisPtr.getDeclDesc()->getType()->getAsCXXRecordDecl();
const auto *StaticDecl = cast<CXXRecordDecl>(Func->getParentDecl());
const auto *InitialFunction = cast<CXXMethodDecl>(Func->getDecl());
const CXXMethodDecl *Overrider = S.getContext().getOverridingFunction(
diff --git a/clang/test/SemaCXX/undefined-internal.cpp b/clang/test/SemaCXX/undefined-internal.cpp
index 790c96c9fe4514..054e71b92f93d2 100644
--- a/clang/test/SemaCXX/undefined-internal.cpp
+++ b/clang/test/SemaCXX/undefined-internal.cpp
@@ -2,11 +2,21 @@
// RUN: %clang_cc1 -fsyntax-only -verify -Wbind-to-temporary-copy -std=c++98 %s
// RUN: %clang_cc1 -fsyntax-only -verify -Wbind-to-temporary-copy -std=c++11 %s
+// RUN: %clang_cc1 -fsyntax-only -verify -Wbind-to-temporary-copy %s -fexperimental-new-constant-interpreter
+// RUN: %clang_cc1 -fsyntax-only -verify -Wbind-to-temporary-copy -std=c++98 %s -fexperimental-new-constant-interpreter
+// RUN: %clang_cc1 -fsyntax-only -verify -Wbind-to-temporary-copy -std=c++11 %s -fexperimental-new-constant-interpreter
+
+
// Make sure we don't produce invalid IR.
// RUN: %clang_cc1 -emit-llvm-only %s
// RUN: %clang_cc1 -emit-llvm-only -std=c++98 %s
// RUN: %clang_cc1 -emit-llvm-only -std=c++11 %s
+// RUN: %clang_cc1 -emit-llvm-only %s -fexperimental-new-constant-interpreter
+// RUN: %clang_cc1 -emit-llvm-only -std=c++98 %s -fexperimental-new-constant-interpreter
+// RUN: %clang_cc1 -emit-llvm-only -std=c++11 %s -fexperimental-new-constant-interpreter
+
+
namespace test1 {
static void foo(); // expected-warning {{function 'test1::foo' has internal linkage but is not defined}}
template <class T> static void bar(); // expected-warning {{function 'test1::bar<int>' has internal linkage but is not defined}}
>From 06bd74ba4ac5229f01b64772b49e025be5eb7b53 Mon Sep 17 00:00:00 2001
From: Erich Keane <ekeane at nvidia.com>
Date: Fri, 1 Mar 2024 07:27:06 -0800
Subject: [PATCH 260/406] Fix implementation of [temp.param]p14's first
sentence. (#83487)
The first sentence says:
If a template-parameter of a class template, variable template, or alias
template has a default template-argument, each subsequent
template-parameter shall either have a default template-argument
supplied or be a template parameter pack.
However, we were only testing for "not a function function template",
and referring to an older version of the standard. As far as I can tell,
CWG2032 added the variable-template, and the alias-template pre-dates
the standard on github.
This patch started as a bug fix for #83461 , but ended up fixing a
number of similar cases, so those are validated as well.
---
clang/docs/ReleaseNotes.rst | 6 ++++
clang/lib/Sema/SemaTemplate.cpp | 14 ++++----
clang/test/SemaCXX/GH83461.cpp | 60 +++++++++++++++++++++++++++++++++
3 files changed, 74 insertions(+), 6 deletions(-)
create mode 100644 clang/test/SemaCXX/GH83461.cpp
diff --git a/clang/docs/ReleaseNotes.rst b/clang/docs/ReleaseNotes.rst
index 4e5c870e4177fe..1286263700963c 100644
--- a/clang/docs/ReleaseNotes.rst
+++ b/clang/docs/ReleaseNotes.rst
@@ -301,6 +301,12 @@ Bug Fixes to C++ Support
- Clang now properly reports supported C++11 attributes when using
``__has_cpp_attribute`` and parses attributes with arguments in C++03
(`#82995 <https://github.com/llvm/llvm-project/issues/82995>`_)
+- Clang now properly diagnoses missing 'default' template arguments on a variety
+ of templates. Previously we were diagnosing on any non-function template
+ instead of only on class, alias, and variable templates, as last updated by
+ CWG2032.
+ Fixes (`#83461 <https://github.com/llvm/llvm-project/issues/83461>`_)
+
Bug Fixes to AST Handling
^^^^^^^^^^^^^^^^^^^^^^^^^
diff --git a/clang/lib/Sema/SemaTemplate.cpp b/clang/lib/Sema/SemaTemplate.cpp
index e91033dd886891..a7910bda874c8d 100644
--- a/clang/lib/Sema/SemaTemplate.cpp
+++ b/clang/lib/Sema/SemaTemplate.cpp
@@ -3141,12 +3141,14 @@ bool Sema::CheckTemplateParameterList(TemplateParameterList *NewParams,
diag::note_template_param_prev_default_arg_in_other_module)
<< PrevModuleName;
Invalid = true;
- } else if (MissingDefaultArg && TPC != TPC_FunctionTemplate) {
- // C++ [temp.param]p11:
- // If a template-parameter of a class template has a default
- // template-argument, each subsequent template-parameter shall either
- // have a default template-argument supplied or be a template parameter
- // pack.
+ } else if (MissingDefaultArg &&
+ (TPC == TPC_ClassTemplate || TPC == TPC_FriendClassTemplate ||
+ TPC == TPC_VarTemplate || TPC == TPC_TypeAliasTemplate)) {
+ // C++ 23[temp.param]p14:
+ // If a template-parameter of a class template, variable template, or
+ // alias template has a default template argument, each subsequent
+ // template-parameter shall either have a default template argument
+ // supplied or be a template parameter pack.
Diag((*NewParam)->getLocation(),
diag::err_template_param_default_arg_missing);
Diag(PreviousDefaultArgLoc, diag::note_template_param_prev_default_arg);
diff --git a/clang/test/SemaCXX/GH83461.cpp b/clang/test/SemaCXX/GH83461.cpp
new file mode 100644
index 00000000000000..509535e883e6d9
--- /dev/null
+++ b/clang/test/SemaCXX/GH83461.cpp
@@ -0,0 +1,60 @@
+// RUN: %clang_cc1 -std=c++20 -fsyntax-only -verify %s
+
+struct S {
+ template<typename Ty = int>
+ friend void foo(auto){}
+
+ template<typename Ty = int, typename Tz>
+ friend void foo2(){}
+};
+
+template<typename T>
+struct TemplS {
+ template<typename Ty = int>
+ friend void foo3(auto){}
+
+ template<typename Ty = int, typename Tz>
+ friend void foo4(){}
+};
+
+void Inst() {
+ TemplS<int>();
+}
+// expected-error at +2{{template parameter missing a default argument}}
+// expected-note at +1{{previous default template argument defined here}}
+template<typename T = int, typename U>
+struct ClassTempl{};
+
+struct HasFriendClassTempl {
+ // expected-error at +1{{default template argument not permitted on a friend template}}
+ template<typename T = int, typename U>
+ friend struct Friend;
+
+ // expected-error at +3{{cannot define a type in a friend declaration}}
+ // expected-error at +1{{default template argument not permitted on a friend template}}
+ template<typename T = int, typename U>
+ friend struct Friend2{};
+};
+
+template<typename Ty>
+struct HasFriendClassTempl2 {
+ // expected-error at +3{{template parameter missing a default argument}}
+ // expected-note at +2{{previous default template argument defined here}}
+ // expected-note@#INST2{{in instantiation of template class}}
+ template<typename T = int, typename U>
+ friend struct Friend;
+};
+
+void Inst2() {
+ HasFriendClassTempl2<int>(); // #INST2
+}
+
+// expected-error at +2{{template parameter missing a default argument}}
+// expected-note at +1{{previous default template argument defined here}}
+template<typename T = int, typename U>
+static constexpr U VarTempl;
+
+// expected-error at +2{{template parameter missing a default argument}}
+// expected-note at +1{{previous default template argument defined here}}
+template<typename T = int, typename U>
+using TypeAlias = U;
>From 601a9587a1a7eb8dd6377c4ab332edd3bce97a98 Mon Sep 17 00:00:00 2001
From: Mats Petersson <mats.petersson at arm.com>
Date: Fri, 1 Mar 2024 15:28:20 +0000
Subject: [PATCH 261/406] [Flang] Add support for assume_aligned directive
(#81747)
This adds the parsing (and unparse) of the compiler drective assume_aligned.
The compiler will issue a warning that the directive is ignored.
---
flang/docs/Directives.md | 6 +++
flang/include/flang/Parser/dump-parse-tree.h | 1 +
flang/include/flang/Parser/parse-tree.h | 8 ++-
flang/lib/Parser/Fortran-parsers.cpp | 4 ++
flang/lib/Parser/unparse.cpp | 10 ++++
flang/test/Parser/assume-aligned.f90 | 57 ++++++++++++++++++++
6 files changed, 85 insertions(+), 1 deletion(-)
create mode 100644 flang/test/Parser/assume-aligned.f90
diff --git a/flang/docs/Directives.md b/flang/docs/Directives.md
index 134de36f884d70..fe08b4f855f23c 100644
--- a/flang/docs/Directives.md
+++ b/flang/docs/Directives.md
@@ -30,3 +30,9 @@ A list of non-standard directives supported by Flang
end
end interface
```
+* `!dir$ assume_aligned desginator:alignment`, where designator is a variable,
+ maybe with array indices, and alignment is what the compiler should assume the
+ alignment to be. E.g A:64 or B(1,1,1):128. The alignment should be a power of 2,
+ and is limited to 256.
+ [This directive is currently recognised by the parser, but not
+ handled by the other parts of the compiler].
diff --git a/flang/include/flang/Parser/dump-parse-tree.h b/flang/include/flang/Parser/dump-parse-tree.h
index d067a7273540f0..048008a8d80c79 100644
--- a/flang/include/flang/Parser/dump-parse-tree.h
+++ b/flang/include/flang/Parser/dump-parse-tree.h
@@ -205,6 +205,7 @@ class ParseTreeDumper {
NODE(parser, CompilerDirective)
NODE(CompilerDirective, IgnoreTKR)
NODE(CompilerDirective, LoopCount)
+ NODE(CompilerDirective, AssumeAligned)
NODE(CompilerDirective, NameValue)
NODE(parser, ComplexLiteralConstant)
NODE(parser, ComplexPart)
diff --git a/flang/include/flang/Parser/parse-tree.h b/flang/include/flang/Parser/parse-tree.h
index e9bfb728a2bef6..a32676be0d6d97 100644
--- a/flang/include/flang/Parser/parse-tree.h
+++ b/flang/include/flang/Parser/parse-tree.h
@@ -3309,12 +3309,18 @@ struct CompilerDirective {
struct LoopCount {
WRAPPER_CLASS_BOILERPLATE(LoopCount, std::list<std::uint64_t>);
};
+ struct AssumeAligned {
+ TUPLE_CLASS_BOILERPLATE(AssumeAligned);
+ std::tuple<common::Indirection<Designator>, uint64_t> t;
+ };
struct NameValue {
TUPLE_CLASS_BOILERPLATE(NameValue);
std::tuple<Name, std::optional<std::uint64_t>> t;
};
CharBlock source;
- std::variant<std::list<IgnoreTKR>, LoopCount, std::list<NameValue>> u;
+ std::variant<std::list<IgnoreTKR>, LoopCount, std::list<AssumeAligned>,
+ std::list<NameValue>>
+ u;
};
// (CUDA) ATTRIBUTE(attribute) [::] name-list
diff --git a/flang/lib/Parser/Fortran-parsers.cpp b/flang/lib/Parser/Fortran-parsers.cpp
index 0dd95d69d3c662..fc81a477897a3c 100644
--- a/flang/lib/Parser/Fortran-parsers.cpp
+++ b/flang/lib/Parser/Fortran-parsers.cpp
@@ -1268,9 +1268,13 @@ constexpr auto ignore_tkr{
constexpr auto loopCount{
"DIR$ LOOP COUNT" >> construct<CompilerDirective::LoopCount>(
parenthesized(nonemptyList(digitString64)))};
+constexpr auto assumeAligned{"DIR$ ASSUME_ALIGNED" >>
+ optionalList(construct<CompilerDirective::AssumeAligned>(
+ indirect(designator), ":"_tok >> digitString64))};
TYPE_PARSER(beginDirective >>
sourced(construct<CompilerDirective>(ignore_tkr) ||
construct<CompilerDirective>(loopCount) ||
+ construct<CompilerDirective>(assumeAligned) ||
construct<CompilerDirective>(
"DIR$" >> many(construct<CompilerDirective::NameValue>(name,
maybe(("="_tok || ":"_tok) >> digitString64))))) /
diff --git a/flang/lib/Parser/unparse.cpp b/flang/lib/Parser/unparse.cpp
index 1df49a688a12a0..600aa01999dab7 100644
--- a/flang/lib/Parser/unparse.cpp
+++ b/flang/lib/Parser/unparse.cpp
@@ -1819,6 +1819,11 @@ class UnparseVisitor {
[&](const CompilerDirective::LoopCount &lcount) {
Walk("!DIR$ LOOP COUNT (", lcount.v, ", ", ")");
},
+ [&](const std::list<CompilerDirective::AssumeAligned>
+ &assumeAligned) {
+ Word("!DIR$ ASSUME_ALIGNED ");
+ Walk(" ", assumeAligned, ", ");
+ },
[&](const std::list<CompilerDirective::NameValue> &names) {
Walk("!DIR$ ", names, " ");
},
@@ -1841,6 +1846,11 @@ class UnparseVisitor {
Walk(std::get<Name>(x.t));
Walk("=", std::get<std::optional<std::uint64_t>>(x.t));
}
+ void Unparse(const CompilerDirective::AssumeAligned &x) {
+ Walk(std::get<common::Indirection<Designator>>(x.t));
+ Put(":");
+ Walk(std::get<uint64_t>(x.t));
+ }
// OpenACC Directives & Clauses
void Unparse(const AccAtomicCapture &x) {
diff --git a/flang/test/Parser/assume-aligned.f90 b/flang/test/Parser/assume-aligned.f90
new file mode 100644
index 00000000000000..c61c10d61d72fe
--- /dev/null
+++ b/flang/test/Parser/assume-aligned.f90
@@ -0,0 +1,57 @@
+! RUN: %flang_fc1 -fdebug-unparse-no-sema %s 2>&1 | FileCheck %s
+
+SUBROUTINE aa(a, nn)
+ IMPLICIT NONE
+ INTEGER, INTENT(IN) :: nn
+ COMPLEX(8), INTENT(INOUT), DIMENSION(1:nn) :: a
+ INTEGER :: i
+ !DIR$ assume_aligned a:16
+!CHECK: !DIR$ ASSUME_ALIGNED a:16
+ !DIR$ assume_aligned a (1):16
+!CHECK: !DIR$ ASSUME_ALIGNED a(1):16
+ !DIR$ assume_aligned a(1):16
+!CHECK: !DIR$ ASSUME_ALIGNED a(1):16
+ !DIR$ assume_aligned a(nn):16
+!CHECK: !DIR$ ASSUME_ALIGNED a(nn):16
+ !DIR$ assume_aligned a(44):16
+!CHECK: !DIR$ ASSUME_ALIGNED a(44):16
+ DO i=1,nn
+ a(i)=a(i)+1.5
+ END DO
+END SUBROUTINE aa
+
+SUBROUTINE bb(v, s, e)
+ IMPLICIT NONE
+ INTEGER, INTENT(IN) :: s(3), e(3)
+ INTEGER :: y,z
+ REAL(8), INTENT(IN) :: v(s(1):e(1),s(2):e(2),s(3):e(3))
+ !DIR$ assume_aligned v(s(1),y,z) :64
+!CHECK: !DIR$ ASSUME_ALIGNED v(s(1),y,z):64
+END SUBROUTINE bb
+
+SUBROUTINE f(n)
+ IMPLICIT NONE
+ TYPE node
+ REAL(KIND=8), POINTER :: a(:,:)
+ END TYPE NODE
+
+ TYPE(NODE), POINTER :: nodes
+ INTEGER :: i
+ INTEGER, INTENT(IN) :: n
+
+ ALLOCATE(nodes)
+ ALLOCATE(nodes%a(1000,1000))
+
+ !DIR$ ASSUME_ALIGNED nodes%a(1,1) : 16
+!CHECK: !DIR$ ASSUME_ALIGNED nodes%a(1,1):16
+ DO i=1,n
+ nodes%a(1,i) = nodes%a(1,i)+1
+ END DO
+END SUBROUTINE f
+
+SUBROUTINE g(a, b)
+ IMPLICIT NONE
+ INTEGER, INTENT(in) :: a(128), b(128)
+ !DIR$ ASSUME_ALIGNED a:32, b:64
+!CHECK: !DIR$ ASSUME_ALIGNED a:32, b:64
+END SUBROUTINE g
>From 2b4d67bf59d609321701540a15f48eda04688652 Mon Sep 17 00:00:00 2001
From: Vinayak Dev <104419489+vinayakdsci at users.noreply.github.com>
Date: Fri, 1 Mar 2024 21:10:46 +0530
Subject: [PATCH 262/406] [Clang][Sema]: Allow copy constructor side effects
(#81127)
Copy constructors can have initialization with side effects, and thus
clang should not emit a warning when -Wunused-variable is used in this
context. Currently however, a warning is emitted.
Now, compilation happens without warnings.
Fixes #79518
---
clang/docs/ReleaseNotes.rst | 4 +++
clang/lib/Sema/SemaDecl.cpp | 3 +-
clang/test/SemaCXX/warn-unused-variables.cpp | 33 ++++++++++++++++++--
3 files changed, 37 insertions(+), 3 deletions(-)
diff --git a/clang/docs/ReleaseNotes.rst b/clang/docs/ReleaseNotes.rst
index 1286263700963c..cfe0ac6a5dca61 100644
--- a/clang/docs/ReleaseNotes.rst
+++ b/clang/docs/ReleaseNotes.rst
@@ -218,6 +218,10 @@ Bug Fixes in This Version
for logical operators in C23.
Fixes (`#64356 <https://github.com/llvm/llvm-project/issues/64356>`_).
+- Clang no longer produces a false-positive `-Wunused-variable` warning
+ for variables created through copy initialization having side-effects in C++17 and later.
+ Fixes (`#79518 <https://github.com/llvm/llvm-project/issues/79518>`_).
+
Bug Fixes to Compiler Builtins
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
diff --git a/clang/lib/Sema/SemaDecl.cpp b/clang/lib/Sema/SemaDecl.cpp
index 9fdd8eb236d1ee..6289cf75e17413 100644
--- a/clang/lib/Sema/SemaDecl.cpp
+++ b/clang/lib/Sema/SemaDecl.cpp
@@ -2044,7 +2044,8 @@ static bool ShouldDiagnoseUnusedDecl(const LangOptions &LangOpts,
return false;
if (Init) {
- const auto *Construct = dyn_cast<CXXConstructExpr>(Init);
+ const auto *Construct =
+ dyn_cast<CXXConstructExpr>(Init->IgnoreImpCasts());
if (Construct && !Construct->isElidable()) {
const CXXConstructorDecl *CD = Construct->getConstructor();
if (!CD->isTrivial() && !RD->hasAttr<WarnUnusedAttr>() &&
diff --git a/clang/test/SemaCXX/warn-unused-variables.cpp b/clang/test/SemaCXX/warn-unused-variables.cpp
index b649c7d8089355..29e8d08d37d8c6 100644
--- a/clang/test/SemaCXX/warn-unused-variables.cpp
+++ b/clang/test/SemaCXX/warn-unused-variables.cpp
@@ -1,5 +1,7 @@
// RUN: %clang_cc1 -fsyntax-only -Wunused-variable -Wunused-label -Wno-c++1y-extensions -verify %s
-// RUN: %clang_cc1 -fsyntax-only -Wunused-variable -Wunused-label -Wno-c++1y-extensions -verify -std=gnu++11 %s
+// RUN: %clang_cc1 -fsyntax-only -Wunused-variable -Wunused-label -Wno-c++1y-extensions -verify=expected,cxx98-14 -std=gnu++11 %s
+// RUN: %clang_cc1 -fsyntax-only -Wunused-variable -Wunused-label -Wno-c++1y-extensions -verify=expected,cxx98-14 -std=gnu++14 %s
+// RUN: %clang_cc1 -fsyntax-only -Wunused-variable -Wunused-label -Wno-c++1y-extensions -verify -std=gnu++17 %s
template<typename T> void f() {
T t;
t = 17;
@@ -183,7 +185,8 @@ void foo(int size) {
NonTriviallyDestructible array[2]; // no warning
NonTriviallyDestructible nestedArray[2][2]; // no warning
- Foo fooScalar = 1; // expected-warning {{unused variable 'fooScalar'}}
+ // Copy initialzation gives warning before C++17
+ Foo fooScalar = 1; // cxx98-14-warning {{unused variable 'fooScalar'}}
Foo fooArray[] = {1,2}; // expected-warning {{unused variable 'fooArray'}}
Foo fooNested[2][2] = { {1,2}, {3,4} }; // expected-warning {{unused variable 'fooNested'}}
}
@@ -297,3 +300,29 @@ void RAIIWrapperTest() {
}
} // namespace gh54489
+
+// Ensure that -Wunused-variable does not emit warning
+// on copy constructors with side effects (C++17 and later)
+#if __cplusplus >= 201703L
+namespace gh79518 {
+
+struct S {
+ S(int);
+};
+
+// With an initializer list
+struct A {
+ int x;
+ A(int x) : x(x) {}
+};
+
+void foo() {
+ S s(0); // no warning
+ S s2 = 0; // no warning
+ S s3{0}; // no warning
+
+ A a = 1; // no warning
+}
+
+} // namespace gh79518
+#endif
>From b92c3fe0274f3ba3bb7c58a8529bd9c4303a3b51 Mon Sep 17 00:00:00 2001
From: Joseph Huber <huberjn at outlook.com>
Date: Fri, 1 Mar 2024 09:48:14 -0600
Subject: [PATCH 263/406] [OpenMP] Fix test after updating library search paths
(#83573)
Summary:
We still use this bitcode library in one case, the NVPTX non-LTO build.
The patch updated the search paths to treat it the same as other
libraries, which unintentionally prioritized system paths over
LIBRARY_PATH which is generally not correct. Also we had a test that
relied on system state so remove that.
---
clang/lib/Driver/ToolChains/CommonArgs.cpp | 8 ++++----
clang/test/Driver/openmp-offload-gpu.c | 11 -----------
2 files changed, 4 insertions(+), 15 deletions(-)
diff --git a/clang/lib/Driver/ToolChains/CommonArgs.cpp b/clang/lib/Driver/ToolChains/CommonArgs.cpp
index 382c8b3612a0af..7f0f78b41e79ed 100644
--- a/clang/lib/Driver/ToolChains/CommonArgs.cpp
+++ b/clang/lib/Driver/ToolChains/CommonArgs.cpp
@@ -2767,10 +2767,6 @@ void tools::addOpenMPDeviceRTL(const Driver &D,
const ToolChain &HostTC) {
SmallVector<StringRef, 8> LibraryPaths;
- // Check all of the standard library search paths used by the compiler.
- for (const auto &LibPath : HostTC.getFilePaths())
- LibraryPaths.emplace_back(LibPath);
-
// Add user defined library paths from LIBRARY_PATH.
std::optional<std::string> LibPath =
llvm::sys::Process::GetEnv("LIBRARY_PATH");
@@ -2782,6 +2778,10 @@ void tools::addOpenMPDeviceRTL(const Driver &D,
LibraryPaths.emplace_back(Path.trim());
}
+ // Check all of the standard library search paths used by the compiler.
+ for (const auto &LibPath : HostTC.getFilePaths())
+ LibraryPaths.emplace_back(LibPath);
+
OptSpecifier LibomptargetBCPathOpt =
Triple.isAMDGCN() ? options::OPT_libomptarget_amdgpu_bc_path_EQ
: options::OPT_libomptarget_nvptx_bc_path_EQ;
diff --git a/clang/test/Driver/openmp-offload-gpu.c b/clang/test/Driver/openmp-offload-gpu.c
index 5da74a35d87ad9..f7b06c9ec59580 100644
--- a/clang/test/Driver/openmp-offload-gpu.c
+++ b/clang/test/Driver/openmp-offload-gpu.c
@@ -101,17 +101,6 @@
/// ###########################################################################
-/// Check that the warning is thrown when the libomptarget bitcode library is not found.
-/// Libomptarget requires sm_52 or newer so an sm_52 bitcode library should never exist.
-// RUN: not %clang -### -fopenmp=libomp -fopenmp-targets=nvptx64-nvidia-cuda \
-// RUN: -Xopenmp-target -march=sm_52 --cuda-path=%S/Inputs/CUDA_102/usr/local/cuda \
-// RUN: -fopenmp-relocatable-target -save-temps %s 2>&1 \
-// RUN: | FileCheck -check-prefix=CHK-BCLIB-WARN %s
-
-// CHK-BCLIB-WARN: no library 'libomptarget-nvptx-sm_52.bc' found in the default clang lib directory or in LIBRARY_PATH; use '--libomptarget-nvptx-bc-path' to specify nvptx bitcode library
-
-/// ###########################################################################
-
/// Check that the error is thrown when the libomptarget bitcode library does not exist.
// RUN: not %clang -### -fopenmp=libomp -fopenmp-targets=nvptx64-nvidia-cuda \
// RUN: -Xopenmp-target -march=sm_52 --cuda-path=%S/Inputs/CUDA_102/usr/local/cuda \
>From 92fe6c61f900d6479f7ab708784c9e62d7523768 Mon Sep 17 00:00:00 2001
From: Martin Wehking <martin.wehking at codeplay.com>
Date: Fri, 1 Mar 2024 16:11:12 +0000
Subject: [PATCH 264/406] Silence illegal address computation warning (#83244)
Add an assertion before an access of ValMappings to ensure that it is
within the array bounds.
Silence a static analyzer warning through this.
---
llvm/lib/Target/AMDGPU/AMDGPUGenRegisterBankInfo.def | 1 +
1 file changed, 1 insertion(+)
diff --git a/llvm/lib/Target/AMDGPU/AMDGPUGenRegisterBankInfo.def b/llvm/lib/Target/AMDGPU/AMDGPUGenRegisterBankInfo.def
index d6a94c972340ea..0d41d5d2186fd8 100644
--- a/llvm/lib/Target/AMDGPU/AMDGPUGenRegisterBankInfo.def
+++ b/llvm/lib/Target/AMDGPU/AMDGPUGenRegisterBankInfo.def
@@ -284,6 +284,7 @@ const RegisterBankInfo::ValueMapping *getValueMapping(unsigned BankID,
break;
}
+ assert(Idx < std::size(ValMappings));
assert(Log2_32_Ceil(Size) == Log2_32_Ceil(ValMappings[Idx].BreakDown->Length));
assert(BankID == ValMappings[Idx].BreakDown->RegBank->getID());
>From 8fa33013de5d2c47da93083642cf9f655a3d9722 Mon Sep 17 00:00:00 2001
From: Jonas Devlieghere <jonas at devlieghere.com>
Date: Fri, 1 Mar 2024 08:34:36 -0800
Subject: [PATCH 265/406] [lldb] Add support for sorting by size to `target
module dump symtab` (#83527)
This patch adds support to sort the symbol table by size. The command
already supports sorting and it already reports sizes. Sorting by size
helps diagnosing size issues.
rdar://123788375
---
.../Interpreter/CommandOptionArgumentTable.h | 5 ++++
lldb/include/lldb/lldb-private-enumerations.h | 7 +++++-
lldb/source/Symbol/Symtab.cpp | 23 ++++++++++++++-----
.../Breakpad/symtab-sorted-by-size.test | 11 +++++++++
4 files changed, 39 insertions(+), 7 deletions(-)
create mode 100644 lldb/test/Shell/SymbolFile/Breakpad/symtab-sorted-by-size.test
diff --git a/lldb/include/lldb/Interpreter/CommandOptionArgumentTable.h b/lldb/include/lldb/Interpreter/CommandOptionArgumentTable.h
index 9248e2ac814461..b5e989633ea3fc 100644
--- a/lldb/include/lldb/Interpreter/CommandOptionArgumentTable.h
+++ b/lldb/include/lldb/Interpreter/CommandOptionArgumentTable.h
@@ -50,6 +50,11 @@ static constexpr OptionEnumValueElement g_sort_option_enumeration[] = {
"name",
"Sort output by symbol name.",
},
+ {
+ eSortOrderBySize,
+ "size",
+ "Sort output by symbol byte size.",
+ },
};
// Note that the negation in the argument name causes a slightly confusing
diff --git a/lldb/include/lldb/lldb-private-enumerations.h b/lldb/include/lldb/lldb-private-enumerations.h
index 9e8ab56305bef3..b8f504529683ad 100644
--- a/lldb/include/lldb/lldb-private-enumerations.h
+++ b/lldb/include/lldb/lldb-private-enumerations.h
@@ -108,7 +108,12 @@ enum ArgumentRepetitionType {
// optional
};
-enum SortOrder { eSortOrderNone, eSortOrderByAddress, eSortOrderByName };
+enum SortOrder {
+ eSortOrderNone,
+ eSortOrderByAddress,
+ eSortOrderByName,
+ eSortOrderBySize
+};
// LazyBool is for boolean values that need to be calculated lazily. Values
// start off set to eLazyBoolCalculate, and then they can be calculated once
diff --git a/lldb/source/Symbol/Symtab.cpp b/lldb/source/Symbol/Symtab.cpp
index 564a3a94cfa202..b7837892d7e26d 100644
--- a/lldb/source/Symbol/Symtab.cpp
+++ b/lldb/source/Symbol/Symtab.cpp
@@ -124,12 +124,8 @@ void Symtab::Dump(Stream *s, Target *target, SortOrder sort_order,
DumpSymbolHeader(s);
std::multimap<llvm::StringRef, const Symbol *> name_map;
- for (const_iterator pos = m_symbols.begin(), end = m_symbols.end();
- pos != end; ++pos) {
- const char *name = pos->GetName().AsCString();
- if (name && name[0])
- name_map.insert(std::make_pair(name, &(*pos)));
- }
+ for (const Symbol &symbol : m_symbols)
+ name_map.emplace(llvm::StringRef(symbol.GetName()), &symbol);
for (const auto &name_to_symbol : name_map) {
const Symbol *symbol = name_to_symbol.second;
@@ -138,6 +134,21 @@ void Symtab::Dump(Stream *s, Target *target, SortOrder sort_order,
}
} break;
+ case eSortOrderBySize: {
+ s->PutCString(" (sorted by size):\n");
+ DumpSymbolHeader(s);
+
+ std::multimap<size_t, const Symbol *, std::greater<size_t>> size_map;
+ for (const Symbol &symbol : m_symbols)
+ size_map.emplace(symbol.GetByteSize(), &symbol);
+
+ for (const auto &size_to_symbol : size_map) {
+ const Symbol *symbol = size_to_symbol.second;
+ s->Indent();
+ symbol->Dump(s, target, symbol - &m_symbols[0], name_preference);
+ }
+ } break;
+
case eSortOrderByAddress:
s->PutCString(" (sorted by address):\n");
DumpSymbolHeader(s);
diff --git a/lldb/test/Shell/SymbolFile/Breakpad/symtab-sorted-by-size.test b/lldb/test/Shell/SymbolFile/Breakpad/symtab-sorted-by-size.test
new file mode 100644
index 00000000000000..a9b6c0b1ef09b0
--- /dev/null
+++ b/lldb/test/Shell/SymbolFile/Breakpad/symtab-sorted-by-size.test
@@ -0,0 +1,11 @@
+# RUN: yaml2obj %S/Inputs/basic-elf.yaml -o %T/symtab.out
+# RUN: %lldb %T/symtab.out -o "target symbols add -s symtab.out %S/Inputs/symtab.syms" \
+# RUN: -s %s | FileCheck %s
+
+# CHECK: num_symbols = 4 (sorted by size):
+# CHECK: [ 0] 0 SX Code 0x0000000000400000 0x00000000000000b0 0x00000000 ___lldb_unnamed_symbol0
+# CHECK: [ 3] 0 X Code 0x00000000004000d0 0x0000000000000022 0x00000000 _start
+# CHECK: [ 1] 0 X Code 0x00000000004000b0 0x0000000000000010 0x00000000 f1
+# CHECK: [ 2] 0 X Code 0x00000000004000c0 0x0000000000000010 0x00000000 f2
+
+image dump symtab -s size symtab.out
>From 8f65e7b917c580d1b58b024db6fc889cbcd964c7 Mon Sep 17 00:00:00 2001
From: Daniil Kovalev <dkovalev at accesssoftek.com>
Date: Fri, 1 Mar 2024 19:48:08 +0300
Subject: [PATCH 266/406] [Dwarf] Support `__ptrauth` qualifier in metadata
nodes (#82363)
Emit `__ptrauth`-qualified types as `DIDerivedType` metadata nodes in IR
with tag `DW_TAG_LLVM_ptrauth_type`, baseType referring to the type
which has the qualifier applied, and the following parameters
representing the signing schema:
- `ptrAuthKey` (integer)
- `ptrAuthIsAddressDiscriminated` (boolean)
- `ptrAuthExtraDiscriminator` (integer)
- `ptrAuthIsaPointer` (boolean)
- `ptrAuthAuthenticatesNullValues` (boolean)
Co-authored-by: Ahmed Bougacha <ahmed at bougacha.org>
---
llvm/include/llvm/IR/DIBuilder.h | 7 ++
llvm/include/llvm/IR/DebugInfoMetadata.h | 124 ++++++++++++++++----
llvm/lib/AsmParser/LLParser.cpp | 23 +++-
llvm/lib/Bitcode/Reader/MetadataLoader.cpp | 18 ++-
llvm/lib/Bitcode/Writer/BitcodeWriter.cpp | 5 +
llvm/lib/CodeGen/AsmPrinter/DwarfUnit.cpp | 14 +++
llvm/lib/IR/AsmWriter.cpp | 11 ++
llvm/lib/IR/DIBuilder.cpp | 58 +++++----
llvm/lib/IR/DebugInfo.cpp | 6 +-
llvm/lib/IR/DebugInfoMetadata.cpp | 32 +++--
llvm/lib/IR/LLVMContextImpl.h | 15 ++-
llvm/lib/IR/Verifier.cpp | 1 +
llvm/test/Assembler/debug-info.ll | 16 ++-
llvm/test/DebugInfo/AArch64/ptrauth.ll | 70 +++++++++++
llvm/unittests/IR/MetadataTest.cpp | 85 ++++++++++----
mlir/lib/Target/LLVMIR/DebugTranslation.cpp | 3 +-
16 files changed, 388 insertions(+), 100 deletions(-)
create mode 100644 llvm/test/DebugInfo/AArch64/ptrauth.ll
diff --git a/llvm/include/llvm/IR/DIBuilder.h b/llvm/include/llvm/IR/DIBuilder.h
index edec161b397155..010dcbfdadcac2 100644
--- a/llvm/include/llvm/IR/DIBuilder.h
+++ b/llvm/include/llvm/IR/DIBuilder.h
@@ -262,6 +262,13 @@ namespace llvm {
std::optional<unsigned> DWARFAddressSpace = std::nullopt,
StringRef Name = "", DINodeArray Annotations = nullptr);
+ /// Create a __ptrauth qualifier.
+ DIDerivedType *createPtrAuthQualifiedType(DIType *FromTy, unsigned Key,
+ bool IsAddressDiscriminated,
+ unsigned ExtraDiscriminator,
+ bool IsaPointer,
+ bool authenticatesNullValues);
+
/// Create debugging information entry for a pointer to member.
/// \param PointeeTy Type pointed to by this pointer.
/// \param SizeInBits Size.
diff --git a/llvm/include/llvm/IR/DebugInfoMetadata.h b/llvm/include/llvm/IR/DebugInfoMetadata.h
index 156f6eb49253de..1a953c53c17a14 100644
--- a/llvm/include/llvm/IR/DebugInfoMetadata.h
+++ b/llvm/include/llvm/IR/DebugInfoMetadata.h
@@ -745,7 +745,7 @@ class DIType : public DIScope {
unsigned getLine() const { return Line; }
uint64_t getSizeInBits() const { return SizeInBits; }
- uint32_t getAlignInBits() const { return SubclassData32; }
+ uint32_t getAlignInBits() const;
uint32_t getAlignInBytes() const { return getAlignInBits() / CHAR_BIT; }
uint64_t getOffsetInBits() const { return OffsetInBits; }
DIFlags getFlags() const { return Flags; }
@@ -972,6 +972,40 @@ class DIStringType : public DIType {
///
/// TODO: Split out members (inheritance, fields, methods, etc.).
class DIDerivedType : public DIType {
+public:
+ /// Pointer authentication (__ptrauth) metadata.
+ struct PtrAuthData {
+ union {
+ struct {
+ unsigned Key : 4;
+ unsigned IsAddressDiscriminated : 1;
+ unsigned ExtraDiscriminator : 16;
+ unsigned IsaPointer : 1;
+ unsigned AuthenticatesNullValues : 1;
+ } Data;
+ unsigned RawData;
+ } Payload;
+
+ PtrAuthData(unsigned FromRawData) { Payload.RawData = FromRawData; }
+ PtrAuthData(unsigned Key, bool IsDiscr, unsigned Discriminator,
+ bool IsaPointer, bool AuthenticatesNullValues) {
+ assert(Key < 16);
+ assert(Discriminator <= 0xffff);
+ Payload.Data.Key = Key;
+ Payload.Data.IsAddressDiscriminated = IsDiscr;
+ Payload.Data.ExtraDiscriminator = Discriminator;
+ Payload.Data.IsaPointer = IsaPointer;
+ Payload.Data.AuthenticatesNullValues = AuthenticatesNullValues;
+ }
+ bool operator==(struct PtrAuthData Other) const {
+ return Payload.RawData == Other.Payload.RawData;
+ }
+ bool operator!=(struct PtrAuthData Other) const {
+ return !(*this == Other);
+ }
+ };
+
+private:
friend class LLVMContextImpl;
friend class MDNode;
@@ -982,59 +1016,70 @@ class DIDerivedType : public DIType {
DIDerivedType(LLVMContext &C, StorageType Storage, unsigned Tag,
unsigned Line, uint64_t SizeInBits, uint32_t AlignInBits,
uint64_t OffsetInBits,
- std::optional<unsigned> DWARFAddressSpace, DIFlags Flags,
+ std::optional<unsigned> DWARFAddressSpace,
+ std::optional<PtrAuthData> PtrAuthData, DIFlags Flags,
ArrayRef<Metadata *> Ops)
: DIType(C, DIDerivedTypeKind, Storage, Tag, Line, SizeInBits,
AlignInBits, OffsetInBits, Flags, Ops),
- DWARFAddressSpace(DWARFAddressSpace) {}
+ DWARFAddressSpace(DWARFAddressSpace) {
+ if (PtrAuthData)
+ SubclassData32 = PtrAuthData->Payload.RawData;
+ }
~DIDerivedType() = default;
static DIDerivedType *
getImpl(LLVMContext &Context, unsigned Tag, StringRef Name, DIFile *File,
unsigned Line, DIScope *Scope, DIType *BaseType, uint64_t SizeInBits,
uint32_t AlignInBits, uint64_t OffsetInBits,
- std::optional<unsigned> DWARFAddressSpace, DIFlags Flags,
+ std::optional<unsigned> DWARFAddressSpace,
+ std::optional<PtrAuthData> PtrAuthData, DIFlags Flags,
Metadata *ExtraData, DINodeArray Annotations, StorageType Storage,
bool ShouldCreate = true) {
return getImpl(Context, Tag, getCanonicalMDString(Context, Name), File,
Line, Scope, BaseType, SizeInBits, AlignInBits, OffsetInBits,
- DWARFAddressSpace, Flags, ExtraData, Annotations.get(),
- Storage, ShouldCreate);
+ DWARFAddressSpace, PtrAuthData, Flags, ExtraData,
+ Annotations.get(), Storage, ShouldCreate);
}
static DIDerivedType *
getImpl(LLVMContext &Context, unsigned Tag, MDString *Name, Metadata *File,
unsigned Line, Metadata *Scope, Metadata *BaseType,
uint64_t SizeInBits, uint32_t AlignInBits, uint64_t OffsetInBits,
- std::optional<unsigned> DWARFAddressSpace, DIFlags Flags,
+ std::optional<unsigned> DWARFAddressSpace,
+ std::optional<PtrAuthData> PtrAuthData, DIFlags Flags,
Metadata *ExtraData, Metadata *Annotations, StorageType Storage,
bool ShouldCreate = true);
TempDIDerivedType cloneImpl() const {
- return getTemporary(
- getContext(), getTag(), getName(), getFile(), getLine(), getScope(),
- getBaseType(), getSizeInBits(), getAlignInBits(), getOffsetInBits(),
- getDWARFAddressSpace(), getFlags(), getExtraData(), getAnnotations());
+ return getTemporary(getContext(), getTag(), getName(), getFile(), getLine(),
+ getScope(), getBaseType(), getSizeInBits(),
+ getAlignInBits(), getOffsetInBits(),
+ getDWARFAddressSpace(), getPtrAuthData(), getFlags(),
+ getExtraData(), getAnnotations());
}
public:
- DEFINE_MDNODE_GET(
- DIDerivedType,
- (unsigned Tag, MDString *Name, Metadata *File, unsigned Line,
- Metadata *Scope, Metadata *BaseType, uint64_t SizeInBits,
- uint32_t AlignInBits, uint64_t OffsetInBits,
- std::optional<unsigned> DWARFAddressSpace, DIFlags Flags,
- Metadata *ExtraData = nullptr, Metadata *Annotations = nullptr),
- (Tag, Name, File, Line, Scope, BaseType, SizeInBits, AlignInBits,
- OffsetInBits, DWARFAddressSpace, Flags, ExtraData, Annotations))
+ DEFINE_MDNODE_GET(DIDerivedType,
+ (unsigned Tag, MDString *Name, Metadata *File,
+ unsigned Line, Metadata *Scope, Metadata *BaseType,
+ uint64_t SizeInBits, uint32_t AlignInBits,
+ uint64_t OffsetInBits,
+ std::optional<unsigned> DWARFAddressSpace,
+ std::optional<PtrAuthData> PtrAuthData, DIFlags Flags,
+ Metadata *ExtraData = nullptr,
+ Metadata *Annotations = nullptr),
+ (Tag, Name, File, Line, Scope, BaseType, SizeInBits,
+ AlignInBits, OffsetInBits, DWARFAddressSpace, PtrAuthData,
+ Flags, ExtraData, Annotations))
DEFINE_MDNODE_GET(DIDerivedType,
(unsigned Tag, StringRef Name, DIFile *File, unsigned Line,
DIScope *Scope, DIType *BaseType, uint64_t SizeInBits,
uint32_t AlignInBits, uint64_t OffsetInBits,
- std::optional<unsigned> DWARFAddressSpace, DIFlags Flags,
+ std::optional<unsigned> DWARFAddressSpace,
+ std::optional<PtrAuthData> PtrAuthData, DIFlags Flags,
Metadata *ExtraData = nullptr,
DINodeArray Annotations = nullptr),
(Tag, Name, File, Line, Scope, BaseType, SizeInBits,
- AlignInBits, OffsetInBits, DWARFAddressSpace, Flags,
- ExtraData, Annotations))
+ AlignInBits, OffsetInBits, DWARFAddressSpace, PtrAuthData,
+ Flags, ExtraData, Annotations))
TempDIDerivedType clone() const { return cloneImpl(); }
@@ -1048,6 +1093,39 @@ class DIDerivedType : public DIType {
return DWARFAddressSpace;
}
+ std::optional<PtrAuthData> getPtrAuthData() const;
+
+ /// \returns The PointerAuth key.
+ std::optional<unsigned> getPtrAuthKey() const {
+ if (auto PtrAuthData = getPtrAuthData())
+ return (unsigned)PtrAuthData->Payload.Data.Key;
+ return std::nullopt;
+ }
+ /// \returns The PointerAuth address discrimination bit.
+ std::optional<bool> isPtrAuthAddressDiscriminated() const {
+ if (auto PtrAuthData = getPtrAuthData())
+ return (bool)PtrAuthData->Payload.Data.IsAddressDiscriminated;
+ return std::nullopt;
+ }
+ /// \returns The PointerAuth extra discriminator.
+ std::optional<unsigned> getPtrAuthExtraDiscriminator() const {
+ if (auto PtrAuthData = getPtrAuthData())
+ return (unsigned)PtrAuthData->Payload.Data.ExtraDiscriminator;
+ return std::nullopt;
+ }
+ /// \returns The PointerAuth IsaPointer bit.
+ std::optional<bool> isPtrAuthIsaPointer() const {
+ if (auto PtrAuthData = getPtrAuthData())
+ return (bool)PtrAuthData->Payload.Data.IsaPointer;
+ return std::nullopt;
+ }
+ /// \returns The PointerAuth authenticates null values bit.
+ std::optional<bool> getPtrAuthAuthenticatesNullValues() const {
+ if (auto PtrAuthData = getPtrAuthData())
+ return (bool)PtrAuthData->Payload.Data.AuthenticatesNullValues;
+ return std::nullopt;
+ }
+
/// Get extra data associated with this derived type.
///
/// Class type for pointer-to-members, objective-c property node for ivars,
diff --git a/llvm/lib/AsmParser/LLParser.cpp b/llvm/lib/AsmParser/LLParser.cpp
index a91e2f690999e0..e91abaf0780a3d 100644
--- a/llvm/lib/AsmParser/LLParser.cpp
+++ b/llvm/lib/AsmParser/LLParser.cpp
@@ -5130,7 +5130,11 @@ bool LLParser::parseDIStringType(MDNode *&Result, bool IsDistinct) {
/// ::= !DIDerivedType(tag: DW_TAG_pointer_type, name: "int", file: !0,
/// line: 7, scope: !1, baseType: !2, size: 32,
/// align: 32, offset: 0, flags: 0, extraData: !3,
-/// dwarfAddressSpace: 3)
+/// dwarfAddressSpace: 3, ptrAuthKey: 1,
+/// ptrAuthIsAddressDiscriminated: true,
+/// ptrAuthExtraDiscriminator: 0x1234,
+/// ptrAuthIsaPointer: 1, ptrAuthAuthenticatesNullValues:1
+/// )
bool LLParser::parseDIDerivedType(MDNode *&Result, bool IsDistinct) {
#define VISIT_MD_FIELDS(OPTIONAL, REQUIRED) \
REQUIRED(tag, DwarfTagField, ); \
@@ -5145,19 +5149,30 @@ bool LLParser::parseDIDerivedType(MDNode *&Result, bool IsDistinct) {
OPTIONAL(flags, DIFlagField, ); \
OPTIONAL(extraData, MDField, ); \
OPTIONAL(dwarfAddressSpace, MDUnsignedField, (UINT32_MAX, UINT32_MAX)); \
- OPTIONAL(annotations, MDField, );
+ OPTIONAL(annotations, MDField, ); \
+ OPTIONAL(ptrAuthKey, MDUnsignedField, (0, 7)); \
+ OPTIONAL(ptrAuthIsAddressDiscriminated, MDBoolField, ); \
+ OPTIONAL(ptrAuthExtraDiscriminator, MDUnsignedField, (0, 0xffff)); \
+ OPTIONAL(ptrAuthIsaPointer, MDBoolField, ); \
+ OPTIONAL(ptrAuthAuthenticatesNullValues, MDBoolField, );
PARSE_MD_FIELDS();
#undef VISIT_MD_FIELDS
std::optional<unsigned> DWARFAddressSpace;
if (dwarfAddressSpace.Val != UINT32_MAX)
DWARFAddressSpace = dwarfAddressSpace.Val;
+ std::optional<DIDerivedType::PtrAuthData> PtrAuthData;
+ if (ptrAuthKey.Val)
+ PtrAuthData = DIDerivedType::PtrAuthData(
+ (unsigned)ptrAuthKey.Val, ptrAuthIsAddressDiscriminated.Val,
+ (unsigned)ptrAuthExtraDiscriminator.Val, ptrAuthIsaPointer.Val,
+ ptrAuthAuthenticatesNullValues.Val);
Result = GET_OR_DISTINCT(DIDerivedType,
(Context, tag.Val, name.Val, file.Val, line.Val,
scope.Val, baseType.Val, size.Val, align.Val,
- offset.Val, DWARFAddressSpace, flags.Val,
- extraData.Val, annotations.Val));
+ offset.Val, DWARFAddressSpace, PtrAuthData,
+ flags.Val, extraData.Val, annotations.Val));
return false;
}
diff --git a/llvm/lib/Bitcode/Reader/MetadataLoader.cpp b/llvm/lib/Bitcode/Reader/MetadataLoader.cpp
index 770eb83af17f9b..bdc2db82dfbe0e 100644
--- a/llvm/lib/Bitcode/Reader/MetadataLoader.cpp
+++ b/llvm/lib/Bitcode/Reader/MetadataLoader.cpp
@@ -1556,7 +1556,7 @@ Error MetadataLoader::MetadataLoaderImpl::parseOneMetadata(
break;
}
case bitc::METADATA_DERIVED_TYPE: {
- if (Record.size() < 12 || Record.size() > 14)
+ if (Record.size() < 12 || Record.size() > 15)
return error("Invalid record");
// DWARF address space is encoded as N->getDWARFAddressSpace() + 1. 0 means
@@ -1566,8 +1566,18 @@ Error MetadataLoader::MetadataLoaderImpl::parseOneMetadata(
DWARFAddressSpace = Record[12] - 1;
Metadata *Annotations = nullptr;
- if (Record.size() > 13 && Record[13])
- Annotations = getMDOrNull(Record[13]);
+ std::optional<DIDerivedType::PtrAuthData> PtrAuthData;
+
+ // Only look for annotations/ptrauth if both are allocated.
+ // If not, we can't tell which was intended to be embedded, as both ptrauth
+ // and annotations have been expected at Record[13] at various times.
+ if (Record.size() > 14) {
+ if (Record[13])
+ Annotations = getMDOrNull(Record[13]);
+
+ if (Record[14])
+ PtrAuthData = DIDerivedType::PtrAuthData(Record[14]);
+ }
IsDistinct = Record[0];
DINode::DIFlags Flags = static_cast<DINode::DIFlags>(Record[10]);
@@ -1577,7 +1587,7 @@ Error MetadataLoader::MetadataLoaderImpl::parseOneMetadata(
getMDOrNull(Record[3]), Record[4],
getDITypeRefOrNull(Record[5]),
getDITypeRefOrNull(Record[6]), Record[7], Record[8],
- Record[9], DWARFAddressSpace, Flags,
+ Record[9], DWARFAddressSpace, PtrAuthData, Flags,
getDITypeRefOrNull(Record[11]), Annotations)),
NextMetadataNo);
NextMetadataNo++;
diff --git a/llvm/lib/Bitcode/Writer/BitcodeWriter.cpp b/llvm/lib/Bitcode/Writer/BitcodeWriter.cpp
index 656f2a6ce870f5..85319dc69e945c 100644
--- a/llvm/lib/Bitcode/Writer/BitcodeWriter.cpp
+++ b/llvm/lib/Bitcode/Writer/BitcodeWriter.cpp
@@ -1804,6 +1804,11 @@ void ModuleBitcodeWriter::writeDIDerivedType(const DIDerivedType *N,
Record.push_back(VE.getMetadataOrNullID(N->getAnnotations().get()));
+ if (auto PtrAuthData = N->getPtrAuthData())
+ Record.push_back(PtrAuthData->Payload.RawData);
+ else
+ Record.push_back(0);
+
Stream.EmitRecord(bitc::METADATA_DERIVED_TYPE, Record, Abbrev);
Record.clear();
}
diff --git a/llvm/lib/CodeGen/AsmPrinter/DwarfUnit.cpp b/llvm/lib/CodeGen/AsmPrinter/DwarfUnit.cpp
index d462859e489465..ae0226934804f7 100644
--- a/llvm/lib/CodeGen/AsmPrinter/DwarfUnit.cpp
+++ b/llvm/lib/CodeGen/AsmPrinter/DwarfUnit.cpp
@@ -803,6 +803,20 @@ void DwarfUnit::constructTypeDIE(DIE &Buffer, const DIDerivedType *DTy) {
if (DTy->getDWARFAddressSpace())
addUInt(Buffer, dwarf::DW_AT_address_class, dwarf::DW_FORM_data4,
*DTy->getDWARFAddressSpace());
+ if (auto Key = DTy->getPtrAuthKey())
+ addUInt(Buffer, dwarf::DW_AT_LLVM_ptrauth_key, dwarf::DW_FORM_data1, *Key);
+ if (auto AddrDisc = DTy->isPtrAuthAddressDiscriminated())
+ if (AddrDisc.value())
+ addFlag(Buffer, dwarf::DW_AT_LLVM_ptrauth_address_discriminated);
+ if (auto Disc = DTy->getPtrAuthExtraDiscriminator())
+ addUInt(Buffer, dwarf::DW_AT_LLVM_ptrauth_extra_discriminator,
+ dwarf::DW_FORM_data2, *Disc);
+ if (auto IsaPointer = DTy->isPtrAuthIsaPointer())
+ if (*IsaPointer)
+ addFlag(Buffer, dwarf::DW_AT_LLVM_ptrauth_isa_pointer);
+ if (auto AuthenticatesNullValues = DTy->getPtrAuthAuthenticatesNullValues())
+ if (*AuthenticatesNullValues)
+ addFlag(Buffer, dwarf::DW_AT_LLVM_ptrauth_authenticates_null_values);
}
void DwarfUnit::constructSubprogramArguments(DIE &Buffer, DITypeRefArray Args) {
diff --git a/llvm/lib/IR/AsmWriter.cpp b/llvm/lib/IR/AsmWriter.cpp
index 4e1e48b4ad4a35..479622cd1bdcf0 100644
--- a/llvm/lib/IR/AsmWriter.cpp
+++ b/llvm/lib/IR/AsmWriter.cpp
@@ -2135,6 +2135,17 @@ static void writeDIDerivedType(raw_ostream &Out, const DIDerivedType *N,
Printer.printInt("dwarfAddressSpace", *DWARFAddressSpace,
/* ShouldSkipZero */ false);
Printer.printMetadata("annotations", N->getRawAnnotations());
+ if (auto Key = N->getPtrAuthKey())
+ Printer.printInt("ptrAuthKey", *Key);
+ if (auto AddrDisc = N->isPtrAuthAddressDiscriminated())
+ Printer.printBool("ptrAuthIsAddressDiscriminated", *AddrDisc);
+ if (auto Disc = N->getPtrAuthExtraDiscriminator())
+ Printer.printInt("ptrAuthExtraDiscriminator", *Disc);
+ if (auto IsaPointer = N->isPtrAuthIsaPointer())
+ Printer.printBool("ptrAuthIsaPointer", *IsaPointer);
+ if (auto AuthenticatesNullValues = N->getPtrAuthAuthenticatesNullValues())
+ Printer.printBool("ptrAuthAuthenticatesNullValues",
+ *AuthenticatesNullValues);
Out << ")";
}
diff --git a/llvm/lib/IR/DIBuilder.cpp b/llvm/lib/IR/DIBuilder.cpp
index 62efaba025344b..2842cb15e78fb3 100644
--- a/llvm/lib/IR/DIBuilder.cpp
+++ b/llvm/lib/IR/DIBuilder.cpp
@@ -296,7 +296,20 @@ DIStringType *DIBuilder::createStringType(StringRef Name,
DIDerivedType *DIBuilder::createQualifiedType(unsigned Tag, DIType *FromTy) {
return DIDerivedType::get(VMContext, Tag, "", nullptr, 0, nullptr, FromTy, 0,
- 0, 0, std::nullopt, DINode::FlagZero);
+ 0, 0, std::nullopt, std::nullopt, DINode::FlagZero);
+}
+
+DIDerivedType *DIBuilder::createPtrAuthQualifiedType(
+ DIType *FromTy, unsigned Key, bool IsAddressDiscriminated,
+ unsigned ExtraDiscriminator, bool IsaPointer,
+ bool AuthenticatesNullValues) {
+ return DIDerivedType::get(
+ VMContext, dwarf::DW_TAG_LLVM_ptrauth_type, "", nullptr, 0, nullptr,
+ FromTy, 0, 0, 0, std::nullopt,
+ std::optional<DIDerivedType::PtrAuthData>({Key, IsAddressDiscriminated,
+ ExtraDiscriminator, IsaPointer,
+ AuthenticatesNullValues}),
+ DINode::FlagZero);
}
DIDerivedType *
@@ -307,8 +320,8 @@ DIBuilder::createPointerType(DIType *PointeeTy, uint64_t SizeInBits,
// FIXME: Why is there a name here?
return DIDerivedType::get(VMContext, dwarf::DW_TAG_pointer_type, Name,
nullptr, 0, nullptr, PointeeTy, SizeInBits,
- AlignInBits, 0, DWARFAddressSpace, DINode::FlagZero,
- nullptr, Annotations);
+ AlignInBits, 0, DWARFAddressSpace, std::nullopt,
+ DINode::FlagZero, nullptr, Annotations);
}
DIDerivedType *DIBuilder::createMemberPointerType(DIType *PointeeTy,
@@ -318,7 +331,8 @@ DIDerivedType *DIBuilder::createMemberPointerType(DIType *PointeeTy,
DINode::DIFlags Flags) {
return DIDerivedType::get(VMContext, dwarf::DW_TAG_ptr_to_member_type, "",
nullptr, 0, nullptr, PointeeTy, SizeInBits,
- AlignInBits, 0, std::nullopt, Flags, Base);
+ AlignInBits, 0, std::nullopt, std::nullopt, Flags,
+ Base);
}
DIDerivedType *
@@ -327,7 +341,7 @@ DIBuilder::createReferenceType(unsigned Tag, DIType *RTy, uint64_t SizeInBits,
std::optional<unsigned> DWARFAddressSpace) {
assert(RTy && "Unable to create reference type");
return DIDerivedType::get(VMContext, Tag, "", nullptr, 0, nullptr, RTy,
- SizeInBits, AlignInBits, 0, DWARFAddressSpace,
+ SizeInBits, AlignInBits, 0, DWARFAddressSpace, {},
DINode::FlagZero);
}
@@ -338,15 +352,16 @@ DIDerivedType *DIBuilder::createTypedef(DIType *Ty, StringRef Name,
DINodeArray Annotations) {
return DIDerivedType::get(VMContext, dwarf::DW_TAG_typedef, Name, File,
LineNo, getNonCompileUnitScope(Context), Ty, 0,
- AlignInBits, 0, std::nullopt, Flags, nullptr,
- Annotations);
+ AlignInBits, 0, std::nullopt, std::nullopt, Flags,
+ nullptr, Annotations);
}
DIDerivedType *DIBuilder::createFriend(DIType *Ty, DIType *FriendTy) {
assert(Ty && "Invalid type!");
assert(FriendTy && "Invalid friend type!");
return DIDerivedType::get(VMContext, dwarf::DW_TAG_friend, "", nullptr, 0, Ty,
- FriendTy, 0, 0, 0, std::nullopt, DINode::FlagZero);
+ FriendTy, 0, 0, 0, std::nullopt, std::nullopt,
+ DINode::FlagZero);
}
DIDerivedType *DIBuilder::createInheritance(DIType *Ty, DIType *BaseTy,
@@ -358,7 +373,7 @@ DIDerivedType *DIBuilder::createInheritance(DIType *Ty, DIType *BaseTy,
ConstantInt::get(IntegerType::get(VMContext, 32), VBPtrOffset));
return DIDerivedType::get(VMContext, dwarf::DW_TAG_inheritance, "", nullptr,
0, Ty, BaseTy, 0, 0, BaseOffset, std::nullopt,
- Flags, ExtraData);
+ std::nullopt, Flags, ExtraData);
}
DIDerivedType *DIBuilder::createMemberType(
@@ -368,7 +383,7 @@ DIDerivedType *DIBuilder::createMemberType(
return DIDerivedType::get(VMContext, dwarf::DW_TAG_member, Name, File,
LineNumber, getNonCompileUnitScope(Scope), Ty,
SizeInBits, AlignInBits, OffsetInBits, std::nullopt,
- Flags, nullptr, Annotations);
+ std::nullopt, Flags, nullptr, Annotations);
}
static ConstantAsMetadata *getConstantOrNull(Constant *C) {
@@ -381,10 +396,10 @@ DIDerivedType *DIBuilder::createVariantMemberType(
DIScope *Scope, StringRef Name, DIFile *File, unsigned LineNumber,
uint64_t SizeInBits, uint32_t AlignInBits, uint64_t OffsetInBits,
Constant *Discriminant, DINode::DIFlags Flags, DIType *Ty) {
- return DIDerivedType::get(VMContext, dwarf::DW_TAG_member, Name, File,
- LineNumber, getNonCompileUnitScope(Scope), Ty,
- SizeInBits, AlignInBits, OffsetInBits, std::nullopt,
- Flags, getConstantOrNull(Discriminant));
+ return DIDerivedType::get(
+ VMContext, dwarf::DW_TAG_member, Name, File, LineNumber,
+ getNonCompileUnitScope(Scope), Ty, SizeInBits, AlignInBits, OffsetInBits,
+ std::nullopt, std::nullopt, Flags, getConstantOrNull(Discriminant));
}
DIDerivedType *DIBuilder::createBitFieldMemberType(
@@ -395,7 +410,7 @@ DIDerivedType *DIBuilder::createBitFieldMemberType(
return DIDerivedType::get(
VMContext, dwarf::DW_TAG_member, Name, File, LineNumber,
getNonCompileUnitScope(Scope), Ty, SizeInBits, /*AlignInBits=*/0,
- OffsetInBits, std::nullopt, Flags,
+ OffsetInBits, std::nullopt, std::nullopt, Flags,
ConstantAsMetadata::get(ConstantInt::get(IntegerType::get(VMContext, 64),
StorageOffsetInBits)),
Annotations);
@@ -409,7 +424,8 @@ DIBuilder::createStaticMemberType(DIScope *Scope, StringRef Name, DIFile *File,
Flags |= DINode::FlagStaticMember;
return DIDerivedType::get(VMContext, Tag, Name, File, LineNumber,
getNonCompileUnitScope(Scope), Ty, 0, AlignInBits,
- 0, std::nullopt, Flags, getConstantOrNull(Val));
+ 0, std::nullopt, std::nullopt, Flags,
+ getConstantOrNull(Val));
}
DIDerivedType *
@@ -420,7 +436,7 @@ DIBuilder::createObjCIVar(StringRef Name, DIFile *File, unsigned LineNumber,
return DIDerivedType::get(VMContext, dwarf::DW_TAG_member, Name, File,
LineNumber, getNonCompileUnitScope(File), Ty,
SizeInBits, AlignInBits, OffsetInBits, std::nullopt,
- Flags, PropertyNode);
+ std::nullopt, Flags, PropertyNode);
}
DIObjCProperty *
@@ -555,10 +571,10 @@ DIDerivedType *DIBuilder::createSetType(DIScope *Scope, StringRef Name,
DIFile *File, unsigned LineNo,
uint64_t SizeInBits,
uint32_t AlignInBits, DIType *Ty) {
- auto *R =
- DIDerivedType::get(VMContext, dwarf::DW_TAG_set_type, Name, File, LineNo,
- getNonCompileUnitScope(Scope), Ty, SizeInBits,
- AlignInBits, 0, std::nullopt, DINode::FlagZero);
+ auto *R = DIDerivedType::get(VMContext, dwarf::DW_TAG_set_type, Name, File,
+ LineNo, getNonCompileUnitScope(Scope), Ty,
+ SizeInBits, AlignInBits, 0, std::nullopt,
+ std::nullopt, DINode::FlagZero);
trackIfUnresolved(R);
return R;
}
diff --git a/llvm/lib/IR/DebugInfo.cpp b/llvm/lib/IR/DebugInfo.cpp
index 1f3ff2246a4453..510cc31da6ca5f 100644
--- a/llvm/lib/IR/DebugInfo.cpp
+++ b/llvm/lib/IR/DebugInfo.cpp
@@ -1336,9 +1336,9 @@ LLVMMetadataRef LLVMDIBuilderCreatePointerType(
LLVMDIBuilderRef Builder, LLVMMetadataRef PointeeTy,
uint64_t SizeInBits, uint32_t AlignInBits, unsigned AddressSpace,
const char *Name, size_t NameLen) {
- return wrap(unwrap(Builder)->createPointerType(unwrapDI<DIType>(PointeeTy),
- SizeInBits, AlignInBits,
- AddressSpace, {Name, NameLen}));
+ return wrap(unwrap(Builder)->createPointerType(
+ unwrapDI<DIType>(PointeeTy), SizeInBits, AlignInBits, AddressSpace,
+ {Name, NameLen}));
}
LLVMMetadataRef LLVMDIBuilderCreateStructType(
diff --git a/llvm/lib/IR/DebugInfoMetadata.cpp b/llvm/lib/IR/DebugInfoMetadata.cpp
index 28f96653d815b5..36c13e79a64925 100644
--- a/llvm/lib/IR/DebugInfoMetadata.cpp
+++ b/llvm/lib/IR/DebugInfoMetadata.cpp
@@ -34,6 +34,10 @@ cl::opt<bool> EnableFSDiscriminator(
cl::desc("Enable adding flow sensitive discriminators"));
} // namespace llvm
+uint32_t DIType::getAlignInBits() const {
+ return (getTag() == dwarf::DW_TAG_LLVM_ptrauth_type ? 0 : SubclassData32);
+}
+
const DIExpression::FragmentInfo DebugVariable::DefaultFragment = {
std::numeric_limits<uint64_t>::max(), std::numeric_limits<uint64_t>::min()};
@@ -731,26 +735,32 @@ Constant *DIDerivedType::getDiscriminantValue() const {
return nullptr;
}
-DIDerivedType *
-DIDerivedType::getImpl(LLVMContext &Context, unsigned Tag, MDString *Name,
- Metadata *File, unsigned Line, Metadata *Scope,
- Metadata *BaseType, uint64_t SizeInBits,
- uint32_t AlignInBits, uint64_t OffsetInBits,
- std::optional<unsigned> DWARFAddressSpace, DIFlags Flags,
- Metadata *ExtraData, Metadata *Annotations,
- StorageType Storage, bool ShouldCreate) {
+DIDerivedType *DIDerivedType::getImpl(
+ LLVMContext &Context, unsigned Tag, MDString *Name, Metadata *File,
+ unsigned Line, Metadata *Scope, Metadata *BaseType, uint64_t SizeInBits,
+ uint32_t AlignInBits, uint64_t OffsetInBits,
+ std::optional<unsigned> DWARFAddressSpace,
+ std::optional<PtrAuthData> PtrAuthData, DIFlags Flags, Metadata *ExtraData,
+ Metadata *Annotations, StorageType Storage, bool ShouldCreate) {
assert(isCanonical(Name) && "Expected canonical MDString");
DEFINE_GETIMPL_LOOKUP(DIDerivedType,
(Tag, Name, File, Line, Scope, BaseType, SizeInBits,
- AlignInBits, OffsetInBits, DWARFAddressSpace, Flags,
- ExtraData, Annotations));
+ AlignInBits, OffsetInBits, DWARFAddressSpace,
+ PtrAuthData, Flags, ExtraData, Annotations));
Metadata *Ops[] = {File, Scope, Name, BaseType, ExtraData, Annotations};
DEFINE_GETIMPL_STORE(DIDerivedType,
(Tag, Line, SizeInBits, AlignInBits, OffsetInBits,
- DWARFAddressSpace, Flags),
+ DWARFAddressSpace, PtrAuthData, Flags),
Ops);
}
+std::optional<DIDerivedType::PtrAuthData>
+DIDerivedType::getPtrAuthData() const {
+ return getTag() == dwarf::DW_TAG_LLVM_ptrauth_type
+ ? std::optional<PtrAuthData>(PtrAuthData(SubclassData32))
+ : std::nullopt;
+}
+
DICompositeType *DICompositeType::getImpl(
LLVMContext &Context, unsigned Tag, MDString *Name, Metadata *File,
unsigned Line, Metadata *Scope, Metadata *BaseType, uint64_t SizeInBits,
diff --git a/llvm/lib/IR/LLVMContextImpl.h b/llvm/lib/IR/LLVMContextImpl.h
index 2ee1080a1ffa29..05e2b56587b2eb 100644
--- a/llvm/lib/IR/LLVMContextImpl.h
+++ b/llvm/lib/IR/LLVMContextImpl.h
@@ -539,6 +539,7 @@ template <> struct MDNodeKeyImpl<DIDerivedType> {
uint64_t OffsetInBits;
uint32_t AlignInBits;
std::optional<unsigned> DWARFAddressSpace;
+ std::optional<DIDerivedType::PtrAuthData> PtrAuthData;
unsigned Flags;
Metadata *ExtraData;
Metadata *Annotations;
@@ -546,18 +547,21 @@ template <> struct MDNodeKeyImpl<DIDerivedType> {
MDNodeKeyImpl(unsigned Tag, MDString *Name, Metadata *File, unsigned Line,
Metadata *Scope, Metadata *BaseType, uint64_t SizeInBits,
uint32_t AlignInBits, uint64_t OffsetInBits,
- std::optional<unsigned> DWARFAddressSpace, unsigned Flags,
- Metadata *ExtraData, Metadata *Annotations)
+ std::optional<unsigned> DWARFAddressSpace,
+ std::optional<DIDerivedType::PtrAuthData> PtrAuthData,
+ unsigned Flags, Metadata *ExtraData, Metadata *Annotations)
: Tag(Tag), Name(Name), File(File), Line(Line), Scope(Scope),
BaseType(BaseType), SizeInBits(SizeInBits), OffsetInBits(OffsetInBits),
AlignInBits(AlignInBits), DWARFAddressSpace(DWARFAddressSpace),
- Flags(Flags), ExtraData(ExtraData), Annotations(Annotations) {}
+ PtrAuthData(PtrAuthData), Flags(Flags), ExtraData(ExtraData),
+ Annotations(Annotations) {}
MDNodeKeyImpl(const DIDerivedType *N)
: Tag(N->getTag()), Name(N->getRawName()), File(N->getRawFile()),
Line(N->getLine()), Scope(N->getRawScope()),
BaseType(N->getRawBaseType()), SizeInBits(N->getSizeInBits()),
OffsetInBits(N->getOffsetInBits()), AlignInBits(N->getAlignInBits()),
- DWARFAddressSpace(N->getDWARFAddressSpace()), Flags(N->getFlags()),
+ DWARFAddressSpace(N->getDWARFAddressSpace()),
+ PtrAuthData(N->getPtrAuthData()), Flags(N->getFlags()),
ExtraData(N->getRawExtraData()), Annotations(N->getRawAnnotations()) {}
bool isKeyOf(const DIDerivedType *RHS) const {
@@ -568,7 +572,8 @@ template <> struct MDNodeKeyImpl<DIDerivedType> {
AlignInBits == RHS->getAlignInBits() &&
OffsetInBits == RHS->getOffsetInBits() &&
DWARFAddressSpace == RHS->getDWARFAddressSpace() &&
- Flags == RHS->getFlags() && ExtraData == RHS->getRawExtraData() &&
+ PtrAuthData == RHS->getPtrAuthData() && Flags == RHS->getFlags() &&
+ ExtraData == RHS->getRawExtraData() &&
Annotations == RHS->getRawAnnotations();
}
diff --git a/llvm/lib/IR/Verifier.cpp b/llvm/lib/IR/Verifier.cpp
index e0de179e57146f..1b02d11ff4e7b3 100644
--- a/llvm/lib/IR/Verifier.cpp
+++ b/llvm/lib/IR/Verifier.cpp
@@ -1223,6 +1223,7 @@ void Verifier::visitDIDerivedType(const DIDerivedType &N) {
N.getTag() == dwarf::DW_TAG_volatile_type ||
N.getTag() == dwarf::DW_TAG_restrict_type ||
N.getTag() == dwarf::DW_TAG_atomic_type ||
+ N.getTag() == dwarf::DW_TAG_LLVM_ptrauth_type ||
N.getTag() == dwarf::DW_TAG_member ||
(N.getTag() == dwarf::DW_TAG_variable && N.isStaticMember()) ||
N.getTag() == dwarf::DW_TAG_inheritance ||
diff --git a/llvm/test/Assembler/debug-info.ll b/llvm/test/Assembler/debug-info.ll
index 419623a2cb7d14..06144b261373f4 100644
--- a/llvm/test/Assembler/debug-info.ll
+++ b/llvm/test/Assembler/debug-info.ll
@@ -1,8 +1,8 @@
; RUN: llvm-as < %s | llvm-dis | llvm-as | llvm-dis | FileCheck %s
; RUN: verify-uselistorder %s
-; CHECK: !named = !{!0, !0, !1, !2, !3, !4, !5, !6, !7, !8, !8, !9, !10, !11, !12, !13, !14, !15, !16, !17, !18, !19, !20, !21, !22, !23, !24, !25, !26, !27, !27, !28, !29, !30, !31, !32, !33, !34, !35, !36, !37, !38, !39}
-!named = !{!0, !1, !2, !3, !4, !5, !6, !7, !8, !9, !10, !11, !12, !13, !14, !15, !16, !17, !18, !19, !20, !21, !22, !23, !24, !25, !26, !27, !28, !29, !30, !31, !32, !33, !34, !35, !36, !37, !38, !39, !40, !41, !42}
+; CHECK: !named = !{!0, !0, !1, !2, !3, !4, !5, !6, !7, !8, !8, !9, !10, !11, !12, !13, !14, !15, !16, !17, !18, !19, !20, !21, !22, !23, !24, !25, !26, !27, !27, !28, !29, !30, !31, !32, !33, !34, !35, !36, !37, !38, !39, !40, !41, !42, !43}
+!named = !{!0, !1, !2, !3, !4, !5, !6, !7, !8, !9, !10, !11, !12, !13, !14, !15, !16, !17, !18, !19, !20, !21, !22, !23, !24, !25, !26, !27, !28, !29, !30, !31, !32, !33, !34, !35, !36, !37, !38, !39, !40, !41, !42, !43, !44, !45, !46}
; CHECK: !0 = !DISubrange(count: 3, lowerBound: 0)
; CHECK-NEXT: !1 = !DISubrange(count: 3, lowerBound: 4)
@@ -99,3 +99,15 @@
; CHECK-NEXT: !39 = !DIBasicType(name: "u64.le", size: 64, align: 1, encoding: DW_ATE_unsigned, flags: DIFlagLittleEndian)
!41 = !DIBasicType(name: "u64.be", size: 64, align: 1, encoding: DW_ATE_unsigned, flags: DIFlagBigEndian)
!42 = !DIBasicType(name: "u64.le", size: 64, align: 1, encoding: DW_ATE_unsigned, flags: DIFlagLittleEndian)
+
+; CHECK: !DIDerivedType(tag: DW_TAG_LLVM_ptrauth_type, baseType: !13, ptrAuthKey: 2, ptrAuthIsAddressDiscriminated: true, ptrAuthExtraDiscriminator: 1234, ptrAuthIsaPointer: false, ptrAuthAuthenticatesNullValues: false)
+!43 = !DIDerivedType(tag: DW_TAG_LLVM_ptrauth_type, baseType: !15, ptrAuthKey: 2, ptrAuthIsAddressDiscriminated: true, ptrAuthExtraDiscriminator: 1234)
+
+; CHECK: !DIDerivedType(tag: DW_TAG_LLVM_ptrauth_type, baseType: !13, ptrAuthKey: 2, ptrAuthIsAddressDiscriminated: true, ptrAuthExtraDiscriminator: 1234, ptrAuthIsaPointer: true, ptrAuthAuthenticatesNullValues: false)
+!44 = !DIDerivedType(tag: DW_TAG_LLVM_ptrauth_type, baseType: !15, ptrAuthKey: 2, ptrAuthIsAddressDiscriminated: true, ptrAuthExtraDiscriminator: 1234, ptrAuthIsaPointer: true)
+
+; CHECK: !DIDerivedType(tag: DW_TAG_LLVM_ptrauth_type, baseType: !13, ptrAuthKey: 2, ptrAuthIsAddressDiscriminated: true, ptrAuthExtraDiscriminator: 1234, ptrAuthIsaPointer: false, ptrAuthAuthenticatesNullValues: true)
+!45 = !DIDerivedType(tag: DW_TAG_LLVM_ptrauth_type, baseType: !15, ptrAuthKey: 2, ptrAuthIsAddressDiscriminated: true, ptrAuthExtraDiscriminator: 1234, ptrAuthAuthenticatesNullValues: true)
+
+; CHECK: !DIDerivedType(tag: DW_TAG_LLVM_ptrauth_type, baseType: !13, ptrAuthKey: 2, ptrAuthIsAddressDiscriminated: true, ptrAuthExtraDiscriminator: 1234, ptrAuthIsaPointer: true, ptrAuthAuthenticatesNullValues: true)
+!46 = !DIDerivedType(tag: DW_TAG_LLVM_ptrauth_type, baseType: !15, ptrAuthKey: 2, ptrAuthIsAddressDiscriminated: true, ptrAuthExtraDiscriminator: 1234, ptrAuthIsaPointer: true, ptrAuthAuthenticatesNullValues: true)
diff --git a/llvm/test/DebugInfo/AArch64/ptrauth.ll b/llvm/test/DebugInfo/AArch64/ptrauth.ll
new file mode 100644
index 00000000000000..4f84fe4f962977
--- /dev/null
+++ b/llvm/test/DebugInfo/AArch64/ptrauth.ll
@@ -0,0 +1,70 @@
+; RUN: llc %s -filetype=obj -mtriple arm64e-apple-darwin -o - \
+; RUN: | llvm-dwarfdump - | FileCheck %s
+
+; CHECK: DW_AT_type (0x{{0+}}[[TY:.*]] "void *__ptrauth(4, 0, 0x04d2)")
+; CHECK: 0x{{0+}}[[TY]]: DW_TAG_LLVM_ptrauth_type
+; CHECK-NEXT: DW_AT_type {{.*}}"void *"
+; CHECK-NEXT: DW_AT_LLVM_ptrauth_key (0x04)
+; CHECK-NEXT: DW_AT_LLVM_ptrauth_extra_discriminator (0x04d2)
+
+; CHECK: DW_AT_type (0x{{0+}}[[TY:.*]] "void *__ptrauth(4, 1, 0x04d3)")
+; CHECK: 0x{{0+}}[[TY]]: DW_TAG_LLVM_ptrauth_type
+; CHECK-NEXT: DW_AT_type {{.*}}"void *"
+; CHECK-NEXT: DW_AT_LLVM_ptrauth_key (0x04)
+; CHECK-NEXT: DW_AT_LLVM_ptrauth_address_discriminated (true)
+; CHECK-NEXT: DW_AT_LLVM_ptrauth_extra_discriminator (0x04d3)
+
+; CHECK: DW_AT_type (0x{{0+}}[[TY:.*]] "void *__ptrauth(4, 1, 0x04d4, "isa-pointer")")
+; CHECK: 0x{{0+}}[[TY]]: DW_TAG_LLVM_ptrauth_type
+; CHECK-NEXT: DW_AT_type {{.*}}"void *"
+; CHECK-NEXT: DW_AT_LLVM_ptrauth_key (0x04)
+; CHECK-NEXT: DW_AT_LLVM_ptrauth_address_discriminated (true)
+; CHECK-NEXT: DW_AT_LLVM_ptrauth_extra_discriminator (0x04d4)
+; CHECK-NEXT: DW_AT_LLVM_ptrauth_isa_pointer (true)
+
+; CHECK: DW_AT_type (0x{{0+}}[[TY:.*]] "void *__ptrauth(4, 1, 0x04d5, "authenticates-null-values")")
+; CHECK: 0x{{0+}}[[TY]]: DW_TAG_LLVM_ptrauth_type
+; CHECK-NEXT: DW_AT_type {{.*}}"void *"
+; CHECK-NEXT: DW_AT_LLVM_ptrauth_key (0x04)
+; CHECK-NEXT: DW_AT_LLVM_ptrauth_address_discriminated (true)
+; CHECK-NEXT: DW_AT_LLVM_ptrauth_extra_discriminator (0x04d5)
+; CHECK-NEXT: DW_AT_LLVM_ptrauth_authenticates_null_values (true)
+
+; CHECK: DW_AT_type (0x{{0+}}[[TY:.*]] "void *__ptrauth(4, 1, 0x04d6, "isa-pointer,authenticates-null-values")")
+; CHECK: 0x{{0+}}[[TY]]: DW_TAG_LLVM_ptrauth_type
+; CHECK-NEXT: DW_AT_type {{.*}}"void *"
+; CHECK-NEXT: DW_AT_LLVM_ptrauth_key (0x04)
+; CHECK-NEXT: DW_AT_LLVM_ptrauth_address_discriminated (true)
+; CHECK-NEXT: DW_AT_LLVM_ptrauth_extra_discriminator (0x04d6)
+; CHECK-NEXT: DW_AT_LLVM_ptrauth_isa_pointer (true)
+; CHECK-NEXT: DW_AT_LLVM_ptrauth_authenticates_null_values (true)
+
+target datalayout = "e-m:o-i64:64-i128:128-n32:64-S128"
+
+ at p = common global i8* null, align 8, !dbg !0
+
+!llvm.dbg.cu = !{!10}
+!llvm.module.flags = !{!19, !20}
+
+!0 = !DIGlobalVariableExpression(var: !5, expr: !DIExpression())
+!1 = !DIGlobalVariableExpression(var: !6, expr: !DIExpression())
+!2 = !DIGlobalVariableExpression(var: !7, expr: !DIExpression())
+!3 = !DIGlobalVariableExpression(var: !8, expr: !DIExpression())
+!4 = !DIGlobalVariableExpression(var: !9, expr: !DIExpression())
+!5 = distinct !DIGlobalVariable(name: "p1", scope: !10, file: !11, line: 1, type: !14, isLocal: false, isDefinition: true)
+!6 = distinct !DIGlobalVariable(name: "p2", scope: !10, file: !11, line: 1, type: !15, isLocal: false, isDefinition: true)
+!7 = distinct !DIGlobalVariable(name: "p3", scope: !10, file: !11, line: 1, type: !16, isLocal: false, isDefinition: true)
+!8 = distinct !DIGlobalVariable(name: "p4", scope: !10, file: !11, line: 1, type: !17, isLocal: false, isDefinition: true)
+!9 = distinct !DIGlobalVariable(name: "p5", scope: !10, file: !11, line: 1, type: !18, isLocal: false, isDefinition: true)
+!10 = distinct !DICompileUnit(language: DW_LANG_C99, file: !11, emissionKind: FullDebug, globals: !13)
+!11 = !DIFile(filename: "/tmp/p.c", directory: "/")
+!12 = !{}
+!13 = !{!0,!1,!2,!3,!4}
+!14 = !DIDerivedType(tag: DW_TAG_LLVM_ptrauth_type, baseType: !21, ptrAuthKey: 4, ptrAuthIsAddressDiscriminated: false, ptrAuthExtraDiscriminator: 1234)
+!15 = !DIDerivedType(tag: DW_TAG_LLVM_ptrauth_type, baseType: !21, ptrAuthKey: 4, ptrAuthIsAddressDiscriminated: true, ptrAuthExtraDiscriminator: 1235)
+!16 = !DIDerivedType(tag: DW_TAG_LLVM_ptrauth_type, baseType: !21, ptrAuthKey: 4, ptrAuthIsAddressDiscriminated: true, ptrAuthExtraDiscriminator: 1236, ptrAuthIsaPointer: true)
+!17 = !DIDerivedType(tag: DW_TAG_LLVM_ptrauth_type, baseType: !21, ptrAuthKey: 4, ptrAuthIsAddressDiscriminated: true, ptrAuthExtraDiscriminator: 1237, ptrAuthAuthenticatesNullValues: true)
+!18 = !DIDerivedType(tag: DW_TAG_LLVM_ptrauth_type, baseType: !21, ptrAuthKey: 4, ptrAuthIsAddressDiscriminated: true, ptrAuthExtraDiscriminator: 1238, ptrAuthIsaPointer: true, ptrAuthAuthenticatesNullValues: true)
+!19 = !{i32 2, !"Dwarf Version", i32 4}
+!20 = !{i32 2, !"Debug Info Version", i32 3}
+!21 = !DIDerivedType(tag: DW_TAG_pointer_type, baseType: null)
diff --git a/llvm/unittests/IR/MetadataTest.cpp b/llvm/unittests/IR/MetadataTest.cpp
index 767dd1a59d2b9e..20d4090135dd43 100644
--- a/llvm/unittests/IR/MetadataTest.cpp
+++ b/llvm/unittests/IR/MetadataTest.cpp
@@ -106,7 +106,7 @@ class MetadataTest : public testing::Test {
DIType *getDerivedType() {
return DIDerivedType::getDistinct(
Context, dwarf::DW_TAG_pointer_type, "", nullptr, 0, nullptr,
- getBasicType("basictype"), 1, 2, 0, std::nullopt, DINode::FlagZero);
+ getBasicType("basictype"), 1, 2, 0, std::nullopt, {}, DINode::FlagZero);
}
Constant *getConstant() {
return ConstantInt::get(Type::getInt32Ty(Context), Counter++);
@@ -461,7 +461,7 @@ TEST_F(MDNodeTest, PrintTree) {
auto *StructTy = cast<DICompositeType>(getCompositeType());
DIType *PointerTy = DIDerivedType::getDistinct(
Context, dwarf::DW_TAG_pointer_type, "", nullptr, 0, nullptr, StructTy,
- 1, 2, 0, std::nullopt, DINode::FlagZero);
+ 1, 2, 0, std::nullopt, {}, DINode::FlagZero);
StructTy->replaceElements(MDTuple::get(Context, PointerTy));
auto *Var = DILocalVariable::get(Context, Scope, "foo", File,
@@ -1864,13 +1864,17 @@ TEST_F(DIDerivedTypeTest, get) {
DIType *BaseType = getBasicType("basic");
MDTuple *ExtraData = getTuple();
unsigned DWARFAddressSpace = 8;
+ DIDerivedType::PtrAuthData PtrAuthData(1, false, 1234, true, true);
+ DIDerivedType::PtrAuthData PtrAuthData2(1, false, 1234, true, false);
DINode::DIFlags Flags5 = static_cast<DINode::DIFlags>(5);
DINode::DIFlags Flags4 = static_cast<DINode::DIFlags>(4);
- auto *N =
- DIDerivedType::get(Context, dwarf::DW_TAG_pointer_type, "something", File,
- 1, Scope, BaseType, 2, 3, 4, DWARFAddressSpace, Flags5,
- ExtraData);
+ auto *N = DIDerivedType::get(
+ Context, dwarf::DW_TAG_pointer_type, "something", File, 1, Scope,
+ BaseType, 2, 3, 4, DWARFAddressSpace, std::nullopt, Flags5, ExtraData);
+ auto *N1 = DIDerivedType::get(Context, dwarf::DW_TAG_LLVM_ptrauth_type, "",
+ File, 1, Scope, N, 2, 3, 4, DWARFAddressSpace,
+ PtrAuthData, Flags5, ExtraData);
EXPECT_EQ(dwarf::DW_TAG_pointer_type, N->getTag());
EXPECT_EQ("something", N->getName());
EXPECT_EQ(File, N->getFile());
@@ -1881,53 +1885,73 @@ TEST_F(DIDerivedTypeTest, get) {
EXPECT_EQ(3u, N->getAlignInBits());
EXPECT_EQ(4u, N->getOffsetInBits());
EXPECT_EQ(DWARFAddressSpace, *N->getDWARFAddressSpace());
+ EXPECT_EQ(std::nullopt, N->getPtrAuthData());
+ EXPECT_EQ(PtrAuthData, N1->getPtrAuthData());
+ EXPECT_NE(PtrAuthData2, N1->getPtrAuthData());
EXPECT_EQ(5u, N->getFlags());
EXPECT_EQ(ExtraData, N->getExtraData());
EXPECT_EQ(N, DIDerivedType::get(Context, dwarf::DW_TAG_pointer_type,
"something", File, 1, Scope, BaseType, 2, 3,
- 4, DWARFAddressSpace, Flags5, ExtraData));
+ 4, DWARFAddressSpace, std::nullopt, Flags5,
+ ExtraData));
EXPECT_NE(N, DIDerivedType::get(Context, dwarf::DW_TAG_reference_type,
"something", File, 1, Scope, BaseType, 2, 3,
- 4, DWARFAddressSpace, Flags5, ExtraData));
+ 4, DWARFAddressSpace, std::nullopt, Flags5,
+ ExtraData));
EXPECT_NE(N, DIDerivedType::get(Context, dwarf::DW_TAG_pointer_type, "else",
- File, 1, Scope, BaseType, 2, 3,
- 4, DWARFAddressSpace, Flags5, ExtraData));
+ File, 1, Scope, BaseType, 2, 3, 4,
+ DWARFAddressSpace, std::nullopt, Flags5,
+ ExtraData));
EXPECT_NE(N, DIDerivedType::get(Context, dwarf::DW_TAG_pointer_type,
"something", getFile(), 1, Scope, BaseType, 2,
- 3, 4, DWARFAddressSpace, Flags5, ExtraData));
+ 3, 4, DWARFAddressSpace, std::nullopt, Flags5,
+ ExtraData));
EXPECT_NE(N, DIDerivedType::get(Context, dwarf::DW_TAG_pointer_type,
"something", File, 2, Scope, BaseType, 2, 3,
- 4, DWARFAddressSpace, Flags5, ExtraData));
+ 4, DWARFAddressSpace, std::nullopt, Flags5,
+ ExtraData));
EXPECT_NE(N, DIDerivedType::get(Context, dwarf::DW_TAG_pointer_type,
"something", File, 1, getSubprogram(),
- BaseType, 2, 3, 4, DWARFAddressSpace, Flags5,
- ExtraData));
+ BaseType, 2, 3, 4, DWARFAddressSpace,
+ std::nullopt, Flags5, ExtraData));
EXPECT_NE(N, DIDerivedType::get(
Context, dwarf::DW_TAG_pointer_type, "something", File, 1,
Scope, getBasicType("basic2"), 2, 3, 4, DWARFAddressSpace,
- Flags5, ExtraData));
+ std::nullopt, Flags5, ExtraData));
EXPECT_NE(N, DIDerivedType::get(Context, dwarf::DW_TAG_pointer_type,
"something", File, 1, Scope, BaseType, 3, 3,
- 4, DWARFAddressSpace, Flags5, ExtraData));
+ 4, DWARFAddressSpace, std::nullopt, Flags5,
+ ExtraData));
EXPECT_NE(N, DIDerivedType::get(Context, dwarf::DW_TAG_pointer_type,
"something", File, 1, Scope, BaseType, 2, 2,
- 4, DWARFAddressSpace, Flags5, ExtraData));
+ 4, DWARFAddressSpace, std::nullopt, Flags5,
+ ExtraData));
EXPECT_NE(N, DIDerivedType::get(Context, dwarf::DW_TAG_pointer_type,
"something", File, 1, Scope, BaseType, 2, 3,
- 5, DWARFAddressSpace, Flags5, ExtraData));
+ 5, DWARFAddressSpace, std::nullopt, Flags5,
+ ExtraData));
EXPECT_NE(N, DIDerivedType::get(Context, dwarf::DW_TAG_pointer_type,
"something", File, 1, Scope, BaseType, 2, 3,
- 4, DWARFAddressSpace + 1, Flags5, ExtraData));
+ 4, DWARFAddressSpace + 1, std::nullopt,
+ Flags5, ExtraData));
+ EXPECT_NE(N1,
+ DIDerivedType::get(Context, dwarf::DW_TAG_LLVM_ptrauth_type, "",
+ File, 1, Scope, N, 2, 3, 4, DWARFAddressSpace,
+ std::nullopt, Flags5, ExtraData));
EXPECT_NE(N, DIDerivedType::get(Context, dwarf::DW_TAG_pointer_type,
"something", File, 1, Scope, BaseType, 2, 3,
- 4, DWARFAddressSpace, Flags4, ExtraData));
+ 4, DWARFAddressSpace, std::nullopt, Flags4,
+ ExtraData));
EXPECT_NE(N, DIDerivedType::get(Context, dwarf::DW_TAG_pointer_type,
"something", File, 1, Scope, BaseType, 2, 3,
- 4, DWARFAddressSpace, Flags5, getTuple()));
+ 4, DWARFAddressSpace, std::nullopt, Flags5,
+ getTuple()));
TempDIDerivedType Temp = N->clone();
EXPECT_EQ(N, MDNode::replaceWithUniqued(std::move(Temp)));
+ TempDIDerivedType Temp1 = N1->clone();
+ EXPECT_EQ(N1, MDNode::replaceWithUniqued(std::move(Temp1)));
}
TEST_F(DIDerivedTypeTest, getWithLargeValues) {
@@ -1937,14 +1961,23 @@ TEST_F(DIDerivedTypeTest, getWithLargeValues) {
MDTuple *ExtraData = getTuple();
DINode::DIFlags Flags = static_cast<DINode::DIFlags>(5);
- auto *N = DIDerivedType::get(
- Context, dwarf::DW_TAG_pointer_type, "something", File, 1, Scope,
- BaseType, UINT64_MAX, UINT32_MAX - 1, UINT64_MAX - 2, UINT32_MAX - 3,
- Flags, ExtraData);
+ auto *N = DIDerivedType::get(Context, dwarf::DW_TAG_pointer_type, "something",
+ File, 1, Scope, BaseType, UINT64_MAX,
+ UINT32_MAX - 1, UINT64_MAX - 2, UINT32_MAX - 3,
+ std::nullopt, Flags, ExtraData);
EXPECT_EQ(UINT64_MAX, N->getSizeInBits());
EXPECT_EQ(UINT32_MAX - 1, N->getAlignInBits());
EXPECT_EQ(UINT64_MAX - 2, N->getOffsetInBits());
EXPECT_EQ(UINT32_MAX - 3, *N->getDWARFAddressSpace());
+
+ auto *N1 = DIDerivedType::get(
+ Context, dwarf::DW_TAG_LLVM_ptrauth_type, "", File, 1, Scope, N,
+ UINT64_MAX, UINT32_MAX - 1, UINT64_MAX - 2, UINT32_MAX - 3,
+ DIDerivedType::PtrAuthData(7, true, 0xffff, true, false), Flags,
+ ExtraData);
+ EXPECT_EQ(7U, *N1->getPtrAuthKey());
+ EXPECT_EQ(true, *N1->isPtrAuthAddressDiscriminated());
+ EXPECT_EQ(0xffffU, *N1->getPtrAuthExtraDiscriminator());
}
typedef MetadataTest DICompositeTypeTest;
@@ -4268,7 +4301,7 @@ TEST_F(MDTupleAllocationTest, Tracking2) {
#if defined(GTEST_HAS_DEATH_TEST) && !defined(NDEBUG) && !defined(GTEST_HAS_SEH)
typedef MetadataTest MDTupleAllocationDeathTest;
TEST_F(MDTupleAllocationDeathTest, ResizeRejected) {
- MDTuple *A = MDTuple::get(Context, None);
+ MDTuple *A = MDTuple::get(Context, std::nullopt);
auto *Value1 = getConstantAsMetadata();
EXPECT_DEATH(A->push_back(Value1),
"Resizing is not supported for uniqued nodes");
diff --git a/mlir/lib/Target/LLVMIR/DebugTranslation.cpp b/mlir/lib/Target/LLVMIR/DebugTranslation.cpp
index 16918aab549788..420bb8d8274ecb 100644
--- a/mlir/lib/Target/LLVMIR/DebugTranslation.cpp
+++ b/mlir/lib/Target/LLVMIR/DebugTranslation.cpp
@@ -150,7 +150,8 @@ llvm::DIDerivedType *DebugTranslation::translateImpl(DIDerivedTypeAttr attr) {
/*File=*/nullptr, /*Line=*/0,
/*Scope=*/nullptr, translate(attr.getBaseType()), attr.getSizeInBits(),
attr.getAlignInBits(), attr.getOffsetInBits(),
- /*DWARFAddressSpace=*/std::nullopt, /*Flags=*/llvm::DINode::FlagZero);
+ /*DWARFAddressSpace=*/std::nullopt, /*PtrAuthData=*/std::nullopt,
+ /*Flags=*/llvm::DINode::FlagZero);
}
llvm::DIFile *DebugTranslation::translateImpl(DIFileAttr attr) {
>From 18d0d9b9b2e99ba1d22b9c7c3352f5f9df978d2c Mon Sep 17 00:00:00 2001
From: Joseph Huber <huberjn at outlook.com>
Date: Fri, 1 Mar 2024 10:48:32 -0600
Subject: [PATCH 267/406] [libc] Update install directory for offloading
versions of libraries (#83592)
Summary:
These currently go to `lib/`, but if the user has `lib/<triple>` they
should go there because it's always searched first.
---
libc/CMakeLists.txt | 2 +-
libc/lib/CMakeLists.txt | 6 +++++-
2 files changed, 6 insertions(+), 2 deletions(-)
diff --git a/libc/CMakeLists.txt b/libc/CMakeLists.txt
index 75fcc91757b807..7c7322e3043393 100644
--- a/libc/CMakeLists.txt
+++ b/libc/CMakeLists.txt
@@ -232,7 +232,7 @@ else()
set(LIBC_LIBRARY_DIR ${CMAKE_BINARY_DIR}/lib${LLVM_LIBDIR_SUFFIX})
endif()
if(LIBC_TARGET_OS_IS_GPU)
- set(LIBC_INSTALL_INCLUDE_DIR ${CMAKE_INSTALL_INCLUDEDIR}/${LLVM_DEFAULT_TARGET_TRIPLE})
+ set(LIBC_INSTALL_INCLUDE_DIR ${CMAKE_INSTALL_INCLUDEDIR}/${LIBC_TARGET_TRIPLE})
else()
set(LIBC_INSTALL_INCLUDE_DIR ${CMAKE_INSTALL_INCLUDEDIR})
endif()
diff --git a/libc/lib/CMakeLists.txt b/libc/lib/CMakeLists.txt
index e5ebd1e10084d7..37acf3950b4602 100644
--- a/libc/lib/CMakeLists.txt
+++ b/libc/lib/CMakeLists.txt
@@ -77,9 +77,13 @@ install(
)
if(LIBC_TARGET_OS_IS_GPU)
+ set(gpu_install_dir lib${LLVM_LIBDIR_SUFFIX})
+ if(LLVM_ENABLE_PER_TARGET_RUNTIME_DIR)
+ set(gpu_install_dir lib${LLVM_LIBDIR_SUFFIX}/${LLVM_HOST_TRIPLE})
+ endif()
install(
TARGETS ${added_gpu_archive_targets}
- ARCHIVE DESTINATION lib${LLVM_LIBDIR_SUFFIX}
+ ARCHIVE DESTINATION ${gpu_install_dir}
COMPONENT libc
)
foreach(file ${added_gpu_bitcode_targets})
>From 64216ba1e427fab1ee38ef9492d3fbca907606b9 Mon Sep 17 00:00:00 2001
From: Fangrui Song <i at maskray.me>
Date: Fri, 1 Mar 2024 08:57:54 -0800
Subject: [PATCH 268/406] [Sema] -Wpointer-bool-conversion: suppress lambda
function pointer conversion diagnostic during instantiation (#83497)
I have seen two internal pieces of code that uses a template type
parameter to accept any callable type (function pointer, std::function,
closure type, etc). The diagnostic added in #83152 would require
adaptation to the template, which is difficult and also seems
unnecessary. Example:
```cpp
template <typename... Ts>
static bool IsFalse(const Ts&...) { return false; }
template <typename T, typename... Ts,
typename = typename std::enable_if<std::is_constructible<bool, const T&>::value>::type>
static bool IsFalse(const T& p, const Ts&...) {
return p ? false : true;
}
template <typename... Args>
void Init(Args&&... args) {
if (IsFalse(absl::implicit_cast<const typename std::decay<Args>::type&>(
args)...)) {
// A callable object convertible to false is either a null pointer or a
// null functor (e.g., a default-constructed std::function).
empty_ = true;
} else {
empty_ = false;
new (&factory_) Factory(std::forward<Args>(args)...);
}
}
```
---
clang/lib/Sema/SemaChecking.cpp | 17 ++++++++++-------
clang/test/SemaCXX/warn-bool-conversion.cpp | 15 +++++++++++++++
2 files changed, 25 insertions(+), 7 deletions(-)
diff --git a/clang/lib/Sema/SemaChecking.cpp b/clang/lib/Sema/SemaChecking.cpp
index 7be2b31df2413f..9f9b0a0baba666 100644
--- a/clang/lib/Sema/SemaChecking.cpp
+++ b/clang/lib/Sema/SemaChecking.cpp
@@ -16588,13 +16588,16 @@ void Sema::DiagnoseAlwaysNonNullPointer(Expr *E,
}
// Complain if we are converting a lambda expression to a boolean value
- if (const auto *MCallExpr = dyn_cast<CXXMemberCallExpr>(E)) {
- if (const auto *MRecordDecl = MCallExpr->getRecordDecl();
- MRecordDecl && MRecordDecl->isLambda()) {
- Diag(E->getExprLoc(), diag::warn_impcast_pointer_to_bool)
- << /*LambdaPointerConversionOperatorType=*/3
- << MRecordDecl->getSourceRange() << Range << IsEqual;
- return;
+ // outside of instantiation.
+ if (!inTemplateInstantiation()) {
+ if (const auto *MCallExpr = dyn_cast<CXXMemberCallExpr>(E)) {
+ if (const auto *MRecordDecl = MCallExpr->getRecordDecl();
+ MRecordDecl && MRecordDecl->isLambda()) {
+ Diag(E->getExprLoc(), diag::warn_impcast_pointer_to_bool)
+ << /*LambdaPointerConversionOperatorType=*/3
+ << MRecordDecl->getSourceRange() << Range << IsEqual;
+ return;
+ }
}
}
diff --git a/clang/test/SemaCXX/warn-bool-conversion.cpp b/clang/test/SemaCXX/warn-bool-conversion.cpp
index 9e8cf0e4f8944a..18c35776b17bc7 100644
--- a/clang/test/SemaCXX/warn-bool-conversion.cpp
+++ b/clang/test/SemaCXX/warn-bool-conversion.cpp
@@ -92,6 +92,21 @@ void foo() {
bool is_true = [](){ return true; };
// expected-warning at -1{{address of lambda function pointer conversion operator will always evaluate to 'true'}}
}
+
+template <typename... Ts>
+static bool IsFalse(const Ts&...) { return false; }
+template <typename T>
+static bool IsFalse(const T& p) {
+ bool b;
+ b = f7; // expected-warning {{address of lambda function pointer conversion operator will always evaluate to 'true'}}
+ // Intentionally not warned on because p could be a lambda type in one
+ // instantiation, but a pointer type in another.
+ return p ? false : true;
+}
+
+bool use_instantiation() {
+ return IsFalse([]() { return 0; });
+}
#endif
void bar() {
>From 68516bfd2f086736dfd88374a11017276e61ad3d Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?Timm=20B=C3=A4der?= <tbaeder at redhat.com>
Date: Fri, 1 Mar 2024 17:47:38 +0100
Subject: [PATCH 269/406] [clang][Interp] Lambda This captures can be
non-pointers
If they are captured by value.
---
clang/lib/AST/Interp/ByteCodeEmitter.cpp | 8 ++++++--
clang/lib/AST/Interp/ByteCodeEmitter.h | 2 +-
clang/lib/AST/Interp/ByteCodeExprGen.cpp | 7 +++++--
clang/lib/AST/Interp/EvalEmitter.h | 2 +-
clang/test/AST/Interp/lambda.cpp | 13 +++++++++++++
5 files changed, 26 insertions(+), 6 deletions(-)
diff --git a/clang/lib/AST/Interp/ByteCodeEmitter.cpp b/clang/lib/AST/Interp/ByteCodeEmitter.cpp
index 60d8afecb2b3bb..e1b954fcc68486 100644
--- a/clang/lib/AST/Interp/ByteCodeEmitter.cpp
+++ b/clang/lib/AST/Interp/ByteCodeEmitter.cpp
@@ -108,8 +108,12 @@ Function *ByteCodeEmitter::compileFunc(const FunctionDecl *FuncDecl) {
this->LambdaCaptures[Cap.first] = {
Offset, Cap.second->getType()->isReferenceType()};
}
- if (LTC)
- this->LambdaThisCapture = R->getField(LTC)->Offset;
+ if (LTC) {
+ QualType CaptureType = R->getField(LTC)->Decl->getType();
+ this->LambdaThisCapture = {R->getField(LTC)->Offset,
+ CaptureType->isReferenceType() ||
+ CaptureType->isPointerType()};
+ }
}
}
diff --git a/clang/lib/AST/Interp/ByteCodeEmitter.h b/clang/lib/AST/Interp/ByteCodeEmitter.h
index 03de286582c916..548769329b7f8c 100644
--- a/clang/lib/AST/Interp/ByteCodeEmitter.h
+++ b/clang/lib/AST/Interp/ByteCodeEmitter.h
@@ -62,7 +62,7 @@ class ByteCodeEmitter {
/// Lambda captures.
llvm::DenseMap<const ValueDecl *, ParamOffset> LambdaCaptures;
/// Offset of the This parameter in a lambda record.
- unsigned LambdaThisCapture = 0;
+ ParamOffset LambdaThisCapture{0, false};
/// Local descriptors.
llvm::SmallVector<SmallVector<Local, 8>, 2> Descriptors;
diff --git a/clang/lib/AST/Interp/ByteCodeExprGen.cpp b/clang/lib/AST/Interp/ByteCodeExprGen.cpp
index 388da0e324c732..63ab80f59dac46 100644
--- a/clang/lib/AST/Interp/ByteCodeExprGen.cpp
+++ b/clang/lib/AST/Interp/ByteCodeExprGen.cpp
@@ -2934,8 +2934,11 @@ bool ByteCodeExprGen<Emitter>::VisitCXXThisExpr(const CXXThisExpr *E) {
if (DiscardResult)
return true;
- if (this->LambdaThisCapture > 0)
- return this->emitGetThisFieldPtr(this->LambdaThisCapture, E);
+ if (this->LambdaThisCapture.Offset > 0) {
+ if (this->LambdaThisCapture.IsPtr)
+ return this->emitGetThisFieldPtr(this->LambdaThisCapture.Offset, E);
+ return this->emitGetPtrThisField(this->LambdaThisCapture.Offset, E);
+ }
return this->emitThis(E);
}
diff --git a/clang/lib/AST/Interp/EvalEmitter.h b/clang/lib/AST/Interp/EvalEmitter.h
index 5b02b992fef6f7..116f1d6fc134a7 100644
--- a/clang/lib/AST/Interp/EvalEmitter.h
+++ b/clang/lib/AST/Interp/EvalEmitter.h
@@ -73,7 +73,7 @@ class EvalEmitter : public SourceMapper {
/// Lambda captures.
llvm::DenseMap<const ValueDecl *, ParamOffset> LambdaCaptures;
/// Offset of the This parameter in a lambda record.
- unsigned LambdaThisCapture = 0;
+ ParamOffset LambdaThisCapture{0, false};
/// Local descriptors.
llvm::SmallVector<SmallVector<Local, 8>, 2> Descriptors;
diff --git a/clang/test/AST/Interp/lambda.cpp b/clang/test/AST/Interp/lambda.cpp
index a5e0d0f1fd9f48..d056bb304eeb30 100644
--- a/clang/test/AST/Interp/lambda.cpp
+++ b/clang/test/AST/Interp/lambda.cpp
@@ -235,3 +235,16 @@ namespace LambdaToAPValue {
static_assert(g() == f(), "");
}
}
+
+namespace ns2_capture_this_byval {
+ struct S {
+ int s;
+ constexpr S(int s) : s{s} { }
+ constexpr auto f(S o) {
+ return [*this,o] (auto a) { return s + o.s + a.s; };
+ }
+ };
+
+ constexpr auto L = S{5}.f(S{10});
+ static_assert(L(S{100}) == 115, "");
+} // end test_captures_1::ns2_capture_this_byval
>From 0813b90ff5d195d8a40c280f6b745f1cc43e087a Mon Sep 17 00:00:00 2001
From: Craig Topper <craig.topper at sifive.com>
Date: Fri, 1 Mar 2024 09:17:14 -0800
Subject: [PATCH 270/406] [TypePromotion] Support positive addition amounts in
isSafeWrap. (#81690)
We can support these by changing the sext promotion to -zext(-C) and
replacing a sgt check with ugt. Reframing the logic in terms of how the
unsigned range are affected. More comments in the patch.
The new cases check isLegalAddImmediate to avoid some
regressions in lit tests.
---
llvm/lib/CodeGen/TypePromotion.cpp | 125 ++++++++++--------
llvm/test/CodeGen/AArch64/and-mask-removal.ll | 18 +--
.../AArch64/signed-truncation-check.ll | 2 +-
.../CodeGen/AArch64/typepromotion-overflow.ll | 5 +-
.../CodeGen/RISCV/typepromotion-overflow.ll | 5 +-
.../Transforms/TypePromotion/ARM/icmps.ll | 7 +-
.../Transforms/TypePromotion/ARM/wrapping.ll | 10 +-
7 files changed, 91 insertions(+), 81 deletions(-)
diff --git a/llvm/lib/CodeGen/TypePromotion.cpp b/llvm/lib/CodeGen/TypePromotion.cpp
index 48ad8de778010e..34aeb62a87a026 100644
--- a/llvm/lib/CodeGen/TypePromotion.cpp
+++ b/llvm/lib/CodeGen/TypePromotion.cpp
@@ -136,6 +136,7 @@ class IRPromoter {
class TypePromotionImpl {
unsigned TypeSize = 0;
+ const TargetLowering *TLI = nullptr;
LLVMContext *Ctx = nullptr;
unsigned RegisterBitWidth = 0;
SmallPtrSet<Value *, 16> AllVisited;
@@ -272,64 +273,58 @@ bool TypePromotionImpl::isSink(Value *V) {
/// Return whether this instruction can safely wrap.
bool TypePromotionImpl::isSafeWrap(Instruction *I) {
- // We can support a potentially wrapping instruction (I) if:
+ // We can support a potentially wrapping Add/Sub instruction (I) if:
// - It is only used by an unsigned icmp.
// - The icmp uses a constant.
- // - The wrapping value (I) is decreasing, i.e would underflow - wrapping
- // around zero to become a larger number than before.
// - The wrapping instruction (I) also uses a constant.
//
- // We can then use the two constants to calculate whether the result would
- // wrap in respect to itself in the original bitwidth. If it doesn't wrap,
- // just underflows the range, the icmp would give the same result whether the
- // result has been truncated or not. We calculate this by:
- // - Zero extending both constants, if needed, to RegisterBitWidth.
- // - Take the absolute value of I's constant, adding this to the icmp const.
- // - Check that this value is not out of range for small type. If it is, it
- // means that it has underflowed enough to wrap around the icmp constant.
+ // This a common pattern emitted to check if a value is within a range.
//
// For example:
//
- // %sub = sub i8 %a, 2
- // %cmp = icmp ule i8 %sub, 254
+ // %sub = sub i8 %a, C1
+ // %cmp = icmp ule i8 %sub, C2
+ //
+ // or
+ //
+ // %add = add i8 %a, C1
+ // %cmp = icmp ule i8 %add, C2.
//
- // If %a = 0, %sub = -2 == FE == 254
- // But if this is evalulated as a i32
- // %sub = -2 == FF FF FF FE == 4294967294
- // So the unsigned compares (i8 and i32) would not yield the same result.
+ // We will treat an add as though it were a subtract by -C1. To promote
+ // the Add/Sub we will zero extend the LHS and the subtracted amount. For Add,
+ // this means we need to negate the constant, zero extend to RegisterBitWidth,
+ // and negate in the larger type.
//
- // Another way to look at it is:
- // %a - 2 <= 254
- // %a + 2 <= 254 + 2
- // %a <= 256
- // And we can't represent 256 in the i8 format, so we don't support it.
+ // This will produce a value in the range [-zext(C1), zext(X)-zext(C1)] where
+ // C1 is the subtracted amount. This is either a small unsigned number or a
+ // large unsigned number in the promoted type.
//
- // Whereas:
+ // Now we need to correct the compare constant C2. Values >= C1 in the
+ // original add result range have been remapped to large values in the
+ // promoted range. If the compare constant fell into this range we need to
+ // remap it as well. We can do this as -(zext(-C2)).
//
- // %sub i8 %a, 1
+ // For example:
+ //
+ // %sub = sub i8 %a, 2
// %cmp = icmp ule i8 %sub, 254
//
- // If %a = 0, %sub = -1 == FF == 255
- // As i32:
- // %sub = -1 == FF FF FF FF == 4294967295
+ // becomes
//
- // In this case, the unsigned compare results would be the same and this
- // would also be true for ult, uge and ugt:
- // - (255 < 254) == (0xFFFFFFFF < 254) == false
- // - (255 <= 254) == (0xFFFFFFFF <= 254) == false
- // - (255 > 254) == (0xFFFFFFFF > 254) == true
- // - (255 >= 254) == (0xFFFFFFFF >= 254) == true
+ // %zext = zext %a to i32
+ // %sub = sub i32 %zext, 2
+ // %cmp = icmp ule i32 %sub, 4294967294
//
- // To demonstrate why we can't handle increasing values:
+ // Another example:
//
- // %add = add i8 %a, 2
- // %cmp = icmp ult i8 %add, 127
+ // %sub = sub i8 %a, 1
+ // %cmp = icmp ule i8 %sub, 254
//
- // If %a = 254, %add = 256 == (i8 1)
- // As i32:
- // %add = 256
+ // becomes
//
- // (1 < 127) != (256 < 127)
+ // %zext = zext %a to i32
+ // %sub = sub i32 %zext, 1
+ // %cmp = icmp ule i32 %sub, 254
unsigned Opc = I->getOpcode();
if (Opc != Instruction::Add && Opc != Instruction::Sub)
@@ -356,15 +351,23 @@ bool TypePromotionImpl::isSafeWrap(Instruction *I) {
APInt OverflowConst = cast<ConstantInt>(I->getOperand(1))->getValue();
if (Opc == Instruction::Sub)
OverflowConst = -OverflowConst;
- if (!OverflowConst.isNonPositive())
- return false;
+
+ // If the constant is positive, we will end up filling the promoted bits with
+ // all 1s. Make sure that results in a cheap add constant.
+ if (!OverflowConst.isNonPositive()) {
+ // We don't have the true promoted width, just use 64 so we can create an
+ // int64_t for the isLegalAddImmediate call.
+ if (OverflowConst.getBitWidth() >= 64)
+ return false;
+
+ APInt NewConst = -((-OverflowConst).zext(64));
+ if (!TLI->isLegalAddImmediate(NewConst.getSExtValue()))
+ return false;
+ }
SafeWrap.insert(I);
- // Using C1 = OverflowConst and C2 = ICmpConst, we can either prove that:
- // zext(x) + sext(C1) <u zext(C2) if C1 < 0 and C1 >s C2
- // zext(x) + sext(C1) <u sext(C2) if C1 < 0 and C1 <=s C2
- if (OverflowConst.sgt(ICmpConst)) {
+ if (OverflowConst.ugt(ICmpConst)) {
LLVM_DEBUG(dbgs() << "IR Promotion: Allowing safe overflow for sext "
<< "const of " << *I << "\n");
return true;
@@ -487,18 +490,24 @@ void IRPromoter::PromoteTree() {
continue;
if (auto *Const = dyn_cast<ConstantInt>(Op)) {
- // For subtract, we don't need to sext the constant. We only put it in
+ // For subtract, we only need to zext the constant. We only put it in
// SafeWrap because SafeWrap.size() is used elsewhere.
- // For cmp, we need to sign extend a constant appearing in either
- // operand. For add, we should only sign extend the RHS.
- Constant *NewConst =
- ConstantInt::get(Const->getContext(),
- (SafeWrap.contains(I) &&
- (I->getOpcode() == Instruction::ICmp || i == 1) &&
- I->getOpcode() != Instruction::Sub)
- ? Const->getValue().sext(PromotedWidth)
- : Const->getValue().zext(PromotedWidth));
- I->setOperand(i, NewConst);
+ // For Add and ICmp we need to find how far the constant is from the
+ // top of its original unsigned range and place it the same distance
+ // from the top of its new unsigned range. We can do this by negating
+ // the constant, zero extending it, then negating in the new type.
+ APInt NewConst;
+ if (SafeWrap.contains(I)) {
+ if (I->getOpcode() == Instruction::ICmp)
+ NewConst = -((-Const->getValue()).zext(PromotedWidth));
+ else if (I->getOpcode() == Instruction::Add && i == 1)
+ NewConst = -((-Const->getValue()).zext(PromotedWidth));
+ else
+ NewConst = Const->getValue().zext(PromotedWidth);
+ } else
+ NewConst = Const->getValue().zext(PromotedWidth);
+
+ I->setOperand(i, ConstantInt::get(Const->getContext(), NewConst));
} else if (isa<UndefValue>(Op))
I->setOperand(i, ConstantInt::get(ExtTy, 0));
}
@@ -917,7 +926,7 @@ bool TypePromotionImpl::run(Function &F, const TargetMachine *TM,
bool MadeChange = false;
const DataLayout &DL = F.getParent()->getDataLayout();
const TargetSubtargetInfo *SubtargetInfo = TM->getSubtargetImpl(F);
- const TargetLowering *TLI = SubtargetInfo->getTargetLowering();
+ TLI = SubtargetInfo->getTargetLowering();
RegisterBitWidth =
TTI.getRegisterBitWidth(TargetTransformInfo::RGK_Scalar).getFixedValue();
Ctx = &F.getParent()->getContext();
diff --git a/llvm/test/CodeGen/AArch64/and-mask-removal.ll b/llvm/test/CodeGen/AArch64/and-mask-removal.ll
index 17ff0159701689..a8a59f1591268f 100644
--- a/llvm/test/CodeGen/AArch64/and-mask-removal.ll
+++ b/llvm/test/CodeGen/AArch64/and-mask-removal.ll
@@ -65,9 +65,8 @@ if.end: ; preds = %if.then, %entry
define zeroext i1 @test8_0(i8 zeroext %x) align 2 {
; CHECK-LABEL: test8_0:
; CHECK: ; %bb.0: ; %entry
-; CHECK-NEXT: add w8, w0, #74
-; CHECK-NEXT: and w8, w8, #0xff
-; CHECK-NEXT: cmp w8, #236
+; CHECK-NEXT: sub w8, w0, #182
+; CHECK-NEXT: cmn w8, #20
; CHECK-NEXT: cset w0, lo
; CHECK-NEXT: ret
entry:
@@ -508,16 +507,17 @@ define i64 @pr58109(i8 signext %0) {
define i64 @pr58109b(i8 signext %0, i64 %a, i64 %b) {
; CHECK-SD-LABEL: pr58109b:
; CHECK-SD: ; %bb.0:
-; CHECK-SD-NEXT: add w8, w0, #1
-; CHECK-SD-NEXT: tst w8, #0xfe
-; CHECK-SD-NEXT: csel x0, x1, x2, eq
+; CHECK-SD-NEXT: and w8, w0, #0xff
+; CHECK-SD-NEXT: sub w8, w8, #255
+; CHECK-SD-NEXT: cmn w8, #254
+; CHECK-SD-NEXT: csel x0, x1, x2, lo
; CHECK-SD-NEXT: ret
;
; CHECK-GI-LABEL: pr58109b:
; CHECK-GI: ; %bb.0:
-; CHECK-GI-NEXT: add w8, w0, #1
-; CHECK-GI-NEXT: and w8, w8, #0xff
-; CHECK-GI-NEXT: cmp w8, #2
+; CHECK-GI-NEXT: mov w8, #-255 ; =0xffffff01
+; CHECK-GI-NEXT: add w8, w8, w0, uxtb
+; CHECK-GI-NEXT: cmn w8, #254
; CHECK-GI-NEXT: csel x0, x1, x2, lo
; CHECK-GI-NEXT: ret
%2 = add i8 %0, 1
diff --git a/llvm/test/CodeGen/AArch64/signed-truncation-check.ll b/llvm/test/CodeGen/AArch64/signed-truncation-check.ll
index ab42e6463feeed..bb4df6d8935b1b 100644
--- a/llvm/test/CodeGen/AArch64/signed-truncation-check.ll
+++ b/llvm/test/CodeGen/AArch64/signed-truncation-check.ll
@@ -396,7 +396,7 @@ define i1 @add_ultcmp_bad_i24_i8(i24 %x) nounwind {
define i1 @add_ulecmp_bad_i16_i8(i16 %x) nounwind {
; CHECK-LABEL: add_ulecmp_bad_i16_i8:
; CHECK: // %bb.0:
-; CHECK-NEXT: mov w0, #1
+; CHECK-NEXT: mov w0, #1 // =0x1
; CHECK-NEXT: ret
%tmp0 = add i16 %x, 128 ; 1U << (8-1)
%tmp1 = icmp ule i16 %tmp0, -1 ; when we +1 it, it will wrap to 0
diff --git a/llvm/test/CodeGen/AArch64/typepromotion-overflow.ll b/llvm/test/CodeGen/AArch64/typepromotion-overflow.ll
index ccfbf456693d7a..39edc03ced442e 100644
--- a/llvm/test/CodeGen/AArch64/typepromotion-overflow.ll
+++ b/llvm/test/CodeGen/AArch64/typepromotion-overflow.ll
@@ -246,9 +246,8 @@ define i32 @safe_sub_var_imm(ptr nocapture readonly %b) local_unnamed_addr #1 {
; CHECK-LABEL: safe_sub_var_imm:
; CHECK: // %bb.0: // %entry
; CHECK-NEXT: ldrb w8, [x0]
-; CHECK-NEXT: add w8, w8, #8
-; CHECK-NEXT: and w8, w8, #0xff
-; CHECK-NEXT: cmp w8, #252
+; CHECK-NEXT: sub w8, w8, #248
+; CHECK-NEXT: cmn w8, #4
; CHECK-NEXT: cset w0, hi
; CHECK-NEXT: ret
entry:
diff --git a/llvm/test/CodeGen/RISCV/typepromotion-overflow.ll b/llvm/test/CodeGen/RISCV/typepromotion-overflow.ll
index 3740dc675949fa..ec7e0ecce80caa 100644
--- a/llvm/test/CodeGen/RISCV/typepromotion-overflow.ll
+++ b/llvm/test/CodeGen/RISCV/typepromotion-overflow.ll
@@ -283,9 +283,8 @@ define i32 @safe_sub_var_imm(ptr nocapture readonly %b) local_unnamed_addr #1 {
; CHECK-LABEL: safe_sub_var_imm:
; CHECK: # %bb.0: # %entry
; CHECK-NEXT: lbu a0, 0(a0)
-; CHECK-NEXT: addi a0, a0, 8
-; CHECK-NEXT: andi a0, a0, 255
-; CHECK-NEXT: sltiu a0, a0, 253
+; CHECK-NEXT: addi a0, a0, -248
+; CHECK-NEXT: sltiu a0, a0, -3
; CHECK-NEXT: xori a0, a0, 1
; CHECK-NEXT: ret
entry:
diff --git a/llvm/test/Transforms/TypePromotion/ARM/icmps.ll b/llvm/test/Transforms/TypePromotion/ARM/icmps.ll
index 842aab121b96fb..fb537a1f64705c 100644
--- a/llvm/test/Transforms/TypePromotion/ARM/icmps.ll
+++ b/llvm/test/Transforms/TypePromotion/ARM/icmps.ll
@@ -4,8 +4,9 @@
define i32 @test_ult_254_inc_imm(i8 zeroext %x) {
; CHECK-LABEL: @test_ult_254_inc_imm(
; CHECK-NEXT: entry:
-; CHECK-NEXT: [[ADD:%.*]] = add i8 [[X:%.*]], 1
-; CHECK-NEXT: [[CMP:%.*]] = icmp ult i8 [[ADD]], -2
+; CHECK-NEXT: [[TMP0:%.*]] = zext i8 [[X:%.*]] to i32
+; CHECK-NEXT: [[ADD:%.*]] = add i32 [[TMP0]], -255
+; CHECK-NEXT: [[CMP:%.*]] = icmp ult i32 [[ADD]], -2
; CHECK-NEXT: [[RES:%.*]] = select i1 [[CMP]], i32 35, i32 47
; CHECK-NEXT: ret i32 [[RES]]
;
@@ -368,7 +369,7 @@ if.end:
define i32 @degenerateicmp() {
; CHECK-LABEL: @degenerateicmp(
; CHECK-NEXT: [[TMP1:%.*]] = sub i32 190, 0
-; CHECK-NEXT: [[TMP2:%.*]] = icmp ugt i32 225, [[TMP1]]
+; CHECK-NEXT: [[TMP2:%.*]] = icmp ugt i32 -31, [[TMP1]]
; CHECK-NEXT: [[TMP3:%.*]] = select i1 [[TMP2]], i32 1, i32 0
; CHECK-NEXT: ret i32 [[TMP3]]
;
diff --git a/llvm/test/Transforms/TypePromotion/ARM/wrapping.ll b/llvm/test/Transforms/TypePromotion/ARM/wrapping.ll
index 377708cf71134a..78c5e7323ceab3 100644
--- a/llvm/test/Transforms/TypePromotion/ARM/wrapping.ll
+++ b/llvm/test/Transforms/TypePromotion/ARM/wrapping.ll
@@ -89,8 +89,9 @@ define i32 @overflow_add_const_limit(i8 zeroext %a, i8 zeroext %b) {
define i32 @overflow_add_positive_const_limit(i8 zeroext %a) {
; CHECK-LABEL: @overflow_add_positive_const_limit(
-; CHECK-NEXT: [[ADD:%.*]] = add i8 [[A:%.*]], 1
-; CHECK-NEXT: [[CMP:%.*]] = icmp ugt i8 [[ADD]], -128
+; CHECK-NEXT: [[TMP1:%.*]] = zext i8 [[A:%.*]] to i32
+; CHECK-NEXT: [[ADD:%.*]] = add i32 [[TMP1]], -255
+; CHECK-NEXT: [[CMP:%.*]] = icmp ugt i32 [[ADD]], -128
; CHECK-NEXT: [[RES:%.*]] = select i1 [[CMP]], i32 8, i32 16
; CHECK-NEXT: ret i32 [[RES]]
;
@@ -144,8 +145,9 @@ define i32 @safe_add_underflow_neg(i8 zeroext %a) {
define i32 @overflow_sub_negative_const_limit(i8 zeroext %a) {
; CHECK-LABEL: @overflow_sub_negative_const_limit(
-; CHECK-NEXT: [[SUB:%.*]] = sub i8 [[A:%.*]], -1
-; CHECK-NEXT: [[CMP:%.*]] = icmp ugt i8 [[SUB]], -128
+; CHECK-NEXT: [[TMP1:%.*]] = zext i8 [[A:%.*]] to i32
+; CHECK-NEXT: [[SUB:%.*]] = sub i32 [[TMP1]], 255
+; CHECK-NEXT: [[CMP:%.*]] = icmp ugt i32 [[SUB]], -128
; CHECK-NEXT: [[RES:%.*]] = select i1 [[CMP]], i32 8, i32 16
; CHECK-NEXT: ret i32 [[RES]]
;
>From f6f79d46e580b34b2c98bd9bda7ede3a38f43f77 Mon Sep 17 00:00:00 2001
From: Kirill Stoimenov <kstoimenov at google.com>
Date: Fri, 1 Mar 2024 17:16:17 +0000
Subject: [PATCH 271/406] Revert "[HWASAN] Implement selective instrumentation
based on profiling information (#83503)"
Broke a build bot: https://lab.llvm.org/buildbot/#/builders/124/builds/9846
This reverts commit e7c3cd245665042bbae163f7280aceed35f0fee5.
---
.../Instrumentation/HWAddressSanitizer.cpp | 36 -------------------
.../HWAddressSanitizer/pgo-opt-out-no-ps.ll | 14 --------
.../HWAddressSanitizer/pgo-opt-out.ll | 31 ----------------
3 files changed, 81 deletions(-)
delete mode 100644 llvm/test/Instrumentation/HWAddressSanitizer/pgo-opt-out-no-ps.ll
delete mode 100644 llvm/test/Instrumentation/HWAddressSanitizer/pgo-opt-out.ll
diff --git a/llvm/lib/Transforms/Instrumentation/HWAddressSanitizer.cpp b/llvm/lib/Transforms/Instrumentation/HWAddressSanitizer.cpp
index 4404382a85b7e3..33add6d4cd767b 100644
--- a/llvm/lib/Transforms/Instrumentation/HWAddressSanitizer.cpp
+++ b/llvm/lib/Transforms/Instrumentation/HWAddressSanitizer.cpp
@@ -15,14 +15,11 @@
#include "llvm/ADT/MapVector.h"
#include "llvm/ADT/STLExtras.h"
#include "llvm/ADT/SmallVector.h"
-#include "llvm/ADT/Statistic.h"
#include "llvm/ADT/StringExtras.h"
#include "llvm/ADT/StringRef.h"
-#include "llvm/Analysis/BlockFrequencyInfo.h"
#include "llvm/Analysis/DomTreeUpdater.h"
#include "llvm/Analysis/GlobalsModRef.h"
#include "llvm/Analysis/PostDominators.h"
-#include "llvm/Analysis/ProfileSummaryInfo.h"
#include "llvm/Analysis/StackSafetyAnalysis.h"
#include "llvm/Analysis/TargetLibraryInfo.h"
#include "llvm/Analysis/ValueTracking.h"
@@ -180,18 +177,6 @@ static cl::opt<bool> ClWithTls(
"platforms that support this"),
cl::Hidden, cl::init(true));
-static cl::opt<bool>
- CSkipHotCode("hwasan-skip-hot-code",
- cl::desc("Do not instument hot functions based on FDO."),
- cl::Hidden, cl::init(false));
-
-static cl::opt<int> HotPercentileCutoff("hwasan-percentile-cutoff-hot",
- cl::init(0));
-
-STATISTIC(NumTotalFuncs, "Number of total funcs HWASAN");
-STATISTIC(NumInstrumentedFuncs, "Number of HWASAN instrumented funcs");
-STATISTIC(NumNoProfileSummaryFuncs, "Number of HWASAN funcs without PS");
-
// Mode for selecting how to insert frame record info into the stack ring
// buffer.
enum RecordStackHistoryMode {
@@ -1522,27 +1507,6 @@ void HWAddressSanitizer::sanitizeFunction(Function &F,
if (!F.hasFnAttribute(Attribute::SanitizeHWAddress))
return;
- if (F.empty())
- return;
-
- NumTotalFuncs++;
- if (CSkipHotCode) {
- auto &MAMProxy = FAM.getResult<ModuleAnalysisManagerFunctionProxy>(F);
- ProfileSummaryInfo *PSI =
- MAMProxy.getCachedResult<ProfileSummaryAnalysis>(*F.getParent());
- if (PSI && PSI->hasProfileSummary()) {
- auto &BFI = FAM.getResult<BlockFrequencyAnalysis>(F);
- if ((HotPercentileCutoff.getNumOccurrences() && HotPercentileCutoff >= 0)
- ? PSI->isFunctionHotInCallGraphNthPercentile(HotPercentileCutoff,
- &F, BFI)
- : PSI->isFunctionHotInCallGraph(&F, BFI))
- return;
- } else {
- ++NumNoProfileSummaryFuncs;
- }
- }
- NumInstrumentedFuncs++;
-
LLVM_DEBUG(dbgs() << "Function: " << F.getName() << "\n");
SmallVector<InterestingMemoryOperand, 16> OperandsToInstrument;
diff --git a/llvm/test/Instrumentation/HWAddressSanitizer/pgo-opt-out-no-ps.ll b/llvm/test/Instrumentation/HWAddressSanitizer/pgo-opt-out-no-ps.ll
deleted file mode 100644
index ebc03668a89142..00000000000000
--- a/llvm/test/Instrumentation/HWAddressSanitizer/pgo-opt-out-no-ps.ll
+++ /dev/null
@@ -1,14 +0,0 @@
-; RUN: opt < %s -passes='require<profile-summary>,hwasan' -S -stats 2>&1 \
-; RUN: -hwasan-skip-hot-code=0 | FileCheck %s --check-prefix=FULL
-; RUN: opt < %s -passes='require<profile-summary>,hwasan' -S -stats 2>&1 \
-; RUN: -hwasan-skip-hot-code=1 | FileCheck %s --check-prefix=SELSAN
-
-; FULL: 1 hwasan - Number of HWASAN instrumented funcs
-; FULL: 1 hwasan - Number of total funcs HWASAN
-
-; SELSAN: 1 hwasan - Number of HWASAN instrumented funcs
-; SELSAN: 1 hwasan - Number of HWASAN funcs without PS
-; SELSAN: 1 hwasan - Number of total funcs HWASAN
-
-define void @not_sanitized() { ret void }
-define void @sanitized_no_ps() sanitize_hwaddress { ret void }
diff --git a/llvm/test/Instrumentation/HWAddressSanitizer/pgo-opt-out.ll b/llvm/test/Instrumentation/HWAddressSanitizer/pgo-opt-out.ll
deleted file mode 100644
index ea5366c8759441..00000000000000
--- a/llvm/test/Instrumentation/HWAddressSanitizer/pgo-opt-out.ll
+++ /dev/null
@@ -1,31 +0,0 @@
-; RUN: opt < %s -passes='require<profile-summary>,hwasan' -S -stats 2>&1 \
-; RUN: -hwasan-skip-hot-code=1 | FileCheck %s --check-prefix=DEFAULT
-; RUN: opt < %s -passes='require<profile-summary>,hwasan' -S -stats 2>&1 \
-; RUN: -hwasan-skip-hot-code=1 -hwasan-percentile-cutoff-hot=700000 | FileCheck %s --check-prefix=PERCENT
-
-; DEFAULT: 1 hwasan - Number of total funcs HWASAN
-
-; PERCENT: 1 hwasan - Number of HWASAN instrumented funcs
-; PERCENT: 1 hwasan - Number of total funcs HWASAN
-
-define void @sanitized() sanitize_hwaddress !prof !36 { ret void }
-
-!llvm.module.flags = !{!6}
-!6 = !{i32 1, !"ProfileSummary", !7}
-!7 = !{!8, !9, !10, !11, !12, !13, !14, !17}
-!8 = !{!"ProfileFormat", !"InstrProf"}
-!9 = !{!"TotalCount", i64 30000}
-!10 = !{!"MaxCount", i64 10000}
-!11 = !{!"MaxInternalCount", i64 10000}
-!12 = !{!"MaxFunctionCount", i64 10000}
-!13 = !{!"NumCounts", i64 3}
-!14 = !{!"NumFunctions", i64 5}
-!17 = !{!"DetailedSummary", !18}
-!18 = !{!19, !29, !30, !32, !34}
-!19 = !{i32 10000, i64 10000, i32 3}
-!29 = !{i32 950000, i64 5000, i32 3}
-!30 = !{i32 990000, i64 500, i32 4}
-!32 = !{i32 999900, i64 250, i32 4}
-!34 = !{i32 999999, i64 1, i32 6}
-
-!36 = !{!"function_entry_count", i64 1000}
>From 53f89a0bb7695ef2f7a34472b0e6799122896ae4 Mon Sep 17 00:00:00 2001
From: Jay Foad <jay.foad at amd.com>
Date: Fri, 1 Mar 2024 17:18:55 +0000
Subject: [PATCH 272/406] [AMDGPU] Remove AtomicNoRet class and
getAtomicNoRetOp table (#83593)
---
.../AMDGPU/AsmParser/AMDGPUAsmParser.cpp | 14 --
llvm/lib/Target/AMDGPU/BUFInstructions.td | 88 ++++--------
llvm/lib/Target/AMDGPU/DSInstructions.td | 129 ++++++++----------
llvm/lib/Target/AMDGPU/FLATInstructions.td | 18 +--
llvm/lib/Target/AMDGPU/SIInstrInfo.h | 3 -
llvm/lib/Target/AMDGPU/SIInstrInfo.td | 14 --
llvm/lib/Target/AMDGPU/SMInstructions.td | 9 +-
7 files changed, 95 insertions(+), 180 deletions(-)
diff --git a/llvm/lib/Target/AMDGPU/AsmParser/AMDGPUAsmParser.cpp b/llvm/lib/Target/AMDGPU/AsmParser/AMDGPUAsmParser.cpp
index 18d51087ff5fba..cb4eddfe5320fa 100644
--- a/llvm/lib/Target/AMDGPU/AsmParser/AMDGPUAsmParser.cpp
+++ b/llvm/lib/Target/AMDGPU/AsmParser/AMDGPUAsmParser.cpp
@@ -8168,20 +8168,6 @@ void AMDGPUAsmParser::cvtMubufImpl(MCInst &Inst,
bool IsAtomicReturn = false;
if (IsAtomic) {
- for (unsigned i = FirstOperandIdx, e = Operands.size(); i != e; ++i) {
- AMDGPUOperand &Op = ((AMDGPUOperand &)*Operands[i]);
- if (!Op.isCPol())
- continue;
- IsAtomicReturn = Op.getImm() & AMDGPU::CPol::GLC;
- break;
- }
-
- if (!IsAtomicReturn) {
- int NewOpc = AMDGPU::getAtomicNoRetOp(Inst.getOpcode());
- if (NewOpc != -1)
- Inst.setOpcode(NewOpc);
- }
-
IsAtomicReturn = MII.get(Inst.getOpcode()).TSFlags &
SIInstrFlags::IsAtomicRet;
}
diff --git a/llvm/lib/Target/AMDGPU/BUFInstructions.td b/llvm/lib/Target/AMDGPU/BUFInstructions.td
index 0636a74a61dc5c..7bb92256fbddd0 100644
--- a/llvm/lib/Target/AMDGPU/BUFInstructions.td
+++ b/llvm/lib/Target/AMDGPU/BUFInstructions.td
@@ -747,8 +747,7 @@ class MUBUF_AtomicNoRet_Pseudo<string opName, int addrKind,
(outs),
getMUBUFAtomicIns<addrKindCopy, vdataClassCopy, 0, hasRestrictedSOffset>.ret,
getMUBUFAsmOps<addrKindCopy>.ret,
- pattern>,
- AtomicNoRet<opName # "_" # getAddrName<addrKindCopy>.ret, 0> {
+ pattern> {
let PseudoInstr = opName # "_" # getAddrName<addrKindCopy>.ret;
let glc_value = 0;
let dlc_value = 0;
@@ -768,8 +767,7 @@ class MUBUF_AtomicRet_Pseudo<string opName, int addrKind,
(outs vdata_op:$vdata),
getMUBUFAtomicIns<addrKindCopy, vdataClassCopy, 1, hasRestrictedSOffset>.ret,
getMUBUFAsmOps<addrKindCopy>.ret,
- pattern>,
- AtomicNoRet<opName # "_" # getAddrName<addrKindCopy>.ret, 1> {
+ pattern> {
let PseudoInstr = opName # "_rtn_" # getAddrName<addrKindCopy>.ret;
let glc_value = 1;
let dlc_value = 0;
@@ -2511,34 +2509,26 @@ multiclass MUBUF_Real_Atomic_gfx11_Renamed_impl<bits<8> op, bit is_return,
string real_name> {
defvar Rtn = !if(is_return, "_RTN", "");
def _BOTHEN#Rtn#_gfx11 :
- MUBUF_Real_Atomic_gfx11_impl<op, NAME # "_BOTHEN" # Rtn, real_name>,
- AtomicNoRet<NAME # "_BOTHEN_gfx11", is_return>;
+ MUBUF_Real_Atomic_gfx11_impl<op, NAME # "_BOTHEN" # Rtn, real_name>;
def _IDXEN#Rtn#_gfx11 :
- MUBUF_Real_Atomic_gfx11_impl<op, NAME # "_IDXEN" # Rtn, real_name>,
- AtomicNoRet<NAME # "_IDXEN_gfx11", is_return>;
+ MUBUF_Real_Atomic_gfx11_impl<op, NAME # "_IDXEN" # Rtn, real_name>;
def _OFFEN#Rtn#_gfx11 :
- MUBUF_Real_Atomic_gfx11_impl<op, NAME # "_OFFEN" # Rtn, real_name>,
- AtomicNoRet<NAME # "_OFFEN_gfx11", is_return>;
+ MUBUF_Real_Atomic_gfx11_impl<op, NAME # "_OFFEN" # Rtn, real_name>;
def _OFFSET#Rtn#_gfx11 :
- MUBUF_Real_Atomic_gfx11_impl<op, NAME # "_OFFSET" # Rtn, real_name>,
- AtomicNoRet<NAME # "_OFFSET_gfx11", is_return>;
+ MUBUF_Real_Atomic_gfx11_impl<op, NAME # "_OFFSET" # Rtn, real_name>;
}
multiclass MUBUF_Real_Atomic_gfx12_Renamed_impl<bits<8> op, bit is_return,
string real_name> {
defvar Rtn = !if(is_return, "_RTN", "");
def _BOTHEN#Rtn#_gfx12 :
- MUBUF_Real_Atomic_gfx12_impl<op, NAME # "_VBUFFER_BOTHEN" # Rtn, real_name>,
- AtomicNoRet<NAME # "_BOTHEN_gfx12", is_return>;
+ MUBUF_Real_Atomic_gfx12_impl<op, NAME # "_VBUFFER_BOTHEN" # Rtn, real_name>;
def _IDXEN#Rtn#_gfx12 :
- MUBUF_Real_Atomic_gfx12_impl<op, NAME # "_VBUFFER_IDXEN" # Rtn, real_name>,
- AtomicNoRet<NAME # "_IDXEN_gfx12", is_return>;
+ MUBUF_Real_Atomic_gfx12_impl<op, NAME # "_VBUFFER_IDXEN" # Rtn, real_name>;
def _OFFEN#Rtn#_gfx12 :
- MUBUF_Real_Atomic_gfx12_impl<op, NAME # "_VBUFFER_OFFEN" # Rtn, real_name>,
- AtomicNoRet<NAME # "_OFFEN_gfx12", is_return>;
+ MUBUF_Real_Atomic_gfx12_impl<op, NAME # "_VBUFFER_OFFEN" # Rtn, real_name>;
def _OFFSET#Rtn#_gfx12 :
- MUBUF_Real_Atomic_gfx12_impl<op, NAME # "_VBUFFER_OFFSET" # Rtn, real_name>,
- AtomicNoRet<NAME # "_OFFSET_gfx12", is_return>;
+ MUBUF_Real_Atomic_gfx12_impl<op, NAME # "_VBUFFER_OFFSET" # Rtn, real_name>;
}
multiclass MUBUF_Real_Atomic_gfx11_gfx12_Renamed_impl<bits<8> op, bit is_return,
@@ -2695,32 +2685,24 @@ multiclass MUBUF_Real_AllAddr_Lds_gfx10<bits<8> op, bit isTFE = 0> {
}
multiclass MUBUF_Real_Atomics_RTN_gfx10<bits<8> op> {
def _BOTHEN_RTN_gfx10 :
- MUBUF_Real_gfx10<op, !cast<MUBUF_Pseudo>(NAME#"_BOTHEN_RTN")>,
- AtomicNoRet<NAME # "_BOTHEN_gfx10", 1>;
+ MUBUF_Real_gfx10<op, !cast<MUBUF_Pseudo>(NAME#"_BOTHEN_RTN")>;
def _IDXEN_RTN_gfx10 :
- MUBUF_Real_gfx10<op, !cast<MUBUF_Pseudo>(NAME#"_IDXEN_RTN")>,
- AtomicNoRet<NAME # "_IDXEN_gfx10", 1>;
+ MUBUF_Real_gfx10<op, !cast<MUBUF_Pseudo>(NAME#"_IDXEN_RTN")>;
def _OFFEN_RTN_gfx10 :
- MUBUF_Real_gfx10<op, !cast<MUBUF_Pseudo>(NAME#"_OFFEN_RTN")>,
- AtomicNoRet<NAME # "_OFFEN_gfx10", 1>;
+ MUBUF_Real_gfx10<op, !cast<MUBUF_Pseudo>(NAME#"_OFFEN_RTN")>;
def _OFFSET_RTN_gfx10 :
- MUBUF_Real_gfx10<op, !cast<MUBUF_Pseudo>(NAME#"_OFFSET_RTN")>,
- AtomicNoRet<NAME # "_OFFSET_gfx10", 1>;
+ MUBUF_Real_gfx10<op, !cast<MUBUF_Pseudo>(NAME#"_OFFSET_RTN")>;
}
multiclass MUBUF_Real_Atomics_gfx10<bits<8> op> :
MUBUF_Real_Atomics_RTN_gfx10<op> {
def _BOTHEN_gfx10 :
- MUBUF_Real_gfx10<op, !cast<MUBUF_Pseudo>(NAME#"_BOTHEN")>,
- AtomicNoRet<NAME # "_BOTHEN_gfx10", 0>;
+ MUBUF_Real_gfx10<op, !cast<MUBUF_Pseudo>(NAME#"_BOTHEN")>;
def _IDXEN_gfx10 :
- MUBUF_Real_gfx10<op, !cast<MUBUF_Pseudo>(NAME#"_IDXEN")>,
- AtomicNoRet<NAME # "_IDXEN_gfx10", 0>;
+ MUBUF_Real_gfx10<op, !cast<MUBUF_Pseudo>(NAME#"_IDXEN")>;
def _OFFEN_gfx10 :
- MUBUF_Real_gfx10<op, !cast<MUBUF_Pseudo>(NAME#"_OFFEN")>,
- AtomicNoRet<NAME # "_OFFEN_gfx10", 0>;
+ MUBUF_Real_gfx10<op, !cast<MUBUF_Pseudo>(NAME#"_OFFEN")>;
def _OFFSET_gfx10 :
- MUBUF_Real_gfx10<op, !cast<MUBUF_Pseudo>(NAME#"_OFFSET")>,
- AtomicNoRet<NAME # "_OFFSET_gfx10", 0>;
+ MUBUF_Real_gfx10<op, !cast<MUBUF_Pseudo>(NAME#"_OFFSET")>;
}
defm BUFFER_STORE_BYTE_D16_HI : MUBUF_Real_AllAddr_gfx10<0x019>;
@@ -2795,36 +2777,26 @@ multiclass MUBUF_Real_AllAddr_Lds_gfx6_gfx7<bits<8> op, bit isTFE = 0> {
}
multiclass MUBUF_Real_Atomics_gfx6_gfx7<bits<8> op> {
def _ADDR64_gfx6_gfx7 :
- MUBUF_Real_gfx6_gfx7<op, !cast<MUBUF_Pseudo>(NAME#"_ADDR64")>,
- AtomicNoRet<NAME # "_ADDR64_gfx6_gfx7", 0>;
+ MUBUF_Real_gfx6_gfx7<op, !cast<MUBUF_Pseudo>(NAME#"_ADDR64")>;
def _BOTHEN_gfx6_gfx7 :
- MUBUF_Real_gfx6_gfx7<op, !cast<MUBUF_Pseudo>(NAME#"_BOTHEN")>,
- AtomicNoRet<NAME # "_BOTHEN_gfx6_gfx7", 0>;
+ MUBUF_Real_gfx6_gfx7<op, !cast<MUBUF_Pseudo>(NAME#"_BOTHEN")>;
def _IDXEN_gfx6_gfx7 :
- MUBUF_Real_gfx6_gfx7<op, !cast<MUBUF_Pseudo>(NAME#"_IDXEN")>,
- AtomicNoRet<NAME # "_IDXEN_gfx6_gfx7", 0>;
+ MUBUF_Real_gfx6_gfx7<op, !cast<MUBUF_Pseudo>(NAME#"_IDXEN")>;
def _OFFEN_gfx6_gfx7 :
- MUBUF_Real_gfx6_gfx7<op, !cast<MUBUF_Pseudo>(NAME#"_OFFEN")>,
- AtomicNoRet<NAME # "_OFFEN_gfx6_gfx7", 0>;
+ MUBUF_Real_gfx6_gfx7<op, !cast<MUBUF_Pseudo>(NAME#"_OFFEN")>;
def _OFFSET_gfx6_gfx7 :
- MUBUF_Real_gfx6_gfx7<op, !cast<MUBUF_Pseudo>(NAME#"_OFFSET")>,
- AtomicNoRet<NAME # "_OFFSET_gfx6_gfx7", 0>;
+ MUBUF_Real_gfx6_gfx7<op, !cast<MUBUF_Pseudo>(NAME#"_OFFSET")>;
def _ADDR64_RTN_gfx6_gfx7 :
- MUBUF_Real_gfx6_gfx7<op, !cast<MUBUF_Pseudo>(NAME#"_ADDR64_RTN")>,
- AtomicNoRet<NAME # "_ADDR64_gfx6_gfx7", 1>;
+ MUBUF_Real_gfx6_gfx7<op, !cast<MUBUF_Pseudo>(NAME#"_ADDR64_RTN")>;
def _BOTHEN_RTN_gfx6_gfx7 :
- MUBUF_Real_gfx6_gfx7<op, !cast<MUBUF_Pseudo>(NAME#"_BOTHEN_RTN")>,
- AtomicNoRet<NAME # "_BOTHEN_gfx6_gfx7", 1>;
+ MUBUF_Real_gfx6_gfx7<op, !cast<MUBUF_Pseudo>(NAME#"_BOTHEN_RTN")>;
def _IDXEN_RTN_gfx6_gfx7 :
- MUBUF_Real_gfx6_gfx7<op, !cast<MUBUF_Pseudo>(NAME#"_IDXEN_RTN")>,
- AtomicNoRet<NAME # "_IDXEN_gfx6_gfx7", 1>;
+ MUBUF_Real_gfx6_gfx7<op, !cast<MUBUF_Pseudo>(NAME#"_IDXEN_RTN")>;
def _OFFEN_RTN_gfx6_gfx7 :
- MUBUF_Real_gfx6_gfx7<op, !cast<MUBUF_Pseudo>(NAME#"_OFFEN_RTN")>,
- AtomicNoRet<NAME # "_OFFEN_gfx6_gfx7", 1>;
+ MUBUF_Real_gfx6_gfx7<op, !cast<MUBUF_Pseudo>(NAME#"_OFFEN_RTN")>;
def _OFFSET_RTN_gfx6_gfx7 :
- MUBUF_Real_gfx6_gfx7<op, !cast<MUBUF_Pseudo>(NAME#"_OFFSET_RTN")>,
- AtomicNoRet<NAME # "_OFFSET_gfx6_gfx7", 1>;
+ MUBUF_Real_gfx6_gfx7<op, !cast<MUBUF_Pseudo>(NAME#"_OFFSET_RTN")>;
}
multiclass MUBUF_Real_AllAddr_gfx6_gfx7_gfx10<bits<8> op> :
@@ -3081,9 +3053,7 @@ class MUBUF_Real_Base_vi <bits<7> op, MUBUF_Pseudo ps, int Enc,
bit has_sccb = ps.has_sccb> :
MUBUF_Real<ps>,
Enc64,
- SIMCInstr<ps.PseudoInstr, Enc>,
- AtomicNoRet<!subst("_RTN","",NAME), !if(ps.IsAtomicNoRet, 0,
- !if(ps.IsAtomicRet, 1, ?))> {
+ SIMCInstr<ps.PseudoInstr, Enc> {
let Inst{11-0} = !if(ps.has_offset, offset, ?);
let Inst{12} = ps.offen;
diff --git a/llvm/lib/Target/AMDGPU/DSInstructions.td b/llvm/lib/Target/AMDGPU/DSInstructions.td
index 7d79b9bba243cf..219ff37b0a15c5 100644
--- a/llvm/lib/Target/AMDGPU/DSInstructions.td
+++ b/llvm/lib/Target/AMDGPU/DSInstructions.td
@@ -116,19 +116,16 @@ class DS_1A1D_NORET<string opName, RegisterClass rc = VGPR_32>
}
multiclass DS_1A1D_NORET_mc<string opName, RegisterClass rc = VGPR_32> {
- def "" : DS_1A1D_NORET<opName, rc>,
- AtomicNoRet<opName, 0>;
+ def "" : DS_1A1D_NORET<opName, rc>;
let has_m0_read = 0 in {
- def _gfx9 : DS_1A1D_NORET<opName, rc>,
- AtomicNoRet<opName#"_gfx9", 0>;
+ def _gfx9 : DS_1A1D_NORET<opName, rc>;
}
}
multiclass DS_1A1D_NORET_mc_gfx9<string opName, RegisterClass rc = VGPR_32> {
let has_m0_read = 0 in {
- def "" : DS_1A1D_NORET<opName, rc>,
- AtomicNoRet<opName, 0>;
+ def "" : DS_1A1D_NORET<opName, rc>;
}
}
@@ -144,12 +141,10 @@ class DS_1A2D_NORET<string opName, RegisterClass rc = VGPR_32,
}
multiclass DS_1A2D_NORET_mc<string opName, RegisterClass rc = VGPR_32> {
- def "" : DS_1A2D_NORET<opName, rc>,
- AtomicNoRet<opName, 0>;
+ def "" : DS_1A2D_NORET<opName, rc>;
let has_m0_read = 0 in {
- def _gfx9 : DS_1A2D_NORET<opName, rc>,
- AtomicNoRet<opName#"_gfx9", 0>;
+ def _gfx9 : DS_1A2D_NORET<opName, rc>;
}
}
@@ -200,24 +195,17 @@ class DS_1A1D_RET <string opName, RegisterClass rc = VGPR_32,
let IsAtomicRet = 1;
}
-multiclass DS_1A1D_RET_mc <string opName, RegisterClass rc = VGPR_32,
- string NoRetOp = ""> {
- def "" : DS_1A1D_RET<opName, rc>,
- AtomicNoRet<NoRetOp, !ne(NoRetOp, "")>;
+multiclass DS_1A1D_RET_mc <string opName, RegisterClass rc = VGPR_32> {
+ def "" : DS_1A1D_RET<opName, rc>;
let has_m0_read = 0 in {
- def _gfx9 : DS_1A1D_RET<opName, rc>,
- AtomicNoRet<!if(!eq(NoRetOp, ""), "", NoRetOp#"_gfx9"),
- !ne(NoRetOp, "")>;
+ def _gfx9 : DS_1A1D_RET<opName, rc>;
}
}
-multiclass DS_1A1D_RET_mc_gfx9 <string opName, RegisterClass rc = VGPR_32,
- string NoRetOp = ""> {
+multiclass DS_1A1D_RET_mc_gfx9 <string opName, RegisterClass rc = VGPR_32> {
let has_m0_read = 0 in {
- def "" : DS_1A1D_RET<opName, rc>,
- AtomicNoRet<!if(!eq(NoRetOp, ""), "", NoRetOp),
- !ne(NoRetOp, "")>;
+ def "" : DS_1A1D_RET<opName, rc>;
}
}
@@ -237,14 +225,11 @@ class DS_1A2D_RET<string opName,
multiclass DS_1A2D_RET_mc<string opName,
RegisterClass rc = VGPR_32,
- string NoRetOp = "",
RegisterClass src = rc> {
- def "" : DS_1A2D_RET<opName, rc, src>,
- AtomicNoRet<NoRetOp, !ne(NoRetOp, "")>;
+ def "" : DS_1A2D_RET<opName, rc, src>;
let has_m0_read = 0 in {
- def _gfx9 : DS_1A2D_RET<opName, rc, src>,
- AtomicNoRet<NoRetOp#"_gfx9", !ne(NoRetOp, "")>;
+ def _gfx9 : DS_1A2D_RET<opName, rc, src>;
}
}
@@ -489,24 +474,24 @@ def DS_WRITE_ADDTID_B32 : DS_0A1D_NORET<"ds_write_addtid_b32">;
let SubtargetPredicate = HasLdsAtomicAddF64 in {
defm DS_ADD_F64 : DS_1A1D_NORET_mc_gfx9<"ds_add_f64", VReg_64>;
- defm DS_ADD_RTN_F64 : DS_1A1D_RET_mc_gfx9<"ds_add_rtn_f64", VReg_64, "ds_add_f64">;
+ defm DS_ADD_RTN_F64 : DS_1A1D_RET_mc_gfx9<"ds_add_rtn_f64", VReg_64>;
} // End SubtargetPredicate = HasLdsAtomicAddF64
let SubtargetPredicate = HasAtomicDsPkAdd16Insts in {
defm DS_PK_ADD_F16 : DS_1A1D_NORET_mc<"ds_pk_add_f16">;
- defm DS_PK_ADD_RTN_F16 : DS_1A1D_RET_mc<"ds_pk_add_rtn_f16", VGPR_32, "ds_pk_add_f16">;
+ defm DS_PK_ADD_RTN_F16 : DS_1A1D_RET_mc<"ds_pk_add_rtn_f16", VGPR_32>;
defm DS_PK_ADD_BF16 : DS_1A1D_NORET_mc<"ds_pk_add_bf16">;
- defm DS_PK_ADD_RTN_BF16 : DS_1A1D_RET_mc<"ds_pk_add_rtn_bf16", VGPR_32, "ds_pk_add_bf16">;
+ defm DS_PK_ADD_RTN_BF16 : DS_1A1D_RET_mc<"ds_pk_add_rtn_bf16", VGPR_32>;
} // End SubtargetPredicate = HasAtomicDsPkAdd16Insts
defm DS_CMPSTORE_B32 : DS_1A2D_NORET_mc<"ds_cmpstore_b32">;
defm DS_CMPSTORE_F32 : DS_1A2D_NORET_mc<"ds_cmpstore_f32">;
defm DS_CMPSTORE_B64 : DS_1A2D_NORET_mc<"ds_cmpstore_b64", VReg_64>;
defm DS_CMPSTORE_F64 : DS_1A2D_NORET_mc<"ds_cmpstore_f64", VReg_64>;
-defm DS_CMPSTORE_RTN_B32 : DS_1A2D_RET_mc<"ds_cmpstore_rtn_b32", VGPR_32, "ds_cmpstore_b32">;
-defm DS_CMPSTORE_RTN_F32 : DS_1A2D_RET_mc<"ds_cmpstore_rtn_f32", VGPR_32, "ds_cmpstore_f32">;
-defm DS_CMPSTORE_RTN_B64 : DS_1A2D_RET_mc<"ds_cmpstore_rtn_b64", VReg_64, "ds_cmpstore_b64">;
-defm DS_CMPSTORE_RTN_F64 : DS_1A2D_RET_mc<"ds_cmpstore_rtn_f64", VReg_64, "ds_cmpstore_f64">;
+defm DS_CMPSTORE_RTN_B32 : DS_1A2D_RET_mc<"ds_cmpstore_rtn_b32", VGPR_32>;
+defm DS_CMPSTORE_RTN_F32 : DS_1A2D_RET_mc<"ds_cmpstore_rtn_f32", VGPR_32>;
+defm DS_CMPSTORE_RTN_B64 : DS_1A2D_RET_mc<"ds_cmpstore_rtn_b64", VReg_64>;
+defm DS_CMPSTORE_RTN_F64 : DS_1A2D_RET_mc<"ds_cmpstore_rtn_f64", VReg_64>;
defm DS_MSKOR_B32 : DS_1A2D_NORET_mc<"ds_mskor_b32">;
defm DS_CMPST_B32 : DS_1A2D_NORET_mc<"ds_cmpst_b32">;
@@ -535,49 +520,49 @@ defm DS_CMPST_F64 : DS_1A2D_NORET_mc<"ds_cmpst_f64", VReg_64>;
defm DS_MIN_F64 : DS_1A1D_NORET_mc<"ds_min_f64", VReg_64>;
defm DS_MAX_F64 : DS_1A1D_NORET_mc<"ds_max_f64", VReg_64>;
-defm DS_ADD_RTN_U32 : DS_1A1D_RET_mc<"ds_add_rtn_u32", VGPR_32, "ds_add_u32">;
+defm DS_ADD_RTN_U32 : DS_1A1D_RET_mc<"ds_add_rtn_u32", VGPR_32>;
let SubtargetPredicate = HasLDSFPAtomicAdd in {
-defm DS_ADD_RTN_F32 : DS_1A1D_RET_mc<"ds_add_rtn_f32", VGPR_32, "ds_add_f32">;
-}
-defm DS_SUB_RTN_U32 : DS_1A1D_RET_mc<"ds_sub_rtn_u32", VGPR_32, "ds_sub_u32">;
-defm DS_RSUB_RTN_U32 : DS_1A1D_RET_mc<"ds_rsub_rtn_u32", VGPR_32, "ds_rsub_u32">;
-defm DS_INC_RTN_U32 : DS_1A1D_RET_mc<"ds_inc_rtn_u32", VGPR_32, "ds_inc_u32">;
-defm DS_DEC_RTN_U32 : DS_1A1D_RET_mc<"ds_dec_rtn_u32", VGPR_32, "ds_dec_u32">;
-defm DS_MIN_RTN_I32 : DS_1A1D_RET_mc<"ds_min_rtn_i32", VGPR_32, "ds_min_i32">;
-defm DS_MAX_RTN_I32 : DS_1A1D_RET_mc<"ds_max_rtn_i32", VGPR_32, "ds_max_i32">;
-defm DS_MIN_RTN_U32 : DS_1A1D_RET_mc<"ds_min_rtn_u32", VGPR_32, "ds_min_u32">;
-defm DS_MAX_RTN_U32 : DS_1A1D_RET_mc<"ds_max_rtn_u32", VGPR_32, "ds_max_u32">;
-defm DS_AND_RTN_B32 : DS_1A1D_RET_mc<"ds_and_rtn_b32", VGPR_32, "ds_and_b32">;
-defm DS_OR_RTN_B32 : DS_1A1D_RET_mc<"ds_or_rtn_b32", VGPR_32, "ds_or_b32">;
-defm DS_XOR_RTN_B32 : DS_1A1D_RET_mc<"ds_xor_rtn_b32", VGPR_32, "ds_xor_b32">;
-defm DS_MSKOR_RTN_B32 : DS_1A2D_RET_mc<"ds_mskor_rtn_b32", VGPR_32, "ds_mskor_b32">;
-defm DS_CMPST_RTN_B32 : DS_1A2D_RET_mc<"ds_cmpst_rtn_b32", VGPR_32, "ds_cmpst_b32">;
-defm DS_CMPST_RTN_F32 : DS_1A2D_RET_mc<"ds_cmpst_rtn_f32", VGPR_32, "ds_cmpst_f32">;
-defm DS_MIN_RTN_F32 : DS_1A1D_RET_mc<"ds_min_rtn_f32", VGPR_32, "ds_min_f32">;
-defm DS_MAX_RTN_F32 : DS_1A1D_RET_mc<"ds_max_rtn_f32", VGPR_32, "ds_max_f32">;
+defm DS_ADD_RTN_F32 : DS_1A1D_RET_mc<"ds_add_rtn_f32", VGPR_32>;
+}
+defm DS_SUB_RTN_U32 : DS_1A1D_RET_mc<"ds_sub_rtn_u32", VGPR_32>;
+defm DS_RSUB_RTN_U32 : DS_1A1D_RET_mc<"ds_rsub_rtn_u32", VGPR_32>;
+defm DS_INC_RTN_U32 : DS_1A1D_RET_mc<"ds_inc_rtn_u32", VGPR_32>;
+defm DS_DEC_RTN_U32 : DS_1A1D_RET_mc<"ds_dec_rtn_u32", VGPR_32>;
+defm DS_MIN_RTN_I32 : DS_1A1D_RET_mc<"ds_min_rtn_i32", VGPR_32>;
+defm DS_MAX_RTN_I32 : DS_1A1D_RET_mc<"ds_max_rtn_i32", VGPR_32>;
+defm DS_MIN_RTN_U32 : DS_1A1D_RET_mc<"ds_min_rtn_u32", VGPR_32>;
+defm DS_MAX_RTN_U32 : DS_1A1D_RET_mc<"ds_max_rtn_u32", VGPR_32>;
+defm DS_AND_RTN_B32 : DS_1A1D_RET_mc<"ds_and_rtn_b32", VGPR_32>;
+defm DS_OR_RTN_B32 : DS_1A1D_RET_mc<"ds_or_rtn_b32", VGPR_32>;
+defm DS_XOR_RTN_B32 : DS_1A1D_RET_mc<"ds_xor_rtn_b32", VGPR_32>;
+defm DS_MSKOR_RTN_B32 : DS_1A2D_RET_mc<"ds_mskor_rtn_b32", VGPR_32>;
+defm DS_CMPST_RTN_B32 : DS_1A2D_RET_mc<"ds_cmpst_rtn_b32", VGPR_32>;
+defm DS_CMPST_RTN_F32 : DS_1A2D_RET_mc<"ds_cmpst_rtn_f32", VGPR_32>;
+defm DS_MIN_RTN_F32 : DS_1A1D_RET_mc<"ds_min_rtn_f32", VGPR_32>;
+defm DS_MAX_RTN_F32 : DS_1A1D_RET_mc<"ds_max_rtn_f32", VGPR_32>;
defm DS_WRXCHG_RTN_B32 : DS_1A1D_RET_mc<"ds_wrxchg_rtn_b32">;
defm DS_WRXCHG2_RTN_B32 : DS_1A2D_Off8_RET_mc<"ds_wrxchg2_rtn_b32", VReg_64, VGPR_32>;
defm DS_WRXCHG2ST64_RTN_B32 : DS_1A2D_Off8_RET_mc<"ds_wrxchg2st64_rtn_b32", VReg_64, VGPR_32>;
-defm DS_ADD_RTN_U64 : DS_1A1D_RET_mc<"ds_add_rtn_u64", VReg_64, "ds_add_u64">;
-defm DS_SUB_RTN_U64 : DS_1A1D_RET_mc<"ds_sub_rtn_u64", VReg_64, "ds_sub_u64">;
-defm DS_RSUB_RTN_U64 : DS_1A1D_RET_mc<"ds_rsub_rtn_u64", VReg_64, "ds_rsub_u64">;
-defm DS_INC_RTN_U64 : DS_1A1D_RET_mc<"ds_inc_rtn_u64", VReg_64, "ds_inc_u64">;
-defm DS_DEC_RTN_U64 : DS_1A1D_RET_mc<"ds_dec_rtn_u64", VReg_64, "ds_dec_u64">;
-defm DS_MIN_RTN_I64 : DS_1A1D_RET_mc<"ds_min_rtn_i64", VReg_64, "ds_min_i64">;
-defm DS_MAX_RTN_I64 : DS_1A1D_RET_mc<"ds_max_rtn_i64", VReg_64, "ds_max_i64">;
-defm DS_MIN_RTN_U64 : DS_1A1D_RET_mc<"ds_min_rtn_u64", VReg_64, "ds_min_u64">;
-defm DS_MAX_RTN_U64 : DS_1A1D_RET_mc<"ds_max_rtn_u64", VReg_64, "ds_max_u64">;
-defm DS_AND_RTN_B64 : DS_1A1D_RET_mc<"ds_and_rtn_b64", VReg_64, "ds_and_b64">;
-defm DS_OR_RTN_B64 : DS_1A1D_RET_mc<"ds_or_rtn_b64", VReg_64, "ds_or_b64">;
-defm DS_XOR_RTN_B64 : DS_1A1D_RET_mc<"ds_xor_rtn_b64", VReg_64, "ds_xor_b64">;
-defm DS_MSKOR_RTN_B64 : DS_1A2D_RET_mc<"ds_mskor_rtn_b64", VReg_64, "ds_mskor_b64">;
-defm DS_CMPST_RTN_B64 : DS_1A2D_RET_mc<"ds_cmpst_rtn_b64", VReg_64, "ds_cmpst_b64">;
-defm DS_CMPST_RTN_F64 : DS_1A2D_RET_mc<"ds_cmpst_rtn_f64", VReg_64, "ds_cmpst_f64">;
-defm DS_MIN_RTN_F64 : DS_1A1D_RET_mc<"ds_min_rtn_f64", VReg_64, "ds_min_f64">;
-defm DS_MAX_RTN_F64 : DS_1A1D_RET_mc<"ds_max_rtn_f64", VReg_64, "ds_max_f64">;
+defm DS_ADD_RTN_U64 : DS_1A1D_RET_mc<"ds_add_rtn_u64", VReg_64>;
+defm DS_SUB_RTN_U64 : DS_1A1D_RET_mc<"ds_sub_rtn_u64", VReg_64>;
+defm DS_RSUB_RTN_U64 : DS_1A1D_RET_mc<"ds_rsub_rtn_u64", VReg_64>;
+defm DS_INC_RTN_U64 : DS_1A1D_RET_mc<"ds_inc_rtn_u64", VReg_64>;
+defm DS_DEC_RTN_U64 : DS_1A1D_RET_mc<"ds_dec_rtn_u64", VReg_64>;
+defm DS_MIN_RTN_I64 : DS_1A1D_RET_mc<"ds_min_rtn_i64", VReg_64>;
+defm DS_MAX_RTN_I64 : DS_1A1D_RET_mc<"ds_max_rtn_i64", VReg_64>;
+defm DS_MIN_RTN_U64 : DS_1A1D_RET_mc<"ds_min_rtn_u64", VReg_64>;
+defm DS_MAX_RTN_U64 : DS_1A1D_RET_mc<"ds_max_rtn_u64", VReg_64>;
+defm DS_AND_RTN_B64 : DS_1A1D_RET_mc<"ds_and_rtn_b64", VReg_64>;
+defm DS_OR_RTN_B64 : DS_1A1D_RET_mc<"ds_or_rtn_b64", VReg_64>;
+defm DS_XOR_RTN_B64 : DS_1A1D_RET_mc<"ds_xor_rtn_b64", VReg_64>;
+defm DS_MSKOR_RTN_B64 : DS_1A2D_RET_mc<"ds_mskor_rtn_b64", VReg_64>;
+defm DS_CMPST_RTN_B64 : DS_1A2D_RET_mc<"ds_cmpst_rtn_b64", VReg_64>;
+defm DS_CMPST_RTN_F64 : DS_1A2D_RET_mc<"ds_cmpst_rtn_f64", VReg_64>;
+defm DS_MIN_RTN_F64 : DS_1A1D_RET_mc<"ds_min_rtn_f64", VReg_64>;
+defm DS_MAX_RTN_F64 : DS_1A1D_RET_mc<"ds_max_rtn_f64", VReg_64>;
defm DS_WRXCHG_RTN_B64 : DS_1A1D_RET_mc<"ds_wrxchg_rtn_b64", VReg_64>;
defm DS_WRXCHG2_RTN_B64 : DS_1A2D_Off8_RET_mc<"ds_wrxchg2_rtn_b64", VReg_128, VReg_64>;
@@ -740,9 +725,9 @@ def DS_BVH_STACK_RTN_B32 : DS_BVH_STACK<"ds_bvh_stack_rtn_b32">;
let SubtargetPredicate = isGFX12Plus in {
defm DS_COND_SUB_U32 : DS_1A1D_NORET_mc<"ds_cond_sub_u32">;
-defm DS_COND_SUB_RTN_U32 : DS_1A1D_RET_mc<"ds_cond_sub_rtn_u32", VGPR_32, "ds_cond_sub_u32">;
+defm DS_COND_SUB_RTN_U32 : DS_1A1D_RET_mc<"ds_cond_sub_rtn_u32", VGPR_32>;
defm DS_SUB_CLAMP_U32 : DS_1A1D_NORET_mc<"ds_sub_clamp_u32">;
-defm DS_SUB_CLAMP_RTN_U32 : DS_1A1D_RET_mc<"ds_sub_clamp_rtn_u32", VGPR_32, "ds_sub_clamp_u32">;
+defm DS_SUB_CLAMP_RTN_U32 : DS_1A1D_RET_mc<"ds_sub_clamp_rtn_u32", VGPR_32>;
multiclass DSAtomicRetNoRetPatIntrinsic_mc<DS_Pseudo inst, DS_Pseudo noRetInst,
ValueType vt, string frag> {
diff --git a/llvm/lib/Target/AMDGPU/FLATInstructions.td b/llvm/lib/Target/AMDGPU/FLATInstructions.td
index 8a6016862426a9..87bd682611521c 100644
--- a/llvm/lib/Target/AMDGPU/FLATInstructions.td
+++ b/llvm/lib/Target/AMDGPU/FLATInstructions.td
@@ -541,8 +541,7 @@ multiclass FLAT_Atomic_Pseudo_NO_RTN<
(outs),
(ins VReg_64:$vaddr, data_op:$vdata, flat_offset:$offset, CPol_0:$cpol),
" $vaddr, $vdata$offset$cpol">,
- GlobalSaddrTable<0, opName>,
- AtomicNoRet <opName, 0> {
+ GlobalSaddrTable<0, opName> {
let PseudoInstr = NAME;
let FPAtomic = data_vt.isFP;
let AddedComplexity = -1; // Prefer global atomics if available
@@ -560,8 +559,7 @@ multiclass FLAT_Atomic_Pseudo_RTN<
(outs getLdStRegisterOperand<vdst_rc>.ret:$vdst),
(ins VReg_64:$vaddr, data_op:$vdata, flat_offset:$offset, CPol_GLC1:$cpol),
" $vdst, $vaddr, $vdata$offset$cpol">,
- GlobalSaddrTable<0, opName#"_rtn">,
- AtomicNoRet <opName, 1> {
+ GlobalSaddrTable<0, opName#"_rtn"> {
let FPAtomic = data_vt.isFP;
let AddedComplexity = -1; // Prefer global atomics if available
}
@@ -590,8 +588,7 @@ multiclass FLAT_Global_Atomic_Pseudo_NO_RTN<
(outs),
(ins VReg_64:$vaddr, data_op:$vdata, flat_offset:$offset, CPol_0:$cpol),
" $vaddr, $vdata, off$offset$cpol">,
- GlobalSaddrTable<0, opName>,
- AtomicNoRet <opName, 0> {
+ GlobalSaddrTable<0, opName> {
let has_saddr = 1;
let PseudoInstr = NAME;
let FPAtomic = data_vt.isFP;
@@ -601,8 +598,7 @@ multiclass FLAT_Global_Atomic_Pseudo_NO_RTN<
(outs),
(ins VGPR_32:$vaddr, data_op:$vdata, SReg_64:$saddr, flat_offset:$offset, CPol_0:$cpol),
" $vaddr, $vdata, $saddr$offset$cpol">,
- GlobalSaddrTable<1, opName>,
- AtomicNoRet <opName#"_saddr", 0> {
+ GlobalSaddrTable<1, opName> {
let has_saddr = 1;
let enabled_saddr = 1;
let PseudoInstr = NAME#"_SADDR";
@@ -623,8 +619,7 @@ multiclass FLAT_Global_Atomic_Pseudo_RTN<
(outs vdst_op:$vdst),
(ins VReg_64:$vaddr, data_op:$vdata, flat_offset:$offset, CPol_GLC1:$cpol),
" $vdst, $vaddr, $vdata, off$offset$cpol">,
- GlobalSaddrTable<0, opName#"_rtn">,
- AtomicNoRet <opName, 1> {
+ GlobalSaddrTable<0, opName#"_rtn"> {
let has_saddr = 1;
let FPAtomic = data_vt.isFP;
}
@@ -633,8 +628,7 @@ multiclass FLAT_Global_Atomic_Pseudo_RTN<
(outs vdst_op:$vdst),
(ins VGPR_32:$vaddr, data_op:$vdata, SReg_64:$saddr, flat_offset:$offset, CPol_GLC1:$cpol),
" $vdst, $vaddr, $vdata, $saddr$offset$cpol">,
- GlobalSaddrTable<1, opName#"_rtn">,
- AtomicNoRet <opName#"_saddr", 1> {
+ GlobalSaddrTable<1, opName#"_rtn"> {
let has_saddr = 1;
let enabled_saddr = 1;
let PseudoInstr = NAME#"_SADDR_RTN";
diff --git a/llvm/lib/Target/AMDGPU/SIInstrInfo.h b/llvm/lib/Target/AMDGPU/SIInstrInfo.h
index a8a33a5fecb413..82c6117292aee1 100644
--- a/llvm/lib/Target/AMDGPU/SIInstrInfo.h
+++ b/llvm/lib/Target/AMDGPU/SIInstrInfo.h
@@ -1459,9 +1459,6 @@ namespace AMDGPU {
LLVM_READONLY
int getIfAddr64Inst(uint16_t Opcode);
- LLVM_READONLY
- int getAtomicNoRetOp(uint16_t Opcode);
-
LLVM_READONLY
int getSOPKOp(uint16_t Opcode);
diff --git a/llvm/lib/Target/AMDGPU/SIInstrInfo.td b/llvm/lib/Target/AMDGPU/SIInstrInfo.td
index 34cdb09b0e15da..835a5a24723154 100644
--- a/llvm/lib/Target/AMDGPU/SIInstrInfo.td
+++ b/llvm/lib/Target/AMDGPU/SIInstrInfo.td
@@ -2591,11 +2591,6 @@ class Commutable_REV <string revOp, bit isOrig> {
bit IsOrig = isOrig;
}
-class AtomicNoRet <string noRetOp, bit isRet> {
- string NoRetOp = noRetOp;
- bit IsRet = isRet;
-}
-
//===----------------------------------------------------------------------===//
// Interpolation opcodes
//===----------------------------------------------------------------------===//
@@ -2766,15 +2761,6 @@ def getIfAddr64Inst : InstrMapping {
let ValueCols = [["1"]];
}
-// Maps an atomic opcode to its returnless version.
-def getAtomicNoRetOp : InstrMapping {
- let FilterClass = "AtomicNoRet";
- let RowFields = ["NoRetOp"];
- let ColFields = ["IsRet"];
- let KeyCol = ["1"];
- let ValueCols = [["0"]];
-}
-
// Maps a GLOBAL to its SADDR form.
def getGlobalSaddrOp : InstrMapping {
let FilterClass = "GlobalSaddrTable";
diff --git a/llvm/lib/Target/AMDGPU/SMInstructions.td b/llvm/lib/Target/AMDGPU/SMInstructions.td
index 29651a8390399c..a91fb87998fe59 100644
--- a/llvm/lib/Target/AMDGPU/SMInstructions.td
+++ b/llvm/lib/Target/AMDGPU/SMInstructions.td
@@ -277,8 +277,7 @@ class SM_Pseudo_Atomic<string opName,
(ins CPolTy:$cpol)),
!if(isRet, " $sdst", " $sdata") #
", $sbase, " # offsets.Asm # "$cpol",
- isRet>,
- AtomicNoRet <opNameWithSuffix, isRet> {
+ isRet> {
let has_offset = offsets.HasOffset;
let has_soffset = offsets.HasSOffset;
let PseudoInstr = opNameWithSuffix;
@@ -662,8 +661,7 @@ defm S_ATC_PROBE_BUFFER : SM_Real_Probe_vi <0x27>;
//===----------------------------------------------------------------------===//
class SMEM_Atomic_Real_vi <bits<8> op, SM_Atomic_Pseudo ps>
- : SMEM_Real_vi <op, ps>,
- AtomicNoRet <!subst("_RTN","",NAME), ps.glc> {
+ : SMEM_Real_vi <op, ps> {
bits<7> sdata;
@@ -1222,8 +1220,7 @@ defm S_ATC_PROBE : SM_Real_Probe_gfx10 <0x26>;
defm S_ATC_PROBE_BUFFER : SM_Real_Probe_gfx10 <0x27>;
class SMEM_Atomic_Real_gfx10 <bits<8> op, SM_Atomic_Pseudo ps>
- : SMEM_Real_gfx10 <op, ps>,
- AtomicNoRet <!subst("_RTN","",NAME), ps.glc> {
+ : SMEM_Real_gfx10 <op, ps> {
bits<7> sdata;
>From b542501ad7020bc03437e0c5b12b3e89c05c05af Mon Sep 17 00:00:00 2001
From: Farzon Lotfi <1802579+farzonl at users.noreply.github.com>
Date: Fri, 1 Mar 2024 12:27:25 -0500
Subject: [PATCH 273/406] [HLSL][DXIL] Implementation of round intrinsic
(#83570)
hlsl_intrinsics.h - add the round api
DXIL.td add the llvm intrinsic to DXIL lowering mapping
This change reuses llvm's existing intrinsic
`__builtin_elementwise_round`\ `int_round`
This change implements: #70077
---
clang/lib/Headers/hlsl/hlsl_intrinsics.h | 34 ++++++++++++
clang/test/CodeGenHLSL/builtins/round.hlsl | 53 +++++++++++++++++++
.../test/SemaHLSL/BuiltIns/round-errors.hlsl | 27 ++++++++++
llvm/lib/Target/DirectX/DXIL.td | 3 ++
llvm/test/CodeGen/DirectX/round.ll | 31 +++++++++++
5 files changed, 148 insertions(+)
create mode 100644 clang/test/CodeGenHLSL/builtins/round.hlsl
create mode 100644 clang/test/SemaHLSL/BuiltIns/round-errors.hlsl
create mode 100644 llvm/test/CodeGen/DirectX/round.ll
diff --git a/clang/lib/Headers/hlsl/hlsl_intrinsics.h b/clang/lib/Headers/hlsl/hlsl_intrinsics.h
index 0aa8651ba80dc4..5180530363889f 100644
--- a/clang/lib/Headers/hlsl/hlsl_intrinsics.h
+++ b/clang/lib/Headers/hlsl/hlsl_intrinsics.h
@@ -831,6 +831,40 @@ uint64_t3 reversebits(uint64_t3);
_HLSL_BUILTIN_ALIAS(__builtin_elementwise_bitreverse)
uint64_t4 reversebits(uint64_t4);
+//===----------------------------------------------------------------------===//
+// round builtins
+//===----------------------------------------------------------------------===//
+
+/// \fn T round(T x)
+/// \brief Rounds the specified value \a x to the nearest integer.
+/// \param x The specified input value.
+///
+/// The return value is the \a x parameter, rounded to the nearest integer
+/// within a floating-point type. Halfway cases are
+/// rounded to the nearest even value.
+
+_HLSL_16BIT_AVAILABILITY(shadermodel, 6.2)
+_HLSL_BUILTIN_ALIAS(__builtin_elementwise_round)
+half round(half);
+_HLSL_16BIT_AVAILABILITY(shadermodel, 6.2)
+_HLSL_BUILTIN_ALIAS(__builtin_elementwise_round)
+half2 round(half2);
+_HLSL_16BIT_AVAILABILITY(shadermodel, 6.2)
+_HLSL_BUILTIN_ALIAS(__builtin_elementwise_round)
+half3 round(half3);
+_HLSL_16BIT_AVAILABILITY(shadermodel, 6.2)
+_HLSL_BUILTIN_ALIAS(__builtin_elementwise_round)
+half4 round(half4);
+
+_HLSL_BUILTIN_ALIAS(__builtin_elementwise_round)
+float round(float);
+_HLSL_BUILTIN_ALIAS(__builtin_elementwise_round)
+float2 round(float2);
+_HLSL_BUILTIN_ALIAS(__builtin_elementwise_round)
+float3 round(float3);
+_HLSL_BUILTIN_ALIAS(__builtin_elementwise_round)
+float4 round(float4);
+
//===----------------------------------------------------------------------===//
// sin builtins
//===----------------------------------------------------------------------===//
diff --git a/clang/test/CodeGenHLSL/builtins/round.hlsl b/clang/test/CodeGenHLSL/builtins/round.hlsl
new file mode 100644
index 00000000000000..b9f35bd3712d18
--- /dev/null
+++ b/clang/test/CodeGenHLSL/builtins/round.hlsl
@@ -0,0 +1,53 @@
+// RUN: %clang_cc1 -finclude-default-header -x hlsl -triple \
+// RUN: dxil-pc-shadermodel6.3-library %s -fnative-half-type \
+// RUN: -emit-llvm -disable-llvm-passes -o - | FileCheck %s \
+// RUN: --check-prefixes=CHECK,NATIVE_HALF
+// RUN: %clang_cc1 -finclude-default-header -x hlsl -triple \
+// RUN: dxil-pc-shadermodel6.3-library %s -emit-llvm -disable-llvm-passes \
+// RUN: -o - | FileCheck %s --check-prefixes=CHECK,NO_HALF
+
+// NATIVE_HALF: define noundef half @
+// NATIVE_HALF: %elt.round = call half @llvm.round.f16(
+// NATIVE_HALF: ret half %elt.round
+// NO_HALF: define noundef float @"?test_round_half@@YA$halff@$halff@@Z"(
+// NO_HALF: %elt.round = call float @llvm.round.f32(
+// NO_HALF: ret float %elt.round
+half test_round_half(half p0) { return round(p0); }
+// NATIVE_HALF: define noundef <2 x half> @
+// NATIVE_HALF: %elt.round = call <2 x half> @llvm.round.v2f16
+// NATIVE_HALF: ret <2 x half> %elt.round
+// NO_HALF: define noundef <2 x float> @
+// NO_HALF: %elt.round = call <2 x float> @llvm.round.v2f32(
+// NO_HALF: ret <2 x float> %elt.round
+half2 test_round_half2(half2 p0) { return round(p0); }
+// NATIVE_HALF: define noundef <3 x half> @
+// NATIVE_HALF: %elt.round = call <3 x half> @llvm.round.v3f16
+// NATIVE_HALF: ret <3 x half> %elt.round
+// NO_HALF: define noundef <3 x float> @
+// NO_HALF: %elt.round = call <3 x float> @llvm.round.v3f32(
+// NO_HALF: ret <3 x float> %elt.round
+half3 test_round_half3(half3 p0) { return round(p0); }
+// NATIVE_HALF: define noundef <4 x half> @
+// NATIVE_HALF: %elt.round = call <4 x half> @llvm.round.v4f16
+// NATIVE_HALF: ret <4 x half> %elt.round
+// NO_HALF: define noundef <4 x float> @
+// NO_HALF: %elt.round = call <4 x float> @llvm.round.v4f32(
+// NO_HALF: ret <4 x float> %elt.round
+half4 test_round_half4(half4 p0) { return round(p0); }
+
+// CHECK: define noundef float @
+// CHECK: %elt.round = call float @llvm.round.f32(
+// CHECK: ret float %elt.round
+float test_round_float(float p0) { return round(p0); }
+// CHECK: define noundef <2 x float> @
+// CHECK: %elt.round = call <2 x float> @llvm.round.v2f32
+// CHECK: ret <2 x float> %elt.round
+float2 test_round_float2(float2 p0) { return round(p0); }
+// CHECK: define noundef <3 x float> @
+// CHECK: %elt.round = call <3 x float> @llvm.round.v3f32
+// CHECK: ret <3 x float> %elt.round
+float3 test_round_float3(float3 p0) { return round(p0); }
+// CHECK: define noundef <4 x float> @
+// CHECK: %elt.round = call <4 x float> @llvm.round.v4f32
+// CHECK: ret <4 x float> %elt.round
+float4 test_round_float4(float4 p0) { return round(p0); }
diff --git a/clang/test/SemaHLSL/BuiltIns/round-errors.hlsl b/clang/test/SemaHLSL/BuiltIns/round-errors.hlsl
new file mode 100644
index 00000000000000..fed4573063acb5
--- /dev/null
+++ b/clang/test/SemaHLSL/BuiltIns/round-errors.hlsl
@@ -0,0 +1,27 @@
+
+// RUN: %clang_cc1 -finclude-default-header -triple dxil-pc-shadermodel6.6-library %s -fnative-half-type -emit-llvm -disable-llvm-passes -verify -verify-ignore-unexpected
+
+float test_too_few_arg() {
+ return __builtin_elementwise_round();
+ // expected-error at -1 {{too few arguments to function call, expected 1, have 0}}
+}
+
+float2 test_too_many_arg(float2 p0) {
+ return __builtin_elementwise_round(p0, p0);
+ // expected-error at -1 {{too many arguments to function call, expected 1, have 2}}
+}
+
+float builtin_bool_to_float_type_promotion(bool p1) {
+ return __builtin_elementwise_round(p1);
+ // expected-error at -1 {{1st argument must be a vector, integer or floating point type (was 'bool')}}
+}
+
+float builtin_round_int_to_float_promotion(int p1) {
+ return __builtin_elementwise_round(p1);
+ // expected-error at -1 {{1st argument must be a floating point type (was 'int')}}
+}
+
+float2 builtin_round_int2_to_float2_promotion(int2 p1) {
+ return __builtin_elementwise_round(p1);
+ // expected-error at -1 {{1st argument must be a floating point type (was 'int2' (aka 'vector<int, 2>'))}}
+}
diff --git a/llvm/lib/Target/DirectX/DXIL.td b/llvm/lib/Target/DirectX/DXIL.td
index 67ef7986622092..f6edd1eb56c1ad 100644
--- a/llvm/lib/Target/DirectX/DXIL.td
+++ b/llvm/lib/Target/DirectX/DXIL.td
@@ -218,6 +218,9 @@ class DXILOpMapping<int opCode, DXILOpClass opClass, Intrinsic intrinsic, string
// Concrete definition of DXIL Operation mapping to corresponding LLVM intrinsic
def Sin : DXILOpMapping<13, unary, int_sin,
"Returns sine(theta) for theta in radians.">;
+def Round : DXILOpMapping<26, unary, int_round,
+ "Returns the input rounded to the nearest integer"
+ "within a floating-point type.">;
def UMax : DXILOpMapping<39, binary, int_umax,
"Unsigned integer maximum. UMax(a,b) = a > b ? a : b">;
def ThreadId : DXILOpMapping<93, threadId, int_dx_thread_id,
diff --git a/llvm/test/CodeGen/DirectX/round.ll b/llvm/test/CodeGen/DirectX/round.ll
new file mode 100644
index 00000000000000..5d53a794b763a6
--- /dev/null
+++ b/llvm/test/CodeGen/DirectX/round.ll
@@ -0,0 +1,31 @@
+; RUN: opt -S -dxil-op-lower < %s | FileCheck %s
+
+; Make sure dxil operation function calls for round are generated for float and half.
+; CHECK:call float @dx.op.unary.f32(i32 26, float %{{.*}})
+; CHECK:call half @dx.op.unary.f16(i32 26, half %{{.*}})
+
+target datalayout = "e-m:e-p:32:32-i1:32-i8:8-i16:16-i32:32-i64:64-f16:16-f32:32-f64:64-n8:16:32:64"
+target triple = "dxil-pc-shadermodel6.7-library"
+
+; Function Attrs: noinline nounwind optnone
+define noundef float @round_float(float noundef %a) #0 {
+entry:
+ %a.addr = alloca float, align 4
+ store float %a, ptr %a.addr, align 4
+ %0 = load float, ptr %a.addr, align 4
+ %elt.round = call float @llvm.round.f32(float %0)
+ ret float %elt.round
+}
+
+; Function Attrs: nocallback nofree nosync nounwind readnone speculatable willreturn
+declare float @llvm.round.f32(float) #1
+
+; Function Attrs: noinline nounwind optnone
+define noundef half @round_half(half noundef %a) #0 {
+entry:
+ %a.addr = alloca half, align 2
+ store half %a, ptr %a.addr, align 2
+ %0 = load half, ptr %a.addr, align 2
+ %elt.round = call half @llvm.round.f16(half %0)
+ ret half %elt.round
+}
>From ae58b676f1716b381b1232d47ed308f3eec590fc Mon Sep 17 00:00:00 2001
From: Slava Zakharin <szakharin at nvidia.com>
Date: Fri, 1 Mar 2024 09:41:07 -0800
Subject: [PATCH 274/406] [flang] Fixed ieee_logb to behave for denormals.
(#83518)
For denormals we have to account for the exponent coming
from the significand.
---
flang/lib/Optimizer/Builder/IntrinsicCall.cpp | 30 ++++++++++++++++++-
1 file changed, 29 insertions(+), 1 deletion(-)
diff --git a/flang/lib/Optimizer/Builder/IntrinsicCall.cpp b/flang/lib/Optimizer/Builder/IntrinsicCall.cpp
index 837ef0576ef696..fb9b58ef69c6ae 100644
--- a/flang/lib/Optimizer/Builder/IntrinsicCall.cpp
+++ b/flang/lib/Optimizer/Builder/IntrinsicCall.cpp
@@ -4195,39 +4195,45 @@ mlir::Value IntrinsicLibrary::genIeeeLogb(mlir::Type resultType,
builder.create<mlir::arith::BitcastOp>(loc, intType, realVal);
mlir::Type i1Ty = builder.getI1Type();
- int exponentBias, significandSize;
+ int exponentBias, significandSize, nonSignificandSize;
switch (bitWidth) {
case 16:
if (realType.isF16()) {
// kind=2: 1 sign bit, 5 exponent bits, 10 significand bits
exponentBias = (1 << (5 - 1)) - 1; // 15
significandSize = 10;
+ nonSignificandSize = 6;
break;
}
assert(realType.isBF16() && "unknown 16-bit real type");
// kind=3: 1 sign bit, 8 exponent bits, 7 significand bits
exponentBias = (1 << (8 - 1)) - 1; // 127
significandSize = 7;
+ nonSignificandSize = 9;
break;
case 32:
// kind=4: 1 sign bit, 8 exponent bits, 23 significand bits
exponentBias = (1 << (8 - 1)) - 1; // 127
significandSize = 23;
+ nonSignificandSize = 9;
break;
case 64:
// kind=8: 1 sign bit, 11 exponent bits, 52 significand bits
exponentBias = (1 << (11 - 1)) - 1; // 1023
significandSize = 52;
+ nonSignificandSize = 12;
break;
case 80:
// kind=10: 1 sign bit, 15 exponent bits, 1+63 significand bits
exponentBias = (1 << (15 - 1)) - 1; // 16383
significandSize = 64;
+ nonSignificandSize = 16 + 1;
break;
case 128:
// kind=16: 1 sign bit, 15 exponent bits, 112 significand bits
exponentBias = (1 << (15 - 1)) - 1; // 16383
significandSize = 112;
+ nonSignificandSize = 16;
break;
default:
llvm_unreachable("unknown real type");
@@ -4259,6 +4265,11 @@ mlir::Value IntrinsicLibrary::genIeeeLogb(mlir::Type resultType,
/*withElseRegion=*/true);
// X is non-zero finite -- result is unbiased exponent of X
builder.setInsertionPointToStart(&innerIfOp.getThenRegion().front());
+ mlir::Value isNormal = genIsFPClass(i1Ty, args, normalTest);
+ auto normalIfOp = builder.create<fir::IfOp>(loc, resultType, isNormal,
+ /*withElseRegion=*/true);
+ // X is normal
+ builder.setInsertionPointToStart(&normalIfOp.getThenRegion().front());
mlir::Value biasedExponent = builder.create<mlir::arith::ShRUIOp>(
loc, shiftLeftOne,
builder.createIntegerConstant(loc, intType, significandSize + 1));
@@ -4268,6 +4279,23 @@ mlir::Value IntrinsicLibrary::genIeeeLogb(mlir::Type resultType,
result = builder.create<fir::ConvertOp>(loc, resultType, result);
builder.create<fir::ResultOp>(loc, result);
+ // X is denormal -- result is (-exponentBias - ctlz(significand))
+ builder.setInsertionPointToStart(&normalIfOp.getElseRegion().front());
+ mlir::Value significand = builder.create<mlir::arith::ShLIOp>(
+ loc, intVal,
+ builder.createIntegerConstant(loc, intType, nonSignificandSize));
+ mlir::Value ctlz =
+ builder.create<mlir::math::CountLeadingZerosOp>(loc, significand);
+ mlir::Type i32Ty = builder.getI32Type();
+ result = builder.create<mlir::arith::SubIOp>(
+ loc, builder.createIntegerConstant(loc, i32Ty, -exponentBias),
+ builder.create<fir::ConvertOp>(loc, i32Ty, ctlz));
+ result = builder.create<fir::ConvertOp>(loc, resultType, result);
+ builder.create<fir::ResultOp>(loc, result);
+
+ builder.setInsertionPointToEnd(&innerIfOp.getThenRegion().front());
+ builder.create<fir::ResultOp>(loc, normalIfOp.getResult(0));
+
// X is infinity or NaN -- result is +infinity or NaN
builder.setInsertionPointToStart(&innerIfOp.getElseRegion().front());
result = builder.create<mlir::arith::ShRUIOp>(loc, shiftLeftOne, one);
>From 3337d693735d6a361cde87de82624d89ca9660f1 Mon Sep 17 00:00:00 2001
From: Francesco Petrogalli <francesco.petrogalli at apple.com>
Date: Fri, 1 Mar 2024 18:41:54 +0100
Subject: [PATCH 275/406] [llvm][Intrinsics] Add llvm_v3i8_ty. [NFCI] (#83576)
---
llvm/include/llvm/IR/Intrinsics.td | 1 +
1 file changed, 1 insertion(+)
diff --git a/llvm/include/llvm/IR/Intrinsics.td b/llvm/include/llvm/IR/Intrinsics.td
index 0d33e374af7896..c2c0f74c315bab 100644
--- a/llvm/include/llvm/IR/Intrinsics.td
+++ b/llvm/include/llvm/IR/Intrinsics.td
@@ -514,6 +514,7 @@ def llvm_v2048i1_ty : LLVMType<v2048i1>; //2048 x i1
def llvm_v1i8_ty : LLVMType<v1i8>; // 1 x i8
def llvm_v2i8_ty : LLVMType<v2i8>; // 2 x i8
+def llvm_v3i8_ty : LLVMType<v3i8>; // 3 x i8
def llvm_v4i8_ty : LLVMType<v4i8>; // 4 x i8
def llvm_v8i8_ty : LLVMType<v8i8>; // 8 x i8
def llvm_v16i8_ty : LLVMType<v16i8>; // 16 x i8
>From ce95a56db552fde4836d71992b2c42cadd0088c8 Mon Sep 17 00:00:00 2001
From: Mircea Trofin <mtrofin at google.com>
Date: Fri, 1 Mar 2024 09:44:22 -0800
Subject: [PATCH 276/406] [pgo][nfc] Model `Count` as a `std::optional` in
`PGOUseEdge` (#83505)
Similar to PR #83364.
---
.../Instrumentation/PGOInstrumentation.cpp | 22 ++++++++-----------
1 file changed, 9 insertions(+), 13 deletions(-)
diff --git a/llvm/lib/Transforms/Instrumentation/PGOInstrumentation.cpp b/llvm/lib/Transforms/Instrumentation/PGOInstrumentation.cpp
index 0c042e73ba0836..55728709cde556 100644
--- a/llvm/lib/Transforms/Instrumentation/PGOInstrumentation.cpp
+++ b/llvm/lib/Transforms/Instrumentation/PGOInstrumentation.cpp
@@ -961,21 +961,16 @@ namespace {
struct PGOUseEdge : public PGOEdge {
using PGOEdge::PGOEdge;
- bool CountValid = false;
- uint64_t CountValue = 0;
+ std::optional<uint64_t> Count;
// Set edge count value
- void setEdgeCount(uint64_t Value) {
- CountValue = Value;
- CountValid = true;
- }
+ void setEdgeCount(uint64_t Value) { Count = Value; }
// Return the information string for this object.
std::string infoString() const {
- if (!CountValid)
+ if (!Count)
return PGOEdge::infoString();
- return (Twine(PGOEdge::infoString()) + " Count=" + Twine(CountValue))
- .str();
+ return (Twine(PGOEdge::infoString()) + " Count=" + Twine(*Count)).str();
}
};
@@ -1022,7 +1017,8 @@ static uint64_t sumEdgeCount(const ArrayRef<PGOUseEdge *> Edges) {
for (const auto &E : Edges) {
if (E->Removed)
continue;
- Total += E->CountValue;
+ if (E->Count)
+ Total += *E->Count;
}
return Total;
}
@@ -1221,7 +1217,7 @@ bool PGOUseFunc::setInstrumentedCounts(
if (DestInfo.Count && DestInfo.InEdges.size() == 1)
setEdgeCount(E.get(), *DestInfo.Count);
}
- if (E->CountValid)
+ if (E->Count)
continue;
// E's count should have been set from profile. If not, this meenas E skips
// the instrumentation. We set the count to 0.
@@ -1234,7 +1230,7 @@ bool PGOUseFunc::setInstrumentedCounts(
// unknown edge in Edges vector.
void PGOUseFunc::setEdgeCount(DirectEdges &Edges, uint64_t Value) {
for (auto &E : Edges) {
- if (E->CountValid)
+ if (E->Count)
continue;
E->setEdgeCount(Value);
@@ -1574,7 +1570,7 @@ void PGOUseFunc::setBranchWeights() {
if (DestBB == nullptr)
continue;
unsigned SuccNum = GetSuccessorNumber(SrcBB, DestBB);
- uint64_t EdgeCount = E->CountValue;
+ uint64_t EdgeCount = *E->Count;
if (EdgeCount > MaxCount)
MaxCount = EdgeCount;
EdgeCounts[SuccNum] = EdgeCount;
>From df0fd3a80e964a4b28b2c1b6a8f139b3b4e14ffa Mon Sep 17 00:00:00 2001
From: Alexey Bataev <5361294+alexey-bataev at users.noreply.github.com>
Date: Fri, 1 Mar 2024 12:48:45 -0500
Subject: [PATCH 277/406] [SLP]Try to vectorize small graph with
extractelements, used in buildvector.
If the graph incudes only single "gather" node with only
extractelements/undefs, which used only in insertelement-based
buildvector sequences, it still might be profitable to vectorize it.
Need to rely on the cost model, not throw this graph away immediately.
Reviewers: RKSimon
Reviewed By: RKSimon
Pull Request: https://github.com/llvm/llvm-project/pull/83581
---
.../Transforms/Vectorize/SLPVectorizer.cpp | 14 +
.../SLPVectorizer/RISCV/complex-loads.ll | 649 +++++++++---------
.../Transforms/SLPVectorizer/X86/PR39774.ll | 18 +-
...nsert-element-build-vector-inseltpoison.ll | 2 +
.../X86/insert-element-build-vector.ll | 2 +
.../SLPVectorizer/X86/reduction-transpose.ll | 115 ++--
6 files changed, 413 insertions(+), 387 deletions(-)
diff --git a/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp b/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
index 3e75b5ed485770..f49ca17a67cb40 100644
--- a/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
+++ b/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
@@ -8985,6 +8985,20 @@ bool BoUpSLP::isTreeTinyAndNotFullyVectorizable(bool ForReduction) const {
if (isFullyVectorizableTinyTree(ForReduction))
return false;
+ // Check if any of the gather node forms an insertelement buildvector
+ // somewhere.
+ if (any_of(VectorizableTree, [](const std::unique_ptr<TreeEntry> &TE) {
+ return TE->State == TreeEntry::NeedToGather &&
+ all_of(TE->Scalars, [](Value *V) {
+ return isa<ExtractElementInst, UndefValue>(V) ||
+ (!V->hasNUsesOrMore(UsesLimit) &&
+ any_of(V->users(), [](User *U) {
+ return isa<InsertElementInst>(U);
+ }));
+ });
+ }))
+ return false;
+
assert(VectorizableTree.empty()
? ExternalUses.empty()
: true && "We shouldn't have any external users");
diff --git a/llvm/test/Transforms/SLPVectorizer/RISCV/complex-loads.ll b/llvm/test/Transforms/SLPVectorizer/RISCV/complex-loads.ll
index 97008ac6785961..ed73f7b134465a 100644
--- a/llvm/test/Transforms/SLPVectorizer/RISCV/complex-loads.ll
+++ b/llvm/test/Transforms/SLPVectorizer/RISCV/complex-loads.ll
@@ -1,375 +1,362 @@
; NOTE: Assertions have been autogenerated by utils/update_test_checks.py UTC_ARGS: --version 3
-; RUN: opt -S -mtriple riscv64-unknown-linux-gnu < %s --passes=slp-vectorizer -mattr=+v -slp-threshold=-40 | FileCheck %s
+; RUN: opt -S -mtriple riscv64-unknown-linux-gnu < %s --passes=slp-vectorizer -mattr=+v -slp-threshold=-20 | FileCheck %s
define i32 @test(ptr %pix1, ptr %pix2, i64 %idx.ext, i64 %idx.ext63, ptr %add.ptr, ptr %add.ptr64) {
; CHECK-LABEL: define i32 @test(
; CHECK-SAME: ptr [[PIX1:%.*]], ptr [[PIX2:%.*]], i64 [[IDX_EXT:%.*]], i64 [[IDX_EXT63:%.*]], ptr [[ADD_PTR:%.*]], ptr [[ADD_PTR64:%.*]]) #[[ATTR0:[0-9]+]] {
; CHECK-NEXT: entry:
-; CHECK-NEXT: [[TMP0:%.*]] = insertelement <2 x ptr> poison, ptr [[PIX1]], i32 0
-; CHECK-NEXT: [[TMP1:%.*]] = shufflevector <2 x ptr> [[TMP0]], <2 x ptr> poison, <2 x i32> zeroinitializer
-; CHECK-NEXT: [[TMP2:%.*]] = getelementptr i8, <2 x ptr> [[TMP1]], <2 x i64> <i64 4, i64 6>
-; CHECK-NEXT: [[TMP3:%.*]] = insertelement <2 x ptr> poison, ptr [[PIX2]], i32 0
-; CHECK-NEXT: [[TMP4:%.*]] = shufflevector <2 x ptr> [[TMP3]], <2 x ptr> poison, <2 x i32> zeroinitializer
-; CHECK-NEXT: [[TMP5:%.*]] = getelementptr i8, <2 x ptr> [[TMP4]], <2 x i64> <i64 4, i64 6>
-; CHECK-NEXT: [[TMP6:%.*]] = getelementptr i8, <2 x ptr> [[TMP4]], <2 x i64> <i64 1, i64 3>
-; CHECK-NEXT: [[TMP7:%.*]] = getelementptr i8, <2 x ptr> [[TMP1]], <2 x i64> <i64 5, i64 7>
-; CHECK-NEXT: [[TMP8:%.*]] = getelementptr i8, <2 x ptr> [[TMP4]], <2 x i64> <i64 5, i64 7>
-; CHECK-NEXT: [[ARRAYIDX20:%.*]] = getelementptr i8, ptr [[PIX1]], i64 2
+; CHECK-NEXT: [[TMP0:%.*]] = load i8, ptr [[PIX1]], align 1
+; CHECK-NEXT: [[CONV:%.*]] = zext i8 [[TMP0]] to i32
+; CHECK-NEXT: [[TMP1:%.*]] = insertelement <2 x ptr> poison, ptr [[PIX1]], i32 0
+; CHECK-NEXT: [[TMP2:%.*]] = shufflevector <2 x ptr> [[TMP1]], <2 x ptr> poison, <2 x i32> zeroinitializer
+; CHECK-NEXT: [[TMP3:%.*]] = getelementptr i8, <2 x ptr> [[TMP2]], <2 x i64> <i64 4, i64 6>
+; CHECK-NEXT: [[TMP4:%.*]] = insertelement <2 x ptr> poison, ptr [[PIX2]], i32 0
+; CHECK-NEXT: [[TMP5:%.*]] = shufflevector <2 x ptr> [[TMP4]], <2 x ptr> poison, <2 x i32> zeroinitializer
+; CHECK-NEXT: [[TMP6:%.*]] = getelementptr i8, <2 x ptr> [[TMP5]], <2 x i64> <i64 4, i64 6>
+; CHECK-NEXT: [[ARRAYIDX8:%.*]] = getelementptr i8, ptr [[PIX1]], i64 1
+; CHECK-NEXT: [[TMP7:%.*]] = getelementptr i8, <2 x ptr> [[TMP5]], <2 x i64> <i64 1, i64 3>
+; CHECK-NEXT: [[TMP8:%.*]] = getelementptr i8, <2 x ptr> [[TMP2]], <2 x i64> <i64 5, i64 7>
+; CHECK-NEXT: [[TMP9:%.*]] = getelementptr i8, <2 x ptr> [[TMP5]], <2 x i64> <i64 5, i64 7>
; CHECK-NEXT: [[ARRAYIDX22:%.*]] = getelementptr i8, ptr [[PIX2]], i64 2
+; CHECK-NEXT: [[ARRAYIDX32:%.*]] = getelementptr i8, ptr [[PIX1]], i64 3
+; CHECK-NEXT: [[TMP10:%.*]] = load i8, ptr [[ARRAYIDX32]], align 1
+; CHECK-NEXT: [[CONV33:%.*]] = zext i8 [[TMP10]] to i32
; CHECK-NEXT: [[ADD_PTR3:%.*]] = getelementptr i8, ptr [[PIX1]], i64 [[IDX_EXT]]
; CHECK-NEXT: [[ADD_PTR644:%.*]] = getelementptr i8, ptr [[PIX2]], i64 [[IDX_EXT63]]
-; CHECK-NEXT: [[TMP9:%.*]] = load i8, ptr [[ADD_PTR3]], align 1
-; CHECK-NEXT: [[CONV_1:%.*]] = zext i8 [[TMP9]] to i32
-; CHECK-NEXT: [[TMP10:%.*]] = load i8, ptr [[ADD_PTR644]], align 1
+; CHECK-NEXT: [[TMP11:%.*]] = load i8, ptr [[ADD_PTR3]], align 1
+; CHECK-NEXT: [[CONV_1:%.*]] = zext i8 [[TMP11]] to i32
+; CHECK-NEXT: [[TMP12:%.*]] = load i8, ptr [[ADD_PTR644]], align 1
; CHECK-NEXT: [[ARRAYIDX8_1:%.*]] = getelementptr i8, ptr [[ADD_PTR3]], i64 1
; CHECK-NEXT: [[ARRAYIDX22_1:%.*]] = getelementptr i8, ptr [[ADD_PTR644]], i64 2
-; CHECK-NEXT: [[TMP11:%.*]] = load i8, ptr [[ARRAYIDX22_1]], align 1
+; CHECK-NEXT: [[TMP13:%.*]] = load i8, ptr [[ARRAYIDX22_1]], align 1
; CHECK-NEXT: [[ARRAYIDX32_1:%.*]] = getelementptr i8, ptr [[ADD_PTR3]], i64 3
-; CHECK-NEXT: [[TMP12:%.*]] = load i8, ptr [[ARRAYIDX32_1]], align 1
-; CHECK-NEXT: [[CONV33_1:%.*]] = zext i8 [[TMP12]] to i32
+; CHECK-NEXT: [[TMP14:%.*]] = load i8, ptr [[ARRAYIDX32_1]], align 1
+; CHECK-NEXT: [[CONV33_1:%.*]] = zext i8 [[TMP14]] to i32
; CHECK-NEXT: [[ADD_PTR_1:%.*]] = getelementptr i8, ptr [[ADD_PTR]], i64 [[IDX_EXT]]
; CHECK-NEXT: [[ADD_PTR64_1:%.*]] = getelementptr i8, ptr [[ADD_PTR64]], i64 [[IDX_EXT63]]
-; CHECK-NEXT: [[TMP13:%.*]] = load i8, ptr [[ADD_PTR_1]], align 1
-; CHECK-NEXT: [[TMP14:%.*]] = load i8, ptr [[ADD_PTR64_1]], align 1
+; CHECK-NEXT: [[ARRAYIDX3_2:%.*]] = getelementptr i8, ptr [[ADD_PTR_1]], i64 4
+; CHECK-NEXT: [[ARRAYIDX5_2:%.*]] = getelementptr i8, ptr [[ADD_PTR64_1]], i64 4
+; CHECK-NEXT: [[TMP15:%.*]] = load <2 x i8>, ptr [[ADD_PTR_1]], align 1
+; CHECK-NEXT: [[TMP16:%.*]] = zext <2 x i8> [[TMP15]] to <2 x i32>
+; CHECK-NEXT: [[TMP17:%.*]] = load <2 x i8>, ptr [[ADD_PTR64_1]], align 1
+; CHECK-NEXT: [[TMP18:%.*]] = zext <2 x i8> [[TMP17]] to <2 x i32>
+; CHECK-NEXT: [[TMP19:%.*]] = sub <2 x i32> [[TMP16]], [[TMP18]]
+; CHECK-NEXT: [[TMP20:%.*]] = load <2 x i8>, ptr [[ARRAYIDX3_2]], align 1
+; CHECK-NEXT: [[TMP21:%.*]] = zext <2 x i8> [[TMP20]] to <2 x i32>
+; CHECK-NEXT: [[TMP22:%.*]] = load <2 x i8>, ptr [[ARRAYIDX5_2]], align 1
+; CHECK-NEXT: [[TMP23:%.*]] = zext <2 x i8> [[TMP22]] to <2 x i32>
+; CHECK-NEXT: [[TMP24:%.*]] = sub <2 x i32> [[TMP21]], [[TMP23]]
+; CHECK-NEXT: [[TMP25:%.*]] = shl <2 x i32> [[TMP24]], <i32 16, i32 16>
+; CHECK-NEXT: [[TMP26:%.*]] = add <2 x i32> [[TMP25]], [[TMP19]]
; CHECK-NEXT: [[ARRAYIDX20_2:%.*]] = getelementptr i8, ptr [[ADD_PTR_1]], i64 2
-; CHECK-NEXT: [[TMP15:%.*]] = load i8, ptr [[ARRAYIDX20_2]], align 1
; CHECK-NEXT: [[ARRAYIDX22_2:%.*]] = getelementptr i8, ptr [[ADD_PTR64_1]], i64 2
-; CHECK-NEXT: [[TMP16:%.*]] = load i8, ptr [[ARRAYIDX22_2]], align 1
-; CHECK-NEXT: [[TMP17:%.*]] = insertelement <2 x i8> poison, i8 [[TMP13]], i32 0
-; CHECK-NEXT: [[TMP18:%.*]] = insertelement <2 x i8> [[TMP17]], i8 [[TMP15]], i32 1
-; CHECK-NEXT: [[TMP19:%.*]] = zext <2 x i8> [[TMP18]] to <2 x i32>
-; CHECK-NEXT: [[TMP20:%.*]] = insertelement <2 x i8> poison, i8 [[TMP14]], i32 0
-; CHECK-NEXT: [[TMP21:%.*]] = insertelement <2 x i8> [[TMP20]], i8 [[TMP16]], i32 1
-; CHECK-NEXT: [[TMP22:%.*]] = zext <2 x i8> [[TMP21]] to <2 x i32>
-; CHECK-NEXT: [[TMP23:%.*]] = sub <2 x i32> [[TMP19]], [[TMP22]]
-; CHECK-NEXT: [[TMP24:%.*]] = insertelement <2 x ptr> poison, ptr [[ADD_PTR_1]], i32 0
-; CHECK-NEXT: [[TMP25:%.*]] = shufflevector <2 x ptr> [[TMP24]], <2 x ptr> poison, <2 x i32> zeroinitializer
-; CHECK-NEXT: [[TMP26:%.*]] = getelementptr i8, <2 x ptr> [[TMP25]], <2 x i64> <i64 4, i64 6>
-; CHECK-NEXT: [[TMP27:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP26]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[ARRAYIDX25_2:%.*]] = getelementptr i8, ptr [[ADD_PTR_1]], i64 6
+; CHECK-NEXT: [[ARRAYIDX27_2:%.*]] = getelementptr i8, ptr [[ADD_PTR64_1]], i64 6
+; CHECK-NEXT: [[TMP27:%.*]] = load <2 x i8>, ptr [[ARRAYIDX20_2]], align 1
; CHECK-NEXT: [[TMP28:%.*]] = zext <2 x i8> [[TMP27]] to <2 x i32>
-; CHECK-NEXT: [[TMP29:%.*]] = insertelement <2 x ptr> poison, ptr [[ADD_PTR64_1]], i32 0
-; CHECK-NEXT: [[TMP30:%.*]] = shufflevector <2 x ptr> [[TMP29]], <2 x ptr> poison, <2 x i32> zeroinitializer
-; CHECK-NEXT: [[TMP31:%.*]] = getelementptr i8, <2 x ptr> [[TMP30]], <2 x i64> <i64 4, i64 6>
-; CHECK-NEXT: [[TMP32:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP31]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP29:%.*]] = load <2 x i8>, ptr [[ARRAYIDX22_2]], align 1
+; CHECK-NEXT: [[TMP30:%.*]] = zext <2 x i8> [[TMP29]] to <2 x i32>
+; CHECK-NEXT: [[TMP31:%.*]] = sub <2 x i32> [[TMP28]], [[TMP30]]
+; CHECK-NEXT: [[TMP32:%.*]] = load <2 x i8>, ptr [[ARRAYIDX25_2]], align 1
; CHECK-NEXT: [[TMP33:%.*]] = zext <2 x i8> [[TMP32]] to <2 x i32>
-; CHECK-NEXT: [[TMP34:%.*]] = sub <2 x i32> [[TMP28]], [[TMP33]]
-; CHECK-NEXT: [[TMP35:%.*]] = shl <2 x i32> [[TMP34]], <i32 16, i32 16>
-; CHECK-NEXT: [[TMP36:%.*]] = add <2 x i32> [[TMP35]], [[TMP23]]
-; CHECK-NEXT: [[TMP37:%.*]] = getelementptr i8, <2 x ptr> [[TMP25]], <2 x i64> <i64 1, i64 3>
-; CHECK-NEXT: [[TMP38:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP37]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP39:%.*]] = zext <2 x i8> [[TMP38]] to <2 x i32>
-; CHECK-NEXT: [[TMP40:%.*]] = getelementptr i8, <2 x ptr> [[TMP30]], <2 x i64> <i64 1, i64 3>
-; CHECK-NEXT: [[TMP41:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP40]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP42:%.*]] = zext <2 x i8> [[TMP41]] to <2 x i32>
-; CHECK-NEXT: [[TMP43:%.*]] = sub <2 x i32> [[TMP39]], [[TMP42]]
-; CHECK-NEXT: [[TMP44:%.*]] = getelementptr i8, <2 x ptr> [[TMP25]], <2 x i64> <i64 5, i64 7>
-; CHECK-NEXT: [[TMP45:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP44]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP46:%.*]] = zext <2 x i8> [[TMP45]] to <2 x i32>
-; CHECK-NEXT: [[TMP47:%.*]] = getelementptr i8, <2 x ptr> [[TMP30]], <2 x i64> <i64 5, i64 7>
-; CHECK-NEXT: [[TMP48:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP47]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP49:%.*]] = zext <2 x i8> [[TMP48]] to <2 x i32>
-; CHECK-NEXT: [[TMP50:%.*]] = sub <2 x i32> [[TMP46]], [[TMP49]]
-; CHECK-NEXT: [[TMP51:%.*]] = shl <2 x i32> [[TMP50]], <i32 16, i32 16>
-; CHECK-NEXT: [[TMP52:%.*]] = add <2 x i32> [[TMP51]], [[TMP43]]
-; CHECK-NEXT: [[TMP53:%.*]] = sub <2 x i32> [[TMP36]], [[TMP52]]
-; CHECK-NEXT: [[TMP54:%.*]] = extractelement <2 x i32> [[TMP53]], i32 0
-; CHECK-NEXT: [[TMP55:%.*]] = extractelement <2 x i32> [[TMP53]], i32 1
-; CHECK-NEXT: [[SUB59_2:%.*]] = sub i32 [[TMP54]], [[TMP55]]
-; CHECK-NEXT: [[TMP56:%.*]] = load i8, ptr null, align 1
+; CHECK-NEXT: [[TMP34:%.*]] = load <2 x i8>, ptr [[ARRAYIDX27_2]], align 1
+; CHECK-NEXT: [[TMP35:%.*]] = zext <2 x i8> [[TMP34]] to <2 x i32>
+; CHECK-NEXT: [[TMP36:%.*]] = sub <2 x i32> [[TMP33]], [[TMP35]]
+; CHECK-NEXT: [[TMP37:%.*]] = shl <2 x i32> [[TMP36]], <i32 16, i32 16>
+; CHECK-NEXT: [[TMP38:%.*]] = add <2 x i32> [[TMP37]], [[TMP31]]
+; CHECK-NEXT: [[TMP39:%.*]] = extractelement <2 x i32> [[TMP26]], i32 0
+; CHECK-NEXT: [[TMP40:%.*]] = extractelement <2 x i32> [[TMP26]], i32 1
+; CHECK-NEXT: [[ADD44_2:%.*]] = add i32 [[TMP40]], [[TMP39]]
+; CHECK-NEXT: [[SUB45_2:%.*]] = sub i32 [[TMP39]], [[TMP40]]
+; CHECK-NEXT: [[TMP41:%.*]] = extractelement <2 x i32> [[TMP38]], i32 0
+; CHECK-NEXT: [[TMP42:%.*]] = extractelement <2 x i32> [[TMP38]], i32 1
+; CHECK-NEXT: [[ADD46_2:%.*]] = add i32 [[TMP42]], [[TMP41]]
+; CHECK-NEXT: [[SUB47_2:%.*]] = sub i32 [[TMP41]], [[TMP42]]
+; CHECK-NEXT: [[ADD48_2:%.*]] = add i32 [[ADD46_2]], [[ADD44_2]]
+; CHECK-NEXT: [[TMP43:%.*]] = load i8, ptr null, align 1
; CHECK-NEXT: [[ARRAYIDX20_3:%.*]] = getelementptr i8, ptr null, i64 2
; CHECK-NEXT: [[ARRAYIDX22_3:%.*]] = getelementptr i8, ptr null, i64 2
-; CHECK-NEXT: [[TMP57:%.*]] = load i8, ptr null, align 1
-; CHECK-NEXT: [[TMP58:%.*]] = insertelement <2 x ptr> <ptr poison, ptr null>, ptr [[ARRAYIDX20_3]], i32 0
-; CHECK-NEXT: [[TMP59:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP58]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP44:%.*]] = load i8, ptr null, align 1
+; CHECK-NEXT: [[TMP45:%.*]] = insertelement <2 x ptr> <ptr poison, ptr null>, ptr [[ARRAYIDX20_3]], i32 0
+; CHECK-NEXT: [[TMP46:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP45]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP47:%.*]] = zext <2 x i8> [[TMP46]] to <2 x i32>
+; CHECK-NEXT: [[TMP48:%.*]] = insertelement <2 x ptr> <ptr poison, ptr null>, ptr [[ARRAYIDX22_3]], i32 0
+; CHECK-NEXT: [[TMP49:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP48]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP50:%.*]] = zext <2 x i8> [[TMP49]] to <2 x i32>
+; CHECK-NEXT: [[TMP51:%.*]] = sub <2 x i32> [[TMP47]], [[TMP50]]
+; CHECK-NEXT: [[TMP52:%.*]] = call <2 x i8> @llvm.experimental.vp.strided.load.v2i8.p0.i64(ptr align 1 null, i64 4, <2 x i1> <i1 true, i1 true>, i32 2)
+; CHECK-NEXT: [[TMP53:%.*]] = zext <2 x i8> [[TMP52]] to <2 x i32>
+; CHECK-NEXT: [[TMP54:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> getelementptr (i8, <2 x ptr> zeroinitializer, <2 x i64> <i64 6, i64 4>), i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP55:%.*]] = zext <2 x i8> [[TMP54]] to <2 x i32>
+; CHECK-NEXT: [[TMP56:%.*]] = sub <2 x i32> [[TMP53]], [[TMP55]]
+; CHECK-NEXT: [[TMP57:%.*]] = shl <2 x i32> [[TMP56]], <i32 16, i32 16>
+; CHECK-NEXT: [[TMP58:%.*]] = add <2 x i32> [[TMP57]], [[TMP51]]
+; CHECK-NEXT: [[TMP59:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> getelementptr (i8, <2 x ptr> zeroinitializer, <2 x i64> <i64 3, i64 1>), i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
; CHECK-NEXT: [[TMP60:%.*]] = zext <2 x i8> [[TMP59]] to <2 x i32>
-; CHECK-NEXT: [[TMP61:%.*]] = insertelement <2 x ptr> <ptr poison, ptr null>, ptr [[ARRAYIDX22_3]], i32 0
-; CHECK-NEXT: [[TMP62:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP61]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP63:%.*]] = zext <2 x i8> [[TMP62]] to <2 x i32>
-; CHECK-NEXT: [[TMP64:%.*]] = sub <2 x i32> [[TMP60]], [[TMP63]]
-; CHECK-NEXT: [[TMP65:%.*]] = call <2 x i8> @llvm.experimental.vp.strided.load.v2i8.p0.i64(ptr align 1 null, i64 4, <2 x i1> <i1 true, i1 true>, i32 2)
+; CHECK-NEXT: [[TMP61:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> getelementptr (i8, <2 x ptr> zeroinitializer, <2 x i64> <i64 3, i64 1>), i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP62:%.*]] = zext <2 x i8> [[TMP61]] to <2 x i32>
+; CHECK-NEXT: [[TMP63:%.*]] = sub <2 x i32> [[TMP60]], [[TMP62]]
+; CHECK-NEXT: [[TMP64:%.*]] = insertelement <2 x i8> poison, i8 [[TMP44]], i32 0
+; CHECK-NEXT: [[TMP65:%.*]] = insertelement <2 x i8> [[TMP64]], i8 [[TMP43]], i32 1
; CHECK-NEXT: [[TMP66:%.*]] = zext <2 x i8> [[TMP65]] to <2 x i32>
-; CHECK-NEXT: [[TMP67:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> getelementptr (i8, <2 x ptr> zeroinitializer, <2 x i64> <i64 6, i64 4>), i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP67:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> getelementptr (i8, <2 x ptr> zeroinitializer, <2 x i64> <i64 7, i64 5>), i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
; CHECK-NEXT: [[TMP68:%.*]] = zext <2 x i8> [[TMP67]] to <2 x i32>
; CHECK-NEXT: [[TMP69:%.*]] = sub <2 x i32> [[TMP66]], [[TMP68]]
; CHECK-NEXT: [[TMP70:%.*]] = shl <2 x i32> [[TMP69]], <i32 16, i32 16>
-; CHECK-NEXT: [[TMP71:%.*]] = add <2 x i32> [[TMP70]], [[TMP64]]
-; CHECK-NEXT: [[TMP72:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> getelementptr (i8, <2 x ptr> zeroinitializer, <2 x i64> <i64 3, i64 1>), i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP73:%.*]] = zext <2 x i8> [[TMP72]] to <2 x i32>
-; CHECK-NEXT: [[TMP74:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> getelementptr (i8, <2 x ptr> zeroinitializer, <2 x i64> <i64 3, i64 1>), i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP75:%.*]] = zext <2 x i8> [[TMP74]] to <2 x i32>
-; CHECK-NEXT: [[TMP76:%.*]] = sub <2 x i32> [[TMP73]], [[TMP75]]
-; CHECK-NEXT: [[TMP77:%.*]] = insertelement <2 x i8> poison, i8 [[TMP57]], i32 0
-; CHECK-NEXT: [[TMP78:%.*]] = insertelement <2 x i8> [[TMP77]], i8 [[TMP56]], i32 1
-; CHECK-NEXT: [[TMP79:%.*]] = zext <2 x i8> [[TMP78]] to <2 x i32>
-; CHECK-NEXT: [[TMP80:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> getelementptr (i8, <2 x ptr> zeroinitializer, <2 x i64> <i64 7, i64 5>), i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP81:%.*]] = zext <2 x i8> [[TMP80]] to <2 x i32>
-; CHECK-NEXT: [[TMP82:%.*]] = sub <2 x i32> [[TMP79]], [[TMP81]]
-; CHECK-NEXT: [[TMP83:%.*]] = shl <2 x i32> [[TMP82]], <i32 16, i32 16>
-; CHECK-NEXT: [[TMP84:%.*]] = add <2 x i32> [[TMP83]], [[TMP76]]
-; CHECK-NEXT: [[TMP85:%.*]] = sub <2 x i32> [[TMP71]], [[TMP84]]
-; CHECK-NEXT: [[TMP86:%.*]] = shufflevector <2 x i32> [[TMP84]], <2 x i32> [[TMP52]], <2 x i32> <i32 1, i32 2>
-; CHECK-NEXT: [[TMP87:%.*]] = shufflevector <2 x i32> [[TMP71]], <2 x i32> [[TMP36]], <2 x i32> <i32 1, i32 2>
-; CHECK-NEXT: [[TMP88:%.*]] = add <2 x i32> [[TMP86]], [[TMP87]]
-; CHECK-NEXT: [[TMP89:%.*]] = shufflevector <2 x i32> [[TMP84]], <2 x i32> [[TMP52]], <2 x i32> <i32 0, i32 3>
-; CHECK-NEXT: [[TMP90:%.*]] = shufflevector <2 x i32> [[TMP71]], <2 x i32> [[TMP36]], <2 x i32> <i32 0, i32 3>
-; CHECK-NEXT: [[TMP91:%.*]] = add <2 x i32> [[TMP89]], [[TMP90]]
-; CHECK-NEXT: [[TMP92:%.*]] = add <2 x i32> [[TMP91]], [[TMP88]]
-; CHECK-NEXT: [[TMP93:%.*]] = sub <2 x i32> [[TMP88]], [[TMP91]]
-; CHECK-NEXT: [[TMP94:%.*]] = extractelement <2 x i32> [[TMP85]], i32 0
-; CHECK-NEXT: [[TMP95:%.*]] = extractelement <2 x i32> [[TMP85]], i32 1
-; CHECK-NEXT: [[SUB59_3:%.*]] = sub i32 [[TMP95]], [[TMP94]]
-; CHECK-NEXT: [[TMP96:%.*]] = extractelement <2 x i32> [[TMP92]], i32 0
-; CHECK-NEXT: [[TMP97:%.*]] = extractelement <2 x i32> [[TMP92]], i32 1
-; CHECK-NEXT: [[ADD94:%.*]] = add i32 [[TMP96]], [[TMP97]]
-; CHECK-NEXT: [[SUB102:%.*]] = sub i32 [[TMP97]], [[TMP96]]
-; CHECK-NEXT: [[TMP98:%.*]] = extractelement <2 x i32> [[TMP60]], i32 1
-; CHECK-NEXT: [[SHR_I:%.*]] = lshr i32 [[TMP98]], 15
+; CHECK-NEXT: [[TMP71:%.*]] = add <2 x i32> [[TMP70]], [[TMP63]]
+; CHECK-NEXT: [[TMP72:%.*]] = add <2 x i32> [[TMP71]], [[TMP58]]
+; CHECK-NEXT: [[TMP73:%.*]] = sub <2 x i32> [[TMP58]], [[TMP71]]
+; CHECK-NEXT: [[TMP74:%.*]] = extractelement <2 x i32> [[TMP72]], i32 0
+; CHECK-NEXT: [[TMP75:%.*]] = extractelement <2 x i32> [[TMP72]], i32 1
+; CHECK-NEXT: [[ADD48_3:%.*]] = add i32 [[TMP74]], [[TMP75]]
+; CHECK-NEXT: [[ADD94:%.*]] = add i32 [[ADD48_3]], [[ADD48_2]]
+; CHECK-NEXT: [[SUB102:%.*]] = sub i32 [[ADD48_2]], [[ADD48_3]]
+; CHECK-NEXT: [[TMP76:%.*]] = extractelement <2 x i32> [[TMP47]], i32 1
+; CHECK-NEXT: [[SHR_I:%.*]] = lshr i32 [[TMP76]], 15
; CHECK-NEXT: [[AND_I:%.*]] = and i32 [[SHR_I]], 65537
; CHECK-NEXT: [[MUL_I:%.*]] = mul i32 [[AND_I]], 65535
-; CHECK-NEXT: [[TMP99:%.*]] = extractelement <2 x i32> [[TMP91]], i32 1
-; CHECK-NEXT: [[SHR_I49:%.*]] = lshr i32 [[TMP99]], 15
+; CHECK-NEXT: [[SHR_I49:%.*]] = lshr i32 [[ADD46_2]], 15
; CHECK-NEXT: [[AND_I50:%.*]] = and i32 [[SHR_I49]], 65537
; CHECK-NEXT: [[MUL_I51:%.*]] = mul i32 [[AND_I50]], 65535
-; CHECK-NEXT: [[TMP100:%.*]] = extractelement <2 x i32> [[TMP93]], i32 0
-; CHECK-NEXT: [[TMP101:%.*]] = extractelement <2 x i32> [[TMP93]], i32 1
-; CHECK-NEXT: [[ADD94_2:%.*]] = add i32 [[TMP100]], [[TMP101]]
-; CHECK-NEXT: [[TMP102:%.*]] = load <2 x i8>, ptr [[ARRAYIDX20]], align 1
-; CHECK-NEXT: [[TMP103:%.*]] = zext <2 x i8> [[TMP102]] to <2 x i32>
-; CHECK-NEXT: [[TMP104:%.*]] = insertelement <2 x i32> poison, i32 [[SUB59_2]], i32 0
-; CHECK-NEXT: [[TMP105:%.*]] = shufflevector <2 x i32> [[TMP104]], <2 x i32> poison, <2 x i32> zeroinitializer
-; CHECK-NEXT: [[TMP106:%.*]] = insertelement <2 x i32> poison, i32 [[SUB59_3]], i32 0
-; CHECK-NEXT: [[TMP107:%.*]] = shufflevector <2 x i32> [[TMP106]], <2 x i32> poison, <2 x i32> zeroinitializer
-; CHECK-NEXT: [[TMP108:%.*]] = add <2 x i32> [[TMP105]], [[TMP107]]
-; CHECK-NEXT: [[TMP109:%.*]] = sub <2 x i32> [[TMP105]], [[TMP107]]
-; CHECK-NEXT: [[TMP110:%.*]] = shufflevector <2 x i32> [[TMP108]], <2 x i32> [[TMP109]], <2 x i32> <i32 0, i32 3>
-; CHECK-NEXT: [[TMP111:%.*]] = load <2 x i8>, ptr [[PIX1]], align 1
-; CHECK-NEXT: [[TMP112:%.*]] = zext <2 x i8> [[TMP111]] to <2 x i32>
-; CHECK-NEXT: [[TMP113:%.*]] = shufflevector <2 x i32> [[TMP112]], <2 x i32> poison, <2 x i32> <i32 1, i32 0>
-; CHECK-NEXT: [[TMP114:%.*]] = insertelement <2 x ptr> [[TMP4]], ptr [[ARRAYIDX22]], i32 1
-; CHECK-NEXT: [[TMP115:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP114]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP116:%.*]] = zext <2 x i8> [[TMP115]] to <2 x i32>
-; CHECK-NEXT: [[TMP117:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP2]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP77:%.*]] = extractelement <2 x i32> [[TMP16]], i32 0
+; CHECK-NEXT: [[SHR_I49_1:%.*]] = lshr i32 [[TMP77]], 15
+; CHECK-NEXT: [[AND_I50_1:%.*]] = and i32 [[SHR_I49_1]], 65537
+; CHECK-NEXT: [[MUL_I51_1:%.*]] = mul i32 [[AND_I50_1]], 65535
+; CHECK-NEXT: [[SHR_I49_2:%.*]] = lshr i32 [[CONV_1]], 15
+; CHECK-NEXT: [[AND_I50_2:%.*]] = and i32 [[SHR_I49_2]], 65537
+; CHECK-NEXT: [[MUL_I51_2:%.*]] = mul i32 [[AND_I50_2]], 65535
+; CHECK-NEXT: [[SHR_I49_3:%.*]] = lshr i32 [[CONV]], 15
+; CHECK-NEXT: [[AND_I50_3:%.*]] = and i32 [[SHR_I49_3]], 65537
+; CHECK-NEXT: [[MUL_I51_3:%.*]] = mul i32 [[AND_I50_3]], 65535
+; CHECK-NEXT: [[TMP78:%.*]] = load <2 x i8>, ptr [[ARRAYIDX8]], align 1
+; CHECK-NEXT: [[TMP79:%.*]] = zext <2 x i8> [[TMP78]] to <2 x i32>
+; CHECK-NEXT: [[TMP80:%.*]] = insertelement <2 x ptr> [[TMP5]], ptr [[ARRAYIDX22]], i32 1
+; CHECK-NEXT: [[TMP81:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP80]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP82:%.*]] = zext <2 x i8> [[TMP81]] to <2 x i32>
+; CHECK-NEXT: [[TMP83:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP3]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP84:%.*]] = zext <2 x i8> [[TMP83]] to <2 x i32>
+; CHECK-NEXT: [[TMP85:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP6]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP86:%.*]] = zext <2 x i8> [[TMP85]] to <2 x i32>
+; CHECK-NEXT: [[TMP87:%.*]] = sub <2 x i32> [[TMP84]], [[TMP86]]
+; CHECK-NEXT: [[TMP88:%.*]] = shl <2 x i32> [[TMP87]], <i32 16, i32 16>
+; CHECK-NEXT: [[TMP89:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP7]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP90:%.*]] = zext <2 x i8> [[TMP89]] to <2 x i32>
+; CHECK-NEXT: [[TMP91:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP8]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP92:%.*]] = zext <2 x i8> [[TMP91]] to <2 x i32>
+; CHECK-NEXT: [[TMP93:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP9]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP94:%.*]] = zext <2 x i8> [[TMP93]] to <2 x i32>
+; CHECK-NEXT: [[TMP95:%.*]] = sub <2 x i32> [[TMP92]], [[TMP94]]
+; CHECK-NEXT: [[TMP96:%.*]] = shl <2 x i32> [[TMP95]], <i32 16, i32 16>
+; CHECK-NEXT: [[TMP97:%.*]] = insertelement <2 x i32> [[TMP79]], i32 [[CONV33]], i32 1
+; CHECK-NEXT: [[TMP98:%.*]] = sub <2 x i32> [[TMP97]], [[TMP90]]
+; CHECK-NEXT: [[TMP99:%.*]] = add <2 x i32> [[TMP96]], [[TMP98]]
+; CHECK-NEXT: [[TMP100:%.*]] = insertelement <2 x i32> [[TMP79]], i32 [[CONV]], i32 0
+; CHECK-NEXT: [[TMP101:%.*]] = sub <2 x i32> [[TMP100]], [[TMP82]]
+; CHECK-NEXT: [[TMP102:%.*]] = add <2 x i32> [[TMP88]], [[TMP101]]
+; CHECK-NEXT: [[TMP103:%.*]] = shufflevector <2 x i32> [[TMP99]], <2 x i32> [[TMP102]], <2 x i32> <i32 0, i32 2>
+; CHECK-NEXT: [[TMP104:%.*]] = add <2 x i32> [[TMP99]], [[TMP102]]
+; CHECK-NEXT: [[TMP105:%.*]] = sub <2 x i32> [[TMP102]], [[TMP99]]
+; CHECK-NEXT: [[TMP106:%.*]] = extractelement <2 x i32> [[TMP104]], i32 0
+; CHECK-NEXT: [[TMP107:%.*]] = extractelement <2 x i32> [[TMP104]], i32 1
+; CHECK-NEXT: [[ADD48:%.*]] = add i32 [[TMP107]], [[TMP106]]
+; CHECK-NEXT: [[TMP108:%.*]] = extractelement <2 x i32> [[TMP105]], i32 1
+; CHECK-NEXT: [[SHR_I59:%.*]] = lshr i32 [[TMP107]], 15
+; CHECK-NEXT: [[AND_I60:%.*]] = and i32 [[SHR_I59]], 65537
+; CHECK-NEXT: [[MUL_I61:%.*]] = mul i32 [[AND_I60]], 65535
+; CHECK-NEXT: [[SHR_I59_1:%.*]] = lshr i32 [[TMP108]], 15
+; CHECK-NEXT: [[AND_I60_1:%.*]] = and i32 [[SHR_I59_1]], 65537
+; CHECK-NEXT: [[MUL_I61_1:%.*]] = mul i32 [[AND_I60_1]], 65535
+; CHECK-NEXT: [[TMP109:%.*]] = load <2 x i8>, ptr [[ARRAYIDX8_1]], align 1
+; CHECK-NEXT: [[TMP110:%.*]] = zext <2 x i8> [[TMP109]] to <2 x i32>
+; CHECK-NEXT: [[TMP111:%.*]] = insertelement <2 x i8> poison, i8 [[TMP12]], i32 0
+; CHECK-NEXT: [[TMP112:%.*]] = insertelement <2 x i8> [[TMP111]], i8 [[TMP13]], i32 1
+; CHECK-NEXT: [[TMP113:%.*]] = zext <2 x i8> [[TMP112]] to <2 x i32>
+; CHECK-NEXT: [[TMP114:%.*]] = insertelement <2 x ptr> poison, ptr [[ADD_PTR3]], i32 0
+; CHECK-NEXT: [[TMP115:%.*]] = shufflevector <2 x ptr> [[TMP114]], <2 x ptr> poison, <2 x i32> zeroinitializer
+; CHECK-NEXT: [[TMP116:%.*]] = getelementptr i8, <2 x ptr> [[TMP115]], <2 x i64> <i64 4, i64 6>
+; CHECK-NEXT: [[TMP117:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP116]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
; CHECK-NEXT: [[TMP118:%.*]] = zext <2 x i8> [[TMP117]] to <2 x i32>
-; CHECK-NEXT: [[TMP119:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP5]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP120:%.*]] = zext <2 x i8> [[TMP119]] to <2 x i32>
-; CHECK-NEXT: [[TMP121:%.*]] = sub <2 x i32> [[TMP118]], [[TMP120]]
-; CHECK-NEXT: [[TMP122:%.*]] = shl <2 x i32> [[TMP121]], <i32 16, i32 16>
-; CHECK-NEXT: [[TMP123:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP6]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP124:%.*]] = zext <2 x i8> [[TMP123]] to <2 x i32>
-; CHECK-NEXT: [[TMP125:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP7]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP126:%.*]] = zext <2 x i8> [[TMP125]] to <2 x i32>
-; CHECK-NEXT: [[TMP127:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP8]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP119:%.*]] = insertelement <2 x ptr> poison, ptr [[ADD_PTR644]], i32 0
+; CHECK-NEXT: [[TMP120:%.*]] = shufflevector <2 x ptr> [[TMP119]], <2 x ptr> poison, <2 x i32> zeroinitializer
+; CHECK-NEXT: [[TMP121:%.*]] = getelementptr i8, <2 x ptr> [[TMP120]], <2 x i64> <i64 4, i64 6>
+; CHECK-NEXT: [[TMP122:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP121]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP123:%.*]] = zext <2 x i8> [[TMP122]] to <2 x i32>
+; CHECK-NEXT: [[TMP124:%.*]] = sub <2 x i32> [[TMP118]], [[TMP123]]
+; CHECK-NEXT: [[TMP125:%.*]] = shl <2 x i32> [[TMP124]], <i32 16, i32 16>
+; CHECK-NEXT: [[TMP126:%.*]] = getelementptr i8, <2 x ptr> [[TMP120]], <2 x i64> <i64 1, i64 3>
+; CHECK-NEXT: [[TMP127:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP126]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
; CHECK-NEXT: [[TMP128:%.*]] = zext <2 x i8> [[TMP127]] to <2 x i32>
-; CHECK-NEXT: [[TMP129:%.*]] = sub <2 x i32> [[TMP126]], [[TMP128]]
-; CHECK-NEXT: [[TMP130:%.*]] = shl <2 x i32> [[TMP129]], <i32 16, i32 16>
-; CHECK-NEXT: [[TMP131:%.*]] = shufflevector <2 x i32> [[TMP112]], <2 x i32> [[TMP103]], <2 x i32> <i32 0, i32 2>
-; CHECK-NEXT: [[TMP132:%.*]] = sub <2 x i32> [[TMP131]], [[TMP116]]
-; CHECK-NEXT: [[TMP133:%.*]] = add <2 x i32> [[TMP122]], [[TMP132]]
-; CHECK-NEXT: [[TMP134:%.*]] = shufflevector <2 x i32> [[TMP113]], <2 x i32> [[TMP103]], <2 x i32> <i32 0, i32 3>
-; CHECK-NEXT: [[TMP135:%.*]] = sub <2 x i32> [[TMP134]], [[TMP124]]
-; CHECK-NEXT: [[TMP136:%.*]] = add <2 x i32> [[TMP130]], [[TMP135]]
-; CHECK-NEXT: [[TMP137:%.*]] = extractelement <2 x i32> [[TMP133]], i32 1
-; CHECK-NEXT: [[TMP138:%.*]] = extractelement <2 x i32> [[TMP136]], i32 1
-; CHECK-NEXT: [[ADD46:%.*]] = add i32 [[TMP138]], [[TMP137]]
-; CHECK-NEXT: [[TMP139:%.*]] = sub <2 x i32> [[TMP133]], [[TMP136]]
-; CHECK-NEXT: [[TMP140:%.*]] = extractelement <2 x i32> [[TMP133]], i32 0
-; CHECK-NEXT: [[TMP141:%.*]] = extractelement <2 x i32> [[TMP136]], i32 0
-; CHECK-NEXT: [[ADD44:%.*]] = add i32 [[TMP141]], [[TMP140]]
-; CHECK-NEXT: [[TMP142:%.*]] = lshr <2 x i32> [[TMP113]], <i32 15, i32 15>
-; CHECK-NEXT: [[TMP143:%.*]] = and <2 x i32> [[TMP142]], <i32 65537, i32 65537>
-; CHECK-NEXT: [[TMP144:%.*]] = mul <2 x i32> [[TMP143]], <i32 65535, i32 65535>
-; CHECK-NEXT: [[TMP145:%.*]] = extractelement <2 x i32> [[TMP139]], i32 0
-; CHECK-NEXT: [[TMP146:%.*]] = extractelement <2 x i32> [[TMP139]], i32 1
-; CHECK-NEXT: [[SUB59:%.*]] = sub i32 [[TMP145]], [[TMP146]]
-; CHECK-NEXT: [[TMP147:%.*]] = load <2 x i8>, ptr [[ARRAYIDX8_1]], align 1
-; CHECK-NEXT: [[TMP148:%.*]] = zext <2 x i8> [[TMP147]] to <2 x i32>
-; CHECK-NEXT: [[TMP149:%.*]] = insertelement <2 x i8> poison, i8 [[TMP10]], i32 0
-; CHECK-NEXT: [[TMP150:%.*]] = insertelement <2 x i8> [[TMP149]], i8 [[TMP11]], i32 1
-; CHECK-NEXT: [[TMP151:%.*]] = zext <2 x i8> [[TMP150]] to <2 x i32>
-; CHECK-NEXT: [[TMP152:%.*]] = insertelement <2 x ptr> poison, ptr [[ADD_PTR3]], i32 0
-; CHECK-NEXT: [[TMP153:%.*]] = shufflevector <2 x ptr> [[TMP152]], <2 x ptr> poison, <2 x i32> zeroinitializer
-; CHECK-NEXT: [[TMP154:%.*]] = getelementptr i8, <2 x ptr> [[TMP153]], <2 x i64> <i64 4, i64 6>
-; CHECK-NEXT: [[TMP155:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP154]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP156:%.*]] = zext <2 x i8> [[TMP155]] to <2 x i32>
-; CHECK-NEXT: [[TMP157:%.*]] = insertelement <2 x ptr> poison, ptr [[ADD_PTR644]], i32 0
-; CHECK-NEXT: [[TMP158:%.*]] = shufflevector <2 x ptr> [[TMP157]], <2 x ptr> poison, <2 x i32> zeroinitializer
-; CHECK-NEXT: [[TMP159:%.*]] = getelementptr i8, <2 x ptr> [[TMP158]], <2 x i64> <i64 4, i64 6>
-; CHECK-NEXT: [[TMP160:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP159]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP161:%.*]] = zext <2 x i8> [[TMP160]] to <2 x i32>
-; CHECK-NEXT: [[TMP162:%.*]] = sub <2 x i32> [[TMP156]], [[TMP161]]
-; CHECK-NEXT: [[TMP163:%.*]] = shl <2 x i32> [[TMP162]], <i32 16, i32 16>
-; CHECK-NEXT: [[TMP164:%.*]] = getelementptr i8, <2 x ptr> [[TMP158]], <2 x i64> <i64 1, i64 3>
-; CHECK-NEXT: [[TMP165:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP164]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP166:%.*]] = zext <2 x i8> [[TMP165]] to <2 x i32>
-; CHECK-NEXT: [[TMP167:%.*]] = getelementptr i8, <2 x ptr> [[TMP153]], <2 x i64> <i64 5, i64 7>
-; CHECK-NEXT: [[TMP168:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP167]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP169:%.*]] = zext <2 x i8> [[TMP168]] to <2 x i32>
-; CHECK-NEXT: [[TMP170:%.*]] = getelementptr i8, <2 x ptr> [[TMP158]], <2 x i64> <i64 5, i64 7>
-; CHECK-NEXT: [[TMP171:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP170]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
-; CHECK-NEXT: [[TMP172:%.*]] = zext <2 x i8> [[TMP171]] to <2 x i32>
-; CHECK-NEXT: [[TMP173:%.*]] = sub <2 x i32> [[TMP169]], [[TMP172]]
-; CHECK-NEXT: [[TMP174:%.*]] = shl <2 x i32> [[TMP173]], <i32 16, i32 16>
-; CHECK-NEXT: [[TMP175:%.*]] = insertelement <2 x i32> [[TMP148]], i32 [[CONV33_1]], i32 1
-; CHECK-NEXT: [[TMP176:%.*]] = sub <2 x i32> [[TMP175]], [[TMP166]]
-; CHECK-NEXT: [[TMP177:%.*]] = add <2 x i32> [[TMP174]], [[TMP176]]
-; CHECK-NEXT: [[TMP178:%.*]] = insertelement <2 x i32> [[TMP148]], i32 [[CONV_1]], i32 0
-; CHECK-NEXT: [[TMP179:%.*]] = sub <2 x i32> [[TMP178]], [[TMP151]]
-; CHECK-NEXT: [[TMP180:%.*]] = add <2 x i32> [[TMP163]], [[TMP179]]
-; CHECK-NEXT: [[TMP181:%.*]] = add <2 x i32> [[TMP177]], [[TMP180]]
-; CHECK-NEXT: [[TMP182:%.*]] = sub <2 x i32> [[TMP180]], [[TMP177]]
-; CHECK-NEXT: [[TMP183:%.*]] = extractelement <2 x i32> [[TMP181]], i32 0
-; CHECK-NEXT: [[TMP184:%.*]] = extractelement <2 x i32> [[TMP181]], i32 1
-; CHECK-NEXT: [[SUB51_1:%.*]] = sub i32 [[TMP183]], [[TMP184]]
-; CHECK-NEXT: [[TMP185:%.*]] = shufflevector <2 x i32> [[TMP182]], <2 x i32> [[TMP139]], <2 x i32> <i32 1, i32 3>
-; CHECK-NEXT: [[TMP186:%.*]] = shufflevector <2 x i32> [[TMP182]], <2 x i32> [[TMP139]], <2 x i32> <i32 0, i32 2>
-; CHECK-NEXT: [[TMP187:%.*]] = add <2 x i32> [[TMP185]], [[TMP186]]
-; CHECK-NEXT: [[TMP188:%.*]] = extractelement <2 x i32> [[TMP182]], i32 0
-; CHECK-NEXT: [[TMP189:%.*]] = extractelement <2 x i32> [[TMP182]], i32 1
-; CHECK-NEXT: [[SUB59_1:%.*]] = sub i32 [[TMP188]], [[TMP189]]
-; CHECK-NEXT: [[SHR_I54:%.*]] = lshr i32 [[TMP184]], 15
+; CHECK-NEXT: [[TMP129:%.*]] = getelementptr i8, <2 x ptr> [[TMP115]], <2 x i64> <i64 5, i64 7>
+; CHECK-NEXT: [[TMP130:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP129]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP131:%.*]] = zext <2 x i8> [[TMP130]] to <2 x i32>
+; CHECK-NEXT: [[TMP132:%.*]] = getelementptr i8, <2 x ptr> [[TMP120]], <2 x i64> <i64 5, i64 7>
+; CHECK-NEXT: [[TMP133:%.*]] = call <2 x i8> @llvm.masked.gather.v2i8.v2p0(<2 x ptr> [[TMP132]], i32 1, <2 x i1> <i1 true, i1 true>, <2 x i8> poison)
+; CHECK-NEXT: [[TMP134:%.*]] = zext <2 x i8> [[TMP133]] to <2 x i32>
+; CHECK-NEXT: [[TMP135:%.*]] = sub <2 x i32> [[TMP131]], [[TMP134]]
+; CHECK-NEXT: [[TMP136:%.*]] = shl <2 x i32> [[TMP135]], <i32 16, i32 16>
+; CHECK-NEXT: [[TMP137:%.*]] = insertelement <2 x i32> [[TMP110]], i32 [[CONV33_1]], i32 1
+; CHECK-NEXT: [[TMP138:%.*]] = sub <2 x i32> [[TMP137]], [[TMP128]]
+; CHECK-NEXT: [[TMP139:%.*]] = add <2 x i32> [[TMP136]], [[TMP138]]
+; CHECK-NEXT: [[TMP140:%.*]] = insertelement <2 x i32> [[TMP110]], i32 [[CONV_1]], i32 0
+; CHECK-NEXT: [[TMP141:%.*]] = sub <2 x i32> [[TMP140]], [[TMP113]]
+; CHECK-NEXT: [[TMP142:%.*]] = add <2 x i32> [[TMP125]], [[TMP141]]
+; CHECK-NEXT: [[TMP143:%.*]] = add <2 x i32> [[TMP139]], [[TMP142]]
+; CHECK-NEXT: [[TMP144:%.*]] = sub <2 x i32> [[TMP142]], [[TMP139]]
+; CHECK-NEXT: [[TMP145:%.*]] = extractelement <2 x i32> [[TMP143]], i32 0
+; CHECK-NEXT: [[TMP146:%.*]] = extractelement <2 x i32> [[TMP143]], i32 1
+; CHECK-NEXT: [[ADD48_1:%.*]] = add i32 [[TMP146]], [[TMP145]]
+; CHECK-NEXT: [[SHR_I54:%.*]] = lshr i32 [[TMP146]], 15
; CHECK-NEXT: [[AND_I55:%.*]] = and i32 [[SHR_I54]], 65537
; CHECK-NEXT: [[MUL_I56:%.*]] = mul i32 [[AND_I55]], 65535
-; CHECK-NEXT: [[TMP190:%.*]] = lshr <2 x i32> [[TMP148]], <i32 15, i32 15>
-; CHECK-NEXT: [[TMP191:%.*]] = and <2 x i32> [[TMP190]], <i32 65537, i32 65537>
-; CHECK-NEXT: [[TMP192:%.*]] = mul <2 x i32> [[TMP191]], <i32 65535, i32 65535>
-; CHECK-NEXT: [[TMP193:%.*]] = insertelement <2 x i32> poison, i32 [[SUB59_1]], i32 0
-; CHECK-NEXT: [[TMP194:%.*]] = shufflevector <2 x i32> [[TMP193]], <2 x i32> poison, <2 x i32> zeroinitializer
-; CHECK-NEXT: [[TMP195:%.*]] = extractelement <2 x i32> [[TMP187]], i32 0
-; CHECK-NEXT: [[TMP196:%.*]] = extractelement <2 x i32> [[TMP187]], i32 1
-; CHECK-NEXT: [[ADD78_1:%.*]] = add i32 [[TMP195]], [[TMP196]]
-; CHECK-NEXT: [[TMP197:%.*]] = shufflevector <2 x i32> [[TMP39]], <2 x i32> [[TMP182]], <2 x i32> <i32 0, i32 3>
-; CHECK-NEXT: [[TMP198:%.*]] = lshr <2 x i32> [[TMP197]], <i32 15, i32 15>
-; CHECK-NEXT: [[TMP199:%.*]] = and <2 x i32> [[TMP198]], <i32 65537, i32 65537>
-; CHECK-NEXT: [[TMP200:%.*]] = mul <2 x i32> [[TMP199]], <i32 65535, i32 65535>
-; CHECK-NEXT: [[TMP201:%.*]] = insertelement <2 x i32> poison, i32 [[ADD78_1]], i32 0
-; CHECK-NEXT: [[TMP202:%.*]] = shufflevector <2 x i32> [[TMP201]], <2 x i32> poison, <2 x i32> zeroinitializer
-; CHECK-NEXT: [[TMP203:%.*]] = insertelement <2 x i32> poison, i32 [[ADD94_2]], i32 0
-; CHECK-NEXT: [[TMP204:%.*]] = shufflevector <2 x i32> [[TMP203]], <2 x i32> poison, <2 x i32> zeroinitializer
-; CHECK-NEXT: [[TMP205:%.*]] = insertelement <2 x i32> poison, i32 [[ADD44]], i32 0
-; CHECK-NEXT: [[TMP206:%.*]] = shufflevector <2 x i32> [[TMP205]], <2 x i32> poison, <2 x i32> zeroinitializer
-; CHECK-NEXT: [[TMP207:%.*]] = insertelement <2 x i32> <i32 15, i32 poison>, i32 [[ADD46]], i32 1
-; CHECK-NEXT: [[TMP208:%.*]] = lshr <2 x i32> [[TMP206]], [[TMP207]]
-; CHECK-NEXT: [[TMP209:%.*]] = sub <2 x i32> [[TMP206]], [[TMP207]]
-; CHECK-NEXT: [[TMP210:%.*]] = shufflevector <2 x i32> [[TMP208]], <2 x i32> [[TMP209]], <2 x i32> <i32 0, i32 3>
-; CHECK-NEXT: [[TMP211:%.*]] = extractelement <2 x i32> [[TMP210]], i32 1
-; CHECK-NEXT: [[ADD78_2:%.*]] = add i32 [[SUB51_1]], [[TMP211]]
-; CHECK-NEXT: [[TMP212:%.*]] = insertelement <2 x i32> <i32 65537, i32 poison>, i32 [[SUB51_1]], i32 1
-; CHECK-NEXT: [[TMP213:%.*]] = and <2 x i32> [[TMP210]], [[TMP212]]
-; CHECK-NEXT: [[TMP214:%.*]] = sub <2 x i32> [[TMP210]], [[TMP212]]
-; CHECK-NEXT: [[TMP215:%.*]] = shufflevector <2 x i32> [[TMP213]], <2 x i32> [[TMP214]], <2 x i32> <i32 0, i32 3>
-; CHECK-NEXT: [[TMP216:%.*]] = insertelement <2 x i32> poison, i32 [[ADD78_2]], i32 0
-; CHECK-NEXT: [[TMP217:%.*]] = shufflevector <2 x i32> [[TMP216]], <2 x i32> poison, <2 x i32> zeroinitializer
-; CHECK-NEXT: [[TMP218:%.*]] = add <2 x i32> [[TMP217]], [[TMP204]]
-; CHECK-NEXT: [[TMP219:%.*]] = sub <2 x i32> [[TMP217]], [[TMP204]]
-; CHECK-NEXT: [[TMP220:%.*]] = shufflevector <2 x i32> [[TMP218]], <2 x i32> [[TMP219]], <2 x i32> <i32 0, i32 3>
-; CHECK-NEXT: [[TMP221:%.*]] = insertelement <2 x i32> [[TMP139]], i32 [[CONV_1]], i32 0
-; CHECK-NEXT: [[TMP222:%.*]] = lshr <2 x i32> [[TMP221]], <i32 15, i32 15>
-; CHECK-NEXT: [[TMP223:%.*]] = and <2 x i32> [[TMP222]], <i32 65537, i32 65537>
-; CHECK-NEXT: [[TMP224:%.*]] = mul <2 x i32> [[TMP223]], <i32 65535, i32 65535>
-; CHECK-NEXT: [[TMP225:%.*]] = shufflevector <2 x i32> [[TMP93]], <2 x i32> poison, <2 x i32> <i32 1, i32 poison>
-; CHECK-NEXT: [[TMP226:%.*]] = shufflevector <2 x i32> [[TMP225]], <2 x i32> [[TMP187]], <2 x i32> <i32 0, i32 3>
-; CHECK-NEXT: [[TMP227:%.*]] = shufflevector <2 x i32> [[TMP93]], <2 x i32> [[TMP187]], <2 x i32> <i32 0, i32 2>
-; CHECK-NEXT: [[TMP228:%.*]] = sub <2 x i32> [[TMP226]], [[TMP227]]
-; CHECK-NEXT: [[TMP229:%.*]] = shufflevector <2 x i32> [[TMP53]], <2 x i32> poison, <2 x i32> <i32 1, i32 poison>
-; CHECK-NEXT: [[TMP230:%.*]] = insertelement <2 x i32> [[TMP229]], i32 [[ADD46]], i32 1
-; CHECK-NEXT: [[TMP231:%.*]] = insertelement <2 x i32> [[TMP53]], i32 [[ADD44]], i32 1
-; CHECK-NEXT: [[TMP232:%.*]] = add <2 x i32> [[TMP230]], [[TMP231]]
-; CHECK-NEXT: [[TMP233:%.*]] = shufflevector <2 x i32> [[TMP85]], <2 x i32> [[TMP181]], <2 x i32> <i32 0, i32 3>
-; CHECK-NEXT: [[TMP234:%.*]] = shufflevector <2 x i32> [[TMP85]], <2 x i32> [[TMP181]], <2 x i32> <i32 1, i32 2>
-; CHECK-NEXT: [[TMP235:%.*]] = add <2 x i32> [[TMP233]], [[TMP234]]
-; CHECK-NEXT: [[TMP236:%.*]] = extractelement <2 x i32> [[TMP232]], i32 0
-; CHECK-NEXT: [[TMP237:%.*]] = extractelement <2 x i32> [[TMP235]], i32 0
-; CHECK-NEXT: [[ADD94_1:%.*]] = add i32 [[TMP237]], [[TMP236]]
-; CHECK-NEXT: [[TMP238:%.*]] = insertelement <2 x i32> [[TMP19]], i32 [[ADD46]], i32 1
-; CHECK-NEXT: [[TMP239:%.*]] = lshr <2 x i32> [[TMP238]], <i32 15, i32 15>
-; CHECK-NEXT: [[TMP240:%.*]] = and <2 x i32> [[TMP239]], <i32 65537, i32 65537>
-; CHECK-NEXT: [[TMP241:%.*]] = mul <2 x i32> [[TMP240]], <i32 65535, i32 65535>
-; CHECK-NEXT: [[TMP242:%.*]] = extractelement <2 x i32> [[TMP232]], i32 1
-; CHECK-NEXT: [[TMP243:%.*]] = extractelement <2 x i32> [[TMP235]], i32 1
-; CHECK-NEXT: [[ADD78:%.*]] = add i32 [[TMP243]], [[TMP242]]
-; CHECK-NEXT: [[TMP244:%.*]] = sub <2 x i32> [[TMP232]], [[TMP235]]
+; CHECK-NEXT: [[TMP147:%.*]] = lshr <2 x i32> [[TMP110]], <i32 15, i32 15>
+; CHECK-NEXT: [[TMP148:%.*]] = and <2 x i32> [[TMP147]], <i32 65537, i32 65537>
+; CHECK-NEXT: [[TMP149:%.*]] = mul <2 x i32> [[TMP148]], <i32 65535, i32 65535>
+; CHECK-NEXT: [[ADD78:%.*]] = add i32 [[ADD48_1]], [[ADD48]]
+; CHECK-NEXT: [[SUB86:%.*]] = sub i32 [[ADD48]], [[ADD48_1]]
; CHECK-NEXT: [[ADD103:%.*]] = add i32 [[ADD94]], [[ADD78]]
; CHECK-NEXT: [[SUB104:%.*]] = sub i32 [[ADD78]], [[ADD94]]
-; CHECK-NEXT: [[TMP245:%.*]] = extractelement <2 x i32> [[TMP244]], i32 1
-; CHECK-NEXT: [[ADD105:%.*]] = add i32 [[SUB102]], [[TMP245]]
+; CHECK-NEXT: [[ADD105:%.*]] = add i32 [[SUB102]], [[SUB86]]
+; CHECK-NEXT: [[SUB106:%.*]] = sub i32 [[SUB86]], [[SUB102]]
; CHECK-NEXT: [[ADD_I:%.*]] = add i32 [[MUL_I]], [[ADD103]]
-; CHECK-NEXT: [[XOR_I:%.*]] = xor i32 [[ADD_I]], [[TMP98]]
+; CHECK-NEXT: [[XOR_I:%.*]] = xor i32 [[ADD_I]], [[TMP76]]
; CHECK-NEXT: [[ADD_I52:%.*]] = add i32 [[MUL_I51]], [[ADD105]]
-; CHECK-NEXT: [[XOR_I53:%.*]] = xor i32 [[ADD_I52]], [[TMP99]]
+; CHECK-NEXT: [[XOR_I53:%.*]] = xor i32 [[ADD_I52]], [[ADD46_2]]
; CHECK-NEXT: [[ADD_I57:%.*]] = add i32 [[MUL_I56]], [[SUB104]]
-; CHECK-NEXT: [[XOR_I58:%.*]] = xor i32 [[ADD_I57]], [[TMP184]]
+; CHECK-NEXT: [[XOR_I58:%.*]] = xor i32 [[ADD_I57]], [[TMP146]]
+; CHECK-NEXT: [[ADD_I62:%.*]] = add i32 [[MUL_I61]], [[SUB106]]
+; CHECK-NEXT: [[XOR_I63:%.*]] = xor i32 [[ADD_I62]], [[TMP107]]
; CHECK-NEXT: [[ADD110:%.*]] = add i32 [[XOR_I53]], [[XOR_I]]
; CHECK-NEXT: [[ADD112:%.*]] = add i32 [[ADD110]], [[XOR_I58]]
-; CHECK-NEXT: [[TMP246:%.*]] = shufflevector <2 x i32> [[TMP228]], <2 x i32> poison, <2 x i32> <i32 1, i32 poison>
-; CHECK-NEXT: [[TMP247:%.*]] = insertelement <2 x i32> [[TMP246]], i32 [[SUB102]], i32 1
-; CHECK-NEXT: [[TMP248:%.*]] = add <2 x i32> [[TMP244]], [[TMP247]]
-; CHECK-NEXT: [[TMP249:%.*]] = sub <2 x i32> [[TMP244]], [[TMP247]]
-; CHECK-NEXT: [[TMP250:%.*]] = shufflevector <2 x i32> [[TMP248]], <2 x i32> [[TMP249]], <2 x i32> <i32 0, i32 3>
-; CHECK-NEXT: [[TMP251:%.*]] = add <2 x i32> [[TMP241]], [[TMP250]]
-; CHECK-NEXT: [[TMP252:%.*]] = xor <2 x i32> [[TMP251]], [[TMP238]]
-; CHECK-NEXT: [[TMP253:%.*]] = extractelement <2 x i32> [[TMP252]], i32 1
-; CHECK-NEXT: [[ADD113:%.*]] = add i32 [[ADD112]], [[TMP253]]
-; CHECK-NEXT: [[TMP254:%.*]] = insertelement <2 x i32> poison, i32 [[ADD94_1]], i32 0
-; CHECK-NEXT: [[TMP255:%.*]] = shufflevector <2 x i32> [[TMP254]], <2 x i32> poison, <2 x i32> zeroinitializer
-; CHECK-NEXT: [[TMP256:%.*]] = add <2 x i32> [[TMP202]], [[TMP255]]
-; CHECK-NEXT: [[TMP257:%.*]] = sub <2 x i32> [[TMP202]], [[TMP255]]
-; CHECK-NEXT: [[TMP258:%.*]] = shufflevector <2 x i32> [[TMP256]], <2 x i32> [[TMP257]], <2 x i32> <i32 0, i32 3>
-; CHECK-NEXT: [[TMP259:%.*]] = add <2 x i32> [[TMP200]], [[TMP258]]
-; CHECK-NEXT: [[TMP260:%.*]] = xor <2 x i32> [[TMP259]], [[TMP197]]
-; CHECK-NEXT: [[TMP261:%.*]] = extractelement <2 x i32> [[TMP252]], i32 0
-; CHECK-NEXT: [[ADD108_1:%.*]] = add i32 [[TMP261]], [[ADD113]]
-; CHECK-NEXT: [[TMP262:%.*]] = extractelement <2 x i32> [[TMP260]], i32 0
-; CHECK-NEXT: [[ADD110_1:%.*]] = add i32 [[ADD108_1]], [[TMP262]]
-; CHECK-NEXT: [[TMP263:%.*]] = extractelement <2 x i32> [[TMP260]], i32 1
-; CHECK-NEXT: [[ADD112_1:%.*]] = add i32 [[ADD110_1]], [[TMP263]]
-; CHECK-NEXT: [[TMP264:%.*]] = shufflevector <2 x i32> [[TMP215]], <2 x i32> poison, <2 x i32> <i32 1, i32 poison>
-; CHECK-NEXT: [[TMP265:%.*]] = shufflevector <2 x i32> [[TMP264]], <2 x i32> [[TMP244]], <2 x i32> <i32 0, i32 2>
-; CHECK-NEXT: [[TMP266:%.*]] = add <2 x i32> [[TMP228]], [[TMP265]]
-; CHECK-NEXT: [[TMP267:%.*]] = sub <2 x i32> [[TMP228]], [[TMP265]]
-; CHECK-NEXT: [[TMP268:%.*]] = shufflevector <2 x i32> [[TMP266]], <2 x i32> [[TMP267]], <2 x i32> <i32 0, i32 3>
-; CHECK-NEXT: [[TMP269:%.*]] = add <2 x i32> [[TMP224]], [[TMP268]]
-; CHECK-NEXT: [[TMP270:%.*]] = xor <2 x i32> [[TMP269]], [[TMP221]]
-; CHECK-NEXT: [[TMP271:%.*]] = extractelement <2 x i32> [[TMP270]], i32 1
-; CHECK-NEXT: [[ADD113_1:%.*]] = add i32 [[ADD112_1]], [[TMP271]]
-; CHECK-NEXT: [[TMP272:%.*]] = shufflevector <2 x i32> <i32 65535, i32 poison>, <2 x i32> [[TMP228]], <2 x i32> <i32 0, i32 2>
-; CHECK-NEXT: [[TMP273:%.*]] = mul <2 x i32> [[TMP215]], [[TMP272]]
-; CHECK-NEXT: [[TMP274:%.*]] = sub <2 x i32> [[TMP215]], [[TMP272]]
-; CHECK-NEXT: [[TMP275:%.*]] = shufflevector <2 x i32> [[TMP273]], <2 x i32> [[TMP274]], <2 x i32> <i32 0, i32 3>
-; CHECK-NEXT: [[TMP276:%.*]] = add <2 x i32> [[TMP192]], [[TMP220]]
-; CHECK-NEXT: [[TMP277:%.*]] = xor <2 x i32> [[TMP276]], [[TMP148]]
-; CHECK-NEXT: [[TMP278:%.*]] = extractelement <2 x i32> [[TMP275]], i32 0
-; CHECK-NEXT: [[TMP279:%.*]] = extractelement <2 x i32> [[TMP275]], i32 1
-; CHECK-NEXT: [[ADD_I62_2:%.*]] = add i32 [[TMP278]], [[TMP279]]
-; CHECK-NEXT: [[XOR_I63_2:%.*]] = xor i32 [[ADD_I62_2]], [[ADD44]]
-; CHECK-NEXT: [[TMP280:%.*]] = extractelement <2 x i32> [[TMP270]], i32 0
-; CHECK-NEXT: [[ADD108_2:%.*]] = add i32 [[TMP280]], [[ADD113_1]]
-; CHECK-NEXT: [[TMP281:%.*]] = extractelement <2 x i32> [[TMP277]], i32 0
-; CHECK-NEXT: [[ADD110_2:%.*]] = add i32 [[ADD108_2]], [[TMP281]]
-; CHECK-NEXT: [[TMP282:%.*]] = extractelement <2 x i32> [[TMP277]], i32 1
-; CHECK-NEXT: [[ADD112_2:%.*]] = add i32 [[ADD110_2]], [[TMP282]]
+; CHECK-NEXT: [[ADD113:%.*]] = add i32 [[ADD112]], [[XOR_I63]]
+; CHECK-NEXT: [[TMP150:%.*]] = shufflevector <2 x i32> [[TMP105]], <2 x i32> poison, <2 x i32> <i32 1, i32 0>
+; CHECK-NEXT: [[TMP151:%.*]] = insertelement <2 x i32> [[TMP150]], i32 [[SUB47_2]], i32 1
+; CHECK-NEXT: [[TMP152:%.*]] = insertelement <2 x i32> [[TMP105]], i32 [[SUB45_2]], i32 1
+; CHECK-NEXT: [[TMP153:%.*]] = add <2 x i32> [[TMP151]], [[TMP152]]
+; CHECK-NEXT: [[TMP154:%.*]] = shufflevector <2 x i32> [[TMP144]], <2 x i32> [[TMP73]], <2 x i32> <i32 1, i32 2>
+; CHECK-NEXT: [[TMP155:%.*]] = shufflevector <2 x i32> [[TMP144]], <2 x i32> [[TMP73]], <2 x i32> <i32 0, i32 3>
+; CHECK-NEXT: [[TMP156:%.*]] = add <2 x i32> [[TMP154]], [[TMP155]]
+; CHECK-NEXT: [[TMP157:%.*]] = extractelement <2 x i32> [[TMP153]], i32 1
+; CHECK-NEXT: [[TMP158:%.*]] = extractelement <2 x i32> [[TMP156]], i32 1
+; CHECK-NEXT: [[TMP159:%.*]] = shufflevector <2 x i32> [[TMP156]], <2 x i32> [[TMP153]], <2 x i32> <i32 1, i32 3>
+; CHECK-NEXT: [[ADD94_1:%.*]] = add i32 [[TMP158]], [[TMP157]]
+; CHECK-NEXT: [[TMP160:%.*]] = extractelement <2 x i32> [[TMP153]], i32 0
+; CHECK-NEXT: [[TMP161:%.*]] = extractelement <2 x i32> [[TMP156]], i32 0
+; CHECK-NEXT: [[TMP162:%.*]] = shufflevector <2 x i32> [[TMP156]], <2 x i32> [[TMP153]], <2 x i32> <i32 0, i32 2>
+; CHECK-NEXT: [[ADD78_1:%.*]] = add i32 [[TMP161]], [[TMP160]]
+; CHECK-NEXT: [[TMP163:%.*]] = sub <2 x i32> [[TMP153]], [[TMP156]]
+; CHECK-NEXT: [[TMP164:%.*]] = extractelement <2 x i32> [[TMP163]], i32 0
+; CHECK-NEXT: [[TMP165:%.*]] = extractelement <2 x i32> [[TMP163]], i32 1
+; CHECK-NEXT: [[ADD105_1:%.*]] = add i32 [[TMP165]], [[TMP164]]
+; CHECK-NEXT: [[SUB106_1:%.*]] = sub i32 [[TMP164]], [[TMP165]]
+; CHECK-NEXT: [[ADD_I52_1:%.*]] = add i32 [[MUL_I51_1]], [[ADD105_1]]
+; CHECK-NEXT: [[XOR_I53_1:%.*]] = xor i32 [[ADD_I52_1]], [[TMP77]]
+; CHECK-NEXT: [[TMP166:%.*]] = shufflevector <2 x i32> [[TMP16]], <2 x i32> [[TMP144]], <2 x i32> <i32 1, i32 3>
+; CHECK-NEXT: [[TMP167:%.*]] = lshr <2 x i32> [[TMP166]], <i32 15, i32 15>
+; CHECK-NEXT: [[TMP168:%.*]] = and <2 x i32> [[TMP167]], <i32 65537, i32 65537>
+; CHECK-NEXT: [[TMP169:%.*]] = mul <2 x i32> [[TMP168]], <i32 65535, i32 65535>
+; CHECK-NEXT: [[TMP170:%.*]] = insertelement <2 x i32> poison, i32 [[ADD78_1]], i32 0
+; CHECK-NEXT: [[TMP171:%.*]] = shufflevector <2 x i32> [[TMP170]], <2 x i32> poison, <2 x i32> zeroinitializer
+; CHECK-NEXT: [[TMP172:%.*]] = insertelement <2 x i32> poison, i32 [[ADD94_1]], i32 0
+; CHECK-NEXT: [[TMP173:%.*]] = shufflevector <2 x i32> [[TMP172]], <2 x i32> poison, <2 x i32> zeroinitializer
+; CHECK-NEXT: [[TMP174:%.*]] = add <2 x i32> [[TMP171]], [[TMP173]]
+; CHECK-NEXT: [[TMP175:%.*]] = sub <2 x i32> [[TMP171]], [[TMP173]]
+; CHECK-NEXT: [[TMP176:%.*]] = shufflevector <2 x i32> [[TMP174]], <2 x i32> [[TMP175]], <2 x i32> <i32 0, i32 3>
+; CHECK-NEXT: [[TMP177:%.*]] = add <2 x i32> [[TMP169]], [[TMP176]]
+; CHECK-NEXT: [[TMP178:%.*]] = xor <2 x i32> [[TMP177]], [[TMP166]]
+; CHECK-NEXT: [[ADD_I62_1:%.*]] = add i32 [[MUL_I61_1]], [[SUB106_1]]
+; CHECK-NEXT: [[XOR_I63_1:%.*]] = xor i32 [[ADD_I62_1]], [[TMP108]]
+; CHECK-NEXT: [[ADD108_1:%.*]] = add i32 [[XOR_I53_1]], [[ADD113]]
+; CHECK-NEXT: [[TMP179:%.*]] = extractelement <2 x i32> [[TMP178]], i32 0
+; CHECK-NEXT: [[ADD110_1:%.*]] = add i32 [[ADD108_1]], [[TMP179]]
+; CHECK-NEXT: [[TMP180:%.*]] = extractelement <2 x i32> [[TMP178]], i32 1
+; CHECK-NEXT: [[ADD112_1:%.*]] = add i32 [[ADD110_1]], [[TMP180]]
+; CHECK-NEXT: [[ADD113_1:%.*]] = add i32 [[ADD112_1]], [[XOR_I63_1]]
+; CHECK-NEXT: [[TMP181:%.*]] = shufflevector <2 x i32> [[TMP104]], <2 x i32> poison, <2 x i32> <i32 poison, i32 0>
+; CHECK-NEXT: [[TMP182:%.*]] = insertelement <2 x i32> [[TMP181]], i32 [[ADD44_2]], i32 0
+; CHECK-NEXT: [[TMP183:%.*]] = insertelement <2 x i32> [[TMP104]], i32 [[ADD46_2]], i32 0
+; CHECK-NEXT: [[TMP184:%.*]] = sub <2 x i32> [[TMP182]], [[TMP183]]
+; CHECK-NEXT: [[TMP185:%.*]] = shufflevector <2 x i32> [[TMP72]], <2 x i32> [[TMP143]], <2 x i32> <i32 1, i32 2>
+; CHECK-NEXT: [[TMP186:%.*]] = shufflevector <2 x i32> [[TMP72]], <2 x i32> [[TMP143]], <2 x i32> <i32 0, i32 3>
+; CHECK-NEXT: [[TMP187:%.*]] = sub <2 x i32> [[TMP185]], [[TMP186]]
+; CHECK-NEXT: [[TMP188:%.*]] = extractelement <2 x i32> [[TMP184]], i32 0
+; CHECK-NEXT: [[TMP189:%.*]] = extractelement <2 x i32> [[TMP187]], i32 0
+; CHECK-NEXT: [[TMP190:%.*]] = shufflevector <2 x i32> [[TMP187]], <2 x i32> [[TMP184]], <2 x i32> <i32 0, i32 2>
+; CHECK-NEXT: [[ADD94_2:%.*]] = add i32 [[TMP189]], [[TMP188]]
+; CHECK-NEXT: [[TMP191:%.*]] = extractelement <2 x i32> [[TMP184]], i32 1
+; CHECK-NEXT: [[TMP192:%.*]] = extractelement <2 x i32> [[TMP187]], i32 1
+; CHECK-NEXT: [[TMP193:%.*]] = shufflevector <2 x i32> [[TMP187]], <2 x i32> [[TMP184]], <2 x i32> <i32 1, i32 3>
+; CHECK-NEXT: [[ADD78_2:%.*]] = add i32 [[TMP192]], [[TMP191]]
+; CHECK-NEXT: [[TMP194:%.*]] = sub <2 x i32> [[TMP184]], [[TMP187]]
+; CHECK-NEXT: [[TMP195:%.*]] = insertelement <2 x i32> poison, i32 [[ADD78_2]], i32 0
+; CHECK-NEXT: [[TMP196:%.*]] = shufflevector <2 x i32> [[TMP195]], <2 x i32> poison, <2 x i32> zeroinitializer
+; CHECK-NEXT: [[TMP197:%.*]] = insertelement <2 x i32> poison, i32 [[ADD94_2]], i32 0
+; CHECK-NEXT: [[TMP198:%.*]] = shufflevector <2 x i32> [[TMP197]], <2 x i32> poison, <2 x i32> zeroinitializer
+; CHECK-NEXT: [[TMP199:%.*]] = add <2 x i32> [[TMP196]], [[TMP198]]
+; CHECK-NEXT: [[TMP200:%.*]] = sub <2 x i32> [[TMP196]], [[TMP198]]
+; CHECK-NEXT: [[TMP201:%.*]] = shufflevector <2 x i32> [[TMP199]], <2 x i32> [[TMP200]], <2 x i32> <i32 0, i32 3>
+; CHECK-NEXT: [[TMP202:%.*]] = extractelement <2 x i32> [[TMP194]], i32 0
+; CHECK-NEXT: [[TMP203:%.*]] = extractelement <2 x i32> [[TMP194]], i32 1
+; CHECK-NEXT: [[ADD105_2:%.*]] = add i32 [[TMP202]], [[TMP203]]
+; CHECK-NEXT: [[SUB106_2:%.*]] = sub i32 [[TMP203]], [[TMP202]]
+; CHECK-NEXT: [[ADD_I52_2:%.*]] = add i32 [[MUL_I51_2]], [[ADD105_2]]
+; CHECK-NEXT: [[XOR_I53_2:%.*]] = xor i32 [[ADD_I52_2]], [[CONV_1]]
+; CHECK-NEXT: [[TMP204:%.*]] = add <2 x i32> [[TMP149]], [[TMP201]]
+; CHECK-NEXT: [[TMP205:%.*]] = xor <2 x i32> [[TMP204]], [[TMP110]]
+; CHECK-NEXT: [[SHR_I59_2:%.*]] = lshr i32 [[TMP106]], 15
+; CHECK-NEXT: [[AND_I60_2:%.*]] = and i32 [[SHR_I59_2]], 65537
+; CHECK-NEXT: [[MUL_I61_2:%.*]] = mul i32 [[AND_I60_2]], 65535
+; CHECK-NEXT: [[ADD_I62_2:%.*]] = add i32 [[MUL_I61_2]], [[SUB106_2]]
+; CHECK-NEXT: [[XOR_I63_2:%.*]] = xor i32 [[ADD_I62_2]], [[TMP106]]
+; CHECK-NEXT: [[ADD108_2:%.*]] = add i32 [[XOR_I53_2]], [[ADD113_1]]
+; CHECK-NEXT: [[TMP206:%.*]] = extractelement <2 x i32> [[TMP205]], i32 0
+; CHECK-NEXT: [[ADD110_2:%.*]] = add i32 [[ADD108_2]], [[TMP206]]
+; CHECK-NEXT: [[TMP207:%.*]] = extractelement <2 x i32> [[TMP205]], i32 1
+; CHECK-NEXT: [[ADD112_2:%.*]] = add i32 [[ADD110_2]], [[TMP207]]
; CHECK-NEXT: [[ADD113_2:%.*]] = add i32 [[ADD112_2]], [[XOR_I63_2]]
-; CHECK-NEXT: [[TMP283:%.*]] = insertelement <2 x i32> poison, i32 [[SUB59]], i32 0
-; CHECK-NEXT: [[TMP284:%.*]] = shufflevector <2 x i32> [[TMP283]], <2 x i32> poison, <2 x i32> zeroinitializer
-; CHECK-NEXT: [[TMP285:%.*]] = add <2 x i32> [[TMP284]], [[TMP194]]
-; CHECK-NEXT: [[TMP286:%.*]] = sub <2 x i32> [[TMP284]], [[TMP194]]
-; CHECK-NEXT: [[TMP287:%.*]] = shufflevector <2 x i32> [[TMP285]], <2 x i32> [[TMP286]], <2 x i32> <i32 0, i32 3>
-; CHECK-NEXT: [[TMP288:%.*]] = add <2 x i32> [[TMP110]], [[TMP287]]
-; CHECK-NEXT: [[TMP289:%.*]] = sub <2 x i32> [[TMP287]], [[TMP110]]
-; CHECK-NEXT: [[TMP290:%.*]] = add <2 x i32> [[TMP144]], [[TMP288]]
-; CHECK-NEXT: [[TMP291:%.*]] = xor <2 x i32> [[TMP290]], [[TMP113]]
-; CHECK-NEXT: [[TMP292:%.*]] = lshr <2 x i32> [[TMP103]], <i32 15, i32 15>
-; CHECK-NEXT: [[TMP293:%.*]] = and <2 x i32> [[TMP292]], <i32 65537, i32 65537>
-; CHECK-NEXT: [[TMP294:%.*]] = mul <2 x i32> [[TMP293]], <i32 65535, i32 65535>
-; CHECK-NEXT: [[TMP295:%.*]] = add <2 x i32> [[TMP294]], [[TMP289]]
-; CHECK-NEXT: [[TMP296:%.*]] = xor <2 x i32> [[TMP295]], [[TMP103]]
-; CHECK-NEXT: [[TMP297:%.*]] = extractelement <2 x i32> [[TMP291]], i32 1
-; CHECK-NEXT: [[ADD108_3:%.*]] = add i32 [[TMP297]], [[ADD113_2]]
-; CHECK-NEXT: [[TMP298:%.*]] = extractelement <2 x i32> [[TMP291]], i32 0
-; CHECK-NEXT: [[ADD110_3:%.*]] = add i32 [[ADD108_3]], [[TMP298]]
-; CHECK-NEXT: [[TMP299:%.*]] = extractelement <2 x i32> [[TMP296]], i32 0
-; CHECK-NEXT: [[ADD112_3:%.*]] = add i32 [[ADD110_3]], [[TMP299]]
-; CHECK-NEXT: [[TMP300:%.*]] = extractelement <2 x i32> [[TMP296]], i32 1
-; CHECK-NEXT: [[ADD113_3:%.*]] = add i32 [[ADD112_3]], [[TMP300]]
+; CHECK-NEXT: [[TMP208:%.*]] = insertelement <2 x i32> [[TMP150]], i32 [[SUB45_2]], i32 0
+; CHECK-NEXT: [[TMP209:%.*]] = insertelement <2 x i32> [[TMP105]], i32 [[SUB47_2]], i32 0
+; CHECK-NEXT: [[TMP210:%.*]] = sub <2 x i32> [[TMP208]], [[TMP209]]
+; CHECK-NEXT: [[TMP211:%.*]] = shufflevector <2 x i32> [[TMP73]], <2 x i32> [[TMP144]], <2 x i32> <i32 1, i32 2>
+; CHECK-NEXT: [[TMP212:%.*]] = shufflevector <2 x i32> [[TMP73]], <2 x i32> [[TMP144]], <2 x i32> <i32 0, i32 3>
+; CHECK-NEXT: [[TMP213:%.*]] = sub <2 x i32> [[TMP211]], [[TMP212]]
+; CHECK-NEXT: [[TMP214:%.*]] = extractelement <2 x i32> [[TMP210]], i32 0
+; CHECK-NEXT: [[TMP215:%.*]] = extractelement <2 x i32> [[TMP213]], i32 0
+; CHECK-NEXT: [[TMP216:%.*]] = shufflevector <2 x i32> [[TMP213]], <2 x i32> [[TMP210]], <2 x i32> <i32 0, i32 2>
+; CHECK-NEXT: [[ADD94_3:%.*]] = add i32 [[TMP215]], [[TMP214]]
+; CHECK-NEXT: [[TMP217:%.*]] = extractelement <2 x i32> [[TMP210]], i32 1
+; CHECK-NEXT: [[TMP218:%.*]] = extractelement <2 x i32> [[TMP213]], i32 1
+; CHECK-NEXT: [[TMP219:%.*]] = shufflevector <2 x i32> [[TMP213]], <2 x i32> [[TMP210]], <2 x i32> <i32 1, i32 3>
+; CHECK-NEXT: [[ADD78_3:%.*]] = add i32 [[TMP218]], [[TMP217]]
+; CHECK-NEXT: [[TMP220:%.*]] = sub <2 x i32> [[TMP210]], [[TMP213]]
+; CHECK-NEXT: [[TMP221:%.*]] = insertelement <2 x i32> poison, i32 [[ADD78_3]], i32 0
+; CHECK-NEXT: [[TMP222:%.*]] = shufflevector <2 x i32> [[TMP221]], <2 x i32> poison, <2 x i32> zeroinitializer
+; CHECK-NEXT: [[TMP223:%.*]] = insertelement <2 x i32> poison, i32 [[ADD94_3]], i32 0
+; CHECK-NEXT: [[TMP224:%.*]] = shufflevector <2 x i32> [[TMP223]], <2 x i32> poison, <2 x i32> zeroinitializer
+; CHECK-NEXT: [[TMP225:%.*]] = add <2 x i32> [[TMP222]], [[TMP224]]
+; CHECK-NEXT: [[TMP226:%.*]] = sub <2 x i32> [[TMP222]], [[TMP224]]
+; CHECK-NEXT: [[TMP227:%.*]] = shufflevector <2 x i32> [[TMP225]], <2 x i32> [[TMP226]], <2 x i32> <i32 0, i32 3>
+; CHECK-NEXT: [[TMP228:%.*]] = extractelement <2 x i32> [[TMP220]], i32 0
+; CHECK-NEXT: [[TMP229:%.*]] = extractelement <2 x i32> [[TMP220]], i32 1
+; CHECK-NEXT: [[ADD105_3:%.*]] = add i32 [[TMP228]], [[TMP229]]
+; CHECK-NEXT: [[SUB106_3:%.*]] = sub i32 [[TMP229]], [[TMP228]]
+; CHECK-NEXT: [[ADD_I52_3:%.*]] = add i32 [[MUL_I51_3]], [[ADD105_3]]
+; CHECK-NEXT: [[XOR_I53_3:%.*]] = xor i32 [[ADD_I52_3]], [[CONV]]
+; CHECK-NEXT: [[TMP230:%.*]] = lshr <2 x i32> [[TMP79]], <i32 15, i32 15>
+; CHECK-NEXT: [[TMP231:%.*]] = and <2 x i32> [[TMP230]], <i32 65537, i32 65537>
+; CHECK-NEXT: [[TMP232:%.*]] = mul <2 x i32> [[TMP231]], <i32 65535, i32 65535>
+; CHECK-NEXT: [[TMP233:%.*]] = add <2 x i32> [[TMP232]], [[TMP227]]
+; CHECK-NEXT: [[TMP234:%.*]] = xor <2 x i32> [[TMP233]], [[TMP79]]
+; CHECK-NEXT: [[SHR_I59_3:%.*]] = lshr i32 [[CONV33]], 15
+; CHECK-NEXT: [[AND_I60_3:%.*]] = and i32 [[SHR_I59_3]], 65537
+; CHECK-NEXT: [[MUL_I61_3:%.*]] = mul i32 [[AND_I60_3]], 65535
+; CHECK-NEXT: [[ADD_I62_3:%.*]] = add i32 [[MUL_I61_3]], [[SUB106_3]]
+; CHECK-NEXT: [[XOR_I63_3:%.*]] = xor i32 [[ADD_I62_3]], [[CONV33]]
+; CHECK-NEXT: [[ADD108_3:%.*]] = add i32 [[XOR_I53_3]], [[ADD113_2]]
+; CHECK-NEXT: [[TMP235:%.*]] = extractelement <2 x i32> [[TMP234]], i32 0
+; CHECK-NEXT: [[ADD110_3:%.*]] = add i32 [[ADD108_3]], [[TMP235]]
+; CHECK-NEXT: [[TMP236:%.*]] = extractelement <2 x i32> [[TMP234]], i32 1
+; CHECK-NEXT: [[ADD112_3:%.*]] = add i32 [[ADD110_3]], [[TMP236]]
+; CHECK-NEXT: [[ADD113_3:%.*]] = add i32 [[ADD112_3]], [[XOR_I63_3]]
; CHECK-NEXT: ret i32 [[ADD113_3]]
;
entry:
diff --git a/llvm/test/Transforms/SLPVectorizer/X86/PR39774.ll b/llvm/test/Transforms/SLPVectorizer/X86/PR39774.ll
index abf1d7abdc1226..5c261d69cd53e8 100644
--- a/llvm/test/Transforms/SLPVectorizer/X86/PR39774.ll
+++ b/llvm/test/Transforms/SLPVectorizer/X86/PR39774.ll
@@ -23,16 +23,16 @@ define void @Test(i32) {
; FORCE_REDUCTION-NEXT: entry:
; FORCE_REDUCTION-NEXT: br label [[LOOP:%.*]]
; FORCE_REDUCTION: loop:
-; FORCE_REDUCTION-NEXT: [[TMP1:%.*]] = phi <2 x i32> [ [[TMP7:%.*]], [[LOOP]] ], [ zeroinitializer, [[ENTRY:%.*]] ]
+; FORCE_REDUCTION-NEXT: [[TMP1:%.*]] = phi <2 x i32> [ [[TMP9:%.*]], [[LOOP]] ], [ zeroinitializer, [[ENTRY:%.*]] ]
; FORCE_REDUCTION-NEXT: [[TMP2:%.*]] = shufflevector <2 x i32> [[TMP1]], <2 x i32> poison, <8 x i32> <i32 0, i32 1, i32 1, i32 1, i32 1, i32 1, i32 1, i32 1>
-; FORCE_REDUCTION-NEXT: [[TMP3:%.*]] = extractelement <8 x i32> [[TMP2]], i32 1
-; FORCE_REDUCTION-NEXT: [[TMP4:%.*]] = add <8 x i32> [[TMP2]], <i32 0, i32 55, i32 285, i32 1240, i32 1496, i32 8555, i32 12529, i32 13685>
-; FORCE_REDUCTION-NEXT: [[TMP5:%.*]] = call i32 @llvm.vector.reduce.and.v8i32(<8 x i32> [[TMP4]])
-; FORCE_REDUCTION-NEXT: [[OP_RDX:%.*]] = and i32 [[TMP0:%.*]], [[TMP5]]
-; FORCE_REDUCTION-NEXT: [[OP_RDX1:%.*]] = and i32 [[OP_RDX]], [[TMP3]]
-; FORCE_REDUCTION-NEXT: [[VAL_43:%.*]] = add i32 [[TMP3]], 14910
-; FORCE_REDUCTION-NEXT: [[TMP6:%.*]] = insertelement <2 x i32> poison, i32 [[OP_RDX1]], i32 0
-; FORCE_REDUCTION-NEXT: [[TMP7]] = insertelement <2 x i32> [[TMP6]], i32 [[VAL_43]], i32 1
+; FORCE_REDUCTION-NEXT: [[TMP3:%.*]] = add <8 x i32> [[TMP2]], <i32 0, i32 55, i32 285, i32 1240, i32 1496, i32 8555, i32 12529, i32 13685>
+; FORCE_REDUCTION-NEXT: [[TMP4:%.*]] = call i32 @llvm.vector.reduce.and.v8i32(<8 x i32> [[TMP3]])
+; FORCE_REDUCTION-NEXT: [[OP_RDX:%.*]] = and i32 [[TMP0:%.*]], [[TMP4]]
+; FORCE_REDUCTION-NEXT: [[TMP5:%.*]] = insertelement <2 x i32> <i32 poison, i32 14910>, i32 [[OP_RDX]], i32 0
+; FORCE_REDUCTION-NEXT: [[TMP6:%.*]] = shufflevector <2 x i32> [[TMP1]], <2 x i32> poison, <2 x i32> <i32 1, i32 1>
+; FORCE_REDUCTION-NEXT: [[TMP7:%.*]] = and <2 x i32> [[TMP5]], [[TMP6]]
+; FORCE_REDUCTION-NEXT: [[TMP8:%.*]] = add <2 x i32> [[TMP5]], [[TMP6]]
+; FORCE_REDUCTION-NEXT: [[TMP9]] = shufflevector <2 x i32> [[TMP7]], <2 x i32> [[TMP8]], <2 x i32> <i32 0, i32 3>
; FORCE_REDUCTION-NEXT: br label [[LOOP]]
;
entry:
diff --git a/llvm/test/Transforms/SLPVectorizer/X86/insert-element-build-vector-inseltpoison.ll b/llvm/test/Transforms/SLPVectorizer/X86/insert-element-build-vector-inseltpoison.ll
index 10369e3aa270eb..fd9528aa8df3ab 100644
--- a/llvm/test/Transforms/SLPVectorizer/X86/insert-element-build-vector-inseltpoison.ll
+++ b/llvm/test/Transforms/SLPVectorizer/X86/insert-element-build-vector-inseltpoison.ll
@@ -70,8 +70,10 @@ define <4 x float> @simple_select_eph(<4 x float> %a, <4 x float> %b, <4 x i32>
; THRESHOLD-NEXT: [[RD:%.*]] = insertelement <4 x float> [[RC]], float [[S3]], i32 3
; THRESHOLD-NEXT: [[Q0:%.*]] = extractelement <4 x float> [[RD]], i32 0
; THRESHOLD-NEXT: [[Q1:%.*]] = extractelement <4 x float> [[RD]], i32 1
+; THRESHOLD-NEXT: [[TMP1:%.*]] = shufflevector <4 x float> [[RD]], <4 x float> poison, <2 x i32> <i32 0, i32 1>
; THRESHOLD-NEXT: [[Q2:%.*]] = extractelement <4 x float> [[RD]], i32 2
; THRESHOLD-NEXT: [[Q3:%.*]] = extractelement <4 x float> [[RD]], i32 3
+; THRESHOLD-NEXT: [[TMP2:%.*]] = shufflevector <4 x float> [[RD]], <4 x float> poison, <2 x i32> <i32 2, i32 3>
; THRESHOLD-NEXT: [[Q4:%.*]] = fadd float [[Q0]], [[Q1]]
; THRESHOLD-NEXT: [[Q5:%.*]] = fadd float [[Q2]], [[Q3]]
; THRESHOLD-NEXT: [[Q6:%.*]] = fadd float [[Q4]], [[Q5]]
diff --git a/llvm/test/Transforms/SLPVectorizer/X86/insert-element-build-vector.ll b/llvm/test/Transforms/SLPVectorizer/X86/insert-element-build-vector.ll
index 9376bcd220a2c3..18d5b09001762b 100644
--- a/llvm/test/Transforms/SLPVectorizer/X86/insert-element-build-vector.ll
+++ b/llvm/test/Transforms/SLPVectorizer/X86/insert-element-build-vector.ll
@@ -104,8 +104,10 @@ define <4 x float> @simple_select_eph(<4 x float> %a, <4 x float> %b, <4 x i32>
; THRESHOLD-NEXT: [[RD:%.*]] = insertelement <4 x float> [[RC]], float [[S3]], i32 3
; THRESHOLD-NEXT: [[Q0:%.*]] = extractelement <4 x float> [[RD]], i32 0
; THRESHOLD-NEXT: [[Q1:%.*]] = extractelement <4 x float> [[RD]], i32 1
+; THRESHOLD-NEXT: [[TMP1:%.*]] = shufflevector <4 x float> [[RD]], <4 x float> poison, <2 x i32> <i32 0, i32 1>
; THRESHOLD-NEXT: [[Q2:%.*]] = extractelement <4 x float> [[RD]], i32 2
; THRESHOLD-NEXT: [[Q3:%.*]] = extractelement <4 x float> [[RD]], i32 3
+; THRESHOLD-NEXT: [[TMP2:%.*]] = shufflevector <4 x float> [[RD]], <4 x float> poison, <2 x i32> <i32 2, i32 3>
; THRESHOLD-NEXT: [[Q4:%.*]] = fadd float [[Q0]], [[Q1]]
; THRESHOLD-NEXT: [[Q5:%.*]] = fadd float [[Q2]], [[Q3]]
; THRESHOLD-NEXT: [[Q6:%.*]] = fadd float [[Q4]], [[Q5]]
diff --git a/llvm/test/Transforms/SLPVectorizer/X86/reduction-transpose.ll b/llvm/test/Transforms/SLPVectorizer/X86/reduction-transpose.ll
index ec90ca9bc674df..2cdbd5cff4468c 100644
--- a/llvm/test/Transforms/SLPVectorizer/X86/reduction-transpose.ll
+++ b/llvm/test/Transforms/SLPVectorizer/X86/reduction-transpose.ll
@@ -1,8 +1,8 @@
; NOTE: Assertions have been autogenerated by utils/update_test_checks.py
; RUN: opt < %s -passes=slp-vectorizer -mtriple=x86_64-- -mcpu=x86-64 -S | FileCheck %s --check-prefixes=SSE2
; RUN: opt < %s -passes=slp-vectorizer -mtriple=x86_64-- -mcpu=x86-64-v2 -S | FileCheck %s --check-prefixes=SSE42
-; RUN: opt < %s -passes=slp-vectorizer -mtriple=x86_64-- -mcpu=x86-64-v3 -S | FileCheck %s --check-prefixes=AVX
-; RUN: opt < %s -passes=slp-vectorizer -mtriple=x86_64-- -mcpu=x86-64-v4 -S | FileCheck %s --check-prefixes=AVX
+; RUN: opt < %s -passes=slp-vectorizer -mtriple=x86_64-- -mcpu=x86-64-v3 -S | FileCheck %s --check-prefixes=AVX2
+; RUN: opt < %s -passes=slp-vectorizer -mtriple=x86_64-- -mcpu=x86-64-v4 -S | FileCheck %s --check-prefixes=AVX512
; PR51746
; typedef int v4si __attribute__ ((vector_size (16)));
@@ -18,33 +18,44 @@
define i32 @reduce_and4(i32 %acc, <4 x i32> %v1, <4 x i32> %v2, <4 x i32> %v3, <4 x i32> %v4) {
; SSE2-LABEL: @reduce_and4(
; SSE2-NEXT: entry:
-; SSE2-NEXT: [[TMP0:%.*]] = shufflevector <4 x i32> [[V4:%.*]], <4 x i32> [[V3:%.*]], <8 x i32> <i32 0, i32 1, i32 2, i32 3, i32 4, i32 5, i32 6, i32 7>
-; SSE2-NEXT: [[TMP1:%.*]] = call i32 @llvm.vector.reduce.and.v8i32(<8 x i32> [[TMP0]])
-; SSE2-NEXT: [[TMP2:%.*]] = shufflevector <4 x i32> [[V2:%.*]], <4 x i32> [[V1:%.*]], <8 x i32> <i32 0, i32 1, i32 2, i32 3, i32 4, i32 5, i32 6, i32 7>
-; SSE2-NEXT: [[TMP3:%.*]] = call i32 @llvm.vector.reduce.and.v8i32(<8 x i32> [[TMP2]])
-; SSE2-NEXT: [[OP_RDX:%.*]] = and i32 [[TMP1]], [[TMP3]]
-; SSE2-NEXT: [[OP_RDX1:%.*]] = and i32 [[OP_RDX]], [[ACC:%.*]]
-; SSE2-NEXT: ret i32 [[OP_RDX1]]
+; SSE2-NEXT: [[TMP0:%.*]] = shufflevector <4 x i32> [[V4:%.*]], <4 x i32> [[V3:%.*]], <16 x i32> <i32 0, i32 1, i32 2, i32 3, i32 4, i32 5, i32 6, i32 7, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison>
+; SSE2-NEXT: [[TMP1:%.*]] = shufflevector <4 x i32> [[V2:%.*]], <4 x i32> poison, <16 x i32> <i32 0, i32 1, i32 2, i32 3, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison>
+; SSE2-NEXT: [[TMP2:%.*]] = shufflevector <16 x i32> [[TMP0]], <16 x i32> [[TMP1]], <16 x i32> <i32 0, i32 1, i32 2, i32 3, i32 4, i32 5, i32 6, i32 7, i32 16, i32 17, i32 18, i32 19, i32 poison, i32 poison, i32 poison, i32 poison>
+; SSE2-NEXT: [[TMP3:%.*]] = shufflevector <4 x i32> [[V1:%.*]], <4 x i32> poison, <16 x i32> <i32 0, i32 1, i32 2, i32 3, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison>
+; SSE2-NEXT: [[TMP4:%.*]] = shufflevector <16 x i32> [[TMP2]], <16 x i32> [[TMP3]], <16 x i32> <i32 0, i32 1, i32 2, i32 3, i32 4, i32 5, i32 6, i32 7, i32 8, i32 9, i32 10, i32 11, i32 16, i32 17, i32 18, i32 19>
+; SSE2-NEXT: [[TMP5:%.*]] = call i32 @llvm.vector.reduce.and.v16i32(<16 x i32> [[TMP4]])
+; SSE2-NEXT: [[OP_RDX:%.*]] = and i32 [[TMP5]], [[ACC:%.*]]
+; SSE2-NEXT: ret i32 [[OP_RDX]]
;
; SSE42-LABEL: @reduce_and4(
; SSE42-NEXT: entry:
-; SSE42-NEXT: [[TMP0:%.*]] = shufflevector <4 x i32> [[V4:%.*]], <4 x i32> [[V3:%.*]], <8 x i32> <i32 0, i32 1, i32 2, i32 3, i32 4, i32 5, i32 6, i32 7>
-; SSE42-NEXT: [[TMP1:%.*]] = call i32 @llvm.vector.reduce.and.v8i32(<8 x i32> [[TMP0]])
-; SSE42-NEXT: [[TMP2:%.*]] = shufflevector <4 x i32> [[V2:%.*]], <4 x i32> [[V1:%.*]], <8 x i32> <i32 0, i32 1, i32 2, i32 3, i32 4, i32 5, i32 6, i32 7>
-; SSE42-NEXT: [[TMP3:%.*]] = call i32 @llvm.vector.reduce.and.v8i32(<8 x i32> [[TMP2]])
-; SSE42-NEXT: [[OP_RDX:%.*]] = and i32 [[TMP1]], [[TMP3]]
-; SSE42-NEXT: [[OP_RDX1:%.*]] = and i32 [[OP_RDX]], [[ACC:%.*]]
-; SSE42-NEXT: ret i32 [[OP_RDX1]]
+; SSE42-NEXT: [[TMP0:%.*]] = shufflevector <4 x i32> [[V4:%.*]], <4 x i32> [[V3:%.*]], <16 x i32> <i32 0, i32 1, i32 2, i32 3, i32 4, i32 5, i32 6, i32 7, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison>
+; SSE42-NEXT: [[TMP1:%.*]] = shufflevector <4 x i32> [[V2:%.*]], <4 x i32> poison, <16 x i32> <i32 0, i32 1, i32 2, i32 3, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison>
+; SSE42-NEXT: [[TMP2:%.*]] = shufflevector <16 x i32> [[TMP0]], <16 x i32> [[TMP1]], <16 x i32> <i32 0, i32 1, i32 2, i32 3, i32 4, i32 5, i32 6, i32 7, i32 16, i32 17, i32 18, i32 19, i32 poison, i32 poison, i32 poison, i32 poison>
+; SSE42-NEXT: [[TMP3:%.*]] = shufflevector <4 x i32> [[V1:%.*]], <4 x i32> poison, <16 x i32> <i32 0, i32 1, i32 2, i32 3, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison>
+; SSE42-NEXT: [[TMP4:%.*]] = shufflevector <16 x i32> [[TMP2]], <16 x i32> [[TMP3]], <16 x i32> <i32 0, i32 1, i32 2, i32 3, i32 4, i32 5, i32 6, i32 7, i32 8, i32 9, i32 10, i32 11, i32 16, i32 17, i32 18, i32 19>
+; SSE42-NEXT: [[TMP5:%.*]] = call i32 @llvm.vector.reduce.and.v16i32(<16 x i32> [[TMP4]])
+; SSE42-NEXT: [[OP_RDX:%.*]] = and i32 [[TMP5]], [[ACC:%.*]]
+; SSE42-NEXT: ret i32 [[OP_RDX]]
;
-; AVX-LABEL: @reduce_and4(
-; AVX-NEXT: entry:
-; AVX-NEXT: [[TMP0:%.*]] = shufflevector <4 x i32> [[V4:%.*]], <4 x i32> [[V3:%.*]], <8 x i32> <i32 1, i32 0, i32 2, i32 3, i32 5, i32 4, i32 6, i32 7>
-; AVX-NEXT: [[TMP1:%.*]] = call i32 @llvm.vector.reduce.and.v8i32(<8 x i32> [[TMP0]])
-; AVX-NEXT: [[TMP2:%.*]] = shufflevector <4 x i32> [[V2:%.*]], <4 x i32> [[V1:%.*]], <8 x i32> <i32 1, i32 0, i32 2, i32 3, i32 5, i32 4, i32 6, i32 7>
-; AVX-NEXT: [[TMP3:%.*]] = call i32 @llvm.vector.reduce.and.v8i32(<8 x i32> [[TMP2]])
-; AVX-NEXT: [[OP_RDX:%.*]] = and i32 [[TMP1]], [[TMP3]]
-; AVX-NEXT: [[OP_RDX1:%.*]] = and i32 [[OP_RDX]], [[ACC:%.*]]
-; AVX-NEXT: ret i32 [[OP_RDX1]]
+; AVX2-LABEL: @reduce_and4(
+; AVX2-NEXT: entry:
+; AVX2-NEXT: [[TMP0:%.*]] = shufflevector <4 x i32> [[V4:%.*]], <4 x i32> [[V3:%.*]], <8 x i32> <i32 1, i32 0, i32 2, i32 3, i32 5, i32 4, i32 6, i32 7>
+; AVX2-NEXT: [[TMP1:%.*]] = shufflevector <4 x i32> [[V2:%.*]], <4 x i32> [[V1:%.*]], <8 x i32> <i32 1, i32 0, i32 2, i32 3, i32 5, i32 4, i32 6, i32 7>
+; AVX2-NEXT: [[TMP2:%.*]] = shufflevector <8 x i32> [[TMP0]], <8 x i32> [[TMP1]], <16 x i32> <i32 0, i32 1, i32 2, i32 3, i32 4, i32 5, i32 6, i32 7, i32 8, i32 9, i32 10, i32 11, i32 12, i32 13, i32 14, i32 15>
+; AVX2-NEXT: [[TMP3:%.*]] = call i32 @llvm.vector.reduce.and.v16i32(<16 x i32> [[TMP2]])
+; AVX2-NEXT: [[OP_RDX:%.*]] = and i32 [[TMP3]], [[ACC:%.*]]
+; AVX2-NEXT: ret i32 [[OP_RDX]]
+;
+; AVX512-LABEL: @reduce_and4(
+; AVX512-NEXT: entry:
+; AVX512-NEXT: [[TMP0:%.*]] = shufflevector <4 x i32> [[V4:%.*]], <4 x i32> [[V3:%.*]], <8 x i32> <i32 1, i32 0, i32 2, i32 3, i32 5, i32 4, i32 6, i32 7>
+; AVX512-NEXT: [[TMP1:%.*]] = call i32 @llvm.vector.reduce.and.v8i32(<8 x i32> [[TMP0]])
+; AVX512-NEXT: [[TMP2:%.*]] = shufflevector <4 x i32> [[V2:%.*]], <4 x i32> [[V1:%.*]], <8 x i32> <i32 1, i32 0, i32 2, i32 3, i32 5, i32 4, i32 6, i32 7>
+; AVX512-NEXT: [[TMP3:%.*]] = call i32 @llvm.vector.reduce.and.v8i32(<8 x i32> [[TMP2]])
+; AVX512-NEXT: [[OP_RDX:%.*]] = and i32 [[TMP1]], [[TMP3]]
+; AVX512-NEXT: [[OP_RDX1:%.*]] = and i32 [[OP_RDX]], [[ACC:%.*]]
+; AVX512-NEXT: ret i32 [[OP_RDX1]]
;
entry:
%vecext = extractelement <4 x i32> %v1, i64 0
@@ -92,31 +103,41 @@ entry:
define i32 @reduce_and4_transpose(i32 %acc, <4 x i32> %v1, <4 x i32> %v2, <4 x i32> %v3, <4 x i32> %v4) {
; SSE2-LABEL: @reduce_and4_transpose(
-; SSE2-NEXT: [[TMP1:%.*]] = shufflevector <4 x i32> [[V4:%.*]], <4 x i32> [[V3:%.*]], <8 x i32> <i32 0, i32 1, i32 2, i32 3, i32 4, i32 5, i32 6, i32 7>
-; SSE2-NEXT: [[TMP2:%.*]] = call i32 @llvm.vector.reduce.and.v8i32(<8 x i32> [[TMP1]])
-; SSE2-NEXT: [[TMP3:%.*]] = shufflevector <4 x i32> [[V2:%.*]], <4 x i32> [[V1:%.*]], <8 x i32> <i32 0, i32 1, i32 2, i32 3, i32 4, i32 5, i32 6, i32 7>
-; SSE2-NEXT: [[TMP4:%.*]] = call i32 @llvm.vector.reduce.and.v8i32(<8 x i32> [[TMP3]])
-; SSE2-NEXT: [[OP_RDX:%.*]] = and i32 [[TMP2]], [[TMP4]]
-; SSE2-NEXT: [[OP_RDX1:%.*]] = and i32 [[OP_RDX]], [[ACC:%.*]]
-; SSE2-NEXT: ret i32 [[OP_RDX1]]
+; SSE2-NEXT: [[TMP1:%.*]] = shufflevector <4 x i32> [[V4:%.*]], <4 x i32> [[V3:%.*]], <16 x i32> <i32 0, i32 1, i32 2, i32 3, i32 4, i32 5, i32 6, i32 7, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison>
+; SSE2-NEXT: [[TMP2:%.*]] = shufflevector <4 x i32> [[V2:%.*]], <4 x i32> poison, <16 x i32> <i32 0, i32 1, i32 2, i32 3, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison>
+; SSE2-NEXT: [[TMP3:%.*]] = shufflevector <16 x i32> [[TMP1]], <16 x i32> [[TMP2]], <16 x i32> <i32 0, i32 1, i32 2, i32 3, i32 4, i32 5, i32 6, i32 7, i32 16, i32 17, i32 18, i32 19, i32 poison, i32 poison, i32 poison, i32 poison>
+; SSE2-NEXT: [[TMP4:%.*]] = shufflevector <4 x i32> [[V1:%.*]], <4 x i32> poison, <16 x i32> <i32 0, i32 1, i32 2, i32 3, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison>
+; SSE2-NEXT: [[TMP5:%.*]] = shufflevector <16 x i32> [[TMP3]], <16 x i32> [[TMP4]], <16 x i32> <i32 0, i32 1, i32 2, i32 3, i32 4, i32 5, i32 6, i32 7, i32 8, i32 9, i32 10, i32 11, i32 16, i32 17, i32 18, i32 19>
+; SSE2-NEXT: [[TMP6:%.*]] = call i32 @llvm.vector.reduce.and.v16i32(<16 x i32> [[TMP5]])
+; SSE2-NEXT: [[OP_RDX:%.*]] = and i32 [[TMP6]], [[ACC:%.*]]
+; SSE2-NEXT: ret i32 [[OP_RDX]]
;
; SSE42-LABEL: @reduce_and4_transpose(
-; SSE42-NEXT: [[TMP1:%.*]] = shufflevector <4 x i32> [[V4:%.*]], <4 x i32> [[V3:%.*]], <8 x i32> <i32 0, i32 1, i32 2, i32 3, i32 4, i32 5, i32 6, i32 7>
-; SSE42-NEXT: [[TMP2:%.*]] = call i32 @llvm.vector.reduce.and.v8i32(<8 x i32> [[TMP1]])
-; SSE42-NEXT: [[TMP3:%.*]] = shufflevector <4 x i32> [[V2:%.*]], <4 x i32> [[V1:%.*]], <8 x i32> <i32 0, i32 1, i32 2, i32 3, i32 4, i32 5, i32 6, i32 7>
-; SSE42-NEXT: [[TMP4:%.*]] = call i32 @llvm.vector.reduce.and.v8i32(<8 x i32> [[TMP3]])
-; SSE42-NEXT: [[OP_RDX:%.*]] = and i32 [[TMP2]], [[TMP4]]
-; SSE42-NEXT: [[OP_RDX1:%.*]] = and i32 [[OP_RDX]], [[ACC:%.*]]
-; SSE42-NEXT: ret i32 [[OP_RDX1]]
+; SSE42-NEXT: [[TMP1:%.*]] = shufflevector <4 x i32> [[V4:%.*]], <4 x i32> [[V3:%.*]], <16 x i32> <i32 0, i32 1, i32 2, i32 3, i32 4, i32 5, i32 6, i32 7, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison>
+; SSE42-NEXT: [[TMP2:%.*]] = shufflevector <4 x i32> [[V2:%.*]], <4 x i32> poison, <16 x i32> <i32 0, i32 1, i32 2, i32 3, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison>
+; SSE42-NEXT: [[TMP3:%.*]] = shufflevector <16 x i32> [[TMP1]], <16 x i32> [[TMP2]], <16 x i32> <i32 0, i32 1, i32 2, i32 3, i32 4, i32 5, i32 6, i32 7, i32 16, i32 17, i32 18, i32 19, i32 poison, i32 poison, i32 poison, i32 poison>
+; SSE42-NEXT: [[TMP4:%.*]] = shufflevector <4 x i32> [[V1:%.*]], <4 x i32> poison, <16 x i32> <i32 0, i32 1, i32 2, i32 3, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison, i32 poison>
+; SSE42-NEXT: [[TMP5:%.*]] = shufflevector <16 x i32> [[TMP3]], <16 x i32> [[TMP4]], <16 x i32> <i32 0, i32 1, i32 2, i32 3, i32 4, i32 5, i32 6, i32 7, i32 8, i32 9, i32 10, i32 11, i32 16, i32 17, i32 18, i32 19>
+; SSE42-NEXT: [[TMP6:%.*]] = call i32 @llvm.vector.reduce.and.v16i32(<16 x i32> [[TMP5]])
+; SSE42-NEXT: [[OP_RDX:%.*]] = and i32 [[TMP6]], [[ACC:%.*]]
+; SSE42-NEXT: ret i32 [[OP_RDX]]
+;
+; AVX2-LABEL: @reduce_and4_transpose(
+; AVX2-NEXT: [[TMP1:%.*]] = shufflevector <4 x i32> [[V4:%.*]], <4 x i32> [[V3:%.*]], <8 x i32> <i32 3, i32 2, i32 1, i32 0, i32 7, i32 6, i32 5, i32 4>
+; AVX2-NEXT: [[TMP2:%.*]] = shufflevector <4 x i32> [[V2:%.*]], <4 x i32> [[V1:%.*]], <8 x i32> <i32 3, i32 2, i32 1, i32 0, i32 7, i32 6, i32 5, i32 4>
+; AVX2-NEXT: [[TMP3:%.*]] = shufflevector <8 x i32> [[TMP1]], <8 x i32> [[TMP2]], <16 x i32> <i32 0, i32 1, i32 2, i32 3, i32 4, i32 5, i32 6, i32 7, i32 8, i32 9, i32 10, i32 11, i32 12, i32 13, i32 14, i32 15>
+; AVX2-NEXT: [[TMP4:%.*]] = call i32 @llvm.vector.reduce.and.v16i32(<16 x i32> [[TMP3]])
+; AVX2-NEXT: [[OP_RDX:%.*]] = and i32 [[TMP4]], [[ACC:%.*]]
+; AVX2-NEXT: ret i32 [[OP_RDX]]
;
-; AVX-LABEL: @reduce_and4_transpose(
-; AVX-NEXT: [[TMP1:%.*]] = shufflevector <4 x i32> [[V4:%.*]], <4 x i32> [[V3:%.*]], <8 x i32> <i32 3, i32 2, i32 1, i32 0, i32 7, i32 6, i32 5, i32 4>
-; AVX-NEXT: [[TMP2:%.*]] = call i32 @llvm.vector.reduce.and.v8i32(<8 x i32> [[TMP1]])
-; AVX-NEXT: [[TMP3:%.*]] = shufflevector <4 x i32> [[V2:%.*]], <4 x i32> [[V1:%.*]], <8 x i32> <i32 3, i32 2, i32 1, i32 0, i32 7, i32 6, i32 5, i32 4>
-; AVX-NEXT: [[TMP4:%.*]] = call i32 @llvm.vector.reduce.and.v8i32(<8 x i32> [[TMP3]])
-; AVX-NEXT: [[OP_RDX:%.*]] = and i32 [[TMP2]], [[TMP4]]
-; AVX-NEXT: [[OP_RDX1:%.*]] = and i32 [[OP_RDX]], [[ACC:%.*]]
-; AVX-NEXT: ret i32 [[OP_RDX1]]
+; AVX512-LABEL: @reduce_and4_transpose(
+; AVX512-NEXT: [[TMP1:%.*]] = shufflevector <4 x i32> [[V4:%.*]], <4 x i32> [[V3:%.*]], <8 x i32> <i32 3, i32 2, i32 1, i32 0, i32 7, i32 6, i32 5, i32 4>
+; AVX512-NEXT: [[TMP2:%.*]] = call i32 @llvm.vector.reduce.and.v8i32(<8 x i32> [[TMP1]])
+; AVX512-NEXT: [[TMP3:%.*]] = shufflevector <4 x i32> [[V2:%.*]], <4 x i32> [[V1:%.*]], <8 x i32> <i32 3, i32 2, i32 1, i32 0, i32 7, i32 6, i32 5, i32 4>
+; AVX512-NEXT: [[TMP4:%.*]] = call i32 @llvm.vector.reduce.and.v8i32(<8 x i32> [[TMP3]])
+; AVX512-NEXT: [[OP_RDX:%.*]] = and i32 [[TMP2]], [[TMP4]]
+; AVX512-NEXT: [[OP_RDX1:%.*]] = and i32 [[OP_RDX]], [[ACC:%.*]]
+; AVX512-NEXT: ret i32 [[OP_RDX1]]
;
%vecext = extractelement <4 x i32> %v1, i64 0
%vecext1 = extractelement <4 x i32> %v2, i64 0
>From e741d889f481f6d49562f7b513cf1709e3ddf952 Mon Sep 17 00:00:00 2001
From: Farzon Lotfi <1802579+farzonl at users.noreply.github.com>
Date: Fri, 1 Mar 2024 12:53:05 -0500
Subject: [PATCH 278/406] [DXIL] Add frac unary lowering (#83465)
This change adds lowering for HLSL's frac intrinsic to DXIL.
This change should complete #70099
---
llvm/lib/Target/DirectX/DXIL.td | 3 +++
llvm/test/CodeGen/DirectX/frac.ll | 34 +++++++++++++++++++++++++++++++
2 files changed, 37 insertions(+)
create mode 100644 llvm/test/CodeGen/DirectX/frac.ll
diff --git a/llvm/lib/Target/DirectX/DXIL.td b/llvm/lib/Target/DirectX/DXIL.td
index f6edd1eb56c1ad..33b08ed93e3d0a 100644
--- a/llvm/lib/Target/DirectX/DXIL.td
+++ b/llvm/lib/Target/DirectX/DXIL.td
@@ -218,6 +218,9 @@ class DXILOpMapping<int opCode, DXILOpClass opClass, Intrinsic intrinsic, string
// Concrete definition of DXIL Operation mapping to corresponding LLVM intrinsic
def Sin : DXILOpMapping<13, unary, int_sin,
"Returns sine(theta) for theta in radians.">;
+def Frac : DXILOpMapping<22, unary, int_dx_frac,
+ "Returns a fraction from 0 to 1 that represents the "
+ "decimal part of the input.">;
def Round : DXILOpMapping<26, unary, int_round,
"Returns the input rounded to the nearest integer"
"within a floating-point type.">;
diff --git a/llvm/test/CodeGen/DirectX/frac.ll b/llvm/test/CodeGen/DirectX/frac.ll
new file mode 100644
index 00000000000000..ab605ed6084aa4
--- /dev/null
+++ b/llvm/test/CodeGen/DirectX/frac.ll
@@ -0,0 +1,34 @@
+; RUN: opt -S -dxil-op-lower < %s | FileCheck %s
+
+; Make sure dxil operation function calls for frac are generated for float and half.
+; CHECK:call float @dx.op.unary.f32(i32 22, float %{{.*}})
+; CHECK:call half @dx.op.unary.f16(i32 22, half %{{.*}})
+
+target datalayout = "e-m:e-p:32:32-i1:32-i8:8-i16:16-i32:32-i64:64-f16:16-f32:32-f64:64-n8:16:32:64"
+target triple = "dxil-pc-shadermodel6.7-library"
+
+; Function Attrs: noinline nounwind optnone
+define noundef float @frac_float(float noundef %a) #0 {
+entry:
+ %a.addr = alloca float, align 4
+ store float %a, ptr %a.addr, align 4
+ %0 = load float, ptr %a.addr, align 4
+ %dx.frac = call float @llvm.dx.frac.f32(float %0)
+ ret float %dx.frac
+}
+
+; Function Attrs: nocallback nofree nosync nounwind readnone speculatable willreturn
+declare float @llvm.dx.frac.f32(float) #1
+
+; Function Attrs: noinline nounwind optnone
+define noundef half @frac_half(half noundef %a) #0 {
+entry:
+ %a.addr = alloca half, align 2
+ store half %a, ptr %a.addr, align 2
+ %0 = load half, ptr %a.addr, align 2
+ %dx.frac = call half @llvm.dx.frac.f16(half %0)
+ ret half %dx.frac
+}
+
+; Function Attrs: nocallback nofree nosync nounwind readnone speculatable willreturn
+declare half @llvm.dx.frac.f16(half) #1
>From 84927a6728109ad01ee87b12f42f403756c0f2c3 Mon Sep 17 00:00:00 2001
From: Changpeng Fang <changpeng.fang at amd.com>
Date: Fri, 1 Mar 2024 10:03:54 -0800
Subject: [PATCH 279/406] AMDGPU: Simplify instruction definitions for
global_load_tr_b64(b128) (#83601)
WaveSizePredicate is copied from pseudo to real
---
llvm/lib/Target/AMDGPU/FLATInstructions.td | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/llvm/lib/Target/AMDGPU/FLATInstructions.td b/llvm/lib/Target/AMDGPU/FLATInstructions.td
index 87bd682611521c..f42d4ae416bd76 100644
--- a/llvm/lib/Target/AMDGPU/FLATInstructions.td
+++ b/llvm/lib/Target/AMDGPU/FLATInstructions.td
@@ -2746,12 +2746,12 @@ defm GLOBAL_ATOMIC_MIN_NUM_F32 : VGLOBAL_Real_Atomics_gfx12<0x051, "GLOBAL_A
defm GLOBAL_ATOMIC_MAX_NUM_F32 : VGLOBAL_Real_Atomics_gfx12<0x052, "GLOBAL_ATOMIC_FMAX", "global_atomic_max_num_f32", true, "global_atomic_max_f32">;
defm GLOBAL_ATOMIC_ADD_F32 : VGLOBAL_Real_Atomics_gfx12<0x056>;
-let WaveSizePredicate = isWave32, DecoderNamespace = "GFX12" in {
+let DecoderNamespace = "GFX12" in {
defm GLOBAL_LOAD_TR_B128_w32 : VGLOBAL_Real_AllAddr_gfx12<0x057, "GLOBAL_LOAD_TR_B128_w32", "global_load_tr_b128">;
defm GLOBAL_LOAD_TR_B64_w32 : VGLOBAL_Real_AllAddr_gfx12<0x058, "GLOBAL_LOAD_TR_B64_w32", "global_load_tr_b64">;
}
-let WaveSizePredicate = isWave64, DecoderNamespace = "GFX12W64" in {
+let DecoderNamespace = "GFX12W64" in {
defm GLOBAL_LOAD_TR_B128_w64 : VGLOBAL_Real_AllAddr_gfx12<0x057, "GLOBAL_LOAD_TR_B128_w64", "global_load_tr_b128">;
defm GLOBAL_LOAD_TR_B64_w64 : VGLOBAL_Real_AllAddr_gfx12<0x058, "GLOBAL_LOAD_TR_B64_w64", "global_load_tr_b64">;
}
>From dd426fa5f931f98251bfb3dbd29ecb06e4ce8d46 Mon Sep 17 00:00:00 2001
From: sylvain-audi <62035306+sylvain-audi at users.noreply.github.com>
Date: Fri, 1 Mar 2024 13:34:57 -0500
Subject: [PATCH 280/406] [Asan] Pre-commit test for asan support of funclet
token (#82631)
This is in preparation for PR
https://github.com/llvm/llvm-project/pull/82533.
Here we Introduce a test for asan instrumentation where invalid code is
output (see bug https://github.com/llvm/llvm-project/issues/64990)
The `CHECK` lines are generated using `update_test_checks.py` script.
The actual fix PR will udpate this test to highlight the changes in the
generated code.
---
.../AddressSanitizer/asan-funclet.ll | 459 ++++++++++++++++++
1 file changed, 459 insertions(+)
create mode 100644 llvm/test/Instrumentation/AddressSanitizer/asan-funclet.ll
diff --git a/llvm/test/Instrumentation/AddressSanitizer/asan-funclet.ll b/llvm/test/Instrumentation/AddressSanitizer/asan-funclet.ll
new file mode 100644
index 00000000000000..f0a5c67365ab5f
--- /dev/null
+++ b/llvm/test/Instrumentation/AddressSanitizer/asan-funclet.ll
@@ -0,0 +1,459 @@
+; NOTE: Assertions have been autogenerated by utils/update_test_checks.py UTC_ARGS: --version 4
+
+; Warning! The output of this test is currently invalid.
+; It serves as a base for the bugfix patch to highlight the modified generated code.
+
+; Test appropriate tagging of funclet for function calls generated by asan.
+; RUN: opt -S -passes=asan,win-eh-prepare -asan-use-stack-safety=0 -asan-max-inline-poisoning-size=0 \
+; RUN: -asan-detect-invalid-pointer-cmp -asan-detect-invalid-pointer-sub -asan-use-after-scope < %s | FileCheck %s --check-prefixes=CHECK,CHECK-INLINE
+; RUN: opt -S -passes=asan,win-eh-prepare -asan-use-stack-safety=0 -asan-max-inline-poisoning-size=0 -asan-instrumentation-with-call-threshold=0 \
+; RUN: -asan-detect-invalid-pointer-cmp -asan-detect-invalid-pointer-sub -asan-use-after-scope < %s | FileCheck %s --check-prefixes=CHECK,CHECK-OUTLINE
+
+; REQUIRES: x86-registered-target
+
+target triple = "x86_64-pc-windows-msvc"
+
+declare void @DeInit(ptr)
+declare void @MayThrowFunc()
+declare void @NoReturn() noreturn
+
+declare void @llvm.memmove.p0.p0.i64(ptr nocapture, ptr nocapture readonly, i64, i1)
+declare void @llvm.memcpy.p0.p0.i64(ptr noalias nocapture writeonly, ptr noalias nocapture readonly, i64, i1)
+declare void @llvm.memset.p0.i64(ptr nocapture writeonly, i8, i64, i1)
+declare void @llvm.lifetime.start.p0(i64, ptr nocapture) nounwind
+declare void @llvm.lifetime.end.p0(i64, ptr nocapture) nounwind
+
+declare i32 @__CxxFrameHandler3(...)
+declare i32 @dummyPersonality(...)
+
+define void @FuncletPersonality(ptr %ptrParam) sanitize_address personality ptr @__CxxFrameHandler3 {
+; CHECK-INLINE-LABEL: define void @FuncletPersonality(
+; CHECK-INLINE-SAME: ptr [[PTRPARAM:%.*]]) #[[ATTR4:[0-9]+]] personality ptr @__CxxFrameHandler3 {
+; CHECK-INLINE-NEXT: entry:
+; CHECK-INLINE-NEXT: [[TMP0:%.*]] = alloca i64, align 32
+; CHECK-INLINE-NEXT: store i64 0, ptr [[TMP0]], align 8
+; CHECK-INLINE-NEXT: [[TMP1:%.*]] = load i64, ptr @__asan_shadow_memory_dynamic_address, align 8
+; CHECK-INLINE-NEXT: [[ASAN_LOCAL_STACK_BASE:%.*]] = alloca i64, align 8
+; CHECK-INLINE-NEXT: [[TMP2:%.*]] = load i32, ptr @__asan_option_detect_stack_use_after_return, align 4
+; CHECK-INLINE-NEXT: [[TMP3:%.*]] = icmp ne i32 [[TMP2]], 0
+; CHECK-INLINE-NEXT: br i1 [[TMP3]], label [[TMP4:%.*]], label [[TMP6:%.*]]
+; CHECK-INLINE: 4:
+; CHECK-INLINE-NEXT: [[TMP5:%.*]] = call i64 @__asan_stack_malloc_8(i64 8544)
+; CHECK-INLINE-NEXT: br label [[TMP6]]
+; CHECK-INLINE: 6:
+; CHECK-INLINE-NEXT: [[TMP7:%.*]] = phi i64 [ 0, [[ENTRY:%.*]] ], [ [[TMP5]], [[TMP4]] ]
+; CHECK-INLINE-NEXT: [[TMP8:%.*]] = icmp eq i64 [[TMP7]], 0
+; CHECK-INLINE-NEXT: br i1 [[TMP8]], label [[TMP9:%.*]], label [[TMP11:%.*]]
+; CHECK-INLINE: 9:
+; CHECK-INLINE-NEXT: [[MYALLOCA:%.*]] = alloca i8, i64 8544, align 32
+; CHECK-INLINE-NEXT: [[TMP10:%.*]] = ptrtoint ptr [[MYALLOCA]] to i64
+; CHECK-INLINE-NEXT: br label [[TMP11]]
+; CHECK-INLINE: 11:
+; CHECK-INLINE-NEXT: [[TMP12:%.*]] = phi i64 [ [[TMP7]], [[TMP6]] ], [ [[TMP10]], [[TMP9]] ]
+; CHECK-INLINE-NEXT: store i64 [[TMP12]], ptr [[ASAN_LOCAL_STACK_BASE]], align 8
+; CHECK-INLINE-NEXT: [[TMP13:%.*]] = add i64 [[TMP12]], 32
+; CHECK-INLINE-NEXT: [[TMP14:%.*]] = inttoptr i64 [[TMP13]] to ptr
+; CHECK-INLINE-NEXT: [[TMP15:%.*]] = add i64 [[TMP12]], 8528
+; CHECK-INLINE-NEXT: [[TMP16:%.*]] = inttoptr i64 [[TMP15]] to ptr
+; CHECK-INLINE-NEXT: [[TMP17:%.*]] = inttoptr i64 [[TMP12]] to ptr
+; CHECK-INLINE-NEXT: store i64 1102416563, ptr [[TMP17]], align 8
+; CHECK-INLINE-NEXT: [[TMP18:%.*]] = add i64 [[TMP12]], 8
+; CHECK-INLINE-NEXT: [[TMP19:%.*]] = inttoptr i64 [[TMP18]] to ptr
+; CHECK-INLINE-NEXT: store i64 ptrtoint (ptr @___asan_gen_ to i64), ptr [[TMP19]], align 8
+; CHECK-INLINE-NEXT: [[TMP20:%.*]] = add i64 [[TMP12]], 16
+; CHECK-INLINE-NEXT: [[TMP21:%.*]] = inttoptr i64 [[TMP20]] to ptr
+; CHECK-INLINE-NEXT: store i64 ptrtoint (ptr @FuncletPersonality to i64), ptr [[TMP21]], align 8
+; CHECK-INLINE-NEXT: [[TMP22:%.*]] = lshr i64 [[TMP12]], 3
+; CHECK-INLINE-NEXT: [[TMP23:%.*]] = add i64 [[TMP22]], [[TMP1]]
+; CHECK-INLINE-NEXT: call void @__asan_set_shadow_f1(i64 [[TMP23]], i64 4)
+; CHECK-INLINE-NEXT: [[TMP24:%.*]] = add i64 [[TMP23]], 1028
+; CHECK-INLINE-NEXT: call void @__asan_set_shadow_f2(i64 [[TMP24]], i64 32)
+; CHECK-INLINE-NEXT: [[TMP25:%.*]] = add i64 [[TMP23]], 1060
+; CHECK-INLINE-NEXT: call void @__asan_set_shadow_04(i64 [[TMP25]], i64 1)
+; CHECK-INLINE-NEXT: [[TMP26:%.*]] = add i64 [[TMP23]], 1061
+; CHECK-INLINE-NEXT: call void @__asan_set_shadow_f2(i64 [[TMP26]], i64 1)
+; CHECK-INLINE-NEXT: [[TMP27:%.*]] = add i64 [[TMP23]], 1062
+; CHECK-INLINE-NEXT: call void @__asan_set_shadow_04(i64 [[TMP27]], i64 1)
+; CHECK-INLINE-NEXT: [[TMP28:%.*]] = add i64 [[TMP23]], 1063
+; CHECK-INLINE-NEXT: call void @__asan_set_shadow_f2(i64 [[TMP28]], i64 1)
+; CHECK-INLINE-NEXT: [[TMP29:%.*]] = add i64 [[TMP23]], 1064
+; CHECK-INLINE-NEXT: call void @__asan_set_shadow_04(i64 [[TMP29]], i64 1)
+; CHECK-INLINE-NEXT: [[TMP30:%.*]] = add i64 [[TMP23]], 1065
+; CHECK-INLINE-NEXT: call void @__asan_set_shadow_f2(i64 [[TMP30]], i64 1)
+; CHECK-INLINE-NEXT: [[TMP31:%.*]] = add i64 [[TMP23]], 1066
+; CHECK-INLINE-NEXT: call void @__asan_set_shadow_f8(i64 [[TMP31]], i64 1)
+; CHECK-INLINE-NEXT: [[TMP32:%.*]] = add i64 [[TMP23]], 1067
+; CHECK-INLINE-NEXT: call void @__asan_set_shadow_f3(i64 [[TMP32]], i64 1)
+; CHECK-INLINE-NEXT: [[TMP33:%.*]] = add i64 [[TMP23]], 1066
+; CHECK-INLINE-NEXT: call void @__asan_set_shadow_04(i64 [[TMP33]], i64 1)
+; CHECK-INLINE-NEXT: call void @llvm.lifetime.start.p0(i64 4, ptr [[TMP16]])
+; CHECK-INLINE-NEXT: [[TMP34:%.*]] = lshr i64 [[TMP15]], 3
+; CHECK-INLINE-NEXT: [[TMP35:%.*]] = add i64 [[TMP34]], [[TMP1]]
+; CHECK-INLINE-NEXT: [[TMP36:%.*]] = inttoptr i64 [[TMP35]] to ptr
+; CHECK-INLINE-NEXT: [[TMP37:%.*]] = load i8, ptr [[TMP36]], align 1
+; CHECK-INLINE-NEXT: [[TMP38:%.*]] = icmp ne i8 [[TMP37]], 0
+; CHECK-INLINE-NEXT: br i1 [[TMP38]], label [[TMP39:%.*]], label [[TMP44:%.*]], !prof [[PROF0:![0-9]+]]
+; CHECK-INLINE: 39:
+; CHECK-INLINE-NEXT: [[TMP40:%.*]] = and i64 [[TMP15]], 7
+; CHECK-INLINE-NEXT: [[TMP41:%.*]] = trunc i64 [[TMP40]] to i8
+; CHECK-INLINE-NEXT: [[TMP42:%.*]] = icmp sge i8 [[TMP41]], [[TMP37]]
+; CHECK-INLINE-NEXT: br i1 [[TMP42]], label [[TMP43:%.*]], label [[TMP44]]
+; CHECK-INLINE: 43:
+; CHECK-INLINE-NEXT: call void @__asan_report_store1(i64 [[TMP15]]) #[[ATTR8:[0-9]+]]
+; CHECK-INLINE-NEXT: unreachable
+; CHECK-INLINE: 44:
+; CHECK-INLINE-NEXT: store volatile i8 0, ptr [[TMP16]], align 1
+; CHECK-INLINE-NEXT: [[TMP45:%.*]] = add i64 [[TMP23]], 1066
+; CHECK-INLINE-NEXT: call void @__asan_set_shadow_f8(i64 [[TMP45]], i64 1)
+; CHECK-INLINE-NEXT: call void @llvm.lifetime.end.p0(i64 4, ptr [[TMP16]])
+; CHECK-INLINE-NEXT: [[TMP46:%.*]] = alloca i8, i64 96, align 32
+; CHECK-INLINE-NEXT: [[TMP47:%.*]] = ptrtoint ptr [[TMP46]] to i64
+; CHECK-INLINE-NEXT: [[TMP48:%.*]] = add i64 [[TMP47]], 32
+; CHECK-INLINE-NEXT: call void @__asan_alloca_poison(i64 [[TMP48]], i64 4)
+; CHECK-INLINE-NEXT: [[TMP49:%.*]] = ptrtoint ptr [[TMP46]] to i64
+; CHECK-INLINE-NEXT: store i64 [[TMP49]], ptr [[TMP0]], align 8
+; CHECK-INLINE-NEXT: [[TMP50:%.*]] = inttoptr i64 [[TMP48]] to ptr
+; CHECK-INLINE-NEXT: [[TMP51:%.*]] = alloca i8, i64 96, align 32
+; CHECK-INLINE-NEXT: [[TMP52:%.*]] = ptrtoint ptr [[TMP51]] to i64
+; CHECK-INLINE-NEXT: [[TMP53:%.*]] = add i64 [[TMP52]], 32
+; CHECK-INLINE-NEXT: call void @__asan_alloca_poison(i64 [[TMP53]], i64 8)
+; CHECK-INLINE-NEXT: [[TMP54:%.*]] = ptrtoint ptr [[TMP51]] to i64
+; CHECK-INLINE-NEXT: store i64 [[TMP54]], ptr [[TMP0]], align 8
+; CHECK-INLINE-NEXT: [[TMP55:%.*]] = inttoptr i64 [[TMP53]] to ptr
+; CHECK-INLINE-NEXT: [[TMP56:%.*]] = lshr i64 [[TMP53]], 3
+; CHECK-INLINE-NEXT: [[TMP57:%.*]] = add i64 [[TMP56]], [[TMP1]]
+; CHECK-INLINE-NEXT: [[TMP58:%.*]] = inttoptr i64 [[TMP57]] to ptr
+; CHECK-INLINE-NEXT: [[TMP59:%.*]] = load i8, ptr [[TMP58]], align 1
+; CHECK-INLINE-NEXT: [[TMP60:%.*]] = icmp ne i8 [[TMP59]], 0
+; CHECK-INLINE-NEXT: br i1 [[TMP60]], label [[TMP61:%.*]], label [[TMP62:%.*]]
+; CHECK-INLINE: 61:
+; CHECK-INLINE-NEXT: call void @__asan_report_store8(i64 [[TMP53]]) #[[ATTR8]]
+; CHECK-INLINE-NEXT: unreachable
+; CHECK-INLINE: 62:
+; CHECK-INLINE-NEXT: store volatile i64 0, ptr [[TMP55]], align 8
+; CHECK-INLINE-NEXT: [[TMPCOPYI64:%.*]] = load i64, ptr [[TMP55]], align 8
+; CHECK-INLINE-NEXT: [[TMP63:%.*]] = and i64 [[TMPCOPYI64]], 31
+; CHECK-INLINE-NEXT: [[TMP64:%.*]] = sub i64 32, [[TMP63]]
+; CHECK-INLINE-NEXT: [[TMP65:%.*]] = icmp ne i64 [[TMP64]], 32
+; CHECK-INLINE-NEXT: [[TMP66:%.*]] = select i1 [[TMP65]], i64 [[TMP64]], i64 0
+; CHECK-INLINE-NEXT: [[TMP67:%.*]] = add i64 64, [[TMP66]]
+; CHECK-INLINE-NEXT: [[TMP68:%.*]] = add i64 [[TMPCOPYI64]], [[TMP67]]
+; CHECK-INLINE-NEXT: [[TMP69:%.*]] = alloca i8, i64 [[TMP68]], align 32
+; CHECK-INLINE-NEXT: [[TMP70:%.*]] = ptrtoint ptr [[TMP69]] to i64
+; CHECK-INLINE-NEXT: [[TMP71:%.*]] = add i64 [[TMP70]], 32
+; CHECK-INLINE-NEXT: call void @__asan_alloca_poison(i64 [[TMP71]], i64 [[TMPCOPYI64]])
+; CHECK-INLINE-NEXT: [[TMP72:%.*]] = ptrtoint ptr [[TMP69]] to i64
+; CHECK-INLINE-NEXT: store i64 [[TMP72]], ptr [[TMP0]], align 8
+; CHECK-INLINE-NEXT: [[TMP73:%.*]] = inttoptr i64 [[TMP71]] to ptr
+; CHECK-INLINE-NEXT: [[TMP74:%.*]] = lshr i64 [[TMP71]], 3
+; CHECK-INLINE-NEXT: [[TMP75:%.*]] = add i64 [[TMP74]], [[TMP1]]
+; CHECK-INLINE-NEXT: [[TMP76:%.*]] = inttoptr i64 [[TMP75]] to ptr
+; CHECK-INLINE-NEXT: [[TMP77:%.*]] = load i8, ptr [[TMP76]], align 1
+; CHECK-INLINE-NEXT: [[TMP78:%.*]] = icmp ne i8 [[TMP77]], 0
+; CHECK-INLINE-NEXT: br i1 [[TMP78]], label [[TMP79:%.*]], label [[TMP84:%.*]], !prof [[PROF0]]
+; CHECK-INLINE: 79:
+; CHECK-INLINE-NEXT: [[TMP80:%.*]] = and i64 [[TMP71]], 7
+; CHECK-INLINE-NEXT: [[TMP81:%.*]] = trunc i64 [[TMP80]] to i8
+; CHECK-INLINE-NEXT: [[TMP82:%.*]] = icmp sge i8 [[TMP81]], [[TMP77]]
+; CHECK-INLINE-NEXT: br i1 [[TMP82]], label [[TMP83:%.*]], label [[TMP84]]
+; CHECK-INLINE: 83:
+; CHECK-INLINE-NEXT: call void @__asan_report_store1(i64 [[TMP71]]) #[[ATTR8]]
+; CHECK-INLINE-NEXT: unreachable
+; CHECK-INLINE: 84:
+; CHECK-INLINE-NEXT: store volatile i8 0, ptr [[TMP73]], align 1
+; CHECK-INLINE-NEXT: invoke void @MayThrowFunc()
+; CHECK-INLINE-NEXT: to label [[INVOKE_CONT:%.*]] unwind label [[EHCLEANUP:%.*]]
+; CHECK-INLINE: invoke.cont:
+; CHECK-INLINE-NEXT: call void @DeInit(ptr [[TMP14]])
+; CHECK-INLINE-NEXT: [[TMP85:%.*]] = ptrtoint ptr [[TMP0]] to i64
+; CHECK-INLINE-NEXT: [[TMP86:%.*]] = load i64, ptr [[TMP0]], align 8
+; CHECK-INLINE-NEXT: call void @__asan_allocas_unpoison(i64 [[TMP86]], i64 [[TMP85]])
+; CHECK-INLINE-NEXT: store i64 1172321806, ptr [[TMP17]], align 8
+; CHECK-INLINE-NEXT: [[TMP87:%.*]] = icmp ne i64 [[TMP7]], 0
+; CHECK-INLINE-NEXT: br i1 [[TMP87]], label [[TMP88:%.*]], label [[TMP89:%.*]]
+; CHECK-INLINE: 88:
+; CHECK-INLINE-NEXT: call void @__asan_stack_free_8(i64 [[TMP7]], i64 8544)
+; CHECK-INLINE-NEXT: br label [[TMP91:%.*]]
+; CHECK-INLINE: 89:
+; CHECK-INLINE-NEXT: call void @__asan_set_shadow_00(i64 [[TMP23]], i64 4)
+; CHECK-INLINE-NEXT: [[TMP90:%.*]] = add i64 [[TMP23]], 1028
+; CHECK-INLINE-NEXT: call void @__asan_set_shadow_00(i64 [[TMP90]], i64 40)
+; CHECK-INLINE-NEXT: br label [[TMP91]]
+; CHECK-INLINE: 91:
+; CHECK-INLINE-NEXT: ret void
+; CHECK-INLINE: ehcleanup:
+; CHECK-INLINE-NEXT: [[TMP92:%.*]] = cleanuppad within none []
+; CHECK-INLINE-NEXT: unreachable
+;
+; CHECK-OUTLINE-LABEL: define void @FuncletPersonality(
+; CHECK-OUTLINE-SAME: ptr [[PTRPARAM:%.*]]) #[[ATTR4:[0-9]+]] personality ptr @__CxxFrameHandler3 {
+; CHECK-OUTLINE-NEXT: entry:
+; CHECK-OUTLINE-NEXT: [[TMP0:%.*]] = alloca i64, align 32
+; CHECK-OUTLINE-NEXT: store i64 0, ptr [[TMP0]], align 8
+; CHECK-OUTLINE-NEXT: [[TMP1:%.*]] = load i64, ptr @__asan_shadow_memory_dynamic_address, align 8
+; CHECK-OUTLINE-NEXT: [[ASAN_LOCAL_STACK_BASE:%.*]] = alloca i64, align 8
+; CHECK-OUTLINE-NEXT: [[TMP2:%.*]] = load i32, ptr @__asan_option_detect_stack_use_after_return, align 4
+; CHECK-OUTLINE-NEXT: [[TMP3:%.*]] = icmp ne i32 [[TMP2]], 0
+; CHECK-OUTLINE-NEXT: br i1 [[TMP3]], label [[TMP4:%.*]], label [[TMP6:%.*]]
+; CHECK-OUTLINE: 4:
+; CHECK-OUTLINE-NEXT: [[TMP5:%.*]] = call i64 @__asan_stack_malloc_8(i64 8608)
+; CHECK-OUTLINE-NEXT: br label [[TMP6]]
+; CHECK-OUTLINE: 6:
+; CHECK-OUTLINE-NEXT: [[TMP7:%.*]] = phi i64 [ 0, [[ENTRY:%.*]] ], [ [[TMP5]], [[TMP4]] ]
+; CHECK-OUTLINE-NEXT: [[TMP8:%.*]] = icmp eq i64 [[TMP7]], 0
+; CHECK-OUTLINE-NEXT: br i1 [[TMP8]], label [[TMP9:%.*]], label [[TMP11:%.*]]
+; CHECK-OUTLINE: 9:
+; CHECK-OUTLINE-NEXT: [[MYALLOCA:%.*]] = alloca i8, i64 8608, align 32
+; CHECK-OUTLINE-NEXT: [[TMP10:%.*]] = ptrtoint ptr [[MYALLOCA]] to i64
+; CHECK-OUTLINE-NEXT: br label [[TMP11]]
+; CHECK-OUTLINE: 11:
+; CHECK-OUTLINE-NEXT: [[TMP12:%.*]] = phi i64 [ [[TMP7]], [[TMP6]] ], [ [[TMP10]], [[TMP9]] ]
+; CHECK-OUTLINE-NEXT: store i64 [[TMP12]], ptr [[ASAN_LOCAL_STACK_BASE]], align 8
+; CHECK-OUTLINE-NEXT: [[TMP13:%.*]] = add i64 [[TMP12]], 32
+; CHECK-OUTLINE-NEXT: [[TMP14:%.*]] = inttoptr i64 [[TMP13]] to ptr
+; CHECK-OUTLINE-NEXT: [[TMP15:%.*]] = add i64 [[TMP12]], 8528
+; CHECK-OUTLINE-NEXT: [[TMP16:%.*]] = inttoptr i64 [[TMP15]] to ptr
+; CHECK-OUTLINE-NEXT: [[TMP17:%.*]] = add i64 [[TMP12]], 8560
+; CHECK-OUTLINE-NEXT: [[TMP18:%.*]] = inttoptr i64 [[TMP17]] to ptr
+; CHECK-OUTLINE-NEXT: [[TMP19:%.*]] = inttoptr i64 [[TMP12]] to ptr
+; CHECK-OUTLINE-NEXT: store i64 1102416563, ptr [[TMP19]], align 8
+; CHECK-OUTLINE-NEXT: [[TMP20:%.*]] = add i64 [[TMP12]], 8
+; CHECK-OUTLINE-NEXT: [[TMP21:%.*]] = inttoptr i64 [[TMP20]] to ptr
+; CHECK-OUTLINE-NEXT: store i64 ptrtoint (ptr @___asan_gen_ to i64), ptr [[TMP21]], align 8
+; CHECK-OUTLINE-NEXT: [[TMP22:%.*]] = add i64 [[TMP12]], 16
+; CHECK-OUTLINE-NEXT: [[TMP23:%.*]] = inttoptr i64 [[TMP22]] to ptr
+; CHECK-OUTLINE-NEXT: store i64 ptrtoint (ptr @FuncletPersonality to i64), ptr [[TMP23]], align 8
+; CHECK-OUTLINE-NEXT: [[TMP24:%.*]] = lshr i64 [[TMP12]], 3
+; CHECK-OUTLINE-NEXT: [[TMP25:%.*]] = add i64 [[TMP24]], [[TMP1]]
+; CHECK-OUTLINE-NEXT: call void @__asan_set_shadow_f1(i64 [[TMP25]], i64 4)
+; CHECK-OUTLINE-NEXT: [[TMP26:%.*]] = add i64 [[TMP25]], 1028
+; CHECK-OUTLINE-NEXT: call void @__asan_set_shadow_f2(i64 [[TMP26]], i64 32)
+; CHECK-OUTLINE-NEXT: [[TMP27:%.*]] = add i64 [[TMP25]], 1060
+; CHECK-OUTLINE-NEXT: call void @__asan_set_shadow_04(i64 [[TMP27]], i64 1)
+; CHECK-OUTLINE-NEXT: [[TMP28:%.*]] = add i64 [[TMP25]], 1061
+; CHECK-OUTLINE-NEXT: call void @__asan_set_shadow_f2(i64 [[TMP28]], i64 1)
+; CHECK-OUTLINE-NEXT: [[TMP29:%.*]] = add i64 [[TMP25]], 1062
+; CHECK-OUTLINE-NEXT: call void @__asan_set_shadow_04(i64 [[TMP29]], i64 1)
+; CHECK-OUTLINE-NEXT: [[TMP30:%.*]] = add i64 [[TMP25]], 1063
+; CHECK-OUTLINE-NEXT: call void @__asan_set_shadow_f2(i64 [[TMP30]], i64 1)
+; CHECK-OUTLINE-NEXT: [[TMP31:%.*]] = add i64 [[TMP25]], 1064
+; CHECK-OUTLINE-NEXT: call void @__asan_set_shadow_04(i64 [[TMP31]], i64 1)
+; CHECK-OUTLINE-NEXT: [[TMP32:%.*]] = add i64 [[TMP25]], 1065
+; CHECK-OUTLINE-NEXT: call void @__asan_set_shadow_f2(i64 [[TMP32]], i64 1)
+; CHECK-OUTLINE-NEXT: [[TMP33:%.*]] = add i64 [[TMP25]], 1066
+; CHECK-OUTLINE-NEXT: call void @__asan_set_shadow_f8(i64 [[TMP33]], i64 1)
+; CHECK-OUTLINE-NEXT: [[TMP34:%.*]] = add i64 [[TMP25]], 1067
+; CHECK-OUTLINE-NEXT: call void @__asan_set_shadow_f2(i64 [[TMP34]], i64 1)
+; CHECK-OUTLINE-NEXT: [[TMP35:%.*]] = add i64 [[TMP25]], 1068
+; CHECK-OUTLINE-NEXT: call void @__asan_set_shadow_f8(i64 [[TMP35]], i64 1)
+; CHECK-OUTLINE-NEXT: [[TMP36:%.*]] = add i64 [[TMP25]], 1069
+; CHECK-OUTLINE-NEXT: call void @__asan_set_shadow_f2(i64 [[TMP36]], i64 1)
+; CHECK-OUTLINE-NEXT: [[TMP37:%.*]] = add i64 [[TMP25]], 1071
+; CHECK-OUTLINE-NEXT: call void @__asan_set_shadow_f3(i64 [[TMP37]], i64 5)
+; CHECK-OUTLINE-NEXT: [[TMP38:%.*]] = add i64 [[TMP25]], 1066
+; CHECK-OUTLINE-NEXT: call void @__asan_set_shadow_04(i64 [[TMP38]], i64 1)
+; CHECK-OUTLINE-NEXT: call void @llvm.lifetime.start.p0(i64 4, ptr [[TMP16]])
+; CHECK-OUTLINE-NEXT: call void @__asan_store1(i64 [[TMP15]])
+; CHECK-OUTLINE-NEXT: store volatile i8 0, ptr [[TMP16]], align 1
+; CHECK-OUTLINE-NEXT: [[TMP39:%.*]] = add i64 [[TMP25]], 1066
+; CHECK-OUTLINE-NEXT: call void @__asan_set_shadow_f8(i64 [[TMP39]], i64 1)
+; CHECK-OUTLINE-NEXT: call void @llvm.lifetime.end.p0(i64 4, ptr [[TMP16]])
+; CHECK-OUTLINE-NEXT: call void @__asan_store8(i64 [[TMP17]])
+; CHECK-OUTLINE-NEXT: store volatile i64 0, ptr [[TMP18]], align 8
+; CHECK-OUTLINE-NEXT: [[TMPCOPYI64:%.*]] = load i64, ptr [[TMP18]], align 8
+; CHECK-OUTLINE-NEXT: [[TMP40:%.*]] = and i64 [[TMPCOPYI64]], 31
+; CHECK-OUTLINE-NEXT: [[TMP41:%.*]] = sub i64 32, [[TMP40]]
+; CHECK-OUTLINE-NEXT: [[TMP42:%.*]] = icmp ne i64 [[TMP41]], 32
+; CHECK-OUTLINE-NEXT: [[TMP43:%.*]] = select i1 [[TMP42]], i64 [[TMP41]], i64 0
+; CHECK-OUTLINE-NEXT: [[TMP44:%.*]] = add i64 64, [[TMP43]]
+; CHECK-OUTLINE-NEXT: [[TMP45:%.*]] = add i64 [[TMPCOPYI64]], [[TMP44]]
+; CHECK-OUTLINE-NEXT: [[TMP46:%.*]] = alloca i8, i64 [[TMP45]], align 32
+; CHECK-OUTLINE-NEXT: [[TMP47:%.*]] = ptrtoint ptr [[TMP46]] to i64
+; CHECK-OUTLINE-NEXT: [[TMP48:%.*]] = add i64 [[TMP47]], 32
+; CHECK-OUTLINE-NEXT: call void @__asan_alloca_poison(i64 [[TMP48]], i64 [[TMPCOPYI64]])
+; CHECK-OUTLINE-NEXT: [[TMP49:%.*]] = ptrtoint ptr [[TMP46]] to i64
+; CHECK-OUTLINE-NEXT: store i64 [[TMP49]], ptr [[TMP0]], align 8
+; CHECK-OUTLINE-NEXT: [[TMP50:%.*]] = inttoptr i64 [[TMP48]] to ptr
+; CHECK-OUTLINE-NEXT: call void @__asan_store1(i64 [[TMP48]])
+; CHECK-OUTLINE-NEXT: store volatile i8 0, ptr [[TMP50]], align 1
+; CHECK-OUTLINE-NEXT: invoke void @MayThrowFunc()
+; CHECK-OUTLINE-NEXT: to label [[INVOKE_CONT:%.*]] unwind label [[EHCLEANUP:%.*]]
+; CHECK-OUTLINE: invoke.cont:
+; CHECK-OUTLINE-NEXT: call void @DeInit(ptr [[TMP14]])
+; CHECK-OUTLINE-NEXT: [[TMP51:%.*]] = ptrtoint ptr [[TMP0]] to i64
+; CHECK-OUTLINE-NEXT: [[TMP52:%.*]] = load i64, ptr [[TMP0]], align 8
+; CHECK-OUTLINE-NEXT: call void @__asan_allocas_unpoison(i64 [[TMP52]], i64 [[TMP51]])
+; CHECK-OUTLINE-NEXT: store i64 1172321806, ptr [[TMP19]], align 8
+; CHECK-OUTLINE-NEXT: [[TMP53:%.*]] = icmp ne i64 [[TMP7]], 0
+; CHECK-OUTLINE-NEXT: br i1 [[TMP53]], label [[TMP54:%.*]], label [[TMP55:%.*]]
+; CHECK-OUTLINE: 54:
+; CHECK-OUTLINE-NEXT: call void @__asan_stack_free_8(i64 [[TMP7]], i64 8608)
+; CHECK-OUTLINE-NEXT: br label [[TMP58:%.*]]
+; CHECK-OUTLINE: 55:
+; CHECK-OUTLINE-NEXT: call void @__asan_set_shadow_00(i64 [[TMP25]], i64 4)
+; CHECK-OUTLINE-NEXT: [[TMP56:%.*]] = add i64 [[TMP25]], 1028
+; CHECK-OUTLINE-NEXT: call void @__asan_set_shadow_00(i64 [[TMP56]], i64 42)
+; CHECK-OUTLINE-NEXT: [[TMP57:%.*]] = add i64 [[TMP25]], 1071
+; CHECK-OUTLINE-NEXT: call void @__asan_set_shadow_00(i64 [[TMP57]], i64 5)
+; CHECK-OUTLINE-NEXT: br label [[TMP58]]
+; CHECK-OUTLINE: 58:
+; CHECK-OUTLINE-NEXT: ret void
+; CHECK-OUTLINE: ehcleanup:
+; CHECK-OUTLINE-NEXT: [[TMP59:%.*]] = cleanuppad within none []
+; CHECK-OUTLINE-NEXT: unreachable
+;
+
+
+entry:
+ ; Large enough local alloca to have asan generate a __asan_stack_free_#() call
+ %largeObj = alloca [2048 x i32], align 16
+ %tmpInt1 = alloca i32, align 4
+ %tmpInt2 = alloca i32, align 4
+ %tmpInt3 = alloca i32, align 4
+
+ ; Creating %lifetimeInt and %lifetimeArr, and managing their lifetimes
+ ; to make asan generate stack poisoning calls
+ %lifetimeInt = alloca i32, align 4
+ call void @llvm.lifetime.start.p0(i64 4, ptr %lifetimeInt)
+ store volatile i8 0, ptr %lifetimeInt
+ call void @llvm.lifetime.end.p0(i64 4, ptr %lifetimeInt)
+ %lifetimeArr = alloca i32, align 4
+
+ ; Dynamic alloca to generate a @__asan_allocas_unpoison call in ehcleanup
+ %tmpVolatilei64 = alloca i64, align 8
+ store volatile i64 0, ptr %tmpVolatilei64, align 8
+ %tmpCopyi64 = load i64, ptr %tmpVolatilei64, align 8
+ %tmpVolatilei8 = alloca i8, i64 %tmpCopyi64, align 32
+ store volatile i8 0, ptr %tmpVolatilei8
+
+ invoke void @MayThrowFunc()
+ to label %invoke.cont unwind label %ehcleanup
+invoke.cont: ; preds = %entry
+ call void @DeInit(ptr %largeObj)
+ ret void
+
+ehcleanup: ; preds = %entry
+ %0 = cleanuppad within none []
+
+ ; Make asan add a call to __asan_unpoison_stack_memory
+ call void @llvm.lifetime.start.p0(i64 4, ptr %lifetimeArr)
+ ; Make asan add a call to __asan_report_store1
+ store volatile i8 0, ptr %lifetimeArr
+ ; Make asan add a call to __asan_poison_stack_memory
+ call void @llvm.lifetime.end.p0(i64 4, ptr %lifetimeArr)
+
+ call void @DeInit(ptr %largeObj) [ "funclet"(token %0) ]
+ call void @llvm.memset.p0.i64(ptr align 4 %tmpInt1, i8 0, i64 4, i1 false)
+ call void @llvm.memcpy.p0.p0.i64(ptr align 4 %tmpInt2, ptr align 4 %tmpInt1, i64 4, i1 false)
+ call void @llvm.memmove.p0.p0.i64(ptr align 4 %tmpInt3, ptr align 4 %tmpInt1, i64 4, i1 false)
+ %cmpAddr = icmp ule ptr %tmpInt1, %tmpInt2
+ %addr1 = ptrtoint ptr %tmpInt1 to i64
+ %addr2 = ptrtoint ptr %tmpInt2 to i64
+ %subAddr = sub i64 %addr1, %addr2
+
+ store i64 0, ptr %ptrParam, align 1
+
+ %cmp = icmp ne i64 %subAddr, 0
+ br i1 %cmp, label %ehexit, label %noreturncall
+
+noreturncall:
+ call void @NoReturn(ptr null, ptr null) noreturn [ "funclet"(token %0) ]
+ unreachable
+
+ehexit:
+ cleanupret from %0 unwind to caller
+
+; Ensure unreachable basic block doesn't make the compiler assert, as it's a special case for coloring computation.
+nopredecessor:
+ call void @llvm.memset.p0.i64(ptr align 4 %tmpInt1, i8 0, i64 4, i1 false)
+ unreachable
+}
+
+; Non-Windows personality, ensure no funclet gets attached to asan runtime call.
+define void @OtherPersonality(ptr %ptrParam) sanitize_address personality ptr @dummyPersonality {
+; CHECK-LABEL: define void @OtherPersonality(
+; CHECK-SAME: ptr [[PTRPARAM:%.*]]) #[[ATTR4:[0-9]+]] personality ptr @dummyPersonality {
+; CHECK-NEXT: entry:
+; CHECK-NEXT: [[TMP0:%.*]] = load i64, ptr @__asan_shadow_memory_dynamic_address, align 8
+; CHECK-NEXT: [[ASAN_LOCAL_STACK_BASE:%.*]] = alloca i64, align 8
+; CHECK-NEXT: [[TMP1:%.*]] = load i32, ptr @__asan_option_detect_stack_use_after_return, align 4
+; CHECK-NEXT: [[TMP2:%.*]] = icmp ne i32 [[TMP1]], 0
+; CHECK-NEXT: br i1 [[TMP2]], label [[TMP3:%.*]], label [[TMP5:%.*]]
+; CHECK: 3:
+; CHECK-NEXT: [[TMP4:%.*]] = call i64 @__asan_stack_malloc_0(i64 64)
+; CHECK-NEXT: br label [[TMP5]]
+; CHECK: 5:
+; CHECK-NEXT: [[TMP6:%.*]] = phi i64 [ 0, [[ENTRY:%.*]] ], [ [[TMP4]], [[TMP3]] ]
+; CHECK-NEXT: [[TMP7:%.*]] = icmp eq i64 [[TMP6]], 0
+; CHECK-NEXT: br i1 [[TMP7]], label [[TMP8:%.*]], label [[TMP10:%.*]]
+; CHECK: 8:
+; CHECK-NEXT: [[MYALLOCA:%.*]] = alloca i8, i64 64, align 32
+; CHECK-NEXT: [[TMP9:%.*]] = ptrtoint ptr [[MYALLOCA]] to i64
+; CHECK-NEXT: br label [[TMP10]]
+; CHECK: 10:
+; CHECK-NEXT: [[TMP11:%.*]] = phi i64 [ [[TMP6]], [[TMP5]] ], [ [[TMP9]], [[TMP8]] ]
+; CHECK-NEXT: store i64 [[TMP11]], ptr [[ASAN_LOCAL_STACK_BASE]], align 8
+; CHECK-NEXT: [[TMP12:%.*]] = add i64 [[TMP11]], 32
+; CHECK-NEXT: [[TMP13:%.*]] = inttoptr i64 [[TMP12]] to ptr
+; CHECK-NEXT: [[TMP14:%.*]] = inttoptr i64 [[TMP11]] to ptr
+; CHECK-NEXT: store i64 1102416563, ptr [[TMP14]], align 8
+; CHECK-NEXT: [[TMP15:%.*]] = add i64 [[TMP11]], 8
+; CHECK-NEXT: [[TMP16:%.*]] = inttoptr i64 [[TMP15]] to ptr
+; CHECK-NEXT: store i64 ptrtoint (ptr @___asan_gen_.1 to i64), ptr [[TMP16]], align 8
+; CHECK-NEXT: [[TMP17:%.*]] = add i64 [[TMP11]], 16
+; CHECK-NEXT: [[TMP18:%.*]] = inttoptr i64 [[TMP17]] to ptr
+; CHECK-NEXT: store i64 ptrtoint (ptr @OtherPersonality to i64), ptr [[TMP18]], align 8
+; CHECK-NEXT: [[TMP19:%.*]] = lshr i64 [[TMP11]], 3
+; CHECK-NEXT: [[TMP20:%.*]] = add i64 [[TMP19]], [[TMP0]]
+; CHECK-NEXT: [[TMP21:%.*]] = add i64 [[TMP20]], 0
+; CHECK-NEXT: call void @__asan_set_shadow_f1(i64 [[TMP21]], i64 4)
+; CHECK-NEXT: [[TMP22:%.*]] = add i64 [[TMP20]], 4
+; CHECK-NEXT: call void @__asan_set_shadow_04(i64 [[TMP22]], i64 1)
+; CHECK-NEXT: [[TMP23:%.*]] = add i64 [[TMP20]], 5
+; CHECK-NEXT: call void @__asan_set_shadow_f3(i64 [[TMP23]], i64 3)
+; CHECK-NEXT: invoke void @MayThrowFunc()
+; CHECK-NEXT: to label [[INVOKE_CONT:%.*]] unwind label [[EHCLEANUP:%.*]]
+; CHECK: invoke.cont:
+; CHECK-NEXT: store i64 1172321806, ptr [[TMP14]], align 8
+; CHECK-NEXT: [[TMP24:%.*]] = icmp ne i64 [[TMP6]], 0
+; CHECK-NEXT: br i1 [[TMP24]], label [[TMP25:%.*]], label [[TMP26:%.*]]
+; CHECK: 25:
+; CHECK-NEXT: call void @__asan_stack_free_0(i64 [[TMP6]], i64 64)
+; CHECK-NEXT: br label [[TMP28:%.*]]
+; CHECK: 26:
+; CHECK-NEXT: [[TMP27:%.*]] = add i64 [[TMP20]], 0
+; CHECK-NEXT: call void @__asan_set_shadow_00(i64 [[TMP27]], i64 8)
+; CHECK-NEXT: br label [[TMP28]]
+; CHECK: 28:
+; CHECK-NEXT: ret void
+; CHECK: ehcleanup:
+; CHECK-NEXT: [[TMP29:%.*]] = cleanuppad within none []
+; CHECK-NEXT: [[TMP30:%.*]] = call ptr @__asan_memset(ptr [[TMP13]], i32 0, i64 4)
+; CHECK-NEXT: store i64 1172321806, ptr [[TMP14]], align 8
+; CHECK-NEXT: [[TMP31:%.*]] = icmp ne i64 [[TMP6]], 0
+; CHECK-NEXT: br i1 [[TMP31]], label [[TMP32:%.*]], label [[TMP33:%.*]]
+; CHECK: 32:
+; CHECK-NEXT: call void @__asan_stack_free_0(i64 [[TMP6]], i64 64)
+; CHECK-NEXT: br label [[TMP35:%.*]]
+; CHECK: 33:
+; CHECK-NEXT: [[TMP34:%.*]] = add i64 [[TMP20]], 0
+; CHECK-NEXT: call void @__asan_set_shadow_00(i64 [[TMP34]], i64 8)
+; CHECK-NEXT: br label [[TMP35]]
+; CHECK: 35:
+; CHECK-NEXT: cleanupret from [[TMP29]] unwind to caller
+;
+entry:
+ %tmpInt = alloca i32, align 4
+ invoke void @MayThrowFunc()
+ to label %invoke.cont unwind label %ehcleanup
+invoke.cont: ; preds = %entry
+ ret void
+
+ehcleanup: ; preds = %entry
+ %0 = cleanuppad within none []
+ call void @llvm.memset.p0.i64(ptr align 4 %tmpInt, i8 0, i64 4, i1 false)
+ cleanupret from %0 unwind to caller
+}
+;.
+; CHECK-INLINE: [[PROF0]] = !{!"branch_weights", i32 1, i32 100000}
+;.
>From 3a30d8e9e59c152caec7abc5cf5437b21cac428e Mon Sep 17 00:00:00 2001
From: Alexey Bataev <5361294+alexey-bataev at users.noreply.github.com>
Date: Fri, 1 Mar 2024 13:49:29 -0500
Subject: [PATCH 281/406] [SLP]Check if masked gather can be emitted as a serie
of loads/insert subvector.
Masked gather is very expensive operation and sometimes better to
represent it as a serie of consecutive/strided loads + insertsubvectors
sequences. Patch adds some basic estimation and if loads+insertsubvector
is cheaper, decides to represent it in this way rather than masked
gather.
Reviewers: RKSimon
Reviewed By: RKSimon
Pull Request: https://github.com/llvm/llvm-project/pull/83481
---
.../Transforms/Vectorize/SLPVectorizer.cpp | 96 +++++++++++++++++--
.../X86/scatter-vectorize-reused-pointer.ll | 22 +++--
2 files changed, 102 insertions(+), 16 deletions(-)
diff --git a/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp b/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
index f49ca17a67cb40..629d0a0e3a282b 100644
--- a/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
+++ b/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
@@ -4000,12 +4000,14 @@ static bool isReverseOrder(ArrayRef<unsigned> Order) {
/// Checks if the given array of loads can be represented as a vectorized,
/// scatter or just simple gather.
-static LoadsState canVectorizeLoads(ArrayRef<Value *> VL, const Value *VL0,
+static LoadsState canVectorizeLoads(const BoUpSLP &R, ArrayRef<Value *> VL,
+ const Value *VL0,
const TargetTransformInfo &TTI,
const DataLayout &DL, ScalarEvolution &SE,
LoopInfo &LI, const TargetLibraryInfo &TLI,
SmallVectorImpl<unsigned> &Order,
- SmallVectorImpl<Value *> &PointerOps) {
+ SmallVectorImpl<Value *> &PointerOps,
+ bool TryRecursiveCheck = true) {
// Check that a vectorized load would load the same memory as a scalar
// load. For example, we don't want to vectorize loads that are smaller
// than 8-bit. Even though we have a packed struct {<i2, i2, i2, i2>} LLVM
@@ -4098,6 +4100,78 @@ static LoadsState canVectorizeLoads(ArrayRef<Value *> VL, const Value *VL0,
}
}
}
+ auto CheckForShuffledLoads = [&](Align CommonAlignment) {
+ unsigned Sz = DL.getTypeSizeInBits(ScalarTy);
+ unsigned MinVF = R.getMinVF(Sz);
+ unsigned MaxVF = std::max<unsigned>(bit_floor(VL.size() / 2), MinVF);
+ MaxVF = std::min(R.getMaximumVF(Sz, Instruction::Load), MaxVF);
+ for (unsigned VF = MaxVF; VF >= MinVF; VF /= 2) {
+ unsigned VectorizedCnt = 0;
+ SmallVector<LoadsState> States;
+ for (unsigned Cnt = 0, End = VL.size(); Cnt + VF <= End;
+ Cnt += VF, ++VectorizedCnt) {
+ ArrayRef<Value *> Slice = VL.slice(Cnt, VF);
+ SmallVector<unsigned> Order;
+ SmallVector<Value *> PointerOps;
+ LoadsState LS =
+ canVectorizeLoads(R, Slice, Slice.front(), TTI, DL, SE, LI, TLI,
+ Order, PointerOps, /*TryRecursiveCheck=*/false);
+ // Check that the sorted loads are consecutive.
+ if (LS == LoadsState::Gather)
+ break;
+ // If need the reorder - consider as high-cost masked gather for now.
+ if ((LS == LoadsState::Vectorize ||
+ LS == LoadsState::StridedVectorize) &&
+ !Order.empty() && !isReverseOrder(Order))
+ LS = LoadsState::ScatterVectorize;
+ States.push_back(LS);
+ }
+ // Can be vectorized later as a serie of loads/insertelements.
+ if (VectorizedCnt == VL.size() / VF) {
+ // Compare masked gather cost and loads + insersubvector costs.
+ TTI::TargetCostKind CostKind = TTI::TCK_RecipThroughput;
+ InstructionCost MaskedGatherCost = TTI.getGatherScatterOpCost(
+ Instruction::Load, VecTy,
+ cast<LoadInst>(VL0)->getPointerOperand(),
+ /*VariableMask=*/false, CommonAlignment, CostKind);
+ InstructionCost VecLdCost = 0;
+ auto *SubVecTy = FixedVectorType::get(ScalarTy, VF);
+ for (auto [I, LS] : enumerate(States)) {
+ auto *LI0 = cast<LoadInst>(VL[I * VF]);
+ switch (LS) {
+ case LoadsState::Vectorize:
+ VecLdCost += TTI.getMemoryOpCost(
+ Instruction::Load, SubVecTy, LI0->getAlign(),
+ LI0->getPointerAddressSpace(), CostKind,
+ TTI::OperandValueInfo());
+ break;
+ case LoadsState::StridedVectorize:
+ VecLdCost += TTI.getStridedMemoryOpCost(
+ Instruction::Load, SubVecTy, LI0->getPointerOperand(),
+ /*VariableMask=*/false, CommonAlignment, CostKind);
+ break;
+ case LoadsState::ScatterVectorize:
+ VecLdCost += TTI.getGatherScatterOpCost(
+ Instruction::Load, SubVecTy, LI0->getPointerOperand(),
+ /*VariableMask=*/false, CommonAlignment, CostKind);
+ break;
+ case LoadsState::Gather:
+ llvm_unreachable(
+ "Expected only consecutive, strided or masked gather loads.");
+ }
+ VecLdCost +=
+ TTI.getShuffleCost(TTI ::SK_InsertSubvector, VecTy,
+ std::nullopt, CostKind, I * VF, SubVecTy);
+ }
+ // If masked gather cost is higher - better to vectorize, so
+ // consider it as a gather node. It will be better estimated
+ // later.
+ if (MaskedGatherCost > VecLdCost)
+ return true;
+ }
+ }
+ return false;
+ };
// TODO: need to improve analysis of the pointers, if not all of them are
// GEPs or have > 2 operands, we end up with a gather node, which just
// increases the cost.
@@ -4114,8 +4188,17 @@ static LoadsState canVectorizeLoads(ArrayRef<Value *> VL, const Value *VL0,
})) {
Align CommonAlignment = computeCommonAlignment<LoadInst>(VL);
if (TTI.isLegalMaskedGather(VecTy, CommonAlignment) &&
- !TTI.forceScalarizeMaskedGather(VecTy, CommonAlignment))
+ !TTI.forceScalarizeMaskedGather(VecTy, CommonAlignment)) {
+ // Check if potential masked gather can be represented as series
+ // of loads + insertsubvectors.
+ if (TryRecursiveCheck && CheckForShuffledLoads(CommonAlignment)) {
+ // If masked gather cost is higher - better to vectorize, so
+ // consider it as a gather node. It will be better estimated
+ // later.
+ return LoadsState::Gather;
+ }
return LoadsState::ScatterVectorize;
+ }
}
}
@@ -5554,8 +5637,8 @@ BoUpSLP::TreeEntry::EntryState BoUpSLP::getScalarsVectorizationState(
// treats loading/storing it as an i8 struct. If we vectorize loads/stores
// from such a struct, we read/write packed bits disagreeing with the
// unvectorized version.
- switch (canVectorizeLoads(VL, VL0, *TTI, *DL, *SE, *LI, *TLI, CurrentOrder,
- PointerOps)) {
+ switch (canVectorizeLoads(*this, VL, VL0, *TTI, *DL, *SE, *LI, *TLI,
+ CurrentOrder, PointerOps)) {
case LoadsState::Vectorize:
return TreeEntry::Vectorize;
case LoadsState::ScatterVectorize:
@@ -7336,7 +7419,7 @@ class BoUpSLP::ShuffleCostEstimator : public BaseShuffleAnalysis {
SmallVector<Value *> PointerOps;
OrdersType CurrentOrder;
LoadsState LS =
- canVectorizeLoads(Slice, Slice.front(), TTI, *R.DL, *R.SE,
+ canVectorizeLoads(R, Slice, Slice.front(), TTI, *R.DL, *R.SE,
*R.LI, *R.TLI, CurrentOrder, PointerOps);
switch (LS) {
case LoadsState::Vectorize:
@@ -7599,7 +7682,6 @@ class BoUpSLP::ShuffleCostEstimator : public BaseShuffleAnalysis {
transformMaskAfterShuffle(CommonMask, CommonMask);
}
SameNodesEstimated = false;
- Cost += createShuffle(&E1, E2, Mask);
if (!E2 && InVectors.size() == 1) {
unsigned VF = E1.getVectorFactor();
if (Value *V1 = InVectors.front().dyn_cast<Value *>()) {
diff --git a/llvm/test/Transforms/SLPVectorizer/X86/scatter-vectorize-reused-pointer.ll b/llvm/test/Transforms/SLPVectorizer/X86/scatter-vectorize-reused-pointer.ll
index bb16b52f44ecf7..dadf5992ba288d 100644
--- a/llvm/test/Transforms/SLPVectorizer/X86/scatter-vectorize-reused-pointer.ll
+++ b/llvm/test/Transforms/SLPVectorizer/X86/scatter-vectorize-reused-pointer.ll
@@ -5,19 +5,23 @@ define void @test(i1 %c, ptr %arg) {
; CHECK-LABEL: @test(
; CHECK-NEXT: br i1 [[C:%.*]], label [[IF:%.*]], label [[ELSE:%.*]]
; CHECK: if:
-; CHECK-NEXT: [[TMP1:%.*]] = insertelement <4 x ptr> poison, ptr [[ARG:%.*]], i32 0
-; CHECK-NEXT: [[TMP2:%.*]] = shufflevector <4 x ptr> [[TMP1]], <4 x ptr> poison, <4 x i32> zeroinitializer
-; CHECK-NEXT: [[TMP3:%.*]] = getelementptr i8, <4 x ptr> [[TMP2]], <4 x i64> <i64 32, i64 24, i64 8, i64 0>
-; CHECK-NEXT: [[TMP4:%.*]] = call <4 x i64> @llvm.masked.gather.v4i64.v4p0(<4 x ptr> [[TMP3]], i32 8, <4 x i1> <i1 true, i1 true, i1 true, i1 true>, <4 x i64> poison)
+; CHECK-NEXT: [[TMP1:%.*]] = load <2 x i64>, ptr [[ARG:%.*]], align 8
+; CHECK-NEXT: [[ARG2_2:%.*]] = getelementptr inbounds i8, ptr [[ARG]], i64 24
+; CHECK-NEXT: [[TMP2:%.*]] = load <2 x i64>, ptr [[ARG2_2]], align 8
+; CHECK-NEXT: [[TMP3:%.*]] = shufflevector <2 x i64> [[TMP2]], <2 x i64> poison, <4 x i32> <i32 1, i32 0, i32 poison, i32 poison>
+; CHECK-NEXT: [[TMP4:%.*]] = shufflevector <2 x i64> [[TMP1]], <2 x i64> poison, <4 x i32> <i32 1, i32 0, i32 poison, i32 poison>
+; CHECK-NEXT: [[TMP5:%.*]] = shufflevector <4 x i64> [[TMP3]], <4 x i64> [[TMP4]], <4 x i32> <i32 0, i32 1, i32 4, i32 5>
; CHECK-NEXT: br label [[JOIN:%.*]]
; CHECK: else:
-; CHECK-NEXT: [[TMP5:%.*]] = insertelement <4 x ptr> poison, ptr [[ARG]], i32 0
-; CHECK-NEXT: [[TMP6:%.*]] = shufflevector <4 x ptr> [[TMP5]], <4 x ptr> poison, <4 x i32> zeroinitializer
-; CHECK-NEXT: [[TMP7:%.*]] = getelementptr i8, <4 x ptr> [[TMP6]], <4 x i64> <i64 32, i64 24, i64 8, i64 0>
-; CHECK-NEXT: [[TMP8:%.*]] = call <4 x i64> @llvm.masked.gather.v4i64.v4p0(<4 x ptr> [[TMP7]], i32 8, <4 x i1> <i1 true, i1 true, i1 true, i1 true>, <4 x i64> poison)
+; CHECK-NEXT: [[TMP6:%.*]] = load <2 x i64>, ptr [[ARG]], align 8
+; CHECK-NEXT: [[ARG_2:%.*]] = getelementptr inbounds i8, ptr [[ARG]], i64 24
+; CHECK-NEXT: [[TMP7:%.*]] = load <2 x i64>, ptr [[ARG_2]], align 8
+; CHECK-NEXT: [[TMP8:%.*]] = shufflevector <2 x i64> [[TMP7]], <2 x i64> poison, <4 x i32> <i32 1, i32 0, i32 poison, i32 poison>
+; CHECK-NEXT: [[TMP9:%.*]] = shufflevector <2 x i64> [[TMP6]], <2 x i64> poison, <4 x i32> <i32 1, i32 0, i32 poison, i32 poison>
+; CHECK-NEXT: [[TMP10:%.*]] = shufflevector <4 x i64> [[TMP8]], <4 x i64> [[TMP9]], <4 x i32> <i32 0, i32 1, i32 4, i32 5>
; CHECK-NEXT: br label [[JOIN]]
; CHECK: join:
-; CHECK-NEXT: [[TMP9:%.*]] = phi <4 x i64> [ [[TMP4]], [[IF]] ], [ [[TMP8]], [[ELSE]] ]
+; CHECK-NEXT: [[TMP11:%.*]] = phi <4 x i64> [ [[TMP5]], [[IF]] ], [ [[TMP10]], [[ELSE]] ]
; CHECK-NEXT: ret void
;
br i1 %c, label %if, label %else
>From 137ed17016757a6caea9db70ee6408dc3e2f6232 Mon Sep 17 00:00:00 2001
From: Chelsea Cassanova <chelsea_cassanova at apple.com>
Date: Fri, 1 Mar 2024 10:56:45 -0800
Subject: [PATCH 282/406] [lldb][progress] Hook up new broadcast bit and
progress manager (#83069)
This commit adds the functionality to broadcast events using the
`Debugger::eBroadcastProgressCategory`
bit (https://github.com/llvm/llvm-project/pull/81169) by keeping track
of these reports with the `ProgressManager`
class (https://github.com/llvm/llvm-project/pull/81319). The new bit is
used in such a way that it will only broadcast the initial and final
progress reports for specific progress categories that are managed by
the progress manager.
This commit also adds a new test to the progress report unit test that
checks that only the initial/final reports are broadcasted when using
the new bit.
---
lldb/include/lldb/Core/Debugger.h | 10 ++-
lldb/include/lldb/Core/Progress.h | 37 ++++++---
lldb/source/Core/Debugger.cpp | 19 +++--
lldb/source/Core/Progress.cpp | 56 +++++++++----
lldb/unittests/Core/ProgressReportTest.cpp | 93 +++++++++++++++++++++-
5 files changed, 177 insertions(+), 38 deletions(-)
diff --git a/lldb/include/lldb/Core/Debugger.h b/lldb/include/lldb/Core/Debugger.h
index 6ba90eb6ed8fdf..b65ec1029ab24b 100644
--- a/lldb/include/lldb/Core/Debugger.h
+++ b/lldb/include/lldb/Core/Debugger.h
@@ -593,6 +593,7 @@ class Debugger : public std::enable_shared_from_this<Debugger>,
friend class CommandInterpreter;
friend class REPL;
friend class Progress;
+ friend class ProgressManager;
/// Report progress events.
///
@@ -623,10 +624,11 @@ class Debugger : public std::enable_shared_from_this<Debugger>,
/// debugger identifier that this progress should be delivered to. If this
/// optional parameter does not have a value, the progress will be
/// delivered to all debuggers.
- static void ReportProgress(uint64_t progress_id, std::string title,
- std::string details, uint64_t completed,
- uint64_t total,
- std::optional<lldb::user_id_t> debugger_id);
+ static void
+ ReportProgress(uint64_t progress_id, std::string title, std::string details,
+ uint64_t completed, uint64_t total,
+ std::optional<lldb::user_id_t> debugger_id,
+ uint32_t progress_category_bit = eBroadcastBitProgress);
static void ReportDiagnosticImpl(DiagnosticEventData::Type type,
std::string message,
diff --git a/lldb/include/lldb/Core/Progress.h b/lldb/include/lldb/Core/Progress.h
index 9549e3b5aea950..c6fc861fb71d86 100644
--- a/lldb/include/lldb/Core/Progress.h
+++ b/lldb/include/lldb/Core/Progress.h
@@ -9,10 +9,11 @@
#ifndef LLDB_CORE_PROGRESS_H
#define LLDB_CORE_PROGRESS_H
-#include "lldb/Utility/ConstString.h"
+#include "lldb/lldb-forward.h"
#include "lldb/lldb-types.h"
#include "llvm/ADT/StringMap.h"
#include <atomic>
+#include <cstdint>
#include <mutex>
#include <optional>
@@ -100,27 +101,36 @@ class Progress {
/// Used to indicate a non-deterministic progress report
static constexpr uint64_t kNonDeterministicTotal = UINT64_MAX;
+ /// Data belonging to this Progress event that is used for bookkeeping by
+ /// ProgressManager.
+ struct ProgressData {
+ /// The title of the progress activity, also used as a category.
+ std::string title;
+ /// A unique integer identifier for progress reporting.
+ uint64_t progress_id;
+ /// The optional debugger ID to report progress to. If this has no value
+ /// then all debuggers will receive this event.
+ std::optional<lldb::user_id_t> debugger_id;
+ };
+
private:
void ReportProgress();
static std::atomic<uint64_t> g_id;
- /// The title of the progress activity.
- std::string m_title;
+ /// More specific information about the current file being displayed in the
+ /// report.
std::string m_details;
- std::mutex m_mutex;
- /// A unique integer identifier for progress reporting.
- const uint64_t m_id;
/// How much work ([0...m_total]) that has been completed.
uint64_t m_completed;
/// Total amount of work, use a std::nullopt in the constructor for non
/// deterministic progress.
uint64_t m_total;
- /// The optional debugger ID to report progress to. If this has no value then
- /// all debuggers will receive this event.
- std::optional<lldb::user_id_t> m_debugger_id;
+ std::mutex m_mutex;
/// Set to true when progress has been reported where m_completed == m_total
/// to ensure that we don't send progress updates after progress has
/// completed.
bool m_complete = false;
+ /// Data needed by the debugger to broadcast a progress event.
+ ProgressData m_progress_data;
};
/// A class used to group progress reports by category. This is done by using a
@@ -133,13 +143,16 @@ class ProgressManager {
~ProgressManager();
/// Control the refcount of the progress report category as needed.
- void Increment(std::string category);
- void Decrement(std::string category);
+ void Increment(const Progress::ProgressData &);
+ void Decrement(const Progress::ProgressData &);
static ProgressManager &Instance();
+ static void ReportProgress(const Progress::ProgressData &);
+
private:
- llvm::StringMap<uint64_t> m_progress_category_map;
+ llvm::StringMap<std::pair<uint64_t, Progress::ProgressData>>
+ m_progress_category_map;
std::mutex m_progress_map_mutex;
};
diff --git a/lldb/source/Core/Debugger.cpp b/lldb/source/Core/Debugger.cpp
index c3e603dbae8961..217474d1060ac2 100644
--- a/lldb/source/Core/Debugger.cpp
+++ b/lldb/source/Core/Debugger.cpp
@@ -15,6 +15,7 @@
#include "lldb/Core/ModuleList.h"
#include "lldb/Core/ModuleSpec.h"
#include "lldb/Core/PluginManager.h"
+#include "lldb/Core/Progress.h"
#include "lldb/Core/StreamAsynchronousIO.h"
#include "lldb/DataFormatters/DataVisualization.h"
#include "lldb/Expression/REPL.h"
@@ -1433,13 +1434,14 @@ void Debugger::SetDestroyCallback(
static void PrivateReportProgress(Debugger &debugger, uint64_t progress_id,
std::string title, std::string details,
uint64_t completed, uint64_t total,
- bool is_debugger_specific) {
+ bool is_debugger_specific,
+ uint32_t progress_broadcast_bit) {
// Only deliver progress events if we have any progress listeners.
- const uint32_t event_type = Debugger::eBroadcastBitProgress;
- if (!debugger.GetBroadcaster().EventTypeHasListeners(event_type))
+ if (!debugger.GetBroadcaster().EventTypeHasListeners(progress_broadcast_bit))
return;
+
EventSP event_sp(new Event(
- event_type,
+ progress_broadcast_bit,
new ProgressEventData(progress_id, std::move(title), std::move(details),
completed, total, is_debugger_specific)));
debugger.GetBroadcaster().BroadcastEvent(event_sp);
@@ -1448,7 +1450,8 @@ static void PrivateReportProgress(Debugger &debugger, uint64_t progress_id,
void Debugger::ReportProgress(uint64_t progress_id, std::string title,
std::string details, uint64_t completed,
uint64_t total,
- std::optional<lldb::user_id_t> debugger_id) {
+ std::optional<lldb::user_id_t> debugger_id,
+ uint32_t progress_category_bit) {
// Check if this progress is for a specific debugger.
if (debugger_id) {
// It is debugger specific, grab it and deliver the event if the debugger
@@ -1457,7 +1460,8 @@ void Debugger::ReportProgress(uint64_t progress_id, std::string title,
if (debugger_sp)
PrivateReportProgress(*debugger_sp, progress_id, std::move(title),
std::move(details), completed, total,
- /*is_debugger_specific*/ true);
+ /*is_debugger_specific*/ true,
+ progress_category_bit);
return;
}
// The progress event is not debugger specific, iterate over all debuggers
@@ -1467,7 +1471,8 @@ void Debugger::ReportProgress(uint64_t progress_id, std::string title,
DebuggerList::iterator pos, end = g_debugger_list_ptr->end();
for (pos = g_debugger_list_ptr->begin(); pos != end; ++pos)
PrivateReportProgress(*(*pos), progress_id, title, details, completed,
- total, /*is_debugger_specific*/ false);
+ total, /*is_debugger_specific*/ false,
+ progress_category_bit);
}
}
diff --git a/lldb/source/Core/Progress.cpp b/lldb/source/Core/Progress.cpp
index 9e8deb1ad4e731..9dcd7cf75ae057 100644
--- a/lldb/source/Core/Progress.cpp
+++ b/lldb/source/Core/Progress.cpp
@@ -11,6 +11,7 @@
#include "lldb/Core/Debugger.h"
#include "lldb/Utility/StreamString.h"
+#include <cstdint>
#include <mutex>
#include <optional>
@@ -22,15 +23,19 @@ std::atomic<uint64_t> Progress::g_id(0);
Progress::Progress(std::string title, std::string details,
std::optional<uint64_t> total,
lldb_private::Debugger *debugger)
- : m_title(title), m_details(details), m_id(++g_id), m_completed(0),
- m_total(Progress::kNonDeterministicTotal) {
+ : m_details(details), m_completed(0),
+ m_total(Progress::kNonDeterministicTotal),
+ m_progress_data{title, ++g_id,
+ /*m_progress_data.debugger_id=*/std::nullopt} {
if (total)
m_total = *total;
if (debugger)
- m_debugger_id = debugger->GetID();
+ m_progress_data.debugger_id = debugger->GetID();
+
std::lock_guard<std::mutex> guard(m_mutex);
ReportProgress();
+ ProgressManager::Instance().Increment(m_progress_data);
}
Progress::~Progress() {
@@ -40,6 +45,7 @@ Progress::~Progress() {
if (!m_completed)
m_completed = m_total;
ReportProgress();
+ ProgressManager::Instance().Decrement(m_progress_data);
}
void Progress::Increment(uint64_t amount,
@@ -49,7 +55,7 @@ void Progress::Increment(uint64_t amount,
if (updated_detail)
m_details = std::move(updated_detail.value());
// Watch out for unsigned overflow and make sure we don't increment too
- // much and exceed m_total.
+ // much and exceed the total.
if (m_total && (amount > (m_total - m_completed)))
m_completed = m_total;
else
@@ -63,8 +69,9 @@ void Progress::ReportProgress() {
// Make sure we only send one notification that indicates the progress is
// complete
m_complete = m_completed == m_total;
- Debugger::ReportProgress(m_id, m_title, m_details, m_completed, m_total,
- m_debugger_id);
+ Debugger::ReportProgress(m_progress_data.progress_id, m_progress_data.title,
+ m_details, m_completed, m_total,
+ m_progress_data.debugger_id);
}
}
@@ -82,20 +89,41 @@ ProgressManager &ProgressManager::Instance() {
return *g_progress_manager;
}
-void ProgressManager::Increment(std::string title) {
+void ProgressManager::Increment(const Progress::ProgressData &progress_data) {
std::lock_guard<std::mutex> lock(m_progress_map_mutex);
- m_progress_category_map[title]++;
+ // If the current category exists in the map then it is not an initial report,
+ // therefore don't broadcast to the category bit. Also, store the current
+ // progress data in the map so that we have a note of the ID used for the
+ // initial progress report.
+ if (!m_progress_category_map.contains(progress_data.title)) {
+ m_progress_category_map[progress_data.title].second = progress_data;
+ ReportProgress(progress_data);
+ }
+ m_progress_category_map[progress_data.title].first++;
}
-void ProgressManager::Decrement(std::string title) {
+void ProgressManager::Decrement(const Progress::ProgressData &progress_data) {
std::lock_guard<std::mutex> lock(m_progress_map_mutex);
- auto pos = m_progress_category_map.find(title);
+ auto pos = m_progress_category_map.find(progress_data.title);
if (pos == m_progress_category_map.end())
return;
- if (pos->second <= 1)
- m_progress_category_map.erase(title);
- else
- --pos->second;
+ if (pos->second.first <= 1) {
+ ReportProgress(pos->second.second);
+ m_progress_category_map.erase(progress_data.title);
+ } else {
+ --pos->second.first;
+ }
+}
+
+void ProgressManager::ReportProgress(
+ const Progress::ProgressData &progress_data) {
+ // The category bit only keeps track of when progress report categories have
+ // started and ended, so clear the details and reset other fields when
+ // broadcasting to it since that bit doesn't need that information.
+ Debugger::ReportProgress(
+ progress_data.progress_id, progress_data.title, "",
+ Progress::kNonDeterministicTotal, Progress::kNonDeterministicTotal,
+ progress_data.debugger_id, Debugger::eBroadcastBitProgressCategory);
}
diff --git a/lldb/unittests/Core/ProgressReportTest.cpp b/lldb/unittests/Core/ProgressReportTest.cpp
index 559f3ef1ae46bf..98cbc475ce2835 100644
--- a/lldb/unittests/Core/ProgressReportTest.cpp
+++ b/lldb/unittests/Core/ProgressReportTest.cpp
@@ -16,8 +16,8 @@
#include "lldb/Host/HostInfo.h"
#include "lldb/Utility/Listener.h"
#include "gtest/gtest.h"
+#include <memory>
#include <mutex>
-#include <thread>
using namespace lldb;
using namespace lldb_private;
@@ -126,3 +126,94 @@ TEST_F(ProgressReportTest, TestReportCreation) {
ASSERT_FALSE(data->IsFinite());
ASSERT_EQ(data->GetMessage(), "Progress report 1: Starting report 1");
}
+
+TEST_F(ProgressReportTest, TestProgressManager) {
+ std::chrono::milliseconds timeout(100);
+
+ // Set up the debugger, make sure that was done properly.
+ ArchSpec arch("x86_64-apple-macosx-");
+ Platform::SetHostPlatform(PlatformRemoteMacOSX::CreateInstance(true, &arch));
+
+ DebuggerSP debugger_sp = Debugger::CreateInstance();
+ ASSERT_TRUE(debugger_sp);
+
+ // Get the debugger's broadcaster.
+ Broadcaster &broadcaster = debugger_sp->GetBroadcaster();
+
+ // Create a listener, make sure it can receive events and that it's
+ // listening to the correct broadcast bit.
+ ListenerSP listener_sp = Listener::MakeListener("progress-category-listener");
+
+ listener_sp->StartListeningForEvents(&broadcaster,
+ Debugger::eBroadcastBitProgressCategory);
+ EXPECT_TRUE(broadcaster.EventTypeHasListeners(
+ Debugger::eBroadcastBitProgressCategory));
+
+ EventSP event_sp;
+ const ProgressEventData *data;
+
+ // Create three progress events with the same category then try to pop 2
+ // events from the queue in a row before the progress reports are destroyed.
+ // Since only 1 event should've been broadcast for this category, the second
+ // GetEvent() call should return false.
+ {
+ Progress progress1("Progress report 1", "Starting report 1");
+ Progress progress2("Progress report 1", "Starting report 2");
+ Progress progress3("Progress report 1", "Starting report 3");
+ EXPECT_TRUE(listener_sp->GetEvent(event_sp, timeout));
+ EXPECT_FALSE(listener_sp->GetEvent(event_sp, timeout));
+ }
+
+ data = ProgressEventData::GetEventDataFromEvent(event_sp.get());
+
+ ASSERT_EQ(data->GetDetails(), "");
+ ASSERT_FALSE(data->IsFinite());
+ ASSERT_TRUE(data->GetCompleted());
+ ASSERT_EQ(data->GetTotal(), Progress::kNonDeterministicTotal);
+ ASSERT_EQ(data->GetMessage(), "Progress report 1");
+
+ // Pop another event from the queue, this should be the event for the final
+ // report for this category.
+ EXPECT_TRUE(listener_sp->GetEvent(event_sp, timeout));
+
+ data = ProgressEventData::GetEventDataFromEvent(event_sp.get());
+ ASSERT_EQ(data->GetDetails(), "");
+ ASSERT_FALSE(data->IsFinite());
+ ASSERT_TRUE(data->GetCompleted());
+ ASSERT_EQ(data->GetTotal(), Progress::kNonDeterministicTotal);
+ ASSERT_EQ(data->GetMessage(), "Progress report 1");
+
+ // Create two progress reports of the same category that overlap with each
+ // other. Here we want to ensure that the ID broadcasted for the initial and
+ // final reports for this category are the same.
+ std::unique_ptr<Progress> overlap_progress1 =
+ std::make_unique<Progress>("Overlapping report 1", "Starting report 1");
+ std::unique_ptr<Progress> overlap_progress2 =
+ std::make_unique<Progress>("Overlapping report 1", "Starting report 2");
+ overlap_progress1.reset();
+
+ EXPECT_TRUE(listener_sp->GetEvent(event_sp, timeout));
+ data = ProgressEventData::GetEventDataFromEvent(event_sp.get());
+ // Get the ID used in the first report for this category.
+ uint64_t expected_progress_id = data->GetID();
+
+ ASSERT_EQ(data->GetDetails(), "");
+ ASSERT_FALSE(data->IsFinite());
+ ASSERT_TRUE(data->GetCompleted());
+ ASSERT_EQ(data->GetTotal(), Progress::kNonDeterministicTotal);
+ ASSERT_EQ(data->GetMessage(), "Overlapping report 1");
+
+ overlap_progress2.reset();
+
+ EXPECT_TRUE(listener_sp->GetEvent(event_sp, timeout));
+ data = ProgressEventData::GetEventDataFromEvent(event_sp.get());
+
+ ASSERT_EQ(data->GetDetails(), "");
+ ASSERT_FALSE(data->IsFinite());
+ ASSERT_TRUE(data->GetCompleted());
+ ASSERT_EQ(data->GetTotal(), Progress::kNonDeterministicTotal);
+ ASSERT_EQ(data->GetMessage(), "Overlapping report 1");
+ // The progress ID for the final report should be the same as that for the
+ // initial report.
+ ASSERT_EQ(data->GetID(), expected_progress_id);
+}
>From 2ab6d1e18e120430fbf454a074c52fa054e08537 Mon Sep 17 00:00:00 2001
From: Alexey Bataev <a.bataev at outlook.com>
Date: Fri, 1 Mar 2024 10:58:05 -0800
Subject: [PATCH 283/406] [SLP][NFC]Move some check to the outer if to simplify
inner checks.
---
llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp | 16 +++++++---------
1 file changed, 7 insertions(+), 9 deletions(-)
diff --git a/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp b/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
index 629d0a0e3a282b..47681342239e1d 100644
--- a/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
+++ b/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
@@ -4510,23 +4510,21 @@ BoUpSLP::getReorderingData(const TreeEntry &TE, bool TopToBottom) {
return std::nullopt; // No need to reorder.
return std::move(ResOrder);
}
- if (TE.State == TreeEntry::NeedToGather) {
+ if (TE.State == TreeEntry::NeedToGather && !TE.isAltShuffle() &&
+ allSameType(TE.Scalars)) {
// TODO: add analysis of other gather nodes with extractelement
// instructions and other values/instructions, not only undefs.
- if (((TE.getOpcode() == Instruction::ExtractElement &&
- !TE.isAltShuffle()) ||
+ if ((TE.getOpcode() == Instruction::ExtractElement ||
(all_of(TE.Scalars,
[](Value *V) {
return isa<UndefValue, ExtractElementInst>(V);
}) &&
any_of(TE.Scalars,
[](Value *V) { return isa<ExtractElementInst>(V); }))) &&
- all_of(TE.Scalars,
- [](Value *V) {
- auto *EE = dyn_cast<ExtractElementInst>(V);
- return !EE || isa<FixedVectorType>(EE->getVectorOperandType());
- }) &&
- allSameType(TE.Scalars)) {
+ all_of(TE.Scalars, [](Value *V) {
+ auto *EE = dyn_cast<ExtractElementInst>(V);
+ return !EE || isa<FixedVectorType>(EE->getVectorOperandType());
+ })) {
// Check that gather of extractelements can be represented as
// just a shuffle of a single vector.
OrdersType CurrentOrder;
>From 00570c36a3a982f9cf8b30f366a07e6c70014383 Mon Sep 17 00:00:00 2001
From: Joseph Huber <huberjn at outlook.com>
Date: Fri, 1 Mar 2024 13:02:27 -0600
Subject: [PATCH 284/406] [libc] Fix incorrectly enabled GPU math functions
(#83594)
Summary:
These functions were implemented via builtins that aren't acually
supported. See https://godbolt.org/z/Wq6q6T1za. This caused the build to
crash if they were included. Remove these and replace with correct
implementations.
---
libc/src/math/amdgpu/CMakeLists.txt | 40 -----------------------------
libc/src/math/amdgpu/exp.cpp | 2 +-
libc/src/math/amdgpu/expf.cpp | 2 +-
libc/src/math/amdgpu/llround.cpp | 18 -------------
libc/src/math/amdgpu/llroundf.cpp | 18 -------------
libc/src/math/amdgpu/lround.cpp | 16 ------------
libc/src/math/amdgpu/lroundf.cpp | 16 ------------
libc/src/math/nvptx/CMakeLists.txt | 40 -----------------------------
libc/src/math/nvptx/llround.cpp | 18 -------------
libc/src/math/nvptx/llroundf.cpp | 18 -------------
libc/src/math/nvptx/lround.cpp | 16 ------------
libc/src/math/nvptx/lroundf.cpp | 16 ------------
12 files changed, 2 insertions(+), 218 deletions(-)
delete mode 100644 libc/src/math/amdgpu/llround.cpp
delete mode 100644 libc/src/math/amdgpu/llroundf.cpp
delete mode 100644 libc/src/math/amdgpu/lround.cpp
delete mode 100644 libc/src/math/amdgpu/lroundf.cpp
delete mode 100644 libc/src/math/nvptx/llround.cpp
delete mode 100644 libc/src/math/nvptx/llroundf.cpp
delete mode 100644 libc/src/math/nvptx/lround.cpp
delete mode 100644 libc/src/math/nvptx/lroundf.cpp
diff --git a/libc/src/math/amdgpu/CMakeLists.txt b/libc/src/math/amdgpu/CMakeLists.txt
index cb77341aa50522..c300730208d509 100644
--- a/libc/src/math/amdgpu/CMakeLists.txt
+++ b/libc/src/math/amdgpu/CMakeLists.txt
@@ -176,46 +176,6 @@ add_entrypoint_object(
-O2
)
-add_entrypoint_object(
- lround
- SRCS
- lround.cpp
- HDRS
- ../lround.h
- COMPILE_OPTIONS
- -O2
-)
-
-add_entrypoint_object(
- lroundf
- SRCS
- lroundf.cpp
- HDRS
- ../lroundf.h
- COMPILE_OPTIONS
- -O2
-)
-
-add_entrypoint_object(
- llround
- SRCS
- llround.cpp
- HDRS
- ../llround.h
- COMPILE_OPTIONS
- -O2
-)
-
-add_entrypoint_object(
- llroundf
- SRCS
- llroundf.cpp
- HDRS
- ../llroundf.h
- COMPILE_OPTIONS
- -O2
-)
-
add_entrypoint_object(
modf
SRCS
diff --git a/libc/src/math/amdgpu/exp.cpp b/libc/src/math/amdgpu/exp.cpp
index 8590ac75901930..d19c73dd024266 100644
--- a/libc/src/math/amdgpu/exp.cpp
+++ b/libc/src/math/amdgpu/exp.cpp
@@ -13,6 +13,6 @@
namespace LIBC_NAMESPACE {
-LLVM_LIBC_FUNCTION(double, exp, (double x)) { return __builtin_exp(x); }
+LLVM_LIBC_FUNCTION(double, exp, (double x)) { return __ocml_exp_f64(x); }
} // namespace LIBC_NAMESPACE
diff --git a/libc/src/math/amdgpu/expf.cpp b/libc/src/math/amdgpu/expf.cpp
index d682f6293a6cb7..33393078cfa3a4 100644
--- a/libc/src/math/amdgpu/expf.cpp
+++ b/libc/src/math/amdgpu/expf.cpp
@@ -13,6 +13,6 @@
namespace LIBC_NAMESPACE {
-LLVM_LIBC_FUNCTION(float, expf, (float x)) { return __builtin_expf(x); }
+LLVM_LIBC_FUNCTION(float, expf, (float x)) { return __ocml_exp_f32(x); }
} // namespace LIBC_NAMESPACE
diff --git a/libc/src/math/amdgpu/llround.cpp b/libc/src/math/amdgpu/llround.cpp
deleted file mode 100644
index afd98308730a62..00000000000000
--- a/libc/src/math/amdgpu/llround.cpp
+++ /dev/null
@@ -1,18 +0,0 @@
-//===-- Implementation of the GPU llround function ------------------------===//
-//
-// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
-// See https://llvm.org/LICENSE.txt for license information.
-// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
-//
-//===----------------------------------------------------------------------===//
-
-#include "src/math/llround.h"
-#include "src/__support/common.h"
-
-namespace LIBC_NAMESPACE {
-
-LLVM_LIBC_FUNCTION(long long, llround, (double x)) {
- return __builtin_llround(x);
-}
-
-} // namespace LIBC_NAMESPACE
diff --git a/libc/src/math/amdgpu/llroundf.cpp b/libc/src/math/amdgpu/llroundf.cpp
deleted file mode 100644
index 897ed15b692848..00000000000000
--- a/libc/src/math/amdgpu/llroundf.cpp
+++ /dev/null
@@ -1,18 +0,0 @@
-//===-- Implementation of the GPU llroundf function -----------------------===//
-//
-// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
-// See https://llvm.org/LICENSE.txt for license information.
-// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
-//
-//===----------------------------------------------------------------------===//
-
-#include "src/math/llroundf.h"
-#include "src/__support/common.h"
-
-namespace LIBC_NAMESPACE {
-
-LLVM_LIBC_FUNCTION(long long, llroundf, (float x)) {
- return __builtin_lroundf(x);
-}
-
-} // namespace LIBC_NAMESPACE
diff --git a/libc/src/math/amdgpu/lround.cpp b/libc/src/math/amdgpu/lround.cpp
deleted file mode 100644
index 51e8f2245af8ea..00000000000000
--- a/libc/src/math/amdgpu/lround.cpp
+++ /dev/null
@@ -1,16 +0,0 @@
-//===-- Implementation of the GPU lround function -------------------------===//
-//
-// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
-// See https://llvm.org/LICENSE.txt for license information.
-// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
-//
-//===----------------------------------------------------------------------===//
-
-#include "src/math/lround.h"
-#include "src/__support/common.h"
-
-namespace LIBC_NAMESPACE {
-
-LLVM_LIBC_FUNCTION(long, lround, (double x)) { return __builtin_lround(x); }
-
-} // namespace LIBC_NAMESPACE
diff --git a/libc/src/math/amdgpu/lroundf.cpp b/libc/src/math/amdgpu/lroundf.cpp
deleted file mode 100644
index 2a6fe7200d8cba..00000000000000
--- a/libc/src/math/amdgpu/lroundf.cpp
+++ /dev/null
@@ -1,16 +0,0 @@
-//===-- Implementation of the GPU lroundf function ------------------------===//
-//
-// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
-// See https://llvm.org/LICENSE.txt for license information.
-// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
-//
-//===----------------------------------------------------------------------===//
-
-#include "src/math/lroundf.h"
-#include "src/__support/common.h"
-
-namespace LIBC_NAMESPACE {
-
-LLVM_LIBC_FUNCTION(long, lroundf, (float x)) { return __builtin_lroundf(x); }
-
-} // namespace LIBC_NAMESPACE
diff --git a/libc/src/math/nvptx/CMakeLists.txt b/libc/src/math/nvptx/CMakeLists.txt
index 194e1fa7af491e..56bff1472f134f 100644
--- a/libc/src/math/nvptx/CMakeLists.txt
+++ b/libc/src/math/nvptx/CMakeLists.txt
@@ -177,46 +177,6 @@ add_entrypoint_object(
-O2
)
-add_entrypoint_object(
- lround
- SRCS
- lround.cpp
- HDRS
- ../lround.h
- COMPILE_OPTIONS
- -O2
-)
-
-add_entrypoint_object(
- lroundf
- SRCS
- lroundf.cpp
- HDRS
- ../lroundf.h
- COMPILE_OPTIONS
- -O2
-)
-
-add_entrypoint_object(
- llround
- SRCS
- llround.cpp
- HDRS
- ../llround.h
- COMPILE_OPTIONS
- -O2
-)
-
-add_entrypoint_object(
- llroundf
- SRCS
- llroundf.cpp
- HDRS
- ../llroundf.h
- COMPILE_OPTIONS
- -O2
-)
-
add_entrypoint_object(
modf
SRCS
diff --git a/libc/src/math/nvptx/llround.cpp b/libc/src/math/nvptx/llround.cpp
deleted file mode 100644
index afd98308730a62..00000000000000
--- a/libc/src/math/nvptx/llround.cpp
+++ /dev/null
@@ -1,18 +0,0 @@
-//===-- Implementation of the GPU llround function ------------------------===//
-//
-// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
-// See https://llvm.org/LICENSE.txt for license information.
-// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
-//
-//===----------------------------------------------------------------------===//
-
-#include "src/math/llround.h"
-#include "src/__support/common.h"
-
-namespace LIBC_NAMESPACE {
-
-LLVM_LIBC_FUNCTION(long long, llround, (double x)) {
- return __builtin_llround(x);
-}
-
-} // namespace LIBC_NAMESPACE
diff --git a/libc/src/math/nvptx/llroundf.cpp b/libc/src/math/nvptx/llroundf.cpp
deleted file mode 100644
index 897ed15b692848..00000000000000
--- a/libc/src/math/nvptx/llroundf.cpp
+++ /dev/null
@@ -1,18 +0,0 @@
-//===-- Implementation of the GPU llroundf function -----------------------===//
-//
-// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
-// See https://llvm.org/LICENSE.txt for license information.
-// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
-//
-//===----------------------------------------------------------------------===//
-
-#include "src/math/llroundf.h"
-#include "src/__support/common.h"
-
-namespace LIBC_NAMESPACE {
-
-LLVM_LIBC_FUNCTION(long long, llroundf, (float x)) {
- return __builtin_lroundf(x);
-}
-
-} // namespace LIBC_NAMESPACE
diff --git a/libc/src/math/nvptx/lround.cpp b/libc/src/math/nvptx/lround.cpp
deleted file mode 100644
index 51e8f2245af8ea..00000000000000
--- a/libc/src/math/nvptx/lround.cpp
+++ /dev/null
@@ -1,16 +0,0 @@
-//===-- Implementation of the GPU lround function -------------------------===//
-//
-// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
-// See https://llvm.org/LICENSE.txt for license information.
-// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
-//
-//===----------------------------------------------------------------------===//
-
-#include "src/math/lround.h"
-#include "src/__support/common.h"
-
-namespace LIBC_NAMESPACE {
-
-LLVM_LIBC_FUNCTION(long, lround, (double x)) { return __builtin_lround(x); }
-
-} // namespace LIBC_NAMESPACE
diff --git a/libc/src/math/nvptx/lroundf.cpp b/libc/src/math/nvptx/lroundf.cpp
deleted file mode 100644
index 2a6fe7200d8cba..00000000000000
--- a/libc/src/math/nvptx/lroundf.cpp
+++ /dev/null
@@ -1,16 +0,0 @@
-//===-- Implementation of the GPU lroundf function ------------------------===//
-//
-// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
-// See https://llvm.org/LICENSE.txt for license information.
-// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
-//
-//===----------------------------------------------------------------------===//
-
-#include "src/math/lroundf.h"
-#include "src/__support/common.h"
-
-namespace LIBC_NAMESPACE {
-
-LLVM_LIBC_FUNCTION(long, lroundf, (float x)) { return __builtin_lroundf(x); }
-
-} // namespace LIBC_NAMESPACE
>From af009451ec439593554f03bc714e46ad2cd41738 Mon Sep 17 00:00:00 2001
From: Jonas Devlieghere <jonas at devlieghere.com>
Date: Fri, 1 Mar 2024 11:06:58 -0800
Subject: [PATCH 285/406] [lldb] Fix `thread backtrace --count` (#83602)
The help output for `thread backtrace` specifies that you can pass -1 to
`--count` to display all the frames.
```
-c <count> ( --count <count> )
How many frames to display (-1 for all)
```
However, that doesn't work:
```
(lldb) thread backtrace --count -1
error: invalid integer value for option 'c'
```
The problem is that we store the option value as an unsigned and the
code to parse the string correctly rejects it. There's two ways to fix
this:
1. Make `m_count` a signed value so that it accepts negative values and
appease the parser. The function that prints the frames takes an
unsigned so a negative value will just become a really large positive
value, which is what the current implementation relies on.
2. Keep `m_count` unsigned and instead use 0 the magic value to show all
frames. I don't really see a point in not showing any frames at all,
plus that's already broken (`error: error displaying backtrace for
thread: "0x0001"`).
This patch implements (2) and at the same time improve the error
reporting so that we print the invalid value when we cannot parse it.
rdar://123881767
---
lldb/source/Commands/CommandObjectThread.cpp | 33 ++++++++++++-------
lldb/source/Commands/Options.td | 6 ++--
.../Commands/command-thread-backtrace.test | 14 ++++++++
3 files changed, 38 insertions(+), 15 deletions(-)
create mode 100644 lldb/test/Shell/Commands/command-thread-backtrace.test
diff --git a/lldb/source/Commands/CommandObjectThread.cpp b/lldb/source/Commands/CommandObjectThread.cpp
index 9cfff059d6bfa4..6d84315a471d95 100644
--- a/lldb/source/Commands/CommandObjectThread.cpp
+++ b/lldb/source/Commands/CommandObjectThread.cpp
@@ -67,13 +67,18 @@ class CommandObjectThreadBacktrace : public CommandObjectIterateOverThreads {
if (option_arg.getAsInteger(0, m_count)) {
m_count = UINT32_MAX;
error.SetErrorStringWithFormat(
- "invalid integer value for option '%c'", short_option);
+ "invalid integer value for option '%c': %s", short_option,
+ option_arg.data());
}
+ // A count of 0 means all frames.
+ if (m_count == 0)
+ m_count = UINT32_MAX;
break;
case 's':
if (option_arg.getAsInteger(0, m_start))
error.SetErrorStringWithFormat(
- "invalid integer value for option '%c'", short_option);
+ "invalid integer value for option '%c': %s", short_option,
+ option_arg.data());
break;
case 'e': {
bool success;
@@ -81,7 +86,8 @@ class CommandObjectThreadBacktrace : public CommandObjectIterateOverThreads {
OptionArgParser::ToBoolean(option_arg, false, &success);
if (!success)
error.SetErrorStringWithFormat(
- "invalid boolean value for option '%c'", short_option);
+ "invalid boolean value for option '%c': %s", short_option,
+ option_arg.data());
} break;
default:
llvm_unreachable("Unimplemented option");
@@ -228,9 +234,9 @@ class CommandObjectThreadBacktrace : public CommandObjectIterateOverThreads {
thread->GetIndexID());
return false;
}
- if (m_options.m_extended_backtrace) {
- if (!INTERRUPT_REQUESTED(GetDebugger(),
- "Interrupt skipped extended backtrace")) {
+ if (m_options.m_extended_backtrace) {
+ if (!INTERRUPT_REQUESTED(GetDebugger(),
+ "Interrupt skipped extended backtrace")) {
DoExtendedBacktrace(thread, result);
}
}
@@ -272,8 +278,9 @@ class ThreadStepScopeOptionGroup : public OptionGroup {
bool avoid_no_debug =
OptionArgParser::ToBoolean(option_arg, true, &success);
if (!success)
- error.SetErrorStringWithFormat("invalid boolean value for option '%c'",
- short_option);
+ error.SetErrorStringWithFormat(
+ "invalid boolean value for option '%c': %s", short_option,
+ option_arg);
else {
m_step_in_avoid_no_debug = avoid_no_debug ? eLazyBoolYes : eLazyBoolNo;
}
@@ -284,8 +291,9 @@ class ThreadStepScopeOptionGroup : public OptionGroup {
bool avoid_no_debug =
OptionArgParser::ToBoolean(option_arg, true, &success);
if (!success)
- error.SetErrorStringWithFormat("invalid boolean value for option '%c'",
- short_option);
+ error.SetErrorStringWithFormat(
+ "invalid boolean value for option '%c': %s", short_option,
+ option_arg);
else {
m_step_out_avoid_no_debug = avoid_no_debug ? eLazyBoolYes : eLazyBoolNo;
}
@@ -293,8 +301,9 @@ class ThreadStepScopeOptionGroup : public OptionGroup {
case 'c':
if (option_arg.getAsInteger(0, m_step_count))
- error.SetErrorStringWithFormat("invalid step count '%s'",
- option_arg.str().c_str());
+ error.SetErrorStringWithFormat(
+ "invalid integer value for option '%c': %s", short_option,
+ option_arg.data());
break;
case 'm': {
diff --git a/lldb/source/Commands/Options.td b/lldb/source/Commands/Options.td
index 91d5eea830dedf..62bbfdc117834f 100644
--- a/lldb/source/Commands/Options.td
+++ b/lldb/source/Commands/Options.td
@@ -805,7 +805,7 @@ let Command = "script add" in {
def script_add_function : Option<"function", "f">, Group<1>,
Arg<"PythonFunction">,
Desc<"Name of the Python function to bind to this command name.">;
- def script_add_class : Option<"class", "c">, Groups<[2,3]>,
+ def script_add_class : Option<"class", "c">, Groups<[2,3]>,
Arg<"PythonClass">,
Desc<"Name of the Python class to bind to this command name.">;
def script_add_help : Option<"help", "h">, Group<1>, Arg<"HelpText">,
@@ -816,7 +816,7 @@ let Command = "script add" in {
EnumArg<"ScriptedCommandSynchronicity">,
Desc<"Set the synchronicity of this command's executions with regard to "
"LLDB event system.">;
- def script_add_completion_type : Option<"completion-type", "C">,
+ def script_add_completion_type : Option<"completion-type", "C">,
Groups<[1,2]>, EnumArg<"CompletionType">,
Desc<"Specify which completion type the command should use - if none is "
"specified, the command won't use auto-completion.">;
@@ -1037,7 +1037,7 @@ let Command = "target stop hook add" in {
let Command = "thread backtrace" in {
def thread_backtrace_count : Option<"count", "c">, Group<1>, Arg<"Count">,
- Desc<"How many frames to display (-1 for all)">;
+ Desc<"How many frames to display (0 for all)">;
def thread_backtrace_start : Option<"start", "s">, Group<1>,
Arg<"FrameIndex">, Desc<"Frame in which to start the backtrace">;
def thread_backtrace_extended : Option<"extended", "e">, Group<1>,
diff --git a/lldb/test/Shell/Commands/command-thread-backtrace.test b/lldb/test/Shell/Commands/command-thread-backtrace.test
new file mode 100644
index 00000000000000..dacef8d7fa6a8b
--- /dev/null
+++ b/lldb/test/Shell/Commands/command-thread-backtrace.test
@@ -0,0 +1,14 @@
+# RUN: %clang_host -g %S/Inputs/main.c -o %t
+
+# RUN: not %lldb %t -b -o 'b foo' -o 'r' -o 'thread backtrace --count -1' 2>&1 | FileCheck %s --check-prefix COUNT
+# COUNT: error: invalid integer value for option 'c': -1
+
+# RUN: not %lldb %t -b -o 'b foo' -o 'r' -o 'thread backtrace --extended nah' 2>&1 | FileCheck %s --check-prefix EXTENDED
+# EXTENDED: error: invalid boolean value for option 'e': nah
+
+# RUN: not %lldb %t -b -o 'b foo' -o 'r' -o 'thread backtrace --start -1' 2>&1 | FileCheck %s --check-prefix START
+# START: error: invalid integer value for option 's': -1
+
+# RUN: %lldb %t -b -o 'b foo' -o 'r' -o 'thread backtrace --count 0' | FileCheck %s
+# CHECK: frame #0:
+# CHECK: frame #1:
>From 4a3f7e798a31072a80a0731b8fb1da21b9c626ed Mon Sep 17 00:00:00 2001
From: Fangrui Song <i at maskray.me>
Date: Fri, 1 Mar 2024 11:17:22 -0800
Subject: [PATCH 286/406] [ELF] Internalize enum
g++ -flto has a diagnostic `-Wodr` about mismatched redeclarations,
which even apply to `enum`.
Fix #83529
Reviewers: thesamesam
Reviewed By: thesamesam
Pull Request: https://github.com/llvm/llvm-project/pull/83604
---
lld/ELF/Arch/LoongArch.cpp | 2 ++
lld/ELF/Arch/PPC64.cpp | 3 ++-
lld/ELF/Arch/RISCV.cpp | 2 ++
3 files changed, 6 insertions(+), 1 deletion(-)
diff --git a/lld/ELF/Arch/LoongArch.cpp b/lld/ELF/Arch/LoongArch.cpp
index 49fd979bd0a55c..e0f9abfb382af0 100644
--- a/lld/ELF/Arch/LoongArch.cpp
+++ b/lld/ELF/Arch/LoongArch.cpp
@@ -41,6 +41,7 @@ class LoongArch final : public TargetInfo {
};
} // end anonymous namespace
+namespace {
enum Op {
SUB_W = 0x00110000,
SUB_D = 0x00118000,
@@ -65,6 +66,7 @@ enum Reg {
R_T2 = 14,
R_T3 = 15,
};
+} // namespace
// Mask out the input's lowest 12 bits for use with `pcalau12i`, in sequences
// like `pcalau12i + addi.[wd]` or `pcalau12i + {ld,st}.*` where the `pcalau12i`
diff --git a/lld/ELF/Arch/PPC64.cpp b/lld/ELF/Arch/PPC64.cpp
index de52f6a79a40b9..019c073bd541b6 100644
--- a/lld/ELF/Arch/PPC64.cpp
+++ b/lld/ELF/Arch/PPC64.cpp
@@ -26,6 +26,7 @@ using namespace lld::elf;
constexpr uint64_t ppc64TocOffset = 0x8000;
constexpr uint64_t dynamicThreadPointerOffset = 0x8000;
+namespace {
// The instruction encoding of bits 21-30 from the ISA for the Xform and Dform
// instructions that can be used as part of the initial exec TLS sequence.
enum XFormOpcd {
@@ -139,6 +140,7 @@ enum class PPCPrefixedInsn : uint64_t {
PSTXV = PREFIX_8LS | 0xd8000000,
PSTXVP = PREFIX_8LS | 0xf8000000
};
+
static bool checkPPCLegacyInsn(uint32_t encoding) {
PPCLegacyInsn insn = static_cast<PPCLegacyInsn>(encoding);
if (insn == PPCLegacyInsn::NOINSN)
@@ -164,7 +166,6 @@ enum class LegacyToPrefixMask : uint64_t {
0x8000000003e00000, // S/T (6-10) - The [S/T]X bit moves from 28 to 5.
};
-namespace {
class PPC64 final : public TargetInfo {
public:
PPC64();
diff --git a/lld/ELF/Arch/RISCV.cpp b/lld/ELF/Arch/RISCV.cpp
index 5fcab4d39d43a8..4798c86f7d1b61 100644
--- a/lld/ELF/Arch/RISCV.cpp
+++ b/lld/ELF/Arch/RISCV.cpp
@@ -57,6 +57,7 @@ class RISCV final : public TargetInfo {
const uint64_t dtpOffset = 0x800;
+namespace {
enum Op {
ADDI = 0x13,
AUIPC = 0x17,
@@ -78,6 +79,7 @@ enum Reg {
X_A0 = 10,
X_T3 = 28,
};
+} // namespace
static uint32_t hi20(uint32_t val) { return (val + 0x800) >> 12; }
static uint32_t lo12(uint32_t val) { return val & 4095; }
>From 582718fe61a61001aa957d515dbd094df93dae81 Mon Sep 17 00:00:00 2001
From: Simon Pilgrim <llvm-dev at redking.me.uk>
Date: Fri, 1 Mar 2024 18:23:08 +0000
Subject: [PATCH 287/406] [X86] cmp-shiftX-maskX.ll - add AVX1 test coverage
---
llvm/test/CodeGen/X86/cmp-shiftX-maskX.ll | 63 +++++++++++++++++++----
1 file changed, 54 insertions(+), 9 deletions(-)
diff --git a/llvm/test/CodeGen/X86/cmp-shiftX-maskX.ll b/llvm/test/CodeGen/X86/cmp-shiftX-maskX.ll
index 7996454a0158ea..c77867d95c8a17 100644
--- a/llvm/test/CodeGen/X86/cmp-shiftX-maskX.ll
+++ b/llvm/test/CodeGen/X86/cmp-shiftX-maskX.ll
@@ -1,7 +1,8 @@
; NOTE: Assertions have been autogenerated by utils/update_llc_test_checks.py UTC_ARGS: --version 3
; RUN: llc < %s -mtriple=x86_64-unknown-unknown | FileCheck %s --check-prefixes=CHECK,CHECK-NOBMI,CHECK-NOBMI-SSE2
; RUN: llc < %s -mtriple=x86_64-unknown-unknown -mattr=+bmi2 | FileCheck %s --check-prefixes=CHECK,CHECK-BMI2,CHECK-BMI2-SSE2
-; RUN: llc < %s -mtriple=x86_64-unknown-unknown -mattr=+bmi2,+avx2 | FileCheck %s --check-prefixes=CHECK,CHECK-BMI2,CHECK-AVX,CHECK-AVX2
+; RUN: llc < %s -mtriple=x86_64-unknown-unknown -mattr=+bmi2,+avx | FileCheck %s --check-prefixes=CHECK,CHECK-BMI2,CHECK-AVX,CHECK-AVX12,CHECK-AVX1
+; RUN: llc < %s -mtriple=x86_64-unknown-unknown -mattr=+bmi2,+avx2 | FileCheck %s --check-prefixes=CHECK,CHECK-BMI2,CHECK-AVX,CHECK-AVX12,CHECK-AVX2
; RUN: llc < %s -mtriple=x86_64-unknown-unknown -mattr=+bmi2,+avx512f,+avx512vl | FileCheck %s --check-prefixes=CHECK,CHECK-BMI2,CHECK-AVX,CHECK-AVX512
declare <4 x i32> @llvm.fshl.v4i32(<4 x i32>, <4 x i32>, <4 x i32>)
declare <4 x i32> @llvm.fshr.v4i32(<4 x i32>, <4 x i32>, <4 x i32>)
@@ -353,6 +354,15 @@ define <4 x i1> @shr_to_ror_eq_4xi32_s4(<4 x i32> %x) {
; CHECK-BMI2-SSE2-NEXT: pxor %xmm1, %xmm0
; CHECK-BMI2-SSE2-NEXT: retq
;
+; CHECK-AVX1-LABEL: shr_to_ror_eq_4xi32_s4:
+; CHECK-AVX1: # %bb.0:
+; CHECK-AVX1-NEXT: vpsrld $4, %xmm0, %xmm1
+; CHECK-AVX1-NEXT: vpand {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0, %xmm0
+; CHECK-AVX1-NEXT: vpcmpeqd %xmm0, %xmm1, %xmm0
+; CHECK-AVX1-NEXT: vpcmpeqd %xmm1, %xmm1, %xmm1
+; CHECK-AVX1-NEXT: vpxor %xmm1, %xmm0, %xmm0
+; CHECK-AVX1-NEXT: retq
+;
; CHECK-AVX2-LABEL: shr_to_ror_eq_4xi32_s4:
; CHECK-AVX2: # %bb.0:
; CHECK-AVX2-NEXT: vpsrld $4, %xmm0, %xmm1
@@ -396,14 +406,14 @@ define <4 x i1> @shl_to_ror_eq_4xi32_s8(<4 x i32> %x) {
; CHECK-BMI2-SSE2-NEXT: pxor %xmm1, %xmm0
; CHECK-BMI2-SSE2-NEXT: retq
;
-; CHECK-AVX2-LABEL: shl_to_ror_eq_4xi32_s8:
-; CHECK-AVX2: # %bb.0:
-; CHECK-AVX2-NEXT: vpslld $8, %xmm0, %xmm1
-; CHECK-AVX2-NEXT: vpand {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0, %xmm0
-; CHECK-AVX2-NEXT: vpcmpeqd %xmm0, %xmm1, %xmm0
-; CHECK-AVX2-NEXT: vpcmpeqd %xmm1, %xmm1, %xmm1
-; CHECK-AVX2-NEXT: vpxor %xmm1, %xmm0, %xmm0
-; CHECK-AVX2-NEXT: retq
+; CHECK-AVX12-LABEL: shl_to_ror_eq_4xi32_s8:
+; CHECK-AVX12: # %bb.0:
+; CHECK-AVX12-NEXT: vpslld $8, %xmm0, %xmm1
+; CHECK-AVX12-NEXT: vpand {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0, %xmm0
+; CHECK-AVX12-NEXT: vpcmpeqd %xmm0, %xmm1, %xmm0
+; CHECK-AVX12-NEXT: vpcmpeqd %xmm1, %xmm1, %xmm1
+; CHECK-AVX12-NEXT: vpxor %xmm1, %xmm0, %xmm0
+; CHECK-AVX12-NEXT: retq
;
; CHECK-AVX512-LABEL: shl_to_ror_eq_4xi32_s8:
; CHECK-AVX512: # %bb.0:
@@ -438,6 +448,15 @@ define <4 x i1> @shl_to_ror_eq_4xi32_s7_fail_no_p2(<4 x i32> %x) {
; CHECK-BMI2-SSE2-NEXT: pxor %xmm1, %xmm0
; CHECK-BMI2-SSE2-NEXT: retq
;
+; CHECK-AVX1-LABEL: shl_to_ror_eq_4xi32_s7_fail_no_p2:
+; CHECK-AVX1: # %bb.0:
+; CHECK-AVX1-NEXT: vpslld $7, %xmm0, %xmm1
+; CHECK-AVX1-NEXT: vpand {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0, %xmm0
+; CHECK-AVX1-NEXT: vpcmpeqd %xmm0, %xmm1, %xmm0
+; CHECK-AVX1-NEXT: vpcmpeqd %xmm1, %xmm1, %xmm1
+; CHECK-AVX1-NEXT: vpxor %xmm1, %xmm0, %xmm0
+; CHECK-AVX1-NEXT: retq
+;
; CHECK-AVX2-LABEL: shl_to_ror_eq_4xi32_s7_fail_no_p2:
; CHECK-AVX2: # %bb.0:
; CHECK-AVX2-NEXT: vpslld $7, %xmm0, %xmm1
@@ -490,6 +509,17 @@ define <4 x i1> @shr_to_ror_eq_4xi32_s4_fail_no_splat(<4 x i32> %x) {
; CHECK-BMI2-SSE2-NEXT: pxor %xmm1, %xmm0
; CHECK-BMI2-SSE2-NEXT: retq
;
+; CHECK-AVX1-LABEL: shr_to_ror_eq_4xi32_s4_fail_no_splat:
+; CHECK-AVX1: # %bb.0:
+; CHECK-AVX1-NEXT: vpsrld $8, %xmm0, %xmm1
+; CHECK-AVX1-NEXT: vpsrld $4, %xmm0, %xmm2
+; CHECK-AVX1-NEXT: vpblendw {{.*#+}} xmm1 = xmm2[0,1,2,3,4,5],xmm1[6,7]
+; CHECK-AVX1-NEXT: vpand {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0, %xmm0
+; CHECK-AVX1-NEXT: vpcmpeqd %xmm0, %xmm1, %xmm0
+; CHECK-AVX1-NEXT: vpcmpeqd %xmm1, %xmm1, %xmm1
+; CHECK-AVX1-NEXT: vpxor %xmm1, %xmm0, %xmm0
+; CHECK-AVX1-NEXT: retq
+;
; CHECK-AVX2-LABEL: shr_to_ror_eq_4xi32_s4_fail_no_splat:
; CHECK-AVX2: # %bb.0:
; CHECK-AVX2-NEXT: vpsrlvd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0, %xmm1
@@ -546,6 +576,21 @@ define <16 x i1> @shl_to_ror_eq_16xi16_s8_fail_preserve_i16(<16 x i16> %x) {
; CHECK-BMI2-SSE2-NEXT: pxor %xmm1, %xmm0
; CHECK-BMI2-SSE2-NEXT: retq
;
+; CHECK-AVX1-LABEL: shl_to_ror_eq_16xi16_s8_fail_preserve_i16:
+; CHECK-AVX1: # %bb.0:
+; CHECK-AVX1-NEXT: vpsllw $8, %xmm0, %xmm1
+; CHECK-AVX1-NEXT: vextractf128 $1, %ymm0, %xmm2
+; CHECK-AVX1-NEXT: vpsllw $8, %xmm2, %xmm2
+; CHECK-AVX1-NEXT: vandps {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %ymm0, %ymm0
+; CHECK-AVX1-NEXT: vextractf128 $1, %ymm0, %xmm3
+; CHECK-AVX1-NEXT: vpcmpeqw %xmm3, %xmm2, %xmm2
+; CHECK-AVX1-NEXT: vpcmpeqw %xmm0, %xmm1, %xmm0
+; CHECK-AVX1-NEXT: vpacksswb %xmm2, %xmm0, %xmm0
+; CHECK-AVX1-NEXT: vpcmpeqd %xmm1, %xmm1, %xmm1
+; CHECK-AVX1-NEXT: vpxor %xmm1, %xmm0, %xmm0
+; CHECK-AVX1-NEXT: vzeroupper
+; CHECK-AVX1-NEXT: retq
+;
; CHECK-AVX2-LABEL: shl_to_ror_eq_16xi16_s8_fail_preserve_i16:
; CHECK-AVX2: # %bb.0:
; CHECK-AVX2-NEXT: vpsllw $8, %ymm0, %ymm1
>From 1e8d3c357e1fd79bf3a641767d95147a8c0f54bd Mon Sep 17 00:00:00 2001
From: Simon Pilgrim <llvm-dev at redking.me.uk>
Date: Fri, 1 Mar 2024 18:28:46 +0000
Subject: [PATCH 288/406] [X86] cmp-shiftX-maskX.ll - add additional tests for
#83596
Shows cases where logical shifts of allsignbits values can be profitably converted to masks
---
llvm/test/CodeGen/X86/cmp-shiftX-maskX.ll | 156 ++++++++++++++++++++++
1 file changed, 156 insertions(+)
diff --git a/llvm/test/CodeGen/X86/cmp-shiftX-maskX.ll b/llvm/test/CodeGen/X86/cmp-shiftX-maskX.ll
index c77867d95c8a17..3887d9547fd06e 100644
--- a/llvm/test/CodeGen/X86/cmp-shiftX-maskX.ll
+++ b/llvm/test/CodeGen/X86/cmp-shiftX-maskX.ll
@@ -619,6 +619,162 @@ define <16 x i1> @shl_to_ror_eq_16xi16_s8_fail_preserve_i16(<16 x i16> %x) {
ret <16 x i1> %r
}
+define <16 x i8> @shl_s3_cmp_v16i8(<16 x i8> %x, <16 x i8> %y) {
+; CHECK-NOBMI-LABEL: shl_s3_cmp_v16i8:
+; CHECK-NOBMI: # %bb.0:
+; CHECK-NOBMI-NEXT: pcmpeqb %xmm1, %xmm0
+; CHECK-NOBMI-NEXT: psllw $3, %xmm0
+; CHECK-NOBMI-NEXT: pand {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
+; CHECK-NOBMI-NEXT: retq
+;
+; CHECK-BMI2-SSE2-LABEL: shl_s3_cmp_v16i8:
+; CHECK-BMI2-SSE2: # %bb.0:
+; CHECK-BMI2-SSE2-NEXT: pcmpeqb %xmm1, %xmm0
+; CHECK-BMI2-SSE2-NEXT: psllw $3, %xmm0
+; CHECK-BMI2-SSE2-NEXT: pand {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
+; CHECK-BMI2-SSE2-NEXT: retq
+;
+; CHECK-AVX12-LABEL: shl_s3_cmp_v16i8:
+; CHECK-AVX12: # %bb.0:
+; CHECK-AVX12-NEXT: vpcmpeqb %xmm1, %xmm0, %xmm0
+; CHECK-AVX12-NEXT: vpsllw $3, %xmm0, %xmm0
+; CHECK-AVX12-NEXT: vpand {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0, %xmm0
+; CHECK-AVX12-NEXT: retq
+;
+; CHECK-AVX512-LABEL: shl_s3_cmp_v16i8:
+; CHECK-AVX512: # %bb.0:
+; CHECK-AVX512-NEXT: vpcmpeqb %xmm1, %xmm0, %xmm0
+; CHECK-AVX512-NEXT: vpsllw $3, %xmm0, %xmm0
+; CHECK-AVX512-NEXT: vpandd {{\.?LCPI[0-9]+_[0-9]+}}(%rip){1to4}, %xmm0, %xmm0
+; CHECK-AVX512-NEXT: retq
+ %cmp = icmp eq <16 x i8> %x, %y
+ %ext = sext <16 x i1> %cmp to <16 x i8>
+ %shr = shl <16 x i8> %ext, <i8 3, i8 3, i8 3, i8 3, i8 3, i8 3, i8 3, i8 3, i8 3, i8 3, i8 3, i8 3, i8 3, i8 3, i8 3, i8 3>
+ ret <16 x i8> %shr
+}
+
+define <4 x i64> @shl_s31_cmp_v4f64(<4 x double> %x, <4 x double> %y) {
+; CHECK-NOBMI-LABEL: shl_s31_cmp_v4f64:
+; CHECK-NOBMI: # %bb.0:
+; CHECK-NOBMI-NEXT: cmpeqpd %xmm3, %xmm1
+; CHECK-NOBMI-NEXT: cmpeqpd %xmm2, %xmm0
+; CHECK-NOBMI-NEXT: psllq $31, %xmm0
+; CHECK-NOBMI-NEXT: psllq $31, %xmm1
+; CHECK-NOBMI-NEXT: retq
+;
+; CHECK-BMI2-SSE2-LABEL: shl_s31_cmp_v4f64:
+; CHECK-BMI2-SSE2: # %bb.0:
+; CHECK-BMI2-SSE2-NEXT: cmpeqpd %xmm3, %xmm1
+; CHECK-BMI2-SSE2-NEXT: cmpeqpd %xmm2, %xmm0
+; CHECK-BMI2-SSE2-NEXT: psllq $31, %xmm0
+; CHECK-BMI2-SSE2-NEXT: psllq $31, %xmm1
+; CHECK-BMI2-SSE2-NEXT: retq
+;
+; CHECK-AVX1-LABEL: shl_s31_cmp_v4f64:
+; CHECK-AVX1: # %bb.0:
+; CHECK-AVX1-NEXT: vcmpeqpd %ymm1, %ymm0, %ymm0
+; CHECK-AVX1-NEXT: vpsllq $31, %xmm0, %xmm1
+; CHECK-AVX1-NEXT: vextractf128 $1, %ymm0, %xmm0
+; CHECK-AVX1-NEXT: vpsllq $31, %xmm0, %xmm0
+; CHECK-AVX1-NEXT: vinsertf128 $1, %xmm0, %ymm1, %ymm0
+; CHECK-AVX1-NEXT: retq
+;
+; CHECK-AVX2-LABEL: shl_s31_cmp_v4f64:
+; CHECK-AVX2: # %bb.0:
+; CHECK-AVX2-NEXT: vcmpeqpd %ymm1, %ymm0, %ymm0
+; CHECK-AVX2-NEXT: vpsllq $31, %ymm0, %ymm0
+; CHECK-AVX2-NEXT: retq
+;
+; CHECK-AVX512-LABEL: shl_s31_cmp_v4f64:
+; CHECK-AVX512: # %bb.0:
+; CHECK-AVX512-NEXT: vcmpeqpd %ymm1, %ymm0, %ymm0
+; CHECK-AVX512-NEXT: vpsllq $31, %ymm0, %ymm0
+; CHECK-AVX512-NEXT: retq
+ %cmp = fcmp oeq <4 x double> %x, %y
+ %ext = sext <4 x i1> %cmp to <4 x i64>
+ %shr = shl <4 x i64> %ext, <i64 31, i64 31, i64 31, i64 31>
+ ret <4 x i64> %shr
+}
+
+define <16 x i8> @shr_s1_cmp_v16i8(<16 x i8> %x, <16 x i8> %y) {
+; CHECK-NOBMI-LABEL: shr_s1_cmp_v16i8:
+; CHECK-NOBMI: # %bb.0:
+; CHECK-NOBMI-NEXT: pcmpeqb %xmm1, %xmm0
+; CHECK-NOBMI-NEXT: psrlw $1, %xmm0
+; CHECK-NOBMI-NEXT: pand {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
+; CHECK-NOBMI-NEXT: retq
+;
+; CHECK-BMI2-SSE2-LABEL: shr_s1_cmp_v16i8:
+; CHECK-BMI2-SSE2: # %bb.0:
+; CHECK-BMI2-SSE2-NEXT: pcmpeqb %xmm1, %xmm0
+; CHECK-BMI2-SSE2-NEXT: psrlw $1, %xmm0
+; CHECK-BMI2-SSE2-NEXT: pand {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
+; CHECK-BMI2-SSE2-NEXT: retq
+;
+; CHECK-AVX12-LABEL: shr_s1_cmp_v16i8:
+; CHECK-AVX12: # %bb.0:
+; CHECK-AVX12-NEXT: vpcmpeqb %xmm1, %xmm0, %xmm0
+; CHECK-AVX12-NEXT: vpsrlw $1, %xmm0, %xmm0
+; CHECK-AVX12-NEXT: vpand {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0, %xmm0
+; CHECK-AVX12-NEXT: retq
+;
+; CHECK-AVX512-LABEL: shr_s1_cmp_v16i8:
+; CHECK-AVX512: # %bb.0:
+; CHECK-AVX512-NEXT: vpcmpeqb %xmm1, %xmm0, %xmm0
+; CHECK-AVX512-NEXT: vpsrlw $1, %xmm0, %xmm0
+; CHECK-AVX512-NEXT: vpandd {{\.?LCPI[0-9]+_[0-9]+}}(%rip){1to4}, %xmm0, %xmm0
+; CHECK-AVX512-NEXT: retq
+ %cmp = icmp eq <16 x i8> %x, %y
+ %ext = sext <16 x i1> %cmp to <16 x i8>
+ %shr = lshr <16 x i8> %ext, <i8 1, i8 1, i8 1, i8 1, i8 1, i8 1, i8 1, i8 1, i8 1, i8 1, i8 1, i8 1, i8 1, i8 1, i8 1, i8 1>
+ ret <16 x i8> %shr
+}
+
+define <8 x i32> @shr_s9_cmp_v8i32(<8 x i32> %x, <8 x i32> %y) {
+; CHECK-NOBMI-LABEL: shr_s9_cmp_v8i32:
+; CHECK-NOBMI: # %bb.0:
+; CHECK-NOBMI-NEXT: pcmpgtd %xmm3, %xmm1
+; CHECK-NOBMI-NEXT: pcmpgtd %xmm2, %xmm0
+; CHECK-NOBMI-NEXT: psrld $9, %xmm0
+; CHECK-NOBMI-NEXT: psrld $9, %xmm1
+; CHECK-NOBMI-NEXT: retq
+;
+; CHECK-BMI2-SSE2-LABEL: shr_s9_cmp_v8i32:
+; CHECK-BMI2-SSE2: # %bb.0:
+; CHECK-BMI2-SSE2-NEXT: pcmpgtd %xmm3, %xmm1
+; CHECK-BMI2-SSE2-NEXT: pcmpgtd %xmm2, %xmm0
+; CHECK-BMI2-SSE2-NEXT: psrld $9, %xmm0
+; CHECK-BMI2-SSE2-NEXT: psrld $9, %xmm1
+; CHECK-BMI2-SSE2-NEXT: retq
+;
+; CHECK-AVX1-LABEL: shr_s9_cmp_v8i32:
+; CHECK-AVX1: # %bb.0:
+; CHECK-AVX1-NEXT: vextractf128 $1, %ymm1, %xmm2
+; CHECK-AVX1-NEXT: vextractf128 $1, %ymm0, %xmm3
+; CHECK-AVX1-NEXT: vpcmpgtd %xmm2, %xmm3, %xmm2
+; CHECK-AVX1-NEXT: vpcmpgtd %xmm1, %xmm0, %xmm0
+; CHECK-AVX1-NEXT: vpsrld $9, %xmm0, %xmm0
+; CHECK-AVX1-NEXT: vpsrld $9, %xmm2, %xmm1
+; CHECK-AVX1-NEXT: vinsertf128 $1, %xmm1, %ymm0, %ymm0
+; CHECK-AVX1-NEXT: retq
+;
+; CHECK-AVX2-LABEL: shr_s9_cmp_v8i32:
+; CHECK-AVX2: # %bb.0:
+; CHECK-AVX2-NEXT: vpcmpgtd %ymm1, %ymm0, %ymm0
+; CHECK-AVX2-NEXT: vpsrld $9, %ymm0, %ymm0
+; CHECK-AVX2-NEXT: retq
+;
+; CHECK-AVX512-LABEL: shr_s9_cmp_v8i32:
+; CHECK-AVX512: # %bb.0:
+; CHECK-AVX512-NEXT: vpcmpgtd %ymm1, %ymm0, %ymm0
+; CHECK-AVX512-NEXT: vpsrld $9, %ymm0, %ymm0
+; CHECK-AVX512-NEXT: retq
+ %cmp = icmp sgt <8 x i32> %x, %y
+ %ext = sext <8 x i1> %cmp to <8 x i32>
+ %shr = lshr <8 x i32> %ext, <i32 9, i32 9, i32 9, i32 9, i32 9, i32 9, i32 9, i32 9>
+ ret <8 x i32> %shr
+}
+
define i1 @shr_to_shl_eq_i32_s5_fail_doesnt_add_up(i32 %x) {
; CHECK-LABEL: shr_to_shl_eq_i32_s5_fail_doesnt_add_up:
; CHECK: # %bb.0:
>From fcdf818a7779871990214cc1035bb2c36426f459 Mon Sep 17 00:00:00 2001
From: Simon Pilgrim <RKSimon at users.noreply.github.com>
Date: Fri, 1 Mar 2024 19:24:27 +0000
Subject: [PATCH 289/406] [KnownBits] Add KnownBits::absdiff to compute the
absolute difference of 2 unsigned values (#82354)
Equivalent to "umax(A, B) - umin(A, B)"
This is just an initial correctness implementation, hopefully we can make this optimal in the future.
---
llvm/include/llvm/Support/KnownBits.h | 3 ++
llvm/lib/Support/KnownBits.cpp | 16 +++++++++++
llvm/unittests/Support/KnownBitsTest.cpp | 35 +++++++++++++++++++++++-
3 files changed, 53 insertions(+), 1 deletion(-)
diff --git a/llvm/include/llvm/Support/KnownBits.h b/llvm/include/llvm/Support/KnownBits.h
index fb034e0b9e3baf..69c569b97ccae1 100644
--- a/llvm/include/llvm/Support/KnownBits.h
+++ b/llvm/include/llvm/Support/KnownBits.h
@@ -385,6 +385,9 @@ struct KnownBits {
/// Compute known bits for smin(LHS, RHS).
static KnownBits smin(const KnownBits &LHS, const KnownBits &RHS);
+ /// Compute known bits for absdiff(LHS, RHS).
+ static KnownBits absdiff(const KnownBits &LHS, const KnownBits &RHS);
+
/// Compute known bits for shl(LHS, RHS).
/// NOTE: RHS (shift amount) bitwidth doesn't need to be the same as LHS.
static KnownBits shl(const KnownBits &LHS, const KnownBits &RHS,
diff --git a/llvm/lib/Support/KnownBits.cpp b/llvm/lib/Support/KnownBits.cpp
index 770e4051ca3ffa..c44a08cc1c2e6a 100644
--- a/llvm/lib/Support/KnownBits.cpp
+++ b/llvm/lib/Support/KnownBits.cpp
@@ -176,6 +176,22 @@ KnownBits KnownBits::smin(const KnownBits &LHS, const KnownBits &RHS) {
return Flip(umax(Flip(LHS), Flip(RHS)));
}
+KnownBits KnownBits::absdiff(const KnownBits &LHS, const KnownBits &RHS) {
+ // absdiff(LHS,RHS) = sub(umax(LHS,RHS), umin(LHS,RHS)).
+ KnownBits UMaxValue = umax(LHS, RHS);
+ KnownBits UMinValue = umin(LHS, RHS);
+ KnownBits MinMaxDiff = computeForAddSub(false, false, UMaxValue, UMinValue);
+
+ // find the common bits between sub(LHS,RHS) and sub(RHS,LHS).
+ KnownBits Diff0 = computeForAddSub(false, false, LHS, RHS);
+ KnownBits Diff1 = computeForAddSub(false, false, RHS, LHS);
+ KnownBits SubDiff = Diff0.intersectWith(Diff1);
+
+ KnownBits KnownAbsDiff = MinMaxDiff.unionWith(SubDiff);
+ assert(!KnownAbsDiff.hasConflict() && "Bad Output");
+ return KnownAbsDiff;
+}
+
static unsigned getMaxShiftAmount(const APInt &MaxValue, unsigned BitWidth) {
if (isPowerOf2_32(BitWidth))
return MaxValue.extractBitsAsZExtValue(Log2_32(BitWidth), 0);
diff --git a/llvm/unittests/Support/KnownBitsTest.cpp b/llvm/unittests/Support/KnownBitsTest.cpp
index c0377d45c303a1..9cc5741ad73c45 100644
--- a/llvm/unittests/Support/KnownBitsTest.cpp
+++ b/llvm/unittests/Support/KnownBitsTest.cpp
@@ -244,6 +244,32 @@ TEST(KnownBitsTest, SubBorrowExhaustive) {
});
}
+TEST(KnownBitsTest, AbsDiffSpecialCase) {
+ // There are 2 implementation of absdiff - both are currently needed to cover
+ // extra cases.
+ KnownBits LHS, RHS, Res;
+
+ // absdiff(LHS,RHS) = sub(umax(LHS,RHS), umin(LHS,RHS)).
+ // Actual: false (Inputs = 1011, 101?, Computed = 000?, Exact = 000?)
+ LHS.One = APInt(4, 0b1011);
+ RHS.One = APInt(4, 0b1010);
+ LHS.Zero = APInt(4, 0b0100);
+ RHS.Zero = APInt(4, 0b0100);
+ Res = KnownBits::absdiff(LHS, RHS);
+ EXPECT_EQ(0b0000, Res.One.getZExtValue());
+ EXPECT_EQ(0b1110, Res.Zero.getZExtValue());
+
+ // find the common bits between sub(LHS,RHS) and sub(RHS,LHS).
+ // Actual: false (Inputs = ???1, 1000, Computed = ???1, Exact = 0??1)
+ LHS.One = APInt(4, 0b0001);
+ RHS.One = APInt(4, 0b1000);
+ LHS.Zero = APInt(4, 0b0000);
+ RHS.Zero = APInt(4, 0b0111);
+ Res = KnownBits::absdiff(LHS, RHS);
+ EXPECT_EQ(0b0001, Res.One.getZExtValue());
+ EXPECT_EQ(0b0000, Res.Zero.getZExtValue());
+}
+
TEST(KnownBitsTest, BinaryExhaustive) {
testBinaryOpExhaustive(
[](const KnownBits &Known1, const KnownBits &Known2) {
@@ -281,7 +307,14 @@ TEST(KnownBitsTest, BinaryExhaustive) {
return KnownBits::smin(Known1, Known2);
},
[](const APInt &N1, const APInt &N2) { return APIntOps::smin(N1, N2); });
-
+ testBinaryOpExhaustive(
+ [](const KnownBits &Known1, const KnownBits &Known2) {
+ return KnownBits::absdiff(Known1, Known2);
+ },
+ [](const APInt &N1, const APInt &N2) {
+ return APIntOps::absdiff(N1, N2);
+ },
+ checkCorrectnessOnlyBinary);
testBinaryOpExhaustive(
[](const KnownBits &Known1, const KnownBits &Known2) {
return KnownBits::udiv(Known1, Known2);
>From 09ffd3390852b046369405cf29b3a7ae424bfaa5 Mon Sep 17 00:00:00 2001
From: yelleyee <22870466+yelleyee at users.noreply.github.com>
Date: Sat, 2 Mar 2024 03:30:36 +0800
Subject: [PATCH 290/406] [llvm][vfs] Remove blank comment after \endverbatim
doxygen command (#83240)
Blank comment line afer \endverbatim malfunctions the doxygen parser.
Check the "Detailed Description" section on
https://llvm.org/doxygen/classllvm_1_1vfs_1_1RedirectingFileSystem.html
Screenshot is attached below
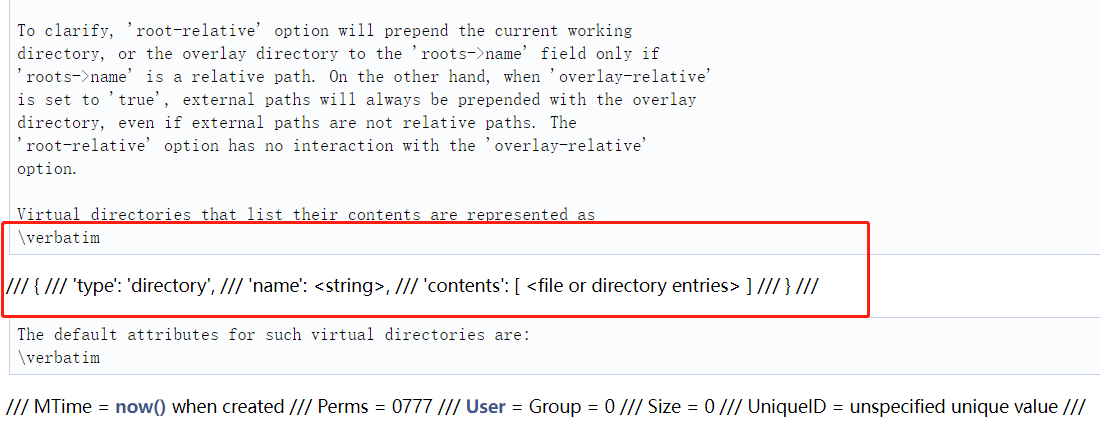
---
llvm/include/llvm/Support/VirtualFileSystem.h | 5 -----
1 file changed, 5 deletions(-)
diff --git a/llvm/include/llvm/Support/VirtualFileSystem.h b/llvm/include/llvm/Support/VirtualFileSystem.h
index 1a5ea677db74da..ef1fac92c2fa4a 100644
--- a/llvm/include/llvm/Support/VirtualFileSystem.h
+++ b/llvm/include/llvm/Support/VirtualFileSystem.h
@@ -672,7 +672,6 @@ class RedirectingFileSystemParser;
/// ]
/// }
/// \endverbatim
-///
/// The roots may be absolute or relative. If relative they will be made
/// absolute against either current working directory or the directory where
/// the Overlay YAML file is located, depending on the 'root-relative'
@@ -704,7 +703,6 @@ class RedirectingFileSystemParser;
/// 'contents': [ <file or directory entries> ]
/// }
/// \endverbatim
-///
/// The default attributes for such virtual directories are:
/// \verbatim
/// MTime = now() when created
@@ -713,7 +711,6 @@ class RedirectingFileSystemParser;
/// Size = 0
/// UniqueID = unspecified unique value
/// \endverbatim
-///
/// When a path prefix matches such a directory, the next component in the path
/// is matched against the entries in the 'contents' array.
///
@@ -726,7 +723,6 @@ class RedirectingFileSystemParser;
/// 'external-contents': <path to external directory>
/// }
/// \endverbatim
-///
/// and inherit their attributes from the external directory. When a path
/// prefix matches such an entry, the unmatched components are appended to the
/// 'external-contents' path, and the resulting path is looked up in the
@@ -741,7 +737,6 @@ class RedirectingFileSystemParser;
/// 'external-contents': <path to external file>
/// }
/// \endverbatim
-///
/// Their attributes and file contents are determined by looking up the file at
/// their 'external-contents' path in the external file system.
///
>From 6fe60bd89fc72398795de6ee2a6120b8af44a977 Mon Sep 17 00:00:00 2001
From: Florian Hahn <flo at fhahn.com>
Date: Fri, 1 Mar 2024 19:43:06 +0000
Subject: [PATCH 291/406] [SLP] Exit early if MaxVF < MinVF (NFCI). (#83283)
Exit early if MaxVF < MinVF. In that case, the loop body below will
never get entered. Note that this adjusts the condition from MaxVF <=
MinVF. If MaxVF == MinVF, vectorization may still be feasible (and the
loop below gets entered).
PR: https://github.com/llvm/llvm-project/pull/83283
---
llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp | 5 +++--
1 file changed, 3 insertions(+), 2 deletions(-)
diff --git a/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp b/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
index 47681342239e1d..5e487a6b8a5daf 100644
--- a/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
+++ b/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
@@ -14019,10 +14019,11 @@ bool SLPVectorizerPass::vectorizeStores(ArrayRef<StoreInst *> Stores,
unsigned MinVF = TTI->getStoreMinimumVF(
R.getMinVF(DL->getTypeSizeInBits(ValueTy)), StoreTy, ValueTy);
- if (MaxVF <= MinVF) {
+ if (MaxVF < MinVF) {
LLVM_DEBUG(dbgs() << "SLP: Vectorization infeasible as MaxVF (" << MaxVF
- << ") <= "
+ << ") < "
<< "MinVF (" << MinVF << ")\n");
+ continue;
}
// FIXME: Is division-by-2 the correct step? Should we assert that the
>From a490bbf5391de358ad400a23ae8e9ed494e5004e Mon Sep 17 00:00:00 2001
From: Michael Liao <michael.hliao at gmail.com>
Date: Fri, 1 Mar 2024 14:47:54 -0500
Subject: [PATCH 292/406] [M68k] Fix compilation pipeline check
- Add 'Init Undef Pass', which is target-independent now.
---
llvm/test/CodeGen/M68k/pipeline.ll | 1 +
1 file changed, 1 insertion(+)
diff --git a/llvm/test/CodeGen/M68k/pipeline.ll b/llvm/test/CodeGen/M68k/pipeline.ll
index dfaa149b7a4744..db047da943c5b3 100644
--- a/llvm/test/CodeGen/M68k/pipeline.ll
+++ b/llvm/test/CodeGen/M68k/pipeline.ll
@@ -76,6 +76,7 @@
; CHECK-NEXT: Peephole Optimizations
; CHECK-NEXT: Remove dead machine instructions
; CHECK-NEXT: Detect Dead Lanes
+; CHECK-NEXT: Init Undef Pass
; CHECK-NEXT: Process Implicit Definitions
; CHECK-NEXT: Remove unreachable machine basic blocks
; CHECK-NEXT: Live Variable Analysis
>From 1a0c988ebddd83bd34393a1500b5f3ce80888fbc Mon Sep 17 00:00:00 2001
From: Hui <hui.xie0621 at gmail.com>
Date: Fri, 1 Mar 2024 19:50:55 +0000
Subject: [PATCH 293/406] [libc++][NFC] rename variable in atomic_sync
As discussed in https://github.com/llvm/llvm-project/pull/81427/files#r1509266817
rename the variable as a separate commit
---
libcxx/include/__atomic/atomic_sync.h | 6 +++---
1 file changed, 3 insertions(+), 3 deletions(-)
diff --git a/libcxx/include/__atomic/atomic_sync.h b/libcxx/include/__atomic/atomic_sync.h
index d07b35878493bc..2997bad83344b2 100644
--- a/libcxx/include/__atomic/atomic_sync.h
+++ b/libcxx/include/__atomic/atomic_sync.h
@@ -137,9 +137,9 @@ _LIBCPP_HIDE_FROM_ABI bool __cxx_nonatomic_compare_equal(_Tp const& __lhs, _Tp c
template <class _Tp>
struct __atomic_compare_unequal_to {
- _Tp __val;
- _LIBCPP_HIDE_FROM_ABI bool operator()(_Tp& __current_val) const {
- return !std::__cxx_nonatomic_compare_equal(__current_val, __val);
+ _Tp __val_;
+ _LIBCPP_HIDE_FROM_ABI bool operator()(const _Tp& __arg) const {
+ return !std::__cxx_nonatomic_compare_equal(__arg, __val_);
}
};
>From 1685e7fdab3f1b3fc654f7c93219594532becb81 Mon Sep 17 00:00:00 2001
From: Fabian Schiebel <52407375+fabianbs96 at users.noreply.github.com>
Date: Fri, 1 Mar 2024 20:53:54 +0100
Subject: [PATCH 294/406] =?UTF-8?q?[Support]=C2=A0Fix=20crash=20in=20insta?=
=?UTF-8?q?ll=5Fbad=5Falloc=5Ferror=5Fhandler=20(#83160)?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
Previously, the function `install_bad_alloc_error_handler` was asserting that a bad_alloc error handler was not already installed. However, it was actually checking for the fatal-error handler, not for the bad_alloc error handler, causing an assertion failure if a fatal-error handler was already installed.
Fixes #83040
---
llvm/lib/Support/ErrorHandling.cpp | 3 ++-
llvm/unittests/Support/ErrorTest.cpp | 26 ++++++++++++++++++++++++++
2 files changed, 28 insertions(+), 1 deletion(-)
diff --git a/llvm/lib/Support/ErrorHandling.cpp b/llvm/lib/Support/ErrorHandling.cpp
index b8b3b7424ac6b1..d2d3dcc2f478c5 100644
--- a/llvm/lib/Support/ErrorHandling.cpp
+++ b/llvm/lib/Support/ErrorHandling.cpp
@@ -130,7 +130,8 @@ void llvm::install_bad_alloc_error_handler(fatal_error_handler_t handler,
#if LLVM_ENABLE_THREADS == 1
std::lock_guard<std::mutex> Lock(BadAllocErrorHandlerMutex);
#endif
- assert(!ErrorHandler && "Bad alloc error handler already registered!\n");
+ assert(!BadAllocErrorHandler &&
+ "Bad alloc error handler already registered!\n");
BadAllocErrorHandler = handler;
BadAllocErrorHandlerUserData = user_data;
}
diff --git a/llvm/unittests/Support/ErrorTest.cpp b/llvm/unittests/Support/ErrorTest.cpp
index 11f93203597bf0..1229282cf0def5 100644
--- a/llvm/unittests/Support/ErrorTest.cpp
+++ b/llvm/unittests/Support/ErrorTest.cpp
@@ -1132,4 +1132,30 @@ TEST(Error, moveInto) {
}
}
+TEST(Error, FatalBadAllocErrorHandlersInteraction) {
+ auto ErrorHandler = [](void *Data, const char *, bool) {};
+ install_fatal_error_handler(ErrorHandler, nullptr);
+ // The following call should not crash; previously, a bug in
+ // install_bad_alloc_error_handler asserted that no fatal-error handler is
+ // installed already.
+ install_bad_alloc_error_handler(ErrorHandler, nullptr);
+
+ // Don't interfere with other tests.
+ remove_fatal_error_handler();
+ remove_bad_alloc_error_handler();
+}
+
+TEST(Error, BadAllocFatalErrorHandlersInteraction) {
+ auto ErrorHandler = [](void *Data, const char *, bool) {};
+ install_bad_alloc_error_handler(ErrorHandler, nullptr);
+ // The following call should not crash; related to
+ // FatalBadAllocErrorHandlersInteraction: Ensure that the error does not occur
+ // in the other direction.
+ install_fatal_error_handler(ErrorHandler, nullptr);
+
+ // Don't interfere with other tests.
+ remove_fatal_error_handler();
+ remove_bad_alloc_error_handler();
+}
+
} // namespace
>From 7b0b64a7016d67d6d8c538fe406a2ffd93c11602 Mon Sep 17 00:00:00 2001
From: Fangrui Song <i at maskray.me>
Date: Fri, 1 Mar 2024 12:02:10 -0800
Subject: [PATCH 295/406] [DWARF] Use std::tie after #83047. NFC
The code suggestion was neglected when the patch landed.
---
llvm/lib/CodeGen/AsmPrinter/AccelTable.cpp | 5 ++---
1 file changed, 2 insertions(+), 3 deletions(-)
diff --git a/llvm/lib/CodeGen/AsmPrinter/AccelTable.cpp b/llvm/lib/CodeGen/AsmPrinter/AccelTable.cpp
index 9e1727a0b8d138..55cdc3c9286420 100644
--- a/llvm/lib/CodeGen/AsmPrinter/AccelTable.cpp
+++ b/llvm/lib/CodeGen/AsmPrinter/AccelTable.cpp
@@ -38,9 +38,8 @@ void AccelTableBase::computeBucketCount() {
for (const auto &E : Entries)
Uniques.push_back(E.second.HashValue);
- auto Counts = llvm::dwarf::getDebugNamesBucketAndHashCount(Uniques);
- BucketCount = Counts.first;
- UniqueHashCount = Counts.second;
+ std::tie(BucketCount, UniqueHashCount) =
+ llvm::dwarf::getDebugNamesBucketAndHashCount(Uniques);
}
void AccelTableBase::finalize(AsmPrinter *Asm, StringRef Prefix) {
>From 214f8972793ccc2e062ca56c04d93e799d4c17eb Mon Sep 17 00:00:00 2001
From: Fangrui Song <i at maskray.me>
Date: Fri, 1 Mar 2024 12:06:12 -0800
Subject: [PATCH 296/406] [unittest] Fix -Wsign-compare warnings in
KnownBits.cpp after #82354
---
llvm/unittests/Support/KnownBitsTest.cpp | 8 ++++----
1 file changed, 4 insertions(+), 4 deletions(-)
diff --git a/llvm/unittests/Support/KnownBitsTest.cpp b/llvm/unittests/Support/KnownBitsTest.cpp
index 9cc5741ad73c45..fb9210bffcb433 100644
--- a/llvm/unittests/Support/KnownBitsTest.cpp
+++ b/llvm/unittests/Support/KnownBitsTest.cpp
@@ -256,8 +256,8 @@ TEST(KnownBitsTest, AbsDiffSpecialCase) {
LHS.Zero = APInt(4, 0b0100);
RHS.Zero = APInt(4, 0b0100);
Res = KnownBits::absdiff(LHS, RHS);
- EXPECT_EQ(0b0000, Res.One.getZExtValue());
- EXPECT_EQ(0b1110, Res.Zero.getZExtValue());
+ EXPECT_EQ(0b0000ul, Res.One.getZExtValue());
+ EXPECT_EQ(0b1110ul, Res.Zero.getZExtValue());
// find the common bits between sub(LHS,RHS) and sub(RHS,LHS).
// Actual: false (Inputs = ???1, 1000, Computed = ???1, Exact = 0??1)
@@ -266,8 +266,8 @@ TEST(KnownBitsTest, AbsDiffSpecialCase) {
LHS.Zero = APInt(4, 0b0000);
RHS.Zero = APInt(4, 0b0111);
Res = KnownBits::absdiff(LHS, RHS);
- EXPECT_EQ(0b0001, Res.One.getZExtValue());
- EXPECT_EQ(0b0000, Res.Zero.getZExtValue());
+ EXPECT_EQ(0b0001ul, Res.One.getZExtValue());
+ EXPECT_EQ(0b0000ul, Res.Zero.getZExtValue());
}
TEST(KnownBitsTest, BinaryExhaustive) {
>From ebaf26dabec00c32177cd4fa47f3bf5902b194b7 Mon Sep 17 00:00:00 2001
From: Fangrui Song <i at maskray.me>
Date: Fri, 1 Mar 2024 12:09:32 -0800
Subject: [PATCH 297/406] [lldb] Fix -Wformat after #83602
---
lldb/source/Commands/CommandObjectThread.cpp | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/lldb/source/Commands/CommandObjectThread.cpp b/lldb/source/Commands/CommandObjectThread.cpp
index 6d84315a471d95..cf4f8ccaa0c4aa 100644
--- a/lldb/source/Commands/CommandObjectThread.cpp
+++ b/lldb/source/Commands/CommandObjectThread.cpp
@@ -280,7 +280,7 @@ class ThreadStepScopeOptionGroup : public OptionGroup {
if (!success)
error.SetErrorStringWithFormat(
"invalid boolean value for option '%c': %s", short_option,
- option_arg);
+ option_arg.data());
else {
m_step_in_avoid_no_debug = avoid_no_debug ? eLazyBoolYes : eLazyBoolNo;
}
@@ -293,7 +293,7 @@ class ThreadStepScopeOptionGroup : public OptionGroup {
if (!success)
error.SetErrorStringWithFormat(
"invalid boolean value for option '%c': %s", short_option,
- option_arg);
+ option_arg.data());
else {
m_step_out_avoid_no_debug = avoid_no_debug ? eLazyBoolYes : eLazyBoolNo;
}
>From 617398e5e28665ca49810ff5db684292f4b2eb1f Mon Sep 17 00:00:00 2001
From: Florian Hahn <flo at fhahn.com>
Date: Fri, 1 Mar 2024 20:13:49 +0000
Subject: [PATCH 298/406] [SLP] Collect candidate VFs in vector in
vectorizeStores (NFC). (#82793)
This is in preparation for
https://github.com/llvm/llvm-project/pull/77790 and makes it easy to add
other, non-power-of-2 VFs for processing.
PR: https://github.com/llvm/llvm-project/pull/82793
---
llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp | 9 ++++++++-
1 file changed, 8 insertions(+), 1 deletion(-)
diff --git a/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp b/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
index 5e487a6b8a5daf..daea3bdce68893 100644
--- a/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
+++ b/llvm/lib/Transforms/Vectorize/SLPVectorizer.cpp
@@ -14026,10 +14026,17 @@ bool SLPVectorizerPass::vectorizeStores(ArrayRef<StoreInst *> Stores,
continue;
}
+ unsigned Sz = 1 + Log2_32(MaxVF) - Log2_32(MinVF);
+ SmallVector<unsigned> CandidateVFs(Sz);
// FIXME: Is division-by-2 the correct step? Should we assert that the
// register size is a power-of-2?
+ unsigned Size = MaxVF;
+ for_each(CandidateVFs, [&](unsigned &VF) {
+ VF = Size;
+ Size /= 2;
+ });
unsigned StartIdx = 0;
- for (unsigned Size = MaxVF; Size >= MinVF; Size /= 2) {
+ for (unsigned Size : CandidateVFs) {
for (unsigned Cnt = StartIdx, E = Operands.size(); Cnt + Size <= E;) {
ArrayRef<Value *> Slice = ArrayRef(Operands).slice(Cnt, Size);
assert(
>From 76ce3c1bcf82056a61bcbdf776f67ac53d881df0 Mon Sep 17 00:00:00 2001
From: rayroudc <rayroudc at gmail.com>
Date: Fri, 1 Mar 2024 21:24:13 +0100
Subject: [PATCH 299/406] [clang-format] Enable again some operator tests
(#83380)
Multiple formatting operator tests are commented. This change enables
them again.
[PR506629](https://llvm.org/PR50629) fixed by
[D153798](https://reviews.llvm.org/D153798).
Tests in `ConfigurableSpaceBeforeParens` have the same behavior as
before [D110833](https://reviews.llvm.org/D110833).
Update the test for function declaration and definition, as changed in
[D114696](https://reviews.llvm.org/D114696).
---
clang/unittests/Format/FormatTest.cpp | 23 +++++++++--------------
1 file changed, 9 insertions(+), 14 deletions(-)
diff --git a/clang/unittests/Format/FormatTest.cpp b/clang/unittests/Format/FormatTest.cpp
index d9752c73e34e79..fc367a7a5a8981 100644
--- a/clang/unittests/Format/FormatTest.cpp
+++ b/clang/unittests/Format/FormatTest.cpp
@@ -11159,10 +11159,8 @@ TEST_F(FormatTest, UnderstandsOverloadedOperators) {
verifyFormat("void f() { a.operator*(b & b); }");
verifyFormat("void f() { a->operator&(a * b); }");
verifyFormat("void f() { NS::a.operator+(*b * *b); }");
- // TODO: Calling an operator as a non-member function is hard to distinguish.
- // https://llvm.org/PR50629
- // verifyFormat("void f() { operator*(a & a); }");
- // verifyFormat("void f() { operator&(a, b * b); }");
+ verifyFormat("void f() { operator*(a & a); }");
+ verifyFormat("void f() { operator&(a, b * b); }");
verifyFormat("void f() { return operator()(x) * b; }");
verifyFormat("void f() { return operator[](x) * b; }");
@@ -16551,9 +16549,8 @@ TEST_F(FormatTest, ConfigurableSpaceBeforeParens) {
verifyFormat("static_assert (sizeof (char) == 1, \"Impossible!\");", Space);
verifyFormat("int f () throw (Deprecated);", Space);
verifyFormat("typedef void (*cb) (int);", Space);
- // FIXME these tests regressed behaviour.
- // verifyFormat("T A::operator() ();", Space);
- // verifyFormat("X A::operator++ (T);", Space);
+ verifyFormat("T A::operator() ();", Space);
+ verifyFormat("X A::operator++ (T);", Space);
verifyFormat("auto lambda = [] () { return 0; };", Space);
verifyFormat("int x = int (y);", Space);
verifyFormat("#define F(...) __VA_OPT__ (__VA_ARGS__)", Space);
@@ -16612,8 +16609,7 @@ TEST_F(FormatTest, ConfigurableSpaceBeforeParens) {
verifyFormat("int f() throw (Deprecated);", SomeSpace);
verifyFormat("typedef void (*cb) (int);", SomeSpace);
verifyFormat("T A::operator()();", SomeSpace);
- // FIXME these tests regressed behaviour.
- // verifyFormat("X A::operator++ (T);", SomeSpace);
+ verifyFormat("X A::operator++ (T);", SomeSpace);
verifyFormat("int x = int (y);", SomeSpace);
verifyFormat("auto lambda = []() { return 0; };", SomeSpace);
@@ -16671,9 +16667,8 @@ TEST_F(FormatTest, ConfigurableSpaceBeforeParens) {
SpaceFuncDecl);
verifyFormat("int f () throw(Deprecated);", SpaceFuncDecl);
verifyFormat("typedef void (*cb)(int);", SpaceFuncDecl);
- // FIXME these tests regressed behaviour.
- // verifyFormat("T A::operator() ();", SpaceFuncDecl);
- // verifyFormat("X A::operator++ (T);", SpaceFuncDecl);
+ verifyFormat("T A::operator()();", SpaceFuncDecl);
+ verifyFormat("X A::operator++(T);", SpaceFuncDecl);
verifyFormat("T A::operator()() {}", SpaceFuncDecl);
verifyFormat("auto lambda = []() { return 0; };", SpaceFuncDecl);
verifyFormat("int x = int(y);", SpaceFuncDecl);
@@ -16710,7 +16705,7 @@ TEST_F(FormatTest, ConfigurableSpaceBeforeParens) {
verifyFormat("typedef void (*cb)(int);", SpaceFuncDef);
verifyFormat("T A::operator()();", SpaceFuncDef);
verifyFormat("X A::operator++(T);", SpaceFuncDef);
- // verifyFormat("T A::operator() () {}", SpaceFuncDef);
+ verifyFormat("T A::operator()() {}", SpaceFuncDef);
verifyFormat("auto lambda = [] () { return 0; };", SpaceFuncDef);
verifyFormat("int x = int(y);", SpaceFuncDef);
verifyFormat("M(std::size_t R, std::size_t C) : C(C), data(R) {}",
@@ -16797,7 +16792,7 @@ TEST_F(FormatTest, ConfigurableSpaceBeforeParens) {
verifyFormat("int f() throw (Deprecated);", SomeSpace2);
verifyFormat("typedef void (*cb) (int);", SomeSpace2);
verifyFormat("T A::operator()();", SomeSpace2);
- // verifyFormat("X A::operator++ (T);", SomeSpace2);
+ verifyFormat("X A::operator++ (T);", SomeSpace2);
verifyFormat("int x = int (y);", SomeSpace2);
verifyFormat("auto lambda = []() { return 0; };", SomeSpace2);
>From d01576bb6033865c20a4c0da581939dcae5b30be Mon Sep 17 00:00:00 2001
From: Alexandros Lamprineas <alexandros.lamprineas at arm.com>
Date: Fri, 1 Mar 2024 21:06:08 +0000
Subject: [PATCH 300/406] [TargetParser][AArch64] Add alias for FEAT_RDM.
(#80540)
This patch allows using the name "rdma" as an alias for "rdm". The name
makes its way to target attributes as well as the command line via the
-march and -mcpu options. The motivation was originally to support this
in Function Multi Versioning but it also makes sense to align with GCC
on the command line.
---
clang/docs/ReleaseNotes.rst | 5 +++++
clang/test/CodeGen/attr-target-version.c | 12 ++++++------
clang/test/Driver/aarch64-rdm.c | 3 +++
clang/test/Sema/attr-target-clones-aarch64.c | 2 +-
clang/test/SemaCXX/attr-target-version.cpp | 1 +
.../llvm/TargetParser/AArch64TargetParser.h | 13 ++++++++-----
llvm/lib/TargetParser/AArch64TargetParser.cpp | 15 +++++++++++++--
7 files changed, 37 insertions(+), 14 deletions(-)
diff --git a/clang/docs/ReleaseNotes.rst b/clang/docs/ReleaseNotes.rst
index cfe0ac6a5dca61..6f6ce7c68a7a71 100644
--- a/clang/docs/ReleaseNotes.rst
+++ b/clang/docs/ReleaseNotes.rst
@@ -346,6 +346,11 @@ Arm and AArch64 Support
improvements for most targets. We have not changed the default behavior for
ARMv6, but may revisit that decision in the future. Users can restore the old
behavior with -m[no-]unaligned-access.
+- An alias identifier (rdma) has been added for targeting the AArch64
+ Architecture Extension which uses Rounding Doubling Multiply Accumulate
+ instructions (rdm). The identifier is available on the command line as
+ a feature modifier for -march and -mcpu as well as via target attributes
+ like ``target_version`` or ``target_clones``.
Android Support
^^^^^^^^^^^^^^^
diff --git a/clang/test/CodeGen/attr-target-version.c b/clang/test/CodeGen/attr-target-version.c
index ae97977a9144f6..56a42499d0a7ca 100644
--- a/clang/test/CodeGen/attr-target-version.c
+++ b/clang/test/CodeGen/attr-target-version.c
@@ -25,7 +25,7 @@ int foo() {
}
inline int __attribute__((target_version("sha1+pmull+f64mm"))) fmv_inline(void) { return 1; }
-inline int __attribute__((target_version("fp16+fcma+sme+ fp16 "))) fmv_inline(void) { return 2; }
+inline int __attribute__((target_version("fp16+fcma+rdma+sme+ fp16 "))) fmv_inline(void) { return 2; }
inline int __attribute__((target_version("sha3+i8mm+f32mm"))) fmv_inline(void) { return 12; }
inline int __attribute__((target_version("dit+sve-ebf16"))) fmv_inline(void) { return 8; }
inline int __attribute__((target_version("dpb+rcpc2 "))) fmv_inline(void) { return 6; }
@@ -261,12 +261,12 @@ int hoo(void) {
// CHECK-NEXT: resolver_entry:
// CHECK-NEXT: call void @__init_cpu_features_resolver()
// CHECK-NEXT: [[TMP0:%.*]] = load i64, ptr @__aarch64_cpu_features, align 8
-// CHECK-NEXT: [[TMP1:%.*]] = and i64 [[TMP0]], 4398048608256
-// CHECK-NEXT: [[TMP2:%.*]] = icmp eq i64 [[TMP1]], 4398048608256
+// CHECK-NEXT: [[TMP1:%.*]] = and i64 [[TMP0]], 4398048608320
+// CHECK-NEXT: [[TMP2:%.*]] = icmp eq i64 [[TMP1]], 4398048608320
// CHECK-NEXT: [[TMP3:%.*]] = and i1 true, [[TMP2]]
// CHECK-NEXT: br i1 [[TMP3]], label [[RESOLVER_RETURN:%.*]], label [[RESOLVER_ELSE:%.*]]
// CHECK: resolver_return:
-// CHECK-NEXT: ret ptr @fmv_inline._MfcmaMfp16Mfp16Msme
+// CHECK-NEXT: ret ptr @fmv_inline._MfcmaMfp16Mfp16MrdmMsme
// CHECK: resolver_else:
// CHECK-NEXT: [[TMP4:%.*]] = load i64, ptr @__aarch64_cpu_features, align 8
// CHECK-NEXT: [[TMP5:%.*]] = and i64 [[TMP4]], 864726312827224064
@@ -575,7 +575,7 @@ int hoo(void) {
//
//
// CHECK: Function Attrs: noinline nounwind optnone
-// CHECK-LABEL: define {{[^@]+}}@fmv_inline._MfcmaMfp16Mfp16Msme
+// CHECK-LABEL: define {{[^@]+}}@fmv_inline._MfcmaMfp16Mfp16MrdmMsme
// CHECK-SAME: () #[[ATTR13:[0-9]+]] {
// CHECK-NEXT: entry:
// CHECK-NEXT: ret i32 2
@@ -829,7 +829,7 @@ int hoo(void) {
// CHECK: attributes #[[ATTR10]] = { noinline nounwind optnone "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-features"="+bf16,+fullfp16,+ls64,+sme,+sme2" }
// CHECK: attributes #[[ATTR11]] = { noinline nounwind optnone "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-features"="+ccpp,+fullfp16,+ls64" }
// CHECK: attributes #[[ATTR12]] = { noinline nounwind optnone "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-features"="+aes,+f64mm,+fp-armv8,+fullfp16,+ls64,+neon,+sve" }
-// CHECK: attributes #[[ATTR13]] = { noinline nounwind optnone "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-features"="+bf16,+complxnum,+fp-armv8,+fullfp16,+ls64,+neon,+sme" }
+// CHECK: attributes #[[ATTR13]] = { noinline nounwind optnone "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-features"="+bf16,+complxnum,+fp-armv8,+fullfp16,+ls64,+neon,+rdm,+sme" }
// CHECK: attributes #[[ATTR14]] = { noinline nounwind optnone "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-features"="+f32mm,+fp-armv8,+fullfp16,+i8mm,+ls64,+neon,+sha2,+sha3,+sve" }
// CHECK: attributes #[[ATTR15]] = { noinline nounwind optnone "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-features"="+bf16,+dit,+fp-armv8,+fullfp16,+ls64,+neon,+sve" }
// CHECK: attributes #[[ATTR16]] = { noinline nounwind optnone "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-features"="+ccpp,+fullfp16,+ls64,+rcpc" }
diff --git a/clang/test/Driver/aarch64-rdm.c b/clang/test/Driver/aarch64-rdm.c
index f2542b381e7c26..62e1a4def4ce12 100644
--- a/clang/test/Driver/aarch64-rdm.c
+++ b/clang/test/Driver/aarch64-rdm.c
@@ -1,13 +1,16 @@
// RUN: %clang --target=aarch64-none-elf -march=armv8a+rdm -### -c %s 2>&1 | FileCheck --check-prefix=CHECK-RDM %s
+// RUN: %clang --target=aarch64-none-elf -march=armv8a+rdma -### -c %s 2>&1 | FileCheck --check-prefix=CHECK-RDM %s
// RUN: %clang --target=aarch64-none-elf -mcpu=generic+rdm -### -c %s 2>&1 | FileCheck --check-prefix=CHECK-RDM %s
// RUN: %clang --target=aarch64-none-elf -mcpu=falkor -### -c %s 2>&1 | FileCheck --check-prefix=CHECK-RDM %s
// RUN: %clang --target=aarch64-none-elf -mcpu=thunderx2t99 -### -c %s 2>&1 | FileCheck --check-prefix=CHECK-RDM %s
// CHECK-RDM: "-target-feature" "+rdm"
// RUN: %clang --target=aarch64-none-elf -march=armv8a+nordm -### -c %s 2>&1 | FileCheck --check-prefix=CHECK-NORDM %s
+// RUN: %clang --target=aarch64-none-elf -march=armv8a+nordma -### -c %s 2>&1 | FileCheck --check-prefix=CHECK-NORDM %s
// RUN: %clang --target=aarch64-none-elf -mcpu=generic+nordm -### -c %s 2>&1 | FileCheck --check-prefix=CHECK-NORDM %s
// CHECK-NORDM-NOT: "-target-feature" "+rdm"
//
// RUN: %clang --target=aarch64-none-elf -march=armv8.1a -### -c %s 2>&1 | FileCheck --check-prefix=CHECK-RDM %s
// RUN: %clang --target=aarch64-none-elf -march=armv8.1a+nordm -### -c %s 2>&1 | FileCheck --check-prefix=CHECK-NORDM-DEFAULT %s
+// RUN: %clang --target=aarch64-none-elf -march=armv8.1a+nordma -### -c %s 2>&1 | FileCheck --check-prefix=CHECK-NORDM-DEFAULT %s
// CHECK-NORDM-DEFAULT: "-target-feature" "-rdm"
diff --git a/clang/test/Sema/attr-target-clones-aarch64.c b/clang/test/Sema/attr-target-clones-aarch64.c
index 4054b7c837ec99..0ce277f41884c6 100644
--- a/clang/test/Sema/attr-target-clones-aarch64.c
+++ b/clang/test/Sema/attr-target-clones-aarch64.c
@@ -1,6 +1,6 @@
// RUN: %clang_cc1 -triple aarch64-linux-gnu -fsyntax-only -verify %s
-void __attribute__((target_clones("fp16+sve2-aes", "sb+sve2-sha3+rcpc3+mops"))) no_def(void);
+void __attribute__((target_clones("fp16+sve2-aes", "sb+sve2-sha3+rcpc3+mops", "rdma"))) no_def(void);
// expected-warning at +1 {{unsupported 'default' in the 'target_clones' attribute string; 'target_clones' attribute ignored}}
void __attribute__((target_clones("default+sha3"))) warn1(void);
diff --git a/clang/test/SemaCXX/attr-target-version.cpp b/clang/test/SemaCXX/attr-target-version.cpp
index 5c542ad2e2dcab..0bd710c4e282ad 100644
--- a/clang/test/SemaCXX/attr-target-version.cpp
+++ b/clang/test/SemaCXX/attr-target-version.cpp
@@ -7,6 +7,7 @@ void __attribute__((target_version("dotprod"))) no_def(void);
void __attribute__((target_version("rdm+fp"))) no_def(void);
void __attribute__((target_version("rcpc3"))) no_def(void);
void __attribute__((target_version("mops"))) no_def(void);
+void __attribute__((target_version("rdma"))) no_def(void);
// expected-error at +1 {{no matching function for call to 'no_def'}}
void foo(void) { no_def(); }
diff --git a/llvm/include/llvm/TargetParser/AArch64TargetParser.h b/llvm/include/llvm/TargetParser/AArch64TargetParser.h
index 404424beb01931..b539627604c376 100644
--- a/llvm/include/llvm/TargetParser/AArch64TargetParser.h
+++ b/llvm/include/llvm/TargetParser/AArch64TargetParser.h
@@ -813,14 +813,16 @@ inline constexpr CpuInfo CpuInfos[] = {
AArch64::AEK_SSBS, AArch64::AEK_CSSC}))},
};
-// An alias for a CPU.
-struct CpuAlias {
- StringRef Alias;
+// Name alias.
+struct Alias {
+ StringRef AltName;
StringRef Name;
};
-inline constexpr CpuAlias CpuAliases[] = {{"cobalt-100", "neoverse-n2"},
- {"grace", "neoverse-v2"}};
+inline constexpr Alias CpuAliases[] = {{"cobalt-100", "neoverse-n2"},
+ {"grace", "neoverse-v2"}};
+
+inline constexpr Alias ExtAliases[] = {{"rdma", "rdm"}};
bool getExtensionFeatures(
const AArch64::ExtensionBitset &Extensions,
@@ -828,6 +830,7 @@ bool getExtensionFeatures(
StringRef getArchExtFeature(StringRef ArchExt);
StringRef resolveCPUAlias(StringRef CPU);
+StringRef resolveExtAlias(StringRef ArchExt);
// Information by Name
const ArchInfo *getArchForCpu(StringRef CPU);
diff --git a/llvm/lib/TargetParser/AArch64TargetParser.cpp b/llvm/lib/TargetParser/AArch64TargetParser.cpp
index 6f7b421f4e080e..e36832f563eed8 100644
--- a/llvm/lib/TargetParser/AArch64TargetParser.cpp
+++ b/llvm/lib/TargetParser/AArch64TargetParser.cpp
@@ -69,7 +69,14 @@ bool AArch64::getExtensionFeatures(
StringRef AArch64::resolveCPUAlias(StringRef Name) {
for (const auto &A : CpuAliases)
- if (A.Alias == Name)
+ if (A.AltName == Name)
+ return A.Name;
+ return Name;
+}
+
+StringRef AArch64::resolveExtAlias(StringRef Name) {
+ for (const auto &A : ExtAliases)
+ if (A.AltName == Name)
return A.Name;
return Name;
}
@@ -91,7 +98,7 @@ void AArch64::fillValidCPUArchList(SmallVectorImpl<StringRef> &Values) {
Values.push_back(C.Name);
for (const auto &Alias : CpuAliases)
- Values.push_back(Alias.Alias);
+ Values.push_back(Alias.AltName);
}
bool AArch64::isX18ReservedByDefault(const Triple &TT) {
@@ -114,6 +121,10 @@ const AArch64::ArchInfo *AArch64::parseArch(StringRef Arch) {
}
std::optional<AArch64::ExtensionInfo> AArch64::parseArchExtension(StringRef ArchExt) {
+ // Resolve aliases first.
+ ArchExt = resolveExtAlias(ArchExt);
+
+ // Then find the Extension name.
for (const auto &A : Extensions) {
if (ArchExt == A.Name)
return A;
>From ec415aff63fc0cc194b668137362d7618d0271c8 Mon Sep 17 00:00:00 2001
From: Noah Goldstein <goldstein.w.n at gmail.com>
Date: Wed, 21 Feb 2024 11:44:06 -0600
Subject: [PATCH 301/406] [X86] Regenerate X86/lsr-addrecloops.ll test; NFC
---
llvm/test/CodeGen/X86/lsr-addrecloops.ll | 95 +++++++++++++++++++++++-
1 file changed, 93 insertions(+), 2 deletions(-)
diff --git a/llvm/test/CodeGen/X86/lsr-addrecloops.ll b/llvm/test/CodeGen/X86/lsr-addrecloops.ll
index 74a8d68a850f80..963405c8b0b3d3 100644
--- a/llvm/test/CodeGen/X86/lsr-addrecloops.ll
+++ b/llvm/test/CodeGen/X86/lsr-addrecloops.ll
@@ -1,3 +1,4 @@
+; NOTE: Assertions have been autogenerated by utils/update_llc_test_checks.py UTC_ARGS: --version 4
; RUN: llc < %s | FileCheck %s
; Check that the SCEVs produced from the multiple loops don't attempt to get
@@ -9,7 +10,44 @@ target triple = "x86_64-unknown-linux-gnu"
define void @in4dob_(ptr nocapture writeonly %0, ptr nocapture readonly %1, ptr nocapture readonly %2, i64 %3, i1 %min.iters.check840) "target-cpu"="icelake-server" {
; CHECK-LABEL: in4dob_:
-; CHECK: .LBB0_6: # %vector.body807
+; CHECK: # %bb.0: # %.preheader263
+; CHECK-NEXT: leaq (,%rcx,4), %r9
+; CHECK-NEXT: movl $1, %r10d
+; CHECK-NEXT: xorl %eax, %eax
+; CHECK-NEXT: vxorps %xmm0, %xmm0, %xmm0
+; CHECK-NEXT: jmp .LBB0_1
+; CHECK-NEXT: .p2align 4, 0x90
+; CHECK-NEXT: .LBB0_20: # in Loop: Header=BB0_1 Depth=1
+; CHECK-NEXT: incq %r10
+; CHECK-NEXT: addq %r9, %rax
+; CHECK-NEXT: cmpq %r10, %rcx
+; CHECK-NEXT: je .LBB0_18
+; CHECK-NEXT: .LBB0_1: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: vmovss {{.*#+}} xmm1 = mem[0],zero,zero,zero
+; CHECK-NEXT: vucomiss %xmm0, %xmm1
+; CHECK-NEXT: jne .LBB0_20
+; CHECK-NEXT: jp .LBB0_20
+; CHECK-NEXT: # %bb.2: # in Loop: Header=BB0_1 Depth=1
+; CHECK-NEXT: vmovss {{.*#+}} xmm1 = mem[0],zero,zero,zero
+; CHECK-NEXT: vucomiss %xmm0, %xmm1
+; CHECK-NEXT: jne .LBB0_20
+; CHECK-NEXT: jp .LBB0_20
+; CHECK-NEXT: # %bb.3: # %vector.body807.preheader
+; CHECK-NEXT: leaq 1(%rcx), %rdx
+; CHECK-NEXT: movl %edx, %esi
+; CHECK-NEXT: andl $7, %esi
+; CHECK-NEXT: cmpq $7, %rcx
+; CHECK-NEXT: jae .LBB0_5
+; CHECK-NEXT: # %bb.4:
+; CHECK-NEXT: xorl %r9d, %r9d
+; CHECK-NEXT: jmp .LBB0_7
+; CHECK-NEXT: .LBB0_5: # %vector.body807.preheader.new
+; CHECK-NEXT: movq %rdx, %r10
+; CHECK-NEXT: andq $-8, %r10
+; CHECK-NEXT: xorl %r9d, %r9d
+; CHECK-NEXT: vxorps %xmm0, %xmm0, %xmm0
+; CHECK-NEXT: .p2align 4, 0x90
+; CHECK-NEXT: .LBB0_6: # %vector.body807
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: leaq (%rdi,%r9), %r11
; CHECK-NEXT: vmovups %ymm0, (%rax,%r11)
@@ -23,7 +61,42 @@ define void @in4dob_(ptr nocapture writeonly %0, ptr nocapture readonly %1, ptr
; CHECK-NEXT: addq $8, %r9
; CHECK-NEXT: cmpq %r9, %r10
; CHECK-NEXT: jne .LBB0_6
-; CHECK: .LBB0_14: # %vector.body847
+; CHECK-NEXT: .LBB0_7: # %.lr.ph373.unr-lcssa
+; CHECK-NEXT: testq %rsi, %rsi
+; CHECK-NEXT: je .LBB0_10
+; CHECK-NEXT: # %bb.8: # %vector.body807.epil.preheader
+; CHECK-NEXT: addq %rdi, %r9
+; CHECK-NEXT: xorl %r10d, %r10d
+; CHECK-NEXT: vxorps %xmm0, %xmm0, %xmm0
+; CHECK-NEXT: .p2align 4, 0x90
+; CHECK-NEXT: .LBB0_9: # %vector.body807.epil
+; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: leaq (%r9,%r10), %r11
+; CHECK-NEXT: vmovups %ymm0, (%rax,%r11)
+; CHECK-NEXT: incq %r10
+; CHECK-NEXT: cmpq %r10, %rsi
+; CHECK-NEXT: jne .LBB0_9
+; CHECK-NEXT: .LBB0_10: # %.lr.ph373
+; CHECK-NEXT: testb $1, %r8b
+; CHECK-NEXT: je .LBB0_11
+; CHECK-NEXT: # %bb.19: # %scalar.ph839.preheader
+; CHECK-NEXT: movl $0, (%rdi)
+; CHECK-NEXT: vzeroupper
+; CHECK-NEXT: retq
+; CHECK-NEXT: .LBB0_11: # %vector.body847.preheader
+; CHECK-NEXT: movl %edx, %esi
+; CHECK-NEXT: andl $7, %esi
+; CHECK-NEXT: cmpq $7, %rcx
+; CHECK-NEXT: jae .LBB0_13
+; CHECK-NEXT: # %bb.12:
+; CHECK-NEXT: xorl %ecx, %ecx
+; CHECK-NEXT: jmp .LBB0_15
+; CHECK-NEXT: .LBB0_13: # %vector.body847.preheader.new
+; CHECK-NEXT: andq $-8, %rdx
+; CHECK-NEXT: xorl %ecx, %ecx
+; CHECK-NEXT: vxorps %xmm0, %xmm0, %xmm0
+; CHECK-NEXT: .p2align 4, 0x90
+; CHECK-NEXT: .LBB0_14: # %vector.body847
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: leaq (%rdi,%rcx), %r8
; CHECK-NEXT: vmovups %ymm0, 96(%rax,%r8)
@@ -37,6 +110,24 @@ define void @in4dob_(ptr nocapture writeonly %0, ptr nocapture readonly %1, ptr
; CHECK-NEXT: addq $8, %rcx
; CHECK-NEXT: cmpq %rcx, %rdx
; CHECK-NEXT: jne .LBB0_14
+; CHECK-NEXT: .LBB0_15: # %common.ret.loopexit.unr-lcssa
+; CHECK-NEXT: testq %rsi, %rsi
+; CHECK-NEXT: je .LBB0_18
+; CHECK-NEXT: # %bb.16: # %vector.body847.epil.preheader
+; CHECK-NEXT: leaq 96(%rcx,%rdi), %rcx
+; CHECK-NEXT: xorl %edx, %edx
+; CHECK-NEXT: vxorps %xmm0, %xmm0, %xmm0
+; CHECK-NEXT: .p2align 4, 0x90
+; CHECK-NEXT: .LBB0_17: # %vector.body847.epil
+; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: leaq (%rcx,%rdx), %rdi
+; CHECK-NEXT: vmovups %ymm0, (%rax,%rdi)
+; CHECK-NEXT: incq %rdx
+; CHECK-NEXT: cmpq %rdx, %rsi
+; CHECK-NEXT: jne .LBB0_17
+; CHECK-NEXT: .LBB0_18: # %common.ret
+; CHECK-NEXT: vzeroupper
+; CHECK-NEXT: retq
.preheader263:
%4 = shl i64 %3, 2
br label %5
>From ae76dfb74701e05e5ab4be194e20e49f10768e46 Mon Sep 17 00:00:00 2001
From: Noah Goldstein <goldstein.w.n at gmail.com>
Date: Fri, 29 Sep 2023 14:27:36 -0500
Subject: [PATCH 302/406] [X86] Don't always separate conditions in `(br
(and/or cond0, cond1))` into separate branches
It makes sense to split if the cost of computing `cond1` is high
(proportionally to how likely `cond0` is), but it doesn't really make
sense to introduce a second branch if its only a few instructions.
Splitting can also get in the way of potentially folding patterns.
This patch introduces some logic to try to check if the cost of
computing `cond1` is relatively low, and if so don't split the
branches.
Modest improvement on clang bootstrap build:
https://llvm-compile-time-tracker.com/compare.php?from=79ce933114e46c891a5632f7ad4a004b93a5b808&to=978278eabc0bafe2f390ca8fcdad24154f954020&stat=cycles
Average stage2-O3: 0.59% Improvement (cycles)
Average stage2-O0-g: 1.20% Improvement (cycles)
Likewise on llvm-test-suite on SKX saw a net 0.84% improvement (cycles)
There is also a modest compile time improvement with this patch:
https://llvm-compile-time-tracker.com/compare.php?from=79ce933114e46c891a5632f7ad4a004b93a5b808&to=978278eabc0bafe2f390ca8fcdad24154f954020&stat=instructions%3Au
Note that the stage2 instruction count increases is expected, this
patch trades instructions for decreasing branch-misses (which is
proportionately lower):
https://llvm-compile-time-tracker.com/compare.php?from=79ce933114e46c891a5632f7ad4a004b93a5b808&to=978278eabc0bafe2f390ca8fcdad24154f954020&stat=branch-misses
NB: This will also likely help for APX targets with the new `CCMP` and
`CTEST` instructions.
Closes #81689
---
llvm/include/llvm/CodeGen/TargetLowering.h | 36 +++
.../SelectionDAG/SelectionDAGBuilder.cpp | 152 ++++++++-
.../SelectionDAG/SelectionDAGBuilder.h | 5 +
llvm/lib/Target/X86/X86ISelLowering.cpp | 49 +++
llvm/lib/Target/X86/X86ISelLowering.h | 4 +
.../CodeGen/X86/2006-04-27-ISelFoldingBug.ll | 11 +-
.../X86/2007-08-09-IllegalX86-64Asm.ll | 109 ++++---
.../test/CodeGen/X86/2007-12-18-LoadCSEBug.ll | 13 +-
.../CodeGen/X86/2008-02-18-TailMergingBug.ll | 4 +-
llvm/test/CodeGen/X86/avx-cmp.ll | 27 +-
llvm/test/CodeGen/X86/cmp.ll | 52 +--
llvm/test/CodeGen/X86/dagcombine-and-setcc.ll | 3 +-
.../div-rem-pair-recomposition-unsigned.ll | 306 +++++++++---------
...iller-impdef-on-implicit-def-regression.ll | 70 ++--
llvm/test/CodeGen/X86/lsr-addrecloops.ll | 81 +++--
llvm/test/CodeGen/X86/movmsk-cmp.ll | 97 +++---
llvm/test/CodeGen/X86/or-branch.ll | 9 +-
.../X86/peephole-na-phys-copy-folding.ll | 142 ++++----
llvm/test/CodeGen/X86/pr33747.ll | 17 +-
llvm/test/CodeGen/X86/pr37025.ll | 38 ++-
llvm/test/CodeGen/X86/pr38795.ll | 131 ++++----
llvm/test/CodeGen/X86/setcc-logic.ll | 76 ++---
llvm/test/CodeGen/X86/swifterror.ll | 10 -
.../X86/tail-dup-merge-loop-headers.ll | 119 +++----
llvm/test/CodeGen/X86/tail-opts.ll | 5 +-
llvm/test/CodeGen/X86/tailcall-extract.ll | 8 +-
llvm/test/CodeGen/X86/test-shrink-bug.ll | 34 +-
.../CodeGen/X86/x86-shrink-wrap-unwind.ll | 52 +--
28 files changed, 920 insertions(+), 740 deletions(-)
diff --git a/llvm/include/llvm/CodeGen/TargetLowering.h b/llvm/include/llvm/CodeGen/TargetLowering.h
index f2e00aab8d5da2..4c2815679efc92 100644
--- a/llvm/include/llvm/CodeGen/TargetLowering.h
+++ b/llvm/include/llvm/CodeGen/TargetLowering.h
@@ -596,6 +596,42 @@ class TargetLoweringBase {
/// avoided.
bool isJumpExpensive() const { return JumpIsExpensive; }
+ // Costs parameters used by
+ // SelectionDAGBuilder::shouldKeepJumpConditionsTogether.
+ // shouldKeepJumpConditionsTogether will use these parameter value to
+ // determine if two conditions in the form `br (and/or cond1, cond2)` should
+ // be split into two branches or left as one.
+ //
+ // BaseCost is the cost threshold (in latency). If the estimated latency of
+ // computing both `cond1` and `cond2` is below the cost of just computing
+ // `cond1` + BaseCost, the two conditions will be kept together. Otherwise
+ // they will be split.
+ //
+ // LikelyBias increases BaseCost if branch probability info indicates that it
+ // is likely that both `cond1` and `cond2` will be computed.
+ //
+ // UnlikelyBias decreases BaseCost if branch probability info indicates that
+ // it is likely that both `cond1` and `cond2` will be computed.
+ //
+ // Set any field to -1 to make it ignored (setting BaseCost to -1 results in
+ // `shouldKeepJumpConditionsTogether` always returning false).
+ struct CondMergingParams {
+ int BaseCost;
+ int LikelyBias;
+ int UnlikelyBias;
+ };
+ // Return params for deciding if we should keep two branch conditions merged
+ // or split them into two separate branches.
+ // Arg0: The binary op joining the two conditions (and/or).
+ // Arg1: The first condition (cond1)
+ // Arg2: The second condition (cond2)
+ virtual CondMergingParams
+ getJumpConditionMergingParams(Instruction::BinaryOps, const Value *,
+ const Value *) const {
+ // -1 will always result in splitting.
+ return {-1, -1, -1};
+ }
+
/// Return true if selects are only cheaper than branches if the branch is
/// unlikely to be predicted right.
bool isPredictableSelectExpensive() const {
diff --git a/llvm/lib/CodeGen/SelectionDAG/SelectionDAGBuilder.cpp b/llvm/lib/CodeGen/SelectionDAG/SelectionDAGBuilder.cpp
index ab2f42d2024ccc..4f6263cc492fe3 100644
--- a/llvm/lib/CodeGen/SelectionDAG/SelectionDAGBuilder.cpp
+++ b/llvm/lib/CodeGen/SelectionDAG/SelectionDAGBuilder.cpp
@@ -26,6 +26,7 @@
#include "llvm/Analysis/Loads.h"
#include "llvm/Analysis/MemoryLocation.h"
#include "llvm/Analysis/TargetLibraryInfo.h"
+#include "llvm/Analysis/TargetTransformInfo.h"
#include "llvm/Analysis/ValueTracking.h"
#include "llvm/Analysis/VectorUtils.h"
#include "llvm/CodeGen/Analysis.h"
@@ -93,6 +94,7 @@
#include "llvm/Support/CommandLine.h"
#include "llvm/Support/Compiler.h"
#include "llvm/Support/Debug.h"
+#include "llvm/Support/InstructionCost.h"
#include "llvm/Support/MathExtras.h"
#include "llvm/Support/raw_ostream.h"
#include "llvm/Target/TargetIntrinsicInfo.h"
@@ -2446,6 +2448,147 @@ SelectionDAGBuilder::EmitBranchForMergedCondition(const Value *Cond,
SL->SwitchCases.push_back(CB);
}
+// Collect dependencies on V recursively. This is used for the cost analysis in
+// `shouldKeepJumpConditionsTogether`.
+static bool
+collectInstructionDeps(SmallPtrSet<const Instruction *, 8> *Deps,
+ const Value *V,
+ SmallPtrSet<const Instruction *, 8> *Necessary = nullptr,
+ unsigned Depth = 0) {
+ // Return false if we have an incomplete count.
+ if (Depth >= SelectionDAG::MaxRecursionDepth)
+ return false;
+
+ auto *I = dyn_cast<Instruction>(V);
+ if (I == nullptr)
+ return true;
+
+ if (Necessary != nullptr) {
+ // This instruction is necessary for the other side of the condition so
+ // don't count it.
+ if (Necessary->contains(I))
+ return true;
+ }
+
+ // Already added this dep.
+ if (!Deps->insert(I).second)
+ return true;
+
+ for (unsigned OpIdx = 0, E = I->getNumOperands(); OpIdx < E; ++OpIdx)
+ if (!collectInstructionDeps(Deps, I->getOperand(OpIdx), Necessary,
+ Depth + 1))
+ return false;
+ return true;
+}
+
+bool SelectionDAGBuilder::shouldKeepJumpConditionsTogether(
+ const FunctionLoweringInfo &FuncInfo, const BranchInst &I,
+ Instruction::BinaryOps Opc, const Value *Lhs, const Value *Rhs,
+ TargetLoweringBase::CondMergingParams Params) const {
+ if (I.getNumSuccessors() != 2)
+ return false;
+
+ if (Params.BaseCost < 0)
+ return false;
+
+ // Baseline cost.
+ InstructionCost CostThresh = Params.BaseCost;
+
+ BranchProbabilityInfo *BPI = nullptr;
+ if (Params.LikelyBias || Params.UnlikelyBias)
+ BPI = FuncInfo.BPI;
+ if (BPI != nullptr) {
+ // See if we are either likely to get an early out or compute both lhs/rhs
+ // of the condition.
+ BasicBlock *IfFalse = I.getSuccessor(0);
+ BasicBlock *IfTrue = I.getSuccessor(1);
+
+ std::optional<bool> Likely;
+ if (BPI->isEdgeHot(I.getParent(), IfTrue))
+ Likely = true;
+ else if (BPI->isEdgeHot(I.getParent(), IfFalse))
+ Likely = false;
+
+ if (Likely) {
+ if (Opc == (*Likely ? Instruction::And : Instruction::Or))
+ // Its likely we will have to compute both lhs and rhs of condition
+ CostThresh += Params.LikelyBias;
+ else {
+ if (Params.UnlikelyBias < 0)
+ return false;
+ // Its likely we will get an early out.
+ CostThresh -= Params.UnlikelyBias;
+ }
+ }
+ }
+
+ if (CostThresh <= 0)
+ return false;
+
+ // Collect "all" instructions that lhs condition is dependent on.
+ SmallPtrSet<const Instruction *, 8> LhsDeps, RhsDeps;
+ collectInstructionDeps(&LhsDeps, Lhs);
+ // Collect "all" instructions that rhs condition is dependent on AND are
+ // dependencies of lhs. This gives us an estimate on which instructions we
+ // stand to save by splitting the condition.
+ if (!collectInstructionDeps(&RhsDeps, Rhs, &LhsDeps))
+ return false;
+ // Add the compare instruction itself unless its a dependency on the LHS.
+ if (const auto *RhsI = dyn_cast<Instruction>(Rhs))
+ if (!LhsDeps.contains(RhsI))
+ RhsDeps.insert(RhsI);
+
+ const auto &TLI = DAG.getTargetLoweringInfo();
+ const auto &TTI =
+ TLI.getTargetMachine().getTargetTransformInfo(*I.getFunction());
+
+ InstructionCost CostOfIncluding = 0;
+ // See if this instruction will need to computed independently of whether RHS
+ // is.
+ auto ShouldCountInsn = [&RhsDeps](const Instruction *Ins) {
+ for (const auto *U : Ins->users()) {
+ // If user is independent of RHS calculation we don't need to count it.
+ if (auto *UIns = dyn_cast<Instruction>(U))
+ if (!RhsDeps.contains(UIns))
+ return false;
+ }
+ return true;
+ };
+
+ // Prune instructions from RHS Deps that are dependencies of unrelated
+ // instructions. The value (SelectionDAG::MaxRecursionDepth) is fairly
+ // arbitrary and just meant to cap the how much time we spend in the pruning
+ // loop. Its highly unlikely to come into affect.
+ const unsigned MaxPruneIters = SelectionDAG::MaxRecursionDepth;
+ // Stop after a certain point. No incorrectness from including too many
+ // instructions.
+ for (unsigned PruneIters = 0; PruneIters < MaxPruneIters; ++PruneIters) {
+ const Instruction *ToDrop = nullptr;
+ for (const auto *Ins : RhsDeps) {
+ if (!ShouldCountInsn(Ins)) {
+ ToDrop = Ins;
+ break;
+ }
+ }
+ if (ToDrop == nullptr)
+ break;
+ RhsDeps.erase(ToDrop);
+ }
+
+ for (const auto *Ins : RhsDeps) {
+ // Finally accumulate latency that we can only attribute to computing the
+ // RHS condition. Use latency because we are essentially trying to calculate
+ // the cost of the dependency chain.
+ // Possible TODO: We could try to estimate ILP and make this more precise.
+ CostOfIncluding +=
+ TTI.getInstructionCost(Ins, TargetTransformInfo::TCK_Latency);
+
+ if (CostOfIncluding > CostThresh)
+ return false;
+ }
+ return true;
+}
+
void SelectionDAGBuilder::FindMergedConditions(const Value *Cond,
MachineBasicBlock *TBB,
MachineBasicBlock *FBB,
@@ -2660,8 +2803,13 @@ void SelectionDAGBuilder::visitBr(const BranchInst &I) {
else if (match(BOp, m_LogicalOr(m_Value(BOp0), m_Value(BOp1))))
Opcode = Instruction::Or;
- if (Opcode && !(match(BOp0, m_ExtractElt(m_Value(Vec), m_Value())) &&
- match(BOp1, m_ExtractElt(m_Specific(Vec), m_Value())))) {
+ if (Opcode &&
+ !(match(BOp0, m_ExtractElt(m_Value(Vec), m_Value())) &&
+ match(BOp1, m_ExtractElt(m_Specific(Vec), m_Value()))) &&
+ !shouldKeepJumpConditionsTogether(
+ FuncInfo, I, Opcode, BOp0, BOp1,
+ DAG.getTargetLoweringInfo().getJumpConditionMergingParams(
+ Opcode, BOp0, BOp1))) {
FindMergedConditions(BOp, Succ0MBB, Succ1MBB, BrMBB, BrMBB, Opcode,
getEdgeProbability(BrMBB, Succ0MBB),
getEdgeProbability(BrMBB, Succ1MBB),
diff --git a/llvm/lib/CodeGen/SelectionDAG/SelectionDAGBuilder.h b/llvm/lib/CodeGen/SelectionDAG/SelectionDAGBuilder.h
index 47657313cb6a3b..2084de473b8062 100644
--- a/llvm/lib/CodeGen/SelectionDAG/SelectionDAGBuilder.h
+++ b/llvm/lib/CodeGen/SelectionDAG/SelectionDAGBuilder.h
@@ -385,6 +385,11 @@ class SelectionDAGBuilder {
N = NewN;
}
+ bool shouldKeepJumpConditionsTogether(
+ const FunctionLoweringInfo &FuncInfo, const BranchInst &I,
+ Instruction::BinaryOps Opc, const Value *Lhs, const Value *Rhs,
+ TargetLoweringBase::CondMergingParams Params) const;
+
void FindMergedConditions(const Value *Cond, MachineBasicBlock *TBB,
MachineBasicBlock *FBB, MachineBasicBlock *CurBB,
MachineBasicBlock *SwitchBB,
diff --git a/llvm/lib/Target/X86/X86ISelLowering.cpp b/llvm/lib/Target/X86/X86ISelLowering.cpp
index 0162bb65afe3b0..aea046b119d49d 100644
--- a/llvm/lib/Target/X86/X86ISelLowering.cpp
+++ b/llvm/lib/Target/X86/X86ISelLowering.cpp
@@ -77,6 +77,37 @@ static cl::opt<int> ExperimentalPrefInnermostLoopAlignment(
"alignment set by x86-experimental-pref-loop-alignment."),
cl::Hidden);
+static cl::opt<int> BrMergingBaseCostThresh(
+ "x86-br-merging-base-cost", cl::init(1),
+ cl::desc(
+ "Sets the cost threshold for when multiple conditionals will be merged "
+ "into one branch versus be split in multiple branches. Merging "
+ "conditionals saves branches at the cost of additional instructions. "
+ "This value sets the instruction cost limit, below which conditionals "
+ "will be merged, and above which conditionals will be split."),
+ cl::Hidden);
+
+static cl::opt<int> BrMergingLikelyBias(
+ "x86-br-merging-likely-bias", cl::init(0),
+ cl::desc("Increases 'x86-br-merging-base-cost' in cases that it is likely "
+ "that all conditionals will be executed. For example for merging "
+ "the conditionals (a == b && c > d), if its known that a == b is "
+ "likely, then it is likely that if the conditionals are split "
+ "both sides will be executed, so it may be desirable to increase "
+ "the instruction cost threshold."),
+ cl::Hidden);
+
+static cl::opt<int> BrMergingUnlikelyBias(
+ "x86-br-merging-unlikely-bias", cl::init(1),
+ cl::desc(
+ "Decreases 'x86-br-merging-base-cost' in cases that it is unlikely "
+ "that all conditionals will be executed. For example for merging "
+ "the conditionals (a == b && c > d), if its known that a == b is "
+ "unlikely, then it is unlikely that if the conditionals are split "
+ "both sides will be executed, so it may be desirable to decrease "
+ "the instruction cost threshold."),
+ cl::Hidden);
+
static cl::opt<bool> MulConstantOptimization(
"mul-constant-optimization", cl::init(true),
cl::desc("Replace 'mul x, Const' with more effective instructions like "
@@ -3333,6 +3364,24 @@ unsigned X86TargetLowering::preferedOpcodeForCmpEqPiecesOfOperand(
return ISD::SRL;
}
+TargetLoweringBase::CondMergingParams
+X86TargetLowering::getJumpConditionMergingParams(Instruction::BinaryOps Opc,
+ const Value *Lhs,
+ const Value *Rhs) const {
+ using namespace llvm::PatternMatch;
+ int BaseCost = BrMergingBaseCostThresh.getValue();
+ // a == b && a == c is a fast pattern on x86.
+ ICmpInst::Predicate Pred;
+ if (BaseCost >= 0 && Opc == Instruction::And &&
+ match(Lhs, m_ICmp(Pred, m_Value(), m_Value())) &&
+ Pred == ICmpInst::ICMP_EQ &&
+ match(Rhs, m_ICmp(Pred, m_Value(), m_Value())) &&
+ Pred == ICmpInst::ICMP_EQ)
+ BaseCost += 1;
+ return {BaseCost, BrMergingLikelyBias.getValue(),
+ BrMergingUnlikelyBias.getValue()};
+}
+
bool X86TargetLowering::preferScalarizeSplat(SDNode *N) const {
return N->getOpcode() != ISD::FP_EXTEND;
}
diff --git a/llvm/lib/Target/X86/X86ISelLowering.h b/llvm/lib/Target/X86/X86ISelLowering.h
index f93c54781846bf..fe1943b5760844 100644
--- a/llvm/lib/Target/X86/X86ISelLowering.h
+++ b/llvm/lib/Target/X86/X86ISelLowering.h
@@ -1150,6 +1150,10 @@ namespace llvm {
bool preferScalarizeSplat(SDNode *N) const override;
+ CondMergingParams
+ getJumpConditionMergingParams(Instruction::BinaryOps Opc, const Value *Lhs,
+ const Value *Rhs) const override;
+
bool shouldFoldConstantShiftPairToMask(const SDNode *N,
CombineLevel Level) const override;
diff --git a/llvm/test/CodeGen/X86/2006-04-27-ISelFoldingBug.ll b/llvm/test/CodeGen/X86/2006-04-27-ISelFoldingBug.ll
index 0044d1c3568377..e6f28c2057f775 100644
--- a/llvm/test/CodeGen/X86/2006-04-27-ISelFoldingBug.ll
+++ b/llvm/test/CodeGen/X86/2006-04-27-ISelFoldingBug.ll
@@ -18,15 +18,16 @@ define i1 @loadAndRLEsource_no_exit_2E_1_label_2E_0(i32 %tmp.21.reload, i32 %tmp
; CHECK-NEXT: movl _block, %esi
; CHECK-NEXT: movb %al, 1(%esi,%edx)
; CHECK-NEXT: cmpl %ecx, _last
-; CHECK-NEXT: jge LBB0_3
-; CHECK-NEXT: ## %bb.1: ## %label.0
+; CHECK-NEXT: setl %cl
; CHECK-NEXT: cmpl $257, %eax ## imm = 0x101
-; CHECK-NEXT: je LBB0_3
-; CHECK-NEXT: ## %bb.2: ## %label.0.no_exit.1_crit_edge.exitStub
+; CHECK-NEXT: setne %al
+; CHECK-NEXT: testb %al, %cl
+; CHECK-NEXT: je LBB0_2
+; CHECK-NEXT: ## %bb.1: ## %label.0.no_exit.1_crit_edge.exitStub
; CHECK-NEXT: movb $1, %al
; CHECK-NEXT: popl %esi
; CHECK-NEXT: retl
-; CHECK-NEXT: LBB0_3: ## %codeRepl5.exitStub
+; CHECK-NEXT: LBB0_2: ## %codeRepl5.exitStub
; CHECK-NEXT: xorl %eax, %eax
; CHECK-NEXT: popl %esi
; CHECK-NEXT: retl
diff --git a/llvm/test/CodeGen/X86/2007-08-09-IllegalX86-64Asm.ll b/llvm/test/CodeGen/X86/2007-08-09-IllegalX86-64Asm.ll
index 7bdc4e19a1cf66..28b4541c1bfc7f 100644
--- a/llvm/test/CodeGen/X86/2007-08-09-IllegalX86-64Asm.ll
+++ b/llvm/test/CodeGen/X86/2007-08-09-IllegalX86-64Asm.ll
@@ -44,7 +44,7 @@ define ptr @ubyte_divmod(ptr %a, ptr %b) {
; CHECK-NEXT: leaq {{[0-9]+}}(%rsp), %rsi
; CHECK-NEXT: callq __ubyte_convert_to_ctype
; CHECK-NEXT: testl %eax, %eax
-; CHECK-NEXT: js LBB0_4
+; CHECK-NEXT: js LBB0_6
; CHECK-NEXT: ## %bb.1: ## %cond_next.i
; CHECK-NEXT: leaq {{[0-9]+}}(%rsp), %rsi
; CHECK-NEXT: movq %rbx, %rdi
@@ -53,81 +53,84 @@ define ptr @ubyte_divmod(ptr %a, ptr %b) {
; CHECK-NEXT: sarl $31, %ecx
; CHECK-NEXT: andl %eax, %ecx
; CHECK-NEXT: cmpl $-2, %ecx
-; CHECK-NEXT: je LBB0_8
+; CHECK-NEXT: je LBB0_10
; CHECK-NEXT: ## %bb.2: ## %cond_next.i
; CHECK-NEXT: cmpl $-1, %ecx
-; CHECK-NEXT: jne LBB0_6
-; CHECK-NEXT: LBB0_3: ## %bb4
+; CHECK-NEXT: jne LBB0_3
+; CHECK-NEXT: LBB0_8: ## %bb4
; CHECK-NEXT: movq _PyArray_API at GOTPCREL(%rip), %rax
; CHECK-NEXT: movq (%rax), %rax
; CHECK-NEXT: movq 16(%rax), %rax
-; CHECK-NEXT: jmp LBB0_10
-; CHECK-NEXT: LBB0_4: ## %_ubyte_convert2_to_ctypes.exit
+; CHECK-NEXT: jmp LBB0_9
+; CHECK-NEXT: LBB0_6: ## %_ubyte_convert2_to_ctypes.exit
; CHECK-NEXT: cmpl $-2, %eax
-; CHECK-NEXT: je LBB0_8
-; CHECK-NEXT: ## %bb.5: ## %_ubyte_convert2_to_ctypes.exit
+; CHECK-NEXT: je LBB0_10
+; CHECK-NEXT: ## %bb.7: ## %_ubyte_convert2_to_ctypes.exit
; CHECK-NEXT: cmpl $-1, %eax
-; CHECK-NEXT: je LBB0_3
-; CHECK-NEXT: LBB0_6: ## %bb35
+; CHECK-NEXT: je LBB0_8
+; CHECK-NEXT: LBB0_3: ## %bb35
; CHECK-NEXT: movq _PyUFunc_API at GOTPCREL(%rip), %r14
; CHECK-NEXT: movq (%r14), %rax
; CHECK-NEXT: callq *216(%rax)
; CHECK-NEXT: movzbl {{[0-9]+}}(%rsp), %edx
; CHECK-NEXT: testb %dl, %dl
-; CHECK-NEXT: je LBB0_11
-; CHECK-NEXT: ## %bb.7: ## %cond_false.i
+; CHECK-NEXT: je LBB0_4
+; CHECK-NEXT: ## %bb.12: ## %cond_false.i
+; CHECK-NEXT: setne %dil
; CHECK-NEXT: movzbl {{[0-9]+}}(%rsp), %esi
; CHECK-NEXT: movzbl %sil, %ecx
; CHECK-NEXT: movl %ecx, %eax
; CHECK-NEXT: divb %dl
; CHECK-NEXT: movl %eax, %r15d
; CHECK-NEXT: testb %cl, %cl
-; CHECK-NEXT: jne LBB0_12
-; CHECK-NEXT: jmp LBB0_14
-; CHECK-NEXT: LBB0_8: ## %bb17
+; CHECK-NEXT: setne %al
+; CHECK-NEXT: testb %dil, %al
+; CHECK-NEXT: jne LBB0_5
+; CHECK-NEXT: LBB0_13: ## %cond_true.i200
+; CHECK-NEXT: testb %dl, %dl
+; CHECK-NEXT: jne LBB0_15
+; CHECK-NEXT: ## %bb.14: ## %cond_true14.i
+; CHECK-NEXT: movl $4, %edi
+; CHECK-NEXT: callq _feraiseexcept
+; CHECK-NEXT: LBB0_15: ## %ubyte_ctype_remainder.exit
+; CHECK-NEXT: xorl %ebx, %ebx
+; CHECK-NEXT: jmp LBB0_16
+; CHECK-NEXT: LBB0_10: ## %bb17
; CHECK-NEXT: callq _PyErr_Occurred
; CHECK-NEXT: testq %rax, %rax
-; CHECK-NEXT: jne LBB0_27
-; CHECK-NEXT: ## %bb.9: ## %cond_next
+; CHECK-NEXT: jne LBB0_23
+; CHECK-NEXT: ## %bb.11: ## %cond_next
; CHECK-NEXT: movq _PyArray_API at GOTPCREL(%rip), %rax
; CHECK-NEXT: movq (%rax), %rax
; CHECK-NEXT: movq 80(%rax), %rax
-; CHECK-NEXT: LBB0_10: ## %bb4
+; CHECK-NEXT: LBB0_9: ## %bb4
; CHECK-NEXT: movq 96(%rax), %rax
; CHECK-NEXT: movq %r14, %rdi
; CHECK-NEXT: movq %rbx, %rsi
; CHECK-NEXT: callq *40(%rax)
-; CHECK-NEXT: jmp LBB0_28
-; CHECK-NEXT: LBB0_11: ## %cond_true.i
+; CHECK-NEXT: jmp LBB0_24
+; CHECK-NEXT: LBB0_4: ## %cond_true.i
; CHECK-NEXT: movl $4, %edi
; CHECK-NEXT: callq _feraiseexcept
; CHECK-NEXT: movzbl {{[0-9]+}}(%rsp), %edx
; CHECK-NEXT: movzbl {{[0-9]+}}(%rsp), %esi
-; CHECK-NEXT: xorl %r15d, %r15d
; CHECK-NEXT: testb %sil, %sil
-; CHECK-NEXT: je LBB0_14
-; CHECK-NEXT: LBB0_12: ## %cond_false.i
+; CHECK-NEXT: sete %al
; CHECK-NEXT: testb %dl, %dl
-; CHECK-NEXT: je LBB0_14
-; CHECK-NEXT: ## %bb.13: ## %cond_next17.i
+; CHECK-NEXT: sete %cl
+; CHECK-NEXT: xorl %r15d, %r15d
+; CHECK-NEXT: orb %al, %cl
+; CHECK-NEXT: jne LBB0_13
+; CHECK-NEXT: LBB0_5: ## %cond_next17.i
; CHECK-NEXT: movzbl %sil, %eax
; CHECK-NEXT: divb %dl
; CHECK-NEXT: movzbl %ah, %ebx
-; CHECK-NEXT: jmp LBB0_18
-; CHECK-NEXT: LBB0_14: ## %cond_true.i200
-; CHECK-NEXT: testb %dl, %dl
-; CHECK-NEXT: jne LBB0_17
-; CHECK-NEXT: ## %bb.16: ## %cond_true14.i
-; CHECK-NEXT: movl $4, %edi
-; CHECK-NEXT: callq _feraiseexcept
-; CHECK-NEXT: LBB0_17: ## %ubyte_ctype_remainder.exit
-; CHECK-NEXT: xorl %ebx, %ebx
-; CHECK-NEXT: LBB0_18: ## %ubyte_ctype_remainder.exit
+; CHECK-NEXT: LBB0_16: ## %ubyte_ctype_remainder.exit
; CHECK-NEXT: movq (%r14), %rax
; CHECK-NEXT: callq *224(%rax)
; CHECK-NEXT: testl %eax, %eax
-; CHECK-NEXT: je LBB0_21
-; CHECK-NEXT: ## %bb.19: ## %cond_true61
+; CHECK-NEXT: je LBB0_19
+; CHECK-NEXT: ## %bb.17: ## %cond_true61
; CHECK-NEXT: movl %eax, %ebp
; CHECK-NEXT: movq (%r14), %rax
; CHECK-NEXT: movq _.str5 at GOTPCREL(%rip), %rdi
@@ -136,8 +139,8 @@ define ptr @ubyte_divmod(ptr %a, ptr %b) {
; CHECK-NEXT: leaq {{[0-9]+}}(%rsp), %rcx
; CHECK-NEXT: callq *200(%rax)
; CHECK-NEXT: testl %eax, %eax
-; CHECK-NEXT: js LBB0_27
-; CHECK-NEXT: ## %bb.20: ## %cond_next73
+; CHECK-NEXT: js LBB0_23
+; CHECK-NEXT: ## %bb.18: ## %cond_next73
; CHECK-NEXT: movl $1, {{[0-9]+}}(%rsp)
; CHECK-NEXT: movq (%r14), %rax
; CHECK-NEXT: movq {{[0-9]+}}(%rsp), %rsi
@@ -146,13 +149,13 @@ define ptr @ubyte_divmod(ptr %a, ptr %b) {
; CHECK-NEXT: movl %ebp, %edx
; CHECK-NEXT: callq *232(%rax)
; CHECK-NEXT: testl %eax, %eax
-; CHECK-NEXT: jne LBB0_27
-; CHECK-NEXT: LBB0_21: ## %cond_next89
+; CHECK-NEXT: jne LBB0_23
+; CHECK-NEXT: LBB0_19: ## %cond_next89
; CHECK-NEXT: movl $2, %edi
; CHECK-NEXT: callq _PyTuple_New
; CHECK-NEXT: testq %rax, %rax
-; CHECK-NEXT: je LBB0_27
-; CHECK-NEXT: ## %bb.22: ## %cond_next97
+; CHECK-NEXT: je LBB0_23
+; CHECK-NEXT: ## %bb.20: ## %cond_next97
; CHECK-NEXT: movq %rax, %r14
; CHECK-NEXT: movq _PyArray_API at GOTPCREL(%rip), %r12
; CHECK-NEXT: movq (%r12), %rax
@@ -160,8 +163,8 @@ define ptr @ubyte_divmod(ptr %a, ptr %b) {
; CHECK-NEXT: xorl %esi, %esi
; CHECK-NEXT: callq *304(%rdi)
; CHECK-NEXT: testq %rax, %rax
-; CHECK-NEXT: je LBB0_25
-; CHECK-NEXT: ## %bb.23: ## %cond_next135
+; CHECK-NEXT: je LBB0_21
+; CHECK-NEXT: ## %bb.25: ## %cond_next135
; CHECK-NEXT: movb %r15b, 16(%rax)
; CHECK-NEXT: movq %rax, 24(%r14)
; CHECK-NEXT: movq (%r12), %rax
@@ -169,22 +172,22 @@ define ptr @ubyte_divmod(ptr %a, ptr %b) {
; CHECK-NEXT: xorl %esi, %esi
; CHECK-NEXT: callq *304(%rdi)
; CHECK-NEXT: testq %rax, %rax
-; CHECK-NEXT: je LBB0_25
-; CHECK-NEXT: ## %bb.24: ## %cond_next182
+; CHECK-NEXT: je LBB0_21
+; CHECK-NEXT: ## %bb.26: ## %cond_next182
; CHECK-NEXT: movb %bl, 16(%rax)
; CHECK-NEXT: movq %rax, 32(%r14)
; CHECK-NEXT: movq %r14, %rax
-; CHECK-NEXT: jmp LBB0_28
-; CHECK-NEXT: LBB0_25: ## %cond_true113
+; CHECK-NEXT: jmp LBB0_24
+; CHECK-NEXT: LBB0_21: ## %cond_true113
; CHECK-NEXT: decq (%r14)
-; CHECK-NEXT: jne LBB0_27
-; CHECK-NEXT: ## %bb.26: ## %cond_true126
+; CHECK-NEXT: jne LBB0_23
+; CHECK-NEXT: ## %bb.22: ## %cond_true126
; CHECK-NEXT: movq 8(%r14), %rax
; CHECK-NEXT: movq %r14, %rdi
; CHECK-NEXT: callq *48(%rax)
-; CHECK-NEXT: LBB0_27: ## %UnifiedReturnBlock
+; CHECK-NEXT: LBB0_23: ## %UnifiedReturnBlock
; CHECK-NEXT: xorl %eax, %eax
-; CHECK-NEXT: LBB0_28: ## %UnifiedReturnBlock
+; CHECK-NEXT: LBB0_24: ## %UnifiedReturnBlock
; CHECK-NEXT: addq $32, %rsp
; CHECK-NEXT: popq %rbx
; CHECK-NEXT: popq %r12
diff --git a/llvm/test/CodeGen/X86/2007-12-18-LoadCSEBug.ll b/llvm/test/CodeGen/X86/2007-12-18-LoadCSEBug.ll
index 4482c5aec8e816..d9d4424267d733 100644
--- a/llvm/test/CodeGen/X86/2007-12-18-LoadCSEBug.ll
+++ b/llvm/test/CodeGen/X86/2007-12-18-LoadCSEBug.ll
@@ -16,15 +16,12 @@ define void @_ada_c34007g() {
; CHECK-NEXT: andl $-8, %esp
; CHECK-NEXT: subl $8, %esp
; CHECK-NEXT: movl (%esp), %eax
+; CHECK-NEXT: movl {{[0-9]+}}(%esp), %ecx
+; CHECK-NEXT: orl %eax, %ecx
+; CHECK-NEXT: sete %cl
; CHECK-NEXT: testl %eax, %eax
-; CHECK-NEXT: je .LBB0_3
-; CHECK-NEXT: # %bb.1: # %entry
-; CHECK-NEXT: orl {{[0-9]+}}(%esp), %eax
-; CHECK-NEXT: jne .LBB0_3
-; CHECK-NEXT: # %bb.2: # %entry
-; CHECK-NEXT: movb $1, %al
-; CHECK-NEXT: testb %al, %al
-; CHECK-NEXT: .LBB0_3: # %bb5507
+; CHECK-NEXT: setne %al
+; CHECK-NEXT: testb %cl, %al
; CHECK-NEXT: movl %ebp, %esp
; CHECK-NEXT: popl %ebp
; CHECK-NEXT: .cfi_def_cfa %esp, 4
diff --git a/llvm/test/CodeGen/X86/2008-02-18-TailMergingBug.ll b/llvm/test/CodeGen/X86/2008-02-18-TailMergingBug.ll
index dd60e641df2543..e0b6e38647d801 100644
--- a/llvm/test/CodeGen/X86/2008-02-18-TailMergingBug.ll
+++ b/llvm/test/CodeGen/X86/2008-02-18-TailMergingBug.ll
@@ -1,5 +1,5 @@
; REQUIRES: asserts
-; RUN: llc < %s -mtriple=i686-- -mcpu=yonah -stats 2>&1 | grep "Number of block tails merged" | grep 16
+; RUN: llc < %s -mtriple=i686-- -mcpu=yonah -stats 2>&1 | grep "Number of block tails merged" | grep 9
; PR1909
@.str = internal constant [48 x i8] c"transformed bounds: (%.2f, %.2f), (%.2f, %.2f)\0A\00" ; <ptr> [#uses=1]
@@ -217,4 +217,4 @@ bb456: ; preds = %bb448, %bb425, %bb417, %bb395, %bb385, %bb371
ret void
}
-declare i32 @printf(ptr, ...) nounwind
+declare i32 @printf(ptr, ...) nounwind
diff --git a/llvm/test/CodeGen/X86/avx-cmp.ll b/llvm/test/CodeGen/X86/avx-cmp.ll
index 502bbf3f5d118b..4ab9c545ed90da 100644
--- a/llvm/test/CodeGen/X86/avx-cmp.ll
+++ b/llvm/test/CodeGen/X86/avx-cmp.ll
@@ -26,40 +26,33 @@ declare void @scale() nounwind
define void @render(double %a0) nounwind {
; CHECK-LABEL: render:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: pushq %rbp
; CHECK-NEXT: pushq %rbx
-; CHECK-NEXT: pushq %rax
-; CHECK-NEXT: vmovsd %xmm0, (%rsp) # 8-byte Spill
+; CHECK-NEXT: subq $16, %rsp
+; CHECK-NEXT: vmovsd %xmm0, {{[-0-9]+}}(%r{{[sb]}}p) # 8-byte Spill
; CHECK-NEXT: xorl %eax, %eax
; CHECK-NEXT: testb %al, %al
-; CHECK-NEXT: jne .LBB2_6
+; CHECK-NEXT: jne .LBB2_5
; CHECK-NEXT: # %bb.1: # %for.cond5.preheader
-; CHECK-NEXT: xorl %ebx, %ebx
-; CHECK-NEXT: movb $1, %bpl
+; CHECK-NEXT: movb $1, %bl
; CHECK-NEXT: .p2align 4, 0x90
; CHECK-NEXT: .LBB2_2: # %for.cond5
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: testb %bl, %bl
; CHECK-NEXT: jne .LBB2_2
-; CHECK-NEXT: # %bb.3: # %for.cond5
-; CHECK-NEXT: # in Loop: Header=BB2_2 Depth=1
-; CHECK-NEXT: testb %bpl, %bpl
-; CHECK-NEXT: jne .LBB2_2
-; CHECK-NEXT: # %bb.4: # %for.body33.preheader
+; CHECK-NEXT: # %bb.3: # %for.body33.preheader
; CHECK-NEXT: # in Loop: Header=BB2_2 Depth=1
-; CHECK-NEXT: vmovsd (%rsp), %xmm0 # 8-byte Reload
+; CHECK-NEXT: vmovsd {{[-0-9]+}}(%r{{[sb]}}p), %xmm0 # 8-byte Reload
; CHECK-NEXT: # xmm0 = mem[0],zero
; CHECK-NEXT: vucomisd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
-; CHECK-NEXT: jne .LBB2_5
+; CHECK-NEXT: jne .LBB2_4
; CHECK-NEXT: jnp .LBB2_2
-; CHECK-NEXT: .LBB2_5: # %if.then
+; CHECK-NEXT: .LBB2_4: # %if.then
; CHECK-NEXT: # in Loop: Header=BB2_2 Depth=1
; CHECK-NEXT: callq scale at PLT
; CHECK-NEXT: jmp .LBB2_2
-; CHECK-NEXT: .LBB2_6: # %for.end52
-; CHECK-NEXT: addq $8, %rsp
+; CHECK-NEXT: .LBB2_5: # %for.end52
+; CHECK-NEXT: addq $16, %rsp
; CHECK-NEXT: popq %rbx
-; CHECK-NEXT: popq %rbp
; CHECK-NEXT: retq
entry:
br i1 undef, label %for.cond5, label %for.end52
diff --git a/llvm/test/CodeGen/X86/cmp.ll b/llvm/test/CodeGen/X86/cmp.ll
index cd1953bec774d9..09419f870b7091 100644
--- a/llvm/test/CodeGen/X86/cmp.ll
+++ b/llvm/test/CodeGen/X86/cmp.ll
@@ -159,43 +159,51 @@ define i64 @test4(i64 %x) nounwind {
define i32 @test5(double %A) nounwind {
; CHECK-LABEL: test5:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: ucomisd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0 # encoding: [0x66,0x0f,0x2e,0x05,A,A,A,A]
+; CHECK-NEXT: movsd {{.*#+}} xmm1 = [7.5E+1,0.0E+0]
+; CHECK-NEXT: # encoding: [0xf2,0x0f,0x10,0x0d,A,A,A,A]
; CHECK-NEXT: # fixup A - offset: 4, value: {{\.?LCPI[0-9]+_[0-9]+}}-4, kind: reloc_riprel_4byte
-; CHECK-NEXT: ja .LBB5_3 # encoding: [0x77,A]
-; CHECK-NEXT: # fixup A - offset: 1, value: .LBB5_3-1, kind: FK_PCRel_1
-; CHECK-NEXT: # %bb.1: # %entry
-; CHECK-NEXT: ucomisd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0 # encoding: [0x66,0x0f,0x2e,0x05,A,A,A,A]
+; CHECK-NEXT: cmplepd %xmm0, %xmm1 # encoding: [0x66,0x0f,0xc2,0xc8,0x02]
+; CHECK-NEXT: movsd {{.*#+}} xmm2 = [1.5E+2,0.0E+0]
+; CHECK-NEXT: # encoding: [0xf2,0x0f,0x10,0x15,A,A,A,A]
; CHECK-NEXT: # fixup A - offset: 4, value: {{\.?LCPI[0-9]+_[0-9]+}}-4, kind: reloc_riprel_4byte
-; CHECK-NEXT: jb .LBB5_3 # encoding: [0x72,A]
-; CHECK-NEXT: # fixup A - offset: 1, value: .LBB5_3-1, kind: FK_PCRel_1
-; CHECK-NEXT: # %bb.2: # %bb12
-; CHECK-NEXT: movl $32, %eax # encoding: [0xb8,0x20,0x00,0x00,0x00]
-; CHECK-NEXT: retq # encoding: [0xc3]
-; CHECK-NEXT: .LBB5_3: # %bb8
+; CHECK-NEXT: cmpnltpd %xmm0, %xmm2 # encoding: [0x66,0x0f,0xc2,0xd0,0x05]
+; CHECK-NEXT: andpd %xmm1, %xmm2 # encoding: [0x66,0x0f,0x54,0xd1]
+; CHECK-NEXT: movd %xmm2, %eax # encoding: [0x66,0x0f,0x7e,0xd0]
+; CHECK-NEXT: testb $1, %al # encoding: [0xa8,0x01]
+; CHECK-NEXT: jne .LBB5_1 # encoding: [0x75,A]
+; CHECK-NEXT: # fixup A - offset: 1, value: .LBB5_1-1, kind: FK_PCRel_1
+; CHECK-NEXT: # %bb.2: # %bb8
; CHECK-NEXT: xorl %eax, %eax # encoding: [0x31,0xc0]
; CHECK-NEXT: jmp foo at PLT # TAILCALL
; CHECK-NEXT: # encoding: [0xeb,A]
; CHECK-NEXT: # fixup A - offset: 1, value: foo at PLT-1, kind: FK_PCRel_1
+; CHECK-NEXT: .LBB5_1: # %bb12
+; CHECK-NEXT: movl $32, %eax # encoding: [0xb8,0x20,0x00,0x00,0x00]
+; CHECK-NEXT: retq # encoding: [0xc3]
;
; NDD-LABEL: test5:
; NDD: # %bb.0: # %entry
-; NDD-NEXT: ucomisd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0 # encoding: [0x66,0x0f,0x2e,0x05,A,A,A,A]
+; NDD-NEXT: movsd {{.*#+}} xmm1 = [7.5E+1,0.0E+0]
+; NDD-NEXT: # encoding: [0xf2,0x0f,0x10,0x0d,A,A,A,A]
; NDD-NEXT: # fixup A - offset: 4, value: {{\.?LCPI[0-9]+_[0-9]+}}-4, kind: reloc_riprel_4byte
-; NDD-NEXT: ja .LBB5_3 # encoding: [0x77,A]
-; NDD-NEXT: # fixup A - offset: 1, value: .LBB5_3-1, kind: FK_PCRel_1
-; NDD-NEXT: # %bb.1: # %entry
-; NDD-NEXT: ucomisd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0 # encoding: [0x66,0x0f,0x2e,0x05,A,A,A,A]
+; NDD-NEXT: cmplepd %xmm0, %xmm1 # encoding: [0x66,0x0f,0xc2,0xc8,0x02]
+; NDD-NEXT: movsd {{.*#+}} xmm2 = [1.5E+2,0.0E+0]
+; NDD-NEXT: # encoding: [0xf2,0x0f,0x10,0x15,A,A,A,A]
; NDD-NEXT: # fixup A - offset: 4, value: {{\.?LCPI[0-9]+_[0-9]+}}-4, kind: reloc_riprel_4byte
-; NDD-NEXT: jb .LBB5_3 # encoding: [0x72,A]
-; NDD-NEXT: # fixup A - offset: 1, value: .LBB5_3-1, kind: FK_PCRel_1
-; NDD-NEXT: # %bb.2: # %bb12
-; NDD-NEXT: movl $32, %eax # encoding: [0xb8,0x20,0x00,0x00,0x00]
-; NDD-NEXT: retq # encoding: [0xc3]
-; NDD-NEXT: .LBB5_3: # %bb8
+; NDD-NEXT: cmpnltpd %xmm0, %xmm2 # encoding: [0x66,0x0f,0xc2,0xd0,0x05]
+; NDD-NEXT: andpd %xmm1, %xmm2 # encoding: [0x66,0x0f,0x54,0xd1]
+; NDD-NEXT: movd %xmm2, %eax # encoding: [0x66,0x0f,0x7e,0xd0]
+; NDD-NEXT: testb $1, %al # encoding: [0xa8,0x01]
+; NDD-NEXT: jne .LBB5_1 # encoding: [0x75,A]
+; NDD-NEXT: # fixup A - offset: 1, value: .LBB5_1-1, kind: FK_PCRel_1
+; NDD-NEXT: # %bb.2: # %bb8
; NDD-NEXT: xorl %eax, %eax # encoding: [0x31,0xc0]
; NDD-NEXT: jmp foo at PLT # TAILCALL
; NDD-NEXT: # encoding: [0xeb,A]
; NDD-NEXT: # fixup A - offset: 1, value: foo at PLT-1, kind: FK_PCRel_1
+; NDD-NEXT: .LBB5_1: # %bb12
+; NDD-NEXT: movl $32, %eax # encoding: [0xb8,0x20,0x00,0x00,0x00]
+; NDD-NEXT: retq # encoding: [0xc3]
entry:
%tmp2 = fcmp ogt double %A, 1.500000e+02
%tmp5 = fcmp ult double %A, 7.500000e+01
diff --git a/llvm/test/CodeGen/X86/dagcombine-and-setcc.ll b/llvm/test/CodeGen/X86/dagcombine-and-setcc.ll
index 842ee55d255aa3..6fded2eeaf35d9 100644
--- a/llvm/test/CodeGen/X86/dagcombine-and-setcc.ll
+++ b/llvm/test/CodeGen/X86/dagcombine-and-setcc.ll
@@ -16,7 +16,8 @@ declare i32 @printf(ptr nocapture readonly, ...)
;CHECK: cmpl
;CHECK: setl
;CHECK: orb
-;CHECK: je
+;CHECK: testb
+;CHECK: jne
@.str = private unnamed_addr constant [4 x i8] c"%d\0A\00", align 1
; Function Attrs: optsize ssp uwtable
diff --git a/llvm/test/CodeGen/X86/div-rem-pair-recomposition-unsigned.ll b/llvm/test/CodeGen/X86/div-rem-pair-recomposition-unsigned.ll
index 1372bd80473518..fa45afbb634c4d 100644
--- a/llvm/test/CodeGen/X86/div-rem-pair-recomposition-unsigned.ll
+++ b/llvm/test/CodeGen/X86/div-rem-pair-recomposition-unsigned.ll
@@ -178,13 +178,13 @@ define i128 @scalar_i128(i128 %x, i128 %y, ptr %divdst) nounwind {
; X86-NEXT: pushl %edi
; X86-NEXT: pushl %esi
; X86-NEXT: subl $136, %esp
-; X86-NEXT: movl {{[0-9]+}}(%esp), %edx
-; X86-NEXT: movl {{[0-9]+}}(%esp), %ecx
; X86-NEXT: movl {{[0-9]+}}(%esp), %esi
+; X86-NEXT: movl {{[0-9]+}}(%esp), %ebp
+; X86-NEXT: movl {{[0-9]+}}(%esp), %edi
; X86-NEXT: movl {{[0-9]+}}(%esp), %eax
-; X86-NEXT: orl %esi, %eax
-; X86-NEXT: orl %edx, %ecx
-; X86-NEXT: movl %edx, %edi
+; X86-NEXT: orl %edi, %eax
+; X86-NEXT: movl %ebp, %ecx
+; X86-NEXT: orl %esi, %ecx
; X86-NEXT: orl %eax, %ecx
; X86-NEXT: movl {{[0-9]+}}(%esp), %eax
; X86-NEXT: sete %bl
@@ -195,30 +195,33 @@ define i128 @scalar_i128(i128 %x, i128 %y, ptr %divdst) nounwind {
; X86-NEXT: sete %al
; X86-NEXT: orb %bl, %al
; X86-NEXT: movb %al, (%esp) # 1-byte Spill
-; X86-NEXT: bsrl %esi, %edx
+; X86-NEXT: bsrl %edi, %edx
; X86-NEXT: xorl $31, %edx
-; X86-NEXT: bsrl %edi, %ecx
+; X86-NEXT: bsrl %esi, %ecx
; X86-NEXT: xorl $31, %ecx
; X86-NEXT: addl $32, %ecx
-; X86-NEXT: testl %esi, %esi
+; X86-NEXT: testl %edi, %edi
+; X86-NEXT: movl %edi, %ebx
; X86-NEXT: cmovnel %edx, %ecx
; X86-NEXT: movl {{[0-9]+}}(%esp), %eax
; X86-NEXT: bsrl %eax, %edx
; X86-NEXT: xorl $31, %edx
-; X86-NEXT: bsrl {{[0-9]+}}(%esp), %ebp
-; X86-NEXT: movl %esi, %ebx
+; X86-NEXT: bsrl %ebp, %ebp
+; X86-NEXT: movl %esi, %edi
; X86-NEXT: movl {{[0-9]+}}(%esp), %esi
; X86-NEXT: xorl $31, %ebp
; X86-NEXT: addl $32, %ebp
; X86-NEXT: testl %eax, %eax
; X86-NEXT: cmovnel %edx, %ebp
; X86-NEXT: addl $64, %ebp
-; X86-NEXT: orl %ebx, %edi
+; X86-NEXT: movl %edi, %edx
+; X86-NEXT: orl %ebx, %edx
; X86-NEXT: cmovnel %ecx, %ebp
; X86-NEXT: bsrl %esi, %edx
+; X86-NEXT: movl %esi, %ebx
; X86-NEXT: xorl $31, %edx
-; X86-NEXT: movl {{[0-9]+}}(%esp), %ebx
-; X86-NEXT: bsrl %ebx, %ecx
+; X86-NEXT: movl {{[0-9]+}}(%esp), %eax
+; X86-NEXT: bsrl %eax, %ecx
; X86-NEXT: xorl $31, %ecx
; X86-NEXT: addl $32, %ecx
; X86-NEXT: testl %esi, %esi
@@ -230,51 +233,51 @@ define i128 @scalar_i128(i128 %x, i128 %y, ptr %divdst) nounwind {
; X86-NEXT: xorl $31, %edx
; X86-NEXT: addl $32, %edx
; X86-NEXT: testl %edi, %edi
-; X86-NEXT: movl %edi, %eax
; X86-NEXT: cmovnel %esi, %edx
; X86-NEXT: addl $64, %edx
-; X86-NEXT: movl %ebx, %esi
-; X86-NEXT: orl {{[0-9]+}}(%esp), %esi
+; X86-NEXT: orl %ebx, %eax
; X86-NEXT: cmovnel %ecx, %edx
-; X86-NEXT: xorl %ecx, %ecx
; X86-NEXT: subl %edx, %ebp
+; X86-NEXT: movl $0, %edx
+; X86-NEXT: sbbl %edx, %edx
; X86-NEXT: movl $0, %esi
; X86-NEXT: sbbl %esi, %esi
; X86-NEXT: movl $0, %edi
; X86-NEXT: sbbl %edi, %edi
-; X86-NEXT: movl $0, %ebx
-; X86-NEXT: sbbl %ebx, %ebx
-; X86-NEXT: movl $127, %edx
+; X86-NEXT: movl $127, %ecx
+; X86-NEXT: cmpl %ebp, %ecx
+; X86-NEXT: movl $0, %ecx
+; X86-NEXT: sbbl %edx, %ecx
+; X86-NEXT: movl $0, %ecx
+; X86-NEXT: sbbl %esi, %ecx
+; X86-NEXT: movl $0, %ecx
+; X86-NEXT: sbbl %edi, %ecx
+; X86-NEXT: setb %cl
+; X86-NEXT: orb (%esp), %cl # 1-byte Folded Reload
; X86-NEXT: movl %ebp, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: cmpl %ebp, %edx
-; X86-NEXT: movl $0, %edx
+; X86-NEXT: movl %ebp, %eax
+; X86-NEXT: xorl $127, %eax
; X86-NEXT: movl %esi, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: sbbl %esi, %edx
-; X86-NEXT: movl $0, %edx
+; X86-NEXT: orl %esi, %eax
+; X86-NEXT: movl %edx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
; X86-NEXT: movl %edi, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: sbbl %edi, %edx
-; X86-NEXT: movl $0, %edx
-; X86-NEXT: sbbl %ebx, %edx
-; X86-NEXT: setb %dl
-; X86-NEXT: orb (%esp), %dl # 1-byte Folded Reload
-; X86-NEXT: movl {{[0-9]+}}(%esp), %edx
-; X86-NEXT: cmovnel %ecx, %edx
+; X86-NEXT: orl %edi, %edx
+; X86-NEXT: orl %eax, %edx
+; X86-NEXT: sete %al
+; X86-NEXT: testb %cl, %cl
+; X86-NEXT: movl %ebx, %edx
+; X86-NEXT: movl $0, %edi
+; X86-NEXT: cmovnel %edi, %edx
; X86-NEXT: movl {{[0-9]+}}(%esp), %esi
-; X86-NEXT: cmovnel %ecx, %esi
-; X86-NEXT: cmovnel %ecx, %eax
-; X86-NEXT: movl %eax, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
+; X86-NEXT: cmovnel %edi, %esi
; X86-NEXT: movl {{[0-9]+}}(%esp), %ebp
-; X86-NEXT: cmovnel %ecx, %ebp
-; X86-NEXT: jne .LBB4_8
-; X86-NEXT: # %bb.1: # %_udiv-special-cases
-; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %eax # 4-byte Reload
-; X86-NEXT: xorl $127, %eax
-; X86-NEXT: orl {{[-0-9]+}}(%e{{[sb]}}p), %eax # 4-byte Folded Reload
-; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ecx # 4-byte Reload
-; X86-NEXT: orl %ebx, %ecx
-; X86-NEXT: orl %eax, %ecx
-; X86-NEXT: je .LBB4_8
-; X86-NEXT: # %bb.2: # %udiv-bb1
+; X86-NEXT: cmovnel %edi, %ebp
+; X86-NEXT: movl {{[0-9]+}}(%esp), %ebx
+; X86-NEXT: cmovnel %edi, %ebx
+; X86-NEXT: orb %cl, %al
+; X86-NEXT: movl {{[0-9]+}}(%esp), %eax
+; X86-NEXT: jne .LBB4_7
+; X86-NEXT: # %bb.1: # %udiv-bb1
; X86-NEXT: movl {{[0-9]+}}(%esp), %eax
; X86-NEXT: movl %eax, {{[0-9]+}}(%esp)
; X86-NEXT: movl {{[0-9]+}}(%esp), %eax
@@ -287,9 +290,8 @@ define i128 @scalar_i128(i128 %x, i128 %y, ptr %divdst) nounwind {
; X86-NEXT: movl $0, {{[0-9]+}}(%esp)
; X86-NEXT: movl $0, {{[0-9]+}}(%esp)
; X86-NEXT: movl $0, {{[0-9]+}}(%esp)
-; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ecx # 4-byte Reload
-; X86-NEXT: movl %ecx, %eax
-; X86-NEXT: movl %ecx, %edi
+; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ebx # 4-byte Reload
+; X86-NEXT: movl %ebx, %eax
; X86-NEXT: xorb $127, %al
; X86-NEXT: movb %al, %ch
; X86-NEXT: andb $7, %ch
@@ -301,7 +303,7 @@ define i128 @scalar_i128(i128 %x, i128 %y, ptr %divdst) nounwind {
; X86-NEXT: movl 132(%esp,%eax), %esi
; X86-NEXT: movb %ch, %cl
; X86-NEXT: shldl %cl, %edx, %esi
-; X86-NEXT: movl %esi, (%esp) # 4-byte Spill
+; X86-NEXT: movl %esi, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
; X86-NEXT: shll %cl, %edx
; X86-NEXT: notb %cl
; X86-NEXT: movl 124(%esp,%eax), %ebp
@@ -309,68 +311,69 @@ define i128 @scalar_i128(i128 %x, i128 %y, ptr %divdst) nounwind {
; X86-NEXT: shrl %esi
; X86-NEXT: shrl %cl, %esi
; X86-NEXT: orl %edx, %esi
-; X86-NEXT: movl %ebp, %edx
-; X86-NEXT: movl 120(%esp,%eax), %ebp
+; X86-NEXT: movl 120(%esp,%eax), %eax
; X86-NEXT: movb %ch, %cl
-; X86-NEXT: shldl %cl, %ebp, %edx
-; X86-NEXT: shll %cl, %ebp
-; X86-NEXT: addl $1, %edi
-; X86-NEXT: movl %edi, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
+; X86-NEXT: shldl %cl, %eax, %ebp
+; X86-NEXT: shll %cl, %eax
+; X86-NEXT: movl %eax, (%esp) # 4-byte Spill
+; X86-NEXT: addl $1, %ebx
+; X86-NEXT: movl %ebx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ecx # 4-byte Reload
; X86-NEXT: adcl $0, %ecx
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %eax # 4-byte Reload
; X86-NEXT: adcl $0, %eax
+; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ebx # 4-byte Reload
; X86-NEXT: adcl $0, %ebx
-; X86-NEXT: jae .LBB4_3
-; X86-NEXT: # %bb.6:
+; X86-NEXT: jae .LBB4_2
+; X86-NEXT: # %bb.5:
; X86-NEXT: xorl %eax, %eax
; X86-NEXT: xorl %ecx, %ecx
-; X86-NEXT: movl %edx, %ebx
-; X86-NEXT: jmp .LBB4_7
-; X86-NEXT: .LBB4_3: # %udiv-preheader
-; X86-NEXT: movl {{[0-9]+}}(%esp), %edi
-; X86-NEXT: movl %edi, {{[0-9]+}}(%esp)
-; X86-NEXT: movl {{[0-9]+}}(%esp), %edi
-; X86-NEXT: movl %edi, {{[0-9]+}}(%esp)
-; X86-NEXT: movl {{[0-9]+}}(%esp), %edi
-; X86-NEXT: movl %edi, {{[0-9]+}}(%esp)
-; X86-NEXT: movl %ecx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
+; X86-NEXT: jmp .LBB4_6
+; X86-NEXT: .LBB4_2: # %udiv-preheader
+; X86-NEXT: movl {{[0-9]+}}(%esp), %edx
+; X86-NEXT: movl %edx, {{[0-9]+}}(%esp)
+; X86-NEXT: movl {{[0-9]+}}(%esp), %edx
+; X86-NEXT: movl %edx, {{[0-9]+}}(%esp)
+; X86-NEXT: movl {{[0-9]+}}(%esp), %edx
+; X86-NEXT: movl %edx, {{[0-9]+}}(%esp)
; X86-NEXT: movl %eax, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: movl {{[0-9]+}}(%esp), %ecx
-; X86-NEXT: movl %ecx, {{[0-9]+}}(%esp)
+; X86-NEXT: movl %ebx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
+; X86-NEXT: movl {{[0-9]+}}(%esp), %eax
+; X86-NEXT: movl %eax, {{[0-9]+}}(%esp)
; X86-NEXT: movl $0, {{[0-9]+}}(%esp)
; X86-NEXT: movl $0, {{[0-9]+}}(%esp)
; X86-NEXT: movl $0, {{[0-9]+}}(%esp)
; X86-NEXT: movl $0, {{[0-9]+}}(%esp)
+; X86-NEXT: movl %ecx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %eax # 4-byte Reload
; X86-NEXT: movb %al, %ch
; X86-NEXT: andb $7, %ch
-; X86-NEXT: movl %ebp, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: movl %ebx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
; X86-NEXT: # kill: def $al killed $al killed $eax
; X86-NEXT: shrb $3, %al
; X86-NEXT: andb $15, %al
; X86-NEXT: movzbl %al, %eax
-; X86-NEXT: movl 84(%esp,%eax), %ebp
-; X86-NEXT: movl %esi, %edi
-; X86-NEXT: movl 80(%esp,%eax), %ebx
-; X86-NEXT: movl %edx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: movl %ebx, %esi
-; X86-NEXT: movb %ch, %cl
-; X86-NEXT: shrdl %cl, %ebp, %esi
+; X86-NEXT: movl 84(%esp,%eax), %ebx
; X86-NEXT: movl %esi, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: movl 72(%esp,%eax), %esi
-; X86-NEXT: movl 76(%esp,%eax), %eax
-; X86-NEXT: movl %eax, %edx
-; X86-NEXT: shrl %cl, %edx
-; X86-NEXT: notb %cl
-; X86-NEXT: addl %ebx, %ebx
-; X86-NEXT: shll %cl, %ebx
-; X86-NEXT: orl %edx, %ebx
+; X86-NEXT: movl 80(%esp,%eax), %esi
+; X86-NEXT: movl %ebp, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
+; X86-NEXT: movl %esi, %edx
; X86-NEXT: movb %ch, %cl
-; X86-NEXT: shrl %cl, %ebp
-; X86-NEXT: shrdl %cl, %eax, %esi
+; X86-NEXT: shrdl %cl, %ebx, %edx
+; X86-NEXT: movl %edx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
+; X86-NEXT: movl 72(%esp,%eax), %ebp
+; X86-NEXT: movl 76(%esp,%eax), %edx
+; X86-NEXT: movl %edx, %eax
+; X86-NEXT: shrl %cl, %eax
+; X86-NEXT: notb %cl
+; X86-NEXT: addl %esi, %esi
+; X86-NEXT: shll %cl, %esi
+; X86-NEXT: orl %eax, %esi
; X86-NEXT: movl %esi, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
+; X86-NEXT: movb %ch, %cl
+; X86-NEXT: shrl %cl, %ebx
+; X86-NEXT: movl %ebx, %edi
+; X86-NEXT: shrdl %cl, %edx, %ebp
+; X86-NEXT: movl %ebp, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
; X86-NEXT: movl {{[0-9]+}}(%esp), %eax
; X86-NEXT: addl $-1, %eax
; X86-NEXT: movl %eax, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
@@ -380,25 +383,25 @@ define i128 @scalar_i128(i128 %x, i128 %y, ptr %divdst) nounwind {
; X86-NEXT: movl {{[0-9]+}}(%esp), %ecx
; X86-NEXT: adcl $-1, %ecx
; X86-NEXT: movl %ecx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: movl {{[0-9]+}}(%esp), %esi
-; X86-NEXT: adcl $-1, %esi
-; X86-NEXT: movl %esi, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
+; X86-NEXT: movl {{[0-9]+}}(%esp), %edx
+; X86-NEXT: adcl $-1, %edx
+; X86-NEXT: movl %edx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
; X86-NEXT: xorl %ecx, %ecx
; X86-NEXT: movl $0, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Folded Spill
-; X86-NEXT: movl (%esp), %esi # 4-byte Reload
+; X86-NEXT: movl (%esp), %edx # 4-byte Reload
; X86-NEXT: .p2align 4, 0x90
-; X86-NEXT: .LBB4_4: # %udiv-do-while
+; X86-NEXT: .LBB4_3: # %udiv-do-while
; X86-NEXT: # =>This Inner Loop Header: Depth=1
; X86-NEXT: movl %ecx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %edx # 4-byte Reload
-; X86-NEXT: shldl $1, %edx, %ebp
-; X86-NEXT: movl %ebp, (%esp) # 4-byte Spill
-; X86-NEXT: shldl $1, %ebx, %edx
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ebp # 4-byte Reload
-; X86-NEXT: shldl $1, %ebp, %ebx
-; X86-NEXT: shldl $1, %esi, %ebp
+; X86-NEXT: shldl $1, %ebp, %edi
+; X86-NEXT: movl %edi, (%esp) # 4-byte Spill
+; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ebx # 4-byte Reload
+; X86-NEXT: shldl $1, %ebx, %ebp
+; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %esi # 4-byte Reload
+; X86-NEXT: shldl $1, %esi, %ebx
+; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %edi # 4-byte Reload
; X86-NEXT: shldl $1, %edi, %esi
-; X86-NEXT: orl %ecx, %esi
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %eax # 4-byte Reload
; X86-NEXT: shldl $1, %eax, %edi
; X86-NEXT: orl %ecx, %edi
@@ -407,14 +410,16 @@ define i128 @scalar_i128(i128 %x, i128 %y, ptr %divdst) nounwind {
; X86-NEXT: shldl $1, %edi, %eax
; X86-NEXT: orl %ecx, %eax
; X86-NEXT: movl %eax, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: addl %edi, %edi
-; X86-NEXT: orl {{[-0-9]+}}(%e{{[sb]}}p), %edi # 4-byte Folded Reload
+; X86-NEXT: shldl $1, %edx, %edi
+; X86-NEXT: orl %ecx, %edi
; X86-NEXT: movl %edi, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: cmpl %ebp, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Folded Reload
+; X86-NEXT: addl %edx, %edx
+; X86-NEXT: orl {{[-0-9]+}}(%e{{[sb]}}p), %edx # 4-byte Folded Reload
+; X86-NEXT: cmpl %esi, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Folded Reload
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ecx # 4-byte Reload
; X86-NEXT: sbbl %ebx, %ecx
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ecx # 4-byte Reload
-; X86-NEXT: sbbl %edx, %ecx
+; X86-NEXT: sbbl %ebp, %ecx
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ecx # 4-byte Reload
; X86-NEXT: sbbl (%esp), %ecx # 4-byte Folded Reload
; X86-NEXT: sarl $31, %ecx
@@ -429,84 +434,81 @@ define i128 @scalar_i128(i128 %x, i128 %y, ptr %divdst) nounwind {
; X86-NEXT: movl %ecx, %eax
; X86-NEXT: andl {{[0-9]+}}(%esp), %eax
; X86-NEXT: andl {{[0-9]+}}(%esp), %ecx
-; X86-NEXT: subl %ecx, %ebp
-; X86-NEXT: movl %ebp, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
+; X86-NEXT: subl %ecx, %esi
+; X86-NEXT: movl %esi, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
; X86-NEXT: sbbl %eax, %ebx
; X86-NEXT: movl %ebx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: sbbl %edi, %edx
-; X86-NEXT: movl %edx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %edi # 4-byte Reload
+; X86-NEXT: sbbl %edi, %ebp
+; X86-NEXT: movl %ebp, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %eax # 4-byte Reload
; X86-NEXT: sbbl %eax, (%esp) # 4-byte Folded Spill
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ecx # 4-byte Reload
; X86-NEXT: addl $-1, %ecx
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %eax # 4-byte Reload
; X86-NEXT: adcl $-1, %eax
-; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %edx # 4-byte Reload
-; X86-NEXT: adcl $-1, %edx
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ebx # 4-byte Reload
; X86-NEXT: adcl $-1, %ebx
+; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %edi # 4-byte Reload
+; X86-NEXT: adcl $-1, %edi
; X86-NEXT: movl %eax, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: movl %ebx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: orl %ebx, %eax
-; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ebx # 4-byte Reload
+; X86-NEXT: movl %edi, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
+; X86-NEXT: orl %edi, %eax
; X86-NEXT: movl %ecx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: movl %edx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: orl %edx, %ecx
-; X86-NEXT: movl (%esp), %ebp # 4-byte Reload
+; X86-NEXT: movl %ebx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
+; X86-NEXT: orl %ebx, %ecx
+; X86-NEXT: movl (%esp), %edi # 4-byte Reload
; X86-NEXT: orl %eax, %ecx
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ecx # 4-byte Reload
-; X86-NEXT: jne .LBB4_4
-; X86-NEXT: # %bb.5:
-; X86-NEXT: movl %esi, (%esp) # 4-byte Spill
-; X86-NEXT: movl %edi, %esi
-; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ebx # 4-byte Reload
+; X86-NEXT: jne .LBB4_3
+; X86-NEXT: # %bb.4:
+; X86-NEXT: movl %edx, (%esp) # 4-byte Spill
+; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %esi # 4-byte Reload
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ebp # 4-byte Reload
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %eax # 4-byte Reload
-; X86-NEXT: .LBB4_7: # %udiv-loop-exit
-; X86-NEXT: movl (%esp), %edx # 4-byte Reload
+; X86-NEXT: .LBB4_6: # %udiv-loop-exit
+; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %edx # 4-byte Reload
; X86-NEXT: shldl $1, %esi, %edx
; X86-NEXT: orl %ecx, %edx
-; X86-NEXT: shldl $1, %ebx, %esi
+; X86-NEXT: shldl $1, %ebp, %esi
; X86-NEXT: orl %ecx, %esi
-; X86-NEXT: shldl $1, %ebp, %ebx
-; X86-NEXT: orl %ecx, %ebx
-; X86-NEXT: movl %ebx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: addl %ebp, %ebp
-; X86-NEXT: orl %eax, %ebp
-; X86-NEXT: .LBB4_8: # %udiv-end
+; X86-NEXT: movl (%esp), %ebx # 4-byte Reload
+; X86-NEXT: shldl $1, %ebx, %ebp
+; X86-NEXT: orl %ecx, %ebp
+; X86-NEXT: addl %ebx, %ebx
+; X86-NEXT: orl %eax, %ebx
; X86-NEXT: movl {{[0-9]+}}(%esp), %eax
-; X86-NEXT: movl %ebp, (%eax)
-; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ecx # 4-byte Reload
-; X86-NEXT: movl %ecx, 4(%eax)
+; X86-NEXT: .LBB4_7: # %udiv-end
+; X86-NEXT: movl %ebp, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
+; X86-NEXT: movl %ebx, (%eax)
+; X86-NEXT: movl %ebp, 4(%eax)
; X86-NEXT: movl %esi, 8(%eax)
; X86-NEXT: movl %edx, 12(%eax)
+; X86-NEXT: movl %ebx, %ecx
+; X86-NEXT: movl %ebx, (%esp) # 4-byte Spill
; X86-NEXT: movl %esi, %ebx
; X86-NEXT: movl {{[0-9]+}}(%esp), %eax
; X86-NEXT: movl %eax, %esi
-; X86-NEXT: imull %ecx, %esi
-; X86-NEXT: movl %ebp, %ecx
-; X86-NEXT: movl %ebp, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: movl %edx, %ebp
+; X86-NEXT: imull %ebp, %esi
+; X86-NEXT: movl %edx, %edi
; X86-NEXT: mull %ecx
-; X86-NEXT: movl %eax, (%esp) # 4-byte Spill
+; X86-NEXT: movl %eax, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
; X86-NEXT: addl %esi, %edx
-; X86-NEXT: movl {{[0-9]+}}(%esp), %edi
-; X86-NEXT: imull %ecx, %edi
-; X86-NEXT: addl %edx, %edi
+; X86-NEXT: movl {{[0-9]+}}(%esp), %ebp
+; X86-NEXT: imull %ecx, %ebp
+; X86-NEXT: addl %edx, %ebp
; X86-NEXT: movl {{[0-9]+}}(%esp), %esi
; X86-NEXT: movl %esi, %eax
; X86-NEXT: mull %ebx
; X86-NEXT: movl %eax, %ecx
-; X86-NEXT: imull %esi, %ebp
-; X86-NEXT: addl %edx, %ebp
+; X86-NEXT: imull %esi, %edi
+; X86-NEXT: addl %edx, %edi
; X86-NEXT: movl {{[0-9]+}}(%esp), %eax
; X86-NEXT: imull %eax, %ebx
-; X86-NEXT: addl %ebp, %ebx
-; X86-NEXT: addl (%esp), %ecx # 4-byte Folded Reload
-; X86-NEXT: movl %ecx, (%esp) # 4-byte Spill
-; X86-NEXT: adcl %edi, %ebx
-; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ebp # 4-byte Reload
+; X86-NEXT: addl %edi, %ebx
+; X86-NEXT: addl {{[-0-9]+}}(%e{{[sb]}}p), %ecx # 4-byte Folded Reload
+; X86-NEXT: movl %ecx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
+; X86-NEXT: adcl %ebp, %ebx
+; X86-NEXT: movl (%esp), %ebp # 4-byte Reload
; X86-NEXT: movl %ebp, %eax
; X86-NEXT: mull %esi
; X86-NEXT: movl %edx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
@@ -522,7 +524,7 @@ define i128 @scalar_i128(i128 %x, i128 %y, ptr %divdst) nounwind {
; X86-NEXT: movl {{[0-9]+}}(%esp), %esi
; X86-NEXT: movl %edx, %ebp
; X86-NEXT: addl %ecx, %eax
-; X86-NEXT: movl %eax, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
+; X86-NEXT: movl %eax, (%esp) # 4-byte Spill
; X86-NEXT: adcl %edi, %ebp
; X86-NEXT: setb %cl
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %eax # 4-byte Reload
@@ -530,11 +532,11 @@ define i128 @scalar_i128(i128 %x, i128 %y, ptr %divdst) nounwind {
; X86-NEXT: addl %ebp, %eax
; X86-NEXT: movzbl %cl, %ecx
; X86-NEXT: adcl %ecx, %edx
-; X86-NEXT: addl (%esp), %eax # 4-byte Folded Reload
+; X86-NEXT: addl {{[-0-9]+}}(%e{{[sb]}}p), %eax # 4-byte Folded Reload
; X86-NEXT: adcl %ebx, %edx
; X86-NEXT: subl {{[-0-9]+}}(%e{{[sb]}}p), %esi # 4-byte Folded Reload
; X86-NEXT: movl {{[0-9]+}}(%esp), %edi
-; X86-NEXT: sbbl {{[-0-9]+}}(%e{{[sb]}}p), %edi # 4-byte Folded Reload
+; X86-NEXT: sbbl (%esp), %edi # 4-byte Folded Reload
; X86-NEXT: movl {{[0-9]+}}(%esp), %ebx
; X86-NEXT: sbbl %eax, %ebx
; X86-NEXT: movl {{[0-9]+}}(%esp), %ecx
diff --git a/llvm/test/CodeGen/X86/inline-spiller-impdef-on-implicit-def-regression.ll b/llvm/test/CodeGen/X86/inline-spiller-impdef-on-implicit-def-regression.ll
index 0250b1b4a7f861..f42c2f8f144763 100644
--- a/llvm/test/CodeGen/X86/inline-spiller-impdef-on-implicit-def-regression.ll
+++ b/llvm/test/CodeGen/X86/inline-spiller-impdef-on-implicit-def-regression.ll
@@ -28,78 +28,70 @@ define i32 @decode_sb(ptr %t, i32 %bl, i32 %_msprop1966, i32 %sub.i, i64 %idxpro
; CHECK-NEXT: .cfi_offset %r15, -24
; CHECK-NEXT: movl %r9d, %ebx
; CHECK-NEXT: # kill: def $edx killed $edx def $rdx
-; CHECK-NEXT: movabsq $87960930222080, %r15 # imm = 0x500000000000
-; CHECK-NEXT: movl 0, %r11d
-; CHECK-NEXT: movl %esi, %r12d
-; CHECK-NEXT: # implicit-def: $r13d
+; CHECK-NEXT: movabsq $87960930222080, %r14 # imm = 0x500000000000
+; CHECK-NEXT: movl 0, %r13d
+; CHECK-NEXT: movl %esi, %r15d
+; CHECK-NEXT: # implicit-def: $r12d
; CHECK-NEXT: testb $1, %bl
-; CHECK-NEXT: jne .LBB0_7
+; CHECK-NEXT: jne .LBB0_6
; CHECK-NEXT: # %bb.1: # %if.else
-; CHECK-NEXT: movq %r8, %r14
-; CHECK-NEXT: movl %ecx, %r13d
-; CHECK-NEXT: andl $1, %r13d
-; CHECK-NEXT: movzbl 544(%r13), %r8d
-; CHECK-NEXT: andl $1, %r8d
-; CHECK-NEXT: movl %r15d, %r9d
+; CHECK-NEXT: movl %ecx, %r12d
+; CHECK-NEXT: andl $1, %r12d
+; CHECK-NEXT: movzbl 544(%r12), %r9d
; CHECK-NEXT: andl $1, %r9d
; CHECK-NEXT: movl %r14d, %r10d
; CHECK-NEXT: andl $1, %r10d
+; CHECK-NEXT: andl $1, %r8d
; CHECK-NEXT: movabsq $17592186044416, %rax # imm = 0x100000000000
-; CHECK-NEXT: orq %r10, %rax
-; CHECK-NEXT: movl %esi, %r10d
+; CHECK-NEXT: orq %r8, %rax
+; CHECK-NEXT: movl %esi, %r8d
; CHECK-NEXT: # kill: def $cl killed $cl killed $ecx
-; CHECK-NEXT: shrl %cl, %r10d
-; CHECK-NEXT: andl $2, %r10d
+; CHECK-NEXT: shrl %cl, %r8d
+; CHECK-NEXT: andl $2, %r8d
; CHECK-NEXT: testb $1, %bl
-; CHECK-NEXT: cmoveq %r9, %rax
-; CHECK-NEXT: orl %r8d, %edx
-; CHECK-NEXT: movq %r11, {{[-0-9]+}}(%r{{[sb]}}p) # 8-byte Spill
-; CHECK-NEXT: movq %r11, %rcx
+; CHECK-NEXT: cmoveq %r10, %rax
+; CHECK-NEXT: orl %r9d, %edx
+; CHECK-NEXT: movq %r13, %rcx
; CHECK-NEXT: orq $1, %rcx
-; CHECK-NEXT: orl %esi, %r10d
+; CHECK-NEXT: orl %esi, %r8d
; CHECK-NEXT: movl $1, %r8d
; CHECK-NEXT: je .LBB0_3
; CHECK-NEXT: # %bb.2: # %if.else
; CHECK-NEXT: movl (%rax), %r8d
; CHECK-NEXT: .LBB0_3: # %if.else
; CHECK-NEXT: shlq $5, %rdx
-; CHECK-NEXT: movq %r12, %rax
+; CHECK-NEXT: movq %r15, %rax
; CHECK-NEXT: shlq $7, %rax
; CHECK-NEXT: leaq (%rax,%rdx), %rsi
; CHECK-NEXT: addq $1248, %rsi # imm = 0x4E0
; CHECK-NEXT: movq %rcx, 0
-; CHECK-NEXT: movq %rdi, %r15
+; CHECK-NEXT: movq %rdi, %r14
; CHECK-NEXT: movl %r8d, (%rdi)
; CHECK-NEXT: xorl %eax, %eax
; CHECK-NEXT: xorl %edi, %edi
; CHECK-NEXT: xorl %edx, %edx
; CHECK-NEXT: callq *%rax
-; CHECK-NEXT: xorq $1, %r14
-; CHECK-NEXT: cmpl $0, (%r14)
-; CHECK-NEXT: je .LBB0_6
-; CHECK-NEXT: # %bb.4: # %if.else
; CHECK-NEXT: movb $1, %al
; CHECK-NEXT: testb %al, %al
-; CHECK-NEXT: je .LBB0_5
-; CHECK-NEXT: .LBB0_6: # %bb19
+; CHECK-NEXT: je .LBB0_4
+; CHECK-NEXT: # %bb.5: # %bb19
; CHECK-NEXT: testb $1, %bl
-; CHECK-NEXT: movq %r15, %rdi
-; CHECK-NEXT: movabsq $87960930222080, %r15 # imm = 0x500000000000
-; CHECK-NEXT: movq {{[-0-9]+}}(%r{{[sb]}}p), %r11 # 8-byte Reload
-; CHECK-NEXT: jne .LBB0_8
-; CHECK-NEXT: .LBB0_7: # %if.end69
-; CHECK-NEXT: movl %r11d, 0
+; CHECK-NEXT: movq %r14, %rdi
+; CHECK-NEXT: movabsq $87960930222080, %r14 # imm = 0x500000000000
+; CHECK-NEXT: jne .LBB0_7
+; CHECK-NEXT: .LBB0_6: # %if.end69
+; CHECK-NEXT: movl %r13d, 0
; CHECK-NEXT: xorl %eax, %eax
; CHECK-NEXT: xorl %esi, %esi
; CHECK-NEXT: xorl %edx, %edx
; CHECK-NEXT: xorl %ecx, %ecx
; CHECK-NEXT: xorl %r8d, %r8d
; CHECK-NEXT: callq *%rax
-; CHECK-NEXT: xorq %r15, %r12
-; CHECK-NEXT: movslq %r13d, %rax
-; CHECK-NEXT: movzbl (%r12), %ecx
+; CHECK-NEXT: xorq %r14, %r15
+; CHECK-NEXT: movslq %r12d, %rax
+; CHECK-NEXT: movzbl (%r15), %ecx
; CHECK-NEXT: movb %cl, 544(%rax)
-; CHECK-NEXT: .LBB0_8: # %land.lhs.true56
+; CHECK-NEXT: .LBB0_7: # %land.lhs.true56
; CHECK-NEXT: xorl %eax, %eax
; CHECK-NEXT: addq $8, %rsp
; CHECK-NEXT: popq %rbx
@@ -110,7 +102,7 @@ define i32 @decode_sb(ptr %t, i32 %bl, i32 %_msprop1966, i32 %sub.i, i64 %idxpro
; CHECK-NEXT: popq %rbp
; CHECK-NEXT: .cfi_def_cfa %rsp, 8
; CHECK-NEXT: retq
-; CHECK-NEXT: .LBB0_5: # %bb
+; CHECK-NEXT: .LBB0_4: # %bb
entry:
%i = load i32, ptr null, align 8
br i1 %cmp54, label %if.end69, label %if.else
diff --git a/llvm/test/CodeGen/X86/lsr-addrecloops.ll b/llvm/test/CodeGen/X86/lsr-addrecloops.ll
index 963405c8b0b3d3..d41942bea69da1 100644
--- a/llvm/test/CodeGen/X86/lsr-addrecloops.ll
+++ b/llvm/test/CodeGen/X86/lsr-addrecloops.ll
@@ -15,39 +15,38 @@ define void @in4dob_(ptr nocapture writeonly %0, ptr nocapture readonly %1, ptr
; CHECK-NEXT: movl $1, %r10d
; CHECK-NEXT: xorl %eax, %eax
; CHECK-NEXT: vxorps %xmm0, %xmm0, %xmm0
-; CHECK-NEXT: jmp .LBB0_1
; CHECK-NEXT: .p2align 4, 0x90
-; CHECK-NEXT: .LBB0_20: # in Loop: Header=BB0_1 Depth=1
-; CHECK-NEXT: incq %r10
-; CHECK-NEXT: addq %r9, %rax
-; CHECK-NEXT: cmpq %r10, %rcx
-; CHECK-NEXT: je .LBB0_18
; CHECK-NEXT: .LBB0_1: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: vmovss {{.*#+}} xmm1 = mem[0],zero,zero,zero
-; CHECK-NEXT: vucomiss %xmm0, %xmm1
-; CHECK-NEXT: jne .LBB0_20
-; CHECK-NEXT: jp .LBB0_20
-; CHECK-NEXT: # %bb.2: # in Loop: Header=BB0_1 Depth=1
+; CHECK-NEXT: vcmpneqps %xmm0, %xmm1, %k0
; CHECK-NEXT: vmovss {{.*#+}} xmm1 = mem[0],zero,zero,zero
-; CHECK-NEXT: vucomiss %xmm0, %xmm1
-; CHECK-NEXT: jne .LBB0_20
-; CHECK-NEXT: jp .LBB0_20
-; CHECK-NEXT: # %bb.3: # %vector.body807.preheader
+; CHECK-NEXT: vcmpneqps %xmm0, %xmm1, %k1
+; CHECK-NEXT: korw %k0, %k1, %k0
+; CHECK-NEXT: kmovd %k0, %r11d
+; CHECK-NEXT: testb $1, %r11b
+; CHECK-NEXT: je .LBB0_2
+; CHECK-NEXT: # %bb.19: # in Loop: Header=BB0_1 Depth=1
+; CHECK-NEXT: incq %r10
+; CHECK-NEXT: addq %r9, %rax
+; CHECK-NEXT: cmpq %r10, %rcx
+; CHECK-NEXT: jne .LBB0_1
+; CHECK-NEXT: jmp .LBB0_17
+; CHECK-NEXT: .LBB0_2: # %vector.body807.preheader
; CHECK-NEXT: leaq 1(%rcx), %rdx
; CHECK-NEXT: movl %edx, %esi
; CHECK-NEXT: andl $7, %esi
; CHECK-NEXT: cmpq $7, %rcx
-; CHECK-NEXT: jae .LBB0_5
-; CHECK-NEXT: # %bb.4:
+; CHECK-NEXT: jae .LBB0_4
+; CHECK-NEXT: # %bb.3:
; CHECK-NEXT: xorl %r9d, %r9d
-; CHECK-NEXT: jmp .LBB0_7
-; CHECK-NEXT: .LBB0_5: # %vector.body807.preheader.new
+; CHECK-NEXT: jmp .LBB0_6
+; CHECK-NEXT: .LBB0_4: # %vector.body807.preheader.new
; CHECK-NEXT: movq %rdx, %r10
; CHECK-NEXT: andq $-8, %r10
; CHECK-NEXT: xorl %r9d, %r9d
; CHECK-NEXT: vxorps %xmm0, %xmm0, %xmm0
; CHECK-NEXT: .p2align 4, 0x90
-; CHECK-NEXT: .LBB0_6: # %vector.body807
+; CHECK-NEXT: .LBB0_5: # %vector.body807
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: leaq (%rdi,%r9), %r11
; CHECK-NEXT: vmovups %ymm0, (%rax,%r11)
@@ -60,43 +59,43 @@ define void @in4dob_(ptr nocapture writeonly %0, ptr nocapture readonly %1, ptr
; CHECK-NEXT: vmovups %ymm0, 7(%rax,%r11)
; CHECK-NEXT: addq $8, %r9
; CHECK-NEXT: cmpq %r9, %r10
-; CHECK-NEXT: jne .LBB0_6
-; CHECK-NEXT: .LBB0_7: # %.lr.ph373.unr-lcssa
+; CHECK-NEXT: jne .LBB0_5
+; CHECK-NEXT: .LBB0_6: # %.lr.ph373.unr-lcssa
; CHECK-NEXT: testq %rsi, %rsi
-; CHECK-NEXT: je .LBB0_10
-; CHECK-NEXT: # %bb.8: # %vector.body807.epil.preheader
+; CHECK-NEXT: je .LBB0_9
+; CHECK-NEXT: # %bb.7: # %vector.body807.epil.preheader
; CHECK-NEXT: addq %rdi, %r9
; CHECK-NEXT: xorl %r10d, %r10d
; CHECK-NEXT: vxorps %xmm0, %xmm0, %xmm0
; CHECK-NEXT: .p2align 4, 0x90
-; CHECK-NEXT: .LBB0_9: # %vector.body807.epil
+; CHECK-NEXT: .LBB0_8: # %vector.body807.epil
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: leaq (%r9,%r10), %r11
; CHECK-NEXT: vmovups %ymm0, (%rax,%r11)
; CHECK-NEXT: incq %r10
; CHECK-NEXT: cmpq %r10, %rsi
-; CHECK-NEXT: jne .LBB0_9
-; CHECK-NEXT: .LBB0_10: # %.lr.ph373
+; CHECK-NEXT: jne .LBB0_8
+; CHECK-NEXT: .LBB0_9: # %.lr.ph373
; CHECK-NEXT: testb $1, %r8b
-; CHECK-NEXT: je .LBB0_11
-; CHECK-NEXT: # %bb.19: # %scalar.ph839.preheader
+; CHECK-NEXT: je .LBB0_10
+; CHECK-NEXT: # %bb.18: # %scalar.ph839.preheader
; CHECK-NEXT: movl $0, (%rdi)
; CHECK-NEXT: vzeroupper
; CHECK-NEXT: retq
-; CHECK-NEXT: .LBB0_11: # %vector.body847.preheader
+; CHECK-NEXT: .LBB0_10: # %vector.body847.preheader
; CHECK-NEXT: movl %edx, %esi
; CHECK-NEXT: andl $7, %esi
; CHECK-NEXT: cmpq $7, %rcx
-; CHECK-NEXT: jae .LBB0_13
-; CHECK-NEXT: # %bb.12:
+; CHECK-NEXT: jae .LBB0_12
+; CHECK-NEXT: # %bb.11:
; CHECK-NEXT: xorl %ecx, %ecx
-; CHECK-NEXT: jmp .LBB0_15
-; CHECK-NEXT: .LBB0_13: # %vector.body847.preheader.new
+; CHECK-NEXT: jmp .LBB0_14
+; CHECK-NEXT: .LBB0_12: # %vector.body847.preheader.new
; CHECK-NEXT: andq $-8, %rdx
; CHECK-NEXT: xorl %ecx, %ecx
; CHECK-NEXT: vxorps %xmm0, %xmm0, %xmm0
; CHECK-NEXT: .p2align 4, 0x90
-; CHECK-NEXT: .LBB0_14: # %vector.body847
+; CHECK-NEXT: .LBB0_13: # %vector.body847
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: leaq (%rdi,%rcx), %r8
; CHECK-NEXT: vmovups %ymm0, 96(%rax,%r8)
@@ -109,23 +108,23 @@ define void @in4dob_(ptr nocapture writeonly %0, ptr nocapture readonly %1, ptr
; CHECK-NEXT: vmovups %ymm0, 103(%rax,%r8)
; CHECK-NEXT: addq $8, %rcx
; CHECK-NEXT: cmpq %rcx, %rdx
-; CHECK-NEXT: jne .LBB0_14
-; CHECK-NEXT: .LBB0_15: # %common.ret.loopexit.unr-lcssa
+; CHECK-NEXT: jne .LBB0_13
+; CHECK-NEXT: .LBB0_14: # %common.ret.loopexit.unr-lcssa
; CHECK-NEXT: testq %rsi, %rsi
-; CHECK-NEXT: je .LBB0_18
-; CHECK-NEXT: # %bb.16: # %vector.body847.epil.preheader
+; CHECK-NEXT: je .LBB0_17
+; CHECK-NEXT: # %bb.15: # %vector.body847.epil.preheader
; CHECK-NEXT: leaq 96(%rcx,%rdi), %rcx
; CHECK-NEXT: xorl %edx, %edx
; CHECK-NEXT: vxorps %xmm0, %xmm0, %xmm0
; CHECK-NEXT: .p2align 4, 0x90
-; CHECK-NEXT: .LBB0_17: # %vector.body847.epil
+; CHECK-NEXT: .LBB0_16: # %vector.body847.epil
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: leaq (%rcx,%rdx), %rdi
; CHECK-NEXT: vmovups %ymm0, (%rax,%rdi)
; CHECK-NEXT: incq %rdx
; CHECK-NEXT: cmpq %rdx, %rsi
-; CHECK-NEXT: jne .LBB0_17
-; CHECK-NEXT: .LBB0_18: # %common.ret
+; CHECK-NEXT: jne .LBB0_16
+; CHECK-NEXT: .LBB0_17: # %common.ret
; CHECK-NEXT: vzeroupper
; CHECK-NEXT: retq
.preheader263:
diff --git a/llvm/test/CodeGen/X86/movmsk-cmp.ll b/llvm/test/CodeGen/X86/movmsk-cmp.ll
index a7564c9622c5ca..e8b3121ecfb523 100644
--- a/llvm/test/CodeGen/X86/movmsk-cmp.ll
+++ b/llvm/test/CodeGen/X86/movmsk-cmp.ll
@@ -4440,16 +4440,14 @@ define i32 @pr67287(<2 x i64> %broadcast.splatinsert25) {
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm1[1,0,3,2]
; SSE2-NEXT: movmskpd %xmm0, %eax
; SSE2-NEXT: testl %eax, %eax
-; SSE2-NEXT: jne .LBB97_2
-; SSE2-NEXT: # %bb.1: # %entry
-; SSE2-NEXT: movd %xmm1, %eax
-; SSE2-NEXT: testb $1, %al
-; SSE2-NEXT: jne .LBB97_2
-; SSE2-NEXT: # %bb.3: # %middle.block
-; SSE2-NEXT: xorl %eax, %eax
-; SSE2-NEXT: retq
-; SSE2-NEXT: .LBB97_2:
+; SSE2-NEXT: setne %al
+; SSE2-NEXT: movd %xmm1, %ecx
+; SSE2-NEXT: orb %al, %cl
+; SSE2-NEXT: testb $1, %cl
+; SSE2-NEXT: je .LBB97_2
+; SSE2-NEXT: # %bb.1:
; SSE2-NEXT: movw $0, 0
+; SSE2-NEXT: .LBB97_2: # %middle.block
; SSE2-NEXT: xorl %eax, %eax
; SSE2-NEXT: retq
;
@@ -4460,16 +4458,14 @@ define i32 @pr67287(<2 x i64> %broadcast.splatinsert25) {
; SSE41-NEXT: pcmpeqq %xmm1, %xmm0
; SSE41-NEXT: movmskpd %xmm0, %eax
; SSE41-NEXT: testl %eax, %eax
-; SSE41-NEXT: jne .LBB97_2
-; SSE41-NEXT: # %bb.1: # %entry
-; SSE41-NEXT: movd %xmm0, %eax
-; SSE41-NEXT: testb $1, %al
-; SSE41-NEXT: jne .LBB97_2
-; SSE41-NEXT: # %bb.3: # %middle.block
-; SSE41-NEXT: xorl %eax, %eax
-; SSE41-NEXT: retq
-; SSE41-NEXT: .LBB97_2:
+; SSE41-NEXT: setne %al
+; SSE41-NEXT: movd %xmm0, %ecx
+; SSE41-NEXT: orb %al, %cl
+; SSE41-NEXT: testb $1, %cl
+; SSE41-NEXT: je .LBB97_2
+; SSE41-NEXT: # %bb.1:
; SSE41-NEXT: movw $0, 0
+; SSE41-NEXT: .LBB97_2: # %middle.block
; SSE41-NEXT: xorl %eax, %eax
; SSE41-NEXT: retq
;
@@ -4479,16 +4475,14 @@ define i32 @pr67287(<2 x i64> %broadcast.splatinsert25) {
; AVX1-NEXT: vpblendw {{.*#+}} xmm0 = xmm0[0,1],xmm1[2,3],xmm0[4,5],xmm1[6,7]
; AVX1-NEXT: vpcmpeqq %xmm1, %xmm0, %xmm0
; AVX1-NEXT: vtestpd %xmm0, %xmm0
-; AVX1-NEXT: jne .LBB97_2
-; AVX1-NEXT: # %bb.1: # %entry
-; AVX1-NEXT: vmovd %xmm0, %eax
-; AVX1-NEXT: testb $1, %al
-; AVX1-NEXT: jne .LBB97_2
-; AVX1-NEXT: # %bb.3: # %middle.block
-; AVX1-NEXT: xorl %eax, %eax
-; AVX1-NEXT: retq
-; AVX1-NEXT: .LBB97_2:
+; AVX1-NEXT: setne %al
+; AVX1-NEXT: vmovd %xmm0, %ecx
+; AVX1-NEXT: orb %al, %cl
+; AVX1-NEXT: testb $1, %cl
+; AVX1-NEXT: je .LBB97_2
+; AVX1-NEXT: # %bb.1:
; AVX1-NEXT: movw $0, 0
+; AVX1-NEXT: .LBB97_2: # %middle.block
; AVX1-NEXT: xorl %eax, %eax
; AVX1-NEXT: retq
;
@@ -4498,16 +4492,14 @@ define i32 @pr67287(<2 x i64> %broadcast.splatinsert25) {
; AVX2-NEXT: vpblendd {{.*#+}} xmm0 = xmm0[0],xmm1[1],xmm0[2],xmm1[3]
; AVX2-NEXT: vpcmpeqq %xmm1, %xmm0, %xmm0
; AVX2-NEXT: vtestpd %xmm0, %xmm0
-; AVX2-NEXT: jne .LBB97_2
-; AVX2-NEXT: # %bb.1: # %entry
-; AVX2-NEXT: vmovd %xmm0, %eax
-; AVX2-NEXT: testb $1, %al
-; AVX2-NEXT: jne .LBB97_2
-; AVX2-NEXT: # %bb.3: # %middle.block
-; AVX2-NEXT: xorl %eax, %eax
-; AVX2-NEXT: retq
-; AVX2-NEXT: .LBB97_2:
+; AVX2-NEXT: setne %al
+; AVX2-NEXT: vmovd %xmm0, %ecx
+; AVX2-NEXT: orb %al, %cl
+; AVX2-NEXT: testb $1, %cl
+; AVX2-NEXT: je .LBB97_2
+; AVX2-NEXT: # %bb.1:
; AVX2-NEXT: movw $0, 0
+; AVX2-NEXT: .LBB97_2: # %middle.block
; AVX2-NEXT: xorl %eax, %eax
; AVX2-NEXT: retq
;
@@ -4517,18 +4509,15 @@ define i32 @pr67287(<2 x i64> %broadcast.splatinsert25) {
; KNL-NEXT: vpblendd {{.*#+}} xmm0 = xmm0[0],xmm1[1],xmm0[2],xmm1[3]
; KNL-NEXT: vptestnmq %zmm0, %zmm0, %k0
; KNL-NEXT: kmovw %k0, %eax
-; KNL-NEXT: testb $3, %al
-; KNL-NEXT: jne .LBB97_2
-; KNL-NEXT: # %bb.1: # %entry
-; KNL-NEXT: kmovw %k0, %eax
+; KNL-NEXT: kmovw %k0, %ecx
+; KNL-NEXT: testb $3, %cl
+; KNL-NEXT: setne %cl
+; KNL-NEXT: orb %cl, %al
; KNL-NEXT: testb $1, %al
-; KNL-NEXT: jne .LBB97_2
-; KNL-NEXT: # %bb.3: # %middle.block
-; KNL-NEXT: xorl %eax, %eax
-; KNL-NEXT: vzeroupper
-; KNL-NEXT: retq
-; KNL-NEXT: .LBB97_2:
+; KNL-NEXT: je .LBB97_2
+; KNL-NEXT: # %bb.1:
; KNL-NEXT: movw $0, 0
+; KNL-NEXT: .LBB97_2: # %middle.block
; KNL-NEXT: xorl %eax, %eax
; KNL-NEXT: vzeroupper
; KNL-NEXT: retq
@@ -4539,16 +4528,14 @@ define i32 @pr67287(<2 x i64> %broadcast.splatinsert25) {
; SKX-NEXT: vpblendd {{.*#+}} xmm0 = xmm0[0],xmm1[1],xmm0[2],xmm1[3]
; SKX-NEXT: vptestnmq %xmm0, %xmm0, %k0
; SKX-NEXT: kortestb %k0, %k0
-; SKX-NEXT: jne .LBB97_2
-; SKX-NEXT: # %bb.1: # %entry
-; SKX-NEXT: kmovd %k0, %eax
-; SKX-NEXT: testb $1, %al
-; SKX-NEXT: jne .LBB97_2
-; SKX-NEXT: # %bb.3: # %middle.block
-; SKX-NEXT: xorl %eax, %eax
-; SKX-NEXT: retq
-; SKX-NEXT: .LBB97_2:
+; SKX-NEXT: setne %al
+; SKX-NEXT: kmovd %k0, %ecx
+; SKX-NEXT: orb %al, %cl
+; SKX-NEXT: testb $1, %cl
+; SKX-NEXT: je .LBB97_2
+; SKX-NEXT: # %bb.1:
; SKX-NEXT: movw $0, 0
+; SKX-NEXT: .LBB97_2: # %middle.block
; SKX-NEXT: xorl %eax, %eax
; SKX-NEXT: retq
entry:
diff --git a/llvm/test/CodeGen/X86/or-branch.ll b/llvm/test/CodeGen/X86/or-branch.ll
index 5d5cc2cb32f1ce..c6df237393e4a0 100644
--- a/llvm/test/CodeGen/X86/or-branch.ll
+++ b/llvm/test/CodeGen/X86/or-branch.ll
@@ -5,12 +5,13 @@
define void @foo(i32 %X, i32 %Y, i32 %Z) nounwind {
; JUMP2-LABEL: foo:
; JUMP2: # %bb.0: # %entry
-; JUMP2-NEXT: cmpl $5, {{[0-9]+}}(%esp)
-; JUMP2-NEXT: jl bar at PLT # TAILCALL
-; JUMP2-NEXT: # %bb.1: # %entry
; JUMP2-NEXT: cmpl $0, {{[0-9]+}}(%esp)
+; JUMP2-NEXT: setne %al
+; JUMP2-NEXT: cmpl $5, {{[0-9]+}}(%esp)
+; JUMP2-NEXT: setge %cl
+; JUMP2-NEXT: testb %al, %cl
; JUMP2-NEXT: je bar at PLT # TAILCALL
-; JUMP2-NEXT: # %bb.2: # %UnifiedReturnBlock
+; JUMP2-NEXT: # %bb.1: # %UnifiedReturnBlock
; JUMP2-NEXT: retl
;
; JUMP1-LABEL: foo:
diff --git a/llvm/test/CodeGen/X86/peephole-na-phys-copy-folding.ll b/llvm/test/CodeGen/X86/peephole-na-phys-copy-folding.ll
index 9069688c8037c7..3354c99a361bf6 100644
--- a/llvm/test/CodeGen/X86/peephole-na-phys-copy-folding.ll
+++ b/llvm/test/CodeGen/X86/peephole-na-phys-copy-folding.ll
@@ -14,31 +14,33 @@ declare i32 @bar(i64)
define i1 @plus_one() nounwind {
; CHECK32-LABEL: plus_one:
; CHECK32: # %bb.0: # %entry
-; CHECK32-NEXT: movzbl M, %eax
; CHECK32-NEXT: incl L
-; CHECK32-NEXT: jne .LBB0_2
-; CHECK32-NEXT: # %bb.1: # %entry
-; CHECK32-NEXT: andb $8, %al
-; CHECK32-NEXT: je .LBB0_2
-; CHECK32-NEXT: # %bb.3: # %exit2
+; CHECK32-NEXT: sete %al
+; CHECK32-NEXT: movzbl M, %ecx
+; CHECK32-NEXT: andb $8, %cl
+; CHECK32-NEXT: shrb $3, %cl
+; CHECK32-NEXT: testb %cl, %al
+; CHECK32-NEXT: je .LBB0_1
+; CHECK32-NEXT: # %bb.2: # %exit2
; CHECK32-NEXT: xorl %eax, %eax
; CHECK32-NEXT: retl
-; CHECK32-NEXT: .LBB0_2: # %exit
+; CHECK32-NEXT: .LBB0_1: # %exit
; CHECK32-NEXT: movb $1, %al
; CHECK32-NEXT: retl
;
; CHECK64-LABEL: plus_one:
; CHECK64: # %bb.0: # %entry
-; CHECK64-NEXT: movzbl M(%rip), %eax
; CHECK64-NEXT: incl L(%rip)
-; CHECK64-NEXT: jne .LBB0_2
-; CHECK64-NEXT: # %bb.1: # %entry
-; CHECK64-NEXT: andb $8, %al
-; CHECK64-NEXT: je .LBB0_2
-; CHECK64-NEXT: # %bb.3: # %exit2
+; CHECK64-NEXT: sete %al
+; CHECK64-NEXT: movzbl M(%rip), %ecx
+; CHECK64-NEXT: andb $8, %cl
+; CHECK64-NEXT: shrb $3, %cl
+; CHECK64-NEXT: testb %cl, %al
+; CHECK64-NEXT: je .LBB0_1
+; CHECK64-NEXT: # %bb.2: # %exit2
; CHECK64-NEXT: xorl %eax, %eax
; CHECK64-NEXT: retq
-; CHECK64-NEXT: .LBB0_2: # %exit
+; CHECK64-NEXT: .LBB0_1: # %exit
; CHECK64-NEXT: movb $1, %al
; CHECK64-NEXT: retq
entry:
@@ -63,30 +65,32 @@ define i1 @plus_forty_two() nounwind {
; CHECK32-LABEL: plus_forty_two:
; CHECK32: # %bb.0: # %entry
; CHECK32-NEXT: movzbl M, %eax
-; CHECK32-NEXT: addl $42, L
-; CHECK32-NEXT: jne .LBB1_2
-; CHECK32-NEXT: # %bb.1: # %entry
; CHECK32-NEXT: andb $8, %al
-; CHECK32-NEXT: je .LBB1_2
-; CHECK32-NEXT: # %bb.3: # %exit2
+; CHECK32-NEXT: shrb $3, %al
+; CHECK32-NEXT: addl $42, L
+; CHECK32-NEXT: sete %cl
+; CHECK32-NEXT: testb %al, %cl
+; CHECK32-NEXT: je .LBB1_1
+; CHECK32-NEXT: # %bb.2: # %exit2
; CHECK32-NEXT: xorl %eax, %eax
; CHECK32-NEXT: retl
-; CHECK32-NEXT: .LBB1_2: # %exit
+; CHECK32-NEXT: .LBB1_1: # %exit
; CHECK32-NEXT: movb $1, %al
; CHECK32-NEXT: retl
;
; CHECK64-LABEL: plus_forty_two:
; CHECK64: # %bb.0: # %entry
; CHECK64-NEXT: movzbl M(%rip), %eax
-; CHECK64-NEXT: addl $42, L(%rip)
-; CHECK64-NEXT: jne .LBB1_2
-; CHECK64-NEXT: # %bb.1: # %entry
; CHECK64-NEXT: andb $8, %al
-; CHECK64-NEXT: je .LBB1_2
-; CHECK64-NEXT: # %bb.3: # %exit2
+; CHECK64-NEXT: shrb $3, %al
+; CHECK64-NEXT: addl $42, L(%rip)
+; CHECK64-NEXT: sete %cl
+; CHECK64-NEXT: testb %al, %cl
+; CHECK64-NEXT: je .LBB1_1
+; CHECK64-NEXT: # %bb.2: # %exit2
; CHECK64-NEXT: xorl %eax, %eax
; CHECK64-NEXT: retq
-; CHECK64-NEXT: .LBB1_2: # %exit
+; CHECK64-NEXT: .LBB1_1: # %exit
; CHECK64-NEXT: movb $1, %al
; CHECK64-NEXT: retq
entry:
@@ -111,30 +115,32 @@ define i1 @minus_one() nounwind {
; CHECK32-LABEL: minus_one:
; CHECK32: # %bb.0: # %entry
; CHECK32-NEXT: movzbl M, %eax
-; CHECK32-NEXT: decl L
-; CHECK32-NEXT: jne .LBB2_2
-; CHECK32-NEXT: # %bb.1: # %entry
; CHECK32-NEXT: andb $8, %al
-; CHECK32-NEXT: je .LBB2_2
-; CHECK32-NEXT: # %bb.3: # %exit2
+; CHECK32-NEXT: shrb $3, %al
+; CHECK32-NEXT: decl L
+; CHECK32-NEXT: sete %cl
+; CHECK32-NEXT: testb %al, %cl
+; CHECK32-NEXT: je .LBB2_1
+; CHECK32-NEXT: # %bb.2: # %exit2
; CHECK32-NEXT: xorl %eax, %eax
; CHECK32-NEXT: retl
-; CHECK32-NEXT: .LBB2_2: # %exit
+; CHECK32-NEXT: .LBB2_1: # %exit
; CHECK32-NEXT: movb $1, %al
; CHECK32-NEXT: retl
;
; CHECK64-LABEL: minus_one:
; CHECK64: # %bb.0: # %entry
; CHECK64-NEXT: movzbl M(%rip), %eax
-; CHECK64-NEXT: decl L(%rip)
-; CHECK64-NEXT: jne .LBB2_2
-; CHECK64-NEXT: # %bb.1: # %entry
; CHECK64-NEXT: andb $8, %al
-; CHECK64-NEXT: je .LBB2_2
-; CHECK64-NEXT: # %bb.3: # %exit2
+; CHECK64-NEXT: shrb $3, %al
+; CHECK64-NEXT: decl L(%rip)
+; CHECK64-NEXT: sete %cl
+; CHECK64-NEXT: testb %al, %cl
+; CHECK64-NEXT: je .LBB2_1
+; CHECK64-NEXT: # %bb.2: # %exit2
; CHECK64-NEXT: xorl %eax, %eax
; CHECK64-NEXT: retq
-; CHECK64-NEXT: .LBB2_2: # %exit
+; CHECK64-NEXT: .LBB2_1: # %exit
; CHECK64-NEXT: movb $1, %al
; CHECK64-NEXT: retq
entry:
@@ -159,30 +165,32 @@ define i1 @minus_forty_two() nounwind {
; CHECK32-LABEL: minus_forty_two:
; CHECK32: # %bb.0: # %entry
; CHECK32-NEXT: movzbl M, %eax
-; CHECK32-NEXT: addl $-42, L
-; CHECK32-NEXT: jne .LBB3_2
-; CHECK32-NEXT: # %bb.1: # %entry
; CHECK32-NEXT: andb $8, %al
-; CHECK32-NEXT: je .LBB3_2
-; CHECK32-NEXT: # %bb.3: # %exit2
+; CHECK32-NEXT: shrb $3, %al
+; CHECK32-NEXT: addl $-42, L
+; CHECK32-NEXT: sete %cl
+; CHECK32-NEXT: testb %al, %cl
+; CHECK32-NEXT: je .LBB3_1
+; CHECK32-NEXT: # %bb.2: # %exit2
; CHECK32-NEXT: xorl %eax, %eax
; CHECK32-NEXT: retl
-; CHECK32-NEXT: .LBB3_2: # %exit
+; CHECK32-NEXT: .LBB3_1: # %exit
; CHECK32-NEXT: movb $1, %al
; CHECK32-NEXT: retl
;
; CHECK64-LABEL: minus_forty_two:
; CHECK64: # %bb.0: # %entry
; CHECK64-NEXT: movzbl M(%rip), %eax
-; CHECK64-NEXT: addl $-42, L(%rip)
-; CHECK64-NEXT: jne .LBB3_2
-; CHECK64-NEXT: # %bb.1: # %entry
; CHECK64-NEXT: andb $8, %al
-; CHECK64-NEXT: je .LBB3_2
-; CHECK64-NEXT: # %bb.3: # %exit2
+; CHECK64-NEXT: shrb $3, %al
+; CHECK64-NEXT: addl $-42, L(%rip)
+; CHECK64-NEXT: sete %cl
+; CHECK64-NEXT: testb %al, %cl
+; CHECK64-NEXT: je .LBB3_1
+; CHECK64-NEXT: # %bb.2: # %exit2
; CHECK64-NEXT: xorl %eax, %eax
; CHECK64-NEXT: retq
-; CHECK64-NEXT: .LBB3_2: # %exit
+; CHECK64-NEXT: .LBB3_1: # %exit
; CHECK64-NEXT: movb $1, %al
; CHECK64-NEXT: retq
entry:
@@ -284,7 +292,7 @@ define i64 @test_two_live_flags(ptr %foo0, i64 %bar0, i64 %baz0, ptr %foo1, i64
; CHECK32-NEXT: movl {{[0-9]+}}(%esp), %ecx
; CHECK32-NEXT: movl {{[0-9]+}}(%esp), %esi
; CHECK32-NEXT: lock cmpxchg8b (%esi)
-; CHECK32-NEXT: setne {{[-0-9]+}}(%e{{[sb]}}p) # 1-byte Folded Spill
+; CHECK32-NEXT: sete {{[-0-9]+}}(%e{{[sb]}}p) # 1-byte Folded Spill
; CHECK32-NEXT: movl {{[0-9]+}}(%esp), %eax
; CHECK32-NEXT: movl %ebp, %edx
; CHECK32-NEXT: movl %edi, %ecx
@@ -292,17 +300,15 @@ define i64 @test_two_live_flags(ptr %foo0, i64 %bar0, i64 %baz0, ptr %foo1, i64
; CHECK32-NEXT: movl {{[0-9]+}}(%esp), %esi
; CHECK32-NEXT: lock cmpxchg8b (%esi)
; CHECK32-NEXT: sete %al
-; CHECK32-NEXT: cmpb $0, {{[-0-9]+}}(%e{{[sb]}}p) # 1-byte Folded Reload
-; CHECK32-NEXT: jne .LBB5_4
-; CHECK32-NEXT: # %bb.1: # %entry
-; CHECK32-NEXT: testb %al, %al
-; CHECK32-NEXT: je .LBB5_4
-; CHECK32-NEXT: # %bb.2: # %t
+; CHECK32-NEXT: andb {{[-0-9]+}}(%e{{[sb]}}p), %al # 1-byte Folded Reload
+; CHECK32-NEXT: cmpb $1, %al
+; CHECK32-NEXT: jne .LBB5_3
+; CHECK32-NEXT: # %bb.1: # %t
; CHECK32-NEXT: movl $42, %eax
-; CHECK32-NEXT: jmp .LBB5_3
-; CHECK32-NEXT: .LBB5_4: # %f
+; CHECK32-NEXT: jmp .LBB5_2
+; CHECK32-NEXT: .LBB5_3: # %f
; CHECK32-NEXT: xorl %eax, %eax
-; CHECK32-NEXT: .LBB5_3: # %t
+; CHECK32-NEXT: .LBB5_2: # %t
; CHECK32-NEXT: xorl %edx, %edx
; CHECK32-NEXT: addl $4, %esp
; CHECK32-NEXT: popl %esi
@@ -315,19 +321,17 @@ define i64 @test_two_live_flags(ptr %foo0, i64 %bar0, i64 %baz0, ptr %foo1, i64
; CHECK64: # %bb.0: # %entry
; CHECK64-NEXT: movq %rsi, %rax
; CHECK64-NEXT: lock cmpxchgq %rdx, (%rdi)
-; CHECK64-NEXT: setne %dl
+; CHECK64-NEXT: sete %dl
; CHECK64-NEXT: movq %r8, %rax
; CHECK64-NEXT: lock cmpxchgq %r9, (%rcx)
; CHECK64-NEXT: sete %al
-; CHECK64-NEXT: testb %dl, %dl
-; CHECK64-NEXT: jne .LBB5_3
-; CHECK64-NEXT: # %bb.1: # %entry
-; CHECK64-NEXT: testb %al, %al
-; CHECK64-NEXT: je .LBB5_3
-; CHECK64-NEXT: # %bb.2: # %t
+; CHECK64-NEXT: andb %dl, %al
+; CHECK64-NEXT: cmpb $1, %al
+; CHECK64-NEXT: jne .LBB5_2
+; CHECK64-NEXT: # %bb.1: # %t
; CHECK64-NEXT: movl $42, %eax
; CHECK64-NEXT: retq
-; CHECK64-NEXT: .LBB5_3: # %f
+; CHECK64-NEXT: .LBB5_2: # %f
; CHECK64-NEXT: xorl %eax, %eax
; CHECK64-NEXT: retq
entry:
@@ -353,7 +357,6 @@ define i1 @asm_clobbering_flags(ptr %mem) nounwind {
; CHECK32-NEXT: testl %edx, %edx
; CHECK32-NEXT: setg %al
; CHECK32-NEXT: #APP
-; CHECK32-NOT: rep
; CHECK32-NEXT: bsfl %edx, %edx
; CHECK32-NEXT: #NO_APP
; CHECK32-NEXT: movl %edx, (%ecx)
@@ -365,7 +368,6 @@ define i1 @asm_clobbering_flags(ptr %mem) nounwind {
; CHECK64-NEXT: testl %ecx, %ecx
; CHECK64-NEXT: setg %al
; CHECK64-NEXT: #APP
-; CHECK64-NOT: rep
; CHECK64-NEXT: bsfl %ecx, %ecx
; CHECK64-NEXT: #NO_APP
; CHECK64-NEXT: movl %ecx, (%rdi)
diff --git a/llvm/test/CodeGen/X86/pr33747.ll b/llvm/test/CodeGen/X86/pr33747.ll
index e261486dd59246..c8ba2b2e3a7909 100644
--- a/llvm/test/CodeGen/X86/pr33747.ll
+++ b/llvm/test/CodeGen/X86/pr33747.ll
@@ -5,18 +5,19 @@ define void @PR33747(ptr nocapture) {
; CHECK-LABEL: PR33747:
; CHECK: # %bb.0:
; CHECK-NEXT: movl 24(%rdi), %eax
+; CHECK-NEXT: leal 1(%rax), %ecx
+; CHECK-NEXT: cmpl $3, %ecx
+; CHECK-NEXT: setb %cl
; CHECK-NEXT: testl %eax, %eax
-; CHECK-NEXT: je .LBB0_3
-; CHECK-NEXT: # %bb.1:
-; CHECK-NEXT: incl %eax
-; CHECK-NEXT: cmpl $3, %eax
-; CHECK-NEXT: jae .LBB0_3
+; CHECK-NEXT: setne %al
+; CHECK-NEXT: testb %cl, %al
+; CHECK-NEXT: je .LBB0_2
+; CHECK-NEXT: .p2align 4, 0x90
+; CHECK-NEXT: .LBB0_1: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: jmp .LBB0_1
; CHECK-NEXT: .p2align 4, 0x90
; CHECK-NEXT: .LBB0_2: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: jmp .LBB0_2
-; CHECK-NEXT: .p2align 4, 0x90
-; CHECK-NEXT: .LBB0_3: # =>This Inner Loop Header: Depth=1
-; CHECK-NEXT: jmp .LBB0_3
%2 = getelementptr inbounds i32, ptr %0, i64 6
%3 = load i32, ptr %2, align 4
%4 = add i32 %3, 1
diff --git a/llvm/test/CodeGen/X86/pr37025.ll b/llvm/test/CodeGen/X86/pr37025.ll
index a758ddc91541bc..8ac28d6286a607 100644
--- a/llvm/test/CodeGen/X86/pr37025.ll
+++ b/llvm/test/CodeGen/X86/pr37025.ll
@@ -18,11 +18,13 @@ define void @test_dec_select(ptr nocapture %0, ptr readnone %1) {
; CHECK-LABEL: test_dec_select:
; CHECK: # %bb.0:
; CHECK-NEXT: lock decq (%rdi)
-; CHECK-NEXT: jne .LBB0_2
-; CHECK-NEXT: # %bb.1:
+; CHECK-NEXT: sete %al
; CHECK-NEXT: testq %rsi, %rsi
-; CHECK-NEXT: jne func2 # TAILCALL
-; CHECK-NEXT: .LBB0_2:
+; CHECK-NEXT: setne %cl
+; CHECK-NEXT: andb %al, %cl
+; CHECK-NEXT: cmpb $1, %cl
+; CHECK-NEXT: je func2 # TAILCALL
+; CHECK-NEXT: # %bb.1:
; CHECK-NEXT: retq
%3 = atomicrmw sub ptr %0, i64 1 seq_cst
%4 = icmp eq i64 %3, 1
@@ -44,11 +46,11 @@ define void @test_dec_select_commute(ptr nocapture %0, ptr readnone %1) {
; CHECK-NEXT: lock decq (%rdi)
; CHECK-NEXT: sete %al
; CHECK-NEXT: testq %rsi, %rsi
-; CHECK-NEXT: je .LBB1_2
+; CHECK-NEXT: setne %cl
+; CHECK-NEXT: andb %al, %cl
+; CHECK-NEXT: cmpb $1, %cl
+; CHECK-NEXT: je func2 # TAILCALL
; CHECK-NEXT: # %bb.1:
-; CHECK-NEXT: testb %al, %al
-; CHECK-NEXT: jne func2 # TAILCALL
-; CHECK-NEXT: .LBB1_2:
; CHECK-NEXT: retq
%3 = atomicrmw sub ptr %0, i64 1 seq_cst
%4 = icmp eq i64 %3, 1
@@ -69,12 +71,13 @@ define void @test_dec_and(ptr nocapture %0, ptr readnone %1) {
; CHECK: # %bb.0:
; CHECK-NEXT: lock decq (%rdi)
; CHECK-NEXT: sete %al
+; CHECK-NEXT: notb %al
; CHECK-NEXT: testq %rsi, %rsi
-; CHECK-NEXT: je .LBB2_2
+; CHECK-NEXT: sete %cl
+; CHECK-NEXT: orb %al, %cl
+; CHECK-NEXT: testb $1, %cl
+; CHECK-NEXT: je func2 # TAILCALL
; CHECK-NEXT: # %bb.1:
-; CHECK-NEXT: testb %al, %al
-; CHECK-NEXT: jne func2 # TAILCALL
-; CHECK-NEXT: .LBB2_2:
; CHECK-NEXT: retq
%3 = atomicrmw sub ptr %0, i64 1 seq_cst
%4 = icmp eq i64 %3, 1
@@ -94,11 +97,14 @@ define void @test_dec_and_commute(ptr nocapture %0, ptr readnone %1) {
; CHECK-LABEL: test_dec_and_commute:
; CHECK: # %bb.0:
; CHECK-NEXT: lock decq (%rdi)
-; CHECK-NEXT: jne .LBB3_2
-; CHECK-NEXT: # %bb.1:
+; CHECK-NEXT: sete %al
+; CHECK-NEXT: notb %al
; CHECK-NEXT: testq %rsi, %rsi
-; CHECK-NEXT: jne func2 # TAILCALL
-; CHECK-NEXT: .LBB3_2:
+; CHECK-NEXT: sete %cl
+; CHECK-NEXT: orb %al, %cl
+; CHECK-NEXT: testb $1, %cl
+; CHECK-NEXT: je func2 # TAILCALL
+; CHECK-NEXT: # %bb.1:
; CHECK-NEXT: retq
%3 = atomicrmw sub ptr %0, i64 1 seq_cst
%4 = icmp eq i64 %3, 1
diff --git a/llvm/test/CodeGen/X86/pr38795.ll b/llvm/test/CodeGen/X86/pr38795.ll
index 03629a353d84dc..f64c70e8fc79a4 100644
--- a/llvm/test/CodeGen/X86/pr38795.ll
+++ b/llvm/test/CodeGen/X86/pr38795.ll
@@ -25,141 +25,126 @@ define dso_local void @fn() {
; CHECK-NEXT: xorl %ebx, %ebx
; CHECK-NEXT: # implicit-def: $ecx
; CHECK-NEXT: # implicit-def: $edi
+; CHECK-NEXT: # implicit-def: $dh
; CHECK-NEXT: # implicit-def: $al
; CHECK-NEXT: # kill: killed $al
-; CHECK-NEXT: # implicit-def: $al
; CHECK-NEXT: # implicit-def: $ebp
; CHECK-NEXT: jmp .LBB0_1
; CHECK-NEXT: .p2align 4, 0x90
-; CHECK-NEXT: .LBB0_16: # in Loop: Header=BB0_1 Depth=1
-; CHECK-NEXT: movb %al, {{[-0-9]+}}(%e{{[sb]}}p) # 1-byte Spill
-; CHECK-NEXT: movb %dh, %al
+; CHECK-NEXT: .LBB0_15: # %for.inc
+; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
+; CHECK-NEXT: movb %dl, {{[-0-9]+}}(%e{{[sb]}}p) # 1-byte Spill
; CHECK-NEXT: .LBB0_1: # %for.cond
; CHECK-NEXT: # =>This Loop Header: Depth=1
-; CHECK-NEXT: # Child Loop BB0_22 Depth 2
-; CHECK-NEXT: movb %al, {{[-0-9]+}}(%e{{[sb]}}p) # 1-byte Spill
-; CHECK-NEXT: cmpb $8, %al
-; CHECK-NEXT: ja .LBB0_3
-; CHECK-NEXT: # %bb.2: # %for.cond
-; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
+; CHECK-NEXT: # Child Loop BB0_19 Depth 2
; CHECK-NEXT: testb %bl, %bl
-; CHECK-NEXT: je .LBB0_3
-; CHECK-NEXT: # %bb.4: # %if.end
+; CHECK-NEXT: jne .LBB0_3
+; CHECK-NEXT: # %bb.2: # %if.then
+; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
+; CHECK-NEXT: movb %dh, {{[-0-9]+}}(%e{{[sb]}}p) # 1-byte Spill
+; CHECK-NEXT: movl $.str, (%esp)
+; CHECK-NEXT: calll printf
+; CHECK-NEXT: # implicit-def: $eax
+; CHECK-NEXT: movzbl {{[-0-9]+}}(%e{{[sb]}}p), %edx # 1-byte Folded Reload
+; CHECK-NEXT: testl %edi, %edi
+; CHECK-NEXT: jne .LBB0_10
+; CHECK-NEXT: jmp .LBB0_6
+; CHECK-NEXT: .p2align 4, 0x90
+; CHECK-NEXT: .LBB0_3: # %if.end
; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
; CHECK-NEXT: movl %ecx, %eax
; CHECK-NEXT: cltd
; CHECK-NEXT: idivl a
-; CHECK-NEXT: movl %eax, %esi
-; CHECK-NEXT: movb %cl, %dh
+; CHECK-NEXT: movl %ecx, %edx
; CHECK-NEXT: movl $0, h
-; CHECK-NEXT: movzbl {{[-0-9]+}}(%e{{[sb]}}p), %eax # 1-byte Folded Reload
-; CHECK-NEXT: cmpb $8, %al
-; CHECK-NEXT: jg .LBB0_8
-; CHECK-NEXT: # %bb.5: # %if.then13
+; CHECK-NEXT: movb {{[-0-9]+}}(%e{{[sb]}}p), %dh # 1-byte Reload
+; CHECK-NEXT: cmpb $8, %dh
+; CHECK-NEXT: jg .LBB0_7
+; CHECK-NEXT: # %bb.4: # %if.then13
; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
+; CHECK-NEXT: movl %eax, %esi
; CHECK-NEXT: movl $.str, (%esp)
-; CHECK-NEXT: movb %dh, {{[-0-9]+}}(%e{{[sb]}}p) # 1-byte Spill
+; CHECK-NEXT: movb %dl, {{[-0-9]+}}(%e{{[sb]}}p) # 1-byte Spill
; CHECK-NEXT: calll printf
; CHECK-NEXT: movb {{[-0-9]+}}(%e{{[sb]}}p), %dh # 1-byte Reload
+; CHECK-NEXT: movb {{[-0-9]+}}(%e{{[sb]}}p), %dl # 1-byte Reload
; CHECK-NEXT: testb %bl, %bl
; CHECK-NEXT: movl %esi, %ecx
; CHECK-NEXT: # implicit-def: $eax
-; CHECK-NEXT: movb {{[-0-9]+}}(%e{{[sb]}}p), %dl # 1-byte Reload
-; CHECK-NEXT: movb %dl, {{[-0-9]+}}(%e{{[sb]}}p) # 1-byte Spill
-; CHECK-NEXT: movb %dh, %dl
-; CHECK-NEXT: je .LBB0_6
-; CHECK-NEXT: jmp .LBB0_18
+; CHECK-NEXT: movb %dh, {{[-0-9]+}}(%e{{[sb]}}p) # 1-byte Spill
+; CHECK-NEXT: jne .LBB0_15
; CHECK-NEXT: .p2align 4, 0x90
-; CHECK-NEXT: .LBB0_3: # %if.then
-; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
-; CHECK-NEXT: movl $.str, (%esp)
-; CHECK-NEXT: calll printf
-; CHECK-NEXT: # implicit-def: $eax
-; CHECK-NEXT: movzbl {{[-0-9]+}}(%e{{[sb]}}p), %edx # 1-byte Folded Reload
-; CHECK-NEXT: .LBB0_6: # %for.cond35
+; CHECK-NEXT: # %bb.5: # %for.cond35
; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
; CHECK-NEXT: testl %edi, %edi
-; CHECK-NEXT: je .LBB0_7
-; CHECK-NEXT: .LBB0_11: # %af
+; CHECK-NEXT: je .LBB0_6
+; CHECK-NEXT: .LBB0_10: # %af
; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
; CHECK-NEXT: testb %bl, %bl
-; CHECK-NEXT: jne .LBB0_12
-; CHECK-NEXT: .LBB0_19: # %if.end39
+; CHECK-NEXT: jne .LBB0_11
+; CHECK-NEXT: .LBB0_16: # %if.end39
; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
; CHECK-NEXT: testl %eax, %eax
-; CHECK-NEXT: je .LBB0_21
-; CHECK-NEXT: # %bb.20: # %if.then41
+; CHECK-NEXT: je .LBB0_18
+; CHECK-NEXT: # %bb.17: # %if.then41
; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
; CHECK-NEXT: movl $0, {{[0-9]+}}(%esp)
; CHECK-NEXT: movl $fn, {{[0-9]+}}(%esp)
; CHECK-NEXT: movl $.str, (%esp)
; CHECK-NEXT: calll printf
-; CHECK-NEXT: .LBB0_21: # %for.end46
+; CHECK-NEXT: .LBB0_18: # %for.end46
; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
-; CHECK-NEXT: # implicit-def: $al
; CHECK-NEXT: # implicit-def: $dh
+; CHECK-NEXT: # implicit-def: $dl
; CHECK-NEXT: # implicit-def: $ebp
-; CHECK-NEXT: jmp .LBB0_22
+; CHECK-NEXT: jmp .LBB0_19
; CHECK-NEXT: .p2align 4, 0x90
-; CHECK-NEXT: .LBB0_8: # %if.end21
+; CHECK-NEXT: .LBB0_7: # %if.end21
; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
; CHECK-NEXT: # implicit-def: $ebp
-; CHECK-NEXT: jmp .LBB0_9
+; CHECK-NEXT: jmp .LBB0_8
; CHECK-NEXT: .p2align 4, 0x90
-; CHECK-NEXT: .LBB0_7: # in Loop: Header=BB0_1 Depth=1
+; CHECK-NEXT: .LBB0_6: # in Loop: Header=BB0_1 Depth=1
; CHECK-NEXT: xorl %edi, %edi
-; CHECK-NEXT: movb %dl, %dh
-; CHECK-NEXT: movzbl {{[-0-9]+}}(%e{{[sb]}}p), %eax # 1-byte Folded Reload
+; CHECK-NEXT: movb {{[-0-9]+}}(%e{{[sb]}}p), %dh # 1-byte Reload
; CHECK-NEXT: .p2align 4, 0x90
-; CHECK-NEXT: .LBB0_22: # %for.cond47
+; CHECK-NEXT: .LBB0_19: # %for.cond47
; CHECK-NEXT: # Parent Loop BB0_1 Depth=1
; CHECK-NEXT: # => This Inner Loop Header: Depth=2
; CHECK-NEXT: testb %bl, %bl
-; CHECK-NEXT: jne .LBB0_22
-; CHECK-NEXT: # %bb.23: # %for.cond47
-; CHECK-NEXT: # in Loop: Header=BB0_22 Depth=2
-; CHECK-NEXT: jne .LBB0_22
-; CHECK-NEXT: .LBB0_9: # %ae
+; CHECK-NEXT: jne .LBB0_19
+; CHECK-NEXT: .LBB0_8: # %ae
; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
; CHECK-NEXT: testb %bl, %bl
-; CHECK-NEXT: jne .LBB0_10
-; CHECK-NEXT: # %bb.13: # %if.end26
+; CHECK-NEXT: jne .LBB0_9
+; CHECK-NEXT: # %bb.12: # %if.end26
; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
; CHECK-NEXT: xorl %ecx, %ecx
-; CHECK-NEXT: testb %al, %al
-; CHECK-NEXT: je .LBB0_14
-; CHECK-NEXT: # %bb.15: # %if.end26
+; CHECK-NEXT: testb %dh, %dh
+; CHECK-NEXT: je .LBB0_15
+; CHECK-NEXT: # %bb.13: # %if.end26
; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
; CHECK-NEXT: testl %ebp, %ebp
-; CHECK-NEXT: jne .LBB0_16
-; CHECK-NEXT: # %bb.17: # %if.then31
+; CHECK-NEXT: jne .LBB0_15
+; CHECK-NEXT: # %bb.14: # %if.then31
; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
; CHECK-NEXT: xorl %ecx, %ecx
-; CHECK-NEXT: movb %al, {{[-0-9]+}}(%e{{[sb]}}p) # 1-byte Spill
; CHECK-NEXT: xorl %ebp, %ebp
-; CHECK-NEXT: .LBB0_18: # %for.inc
-; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
-; CHECK-NEXT: movb %dh, %al
-; CHECK-NEXT: jmp .LBB0_1
+; CHECK-NEXT: jmp .LBB0_15
; CHECK-NEXT: .p2align 4, 0x90
-; CHECK-NEXT: .LBB0_10: # in Loop: Header=BB0_1 Depth=1
+; CHECK-NEXT: .LBB0_9: # in Loop: Header=BB0_1 Depth=1
; CHECK-NEXT: # implicit-def: $eax
; CHECK-NEXT: testb %bl, %bl
-; CHECK-NEXT: je .LBB0_19
-; CHECK-NEXT: .LBB0_12: # in Loop: Header=BB0_1 Depth=1
+; CHECK-NEXT: je .LBB0_16
+; CHECK-NEXT: .LBB0_11: # in Loop: Header=BB0_1 Depth=1
; CHECK-NEXT: # implicit-def: $edi
; CHECK-NEXT: # implicit-def: $cl
; CHECK-NEXT: # kill: killed $cl
; CHECK-NEXT: # implicit-def: $dl
; CHECK-NEXT: # implicit-def: $ebp
; CHECK-NEXT: testl %edi, %edi
-; CHECK-NEXT: jne .LBB0_11
-; CHECK-NEXT: jmp .LBB0_7
-; CHECK-NEXT: .p2align 4, 0x90
-; CHECK-NEXT: .LBB0_14: # in Loop: Header=BB0_1 Depth=1
-; CHECK-NEXT: movb %al, {{[-0-9]+}}(%e{{[sb]}}p) # 1-byte Spill
-; CHECK-NEXT: movb %dh, %al
-; CHECK-NEXT: jmp .LBB0_1
+; CHECK-NEXT: jne .LBB0_10
+; CHECK-NEXT: jmp .LBB0_6
entry:
br label %for.cond
diff --git a/llvm/test/CodeGen/X86/setcc-logic.ll b/llvm/test/CodeGen/X86/setcc-logic.ll
index 3faa493ebccd0d..c98aae7fbf4059 100644
--- a/llvm/test/CodeGen/X86/setcc-logic.ll
+++ b/llvm/test/CodeGen/X86/setcc-logic.ll
@@ -132,15 +132,12 @@ return:
define i32 @all_sign_bits_clear_branch(i32 %P, i32 %Q) nounwind {
; CHECK-LABEL: all_sign_bits_clear_branch:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: testl %edi, %edi
-; CHECK-NEXT: js .LBB9_3
-; CHECK-NEXT: # %bb.1: # %entry
-; CHECK-NEXT: testl %esi, %esi
-; CHECK-NEXT: js .LBB9_3
-; CHECK-NEXT: # %bb.2: # %bb1
+; CHECK-NEXT: orl %esi, %edi
+; CHECK-NEXT: js .LBB9_2
+; CHECK-NEXT: # %bb.1: # %bb1
; CHECK-NEXT: movl $4, %eax
; CHECK-NEXT: retq
-; CHECK-NEXT: .LBB9_3: # %return
+; CHECK-NEXT: .LBB9_2: # %return
; CHECK-NEXT: movl $192, %eax
; CHECK-NEXT: retq
entry:
@@ -159,15 +156,13 @@ return:
define i32 @all_bits_set_branch(i32 %P, i32 %Q) nounwind {
; CHECK-LABEL: all_bits_set_branch:
; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: andl %esi, %edi
; CHECK-NEXT: cmpl $-1, %edi
-; CHECK-NEXT: jne .LBB10_3
-; CHECK-NEXT: # %bb.1: # %entry
-; CHECK-NEXT: cmpl $-1, %esi
-; CHECK-NEXT: jne .LBB10_3
-; CHECK-NEXT: # %bb.2: # %bb1
+; CHECK-NEXT: jne .LBB10_2
+; CHECK-NEXT: # %bb.1: # %bb1
; CHECK-NEXT: movl $4, %eax
; CHECK-NEXT: retq
-; CHECK-NEXT: .LBB10_3: # %return
+; CHECK-NEXT: .LBB10_2: # %return
; CHECK-NEXT: movl $192, %eax
; CHECK-NEXT: retq
entry:
@@ -186,15 +181,12 @@ return:
define i32 @all_sign_bits_set_branch(i32 %P, i32 %Q) nounwind {
; CHECK-LABEL: all_sign_bits_set_branch:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: testl %edi, %edi
-; CHECK-NEXT: jns .LBB11_3
-; CHECK-NEXT: # %bb.1: # %entry
-; CHECK-NEXT: testl %esi, %esi
-; CHECK-NEXT: jns .LBB11_3
-; CHECK-NEXT: # %bb.2: # %bb1
+; CHECK-NEXT: testl %esi, %edi
+; CHECK-NEXT: jns .LBB11_2
+; CHECK-NEXT: # %bb.1: # %bb1
; CHECK-NEXT: movl $4, %eax
; CHECK-NEXT: retq
-; CHECK-NEXT: .LBB11_3: # %return
+; CHECK-NEXT: .LBB11_2: # %return
; CHECK-NEXT: movl $192, %eax
; CHECK-NEXT: retq
entry:
@@ -238,17 +230,14 @@ return:
define i32 @any_sign_bits_set_branch(i32 %P, i32 %Q) nounwind {
; CHECK-LABEL: any_sign_bits_set_branch:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: testl %edi, %edi
-; CHECK-NEXT: js .LBB13_2
-; CHECK-NEXT: # %bb.1: # %entry
-; CHECK-NEXT: testl %esi, %esi
-; CHECK-NEXT: js .LBB13_2
-; CHECK-NEXT: # %bb.3: # %return
-; CHECK-NEXT: movl $192, %eax
-; CHECK-NEXT: retq
-; CHECK-NEXT: .LBB13_2: # %bb1
+; CHECK-NEXT: orl %esi, %edi
+; CHECK-NEXT: jns .LBB13_2
+; CHECK-NEXT: # %bb.1: # %bb1
; CHECK-NEXT: movl $4, %eax
; CHECK-NEXT: retq
+; CHECK-NEXT: .LBB13_2: # %return
+; CHECK-NEXT: movl $192, %eax
+; CHECK-NEXT: retq
entry:
%a = icmp slt i32 %P, 0
%b = icmp slt i32 %Q, 0
@@ -265,17 +254,15 @@ return:
define i32 @any_bits_clear_branch(i32 %P, i32 %Q) nounwind {
; CHECK-LABEL: any_bits_clear_branch:
; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: andl %esi, %edi
; CHECK-NEXT: cmpl $-1, %edi
-; CHECK-NEXT: jne .LBB14_2
-; CHECK-NEXT: # %bb.1: # %entry
-; CHECK-NEXT: cmpl $-1, %esi
-; CHECK-NEXT: jne .LBB14_2
-; CHECK-NEXT: # %bb.3: # %return
-; CHECK-NEXT: movl $192, %eax
-; CHECK-NEXT: retq
-; CHECK-NEXT: .LBB14_2: # %bb1
+; CHECK-NEXT: je .LBB14_2
+; CHECK-NEXT: # %bb.1: # %bb1
; CHECK-NEXT: movl $4, %eax
; CHECK-NEXT: retq
+; CHECK-NEXT: .LBB14_2: # %return
+; CHECK-NEXT: movl $192, %eax
+; CHECK-NEXT: retq
entry:
%a = icmp ne i32 %P, -1
%b = icmp ne i32 %Q, -1
@@ -292,17 +279,14 @@ return:
define i32 @any_sign_bits_clear_branch(i32 %P, i32 %Q) nounwind {
; CHECK-LABEL: any_sign_bits_clear_branch:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: testl %edi, %edi
-; CHECK-NEXT: jns .LBB15_2
-; CHECK-NEXT: # %bb.1: # %entry
-; CHECK-NEXT: testl %esi, %esi
-; CHECK-NEXT: jns .LBB15_2
-; CHECK-NEXT: # %bb.3: # %return
-; CHECK-NEXT: movl $192, %eax
-; CHECK-NEXT: retq
-; CHECK-NEXT: .LBB15_2: # %bb1
+; CHECK-NEXT: testl %esi, %edi
+; CHECK-NEXT: js .LBB15_2
+; CHECK-NEXT: # %bb.1: # %bb1
; CHECK-NEXT: movl $4, %eax
; CHECK-NEXT: retq
+; CHECK-NEXT: .LBB15_2: # %return
+; CHECK-NEXT: movl $192, %eax
+; CHECK-NEXT: retq
entry:
%a = icmp sgt i32 %P, -1
%b = icmp sgt i32 %Q, -1
diff --git a/llvm/test/CodeGen/X86/swifterror.ll b/llvm/test/CodeGen/X86/swifterror.ll
index 75252309790b1b..1489b0295e9356 100644
--- a/llvm/test/CodeGen/X86/swifterror.ll
+++ b/llvm/test/CodeGen/X86/swifterror.ll
@@ -1259,12 +1259,7 @@ entry:
define swiftcc void @dont_crash_on_new_isel_blocks(ptr nocapture swifterror, i1, ptr) {
; CHECK-APPLE-LABEL: dont_crash_on_new_isel_blocks:
; CHECK-APPLE: ## %bb.0: ## %entry
-; CHECK-APPLE-NEXT: xorl %eax, %eax
-; CHECK-APPLE-NEXT: testb %al, %al
-; CHECK-APPLE-NEXT: jne LBB15_2
-; CHECK-APPLE-NEXT: ## %bb.1: ## %entry
; CHECK-APPLE-NEXT: testb $1, %dil
-; CHECK-APPLE-NEXT: LBB15_2: ## %cont
; CHECK-APPLE-NEXT: pushq %rax
; CHECK-APPLE-NEXT: .cfi_def_cfa_offset 16
; CHECK-APPLE-NEXT: callq *%rax
@@ -1290,12 +1285,7 @@ define swiftcc void @dont_crash_on_new_isel_blocks(ptr nocapture swifterror, i1,
;
; CHECK-i386-LABEL: dont_crash_on_new_isel_blocks:
; CHECK-i386: ## %bb.0: ## %entry
-; CHECK-i386-NEXT: xorl %eax, %eax
-; CHECK-i386-NEXT: testb %al, %al
-; CHECK-i386-NEXT: jne LBB15_2
-; CHECK-i386-NEXT: ## %bb.1: ## %entry
; CHECK-i386-NEXT: testb $1, 8(%esp)
-; CHECK-i386-NEXT: LBB15_2: ## %cont
; CHECK-i386-NEXT: jmpl *%eax ## TAILCALL
entry:
%3 = or i1 false, %1
diff --git a/llvm/test/CodeGen/X86/tail-dup-merge-loop-headers.ll b/llvm/test/CodeGen/X86/tail-dup-merge-loop-headers.ll
index 9cd37315181209..8d84e887d3f279 100644
--- a/llvm/test/CodeGen/X86/tail-dup-merge-loop-headers.ll
+++ b/llvm/test/CodeGen/X86/tail-dup-merge-loop-headers.ll
@@ -91,116 +91,97 @@ define i32 @loop_shared_header(ptr %exe, i32 %exesz, i32 %headsize, i32 %min, i3
; CHECK-NEXT: pushq %rbp
; CHECK-NEXT: pushq %r15
; CHECK-NEXT: pushq %r14
-; CHECK-NEXT: pushq %r13
; CHECK-NEXT: pushq %r12
; CHECK-NEXT: pushq %rbx
-; CHECK-NEXT: pushq %rax
; CHECK-NEXT: movl $1, %ebx
; CHECK-NEXT: xorl %eax, %eax
; CHECK-NEXT: testb %al, %al
-; CHECK-NEXT: jne .LBB1_24
+; CHECK-NEXT: jne .LBB1_12
; CHECK-NEXT: # %bb.1: # %if.end19
-; CHECK-NEXT: movl %esi, %ebp
-; CHECK-NEXT: movq %rdi, %r15
-; CHECK-NEXT: movl (%rax), %r13d
-; CHECK-NEXT: leal (,%r13,4), %ebx
-; CHECK-NEXT: movl %ebx, %r12d
+; CHECK-NEXT: movl (%rax), %r12d
+; CHECK-NEXT: leal (,%r12,4), %ebp
+; CHECK-NEXT: movl %ebp, %r15d
; CHECK-NEXT: movl $1, %esi
-; CHECK-NEXT: movq %r12, %rdi
+; CHECK-NEXT: movq %r15, %rdi
; CHECK-NEXT: callq cli_calloc at PLT
-; CHECK-NEXT: testl %ebp, %ebp
-; CHECK-NEXT: je .LBB1_23
-; CHECK-NEXT: # %bb.2: # %if.end19
-; CHECK-NEXT: testl %r13d, %r13d
-; CHECK-NEXT: je .LBB1_23
-; CHECK-NEXT: # %bb.3: # %if.end19
; CHECK-NEXT: movq %rax, %r14
-; CHECK-NEXT: xorl %eax, %eax
+; CHECK-NEXT: movb $1, %al
; CHECK-NEXT: testb %al, %al
-; CHECK-NEXT: jne .LBB1_23
-; CHECK-NEXT: # %bb.4: # %if.end19
-; CHECK-NEXT: cmpq %r15, %r14
-; CHECK-NEXT: jb .LBB1_23
-; CHECK-NEXT: # %bb.5: # %if.end50
+; CHECK-NEXT: jne .LBB1_12
+; CHECK-NEXT: # %bb.2: # %if.end50
; CHECK-NEXT: movq %r14, %rdi
-; CHECK-NEXT: movq %r12, %rdx
+; CHECK-NEXT: movq %r15, %rdx
; CHECK-NEXT: callq memcpy at PLT
-; CHECK-NEXT: cmpl $4, %ebx
-; CHECK-NEXT: jb .LBB1_26
-; CHECK-NEXT: # %bb.6: # %shared_preheader
+; CHECK-NEXT: cmpl $4, %ebp
+; CHECK-NEXT: jb .LBB1_19
+; CHECK-NEXT: # %bb.3: # %shared_preheader
; CHECK-NEXT: movb $32, %cl
; CHECK-NEXT: xorl %eax, %eax
-; CHECK-NEXT: jmp .LBB1_8
+; CHECK-NEXT: jmp .LBB1_4
; CHECK-NEXT: .p2align 4, 0x90
-; CHECK-NEXT: .LBB1_7: # %merge_predecessor_split
-; CHECK-NEXT: # in Loop: Header=BB1_8 Depth=1
+; CHECK-NEXT: .LBB1_15: # %merge_predecessor_split
+; CHECK-NEXT: # in Loop: Header=BB1_4 Depth=1
; CHECK-NEXT: movb $32, %cl
-; CHECK-NEXT: .LBB1_8: # %outer_loop_header
+; CHECK-NEXT: .LBB1_4: # %outer_loop_header
; CHECK-NEXT: # =>This Loop Header: Depth=1
-; CHECK-NEXT: # Child Loop BB1_9 Depth 2
-; CHECK-NEXT: testl %r13d, %r13d
-; CHECK-NEXT: je .LBB1_16
+; CHECK-NEXT: # Child Loop BB1_8 Depth 2
+; CHECK-NEXT: testl %r12d, %r12d
+; CHECK-NEXT: je .LBB1_5
; CHECK-NEXT: .p2align 4, 0x90
-; CHECK-NEXT: .LBB1_9: # %shared_loop_header
-; CHECK-NEXT: # Parent Loop BB1_8 Depth=1
+; CHECK-NEXT: .LBB1_8: # %shared_loop_header
+; CHECK-NEXT: # Parent Loop BB1_4 Depth=1
; CHECK-NEXT: # => This Inner Loop Header: Depth=2
; CHECK-NEXT: testq %r14, %r14
-; CHECK-NEXT: jne .LBB1_25
-; CHECK-NEXT: # %bb.10: # %inner_loop_body
-; CHECK-NEXT: # in Loop: Header=BB1_9 Depth=2
+; CHECK-NEXT: jne .LBB1_18
+; CHECK-NEXT: # %bb.9: # %inner_loop_body
+; CHECK-NEXT: # in Loop: Header=BB1_8 Depth=2
; CHECK-NEXT: testb %al, %al
-; CHECK-NEXT: je .LBB1_9
-; CHECK-NEXT: # %bb.11: # %if.end96.i
-; CHECK-NEXT: # in Loop: Header=BB1_8 Depth=1
-; CHECK-NEXT: cmpl $3, %r13d
-; CHECK-NEXT: jae .LBB1_20
-; CHECK-NEXT: # %bb.12: # %if.end287.i
-; CHECK-NEXT: # in Loop: Header=BB1_8 Depth=1
+; CHECK-NEXT: je .LBB1_8
+; CHECK-NEXT: # %bb.10: # %if.end96.i
+; CHECK-NEXT: # in Loop: Header=BB1_4 Depth=1
+; CHECK-NEXT: cmpl $3, %r12d
+; CHECK-NEXT: jae .LBB1_11
+; CHECK-NEXT: # %bb.13: # %if.end287.i
+; CHECK-NEXT: # in Loop: Header=BB1_4 Depth=1
; CHECK-NEXT: testb %al, %al
; CHECK-NEXT: # implicit-def: $cl
-; CHECK-NEXT: jne .LBB1_8
-; CHECK-NEXT: # %bb.13: # %if.end308.i
-; CHECK-NEXT: # in Loop: Header=BB1_8 Depth=1
+; CHECK-NEXT: jne .LBB1_4
+; CHECK-NEXT: # %bb.14: # %if.end308.i
+; CHECK-NEXT: # in Loop: Header=BB1_4 Depth=1
; CHECK-NEXT: testb %al, %al
-; CHECK-NEXT: je .LBB1_7
-; CHECK-NEXT: # %bb.14: # %if.end335.i
-; CHECK-NEXT: # in Loop: Header=BB1_8 Depth=1
+; CHECK-NEXT: je .LBB1_15
+; CHECK-NEXT: # %bb.16: # %if.end335.i
+; CHECK-NEXT: # in Loop: Header=BB1_4 Depth=1
; CHECK-NEXT: xorl %ecx, %ecx
; CHECK-NEXT: testb %cl, %cl
-; CHECK-NEXT: jne .LBB1_8
-; CHECK-NEXT: # %bb.15: # %merge_other
-; CHECK-NEXT: # in Loop: Header=BB1_8 Depth=1
+; CHECK-NEXT: jne .LBB1_4
+; CHECK-NEXT: # %bb.17: # %merge_other
+; CHECK-NEXT: # in Loop: Header=BB1_4 Depth=1
; CHECK-NEXT: # implicit-def: $cl
-; CHECK-NEXT: jmp .LBB1_8
-; CHECK-NEXT: .LBB1_23:
-; CHECK-NEXT: movl $1, %ebx
-; CHECK-NEXT: jmp .LBB1_24
-; CHECK-NEXT: .LBB1_16: # %while.cond.us1412.i
+; CHECK-NEXT: jmp .LBB1_4
+; CHECK-NEXT: .LBB1_5: # %while.cond.us1412.i
; CHECK-NEXT: xorl %eax, %eax
; CHECK-NEXT: testb %al, %al
-; CHECK-NEXT: movl $1, %ebx
-; CHECK-NEXT: jne .LBB1_18
-; CHECK-NEXT: # %bb.17: # %while.cond.us1412.i
+; CHECK-NEXT: jne .LBB1_7
+; CHECK-NEXT: # %bb.6: # %while.cond.us1412.i
; CHECK-NEXT: decb %cl
-; CHECK-NEXT: jne .LBB1_24
-; CHECK-NEXT: .LBB1_18: # %if.end41.us1436.i
-; CHECK-NEXT: .LBB1_20: # %if.then99.i
+; CHECK-NEXT: jne .LBB1_12
+; CHECK-NEXT: .LBB1_7: # %if.end41.us1436.i
+; CHECK-NEXT: .LBB1_11: # %if.then99.i
; CHECK-NEXT: movq .str.6 at GOTPCREL(%rip), %rdi
; CHECK-NEXT: xorl %ebx, %ebx
; CHECK-NEXT: xorl %eax, %eax
; CHECK-NEXT: callq cli_dbgmsg at PLT
-; CHECK-NEXT: .LBB1_24: # %cleanup
+; CHECK-NEXT: .LBB1_12: # %cleanup
; CHECK-NEXT: movl %ebx, %eax
-; CHECK-NEXT: addq $8, %rsp
; CHECK-NEXT: popq %rbx
; CHECK-NEXT: popq %r12
-; CHECK-NEXT: popq %r13
; CHECK-NEXT: popq %r14
; CHECK-NEXT: popq %r15
; CHECK-NEXT: popq %rbp
; CHECK-NEXT: retq
-; CHECK-NEXT: .LBB1_25: # %wunpsect.exit.thread.loopexit389
-; CHECK-NEXT: .LBB1_26: # %wunpsect.exit.thread.loopexit391
+; CHECK-NEXT: .LBB1_18: # %wunpsect.exit.thread.loopexit389
+; CHECK-NEXT: .LBB1_19: # %wunpsect.exit.thread.loopexit391
entry:
%0 = load i32, ptr undef, align 4
%mul = shl nsw i32 %0, 2
diff --git a/llvm/test/CodeGen/X86/tail-opts.ll b/llvm/test/CodeGen/X86/tail-opts.ll
index d54110d1fa8119..d9ab2f7d1f5fb6 100644
--- a/llvm/test/CodeGen/X86/tail-opts.ll
+++ b/llvm/test/CodeGen/X86/tail-opts.ll
@@ -300,10 +300,9 @@ define fastcc void @c_expand_expr_stmt(ptr %expr) nounwind {
; CHECK-NEXT: cmpl $23, %ecx
; CHECK-NEXT: jne .LBB3_9
; CHECK-NEXT: .LBB3_16: # %lvalue_p.exit4
-; CHECK-NEXT: testb %al, %al
-; CHECK-NEXT: jne .LBB3_9
-; CHECK-NEXT: # %bb.17: # %lvalue_p.exit4
; CHECK-NEXT: testb %bl, %bl
+; CHECK-NEXT: sete %cl
+; CHECK-NEXT: orb %al, %cl
entry:
%tmp4 = load i8, ptr null, align 8 ; <i8> [#uses=3]
switch i8 %tmp4, label %bb3 [
diff --git a/llvm/test/CodeGen/X86/tailcall-extract.ll b/llvm/test/CodeGen/X86/tailcall-extract.ll
index 7a6c75c44ca7dd..aff6146198c899 100644
--- a/llvm/test/CodeGen/X86/tailcall-extract.ll
+++ b/llvm/test/CodeGen/X86/tailcall-extract.ll
@@ -6,7 +6,7 @@
; containing call. And later tail call can be generated.
; CHECK-LABEL: test1:
-; CHECK: je foo # TAILCALL
+; CHECK: jne foo # TAILCALL
; CHECK: jmp bar # TAILCALL
; OPT-LABEL: test1
@@ -48,8 +48,8 @@ exit:
; can't be duplicated.
; CHECK-LABEL: test2:
-; CHECK: callq bar
; CHECK: callq foo
+; CHECK: callq bar
; OPT-LABEL: test2
; OPT: if.then.i:
@@ -93,7 +93,7 @@ exit:
; offset, so the exit block can still be duplicated, and tail call generated.
; CHECK-LABEL: test3:
-; CHECK: je qux # TAILCALL
+; CHECK: jne qux # TAILCALL
; CHECK: jmp baz # TAILCALL
; OPT-LABEL: test3
@@ -136,8 +136,8 @@ exit:
; block can't be duplicated.
; CHECK-LABEL: test4:
-; CHECK: callq baz
; CHECK: callq qux
+; CHECK: callq baz
; OPT-LABEL: test4
; OPT: if.then.i:
diff --git a/llvm/test/CodeGen/X86/test-shrink-bug.ll b/llvm/test/CodeGen/X86/test-shrink-bug.ll
index ed43cabbdaee11..953a0d65c5386c 100644
--- a/llvm/test/CodeGen/X86/test-shrink-bug.ll
+++ b/llvm/test/CodeGen/X86/test-shrink-bug.ll
@@ -48,37 +48,39 @@ define dso_local void @fail(i16 %a, <2 x i8> %b) {
; CHECK-X86: ## %bb.0:
; CHECK-X86-NEXT: subl $12, %esp
; CHECK-X86-NEXT: .cfi_def_cfa_offset 16
-; CHECK-X86-NEXT: movzwl {{[0-9]+}}(%esp), %ecx
+; CHECK-X86-NEXT: movzwl {{[0-9]+}}(%esp), %eax
; CHECK-X86-NEXT: cmpb $123, {{[0-9]+}}(%esp)
-; CHECK-X86-NEXT: sete %al
-; CHECK-X86-NEXT: testl $263, %ecx ## imm = 0x107
-; CHECK-X86-NEXT: je LBB1_3
-; CHECK-X86-NEXT: ## %bb.1:
-; CHECK-X86-NEXT: testb %al, %al
-; CHECK-X86-NEXT: jne LBB1_3
-; CHECK-X86-NEXT: ## %bb.2: ## %no
+; CHECK-X86-NEXT: setne %cl
+; CHECK-X86-NEXT: testl $263, %eax ## imm = 0x107
+; CHECK-X86-NEXT: setne %al
+; CHECK-X86-NEXT: testb %cl, %al
+; CHECK-X86-NEXT: jne LBB1_2
+; CHECK-X86-NEXT: ## %bb.1: ## %yes
+; CHECK-X86-NEXT: addl $12, %esp
+; CHECK-X86-NEXT: retl
+; CHECK-X86-NEXT: LBB1_2: ## %no
; CHECK-X86-NEXT: calll _bar
-; CHECK-X86-NEXT: LBB1_3: ## %yes
; CHECK-X86-NEXT: addl $12, %esp
; CHECK-X86-NEXT: retl
;
; CHECK-X64-LABEL: fail:
; CHECK-X64: # %bb.0:
-; CHECK-X64-NEXT: testl $263, %edi # imm = 0x107
-; CHECK-X64-NEXT: je .LBB1_3
-; CHECK-X64-NEXT: # %bb.1:
; CHECK-X64-NEXT: pslld $8, %xmm0
; CHECK-X64-NEXT: pcmpeqb {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; CHECK-X64-NEXT: pextrw $1, %xmm0, %eax
-; CHECK-X64-NEXT: testb $1, %al
-; CHECK-X64-NEXT: jne .LBB1_3
-; CHECK-X64-NEXT: # %bb.2: # %no
+; CHECK-X64-NEXT: xorb $1, %al
+; CHECK-X64-NEXT: testl $263, %edi # imm = 0x107
+; CHECK-X64-NEXT: setne %cl
+; CHECK-X64-NEXT: testb %al, %cl
+; CHECK-X64-NEXT: jne .LBB1_2
+; CHECK-X64-NEXT: # %bb.1: # %yes
+; CHECK-X64-NEXT: retq
+; CHECK-X64-NEXT: .LBB1_2: # %no
; CHECK-X64-NEXT: pushq %rax
; CHECK-X64-NEXT: .cfi_def_cfa_offset 16
; CHECK-X64-NEXT: callq bar at PLT
; CHECK-X64-NEXT: popq %rax
; CHECK-X64-NEXT: .cfi_def_cfa_offset 8
-; CHECK-X64-NEXT: .LBB1_3: # %yes
; CHECK-X64-NEXT: retq
%1 = icmp eq <2 x i8> %b, <i8 40, i8 123>
%2 = extractelement <2 x i1> %1, i32 1
diff --git a/llvm/test/CodeGen/X86/x86-shrink-wrap-unwind.ll b/llvm/test/CodeGen/X86/x86-shrink-wrap-unwind.ll
index b9e490888d9bfc..3349d31cad4b97 100644
--- a/llvm/test/CodeGen/X86/x86-shrink-wrap-unwind.ll
+++ b/llvm/test/CodeGen/X86/x86-shrink-wrap-unwind.ll
@@ -181,38 +181,40 @@ define zeroext i1 @segmentedStack(ptr readonly %vk1, ptr readonly %vk2, i64 %key
; CHECK-LABEL: segmentedStack:
; CHECK: ## %bb.0:
; CHECK-NEXT: cmpq %gs:816, %rsp
-; CHECK-NEXT: jbe LBB3_7
+; CHECK-NEXT: jbe LBB3_6
; CHECK-NEXT: LBB3_1: ## %entry
; CHECK-NEXT: pushq %rax
; CHECK-NEXT: .cfi_def_cfa_offset 16
+; CHECK-NEXT: testq %rdi, %rdi
+; CHECK-NEXT: sete %al
+; CHECK-NEXT: testq %rsi, %rsi
+; CHECK-NEXT: sete %cl
+; CHECK-NEXT: orb %al, %cl
; CHECK-NEXT: movq %rdi, %rax
; CHECK-NEXT: orq %rsi, %rax
; CHECK-NEXT: sete %al
-; CHECK-NEXT: testq %rdi, %rdi
-; CHECK-NEXT: je LBB3_5
-; CHECK-NEXT: ## %bb.2: ## %entry
-; CHECK-NEXT: testq %rsi, %rsi
-; CHECK-NEXT: je LBB3_5
-; CHECK-NEXT: ## %bb.3: ## %if.end4.i
+; CHECK-NEXT: testb %cl, %cl
+; CHECK-NEXT: jne LBB3_4
+; CHECK-NEXT: ## %bb.2: ## %if.end4.i
; CHECK-NEXT: movq 8(%rdi), %rdx
; CHECK-NEXT: cmpq 8(%rsi), %rdx
-; CHECK-NEXT: jne LBB3_6
-; CHECK-NEXT: ## %bb.4: ## %land.rhs.i.i
+; CHECK-NEXT: jne LBB3_5
+; CHECK-NEXT: ## %bb.3: ## %land.rhs.i.i
; CHECK-NEXT: movq (%rsi), %rsi
; CHECK-NEXT: movq (%rdi), %rdi
; CHECK-NEXT: callq _memcmp
; CHECK-NEXT: testl %eax, %eax
; CHECK-NEXT: sete %al
-; CHECK-NEXT: LBB3_5: ## %__go_ptr_strings_equal.exit
+; CHECK-NEXT: LBB3_4: ## %__go_ptr_strings_equal.exit
; CHECK-NEXT: ## kill: def $al killed $al killed $eax
; CHECK-NEXT: popq %rcx
; CHECK-NEXT: retq
-; CHECK-NEXT: LBB3_6:
+; CHECK-NEXT: LBB3_5:
; CHECK-NEXT: xorl %eax, %eax
; CHECK-NEXT: ## kill: def $al killed $al killed $eax
; CHECK-NEXT: popq %rcx
; CHECK-NEXT: retq
-; CHECK-NEXT: LBB3_7:
+; CHECK-NEXT: LBB3_6:
; CHECK-NEXT: movl $8, %r10d
; CHECK-NEXT: movl $0, %r11d
; CHECK-NEXT: callq ___morestack
@@ -222,41 +224,43 @@ define zeroext i1 @segmentedStack(ptr readonly %vk1, ptr readonly %vk2, i64 %key
; NOCOMPACTUNWIND-LABEL: segmentedStack:
; NOCOMPACTUNWIND: # %bb.0:
; NOCOMPACTUNWIND-NEXT: cmpq %fs:112, %rsp
-; NOCOMPACTUNWIND-NEXT: jbe .LBB3_7
+; NOCOMPACTUNWIND-NEXT: jbe .LBB3_6
; NOCOMPACTUNWIND-NEXT: .LBB3_1: # %entry
; NOCOMPACTUNWIND-NEXT: pushq %rax
; NOCOMPACTUNWIND-NEXT: .cfi_def_cfa_offset 16
+; NOCOMPACTUNWIND-NEXT: testq %rdi, %rdi
+; NOCOMPACTUNWIND-NEXT: sete %al
+; NOCOMPACTUNWIND-NEXT: testq %rsi, %rsi
+; NOCOMPACTUNWIND-NEXT: sete %cl
+; NOCOMPACTUNWIND-NEXT: orb %al, %cl
; NOCOMPACTUNWIND-NEXT: movq %rdi, %rax
; NOCOMPACTUNWIND-NEXT: orq %rsi, %rax
; NOCOMPACTUNWIND-NEXT: sete %al
-; NOCOMPACTUNWIND-NEXT: testq %rdi, %rdi
-; NOCOMPACTUNWIND-NEXT: je .LBB3_5
-; NOCOMPACTUNWIND-NEXT: # %bb.2: # %entry
-; NOCOMPACTUNWIND-NEXT: testq %rsi, %rsi
-; NOCOMPACTUNWIND-NEXT: je .LBB3_5
-; NOCOMPACTUNWIND-NEXT: # %bb.3: # %if.end4.i
+; NOCOMPACTUNWIND-NEXT: testb %cl, %cl
+; NOCOMPACTUNWIND-NEXT: jne .LBB3_4
+; NOCOMPACTUNWIND-NEXT: # %bb.2: # %if.end4.i
; NOCOMPACTUNWIND-NEXT: movq 8(%rdi), %rdx
; NOCOMPACTUNWIND-NEXT: cmpq 8(%rsi), %rdx
-; NOCOMPACTUNWIND-NEXT: jne .LBB3_6
-; NOCOMPACTUNWIND-NEXT: # %bb.4: # %land.rhs.i.i
+; NOCOMPACTUNWIND-NEXT: jne .LBB3_5
+; NOCOMPACTUNWIND-NEXT: # %bb.3: # %land.rhs.i.i
; NOCOMPACTUNWIND-NEXT: movq (%rsi), %rsi
; NOCOMPACTUNWIND-NEXT: movq (%rdi), %rdi
; NOCOMPACTUNWIND-NEXT: callq memcmp at PLT
; NOCOMPACTUNWIND-NEXT: testl %eax, %eax
; NOCOMPACTUNWIND-NEXT: sete %al
-; NOCOMPACTUNWIND-NEXT: .LBB3_5: # %__go_ptr_strings_equal.exit
+; NOCOMPACTUNWIND-NEXT: .LBB3_4: # %__go_ptr_strings_equal.exit
; NOCOMPACTUNWIND-NEXT: # kill: def $al killed $al killed $eax
; NOCOMPACTUNWIND-NEXT: popq %rcx
; NOCOMPACTUNWIND-NEXT: .cfi_def_cfa_offset 8
; NOCOMPACTUNWIND-NEXT: retq
-; NOCOMPACTUNWIND-NEXT: .LBB3_6:
+; NOCOMPACTUNWIND-NEXT: .LBB3_5:
; NOCOMPACTUNWIND-NEXT: .cfi_def_cfa_offset 16
; NOCOMPACTUNWIND-NEXT: xorl %eax, %eax
; NOCOMPACTUNWIND-NEXT: # kill: def $al killed $al killed $eax
; NOCOMPACTUNWIND-NEXT: popq %rcx
; NOCOMPACTUNWIND-NEXT: .cfi_def_cfa_offset 8
; NOCOMPACTUNWIND-NEXT: retq
-; NOCOMPACTUNWIND-NEXT: .LBB3_7:
+; NOCOMPACTUNWIND-NEXT: .LBB3_6:
; NOCOMPACTUNWIND-NEXT: movl $8, %r10d
; NOCOMPACTUNWIND-NEXT: movl $0, %r11d
; NOCOMPACTUNWIND-NEXT: callq __morestack
>From 2fb764d2dae288f24335dfc168b5491a1017fc83 Mon Sep 17 00:00:00 2001
From: Joseph Huber <huberjn at outlook.com>
Date: Fri, 1 Mar 2024 15:52:20 -0600
Subject: [PATCH 303/406] [libomptarget] Fix 'libomptarget' libraries being
installed twice (#83624)
Summary:
We use `add_llvm_library` as a shorthand for setting up all the
dependencies and libraries we need for the OpenMP offloading runtime as
they depend on a lot of the LLVM utilities. However, we always
explicitly installed these manually. Behind the scenes the function
would then install it again. This was unnoticed because until now the
destinations matched. Now that we want it to optionally go into the
other directory it is duplicating them. Fix this by stating that this is
a build tree only library so we can handle it ourselves.
---
openmp/libomptarget/plugins-nextgen/CMakeLists.txt | 1 +
openmp/libomptarget/plugins-nextgen/amdgpu/CMakeLists.txt | 1 +
openmp/libomptarget/plugins-nextgen/cuda/CMakeLists.txt | 1 +
openmp/libomptarget/src/CMakeLists.txt | 1 +
4 files changed, 4 insertions(+)
diff --git a/openmp/libomptarget/plugins-nextgen/CMakeLists.txt b/openmp/libomptarget/plugins-nextgen/CMakeLists.txt
index 3cc2b8512b77f6..3ca02368253ef8 100644
--- a/openmp/libomptarget/plugins-nextgen/CMakeLists.txt
+++ b/openmp/libomptarget/plugins-nextgen/CMakeLists.txt
@@ -46,6 +46,7 @@ if(CMAKE_SYSTEM_PROCESSOR MATCHES "${tmachine}$")
${OPENMP_PTHREAD_LIB}
NO_INSTALL_RPATH
+ BUILDTREE_ONLY
)
if(LIBOMPTARGET_DEP_LIBFFI_FOUND)
diff --git a/openmp/libomptarget/plugins-nextgen/amdgpu/CMakeLists.txt b/openmp/libomptarget/plugins-nextgen/amdgpu/CMakeLists.txt
index 68ce63467a6c81..9e0ea08d8375fd 100644
--- a/openmp/libomptarget/plugins-nextgen/amdgpu/CMakeLists.txt
+++ b/openmp/libomptarget/plugins-nextgen/amdgpu/CMakeLists.txt
@@ -78,6 +78,7 @@ add_llvm_library(omptarget.rtl.amdgpu SHARED
${LDFLAGS_UNDEFINED}
NO_INSTALL_RPATH
+ BUILDTREE_ONLY
)
if ((OMPT_TARGET_DEFAULT) AND (LIBOMPTARGET_OMPT_SUPPORT))
diff --git a/openmp/libomptarget/plugins-nextgen/cuda/CMakeLists.txt b/openmp/libomptarget/plugins-nextgen/cuda/CMakeLists.txt
index 95b288cab31149..2bfb47168a7f3b 100644
--- a/openmp/libomptarget/plugins-nextgen/cuda/CMakeLists.txt
+++ b/openmp/libomptarget/plugins-nextgen/cuda/CMakeLists.txt
@@ -38,6 +38,7 @@ add_llvm_library(omptarget.rtl.cuda SHARED
${OPENMP_PTHREAD_LIB}
NO_INSTALL_RPATH
+ BUILDTREE_ONLY
)
if ((OMPT_TARGET_DEFAULT) AND (LIBOMPTARGET_OMPT_SUPPORT))
diff --git a/openmp/libomptarget/src/CMakeLists.txt b/openmp/libomptarget/src/CMakeLists.txt
index 1a0e26f104be63..9bc3f3339583d9 100644
--- a/openmp/libomptarget/src/CMakeLists.txt
+++ b/openmp/libomptarget/src/CMakeLists.txt
@@ -41,6 +41,7 @@ add_llvm_library(omptarget
omp
NO_INSTALL_RPATH
+ BUILDTREE_ONLY
)
target_include_directories(omptarget PRIVATE ${LIBOMPTARGET_INCLUDE_DIR})
>From f7a15e0021697e2346d3aa335dedf2bb3cf468f9 Mon Sep 17 00:00:00 2001
From: Peter Klausler <35819229+klausler at users.noreply.github.com>
Date: Fri, 1 Mar 2024 13:58:36 -0800
Subject: [PATCH 304/406] [flang] Use module file hashes for more checking and
disambiguation (#80354)
f18's module files are Fortran with a leading header comment containing
the module file format version and a hash of the following contents.
This hash is currently used only to protect module files against
corruption and truncation.
Extend the use of these hashes to catch or avoid some error cases. When
one module file depends upon another, note its hash in additional module
file header comments. This allows the compiler to detect when the module
dependency is on a module file that has been updated. Further, it allows
the compiler to find the right module file dependency when the same
module file name appears in multiple directories on the module search
path.
The order in which module files are written, when multiple modules
appear in a source file, is such that every dependency is written before
the module(s) that depend upon it, so that their hashes are known.
A warning is emitted when a module file is not the first hit on the
module file search path.
Further work is needed to add a compiler option that emits (larger)
stand-alone module files that incorporate copies of their dependencies
rather than relying on search paths. This will be desirable for
application libraries that want to ship only "top-level" module files
without needing to include their dependencies.
Another future work item would be to admit multiple modules in the same
compilation with the same name if they have distinct hashes.
---
flang/include/flang/Parser/provenance.h | 1 +
flang/include/flang/Parser/source.h | 2 +
.../flang/Semantics/module-dependences.h | 51 +++++
flang/include/flang/Semantics/semantics.h | 3 +
flang/include/flang/Semantics/symbol.h | 8 +-
flang/lib/Parser/provenance.cpp | 18 +-
flang/lib/Parser/source.cpp | 18 ++
flang/lib/Semantics/mod-file.cpp | 208 +++++++++++++++---
flang/lib/Semantics/mod-file.h | 11 +-
flang/lib/Semantics/resolve-names.cpp | 3 +-
flang/lib/Semantics/resolve-names.h | 4 -
flang/lib/Semantics/semantics.cpp | 2 +-
.../test/Semantics/Inputs/dir1/modfile63a.mod | 6 +
.../test/Semantics/Inputs/dir1/modfile63b.mod | 8 +
.../test/Semantics/Inputs/dir2/modfile63a.mod | 6 +
.../test/Semantics/Inputs/dir2/modfile63b.mod | 8 +
flang/test/Semantics/getsymbols02.f90 | 2 +-
flang/test/Semantics/modfile63.f90 | 19 ++
flang/test/Semantics/test_modfile.py | 2 +-
19 files changed, 334 insertions(+), 46 deletions(-)
create mode 100644 flang/include/flang/Semantics/module-dependences.h
create mode 100644 flang/test/Semantics/Inputs/dir1/modfile63a.mod
create mode 100644 flang/test/Semantics/Inputs/dir1/modfile63b.mod
create mode 100644 flang/test/Semantics/Inputs/dir2/modfile63a.mod
create mode 100644 flang/test/Semantics/Inputs/dir2/modfile63b.mod
create mode 100644 flang/test/Semantics/modfile63.f90
diff --git a/flang/include/flang/Parser/provenance.h b/flang/include/flang/Parser/provenance.h
index a5a5211144285d..73d500f32831b2 100644
--- a/flang/include/flang/Parser/provenance.h
+++ b/flang/include/flang/Parser/provenance.h
@@ -151,6 +151,7 @@ class AllSources {
void ClearSearchPath();
void AppendSearchPathDirectory(std::string); // new last directory
+ const SourceFile *OpenPath(std::string path, llvm::raw_ostream &error);
const SourceFile *Open(std::string path, llvm::raw_ostream &error,
std::optional<std::string> &&prependPath = std::nullopt);
const SourceFile *ReadStandardInput(llvm::raw_ostream &error);
diff --git a/flang/include/flang/Parser/source.h b/flang/include/flang/Parser/source.h
index f0ae97a3ef0485..a6efdf9546c7f3 100644
--- a/flang/include/flang/Parser/source.h
+++ b/flang/include/flang/Parser/source.h
@@ -36,6 +36,8 @@ namespace Fortran::parser {
std::string DirectoryName(std::string path);
std::optional<std::string> LocateSourceFile(
std::string name, const std::list<std::string> &searchPath);
+std::vector<std::string> LocateSourceFileAll(
+ std::string name, const std::vector<std::string> &searchPath);
class SourceFile;
diff --git a/flang/include/flang/Semantics/module-dependences.h b/flang/include/flang/Semantics/module-dependences.h
new file mode 100644
index 00000000000000..29813a19a4b1bc
--- /dev/null
+++ b/flang/include/flang/Semantics/module-dependences.h
@@ -0,0 +1,51 @@
+//===-- include/flang/Semantics/module-dependences.h ------------*- C++ -*-===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+
+#ifndef FORTRAN_SEMANTICS_MODULE_DEPENDENCES_H_
+#define FORTRAN_SEMANTICS_MODULE_DEPENDENCES_H_
+
+#include <cinttypes>
+#include <map>
+#include <optional>
+#include <string>
+
+namespace Fortran::semantics {
+
+using ModuleCheckSumType = std::uint64_t;
+
+class ModuleDependences {
+public:
+ void AddDependence(
+ std::string &&name, bool intrinsic, ModuleCheckSumType hash) {
+ if (intrinsic) {
+ intrinsicMap_.emplace(std::move(name), hash);
+ } else {
+ nonIntrinsicMap_.emplace(std::move(name), hash);
+ }
+ }
+ std::optional<ModuleCheckSumType> GetRequiredHash(
+ const std::string &name, bool intrinsic) {
+ if (intrinsic) {
+ if (auto iter{intrinsicMap_.find(name)}; iter != intrinsicMap_.end()) {
+ return iter->second;
+ }
+ } else {
+ if (auto iter{nonIntrinsicMap_.find(name)};
+ iter != nonIntrinsicMap_.end()) {
+ return iter->second;
+ }
+ }
+ return std::nullopt;
+ }
+
+private:
+ std::map<std::string, ModuleCheckSumType> intrinsicMap_, nonIntrinsicMap_;
+};
+
+} // namespace Fortran::semantics
+#endif // FORTRAN_SEMANTICS_MODULE_DEPENDENCES_H_
diff --git a/flang/include/flang/Semantics/semantics.h b/flang/include/flang/Semantics/semantics.h
index 4e8b71fa652f5c..c8ee71945d8bde 100644
--- a/flang/include/flang/Semantics/semantics.h
+++ b/flang/include/flang/Semantics/semantics.h
@@ -16,6 +16,7 @@
#include "flang/Evaluate/intrinsics.h"
#include "flang/Evaluate/target.h"
#include "flang/Parser/message.h"
+#include "flang/Semantics/module-dependences.h"
#include <iosfwd>
#include <set>
#include <string>
@@ -108,6 +109,7 @@ class SemanticsContext {
parser::Messages &messages() { return messages_; }
evaluate::FoldingContext &foldingContext() { return foldingContext_; }
parser::AllCookedSources &allCookedSources() { return allCookedSources_; }
+ ModuleDependences &moduleDependences() { return moduleDependences_; }
SemanticsContext &set_location(
const std::optional<parser::CharBlock> &location) {
@@ -293,6 +295,7 @@ class SemanticsContext {
const Scope *ppcBuiltinsScope_{nullptr}; // module __ppc_intrinsics
std::list<parser::Program> modFileParseTrees_;
std::unique_ptr<CommonBlockMap> commonBlockMap_;
+ ModuleDependences moduleDependences_;
};
class Semantics {
diff --git a/flang/include/flang/Semantics/symbol.h b/flang/include/flang/Semantics/symbol.h
index 4535a92ce3dd8e..d8b372bea10f04 100644
--- a/flang/include/flang/Semantics/symbol.h
+++ b/flang/include/flang/Semantics/symbol.h
@@ -14,6 +14,7 @@
#include "flang/Common/enum-set.h"
#include "flang/Common/reference.h"
#include "flang/Common/visit.h"
+#include "flang/Semantics/module-dependences.h"
#include "llvm/ADT/DenseMapInfo.h"
#include <array>
@@ -86,11 +87,16 @@ class ModuleDetails : public WithOmpDeclarative {
void set_scope(const Scope *);
bool isDefaultPrivate() const { return isDefaultPrivate_; }
void set_isDefaultPrivate(bool yes = true) { isDefaultPrivate_ = yes; }
+ std::optional<ModuleCheckSumType> moduleFileHash() const {
+ return moduleFileHash_;
+ }
+ void set_moduleFileHash(ModuleCheckSumType x) { moduleFileHash_ = x; }
private:
bool isSubmodule_;
bool isDefaultPrivate_{false};
const Scope *scope_{nullptr};
+ std::optional<ModuleCheckSumType> moduleFileHash_;
};
class MainProgramDetails : public WithOmpDeclarative {
@@ -1035,7 +1041,7 @@ struct SymbolAddressCompare {
// Symbol comparison is usually based on the order of cooked source
// stream creation and, when both are from the same cooked source,
// their positions in that cooked source stream.
-// Don't use this comparator or OrderedSymbolSet to hold
+// Don't use this comparator or SourceOrderedSymbolSet to hold
// Symbols that might be subject to ReplaceName().
struct SymbolSourcePositionCompare {
// These functions are implemented in Evaluate/tools.cpp to
diff --git a/flang/lib/Parser/provenance.cpp b/flang/lib/Parser/provenance.cpp
index 3f185ffeb1b112..55ef67fd6288df 100644
--- a/flang/lib/Parser/provenance.cpp
+++ b/flang/lib/Parser/provenance.cpp
@@ -167,6 +167,16 @@ void AllSources::AppendSearchPathDirectory(std::string directory) {
searchPath_.push_back(directory);
}
+const SourceFile *AllSources::OpenPath(
+ std::string path, llvm::raw_ostream &error) {
+ std::unique_ptr<SourceFile> source{std::make_unique<SourceFile>(encoding_)};
+ if (source->Open(path, error)) {
+ return ownedSourceFiles_.emplace_back(std::move(source)).get();
+ } else {
+ return nullptr;
+ }
+}
+
const SourceFile *AllSources::Open(std::string path, llvm::raw_ostream &error,
std::optional<std::string> &&prependPath) {
std::unique_ptr<SourceFile> source{std::make_unique<SourceFile>(encoding_)};
@@ -180,12 +190,10 @@ const SourceFile *AllSources::Open(std::string path, llvm::raw_ostream &error,
if (prependPath) {
searchPath_.pop_front();
}
- if (!found) {
- error << "Source file '" << path << "' was not found";
- return nullptr;
- } else if (source->Open(*found, error)) {
- return ownedSourceFiles_.emplace_back(std::move(source)).get();
+ if (found) {
+ return OpenPath(*found, error);
} else {
+ error << "Source file '" << path << "' was not found";
return nullptr;
}
}
diff --git a/flang/lib/Parser/source.cpp b/flang/lib/Parser/source.cpp
index 4b4fed64a1a40a..ae834dc2416529 100644
--- a/flang/lib/Parser/source.cpp
+++ b/flang/lib/Parser/source.cpp
@@ -75,6 +75,24 @@ std::optional<std::string> LocateSourceFile(
return std::nullopt;
}
+std::vector<std::string> LocateSourceFileAll(
+ std::string name, const std::vector<std::string> &searchPath) {
+ if (name == "-" || llvm::sys::path::is_absolute(name)) {
+ return {name};
+ }
+ std::vector<std::string> result;
+ for (const std::string &dir : searchPath) {
+ llvm::SmallString<128> path{dir};
+ llvm::sys::path::append(path, name);
+ bool isDir{false};
+ auto er = llvm::sys::fs::is_directory(path, isDir);
+ if (!er && !isDir) {
+ result.emplace_back(path.str().str());
+ }
+ }
+ return result;
+}
+
std::size_t RemoveCarriageReturns(llvm::MutableArrayRef<char> buf) {
std::size_t wrote{0};
char *buffer{buf.data()};
diff --git a/flang/lib/Semantics/mod-file.cpp b/flang/lib/Semantics/mod-file.cpp
index 7072ddee18ebef..37fe0240537b8e 100644
--- a/flang/lib/Semantics/mod-file.cpp
+++ b/flang/lib/Semantics/mod-file.cpp
@@ -41,11 +41,13 @@ struct ModHeader {
static constexpr const char magic[magicLen + 1]{"!mod$ v1 sum:"};
static constexpr char terminator{'\n'};
static constexpr int len{magicLen + 1 + sumLen};
+ static constexpr int needLen{7};
+ static constexpr const char need[needLen + 1]{"!need$ "};
};
static std::optional<SourceName> GetSubmoduleParent(const parser::Program &);
static void CollectSymbols(const Scope &, SymbolVector &, SymbolVector &,
- std::map<const Symbol *, SourceName> &);
+ std::map<const Symbol *, SourceName> &, UnorderedSymbolSet &);
static void PutPassName(llvm::raw_ostream &, const std::optional<SourceName> &);
static void PutInit(llvm::raw_ostream &, const Symbol &, const MaybeExpr &,
const parser::Expr *, const std::map<const Symbol *, SourceName> &);
@@ -58,11 +60,12 @@ static void PutShape(
static llvm::raw_ostream &PutAttr(llvm::raw_ostream &, Attr);
static llvm::raw_ostream &PutType(llvm::raw_ostream &, const DeclTypeSpec &);
static llvm::raw_ostream &PutLower(llvm::raw_ostream &, std::string_view);
-static std::error_code WriteFile(
- const std::string &, const std::string &, bool = true);
+static std::error_code WriteFile(const std::string &, const std::string &,
+ ModuleCheckSumType &, bool debug = true);
static bool FileContentsMatch(
const std::string &, const std::string &, const std::string &);
-static std::string CheckSum(const std::string_view &);
+static ModuleCheckSumType ComputeCheckSum(const std::string_view &);
+static std::string CheckSumString(ModuleCheckSumType);
// Collect symbols needed for a subprogram interface
class SubprogramSymbolCollector {
@@ -129,17 +132,23 @@ static std::string ModFileName(const SourceName &name,
// Write the module file for symbol, which must be a module or submodule.
void ModFileWriter::Write(const Symbol &symbol) {
- auto *ancestor{symbol.get<ModuleDetails>().ancestor()};
+ auto &module{symbol.get<ModuleDetails>()};
+ if (module.moduleFileHash()) {
+ return; // already written
+ }
+ auto *ancestor{module.ancestor()};
isSubmodule_ = ancestor != nullptr;
auto ancestorName{ancestor ? ancestor->GetName().value().ToString() : ""s};
auto path{context_.moduleDirectory() + '/' +
ModFileName(symbol.name(), ancestorName, context_.moduleFileSuffix())};
PutSymbols(DEREF(symbol.scope()));
- if (std::error_code error{
- WriteFile(path, GetAsString(symbol), context_.debugModuleWriter())}) {
+ ModuleCheckSumType checkSum;
+ if (std::error_code error{WriteFile(
+ path, GetAsString(symbol), checkSum, context_.debugModuleWriter())}) {
context_.Say(
symbol.name(), "Error writing %s: %s"_err_en_US, path, error.message());
}
+ const_cast<ModuleDetails &>(module).set_moduleFileHash(checkSum);
}
// Return the entire body of the module file
@@ -147,6 +156,8 @@ void ModFileWriter::Write(const Symbol &symbol) {
std::string ModFileWriter::GetAsString(const Symbol &symbol) {
std::string buf;
llvm::raw_string_ostream all{buf};
+ all << needs_.str();
+ needs_.str().clear();
auto &details{symbol.get<ModuleDetails>()};
if (!details.isSubmodule()) {
all << "module " << symbol.name();
@@ -258,7 +269,17 @@ void ModFileWriter::PutSymbols(const Scope &scope) {
SymbolVector sorted;
SymbolVector uses;
PrepareRenamings(scope);
- CollectSymbols(scope, sorted, uses, renamings_);
+ UnorderedSymbolSet modules;
+ CollectSymbols(scope, sorted, uses, renamings_, modules);
+ // Write module files for dependencies first so that their
+ // hashes are known.
+ for (auto ref : modules) {
+ Write(*ref);
+ needs_ << ModHeader::need
+ << CheckSumString(ref->get<ModuleDetails>().moduleFileHash().value())
+ << (ref->owner().IsIntrinsicModules() ? " i " : " n ")
+ << ref->name().ToString() << '\n';
+ }
std::string buf; // stuff after CONTAINS in derived type
llvm::raw_string_ostream typeBindings{buf};
for (const Symbol &symbol : sorted) {
@@ -730,16 +751,26 @@ static inline SourceName NameInModuleFile(const Symbol &symbol) {
// Collect the symbols of this scope sorted by their original order, not name.
// Generics and namelists are exceptions: they are sorted after other symbols.
void CollectSymbols(const Scope &scope, SymbolVector &sorted,
- SymbolVector &uses, std::map<const Symbol *, SourceName> &renamings) {
+ SymbolVector &uses, std::map<const Symbol *, SourceName> &renamings,
+ UnorderedSymbolSet &modules) {
SymbolVector namelist, generics;
auto symbols{scope.GetSymbols()};
std::size_t commonSize{scope.commonBlocks().size()};
sorted.reserve(symbols.size() + commonSize);
for (SymbolRef symbol : symbols) {
+ const auto *generic{symbol->detailsIf<GenericDetails>()};
+ if (generic) {
+ uses.insert(uses.end(), generic->uses().begin(), generic->uses().end());
+ for (auto ref : generic->uses()) {
+ modules.insert(GetUsedModule(ref->get<UseDetails>()));
+ }
+ } else if (const auto *use{symbol->detailsIf<UseDetails>()}) {
+ modules.insert(GetUsedModule(*use));
+ }
if (symbol->test(Symbol::Flag::ParentComp)) {
} else if (symbol->has<NamelistDetails>()) {
namelist.push_back(symbol);
- } else if (const auto *generic{symbol->detailsIf<GenericDetails>()}) {
+ } else if (generic) {
if (generic->specific() &&
&generic->specific()->owner() == &symbol->owner()) {
sorted.push_back(*generic->specific());
@@ -751,9 +782,6 @@ void CollectSymbols(const Scope &scope, SymbolVector &sorted,
} else {
sorted.push_back(symbol);
}
- if (const auto *details{symbol->detailsIf<GenericDetails>()}) {
- uses.insert(uses.end(), details->uses().begin(), details->uses().end());
- }
}
// Sort most symbols by name: use of Symbol::ReplaceName ensures the source
// location of a symbol's name is the first "real" use.
@@ -1100,10 +1128,11 @@ static llvm::ErrorOr<Temp> MkTemp(const std::string &path) {
// Write the module file at path, prepending header. If an error occurs,
// return errno, otherwise 0.
-static std::error_code WriteFile(
- const std::string &path, const std::string &contents, bool debug) {
+static std::error_code WriteFile(const std::string &path,
+ const std::string &contents, ModuleCheckSumType &checkSum, bool debug) {
+ checkSum = ComputeCheckSum(contents);
auto header{std::string{ModHeader::bom} + ModHeader::magic +
- CheckSum(contents) + ModHeader::terminator};
+ CheckSumString(checkSum) + ModHeader::terminator};
if (debug) {
llvm::dbgs() << "Processing module " << path << ": ";
}
@@ -1155,12 +1184,16 @@ static bool FileContentsMatch(const std::string &path,
// Compute a simple hash of the contents of a module file and
// return it as a string of hex digits.
// This uses the Fowler-Noll-Vo hash function.
-static std::string CheckSum(const std::string_view &contents) {
- std::uint64_t hash{0xcbf29ce484222325ull};
+static ModuleCheckSumType ComputeCheckSum(const std::string_view &contents) {
+ ModuleCheckSumType hash{0xcbf29ce484222325ull};
for (char c : contents) {
hash ^= c & 0xff;
hash *= 0x100000001b3;
}
+ return hash;
+}
+
+static std::string CheckSumString(ModuleCheckSumType hash) {
static const char *digits = "0123456789abcdef";
std::string result(ModHeader::sumLen, '0');
for (size_t i{ModHeader::sumLen}; hash != 0; hash >>= 4) {
@@ -1169,18 +1202,74 @@ static std::string CheckSum(const std::string_view &contents) {
return result;
}
-static bool VerifyHeader(llvm::ArrayRef<char> content) {
+std::optional<ModuleCheckSumType> ExtractCheckSum(const std::string_view &str) {
+ if (str.size() == ModHeader::sumLen) {
+ ModuleCheckSumType hash{0};
+ for (size_t j{0}; j < ModHeader::sumLen; ++j) {
+ hash <<= 4;
+ char ch{str.at(j)};
+ if (ch >= '0' && ch <= '9') {
+ hash += ch - '0';
+ } else if (ch >= 'a' && ch <= 'f') {
+ hash += ch - 'a' + 10;
+ } else {
+ return std::nullopt;
+ }
+ }
+ return hash;
+ }
+ return std::nullopt;
+}
+
+static std::optional<ModuleCheckSumType> VerifyHeader(
+ llvm::ArrayRef<char> content) {
std::string_view sv{content.data(), content.size()};
if (sv.substr(0, ModHeader::magicLen) != ModHeader::magic) {
- return false;
+ return std::nullopt;
}
+ ModuleCheckSumType checkSum{ComputeCheckSum(sv.substr(ModHeader::len))};
std::string_view expectSum{sv.substr(ModHeader::magicLen, ModHeader::sumLen)};
- std::string actualSum{CheckSum(sv.substr(ModHeader::len))};
- return expectSum == actualSum;
+ if (auto extracted{ExtractCheckSum(expectSum)};
+ extracted && *extracted == checkSum) {
+ return checkSum;
+ } else {
+ return std::nullopt;
+ }
}
-Scope *ModFileReader::Read(const SourceName &name,
- std::optional<bool> isIntrinsic, Scope *ancestor, bool silent) {
+static void GetModuleDependences(
+ ModuleDependences &dependences, llvm::ArrayRef<char> content) {
+ std::size_t limit{content.size()};
+ std::string_view str{content.data(), limit};
+ for (std::size_t j{ModHeader::len};
+ str.substr(j, ModHeader::needLen) == ModHeader::need;) {
+ j += 7;
+ auto checkSum{ExtractCheckSum(str.substr(j, ModHeader::sumLen))};
+ if (!checkSum) {
+ break;
+ }
+ j += ModHeader::sumLen;
+ bool intrinsic{false};
+ if (str.substr(j, 3) == " i ") {
+ intrinsic = true;
+ } else if (str.substr(j, 3) != " n ") {
+ break;
+ }
+ j += 3;
+ std::size_t start{j};
+ for (; j < limit && str.at(j) != '\n'; ++j) {
+ }
+ if (j > start && j < limit && str.at(j) == '\n') {
+ dependences.AddDependence(
+ std::string{str.substr(start, j - start)}, intrinsic, *checkSum);
+ } else {
+ break;
+ }
+ }
+}
+
+Scope *ModFileReader::Read(SourceName name, std::optional<bool> isIntrinsic,
+ Scope *ancestor, bool silent) {
std::string ancestorName; // empty for module
Symbol *notAModule{nullptr};
bool fatalError{false};
@@ -1190,12 +1279,26 @@ Scope *ModFileReader::Read(const SourceName &name,
}
ancestorName = ancestor->GetName().value().ToString();
}
+ auto requiredHash{context_.moduleDependences().GetRequiredHash(
+ name.ToString(), isIntrinsic.value_or(false))};
if (!isIntrinsic.value_or(false) && !ancestor) {
// Already present in the symbol table as a usable non-intrinsic module?
auto it{context_.globalScope().find(name)};
if (it != context_.globalScope().end()) {
Scope *scope{it->second->scope()};
if (scope->kind() == Scope::Kind::Module) {
+ if (requiredHash) {
+ if (const Symbol * foundModule{scope->symbol()}) {
+ if (const auto *module{foundModule->detailsIf<ModuleDetails>()};
+ module && module->moduleFileHash() &&
+ *requiredHash != *module->moduleFileHash()) {
+ Say(name, ancestorName,
+ "Multiple versions of the module '%s' cannot be required by the same compilation"_err_en_US,
+ name.ToString());
+ return nullptr;
+ }
+ }
+ }
return scope;
} else {
notAModule = scope->symbol();
@@ -1249,7 +1352,50 @@ Scope *ModFileReader::Read(const SourceName &name,
for (const auto &dir : context_.intrinsicModuleDirectories()) {
options.searchDirectories.push_back(dir);
}
+ if (!requiredHash) {
+ requiredHash =
+ context_.moduleDependences().GetRequiredHash(name.ToString(), true);
+ }
}
+
+ // Look for the right module file if its hash is known
+ if (requiredHash && !fatalError) {
+ std::vector<std::string> misses;
+ for (const std::string &maybe :
+ parser::LocateSourceFileAll(path, options.searchDirectories)) {
+ if (const auto *srcFile{context_.allCookedSources().allSources().OpenPath(
+ maybe, llvm::errs())}) {
+ if (auto checkSum{VerifyHeader(srcFile->content())}) {
+ if (*checkSum == *requiredHash) {
+ path = maybe;
+ if (!misses.empty()) {
+ auto &msg{context_.Say(name,
+ "Module file for '%s' appears later in the module search path than conflicting modules with different checksums"_warn_en_US,
+ name.ToString())};
+ for (const std::string &m : misses) {
+ msg.Attach(
+ name, "Module file with a conflicting name: '%s'"_en_US, m);
+ }
+ }
+ misses.clear();
+ break;
+ } else {
+ misses.emplace_back(maybe);
+ }
+ }
+ }
+ }
+ if (!misses.empty()) {
+ auto &msg{Say(name, ancestorName,
+ "Could not find a module file for '%s' in the module search path with the expected checksum"_err_en_US,
+ name.ToString())};
+ for (const std::string &m : misses) {
+ msg.Attach(name, "Module file with different checksum: '%s'"_en_US, m);
+ }
+ return nullptr;
+ }
+ }
+
const auto *sourceFile{fatalError ? nullptr : parsing.Prescan(path, options)};
if (fatalError || parsing.messages().AnyFatalError()) {
if (!silent) {
@@ -1270,10 +1416,17 @@ Scope *ModFileReader::Read(const SourceName &name,
return nullptr;
}
CHECK(sourceFile);
- if (!VerifyHeader(sourceFile->content())) {
+ std::optional<ModuleCheckSumType> checkSum{
+ VerifyHeader(sourceFile->content())};
+ if (!checkSum) {
Say(name, ancestorName, "File has invalid checksum: %s"_warn_en_US,
sourceFile->path());
return nullptr;
+ } else if (requiredHash && *requiredHash != *checkSum) {
+ Say(name, ancestorName,
+ "File is not the right module file for %s"_warn_en_US,
+ "'"s + name.ToString() + "': "s + sourceFile->path());
+ return nullptr;
}
llvm::raw_null_ostream NullStream;
parsing.Parse(NullStream);
@@ -1316,6 +1469,7 @@ Scope *ModFileReader::Read(const SourceName &name,
// Process declarations from the module file
bool wasInModuleFile{context_.foldingContext().inModuleFile()};
context_.foldingContext().set_inModuleFile(true);
+ GetModuleDependences(context_.moduleDependences(), sourceFile->content());
ResolveNames(context_, parseTree, topScope);
context_.foldingContext().set_inModuleFile(wasInModuleFile);
if (!moduleSymbol) {
@@ -1331,8 +1485,8 @@ Scope *ModFileReader::Read(const SourceName &name,
}
}
if (moduleSymbol) {
- CHECK(moduleSymbol->has<ModuleDetails>());
CHECK(moduleSymbol->test(Symbol::Flag::ModFile));
+ moduleSymbol->get<ModuleDetails>().set_moduleFileHash(checkSum.value());
if (isIntrinsic.value_or(false)) {
moduleSymbol->attrs().set(Attr::INTRINSIC);
}
@@ -1342,7 +1496,7 @@ Scope *ModFileReader::Read(const SourceName &name,
}
}
-parser::Message &ModFileReader::Say(const SourceName &name,
+parser::Message &ModFileReader::Say(SourceName name,
const std::string &ancestor, parser::MessageFixedText &&msg,
const std::string &arg) {
return context_.Say(name, "Cannot read module file for %s: %s"_err_en_US,
diff --git a/flang/lib/Semantics/mod-file.h b/flang/lib/Semantics/mod-file.h
index 5be117153dd4d1..b4ece4018c054d 100644
--- a/flang/lib/Semantics/mod-file.h
+++ b/flang/lib/Semantics/mod-file.h
@@ -38,7 +38,8 @@ class ModFileWriter {
private:
SemanticsContext &context_;
- // Buffer to use with raw_string_ostream
+ // Buffers to use with raw_string_ostream
+ std::string needsBuf_;
std::string usesBuf_;
std::string useExtraAttrsBuf_;
std::string declsBuf_;
@@ -46,6 +47,7 @@ class ModFileWriter {
// Tracks nested DEC structures and fields of that type
UnorderedSymbolSet emittedDECStructures_, emittedDECFields_;
+ llvm::raw_string_ostream needs_{needsBuf_};
llvm::raw_string_ostream uses_{usesBuf_};
llvm::raw_string_ostream useExtraAttrs_{
useExtraAttrsBuf_}; // attrs added to used entity
@@ -83,18 +85,17 @@ class ModFileWriter {
class ModFileReader {
public:
- // directories specifies where to search for module files
ModFileReader(SemanticsContext &context) : context_{context} {}
// Find and read the module file for a module or submodule.
// If ancestor is specified, look for a submodule of that module.
// Return the Scope for that module/submodule or nullptr on error.
- Scope *Read(const SourceName &, std::optional<bool> isIntrinsic,
- Scope *ancestor, bool silent = false);
+ Scope *Read(SourceName, std::optional<bool> isIntrinsic, Scope *ancestor,
+ bool silent);
private:
SemanticsContext &context_;
- parser::Message &Say(const SourceName &, const std::string &,
+ parser::Message &Say(SourceName, const std::string &,
parser::MessageFixedText &&, const std::string &);
};
diff --git a/flang/lib/Semantics/resolve-names.cpp b/flang/lib/Semantics/resolve-names.cpp
index 0cbe0b492fa44a..7b40e2bbc53328 100644
--- a/flang/lib/Semantics/resolve-names.cpp
+++ b/flang/lib/Semantics/resolve-names.cpp
@@ -3375,7 +3375,8 @@ void ModuleVisitor::BeginModule(const parser::Name &name, bool isSubmodule) {
Scope *ModuleVisitor::FindModule(const parser::Name &name,
std::optional<bool> isIntrinsic, Scope *ancestor) {
ModFileReader reader{context()};
- Scope *scope{reader.Read(name.source, isIntrinsic, ancestor)};
+ Scope *scope{
+ reader.Read(name.source, isIntrinsic, ancestor, /*silent=*/false)};
if (!scope) {
return nullptr;
}
diff --git a/flang/lib/Semantics/resolve-names.h b/flang/lib/Semantics/resolve-names.h
index 78fdc2edc54a99..a6797b45635936 100644
--- a/flang/lib/Semantics/resolve-names.h
+++ b/flang/lib/Semantics/resolve-names.h
@@ -9,10 +9,6 @@
#ifndef FORTRAN_SEMANTICS_RESOLVE_NAMES_H_
#define FORTRAN_SEMANTICS_RESOLVE_NAMES_H_
-#include <iosfwd>
-#include <string>
-#include <vector>
-
namespace llvm {
class raw_ostream;
}
diff --git a/flang/lib/Semantics/semantics.cpp b/flang/lib/Semantics/semantics.cpp
index a76c42ae4f44f5..e58a8f3b22c06c 100644
--- a/flang/lib/Semantics/semantics.cpp
+++ b/flang/lib/Semantics/semantics.cpp
@@ -515,7 +515,7 @@ bool SemanticsContext::IsTempName(const std::string &name) {
Scope *SemanticsContext::GetBuiltinModule(const char *name) {
return ModFileReader{*this}.Read(SourceName{name, std::strlen(name)},
- true /*intrinsic*/, nullptr, true /*silence errors*/);
+ true /*intrinsic*/, nullptr, /*silent=*/true);
}
void SemanticsContext::UseFortranBuiltinsModule() {
diff --git a/flang/test/Semantics/Inputs/dir1/modfile63a.mod b/flang/test/Semantics/Inputs/dir1/modfile63a.mod
new file mode 100644
index 00000000000000..acaa125819b39e
--- /dev/null
+++ b/flang/test/Semantics/Inputs/dir1/modfile63a.mod
@@ -0,0 +1,6 @@
+!mod$ v1 sum:cbe36d213d935559
+module modfile63a
+contains
+subroutine s1()
+end
+end
diff --git a/flang/test/Semantics/Inputs/dir1/modfile63b.mod b/flang/test/Semantics/Inputs/dir1/modfile63b.mod
new file mode 100644
index 00000000000000..af5fec9e69bf64
--- /dev/null
+++ b/flang/test/Semantics/Inputs/dir1/modfile63b.mod
@@ -0,0 +1,8 @@
+!mod$ v1 sum:ddea620dc2aa0520
+!need$ cbe36d213d935559 n modfile63a
+module modfile63b
+use modfile63a,only:s1
+contains
+subroutine s2()
+end
+end
diff --git a/flang/test/Semantics/Inputs/dir2/modfile63a.mod b/flang/test/Semantics/Inputs/dir2/modfile63a.mod
new file mode 100644
index 00000000000000..8236d36c575888
--- /dev/null
+++ b/flang/test/Semantics/Inputs/dir2/modfile63a.mod
@@ -0,0 +1,6 @@
+!mod$ v1 sum:00761f8b3a4c5780
+module modfile63a
+contains
+subroutine s1a()
+end
+end
diff --git a/flang/test/Semantics/Inputs/dir2/modfile63b.mod b/flang/test/Semantics/Inputs/dir2/modfile63b.mod
new file mode 100644
index 00000000000000..af5fec9e69bf64
--- /dev/null
+++ b/flang/test/Semantics/Inputs/dir2/modfile63b.mod
@@ -0,0 +1,8 @@
+!mod$ v1 sum:ddea620dc2aa0520
+!need$ cbe36d213d935559 n modfile63a
+module modfile63b
+use modfile63a,only:s1
+contains
+subroutine s2()
+end
+end
diff --git a/flang/test/Semantics/getsymbols02.f90 b/flang/test/Semantics/getsymbols02.f90
index 25a4c30809fb29..2605a593e814de 100644
--- a/flang/test/Semantics/getsymbols02.f90
+++ b/flang/test/Semantics/getsymbols02.f90
@@ -11,4 +11,4 @@ PROGRAM helloworld
! RUN: %flang_fc1 -fsyntax-only %S/Inputs/getsymbols02-b.f90
! RUN: %flang_fc1 -fget-symbols-sources %s 2>&1 | FileCheck %s
! CHECK: callget5: .{{[/\\]}}mm2b.mod,
-! CHECK: get5: .{{[/\\]}}mm2a.mod,
+! CHECK: get5: .{{[/\\]}}.{{[/\\]}}mm2a.mod,
diff --git a/flang/test/Semantics/modfile63.f90 b/flang/test/Semantics/modfile63.f90
new file mode 100644
index 00000000000000..aaf1f7beaa48fa
--- /dev/null
+++ b/flang/test/Semantics/modfile63.f90
@@ -0,0 +1,19 @@
+! RUN: %flang_fc1 -fsyntax-only -I%S/Inputs/dir1 %s
+! RUN: not %flang_fc1 -fsyntax-only -I%S/Inputs/dir2 %s 2>&1 | FileCheck --check-prefix=ERROR %s
+! RUN: %flang_fc1 -Werror -fsyntax-only -I%S/Inputs/dir1 -I%S/Inputs/dir2 %s
+! RUN: not %flang_fc1 -Werror -fsyntax-only -I%S/Inputs/dir2 -I%S/Inputs/dir1 %s 2>&1 | FileCheck --check-prefix=WARNING %s
+
+! Inputs/dir1 and Inputs/dir2 each have identical copies of modfile63b.mod.
+! modfile63b.mod depends on Inputs/dir1/modfile63a.mod - the version in
+! Inputs/dir2/modfile63a.mod has a distinct checksum and should be
+! ignored with a warning.
+
+! If it becomes necessary to recompile those modules, just use the
+! module files as Fortran source.
+
+use modfile63b
+call s2
+end
+
+! ERROR: Could not find a module file for 'modfile63a' in the module search path with the expected checksum
+! WARNING: Module file for 'modfile63a' appears later in the module search path than conflicting modules with different checksums
diff --git a/flang/test/Semantics/test_modfile.py b/flang/test/Semantics/test_modfile.py
index 87bd7dd0b55b80..0e7806f27aa90f 100755
--- a/flang/test/Semantics/test_modfile.py
+++ b/flang/test/Semantics/test_modfile.py
@@ -65,7 +65,7 @@
sys.exit(1)
with open(mod, "r", encoding="utf-8", errors="strict") as f:
for line in f:
- if "!mod$" in line:
+ if "!mod$" in line or "!need$" in line:
continue
actual += line
>From 7a2d9347d333afad4c78f61949b51b1363525ed9 Mon Sep 17 00:00:00 2001
From: alx32 <103613512+alx32 at users.noreply.github.com>
Date: Fri, 1 Mar 2024 14:12:56 -0800
Subject: [PATCH 305/406] [lld][macho][NFC] Add specific namespace scope for
objc symbol names (#83618)
Move symbol names from directly under `objc` scope to
`objc::symbol_names`.
Ex: `objc::klass` -> `objc::symbol_names::klass`
Co-authored-by: Alex B <alexborcan at meta.com>
---
lld/MachO/Driver.cpp | 4 ++--
lld/MachO/InputFiles.cpp | 8 ++++----
lld/MachO/ObjC.h | 2 ++
3 files changed, 8 insertions(+), 6 deletions(-)
diff --git a/lld/MachO/Driver.cpp b/lld/MachO/Driver.cpp
index 018ceec97f204a..9edb6b9c60a1fe 100644
--- a/lld/MachO/Driver.cpp
+++ b/lld/MachO/Driver.cpp
@@ -340,7 +340,7 @@ static InputFile *addFile(StringRef path, LoadType loadType,
}
} else if (isCommandLineLoad && config->forceLoadObjC) {
for (const object::Archive::Symbol &sym : file->getArchive().symbols())
- if (sym.getName().starts_with(objc::klass))
+ if (sym.getName().starts_with(objc::symbol_names::klass))
file->fetch(sym);
// TODO: no need to look for ObjC sections for a given archive member if
@@ -395,7 +395,7 @@ static InputFile *addFile(StringRef path, LoadType loadType,
if ((isa<ObjFile>(newFile) || isa<BitcodeFile>(newFile)) && newFile->lazy &&
config->forceLoadObjC) {
for (Symbol *sym : newFile->symbols)
- if (sym && sym->getName().starts_with(objc::klass)) {
+ if (sym && sym->getName().starts_with(objc::symbol_names::klass)) {
extract(*newFile, "-ObjC");
break;
}
diff --git a/lld/MachO/InputFiles.cpp b/lld/MachO/InputFiles.cpp
index 158c3fbf7b0fca..b36d390cc16ade 100644
--- a/lld/MachO/InputFiles.cpp
+++ b/lld/MachO/InputFiles.cpp
@@ -1921,14 +1921,14 @@ DylibFile::DylibFile(const InterfaceFile &interface, DylibFile *umbrella,
case EncodeKind::ObjectiveCClass:
// XXX ld64 only creates these symbols when -ObjC is passed in. We may
// want to emulate that.
- addSymbol(*symbol, objc::klass + symbol->getName());
- addSymbol(*symbol, objc::metaclass + symbol->getName());
+ addSymbol(*symbol, objc::symbol_names::klass + symbol->getName());
+ addSymbol(*symbol, objc::symbol_names::metaclass + symbol->getName());
break;
case EncodeKind::ObjectiveCClassEHType:
- addSymbol(*symbol, objc::ehtype + symbol->getName());
+ addSymbol(*symbol, objc::symbol_names::ehtype + symbol->getName());
break;
case EncodeKind::ObjectiveCInstanceVariable:
- addSymbol(*symbol, objc::ivar + symbol->getName());
+ addSymbol(*symbol, objc::symbol_names::ivar + symbol->getName());
break;
}
}
diff --git a/lld/MachO/ObjC.h b/lld/MachO/ObjC.h
index 560c5cc0bc509c..4c65f9a1f78812 100644
--- a/lld/MachO/ObjC.h
+++ b/lld/MachO/ObjC.h
@@ -15,10 +15,12 @@ namespace lld::macho {
namespace objc {
+namespace symbol_names {
constexpr const char klass[] = "_OBJC_CLASS_$_";
constexpr const char metaclass[] = "_OBJC_METACLASS_$_";
constexpr const char ehtype[] = "_OBJC_EHTYPE_$_";
constexpr const char ivar[] = "_OBJC_IVAR_$_";
+} // namespace symbol_names
// Check for duplicate method names within related categories / classes.
void checkCategories();
>From 4762c6557d15ba45594793749fea8df6c911f0a8 Mon Sep 17 00:00:00 2001
From: Peter Klausler <35819229+klausler at users.noreply.github.com>
Date: Fri, 1 Mar 2024 14:15:48 -0800
Subject: [PATCH 306/406] [flang][runtime] Underflow real input to -0. when
negative (#82443)
When the result of real input editing underflows to zero, return -0.
when the input field had a minus sign.
---
flang/lib/Decimal/decimal-to-binary.cpp | 8 +++++++-
flang/unittests/Runtime/NumericalFormatTest.cpp | 2 +-
2 files changed, 8 insertions(+), 2 deletions(-)
diff --git a/flang/lib/Decimal/decimal-to-binary.cpp b/flang/lib/Decimal/decimal-to-binary.cpp
index d38af0f9b80050..c5cdb72e355f62 100644
--- a/flang/lib/Decimal/decimal-to-binary.cpp
+++ b/flang/lib/Decimal/decimal-to-binary.cpp
@@ -14,6 +14,7 @@
#include <cinttypes>
#include <cstring>
#include <ctype.h>
+#include <utility>
namespace Fortran::decimal {
@@ -275,7 +276,12 @@ ConversionToBinaryResult<PREC> IntermediateFloat<PREC>::ToBinary(
if (guard != 0) {
flags |= Underflow;
}
- return {Binary{}, static_cast<enum ConversionResultFlags>(flags)};
+ Binary zero;
+ if (isNegative) {
+ zero.Negate();
+ }
+ return {
+ std::move(zero), static_cast<enum ConversionResultFlags>(flags)};
}
}
} else {
diff --git a/flang/unittests/Runtime/NumericalFormatTest.cpp b/flang/unittests/Runtime/NumericalFormatTest.cpp
index 03a2be3ca56df7..37eecd7708a1eb 100644
--- a/flang/unittests/Runtime/NumericalFormatTest.cpp
+++ b/flang/unittests/Runtime/NumericalFormatTest.cpp
@@ -916,7 +916,7 @@ TEST(IOApiTests, EditDoubleInputValues) {
{"(RU,F7.0)", "-1.e999", 0xffefffffffffffff, 0}, // -HUGE()
{"(E9.1)", " 1.0E-325", 0x0, 0},
{"(RU,E9.1)", " 1.0E-325", 0x1, 0},
- {"(E9.1)", "-1.0E-325", 0x0, 0},
+ {"(E9.1)", "-1.0E-325", 0x8000000000000000, 0},
{"(RD,E9.1)", "-1.0E-325", 0x8000000000000001, 0},
};
for (auto const &[format, data, want, iostat] : testCases) {
>From 24aec16ddad465cc1c2fce528bb3eca49ac9fcdb Mon Sep 17 00:00:00 2001
From: erichkeane <ekeane at nvidia.com>
Date: Fri, 1 Mar 2024 14:01:07 -0800
Subject: [PATCH 307/406] [OpenACC] Implement no throw out of Compute construct
Exception handling SHOULD be possible depending on codegen (and if not,
we can make it trap and add a warning when we make that decision), but
throwing out of a compute construct is ill formed.
This patch adds an error for a 'throw' that isn't in a 'try' scope. This
error is imperfect as it won't diagnose a 'throw' that escapes its
'try', or one in a separate function, but it catches the obvious
mistakes. The other cases will need to be handled as runtime failures.
---
.../clang/Basic/DiagnosticSemaKinds.td | 4 +-
clang/include/clang/Sema/Scope.h | 33 ++++------
clang/lib/Sema/SemaExprCXX.cpp | 6 ++
clang/lib/Sema/SemaStmt.cpp | 4 +-
clang/test/SemaOpenACC/no-branch-in-out.cpp | 60 +++++++++++++++++++
5 files changed, 82 insertions(+), 25 deletions(-)
diff --git a/clang/include/clang/Basic/DiagnosticSemaKinds.td b/clang/include/clang/Basic/DiagnosticSemaKinds.td
index 938de5859513f8..b2ea52258fb467 100644
--- a/clang/include/clang/Basic/DiagnosticSemaKinds.td
+++ b/clang/include/clang/Basic/DiagnosticSemaKinds.td
@@ -12217,8 +12217,8 @@ def err_acc_construct_appertainment
: Error<"OpenACC construct '%0' cannot be used here; it can only "
"be used in a statement context">;
def err_acc_branch_in_out_compute_construct
- : Error<"invalid %select{branch|return}0 %select{out of|into}1 OpenACC "
- "Compute Construct">;
+ : Error<"invalid %select{branch|return|throw}0 %select{out of|into}1 "
+ "OpenACC Compute Construct">;
def note_acc_branch_into_compute_construct
: Note<"invalid branch into OpenACC Compute Construct">;
def note_acc_branch_out_of_compute_construct
diff --git a/clang/include/clang/Sema/Scope.h b/clang/include/clang/Sema/Scope.h
index 1cb2fa83e0bb33..536c12cb9d64e1 100644
--- a/clang/include/clang/Sema/Scope.h
+++ b/clang/include/clang/Sema/Scope.h
@@ -43,6 +43,9 @@ class Scope {
/// ScopeFlags - These are bitfields that are or'd together when creating a
/// scope, which defines the sorts of things the scope contains.
enum ScopeFlags {
+ // A bitfield value representing no scopes.
+ NoScope = 0,
+
/// This indicates that the scope corresponds to a function, which
/// means that labels are set here.
FnScope = 0x01,
@@ -521,10 +524,17 @@ class Scope {
return getFlags() & Scope::OpenACCComputeConstructScope;
}
- bool isInOpenACCComputeConstructScope() const {
+ /// Determine if this scope (or its parents) are a compute construct. If the
+ /// argument is provided, the search will stop at any of the specified scopes.
+ /// Otherwise, it will stop only at the normal 'no longer search' scopes.
+ bool isInOpenACCComputeConstructScope(ScopeFlags Flags = NoScope) const {
for (const Scope *S = this; S; S = S->getParent()) {
- if (S->getFlags() & Scope::OpenACCComputeConstructScope)
+ if (S->isOpenACCComputeConstructScope())
return true;
+
+ if (S->getFlags() & Flags)
+ return false;
+
else if (S->getFlags() &
(Scope::FnScope | Scope::ClassScope | Scope::BlockScope |
Scope::TemplateParamScope | Scope::FunctionPrototypeScope |
@@ -534,25 +544,6 @@ class Scope {
return false;
}
- /// Determine if this scope (or its parents) are a compute construct inside of
- /// the nearest 'switch' scope. This is needed to check whether we are inside
- /// of a 'duffs' device, which is an illegal branch into a compute construct.
- bool isInOpenACCComputeConstructBeforeSwitch() const {
- for (const Scope *S = this; S; S = S->getParent()) {
- if (S->getFlags() & Scope::OpenACCComputeConstructScope)
- return true;
- if (S->getFlags() & Scope::SwitchScope)
- return false;
-
- if (S->getFlags() &
- (Scope::FnScope | Scope::ClassScope | Scope::BlockScope |
- Scope::TemplateParamScope | Scope::FunctionPrototypeScope |
- Scope::AtCatchScope | Scope::ObjCMethodScope))
- return false;
- }
- return false;
- }
-
/// Determine whether this scope is a while/do/for statement, which can have
/// continue statements embedded into it.
bool isContinueScope() const {
diff --git a/clang/lib/Sema/SemaExprCXX.cpp b/clang/lib/Sema/SemaExprCXX.cpp
index c4750ce78fa9c1..c34a40fa7c81ac 100644
--- a/clang/lib/Sema/SemaExprCXX.cpp
+++ b/clang/lib/Sema/SemaExprCXX.cpp
@@ -890,6 +890,12 @@ ExprResult Sema::BuildCXXThrow(SourceLocation OpLoc, Expr *Ex,
if (getCurScope() && getCurScope()->isOpenMPSimdDirectiveScope())
Diag(OpLoc, diag::err_omp_simd_region_cannot_use_stmt) << "throw";
+ // Exceptions that escape a compute construct are ill-formed.
+ if (getLangOpts().OpenACC && getCurScope() &&
+ getCurScope()->isInOpenACCComputeConstructScope(Scope::TryScope))
+ Diag(OpLoc, diag::err_acc_branch_in_out_compute_construct)
+ << /*throw*/ 2 << /*out of*/ 0;
+
if (Ex && !Ex->isTypeDependent()) {
// Initialize the exception result. This implicitly weeds out
// abstract types or types with inaccessible copy constructors.
diff --git a/clang/lib/Sema/SemaStmt.cpp b/clang/lib/Sema/SemaStmt.cpp
index 4a15a8f6effd31..e72397adec24fb 100644
--- a/clang/lib/Sema/SemaStmt.cpp
+++ b/clang/lib/Sema/SemaStmt.cpp
@@ -528,7 +528,7 @@ Sema::ActOnCaseStmt(SourceLocation CaseLoc, ExprResult LHSVal,
}
if (LangOpts.OpenACC &&
- getCurScope()->isInOpenACCComputeConstructBeforeSwitch()) {
+ getCurScope()->isInOpenACCComputeConstructScope(Scope::SwitchScope)) {
Diag(CaseLoc, diag::err_acc_branch_in_out_compute_construct)
<< /*branch*/ 0 << /*into*/ 1;
return StmtError();
@@ -554,7 +554,7 @@ Sema::ActOnDefaultStmt(SourceLocation DefaultLoc, SourceLocation ColonLoc,
}
if (LangOpts.OpenACC &&
- getCurScope()->isInOpenACCComputeConstructBeforeSwitch()) {
+ getCurScope()->isInOpenACCComputeConstructScope(Scope::SwitchScope)) {
Diag(DefaultLoc, diag::err_acc_branch_in_out_compute_construct)
<< /*branch*/ 0 << /*into*/ 1;
return StmtError();
diff --git a/clang/test/SemaOpenACC/no-branch-in-out.cpp b/clang/test/SemaOpenACC/no-branch-in-out.cpp
index e7d5683f9bc78b..6ee4553cd30351 100644
--- a/clang/test/SemaOpenACC/no-branch-in-out.cpp
+++ b/clang/test/SemaOpenACC/no-branch-in-out.cpp
@@ -136,6 +136,66 @@ void DuffsDevice() {
}
}
+void Exceptions() {
+#pragma acc parallel
+ for(int i = 0; i < 5; ++i) {
+ throw 5; // expected-error{{invalid throw out of OpenACC Compute Construct}}
+ }
+
+#pragma acc parallel
+ for(int i = 0; i < 5; ++i) {
+ throw; // expected-error{{invalid throw out of OpenACC Compute Construct}}
+ }
+
+#pragma acc parallel
+ for(int i = 0; i < 5; ++i) {
+ try {
+ throw 5;
+ } catch(float f) {
+ }
+ }
+
+#pragma acc parallel
+ for(int i = 0; i < 5; ++i) {
+ try {
+ throw 5;
+ } catch(int f) {
+ }
+ }
+
+#pragma acc parallel
+ for(int i = 0; i < 5; ++i) {
+ try {
+ throw 5;
+ } catch(...) {
+ }
+ }
+#pragma acc parallel
+ for(int i = 0; i < 5; ++i) {
+ try {
+ throw;
+ } catch(...) {
+ }
+ }
+
+#pragma acc parallel
+ for(int i = 0; i < 5; ++i) {
+ try {
+ throw;
+ } catch(...) {
+ throw; // expected-error{{invalid throw out of OpenACC Compute Construct}}
+ }
+ }
+#pragma acc parallel
+ for(int i = 0; i < 5; ++i) {
+ try {
+ throw;
+ } catch(int f) {
+ throw; // expected-error{{invalid throw out of OpenACC Compute Construct}}
+ }
+ }
+}
+
void Instantiate() {
BreakContinue<int>();
DuffsDevice<int>();
>From c21ef15ec651b5570a44a63e01ee4afdbabc3623 Mon Sep 17 00:00:00 2001
From: Peter Klausler <35819229+klausler at users.noreply.github.com>
Date: Fri, 1 Mar 2024 14:28:39 -0800
Subject: [PATCH 308/406] [flang][runtime] Allow 1023 active asynchronous IDs
(#82446)
The present limit of 63 is too low for some tests; bump it up to 1023 by
using an array of bit-sets.
---
flang/runtime/unit.cpp | 21 +++++++++++++--------
flang/runtime/unit.h | 10 +++++++---
2 files changed, 20 insertions(+), 11 deletions(-)
diff --git a/flang/runtime/unit.cpp b/flang/runtime/unit.cpp
index 58ca313d9e4454..09782d2f849278 100644
--- a/flang/runtime/unit.cpp
+++ b/flang/runtime/unit.cpp
@@ -1001,25 +1001,30 @@ int ExternalFileUnit::GetAsynchronousId(IoErrorHandler &handler) {
if (!mayAsynchronous()) {
handler.SignalError(IostatBadAsynchronous);
return -1;
- } else if (auto least{asyncIdAvailable_.LeastElement()}) {
- asyncIdAvailable_.reset(*least);
- return static_cast<int>(*least);
} else {
+ for (int j{0}; 64 * j < maxAsyncIds; ++j) {
+ if (auto least{asyncIdAvailable_[j].LeastElement()}) {
+ asyncIdAvailable_[j].reset(*least);
+ return 64 * j + static_cast<int>(*least);
+ }
+ }
handler.SignalError(IostatTooManyAsyncOps);
return -1;
}
}
bool ExternalFileUnit::Wait(int id) {
- if (static_cast<std::size_t>(id) >= asyncIdAvailable_.size() ||
- asyncIdAvailable_.test(id)) {
+ if (static_cast<std::size_t>(id) >= maxAsyncIds ||
+ asyncIdAvailable_[id / 64].test(id % 64)) {
return false;
} else {
if (id == 0) { // means "all IDs"
- asyncIdAvailable_.set();
- asyncIdAvailable_.reset(0);
+ for (int j{0}; 64 * j < maxAsyncIds; ++j) {
+ asyncIdAvailable_[j].set();
+ }
+ asyncIdAvailable_[0].reset(0);
} else {
- asyncIdAvailable_.set(id);
+ asyncIdAvailable_[id / 64].set(id % 64);
}
return true;
}
diff --git a/flang/runtime/unit.h b/flang/runtime/unit.h
index 140fda3c4d2a81..e3c8757645bb9e 100644
--- a/flang/runtime/unit.h
+++ b/flang/runtime/unit.h
@@ -36,10 +36,14 @@ class ExternalFileUnit : public ConnectionState,
public OpenFile,
public FileFrame<ExternalFileUnit> {
public:
+ static constexpr int maxAsyncIds{64 * 16};
+
explicit ExternalFileUnit(int unitNumber) : unitNumber_{unitNumber} {
isUTF8 = executionEnvironment.defaultUTF8;
- asyncIdAvailable_.set();
- asyncIdAvailable_.reset(0);
+ for (int j{0}; 64 * j < maxAsyncIds; ++j) {
+ asyncIdAvailable_[j].set();
+ }
+ asyncIdAvailable_[0].reset(0);
}
~ExternalFileUnit() {}
@@ -150,7 +154,7 @@ class ExternalFileUnit : public ConnectionState,
std::size_t recordOffsetInFrame_{0}; // of currentRecordNumber
bool swapEndianness_{false};
bool createdForInternalChildIo_{false};
- common::BitSet<64> asyncIdAvailable_;
+ common::BitSet<64> asyncIdAvailable_[maxAsyncIds / 64];
// When a synchronous I/O statement is in progress on this unit, holds its
// state.
>From f31ac3cb1ff7958fadf6e3e431790f2d668583b4 Mon Sep 17 00:00:00 2001
From: Peter Klausler <35819229+klausler at users.noreply.github.com>
Date: Fri, 1 Mar 2024 14:43:31 -0800
Subject: [PATCH 309/406] [flang] Handle implied ASYNCHRONOUS attribute
(#82638)
The standard states that data objects involved in an asynchronous data
transfer statement gain the ASYNCHRONOUS attribute implicitly in the
surrounding subprogram or BLOCK scope. This attribute affects the checks
in call semantics, as an ASYNCHRONOUS actual object associated with an
ASYNCHRONOUS dummy argument must not require data copies in or out.
(Most compilers don't implement implied ASYNCHRONOUS attributes
correctly; XLF gets these right, and GNU is close.)
---
flang/docs/Extensions.md | 5 +
flang/include/flang/Parser/parse-tree.h | 7 +-
flang/lib/Evaluate/characteristics.cpp | 1 +
flang/lib/Semantics/check-call.cpp | 2 +-
flang/lib/Semantics/resolve-names.cpp | 365 ++++++++++++++++--------
flang/test/Semantics/call03.f90 | 74 ++++-
6 files changed, 315 insertions(+), 139 deletions(-)
diff --git a/flang/docs/Extensions.md b/flang/docs/Extensions.md
index 46ef8f07b4a8b3..4bd93f6b6d0f2f 100644
--- a/flang/docs/Extensions.md
+++ b/flang/docs/Extensions.md
@@ -481,6 +481,11 @@ end
* Many compilers disallow a `VALUE` assumed-length character dummy
argument, which has been standard since F'2008.
We accept this usage with an optional portability warning.
+* The `ASYNCHRONOUS` attribute can be implied by usage in data
+ transfer I/O statements. Only one other compiler supports this
+ correctly. This compiler does, apart from objects in asynchronous
+ NAMELIST I/O, for which an actual asynchronous runtime implementation
+ seems unlikely.
## Behavior in cases where the standard is ambiguous or indefinite
diff --git a/flang/include/flang/Parser/parse-tree.h b/flang/include/flang/Parser/parse-tree.h
index a32676be0d6d97..f7b72c3af09164 100644
--- a/flang/include/flang/Parser/parse-tree.h
+++ b/flang/include/flang/Parser/parse-tree.h
@@ -551,7 +551,9 @@ struct ExecutionPartConstruct {
};
// R509 execution-part -> executable-construct [execution-part-construct]...
-WRAPPER_CLASS(ExecutionPart, std::list<ExecutionPartConstruct>);
+// R1101 block -> [execution-part-construct]...
+using Block = std::list<ExecutionPartConstruct>;
+WRAPPER_CLASS(ExecutionPart, Block);
// R502 program-unit ->
// main-program | external-subprogram | module | submodule | block-data
@@ -2115,9 +2117,6 @@ struct ForallConstruct {
t;
};
-// R1101 block -> [execution-part-construct]...
-using Block = std::list<ExecutionPartConstruct>;
-
// R1105 selector -> expr | variable
struct Selector {
UNION_CLASS_BOILERPLATE(Selector);
diff --git a/flang/lib/Evaluate/characteristics.cpp b/flang/lib/Evaluate/characteristics.cpp
index 80b0f346c32d38..5ec9f757b68173 100644
--- a/flang/lib/Evaluate/characteristics.cpp
+++ b/flang/lib/Evaluate/characteristics.cpp
@@ -25,6 +25,7 @@ using namespace Fortran::parser::literals;
namespace Fortran::evaluate::characteristics {
// Copy attributes from a symbol to dst based on the mapping in pairs.
+// An ASYNCHRONOUS attribute counts even if it is implied.
template <typename A, typename B>
static void CopyAttrs(const semantics::Symbol &src, A &dst,
const std::initializer_list<std::pair<semantics::Attr, B>> &pairs) {
diff --git a/flang/lib/Semantics/check-call.cpp b/flang/lib/Semantics/check-call.cpp
index fdf7805beab7ed..cd9150bdda4bd3 100644
--- a/flang/lib/Semantics/check-call.cpp
+++ b/flang/lib/Semantics/check-call.cpp
@@ -674,7 +674,7 @@ static void CheckExplicitDataArg(const characteristics::DummyDataObject &dummy,
!(dummyIsAssumedShape || dummyIsAssumedRank ||
(actualIsPointer && dummyIsPointer))) { // C1539 & C1540
messages.Say(
- "ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous %s"_err_en_US,
+ "ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous ASYNCHRONOUS or VOLATILE %s"_err_en_US,
dummyName);
}
}
diff --git a/flang/lib/Semantics/resolve-names.cpp b/flang/lib/Semantics/resolve-names.cpp
index 7b40e2bbc53328..7de513d8769aed 100644
--- a/flang/lib/Semantics/resolve-names.cpp
+++ b/flang/lib/Semantics/resolve-names.cpp
@@ -1225,8 +1225,7 @@ class ConstructVisitor : public virtual DeclarationVisitor {
void Post(const parser::ForallConstruct &);
bool Pre(const parser::ForallStmt &);
void Post(const parser::ForallStmt &);
- bool Pre(const parser::BlockStmt &);
- bool Pre(const parser::EndBlockStmt &);
+ bool Pre(const parser::BlockConstruct &);
void Post(const parser::Selector &);
void Post(const parser::AssociateStmt &);
void Post(const parser::EndAssociateStmt &);
@@ -1283,6 +1282,8 @@ class ConstructVisitor : public virtual DeclarationVisitor {
void Post(const parser::CycleStmt &x) { CheckRef(x.v); }
void Post(const parser::ExitStmt &x) { CheckRef(x.v); }
+ void HandleImpliedAsynchronousInScope(const parser::Block &);
+
private:
// R1105 selector -> expr | variable
// expr is set in either case unless there were errors
@@ -6957,14 +6958,17 @@ bool ConstructVisitor::Pre(const parser::ForallStmt &) {
}
void ConstructVisitor::Post(const parser::ForallStmt &) { PopScope(); }
-bool ConstructVisitor::Pre(const parser::BlockStmt &x) {
- CheckDef(x.v);
+bool ConstructVisitor::Pre(const parser::BlockConstruct &x) {
+ const auto &[blockStmt, specPart, execPart, endBlockStmt] = x.t;
+ Walk(blockStmt);
+ CheckDef(blockStmt.statement.v);
PushScope(Scope::Kind::BlockConstruct, nullptr);
- return false;
-}
-bool ConstructVisitor::Pre(const parser::EndBlockStmt &x) {
+ Walk(specPart);
+ HandleImpliedAsynchronousInScope(execPart);
+ Walk(execPart);
+ Walk(endBlockStmt);
PopScope();
- CheckRef(x.v);
+ CheckRef(endBlockStmt.statement.v);
return false;
}
@@ -7338,6 +7342,224 @@ const DeclTypeSpec &ConstructVisitor::ToDeclTypeSpec(
}
}
+class ExecutionPartSkimmerBase {
+public:
+ template <typename A> bool Pre(const A &) { return true; }
+ template <typename A> void Post(const A &) {}
+
+ bool InNestedBlockConstruct() const { return blockDepth_ > 0; }
+
+ bool Pre(const parser::AssociateConstruct &) {
+ PushScope();
+ return true;
+ }
+ void Post(const parser::AssociateConstruct &) { PopScope(); }
+ bool Pre(const parser::Association &x) {
+ Hide(std::get<parser::Name>(x.t));
+ return true;
+ }
+ bool Pre(const parser::BlockConstruct &) {
+ PushScope();
+ ++blockDepth_;
+ return true;
+ }
+ void Post(const parser::BlockConstruct &) {
+ --blockDepth_;
+ PopScope();
+ }
+ bool Pre(const parser::EntityDecl &x) {
+ Hide(std::get<parser::ObjectName>(x.t));
+ return true;
+ }
+ void Post(const parser::ImportStmt &x) {
+ if (x.kind == common::ImportKind::None ||
+ x.kind == common::ImportKind::Only) {
+ if (!nestedScopes_.front().importOnly.has_value()) {
+ nestedScopes_.front().importOnly.emplace();
+ }
+ for (const auto &name : x.names) {
+ nestedScopes_.front().importOnly->emplace(name.source);
+ }
+ } else {
+ // no special handling needed for explicit names or IMPORT, ALL
+ }
+ }
+ void Post(const parser::UseStmt &x) {
+ if (const auto *onlyList{std::get_if<std::list<parser::Only>>(&x.u)}) {
+ for (const auto &only : *onlyList) {
+ if (const auto *name{std::get_if<parser::Name>(&only.u)}) {
+ Hide(*name);
+ } else if (const auto *rename{std::get_if<parser::Rename>(&only.u)}) {
+ if (const auto *names{
+ std::get_if<parser::Rename::Names>(&rename->u)}) {
+ Hide(std::get<0>(names->t));
+ }
+ }
+ }
+ } else {
+ // USE may or may not shadow symbols in host scopes
+ nestedScopes_.front().hasUseWithoutOnly = true;
+ }
+ }
+ bool Pre(const parser::DerivedTypeStmt &x) {
+ Hide(std::get<parser::Name>(x.t));
+ PushScope();
+ return true;
+ }
+ void Post(const parser::DerivedTypeDef &) { PopScope(); }
+ bool Pre(const parser::SelectTypeConstruct &) {
+ PushScope();
+ return true;
+ }
+ void Post(const parser::SelectTypeConstruct &) { PopScope(); }
+ bool Pre(const parser::SelectTypeStmt &x) {
+ if (const auto &maybeName{std::get<1>(x.t)}) {
+ Hide(*maybeName);
+ }
+ return true;
+ }
+ bool Pre(const parser::SelectRankConstruct &) {
+ PushScope();
+ return true;
+ }
+ void Post(const parser::SelectRankConstruct &) { PopScope(); }
+ bool Pre(const parser::SelectRankStmt &x) {
+ if (const auto &maybeName{std::get<1>(x.t)}) {
+ Hide(*maybeName);
+ }
+ return true;
+ }
+
+protected:
+ bool IsHidden(SourceName name) {
+ for (const auto &scope : nestedScopes_) {
+ if (scope.locals.find(name) != scope.locals.end()) {
+ return true; // shadowed by nested declaration
+ }
+ if (scope.hasUseWithoutOnly) {
+ break;
+ }
+ if (scope.importOnly &&
+ scope.importOnly->find(name) == scope.importOnly->end()) {
+ return true; // not imported
+ }
+ }
+ return false;
+ }
+
+ void EndWalk() { CHECK(nestedScopes_.empty()); }
+
+private:
+ void PushScope() { nestedScopes_.emplace_front(); }
+ void PopScope() { nestedScopes_.pop_front(); }
+ void Hide(const parser::Name &name) {
+ nestedScopes_.front().locals.emplace(name.source);
+ }
+
+ int blockDepth_{0};
+ struct NestedScopeInfo {
+ bool hasUseWithoutOnly{false};
+ std::set<SourceName> locals;
+ std::optional<std::set<SourceName>> importOnly;
+ };
+ std::list<NestedScopeInfo> nestedScopes_;
+};
+
+class ExecutionPartAsyncIOSkimmer : public ExecutionPartSkimmerBase {
+public:
+ explicit ExecutionPartAsyncIOSkimmer(SemanticsContext &context)
+ : context_{context} {}
+
+ void Walk(const parser::Block &block) {
+ parser::Walk(block, *this);
+ EndWalk();
+ }
+
+ const std::set<SourceName> asyncIONames() const { return asyncIONames_; }
+
+ using ExecutionPartSkimmerBase::Post;
+ using ExecutionPartSkimmerBase::Pre;
+
+ bool Pre(const parser::IoControlSpec::Asynchronous &async) {
+ if (auto folded{evaluate::Fold(
+ context_.foldingContext(), AnalyzeExpr(context_, async.v))}) {
+ if (auto str{
+ evaluate::GetScalarConstantValue<evaluate::Ascii>(*folded)}) {
+ for (char ch : *str) {
+ if (ch != ' ') {
+ inAsyncIO_ = ch == 'y' || ch == 'Y';
+ break;
+ }
+ }
+ }
+ }
+ return true;
+ }
+ void Post(const parser::ReadStmt &) { inAsyncIO_ = false; }
+ void Post(const parser::WriteStmt &) { inAsyncIO_ = false; }
+ void Post(const parser::IoControlSpec::Size &size) {
+ if (const auto *designator{
+ std::get_if<common::Indirection<parser::Designator>>(
+ &size.v.thing.thing.u)}) {
+ NoteAsyncIODesignator(designator->value());
+ }
+ }
+ void Post(const parser::InputItem &x) {
+ if (const auto *var{std::get_if<parser::Variable>(&x.u)}) {
+ if (const auto *designator{
+ std::get_if<common::Indirection<parser::Designator>>(&var->u)}) {
+ NoteAsyncIODesignator(designator->value());
+ }
+ }
+ }
+ void Post(const parser::OutputItem &x) {
+ if (const auto *expr{std::get_if<parser::Expr>(&x.u)}) {
+ if (const auto *designator{
+ std::get_if<common::Indirection<parser::Designator>>(&expr->u)}) {
+ NoteAsyncIODesignator(designator->value());
+ }
+ }
+ }
+
+private:
+ void NoteAsyncIODesignator(const parser::Designator &designator) {
+ if (inAsyncIO_ && !InNestedBlockConstruct()) {
+ const parser::Name &name{parser::GetFirstName(designator)};
+ if (!IsHidden(name.source)) {
+ asyncIONames_.insert(name.source);
+ }
+ }
+ }
+
+ SemanticsContext &context_;
+ bool inAsyncIO_{false};
+ std::set<SourceName> asyncIONames_;
+};
+
+// Any data list item or SIZE= specifier of an I/O data transfer statement
+// with ASYNCHRONOUS="YES" implicitly has the ASYNCHRONOUS attribute in the
+// local scope.
+void ConstructVisitor::HandleImpliedAsynchronousInScope(
+ const parser::Block &block) {
+ ExecutionPartAsyncIOSkimmer skimmer{context()};
+ skimmer.Walk(block);
+ for (auto name : skimmer.asyncIONames()) {
+ if (Symbol * symbol{currScope().FindSymbol(name)}) {
+ if (!symbol->attrs().test(Attr::ASYNCHRONOUS)) {
+ if (&symbol->owner() != &currScope()) {
+ symbol = &*currScope()
+ .try_emplace(name, HostAssocDetails{*symbol})
+ .first->second;
+ }
+ if (symbol->has<AssocEntityDetails>()) {
+ symbol = const_cast<Symbol *>(&GetAssociationRoot(*symbol));
+ }
+ SetImplicitAttr(*symbol, Attr::ASYNCHRONOUS);
+ }
+ }
+ }
+}
+
// ResolveNamesVisitor implementation
bool ResolveNamesVisitor::Pre(const parser::FunctionReference &x) {
@@ -8668,138 +8890,38 @@ bool ResolveNamesVisitor::Pre(const parser::Program &x) {
// References to procedures need to record that their symbols are known
// to be procedures, so that they don't get converted to objects by default.
-class ExecutionPartSkimmer {
+class ExecutionPartCallSkimmer : public ExecutionPartSkimmerBase {
public:
- explicit ExecutionPartSkimmer(ResolveNamesVisitor &resolver)
+ explicit ExecutionPartCallSkimmer(ResolveNamesVisitor &resolver)
: resolver_{resolver} {}
- void Walk(const parser::ExecutionPart *exec) {
- if (exec) {
- parser::Walk(*exec, *this);
- CHECK(nestedScopes_.empty());
- }
+ void Walk(const parser::ExecutionPart &exec) {
+ parser::Walk(exec, *this);
+ EndWalk();
}
- template <typename A> bool Pre(const A &) { return true; }
- template <typename A> void Post(const A &) {}
+ using ExecutionPartSkimmerBase::Post;
+ using ExecutionPartSkimmerBase::Pre;
+
void Post(const parser::FunctionReference &fr) {
NoteCall(Symbol::Flag::Function, fr.v, false);
}
void Post(const parser::CallStmt &cs) {
NoteCall(Symbol::Flag::Subroutine, cs.call, cs.chevrons.has_value());
}
- bool Pre(const parser::AssociateConstruct &) {
- PushScope();
- return true;
- }
- void Post(const parser::AssociateConstruct &) { PopScope(); }
- bool Pre(const parser::Association &x) {
- Hide(std::get<parser::Name>(x.t));
- return true;
- }
- bool Pre(const parser::BlockConstruct &) {
- PushScope();
- return true;
- }
- void Post(const parser::BlockConstruct &) { PopScope(); }
- bool Pre(const parser::EntityDecl &x) {
- Hide(std::get<parser::ObjectName>(x.t));
- return true;
- }
- void Post(const parser::ImportStmt &x) {
- if (x.kind == common::ImportKind::None ||
- x.kind == common::ImportKind::Only) {
- if (!nestedScopes_.front().importOnly.has_value()) {
- nestedScopes_.front().importOnly.emplace();
- }
- for (const auto &name : x.names) {
- nestedScopes_.front().importOnly->emplace(name.source);
- }
- } else {
- // no special handling needed for explicit names or IMPORT, ALL
- }
- }
- void Post(const parser::UseStmt &x) {
- if (const auto *onlyList{std::get_if<std::list<parser::Only>>(&x.u)}) {
- for (const auto &only : *onlyList) {
- if (const auto *name{std::get_if<parser::Name>(&only.u)}) {
- Hide(*name);
- } else if (const auto *rename{std::get_if<parser::Rename>(&only.u)}) {
- if (const auto *names{
- std::get_if<parser::Rename::Names>(&rename->u)}) {
- Hide(std::get<0>(names->t));
- }
- }
- }
- } else {
- // USE may or may not shadow symbols in host scopes
- nestedScopes_.front().hasUseWithoutOnly = true;
- }
- }
- bool Pre(const parser::DerivedTypeStmt &x) {
- Hide(std::get<parser::Name>(x.t));
- PushScope();
- return true;
- }
- void Post(const parser::DerivedTypeDef &) { PopScope(); }
- bool Pre(const parser::SelectTypeConstruct &) {
- PushScope();
- return true;
- }
- void Post(const parser::SelectTypeConstruct &) { PopScope(); }
- bool Pre(const parser::SelectTypeStmt &x) {
- if (const auto &maybeName{std::get<1>(x.t)}) {
- Hide(*maybeName);
- }
- return true;
- }
- bool Pre(const parser::SelectRankConstruct &) {
- PushScope();
- return true;
- }
- void Post(const parser::SelectRankConstruct &) { PopScope(); }
- bool Pre(const parser::SelectRankStmt &x) {
- if (const auto &maybeName{std::get<1>(x.t)}) {
- Hide(*maybeName);
- }
- return true;
- }
private:
void NoteCall(
Symbol::Flag flag, const parser::Call &call, bool hasCUDAChevrons) {
auto &designator{std::get<parser::ProcedureDesignator>(call.t)};
if (const auto *name{std::get_if<parser::Name>(&designator.u)}) {
- for (const auto &scope : nestedScopes_) {
- if (scope.locals.find(name->source) != scope.locals.end()) {
- return; // shadowed by nested declaration
- }
- if (scope.hasUseWithoutOnly) {
- break;
- }
- if (scope.importOnly &&
- scope.importOnly->find(name->source) == scope.importOnly->end()) {
- return; // not imported
- }
+ if (!IsHidden(name->source)) {
+ resolver_.NoteExecutablePartCall(flag, name->source, hasCUDAChevrons);
}
- resolver_.NoteExecutablePartCall(flag, name->source, hasCUDAChevrons);
}
}
- void PushScope() { nestedScopes_.emplace_front(); }
- void PopScope() { nestedScopes_.pop_front(); }
- void Hide(const parser::Name &name) {
- nestedScopes_.front().locals.emplace(name.source);
- }
-
ResolveNamesVisitor &resolver_;
-
- struct NestedScopeInfo {
- bool hasUseWithoutOnly{false};
- std::set<SourceName> locals;
- std::optional<std::set<SourceName>> importOnly;
- };
- std::list<NestedScopeInfo> nestedScopes_;
};
// Build the scope tree and resolve names in the specification parts of this
@@ -8844,7 +8966,10 @@ void ResolveNamesVisitor::ResolveSpecificationParts(ProgramTree &node) {
for (auto &child : node.children()) {
ResolveSpecificationParts(child);
}
- ExecutionPartSkimmer{*this}.Walk(node.exec());
+ if (node.exec()) {
+ ExecutionPartCallSkimmer{*this}.Walk(*node.exec());
+ HandleImpliedAsynchronousInScope(node.exec()->v);
+ }
EndScopeForNode(node);
// Ensure that every object entity has a type.
for (auto &pair : *node.scope()) {
@@ -8979,8 +9104,6 @@ class DeferredCheckVisitor {
}
}
- bool Pre(const parser::BlockConstruct &x) { return true; }
-
void Post(const parser::ProcInterface &pi) {
if (const auto *name{std::get_if<parser::Name>(&pi.u)}) {
resolver_.CheckExplicitInterface(*name);
diff --git a/flang/test/Semantics/call03.f90 b/flang/test/Semantics/call03.f90
index 2aca8de93acb05..bb7a8cb05c5acb 100644
--- a/flang/test/Semantics/call03.f90
+++ b/flang/test/Semantics/call03.f90
@@ -357,19 +357,19 @@ subroutine test15(assumedrank) ! C1539
call valueassumedsize(b(::2)) ! ok
call valueassumedsize(c(::2)) ! ok
call valueassumedsize(d(::2)) ! ok
- !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous dummy argument 'x='
+ !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous ASYNCHRONOUS or VOLATILE dummy argument 'x='
call volatileassumedsize(b(::2))
- !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous dummy argument 'x='
+ !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous ASYNCHRONOUS or VOLATILE dummy argument 'x='
call volatilecontiguous(b(::2))
- !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous dummy argument 'x='
+ !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous ASYNCHRONOUS or VOLATILE dummy argument 'x='
call volatileassumedsize(c(::2))
- !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous dummy argument 'x='
+ !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous ASYNCHRONOUS or VOLATILE dummy argument 'x='
call volatilecontiguous(c(::2))
- !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous dummy argument 'x='
+ !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous ASYNCHRONOUS or VOLATILE dummy argument 'x='
call volatileassumedsize(d(::2))
- !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous dummy argument 'x='
+ !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous ASYNCHRONOUS or VOLATILE dummy argument 'x='
call volatilecontiguous(d(::2))
- !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous dummy argument 'x='
+ !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous ASYNCHRONOUS or VOLATILE dummy argument 'x='
call volatilecontiguous(assumedrank)
end subroutine
@@ -388,18 +388,66 @@ subroutine test16() ! C1540
call valueassumedsize(b) ! ok
call valueassumedsize(c) ! ok
call valueassumedsize(d) ! ok
- !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous dummy argument 'x='
+ !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous ASYNCHRONOUS or VOLATILE dummy argument 'x='
call volatileassumedsize(b)
- !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous dummy argument 'x='
+ !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous ASYNCHRONOUS or VOLATILE dummy argument 'x='
call volatilecontiguous(b)
- !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous dummy argument 'x='
+ !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous ASYNCHRONOUS or VOLATILE dummy argument 'x='
call volatileassumedsize(c)
- !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous dummy argument 'x='
+ !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous ASYNCHRONOUS or VOLATILE dummy argument 'x='
call volatilecontiguous(c)
- !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous dummy argument 'x='
+ !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous ASYNCHRONOUS or VOLATILE dummy argument 'x='
call volatileassumedsize(d)
- !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous dummy argument 'x='
+ !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous ASYNCHRONOUS or VOLATILE dummy argument 'x='
call volatilecontiguous(d)
end subroutine
+ subroutine explicitAsyncContig(x)
+ real, asynchronous, intent(in out), contiguous :: x(:)
+ end
+ subroutine implicitAsyncContig(x)
+ real, intent(in out), contiguous :: x(:)
+ read(1,id=id,asynchronous="yes") x
+ end
+ subroutine test17explicit(x)
+ real, asynchronous, intent(in out) :: x(:)
+ !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous ASYNCHRONOUS or VOLATILE dummy argument 'x='
+ call explicitAsyncContig(x)
+ !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous ASYNCHRONOUS or VOLATILE dummy argument 'x='
+ call implicitAsyncContig(x)
+ end
+ subroutine test17implicit(x)
+ real, intent(in out) :: x(:)
+ read(1,id=id,asynchronous="yes") x
+ !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous ASYNCHRONOUS or VOLATILE dummy argument 'x='
+ call explicitAsyncContig(x)
+ !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous ASYNCHRONOUS or VOLATILE dummy argument 'x='
+ call implicitAsyncContig(x)
+ end
+ subroutine test17block(x)
+ real, intent(in out) :: x(:)
+ call explicitAsyncContig(x) ! ok
+ call implicitAsyncContig(x) ! ok
+ block
+ read(1,id=id,asynchronous="yes") x
+ !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous ASYNCHRONOUS or VOLATILE dummy argument 'x='
+ call explicitAsyncContig(x)
+ !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous ASYNCHRONOUS or VOLATILE dummy argument 'x='
+ call implicitAsyncContig(x)
+ end block
+ end
+ subroutine test17internal(x)
+ real, intent(in out) :: x(:)
+ call explicitAsyncContig(x) ! ok
+ call implicitAsyncContig(x) ! ok
+ contains
+ subroutine internal
+ read(1,id=id,asynchronous="yes") x
+ !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous ASYNCHRONOUS or VOLATILE dummy argument 'x='
+ call explicitAsyncContig(x)
+ !ERROR: ASYNCHRONOUS or VOLATILE actual argument that is not simply contiguous may not be associated with a contiguous ASYNCHRONOUS or VOLATILE dummy argument 'x='
+ call implicitAsyncContig(x)
+ end
+ end
+
end module
>From 17ede03a926a8d8d35d887f1fe805b35e2078d5a Mon Sep 17 00:00:00 2001
From: Cyndy Ishida <cyndy_ishida at apple.com>
Date: Fri, 1 Mar 2024 14:56:20 -0800
Subject: [PATCH 310/406] [InstallAPI] Collect frontend attributes &
ObjCInterface decls (#83378)
* This patch introduces a container class, for holding records and
attributes only collectible from the clang frontend, which is a subclass
of `llvm::MachO::RecordsSlice`
* This also prunes out collecting declarations from headers that aren't
considered input to installapi.
* Uses these constructs for collecting global objective-c interfaces.
---
clang/include/clang/InstallAPI/Context.h | 30 ++++++-
clang/include/clang/InstallAPI/Frontend.h | 68 +++++++++++++--
clang/include/clang/InstallAPI/Visitor.h | 17 +++-
clang/lib/InstallAPI/Frontend.cpp | 71 +++++++++++++++-
clang/lib/InstallAPI/Visitor.cpp | 74 ++++++++++++++--
clang/test/InstallAPI/objcclasses.test | 85 +++++++++++++++++++
.../clang-installapi/ClangInstallAPI.cpp | 8 +-
7 files changed, 331 insertions(+), 22 deletions(-)
create mode 100644 clang/test/InstallAPI/objcclasses.test
diff --git a/clang/include/clang/InstallAPI/Context.h b/clang/include/clang/InstallAPI/Context.h
index 3e2046642c7fe8..4e9e90e5d2dbec 100644
--- a/clang/include/clang/InstallAPI/Context.h
+++ b/clang/include/clang/InstallAPI/Context.h
@@ -12,12 +12,12 @@
#include "clang/Basic/Diagnostic.h"
#include "clang/Basic/FileManager.h"
#include "clang/InstallAPI/HeaderFile.h"
+#include "llvm/ADT/DenseMap.h"
#include "llvm/TextAPI/InterfaceFile.h"
-#include "llvm/TextAPI/RecordVisitor.h"
-#include "llvm/TextAPI/RecordsSlice.h"
namespace clang {
namespace installapi {
+class FrontendRecordsSlice;
/// Struct used for generating validating InstallAPI.
/// The attributes captured represent all necessary information
@@ -37,7 +37,7 @@ struct InstallAPIContext {
HeaderType Type = HeaderType::Unknown;
/// Active TargetSlice for symbol record collection.
- std::shared_ptr<llvm::MachO::RecordsSlice> Slice;
+ std::shared_ptr<FrontendRecordsSlice> Slice;
/// FileManager for all I/O operations.
FileManager *FM = nullptr;
@@ -50,6 +50,30 @@ struct InstallAPIContext {
/// What encoding to write output as.
llvm::MachO::FileType FT = llvm::MachO::FileType::TBD_V5;
+
+ /// Populate entries of headers that should be included for TextAPI
+ /// generation.
+ void addKnownHeader(const HeaderFile &H);
+
+ /// Record visited files during frontend actions to determine whether to
+ /// include their declarations for TextAPI generation.
+ ///
+ /// \param FE Header that is being parsed.
+ /// \param PP Preprocesser used for querying how header was imported.
+ /// \return Access level of header if it should be included for TextAPI
+ /// generation.
+ std::optional<HeaderType> findAndRecordFile(const FileEntry *FE,
+ const Preprocessor &PP);
+
+private:
+ using HeaderMap = llvm::DenseMap<const FileEntry *, HeaderType>;
+
+ // Collection of parsed header files and their access level. If set to
+ // HeaderType::Unknown, they are not used for TextAPI generation.
+ HeaderMap KnownFiles;
+
+ // Collection of expected header includes and the access level for them.
+ llvm::DenseMap<StringRef, HeaderType> KnownIncludes;
};
} // namespace installapi
diff --git a/clang/include/clang/InstallAPI/Frontend.h b/clang/include/clang/InstallAPI/Frontend.h
index 7ee87ae028d079..d72b4680fde400 100644
--- a/clang/include/clang/InstallAPI/Frontend.h
+++ b/clang/include/clang/InstallAPI/Frontend.h
@@ -14,6 +14,7 @@
#define LLVM_CLANG_INSTALLAPI_FRONTEND_H
#include "clang/AST/ASTConsumer.h"
+#include "clang/AST/Availability.h"
#include "clang/Frontend/CompilerInstance.h"
#include "clang/Frontend/FrontendActions.h"
#include "clang/InstallAPI/Context.h"
@@ -24,23 +25,78 @@
namespace clang {
namespace installapi {
+using SymbolFlags = llvm::MachO::SymbolFlags;
+using RecordLinkage = llvm::MachO::RecordLinkage;
+using GlobalRecord = llvm::MachO::GlobalRecord;
+using ObjCInterfaceRecord = llvm::MachO::ObjCInterfaceRecord;
+
+// Represents a collection of frontend records for a library that are tied to a
+// darwin target triple.
+class FrontendRecordsSlice : public llvm::MachO::RecordsSlice {
+public:
+ FrontendRecordsSlice(const llvm::Triple &T)
+ : llvm::MachO::RecordsSlice({T}) {}
+
+ /// Add non-ObjC global record with attributes from AST.
+ ///
+ /// \param Name The name of symbol.
+ /// \param Linkage The linkage of symbol.
+ /// \param GV The kind of global.
+ /// \param Avail The availability information tied to the active target
+ /// triple.
+ /// \param D The pointer to the declaration from traversing AST.
+ /// \param Access The intended access level of symbol.
+ /// \param Flags The flags that describe attributes of the symbol.
+ /// \return The non-owning pointer to added record in slice.
+ GlobalRecord *addGlobal(StringRef Name, RecordLinkage Linkage,
+ GlobalRecord::Kind GV,
+ const clang::AvailabilityInfo Avail, const Decl *D,
+ const HeaderType Access,
+ SymbolFlags Flags = SymbolFlags::None);
+
+ /// Add ObjC Class record with attributes from AST.
+ ///
+ /// \param Name The name of class, not symbol.
+ /// \param Linkage The linkage of symbol.
+ /// \param Avail The availability information tied to the active target
+ /// triple.
+ /// \param D The pointer to the declaration from traversing AST.
+ /// \param Access The intended access level of symbol.
+ /// \param IsEHType Whether declaration has an exception attribute.
+ /// \return The non-owning pointer to added record in slice.
+ ObjCInterfaceRecord *addObjCInterface(StringRef Name, RecordLinkage Linkage,
+ const clang::AvailabilityInfo Avail,
+ const Decl *D, HeaderType Access,
+ bool IsEHType);
+
+private:
+ /// Frontend information captured about records.
+ struct FrontendAttrs {
+ const AvailabilityInfo Avail;
+ const Decl *D;
+ const HeaderType Access;
+ };
+
+ /// Mapping of records stored in slice to their frontend attributes.
+ llvm::DenseMap<llvm::MachO::Record *, FrontendAttrs> FrontendRecords;
+};
+
/// Create a buffer that contains all headers to scan
/// for global symbols with.
-std::unique_ptr<llvm::MemoryBuffer>
-createInputBuffer(const InstallAPIContext &Ctx);
+std::unique_ptr<llvm::MemoryBuffer> createInputBuffer(InstallAPIContext &Ctx);
class InstallAPIAction : public ASTFrontendAction {
public:
- explicit InstallAPIAction(llvm::MachO::RecordsSlice &Records)
- : Records(Records) {}
+ explicit InstallAPIAction(InstallAPIContext &Ctx) : Ctx(Ctx) {}
std::unique_ptr<ASTConsumer> CreateASTConsumer(CompilerInstance &CI,
StringRef InFile) override {
- return std::make_unique<InstallAPIVisitor>(CI.getASTContext(), Records);
+ return std::make_unique<InstallAPIVisitor>(
+ CI.getASTContext(), Ctx, CI.getSourceManager(), CI.getPreprocessor());
}
private:
- llvm::MachO::RecordsSlice &Records;
+ InstallAPIContext &Ctx;
};
} // namespace installapi
} // namespace clang
diff --git a/clang/include/clang/InstallAPI/Visitor.h b/clang/include/clang/InstallAPI/Visitor.h
index 95d669688e4f9c..60a05005df841a 100644
--- a/clang/include/clang/InstallAPI/Visitor.h
+++ b/clang/include/clang/InstallAPI/Visitor.h
@@ -17,8 +17,8 @@
#include "clang/AST/RecursiveASTVisitor.h"
#include "clang/Basic/TargetInfo.h"
#include "clang/Frontend/FrontendActions.h"
+#include "clang/InstallAPI/Context.h"
#include "llvm/ADT/Twine.h"
-#include "llvm/TextAPI/RecordsSlice.h"
namespace clang {
namespace installapi {
@@ -27,8 +27,9 @@ namespace installapi {
class InstallAPIVisitor final : public ASTConsumer,
public RecursiveASTVisitor<InstallAPIVisitor> {
public:
- InstallAPIVisitor(ASTContext &ASTCtx, llvm::MachO::RecordsSlice &Slice)
- : Slice(Slice),
+ InstallAPIVisitor(ASTContext &ASTCtx, InstallAPIContext &Ctx,
+ SourceManager &SrcMgr, Preprocessor &PP)
+ : Ctx(Ctx), SrcMgr(SrcMgr), PP(PP),
MC(ItaniumMangleContext::create(ASTCtx, ASTCtx.getDiagnostics())),
Layout(ASTCtx.getTargetInfo().getDataLayoutString()) {}
void HandleTranslationUnit(ASTContext &ASTCtx) override;
@@ -36,11 +37,19 @@ class InstallAPIVisitor final : public ASTConsumer,
/// Collect global variables.
bool VisitVarDecl(const VarDecl *D);
+ /// Collect Objective-C Interface declarations.
+ /// Every Objective-C class has an interface declaration that lists all the
+ /// ivars, properties, and methods of the class.
+ bool VisitObjCInterfaceDecl(const ObjCInterfaceDecl *D);
+
private:
std::string getMangledName(const NamedDecl *D) const;
std::string getBackendMangledName(llvm::Twine Name) const;
+ std::optional<HeaderType> getAccessForDecl(const NamedDecl *D) const;
- llvm::MachO::RecordsSlice &Slice;
+ InstallAPIContext &Ctx;
+ SourceManager &SrcMgr;
+ Preprocessor &PP;
std::unique_ptr<clang::ItaniumMangleContext> MC;
StringRef Layout;
};
diff --git a/clang/lib/InstallAPI/Frontend.cpp b/clang/lib/InstallAPI/Frontend.cpp
index 133e49230ffa9b..caa6e7e8a40544 100644
--- a/clang/lib/InstallAPI/Frontend.cpp
+++ b/clang/lib/InstallAPI/Frontend.cpp
@@ -16,6 +16,73 @@ using namespace llvm::MachO;
namespace clang::installapi {
+GlobalRecord *FrontendRecordsSlice::addGlobal(
+ StringRef Name, RecordLinkage Linkage, GlobalRecord::Kind GV,
+ const clang::AvailabilityInfo Avail, const Decl *D, const HeaderType Access,
+ SymbolFlags Flags) {
+
+ auto *GR = llvm::MachO::RecordsSlice::addGlobal(Name, Linkage, GV, Flags);
+ FrontendRecords.insert({GR, FrontendAttrs{Avail, D, Access}});
+ return GR;
+}
+
+ObjCInterfaceRecord *FrontendRecordsSlice::addObjCInterface(
+ StringRef Name, RecordLinkage Linkage, const clang::AvailabilityInfo Avail,
+ const Decl *D, HeaderType Access, bool IsEHType) {
+ ObjCIFSymbolKind SymType =
+ ObjCIFSymbolKind::Class | ObjCIFSymbolKind::MetaClass;
+ if (IsEHType)
+ SymType |= ObjCIFSymbolKind::EHType;
+ auto *ObjCR =
+ llvm::MachO::RecordsSlice::addObjCInterface(Name, Linkage, SymType);
+ FrontendRecords.insert({ObjCR, FrontendAttrs{Avail, D, Access}});
+ return ObjCR;
+}
+
+std::optional<HeaderType>
+InstallAPIContext::findAndRecordFile(const FileEntry *FE,
+ const Preprocessor &PP) {
+ if (!FE)
+ return std::nullopt;
+
+ // Check if header has been looked up already and whether it is something
+ // installapi should use.
+ auto It = KnownFiles.find(FE);
+ if (It != KnownFiles.end()) {
+ if (It->second != HeaderType::Unknown)
+ return It->second;
+ else
+ return std::nullopt;
+ }
+
+ // If file was not found, search by how the header was
+ // included. This is primarily to resolve headers found
+ // in a different location than what passed directly as input.
+ StringRef IncludeName = PP.getHeaderSearchInfo().getIncludeNameForHeader(FE);
+ auto BackupIt = KnownIncludes.find(IncludeName.str());
+ if (BackupIt != KnownIncludes.end()) {
+ KnownFiles[FE] = BackupIt->second;
+ return BackupIt->second;
+ }
+
+ // Record that the file was found to avoid future string searches for the
+ // same file.
+ KnownFiles.insert({FE, HeaderType::Unknown});
+ return std::nullopt;
+}
+
+void InstallAPIContext::addKnownHeader(const HeaderFile &H) {
+ auto FE = FM->getFile(H.getPath());
+ if (!FE)
+ return; // File does not exist.
+ KnownFiles[*FE] = H.getType();
+
+ if (!H.useIncludeName())
+ return;
+
+ KnownIncludes[H.getIncludeName()] = H.getType();
+}
+
static StringRef getFileExtension(clang::Language Lang) {
switch (Lang) {
default:
@@ -31,7 +98,7 @@ static StringRef getFileExtension(clang::Language Lang) {
}
}
-std::unique_ptr<MemoryBuffer> createInputBuffer(const InstallAPIContext &Ctx) {
+std::unique_ptr<MemoryBuffer> createInputBuffer(InstallAPIContext &Ctx) {
assert(Ctx.Type != HeaderType::Unknown &&
"unexpected access level for parsing");
SmallString<4096> Contents;
@@ -47,6 +114,8 @@ std::unique_ptr<MemoryBuffer> createInputBuffer(const InstallAPIContext &Ctx) {
OS << "<" << H.getIncludeName() << ">";
else
OS << "\"" << H.getPath() << "\"";
+
+ Ctx.addKnownHeader(H);
}
if (Contents.empty())
return nullptr;
diff --git a/clang/lib/InstallAPI/Visitor.cpp b/clang/lib/InstallAPI/Visitor.cpp
index 3806a69b52399b..355a092520c3cd 100644
--- a/clang/lib/InstallAPI/Visitor.cpp
+++ b/clang/lib/InstallAPI/Visitor.cpp
@@ -7,8 +7,8 @@
//===----------------------------------------------------------------------===//
#include "clang/InstallAPI/Visitor.h"
-#include "clang/AST/Availability.h"
#include "clang/Basic/Linkage.h"
+#include "clang/InstallAPI/Frontend.h"
#include "llvm/ADT/SmallString.h"
#include "llvm/ADT/StringRef.h"
#include "llvm/IR/DataLayout.h"
@@ -62,7 +62,66 @@ std::string InstallAPIVisitor::getBackendMangledName(Twine Name) const {
return std::string(FinalName);
}
-/// Collect all global variables.
+std::optional<HeaderType>
+InstallAPIVisitor::getAccessForDecl(const NamedDecl *D) const {
+ SourceLocation Loc = D->getLocation();
+ if (Loc.isInvalid())
+ return std::nullopt;
+
+ // If the loc refers to a macro expansion, InstallAPI needs to first get the
+ // file location of the expansion.
+ auto FileLoc = SrcMgr.getFileLoc(Loc);
+ FileID ID = SrcMgr.getFileID(FileLoc);
+ if (ID.isInvalid())
+ return std::nullopt;
+
+ const FileEntry *FE = SrcMgr.getFileEntryForID(ID);
+ if (!FE)
+ return std::nullopt;
+
+ auto Header = Ctx.findAndRecordFile(FE, PP);
+ if (!Header.has_value())
+ return std::nullopt;
+
+ HeaderType Access = Header.value();
+ assert(Access != HeaderType::Unknown && "unexpected access level for global");
+ return Access;
+}
+
+/// Check if the interface itself or any of its super classes have an
+/// exception attribute. InstallAPI needs to export an additional symbol
+/// ("OBJC_EHTYPE_$CLASS_NAME") if any of the classes have the exception
+/// attribute.
+static bool hasObjCExceptionAttribute(const ObjCInterfaceDecl *D) {
+ for (; D != nullptr; D = D->getSuperClass())
+ if (D->hasAttr<ObjCExceptionAttr>())
+ return true;
+
+ return false;
+}
+
+bool InstallAPIVisitor::VisitObjCInterfaceDecl(const ObjCInterfaceDecl *D) {
+ // Skip forward declaration for classes (@class)
+ if (!D->isThisDeclarationADefinition())
+ return true;
+
+ // Skip over declarations that access could not be collected for.
+ auto Access = getAccessForDecl(D);
+ if (!Access)
+ return true;
+
+ StringRef Name = D->getObjCRuntimeNameAsString();
+ const RecordLinkage Linkage =
+ isExported(D) ? RecordLinkage::Exported : RecordLinkage::Internal;
+ const AvailabilityInfo Avail = AvailabilityInfo::createFromDecl(D);
+ const bool IsEHType =
+ (!D->getASTContext().getLangOpts().ObjCRuntime.isFragile() &&
+ hasObjCExceptionAttribute(D));
+
+ Ctx.Slice->addObjCInterface(Name, Linkage, Avail, D, *Access, IsEHType);
+ return true;
+}
+
bool InstallAPIVisitor::VisitVarDecl(const VarDecl *D) {
// Skip function parameters.
if (isa<ParmVarDecl>(D))
@@ -81,13 +140,18 @@ bool InstallAPIVisitor::VisitVarDecl(const VarDecl *D) {
D->getTemplateSpecializationKind() == TSK_Undeclared)
return true;
- // TODO: Capture SourceLocation & Availability for Decls.
+ // Skip over declarations that access could not collected for.
+ auto Access = getAccessForDecl(D);
+ if (!Access)
+ return true;
+
const RecordLinkage Linkage =
isExported(D) ? RecordLinkage::Exported : RecordLinkage::Internal;
const bool WeakDef = D->hasAttr<WeakAttr>();
const bool ThreadLocal = D->getTLSKind() != VarDecl::TLS_None;
- Slice.addGlobal(getMangledName(D), Linkage, GlobalRecord::Kind::Variable,
- getFlags(WeakDef, ThreadLocal));
+ const AvailabilityInfo Avail = AvailabilityInfo::createFromDecl(D);
+ Ctx.Slice->addGlobal(getMangledName(D), Linkage, GlobalRecord::Kind::Variable,
+ Avail, D, *Access, getFlags(WeakDef, ThreadLocal));
return true;
}
diff --git a/clang/test/InstallAPI/objcclasses.test b/clang/test/InstallAPI/objcclasses.test
new file mode 100644
index 00000000000000..d32291c64c472d
--- /dev/null
+++ b/clang/test/InstallAPI/objcclasses.test
@@ -0,0 +1,85 @@
+// RUN: rm -rf %t
+// RUN: split-file %s %t
+// RUN: sed -e "s|DSTROOT|%/t|g" %t/inputs.json.in > %t/inputs.json
+
+// RUN: clang-installapi -target arm64-apple-macos13.1 \
+// RUN: -F%t -install_name /System/Library/Frameworks/Foo.framework/Foo \
+// RUN: %t/inputs.json -o %t/outputs.tbd -v 2>&1 | FileCheck %s --check-prefix=VERBOSE
+// RUN: llvm-readtapi -compare %t/outputs.tbd %t/expected.tbd 2>&1 | FileCheck %s --allow-empty
+
+// VERBOSE: Public Headers:
+// VERBOSE-NEXT: #import <Foo/Foo.h>
+// CHECK-NOT: error:
+// CHECK-NOT: warning:
+
+//--- Foo.framework/Headers/Foo.h
+// Ignore forward declaration.
+ at class NSObject;
+
+ at interface Visible
+ at end
+
+__attribute__((visibility("hidden")))
+ at interface Hidden
+ at end
+
+__attribute__((objc_exception))
+ at interface Exception
+ at end
+
+//--- inputs.json.in
+{
+ "headers": [ {
+ "path" : "DSTROOT/Foo.framework/Headers/Foo.h",
+ "type" : "public"
+ }],
+ "version": "3"
+}
+
+//--- expected.tbd
+{
+ "main_library": {
+ "compatibility_versions": [
+ {
+ "version": "0"
+ }
+ ],
+ "current_versions": [
+ {
+ "version": "0"
+ }
+ ],
+ "exported_symbols": [
+ {
+ "data": {
+ "objc_class": [
+ "Exception",
+ "Visible"
+ ],
+ "objc_eh_type": [
+ "Exception"
+ ]
+ }
+ }
+ ],
+ "flags": [
+ {
+ "attributes": [
+ "not_app_extension_safe"
+ ]
+ }
+ ],
+ "install_names": [
+ {
+ "name": "/System/Library/Frameworks/Foo.framework/Foo"
+ }
+ ],
+ "target_info": [
+ {
+ "min_deployment": "13.1",
+ "target": "arm64-macos"
+ }
+ ]
+ },
+ "tapi_tbd_version": 5
+}
diff --git a/clang/tools/clang-installapi/ClangInstallAPI.cpp b/clang/tools/clang-installapi/ClangInstallAPI.cpp
index ff031e0236d0bc..c6da1c80a673f9 100644
--- a/clang/tools/clang-installapi/ClangInstallAPI.cpp
+++ b/clang/tools/clang-installapi/ClangInstallAPI.cpp
@@ -40,7 +40,7 @@ using namespace llvm::opt;
using namespace llvm::MachO;
static bool runFrontend(StringRef ProgName, bool Verbose,
- const InstallAPIContext &Ctx,
+ InstallAPIContext &Ctx,
llvm::vfs::InMemoryFileSystem *FS,
const ArrayRef<std::string> InitialArgs) {
@@ -64,7 +64,7 @@ static bool runFrontend(StringRef ProgName, bool Verbose,
// Create & run invocation.
clang::tooling::ToolInvocation Invocation(
- std::move(Args), std::make_unique<InstallAPIAction>(*Ctx.Slice), Ctx.FM);
+ std::move(Args), std::make_unique<InstallAPIAction>(Ctx), Ctx.FM);
return Invocation.run();
}
@@ -123,11 +123,13 @@ static bool run(ArrayRef<const char *> Args, const char *ProgName) {
return EXIT_FAILURE;
// Execute and gather AST results.
+ // An invocation is ran for each unique target triple and for each header
+ // access level.
llvm::MachO::Records FrontendResults;
for (const auto &[Targ, Trip] : Opts.DriverOpts.Targets) {
for (const HeaderType Type :
{HeaderType::Public, HeaderType::Private, HeaderType::Project}) {
- Ctx.Slice = std::make_shared<RecordsSlice>(Trip);
+ Ctx.Slice = std::make_shared<FrontendRecordsSlice>(Trip);
Ctx.Type = Type;
if (!runFrontend(ProgName, Opts.DriverOpts.Verbose, Ctx,
InMemoryFileSystem.get(), Opts.getClangFrontendArgs()))
>From 8f141490b996ba87323f75bf54b3d868efdaaf4a Mon Sep 17 00:00:00 2001
From: Peter Klausler <35819229+klausler at users.noreply.github.com>
Date: Fri, 1 Mar 2024 14:57:28 -0800
Subject: [PATCH 311/406] [flang] Fix separate MODULE PROCEDURE when binding
label exists (#82686)
When a separate module procedure is defined with a MODULE PROCEDURE and
its corresponding interface has a binding label, the compiler was
emitting an error about mismatching binding labels because the binding
label wasn't being copied into the subprogram's definition.
---
flang/lib/Semantics/resolve-names.cpp | 7 ++++++-
flang/test/Semantics/separate-mp02.f90 | 4 ++++
2 files changed, 10 insertions(+), 1 deletion(-)
diff --git a/flang/lib/Semantics/resolve-names.cpp b/flang/lib/Semantics/resolve-names.cpp
index 7de513d8769aed..7f9909ee937d59 100644
--- a/flang/lib/Semantics/resolve-names.cpp
+++ b/flang/lib/Semantics/resolve-names.cpp
@@ -4218,7 +4218,12 @@ bool SubprogramVisitor::BeginMpSubprogram(const parser::Name &name) {
EraseSymbol(name);
Symbol &newSymbol{MakeSymbol(name, SubprogramDetails{})};
PushScope(Scope::Kind::Subprogram, &newSymbol);
- newSymbol.get<SubprogramDetails>().set_moduleInterface(*symbol);
+ auto &newSubprogram{newSymbol.get<SubprogramDetails>()};
+ newSubprogram.set_moduleInterface(*symbol);
+ auto &subprogram{symbol->get<SubprogramDetails>()};
+ if (const auto *name{subprogram.bindName()}) {
+ newSubprogram.set_bindName(std::string{*name});
+ }
newSymbol.attrs() |= symbol->attrs();
newSymbol.set(symbol->test(Symbol::Flag::Subroutine)
? Symbol::Flag::Subroutine
diff --git a/flang/test/Semantics/separate-mp02.f90 b/flang/test/Semantics/separate-mp02.f90
index 5d13b6b693c8f7..c63ab6f41a1326 100644
--- a/flang/test/Semantics/separate-mp02.f90
+++ b/flang/test/Semantics/separate-mp02.f90
@@ -148,6 +148,8 @@ module subroutine s5() bind(c)
end
module subroutine s6() bind(c)
end
+ module subroutine s7() bind(c, name="s7")
+ end
end interface
end
@@ -172,6 +174,8 @@ module subroutine s5() bind(c, name=" s5")
!ERROR: Module subprogram 's6' has binding label 'not_s6' but the corresponding interface body has 's6'
module subroutine s6() bind(c, name="not_s6")
end
+ module procedure s7
+ end
end
>From bcc6ca7ff86518caa97c6f20735a4728e18caa78 Mon Sep 17 00:00:00 2001
From: Cyndy Ishida <cyndy_ishida at apple.com>
Date: Fri, 1 Mar 2024 15:02:38 -0800
Subject: [PATCH 312/406] [InstallAPI] Add missing link to clangLex
---
clang/lib/InstallAPI/CMakeLists.txt | 1 +
1 file changed, 1 insertion(+)
diff --git a/clang/lib/InstallAPI/CMakeLists.txt b/clang/lib/InstallAPI/CMakeLists.txt
index 19fc4c3abde53a..dc90d6370de418 100644
--- a/clang/lib/InstallAPI/CMakeLists.txt
+++ b/clang/lib/InstallAPI/CMakeLists.txt
@@ -13,4 +13,5 @@ add_clang_library(clangInstallAPI
LINK_LIBS
clangAST
clangBasic
+ clangLex
)
>From 8f80d466d580d0fb97383eac8a2d7d9a1e3f15f4 Mon Sep 17 00:00:00 2001
From: Peter Klausler <35819229+klausler at users.noreply.github.com>
Date: Fri, 1 Mar 2024 15:10:47 -0800
Subject: [PATCH 313/406] [flang] Fix crash in statement function semantics
(bug #80532) (#82702)
When statement function expressions are analyzed, ensure that the
semantics context has a valid location set, otherwise a type spec (like
"integer::") can lead to a crash.
Fixes https://github.com/llvm/llvm-project/issues/80532.
---
flang/lib/Semantics/expression.cpp | 3 ++-
flang/lib/Semantics/resolve-names.cpp | 1 +
2 files changed, 3 insertions(+), 1 deletion(-)
diff --git a/flang/lib/Semantics/expression.cpp b/flang/lib/Semantics/expression.cpp
index 8d817f077880b9..b957f773816b1b 100644
--- a/flang/lib/Semantics/expression.cpp
+++ b/flang/lib/Semantics/expression.cpp
@@ -4613,8 +4613,9 @@ evaluate::Expr<evaluate::SubscriptInteger> AnalyzeKindSelector(
SemanticsContext &context, common::TypeCategory category,
const std::optional<parser::KindSelector> &selector) {
evaluate::ExpressionAnalyzer analyzer{context};
+ CHECK(context.location().has_value());
auto restorer{
- analyzer.GetContextualMessages().SetLocation(context.location().value())};
+ analyzer.GetContextualMessages().SetLocation(*context.location())};
return analyzer.AnalyzeKindSelector(category, selector);
}
diff --git a/flang/lib/Semantics/resolve-names.cpp b/flang/lib/Semantics/resolve-names.cpp
index 7f9909ee937d59..eb61a76f10874c 100644
--- a/flang/lib/Semantics/resolve-names.cpp
+++ b/flang/lib/Semantics/resolve-names.cpp
@@ -8475,6 +8475,7 @@ void ResolveNamesVisitor::FinishSpecificationPart(
if (const auto *statement{std::get_if<
parser::Statement<common::Indirection<parser::StmtFunctionStmt>>>(
&decl.u)}) {
+ messageHandler().set_currStmtSource(statement->source);
AnalyzeStmtFunctionStmt(statement->statement.value());
}
}
>From a56ef9f9ced6c279e00671f4f8270e717517de46 Mon Sep 17 00:00:00 2001
From: Peter Klausler <35819229+klausler at users.noreply.github.com>
Date: Fri, 1 Mar 2024 15:23:24 -0800
Subject: [PATCH 314/406] [flang] Catch attempt to type a subroutine (#82704)
The presence of a type in the prefix of a SUBROUTINE statement should
elicit an error message, not a crash.
Fixes https://github.com/llvm/llvm-project/issues/80530.
---
flang/lib/Semantics/resolve-names.cpp | 16 ++++++++++------
flang/test/Semantics/typed-subr.f90 | 4 ++++
2 files changed, 14 insertions(+), 6 deletions(-)
create mode 100644 flang/test/Semantics/typed-subr.f90
diff --git a/flang/lib/Semantics/resolve-names.cpp b/flang/lib/Semantics/resolve-names.cpp
index eb61a76f10874c..87b61308808088 100644
--- a/flang/lib/Semantics/resolve-names.cpp
+++ b/flang/lib/Semantics/resolve-names.cpp
@@ -3711,13 +3711,17 @@ bool SubprogramVisitor::Pre(const parser::Suffix &suffix) {
bool SubprogramVisitor::Pre(const parser::PrefixSpec &x) {
// Save this to process after UseStmt and ImplicitPart
if (const auto *parsedType{std::get_if<parser::DeclarationTypeSpec>(&x.u)}) {
- FuncResultStack::FuncInfo &info{DEREF(funcResultStack().Top())};
- if (info.parsedType) { // C1543
- Say(currStmtSource().value(),
- "FUNCTION prefix cannot specify the type more than once"_err_en_US);
+ if (FuncResultStack::FuncInfo * info{funcResultStack().Top()}) {
+ if (info->parsedType) { // C1543
+ Say(currStmtSource().value(),
+ "FUNCTION prefix cannot specify the type more than once"_err_en_US);
+ } else {
+ info->parsedType = parsedType;
+ info->source = currStmtSource();
+ }
} else {
- info.parsedType = parsedType;
- info.source = currStmtSource();
+ Say(currStmtSource().value(),
+ "SUBROUTINE prefix cannot specify a type"_err_en_US);
}
return false;
} else {
diff --git a/flang/test/Semantics/typed-subr.f90 b/flang/test/Semantics/typed-subr.f90
new file mode 100644
index 00000000000000..c6637c95bdfd74
--- /dev/null
+++ b/flang/test/Semantics/typed-subr.f90
@@ -0,0 +1,4 @@
+! RUN: %python %S/test_errors.py %s %flang_fc1
+! ERROR: SUBROUTINE prefix cannot specify a type
+integer subroutine foo
+end
>From 081e202c8e124780cf77fea461c16f58b26d8d34 Mon Sep 17 00:00:00 2001
From: Peter Klausler <35819229+klausler at users.noreply.github.com>
Date: Fri, 1 Mar 2024 15:33:58 -0800
Subject: [PATCH 315/406] [flang] Fix DATA-like default component
initialization (#82784)
Ensure that the values in a DATA-like default component initialization
pass through expression analysis.
Fixes https://github.com/llvm/llvm-project/issues/81097.
---
flang/include/flang/Semantics/expression.h | 16 +++++++++++++---
flang/test/Semantics/data21.f90 | 7 +++++++
2 files changed, 20 insertions(+), 3 deletions(-)
create mode 100644 flang/test/Semantics/data21.f90
diff --git a/flang/include/flang/Semantics/expression.h b/flang/include/flang/Semantics/expression.h
index a330e241c2cdaa..a224b08da21da7 100644
--- a/flang/include/flang/Semantics/expression.h
+++ b/flang/include/flang/Semantics/expression.h
@@ -506,9 +506,18 @@ class ExprChecker {
}
bool Pre(const parser::ComponentDefStmt &) {
- // Already analyzed in name resolution and PDT instantiation;
- // do not attempt to re-analyze now without type parameters.
- return false;
+ inComponentDefStmt_ = true;
+ return true;
+ }
+ void Post(const parser::ComponentDefStmt &) { inComponentDefStmt_ = false; }
+ bool Pre(const parser::Initialization &x) {
+ // Default component initialization expressions (but not DATA-like ones
+ // as in DEC STRUCTUREs) were already analyzed in name resolution
+ // and PDT instantiation; do not attempt to re-analyze them without
+ // type parameters.
+ return !inComponentDefStmt_ ||
+ std::holds_alternative<
+ std::list<common::Indirection<parser::DataStmtValue>>>(x.u);
}
template <typename A> bool Pre(const parser::Scalar<A> &x) {
@@ -538,6 +547,7 @@ class ExprChecker {
SemanticsContext &context_;
evaluate::ExpressionAnalyzer exprAnalyzer_{context_};
int whereDepth_{0}; // nesting of WHERE statements & constructs
+ bool inComponentDefStmt_{false};
};
} // namespace Fortran::semantics
#endif // FORTRAN_SEMANTICS_EXPRESSION_H_
diff --git a/flang/test/Semantics/data21.f90 b/flang/test/Semantics/data21.f90
new file mode 100644
index 00000000000000..639f78440840a8
--- /dev/null
+++ b/flang/test/Semantics/data21.f90
@@ -0,0 +1,7 @@
+! RUN: %flang_fc1 -fdebug-dump-symbols %s 2>&1 | FileCheck %s
+! Ensure that DATA-like default component initializers work.
+! CHECK: j (InDataStmt) size=4 offset=0: ObjectEntity type: INTEGER(4) init:123_4
+type t
+ integer j/123/
+end type
+end
>From e8a9aa26f708ec59cb3a0c37767817c069fb12f0 Mon Sep 17 00:00:00 2001
From: Peter Klausler <35819229+klausler at users.noreply.github.com>
Date: Fri, 1 Mar 2024 15:46:12 -0800
Subject: [PATCH 316/406] [flang] Fix "suspicious condition" in C++ usage
(#82790)
Address a reported C++ coding "suspicious condition".
Fixes https://github.com/llvm/llvm-project/issues/80807.
---
flang/lib/Semantics/data-to-inits.cpp | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/flang/lib/Semantics/data-to-inits.cpp b/flang/lib/Semantics/data-to-inits.cpp
index c12af1bb0165cd..fa22d498679053 100644
--- a/flang/lib/Semantics/data-to-inits.cpp
+++ b/flang/lib/Semantics/data-to-inits.cpp
@@ -524,7 +524,7 @@ static const DerivedTypeSpec *HasDefaultInitialization(const Symbol &symbol) {
directs.begin(), directs.end(), [](const Symbol &component) {
return !IsAllocatable(component) &&
HasDeclarationInitializer(component);
- })) {
+ }) != directs.end()) {
return derived;
}
}
>From 1c530b3d9f86422cbc0417ea8ec97a462e9abe26 Mon Sep 17 00:00:00 2001
From: Peter Klausler <35819229+klausler at users.noreply.github.com>
Date: Fri, 1 Mar 2024 15:56:40 -0800
Subject: [PATCH 317/406] =?UTF-8?q?[flang]=20Whether=20a=20procedure's=20i?=
=?UTF-8?q?nterface=20is=20explicit=20or=20not=20is=20not=20a=20d=E2=80=A6?=
=?UTF-8?q?=20(#82796)?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
…istinguishing characteristic
We note whether a procedure's interface is explicit or implicit as an
attribute of its characteristics, so that other semantics can be checked
appropriately, but this internal attribute should not be used as a
distinguishing characteristic in itself.
Fixes https://github.com/llvm/llvm-project/issues/81876.
---
.../include/flang/Evaluate/characteristics.h | 4 +-
flang/include/flang/Evaluate/tools.h | 2 +-
flang/lib/Evaluate/characteristics.cpp | 12 +++--
flang/lib/Evaluate/tools.cpp | 7 +--
flang/lib/Semantics/check-call.cpp | 29 ++++++----
flang/lib/Semantics/check-call.h | 2 +-
flang/lib/Semantics/check-declarations.cpp | 6 ++-
flang/lib/Semantics/expression.cpp | 8 +--
flang/lib/Semantics/pointer-assignment.cpp | 3 +-
flang/lib/Semantics/resolve-names.cpp | 21 +++++---
flang/test/Semantics/implicit14.f90 | 54 +++++++++++++++++++
11 files changed, 116 insertions(+), 32 deletions(-)
create mode 100644 flang/test/Semantics/implicit14.f90
diff --git a/flang/include/flang/Evaluate/characteristics.h b/flang/include/flang/Evaluate/characteristics.h
index 04a0d71e1adebe..f2f37866ecde86 100644
--- a/flang/include/flang/Evaluate/characteristics.h
+++ b/flang/include/flang/Evaluate/characteristics.h
@@ -381,8 +381,8 @@ struct Procedure {
int FindPassIndex(std::optional<parser::CharBlock>) const;
bool CanBeCalledViaImplicitInterface(std::string *whyNot = nullptr) const;
bool CanOverride(const Procedure &, std::optional<int> passIndex) const;
- bool IsCompatibleWith(const Procedure &, std::string *whyNot = nullptr,
- const SpecificIntrinsic * = nullptr,
+ bool IsCompatibleWith(const Procedure &, bool ignoreImplicitVsExplicit,
+ std::string *whyNot = nullptr, const SpecificIntrinsic * = nullptr,
std::optional<std::string> *warning = nullptr) const;
llvm::raw_ostream &Dump(llvm::raw_ostream &) const;
diff --git a/flang/include/flang/Evaluate/tools.h b/flang/include/flang/Evaluate/tools.h
index d257da1a709642..53896072675abc 100644
--- a/flang/include/flang/Evaluate/tools.h
+++ b/flang/include/flang/Evaluate/tools.h
@@ -1094,7 +1094,7 @@ std::optional<parser::MessageFixedText> CheckProcCompatibility(bool isCall,
const std::optional<characteristics::Procedure> &lhsProcedure,
const characteristics::Procedure *rhsProcedure,
const SpecificIntrinsic *specificIntrinsic, std::string &whyNotCompatible,
- std::optional<std::string> &warning);
+ std::optional<std::string> &warning, bool ignoreImplicitVsExplicit);
// Scalar constant expansion
class ScalarConstantExpander {
diff --git a/flang/lib/Evaluate/characteristics.cpp b/flang/lib/Evaluate/characteristics.cpp
index 5ec9f757b68173..688a856220a117 100644
--- a/flang/lib/Evaluate/characteristics.cpp
+++ b/flang/lib/Evaluate/characteristics.cpp
@@ -534,7 +534,8 @@ bool DummyProcedure::IsCompatibleWith(
}
return false;
}
- if (!procedure.value().IsCompatibleWith(actual.procedure.value(), whyNot)) {
+ if (!procedure.value().IsCompatibleWith(actual.procedure.value(),
+ /*ignoreImplicitVsExplicit=*/false, whyNot)) {
if (whyNot) {
*whyNot = "incompatible dummy procedure interfaces: "s + *whyNot;
}
@@ -1207,7 +1208,8 @@ bool FunctionResult::IsCompatibleWith(
CHECK(ifaceProc != nullptr);
if (const auto *actualProc{
std::get_if<CopyableIndirection<Procedure>>(&actual.u)}) {
- if (ifaceProc->value().IsCompatibleWith(actualProc->value(), whyNot)) {
+ if (ifaceProc->value().IsCompatibleWith(actualProc->value(),
+ /*ignoreImplicitVsExplicit=*/false, whyNot)) {
return true;
}
if (whyNot) {
@@ -1252,7 +1254,8 @@ bool Procedure::operator==(const Procedure &that) const {
cudaSubprogramAttrs == that.cudaSubprogramAttrs;
}
-bool Procedure::IsCompatibleWith(const Procedure &actual, std::string *whyNot,
+bool Procedure::IsCompatibleWith(const Procedure &actual,
+ bool ignoreImplicitVsExplicit, std::string *whyNot,
const SpecificIntrinsic *specificIntrinsic,
std::optional<std::string> *warning) const {
// 15.5.2.9(1): if dummy is not pure, actual need not be.
@@ -1266,6 +1269,9 @@ bool Procedure::IsCompatibleWith(const Procedure &actual, std::string *whyNot,
}
Attrs differences{attrs ^ actualAttrs};
differences.reset(Attr::Subroutine); // dealt with specifically later
+ if (ignoreImplicitVsExplicit) {
+ differences.reset(Attr::ImplicitInterface);
+ }
if (!differences.empty()) {
if (whyNot) {
auto sep{": "s};
diff --git a/flang/lib/Evaluate/tools.cpp b/flang/lib/Evaluate/tools.cpp
index 131bbd97ce1632..e7fc651b9173fe 100644
--- a/flang/lib/Evaluate/tools.cpp
+++ b/flang/lib/Evaluate/tools.cpp
@@ -1083,7 +1083,7 @@ std::optional<parser::MessageFixedText> CheckProcCompatibility(bool isCall,
const std::optional<characteristics::Procedure> &lhsProcedure,
const characteristics::Procedure *rhsProcedure,
const SpecificIntrinsic *specificIntrinsic, std::string &whyNotCompatible,
- std::optional<std::string> &warning) {
+ std::optional<std::string> &warning, bool ignoreImplicitVsExplicit) {
std::optional<parser::MessageFixedText> msg;
if (!lhsProcedure) {
msg = "In assignment to object %s, the target '%s' is a procedure"
@@ -1097,8 +1097,9 @@ std::optional<parser::MessageFixedText> CheckProcCompatibility(bool isCall,
*rhsProcedure->functionResult, &whyNotCompatible)) {
msg =
"Function %s associated with incompatible function designator '%s': %s"_err_en_US;
- } else if (lhsProcedure->IsCompatibleWith(*rhsProcedure, &whyNotCompatible,
- specificIntrinsic, &warning)) {
+ } else if (lhsProcedure->IsCompatibleWith(*rhsProcedure,
+ ignoreImplicitVsExplicit, &whyNotCompatible, specificIntrinsic,
+ &warning)) {
// OK
} else if (isCall) {
msg = "Procedure %s associated with result of reference to function '%s'"
diff --git a/flang/lib/Semantics/check-call.cpp b/flang/lib/Semantics/check-call.cpp
index cd9150bdda4bd3..3adbd7cc41774d 100644
--- a/flang/lib/Semantics/check-call.cpp
+++ b/flang/lib/Semantics/check-call.cpp
@@ -912,7 +912,7 @@ static void CheckExplicitDataArg(const characteristics::DummyDataObject &dummy,
static void CheckProcedureArg(evaluate::ActualArgument &arg,
const characteristics::Procedure &proc,
const characteristics::DummyProcedure &dummy, const std::string &dummyName,
- SemanticsContext &context) {
+ SemanticsContext &context, bool ignoreImplicitVsExplicit) {
evaluate::FoldingContext &foldingContext{context.foldingContext()};
parser::ContextualMessages &messages{foldingContext.messages()};
auto restorer{
@@ -975,7 +975,8 @@ static void CheckProcedureArg(evaluate::ActualArgument &arg,
if (interface.HasExplicitInterface()) {
std::string whyNot;
std::optional<std::string> warning;
- if (!interface.IsCompatibleWith(argInterface, &whyNot,
+ if (!interface.IsCompatibleWith(argInterface,
+ ignoreImplicitVsExplicit, &whyNot,
/*specificIntrinsic=*/nullptr, &warning)) {
// 15.5.2.9(1): Explicit interfaces must match
if (argInterface.HasExplicitInterface()) {
@@ -1081,7 +1082,8 @@ static void CheckExplicitInterfaceArg(evaluate::ActualArgument &arg,
const characteristics::DummyArgument &dummy,
const characteristics::Procedure &proc, SemanticsContext &context,
const Scope *scope, const evaluate::SpecificIntrinsic *intrinsic,
- bool allowActualArgumentConversions, bool extentErrors) {
+ bool allowActualArgumentConversions, bool extentErrors,
+ bool ignoreImplicitVsExplicit) {
evaluate::FoldingContext &foldingContext{context.foldingContext()};
auto &messages{foldingContext.messages()};
std::string dummyName{"dummy argument"};
@@ -1185,7 +1187,8 @@ static void CheckExplicitInterfaceArg(evaluate::ActualArgument &arg,
},
[&](const characteristics::DummyProcedure &dummy) {
if (!checkActualArgForLabel(arg)) {
- CheckProcedureArg(arg, proc, dummy, dummyName, context);
+ CheckProcedureArg(arg, proc, dummy, dummyName, context,
+ ignoreImplicitVsExplicit);
}
},
[&](const characteristics::AlternateReturn &) {
@@ -1371,7 +1374,8 @@ static void CheckAssociated(evaluate::ActualArguments &arguments,
: nullptr};
std::optional<parser::MessageFixedText> msg{
CheckProcCompatibility(isCall, pointerProc, &*targetProc,
- specificIntrinsic, whyNot, warning)};
+ specificIntrinsic, whyNot, warning,
+ /*ignoreImplicitVsExplicit=*/false)};
if (!msg && warning &&
semanticsContext.ShouldWarn(
common::UsageWarning::ProcDummyArgShapes)) {
@@ -1740,7 +1744,8 @@ static parser::Messages CheckExplicitInterface(
const characteristics::Procedure &proc, evaluate::ActualArguments &actuals,
SemanticsContext &context, const Scope *scope,
const evaluate::SpecificIntrinsic *intrinsic,
- bool allowActualArgumentConversions, bool extentErrors) {
+ bool allowActualArgumentConversions, bool extentErrors,
+ bool ignoreImplicitVsExplicit) {
evaluate::FoldingContext &foldingContext{context.foldingContext()};
parser::ContextualMessages &messages{foldingContext.messages()};
parser::Messages buffer;
@@ -1754,7 +1759,8 @@ static parser::Messages CheckExplicitInterface(
const auto &dummy{proc.dummyArguments.at(index++)};
if (actual) {
CheckExplicitInterfaceArg(*actual, dummy, proc, context, scope, intrinsic,
- allowActualArgumentConversions, extentErrors);
+ allowActualArgumentConversions, extentErrors,
+ ignoreImplicitVsExplicit);
} else if (!dummy.IsOptional()) {
if (dummy.name.empty()) {
messages.Say(
@@ -1783,7 +1789,8 @@ bool CheckInterfaceForGeneric(const characteristics::Procedure &proc,
bool allowActualArgumentConversions) {
return proc.HasExplicitInterface() &&
!CheckExplicitInterface(proc, actuals, context, nullptr, nullptr,
- allowActualArgumentConversions, false /*extentErrors*/)
+ allowActualArgumentConversions, /*extentErrors=*/false,
+ /*ignoreImplicitVsExplicit=*/false)
.AnyFatalError();
}
@@ -1876,6 +1883,7 @@ bool CheckPPCIntrinsic(const Symbol &generic, const Symbol &specific,
bool CheckArguments(const characteristics::Procedure &proc,
evaluate::ActualArguments &actuals, SemanticsContext &context,
const Scope &scope, bool treatingExternalAsImplicit,
+ bool ignoreImplicitVsExplicit,
const evaluate::SpecificIntrinsic *intrinsic) {
bool explicitInterface{proc.HasExplicitInterface()};
evaluate::FoldingContext foldingContext{context.foldingContext()};
@@ -1898,8 +1906,9 @@ bool CheckArguments(const characteristics::Procedure &proc,
}
}
if (explicitInterface) {
- auto buffer{CheckExplicitInterface(
- proc, actuals, context, &scope, intrinsic, true, true)};
+ auto buffer{CheckExplicitInterface(proc, actuals, context, &scope,
+ intrinsic, /*allowArgumentConversions=*/true, /*extentErrors=*/true,
+ ignoreImplicitVsExplicit)};
if (!buffer.empty()) {
if (treatingExternalAsImplicit) {
if (auto *msg{messages.Say(
diff --git a/flang/lib/Semantics/check-call.h b/flang/lib/Semantics/check-call.h
index 4275606225eb8a..8553f3a31efb52 100644
--- a/flang/lib/Semantics/check-call.h
+++ b/flang/lib/Semantics/check-call.h
@@ -35,7 +35,7 @@ class SemanticsContext;
// messages were created, true if all is well.
bool CheckArguments(const evaluate::characteristics::Procedure &,
evaluate::ActualArguments &, SemanticsContext &, const Scope &,
- bool treatingExternalAsImplicit,
+ bool treatingExternalAsImplicit, bool ignoreImplicitVsExplicit,
const evaluate::SpecificIntrinsic *intrinsic);
bool CheckPPCIntrinsic(const Symbol &generic, const Symbol &specific,
diff --git a/flang/lib/Semantics/check-declarations.cpp b/flang/lib/Semantics/check-declarations.cpp
index e9adc086402d63..719bea34406aa0 100644
--- a/flang/lib/Semantics/check-declarations.cpp
+++ b/flang/lib/Semantics/check-declarations.cpp
@@ -1481,7 +1481,8 @@ void CheckHelper::CheckExternal(const Symbol &symbol) {
if (auto globalChars{Characterize(*global)}) {
if (chars->HasExplicitInterface()) {
std::string whyNot;
- if (!chars->IsCompatibleWith(*globalChars, &whyNot)) {
+ if (!chars->IsCompatibleWith(*globalChars,
+ /*ignoreImplicitVsExplicit=*/false, &whyNot)) {
msg = WarnIfNotInModuleFile(
"The global subprogram '%s' is not compatible with its local procedure declaration (%s)"_warn_en_US,
global->name(), whyNot);
@@ -1507,7 +1508,8 @@ void CheckHelper::CheckExternal(const Symbol &symbol) {
if (auto chars{Characterize(symbol)}) {
if (auto previousChars{Characterize(previous)}) {
std::string whyNot;
- if (!chars->IsCompatibleWith(*previousChars, &whyNot)) {
+ if (!chars->IsCompatibleWith(*previousChars,
+ /*ignoreImplicitVsExplicit=*/false, &whyNot)) {
if (auto *msg{WarnIfNotInModuleFile(
"The external interface '%s' is not compatible with an earlier definition (%s)"_warn_en_US,
symbol.name(), whyNot)}) {
diff --git a/flang/lib/Semantics/expression.cpp b/flang/lib/Semantics/expression.cpp
index b957f773816b1b..0132562bc6c90f 100644
--- a/flang/lib/Semantics/expression.cpp
+++ b/flang/lib/Semantics/expression.cpp
@@ -3129,7 +3129,8 @@ std::optional<characteristics::Procedure> ExpressionAnalyzer::CheckCall(
if (auto iter{implicitInterfaces_.find(name)};
iter != implicitInterfaces_.end()) {
std::string whyNot;
- if (!chars->IsCompatibleWith(iter->second.second, &whyNot)) {
+ if (!chars->IsCompatibleWith(iter->second.second,
+ /*ignoreImplicitVsExplicit=*/false, &whyNot)) {
if (auto *msg{Say(callSite,
"Reference to the procedure '%s' has an implicit interface that is distinct from another reference: %s"_warn_en_US,
name, whyNot)}) {
@@ -3169,7 +3170,7 @@ std::optional<characteristics::Procedure> ExpressionAnalyzer::CheckCall(
}
ok &= semantics::CheckArguments(*chars, arguments, context_,
context_.FindScope(callSite), treatExternalAsImplicit,
- specificIntrinsic);
+ /*ignoreImplicitVsExplicit=*/false, specificIntrinsic);
}
if (procSymbol && !IsPureProcedure(*procSymbol)) {
if (const semantics::Scope *
@@ -3188,7 +3189,8 @@ std::optional<characteristics::Procedure> ExpressionAnalyzer::CheckCall(
if (auto globalChars{characteristics::Procedure::Characterize(
*global, context_.foldingContext())}) {
semantics::CheckArguments(*globalChars, arguments, context_,
- context_.FindScope(callSite), true,
+ context_.FindScope(callSite), /*treatExternalAsImplicit=*/true,
+ /*ignoreImplicitVsExplicit=*/false,
nullptr /*not specific intrinsic*/);
}
}
diff --git a/flang/lib/Semantics/pointer-assignment.cpp b/flang/lib/Semantics/pointer-assignment.cpp
index 4c293e85cf9de9..58155a29da1ee5 100644
--- a/flang/lib/Semantics/pointer-assignment.cpp
+++ b/flang/lib/Semantics/pointer-assignment.cpp
@@ -362,7 +362,8 @@ bool PointerAssignmentChecker::Check(parser::CharBlock rhsName, bool isCall,
std::optional<std::string> warning;
CharacterizeProcedure();
if (std::optional<MessageFixedText> msg{evaluate::CheckProcCompatibility(
- isCall, procedure_, rhsProcedure, specific, whyNot, warning)}) {
+ isCall, procedure_, rhsProcedure, specific, whyNot, warning,
+ /*ignoreImplicitVsExplicit=*/isCall)}) {
Say(std::move(*msg), description_, rhsName, whyNot);
return false;
}
diff --git a/flang/lib/Semantics/resolve-names.cpp b/flang/lib/Semantics/resolve-names.cpp
index 87b61308808088..4646bb01ee7254 100644
--- a/flang/lib/Semantics/resolve-names.cpp
+++ b/flang/lib/Semantics/resolve-names.cpp
@@ -8595,16 +8595,25 @@ bool ResolveNamesVisitor::Pre(const parser::PointerAssignmentStmt &x) {
const auto &bounds{std::get<parser::PointerAssignmentStmt::Bounds>(x.t)};
const auto &expr{std::get<parser::Expr>(x.t)};
ResolveDataRef(dataRef);
+ Symbol *ptrSymbol{parser::GetLastName(dataRef).symbol};
Walk(bounds);
// Resolve unrestricted specific intrinsic procedures as in "p => cos".
if (const parser::Name * name{parser::Unwrap<parser::Name>(expr)}) {
if (NameIsKnownOrIntrinsic(*name)) {
- // If the name is known because it is an object entity from a host
- // procedure, create a host associated symbol.
- if (Symbol * symbol{name->symbol}; symbol &&
- symbol->GetUltimate().has<ObjectEntityDetails>() &&
- IsUplevelReference(*symbol)) {
- MakeHostAssocSymbol(*name, *symbol);
+ if (Symbol * symbol{name->symbol}) {
+ if (IsProcedurePointer(ptrSymbol) &&
+ !ptrSymbol->test(Symbol::Flag::Function) &&
+ !ptrSymbol->test(Symbol::Flag::Subroutine)) {
+ if (symbol->test(Symbol::Flag::Function)) {
+ ApplyImplicitRules(*ptrSymbol);
+ }
+ }
+ // If the name is known because it is an object entity from a host
+ // procedure, create a host associated symbol.
+ if (symbol->GetUltimate().has<ObjectEntityDetails>() &&
+ IsUplevelReference(*symbol)) {
+ MakeHostAssocSymbol(*name, *symbol);
+ }
}
return false;
}
diff --git a/flang/test/Semantics/implicit14.f90 b/flang/test/Semantics/implicit14.f90
new file mode 100644
index 00000000000000..d688049a587f7a
--- /dev/null
+++ b/flang/test/Semantics/implicit14.f90
@@ -0,0 +1,54 @@
+! RUN: %python %S/test_errors.py %s %flang_fc1
+module m
+ type dt
+ procedure(explicit), pointer, nopass :: p
+ end type
+ contains
+ integer function one()
+ one = 1
+ end
+ function onePtr()
+ procedure(one), pointer :: onePtr
+ onePtr => one
+ end
+ function explicit
+ character(:), allocatable :: explicit
+ explicit = "abc"
+ end
+end
+
+program test
+ use m
+ procedure(), pointer :: p0
+ procedure(one), pointer :: p1
+ procedure(integer), pointer :: p2
+ procedure(explicit), pointer :: p3
+ external implicit
+ type(dt) x
+ p0 => one ! ok
+ p0 => onePtr() ! ok
+ p0 => implicit ! ok
+ !ERROR: Procedure pointer 'p0' with implicit interface may not be associated with procedure designator 'explicit' with explicit interface that cannot be called via an implicit interface
+ p0 => explicit
+ p1 => one ! ok
+ p1 => onePtr() ! ok
+ p1 => implicit ! ok
+ !ERROR: Function pointer 'p1' associated with incompatible function designator 'explicit': function results have incompatible attributes
+ p1 => explicit
+ p2 => one ! ok
+ p2 => onePtr() ! ok
+ p2 => implicit ! ok
+ !ERROR: Function pointer 'p2' associated with incompatible function designator 'explicit': function results have incompatible attributes
+ p2 => explicit
+ !ERROR: Function pointer 'p3' associated with incompatible function designator 'one': function results have incompatible attributes
+ p3 => one
+ !ERROR: Procedure pointer 'p3' associated with result of reference to function 'oneptr' that is an incompatible procedure pointer: function results have incompatible attributes
+ p3 => onePtr()
+ p3 => explicit ! ok
+ !ERROR: Procedure pointer 'p3' with explicit interface that cannot be called via an implicit interface cannot be associated with procedure designator with an implicit interface
+ p3 => implicit
+ !ERROR: Procedure pointer 'p' with explicit interface that cannot be called via an implicit interface cannot be associated with procedure designator with an implicit interface
+ x = dt(implicit)
+ !ERROR: Procedure pointer 'p' with explicit interface that cannot be called via an implicit interface cannot be associated with procedure designator with an implicit interface
+ x%p => implicit
+end
>From 147f54e36a182934d926bc311a5d63c64425664f Mon Sep 17 00:00:00 2001
From: Peter Klausler <35819229+klausler at users.noreply.github.com>
Date: Fri, 1 Mar 2024 16:08:45 -0800
Subject: [PATCH 318/406] [flang] Accept whole assumed-size arrays as variable
selectors (#82806)
Include variable selectors ("select type (x => y)") as a context in
which a whole assumed-size array may legitimately appear.
Fixes https://github.com/llvm/llvm-project/issues/81910.
---
flang/lib/Semantics/expression.cpp | 37 ++++++++++++++++++++++--------
flang/test/Semantics/assign04.f90 | 7 ++++++
2 files changed, 34 insertions(+), 10 deletions(-)
diff --git a/flang/lib/Semantics/expression.cpp b/flang/lib/Semantics/expression.cpp
index 0132562bc6c90f..54bfe0f2e1563d 100644
--- a/flang/lib/Semantics/expression.cpp
+++ b/flang/lib/Semantics/expression.cpp
@@ -973,7 +973,8 @@ MaybeExpr ExpressionAnalyzer::Analyze(const parser::Name &n) {
}
}
if (!isWholeAssumedSizeArrayOk_ &&
- semantics::IsAssumedSizeArray(*n.symbol)) { // C1002, C1014, C1231
+ semantics::IsAssumedSizeArray(
+ ResolveAssociations(*n.symbol))) { // C1002, C1014, C1231
AttachDeclaration(
SayAt(n,
"Whole assumed-size array '%s' may not appear here without subscripts"_err_en_US,
@@ -1329,15 +1330,29 @@ std::optional<Component> ExpressionAnalyzer::CreateComponent(DataRef &&base,
// Derived type component references and type parameter inquiries
MaybeExpr ExpressionAnalyzer::Analyze(const parser::StructureComponent &sc) {
- MaybeExpr base{Analyze(sc.base)};
Symbol *sym{sc.component.symbol};
- if (!base || !sym || context_.HasError(sym)) {
+ if (context_.HasError(sym)) {
+ return std::nullopt;
+ }
+ const auto *misc{sym->detailsIf<semantics::MiscDetails>()};
+ bool isTypeParamInquiry{sym->has<semantics::TypeParamDetails>() ||
+ (misc &&
+ (misc->kind() == semantics::MiscDetails::Kind::KindParamInquiry ||
+ misc->kind() == semantics::MiscDetails::Kind::LenParamInquiry))};
+ MaybeExpr base;
+ if (isTypeParamInquiry) {
+ auto restorer{AllowWholeAssumedSizeArray()};
+ base = Analyze(sc.base);
+ } else {
+ base = Analyze(sc.base);
+ }
+ if (!base) {
return std::nullopt;
}
const auto &name{sc.component.source};
if (auto *dtExpr{UnwrapExpr<Expr<SomeDerived>>(*base)}) {
const auto *dtSpec{GetDerivedTypeSpec(dtExpr->GetType())};
- if (sym->detailsIf<semantics::TypeParamDetails>()) {
+ if (isTypeParamInquiry) {
if (auto *designator{UnwrapExpr<Designator<SomeDerived>>(*dtExpr)}) {
if (std::optional<DynamicType> dyType{DynamicType::From(*sym)}) {
if (dyType->category() == TypeCategory::Integer) {
@@ -1350,8 +1365,7 @@ MaybeExpr ExpressionAnalyzer::Analyze(const parser::StructureComponent &sc) {
Say(name, "Type parameter is not INTEGER"_err_en_US);
} else {
Say(name,
- "A type parameter inquiry must be applied to "
- "a designator"_err_en_US);
+ "A type parameter inquiry must be applied to a designator"_err_en_US);
}
} else if (!dtSpec || !dtSpec->scope()) {
CHECK(context_.AnyFatalError() || !foldingContext_.messages().empty());
@@ -1393,8 +1407,7 @@ MaybeExpr ExpressionAnalyzer::Analyze(const parser::StructureComponent &sc) {
return AsGenericExpr(std::move(realExpr));
}
}
- } else if (kind == MiscKind::KindParamInquiry ||
- kind == MiscKind::LenParamInquiry) {
+ } else if (isTypeParamInquiry) { // %kind or %len
ActualArgument arg{std::move(*base)};
SetArgSourceLocation(arg, name);
return MakeFunctionRef(name, ActualArguments{std::move(arg)});
@@ -3743,9 +3756,12 @@ MaybeExpr ExpressionAnalyzer::Analyze(const parser::Selector &selector) {
}
}
}
+ // Not a Variable -> FunctionReference
+ auto restorer{AllowWholeAssumedSizeArray()};
+ return Analyze(selector.u);
+ } else { // Expr
+ return Analyze(selector.u);
}
- // Not a Variable -> FunctionReference; handle normally as Variable or Expr
- return Analyze(selector.u);
}
MaybeExpr ExpressionAnalyzer::Analyze(const parser::DataStmtConstant &x) {
@@ -4001,6 +4017,7 @@ void ArgumentAnalyzer::Analyze(
const parser::ActualArgSpec &arg, bool isSubroutine) {
// TODO: C1534: Don't allow a "restricted" specific intrinsic to be passed.
std::optional<ActualArgument> actual;
+ auto restorer{context_.AllowWholeAssumedSizeArray()};
common::visit(
common::visitors{
[&](const common::Indirection<parser::Expr> &x) {
diff --git a/flang/test/Semantics/assign04.f90 b/flang/test/Semantics/assign04.f90
index a00ca5213a7aae..14d90a8d5a2244 100644
--- a/flang/test/Semantics/assign04.f90
+++ b/flang/test/Semantics/assign04.f90
@@ -105,6 +105,13 @@ subroutine s6(x)
x(:) = [1, 2, 3]
!ERROR: Whole assumed-size array 'x' may not appear here without subscripts
x = [1, 2, 3]
+ associate (y => x) ! ok
+ !ERROR: Whole assumed-size array 'y' may not appear here without subscripts
+ y = [1, 2, 3]
+ end associate
+ !ERROR: Whole assumed-size array 'x' may not appear here without subscripts
+ associate (y => (x))
+ end associate
end
module m7
>From 69b837203fb84774dbc4333ebd06654ab2249fe0 Mon Sep 17 00:00:00 2001
From: Farzon Lotfi <1802579+farzonl at users.noreply.github.com>
Date: Fri, 1 Mar 2024 19:11:28 -0500
Subject: [PATCH 319/406] [clang][sema] consolidate diags for
incompatible_vector_* (#83609)
removing the additions of `err_vec_builtin_non_vector_all` &
`err_vec_builtin_incompatible_vector_all`
caused by https://github.com/llvm/llvm-project/pull/83077.
Instead adding a select option to `err_vec_builtin_non_vector` &
`err_vec_builtin_incompatible_vector` to account for uses where there
are more than two arguments.
---
.../clang/Basic/DiagnosticSemaKinds.td | 9 ++-----
clang/lib/Sema/SemaChecking.cpp | 24 +++++++++++--------
clang/test/SemaHLSL/BuiltIns/dot-errors.hlsl | 16 ++++++-------
clang/test/SemaHLSL/BuiltIns/lerp-errors.hlsl | 2 +-
4 files changed, 25 insertions(+), 26 deletions(-)
diff --git a/clang/include/clang/Basic/DiagnosticSemaKinds.td b/clang/include/clang/Basic/DiagnosticSemaKinds.td
index b2ea52258fb467..91105d4231f06a 100644
--- a/clang/include/clang/Basic/DiagnosticSemaKinds.td
+++ b/clang/include/clang/Basic/DiagnosticSemaKinds.td
@@ -10266,15 +10266,10 @@ def err_block_on_vm : Error<
def err_sizeless_nonlocal : Error<
"non-local variable with sizeless type %0">;
-def err_vec_builtin_non_vector_all : Error<
- "all arguments to %0 must be vectors">;
-def err_vec_builtin_incompatible_vector_all : Error<
- "all arguments to %0 must have vectors of the same type">;
-
def err_vec_builtin_non_vector : Error<
- "first two arguments to %0 must be vectors">;
+ "%select{first two|all}1 arguments to %0 must be vectors">;
def err_vec_builtin_incompatible_vector : Error<
- "first two arguments to %0 must have the same type">;
+ "%select{first two|all}1 arguments to %0 must have the same type">;
def err_vsx_builtin_nonconstant_argument : Error<
"argument %0 to %1 must be a 2-bit unsigned literal (i.e. 0, 1, 2 or 3)">;
diff --git a/clang/lib/Sema/SemaChecking.cpp b/clang/lib/Sema/SemaChecking.cpp
index 9f9b0a0baba666..0d4d57db01c93a 100644
--- a/clang/lib/Sema/SemaChecking.cpp
+++ b/clang/lib/Sema/SemaChecking.cpp
@@ -5218,15 +5218,17 @@ bool CheckVectorElementCallArgs(Sema *S, CallExpr *TheCall) {
// Note: type promotion is intended to be handeled via the intrinsics
// and not the builtin itself.
S->Diag(TheCall->getBeginLoc(),
- diag::err_vec_builtin_incompatible_vector_all)
- << TheCall->getDirectCallee()
+ diag::err_vec_builtin_incompatible_vector)
+ << TheCall->getDirectCallee() << /*useAllTerminology*/ true
<< SourceRange(A.get()->getBeginLoc(), B.get()->getEndLoc());
retValue = true;
}
if (VecTyA->getNumElements() != VecTyB->getNumElements()) {
- // if we get here a HLSLVectorTruncation is needed.
- S->Diag(BuiltinLoc, diag::err_vec_builtin_incompatible_vector_all)
- << TheCall->getDirectCallee()
+ // You should only be hitting this case if you are calling the builtin
+ // directly. HLSL intrinsics should avoid this case via a
+ // HLSLVectorTruncation.
+ S->Diag(BuiltinLoc, diag::err_vec_builtin_incompatible_vector)
+ << TheCall->getDirectCallee() << /*useAllTerminology*/ true
<< SourceRange(TheCall->getArg(0)->getBeginLoc(),
TheCall->getArg(1)->getEndLoc());
retValue = true;
@@ -5241,8 +5243,8 @@ bool CheckVectorElementCallArgs(Sema *S, CallExpr *TheCall) {
// Note: if we get here one of the args is a scalar which
// requires a VectorSplat on Arg0 or Arg1
- S->Diag(BuiltinLoc, diag::err_vec_builtin_non_vector_all)
- << TheCall->getDirectCallee()
+ S->Diag(BuiltinLoc, diag::err_vec_builtin_non_vector)
+ << TheCall->getDirectCallee() << /*useAllTerminology*/ true
<< SourceRange(TheCall->getArg(0)->getBeginLoc(),
TheCall->getArg(1)->getEndLoc());
return true;
@@ -9472,7 +9474,7 @@ bool Sema::SemaBuiltinVSX(CallExpr *TheCall) {
if ((!Arg1Ty->isVectorType() && !Arg1Ty->isDependentType()) ||
(!Arg2Ty->isVectorType() && !Arg2Ty->isDependentType())) {
return Diag(BuiltinLoc, diag::err_vec_builtin_non_vector)
- << TheCall->getDirectCallee()
+ << TheCall->getDirectCallee() << /*isMorethantwoArgs*/ false
<< SourceRange(TheCall->getArg(0)->getBeginLoc(),
TheCall->getArg(1)->getEndLoc());
}
@@ -9480,7 +9482,7 @@ bool Sema::SemaBuiltinVSX(CallExpr *TheCall) {
// Check the first two arguments are the same type.
if (!Context.hasSameUnqualifiedType(Arg1Ty, Arg2Ty)) {
return Diag(BuiltinLoc, diag::err_vec_builtin_incompatible_vector)
- << TheCall->getDirectCallee()
+ << TheCall->getDirectCallee() << /*isMorethantwoArgs*/ false
<< SourceRange(TheCall->getArg(0)->getBeginLoc(),
TheCall->getArg(1)->getEndLoc());
}
@@ -9516,7 +9518,7 @@ ExprResult Sema::SemaBuiltinShuffleVector(CallExpr *TheCall) {
if (!LHSType->isVectorType() || !RHSType->isVectorType())
return ExprError(
Diag(TheCall->getBeginLoc(), diag::err_vec_builtin_non_vector)
- << TheCall->getDirectCallee()
+ << TheCall->getDirectCallee() << /*isMorethantwoArgs*/ false
<< SourceRange(TheCall->getArg(0)->getBeginLoc(),
TheCall->getArg(1)->getEndLoc()));
@@ -9532,12 +9534,14 @@ ExprResult Sema::SemaBuiltinShuffleVector(CallExpr *TheCall) {
return ExprError(Diag(TheCall->getBeginLoc(),
diag::err_vec_builtin_incompatible_vector)
<< TheCall->getDirectCallee()
+ << /*isMorethantwoArgs*/ false
<< SourceRange(TheCall->getArg(1)->getBeginLoc(),
TheCall->getArg(1)->getEndLoc()));
} else if (!Context.hasSameUnqualifiedType(LHSType, RHSType)) {
return ExprError(Diag(TheCall->getBeginLoc(),
diag::err_vec_builtin_incompatible_vector)
<< TheCall->getDirectCallee()
+ << /*isMorethantwoArgs*/ false
<< SourceRange(TheCall->getArg(0)->getBeginLoc(),
TheCall->getArg(1)->getEndLoc()));
} else if (numElements != numResElements) {
diff --git a/clang/test/SemaHLSL/BuiltIns/dot-errors.hlsl b/clang/test/SemaHLSL/BuiltIns/dot-errors.hlsl
index 8de8f86d7eb260..59eb9482b9ef92 100644
--- a/clang/test/SemaHLSL/BuiltIns/dot-errors.hlsl
+++ b/clang/test/SemaHLSL/BuiltIns/dot-errors.hlsl
@@ -22,7 +22,7 @@ float test_dot_vector_size_mismatch(float3 p0, float2 p1) {
float test_dot_builtin_vector_size_mismatch(float3 p0, float2 p1) {
return __builtin_hlsl_dot(p0, p1);
- // expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have vectors of the same type}}
+ // expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have the same type}}
}
float test_dot_scalar_mismatch(float p0, int p1) {
@@ -38,39 +38,39 @@ float test_dot_element_type_mismatch(int2 p0, float2 p1) {
//NOTE: for all the *_promotion we are intentionally not handling type promotion in builtins
float test_builtin_dot_vec_int_to_float_promotion(int2 p0, float2 p1) {
return __builtin_hlsl_dot(p0, p1);
- // expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have vectors of the same type}}
+ // expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have the same type}}
}
int64_t test_builtin_dot_vec_int_to_int64_promotion(int64_t2 p0, int2 p1) {
return __builtin_hlsl_dot(p0, p1);
- // expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have vectors of the same type}}
+ // expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have the same type}}
}
float test_builtin_dot_vec_half_to_float_promotion(float2 p0, half2 p1) {
return __builtin_hlsl_dot(p0, p1);
- // expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have vectors of the same type}}
+ // expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have the same type}}
}
#ifdef __HLSL_ENABLE_16_BIT
float test_builtin_dot_vec_int16_to_float_promotion(float2 p0, int16_t2 p1) {
return __builtin_hlsl_dot(p0, p1);
- // expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have vectors of the same type}}
+ // expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have the same type}}
}
half test_builtin_dot_vec_int16_to_half_promotion(half2 p0, int16_t2 p1) {
return __builtin_hlsl_dot(p0, p1);
- // expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have vectors of the same type}}
+ // expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have the same type}}
}
int test_builtin_dot_vec_int16_to_int_promotion(int2 p0, int16_t2 p1) {
return __builtin_hlsl_dot(p0, p1);
- // expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have vectors of the same type}}
+ // expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have the same type}}
}
int64_t test_builtin_dot_vec_int16_to_int64_promotion(int64_t2 p0,
int16_t2 p1) {
return __builtin_hlsl_dot(p0, p1);
- // expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have vectors of the same type}}
+ // expected-error at -1 {{all arguments to '__builtin_hlsl_dot' must have the same type}}
}
#endif
diff --git a/clang/test/SemaHLSL/BuiltIns/lerp-errors.hlsl b/clang/test/SemaHLSL/BuiltIns/lerp-errors.hlsl
index 4ec5a4cdd26a30..f6ce87e7c33e3e 100644
--- a/clang/test/SemaHLSL/BuiltIns/lerp-errors.hlsl
+++ b/clang/test/SemaHLSL/BuiltIns/lerp-errors.hlsl
@@ -27,7 +27,7 @@ float2 test_lerp_vector_size_mismatch(float3 p0, float2 p1) {
float2 test_lerp_builtin_vector_size_mismatch(float3 p0, float2 p1) {
return __builtin_hlsl_lerp(p0, p1, p1);
- // expected-error at -1 {{all arguments to '__builtin_hlsl_lerp' must have vectors of the same type}}
+ // expected-error at -1 {{all arguments to '__builtin_hlsl_lerp' must have the same type}}
}
float test_lerp_scalar_mismatch(float p0, half p1) {
>From 21c83feca5eacfd521f8ab23135d1201984d44cc Mon Sep 17 00:00:00 2001
From: Fangrui Song <i at maskray.me>
Date: Fri, 1 Mar 2024 16:14:48 -0800
Subject: [PATCH 320/406] [ARM] Simplify shouldAssumeDSOLocal for ELF. NFC
---
llvm/lib/Target/ARM/ARMFastISel.cpp | 3 +--
llvm/lib/Target/ARM/ARMISelLowering.cpp | 10 ++++------
llvm/lib/Target/ARM/ARMSubtarget.cpp | 3 +--
3 files changed, 6 insertions(+), 10 deletions(-)
diff --git a/llvm/lib/Target/ARM/ARMFastISel.cpp b/llvm/lib/Target/ARM/ARMFastISel.cpp
index a77aeda96aae39..61d2928fe6d412 100644
--- a/llvm/lib/Target/ARM/ARMFastISel.cpp
+++ b/llvm/lib/Target/ARM/ARMFastISel.cpp
@@ -2953,8 +2953,7 @@ bool ARMFastISel::tryToFoldLoadIntoMI(MachineInstr *MI, unsigned OpNo,
}
unsigned ARMFastISel::ARMLowerPICELF(const GlobalValue *GV, MVT VT) {
- bool UseGOT_PREL = !TM.shouldAssumeDSOLocal(*GV->getParent(), GV);
-
+ bool UseGOT_PREL = !GV->isDSOLocal();
LLVMContext *Context = &MF->getFunction().getContext();
unsigned ARMPCLabelIndex = AFI->createPICLabelUId();
unsigned PCAdj = Subtarget->isThumb() ? 4 : 8;
diff --git a/llvm/lib/Target/ARM/ARMISelLowering.cpp b/llvm/lib/Target/ARM/ARMISelLowering.cpp
index b98006ed0cb3f4..06d4a39cde7747 100644
--- a/llvm/lib/Target/ARM/ARMISelLowering.cpp
+++ b/llvm/lib/Target/ARM/ARMISelLowering.cpp
@@ -3921,20 +3921,18 @@ SDValue ARMTargetLowering::LowerGlobalAddressELF(SDValue Op,
EVT PtrVT = getPointerTy(DAG.getDataLayout());
SDLoc dl(Op);
const GlobalValue *GV = cast<GlobalAddressSDNode>(Op)->getGlobal();
- const TargetMachine &TM = getTargetMachine();
bool IsRO = isReadOnly(GV);
// promoteToConstantPool only if not generating XO text section
- if (TM.shouldAssumeDSOLocal(*GV->getParent(), GV) && !Subtarget->genExecuteOnly())
+ if (GV->isDSOLocal() && !Subtarget->genExecuteOnly())
if (SDValue V = promoteToConstantPool(this, GV, DAG, PtrVT, dl))
return V;
if (isPositionIndependent()) {
- bool UseGOT_PREL = !TM.shouldAssumeDSOLocal(*GV->getParent(), GV);
- SDValue G = DAG.getTargetGlobalAddress(GV, dl, PtrVT, 0,
- UseGOT_PREL ? ARMII::MO_GOT : 0);
+ SDValue G = DAG.getTargetGlobalAddress(
+ GV, dl, PtrVT, 0, GV->isDSOLocal() ? 0 : ARMII::MO_GOT);
SDValue Result = DAG.getNode(ARMISD::WrapperPIC, dl, PtrVT, G);
- if (UseGOT_PREL)
+ if (!GV->isDSOLocal())
Result =
DAG.getLoad(PtrVT, dl, DAG.getEntryNode(), Result,
MachinePointerInfo::getGOT(DAG.getMachineFunction()));
diff --git a/llvm/lib/Target/ARM/ARMSubtarget.cpp b/llvm/lib/Target/ARM/ARMSubtarget.cpp
index 922fa93226f298..691715dc29637c 100644
--- a/llvm/lib/Target/ARM/ARMSubtarget.cpp
+++ b/llvm/lib/Target/ARM/ARMSubtarget.cpp
@@ -366,8 +366,7 @@ bool ARMSubtarget::isGVIndirectSymbol(const GlobalValue *GV) const {
}
bool ARMSubtarget::isGVInGOT(const GlobalValue *GV) const {
- return isTargetELF() && TM.isPositionIndependent() &&
- !TM.shouldAssumeDSOLocal(*GV->getParent(), GV);
+ return isTargetELF() && TM.isPositionIndependent() && !GV->isDSOLocal();
}
unsigned ARMSubtarget::getMispredictionPenalty() const {
>From 189d89a92cd65aa6b1c6608ab91a472a8c1a7c91 Mon Sep 17 00:00:00 2001
From: Peter Klausler <35819229+klausler at users.noreply.github.com>
Date: Fri, 1 Mar 2024 16:19:01 -0800
Subject: [PATCH 321/406] [flang] Ensure names resolve in DATA statement
objects (#82825)
When DATA statement objects have derived types obtained by implicit
typing rules, their types aren't known until specification part
processing is complete. In the case of a derived type, any component
name in a designator may still be in need of name resolution. Take care
of it in the deferred check visitor that runs at the end of name
resolution in each specification and execution part.
Fixes https://github.com/llvm/llvm-project/issues/82069.
---
flang/lib/Semantics/resolve-names.cpp | 28 ++++++++++++++++++++-------
flang/test/Semantics/data22.f90 | 17 ++++++++++++++++
2 files changed, 38 insertions(+), 7 deletions(-)
create mode 100644 flang/test/Semantics/data22.f90
diff --git a/flang/lib/Semantics/resolve-names.cpp b/flang/lib/Semantics/resolve-names.cpp
index 4646bb01ee7254..ca2a52c24a1645 100644
--- a/flang/lib/Semantics/resolve-names.cpp
+++ b/flang/lib/Semantics/resolve-names.cpp
@@ -9095,6 +9095,8 @@ void ResolveNamesVisitor::EndScopeForNode(const ProgramTree &node) {
// pointers, are deferred until all of the pertinent specification parts
// have been visited. This deferred processing enables the use of forward
// references in these circumstances.
+// Data statement objects with implicit derived types are finally
+// resolved here.
class DeferredCheckVisitor {
public:
explicit DeferredCheckVisitor(ResolveNamesVisitor &resolver)
@@ -9110,16 +9112,17 @@ class DeferredCheckVisitor {
if (Symbol * symbol{name.symbol}) {
if (Scope * scope{symbol->scope()}) {
if (scope->IsDerivedType()) {
- resolver_.PushScope(*scope);
- pushedScope_ = true;
+ CHECK(outerScope_ == nullptr);
+ outerScope_ = &resolver_.currScope();
+ resolver_.SetScope(*scope);
}
}
}
}
void Post(const parser::EndTypeStmt &) {
- if (pushedScope_) {
- resolver_.PopScope();
- pushedScope_ = false;
+ if (outerScope_) {
+ resolver_.SetScope(*outerScope_);
+ outerScope_ = nullptr;
}
}
@@ -9149,10 +9152,20 @@ class DeferredCheckVisitor {
resolver_.CheckExplicitInterface(tbps.interfaceName);
}
void Post(const parser::TypeBoundProcedureStmt::WithoutInterface &tbps) {
- if (pushedScope_) {
+ if (outerScope_) {
resolver_.CheckBindings(tbps);
}
}
+ bool Pre(const parser::DataStmtObject &) {
+ ++dataStmtObjectNesting_;
+ return true;
+ }
+ void Post(const parser::DataStmtObject &) { --dataStmtObjectNesting_; }
+ void Post(const parser::Designator &x) {
+ if (dataStmtObjectNesting_ > 0) {
+ resolver_.ResolveDesignator(x);
+ }
+ }
private:
void Init(const parser::Name &name,
@@ -9174,7 +9187,8 @@ class DeferredCheckVisitor {
}
ResolveNamesVisitor &resolver_;
- bool pushedScope_{false};
+ Scope *outerScope_{nullptr};
+ int dataStmtObjectNesting_{0};
};
// Perform checks and completions that need to happen after all of
diff --git a/flang/test/Semantics/data22.f90 b/flang/test/Semantics/data22.f90
new file mode 100644
index 00000000000000..365958dbe7579c
--- /dev/null
+++ b/flang/test/Semantics/data22.f90
@@ -0,0 +1,17 @@
+! RUN: %flang_fc1 -fdebug-dump-symbols %s 2>&1 | FileCheck %s
+! Ensure that implicitly typed DATA statement objects with derived
+! types get their symbols resolved by the end of the name resolution pass.
+! CHECK: x1 (Implicit, InDataStmt) size=4 offset=0: ObjectEntity type: TYPE(t1) shape: 1_8:1_8 init:[t1::t1(n=123_4)]
+! CHECK: x2 (InDataStmt) size=4 offset=4: ObjectEntity type: TYPE(t2) shape: 1_8:1_8 init:[t2::t2(m=456_4)]
+implicit type(t1)(x)
+type t1
+ integer n
+end type
+dimension x1(1), x2(1)
+data x1(1)%n /123/
+data x2(1)%m /456/
+type t2
+ integer m
+end type
+type(t2) x2
+end
>From 8bcb1cededa410016f9a00bebbce09b54e5c9f88 Mon Sep 17 00:00:00 2001
From: Peter Klausler <35819229+klausler at users.noreply.github.com>
Date: Fri, 1 Mar 2024 16:31:13 -0800
Subject: [PATCH 322/406] [flang] Allow PROCEDURE() with explicit type
elsewhere (#82835)
Fortran allows a procedure declaration statement with no interface or
type, with an explicit type declaration statement elsewhere being used
to define a function's result.
Fixes https://github.com/llvm/llvm-project/issues/82006.
---
flang/include/flang/Semantics/symbol.h | 1 -
flang/lib/Semantics/resolve-names.cpp | 10 +++++-----
flang/test/Semantics/resolve91.f90 | 9 ++++++++-
3 files changed, 13 insertions(+), 7 deletions(-)
diff --git a/flang/include/flang/Semantics/symbol.h b/flang/include/flang/Semantics/symbol.h
index d8b372bea10f04..125025dab5f448 100644
--- a/flang/include/flang/Semantics/symbol.h
+++ b/flang/include/flang/Semantics/symbol.h
@@ -419,7 +419,6 @@ class ProcEntityDetails : public EntityDetails, public WithPassArg {
const Symbol *procInterface() const { return procInterface_; }
void set_procInterface(const Symbol &sym) { procInterface_ = &sym; }
- bool IsInterfaceSet() { return procInterface_ || type(); }
inline bool HasExplicitInterface() const;
// Be advised: !init().has_value() => uninitialized pointer,
diff --git a/flang/lib/Semantics/resolve-names.cpp b/flang/lib/Semantics/resolve-names.cpp
index ca2a52c24a1645..61d7ba5fc95c31 100644
--- a/flang/lib/Semantics/resolve-names.cpp
+++ b/flang/lib/Semantics/resolve-names.cpp
@@ -4976,13 +4976,13 @@ Symbol &DeclarationVisitor::DeclareProcEntity(
const parser::Name &name, Attrs attrs, const Symbol *interface) {
Symbol &symbol{DeclareEntity<ProcEntityDetails>(name, attrs)};
if (auto *details{symbol.detailsIf<ProcEntityDetails>()}) {
- if (details->IsInterfaceSet()) {
- SayWithDecl(name, symbol,
- "The interface for procedure '%s' has already been "
- "declared"_err_en_US);
- context().SetError(symbol);
+ if (context().HasError(symbol)) {
} else if (HasCycle(symbol, interface)) {
return symbol;
+ } else if (interface && (details->procInterface() || details->type())) {
+ SayWithDecl(name, symbol,
+ "The interface for procedure '%s' has already been declared"_err_en_US);
+ context().SetError(symbol);
} else if (interface) {
details->set_procInterface(*interface);
if (interface->test(Symbol::Flag::Function)) {
diff --git a/flang/test/Semantics/resolve91.f90 b/flang/test/Semantics/resolve91.f90
index 9873c5a351a409..2b0c4b6aa57e98 100644
--- a/flang/test/Semantics/resolve91.f90
+++ b/flang/test/Semantics/resolve91.f90
@@ -4,7 +4,7 @@ module m
procedure(real), pointer :: p
!ERROR: EXTERNAL attribute was already specified on 'p'
!ERROR: POINTER attribute was already specified on 'p'
- !ERROR: The interface for procedure 'p' has already been declared
+ !ERROR: The type of 'p' has already been declared
procedure(integer), pointer :: p
end
@@ -82,3 +82,10 @@ module m8
!ERROR: The type of 'pvar' has already been declared
integer, pointer :: pVar => kVar
end module m8
+
+module m9
+ integer :: p, q
+ procedure() p ! ok
+ !ERROR: The type of 'q' has already been declared
+ procedure(real) q
+end module m9
>From ed0aa344a8aaab4d8eedbe800750b8dcd36b0bcd Mon Sep 17 00:00:00 2001
From: Fangrui Song <i at maskray.me>
Date: Fri, 1 Mar 2024 16:40:26 -0800
Subject: [PATCH 323/406] [Driver] Add BoolMOption to simplify boolean -m*
options
Similar to BoolFOption/BoolGOption for -f* and -g*
---
clang/include/clang/Driver/Options.td | 31 ++++++++++++++++-----------
1 file changed, 18 insertions(+), 13 deletions(-)
diff --git a/clang/include/clang/Driver/Options.td b/clang/include/clang/Driver/Options.td
index 3a028fadb25b18..bef38738fde82e 100644
--- a/clang/include/clang/Driver/Options.td
+++ b/clang/include/clang/Driver/Options.td
@@ -550,6 +550,13 @@ multiclass BoolGOption<string flag_base, KeyPathAndMacro kpm,
Group<g_Group>;
}
+multiclass BoolMOption<string flag_base, KeyPathAndMacro kpm,
+ Default default, FlagDef flag1, FlagDef flag2,
+ BothFlags both = BothFlags<[]>> {
+ defm NAME : BoolOption<"m", flag_base, kpm, default, flag1, flag2, both>,
+ Group<m_Group>;
+}
+
// Works like BoolOption except without marshalling
multiclass BoolOptionWithoutMarshalling<string prefix = "", string spelling_base,
FlagDef flag1_base, FlagDef flag2_base,
@@ -4600,11 +4607,10 @@ def mretpoline : Flag<["-"], "mretpoline">, Group<m_Group>,
Visibility<[ClangOption, CLOption]>;
def mno_retpoline : Flag<["-"], "mno-retpoline">, Group<m_Group>,
Visibility<[ClangOption, CLOption]>;
-defm speculative_load_hardening : BoolOption<"m", "speculative-load-hardening",
+defm speculative_load_hardening : BoolMOption<"speculative-load-hardening",
CodeGenOpts<"SpeculativeLoadHardening">, DefaultFalse,
PosFlag<SetTrue, [], [ClangOption, CC1Option]>,
- NegFlag<SetFalse>, BothFlags<[], [ClangOption, CLOption]>>,
- Group<m_Group>;
+ NegFlag<SetFalse>, BothFlags<[], [ClangOption, CLOption]>>;
def mlvi_hardening : Flag<["-"], "mlvi-hardening">, Group<m_Group>,
Visibility<[ClangOption, CLOption]>,
HelpText<"Enable all mitigations for Load Value Injection (LVI)">;
@@ -4821,13 +4827,13 @@ def mexec_model_EQ : Joined<["-"], "mexec-model=">, Group<m_wasm_Features_Driver
"explicitly terminated.">;
} // let Flags = [TargetSpecific]
-defm amdgpu_ieee : BoolOption<"m", "amdgpu-ieee",
+defm amdgpu_ieee : BoolMOption<"amdgpu-ieee",
CodeGenOpts<"EmitIEEENaNCompliantInsts">, DefaultTrue,
PosFlag<SetTrue, [], [ClangOption], "Sets the IEEE bit in the expected default floating point "
" mode register. Floating point opcodes that support exception flag "
"gathering quiet and propagate signaling NaN inputs per IEEE 754-2008. "
"This option changes the ABI. (AMDGPU only)">,
- NegFlag<SetFalse, [], [ClangOption, CC1Option]>>, Group<m_Group>;
+ NegFlag<SetFalse, [], [ClangOption, CC1Option]>>;
def mcode_object_version_EQ : Joined<["-"], "mcode-object-version=">, Group<m_Group>,
HelpText<"Specify code object ABI version. Defaults to 5. (AMDGPU only)">,
@@ -4846,14 +4852,14 @@ defm wavefrontsize64 : SimpleMFlag<"wavefrontsize64",
"Specify wavefront size 64", "Specify wavefront size 32",
" mode (AMDGPU only)">;
-defm unsafe_fp_atomics : BoolOption<"m", "unsafe-fp-atomics",
+defm unsafe_fp_atomics : BoolMOption<"unsafe-fp-atomics",
TargetOpts<"AllowAMDGPUUnsafeFPAtomics">, DefaultFalse,
PosFlag<SetTrue, [], [ClangOption, CC1Option],
"Enable generation of unsafe floating point "
"atomic instructions. May generate more efficient code, but may not "
"respect rounding and denormal modes, and may give incorrect results "
"for certain memory destinations. (AMDGPU only)">,
- NegFlag<SetFalse>>, Group<m_Group>;
+ NegFlag<SetFalse>>;
def faltivec : Flag<["-"], "faltivec">, Group<f_Group>;
def fno_altivec : Flag<["-"], "fno-altivec">, Group<f_Group>;
@@ -4941,11 +4947,10 @@ def mrop_protect : Flag<["-"], "mrop-protect">,
def mprivileged : Flag<["-"], "mprivileged">,
Group<m_ppc_Features_Group>;
-defm regnames : BoolOption<"m", "regnames",
+defm regnames : BoolMOption<"regnames",
CodeGenOpts<"PPCUseFullRegisterNames">, DefaultFalse,
PosFlag<SetTrue, [], [ClangOption, CC1Option], "Use full register names when writing assembly output">,
- NegFlag<SetFalse, [], [ClangOption], "Use only register numbers when writing assembly output">>,
- Group<m_Group>;
+ NegFlag<SetFalse, [], [ClangOption], "Use only register numbers when writing assembly output">>;
} // let Flags = [TargetSpecific]
def maix_small_local_exec_tls : Flag<["-"], "maix-small-local-exec-tls">,
Group<m_ppc_Features_Group>,
@@ -4987,10 +4992,10 @@ def mxcoff_build_id_EQ : Joined<["-"], "mxcoff-build-id=">, Group<Link_Group>, M
def mignore_xcoff_visibility : Flag<["-"], "mignore-xcoff-visibility">, Group<m_Group>,
HelpText<"Not emit the visibility attribute for asm in AIX OS or give all symbols 'unspecified' visibility in XCOFF object file">,
Flags<[TargetSpecific]>, Visibility<[ClangOption, CC1Option]>;
-defm backchain : BoolOption<"m", "backchain",
+defm backchain : BoolMOption<"backchain",
CodeGenOpts<"Backchain">, DefaultFalse,
PosFlag<SetTrue, [], [ClangOption], "Link stack frames through backchain on System Z">,
- NegFlag<SetFalse>, BothFlags<[], [ClangOption, CC1Option]>>, Group<m_Group>;
+ NegFlag<SetFalse>, BothFlags<[], [ClangOption, CC1Option]>>;
def mno_warn_nonportable_cfstrings : Flag<["-"], "mno-warn-nonportable-cfstrings">, Group<m_Group>;
def mno_omit_leaf_frame_pointer : Flag<["-"], "mno-omit-leaf-frame-pointer">, Group<m_Group>;
@@ -6952,7 +6957,7 @@ def msmall_data_limit : Separate<["-"], "msmall-data-limit">,
def funwind_tables_EQ : Joined<["-"], "funwind-tables=">,
HelpText<"Generate unwinding tables for all functions">,
MarshallingInfoInt<CodeGenOpts<"UnwindTables">>;
-defm constructor_aliases : BoolOption<"m", "constructor-aliases",
+defm constructor_aliases : BoolMOption<"constructor-aliases",
CodeGenOpts<"CXXCtorDtorAliases">, DefaultFalse,
PosFlag<SetTrue, [], [ClangOption], "Enable">,
NegFlag<SetFalse, [], [ClangOption], "Disable">,
>From f4215f71402dccc9c6a6f7ad51bbc1d08c4a48c2 Mon Sep 17 00:00:00 2001
From: Peter Klausler <35819229+klausler at users.noreply.github.com>
Date: Fri, 1 Mar 2024 16:42:00 -0800
Subject: [PATCH 324/406] [flang] Fix handling of shadowed procedure name used
as interface (#82837)
Use BypassGeneric() to process the name of an interface in a procedure
declaration statement, so that if it's the name of a generic with a
homonymous specific procedure, that's what defines the interface.
Fixes https://github.com/llvm/llvm-project/issues/82267.
---
flang/lib/Semantics/resolve-names.cpp | 6 ++----
flang/test/Semantics/bind-c03.f90 | 6 ++++++
2 files changed, 8 insertions(+), 4 deletions(-)
diff --git a/flang/lib/Semantics/resolve-names.cpp b/flang/lib/Semantics/resolve-names.cpp
index 61d7ba5fc95c31..7fa9b0d8459c04 100644
--- a/flang/lib/Semantics/resolve-names.cpp
+++ b/flang/lib/Semantics/resolve-names.cpp
@@ -5658,10 +5658,8 @@ void DeclarationVisitor::Post(const parser::ProcInterface &x) {
void DeclarationVisitor::Post(const parser::ProcDecl &x) {
const auto &name{std::get<parser::Name>(x.t)};
const Symbol *procInterface{nullptr};
- if (interfaceName_) {
- procInterface = interfaceName_->symbol->has<GenericDetails>()
- ? interfaceName_->symbol->get<GenericDetails>().specific()
- : interfaceName_->symbol;
+ if (interfaceName_ && interfaceName_->symbol) {
+ procInterface = &BypassGeneric(*interfaceName_->symbol);
}
auto attrs{HandleSaveName(name.source, GetAttrs())};
DerivedTypeDetails *dtDetails{nullptr};
diff --git a/flang/test/Semantics/bind-c03.f90 b/flang/test/Semantics/bind-c03.f90
index 03a544b1954d7c..65d52e964ca46e 100644
--- a/flang/test/Semantics/bind-c03.f90
+++ b/flang/test/Semantics/bind-c03.f90
@@ -13,7 +13,13 @@ subroutine proc2()
end
end interface
+ interface proc3
+ subroutine proc3() bind(c)
+ end
+ end interface
+
procedure(proc1), bind(c) :: pc1 ! no error
+ procedure(proc3), bind(c) :: pc4 ! no error
!ERROR: An interface name with BIND attribute must be specified if the BIND attribute is specified in a procedure declaration statement
procedure(proc2), bind(c) :: pc2
>From 2445a96ff2bd038295b313ee15d0d9ec3d033dbf Mon Sep 17 00:00:00 2001
From: Peter Klausler <35819229+klausler at users.noreply.github.com>
Date: Fri, 1 Mar 2024 16:49:43 -0800
Subject: [PATCH 325/406] [flang] Enforce F'2023 C1520 correctly (#82842)
When a procedure declaration statement has a binding label, it must
declare no more than one procedure.
Fixes https://github.com/llvm/llvm-project/issues/82528.
---
flang/lib/Semantics/resolve-names.cpp | 7 ++++---
flang/test/Semantics/bind-c04.f90 | 2 +-
2 files changed, 5 insertions(+), 4 deletions(-)
diff --git a/flang/lib/Semantics/resolve-names.cpp b/flang/lib/Semantics/resolve-names.cpp
index 7fa9b0d8459c04..b7b46257169e36 100644
--- a/flang/lib/Semantics/resolve-names.cpp
+++ b/flang/lib/Semantics/resolve-names.cpp
@@ -1118,7 +1118,6 @@ class DeclarationVisitor : public ArraySpecVisitor,
// Set when walking DATA & array constructor implied DO loop bounds
// to warn about use of the implied DO intex therein.
std::optional<SourceName> checkIndexUseInOwnBounds_;
- bool hasBindCName_{false};
bool isVectorType_{false};
UnorderedSymbolSet mustBeScalar_;
@@ -5589,7 +5588,10 @@ bool DeclarationVisitor::Pre(const parser::ProcedureDeclarationStmt &x) {
for (const parser::ProcAttrSpec &procAttr : procAttrSpec) {
if (auto *bindC{std::get_if<parser::LanguageBindingSpec>(&procAttr.u)}) {
if (bindC->v.has_value()) {
- hasBindCName_ = true;
+ if (std::get<std::list<parser::ProcDecl>>(x.t).size() > 1) {
+ Say(context().location().value(),
+ "A procedure declaration statement with a binding name may not declare multiple procedures"_err_en_US);
+ }
break;
}
}
@@ -5598,7 +5600,6 @@ bool DeclarationVisitor::Pre(const parser::ProcedureDeclarationStmt &x) {
}
void DeclarationVisitor::Post(const parser::ProcedureDeclarationStmt &) {
interfaceName_ = nullptr;
- hasBindCName_ = false;
EndDecl();
}
bool DeclarationVisitor::Pre(const parser::DataComponentDefStmt &x) {
diff --git a/flang/test/Semantics/bind-c04.f90 b/flang/test/Semantics/bind-c04.f90
index a4aaffb239fde2..27119e375ce057 100644
--- a/flang/test/Semantics/bind-c04.f90
+++ b/flang/test/Semantics/bind-c04.f90
@@ -19,7 +19,7 @@ subroutine aproc2() bind(c) ! ok
end
end interface
- !Acceptable (as an extension)
+ !ERROR: A procedure declaration statement with a binding name may not declare multiple procedures
procedure(proc), bind(c, name="aaa") :: pc1, pc2
!ERROR: A procedure pointer may not have a BIND attribute with a name
>From ecd7fce0d4e14cbae7beb9b0b30966435f8ee851 Mon Sep 17 00:00:00 2001
From: Jan Svoboda <jan_svoboda at apple.com>
Date: Fri, 1 Mar 2024 16:35:54 -0800
Subject: [PATCH 326/406] [clang][sema] NFC: Stylistic changes
---
clang/lib/Sema/SemaDeclCXX.cpp | 2 +-
clang/lib/Sema/SemaDeclObjC.cpp | 8 ++++++--
clang/lib/Sema/SemaExpr.cpp | 1 -
3 files changed, 7 insertions(+), 4 deletions(-)
diff --git a/clang/lib/Sema/SemaDeclCXX.cpp b/clang/lib/Sema/SemaDeclCXX.cpp
index d4e1dc67cb50a1..5bbe381f5c4cfd 100644
--- a/clang/lib/Sema/SemaDeclCXX.cpp
+++ b/clang/lib/Sema/SemaDeclCXX.cpp
@@ -7294,7 +7294,7 @@ void Sema::CheckCompletedCXXClass(Scope *S, CXXRecordDecl *Record) {
bool CanPass = canPassInRegisters(*this, Record, CCK);
// Do not change ArgPassingRestrictions if it has already been set to
- // ArgPassingKind::CanNeverPassInRegs.
+ // RecordArgPassingKind::CanNeverPassInRegs.
if (Record->getArgPassingRestrictions() !=
RecordArgPassingKind::CanNeverPassInRegs)
Record->setArgPassingRestrictions(
diff --git a/clang/lib/Sema/SemaDeclObjC.cpp b/clang/lib/Sema/SemaDeclObjC.cpp
index 2011f4084dd2ab..94a245f0f905f3 100644
--- a/clang/lib/Sema/SemaDeclObjC.cpp
+++ b/clang/lib/Sema/SemaDeclObjC.cpp
@@ -2233,12 +2233,16 @@ void Sema::CheckImplementationIvars(ObjCImplementationDecl *ImpDecl,
Diag(IVI->getLocation(), diag::err_inconsistent_ivar_count);
}
+static bool shouldWarnUndefinedMethod(const ObjCMethodDecl *M) {
+ // No point warning no definition of method which is 'unavailable'.
+ return M->getAvailability() != AR_Unavailable;
+}
+
static void WarnUndefinedMethod(Sema &S, ObjCImplDecl *Impl,
ObjCMethodDecl *method, bool &IncompleteImpl,
unsigned DiagID,
NamedDecl *NeededFor = nullptr) {
- // No point warning no definition of method which is 'unavailable'.
- if (method->getAvailability() == AR_Unavailable)
+ if (!shouldWarnUndefinedMethod(method))
return;
// FIXME: For now ignore 'IncompleteImpl'.
diff --git a/clang/lib/Sema/SemaExpr.cpp b/clang/lib/Sema/SemaExpr.cpp
index 2a0e86c37f1bfc..0a449fc1082bd4 100644
--- a/clang/lib/Sema/SemaExpr.cpp
+++ b/clang/lib/Sema/SemaExpr.cpp
@@ -17772,7 +17772,6 @@ bool Sema::DiagnoseAssignmentResult(AssignConvertType ConvTy,
if (lhq.getAddressSpace() != rhq.getAddressSpace()) {
DiagKind = diag::err_typecheck_incompatible_address_space;
break;
-
} else if (lhq.getObjCLifetime() != rhq.getObjCLifetime()) {
DiagKind = diag::err_typecheck_incompatible_ownership;
break;
>From 70467dd0ee0fee2877bf17a465ab975a84baa360 Mon Sep 17 00:00:00 2001
From: Jan Svoboda <jan_svoboda at apple.com>
Date: Fri, 1 Mar 2024 16:36:16 -0800
Subject: [PATCH 327/406] [clang][index] NFC: Stylistic changes
---
clang/lib/Index/IndexSymbol.cpp | 3 +--
clang/lib/Index/IndexingAction.cpp | 2 +-
2 files changed, 2 insertions(+), 3 deletions(-)
diff --git a/clang/lib/Index/IndexSymbol.cpp b/clang/lib/Index/IndexSymbol.cpp
index 0f79694d1faac7..419ff79a5cbab0 100644
--- a/clang/lib/Index/IndexSymbol.cpp
+++ b/clang/lib/Index/IndexSymbol.cpp
@@ -552,8 +552,7 @@ StringRef index::getSymbolSubKindString(SymbolSubKind K) {
case SymbolSubKind::AccessorSetter: return "acc-set";
case SymbolSubKind::UsingTypename: return "using-typename";
case SymbolSubKind::UsingValue: return "using-value";
- case SymbolSubKind::UsingEnum:
- return "using-enum";
+ case SymbolSubKind::UsingEnum: return "using-enum";
}
llvm_unreachable("invalid symbol subkind");
}
diff --git a/clang/lib/Index/IndexingAction.cpp b/clang/lib/Index/IndexingAction.cpp
index c9fcaad311282e..81c46a0d08de66 100644
--- a/clang/lib/Index/IndexingAction.cpp
+++ b/clang/lib/Index/IndexingAction.cpp
@@ -199,7 +199,7 @@ index::createIndexingAction(std::shared_ptr<IndexDataConsumer> DataConsumer,
}
static bool topLevelDeclVisitor(void *context, const Decl *D) {
- IndexingContext &IndexCtx = *static_cast<IndexingContext*>(context);
+ IndexingContext &IndexCtx = *static_cast<IndexingContext *>(context);
return IndexCtx.indexTopLevelDecl(D);
}
>From 5594d12af540dfcc684a02a232484c2b4dd2f5b5 Mon Sep 17 00:00:00 2001
From: Jan Svoboda <jan_svoboda at apple.com>
Date: Fri, 1 Mar 2024 16:36:41 -0800
Subject: [PATCH 328/406] [clang][driver] NFC: Upstream comment
---
clang/lib/Driver/ToolChains/Arch/AArch64.cpp | 3 +++
1 file changed, 3 insertions(+)
diff --git a/clang/lib/Driver/ToolChains/Arch/AArch64.cpp b/clang/lib/Driver/ToolChains/Arch/AArch64.cpp
index 0cf96bb5c9cb02..aa3b80cb16e55a 100644
--- a/clang/lib/Driver/ToolChains/Arch/AArch64.cpp
+++ b/clang/lib/Driver/ToolChains/Arch/AArch64.cpp
@@ -165,11 +165,14 @@ getAArch64MicroArchFeaturesFromMtune(const Driver &D, StringRef Mtune,
// Handle CPU name is 'native'.
if (MtuneLowerCase == "native")
MtuneLowerCase = std::string(llvm::sys::getHostCPUName());
+
+ // 'cyclone' and later have zero-cycle register moves and zeroing.
if (MtuneLowerCase == "cyclone" ||
StringRef(MtuneLowerCase).starts_with("apple")) {
Features.push_back("+zcm");
Features.push_back("+zcz");
}
+
return true;
}
>From 39b67c03214b24da103863abc77c625e71aadd34 Mon Sep 17 00:00:00 2001
From: Jan Svoboda <jan_svoboda at apple.com>
Date: Fri, 1 Mar 2024 16:37:24 -0800
Subject: [PATCH 329/406] [clang] NFC: Extract `CompilerInstance` function
---
.../include/clang/Frontend/CompilerInstance.h | 3 +
clang/lib/Frontend/CompilerInstance.cpp | 55 +++++++++++--------
2 files changed, 34 insertions(+), 24 deletions(-)
diff --git a/clang/include/clang/Frontend/CompilerInstance.h b/clang/include/clang/Frontend/CompilerInstance.h
index b97d0c636806a9..cce91862ae3d03 100644
--- a/clang/include/clang/Frontend/CompilerInstance.h
+++ b/clang/include/clang/Frontend/CompilerInstance.h
@@ -225,6 +225,9 @@ class CompilerInstance : public ModuleLoader {
// of the context or else not CompilerInstance specific.
bool ExecuteAction(FrontendAction &Act);
+ /// At the end of a compilation, print the number of warnings/errors.
+ void printDiagnosticStats();
+
/// Load the list of plugins requested in the \c FrontendOptions.
void LoadRequestedPlugins();
diff --git a/clang/lib/Frontend/CompilerInstance.cpp b/clang/lib/Frontend/CompilerInstance.cpp
index a25aa88bd85ef4..444ffff3073775 100644
--- a/clang/lib/Frontend/CompilerInstance.cpp
+++ b/clang/lib/Frontend/CompilerInstance.cpp
@@ -1061,30 +1061,7 @@ bool CompilerInstance::ExecuteAction(FrontendAction &Act) {
}
}
- if (getDiagnosticOpts().ShowCarets) {
- // We can have multiple diagnostics sharing one diagnostic client.
- // Get the total number of warnings/errors from the client.
- unsigned NumWarnings = getDiagnostics().getClient()->getNumWarnings();
- unsigned NumErrors = getDiagnostics().getClient()->getNumErrors();
-
- if (NumWarnings)
- OS << NumWarnings << " warning" << (NumWarnings == 1 ? "" : "s");
- if (NumWarnings && NumErrors)
- OS << " and ";
- if (NumErrors)
- OS << NumErrors << " error" << (NumErrors == 1 ? "" : "s");
- if (NumWarnings || NumErrors) {
- OS << " generated";
- if (getLangOpts().CUDA) {
- if (!getLangOpts().CUDAIsDevice) {
- OS << " when compiling for host";
- } else {
- OS << " when compiling for " << getTargetOpts().CPU;
- }
- }
- OS << ".\n";
- }
- }
+ printDiagnosticStats();
if (getFrontendOpts().ShowStats) {
if (hasFileManager()) {
@@ -1112,6 +1089,36 @@ bool CompilerInstance::ExecuteAction(FrontendAction &Act) {
return !getDiagnostics().getClient()->getNumErrors();
}
+void CompilerInstance::printDiagnosticStats() {
+ if (!getDiagnosticOpts().ShowCarets)
+ return;
+
+ raw_ostream &OS = getVerboseOutputStream();
+
+ // We can have multiple diagnostics sharing one diagnostic client.
+ // Get the total number of warnings/errors from the client.
+ unsigned NumWarnings = getDiagnostics().getClient()->getNumWarnings();
+ unsigned NumErrors = getDiagnostics().getClient()->getNumErrors();
+
+ if (NumWarnings)
+ OS << NumWarnings << " warning" << (NumWarnings == 1 ? "" : "s");
+ if (NumWarnings && NumErrors)
+ OS << " and ";
+ if (NumErrors)
+ OS << NumErrors << " error" << (NumErrors == 1 ? "" : "s");
+ if (NumWarnings || NumErrors) {
+ OS << " generated";
+ if (getLangOpts().CUDA) {
+ if (!getLangOpts().CUDAIsDevice) {
+ OS << " when compiling for host";
+ } else {
+ OS << " when compiling for " << getTargetOpts().CPU;
+ }
+ }
+ OS << ".\n";
+ }
+}
+
void CompilerInstance::LoadRequestedPlugins() {
// Load any requested plugins.
for (const std::string &Path : getFrontendOpts().Plugins) {
>From 864593b91d289c57c64a0f12658b9ff415da1ad8 Mon Sep 17 00:00:00 2001
From: Jan Svoboda <jan_svoboda at apple.com>
Date: Fri, 1 Mar 2024 16:42:22 -0800
Subject: [PATCH 330/406] [clang][api-notes] NFC: Upstream some documentation
---
clang/include/clang/APINotes/APINotesWriter.h | 13 ++++++++++++-
clang/lib/APINotes/APINotesReader.cpp | 8 +++++++-
2 files changed, 19 insertions(+), 2 deletions(-)
diff --git a/clang/include/clang/APINotes/APINotesWriter.h b/clang/include/clang/APINotes/APINotesWriter.h
index dad44623e16aeb..c5ca3e4617796e 100644
--- a/clang/include/clang/APINotes/APINotesWriter.h
+++ b/clang/include/clang/APINotes/APINotesWriter.h
@@ -5,7 +5,13 @@
// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
//
//===----------------------------------------------------------------------===//
-
+//
+// This file defines the \c APINotesWriter class that writes out source
+// API notes data providing additional information about source code as
+// a separate input, such as the non-nil/nilable annotations for
+// method parameters.
+//
+//===----------------------------------------------------------------------===//
#ifndef LLVM_CLANG_APINOTES_WRITER_H
#define LLVM_CLANG_APINOTES_WRITER_H
@@ -20,11 +26,16 @@ namespace clang {
class FileEntry;
namespace api_notes {
+
+/// A class that writes API notes data to a binary representation that can be
+/// read by the \c APINotesReader.
class APINotesWriter {
class Implementation;
std::unique_ptr<Implementation> Implementation;
public:
+ /// Create a new API notes writer with the given module name and
+ /// (optional) source file.
APINotesWriter(llvm::StringRef ModuleName, const FileEntry *SF);
~APINotesWriter();
diff --git a/clang/lib/APINotes/APINotesReader.cpp b/clang/lib/APINotes/APINotesReader.cpp
index 55ea4bae81e6e8..fbbe9c32ce1258 100644
--- a/clang/lib/APINotes/APINotesReader.cpp
+++ b/clang/lib/APINotes/APINotesReader.cpp
@@ -5,7 +5,13 @@
// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
//
//===----------------------------------------------------------------------===//
-
+//
+// This file implements the \c APINotesReader class that reads source
+// API notes data providing additional information about source code as
+// a separate input, such as the non-nil/nilable annotations for
+// method parameters.
+//
+//===----------------------------------------------------------------------===//
#include "clang/APINotes/APINotesReader.h"
#include "APINotesFormat.h"
#include "llvm/ADT/Hashing.h"
>From 164c0985681648cf18bef69d75ece2b327525737 Mon Sep 17 00:00:00 2001
From: Jan Svoboda <jan_svoboda at apple.com>
Date: Fri, 1 Mar 2024 16:49:52 -0800
Subject: [PATCH 331/406] [clang][deps] Implement move-conversion for
`CowCompilerInvocation` (follow-up)
---
clang/include/clang/Frontend/CompilerInvocation.h | 5 +++++
clang/lib/Frontend/CompilerInvocation.cpp | 11 +++++++++++
2 files changed, 16 insertions(+)
diff --git a/clang/include/clang/Frontend/CompilerInvocation.h b/clang/include/clang/Frontend/CompilerInvocation.h
index 8fc51e6ec03b64..1a2a39411e58d8 100644
--- a/clang/include/clang/Frontend/CompilerInvocation.h
+++ b/clang/include/clang/Frontend/CompilerInvocation.h
@@ -201,6 +201,8 @@ class CompilerInvocationBase {
/// @}
};
+class CowCompilerInvocation;
+
/// Helper class for holding the data necessary to invoke the compiler.
///
/// This class is designed to represent an abstract "invocation" of the
@@ -220,6 +222,9 @@ class CompilerInvocation : public CompilerInvocationBase {
}
~CompilerInvocation() = default;
+ explicit CompilerInvocation(const CowCompilerInvocation &X);
+ CompilerInvocation &operator=(const CowCompilerInvocation &X);
+
/// Const getters.
/// @{
// Note: These need to be pulled in manually. Otherwise, they get hidden by
diff --git a/clang/lib/Frontend/CompilerInvocation.cpp b/clang/lib/Frontend/CompilerInvocation.cpp
index 9555dbf663d334..691f3b989b81e5 100644
--- a/clang/lib/Frontend/CompilerInvocation.cpp
+++ b/clang/lib/Frontend/CompilerInvocation.cpp
@@ -191,6 +191,17 @@ CompilerInvocationBase::shallow_copy_assign(const CompilerInvocationBase &X) {
return *this;
}
+CompilerInvocation::CompilerInvocation(const CowCompilerInvocation &X)
+ : CompilerInvocationBase(EmptyConstructor{}) {
+ CompilerInvocationBase::deep_copy_assign(X);
+}
+
+CompilerInvocation &
+CompilerInvocation::operator=(const CowCompilerInvocation &X) {
+ CompilerInvocationBase::deep_copy_assign(X);
+ return *this;
+}
+
namespace {
template <typename T>
T &ensureOwned(std::shared_ptr<T> &Storage) {
>From e09e9567fc1cfc949810cc85f09e1b894ce946df Mon Sep 17 00:00:00 2001
From: Peter Klausler <35819229+klausler at users.noreply.github.com>
Date: Fri, 1 Mar 2024 16:54:35 -0800
Subject: [PATCH 332/406] [flang] Downgrade error to warning (#83032)
It's probably a bad idea to have a Cray pointer whose type is a derived
type that is not a sequence type, but the feature is a nonstandard
extension in the first place. Downgrade the message to a warning.
Fixes https://github.com/llvm/llvm-project/issues/82210.
---
flang/lib/Semantics/resolve-names.cpp | 2 +-
flang/test/Semantics/resolve61.f90 | 2 +-
2 files changed, 2 insertions(+), 2 deletions(-)
diff --git a/flang/lib/Semantics/resolve-names.cpp b/flang/lib/Semantics/resolve-names.cpp
index b7b46257169e36..5a95d3a98992a7 100644
--- a/flang/lib/Semantics/resolve-names.cpp
+++ b/flang/lib/Semantics/resolve-names.cpp
@@ -6037,7 +6037,7 @@ void DeclarationVisitor::Post(const parser::BasedPointer &bp) {
if (const auto *derived{pointeeType->AsDerived()}) {
if (!IsSequenceOrBindCType(derived)) {
Say(pointeeName,
- "Type of Cray pointee '%s' is a derived type that is neither SEQUENCE nor BIND(C)"_err_en_US);
+ "Type of Cray pointee '%s' is a derived type that is neither SEQUENCE nor BIND(C)"_warn_en_US);
}
}
}
diff --git a/flang/test/Semantics/resolve61.f90 b/flang/test/Semantics/resolve61.f90
index d6499f07b86091..32bf9091a85651 100644
--- a/flang/test/Semantics/resolve61.f90
+++ b/flang/test/Semantics/resolve61.f90
@@ -114,7 +114,7 @@ subroutine p12
type(t2) :: x2
type(t3) :: x3
pointer(a, x1)
- !ERROR: Type of Cray pointee 'x2' is a derived type that is neither SEQUENCE nor BIND(C)
+ !WARNING: Type of Cray pointee 'x2' is a derived type that is neither SEQUENCE nor BIND(C)
pointer(b, x2)
pointer(c, x3)
end
>From 463fb9f2140a4b37afb2f2a53cc766fac84203e3 Mon Sep 17 00:00:00 2001
From: Peter Klausler <35819229+klausler at users.noreply.github.com>
Date: Fri, 1 Mar 2024 16:59:36 -0800
Subject: [PATCH 333/406] [flang] Support INDEX as a procedure interface
(#83073)
The specific intrinsic function INDEX should work as a PROCEDURE
interface in the declaration of a procedure pointer or dummy procedure,
and it should be compatible with a user-defined interface.
Fixes https://github.com/llvm/llvm-project/issues/82397.
---
flang/docs/Extensions.md | 14 +++
flang/lib/Evaluate/intrinsics.cpp | 12 +++
flang/test/Semantics/intrinsics03.f90 | 125 ++++++++++++++++++++++++++
3 files changed, 151 insertions(+)
create mode 100644 flang/test/Semantics/intrinsics03.f90
diff --git a/flang/docs/Extensions.md b/flang/docs/Extensions.md
index 4bd93f6b6d0f2f..baecfd7c48fd06 100644
--- a/flang/docs/Extensions.md
+++ b/flang/docs/Extensions.md
@@ -692,6 +692,20 @@ end
essentially ignored unless there are some unmasked array entries and
*all* of them are NaNs.
+* When `INDEX` is used as an unrestricted specific intrinsic function
+ in the context of an actual procedure, as the explicit interface in
+ a `PROCEDURE` declaration statement, or as the target of a procedure
+ pointer assignment, its interface has exactly two dummy arguments
+ (`STRING=` and `SUBSTRING=`), and includes neither `BACK=` nor
+ `KIND=`.
+ This is how `INDEX` as an unrestricted specific intrinsic function was
+ documented in FORTRAN '77 and Fortran '90; later revisions of the
+ standard deleted the argument information from the section on
+ unrestricted specific intrinsic functions.
+ At least one other compiler (XLF) seems to expect that the interface for
+ `INDEX` include an optional `BACK=` argument, but it doesn't actually
+ work.
+
## De Facto Standard Features
* `EXTENDS_TYPE_OF()` returns `.TRUE.` if both of its arguments have the
diff --git a/flang/lib/Evaluate/intrinsics.cpp b/flang/lib/Evaluate/intrinsics.cpp
index 61bf0f2b48ad88..a8f2e5b445ed2b 100644
--- a/flang/lib/Evaluate/intrinsics.cpp
+++ b/flang/lib/Evaluate/intrinsics.cpp
@@ -1120,6 +1120,12 @@ static const SpecificIntrinsicInterface specificIntrinsicFunction[]{
{{"iiabs", {{"a", TypePattern{IntType, KindCode::exactKind, 2}}},
TypePattern{IntType, KindCode::exactKind, 2}},
"abs"},
+ // The definition of the unrestricted specific intrinsic function INDEX
+ // in F'77 and F'90 has only two arguments; later standards omit the
+ // argument information for all unrestricted specific intrinsic
+ // procedures. No compiler supports an implementation that allows
+ // INDEX with BACK= to work when associated as an actual procedure or
+ // procedure pointer target.
{{"index", {{"string", DefaultChar}, {"substring", DefaultChar}},
DefaultInt}},
{{"isign", {{"a", DefaultInt}, {"b", DefaultInt}}, DefaultInt}, "sign"},
@@ -2505,6 +2511,8 @@ class IntrinsicProcTable::Implementation {
std::multimap<std::string, const IntrinsicInterface *> subroutines_;
const semantics::Scope *builtinsScope_{nullptr};
std::map<std::string, std::string> aliases_;
+ semantics::ParamValue assumedLen_{
+ semantics::ParamValue::Assumed(common::TypeParamAttr::Len)};
};
bool IntrinsicProcTable::Implementation::IsIntrinsicFunction(
@@ -3241,6 +3249,10 @@ DynamicType IntrinsicProcTable::Implementation::GetSpecificType(
TypeCategory category{set.LeastElement().value()};
if (pattern.kindCode == KindCode::doublePrecision) {
return DynamicType{category, defaults_.doublePrecisionKind()};
+ } else if (category == TypeCategory::Character) {
+ // All character arguments to specific intrinsic functions are
+ // assumed-length.
+ return DynamicType{defaults_.GetDefaultKind(category), assumedLen_};
} else {
return DynamicType{category, defaults_.GetDefaultKind(category)};
}
diff --git a/flang/test/Semantics/intrinsics03.f90 b/flang/test/Semantics/intrinsics03.f90
new file mode 100644
index 00000000000000..03109bc300caf3
--- /dev/null
+++ b/flang/test/Semantics/intrinsics03.f90
@@ -0,0 +1,125 @@
+! RUN: %python %S/test_errors.py %s %flang_fc1
+! Ensure that INDEX is a usable specific intrinsic procedure.
+
+program test
+ interface
+ pure integer function index1(string, substring)
+ character(*), intent(in) :: string, substring ! ok
+ end
+ pure integer function index2(x1, x2)
+ character(*), intent(in) :: x1, x2 ! ok
+ end
+ pure integer function index3(string, substring)
+ character, intent(in) :: string, substring ! not assumed length
+ end
+ pure integer function index4(string, substring, back)
+ character(*), intent(in) :: string, substring
+ logical, optional, intent(in) :: back ! not ok
+ end
+ subroutine s0(ix)
+ procedure(index) :: ix
+ end
+ subroutine s1(ix)
+ import index1
+ procedure(index1) :: ix
+ end
+ subroutine s2(ix)
+ import index2
+ procedure(index2) :: ix
+ end
+ subroutine s3(ix)
+ import index3
+ procedure(index3) :: ix
+ end
+ subroutine s4(ix)
+ import index4
+ procedure(index4) :: ix
+ end
+ end interface
+
+ procedure(index), pointer :: p0
+ procedure(index1), pointer :: p1
+ procedure(index2), pointer :: p2
+ procedure(index3), pointer :: p3
+ procedure(index4), pointer :: p4
+
+ p0 => index ! ok
+ p0 => index1 ! ok
+ p0 => index2 ! ok
+ !ERROR: Procedure pointer 'p0' associated with incompatible procedure designator 'index3': incompatible dummy argument #1: assumed-length character vs explicit-length character
+ p0 => index3
+ !ERROR: Procedure pointer 'p0' associated with incompatible procedure designator 'index4': distinct numbers of dummy arguments
+ p0 => index4
+ p1 => index ! ok
+ p1 => index1 ! ok
+ p1 => index2 ! ok
+ !ERROR: Procedure pointer 'p1' associated with incompatible procedure designator 'index3': incompatible dummy argument #1: assumed-length character vs explicit-length character
+ p1 => index3
+ !ERROR: Procedure pointer 'p1' associated with incompatible procedure designator 'index4': distinct numbers of dummy arguments
+ p1 => index4
+ p2 => index ! ok
+ p2 => index1 ! ok
+ p2 => index2 ! ok
+ !ERROR: Procedure pointer 'p2' associated with incompatible procedure designator 'index3': incompatible dummy argument #1: assumed-length character vs explicit-length character
+ p2 => index3
+ !ERROR: Procedure pointer 'p2' associated with incompatible procedure designator 'index4': distinct numbers of dummy arguments
+ p2 => index4
+ !ERROR: Procedure pointer 'p3' associated with incompatible procedure designator 'index': incompatible dummy argument #1: assumed-length character vs explicit-length character
+ p3 => index
+ !ERROR: Procedure pointer 'p3' associated with incompatible procedure designator 'index1': incompatible dummy argument #1: assumed-length character vs explicit-length character
+ p3 => index1
+ !ERROR: Procedure pointer 'p3' associated with incompatible procedure designator 'index2': incompatible dummy argument #1: assumed-length character vs explicit-length character
+ p3 => index2
+ p3 => index3 ! ok
+ !ERROR: Procedure pointer 'p3' associated with incompatible procedure designator 'index4': distinct numbers of dummy arguments
+ p3 => index4
+ !ERROR: Procedure pointer 'p4' associated with incompatible procedure designator 'index': distinct numbers of dummy arguments
+ p4 => index
+ !ERROR: Procedure pointer 'p4' associated with incompatible procedure designator 'index1': distinct numbers of dummy arguments
+ p4 => index1
+ !ERROR: Procedure pointer 'p4' associated with incompatible procedure designator 'index2': distinct numbers of dummy arguments
+ p4 => index2
+ !ERROR: Procedure pointer 'p4' associated with incompatible procedure designator 'index3': distinct numbers of dummy arguments
+ p4 => index3
+ p4 => index4 ! ok
+
+ call s0(index) ! ok
+ call s0(index1) ! ok
+ call s0(index2)
+ !ERROR: Actual procedure argument has interface incompatible with dummy argument 'ix=': incompatible dummy argument #1: assumed-length character vs explicit-length character
+ call s0(index3)
+ !ERROR: Actual procedure argument has interface incompatible with dummy argument 'ix=': distinct numbers of dummy arguments
+ call s0(index4)
+ call s1(index) ! ok
+ call s1(index1) ! ok
+ call s1(index2) ! ok
+ !ERROR: Actual procedure argument has interface incompatible with dummy argument 'ix=': incompatible dummy argument #1: assumed-length character vs explicit-length character
+ call s1(index3)
+ !ERROR: Actual procedure argument has interface incompatible with dummy argument 'ix=': distinct numbers of dummy arguments
+ call s1(index4)
+ call s2(index) ! ok
+ call s2(index1) ! ok
+ call s2(index2) ! ok
+ !ERROR: Actual procedure argument has interface incompatible with dummy argument 'ix=': incompatible dummy argument #1: assumed-length character vs explicit-length character
+ call s2(index3)
+ !ERROR: Actual procedure argument has interface incompatible with dummy argument 'ix=': distinct numbers of dummy arguments
+ call s2(index4)
+ !ERROR: Actual procedure argument has interface incompatible with dummy argument 'ix=': incompatible dummy argument #1: assumed-length character vs explicit-length character
+ call s3(index)
+ !ERROR: Actual procedure argument has interface incompatible with dummy argument 'ix=': incompatible dummy argument #1: assumed-length character vs explicit-length character
+ call s3(index1)
+ !ERROR: Actual procedure argument has interface incompatible with dummy argument 'ix=': incompatible dummy argument #1: assumed-length character vs explicit-length character
+ call s3(index2)
+ call s3(index3) ! ok
+ !ERROR: Actual procedure argument has interface incompatible with dummy argument 'ix=': distinct numbers of dummy arguments
+ call s3(index4)
+ !ERROR: Actual procedure argument has interface incompatible with dummy argument 'ix=': distinct numbers of dummy arguments
+ call s4(index)
+ !ERROR: Actual procedure argument has interface incompatible with dummy argument 'ix=': distinct numbers of dummy arguments
+ call s4(index1)
+ !ERROR: Actual procedure argument has interface incompatible with dummy argument 'ix=': distinct numbers of dummy arguments
+ call s4(index2)
+ !ERROR: Actual procedure argument has interface incompatible with dummy argument 'ix=': distinct numbers of dummy arguments
+ call s4(index3)
+ call s4(index4) ! ok
+end
>From cb807ff3d3fd4eb72f2c6151001c2366d2725815 Mon Sep 17 00:00:00 2001
From: Joseph Huber <huberjn at outlook.com>
Date: Fri, 1 Mar 2024 19:28:45 -0600
Subject: [PATCH 334/406] [libc] Fix GPU include install directory
---
libc/CMakeLists.txt | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/libc/CMakeLists.txt b/libc/CMakeLists.txt
index 7c7322e3043393..0b72b1c5481651 100644
--- a/libc/CMakeLists.txt
+++ b/libc/CMakeLists.txt
@@ -232,7 +232,7 @@ else()
set(LIBC_LIBRARY_DIR ${CMAKE_BINARY_DIR}/lib${LLVM_LIBDIR_SUFFIX})
endif()
if(LIBC_TARGET_OS_IS_GPU)
- set(LIBC_INSTALL_INCLUDE_DIR ${CMAKE_INSTALL_INCLUDEDIR}/${LIBC_TARGET_TRIPLE})
+ set(LIBC_INSTALL_INCLUDE_DIR ${CMAKE_INSTALL_INCLUDEDIR}/${LLVM_DEFAULT_TARGET_TRIPLE})
else()
set(LIBC_INSTALL_INCLUDE_DIR ${CMAKE_INSTALL_INCLUDEDIR})
endif()
@@ -240,7 +240,7 @@ endif()
if(LIBC_TARGET_TRIPLE)
set(LIBC_INSTALL_LIBRARY_DIR lib${LLVM_LIBDIR_SUFFIX}/${LIBC_TARGET_TRIPLE})
-elseif(LLVM_ENABLE_PER_TARGET_RUNTIME_DIR AND NOT LIBC_GPU_BUILD)
+elseif(LLVM_ENABLE_PER_TARGET_RUNTIME_DIR)
set(LIBC_INSTALL_LIBRARY_DIR
lib${LLVM_LIBDIR_SUFFIX}/${LLVM_DEFAULT_TARGET_TRIPLE})
else()
>From 057e7252608e680348484c7942ac0d78bd174ec1 Mon Sep 17 00:00:00 2001
From: Sergei Barannikov <barannikov88 at gmail.com>
Date: Sat, 2 Mar 2024 05:17:41 +0300
Subject: [PATCH 335/406] [Sparc] Use generated MatchRegisterName (NFCI)
(#82165)
---
.../Target/Sparc/AsmParser/SparcAsmParser.cpp | 440 +++++-------------
llvm/lib/Target/Sparc/Sparc.td | 3 +-
2 files changed, 115 insertions(+), 328 deletions(-)
diff --git a/llvm/lib/Target/Sparc/AsmParser/SparcAsmParser.cpp b/llvm/lib/Target/Sparc/AsmParser/SparcAsmParser.cpp
index 7a956636831df7..be4ec1e9dce2a6 100644
--- a/llvm/lib/Target/Sparc/AsmParser/SparcAsmParser.cpp
+++ b/llvm/lib/Target/Sparc/AsmParser/SparcAsmParser.cpp
@@ -57,6 +57,7 @@ class SparcOperand;
class SparcAsmParser : public MCTargetAsmParser {
MCAsmParser &Parser;
+ const MCRegisterInfo &MRI;
enum class TailRelocKind { Load_GOT, Add_TLS, Load_TLS, Call_TLS };
@@ -109,8 +110,7 @@ class SparcAsmParser : public MCTargetAsmParser {
const MCExpr *subExpr);
// returns true if Tok is matched to a register and returns register in RegNo.
- bool matchRegisterName(const AsmToken &Tok, MCRegister &RegNo,
- unsigned &RegKind);
+ MCRegister matchRegisterName(const AsmToken &Tok, unsigned &RegKind);
bool matchSparcAsmModifiers(const MCExpr *&EVal, SMLoc &EndLoc);
@@ -128,9 +128,9 @@ class SparcAsmParser : public MCTargetAsmParser {
public:
SparcAsmParser(const MCSubtargetInfo &sti, MCAsmParser &parser,
- const MCInstrInfo &MII,
- const MCTargetOptions &Options)
- : MCTargetAsmParser(Options, sti, MII), Parser(parser) {
+ const MCInstrInfo &MII, const MCTargetOptions &Options)
+ : MCTargetAsmParser(Options, sti, MII), Parser(parser),
+ MRI(*Parser.getContext().getRegisterInfo()) {
Parser.addAliasForDirective(".half", ".2byte");
Parser.addAliasForDirective(".uahalf", ".2byte");
Parser.addAliasForDirective(".word", ".4byte");
@@ -156,16 +156,6 @@ class SparcAsmParser : public MCTargetAsmParser {
Sparc::I0, Sparc::I1, Sparc::I2, Sparc::I3,
Sparc::I4, Sparc::I5, Sparc::I6, Sparc::I7 };
- static const MCPhysReg FloatRegs[32] = {
- Sparc::F0, Sparc::F1, Sparc::F2, Sparc::F3,
- Sparc::F4, Sparc::F5, Sparc::F6, Sparc::F7,
- Sparc::F8, Sparc::F9, Sparc::F10, Sparc::F11,
- Sparc::F12, Sparc::F13, Sparc::F14, Sparc::F15,
- Sparc::F16, Sparc::F17, Sparc::F18, Sparc::F19,
- Sparc::F20, Sparc::F21, Sparc::F22, Sparc::F23,
- Sparc::F24, Sparc::F25, Sparc::F26, Sparc::F27,
- Sparc::F28, Sparc::F29, Sparc::F30, Sparc::F31 };
-
static const MCPhysReg DoubleRegs[32] = {
Sparc::D0, Sparc::D1, Sparc::D2, Sparc::D3,
Sparc::D4, Sparc::D5, Sparc::D6, Sparc::D7,
@@ -182,32 +172,12 @@ class SparcAsmParser : public MCTargetAsmParser {
Sparc::Q8, Sparc::Q9, Sparc::Q10, Sparc::Q11,
Sparc::Q12, Sparc::Q13, Sparc::Q14, Sparc::Q15 };
- static const MCPhysReg ASRRegs[32] = {
- SP::Y, SP::ASR1, SP::ASR2, SP::ASR3,
- SP::ASR4, SP::ASR5, SP::ASR6, SP::ASR7,
- SP::ASR8, SP::ASR9, SP::ASR10, SP::ASR11,
- SP::ASR12, SP::ASR13, SP::ASR14, SP::ASR15,
- SP::ASR16, SP::ASR17, SP::ASR18, SP::ASR19,
- SP::ASR20, SP::ASR21, SP::ASR22, SP::ASR23,
- SP::ASR24, SP::ASR25, SP::ASR26, SP::ASR27,
- SP::ASR28, SP::ASR29, SP::ASR30, SP::ASR31};
-
static const MCPhysReg IntPairRegs[] = {
Sparc::G0_G1, Sparc::G2_G3, Sparc::G4_G5, Sparc::G6_G7,
Sparc::O0_O1, Sparc::O2_O3, Sparc::O4_O5, Sparc::O6_O7,
Sparc::L0_L1, Sparc::L2_L3, Sparc::L4_L5, Sparc::L6_L7,
Sparc::I0_I1, Sparc::I2_I3, Sparc::I4_I5, Sparc::I6_I7};
- static const MCPhysReg CoprocRegs[32] = {
- Sparc::C0, Sparc::C1, Sparc::C2, Sparc::C3,
- Sparc::C4, Sparc::C5, Sparc::C6, Sparc::C7,
- Sparc::C8, Sparc::C9, Sparc::C10, Sparc::C11,
- Sparc::C12, Sparc::C13, Sparc::C14, Sparc::C15,
- Sparc::C16, Sparc::C17, Sparc::C18, Sparc::C19,
- Sparc::C20, Sparc::C21, Sparc::C22, Sparc::C23,
- Sparc::C24, Sparc::C25, Sparc::C26, Sparc::C27,
- Sparc::C28, Sparc::C29, Sparc::C30, Sparc::C31 };
-
static const MCPhysReg CoprocPairRegs[] = {
Sparc::C0_C1, Sparc::C2_C3, Sparc::C4_C5, Sparc::C6_C7,
Sparc::C8_C9, Sparc::C10_C11, Sparc::C12_C13, Sparc::C14_C15,
@@ -816,8 +786,9 @@ ParseStatus SparcAsmParser::tryParseRegister(MCRegister &Reg, SMLoc &StartLoc,
if (getLexer().getKind() != AsmToken::Percent)
return ParseStatus::NoMatch;
Parser.Lex();
- unsigned regKind = SparcOperand::rk_None;
- if (matchRegisterName(Tok, Reg, regKind)) {
+ unsigned RegKind = SparcOperand::rk_None;
+ Reg = matchRegisterName(Tok, RegKind);
+ if (Reg) {
Parser.Lex();
return ParseStatus::Success;
}
@@ -1168,14 +1139,14 @@ ParseStatus SparcAsmParser::parseOperand(OperandVector &Operands,
return ParseStatus::NoMatch;
Parser.Lex(); // eat %
- MCRegister RegNo;
unsigned RegKind;
- if (!matchRegisterName(Parser.getTok(), RegNo, RegKind))
+ MCRegister Reg = matchRegisterName(Parser.getTok(), RegKind);
+ if (!Reg)
return ParseStatus::NoMatch;
Parser.Lex(); // Eat the identifier token.
SMLoc E = SMLoc::getFromPointer(Parser.getTok().getLoc().getPointer()-1);
- Operands.push_back(SparcOperand::CreateReg(RegNo, RegKind, S, E));
+ Operands.push_back(SparcOperand::CreateReg(Reg, RegKind, S, E));
Res = ParseStatus::Success;
} else {
Res = parseMEMOperand(Operands);
@@ -1261,9 +1232,8 @@ SparcAsmParser::parseSparcAsmOperand(std::unique_ptr<SparcOperand> &Op,
case AsmToken::Percent: {
Parser.Lex(); // Eat the '%'.
- MCRegister Reg;
unsigned RegKind;
- if (matchRegisterName(Parser.getTok(), Reg, RegKind)) {
+ if (MCRegister Reg = matchRegisterName(Parser.getTok(), RegKind)) {
StringRef Name = Parser.getTok().getString();
Parser.Lex(); // Eat the identifier token.
E = SMLoc::getFromPointer(Parser.getTok().getLoc().getPointer() - 1);
@@ -1325,314 +1295,131 @@ ParseStatus SparcAsmParser::parseBranchModifiers(OperandVector &Operands) {
return ParseStatus::Success;
}
-bool SparcAsmParser::matchRegisterName(const AsmToken &Tok, MCRegister &RegNo,
- unsigned &RegKind) {
- int64_t intVal = 0;
- RegNo = 0;
- RegKind = SparcOperand::rk_None;
- if (Tok.is(AsmToken::Identifier)) {
- StringRef name = Tok.getString();
-
- // %fp
- if (name.equals("fp")) {
- RegNo = Sparc::I6;
- RegKind = SparcOperand::rk_IntReg;
- return true;
- }
- // %sp
- if (name.equals("sp")) {
- RegNo = Sparc::O6;
- RegKind = SparcOperand::rk_IntReg;
- return true;
- }
-
- if (name.equals("y")) {
- RegNo = Sparc::Y;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
+#define GET_REGISTER_MATCHER
+#include "SparcGenAsmMatcher.inc"
- if (name.starts_with_insensitive("asr") &&
- !name.substr(3).getAsInteger(10, intVal) && intVal > 0 && intVal < 32) {
- RegNo = ASRRegs[intVal];
- RegKind = SparcOperand::rk_Special;
- return true;
- }
+MCRegister SparcAsmParser::matchRegisterName(const AsmToken &Tok,
+ unsigned &RegKind) {
+ RegKind = SparcOperand::rk_None;
+ if (!Tok.is(AsmToken::Identifier))
+ return SP::NoRegister;
- if (name.equals("fprs")) {
- RegNo = Sparc::ASR6;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
+ StringRef Name = Tok.getString();
+ MCRegister Reg = MatchRegisterName(Name.lower());
+ if (!Reg)
+ Reg = MatchRegisterAltName(Name.lower());
- if (name.equals("icc")) {
- RegNo = Sparc::ICC;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
+ if (Reg) {
+ // Some registers have identical spellings. The generated matcher might
+ // have chosen one or another spelling, e.g. "%fp" or "%i6" might have been
+ // matched to either SP::I6 or SP::I6_I7. Other parts of SparcAsmParser
+ // are not prepared for this, so we do some canonicalization.
- if (name.equals("psr")) {
- RegNo = Sparc::PSR;
+ // See the note in SparcRegisterInfo.td near ASRRegs register class.
+ if (Reg == SP::ASR4 && Name == "tick") {
RegKind = SparcOperand::rk_Special;
- return true;
+ return SP::TICK;
}
- if (name.equals("fsr")) {
- RegNo = Sparc::FSR;
- RegKind = SparcOperand::rk_Special;
- return true;
+ if (MRI.getRegClass(SP::IntRegsRegClassID).contains(Reg)) {
+ RegKind = SparcOperand::rk_IntReg;
+ return Reg;
}
-
- if (name.equals("fq")) {
- RegNo = Sparc::FQ;
- RegKind = SparcOperand::rk_Special;
- return true;
+ if (MRI.getRegClass(SP::FPRegsRegClassID).contains(Reg)) {
+ RegKind = SparcOperand::rk_FloatReg;
+ return Reg;
}
-
- if (name.equals("csr")) {
- RegNo = Sparc::CPSR;
- RegKind = SparcOperand::rk_Special;
- return true;
+ if (MRI.getRegClass(SP::CoprocRegsRegClassID).contains(Reg)) {
+ RegKind = SparcOperand::rk_CoprocReg;
+ return Reg;
}
- if (name.equals("cq")) {
- RegNo = Sparc::CPQ;
- RegKind = SparcOperand::rk_Special;
- return true;
+ // Canonicalize G0_G1 ... G30_G31 etc. to G0 ... G30.
+ if (MRI.getRegClass(SP::IntPairRegClassID).contains(Reg)) {
+ RegKind = SparcOperand::rk_IntReg;
+ return MRI.getSubReg(Reg, SP::sub_even);
}
- if (name.equals("wim")) {
- RegNo = Sparc::WIM;
- RegKind = SparcOperand::rk_Special;
- return true;
+ // Canonicalize D0 ... D15 to F0 ... F30.
+ if (MRI.getRegClass(SP::DFPRegsRegClassID).contains(Reg)) {
+ // D16 ... D31 do not have sub-registers.
+ if (MCRegister SubReg = MRI.getSubReg(Reg, SP::sub_even)) {
+ RegKind = SparcOperand::rk_FloatReg;
+ return SubReg;
+ }
+ RegKind = SparcOperand::rk_DoubleReg;
+ return Reg;
}
- if (name.equals("tbr")) {
- RegNo = Sparc::TBR;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
+ // The generated matcher does not currently return QFP registers.
+ // If it changes, we will need to handle them in a similar way.
+ assert(!MRI.getRegClass(SP::QFPRegsRegClassID).contains(Reg));
- if (name.equals("xcc")) {
- // FIXME:: check 64bit.
- RegNo = Sparc::ICC;
- RegKind = SparcOperand::rk_Special;
- return true;
+ // Canonicalize C0_C1 ... C30_C31 to C0 ... C30.
+ if (MRI.getRegClass(SP::CoprocPairRegClassID).contains(Reg)) {
+ RegKind = SparcOperand::rk_CoprocReg;
+ return MRI.getSubReg(Reg, SP::sub_even);
}
- // %fcc0 - %fcc3
- if (name.starts_with_insensitive("fcc") &&
- !name.substr(3).getAsInteger(10, intVal) && intVal < 4) {
- // FIXME: check 64bit and handle %fcc1 - %fcc3
- RegNo = Sparc::FCC0 + intVal;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
+ // Other registers do not need special handling.
+ RegKind = SparcOperand::rk_Special;
+ return Reg;
+ }
- // %g0 - %g7
- if (name.starts_with_insensitive("g") &&
- !name.substr(1).getAsInteger(10, intVal) && intVal < 8) {
- RegNo = IntRegs[intVal];
- RegKind = SparcOperand::rk_IntReg;
- return true;
- }
- // %o0 - %o7
- if (name.starts_with_insensitive("o") &&
- !name.substr(1).getAsInteger(10, intVal) && intVal < 8) {
- RegNo = IntRegs[8 + intVal];
- RegKind = SparcOperand::rk_IntReg;
- return true;
- }
- if (name.starts_with_insensitive("l") &&
- !name.substr(1).getAsInteger(10, intVal) && intVal < 8) {
- RegNo = IntRegs[16 + intVal];
- RegKind = SparcOperand::rk_IntReg;
- return true;
- }
- if (name.starts_with_insensitive("i") &&
- !name.substr(1).getAsInteger(10, intVal) && intVal < 8) {
- RegNo = IntRegs[24 + intVal];
- RegKind = SparcOperand::rk_IntReg;
- return true;
- }
- // %f0 - %f31
- if (name.starts_with_insensitive("f") &&
- !name.substr(1, 2).getAsInteger(10, intVal) && intVal < 32) {
- RegNo = FloatRegs[intVal];
- RegKind = SparcOperand::rk_FloatReg;
- return true;
- }
- // %f32 - %f62
- if (name.starts_with_insensitive("f") &&
- !name.substr(1, 2).getAsInteger(10, intVal) && intVal >= 32 &&
- intVal <= 62 && (intVal % 2 == 0)) {
- // FIXME: Check V9
- RegNo = DoubleRegs[intVal/2];
- RegKind = SparcOperand::rk_DoubleReg;
- return true;
- }
+ // If we still have no match, try custom parsing.
+ // Not all registers and their spellings are modeled in td files.
- // %r0 - %r31
- if (name.starts_with_insensitive("r") &&
- !name.substr(1, 2).getAsInteger(10, intVal) && intVal < 31) {
- RegNo = IntRegs[intVal];
- RegKind = SparcOperand::rk_IntReg;
- return true;
- }
+ // %r0 - %r31
+ int64_t RegNo = 0;
+ if (Name.starts_with_insensitive("r") &&
+ !Name.substr(1, 2).getAsInteger(10, RegNo) && RegNo < 31) {
+ RegKind = SparcOperand::rk_IntReg;
+ return IntRegs[RegNo];
+ }
- // %c0 - %c31
- if (name.starts_with_insensitive("c") &&
- !name.substr(1).getAsInteger(10, intVal) && intVal < 32) {
- RegNo = CoprocRegs[intVal];
- RegKind = SparcOperand::rk_CoprocReg;
- return true;
- }
+ if (Name.equals("xcc")) {
+ // FIXME:: check 64bit.
+ RegKind = SparcOperand::rk_Special;
+ return SP::ICC;
+ }
- if (name.equals("tpc")) {
- RegNo = Sparc::TPC;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
- if (name.equals("tnpc")) {
- RegNo = Sparc::TNPC;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
- if (name.equals("tstate")) {
- RegNo = Sparc::TSTATE;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
- if (name.equals("tt")) {
- RegNo = Sparc::TT;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
- if (name.equals("tick")) {
- RegNo = Sparc::TICK;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
- if (name.equals("tba")) {
- RegNo = Sparc::TBA;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
- if (name.equals("pstate")) {
- RegNo = Sparc::PSTATE;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
- if (name.equals("tl")) {
- RegNo = Sparc::TL;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
- if (name.equals("pil")) {
- RegNo = Sparc::PIL;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
- if (name.equals("cwp")) {
- RegNo = Sparc::CWP;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
- if (name.equals("cansave")) {
- RegNo = Sparc::CANSAVE;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
- if (name.equals("canrestore")) {
- RegNo = Sparc::CANRESTORE;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
- if (name.equals("cleanwin")) {
- RegNo = Sparc::CLEANWIN;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
- if (name.equals("otherwin")) {
- RegNo = Sparc::OTHERWIN;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
- if (name.equals("wstate")) {
- RegNo = Sparc::WSTATE;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
- if (name.equals("pc")) {
- RegNo = Sparc::ASR5;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
- if (name.equals("asi")) {
- RegNo = Sparc::ASR3;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
- if (name.equals("ccr")) {
- RegNo = Sparc::ASR2;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
- if (name.equals("gl")) {
- RegNo = Sparc::GL;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
- if (name.equals("ver")) {
- RegNo = Sparc::VER;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
+ // JPS1 extension - aliases for ASRs
+ // Section A.51 - Read State Register
+ if (Name.equals("pcr")) {
+ RegKind = SparcOperand::rk_Special;
+ return SP::ASR16;
+ }
- // JPS1 extension - aliases for ASRs
- // Section A.51 - Read State Register
- if (name.equals("pcr")) {
- RegNo = Sparc::ASR16;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
- if (name.equals("pic")) {
- RegNo = Sparc::ASR17;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
- if (name.equals("dcr")) {
- RegNo = Sparc::ASR18;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
- if (name.equals("gsr")) {
- RegNo = Sparc::ASR19;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
- if (name.equals("softint")) {
- RegNo = Sparc::ASR22;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
- if (name.equals("tick_cmpr")) {
- RegNo = Sparc::ASR23;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
- if (name.equals("stick") || name.equals("sys_tick")) {
- RegNo = Sparc::ASR24;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
- if (name.equals("stick_cmpr") || name.equals("sys_tick_cmpr")) {
- RegNo = Sparc::ASR25;
- RegKind = SparcOperand::rk_Special;
- return true;
- }
+ if (Name.equals("pic")) {
+ RegKind = SparcOperand::rk_Special;
+ return SP::ASR17;
}
- return false;
+ if (Name.equals("dcr")) {
+ RegKind = SparcOperand::rk_Special;
+ return SP::ASR18;
+ }
+ if (Name.equals("gsr")) {
+ RegKind = SparcOperand::rk_Special;
+ return SP::ASR19;
+ }
+ if (Name.equals("softint")) {
+ RegKind = SparcOperand::rk_Special;
+ return SP::ASR22;
+ }
+ if (Name.equals("tick_cmpr")) {
+ RegKind = SparcOperand::rk_Special;
+ return SP::ASR23;
+ }
+ if (Name.equals("stick") || Name.equals("sys_tick")) {
+ RegKind = SparcOperand::rk_Special;
+ return SP::ASR24;
+ }
+ if (Name.equals("stick_cmpr") || Name.equals("sys_tick_cmpr")) {
+ RegKind = SparcOperand::rk_Special;
+ return SP::ASR25;
+ }
+
+ return SP::NoRegister;
}
// Determine if an expression contains a reference to the symbol
@@ -1737,7 +1524,6 @@ extern "C" LLVM_EXTERNAL_VISIBILITY void LLVMInitializeSparcAsmParser() {
RegisterMCAsmParser<SparcAsmParser> C(getTheSparcelTarget());
}
-#define GET_REGISTER_MATCHER
#define GET_MATCHER_IMPLEMENTATION
#include "SparcGenAsmMatcher.inc"
diff --git a/llvm/lib/Target/Sparc/Sparc.td b/llvm/lib/Target/Sparc/Sparc.td
index 38a59e650f33c7..45cf985cfa0627 100644
--- a/llvm/lib/Target/Sparc/Sparc.td
+++ b/llvm/lib/Target/Sparc/Sparc.td
@@ -99,7 +99,8 @@ include "SparcInstrInfo.td"
def SparcInstrInfo : InstrInfo;
def SparcAsmParser : AsmParser {
- bit ShouldEmitMatchRegisterName = 0;
+ let ShouldEmitMatchRegisterAltName = true;
+ let AllowDuplicateRegisterNames = true;
}
def SparcAsmParserVariant : AsmParserVariant {
>From 06ac828dc1076413b3c2649e9c1d3de33467d308 Mon Sep 17 00:00:00 2001
From: Joseph Huber <huberjn at outlook.com>
Date: Fri, 1 Mar 2024 20:56:07 -0600
Subject: [PATCH 336/406] [libc] Fix flipped AMDGPU kernel launch arguments
(#83648)
Summary:
These values were incorrectly flipped, setting the size of the blocks to
the threads and vice-versa. When I originally wrote the thread utilities
it was using COV4 which used an implicit format. Then when I updated I
accidentally flipped them and never noticed because nothing depended on
the size of the threads until I checked it manually.
---
libc/utils/gpu/loader/amdgpu/Loader.cpp | 12 ++++++------
1 file changed, 6 insertions(+), 6 deletions(-)
diff --git a/libc/utils/gpu/loader/amdgpu/Loader.cpp b/libc/utils/gpu/loader/amdgpu/Loader.cpp
index 0ff2dce813ed2b..e3911eda2bd82a 100644
--- a/libc/utils/gpu/loader/amdgpu/Loader.cpp
+++ b/libc/utils/gpu/loader/amdgpu/Loader.cpp
@@ -230,12 +230,12 @@ hsa_status_t launch_kernel(hsa_agent_t dev_agent, hsa_executable_t executable,
implicit_args_t *implicit_args = reinterpret_cast<implicit_args_t *>(
reinterpret_cast<uint8_t *>(args) + sizeof(args_t));
implicit_args->grid_dims = dims;
- implicit_args->grid_size_x = params.num_threads_x;
- implicit_args->grid_size_y = params.num_threads_y;
- implicit_args->grid_size_z = params.num_threads_z;
- implicit_args->workgroup_size_x = params.num_blocks_x;
- implicit_args->workgroup_size_y = params.num_blocks_y;
- implicit_args->workgroup_size_z = params.num_blocks_z;
+ implicit_args->grid_size_x = params.num_blocks_x;
+ implicit_args->grid_size_y = params.num_blocks_y;
+ implicit_args->grid_size_z = params.num_blocks_z;
+ implicit_args->workgroup_size_x = params.num_threads_x;
+ implicit_args->workgroup_size_y = params.num_threads_y;
+ implicit_args->workgroup_size_z = params.num_threads_z;
// Obtain a packet from the queue.
uint64_t packet_id = hsa_queue_add_write_index_relaxed(queue, 1);
>From 73dfc7bbadddeb2930b11e4ad07f9a8e8b498cc7 Mon Sep 17 00:00:00 2001
From: lntue <35648136+lntue at users.noreply.github.com>
Date: Fri, 1 Mar 2024 21:59:41 -0500
Subject: [PATCH 337/406] [libc] Fix a bug in fx_bits.h due to integer
promotion of bitwise ops. (#83647)
---
libc/src/__support/fixed_point/fx_bits.h | 2 +-
.../__support/fixed_point/fx_bits_test.cpp | 77 +++++++++++++++----
2 files changed, 64 insertions(+), 15 deletions(-)
diff --git a/libc/src/__support/fixed_point/fx_bits.h b/libc/src/__support/fixed_point/fx_bits.h
index 41da45c01e4e19..53e693d4ddfd12 100644
--- a/libc/src/__support/fixed_point/fx_bits.h
+++ b/libc/src/__support/fixed_point/fx_bits.h
@@ -126,7 +126,7 @@ bit_not(T x) {
using BitType = typename FXRep<T>::StorageType;
BitType x_bit = cpp::bit_cast<BitType>(x);
// For some reason, bit_cast cannot deduce BitType from the input.
- return cpp::bit_cast<T, BitType>(~x_bit);
+ return cpp::bit_cast<T, BitType>(static_cast<BitType>(~x_bit));
}
template <typename T> LIBC_INLINE constexpr T abs(T x) {
diff --git a/libc/test/src/__support/fixed_point/fx_bits_test.cpp b/libc/test/src/__support/fixed_point/fx_bits_test.cpp
index 58627816eb8d97..3cbd800adc3c35 100644
--- a/libc/test/src/__support/fixed_point/fx_bits_test.cpp
+++ b/libc/test/src/__support/fixed_point/fx_bits_test.cpp
@@ -20,9 +20,22 @@ using LIBC_NAMESPACE::operator""_u16;
using LIBC_NAMESPACE::operator""_u32;
using LIBC_NAMESPACE::operator""_u64;
+class LlvmLibcFxBitsTest : public LIBC_NAMESPACE::testing::Test {
+public:
+ template <typename T> void testBitwiseOps() {
+ EXPECT_EQ(LIBC_NAMESPACE::fixed_point::bit_and(T(0.75), T(0.375)), T(0.25));
+ EXPECT_EQ(LIBC_NAMESPACE::fixed_point::bit_or(T(0.75), T(0.375)), T(0.875));
+ using StorageType = typename FXRep<T>::StorageType;
+ StorageType a = LIBC_NAMESPACE::cpp::bit_cast<StorageType>(T(0.75));
+ a = ~a;
+ EXPECT_EQ(LIBC_NAMESPACE::fixed_point::bit_not(T(0.75)),
+ FXBits<T>(a).get_val());
+ }
+};
+
// -------------------------------- SHORT TESTS --------------------------------
-TEST(LlvmLibcFxBitsTest, FXBits_UnsignedShortFract) {
+TEST_F(LlvmLibcFxBitsTest, FXBits_UnsignedShortFract) {
auto bits_var = FXBits<unsigned short fract>(0b00000000_u8);
EXPECT_EQ(bits_var.get_sign(), false);
@@ -51,9 +64,12 @@ TEST(LlvmLibcFxBitsTest, FXBits_UnsignedShortFract) {
EXPECT_EQ(bits_var.get_sign(), false);
EXPECT_EQ(bits_var.get_integral(), 0x00_u8);
EXPECT_EQ(bits_var.get_fraction(), 0xcd_u8);
+
+ // Bitwise ops
+ testBitwiseOps<unsigned short fract>();
}
-TEST(LlvmLibcFxBitsTest, FXBits_UnsignedShortAccum) {
+TEST_F(LlvmLibcFxBitsTest, FXBits_UnsignedShortAccum) {
auto bits_var = FXBits<unsigned short accum>(0b00000000'00000000_u16);
EXPECT_EQ(bits_var.get_sign(), false);
@@ -77,9 +93,12 @@ TEST(LlvmLibcFxBitsTest, FXBits_UnsignedShortAccum) {
EXPECT_EQ(bits_var.get_sign(), false);
EXPECT_EQ(bits_var.get_integral(), 0x00cd_u16);
EXPECT_EQ(bits_var.get_fraction(), 0x00fe_u16);
+
+ // Bitwise ops
+ testBitwiseOps<unsigned short accum>();
}
-TEST(LlvmLibcFxBitsTest, FXBits_ShortFract) {
+TEST_F(LlvmLibcFxBitsTest, FXBits_ShortFract) {
auto bits_var = FXBits<short fract>(0b0'0000000_u8);
EXPECT_EQ(bits_var.get_sign(), false);
@@ -103,9 +122,12 @@ TEST(LlvmLibcFxBitsTest, FXBits_ShortFract) {
EXPECT_EQ(bits_var.get_sign(), true);
EXPECT_EQ(bits_var.get_integral(), 0x00_u8);
EXPECT_EQ(bits_var.get_fraction(), 0x4d_u8);
+
+ // Bitwise ops
+ testBitwiseOps<short fract>();
}
-TEST(LlvmLibcFxBitsTest, FXBits_ShortAccum) {
+TEST_F(LlvmLibcFxBitsTest, FXBits_ShortAccum) {
auto bits_var = FXBits<short accum>(0b0'00000000'0000000_u16);
EXPECT_EQ(bits_var.get_sign(), false);
@@ -129,9 +151,14 @@ TEST(LlvmLibcFxBitsTest, FXBits_ShortAccum) {
EXPECT_EQ(bits_var.get_sign(), true);
EXPECT_EQ(bits_var.get_integral(), 0x00cd_u16);
EXPECT_EQ(bits_var.get_fraction(), 0x007e_u16);
+
+ // Bitwise ops
+ testBitwiseOps<short accum>();
}
-TEST(LlvmLibcFxBitsTest, FXBits_UnsignedFract) {
+// -------------------------------- NORMAL TESTS -------------------------------
+
+TEST_F(LlvmLibcFxBitsTest, FXBits_UnsignedFract) {
auto bits_var = FXBits<unsigned fract>(0b0000000000000000_u16);
EXPECT_EQ(bits_var.get_sign(), false);
@@ -155,11 +182,12 @@ TEST(LlvmLibcFxBitsTest, FXBits_UnsignedFract) {
EXPECT_EQ(bits_var.get_sign(), false);
EXPECT_EQ(bits_var.get_integral(), 0x0000_u16);
EXPECT_EQ(bits_var.get_fraction(), 0xef12_u16);
-}
-// -------------------------------- NORMAL TESTS -------------------------------
+ // Bitwise ops
+ testBitwiseOps<unsigned fract>();
+}
-TEST(LlvmLibcFxBitsTest, FXBits_UnsignedAccum) {
+TEST_F(LlvmLibcFxBitsTest, FXBits_UnsignedAccum) {
auto bits_var =
FXBits<unsigned accum>(0b0000000000000000'0000000000000000_u32);
@@ -184,9 +212,12 @@ TEST(LlvmLibcFxBitsTest, FXBits_UnsignedAccum) {
EXPECT_EQ(bits_var.get_sign(), false);
EXPECT_EQ(bits_var.get_integral(), 0x0000abcd_u32);
EXPECT_EQ(bits_var.get_fraction(), 0x0000ef12_u32);
+
+ // Bitwise ops
+ testBitwiseOps<unsigned accum>();
}
-TEST(LlvmLibcFxBitsTest, FXBits_Fract) {
+TEST_F(LlvmLibcFxBitsTest, FXBits_Fract) {
auto bits_var = FXBits<fract>(0b0'000000000000000_u16);
EXPECT_EQ(bits_var.get_sign(), false);
@@ -210,9 +241,12 @@ TEST(LlvmLibcFxBitsTest, FXBits_Fract) {
EXPECT_EQ(bits_var.get_sign(), true);
EXPECT_EQ(bits_var.get_integral(), 0x0000_u16);
EXPECT_EQ(bits_var.get_fraction(), 0x6f12_u16);
+
+ // Bitwise ops
+ testBitwiseOps<fract>();
}
-TEST(LlvmLibcFxBitsTest, FXBits_Accum) {
+TEST_F(LlvmLibcFxBitsTest, FXBits_Accum) {
auto bits_var = FXBits<accum>(0b0'0000000000000000'000000000000000_u32);
EXPECT_EQ(bits_var.get_sign(), false);
@@ -236,11 +270,14 @@ TEST(LlvmLibcFxBitsTest, FXBits_Accum) {
EXPECT_EQ(bits_var.get_sign(), true);
EXPECT_EQ(bits_var.get_integral(), 0x0000abcd_u32);
EXPECT_EQ(bits_var.get_fraction(), 0x00006f12_u32);
+
+ // Bitwise ops
+ testBitwiseOps<accum>();
}
// --------------------------------- LONG TESTS --------------------------------
-TEST(LlvmLibcFxBitsTest, FXBits_UnsignedLongFract) {
+TEST_F(LlvmLibcFxBitsTest, FXBits_UnsignedLongFract) {
auto bits_var =
FXBits<unsigned long fract>(0b00000000000000000000000000000000_u32);
@@ -265,9 +302,12 @@ TEST(LlvmLibcFxBitsTest, FXBits_UnsignedLongFract) {
EXPECT_EQ(bits_var.get_sign(), false);
EXPECT_EQ(bits_var.get_integral(), 0x00000000_u32);
EXPECT_EQ(bits_var.get_fraction(), 0xfedcba98_u32);
+
+ // Bitwise ops
+ testBitwiseOps<unsigned long fract>();
}
-TEST(LlvmLibcFxBitsTest, FXBits_UnsignedLongAccum) {
+TEST_F(LlvmLibcFxBitsTest, FXBits_UnsignedLongAccum) {
auto bits_var = FXBits<unsigned long accum>(
0b00000000000000000000000000000000'00000000000000000000000000000000_u64);
@@ -292,9 +332,12 @@ TEST(LlvmLibcFxBitsTest, FXBits_UnsignedLongAccum) {
EXPECT_EQ(bits_var.get_sign(), false);
EXPECT_EQ(bits_var.get_integral(), 0x00000000abcdef12_u64);
EXPECT_EQ(bits_var.get_fraction(), 0x00000000fedcba98_u64);
+
+ // Bitwise ops
+ testBitwiseOps<unsigned long accum>();
}
-TEST(LlvmLibcFxBitsTest, FXBits_LongFract) {
+TEST_F(LlvmLibcFxBitsTest, FXBits_LongFract) {
auto bits_var = FXBits<long fract>(0b0'0000000000000000000000000000000_u32);
EXPECT_EQ(bits_var.get_sign(), false);
@@ -318,9 +361,12 @@ TEST(LlvmLibcFxBitsTest, FXBits_LongFract) {
EXPECT_EQ(bits_var.get_sign(), true);
EXPECT_EQ(bits_var.get_integral(), 0x00000000_u32);
EXPECT_EQ(bits_var.get_fraction(), 0x7edcba98_u32);
+
+ // Bitwise ops
+ testBitwiseOps<long fract>();
}
-TEST(LlvmLibcFxBitsTest, FXBits_LongAccum) {
+TEST_F(LlvmLibcFxBitsTest, FXBits_LongAccum) {
auto bits_var = FXBits<long accum>(
0b0'00000000000000000000000000000000'0000000000000000000000000000000_u64);
@@ -345,4 +391,7 @@ TEST(LlvmLibcFxBitsTest, FXBits_LongAccum) {
EXPECT_EQ(bits_var.get_sign(), true);
EXPECT_EQ(bits_var.get_integral(), 0x00000000abcdef12_u64);
EXPECT_EQ(bits_var.get_fraction(), 0x000000007edcba98_u64);
+
+ // Bitwise ops
+ testBitwiseOps<long accum>();
}
>From a2e7827fde0d87b7e8665926b2b9e73171e07369 Mon Sep 17 00:00:00 2001
From: Alexander Richardson <alexrichardson at google.com>
Date: Fri, 1 Mar 2024 19:11:31 -0800
Subject: [PATCH 338/406] [compiler-rt] Relax CHECK line in reaches_function.c
In my build environment, the output is a relative path:
```
test/dfsan/reaches_function.c:34 add.dfsan
test/dfsan/reaches_function.c:56 main
```
This fixes check-dfsan in my configuration:
```
cmake -DCMAKE_BUILD_TYPE=RelWithDebInfo -G Ninja
-DCMAKE_C_COMPILER=$HOME/output/upstream-llvm/bin/clang
-DCMAKE_CXX_COMPILER=$HOME/output/upstream-llvm/bin/clang++
-DCOMPILER_RT_INCLUDE_TESTS=ON
-DLLVM_EXTERNAL_LIT=$HOME/build/upstream-llvm-project-build/bin/llvm-lit
-DLLVM_CMAKE_DIR=$HOME/output/upstream-llvm
-DCOMPILER_RT_DEBUG=OFF
-S $HOME/src/upstream-llvm-project/compiler-rt
-B $HOME/src/upstream-llvm-project/compiler-rt/cmake-build-all-sanitizers
```
Reviewers: browneee, vitalybuka
Reviewed By: vitalybuka
Pull Request: https://github.com/llvm/llvm-project/pull/83089
---
compiler-rt/test/dfsan/reaches_function.c | 12 ++++++------
1 file changed, 6 insertions(+), 6 deletions(-)
diff --git a/compiler-rt/test/dfsan/reaches_function.c b/compiler-rt/test/dfsan/reaches_function.c
index 9e2bcee935b2ac..a00654e7ae132d 100644
--- a/compiler-rt/test/dfsan/reaches_function.c
+++ b/compiler-rt/test/dfsan/reaches_function.c
@@ -32,11 +32,11 @@ void my_dfsan_reaches_function_callback(dfsan_label label, dfsan_origin origin,
__attribute__((noinline)) uint64_t add(uint64_t *a, uint64_t *b) {
return *a + *b;
- // CHECK: {{.*}}compiler-rt/test/dfsan/reaches_function.c:[[# @LINE - 1]] add.dfsan
+ // CHECK: reaches_function.c:[[# @LINE - 1]] add.dfsan
// CHECK-ORIGIN-TRACKING: Origin value: 0x10000002, Taint value was stored to memory at
- // CHECK-ORIGIN-TRACKING: #0 {{.*}} in add.dfsan {{.*}}compiler-rt/test/dfsan/reaches_function.c:[[# @LINE - 3]]:{{.*}}
+ // CHECK-ORIGIN-TRACKING: #0 {{.*}} in add.dfsan {{.*}}reaches_function.c:[[# @LINE - 3]]:{{.*}}
// CHECK-ORIGIN-TRACKING: Origin value: 0x1, Taint value was created at
- // CHECK-ORIGIN-TRACKING: #0 {{.*}} in main {{.*}}compiler-rt/test/dfsan/reaches_function.c:{{.*}}
+ // CHECK-ORIGIN-TRACKING: #0 {{.*}} in main {{.*}}reaches_function.c:{{.*}}
}
extern void my_dfsan_reaches_function_callback(dfsan_label label,
@@ -54,11 +54,11 @@ int main(int argc, char *argv[]) {
dfsan_set_label(8, &a, sizeof(a));
uint64_t c = add(&a, &b);
- // CHECK: {{.*}}compiler-rt/test/dfsan/reaches_function.c:[[# @LINE - 1]] main
+ // CHECK: reaches_function.c:[[# @LINE - 1]] main
// CHECK-ORIGIN-TRACKING: Origin value: 0x10000002, Taint value was stored to memory at
- // CHECK-ORIGIN-TRACKING: #0 {{.*}} in add.dfsan {{.*}}compiler-rt/test/dfsan/reaches_function.c:{{.*}}
+ // CHECK-ORIGIN-TRACKING: #0 {{.*}} in add.dfsan {{.*}}reaches_function.c:{{.*}}
// CHECK-ORIGIN-TRACKING: Origin value: 0x1, Taint value was created at
- // CHECK-ORIGIN-TRACKING: #0 {{.*}} in main {{.*}}compiler-rt/test/dfsan/reaches_function.c:[[# @LINE - 6]]:{{.*}}
+ // CHECK-ORIGIN-TRACKING: #0 {{.*}} in main {{.*}}reaches_function.c:[[# @LINE - 6]]:{{.*}}
return c;
}
>From 07317bbc66d1f2d7663af3c9f04d0f6c0487ac03 Mon Sep 17 00:00:00 2001
From: Alex Richardson <alexrichardson at google.com>
Date: Mon, 26 Feb 2024 15:02:39 -0800
Subject: [PATCH 339/406] [compiler-rt] Build libfuzzer sources with the chosen
C++ compiler
I was getting build failures due to missing <cstddef> when building the
libfuzzer tests. It turns out that the custom command was using
COMPILER_RT_TEST_COMPILER when building the source file rather than
the COMPILER_RT_TEST_CXX_COMPILER.
Pull Request: https://github.com/llvm/llvm-project/pull/83090
---
compiler-rt/cmake/Modules/CompilerRTCompile.cmake | 9 +++++++--
1 file changed, 7 insertions(+), 2 deletions(-)
diff --git a/compiler-rt/cmake/Modules/CompilerRTCompile.cmake b/compiler-rt/cmake/Modules/CompilerRTCompile.cmake
index 64e7acb9afd833..2bf115973a49b3 100644
--- a/compiler-rt/cmake/Modules/CompilerRTCompile.cmake
+++ b/compiler-rt/cmake/Modules/CompilerRTCompile.cmake
@@ -70,9 +70,14 @@ function(clang_compile object_file source)
if (TARGET CompilerRTUnitTestCheckCxx)
list(APPEND SOURCE_DEPS CompilerRTUnitTestCheckCxx)
endif()
+ string(REGEX MATCH "[.](cc|cpp)$" is_cxx ${source_rpath})
+ if (is_cxx)
+ set(compiler ${COMPILER_RT_TEST_COMPILER})
+ else()
+ set(compiler ${COMPILER_RT_TEST_CXX_COMPILER})
+ endif()
if(COMPILER_RT_STANDALONE_BUILD)
# Only add global flags in standalone build.
- string(REGEX MATCH "[.](cc|cpp)$" is_cxx ${source_rpath})
if(is_cxx)
string(REPLACE " " ";" global_flags "${CMAKE_CXX_FLAGS}")
else()
@@ -102,7 +107,7 @@ function(clang_compile object_file source)
add_custom_command(
OUTPUT ${object_file}
- COMMAND ${COMPILER_RT_TEST_COMPILER} ${compile_flags} -c
+ COMMAND ${compiler} ${compile_flags} -c
-o "${object_file}"
${source_rpath}
MAIN_DEPENDENCY ${source}
>From aab3d13179dc5a37465a0e6fbf1b9369a4e6e50f Mon Sep 17 00:00:00 2001
From: Daniil Kovalev <dkovalev at accesssoftek.com>
Date: Sat, 2 Mar 2024 07:03:50 +0300
Subject: [PATCH 340/406] [FileCheck] Fix parsing empty global and pseudo
variable names (#82595)
In `Pattern::parseVariable`, for global variables (those starting with
'$') and for pseudo variables (those starting with '@') the first
character is consumed before actual variable name parsing. If the name
is empty, it leads to out-of-bound access to the corresponding
`StringRef`.
This patch adds an if statement against the case described.
---
llvm/lib/FileCheck/FileCheck.cpp | 6 ++++
llvm/test/FileCheck/empty-variable-name.txt | 32 +++++++++++++++++++++
2 files changed, 38 insertions(+)
create mode 100644 llvm/test/FileCheck/empty-variable-name.txt
diff --git a/llvm/lib/FileCheck/FileCheck.cpp b/llvm/lib/FileCheck/FileCheck.cpp
index 6d3a2b9cf46f7c..8f80a69c4abd3a 100644
--- a/llvm/lib/FileCheck/FileCheck.cpp
+++ b/llvm/lib/FileCheck/FileCheck.cpp
@@ -297,6 +297,12 @@ Pattern::parseVariable(StringRef &Str, const SourceMgr &SM) {
if (Str[0] == '$' || IsPseudo)
++I;
+ if (I == Str.size())
+ return ErrorDiagnostic::get(SM, Str.slice(I, StringRef::npos),
+ StringRef("empty ") +
+ (IsPseudo ? "pseudo " : "global ") +
+ "variable name");
+
if (!isValidVarNameStart(Str[I++]))
return ErrorDiagnostic::get(SM, Str, "invalid variable name");
diff --git a/llvm/test/FileCheck/empty-variable-name.txt b/llvm/test/FileCheck/empty-variable-name.txt
new file mode 100644
index 00000000000000..29c6317e6bb17e
--- /dev/null
+++ b/llvm/test/FileCheck/empty-variable-name.txt
@@ -0,0 +1,32 @@
+a
+
+; RUN: not FileCheck -input-file %s %s 2>&1 | \
+; RUN: FileCheck -check-prefix CHECK-ERROR -DDIR=%S \
+; RUN: --match-full-lines --strict-whitespace %s
+
+; CHECK: a[[]]
+; CHECK-ERROR:[[DIR]]{{/|\\}}empty-variable-name.txt:7:13: error: empty variable name
+; CHECK-ERROR-NEXT:; CHECK: a{{\[\[\]\]}}
+; CHECK-ERROR-NEXT: ^
+
+b
+
+; RUN: not FileCheck -input-file %s -check-prefix CHECK-PSEUDO %s 2>&1 | \
+; RUN: FileCheck -check-prefix CHECK-ERROR-PSEUDO -DDIR=%S \
+; RUN: --match-full-lines --strict-whitespace %s
+
+; CHECK-PSEUDO: b[[@]]
+; CHECK-ERROR-PSEUDO:[[DIR]]{{/|\\}}empty-variable-name.txt:18:21: error: empty pseudo variable name
+; CHECK-ERROR-PSEUDO-NEXT:; CHECK-PSEUDO: b{{\[\[@\]\]}}
+; CHECK-ERROR-PSEUDO-NEXT: ^
+
+c
+
+; RUN: not FileCheck -input-file %s -check-prefix CHECK-GLOBAL %s 2>&1 | \
+; RUN: FileCheck -check-prefix CHECK-ERROR-GLOBAL -DDIR=%S \
+; RUN: --match-full-lines --strict-whitespace %s
+
+; CHECK-GLOBAL: c[[$]]
+; CHECK-ERROR-GLOBAL:[[DIR]]{{/|\\}}empty-variable-name.txt:29:21: error: empty global variable name
+; CHECK-ERROR-GLOBAL-NEXT:; CHECK-GLOBAL: c{{\[\[\$\]\]}}
+; CHECK-ERROR-GLOBAL-NEXT: ^
>From e4b15fc854b6eaebe63ba3acfcd39bf6dd7748b5 Mon Sep 17 00:00:00 2001
From: Joseph Huber <huberjn at outlook.com>
Date: Fri, 1 Mar 2024 22:25:55 -0600
Subject: [PATCH 341/406] [libc] Fix '/gpu' directory not being made for the
declarations
Summary:
We use this extra directory for offloading languages like CUDA or
OpenMP. We made the '/gpu' directory for the regular headers but not the
others. Fix that for now.
---
libc/cmake/modules/LLVMLibCHeaderRules.cmake | 1 +
1 file changed, 1 insertion(+)
diff --git a/libc/cmake/modules/LLVMLibCHeaderRules.cmake b/libc/cmake/modules/LLVMLibCHeaderRules.cmake
index 19515b1cbcc185..7fc6860f23eb2e 100644
--- a/libc/cmake/modules/LLVMLibCHeaderRules.cmake
+++ b/libc/cmake/modules/LLVMLibCHeaderRules.cmake
@@ -141,6 +141,7 @@ function(add_gen_header target_name)
if(LIBC_TARGET_OS_IS_GPU)
file(MAKE_DIRECTORY ${LIBC_INCLUDE_DIR}/llvm-libc-decls)
+ file(MAKE_DIRECTORY ${LIBC_INCLUDE_DIR}/llvm-libc-decls/gpu)
set(decl_out_file ${LIBC_INCLUDE_DIR}/llvm-libc-decls/${relative_path})
add_custom_command(
OUTPUT ${decl_out_file}
>From fb67dce1cb87e279593c27bd4122fe63bad75f04 Mon Sep 17 00:00:00 2001
From: Shih-Po Hung <shihpo.hung at sifive.com>
Date: Sat, 2 Mar 2024 12:33:55 +0800
Subject: [PATCH 342/406] [RISCV] Fix crash when unrolling loop containing
vector instructions (#83384)
When MVT is not a vector type, TCK_CodeSize should return an invalid
cost. This patch adds a check in the beginning to make sure all cost
kinds return invalid costs consistently.
Before this patch, TCK_CodeSize returns a valid cost on scalar MVT but
other cost kinds doesn't.
This fixes the issue #83294 where a loop contains vector instructions
and MVT is scalar after type legalization when the vector extension is
not enabled,
---
.../Target/RISCV/RISCVTargetTransformInfo.cpp | 3 ++
.../CostModel/RISCV/vector-cost-without-v.ll | 53 +++++++++++++++++++
2 files changed, 56 insertions(+)
create mode 100644 llvm/test/Analysis/CostModel/RISCV/vector-cost-without-v.ll
diff --git a/llvm/lib/Target/RISCV/RISCVTargetTransformInfo.cpp b/llvm/lib/Target/RISCV/RISCVTargetTransformInfo.cpp
index 2e4e69fb4f920f..504970c0a9ac74 100644
--- a/llvm/lib/Target/RISCV/RISCVTargetTransformInfo.cpp
+++ b/llvm/lib/Target/RISCV/RISCVTargetTransformInfo.cpp
@@ -37,6 +37,9 @@ static cl::opt<unsigned> SLPMaxVF(
InstructionCost
RISCVTTIImpl::getRISCVInstructionCost(ArrayRef<unsigned> OpCodes, MVT VT,
TTI::TargetCostKind CostKind) {
+ // Check if the type is valid for all CostKind
+ if (!VT.isVector())
+ return InstructionCost::getInvalid();
size_t NumInstr = OpCodes.size();
if (CostKind == TTI::TCK_CodeSize)
return NumInstr;
diff --git a/llvm/test/Analysis/CostModel/RISCV/vector-cost-without-v.ll b/llvm/test/Analysis/CostModel/RISCV/vector-cost-without-v.ll
new file mode 100644
index 00000000000000..cd99065f0285cd
--- /dev/null
+++ b/llvm/test/Analysis/CostModel/RISCV/vector-cost-without-v.ll
@@ -0,0 +1,53 @@
+; NOTE: Assertions have been autogenerated by utils/update_test_checks.py UTC_ARGS: --version 4
+; RUN: opt < %s -mtriple=riscv64 -mattr=+f,+d --passes=loop-unroll-full -S | FileCheck %s
+
+; Check it doesn't crash when the vector extension is not enabled.
+define void @foo() {
+; CHECK-LABEL: define void @foo(
+; CHECK-SAME: ) #[[ATTR0:[0-9]+]] {
+; CHECK-NEXT: entry:
+; CHECK-NEXT: br label [[FOR_BODY:%.*]]
+; CHECK: for.body:
+; CHECK-NEXT: [[INDVARS_IV1:%.*]] = phi i64 [ [[INDVARS_IV_NEXT:%.*]], [[FOR_BODY]] ], [ 0, [[ENTRY:%.*]] ]
+; CHECK-NEXT: [[TMP0:%.*]] = load float, ptr null, align 4
+; CHECK-NEXT: [[SPLAT_SPLAT_I_I_I:%.*]] = shufflevector <2 x float> zeroinitializer, <2 x float> zeroinitializer, <2 x i32> zeroinitializer
+; CHECK-NEXT: [[CMP1_I_I_I:%.*]] = fcmp ogt <2 x float> zeroinitializer, zeroinitializer
+; CHECK-NEXT: [[SPLAT_SPLAT3_I_I_I:%.*]] = shufflevector <2 x i32> zeroinitializer, <2 x i32> zeroinitializer, <2 x i32> zeroinitializer
+; CHECK-NEXT: [[XOR3_I_I_I_I_I:%.*]] = select <2 x i1> zeroinitializer, <2 x i32> zeroinitializer, <2 x i32> zeroinitializer
+; CHECK-NEXT: [[TMP1:%.*]] = load float, ptr null, align 4
+; CHECK-NEXT: [[SPLAT_SPLAT8_I_I_I:%.*]] = shufflevector <2 x float> zeroinitializer, <2 x float> zeroinitializer, <2 x i32> zeroinitializer
+; CHECK-NEXT: [[SUB_I_I_I:%.*]] = fsub <2 x float> zeroinitializer, zeroinitializer
+; CHECK-NEXT: [[MUL_I_I_I:%.*]] = shl i64 0, 0
+; CHECK-NEXT: [[TMP2:%.*]] = load float, ptr null, align 4
+; CHECK-NEXT: [[SPLAT_SPLAT_I_I_I_I:%.*]] = shufflevector <2 x float> zeroinitializer, <2 x float> zeroinitializer, <2 x i32> zeroinitializer
+; CHECK-NEXT: [[XOR3_I_I_I_V_I_I:%.*]] = select <2 x i1> zeroinitializer, <2 x float> zeroinitializer, <2 x float> zeroinitializer
+; CHECK-NEXT: [[INDVARS_IV_NEXT]] = add i64 [[INDVARS_IV1]], 1
+; CHECK-NEXT: [[EXITCOND:%.*]] = icmp ne i64 [[INDVARS_IV1]], 8
+; CHECK-NEXT: br i1 [[EXITCOND]], label [[FOR_BODY]], label [[EXIT:%.*]]
+; CHECK: exit:
+; CHECK-NEXT: ret void
+;
+entry:
+ br label %for.body
+
+for.body: ; preds = %for.body, %entry
+ %indvars.iv1 = phi i64 [ %indvars.iv.next, %for.body ], [ 0, %entry ]
+ %0 = load float, ptr null, align 4
+ %splat.splat.i.i.i = shufflevector <2 x float> zeroinitializer, <2 x float> zeroinitializer, <2 x i32> zeroinitializer
+ %cmp1.i.i.i = fcmp ogt <2 x float> zeroinitializer, zeroinitializer
+ %splat.splat3.i.i.i = shufflevector <2 x i32> zeroinitializer, <2 x i32> zeroinitializer, <2 x i32> zeroinitializer
+ %xor3.i.i.i.i.i = select <2 x i1> zeroinitializer, <2 x i32> zeroinitializer, <2 x i32> zeroinitializer
+ %1 = load float, ptr null, align 4
+ %splat.splat8.i.i.i = shufflevector <2 x float> zeroinitializer, <2 x float> zeroinitializer, <2 x i32> zeroinitializer
+ %sub.i.i.i = fsub <2 x float> zeroinitializer, zeroinitializer
+ %mul.i.i.i = shl i64 0, 0
+ %2 = load float, ptr null, align 4
+ %splat.splat.i.i.i.i = shufflevector <2 x float> zeroinitializer, <2 x float> zeroinitializer, <2 x i32> zeroinitializer
+ %xor3.i.i.i.v.i.i = select <2 x i1> zeroinitializer, <2 x float> zeroinitializer, <2 x float> zeroinitializer
+ %indvars.iv.next = add i64 %indvars.iv1, 1
+ %exitcond = icmp ne i64 %indvars.iv1, 8
+ br i1 %exitcond, label %for.body, label %exit
+
+exit: ; preds = %for.body
+ ret void
+}
>From 28b354a96054196cc3c50c2517b0509d0d316d42 Mon Sep 17 00:00:00 2001
From: Daniil Kovalev <dkovalev at accesssoftek.com>
Date: Sat, 2 Mar 2024 08:09:10 +0300
Subject: [PATCH 343/406] Revert "[FileCheck] Fix parsing empty global and
pseudo variable names" (#83657)
Reverts llvm/llvm-project#82595
See build failure
https://lab.llvm.org/buildbot/#/builders/139/builds/60549
---
llvm/lib/FileCheck/FileCheck.cpp | 6 ----
llvm/test/FileCheck/empty-variable-name.txt | 32 ---------------------
2 files changed, 38 deletions(-)
delete mode 100644 llvm/test/FileCheck/empty-variable-name.txt
diff --git a/llvm/lib/FileCheck/FileCheck.cpp b/llvm/lib/FileCheck/FileCheck.cpp
index 8f80a69c4abd3a..6d3a2b9cf46f7c 100644
--- a/llvm/lib/FileCheck/FileCheck.cpp
+++ b/llvm/lib/FileCheck/FileCheck.cpp
@@ -297,12 +297,6 @@ Pattern::parseVariable(StringRef &Str, const SourceMgr &SM) {
if (Str[0] == '$' || IsPseudo)
++I;
- if (I == Str.size())
- return ErrorDiagnostic::get(SM, Str.slice(I, StringRef::npos),
- StringRef("empty ") +
- (IsPseudo ? "pseudo " : "global ") +
- "variable name");
-
if (!isValidVarNameStart(Str[I++]))
return ErrorDiagnostic::get(SM, Str, "invalid variable name");
diff --git a/llvm/test/FileCheck/empty-variable-name.txt b/llvm/test/FileCheck/empty-variable-name.txt
deleted file mode 100644
index 29c6317e6bb17e..00000000000000
--- a/llvm/test/FileCheck/empty-variable-name.txt
+++ /dev/null
@@ -1,32 +0,0 @@
-a
-
-; RUN: not FileCheck -input-file %s %s 2>&1 | \
-; RUN: FileCheck -check-prefix CHECK-ERROR -DDIR=%S \
-; RUN: --match-full-lines --strict-whitespace %s
-
-; CHECK: a[[]]
-; CHECK-ERROR:[[DIR]]{{/|\\}}empty-variable-name.txt:7:13: error: empty variable name
-; CHECK-ERROR-NEXT:; CHECK: a{{\[\[\]\]}}
-; CHECK-ERROR-NEXT: ^
-
-b
-
-; RUN: not FileCheck -input-file %s -check-prefix CHECK-PSEUDO %s 2>&1 | \
-; RUN: FileCheck -check-prefix CHECK-ERROR-PSEUDO -DDIR=%S \
-; RUN: --match-full-lines --strict-whitespace %s
-
-; CHECK-PSEUDO: b[[@]]
-; CHECK-ERROR-PSEUDO:[[DIR]]{{/|\\}}empty-variable-name.txt:18:21: error: empty pseudo variable name
-; CHECK-ERROR-PSEUDO-NEXT:; CHECK-PSEUDO: b{{\[\[@\]\]}}
-; CHECK-ERROR-PSEUDO-NEXT: ^
-
-c
-
-; RUN: not FileCheck -input-file %s -check-prefix CHECK-GLOBAL %s 2>&1 | \
-; RUN: FileCheck -check-prefix CHECK-ERROR-GLOBAL -DDIR=%S \
-; RUN: --match-full-lines --strict-whitespace %s
-
-; CHECK-GLOBAL: c[[$]]
-; CHECK-ERROR-GLOBAL:[[DIR]]{{/|\\}}empty-variable-name.txt:29:21: error: empty global variable name
-; CHECK-ERROR-GLOBAL-NEXT:; CHECK-GLOBAL: c{{\[\[\$\]\]}}
-; CHECK-ERROR-GLOBAL-NEXT: ^
>From 597f9761c3a5ba278fa930d2fac13f156287d505 Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?W=C3=81NG=20Xu=C4=9Bru=C3=AC?= <git at xen0n.name>
Date: Sat, 2 Mar 2024 13:58:18 +0800
Subject: [PATCH 344/406] [scudo] Add support for LoongArch hardware CRC32
checksumming (#83113)
One has to probe for platform capability prior to use with HWCAP,
according to LoongArch documentation.
---
compiler-rt/lib/scudo/standalone/checksum.cpp | 16 ++++++++++++++++
compiler-rt/lib/scudo/standalone/checksum.h | 4 ++++
compiler-rt/lib/scudo/standalone/crc32_hw.cpp | 9 +++++++++
3 files changed, 29 insertions(+)
diff --git a/compiler-rt/lib/scudo/standalone/checksum.cpp b/compiler-rt/lib/scudo/standalone/checksum.cpp
index 2c277391a2ec16..efa4055bcbc1e6 100644
--- a/compiler-rt/lib/scudo/standalone/checksum.cpp
+++ b/compiler-rt/lib/scudo/standalone/checksum.cpp
@@ -19,6 +19,8 @@
#else
#include <sys/auxv.h>
#endif
+#elif defined(__loongarch__)
+#include <sys/auxv.h>
#endif
namespace scudo {
@@ -75,6 +77,20 @@ bool hasHardwareCRC32() {
return !!(getauxval(AT_HWCAP) & HWCAP_CRC32);
#endif // SCUDO_FUCHSIA
}
+#elif defined(__loongarch__)
+// The definition is only pulled in by <sys/auxv.h> since glibc 2.38, so
+// supply it if missing.
+#ifndef HWCAP_LOONGARCH_CRC32
+#define HWCAP_LOONGARCH_CRC32 (1 << 6)
+#endif
+// Query HWCAP for platform capability, according to *Software Development and
+// Build Convention for LoongArch Architectures* v0.1, Section 9.1.
+//
+// Link:
+// https://github.com/loongson/la-softdev-convention/blob/v0.1/la-softdev-convention.adoc#kernel-development
+bool hasHardwareCRC32() {
+ return !!(getauxval(AT_HWCAP) & HWCAP_LOONGARCH_CRC32);
+}
#else
// No hardware CRC32 implemented in Scudo for other architectures.
bool hasHardwareCRC32() { return false; }
diff --git a/compiler-rt/lib/scudo/standalone/checksum.h b/compiler-rt/lib/scudo/standalone/checksum.h
index f8eda81fd91288..32ca372b097f68 100644
--- a/compiler-rt/lib/scudo/standalone/checksum.h
+++ b/compiler-rt/lib/scudo/standalone/checksum.h
@@ -30,6 +30,10 @@
#include <arm_acle.h>
#define CRC32_INTRINSIC FIRST_32_SECOND_64(__crc32cw, __crc32cd)
#endif
+#ifdef __loongarch__
+#include <larchintrin.h>
+#define CRC32_INTRINSIC FIRST_32_SECOND_64(__crcc_w_w_w, __crcc_w_d_w)
+#endif
namespace scudo {
diff --git a/compiler-rt/lib/scudo/standalone/crc32_hw.cpp b/compiler-rt/lib/scudo/standalone/crc32_hw.cpp
index 73f2ae000c63d6..910cf9460313f6 100644
--- a/compiler-rt/lib/scudo/standalone/crc32_hw.cpp
+++ b/compiler-rt/lib/scudo/standalone/crc32_hw.cpp
@@ -17,4 +17,13 @@ u32 computeHardwareCRC32(u32 Crc, uptr Data) {
#endif // defined(__CRC32__) || defined(__SSE4_2__) ||
// defined(__ARM_FEATURE_CRC32)
+#if defined(__loongarch__)
+u32 computeHardwareCRC32(u32 Crc, uptr Data) {
+ // The LoongArch CRC intrinsics have the two input arguments swapped, and
+ // expect them to be signed.
+ return static_cast<u32>(
+ CRC32_INTRINSIC(static_cast<long>(Data), static_cast<int>(Crc)));
+}
+#endif // defined(__loongarch__)
+
} // namespace scudo
>From b14220e075fe47f4d61632e80a6d0a4a955a7c97 Mon Sep 17 00:00:00 2001
From: Daniil Kovalev <dkovalev at accesssoftek.com>
Date: Sat, 2 Mar 2024 13:09:47 +0300
Subject: [PATCH 345/406] [lldb][X86] Fix setting target features in
ClangExpressionParser (#82364)
Currently, for x86 and x86_64 triples, "+sse" and "+sse2" are appended
to `Features` vector of `TargetOptions` unconditionally. This vector is
later reset in `TargetInfo::CreateTargetInfo` and filled using info from
`FeaturesAsWritten` vector, so previous modifications of the `Features`
vector have no effect. For x86_64 triple, we append "sse2"
unconditionally in `X86TargetInfo::initFeatureMap`, so despite the
`Features` vector reset, we still have the desired sse features enabled.
The corresponding code in `X86TargetInfo::initFeatureMap` is marked as
FIXME, so we should not probably rely on it and should set desired
features properly in `ClangExpressionParser`.
This patch changes the vector the features are appended to from
`Features` to `FeaturesAsWritten`. It's not reset later and is used to
compute resulting `Features` vector.
---
.../Plugins/ExpressionParser/Clang/ClangExpressionParser.cpp | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/lldb/source/Plugins/ExpressionParser/Clang/ClangExpressionParser.cpp b/lldb/source/Plugins/ExpressionParser/Clang/ClangExpressionParser.cpp
index 574d661e2a215e..822d286cd6c3c4 100644
--- a/lldb/source/Plugins/ExpressionParser/Clang/ClangExpressionParser.cpp
+++ b/lldb/source/Plugins/ExpressionParser/Clang/ClangExpressionParser.cpp
@@ -445,8 +445,8 @@ ClangExpressionParser::ClangExpressionParser(
// Supported subsets of x86
if (target_machine == llvm::Triple::x86 ||
target_machine == llvm::Triple::x86_64) {
- m_compiler->getTargetOpts().Features.push_back("+sse");
- m_compiler->getTargetOpts().Features.push_back("+sse2");
+ m_compiler->getTargetOpts().FeaturesAsWritten.push_back("+sse");
+ m_compiler->getTargetOpts().FeaturesAsWritten.push_back("+sse2");
}
// Set the target CPU to generate code for. This will be empty for any CPU
>From c4f59937cae95a576635848b36a23b0d672f71d6 Mon Sep 17 00:00:00 2001
From: Michael Spencer <bigcheesegs at gmail.com>
Date: Sat, 2 Mar 2024 02:29:08 -0800
Subject: [PATCH 346/406] [llvm][Support] Call clear_error in LockFileManager
to avoid report_fatal_error (#83655)
As per the comment in `raw_fd_ostream`'s destructor, you must call
`clear_error()` to prevent a call to `report_fatal_error()`. There's not
really a way to test this, but we did encounter it in the wild.
rdar://117347895
---
llvm/lib/Support/LockFileManager.cpp | 2 ++
1 file changed, 2 insertions(+)
diff --git a/llvm/lib/Support/LockFileManager.cpp b/llvm/lib/Support/LockFileManager.cpp
index 34c7a16b24be41..facdc5a0d7d421 100644
--- a/llvm/lib/Support/LockFileManager.cpp
+++ b/llvm/lib/Support/LockFileManager.cpp
@@ -205,6 +205,8 @@ LockFileManager::LockFileManager(StringRef FileName)
S.append(std::string(UniqueLockFileName));
setError(Out.error(), S);
sys::fs::remove(UniqueLockFileName);
+ // Don't call report_fatal_error.
+ Out.clear_error();
return;
}
}
>From bf08d0286825eb3e482bcfdc1cc7c19a28441ae7 Mon Sep 17 00:00:00 2001
From: Daniil Kovalev <dkovalev at accesssoftek.com>
Date: Sat, 2 Mar 2024 14:48:46 +0300
Subject: [PATCH 347/406] Revert "[Dwarf] Support `__ptrauth` qualifier in
metadata nodes" (#83672)
Reverts llvm/llvm-project#82363
See a build failure related to an issue discovered by memory sanitizer
(use of uninitialized value):
https://lab.llvm.org/buildbot/#/builders/37/builds/31965
---
llvm/include/llvm/IR/DIBuilder.h | 7 --
llvm/include/llvm/IR/DebugInfoMetadata.h | 124 ++++----------------
llvm/lib/AsmParser/LLParser.cpp | 23 +---
llvm/lib/Bitcode/Reader/MetadataLoader.cpp | 18 +--
llvm/lib/Bitcode/Writer/BitcodeWriter.cpp | 5 -
llvm/lib/CodeGen/AsmPrinter/DwarfUnit.cpp | 14 ---
llvm/lib/IR/AsmWriter.cpp | 11 --
llvm/lib/IR/DIBuilder.cpp | 58 ++++-----
llvm/lib/IR/DebugInfo.cpp | 6 +-
llvm/lib/IR/DebugInfoMetadata.cpp | 32 ++---
llvm/lib/IR/LLVMContextImpl.h | 15 +--
llvm/lib/IR/Verifier.cpp | 1 -
llvm/test/Assembler/debug-info.ll | 16 +--
llvm/test/DebugInfo/AArch64/ptrauth.ll | 70 -----------
llvm/unittests/IR/MetadataTest.cpp | 85 ++++----------
mlir/lib/Target/LLVMIR/DebugTranslation.cpp | 3 +-
16 files changed, 100 insertions(+), 388 deletions(-)
delete mode 100644 llvm/test/DebugInfo/AArch64/ptrauth.ll
diff --git a/llvm/include/llvm/IR/DIBuilder.h b/llvm/include/llvm/IR/DIBuilder.h
index 010dcbfdadcac2..edec161b397155 100644
--- a/llvm/include/llvm/IR/DIBuilder.h
+++ b/llvm/include/llvm/IR/DIBuilder.h
@@ -262,13 +262,6 @@ namespace llvm {
std::optional<unsigned> DWARFAddressSpace = std::nullopt,
StringRef Name = "", DINodeArray Annotations = nullptr);
- /// Create a __ptrauth qualifier.
- DIDerivedType *createPtrAuthQualifiedType(DIType *FromTy, unsigned Key,
- bool IsAddressDiscriminated,
- unsigned ExtraDiscriminator,
- bool IsaPointer,
- bool authenticatesNullValues);
-
/// Create debugging information entry for a pointer to member.
/// \param PointeeTy Type pointed to by this pointer.
/// \param SizeInBits Size.
diff --git a/llvm/include/llvm/IR/DebugInfoMetadata.h b/llvm/include/llvm/IR/DebugInfoMetadata.h
index 1a953c53c17a14..156f6eb49253de 100644
--- a/llvm/include/llvm/IR/DebugInfoMetadata.h
+++ b/llvm/include/llvm/IR/DebugInfoMetadata.h
@@ -745,7 +745,7 @@ class DIType : public DIScope {
unsigned getLine() const { return Line; }
uint64_t getSizeInBits() const { return SizeInBits; }
- uint32_t getAlignInBits() const;
+ uint32_t getAlignInBits() const { return SubclassData32; }
uint32_t getAlignInBytes() const { return getAlignInBits() / CHAR_BIT; }
uint64_t getOffsetInBits() const { return OffsetInBits; }
DIFlags getFlags() const { return Flags; }
@@ -972,40 +972,6 @@ class DIStringType : public DIType {
///
/// TODO: Split out members (inheritance, fields, methods, etc.).
class DIDerivedType : public DIType {
-public:
- /// Pointer authentication (__ptrauth) metadata.
- struct PtrAuthData {
- union {
- struct {
- unsigned Key : 4;
- unsigned IsAddressDiscriminated : 1;
- unsigned ExtraDiscriminator : 16;
- unsigned IsaPointer : 1;
- unsigned AuthenticatesNullValues : 1;
- } Data;
- unsigned RawData;
- } Payload;
-
- PtrAuthData(unsigned FromRawData) { Payload.RawData = FromRawData; }
- PtrAuthData(unsigned Key, bool IsDiscr, unsigned Discriminator,
- bool IsaPointer, bool AuthenticatesNullValues) {
- assert(Key < 16);
- assert(Discriminator <= 0xffff);
- Payload.Data.Key = Key;
- Payload.Data.IsAddressDiscriminated = IsDiscr;
- Payload.Data.ExtraDiscriminator = Discriminator;
- Payload.Data.IsaPointer = IsaPointer;
- Payload.Data.AuthenticatesNullValues = AuthenticatesNullValues;
- }
- bool operator==(struct PtrAuthData Other) const {
- return Payload.RawData == Other.Payload.RawData;
- }
- bool operator!=(struct PtrAuthData Other) const {
- return !(*this == Other);
- }
- };
-
-private:
friend class LLVMContextImpl;
friend class MDNode;
@@ -1016,70 +982,59 @@ class DIDerivedType : public DIType {
DIDerivedType(LLVMContext &C, StorageType Storage, unsigned Tag,
unsigned Line, uint64_t SizeInBits, uint32_t AlignInBits,
uint64_t OffsetInBits,
- std::optional<unsigned> DWARFAddressSpace,
- std::optional<PtrAuthData> PtrAuthData, DIFlags Flags,
+ std::optional<unsigned> DWARFAddressSpace, DIFlags Flags,
ArrayRef<Metadata *> Ops)
: DIType(C, DIDerivedTypeKind, Storage, Tag, Line, SizeInBits,
AlignInBits, OffsetInBits, Flags, Ops),
- DWARFAddressSpace(DWARFAddressSpace) {
- if (PtrAuthData)
- SubclassData32 = PtrAuthData->Payload.RawData;
- }
+ DWARFAddressSpace(DWARFAddressSpace) {}
~DIDerivedType() = default;
static DIDerivedType *
getImpl(LLVMContext &Context, unsigned Tag, StringRef Name, DIFile *File,
unsigned Line, DIScope *Scope, DIType *BaseType, uint64_t SizeInBits,
uint32_t AlignInBits, uint64_t OffsetInBits,
- std::optional<unsigned> DWARFAddressSpace,
- std::optional<PtrAuthData> PtrAuthData, DIFlags Flags,
+ std::optional<unsigned> DWARFAddressSpace, DIFlags Flags,
Metadata *ExtraData, DINodeArray Annotations, StorageType Storage,
bool ShouldCreate = true) {
return getImpl(Context, Tag, getCanonicalMDString(Context, Name), File,
Line, Scope, BaseType, SizeInBits, AlignInBits, OffsetInBits,
- DWARFAddressSpace, PtrAuthData, Flags, ExtraData,
- Annotations.get(), Storage, ShouldCreate);
+ DWARFAddressSpace, Flags, ExtraData, Annotations.get(),
+ Storage, ShouldCreate);
}
static DIDerivedType *
getImpl(LLVMContext &Context, unsigned Tag, MDString *Name, Metadata *File,
unsigned Line, Metadata *Scope, Metadata *BaseType,
uint64_t SizeInBits, uint32_t AlignInBits, uint64_t OffsetInBits,
- std::optional<unsigned> DWARFAddressSpace,
- std::optional<PtrAuthData> PtrAuthData, DIFlags Flags,
+ std::optional<unsigned> DWARFAddressSpace, DIFlags Flags,
Metadata *ExtraData, Metadata *Annotations, StorageType Storage,
bool ShouldCreate = true);
TempDIDerivedType cloneImpl() const {
- return getTemporary(getContext(), getTag(), getName(), getFile(), getLine(),
- getScope(), getBaseType(), getSizeInBits(),
- getAlignInBits(), getOffsetInBits(),
- getDWARFAddressSpace(), getPtrAuthData(), getFlags(),
- getExtraData(), getAnnotations());
+ return getTemporary(
+ getContext(), getTag(), getName(), getFile(), getLine(), getScope(),
+ getBaseType(), getSizeInBits(), getAlignInBits(), getOffsetInBits(),
+ getDWARFAddressSpace(), getFlags(), getExtraData(), getAnnotations());
}
public:
- DEFINE_MDNODE_GET(DIDerivedType,
- (unsigned Tag, MDString *Name, Metadata *File,
- unsigned Line, Metadata *Scope, Metadata *BaseType,
- uint64_t SizeInBits, uint32_t AlignInBits,
- uint64_t OffsetInBits,
- std::optional<unsigned> DWARFAddressSpace,
- std::optional<PtrAuthData> PtrAuthData, DIFlags Flags,
- Metadata *ExtraData = nullptr,
- Metadata *Annotations = nullptr),
- (Tag, Name, File, Line, Scope, BaseType, SizeInBits,
- AlignInBits, OffsetInBits, DWARFAddressSpace, PtrAuthData,
- Flags, ExtraData, Annotations))
+ DEFINE_MDNODE_GET(
+ DIDerivedType,
+ (unsigned Tag, MDString *Name, Metadata *File, unsigned Line,
+ Metadata *Scope, Metadata *BaseType, uint64_t SizeInBits,
+ uint32_t AlignInBits, uint64_t OffsetInBits,
+ std::optional<unsigned> DWARFAddressSpace, DIFlags Flags,
+ Metadata *ExtraData = nullptr, Metadata *Annotations = nullptr),
+ (Tag, Name, File, Line, Scope, BaseType, SizeInBits, AlignInBits,
+ OffsetInBits, DWARFAddressSpace, Flags, ExtraData, Annotations))
DEFINE_MDNODE_GET(DIDerivedType,
(unsigned Tag, StringRef Name, DIFile *File, unsigned Line,
DIScope *Scope, DIType *BaseType, uint64_t SizeInBits,
uint32_t AlignInBits, uint64_t OffsetInBits,
- std::optional<unsigned> DWARFAddressSpace,
- std::optional<PtrAuthData> PtrAuthData, DIFlags Flags,
+ std::optional<unsigned> DWARFAddressSpace, DIFlags Flags,
Metadata *ExtraData = nullptr,
DINodeArray Annotations = nullptr),
(Tag, Name, File, Line, Scope, BaseType, SizeInBits,
- AlignInBits, OffsetInBits, DWARFAddressSpace, PtrAuthData,
- Flags, ExtraData, Annotations))
+ AlignInBits, OffsetInBits, DWARFAddressSpace, Flags,
+ ExtraData, Annotations))
TempDIDerivedType clone() const { return cloneImpl(); }
@@ -1093,39 +1048,6 @@ class DIDerivedType : public DIType {
return DWARFAddressSpace;
}
- std::optional<PtrAuthData> getPtrAuthData() const;
-
- /// \returns The PointerAuth key.
- std::optional<unsigned> getPtrAuthKey() const {
- if (auto PtrAuthData = getPtrAuthData())
- return (unsigned)PtrAuthData->Payload.Data.Key;
- return std::nullopt;
- }
- /// \returns The PointerAuth address discrimination bit.
- std::optional<bool> isPtrAuthAddressDiscriminated() const {
- if (auto PtrAuthData = getPtrAuthData())
- return (bool)PtrAuthData->Payload.Data.IsAddressDiscriminated;
- return std::nullopt;
- }
- /// \returns The PointerAuth extra discriminator.
- std::optional<unsigned> getPtrAuthExtraDiscriminator() const {
- if (auto PtrAuthData = getPtrAuthData())
- return (unsigned)PtrAuthData->Payload.Data.ExtraDiscriminator;
- return std::nullopt;
- }
- /// \returns The PointerAuth IsaPointer bit.
- std::optional<bool> isPtrAuthIsaPointer() const {
- if (auto PtrAuthData = getPtrAuthData())
- return (bool)PtrAuthData->Payload.Data.IsaPointer;
- return std::nullopt;
- }
- /// \returns The PointerAuth authenticates null values bit.
- std::optional<bool> getPtrAuthAuthenticatesNullValues() const {
- if (auto PtrAuthData = getPtrAuthData())
- return (bool)PtrAuthData->Payload.Data.AuthenticatesNullValues;
- return std::nullopt;
- }
-
/// Get extra data associated with this derived type.
///
/// Class type for pointer-to-members, objective-c property node for ivars,
diff --git a/llvm/lib/AsmParser/LLParser.cpp b/llvm/lib/AsmParser/LLParser.cpp
index e91abaf0780a3d..a91e2f690999e0 100644
--- a/llvm/lib/AsmParser/LLParser.cpp
+++ b/llvm/lib/AsmParser/LLParser.cpp
@@ -5130,11 +5130,7 @@ bool LLParser::parseDIStringType(MDNode *&Result, bool IsDistinct) {
/// ::= !DIDerivedType(tag: DW_TAG_pointer_type, name: "int", file: !0,
/// line: 7, scope: !1, baseType: !2, size: 32,
/// align: 32, offset: 0, flags: 0, extraData: !3,
-/// dwarfAddressSpace: 3, ptrAuthKey: 1,
-/// ptrAuthIsAddressDiscriminated: true,
-/// ptrAuthExtraDiscriminator: 0x1234,
-/// ptrAuthIsaPointer: 1, ptrAuthAuthenticatesNullValues:1
-/// )
+/// dwarfAddressSpace: 3)
bool LLParser::parseDIDerivedType(MDNode *&Result, bool IsDistinct) {
#define VISIT_MD_FIELDS(OPTIONAL, REQUIRED) \
REQUIRED(tag, DwarfTagField, ); \
@@ -5149,30 +5145,19 @@ bool LLParser::parseDIDerivedType(MDNode *&Result, bool IsDistinct) {
OPTIONAL(flags, DIFlagField, ); \
OPTIONAL(extraData, MDField, ); \
OPTIONAL(dwarfAddressSpace, MDUnsignedField, (UINT32_MAX, UINT32_MAX)); \
- OPTIONAL(annotations, MDField, ); \
- OPTIONAL(ptrAuthKey, MDUnsignedField, (0, 7)); \
- OPTIONAL(ptrAuthIsAddressDiscriminated, MDBoolField, ); \
- OPTIONAL(ptrAuthExtraDiscriminator, MDUnsignedField, (0, 0xffff)); \
- OPTIONAL(ptrAuthIsaPointer, MDBoolField, ); \
- OPTIONAL(ptrAuthAuthenticatesNullValues, MDBoolField, );
+ OPTIONAL(annotations, MDField, );
PARSE_MD_FIELDS();
#undef VISIT_MD_FIELDS
std::optional<unsigned> DWARFAddressSpace;
if (dwarfAddressSpace.Val != UINT32_MAX)
DWARFAddressSpace = dwarfAddressSpace.Val;
- std::optional<DIDerivedType::PtrAuthData> PtrAuthData;
- if (ptrAuthKey.Val)
- PtrAuthData = DIDerivedType::PtrAuthData(
- (unsigned)ptrAuthKey.Val, ptrAuthIsAddressDiscriminated.Val,
- (unsigned)ptrAuthExtraDiscriminator.Val, ptrAuthIsaPointer.Val,
- ptrAuthAuthenticatesNullValues.Val);
Result = GET_OR_DISTINCT(DIDerivedType,
(Context, tag.Val, name.Val, file.Val, line.Val,
scope.Val, baseType.Val, size.Val, align.Val,
- offset.Val, DWARFAddressSpace, PtrAuthData,
- flags.Val, extraData.Val, annotations.Val));
+ offset.Val, DWARFAddressSpace, flags.Val,
+ extraData.Val, annotations.Val));
return false;
}
diff --git a/llvm/lib/Bitcode/Reader/MetadataLoader.cpp b/llvm/lib/Bitcode/Reader/MetadataLoader.cpp
index bdc2db82dfbe0e..770eb83af17f9b 100644
--- a/llvm/lib/Bitcode/Reader/MetadataLoader.cpp
+++ b/llvm/lib/Bitcode/Reader/MetadataLoader.cpp
@@ -1556,7 +1556,7 @@ Error MetadataLoader::MetadataLoaderImpl::parseOneMetadata(
break;
}
case bitc::METADATA_DERIVED_TYPE: {
- if (Record.size() < 12 || Record.size() > 15)
+ if (Record.size() < 12 || Record.size() > 14)
return error("Invalid record");
// DWARF address space is encoded as N->getDWARFAddressSpace() + 1. 0 means
@@ -1566,18 +1566,8 @@ Error MetadataLoader::MetadataLoaderImpl::parseOneMetadata(
DWARFAddressSpace = Record[12] - 1;
Metadata *Annotations = nullptr;
- std::optional<DIDerivedType::PtrAuthData> PtrAuthData;
-
- // Only look for annotations/ptrauth if both are allocated.
- // If not, we can't tell which was intended to be embedded, as both ptrauth
- // and annotations have been expected at Record[13] at various times.
- if (Record.size() > 14) {
- if (Record[13])
- Annotations = getMDOrNull(Record[13]);
-
- if (Record[14])
- PtrAuthData = DIDerivedType::PtrAuthData(Record[14]);
- }
+ if (Record.size() > 13 && Record[13])
+ Annotations = getMDOrNull(Record[13]);
IsDistinct = Record[0];
DINode::DIFlags Flags = static_cast<DINode::DIFlags>(Record[10]);
@@ -1587,7 +1577,7 @@ Error MetadataLoader::MetadataLoaderImpl::parseOneMetadata(
getMDOrNull(Record[3]), Record[4],
getDITypeRefOrNull(Record[5]),
getDITypeRefOrNull(Record[6]), Record[7], Record[8],
- Record[9], DWARFAddressSpace, PtrAuthData, Flags,
+ Record[9], DWARFAddressSpace, Flags,
getDITypeRefOrNull(Record[11]), Annotations)),
NextMetadataNo);
NextMetadataNo++;
diff --git a/llvm/lib/Bitcode/Writer/BitcodeWriter.cpp b/llvm/lib/Bitcode/Writer/BitcodeWriter.cpp
index 85319dc69e945c..656f2a6ce870f5 100644
--- a/llvm/lib/Bitcode/Writer/BitcodeWriter.cpp
+++ b/llvm/lib/Bitcode/Writer/BitcodeWriter.cpp
@@ -1804,11 +1804,6 @@ void ModuleBitcodeWriter::writeDIDerivedType(const DIDerivedType *N,
Record.push_back(VE.getMetadataOrNullID(N->getAnnotations().get()));
- if (auto PtrAuthData = N->getPtrAuthData())
- Record.push_back(PtrAuthData->Payload.RawData);
- else
- Record.push_back(0);
-
Stream.EmitRecord(bitc::METADATA_DERIVED_TYPE, Record, Abbrev);
Record.clear();
}
diff --git a/llvm/lib/CodeGen/AsmPrinter/DwarfUnit.cpp b/llvm/lib/CodeGen/AsmPrinter/DwarfUnit.cpp
index ae0226934804f7..d462859e489465 100644
--- a/llvm/lib/CodeGen/AsmPrinter/DwarfUnit.cpp
+++ b/llvm/lib/CodeGen/AsmPrinter/DwarfUnit.cpp
@@ -803,20 +803,6 @@ void DwarfUnit::constructTypeDIE(DIE &Buffer, const DIDerivedType *DTy) {
if (DTy->getDWARFAddressSpace())
addUInt(Buffer, dwarf::DW_AT_address_class, dwarf::DW_FORM_data4,
*DTy->getDWARFAddressSpace());
- if (auto Key = DTy->getPtrAuthKey())
- addUInt(Buffer, dwarf::DW_AT_LLVM_ptrauth_key, dwarf::DW_FORM_data1, *Key);
- if (auto AddrDisc = DTy->isPtrAuthAddressDiscriminated())
- if (AddrDisc.value())
- addFlag(Buffer, dwarf::DW_AT_LLVM_ptrauth_address_discriminated);
- if (auto Disc = DTy->getPtrAuthExtraDiscriminator())
- addUInt(Buffer, dwarf::DW_AT_LLVM_ptrauth_extra_discriminator,
- dwarf::DW_FORM_data2, *Disc);
- if (auto IsaPointer = DTy->isPtrAuthIsaPointer())
- if (*IsaPointer)
- addFlag(Buffer, dwarf::DW_AT_LLVM_ptrauth_isa_pointer);
- if (auto AuthenticatesNullValues = DTy->getPtrAuthAuthenticatesNullValues())
- if (*AuthenticatesNullValues)
- addFlag(Buffer, dwarf::DW_AT_LLVM_ptrauth_authenticates_null_values);
}
void DwarfUnit::constructSubprogramArguments(DIE &Buffer, DITypeRefArray Args) {
diff --git a/llvm/lib/IR/AsmWriter.cpp b/llvm/lib/IR/AsmWriter.cpp
index 479622cd1bdcf0..4e1e48b4ad4a35 100644
--- a/llvm/lib/IR/AsmWriter.cpp
+++ b/llvm/lib/IR/AsmWriter.cpp
@@ -2135,17 +2135,6 @@ static void writeDIDerivedType(raw_ostream &Out, const DIDerivedType *N,
Printer.printInt("dwarfAddressSpace", *DWARFAddressSpace,
/* ShouldSkipZero */ false);
Printer.printMetadata("annotations", N->getRawAnnotations());
- if (auto Key = N->getPtrAuthKey())
- Printer.printInt("ptrAuthKey", *Key);
- if (auto AddrDisc = N->isPtrAuthAddressDiscriminated())
- Printer.printBool("ptrAuthIsAddressDiscriminated", *AddrDisc);
- if (auto Disc = N->getPtrAuthExtraDiscriminator())
- Printer.printInt("ptrAuthExtraDiscriminator", *Disc);
- if (auto IsaPointer = N->isPtrAuthIsaPointer())
- Printer.printBool("ptrAuthIsaPointer", *IsaPointer);
- if (auto AuthenticatesNullValues = N->getPtrAuthAuthenticatesNullValues())
- Printer.printBool("ptrAuthAuthenticatesNullValues",
- *AuthenticatesNullValues);
Out << ")";
}
diff --git a/llvm/lib/IR/DIBuilder.cpp b/llvm/lib/IR/DIBuilder.cpp
index 2842cb15e78fb3..62efaba025344b 100644
--- a/llvm/lib/IR/DIBuilder.cpp
+++ b/llvm/lib/IR/DIBuilder.cpp
@@ -296,20 +296,7 @@ DIStringType *DIBuilder::createStringType(StringRef Name,
DIDerivedType *DIBuilder::createQualifiedType(unsigned Tag, DIType *FromTy) {
return DIDerivedType::get(VMContext, Tag, "", nullptr, 0, nullptr, FromTy, 0,
- 0, 0, std::nullopt, std::nullopt, DINode::FlagZero);
-}
-
-DIDerivedType *DIBuilder::createPtrAuthQualifiedType(
- DIType *FromTy, unsigned Key, bool IsAddressDiscriminated,
- unsigned ExtraDiscriminator, bool IsaPointer,
- bool AuthenticatesNullValues) {
- return DIDerivedType::get(
- VMContext, dwarf::DW_TAG_LLVM_ptrauth_type, "", nullptr, 0, nullptr,
- FromTy, 0, 0, 0, std::nullopt,
- std::optional<DIDerivedType::PtrAuthData>({Key, IsAddressDiscriminated,
- ExtraDiscriminator, IsaPointer,
- AuthenticatesNullValues}),
- DINode::FlagZero);
+ 0, 0, std::nullopt, DINode::FlagZero);
}
DIDerivedType *
@@ -320,8 +307,8 @@ DIBuilder::createPointerType(DIType *PointeeTy, uint64_t SizeInBits,
// FIXME: Why is there a name here?
return DIDerivedType::get(VMContext, dwarf::DW_TAG_pointer_type, Name,
nullptr, 0, nullptr, PointeeTy, SizeInBits,
- AlignInBits, 0, DWARFAddressSpace, std::nullopt,
- DINode::FlagZero, nullptr, Annotations);
+ AlignInBits, 0, DWARFAddressSpace, DINode::FlagZero,
+ nullptr, Annotations);
}
DIDerivedType *DIBuilder::createMemberPointerType(DIType *PointeeTy,
@@ -331,8 +318,7 @@ DIDerivedType *DIBuilder::createMemberPointerType(DIType *PointeeTy,
DINode::DIFlags Flags) {
return DIDerivedType::get(VMContext, dwarf::DW_TAG_ptr_to_member_type, "",
nullptr, 0, nullptr, PointeeTy, SizeInBits,
- AlignInBits, 0, std::nullopt, std::nullopt, Flags,
- Base);
+ AlignInBits, 0, std::nullopt, Flags, Base);
}
DIDerivedType *
@@ -341,7 +327,7 @@ DIBuilder::createReferenceType(unsigned Tag, DIType *RTy, uint64_t SizeInBits,
std::optional<unsigned> DWARFAddressSpace) {
assert(RTy && "Unable to create reference type");
return DIDerivedType::get(VMContext, Tag, "", nullptr, 0, nullptr, RTy,
- SizeInBits, AlignInBits, 0, DWARFAddressSpace, {},
+ SizeInBits, AlignInBits, 0, DWARFAddressSpace,
DINode::FlagZero);
}
@@ -352,16 +338,15 @@ DIDerivedType *DIBuilder::createTypedef(DIType *Ty, StringRef Name,
DINodeArray Annotations) {
return DIDerivedType::get(VMContext, dwarf::DW_TAG_typedef, Name, File,
LineNo, getNonCompileUnitScope(Context), Ty, 0,
- AlignInBits, 0, std::nullopt, std::nullopt, Flags,
- nullptr, Annotations);
+ AlignInBits, 0, std::nullopt, Flags, nullptr,
+ Annotations);
}
DIDerivedType *DIBuilder::createFriend(DIType *Ty, DIType *FriendTy) {
assert(Ty && "Invalid type!");
assert(FriendTy && "Invalid friend type!");
return DIDerivedType::get(VMContext, dwarf::DW_TAG_friend, "", nullptr, 0, Ty,
- FriendTy, 0, 0, 0, std::nullopt, std::nullopt,
- DINode::FlagZero);
+ FriendTy, 0, 0, 0, std::nullopt, DINode::FlagZero);
}
DIDerivedType *DIBuilder::createInheritance(DIType *Ty, DIType *BaseTy,
@@ -373,7 +358,7 @@ DIDerivedType *DIBuilder::createInheritance(DIType *Ty, DIType *BaseTy,
ConstantInt::get(IntegerType::get(VMContext, 32), VBPtrOffset));
return DIDerivedType::get(VMContext, dwarf::DW_TAG_inheritance, "", nullptr,
0, Ty, BaseTy, 0, 0, BaseOffset, std::nullopt,
- std::nullopt, Flags, ExtraData);
+ Flags, ExtraData);
}
DIDerivedType *DIBuilder::createMemberType(
@@ -383,7 +368,7 @@ DIDerivedType *DIBuilder::createMemberType(
return DIDerivedType::get(VMContext, dwarf::DW_TAG_member, Name, File,
LineNumber, getNonCompileUnitScope(Scope), Ty,
SizeInBits, AlignInBits, OffsetInBits, std::nullopt,
- std::nullopt, Flags, nullptr, Annotations);
+ Flags, nullptr, Annotations);
}
static ConstantAsMetadata *getConstantOrNull(Constant *C) {
@@ -396,10 +381,10 @@ DIDerivedType *DIBuilder::createVariantMemberType(
DIScope *Scope, StringRef Name, DIFile *File, unsigned LineNumber,
uint64_t SizeInBits, uint32_t AlignInBits, uint64_t OffsetInBits,
Constant *Discriminant, DINode::DIFlags Flags, DIType *Ty) {
- return DIDerivedType::get(
- VMContext, dwarf::DW_TAG_member, Name, File, LineNumber,
- getNonCompileUnitScope(Scope), Ty, SizeInBits, AlignInBits, OffsetInBits,
- std::nullopt, std::nullopt, Flags, getConstantOrNull(Discriminant));
+ return DIDerivedType::get(VMContext, dwarf::DW_TAG_member, Name, File,
+ LineNumber, getNonCompileUnitScope(Scope), Ty,
+ SizeInBits, AlignInBits, OffsetInBits, std::nullopt,
+ Flags, getConstantOrNull(Discriminant));
}
DIDerivedType *DIBuilder::createBitFieldMemberType(
@@ -410,7 +395,7 @@ DIDerivedType *DIBuilder::createBitFieldMemberType(
return DIDerivedType::get(
VMContext, dwarf::DW_TAG_member, Name, File, LineNumber,
getNonCompileUnitScope(Scope), Ty, SizeInBits, /*AlignInBits=*/0,
- OffsetInBits, std::nullopt, std::nullopt, Flags,
+ OffsetInBits, std::nullopt, Flags,
ConstantAsMetadata::get(ConstantInt::get(IntegerType::get(VMContext, 64),
StorageOffsetInBits)),
Annotations);
@@ -424,8 +409,7 @@ DIBuilder::createStaticMemberType(DIScope *Scope, StringRef Name, DIFile *File,
Flags |= DINode::FlagStaticMember;
return DIDerivedType::get(VMContext, Tag, Name, File, LineNumber,
getNonCompileUnitScope(Scope), Ty, 0, AlignInBits,
- 0, std::nullopt, std::nullopt, Flags,
- getConstantOrNull(Val));
+ 0, std::nullopt, Flags, getConstantOrNull(Val));
}
DIDerivedType *
@@ -436,7 +420,7 @@ DIBuilder::createObjCIVar(StringRef Name, DIFile *File, unsigned LineNumber,
return DIDerivedType::get(VMContext, dwarf::DW_TAG_member, Name, File,
LineNumber, getNonCompileUnitScope(File), Ty,
SizeInBits, AlignInBits, OffsetInBits, std::nullopt,
- std::nullopt, Flags, PropertyNode);
+ Flags, PropertyNode);
}
DIObjCProperty *
@@ -571,10 +555,10 @@ DIDerivedType *DIBuilder::createSetType(DIScope *Scope, StringRef Name,
DIFile *File, unsigned LineNo,
uint64_t SizeInBits,
uint32_t AlignInBits, DIType *Ty) {
- auto *R = DIDerivedType::get(VMContext, dwarf::DW_TAG_set_type, Name, File,
- LineNo, getNonCompileUnitScope(Scope), Ty,
- SizeInBits, AlignInBits, 0, std::nullopt,
- std::nullopt, DINode::FlagZero);
+ auto *R =
+ DIDerivedType::get(VMContext, dwarf::DW_TAG_set_type, Name, File, LineNo,
+ getNonCompileUnitScope(Scope), Ty, SizeInBits,
+ AlignInBits, 0, std::nullopt, DINode::FlagZero);
trackIfUnresolved(R);
return R;
}
diff --git a/llvm/lib/IR/DebugInfo.cpp b/llvm/lib/IR/DebugInfo.cpp
index 510cc31da6ca5f..1f3ff2246a4453 100644
--- a/llvm/lib/IR/DebugInfo.cpp
+++ b/llvm/lib/IR/DebugInfo.cpp
@@ -1336,9 +1336,9 @@ LLVMMetadataRef LLVMDIBuilderCreatePointerType(
LLVMDIBuilderRef Builder, LLVMMetadataRef PointeeTy,
uint64_t SizeInBits, uint32_t AlignInBits, unsigned AddressSpace,
const char *Name, size_t NameLen) {
- return wrap(unwrap(Builder)->createPointerType(
- unwrapDI<DIType>(PointeeTy), SizeInBits, AlignInBits, AddressSpace,
- {Name, NameLen}));
+ return wrap(unwrap(Builder)->createPointerType(unwrapDI<DIType>(PointeeTy),
+ SizeInBits, AlignInBits,
+ AddressSpace, {Name, NameLen}));
}
LLVMMetadataRef LLVMDIBuilderCreateStructType(
diff --git a/llvm/lib/IR/DebugInfoMetadata.cpp b/llvm/lib/IR/DebugInfoMetadata.cpp
index 36c13e79a64925..28f96653d815b5 100644
--- a/llvm/lib/IR/DebugInfoMetadata.cpp
+++ b/llvm/lib/IR/DebugInfoMetadata.cpp
@@ -34,10 +34,6 @@ cl::opt<bool> EnableFSDiscriminator(
cl::desc("Enable adding flow sensitive discriminators"));
} // namespace llvm
-uint32_t DIType::getAlignInBits() const {
- return (getTag() == dwarf::DW_TAG_LLVM_ptrauth_type ? 0 : SubclassData32);
-}
-
const DIExpression::FragmentInfo DebugVariable::DefaultFragment = {
std::numeric_limits<uint64_t>::max(), std::numeric_limits<uint64_t>::min()};
@@ -735,32 +731,26 @@ Constant *DIDerivedType::getDiscriminantValue() const {
return nullptr;
}
-DIDerivedType *DIDerivedType::getImpl(
- LLVMContext &Context, unsigned Tag, MDString *Name, Metadata *File,
- unsigned Line, Metadata *Scope, Metadata *BaseType, uint64_t SizeInBits,
- uint32_t AlignInBits, uint64_t OffsetInBits,
- std::optional<unsigned> DWARFAddressSpace,
- std::optional<PtrAuthData> PtrAuthData, DIFlags Flags, Metadata *ExtraData,
- Metadata *Annotations, StorageType Storage, bool ShouldCreate) {
+DIDerivedType *
+DIDerivedType::getImpl(LLVMContext &Context, unsigned Tag, MDString *Name,
+ Metadata *File, unsigned Line, Metadata *Scope,
+ Metadata *BaseType, uint64_t SizeInBits,
+ uint32_t AlignInBits, uint64_t OffsetInBits,
+ std::optional<unsigned> DWARFAddressSpace, DIFlags Flags,
+ Metadata *ExtraData, Metadata *Annotations,
+ StorageType Storage, bool ShouldCreate) {
assert(isCanonical(Name) && "Expected canonical MDString");
DEFINE_GETIMPL_LOOKUP(DIDerivedType,
(Tag, Name, File, Line, Scope, BaseType, SizeInBits,
- AlignInBits, OffsetInBits, DWARFAddressSpace,
- PtrAuthData, Flags, ExtraData, Annotations));
+ AlignInBits, OffsetInBits, DWARFAddressSpace, Flags,
+ ExtraData, Annotations));
Metadata *Ops[] = {File, Scope, Name, BaseType, ExtraData, Annotations};
DEFINE_GETIMPL_STORE(DIDerivedType,
(Tag, Line, SizeInBits, AlignInBits, OffsetInBits,
- DWARFAddressSpace, PtrAuthData, Flags),
+ DWARFAddressSpace, Flags),
Ops);
}
-std::optional<DIDerivedType::PtrAuthData>
-DIDerivedType::getPtrAuthData() const {
- return getTag() == dwarf::DW_TAG_LLVM_ptrauth_type
- ? std::optional<PtrAuthData>(PtrAuthData(SubclassData32))
- : std::nullopt;
-}
-
DICompositeType *DICompositeType::getImpl(
LLVMContext &Context, unsigned Tag, MDString *Name, Metadata *File,
unsigned Line, Metadata *Scope, Metadata *BaseType, uint64_t SizeInBits,
diff --git a/llvm/lib/IR/LLVMContextImpl.h b/llvm/lib/IR/LLVMContextImpl.h
index 05e2b56587b2eb..2ee1080a1ffa29 100644
--- a/llvm/lib/IR/LLVMContextImpl.h
+++ b/llvm/lib/IR/LLVMContextImpl.h
@@ -539,7 +539,6 @@ template <> struct MDNodeKeyImpl<DIDerivedType> {
uint64_t OffsetInBits;
uint32_t AlignInBits;
std::optional<unsigned> DWARFAddressSpace;
- std::optional<DIDerivedType::PtrAuthData> PtrAuthData;
unsigned Flags;
Metadata *ExtraData;
Metadata *Annotations;
@@ -547,21 +546,18 @@ template <> struct MDNodeKeyImpl<DIDerivedType> {
MDNodeKeyImpl(unsigned Tag, MDString *Name, Metadata *File, unsigned Line,
Metadata *Scope, Metadata *BaseType, uint64_t SizeInBits,
uint32_t AlignInBits, uint64_t OffsetInBits,
- std::optional<unsigned> DWARFAddressSpace,
- std::optional<DIDerivedType::PtrAuthData> PtrAuthData,
- unsigned Flags, Metadata *ExtraData, Metadata *Annotations)
+ std::optional<unsigned> DWARFAddressSpace, unsigned Flags,
+ Metadata *ExtraData, Metadata *Annotations)
: Tag(Tag), Name(Name), File(File), Line(Line), Scope(Scope),
BaseType(BaseType), SizeInBits(SizeInBits), OffsetInBits(OffsetInBits),
AlignInBits(AlignInBits), DWARFAddressSpace(DWARFAddressSpace),
- PtrAuthData(PtrAuthData), Flags(Flags), ExtraData(ExtraData),
- Annotations(Annotations) {}
+ Flags(Flags), ExtraData(ExtraData), Annotations(Annotations) {}
MDNodeKeyImpl(const DIDerivedType *N)
: Tag(N->getTag()), Name(N->getRawName()), File(N->getRawFile()),
Line(N->getLine()), Scope(N->getRawScope()),
BaseType(N->getRawBaseType()), SizeInBits(N->getSizeInBits()),
OffsetInBits(N->getOffsetInBits()), AlignInBits(N->getAlignInBits()),
- DWARFAddressSpace(N->getDWARFAddressSpace()),
- PtrAuthData(N->getPtrAuthData()), Flags(N->getFlags()),
+ DWARFAddressSpace(N->getDWARFAddressSpace()), Flags(N->getFlags()),
ExtraData(N->getRawExtraData()), Annotations(N->getRawAnnotations()) {}
bool isKeyOf(const DIDerivedType *RHS) const {
@@ -572,8 +568,7 @@ template <> struct MDNodeKeyImpl<DIDerivedType> {
AlignInBits == RHS->getAlignInBits() &&
OffsetInBits == RHS->getOffsetInBits() &&
DWARFAddressSpace == RHS->getDWARFAddressSpace() &&
- PtrAuthData == RHS->getPtrAuthData() && Flags == RHS->getFlags() &&
- ExtraData == RHS->getRawExtraData() &&
+ Flags == RHS->getFlags() && ExtraData == RHS->getRawExtraData() &&
Annotations == RHS->getRawAnnotations();
}
diff --git a/llvm/lib/IR/Verifier.cpp b/llvm/lib/IR/Verifier.cpp
index 1b02d11ff4e7b3..e0de179e57146f 100644
--- a/llvm/lib/IR/Verifier.cpp
+++ b/llvm/lib/IR/Verifier.cpp
@@ -1223,7 +1223,6 @@ void Verifier::visitDIDerivedType(const DIDerivedType &N) {
N.getTag() == dwarf::DW_TAG_volatile_type ||
N.getTag() == dwarf::DW_TAG_restrict_type ||
N.getTag() == dwarf::DW_TAG_atomic_type ||
- N.getTag() == dwarf::DW_TAG_LLVM_ptrauth_type ||
N.getTag() == dwarf::DW_TAG_member ||
(N.getTag() == dwarf::DW_TAG_variable && N.isStaticMember()) ||
N.getTag() == dwarf::DW_TAG_inheritance ||
diff --git a/llvm/test/Assembler/debug-info.ll b/llvm/test/Assembler/debug-info.ll
index 06144b261373f4..419623a2cb7d14 100644
--- a/llvm/test/Assembler/debug-info.ll
+++ b/llvm/test/Assembler/debug-info.ll
@@ -1,8 +1,8 @@
; RUN: llvm-as < %s | llvm-dis | llvm-as | llvm-dis | FileCheck %s
; RUN: verify-uselistorder %s
-; CHECK: !named = !{!0, !0, !1, !2, !3, !4, !5, !6, !7, !8, !8, !9, !10, !11, !12, !13, !14, !15, !16, !17, !18, !19, !20, !21, !22, !23, !24, !25, !26, !27, !27, !28, !29, !30, !31, !32, !33, !34, !35, !36, !37, !38, !39, !40, !41, !42, !43}
-!named = !{!0, !1, !2, !3, !4, !5, !6, !7, !8, !9, !10, !11, !12, !13, !14, !15, !16, !17, !18, !19, !20, !21, !22, !23, !24, !25, !26, !27, !28, !29, !30, !31, !32, !33, !34, !35, !36, !37, !38, !39, !40, !41, !42, !43, !44, !45, !46}
+; CHECK: !named = !{!0, !0, !1, !2, !3, !4, !5, !6, !7, !8, !8, !9, !10, !11, !12, !13, !14, !15, !16, !17, !18, !19, !20, !21, !22, !23, !24, !25, !26, !27, !27, !28, !29, !30, !31, !32, !33, !34, !35, !36, !37, !38, !39}
+!named = !{!0, !1, !2, !3, !4, !5, !6, !7, !8, !9, !10, !11, !12, !13, !14, !15, !16, !17, !18, !19, !20, !21, !22, !23, !24, !25, !26, !27, !28, !29, !30, !31, !32, !33, !34, !35, !36, !37, !38, !39, !40, !41, !42}
; CHECK: !0 = !DISubrange(count: 3, lowerBound: 0)
; CHECK-NEXT: !1 = !DISubrange(count: 3, lowerBound: 4)
@@ -99,15 +99,3 @@
; CHECK-NEXT: !39 = !DIBasicType(name: "u64.le", size: 64, align: 1, encoding: DW_ATE_unsigned, flags: DIFlagLittleEndian)
!41 = !DIBasicType(name: "u64.be", size: 64, align: 1, encoding: DW_ATE_unsigned, flags: DIFlagBigEndian)
!42 = !DIBasicType(name: "u64.le", size: 64, align: 1, encoding: DW_ATE_unsigned, flags: DIFlagLittleEndian)
-
-; CHECK: !DIDerivedType(tag: DW_TAG_LLVM_ptrauth_type, baseType: !13, ptrAuthKey: 2, ptrAuthIsAddressDiscriminated: true, ptrAuthExtraDiscriminator: 1234, ptrAuthIsaPointer: false, ptrAuthAuthenticatesNullValues: false)
-!43 = !DIDerivedType(tag: DW_TAG_LLVM_ptrauth_type, baseType: !15, ptrAuthKey: 2, ptrAuthIsAddressDiscriminated: true, ptrAuthExtraDiscriminator: 1234)
-
-; CHECK: !DIDerivedType(tag: DW_TAG_LLVM_ptrauth_type, baseType: !13, ptrAuthKey: 2, ptrAuthIsAddressDiscriminated: true, ptrAuthExtraDiscriminator: 1234, ptrAuthIsaPointer: true, ptrAuthAuthenticatesNullValues: false)
-!44 = !DIDerivedType(tag: DW_TAG_LLVM_ptrauth_type, baseType: !15, ptrAuthKey: 2, ptrAuthIsAddressDiscriminated: true, ptrAuthExtraDiscriminator: 1234, ptrAuthIsaPointer: true)
-
-; CHECK: !DIDerivedType(tag: DW_TAG_LLVM_ptrauth_type, baseType: !13, ptrAuthKey: 2, ptrAuthIsAddressDiscriminated: true, ptrAuthExtraDiscriminator: 1234, ptrAuthIsaPointer: false, ptrAuthAuthenticatesNullValues: true)
-!45 = !DIDerivedType(tag: DW_TAG_LLVM_ptrauth_type, baseType: !15, ptrAuthKey: 2, ptrAuthIsAddressDiscriminated: true, ptrAuthExtraDiscriminator: 1234, ptrAuthAuthenticatesNullValues: true)
-
-; CHECK: !DIDerivedType(tag: DW_TAG_LLVM_ptrauth_type, baseType: !13, ptrAuthKey: 2, ptrAuthIsAddressDiscriminated: true, ptrAuthExtraDiscriminator: 1234, ptrAuthIsaPointer: true, ptrAuthAuthenticatesNullValues: true)
-!46 = !DIDerivedType(tag: DW_TAG_LLVM_ptrauth_type, baseType: !15, ptrAuthKey: 2, ptrAuthIsAddressDiscriminated: true, ptrAuthExtraDiscriminator: 1234, ptrAuthIsaPointer: true, ptrAuthAuthenticatesNullValues: true)
diff --git a/llvm/test/DebugInfo/AArch64/ptrauth.ll b/llvm/test/DebugInfo/AArch64/ptrauth.ll
deleted file mode 100644
index 4f84fe4f962977..00000000000000
--- a/llvm/test/DebugInfo/AArch64/ptrauth.ll
+++ /dev/null
@@ -1,70 +0,0 @@
-; RUN: llc %s -filetype=obj -mtriple arm64e-apple-darwin -o - \
-; RUN: | llvm-dwarfdump - | FileCheck %s
-
-; CHECK: DW_AT_type (0x{{0+}}[[TY:.*]] "void *__ptrauth(4, 0, 0x04d2)")
-; CHECK: 0x{{0+}}[[TY]]: DW_TAG_LLVM_ptrauth_type
-; CHECK-NEXT: DW_AT_type {{.*}}"void *"
-; CHECK-NEXT: DW_AT_LLVM_ptrauth_key (0x04)
-; CHECK-NEXT: DW_AT_LLVM_ptrauth_extra_discriminator (0x04d2)
-
-; CHECK: DW_AT_type (0x{{0+}}[[TY:.*]] "void *__ptrauth(4, 1, 0x04d3)")
-; CHECK: 0x{{0+}}[[TY]]: DW_TAG_LLVM_ptrauth_type
-; CHECK-NEXT: DW_AT_type {{.*}}"void *"
-; CHECK-NEXT: DW_AT_LLVM_ptrauth_key (0x04)
-; CHECK-NEXT: DW_AT_LLVM_ptrauth_address_discriminated (true)
-; CHECK-NEXT: DW_AT_LLVM_ptrauth_extra_discriminator (0x04d3)
-
-; CHECK: DW_AT_type (0x{{0+}}[[TY:.*]] "void *__ptrauth(4, 1, 0x04d4, "isa-pointer")")
-; CHECK: 0x{{0+}}[[TY]]: DW_TAG_LLVM_ptrauth_type
-; CHECK-NEXT: DW_AT_type {{.*}}"void *"
-; CHECK-NEXT: DW_AT_LLVM_ptrauth_key (0x04)
-; CHECK-NEXT: DW_AT_LLVM_ptrauth_address_discriminated (true)
-; CHECK-NEXT: DW_AT_LLVM_ptrauth_extra_discriminator (0x04d4)
-; CHECK-NEXT: DW_AT_LLVM_ptrauth_isa_pointer (true)
-
-; CHECK: DW_AT_type (0x{{0+}}[[TY:.*]] "void *__ptrauth(4, 1, 0x04d5, "authenticates-null-values")")
-; CHECK: 0x{{0+}}[[TY]]: DW_TAG_LLVM_ptrauth_type
-; CHECK-NEXT: DW_AT_type {{.*}}"void *"
-; CHECK-NEXT: DW_AT_LLVM_ptrauth_key (0x04)
-; CHECK-NEXT: DW_AT_LLVM_ptrauth_address_discriminated (true)
-; CHECK-NEXT: DW_AT_LLVM_ptrauth_extra_discriminator (0x04d5)
-; CHECK-NEXT: DW_AT_LLVM_ptrauth_authenticates_null_values (true)
-
-; CHECK: DW_AT_type (0x{{0+}}[[TY:.*]] "void *__ptrauth(4, 1, 0x04d6, "isa-pointer,authenticates-null-values")")
-; CHECK: 0x{{0+}}[[TY]]: DW_TAG_LLVM_ptrauth_type
-; CHECK-NEXT: DW_AT_type {{.*}}"void *"
-; CHECK-NEXT: DW_AT_LLVM_ptrauth_key (0x04)
-; CHECK-NEXT: DW_AT_LLVM_ptrauth_address_discriminated (true)
-; CHECK-NEXT: DW_AT_LLVM_ptrauth_extra_discriminator (0x04d6)
-; CHECK-NEXT: DW_AT_LLVM_ptrauth_isa_pointer (true)
-; CHECK-NEXT: DW_AT_LLVM_ptrauth_authenticates_null_values (true)
-
-target datalayout = "e-m:o-i64:64-i128:128-n32:64-S128"
-
- at p = common global i8* null, align 8, !dbg !0
-
-!llvm.dbg.cu = !{!10}
-!llvm.module.flags = !{!19, !20}
-
-!0 = !DIGlobalVariableExpression(var: !5, expr: !DIExpression())
-!1 = !DIGlobalVariableExpression(var: !6, expr: !DIExpression())
-!2 = !DIGlobalVariableExpression(var: !7, expr: !DIExpression())
-!3 = !DIGlobalVariableExpression(var: !8, expr: !DIExpression())
-!4 = !DIGlobalVariableExpression(var: !9, expr: !DIExpression())
-!5 = distinct !DIGlobalVariable(name: "p1", scope: !10, file: !11, line: 1, type: !14, isLocal: false, isDefinition: true)
-!6 = distinct !DIGlobalVariable(name: "p2", scope: !10, file: !11, line: 1, type: !15, isLocal: false, isDefinition: true)
-!7 = distinct !DIGlobalVariable(name: "p3", scope: !10, file: !11, line: 1, type: !16, isLocal: false, isDefinition: true)
-!8 = distinct !DIGlobalVariable(name: "p4", scope: !10, file: !11, line: 1, type: !17, isLocal: false, isDefinition: true)
-!9 = distinct !DIGlobalVariable(name: "p5", scope: !10, file: !11, line: 1, type: !18, isLocal: false, isDefinition: true)
-!10 = distinct !DICompileUnit(language: DW_LANG_C99, file: !11, emissionKind: FullDebug, globals: !13)
-!11 = !DIFile(filename: "/tmp/p.c", directory: "/")
-!12 = !{}
-!13 = !{!0,!1,!2,!3,!4}
-!14 = !DIDerivedType(tag: DW_TAG_LLVM_ptrauth_type, baseType: !21, ptrAuthKey: 4, ptrAuthIsAddressDiscriminated: false, ptrAuthExtraDiscriminator: 1234)
-!15 = !DIDerivedType(tag: DW_TAG_LLVM_ptrauth_type, baseType: !21, ptrAuthKey: 4, ptrAuthIsAddressDiscriminated: true, ptrAuthExtraDiscriminator: 1235)
-!16 = !DIDerivedType(tag: DW_TAG_LLVM_ptrauth_type, baseType: !21, ptrAuthKey: 4, ptrAuthIsAddressDiscriminated: true, ptrAuthExtraDiscriminator: 1236, ptrAuthIsaPointer: true)
-!17 = !DIDerivedType(tag: DW_TAG_LLVM_ptrauth_type, baseType: !21, ptrAuthKey: 4, ptrAuthIsAddressDiscriminated: true, ptrAuthExtraDiscriminator: 1237, ptrAuthAuthenticatesNullValues: true)
-!18 = !DIDerivedType(tag: DW_TAG_LLVM_ptrauth_type, baseType: !21, ptrAuthKey: 4, ptrAuthIsAddressDiscriminated: true, ptrAuthExtraDiscriminator: 1238, ptrAuthIsaPointer: true, ptrAuthAuthenticatesNullValues: true)
-!19 = !{i32 2, !"Dwarf Version", i32 4}
-!20 = !{i32 2, !"Debug Info Version", i32 3}
-!21 = !DIDerivedType(tag: DW_TAG_pointer_type, baseType: null)
diff --git a/llvm/unittests/IR/MetadataTest.cpp b/llvm/unittests/IR/MetadataTest.cpp
index 20d4090135dd43..767dd1a59d2b9e 100644
--- a/llvm/unittests/IR/MetadataTest.cpp
+++ b/llvm/unittests/IR/MetadataTest.cpp
@@ -106,7 +106,7 @@ class MetadataTest : public testing::Test {
DIType *getDerivedType() {
return DIDerivedType::getDistinct(
Context, dwarf::DW_TAG_pointer_type, "", nullptr, 0, nullptr,
- getBasicType("basictype"), 1, 2, 0, std::nullopt, {}, DINode::FlagZero);
+ getBasicType("basictype"), 1, 2, 0, std::nullopt, DINode::FlagZero);
}
Constant *getConstant() {
return ConstantInt::get(Type::getInt32Ty(Context), Counter++);
@@ -461,7 +461,7 @@ TEST_F(MDNodeTest, PrintTree) {
auto *StructTy = cast<DICompositeType>(getCompositeType());
DIType *PointerTy = DIDerivedType::getDistinct(
Context, dwarf::DW_TAG_pointer_type, "", nullptr, 0, nullptr, StructTy,
- 1, 2, 0, std::nullopt, {}, DINode::FlagZero);
+ 1, 2, 0, std::nullopt, DINode::FlagZero);
StructTy->replaceElements(MDTuple::get(Context, PointerTy));
auto *Var = DILocalVariable::get(Context, Scope, "foo", File,
@@ -1864,17 +1864,13 @@ TEST_F(DIDerivedTypeTest, get) {
DIType *BaseType = getBasicType("basic");
MDTuple *ExtraData = getTuple();
unsigned DWARFAddressSpace = 8;
- DIDerivedType::PtrAuthData PtrAuthData(1, false, 1234, true, true);
- DIDerivedType::PtrAuthData PtrAuthData2(1, false, 1234, true, false);
DINode::DIFlags Flags5 = static_cast<DINode::DIFlags>(5);
DINode::DIFlags Flags4 = static_cast<DINode::DIFlags>(4);
- auto *N = DIDerivedType::get(
- Context, dwarf::DW_TAG_pointer_type, "something", File, 1, Scope,
- BaseType, 2, 3, 4, DWARFAddressSpace, std::nullopt, Flags5, ExtraData);
- auto *N1 = DIDerivedType::get(Context, dwarf::DW_TAG_LLVM_ptrauth_type, "",
- File, 1, Scope, N, 2, 3, 4, DWARFAddressSpace,
- PtrAuthData, Flags5, ExtraData);
+ auto *N =
+ DIDerivedType::get(Context, dwarf::DW_TAG_pointer_type, "something", File,
+ 1, Scope, BaseType, 2, 3, 4, DWARFAddressSpace, Flags5,
+ ExtraData);
EXPECT_EQ(dwarf::DW_TAG_pointer_type, N->getTag());
EXPECT_EQ("something", N->getName());
EXPECT_EQ(File, N->getFile());
@@ -1885,73 +1881,53 @@ TEST_F(DIDerivedTypeTest, get) {
EXPECT_EQ(3u, N->getAlignInBits());
EXPECT_EQ(4u, N->getOffsetInBits());
EXPECT_EQ(DWARFAddressSpace, *N->getDWARFAddressSpace());
- EXPECT_EQ(std::nullopt, N->getPtrAuthData());
- EXPECT_EQ(PtrAuthData, N1->getPtrAuthData());
- EXPECT_NE(PtrAuthData2, N1->getPtrAuthData());
EXPECT_EQ(5u, N->getFlags());
EXPECT_EQ(ExtraData, N->getExtraData());
EXPECT_EQ(N, DIDerivedType::get(Context, dwarf::DW_TAG_pointer_type,
"something", File, 1, Scope, BaseType, 2, 3,
- 4, DWARFAddressSpace, std::nullopt, Flags5,
- ExtraData));
+ 4, DWARFAddressSpace, Flags5, ExtraData));
EXPECT_NE(N, DIDerivedType::get(Context, dwarf::DW_TAG_reference_type,
"something", File, 1, Scope, BaseType, 2, 3,
- 4, DWARFAddressSpace, std::nullopt, Flags5,
- ExtraData));
+ 4, DWARFAddressSpace, Flags5, ExtraData));
EXPECT_NE(N, DIDerivedType::get(Context, dwarf::DW_TAG_pointer_type, "else",
- File, 1, Scope, BaseType, 2, 3, 4,
- DWARFAddressSpace, std::nullopt, Flags5,
- ExtraData));
+ File, 1, Scope, BaseType, 2, 3,
+ 4, DWARFAddressSpace, Flags5, ExtraData));
EXPECT_NE(N, DIDerivedType::get(Context, dwarf::DW_TAG_pointer_type,
"something", getFile(), 1, Scope, BaseType, 2,
- 3, 4, DWARFAddressSpace, std::nullopt, Flags5,
- ExtraData));
+ 3, 4, DWARFAddressSpace, Flags5, ExtraData));
EXPECT_NE(N, DIDerivedType::get(Context, dwarf::DW_TAG_pointer_type,
"something", File, 2, Scope, BaseType, 2, 3,
- 4, DWARFAddressSpace, std::nullopt, Flags5,
- ExtraData));
+ 4, DWARFAddressSpace, Flags5, ExtraData));
EXPECT_NE(N, DIDerivedType::get(Context, dwarf::DW_TAG_pointer_type,
"something", File, 1, getSubprogram(),
- BaseType, 2, 3, 4, DWARFAddressSpace,
- std::nullopt, Flags5, ExtraData));
+ BaseType, 2, 3, 4, DWARFAddressSpace, Flags5,
+ ExtraData));
EXPECT_NE(N, DIDerivedType::get(
Context, dwarf::DW_TAG_pointer_type, "something", File, 1,
Scope, getBasicType("basic2"), 2, 3, 4, DWARFAddressSpace,
- std::nullopt, Flags5, ExtraData));
+ Flags5, ExtraData));
EXPECT_NE(N, DIDerivedType::get(Context, dwarf::DW_TAG_pointer_type,
"something", File, 1, Scope, BaseType, 3, 3,
- 4, DWARFAddressSpace, std::nullopt, Flags5,
- ExtraData));
+ 4, DWARFAddressSpace, Flags5, ExtraData));
EXPECT_NE(N, DIDerivedType::get(Context, dwarf::DW_TAG_pointer_type,
"something", File, 1, Scope, BaseType, 2, 2,
- 4, DWARFAddressSpace, std::nullopt, Flags5,
- ExtraData));
+ 4, DWARFAddressSpace, Flags5, ExtraData));
EXPECT_NE(N, DIDerivedType::get(Context, dwarf::DW_TAG_pointer_type,
"something", File, 1, Scope, BaseType, 2, 3,
- 5, DWARFAddressSpace, std::nullopt, Flags5,
- ExtraData));
+ 5, DWARFAddressSpace, Flags5, ExtraData));
EXPECT_NE(N, DIDerivedType::get(Context, dwarf::DW_TAG_pointer_type,
"something", File, 1, Scope, BaseType, 2, 3,
- 4, DWARFAddressSpace + 1, std::nullopt,
- Flags5, ExtraData));
- EXPECT_NE(N1,
- DIDerivedType::get(Context, dwarf::DW_TAG_LLVM_ptrauth_type, "",
- File, 1, Scope, N, 2, 3, 4, DWARFAddressSpace,
- std::nullopt, Flags5, ExtraData));
+ 4, DWARFAddressSpace + 1, Flags5, ExtraData));
EXPECT_NE(N, DIDerivedType::get(Context, dwarf::DW_TAG_pointer_type,
"something", File, 1, Scope, BaseType, 2, 3,
- 4, DWARFAddressSpace, std::nullopt, Flags4,
- ExtraData));
+ 4, DWARFAddressSpace, Flags4, ExtraData));
EXPECT_NE(N, DIDerivedType::get(Context, dwarf::DW_TAG_pointer_type,
"something", File, 1, Scope, BaseType, 2, 3,
- 4, DWARFAddressSpace, std::nullopt, Flags5,
- getTuple()));
+ 4, DWARFAddressSpace, Flags5, getTuple()));
TempDIDerivedType Temp = N->clone();
EXPECT_EQ(N, MDNode::replaceWithUniqued(std::move(Temp)));
- TempDIDerivedType Temp1 = N1->clone();
- EXPECT_EQ(N1, MDNode::replaceWithUniqued(std::move(Temp1)));
}
TEST_F(DIDerivedTypeTest, getWithLargeValues) {
@@ -1961,23 +1937,14 @@ TEST_F(DIDerivedTypeTest, getWithLargeValues) {
MDTuple *ExtraData = getTuple();
DINode::DIFlags Flags = static_cast<DINode::DIFlags>(5);
- auto *N = DIDerivedType::get(Context, dwarf::DW_TAG_pointer_type, "something",
- File, 1, Scope, BaseType, UINT64_MAX,
- UINT32_MAX - 1, UINT64_MAX - 2, UINT32_MAX - 3,
- std::nullopt, Flags, ExtraData);
+ auto *N = DIDerivedType::get(
+ Context, dwarf::DW_TAG_pointer_type, "something", File, 1, Scope,
+ BaseType, UINT64_MAX, UINT32_MAX - 1, UINT64_MAX - 2, UINT32_MAX - 3,
+ Flags, ExtraData);
EXPECT_EQ(UINT64_MAX, N->getSizeInBits());
EXPECT_EQ(UINT32_MAX - 1, N->getAlignInBits());
EXPECT_EQ(UINT64_MAX - 2, N->getOffsetInBits());
EXPECT_EQ(UINT32_MAX - 3, *N->getDWARFAddressSpace());
-
- auto *N1 = DIDerivedType::get(
- Context, dwarf::DW_TAG_LLVM_ptrauth_type, "", File, 1, Scope, N,
- UINT64_MAX, UINT32_MAX - 1, UINT64_MAX - 2, UINT32_MAX - 3,
- DIDerivedType::PtrAuthData(7, true, 0xffff, true, false), Flags,
- ExtraData);
- EXPECT_EQ(7U, *N1->getPtrAuthKey());
- EXPECT_EQ(true, *N1->isPtrAuthAddressDiscriminated());
- EXPECT_EQ(0xffffU, *N1->getPtrAuthExtraDiscriminator());
}
typedef MetadataTest DICompositeTypeTest;
@@ -4301,7 +4268,7 @@ TEST_F(MDTupleAllocationTest, Tracking2) {
#if defined(GTEST_HAS_DEATH_TEST) && !defined(NDEBUG) && !defined(GTEST_HAS_SEH)
typedef MetadataTest MDTupleAllocationDeathTest;
TEST_F(MDTupleAllocationDeathTest, ResizeRejected) {
- MDTuple *A = MDTuple::get(Context, std::nullopt);
+ MDTuple *A = MDTuple::get(Context, None);
auto *Value1 = getConstantAsMetadata();
EXPECT_DEATH(A->push_back(Value1),
"Resizing is not supported for uniqued nodes");
diff --git a/mlir/lib/Target/LLVMIR/DebugTranslation.cpp b/mlir/lib/Target/LLVMIR/DebugTranslation.cpp
index 420bb8d8274ecb..16918aab549788 100644
--- a/mlir/lib/Target/LLVMIR/DebugTranslation.cpp
+++ b/mlir/lib/Target/LLVMIR/DebugTranslation.cpp
@@ -150,8 +150,7 @@ llvm::DIDerivedType *DebugTranslation::translateImpl(DIDerivedTypeAttr attr) {
/*File=*/nullptr, /*Line=*/0,
/*Scope=*/nullptr, translate(attr.getBaseType()), attr.getSizeInBits(),
attr.getAlignInBits(), attr.getOffsetInBits(),
- /*DWARFAddressSpace=*/std::nullopt, /*PtrAuthData=*/std::nullopt,
- /*Flags=*/llvm::DINode::FlagZero);
+ /*DWARFAddressSpace=*/std::nullopt, /*Flags=*/llvm::DINode::FlagZero);
}
llvm::DIFile *DebugTranslation::translateImpl(DIFileAttr attr) {
>From 10f5e983a9e3162a569cbebeb32168716e391340 Mon Sep 17 00:00:00 2001
From: Florian Hahn <flo at fhahn.com>
Date: Sat, 2 Mar 2024 12:34:36 +0000
Subject: [PATCH 348/406] [DSE] Delay deleting non-memory-defs until end of
DSE. (#83411)
DSE uses BatchAA, which caches queries using pairs of MemoryLocations.
At the moment, DSE may remove instructions that are used as pointers in
cached MemoryLocations. If a new instruction used by a new MemoryLoation
and this instruction gets allocated at the same address as a previosuly
cached and then removed instruction, we may access an incorrect entry in
the cache.
To avoid this delay removing all instructions except MemoryDefs until
the end of DSE. This should avoid removing any values used in BatchAA's
cache.
Test case by @vporpo from
https://github.com/llvm/llvm-project/pull/83181.
(Test not precommitted because the results are non-determinstic - memset
only sometimes gets removed)
PR: https://github.com/llvm/llvm-project/pull/83411
---
.../Scalar/DeadStoreElimination.cpp | 31 ++-
.../batchaa-caching-new-pointers.ll | 189 ++++++++++++++++++
2 files changed, 215 insertions(+), 5 deletions(-)
create mode 100644 llvm/test/Transforms/DeadStoreElimination/batchaa-caching-new-pointers.ll
diff --git a/llvm/lib/Transforms/Scalar/DeadStoreElimination.cpp b/llvm/lib/Transforms/Scalar/DeadStoreElimination.cpp
index d30c68a2f08712..c2c63d100014f7 100644
--- a/llvm/lib/Transforms/Scalar/DeadStoreElimination.cpp
+++ b/llvm/lib/Transforms/Scalar/DeadStoreElimination.cpp
@@ -857,6 +857,9 @@ struct DSEState {
// no longer be captured.
bool ShouldIterateEndOfFunctionDSE;
+ /// Dead instructions to be removed at the end of DSE.
+ SmallVector<Instruction *> ToRemove;
+
// Class contains self-reference, make sure it's not copied/moved.
DSEState(const DSEState &) = delete;
DSEState &operator=(const DSEState &) = delete;
@@ -1692,7 +1695,8 @@ struct DSEState {
return {MaybeDeadAccess};
}
- // Delete dead memory defs
+ /// Delete dead memory defs and recursively add their operands to ToRemove if
+ /// they became dead.
void deleteDeadInstruction(Instruction *SI) {
MemorySSAUpdater Updater(&MSSA);
SmallVector<Instruction *, 32> NowDeadInsts;
@@ -1708,8 +1712,11 @@ struct DSEState {
salvageKnowledge(DeadInst);
// Remove the Instruction from MSSA.
- if (MemoryAccess *MA = MSSA.getMemoryAccess(DeadInst)) {
- if (MemoryDef *MD = dyn_cast<MemoryDef>(MA)) {
+ MemoryAccess *MA = MSSA.getMemoryAccess(DeadInst);
+ bool IsMemDef = MA && isa<MemoryDef>(MA);
+ if (MA) {
+ if (IsMemDef) {
+ auto *MD = cast<MemoryDef>(MA);
SkipStores.insert(MD);
if (auto *SI = dyn_cast<StoreInst>(MD->getMemoryInst())) {
if (SI->getValueOperand()->getType()->isPointerTy()) {
@@ -1730,13 +1737,21 @@ struct DSEState {
// Remove its operands
for (Use &O : DeadInst->operands())
if (Instruction *OpI = dyn_cast<Instruction>(O)) {
- O = nullptr;
+ O.set(PoisonValue::get(O->getType()));
if (isInstructionTriviallyDead(OpI, &TLI))
NowDeadInsts.push_back(OpI);
}
EI.removeInstruction(DeadInst);
- DeadInst->eraseFromParent();
+ // Remove memory defs directly if they don't produce results, but only
+ // queue other dead instructions for later removal. They may have been
+ // used as memory locations that have been cached by BatchAA. Removing
+ // them here may lead to newly created instructions to be allocated at the
+ // same address, yielding stale cache entries.
+ if (IsMemDef && DeadInst->getType()->isVoidTy())
+ DeadInst->eraseFromParent();
+ else
+ ToRemove.push_back(DeadInst);
}
}
@@ -2287,6 +2302,12 @@ static bool eliminateDeadStores(Function &F, AliasAnalysis &AA, MemorySSA &MSSA,
MadeChange |= State.eliminateRedundantStoresOfExistingValues();
MadeChange |= State.eliminateDeadWritesAtEndOfFunction();
+
+ while (!State.ToRemove.empty()) {
+ Instruction *DeadInst = State.ToRemove.pop_back_val();
+ DeadInst->eraseFromParent();
+ }
+
return MadeChange;
}
} // end anonymous namespace
diff --git a/llvm/test/Transforms/DeadStoreElimination/batchaa-caching-new-pointers.ll b/llvm/test/Transforms/DeadStoreElimination/batchaa-caching-new-pointers.ll
new file mode 100644
index 00000000000000..ee9bd6912e2ae4
--- /dev/null
+++ b/llvm/test/Transforms/DeadStoreElimination/batchaa-caching-new-pointers.ll
@@ -0,0 +1,189 @@
+; NOTE: Assertions have been autogenerated by utils/update_test_checks.py UTC_ARGS: --version 4
+; RUN: opt -S -passes=dse < %s | FileCheck %s
+;
+; DSE kills `store i32 44, ptr %struct.byte.4, align 4` but should not kill
+; `call void @llvm.memset.p0.i64(...)` because it has a clobber read:
+; `%ret = load ptr, ptr %struct.byte.8`
+
+
+%struct.type = type { ptr, ptr }
+
+define ptr @foo(ptr noundef %ptr) {
+; CHECK-LABEL: define ptr @foo(
+; CHECK-SAME: ptr noundef [[PTR:%.*]]) {
+; CHECK-NEXT: [[STRUCT_ALLOCA:%.*]] = alloca [[STRUCT_TYPE:%.*]], align 8
+; CHECK-NEXT: call void @llvm.lifetime.start.p0(i64 56, ptr nonnull [[STRUCT_ALLOCA]]) #[[ATTR6:[0-9]+]]
+; CHECK-NEXT: [[STRUCT_BYTE_8:%.*]] = getelementptr inbounds i8, ptr [[STRUCT_ALLOCA]], i64 8
+; CHECK-NEXT: [[TMP1:%.*]] = getelementptr inbounds i8, ptr [[STRUCT_BYTE_8]], i64 4
+; CHECK-NEXT: call void @llvm.memset.p0.i64(ptr noundef nonnull align 4 [[TMP1]], i8 42, i64 4, i1 false)
+; CHECK-NEXT: store i32 43, ptr [[STRUCT_BYTE_8]], align 4
+; CHECK-NEXT: [[RET:%.*]] = load ptr, ptr [[STRUCT_BYTE_8]], align 8
+; CHECK-NEXT: call void @llvm.lifetime.end.p0(i64 56, ptr nonnull [[STRUCT_ALLOCA]]) #[[ATTR6]]
+; CHECK-NEXT: ret ptr [[RET]]
+;
+ %struct.alloca = alloca %struct.type, align 8
+ call void @llvm.lifetime.start.p0(i64 56, ptr nonnull %struct.alloca) nounwind
+ %struct.byte.8 = getelementptr inbounds i8, ptr %struct.alloca, i64 8
+ ; Set %struct.alloca[8, 16) to 42.
+ call void @llvm.memset.p0.i64(ptr noundef nonnull align 4 %struct.byte.8, i8 42, i64 8, i1 false)
+ ; Set %struct.alloca[8, 12) to 43.
+ store i32 43, ptr %struct.byte.8, align 4
+ ; Set %struct.alloca[4, 8) to 44.
+ %struct.byte.4 = getelementptr inbounds i8, ptr %struct.alloca, i64 4
+ store i32 44, ptr %struct.byte.4, align 4
+ ; Return %struct.alloca[8, 16).
+ %ret = load ptr, ptr %struct.byte.8
+ call void @llvm.lifetime.end.p0(i64 56, ptr nonnull %struct.alloca) nounwind
+ ret ptr %ret
+}
+
+; Set of tests based on @foo, but where the memset's operands cannot be erased
+; due to other uses. Instead, they contain a number of removable MemoryDefs;
+; with non-void types result types.
+
+define ptr @foo_with_removable_malloc() {
+; CHECK-LABEL: define ptr @foo_with_removable_malloc() {
+; CHECK-NEXT: [[STRUCT_ALLOCA:%.*]] = alloca [[STRUCT_TYPE:%.*]], align 8
+; CHECK-NEXT: call void @llvm.lifetime.start.p0(i64 56, ptr nonnull [[STRUCT_ALLOCA]]) #[[ATTR6]]
+; CHECK-NEXT: [[STRUCT_BYTE_4:%.*]] = getelementptr inbounds i8, ptr [[STRUCT_ALLOCA]], i64 4
+; CHECK-NEXT: [[STRUCT_BYTE_8:%.*]] = getelementptr inbounds i8, ptr [[STRUCT_ALLOCA]], i64 8
+; CHECK-NEXT: [[TMP1:%.*]] = getelementptr inbounds i8, ptr [[STRUCT_BYTE_8]], i64 4
+; CHECK-NEXT: call void @llvm.memset.p0.i64(ptr noundef nonnull align 4 [[TMP1]], i8 42, i64 4, i1 false)
+; CHECK-NEXT: store i32 43, ptr [[STRUCT_BYTE_8]], align 4
+; CHECK-NEXT: [[RET:%.*]] = load ptr, ptr [[STRUCT_BYTE_8]], align 8
+; CHECK-NEXT: call void @readnone(ptr [[STRUCT_BYTE_4]])
+; CHECK-NEXT: call void @readnone(ptr [[STRUCT_BYTE_8]])
+; CHECK-NEXT: call void @llvm.lifetime.end.p0(i64 56, ptr nonnull [[STRUCT_ALLOCA]]) #[[ATTR6]]
+; CHECK-NEXT: ret ptr [[RET]]
+;
+ %struct.alloca = alloca %struct.type, align 8
+ call void @llvm.lifetime.start.p0(i64 56, ptr nonnull %struct.alloca) nounwind
+ %struct.byte.4 = getelementptr inbounds i8, ptr %struct.alloca, i64 4
+ %struct.byte.8 = getelementptr inbounds i8, ptr %struct.alloca, i64 8
+
+ ; Set of removable memory deffs
+ %m2 = tail call ptr @malloc(i64 4)
+ %m1 = tail call ptr @malloc(i64 4)
+ store i32 0, ptr %struct.byte.8
+ store i32 0, ptr %struct.byte.8
+ store i32 123, ptr %m1
+ store i32 123, ptr %m2
+
+ ; Set %struct.alloca[8, 16) to 42.
+ call void @llvm.memset.p0.i64(ptr noundef nonnull align 4 %struct.byte.8, i8 42, i64 8, i1 false)
+ ; Set %struct.alloca[8, 12) to 43.
+ store i32 43, ptr %struct.byte.8, align 4
+ ; Set %struct.alloca[4, 8) to 44.
+ store i32 44, ptr %struct.byte.4, align 4
+ ; Return %struct.alloca[8, 16).
+ %ret = load ptr, ptr %struct.byte.8
+ call void @readnone(ptr %struct.byte.4);
+ call void @readnone(ptr %struct.byte.8);
+ call void @llvm.lifetime.end.p0(i64 56, ptr nonnull %struct.alloca) nounwind
+ ret ptr %ret
+}
+
+define ptr @foo_with_removable_malloc_free() {
+; CHECK-LABEL: define ptr @foo_with_removable_malloc_free() {
+; CHECK-NEXT: [[STRUCT_ALLOCA:%.*]] = alloca [[STRUCT_TYPE:%.*]], align 8
+; CHECK-NEXT: [[M1:%.*]] = tail call ptr @malloc(i64 4)
+; CHECK-NEXT: call void @llvm.lifetime.start.p0(i64 56, ptr nonnull [[STRUCT_ALLOCA]]) #[[ATTR6]]
+; CHECK-NEXT: [[STRUCT_BYTE_4:%.*]] = getelementptr inbounds i8, ptr [[STRUCT_ALLOCA]], i64 4
+; CHECK-NEXT: [[STRUCT_BYTE_8:%.*]] = getelementptr inbounds i8, ptr [[STRUCT_ALLOCA]], i64 8
+; CHECK-NEXT: [[M2:%.*]] = tail call ptr @malloc(i64 4)
+; CHECK-NEXT: call void @free(ptr [[M1]])
+; CHECK-NEXT: call void @free(ptr [[M2]])
+; CHECK-NEXT: [[TMP1:%.*]] = getelementptr inbounds i8, ptr [[STRUCT_BYTE_8]], i64 4
+; CHECK-NEXT: call void @llvm.memset.p0.i64(ptr noundef nonnull align 4 [[TMP1]], i8 42, i64 4, i1 false)
+; CHECK-NEXT: store i32 43, ptr [[STRUCT_BYTE_8]], align 4
+; CHECK-NEXT: [[RET:%.*]] = load ptr, ptr [[STRUCT_BYTE_8]], align 8
+; CHECK-NEXT: call void @readnone(ptr [[STRUCT_BYTE_4]])
+; CHECK-NEXT: call void @readnone(ptr [[STRUCT_BYTE_8]])
+; CHECK-NEXT: call void @llvm.lifetime.end.p0(i64 56, ptr nonnull [[STRUCT_ALLOCA]]) #[[ATTR6]]
+; CHECK-NEXT: ret ptr [[RET]]
+;
+ %struct.alloca = alloca %struct.type, align 8
+ %m1 = tail call ptr @malloc(i64 4)
+ call void @llvm.lifetime.start.p0(i64 56, ptr nonnull %struct.alloca) nounwind
+ %struct.byte.4 = getelementptr inbounds i8, ptr %struct.alloca, i64 4
+ %struct.byte.8 = getelementptr inbounds i8, ptr %struct.alloca, i64 8
+
+ store i32 0, ptr %struct.byte.4
+ store i32 0, ptr %struct.byte.8
+ %m2 = tail call ptr @malloc(i64 4)
+ store i32 123, ptr %m1
+ call void @free(ptr %m1);
+ store i32 123, ptr %m2
+ call void @free(ptr %m2);
+
+ ; Set %struct.alloca[8, 16) to 42.
+ call void @llvm.memset.p0.i64(ptr noundef nonnull align 4 %struct.byte.8, i8 42, i64 8, i1 false)
+ ; Set %struct.alloca[8, 12) to 43.
+ store i32 43, ptr %struct.byte.8, align 4
+ ; Set %struct.alloca[4, 8) to 44.
+ store i32 44, ptr %struct.byte.4, align 4
+ ; Return %struct.alloca[8, 16).
+ %ret = load ptr, ptr %struct.byte.8
+ call void @readnone(ptr %struct.byte.4);
+ call void @readnone(ptr %struct.byte.8);
+ call void @llvm.lifetime.end.p0(i64 56, ptr nonnull %struct.alloca) nounwind
+ ret ptr %ret
+}
+
+define ptr @foo_with_malloc_to_calloc() {
+; CHECK-LABEL: define ptr @foo_with_malloc_to_calloc() {
+; CHECK-NEXT: [[STRUCT_ALLOCA:%.*]] = alloca [[STRUCT_TYPE:%.*]], align 8
+; CHECK-NEXT: call void @llvm.lifetime.start.p0(i64 56, ptr nonnull [[STRUCT_ALLOCA]]) #[[ATTR6]]
+; CHECK-NEXT: [[STRUCT_BYTE_8:%.*]] = getelementptr inbounds i8, ptr [[STRUCT_ALLOCA]], i64 8
+; CHECK-NEXT: [[STRUCT_BYTE_4:%.*]] = getelementptr inbounds i8, ptr [[STRUCT_ALLOCA]], i64 4
+; CHECK-NEXT: [[CALLOC1:%.*]] = call ptr @calloc(i64 1, i64 4)
+; CHECK-NEXT: [[CALLOC:%.*]] = call ptr @calloc(i64 1, i64 4)
+; CHECK-NEXT: [[TMP1:%.*]] = getelementptr inbounds i8, ptr [[STRUCT_BYTE_8]], i64 4
+; CHECK-NEXT: call void @llvm.memset.p0.i64(ptr noundef nonnull align 4 [[TMP1]], i8 42, i64 4, i1 false)
+; CHECK-NEXT: store i32 43, ptr [[STRUCT_BYTE_8]], align 4
+; CHECK-NEXT: [[RET:%.*]] = load ptr, ptr [[STRUCT_BYTE_8]], align 8
+; CHECK-NEXT: call void @readnone(ptr [[STRUCT_BYTE_4]])
+; CHECK-NEXT: call void @readnone(ptr [[STRUCT_BYTE_8]])
+; CHECK-NEXT: call void @llvm.lifetime.end.p0(i64 56, ptr nonnull [[STRUCT_ALLOCA]]) #[[ATTR6]]
+; CHECK-NEXT: call void @use(ptr [[CALLOC1]])
+; CHECK-NEXT: call void @use(ptr [[CALLOC]])
+; CHECK-NEXT: ret ptr [[RET]]
+;
+ %struct.alloca = alloca %struct.type, align 8
+ call void @llvm.lifetime.start.p0(i64 56, ptr nonnull %struct.alloca) nounwind
+ %struct.byte.8 = getelementptr inbounds i8, ptr %struct.alloca, i64 8
+ %struct.byte.4 = getelementptr inbounds i8, ptr %struct.alloca, i64 4
+
+ ; Set of removable memory deffs
+ %m1 = tail call ptr @malloc(i64 4)
+ %m2 = tail call ptr @malloc(i64 4)
+ store i32 0, ptr %struct.byte.4
+ store i32 0, ptr %struct.byte.8
+ call void @llvm.memset.p0.i64(ptr noundef nonnull align 4 %m2, i8 0, i64 4, i1 false)
+ call void @llvm.memset.p0.i64(ptr noundef nonnull align 4 %m1, i8 0, i64 4, i1 false)
+
+ ; Set %struct.alloca[8, 16) to 42.
+ call void @llvm.memset.p0.i64(ptr noundef nonnull align 4 %struct.byte.8, i8 42, i64 8, i1 false)
+ ; Set %struct.alloca[8, 12) to 43.
+ store i32 43, ptr %struct.byte.8, align 4
+ ; Set %struct.alloca[4, 8) to 44.
+ store i32 44, ptr %struct.byte.4, align 4
+ ; Return %struct.alloca[8, 16).
+ %ret = load ptr, ptr %struct.byte.8
+ call void @readnone(ptr %struct.byte.4);
+ call void @readnone(ptr %struct.byte.8);
+ call void @llvm.lifetime.end.p0(i64 56, ptr nonnull %struct.alloca) nounwind
+ call void @use(ptr %m1)
+ call void @use(ptr %m2)
+ ret ptr %ret
+}
+
+declare void @llvm.memset.p0.i64(ptr nocapture writeonly, i8, i64, i1 immarg)
+declare void @llvm.lifetime.end.p0(i64 immarg, ptr nocapture)
+declare void @llvm.lifetime.start.p0(i64 immarg, ptr nocapture)
+
+declare noalias ptr @malloc(i64) willreturn allockind("alloc,uninitialized") "alloc-family"="malloc"
+declare void @readnone(ptr) readnone nounwind
+declare void @free(ptr nocapture) allockind("free") "alloc-family"="malloc"
+
+declare void @use(ptr)
>From ca827d53c5524409dcca5ade3949b25f38a60fef Mon Sep 17 00:00:00 2001
From: Simon Pilgrim <RKSimon at users.noreply.github.com>
Date: Sat, 2 Mar 2024 12:44:33 +0000
Subject: [PATCH 349/406] [X86] Convert logicalshift(x, C) -> and(x, M) iff x
is allsignbits (#83596)
If we're logical shifting an all-signbits value, then we can just mask out the shifted bits.
This helps removes some unnecessary bitcasted vXi16 shifts used for vXi8 shifts (which SimplifyDemandedBits will struggle to remove through the bitcast), and allows some AVX1 shifts of 256-bit values to stay as a YMM instruction.
Noticed in codegen from #82290
---
llvm/lib/Target/X86/X86ISelLowering.cpp | 12 +-
.../X86/bitcast-int-to-vector-bool-zext.ll | 103 +++++++-----------
.../CodeGen/X86/bitcast-int-to-vector-bool.ll | 11 +-
llvm/test/CodeGen/X86/cmp-shiftX-maskX.ll | 18 +--
4 files changed, 52 insertions(+), 92 deletions(-)
diff --git a/llvm/lib/Target/X86/X86ISelLowering.cpp b/llvm/lib/Target/X86/X86ISelLowering.cpp
index aea046b119d49d..6de0ae8a206482 100644
--- a/llvm/lib/Target/X86/X86ISelLowering.cpp
+++ b/llvm/lib/Target/X86/X86ISelLowering.cpp
@@ -28981,6 +28981,7 @@ static SDValue LowerShiftByScalarImmediate(SDValue Op, SelectionDAG &DAG,
SDValue R = Op.getOperand(0);
SDValue Amt = Op.getOperand(1);
unsigned X86Opc = getTargetVShiftUniformOpcode(Op.getOpcode(), false);
+ unsigned EltSizeInBits = VT.getScalarSizeInBits();
auto ArithmeticShiftRight64 = [&](uint64_t ShiftAmt) {
assert((VT == MVT::v2i64 || VT == MVT::v4i64) && "Unexpected SRA type");
@@ -29027,7 +29028,7 @@ static SDValue LowerShiftByScalarImmediate(SDValue Op, SelectionDAG &DAG,
return SDValue();
// If the shift amount is out of range, return undef.
- if (APIntShiftAmt.uge(VT.getScalarSizeInBits()))
+ if (APIntShiftAmt.uge(EltSizeInBits))
return DAG.getUNDEF(VT);
uint64_t ShiftAmt = APIntShiftAmt.getZExtValue();
@@ -29055,6 +29056,15 @@ static SDValue LowerShiftByScalarImmediate(SDValue Op, SelectionDAG &DAG,
Op.getOpcode() == ISD::SRA)
return ArithmeticShiftRight64(ShiftAmt);
+ // If we're logical shifting an all-signbits value then we can just perform as
+ // a mask.
+ if ((Op.getOpcode() == ISD::SHL || Op.getOpcode() == ISD::SRL) &&
+ DAG.ComputeNumSignBits(R) == EltSizeInBits) {
+ SDValue Mask = DAG.getAllOnesConstant(dl, VT);
+ Mask = DAG.getNode(Op.getOpcode(), dl, VT, Mask, Amt);
+ return DAG.getNode(ISD::AND, dl, VT, R, Mask);
+ }
+
if (VT == MVT::v16i8 || (Subtarget.hasInt256() && VT == MVT::v32i8) ||
(Subtarget.hasBWI() && VT == MVT::v64i8)) {
unsigned NumElts = VT.getVectorNumElements();
diff --git a/llvm/test/CodeGen/X86/bitcast-int-to-vector-bool-zext.ll b/llvm/test/CodeGen/X86/bitcast-int-to-vector-bool-zext.ll
index ee39b1333fff31..d2794df731b65d 100644
--- a/llvm/test/CodeGen/X86/bitcast-int-to-vector-bool-zext.ll
+++ b/llvm/test/CodeGen/X86/bitcast-int-to-vector-bool-zext.ll
@@ -180,7 +180,6 @@ define <16 x i8> @ext_i16_16i8(i16 %a0) {
; SSE2-NEXT: movdqa {{.*#+}} xmm1 = [1,2,4,8,16,32,64,128,1,2,4,8,16,32,64,128]
; SSE2-NEXT: pand %xmm1, %xmm0
; SSE2-NEXT: pcmpeqb %xmm1, %xmm0
-; SSE2-NEXT: psrlw $7, %xmm0
; SSE2-NEXT: pand {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -191,7 +190,6 @@ define <16 x i8> @ext_i16_16i8(i16 %a0) {
; SSSE3-NEXT: movdqa {{.*#+}} xmm1 = [1,2,4,8,16,32,64,128,1,2,4,8,16,32,64,128]
; SSSE3-NEXT: pand %xmm1, %xmm0
; SSSE3-NEXT: pcmpeqb %xmm1, %xmm0
-; SSSE3-NEXT: psrlw $7, %xmm0
; SSSE3-NEXT: pand {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -203,7 +201,6 @@ define <16 x i8> @ext_i16_16i8(i16 %a0) {
; AVX1-NEXT: # xmm1 = mem[0,0]
; AVX1-NEXT: vpand %xmm1, %xmm0, %xmm0
; AVX1-NEXT: vpcmpeqb %xmm1, %xmm0, %xmm0
-; AVX1-NEXT: vpsrlw $7, %xmm0, %xmm0
; AVX1-NEXT: vpand {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0, %xmm0
; AVX1-NEXT: retq
;
@@ -214,7 +211,6 @@ define <16 x i8> @ext_i16_16i8(i16 %a0) {
; AVX2-NEXT: vpbroadcastq {{.*#+}} xmm1 = [1,2,4,8,16,32,64,128,1,2,4,8,16,32,64,128]
; AVX2-NEXT: vpand %xmm1, %xmm0, %xmm0
; AVX2-NEXT: vpcmpeqb %xmm1, %xmm0, %xmm0
-; AVX2-NEXT: vpsrlw $7, %xmm0, %xmm0
; AVX2-NEXT: vpand {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0, %xmm0
; AVX2-NEXT: retq
;
@@ -268,11 +264,10 @@ define <4 x i64> @ext_i4_4i64(i4 %a0) {
; AVX1-NEXT: vmovaps {{.*#+}} ymm1 = [1,2,4,8]
; AVX1-NEXT: vandps %ymm1, %ymm0, %ymm0
; AVX1-NEXT: vpcmpeqq %xmm1, %xmm0, %xmm1
-; AVX1-NEXT: vpsrlq $63, %xmm1, %xmm1
; AVX1-NEXT: vextractf128 $1, %ymm0, %xmm0
; AVX1-NEXT: vpcmpeqq {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0, %xmm0
-; AVX1-NEXT: vpsrlq $63, %xmm0, %xmm0
; AVX1-NEXT: vinsertf128 $1, %xmm0, %ymm1, %ymm0
+; AVX1-NEXT: vandps {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %ymm0, %ymm0
; AVX1-NEXT: retq
;
; AVX2-LABEL: ext_i4_4i64:
@@ -328,11 +323,10 @@ define <8 x i32> @ext_i8_8i32(i8 %a0) {
; AVX1-NEXT: vmovaps {{.*#+}} ymm1 = [1,2,4,8,16,32,64,128]
; AVX1-NEXT: vandps %ymm1, %ymm0, %ymm0
; AVX1-NEXT: vpcmpeqd %xmm1, %xmm0, %xmm1
-; AVX1-NEXT: vpsrld $31, %xmm1, %xmm1
; AVX1-NEXT: vextractf128 $1, %ymm0, %xmm0
; AVX1-NEXT: vpcmpeqd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0, %xmm0
-; AVX1-NEXT: vpsrld $31, %xmm0, %xmm0
; AVX1-NEXT: vinsertf128 $1, %xmm0, %ymm1, %ymm0
+; AVX1-NEXT: vandps {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %ymm0, %ymm0
; AVX1-NEXT: retq
;
; AVX2-LABEL: ext_i8_8i32:
@@ -390,11 +384,10 @@ define <16 x i16> @ext_i16_16i16(i16 %a0) {
; AVX1-NEXT: vmovaps {{.*#+}} ymm1 = [1,2,4,8,16,32,64,128,256,512,1024,2048,4096,8192,16384,32768]
; AVX1-NEXT: vandps %ymm1, %ymm0, %ymm0
; AVX1-NEXT: vpcmpeqw %xmm1, %xmm0, %xmm1
-; AVX1-NEXT: vpsrlw $15, %xmm1, %xmm1
; AVX1-NEXT: vextractf128 $1, %ymm0, %xmm0
; AVX1-NEXT: vpcmpeqw {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0, %xmm0
-; AVX1-NEXT: vpsrlw $15, %xmm0, %xmm0
; AVX1-NEXT: vinsertf128 $1, %xmm0, %ymm1, %ymm0
+; AVX1-NEXT: vandps {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %ymm0, %ymm0
; AVX1-NEXT: retq
;
; AVX2-LABEL: ext_i16_16i16:
@@ -436,14 +429,12 @@ define <32 x i8> @ext_i32_32i8(i32 %a0) {
; SSE2-SSSE3-NEXT: movdqa {{.*#+}} xmm2 = [1,2,4,8,16,32,64,128,1,2,4,8,16,32,64,128]
; SSE2-SSSE3-NEXT: pand %xmm2, %xmm0
; SSE2-SSSE3-NEXT: pcmpeqb %xmm2, %xmm0
-; SSE2-SSSE3-NEXT: psrlw $7, %xmm0
; SSE2-SSSE3-NEXT: movdqa {{.*#+}} xmm3 = [1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1]
; SSE2-SSSE3-NEXT: pand %xmm3, %xmm0
; SSE2-SSSE3-NEXT: pshuflw {{.*#+}} xmm1 = xmm1[2,2,3,3,4,5,6,7]
; SSE2-SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm1[0,0,1,1]
; SSE2-SSSE3-NEXT: pand %xmm2, %xmm1
; SSE2-SSSE3-NEXT: pcmpeqb %xmm2, %xmm1
-; SSE2-SSSE3-NEXT: psrlw $7, %xmm1
; SSE2-SSSE3-NEXT: pand %xmm3, %xmm1
; SSE2-SSSE3-NEXT: retq
;
@@ -460,13 +451,9 @@ define <32 x i8> @ext_i32_32i8(i32 %a0) {
; AVX1-NEXT: vmovddup {{.*#+}} xmm2 = [1,2,4,8,16,32,64,128,1,2,4,8,16,32,64,128]
; AVX1-NEXT: # xmm2 = mem[0,0]
; AVX1-NEXT: vpcmpeqb %xmm2, %xmm1, %xmm1
-; AVX1-NEXT: vpsrlw $7, %xmm1, %xmm1
-; AVX1-NEXT: vbroadcastss {{.*#+}} xmm3 = [1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1]
-; AVX1-NEXT: vpand %xmm3, %xmm1, %xmm1
; AVX1-NEXT: vpcmpeqb %xmm2, %xmm0, %xmm0
-; AVX1-NEXT: vpsrlw $7, %xmm0, %xmm0
-; AVX1-NEXT: vpand %xmm3, %xmm0, %xmm0
; AVX1-NEXT: vinsertf128 $1, %xmm1, %ymm0, %ymm0
+; AVX1-NEXT: vandps {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %ymm0, %ymm0
; AVX1-NEXT: retq
;
; AVX2-LABEL: ext_i32_32i8:
@@ -477,7 +464,6 @@ define <32 x i8> @ext_i32_32i8(i32 %a0) {
; AVX2-NEXT: vpbroadcastq {{.*#+}} ymm1 = [1,2,4,8,16,32,64,128,1,2,4,8,16,32,64,128,1,2,4,8,16,32,64,128,1,2,4,8,16,32,64,128]
; AVX2-NEXT: vpand %ymm1, %ymm0, %ymm0
; AVX2-NEXT: vpcmpeqb %ymm1, %ymm0, %ymm0
-; AVX2-NEXT: vpsrlw $7, %ymm0, %ymm0
; AVX2-NEXT: vpand {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %ymm0, %ymm0
; AVX2-NEXT: retq
;
@@ -550,19 +536,18 @@ define <8 x i64> @ext_i8_8i64(i8 %a0) {
; AVX1-NEXT: vmovaps {{.*#+}} ymm0 = [1,2,4,8]
; AVX1-NEXT: vandps %ymm0, %ymm1, %ymm2
; AVX1-NEXT: vpcmpeqq %xmm0, %xmm2, %xmm0
-; AVX1-NEXT: vpsrlq $63, %xmm0, %xmm0
; AVX1-NEXT: vextractf128 $1, %ymm2, %xmm2
; AVX1-NEXT: vpcmpeqq {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm2, %xmm2
-; AVX1-NEXT: vpsrlq $63, %xmm2, %xmm2
; AVX1-NEXT: vinsertf128 $1, %xmm2, %ymm0, %ymm0
-; AVX1-NEXT: vmovaps {{.*#+}} ymm2 = [16,32,64,128]
-; AVX1-NEXT: vandps %ymm2, %ymm1, %ymm1
-; AVX1-NEXT: vpcmpeqq %xmm2, %xmm1, %xmm2
-; AVX1-NEXT: vpsrlq $63, %xmm2, %xmm2
+; AVX1-NEXT: vbroadcastsd {{.*#+}} ymm2 = [1,1,1,1]
+; AVX1-NEXT: vandps %ymm2, %ymm0, %ymm0
+; AVX1-NEXT: vmovaps {{.*#+}} ymm3 = [16,32,64,128]
+; AVX1-NEXT: vandps %ymm3, %ymm1, %ymm1
+; AVX1-NEXT: vpcmpeqq %xmm3, %xmm1, %xmm3
; AVX1-NEXT: vextractf128 $1, %ymm1, %xmm1
; AVX1-NEXT: vpcmpeqq {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1, %xmm1
-; AVX1-NEXT: vpsrlq $63, %xmm1, %xmm1
-; AVX1-NEXT: vinsertf128 $1, %xmm1, %ymm2, %ymm1
+; AVX1-NEXT: vinsertf128 $1, %xmm1, %ymm3, %ymm1
+; AVX1-NEXT: vandps %ymm2, %ymm1, %ymm1
; AVX1-NEXT: retq
;
; AVX2-LABEL: ext_i8_8i64:
@@ -631,19 +616,18 @@ define <16 x i32> @ext_i16_16i32(i16 %a0) {
; AVX1-NEXT: vmovaps {{.*#+}} ymm0 = [1,2,4,8,16,32,64,128]
; AVX1-NEXT: vandps %ymm0, %ymm1, %ymm2
; AVX1-NEXT: vpcmpeqd %xmm0, %xmm2, %xmm0
-; AVX1-NEXT: vpsrld $31, %xmm0, %xmm0
; AVX1-NEXT: vextractf128 $1, %ymm2, %xmm2
; AVX1-NEXT: vpcmpeqd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm2, %xmm2
-; AVX1-NEXT: vpsrld $31, %xmm2, %xmm2
; AVX1-NEXT: vinsertf128 $1, %xmm2, %ymm0, %ymm0
-; AVX1-NEXT: vmovaps {{.*#+}} ymm2 = [256,512,1024,2048,4096,8192,16384,32768]
-; AVX1-NEXT: vandps %ymm2, %ymm1, %ymm1
-; AVX1-NEXT: vpcmpeqd %xmm2, %xmm1, %xmm2
-; AVX1-NEXT: vpsrld $31, %xmm2, %xmm2
+; AVX1-NEXT: vbroadcastss {{.*#+}} ymm2 = [1,1,1,1,1,1,1,1]
+; AVX1-NEXT: vandps %ymm2, %ymm0, %ymm0
+; AVX1-NEXT: vmovaps {{.*#+}} ymm3 = [256,512,1024,2048,4096,8192,16384,32768]
+; AVX1-NEXT: vandps %ymm3, %ymm1, %ymm1
+; AVX1-NEXT: vpcmpeqd %xmm3, %xmm1, %xmm3
; AVX1-NEXT: vextractf128 $1, %ymm1, %xmm1
; AVX1-NEXT: vpcmpeqd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm1, %xmm1
-; AVX1-NEXT: vpsrld $31, %xmm1, %xmm1
-; AVX1-NEXT: vinsertf128 $1, %xmm1, %ymm2, %ymm1
+; AVX1-NEXT: vinsertf128 $1, %xmm1, %ymm3, %ymm1
+; AVX1-NEXT: vandps %ymm2, %ymm1, %ymm1
; AVX1-NEXT: retq
;
; AVX2-LABEL: ext_i16_16i32:
@@ -712,23 +696,22 @@ define <32 x i16> @ext_i32_32i16(i32 %a0) {
; AVX1-NEXT: vinsertf128 $1, %xmm0, %ymm0, %ymm0
; AVX1-NEXT: vmovaps {{.*#+}} ymm2 = [1,2,4,8,16,32,64,128,256,512,1024,2048,4096,8192,16384,32768]
; AVX1-NEXT: vandps %ymm2, %ymm0, %ymm0
-; AVX1-NEXT: vpcmpeqw %xmm2, %xmm0, %xmm3
-; AVX1-NEXT: vpsrlw $15, %xmm3, %xmm3
-; AVX1-NEXT: vextractf128 $1, %ymm0, %xmm0
+; AVX1-NEXT: vextractf128 $1, %ymm0, %xmm3
; AVX1-NEXT: vmovdqa {{.*#+}} xmm4 = [256,512,1024,2048,4096,8192,16384,32768]
-; AVX1-NEXT: vpcmpeqw %xmm4, %xmm0, %xmm0
-; AVX1-NEXT: vpsrlw $15, %xmm0, %xmm0
-; AVX1-NEXT: vinsertf128 $1, %xmm0, %ymm3, %ymm0
+; AVX1-NEXT: vpcmpeqw %xmm4, %xmm3, %xmm3
+; AVX1-NEXT: vpcmpeqw %xmm2, %xmm0, %xmm0
+; AVX1-NEXT: vinsertf128 $1, %xmm3, %ymm0, %ymm0
+; AVX1-NEXT: vbroadcastss {{.*#+}} ymm3 = [1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1]
+; AVX1-NEXT: vandps %ymm3, %ymm0, %ymm0
; AVX1-NEXT: vpshuflw {{.*#+}} xmm1 = xmm1[1,1,1,1,4,5,6,7]
; AVX1-NEXT: vpshufd {{.*#+}} xmm1 = xmm1[0,0,0,0]
; AVX1-NEXT: vinsertf128 $1, %xmm1, %ymm1, %ymm1
; AVX1-NEXT: vandps %ymm2, %ymm1, %ymm1
-; AVX1-NEXT: vpcmpeqw %xmm2, %xmm1, %xmm2
-; AVX1-NEXT: vpsrlw $15, %xmm2, %xmm2
-; AVX1-NEXT: vextractf128 $1, %ymm1, %xmm1
-; AVX1-NEXT: vpcmpeqw %xmm4, %xmm1, %xmm1
-; AVX1-NEXT: vpsrlw $15, %xmm1, %xmm1
-; AVX1-NEXT: vinsertf128 $1, %xmm1, %ymm2, %ymm1
+; AVX1-NEXT: vextractf128 $1, %ymm1, %xmm5
+; AVX1-NEXT: vpcmpeqw %xmm4, %xmm5, %xmm4
+; AVX1-NEXT: vpcmpeqw %xmm2, %xmm1, %xmm1
+; AVX1-NEXT: vinsertf128 $1, %xmm4, %ymm1, %ymm1
+; AVX1-NEXT: vandps %ymm3, %ymm1, %ymm1
; AVX1-NEXT: retq
;
; AVX2-LABEL: ext_i32_32i16:
@@ -782,26 +765,22 @@ define <64 x i8> @ext_i64_64i8(i64 %a0) {
; SSE2-SSSE3-NEXT: movdqa {{.*#+}} xmm4 = [1,2,4,8,16,32,64,128,1,2,4,8,16,32,64,128]
; SSE2-SSSE3-NEXT: pand %xmm4, %xmm0
; SSE2-SSSE3-NEXT: pcmpeqb %xmm4, %xmm0
-; SSE2-SSSE3-NEXT: psrlw $7, %xmm0
; SSE2-SSSE3-NEXT: movdqa {{.*#+}} xmm5 = [1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1]
; SSE2-SSSE3-NEXT: pand %xmm5, %xmm0
; SSE2-SSSE3-NEXT: pshuflw {{.*#+}} xmm1 = xmm3[2,2,3,3,4,5,6,7]
; SSE2-SSSE3-NEXT: pshufd {{.*#+}} xmm1 = xmm1[0,0,1,1]
; SSE2-SSSE3-NEXT: pand %xmm4, %xmm1
; SSE2-SSSE3-NEXT: pcmpeqb %xmm4, %xmm1
-; SSE2-SSSE3-NEXT: psrlw $7, %xmm1
; SSE2-SSSE3-NEXT: pand %xmm5, %xmm1
; SSE2-SSSE3-NEXT: pshufhw {{.*#+}} xmm2 = xmm3[0,1,2,3,4,4,5,5]
; SSE2-SSSE3-NEXT: pshufd {{.*#+}} xmm2 = xmm2[2,2,3,3]
; SSE2-SSSE3-NEXT: pand %xmm4, %xmm2
; SSE2-SSSE3-NEXT: pcmpeqb %xmm4, %xmm2
-; SSE2-SSSE3-NEXT: psrlw $7, %xmm2
; SSE2-SSSE3-NEXT: pand %xmm5, %xmm2
; SSE2-SSSE3-NEXT: pshufhw {{.*#+}} xmm3 = xmm3[0,1,2,3,6,6,7,7]
; SSE2-SSSE3-NEXT: pshufd {{.*#+}} xmm3 = xmm3[2,2,3,3]
; SSE2-SSSE3-NEXT: pand %xmm4, %xmm3
; SSE2-SSSE3-NEXT: pcmpeqb %xmm4, %xmm3
-; SSE2-SSSE3-NEXT: psrlw $7, %xmm3
; SSE2-SSSE3-NEXT: pand %xmm5, %xmm3
; SSE2-SSSE3-NEXT: retq
;
@@ -817,26 +796,20 @@ define <64 x i8> @ext_i64_64i8(i64 %a0) {
; AVX1-NEXT: vandps %ymm2, %ymm0, %ymm0
; AVX1-NEXT: vextractf128 $1, %ymm0, %xmm3
; AVX1-NEXT: vpcmpeqb %xmm2, %xmm3, %xmm3
-; AVX1-NEXT: vpsrlw $7, %xmm3, %xmm3
-; AVX1-NEXT: vbroadcastss {{.*#+}} xmm4 = [1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1]
-; AVX1-NEXT: vpand %xmm4, %xmm3, %xmm3
; AVX1-NEXT: vpcmpeqb %xmm2, %xmm0, %xmm0
-; AVX1-NEXT: vpsrlw $7, %xmm0, %xmm0
-; AVX1-NEXT: vpand %xmm4, %xmm0, %xmm0
; AVX1-NEXT: vinsertf128 $1, %xmm3, %ymm0, %ymm0
-; AVX1-NEXT: vpshufhw {{.*#+}} xmm3 = xmm1[0,1,2,3,4,4,5,5]
+; AVX1-NEXT: vbroadcastss {{.*#+}} ymm3 = [1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1]
+; AVX1-NEXT: vandps %ymm3, %ymm0, %ymm0
+; AVX1-NEXT: vpshufhw {{.*#+}} xmm4 = xmm1[0,1,2,3,4,4,5,5]
; AVX1-NEXT: vpshufhw {{.*#+}} xmm1 = xmm1[0,1,2,3,6,6,7,7]
-; AVX1-NEXT: vinsertf128 $1, %xmm1, %ymm3, %ymm1
+; AVX1-NEXT: vinsertf128 $1, %xmm1, %ymm4, %ymm1
; AVX1-NEXT: vshufps {{.*#+}} ymm1 = ymm1[2,2,3,3,6,6,7,7]
; AVX1-NEXT: vandps %ymm2, %ymm1, %ymm1
-; AVX1-NEXT: vextractf128 $1, %ymm1, %xmm3
-; AVX1-NEXT: vpcmpeqb %xmm2, %xmm3, %xmm3
-; AVX1-NEXT: vpsrlw $7, %xmm3, %xmm3
-; AVX1-NEXT: vpand %xmm4, %xmm3, %xmm3
+; AVX1-NEXT: vextractf128 $1, %ymm1, %xmm4
+; AVX1-NEXT: vpcmpeqb %xmm2, %xmm4, %xmm4
; AVX1-NEXT: vpcmpeqb %xmm2, %xmm1, %xmm1
-; AVX1-NEXT: vpsrlw $7, %xmm1, %xmm1
-; AVX1-NEXT: vpand %xmm4, %xmm1, %xmm1
-; AVX1-NEXT: vinsertf128 $1, %xmm3, %ymm1, %ymm1
+; AVX1-NEXT: vinsertf128 $1, %xmm4, %ymm1, %ymm1
+; AVX1-NEXT: vandps %ymm3, %ymm1, %ymm1
; AVX1-NEXT: retq
;
; AVX2-LABEL: ext_i64_64i8:
@@ -847,13 +820,11 @@ define <64 x i8> @ext_i64_64i8(i64 %a0) {
; AVX2-NEXT: vpbroadcastq {{.*#+}} ymm2 = [1,2,4,8,16,32,64,128,1,2,4,8,16,32,64,128,1,2,4,8,16,32,64,128,1,2,4,8,16,32,64,128]
; AVX2-NEXT: vpand %ymm2, %ymm0, %ymm0
; AVX2-NEXT: vpcmpeqb %ymm2, %ymm0, %ymm0
-; AVX2-NEXT: vpsrlw $7, %ymm0, %ymm0
; AVX2-NEXT: vpbroadcastb {{.*#+}} ymm3 = [1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1]
; AVX2-NEXT: vpand %ymm3, %ymm0, %ymm0
; AVX2-NEXT: vpshufb {{.*#+}} ymm1 = ymm1[4,4,4,4,4,4,4,4,5,5,5,5,5,5,5,5,22,22,22,22,22,22,22,22,23,23,23,23,23,23,23,23]
; AVX2-NEXT: vpand %ymm2, %ymm1, %ymm1
; AVX2-NEXT: vpcmpeqb %ymm2, %ymm1, %ymm1
-; AVX2-NEXT: vpsrlw $7, %ymm1, %ymm1
; AVX2-NEXT: vpand %ymm3, %ymm1, %ymm1
; AVX2-NEXT: retq
;
diff --git a/llvm/test/CodeGen/X86/bitcast-int-to-vector-bool.ll b/llvm/test/CodeGen/X86/bitcast-int-to-vector-bool.ll
index 79d8e4acbba5a5..c27b5b289e1fa9 100644
--- a/llvm/test/CodeGen/X86/bitcast-int-to-vector-bool.ll
+++ b/llvm/test/CodeGen/X86/bitcast-int-to-vector-bool.ll
@@ -185,7 +185,6 @@ define <16 x i1> @bitcast_i16_16i1(i16 zeroext %a0) {
; SSE2-NEXT: movdqa {{.*#+}} xmm1 = [1,2,4,8,16,32,64,128,1,2,4,8,16,32,64,128]
; SSE2-NEXT: pand %xmm1, %xmm0
; SSE2-NEXT: pcmpeqb %xmm1, %xmm0
-; SSE2-NEXT: psrlw $7, %xmm0
; SSE2-NEXT: pand {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSE2-NEXT: retq
;
@@ -196,7 +195,6 @@ define <16 x i1> @bitcast_i16_16i1(i16 zeroext %a0) {
; SSSE3-NEXT: movdqa {{.*#+}} xmm1 = [1,2,4,8,16,32,64,128,1,2,4,8,16,32,64,128]
; SSSE3-NEXT: pand %xmm1, %xmm0
; SSSE3-NEXT: pcmpeqb %xmm1, %xmm0
-; SSSE3-NEXT: psrlw $7, %xmm0
; SSSE3-NEXT: pand {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; SSSE3-NEXT: retq
;
@@ -208,7 +206,6 @@ define <16 x i1> @bitcast_i16_16i1(i16 zeroext %a0) {
; AVX1-NEXT: # xmm1 = mem[0,0]
; AVX1-NEXT: vpand %xmm1, %xmm0, %xmm0
; AVX1-NEXT: vpcmpeqb %xmm1, %xmm0, %xmm0
-; AVX1-NEXT: vpsrlw $7, %xmm0, %xmm0
; AVX1-NEXT: vpand {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0, %xmm0
; AVX1-NEXT: retq
;
@@ -219,7 +216,6 @@ define <16 x i1> @bitcast_i16_16i1(i16 zeroext %a0) {
; AVX2-NEXT: vpbroadcastq {{.*#+}} xmm1 = [1,2,4,8,16,32,64,128,1,2,4,8,16,32,64,128]
; AVX2-NEXT: vpand %xmm1, %xmm0, %xmm0
; AVX2-NEXT: vpcmpeqb %xmm1, %xmm0, %xmm0
-; AVX2-NEXT: vpsrlw $7, %xmm0, %xmm0
; AVX2-NEXT: vpand {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0, %xmm0
; AVX2-NEXT: retq
;
@@ -252,13 +248,9 @@ define <32 x i1> @bitcast_i32_32i1(i32 %a0) {
; AVX1-NEXT: vmovddup {{.*#+}} xmm2 = [1,2,4,8,16,32,64,128,1,2,4,8,16,32,64,128]
; AVX1-NEXT: # xmm2 = mem[0,0]
; AVX1-NEXT: vpcmpeqb %xmm2, %xmm1, %xmm1
-; AVX1-NEXT: vpsrlw $7, %xmm1, %xmm1
-; AVX1-NEXT: vbroadcastss {{.*#+}} xmm3 = [1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1]
-; AVX1-NEXT: vpand %xmm3, %xmm1, %xmm1
; AVX1-NEXT: vpcmpeqb %xmm2, %xmm0, %xmm0
-; AVX1-NEXT: vpsrlw $7, %xmm0, %xmm0
-; AVX1-NEXT: vpand %xmm3, %xmm0, %xmm0
; AVX1-NEXT: vinsertf128 $1, %xmm1, %ymm0, %ymm0
+; AVX1-NEXT: vandps {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %ymm0, %ymm0
; AVX1-NEXT: retq
;
; AVX2-LABEL: bitcast_i32_32i1:
@@ -269,7 +261,6 @@ define <32 x i1> @bitcast_i32_32i1(i32 %a0) {
; AVX2-NEXT: vpbroadcastq {{.*#+}} ymm1 = [1,2,4,8,16,32,64,128,1,2,4,8,16,32,64,128,1,2,4,8,16,32,64,128,1,2,4,8,16,32,64,128]
; AVX2-NEXT: vpand %ymm1, %ymm0, %ymm0
; AVX2-NEXT: vpcmpeqb %ymm1, %ymm0, %ymm0
-; AVX2-NEXT: vpsrlw $7, %ymm0, %ymm0
; AVX2-NEXT: vpand {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %ymm0, %ymm0
; AVX2-NEXT: retq
;
diff --git a/llvm/test/CodeGen/X86/cmp-shiftX-maskX.ll b/llvm/test/CodeGen/X86/cmp-shiftX-maskX.ll
index 3887d9547fd06e..bc546fe857a3ed 100644
--- a/llvm/test/CodeGen/X86/cmp-shiftX-maskX.ll
+++ b/llvm/test/CodeGen/X86/cmp-shiftX-maskX.ll
@@ -623,28 +623,24 @@ define <16 x i8> @shl_s3_cmp_v16i8(<16 x i8> %x, <16 x i8> %y) {
; CHECK-NOBMI-LABEL: shl_s3_cmp_v16i8:
; CHECK-NOBMI: # %bb.0:
; CHECK-NOBMI-NEXT: pcmpeqb %xmm1, %xmm0
-; CHECK-NOBMI-NEXT: psllw $3, %xmm0
; CHECK-NOBMI-NEXT: pand {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; CHECK-NOBMI-NEXT: retq
;
; CHECK-BMI2-SSE2-LABEL: shl_s3_cmp_v16i8:
; CHECK-BMI2-SSE2: # %bb.0:
; CHECK-BMI2-SSE2-NEXT: pcmpeqb %xmm1, %xmm0
-; CHECK-BMI2-SSE2-NEXT: psllw $3, %xmm0
; CHECK-BMI2-SSE2-NEXT: pand {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; CHECK-BMI2-SSE2-NEXT: retq
;
; CHECK-AVX12-LABEL: shl_s3_cmp_v16i8:
; CHECK-AVX12: # %bb.0:
; CHECK-AVX12-NEXT: vpcmpeqb %xmm1, %xmm0, %xmm0
-; CHECK-AVX12-NEXT: vpsllw $3, %xmm0, %xmm0
; CHECK-AVX12-NEXT: vpand {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0, %xmm0
; CHECK-AVX12-NEXT: retq
;
; CHECK-AVX512-LABEL: shl_s3_cmp_v16i8:
; CHECK-AVX512: # %bb.0:
; CHECK-AVX512-NEXT: vpcmpeqb %xmm1, %xmm0, %xmm0
-; CHECK-AVX512-NEXT: vpsllw $3, %xmm0, %xmm0
; CHECK-AVX512-NEXT: vpandd {{\.?LCPI[0-9]+_[0-9]+}}(%rip){1to4}, %xmm0, %xmm0
; CHECK-AVX512-NEXT: retq
%cmp = icmp eq <16 x i8> %x, %y
@@ -673,10 +669,7 @@ define <4 x i64> @shl_s31_cmp_v4f64(<4 x double> %x, <4 x double> %y) {
; CHECK-AVX1-LABEL: shl_s31_cmp_v4f64:
; CHECK-AVX1: # %bb.0:
; CHECK-AVX1-NEXT: vcmpeqpd %ymm1, %ymm0, %ymm0
-; CHECK-AVX1-NEXT: vpsllq $31, %xmm0, %xmm1
-; CHECK-AVX1-NEXT: vextractf128 $1, %ymm0, %xmm0
-; CHECK-AVX1-NEXT: vpsllq $31, %xmm0, %xmm0
-; CHECK-AVX1-NEXT: vinsertf128 $1, %xmm0, %ymm1, %ymm0
+; CHECK-AVX1-NEXT: vandpd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %ymm0, %ymm0
; CHECK-AVX1-NEXT: retq
;
; CHECK-AVX2-LABEL: shl_s31_cmp_v4f64:
@@ -700,28 +693,24 @@ define <16 x i8> @shr_s1_cmp_v16i8(<16 x i8> %x, <16 x i8> %y) {
; CHECK-NOBMI-LABEL: shr_s1_cmp_v16i8:
; CHECK-NOBMI: # %bb.0:
; CHECK-NOBMI-NEXT: pcmpeqb %xmm1, %xmm0
-; CHECK-NOBMI-NEXT: psrlw $1, %xmm0
; CHECK-NOBMI-NEXT: pand {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; CHECK-NOBMI-NEXT: retq
;
; CHECK-BMI2-SSE2-LABEL: shr_s1_cmp_v16i8:
; CHECK-BMI2-SSE2: # %bb.0:
; CHECK-BMI2-SSE2-NEXT: pcmpeqb %xmm1, %xmm0
-; CHECK-BMI2-SSE2-NEXT: psrlw $1, %xmm0
; CHECK-BMI2-SSE2-NEXT: pand {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; CHECK-BMI2-SSE2-NEXT: retq
;
; CHECK-AVX12-LABEL: shr_s1_cmp_v16i8:
; CHECK-AVX12: # %bb.0:
; CHECK-AVX12-NEXT: vpcmpeqb %xmm1, %xmm0, %xmm0
-; CHECK-AVX12-NEXT: vpsrlw $1, %xmm0, %xmm0
; CHECK-AVX12-NEXT: vpand {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0, %xmm0
; CHECK-AVX12-NEXT: retq
;
; CHECK-AVX512-LABEL: shr_s1_cmp_v16i8:
; CHECK-AVX512: # %bb.0:
; CHECK-AVX512-NEXT: vpcmpeqb %xmm1, %xmm0, %xmm0
-; CHECK-AVX512-NEXT: vpsrlw $1, %xmm0, %xmm0
; CHECK-AVX512-NEXT: vpandd {{\.?LCPI[0-9]+_[0-9]+}}(%rip){1to4}, %xmm0, %xmm0
; CHECK-AVX512-NEXT: retq
%cmp = icmp eq <16 x i8> %x, %y
@@ -753,9 +742,8 @@ define <8 x i32> @shr_s9_cmp_v8i32(<8 x i32> %x, <8 x i32> %y) {
; CHECK-AVX1-NEXT: vextractf128 $1, %ymm0, %xmm3
; CHECK-AVX1-NEXT: vpcmpgtd %xmm2, %xmm3, %xmm2
; CHECK-AVX1-NEXT: vpcmpgtd %xmm1, %xmm0, %xmm0
-; CHECK-AVX1-NEXT: vpsrld $9, %xmm0, %xmm0
-; CHECK-AVX1-NEXT: vpsrld $9, %xmm2, %xmm1
-; CHECK-AVX1-NEXT: vinsertf128 $1, %xmm1, %ymm0, %ymm0
+; CHECK-AVX1-NEXT: vinsertf128 $1, %xmm2, %ymm0, %ymm0
+; CHECK-AVX1-NEXT: vandps {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %ymm0, %ymm0
; CHECK-AVX1-NEXT: retq
;
; CHECK-AVX2-LABEL: shr_s9_cmp_v8i32:
>From 2a95fe481d18e273b9654322135a08d7c2937536 Mon Sep 17 00:00:00 2001
From: David Green <david.green at arm.com>
Date: Sat, 2 Mar 2024 14:39:59 +0000
Subject: [PATCH 350/406] [Flang] Allow Intrinsic simpification with min/maxloc
dim and scalar result (#81619)
This makes an adjustment to the existing fir minloc/maxloc generation
code to handle functions with a dim=1 that produce a scalar result. This
should allow us to get the same benefits as the existing generated
minmax reductions.
This is a recommit of #76194 with an extra alteration to the end of
genRuntimeMinMaxlocBody to make sure we convert the output array to the
correct type (a `box<heap<i32>>`, not `box<heap<array<1xi32>>>`) to
prevent writing the wrong type of box into it. This still allocates the
data as a `array<1xi32>`, converting it into a i32 assuming that is
safe. An alternative would be to allocate the data as a i32 and change
more of the accesses to it throughout genRuntimeMinMaxlocBody.
---
.../Transforms/SimplifyIntrinsics.cpp | 54 +++++++++------
flang/test/Transforms/simplifyintrinsics.fir | 65 +++++++++++++++++--
2 files changed, 92 insertions(+), 27 deletions(-)
diff --git a/flang/lib/Optimizer/Transforms/SimplifyIntrinsics.cpp b/flang/lib/Optimizer/Transforms/SimplifyIntrinsics.cpp
index f483651a68dc17..a11aa38c771bd1 100644
--- a/flang/lib/Optimizer/Transforms/SimplifyIntrinsics.cpp
+++ b/flang/lib/Optimizer/Transforms/SimplifyIntrinsics.cpp
@@ -656,7 +656,7 @@ static void genRuntimeMinMaxlocBody(fir::FirOpBuilder &builder,
unsigned rank, int maskRank,
mlir::Type elementType,
mlir::Type maskElemType,
- mlir::Type resultElemTy) {
+ mlir::Type resultElemTy, bool isDim) {
auto init = [isMax](fir::FirOpBuilder builder, mlir::Location loc,
mlir::Type elementType) {
if (auto ty = elementType.dyn_cast<mlir::FloatType>()) {
@@ -858,16 +858,27 @@ static void genRuntimeMinMaxlocBody(fir::FirOpBuilder &builder,
maskElemType, resultArr, maskRank == 0);
// Store newly created output array to the reference passed in
- fir::SequenceType::Shape resultShape(1, rank);
- mlir::Type outputArrTy = fir::SequenceType::get(resultShape, resultElemTy);
- mlir::Type outputHeapTy = fir::HeapType::get(outputArrTy);
- mlir::Type outputBoxTy = fir::BoxType::get(outputHeapTy);
- mlir::Type outputRefTy = builder.getRefType(outputBoxTy);
- mlir::Value outputArr = builder.create<fir::ConvertOp>(
- loc, outputRefTy, funcOp.front().getArgument(0));
-
- // Store nearly created array to output array
- builder.create<fir::StoreOp>(loc, resultArr, outputArr);
+ if (isDim) {
+ mlir::Type resultBoxTy =
+ fir::BoxType::get(fir::HeapType::get(resultElemTy));
+ mlir::Value outputArr = builder.create<fir::ConvertOp>(
+ loc, builder.getRefType(resultBoxTy), funcOp.front().getArgument(0));
+ mlir::Value resultArrScalar = builder.create<fir::ConvertOp>(
+ loc, fir::HeapType::get(resultElemTy), resultArrInit);
+ mlir::Value resultBox =
+ builder.create<fir::EmboxOp>(loc, resultBoxTy, resultArrScalar);
+ builder.create<fir::StoreOp>(loc, resultBox, outputArr);
+ } else {
+ fir::SequenceType::Shape resultShape(1, rank);
+ mlir::Type outputArrTy = fir::SequenceType::get(resultShape, resultElemTy);
+ mlir::Type outputHeapTy = fir::HeapType::get(outputArrTy);
+ mlir::Type outputBoxTy = fir::BoxType::get(outputHeapTy);
+ mlir::Type outputRefTy = builder.getRefType(outputBoxTy);
+ mlir::Value outputArr = builder.create<fir::ConvertOp>(
+ loc, outputRefTy, funcOp.front().getArgument(0));
+ builder.create<fir::StoreOp>(loc, resultArr, outputArr);
+ }
+
builder.create<mlir::func::ReturnOp>(loc);
}
@@ -1146,11 +1157,14 @@ void SimplifyIntrinsicsPass::simplifyMinMaxlocReduction(
mlir::Operation::operand_range args = call.getArgs();
- mlir::Value back = args[6];
+ mlir::SymbolRefAttr callee = call.getCalleeAttr();
+ mlir::StringRef funcNameBase = callee.getLeafReference().getValue();
+ bool isDim = funcNameBase.ends_with("Dim");
+ mlir::Value back = args[isDim ? 7 : 6];
if (isTrueOrNotConstant(back))
return;
- mlir::Value mask = args[5];
+ mlir::Value mask = args[isDim ? 6 : 5];
mlir::Value maskDef = findMaskDef(mask);
// maskDef is set to NULL when the defining op is not one we accept.
@@ -1159,10 +1173,8 @@ void SimplifyIntrinsicsPass::simplifyMinMaxlocReduction(
if (maskDef == NULL)
return;
- mlir::SymbolRefAttr callee = call.getCalleeAttr();
- mlir::StringRef funcNameBase = callee.getLeafReference().getValue();
unsigned rank = getDimCount(args[1]);
- if (funcNameBase.ends_with("Dim") || !(rank > 0))
+ if ((isDim && rank != 1) || !(rank > 0))
return;
fir::FirOpBuilder builder{getSimplificationBuilder(call, kindMap)};
@@ -1203,22 +1215,24 @@ void SimplifyIntrinsicsPass::simplifyMinMaxlocReduction(
llvm::raw_string_ostream nameOS(funcName);
outType.print(nameOS);
+ if (isDim)
+ nameOS << '_' << inputType;
nameOS << '_' << fmfString;
auto typeGenerator = [rank](fir::FirOpBuilder &builder) {
return genRuntimeMinlocType(builder, rank);
};
auto bodyGenerator = [rank, maskRank, inputType, logicalElemType, outType,
- isMax](fir::FirOpBuilder &builder,
- mlir::func::FuncOp &funcOp) {
+ isMax, isDim](fir::FirOpBuilder &builder,
+ mlir::func::FuncOp &funcOp) {
genRuntimeMinMaxlocBody(builder, funcOp, isMax, rank, maskRank, inputType,
- logicalElemType, outType);
+ logicalElemType, outType, isDim);
};
mlir::func::FuncOp newFunc =
getOrCreateFunction(builder, funcName, typeGenerator, bodyGenerator);
builder.create<fir::CallOp>(loc, newFunc,
- mlir::ValueRange{args[0], args[1], args[5]});
+ mlir::ValueRange{args[0], args[1], mask});
call->dropAllReferences();
call->erase();
}
diff --git a/flang/test/Transforms/simplifyintrinsics.fir b/flang/test/Transforms/simplifyintrinsics.fir
index ce9f2dbd3e0fbb..f21776e03ded8f 100644
--- a/flang/test/Transforms/simplifyintrinsics.fir
+++ b/flang/test/Transforms/simplifyintrinsics.fir
@@ -2098,13 +2098,13 @@ func.func @_QPtestminloc_doesntwork1d_back(%arg0: !fir.ref<!fir.array<10xi32>> {
// CHECK-NOT: fir.call @_FortranAMinlocInteger4x1_i32_contract_simplified({{.*}}) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, !fir.box<none>) -> ()
// -----
-// Check Minloc is not simplified when DIM arg is set
+// Check Minloc is simplified when DIM arg is set so long as the result is scalar
-func.func @_QPtestminloc_doesntwork1d_dim(%arg0: !fir.ref<!fir.array<10xi32>> {fir.bindc_name = "a"}) -> !fir.array<1xi32> {
+func.func @_QPtestminloc_1d_dim(%arg0: !fir.ref<!fir.array<10xi32>> {fir.bindc_name = "a"}) -> !fir.array<1xi32> {
%0 = fir.alloca !fir.box<!fir.heap<i32>>
%c10 = arith.constant 10 : index
%c1 = arith.constant 1 : index
- %1 = fir.alloca !fir.array<1xi32> {bindc_name = "testminloc_doesntwork1d_dim", uniq_name = "_QFtestminloc_doesntwork1d_dimEtestminloc_doesntwork1d_dim"}
+ %1 = fir.alloca !fir.array<1xi32> {bindc_name = "testminloc_1d_dim", uniq_name = "_QFtestminloc_1d_dimEtestminloc_1d_dim"}
%2 = fir.shape %c1 : (index) -> !fir.shape<1>
%3 = fir.array_load %1(%2) : (!fir.ref<!fir.array<1xi32>>, !fir.shape<1>) -> !fir.array<1xi32>
%4 = fir.shape %c10 : (index) -> !fir.shape<1>
@@ -2139,11 +2139,62 @@ func.func @_QPtestminloc_doesntwork1d_dim(%arg0: !fir.ref<!fir.array<10xi32>> {f
%21 = fir.load %1 : !fir.ref<!fir.array<1xi32>>
return %21 : !fir.array<1xi32>
}
-// CHECK-LABEL: func.func @_QPtestminloc_doesntwork1d_dim(
+// CHECK-LABEL: func.func @_QPtestminloc_1d_dim(
// CHECK-SAME: %[[ARR:.*]]: !fir.ref<!fir.array<10xi32>> {fir.bindc_name = "a"}) -> !fir.array<1xi32> {
-// CHECK-NOT: fir.call @_FortranAMinlocDimx1_i32_contract_simplified({{.*}}) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, !fir.box<none>) -> ()
-// CHECK: fir.call @_FortranAMinlocDim({{.*}}) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, i32, i32, !fir.ref<i8>, i32, !fir.box<none>, i1) -> none
-// CHECK-NOT: fir.call @_FortranAMinlocDimx1_i32_contract_simplified({{.*}}) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, !fir.box<none>) -> ()
+// CHECK: fir.call @_FortranAMinlocDimx1_i32_i32_contract_simplified({{.*}}) fastmath<contract> : (!fir.ref<!fir.box<none>>, !fir.box<none>, !fir.box<none>) -> ()
+
+// CHECK-LABEL: func.func private @_FortranAMinlocDimx1_i32_i32_contract_simplified(%arg0: !fir.ref<!fir.box<none>>, %arg1: !fir.box<none>, %arg2: !fir.box<none>) attributes {llvm.linkage = #llvm.linkage<linkonce_odr>} {
+// CHECK-NEXT: %[[V0:.*]] = fir.alloca i32
+// CHECK-NEXT: %c0_i32 = arith.constant 0 : i32
+// CHECK-NEXT: %c1 = arith.constant 1 : index
+// CHECK-NEXT: %[[V1:.*]] = fir.allocmem !fir.array<1xi32>
+// CHECK-NEXT: %[[V2:.*]] = fir.shape %c1 : (index) -> !fir.shape<1>
+// CHECK-NEXT: %[[V3:.*]] = fir.embox %[[V1]](%[[V2]]) : (!fir.heap<!fir.array<1xi32>>, !fir.shape<1>) -> !fir.box<!fir.heap<!fir.array<1xi32>>>
+// CHECK-NEXT: %c0 = arith.constant 0 : index
+// CHECK-NEXT: %[[V4:.*]] = fir.coordinate_of %[[V3]], %c0 : (!fir.box<!fir.heap<!fir.array<1xi32>>>, index) -> !fir.ref<i32>
+// CHECK-NEXT: fir.store %c0_i32 to %[[V4]] : !fir.ref<i32>
+// CHECK-NEXT: %c0_0 = arith.constant 0 : index
+// CHECK-NEXT: %[[V5:.*]] = fir.convert %arg1 : (!fir.box<none>) -> !fir.box<!fir.array<?xi32>>
+// CHECK-NEXT: %c1_i32 = arith.constant 1 : i32
+// CHECK-NEXT: %c0_i32_1 = arith.constant 0 : i32
+// CHECK-NEXT: fir.store %c0_i32_1 to %[[V0]] : !fir.ref<i32>
+// CHECK-NEXT: %c2147483647_i32 = arith.constant 2147483647 : i32
+// CHECK-NEXT: %c1_2 = arith.constant 1 : index
+// CHECK-NEXT: %c0_3 = arith.constant 0 : index
+// CHECK-NEXT: %[[V6:.*]]:3 = fir.box_dims %[[V5]], %c0_3 : (!fir.box<!fir.array<?xi32>>, index) -> (index, index, index)
+// CHECK-NEXT: %[[V7:.*]] = arith.subi %[[V6]]#1, %c1_2 : index
+// CHECK-NEXT: %[[V8:.*]] = fir.do_loop %arg3 = %c0_0 to %[[V7]] step %c1_2 iter_args(%arg4 = %c2147483647_i32) -> (i32) {
+// CHECK-NEXT: %c1_i32_4 = arith.constant 1 : i32
+// CHECK-NEXT: %[[ISFIRST:.*]] = fir.load %[[FLAG_ALLOC]] : !fir.ref<i32>
+// CHECK-NEXT: %[[V12:.*]] = fir.coordinate_of %[[V5]], %arg3 : (!fir.box<!fir.array<?xi32>>, index) -> !fir.ref<i32>
+// CHECK-NEXT: %[[V13:.*]] = fir.load %[[V12]] : !fir.ref<i32>
+// CHECK-NEXT: %[[V14:.*]] = arith.cmpi slt, %[[V13]], %arg4 : i32
+// CHECK-NEXT: %[[ISFIRSTL:.*]] = fir.convert %[[ISFIRST]] : (i32) -> i1
+// CHECK-NEXT: %true = arith.constant true
+// CHECK-NEXT: %[[ISFIRSTNOT:.*]] = arith.xori %[[ISFIRSTL]], %true : i1
+// CHECK-NEXT: %[[ORCOND:.*]] = arith.ori %[[V14]], %[[ISFIRSTNOT]] : i1
+// CHECK-NEXT: %[[V15:.*]] = fir.if %[[ORCOND]] -> (i32) {
+// CHECK-NEXT: fir.store %c1_i32_4 to %[[V0]] : !fir.ref<i32>
+// CHECK-NEXT: %c1_i32_5 = arith.constant 1 : i32
+// CHECK-NEXT: %c0_6 = arith.constant 0 : index
+// CHECK-NEXT: %[[V16:.*]] = fir.coordinate_of %[[V3]], %c0_6 : (!fir.box<!fir.heap<!fir.array<1xi32>>>, index) -> !fir.ref<i32>
+// CHECK-NEXT: %[[V17:.*]] = fir.convert %arg3 : (index) -> i32
+// CHECK-NEXT: %[[V18:.*]] = arith.addi %[[V17]], %c1_i32_5 : i32
+// CHECK-NEXT: fir.store %[[V18]] to %[[V16]] : !fir.ref<i32>
+// CHECK-NEXT: fir.result %[[V13]] : i32
+// CHECK-NEXT: } else {
+// CHECK-NEXT: fir.result %arg4 : i32
+// CHECK-NEXT: }
+// CHECK-NEXT: fir.result %[[V15]] : i32
+// CHECK-NEXT: }
+// CHECK-NEXT: %[[V11:.*]] = fir.convert %arg0 : (!fir.ref<!fir.box<none>>) -> !fir.ref<!fir.box<!fir.heap<i32>>>
+// CHECK-NEXT: %[[V12:.*]] = fir.convert %[[V1]] : (!fir.heap<!fir.array<1xi32>>) -> !fir.heap<i32>
+// CHECK-NEXT: %[[V13:.*]] = fir.embox %[[V12]] : (!fir.heap<i32>) -> !fir.box<!fir.heap<i32>>
+// CHECK-NEXT: fir.store %[[V13]] to %[[V11]] : !fir.ref<!fir.box<!fir.heap<i32>>>
+// CHECK-NEXT: return
+// CHECK-NEXT: }
+
+
// -----
// Check Minloc is not simplified when dimension of inputArr is unknown
>From 1f613bce19ea78789934b2a47be8c6a13925f0fa Mon Sep 17 00:00:00 2001
From: Hui <hui.xie1990 at gmail.com>
Date: Sat, 2 Mar 2024 14:50:52 +0000
Subject: [PATCH 351/406] [libc++] refactor `cxx_atomic_wait` to make it
reusable for atomic_ref (#81427)
The goal of this patch is to make `atomic`'s wait functions to be
reusable by `atomic_ref`.
https://github.com/llvm/llvm-project/pull/76647
First, this patch is built on top of
https://github.com/llvm/llvm-project/pull/80596 , to reduce the future
merge conflicts.
This patch made the following functions as "API"s to be used by
`atomic`, `atomic_flag`, `semaphore`, `latch`, `atomic_ref`
```
__atomic_wait
__atomic_wait_unless
__atomic_notify_one
__atomic_notify_all
```
These functions are made generic to support `atomic` type and
`atomic_ref`. There are two customisation points.
```
// How to load the value from the given type (with a memory order)
__atomic_load
```
```
// what is the contention address that the platform `wait` function is going to monitor
__atomic_contention_address
```
For `atomic_ref` (not implemented in this patch), the `load` and
`address` function will be different, because
- it does not use the "atomic abstraction layer" so the `load` operation
will be some gcc builtin
- the contention address will be the user's actual type that the
`atomic_ref` is pointing to
---
libcxx/include/__atomic/atomic_base.h | 42 +++++++--
libcxx/include/__atomic/atomic_flag.h | 35 +++++--
libcxx/include/__atomic/atomic_sync.h | 128 ++++++++++++++++++--------
libcxx/include/latch | 6 +-
libcxx/include/semaphore | 4 +-
5 files changed, 154 insertions(+), 61 deletions(-)
diff --git a/libcxx/include/__atomic/atomic_base.h b/libcxx/include/__atomic/atomic_base.h
index 3ad3b562c59805..6ca01a7f1bf9b9 100644
--- a/libcxx/include/__atomic/atomic_base.h
+++ b/libcxx/include/__atomic/atomic_base.h
@@ -104,24 +104,20 @@ struct __atomic_base // false
_LIBCPP_AVAILABILITY_SYNC _LIBCPP_HIDE_FROM_ABI void wait(_Tp __v, memory_order __m = memory_order_seq_cst) const
volatile _NOEXCEPT {
- std::__cxx_atomic_wait(std::addressof(__a_), __v, __m);
+ std::__atomic_wait(*this, __v, __m);
}
_LIBCPP_AVAILABILITY_SYNC _LIBCPP_HIDE_FROM_ABI void
wait(_Tp __v, memory_order __m = memory_order_seq_cst) const _NOEXCEPT {
- std::__cxx_atomic_wait(std::addressof(__a_), __v, __m);
+ std::__atomic_wait(*this, __v, __m);
}
_LIBCPP_AVAILABILITY_SYNC _LIBCPP_HIDE_FROM_ABI void notify_one() volatile _NOEXCEPT {
- std::__cxx_atomic_notify_one(std::addressof(__a_));
- }
- _LIBCPP_AVAILABILITY_SYNC _LIBCPP_HIDE_FROM_ABI void notify_one() _NOEXCEPT {
- std::__cxx_atomic_notify_one(std::addressof(__a_));
+ std::__atomic_notify_one(*this);
}
+ _LIBCPP_AVAILABILITY_SYNC _LIBCPP_HIDE_FROM_ABI void notify_one() _NOEXCEPT { std::__atomic_notify_one(*this); }
_LIBCPP_AVAILABILITY_SYNC _LIBCPP_HIDE_FROM_ABI void notify_all() volatile _NOEXCEPT {
- std::__cxx_atomic_notify_all(std::addressof(__a_));
- }
- _LIBCPP_AVAILABILITY_SYNC _LIBCPP_HIDE_FROM_ABI void notify_all() _NOEXCEPT {
- std::__cxx_atomic_notify_all(std::addressof(__a_));
+ std::__atomic_notify_all(*this);
}
+ _LIBCPP_AVAILABILITY_SYNC _LIBCPP_HIDE_FROM_ABI void notify_all() _NOEXCEPT { std::__atomic_notify_all(*this); }
#if _LIBCPP_STD_VER >= 20
_LIBCPP_HIDE_FROM_ABI constexpr __atomic_base() noexcept(is_nothrow_default_constructible_v<_Tp>) : __a_(_Tp()) {}
@@ -200,6 +196,32 @@ struct __atomic_base<_Tp, true> : public __atomic_base<_Tp, false> {
_LIBCPP_HIDE_FROM_ABI _Tp operator^=(_Tp __op) _NOEXCEPT { return fetch_xor(__op) ^ __op; }
};
+// Here we need _IsIntegral because the default template argument is not enough
+// e.g __atomic_base<int> is __atomic_base<int, true>, which inherits from
+// __atomic_base<int, false> and the caller of the wait function is
+// __atomic_base<int, false>. So specializing __atomic_base<_Tp> does not work
+template <class _Tp, bool _IsIntegral>
+struct __atomic_waitable_traits<__atomic_base<_Tp, _IsIntegral> > {
+ static _LIBCPP_HIDE_FROM_ABI _Tp __atomic_load(const __atomic_base<_Tp, _IsIntegral>& __a, memory_order __order) {
+ return __a.load(__order);
+ }
+
+ static _LIBCPP_HIDE_FROM_ABI _Tp
+ __atomic_load(const volatile __atomic_base<_Tp, _IsIntegral>& __this, memory_order __order) {
+ return __this.load(__order);
+ }
+
+ static _LIBCPP_HIDE_FROM_ABI const __cxx_atomic_impl<_Tp>*
+ __atomic_contention_address(const __atomic_base<_Tp, _IsIntegral>& __a) {
+ return std::addressof(__a.__a_);
+ }
+
+ static _LIBCPP_HIDE_FROM_ABI const volatile __cxx_atomic_impl<_Tp>*
+ __atomic_contention_address(const volatile __atomic_base<_Tp, _IsIntegral>& __this) {
+ return std::addressof(__this.__a_);
+ }
+};
+
_LIBCPP_END_NAMESPACE_STD
#endif // _LIBCPP___ATOMIC_ATOMIC_BASE_H
diff --git a/libcxx/include/__atomic/atomic_flag.h b/libcxx/include/__atomic/atomic_flag.h
index 18a864523de06f..084366237c16eb 100644
--- a/libcxx/include/__atomic/atomic_flag.h
+++ b/libcxx/include/__atomic/atomic_flag.h
@@ -16,6 +16,7 @@
#include <__availability>
#include <__chrono/duration.h>
#include <__config>
+#include <__memory/addressof.h>
#include <__thread/support.h>
#include <cstdint>
@@ -50,20 +51,20 @@ struct atomic_flag {
_LIBCPP_AVAILABILITY_SYNC _LIBCPP_HIDE_FROM_ABI void wait(bool __v, memory_order __m = memory_order_seq_cst) const
volatile _NOEXCEPT {
- __cxx_atomic_wait(&__a_, _LIBCPP_ATOMIC_FLAG_TYPE(__v), __m);
+ std::__atomic_wait(*this, _LIBCPP_ATOMIC_FLAG_TYPE(__v), __m);
}
_LIBCPP_AVAILABILITY_SYNC _LIBCPP_HIDE_FROM_ABI void
wait(bool __v, memory_order __m = memory_order_seq_cst) const _NOEXCEPT {
- __cxx_atomic_wait(&__a_, _LIBCPP_ATOMIC_FLAG_TYPE(__v), __m);
+ std::__atomic_wait(*this, _LIBCPP_ATOMIC_FLAG_TYPE(__v), __m);
}
_LIBCPP_AVAILABILITY_SYNC _LIBCPP_HIDE_FROM_ABI void notify_one() volatile _NOEXCEPT {
- __cxx_atomic_notify_one(&__a_);
+ std::__atomic_notify_one(*this);
}
- _LIBCPP_AVAILABILITY_SYNC _LIBCPP_HIDE_FROM_ABI void notify_one() _NOEXCEPT { __cxx_atomic_notify_one(&__a_); }
+ _LIBCPP_AVAILABILITY_SYNC _LIBCPP_HIDE_FROM_ABI void notify_one() _NOEXCEPT { std::__atomic_notify_one(*this); }
_LIBCPP_AVAILABILITY_SYNC _LIBCPP_HIDE_FROM_ABI void notify_all() volatile _NOEXCEPT {
- __cxx_atomic_notify_all(&__a_);
+ std::__atomic_notify_all(*this);
}
- _LIBCPP_AVAILABILITY_SYNC _LIBCPP_HIDE_FROM_ABI void notify_all() _NOEXCEPT { __cxx_atomic_notify_all(&__a_); }
+ _LIBCPP_AVAILABILITY_SYNC _LIBCPP_HIDE_FROM_ABI void notify_all() _NOEXCEPT { std::__atomic_notify_all(*this); }
#if _LIBCPP_STD_VER >= 20
_LIBCPP_HIDE_FROM_ABI constexpr atomic_flag() _NOEXCEPT : __a_(false) {}
@@ -78,6 +79,28 @@ struct atomic_flag {
atomic_flag& operator=(const atomic_flag&) volatile = delete;
};
+template <>
+struct __atomic_waitable_traits<atomic_flag> {
+ static _LIBCPP_HIDE_FROM_ABI _LIBCPP_ATOMIC_FLAG_TYPE __atomic_load(const atomic_flag& __a, memory_order __order) {
+ return std::__cxx_atomic_load(&__a.__a_, __order);
+ }
+
+ static _LIBCPP_HIDE_FROM_ABI _LIBCPP_ATOMIC_FLAG_TYPE
+ __atomic_load(const volatile atomic_flag& __a, memory_order __order) {
+ return std::__cxx_atomic_load(&__a.__a_, __order);
+ }
+
+ static _LIBCPP_HIDE_FROM_ABI const __cxx_atomic_impl<_LIBCPP_ATOMIC_FLAG_TYPE>*
+ __atomic_contention_address(const atomic_flag& __a) {
+ return std::addressof(__a.__a_);
+ }
+
+ static _LIBCPP_HIDE_FROM_ABI const volatile __cxx_atomic_impl<_LIBCPP_ATOMIC_FLAG_TYPE>*
+ __atomic_contention_address(const volatile atomic_flag& __a) {
+ return std::addressof(__a.__a_);
+ }
+};
+
inline _LIBCPP_HIDE_FROM_ABI bool atomic_flag_test(const volatile atomic_flag* __o) _NOEXCEPT { return __o->test(); }
inline _LIBCPP_HIDE_FROM_ABI bool atomic_flag_test(const atomic_flag* __o) _NOEXCEPT { return __o->test(); }
diff --git a/libcxx/include/__atomic/atomic_sync.h b/libcxx/include/__atomic/atomic_sync.h
index 2997bad83344b2..e583dca38c4c73 100644
--- a/libcxx/include/__atomic/atomic_sync.h
+++ b/libcxx/include/__atomic/atomic_sync.h
@@ -18,7 +18,11 @@
#include <__memory/addressof.h>
#include <__thread/poll_with_backoff.h>
#include <__thread/support.h>
+#include <__type_traits/conjunction.h>
#include <__type_traits/decay.h>
+#include <__type_traits/invoke.h>
+#include <__type_traits/void_t.h>
+#include <__utility/declval.h>
#include <cstring>
#if !defined(_LIBCPP_HAS_NO_PRAGMA_SYSTEM_HEADER)
@@ -27,15 +31,40 @@
_LIBCPP_BEGIN_NAMESPACE_STD
-template <class _Atp, class _Poll>
-struct __libcpp_atomic_wait_poll_impl {
- _Atp* __a_;
+// The customisation points to enable the following functions:
+// - __atomic_wait
+// - __atomic_wait_unless
+// - __atomic_notify_one
+// - __atomic_notify_all
+// Note that std::atomic<T>::wait was back-ported to C++03
+// The below implementations look ugly to support C++03
+template <class _Tp, class = void>
+struct __atomic_waitable_traits {
+ template <class _AtomicWaitable>
+ static void __atomic_load(_AtomicWaitable&&, memory_order) = delete;
+
+ template <class _AtomicWaitable>
+ static void __atomic_contention_address(_AtomicWaitable&&) = delete;
+};
+
+template <class _Tp, class = void>
+struct __atomic_waitable : false_type {};
+
+template <class _Tp>
+struct __atomic_waitable< _Tp,
+ __void_t<decltype(__atomic_waitable_traits<__decay_t<_Tp> >::__atomic_load(
+ std::declval<const _Tp&>(), std::declval<memory_order>())),
+ decltype(__atomic_waitable_traits<__decay_t<_Tp> >::__atomic_contention_address(
+ std::declval<const _Tp&>()))> > : true_type {};
+
+template <class _AtomicWaitable, class _Poll>
+struct __atomic_wait_poll_impl {
+ const _AtomicWaitable& __a_;
_Poll __poll_;
memory_order __order_;
- _LIBCPP_AVAILABILITY_SYNC
_LIBCPP_HIDE_FROM_ABI bool operator()() const {
- auto __current_val = std::__cxx_atomic_load(__a_, __order_);
+ auto __current_val = __atomic_waitable_traits<__decay_t<_AtomicWaitable> >::__atomic_load(__a_, __order_);
return __poll_(__current_val);
}
};
@@ -56,42 +85,45 @@ __libcpp_atomic_monitor(__cxx_atomic_contention_t const volatile*);
_LIBCPP_AVAILABILITY_SYNC _LIBCPP_EXPORTED_FROM_ABI void
__libcpp_atomic_wait(__cxx_atomic_contention_t const volatile*, __cxx_contention_t);
-template <class _Atp, class _Poll>
-struct __libcpp_atomic_wait_backoff_impl {
- _Atp* __a_;
+template <class _AtomicWaitable, class _Poll>
+struct __atomic_wait_backoff_impl {
+ const _AtomicWaitable& __a_;
_Poll __poll_;
memory_order __order_;
+ using __waitable_traits = __atomic_waitable_traits<__decay_t<_AtomicWaitable> >;
+
_LIBCPP_AVAILABILITY_SYNC
_LIBCPP_HIDE_FROM_ABI bool
- __poll_or_get_monitor(__cxx_atomic_contention_t const volatile*, __cxx_contention_t& __monitor) const {
- // In case the atomic can be waited on directly, the monitor value is just
- // the value of the atomic.
+ __update_monitor_val_and_poll(__cxx_atomic_contention_t const volatile*, __cxx_contention_t& __monitor_val) const {
+ // In case the contention type happens to be __cxx_atomic_contention_t, i.e. __cxx_atomic_impl<int64_t>,
+ // the platform wait is directly monitoring the atomic value itself.
// `__poll_` takes the current value of the atomic as an in-out argument
// to potentially modify it. After it returns, `__monitor` has a value
// which can be safely waited on by `std::__libcpp_atomic_wait` without any
// ABA style issues.
- __monitor = std::__cxx_atomic_load(__a_, __order_);
- return __poll_(__monitor);
+ __monitor_val = __waitable_traits::__atomic_load(__a_, __order_);
+ return __poll_(__monitor_val);
}
_LIBCPP_AVAILABILITY_SYNC
- _LIBCPP_HIDE_FROM_ABI bool __poll_or_get_monitor(void const volatile*, __cxx_contention_t& __monitor) const {
- // In case we must wait on an atomic from the pool, the monitor comes from
- // `std::__libcpp_atomic_monitor`.
- // Only then we may read from `__a_`. This is the "event count" pattern.
- __monitor = std::__libcpp_atomic_monitor(__a_);
- auto __current_val = std::__cxx_atomic_load(__a_, __order_);
+ _LIBCPP_HIDE_FROM_ABI bool
+ __update_monitor_val_and_poll(void const volatile* __contention_address, __cxx_contention_t& __monitor_val) const {
+ // In case the contention type is anything else, platform wait is monitoring a __cxx_atomic_contention_t
+ // from the global pool, the monitor comes from __libcpp_atomic_monitor
+ __monitor_val = std::__libcpp_atomic_monitor(__contention_address);
+ auto __current_val = __waitable_traits::__atomic_load(__a_, __order_);
return __poll_(__current_val);
}
_LIBCPP_AVAILABILITY_SYNC
_LIBCPP_HIDE_FROM_ABI bool operator()(chrono::nanoseconds __elapsed) const {
if (__elapsed > chrono::microseconds(64)) {
- __cxx_contention_t __monitor;
- if (__poll_or_get_monitor(__a_, __monitor))
+ auto __contention_address = __waitable_traits::__atomic_contention_address(__a_);
+ __cxx_contention_t __monitor_val;
+ if (__update_monitor_val_and_poll(__contention_address, __monitor_val))
return true;
- std::__libcpp_atomic_wait(__a_, __monitor);
+ std::__libcpp_atomic_wait(__contention_address, __monitor_val);
} else if (__elapsed > chrono::microseconds(4))
__libcpp_thread_yield();
else {
@@ -105,29 +137,44 @@ struct __libcpp_atomic_wait_backoff_impl {
// predicate (is the loaded value unequal to `old`?), the predicate function is
// specified as an argument. The loaded value is given as an in-out argument to
// the predicate. If the predicate function returns `true`,
-// `_cxx_atomic_wait_unless` will return. If the predicate function returns
+// `__atomic_wait_unless` will return. If the predicate function returns
// `false`, it must set the argument to its current understanding of the atomic
// value. The predicate function must not return `false` spuriously.
-template <class _Atp, class _Poll>
+template <class _AtomicWaitable, class _Poll>
_LIBCPP_AVAILABILITY_SYNC _LIBCPP_HIDE_FROM_ABI void
-__cxx_atomic_wait_unless(_Atp* __a, _Poll&& __poll, memory_order __order) {
- __libcpp_atomic_wait_poll_impl<_Atp, __decay_t<_Poll> > __poll_fn = {__a, __poll, __order};
- __libcpp_atomic_wait_backoff_impl<_Atp, __decay_t<_Poll> > __backoff_fn = {__a, __poll, __order};
- (void)std::__libcpp_thread_poll_with_backoff(__poll_fn, __backoff_fn);
+__atomic_wait_unless(const _AtomicWaitable& __a, _Poll&& __poll, memory_order __order) {
+ static_assert(__atomic_waitable<_AtomicWaitable>::value, "");
+ __atomic_wait_poll_impl<_AtomicWaitable, __decay_t<_Poll> > __poll_impl = {__a, __poll, __order};
+ __atomic_wait_backoff_impl<_AtomicWaitable, __decay_t<_Poll> > __backoff_fn = {__a, __poll, __order};
+ std::__libcpp_thread_poll_with_backoff(__poll_impl, __backoff_fn);
+}
+
+template <class _AtomicWaitable>
+_LIBCPP_AVAILABILITY_SYNC _LIBCPP_HIDE_FROM_ABI void __atomic_notify_one(const _AtomicWaitable& __a) {
+ static_assert(__atomic_waitable<_AtomicWaitable>::value, "");
+ std::__cxx_atomic_notify_one(__atomic_waitable_traits<__decay_t<_AtomicWaitable> >::__atomic_contention_address(__a));
+}
+
+template <class _AtomicWaitable>
+_LIBCPP_AVAILABILITY_SYNC _LIBCPP_HIDE_FROM_ABI void __atomic_notify_all(const _AtomicWaitable& __a) {
+ static_assert(__atomic_waitable<_AtomicWaitable>::value, "");
+ std::__cxx_atomic_notify_all(__atomic_waitable_traits<__decay_t<_AtomicWaitable> >::__atomic_contention_address(__a));
}
#else // _LIBCPP_HAS_NO_THREADS
-template <class _Tp>
-_LIBCPP_HIDE_FROM_ABI void __cxx_atomic_notify_all(__cxx_atomic_impl<_Tp> const volatile*) {}
-template <class _Tp>
-_LIBCPP_HIDE_FROM_ABI void __cxx_atomic_notify_one(__cxx_atomic_impl<_Tp> const volatile*) {}
-template <class _Atp, class _Poll>
-_LIBCPP_HIDE_FROM_ABI void __cxx_atomic_wait_unless(_Atp* __a, _Poll&& __poll, memory_order __order) {
- __libcpp_atomic_wait_poll_impl<_Atp, __decay_t<_Poll> > __poll_fn = {__a, __poll, __order};
- (void)std::__libcpp_thread_poll_with_backoff(__poll_fn, __spinning_backoff_policy());
+template <class _AtomicWaitable, class _Poll>
+_LIBCPP_HIDE_FROM_ABI void __atomic_wait_unless(const _AtomicWaitable& __a, _Poll&& __poll, memory_order __order) {
+ __atomic_wait_poll_impl<_AtomicWaitable, __decay_t<_Poll> > __poll_fn = {__a, __poll, __order};
+ std::__libcpp_thread_poll_with_backoff(__poll_fn, __spinning_backoff_policy());
}
+template <class _AtomicWaitable>
+_LIBCPP_HIDE_FROM_ABI void __atomic_notify_one(const _AtomicWaitable&) {}
+
+template <class _AtomicWaitable>
+_LIBCPP_HIDE_FROM_ABI void __atomic_notify_all(const _AtomicWaitable&) {}
+
#endif // _LIBCPP_HAS_NO_THREADS
template <typename _Tp>
@@ -143,11 +190,12 @@ struct __atomic_compare_unequal_to {
}
};
-template <class _Atp, class _Tp>
+template <class _AtomicWaitable, class _Up>
_LIBCPP_AVAILABILITY_SYNC _LIBCPP_HIDE_FROM_ABI void
-__cxx_atomic_wait(_Atp* __a, _Tp const __val, memory_order __order) {
- __atomic_compare_unequal_to<_Tp> __poll_fn = {__val};
- std::__cxx_atomic_wait_unless(__a, __poll_fn, __order);
+__atomic_wait(_AtomicWaitable& __a, _Up __val, memory_order __order) {
+ static_assert(__atomic_waitable<_AtomicWaitable>::value, "");
+ __atomic_compare_unequal_to<_Up> __nonatomic_equal = {__val};
+ std::__atomic_wait_unless(__a, __nonatomic_equal, __order);
}
_LIBCPP_END_NAMESPACE_STD
diff --git a/libcxx/include/latch b/libcxx/include/latch
index 3fe201b63d1385..3cc72583811434 100644
--- a/libcxx/include/latch
+++ b/libcxx/include/latch
@@ -102,8 +102,8 @@ public:
return try_wait_impl(__value);
}
inline _LIBCPP_AVAILABILITY_SYNC _LIBCPP_HIDE_FROM_ABI void wait() const {
- __cxx_atomic_wait_unless(
- &__a_.__a_, [this](ptrdiff_t& __value) -> bool { return try_wait_impl(__value); }, memory_order_acquire);
+ std::__atomic_wait_unless(
+ __a_, [this](ptrdiff_t& __value) -> bool { return try_wait_impl(__value); }, memory_order_acquire);
}
inline _LIBCPP_AVAILABILITY_SYNC _LIBCPP_HIDE_FROM_ABI void arrive_and_wait(ptrdiff_t __update = 1) {
_LIBCPP_ASSERT_ARGUMENT_WITHIN_DOMAIN(__update >= 0, "latch::arrive_and_wait called with a negative value");
@@ -114,7 +114,7 @@ public:
}
private:
- inline _LIBCPP_HIDE_FROM_ABI bool try_wait_impl(ptrdiff_t& __value) const noexcept { return __value == 0; }
+ _LIBCPP_HIDE_FROM_ABI bool try_wait_impl(ptrdiff_t& __value) const noexcept { return __value == 0; }
};
_LIBCPP_END_NAMESPACE_STD
diff --git a/libcxx/include/semaphore b/libcxx/include/semaphore
index 2dfdae9aa148c1..1375ec3f7c04b1 100644
--- a/libcxx/include/semaphore
+++ b/libcxx/include/semaphore
@@ -99,8 +99,8 @@ public:
}
}
_LIBCPP_AVAILABILITY_SYNC _LIBCPP_HIDE_FROM_ABI void acquire() {
- __cxx_atomic_wait_unless(
- &__a_.__a_, [this](ptrdiff_t& __old) { return __try_acquire_impl(__old); }, memory_order_relaxed);
+ std::__atomic_wait_unless(
+ __a_, [this](ptrdiff_t& __old) { return __try_acquire_impl(__old); }, memory_order_relaxed);
}
template <class _Rep, class _Period>
_LIBCPP_AVAILABILITY_SYNC _LIBCPP_HIDE_FROM_ABI bool
>From 57f599d6443a910a213094646e7e26837a1d4417 Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?Timm=20B=C3=A4der?= <tbaeder at redhat.com>
Date: Fri, 1 Mar 2024 19:25:38 +0100
Subject: [PATCH 352/406] [clang][Interp] Improve handling of external
variables
Further down in this function, we assert that the variable has
an initializer, which didn't work for external declarations.
---
clang/lib/AST/Interp/ByteCodeExprGen.cpp | 5 +++++
clang/test/AST/Interp/literals.cpp | 7 +++++++
2 files changed, 12 insertions(+)
diff --git a/clang/lib/AST/Interp/ByteCodeExprGen.cpp b/clang/lib/AST/Interp/ByteCodeExprGen.cpp
index 63ab80f59dac46..b4110d5856d512 100644
--- a/clang/lib/AST/Interp/ByteCodeExprGen.cpp
+++ b/clang/lib/AST/Interp/ByteCodeExprGen.cpp
@@ -2663,6 +2663,11 @@ bool ByteCodeExprGen<Emitter>::visitVarDecl(const VarDecl *VD) {
if (P.getGlobal(VD))
return true;
+ // Ignore external declarations. We will instead emit a dummy
+ // pointer when we see a DeclRefExpr for them.
+ if (VD->hasExternalStorage())
+ return true;
+
std::optional<unsigned> GlobalIndex = P.createGlobal(VD, Init);
if (!GlobalIndex)
diff --git a/clang/test/AST/Interp/literals.cpp b/clang/test/AST/Interp/literals.cpp
index 10b687c1408ac3..d86609108ca446 100644
--- a/clang/test/AST/Interp/literals.cpp
+++ b/clang/test/AST/Interp/literals.cpp
@@ -1168,3 +1168,10 @@ namespace incdecbool {
}
+
+#if __cplusplus >= 201402L
+constexpr int externvar1() { // both-error {{never produces a constant expression}}
+ extern char arr[]; // both-note {{declared here}}
+ return arr[0]; // both-note {{read of non-constexpr variable 'arr'}}
+}
+#endif
>From a30ba2ca21b0da49631c6d0c52108e4a080a451e Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?Timm=20B=C3=A4der?= <tbaeder at redhat.com>
Date: Fri, 1 Mar 2024 19:27:37 +0100
Subject: [PATCH 353/406] [clang][Interp][NFC] Emit diagnostic for unknown
builtins
Instead of just returning false.
---
clang/lib/AST/Interp/InterpBuiltin.cpp | 4 ++++
1 file changed, 4 insertions(+)
diff --git a/clang/lib/AST/Interp/InterpBuiltin.cpp b/clang/lib/AST/Interp/InterpBuiltin.cpp
index 4ba518e5f0619c..371240065179e3 100644
--- a/clang/lib/AST/Interp/InterpBuiltin.cpp
+++ b/clang/lib/AST/Interp/InterpBuiltin.cpp
@@ -1207,6 +1207,10 @@ bool InterpretBuiltin(InterpState &S, CodePtr OpPC, const Function *F,
break;
default:
+ S.FFDiag(S.Current->getLocation(OpPC),
+ diag::note_invalid_subexpr_in_const_expr)
+ << S.Current->getRange(OpPC);
+
return false;
}
>From b901b0d3edeaa30e363af4cb9dc76d6a7072e6cf Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?Timm=20B=C3=A4der?= <tbaeder at redhat.com>
Date: Fri, 1 Mar 2024 19:28:13 +0100
Subject: [PATCH 354/406] [clang][Interp] Reject dummy pointers from
__builtin_strcmp()
We can't load anything from them, so reject them here.
---
clang/lib/AST/Interp/InterpBuiltin.cpp | 3 +++
clang/test/AST/Interp/builtin-functions.cpp | 8 ++++++++
2 files changed, 11 insertions(+)
diff --git a/clang/lib/AST/Interp/InterpBuiltin.cpp b/clang/lib/AST/Interp/InterpBuiltin.cpp
index 371240065179e3..de3d72169432fd 100644
--- a/clang/lib/AST/Interp/InterpBuiltin.cpp
+++ b/clang/lib/AST/Interp/InterpBuiltin.cpp
@@ -132,6 +132,9 @@ static bool interp__builtin_strcmp(InterpState &S, CodePtr OpPC,
if (!CheckLive(S, OpPC, A, AK_Read) || !CheckLive(S, OpPC, B, AK_Read))
return false;
+ if (A.isDummy() || B.isDummy())
+ return false;
+
assert(A.getFieldDesc()->isPrimitiveArray());
assert(B.getFieldDesc()->isPrimitiveArray());
diff --git a/clang/test/AST/Interp/builtin-functions.cpp b/clang/test/AST/Interp/builtin-functions.cpp
index 3701106e02f05b..ab8abac4b36e34 100644
--- a/clang/test/AST/Interp/builtin-functions.cpp
+++ b/clang/test/AST/Interp/builtin-functions.cpp
@@ -34,6 +34,14 @@ namespace strcmp {
static_assert(__builtin_strcmp(kFoobar, kFoobazfoobar + 6) == 0, ""); // both-error {{not an integral constant}} \
// both-note {{dereferenced one-past-the-end}} \
// expected-note {{in call to}}
+
+ /// Used to assert because we're passing a dummy pointer to
+ /// __builtin_strcmp() when evaluating the return statement.
+ constexpr bool char_memchr_mutable() {
+ char buffer[] = "mutable";
+ return __builtin_strcmp(buffer, "mutable") == 0;
+ }
+ static_assert(char_memchr_mutable(), "");
}
/// Copied from constant-expression-cxx11.cpp
>From dfb8a1531c962238a63db199dff973deec47e4ff Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?Timm=20B=C3=A4der?= <tbaeder at redhat.com>
Date: Fri, 1 Mar 2024 19:44:16 +0100
Subject: [PATCH 355/406] [clang][Interp][NFC] Make a local variable const
---
clang/lib/AST/Interp/InterpBuiltin.cpp | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/clang/lib/AST/Interp/InterpBuiltin.cpp b/clang/lib/AST/Interp/InterpBuiltin.cpp
index de3d72169432fd..6550a07650c887 100644
--- a/clang/lib/AST/Interp/InterpBuiltin.cpp
+++ b/clang/lib/AST/Interp/InterpBuiltin.cpp
@@ -1237,7 +1237,7 @@ bool InterpretOffsetOf(InterpState &S, CodePtr OpPC, const OffsetOfExpr *E,
const RecordType *RT = CurrentType->getAs<RecordType>();
if (!RT)
return false;
- RecordDecl *RD = RT->getDecl();
+ const RecordDecl *RD = RT->getDecl();
if (RD->isInvalidDecl())
return false;
const ASTRecordLayout &RL = S.getCtx().getASTRecordLayout(RD);
>From f25debe58b61a6d66e662d60fd4c060adcd74630 Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?Timm=20B=C3=A4der?= <tbaeder at redhat.com>
Date: Fri, 1 Mar 2024 19:47:32 +0100
Subject: [PATCH 356/406] [clang][Interp][NFC] Remove some leftover debug
output
---
clang/lib/AST/Interp/InterpBuiltin.cpp | 3 ---
1 file changed, 3 deletions(-)
diff --git a/clang/lib/AST/Interp/InterpBuiltin.cpp b/clang/lib/AST/Interp/InterpBuiltin.cpp
index 6550a07650c887..cc457ce41af595 100644
--- a/clang/lib/AST/Interp/InterpBuiltin.cpp
+++ b/clang/lib/AST/Interp/InterpBuiltin.cpp
@@ -463,9 +463,6 @@ static bool interp__builtin_popcount(InterpState &S, CodePtr OpPC,
const InterpFrame *Frame,
const Function *Func,
const CallExpr *Call) {
-
- Func->getDecl()->dump();
-
PrimType ArgT = *S.getContext().classify(Call->getArg(0)->getType());
APSInt Val = peekToAPSInt(S.Stk, ArgT);
pushInteger(S, Val.popcount(), Call->getType());
>From d89b771ef5fe39403a2ad525fa36efbc4ce2a517 Mon Sep 17 00:00:00 2001
From: Fangrui Song <i at maskray.me>
Date: Sat, 2 Mar 2024 10:33:57 -0800
Subject: [PATCH 357/406] [ARM] Add alias tests for ROPI/RWPI
https://reviews.llvm.org/D23195 does not test aliases.
---
.../CodeGen/ARM/arm-position-independence.ll | 34 +++++++++++++++++++
1 file changed, 34 insertions(+)
diff --git a/llvm/test/CodeGen/ARM/arm-position-independence.ll b/llvm/test/CodeGen/ARM/arm-position-independence.ll
index 54b525b879d926..f6be5866c2838c 100644
--- a/llvm/test/CodeGen/ARM/arm-position-independence.ll
+++ b/llvm/test/CodeGen/ARM/arm-position-independence.ll
@@ -23,6 +23,11 @@ target datalayout = "e-m:e-p:32:32-i64:64-v128:64:128-a:0:32-n32-S64"
@a = external global i32, align 4
@b = external constant i32, align 4
+ at c0 = global i32 42, align 4
+ at c1 = alias i32, ptr @c0
+ at d0 = constant i32 42, align 4
+ at d1 = alias i32, ptr @d0
+ at take_addr_func_alias1 = alias ptr (), ptr @take_addr_func_alias
define i32 @read() {
entry:
@@ -360,6 +365,35 @@ entry:
; THUMB1_RO_PC-NEXT: .long take_addr_func-([[LPC]]+4)
}
+define ptr @take_addr_alias() {
+entry:
+ ret ptr @c1
+}
+; CHECK-LABEL: take_addr_alias:
+; ARM_RW_SB: movw r[[REG:[0-9]]], :lower16:c1(sbrel)
+; ARM_RW_SB: movt r[[REG]], :upper16:c1(sbrel)
+; ARM_RW_SB: add r0, r9, r[[REG]]
+
+define ptr @take_addr_const_alias() {
+entry:
+ ret ptr @d1
+}
+; CHECK-LABEL: take_addr_const_alias:
+; ARM_RO_PC: movw [[REG:r[0-9]]], :lower16:(d1-([[LPC:.LPC[0-9]+_[0-9]+]]+8))
+; ARM_RO_PC-NEXT: movt [[REG]], :upper16:(d1-([[LPC]]+8))
+; ARM_RO_PC-NEXT: [[LPC]]:
+; ARM_RO_PC-NEXT: add r0, pc, [[REG]]
+
+define weak ptr @take_addr_func_alias() {
+entry:
+ ret ptr @take_addr_func_alias1
+}
+; CHECK-LABEL: take_addr_func_alias:
+; ARM_RO_PC: movw [[REG:r[0-9]]], :lower16:(take_addr_func_alias1-([[LPC:.LPC[0-9]+_[0-9]+]]+8))
+; ARM_RO_PC-NEXT: movt [[REG]], :upper16:(take_addr_func_alias1-([[LPC]]+8))
+; ARM_RO_PC-NEXT: [[LPC]]:
+; ARM_RO_PC-NEXT: add r0, pc, [[REG]]
+
define ptr @block_addr() {
entry:
br label %lab1
>From af83a2add5687d0c2f70e538612b7e86ccbf47a5 Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?Micha=C5=82=20G=C3=B3rny?= <mgorny at gentoo.org>
Date: Sat, 2 Mar 2024 20:08:44 +0100
Subject: [PATCH 358/406] [lld] Fixes for unitests in standalone builds
(#83670)
1. Replace the obsolete `llvm_add_unittests()` CMake function with an
explicit check for `TARGET llvm_gtest`. This is more consistent with the
rest of the code, and it makes it possible to avoid checking out
`third-party` tree.
2. Add `LLDUnitTests` test dependency to standalone builds. It is
defined unconditionally, and actually necessary to ensure that unit
tests will be built.
---
lld/CMakeLists.txt | 4 +++-
lld/test/CMakeLists.txt | 3 +--
llvm/cmake/modules/AddLLVM.cmake | 10 ----------
3 files changed, 4 insertions(+), 13 deletions(-)
diff --git a/lld/CMakeLists.txt b/lld/CMakeLists.txt
index 595c286abd91a6..cd8ba627306edb 100644
--- a/lld/CMakeLists.txt
+++ b/lld/CMakeLists.txt
@@ -192,7 +192,9 @@ add_subdirectory(tools/lld)
if (LLVM_INCLUDE_TESTS)
add_custom_target(LLDUnitTests)
- llvm_add_unittests(LLD_UNITTESTS_ADDED)
+ if (TARGET llvm_gtest)
+ add_subdirectory(unittests)
+ endif()
add_subdirectory(test)
endif()
diff --git a/lld/test/CMakeLists.txt b/lld/test/CMakeLists.txt
index 558da2b4421a2c..bb6164f19dcef3 100644
--- a/lld/test/CMakeLists.txt
+++ b/lld/test/CMakeLists.txt
@@ -38,11 +38,10 @@ configure_lit_site_cfg(
"LLD_SOURCE_DIR"
)
-set(LLD_TEST_DEPS lld)
+set(LLD_TEST_DEPS lld LLDUnitTests)
if (NOT LLD_BUILT_STANDALONE)
list(APPEND LLD_TEST_DEPS
FileCheck
- LLDUnitTests
count
dsymutil
llc
diff --git a/llvm/cmake/modules/AddLLVM.cmake b/llvm/cmake/modules/AddLLVM.cmake
index 0f1734a64ee6e6..828de4bd9940d6 100644
--- a/llvm/cmake/modules/AddLLVM.cmake
+++ b/llvm/cmake/modules/AddLLVM.cmake
@@ -2509,13 +2509,3 @@ function(setup_host_tool tool_name setting_name exe_var_name target_var_name)
add_custom_target(${target_var_name} DEPENDS ${exe_name})
endif()
endfunction()
-
-# Adds the unittests folder if gtest is available.
-function(llvm_add_unittests tests_added)
- if (EXISTS ${LLVM_THIRD_PARTY_DIR}/unittest/googletest/include/gtest/gtest.h)
- add_subdirectory(unittests)
- set(${tests_added} ON PARENT_SCOPE)
- else()
- message(WARNING "gtest not found, unittests will not be available")
- endif()
-endfunction()
>From da591d390e7f865c846d12dc5559875eca347c28 Mon Sep 17 00:00:00 2001
From: Bjorn Pettersson <bjorn.a.pettersson at ericsson.com>
Date: Fri, 3 Nov 2023 12:44:38 +0100
Subject: [PATCH 359/406] [GlobalISel][TableGen] Take first result for
multi-output instructions (#81130)
Previously, tblgen would reject patterns where one of its nested
instructions produced more than one result. These arise when the
instruction definition contains 'outs' as well as 'Defs'. This patch
fixes that by always taking the first result, which is how these
situations are handled in SelectionIDAG.
Original patch: https://reviews.llvm.org/D86617
Continued as: https://github.com/llvm/llvm-project/pull/81130
---
.../AMDGPU/GlobalISel/inst-select-fabs.mir | 72 ++++++++++---------
.../AMDGPU/GlobalISel/inst-select-fneg.mir | 72 ++++++++++---------
.../AMDGPU/GlobalISel/inst-select-sext.mir | 16 +++--
.../AMDGPU/GlobalISel/inst-select-zext.mir | 10 +--
...lobalISelEmitter-multiple-output-reject.td | 14 ++++
.../GlobalISelEmitter-multiple-output.td | 33 +++++++++
llvm/utils/TableGen/GlobalISelEmitter.cpp | 29 +++++---
7 files changed, 164 insertions(+), 82 deletions(-)
create mode 100644 llvm/test/TableGen/GlobalISelEmitter-multiple-output-reject.td
diff --git a/llvm/test/CodeGen/AMDGPU/GlobalISel/inst-select-fabs.mir b/llvm/test/CodeGen/AMDGPU/GlobalISel/inst-select-fabs.mir
index aca51802511b92..ca75fd207607a5 100644
--- a/llvm/test/CodeGen/AMDGPU/GlobalISel/inst-select-fabs.mir
+++ b/llvm/test/CodeGen/AMDGPU/GlobalISel/inst-select-fabs.mir
@@ -426,44 +426,48 @@ body: |
; SI: liveins: $sgpr0_sgpr1
; SI-NEXT: {{ $}}
; SI-NEXT: [[COPY:%[0-9]+]]:sreg_64 = COPY $sgpr0_sgpr1
- ; SI-NEXT: [[COPY1:%[0-9]+]]:sreg_32 = COPY [[COPY]].sub0
- ; SI-NEXT: [[COPY2:%[0-9]+]]:sreg_32 = COPY [[COPY]].sub1
; SI-NEXT: [[S_MOV_B32_:%[0-9]+]]:sreg_32 = S_MOV_B32 2147483647
- ; SI-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32 = S_AND_B32 [[COPY2]], [[S_MOV_B32_]], implicit-def dead $scc
- ; SI-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY1]], %subreg.sub0, [[S_AND_B32_]], %subreg.sub1
+ ; SI-NEXT: [[COPY1:%[0-9]+]]:sreg_32_xm0 = COPY [[COPY]].sub1
+ ; SI-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32 = S_AND_B32 [[COPY1]], [[S_MOV_B32_]], implicit-def dead $scc
+ ; SI-NEXT: [[COPY2:%[0-9]+]]:sreg_32_xm0 = COPY [[S_AND_B32_]]
+ ; SI-NEXT: [[COPY3:%[0-9]+]]:sreg_32_xexec_hi_and_sreg_32_xm0 = COPY [[COPY]].sub0
+ ; SI-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY3]], %subreg.sub0, [[COPY2]], %subreg.sub1
; SI-NEXT: S_ENDPGM 0, implicit [[REG_SEQUENCE]]
;
; VI-LABEL: name: fabs_s64_ss
; VI: liveins: $sgpr0_sgpr1
; VI-NEXT: {{ $}}
; VI-NEXT: [[COPY:%[0-9]+]]:sreg_64 = COPY $sgpr0_sgpr1
- ; VI-NEXT: [[COPY1:%[0-9]+]]:sreg_32 = COPY [[COPY]].sub0
- ; VI-NEXT: [[COPY2:%[0-9]+]]:sreg_32 = COPY [[COPY]].sub1
; VI-NEXT: [[S_MOV_B32_:%[0-9]+]]:sreg_32 = S_MOV_B32 2147483647
- ; VI-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32 = S_AND_B32 [[COPY2]], [[S_MOV_B32_]], implicit-def dead $scc
- ; VI-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY1]], %subreg.sub0, [[S_AND_B32_]], %subreg.sub1
+ ; VI-NEXT: [[COPY1:%[0-9]+]]:sreg_32_xm0 = COPY [[COPY]].sub1
+ ; VI-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32 = S_AND_B32 [[COPY1]], [[S_MOV_B32_]], implicit-def dead $scc
+ ; VI-NEXT: [[COPY2:%[0-9]+]]:sreg_32_xm0 = COPY [[S_AND_B32_]]
+ ; VI-NEXT: [[COPY3:%[0-9]+]]:sreg_32_xexec_hi_and_sreg_32_xm0 = COPY [[COPY]].sub0
+ ; VI-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY3]], %subreg.sub0, [[COPY2]], %subreg.sub1
; VI-NEXT: S_ENDPGM 0, implicit [[REG_SEQUENCE]]
;
; GFX9-LABEL: name: fabs_s64_ss
; GFX9: liveins: $sgpr0_sgpr1
; GFX9-NEXT: {{ $}}
; GFX9-NEXT: [[COPY:%[0-9]+]]:sreg_64 = COPY $sgpr0_sgpr1
- ; GFX9-NEXT: [[COPY1:%[0-9]+]]:sreg_32 = COPY [[COPY]].sub0
- ; GFX9-NEXT: [[COPY2:%[0-9]+]]:sreg_32 = COPY [[COPY]].sub1
; GFX9-NEXT: [[S_MOV_B32_:%[0-9]+]]:sreg_32 = S_MOV_B32 2147483647
- ; GFX9-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32 = S_AND_B32 [[COPY2]], [[S_MOV_B32_]], implicit-def dead $scc
- ; GFX9-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY1]], %subreg.sub0, [[S_AND_B32_]], %subreg.sub1
+ ; GFX9-NEXT: [[COPY1:%[0-9]+]]:sreg_32_xm0 = COPY [[COPY]].sub1
+ ; GFX9-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32 = S_AND_B32 [[COPY1]], [[S_MOV_B32_]], implicit-def dead $scc
+ ; GFX9-NEXT: [[COPY2:%[0-9]+]]:sreg_32_xm0 = COPY [[S_AND_B32_]]
+ ; GFX9-NEXT: [[COPY3:%[0-9]+]]:sreg_32_xexec_hi_and_sreg_32_xm0 = COPY [[COPY]].sub0
+ ; GFX9-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY3]], %subreg.sub0, [[COPY2]], %subreg.sub1
; GFX9-NEXT: S_ENDPGM 0, implicit [[REG_SEQUENCE]]
;
; GFX10-LABEL: name: fabs_s64_ss
; GFX10: liveins: $sgpr0_sgpr1
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: [[COPY:%[0-9]+]]:sreg_64 = COPY $sgpr0_sgpr1
- ; GFX10-NEXT: [[COPY1:%[0-9]+]]:sreg_32 = COPY [[COPY]].sub0
- ; GFX10-NEXT: [[COPY2:%[0-9]+]]:sreg_32 = COPY [[COPY]].sub1
; GFX10-NEXT: [[S_MOV_B32_:%[0-9]+]]:sreg_32 = S_MOV_B32 2147483647
- ; GFX10-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32 = S_AND_B32 [[COPY2]], [[S_MOV_B32_]], implicit-def dead $scc
- ; GFX10-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY1]], %subreg.sub0, [[S_AND_B32_]], %subreg.sub1
+ ; GFX10-NEXT: [[COPY1:%[0-9]+]]:sreg_32_xm0 = COPY [[COPY]].sub1
+ ; GFX10-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32 = S_AND_B32 [[COPY1]], [[S_MOV_B32_]], implicit-def dead $scc
+ ; GFX10-NEXT: [[COPY2:%[0-9]+]]:sreg_32_xm0 = COPY [[S_AND_B32_]]
+ ; GFX10-NEXT: [[COPY3:%[0-9]+]]:sreg_32_xexec_hi_and_sreg_32_xm0 = COPY [[COPY]].sub0
+ ; GFX10-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY3]], %subreg.sub0, [[COPY2]], %subreg.sub1
; GFX10-NEXT: S_ENDPGM 0, implicit [[REG_SEQUENCE]]
%0:sgpr(s64) = COPY $sgpr0_sgpr1
%1:sgpr(s64) = G_FABS %0
@@ -639,44 +643,48 @@ body: |
; SI: liveins: $sgpr0_sgpr1
; SI-NEXT: {{ $}}
; SI-NEXT: [[DEF:%[0-9]+]]:sreg_64 = IMPLICIT_DEF
- ; SI-NEXT: [[COPY:%[0-9]+]]:sreg_32 = COPY [[DEF]].sub0
- ; SI-NEXT: [[COPY1:%[0-9]+]]:sreg_32 = COPY [[DEF]].sub1
; SI-NEXT: [[S_MOV_B32_:%[0-9]+]]:sreg_32 = S_MOV_B32 2147483647
- ; SI-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32 = S_AND_B32 [[COPY1]], [[S_MOV_B32_]], implicit-def dead $scc
- ; SI-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY]], %subreg.sub0, [[S_AND_B32_]], %subreg.sub1
+ ; SI-NEXT: [[COPY:%[0-9]+]]:sreg_32_xm0 = COPY [[DEF]].sub1
+ ; SI-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32 = S_AND_B32 [[COPY]], [[S_MOV_B32_]], implicit-def dead $scc
+ ; SI-NEXT: [[COPY1:%[0-9]+]]:sreg_32_xm0 = COPY [[S_AND_B32_]]
+ ; SI-NEXT: [[COPY2:%[0-9]+]]:sreg_32_xexec_hi_and_sreg_32_xm0 = COPY [[DEF]].sub0
+ ; SI-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY2]], %subreg.sub0, [[COPY1]], %subreg.sub1
; SI-NEXT: S_ENDPGM 0, implicit [[REG_SEQUENCE]]
;
; VI-LABEL: name: fabs_s64_ss_no_src_constraint
; VI: liveins: $sgpr0_sgpr1
; VI-NEXT: {{ $}}
; VI-NEXT: [[DEF:%[0-9]+]]:sreg_64 = IMPLICIT_DEF
- ; VI-NEXT: [[COPY:%[0-9]+]]:sreg_32 = COPY [[DEF]].sub0
- ; VI-NEXT: [[COPY1:%[0-9]+]]:sreg_32 = COPY [[DEF]].sub1
; VI-NEXT: [[S_MOV_B32_:%[0-9]+]]:sreg_32 = S_MOV_B32 2147483647
- ; VI-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32 = S_AND_B32 [[COPY1]], [[S_MOV_B32_]], implicit-def dead $scc
- ; VI-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY]], %subreg.sub0, [[S_AND_B32_]], %subreg.sub1
+ ; VI-NEXT: [[COPY:%[0-9]+]]:sreg_32_xm0 = COPY [[DEF]].sub1
+ ; VI-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32 = S_AND_B32 [[COPY]], [[S_MOV_B32_]], implicit-def dead $scc
+ ; VI-NEXT: [[COPY1:%[0-9]+]]:sreg_32_xm0 = COPY [[S_AND_B32_]]
+ ; VI-NEXT: [[COPY2:%[0-9]+]]:sreg_32_xexec_hi_and_sreg_32_xm0 = COPY [[DEF]].sub0
+ ; VI-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY2]], %subreg.sub0, [[COPY1]], %subreg.sub1
; VI-NEXT: S_ENDPGM 0, implicit [[REG_SEQUENCE]]
;
; GFX9-LABEL: name: fabs_s64_ss_no_src_constraint
; GFX9: liveins: $sgpr0_sgpr1
; GFX9-NEXT: {{ $}}
; GFX9-NEXT: [[DEF:%[0-9]+]]:sreg_64 = IMPLICIT_DEF
- ; GFX9-NEXT: [[COPY:%[0-9]+]]:sreg_32 = COPY [[DEF]].sub0
- ; GFX9-NEXT: [[COPY1:%[0-9]+]]:sreg_32 = COPY [[DEF]].sub1
; GFX9-NEXT: [[S_MOV_B32_:%[0-9]+]]:sreg_32 = S_MOV_B32 2147483647
- ; GFX9-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32 = S_AND_B32 [[COPY1]], [[S_MOV_B32_]], implicit-def dead $scc
- ; GFX9-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY]], %subreg.sub0, [[S_AND_B32_]], %subreg.sub1
+ ; GFX9-NEXT: [[COPY:%[0-9]+]]:sreg_32_xm0 = COPY [[DEF]].sub1
+ ; GFX9-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32 = S_AND_B32 [[COPY]], [[S_MOV_B32_]], implicit-def dead $scc
+ ; GFX9-NEXT: [[COPY1:%[0-9]+]]:sreg_32_xm0 = COPY [[S_AND_B32_]]
+ ; GFX9-NEXT: [[COPY2:%[0-9]+]]:sreg_32_xexec_hi_and_sreg_32_xm0 = COPY [[DEF]].sub0
+ ; GFX9-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY2]], %subreg.sub0, [[COPY1]], %subreg.sub1
; GFX9-NEXT: S_ENDPGM 0, implicit [[REG_SEQUENCE]]
;
; GFX10-LABEL: name: fabs_s64_ss_no_src_constraint
; GFX10: liveins: $sgpr0_sgpr1
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: [[DEF:%[0-9]+]]:sreg_64 = IMPLICIT_DEF
- ; GFX10-NEXT: [[COPY:%[0-9]+]]:sreg_32 = COPY [[DEF]].sub0
- ; GFX10-NEXT: [[COPY1:%[0-9]+]]:sreg_32 = COPY [[DEF]].sub1
; GFX10-NEXT: [[S_MOV_B32_:%[0-9]+]]:sreg_32 = S_MOV_B32 2147483647
- ; GFX10-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32 = S_AND_B32 [[COPY1]], [[S_MOV_B32_]], implicit-def dead $scc
- ; GFX10-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY]], %subreg.sub0, [[S_AND_B32_]], %subreg.sub1
+ ; GFX10-NEXT: [[COPY:%[0-9]+]]:sreg_32_xm0 = COPY [[DEF]].sub1
+ ; GFX10-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32 = S_AND_B32 [[COPY]], [[S_MOV_B32_]], implicit-def dead $scc
+ ; GFX10-NEXT: [[COPY1:%[0-9]+]]:sreg_32_xm0 = COPY [[S_AND_B32_]]
+ ; GFX10-NEXT: [[COPY2:%[0-9]+]]:sreg_32_xexec_hi_and_sreg_32_xm0 = COPY [[DEF]].sub0
+ ; GFX10-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY2]], %subreg.sub0, [[COPY1]], %subreg.sub1
; GFX10-NEXT: S_ENDPGM 0, implicit [[REG_SEQUENCE]]
%0:sgpr(s64) = IMPLICIT_DEF
%1:sgpr(s64) = G_FABS %0:sgpr(s64)
diff --git a/llvm/test/CodeGen/AMDGPU/GlobalISel/inst-select-fneg.mir b/llvm/test/CodeGen/AMDGPU/GlobalISel/inst-select-fneg.mir
index e7a52873225ead..acda00231ec612 100644
--- a/llvm/test/CodeGen/AMDGPU/GlobalISel/inst-select-fneg.mir
+++ b/llvm/test/CodeGen/AMDGPU/GlobalISel/inst-select-fneg.mir
@@ -426,44 +426,48 @@ body: |
; SI: liveins: $sgpr0_sgpr1
; SI-NEXT: {{ $}}
; SI-NEXT: [[COPY:%[0-9]+]]:sreg_64 = COPY $sgpr0_sgpr1
- ; SI-NEXT: [[COPY1:%[0-9]+]]:sreg_32 = COPY [[COPY]].sub0
- ; SI-NEXT: [[COPY2:%[0-9]+]]:sreg_32 = COPY [[COPY]].sub1
; SI-NEXT: [[S_MOV_B32_:%[0-9]+]]:sreg_32 = S_MOV_B32 2147483648
- ; SI-NEXT: [[S_XOR_B32_:%[0-9]+]]:sreg_32 = S_XOR_B32 [[COPY2]], [[S_MOV_B32_]], implicit-def dead $scc
- ; SI-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY1]], %subreg.sub0, [[S_XOR_B32_]], %subreg.sub1
+ ; SI-NEXT: [[COPY1:%[0-9]+]]:sreg_32_xm0 = COPY [[COPY]].sub1
+ ; SI-NEXT: [[S_XOR_B32_:%[0-9]+]]:sreg_32 = S_XOR_B32 [[COPY1]], [[S_MOV_B32_]], implicit-def dead $scc
+ ; SI-NEXT: [[COPY2:%[0-9]+]]:sreg_32_xm0 = COPY [[S_XOR_B32_]]
+ ; SI-NEXT: [[COPY3:%[0-9]+]]:sreg_32_xexec_hi_and_sreg_32_xm0 = COPY [[COPY]].sub0
+ ; SI-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY3]], %subreg.sub0, [[COPY2]], %subreg.sub1
; SI-NEXT: S_ENDPGM 0, implicit [[REG_SEQUENCE]]
;
; VI-LABEL: name: fneg_s64_ss
; VI: liveins: $sgpr0_sgpr1
; VI-NEXT: {{ $}}
; VI-NEXT: [[COPY:%[0-9]+]]:sreg_64 = COPY $sgpr0_sgpr1
- ; VI-NEXT: [[COPY1:%[0-9]+]]:sreg_32 = COPY [[COPY]].sub0
- ; VI-NEXT: [[COPY2:%[0-9]+]]:sreg_32 = COPY [[COPY]].sub1
; VI-NEXT: [[S_MOV_B32_:%[0-9]+]]:sreg_32 = S_MOV_B32 2147483648
- ; VI-NEXT: [[S_XOR_B32_:%[0-9]+]]:sreg_32 = S_XOR_B32 [[COPY2]], [[S_MOV_B32_]], implicit-def dead $scc
- ; VI-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY1]], %subreg.sub0, [[S_XOR_B32_]], %subreg.sub1
+ ; VI-NEXT: [[COPY1:%[0-9]+]]:sreg_32_xm0 = COPY [[COPY]].sub1
+ ; VI-NEXT: [[S_XOR_B32_:%[0-9]+]]:sreg_32 = S_XOR_B32 [[COPY1]], [[S_MOV_B32_]], implicit-def dead $scc
+ ; VI-NEXT: [[COPY2:%[0-9]+]]:sreg_32_xm0 = COPY [[S_XOR_B32_]]
+ ; VI-NEXT: [[COPY3:%[0-9]+]]:sreg_32_xexec_hi_and_sreg_32_xm0 = COPY [[COPY]].sub0
+ ; VI-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY3]], %subreg.sub0, [[COPY2]], %subreg.sub1
; VI-NEXT: S_ENDPGM 0, implicit [[REG_SEQUENCE]]
;
; GFX9-LABEL: name: fneg_s64_ss
; GFX9: liveins: $sgpr0_sgpr1
; GFX9-NEXT: {{ $}}
; GFX9-NEXT: [[COPY:%[0-9]+]]:sreg_64 = COPY $sgpr0_sgpr1
- ; GFX9-NEXT: [[COPY1:%[0-9]+]]:sreg_32 = COPY [[COPY]].sub0
- ; GFX9-NEXT: [[COPY2:%[0-9]+]]:sreg_32 = COPY [[COPY]].sub1
; GFX9-NEXT: [[S_MOV_B32_:%[0-9]+]]:sreg_32 = S_MOV_B32 2147483648
- ; GFX9-NEXT: [[S_XOR_B32_:%[0-9]+]]:sreg_32 = S_XOR_B32 [[COPY2]], [[S_MOV_B32_]], implicit-def dead $scc
- ; GFX9-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY1]], %subreg.sub0, [[S_XOR_B32_]], %subreg.sub1
+ ; GFX9-NEXT: [[COPY1:%[0-9]+]]:sreg_32_xm0 = COPY [[COPY]].sub1
+ ; GFX9-NEXT: [[S_XOR_B32_:%[0-9]+]]:sreg_32 = S_XOR_B32 [[COPY1]], [[S_MOV_B32_]], implicit-def dead $scc
+ ; GFX9-NEXT: [[COPY2:%[0-9]+]]:sreg_32_xm0 = COPY [[S_XOR_B32_]]
+ ; GFX9-NEXT: [[COPY3:%[0-9]+]]:sreg_32_xexec_hi_and_sreg_32_xm0 = COPY [[COPY]].sub0
+ ; GFX9-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY3]], %subreg.sub0, [[COPY2]], %subreg.sub1
; GFX9-NEXT: S_ENDPGM 0, implicit [[REG_SEQUENCE]]
;
; GFX10-LABEL: name: fneg_s64_ss
; GFX10: liveins: $sgpr0_sgpr1
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: [[COPY:%[0-9]+]]:sreg_64 = COPY $sgpr0_sgpr1
- ; GFX10-NEXT: [[COPY1:%[0-9]+]]:sreg_32 = COPY [[COPY]].sub0
- ; GFX10-NEXT: [[COPY2:%[0-9]+]]:sreg_32 = COPY [[COPY]].sub1
; GFX10-NEXT: [[S_MOV_B32_:%[0-9]+]]:sreg_32 = S_MOV_B32 2147483648
- ; GFX10-NEXT: [[S_XOR_B32_:%[0-9]+]]:sreg_32 = S_XOR_B32 [[COPY2]], [[S_MOV_B32_]], implicit-def dead $scc
- ; GFX10-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY1]], %subreg.sub0, [[S_XOR_B32_]], %subreg.sub1
+ ; GFX10-NEXT: [[COPY1:%[0-9]+]]:sreg_32_xm0 = COPY [[COPY]].sub1
+ ; GFX10-NEXT: [[S_XOR_B32_:%[0-9]+]]:sreg_32 = S_XOR_B32 [[COPY1]], [[S_MOV_B32_]], implicit-def dead $scc
+ ; GFX10-NEXT: [[COPY2:%[0-9]+]]:sreg_32_xm0 = COPY [[S_XOR_B32_]]
+ ; GFX10-NEXT: [[COPY3:%[0-9]+]]:sreg_32_xexec_hi_and_sreg_32_xm0 = COPY [[COPY]].sub0
+ ; GFX10-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY3]], %subreg.sub0, [[COPY2]], %subreg.sub1
; GFX10-NEXT: S_ENDPGM 0, implicit [[REG_SEQUENCE]]
%0:sgpr(s64) = COPY $sgpr0_sgpr1
%1:sgpr(s64) = G_FNEG %0
@@ -1023,44 +1027,48 @@ body: |
; SI: liveins: $sgpr0_sgpr1
; SI-NEXT: {{ $}}
; SI-NEXT: [[COPY:%[0-9]+]]:sreg_64 = COPY $sgpr0_sgpr1
- ; SI-NEXT: [[COPY1:%[0-9]+]]:sreg_32 = COPY [[COPY]].sub0
- ; SI-NEXT: [[COPY2:%[0-9]+]]:sreg_32 = COPY [[COPY]].sub1
; SI-NEXT: [[S_MOV_B32_:%[0-9]+]]:sreg_32 = S_MOV_B32 2147483648
- ; SI-NEXT: [[S_OR_B32_:%[0-9]+]]:sreg_32 = S_OR_B32 [[COPY2]], [[S_MOV_B32_]], implicit-def dead $scc
- ; SI-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY1]], %subreg.sub0, [[S_OR_B32_]], %subreg.sub1
+ ; SI-NEXT: [[COPY1:%[0-9]+]]:sreg_32_xm0 = COPY [[COPY]].sub1
+ ; SI-NEXT: [[S_OR_B32_:%[0-9]+]]:sreg_32 = S_OR_B32 [[COPY1]], [[S_MOV_B32_]], implicit-def dead $scc
+ ; SI-NEXT: [[COPY2:%[0-9]+]]:sreg_32_xm0 = COPY [[S_OR_B32_]]
+ ; SI-NEXT: [[COPY3:%[0-9]+]]:sreg_32_xexec_hi_and_sreg_32_xm0 = COPY [[COPY]].sub0
+ ; SI-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY3]], %subreg.sub0, [[COPY2]], %subreg.sub1
; SI-NEXT: S_ENDPGM 0, implicit [[REG_SEQUENCE]]
;
; VI-LABEL: name: fneg_fabs_s64_ss
; VI: liveins: $sgpr0_sgpr1
; VI-NEXT: {{ $}}
; VI-NEXT: [[COPY:%[0-9]+]]:sreg_64 = COPY $sgpr0_sgpr1
- ; VI-NEXT: [[COPY1:%[0-9]+]]:sreg_32 = COPY [[COPY]].sub0
- ; VI-NEXT: [[COPY2:%[0-9]+]]:sreg_32 = COPY [[COPY]].sub1
; VI-NEXT: [[S_MOV_B32_:%[0-9]+]]:sreg_32 = S_MOV_B32 2147483648
- ; VI-NEXT: [[S_OR_B32_:%[0-9]+]]:sreg_32 = S_OR_B32 [[COPY2]], [[S_MOV_B32_]], implicit-def dead $scc
- ; VI-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY1]], %subreg.sub0, [[S_OR_B32_]], %subreg.sub1
+ ; VI-NEXT: [[COPY1:%[0-9]+]]:sreg_32_xm0 = COPY [[COPY]].sub1
+ ; VI-NEXT: [[S_OR_B32_:%[0-9]+]]:sreg_32 = S_OR_B32 [[COPY1]], [[S_MOV_B32_]], implicit-def dead $scc
+ ; VI-NEXT: [[COPY2:%[0-9]+]]:sreg_32_xm0 = COPY [[S_OR_B32_]]
+ ; VI-NEXT: [[COPY3:%[0-9]+]]:sreg_32_xexec_hi_and_sreg_32_xm0 = COPY [[COPY]].sub0
+ ; VI-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY3]], %subreg.sub0, [[COPY2]], %subreg.sub1
; VI-NEXT: S_ENDPGM 0, implicit [[REG_SEQUENCE]]
;
; GFX9-LABEL: name: fneg_fabs_s64_ss
; GFX9: liveins: $sgpr0_sgpr1
; GFX9-NEXT: {{ $}}
; GFX9-NEXT: [[COPY:%[0-9]+]]:sreg_64 = COPY $sgpr0_sgpr1
- ; GFX9-NEXT: [[COPY1:%[0-9]+]]:sreg_32 = COPY [[COPY]].sub0
- ; GFX9-NEXT: [[COPY2:%[0-9]+]]:sreg_32 = COPY [[COPY]].sub1
; GFX9-NEXT: [[S_MOV_B32_:%[0-9]+]]:sreg_32 = S_MOV_B32 2147483648
- ; GFX9-NEXT: [[S_OR_B32_:%[0-9]+]]:sreg_32 = S_OR_B32 [[COPY2]], [[S_MOV_B32_]], implicit-def dead $scc
- ; GFX9-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY1]], %subreg.sub0, [[S_OR_B32_]], %subreg.sub1
+ ; GFX9-NEXT: [[COPY1:%[0-9]+]]:sreg_32_xm0 = COPY [[COPY]].sub1
+ ; GFX9-NEXT: [[S_OR_B32_:%[0-9]+]]:sreg_32 = S_OR_B32 [[COPY1]], [[S_MOV_B32_]], implicit-def dead $scc
+ ; GFX9-NEXT: [[COPY2:%[0-9]+]]:sreg_32_xm0 = COPY [[S_OR_B32_]]
+ ; GFX9-NEXT: [[COPY3:%[0-9]+]]:sreg_32_xexec_hi_and_sreg_32_xm0 = COPY [[COPY]].sub0
+ ; GFX9-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY3]], %subreg.sub0, [[COPY2]], %subreg.sub1
; GFX9-NEXT: S_ENDPGM 0, implicit [[REG_SEQUENCE]]
;
; GFX10-LABEL: name: fneg_fabs_s64_ss
; GFX10: liveins: $sgpr0_sgpr1
; GFX10-NEXT: {{ $}}
; GFX10-NEXT: [[COPY:%[0-9]+]]:sreg_64 = COPY $sgpr0_sgpr1
- ; GFX10-NEXT: [[COPY1:%[0-9]+]]:sreg_32 = COPY [[COPY]].sub0
- ; GFX10-NEXT: [[COPY2:%[0-9]+]]:sreg_32 = COPY [[COPY]].sub1
; GFX10-NEXT: [[S_MOV_B32_:%[0-9]+]]:sreg_32 = S_MOV_B32 2147483648
- ; GFX10-NEXT: [[S_OR_B32_:%[0-9]+]]:sreg_32 = S_OR_B32 [[COPY2]], [[S_MOV_B32_]], implicit-def dead $scc
- ; GFX10-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY1]], %subreg.sub0, [[S_OR_B32_]], %subreg.sub1
+ ; GFX10-NEXT: [[COPY1:%[0-9]+]]:sreg_32_xm0 = COPY [[COPY]].sub1
+ ; GFX10-NEXT: [[S_OR_B32_:%[0-9]+]]:sreg_32 = S_OR_B32 [[COPY1]], [[S_MOV_B32_]], implicit-def dead $scc
+ ; GFX10-NEXT: [[COPY2:%[0-9]+]]:sreg_32_xm0 = COPY [[S_OR_B32_]]
+ ; GFX10-NEXT: [[COPY3:%[0-9]+]]:sreg_32_xexec_hi_and_sreg_32_xm0 = COPY [[COPY]].sub0
+ ; GFX10-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY3]], %subreg.sub0, [[COPY2]], %subreg.sub1
; GFX10-NEXT: S_ENDPGM 0, implicit [[REG_SEQUENCE]]
%0:sgpr(s64) = COPY $sgpr0_sgpr1
%1:sgpr(s64) = G_FABS %0
diff --git a/llvm/test/CodeGen/AMDGPU/GlobalISel/inst-select-sext.mir b/llvm/test/CodeGen/AMDGPU/GlobalISel/inst-select-sext.mir
index 4a91afc88fa599..150d9b72afcee5 100644
--- a/llvm/test/CodeGen/AMDGPU/GlobalISel/inst-select-sext.mir
+++ b/llvm/test/CodeGen/AMDGPU/GlobalISel/inst-select-sext.mir
@@ -104,10 +104,13 @@ body: |
; GCN: liveins: $sgpr0
; GCN-NEXT: {{ $}}
; GCN-NEXT: [[COPY:%[0-9]+]]:sreg_32 = COPY $sgpr0
- ; GCN-NEXT: [[DEF:%[0-9]+]]:sreg_32 = IMPLICIT_DEF
- ; GCN-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY]], %subreg.sub0, [[DEF]], %subreg.sub1
- ; GCN-NEXT: [[S_BFE_I64_:%[0-9]+]]:sreg_64 = S_BFE_I64 [[REG_SEQUENCE]], 1048576, implicit-def $scc
- ; GCN-NEXT: $sgpr0_sgpr1 = COPY [[S_BFE_I64_]]
+ ; GCN-NEXT: [[S_MOV_B32_:%[0-9]+]]:sreg_32 = S_MOV_B32 31
+ ; GCN-NEXT: [[S_SEXT_I32_I16_:%[0-9]+]]:sreg_32 = S_SEXT_I32_I16 [[COPY]]
+ ; GCN-NEXT: [[S_ASHR_I32_:%[0-9]+]]:sreg_32 = S_ASHR_I32 [[S_SEXT_I32_I16_]], [[S_MOV_B32_]], implicit-def dead $scc
+ ; GCN-NEXT: [[COPY1:%[0-9]+]]:sreg_32_xm0 = COPY [[S_ASHR_I32_]]
+ ; GCN-NEXT: [[S_SEXT_I32_I16_1:%[0-9]+]]:sreg_32_xexec_hi_and_sreg_32_xm0 = S_SEXT_I32_I16 [[COPY]]
+ ; GCN-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[S_SEXT_I32_I16_1]], %subreg.sub0, [[COPY1]], %subreg.sub1
+ ; GCN-NEXT: $sgpr0_sgpr1 = COPY [[REG_SEQUENCE]]
%0:sgpr(s32) = COPY $sgpr0
%1:sgpr(s16) = G_TRUNC %0
%2:sgpr(s64) = G_SEXT %1
@@ -127,9 +130,10 @@ body: |
; GCN-LABEL: name: sext_sgpr_s32_to_sgpr_s64
; GCN: liveins: $sgpr0
; GCN-NEXT: {{ $}}
- ; GCN-NEXT: [[COPY:%[0-9]+]]:sreg_32 = COPY $sgpr0
+ ; GCN-NEXT: [[COPY:%[0-9]+]]:sreg_32_xexec_hi_and_sreg_32_xm0 = COPY $sgpr0
; GCN-NEXT: [[S_ASHR_I32_:%[0-9]+]]:sreg_32 = S_ASHR_I32 [[COPY]], 31, implicit-def dead $scc
- ; GCN-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY]], %subreg.sub0, [[S_ASHR_I32_]], %subreg.sub1
+ ; GCN-NEXT: [[COPY1:%[0-9]+]]:sreg_32_xm0 = COPY [[S_ASHR_I32_]]
+ ; GCN-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY]], %subreg.sub0, [[COPY1]], %subreg.sub1
; GCN-NEXT: $sgpr0_sgpr1 = COPY [[REG_SEQUENCE]]
%0:sgpr(s32) = COPY $sgpr0
%1:sgpr(s64) = G_SEXT %0
diff --git a/llvm/test/CodeGen/AMDGPU/GlobalISel/inst-select-zext.mir b/llvm/test/CodeGen/AMDGPU/GlobalISel/inst-select-zext.mir
index 577a2e7d7d3660..1589172a028265 100644
--- a/llvm/test/CodeGen/AMDGPU/GlobalISel/inst-select-zext.mir
+++ b/llvm/test/CodeGen/AMDGPU/GlobalISel/inst-select-zext.mir
@@ -104,10 +104,12 @@ body: |
; GCN: liveins: $sgpr0
; GCN-NEXT: {{ $}}
; GCN-NEXT: [[COPY:%[0-9]+]]:sreg_32 = COPY $sgpr0
- ; GCN-NEXT: [[DEF:%[0-9]+]]:sreg_32 = IMPLICIT_DEF
- ; GCN-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY]], %subreg.sub0, [[DEF]], %subreg.sub1
- ; GCN-NEXT: [[S_BFE_U64_:%[0-9]+]]:sreg_64 = S_BFE_U64 [[REG_SEQUENCE]], 1048576, implicit-def $scc
- ; GCN-NEXT: $sgpr0_sgpr1 = COPY [[S_BFE_U64_]]
+ ; GCN-NEXT: [[S_MOV_B32_:%[0-9]+]]:sreg_32_xm0 = S_MOV_B32 0
+ ; GCN-NEXT: [[S_MOV_B32_1:%[0-9]+]]:sreg_32 = S_MOV_B32 65535
+ ; GCN-NEXT: [[S_AND_B32_:%[0-9]+]]:sreg_32 = S_AND_B32 [[COPY]], [[S_MOV_B32_1]], implicit-def dead $scc
+ ; GCN-NEXT: [[COPY1:%[0-9]+]]:sreg_32_xexec_hi_and_sreg_32_xm0 = COPY [[S_AND_B32_]]
+ ; GCN-NEXT: [[REG_SEQUENCE:%[0-9]+]]:sreg_64 = REG_SEQUENCE [[COPY1]], %subreg.sub0, [[S_MOV_B32_]], %subreg.sub1
+ ; GCN-NEXT: $sgpr0_sgpr1 = COPY [[REG_SEQUENCE]]
%0:sgpr(s32) = COPY $sgpr0
%1:sgpr(s16) = G_TRUNC %0
%2:sgpr(s64) = G_ZEXT %1
diff --git a/llvm/test/TableGen/GlobalISelEmitter-multiple-output-reject.td b/llvm/test/TableGen/GlobalISelEmitter-multiple-output-reject.td
new file mode 100644
index 00000000000000..bce2d8cb096bbc
--- /dev/null
+++ b/llvm/test/TableGen/GlobalISelEmitter-multiple-output-reject.td
@@ -0,0 +1,14 @@
+// RUN: llvm-tblgen -gen-global-isel -optimize-match-table=false -warn-on-skipped-patterns -I %p/../../include -I %p/Common %s -o - < %s 2>&1 | FileCheck %s
+
+include "llvm/Target/Target.td"
+include "GlobalISelEmitterCommon.td"
+
+// Test when the inner instruction in the output pattern has two outs
+
+def TwoOutsInstr : I<(outs GPR32:$out1, GPR32:$out2), (ins GPR32:$src), []>;
+def OtherInstr : I<(outs GPR32:$dst), (ins GPR32:$src), []>;
+
+def : Pat<(i32 (add i32:$src, i32:$src)),
+ (OtherInstr (TwoOutsInstr GPR32:$src))>;
+
+// CHECK: warning: Skipped pattern: Dst pattern child only supported with exactly one result
diff --git a/llvm/test/TableGen/GlobalISelEmitter-multiple-output.td b/llvm/test/TableGen/GlobalISelEmitter-multiple-output.td
index f75988dadc73b1..e063ebd4c2bbdd 100644
--- a/llvm/test/TableGen/GlobalISelEmitter-multiple-output.td
+++ b/llvm/test/TableGen/GlobalISelEmitter-multiple-output.td
@@ -10,6 +10,7 @@ include "GlobalISelEmitterCommon.td"
// Verify that patterns with multiple outputs are translated
+//-----------------------------------------------------------------------------
// Test where only the opcode is mutated during ISel
let Constraints = "$ptr_out = $addr" in
@@ -46,6 +47,7 @@ def : Pat<(loadpost (p0 GPR32:$addr), (i32 GPR32:$off)),
// CHECK-NEXT: GIR_MutateOpcode, /*InsnID*/0, /*RecycleInsnID*/0, /*Opcode*/GIMT_Encode2(MyTarget::LDPost),
// CHECK-NEXT: GIR_ConstrainSelectedInstOperands, /*InsnID*/0,
+//-----------------------------------------------------------------------------
// Test where a whole new MIR instruction is created during ISel
def TWO_INS : I<(outs GPR32:$out1, GPR32:$out2), (ins GPR32:$in1, GPR32:$in2), []>;
@@ -84,3 +86,34 @@ def : Pat<(two_in GPR32:$i1, GPR32:$i2), (TWO_INS GPR32:$i2, GPR32:$i1)>;
// CHECK-NEXT: GIR_Copy, /*NewInsnID*/0, /*OldInsnID*/0, /*OpIdx*/2, // i1
// CHECK-NEXT: GIR_ConstrainSelectedInstOperands, /*InsnID*/0,
// CHECK-NEXT: GIR_EraseFromParent, /*InsnID*/0,
+
+//-----------------------------------------------------------------------------
+// Test where implicit defs are added using Defs.
+
+let Defs = [R0] in
+def ImplicitDefInstr : I<(outs GPR32:$dst), (ins GPR32:$src), []>;
+def OtherInstr : I<(outs GPR32:$dst), (ins GPR32:$src), []>;
+
+def : Pat<(i32 (add i32:$src, i32:$src)),
+ (OtherInstr (ImplicitDefInstr GPR32:$src))>;
+
+// CHECK: GIM_CheckOpcode, /*MI*/0, GIMT_Encode2(TargetOpcode::G_ADD),
+// CHECK-NEXT: // MIs[0] DstI[dst]
+// CHECK-NEXT: GIM_CheckType, /*MI*/0, /*Op*/0, /*Type*/GILLT_s32,
+// CHECK-NEXT: GIM_CheckRegBankForClass, /*MI*/0, /*Op*/0, /*RC*/GIMT_Encode2(MyTarget::GPR32RegClassID),
+// CHECK-NEXT: // MIs[0] src
+// CHECK-NEXT: GIM_CheckType, /*MI*/0, /*Op*/1, /*Type*/GILLT_s32,
+// CHECK-NEXT: // MIs[0] src
+// CHECK-NEXT: GIM_CheckIsSameOperand, /*MI*/0, /*OpIdx*/2, /*OtherMI*/0, /*OtherOpIdx*/1,
+// CHECK-NEXT: // (add:{ *:[i32] } i32:{ *:[i32] }:$src, i32:{ *:[i32] }:$src) => (OtherInstr:{ *:[i32] } (ImplicitDefInstr:{ *:[i32] }:{ *:[i32] } GPR32:{ *:[i32] }:$src))
+// CHECK-NEXT: GIR_MakeTempReg, /*TempRegID*/0, /*TypeID*/GILLT_s32,
+// CHECK-NEXT: GIR_BuildMI, /*InsnID*/1, /*Opcode*/GIMT_Encode2(MyTarget::ImplicitDefInstr),
+// CHECK-NEXT: GIR_AddTempRegister, /*InsnID*/1, /*TempRegID*/0, /*TempRegFlags*/GIMT_Encode2(RegState::Define),
+// CHECK-NEXT: GIR_Copy, /*NewInsnID*/1, /*OldInsnID*/0, /*OpIdx*/1, // src
+// CHECK-NEXT: GIR_SetImplicitDefDead, /*InsnID*/1, /*OpIdx for MyTarget::R0*/0,
+// CHECK-NEXT: GIR_ConstrainSelectedInstOperands, /*InsnID*/1,
+// CHECK-NEXT: GIR_BuildMI, /*InsnID*/0, /*Opcode*/GIMT_Encode2(MyTarget::OtherInstr),
+// CHECK-NEXT: GIR_Copy, /*NewInsnID*/0, /*OldInsnID*/0, /*OpIdx*/0, // DstI[dst]
+// CHECK-NEXT: GIR_AddSimpleTempRegister, /*InsnID*/0, /*TempRegID*/0,
+// CHECK-NEXT: GIR_ConstrainSelectedInstOperands, /*InsnID*/0,
+// CHECK-NEXT: GIR_EraseFromParent, /*InsnID*/0,
diff --git a/llvm/utils/TableGen/GlobalISelEmitter.cpp b/llvm/utils/TableGen/GlobalISelEmitter.cpp
index 618cb2fedb9292..6ca6cfb18ccdb8 100644
--- a/llvm/utils/TableGen/GlobalISelEmitter.cpp
+++ b/llvm/utils/TableGen/GlobalISelEmitter.cpp
@@ -1,3 +1,4 @@
+
//===- GlobalISelEmitter.cpp - Generate an instruction selector -----------===//
//
// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
@@ -288,11 +289,22 @@ static std::string getMangledRootDefName(StringRef DefOperandName) {
//===- GlobalISelEmitter class --------------------------------------------===//
-static Expected<LLTCodeGen> getInstResultType(const TreePatternNode &Dst) {
+static Expected<LLTCodeGen> getInstResultType(const TreePatternNode &Dst,
+ const CodeGenTarget &Target) {
+ // While we allow more than one output (both implicit and explicit defs)
+ // below, we only expect one explicit def here.
+ assert(Dst.getOperator()->isSubClassOf("Instruction"));
+ CodeGenInstruction &InstInfo = Target.getInstruction(Dst.getOperator());
+ if (InstInfo.Operands.NumDefs != 1)
+ return failedImport(
+ "Dst pattern child only supported with exactly one result");
+
ArrayRef<TypeSetByHwMode> ChildTypes = Dst.getExtTypes();
- if (ChildTypes.size() != 1)
- return failedImport("Dst pattern child has multiple results");
+ if (ChildTypes.size() < 1)
+ return failedImport("Dst pattern child has no result");
+ // If there are multiple results, just take the first one (this is how
+ // SelectionDAG does it).
std::optional<LLTCodeGen> MaybeOpTy;
if (ChildTypes.front().isMachineValueType()) {
MaybeOpTy = MVTToLLT(ChildTypes.front().getMachineValueType().SimpleTy);
@@ -1220,7 +1232,7 @@ Expected<action_iterator> GlobalISelEmitter::importExplicitUseRenderer(
}
if (DstChild.getOperator()->isSubClassOf("Instruction")) {
- auto OpTy = getInstResultType(DstChild);
+ auto OpTy = getInstResultType(DstChild, Target);
if (!OpTy)
return OpTy.takeError();
@@ -1555,7 +1567,7 @@ Expected<action_iterator> GlobalISelEmitter::importExplicitUseRenderers(
if (!ValChild.isLeaf()) {
// We really have to handle the source instruction, and then insert a
// copy from the subregister.
- auto ExtractSrcTy = getInstResultType(ValChild);
+ auto ExtractSrcTy = getInstResultType(ValChild, Target);
if (!ExtractSrcTy)
return ExtractSrcTy.takeError();
@@ -1773,10 +1785,11 @@ GlobalISelEmitter::inferRegClassFromPattern(const TreePatternNode &N) {
return getRegClassFromLeaf(N);
// We don't have a leaf node, so we have to try and infer something. Check
- // that we have an instruction that we an infer something from.
+ // that we have an instruction that we can infer something from.
- // Only handle things that produce a single type.
- if (N.getNumTypes() != 1)
+ // Only handle things that produce at least one value (if multiple values,
+ // just take the first one).
+ if (N.getNumTypes() < 1)
return std::nullopt;
Record *OpRec = N.getOperator();
>From 8ec28af8eaff5acd0df3e53340159c034f08533d Mon Sep 17 00:00:00 2001
From: Matthias Gehre <matthias.gehre at amd.com>
Date: Fri, 1 Mar 2024 23:32:27 +0100
Subject: [PATCH 360/406] Reapply "[mlir][PDL] Add support for native
constraints with results (#82760)"
with a small stack-use-after-scope fix in getConstraintPredicates()
This reverts commit c80e6edba4a9593f0587e27fa0ac825ebe174afd.
---
mlir/include/mlir/Dialect/PDL/IR/PDLOps.td | 9 +-
.../mlir/Dialect/PDLInterp/IR/PDLInterpOps.td | 8 +-
mlir/include/mlir/IR/PDLPatternMatch.h.inc | 18 ++-
.../PDLToPDLInterp/PDLToPDLInterp.cpp | 41 +++--
.../lib/Conversion/PDLToPDLInterp/Predicate.h | 58 +++++--
.../PDLToPDLInterp/PredicateTree.cpp | 84 +++++++++-
mlir/lib/Dialect/PDL/IR/PDL.cpp | 6 +
mlir/lib/Rewrite/ByteCode.cpp | 144 ++++++++++++------
mlir/lib/Tools/PDLL/Parser/Parser.cpp | 6 -
.../pdl-to-pdl-interp-matcher.mlir | 51 +++++++
.../PDLToPDLInterp/use-constraint-result.mlir | 77 ++++++++++
mlir/test/Dialect/PDL/ops.mlir | 18 +++
mlir/test/Rewrite/pdl-bytecode.mlir | 68 +++++++++
.../TestTransformDialectExtension.cpp | 2 +-
mlir/test/lib/Rewrite/TestPDLByteCode.cpp | 50 ++++++
.../mlir-pdll/Parser/constraint-failure.pdll | 5 -
mlir/test/mlir-pdll/Parser/constraint.pdll | 8 +
mlir/test/python/dialects/pdl_ops.py | 2 +-
18 files changed, 557 insertions(+), 98 deletions(-)
create mode 100644 mlir/test/Conversion/PDLToPDLInterp/use-constraint-result.mlir
diff --git a/mlir/include/mlir/Dialect/PDL/IR/PDLOps.td b/mlir/include/mlir/Dialect/PDL/IR/PDLOps.td
index 4e9ebccba77d88..1e108c3d8ac77a 100644
--- a/mlir/include/mlir/Dialect/PDL/IR/PDLOps.td
+++ b/mlir/include/mlir/Dialect/PDL/IR/PDLOps.td
@@ -35,20 +35,25 @@ def PDL_ApplyNativeConstraintOp
let description = [{
`pdl.apply_native_constraint` operations apply a native C++ constraint, that
has been registered externally with the consumer of PDL, to a given set of
- entities.
+ entities and optionally return a number of values.
Example:
```mlir
// Apply `myConstraint` to the entities defined by `input`, `attr`, and `op`.
pdl.apply_native_constraint "myConstraint"(%input, %attr, %op : !pdl.value, !pdl.attribute, !pdl.operation)
+ // Apply constraint `with_result` to `root`. This constraint returns an attribute.
+ %attr = pdl.apply_native_constraint "with_result"(%root : !pdl.operation) : !pdl.attribute
```
}];
let arguments = (ins StrAttr:$name,
Variadic<PDL_AnyType>:$args,
DefaultValuedAttr<BoolAttr, "false">:$isNegated);
- let assemblyFormat = "$name `(` $args `:` type($args) `)` attr-dict";
+ let results = (outs Variadic<PDL_AnyType>:$results);
+ let assemblyFormat = [{
+ $name `(` $args `:` type($args) `)` (`:` type($results)^ )? attr-dict
+ }];
let hasVerifier = 1;
}
diff --git a/mlir/include/mlir/Dialect/PDLInterp/IR/PDLInterpOps.td b/mlir/include/mlir/Dialect/PDLInterp/IR/PDLInterpOps.td
index 48f625bd1fa3fd..901acc0e6733bb 100644
--- a/mlir/include/mlir/Dialect/PDLInterp/IR/PDLInterpOps.td
+++ b/mlir/include/mlir/Dialect/PDLInterp/IR/PDLInterpOps.td
@@ -88,7 +88,9 @@ def PDLInterp_ApplyConstraintOp : PDLInterp_PredicateOp<"apply_constraint"> {
let description = [{
`pdl_interp.apply_constraint` operations apply a generic constraint, that
has been registered with the interpreter, with a given set of positional
- values. On success, this operation branches to the true destination,
+ values.
+ The constraint function may return any number of results.
+ On success, this operation branches to the true destination,
otherwise the false destination is taken. This behavior can be reversed
by setting the attribute `isNegated` to true.
@@ -104,8 +106,10 @@ def PDLInterp_ApplyConstraintOp : PDLInterp_PredicateOp<"apply_constraint"> {
let arguments = (ins StrAttr:$name,
Variadic<PDL_AnyType>:$args,
DefaultValuedAttr<BoolAttr, "false">:$isNegated);
+ let results = (outs Variadic<PDL_AnyType>:$results);
let assemblyFormat = [{
- $name `(` $args `:` type($args) `)` attr-dict `->` successors
+ $name `(` $args `:` type($args) `)` (`:` type($results)^)? attr-dict
+ `->` successors
}];
}
diff --git a/mlir/include/mlir/IR/PDLPatternMatch.h.inc b/mlir/include/mlir/IR/PDLPatternMatch.h.inc
index a215da8cb6431d..66286ed7a4c898 100644
--- a/mlir/include/mlir/IR/PDLPatternMatch.h.inc
+++ b/mlir/include/mlir/IR/PDLPatternMatch.h.inc
@@ -318,8 +318,9 @@ protected:
/// A generic PDL pattern constraint function. This function applies a
/// constraint to a given set of opaque PDLValue entities. Returns success if
/// the constraint successfully held, failure otherwise.
-using PDLConstraintFunction =
- std::function<LogicalResult(PatternRewriter &, ArrayRef<PDLValue>)>;
+using PDLConstraintFunction = std::function<LogicalResult(
+ PatternRewriter &, PDLResultList &, ArrayRef<PDLValue>)>;
+
/// A native PDL rewrite function. This function performs a rewrite on the
/// given set of values. Any results from this rewrite that should be passed
/// back to PDL should be added to the provided result list. This method is only
@@ -726,7 +727,7 @@ std::enable_if_t<
PDLConstraintFunction>
buildConstraintFn(ConstraintFnT &&constraintFn) {
return [constraintFn = std::forward<ConstraintFnT>(constraintFn)](
- PatternRewriter &rewriter,
+ PatternRewriter &rewriter, PDLResultList &,
ArrayRef<PDLValue> values) -> LogicalResult {
auto argIndices = std::make_index_sequence<
llvm::function_traits<ConstraintFnT>::num_args - 1>();
@@ -842,10 +843,13 @@ public:
/// Register a constraint function with PDL. A constraint function may be
/// specified in one of two ways:
///
- /// * `LogicalResult (PatternRewriter &, ArrayRef<PDLValue>)`
+ /// * `LogicalResult (PatternRewriter &,
+ /// PDLResultList &,
+ /// ArrayRef<PDLValue>)`
///
/// In this overload the arguments of the constraint function are passed via
- /// the low-level PDLValue form.
+ /// the low-level PDLValue form, and the results are manually appended to
+ /// the given result list.
///
/// * `LogicalResult (PatternRewriter &, ValueTs... values)`
///
@@ -960,8 +964,8 @@ public:
}
};
class PDLResultList {};
-using PDLConstraintFunction =
- std::function<LogicalResult(PatternRewriter &, ArrayRef<PDLValue>)>;
+using PDLConstraintFunction = std::function<LogicalResult(
+ PatternRewriter &, PDLResultList &, ArrayRef<PDLValue>)>;
using PDLRewriteFunction = std::function<LogicalResult(
PatternRewriter &, PDLResultList &, ArrayRef<PDLValue>)>;
diff --git a/mlir/lib/Conversion/PDLToPDLInterp/PDLToPDLInterp.cpp b/mlir/lib/Conversion/PDLToPDLInterp/PDLToPDLInterp.cpp
index e911631a4bc52a..b00cd0dee3ae80 100644
--- a/mlir/lib/Conversion/PDLToPDLInterp/PDLToPDLInterp.cpp
+++ b/mlir/lib/Conversion/PDLToPDLInterp/PDLToPDLInterp.cpp
@@ -50,7 +50,8 @@ struct PatternLowering {
/// Generate interpreter operations for the tree rooted at the given matcher
/// node, in the specified region.
- Block *generateMatcher(MatcherNode &node, Region ®ion);
+ Block *generateMatcher(MatcherNode &node, Region ®ion,
+ Block *block = nullptr);
/// Get or create an access to the provided positional value in the current
/// block. This operation may mutate the provided block pointer if nested
@@ -148,6 +149,10 @@ struct PatternLowering {
/// A mapping between pattern operations and the corresponding configuration
/// set.
DenseMap<Operation *, PDLPatternConfigSet *> *configMap;
+
+ /// A mapping from a constraint question to the ApplyConstraintOp
+ /// that implements it.
+ DenseMap<ConstraintQuestion *, pdl_interp::ApplyConstraintOp> constraintOpMap;
};
} // namespace
@@ -182,9 +187,11 @@ void PatternLowering::lower(ModuleOp module) {
firstMatcherBlock->erase();
}
-Block *PatternLowering::generateMatcher(MatcherNode &node, Region ®ion) {
+Block *PatternLowering::generateMatcher(MatcherNode &node, Region ®ion,
+ Block *block) {
// Push a new scope for the values used by this matcher.
- Block *block = ®ion.emplaceBlock();
+ if (!block)
+ block = ®ion.emplaceBlock();
ValueMapScope scope(values);
// If this is the return node, simply insert the corresponding interpreter
@@ -364,6 +371,15 @@ Value PatternLowering::getValueAt(Block *¤tBlock, Position *pos) {
loc, cast<ArrayAttr>(rawTypeAttr));
break;
}
+ case Predicates::ConstraintResultPos: {
+ // Due to the order of traversal, the ApplyConstraintOp has already been
+ // created and we can find it in constraintOpMap.
+ auto *constrResPos = cast<ConstraintPosition>(pos);
+ auto i = constraintOpMap.find(constrResPos->getQuestion());
+ assert(i != constraintOpMap.end());
+ value = i->second->getResult(constrResPos->getIndex());
+ break;
+ }
default:
llvm_unreachable("Generating unknown Position getter");
break;
@@ -390,12 +406,11 @@ void PatternLowering::generate(BoolNode *boolNode, Block *¤tBlock,
args.push_back(getValueAt(currentBlock, position));
}
- // Generate the matcher in the current (potentially nested) region
- // and get the failure successor.
- Block *success = generateMatcher(*boolNode->getSuccessNode(), *region);
+ // Generate a new block as success successor and get the failure successor.
+ Block *success = ®ion->emplaceBlock();
Block *failure = failureBlockStack.back();
- // Finally, create the predicate.
+ // Create the predicate.
builder.setInsertionPointToEnd(currentBlock);
Predicates::Kind kind = question->getKind();
switch (kind) {
@@ -447,14 +462,20 @@ void PatternLowering::generate(BoolNode *boolNode, Block *¤tBlock,
}
case Predicates::ConstraintQuestion: {
auto *cstQuestion = cast<ConstraintQuestion>(question);
- builder.create<pdl_interp::ApplyConstraintOp>(
- loc, cstQuestion->getName(), args, cstQuestion->getIsNegated(), success,
- failure);
+ auto applyConstraintOp = builder.create<pdl_interp::ApplyConstraintOp>(
+ loc, cstQuestion->getResultTypes(), cstQuestion->getName(), args,
+ cstQuestion->getIsNegated(), success, failure);
+
+ constraintOpMap.insert({cstQuestion, applyConstraintOp});
break;
}
default:
llvm_unreachable("Generating unknown Predicate operation");
}
+
+ // Generate the matcher in the current (potentially nested) region.
+ // This might use the results of the current predicate.
+ generateMatcher(*boolNode->getSuccessNode(), *region, success);
}
template <typename OpT, typename PredT, typename ValT = typename PredT::KeyTy>
diff --git a/mlir/lib/Conversion/PDLToPDLInterp/Predicate.h b/mlir/lib/Conversion/PDLToPDLInterp/Predicate.h
index 2c9b63f86d6efa..5ad2c477573a5b 100644
--- a/mlir/lib/Conversion/PDLToPDLInterp/Predicate.h
+++ b/mlir/lib/Conversion/PDLToPDLInterp/Predicate.h
@@ -47,6 +47,7 @@ enum Kind : unsigned {
OperandPos,
OperandGroupPos,
AttributePos,
+ ConstraintResultPos,
ResultPos,
ResultGroupPos,
TypePos,
@@ -279,6 +280,28 @@ struct OperationPosition : public PredicateBase<OperationPosition, Position,
bool isOperandDefiningOp() const;
};
+//===----------------------------------------------------------------------===//
+// ConstraintPosition
+
+struct ConstraintQuestion;
+
+/// A position describing the result of a native constraint. It saves the
+/// corresponding ConstraintQuestion and result index to enable referring
+/// back to them
+struct ConstraintPosition
+ : public PredicateBase<ConstraintPosition, Position,
+ std::pair<ConstraintQuestion *, unsigned>,
+ Predicates::ConstraintResultPos> {
+ using PredicateBase::PredicateBase;
+
+ /// Returns the ConstraintQuestion to enable keeping track of the native
+ /// constraint this position stems from.
+ ConstraintQuestion *getQuestion() const { return key.first; }
+
+ // Returns the result index of this position
+ unsigned getIndex() const { return key.second; }
+};
+
//===----------------------------------------------------------------------===//
// ResultPosition
@@ -447,11 +470,13 @@ struct AttributeQuestion
: public PredicateBase<AttributeQuestion, Qualifier, void,
Predicates::AttributeQuestion> {};
-/// Apply a parameterized constraint to multiple position values.
+/// Apply a parameterized constraint to multiple position values and possibly
+/// produce results.
struct ConstraintQuestion
- : public PredicateBase<ConstraintQuestion, Qualifier,
- std::tuple<StringRef, ArrayRef<Position *>, bool>,
- Predicates::ConstraintQuestion> {
+ : public PredicateBase<
+ ConstraintQuestion, Qualifier,
+ std::tuple<StringRef, ArrayRef<Position *>, ArrayRef<Type>, bool>,
+ Predicates::ConstraintQuestion> {
using Base::Base;
/// Return the name of the constraint.
@@ -460,15 +485,19 @@ struct ConstraintQuestion
/// Return the arguments of the constraint.
ArrayRef<Position *> getArgs() const { return std::get<1>(key); }
+ /// Return the result types of the constraint.
+ ArrayRef<Type> getResultTypes() const { return std::get<2>(key); }
+
/// Return the negation status of the constraint.
- bool getIsNegated() const { return std::get<2>(key); }
+ bool getIsNegated() const { return std::get<3>(key); }
/// Construct an instance with the given storage allocator.
static ConstraintQuestion *construct(StorageUniquer::StorageAllocator &alloc,
KeyTy key) {
return Base::construct(alloc, KeyTy{alloc.copyInto(std::get<0>(key)),
alloc.copyInto(std::get<1>(key)),
- std::get<2>(key)});
+ alloc.copyInto(std::get<2>(key)),
+ std::get<3>(key)});
}
/// Returns a hash suitable for the given keytype.
@@ -526,6 +555,7 @@ class PredicateUniquer : public StorageUniquer {
// Register the types of Positions with the uniquer.
registerParametricStorageType<AttributePosition>();
registerParametricStorageType<AttributeLiteralPosition>();
+ registerParametricStorageType<ConstraintPosition>();
registerParametricStorageType<ForEachPosition>();
registerParametricStorageType<OperandPosition>();
registerParametricStorageType<OperandGroupPosition>();
@@ -588,6 +618,12 @@ class PredicateBuilder {
return OperationPosition::get(uniquer, p);
}
+ // Returns a position for a new value created by a constraint.
+ ConstraintPosition *getConstraintPosition(ConstraintQuestion *q,
+ unsigned index) {
+ return ConstraintPosition::get(uniquer, std::make_pair(q, index));
+ }
+
/// Returns an attribute position for an attribute of the given operation.
Position *getAttribute(OperationPosition *p, StringRef name) {
return AttributePosition::get(uniquer, p, StringAttr::get(ctx, name));
@@ -673,11 +709,11 @@ class PredicateBuilder {
}
/// Create a predicate that applies a generic constraint.
- Predicate getConstraint(StringRef name, ArrayRef<Position *> pos,
- bool isNegated) {
- return {
- ConstraintQuestion::get(uniquer, std::make_tuple(name, pos, isNegated)),
- TrueAnswer::get(uniquer)};
+ Predicate getConstraint(StringRef name, ArrayRef<Position *> args,
+ ArrayRef<Type> resultTypes, bool isNegated) {
+ return {ConstraintQuestion::get(
+ uniquer, std::make_tuple(name, args, resultTypes, isNegated)),
+ TrueAnswer::get(uniquer)};
}
/// Create a predicate comparing a value with null.
diff --git a/mlir/lib/Conversion/PDLToPDLInterp/PredicateTree.cpp b/mlir/lib/Conversion/PDLToPDLInterp/PredicateTree.cpp
index a9c3b0a71ef0d7..419ea863919786 100644
--- a/mlir/lib/Conversion/PDLToPDLInterp/PredicateTree.cpp
+++ b/mlir/lib/Conversion/PDLToPDLInterp/PredicateTree.cpp
@@ -15,6 +15,7 @@
#include "mlir/IR/BuiltinOps.h"
#include "mlir/Interfaces/InferTypeOpInterface.h"
#include "llvm/ADT/MapVector.h"
+#include "llvm/ADT/SmallPtrSet.h"
#include "llvm/ADT/TypeSwitch.h"
#include "llvm/Support/Debug.h"
#include <queue>
@@ -49,14 +50,15 @@ static void getTreePredicates(std::vector<PositionalPredicate> &predList,
DenseMap<Value, Position *> &inputs,
AttributePosition *pos) {
assert(isa<pdl::AttributeType>(val.getType()) && "expected attribute type");
- pdl::AttributeOp attr = cast<pdl::AttributeOp>(val.getDefiningOp());
predList.emplace_back(pos, builder.getIsNotNull());
- // If the attribute has a type or value, add a constraint.
- if (Value type = attr.getValueType())
- getTreePredicates(predList, type, builder, inputs, builder.getType(pos));
- else if (Attribute value = attr.getValueAttr())
- predList.emplace_back(pos, builder.getAttributeConstraint(value));
+ if (auto attr = dyn_cast<pdl::AttributeOp>(val.getDefiningOp())) {
+ // If the attribute has a type or value, add a constraint.
+ if (Value type = attr.getValueType())
+ getTreePredicates(predList, type, builder, inputs, builder.getType(pos));
+ else if (Attribute value = attr.getValueAttr())
+ predList.emplace_back(pos, builder.getAttributeConstraint(value));
+ }
}
/// Collect all of the predicates for the given operand position.
@@ -272,8 +274,27 @@ static void getConstraintPredicates(pdl::ApplyNativeConstraintOp op,
// Push the constraint to the furthest position.
Position *pos = *std::max_element(allPositions.begin(), allPositions.end(),
comparePosDepth);
- PredicateBuilder::Predicate pred =
- builder.getConstraint(op.getName(), allPositions, op.getIsNegated());
+ ResultRange results = op.getResults();
+ PredicateBuilder::Predicate pred = builder.getConstraint(
+ op.getName(), allPositions, SmallVector<Type>(results.getTypes()),
+ op.getIsNegated());
+
+ // For each result register a position so it can be used later
+ for (auto [i, result] : llvm::enumerate(results)) {
+ ConstraintQuestion *q = cast<ConstraintQuestion>(pred.first);
+ ConstraintPosition *pos = builder.getConstraintPosition(q, i);
+ auto [it, inserted] = inputs.try_emplace(result, pos);
+ // If this is an input value that has been visited in the tree, add a
+ // constraint to ensure that both instances refer to the same value.
+ if (!inserted) {
+ Position *first = pos;
+ Position *second = it->second;
+ if (comparePosDepth(second, first))
+ std::tie(second, first) = std::make_pair(first, second);
+
+ predList.emplace_back(second, builder.getEqualTo(first));
+ }
+ }
predList.emplace_back(pos, pred);
}
@@ -875,6 +896,49 @@ static void insertExitNode(std::unique_ptr<MatcherNode> *root) {
*root = std::make_unique<ExitNode>();
}
+/// Sorts the range begin/end with the partial order given by cmp.
+template <typename Iterator, typename Compare>
+static void stableTopologicalSort(Iterator begin, Iterator end, Compare cmp) {
+ while (begin != end) {
+ // Cannot compute sortBeforeOthers in the predicate of stable_partition
+ // because stable_partition will not keep the [begin, end) range intact
+ // while it runs.
+ llvm::SmallPtrSet<typename Iterator::value_type, 16> sortBeforeOthers;
+ for (auto i = begin; i != end; ++i) {
+ if (std::none_of(begin, end, [&](auto const &b) { return cmp(b, *i); }))
+ sortBeforeOthers.insert(*i);
+ }
+
+ auto const next = std::stable_partition(begin, end, [&](auto const &a) {
+ return sortBeforeOthers.contains(a);
+ });
+ assert(next != begin && "not a partial ordering");
+ begin = next;
+ }
+}
+
+/// Returns true if 'b' depends on a result of 'a'.
+static bool dependsOn(OrderedPredicate *a, OrderedPredicate *b) {
+ auto *cqa = dyn_cast<ConstraintQuestion>(a->question);
+ if (!cqa)
+ return false;
+
+ auto positionDependsOnA = [&](Position *p) {
+ auto *cp = dyn_cast<ConstraintPosition>(p);
+ return cp && cp->getQuestion() == cqa;
+ };
+
+ if (auto *cqb = dyn_cast<ConstraintQuestion>(b->question)) {
+ // Does any argument of b use a?
+ return llvm::any_of(cqb->getArgs(), positionDependsOnA);
+ }
+ if (auto *equalTo = dyn_cast<EqualToQuestion>(b->question)) {
+ return positionDependsOnA(b->position) ||
+ positionDependsOnA(equalTo->getValue());
+ }
+ return positionDependsOnA(b->position);
+}
+
/// Given a module containing PDL pattern operations, generate a matcher tree
/// using the patterns within the given module and return the root matcher node.
std::unique_ptr<MatcherNode>
@@ -955,6 +1019,10 @@ MatcherNode::generateMatcherTree(ModuleOp module, PredicateBuilder &builder,
return *lhs < *rhs;
});
+ // Mostly keep the now established order, but also ensure that
+ // ConstraintQuestions come after the results they use.
+ stableTopologicalSort(ordered.begin(), ordered.end(), dependsOn);
+
// Build the matchers for each of the pattern predicate lists.
std::unique_ptr<MatcherNode> root;
for (OrderedPredicateList &list : lists)
diff --git a/mlir/lib/Dialect/PDL/IR/PDL.cpp b/mlir/lib/Dialect/PDL/IR/PDL.cpp
index d5f34679f06c60..428b19f4c74af8 100644
--- a/mlir/lib/Dialect/PDL/IR/PDL.cpp
+++ b/mlir/lib/Dialect/PDL/IR/PDL.cpp
@@ -94,6 +94,12 @@ static void visit(Operation *op, DenseSet<Operation *> &visited) {
LogicalResult ApplyNativeConstraintOp::verify() {
if (getNumOperands() == 0)
return emitOpError("expected at least one argument");
+ if (llvm::any_of(getResults(), [](OpResult result) {
+ return isa<OperationType>(result.getType());
+ })) {
+ return emitOpError(
+ "returning an operation from a constraint is not supported");
+ }
return success();
}
diff --git a/mlir/lib/Rewrite/ByteCode.cpp b/mlir/lib/Rewrite/ByteCode.cpp
index 6e6992dcdeea78..559ce7f466a83d 100644
--- a/mlir/lib/Rewrite/ByteCode.cpp
+++ b/mlir/lib/Rewrite/ByteCode.cpp
@@ -769,11 +769,25 @@ void Generator::generate(Operation *op, ByteCodeWriter &writer) {
void Generator::generate(pdl_interp::ApplyConstraintOp op,
ByteCodeWriter &writer) {
- assert(constraintToMemIndex.count(op.getName()) &&
- "expected index for constraint function");
+ // Constraints that should return a value have to be registered as rewrites.
+ // If a constraint and a rewrite of similar name are registered the
+ // constraint takes precedence
writer.append(OpCode::ApplyConstraint, constraintToMemIndex[op.getName()]);
writer.appendPDLValueList(op.getArgs());
writer.append(ByteCodeField(op.getIsNegated()));
+ ResultRange results = op.getResults();
+ writer.append(ByteCodeField(results.size()));
+ for (Value result : results) {
+ // We record the expected kind of the result, so that we can provide extra
+ // verification of the native rewrite function and handle the failure case
+ // of constraints accordingly.
+ writer.appendPDLValueKind(result);
+
+ // Range results also need to append the range storage index.
+ if (isa<pdl::RangeType>(result.getType()))
+ writer.append(getRangeStorageIndex(result));
+ writer.append(result);
+ }
writer.append(op.getSuccessors());
}
void Generator::generate(pdl_interp::ApplyRewriteOp op,
@@ -786,11 +800,9 @@ void Generator::generate(pdl_interp::ApplyRewriteOp op,
ResultRange results = op.getResults();
writer.append(ByteCodeField(results.size()));
for (Value result : results) {
- // In debug mode we also record the expected kind of the result, so that we
+ // We record the expected kind of the result, so that we
// can provide extra verification of the native rewrite function.
-#ifndef NDEBUG
writer.appendPDLValueKind(result);
-#endif
// Range results also need to append the range storage index.
if (isa<pdl::RangeType>(result.getType()))
@@ -1076,6 +1088,28 @@ void PDLByteCode::initializeMutableState(PDLByteCodeMutableState &state) const {
// ByteCode Execution
namespace {
+/// This class is an instantiation of the PDLResultList that provides access to
+/// the returned results. This API is not on `PDLResultList` to avoid
+/// overexposing access to information specific solely to the ByteCode.
+class ByteCodeRewriteResultList : public PDLResultList {
+public:
+ ByteCodeRewriteResultList(unsigned maxNumResults)
+ : PDLResultList(maxNumResults) {}
+
+ /// Return the list of PDL results.
+ MutableArrayRef<PDLValue> getResults() { return results; }
+
+ /// Return the type ranges allocated by this list.
+ MutableArrayRef<llvm::OwningArrayRef<Type>> getAllocatedTypeRanges() {
+ return allocatedTypeRanges;
+ }
+
+ /// Return the value ranges allocated by this list.
+ MutableArrayRef<llvm::OwningArrayRef<Value>> getAllocatedValueRanges() {
+ return allocatedValueRanges;
+ }
+};
+
/// This class provides support for executing a bytecode stream.
class ByteCodeExecutor {
public:
@@ -1152,6 +1186,9 @@ class ByteCodeExecutor {
void executeSwitchResultCount();
void executeSwitchType();
void executeSwitchTypes();
+ void processNativeFunResults(ByteCodeRewriteResultList &results,
+ unsigned numResults,
+ LogicalResult &rewriteResult);
/// Pushes a code iterator to the stack.
void pushCodeIt(const ByteCodeField *it) { resumeCodeIt.push_back(it); }
@@ -1225,6 +1262,8 @@ class ByteCodeExecutor {
return T::getFromOpaquePointer(pointer);
}
+ void skip(size_t skipN) { curCodeIt += skipN; }
+
/// Jump to a specific successor based on a predicate value.
void selectJump(bool isTrue) { selectJump(size_t(isTrue ? 0 : 1)); }
/// Jump to a specific successor based on a destination index.
@@ -1381,33 +1420,11 @@ class ByteCodeExecutor {
ArrayRef<PDLConstraintFunction> constraintFunctions;
ArrayRef<PDLRewriteFunction> rewriteFunctions;
};
-
-/// This class is an instantiation of the PDLResultList that provides access to
-/// the returned results. This API is not on `PDLResultList` to avoid
-/// overexposing access to information specific solely to the ByteCode.
-class ByteCodeRewriteResultList : public PDLResultList {
-public:
- ByteCodeRewriteResultList(unsigned maxNumResults)
- : PDLResultList(maxNumResults) {}
-
- /// Return the list of PDL results.
- MutableArrayRef<PDLValue> getResults() { return results; }
-
- /// Return the type ranges allocated by this list.
- MutableArrayRef<llvm::OwningArrayRef<Type>> getAllocatedTypeRanges() {
- return allocatedTypeRanges;
- }
-
- /// Return the value ranges allocated by this list.
- MutableArrayRef<llvm::OwningArrayRef<Value>> getAllocatedValueRanges() {
- return allocatedValueRanges;
- }
-};
} // namespace
void ByteCodeExecutor::executeApplyConstraint(PatternRewriter &rewriter) {
LLVM_DEBUG(llvm::dbgs() << "Executing ApplyConstraint:\n");
- const PDLConstraintFunction &constraintFn = constraintFunctions[read()];
+ ByteCodeField fun_idx = read();
SmallVector<PDLValue, 16> args;
readList<PDLValue>(args);
@@ -1422,8 +1439,29 @@ void ByteCodeExecutor::executeApplyConstraint(PatternRewriter &rewriter) {
llvm::dbgs() << " * isNegated: " << isNegated << "\n";
llvm::interleaveComma(args, llvm::dbgs());
});
- // Invoke the constraint and jump to the proper destination.
- selectJump(isNegated != succeeded(constraintFn(rewriter, args)));
+
+ ByteCodeField numResults = read();
+ const PDLRewriteFunction &constraintFn = constraintFunctions[fun_idx];
+ ByteCodeRewriteResultList results(numResults);
+ LogicalResult rewriteResult = constraintFn(rewriter, results, args);
+ ArrayRef<PDLValue> constraintResults = results.getResults();
+ LLVM_DEBUG({
+ if (succeeded(rewriteResult)) {
+ llvm::dbgs() << " * Constraint succeeded\n";
+ llvm::dbgs() << " * Results: ";
+ llvm::interleaveComma(constraintResults, llvm::dbgs());
+ llvm::dbgs() << "\n";
+ } else {
+ llvm::dbgs() << " * Constraint failed\n";
+ }
+ });
+ assert((failed(rewriteResult) || constraintResults.size() == numResults) &&
+ "native PDL rewrite function succeeded but returned "
+ "unexpected number of results");
+ processNativeFunResults(results, numResults, rewriteResult);
+
+ // Depending on the constraint jump to the proper destination.
+ selectJump(isNegated != succeeded(rewriteResult));
}
LogicalResult ByteCodeExecutor::executeApplyRewrite(PatternRewriter &rewriter) {
@@ -1445,16 +1483,39 @@ LogicalResult ByteCodeExecutor::executeApplyRewrite(PatternRewriter &rewriter) {
assert(results.getResults().size() == numResults &&
"native PDL rewrite function returned unexpected number of results");
- // Store the results in the bytecode memory.
- for (PDLValue &result : results.getResults()) {
- LLVM_DEBUG(llvm::dbgs() << " * Result: " << result << "\n");
+ processNativeFunResults(results, numResults, rewriteResult);
-// In debug mode we also verify the expected kind of the result.
-#ifndef NDEBUG
- assert(result.getKind() == read<PDLValue::Kind>() &&
- "native PDL rewrite function returned an unexpected type of result");
-#endif
+ if (failed(rewriteResult)) {
+ LLVM_DEBUG(llvm::dbgs() << " - Failed");
+ return failure();
+ }
+ return success();
+}
+void ByteCodeExecutor::processNativeFunResults(
+ ByteCodeRewriteResultList &results, unsigned numResults,
+ LogicalResult &rewriteResult) {
+ // Store the results in the bytecode memory or handle missing results on
+ // failure.
+ for (unsigned resultIdx = 0; resultIdx < numResults; resultIdx++) {
+ PDLValue::Kind resultKind = read<PDLValue::Kind>();
+
+ // Skip the according number of values on the buffer on failure and exit
+ // early as there are no results to process.
+ if (failed(rewriteResult)) {
+ if (resultKind == PDLValue::Kind::TypeRange ||
+ resultKind == PDLValue::Kind::ValueRange) {
+ skip(2);
+ } else {
+ skip(1);
+ }
+ return;
+ }
+ PDLValue result = results.getResults()[resultIdx];
+ LLVM_DEBUG(llvm::dbgs() << " * Result: " << result << "\n");
+ assert(result.getKind() == resultKind &&
+ "native PDL rewrite function returned an unexpected type of "
+ "result");
// If the result is a range, we need to copy it over to the bytecodes
// range memory.
if (std::optional<TypeRange> typeRange = result.dyn_cast<TypeRange>()) {
@@ -1476,13 +1537,6 @@ LogicalResult ByteCodeExecutor::executeApplyRewrite(PatternRewriter &rewriter) {
allocatedTypeRangeMemory.push_back(std::move(it));
for (auto &it : results.getAllocatedValueRanges())
allocatedValueRangeMemory.push_back(std::move(it));
-
- // Process the result of the rewrite.
- if (failed(rewriteResult)) {
- LLVM_DEBUG(llvm::dbgs() << " - Failed");
- return failure();
- }
- return success();
}
void ByteCodeExecutor::executeAreEqual() {
diff --git a/mlir/lib/Tools/PDLL/Parser/Parser.cpp b/mlir/lib/Tools/PDLL/Parser/Parser.cpp
index 97ff8bd0d8584d..206781ed146692 100644
--- a/mlir/lib/Tools/PDLL/Parser/Parser.cpp
+++ b/mlir/lib/Tools/PDLL/Parser/Parser.cpp
@@ -1362,12 +1362,6 @@ FailureOr<T *> Parser::parseUserNativeConstraintOrRewriteDecl(
if (failed(parseToken(Token::semicolon,
"expected `;` after native declaration")))
return failure();
- // TODO: PDL should be able to support constraint results in certain
- // situations, we should revise this.
- if (std::is_same<ast::UserConstraintDecl, T>::value && !results.empty()) {
- return emitError(
- "native Constraints currently do not support returning results");
- }
return T::createNative(ctx, name, arguments, results, optCodeStr, resultType);
}
diff --git a/mlir/test/Conversion/PDLToPDLInterp/pdl-to-pdl-interp-matcher.mlir b/mlir/test/Conversion/PDLToPDLInterp/pdl-to-pdl-interp-matcher.mlir
index 02bb8316c02db0..92afb765b5ab4e 100644
--- a/mlir/test/Conversion/PDLToPDLInterp/pdl-to-pdl-interp-matcher.mlir
+++ b/mlir/test/Conversion/PDLToPDLInterp/pdl-to-pdl-interp-matcher.mlir
@@ -79,6 +79,57 @@ module @constraints {
// -----
+// CHECK-LABEL: module @constraint_with_result
+module @constraint_with_result {
+ // CHECK: func @matcher(%[[ROOT:.*]]: !pdl.operation)
+ // CHECK: %[[ATTR:.*]] = pdl_interp.apply_constraint "check_op_and_get_attr_constr"(%[[ROOT]]
+ // CHECK: pdl_interp.record_match @rewriters::@pdl_generated_rewriter(%[[ROOT]], %[[ATTR]] : !pdl.operation, !pdl.attribute)
+ pdl.pattern : benefit(1) {
+ %root = operation
+ %attr = pdl.apply_native_constraint "check_op_and_get_attr_constr"(%root : !pdl.operation) : !pdl.attribute
+ rewrite %root with "rewriter"(%attr : !pdl.attribute)
+ }
+}
+
+// -----
+
+// CHECK-LABEL: module @constraint_with_unused_result
+module @constraint_with_unused_result {
+ // CHECK: func @matcher(%[[ROOT:.*]]: !pdl.operation)
+ // CHECK: %[[ATTR:.*]] = pdl_interp.apply_constraint "check_op_and_get_attr_constr"(%[[ROOT]]
+ // CHECK: pdl_interp.record_match @rewriters::@pdl_generated_rewriter(%[[ROOT]] : !pdl.operation)
+ pdl.pattern : benefit(1) {
+ %root = operation
+ %attr = pdl.apply_native_constraint "check_op_and_get_attr_constr"(%root : !pdl.operation) : !pdl.attribute
+ rewrite %root with "rewriter"
+ }
+}
+
+// -----
+
+// CHECK-LABEL: module @constraint_with_result_multiple
+module @constraint_with_result_multiple {
+ // check that native constraints work as expected even when multiple identical constraints are fused
+
+ // CHECK: func @matcher(%[[ROOT:.*]]: !pdl.operation)
+ // CHECK: %[[ATTR:.*]] = pdl_interp.apply_constraint "check_op_and_get_attr_constr"(%[[ROOT]]
+ // CHECK-NOT: pdl_interp.apply_constraint "check_op_and_get_attr_constr"
+ // CHECK: pdl_interp.record_match @rewriters::@pdl_generated_rewriter_0(%[[ROOT]], %[[ATTR]] : !pdl.operation, !pdl.attribute)
+ // CHECK: pdl_interp.record_match @rewriters::@pdl_generated_rewriter(%[[ROOT]], %[[ATTR]] : !pdl.operation, !pdl.attribute)
+ pdl.pattern : benefit(1) {
+ %root = operation
+ %attr = pdl.apply_native_constraint "check_op_and_get_attr_constr"(%root : !pdl.operation) : !pdl.attribute
+ rewrite %root with "rewriter"(%attr : !pdl.attribute)
+ }
+ pdl.pattern : benefit(1) {
+ %root = operation
+ %attr = pdl.apply_native_constraint "check_op_and_get_attr_constr"(%root : !pdl.operation) : !pdl.attribute
+ rewrite %root with "rewriter"(%attr : !pdl.attribute)
+ }
+}
+
+// -----
+
// CHECK-LABEL: module @negated_constraint
module @negated_constraint {
// CHECK: func @matcher(%[[ROOT:.*]]: !pdl.operation)
diff --git a/mlir/test/Conversion/PDLToPDLInterp/use-constraint-result.mlir b/mlir/test/Conversion/PDLToPDLInterp/use-constraint-result.mlir
new file mode 100644
index 00000000000000..4511baff2015a4
--- /dev/null
+++ b/mlir/test/Conversion/PDLToPDLInterp/use-constraint-result.mlir
@@ -0,0 +1,77 @@
+// RUN: mlir-opt -split-input-file -convert-pdl-to-pdl-interp %s | FileCheck %s
+
+// Ensuse that the dependency between add & less
+// causes them to be in the correct order.
+// CHECK-LABEL: matcher
+// CHECK: apply_constraint "return_attr_constraint"
+// CHECK: apply_constraint "use_attr_constraint"
+
+module {
+ pdl.pattern : benefit(1) {
+ %0 = attribute
+ %1 = types
+ %2 = operation "tosa.mul" {"shift" = %0} -> (%1 : !pdl.range<type>)
+ %3 = attribute = 0 : i32
+ %4 = attribute = 1 : i32
+ %5 = apply_native_constraint "return_attr_constraint"(%3, %4 : !pdl.attribute, !pdl.attribute) : !pdl.attribute
+ apply_native_constraint "use_attr_constraint"(%0, %5 : !pdl.attribute, !pdl.attribute)
+ rewrite %2 with "rewriter"
+ }
+}
+
+// -----
+
+// CHECK-LABEL: matcher
+// CHECK: %[[ATTR:.*]] = pdl_interp.get_attribute "attr" of
+// CHECK: %[[CONSTRAINT:.*]] = pdl_interp.apply_constraint "return_attr_constraint"
+// CHECK: pdl_interp.are_equal %[[ATTR:.*]], %[[CONSTRAINT:.*]]
+
+pdl.pattern : benefit(1) {
+ %inputOp = operation
+ %result = result 0 of %inputOp
+ %attr = pdl.apply_native_constraint "return_attr_constraint"(%inputOp : !pdl.operation) : !pdl.attribute
+ %root = operation(%result : !pdl.value) {"attr" = %attr}
+ rewrite %root with "rewriter"(%attr : !pdl.attribute)
+}
+
+// -----
+
+// CHECK-LABEL: matcher
+// CHECK: %[[CONSTRAINT:.*]] = pdl_interp.apply_constraint "return_value_constr"
+// CHECK: %[[VALUE:.*]] = pdl_interp.get_operand 0
+// CHECK: pdl_interp.are_equal %[[VALUE:.*]], %[[CONSTRAINT:.*]]
+
+pdl.pattern : benefit(1) {
+ %attr = attribute = 10
+ %value = pdl.apply_native_constraint "return_value_constr"(%attr: !pdl.attribute) : !pdl.value
+ %root = operation(%value : !pdl.value)
+ rewrite %root with "rewriter"
+}
+
+// -----
+
+// CHECK-LABEL: matcher
+// CHECK: %[[CONSTRAINT:.*]] = pdl_interp.apply_constraint "return_type_constr"
+// CHECK: %[[TYPE:.*]] = pdl_interp.get_value_type of
+// CHECK: pdl_interp.are_equal %[[TYPE:.*]], %[[CONSTRAINT:.*]]
+
+pdl.pattern : benefit(1) {
+ %attr = attribute = 10
+ %type = pdl.apply_native_constraint "return_type_constr"(%attr: !pdl.attribute) : !pdl.type
+ %root = operation -> (%type : !pdl.type)
+ rewrite %root with "rewriter"
+}
+
+// -----
+
+// CHECK-LABEL: matcher
+// CHECK: %[[CONSTRAINT:.*]] = pdl_interp.apply_constraint "return_type_range_constr"
+// CHECK: %[[TYPE:.*]] = pdl_interp.get_value_type of
+// CHECK: pdl_interp.are_equal %[[TYPE:.*]], %[[CONSTRAINT:.*]]
+
+pdl.pattern : benefit(1) {
+ %attr = attribute = 10
+ %types = pdl.apply_native_constraint "return_type_range_constr"(%attr: !pdl.attribute) : !pdl.range<type>
+ %root = operation -> (%types : !pdl.range<type>)
+ rewrite %root with "rewriter"
+}
diff --git a/mlir/test/Dialect/PDL/ops.mlir b/mlir/test/Dialect/PDL/ops.mlir
index 6e6da5cce446ae..20e40deea5f863 100644
--- a/mlir/test/Dialect/PDL/ops.mlir
+++ b/mlir/test/Dialect/PDL/ops.mlir
@@ -134,6 +134,24 @@ pdl.pattern @apply_rewrite_with_no_results : benefit(1) {
// -----
+pdl.pattern @apply_constraint_with_no_results : benefit(1) {
+ %root = operation
+ apply_native_constraint "NativeConstraint"(%root : !pdl.operation)
+ rewrite %root with "rewriter"
+}
+
+// -----
+
+pdl.pattern @apply_constraint_with_results : benefit(1) {
+ %root = operation
+ %attr = apply_native_constraint "NativeConstraint"(%root : !pdl.operation) : !pdl.attribute
+ rewrite %root {
+ apply_native_rewrite "NativeRewrite"(%attr : !pdl.attribute)
+ }
+}
+
+// -----
+
pdl.pattern @attribute_with_dict : benefit(1) {
%root = operation
rewrite %root {
diff --git a/mlir/test/Rewrite/pdl-bytecode.mlir b/mlir/test/Rewrite/pdl-bytecode.mlir
index ae61c1a079548a..f8e4f2e83b296a 100644
--- a/mlir/test/Rewrite/pdl-bytecode.mlir
+++ b/mlir/test/Rewrite/pdl-bytecode.mlir
@@ -109,6 +109,74 @@ module @ir attributes { test.apply_constraint_3 } {
// -----
+// Test returning a type from a native constraint.
+module @patterns {
+ pdl_interp.func @matcher(%root : !pdl.operation) {
+ pdl_interp.check_operation_name of %root is "test.success_op" -> ^pat, ^end
+
+ ^pat:
+ %new_type = pdl_interp.apply_constraint "op_constr_return_type"(%root : !pdl.operation) : !pdl.type -> ^pat2, ^end
+
+ ^pat2:
+ pdl_interp.record_match @rewriters::@success(%root, %new_type : !pdl.operation, !pdl.type) : benefit(1), loc([%root]) -> ^end
+
+ ^end:
+ pdl_interp.finalize
+ }
+
+ module @rewriters {
+ pdl_interp.func @success(%root : !pdl.operation, %new_type : !pdl.type) {
+ %op = pdl_interp.create_operation "test.replaced_by_pattern" -> (%new_type : !pdl.type)
+ pdl_interp.erase %root
+ pdl_interp.finalize
+ }
+ }
+}
+
+// CHECK-LABEL: test.apply_constraint_4
+// CHECK-NOT: "test.replaced_by_pattern"
+// CHECK: "test.replaced_by_pattern"() : () -> f32
+module @ir attributes { test.apply_constraint_4 } {
+ "test.failure_op"() : () -> ()
+ "test.success_op"() : () -> ()
+}
+
+// -----
+
+// Test success and failure cases of native constraints with pdl.range results.
+module @patterns {
+ pdl_interp.func @matcher(%root : !pdl.operation) {
+ pdl_interp.check_operation_name of %root is "test.success_op" -> ^pat, ^end
+
+ ^pat:
+ %num_results = pdl_interp.create_attribute 2 : i32
+ %types = pdl_interp.apply_constraint "op_constr_return_type_range"(%root, %num_results : !pdl.operation, !pdl.attribute) : !pdl.range<type> -> ^pat1, ^end
+
+ ^pat1:
+ pdl_interp.record_match @rewriters::@success(%root, %types : !pdl.operation, !pdl.range<type>) : benefit(1), loc([%root]) -> ^end
+
+ ^end:
+ pdl_interp.finalize
+ }
+
+ module @rewriters {
+ pdl_interp.func @success(%root : !pdl.operation, %types : !pdl.range<type>) {
+ %op = pdl_interp.create_operation "test.replaced_by_pattern" -> (%types : !pdl.range<type>)
+ pdl_interp.erase %root
+ pdl_interp.finalize
+ }
+ }
+}
+
+// CHECK-LABEL: test.apply_constraint_5
+// CHECK-NOT: "test.replaced_by_pattern"
+// CHECK: "test.replaced_by_pattern"() : () -> (f32, f32)
+module @ir attributes { test.apply_constraint_5 } {
+ "test.failure_op"() : () -> ()
+ "test.success_op"() : () -> ()
+}
+
+// -----
//===----------------------------------------------------------------------===//
// pdl_interp::ApplyRewriteOp
diff --git a/mlir/test/lib/Dialect/Transform/TestTransformDialectExtension.cpp b/mlir/test/lib/Dialect/Transform/TestTransformDialectExtension.cpp
index 50caf8f9cfc709..b9424e06bf0318 100644
--- a/mlir/test/lib/Dialect/Transform/TestTransformDialectExtension.cpp
+++ b/mlir/test/lib/Dialect/Transform/TestTransformDialectExtension.cpp
@@ -887,7 +887,7 @@ class TestTransformDialectExtension
#include "TestTransformDialectExtensionTypes.cpp.inc"
>();
- auto verboseConstraint = [](PatternRewriter &rewriter,
+ auto verboseConstraint = [](PatternRewriter &rewriter, PDLResultList &,
ArrayRef<PDLValue> pdlValues) {
for (const PDLValue &pdlValue : pdlValues) {
if (Operation *op = pdlValue.dyn_cast<Operation *>()) {
diff --git a/mlir/test/lib/Rewrite/TestPDLByteCode.cpp b/mlir/test/lib/Rewrite/TestPDLByteCode.cpp
index daa1c371f27c92..56af3c15b905f1 100644
--- a/mlir/test/lib/Rewrite/TestPDLByteCode.cpp
+++ b/mlir/test/lib/Rewrite/TestPDLByteCode.cpp
@@ -30,6 +30,50 @@ static LogicalResult customMultiEntityVariadicConstraint(
return success();
}
+// Custom constraint that returns a value if the op is named test.success_op
+static LogicalResult customValueResultConstraint(PatternRewriter &rewriter,
+ PDLResultList &results,
+ ArrayRef<PDLValue> args) {
+ auto *op = args[0].cast<Operation *>();
+ if (op->getName().getStringRef() == "test.success_op") {
+ StringAttr customAttr = rewriter.getStringAttr("test.success");
+ results.push_back(customAttr);
+ return success();
+ }
+ return failure();
+}
+
+// Custom constraint that returns a type if the op is named test.success_op
+static LogicalResult customTypeResultConstraint(PatternRewriter &rewriter,
+ PDLResultList &results,
+ ArrayRef<PDLValue> args) {
+ auto *op = args[0].cast<Operation *>();
+ if (op->getName().getStringRef() == "test.success_op") {
+ results.push_back(rewriter.getF32Type());
+ return success();
+ }
+ return failure();
+}
+
+// Custom constraint that returns a type range of variable length if the op is
+// named test.success_op
+static LogicalResult customTypeRangeResultConstraint(PatternRewriter &rewriter,
+ PDLResultList &results,
+ ArrayRef<PDLValue> args) {
+ auto *op = args[0].cast<Operation *>();
+ int numTypes = args[1].cast<Attribute>().cast<IntegerAttr>().getInt();
+
+ if (op->getName().getStringRef() == "test.success_op") {
+ SmallVector<Type> types;
+ for (int i = 0; i < numTypes; i++) {
+ types.push_back(rewriter.getF32Type());
+ }
+ results.push_back(TypeRange(types));
+ return success();
+ }
+ return failure();
+}
+
// Custom creator invoked from PDL.
static Operation *customCreate(PatternRewriter &rewriter, Operation *op) {
return rewriter.create(OperationState(op->getLoc(), "test.success"));
@@ -102,6 +146,12 @@ struct TestPDLByteCodePass
customMultiEntityConstraint);
pdlPattern.registerConstraintFunction("multi_entity_var_constraint",
customMultiEntityVariadicConstraint);
+ pdlPattern.registerConstraintFunction("op_constr_return_attr",
+ customValueResultConstraint);
+ pdlPattern.registerConstraintFunction("op_constr_return_type",
+ customTypeResultConstraint);
+ pdlPattern.registerConstraintFunction("op_constr_return_type_range",
+ customTypeRangeResultConstraint);
pdlPattern.registerRewriteFunction("creator", customCreate);
pdlPattern.registerRewriteFunction("var_creator",
customVariadicResultCreate);
diff --git a/mlir/test/mlir-pdll/Parser/constraint-failure.pdll b/mlir/test/mlir-pdll/Parser/constraint-failure.pdll
index 18877b4bcc50ec..48747d3fa2e681 100644
--- a/mlir/test/mlir-pdll/Parser/constraint-failure.pdll
+++ b/mlir/test/mlir-pdll/Parser/constraint-failure.pdll
@@ -158,8 +158,3 @@ Pattern {
// CHECK: expected `;` after native declaration
Constraint Foo() [{}]
-
-// -----
-
-// CHECK: native Constraints currently do not support returning results
-Constraint Foo() -> Op;
diff --git a/mlir/test/mlir-pdll/Parser/constraint.pdll b/mlir/test/mlir-pdll/Parser/constraint.pdll
index 1c0a015ab4a7b4..e2a52ff130cc84 100644
--- a/mlir/test/mlir-pdll/Parser/constraint.pdll
+++ b/mlir/test/mlir-pdll/Parser/constraint.pdll
@@ -12,6 +12,14 @@ Constraint Foo() [{ /* Native Code */ }];
// -----
+// Test that native constraints support returning results.
+
+// CHECK: Module
+// CHECK: `-UserConstraintDecl {{.*}} Name<Foo> ResultType<Attr>
+Constraint Foo() -> Attr;
+
+// -----
+
// CHECK: Module
// CHECK: `-UserConstraintDecl {{.*}} Name<Foo> ResultType<Value>
// CHECK: `Inputs`
diff --git a/mlir/test/python/dialects/pdl_ops.py b/mlir/test/python/dialects/pdl_ops.py
index 0d364f9222a657..95cb25c14873db 100644
--- a/mlir/test/python/dialects/pdl_ops.py
+++ b/mlir/test/python/dialects/pdl_ops.py
@@ -298,6 +298,6 @@ def test_apply_native_constraint():
pattern = PatternOp(1)
with InsertionPoint(pattern.body):
resultType = TypeOp()
- ApplyNativeConstraintOp("typeConstraint", args=[resultType])
+ ApplyNativeConstraintOp([], "typeConstraint", args=[resultType])
root = OperationOp(types=[resultType])
RewriteOp(root, name="rewrite")
>From 051e910b8b6c59fc94d019fa01ae4507b1c81498 Mon Sep 17 00:00:00 2001
From: Owen Pan <owenpiano at gmail.com>
Date: Sat, 2 Mar 2024 12:57:24 -0800
Subject: [PATCH 361/406] [clang-format][NFC] Replace Style.isCpp() with IsCpp
(#83533)
---
clang/lib/Format/FormatToken.h | 4 +--
clang/lib/Format/TokenAnnotator.cpp | 39 ++++++++++-----------
clang/lib/Format/TokenAnnotator.h | 4 ++-
clang/lib/Format/UnwrappedLineParser.cpp | 43 ++++++++++++------------
clang/lib/Format/UnwrappedLineParser.h | 1 +
5 files changed, 45 insertions(+), 46 deletions(-)
diff --git a/clang/lib/Format/FormatToken.h b/clang/lib/Format/FormatToken.h
index 0c1dce7a294082..31245495041960 100644
--- a/clang/lib/Format/FormatToken.h
+++ b/clang/lib/Format/FormatToken.h
@@ -821,8 +821,8 @@ struct FormatToken {
/// Returns whether the token is the left square bracket of a C++
/// structured binding declaration.
- bool isCppStructuredBinding(const FormatStyle &Style) const {
- if (!Style.isCpp() || isNot(tok::l_square))
+ bool isCppStructuredBinding(bool IsCpp) const {
+ if (!IsCpp || isNot(tok::l_square))
return false;
const FormatToken *T = this;
do {
diff --git a/clang/lib/Format/TokenAnnotator.cpp b/clang/lib/Format/TokenAnnotator.cpp
index a60d6ae197a24e..04f0374b674e53 100644
--- a/clang/lib/Format/TokenAnnotator.cpp
+++ b/clang/lib/Format/TokenAnnotator.cpp
@@ -126,7 +126,7 @@ class AnnotatingParser {
const AdditionalKeywords &Keywords,
SmallVector<ScopeType> &Scopes)
: Style(Style), Line(Line), CurrentToken(Line.First), AutoFound(false),
- Keywords(Keywords), Scopes(Scopes) {
+ IsCpp(Style.isCpp()), Keywords(Keywords), Scopes(Scopes) {
Contexts.push_back(Context(tok::unknown, 1, /*IsExpression=*/false));
resetTokenMetadata();
}
@@ -676,13 +676,13 @@ class AnnotatingParser {
// In C++, this can happen either in array of templates (foo<int>[10])
// or when array is a nested template type (unique_ptr<type1<type2>[]>).
bool CppArrayTemplates =
- Style.isCpp() && Parent && Parent->is(TT_TemplateCloser) &&
+ IsCpp && Parent && Parent->is(TT_TemplateCloser) &&
(Contexts.back().CanBeExpression || Contexts.back().IsExpression ||
Contexts.back().ContextType == Context::TemplateArgument);
const bool IsInnerSquare = Contexts.back().InCpp11AttributeSpecifier;
const bool IsCpp11AttributeSpecifier =
- isCppAttribute(Style.isCpp(), *Left) || IsInnerSquare;
+ isCppAttribute(IsCpp, *Left) || IsInnerSquare;
// Treat C# Attributes [STAThread] much like C++ attributes [[...]].
bool IsCSharpAttributeSpecifier =
@@ -690,12 +690,11 @@ class AnnotatingParser {
Contexts.back().InCSharpAttributeSpecifier;
bool InsideInlineASM = Line.startsWith(tok::kw_asm);
- bool IsCppStructuredBinding = Left->isCppStructuredBinding(Style);
+ bool IsCppStructuredBinding = Left->isCppStructuredBinding(IsCpp);
bool StartsObjCMethodExpr =
!IsCppStructuredBinding && !InsideInlineASM && !CppArrayTemplates &&
- Style.isCpp() && !IsCpp11AttributeSpecifier &&
- !IsCSharpAttributeSpecifier && Contexts.back().CanBeExpression &&
- Left->isNot(TT_LambdaLSquare) &&
+ IsCpp && !IsCpp11AttributeSpecifier && !IsCSharpAttributeSpecifier &&
+ Contexts.back().CanBeExpression && Left->isNot(TT_LambdaLSquare) &&
!CurrentToken->isOneOf(tok::l_brace, tok::r_square) &&
(!Parent ||
Parent->isOneOf(tok::colon, tok::l_square, tok::l_paren,
@@ -723,7 +722,7 @@ class AnnotatingParser {
Contexts.back().ContextKind == tok::l_brace &&
Parent->isOneOf(tok::l_brace, tok::comma)) {
Left->setType(TT_JsComputedPropertyName);
- } else if (Style.isCpp() && Contexts.back().ContextKind == tok::l_brace &&
+ } else if (IsCpp && Contexts.back().ContextKind == tok::l_brace &&
Parent && Parent->isOneOf(tok::l_brace, tok::comma)) {
Left->setType(TT_DesignatedInitializerLSquare);
} else if (IsCSharpAttributeSpecifier) {
@@ -1161,7 +1160,7 @@ class AnnotatingParser {
if (Previous->is(TT_JsTypeOptionalQuestion))
Previous = Previous->getPreviousNonComment();
if ((CurrentToken->is(tok::colon) && !Style.isTableGen() &&
- (!Contexts.back().ColonIsDictLiteral || !Style.isCpp())) ||
+ (!Contexts.back().ColonIsDictLiteral || !IsCpp)) ||
Style.isProto()) {
OpeningBrace.setType(TT_DictLiteral);
if (Previous->Tok.getIdentifierInfo() ||
@@ -1230,7 +1229,7 @@ class AnnotatingParser {
}
bool consumeToken() {
- if (Style.isCpp()) {
+ if (IsCpp) {
const auto *Prev = CurrentToken->getPreviousNonComment();
if (Prev && Prev->is(tok::r_square) && Prev->is(TT_AttributeSquare) &&
CurrentToken->isOneOf(tok::kw_if, tok::kw_switch, tok::kw_case,
@@ -1424,7 +1423,7 @@ class AnnotatingParser {
if (CurrentToken && CurrentToken->is(Keywords.kw_await))
next();
}
- if (Style.isCpp() && CurrentToken && CurrentToken->is(tok::kw_co_await))
+ if (IsCpp && CurrentToken && CurrentToken->is(tok::kw_co_await))
next();
Contexts.back().ColonIsForRangeExpr = true;
if (!CurrentToken || CurrentToken->isNot(tok::l_paren))
@@ -2590,7 +2589,7 @@ class AnnotatingParser {
/// Determine whether '(' is starting a C++ cast.
bool lParenStartsCppCast(const FormatToken &Tok) {
// C-style casts are only used in C++.
- if (!Style.isCpp())
+ if (!IsCpp)
return false;
FormatToken *LeftOfParens = Tok.getPreviousNonComment();
@@ -2611,10 +2610,8 @@ class AnnotatingParser {
/// Determine whether ')' is ending a cast.
bool rParenEndsCast(const FormatToken &Tok) {
// C-style casts are only used in C++, C# and Java.
- if (!Style.isCSharp() && !Style.isCpp() &&
- Style.Language != FormatStyle::LK_Java) {
+ if (!Style.isCSharp() && !IsCpp && Style.Language != FormatStyle::LK_Java)
return false;
- }
// Empty parens aren't casts and there are no casts at the end of the line.
if (Tok.Previous == Tok.MatchingParen || !Tok.Next || !Tok.MatchingParen)
@@ -2691,7 +2688,7 @@ class AnnotatingParser {
if (Tok.Next->isOneOf(tok::kw_noexcept, tok::kw_volatile, tok::kw_const,
tok::kw_requires, tok::kw_throw, tok::arrow,
Keywords.kw_override, Keywords.kw_final) ||
- isCppAttribute(Style.isCpp(), *Tok.Next)) {
+ isCppAttribute(IsCpp, *Tok.Next)) {
return false;
}
@@ -3012,6 +3009,7 @@ class AnnotatingParser {
AnnotatedLine &Line;
FormatToken *CurrentToken;
bool AutoFound;
+ bool IsCpp;
const AdditionalKeywords &Keywords;
SmallVector<ScopeType> &Scopes;
@@ -3559,7 +3557,7 @@ void TokenAnnotator::annotate(AnnotatedLine &Line) {
ExpressionParser ExprParser(Style, Keywords, Line);
ExprParser.parse();
- if (Style.isCpp()) {
+ if (IsCpp) {
auto *Tok = getFunctionName(Line);
if (Tok && ((!Scopes.empty() && Scopes.back() == ST_Class) ||
Line.endsWith(TT_FunctionLBrace) || isCtorOrDtorName(Tok))) {
@@ -3766,7 +3764,6 @@ void TokenAnnotator::calculateFormattingInformation(AnnotatedLine &Line) const {
if (AlignArrayOfStructures)
calculateArrayInitializerColumnList(Line);
- const bool IsCpp = Style.isCpp();
bool SeenName = false;
bool LineIsFunctionDeclaration = false;
FormatToken *ClosingParen = nullptr;
@@ -3779,7 +3776,7 @@ void TokenAnnotator::calculateFormattingInformation(AnnotatedLine &Line) const {
AfterLastAttribute = Tok;
if (const bool IsCtorOrDtor = Tok->is(TT_CtorDtorDeclName);
IsCtorOrDtor ||
- isFunctionDeclarationName(Style.isCpp(), *Tok, Line, ClosingParen)) {
+ isFunctionDeclarationName(IsCpp, *Tok, Line, ClosingParen)) {
if (!IsCtorOrDtor)
Tok->setFinalizedType(TT_FunctionDeclarationName);
LineIsFunctionDeclaration = true;
@@ -4717,7 +4714,7 @@ bool TokenAnnotator::spaceRequiredBefore(const AnnotatedLine &Line,
if (Left.is(tok::star) && Right.is(tok::comment))
return true;
- if (Style.isCpp()) {
+ if (IsCpp) {
if (Left.is(TT_OverloadedOperator) &&
Right.isOneOf(TT_TemplateOpener, TT_TemplateCloser)) {
return true;
@@ -5425,7 +5422,7 @@ bool TokenAnnotator::mustBreakBefore(const AnnotatedLine &Line,
if (!Keywords.isVerilogBegin(Right) && Keywords.isVerilogEndOfLabel(Left))
return true;
} else if (Style.BreakAdjacentStringLiterals &&
- (Style.isCpp() || Style.isProto() ||
+ (IsCpp || Style.isProto() ||
Style.Language == FormatStyle::LK_TableGen)) {
if (Left.isStringLiteral() && Right.isStringLiteral())
return true;
diff --git a/clang/lib/Format/TokenAnnotator.h b/clang/lib/Format/TokenAnnotator.h
index 05a6daa87d8034..a631e5f52bc60a 100644
--- a/clang/lib/Format/TokenAnnotator.h
+++ b/clang/lib/Format/TokenAnnotator.h
@@ -212,7 +212,7 @@ class AnnotatedLine {
class TokenAnnotator {
public:
TokenAnnotator(const FormatStyle &Style, const AdditionalKeywords &Keywords)
- : Style(Style), Keywords(Keywords) {}
+ : Style(Style), IsCpp(Style.isCpp()), Keywords(Keywords) {}
/// Adapts the indent levels of comment lines to the indent of the
/// subsequent line.
@@ -260,6 +260,8 @@ class TokenAnnotator {
const FormatStyle &Style;
+ bool IsCpp;
+
const AdditionalKeywords &Keywords;
SmallVector<ScopeType> Scopes;
diff --git a/clang/lib/Format/UnwrappedLineParser.cpp b/clang/lib/Format/UnwrappedLineParser.cpp
index 3a424bdcde793a..2ce291da11b86a 100644
--- a/clang/lib/Format/UnwrappedLineParser.cpp
+++ b/clang/lib/Format/UnwrappedLineParser.cpp
@@ -159,9 +159,9 @@ UnwrappedLineParser::UnwrappedLineParser(
llvm::SpecificBumpPtrAllocator<FormatToken> &Allocator,
IdentifierTable &IdentTable)
: Line(new UnwrappedLine), MustBreakBeforeNextToken(false),
- CurrentLines(&Lines), Style(Style), Keywords(Keywords),
- CommentPragmasRegex(Style.CommentPragmas), Tokens(nullptr),
- Callback(Callback), AllTokens(Tokens), PPBranchLevel(-1),
+ CurrentLines(&Lines), Style(Style), IsCpp(Style.isCpp()),
+ Keywords(Keywords), CommentPragmasRegex(Style.CommentPragmas),
+ Tokens(nullptr), Callback(Callback), AllTokens(Tokens), PPBranchLevel(-1),
IncludeGuard(Style.IndentPPDirectives == FormatStyle::PPDIS_None
? IG_Rejected
: IG_Inited),
@@ -572,8 +572,8 @@ void UnwrappedLineParser::calculateBraceTypes(bool ExpectClassBody) {
(Style.isJavaScript() &&
NextTok->isOneOf(Keywords.kw_of, Keywords.kw_in,
Keywords.kw_as));
- ProbablyBracedList = ProbablyBracedList ||
- (Style.isCpp() && NextTok->is(tok::l_paren));
+ ProbablyBracedList =
+ ProbablyBracedList || (IsCpp && NextTok->is(tok::l_paren));
// If there is a comma, semicolon or right paren after the closing
// brace, we assume this is a braced initializer list.
@@ -1428,7 +1428,7 @@ void UnwrappedLineParser::parseStructuralElement(
return;
}
- if (Style.isCpp()) {
+ if (IsCpp) {
while (FormatTok->is(tok::l_square) && handleCppAttributes()) {
}
} else if (Style.isVerilog()) {
@@ -1602,7 +1602,7 @@ void UnwrappedLineParser::parseStructuralElement(
parseJavaScriptEs6ImportExport();
return;
}
- if (Style.isCpp()) {
+ if (IsCpp) {
nextToken();
if (FormatTok->is(tok::kw_namespace)) {
parseNamespace();
@@ -1646,12 +1646,11 @@ void UnwrappedLineParser::parseStructuralElement(
addUnwrappedLine();
return;
}
- if (Style.isCpp() && parseModuleImport())
+ if (IsCpp && parseModuleImport())
return;
}
- if (Style.isCpp() &&
- FormatTok->isOneOf(Keywords.kw_signals, Keywords.kw_qsignals,
- Keywords.kw_slots, Keywords.kw_qslots)) {
+ if (IsCpp && FormatTok->isOneOf(Keywords.kw_signals, Keywords.kw_qsignals,
+ Keywords.kw_slots, Keywords.kw_qslots)) {
nextToken();
if (FormatTok->is(tok::colon)) {
nextToken();
@@ -1659,11 +1658,11 @@ void UnwrappedLineParser::parseStructuralElement(
return;
}
}
- if (Style.isCpp() && FormatTok->is(TT_StatementMacro)) {
+ if (IsCpp && FormatTok->is(TT_StatementMacro)) {
parseStatementMacro();
return;
}
- if (Style.isCpp() && FormatTok->is(TT_NamespaceMacro)) {
+ if (IsCpp && FormatTok->is(TT_NamespaceMacro)) {
parseNamespace();
return;
}
@@ -1759,7 +1758,7 @@ void UnwrappedLineParser::parseStructuralElement(
}
break;
case tok::kw_requires: {
- if (Style.isCpp()) {
+ if (IsCpp) {
bool ParsedClause = parseRequires();
if (ParsedClause)
return;
@@ -1780,7 +1779,7 @@ void UnwrappedLineParser::parseStructuralElement(
if (!parseEnum())
break;
// This only applies to C++ and Verilog.
- if (!Style.isCpp() && !Style.isVerilog()) {
+ if (!IsCpp && !Style.isVerilog()) {
addUnwrappedLine();
return;
}
@@ -1848,7 +1847,7 @@ void UnwrappedLineParser::parseStructuralElement(
parseParens();
// Break the unwrapped line if a K&R C function definition has a parameter
// declaration.
- if (OpeningBrace || !Style.isCpp() || !Previous || eof())
+ if (OpeningBrace || !IsCpp || !Previous || eof())
break;
if (isC78ParameterDecl(FormatTok,
Tokens->peekNextToken(/*SkipComment=*/true),
@@ -1977,13 +1976,13 @@ void UnwrappedLineParser::parseStructuralElement(
}
}
- if (!Style.isCpp() && FormatTok->is(Keywords.kw_interface)) {
+ if (!IsCpp && FormatTok->is(Keywords.kw_interface)) {
if (parseStructLike())
return;
break;
}
- if (Style.isCpp() && FormatTok->is(TT_StatementMacro)) {
+ if (IsCpp && FormatTok->is(TT_StatementMacro)) {
parseStatementMacro();
return;
}
@@ -2211,7 +2210,7 @@ bool UnwrappedLineParser::tryToParsePropertyAccessor() {
bool UnwrappedLineParser::tryToParseLambda() {
assert(FormatTok->is(tok::l_square));
- if (!Style.isCpp()) {
+ if (!IsCpp) {
nextToken();
return false;
}
@@ -2340,7 +2339,7 @@ bool UnwrappedLineParser::tryToParseLambdaIntroducer() {
!Previous->isOneOf(tok::kw_return, tok::kw_co_await,
tok::kw_co_yield, tok::kw_co_return)) ||
Previous->closesScope())) ||
- LeftSquare->isCppStructuredBinding(Style)) {
+ LeftSquare->isCppStructuredBinding(IsCpp)) {
return false;
}
if (FormatTok->is(tok::l_square) || tok::isLiteral(FormatTok->Tok.getKind()))
@@ -3153,7 +3152,7 @@ void UnwrappedLineParser::parseForOrWhileLoop(bool HasParens) {
// JS' for await ( ...
if (Style.isJavaScript() && FormatTok->is(Keywords.kw_await))
nextToken();
- if (Style.isCpp() && FormatTok->is(tok::kw_co_await))
+ if (IsCpp && FormatTok->is(tok::kw_co_await))
nextToken();
if (HasParens && FormatTok->is(tok::l_paren)) {
// The type is only set for Verilog basically because we were afraid to
@@ -3737,7 +3736,7 @@ bool UnwrappedLineParser::parseEnum() {
nextToken();
// If there are two identifiers in a row, this is likely an elaborate
// return type. In Java, this can be "implements", etc.
- if (Style.isCpp() && FormatTok->is(tok::identifier))
+ if (IsCpp && FormatTok->is(tok::identifier))
return false;
}
}
diff --git a/clang/lib/Format/UnwrappedLineParser.h b/clang/lib/Format/UnwrappedLineParser.h
index 1403533a2d0ef6..619fbb217882b3 100644
--- a/clang/lib/Format/UnwrappedLineParser.h
+++ b/clang/lib/Format/UnwrappedLineParser.h
@@ -324,6 +324,7 @@ class UnwrappedLineParser {
llvm::BitVector DeclarationScopeStack;
const FormatStyle &Style;
+ bool IsCpp;
const AdditionalKeywords &Keywords;
llvm::Regex CommentPragmasRegex;
>From 60fbd6050107875956960c3ce35cf94b202d8675 Mon Sep 17 00:00:00 2001
From: Mehdi Amini <joker.eph at gmail.com>
Date: Sat, 2 Mar 2024 14:41:40 -0800
Subject: [PATCH 362/406] Revert "[mlir][Transforms] Encapsulate dialect
conversion options in `ConversionConfig` (#83662)
This reverts commit 5f1319bb385342c7ef4124b05b83b89ef8588ee8.
A FIR test is broken on Windows
---
.../mlir/Transforms/DialectConversion.h | 72 ++++------
.../Transforms/Utils/DialectConversion.cpp | 134 ++++++++++--------
mlir/test/lib/Dialect/Test/TestPatterns.cpp | 14 +-
3 files changed, 104 insertions(+), 116 deletions(-)
diff --git a/mlir/include/mlir/Transforms/DialectConversion.h b/mlir/include/mlir/Transforms/DialectConversion.h
index 84396529eb7c2e..88eefa69a8003f 100644
--- a/mlir/include/mlir/Transforms/DialectConversion.h
+++ b/mlir/include/mlir/Transforms/DialectConversion.h
@@ -24,7 +24,6 @@ namespace mlir {
// Forward declarations.
class Attribute;
class Block;
-struct ConversionConfig;
class ConversionPatternRewriter;
class MLIRContext;
class Operation;
@@ -768,8 +767,7 @@ class ConversionPatternRewriter final : public PatternRewriter {
/// Conversion pattern rewriters must not be used outside of dialect
/// conversions. They apply some IR rewrites in a delayed fashion and could
/// bring the IR into an inconsistent state when used standalone.
- explicit ConversionPatternRewriter(MLIRContext *ctx,
- const ConversionConfig &config);
+ explicit ConversionPatternRewriter(MLIRContext *ctx);
// Hide unsupported pattern rewriter API.
using OpBuilder::setListener;
@@ -1069,30 +1067,6 @@ class PDLConversionConfig final {
#endif // MLIR_ENABLE_PDL_IN_PATTERNMATCH
-//===----------------------------------------------------------------------===//
-// ConversionConfig
-//===----------------------------------------------------------------------===//
-
-/// Dialect conversion configuration.
-struct ConversionConfig {
- /// An optional callback used to notify about match failure diagnostics during
- /// the conversion. Diagnostics reported to this callback may only be
- /// available in debug mode.
- function_ref<void(Diagnostic &)> notifyCallback = nullptr;
-
- /// Partial conversion only. All operations that are found not to be
- /// legalizable are placed in this set. (Note that if there is an op
- /// explicitly marked as illegal, the conversion terminates and the set will
- /// not necessarily be complete.)
- DenseSet<Operation *> *unlegalizedOps = nullptr;
-
- /// Analysis conversion only. All operations that are found to be legalizable
- /// are placed in this set. Note that no actual rewrites are applied to the
- /// IR during an analysis conversion and only pre-existing operations are
- /// added to the set.
- DenseSet<Operation *> *legalizableOps = nullptr;
-};
-
//===----------------------------------------------------------------------===//
// Op Conversion Entry Points
//===----------------------------------------------------------------------===//
@@ -1106,16 +1080,20 @@ struct ConversionConfig {
/// Apply a partial conversion on the given operations and all nested
/// operations. This method converts as many operations to the target as
/// possible, ignoring operations that failed to legalize. This method only
-/// returns failure if there ops explicitly marked as illegal.
+/// returns failure if there ops explicitly marked as illegal. If an
+/// `unconvertedOps` set is provided, all operations that are found not to be
+/// legalizable to the given `target` are placed within that set. (Note that if
+/// there is an op explicitly marked as illegal, the conversion terminates and
+/// the `unconvertedOps` set will not necessarily be complete.)
LogicalResult
applyPartialConversion(ArrayRef<Operation *> ops,
const ConversionTarget &target,
const FrozenRewritePatternSet &patterns,
- ConversionConfig config = ConversionConfig());
+ DenseSet<Operation *> *unconvertedOps = nullptr);
LogicalResult
applyPartialConversion(Operation *op, const ConversionTarget &target,
const FrozenRewritePatternSet &patterns,
- ConversionConfig config = ConversionConfig());
+ DenseSet<Operation *> *unconvertedOps = nullptr);
/// Apply a complete conversion on the given operations, and all nested
/// operations. This method returns failure if the conversion of any operation
@@ -1123,27 +1101,31 @@ applyPartialConversion(Operation *op, const ConversionTarget &target,
/// within 'ops'.
LogicalResult applyFullConversion(ArrayRef<Operation *> ops,
const ConversionTarget &target,
- const FrozenRewritePatternSet &patterns,
- ConversionConfig config = ConversionConfig());
+ const FrozenRewritePatternSet &patterns);
LogicalResult applyFullConversion(Operation *op, const ConversionTarget &target,
- const FrozenRewritePatternSet &patterns,
- ConversionConfig config = ConversionConfig());
+ const FrozenRewritePatternSet &patterns);
/// Apply an analysis conversion on the given operations, and all nested
/// operations. This method analyzes which operations would be successfully
/// converted to the target if a conversion was applied. All operations that
/// were found to be legalizable to the given 'target' are placed within the
-/// provided 'config.legalizableOps' set; note that no actual rewrites are
-/// applied to the operations on success. This method only returns failure if
-/// there are unreachable blocks in any of the regions nested within 'ops'.
-LogicalResult
-applyAnalysisConversion(ArrayRef<Operation *> ops, ConversionTarget &target,
- const FrozenRewritePatternSet &patterns,
- ConversionConfig config = ConversionConfig());
-LogicalResult
-applyAnalysisConversion(Operation *op, ConversionTarget &target,
- const FrozenRewritePatternSet &patterns,
- ConversionConfig config = ConversionConfig());
+/// provided 'convertedOps' set; note that no actual rewrites are applied to the
+/// operations on success and only pre-existing operations are added to the set.
+/// This method only returns failure if there are unreachable blocks in any of
+/// the regions nested within 'ops'. There's an additional argument
+/// `notifyCallback` which is used for collecting match failure diagnostics
+/// generated during the conversion. Diagnostics are only reported to this
+/// callback may only be available in debug mode.
+LogicalResult applyAnalysisConversion(
+ ArrayRef<Operation *> ops, ConversionTarget &target,
+ const FrozenRewritePatternSet &patterns,
+ DenseSet<Operation *> &convertedOps,
+ function_ref<void(Diagnostic &)> notifyCallback = nullptr);
+LogicalResult applyAnalysisConversion(
+ Operation *op, ConversionTarget &target,
+ const FrozenRewritePatternSet &patterns,
+ DenseSet<Operation *> &convertedOps,
+ function_ref<void(Diagnostic &)> notifyCallback = nullptr);
} // namespace mlir
#endif // MLIR_TRANSFORMS_DIALECTCONVERSION_H_
diff --git a/mlir/lib/Transforms/Utils/DialectConversion.cpp b/mlir/lib/Transforms/Utils/DialectConversion.cpp
index 26899301eb742e..ffdb442033d323 100644
--- a/mlir/lib/Transforms/Utils/DialectConversion.cpp
+++ b/mlir/lib/Transforms/Utils/DialectConversion.cpp
@@ -230,8 +230,6 @@ class IRRewrite {
/// Erase the given block (unless it was already erased).
void eraseBlock(Block *block);
- const ConversionConfig &getConfig() const;
-
const Kind kind;
ConversionPatternRewriterImpl &rewriterImpl;
};
@@ -734,9 +732,8 @@ static RewriteTy *findSingleRewrite(R &&rewrites, Block *block) {
namespace mlir {
namespace detail {
struct ConversionPatternRewriterImpl : public RewriterBase::Listener {
- explicit ConversionPatternRewriterImpl(MLIRContext *ctx,
- const ConversionConfig &config)
- : eraseRewriter(ctx), config(config) {}
+ explicit ConversionPatternRewriterImpl(PatternRewriter &rewriter)
+ : eraseRewriter(rewriter.getContext()) {}
//===--------------------------------------------------------------------===//
// State Management
@@ -936,8 +933,14 @@ struct ConversionPatternRewriterImpl : public RewriterBase::Listener {
/// converting the arguments of blocks within that region.
DenseMap<Region *, const TypeConverter *> regionToConverter;
- /// Dialect conversion configuration.
- const ConversionConfig &config;
+ /// This allows the user to collect the match failure message.
+ function_ref<void(Diagnostic &)> notifyCallback;
+
+ /// A set of pre-existing operations. When mode == OpConversionMode::Analysis,
+ /// this is populated with ops found to be legalizable to the target.
+ /// When mode == OpConversionMode::Partial, this is populated with ops found
+ /// *not* to be legalizable to the target.
+ DenseSet<Operation *> *trackedOps = nullptr;
#ifndef NDEBUG
/// A set of operations that have pending updates. This tracking isn't
@@ -960,10 +963,6 @@ void IRRewrite::eraseBlock(Block *block) {
rewriterImpl.eraseRewriter.eraseBlock(block);
}
-const ConversionConfig &IRRewrite::getConfig() const {
- return rewriterImpl.config;
-}
-
void BlockTypeConversionRewrite::commit() {
// Process the remapping for each of the original arguments.
for (auto [origArg, info] :
@@ -1081,8 +1080,8 @@ void ReplaceOperationRewrite::commit() {
if (Value newValue =
rewriterImpl.mapping.lookupOrNull(result, result.getType()))
result.replaceAllUsesWith(newValue);
- if (getConfig().unlegalizedOps)
- getConfig().unlegalizedOps->erase(op);
+ if (rewriterImpl.trackedOps)
+ rewriterImpl.trackedOps->erase(op);
// Do not erase the operation yet. It may still be referenced in `mapping`.
op->getBlock()->getOperations().remove(op);
}
@@ -1505,8 +1504,8 @@ void ConversionPatternRewriterImpl::notifyMatchFailure(
Diagnostic diag(loc, DiagnosticSeverity::Remark);
reasonCallback(diag);
logger.startLine() << "** Failure : " << diag.str() << "\n";
- if (config.notifyCallback)
- config.notifyCallback(diag);
+ if (notifyCallback)
+ notifyCallback(diag);
});
}
@@ -1514,10 +1513,9 @@ void ConversionPatternRewriterImpl::notifyMatchFailure(
// ConversionPatternRewriter
//===----------------------------------------------------------------------===//
-ConversionPatternRewriter::ConversionPatternRewriter(
- MLIRContext *ctx, const ConversionConfig &config)
+ConversionPatternRewriter::ConversionPatternRewriter(MLIRContext *ctx)
: PatternRewriter(ctx),
- impl(new detail::ConversionPatternRewriterImpl(ctx, config)) {
+ impl(new detail::ConversionPatternRewriterImpl(*this)) {
setListener(impl.get());
}
@@ -1986,12 +1984,12 @@ OperationLegalizer::legalizeWithPattern(Operation *op,
assert(rewriterImpl.pendingRootUpdates.empty() && "dangling root updates");
LLVM_DEBUG({
logFailure(rewriterImpl.logger, "pattern failed to match");
- if (rewriterImpl.config.notifyCallback) {
+ if (rewriterImpl.notifyCallback) {
Diagnostic diag(op->getLoc(), DiagnosticSeverity::Remark);
diag << "Failed to apply pattern \"" << pattern.getDebugName()
<< "\" on op:\n"
<< *op;
- rewriterImpl.config.notifyCallback(diag);
+ rewriterImpl.notifyCallback(diag);
}
});
rewriterImpl.resetState(curState);
@@ -2379,12 +2377,14 @@ namespace mlir {
struct OperationConverter {
explicit OperationConverter(const ConversionTarget &target,
const FrozenRewritePatternSet &patterns,
- const ConversionConfig &config,
- OpConversionMode mode)
- : opLegalizer(target, patterns), config(config), mode(mode) {}
+ OpConversionMode mode,
+ DenseSet<Operation *> *trackedOps = nullptr)
+ : opLegalizer(target, patterns), mode(mode), trackedOps(trackedOps) {}
/// Converts the given operations to the conversion target.
- LogicalResult convertOperations(ArrayRef<Operation *> ops);
+ LogicalResult
+ convertOperations(ArrayRef<Operation *> ops,
+ function_ref<void(Diagnostic &)> notifyCallback = nullptr);
private:
/// Converts an operation with the given rewriter.
@@ -2421,11 +2421,14 @@ struct OperationConverter {
/// The legalizer to use when converting operations.
OperationLegalizer opLegalizer;
- /// Dialect conversion configuration.
- ConversionConfig config;
-
/// The conversion mode to use when legalizing operations.
OpConversionMode mode;
+
+ /// A set of pre-existing operations. When mode == OpConversionMode::Analysis,
+ /// this is populated with ops found to be legalizable to the target.
+ /// When mode == OpConversionMode::Partial, this is populated with ops found
+ /// *not* to be legalizable to the target.
+ DenseSet<Operation *> *trackedOps;
};
} // namespace mlir
@@ -2439,27 +2442,28 @@ LogicalResult OperationConverter::convert(ConversionPatternRewriter &rewriter,
return op->emitError()
<< "failed to legalize operation '" << op->getName() << "'";
// Partial conversions allow conversions to fail iff the operation was not
- // explicitly marked as illegal. If the user provided a `unlegalizedOps`
- // set, non-legalizable ops are added to that set.
+ // explicitly marked as illegal. If the user provided a nonlegalizableOps
+ // set, non-legalizable ops are included.
if (mode == OpConversionMode::Partial) {
if (opLegalizer.isIllegal(op))
return op->emitError()
<< "failed to legalize operation '" << op->getName()
<< "' that was explicitly marked illegal";
- if (config.unlegalizedOps)
- config.unlegalizedOps->insert(op);
+ if (trackedOps)
+ trackedOps->insert(op);
}
} else if (mode == OpConversionMode::Analysis) {
// Analysis conversions don't fail if any operations fail to legalize,
// they are only interested in the operations that were successfully
// legalized.
- if (config.legalizableOps)
- config.legalizableOps->insert(op);
+ trackedOps->insert(op);
}
return success();
}
-LogicalResult OperationConverter::convertOperations(ArrayRef<Operation *> ops) {
+LogicalResult OperationConverter::convertOperations(
+ ArrayRef<Operation *> ops,
+ function_ref<void(Diagnostic &)> notifyCallback) {
if (ops.empty())
return success();
const ConversionTarget &target = opLegalizer.getTarget();
@@ -2480,8 +2484,10 @@ LogicalResult OperationConverter::convertOperations(ArrayRef<Operation *> ops) {
}
// Convert each operation and discard rewrites on failure.
- ConversionPatternRewriter rewriter(ops.front()->getContext(), config);
+ ConversionPatternRewriter rewriter(ops.front()->getContext());
ConversionPatternRewriterImpl &rewriterImpl = rewriter.getImpl();
+ rewriterImpl.notifyCallback = notifyCallback;
+ rewriterImpl.trackedOps = trackedOps;
for (auto *op : toConvert)
if (failed(convert(rewriter, op)))
@@ -3468,51 +3474,57 @@ void mlir::registerConversionPDLFunctions(RewritePatternSet &patterns) {
//===----------------------------------------------------------------------===//
// Partial Conversion
-LogicalResult mlir::applyPartialConversion(
- ArrayRef<Operation *> ops, const ConversionTarget &target,
- const FrozenRewritePatternSet &patterns, ConversionConfig config) {
- OperationConverter opConverter(target, patterns, config,
- OpConversionMode::Partial);
+LogicalResult
+mlir::applyPartialConversion(ArrayRef<Operation *> ops,
+ const ConversionTarget &target,
+ const FrozenRewritePatternSet &patterns,
+ DenseSet<Operation *> *unconvertedOps) {
+ OperationConverter opConverter(target, patterns, OpConversionMode::Partial,
+ unconvertedOps);
return opConverter.convertOperations(ops);
}
LogicalResult
mlir::applyPartialConversion(Operation *op, const ConversionTarget &target,
const FrozenRewritePatternSet &patterns,
- ConversionConfig config) {
- return applyPartialConversion(llvm::ArrayRef(op), target, patterns, config);
+ DenseSet<Operation *> *unconvertedOps) {
+ return applyPartialConversion(llvm::ArrayRef(op), target, patterns,
+ unconvertedOps);
}
//===----------------------------------------------------------------------===//
// Full Conversion
-LogicalResult mlir::applyFullConversion(ArrayRef<Operation *> ops,
- const ConversionTarget &target,
- const FrozenRewritePatternSet &patterns,
- ConversionConfig config) {
- OperationConverter opConverter(target, patterns, config,
- OpConversionMode::Full);
+LogicalResult
+mlir::applyFullConversion(ArrayRef<Operation *> ops,
+ const ConversionTarget &target,
+ const FrozenRewritePatternSet &patterns) {
+ OperationConverter opConverter(target, patterns, OpConversionMode::Full);
return opConverter.convertOperations(ops);
}
-LogicalResult mlir::applyFullConversion(Operation *op,
- const ConversionTarget &target,
- const FrozenRewritePatternSet &patterns,
- ConversionConfig config) {
- return applyFullConversion(llvm::ArrayRef(op), target, patterns, config);
+LogicalResult
+mlir::applyFullConversion(Operation *op, const ConversionTarget &target,
+ const FrozenRewritePatternSet &patterns) {
+ return applyFullConversion(llvm::ArrayRef(op), target, patterns);
}
//===----------------------------------------------------------------------===//
// Analysis Conversion
-LogicalResult mlir::applyAnalysisConversion(
- ArrayRef<Operation *> ops, ConversionTarget &target,
- const FrozenRewritePatternSet &patterns, ConversionConfig config) {
- OperationConverter opConverter(target, patterns, config,
- OpConversionMode::Analysis);
- return opConverter.convertOperations(ops);
+LogicalResult
+mlir::applyAnalysisConversion(ArrayRef<Operation *> ops,
+ ConversionTarget &target,
+ const FrozenRewritePatternSet &patterns,
+ DenseSet<Operation *> &convertedOps,
+ function_ref<void(Diagnostic &)> notifyCallback) {
+ OperationConverter opConverter(target, patterns, OpConversionMode::Analysis,
+ &convertedOps);
+ return opConverter.convertOperations(ops, notifyCallback);
}
LogicalResult
mlir::applyAnalysisConversion(Operation *op, ConversionTarget &target,
const FrozenRewritePatternSet &patterns,
- ConversionConfig config) {
- return applyAnalysisConversion(llvm::ArrayRef(op), target, patterns, config);
+ DenseSet<Operation *> &convertedOps,
+ function_ref<void(Diagnostic &)> notifyCallback) {
+ return applyAnalysisConversion(llvm::ArrayRef(op), target, patterns,
+ convertedOps, notifyCallback);
}
diff --git a/mlir/test/lib/Dialect/Test/TestPatterns.cpp b/mlir/test/lib/Dialect/Test/TestPatterns.cpp
index abc0e43c7b7f2d..157bfcc1eb23be 100644
--- a/mlir/test/lib/Dialect/Test/TestPatterns.cpp
+++ b/mlir/test/lib/Dialect/Test/TestPatterns.cpp
@@ -1152,10 +1152,8 @@ struct TestLegalizePatternDriver
// Handle a partial conversion.
if (mode == ConversionMode::Partial) {
DenseSet<Operation *> unlegalizedOps;
- ConversionConfig config;
- config.unlegalizedOps = &unlegalizedOps;
- if (failed(applyPartialConversion(getOperation(), target,
- std::move(patterns), config))) {
+ if (failed(applyPartialConversion(
+ getOperation(), target, std::move(patterns), &unlegalizedOps))) {
getOperation()->emitRemark() << "applyPartialConversion failed";
}
// Emit remarks for each legalizable operation.
@@ -1183,10 +1181,8 @@ struct TestLegalizePatternDriver
// Analyze the convertible operations.
DenseSet<Operation *> legalizedOps;
- ConversionConfig config;
- config.legalizableOps = &legalizedOps;
if (failed(applyAnalysisConversion(getOperation(), target,
- std::move(patterns), config)))
+ std::move(patterns), legalizedOps)))
return signalPassFailure();
// Emit remarks for each legalizable operation.
@@ -1809,10 +1805,8 @@ struct TestMergeBlocksPatternDriver
});
DenseSet<Operation *> unlegalizedOps;
- ConversionConfig config;
- config.unlegalizedOps = &unlegalizedOps;
(void)applyPartialConversion(getOperation(), target, std::move(patterns),
- config);
+ &unlegalizedOps);
for (auto *op : unlegalizedOps)
op->emitRemark() << "op '" << op->getName() << "' is not legalizable";
}
>From f505a92fc2e965f1fe2e6a25d1ff4f0d9d1297c6 Mon Sep 17 00:00:00 2001
From: MagentaTreehouse <99200384+MagentaTreehouse at users.noreply.github.com>
Date: Sat, 2 Mar 2024 17:44:17 -0500
Subject: [PATCH 363/406] [NFC] Use fold expressions to replace discarded
initializer_lists (#83693)
---
clang/lib/AST/Interp/ByteCodeEmitter.cpp | 5 +----
llvm/lib/Target/AArch64/AArch64SLSHardening.cpp | 9 ++-------
llvm/lib/Target/ARM/ARMSLSHardening.cpp | 9 ++-------
llvm/lib/Target/X86/X86IndirectThunks.cpp | 9 ++-------
4 files changed, 7 insertions(+), 25 deletions(-)
diff --git a/clang/lib/AST/Interp/ByteCodeEmitter.cpp b/clang/lib/AST/Interp/ByteCodeEmitter.cpp
index e1b954fcc68486..4fbfc0930fbaa1 100644
--- a/clang/lib/AST/Interp/ByteCodeEmitter.cpp
+++ b/clang/lib/AST/Interp/ByteCodeEmitter.cpp
@@ -302,10 +302,7 @@ bool ByteCodeEmitter::emitOp(Opcode Op, const Tys &... Args, const SourceInfo &S
if (SI)
SrcMap.emplace_back(Code.size(), SI);
- // The initializer list forces the expression to be evaluated
- // for each argument in the variadic template, in order.
- (void)std::initializer_list<int>{(emit(P, Code, Args, Success), 0)...};
-
+ (..., emit(P, Code, Args, Success));
return Success;
}
diff --git a/llvm/lib/Target/AArch64/AArch64SLSHardening.cpp b/llvm/lib/Target/AArch64/AArch64SLSHardening.cpp
index 76dd5a2d713ebb..ce3bc0b1837558 100644
--- a/llvm/lib/Target/AArch64/AArch64SLSHardening.cpp
+++ b/llvm/lib/Target/AArch64/AArch64SLSHardening.cpp
@@ -412,20 +412,15 @@ class AArch64IndirectThunks : public MachineFunctionPass {
private:
std::tuple<SLSBLRThunkInserter> TIs;
- // FIXME: When LLVM moves to C++17, these can become folds
template <typename... ThunkInserterT>
static void initTIs(Module &M,
std::tuple<ThunkInserterT...> &ThunkInserters) {
- (void)std::initializer_list<int>{
- (std::get<ThunkInserterT>(ThunkInserters).init(M), 0)...};
+ (..., std::get<ThunkInserterT>(ThunkInserters).init(M));
}
template <typename... ThunkInserterT>
static bool runTIs(MachineModuleInfo &MMI, MachineFunction &MF,
std::tuple<ThunkInserterT...> &ThunkInserters) {
- bool Modified = false;
- (void)std::initializer_list<int>{
- Modified |= std::get<ThunkInserterT>(ThunkInserters).run(MMI, MF)...};
- return Modified;
+ return (0 | ... | std::get<ThunkInserterT>(ThunkInserters).run(MMI, MF));
}
};
diff --git a/llvm/lib/Target/ARM/ARMSLSHardening.cpp b/llvm/lib/Target/ARM/ARMSLSHardening.cpp
index 23d72b34902d0e..d9ff14ead60e27 100644
--- a/llvm/lib/Target/ARM/ARMSLSHardening.cpp
+++ b/llvm/lib/Target/ARM/ARMSLSHardening.cpp
@@ -404,20 +404,15 @@ class ARMIndirectThunks : public MachineFunctionPass {
private:
std::tuple<SLSBLRThunkInserter> TIs;
- // FIXME: When LLVM moves to C++17, these can become folds
template <typename... ThunkInserterT>
static void initTIs(Module &M,
std::tuple<ThunkInserterT...> &ThunkInserters) {
- (void)std::initializer_list<int>{
- (std::get<ThunkInserterT>(ThunkInserters).init(M), 0)...};
+ (..., std::get<ThunkInserterT>(ThunkInserters).init(M));
}
template <typename... ThunkInserterT>
static bool runTIs(MachineModuleInfo &MMI, MachineFunction &MF,
std::tuple<ThunkInserterT...> &ThunkInserters) {
- bool Modified = false;
- (void)std::initializer_list<int>{
- Modified |= std::get<ThunkInserterT>(ThunkInserters).run(MMI, MF)...};
- return Modified;
+ return (0 | ... | std::get<ThunkInserterT>(ThunkInserters).run(MMI, MF));
}
};
diff --git a/llvm/lib/Target/X86/X86IndirectThunks.cpp b/llvm/lib/Target/X86/X86IndirectThunks.cpp
index 9db667900bffb3..ecc52600f75933 100644
--- a/llvm/lib/Target/X86/X86IndirectThunks.cpp
+++ b/llvm/lib/Target/X86/X86IndirectThunks.cpp
@@ -118,20 +118,15 @@ class X86IndirectThunks : public MachineFunctionPass {
private:
std::tuple<RetpolineThunkInserter, LVIThunkInserter> TIs;
- // FIXME: When LLVM moves to C++17, these can become folds
template <typename... ThunkInserterT>
static void initTIs(Module &M,
std::tuple<ThunkInserterT...> &ThunkInserters) {
- (void)std::initializer_list<int>{
- (std::get<ThunkInserterT>(ThunkInserters).init(M), 0)...};
+ (..., std::get<ThunkInserterT>(ThunkInserters).init(M));
}
template <typename... ThunkInserterT>
static bool runTIs(MachineModuleInfo &MMI, MachineFunction &MF,
std::tuple<ThunkInserterT...> &ThunkInserters) {
- bool Modified = false;
- (void)std::initializer_list<int>{
- Modified |= std::get<ThunkInserterT>(ThunkInserters).run(MMI, MF)...};
- return Modified;
+ return (0 | ... | std::get<ThunkInserterT>(ThunkInserters).run(MMI, MF));
}
};
>From 205dce6029bed302f354c0bde5d8c5804f214051 Mon Sep 17 00:00:00 2001
From: Quinn Dawkins <quinn.dawkins at gmail.com>
Date: Sat, 2 Mar 2024 17:47:16 -0500
Subject: [PATCH 364/406] [mlir][linalg] Add a folder for transpose(fill) ->
fill (#83623)
This is similar to the existing folder for a linalg.copy. Transposing a
filled tensor is the same as filling the destination of the transpose.
---
mlir/lib/Dialect/Linalg/IR/LinalgOps.cpp | 18 +++++++++++++++++-
mlir/test/Dialect/Linalg/canonicalize.mlir | 14 ++++++++++++++
2 files changed, 31 insertions(+), 1 deletion(-)
diff --git a/mlir/lib/Dialect/Linalg/IR/LinalgOps.cpp b/mlir/lib/Dialect/Linalg/IR/LinalgOps.cpp
index 919f5130e1760f..6954eee93efd14 100644
--- a/mlir/lib/Dialect/Linalg/IR/LinalgOps.cpp
+++ b/mlir/lib/Dialect/Linalg/IR/LinalgOps.cpp
@@ -815,6 +815,22 @@ struct FoldFillWithCopy : OpRewritePattern<linalg::CopyOp> {
}
};
+/// Fold fill with transpose.
+struct FoldFillWithTranspose : OpRewritePattern<linalg::TransposeOp> {
+ using OpRewritePattern<linalg::TransposeOp>::OpRewritePattern;
+
+ LogicalResult matchAndRewrite(linalg::TransposeOp transposeOp,
+ PatternRewriter &rewriter) const override {
+ if (auto fillOp = transposeOp.getInput().getDefiningOp<FillOp>()) {
+ rewriter.replaceOpWithNewOp<FillOp>(
+ transposeOp, transposeOp.getResultTypes(), fillOp.getInputs(),
+ transposeOp.getDpsInitOperand(0)->get());
+ return success();
+ }
+ return failure();
+ }
+};
+
} // namespace
void FillOp::getCanonicalizationPatterns(RewritePatternSet &results,
@@ -823,7 +839,7 @@ void FillOp::getCanonicalizationPatterns(RewritePatternSet &results,
.add<FoldFillWithCopy, FoldFillWithTensorExtract, FoldFillWithPack,
FoldFillWithPad, FoldFillWithTensorReshape<tensor::CollapseShapeOp>,
FoldFillWithTensorReshape<tensor::ExpandShapeOp>,
- FoldInsertPadIntoFill>(context);
+ FoldInsertPadIntoFill, FoldFillWithTranspose>(context);
}
//===----------------------------------------------------------------------===//
diff --git a/mlir/test/Dialect/Linalg/canonicalize.mlir b/mlir/test/Dialect/Linalg/canonicalize.mlir
index 206d7e9f1ce8df..19cea6c2066c92 100644
--- a/mlir/test/Dialect/Linalg/canonicalize.mlir
+++ b/mlir/test/Dialect/Linalg/canonicalize.mlir
@@ -993,6 +993,20 @@ func.func @canonicalize_fill_to_copy_dest(%arg0 : tensor<?x?xf32>, %arg1 : tenso
// -----
+// CHECK-LABEL: func @canonicalize_fill_to_transpose_input(
+// CHECK-SAME: %[[ARG0:[a-zA-Z0-9]+]]: tensor<?x?xf32>
+// CHECK-SAME: %[[ARG1:[a-zA-Z0-9]+]]: tensor<?x?xf32>)
+// CHECK: %[[ZERO:.+]] = arith.constant 0.0
+// CHECK: linalg.fill ins(%[[ZERO]] : f32) outs(%[[ARG1]] : tensor<?x?xf32>)
+func.func @canonicalize_fill_to_transpose_input(%arg0 : tensor<?x?xf32>, %arg1 : tensor<?x?xf32>) -> tensor<?x?xf32> {
+ %c0 = arith.constant 0.0 : f32
+ %fill = linalg.fill ins(%c0 : f32) outs(%arg0 : tensor<?x?xf32>) -> tensor<?x?xf32>
+ %transpose = linalg.transpose ins(%fill : tensor<?x?xf32>) outs(%arg1 : tensor<?x?xf32>) permutation = [1, 0]
+ return %transpose : tensor<?x?xf32>
+}
+
+// -----
+
// CHECK-LABEL: func @broadcast_same_shape(
// CHECK-SAME: %[[ARG0:[a-zA-Z0-9]+]]: tensor<2x3xf32>
// CHECK-SAME: %[[ARG1:[a-zA-Z0-9]+]]: tensor<2x3xf32>)
>From ea628e3d7e78728e8605080ae1ab0ad55e3df191 Mon Sep 17 00:00:00 2001
From: Mircea Trofin <mtrofin at google.com>
Date: Sat, 2 Mar 2024 14:51:06 -0800
Subject: [PATCH 365/406] [Py Reformat] Exclude `third-party` from reformat
(#83491)
---
pyproject.toml | 6 ++++++
1 file changed, 6 insertions(+)
create mode 100644 pyproject.toml
diff --git a/pyproject.toml b/pyproject.toml
new file mode 100644
index 00000000000000..b8313eb9fca450
--- /dev/null
+++ b/pyproject.toml
@@ -0,0 +1,6 @@
+[tool.black]
+extend-exclude = '''
+(
+ third-party/
+)
+'''
>From 0ec318e57b0c7cbc0d9c899390daf3248cbe6a53 Mon Sep 17 00:00:00 2001
From: Matthias Gehre <matthias.gehre at amd.com>
Date: Sat, 2 Mar 2024 23:44:37 +0100
Subject: [PATCH 366/406] Fix unused variable in "[mlir][PDL] Add support for
native constraints with results (#82760)"
---
mlir/lib/Rewrite/ByteCode.cpp | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/mlir/lib/Rewrite/ByteCode.cpp b/mlir/lib/Rewrite/ByteCode.cpp
index 559ce7f466a83d..d2d9ec2787a281 100644
--- a/mlir/lib/Rewrite/ByteCode.cpp
+++ b/mlir/lib/Rewrite/ByteCode.cpp
@@ -1444,7 +1444,7 @@ void ByteCodeExecutor::executeApplyConstraint(PatternRewriter &rewriter) {
const PDLRewriteFunction &constraintFn = constraintFunctions[fun_idx];
ByteCodeRewriteResultList results(numResults);
LogicalResult rewriteResult = constraintFn(rewriter, results, args);
- ArrayRef<PDLValue> constraintResults = results.getResults();
+ [[maybe_unused]] ArrayRef<PDLValue> constraintResults = results.getResults();
LLVM_DEBUG({
if (succeeded(rewriteResult)) {
llvm::dbgs() << " * Constraint succeeded\n";
>From def16bca8133a2f49127a382061aa36406862a15 Mon Sep 17 00:00:00 2001
From: Artem Tyurin <artem.tyurin at gmail.com>
Date: Sun, 3 Mar 2024 00:49:18 +0100
Subject: [PATCH 367/406] [mlir][spirv] Retain nontemporal attribute when
converting memref load/store (#82119)
Fixes #77156.
---
.../MemRefToSPIRV/MemRefToSPIRV.cpp | 101 ++++++++++--------
.../MemRefToSPIRV/memref-to-spirv.mlir | 30 ++++++
2 files changed, 87 insertions(+), 44 deletions(-)
diff --git a/mlir/lib/Conversion/MemRefToSPIRV/MemRefToSPIRV.cpp b/mlir/lib/Conversion/MemRefToSPIRV/MemRefToSPIRV.cpp
index 57d8e894a24b0e..0acb2142f3f68a 100644
--- a/mlir/lib/Conversion/MemRefToSPIRV/MemRefToSPIRV.cpp
+++ b/mlir/lib/Conversion/MemRefToSPIRV/MemRefToSPIRV.cpp
@@ -445,15 +445,30 @@ DeallocOpPattern::matchAndRewrite(memref::DeallocOp operation,
// LoadOp
//===----------------------------------------------------------------------===//
-using AlignmentRequirements =
- FailureOr<std::pair<spirv::MemoryAccessAttr, IntegerAttr>>;
+struct MemoryRequirements {
+ spirv::MemoryAccessAttr memoryAccess;
+ IntegerAttr alignment;
+};
/// Given an accessed SPIR-V pointer, calculates its alignment requirements, if
/// any.
-static AlignmentRequirements calculateRequiredAlignment(Value accessedPtr) {
+static FailureOr<MemoryRequirements>
+calculateMemoryRequirements(Value accessedPtr, bool isNontemporal) {
+ MLIRContext *ctx = accessedPtr.getContext();
+
+ auto memoryAccess = spirv::MemoryAccess::None;
+ if (isNontemporal) {
+ memoryAccess = spirv::MemoryAccess::Nontemporal;
+ }
+
auto ptrType = cast<spirv::PointerType>(accessedPtr.getType());
- if (ptrType.getStorageClass() != spirv::StorageClass::PhysicalStorageBuffer)
- return std::pair{spirv::MemoryAccessAttr{}, IntegerAttr{}};
+ if (ptrType.getStorageClass() != spirv::StorageClass::PhysicalStorageBuffer) {
+ if (memoryAccess == spirv::MemoryAccess::None) {
+ return MemoryRequirements{spirv::MemoryAccessAttr{}, IntegerAttr{}};
+ }
+ return MemoryRequirements{spirv::MemoryAccessAttr::get(ctx, memoryAccess),
+ IntegerAttr{}};
+ }
// PhysicalStorageBuffers require the `Aligned` attribute.
auto pointeeType = dyn_cast<spirv::ScalarType>(ptrType.getPointeeType());
@@ -465,30 +480,32 @@ static AlignmentRequirements calculateRequiredAlignment(Value accessedPtr) {
if (!sizeInBytes.has_value())
return failure();
- MLIRContext *ctx = accessedPtr.getContext();
- auto memAccessAttr =
- spirv::MemoryAccessAttr::get(ctx, spirv::MemoryAccess::Aligned);
+ memoryAccess = memoryAccess | spirv::MemoryAccess::Aligned;
+ auto memAccessAttr = spirv::MemoryAccessAttr::get(ctx, memoryAccess);
auto alignment = IntegerAttr::get(IntegerType::get(ctx, 32), *sizeInBytes);
- return std::pair{memAccessAttr, alignment};
+ return MemoryRequirements{memAccessAttr, alignment};
}
/// Given an accessed SPIR-V pointer and the original memref load/store
/// `memAccess` op, calculates the alignment requirements, if any. Takes into
/// account the alignment attributes applied to the load/store op.
-static AlignmentRequirements
-calculateRequiredAlignment(Value accessedPtr, Operation *memrefAccessOp) {
- assert(memrefAccessOp);
- assert((isa<memref::LoadOp, memref::StoreOp>(memrefAccessOp)) &&
- "Bad op type");
-
+template <class LoadOrStoreOp>
+static FailureOr<MemoryRequirements>
+calculateMemoryRequirements(Value accessedPtr, LoadOrStoreOp loadOrStoreOp) {
+ static_assert(
+ llvm::is_one_of<LoadOrStoreOp, memref::LoadOp, memref::StoreOp>::value,
+ "Must be called on either memref::LoadOp or memref::StoreOp");
+
+ Operation *memrefAccessOp = loadOrStoreOp.getOperation();
auto memrefMemAccess = memrefAccessOp->getAttrOfType<spirv::MemoryAccessAttr>(
spirv::attributeName<spirv::MemoryAccess>());
auto memrefAlignment =
memrefAccessOp->getAttrOfType<IntegerAttr>("alignment");
if (memrefMemAccess && memrefAlignment)
- return std::pair{memrefMemAccess, memrefAlignment};
+ return MemoryRequirements{memrefMemAccess, memrefAlignment};
- return calculateRequiredAlignment(accessedPtr);
+ return calculateMemoryRequirements(accessedPtr,
+ loadOrStoreOp.getNontemporal());
}
LogicalResult
@@ -538,13 +555,12 @@ IntLoadOpPattern::matchAndRewrite(memref::LoadOp loadOp, OpAdaptor adaptor,
// If the rewritten load op has the same bit width, use the loading value
// directly.
if (srcBits == dstBits) {
- AlignmentRequirements alignmentRequirements =
- calculateRequiredAlignment(accessChain, loadOp);
- if (failed(alignmentRequirements))
+ auto memoryRequirements = calculateMemoryRequirements(accessChain, loadOp);
+ if (failed(memoryRequirements))
return rewriter.notifyMatchFailure(
- loadOp, "failed to determine alignment requirements");
+ loadOp, "failed to determine memory requirements");
- auto [memoryAccess, alignment] = *alignmentRequirements;
+ auto [memoryAccess, alignment] = *memoryRequirements;
Value loadVal = rewriter.create<spirv::LoadOp>(loc, accessChain,
memoryAccess, alignment);
if (isBool)
@@ -568,13 +584,12 @@ IntLoadOpPattern::matchAndRewrite(memref::LoadOp loadOp, OpAdaptor adaptor,
assert(accessChainOp.getIndices().size() == 2);
Value adjustedPtr = adjustAccessChainForBitwidth(typeConverter, accessChainOp,
srcBits, dstBits, rewriter);
- AlignmentRequirements alignmentRequirements =
- calculateRequiredAlignment(adjustedPtr, loadOp);
- if (failed(alignmentRequirements))
+ auto memoryRequirements = calculateMemoryRequirements(adjustedPtr, loadOp);
+ if (failed(memoryRequirements))
return rewriter.notifyMatchFailure(
- loadOp, "failed to determine alignment requirements");
+ loadOp, "failed to determine memory requirements");
- auto [memoryAccess, alignment] = *alignmentRequirements;
+ auto [memoryAccess, alignment] = *memoryRequirements;
Value spvLoadOp = rewriter.create<spirv::LoadOp>(loc, dstType, adjustedPtr,
memoryAccess, alignment);
@@ -623,13 +638,13 @@ LoadOpPattern::matchAndRewrite(memref::LoadOp loadOp, OpAdaptor adaptor,
if (!loadPtr)
return failure();
- AlignmentRequirements requiredAlignment = calculateRequiredAlignment(loadPtr);
- if (failed(requiredAlignment))
+ auto memoryRequirements = calculateMemoryRequirements(loadPtr, loadOp);
+ if (failed(memoryRequirements))
return rewriter.notifyMatchFailure(
- loadOp, "failed to determine alignment requirements");
+ loadOp, "failed to determine memory requirements");
- auto [memAccessAttr, alignment] = *requiredAlignment;
- rewriter.replaceOpWithNewOp<spirv::LoadOp>(loadOp, loadPtr, memAccessAttr,
+ auto [memoryAccess, alignment] = *memoryRequirements;
+ rewriter.replaceOpWithNewOp<spirv::LoadOp>(loadOp, loadPtr, memoryAccess,
alignment);
return success();
}
@@ -689,18 +704,17 @@ IntStoreOpPattern::matchAndRewrite(memref::StoreOp storeOp, OpAdaptor adaptor,
assert(dstBits % srcBits == 0);
if (srcBits == dstBits) {
- AlignmentRequirements requiredAlignment =
- calculateRequiredAlignment(accessChain);
- if (failed(requiredAlignment))
+ auto memoryRequirements = calculateMemoryRequirements(accessChain, storeOp);
+ if (failed(memoryRequirements))
return rewriter.notifyMatchFailure(
- storeOp, "failed to determine alignment requirements");
+ storeOp, "failed to determine memory requirements");
- auto [memAccessAttr, alignment] = *requiredAlignment;
+ auto [memoryAccess, alignment] = *memoryRequirements;
Value storeVal = adaptor.getValue();
if (isBool)
storeVal = castBoolToIntN(loc, storeVal, dstType, rewriter);
rewriter.replaceOpWithNewOp<spirv::StoreOp>(storeOp, accessChain, storeVal,
- memAccessAttr, alignment);
+ memoryAccess, alignment);
return success();
}
@@ -847,15 +861,14 @@ StoreOpPattern::matchAndRewrite(memref::StoreOp storeOp, OpAdaptor adaptor,
if (!storePtr)
return rewriter.notifyMatchFailure(storeOp, "type conversion failed");
- AlignmentRequirements requiredAlignment =
- calculateRequiredAlignment(storePtr, storeOp);
- if (failed(requiredAlignment))
+ auto memoryRequirements = calculateMemoryRequirements(storePtr, storeOp);
+ if (failed(memoryRequirements))
return rewriter.notifyMatchFailure(
- storeOp, "failed to determine alignment requirements");
+ storeOp, "failed to determine memory requirements");
- auto [memAccessAttr, alignment] = *requiredAlignment;
+ auto [memoryAccess, alignment] = *memoryRequirements;
rewriter.replaceOpWithNewOp<spirv::StoreOp>(
- storeOp, storePtr, adaptor.getValue(), memAccessAttr, alignment);
+ storeOp, storePtr, adaptor.getValue(), memoryAccess, alignment);
return success();
}
diff --git a/mlir/test/Conversion/MemRefToSPIRV/memref-to-spirv.mlir b/mlir/test/Conversion/MemRefToSPIRV/memref-to-spirv.mlir
index aa05fd9bc8ca89..feb6d4e924015f 100644
--- a/mlir/test/Conversion/MemRefToSPIRV/memref-to-spirv.mlir
+++ b/mlir/test/Conversion/MemRefToSPIRV/memref-to-spirv.mlir
@@ -431,3 +431,33 @@ func.func @cast_to_static_zero_elems(%arg: memref<?xf32, #spirv.storage_class<Cr
}
}
+
+// -----
+
+// Check nontemporal attribute
+
+module attributes {
+ spirv.target_env = #spirv.target_env<#spirv.vce<v1.0, [
+ Shader,
+ PhysicalStorageBufferAddresses
+ ], [
+ SPV_KHR_storage_buffer_storage_class,
+ SPV_KHR_physical_storage_buffer
+ ]>, #spirv.resource_limits<>>
+} {
+ func.func @load_nontemporal(%arg0: memref<f32, #spirv.storage_class<StorageBuffer>>) {
+ %0 = memref.load %arg0[] {nontemporal = true} : memref<f32, #spirv.storage_class<StorageBuffer>>
+// CHECK: spirv.Load "StorageBuffer" %{{.+}} ["Nontemporal"] : f32
+ memref.store %0, %arg0[] {nontemporal = true} : memref<f32, #spirv.storage_class<StorageBuffer>>
+// CHECK: spirv.Store "StorageBuffer" %{{.+}}, %{{.+}} ["Nontemporal"] : f32
+ return
+ }
+
+ func.func @load_nontemporal_aligned(%arg0: memref<f32, #spirv.storage_class<PhysicalStorageBuffer>>) {
+ %0 = memref.load %arg0[] {nontemporal = true} : memref<f32, #spirv.storage_class<PhysicalStorageBuffer>>
+// CHECK: spirv.Load "PhysicalStorageBuffer" %{{.+}} ["Aligned|Nontemporal", 4] : f32
+ memref.store %0, %arg0[] {nontemporal = true} : memref<f32, #spirv.storage_class<PhysicalStorageBuffer>>
+// CHECK: spirv.Store "PhysicalStorageBuffer" %{{.+}}, %{{.+}} ["Aligned|Nontemporal", 4] : f32
+ return
+ }
+}
>From 8b26e609e032b4535b90514e22875bfaa194216c Mon Sep 17 00:00:00 2001
From: Craig Topper <craig.topper at sifive.com>
Date: Sat, 2 Mar 2024 17:06:38 -0800
Subject: [PATCH 368/406] [RISCV] Use the VR register allocation order for VM.
(#83664)
---
llvm/lib/Target/RISCV/RISCVRegisterInfo.td | 4 +---
1 file changed, 1 insertion(+), 3 deletions(-)
diff --git a/llvm/lib/Target/RISCV/RISCVRegisterInfo.td b/llvm/lib/Target/RISCV/RISCVRegisterInfo.td
index 53838d6e540123..225b57554c1dc0 100644
--- a/llvm/lib/Target/RISCV/RISCVRegisterInfo.td
+++ b/llvm/lib/Target/RISCV/RISCVRegisterInfo.td
@@ -585,9 +585,7 @@ def GPRPair : RegisterClass<"RISCV", [XLenPairFVT], 64, (add
)>;
// The register class is added for inline assembly for vector mask types.
-def VM : VReg<VMaskVTs,
- (add (sequence "V%u", 8, 31),
- (sequence "V%u", 0, 7)), 1>;
+def VM : VReg<VMaskVTs, (add VR), 1>;
foreach m = LMULList in {
foreach nf = NFList<m>.L in {
>From 4dd9c2ed3258c38bad4be53f7b2f943c79acd87f Mon Sep 17 00:00:00 2001
From: Craig Topper <craig.topper at sifive.com>
Date: Sat, 2 Mar 2024 17:08:48 -0800
Subject: [PATCH 369/406] [RISCV] Use NewVL in splatPartsI64WithVL. (#83690)
In 7b5cf52f32c09, I added this NewVL and checked that it had been set,
but I didn't use it for the VL of the splat.
---
llvm/lib/Target/RISCV/RISCVISelLowering.cpp | 3 +-
.../RISCV/rvv/fixed-vectors-bitreverse-vp.ll | 36 +++----
.../RISCV/rvv/fixed-vectors-bitreverse.ll | 12 +--
.../RISCV/rvv/fixed-vectors-ctlz-vp.ll | 96 +++++++++----------
.../CodeGen/RISCV/rvv/fixed-vectors-ctlz.ll | 32 +++----
.../RISCV/rvv/fixed-vectors-ctpop-vp.ll | 48 +++++-----
.../CodeGen/RISCV/rvv/fixed-vectors-ctpop.ll | 16 ++--
.../RISCV/rvv/fixed-vectors-cttz-vp.ll | 96 +++++++++----------
.../CodeGen/RISCV/rvv/fixed-vectors-cttz.ll | 32 +++----
9 files changed, 185 insertions(+), 186 deletions(-)
diff --git a/llvm/lib/Target/RISCV/RISCVISelLowering.cpp b/llvm/lib/Target/RISCV/RISCVISelLowering.cpp
index e647f56416bfa6..7da074e055a774 100644
--- a/llvm/lib/Target/RISCV/RISCVISelLowering.cpp
+++ b/llvm/lib/Target/RISCV/RISCVISelLowering.cpp
@@ -4057,8 +4057,7 @@ static SDValue splatPartsI64WithVL(const SDLoc &DL, MVT VT, SDValue Passthru,
MVT InterVT =
MVT::getVectorVT(MVT::i32, VT.getVectorElementCount() * 2);
auto InterVec = DAG.getNode(RISCVISD::VMV_V_X_VL, DL, InterVT,
- DAG.getUNDEF(InterVT), Lo,
- DAG.getRegister(RISCV::X0, MVT::i32));
+ DAG.getUNDEF(InterVT), Lo, NewVL);
return DAG.getNode(ISD::BITCAST, DL, VT, InterVec);
}
}
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-bitreverse-vp.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-bitreverse-vp.ll
index 91bf3e981e0a6c..595c650ffb82a5 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-bitreverse-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-bitreverse-vp.ll
@@ -896,7 +896,7 @@ define <2 x i64> @vp_bitreverse_v2i64(<2 x i64> %va, <2 x i1> %m, i32 zeroext %e
; RV32-NEXT: vsrl.vi v9, v8, 4, v0.t
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v9, v9, v10, v0.t
@@ -906,7 +906,7 @@ define <2 x i64> @vp_bitreverse_v2i64(<2 x i64> %va, <2 x i1> %m, i32 zeroext %e
; RV32-NEXT: vsrl.vi v9, v8, 2, v0.t
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v9, v9, v10, v0.t
@@ -916,7 +916,7 @@ define <2 x i64> @vp_bitreverse_v2i64(<2 x i64> %va, <2 x i1> %m, i32 zeroext %e
; RV32-NEXT: vsrl.vi v9, v8, 1, v0.t
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v9, v9, v10, v0.t
@@ -1031,7 +1031,7 @@ define <2 x i64> @vp_bitreverse_v2i64_unmasked(<2 x i64> %va, i32 zeroext %evl)
; RV32-NEXT: vsrl.vi v9, v8, 4
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v9, v9, v10
@@ -1041,7 +1041,7 @@ define <2 x i64> @vp_bitreverse_v2i64_unmasked(<2 x i64> %va, i32 zeroext %evl)
; RV32-NEXT: vsrl.vi v9, v8, 2
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v9, v9, v10
@@ -1051,7 +1051,7 @@ define <2 x i64> @vp_bitreverse_v2i64_unmasked(<2 x i64> %va, i32 zeroext %evl)
; RV32-NEXT: vsrl.vi v9, v8, 1
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v9, v9, v10
@@ -1170,7 +1170,7 @@ define <4 x i64> @vp_bitreverse_v4i64(<4 x i64> %va, <4 x i1> %m, i32 zeroext %e
; RV32-NEXT: vsrl.vi v10, v8, 4, v0.t
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v10, v10, v12, v0.t
@@ -1180,7 +1180,7 @@ define <4 x i64> @vp_bitreverse_v4i64(<4 x i64> %va, <4 x i1> %m, i32 zeroext %e
; RV32-NEXT: vsrl.vi v10, v8, 2, v0.t
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v10, v10, v12, v0.t
@@ -1190,7 +1190,7 @@ define <4 x i64> @vp_bitreverse_v4i64(<4 x i64> %va, <4 x i1> %m, i32 zeroext %e
; RV32-NEXT: vsrl.vi v10, v8, 1, v0.t
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v10, v10, v12, v0.t
@@ -1305,7 +1305,7 @@ define <4 x i64> @vp_bitreverse_v4i64_unmasked(<4 x i64> %va, i32 zeroext %evl)
; RV32-NEXT: vsrl.vi v10, v8, 4
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v10, v10, v12
@@ -1315,7 +1315,7 @@ define <4 x i64> @vp_bitreverse_v4i64_unmasked(<4 x i64> %va, i32 zeroext %evl)
; RV32-NEXT: vsrl.vi v10, v8, 2
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v10, v10, v12
@@ -1325,7 +1325,7 @@ define <4 x i64> @vp_bitreverse_v4i64_unmasked(<4 x i64> %va, i32 zeroext %evl)
; RV32-NEXT: vsrl.vi v10, v8, 1
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v10, v10, v12
@@ -1444,7 +1444,7 @@ define <8 x i64> @vp_bitreverse_v8i64(<8 x i64> %va, <8 x i1> %m, i32 zeroext %e
; RV32-NEXT: vsrl.vi v12, v8, 4, v0.t
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v16, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v12, v12, v16, v0.t
@@ -1454,7 +1454,7 @@ define <8 x i64> @vp_bitreverse_v8i64(<8 x i64> %va, <8 x i1> %m, i32 zeroext %e
; RV32-NEXT: vsrl.vi v12, v8, 2, v0.t
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v16, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v12, v12, v16, v0.t
@@ -1464,7 +1464,7 @@ define <8 x i64> @vp_bitreverse_v8i64(<8 x i64> %va, <8 x i1> %m, i32 zeroext %e
; RV32-NEXT: vsrl.vi v12, v8, 1, v0.t
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v16, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v12, v12, v16, v0.t
@@ -1579,7 +1579,7 @@ define <8 x i64> @vp_bitreverse_v8i64_unmasked(<8 x i64> %va, i32 zeroext %evl)
; RV32-NEXT: vsrl.vi v12, v8, 4
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v16, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v12, v12, v16
@@ -1589,7 +1589,7 @@ define <8 x i64> @vp_bitreverse_v8i64_unmasked(<8 x i64> %va, i32 zeroext %evl)
; RV32-NEXT: vsrl.vi v12, v8, 2
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v16, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v12, v12, v16
@@ -1599,7 +1599,7 @@ define <8 x i64> @vp_bitreverse_v8i64_unmasked(<8 x i64> %va, i32 zeroext %evl)
; RV32-NEXT: vsrl.vi v12, v8, 1
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v16, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v12, v12, v16
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-bitreverse.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-bitreverse.ll
index 012f943b35d98e..7f211d0f8f9bad 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-bitreverse.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-bitreverse.ll
@@ -147,7 +147,7 @@ define void @bitreverse_v2i64(ptr %x, ptr %y) {
; RV32-NEXT: vsrl.vi v9, v8, 4
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetivli zero, 2, e64, m1, ta, ma
; RV32-NEXT: vand.vv v9, v9, v10
@@ -157,7 +157,7 @@ define void @bitreverse_v2i64(ptr %x, ptr %y) {
; RV32-NEXT: vsrl.vi v9, v8, 2
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetivli zero, 2, e64, m1, ta, ma
; RV32-NEXT: vand.vv v9, v9, v10
@@ -167,7 +167,7 @@ define void @bitreverse_v2i64(ptr %x, ptr %y) {
; RV32-NEXT: vsrl.vi v9, v8, 1
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetivli zero, 2, e64, m1, ta, ma
; RV32-NEXT: vand.vv v9, v9, v10
@@ -398,7 +398,7 @@ define void @bitreverse_v4i64(ptr %x, ptr %y) {
; RV32-NEXT: vsrl.vi v10, v8, 4
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetivli zero, 4, e64, m2, ta, ma
; RV32-NEXT: vand.vv v10, v10, v12
@@ -408,7 +408,7 @@ define void @bitreverse_v4i64(ptr %x, ptr %y) {
; RV32-NEXT: vsrl.vi v10, v8, 2
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetivli zero, 4, e64, m2, ta, ma
; RV32-NEXT: vand.vv v10, v10, v12
@@ -418,7 +418,7 @@ define void @bitreverse_v4i64(ptr %x, ptr %y) {
; RV32-NEXT: vsrl.vi v10, v8, 1
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetivli zero, 4, e64, m2, ta, ma
; RV32-NEXT: vand.vv v10, v10, v12
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-ctlz-vp.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-ctlz-vp.ll
index 37e6c35196c6a4..36f22bd3259cf9 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-ctlz-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-ctlz-vp.ll
@@ -915,14 +915,14 @@ define <2 x i64> @vp_ctlz_v2i64(<2 x i64> %va, <2 x i1> %m, i32 zeroext %evl) {
; RV32-NEXT: vsrl.vi v9, v8, 1, v0.t
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v9, v9, v10, v0.t
; RV32-NEXT: vsub.vv v8, v8, v9, v0.t
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v10, v8, v9, v0.t
@@ -933,13 +933,13 @@ define <2 x i64> @vp_ctlz_v2i64(<2 x i64> %va, <2 x i1> %m, i32 zeroext %evl) {
; RV32-NEXT: vadd.vv v8, v8, v9, v0.t
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v8, v8, v9, v0.t
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v9, v0.t
@@ -1019,14 +1019,14 @@ define <2 x i64> @vp_ctlz_v2i64_unmasked(<2 x i64> %va, i32 zeroext %evl) {
; RV32-NEXT: vsrl.vi v9, v8, 1
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v9, v9, v10
; RV32-NEXT: vsub.vv v8, v8, v9
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v10, v8, v9
@@ -1037,13 +1037,13 @@ define <2 x i64> @vp_ctlz_v2i64_unmasked(<2 x i64> %va, i32 zeroext %evl) {
; RV32-NEXT: vadd.vv v8, v8, v9
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v8, v8, v9
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v9
@@ -1127,14 +1127,14 @@ define <4 x i64> @vp_ctlz_v4i64(<4 x i64> %va, <4 x i1> %m, i32 zeroext %evl) {
; RV32-NEXT: vsrl.vi v10, v8, 1, v0.t
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v10, v10, v12, v0.t
; RV32-NEXT: vsub.vv v8, v8, v10, v0.t
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v12, v8, v10, v0.t
@@ -1145,13 +1145,13 @@ define <4 x i64> @vp_ctlz_v4i64(<4 x i64> %va, <4 x i1> %m, i32 zeroext %evl) {
; RV32-NEXT: vadd.vv v8, v8, v10, v0.t
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v8, v8, v10, v0.t
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v10, v0.t
@@ -1231,14 +1231,14 @@ define <4 x i64> @vp_ctlz_v4i64_unmasked(<4 x i64> %va, i32 zeroext %evl) {
; RV32-NEXT: vsrl.vi v10, v8, 1
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v10, v10, v12
; RV32-NEXT: vsub.vv v8, v8, v10
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v12, v8, v10
@@ -1249,13 +1249,13 @@ define <4 x i64> @vp_ctlz_v4i64_unmasked(<4 x i64> %va, i32 zeroext %evl) {
; RV32-NEXT: vadd.vv v8, v8, v10
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v8, v8, v10
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v10
@@ -1339,14 +1339,14 @@ define <8 x i64> @vp_ctlz_v8i64(<8 x i64> %va, <8 x i1> %m, i32 zeroext %evl) {
; RV32-NEXT: vsrl.vi v12, v8, 1, v0.t
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v16, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v12, v12, v16, v0.t
; RV32-NEXT: vsub.vv v8, v8, v12, v0.t
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v16, v8, v12, v0.t
@@ -1357,13 +1357,13 @@ define <8 x i64> @vp_ctlz_v8i64(<8 x i64> %va, <8 x i1> %m, i32 zeroext %evl) {
; RV32-NEXT: vadd.vv v8, v8, v12, v0.t
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v8, v8, v12, v0.t
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v12, v0.t
@@ -1443,14 +1443,14 @@ define <8 x i64> @vp_ctlz_v8i64_unmasked(<8 x i64> %va, i32 zeroext %evl) {
; RV32-NEXT: vsrl.vi v12, v8, 1
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v16, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v12, v12, v16
; RV32-NEXT: vsub.vv v8, v8, v12
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v16, v8, v12
@@ -1461,13 +1461,13 @@ define <8 x i64> @vp_ctlz_v8i64_unmasked(<8 x i64> %va, i32 zeroext %evl) {
; RV32-NEXT: vadd.vv v8, v8, v12
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v8, v8, v12
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v12
@@ -3514,14 +3514,14 @@ define <2 x i64> @vp_ctlz_zero_undef_v2i64(<2 x i64> %va, <2 x i1> %m, i32 zeroe
; RV32-NEXT: vsrl.vi v9, v8, 1, v0.t
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v9, v9, v10, v0.t
; RV32-NEXT: vsub.vv v8, v8, v9, v0.t
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v10, v8, v9, v0.t
@@ -3532,13 +3532,13 @@ define <2 x i64> @vp_ctlz_zero_undef_v2i64(<2 x i64> %va, <2 x i1> %m, i32 zeroe
; RV32-NEXT: vadd.vv v8, v8, v9, v0.t
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v8, v8, v9, v0.t
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v9, v0.t
@@ -3618,14 +3618,14 @@ define <2 x i64> @vp_ctlz_zero_undef_v2i64_unmasked(<2 x i64> %va, i32 zeroext %
; RV32-NEXT: vsrl.vi v9, v8, 1
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v9, v9, v10
; RV32-NEXT: vsub.vv v8, v8, v9
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v10, v8, v9
@@ -3636,13 +3636,13 @@ define <2 x i64> @vp_ctlz_zero_undef_v2i64_unmasked(<2 x i64> %va, i32 zeroext %
; RV32-NEXT: vadd.vv v8, v8, v9
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v8, v8, v9
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v9
@@ -3724,14 +3724,14 @@ define <4 x i64> @vp_ctlz_zero_undef_v4i64(<4 x i64> %va, <4 x i1> %m, i32 zeroe
; RV32-NEXT: vsrl.vi v10, v8, 1, v0.t
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v10, v10, v12, v0.t
; RV32-NEXT: vsub.vv v8, v8, v10, v0.t
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v12, v8, v10, v0.t
@@ -3742,13 +3742,13 @@ define <4 x i64> @vp_ctlz_zero_undef_v4i64(<4 x i64> %va, <4 x i1> %m, i32 zeroe
; RV32-NEXT: vadd.vv v8, v8, v10, v0.t
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v8, v8, v10, v0.t
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v10, v0.t
@@ -3828,14 +3828,14 @@ define <4 x i64> @vp_ctlz_zero_undef_v4i64_unmasked(<4 x i64> %va, i32 zeroext %
; RV32-NEXT: vsrl.vi v10, v8, 1
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v10, v10, v12
; RV32-NEXT: vsub.vv v8, v8, v10
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v12, v8, v10
@@ -3846,13 +3846,13 @@ define <4 x i64> @vp_ctlz_zero_undef_v4i64_unmasked(<4 x i64> %va, i32 zeroext %
; RV32-NEXT: vadd.vv v8, v8, v10
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v8, v8, v10
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v10
@@ -3934,14 +3934,14 @@ define <8 x i64> @vp_ctlz_zero_undef_v8i64(<8 x i64> %va, <8 x i1> %m, i32 zeroe
; RV32-NEXT: vsrl.vi v12, v8, 1, v0.t
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v16, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v12, v12, v16, v0.t
; RV32-NEXT: vsub.vv v8, v8, v12, v0.t
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v16, v8, v12, v0.t
@@ -3952,13 +3952,13 @@ define <8 x i64> @vp_ctlz_zero_undef_v8i64(<8 x i64> %va, <8 x i1> %m, i32 zeroe
; RV32-NEXT: vadd.vv v8, v8, v12, v0.t
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v8, v8, v12, v0.t
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v12, v0.t
@@ -4038,14 +4038,14 @@ define <8 x i64> @vp_ctlz_zero_undef_v8i64_unmasked(<8 x i64> %va, i32 zeroext %
; RV32-NEXT: vsrl.vi v12, v8, 1
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v16, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v12, v12, v16
; RV32-NEXT: vsub.vv v8, v8, v12
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v16, v8, v12
@@ -4056,13 +4056,13 @@ define <8 x i64> @vp_ctlz_zero_undef_v8i64_unmasked(<8 x i64> %va, i32 zeroext %
; RV32-NEXT: vadd.vv v8, v8, v12
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v8, v8, v12
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v12
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-ctlz.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-ctlz.ll
index 3e5a89b9bce388..277146cc1403e9 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-ctlz.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-ctlz.ll
@@ -264,14 +264,14 @@ define void @ctlz_v2i64(ptr %x, ptr %y) nounwind {
; RV32I-NEXT: vsrl.vi v9, v8, 1
; RV32I-NEXT: lui a1, 349525
; RV32I-NEXT: addi a1, a1, 1365
-; RV32I-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32I-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32I-NEXT: vmv.v.x v10, a1
; RV32I-NEXT: vsetivli zero, 2, e64, m1, ta, ma
; RV32I-NEXT: vand.vv v9, v9, v10
; RV32I-NEXT: vsub.vv v8, v8, v9
; RV32I-NEXT: lui a1, 209715
; RV32I-NEXT: addi a1, a1, 819
-; RV32I-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32I-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32I-NEXT: vmv.v.x v9, a1
; RV32I-NEXT: vsetivli zero, 2, e64, m1, ta, ma
; RV32I-NEXT: vand.vv v10, v8, v9
@@ -282,13 +282,13 @@ define void @ctlz_v2i64(ptr %x, ptr %y) nounwind {
; RV32I-NEXT: vadd.vv v8, v8, v9
; RV32I-NEXT: lui a1, 61681
; RV32I-NEXT: addi a1, a1, -241
-; RV32I-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32I-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32I-NEXT: vmv.v.x v9, a1
; RV32I-NEXT: vsetivli zero, 2, e64, m1, ta, ma
; RV32I-NEXT: vand.vv v8, v8, v9
; RV32I-NEXT: lui a1, 4112
; RV32I-NEXT: addi a1, a1, 257
-; RV32I-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32I-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32I-NEXT: vmv.v.x v9, a1
; RV32I-NEXT: vsetivli zero, 2, e64, m1, ta, ma
; RV32I-NEXT: vmul.vv v8, v8, v9
@@ -673,14 +673,14 @@ define void @ctlz_v4i64(ptr %x, ptr %y) nounwind {
; RV32I-NEXT: vsrl.vi v10, v8, 1
; RV32I-NEXT: lui a1, 349525
; RV32I-NEXT: addi a1, a1, 1365
-; RV32I-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32I-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32I-NEXT: vmv.v.x v12, a1
; RV32I-NEXT: vsetivli zero, 4, e64, m2, ta, ma
; RV32I-NEXT: vand.vv v10, v10, v12
; RV32I-NEXT: vsub.vv v8, v8, v10
; RV32I-NEXT: lui a1, 209715
; RV32I-NEXT: addi a1, a1, 819
-; RV32I-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32I-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32I-NEXT: vmv.v.x v10, a1
; RV32I-NEXT: vsetivli zero, 4, e64, m2, ta, ma
; RV32I-NEXT: vand.vv v12, v8, v10
@@ -691,13 +691,13 @@ define void @ctlz_v4i64(ptr %x, ptr %y) nounwind {
; RV32I-NEXT: vadd.vv v8, v8, v10
; RV32I-NEXT: lui a1, 61681
; RV32I-NEXT: addi a1, a1, -241
-; RV32I-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32I-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32I-NEXT: vmv.v.x v10, a1
; RV32I-NEXT: vsetivli zero, 4, e64, m2, ta, ma
; RV32I-NEXT: vand.vv v8, v8, v10
; RV32I-NEXT: lui a1, 4112
; RV32I-NEXT: addi a1, a1, 257
-; RV32I-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32I-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32I-NEXT: vmv.v.x v10, a1
; RV32I-NEXT: vsetivli zero, 4, e64, m2, ta, ma
; RV32I-NEXT: vmul.vv v8, v8, v10
@@ -1063,14 +1063,14 @@ define void @ctlz_zero_undef_v2i64(ptr %x, ptr %y) nounwind {
; RV32I-NEXT: vsrl.vi v9, v8, 1
; RV32I-NEXT: lui a1, 349525
; RV32I-NEXT: addi a1, a1, 1365
-; RV32I-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32I-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32I-NEXT: vmv.v.x v10, a1
; RV32I-NEXT: vsetivli zero, 2, e64, m1, ta, ma
; RV32I-NEXT: vand.vv v9, v9, v10
; RV32I-NEXT: vsub.vv v8, v8, v9
; RV32I-NEXT: lui a1, 209715
; RV32I-NEXT: addi a1, a1, 819
-; RV32I-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32I-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32I-NEXT: vmv.v.x v9, a1
; RV32I-NEXT: vsetivli zero, 2, e64, m1, ta, ma
; RV32I-NEXT: vand.vv v10, v8, v9
@@ -1081,13 +1081,13 @@ define void @ctlz_zero_undef_v2i64(ptr %x, ptr %y) nounwind {
; RV32I-NEXT: vadd.vv v8, v8, v9
; RV32I-NEXT: lui a1, 61681
; RV32I-NEXT: addi a1, a1, -241
-; RV32I-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32I-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32I-NEXT: vmv.v.x v9, a1
; RV32I-NEXT: vsetivli zero, 2, e64, m1, ta, ma
; RV32I-NEXT: vand.vv v8, v8, v9
; RV32I-NEXT: lui a1, 4112
; RV32I-NEXT: addi a1, a1, 257
-; RV32I-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32I-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32I-NEXT: vmv.v.x v9, a1
; RV32I-NEXT: vsetivli zero, 2, e64, m1, ta, ma
; RV32I-NEXT: vmul.vv v8, v8, v9
@@ -1448,14 +1448,14 @@ define void @ctlz_zero_undef_v4i64(ptr %x, ptr %y) nounwind {
; RV32I-NEXT: vsrl.vi v10, v8, 1
; RV32I-NEXT: lui a1, 349525
; RV32I-NEXT: addi a1, a1, 1365
-; RV32I-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32I-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32I-NEXT: vmv.v.x v12, a1
; RV32I-NEXT: vsetivli zero, 4, e64, m2, ta, ma
; RV32I-NEXT: vand.vv v10, v10, v12
; RV32I-NEXT: vsub.vv v8, v8, v10
; RV32I-NEXT: lui a1, 209715
; RV32I-NEXT: addi a1, a1, 819
-; RV32I-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32I-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32I-NEXT: vmv.v.x v10, a1
; RV32I-NEXT: vsetivli zero, 4, e64, m2, ta, ma
; RV32I-NEXT: vand.vv v12, v8, v10
@@ -1466,13 +1466,13 @@ define void @ctlz_zero_undef_v4i64(ptr %x, ptr %y) nounwind {
; RV32I-NEXT: vadd.vv v8, v8, v10
; RV32I-NEXT: lui a1, 61681
; RV32I-NEXT: addi a1, a1, -241
-; RV32I-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32I-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32I-NEXT: vmv.v.x v10, a1
; RV32I-NEXT: vsetivli zero, 4, e64, m2, ta, ma
; RV32I-NEXT: vand.vv v8, v8, v10
; RV32I-NEXT: lui a1, 4112
; RV32I-NEXT: addi a1, a1, 257
-; RV32I-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32I-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32I-NEXT: vmv.v.x v10, a1
; RV32I-NEXT: vsetivli zero, 4, e64, m2, ta, ma
; RV32I-NEXT: vmul.vv v8, v8, v10
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-ctpop-vp.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-ctpop-vp.ll
index c4162413859921..c4b22955f84c4f 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-ctpop-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-ctpop-vp.ll
@@ -685,14 +685,14 @@ define <2 x i64> @vp_ctpop_v2i64(<2 x i64> %va, <2 x i1> %m, i32 zeroext %evl) {
; RV32-NEXT: vsrl.vi v9, v8, 1, v0.t
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v9, v9, v10, v0.t
; RV32-NEXT: vsub.vv v8, v8, v9, v0.t
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v10, v8, v9, v0.t
@@ -703,13 +703,13 @@ define <2 x i64> @vp_ctpop_v2i64(<2 x i64> %va, <2 x i1> %m, i32 zeroext %evl) {
; RV32-NEXT: vadd.vv v8, v8, v9, v0.t
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v8, v8, v9, v0.t
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v9, v0.t
@@ -761,14 +761,14 @@ define <2 x i64> @vp_ctpop_v2i64_unmasked(<2 x i64> %va, i32 zeroext %evl) {
; RV32-NEXT: vsrl.vi v9, v8, 1
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v9, v9, v10
; RV32-NEXT: vsub.vv v8, v8, v9
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v10, v8, v9
@@ -779,13 +779,13 @@ define <2 x i64> @vp_ctpop_v2i64_unmasked(<2 x i64> %va, i32 zeroext %evl) {
; RV32-NEXT: vadd.vv v8, v8, v9
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v8, v8, v9
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v9
@@ -841,14 +841,14 @@ define <4 x i64> @vp_ctpop_v4i64(<4 x i64> %va, <4 x i1> %m, i32 zeroext %evl) {
; RV32-NEXT: vsrl.vi v10, v8, 1, v0.t
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v10, v10, v12, v0.t
; RV32-NEXT: vsub.vv v8, v8, v10, v0.t
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v12, v8, v10, v0.t
@@ -859,13 +859,13 @@ define <4 x i64> @vp_ctpop_v4i64(<4 x i64> %va, <4 x i1> %m, i32 zeroext %evl) {
; RV32-NEXT: vadd.vv v8, v8, v10, v0.t
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v8, v8, v10, v0.t
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v10, v0.t
@@ -917,14 +917,14 @@ define <4 x i64> @vp_ctpop_v4i64_unmasked(<4 x i64> %va, i32 zeroext %evl) {
; RV32-NEXT: vsrl.vi v10, v8, 1
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v10, v10, v12
; RV32-NEXT: vsub.vv v8, v8, v10
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v12, v8, v10
@@ -935,13 +935,13 @@ define <4 x i64> @vp_ctpop_v4i64_unmasked(<4 x i64> %va, i32 zeroext %evl) {
; RV32-NEXT: vadd.vv v8, v8, v10
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v8, v8, v10
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v10
@@ -997,14 +997,14 @@ define <8 x i64> @vp_ctpop_v8i64(<8 x i64> %va, <8 x i1> %m, i32 zeroext %evl) {
; RV32-NEXT: vsrl.vi v12, v8, 1, v0.t
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v16, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v12, v12, v16, v0.t
; RV32-NEXT: vsub.vv v8, v8, v12, v0.t
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v16, v8, v12, v0.t
@@ -1015,13 +1015,13 @@ define <8 x i64> @vp_ctpop_v8i64(<8 x i64> %va, <8 x i1> %m, i32 zeroext %evl) {
; RV32-NEXT: vadd.vv v8, v8, v12, v0.t
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v8, v8, v12, v0.t
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v12, v0.t
@@ -1073,14 +1073,14 @@ define <8 x i64> @vp_ctpop_v8i64_unmasked(<8 x i64> %va, i32 zeroext %evl) {
; RV32-NEXT: vsrl.vi v12, v8, 1
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v16, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v12, v12, v16
; RV32-NEXT: vsub.vv v8, v8, v12
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v16, v8, v12
@@ -1091,13 +1091,13 @@ define <8 x i64> @vp_ctpop_v8i64_unmasked(<8 x i64> %va, i32 zeroext %evl) {
; RV32-NEXT: vadd.vv v8, v8, v12
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v8, v8, v12
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v12
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-ctpop.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-ctpop.ll
index 147f560633a45f..b5114bbe491896 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-ctpop.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-ctpop.ll
@@ -131,7 +131,7 @@ define void @ctpop_v2i64(ptr %x, ptr %y) {
; RV32-NEXT: vle64.v v8, (a0)
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetivli zero, 2, e64, m1, ta, ma
; RV32-NEXT: vsrl.vi v10, v8, 1
@@ -139,7 +139,7 @@ define void @ctpop_v2i64(ptr %x, ptr %y) {
; RV32-NEXT: vsub.vv v8, v8, v9
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetivli zero, 2, e64, m1, ta, ma
; RV32-NEXT: vand.vv v10, v8, v9
@@ -150,13 +150,13 @@ define void @ctpop_v2i64(ptr %x, ptr %y) {
; RV32-NEXT: vadd.vv v8, v8, v9
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetivli zero, 2, e64, m1, ta, ma
; RV32-NEXT: vand.vv v8, v8, v9
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetivli zero, 2, e64, m1, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v9
@@ -437,7 +437,7 @@ define void @ctpop_v4i64(ptr %x, ptr %y) {
; RV32-NEXT: vle64.v v8, (a0)
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetivli zero, 4, e64, m2, ta, ma
; RV32-NEXT: vsrl.vi v12, v8, 1
@@ -445,7 +445,7 @@ define void @ctpop_v4i64(ptr %x, ptr %y) {
; RV32-NEXT: vsub.vv v8, v8, v10
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetivli zero, 4, e64, m2, ta, ma
; RV32-NEXT: vand.vv v12, v8, v10
@@ -456,13 +456,13 @@ define void @ctpop_v4i64(ptr %x, ptr %y) {
; RV32-NEXT: vadd.vv v8, v8, v10
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetivli zero, 4, e64, m2, ta, ma
; RV32-NEXT: vand.vv v8, v8, v10
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetivli zero, 4, e64, m2, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v10
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-cttz-vp.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-cttz-vp.ll
index 082ac1871e9409..49f6ffd691292a 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-cttz-vp.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-cttz-vp.ll
@@ -785,14 +785,14 @@ define <2 x i64> @vp_cttz_v2i64(<2 x i64> %va, <2 x i1> %m, i32 zeroext %evl) {
; RV32-NEXT: vsrl.vi v9, v8, 1, v0.t
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v9, v9, v10, v0.t
; RV32-NEXT: vsub.vv v8, v8, v9, v0.t
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v10, v8, v9, v0.t
@@ -803,13 +803,13 @@ define <2 x i64> @vp_cttz_v2i64(<2 x i64> %va, <2 x i1> %m, i32 zeroext %evl) {
; RV32-NEXT: vadd.vv v8, v8, v9, v0.t
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v8, v8, v9, v0.t
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v9, v0.t
@@ -869,14 +869,14 @@ define <2 x i64> @vp_cttz_v2i64_unmasked(<2 x i64> %va, i32 zeroext %evl) {
; RV32-NEXT: vsrl.vi v9, v8, 1
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v9, v9, v10
; RV32-NEXT: vsub.vv v8, v8, v9
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v10, v8, v9
@@ -887,13 +887,13 @@ define <2 x i64> @vp_cttz_v2i64_unmasked(<2 x i64> %va, i32 zeroext %evl) {
; RV32-NEXT: vadd.vv v8, v8, v9
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v8, v8, v9
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v9
@@ -957,14 +957,14 @@ define <4 x i64> @vp_cttz_v4i64(<4 x i64> %va, <4 x i1> %m, i32 zeroext %evl) {
; RV32-NEXT: vsrl.vi v10, v8, 1, v0.t
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v10, v10, v12, v0.t
; RV32-NEXT: vsub.vv v8, v8, v10, v0.t
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v12, v8, v10, v0.t
@@ -975,13 +975,13 @@ define <4 x i64> @vp_cttz_v4i64(<4 x i64> %va, <4 x i1> %m, i32 zeroext %evl) {
; RV32-NEXT: vadd.vv v8, v8, v10, v0.t
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v8, v8, v10, v0.t
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v10, v0.t
@@ -1041,14 +1041,14 @@ define <4 x i64> @vp_cttz_v4i64_unmasked(<4 x i64> %va, i32 zeroext %evl) {
; RV32-NEXT: vsrl.vi v10, v8, 1
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v10, v10, v12
; RV32-NEXT: vsub.vv v8, v8, v10
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v12, v8, v10
@@ -1059,13 +1059,13 @@ define <4 x i64> @vp_cttz_v4i64_unmasked(<4 x i64> %va, i32 zeroext %evl) {
; RV32-NEXT: vadd.vv v8, v8, v10
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v8, v8, v10
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v10
@@ -1129,14 +1129,14 @@ define <8 x i64> @vp_cttz_v8i64(<8 x i64> %va, <8 x i1> %m, i32 zeroext %evl) {
; RV32-NEXT: vsrl.vi v12, v8, 1, v0.t
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v16, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v12, v12, v16, v0.t
; RV32-NEXT: vsub.vv v8, v8, v12, v0.t
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v16, v8, v12, v0.t
@@ -1147,13 +1147,13 @@ define <8 x i64> @vp_cttz_v8i64(<8 x i64> %va, <8 x i1> %m, i32 zeroext %evl) {
; RV32-NEXT: vadd.vv v8, v8, v12, v0.t
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v8, v8, v12, v0.t
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v12, v0.t
@@ -1213,14 +1213,14 @@ define <8 x i64> @vp_cttz_v8i64_unmasked(<8 x i64> %va, i32 zeroext %evl) {
; RV32-NEXT: vsrl.vi v12, v8, 1
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v16, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v12, v12, v16
; RV32-NEXT: vsub.vv v8, v8, v12
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v16, v8, v12
@@ -1231,13 +1231,13 @@ define <8 x i64> @vp_cttz_v8i64_unmasked(<8 x i64> %va, i32 zeroext %evl) {
; RV32-NEXT: vadd.vv v8, v8, v12
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v8, v8, v12
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v12
@@ -2984,14 +2984,14 @@ define <2 x i64> @vp_cttz_zero_undef_v2i64(<2 x i64> %va, <2 x i1> %m, i32 zeroe
; RV32-NEXT: vsrl.vi v9, v8, 1, v0.t
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v9, v9, v10, v0.t
; RV32-NEXT: vsub.vv v8, v8, v9, v0.t
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v10, v8, v9, v0.t
@@ -3002,13 +3002,13 @@ define <2 x i64> @vp_cttz_zero_undef_v2i64(<2 x i64> %va, <2 x i1> %m, i32 zeroe
; RV32-NEXT: vadd.vv v8, v8, v9, v0.t
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v8, v8, v9, v0.t
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v9, v0.t
@@ -3068,14 +3068,14 @@ define <2 x i64> @vp_cttz_zero_undef_v2i64_unmasked(<2 x i64> %va, i32 zeroext %
; RV32-NEXT: vsrl.vi v9, v8, 1
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v9, v9, v10
; RV32-NEXT: vsub.vv v8, v8, v9
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v10, v8, v9
@@ -3086,13 +3086,13 @@ define <2 x i64> @vp_cttz_zero_undef_v2i64_unmasked(<2 x i64> %va, i32 zeroext %
; RV32-NEXT: vadd.vv v8, v8, v9
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vand.vv v8, v8, v9
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32-NEXT: vmv.v.x v9, a1
; RV32-NEXT: vsetvli zero, a0, e64, m1, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v9
@@ -3154,14 +3154,14 @@ define <4 x i64> @vp_cttz_zero_undef_v4i64(<4 x i64> %va, <4 x i1> %m, i32 zeroe
; RV32-NEXT: vsrl.vi v10, v8, 1, v0.t
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v10, v10, v12, v0.t
; RV32-NEXT: vsub.vv v8, v8, v10, v0.t
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v12, v8, v10, v0.t
@@ -3172,13 +3172,13 @@ define <4 x i64> @vp_cttz_zero_undef_v4i64(<4 x i64> %va, <4 x i1> %m, i32 zeroe
; RV32-NEXT: vadd.vv v8, v8, v10, v0.t
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v8, v8, v10, v0.t
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v10, v0.t
@@ -3238,14 +3238,14 @@ define <4 x i64> @vp_cttz_zero_undef_v4i64_unmasked(<4 x i64> %va, i32 zeroext %
; RV32-NEXT: vsrl.vi v10, v8, 1
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v10, v10, v12
; RV32-NEXT: vsub.vv v8, v8, v10
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v12, v8, v10
@@ -3256,13 +3256,13 @@ define <4 x i64> @vp_cttz_zero_undef_v4i64_unmasked(<4 x i64> %va, i32 zeroext %
; RV32-NEXT: vadd.vv v8, v8, v10
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vand.vv v8, v8, v10
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32-NEXT: vmv.v.x v10, a1
; RV32-NEXT: vsetvli zero, a0, e64, m2, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v10
@@ -3324,14 +3324,14 @@ define <8 x i64> @vp_cttz_zero_undef_v8i64(<8 x i64> %va, <8 x i1> %m, i32 zeroe
; RV32-NEXT: vsrl.vi v12, v8, 1, v0.t
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v16, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v12, v12, v16, v0.t
; RV32-NEXT: vsub.vv v8, v8, v12, v0.t
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v16, v8, v12, v0.t
@@ -3342,13 +3342,13 @@ define <8 x i64> @vp_cttz_zero_undef_v8i64(<8 x i64> %va, <8 x i1> %m, i32 zeroe
; RV32-NEXT: vadd.vv v8, v8, v12, v0.t
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v8, v8, v12, v0.t
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v12, v0.t
@@ -3408,14 +3408,14 @@ define <8 x i64> @vp_cttz_zero_undef_v8i64_unmasked(<8 x i64> %va, i32 zeroext %
; RV32-NEXT: vsrl.vi v12, v8, 1
; RV32-NEXT: lui a1, 349525
; RV32-NEXT: addi a1, a1, 1365
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v16, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v12, v12, v16
; RV32-NEXT: vsub.vv v8, v8, v12
; RV32-NEXT: lui a1, 209715
; RV32-NEXT: addi a1, a1, 819
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v16, v8, v12
@@ -3426,13 +3426,13 @@ define <8 x i64> @vp_cttz_zero_undef_v8i64_unmasked(<8 x i64> %va, i32 zeroext %
; RV32-NEXT: vadd.vv v8, v8, v12
; RV32-NEXT: lui a1, 61681
; RV32-NEXT: addi a1, a1, -241
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vand.vv v8, v8, v12
; RV32-NEXT: lui a1, 4112
; RV32-NEXT: addi a1, a1, 257
-; RV32-NEXT: vsetvli a2, zero, e32, m4, ta, ma
+; RV32-NEXT: vsetivli zero, 16, e32, m4, ta, ma
; RV32-NEXT: vmv.v.x v12, a1
; RV32-NEXT: vsetvli zero, a0, e64, m4, ta, ma
; RV32-NEXT: vmul.vv v8, v8, v12
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-cttz.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-cttz.ll
index 5802fba2f24545..8c8da6d1e00313 100644
--- a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-cttz.ll
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-cttz.ll
@@ -257,14 +257,14 @@ define void @cttz_v2i64(ptr %x, ptr %y) nounwind {
; RV32I-NEXT: vsrl.vi v9, v8, 1
; RV32I-NEXT: lui a1, 349525
; RV32I-NEXT: addi a1, a1, 1365
-; RV32I-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32I-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32I-NEXT: vmv.v.x v10, a1
; RV32I-NEXT: vsetivli zero, 2, e64, m1, ta, ma
; RV32I-NEXT: vand.vv v9, v9, v10
; RV32I-NEXT: vsub.vv v8, v8, v9
; RV32I-NEXT: lui a1, 209715
; RV32I-NEXT: addi a1, a1, 819
-; RV32I-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32I-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32I-NEXT: vmv.v.x v9, a1
; RV32I-NEXT: vsetivli zero, 2, e64, m1, ta, ma
; RV32I-NEXT: vand.vv v10, v8, v9
@@ -275,13 +275,13 @@ define void @cttz_v2i64(ptr %x, ptr %y) nounwind {
; RV32I-NEXT: vadd.vv v8, v8, v9
; RV32I-NEXT: lui a1, 61681
; RV32I-NEXT: addi a1, a1, -241
-; RV32I-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32I-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32I-NEXT: vmv.v.x v9, a1
; RV32I-NEXT: vsetivli zero, 2, e64, m1, ta, ma
; RV32I-NEXT: vand.vv v8, v8, v9
; RV32I-NEXT: lui a1, 4112
; RV32I-NEXT: addi a1, a1, 257
-; RV32I-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32I-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32I-NEXT: vmv.v.x v9, a1
; RV32I-NEXT: vsetivli zero, 2, e64, m1, ta, ma
; RV32I-NEXT: vmul.vv v8, v8, v9
@@ -658,14 +658,14 @@ define void @cttz_v4i64(ptr %x, ptr %y) nounwind {
; RV32I-NEXT: vsrl.vi v10, v8, 1
; RV32I-NEXT: lui a1, 349525
; RV32I-NEXT: addi a1, a1, 1365
-; RV32I-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32I-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32I-NEXT: vmv.v.x v12, a1
; RV32I-NEXT: vsetivli zero, 4, e64, m2, ta, ma
; RV32I-NEXT: vand.vv v10, v10, v12
; RV32I-NEXT: vsub.vv v8, v8, v10
; RV32I-NEXT: lui a1, 209715
; RV32I-NEXT: addi a1, a1, 819
-; RV32I-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32I-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32I-NEXT: vmv.v.x v10, a1
; RV32I-NEXT: vsetivli zero, 4, e64, m2, ta, ma
; RV32I-NEXT: vand.vv v12, v8, v10
@@ -676,13 +676,13 @@ define void @cttz_v4i64(ptr %x, ptr %y) nounwind {
; RV32I-NEXT: vadd.vv v8, v8, v10
; RV32I-NEXT: lui a1, 61681
; RV32I-NEXT: addi a1, a1, -241
-; RV32I-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32I-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32I-NEXT: vmv.v.x v10, a1
; RV32I-NEXT: vsetivli zero, 4, e64, m2, ta, ma
; RV32I-NEXT: vand.vv v8, v8, v10
; RV32I-NEXT: lui a1, 4112
; RV32I-NEXT: addi a1, a1, 257
-; RV32I-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32I-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32I-NEXT: vmv.v.x v10, a1
; RV32I-NEXT: vsetivli zero, 4, e64, m2, ta, ma
; RV32I-NEXT: vmul.vv v8, v8, v10
@@ -1036,14 +1036,14 @@ define void @cttz_zero_undef_v2i64(ptr %x, ptr %y) nounwind {
; RV32I-NEXT: vsrl.vi v9, v8, 1
; RV32I-NEXT: lui a1, 349525
; RV32I-NEXT: addi a1, a1, 1365
-; RV32I-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32I-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32I-NEXT: vmv.v.x v10, a1
; RV32I-NEXT: vsetivli zero, 2, e64, m1, ta, ma
; RV32I-NEXT: vand.vv v9, v9, v10
; RV32I-NEXT: vsub.vv v8, v8, v9
; RV32I-NEXT: lui a1, 209715
; RV32I-NEXT: addi a1, a1, 819
-; RV32I-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32I-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32I-NEXT: vmv.v.x v9, a1
; RV32I-NEXT: vsetivli zero, 2, e64, m1, ta, ma
; RV32I-NEXT: vand.vv v10, v8, v9
@@ -1054,13 +1054,13 @@ define void @cttz_zero_undef_v2i64(ptr %x, ptr %y) nounwind {
; RV32I-NEXT: vadd.vv v8, v8, v9
; RV32I-NEXT: lui a1, 61681
; RV32I-NEXT: addi a1, a1, -241
-; RV32I-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32I-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32I-NEXT: vmv.v.x v9, a1
; RV32I-NEXT: vsetivli zero, 2, e64, m1, ta, ma
; RV32I-NEXT: vand.vv v8, v8, v9
; RV32I-NEXT: lui a1, 4112
; RV32I-NEXT: addi a1, a1, 257
-; RV32I-NEXT: vsetvli a2, zero, e32, m1, ta, ma
+; RV32I-NEXT: vsetivli zero, 4, e32, m1, ta, ma
; RV32I-NEXT: vmv.v.x v9, a1
; RV32I-NEXT: vsetivli zero, 2, e64, m1, ta, ma
; RV32I-NEXT: vmul.vv v8, v8, v9
@@ -1407,14 +1407,14 @@ define void @cttz_zero_undef_v4i64(ptr %x, ptr %y) nounwind {
; RV32I-NEXT: vsrl.vi v10, v8, 1
; RV32I-NEXT: lui a1, 349525
; RV32I-NEXT: addi a1, a1, 1365
-; RV32I-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32I-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32I-NEXT: vmv.v.x v12, a1
; RV32I-NEXT: vsetivli zero, 4, e64, m2, ta, ma
; RV32I-NEXT: vand.vv v10, v10, v12
; RV32I-NEXT: vsub.vv v8, v8, v10
; RV32I-NEXT: lui a1, 209715
; RV32I-NEXT: addi a1, a1, 819
-; RV32I-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32I-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32I-NEXT: vmv.v.x v10, a1
; RV32I-NEXT: vsetivli zero, 4, e64, m2, ta, ma
; RV32I-NEXT: vand.vv v12, v8, v10
@@ -1425,13 +1425,13 @@ define void @cttz_zero_undef_v4i64(ptr %x, ptr %y) nounwind {
; RV32I-NEXT: vadd.vv v8, v8, v10
; RV32I-NEXT: lui a1, 61681
; RV32I-NEXT: addi a1, a1, -241
-; RV32I-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32I-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32I-NEXT: vmv.v.x v10, a1
; RV32I-NEXT: vsetivli zero, 4, e64, m2, ta, ma
; RV32I-NEXT: vand.vv v8, v8, v10
; RV32I-NEXT: lui a1, 4112
; RV32I-NEXT: addi a1, a1, 257
-; RV32I-NEXT: vsetvli a2, zero, e32, m2, ta, ma
+; RV32I-NEXT: vsetivli zero, 8, e32, m2, ta, ma
; RV32I-NEXT: vmv.v.x v10, a1
; RV32I-NEXT: vsetivli zero, 4, e64, m2, ta, ma
; RV32I-NEXT: vmul.vv v8, v8, v10
>From 8fccf6bf5ccb4404cfe184ceda7c32e349e122c0 Mon Sep 17 00:00:00 2001
From: Craig Topper <craig.topper at sifive.com>
Date: Sat, 2 Mar 2024 17:47:40 -0800
Subject: [PATCH 370/406] [opt] Use static arrays instead of std::vector to
store legacy pass names. NFC (#83634)
A std::vector causes a heap allocation and a memcpy of static
initialization data from the rodata section.
Use a static array instead so we can use the static data directly.
---
llvm/tools/opt/optdriver.cpp | 8 ++++----
1 file changed, 4 insertions(+), 4 deletions(-)
diff --git a/llvm/tools/opt/optdriver.cpp b/llvm/tools/opt/optdriver.cpp
index 7d05cb412b3d5a..948148bb80498c 100644
--- a/llvm/tools/opt/optdriver.cpp
+++ b/llvm/tools/opt/optdriver.cpp
@@ -317,7 +317,7 @@ struct TimeTracerRAII {
// TODO: use a codegen version of PassRegistry.def/PassBuilder::is*Pass() once
// it exists.
static bool shouldPinPassToLegacyPM(StringRef Pass) {
- std::vector<StringRef> PassNameExactToIgnore = {
+ static constexpr StringLiteral PassNameExactToIgnore[] = {
"nvvm-reflect",
"nvvm-intr-range",
"amdgpu-simplifylib",
@@ -334,13 +334,13 @@ static bool shouldPinPassToLegacyPM(StringRef Pass) {
if (llvm::is_contained(PassNameExactToIgnore, Pass))
return false;
- std::vector<StringRef> PassNamePrefix = {
+ static constexpr StringLiteral PassNamePrefix[] = {
"x86-", "xcore-", "wasm-", "systemz-", "ppc-", "nvvm-",
"nvptx-", "mips-", "lanai-", "hexagon-", "bpf-", "avr-",
"thumb2-", "arm-", "si-", "gcn-", "amdgpu-", "aarch64-",
"amdgcn-", "polly-", "riscv-", "dxil-"};
- std::vector<StringRef> PassNameContain = {"-eh-prepare"};
- std::vector<StringRef> PassNameExact = {
+ static constexpr StringLiteral PassNameContain[] = {"-eh-prepare"};
+ static constexpr StringLiteral PassNameExact[] = {
"safe-stack",
"cost-model",
"codegenprepare",
>From d5f77e112e6352d933afa22920a4a0d3bf8d26e5 Mon Sep 17 00:00:00 2001
From: Brad Smith <brad at comstyle.com>
Date: Sat, 2 Mar 2024 21:33:59 -0500
Subject: [PATCH 371/406] [Driver] Remove duplicate -r flag usage when linking
(#82715)
Bug #82010
---
clang/lib/Driver/ToolChains/Darwin.cpp | 5 ++---
clang/lib/Driver/ToolChains/DragonFly.cpp | 2 +-
clang/lib/Driver/ToolChains/FreeBSD.cpp | 4 ++--
clang/lib/Driver/ToolChains/Haiku.cpp | 2 +-
clang/lib/Driver/ToolChains/NetBSD.cpp | 2 +-
clang/lib/Driver/ToolChains/OpenBSD.cpp | 4 ++--
clang/lib/Driver/ToolChains/PS4CPU.cpp | 5 ++---
clang/lib/Driver/ToolChains/Solaris.cpp | 3 +--
8 files changed, 12 insertions(+), 15 deletions(-)
diff --git a/clang/lib/Driver/ToolChains/Darwin.cpp b/clang/lib/Driver/ToolChains/Darwin.cpp
index cc1219d69d9910..fff538d2e5d735 100644
--- a/clang/lib/Driver/ToolChains/Darwin.cpp
+++ b/clang/lib/Driver/ToolChains/Darwin.cpp
@@ -643,9 +643,8 @@ void darwin::Linker::ConstructJob(Compilation &C, const JobAction &JA,
// It seems that the 'e' option is completely ignored for dynamic executables
// (the default), and with static executables, the last one wins, as expected.
- Args.addAllArgs(CmdArgs,
- {options::OPT_d_Flag, options::OPT_s, options::OPT_t,
- options::OPT_Z_Flag, options::OPT_u_Group, options::OPT_r});
+ Args.addAllArgs(CmdArgs, {options::OPT_d_Flag, options::OPT_s, options::OPT_t,
+ options::OPT_Z_Flag, options::OPT_u_Group});
// Forward -ObjC when either -ObjC or -ObjC++ is used, to force loading
// members of static archive libraries which implement Objective-C classes or
diff --git a/clang/lib/Driver/ToolChains/DragonFly.cpp b/clang/lib/Driver/ToolChains/DragonFly.cpp
index 9942fc632e0a91..89e0600277c44c 100644
--- a/clang/lib/Driver/ToolChains/DragonFly.cpp
+++ b/clang/lib/Driver/ToolChains/DragonFly.cpp
@@ -122,7 +122,7 @@ void dragonfly::Linker::ConstructJob(Compilation &C, const JobAction &JA,
}
Args.addAllArgs(CmdArgs, {options::OPT_L, options::OPT_T_Group,
- options::OPT_s, options::OPT_t, options::OPT_r});
+ options::OPT_s, options::OPT_t});
ToolChain.AddFilePathLibArgs(Args, CmdArgs);
AddLinkerInputs(ToolChain, Inputs, Args, CmdArgs, JA);
diff --git a/clang/lib/Driver/ToolChains/FreeBSD.cpp b/clang/lib/Driver/ToolChains/FreeBSD.cpp
index b7c9e0e51cdb66..9d698f77583950 100644
--- a/clang/lib/Driver/ToolChains/FreeBSD.cpp
+++ b/clang/lib/Driver/ToolChains/FreeBSD.cpp
@@ -261,8 +261,8 @@ void freebsd::Linker::ConstructJob(Compilation &C, const JobAction &JA,
Args.AddAllArgs(CmdArgs, options::OPT_L);
ToolChain.AddFilePathLibArgs(Args, CmdArgs);
- Args.addAllArgs(CmdArgs, {options::OPT_T_Group, options::OPT_s,
- options::OPT_t, options::OPT_r});
+ Args.addAllArgs(CmdArgs,
+ {options::OPT_T_Group, options::OPT_s, options::OPT_t});
if (D.isUsingLTO()) {
assert(!Inputs.empty() && "Must have at least one input.");
diff --git a/clang/lib/Driver/ToolChains/Haiku.cpp b/clang/lib/Driver/ToolChains/Haiku.cpp
index e0d94035823fd3..ca7faa68765abf 100644
--- a/clang/lib/Driver/ToolChains/Haiku.cpp
+++ b/clang/lib/Driver/ToolChains/Haiku.cpp
@@ -80,7 +80,7 @@ void haiku::Linker::ConstructJob(Compilation &C, const JobAction &JA,
}
Args.addAllArgs(CmdArgs, {options::OPT_L, options::OPT_T_Group,
- options::OPT_s, options::OPT_t, options::OPT_r});
+ options::OPT_s, options::OPT_t});
ToolChain.AddFilePathLibArgs(Args, CmdArgs);
if (D.isUsingLTO()) {
diff --git a/clang/lib/Driver/ToolChains/NetBSD.cpp b/clang/lib/Driver/ToolChains/NetBSD.cpp
index 240bf5764b9cce..645d0311641f34 100644
--- a/clang/lib/Driver/ToolChains/NetBSD.cpp
+++ b/clang/lib/Driver/ToolChains/NetBSD.cpp
@@ -268,7 +268,7 @@ void netbsd::Linker::ConstructJob(Compilation &C, const JobAction &JA,
}
Args.addAllArgs(CmdArgs, {options::OPT_L, options::OPT_T_Group,
- options::OPT_s, options::OPT_t, options::OPT_r});
+ options::OPT_s, options::OPT_t});
ToolChain.AddFilePathLibArgs(Args, CmdArgs);
bool NeedsSanitizerDeps = addSanitizerRuntimes(ToolChain, Args, CmdArgs);
diff --git a/clang/lib/Driver/ToolChains/OpenBSD.cpp b/clang/lib/Driver/ToolChains/OpenBSD.cpp
index fd6aa4d7e68447..97f88b7b79dfbe 100644
--- a/clang/lib/Driver/ToolChains/OpenBSD.cpp
+++ b/clang/lib/Driver/ToolChains/OpenBSD.cpp
@@ -192,8 +192,8 @@ void openbsd::Linker::ConstructJob(Compilation &C, const JobAction &JA,
Args.AddAllArgs(CmdArgs, options::OPT_L);
ToolChain.AddFilePathLibArgs(Args, CmdArgs);
- Args.addAllArgs(CmdArgs, {options::OPT_T_Group, options::OPT_s,
- options::OPT_t, options::OPT_r});
+ Args.addAllArgs(CmdArgs,
+ {options::OPT_T_Group, options::OPT_s, options::OPT_t});
if (D.isUsingLTO()) {
assert(!Inputs.empty() && "Must have at least one input.");
diff --git a/clang/lib/Driver/ToolChains/PS4CPU.cpp b/clang/lib/Driver/ToolChains/PS4CPU.cpp
index 8ba8b80cfec78e..7bf9aa79384c55 100644
--- a/clang/lib/Driver/ToolChains/PS4CPU.cpp
+++ b/clang/lib/Driver/ToolChains/PS4CPU.cpp
@@ -208,9 +208,8 @@ void tools::PScpu::Linker::ConstructJob(Compilation &C, const JobAction &JA,
CmdArgs.push_back("--lto=full");
}
- Args.addAllArgs(CmdArgs,
- {options::OPT_L, options::OPT_T_Group, options::OPT_s,
- options::OPT_t, options::OPT_r});
+ Args.addAllArgs(CmdArgs, {options::OPT_L, options::OPT_T_Group,
+ options::OPT_s, options::OPT_t});
if (Args.hasArg(options::OPT_Z_Xlinker__no_demangle))
CmdArgs.push_back("--no-demangle");
diff --git a/clang/lib/Driver/ToolChains/Solaris.cpp b/clang/lib/Driver/ToolChains/Solaris.cpp
index 200ac46aa53409..5d7f0ae2a392a6 100644
--- a/clang/lib/Driver/ToolChains/Solaris.cpp
+++ b/clang/lib/Driver/ToolChains/Solaris.cpp
@@ -201,8 +201,7 @@ void solaris::Linker::ConstructJob(Compilation &C, const JobAction &JA,
ToolChain.AddFilePathLibArgs(Args, CmdArgs);
- Args.addAllArgs(CmdArgs,
- {options::OPT_L, options::OPT_T_Group, options::OPT_r});
+ Args.addAllArgs(CmdArgs, {options::OPT_L, options::OPT_T_Group});
bool NeedsSanitizerDeps = addSanitizerRuntimes(ToolChain, Args, CmdArgs);
AddLinkerInputs(ToolChain, Inputs, Args, CmdArgs, JA);
>From 6594f428de91e333c1cbea4f55e79b18d31024c4 Mon Sep 17 00:00:00 2001
From: Mehdi Amini <joker.eph at gmail.com>
Date: Sat, 2 Mar 2024 19:10:50 -0800
Subject: [PATCH 372/406] Split the llvm::ThreadPool into an abstract base
class and an implementation (#82094)
This decouples the public API used to enqueue tasks and wait for
completion from the actual implementation, and opens up the possibility
for clients to set their own thread pool implementation for the pool.
https://discourse.llvm.org/t/construct-threadpool-from-vector-of-existing-threads/76883
---
bolt/include/bolt/Core/ParallelUtilities.h | 3 +-
lldb/include/lldb/Core/Debugger.h | 6 +-
llvm/include/llvm/Debuginfod/Debuginfod.h | 6 +-
.../llvm/Support/BalancedPartitioning.h | 7 +-
llvm/include/llvm/Support/ThreadPool.h | 184 +++++++++++-------
llvm/lib/Debuginfod/Debuginfod.cpp | 3 +-
llvm/lib/Support/ThreadPool.cpp | 41 ++--
llvm/tools/llvm-cov/CoverageReport.h | 4 +-
llvm/tools/llvm-cov/SourceCoverageViewHTML.h | 2 -
llvm/unittests/Support/ThreadPool.cpp | 116 ++++++-----
mlir/include/mlir/CAPI/Support.h | 4 +-
mlir/include/mlir/IR/MLIRContext.h | 6 +-
mlir/include/mlir/IR/Threading.h | 2 +-
mlir/lib/CAPI/IR/IR.cpp | 1 +
mlir/lib/IR/MLIRContext.cpp | 8 +-
mlir/lib/Tools/mlir-opt/MlirOptMain.cpp | 4 +-
16 files changed, 228 insertions(+), 169 deletions(-)
diff --git a/bolt/include/bolt/Core/ParallelUtilities.h b/bolt/include/bolt/Core/ParallelUtilities.h
index 7d3af47757bce6..e510525bc51d00 100644
--- a/bolt/include/bolt/Core/ParallelUtilities.h
+++ b/bolt/include/bolt/Core/ParallelUtilities.h
@@ -18,6 +18,7 @@
#include "bolt/Core/MCPlusBuilder.h"
#include "llvm/Support/CommandLine.h"
+#include "llvm/Support/ThreadPool.h"
using namespace llvm;
@@ -28,8 +29,6 @@ extern cl::opt<unsigned> TaskCount;
} // namespace opts
namespace llvm {
-class ThreadPool;
-
namespace bolt {
class BinaryContext;
class BinaryFunction;
diff --git a/lldb/include/lldb/Core/Debugger.h b/lldb/include/lldb/Core/Debugger.h
index b65ec1029ab24b..418c2403d020f4 100644
--- a/lldb/include/lldb/Core/Debugger.h
+++ b/lldb/include/lldb/Core/Debugger.h
@@ -52,7 +52,7 @@
namespace llvm {
class raw_ostream;
-class ThreadPool;
+class ThreadPoolInterface;
} // namespace llvm
namespace lldb_private {
@@ -499,8 +499,8 @@ class Debugger : public std::enable_shared_from_this<Debugger>,
return m_broadcaster_manager_sp;
}
- /// Shared thread poll. Use only with ThreadPoolTaskGroup.
- static llvm::ThreadPool &GetThreadPool();
+ /// Shared thread pool. Use only with ThreadPoolTaskGroup.
+ static llvm::ThreadPoolInterface &GetThreadPool();
/// Report warning events.
///
diff --git a/llvm/include/llvm/Debuginfod/Debuginfod.h b/llvm/include/llvm/Debuginfod/Debuginfod.h
index ef03948a706c06..99fe15ad859794 100644
--- a/llvm/include/llvm/Debuginfod/Debuginfod.h
+++ b/llvm/include/llvm/Debuginfod/Debuginfod.h
@@ -97,7 +97,7 @@ Expected<std::string> getCachedOrDownloadArtifact(
StringRef UniqueKey, StringRef UrlPath, StringRef CacheDirectoryPath,
ArrayRef<StringRef> DebuginfodUrls, std::chrono::milliseconds Timeout);
-class ThreadPool;
+class ThreadPoolInterface;
struct DebuginfodLogEntry {
std::string Message;
@@ -135,7 +135,7 @@ class DebuginfodCollection {
// error.
Expected<bool> updateIfStale();
DebuginfodLog &Log;
- ThreadPool &Pool;
+ ThreadPoolInterface &Pool;
Timer UpdateTimer;
sys::Mutex UpdateMutex;
@@ -145,7 +145,7 @@ class DebuginfodCollection {
public:
DebuginfodCollection(ArrayRef<StringRef> Paths, DebuginfodLog &Log,
- ThreadPool &Pool, double MinInterval);
+ ThreadPoolInterface &Pool, double MinInterval);
Error update();
Error updateForever(std::chrono::milliseconds Interval);
Expected<std::string> findDebugBinaryPath(object::BuildIDRef);
diff --git a/llvm/include/llvm/Support/BalancedPartitioning.h b/llvm/include/llvm/Support/BalancedPartitioning.h
index a8464ac0fe60e5..9738e742f7f1e9 100644
--- a/llvm/include/llvm/Support/BalancedPartitioning.h
+++ b/llvm/include/llvm/Support/BalancedPartitioning.h
@@ -50,7 +50,7 @@
namespace llvm {
-class ThreadPool;
+class ThreadPoolInterface;
/// A function with a set of utility nodes where it is beneficial to order two
/// functions close together if they have similar utility nodes
class BPFunctionNode {
@@ -115,7 +115,7 @@ class BalancedPartitioning {
/// threads, so we need to track how many active threads that could spawn more
/// threads.
struct BPThreadPool {
- ThreadPool &TheThreadPool;
+ ThreadPoolInterface &TheThreadPool;
std::mutex mtx;
std::condition_variable cv;
/// The number of threads that could spawn more threads
@@ -128,7 +128,8 @@ class BalancedPartitioning {
/// acceptable for other threads to add more tasks while blocking on this
/// call.
void wait();
- BPThreadPool(ThreadPool &TheThreadPool) : TheThreadPool(TheThreadPool) {}
+ BPThreadPool(ThreadPoolInterface &TheThreadPool)
+ : TheThreadPool(TheThreadPool) {}
};
/// Run a recursive bisection of a given list of FunctionNodes
diff --git a/llvm/include/llvm/Support/ThreadPool.h b/llvm/include/llvm/Support/ThreadPool.h
index 03ebd35aa46dc4..93f02729f047aa 100644
--- a/llvm/include/llvm/Support/ThreadPool.h
+++ b/llvm/include/llvm/Support/ThreadPool.h
@@ -32,11 +32,8 @@ namespace llvm {
class ThreadPoolTaskGroup;
-/// A ThreadPool for asynchronous parallel execution on a defined number of
-/// threads.
-///
-/// The pool keeps a vector of threads alive, waiting on a condition variable
-/// for some work to become available.
+/// This defines the abstract base interface for a ThreadPool allowing
+/// asynchronous parallel execution on a defined number of threads.
///
/// It is possible to reuse one thread pool for different groups of tasks
/// by grouping tasks using ThreadPoolTaskGroup. All tasks are processed using
@@ -49,16 +46,31 @@ class ThreadPoolTaskGroup;
/// available threads are used up by tasks waiting for a task that has no thread
/// left to run on (this includes waiting on the returned future). It should be
/// generally safe to wait() for a group as long as groups do not form a cycle.
-class ThreadPool {
+class ThreadPoolInterface {
+ /// The actual method to enqueue a task to be defined by the concrete
+ /// implementation.
+ virtual void asyncEnqueue(std::function<void()> Task,
+ ThreadPoolTaskGroup *Group) = 0;
+
public:
- /// Construct a pool using the hardware strategy \p S for mapping hardware
- /// execution resources (threads, cores, CPUs)
- /// Defaults to using the maximum execution resources in the system, but
- /// accounting for the affinity mask.
- ThreadPool(ThreadPoolStrategy S = hardware_concurrency());
+ /// Destroying the pool will drain the pending tasks and wait. The current
+ /// thread may participate in the execution of the pending tasks.
+ virtual ~ThreadPoolInterface();
- /// Blocking destructor: the pool will wait for all the threads to complete.
- ~ThreadPool();
+ /// Blocking wait for all the threads to complete and the queue to be empty.
+ /// It is an error to try to add new tasks while blocking on this call.
+ /// Calling wait() from a task would deadlock waiting for itself.
+ virtual void wait() = 0;
+
+ /// Blocking wait for only all the threads in the given group to complete.
+ /// It is possible to wait even inside a task, but waiting (directly or
+ /// indirectly) on itself will deadlock. If called from a task running on a
+ /// worker thread, the call may process pending tasks while waiting in order
+ /// not to waste the thread.
+ virtual void wait(ThreadPoolTaskGroup &Group) = 0;
+
+ /// Returns the maximum number of worker this pool can eventually grow to.
+ virtual unsigned getMaxConcurrency() const = 0;
/// Asynchronous submission of a task to the pool. The returned future can be
/// used to wait for the task to finish and is *non-blocking* on destruction.
@@ -92,23 +104,51 @@ class ThreadPool {
&Group);
}
+private:
+ /// Asynchronous submission of a task to the pool. The returned future can be
+ /// used to wait for the task to finish and is *non-blocking* on destruction.
+ template <typename ResTy>
+ std::shared_future<ResTy> asyncImpl(std::function<ResTy()> Task,
+ ThreadPoolTaskGroup *Group) {
+ auto Future = std::async(std::launch::deferred, std::move(Task)).share();
+ asyncEnqueue([Future]() { Future.wait(); }, Group);
+ return Future;
+ }
+};
+
+#if LLVM_ENABLE_THREADS
+/// A ThreadPool implementation using std::threads.
+///
+/// The pool keeps a vector of threads alive, waiting on a condition variable
+/// for some work to become available.
+class StdThreadPool : public ThreadPoolInterface {
+public:
+ /// Construct a pool using the hardware strategy \p S for mapping hardware
+ /// execution resources (threads, cores, CPUs)
+ /// Defaults to using the maximum execution resources in the system, but
+ /// accounting for the affinity mask.
+ StdThreadPool(ThreadPoolStrategy S = hardware_concurrency());
+
+ /// Blocking destructor: the pool will wait for all the threads to complete.
+ ~StdThreadPool() override;
+
/// Blocking wait for all the threads to complete and the queue to be empty.
/// It is an error to try to add new tasks while blocking on this call.
/// Calling wait() from a task would deadlock waiting for itself.
- void wait();
+ void wait() override;
/// Blocking wait for only all the threads in the given group to complete.
/// It is possible to wait even inside a task, but waiting (directly or
/// indirectly) on itself will deadlock. If called from a task running on a
/// worker thread, the call may process pending tasks while waiting in order
/// not to waste the thread.
- void wait(ThreadPoolTaskGroup &Group);
+ void wait(ThreadPoolTaskGroup &Group) override;
- // Returns the maximum number of worker threads in the pool, not the current
- // number of threads!
- unsigned getMaxConcurrency() const { return MaxThreadCount; }
+ /// Returns the maximum number of worker threads in the pool, not the current
+ /// number of threads!
+ unsigned getMaxConcurrency() const override { return MaxThreadCount; }
- // TODO: misleading legacy name warning!
+ // TODO: Remove, misleading legacy name warning!
LLVM_DEPRECATED("Use getMaxConcurrency instead", "getMaxConcurrency")
unsigned getThreadCount() const { return MaxThreadCount; }
@@ -116,46 +156,14 @@ class ThreadPool {
bool isWorkerThread() const;
private:
- /// Helpers to create a promise and a callable wrapper of \p Task that sets
- /// the result of the promise. Returns the callable and a future to access the
- /// result.
- template <typename ResTy>
- static std::pair<std::function<void()>, std::future<ResTy>>
- createTaskAndFuture(std::function<ResTy()> Task) {
- std::shared_ptr<std::promise<ResTy>> Promise =
- std::make_shared<std::promise<ResTy>>();
- auto F = Promise->get_future();
- return {
- [Promise = std::move(Promise), Task]() { Promise->set_value(Task()); },
- std::move(F)};
- }
- static std::pair<std::function<void()>, std::future<void>>
- createTaskAndFuture(std::function<void()> Task) {
- std::shared_ptr<std::promise<void>> Promise =
- std::make_shared<std::promise<void>>();
- auto F = Promise->get_future();
- return {[Promise = std::move(Promise), Task]() {
- Task();
- Promise->set_value();
- },
- std::move(F)};
- }
-
/// Returns true if all tasks in the given group have finished (nullptr means
/// all tasks regardless of their group). QueueLock must be locked.
bool workCompletedUnlocked(ThreadPoolTaskGroup *Group) const;
/// Asynchronous submission of a task to the pool. The returned future can be
/// used to wait for the task to finish and is *non-blocking* on destruction.
- template <typename ResTy>
- std::shared_future<ResTy> asyncImpl(std::function<ResTy()> Task,
- ThreadPoolTaskGroup *Group) {
-
-#if LLVM_ENABLE_THREADS
- /// Wrap the Task in a std::function<void()> that sets the result of the
- /// corresponding future.
- auto R = createTaskAndFuture(Task);
-
+ void asyncEnqueue(std::function<void()> Task,
+ ThreadPoolTaskGroup *Group) override {
int requestedThreads;
{
// Lock the queue and push the new task
@@ -163,31 +171,18 @@ class ThreadPool {
// Don't allow enqueueing after disabling the pool
assert(EnableFlag && "Queuing a thread during ThreadPool destruction");
- Tasks.emplace_back(std::make_pair(std::move(R.first), Group));
+ Tasks.emplace_back(std::make_pair(std::move(Task), Group));
requestedThreads = ActiveThreads + Tasks.size();
}
QueueCondition.notify_one();
grow(requestedThreads);
- return R.second.share();
-
-#else // LLVM_ENABLE_THREADS Disabled
-
- // Get a Future with launch::deferred execution using std::async
- auto Future = std::async(std::launch::deferred, std::move(Task)).share();
- // Wrap the future so that both ThreadPool::wait() can operate and the
- // returned future can be sync'ed on.
- Tasks.emplace_back(std::make_pair([Future]() { Future.get(); }, Group));
- return Future;
-#endif
}
-#if LLVM_ENABLE_THREADS
- // Grow to ensure that we have at least `requested` Threads, but do not go
- // over MaxThreadCount.
+ /// Grow to ensure that we have at least `requested` Threads, but do not go
+ /// over MaxThreadCount.
void grow(int requested);
void processTasks(ThreadPoolTaskGroup *WaitingForGroup);
-#endif
/// Threads in flight
std::vector<llvm::thread> Threads;
@@ -209,10 +204,8 @@ class ThreadPool {
/// Number of threads active for tasks in the given group (only non-zero).
DenseMap<ThreadPoolTaskGroup *, unsigned> ActiveGroups;
-#if LLVM_ENABLE_THREADS // avoids warning for unused variable
/// Signal for the destruction of the pool, asking thread to exit.
bool EnableFlag = true;
-#endif
const ThreadPoolStrategy Strategy;
@@ -220,6 +213,51 @@ class ThreadPool {
const unsigned MaxThreadCount;
};
+#endif // LLVM_ENABLE_THREADS Disabled
+
+/// A non-threaded implementation.
+class SingleThreadExecutor : public ThreadPoolInterface {
+public:
+ /// Construct a non-threaded pool, ignoring using the hardware strategy.
+ SingleThreadExecutor(ThreadPoolStrategy ignored = {});
+
+ /// Blocking destructor: the pool will first execute the pending tasks.
+ ~SingleThreadExecutor() override;
+
+ /// Blocking wait for all the tasks to execute first
+ void wait() override;
+
+ /// Blocking wait for only all the tasks in the given group to complete.
+ void wait(ThreadPoolTaskGroup &Group) override;
+
+ /// Returns always 1: there is no concurrency.
+ unsigned getMaxConcurrency() const override { return 1; }
+
+ // TODO: Remove, misleading legacy name warning!
+ LLVM_DEPRECATED("Use getMaxConcurrency instead", "getMaxConcurrency")
+ unsigned getThreadCount() const { return 1; }
+
+ /// Returns true if the current thread is a worker thread of this thread pool.
+ bool isWorkerThread() const;
+
+private:
+ /// Asynchronous submission of a task to the pool. The returned future can be
+ /// used to wait for the task to finish and is *non-blocking* on destruction.
+ void asyncEnqueue(std::function<void()> Task,
+ ThreadPoolTaskGroup *Group) override {
+ Tasks.emplace_back(std::make_pair(std::move(Task), Group));
+ }
+
+ /// Tasks waiting for execution in the pool.
+ std::deque<std::pair<std::function<void()>, ThreadPoolTaskGroup *>> Tasks;
+};
+
+#if LLVM_ENABLE_THREADS
+using ThreadPool = StdThreadPool;
+#else
+using ThreadPool = SingleThreadExecutor;
+#endif
+
/// A group of tasks to be run on a thread pool. Thread pool tasks in different
/// groups can run on the same threadpool but can be waited for separately.
/// It is even possible for tasks of one group to submit and wait for tasks
@@ -227,7 +265,7 @@ class ThreadPool {
class ThreadPoolTaskGroup {
public:
/// The ThreadPool argument is the thread pool to forward calls to.
- ThreadPoolTaskGroup(ThreadPool &Pool) : Pool(Pool) {}
+ ThreadPoolTaskGroup(ThreadPoolInterface &Pool) : Pool(Pool) {}
/// Blocking destructor: will wait for all the tasks in the group to complete
/// by calling ThreadPool::wait().
@@ -244,7 +282,7 @@ class ThreadPoolTaskGroup {
void wait() { Pool.wait(*this); }
private:
- ThreadPool &Pool;
+ ThreadPoolInterface &Pool;
};
} // namespace llvm
diff --git a/llvm/lib/Debuginfod/Debuginfod.cpp b/llvm/lib/Debuginfod/Debuginfod.cpp
index 1cf550721000eb..4c785117ae8ef7 100644
--- a/llvm/lib/Debuginfod/Debuginfod.cpp
+++ b/llvm/lib/Debuginfod/Debuginfod.cpp
@@ -348,7 +348,8 @@ DebuginfodLogEntry DebuginfodLog::pop() {
}
DebuginfodCollection::DebuginfodCollection(ArrayRef<StringRef> PathsRef,
- DebuginfodLog &Log, ThreadPool &Pool,
+ DebuginfodLog &Log,
+ ThreadPoolInterface &Pool,
double MinInterval)
: Log(Log), Pool(Pool), MinInterval(MinInterval) {
for (StringRef Path : PathsRef)
diff --git a/llvm/lib/Support/ThreadPool.cpp b/llvm/lib/Support/ThreadPool.cpp
index 4eef339000e198..27e0f220ac4ed6 100644
--- a/llvm/lib/Support/ThreadPool.cpp
+++ b/llvm/lib/Support/ThreadPool.cpp
@@ -14,16 +14,13 @@
#include "llvm/Config/llvm-config.h"
-#if LLVM_ENABLE_THREADS
#include "llvm/Support/FormatVariadic.h"
#include "llvm/Support/Threading.h"
-#else
#include "llvm/Support/raw_ostream.h"
-#endif
using namespace llvm;
-#if LLVM_ENABLE_THREADS
+ThreadPoolInterface::~ThreadPoolInterface() = default;
// A note on thread groups: Tasks are by default in no group (represented
// by nullptr ThreadPoolTaskGroup pointer in the Tasks queue) and functionality
@@ -33,10 +30,12 @@ using namespace llvm;
// queue, and functions called to work only on tasks from one group take that
// pointer.
-ThreadPool::ThreadPool(ThreadPoolStrategy S)
+#if LLVM_ENABLE_THREADS
+
+StdThreadPool::StdThreadPool(ThreadPoolStrategy S)
: Strategy(S), MaxThreadCount(S.compute_thread_count()) {}
-void ThreadPool::grow(int requested) {
+void StdThreadPool::grow(int requested) {
llvm::sys::ScopedWriter LockGuard(ThreadsLock);
if (Threads.size() >= MaxThreadCount)
return; // Already hit the max thread pool size.
@@ -58,7 +57,7 @@ static LLVM_THREAD_LOCAL std::vector<ThreadPoolTaskGroup *>
#endif
// WaitingForGroup == nullptr means all tasks regardless of their group.
-void ThreadPool::processTasks(ThreadPoolTaskGroup *WaitingForGroup) {
+void StdThreadPool::processTasks(ThreadPoolTaskGroup *WaitingForGroup) {
while (true) {
std::function<void()> Task;
ThreadPoolTaskGroup *GroupOfTask;
@@ -111,7 +110,7 @@ void ThreadPool::processTasks(ThreadPoolTaskGroup *WaitingForGroup) {
bool Notify;
bool NotifyGroup;
{
- // Adjust `ActiveThreads`, in case someone waits on ThreadPool::wait()
+ // Adjust `ActiveThreads`, in case someone waits on StdThreadPool::wait()
std::lock_guard<std::mutex> LockGuard(QueueLock);
--ActiveThreads;
if (GroupOfTask != nullptr) {
@@ -123,7 +122,7 @@ void ThreadPool::processTasks(ThreadPoolTaskGroup *WaitingForGroup) {
NotifyGroup = GroupOfTask != nullptr && Notify;
}
// Notify task completion if this is the last active thread, in case
- // someone waits on ThreadPool::wait().
+ // someone waits on StdThreadPool::wait().
if (Notify)
CompletionCondition.notify_all();
// If this was a task in a group, notify also threads waiting for tasks
@@ -134,7 +133,7 @@ void ThreadPool::processTasks(ThreadPoolTaskGroup *WaitingForGroup) {
}
}
-bool ThreadPool::workCompletedUnlocked(ThreadPoolTaskGroup *Group) const {
+bool StdThreadPool::workCompletedUnlocked(ThreadPoolTaskGroup *Group) const {
if (Group == nullptr)
return !ActiveThreads && Tasks.empty();
return ActiveGroups.count(Group) == 0 &&
@@ -142,7 +141,7 @@ bool ThreadPool::workCompletedUnlocked(ThreadPoolTaskGroup *Group) const {
[Group](const auto &T) { return T.second == Group; });
}
-void ThreadPool::wait() {
+void StdThreadPool::wait() {
assert(!isWorkerThread()); // Would deadlock waiting for itself.
// Wait for all threads to complete and the queue to be empty
std::unique_lock<std::mutex> LockGuard(QueueLock);
@@ -150,7 +149,7 @@ void ThreadPool::wait() {
[&] { return workCompletedUnlocked(nullptr); });
}
-void ThreadPool::wait(ThreadPoolTaskGroup &Group) {
+void StdThreadPool::wait(ThreadPoolTaskGroup &Group) {
// Wait for all threads in the group to complete.
if (!isWorkerThread()) {
std::unique_lock<std::mutex> LockGuard(QueueLock);
@@ -167,7 +166,7 @@ void ThreadPool::wait(ThreadPoolTaskGroup &Group) {
processTasks(&Group);
}
-bool ThreadPool::isWorkerThread() const {
+bool StdThreadPool::isWorkerThread() const {
llvm::sys::ScopedReader LockGuard(ThreadsLock);
llvm::thread::id CurrentThreadId = llvm::this_thread::get_id();
for (const llvm::thread &Thread : Threads)
@@ -177,7 +176,7 @@ bool ThreadPool::isWorkerThread() const {
}
// The destructor joins all threads, waiting for completion.
-ThreadPool::~ThreadPool() {
+StdThreadPool::~StdThreadPool() {
{
std::unique_lock<std::mutex> LockGuard(QueueLock);
EnableFlag = false;
@@ -188,10 +187,10 @@ ThreadPool::~ThreadPool() {
Worker.join();
}
-#else // LLVM_ENABLE_THREADS Disabled
+#endif // LLVM_ENABLE_THREADS Disabled
// No threads are launched, issue a warning if ThreadCount is not 0
-ThreadPool::ThreadPool(ThreadPoolStrategy S) : MaxThreadCount(1) {
+SingleThreadExecutor::SingleThreadExecutor(ThreadPoolStrategy S) {
int ThreadCount = S.compute_thread_count();
if (ThreadCount != 1) {
errs() << "Warning: request a ThreadPool with " << ThreadCount
@@ -199,7 +198,7 @@ ThreadPool::ThreadPool(ThreadPoolStrategy S) : MaxThreadCount(1) {
}
}
-void ThreadPool::wait() {
+void SingleThreadExecutor::wait() {
// Sequential implementation running the tasks
while (!Tasks.empty()) {
auto Task = std::move(Tasks.front().first);
@@ -208,16 +207,14 @@ void ThreadPool::wait() {
}
}
-void ThreadPool::wait(ThreadPoolTaskGroup &) {
+void SingleThreadExecutor::wait(ThreadPoolTaskGroup &) {
// Simply wait for all, this works even if recursive (the running task
// is already removed from the queue).
wait();
}
-bool ThreadPool::isWorkerThread() const {
+bool SingleThreadExecutor::isWorkerThread() const {
report_fatal_error("LLVM compiled without multithreading");
}
-ThreadPool::~ThreadPool() { wait(); }
-
-#endif
+SingleThreadExecutor::~SingleThreadExecutor() { wait(); }
diff --git a/llvm/tools/llvm-cov/CoverageReport.h b/llvm/tools/llvm-cov/CoverageReport.h
index 60f751ca967528..b25ed5e35f9a77 100644
--- a/llvm/tools/llvm-cov/CoverageReport.h
+++ b/llvm/tools/llvm-cov/CoverageReport.h
@@ -20,7 +20,7 @@
namespace llvm {
-class ThreadPool;
+class ThreadPoolInterface;
/// Displays the code coverage report.
class CoverageReport {
@@ -104,7 +104,7 @@ class DirectoryCoverageReport {
/// For calling CoverageReport::prepareSingleFileReport asynchronously
/// in prepareSubDirectoryReports(). It's not intended to be modified by
/// generateSubDirectoryReport().
- ThreadPool *TPool;
+ ThreadPoolInterface *TPool;
/// One report level may correspond to multiple directory levels as we omit
/// directories which have only one subentry. So we use this Stack to track
diff --git a/llvm/tools/llvm-cov/SourceCoverageViewHTML.h b/llvm/tools/llvm-cov/SourceCoverageViewHTML.h
index 7b97f05b946bd2..32313a3963c430 100644
--- a/llvm/tools/llvm-cov/SourceCoverageViewHTML.h
+++ b/llvm/tools/llvm-cov/SourceCoverageViewHTML.h
@@ -19,8 +19,6 @@ namespace llvm {
using namespace coverage;
-class ThreadPool;
-
struct FileCoverageSummary;
/// A coverage printer for html output.
diff --git a/llvm/unittests/Support/ThreadPool.cpp b/llvm/unittests/Support/ThreadPool.cpp
index cce20b6dd1dfb5..1da8e056019d8d 100644
--- a/llvm/unittests/Support/ThreadPool.cpp
+++ b/llvm/unittests/Support/ThreadPool.cpp
@@ -27,11 +27,25 @@
#include "gtest/gtest.h"
+namespace testing {
+namespace internal {
+// Specialize gtest construct to provide friendlier name in the output.
+#if LLVM_ENABLE_THREADS
+template <> std::string GetTypeName<llvm::StdThreadPool>() {
+ return "llvm::StdThreadPool";
+}
+#endif
+template <> std::string GetTypeName<llvm::SingleThreadExecutor>() {
+ return "llvm::SingleThreadExecutor";
+}
+} // namespace internal
+} // namespace testing
+
using namespace llvm;
// Fixture for the unittests, allowing to *temporarily* disable the unittests
// on a particular platform
-class ThreadPoolTest : public testing::Test {
+template <typename ThreadPoolImpl> class ThreadPoolTest : public testing::Test {
Triple Host;
SmallVector<Triple::ArchType, 4> UnsupportedArchs;
SmallVector<Triple::OSType, 4> UnsupportedOSs;
@@ -106,34 +120,42 @@ class ThreadPoolTest : public testing::Test {
int CurrentPhase; // -1 = error, 0 = setup, 1 = ready, 2+ = custom
};
+using ThreadPoolImpls = ::testing::Types<
+#if LLVM_ENABLE_THREADS
+ StdThreadPool,
+#endif
+ SingleThreadExecutor>;
+
+TYPED_TEST_SUITE(ThreadPoolTest, ThreadPoolImpls);
+
#define CHECK_UNSUPPORTED() \
do { \
- if (isUnsupportedOSOrEnvironment()) \
+ if (this->isUnsupportedOSOrEnvironment()) \
GTEST_SKIP(); \
} while (0);
-TEST_F(ThreadPoolTest, AsyncBarrier) {
+TYPED_TEST(ThreadPoolTest, AsyncBarrier) {
CHECK_UNSUPPORTED();
// test that async & barrier work together properly.
std::atomic_int checked_in{0};
- ThreadPool Pool;
+ TypeParam Pool;
for (size_t i = 0; i < 5; ++i) {
Pool.async([this, &checked_in] {
- waitForMainThread();
+ this->waitForMainThread();
++checked_in;
});
}
ASSERT_EQ(0, checked_in);
- setMainThreadReady();
+ this->setMainThreadReady();
Pool.wait();
ASSERT_EQ(5, checked_in);
}
static void TestFunc(std::atomic_int &checked_in, int i) { checked_in += i; }
-TEST_F(ThreadPoolTest, AsyncBarrierArgs) {
+TYPED_TEST(ThreadPoolTest, AsyncBarrierArgs) {
CHECK_UNSUPPORTED();
// Test that async works with a function requiring multiple parameters.
std::atomic_int checked_in{0};
@@ -146,63 +168,63 @@ TEST_F(ThreadPoolTest, AsyncBarrierArgs) {
ASSERT_EQ(10, checked_in);
}
-TEST_F(ThreadPoolTest, Async) {
+TYPED_TEST(ThreadPoolTest, Async) {
CHECK_UNSUPPORTED();
ThreadPool Pool;
std::atomic_int i{0};
Pool.async([this, &i] {
- waitForMainThread();
+ this->waitForMainThread();
++i;
});
Pool.async([&i] { ++i; });
ASSERT_NE(2, i.load());
- setMainThreadReady();
+ this->setMainThreadReady();
Pool.wait();
ASSERT_EQ(2, i.load());
}
-TEST_F(ThreadPoolTest, GetFuture) {
+TYPED_TEST(ThreadPoolTest, GetFuture) {
CHECK_UNSUPPORTED();
ThreadPool Pool(hardware_concurrency(2));
std::atomic_int i{0};
Pool.async([this, &i] {
- waitForMainThread();
+ this->waitForMainThread();
++i;
});
// Force the future using get()
Pool.async([&i] { ++i; }).get();
ASSERT_NE(2, i.load());
- setMainThreadReady();
+ this->setMainThreadReady();
Pool.wait();
ASSERT_EQ(2, i.load());
}
-TEST_F(ThreadPoolTest, GetFutureWithResult) {
+TYPED_TEST(ThreadPoolTest, GetFutureWithResult) {
CHECK_UNSUPPORTED();
ThreadPool Pool(hardware_concurrency(2));
auto F1 = Pool.async([] { return 1; });
auto F2 = Pool.async([] { return 2; });
- setMainThreadReady();
+ this->setMainThreadReady();
Pool.wait();
ASSERT_EQ(1, F1.get());
ASSERT_EQ(2, F2.get());
}
-TEST_F(ThreadPoolTest, GetFutureWithResultAndArgs) {
+TYPED_TEST(ThreadPoolTest, GetFutureWithResultAndArgs) {
CHECK_UNSUPPORTED();
ThreadPool Pool(hardware_concurrency(2));
auto Fn = [](int x) { return x; };
auto F1 = Pool.async(Fn, 1);
auto F2 = Pool.async(Fn, 2);
- setMainThreadReady();
+ this->setMainThreadReady();
Pool.wait();
ASSERT_EQ(1, F1.get());
ASSERT_EQ(2, F2.get());
}
-TEST_F(ThreadPoolTest, PoolDestruction) {
+TYPED_TEST(ThreadPoolTest, PoolDestruction) {
CHECK_UNSUPPORTED();
// Test that we are waiting on destruction
std::atomic_int checked_in{0};
@@ -210,18 +232,18 @@ TEST_F(ThreadPoolTest, PoolDestruction) {
ThreadPool Pool;
for (size_t i = 0; i < 5; ++i) {
Pool.async([this, &checked_in] {
- waitForMainThread();
+ this->waitForMainThread();
++checked_in;
});
}
ASSERT_EQ(0, checked_in);
- setMainThreadReady();
+ this->setMainThreadReady();
}
ASSERT_EQ(5, checked_in);
}
// Check running tasks in different groups.
-TEST_F(ThreadPoolTest, Groups) {
+TYPED_TEST(ThreadPoolTest, Groups) {
CHECK_UNSUPPORTED();
// Need at least two threads, as the task in group2
// might block a thread until all tasks in group1 finish.
@@ -229,7 +251,7 @@ TEST_F(ThreadPoolTest, Groups) {
if (S.compute_thread_count() < 2)
GTEST_SKIP();
ThreadPool Pool(S);
- PhaseResetHelper Helper(this);
+ typename TestFixture::PhaseResetHelper Helper(this);
ThreadPoolTaskGroup Group1(Pool);
ThreadPoolTaskGroup Group2(Pool);
@@ -241,30 +263,30 @@ TEST_F(ThreadPoolTest, Groups) {
for (size_t i = 0; i < 5; ++i) {
Group1.async([this, &checked_in1] {
- waitForMainThread();
+ this->waitForMainThread();
++checked_in1;
});
}
Group2.async([this, &checked_in2] {
- waitForPhase(2);
+ this->waitForPhase(2);
++checked_in2;
});
ASSERT_EQ(0, checked_in1);
ASSERT_EQ(0, checked_in2);
// Start first group and wait for it.
- setMainThreadReady();
+ this->setMainThreadReady();
Group1.wait();
ASSERT_EQ(5, checked_in1);
// Second group has not yet finished, start it and wait for it.
ASSERT_EQ(0, checked_in2);
- setPhase(2);
+ this->setPhase(2);
Group2.wait();
ASSERT_EQ(5, checked_in1);
ASSERT_EQ(1, checked_in2);
}
// Check recursive tasks.
-TEST_F(ThreadPoolTest, RecursiveGroups) {
+TYPED_TEST(ThreadPoolTest, RecursiveGroups) {
CHECK_UNSUPPORTED();
ThreadPool Pool;
ThreadPoolTaskGroup Group(Pool);
@@ -273,7 +295,7 @@ TEST_F(ThreadPoolTest, RecursiveGroups) {
for (size_t i = 0; i < 5; ++i) {
Group.async([this, &Pool, &checked_in1] {
- waitForMainThread();
+ this->waitForMainThread();
ThreadPoolTaskGroup LocalGroup(Pool);
@@ -291,18 +313,18 @@ TEST_F(ThreadPoolTest, RecursiveGroups) {
});
}
ASSERT_EQ(0, checked_in1);
- setMainThreadReady();
+ this->setMainThreadReady();
Group.wait();
ASSERT_EQ(5, checked_in1);
}
-TEST_F(ThreadPoolTest, RecursiveWaitDeadlock) {
+TYPED_TEST(ThreadPoolTest, RecursiveWaitDeadlock) {
CHECK_UNSUPPORTED();
ThreadPoolStrategy S = hardware_concurrency(2);
if (S.compute_thread_count() < 2)
GTEST_SKIP();
ThreadPool Pool(S);
- PhaseResetHelper Helper(this);
+ typename TestFixture::PhaseResetHelper Helper(this);
ThreadPoolTaskGroup Group(Pool);
// Test that a thread calling wait() for a group and is waiting for more tasks
@@ -312,17 +334,17 @@ TEST_F(ThreadPoolTest, RecursiveWaitDeadlock) {
// Task A runs in the first thread. It finishes and leaves
// the background thread waiting for more tasks.
Group.async([this] {
- waitForMainThread();
- setPhase(2);
+ this->waitForMainThread();
+ this->setPhase(2);
});
// Task B is run in a second thread, it launches yet another
// task C in a different group, which will be handled by the waiting
// thread started above.
Group.async([this, &Pool] {
- waitForPhase(2);
+ this->waitForPhase(2);
ThreadPoolTaskGroup LocalGroup(Pool);
LocalGroup.async([this] {
- waitForPhase(3);
+ this->waitForPhase(3);
// Give the other thread enough time to check that there's no task
// to process and suspend waiting for a notification. This is indeed racy,
// but probably the best that can be done.
@@ -332,10 +354,10 @@ TEST_F(ThreadPoolTest, RecursiveWaitDeadlock) {
// to finish. This test checks that it does not deadlock. If the
// `NotifyGroup` handling in ThreadPool::processTasks() didn't take place,
// this task B would be stuck waiting for tasks to arrive.
- setPhase(3);
+ this->setPhase(3);
LocalGroup.wait();
});
- setMainThreadReady();
+ this->setMainThreadReady();
Group.wait();
}
@@ -346,8 +368,9 @@ TEST_F(ThreadPoolTest, RecursiveWaitDeadlock) {
// isn't implemented for Unix (need AffinityMask in Support/Unix/Program.inc).
#ifdef _WIN32
+template <typename ThreadPoolImpl>
SmallVector<llvm::BitVector, 0>
-ThreadPoolTest::RunOnAllSockets(ThreadPoolStrategy S) {
+ThreadPoolTest<ThreadPoolImpl>::RunOnAllSockets(ThreadPoolStrategy S) {
llvm::SetVector<llvm::BitVector> ThreadsUsed;
std::mutex Lock;
{
@@ -363,7 +386,7 @@ ThreadPoolTest::RunOnAllSockets(ThreadPoolStrategy S) {
++Active;
AllThreads.notify_one();
}
- waitForMainThread();
+ this->waitForMainThread();
std::lock_guard<std::mutex> Guard(Lock);
auto Mask = llvm::get_thread_affinity_mask();
ThreadsUsed.insert(Mask);
@@ -375,30 +398,31 @@ ThreadPoolTest::RunOnAllSockets(ThreadPoolStrategy S) {
AllThreads.wait(Guard,
[&]() { return Active == S.compute_thread_count(); });
}
- setMainThreadReady();
+ this->setMainThreadReady();
}
return ThreadsUsed.takeVector();
}
-TEST_F(ThreadPoolTest, AllThreads_UseAllRessources) {
+TYPED_TEST(ThreadPoolTest, AllThreads_UseAllRessources) {
CHECK_UNSUPPORTED();
// After Windows 11, the OS is free to deploy the threads on any CPU socket.
// We cannot relibly ensure that all thread affinity mask are covered,
// therefore this test should not run.
if (llvm::RunningWindows11OrGreater())
GTEST_SKIP();
- auto ThreadsUsed = RunOnAllSockets({});
+ auto ThreadsUsed = this->RunOnAllSockets({});
ASSERT_EQ(llvm::get_cpus(), ThreadsUsed.size());
}
-TEST_F(ThreadPoolTest, AllThreads_OneThreadPerCore) {
+TYPED_TEST(ThreadPoolTest, AllThreads_OneThreadPerCore) {
CHECK_UNSUPPORTED();
// After Windows 11, the OS is free to deploy the threads on any CPU socket.
// We cannot relibly ensure that all thread affinity mask are covered,
// therefore this test should not run.
if (llvm::RunningWindows11OrGreater())
GTEST_SKIP();
- auto ThreadsUsed = RunOnAllSockets(llvm::heavyweight_hardware_concurrency());
+ auto ThreadsUsed =
+ this->RunOnAllSockets(llvm::heavyweight_hardware_concurrency());
ASSERT_EQ(llvm::get_cpus(), ThreadsUsed.size());
}
@@ -412,7 +436,7 @@ static cl::opt<std::string> ThreadPoolTestStringArg1("thread-pool-string-arg1");
#define setenv(name, var, ignore) _putenv_s(name, var)
#endif
-TEST_F(ThreadPoolTest, AffinityMask) {
+TYPED_TEST(ThreadPoolTest, AffinityMask) {
CHECK_UNSUPPORTED();
// Skip this test if less than 4 threads are available.
@@ -421,7 +445,7 @@ TEST_F(ThreadPoolTest, AffinityMask) {
using namespace llvm::sys;
if (getenv("LLVM_THREADPOOL_AFFINITYMASK")) {
- auto ThreadsUsed = RunOnAllSockets({});
+ auto ThreadsUsed = this->RunOnAllSockets({});
// Ensure the threads only ran on CPUs 0-3.
// NOTE: Don't use ASSERT* here because this runs in a subprocess,
// and will show up as un-executed in the parent.
diff --git a/mlir/include/mlir/CAPI/Support.h b/mlir/include/mlir/CAPI/Support.h
index 82aa05185858e3..622745256111e1 100644
--- a/mlir/include/mlir/CAPI/Support.h
+++ b/mlir/include/mlir/CAPI/Support.h
@@ -22,7 +22,7 @@
#include "llvm/ADT/StringRef.h"
namespace llvm {
-class ThreadPool;
+class ThreadPoolInterface;
} // namespace llvm
/// Converts a StringRef into its MLIR C API equivalent.
@@ -45,7 +45,7 @@ inline mlir::LogicalResult unwrap(MlirLogicalResult res) {
return mlir::success(mlirLogicalResultIsSuccess(res));
}
-DEFINE_C_API_PTR_METHODS(MlirLlvmThreadPool, llvm::ThreadPool)
+DEFINE_C_API_PTR_METHODS(MlirLlvmThreadPool, llvm::ThreadPoolInterface)
DEFINE_C_API_METHODS(MlirTypeID, mlir::TypeID)
DEFINE_C_API_PTR_METHODS(MlirTypeIDAllocator, mlir::TypeIDAllocator)
diff --git a/mlir/include/mlir/IR/MLIRContext.h b/mlir/include/mlir/IR/MLIRContext.h
index d9e140bd75f726..2ad35d8f78ee35 100644
--- a/mlir/include/mlir/IR/MLIRContext.h
+++ b/mlir/include/mlir/IR/MLIRContext.h
@@ -17,7 +17,7 @@
#include <vector>
namespace llvm {
-class ThreadPool;
+class ThreadPoolInterface;
} // namespace llvm
namespace mlir {
@@ -162,7 +162,7 @@ class MLIRContext {
/// The command line debugging flag `--mlir-disable-threading` will still
/// prevent threading from being enabled and threading won't be enabled after
/// this call in this case.
- void setThreadPool(llvm::ThreadPool &pool);
+ void setThreadPool(llvm::ThreadPoolInterface &pool);
/// Return the number of threads used by the thread pool in this context. The
/// number of computed hardware threads can change over the lifetime of a
@@ -175,7 +175,7 @@ class MLIRContext {
/// multithreading be enabled within the context, and should generally not be
/// used directly. Users should instead prefer the threading utilities within
/// Threading.h.
- llvm::ThreadPool &getThreadPool();
+ llvm::ThreadPoolInterface &getThreadPool();
/// Return true if we should attach the operation to diagnostics emitted via
/// Operation::emit.
diff --git a/mlir/include/mlir/IR/Threading.h b/mlir/include/mlir/IR/Threading.h
index 0f71dc27cf391f..3ceab6b3e883a5 100644
--- a/mlir/include/mlir/IR/Threading.h
+++ b/mlir/include/mlir/IR/Threading.h
@@ -66,7 +66,7 @@ LogicalResult failableParallelForEach(MLIRContext *context, IteratorT begin,
};
// Otherwise, process the elements in parallel.
- llvm::ThreadPool &threadPool = context->getThreadPool();
+ llvm::ThreadPoolInterface &threadPool = context->getThreadPool();
llvm::ThreadPoolTaskGroup tasksGroup(threadPool);
size_t numActions = std::min(numElements, threadPool.getMaxConcurrency());
for (unsigned i = 0; i < numActions; ++i)
diff --git a/mlir/lib/CAPI/IR/IR.cpp b/mlir/lib/CAPI/IR/IR.cpp
index a97cfe5b0ea364..cdb64f4ec4a40f 100644
--- a/mlir/lib/CAPI/IR/IR.cpp
+++ b/mlir/lib/CAPI/IR/IR.cpp
@@ -28,6 +28,7 @@
#include "mlir/IR/Visitors.h"
#include "mlir/Interfaces/InferTypeOpInterface.h"
#include "mlir/Parser/Parser.h"
+#include "llvm/Support/ThreadPool.h"
#include <cstddef>
#include <memory>
diff --git a/mlir/lib/IR/MLIRContext.cpp b/mlir/lib/IR/MLIRContext.cpp
index 58ebe4fdec202d..92568bd311e394 100644
--- a/mlir/lib/IR/MLIRContext.cpp
+++ b/mlir/lib/IR/MLIRContext.cpp
@@ -170,11 +170,11 @@ class MLIRContextImpl {
/// It can't be nullptr when multi-threading is enabled. Otherwise if
/// multi-threading is disabled, and the threadpool wasn't externally provided
/// using `setThreadPool`, this will be nullptr.
- llvm::ThreadPool *threadPool = nullptr;
+ llvm::ThreadPoolInterface *threadPool = nullptr;
/// In case where the thread pool is owned by the context, this ensures
/// destruction with the context.
- std::unique_ptr<llvm::ThreadPool> ownedThreadPool;
+ std::unique_ptr<llvm::ThreadPoolInterface> ownedThreadPool;
/// An allocator used for AbstractAttribute and AbstractType objects.
llvm::BumpPtrAllocator abstractDialectSymbolAllocator;
@@ -626,7 +626,7 @@ void MLIRContext::disableMultithreading(bool disable) {
}
}
-void MLIRContext::setThreadPool(llvm::ThreadPool &pool) {
+void MLIRContext::setThreadPool(llvm::ThreadPoolInterface &pool) {
assert(!isMultithreadingEnabled() &&
"expected multi-threading to be disabled when setting a ThreadPool");
impl->threadPool = &pool;
@@ -644,7 +644,7 @@ unsigned MLIRContext::getNumThreads() {
return 1;
}
-llvm::ThreadPool &MLIRContext::getThreadPool() {
+llvm::ThreadPoolInterface &MLIRContext::getThreadPool() {
assert(isMultithreadingEnabled() &&
"expected multi-threading to be enabled within the context");
assert(impl->threadPool &&
diff --git a/mlir/lib/Tools/mlir-opt/MlirOptMain.cpp b/mlir/lib/Tools/mlir-opt/MlirOptMain.cpp
index 2755a949fb947c..b62557153b4167 100644
--- a/mlir/lib/Tools/mlir-opt/MlirOptMain.cpp
+++ b/mlir/lib/Tools/mlir-opt/MlirOptMain.cpp
@@ -431,7 +431,7 @@ static LogicalResult processBuffer(raw_ostream &os,
std::unique_ptr<MemoryBuffer> ownedBuffer,
const MlirOptMainConfig &config,
DialectRegistry ®istry,
- llvm::ThreadPool *threadPool) {
+ llvm::ThreadPoolInterface *threadPool) {
// Tell sourceMgr about this buffer, which is what the parser will pick up.
auto sourceMgr = std::make_shared<SourceMgr>();
sourceMgr->AddNewSourceBuffer(std::move(ownedBuffer), SMLoc());
@@ -517,7 +517,7 @@ LogicalResult mlir::MlirOptMain(llvm::raw_ostream &outputStream,
// up into small pieces and checks each independently.
// We use an explicit threadpool to avoid creating and joining/destroying
// threads for each of the split.
- ThreadPool *threadPool = nullptr;
+ ThreadPoolInterface *threadPool = nullptr;
// Create a temporary context for the sake of checking if
// --mlir-disable-threading was passed on the command line.
>From 6b70c5d79fe44cbe01b0443454c6952c5b541585 Mon Sep 17 00:00:00 2001
From: George Koehler <kernigh at gmail.com>
Date: Sat, 2 Mar 2024 22:18:24 -0500
Subject: [PATCH 373/406] [PowerPC] provide CFI for ELF32 to unwind cr2, cr3,
cr4 (#83098)
Delete the code that skips the CFI for the condition register on ELF32.
The code checked !MustSaveCR, which happened only when
Subtarget.is32BitELFABI(), where spillCalleeSavedRegisters is spilling
cr in a different way. The spill was missing CFI. After deleting this
code, a spill of cr2 to cr4 gets CFI in the same way as a spill of r14
to r31.
Fixes #83094
---
llvm/lib/Target/PowerPC/PPCFrameLowering.cpp | 6 ------
llvm/test/CodeGen/PowerPC/crsave.ll | 5 +++++
2 files changed, 5 insertions(+), 6 deletions(-)
diff --git a/llvm/lib/Target/PowerPC/PPCFrameLowering.cpp b/llvm/lib/Target/PowerPC/PPCFrameLowering.cpp
index 6792842f8550c1..424501c35c043c 100644
--- a/llvm/lib/Target/PowerPC/PPCFrameLowering.cpp
+++ b/llvm/lib/Target/PowerPC/PPCFrameLowering.cpp
@@ -1191,12 +1191,6 @@ void PPCFrameLowering::emitPrologue(MachineFunction &MF,
if ((Reg == PPC::X2 || Reg == PPC::R2) && MustSaveTOC)
continue;
- // For SVR4, don't emit a move for the CR spill slot if we haven't
- // spilled CRs.
- if (isSVR4ABI && (PPC::CR2 <= Reg && Reg <= PPC::CR4)
- && !MustSaveCR)
- continue;
-
// For 64-bit SVR4 when we have spilled CRs, the spill location
// is SP+8, not a frame-relative slot.
if (isSVR4ABI && isPPC64 && (PPC::CR2 <= Reg && Reg <= PPC::CR4)) {
diff --git a/llvm/test/CodeGen/PowerPC/crsave.ll b/llvm/test/CodeGen/PowerPC/crsave.ll
index bde49d02e86ebd..05da108e1fbf87 100644
--- a/llvm/test/CodeGen/PowerPC/crsave.ll
+++ b/llvm/test/CodeGen/PowerPC/crsave.ll
@@ -17,6 +17,7 @@ define i32 @test_cr2() nounwind uwtable {
; PPC32-NEXT: .cfi_offset lr, 4
; PPC32-NEXT: mr 31, 1
; PPC32-NEXT: .cfi_def_cfa_register r31
+; PPC32-NEXT: .cfi_offset cr2, -8
; PPC32-NEXT: mfcr 12
; PPC32-NEXT: stw 12, 24(31)
; PPC32-NEXT: li 3, 1
@@ -227,6 +228,7 @@ define void @cloberOneNvCrField() {
; PPC32-NEXT: .cfi_offset r31, -4
; PPC32-NEXT: mr 31, 1
; PPC32-NEXT: .cfi_def_cfa_register r31
+; PPC32-NEXT: .cfi_offset cr2, -8
; PPC32-NEXT: mfcr 12
; PPC32-NEXT: stw 12, 24(31)
; PPC32-NEXT: #APP
@@ -274,6 +276,9 @@ define void @cloberAllNvCrField() {
; PPC32-NEXT: .cfi_offset r31, -4
; PPC32-NEXT: mr 31, 1
; PPC32-NEXT: .cfi_def_cfa_register r31
+; PPC32-NEXT: .cfi_offset cr2, -8
+; PPC32-NEXT: .cfi_offset cr3, -8
+; PPC32-NEXT: .cfi_offset cr4, -8
; PPC32-NEXT: mfcr 12
; PPC32-NEXT: stw 12, 24(31)
; PPC32-NEXT: #APP
>From 6c6ea9d2b06c57b4c35b3d4bd6cc854a7b9a4590 Mon Sep 17 00:00:00 2001
From: Mehdi Amini <joker.eph at gmail.com>
Date: Sat, 2 Mar 2024 19:22:05 -0800
Subject: [PATCH 374/406] Fix BUILD_SHARED_LIBS=ON build for platforms which
require explicit link of -lpthread (NFC)
---
llvm/lib/DebugInfo/GSYM/CMakeLists.txt | 3 +++
1 file changed, 3 insertions(+)
diff --git a/llvm/lib/DebugInfo/GSYM/CMakeLists.txt b/llvm/lib/DebugInfo/GSYM/CMakeLists.txt
index 0c09c2bf998c46..5447030e903dab 100644
--- a/llvm/lib/DebugInfo/GSYM/CMakeLists.txt
+++ b/llvm/lib/DebugInfo/GSYM/CMakeLists.txt
@@ -18,6 +18,9 @@ add_llvm_component_library(LLVMDebugInfoGSYM
DEPENDS
LLVMMC
+ LINK_LIBS
+ ${LLVM_PTHREAD_LIB}
+
LINK_COMPONENTS
MC
Object
>From e52650cfc3aa5d134186c5a8fd6701a6fd0a1051 Mon Sep 17 00:00:00 2001
From: Mehdi Amini <joker.eph at gmail.com>
Date: Sat, 2 Mar 2024 19:30:33 -0800
Subject: [PATCH 375/406] Fix LLDB build after renaming the base class for
ThreadPool to ThreadPoolInterface
The header was updated but not the implementation.
---
lldb/source/Core/Debugger.cpp | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/lldb/source/Core/Debugger.cpp b/lldb/source/Core/Debugger.cpp
index 217474d1060ac2..1b25527abf981f 100644
--- a/lldb/source/Core/Debugger.cpp
+++ b/lldb/source/Core/Debugger.cpp
@@ -2195,7 +2195,7 @@ Status Debugger::RunREPL(LanguageType language, const char *repl_options) {
return err;
}
-llvm::ThreadPool &Debugger::GetThreadPool() {
+llvm::ThreadPoolInterface &Debugger::GetThreadPool() {
assert(g_thread_pool &&
"Debugger::GetThreadPool called before Debugger::Initialize");
return *g_thread_pool;
>From 1a4f52c84257a2a0083abe37368c526a2f8cd928 Mon Sep 17 00:00:00 2001
From: Mehdi Amini <joker.eph at gmail.com>
Date: Sat, 2 Mar 2024 19:34:56 -0800
Subject: [PATCH 376/406] More fix BUILD_SHARED_LIBS=ON build for platforms
which require explicit link of -lpthread (NFC)
Some systems requires explictly providing -lpthread when linking, I don't
have such system so it is hard to find all the missing cases.
---
llvm/lib/DWARFLinker/Classic/CMakeLists.txt | 3 +++
1 file changed, 3 insertions(+)
diff --git a/llvm/lib/DWARFLinker/Classic/CMakeLists.txt b/llvm/lib/DWARFLinker/Classic/CMakeLists.txt
index 4a3ac0d2220829..5d3b259e4a33a0 100644
--- a/llvm/lib/DWARFLinker/Classic/CMakeLists.txt
+++ b/llvm/lib/DWARFLinker/Classic/CMakeLists.txt
@@ -10,6 +10,9 @@ add_llvm_component_library(LLVMDWARFLinkerClassic
DEPENDS
intrinsics_gen
+ LINK_LIBS
+ ${LLVM_PTHREAD_LIB}
+
LINK_COMPONENTS
AsmPrinter
BinaryFormat
>From e29cad6b3bb1f573ad5340771faa8a01cc05cb65 Mon Sep 17 00:00:00 2001
From: Mehdi Amini <joker.eph at gmail.com>
Date: Sat, 2 Mar 2024 19:36:22 -0800
Subject: [PATCH 377/406] More fix BUILD_SHARED_LIBS=ON build for platforms
which require explicit link of -lpthread (NFC)
Some systems requires explictly providing -lpthread when linking, I don't
have such system so it is hard to find all the missing cases.
---
llvm/lib/DWARFLinker/Parallel/CMakeLists.txt | 3 +++
1 file changed, 3 insertions(+)
diff --git a/llvm/lib/DWARFLinker/Parallel/CMakeLists.txt b/llvm/lib/DWARFLinker/Parallel/CMakeLists.txt
index 209d971be062a2..1e7ff0703d135c 100644
--- a/llvm/lib/DWARFLinker/Parallel/CMakeLists.txt
+++ b/llvm/lib/DWARFLinker/Parallel/CMakeLists.txt
@@ -17,6 +17,9 @@ add_llvm_component_library(LLVMDWARFLinkerParallel
DEPENDS
intrinsics_gen
+ LINK_LIBS
+ ${LLVM_PTHREAD_LIB}
+
LINK_COMPONENTS
AsmPrinter
BinaryFormat
>From 5f70f253c2b8978b50d20d37b25591b40dfe38d5 Mon Sep 17 00:00:00 2001
From: Alex Richardson <alexrichardson at google.com>
Date: Sat, 2 Mar 2024 17:36:26 -0800
Subject: [PATCH 378/406] [sanitizer_common] Remove unnecessary const_cast
This used to be required because rlim was declared volatile, but commit
d657f109d7080bd51ad70e88859acf64931152fe removed that workaround.
---
compiler-rt/lib/sanitizer_common/sanitizer_posix_libcdep.cpp | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/compiler-rt/lib/sanitizer_common/sanitizer_posix_libcdep.cpp b/compiler-rt/lib/sanitizer_common/sanitizer_posix_libcdep.cpp
index e88e654eec5a1c..ef1fc354974396 100644
--- a/compiler-rt/lib/sanitizer_common/sanitizer_posix_libcdep.cpp
+++ b/compiler-rt/lib/sanitizer_common/sanitizer_posix_libcdep.cpp
@@ -91,12 +91,12 @@ static rlim_t getlim(int res) {
static void setlim(int res, rlim_t lim) {
struct rlimit rlim;
- if (getrlimit(res, const_cast<struct rlimit *>(&rlim))) {
+ if (getrlimit(res, &rlim)) {
Report("ERROR: %s getrlimit() failed %d\n", SanitizerToolName, errno);
Die();
}
rlim.rlim_cur = lim;
- if (setrlimit(res, const_cast<struct rlimit *>(&rlim))) {
+ if (setrlimit(res, &rlim)) {
Report("ERROR: %s setrlimit() failed %d\n", SanitizerToolName, errno);
Die();
}
>From 67221ed886b59b2f9b96a154e56e16e27dc3b1a4 Mon Sep 17 00:00:00 2001
From: Mehdi Amini <joker.eph at gmail.com>
Date: Sat, 2 Mar 2024 19:43:47 -0800
Subject: [PATCH 379/406] More fix BUILD_SHARED_LIBS=ON build for platforms
which require explicit link of -lpthread (NFC)
Some systems requires explictly providing -lpthread when linking, I don't
have such system so it is hard to find all the missing cases.
---
llvm/lib/LTO/CMakeLists.txt | 3 +++
1 file changed, 3 insertions(+)
diff --git a/llvm/lib/LTO/CMakeLists.txt b/llvm/lib/LTO/CMakeLists.txt
index 9872a576af1021..9ba7698bc9954b 100644
--- a/llvm/lib/LTO/CMakeLists.txt
+++ b/llvm/lib/LTO/CMakeLists.txt
@@ -13,6 +13,9 @@ add_llvm_component_library(LLVMLTO
intrinsics_gen
llvm_vcsrevision_h
+ LINK_LIBS
+ ${LLVM_PTHREAD_LIB}
+
LINK_COMPONENTS
AggressiveInstCombine
Analysis
>From c4621607245a5feed42cf9f748ff796728ef579a Mon Sep 17 00:00:00 2001
From: Mehdi Amini <joker.eph at gmail.com>
Date: Sat, 2 Mar 2024 19:54:35 -0800
Subject: [PATCH 380/406] More fix BUILD_SHARED_LIBS=ON build for platforms
which require explicit link of -lpthread (NFC)
Some systems requires explictly providing -lpthread when linking, I don't
have such system so it is hard to find all the missing cases.
---
clang/lib/Tooling/CMakeLists.txt | 1 +
1 file changed, 1 insertion(+)
diff --git a/clang/lib/Tooling/CMakeLists.txt b/clang/lib/Tooling/CMakeLists.txt
index aff39e4de13c0b..91e6cbdcbc44f7 100644
--- a/clang/lib/Tooling/CMakeLists.txt
+++ b/clang/lib/Tooling/CMakeLists.txt
@@ -135,4 +135,5 @@ add_clang_library(clangTooling
clangRewrite
clangSerialization
clangToolingCore
+ ${LLVM_PTHREAD_LIB}
)
>From 37293e69e6362e3559c1a4e1ac62b53f2b0edb0a Mon Sep 17 00:00:00 2001
From: Shengchen Kan <shengchen.kan at intel.com>
Date: Sun, 3 Mar 2024 13:03:35 +0800
Subject: [PATCH 381/406] [X86][CodeGen] Support long instruction fixup for APX
NDD instructions (#83578)
RFC:
https://discourse.llvm.org/t/rfc-support-long-instruction-fixup-for-x86/76539
---
.../lib/Target/X86/MCTargetDesc/X86BaseInfo.h | 27 ++
.../X86/MCTargetDesc/X86MCCodeEmitter.cpp | 13 +-
llvm/lib/Target/X86/X86ExpandPseudo.cpp | 85 ++++++
.../X86/apx/long-instruction-fixup-x32.ll | 60 +++++
.../CodeGen/X86/apx/long-instruction-fixup.ll | 254 ++++++++++++++++++
5 files changed, 428 insertions(+), 11 deletions(-)
create mode 100644 llvm/test/CodeGen/X86/apx/long-instruction-fixup-x32.ll
create mode 100644 llvm/test/CodeGen/X86/apx/long-instruction-fixup.ll
diff --git a/llvm/lib/Target/X86/MCTargetDesc/X86BaseInfo.h b/llvm/lib/Target/X86/MCTargetDesc/X86BaseInfo.h
index 4442b80861b61a..28a067d525e010 100644
--- a/llvm/lib/Target/X86/MCTargetDesc/X86BaseInfo.h
+++ b/llvm/lib/Target/X86/MCTargetDesc/X86BaseInfo.h
@@ -1315,6 +1315,33 @@ inline bool isKMasked(uint64_t TSFlags) {
inline bool isKMergeMasked(uint64_t TSFlags) {
return isKMasked(TSFlags) && (TSFlags & X86II::EVEX_Z) == 0;
}
+
+/// \returns true if the intruction needs a SIB.
+inline bool needSIB(unsigned BaseReg, unsigned IndexReg, bool In64BitMode) {
+ // The SIB byte must be used if there is an index register.
+ if (IndexReg)
+ return true;
+
+ // The SIB byte must be used if the base is ESP/RSP/R12/R20/R28, all of
+ // which encode to an R/M value of 4, which indicates that a SIB byte is
+ // present.
+ switch (BaseReg) {
+ default:
+ // If there is no base register and we're in 64-bit mode, we need a SIB
+ // byte to emit an addr that is just 'disp32' (the non-RIP relative form).
+ return In64BitMode && !BaseReg;
+ case X86::ESP:
+ case X86::RSP:
+ case X86::R12:
+ case X86::R12D:
+ case X86::R20:
+ case X86::R20D:
+ case X86::R28:
+ case X86::R28D:
+ return true;
+ }
+}
+
} // namespace X86II
} // namespace llvm
#endif
diff --git a/llvm/lib/Target/X86/MCTargetDesc/X86MCCodeEmitter.cpp b/llvm/lib/Target/X86/MCTargetDesc/X86MCCodeEmitter.cpp
index f7c361393fea62..fdb11d1a408bb6 100644
--- a/llvm/lib/Target/X86/MCTargetDesc/X86MCCodeEmitter.cpp
+++ b/llvm/lib/Target/X86/MCTargetDesc/X86MCCodeEmitter.cpp
@@ -753,17 +753,8 @@ void X86MCCodeEmitter::emitMemModRMByte(
bool AllowDisp8 = !UseDisp32;
// Determine whether a SIB byte is needed.
- if ( // The SIB byte must be used if there is an index register or the
- // encoding requires a SIB byte.
- !ForceSIB && IndexReg.getReg() == 0 &&
- // The SIB byte must be used if the base is ESP/RSP/R12/R20/R28, all of
- // which encode to an R/M value of 4, which indicates that a SIB byte is
- // present.
- BaseRegNo != N86::ESP &&
- // If there is no base register and we're in 64-bit mode, we need a SIB
- // byte to emit an addr that is just 'disp32' (the non-RIP relative form).
- (!STI.hasFeature(X86::Is64Bit) || BaseReg != 0)) {
-
+ if (!ForceSIB && !X86II::needSIB(BaseReg, IndexReg.getReg(),
+ STI.hasFeature(X86::Is64Bit))) {
if (BaseReg == 0) { // [disp32] in X86-32 mode
emitByte(modRMByte(0, RegOpcodeField, 5), CB);
emitImmediate(Disp, MI.getLoc(), 4, FK_Data_4, StartByte, CB, Fixups);
diff --git a/llvm/lib/Target/X86/X86ExpandPseudo.cpp b/llvm/lib/Target/X86/X86ExpandPseudo.cpp
index b9fb3fdb239eef..f4c67f115c9f3d 100644
--- a/llvm/lib/Target/X86/X86ExpandPseudo.cpp
+++ b/llvm/lib/Target/X86/X86ExpandPseudo.cpp
@@ -613,6 +613,91 @@ bool X86ExpandPseudo::expandMI(MachineBasicBlock &MBB,
case X86::CALL64m_RVMARKER:
expandCALL_RVMARKER(MBB, MBBI);
return true;
+ case X86::ADD32mi_ND:
+ case X86::ADD64mi32_ND:
+ case X86::SUB32mi_ND:
+ case X86::SUB64mi32_ND:
+ case X86::AND32mi_ND:
+ case X86::AND64mi32_ND:
+ case X86::OR32mi_ND:
+ case X86::OR64mi32_ND:
+ case X86::XOR32mi_ND:
+ case X86::XOR64mi32_ND:
+ case X86::ADC32mi_ND:
+ case X86::ADC64mi32_ND:
+ case X86::SBB32mi_ND:
+ case X86::SBB64mi32_ND: {
+ // It's possible for an EVEX-encoded legacy instruction to reach the 15-byte
+ // instruction length limit: 4 bytes of EVEX prefix + 1 byte of opcode + 1
+ // byte of ModRM + 1 byte of SIB + 4 bytes of displacement + 4 bytes of
+ // immediate = 15 bytes in total, e.g.
+ //
+ // subq $184, %fs:257(%rbx, %rcx), %rax
+ //
+ // In such a case, no additional (ADSIZE or segment override) prefix can be
+ // used. To resolve the issue, we split the “long” instruction into 2
+ // instructions:
+ //
+ // movq %fs:257(%rbx, %rcx),%rax
+ // subq $184, %rax
+ //
+ // Therefore we consider the OPmi_ND to be a pseudo instruction to some
+ // extent.
+ const MachineOperand &ImmOp =
+ MI.getOperand(MI.getNumExplicitOperands() - 1);
+ // If the immediate is a expr, conservatively estimate 4 bytes.
+ if (ImmOp.isImm() && isInt<8>(ImmOp.getImm()))
+ return false;
+ int MemOpNo = X86::getFirstAddrOperandIdx(MI);
+ const MachineOperand &DispOp = MI.getOperand(MemOpNo + X86::AddrDisp);
+ Register Base = MI.getOperand(MemOpNo + X86::AddrBaseReg).getReg();
+ // If the displacement is a expr, conservatively estimate 4 bytes.
+ if (Base && DispOp.isImm() && isInt<8>(DispOp.getImm()))
+ return false;
+ // There can only be one of three: SIB, segment override register, ADSIZE
+ Register Index = MI.getOperand(MemOpNo + X86::AddrIndexReg).getReg();
+ unsigned Count = !!MI.getOperand(MemOpNo + X86::AddrSegmentReg).getReg();
+ if (X86II::needSIB(Base, Index, /*In64BitMode=*/true))
+ ++Count;
+ if (X86MCRegisterClasses[X86::GR32RegClassID].contains(Base) ||
+ X86MCRegisterClasses[X86::GR32RegClassID].contains(Index))
+ ++Count;
+ if (Count < 2)
+ return false;
+ unsigned Opc, LoadOpc;
+ switch (Opcode) {
+#define MI_TO_RI(OP) \
+ case X86::OP##32mi_ND: \
+ Opc = X86::OP##32ri; \
+ LoadOpc = X86::MOV32rm; \
+ break; \
+ case X86::OP##64mi32_ND: \
+ Opc = X86::OP##64ri32; \
+ LoadOpc = X86::MOV64rm; \
+ break;
+
+ default:
+ llvm_unreachable("Unexpected Opcode");
+ MI_TO_RI(ADD);
+ MI_TO_RI(SUB);
+ MI_TO_RI(AND);
+ MI_TO_RI(OR);
+ MI_TO_RI(XOR);
+ MI_TO_RI(ADC);
+ MI_TO_RI(SBB);
+#undef MI_TO_RI
+ }
+ // Insert OPri.
+ Register DestReg = MI.getOperand(0).getReg();
+ BuildMI(MBB, std::next(MBBI), DL, TII->get(Opc), DestReg)
+ .addReg(DestReg)
+ .add(ImmOp);
+ // Change OPmi_ND to MOVrm.
+ for (unsigned I = MI.getNumImplicitOperands() + 1; I != 0; --I)
+ MI.removeOperand(MI.getNumOperands() - 1);
+ MI.setDesc(TII->get(LoadOpc));
+ return true;
+ }
}
llvm_unreachable("Previous switch has a fallthrough?");
}
diff --git a/llvm/test/CodeGen/X86/apx/long-instruction-fixup-x32.ll b/llvm/test/CodeGen/X86/apx/long-instruction-fixup-x32.ll
new file mode 100644
index 00000000000000..fb24704fe0491a
--- /dev/null
+++ b/llvm/test/CodeGen/X86/apx/long-instruction-fixup-x32.ll
@@ -0,0 +1,60 @@
+; NOTE: Assertions have been autogenerated by utils/update_llc_test_checks.py
+; RUN: llc < %s -mtriple=x86_64-pc-linux-gnux32 -mattr=+ndd -verify-machineinstrs | FileCheck %s
+
+
+define i32 @add32mi_SIB_ADSIZE(ptr nocapture noundef readonly %a, i32 noundef %b) {
+; CHECK-LABEL: add32mi_SIB_ADSIZE:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: movl 1164(%edi,%esi,4), %eax
+; CHECK-NEXT: addl $4660, %eax # imm = 0x1234
+; CHECK-NEXT: retq
+entry:
+ %add.ptr = getelementptr inbounds i32, ptr %a, i32 %b
+ %add.ptr1 = getelementptr inbounds i8, ptr %add.ptr, i32 1164
+ %0 = load i32, ptr %add.ptr1
+ %add = add nsw i32 %0, 4660
+ ret i32 %add
+}
+
+declare ptr @llvm.thread.pointer()
+
+define i32 @add32mi_FS_ADSIZE(i32 %i) {
+; CHECK-LABEL: add32mi_FS_ADSIZE:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: movl %fs:0, %eax
+; CHECK-NEXT: addl $4660, (%eax,%edi,4), %eax # imm = 0x1234
+; CHECK-NEXT: retq
+entry:
+ %0 = tail call ptr @llvm.thread.pointer()
+ %arrayidx = getelementptr inbounds i32, ptr %0, i32 %i
+ %1 = load i32, ptr %arrayidx
+ %add = add nsw i32 %1, 4660
+ ret i32 %add
+}
+
+define i32 @add32mi_FS_SIB(i32 %i) {
+; CHECK-LABEL: add32mi_FS_SIB:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: movl %fs:0, %eax
+; CHECK-NEXT: addl $4660, %eax # imm = 0x1234
+; CHECK-NEXT: retq
+entry:
+ %0 = tail call ptr @llvm.thread.pointer()
+ %arrayidx = getelementptr inbounds i32, ptr %0, i32 0
+ %1 = load i32, ptr %arrayidx
+ %add = add nsw i32 %1, 4660
+ ret i32 %add
+}
+
+define i32 @add32mi_GS_ADSIZE(ptr addrspace(256) %a) {
+; CHECK-LABEL: add32mi_GS_ADSIZE:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: movl %gs:4936(%edi), %eax
+; CHECK-NEXT: addl $123456, %eax # imm = 0x1E240
+; CHECK-NEXT: retq
+entry:
+ %arrayidx = getelementptr inbounds i32, ptr addrspace(256) %a, i32 1234
+ %t = load i32, ptr addrspace(256) %arrayidx
+ %add = add i32 %t, 123456
+ ret i32 %add
+}
diff --git a/llvm/test/CodeGen/X86/apx/long-instruction-fixup.ll b/llvm/test/CodeGen/X86/apx/long-instruction-fixup.ll
new file mode 100644
index 00000000000000..30c485836797f5
--- /dev/null
+++ b/llvm/test/CodeGen/X86/apx/long-instruction-fixup.ll
@@ -0,0 +1,254 @@
+; NOTE: Assertions have been autogenerated by utils/update_llc_test_checks.py
+; RUN: llc < %s -mtriple=x86_64-unknown -mattr=+ndd -verify-machineinstrs | FileCheck %s
+
+define i32 @add32mi_GS() {
+; CHECK-LABEL: add32mi_GS:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: movl %gs:255, %eax
+; CHECK-NEXT: addl $123456, %eax # imm = 0x1E240
+; CHECK-NEXT: retq
+entry:
+ %a= inttoptr i32 255 to ptr addrspace(256)
+ %t = load i32, ptr addrspace(256) %a
+ %add = add i32 %t, 123456
+ ret i32 %add
+}
+
+define i64 @add64mi_FS() {
+; CHECK-LABEL: add64mi_FS:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: movq %fs:255, %rax
+; CHECK-NEXT: addq $123456, %rax # imm = 0x1E240
+; CHECK-NEXT: retq
+entry:
+ %a= inttoptr i64 255 to ptr addrspace(257)
+ %t = load i64, ptr addrspace(257) %a
+ %add = add i64 %t, 123456
+ ret i64 %add
+}
+
+define i32 @sub32mi_GS() {
+; CHECK-LABEL: sub32mi_GS:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: movl %gs:255, %eax
+; CHECK-NEXT: addl $129, %eax
+; CHECK-NEXT: retq
+entry:
+ %a= inttoptr i32 255 to ptr addrspace(256)
+ %t = load i32, ptr addrspace(256) %a
+ %sub = sub i32 %t, -129
+ ret i32 %sub
+}
+
+define i64 @sub64mi_FS() {
+; CHECK-LABEL: sub64mi_FS:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: movq %fs:255, %rax
+; CHECK-NEXT: subq $-2147483648, %rax # imm = 0x80000000
+; CHECK-NEXT: retq
+entry:
+ %a= inttoptr i64 255 to ptr addrspace(257)
+ %t = load i64, ptr addrspace(257) %a
+ %sub = sub i64 %t, -2147483648
+ ret i64 %sub
+}
+
+define i32 @and32mi_GS() {
+; CHECK-LABEL: and32mi_GS:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: movl %gs:255, %eax
+; CHECK-NEXT: andl $-129, %eax
+; CHECK-NEXT: retq
+entry:
+ %a= inttoptr i32 255 to ptr addrspace(256)
+ %t = load i32, ptr addrspace(256) %a
+ %and = and i32 %t, -129
+ ret i32 %and
+}
+
+define i64 @and64mi_FS() {
+; CHECK-LABEL: and64mi_FS:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: movq %fs:255, %rax
+; CHECK-NEXT: andq $-2147483648, %rax # imm = 0x80000000
+; CHECK-NEXT: retq
+entry:
+ %a= inttoptr i64 255 to ptr addrspace(257)
+ %t = load i64, ptr addrspace(257) %a
+ %and = and i64 %t, -2147483648
+ ret i64 %and
+}
+
+define i32 @or32mi_GS() {
+; CHECK-LABEL: or32mi_GS:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: movl %gs:255, %eax
+; CHECK-NEXT: orl $-129, %eax
+; CHECK-NEXT: retq
+entry:
+ %a= inttoptr i32 255 to ptr addrspace(256)
+ %t = load i32, ptr addrspace(256) %a
+ %or = or i32 %t, -129
+ ret i32 %or
+}
+
+define i64 @or64mi_FS() {
+; CHECK-LABEL: or64mi_FS:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: movq %fs:255, %rax
+; CHECK-NEXT: orq $-2147483648, %rax # imm = 0x80000000
+; CHECK-NEXT: retq
+entry:
+ %a= inttoptr i64 255 to ptr addrspace(257)
+ %t = load i64, ptr addrspace(257) %a
+ %or = or i64 %t, -2147483648
+ ret i64 %or
+}
+
+define i32 @xor32mi_GS() {
+; CHECK-LABEL: xor32mi_GS:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: movl %gs:255, %eax
+; CHECK-NEXT: xorl $-129, %eax
+; CHECK-NEXT: retq
+entry:
+ %a= inttoptr i32 255 to ptr addrspace(256)
+ %t = load i32, ptr addrspace(256) %a
+ %xor = xor i32 %t, -129
+ ret i32 %xor
+}
+
+define i64 @xor64mi_FS() {
+; CHECK-LABEL: xor64mi_FS:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: movq %fs:255, %rax
+; CHECK-NEXT: xorq $-2147483648, %rax # imm = 0x80000000
+; CHECK-NEXT: retq
+entry:
+ %a= inttoptr i64 255 to ptr addrspace(257)
+ %t = load i64, ptr addrspace(257) %a
+ %xor = xor i64 %t, -2147483648
+ ret i64 %xor
+}
+
+define i32 @adc32mi_GS(i32 %x, i32 %y) {
+; CHECK-LABEL: adc32mi_GS:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: cmpl %edi, %esi
+; CHECK-NEXT: movl %gs:255, %eax
+; CHECK-NEXT: adcl $123456, %eax # imm = 0x1E240
+; CHECK-NEXT: retq
+entry:
+ %a = inttoptr i32 255 to ptr addrspace(256)
+ %t = load i32, ptr addrspace(256) %a
+ %s = add i32 %t, 123456
+ %k = icmp ugt i32 %x, %y
+ %z = zext i1 %k to i32
+ %r = add i32 %s, %z
+ ret i32 %r
+}
+
+define i64 @adc64mi_FS(i64 %x, i64 %y) {
+; CHECK-LABEL: adc64mi_FS:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: cmpq %rdi, %rsi
+; CHECK-NEXT: movq %fs:255, %rax
+; CHECK-NEXT: adcq $123456, %rax # imm = 0x1E240
+; CHECK-NEXT: retq
+entry:
+ %a = inttoptr i64 255 to ptr addrspace(257)
+ %t = load i64, ptr addrspace(257) %a
+ %s = add i64 %t, 123456
+ %k = icmp ugt i64 %x, %y
+ %z = zext i1 %k to i64
+ %r = add i64 %s, %z
+ ret i64 %r
+}
+
+define i32 @sbb32mi_GS(i32 %x, i32 %y) {
+; CHECK-LABEL: sbb32mi_GS:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: cmpl %edi, %esi
+; CHECK-NEXT: sbbl $0, %gs:255, %eax
+; CHECK-NEXT: addl $-123456, %eax # imm = 0xFFFE1DC0
+; CHECK-NEXT: retq
+entry:
+ %a= inttoptr i32 255 to ptr addrspace(256)
+ %t = load i32, ptr addrspace(256) %a
+ %s = sub i32 %t, 123456
+ %k = icmp ugt i32 %x, %y
+ %z = zext i1 %k to i32
+ %r = sub i32 %s, %z
+ ret i32 %r
+}
+
+define i64 @sbb64mi_FS(i64 %x, i64 %y) {
+; CHECK-LABEL: sbb64mi_FS:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: cmpq %rdi, %rsi
+; CHECK-NEXT: sbbq $0, %fs:255, %rax
+; CHECK-NEXT: addq $-123456, %rax # imm = 0xFFFE1DC0
+; CHECK-NEXT: retq
+entry:
+ %a= inttoptr i64 255 to ptr addrspace(257)
+ %t = load i64, ptr addrspace(257) %a
+ %s = sub i64 %t, 123456
+ %k = icmp ugt i64 %x, %y
+ %z = zext i1 %k to i64
+ %r = sub i64 %s, %z
+ ret i64 %r
+}
+
+define i32 @add32mi8_GS() {
+; CHECK-LABEL: add32mi8_GS:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: addl $127, %gs:255, %eax
+; CHECK-NEXT: retq
+entry:
+ %a= inttoptr i32 255 to ptr addrspace(256)
+ %t = load i32, ptr addrspace(256) %a
+ %add = add i32 %t, 127
+ ret i32 %add
+}
+
+define i32 @add32mi_GS_Disp0(ptr addrspace(256) %a, i32 %i) {
+; CHECK-LABEL: add32mi_GS_Disp0:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: movslq %esi, %rax
+; CHECK-NEXT: addl $123456, %gs:(%rdi,%rax,4), %eax # imm = 0x1E240
+; CHECK-NEXT: retq
+entry:
+ %arrayidx = getelementptr inbounds i32, ptr addrspace(256) %a, i32 %i
+ %t = load i32, ptr addrspace(256) %arrayidx
+ %add = add i32 %t, 123456
+ ret i32 %add
+}
+
+define i32 @add32mi_GS_Disp8(ptr addrspace(256) %a, i32 %i) {
+; CHECK-LABEL: add32mi_GS_Disp8:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: movslq %esi, %rax
+; CHECK-NEXT: addl $123456, %gs:123(%rdi,%rax,4), %eax # imm = 0x1E240
+; CHECK-NEXT: retq
+entry:
+ %arrayidx = getelementptr inbounds i32, ptr addrspace(256) %a, i32 %i
+ %add.ptr = getelementptr inbounds i8, ptr addrspace(256) %arrayidx, i32 123
+ %t = load i32, ptr addrspace(256) %add.ptr
+ %add = add i32 %t, 123456
+ ret i32 %add
+}
+
+define i32 @add32mi_GS_Disp32(ptr addrspace(256) %a, i32 %i) {
+; CHECK-LABEL: add32mi_GS_Disp32:
+; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: movslq %esi, %rax
+; CHECK-NEXT: movl %gs:1234(%rdi,%rax,4), %eax
+; CHECK-NEXT: addl $123456, %eax # imm = 0x1E240
+; CHECK-NEXT: retq
+entry:
+ %arrayidx = getelementptr inbounds i32, ptr addrspace(256) %a, i32 %i
+ %add.ptr = getelementptr inbounds i8, ptr addrspace(256) %arrayidx, i32 1234
+ %t = load i32, ptr addrspace(256) %add.ptr
+ %add = add i32 %t, 123456
+ ret i32 %add
+}
>From 3f18f6a2cfecb080f006477c46d3626102841a17 Mon Sep 17 00:00:00 2001
From: Quinn Dawkins <quinn.dawkins at gmail.com>
Date: Sun, 3 Mar 2024 01:54:03 -0500
Subject: [PATCH 382/406] [mlir][linalg] Enable fusion by expansion of
reduction and named ops (#83473)
This adds support for expansion of named linalg ops and linalg ops with
reduction iterators. This improves the ability to make fusion decisions
WRT reduction operations. To recover the previous behavior, users of the
patterns can add a control function to restrict propagation of reshape
by expansion through linalg ops with reduction iterators.
For named linalg ops, this always converts the named op into a generic.
---
.../Linalg/Transforms/ElementwiseOpFusion.cpp | 108 ++++++------
mlir/test/Dialect/Linalg/reshape_fusion.mlir | 161 ++++++++++++++++++
2 files changed, 219 insertions(+), 50 deletions(-)
diff --git a/mlir/lib/Dialect/Linalg/Transforms/ElementwiseOpFusion.cpp b/mlir/lib/Dialect/Linalg/Transforms/ElementwiseOpFusion.cpp
index 4797bfb2267d7f..9453502a253f16 100644
--- a/mlir/lib/Dialect/Linalg/Transforms/ElementwiseOpFusion.cpp
+++ b/mlir/lib/Dialect/Linalg/Transforms/ElementwiseOpFusion.cpp
@@ -467,10 +467,10 @@ class FuseElementwiseOps : public OpRewritePattern<GenericOp> {
// expanding the dimensionality of the elementwise operations.
//===---------------------------------------------------------------------===//
-/// Conditions for folding a generic operation with a reshape op by expanding
-/// the iteration space dimensionality for tensor operations. These are
-/// preconditions assumed by `foldReshapeByDimExpansion` which implements the
-/// following fusion pattern.
+/// Conditions for folding a structured linalg operation with a reshape op by
+/// expanding the iteration space dimensionality for tensor operations. These
+/// are preconditions assumed by `foldReshapeByDimExpansion` which implements
+/// the following fusion pattern.
///
/// Consider
///
@@ -481,9 +481,9 @@ class FuseElementwiseOps : public OpRewritePattern<GenericOp> {
/// %d = tensor.expand_shape %c [[0, 1], [2], [3, 4, 5]]
/// : tensor<?x?x?xf32> into tensor<?x?x?x?x?x?xf32>
///
-/// The reshape can be folded into the `genericOp` if its loop dimensionality
+/// The reshape can be folded into the `linalgOp` if its loop dimensionality
/// is increased to match the result (operand) of the tensor.expand_shape.
-/// The indexing_map of the fused tensor in the `genericOp` and the
+/// The indexing_map of the fused tensor in the `linalgOp` and the
/// reassociation map helps compute the indexing maps of the modified op.
/// For the above example, based on the reassociation map it
/// can be concluded that
@@ -502,7 +502,7 @@ class FuseElementwiseOps : public OpRewritePattern<GenericOp> {
/// d1 -> e2, e3, e4
/// d2 -> e5
///
-/// substituting this, the generic op can be rewritten as
+/// substituting this, the structured op can be rewritten as
///
/// %d = linalg.generic ins(%0, %1 : )
/// indexing_maps =
@@ -520,23 +520,28 @@ class FuseElementwiseOps : public OpRewritePattern<GenericOp> {
///
/// The added reshapes are again expanding patterns, so they will get fused
/// with its producers if possible.
-static bool isFusableWithReshapeByDimExpansion(GenericOp genericOp,
+static bool isFusableWithReshapeByDimExpansion(LinalgOp linalgOp,
OpOperand *fusableOpOperand) {
// Is fusable only if:
// - All the indexing maps for operands and results are projected
// permutations.
// - The fused tensor is not a scalar.
- // - All the loops are parallel loops.
- return genericOp.hasPureTensorSemantics() &&
- llvm::all_of(genericOp.getIndexingMaps().getValue(),
+ // - All the loops for the reshaped operand are parallel loops.
+ SmallVector<utils::IteratorType> iteratorTypes =
+ linalgOp.getIteratorTypesArray();
+ AffineMap operandMap = linalgOp.getMatchingIndexingMap(fusableOpOperand);
+ return linalgOp.hasPureTensorSemantics() &&
+ llvm::all_of(linalgOp.getIndexingMaps().getValue(),
[](Attribute attr) {
return cast<AffineMapAttr>(attr)
.getValue()
.isProjectedPermutation();
}) &&
- genericOp.getMatchingIndexingMap(fusableOpOperand).getNumResults() >
- 0 &&
- llvm::all_of(genericOp.getIteratorTypesArray(), isParallelIterator);
+ operandMap.getNumResults() > 0 &&
+ llvm::all_of(operandMap.getResults(), [&](AffineExpr expr) {
+ return isParallelIterator(
+ iteratorTypes[cast<AffineDimExpr>(expr).getPosition()]);
+ });
}
namespace {
@@ -628,10 +633,10 @@ LogicalResult ExpansionInfo::compute(LinalgOp linalgOp,
/// Note that this could be extended to handle dynamic case, but the
/// implementation below uses `affine.apply` which seems to have issues when the
/// shapes are not static.
-static LogicalResult isGenericOpExpandable(GenericOp genericOp,
- const ExpansionInfo &expansionInfo,
- PatternRewriter &rewriter) {
- if (!genericOp.hasIndexSemantics())
+static LogicalResult isLinalgOpExpandable(LinalgOp linalgOp,
+ const ExpansionInfo &expansionInfo,
+ PatternRewriter &rewriter) {
+ if (!linalgOp.hasIndexSemantics())
return success();
for (unsigned i : llvm::seq<unsigned>(0, expansionInfo.getOrigOpNumDims())) {
ArrayRef<int64_t> expandedShape = expansionInfo.getExpandedShapeOfDim(i);
@@ -640,7 +645,7 @@ static LogicalResult isGenericOpExpandable(GenericOp genericOp,
for (int64_t shape : expandedShape.drop_front()) {
if (ShapedType::isDynamic(shape)) {
return rewriter.notifyMatchFailure(
- genericOp, "cannot expand due to index semantics and dynamic dims");
+ linalgOp, "cannot expand due to index semantics and dynamic dims");
}
}
}
@@ -749,10 +754,10 @@ static void updateExpandedGenericOpRegion(PatternRewriter &rewriter,
/// and a generic op as explained in `isFusableWithReshapeByExpansion`. Assumes
/// that those conditions have been satisfied.
static std::optional<SmallVector<Value>>
-fuseWithReshapeByExpansion(GenericOp genericOp, Operation *reshapeOp,
+fuseWithReshapeByExpansion(LinalgOp linalgOp, Operation *reshapeOp,
OpOperand *fusableOpOperand,
PatternRewriter &rewriter) {
- assert(isFusableWithReshapeByDimExpansion(genericOp, fusableOpOperand) &&
+ assert(isFusableWithReshapeByDimExpansion(linalgOp, fusableOpOperand) &&
"preconditions for fuse operation failed");
// Check if reshape is expanding or collapsing.
auto expandingReshapeOp = dyn_cast<tensor::ExpandShapeOp>(*reshapeOp);
@@ -767,27 +772,27 @@ fuseWithReshapeByExpansion(GenericOp genericOp, Operation *reshapeOp,
ExpansionInfo expansionInfo;
if (failed(expansionInfo.compute(
- genericOp, fusableOpOperand,
+ linalgOp, fusableOpOperand,
isExpanding ? expandingReshapeOp.getReassociationMaps()
: collapsingReshapeOp.getReassociationMaps(),
expandedType.getShape(), collapsedType.getShape(), rewriter)))
return std::nullopt;
- if (failed(isGenericOpExpandable(genericOp, expansionInfo, rewriter)))
+ if (failed(isLinalgOpExpandable(linalgOp, expansionInfo, rewriter)))
return std::nullopt;
SmallVector<AffineMap, 4> expandedOpIndexingMaps = llvm::to_vector<4>(
- llvm::map_range(genericOp.getIndexingMapsArray(), [&](AffineMap m) {
+ llvm::map_range(linalgOp.getIndexingMapsArray(), [&](AffineMap m) {
return getIndexingMapInExpandedOp(rewriter, m, expansionInfo);
}));
// Set insertion point to the generic op.
OpBuilder::InsertionGuard g(rewriter);
- rewriter.setInsertionPoint(genericOp);
+ rewriter.setInsertionPoint(linalgOp);
SmallVector<Value> expandedOpOperands;
- expandedOpOperands.reserve(genericOp.getNumDpsInputs());
- for (OpOperand *opOperand : genericOp.getDpsInputOperands()) {
+ expandedOpOperands.reserve(linalgOp.getNumDpsInputs());
+ for (OpOperand *opOperand : linalgOp.getDpsInputOperands()) {
if (opOperand == fusableOpOperand) {
expandedOpOperands.push_back(isExpanding ? expandingReshapeOp.getSrc()
: collapsingReshapeOp.getSrc());
@@ -795,7 +800,7 @@ fuseWithReshapeByExpansion(GenericOp genericOp, Operation *reshapeOp,
}
if (auto opOperandType =
dyn_cast<RankedTensorType>(opOperand->get().getType())) {
- AffineMap indexingMap = genericOp.getMatchingIndexingMap(opOperand);
+ AffineMap indexingMap = linalgOp.getMatchingIndexingMap(opOperand);
RankedTensorType expandedOperandType =
getExpandedType(opOperandType, indexingMap, expansionInfo);
if (expandedOperandType != opOperand->get().getType()) {
@@ -804,14 +809,14 @@ fuseWithReshapeByExpansion(GenericOp genericOp, Operation *reshapeOp,
getReassociationForExpansion(indexingMap, expansionInfo);
if (failed(reshapeLikeShapesAreCompatible(
[&](const Twine &msg) {
- return rewriter.notifyMatchFailure(genericOp, msg);
+ return rewriter.notifyMatchFailure(linalgOp, msg);
},
opOperandType.getShape(), expandedOperandType.getShape(),
reassociation,
/*isExpandingReshape=*/true)))
return std::nullopt;
expandedOpOperands.push_back(rewriter.create<tensor::ExpandShapeOp>(
- genericOp.getLoc(), expandedOperandType, opOperand->get(),
+ linalgOp.getLoc(), expandedOperandType, opOperand->get(),
reassociation));
continue;
}
@@ -819,10 +824,10 @@ fuseWithReshapeByExpansion(GenericOp genericOp, Operation *reshapeOp,
expandedOpOperands.push_back(opOperand->get());
}
- Location loc = genericOp.getLoc();
+ Location loc = linalgOp.getLoc();
SmallVector<Value> outputs;
- for (OpOperand &opOperand : genericOp.getDpsInitsMutable()) {
- AffineMap indexingMap = genericOp.getMatchingIndexingMap(&opOperand);
+ for (OpOperand &opOperand : linalgOp.getDpsInitsMutable()) {
+ AffineMap indexingMap = linalgOp.getMatchingIndexingMap(&opOperand);
auto opOperandType = cast<RankedTensorType>(opOperand.get().getType());
RankedTensorType expandedOutputType =
getExpandedType(opOperandType, indexingMap, expansionInfo);
@@ -831,14 +836,14 @@ fuseWithReshapeByExpansion(GenericOp genericOp, Operation *reshapeOp,
getReassociationForExpansion(indexingMap, expansionInfo);
if (failed(reshapeLikeShapesAreCompatible(
[&](const Twine &msg) {
- return rewriter.notifyMatchFailure(genericOp, msg);
+ return rewriter.notifyMatchFailure(linalgOp, msg);
},
opOperandType.getShape(), expandedOutputType.getShape(),
reassociation,
/*isExpandingReshape=*/true)))
return std::nullopt;
outputs.push_back(rewriter.create<tensor::ExpandShapeOp>(
- genericOp.getLoc(), expandedOutputType, opOperand.get(),
+ linalgOp.getLoc(), expandedOutputType, opOperand.get(),
reassociation));
} else {
outputs.push_back(opOperand.get());
@@ -848,14 +853,17 @@ fuseWithReshapeByExpansion(GenericOp genericOp, Operation *reshapeOp,
// The iterator types of the expanded op are all parallel.
SmallVector<utils::IteratorType> iteratorTypes(
expansionInfo.getExpandedOpNumDims(), utils::IteratorType::parallel);
+ for (auto [i, type] : llvm::enumerate(linalgOp.getIteratorTypesArray()))
+ for (auto j : expansionInfo.getExpandedDims(i))
+ iteratorTypes[j] = type;
TypeRange resultTypes = ValueRange(outputs).getTypes();
auto fusedOp =
- rewriter.create<GenericOp>(genericOp.getLoc(), resultTypes,
+ rewriter.create<GenericOp>(linalgOp.getLoc(), resultTypes,
/*inputs=*/expandedOpOperands, outputs,
expandedOpIndexingMaps, iteratorTypes);
Region &fusedRegion = fusedOp->getRegion(0);
- Region &originalRegion = genericOp->getRegion(0);
+ Region &originalRegion = linalgOp->getRegion(0);
rewriter.cloneRegionBefore(originalRegion, fusedRegion, fusedRegion.begin());
// Update the index accesses after the expansion.
@@ -864,16 +872,16 @@ fuseWithReshapeByExpansion(GenericOp genericOp, Operation *reshapeOp,
// Reshape the result values to their original shape if this is a collapsing
// reshape folded into its consumer.
SmallVector<Value> resultVals;
- for (OpResult opResult : genericOp->getOpResults()) {
+ for (OpResult opResult : linalgOp->getOpResults()) {
int64_t resultNumber = opResult.getResultNumber();
if (resultTypes[resultNumber] != opResult.getType()) {
SmallVector<ReassociationIndices> reassociation =
getReassociationForExpansion(
- genericOp.getMatchingIndexingMap(
- genericOp.getDpsInitOperand(resultNumber)),
+ linalgOp.getMatchingIndexingMap(
+ linalgOp.getDpsInitOperand(resultNumber)),
expansionInfo);
resultVals.push_back(rewriter.create<tensor::CollapseShapeOp>(
- genericOp.getLoc(), opResult.getType(),
+ linalgOp.getLoc(), opResult.getType(),
fusedOp->getResult(resultNumber), reassociation));
} else {
resultVals.push_back(fusedOp->getResult(resultNumber));
@@ -885,21 +893,21 @@ fuseWithReshapeByExpansion(GenericOp genericOp, Operation *reshapeOp,
namespace {
-/// Pattern to fuse a tensor.collapse_shape op with its consumer generic op,
+/// Pattern to fuse a tensor.collapse_shape op with its consumer structured op,
/// when the reshape op is collapsing dimensions. The dimensionality of the loop
/// in the consumer is expanded.
class FoldWithProducerReshapeOpByExpansion
- : public OpRewritePattern<GenericOp> {
+ : public OpInterfaceRewritePattern<LinalgOp> {
public:
FoldWithProducerReshapeOpByExpansion(MLIRContext *context,
ControlFusionFn foldReshapes,
PatternBenefit benefit = 1)
- : OpRewritePattern<GenericOp>(context, benefit),
+ : OpInterfaceRewritePattern<LinalgOp>(context, benefit),
controlFoldingReshapes(std::move(foldReshapes)) {}
- LogicalResult matchAndRewrite(GenericOp genericOp,
+ LogicalResult matchAndRewrite(LinalgOp linalgOp,
PatternRewriter &rewriter) const override {
- for (OpOperand *opOperand : genericOp.getDpsInputOperands()) {
+ for (OpOperand *opOperand : linalgOp.getDpsInputOperands()) {
tensor::CollapseShapeOp reshapeOp =
opOperand->get().getDefiningOp<tensor::CollapseShapeOp>();
if (!reshapeOp)
@@ -907,15 +915,15 @@ class FoldWithProducerReshapeOpByExpansion
// Fold only if
// - The tensor reshape op is folding.
// - All constraints of fusing with reshape by expansion are met.
- if (!isFusableWithReshapeByDimExpansion(genericOp, opOperand) ||
+ if (!isFusableWithReshapeByDimExpansion(linalgOp, opOperand) ||
(!controlFoldingReshapes(opOperand)))
continue;
std::optional<SmallVector<Value>> replacementValues =
- fuseWithReshapeByExpansion(genericOp, reshapeOp, opOperand, rewriter);
+ fuseWithReshapeByExpansion(linalgOp, reshapeOp, opOperand, rewriter);
if (!replacementValues)
return failure();
- rewriter.replaceOp(genericOp, *replacementValues);
+ rewriter.replaceOp(linalgOp, *replacementValues);
return success();
}
return failure();
@@ -945,7 +953,7 @@ struct FoldReshapeWithGenericOpByExpansion
"source not produced by an operation");
}
- auto producer = dyn_cast<GenericOp>(producerResult.getOwner());
+ auto producer = dyn_cast<LinalgOp>(producerResult.getOwner());
if (!producer) {
return rewriter.notifyMatchFailure(reshapeOp,
"producer not a generic op");
diff --git a/mlir/test/Dialect/Linalg/reshape_fusion.mlir b/mlir/test/Dialect/Linalg/reshape_fusion.mlir
index 0e40b5fbed97cb..342c067b5c4ba4 100644
--- a/mlir/test/Dialect/Linalg/reshape_fusion.mlir
+++ b/mlir/test/Dialect/Linalg/reshape_fusion.mlir
@@ -573,3 +573,164 @@ module {
// CHECK-SAME: ins(%[[ARG0]], %[[ARG1]] :
// CHECK-SAME: outs(%[[ARG2]], %[[OUTS]] :
// CHECK: return %[[GENERIC]]#1
+
+// -----
+
+#map0 = affine_map<(d0, d1, d2) -> (d0, d2)>
+#map1 = affine_map<(d0, d1, d2) -> (d1, d2)>
+#map2 = affine_map<(d0, d1, d2) -> (d0, d1)>
+func.func @generic_op_reshape_consumer_fusion_reduction(%arg0 : tensor<?x?xf32>,
+ %arg1 : tensor<?x?xf32>,
+ %arg2 : tensor<?x?xf32>) ->
+ tensor<?x?x4x5xf32>
+{
+ %0 = linalg.generic {
+ indexing_maps = [#map0, #map1, #map2],
+ iterator_types = ["parallel", "parallel", "reduction"]}
+ ins(%arg0, %arg1 : tensor<?x?xf32>, tensor<?x?xf32>)
+ outs(%arg2 : tensor<?x?xf32>) {
+ ^bb0(%arg3: f32, %arg4: f32, %s: f32):
+ %1 = arith.mulf %arg3, %arg4 : f32
+ linalg.yield %1 : f32
+ } -> tensor<?x?xf32>
+ %1 = tensor.expand_shape %0 [[0], [1, 2, 3]] :
+ tensor<?x?xf32> into tensor<?x?x4x5xf32>
+ return %1 : tensor<?x?x4x5xf32>
+}
+
+// CHECK-DAG: #[[MAP0:.+]] = affine_map<(d0, d1, d2, d3, d4) -> (d0, d4)>
+// CHECK-DAG: #[[MAP1:.+]] = affine_map<(d0, d1, d2, d3, d4) -> (d1, d2, d3, d4)>
+// CHECK-DAG: #[[MAP2:.+]] = affine_map<(d0, d1, d2, d3, d4) -> (d0, d1, d2, d3)>
+// CHECK: func @generic_op_reshape_consumer_fusion_reduction
+// CHECK-SAME: %[[ARG0:[a-zA-Z0-9_]+]]: tensor<?x?xf32>
+// CHECK-SAME: %[[ARG1:[a-zA-Z0-9_]+]]: tensor<?x?xf32>
+// CHECK-SAME: %[[ARG2:[a-zA-Z0-9_]+]]: tensor<?x?xf32>
+// CHECK: %[[T1:.+]] = tensor.expand_shape %[[ARG1]]
+// CHECK-SAME: [0, 1, 2], [3]
+// CHECK-SAME: tensor<?x?xf32> into tensor<?x4x5x?xf32>
+// CHECK: %[[T2:.+]] = tensor.expand_shape %[[ARG2]]
+// CHECK-SAME: [0], [1, 2, 3]
+// CHECK-SAME: tensor<?x?xf32> into tensor<?x?x4x5xf32>
+// CHECK: %[[T3:.+]] = linalg.generic
+// CHECK-SAME: indexing_maps = [#[[MAP0]], #[[MAP1]], #[[MAP2]]]
+// CHECK-SAME: ["parallel", "parallel", "parallel", "parallel", "reduction"]
+// CHECK-SAME: ins(%[[ARG0]], %[[T1]] : tensor<?x?xf32>, tensor<?x4x5x?xf32>)
+// CHECK-SAME: outs(%[[T2]] : tensor<?x?x4x5xf32>)
+// CHECK: return %[[T3]] : tensor<?x?x4x5xf32>
+
+// -----
+
+#map0 = affine_map<(d0, d1, d2) -> (d2, d0)>
+#map1 = affine_map<(d0, d1, d2) -> (d0, d1, d2)>
+#map2 = affine_map<(d0, d1, d2) -> (d0, d2)>
+func.func @generic_op_reshape_producer_fusion_with_reduction(%arg0 : tensor<?x7x?x8xf32>,
+ %arg1 : tensor<?x4x?xf32>,
+ %arg2 : tensor<?x?xf32>) ->
+ tensor<?x?xf32>
+{
+ %0 = tensor.collapse_shape %arg0 [[0, 1], [2, 3]] :
+ tensor<?x7x?x8xf32> into tensor<?x?xf32>
+ %1 = linalg.generic {
+ indexing_maps = [#map0, #map1, #map2],
+ iterator_types = ["parallel", "reduction", "parallel"]}
+ ins(%0, %arg1 : tensor<?x?xf32>, tensor<?x4x?xf32>)
+ outs(%arg2 : tensor<?x?xf32>) {
+ ^bb0(%arg3: f32, %arg4: f32, %arg5: f32):
+ %1 = arith.mulf %arg3, %arg4 : f32
+ %2 = arith.addf %1, %arg5 : f32
+ linalg.yield %2 : f32
+ } -> tensor<?x?xf32>
+ return %1 : tensor<?x?xf32>
+}
+
+// CHECK-DAG: #[[$MAP0:.+]] = affine_map<(d0, d1, d2, d3, d4) -> (d3, d4, d0, d1)>
+// CHECK-DAG: #[[$MAP1:.+]] = affine_map<(d0, d1, d2, d3, d4) -> (d0, d1, d2, d3, d4)>
+// CHECK-DAG: #[[$MAP2:.+]] = affine_map<(d0, d1, d2, d3, d4) -> (d0, d1, d3, d4)>
+// CHECK: func @generic_op_reshape_producer_fusion_with_reduction
+// CHECK-SAME: %[[ARG0:[a-zA-Z0-9_]+]]: tensor<?x7x?x8xf32>
+// CHECK-SAME: %[[ARG1:[a-zA-Z0-9_]+]]: tensor<?x4x?xf32>
+// CHECK-SAME: %[[ARG2:[a-zA-Z0-9_]+]]: tensor<?x?xf32>
+// CHECK: %[[T1:.+]] = tensor.expand_shape %[[ARG1]]
+// CHECK-SAME: [0, 1], [2], [3, 4]
+// CHECK: %[[T2:.+]] = tensor.expand_shape %[[ARG2]]
+// CHECK-SAME: [0, 1], [2, 3]
+// CHECK: %[[T3:.+]] = linalg.generic
+// CHECK-SAME: indexing_maps = [#[[$MAP0]], #[[$MAP1]], #[[$MAP2]]]
+// CHECK-SAME: ["parallel", "parallel", "reduction", "parallel", "parallel"]
+// CHECK-SAME: ins(%[[ARG0]], %[[T1]] : tensor<?x7x?x8xf32>, tensor<?x8x4x?x7xf32>)
+// CHECK-SAME: outs(%[[T2]] : tensor<?x8x?x7xf32>)
+// CHECK: %[[T4:.+]] = tensor.collapse_shape %[[T3]]
+// CHECK-SAME: [0, 1], [2, 3]
+// CHECK-SAME: tensor<?x8x?x7xf32> into tensor<?x?xf32>
+// CHECK: return %[[T4]]
+
+// -----
+
+func.func @linalg_add_reshape_consumer_fusion(%arg0 : tensor<?x?xf32>,
+ %arg1 : tensor<?x?xf32>,
+ %arg2 : tensor<?x?xf32>) ->
+ tensor<?x?x4x5xf32>
+{
+ %0 = linalg.add ins(%arg0, %arg1 : tensor<?x?xf32>, tensor<?x?xf32>)
+ outs(%arg2 : tensor<?x?xf32>) -> tensor<?x?xf32>
+ %1 = tensor.expand_shape %0 [[0], [1, 2, 3]] :
+ tensor<?x?xf32> into tensor<?x?x4x5xf32>
+ return %1 : tensor<?x?x4x5xf32>
+}
+
+// CHECK-DAG: #[[MAP:.+]] = affine_map<(d0, d1, d2, d3) -> (d0, d1, d2, d3)>
+// CHECK: func @linalg_add_reshape_consumer_fusion
+// CHECK-SAME: %[[ARG0:[a-zA-Z0-9_]+]]: tensor<?x?xf32>
+// CHECK-SAME: %[[ARG1:[a-zA-Z0-9_]+]]: tensor<?x?xf32>
+// CHECK-SAME: %[[ARG2:[a-zA-Z0-9_]+]]: tensor<?x?xf32>
+// CHECK: %[[T1:.+]] = tensor.expand_shape %[[ARG0]]
+// CHECK-SAME: [0], [1, 2, 3]
+// CHECK-SAME: tensor<?x?xf32> into tensor<?x?x4x5xf32>
+// CHECK: %[[T2:.+]] = tensor.expand_shape %[[ARG1]]
+// CHECK-SAME: [0], [1, 2, 3]
+// CHECK-SAME: tensor<?x?xf32> into tensor<?x?x4x5xf32>
+// CHECK: %[[T3:.+]] = tensor.expand_shape %[[ARG2]]
+// CHECK-SAME: [0], [1, 2, 3]
+// CHECK-SAME: tensor<?x?xf32> into tensor<?x?x4x5xf32>
+// CHECK: %[[T4:.+]] = linalg.generic
+// CHECK-SAME: indexing_maps = [#[[MAP]], #[[MAP]], #[[MAP]]]
+// CHECK-SAME: ["parallel", "parallel", "parallel", "parallel"]
+// CHECK-SAME: ins(%[[T1]], %[[T2]] : tensor<?x?x4x5xf32>, tensor<?x?x4x5xf32>)
+// CHECK-SAME: outs(%[[T3]] : tensor<?x?x4x5xf32>)
+// CHECK: return %[[T4]] : tensor<?x?x4x5xf32>
+
+// -----
+
+#map0 = affine_map<(d0, d1, d2) -> (d2, d0)>
+#map1 = affine_map<(d0, d1, d2) -> (d0, d1, d2)>
+#map2 = affine_map<(d0, d1, d2) -> (d0, d2)>
+func.func @linalg_add_reshape_producer_fusion(%arg0 : tensor<?x7x?x8xf32>,
+ %arg1 : tensor<?x?xf32>,
+ %arg2 : tensor<?x?xf32>) ->
+ tensor<?x?xf32>
+{
+ %0 = tensor.collapse_shape %arg0 [[0, 1], [2, 3]] :
+ tensor<?x7x?x8xf32> into tensor<?x?xf32>
+ %1 = linalg.add ins(%0, %arg1 : tensor<?x?xf32>, tensor<?x?xf32>)
+ outs(%arg2 : tensor<?x?xf32>) -> tensor<?x?xf32>
+ return %1 : tensor<?x?xf32>
+}
+
+// CHECK-DAG: #[[$MAP:.+]] = affine_map<(d0, d1, d2, d3) -> (d0, d1, d2, d3)>
+// CHECK: func @linalg_add_reshape_producer_fusion
+// CHECK-SAME: %[[ARG0:[a-zA-Z0-9_]+]]: tensor<?x7x?x8xf32>
+// CHECK-SAME: %[[ARG1:[a-zA-Z0-9_]+]]: tensor<?x?xf32>
+// CHECK-SAME: %[[ARG2:[a-zA-Z0-9_]+]]: tensor<?x?xf32>
+// CHECK: %[[T1:.+]] = tensor.expand_shape %[[ARG1]]
+// CHECK-SAME: [0, 1], [2, 3]
+// CHECK: %[[T2:.+]] = tensor.expand_shape %[[ARG2]]
+// CHECK-SAME: [0, 1], [2, 3]
+// CHECK: %[[T3:.+]] = linalg.generic
+// CHECK-SAME: indexing_maps = [#[[$MAP]], #[[$MAP]], #[[$MAP]]]
+// CHECK-SAME: ["parallel", "parallel", "parallel", "parallel"]
+// CHECK-SAME: ins(%[[ARG0]], %[[T1]] : tensor<?x7x?x8xf32>, tensor<?x7x?x8xf32>)
+// CHECK-SAME: outs(%[[T2]] : tensor<?x7x?x8xf32>)
+// CHECK: %[[T4:.+]] = tensor.collapse_shape %[[T3]]
+// CHECK-SAME: [0, 1], [2, 3]
+// CHECK-SAME: tensor<?x7x?x8xf32> into tensor<?x?xf32>
+// CHECK: return %[[T4]]
>From 800de14fab136f8e17c04cc783e0f8f2b305333b Mon Sep 17 00:00:00 2001
From: David Green <david.green at arm.com>
Date: Sun, 3 Mar 2024 08:30:12 +0000
Subject: [PATCH 383/406] [ARM][AArch64] Reformat target parser. NFC (#82601)
This is something we generally tend to avoid due to it confusing the git
history, but with the new github formatting bots being more noisy we
keep running into issues with the existing formatting when adding or
adjusting CPUs. This patch formats the code to make sure we are in a
good state going forward.
---
.../llvm/TargetParser/AArch64TargetParser.h | 346 +++---
.../llvm/TargetParser/ARMTargetParser.def | 321 ++---
.../llvm/TargetParser/ARMTargetParser.h | 74 +-
.../TargetParser/TargetParserTest.cpp | 1073 +++++++++--------
4 files changed, 923 insertions(+), 891 deletions(-)
diff --git a/llvm/include/llvm/TargetParser/AArch64TargetParser.h b/llvm/include/llvm/TargetParser/AArch64TargetParser.h
index b539627604c376..e74e8fa32a62e1 100644
--- a/llvm/include/llvm/TargetParser/AArch64TargetParser.h
+++ b/llvm/include/llvm/TargetParser/AArch64TargetParser.h
@@ -531,286 +531,278 @@ struct CpuInfo {
inline constexpr CpuInfo CpuInfos[] = {
{"cortex-a34", ARMV8A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_CRC}))},
+ AArch64::ExtensionBitset(
+ {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_CRC})},
{"cortex-a35", ARMV8A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_CRC}))},
+ AArch64::ExtensionBitset(
+ {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_CRC})},
{"cortex-a53", ARMV8A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_CRC}))},
+ AArch64::ExtensionBitset(
+ {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_CRC})},
{"cortex-a55", ARMV8_2A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_FP16,
- AArch64::AEK_DOTPROD, AArch64::AEK_RCPC}))},
+ AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
+ AArch64::AEK_FP16, AArch64::AEK_DOTPROD,
+ AArch64::AEK_RCPC})},
{"cortex-a510", ARMV9A,
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_BF16, AArch64::AEK_I8MM, AArch64::AEK_SB,
AArch64::AEK_PAUTH, AArch64::AEK_MTE, AArch64::AEK_SSBS,
AArch64::AEK_SVE, AArch64::AEK_SVE2, AArch64::AEK_SVE2BITPERM,
- AArch64::AEK_FP16FML}))},
+ AArch64::AEK_FP16FML})},
{"cortex-a520", ARMV9_2A,
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_SB, AArch64::AEK_SSBS, AArch64::AEK_MTE,
AArch64::AEK_FP16FML, AArch64::AEK_PAUTH, AArch64::AEK_SVE2BITPERM,
- AArch64::AEK_FLAGM, AArch64::AEK_PERFMON, AArch64::AEK_PREDRES}))},
+ AArch64::AEK_FLAGM, AArch64::AEK_PERFMON, AArch64::AEK_PREDRES})},
{"cortex-a57", ARMV8A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_CRC}))},
+ AArch64::ExtensionBitset(
+ {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_CRC})},
{"cortex-a65", ARMV8_2A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_DOTPROD,
- AArch64::AEK_FP16, AArch64::AEK_RCPC, AArch64::AEK_SSBS}))},
+ AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
+ AArch64::AEK_DOTPROD, AArch64::AEK_FP16,
+ AArch64::AEK_RCPC, AArch64::AEK_SSBS})},
{"cortex-a65ae", ARMV8_2A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_DOTPROD,
- AArch64::AEK_FP16, AArch64::AEK_RCPC, AArch64::AEK_SSBS}))},
+ AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
+ AArch64::AEK_DOTPROD, AArch64::AEK_FP16,
+ AArch64::AEK_RCPC, AArch64::AEK_SSBS})},
{"cortex-a72", ARMV8A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_CRC}))},
+ AArch64::ExtensionBitset(
+ {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_CRC})},
{"cortex-a73", ARMV8A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_CRC}))},
+ AArch64::ExtensionBitset(
+ {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_CRC})},
{"cortex-a75", ARMV8_2A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_FP16,
- AArch64::AEK_DOTPROD, AArch64::AEK_RCPC}))},
+ AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
+ AArch64::AEK_FP16, AArch64::AEK_DOTPROD,
+ AArch64::AEK_RCPC})},
{"cortex-a76", ARMV8_2A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_FP16,
- AArch64::AEK_DOTPROD, AArch64::AEK_RCPC, AArch64::AEK_SSBS}))},
+ AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
+ AArch64::AEK_FP16, AArch64::AEK_DOTPROD,
+ AArch64::AEK_RCPC, AArch64::AEK_SSBS})},
{"cortex-a76ae", ARMV8_2A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_FP16,
- AArch64::AEK_DOTPROD, AArch64::AEK_RCPC, AArch64::AEK_SSBS}))},
+ AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
+ AArch64::AEK_FP16, AArch64::AEK_DOTPROD,
+ AArch64::AEK_RCPC, AArch64::AEK_SSBS})},
{"cortex-a77", ARMV8_2A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_FP16,
- AArch64::AEK_RCPC, AArch64::AEK_DOTPROD, AArch64::AEK_SSBS}))},
+ AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
+ AArch64::AEK_FP16, AArch64::AEK_RCPC,
+ AArch64::AEK_DOTPROD, AArch64::AEK_SSBS})},
{"cortex-a78", ARMV8_2A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_FP16,
- AArch64::AEK_DOTPROD, AArch64::AEK_RCPC, AArch64::AEK_SSBS,
- AArch64::AEK_PROFILE}))},
+ AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
+ AArch64::AEK_FP16, AArch64::AEK_DOTPROD,
+ AArch64::AEK_RCPC, AArch64::AEK_SSBS,
+ AArch64::AEK_PROFILE})},
{"cortex-a78c", ARMV8_2A,
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_FP16,
AArch64::AEK_DOTPROD, AArch64::AEK_RCPC, AArch64::AEK_SSBS,
- AArch64::AEK_PROFILE, AArch64::AEK_FLAGM, AArch64::AEK_PAUTH}))},
+ AArch64::AEK_PROFILE, AArch64::AEK_FLAGM, AArch64::AEK_PAUTH})},
{"cortex-a710", ARMV9A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_MTE, AArch64::AEK_PAUTH, AArch64::AEK_FLAGM,
- AArch64::AEK_SB, AArch64::AEK_I8MM, AArch64::AEK_FP16FML,
- AArch64::AEK_SVE, AArch64::AEK_SVE2, AArch64::AEK_SVE2BITPERM,
- AArch64::AEK_BF16}))},
+ AArch64::ExtensionBitset({AArch64::AEK_MTE, AArch64::AEK_PAUTH,
+ AArch64::AEK_FLAGM, AArch64::AEK_SB,
+ AArch64::AEK_I8MM, AArch64::AEK_FP16FML,
+ AArch64::AEK_SVE, AArch64::AEK_SVE2,
+ AArch64::AEK_SVE2BITPERM, AArch64::AEK_BF16})},
{"cortex-a715", ARMV9A,
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_SB, AArch64::AEK_SSBS, AArch64::AEK_MTE,
AArch64::AEK_FP16, AArch64::AEK_FP16FML, AArch64::AEK_PAUTH,
AArch64::AEK_I8MM, AArch64::AEK_PREDRES, AArch64::AEK_PERFMON,
AArch64::AEK_PROFILE, AArch64::AEK_SVE, AArch64::AEK_SVE2BITPERM,
- AArch64::AEK_BF16, AArch64::AEK_FLAGM}))},
+ AArch64::AEK_BF16, AArch64::AEK_FLAGM})},
{"cortex-a720", ARMV9_2A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_SB, AArch64::AEK_SSBS, AArch64::AEK_MTE,
- AArch64::AEK_FP16FML, AArch64::AEK_PAUTH, AArch64::AEK_SVE2BITPERM,
- AArch64::AEK_FLAGM, AArch64::AEK_PERFMON, AArch64::AEK_PREDRES,
- AArch64::AEK_PROFILE}))},
- {"cortex-r82", ARMV8R,
- (AArch64::ExtensionBitset({AArch64::AEK_LSE}))},
+ AArch64::ExtensionBitset({AArch64::AEK_SB, AArch64::AEK_SSBS,
+ AArch64::AEK_MTE, AArch64::AEK_FP16FML,
+ AArch64::AEK_PAUTH, AArch64::AEK_SVE2BITPERM,
+ AArch64::AEK_FLAGM, AArch64::AEK_PERFMON,
+ AArch64::AEK_PREDRES, AArch64::AEK_PROFILE})},
+ {"cortex-r82", ARMV8R, AArch64::ExtensionBitset({AArch64::AEK_LSE})},
{"cortex-x1", ARMV8_2A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_FP16,
- AArch64::AEK_DOTPROD, AArch64::AEK_RCPC, AArch64::AEK_SSBS,
- AArch64::AEK_PROFILE}))},
+ AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
+ AArch64::AEK_FP16, AArch64::AEK_DOTPROD,
+ AArch64::AEK_RCPC, AArch64::AEK_SSBS,
+ AArch64::AEK_PROFILE})},
{"cortex-x1c", ARMV8_2A,
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_FP16,
AArch64::AEK_DOTPROD, AArch64::AEK_RCPC, AArch64::AEK_SSBS,
- AArch64::AEK_PAUTH, AArch64::AEK_PROFILE, AArch64::AEK_FLAGM}))},
+ AArch64::AEK_PAUTH, AArch64::AEK_PROFILE, AArch64::AEK_FLAGM})},
{"cortex-x2", ARMV9A,
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_MTE, AArch64::AEK_BF16, AArch64::AEK_I8MM,
AArch64::AEK_PAUTH, AArch64::AEK_SSBS, AArch64::AEK_SB,
AArch64::AEK_SVE, AArch64::AEK_SVE2, AArch64::AEK_SVE2BITPERM,
- AArch64::AEK_FP16FML, AArch64::AEK_FLAGM}))},
+ AArch64::AEK_FP16FML, AArch64::AEK_FLAGM})},
{"cortex-x3", ARMV9A,
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_SVE, AArch64::AEK_PERFMON, AArch64::AEK_PROFILE,
AArch64::AEK_BF16, AArch64::AEK_I8MM, AArch64::AEK_MTE,
AArch64::AEK_SVE2BITPERM, AArch64::AEK_SB, AArch64::AEK_PAUTH,
AArch64::AEK_FP16, AArch64::AEK_FP16FML, AArch64::AEK_PREDRES,
- AArch64::AEK_FLAGM, AArch64::AEK_SSBS}))},
+ AArch64::AEK_FLAGM, AArch64::AEK_SSBS})},
{"cortex-x4", ARMV9_2A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_SB, AArch64::AEK_SSBS, AArch64::AEK_MTE,
- AArch64::AEK_FP16FML, AArch64::AEK_PAUTH, AArch64::AEK_SVE2BITPERM,
- AArch64::AEK_FLAGM, AArch64::AEK_PERFMON, AArch64::AEK_PREDRES,
- AArch64::AEK_PROFILE}))},
+ AArch64::ExtensionBitset({AArch64::AEK_SB, AArch64::AEK_SSBS,
+ AArch64::AEK_MTE, AArch64::AEK_FP16FML,
+ AArch64::AEK_PAUTH, AArch64::AEK_SVE2BITPERM,
+ AArch64::AEK_FLAGM, AArch64::AEK_PERFMON,
+ AArch64::AEK_PREDRES, AArch64::AEK_PROFILE})},
{"neoverse-e1", ARMV8_2A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_DOTPROD,
- AArch64::AEK_FP16, AArch64::AEK_RCPC, AArch64::AEK_SSBS}))},
+ AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
+ AArch64::AEK_DOTPROD, AArch64::AEK_FP16,
+ AArch64::AEK_RCPC, AArch64::AEK_SSBS})},
{"neoverse-n1", ARMV8_2A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_DOTPROD,
- AArch64::AEK_FP16, AArch64::AEK_PROFILE, AArch64::AEK_RCPC,
- AArch64::AEK_SSBS}))},
+ AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
+ AArch64::AEK_DOTPROD, AArch64::AEK_FP16,
+ AArch64::AEK_PROFILE, AArch64::AEK_RCPC,
+ AArch64::AEK_SSBS})},
{"neoverse-n2", ARMV9A,
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_BF16, AArch64::AEK_DOTPROD, AArch64::AEK_FP16,
AArch64::AEK_FP16FML, AArch64::AEK_I8MM, AArch64::AEK_MTE,
AArch64::AEK_SB, AArch64::AEK_SSBS, AArch64::AEK_SVE,
- AArch64::AEK_SVE2, AArch64::AEK_SVE2BITPERM}))},
+ AArch64::AEK_SVE2, AArch64::AEK_SVE2BITPERM})},
{"neoverse-512tvb", ARMV8_4A,
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_SHA3,
AArch64::AEK_SM4, AArch64::AEK_SVE, AArch64::AEK_SSBS,
AArch64::AEK_FP16, AArch64::AEK_BF16, AArch64::AEK_DOTPROD,
AArch64::AEK_PROFILE, AArch64::AEK_RAND, AArch64::AEK_FP16FML,
- AArch64::AEK_I8MM}))},
+ AArch64::AEK_I8MM})},
{"neoverse-v1", ARMV8_4A,
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_SHA3,
AArch64::AEK_SM4, AArch64::AEK_SVE, AArch64::AEK_SSBS,
AArch64::AEK_FP16, AArch64::AEK_BF16, AArch64::AEK_DOTPROD,
AArch64::AEK_PROFILE, AArch64::AEK_RAND, AArch64::AEK_FP16FML,
- AArch64::AEK_I8MM}))},
+ AArch64::AEK_I8MM})},
{"neoverse-v2", ARMV9A,
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_SVE, AArch64::AEK_SVE2, AArch64::AEK_SSBS,
AArch64::AEK_FP16, AArch64::AEK_BF16, AArch64::AEK_RAND,
AArch64::AEK_DOTPROD, AArch64::AEK_PROFILE, AArch64::AEK_SVE2BITPERM,
- AArch64::AEK_FP16FML, AArch64::AEK_I8MM, AArch64::AEK_MTE}))},
+ AArch64::AEK_FP16FML, AArch64::AEK_I8MM, AArch64::AEK_MTE})},
{"cyclone", ARMV8A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_NONE}))},
+ AArch64::ExtensionBitset(
+ {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_NONE})},
{"apple-a7", ARMV8A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_NONE}))},
+ AArch64::ExtensionBitset(
+ {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_NONE})},
{"apple-a8", ARMV8A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_NONE}))},
+ AArch64::ExtensionBitset(
+ {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_NONE})},
{"apple-a9", ARMV8A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_NONE}))},
+ AArch64::ExtensionBitset(
+ {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_NONE})},
{"apple-a10", ARMV8A,
- (AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
- AArch64::AEK_CRC,
- AArch64::AEK_RDM}))},
+ AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
+ AArch64::AEK_CRC, AArch64::AEK_RDM})},
{"apple-a11", ARMV8_2A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_FP16}))},
+ AArch64::ExtensionBitset(
+ {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_FP16})},
{"apple-a12", ARMV8_3A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_FP16}))},
+ AArch64::ExtensionBitset(
+ {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_FP16})},
{"apple-a13", ARMV8_4A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_SHA3,
- AArch64::AEK_FP16, AArch64::AEK_FP16FML}))},
+ AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
+ AArch64::AEK_SHA3, AArch64::AEK_FP16,
+ AArch64::AEK_FP16FML})},
{"apple-a14", ARMV8_5A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_SHA3,
- AArch64::AEK_FP16, AArch64::AEK_FP16FML}))},
+ AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
+ AArch64::AEK_SHA3, AArch64::AEK_FP16,
+ AArch64::AEK_FP16FML})},
{"apple-a15", ARMV8_6A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_SHA3,
- AArch64::AEK_FP16, AArch64::AEK_FP16FML}))},
+ AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
+ AArch64::AEK_SHA3, AArch64::AEK_FP16,
+ AArch64::AEK_FP16FML})},
{"apple-a16", ARMV8_6A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_SHA3,
- AArch64::AEK_FP16, AArch64::AEK_FP16FML}))},
+ AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
+ AArch64::AEK_SHA3, AArch64::AEK_FP16,
+ AArch64::AEK_FP16FML})},
{"apple-a17", ARMV8_6A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_SHA3,
- AArch64::AEK_FP16, AArch64::AEK_FP16FML}))},
+ AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
+ AArch64::AEK_SHA3, AArch64::AEK_FP16,
+ AArch64::AEK_FP16FML})},
{"apple-m1", ARMV8_5A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_SHA3,
- AArch64::AEK_FP16, AArch64::AEK_FP16FML}))},
+ AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
+ AArch64::AEK_SHA3, AArch64::AEK_FP16,
+ AArch64::AEK_FP16FML})},
{"apple-m2", ARMV8_6A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_SHA3,
- AArch64::AEK_FP16, AArch64::AEK_FP16FML}))},
+ AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
+ AArch64::AEK_SHA3, AArch64::AEK_FP16,
+ AArch64::AEK_FP16FML})},
{"apple-m3", ARMV8_6A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_SHA3,
- AArch64::AEK_FP16, AArch64::AEK_FP16FML}))},
+ AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
+ AArch64::AEK_SHA3, AArch64::AEK_FP16,
+ AArch64::AEK_FP16FML})},
{"apple-s4", ARMV8_3A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_FP16}))},
+ AArch64::ExtensionBitset(
+ {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_FP16})},
{"apple-s5", ARMV8_3A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_FP16}))},
+ AArch64::ExtensionBitset(
+ {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_FP16})},
{"exynos-m3", ARMV8A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_CRC}))},
+ AArch64::ExtensionBitset(
+ {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_CRC})},
{"exynos-m4", ARMV8_2A,
- (AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
- AArch64::AEK_DOTPROD,
- AArch64::AEK_FP16}))},
+ AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
+ AArch64::AEK_DOTPROD, AArch64::AEK_FP16})},
{"exynos-m5", ARMV8_2A,
- (AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
- AArch64::AEK_DOTPROD,
- AArch64::AEK_FP16}))},
+ AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
+ AArch64::AEK_DOTPROD, AArch64::AEK_FP16})},
{"falkor", ARMV8A,
- (AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
- AArch64::AEK_CRC,
- AArch64::AEK_RDM}))},
+ AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
+ AArch64::AEK_CRC, AArch64::AEK_RDM})},
{"saphira", ARMV8_3A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_PROFILE}))},
+ AArch64::ExtensionBitset(
+ {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_PROFILE})},
{"kryo", ARMV8A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_CRC}))},
+ AArch64::ExtensionBitset(
+ {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_CRC})},
{"thunderx2t99", ARMV8_1A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2}))},
+ AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2})},
{"thunderx3t110", ARMV8_3A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2}))},
+ AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2})},
{"thunderx", ARMV8A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_CRC}))},
+ AArch64::ExtensionBitset(
+ {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_CRC})},
{"thunderxt88", ARMV8A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_CRC}))},
+ AArch64::ExtensionBitset(
+ {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_CRC})},
{"thunderxt81", ARMV8A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_CRC}))},
+ AArch64::ExtensionBitset(
+ {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_CRC})},
{"thunderxt83", ARMV8A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_CRC}))},
+ AArch64::ExtensionBitset(
+ {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_CRC})},
{"tsv110", ARMV8_2A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_DOTPROD,
- AArch64::AEK_FP16, AArch64::AEK_FP16FML, AArch64::AEK_PROFILE,
- AArch64::AEK_JSCVT, AArch64::AEK_FCMA}))},
+ AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
+ AArch64::AEK_DOTPROD, AArch64::AEK_FP16,
+ AArch64::AEK_FP16FML, AArch64::AEK_PROFILE,
+ AArch64::AEK_JSCVT, AArch64::AEK_FCMA})},
{"a64fx", ARMV8_2A,
- (AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
- AArch64::AEK_FP16,
- AArch64::AEK_SVE}))},
+ AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
+ AArch64::AEK_FP16, AArch64::AEK_SVE})},
{"carmel", ARMV8_2A,
- (AArch64::ExtensionBitset(
- {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_FP16}))},
+ AArch64::ExtensionBitset(
+ {AArch64::AEK_AES, AArch64::AEK_SHA2, AArch64::AEK_FP16})},
{"ampere1", ARMV8_6A,
- (AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
- AArch64::AEK_SHA3, AArch64::AEK_FP16,
- AArch64::AEK_SB, AArch64::AEK_SSBS,
- AArch64::AEK_RAND}))},
+ AArch64::ExtensionBitset({AArch64::AEK_AES, AArch64::AEK_SHA2,
+ AArch64::AEK_SHA3, AArch64::AEK_FP16,
+ AArch64::AEK_SB, AArch64::AEK_SSBS,
+ AArch64::AEK_RAND})},
{"ampere1a", ARMV8_6A,
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_FP16, AArch64::AEK_RAND, AArch64::AEK_SM4,
AArch64::AEK_SHA3, AArch64::AEK_SHA2, AArch64::AEK_AES,
- AArch64::AEK_MTE, AArch64::AEK_SB, AArch64::AEK_SSBS}))},
+ AArch64::AEK_MTE, AArch64::AEK_SB, AArch64::AEK_SSBS})},
{"ampere1b", ARMV8_7A,
- (AArch64::ExtensionBitset({AArch64::AEK_FP16, AArch64::AEK_RAND,
- AArch64::AEK_SM4, AArch64::AEK_SHA3,
- AArch64::AEK_SHA2, AArch64::AEK_AES,
- AArch64::AEK_MTE, AArch64::AEK_SB,
- AArch64::AEK_SSBS, AArch64::AEK_CSSC}))},
+ AArch64::ExtensionBitset({AArch64::AEK_FP16, AArch64::AEK_RAND,
+ AArch64::AEK_SM4, AArch64::AEK_SHA3,
+ AArch64::AEK_SHA2, AArch64::AEK_AES,
+ AArch64::AEK_MTE, AArch64::AEK_SB,
+ AArch64::AEK_SSBS, AArch64::AEK_CSSC})},
};
// Name alias.
diff --git a/llvm/include/llvm/TargetParser/ARMTargetParser.def b/llvm/include/llvm/TargetParser/ARMTargetParser.def
index f0ddaa1459e567..fa6cfdfeda28cf 100644
--- a/llvm/include/llvm/TargetParser/ARMTargetParser.def
+++ b/llvm/include/llvm/TargetParser/ARMTargetParser.def
@@ -15,211 +15,239 @@
#ifndef ARM_FPU
#define ARM_FPU(NAME, KIND, VERSION, NEON_SUPPORT, RESTRICTION)
#endif
-ARM_FPU("invalid", FK_INVALID, FPUVersion::NONE, NeonSupportLevel::None, FPURestriction::None)
-ARM_FPU("none", FK_NONE, FPUVersion::NONE, NeonSupportLevel::None, FPURestriction::None)
-ARM_FPU("vfp", FK_VFP, FPUVersion::VFPV2, NeonSupportLevel::None, FPURestriction::None)
-ARM_FPU("vfpv2", FK_VFPV2, FPUVersion::VFPV2, NeonSupportLevel::None, FPURestriction::None)
-ARM_FPU("vfpv3", FK_VFPV3, FPUVersion::VFPV3, NeonSupportLevel::None, FPURestriction::None)
-ARM_FPU("vfpv3-fp16", FK_VFPV3_FP16, FPUVersion::VFPV3_FP16, NeonSupportLevel::None, FPURestriction::None)
-ARM_FPU("vfpv3-d16", FK_VFPV3_D16, FPUVersion::VFPV3, NeonSupportLevel::None, FPURestriction::D16)
-ARM_FPU("vfpv3-d16-fp16", FK_VFPV3_D16_FP16, FPUVersion::VFPV3_FP16, NeonSupportLevel::None, FPURestriction::D16)
-ARM_FPU("vfpv3xd", FK_VFPV3XD, FPUVersion::VFPV3, NeonSupportLevel::None, FPURestriction::SP_D16)
-ARM_FPU("vfpv3xd-fp16", FK_VFPV3XD_FP16, FPUVersion::VFPV3_FP16, NeonSupportLevel::None, FPURestriction::SP_D16)
-ARM_FPU("vfpv4", FK_VFPV4, FPUVersion::VFPV4, NeonSupportLevel::None, FPURestriction::None)
-ARM_FPU("vfpv4-d16", FK_VFPV4_D16, FPUVersion::VFPV4, NeonSupportLevel::None, FPURestriction::D16)
-ARM_FPU("fpv4-sp-d16", FK_FPV4_SP_D16, FPUVersion::VFPV4, NeonSupportLevel::None, FPURestriction::SP_D16)
-ARM_FPU("fpv5-d16", FK_FPV5_D16, FPUVersion::VFPV5, NeonSupportLevel::None, FPURestriction::D16)
-ARM_FPU("fpv5-sp-d16", FK_FPV5_SP_D16, FPUVersion::VFPV5, NeonSupportLevel::None, FPURestriction::SP_D16)
-ARM_FPU("fp-armv8", FK_FP_ARMV8, FPUVersion::VFPV5, NeonSupportLevel::None, FPURestriction::None)
-ARM_FPU("fp-armv8-fullfp16-d16", FK_FP_ARMV8_FULLFP16_D16, FPUVersion::VFPV5_FULLFP16, NeonSupportLevel::None, FPURestriction::D16)
-ARM_FPU("fp-armv8-fullfp16-sp-d16", FK_FP_ARMV8_FULLFP16_SP_D16, FPUVersion::VFPV5_FULLFP16, NeonSupportLevel::None, FPURestriction::SP_D16)
-ARM_FPU("neon", FK_NEON, FPUVersion::VFPV3, NeonSupportLevel::Neon, FPURestriction::None)
-ARM_FPU("neon-fp16", FK_NEON_FP16, FPUVersion::VFPV3_FP16, NeonSupportLevel::Neon, FPURestriction::None)
-ARM_FPU("neon-vfpv4", FK_NEON_VFPV4, FPUVersion::VFPV4, NeonSupportLevel::Neon, FPURestriction::None)
-ARM_FPU("neon-fp-armv8", FK_NEON_FP_ARMV8, FPUVersion::VFPV5, NeonSupportLevel::Neon, FPURestriction::None)
-ARM_FPU("crypto-neon-fp-armv8", FK_CRYPTO_NEON_FP_ARMV8, FPUVersion::VFPV5, NeonSupportLevel::Crypto,
+ARM_FPU("invalid", FK_INVALID, FPUVersion::NONE, NeonSupportLevel::None,
+ FPURestriction::None)
+ARM_FPU("none", FK_NONE, FPUVersion::NONE, NeonSupportLevel::None,
+ FPURestriction::None)
+ARM_FPU("vfp", FK_VFP, FPUVersion::VFPV2, NeonSupportLevel::None,
+ FPURestriction::None)
+ARM_FPU("vfpv2", FK_VFPV2, FPUVersion::VFPV2, NeonSupportLevel::None,
+ FPURestriction::None)
+ARM_FPU("vfpv3", FK_VFPV3, FPUVersion::VFPV3, NeonSupportLevel::None,
+ FPURestriction::None)
+ARM_FPU("vfpv3-fp16", FK_VFPV3_FP16, FPUVersion::VFPV3_FP16,
+ NeonSupportLevel::None, FPURestriction::None)
+ARM_FPU("vfpv3-d16", FK_VFPV3_D16, FPUVersion::VFPV3, NeonSupportLevel::None,
+ FPURestriction::D16)
+ARM_FPU("vfpv3-d16-fp16", FK_VFPV3_D16_FP16, FPUVersion::VFPV3_FP16,
+ NeonSupportLevel::None, FPURestriction::D16)
+ARM_FPU("vfpv3xd", FK_VFPV3XD, FPUVersion::VFPV3, NeonSupportLevel::None,
+ FPURestriction::SP_D16)
+ARM_FPU("vfpv3xd-fp16", FK_VFPV3XD_FP16, FPUVersion::VFPV3_FP16,
+ NeonSupportLevel::None, FPURestriction::SP_D16)
+ARM_FPU("vfpv4", FK_VFPV4, FPUVersion::VFPV4, NeonSupportLevel::None,
+ FPURestriction::None)
+ARM_FPU("vfpv4-d16", FK_VFPV4_D16, FPUVersion::VFPV4, NeonSupportLevel::None,
+ FPURestriction::D16)
+ARM_FPU("fpv4-sp-d16", FK_FPV4_SP_D16, FPUVersion::VFPV4,
+ NeonSupportLevel::None, FPURestriction::SP_D16)
+ARM_FPU("fpv5-d16", FK_FPV5_D16, FPUVersion::VFPV5, NeonSupportLevel::None,
+ FPURestriction::D16)
+ARM_FPU("fpv5-sp-d16", FK_FPV5_SP_D16, FPUVersion::VFPV5,
+ NeonSupportLevel::None, FPURestriction::SP_D16)
+ARM_FPU("fp-armv8", FK_FP_ARMV8, FPUVersion::VFPV5, NeonSupportLevel::None,
+ FPURestriction::None)
+ARM_FPU("fp-armv8-fullfp16-d16", FK_FP_ARMV8_FULLFP16_D16,
+ FPUVersion::VFPV5_FULLFP16, NeonSupportLevel::None, FPURestriction::D16)
+ARM_FPU("fp-armv8-fullfp16-sp-d16", FK_FP_ARMV8_FULLFP16_SP_D16,
+ FPUVersion::VFPV5_FULLFP16, NeonSupportLevel::None,
+ FPURestriction::SP_D16)
+ARM_FPU("neon", FK_NEON, FPUVersion::VFPV3, NeonSupportLevel::Neon,
+ FPURestriction::None)
+ARM_FPU("neon-fp16", FK_NEON_FP16, FPUVersion::VFPV3_FP16,
+ NeonSupportLevel::Neon, FPURestriction::None)
+ARM_FPU("neon-vfpv4", FK_NEON_VFPV4, FPUVersion::VFPV4, NeonSupportLevel::Neon,
+ FPURestriction::None)
+ARM_FPU("neon-fp-armv8", FK_NEON_FP_ARMV8, FPUVersion::VFPV5,
+ NeonSupportLevel::Neon, FPURestriction::None)
+ARM_FPU("crypto-neon-fp-armv8", FK_CRYPTO_NEON_FP_ARMV8, FPUVersion::VFPV5,
+ NeonSupportLevel::Crypto, FPURestriction::None)
+ARM_FPU("softvfp", FK_SOFTVFP, FPUVersion::NONE, NeonSupportLevel::None,
FPURestriction::None)
-ARM_FPU("softvfp", FK_SOFTVFP, FPUVersion::NONE, NeonSupportLevel::None, FPURestriction::None)
#undef ARM_FPU
#ifndef ARM_ARCH
-#define ARM_ARCH(NAME, ID, CPU_ATTR, ARCH_FEATURE, ARCH_ATTR, ARCH_FPU, ARCH_BASE_EXT)
+#define ARM_ARCH(NAME, ID, CPU_ATTR, ARCH_FEATURE, ARCH_ATTR, ARCH_FPU, \
+ ARCH_BASE_EXT)
#endif
-ARM_ARCH("invalid", INVALID, "", "+",
- ARMBuildAttrs::CPUArch::Pre_v4, FK_NONE, ARM::AEK_NONE)
-ARM_ARCH("armv4", ARMV4, "4", "+v4", ARMBuildAttrs::CPUArch::v4,
- FK_NONE, ARM::AEK_NONE)
-ARM_ARCH("armv4t", ARMV4T, "4T", "+v4t", ARMBuildAttrs::CPUArch::v4T,
- FK_NONE, ARM::AEK_NONE)
-ARM_ARCH("armv5t", ARMV5T, "5T", "+v5", ARMBuildAttrs::CPUArch::v5T,
- FK_NONE, ARM::AEK_NONE)
+ARM_ARCH("invalid", INVALID, "", "+", ARMBuildAttrs::CPUArch::Pre_v4, FK_NONE,
+ ARM::AEK_NONE)
+ARM_ARCH("armv4", ARMV4, "4", "+v4", ARMBuildAttrs::CPUArch::v4, FK_NONE,
+ ARM::AEK_NONE)
+ARM_ARCH("armv4t", ARMV4T, "4T", "+v4t", ARMBuildAttrs::CPUArch::v4T, FK_NONE,
+ ARM::AEK_NONE)
+ARM_ARCH("armv5t", ARMV5T, "5T", "+v5", ARMBuildAttrs::CPUArch::v5T, FK_NONE,
+ ARM::AEK_NONE)
ARM_ARCH("armv5te", ARMV5TE, "5TE", "+v5e", ARMBuildAttrs::CPUArch::v5TE,
- FK_NONE, ARM::AEK_DSP)
+ FK_NONE, ARM::AEK_DSP)
ARM_ARCH("armv5tej", ARMV5TEJ, "5TEJ", "+v5e", ARMBuildAttrs::CPUArch::v5TEJ,
- FK_NONE, ARM::AEK_DSP)
-ARM_ARCH("armv6", ARMV6, "6", "+v6", ARMBuildAttrs::CPUArch::v6,
- FK_VFPV2, ARM::AEK_DSP)
-ARM_ARCH("armv6k", ARMV6K, "6K", "+v6k", ARMBuildAttrs::CPUArch::v6K,
- FK_VFPV2, ARM::AEK_DSP)
+ FK_NONE, ARM::AEK_DSP)
+ARM_ARCH("armv6", ARMV6, "6", "+v6", ARMBuildAttrs::CPUArch::v6, FK_VFPV2,
+ ARM::AEK_DSP)
+ARM_ARCH("armv6k", ARMV6K, "6K", "+v6k", ARMBuildAttrs::CPUArch::v6K, FK_VFPV2,
+ ARM::AEK_DSP)
ARM_ARCH("armv6t2", ARMV6T2, "6T2", "+v6t2", ARMBuildAttrs::CPUArch::v6T2,
- FK_NONE, ARM::AEK_DSP)
+ FK_NONE, ARM::AEK_DSP)
ARM_ARCH("armv6kz", ARMV6KZ, "6KZ", "+v6kz", ARMBuildAttrs::CPUArch::v6KZ,
- FK_VFPV2, (ARM::AEK_SEC | ARM::AEK_DSP))
+ FK_VFPV2, (ARM::AEK_SEC | ARM::AEK_DSP))
ARM_ARCH("armv6-m", ARMV6M, "6-M", "+v6m", ARMBuildAttrs::CPUArch::v6_M,
- FK_NONE, ARM::AEK_NONE)
-ARM_ARCH("armv7-a", ARMV7A, "7-A", "+v7", ARMBuildAttrs::CPUArch::v7,
- FK_NEON, ARM::AEK_DSP)
+ FK_NONE, ARM::AEK_NONE)
+ARM_ARCH("armv7-a", ARMV7A, "7-A", "+v7", ARMBuildAttrs::CPUArch::v7, FK_NEON,
+ ARM::AEK_DSP)
ARM_ARCH("armv7ve", ARMV7VE, "7VE", "+v7ve", ARMBuildAttrs::CPUArch::v7,
- FK_NEON, (ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT |
- ARM::AEK_HWDIVARM | ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP))
-ARM_ARCH("armv7-r", ARMV7R, "7-R", "+v7r", ARMBuildAttrs::CPUArch::v7,
- FK_NONE, (ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP))
-ARM_ARCH("armv7-m", ARMV7M, "7-M", "+v7m", ARMBuildAttrs::CPUArch::v7,
- FK_NONE, ARM::AEK_HWDIVTHUMB)
+ FK_NEON,
+ (ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
+ ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP))
+ARM_ARCH("armv7-r", ARMV7R, "7-R", "+v7r", ARMBuildAttrs::CPUArch::v7, FK_NONE,
+ (ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP))
+ARM_ARCH("armv7-m", ARMV7M, "7-M", "+v7m", ARMBuildAttrs::CPUArch::v7, FK_NONE,
+ ARM::AEK_HWDIVTHUMB)
ARM_ARCH("armv7e-m", ARMV7EM, "7E-M", "+v7em", ARMBuildAttrs::CPUArch::v7E_M,
- FK_NONE, (ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP))
+ FK_NONE, (ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP))
ARM_ARCH("armv8-a", ARMV8A, "8-A", "+v8a", ARMBuildAttrs::CPUArch::v8_A,
FK_CRYPTO_NEON_FP_ARMV8,
(ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP | ARM::AEK_CRC))
-ARM_ARCH("armv8.1-a", ARMV8_1A, "8.1-A", "+v8.1a",
- ARMBuildAttrs::CPUArch::v8_A, FK_CRYPTO_NEON_FP_ARMV8,
+ARM_ARCH("armv8.1-a", ARMV8_1A, "8.1-A", "+v8.1a", ARMBuildAttrs::CPUArch::v8_A,
+ FK_CRYPTO_NEON_FP_ARMV8,
(ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP | ARM::AEK_CRC))
-ARM_ARCH("armv8.2-a", ARMV8_2A, "8.2-A", "+v8.2a",
- ARMBuildAttrs::CPUArch::v8_A, FK_CRYPTO_NEON_FP_ARMV8,
+ARM_ARCH("armv8.2-a", ARMV8_2A, "8.2-A", "+v8.2a", ARMBuildAttrs::CPUArch::v8_A,
+ FK_CRYPTO_NEON_FP_ARMV8,
(ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP | ARM::AEK_CRC | ARM::AEK_RAS))
-ARM_ARCH("armv8.3-a", ARMV8_3A, "8.3-A", "+v8.3a",
- ARMBuildAttrs::CPUArch::v8_A, FK_CRYPTO_NEON_FP_ARMV8,
+ARM_ARCH("armv8.3-a", ARMV8_3A, "8.3-A", "+v8.3a", ARMBuildAttrs::CPUArch::v8_A,
+ FK_CRYPTO_NEON_FP_ARMV8,
(ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP | ARM::AEK_CRC | ARM::AEK_RAS))
-ARM_ARCH("armv8.4-a", ARMV8_4A, "8.4-A", "+v8.4a",
- ARMBuildAttrs::CPUArch::v8_A, FK_CRYPTO_NEON_FP_ARMV8,
+ARM_ARCH("armv8.4-a", ARMV8_4A, "8.4-A", "+v8.4a", ARMBuildAttrs::CPUArch::v8_A,
+ FK_CRYPTO_NEON_FP_ARMV8,
(ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP | ARM::AEK_CRC | ARM::AEK_RAS |
ARM::AEK_DOTPROD))
-ARM_ARCH("armv8.5-a", ARMV8_5A, "8.5-A", "+v8.5a",
- ARMBuildAttrs::CPUArch::v8_A, FK_CRYPTO_NEON_FP_ARMV8,
+ARM_ARCH("armv8.5-a", ARMV8_5A, "8.5-A", "+v8.5a", ARMBuildAttrs::CPUArch::v8_A,
+ FK_CRYPTO_NEON_FP_ARMV8,
(ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP | ARM::AEK_CRC | ARM::AEK_RAS |
ARM::AEK_DOTPROD))
-ARM_ARCH("armv8.6-a", ARMV8_6A, "8.6-A", "+v8.6a",
- ARMBuildAttrs::CPUArch::v8_A, FK_CRYPTO_NEON_FP_ARMV8,
- (ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
- ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP | ARM::AEK_CRC | ARM::AEK_RAS |
- ARM::AEK_DOTPROD | ARM::AEK_BF16 | ARM::AEK_I8MM))
-ARM_ARCH("armv8.7-a", ARMV8_7A, "8.7-A", "+v8.7a",
- ARMBuildAttrs::CPUArch::v8_A, FK_CRYPTO_NEON_FP_ARMV8,
- (ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
- ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP | ARM::AEK_CRC | ARM::AEK_RAS |
- ARM::AEK_DOTPROD | ARM::AEK_BF16 | ARM::AEK_I8MM))
-ARM_ARCH("armv8.8-a", ARMV8_8A, "8.8-A", "+v8.8a",
- ARMBuildAttrs::CPUArch::v8_A, FK_CRYPTO_NEON_FP_ARMV8,
+ARM_ARCH("armv8.6-a", ARMV8_6A, "8.6-A", "+v8.6a", ARMBuildAttrs::CPUArch::v8_A,
+ FK_CRYPTO_NEON_FP_ARMV8,
+ (ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
+ ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP | ARM::AEK_CRC | ARM::AEK_RAS |
+ ARM::AEK_DOTPROD | ARM::AEK_BF16 | ARM::AEK_I8MM))
+ARM_ARCH("armv8.7-a", ARMV8_7A, "8.7-A", "+v8.7a", ARMBuildAttrs::CPUArch::v8_A,
+ FK_CRYPTO_NEON_FP_ARMV8,
+ (ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
+ ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP | ARM::AEK_CRC | ARM::AEK_RAS |
+ ARM::AEK_DOTPROD | ARM::AEK_BF16 | ARM::AEK_I8MM))
+ARM_ARCH("armv8.8-a", ARMV8_8A, "8.8-A", "+v8.8a", ARMBuildAttrs::CPUArch::v8_A,
+ FK_CRYPTO_NEON_FP_ARMV8,
(ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP | ARM::AEK_CRC | ARM::AEK_RAS |
ARM::AEK_DOTPROD | ARM::AEK_BF16 | ARM::AEK_SHA2 | ARM::AEK_AES |
ARM::AEK_I8MM))
-ARM_ARCH("armv8.9-a", ARMV8_9A, "8.9-A", "+v8.9a",
- ARMBuildAttrs::CPUArch::v8_A, FK_CRYPTO_NEON_FP_ARMV8,
+ARM_ARCH("armv8.9-a", ARMV8_9A, "8.9-A", "+v8.9a", ARMBuildAttrs::CPUArch::v8_A,
+ FK_CRYPTO_NEON_FP_ARMV8,
(ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP | ARM::AEK_CRC | ARM::AEK_RAS |
ARM::AEK_DOTPROD | ARM::AEK_BF16 | ARM::AEK_SHA2 | ARM::AEK_AES |
ARM::AEK_I8MM))
-ARM_ARCH("armv9-a", ARMV9A, "9-A", "+v9a",
- ARMBuildAttrs::CPUArch::v9_A, FK_NEON_FP_ARMV8,
+ARM_ARCH("armv9-a", ARMV9A, "9-A", "+v9a", ARMBuildAttrs::CPUArch::v9_A,
+ FK_NEON_FP_ARMV8,
(ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP | ARM::AEK_CRC | ARM::AEK_RAS |
ARM::AEK_DOTPROD))
-ARM_ARCH("armv9.1-a", ARMV9_1A, "9.1-A", "+v9.1a",
- ARMBuildAttrs::CPUArch::v9_A, FK_NEON_FP_ARMV8,
+ARM_ARCH("armv9.1-a", ARMV9_1A, "9.1-A", "+v9.1a", ARMBuildAttrs::CPUArch::v9_A,
+ FK_NEON_FP_ARMV8,
(ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP | ARM::AEK_CRC | ARM::AEK_RAS |
ARM::AEK_DOTPROD | ARM::AEK_BF16 | ARM::AEK_I8MM))
-ARM_ARCH("armv9.2-a", ARMV9_2A, "9.2-A", "+v9.2a",
- ARMBuildAttrs::CPUArch::v9_A, FK_NEON_FP_ARMV8,
+ARM_ARCH("armv9.2-a", ARMV9_2A, "9.2-A", "+v9.2a", ARMBuildAttrs::CPUArch::v9_A,
+ FK_NEON_FP_ARMV8,
(ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP | ARM::AEK_CRC | ARM::AEK_RAS |
ARM::AEK_DOTPROD | ARM::AEK_BF16 | ARM::AEK_I8MM))
-ARM_ARCH("armv9.3-a", ARMV9_3A, "9.3-A", "+v9.3a",
- ARMBuildAttrs::CPUArch::v9_A, FK_CRYPTO_NEON_FP_ARMV8,
+ARM_ARCH("armv9.3-a", ARMV9_3A, "9.3-A", "+v9.3a", ARMBuildAttrs::CPUArch::v9_A,
+ FK_CRYPTO_NEON_FP_ARMV8,
(ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP | ARM::AEK_CRC | ARM::AEK_RAS |
ARM::AEK_DOTPROD | ARM::AEK_BF16 | ARM::AEK_I8MM))
-ARM_ARCH("armv9.4-a", ARMV9_4A, "9.4-A", "+v9.4a",
- ARMBuildAttrs::CPUArch::v9_A, FK_NEON_FP_ARMV8,
+ARM_ARCH("armv9.4-a", ARMV9_4A, "9.4-A", "+v9.4a", ARMBuildAttrs::CPUArch::v9_A,
+ FK_NEON_FP_ARMV8,
(ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP | ARM::AEK_CRC | ARM::AEK_RAS |
ARM::AEK_DOTPROD | ARM::AEK_BF16 | ARM::AEK_I8MM))
-ARM_ARCH("armv9.5-a", ARMV9_5A, "9.5-A", "+v9.5a",
- ARMBuildAttrs::CPUArch::v9_A, FK_NEON_FP_ARMV8,
+ARM_ARCH("armv9.5-a", ARMV9_5A, "9.5-A", "+v9.5a", ARMBuildAttrs::CPUArch::v9_A,
+ FK_NEON_FP_ARMV8,
(ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP | ARM::AEK_CRC | ARM::AEK_RAS |
ARM::AEK_DOTPROD | ARM::AEK_BF16 | ARM::AEK_I8MM))
ARM_ARCH("armv8-r", ARMV8R, "8-R", "+v8r", ARMBuildAttrs::CPUArch::v8_R,
- FK_NEON_FP_ARMV8,
- (ARM::AEK_MP | ARM::AEK_VIRT | ARM::AEK_HWDIVARM | ARM::AEK_HWDIVTHUMB |
- ARM::AEK_DSP | ARM::AEK_CRC))
+ FK_NEON_FP_ARMV8,
+ (ARM::AEK_MP | ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
+ ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP | ARM::AEK_CRC))
ARM_ARCH("armv8-m.base", ARMV8MBaseline, "8-M.Baseline", "+v8m.base",
- ARMBuildAttrs::CPUArch::v8_M_Base, FK_NONE, ARM::AEK_HWDIVTHUMB)
+ ARMBuildAttrs::CPUArch::v8_M_Base, FK_NONE, ARM::AEK_HWDIVTHUMB)
ARM_ARCH("armv8-m.main", ARMV8MMainline, "8-M.Mainline", "+v8m.main",
- ARMBuildAttrs::CPUArch::v8_M_Main, FK_FPV5_D16, ARM::AEK_HWDIVTHUMB)
+ ARMBuildAttrs::CPUArch::v8_M_Main, FK_FPV5_D16, ARM::AEK_HWDIVTHUMB)
ARM_ARCH("armv8.1-m.main", ARMV8_1MMainline, "8.1-M.Mainline", "+v8.1m.main",
- ARMBuildAttrs::CPUArch::v8_1_M_Main, FK_FP_ARMV8_FULLFP16_SP_D16, ARM::AEK_HWDIVTHUMB | ARM::AEK_RAS | ARM::AEK_LOB)
+ ARMBuildAttrs::CPUArch::v8_1_M_Main, FK_FP_ARMV8_FULLFP16_SP_D16,
+ ARM::AEK_HWDIVTHUMB | ARM::AEK_RAS | ARM::AEK_LOB)
// Non-standard Arch names.
-ARM_ARCH("iwmmxt", IWMMXT, "iwmmxt", "+", ARMBuildAttrs::CPUArch::v5TE,
- FK_NONE, ARM::AEK_NONE)
+ARM_ARCH("iwmmxt", IWMMXT, "iwmmxt", "+", ARMBuildAttrs::CPUArch::v5TE, FK_NONE,
+ ARM::AEK_NONE)
ARM_ARCH("iwmmxt2", IWMMXT2, "iwmmxt2", "+", ARMBuildAttrs::CPUArch::v5TE,
- FK_NONE, ARM::AEK_NONE)
+ FK_NONE, ARM::AEK_NONE)
ARM_ARCH("xscale", XSCALE, "xscale", "+v5e", ARMBuildAttrs::CPUArch::v5TE,
- FK_NONE, ARM::AEK_NONE)
+ FK_NONE, ARM::AEK_NONE)
ARM_ARCH("armv7s", ARMV7S, "7-S", "+v7s", ARMBuildAttrs::CPUArch::v7,
- FK_NEON_VFPV4, ARM::AEK_DSP)
-ARM_ARCH("armv7k", ARMV7K, "7-K", "+v7k", ARMBuildAttrs::CPUArch::v7,
- FK_NONE, ARM::AEK_DSP)
+ FK_NEON_VFPV4, ARM::AEK_DSP)
+ARM_ARCH("armv7k", ARMV7K, "7-K", "+v7k", ARMBuildAttrs::CPUArch::v7, FK_NONE,
+ ARM::AEK_DSP)
#undef ARM_ARCH
#ifndef ARM_ARCH_EXT_NAME
#define ARM_ARCH_EXT_NAME(NAME, ID, FEATURE, NEGFEATURE)
#endif
-ARM_ARCH_EXT_NAME("invalid", ARM::AEK_INVALID, {}, {})
-ARM_ARCH_EXT_NAME("none", ARM::AEK_NONE, {}, {})
-ARM_ARCH_EXT_NAME("crc", ARM::AEK_CRC, "+crc", "-crc")
-ARM_ARCH_EXT_NAME("crypto", ARM::AEK_CRYPTO, "+crypto","-crypto")
-ARM_ARCH_EXT_NAME("sha2", ARM::AEK_SHA2, "+sha2", "-sha2")
-ARM_ARCH_EXT_NAME("aes", ARM::AEK_AES, "+aes", "-aes")
-ARM_ARCH_EXT_NAME("dotprod", ARM::AEK_DOTPROD, "+dotprod","-dotprod")
-ARM_ARCH_EXT_NAME("dsp", ARM::AEK_DSP, "+dsp", "-dsp")
-ARM_ARCH_EXT_NAME("fp", ARM::AEK_FP, {}, {})
-ARM_ARCH_EXT_NAME("fp.dp", ARM::AEK_FP_DP, {}, {})
-ARM_ARCH_EXT_NAME("mve", (ARM::AEK_DSP | ARM::AEK_SIMD), "+mve", "-mve")
-ARM_ARCH_EXT_NAME("mve.fp", (ARM::AEK_DSP | ARM::AEK_SIMD | ARM::AEK_FP), "+mve.fp", "-mve.fp")
-ARM_ARCH_EXT_NAME("idiv", (ARM::AEK_HWDIVARM | ARM::AEK_HWDIVTHUMB), {}, {})
-ARM_ARCH_EXT_NAME("mp", ARM::AEK_MP, {}, {})
-ARM_ARCH_EXT_NAME("simd", ARM::AEK_SIMD, {}, {})
-ARM_ARCH_EXT_NAME("sec", ARM::AEK_SEC, {}, {})
-ARM_ARCH_EXT_NAME("virt", ARM::AEK_VIRT, {}, {})
-ARM_ARCH_EXT_NAME("fp16", ARM::AEK_FP16, "+fullfp16", "-fullfp16")
-ARM_ARCH_EXT_NAME("ras", ARM::AEK_RAS, "+ras", "-ras")
-ARM_ARCH_EXT_NAME("os", ARM::AEK_OS, {}, {})
-ARM_ARCH_EXT_NAME("iwmmxt", ARM::AEK_IWMMXT, {}, {})
-ARM_ARCH_EXT_NAME("iwmmxt2", ARM::AEK_IWMMXT2, {}, {})
-ARM_ARCH_EXT_NAME("maverick", ARM::AEK_MAVERICK, {}, {})
-ARM_ARCH_EXT_NAME("xscale", ARM::AEK_XSCALE, {}, {})
-ARM_ARCH_EXT_NAME("fp16fml", ARM::AEK_FP16FML, "+fp16fml", "-fp16fml")
-ARM_ARCH_EXT_NAME("bf16", ARM::AEK_BF16, "+bf16", "-bf16")
-ARM_ARCH_EXT_NAME("sb", ARM::AEK_SB, "+sb", "-sb")
-ARM_ARCH_EXT_NAME("i8mm", ARM::AEK_I8MM, "+i8mm", "-i8mm")
-ARM_ARCH_EXT_NAME("lob", ARM::AEK_LOB, "+lob", "-lob")
-ARM_ARCH_EXT_NAME("cdecp0", ARM::AEK_CDECP0, "+cdecp0", "-cdecp0")
-ARM_ARCH_EXT_NAME("cdecp1", ARM::AEK_CDECP1, "+cdecp1", "-cdecp1")
-ARM_ARCH_EXT_NAME("cdecp2", ARM::AEK_CDECP2, "+cdecp2", "-cdecp2")
-ARM_ARCH_EXT_NAME("cdecp3", ARM::AEK_CDECP3, "+cdecp3", "-cdecp3")
-ARM_ARCH_EXT_NAME("cdecp4", ARM::AEK_CDECP4, "+cdecp4", "-cdecp4")
-ARM_ARCH_EXT_NAME("cdecp5", ARM::AEK_CDECP5, "+cdecp5", "-cdecp5")
-ARM_ARCH_EXT_NAME("cdecp6", ARM::AEK_CDECP6, "+cdecp6", "-cdecp6")
-ARM_ARCH_EXT_NAME("cdecp7", ARM::AEK_CDECP7, "+cdecp7", "-cdecp7")
-ARM_ARCH_EXT_NAME("pacbti", ARM::AEK_PACBTI, "+pacbti", "-pacbti")
+ARM_ARCH_EXT_NAME("invalid", ARM::AEK_INVALID, {}, {})
+ARM_ARCH_EXT_NAME("none", ARM::AEK_NONE, {}, {})
+ARM_ARCH_EXT_NAME("crc", ARM::AEK_CRC, "+crc", "-crc")
+ARM_ARCH_EXT_NAME("crypto", ARM::AEK_CRYPTO, "+crypto", "-crypto")
+ARM_ARCH_EXT_NAME("sha2", ARM::AEK_SHA2, "+sha2", "-sha2")
+ARM_ARCH_EXT_NAME("aes", ARM::AEK_AES, "+aes", "-aes")
+ARM_ARCH_EXT_NAME("dotprod", ARM::AEK_DOTPROD, "+dotprod", "-dotprod")
+ARM_ARCH_EXT_NAME("dsp", ARM::AEK_DSP, "+dsp", "-dsp")
+ARM_ARCH_EXT_NAME("fp", ARM::AEK_FP, {}, {})
+ARM_ARCH_EXT_NAME("fp.dp", ARM::AEK_FP_DP, {}, {})
+ARM_ARCH_EXT_NAME("mve", (ARM::AEK_DSP | ARM::AEK_SIMD), "+mve", "-mve")
+ARM_ARCH_EXT_NAME("mve.fp", (ARM::AEK_DSP | ARM::AEK_SIMD | ARM::AEK_FP),
+ "+mve.fp", "-mve.fp")
+ARM_ARCH_EXT_NAME("idiv", (ARM::AEK_HWDIVARM | ARM::AEK_HWDIVTHUMB), {}, {})
+ARM_ARCH_EXT_NAME("mp", ARM::AEK_MP, {}, {})
+ARM_ARCH_EXT_NAME("simd", ARM::AEK_SIMD, {}, {})
+ARM_ARCH_EXT_NAME("sec", ARM::AEK_SEC, {}, {})
+ARM_ARCH_EXT_NAME("virt", ARM::AEK_VIRT, {}, {})
+ARM_ARCH_EXT_NAME("fp16", ARM::AEK_FP16, "+fullfp16", "-fullfp16")
+ARM_ARCH_EXT_NAME("ras", ARM::AEK_RAS, "+ras", "-ras")
+ARM_ARCH_EXT_NAME("os", ARM::AEK_OS, {}, {})
+ARM_ARCH_EXT_NAME("iwmmxt", ARM::AEK_IWMMXT, {}, {})
+ARM_ARCH_EXT_NAME("iwmmxt2", ARM::AEK_IWMMXT2, {}, {})
+ARM_ARCH_EXT_NAME("maverick", ARM::AEK_MAVERICK, {}, {})
+ARM_ARCH_EXT_NAME("xscale", ARM::AEK_XSCALE, {}, {})
+ARM_ARCH_EXT_NAME("fp16fml", ARM::AEK_FP16FML, "+fp16fml", "-fp16fml")
+ARM_ARCH_EXT_NAME("bf16", ARM::AEK_BF16, "+bf16", "-bf16")
+ARM_ARCH_EXT_NAME("sb", ARM::AEK_SB, "+sb", "-sb")
+ARM_ARCH_EXT_NAME("i8mm", ARM::AEK_I8MM, "+i8mm", "-i8mm")
+ARM_ARCH_EXT_NAME("lob", ARM::AEK_LOB, "+lob", "-lob")
+ARM_ARCH_EXT_NAME("cdecp0", ARM::AEK_CDECP0, "+cdecp0", "-cdecp0")
+ARM_ARCH_EXT_NAME("cdecp1", ARM::AEK_CDECP1, "+cdecp1", "-cdecp1")
+ARM_ARCH_EXT_NAME("cdecp2", ARM::AEK_CDECP2, "+cdecp2", "-cdecp2")
+ARM_ARCH_EXT_NAME("cdecp3", ARM::AEK_CDECP3, "+cdecp3", "-cdecp3")
+ARM_ARCH_EXT_NAME("cdecp4", ARM::AEK_CDECP4, "+cdecp4", "-cdecp4")
+ARM_ARCH_EXT_NAME("cdecp5", ARM::AEK_CDECP5, "+cdecp5", "-cdecp5")
+ARM_ARCH_EXT_NAME("cdecp6", ARM::AEK_CDECP6, "+cdecp6", "-cdecp6")
+ARM_ARCH_EXT_NAME("cdecp7", ARM::AEK_CDECP7, "+cdecp7", "-cdecp7")
+ARM_ARCH_EXT_NAME("pacbti", ARM::AEK_PACBTI, "+pacbti", "-pacbti")
#undef ARM_ARCH_EXT_NAME
#ifndef ARM_HW_DIV_NAME
@@ -280,7 +308,8 @@ ARM_CPU_NAME("cortex-a7", ARMV7A, FK_NEON_VFPV4, false,
(ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
ARM::AEK_HWDIVTHUMB))
ARM_CPU_NAME("cortex-a8", ARMV7A, FK_NEON, false, ARM::AEK_SEC)
-ARM_CPU_NAME("cortex-a9", ARMV7A, FK_NEON_FP16, false, (ARM::AEK_SEC | ARM::AEK_MP))
+ARM_CPU_NAME("cortex-a9", ARMV7A, FK_NEON_FP16, false,
+ (ARM::AEK_SEC | ARM::AEK_MP))
ARM_CPU_NAME("cortex-a12", ARMV7A, FK_NEON_VFPV4, false,
(ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
ARM::AEK_HWDIVTHUMB))
@@ -320,25 +349,25 @@ ARM_CPU_NAME("cortex-a32", ARMV8A, FK_CRYPTO_NEON_FP_ARMV8, false, ARM::AEK_CRC)
ARM_CPU_NAME("cortex-a35", ARMV8A, FK_CRYPTO_NEON_FP_ARMV8, false, ARM::AEK_CRC)
ARM_CPU_NAME("cortex-a53", ARMV8A, FK_CRYPTO_NEON_FP_ARMV8, false, ARM::AEK_CRC)
ARM_CPU_NAME("cortex-a55", ARMV8_2A, FK_CRYPTO_NEON_FP_ARMV8, false,
- (ARM::AEK_FP16 | ARM::AEK_DOTPROD))
+ (ARM::AEK_FP16 | ARM::AEK_DOTPROD))
ARM_CPU_NAME("cortex-a57", ARMV8A, FK_CRYPTO_NEON_FP_ARMV8, false, ARM::AEK_CRC)
ARM_CPU_NAME("cortex-a72", ARMV8A, FK_CRYPTO_NEON_FP_ARMV8, false, ARM::AEK_CRC)
ARM_CPU_NAME("cortex-a73", ARMV8A, FK_CRYPTO_NEON_FP_ARMV8, false, ARM::AEK_CRC)
ARM_CPU_NAME("cortex-a75", ARMV8_2A, FK_CRYPTO_NEON_FP_ARMV8, false,
- (ARM::AEK_FP16 | ARM::AEK_DOTPROD))
+ (ARM::AEK_FP16 | ARM::AEK_DOTPROD))
ARM_CPU_NAME("cortex-a76", ARMV8_2A, FK_CRYPTO_NEON_FP_ARMV8, false,
- (ARM::AEK_FP16 | ARM::AEK_DOTPROD))
+ (ARM::AEK_FP16 | ARM::AEK_DOTPROD))
ARM_CPU_NAME("cortex-a76ae", ARMV8_2A, FK_CRYPTO_NEON_FP_ARMV8, false,
- (ARM::AEK_FP16 | ARM::AEK_DOTPROD))
+ (ARM::AEK_FP16 | ARM::AEK_DOTPROD))
ARM_CPU_NAME("cortex-a77", ARMV8_2A, FK_CRYPTO_NEON_FP_ARMV8, false,
- (ARM::AEK_FP16 | ARM::AEK_DOTPROD))
+ (ARM::AEK_FP16 | ARM::AEK_DOTPROD))
ARM_CPU_NAME("cortex-a78", ARMV8_2A, FK_CRYPTO_NEON_FP_ARMV8, false,
(ARM::AEK_FP16 | ARM::AEK_DOTPROD))
ARM_CPU_NAME("cortex-a78c", ARMV8_2A, FK_CRYPTO_NEON_FP_ARMV8, false,
ARM::AEK_FP16 | ARM::AEK_DOTPROD)
ARM_CPU_NAME("cortex-a710", ARMV9A, FK_NEON_FP_ARMV8, false,
- (ARM::AEK_DOTPROD | ARM::AEK_FP16FML | ARM::AEK_BF16 | ARM::AEK_SB |
- ARM::AEK_I8MM))
+ (ARM::AEK_DOTPROD | ARM::AEK_FP16FML | ARM::AEK_BF16 |
+ ARM::AEK_SB | ARM::AEK_I8MM))
ARM_CPU_NAME("cortex-x1", ARMV8_2A, FK_CRYPTO_NEON_FP_ARMV8, false,
(ARM::AEK_FP16 | ARM::AEK_DOTPROD))
ARM_CPU_NAME("cortex-x1c", ARMV8_2A, FK_CRYPTO_NEON_FP_ARMV8, false,
diff --git a/llvm/include/llvm/TargetParser/ARMTargetParser.h b/llvm/include/llvm/TargetParser/ARMTargetParser.h
index c42d66f048fccc..2b0ef76a6b51f6 100644
--- a/llvm/include/llvm/TargetParser/ARMTargetParser.h
+++ b/llvm/include/llvm/TargetParser/ARMTargetParser.h
@@ -29,44 +29,44 @@ namespace ARM {
// Arch extension modifiers for CPUs.
// Note that this is not the same as the AArch64 list
enum ArchExtKind : uint64_t {
- AEK_INVALID = 0,
- AEK_NONE = 1,
- AEK_CRC = 1 << 1,
- AEK_CRYPTO = 1 << 2,
- AEK_FP = 1 << 3,
- AEK_HWDIVTHUMB = 1 << 4,
- AEK_HWDIVARM = 1 << 5,
- AEK_MP = 1 << 6,
- AEK_SIMD = 1 << 7,
- AEK_SEC = 1 << 8,
- AEK_VIRT = 1 << 9,
- AEK_DSP = 1 << 10,
- AEK_FP16 = 1 << 11,
- AEK_RAS = 1 << 12,
- AEK_DOTPROD = 1 << 13,
- AEK_SHA2 = 1 << 14,
- AEK_AES = 1 << 15,
- AEK_FP16FML = 1 << 16,
- AEK_SB = 1 << 17,
- AEK_FP_DP = 1 << 18,
- AEK_LOB = 1 << 19,
- AEK_BF16 = 1 << 20,
- AEK_I8MM = 1 << 21,
- AEK_CDECP0 = 1 << 22,
- AEK_CDECP1 = 1 << 23,
- AEK_CDECP2 = 1 << 24,
- AEK_CDECP3 = 1 << 25,
- AEK_CDECP4 = 1 << 26,
- AEK_CDECP5 = 1 << 27,
- AEK_CDECP6 = 1 << 28,
- AEK_CDECP7 = 1 << 29,
- AEK_PACBTI = 1 << 30,
+ AEK_INVALID = 0,
+ AEK_NONE = 1,
+ AEK_CRC = 1 << 1,
+ AEK_CRYPTO = 1 << 2,
+ AEK_FP = 1 << 3,
+ AEK_HWDIVTHUMB = 1 << 4,
+ AEK_HWDIVARM = 1 << 5,
+ AEK_MP = 1 << 6,
+ AEK_SIMD = 1 << 7,
+ AEK_SEC = 1 << 8,
+ AEK_VIRT = 1 << 9,
+ AEK_DSP = 1 << 10,
+ AEK_FP16 = 1 << 11,
+ AEK_RAS = 1 << 12,
+ AEK_DOTPROD = 1 << 13,
+ AEK_SHA2 = 1 << 14,
+ AEK_AES = 1 << 15,
+ AEK_FP16FML = 1 << 16,
+ AEK_SB = 1 << 17,
+ AEK_FP_DP = 1 << 18,
+ AEK_LOB = 1 << 19,
+ AEK_BF16 = 1 << 20,
+ AEK_I8MM = 1 << 21,
+ AEK_CDECP0 = 1 << 22,
+ AEK_CDECP1 = 1 << 23,
+ AEK_CDECP2 = 1 << 24,
+ AEK_CDECP3 = 1 << 25,
+ AEK_CDECP4 = 1 << 26,
+ AEK_CDECP5 = 1 << 27,
+ AEK_CDECP6 = 1 << 28,
+ AEK_CDECP7 = 1 << 29,
+ AEK_PACBTI = 1 << 30,
// Unsupported extensions.
- AEK_OS = 1ULL << 59,
- AEK_IWMMXT = 1ULL << 60,
- AEK_IWMMXT2 = 1ULL << 61,
- AEK_MAVERICK = 1ULL << 62,
- AEK_XSCALE = 1ULL << 63,
+ AEK_OS = 1ULL << 59,
+ AEK_IWMMXT = 1ULL << 60,
+ AEK_IWMMXT2 = 1ULL << 61,
+ AEK_MAVERICK = 1ULL << 62,
+ AEK_XSCALE = 1ULL << 63,
};
// List of Arch Extension names.
diff --git a/llvm/unittests/TargetParser/TargetParserTest.cpp b/llvm/unittests/TargetParser/TargetParserTest.cpp
index 297100441113a6..7e57c4fc378aa9 100644
--- a/llvm/unittests/TargetParser/TargetParserTest.cpp
+++ b/llvm/unittests/TargetParser/TargetParserTest.cpp
@@ -30,22 +30,22 @@ using ::testing::StrEq;
namespace {
const char *ARMArch[] = {
- "armv4", "armv4t", "armv5", "armv5t", "armv5e",
- "armv5te", "armv5tej", "armv6", "armv6j", "armv6k",
- "armv6hl", "armv6t2", "armv6kz", "armv6z", "armv6zk",
- "armv6-m", "armv6m", "armv6sm", "armv6s-m", "armv7-a",
- "armv7", "armv7a", "armv7ve", "armv7hl", "armv7l",
- "armv7-r", "armv7r", "armv7-m", "armv7m", "armv7k",
- "armv7s", "armv7e-m", "armv7em", "armv8-a", "armv8",
- "armv8a", "armv8l", "armv8.1-a", "armv8.1a", "armv8.2-a",
- "armv8.2a", "armv8.3-a", "armv8.3a", "armv8.4-a", "armv8.4a",
- "armv8.5-a", "armv8.5a", "armv8.6-a", "armv8.6a", "armv8.7-a",
- "armv8.7a", "armv8.8-a", "armv8.8a", "armv8.9-a", "armv8.9a",
- "armv8-r", "armv8r", "armv8-m.base", "armv8m.base", "armv8-m.main",
- "armv8m.main", "iwmmxt", "iwmmxt2", "xscale", "armv8.1-m.main",
- "armv9-a", "armv9", "armv9a", "armv9.1-a", "armv9.1a",
- "armv9.2-a", "armv9.2a", "armv9.3-a", "armv9.3a", "armv9.4-a",
- "armv9.4a", "armv9.5-a", "armv9.5a",
+ "armv4", "armv4t", "armv5", "armv5t", "armv5e",
+ "armv5te", "armv5tej", "armv6", "armv6j", "armv6k",
+ "armv6hl", "armv6t2", "armv6kz", "armv6z", "armv6zk",
+ "armv6-m", "armv6m", "armv6sm", "armv6s-m", "armv7-a",
+ "armv7", "armv7a", "armv7ve", "armv7hl", "armv7l",
+ "armv7-r", "armv7r", "armv7-m", "armv7m", "armv7k",
+ "armv7s", "armv7e-m", "armv7em", "armv8-a", "armv8",
+ "armv8a", "armv8l", "armv8.1-a", "armv8.1a", "armv8.2-a",
+ "armv8.2a", "armv8.3-a", "armv8.3a", "armv8.4-a", "armv8.4a",
+ "armv8.5-a", "armv8.5a", "armv8.6-a", "armv8.6a", "armv8.7-a",
+ "armv8.7a", "armv8.8-a", "armv8.8a", "armv8.9-a", "armv8.9a",
+ "armv8-r", "armv8r", "armv8-m.base", "armv8m.base", "armv8-m.main",
+ "armv8m.main", "iwmmxt", "iwmmxt2", "xscale", "armv8.1-m.main",
+ "armv9-a", "armv9", "armv9a", "armv9.1-a", "armv9.1a",
+ "armv9.2-a", "armv9.2a", "armv9.3-a", "armv9.3a", "armv9.4-a",
+ "armv9.4a", "armv9.5-a", "armv9.5a",
};
std::string FormatExtensionFlags(int64_t Flags) {
@@ -100,7 +100,7 @@ std::string SerializeExtensionFlags(AArch64::ExtensionBitset Flags) {
}
// check if there are remainig unhandled bits
if ((AArch64::AEK_NUM_EXTENSIONS % 4) != 0)
- ss << std::hex << HexValue;
+ ss << std::hex << HexValue;
SerializedFlags = ss.str();
return SerializedFlags;
@@ -119,26 +119,24 @@ template <ARM::ISAKind ISAKind> struct AssertSameExtensionFlags {
"CPU: {4}\n"
"Expected extension flags: {0} ({1:x})\n"
" Got extension flags: {2} ({3:x})\n",
- FormatExtensionFlags(ExpectedFlags),
- ExpectedFlags, FormatExtensionFlags(GotFlags),
- ExpectedFlags, CPUName);
+ FormatExtensionFlags(ExpectedFlags), ExpectedFlags,
+ FormatExtensionFlags(GotFlags), ExpectedFlags, CPUName);
}
- testing::AssertionResult
- operator()(const char *m_expr, const char *n_expr,
- AArch64::ExtensionBitset ExpectedFlags,
- AArch64::ExtensionBitset GotFlags) {
+ testing::AssertionResult operator()(const char *m_expr, const char *n_expr,
+ AArch64::ExtensionBitset ExpectedFlags,
+ AArch64::ExtensionBitset GotFlags) {
if (ExpectedFlags == GotFlags)
return testing::AssertionSuccess();
- return testing::AssertionFailure() << llvm::formatv(
- "CPU: {4}\n"
- "Expected extension flags: {0} ({1})\n"
- " Got extension flags: {2} ({3})\n",
- FormatExtensionFlags(ExpectedFlags),
- SerializeExtensionFlags(ExpectedFlags),
- FormatExtensionFlags(GotFlags),
- SerializeExtensionFlags(ExpectedFlags), CPUName);
+ return testing::AssertionFailure()
+ << llvm::formatv("CPU: {4}\n"
+ "Expected extension flags: {0} ({1})\n"
+ " Got extension flags: {2} ({3})\n",
+ FormatExtensionFlags(ExpectedFlags),
+ SerializeExtensionFlags(ExpectedFlags),
+ FormatExtensionFlags(GotFlags),
+ SerializeExtensionFlags(ExpectedFlags), CPUName);
}
private:
@@ -167,8 +165,8 @@ template <typename T> struct ARMCPUTestParams {
/// human-readable.
///
/// https://github.com/google/googletest/blob/main/docs/advanced.md#specifying-names-for-value-parameterized-test-parameters
- static std::string
- PrintToStringParamName(const testing::TestParamInfo<ARMCPUTestParams<T>>& Info) {
+ static std::string PrintToStringParamName(
+ const testing::TestParamInfo<ARMCPUTestParams<T>> &Info) {
std::string Name = Info.param.CPUName.str();
for (char &C : Name)
if (!std::isalnum(C))
@@ -210,28 +208,48 @@ TEST_P(ARMCPUTestFixture, ARMCPUTests) {
INSTANTIATE_TEST_SUITE_P(
ARMCPUTestsPart1, ARMCPUTestFixture,
::testing::Values(
- ARMCPUTestParams<uint64_t>("invalid", "invalid", "invalid", ARM::AEK_NONE, ""),
- ARMCPUTestParams<uint64_t>("generic", "invalid", "none", ARM::AEK_NONE, ""),
+ ARMCPUTestParams<uint64_t>("invalid", "invalid", "invalid",
+ ARM::AEK_NONE, ""),
+ ARMCPUTestParams<uint64_t>("generic", "invalid", "none", ARM::AEK_NONE,
+ ""),
ARMCPUTestParams<uint64_t>("arm8", "armv4", "none", ARM::AEK_NONE, "4"),
- ARMCPUTestParams<uint64_t>("arm810", "armv4", "none", ARM::AEK_NONE, "4"),
- ARMCPUTestParams<uint64_t>("strongarm", "armv4", "none", ARM::AEK_NONE, "4"),
- ARMCPUTestParams<uint64_t>("strongarm110", "armv4", "none", ARM::AEK_NONE, "4"),
- ARMCPUTestParams<uint64_t>("strongarm1100", "armv4", "none", ARM::AEK_NONE, "4"),
- ARMCPUTestParams<uint64_t>("strongarm1110", "armv4", "none", ARM::AEK_NONE, "4"),
- ARMCPUTestParams<uint64_t>("arm7tdmi", "armv4t", "none", ARM::AEK_NONE, "4T"),
- ARMCPUTestParams<uint64_t>("arm7tdmi-s", "armv4t", "none", ARM::AEK_NONE, "4T"),
- ARMCPUTestParams<uint64_t>("arm710t", "armv4t", "none", ARM::AEK_NONE, "4T"),
- ARMCPUTestParams<uint64_t>("arm720t", "armv4t", "none", ARM::AEK_NONE, "4T"),
- ARMCPUTestParams<uint64_t>("arm9", "armv4t", "none", ARM::AEK_NONE, "4T"),
- ARMCPUTestParams<uint64_t>("arm9tdmi", "armv4t", "none", ARM::AEK_NONE, "4T"),
- ARMCPUTestParams<uint64_t>("arm920", "armv4t", "none", ARM::AEK_NONE, "4T"),
- ARMCPUTestParams<uint64_t>("arm920t", "armv4t", "none", ARM::AEK_NONE, "4T"),
- ARMCPUTestParams<uint64_t>("arm922t", "armv4t", "none", ARM::AEK_NONE, "4T"),
- ARMCPUTestParams<uint64_t>("arm940t", "armv4t", "none", ARM::AEK_NONE, "4T"),
- ARMCPUTestParams<uint64_t>("ep9312", "armv4t", "none", ARM::AEK_NONE, "4T"),
- ARMCPUTestParams<uint64_t>("arm10tdmi", "armv5t", "none", ARM::AEK_NONE, "5T"),
- ARMCPUTestParams<uint64_t>("arm1020t", "armv5t", "none", ARM::AEK_NONE, "5T"),
+ ARMCPUTestParams<uint64_t>("arm810", "armv4", "none", ARM::AEK_NONE,
+ "4"),
+ ARMCPUTestParams<uint64_t>("strongarm", "armv4", "none", ARM::AEK_NONE,
+ "4"),
+ ARMCPUTestParams<uint64_t>("strongarm110", "armv4", "none",
+ ARM::AEK_NONE, "4"),
+ ARMCPUTestParams<uint64_t>("strongarm1100", "armv4", "none",
+ ARM::AEK_NONE, "4"),
+ ARMCPUTestParams<uint64_t>("strongarm1110", "armv4", "none",
+ ARM::AEK_NONE, "4"),
+ ARMCPUTestParams<uint64_t>("arm7tdmi", "armv4t", "none", ARM::AEK_NONE,
+ "4T"),
+ ARMCPUTestParams<uint64_t>("arm7tdmi-s", "armv4t", "none",
+ ARM::AEK_NONE, "4T"),
+ ARMCPUTestParams<uint64_t>("arm710t", "armv4t", "none", ARM::AEK_NONE,
+ "4T"),
+ ARMCPUTestParams<uint64_t>("arm720t", "armv4t", "none", ARM::AEK_NONE,
+ "4T"),
+ ARMCPUTestParams<uint64_t>("arm9", "armv4t", "none", ARM::AEK_NONE,
+ "4T"),
+ ARMCPUTestParams<uint64_t>("arm9tdmi", "armv4t", "none", ARM::AEK_NONE,
+ "4T"),
+ ARMCPUTestParams<uint64_t>("arm920", "armv4t", "none", ARM::AEK_NONE,
+ "4T"),
+ ARMCPUTestParams<uint64_t>("arm920t", "armv4t", "none", ARM::AEK_NONE,
+ "4T"),
+ ARMCPUTestParams<uint64_t>("arm922t", "armv4t", "none", ARM::AEK_NONE,
+ "4T"),
+ ARMCPUTestParams<uint64_t>("arm940t", "armv4t", "none", ARM::AEK_NONE,
+ "4T"),
+ ARMCPUTestParams<uint64_t>("ep9312", "armv4t", "none", ARM::AEK_NONE,
+ "4T"),
+ ARMCPUTestParams<uint64_t>("arm10tdmi", "armv5t", "none", ARM::AEK_NONE,
+ "5T"),
+ ARMCPUTestParams<uint64_t>("arm1020t", "armv5t", "none", ARM::AEK_NONE,
+ "5T"),
ARMCPUTestParams<uint64_t>("arm9e", "armv5te", "none",
ARM::AEK_NONE | ARM::AEK_DSP, "5TE"),
ARMCPUTestParams<uint64_t>("arm946e-s", "armv5te", "none",
@@ -253,27 +271,34 @@ INSTANTIATE_TEST_SUITE_P(
ARMCPUTestParams<uint64_t>("arm1136jf-s", "armv6", "vfpv2",
ARM::AEK_NONE | ARM::AEK_DSP, "6"),
ARMCPUTestParams<uint64_t>("arm1176jz-s", "armv6kz", "none",
- ARM::AEK_NONE | ARM::AEK_SEC | ARM::AEK_DSP, "6KZ"),
+ ARM::AEK_NONE | ARM::AEK_SEC | ARM::AEK_DSP,
+ "6KZ"),
ARMCPUTestParams<uint64_t>("mpcore", "armv6k", "vfpv2",
ARM::AEK_NONE | ARM::AEK_DSP, "6K"),
ARMCPUTestParams<uint64_t>("mpcorenovfp", "armv6k", "none",
ARM::AEK_NONE | ARM::AEK_DSP, "6K"),
ARMCPUTestParams<uint64_t>("arm1176jzf-s", "armv6kz", "vfpv2",
- ARM::AEK_NONE | ARM::AEK_SEC | ARM::AEK_DSP, "6KZ"),
+ ARM::AEK_NONE | ARM::AEK_SEC | ARM::AEK_DSP,
+ "6KZ"),
ARMCPUTestParams<uint64_t>("arm1156t2-s", "armv6t2", "none",
ARM::AEK_NONE | ARM::AEK_DSP, "6T2"),
ARMCPUTestParams<uint64_t>("arm1156t2f-s", "armv6t2", "vfpv2",
ARM::AEK_NONE | ARM::AEK_DSP, "6T2"),
- ARMCPUTestParams<uint64_t>("cortex-m0", "armv6-m", "none", ARM::AEK_NONE, "6-M"),
- ARMCPUTestParams<uint64_t>("cortex-m0plus", "armv6-m", "none", ARM::AEK_NONE,
+ ARMCPUTestParams<uint64_t>("cortex-m0", "armv6-m", "none",
+ ARM::AEK_NONE, "6-M"),
+ ARMCPUTestParams<uint64_t>("cortex-m0plus", "armv6-m", "none",
+ ARM::AEK_NONE, "6-M"),
+ ARMCPUTestParams<uint64_t>("cortex-m1", "armv6-m", "none",
+ ARM::AEK_NONE, "6-M"),
+ ARMCPUTestParams<uint64_t>("sc000", "armv6-m", "none", ARM::AEK_NONE,
"6-M"),
- ARMCPUTestParams<uint64_t>("cortex-m1", "armv6-m", "none", ARM::AEK_NONE, "6-M"),
- ARMCPUTestParams<uint64_t>("sc000", "armv6-m", "none", ARM::AEK_NONE, "6-M"),
ARMCPUTestParams<uint64_t>("cortex-a5", "armv7-a", "neon-vfpv4",
- ARM::AEK_MP | ARM::AEK_SEC | ARM::AEK_DSP, "7-A"),
+ ARM::AEK_MP | ARM::AEK_SEC | ARM::AEK_DSP,
+ "7-A"),
ARMCPUTestParams<uint64_t>("cortex-a7", "armv7-a", "neon-vfpv4",
- ARM::AEK_HWDIVTHUMB | ARM::AEK_HWDIVARM | ARM::AEK_MP |
- ARM::AEK_SEC | ARM::AEK_VIRT | ARM::AEK_DSP,
+ ARM::AEK_HWDIVTHUMB | ARM::AEK_HWDIVARM |
+ ARM::AEK_MP | ARM::AEK_SEC |
+ ARM::AEK_VIRT | ARM::AEK_DSP,
"7-A"),
ARMCPUTestParams<uint64_t>("cortex-a8", "armv7-a", "neon",
ARM::AEK_SEC | ARM::AEK_DSP, "7-A")),
@@ -285,7 +310,8 @@ INSTANTIATE_TEST_SUITE_P(
ARMCPUTestsPart2, ARMCPUTestFixture,
::testing::Values(
ARMCPUTestParams<uint64_t>("cortex-a9", "armv7-a", "neon-fp16",
- ARM::AEK_MP | ARM::AEK_SEC | ARM::AEK_DSP, "7-A"),
+ ARM::AEK_MP | ARM::AEK_SEC | ARM::AEK_DSP,
+ "7-A"),
ARMCPUTestParams<uint64_t>("cortex-a12", "armv7-a", "neon-vfpv4",
ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT |
ARM::AEK_HWDIVARM | ARM::AEK_HWDIVTHUMB |
@@ -302,25 +328,28 @@ INSTANTIATE_TEST_SUITE_P(
ARM::AEK_DSP,
"7-A"),
ARMCPUTestParams<uint64_t>("krait", "armv7-a", "neon-vfpv4",
- ARM::AEK_HWDIVARM | ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP,
+ ARM::AEK_HWDIVARM | ARM::AEK_HWDIVTHUMB |
+ ARM::AEK_DSP,
"7-A"),
ARMCPUTestParams<uint64_t>("cortex-r4", "armv7-r", "none",
- ARM::AEK_NONE | ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP,
- "7-R"),
+ ARM::AEK_NONE | ARM::AEK_HWDIVTHUMB |
+ ARM::AEK_DSP,
+ "7-R"),
ARMCPUTestParams<uint64_t>("cortex-r4f", "armv7-r", "vfpv3-d16",
- ARM::AEK_NONE | ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP,
- "7-R"),
- ARMCPUTestParams<uint64_t>("cortex-r5", "armv7-r", "vfpv3-d16",
- ARM::AEK_MP | ARM::AEK_HWDIVARM | ARM::AEK_HWDIVTHUMB |
+ ARM::AEK_NONE | ARM::AEK_HWDIVTHUMB |
ARM::AEK_DSP,
"7-R"),
+ ARMCPUTestParams<uint64_t>("cortex-r5", "armv7-r", "vfpv3-d16",
+ ARM::AEK_MP | ARM::AEK_HWDIVARM |
+ ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP,
+ "7-R"),
ARMCPUTestParams<uint64_t>("cortex-r7", "armv7-r", "vfpv3-d16-fp16",
- ARM::AEK_MP | ARM::AEK_HWDIVARM | ARM::AEK_HWDIVTHUMB |
- ARM::AEK_DSP,
+ ARM::AEK_MP | ARM::AEK_HWDIVARM |
+ ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP,
"7-R"),
ARMCPUTestParams<uint64_t>("cortex-r8", "armv7-r", "vfpv3-d16-fp16",
- ARM::AEK_MP | ARM::AEK_HWDIVARM | ARM::AEK_HWDIVTHUMB |
- ARM::AEK_DSP,
+ ARM::AEK_MP | ARM::AEK_HWDIVARM |
+ ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP,
"7-R"),
ARMCPUTestParams<uint64_t>("cortex-r52", "armv8-r", "neon-fp-armv8",
ARM::AEK_NONE | ARM::AEK_CRC | ARM::AEK_MP |
@@ -332,171 +361,184 @@ INSTANTIATE_TEST_SUITE_P(
ARMCPUTestParams<uint64_t>("cortex-m3", "armv7-m", "none",
ARM::AEK_NONE | ARM::AEK_HWDIVTHUMB, "7-M"),
ARMCPUTestParams<uint64_t>("cortex-m4", "armv7e-m", "fpv4-sp-d16",
- ARM::AEK_NONE | ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP,
+ ARM::AEK_NONE | ARM::AEK_HWDIVTHUMB |
+ ARM::AEK_DSP,
"7E-M"),
ARMCPUTestParams<uint64_t>("cortex-m7", "armv7e-m", "fpv5-d16",
- ARM::AEK_NONE | ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP,
+ ARM::AEK_NONE | ARM::AEK_HWDIVTHUMB |
+ ARM::AEK_DSP,
"7E-M"),
- ARMCPUTestParams<uint64_t>("cortex-a32", "armv8-a", "crypto-neon-fp-armv8",
+ ARMCPUTestParams<uint64_t>("cortex-a32", "armv8-a",
+ "crypto-neon-fp-armv8",
ARM::AEK_CRC | ARM::AEK_SEC | ARM::AEK_MP |
ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP,
"8-A"),
- ARMCPUTestParams<uint64_t>("cortex-a35", "armv8-a", "crypto-neon-fp-armv8",
+ ARMCPUTestParams<uint64_t>("cortex-a35", "armv8-a",
+ "crypto-neon-fp-armv8",
ARM::AEK_CRC | ARM::AEK_SEC | ARM::AEK_MP |
ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP,
"8-A"),
- ARMCPUTestParams<uint64_t>("cortex-a53", "armv8-a", "crypto-neon-fp-armv8",
+ ARMCPUTestParams<uint64_t>("cortex-a53", "armv8-a",
+ "crypto-neon-fp-armv8",
ARM::AEK_CRC | ARM::AEK_SEC | ARM::AEK_MP |
ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP,
"8-A"),
- ARMCPUTestParams<uint64_t>("cortex-a55", "armv8.2-a", "crypto-neon-fp-armv8",
- ARM::AEK_CRC | ARM::AEK_SEC | ARM::AEK_MP |
- ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
- ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP |
+ ARMCPUTestParams<uint64_t>(
+ "cortex-a55", "armv8.2-a", "crypto-neon-fp-armv8",
+ ARM::AEK_CRC | ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT |
+ ARM::AEK_HWDIVARM | ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP |
ARM::AEK_FP16 | ARM::AEK_RAS | ARM::AEK_DOTPROD,
"8.2-A"),
- ARMCPUTestParams<uint64_t>("cortex-a57", "armv8-a", "crypto-neon-fp-armv8",
+ ARMCPUTestParams<uint64_t>("cortex-a57", "armv8-a",
+ "crypto-neon-fp-armv8",
ARM::AEK_CRC | ARM::AEK_SEC | ARM::AEK_MP |
ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP,
"8-A"),
- ARMCPUTestParams<uint64_t>("cortex-a72", "armv8-a", "crypto-neon-fp-armv8",
+ ARMCPUTestParams<uint64_t>("cortex-a72", "armv8-a",
+ "crypto-neon-fp-armv8",
ARM::AEK_CRC | ARM::AEK_SEC | ARM::AEK_MP |
ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP,
"8-A"),
- ARMCPUTestParams<uint64_t>("cortex-a73", "armv8-a", "crypto-neon-fp-armv8",
+ ARMCPUTestParams<uint64_t>("cortex-a73", "armv8-a",
+ "crypto-neon-fp-armv8",
ARM::AEK_CRC | ARM::AEK_SEC | ARM::AEK_MP |
ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP,
"8-A"),
- ARMCPUTestParams<uint64_t>("cortex-a75", "armv8.2-a", "crypto-neon-fp-armv8",
- ARM::AEK_CRC | ARM::AEK_SEC | ARM::AEK_MP |
- ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
- ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP |
+ ARMCPUTestParams<uint64_t>(
+ "cortex-a75", "armv8.2-a", "crypto-neon-fp-armv8",
+ ARM::AEK_CRC | ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT |
+ ARM::AEK_HWDIVARM | ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP |
ARM::AEK_FP16 | ARM::AEK_RAS | ARM::AEK_DOTPROD,
"8.2-A"),
- ARMCPUTestParams<uint64_t>("cortex-a76", "armv8.2-a", "crypto-neon-fp-armv8",
- ARM::AEK_CRC | ARM::AEK_SEC | ARM::AEK_MP |
- ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
- ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP |
+ ARMCPUTestParams<uint64_t>(
+ "cortex-a76", "armv8.2-a", "crypto-neon-fp-armv8",
+ ARM::AEK_CRC | ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT |
+ ARM::AEK_HWDIVARM | ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP |
ARM::AEK_FP16 | ARM::AEK_RAS | ARM::AEK_DOTPROD,
"8.2-A"),
- ARMCPUTestParams<uint64_t>("cortex-a76ae", "armv8.2-a", "crypto-neon-fp-armv8",
- ARM::AEK_CRC | ARM::AEK_SEC | ARM::AEK_MP |
- ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
- ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP |
+ ARMCPUTestParams<uint64_t>(
+ "cortex-a76ae", "armv8.2-a", "crypto-neon-fp-armv8",
+ ARM::AEK_CRC | ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT |
+ ARM::AEK_HWDIVARM | ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP |
ARM::AEK_FP16 | ARM::AEK_RAS | ARM::AEK_DOTPROD,
"8.2-A"),
- ARMCPUTestParams<uint64_t>("cortex-a78c", "armv8.2-a", "crypto-neon-fp-armv8",
- ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT |
- ARM::AEK_HWDIVARM | ARM::AEK_HWDIVTHUMB |
- ARM::AEK_DSP | ARM::AEK_CRC | ARM::AEK_RAS |
- ARM::AEK_FP16 | ARM::AEK_DOTPROD,
+ ARMCPUTestParams<uint64_t>(
+ "cortex-a78c", "armv8.2-a", "crypto-neon-fp-armv8",
+ ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
+ ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP | ARM::AEK_CRC |
+ ARM::AEK_RAS | ARM::AEK_FP16 | ARM::AEK_DOTPROD,
"8.2-A"),
ARMCPUTestParams<uint64_t>("cortex-a710", "armv9-a", "neon-fp-armv8",
ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT |
ARM::AEK_HWDIVARM | ARM::AEK_HWDIVTHUMB |
- ARM::AEK_DSP | ARM::AEK_CRC | ARM::AEK_RAS |
- ARM::AEK_DOTPROD | ARM::AEK_FP16FML |
- ARM::AEK_BF16 | ARM::AEK_I8MM | ARM::AEK_SB,
+ ARM::AEK_DSP | ARM::AEK_CRC |
+ ARM::AEK_RAS | ARM::AEK_DOTPROD |
+ ARM::AEK_FP16FML | ARM::AEK_BF16 |
+ ARM::AEK_I8MM | ARM::AEK_SB,
"9-A"),
- ARMCPUTestParams<uint64_t>("cortex-a77", "armv8.2-a", "crypto-neon-fp-armv8",
- ARM::AEK_CRC | ARM::AEK_SEC | ARM::AEK_MP |
- ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
- ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP |
+ ARMCPUTestParams<uint64_t>(
+ "cortex-a77", "armv8.2-a", "crypto-neon-fp-armv8",
+ ARM::AEK_CRC | ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT |
+ ARM::AEK_HWDIVARM | ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP |
ARM::AEK_FP16 | ARM::AEK_RAS | ARM::AEK_DOTPROD,
"8.2-A"),
- ARMCPUTestParams<uint64_t>("cortex-a78", "armv8.2-a", "crypto-neon-fp-armv8",
- ARM::AEK_DOTPROD | ARM::AEK_FP16 | ARM::AEK_SEC |
+ ARMCPUTestParams<uint64_t>(
+ "cortex-a78", "armv8.2-a", "crypto-neon-fp-armv8",
+ ARM::AEK_DOTPROD | ARM::AEK_FP16 | ARM::AEK_SEC | ARM::AEK_MP |
+ ARM::AEK_VIRT | ARM::AEK_HWDIVARM | ARM::AEK_HWDIVTHUMB |
+ ARM::AEK_DSP | ARM::AEK_CRC | ARM::AEK_RAS,
+ "8.2-A"),
+ ARMCPUTestParams<uint64_t>(
+ "cortex-x1", "armv8.2-a", "crypto-neon-fp-armv8",
+ ARM::AEK_RAS | ARM::AEK_FP16 | ARM::AEK_DOTPROD | ARM::AEK_SEC |
ARM::AEK_MP | ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
- ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP | ARM::AEK_CRC |
- ARM::AEK_RAS,
+ ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP | ARM::AEK_CRC,
"8.2-A"),
- ARMCPUTestParams<uint64_t>("cortex-x1", "armv8.2-a", "crypto-neon-fp-armv8",
- ARM::AEK_RAS | ARM::AEK_FP16 | ARM::AEK_DOTPROD |
- ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT |
- ARM::AEK_HWDIVARM | ARM::AEK_HWDIVTHUMB |
- ARM::AEK_DSP | ARM::AEK_CRC,
+ ARMCPUTestParams<uint64_t>(
+ "cortex-x1c", "armv8.2-a", "crypto-neon-fp-armv8",
+ ARM::AEK_RAS | ARM::AEK_FP16 | ARM::AEK_DOTPROD | ARM::AEK_SEC |
+ ARM::AEK_MP | ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
+ ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP | ARM::AEK_CRC,
"8.2-A"),
- ARMCPUTestParams<uint64_t>("cortex-x1c", "armv8.2-a", "crypto-neon-fp-armv8",
- ARM::AEK_RAS | ARM::AEK_FP16 | ARM::AEK_DOTPROD |
- ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT |
- ARM::AEK_HWDIVARM | ARM::AEK_HWDIVTHUMB |
- ARM::AEK_DSP | ARM::AEK_CRC,
- "8.2-A"),
- ARMCPUTestParams<uint64_t>("neoverse-n1", "armv8.2-a", "crypto-neon-fp-armv8",
- ARM::AEK_CRC | ARM::AEK_SEC | ARM::AEK_MP |
- ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
- ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP |
+ ARMCPUTestParams<uint64_t>(
+ "neoverse-n1", "armv8.2-a", "crypto-neon-fp-armv8",
+ ARM::AEK_CRC | ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT |
+ ARM::AEK_HWDIVARM | ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP |
ARM::AEK_FP16 | ARM::AEK_RAS | ARM::AEK_DOTPROD,
"8.2-A"),
- ARMCPUTestParams<uint64_t>("neoverse-n2", "armv9-a", "neon-fp-armv8",
- ARM::AEK_CRC | ARM::AEK_HWDIVTHUMB |
- ARM::AEK_HWDIVARM | ARM::AEK_MP | ARM::AEK_SEC |
- ARM::AEK_VIRT | ARM::AEK_DSP | ARM::AEK_BF16 |
- ARM::AEK_DOTPROD | ARM::AEK_RAS | ARM::AEK_I8MM |
- ARM::AEK_FP16FML | ARM::AEK_SB,
+ ARMCPUTestParams<uint64_t>(
+ "neoverse-n2", "armv9-a", "neon-fp-armv8",
+ ARM::AEK_CRC | ARM::AEK_HWDIVTHUMB | ARM::AEK_HWDIVARM |
+ ARM::AEK_MP | ARM::AEK_SEC | ARM::AEK_VIRT | ARM::AEK_DSP |
+ ARM::AEK_BF16 | ARM::AEK_DOTPROD | ARM::AEK_RAS |
+ ARM::AEK_I8MM | ARM::AEK_FP16FML | ARM::AEK_SB,
"9-A"),
- ARMCPUTestParams<uint64_t>("neoverse-v1", "armv8.4-a", "crypto-neon-fp-armv8",
- ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT |
- ARM::AEK_HWDIVARM | ARM::AEK_HWDIVTHUMB |
- ARM::AEK_DSP | ARM::AEK_CRC | ARM::AEK_RAS |
- ARM::AEK_FP16 | ARM::AEK_BF16 | ARM::AEK_DOTPROD,
+ ARMCPUTestParams<uint64_t>(
+ "neoverse-v1", "armv8.4-a", "crypto-neon-fp-armv8",
+ ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
+ ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP | ARM::AEK_CRC |
+ ARM::AEK_RAS | ARM::AEK_FP16 | ARM::AEK_BF16 | ARM::AEK_DOTPROD,
"8.4-A"),
ARMCPUTestParams<uint64_t>("cyclone", "armv8-a", "crypto-neon-fp-armv8",
ARM::AEK_CRC | ARM::AEK_SEC | ARM::AEK_MP |
ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP,
"8-A"),
- ARMCPUTestParams<uint64_t>("exynos-m3", "armv8-a", "crypto-neon-fp-armv8",
+ ARMCPUTestParams<uint64_t>("exynos-m3", "armv8-a",
+ "crypto-neon-fp-armv8",
ARM::AEK_CRC | ARM::AEK_SEC | ARM::AEK_MP |
ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP,
"8-A"),
- ARMCPUTestParams<uint64_t>("exynos-m4", "armv8.2-a", "crypto-neon-fp-armv8",
- ARM::AEK_CRC | ARM::AEK_SEC | ARM::AEK_MP |
- ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
- ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP |
+ ARMCPUTestParams<uint64_t>(
+ "exynos-m4", "armv8.2-a", "crypto-neon-fp-armv8",
+ ARM::AEK_CRC | ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT |
+ ARM::AEK_HWDIVARM | ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP |
ARM::AEK_DOTPROD | ARM::AEK_FP16 | ARM::AEK_RAS,
"8.2-A"),
- ARMCPUTestParams<uint64_t>("exynos-m5", "armv8.2-a", "crypto-neon-fp-armv8",
- ARM::AEK_CRC | ARM::AEK_SEC | ARM::AEK_MP |
- ARM::AEK_VIRT | ARM::AEK_HWDIVARM |
- ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP |
+ ARMCPUTestParams<uint64_t>(
+ "exynos-m5", "armv8.2-a", "crypto-neon-fp-armv8",
+ ARM::AEK_CRC | ARM::AEK_SEC | ARM::AEK_MP | ARM::AEK_VIRT |
+ ARM::AEK_HWDIVARM | ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP |
ARM::AEK_DOTPROD | ARM::AEK_FP16 | ARM::AEK_RAS,
"8.2-A"),
ARMCPUTestParams<uint64_t>("cortex-m23", "armv8-m.base", "none",
- ARM::AEK_NONE | ARM::AEK_HWDIVTHUMB, "8-M.Baseline"),
+ ARM::AEK_NONE | ARM::AEK_HWDIVTHUMB,
+ "8-M.Baseline"),
ARMCPUTestParams<uint64_t>("cortex-m33", "armv8-m.main", "fpv5-sp-d16",
- ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP, "8-M.Mainline"),
+ ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP,
+ "8-M.Mainline"),
ARMCPUTestParams<uint64_t>("cortex-m35p", "armv8-m.main", "fpv5-sp-d16",
- ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP, "8-M.Mainline"),
- ARMCPUTestParams<uint64_t>("cortex-m55", "armv8.1-m.main",
- "fp-armv8-fullfp16-d16",
- ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP | ARM::AEK_SIMD |
- ARM::AEK_FP | ARM::AEK_RAS | ARM::AEK_LOB |
- ARM::AEK_FP16,
+ ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP,
+ "8-M.Mainline"),
+ ARMCPUTestParams<uint64_t>(
+ "cortex-m55", "armv8.1-m.main", "fp-armv8-fullfp16-d16",
+ ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP | ARM::AEK_SIMD | ARM::AEK_FP |
+ ARM::AEK_RAS | ARM::AEK_LOB | ARM::AEK_FP16,
"8.1-M.Mainline"),
- ARMCPUTestParams<uint64_t>("cortex-m85", "armv8.1-m.main",
- "fp-armv8-fullfp16-d16",
- ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP | ARM::AEK_SIMD |
- ARM::AEK_FP | ARM::AEK_RAS | ARM::AEK_LOB |
- ARM::AEK_FP16 | ARM::AEK_PACBTI,
+ ARMCPUTestParams<uint64_t>(
+ "cortex-m85", "armv8.1-m.main", "fp-armv8-fullfp16-d16",
+ ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP | ARM::AEK_SIMD | ARM::AEK_FP |
+ ARM::AEK_RAS | ARM::AEK_LOB | ARM::AEK_FP16 | ARM::AEK_PACBTI,
"8.1-M.Mainline"),
- ARMCPUTestParams<uint64_t>("cortex-m52", "armv8.1-m.main",
- "fp-armv8-fullfp16-d16",
- ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP | ARM::AEK_SIMD |
- ARM::AEK_FP | ARM::AEK_RAS | ARM::AEK_LOB |
- ARM::AEK_FP16 | ARM::AEK_PACBTI,
- "8.1-M.Mainline"),
- ARMCPUTestParams<uint64_t>("iwmmxt", "iwmmxt", "none", ARM::AEK_NONE, "iwmmxt"),
- ARMCPUTestParams<uint64_t>("xscale", "xscale", "none", ARM::AEK_NONE, "xscale"),
+ ARMCPUTestParams<uint64_t>(
+ "cortex-m52", "armv8.1-m.main", "fp-armv8-fullfp16-d16",
+ ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP | ARM::AEK_SIMD | ARM::AEK_FP |
+ ARM::AEK_RAS | ARM::AEK_LOB | ARM::AEK_FP16 | ARM::AEK_PACBTI,
+ "8.1-M.Mainline"),
+ ARMCPUTestParams<uint64_t>("iwmmxt", "iwmmxt", "none", ARM::AEK_NONE,
+ "iwmmxt"),
+ ARMCPUTestParams<uint64_t>("xscale", "xscale", "none", ARM::AEK_NONE,
+ "xscale"),
ARMCPUTestParams<uint64_t>("swift", "armv7s", "neon-vfpv4",
- ARM::AEK_HWDIVARM | ARM::AEK_HWDIVTHUMB | ARM::AEK_DSP,
+ ARM::AEK_HWDIVARM | ARM::AEK_HWDIVTHUMB |
+ ARM::AEK_DSP,
"7-S")),
ARMCPUTestParams<uint64_t>::PrintToStringParamName);
@@ -509,14 +551,14 @@ TEST(TargetParserTest, testARMCPUArchList) {
// No list exists for these in this test suite, so ensure all are
// valid, and match the expected 'magic' count.
EXPECT_EQ(List.size(), NumARMCPUArchs);
- for(StringRef CPU : List) {
+ for (StringRef CPU : List) {
EXPECT_NE(ARM::parseCPUArch(CPU), ARM::ArchKind::INVALID);
}
}
TEST(TargetParserTest, testInvalidARMArch) {
auto InvalidArchStrings = {"armv", "armv99", "noarm"};
- for (const char* InvalidArch : InvalidArchStrings)
+ for (const char *InvalidArch : InvalidArchStrings)
EXPECT_EQ(ARM::parseArch(InvalidArch), ARM::ArchKind::INVALID);
}
@@ -532,127 +574,89 @@ bool testARMArch(StringRef Arch, StringRef DefaultCPU, StringRef SubArch,
TEST(TargetParserTest, testARMArch) {
EXPECT_TRUE(
- testARMArch("armv4", "strongarm", "v4",
- ARMBuildAttrs::CPUArch::v4));
+ testARMArch("armv4", "strongarm", "v4", ARMBuildAttrs::CPUArch::v4));
EXPECT_TRUE(
- testARMArch("armv4t", "arm7tdmi", "v4t",
- ARMBuildAttrs::CPUArch::v4T));
+ testARMArch("armv4t", "arm7tdmi", "v4t", ARMBuildAttrs::CPUArch::v4T));
EXPECT_TRUE(
- testARMArch("armv5t", "arm10tdmi", "v5",
- ARMBuildAttrs::CPUArch::v5T));
+ testARMArch("armv5t", "arm10tdmi", "v5", ARMBuildAttrs::CPUArch::v5T));
EXPECT_TRUE(
- testARMArch("armv5te", "arm1022e", "v5e",
- ARMBuildAttrs::CPUArch::v5TE));
- EXPECT_TRUE(
- testARMArch("armv5tej", "arm926ej-s", "v5e",
+ testARMArch("armv5te", "arm1022e", "v5e", ARMBuildAttrs::CPUArch::v5TE));
+ EXPECT_TRUE(testARMArch("armv5tej", "arm926ej-s", "v5e",
ARMBuildAttrs::CPUArch::v5TEJ));
EXPECT_TRUE(
- testARMArch("armv6", "arm1136jf-s", "v6",
- ARMBuildAttrs::CPUArch::v6));
- EXPECT_TRUE(
- testARMArch("armv6k", "mpcore", "v6k",
- ARMBuildAttrs::CPUArch::v6K));
+ testARMArch("armv6", "arm1136jf-s", "v6", ARMBuildAttrs::CPUArch::v6));
EXPECT_TRUE(
- testARMArch("armv6t2", "arm1156t2-s", "v6t2",
+ testARMArch("armv6k", "mpcore", "v6k", ARMBuildAttrs::CPUArch::v6K));
+ EXPECT_TRUE(testARMArch("armv6t2", "arm1156t2-s", "v6t2",
ARMBuildAttrs::CPUArch::v6T2));
- EXPECT_TRUE(
- testARMArch("armv6kz", "arm1176jzf-s", "v6kz",
+ EXPECT_TRUE(testARMArch("armv6kz", "arm1176jzf-s", "v6kz",
ARMBuildAttrs::CPUArch::v6KZ));
EXPECT_TRUE(
- testARMArch("armv6-m", "cortex-m0", "v6m",
- ARMBuildAttrs::CPUArch::v6_M));
- EXPECT_TRUE(
- testARMArch("armv7-a", "generic", "v7",
- ARMBuildAttrs::CPUArch::v7));
+ testARMArch("armv6-m", "cortex-m0", "v6m", ARMBuildAttrs::CPUArch::v6_M));
EXPECT_TRUE(
- testARMArch("armv7ve", "generic", "v7ve",
- ARMBuildAttrs::CPUArch::v7));
+ testARMArch("armv7-a", "generic", "v7", ARMBuildAttrs::CPUArch::v7));
EXPECT_TRUE(
- testARMArch("armv7-r", "cortex-r4", "v7r",
- ARMBuildAttrs::CPUArch::v7));
+ testARMArch("armv7ve", "generic", "v7ve", ARMBuildAttrs::CPUArch::v7));
EXPECT_TRUE(
- testARMArch("armv7-m", "cortex-m3", "v7m",
- ARMBuildAttrs::CPUArch::v7));
+ testARMArch("armv7-r", "cortex-r4", "v7r", ARMBuildAttrs::CPUArch::v7));
EXPECT_TRUE(
- testARMArch("armv7e-m", "cortex-m4", "v7em",
+ testARMArch("armv7-m", "cortex-m3", "v7m", ARMBuildAttrs::CPUArch::v7));
+ EXPECT_TRUE(testARMArch("armv7e-m", "cortex-m4", "v7em",
ARMBuildAttrs::CPUArch::v7E_M));
EXPECT_TRUE(
- testARMArch("armv8-a", "generic", "v8a",
+ testARMArch("armv8-a", "generic", "v8a", ARMBuildAttrs::CPUArch::v8_A));
+ EXPECT_TRUE(testARMArch("armv8.1-a", "generic", "v8.1a",
ARMBuildAttrs::CPUArch::v8_A));
- EXPECT_TRUE(
- testARMArch("armv8.1-a", "generic", "v8.1a",
+ EXPECT_TRUE(testARMArch("armv8.2-a", "generic", "v8.2a",
ARMBuildAttrs::CPUArch::v8_A));
- EXPECT_TRUE(
- testARMArch("armv8.2-a", "generic", "v8.2a",
+ EXPECT_TRUE(testARMArch("armv8.3-a", "generic", "v8.3a",
ARMBuildAttrs::CPUArch::v8_A));
- EXPECT_TRUE(
- testARMArch("armv8.3-a", "generic", "v8.3a",
+ EXPECT_TRUE(testARMArch("armv8.4-a", "generic", "v8.4a",
ARMBuildAttrs::CPUArch::v8_A));
- EXPECT_TRUE(
- testARMArch("armv8.4-a", "generic", "v8.4a",
- ARMBuildAttrs::CPUArch::v8_A));
- EXPECT_TRUE(
- testARMArch("armv8.5-a", "generic", "v8.5a",
+ EXPECT_TRUE(testARMArch("armv8.5-a", "generic", "v8.5a",
ARMBuildAttrs::CPUArch::v8_A));
- EXPECT_TRUE(
- testARMArch("armv8.6-a", "generic", "v8.6a",
+ EXPECT_TRUE(testARMArch("armv8.6-a", "generic", "v8.6a",
ARMBuildAttrs::CPUArch::v8_A));
- EXPECT_TRUE(
- testARMArch("armv8.7-a", "generic", "v8.7a",
+ EXPECT_TRUE(testARMArch("armv8.7-a", "generic", "v8.7a",
ARMBuildAttrs::CPUArch::v8_A));
EXPECT_TRUE(testARMArch("armv8.8-a", "generic", "v8.8a",
ARMBuildAttrs::CPUArch::v8_A));
- EXPECT_TRUE(
- testARMArch("armv8.9-a", "generic", "v8.9a",
+ EXPECT_TRUE(testARMArch("armv8.9-a", "generic", "v8.9a",
ARMBuildAttrs::CPUArch::v8_A));
EXPECT_TRUE(
- testARMArch("armv9-a", "generic", "v9a",
+ testARMArch("armv9-a", "generic", "v9a", ARMBuildAttrs::CPUArch::v9_A));
+ EXPECT_TRUE(testARMArch("armv9.1-a", "generic", "v9.1a",
ARMBuildAttrs::CPUArch::v9_A));
- EXPECT_TRUE(
- testARMArch("armv9.1-a", "generic", "v9.1a",
+ EXPECT_TRUE(testARMArch("armv9.2-a", "generic", "v9.2a",
ARMBuildAttrs::CPUArch::v9_A));
- EXPECT_TRUE(
- testARMArch("armv9.2-a", "generic", "v9.2a",
+ EXPECT_TRUE(testARMArch("armv9.3-a", "generic", "v9.3a",
ARMBuildAttrs::CPUArch::v9_A));
- EXPECT_TRUE(
- testARMArch("armv9.3-a", "generic", "v9.3a",
+ EXPECT_TRUE(testARMArch("armv9.4-a", "generic", "v9.4a",
ARMBuildAttrs::CPUArch::v9_A));
- EXPECT_TRUE(
- testARMArch("armv9.4-a", "generic", "v9.4a",
+ EXPECT_TRUE(testARMArch("armv9.5-a", "generic", "v9.5a",
ARMBuildAttrs::CPUArch::v9_A));
- EXPECT_TRUE(
- testARMArch("armv9.5-a", "generic", "v9.5a",
- ARMBuildAttrs::CPUArch::v9_A));
- EXPECT_TRUE(
- testARMArch("armv8-r", "cortex-r52", "v8r",
+ EXPECT_TRUE(testARMArch("armv8-r", "cortex-r52", "v8r",
ARMBuildAttrs::CPUArch::v8_R));
- EXPECT_TRUE(
- testARMArch("armv8-m.base", "generic", "v8m.base",
+ EXPECT_TRUE(testARMArch("armv8-m.base", "generic", "v8m.base",
ARMBuildAttrs::CPUArch::v8_M_Base));
- EXPECT_TRUE(
- testARMArch("armv8-m.main", "generic", "v8m.main",
+ EXPECT_TRUE(testARMArch("armv8-m.main", "generic", "v8m.main",
ARMBuildAttrs::CPUArch::v8_M_Main));
- EXPECT_TRUE(
- testARMArch("armv8.1-m.main", "generic", "v8.1m.main",
+ EXPECT_TRUE(testARMArch("armv8.1-m.main", "generic", "v8.1m.main",
ARMBuildAttrs::CPUArch::v8_1_M_Main));
EXPECT_TRUE(
- testARMArch("iwmmxt", "iwmmxt", "",
- ARMBuildAttrs::CPUArch::v5TE));
+ testARMArch("iwmmxt", "iwmmxt", "", ARMBuildAttrs::CPUArch::v5TE));
EXPECT_TRUE(
- testARMArch("iwmmxt2", "generic", "",
- ARMBuildAttrs::CPUArch::v5TE));
+ testARMArch("iwmmxt2", "generic", "", ARMBuildAttrs::CPUArch::v5TE));
EXPECT_TRUE(
- testARMArch("xscale", "xscale", "v5e",
- ARMBuildAttrs::CPUArch::v5TE));
+ testARMArch("xscale", "xscale", "v5e", ARMBuildAttrs::CPUArch::v5TE));
EXPECT_TRUE(
- testARMArch("armv7s", "swift", "v7s",
- ARMBuildAttrs::CPUArch::v7));
+ testARMArch("armv7s", "swift", "v7s", ARMBuildAttrs::CPUArch::v7));
EXPECT_TRUE(
- testARMArch("armv7k", "generic", "v7k",
- ARMBuildAttrs::CPUArch::v7));
+ testARMArch("armv7k", "generic", "v7k", ARMBuildAttrs::CPUArch::v7));
}
-bool testARMExtension(StringRef CPUName,ARM::ArchKind ArchKind, StringRef ArchExt) {
+bool testARMExtension(StringRef CPUName, ARM::ArchKind ArchKind,
+ StringRef ArchExt) {
return ARM::getDefaultExtensions(CPUName, ArchKind) &
ARM::parseArchExt(ArchExt);
}
@@ -660,39 +664,28 @@ bool testARMExtension(StringRef CPUName,ARM::ArchKind ArchKind, StringRef ArchEx
TEST(TargetParserTest, testARMExtension) {
EXPECT_FALSE(testARMExtension("strongarm", ARM::ArchKind::INVALID, "dsp"));
EXPECT_FALSE(testARMExtension("arm7tdmi", ARM::ArchKind::INVALID, "dsp"));
- EXPECT_FALSE(testARMExtension("arm10tdmi",
- ARM::ArchKind::INVALID, "simd"));
+ EXPECT_FALSE(testARMExtension("arm10tdmi", ARM::ArchKind::INVALID, "simd"));
EXPECT_FALSE(testARMExtension("arm1022e", ARM::ArchKind::INVALID, "simd"));
- EXPECT_FALSE(testARMExtension("arm926ej-s",
- ARM::ArchKind::INVALID, "simd"));
- EXPECT_FALSE(testARMExtension("arm1136jf-s",
- ARM::ArchKind::INVALID, "crypto"));
- EXPECT_FALSE(testARMExtension("arm1156t2-s",
- ARM::ArchKind::INVALID, "crypto"));
- EXPECT_FALSE(testARMExtension("arm1176jzf-s",
- ARM::ArchKind::INVALID, "crypto"));
- EXPECT_FALSE(testARMExtension("cortex-m0",
- ARM::ArchKind::INVALID, "crypto"));
- EXPECT_FALSE(testARMExtension("cortex-a8",
- ARM::ArchKind::INVALID, "crypto"));
- EXPECT_FALSE(testARMExtension("cortex-r4",
- ARM::ArchKind::INVALID, "crypto"));
- EXPECT_FALSE(testARMExtension("cortex-m3",
- ARM::ArchKind::INVALID, "crypto"));
- EXPECT_FALSE(testARMExtension("cortex-a53",
- ARM::ArchKind::INVALID, "ras"));
- EXPECT_FALSE(testARMExtension("cortex-a53",
- ARM::ArchKind::INVALID, "fp16"));
- EXPECT_TRUE(testARMExtension("cortex-a55",
- ARM::ArchKind::INVALID, "fp16"));
- EXPECT_FALSE(testARMExtension("cortex-a55",
- ARM::ArchKind::INVALID, "fp16fml"));
- EXPECT_TRUE(testARMExtension("cortex-a75",
- ARM::ArchKind::INVALID, "fp16"));
- EXPECT_FALSE(testARMExtension("cortex-a75",
- ARM::ArchKind::INVALID, "fp16fml"));
- EXPECT_FALSE(testARMExtension("cortex-r52",
- ARM::ArchKind::INVALID, "ras"));
+ EXPECT_FALSE(testARMExtension("arm926ej-s", ARM::ArchKind::INVALID, "simd"));
+ EXPECT_FALSE(
+ testARMExtension("arm1136jf-s", ARM::ArchKind::INVALID, "crypto"));
+ EXPECT_FALSE(
+ testARMExtension("arm1156t2-s", ARM::ArchKind::INVALID, "crypto"));
+ EXPECT_FALSE(
+ testARMExtension("arm1176jzf-s", ARM::ArchKind::INVALID, "crypto"));
+ EXPECT_FALSE(testARMExtension("cortex-m0", ARM::ArchKind::INVALID, "crypto"));
+ EXPECT_FALSE(testARMExtension("cortex-a8", ARM::ArchKind::INVALID, "crypto"));
+ EXPECT_FALSE(testARMExtension("cortex-r4", ARM::ArchKind::INVALID, "crypto"));
+ EXPECT_FALSE(testARMExtension("cortex-m3", ARM::ArchKind::INVALID, "crypto"));
+ EXPECT_FALSE(testARMExtension("cortex-a53", ARM::ArchKind::INVALID, "ras"));
+ EXPECT_FALSE(testARMExtension("cortex-a53", ARM::ArchKind::INVALID, "fp16"));
+ EXPECT_TRUE(testARMExtension("cortex-a55", ARM::ArchKind::INVALID, "fp16"));
+ EXPECT_FALSE(
+ testARMExtension("cortex-a55", ARM::ArchKind::INVALID, "fp16fml"));
+ EXPECT_TRUE(testARMExtension("cortex-a75", ARM::ArchKind::INVALID, "fp16"));
+ EXPECT_FALSE(
+ testARMExtension("cortex-a75", ARM::ArchKind::INVALID, "fp16fml"));
+ EXPECT_FALSE(testARMExtension("cortex-r52", ARM::ArchKind::INVALID, "ras"));
EXPECT_FALSE(testARMExtension("iwmmxt", ARM::ArchKind::INVALID, "crc"));
EXPECT_FALSE(testARMExtension("xscale", ARM::ArchKind::INVALID, "crc"));
EXPECT_FALSE(testARMExtension("swift", ARM::ArchKind::INVALID, "crc"));
@@ -704,16 +697,13 @@ TEST(TargetParserTest, testARMExtension) {
EXPECT_FALSE(testARMExtension("generic", ARM::ArchKind::ARMV5TEJ, "simd"));
EXPECT_FALSE(testARMExtension("generic", ARM::ArchKind::ARMV6, "crypto"));
EXPECT_FALSE(testARMExtension("generic", ARM::ArchKind::ARMV6K, "crypto"));
- EXPECT_FALSE(testARMExtension("generic",
- ARM::ArchKind::ARMV6T2, "crypto"));
- EXPECT_FALSE(testARMExtension("generic",
- ARM::ArchKind::ARMV6KZ, "crypto"));
+ EXPECT_FALSE(testARMExtension("generic", ARM::ArchKind::ARMV6T2, "crypto"));
+ EXPECT_FALSE(testARMExtension("generic", ARM::ArchKind::ARMV6KZ, "crypto"));
EXPECT_FALSE(testARMExtension("generic", ARM::ArchKind::ARMV6M, "crypto"));
EXPECT_FALSE(testARMExtension("generic", ARM::ArchKind::ARMV7A, "crypto"));
EXPECT_FALSE(testARMExtension("generic", ARM::ArchKind::ARMV7R, "crypto"));
EXPECT_FALSE(testARMExtension("generic", ARM::ArchKind::ARMV7M, "crypto"));
- EXPECT_FALSE(testARMExtension("generic",
- ARM::ArchKind::ARMV7EM, "crypto"));
+ EXPECT_FALSE(testARMExtension("generic", ARM::ArchKind::ARMV7EM, "crypto"));
EXPECT_FALSE(testARMExtension("generic", ARM::ArchKind::ARMV8A, "ras"));
EXPECT_FALSE(testARMExtension("generic", ARM::ArchKind::ARMV8_1A, "ras"));
EXPECT_FALSE(testARMExtension("generic", ARM::ArchKind::ARMV8_2A, "profile"));
@@ -724,10 +714,10 @@ TEST(TargetParserTest, testARMExtension) {
EXPECT_FALSE(testARMExtension("generic", ARM::ArchKind::ARMV8_4A, "fp16"));
EXPECT_FALSE(testARMExtension("generic", ARM::ArchKind::ARMV8_4A, "fp16fml"));
EXPECT_FALSE(testARMExtension("generic", ARM::ArchKind::ARMV8R, "ras"));
- EXPECT_FALSE(testARMExtension("generic",
- ARM::ArchKind::ARMV8MBaseline, "crc"));
- EXPECT_FALSE(testARMExtension("generic",
- ARM::ArchKind::ARMV8MMainline, "crc"));
+ EXPECT_FALSE(
+ testARMExtension("generic", ARM::ArchKind::ARMV8MBaseline, "crc"));
+ EXPECT_FALSE(
+ testARMExtension("generic", ARM::ArchKind::ARMV8MMainline, "crc"));
EXPECT_FALSE(testARMExtension("generic", ARM::ArchKind::IWMMXT, "crc"));
EXPECT_FALSE(testARMExtension("generic", ARM::ArchKind::IWMMXT2, "crc"));
EXPECT_FALSE(testARMExtension("generic", ARM::ArchKind::XSCALE, "crc"));
@@ -752,11 +742,9 @@ TEST(TargetParserTest, ARMFPUNeonSupportLevel) {
FK = static_cast<ARM::FPUKind>(static_cast<unsigned>(FK) + 1))
if (FK == ARM::FK_LAST ||
ARM::getFPUName(FK).find("neon") == std::string::npos)
- EXPECT_EQ(ARM::NeonSupportLevel::None,
- ARM::getFPUNeonSupportLevel(FK));
+ EXPECT_EQ(ARM::NeonSupportLevel::None, ARM::getFPUNeonSupportLevel(FK));
else
- EXPECT_NE(ARM::NeonSupportLevel::None,
- ARM::getFPUNeonSupportLevel(FK));
+ EXPECT_NE(ARM::NeonSupportLevel::None, ARM::getFPUNeonSupportLevel(FK));
}
TEST(TargetParserTest, ARMFPURestriction) {
@@ -780,8 +768,8 @@ TEST(TargetParserTest, ARMExtensionFeatures) {
Extensions[Ext.ID] = {Ext.Feature, Ext.NegFeature};
}
- Extensions[ARM::AEK_HWDIVARM] = { "+hwdiv-arm", "-hwdiv-arm" };
- Extensions[ARM::AEK_HWDIVTHUMB] = { "+hwdiv", "-hwdiv" };
+ Extensions[ARM::AEK_HWDIVARM] = {"+hwdiv-arm", "-hwdiv-arm"};
+ Extensions[ARM::AEK_HWDIVTHUMB] = {"+hwdiv", "-hwdiv"};
std::vector<StringRef> Features;
@@ -1041,11 +1029,12 @@ TEST(TargetParserTest, getARMCPUForArch) {
}
TEST(TargetParserTest, ARMPrintSupportedExtensions) {
- std::string expected = "All available -march extensions for ARM\n\n"
- " Name Description\n"
- " crc This is a long dummy description\n"
- " crypto\n"
- " sha2\n";
+ std::string expected =
+ "All available -march extensions for ARM\n\n"
+ " Name Description\n"
+ " crc This is a long dummy description\n"
+ " crypto\n"
+ " sha2\n";
StringMap<StringRef> DummyMap;
DummyMap["crc"] = "This is a long dummy description";
@@ -1069,9 +1058,9 @@ TEST(TargetParserTest, ARMPrintSupportedExtensions) {
EXPECT_EQ(std::string::npos, captured.find("xscale"));
}
-class AArch64CPUTestFixture
- : public ::testing::TestWithParam<
- ARMCPUTestParams<AArch64::ExtensionBitset>> {};
+class AArch64CPUTestFixture : public ::testing::TestWithParam<
+ ARMCPUTestParams<AArch64::ExtensionBitset>> {
+};
TEST_P(AArch64CPUTestFixture, testAArch64CPU) {
auto params = GetParam();
@@ -1090,154 +1079,164 @@ INSTANTIATE_TEST_SUITE_P(
::testing::Values(
ARMCPUTestParams<AArch64::ExtensionBitset>(
"cortex-a34", "armv8-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
- {AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
- AArch64::AEK_FP, AArch64::AEK_SIMD})),
+ AArch64::ExtensionBitset({AArch64::AEK_CRC, AArch64::AEK_AES,
+ AArch64::AEK_SHA2, AArch64::AEK_FP,
+ AArch64::AEK_SIMD}),
"8-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"cortex-a35", "armv8-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
- {AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
- AArch64::AEK_FP, AArch64::AEK_SIMD})),
+ AArch64::ExtensionBitset({AArch64::AEK_CRC, AArch64::AEK_AES,
+ AArch64::AEK_SHA2, AArch64::AEK_FP,
+ AArch64::AEK_SIMD}),
"8-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"cortex-a53", "armv8-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
- {AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
- AArch64::AEK_FP, AArch64::AEK_SIMD})),
+ AArch64::ExtensionBitset({AArch64::AEK_CRC, AArch64::AEK_AES,
+ AArch64::AEK_SHA2, AArch64::AEK_FP,
+ AArch64::AEK_SIMD}),
"8-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"cortex-a55", "armv8.2-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
AArch64::AEK_FP, AArch64::AEK_SIMD, AArch64::AEK_RAS,
AArch64::AEK_LSE, AArch64::AEK_RDM, AArch64::AEK_FP16,
- AArch64::AEK_DOTPROD, AArch64::AEK_RCPC})),
+ AArch64::AEK_DOTPROD, AArch64::AEK_RCPC}),
"8.2-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"cortex-a510", "armv9-a", "neon-fp-armv8",
- (AArch64::ExtensionBitset(
- {AArch64::AEK_CRC, AArch64::AEK_FP, AArch64::AEK_SIMD,
- AArch64::AEK_RAS, AArch64::AEK_LSE, AArch64::AEK_RDM,
- AArch64::AEK_RCPC, AArch64::AEK_DOTPROD, AArch64::AEK_BF16,
- AArch64::AEK_I8MM, AArch64::AEK_SVE, AArch64::AEK_SVE2,
- AArch64::AEK_SVE2BITPERM, AArch64::AEK_PAUTH, AArch64::AEK_MTE,
- AArch64::AEK_SSBS, AArch64::AEK_FP16, AArch64::AEK_FP16FML,
- AArch64::AEK_SB, AArch64::AEK_JSCVT, AArch64::AEK_FCMA})),
+ AArch64::ExtensionBitset(
+ {AArch64::AEK_CRC, AArch64::AEK_FP,
+ AArch64::AEK_SIMD, AArch64::AEK_RAS,
+ AArch64::AEK_LSE, AArch64::AEK_RDM,
+ AArch64::AEK_RCPC, AArch64::AEK_DOTPROD,
+ AArch64::AEK_BF16, AArch64::AEK_I8MM,
+ AArch64::AEK_SVE, AArch64::AEK_SVE2,
+ AArch64::AEK_SVE2BITPERM, AArch64::AEK_PAUTH,
+ AArch64::AEK_MTE, AArch64::AEK_SSBS,
+ AArch64::AEK_FP16, AArch64::AEK_FP16FML,
+ AArch64::AEK_SB, AArch64::AEK_JSCVT,
+ AArch64::AEK_FCMA}),
"9-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"cortex-a520", "armv9.2-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
- {AArch64::AEK_BF16, AArch64::AEK_I8MM, AArch64::AEK_SVE,
- AArch64::AEK_SVE2, AArch64::AEK_FP16, AArch64::AEK_DOTPROD,
- AArch64::AEK_LSE, AArch64::AEK_RDM, AArch64::AEK_SIMD,
- AArch64::AEK_RCPC, AArch64::AEK_RAS, AArch64::AEK_CRC,
- AArch64::AEK_FP, AArch64::AEK_SB, AArch64::AEK_SSBS,
- AArch64::AEK_MTE, AArch64::AEK_FP16FML, AArch64::AEK_PAUTH,
- AArch64::AEK_SVE2BITPERM, AArch64::AEK_FLAGM,
- AArch64::AEK_PERFMON, AArch64::AEK_PREDRES, AArch64::AEK_JSCVT,
- AArch64::AEK_FCMA})),
+ AArch64::ExtensionBitset(
+ {AArch64::AEK_BF16, AArch64::AEK_I8MM,
+ AArch64::AEK_SVE, AArch64::AEK_SVE2,
+ AArch64::AEK_FP16, AArch64::AEK_DOTPROD,
+ AArch64::AEK_LSE, AArch64::AEK_RDM,
+ AArch64::AEK_SIMD, AArch64::AEK_RCPC,
+ AArch64::AEK_RAS, AArch64::AEK_CRC,
+ AArch64::AEK_FP, AArch64::AEK_SB,
+ AArch64::AEK_SSBS, AArch64::AEK_MTE,
+ AArch64::AEK_FP16FML, AArch64::AEK_PAUTH,
+ AArch64::AEK_SVE2BITPERM, AArch64::AEK_FLAGM,
+ AArch64::AEK_PERFMON, AArch64::AEK_PREDRES,
+ AArch64::AEK_JSCVT, AArch64::AEK_FCMA}),
"9.2-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"cortex-a57", "armv8-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
- {AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
- AArch64::AEK_FP, AArch64::AEK_SIMD})),
+ AArch64::ExtensionBitset({AArch64::AEK_CRC, AArch64::AEK_AES,
+ AArch64::AEK_SHA2, AArch64::AEK_FP,
+ AArch64::AEK_SIMD}),
"8-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"cortex-a65", "armv8.2-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
AArch64::AEK_DOTPROD, AArch64::AEK_FP, AArch64::AEK_FP16,
AArch64::AEK_LSE, AArch64::AEK_RAS, AArch64::AEK_RCPC,
- AArch64::AEK_RDM, AArch64::AEK_SIMD, AArch64::AEK_SSBS})),
+ AArch64::AEK_RDM, AArch64::AEK_SIMD, AArch64::AEK_SSBS}),
"8.2-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"cortex-a65ae", "armv8.2-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
AArch64::AEK_DOTPROD, AArch64::AEK_FP, AArch64::AEK_FP16,
AArch64::AEK_LSE, AArch64::AEK_RAS, AArch64::AEK_RCPC,
- AArch64::AEK_RDM, AArch64::AEK_SIMD, AArch64::AEK_SSBS})),
+ AArch64::AEK_RDM, AArch64::AEK_SIMD, AArch64::AEK_SSBS}),
"8.2-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"cortex-a72", "armv8-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
- {AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
- AArch64::AEK_FP, AArch64::AEK_SIMD})),
+ AArch64::ExtensionBitset({AArch64::AEK_CRC, AArch64::AEK_AES,
+ AArch64::AEK_SHA2, AArch64::AEK_FP,
+ AArch64::AEK_SIMD}),
"8-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"cortex-a73", "armv8-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
- {AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
- AArch64::AEK_FP, AArch64::AEK_SIMD})),
+ AArch64::ExtensionBitset({AArch64::AEK_CRC, AArch64::AEK_AES,
+ AArch64::AEK_SHA2, AArch64::AEK_FP,
+ AArch64::AEK_SIMD}),
"8-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"cortex-a75", "armv8.2-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
AArch64::AEK_FP, AArch64::AEK_SIMD, AArch64::AEK_RAS,
AArch64::AEK_LSE, AArch64::AEK_RDM, AArch64::AEK_FP16,
- AArch64::AEK_DOTPROD, AArch64::AEK_RCPC})),
+ AArch64::AEK_DOTPROD, AArch64::AEK_RCPC}),
"8.2-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"cortex-a76", "armv8.2-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
AArch64::AEK_FP, AArch64::AEK_RDM, AArch64::AEK_SIMD,
AArch64::AEK_RAS, AArch64::AEK_LSE, AArch64::AEK_FP16,
- AArch64::AEK_DOTPROD, AArch64::AEK_RCPC, AArch64::AEK_SSBS})),
+ AArch64::AEK_DOTPROD, AArch64::AEK_RCPC, AArch64::AEK_SSBS}),
"8.2-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"cortex-a76ae", "armv8.2-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
AArch64::AEK_FP, AArch64::AEK_RDM, AArch64::AEK_SIMD,
AArch64::AEK_RAS, AArch64::AEK_LSE, AArch64::AEK_FP16,
- AArch64::AEK_DOTPROD, AArch64::AEK_RCPC, AArch64::AEK_SSBS})),
+ AArch64::AEK_DOTPROD, AArch64::AEK_RCPC, AArch64::AEK_SSBS}),
"8.2-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"cortex-a77", "armv8.2-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
AArch64::AEK_FP, AArch64::AEK_RDM, AArch64::AEK_SIMD,
AArch64::AEK_RAS, AArch64::AEK_LSE, AArch64::AEK_FP16,
- AArch64::AEK_DOTPROD, AArch64::AEK_RCPC, AArch64::AEK_SSBS})),
+ AArch64::AEK_DOTPROD, AArch64::AEK_RCPC, AArch64::AEK_SSBS}),
"8.2-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"cortex-a78", "armv8.2-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
AArch64::AEK_FP, AArch64::AEK_RDM, AArch64::AEK_SIMD,
AArch64::AEK_RAS, AArch64::AEK_LSE, AArch64::AEK_FP16,
AArch64::AEK_DOTPROD, AArch64::AEK_RCPC, AArch64::AEK_SSBS,
- AArch64::AEK_PROFILE})),
+ AArch64::AEK_PROFILE}),
"8.2-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"cortex-a78c", "armv8.2-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_RAS, AArch64::AEK_CRC, AArch64::AEK_AES,
AArch64::AEK_SHA2, AArch64::AEK_FP, AArch64::AEK_SIMD,
AArch64::AEK_RAS, AArch64::AEK_LSE, AArch64::AEK_RDM,
AArch64::AEK_FP16, AArch64::AEK_DOTPROD, AArch64::AEK_RCPC,
AArch64::AEK_SSBS, AArch64::AEK_PROFILE, AArch64::AEK_FLAGM,
- AArch64::AEK_PAUTH})),
+ AArch64::AEK_PAUTH}),
"8.2-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"cortex-a710", "armv9-a", "neon-fp-armv8",
- (AArch64::ExtensionBitset(
- {AArch64::AEK_CRC, AArch64::AEK_FP, AArch64::AEK_SIMD,
- AArch64::AEK_RAS, AArch64::AEK_LSE, AArch64::AEK_RDM,
- AArch64::AEK_RCPC, AArch64::AEK_DOTPROD, AArch64::AEK_MTE,
- AArch64::AEK_FP16, AArch64::AEK_FP16FML, AArch64::AEK_SVE,
- AArch64::AEK_SVE2, AArch64::AEK_SVE2BITPERM,
- AArch64::AEK_PAUTH, AArch64::AEK_FLAGM, AArch64::AEK_SB,
- AArch64::AEK_I8MM, AArch64::AEK_BF16, AArch64::AEK_JSCVT,
- AArch64::AEK_FCMA})),
+ AArch64::ExtensionBitset(
+ {AArch64::AEK_CRC, AArch64::AEK_FP,
+ AArch64::AEK_SIMD, AArch64::AEK_RAS,
+ AArch64::AEK_LSE, AArch64::AEK_RDM,
+ AArch64::AEK_RCPC, AArch64::AEK_DOTPROD,
+ AArch64::AEK_MTE, AArch64::AEK_FP16,
+ AArch64::AEK_FP16FML, AArch64::AEK_SVE,
+ AArch64::AEK_SVE2, AArch64::AEK_SVE2BITPERM,
+ AArch64::AEK_PAUTH, AArch64::AEK_FLAGM,
+ AArch64::AEK_SB, AArch64::AEK_I8MM,
+ AArch64::AEK_BF16, AArch64::AEK_JSCVT,
+ AArch64::AEK_FCMA}),
"9-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"cortex-a715", "armv9-a", "neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_FP,
AArch64::AEK_BF16, AArch64::AEK_SIMD,
AArch64::AEK_RAS, AArch64::AEK_LSE,
@@ -1250,24 +1249,28 @@ INSTANTIATE_TEST_SUITE_P(
AArch64::AEK_PREDRES, AArch64::AEK_PROFILE,
AArch64::AEK_FP16FML, AArch64::AEK_FP16,
AArch64::AEK_FLAGM, AArch64::AEK_JSCVT,
- AArch64::AEK_FCMA})),
+ AArch64::AEK_FCMA}),
"9-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"cortex-a720", "armv9.2-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
- {AArch64::AEK_BF16, AArch64::AEK_I8MM, AArch64::AEK_SVE,
- AArch64::AEK_SVE2, AArch64::AEK_FP16, AArch64::AEK_DOTPROD,
- AArch64::AEK_LSE, AArch64::AEK_RDM, AArch64::AEK_SIMD,
- AArch64::AEK_RCPC, AArch64::AEK_RAS, AArch64::AEK_CRC,
- AArch64::AEK_FP, AArch64::AEK_SB, AArch64::AEK_SSBS,
- AArch64::AEK_MTE, AArch64::AEK_FP16FML, AArch64::AEK_PAUTH,
- AArch64::AEK_SVE2BITPERM, AArch64::AEK_FLAGM,
- AArch64::AEK_PERFMON, AArch64::AEK_PREDRES,
- AArch64::AEK_PROFILE, AArch64::AEK_JSCVT, AArch64::AEK_FCMA})),
+ AArch64::ExtensionBitset(
+ {AArch64::AEK_BF16, AArch64::AEK_I8MM,
+ AArch64::AEK_SVE, AArch64::AEK_SVE2,
+ AArch64::AEK_FP16, AArch64::AEK_DOTPROD,
+ AArch64::AEK_LSE, AArch64::AEK_RDM,
+ AArch64::AEK_SIMD, AArch64::AEK_RCPC,
+ AArch64::AEK_RAS, AArch64::AEK_CRC,
+ AArch64::AEK_FP, AArch64::AEK_SB,
+ AArch64::AEK_SSBS, AArch64::AEK_MTE,
+ AArch64::AEK_FP16FML, AArch64::AEK_PAUTH,
+ AArch64::AEK_SVE2BITPERM, AArch64::AEK_FLAGM,
+ AArch64::AEK_PERFMON, AArch64::AEK_PREDRES,
+ AArch64::AEK_PROFILE, AArch64::AEK_JSCVT,
+ AArch64::AEK_FCMA}),
"9.2-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"neoverse-v1", "armv8.4-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_RAS, AArch64::AEK_SVE, AArch64::AEK_SSBS,
AArch64::AEK_RCPC, AArch64::AEK_CRC, AArch64::AEK_FP,
AArch64::AEK_SIMD, AArch64::AEK_RAS, AArch64::AEK_LSE,
@@ -1276,11 +1279,11 @@ INSTANTIATE_TEST_SUITE_P(
AArch64::AEK_SM4, AArch64::AEK_FP16, AArch64::AEK_BF16,
AArch64::AEK_PROFILE, AArch64::AEK_RAND, AArch64::AEK_FP16FML,
AArch64::AEK_I8MM, AArch64::AEK_JSCVT, AArch64::AEK_FCMA,
- AArch64::AEK_PAUTH})),
+ AArch64::AEK_PAUTH}),
"8.4-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"neoverse-v2", "armv9-a", "neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_RAS, AArch64::AEK_SVE,
AArch64::AEK_SSBS, AArch64::AEK_RCPC,
AArch64::AEK_CRC, AArch64::AEK_FP,
@@ -1292,50 +1295,53 @@ INSTANTIATE_TEST_SUITE_P(
AArch64::AEK_FP16FML, AArch64::AEK_I8MM,
AArch64::AEK_SVE2BITPERM, AArch64::AEK_RAND,
AArch64::AEK_JSCVT, AArch64::AEK_FCMA,
- AArch64::AEK_PAUTH})),
+ AArch64::AEK_PAUTH}),
"9-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"cortex-r82", "armv8-r", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_RDM, AArch64::AEK_SSBS,
AArch64::AEK_DOTPROD, AArch64::AEK_FP, AArch64::AEK_SIMD,
AArch64::AEK_FP16, AArch64::AEK_FP16FML, AArch64::AEK_RAS,
AArch64::AEK_RCPC, AArch64::AEK_LSE, AArch64::AEK_SB,
- AArch64::AEK_JSCVT, AArch64::AEK_FCMA, AArch64::AEK_PAUTH})),
+ AArch64::AEK_JSCVT, AArch64::AEK_FCMA, AArch64::AEK_PAUTH}),
"8-R"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"cortex-x1", "armv8.2-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
AArch64::AEK_FP, AArch64::AEK_RDM, AArch64::AEK_SIMD,
AArch64::AEK_RAS, AArch64::AEK_LSE, AArch64::AEK_FP16,
AArch64::AEK_DOTPROD, AArch64::AEK_RCPC, AArch64::AEK_SSBS,
- AArch64::AEK_PROFILE})),
+ AArch64::AEK_PROFILE}),
"8.2-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"cortex-x1c", "armv8.2-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
AArch64::AEK_FP, AArch64::AEK_RDM, AArch64::AEK_SIMD,
AArch64::AEK_RAS, AArch64::AEK_LSE, AArch64::AEK_FP16,
AArch64::AEK_DOTPROD, AArch64::AEK_RCPC, AArch64::AEK_SSBS,
- AArch64::AEK_PAUTH, AArch64::AEK_PROFILE, AArch64::AEK_FLAGM})),
+ AArch64::AEK_PAUTH, AArch64::AEK_PROFILE, AArch64::AEK_FLAGM}),
"8.2-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"cortex-x2", "armv9-a", "neon-fp-armv8",
- (AArch64::ExtensionBitset(
- {AArch64::AEK_CRC, AArch64::AEK_FP, AArch64::AEK_SIMD,
- AArch64::AEK_RAS, AArch64::AEK_LSE, AArch64::AEK_RDM,
- AArch64::AEK_RCPC, AArch64::AEK_DOTPROD, AArch64::AEK_MTE,
- AArch64::AEK_PAUTH, AArch64::AEK_I8MM, AArch64::AEK_BF16,
- AArch64::AEK_SVE, AArch64::AEK_SVE2, AArch64::AEK_SVE2BITPERM,
- AArch64::AEK_SSBS, AArch64::AEK_SB, AArch64::AEK_FP16,
- AArch64::AEK_FP16FML, AArch64::AEK_FLAGM, AArch64::AEK_JSCVT,
- AArch64::AEK_FCMA})),
+ AArch64::ExtensionBitset(
+ {AArch64::AEK_CRC, AArch64::AEK_FP,
+ AArch64::AEK_SIMD, AArch64::AEK_RAS,
+ AArch64::AEK_LSE, AArch64::AEK_RDM,
+ AArch64::AEK_RCPC, AArch64::AEK_DOTPROD,
+ AArch64::AEK_MTE, AArch64::AEK_PAUTH,
+ AArch64::AEK_I8MM, AArch64::AEK_BF16,
+ AArch64::AEK_SVE, AArch64::AEK_SVE2,
+ AArch64::AEK_SVE2BITPERM, AArch64::AEK_SSBS,
+ AArch64::AEK_SB, AArch64::AEK_FP16,
+ AArch64::AEK_FP16FML, AArch64::AEK_FLAGM,
+ AArch64::AEK_JSCVT, AArch64::AEK_FCMA}),
"9-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"cortex-x3", "armv9-a", "neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_FP,
AArch64::AEK_BF16, AArch64::AEK_SIMD,
AArch64::AEK_RAS, AArch64::AEK_LSE,
@@ -1348,224 +1354,228 @@ INSTANTIATE_TEST_SUITE_P(
AArch64::AEK_FP16, AArch64::AEK_FP16FML,
AArch64::AEK_PREDRES, AArch64::AEK_FLAGM,
AArch64::AEK_SSBS, AArch64::AEK_JSCVT,
- AArch64::AEK_FCMA})),
+ AArch64::AEK_FCMA}),
"9-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"cortex-x4", "armv9.2-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
- {AArch64::AEK_BF16, AArch64::AEK_I8MM, AArch64::AEK_SVE,
- AArch64::AEK_SVE2, AArch64::AEK_FP16, AArch64::AEK_DOTPROD,
- AArch64::AEK_LSE, AArch64::AEK_RDM, AArch64::AEK_SIMD,
- AArch64::AEK_RCPC, AArch64::AEK_RAS, AArch64::AEK_CRC,
- AArch64::AEK_FP, AArch64::AEK_SB, AArch64::AEK_SSBS,
- AArch64::AEK_MTE, AArch64::AEK_FP16FML, AArch64::AEK_PAUTH,
- AArch64::AEK_SVE2BITPERM, AArch64::AEK_FLAGM,
- AArch64::AEK_PERFMON, AArch64::AEK_PREDRES,
- AArch64::AEK_PROFILE, AArch64::AEK_JSCVT, AArch64::AEK_FCMA})),
+ AArch64::ExtensionBitset(
+ {AArch64::AEK_BF16, AArch64::AEK_I8MM,
+ AArch64::AEK_SVE, AArch64::AEK_SVE2,
+ AArch64::AEK_FP16, AArch64::AEK_DOTPROD,
+ AArch64::AEK_LSE, AArch64::AEK_RDM,
+ AArch64::AEK_SIMD, AArch64::AEK_RCPC,
+ AArch64::AEK_RAS, AArch64::AEK_CRC,
+ AArch64::AEK_FP, AArch64::AEK_SB,
+ AArch64::AEK_SSBS, AArch64::AEK_MTE,
+ AArch64::AEK_FP16FML, AArch64::AEK_PAUTH,
+ AArch64::AEK_SVE2BITPERM, AArch64::AEK_FLAGM,
+ AArch64::AEK_PERFMON, AArch64::AEK_PREDRES,
+ AArch64::AEK_PROFILE, AArch64::AEK_JSCVT,
+ AArch64::AEK_FCMA}),
"9.2-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"cyclone", "armv8-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
- {AArch64::AEK_NONE, AArch64::AEK_AES, AArch64::AEK_SHA2,
- AArch64::AEK_FP, AArch64::AEK_SIMD})),
+ AArch64::ExtensionBitset({AArch64::AEK_NONE, AArch64::AEK_AES,
+ AArch64::AEK_SHA2, AArch64::AEK_FP,
+ AArch64::AEK_SIMD}),
"8-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"apple-a7", "armv8-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
- {AArch64::AEK_NONE, AArch64::AEK_AES, AArch64::AEK_SHA2,
- AArch64::AEK_FP, AArch64::AEK_SIMD})),
+ AArch64::ExtensionBitset({AArch64::AEK_NONE, AArch64::AEK_AES,
+ AArch64::AEK_SHA2, AArch64::AEK_FP,
+ AArch64::AEK_SIMD}),
"8-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"apple-a8", "armv8-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
- {AArch64::AEK_NONE, AArch64::AEK_AES, AArch64::AEK_SHA2,
- AArch64::AEK_FP, AArch64::AEK_SIMD})),
+ AArch64::ExtensionBitset({AArch64::AEK_NONE, AArch64::AEK_AES,
+ AArch64::AEK_SHA2, AArch64::AEK_FP,
+ AArch64::AEK_SIMD}),
"8-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"apple-a9", "armv8-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
- {AArch64::AEK_NONE, AArch64::AEK_AES, AArch64::AEK_SHA2,
- AArch64::AEK_FP, AArch64::AEK_SIMD})),
+ AArch64::ExtensionBitset({AArch64::AEK_NONE, AArch64::AEK_AES,
+ AArch64::AEK_SHA2, AArch64::AEK_FP,
+ AArch64::AEK_SIMD}),
"8-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"apple-a10", "armv8-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
- {AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
- AArch64::AEK_FP, AArch64::AEK_RDM, AArch64::AEK_SIMD})),
+ AArch64::ExtensionBitset({AArch64::AEK_CRC, AArch64::AEK_AES,
+ AArch64::AEK_SHA2, AArch64::AEK_FP,
+ AArch64::AEK_RDM, AArch64::AEK_SIMD}),
"8-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"apple-a11", "armv8.2-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
AArch64::AEK_FP, AArch64::AEK_LSE, AArch64::AEK_RAS,
- AArch64::AEK_RDM, AArch64::AEK_SIMD, AArch64::AEK_FP16})),
+ AArch64::AEK_RDM, AArch64::AEK_SIMD, AArch64::AEK_FP16}),
"8.2-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"apple-a12", "armv8.3-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
AArch64::AEK_FP, AArch64::AEK_SIMD, AArch64::AEK_LSE,
AArch64::AEK_RAS, AArch64::AEK_RDM, AArch64::AEK_RCPC,
AArch64::AEK_FP16, AArch64::AEK_JSCVT, AArch64::AEK_FCMA,
- AArch64::AEK_PAUTH})),
+ AArch64::AEK_PAUTH}),
"8.3-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"apple-a13", "armv8.4-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
AArch64::AEK_SHA3, AArch64::AEK_FP, AArch64::AEK_SIMD,
AArch64::AEK_LSE, AArch64::AEK_RAS, AArch64::AEK_RDM,
AArch64::AEK_RCPC, AArch64::AEK_DOTPROD, AArch64::AEK_FP16,
AArch64::AEK_FP16FML, AArch64::AEK_SHA3, AArch64::AEK_JSCVT,
- AArch64::AEK_FCMA, AArch64::AEK_PAUTH})),
+ AArch64::AEK_FCMA, AArch64::AEK_PAUTH}),
"8.4-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"apple-a14", "armv8.5-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
AArch64::AEK_SHA3, AArch64::AEK_FP, AArch64::AEK_SIMD,
AArch64::AEK_LSE, AArch64::AEK_RAS, AArch64::AEK_RDM,
AArch64::AEK_RCPC, AArch64::AEK_DOTPROD, AArch64::AEK_FP16,
AArch64::AEK_FP16FML, AArch64::AEK_SHA3, AArch64::AEK_JSCVT,
- AArch64::AEK_FCMA, AArch64::AEK_PAUTH})),
+ AArch64::AEK_FCMA, AArch64::AEK_PAUTH}),
"8.5-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"apple-a15", "armv8.6-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
AArch64::AEK_SHA3, AArch64::AEK_FP, AArch64::AEK_SIMD,
AArch64::AEK_LSE, AArch64::AEK_RAS, AArch64::AEK_RDM,
AArch64::AEK_RCPC, AArch64::AEK_DOTPROD, AArch64::AEK_FP16,
AArch64::AEK_FP16FML, AArch64::AEK_SHA3, AArch64::AEK_BF16,
AArch64::AEK_I8MM, AArch64::AEK_JSCVT, AArch64::AEK_FCMA,
- AArch64::AEK_PAUTH})),
+ AArch64::AEK_PAUTH}),
"8.6-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"apple-a16", "armv8.6-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
AArch64::AEK_SHA3, AArch64::AEK_FP, AArch64::AEK_SIMD,
AArch64::AEK_LSE, AArch64::AEK_RAS, AArch64::AEK_RDM,
AArch64::AEK_RCPC, AArch64::AEK_DOTPROD, AArch64::AEK_FP16,
AArch64::AEK_FP16FML, AArch64::AEK_SHA3, AArch64::AEK_BF16,
AArch64::AEK_I8MM, AArch64::AEK_JSCVT, AArch64::AEK_FCMA,
- AArch64::AEK_PAUTH})),
+ AArch64::AEK_PAUTH}),
"8.6-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"apple-a17", "armv8.6-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
AArch64::AEK_SHA3, AArch64::AEK_FP, AArch64::AEK_SIMD,
AArch64::AEK_LSE, AArch64::AEK_RAS, AArch64::AEK_RDM,
AArch64::AEK_RCPC, AArch64::AEK_DOTPROD, AArch64::AEK_FP16,
AArch64::AEK_FP16FML, AArch64::AEK_SHA3, AArch64::AEK_BF16,
AArch64::AEK_I8MM, AArch64::AEK_JSCVT, AArch64::AEK_FCMA,
- AArch64::AEK_PAUTH})),
+ AArch64::AEK_PAUTH}),
"8.6-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"apple-m1", "armv8.5-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
AArch64::AEK_SHA3, AArch64::AEK_FP, AArch64::AEK_SIMD,
AArch64::AEK_LSE, AArch64::AEK_RAS, AArch64::AEK_RDM,
AArch64::AEK_RCPC, AArch64::AEK_DOTPROD, AArch64::AEK_FP16,
AArch64::AEK_FP16FML, AArch64::AEK_SHA3, AArch64::AEK_JSCVT,
- AArch64::AEK_FCMA, AArch64::AEK_PAUTH})),
+ AArch64::AEK_FCMA, AArch64::AEK_PAUTH}),
"8.5-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"apple-m2", "armv8.6-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
AArch64::AEK_SHA3, AArch64::AEK_FP, AArch64::AEK_SIMD,
AArch64::AEK_LSE, AArch64::AEK_RAS, AArch64::AEK_RDM,
AArch64::AEK_RCPC, AArch64::AEK_DOTPROD, AArch64::AEK_FP16,
AArch64::AEK_FP16FML, AArch64::AEK_SHA3, AArch64::AEK_BF16,
AArch64::AEK_I8MM, AArch64::AEK_JSCVT, AArch64::AEK_FCMA,
- AArch64::AEK_PAUTH})),
+ AArch64::AEK_PAUTH}),
"8.6-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"apple-m3", "armv8.6-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
AArch64::AEK_SHA3, AArch64::AEK_FP, AArch64::AEK_SIMD,
AArch64::AEK_LSE, AArch64::AEK_RAS, AArch64::AEK_RDM,
AArch64::AEK_RCPC, AArch64::AEK_DOTPROD, AArch64::AEK_FP16,
AArch64::AEK_FP16FML, AArch64::AEK_SHA3, AArch64::AEK_BF16,
AArch64::AEK_I8MM, AArch64::AEK_JSCVT, AArch64::AEK_FCMA,
- AArch64::AEK_PAUTH})),
+ AArch64::AEK_PAUTH}),
"8.6-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"apple-s4", "armv8.3-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
AArch64::AEK_FP, AArch64::AEK_SIMD, AArch64::AEK_LSE,
AArch64::AEK_RAS, AArch64::AEK_RDM, AArch64::AEK_RCPC,
AArch64::AEK_FP16, AArch64::AEK_JSCVT, AArch64::AEK_FCMA,
- AArch64::AEK_PAUTH})),
+ AArch64::AEK_PAUTH}),
"8.3-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"apple-s5", "armv8.3-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
AArch64::AEK_FP, AArch64::AEK_SIMD, AArch64::AEK_LSE,
AArch64::AEK_RAS, AArch64::AEK_RDM, AArch64::AEK_RCPC,
AArch64::AEK_FP16, AArch64::AEK_JSCVT, AArch64::AEK_FCMA,
- AArch64::AEK_PAUTH})),
+ AArch64::AEK_PAUTH}),
"8.3-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"exynos-m3", "armv8-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
- {AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
- AArch64::AEK_FP, AArch64::AEK_SIMD})),
+ AArch64::ExtensionBitset({AArch64::AEK_CRC, AArch64::AEK_AES,
+ AArch64::AEK_SHA2, AArch64::AEK_FP,
+ AArch64::AEK_SIMD}),
"8-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"exynos-m4", "armv8.2-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
- {AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
- AArch64::AEK_DOTPROD, AArch64::AEK_FP, AArch64::AEK_FP16,
- AArch64::AEK_LSE, AArch64::AEK_RAS, AArch64::AEK_RDM,
- AArch64::AEK_SIMD})),
+ AArch64::ExtensionBitset({AArch64::AEK_CRC, AArch64::AEK_AES,
+ AArch64::AEK_SHA2, AArch64::AEK_DOTPROD,
+ AArch64::AEK_FP, AArch64::AEK_FP16,
+ AArch64::AEK_LSE, AArch64::AEK_RAS,
+ AArch64::AEK_RDM, AArch64::AEK_SIMD}),
"8.2-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"exynos-m5", "armv8.2-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
- {AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
- AArch64::AEK_DOTPROD, AArch64::AEK_FP, AArch64::AEK_FP16,
- AArch64::AEK_LSE, AArch64::AEK_RAS, AArch64::AEK_RDM,
- AArch64::AEK_SIMD})),
+ AArch64::ExtensionBitset({AArch64::AEK_CRC, AArch64::AEK_AES,
+ AArch64::AEK_SHA2, AArch64::AEK_DOTPROD,
+ AArch64::AEK_FP, AArch64::AEK_FP16,
+ AArch64::AEK_LSE, AArch64::AEK_RAS,
+ AArch64::AEK_RDM, AArch64::AEK_SIMD}),
"8.2-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"falkor", "armv8-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
- {AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
- AArch64::AEK_FP, AArch64::AEK_SIMD, AArch64::AEK_RDM})),
+ AArch64::ExtensionBitset({AArch64::AEK_CRC, AArch64::AEK_AES,
+ AArch64::AEK_SHA2, AArch64::AEK_FP,
+ AArch64::AEK_SIMD, AArch64::AEK_RDM}),
"8-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"kryo", "armv8-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
- {AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
- AArch64::AEK_FP, AArch64::AEK_SIMD})),
+ AArch64::ExtensionBitset({AArch64::AEK_CRC, AArch64::AEK_AES,
+ AArch64::AEK_SHA2, AArch64::AEK_FP,
+ AArch64::AEK_SIMD}),
"8-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"neoverse-e1", "armv8.2-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
AArch64::AEK_DOTPROD, AArch64::AEK_FP, AArch64::AEK_FP16,
AArch64::AEK_LSE, AArch64::AEK_RAS, AArch64::AEK_RCPC,
- AArch64::AEK_RDM, AArch64::AEK_SIMD, AArch64::AEK_SSBS})),
+ AArch64::AEK_RDM, AArch64::AEK_SIMD, AArch64::AEK_SSBS}),
"8.2-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"neoverse-n1", "armv8.2-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
AArch64::AEK_DOTPROD, AArch64::AEK_FP, AArch64::AEK_FP16,
AArch64::AEK_LSE, AArch64::AEK_PROFILE, AArch64::AEK_RAS,
AArch64::AEK_RCPC, AArch64::AEK_RDM, AArch64::AEK_SIMD,
- AArch64::AEK_SSBS})),
+ AArch64::AEK_SSBS}),
"8.2-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"neoverse-n2", "armv9-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_FP,
AArch64::AEK_SIMD, AArch64::AEK_FP16,
AArch64::AEK_RAS, AArch64::AEK_LSE,
@@ -1576,34 +1586,34 @@ INSTANTIATE_TEST_SUITE_P(
AArch64::AEK_SVE2BITPERM, AArch64::AEK_BF16,
AArch64::AEK_I8MM, AArch64::AEK_JSCVT,
AArch64::AEK_FCMA, AArch64::AEK_PAUTH,
- AArch64::AEK_FP16FML})),
+ AArch64::AEK_FP16FML}),
"9-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"ampere1", "armv8.6-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
- {AArch64::AEK_CRC, AArch64::AEK_FP, AArch64::AEK_FP16,
- AArch64::AEK_SIMD, AArch64::AEK_RAS, AArch64::AEK_LSE,
- AArch64::AEK_RDM, AArch64::AEK_RCPC, AArch64::AEK_DOTPROD,
+ AArch64::ExtensionBitset(
+ {AArch64::AEK_CRC, AArch64::AEK_FP, AArch64::AEK_FP16,
+ AArch64::AEK_SIMD, AArch64::AEK_RAS, AArch64::AEK_LSE,
+ AArch64::AEK_RDM, AArch64::AEK_RCPC, AArch64::AEK_DOTPROD,
AArch64::AEK_SHA3, AArch64::AEK_BF16, AArch64::AEK_SHA2,
- AArch64::AEK_AES, AArch64::AEK_I8MM, AArch64::AEK_SSBS,
- AArch64::AEK_SB, AArch64::AEK_RAND, AArch64::AEK_JSCVT,
- AArch64::AEK_FCMA, AArch64::AEK_PAUTH})),
+ AArch64::AEK_AES, AArch64::AEK_I8MM, AArch64::AEK_SSBS,
+ AArch64::AEK_SB, AArch64::AEK_RAND, AArch64::AEK_JSCVT,
+ AArch64::AEK_FCMA, AArch64::AEK_PAUTH}),
"8.6-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"ampere1a", "armv8.6-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
- {AArch64::AEK_CRC, AArch64::AEK_FP, AArch64::AEK_FP16,
- AArch64::AEK_SIMD, AArch64::AEK_RAS, AArch64::AEK_LSE,
- AArch64::AEK_RDM, AArch64::AEK_RCPC, AArch64::AEK_DOTPROD,
- AArch64::AEK_SM4, AArch64::AEK_SHA3, AArch64::AEK_BF16,
- AArch64::AEK_SHA2, AArch64::AEK_AES, AArch64::AEK_I8MM,
- AArch64::AEK_SSBS, AArch64::AEK_SB, AArch64::AEK_RAND,
- AArch64::AEK_MTE, AArch64::AEK_JSCVT, AArch64::AEK_FCMA,
- AArch64::AEK_PAUTH})),
+ AArch64::ExtensionBitset(
+ {AArch64::AEK_CRC, AArch64::AEK_FP, AArch64::AEK_FP16,
+ AArch64::AEK_SIMD, AArch64::AEK_RAS, AArch64::AEK_LSE,
+ AArch64::AEK_RDM, AArch64::AEK_RCPC, AArch64::AEK_DOTPROD,
+ AArch64::AEK_SM4, AArch64::AEK_SHA3, AArch64::AEK_BF16,
+ AArch64::AEK_SHA2, AArch64::AEK_AES, AArch64::AEK_I8MM,
+ AArch64::AEK_SSBS, AArch64::AEK_SB, AArch64::AEK_RAND,
+ AArch64::AEK_MTE, AArch64::AEK_JSCVT, AArch64::AEK_FCMA,
+ AArch64::AEK_PAUTH}),
"8.6-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"ampere1b", "armv8.7-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_FP, AArch64::AEK_FP16,
AArch64::AEK_SIMD, AArch64::AEK_RAS, AArch64::AEK_LSE,
AArch64::AEK_RDM, AArch64::AEK_RCPC, AArch64::AEK_DOTPROD,
@@ -1611,11 +1621,11 @@ INSTANTIATE_TEST_SUITE_P(
AArch64::AEK_SHA2, AArch64::AEK_AES, AArch64::AEK_I8MM,
AArch64::AEK_SSBS, AArch64::AEK_SB, AArch64::AEK_RAND,
AArch64::AEK_MTE, AArch64::AEK_JSCVT, AArch64::AEK_FCMA,
- AArch64::AEK_PAUTH, AArch64::AEK_CSSC})),
+ AArch64::AEK_PAUTH, AArch64::AEK_CSSC}),
"8.7-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"neoverse-512tvb", "armv8.4-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_RAS, AArch64::AEK_SVE, AArch64::AEK_SSBS,
AArch64::AEK_RCPC, AArch64::AEK_CRC, AArch64::AEK_FP,
AArch64::AEK_SIMD, AArch64::AEK_RAS, AArch64::AEK_LSE,
@@ -1624,70 +1634,70 @@ INSTANTIATE_TEST_SUITE_P(
AArch64::AEK_SM4, AArch64::AEK_FP16, AArch64::AEK_BF16,
AArch64::AEK_PROFILE, AArch64::AEK_RAND, AArch64::AEK_FP16FML,
AArch64::AEK_I8MM, AArch64::AEK_JSCVT, AArch64::AEK_FCMA,
- AArch64::AEK_PAUTH})),
+ AArch64::AEK_PAUTH}),
"8.4-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"thunderx2t99", "armv8.1-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
- {AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
- AArch64::AEK_LSE, AArch64::AEK_RDM, AArch64::AEK_FP,
- AArch64::AEK_SIMD})),
+ AArch64::ExtensionBitset({AArch64::AEK_CRC, AArch64::AEK_AES,
+ AArch64::AEK_SHA2, AArch64::AEK_LSE,
+ AArch64::AEK_RDM, AArch64::AEK_FP,
+ AArch64::AEK_SIMD}),
"8.1-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"thunderx3t110", "armv8.3-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
AArch64::AEK_LSE, AArch64::AEK_RDM, AArch64::AEK_FP,
AArch64::AEK_SIMD, AArch64::AEK_RAS, AArch64::AEK_RCPC,
- AArch64::AEK_JSCVT, AArch64::AEK_FCMA, AArch64::AEK_PAUTH})),
+ AArch64::AEK_JSCVT, AArch64::AEK_FCMA, AArch64::AEK_PAUTH}),
"8.3-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"thunderx", "armv8-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
- {AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
- AArch64::AEK_SIMD, AArch64::AEK_FP})),
+ AArch64::ExtensionBitset({AArch64::AEK_CRC, AArch64::AEK_AES,
+ AArch64::AEK_SHA2, AArch64::AEK_SIMD,
+ AArch64::AEK_FP}),
"8-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"thunderxt81", "armv8-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
- {AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
- AArch64::AEK_SIMD, AArch64::AEK_FP})),
+ AArch64::ExtensionBitset({AArch64::AEK_CRC, AArch64::AEK_AES,
+ AArch64::AEK_SHA2, AArch64::AEK_SIMD,
+ AArch64::AEK_FP}),
"8-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"thunderxt83", "armv8-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
- {AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
- AArch64::AEK_SIMD, AArch64::AEK_FP})),
+ AArch64::ExtensionBitset({AArch64::AEK_CRC, AArch64::AEK_AES,
+ AArch64::AEK_SHA2, AArch64::AEK_SIMD,
+ AArch64::AEK_FP}),
"8-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"thunderxt88", "armv8-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
- {AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
- AArch64::AEK_SIMD, AArch64::AEK_FP})),
+ AArch64::ExtensionBitset({AArch64::AEK_CRC, AArch64::AEK_AES,
+ AArch64::AEK_SHA2, AArch64::AEK_SIMD,
+ AArch64::AEK_FP}),
"8-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"tsv110", "armv8.2-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
AArch64::AEK_FP, AArch64::AEK_SIMD, AArch64::AEK_RAS,
AArch64::AEK_LSE, AArch64::AEK_RDM, AArch64::AEK_PROFILE,
AArch64::AEK_JSCVT, AArch64::AEK_FCMA, AArch64::AEK_FP16,
- AArch64::AEK_FP16FML, AArch64::AEK_DOTPROD})),
+ AArch64::AEK_FP16FML, AArch64::AEK_DOTPROD}),
"8.2-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"a64fx", "armv8.2-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
- {AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
- AArch64::AEK_FP, AArch64::AEK_SIMD, AArch64::AEK_FP16,
- AArch64::AEK_RAS, AArch64::AEK_LSE, AArch64::AEK_SVE,
- AArch64::AEK_RDM})),
+ AArch64::ExtensionBitset({AArch64::AEK_CRC, AArch64::AEK_AES,
+ AArch64::AEK_SHA2, AArch64::AEK_FP,
+ AArch64::AEK_SIMD, AArch64::AEK_FP16,
+ AArch64::AEK_RAS, AArch64::AEK_LSE,
+ AArch64::AEK_SVE, AArch64::AEK_RDM}),
"8.2-A"),
ARMCPUTestParams<AArch64::ExtensionBitset>(
"carmel", "armv8.2-a", "crypto-neon-fp-armv8",
- (AArch64::ExtensionBitset(
+ AArch64::ExtensionBitset(
{AArch64::AEK_CRC, AArch64::AEK_AES, AArch64::AEK_SHA2,
AArch64::AEK_FP, AArch64::AEK_SIMD, AArch64::AEK_FP16,
- AArch64::AEK_RAS, AArch64::AEK_LSE, AArch64::AEK_RDM})),
+ AArch64::AEK_RAS, AArch64::AEK_LSE, AArch64::AEK_RDM}),
"8.2-A")),
ARMCPUTestParams<AArch64::ExtensionBitset>::PrintToStringParamName);
@@ -2121,11 +2131,12 @@ TEST(TargetParserTest, AArch64ArchExtFeature) {
}
TEST(TargetParserTest, AArch64PrintSupportedExtensions) {
- std::string expected = "All available -march extensions for AArch64\n\n"
- " Name Description\n"
- " aes This is a long dummy description\n"
- " b16b16\n"
- " bf16\n";
+ std::string expected =
+ "All available -march extensions for AArch64\n\n"
+ " Name Description\n"
+ " aes This is a long dummy description\n"
+ " b16b16\n"
+ " bf16\n";
StringMap<StringRef> DummyMap;
DummyMap["aes"] = "This is a long dummy description";
>From eb3b063995d6b4f8f3bc22eeecbf239ffaecc29f Mon Sep 17 00:00:00 2001
From: AMS21 <AMS21.github at gmail.com>
Date: Sun, 3 Mar 2024 12:13:25 +0100
Subject: [PATCH 384/406] [clang-tidy] Improve `google-explicit-constructor`
checks handling of `explicit(bool)` (#82689)
We now treat `explicit(false)` the same way we treat `noexcept(false)`
in the noexcept checks, which is ignoring it.
Also introduced a new warning message if a constructor has an `explicit`
declaration which evaluates to false and no longer emit a faulty FixIt.
Fixes #81121
---
.../google/ExplicitConstructorCheck.cpp | 33 ++++++++---
clang-tools-extra/docs/ReleaseNotes.rst | 4 ++
.../google/explicit-constructor-cxx20.cpp | 59 +++++++++++++++++++
3 files changed, 88 insertions(+), 8 deletions(-)
create mode 100644 clang-tools-extra/test/clang-tidy/checkers/google/explicit-constructor-cxx20.cpp
diff --git a/clang-tools-extra/clang-tidy/google/ExplicitConstructorCheck.cpp b/clang-tools-extra/clang-tidy/google/ExplicitConstructorCheck.cpp
index 34d49af9f81e23..6f26de9881357f 100644
--- a/clang-tools-extra/clang-tidy/google/ExplicitConstructorCheck.cpp
+++ b/clang-tools-extra/clang-tidy/google/ExplicitConstructorCheck.cpp
@@ -79,8 +79,10 @@ static bool isStdInitializerList(QualType Type) {
}
void ExplicitConstructorCheck::check(const MatchFinder::MatchResult &Result) {
- constexpr char WarningMessage[] =
+ constexpr char NoExpressionWarningMessage[] =
"%0 must be marked explicit to avoid unintentional implicit conversions";
+ constexpr char WithExpressionWarningMessage[] =
+ "%0 explicit expression evaluates to 'false'";
if (const auto *Conversion =
Result.Nodes.getNodeAs<CXXConversionDecl>("conversion")) {
@@ -91,7 +93,7 @@ void ExplicitConstructorCheck::check(const MatchFinder::MatchResult &Result) {
// gmock to define matchers).
if (Loc.isMacroID())
return;
- diag(Loc, WarningMessage)
+ diag(Loc, NoExpressionWarningMessage)
<< Conversion << FixItHint::CreateInsertion(Loc, "explicit ");
return;
}
@@ -101,9 +103,11 @@ void ExplicitConstructorCheck::check(const MatchFinder::MatchResult &Result) {
Ctor->getMinRequiredArguments() > 1)
return;
+ const ExplicitSpecifier ExplicitSpec = Ctor->getExplicitSpecifier();
+
bool TakesInitializerList = isStdInitializerList(
Ctor->getParamDecl(0)->getType().getNonReferenceType());
- if (Ctor->isExplicit() &&
+ if (ExplicitSpec.isExplicit() &&
(Ctor->isCopyOrMoveConstructor() || TakesInitializerList)) {
auto IsKwExplicit = [](const Token &Tok) {
return Tok.is(tok::raw_identifier) &&
@@ -130,18 +134,31 @@ void ExplicitConstructorCheck::check(const MatchFinder::MatchResult &Result) {
return;
}
- if (Ctor->isExplicit() || Ctor->isCopyOrMoveConstructor() ||
+ if (ExplicitSpec.isExplicit() || Ctor->isCopyOrMoveConstructor() ||
TakesInitializerList)
return;
- bool SingleArgument =
+ // Don't complain about explicit(false) or dependent expressions
+ const Expr *ExplicitExpr = ExplicitSpec.getExpr();
+ if (ExplicitExpr) {
+ ExplicitExpr = ExplicitExpr->IgnoreImplicit();
+ if (isa<CXXBoolLiteralExpr>(ExplicitExpr) ||
+ ExplicitExpr->isInstantiationDependent())
+ return;
+ }
+
+ const bool SingleArgument =
Ctor->getNumParams() == 1 && !Ctor->getParamDecl(0)->isParameterPack();
SourceLocation Loc = Ctor->getLocation();
- diag(Loc, WarningMessage)
+ auto Diag =
+ diag(Loc, ExplicitExpr ? WithExpressionWarningMessage
+ : NoExpressionWarningMessage)
<< (SingleArgument
? "single-argument constructors"
- : "constructors that are callable with a single argument")
- << FixItHint::CreateInsertion(Loc, "explicit ");
+ : "constructors that are callable with a single argument");
+
+ if (!ExplicitExpr)
+ Diag << FixItHint::CreateInsertion(Loc, "explicit ");
}
} // namespace clang::tidy::google
diff --git a/clang-tools-extra/docs/ReleaseNotes.rst b/clang-tools-extra/docs/ReleaseNotes.rst
index 5bae530e942384..0d2467210fc664 100644
--- a/clang-tools-extra/docs/ReleaseNotes.rst
+++ b/clang-tools-extra/docs/ReleaseNotes.rst
@@ -157,6 +157,10 @@ Changes in existing checks
<clang-tidy/checks/google/build-namespaces>` check by replacing the local
option `HeaderFileExtensions` by the global option of the same name.
+- Improved :doc:`google-explicit-constructor
+ <clang-tidy/checks/google/explicit-constructor>` check to better handle
+ ``C++-20`` `explicit(bool)`.
+
- Improved :doc:`google-global-names-in-headers
<clang-tidy/checks/google/global-names-in-headers>` check by replacing the local
option `HeaderFileExtensions` by the global option of the same name.
diff --git a/clang-tools-extra/test/clang-tidy/checkers/google/explicit-constructor-cxx20.cpp b/clang-tools-extra/test/clang-tidy/checkers/google/explicit-constructor-cxx20.cpp
new file mode 100644
index 00000000000000..95206f1ef420c3
--- /dev/null
+++ b/clang-tools-extra/test/clang-tidy/checkers/google/explicit-constructor-cxx20.cpp
@@ -0,0 +1,59 @@
+// RUN: %check_clang_tidy %s google-explicit-constructor %t -std=c++20-or-later
+
+namespace issue_81121
+{
+
+static constexpr bool ConstFalse = false;
+static constexpr bool ConstTrue = true;
+
+struct A {
+ explicit(true) A(int);
+};
+
+struct B {
+ explicit(false) B(int);
+};
+
+struct C {
+ explicit(ConstTrue) C(int);
+};
+
+struct D {
+ explicit(ConstFalse) D(int);
+ // CHECK-MESSAGES: :[[@LINE-1]]:24: warning: single-argument constructors explicit expression evaluates to 'false' [google-explicit-constructor]
+};
+
+template <typename>
+struct E {
+ explicit(true) E(int);
+};
+
+template <typename>
+struct F {
+ explicit(false) F(int);
+};
+
+template <typename>
+struct G {
+ explicit(ConstTrue) G(int);
+};
+
+template <typename>
+struct H {
+ explicit(ConstFalse) H(int);
+ // CHECK-MESSAGES: :[[@LINE-1]]:24: warning: single-argument constructors explicit expression evaluates to 'false' [google-explicit-constructor]
+};
+
+template <int Val>
+struct I {
+ explicit(Val > 0) I(int);
+};
+
+template <int Val>
+struct J {
+ explicit(Val > 0) J(int);
+};
+
+void useJ(J<0>, J<100>);
+
+} // namespace issue_81121
>From 22f34ea3b05537235956c99fe942aa95b88762c0 Mon Sep 17 00:00:00 2001
From: Jacques Pienaar <jpienaar at google.com>
Date: Sun, 3 Mar 2024 03:37:10 -0800
Subject: [PATCH 385/406] Reapply "[mlir-query] Add function extraction feature
to mlir-query"
Fix build deps.
This reverts commit de55c2f869925a3ed7f26e168424021c6bc46799.
---
.../include/mlir/Query/Matcher/ErrorBuilder.h | 7 +-
.../mlir/Query/Matcher/MatchersInternal.h | 7 ++
mlir/lib/Query/CMakeLists.txt | 1 +
mlir/lib/Query/Matcher/Diagnostics.cpp | 10 +++
mlir/lib/Query/Matcher/Parser.cpp | 67 ++++++++++++++--
mlir/lib/Query/Matcher/Parser.h | 18 +++--
mlir/lib/Query/Matcher/RegistryManager.cpp | 15 +++-
mlir/lib/Query/Matcher/RegistryManager.h | 1 +
mlir/lib/Query/Query.cpp | 80 ++++++++++++++++++-
mlir/test/mlir-query/function-extraction.mlir | 19 +++++
10 files changed, 208 insertions(+), 17 deletions(-)
create mode 100644 mlir/test/mlir-query/function-extraction.mlir
diff --git a/mlir/include/mlir/Query/Matcher/ErrorBuilder.h b/mlir/include/mlir/Query/Matcher/ErrorBuilder.h
index 1073daed8703f5..08f1f415cbd3e5 100644
--- a/mlir/include/mlir/Query/Matcher/ErrorBuilder.h
+++ b/mlir/include/mlir/Query/Matcher/ErrorBuilder.h
@@ -37,8 +37,12 @@ enum class ErrorType {
None,
// Parser Errors
+ ParserChainedExprInvalidArg,
+ ParserChainedExprNoCloseParen,
+ ParserChainedExprNoOpenParen,
ParserFailedToBuildMatcher,
ParserInvalidToken,
+ ParserMalformedChainedExpr,
ParserNoCloseParen,
ParserNoCode,
ParserNoComma,
@@ -50,9 +54,10 @@ enum class ErrorType {
// Registry Errors
RegistryMatcherNotFound,
+ RegistryNotBindable,
RegistryValueNotFound,
RegistryWrongArgCount,
- RegistryWrongArgType
+ RegistryWrongArgType,
};
void addError(Diagnostics *error, SourceRange range, ErrorType errorType,
diff --git a/mlir/include/mlir/Query/Matcher/MatchersInternal.h b/mlir/include/mlir/Query/Matcher/MatchersInternal.h
index 67455be592393b..117f7d4edef9e3 100644
--- a/mlir/include/mlir/Query/Matcher/MatchersInternal.h
+++ b/mlir/include/mlir/Query/Matcher/MatchersInternal.h
@@ -63,8 +63,15 @@ class DynMatcher {
bool match(Operation *op) const { return implementation->match(op); }
+ void setFunctionName(StringRef name) { functionName = name.str(); };
+
+ bool hasFunctionName() const { return !functionName.empty(); };
+
+ StringRef getFunctionName() const { return functionName; };
+
private:
llvm::IntrusiveRefCntPtr<MatcherInterface> implementation;
+ std::string functionName;
};
} // namespace mlir::query::matcher
diff --git a/mlir/lib/Query/CMakeLists.txt b/mlir/lib/Query/CMakeLists.txt
index 817583e94c5222..7ecbf6e628b318 100644
--- a/mlir/lib/Query/CMakeLists.txt
+++ b/mlir/lib/Query/CMakeLists.txt
@@ -6,6 +6,7 @@ add_mlir_library(MLIRQuery
${MLIR_MAIN_INCLUDE_DIR}/mlir/Query
LINK_LIBS PUBLIC
+ MLIRFuncDialect
MLIRQueryMatcher
)
diff --git a/mlir/lib/Query/Matcher/Diagnostics.cpp b/mlir/lib/Query/Matcher/Diagnostics.cpp
index 10468dbcc53067..2a137e8fdfab0d 100644
--- a/mlir/lib/Query/Matcher/Diagnostics.cpp
+++ b/mlir/lib/Query/Matcher/Diagnostics.cpp
@@ -38,6 +38,8 @@ static llvm::StringRef errorTypeToFormatString(ErrorType type) {
return "Incorrect type for arg $0. (Expected = $1) != (Actual = $2)";
case ErrorType::RegistryValueNotFound:
return "Value not found: $0";
+ case ErrorType::RegistryNotBindable:
+ return "Matcher does not support binding.";
case ErrorType::ParserStringError:
return "Error parsing string token: <$0>";
@@ -57,6 +59,14 @@ static llvm::StringRef errorTypeToFormatString(ErrorType type) {
return "Unexpected end of code.";
case ErrorType::ParserOverloadedType:
return "Input value has unresolved overloaded type: $0";
+ case ErrorType::ParserMalformedChainedExpr:
+ return "Period not followed by valid chained call.";
+ case ErrorType::ParserChainedExprInvalidArg:
+ return "Missing/Invalid argument for the chained call.";
+ case ErrorType::ParserChainedExprNoCloseParen:
+ return "Missing ')' for the chained call.";
+ case ErrorType::ParserChainedExprNoOpenParen:
+ return "Missing '(' for the chained call.";
case ErrorType::ParserFailedToBuildMatcher:
return "Failed to build matcher: $0.";
diff --git a/mlir/lib/Query/Matcher/Parser.cpp b/mlir/lib/Query/Matcher/Parser.cpp
index 30eb4801fc03c1..3609e24f9939f7 100644
--- a/mlir/lib/Query/Matcher/Parser.cpp
+++ b/mlir/lib/Query/Matcher/Parser.cpp
@@ -26,12 +26,17 @@ struct Parser::TokenInfo {
text = newText;
}
+ // Known identifiers.
+ static const char *const ID_Extract;
+
llvm::StringRef text;
TokenKind kind = TokenKind::Eof;
SourceRange range;
VariantValue value;
};
+const char *const Parser::TokenInfo::ID_Extract = "extract";
+
class Parser::CodeTokenizer {
public:
// Constructor with matcherCode and error
@@ -298,6 +303,36 @@ bool Parser::parseIdentifierPrefixImpl(VariantValue *value) {
return parseMatcherExpressionImpl(nameToken, openToken, ctor, value);
}
+bool Parser::parseChainedExpression(std::string &argument) {
+ // Parse the parenthesized argument to .extract("foo")
+ // Note: EOF is handled inside the consume functions and would fail below when
+ // checking token kind.
+ const TokenInfo openToken = tokenizer->consumeNextToken();
+ const TokenInfo argumentToken = tokenizer->consumeNextTokenIgnoreNewlines();
+ const TokenInfo closeToken = tokenizer->consumeNextTokenIgnoreNewlines();
+
+ if (openToken.kind != TokenKind::OpenParen) {
+ error->addError(openToken.range, ErrorType::ParserChainedExprNoOpenParen);
+ return false;
+ }
+
+ if (argumentToken.kind != TokenKind::Literal ||
+ !argumentToken.value.isString()) {
+ error->addError(argumentToken.range,
+ ErrorType::ParserChainedExprInvalidArg);
+ return false;
+ }
+
+ if (closeToken.kind != TokenKind::CloseParen) {
+ error->addError(closeToken.range, ErrorType::ParserChainedExprNoCloseParen);
+ return false;
+ }
+
+ // If all checks passed, extract the argument and return true.
+ argument = argumentToken.value.getString();
+ return true;
+}
+
// Parse the arguments of a matcher
bool Parser::parseMatcherArgs(std::vector<ParserValue> &args, MatcherCtor ctor,
const TokenInfo &nameToken, TokenInfo &endToken) {
@@ -364,13 +399,34 @@ bool Parser::parseMatcherExpressionImpl(const TokenInfo &nameToken,
return false;
}
+ std::string functionName;
+ if (tokenizer->peekNextToken().kind == TokenKind::Period) {
+ tokenizer->consumeNextToken();
+ TokenInfo chainCallToken = tokenizer->consumeNextToken();
+ if (chainCallToken.kind == TokenKind::CodeCompletion) {
+ addCompletion(chainCallToken, MatcherCompletion("extract(\"", "extract"));
+ return false;
+ }
+
+ if (chainCallToken.kind != TokenKind::Ident ||
+ chainCallToken.text != TokenInfo::ID_Extract) {
+ error->addError(chainCallToken.range,
+ ErrorType::ParserMalformedChainedExpr);
+ return false;
+ }
+
+ if (chainCallToken.text == TokenInfo::ID_Extract &&
+ !parseChainedExpression(functionName))
+ return false;
+ }
+
if (!ctor)
return false;
// Merge the start and end infos.
SourceRange matcherRange = nameToken.range;
matcherRange.end = endToken.range.end;
- VariantMatcher result =
- sema->actOnMatcherExpression(*ctor, matcherRange, args, error);
+ VariantMatcher result = sema->actOnMatcherExpression(
+ *ctor, matcherRange, functionName, args, error);
if (result.isNull())
return false;
*value = result;
@@ -470,9 +526,10 @@ Parser::RegistrySema::lookupMatcherCtor(llvm::StringRef matcherName) {
}
VariantMatcher Parser::RegistrySema::actOnMatcherExpression(
- MatcherCtor ctor, SourceRange nameRange, llvm::ArrayRef<ParserValue> args,
- Diagnostics *error) {
- return RegistryManager::constructMatcher(ctor, nameRange, args, error);
+ MatcherCtor ctor, SourceRange nameRange, llvm::StringRef functionName,
+ llvm::ArrayRef<ParserValue> args, Diagnostics *error) {
+ return RegistryManager::constructMatcher(ctor, nameRange, functionName, args,
+ error);
}
std::vector<ArgKind> Parser::RegistrySema::getAcceptedCompletionTypes(
diff --git a/mlir/lib/Query/Matcher/Parser.h b/mlir/lib/Query/Matcher/Parser.h
index f049af34e9c907..58968023022d56 100644
--- a/mlir/lib/Query/Matcher/Parser.h
+++ b/mlir/lib/Query/Matcher/Parser.h
@@ -64,10 +64,9 @@ class Parser {
// Process a matcher expression. The caller takes ownership of the Matcher
// object returned.
- virtual VariantMatcher
- actOnMatcherExpression(MatcherCtor ctor, SourceRange nameRange,
- llvm::ArrayRef<ParserValue> args,
- Diagnostics *error) = 0;
+ virtual VariantMatcher actOnMatcherExpression(
+ MatcherCtor ctor, SourceRange nameRange, llvm::StringRef functionName,
+ llvm::ArrayRef<ParserValue> args, Diagnostics *error) = 0;
// Look up a matcher by name in the matcher name found by the parser.
virtual std::optional<MatcherCtor>
@@ -93,10 +92,11 @@ class Parser {
std::optional<MatcherCtor>
lookupMatcherCtor(llvm::StringRef matcherName) override;
- VariantMatcher actOnMatcherExpression(MatcherCtor ctor,
- SourceRange nameRange,
- llvm::ArrayRef<ParserValue> args,
- Diagnostics *error) override;
+ VariantMatcher actOnMatcherExpression(MatcherCtor Ctor,
+ SourceRange NameRange,
+ StringRef functionName,
+ ArrayRef<ParserValue> Args,
+ Diagnostics *Error) override;
std::vector<ArgKind> getAcceptedCompletionTypes(
llvm::ArrayRef<std::pair<MatcherCtor, unsigned>> context) override;
@@ -153,6 +153,8 @@ class Parser {
Parser(CodeTokenizer *tokenizer, const Registry &matcherRegistry,
const NamedValueMap *namedValues, Diagnostics *error);
+ bool parseChainedExpression(std::string &argument);
+
bool parseExpressionImpl(VariantValue *value);
bool parseMatcherArgs(std::vector<ParserValue> &args, MatcherCtor ctor,
diff --git a/mlir/lib/Query/Matcher/RegistryManager.cpp b/mlir/lib/Query/Matcher/RegistryManager.cpp
index 01856aa8ffa67f..8c9197f4d00981 100644
--- a/mlir/lib/Query/Matcher/RegistryManager.cpp
+++ b/mlir/lib/Query/Matcher/RegistryManager.cpp
@@ -132,8 +132,19 @@ RegistryManager::getMatcherCompletions(llvm::ArrayRef<ArgKind> acceptedTypes,
VariantMatcher RegistryManager::constructMatcher(
MatcherCtor ctor, internal::SourceRange nameRange,
- llvm::ArrayRef<ParserValue> args, internal::Diagnostics *error) {
- return ctor->create(nameRange, args, error);
+ llvm::StringRef functionName, llvm::ArrayRef<ParserValue> args,
+ internal::Diagnostics *error) {
+ VariantMatcher out = ctor->create(nameRange, args, error);
+ if (functionName.empty() || out.isNull())
+ return out;
+
+ if (std::optional<DynMatcher> result = out.getDynMatcher()) {
+ result->setFunctionName(functionName);
+ return VariantMatcher::SingleMatcher(*result);
+ }
+
+ error->addError(nameRange, internal::ErrorType::RegistryNotBindable);
+ return {};
}
} // namespace mlir::query::matcher
diff --git a/mlir/lib/Query/Matcher/RegistryManager.h b/mlir/lib/Query/Matcher/RegistryManager.h
index 5f2867261225e7..e2026e97f83dcb 100644
--- a/mlir/lib/Query/Matcher/RegistryManager.h
+++ b/mlir/lib/Query/Matcher/RegistryManager.h
@@ -61,6 +61,7 @@ class RegistryManager {
static VariantMatcher constructMatcher(MatcherCtor ctor,
internal::SourceRange nameRange,
+ llvm::StringRef functionName,
ArrayRef<ParserValue> args,
internal::Diagnostics *error);
};
diff --git a/mlir/lib/Query/Query.cpp b/mlir/lib/Query/Query.cpp
index 5c42e5a5f0a116..27db52b37dade0 100644
--- a/mlir/lib/Query/Query.cpp
+++ b/mlir/lib/Query/Query.cpp
@@ -8,6 +8,8 @@
#include "mlir/Query/Query.h"
#include "QueryParser.h"
+#include "mlir/Dialect/Func/IR/FuncOps.h"
+#include "mlir/IR/IRMapping.h"
#include "mlir/Query/Matcher/MatchFinder.h"
#include "mlir/Query/QuerySession.h"
#include "mlir/Support/LogicalResult.h"
@@ -34,6 +36,70 @@ static void printMatch(llvm::raw_ostream &os, QuerySession &qs, Operation *op,
"\"" + binding + "\" binds here");
}
+// TODO: Extract into a helper function that can be reused outside query
+// context.
+static Operation *extractFunction(std::vector<Operation *> &ops,
+ MLIRContext *context,
+ llvm::StringRef functionName) {
+ context->loadDialect<func::FuncDialect>();
+ OpBuilder builder(context);
+
+ // Collect data for function creation
+ std::vector<Operation *> slice;
+ std::vector<Value> values;
+ std::vector<Type> outputTypes;
+
+ for (auto *op : ops) {
+ // Return op's operands are propagated, but the op itself isn't needed.
+ if (!isa<func::ReturnOp>(op))
+ slice.push_back(op);
+
+ // All results are returned by the extracted function.
+ outputTypes.insert(outputTypes.end(), op->getResults().getTypes().begin(),
+ op->getResults().getTypes().end());
+
+ // Track all values that need to be taken as input to function.
+ values.insert(values.end(), op->getOperands().begin(),
+ op->getOperands().end());
+ }
+
+ // Create the function
+ FunctionType funcType =
+ builder.getFunctionType(ValueRange(values), outputTypes);
+ auto loc = builder.getUnknownLoc();
+ func::FuncOp funcOp = func::FuncOp::create(loc, functionName, funcType);
+
+ builder.setInsertionPointToEnd(funcOp.addEntryBlock());
+
+ // Map original values to function arguments
+ IRMapping mapper;
+ for (const auto &arg : llvm::enumerate(values))
+ mapper.map(arg.value(), funcOp.getArgument(arg.index()));
+
+ // Clone operations and build function body
+ std::vector<Operation *> clonedOps;
+ std::vector<Value> clonedVals;
+ for (Operation *slicedOp : slice) {
+ Operation *clonedOp =
+ clonedOps.emplace_back(builder.clone(*slicedOp, mapper));
+ clonedVals.insert(clonedVals.end(), clonedOp->result_begin(),
+ clonedOp->result_end());
+ }
+ // Add return operation
+ builder.create<func::ReturnOp>(loc, clonedVals);
+
+ // Remove unused function arguments
+ size_t currentIndex = 0;
+ while (currentIndex < funcOp.getNumArguments()) {
+ if (funcOp.getArgument(currentIndex).use_empty())
+ funcOp.eraseArgument(currentIndex);
+ else
+ ++currentIndex;
+ }
+
+ return funcOp;
+}
+
Query::~Query() = default;
mlir::LogicalResult InvalidQuery::run(llvm::raw_ostream &os,
@@ -65,9 +131,21 @@ mlir::LogicalResult QuitQuery::run(llvm::raw_ostream &os,
mlir::LogicalResult MatchQuery::run(llvm::raw_ostream &os,
QuerySession &qs) const {
+ Operation *rootOp = qs.getRootOp();
int matchCount = 0;
std::vector<Operation *> matches =
- matcher::MatchFinder().getMatches(qs.getRootOp(), matcher);
+ matcher::MatchFinder().getMatches(rootOp, matcher);
+
+ // An extract call is recognized by considering if the matcher has a name.
+ // TODO: Consider making the extract more explicit.
+ if (matcher.hasFunctionName()) {
+ auto functionName = matcher.getFunctionName();
+ Operation *function =
+ extractFunction(matches, rootOp->getContext(), functionName);
+ os << "\n" << *function << "\n\n";
+ return mlir::success();
+ }
+
os << "\n";
for (Operation *op : matches) {
os << "Match #" << ++matchCount << ":\n\n";
diff --git a/mlir/test/mlir-query/function-extraction.mlir b/mlir/test/mlir-query/function-extraction.mlir
new file mode 100644
index 00000000000000..a783f65c6761bc
--- /dev/null
+++ b/mlir/test/mlir-query/function-extraction.mlir
@@ -0,0 +1,19 @@
+// RUN: mlir-query %s -c "m hasOpName(\"arith.mulf\").extract(\"testmul\")" | FileCheck %s
+
+// CHECK: func.func @testmul({{.*}}) -> (f32, f32, f32) {
+// CHECK: %[[MUL0:.*]] = arith.mulf {{.*}} : f32
+// CHECK: %[[MUL1:.*]] = arith.mulf {{.*}}, %[[MUL0]] : f32
+// CHECK: %[[MUL2:.*]] = arith.mulf {{.*}} : f32
+// CHECK-NEXT: return %[[MUL0]], %[[MUL1]], %[[MUL2]] : f32, f32, f32
+
+func.func @mixedOperations(%a: f32, %b: f32, %c: f32) -> f32 {
+ %sum0 = arith.addf %a, %b : f32
+ %sub0 = arith.subf %sum0, %c : f32
+ %mul0 = arith.mulf %a, %sub0 : f32
+ %sum1 = arith.addf %b, %c : f32
+ %mul1 = arith.mulf %sum1, %mul0 : f32
+ %sub2 = arith.subf %mul1, %a : f32
+ %sum2 = arith.addf %mul1, %b : f32
+ %mul2 = arith.mulf %sub2, %sum2 : f32
+ return %mul2 : f32
+}
>From a5d3a1dbc8c9bd1ea76550a4bac44d25b1e43a5e Mon Sep 17 00:00:00 2001
From: Mark de Wever <koraq at xs4all.nl>
Date: Sun, 3 Mar 2024 13:23:41 +0100
Subject: [PATCH 386/406] [libc++] Refactors fstream open. (#76617)
This moves the duplicated code to one new function.
This is a preparation to fix
https://github.com/llvm/llvm-project/issues/60509
---
libcxx/include/fstream | 218 ++++++++++++++++++-----------------------
1 file changed, 97 insertions(+), 121 deletions(-)
diff --git a/libcxx/include/fstream b/libcxx/include/fstream
index 513c8dc2b127a4..776641b347e6c1 100644
--- a/libcxx/include/fstream
+++ b/libcxx/include/fstream
@@ -279,6 +279,9 @@ public:
# endif // _LIBCPP_STD_VER >= 26
_LIBCPP_HIDE_FROM_ABI inline static const char* __make_mdstring(ios_base::openmode __mode) _NOEXCEPT;
+# ifdef _LIBCPP_HAS_OPEN_WITH_WCHAR
+ _LIBCPP_HIDE_FROM_ABI inline static const wchar_t* __make_mdwstring(ios_base::openmode __mode) _NOEXCEPT;
+# endif
protected:
// 27.9.1.5 Overridden virtual functions:
@@ -314,6 +317,26 @@ private:
void __write_mode();
_LIBCPP_EXPORTED_FROM_ABI friend FILE* __get_ostream_file(ostream&);
+
+ // There are multiple (__)open function, they use different C-API open
+ // function. After that call these functions behave the same. This function
+ // does that part and determines the final return value.
+ _LIBCPP_HIDE_FROM_ABI basic_filebuf* __do_open(FILE* __file, ios_base::openmode __mode) {
+ __file_ = __file;
+ if (!__file_)
+ return nullptr;
+
+ __om_ = __mode;
+ if (__mode & ios_base::ate) {
+ if (fseek(__file_, 0, SEEK_END)) {
+ fclose(__file_);
+ __file_ = nullptr;
+ return nullptr;
+ }
+ }
+
+ return this;
+ }
};
template <class _CharT, class _Traits>
@@ -548,50 +571,79 @@ const char* basic_filebuf<_CharT, _Traits>::__make_mdstring(ios_base::openmode _
__libcpp_unreachable();
}
+# ifdef _LIBCPP_HAS_OPEN_WITH_WCHAR
template <class _CharT, class _Traits>
-basic_filebuf<_CharT, _Traits>* basic_filebuf<_CharT, _Traits>::open(const char* __s, ios_base::openmode __mode) {
- basic_filebuf<_CharT, _Traits>* __rt = nullptr;
- if (__file_ == nullptr) {
- if (const char* __mdstr = __make_mdstring(__mode)) {
- __rt = this;
- __file_ = fopen(__s, __mdstr);
- if (__file_) {
- __om_ = __mode;
- if (__mode & ios_base::ate) {
- if (fseek(__file_, 0, SEEK_END)) {
- fclose(__file_);
- __file_ = nullptr;
- __rt = nullptr;
- }
- }
- } else
- __rt = nullptr;
- }
+const wchar_t* basic_filebuf<_CharT, _Traits>::__make_mdwstring(ios_base::openmode __mode) _NOEXCEPT {
+ switch (__mode & ~ios_base::ate) {
+ case ios_base::out:
+ case ios_base::out | ios_base::trunc:
+ return L"w";
+ case ios_base::out | ios_base::app:
+ case ios_base::app:
+ return L"a";
+ case ios_base::in:
+ return L"r";
+ case ios_base::in | ios_base::out:
+ return L"r+";
+ case ios_base::in | ios_base::out | ios_base::trunc:
+ return L"w+";
+ case ios_base::in | ios_base::out | ios_base::app:
+ case ios_base::in | ios_base::app:
+ return L"a+";
+ case ios_base::out | ios_base::binary:
+ case ios_base::out | ios_base::trunc | ios_base::binary:
+ return L"wb";
+ case ios_base::out | ios_base::app | ios_base::binary:
+ case ios_base::app | ios_base::binary:
+ return L"ab";
+ case ios_base::in | ios_base::binary:
+ return L"rb";
+ case ios_base::in | ios_base::out | ios_base::binary:
+ return L"r+b";
+ case ios_base::in | ios_base::out | ios_base::trunc | ios_base::binary:
+ return L"w+b";
+ case ios_base::in | ios_base::out | ios_base::app | ios_base::binary:
+ case ios_base::in | ios_base::app | ios_base::binary:
+ return L"a+b";
+# if _LIBCPP_STD_VER >= 23
+ case ios_base::out | ios_base::noreplace:
+ case ios_base::out | ios_base::trunc | ios_base::noreplace:
+ return L"wx";
+ case ios_base::in | ios_base::out | ios_base::trunc | ios_base::noreplace:
+ return L"w+x";
+ case ios_base::out | ios_base::binary | ios_base::noreplace:
+ case ios_base::out | ios_base::trunc | ios_base::binary | ios_base::noreplace:
+ return L"wbx";
+ case ios_base::in | ios_base::out | ios_base::trunc | ios_base::binary | ios_base::noreplace:
+ return L"w+bx";
+# endif // _LIBCPP_STD_VER >= 23
+ default:
+ return nullptr;
}
- return __rt;
+ __libcpp_unreachable();
+}
+# endif
+
+template <class _CharT, class _Traits>
+basic_filebuf<_CharT, _Traits>* basic_filebuf<_CharT, _Traits>::open(const char* __s, ios_base::openmode __mode) {
+ if (__file_)
+ return nullptr;
+ const char* __mdstr = __make_mdstring(__mode);
+ if (!__mdstr)
+ return nullptr;
+
+ return __do_open(fopen(__s, __mdstr), __mode);
}
template <class _CharT, class _Traits>
inline basic_filebuf<_CharT, _Traits>* basic_filebuf<_CharT, _Traits>::__open(int __fd, ios_base::openmode __mode) {
- basic_filebuf<_CharT, _Traits>* __rt = nullptr;
- if (__file_ == nullptr) {
- if (const char* __mdstr = __make_mdstring(__mode)) {
- __rt = this;
- __file_ = fdopen(__fd, __mdstr);
- if (__file_) {
- __om_ = __mode;
- if (__mode & ios_base::ate) {
- if (fseek(__file_, 0, SEEK_END)) {
- fclose(__file_);
- __file_ = nullptr;
- __rt = nullptr;
- }
- }
- } else
- __rt = nullptr;
- }
- }
- return __rt;
+ if (__file_)
+ return nullptr;
+ const char* __mdstr = __make_mdstring(__mode);
+ if (!__mdstr)
+ return nullptr;
+
+ return __do_open(fdopen(__fd, __mdstr), __mode);
}
# ifdef _LIBCPP_HAS_OPEN_WITH_WCHAR
@@ -599,89 +651,13 @@ inline basic_filebuf<_CharT, _Traits>* basic_filebuf<_CharT, _Traits>::__open(in
// and long mode strings.
template <class _CharT, class _Traits>
basic_filebuf<_CharT, _Traits>* basic_filebuf<_CharT, _Traits>::open(const wchar_t* __s, ios_base::openmode __mode) {
- basic_filebuf<_CharT, _Traits>* __rt = nullptr;
- if (__file_ == nullptr) {
- __rt = this;
- const wchar_t* __mdstr;
- switch (__mode & ~ios_base::ate) {
- case ios_base::out:
- case ios_base::out | ios_base::trunc:
- __mdstr = L"w";
- break;
- case ios_base::out | ios_base::app:
- case ios_base::app:
- __mdstr = L"a";
- break;
- case ios_base::in:
- __mdstr = L"r";
- break;
- case ios_base::in | ios_base::out:
- __mdstr = L"r+";
- break;
- case ios_base::in | ios_base::out | ios_base::trunc:
- __mdstr = L"w+";
- break;
- case ios_base::in | ios_base::out | ios_base::app:
- case ios_base::in | ios_base::app:
- __mdstr = L"a+";
- break;
- case ios_base::out | ios_base::binary:
- case ios_base::out | ios_base::trunc | ios_base::binary:
- __mdstr = L"wb";
- break;
- case ios_base::out | ios_base::app | ios_base::binary:
- case ios_base::app | ios_base::binary:
- __mdstr = L"ab";
- break;
- case ios_base::in | ios_base::binary:
- __mdstr = L"rb";
- break;
- case ios_base::in | ios_base::out | ios_base::binary:
- __mdstr = L"r+b";
- break;
- case ios_base::in | ios_base::out | ios_base::trunc | ios_base::binary:
- __mdstr = L"w+b";
- break;
- case ios_base::in | ios_base::out | ios_base::app | ios_base::binary:
- case ios_base::in | ios_base::app | ios_base::binary:
- __mdstr = L"a+b";
- break;
-# if _LIBCPP_STD_VER >= 23
- case ios_base::out | ios_base::noreplace:
- case ios_base::out | ios_base::trunc | ios_base::noreplace:
- __mdstr = L"wx";
- break;
- case ios_base::in | ios_base::out | ios_base::trunc | ios_base::noreplace:
- __mdstr = L"w+x";
- break;
- case ios_base::out | ios_base::binary | ios_base::noreplace:
- case ios_base::out | ios_base::trunc | ios_base::binary | ios_base::noreplace:
- __mdstr = L"wbx";
- break;
- case ios_base::in | ios_base::out | ios_base::trunc | ios_base::binary | ios_base::noreplace:
- __mdstr = L"w+bx";
- break;
-# endif // _LIBCPP_STD_VER >= 23
- default:
- __rt = nullptr;
- break;
- }
- if (__rt) {
- __file_ = _wfopen(__s, __mdstr);
- if (__file_) {
- __om_ = __mode;
- if (__mode & ios_base::ate) {
- if (fseek(__file_, 0, SEEK_END)) {
- fclose(__file_);
- __file_ = nullptr;
- __rt = nullptr;
- }
- }
- } else
- __rt = nullptr;
- }
- }
- return __rt;
+ if (__file_)
+ return nullptr;
+ const wchar_t* __mdstr = __make_mdwstring(__mode);
+ if (!__mdstr)
+ return nullptr;
+
+ return __do_open(_wfopen(__s, __mdstr), __mode);
}
# endif
>From 732a5cba8c739ed40a7280b5d74ca717910c2c4c Mon Sep 17 00:00:00 2001
From: Jacques Pienaar <jpienaar at google.com>
Date: Sun, 3 Mar 2024 05:22:41 -0800
Subject: [PATCH 387/406] Revert "Reapply "[mlir-query] Add function extraction
feature to mlir-query""
Commit fails on sanitizers.
This reverts commit 22f34ea3b05537235956c99fe942aa95b88762c0.
---
.../include/mlir/Query/Matcher/ErrorBuilder.h | 7 +-
.../mlir/Query/Matcher/MatchersInternal.h | 7 --
mlir/lib/Query/CMakeLists.txt | 1 -
mlir/lib/Query/Matcher/Diagnostics.cpp | 10 ---
mlir/lib/Query/Matcher/Parser.cpp | 67 ++--------------
mlir/lib/Query/Matcher/Parser.h | 18 ++---
mlir/lib/Query/Matcher/RegistryManager.cpp | 15 +---
mlir/lib/Query/Matcher/RegistryManager.h | 1 -
mlir/lib/Query/Query.cpp | 80 +------------------
mlir/test/mlir-query/function-extraction.mlir | 19 -----
10 files changed, 17 insertions(+), 208 deletions(-)
delete mode 100644 mlir/test/mlir-query/function-extraction.mlir
diff --git a/mlir/include/mlir/Query/Matcher/ErrorBuilder.h b/mlir/include/mlir/Query/Matcher/ErrorBuilder.h
index 08f1f415cbd3e5..1073daed8703f5 100644
--- a/mlir/include/mlir/Query/Matcher/ErrorBuilder.h
+++ b/mlir/include/mlir/Query/Matcher/ErrorBuilder.h
@@ -37,12 +37,8 @@ enum class ErrorType {
None,
// Parser Errors
- ParserChainedExprInvalidArg,
- ParserChainedExprNoCloseParen,
- ParserChainedExprNoOpenParen,
ParserFailedToBuildMatcher,
ParserInvalidToken,
- ParserMalformedChainedExpr,
ParserNoCloseParen,
ParserNoCode,
ParserNoComma,
@@ -54,10 +50,9 @@ enum class ErrorType {
// Registry Errors
RegistryMatcherNotFound,
- RegistryNotBindable,
RegistryValueNotFound,
RegistryWrongArgCount,
- RegistryWrongArgType,
+ RegistryWrongArgType
};
void addError(Diagnostics *error, SourceRange range, ErrorType errorType,
diff --git a/mlir/include/mlir/Query/Matcher/MatchersInternal.h b/mlir/include/mlir/Query/Matcher/MatchersInternal.h
index 117f7d4edef9e3..67455be592393b 100644
--- a/mlir/include/mlir/Query/Matcher/MatchersInternal.h
+++ b/mlir/include/mlir/Query/Matcher/MatchersInternal.h
@@ -63,15 +63,8 @@ class DynMatcher {
bool match(Operation *op) const { return implementation->match(op); }
- void setFunctionName(StringRef name) { functionName = name.str(); };
-
- bool hasFunctionName() const { return !functionName.empty(); };
-
- StringRef getFunctionName() const { return functionName; };
-
private:
llvm::IntrusiveRefCntPtr<MatcherInterface> implementation;
- std::string functionName;
};
} // namespace mlir::query::matcher
diff --git a/mlir/lib/Query/CMakeLists.txt b/mlir/lib/Query/CMakeLists.txt
index 7ecbf6e628b318..817583e94c5222 100644
--- a/mlir/lib/Query/CMakeLists.txt
+++ b/mlir/lib/Query/CMakeLists.txt
@@ -6,7 +6,6 @@ add_mlir_library(MLIRQuery
${MLIR_MAIN_INCLUDE_DIR}/mlir/Query
LINK_LIBS PUBLIC
- MLIRFuncDialect
MLIRQueryMatcher
)
diff --git a/mlir/lib/Query/Matcher/Diagnostics.cpp b/mlir/lib/Query/Matcher/Diagnostics.cpp
index 2a137e8fdfab0d..10468dbcc53067 100644
--- a/mlir/lib/Query/Matcher/Diagnostics.cpp
+++ b/mlir/lib/Query/Matcher/Diagnostics.cpp
@@ -38,8 +38,6 @@ static llvm::StringRef errorTypeToFormatString(ErrorType type) {
return "Incorrect type for arg $0. (Expected = $1) != (Actual = $2)";
case ErrorType::RegistryValueNotFound:
return "Value not found: $0";
- case ErrorType::RegistryNotBindable:
- return "Matcher does not support binding.";
case ErrorType::ParserStringError:
return "Error parsing string token: <$0>";
@@ -59,14 +57,6 @@ static llvm::StringRef errorTypeToFormatString(ErrorType type) {
return "Unexpected end of code.";
case ErrorType::ParserOverloadedType:
return "Input value has unresolved overloaded type: $0";
- case ErrorType::ParserMalformedChainedExpr:
- return "Period not followed by valid chained call.";
- case ErrorType::ParserChainedExprInvalidArg:
- return "Missing/Invalid argument for the chained call.";
- case ErrorType::ParserChainedExprNoCloseParen:
- return "Missing ')' for the chained call.";
- case ErrorType::ParserChainedExprNoOpenParen:
- return "Missing '(' for the chained call.";
case ErrorType::ParserFailedToBuildMatcher:
return "Failed to build matcher: $0.";
diff --git a/mlir/lib/Query/Matcher/Parser.cpp b/mlir/lib/Query/Matcher/Parser.cpp
index 3609e24f9939f7..30eb4801fc03c1 100644
--- a/mlir/lib/Query/Matcher/Parser.cpp
+++ b/mlir/lib/Query/Matcher/Parser.cpp
@@ -26,17 +26,12 @@ struct Parser::TokenInfo {
text = newText;
}
- // Known identifiers.
- static const char *const ID_Extract;
-
llvm::StringRef text;
TokenKind kind = TokenKind::Eof;
SourceRange range;
VariantValue value;
};
-const char *const Parser::TokenInfo::ID_Extract = "extract";
-
class Parser::CodeTokenizer {
public:
// Constructor with matcherCode and error
@@ -303,36 +298,6 @@ bool Parser::parseIdentifierPrefixImpl(VariantValue *value) {
return parseMatcherExpressionImpl(nameToken, openToken, ctor, value);
}
-bool Parser::parseChainedExpression(std::string &argument) {
- // Parse the parenthesized argument to .extract("foo")
- // Note: EOF is handled inside the consume functions and would fail below when
- // checking token kind.
- const TokenInfo openToken = tokenizer->consumeNextToken();
- const TokenInfo argumentToken = tokenizer->consumeNextTokenIgnoreNewlines();
- const TokenInfo closeToken = tokenizer->consumeNextTokenIgnoreNewlines();
-
- if (openToken.kind != TokenKind::OpenParen) {
- error->addError(openToken.range, ErrorType::ParserChainedExprNoOpenParen);
- return false;
- }
-
- if (argumentToken.kind != TokenKind::Literal ||
- !argumentToken.value.isString()) {
- error->addError(argumentToken.range,
- ErrorType::ParserChainedExprInvalidArg);
- return false;
- }
-
- if (closeToken.kind != TokenKind::CloseParen) {
- error->addError(closeToken.range, ErrorType::ParserChainedExprNoCloseParen);
- return false;
- }
-
- // If all checks passed, extract the argument and return true.
- argument = argumentToken.value.getString();
- return true;
-}
-
// Parse the arguments of a matcher
bool Parser::parseMatcherArgs(std::vector<ParserValue> &args, MatcherCtor ctor,
const TokenInfo &nameToken, TokenInfo &endToken) {
@@ -399,34 +364,13 @@ bool Parser::parseMatcherExpressionImpl(const TokenInfo &nameToken,
return false;
}
- std::string functionName;
- if (tokenizer->peekNextToken().kind == TokenKind::Period) {
- tokenizer->consumeNextToken();
- TokenInfo chainCallToken = tokenizer->consumeNextToken();
- if (chainCallToken.kind == TokenKind::CodeCompletion) {
- addCompletion(chainCallToken, MatcherCompletion("extract(\"", "extract"));
- return false;
- }
-
- if (chainCallToken.kind != TokenKind::Ident ||
- chainCallToken.text != TokenInfo::ID_Extract) {
- error->addError(chainCallToken.range,
- ErrorType::ParserMalformedChainedExpr);
- return false;
- }
-
- if (chainCallToken.text == TokenInfo::ID_Extract &&
- !parseChainedExpression(functionName))
- return false;
- }
-
if (!ctor)
return false;
// Merge the start and end infos.
SourceRange matcherRange = nameToken.range;
matcherRange.end = endToken.range.end;
- VariantMatcher result = sema->actOnMatcherExpression(
- *ctor, matcherRange, functionName, args, error);
+ VariantMatcher result =
+ sema->actOnMatcherExpression(*ctor, matcherRange, args, error);
if (result.isNull())
return false;
*value = result;
@@ -526,10 +470,9 @@ Parser::RegistrySema::lookupMatcherCtor(llvm::StringRef matcherName) {
}
VariantMatcher Parser::RegistrySema::actOnMatcherExpression(
- MatcherCtor ctor, SourceRange nameRange, llvm::StringRef functionName,
- llvm::ArrayRef<ParserValue> args, Diagnostics *error) {
- return RegistryManager::constructMatcher(ctor, nameRange, functionName, args,
- error);
+ MatcherCtor ctor, SourceRange nameRange, llvm::ArrayRef<ParserValue> args,
+ Diagnostics *error) {
+ return RegistryManager::constructMatcher(ctor, nameRange, args, error);
}
std::vector<ArgKind> Parser::RegistrySema::getAcceptedCompletionTypes(
diff --git a/mlir/lib/Query/Matcher/Parser.h b/mlir/lib/Query/Matcher/Parser.h
index 58968023022d56..f049af34e9c907 100644
--- a/mlir/lib/Query/Matcher/Parser.h
+++ b/mlir/lib/Query/Matcher/Parser.h
@@ -64,9 +64,10 @@ class Parser {
// Process a matcher expression. The caller takes ownership of the Matcher
// object returned.
- virtual VariantMatcher actOnMatcherExpression(
- MatcherCtor ctor, SourceRange nameRange, llvm::StringRef functionName,
- llvm::ArrayRef<ParserValue> args, Diagnostics *error) = 0;
+ virtual VariantMatcher
+ actOnMatcherExpression(MatcherCtor ctor, SourceRange nameRange,
+ llvm::ArrayRef<ParserValue> args,
+ Diagnostics *error) = 0;
// Look up a matcher by name in the matcher name found by the parser.
virtual std::optional<MatcherCtor>
@@ -92,11 +93,10 @@ class Parser {
std::optional<MatcherCtor>
lookupMatcherCtor(llvm::StringRef matcherName) override;
- VariantMatcher actOnMatcherExpression(MatcherCtor Ctor,
- SourceRange NameRange,
- StringRef functionName,
- ArrayRef<ParserValue> Args,
- Diagnostics *Error) override;
+ VariantMatcher actOnMatcherExpression(MatcherCtor ctor,
+ SourceRange nameRange,
+ llvm::ArrayRef<ParserValue> args,
+ Diagnostics *error) override;
std::vector<ArgKind> getAcceptedCompletionTypes(
llvm::ArrayRef<std::pair<MatcherCtor, unsigned>> context) override;
@@ -153,8 +153,6 @@ class Parser {
Parser(CodeTokenizer *tokenizer, const Registry &matcherRegistry,
const NamedValueMap *namedValues, Diagnostics *error);
- bool parseChainedExpression(std::string &argument);
-
bool parseExpressionImpl(VariantValue *value);
bool parseMatcherArgs(std::vector<ParserValue> &args, MatcherCtor ctor,
diff --git a/mlir/lib/Query/Matcher/RegistryManager.cpp b/mlir/lib/Query/Matcher/RegistryManager.cpp
index 8c9197f4d00981..01856aa8ffa67f 100644
--- a/mlir/lib/Query/Matcher/RegistryManager.cpp
+++ b/mlir/lib/Query/Matcher/RegistryManager.cpp
@@ -132,19 +132,8 @@ RegistryManager::getMatcherCompletions(llvm::ArrayRef<ArgKind> acceptedTypes,
VariantMatcher RegistryManager::constructMatcher(
MatcherCtor ctor, internal::SourceRange nameRange,
- llvm::StringRef functionName, llvm::ArrayRef<ParserValue> args,
- internal::Diagnostics *error) {
- VariantMatcher out = ctor->create(nameRange, args, error);
- if (functionName.empty() || out.isNull())
- return out;
-
- if (std::optional<DynMatcher> result = out.getDynMatcher()) {
- result->setFunctionName(functionName);
- return VariantMatcher::SingleMatcher(*result);
- }
-
- error->addError(nameRange, internal::ErrorType::RegistryNotBindable);
- return {};
+ llvm::ArrayRef<ParserValue> args, internal::Diagnostics *error) {
+ return ctor->create(nameRange, args, error);
}
} // namespace mlir::query::matcher
diff --git a/mlir/lib/Query/Matcher/RegistryManager.h b/mlir/lib/Query/Matcher/RegistryManager.h
index e2026e97f83dcb..5f2867261225e7 100644
--- a/mlir/lib/Query/Matcher/RegistryManager.h
+++ b/mlir/lib/Query/Matcher/RegistryManager.h
@@ -61,7 +61,6 @@ class RegistryManager {
static VariantMatcher constructMatcher(MatcherCtor ctor,
internal::SourceRange nameRange,
- llvm::StringRef functionName,
ArrayRef<ParserValue> args,
internal::Diagnostics *error);
};
diff --git a/mlir/lib/Query/Query.cpp b/mlir/lib/Query/Query.cpp
index 27db52b37dade0..5c42e5a5f0a116 100644
--- a/mlir/lib/Query/Query.cpp
+++ b/mlir/lib/Query/Query.cpp
@@ -8,8 +8,6 @@
#include "mlir/Query/Query.h"
#include "QueryParser.h"
-#include "mlir/Dialect/Func/IR/FuncOps.h"
-#include "mlir/IR/IRMapping.h"
#include "mlir/Query/Matcher/MatchFinder.h"
#include "mlir/Query/QuerySession.h"
#include "mlir/Support/LogicalResult.h"
@@ -36,70 +34,6 @@ static void printMatch(llvm::raw_ostream &os, QuerySession &qs, Operation *op,
"\"" + binding + "\" binds here");
}
-// TODO: Extract into a helper function that can be reused outside query
-// context.
-static Operation *extractFunction(std::vector<Operation *> &ops,
- MLIRContext *context,
- llvm::StringRef functionName) {
- context->loadDialect<func::FuncDialect>();
- OpBuilder builder(context);
-
- // Collect data for function creation
- std::vector<Operation *> slice;
- std::vector<Value> values;
- std::vector<Type> outputTypes;
-
- for (auto *op : ops) {
- // Return op's operands are propagated, but the op itself isn't needed.
- if (!isa<func::ReturnOp>(op))
- slice.push_back(op);
-
- // All results are returned by the extracted function.
- outputTypes.insert(outputTypes.end(), op->getResults().getTypes().begin(),
- op->getResults().getTypes().end());
-
- // Track all values that need to be taken as input to function.
- values.insert(values.end(), op->getOperands().begin(),
- op->getOperands().end());
- }
-
- // Create the function
- FunctionType funcType =
- builder.getFunctionType(ValueRange(values), outputTypes);
- auto loc = builder.getUnknownLoc();
- func::FuncOp funcOp = func::FuncOp::create(loc, functionName, funcType);
-
- builder.setInsertionPointToEnd(funcOp.addEntryBlock());
-
- // Map original values to function arguments
- IRMapping mapper;
- for (const auto &arg : llvm::enumerate(values))
- mapper.map(arg.value(), funcOp.getArgument(arg.index()));
-
- // Clone operations and build function body
- std::vector<Operation *> clonedOps;
- std::vector<Value> clonedVals;
- for (Operation *slicedOp : slice) {
- Operation *clonedOp =
- clonedOps.emplace_back(builder.clone(*slicedOp, mapper));
- clonedVals.insert(clonedVals.end(), clonedOp->result_begin(),
- clonedOp->result_end());
- }
- // Add return operation
- builder.create<func::ReturnOp>(loc, clonedVals);
-
- // Remove unused function arguments
- size_t currentIndex = 0;
- while (currentIndex < funcOp.getNumArguments()) {
- if (funcOp.getArgument(currentIndex).use_empty())
- funcOp.eraseArgument(currentIndex);
- else
- ++currentIndex;
- }
-
- return funcOp;
-}
-
Query::~Query() = default;
mlir::LogicalResult InvalidQuery::run(llvm::raw_ostream &os,
@@ -131,21 +65,9 @@ mlir::LogicalResult QuitQuery::run(llvm::raw_ostream &os,
mlir::LogicalResult MatchQuery::run(llvm::raw_ostream &os,
QuerySession &qs) const {
- Operation *rootOp = qs.getRootOp();
int matchCount = 0;
std::vector<Operation *> matches =
- matcher::MatchFinder().getMatches(rootOp, matcher);
-
- // An extract call is recognized by considering if the matcher has a name.
- // TODO: Consider making the extract more explicit.
- if (matcher.hasFunctionName()) {
- auto functionName = matcher.getFunctionName();
- Operation *function =
- extractFunction(matches, rootOp->getContext(), functionName);
- os << "\n" << *function << "\n\n";
- return mlir::success();
- }
-
+ matcher::MatchFinder().getMatches(qs.getRootOp(), matcher);
os << "\n";
for (Operation *op : matches) {
os << "Match #" << ++matchCount << ":\n\n";
diff --git a/mlir/test/mlir-query/function-extraction.mlir b/mlir/test/mlir-query/function-extraction.mlir
deleted file mode 100644
index a783f65c6761bc..00000000000000
--- a/mlir/test/mlir-query/function-extraction.mlir
+++ /dev/null
@@ -1,19 +0,0 @@
-// RUN: mlir-query %s -c "m hasOpName(\"arith.mulf\").extract(\"testmul\")" | FileCheck %s
-
-// CHECK: func.func @testmul({{.*}}) -> (f32, f32, f32) {
-// CHECK: %[[MUL0:.*]] = arith.mulf {{.*}} : f32
-// CHECK: %[[MUL1:.*]] = arith.mulf {{.*}}, %[[MUL0]] : f32
-// CHECK: %[[MUL2:.*]] = arith.mulf {{.*}} : f32
-// CHECK-NEXT: return %[[MUL0]], %[[MUL1]], %[[MUL2]] : f32, f32, f32
-
-func.func @mixedOperations(%a: f32, %b: f32, %c: f32) -> f32 {
- %sum0 = arith.addf %a, %b : f32
- %sub0 = arith.subf %sum0, %c : f32
- %mul0 = arith.mulf %a, %sub0 : f32
- %sum1 = arith.addf %b, %c : f32
- %mul1 = arith.mulf %sum1, %mul0 : f32
- %sub2 = arith.subf %mul1, %a : f32
- %sum2 = arith.addf %mul1, %b : f32
- %mul2 = arith.mulf %sub2, %sum2 : f32
- return %mul2 : f32
-}
>From 5b4759f9fd1419abc69e656c40f04a0fd9483d2a Mon Sep 17 00:00:00 2001
From: NAKAMURA Takumi <geek4civic at gmail.com>
Date: Sun, 3 Mar 2024 22:31:28 +0900
Subject: [PATCH 388/406] Revert "[X86] Don't always separate conditions in
`(br (and/or cond0, cond1))` into separate branches"
This has been buggy for a while.
Reverts #81689
This reverts commit ae76dfb74701e05e5ab4be194e20e49f10768e46.
---
llvm/include/llvm/CodeGen/TargetLowering.h | 36 ---
.../SelectionDAG/SelectionDAGBuilder.cpp | 152 +--------
.../SelectionDAG/SelectionDAGBuilder.h | 5 -
llvm/lib/Target/X86/X86ISelLowering.cpp | 49 ---
llvm/lib/Target/X86/X86ISelLowering.h | 4 -
.../CodeGen/X86/2006-04-27-ISelFoldingBug.ll | 11 +-
.../X86/2007-08-09-IllegalX86-64Asm.ll | 109 +++----
.../test/CodeGen/X86/2007-12-18-LoadCSEBug.ll | 13 +-
.../CodeGen/X86/2008-02-18-TailMergingBug.ll | 4 +-
llvm/test/CodeGen/X86/avx-cmp.ll | 27 +-
llvm/test/CodeGen/X86/cmp.ll | 52 ++-
llvm/test/CodeGen/X86/dagcombine-and-setcc.ll | 3 +-
.../div-rem-pair-recomposition-unsigned.ll | 306 +++++++++---------
...iller-impdef-on-implicit-def-regression.ll | 70 ++--
llvm/test/CodeGen/X86/lsr-addrecloops.ll | 81 ++---
llvm/test/CodeGen/X86/movmsk-cmp.ll | 97 +++---
llvm/test/CodeGen/X86/or-branch.ll | 9 +-
.../X86/peephole-na-phys-copy-folding.ll | 142 ++++----
llvm/test/CodeGen/X86/pr33747.ll | 17 +-
llvm/test/CodeGen/X86/pr37025.ll | 38 +--
llvm/test/CodeGen/X86/pr38795.ll | 131 ++++----
llvm/test/CodeGen/X86/setcc-logic.ll | 76 +++--
llvm/test/CodeGen/X86/swifterror.ll | 10 +
.../X86/tail-dup-merge-loop-headers.ll | 119 ++++---
llvm/test/CodeGen/X86/tail-opts.ll | 5 +-
llvm/test/CodeGen/X86/tailcall-extract.ll | 8 +-
llvm/test/CodeGen/X86/test-shrink-bug.ll | 34 +-
.../CodeGen/X86/x86-shrink-wrap-unwind.ll | 52 ++-
28 files changed, 740 insertions(+), 920 deletions(-)
diff --git a/llvm/include/llvm/CodeGen/TargetLowering.h b/llvm/include/llvm/CodeGen/TargetLowering.h
index 4c2815679efc92..f2e00aab8d5da2 100644
--- a/llvm/include/llvm/CodeGen/TargetLowering.h
+++ b/llvm/include/llvm/CodeGen/TargetLowering.h
@@ -596,42 +596,6 @@ class TargetLoweringBase {
/// avoided.
bool isJumpExpensive() const { return JumpIsExpensive; }
- // Costs parameters used by
- // SelectionDAGBuilder::shouldKeepJumpConditionsTogether.
- // shouldKeepJumpConditionsTogether will use these parameter value to
- // determine if two conditions in the form `br (and/or cond1, cond2)` should
- // be split into two branches or left as one.
- //
- // BaseCost is the cost threshold (in latency). If the estimated latency of
- // computing both `cond1` and `cond2` is below the cost of just computing
- // `cond1` + BaseCost, the two conditions will be kept together. Otherwise
- // they will be split.
- //
- // LikelyBias increases BaseCost if branch probability info indicates that it
- // is likely that both `cond1` and `cond2` will be computed.
- //
- // UnlikelyBias decreases BaseCost if branch probability info indicates that
- // it is likely that both `cond1` and `cond2` will be computed.
- //
- // Set any field to -1 to make it ignored (setting BaseCost to -1 results in
- // `shouldKeepJumpConditionsTogether` always returning false).
- struct CondMergingParams {
- int BaseCost;
- int LikelyBias;
- int UnlikelyBias;
- };
- // Return params for deciding if we should keep two branch conditions merged
- // or split them into two separate branches.
- // Arg0: The binary op joining the two conditions (and/or).
- // Arg1: The first condition (cond1)
- // Arg2: The second condition (cond2)
- virtual CondMergingParams
- getJumpConditionMergingParams(Instruction::BinaryOps, const Value *,
- const Value *) const {
- // -1 will always result in splitting.
- return {-1, -1, -1};
- }
-
/// Return true if selects are only cheaper than branches if the branch is
/// unlikely to be predicted right.
bool isPredictableSelectExpensive() const {
diff --git a/llvm/lib/CodeGen/SelectionDAG/SelectionDAGBuilder.cpp b/llvm/lib/CodeGen/SelectionDAG/SelectionDAGBuilder.cpp
index 4f6263cc492fe3..ab2f42d2024ccc 100644
--- a/llvm/lib/CodeGen/SelectionDAG/SelectionDAGBuilder.cpp
+++ b/llvm/lib/CodeGen/SelectionDAG/SelectionDAGBuilder.cpp
@@ -26,7 +26,6 @@
#include "llvm/Analysis/Loads.h"
#include "llvm/Analysis/MemoryLocation.h"
#include "llvm/Analysis/TargetLibraryInfo.h"
-#include "llvm/Analysis/TargetTransformInfo.h"
#include "llvm/Analysis/ValueTracking.h"
#include "llvm/Analysis/VectorUtils.h"
#include "llvm/CodeGen/Analysis.h"
@@ -94,7 +93,6 @@
#include "llvm/Support/CommandLine.h"
#include "llvm/Support/Compiler.h"
#include "llvm/Support/Debug.h"
-#include "llvm/Support/InstructionCost.h"
#include "llvm/Support/MathExtras.h"
#include "llvm/Support/raw_ostream.h"
#include "llvm/Target/TargetIntrinsicInfo.h"
@@ -2448,147 +2446,6 @@ SelectionDAGBuilder::EmitBranchForMergedCondition(const Value *Cond,
SL->SwitchCases.push_back(CB);
}
-// Collect dependencies on V recursively. This is used for the cost analysis in
-// `shouldKeepJumpConditionsTogether`.
-static bool
-collectInstructionDeps(SmallPtrSet<const Instruction *, 8> *Deps,
- const Value *V,
- SmallPtrSet<const Instruction *, 8> *Necessary = nullptr,
- unsigned Depth = 0) {
- // Return false if we have an incomplete count.
- if (Depth >= SelectionDAG::MaxRecursionDepth)
- return false;
-
- auto *I = dyn_cast<Instruction>(V);
- if (I == nullptr)
- return true;
-
- if (Necessary != nullptr) {
- // This instruction is necessary for the other side of the condition so
- // don't count it.
- if (Necessary->contains(I))
- return true;
- }
-
- // Already added this dep.
- if (!Deps->insert(I).second)
- return true;
-
- for (unsigned OpIdx = 0, E = I->getNumOperands(); OpIdx < E; ++OpIdx)
- if (!collectInstructionDeps(Deps, I->getOperand(OpIdx), Necessary,
- Depth + 1))
- return false;
- return true;
-}
-
-bool SelectionDAGBuilder::shouldKeepJumpConditionsTogether(
- const FunctionLoweringInfo &FuncInfo, const BranchInst &I,
- Instruction::BinaryOps Opc, const Value *Lhs, const Value *Rhs,
- TargetLoweringBase::CondMergingParams Params) const {
- if (I.getNumSuccessors() != 2)
- return false;
-
- if (Params.BaseCost < 0)
- return false;
-
- // Baseline cost.
- InstructionCost CostThresh = Params.BaseCost;
-
- BranchProbabilityInfo *BPI = nullptr;
- if (Params.LikelyBias || Params.UnlikelyBias)
- BPI = FuncInfo.BPI;
- if (BPI != nullptr) {
- // See if we are either likely to get an early out or compute both lhs/rhs
- // of the condition.
- BasicBlock *IfFalse = I.getSuccessor(0);
- BasicBlock *IfTrue = I.getSuccessor(1);
-
- std::optional<bool> Likely;
- if (BPI->isEdgeHot(I.getParent(), IfTrue))
- Likely = true;
- else if (BPI->isEdgeHot(I.getParent(), IfFalse))
- Likely = false;
-
- if (Likely) {
- if (Opc == (*Likely ? Instruction::And : Instruction::Or))
- // Its likely we will have to compute both lhs and rhs of condition
- CostThresh += Params.LikelyBias;
- else {
- if (Params.UnlikelyBias < 0)
- return false;
- // Its likely we will get an early out.
- CostThresh -= Params.UnlikelyBias;
- }
- }
- }
-
- if (CostThresh <= 0)
- return false;
-
- // Collect "all" instructions that lhs condition is dependent on.
- SmallPtrSet<const Instruction *, 8> LhsDeps, RhsDeps;
- collectInstructionDeps(&LhsDeps, Lhs);
- // Collect "all" instructions that rhs condition is dependent on AND are
- // dependencies of lhs. This gives us an estimate on which instructions we
- // stand to save by splitting the condition.
- if (!collectInstructionDeps(&RhsDeps, Rhs, &LhsDeps))
- return false;
- // Add the compare instruction itself unless its a dependency on the LHS.
- if (const auto *RhsI = dyn_cast<Instruction>(Rhs))
- if (!LhsDeps.contains(RhsI))
- RhsDeps.insert(RhsI);
-
- const auto &TLI = DAG.getTargetLoweringInfo();
- const auto &TTI =
- TLI.getTargetMachine().getTargetTransformInfo(*I.getFunction());
-
- InstructionCost CostOfIncluding = 0;
- // See if this instruction will need to computed independently of whether RHS
- // is.
- auto ShouldCountInsn = [&RhsDeps](const Instruction *Ins) {
- for (const auto *U : Ins->users()) {
- // If user is independent of RHS calculation we don't need to count it.
- if (auto *UIns = dyn_cast<Instruction>(U))
- if (!RhsDeps.contains(UIns))
- return false;
- }
- return true;
- };
-
- // Prune instructions from RHS Deps that are dependencies of unrelated
- // instructions. The value (SelectionDAG::MaxRecursionDepth) is fairly
- // arbitrary and just meant to cap the how much time we spend in the pruning
- // loop. Its highly unlikely to come into affect.
- const unsigned MaxPruneIters = SelectionDAG::MaxRecursionDepth;
- // Stop after a certain point. No incorrectness from including too many
- // instructions.
- for (unsigned PruneIters = 0; PruneIters < MaxPruneIters; ++PruneIters) {
- const Instruction *ToDrop = nullptr;
- for (const auto *Ins : RhsDeps) {
- if (!ShouldCountInsn(Ins)) {
- ToDrop = Ins;
- break;
- }
- }
- if (ToDrop == nullptr)
- break;
- RhsDeps.erase(ToDrop);
- }
-
- for (const auto *Ins : RhsDeps) {
- // Finally accumulate latency that we can only attribute to computing the
- // RHS condition. Use latency because we are essentially trying to calculate
- // the cost of the dependency chain.
- // Possible TODO: We could try to estimate ILP and make this more precise.
- CostOfIncluding +=
- TTI.getInstructionCost(Ins, TargetTransformInfo::TCK_Latency);
-
- if (CostOfIncluding > CostThresh)
- return false;
- }
- return true;
-}
-
void SelectionDAGBuilder::FindMergedConditions(const Value *Cond,
MachineBasicBlock *TBB,
MachineBasicBlock *FBB,
@@ -2803,13 +2660,8 @@ void SelectionDAGBuilder::visitBr(const BranchInst &I) {
else if (match(BOp, m_LogicalOr(m_Value(BOp0), m_Value(BOp1))))
Opcode = Instruction::Or;
- if (Opcode &&
- !(match(BOp0, m_ExtractElt(m_Value(Vec), m_Value())) &&
- match(BOp1, m_ExtractElt(m_Specific(Vec), m_Value()))) &&
- !shouldKeepJumpConditionsTogether(
- FuncInfo, I, Opcode, BOp0, BOp1,
- DAG.getTargetLoweringInfo().getJumpConditionMergingParams(
- Opcode, BOp0, BOp1))) {
+ if (Opcode && !(match(BOp0, m_ExtractElt(m_Value(Vec), m_Value())) &&
+ match(BOp1, m_ExtractElt(m_Specific(Vec), m_Value())))) {
FindMergedConditions(BOp, Succ0MBB, Succ1MBB, BrMBB, BrMBB, Opcode,
getEdgeProbability(BrMBB, Succ0MBB),
getEdgeProbability(BrMBB, Succ1MBB),
diff --git a/llvm/lib/CodeGen/SelectionDAG/SelectionDAGBuilder.h b/llvm/lib/CodeGen/SelectionDAG/SelectionDAGBuilder.h
index 2084de473b8062..47657313cb6a3b 100644
--- a/llvm/lib/CodeGen/SelectionDAG/SelectionDAGBuilder.h
+++ b/llvm/lib/CodeGen/SelectionDAG/SelectionDAGBuilder.h
@@ -385,11 +385,6 @@ class SelectionDAGBuilder {
N = NewN;
}
- bool shouldKeepJumpConditionsTogether(
- const FunctionLoweringInfo &FuncInfo, const BranchInst &I,
- Instruction::BinaryOps Opc, const Value *Lhs, const Value *Rhs,
- TargetLoweringBase::CondMergingParams Params) const;
-
void FindMergedConditions(const Value *Cond, MachineBasicBlock *TBB,
MachineBasicBlock *FBB, MachineBasicBlock *CurBB,
MachineBasicBlock *SwitchBB,
diff --git a/llvm/lib/Target/X86/X86ISelLowering.cpp b/llvm/lib/Target/X86/X86ISelLowering.cpp
index 6de0ae8a206482..866a2a94a0bfe9 100644
--- a/llvm/lib/Target/X86/X86ISelLowering.cpp
+++ b/llvm/lib/Target/X86/X86ISelLowering.cpp
@@ -77,37 +77,6 @@ static cl::opt<int> ExperimentalPrefInnermostLoopAlignment(
"alignment set by x86-experimental-pref-loop-alignment."),
cl::Hidden);
-static cl::opt<int> BrMergingBaseCostThresh(
- "x86-br-merging-base-cost", cl::init(1),
- cl::desc(
- "Sets the cost threshold for when multiple conditionals will be merged "
- "into one branch versus be split in multiple branches. Merging "
- "conditionals saves branches at the cost of additional instructions. "
- "This value sets the instruction cost limit, below which conditionals "
- "will be merged, and above which conditionals will be split."),
- cl::Hidden);
-
-static cl::opt<int> BrMergingLikelyBias(
- "x86-br-merging-likely-bias", cl::init(0),
- cl::desc("Increases 'x86-br-merging-base-cost' in cases that it is likely "
- "that all conditionals will be executed. For example for merging "
- "the conditionals (a == b && c > d), if its known that a == b is "
- "likely, then it is likely that if the conditionals are split "
- "both sides will be executed, so it may be desirable to increase "
- "the instruction cost threshold."),
- cl::Hidden);
-
-static cl::opt<int> BrMergingUnlikelyBias(
- "x86-br-merging-unlikely-bias", cl::init(1),
- cl::desc(
- "Decreases 'x86-br-merging-base-cost' in cases that it is unlikely "
- "that all conditionals will be executed. For example for merging "
- "the conditionals (a == b && c > d), if its known that a == b is "
- "unlikely, then it is unlikely that if the conditionals are split "
- "both sides will be executed, so it may be desirable to decrease "
- "the instruction cost threshold."),
- cl::Hidden);
-
static cl::opt<bool> MulConstantOptimization(
"mul-constant-optimization", cl::init(true),
cl::desc("Replace 'mul x, Const' with more effective instructions like "
@@ -3364,24 +3333,6 @@ unsigned X86TargetLowering::preferedOpcodeForCmpEqPiecesOfOperand(
return ISD::SRL;
}
-TargetLoweringBase::CondMergingParams
-X86TargetLowering::getJumpConditionMergingParams(Instruction::BinaryOps Opc,
- const Value *Lhs,
- const Value *Rhs) const {
- using namespace llvm::PatternMatch;
- int BaseCost = BrMergingBaseCostThresh.getValue();
- // a == b && a == c is a fast pattern on x86.
- ICmpInst::Predicate Pred;
- if (BaseCost >= 0 && Opc == Instruction::And &&
- match(Lhs, m_ICmp(Pred, m_Value(), m_Value())) &&
- Pred == ICmpInst::ICMP_EQ &&
- match(Rhs, m_ICmp(Pred, m_Value(), m_Value())) &&
- Pred == ICmpInst::ICMP_EQ)
- BaseCost += 1;
- return {BaseCost, BrMergingLikelyBias.getValue(),
- BrMergingUnlikelyBias.getValue()};
-}
-
bool X86TargetLowering::preferScalarizeSplat(SDNode *N) const {
return N->getOpcode() != ISD::FP_EXTEND;
}
diff --git a/llvm/lib/Target/X86/X86ISelLowering.h b/llvm/lib/Target/X86/X86ISelLowering.h
index fe1943b5760844..f93c54781846bf 100644
--- a/llvm/lib/Target/X86/X86ISelLowering.h
+++ b/llvm/lib/Target/X86/X86ISelLowering.h
@@ -1150,10 +1150,6 @@ namespace llvm {
bool preferScalarizeSplat(SDNode *N) const override;
- CondMergingParams
- getJumpConditionMergingParams(Instruction::BinaryOps Opc, const Value *Lhs,
- const Value *Rhs) const override;
-
bool shouldFoldConstantShiftPairToMask(const SDNode *N,
CombineLevel Level) const override;
diff --git a/llvm/test/CodeGen/X86/2006-04-27-ISelFoldingBug.ll b/llvm/test/CodeGen/X86/2006-04-27-ISelFoldingBug.ll
index e6f28c2057f775..0044d1c3568377 100644
--- a/llvm/test/CodeGen/X86/2006-04-27-ISelFoldingBug.ll
+++ b/llvm/test/CodeGen/X86/2006-04-27-ISelFoldingBug.ll
@@ -18,16 +18,15 @@ define i1 @loadAndRLEsource_no_exit_2E_1_label_2E_0(i32 %tmp.21.reload, i32 %tmp
; CHECK-NEXT: movl _block, %esi
; CHECK-NEXT: movb %al, 1(%esi,%edx)
; CHECK-NEXT: cmpl %ecx, _last
-; CHECK-NEXT: setl %cl
+; CHECK-NEXT: jge LBB0_3
+; CHECK-NEXT: ## %bb.1: ## %label.0
; CHECK-NEXT: cmpl $257, %eax ## imm = 0x101
-; CHECK-NEXT: setne %al
-; CHECK-NEXT: testb %al, %cl
-; CHECK-NEXT: je LBB0_2
-; CHECK-NEXT: ## %bb.1: ## %label.0.no_exit.1_crit_edge.exitStub
+; CHECK-NEXT: je LBB0_3
+; CHECK-NEXT: ## %bb.2: ## %label.0.no_exit.1_crit_edge.exitStub
; CHECK-NEXT: movb $1, %al
; CHECK-NEXT: popl %esi
; CHECK-NEXT: retl
-; CHECK-NEXT: LBB0_2: ## %codeRepl5.exitStub
+; CHECK-NEXT: LBB0_3: ## %codeRepl5.exitStub
; CHECK-NEXT: xorl %eax, %eax
; CHECK-NEXT: popl %esi
; CHECK-NEXT: retl
diff --git a/llvm/test/CodeGen/X86/2007-08-09-IllegalX86-64Asm.ll b/llvm/test/CodeGen/X86/2007-08-09-IllegalX86-64Asm.ll
index 28b4541c1bfc7f..7bdc4e19a1cf66 100644
--- a/llvm/test/CodeGen/X86/2007-08-09-IllegalX86-64Asm.ll
+++ b/llvm/test/CodeGen/X86/2007-08-09-IllegalX86-64Asm.ll
@@ -44,7 +44,7 @@ define ptr @ubyte_divmod(ptr %a, ptr %b) {
; CHECK-NEXT: leaq {{[0-9]+}}(%rsp), %rsi
; CHECK-NEXT: callq __ubyte_convert_to_ctype
; CHECK-NEXT: testl %eax, %eax
-; CHECK-NEXT: js LBB0_6
+; CHECK-NEXT: js LBB0_4
; CHECK-NEXT: ## %bb.1: ## %cond_next.i
; CHECK-NEXT: leaq {{[0-9]+}}(%rsp), %rsi
; CHECK-NEXT: movq %rbx, %rdi
@@ -53,84 +53,81 @@ define ptr @ubyte_divmod(ptr %a, ptr %b) {
; CHECK-NEXT: sarl $31, %ecx
; CHECK-NEXT: andl %eax, %ecx
; CHECK-NEXT: cmpl $-2, %ecx
-; CHECK-NEXT: je LBB0_10
+; CHECK-NEXT: je LBB0_8
; CHECK-NEXT: ## %bb.2: ## %cond_next.i
; CHECK-NEXT: cmpl $-1, %ecx
-; CHECK-NEXT: jne LBB0_3
-; CHECK-NEXT: LBB0_8: ## %bb4
+; CHECK-NEXT: jne LBB0_6
+; CHECK-NEXT: LBB0_3: ## %bb4
; CHECK-NEXT: movq _PyArray_API at GOTPCREL(%rip), %rax
; CHECK-NEXT: movq (%rax), %rax
; CHECK-NEXT: movq 16(%rax), %rax
-; CHECK-NEXT: jmp LBB0_9
-; CHECK-NEXT: LBB0_6: ## %_ubyte_convert2_to_ctypes.exit
+; CHECK-NEXT: jmp LBB0_10
+; CHECK-NEXT: LBB0_4: ## %_ubyte_convert2_to_ctypes.exit
; CHECK-NEXT: cmpl $-2, %eax
-; CHECK-NEXT: je LBB0_10
-; CHECK-NEXT: ## %bb.7: ## %_ubyte_convert2_to_ctypes.exit
-; CHECK-NEXT: cmpl $-1, %eax
; CHECK-NEXT: je LBB0_8
-; CHECK-NEXT: LBB0_3: ## %bb35
+; CHECK-NEXT: ## %bb.5: ## %_ubyte_convert2_to_ctypes.exit
+; CHECK-NEXT: cmpl $-1, %eax
+; CHECK-NEXT: je LBB0_3
+; CHECK-NEXT: LBB0_6: ## %bb35
; CHECK-NEXT: movq _PyUFunc_API at GOTPCREL(%rip), %r14
; CHECK-NEXT: movq (%r14), %rax
; CHECK-NEXT: callq *216(%rax)
; CHECK-NEXT: movzbl {{[0-9]+}}(%rsp), %edx
; CHECK-NEXT: testb %dl, %dl
-; CHECK-NEXT: je LBB0_4
-; CHECK-NEXT: ## %bb.12: ## %cond_false.i
-; CHECK-NEXT: setne %dil
+; CHECK-NEXT: je LBB0_11
+; CHECK-NEXT: ## %bb.7: ## %cond_false.i
; CHECK-NEXT: movzbl {{[0-9]+}}(%rsp), %esi
; CHECK-NEXT: movzbl %sil, %ecx
; CHECK-NEXT: movl %ecx, %eax
; CHECK-NEXT: divb %dl
; CHECK-NEXT: movl %eax, %r15d
; CHECK-NEXT: testb %cl, %cl
-; CHECK-NEXT: setne %al
-; CHECK-NEXT: testb %dil, %al
-; CHECK-NEXT: jne LBB0_5
-; CHECK-NEXT: LBB0_13: ## %cond_true.i200
-; CHECK-NEXT: testb %dl, %dl
-; CHECK-NEXT: jne LBB0_15
-; CHECK-NEXT: ## %bb.14: ## %cond_true14.i
-; CHECK-NEXT: movl $4, %edi
-; CHECK-NEXT: callq _feraiseexcept
-; CHECK-NEXT: LBB0_15: ## %ubyte_ctype_remainder.exit
-; CHECK-NEXT: xorl %ebx, %ebx
-; CHECK-NEXT: jmp LBB0_16
-; CHECK-NEXT: LBB0_10: ## %bb17
+; CHECK-NEXT: jne LBB0_12
+; CHECK-NEXT: jmp LBB0_14
+; CHECK-NEXT: LBB0_8: ## %bb17
; CHECK-NEXT: callq _PyErr_Occurred
; CHECK-NEXT: testq %rax, %rax
-; CHECK-NEXT: jne LBB0_23
-; CHECK-NEXT: ## %bb.11: ## %cond_next
+; CHECK-NEXT: jne LBB0_27
+; CHECK-NEXT: ## %bb.9: ## %cond_next
; CHECK-NEXT: movq _PyArray_API at GOTPCREL(%rip), %rax
; CHECK-NEXT: movq (%rax), %rax
; CHECK-NEXT: movq 80(%rax), %rax
-; CHECK-NEXT: LBB0_9: ## %bb4
+; CHECK-NEXT: LBB0_10: ## %bb4
; CHECK-NEXT: movq 96(%rax), %rax
; CHECK-NEXT: movq %r14, %rdi
; CHECK-NEXT: movq %rbx, %rsi
; CHECK-NEXT: callq *40(%rax)
-; CHECK-NEXT: jmp LBB0_24
-; CHECK-NEXT: LBB0_4: ## %cond_true.i
+; CHECK-NEXT: jmp LBB0_28
+; CHECK-NEXT: LBB0_11: ## %cond_true.i
; CHECK-NEXT: movl $4, %edi
; CHECK-NEXT: callq _feraiseexcept
; CHECK-NEXT: movzbl {{[0-9]+}}(%rsp), %edx
; CHECK-NEXT: movzbl {{[0-9]+}}(%rsp), %esi
+; CHECK-NEXT: xorl %r15d, %r15d
; CHECK-NEXT: testb %sil, %sil
-; CHECK-NEXT: sete %al
+; CHECK-NEXT: je LBB0_14
+; CHECK-NEXT: LBB0_12: ## %cond_false.i
; CHECK-NEXT: testb %dl, %dl
-; CHECK-NEXT: sete %cl
-; CHECK-NEXT: xorl %r15d, %r15d
-; CHECK-NEXT: orb %al, %cl
-; CHECK-NEXT: jne LBB0_13
-; CHECK-NEXT: LBB0_5: ## %cond_next17.i
+; CHECK-NEXT: je LBB0_14
+; CHECK-NEXT: ## %bb.13: ## %cond_next17.i
; CHECK-NEXT: movzbl %sil, %eax
; CHECK-NEXT: divb %dl
; CHECK-NEXT: movzbl %ah, %ebx
-; CHECK-NEXT: LBB0_16: ## %ubyte_ctype_remainder.exit
+; CHECK-NEXT: jmp LBB0_18
+; CHECK-NEXT: LBB0_14: ## %cond_true.i200
+; CHECK-NEXT: testb %dl, %dl
+; CHECK-NEXT: jne LBB0_17
+; CHECK-NEXT: ## %bb.16: ## %cond_true14.i
+; CHECK-NEXT: movl $4, %edi
+; CHECK-NEXT: callq _feraiseexcept
+; CHECK-NEXT: LBB0_17: ## %ubyte_ctype_remainder.exit
+; CHECK-NEXT: xorl %ebx, %ebx
+; CHECK-NEXT: LBB0_18: ## %ubyte_ctype_remainder.exit
; CHECK-NEXT: movq (%r14), %rax
; CHECK-NEXT: callq *224(%rax)
; CHECK-NEXT: testl %eax, %eax
-; CHECK-NEXT: je LBB0_19
-; CHECK-NEXT: ## %bb.17: ## %cond_true61
+; CHECK-NEXT: je LBB0_21
+; CHECK-NEXT: ## %bb.19: ## %cond_true61
; CHECK-NEXT: movl %eax, %ebp
; CHECK-NEXT: movq (%r14), %rax
; CHECK-NEXT: movq _.str5 at GOTPCREL(%rip), %rdi
@@ -139,8 +136,8 @@ define ptr @ubyte_divmod(ptr %a, ptr %b) {
; CHECK-NEXT: leaq {{[0-9]+}}(%rsp), %rcx
; CHECK-NEXT: callq *200(%rax)
; CHECK-NEXT: testl %eax, %eax
-; CHECK-NEXT: js LBB0_23
-; CHECK-NEXT: ## %bb.18: ## %cond_next73
+; CHECK-NEXT: js LBB0_27
+; CHECK-NEXT: ## %bb.20: ## %cond_next73
; CHECK-NEXT: movl $1, {{[0-9]+}}(%rsp)
; CHECK-NEXT: movq (%r14), %rax
; CHECK-NEXT: movq {{[0-9]+}}(%rsp), %rsi
@@ -149,13 +146,13 @@ define ptr @ubyte_divmod(ptr %a, ptr %b) {
; CHECK-NEXT: movl %ebp, %edx
; CHECK-NEXT: callq *232(%rax)
; CHECK-NEXT: testl %eax, %eax
-; CHECK-NEXT: jne LBB0_23
-; CHECK-NEXT: LBB0_19: ## %cond_next89
+; CHECK-NEXT: jne LBB0_27
+; CHECK-NEXT: LBB0_21: ## %cond_next89
; CHECK-NEXT: movl $2, %edi
; CHECK-NEXT: callq _PyTuple_New
; CHECK-NEXT: testq %rax, %rax
-; CHECK-NEXT: je LBB0_23
-; CHECK-NEXT: ## %bb.20: ## %cond_next97
+; CHECK-NEXT: je LBB0_27
+; CHECK-NEXT: ## %bb.22: ## %cond_next97
; CHECK-NEXT: movq %rax, %r14
; CHECK-NEXT: movq _PyArray_API at GOTPCREL(%rip), %r12
; CHECK-NEXT: movq (%r12), %rax
@@ -163,8 +160,8 @@ define ptr @ubyte_divmod(ptr %a, ptr %b) {
; CHECK-NEXT: xorl %esi, %esi
; CHECK-NEXT: callq *304(%rdi)
; CHECK-NEXT: testq %rax, %rax
-; CHECK-NEXT: je LBB0_21
-; CHECK-NEXT: ## %bb.25: ## %cond_next135
+; CHECK-NEXT: je LBB0_25
+; CHECK-NEXT: ## %bb.23: ## %cond_next135
; CHECK-NEXT: movb %r15b, 16(%rax)
; CHECK-NEXT: movq %rax, 24(%r14)
; CHECK-NEXT: movq (%r12), %rax
@@ -172,22 +169,22 @@ define ptr @ubyte_divmod(ptr %a, ptr %b) {
; CHECK-NEXT: xorl %esi, %esi
; CHECK-NEXT: callq *304(%rdi)
; CHECK-NEXT: testq %rax, %rax
-; CHECK-NEXT: je LBB0_21
-; CHECK-NEXT: ## %bb.26: ## %cond_next182
+; CHECK-NEXT: je LBB0_25
+; CHECK-NEXT: ## %bb.24: ## %cond_next182
; CHECK-NEXT: movb %bl, 16(%rax)
; CHECK-NEXT: movq %rax, 32(%r14)
; CHECK-NEXT: movq %r14, %rax
-; CHECK-NEXT: jmp LBB0_24
-; CHECK-NEXT: LBB0_21: ## %cond_true113
+; CHECK-NEXT: jmp LBB0_28
+; CHECK-NEXT: LBB0_25: ## %cond_true113
; CHECK-NEXT: decq (%r14)
-; CHECK-NEXT: jne LBB0_23
-; CHECK-NEXT: ## %bb.22: ## %cond_true126
+; CHECK-NEXT: jne LBB0_27
+; CHECK-NEXT: ## %bb.26: ## %cond_true126
; CHECK-NEXT: movq 8(%r14), %rax
; CHECK-NEXT: movq %r14, %rdi
; CHECK-NEXT: callq *48(%rax)
-; CHECK-NEXT: LBB0_23: ## %UnifiedReturnBlock
+; CHECK-NEXT: LBB0_27: ## %UnifiedReturnBlock
; CHECK-NEXT: xorl %eax, %eax
-; CHECK-NEXT: LBB0_24: ## %UnifiedReturnBlock
+; CHECK-NEXT: LBB0_28: ## %UnifiedReturnBlock
; CHECK-NEXT: addq $32, %rsp
; CHECK-NEXT: popq %rbx
; CHECK-NEXT: popq %r12
diff --git a/llvm/test/CodeGen/X86/2007-12-18-LoadCSEBug.ll b/llvm/test/CodeGen/X86/2007-12-18-LoadCSEBug.ll
index d9d4424267d733..4482c5aec8e816 100644
--- a/llvm/test/CodeGen/X86/2007-12-18-LoadCSEBug.ll
+++ b/llvm/test/CodeGen/X86/2007-12-18-LoadCSEBug.ll
@@ -16,12 +16,15 @@ define void @_ada_c34007g() {
; CHECK-NEXT: andl $-8, %esp
; CHECK-NEXT: subl $8, %esp
; CHECK-NEXT: movl (%esp), %eax
-; CHECK-NEXT: movl {{[0-9]+}}(%esp), %ecx
-; CHECK-NEXT: orl %eax, %ecx
-; CHECK-NEXT: sete %cl
; CHECK-NEXT: testl %eax, %eax
-; CHECK-NEXT: setne %al
-; CHECK-NEXT: testb %cl, %al
+; CHECK-NEXT: je .LBB0_3
+; CHECK-NEXT: # %bb.1: # %entry
+; CHECK-NEXT: orl {{[0-9]+}}(%esp), %eax
+; CHECK-NEXT: jne .LBB0_3
+; CHECK-NEXT: # %bb.2: # %entry
+; CHECK-NEXT: movb $1, %al
+; CHECK-NEXT: testb %al, %al
+; CHECK-NEXT: .LBB0_3: # %bb5507
; CHECK-NEXT: movl %ebp, %esp
; CHECK-NEXT: popl %ebp
; CHECK-NEXT: .cfi_def_cfa %esp, 4
diff --git a/llvm/test/CodeGen/X86/2008-02-18-TailMergingBug.ll b/llvm/test/CodeGen/X86/2008-02-18-TailMergingBug.ll
index e0b6e38647d801..dd60e641df2543 100644
--- a/llvm/test/CodeGen/X86/2008-02-18-TailMergingBug.ll
+++ b/llvm/test/CodeGen/X86/2008-02-18-TailMergingBug.ll
@@ -1,5 +1,5 @@
; REQUIRES: asserts
-; RUN: llc < %s -mtriple=i686-- -mcpu=yonah -stats 2>&1 | grep "Number of block tails merged" | grep 9
+; RUN: llc < %s -mtriple=i686-- -mcpu=yonah -stats 2>&1 | grep "Number of block tails merged" | grep 16
; PR1909
@.str = internal constant [48 x i8] c"transformed bounds: (%.2f, %.2f), (%.2f, %.2f)\0A\00" ; <ptr> [#uses=1]
@@ -217,4 +217,4 @@ bb456: ; preds = %bb448, %bb425, %bb417, %bb395, %bb385, %bb371
ret void
}
-declare i32 @printf(ptr, ...) nounwind
+declare i32 @printf(ptr, ...) nounwind
diff --git a/llvm/test/CodeGen/X86/avx-cmp.ll b/llvm/test/CodeGen/X86/avx-cmp.ll
index 4ab9c545ed90da..502bbf3f5d118b 100644
--- a/llvm/test/CodeGen/X86/avx-cmp.ll
+++ b/llvm/test/CodeGen/X86/avx-cmp.ll
@@ -26,33 +26,40 @@ declare void @scale() nounwind
define void @render(double %a0) nounwind {
; CHECK-LABEL: render:
; CHECK: # %bb.0: # %entry
+; CHECK-NEXT: pushq %rbp
; CHECK-NEXT: pushq %rbx
-; CHECK-NEXT: subq $16, %rsp
-; CHECK-NEXT: vmovsd %xmm0, {{[-0-9]+}}(%r{{[sb]}}p) # 8-byte Spill
+; CHECK-NEXT: pushq %rax
+; CHECK-NEXT: vmovsd %xmm0, (%rsp) # 8-byte Spill
; CHECK-NEXT: xorl %eax, %eax
; CHECK-NEXT: testb %al, %al
-; CHECK-NEXT: jne .LBB2_5
+; CHECK-NEXT: jne .LBB2_6
; CHECK-NEXT: # %bb.1: # %for.cond5.preheader
-; CHECK-NEXT: movb $1, %bl
+; CHECK-NEXT: xorl %ebx, %ebx
+; CHECK-NEXT: movb $1, %bpl
; CHECK-NEXT: .p2align 4, 0x90
; CHECK-NEXT: .LBB2_2: # %for.cond5
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: testb %bl, %bl
; CHECK-NEXT: jne .LBB2_2
-; CHECK-NEXT: # %bb.3: # %for.body33.preheader
+; CHECK-NEXT: # %bb.3: # %for.cond5
+; CHECK-NEXT: # in Loop: Header=BB2_2 Depth=1
+; CHECK-NEXT: testb %bpl, %bpl
+; CHECK-NEXT: jne .LBB2_2
+; CHECK-NEXT: # %bb.4: # %for.body33.preheader
; CHECK-NEXT: # in Loop: Header=BB2_2 Depth=1
-; CHECK-NEXT: vmovsd {{[-0-9]+}}(%r{{[sb]}}p), %xmm0 # 8-byte Reload
+; CHECK-NEXT: vmovsd (%rsp), %xmm0 # 8-byte Reload
; CHECK-NEXT: # xmm0 = mem[0],zero
; CHECK-NEXT: vucomisd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
-; CHECK-NEXT: jne .LBB2_4
+; CHECK-NEXT: jne .LBB2_5
; CHECK-NEXT: jnp .LBB2_2
-; CHECK-NEXT: .LBB2_4: # %if.then
+; CHECK-NEXT: .LBB2_5: # %if.then
; CHECK-NEXT: # in Loop: Header=BB2_2 Depth=1
; CHECK-NEXT: callq scale at PLT
; CHECK-NEXT: jmp .LBB2_2
-; CHECK-NEXT: .LBB2_5: # %for.end52
-; CHECK-NEXT: addq $16, %rsp
+; CHECK-NEXT: .LBB2_6: # %for.end52
+; CHECK-NEXT: addq $8, %rsp
; CHECK-NEXT: popq %rbx
+; CHECK-NEXT: popq %rbp
; CHECK-NEXT: retq
entry:
br i1 undef, label %for.cond5, label %for.end52
diff --git a/llvm/test/CodeGen/X86/cmp.ll b/llvm/test/CodeGen/X86/cmp.ll
index 09419f870b7091..cd1953bec774d9 100644
--- a/llvm/test/CodeGen/X86/cmp.ll
+++ b/llvm/test/CodeGen/X86/cmp.ll
@@ -159,51 +159,43 @@ define i64 @test4(i64 %x) nounwind {
define i32 @test5(double %A) nounwind {
; CHECK-LABEL: test5:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: movsd {{.*#+}} xmm1 = [7.5E+1,0.0E+0]
-; CHECK-NEXT: # encoding: [0xf2,0x0f,0x10,0x0d,A,A,A,A]
+; CHECK-NEXT: ucomisd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0 # encoding: [0x66,0x0f,0x2e,0x05,A,A,A,A]
; CHECK-NEXT: # fixup A - offset: 4, value: {{\.?LCPI[0-9]+_[0-9]+}}-4, kind: reloc_riprel_4byte
-; CHECK-NEXT: cmplepd %xmm0, %xmm1 # encoding: [0x66,0x0f,0xc2,0xc8,0x02]
-; CHECK-NEXT: movsd {{.*#+}} xmm2 = [1.5E+2,0.0E+0]
-; CHECK-NEXT: # encoding: [0xf2,0x0f,0x10,0x15,A,A,A,A]
+; CHECK-NEXT: ja .LBB5_3 # encoding: [0x77,A]
+; CHECK-NEXT: # fixup A - offset: 1, value: .LBB5_3-1, kind: FK_PCRel_1
+; CHECK-NEXT: # %bb.1: # %entry
+; CHECK-NEXT: ucomisd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0 # encoding: [0x66,0x0f,0x2e,0x05,A,A,A,A]
; CHECK-NEXT: # fixup A - offset: 4, value: {{\.?LCPI[0-9]+_[0-9]+}}-4, kind: reloc_riprel_4byte
-; CHECK-NEXT: cmpnltpd %xmm0, %xmm2 # encoding: [0x66,0x0f,0xc2,0xd0,0x05]
-; CHECK-NEXT: andpd %xmm1, %xmm2 # encoding: [0x66,0x0f,0x54,0xd1]
-; CHECK-NEXT: movd %xmm2, %eax # encoding: [0x66,0x0f,0x7e,0xd0]
-; CHECK-NEXT: testb $1, %al # encoding: [0xa8,0x01]
-; CHECK-NEXT: jne .LBB5_1 # encoding: [0x75,A]
-; CHECK-NEXT: # fixup A - offset: 1, value: .LBB5_1-1, kind: FK_PCRel_1
-; CHECK-NEXT: # %bb.2: # %bb8
+; CHECK-NEXT: jb .LBB5_3 # encoding: [0x72,A]
+; CHECK-NEXT: # fixup A - offset: 1, value: .LBB5_3-1, kind: FK_PCRel_1
+; CHECK-NEXT: # %bb.2: # %bb12
+; CHECK-NEXT: movl $32, %eax # encoding: [0xb8,0x20,0x00,0x00,0x00]
+; CHECK-NEXT: retq # encoding: [0xc3]
+; CHECK-NEXT: .LBB5_3: # %bb8
; CHECK-NEXT: xorl %eax, %eax # encoding: [0x31,0xc0]
; CHECK-NEXT: jmp foo at PLT # TAILCALL
; CHECK-NEXT: # encoding: [0xeb,A]
; CHECK-NEXT: # fixup A - offset: 1, value: foo at PLT-1, kind: FK_PCRel_1
-; CHECK-NEXT: .LBB5_1: # %bb12
-; CHECK-NEXT: movl $32, %eax # encoding: [0xb8,0x20,0x00,0x00,0x00]
-; CHECK-NEXT: retq # encoding: [0xc3]
;
; NDD-LABEL: test5:
; NDD: # %bb.0: # %entry
-; NDD-NEXT: movsd {{.*#+}} xmm1 = [7.5E+1,0.0E+0]
-; NDD-NEXT: # encoding: [0xf2,0x0f,0x10,0x0d,A,A,A,A]
+; NDD-NEXT: ucomisd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0 # encoding: [0x66,0x0f,0x2e,0x05,A,A,A,A]
; NDD-NEXT: # fixup A - offset: 4, value: {{\.?LCPI[0-9]+_[0-9]+}}-4, kind: reloc_riprel_4byte
-; NDD-NEXT: cmplepd %xmm0, %xmm1 # encoding: [0x66,0x0f,0xc2,0xc8,0x02]
-; NDD-NEXT: movsd {{.*#+}} xmm2 = [1.5E+2,0.0E+0]
-; NDD-NEXT: # encoding: [0xf2,0x0f,0x10,0x15,A,A,A,A]
+; NDD-NEXT: ja .LBB5_3 # encoding: [0x77,A]
+; NDD-NEXT: # fixup A - offset: 1, value: .LBB5_3-1, kind: FK_PCRel_1
+; NDD-NEXT: # %bb.1: # %entry
+; NDD-NEXT: ucomisd {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0 # encoding: [0x66,0x0f,0x2e,0x05,A,A,A,A]
; NDD-NEXT: # fixup A - offset: 4, value: {{\.?LCPI[0-9]+_[0-9]+}}-4, kind: reloc_riprel_4byte
-; NDD-NEXT: cmpnltpd %xmm0, %xmm2 # encoding: [0x66,0x0f,0xc2,0xd0,0x05]
-; NDD-NEXT: andpd %xmm1, %xmm2 # encoding: [0x66,0x0f,0x54,0xd1]
-; NDD-NEXT: movd %xmm2, %eax # encoding: [0x66,0x0f,0x7e,0xd0]
-; NDD-NEXT: testb $1, %al # encoding: [0xa8,0x01]
-; NDD-NEXT: jne .LBB5_1 # encoding: [0x75,A]
-; NDD-NEXT: # fixup A - offset: 1, value: .LBB5_1-1, kind: FK_PCRel_1
-; NDD-NEXT: # %bb.2: # %bb8
+; NDD-NEXT: jb .LBB5_3 # encoding: [0x72,A]
+; NDD-NEXT: # fixup A - offset: 1, value: .LBB5_3-1, kind: FK_PCRel_1
+; NDD-NEXT: # %bb.2: # %bb12
+; NDD-NEXT: movl $32, %eax # encoding: [0xb8,0x20,0x00,0x00,0x00]
+; NDD-NEXT: retq # encoding: [0xc3]
+; NDD-NEXT: .LBB5_3: # %bb8
; NDD-NEXT: xorl %eax, %eax # encoding: [0x31,0xc0]
; NDD-NEXT: jmp foo at PLT # TAILCALL
; NDD-NEXT: # encoding: [0xeb,A]
; NDD-NEXT: # fixup A - offset: 1, value: foo at PLT-1, kind: FK_PCRel_1
-; NDD-NEXT: .LBB5_1: # %bb12
-; NDD-NEXT: movl $32, %eax # encoding: [0xb8,0x20,0x00,0x00,0x00]
-; NDD-NEXT: retq # encoding: [0xc3]
entry:
%tmp2 = fcmp ogt double %A, 1.500000e+02
%tmp5 = fcmp ult double %A, 7.500000e+01
diff --git a/llvm/test/CodeGen/X86/dagcombine-and-setcc.ll b/llvm/test/CodeGen/X86/dagcombine-and-setcc.ll
index 6fded2eeaf35d9..842ee55d255aa3 100644
--- a/llvm/test/CodeGen/X86/dagcombine-and-setcc.ll
+++ b/llvm/test/CodeGen/X86/dagcombine-and-setcc.ll
@@ -16,8 +16,7 @@ declare i32 @printf(ptr nocapture readonly, ...)
;CHECK: cmpl
;CHECK: setl
;CHECK: orb
-;CHECK: testb
-;CHECK: jne
+;CHECK: je
@.str = private unnamed_addr constant [4 x i8] c"%d\0A\00", align 1
; Function Attrs: optsize ssp uwtable
diff --git a/llvm/test/CodeGen/X86/div-rem-pair-recomposition-unsigned.ll b/llvm/test/CodeGen/X86/div-rem-pair-recomposition-unsigned.ll
index fa45afbb634c4d..1372bd80473518 100644
--- a/llvm/test/CodeGen/X86/div-rem-pair-recomposition-unsigned.ll
+++ b/llvm/test/CodeGen/X86/div-rem-pair-recomposition-unsigned.ll
@@ -178,13 +178,13 @@ define i128 @scalar_i128(i128 %x, i128 %y, ptr %divdst) nounwind {
; X86-NEXT: pushl %edi
; X86-NEXT: pushl %esi
; X86-NEXT: subl $136, %esp
+; X86-NEXT: movl {{[0-9]+}}(%esp), %edx
+; X86-NEXT: movl {{[0-9]+}}(%esp), %ecx
; X86-NEXT: movl {{[0-9]+}}(%esp), %esi
-; X86-NEXT: movl {{[0-9]+}}(%esp), %ebp
-; X86-NEXT: movl {{[0-9]+}}(%esp), %edi
; X86-NEXT: movl {{[0-9]+}}(%esp), %eax
-; X86-NEXT: orl %edi, %eax
-; X86-NEXT: movl %ebp, %ecx
-; X86-NEXT: orl %esi, %ecx
+; X86-NEXT: orl %esi, %eax
+; X86-NEXT: orl %edx, %ecx
+; X86-NEXT: movl %edx, %edi
; X86-NEXT: orl %eax, %ecx
; X86-NEXT: movl {{[0-9]+}}(%esp), %eax
; X86-NEXT: sete %bl
@@ -195,33 +195,30 @@ define i128 @scalar_i128(i128 %x, i128 %y, ptr %divdst) nounwind {
; X86-NEXT: sete %al
; X86-NEXT: orb %bl, %al
; X86-NEXT: movb %al, (%esp) # 1-byte Spill
-; X86-NEXT: bsrl %edi, %edx
+; X86-NEXT: bsrl %esi, %edx
; X86-NEXT: xorl $31, %edx
-; X86-NEXT: bsrl %esi, %ecx
+; X86-NEXT: bsrl %edi, %ecx
; X86-NEXT: xorl $31, %ecx
; X86-NEXT: addl $32, %ecx
-; X86-NEXT: testl %edi, %edi
-; X86-NEXT: movl %edi, %ebx
+; X86-NEXT: testl %esi, %esi
; X86-NEXT: cmovnel %edx, %ecx
; X86-NEXT: movl {{[0-9]+}}(%esp), %eax
; X86-NEXT: bsrl %eax, %edx
; X86-NEXT: xorl $31, %edx
-; X86-NEXT: bsrl %ebp, %ebp
-; X86-NEXT: movl %esi, %edi
+; X86-NEXT: bsrl {{[0-9]+}}(%esp), %ebp
+; X86-NEXT: movl %esi, %ebx
; X86-NEXT: movl {{[0-9]+}}(%esp), %esi
; X86-NEXT: xorl $31, %ebp
; X86-NEXT: addl $32, %ebp
; X86-NEXT: testl %eax, %eax
; X86-NEXT: cmovnel %edx, %ebp
; X86-NEXT: addl $64, %ebp
-; X86-NEXT: movl %edi, %edx
-; X86-NEXT: orl %ebx, %edx
+; X86-NEXT: orl %ebx, %edi
; X86-NEXT: cmovnel %ecx, %ebp
; X86-NEXT: bsrl %esi, %edx
-; X86-NEXT: movl %esi, %ebx
; X86-NEXT: xorl $31, %edx
-; X86-NEXT: movl {{[0-9]+}}(%esp), %eax
-; X86-NEXT: bsrl %eax, %ecx
+; X86-NEXT: movl {{[0-9]+}}(%esp), %ebx
+; X86-NEXT: bsrl %ebx, %ecx
; X86-NEXT: xorl $31, %ecx
; X86-NEXT: addl $32, %ecx
; X86-NEXT: testl %esi, %esi
@@ -233,51 +230,51 @@ define i128 @scalar_i128(i128 %x, i128 %y, ptr %divdst) nounwind {
; X86-NEXT: xorl $31, %edx
; X86-NEXT: addl $32, %edx
; X86-NEXT: testl %edi, %edi
+; X86-NEXT: movl %edi, %eax
; X86-NEXT: cmovnel %esi, %edx
; X86-NEXT: addl $64, %edx
-; X86-NEXT: orl %ebx, %eax
+; X86-NEXT: movl %ebx, %esi
+; X86-NEXT: orl {{[0-9]+}}(%esp), %esi
; X86-NEXT: cmovnel %ecx, %edx
+; X86-NEXT: xorl %ecx, %ecx
; X86-NEXT: subl %edx, %ebp
-; X86-NEXT: movl $0, %edx
-; X86-NEXT: sbbl %edx, %edx
; X86-NEXT: movl $0, %esi
; X86-NEXT: sbbl %esi, %esi
; X86-NEXT: movl $0, %edi
; X86-NEXT: sbbl %edi, %edi
-; X86-NEXT: movl $127, %ecx
-; X86-NEXT: cmpl %ebp, %ecx
-; X86-NEXT: movl $0, %ecx
-; X86-NEXT: sbbl %edx, %ecx
-; X86-NEXT: movl $0, %ecx
-; X86-NEXT: sbbl %esi, %ecx
-; X86-NEXT: movl $0, %ecx
-; X86-NEXT: sbbl %edi, %ecx
-; X86-NEXT: setb %cl
-; X86-NEXT: orb (%esp), %cl # 1-byte Folded Reload
+; X86-NEXT: movl $0, %ebx
+; X86-NEXT: sbbl %ebx, %ebx
+; X86-NEXT: movl $127, %edx
; X86-NEXT: movl %ebp, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: movl %ebp, %eax
-; X86-NEXT: xorl $127, %eax
+; X86-NEXT: cmpl %ebp, %edx
+; X86-NEXT: movl $0, %edx
; X86-NEXT: movl %esi, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: orl %esi, %eax
-; X86-NEXT: movl %edx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
+; X86-NEXT: sbbl %esi, %edx
+; X86-NEXT: movl $0, %edx
; X86-NEXT: movl %edi, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: orl %edi, %edx
-; X86-NEXT: orl %eax, %edx
-; X86-NEXT: sete %al
-; X86-NEXT: testb %cl, %cl
-; X86-NEXT: movl %ebx, %edx
-; X86-NEXT: movl $0, %edi
-; X86-NEXT: cmovnel %edi, %edx
+; X86-NEXT: sbbl %edi, %edx
+; X86-NEXT: movl $0, %edx
+; X86-NEXT: sbbl %ebx, %edx
+; X86-NEXT: setb %dl
+; X86-NEXT: orb (%esp), %dl # 1-byte Folded Reload
+; X86-NEXT: movl {{[0-9]+}}(%esp), %edx
+; X86-NEXT: cmovnel %ecx, %edx
; X86-NEXT: movl {{[0-9]+}}(%esp), %esi
-; X86-NEXT: cmovnel %edi, %esi
+; X86-NEXT: cmovnel %ecx, %esi
+; X86-NEXT: cmovnel %ecx, %eax
+; X86-NEXT: movl %eax, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
; X86-NEXT: movl {{[0-9]+}}(%esp), %ebp
-; X86-NEXT: cmovnel %edi, %ebp
-; X86-NEXT: movl {{[0-9]+}}(%esp), %ebx
-; X86-NEXT: cmovnel %edi, %ebx
-; X86-NEXT: orb %cl, %al
-; X86-NEXT: movl {{[0-9]+}}(%esp), %eax
-; X86-NEXT: jne .LBB4_7
-; X86-NEXT: # %bb.1: # %udiv-bb1
+; X86-NEXT: cmovnel %ecx, %ebp
+; X86-NEXT: jne .LBB4_8
+; X86-NEXT: # %bb.1: # %_udiv-special-cases
+; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %eax # 4-byte Reload
+; X86-NEXT: xorl $127, %eax
+; X86-NEXT: orl {{[-0-9]+}}(%e{{[sb]}}p), %eax # 4-byte Folded Reload
+; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ecx # 4-byte Reload
+; X86-NEXT: orl %ebx, %ecx
+; X86-NEXT: orl %eax, %ecx
+; X86-NEXT: je .LBB4_8
+; X86-NEXT: # %bb.2: # %udiv-bb1
; X86-NEXT: movl {{[0-9]+}}(%esp), %eax
; X86-NEXT: movl %eax, {{[0-9]+}}(%esp)
; X86-NEXT: movl {{[0-9]+}}(%esp), %eax
@@ -290,8 +287,9 @@ define i128 @scalar_i128(i128 %x, i128 %y, ptr %divdst) nounwind {
; X86-NEXT: movl $0, {{[0-9]+}}(%esp)
; X86-NEXT: movl $0, {{[0-9]+}}(%esp)
; X86-NEXT: movl $0, {{[0-9]+}}(%esp)
-; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ebx # 4-byte Reload
-; X86-NEXT: movl %ebx, %eax
+; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ecx # 4-byte Reload
+; X86-NEXT: movl %ecx, %eax
+; X86-NEXT: movl %ecx, %edi
; X86-NEXT: xorb $127, %al
; X86-NEXT: movb %al, %ch
; X86-NEXT: andb $7, %ch
@@ -303,7 +301,7 @@ define i128 @scalar_i128(i128 %x, i128 %y, ptr %divdst) nounwind {
; X86-NEXT: movl 132(%esp,%eax), %esi
; X86-NEXT: movb %ch, %cl
; X86-NEXT: shldl %cl, %edx, %esi
-; X86-NEXT: movl %esi, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
+; X86-NEXT: movl %esi, (%esp) # 4-byte Spill
; X86-NEXT: shll %cl, %edx
; X86-NEXT: notb %cl
; X86-NEXT: movl 124(%esp,%eax), %ebp
@@ -311,69 +309,68 @@ define i128 @scalar_i128(i128 %x, i128 %y, ptr %divdst) nounwind {
; X86-NEXT: shrl %esi
; X86-NEXT: shrl %cl, %esi
; X86-NEXT: orl %edx, %esi
-; X86-NEXT: movl 120(%esp,%eax), %eax
+; X86-NEXT: movl %ebp, %edx
+; X86-NEXT: movl 120(%esp,%eax), %ebp
; X86-NEXT: movb %ch, %cl
-; X86-NEXT: shldl %cl, %eax, %ebp
-; X86-NEXT: shll %cl, %eax
-; X86-NEXT: movl %eax, (%esp) # 4-byte Spill
-; X86-NEXT: addl $1, %ebx
-; X86-NEXT: movl %ebx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
+; X86-NEXT: shldl %cl, %ebp, %edx
+; X86-NEXT: shll %cl, %ebp
+; X86-NEXT: addl $1, %edi
+; X86-NEXT: movl %edi, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ecx # 4-byte Reload
; X86-NEXT: adcl $0, %ecx
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %eax # 4-byte Reload
; X86-NEXT: adcl $0, %eax
-; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ebx # 4-byte Reload
; X86-NEXT: adcl $0, %ebx
-; X86-NEXT: jae .LBB4_2
-; X86-NEXT: # %bb.5:
+; X86-NEXT: jae .LBB4_3
+; X86-NEXT: # %bb.6:
; X86-NEXT: xorl %eax, %eax
; X86-NEXT: xorl %ecx, %ecx
-; X86-NEXT: jmp .LBB4_6
-; X86-NEXT: .LBB4_2: # %udiv-preheader
-; X86-NEXT: movl {{[0-9]+}}(%esp), %edx
-; X86-NEXT: movl %edx, {{[0-9]+}}(%esp)
-; X86-NEXT: movl {{[0-9]+}}(%esp), %edx
-; X86-NEXT: movl %edx, {{[0-9]+}}(%esp)
-; X86-NEXT: movl {{[0-9]+}}(%esp), %edx
-; X86-NEXT: movl %edx, {{[0-9]+}}(%esp)
+; X86-NEXT: movl %edx, %ebx
+; X86-NEXT: jmp .LBB4_7
+; X86-NEXT: .LBB4_3: # %udiv-preheader
+; X86-NEXT: movl {{[0-9]+}}(%esp), %edi
+; X86-NEXT: movl %edi, {{[0-9]+}}(%esp)
+; X86-NEXT: movl {{[0-9]+}}(%esp), %edi
+; X86-NEXT: movl %edi, {{[0-9]+}}(%esp)
+; X86-NEXT: movl {{[0-9]+}}(%esp), %edi
+; X86-NEXT: movl %edi, {{[0-9]+}}(%esp)
+; X86-NEXT: movl %ecx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
; X86-NEXT: movl %eax, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: movl %ebx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: movl {{[0-9]+}}(%esp), %eax
-; X86-NEXT: movl %eax, {{[0-9]+}}(%esp)
+; X86-NEXT: movl {{[0-9]+}}(%esp), %ecx
+; X86-NEXT: movl %ecx, {{[0-9]+}}(%esp)
; X86-NEXT: movl $0, {{[0-9]+}}(%esp)
; X86-NEXT: movl $0, {{[0-9]+}}(%esp)
; X86-NEXT: movl $0, {{[0-9]+}}(%esp)
; X86-NEXT: movl $0, {{[0-9]+}}(%esp)
-; X86-NEXT: movl %ecx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %eax # 4-byte Reload
; X86-NEXT: movb %al, %ch
; X86-NEXT: andb $7, %ch
+; X86-NEXT: movl %ebp, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
+; X86-NEXT: movl %ebx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
; X86-NEXT: # kill: def $al killed $al killed $eax
; X86-NEXT: shrb $3, %al
; X86-NEXT: andb $15, %al
; X86-NEXT: movzbl %al, %eax
-; X86-NEXT: movl 84(%esp,%eax), %ebx
-; X86-NEXT: movl %esi, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: movl 80(%esp,%eax), %esi
-; X86-NEXT: movl %ebp, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: movl %esi, %edx
-; X86-NEXT: movb %ch, %cl
-; X86-NEXT: shrdl %cl, %ebx, %edx
+; X86-NEXT: movl 84(%esp,%eax), %ebp
+; X86-NEXT: movl %esi, %edi
+; X86-NEXT: movl 80(%esp,%eax), %ebx
; X86-NEXT: movl %edx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: movl 72(%esp,%eax), %ebp
-; X86-NEXT: movl 76(%esp,%eax), %edx
-; X86-NEXT: movl %edx, %eax
-; X86-NEXT: shrl %cl, %eax
-; X86-NEXT: notb %cl
-; X86-NEXT: addl %esi, %esi
-; X86-NEXT: shll %cl, %esi
-; X86-NEXT: orl %eax, %esi
+; X86-NEXT: movl %ebx, %esi
+; X86-NEXT: movb %ch, %cl
+; X86-NEXT: shrdl %cl, %ebp, %esi
; X86-NEXT: movl %esi, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
+; X86-NEXT: movl 72(%esp,%eax), %esi
+; X86-NEXT: movl 76(%esp,%eax), %eax
+; X86-NEXT: movl %eax, %edx
+; X86-NEXT: shrl %cl, %edx
+; X86-NEXT: notb %cl
+; X86-NEXT: addl %ebx, %ebx
+; X86-NEXT: shll %cl, %ebx
+; X86-NEXT: orl %edx, %ebx
; X86-NEXT: movb %ch, %cl
-; X86-NEXT: shrl %cl, %ebx
-; X86-NEXT: movl %ebx, %edi
-; X86-NEXT: shrdl %cl, %edx, %ebp
-; X86-NEXT: movl %ebp, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
+; X86-NEXT: shrl %cl, %ebp
+; X86-NEXT: shrdl %cl, %eax, %esi
+; X86-NEXT: movl %esi, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
; X86-NEXT: movl {{[0-9]+}}(%esp), %eax
; X86-NEXT: addl $-1, %eax
; X86-NEXT: movl %eax, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
@@ -383,25 +380,25 @@ define i128 @scalar_i128(i128 %x, i128 %y, ptr %divdst) nounwind {
; X86-NEXT: movl {{[0-9]+}}(%esp), %ecx
; X86-NEXT: adcl $-1, %ecx
; X86-NEXT: movl %ecx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: movl {{[0-9]+}}(%esp), %edx
-; X86-NEXT: adcl $-1, %edx
-; X86-NEXT: movl %edx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
+; X86-NEXT: movl {{[0-9]+}}(%esp), %esi
+; X86-NEXT: adcl $-1, %esi
+; X86-NEXT: movl %esi, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
; X86-NEXT: xorl %ecx, %ecx
; X86-NEXT: movl $0, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Folded Spill
-; X86-NEXT: movl (%esp), %edx # 4-byte Reload
+; X86-NEXT: movl (%esp), %esi # 4-byte Reload
; X86-NEXT: .p2align 4, 0x90
-; X86-NEXT: .LBB4_3: # %udiv-do-while
+; X86-NEXT: .LBB4_4: # %udiv-do-while
; X86-NEXT: # =>This Inner Loop Header: Depth=1
; X86-NEXT: movl %ecx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
+; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %edx # 4-byte Reload
+; X86-NEXT: shldl $1, %edx, %ebp
+; X86-NEXT: movl %ebp, (%esp) # 4-byte Spill
+; X86-NEXT: shldl $1, %ebx, %edx
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ebp # 4-byte Reload
-; X86-NEXT: shldl $1, %ebp, %edi
-; X86-NEXT: movl %edi, (%esp) # 4-byte Spill
-; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ebx # 4-byte Reload
-; X86-NEXT: shldl $1, %ebx, %ebp
-; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %esi # 4-byte Reload
-; X86-NEXT: shldl $1, %esi, %ebx
-; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %edi # 4-byte Reload
+; X86-NEXT: shldl $1, %ebp, %ebx
+; X86-NEXT: shldl $1, %esi, %ebp
; X86-NEXT: shldl $1, %edi, %esi
+; X86-NEXT: orl %ecx, %esi
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %eax # 4-byte Reload
; X86-NEXT: shldl $1, %eax, %edi
; X86-NEXT: orl %ecx, %edi
@@ -410,16 +407,14 @@ define i128 @scalar_i128(i128 %x, i128 %y, ptr %divdst) nounwind {
; X86-NEXT: shldl $1, %edi, %eax
; X86-NEXT: orl %ecx, %eax
; X86-NEXT: movl %eax, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: shldl $1, %edx, %edi
-; X86-NEXT: orl %ecx, %edi
+; X86-NEXT: addl %edi, %edi
+; X86-NEXT: orl {{[-0-9]+}}(%e{{[sb]}}p), %edi # 4-byte Folded Reload
; X86-NEXT: movl %edi, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: addl %edx, %edx
-; X86-NEXT: orl {{[-0-9]+}}(%e{{[sb]}}p), %edx # 4-byte Folded Reload
-; X86-NEXT: cmpl %esi, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Folded Reload
+; X86-NEXT: cmpl %ebp, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Folded Reload
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ecx # 4-byte Reload
; X86-NEXT: sbbl %ebx, %ecx
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ecx # 4-byte Reload
-; X86-NEXT: sbbl %ebp, %ecx
+; X86-NEXT: sbbl %edx, %ecx
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ecx # 4-byte Reload
; X86-NEXT: sbbl (%esp), %ecx # 4-byte Folded Reload
; X86-NEXT: sarl $31, %ecx
@@ -434,81 +429,84 @@ define i128 @scalar_i128(i128 %x, i128 %y, ptr %divdst) nounwind {
; X86-NEXT: movl %ecx, %eax
; X86-NEXT: andl {{[0-9]+}}(%esp), %eax
; X86-NEXT: andl {{[0-9]+}}(%esp), %ecx
-; X86-NEXT: subl %ecx, %esi
-; X86-NEXT: movl %esi, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
+; X86-NEXT: subl %ecx, %ebp
+; X86-NEXT: movl %ebp, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
; X86-NEXT: sbbl %eax, %ebx
; X86-NEXT: movl %ebx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: sbbl %edi, %ebp
-; X86-NEXT: movl %ebp, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
+; X86-NEXT: sbbl %edi, %edx
+; X86-NEXT: movl %edx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
+; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %edi # 4-byte Reload
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %eax # 4-byte Reload
; X86-NEXT: sbbl %eax, (%esp) # 4-byte Folded Spill
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ecx # 4-byte Reload
; X86-NEXT: addl $-1, %ecx
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %eax # 4-byte Reload
; X86-NEXT: adcl $-1, %eax
+; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %edx # 4-byte Reload
+; X86-NEXT: adcl $-1, %edx
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ebx # 4-byte Reload
; X86-NEXT: adcl $-1, %ebx
-; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %edi # 4-byte Reload
-; X86-NEXT: adcl $-1, %edi
; X86-NEXT: movl %eax, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: movl %edi, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: orl %edi, %eax
-; X86-NEXT: movl %ecx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
; X86-NEXT: movl %ebx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: orl %ebx, %ecx
-; X86-NEXT: movl (%esp), %edi # 4-byte Reload
+; X86-NEXT: orl %ebx, %eax
+; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ebx # 4-byte Reload
+; X86-NEXT: movl %ecx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
+; X86-NEXT: movl %edx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
+; X86-NEXT: orl %edx, %ecx
+; X86-NEXT: movl (%esp), %ebp # 4-byte Reload
; X86-NEXT: orl %eax, %ecx
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ecx # 4-byte Reload
-; X86-NEXT: jne .LBB4_3
-; X86-NEXT: # %bb.4:
-; X86-NEXT: movl %edx, (%esp) # 4-byte Spill
-; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %esi # 4-byte Reload
+; X86-NEXT: jne .LBB4_4
+; X86-NEXT: # %bb.5:
+; X86-NEXT: movl %esi, (%esp) # 4-byte Spill
+; X86-NEXT: movl %edi, %esi
+; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ebx # 4-byte Reload
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ebp # 4-byte Reload
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %eax # 4-byte Reload
-; X86-NEXT: .LBB4_6: # %udiv-loop-exit
-; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %edx # 4-byte Reload
+; X86-NEXT: .LBB4_7: # %udiv-loop-exit
+; X86-NEXT: movl (%esp), %edx # 4-byte Reload
; X86-NEXT: shldl $1, %esi, %edx
; X86-NEXT: orl %ecx, %edx
-; X86-NEXT: shldl $1, %ebp, %esi
+; X86-NEXT: shldl $1, %ebx, %esi
; X86-NEXT: orl %ecx, %esi
-; X86-NEXT: movl (%esp), %ebx # 4-byte Reload
-; X86-NEXT: shldl $1, %ebx, %ebp
-; X86-NEXT: orl %ecx, %ebp
-; X86-NEXT: addl %ebx, %ebx
-; X86-NEXT: orl %eax, %ebx
+; X86-NEXT: shldl $1, %ebp, %ebx
+; X86-NEXT: orl %ecx, %ebx
+; X86-NEXT: movl %ebx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
+; X86-NEXT: addl %ebp, %ebp
+; X86-NEXT: orl %eax, %ebp
+; X86-NEXT: .LBB4_8: # %udiv-end
; X86-NEXT: movl {{[0-9]+}}(%esp), %eax
-; X86-NEXT: .LBB4_7: # %udiv-end
-; X86-NEXT: movl %ebp, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: movl %ebx, (%eax)
-; X86-NEXT: movl %ebp, 4(%eax)
+; X86-NEXT: movl %ebp, (%eax)
+; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ecx # 4-byte Reload
+; X86-NEXT: movl %ecx, 4(%eax)
; X86-NEXT: movl %esi, 8(%eax)
; X86-NEXT: movl %edx, 12(%eax)
-; X86-NEXT: movl %ebx, %ecx
-; X86-NEXT: movl %ebx, (%esp) # 4-byte Spill
; X86-NEXT: movl %esi, %ebx
; X86-NEXT: movl {{[0-9]+}}(%esp), %eax
; X86-NEXT: movl %eax, %esi
-; X86-NEXT: imull %ebp, %esi
-; X86-NEXT: movl %edx, %edi
+; X86-NEXT: imull %ecx, %esi
+; X86-NEXT: movl %ebp, %ecx
+; X86-NEXT: movl %ebp, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
+; X86-NEXT: movl %edx, %ebp
; X86-NEXT: mull %ecx
-; X86-NEXT: movl %eax, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
+; X86-NEXT: movl %eax, (%esp) # 4-byte Spill
; X86-NEXT: addl %esi, %edx
-; X86-NEXT: movl {{[0-9]+}}(%esp), %ebp
-; X86-NEXT: imull %ecx, %ebp
-; X86-NEXT: addl %edx, %ebp
+; X86-NEXT: movl {{[0-9]+}}(%esp), %edi
+; X86-NEXT: imull %ecx, %edi
+; X86-NEXT: addl %edx, %edi
; X86-NEXT: movl {{[0-9]+}}(%esp), %esi
; X86-NEXT: movl %esi, %eax
; X86-NEXT: mull %ebx
; X86-NEXT: movl %eax, %ecx
-; X86-NEXT: imull %esi, %edi
-; X86-NEXT: addl %edx, %edi
+; X86-NEXT: imull %esi, %ebp
+; X86-NEXT: addl %edx, %ebp
; X86-NEXT: movl {{[0-9]+}}(%esp), %eax
; X86-NEXT: imull %eax, %ebx
-; X86-NEXT: addl %edi, %ebx
-; X86-NEXT: addl {{[-0-9]+}}(%e{{[sb]}}p), %ecx # 4-byte Folded Reload
-; X86-NEXT: movl %ecx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
-; X86-NEXT: adcl %ebp, %ebx
-; X86-NEXT: movl (%esp), %ebp # 4-byte Reload
+; X86-NEXT: addl %ebp, %ebx
+; X86-NEXT: addl (%esp), %ecx # 4-byte Folded Reload
+; X86-NEXT: movl %ecx, (%esp) # 4-byte Spill
+; X86-NEXT: adcl %edi, %ebx
+; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %ebp # 4-byte Reload
; X86-NEXT: movl %ebp, %eax
; X86-NEXT: mull %esi
; X86-NEXT: movl %edx, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
@@ -524,7 +522,7 @@ define i128 @scalar_i128(i128 %x, i128 %y, ptr %divdst) nounwind {
; X86-NEXT: movl {{[0-9]+}}(%esp), %esi
; X86-NEXT: movl %edx, %ebp
; X86-NEXT: addl %ecx, %eax
-; X86-NEXT: movl %eax, (%esp) # 4-byte Spill
+; X86-NEXT: movl %eax, {{[-0-9]+}}(%e{{[sb]}}p) # 4-byte Spill
; X86-NEXT: adcl %edi, %ebp
; X86-NEXT: setb %cl
; X86-NEXT: movl {{[-0-9]+}}(%e{{[sb]}}p), %eax # 4-byte Reload
@@ -532,11 +530,11 @@ define i128 @scalar_i128(i128 %x, i128 %y, ptr %divdst) nounwind {
; X86-NEXT: addl %ebp, %eax
; X86-NEXT: movzbl %cl, %ecx
; X86-NEXT: adcl %ecx, %edx
-; X86-NEXT: addl {{[-0-9]+}}(%e{{[sb]}}p), %eax # 4-byte Folded Reload
+; X86-NEXT: addl (%esp), %eax # 4-byte Folded Reload
; X86-NEXT: adcl %ebx, %edx
; X86-NEXT: subl {{[-0-9]+}}(%e{{[sb]}}p), %esi # 4-byte Folded Reload
; X86-NEXT: movl {{[0-9]+}}(%esp), %edi
-; X86-NEXT: sbbl (%esp), %edi # 4-byte Folded Reload
+; X86-NEXT: sbbl {{[-0-9]+}}(%e{{[sb]}}p), %edi # 4-byte Folded Reload
; X86-NEXT: movl {{[0-9]+}}(%esp), %ebx
; X86-NEXT: sbbl %eax, %ebx
; X86-NEXT: movl {{[0-9]+}}(%esp), %ecx
diff --git a/llvm/test/CodeGen/X86/inline-spiller-impdef-on-implicit-def-regression.ll b/llvm/test/CodeGen/X86/inline-spiller-impdef-on-implicit-def-regression.ll
index f42c2f8f144763..0250b1b4a7f861 100644
--- a/llvm/test/CodeGen/X86/inline-spiller-impdef-on-implicit-def-regression.ll
+++ b/llvm/test/CodeGen/X86/inline-spiller-impdef-on-implicit-def-regression.ll
@@ -28,70 +28,78 @@ define i32 @decode_sb(ptr %t, i32 %bl, i32 %_msprop1966, i32 %sub.i, i64 %idxpro
; CHECK-NEXT: .cfi_offset %r15, -24
; CHECK-NEXT: movl %r9d, %ebx
; CHECK-NEXT: # kill: def $edx killed $edx def $rdx
-; CHECK-NEXT: movabsq $87960930222080, %r14 # imm = 0x500000000000
-; CHECK-NEXT: movl 0, %r13d
-; CHECK-NEXT: movl %esi, %r15d
-; CHECK-NEXT: # implicit-def: $r12d
+; CHECK-NEXT: movabsq $87960930222080, %r15 # imm = 0x500000000000
+; CHECK-NEXT: movl 0, %r11d
+; CHECK-NEXT: movl %esi, %r12d
+; CHECK-NEXT: # implicit-def: $r13d
; CHECK-NEXT: testb $1, %bl
-; CHECK-NEXT: jne .LBB0_6
+; CHECK-NEXT: jne .LBB0_7
; CHECK-NEXT: # %bb.1: # %if.else
-; CHECK-NEXT: movl %ecx, %r12d
-; CHECK-NEXT: andl $1, %r12d
-; CHECK-NEXT: movzbl 544(%r12), %r9d
+; CHECK-NEXT: movq %r8, %r14
+; CHECK-NEXT: movl %ecx, %r13d
+; CHECK-NEXT: andl $1, %r13d
+; CHECK-NEXT: movzbl 544(%r13), %r8d
+; CHECK-NEXT: andl $1, %r8d
+; CHECK-NEXT: movl %r15d, %r9d
; CHECK-NEXT: andl $1, %r9d
; CHECK-NEXT: movl %r14d, %r10d
; CHECK-NEXT: andl $1, %r10d
-; CHECK-NEXT: andl $1, %r8d
; CHECK-NEXT: movabsq $17592186044416, %rax # imm = 0x100000000000
-; CHECK-NEXT: orq %r8, %rax
-; CHECK-NEXT: movl %esi, %r8d
+; CHECK-NEXT: orq %r10, %rax
+; CHECK-NEXT: movl %esi, %r10d
; CHECK-NEXT: # kill: def $cl killed $cl killed $ecx
-; CHECK-NEXT: shrl %cl, %r8d
-; CHECK-NEXT: andl $2, %r8d
+; CHECK-NEXT: shrl %cl, %r10d
+; CHECK-NEXT: andl $2, %r10d
; CHECK-NEXT: testb $1, %bl
-; CHECK-NEXT: cmoveq %r10, %rax
-; CHECK-NEXT: orl %r9d, %edx
-; CHECK-NEXT: movq %r13, %rcx
+; CHECK-NEXT: cmoveq %r9, %rax
+; CHECK-NEXT: orl %r8d, %edx
+; CHECK-NEXT: movq %r11, {{[-0-9]+}}(%r{{[sb]}}p) # 8-byte Spill
+; CHECK-NEXT: movq %r11, %rcx
; CHECK-NEXT: orq $1, %rcx
-; CHECK-NEXT: orl %esi, %r8d
+; CHECK-NEXT: orl %esi, %r10d
; CHECK-NEXT: movl $1, %r8d
; CHECK-NEXT: je .LBB0_3
; CHECK-NEXT: # %bb.2: # %if.else
; CHECK-NEXT: movl (%rax), %r8d
; CHECK-NEXT: .LBB0_3: # %if.else
; CHECK-NEXT: shlq $5, %rdx
-; CHECK-NEXT: movq %r15, %rax
+; CHECK-NEXT: movq %r12, %rax
; CHECK-NEXT: shlq $7, %rax
; CHECK-NEXT: leaq (%rax,%rdx), %rsi
; CHECK-NEXT: addq $1248, %rsi # imm = 0x4E0
; CHECK-NEXT: movq %rcx, 0
-; CHECK-NEXT: movq %rdi, %r14
+; CHECK-NEXT: movq %rdi, %r15
; CHECK-NEXT: movl %r8d, (%rdi)
; CHECK-NEXT: xorl %eax, %eax
; CHECK-NEXT: xorl %edi, %edi
; CHECK-NEXT: xorl %edx, %edx
; CHECK-NEXT: callq *%rax
+; CHECK-NEXT: xorq $1, %r14
+; CHECK-NEXT: cmpl $0, (%r14)
+; CHECK-NEXT: je .LBB0_6
+; CHECK-NEXT: # %bb.4: # %if.else
; CHECK-NEXT: movb $1, %al
; CHECK-NEXT: testb %al, %al
-; CHECK-NEXT: je .LBB0_4
-; CHECK-NEXT: # %bb.5: # %bb19
+; CHECK-NEXT: je .LBB0_5
+; CHECK-NEXT: .LBB0_6: # %bb19
; CHECK-NEXT: testb $1, %bl
-; CHECK-NEXT: movq %r14, %rdi
-; CHECK-NEXT: movabsq $87960930222080, %r14 # imm = 0x500000000000
-; CHECK-NEXT: jne .LBB0_7
-; CHECK-NEXT: .LBB0_6: # %if.end69
-; CHECK-NEXT: movl %r13d, 0
+; CHECK-NEXT: movq %r15, %rdi
+; CHECK-NEXT: movabsq $87960930222080, %r15 # imm = 0x500000000000
+; CHECK-NEXT: movq {{[-0-9]+}}(%r{{[sb]}}p), %r11 # 8-byte Reload
+; CHECK-NEXT: jne .LBB0_8
+; CHECK-NEXT: .LBB0_7: # %if.end69
+; CHECK-NEXT: movl %r11d, 0
; CHECK-NEXT: xorl %eax, %eax
; CHECK-NEXT: xorl %esi, %esi
; CHECK-NEXT: xorl %edx, %edx
; CHECK-NEXT: xorl %ecx, %ecx
; CHECK-NEXT: xorl %r8d, %r8d
; CHECK-NEXT: callq *%rax
-; CHECK-NEXT: xorq %r14, %r15
-; CHECK-NEXT: movslq %r12d, %rax
-; CHECK-NEXT: movzbl (%r15), %ecx
+; CHECK-NEXT: xorq %r15, %r12
+; CHECK-NEXT: movslq %r13d, %rax
+; CHECK-NEXT: movzbl (%r12), %ecx
; CHECK-NEXT: movb %cl, 544(%rax)
-; CHECK-NEXT: .LBB0_7: # %land.lhs.true56
+; CHECK-NEXT: .LBB0_8: # %land.lhs.true56
; CHECK-NEXT: xorl %eax, %eax
; CHECK-NEXT: addq $8, %rsp
; CHECK-NEXT: popq %rbx
@@ -102,7 +110,7 @@ define i32 @decode_sb(ptr %t, i32 %bl, i32 %_msprop1966, i32 %sub.i, i64 %idxpro
; CHECK-NEXT: popq %rbp
; CHECK-NEXT: .cfi_def_cfa %rsp, 8
; CHECK-NEXT: retq
-; CHECK-NEXT: .LBB0_4: # %bb
+; CHECK-NEXT: .LBB0_5: # %bb
entry:
%i = load i32, ptr null, align 8
br i1 %cmp54, label %if.end69, label %if.else
diff --git a/llvm/test/CodeGen/X86/lsr-addrecloops.ll b/llvm/test/CodeGen/X86/lsr-addrecloops.ll
index d41942bea69da1..963405c8b0b3d3 100644
--- a/llvm/test/CodeGen/X86/lsr-addrecloops.ll
+++ b/llvm/test/CodeGen/X86/lsr-addrecloops.ll
@@ -15,38 +15,39 @@ define void @in4dob_(ptr nocapture writeonly %0, ptr nocapture readonly %1, ptr
; CHECK-NEXT: movl $1, %r10d
; CHECK-NEXT: xorl %eax, %eax
; CHECK-NEXT: vxorps %xmm0, %xmm0, %xmm0
+; CHECK-NEXT: jmp .LBB0_1
; CHECK-NEXT: .p2align 4, 0x90
-; CHECK-NEXT: .LBB0_1: # =>This Inner Loop Header: Depth=1
-; CHECK-NEXT: vmovss {{.*#+}} xmm1 = mem[0],zero,zero,zero
-; CHECK-NEXT: vcmpneqps %xmm0, %xmm1, %k0
-; CHECK-NEXT: vmovss {{.*#+}} xmm1 = mem[0],zero,zero,zero
-; CHECK-NEXT: vcmpneqps %xmm0, %xmm1, %k1
-; CHECK-NEXT: korw %k0, %k1, %k0
-; CHECK-NEXT: kmovd %k0, %r11d
-; CHECK-NEXT: testb $1, %r11b
-; CHECK-NEXT: je .LBB0_2
-; CHECK-NEXT: # %bb.19: # in Loop: Header=BB0_1 Depth=1
+; CHECK-NEXT: .LBB0_20: # in Loop: Header=BB0_1 Depth=1
; CHECK-NEXT: incq %r10
; CHECK-NEXT: addq %r9, %rax
; CHECK-NEXT: cmpq %r10, %rcx
-; CHECK-NEXT: jne .LBB0_1
-; CHECK-NEXT: jmp .LBB0_17
-; CHECK-NEXT: .LBB0_2: # %vector.body807.preheader
+; CHECK-NEXT: je .LBB0_18
+; CHECK-NEXT: .LBB0_1: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: vmovss {{.*#+}} xmm1 = mem[0],zero,zero,zero
+; CHECK-NEXT: vucomiss %xmm0, %xmm1
+; CHECK-NEXT: jne .LBB0_20
+; CHECK-NEXT: jp .LBB0_20
+; CHECK-NEXT: # %bb.2: # in Loop: Header=BB0_1 Depth=1
+; CHECK-NEXT: vmovss {{.*#+}} xmm1 = mem[0],zero,zero,zero
+; CHECK-NEXT: vucomiss %xmm0, %xmm1
+; CHECK-NEXT: jne .LBB0_20
+; CHECK-NEXT: jp .LBB0_20
+; CHECK-NEXT: # %bb.3: # %vector.body807.preheader
; CHECK-NEXT: leaq 1(%rcx), %rdx
; CHECK-NEXT: movl %edx, %esi
; CHECK-NEXT: andl $7, %esi
; CHECK-NEXT: cmpq $7, %rcx
-; CHECK-NEXT: jae .LBB0_4
-; CHECK-NEXT: # %bb.3:
+; CHECK-NEXT: jae .LBB0_5
+; CHECK-NEXT: # %bb.4:
; CHECK-NEXT: xorl %r9d, %r9d
-; CHECK-NEXT: jmp .LBB0_6
-; CHECK-NEXT: .LBB0_4: # %vector.body807.preheader.new
+; CHECK-NEXT: jmp .LBB0_7
+; CHECK-NEXT: .LBB0_5: # %vector.body807.preheader.new
; CHECK-NEXT: movq %rdx, %r10
; CHECK-NEXT: andq $-8, %r10
; CHECK-NEXT: xorl %r9d, %r9d
; CHECK-NEXT: vxorps %xmm0, %xmm0, %xmm0
; CHECK-NEXT: .p2align 4, 0x90
-; CHECK-NEXT: .LBB0_5: # %vector.body807
+; CHECK-NEXT: .LBB0_6: # %vector.body807
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: leaq (%rdi,%r9), %r11
; CHECK-NEXT: vmovups %ymm0, (%rax,%r11)
@@ -59,43 +60,43 @@ define void @in4dob_(ptr nocapture writeonly %0, ptr nocapture readonly %1, ptr
; CHECK-NEXT: vmovups %ymm0, 7(%rax,%r11)
; CHECK-NEXT: addq $8, %r9
; CHECK-NEXT: cmpq %r9, %r10
-; CHECK-NEXT: jne .LBB0_5
-; CHECK-NEXT: .LBB0_6: # %.lr.ph373.unr-lcssa
+; CHECK-NEXT: jne .LBB0_6
+; CHECK-NEXT: .LBB0_7: # %.lr.ph373.unr-lcssa
; CHECK-NEXT: testq %rsi, %rsi
-; CHECK-NEXT: je .LBB0_9
-; CHECK-NEXT: # %bb.7: # %vector.body807.epil.preheader
+; CHECK-NEXT: je .LBB0_10
+; CHECK-NEXT: # %bb.8: # %vector.body807.epil.preheader
; CHECK-NEXT: addq %rdi, %r9
; CHECK-NEXT: xorl %r10d, %r10d
; CHECK-NEXT: vxorps %xmm0, %xmm0, %xmm0
; CHECK-NEXT: .p2align 4, 0x90
-; CHECK-NEXT: .LBB0_8: # %vector.body807.epil
+; CHECK-NEXT: .LBB0_9: # %vector.body807.epil
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: leaq (%r9,%r10), %r11
; CHECK-NEXT: vmovups %ymm0, (%rax,%r11)
; CHECK-NEXT: incq %r10
; CHECK-NEXT: cmpq %r10, %rsi
-; CHECK-NEXT: jne .LBB0_8
-; CHECK-NEXT: .LBB0_9: # %.lr.ph373
+; CHECK-NEXT: jne .LBB0_9
+; CHECK-NEXT: .LBB0_10: # %.lr.ph373
; CHECK-NEXT: testb $1, %r8b
-; CHECK-NEXT: je .LBB0_10
-; CHECK-NEXT: # %bb.18: # %scalar.ph839.preheader
+; CHECK-NEXT: je .LBB0_11
+; CHECK-NEXT: # %bb.19: # %scalar.ph839.preheader
; CHECK-NEXT: movl $0, (%rdi)
; CHECK-NEXT: vzeroupper
; CHECK-NEXT: retq
-; CHECK-NEXT: .LBB0_10: # %vector.body847.preheader
+; CHECK-NEXT: .LBB0_11: # %vector.body847.preheader
; CHECK-NEXT: movl %edx, %esi
; CHECK-NEXT: andl $7, %esi
; CHECK-NEXT: cmpq $7, %rcx
-; CHECK-NEXT: jae .LBB0_12
-; CHECK-NEXT: # %bb.11:
+; CHECK-NEXT: jae .LBB0_13
+; CHECK-NEXT: # %bb.12:
; CHECK-NEXT: xorl %ecx, %ecx
-; CHECK-NEXT: jmp .LBB0_14
-; CHECK-NEXT: .LBB0_12: # %vector.body847.preheader.new
+; CHECK-NEXT: jmp .LBB0_15
+; CHECK-NEXT: .LBB0_13: # %vector.body847.preheader.new
; CHECK-NEXT: andq $-8, %rdx
; CHECK-NEXT: xorl %ecx, %ecx
; CHECK-NEXT: vxorps %xmm0, %xmm0, %xmm0
; CHECK-NEXT: .p2align 4, 0x90
-; CHECK-NEXT: .LBB0_13: # %vector.body847
+; CHECK-NEXT: .LBB0_14: # %vector.body847
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: leaq (%rdi,%rcx), %r8
; CHECK-NEXT: vmovups %ymm0, 96(%rax,%r8)
@@ -108,23 +109,23 @@ define void @in4dob_(ptr nocapture writeonly %0, ptr nocapture readonly %1, ptr
; CHECK-NEXT: vmovups %ymm0, 103(%rax,%r8)
; CHECK-NEXT: addq $8, %rcx
; CHECK-NEXT: cmpq %rcx, %rdx
-; CHECK-NEXT: jne .LBB0_13
-; CHECK-NEXT: .LBB0_14: # %common.ret.loopexit.unr-lcssa
+; CHECK-NEXT: jne .LBB0_14
+; CHECK-NEXT: .LBB0_15: # %common.ret.loopexit.unr-lcssa
; CHECK-NEXT: testq %rsi, %rsi
-; CHECK-NEXT: je .LBB0_17
-; CHECK-NEXT: # %bb.15: # %vector.body847.epil.preheader
+; CHECK-NEXT: je .LBB0_18
+; CHECK-NEXT: # %bb.16: # %vector.body847.epil.preheader
; CHECK-NEXT: leaq 96(%rcx,%rdi), %rcx
; CHECK-NEXT: xorl %edx, %edx
; CHECK-NEXT: vxorps %xmm0, %xmm0, %xmm0
; CHECK-NEXT: .p2align 4, 0x90
-; CHECK-NEXT: .LBB0_16: # %vector.body847.epil
+; CHECK-NEXT: .LBB0_17: # %vector.body847.epil
; CHECK-NEXT: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: leaq (%rcx,%rdx), %rdi
; CHECK-NEXT: vmovups %ymm0, (%rax,%rdi)
; CHECK-NEXT: incq %rdx
; CHECK-NEXT: cmpq %rdx, %rsi
-; CHECK-NEXT: jne .LBB0_16
-; CHECK-NEXT: .LBB0_17: # %common.ret
+; CHECK-NEXT: jne .LBB0_17
+; CHECK-NEXT: .LBB0_18: # %common.ret
; CHECK-NEXT: vzeroupper
; CHECK-NEXT: retq
.preheader263:
diff --git a/llvm/test/CodeGen/X86/movmsk-cmp.ll b/llvm/test/CodeGen/X86/movmsk-cmp.ll
index e8b3121ecfb523..a7564c9622c5ca 100644
--- a/llvm/test/CodeGen/X86/movmsk-cmp.ll
+++ b/llvm/test/CodeGen/X86/movmsk-cmp.ll
@@ -4440,14 +4440,16 @@ define i32 @pr67287(<2 x i64> %broadcast.splatinsert25) {
; SSE2-NEXT: pshufd {{.*#+}} xmm0 = xmm1[1,0,3,2]
; SSE2-NEXT: movmskpd %xmm0, %eax
; SSE2-NEXT: testl %eax, %eax
-; SSE2-NEXT: setne %al
-; SSE2-NEXT: movd %xmm1, %ecx
-; SSE2-NEXT: orb %al, %cl
-; SSE2-NEXT: testb $1, %cl
-; SSE2-NEXT: je .LBB97_2
-; SSE2-NEXT: # %bb.1:
+; SSE2-NEXT: jne .LBB97_2
+; SSE2-NEXT: # %bb.1: # %entry
+; SSE2-NEXT: movd %xmm1, %eax
+; SSE2-NEXT: testb $1, %al
+; SSE2-NEXT: jne .LBB97_2
+; SSE2-NEXT: # %bb.3: # %middle.block
+; SSE2-NEXT: xorl %eax, %eax
+; SSE2-NEXT: retq
+; SSE2-NEXT: .LBB97_2:
; SSE2-NEXT: movw $0, 0
-; SSE2-NEXT: .LBB97_2: # %middle.block
; SSE2-NEXT: xorl %eax, %eax
; SSE2-NEXT: retq
;
@@ -4458,14 +4460,16 @@ define i32 @pr67287(<2 x i64> %broadcast.splatinsert25) {
; SSE41-NEXT: pcmpeqq %xmm1, %xmm0
; SSE41-NEXT: movmskpd %xmm0, %eax
; SSE41-NEXT: testl %eax, %eax
-; SSE41-NEXT: setne %al
-; SSE41-NEXT: movd %xmm0, %ecx
-; SSE41-NEXT: orb %al, %cl
-; SSE41-NEXT: testb $1, %cl
-; SSE41-NEXT: je .LBB97_2
-; SSE41-NEXT: # %bb.1:
+; SSE41-NEXT: jne .LBB97_2
+; SSE41-NEXT: # %bb.1: # %entry
+; SSE41-NEXT: movd %xmm0, %eax
+; SSE41-NEXT: testb $1, %al
+; SSE41-NEXT: jne .LBB97_2
+; SSE41-NEXT: # %bb.3: # %middle.block
+; SSE41-NEXT: xorl %eax, %eax
+; SSE41-NEXT: retq
+; SSE41-NEXT: .LBB97_2:
; SSE41-NEXT: movw $0, 0
-; SSE41-NEXT: .LBB97_2: # %middle.block
; SSE41-NEXT: xorl %eax, %eax
; SSE41-NEXT: retq
;
@@ -4475,14 +4479,16 @@ define i32 @pr67287(<2 x i64> %broadcast.splatinsert25) {
; AVX1-NEXT: vpblendw {{.*#+}} xmm0 = xmm0[0,1],xmm1[2,3],xmm0[4,5],xmm1[6,7]
; AVX1-NEXT: vpcmpeqq %xmm1, %xmm0, %xmm0
; AVX1-NEXT: vtestpd %xmm0, %xmm0
-; AVX1-NEXT: setne %al
-; AVX1-NEXT: vmovd %xmm0, %ecx
-; AVX1-NEXT: orb %al, %cl
-; AVX1-NEXT: testb $1, %cl
-; AVX1-NEXT: je .LBB97_2
-; AVX1-NEXT: # %bb.1:
+; AVX1-NEXT: jne .LBB97_2
+; AVX1-NEXT: # %bb.1: # %entry
+; AVX1-NEXT: vmovd %xmm0, %eax
+; AVX1-NEXT: testb $1, %al
+; AVX1-NEXT: jne .LBB97_2
+; AVX1-NEXT: # %bb.3: # %middle.block
+; AVX1-NEXT: xorl %eax, %eax
+; AVX1-NEXT: retq
+; AVX1-NEXT: .LBB97_2:
; AVX1-NEXT: movw $0, 0
-; AVX1-NEXT: .LBB97_2: # %middle.block
; AVX1-NEXT: xorl %eax, %eax
; AVX1-NEXT: retq
;
@@ -4492,14 +4498,16 @@ define i32 @pr67287(<2 x i64> %broadcast.splatinsert25) {
; AVX2-NEXT: vpblendd {{.*#+}} xmm0 = xmm0[0],xmm1[1],xmm0[2],xmm1[3]
; AVX2-NEXT: vpcmpeqq %xmm1, %xmm0, %xmm0
; AVX2-NEXT: vtestpd %xmm0, %xmm0
-; AVX2-NEXT: setne %al
-; AVX2-NEXT: vmovd %xmm0, %ecx
-; AVX2-NEXT: orb %al, %cl
-; AVX2-NEXT: testb $1, %cl
-; AVX2-NEXT: je .LBB97_2
-; AVX2-NEXT: # %bb.1:
+; AVX2-NEXT: jne .LBB97_2
+; AVX2-NEXT: # %bb.1: # %entry
+; AVX2-NEXT: vmovd %xmm0, %eax
+; AVX2-NEXT: testb $1, %al
+; AVX2-NEXT: jne .LBB97_2
+; AVX2-NEXT: # %bb.3: # %middle.block
+; AVX2-NEXT: xorl %eax, %eax
+; AVX2-NEXT: retq
+; AVX2-NEXT: .LBB97_2:
; AVX2-NEXT: movw $0, 0
-; AVX2-NEXT: .LBB97_2: # %middle.block
; AVX2-NEXT: xorl %eax, %eax
; AVX2-NEXT: retq
;
@@ -4509,15 +4517,18 @@ define i32 @pr67287(<2 x i64> %broadcast.splatinsert25) {
; KNL-NEXT: vpblendd {{.*#+}} xmm0 = xmm0[0],xmm1[1],xmm0[2],xmm1[3]
; KNL-NEXT: vptestnmq %zmm0, %zmm0, %k0
; KNL-NEXT: kmovw %k0, %eax
-; KNL-NEXT: kmovw %k0, %ecx
-; KNL-NEXT: testb $3, %cl
-; KNL-NEXT: setne %cl
-; KNL-NEXT: orb %cl, %al
+; KNL-NEXT: testb $3, %al
+; KNL-NEXT: jne .LBB97_2
+; KNL-NEXT: # %bb.1: # %entry
+; KNL-NEXT: kmovw %k0, %eax
; KNL-NEXT: testb $1, %al
-; KNL-NEXT: je .LBB97_2
-; KNL-NEXT: # %bb.1:
+; KNL-NEXT: jne .LBB97_2
+; KNL-NEXT: # %bb.3: # %middle.block
+; KNL-NEXT: xorl %eax, %eax
+; KNL-NEXT: vzeroupper
+; KNL-NEXT: retq
+; KNL-NEXT: .LBB97_2:
; KNL-NEXT: movw $0, 0
-; KNL-NEXT: .LBB97_2: # %middle.block
; KNL-NEXT: xorl %eax, %eax
; KNL-NEXT: vzeroupper
; KNL-NEXT: retq
@@ -4528,14 +4539,16 @@ define i32 @pr67287(<2 x i64> %broadcast.splatinsert25) {
; SKX-NEXT: vpblendd {{.*#+}} xmm0 = xmm0[0],xmm1[1],xmm0[2],xmm1[3]
; SKX-NEXT: vptestnmq %xmm0, %xmm0, %k0
; SKX-NEXT: kortestb %k0, %k0
-; SKX-NEXT: setne %al
-; SKX-NEXT: kmovd %k0, %ecx
-; SKX-NEXT: orb %al, %cl
-; SKX-NEXT: testb $1, %cl
-; SKX-NEXT: je .LBB97_2
-; SKX-NEXT: # %bb.1:
+; SKX-NEXT: jne .LBB97_2
+; SKX-NEXT: # %bb.1: # %entry
+; SKX-NEXT: kmovd %k0, %eax
+; SKX-NEXT: testb $1, %al
+; SKX-NEXT: jne .LBB97_2
+; SKX-NEXT: # %bb.3: # %middle.block
+; SKX-NEXT: xorl %eax, %eax
+; SKX-NEXT: retq
+; SKX-NEXT: .LBB97_2:
; SKX-NEXT: movw $0, 0
-; SKX-NEXT: .LBB97_2: # %middle.block
; SKX-NEXT: xorl %eax, %eax
; SKX-NEXT: retq
entry:
diff --git a/llvm/test/CodeGen/X86/or-branch.ll b/llvm/test/CodeGen/X86/or-branch.ll
index c6df237393e4a0..5d5cc2cb32f1ce 100644
--- a/llvm/test/CodeGen/X86/or-branch.ll
+++ b/llvm/test/CodeGen/X86/or-branch.ll
@@ -5,13 +5,12 @@
define void @foo(i32 %X, i32 %Y, i32 %Z) nounwind {
; JUMP2-LABEL: foo:
; JUMP2: # %bb.0: # %entry
-; JUMP2-NEXT: cmpl $0, {{[0-9]+}}(%esp)
-; JUMP2-NEXT: setne %al
; JUMP2-NEXT: cmpl $5, {{[0-9]+}}(%esp)
-; JUMP2-NEXT: setge %cl
-; JUMP2-NEXT: testb %al, %cl
+; JUMP2-NEXT: jl bar at PLT # TAILCALL
+; JUMP2-NEXT: # %bb.1: # %entry
+; JUMP2-NEXT: cmpl $0, {{[0-9]+}}(%esp)
; JUMP2-NEXT: je bar at PLT # TAILCALL
-; JUMP2-NEXT: # %bb.1: # %UnifiedReturnBlock
+; JUMP2-NEXT: # %bb.2: # %UnifiedReturnBlock
; JUMP2-NEXT: retl
;
; JUMP1-LABEL: foo:
diff --git a/llvm/test/CodeGen/X86/peephole-na-phys-copy-folding.ll b/llvm/test/CodeGen/X86/peephole-na-phys-copy-folding.ll
index 3354c99a361bf6..9069688c8037c7 100644
--- a/llvm/test/CodeGen/X86/peephole-na-phys-copy-folding.ll
+++ b/llvm/test/CodeGen/X86/peephole-na-phys-copy-folding.ll
@@ -14,33 +14,31 @@ declare i32 @bar(i64)
define i1 @plus_one() nounwind {
; CHECK32-LABEL: plus_one:
; CHECK32: # %bb.0: # %entry
+; CHECK32-NEXT: movzbl M, %eax
; CHECK32-NEXT: incl L
-; CHECK32-NEXT: sete %al
-; CHECK32-NEXT: movzbl M, %ecx
-; CHECK32-NEXT: andb $8, %cl
-; CHECK32-NEXT: shrb $3, %cl
-; CHECK32-NEXT: testb %cl, %al
-; CHECK32-NEXT: je .LBB0_1
-; CHECK32-NEXT: # %bb.2: # %exit2
+; CHECK32-NEXT: jne .LBB0_2
+; CHECK32-NEXT: # %bb.1: # %entry
+; CHECK32-NEXT: andb $8, %al
+; CHECK32-NEXT: je .LBB0_2
+; CHECK32-NEXT: # %bb.3: # %exit2
; CHECK32-NEXT: xorl %eax, %eax
; CHECK32-NEXT: retl
-; CHECK32-NEXT: .LBB0_1: # %exit
+; CHECK32-NEXT: .LBB0_2: # %exit
; CHECK32-NEXT: movb $1, %al
; CHECK32-NEXT: retl
;
; CHECK64-LABEL: plus_one:
; CHECK64: # %bb.0: # %entry
+; CHECK64-NEXT: movzbl M(%rip), %eax
; CHECK64-NEXT: incl L(%rip)
-; CHECK64-NEXT: sete %al
-; CHECK64-NEXT: movzbl M(%rip), %ecx
-; CHECK64-NEXT: andb $8, %cl
-; CHECK64-NEXT: shrb $3, %cl
-; CHECK64-NEXT: testb %cl, %al
-; CHECK64-NEXT: je .LBB0_1
-; CHECK64-NEXT: # %bb.2: # %exit2
+; CHECK64-NEXT: jne .LBB0_2
+; CHECK64-NEXT: # %bb.1: # %entry
+; CHECK64-NEXT: andb $8, %al
+; CHECK64-NEXT: je .LBB0_2
+; CHECK64-NEXT: # %bb.3: # %exit2
; CHECK64-NEXT: xorl %eax, %eax
; CHECK64-NEXT: retq
-; CHECK64-NEXT: .LBB0_1: # %exit
+; CHECK64-NEXT: .LBB0_2: # %exit
; CHECK64-NEXT: movb $1, %al
; CHECK64-NEXT: retq
entry:
@@ -65,32 +63,30 @@ define i1 @plus_forty_two() nounwind {
; CHECK32-LABEL: plus_forty_two:
; CHECK32: # %bb.0: # %entry
; CHECK32-NEXT: movzbl M, %eax
-; CHECK32-NEXT: andb $8, %al
-; CHECK32-NEXT: shrb $3, %al
; CHECK32-NEXT: addl $42, L
-; CHECK32-NEXT: sete %cl
-; CHECK32-NEXT: testb %al, %cl
-; CHECK32-NEXT: je .LBB1_1
-; CHECK32-NEXT: # %bb.2: # %exit2
+; CHECK32-NEXT: jne .LBB1_2
+; CHECK32-NEXT: # %bb.1: # %entry
+; CHECK32-NEXT: andb $8, %al
+; CHECK32-NEXT: je .LBB1_2
+; CHECK32-NEXT: # %bb.3: # %exit2
; CHECK32-NEXT: xorl %eax, %eax
; CHECK32-NEXT: retl
-; CHECK32-NEXT: .LBB1_1: # %exit
+; CHECK32-NEXT: .LBB1_2: # %exit
; CHECK32-NEXT: movb $1, %al
; CHECK32-NEXT: retl
;
; CHECK64-LABEL: plus_forty_two:
; CHECK64: # %bb.0: # %entry
; CHECK64-NEXT: movzbl M(%rip), %eax
-; CHECK64-NEXT: andb $8, %al
-; CHECK64-NEXT: shrb $3, %al
; CHECK64-NEXT: addl $42, L(%rip)
-; CHECK64-NEXT: sete %cl
-; CHECK64-NEXT: testb %al, %cl
-; CHECK64-NEXT: je .LBB1_1
-; CHECK64-NEXT: # %bb.2: # %exit2
+; CHECK64-NEXT: jne .LBB1_2
+; CHECK64-NEXT: # %bb.1: # %entry
+; CHECK64-NEXT: andb $8, %al
+; CHECK64-NEXT: je .LBB1_2
+; CHECK64-NEXT: # %bb.3: # %exit2
; CHECK64-NEXT: xorl %eax, %eax
; CHECK64-NEXT: retq
-; CHECK64-NEXT: .LBB1_1: # %exit
+; CHECK64-NEXT: .LBB1_2: # %exit
; CHECK64-NEXT: movb $1, %al
; CHECK64-NEXT: retq
entry:
@@ -115,32 +111,30 @@ define i1 @minus_one() nounwind {
; CHECK32-LABEL: minus_one:
; CHECK32: # %bb.0: # %entry
; CHECK32-NEXT: movzbl M, %eax
-; CHECK32-NEXT: andb $8, %al
-; CHECK32-NEXT: shrb $3, %al
; CHECK32-NEXT: decl L
-; CHECK32-NEXT: sete %cl
-; CHECK32-NEXT: testb %al, %cl
-; CHECK32-NEXT: je .LBB2_1
-; CHECK32-NEXT: # %bb.2: # %exit2
+; CHECK32-NEXT: jne .LBB2_2
+; CHECK32-NEXT: # %bb.1: # %entry
+; CHECK32-NEXT: andb $8, %al
+; CHECK32-NEXT: je .LBB2_2
+; CHECK32-NEXT: # %bb.3: # %exit2
; CHECK32-NEXT: xorl %eax, %eax
; CHECK32-NEXT: retl
-; CHECK32-NEXT: .LBB2_1: # %exit
+; CHECK32-NEXT: .LBB2_2: # %exit
; CHECK32-NEXT: movb $1, %al
; CHECK32-NEXT: retl
;
; CHECK64-LABEL: minus_one:
; CHECK64: # %bb.0: # %entry
; CHECK64-NEXT: movzbl M(%rip), %eax
-; CHECK64-NEXT: andb $8, %al
-; CHECK64-NEXT: shrb $3, %al
; CHECK64-NEXT: decl L(%rip)
-; CHECK64-NEXT: sete %cl
-; CHECK64-NEXT: testb %al, %cl
-; CHECK64-NEXT: je .LBB2_1
-; CHECK64-NEXT: # %bb.2: # %exit2
+; CHECK64-NEXT: jne .LBB2_2
+; CHECK64-NEXT: # %bb.1: # %entry
+; CHECK64-NEXT: andb $8, %al
+; CHECK64-NEXT: je .LBB2_2
+; CHECK64-NEXT: # %bb.3: # %exit2
; CHECK64-NEXT: xorl %eax, %eax
; CHECK64-NEXT: retq
-; CHECK64-NEXT: .LBB2_1: # %exit
+; CHECK64-NEXT: .LBB2_2: # %exit
; CHECK64-NEXT: movb $1, %al
; CHECK64-NEXT: retq
entry:
@@ -165,32 +159,30 @@ define i1 @minus_forty_two() nounwind {
; CHECK32-LABEL: minus_forty_two:
; CHECK32: # %bb.0: # %entry
; CHECK32-NEXT: movzbl M, %eax
-; CHECK32-NEXT: andb $8, %al
-; CHECK32-NEXT: shrb $3, %al
; CHECK32-NEXT: addl $-42, L
-; CHECK32-NEXT: sete %cl
-; CHECK32-NEXT: testb %al, %cl
-; CHECK32-NEXT: je .LBB3_1
-; CHECK32-NEXT: # %bb.2: # %exit2
+; CHECK32-NEXT: jne .LBB3_2
+; CHECK32-NEXT: # %bb.1: # %entry
+; CHECK32-NEXT: andb $8, %al
+; CHECK32-NEXT: je .LBB3_2
+; CHECK32-NEXT: # %bb.3: # %exit2
; CHECK32-NEXT: xorl %eax, %eax
; CHECK32-NEXT: retl
-; CHECK32-NEXT: .LBB3_1: # %exit
+; CHECK32-NEXT: .LBB3_2: # %exit
; CHECK32-NEXT: movb $1, %al
; CHECK32-NEXT: retl
;
; CHECK64-LABEL: minus_forty_two:
; CHECK64: # %bb.0: # %entry
; CHECK64-NEXT: movzbl M(%rip), %eax
-; CHECK64-NEXT: andb $8, %al
-; CHECK64-NEXT: shrb $3, %al
; CHECK64-NEXT: addl $-42, L(%rip)
-; CHECK64-NEXT: sete %cl
-; CHECK64-NEXT: testb %al, %cl
-; CHECK64-NEXT: je .LBB3_1
-; CHECK64-NEXT: # %bb.2: # %exit2
+; CHECK64-NEXT: jne .LBB3_2
+; CHECK64-NEXT: # %bb.1: # %entry
+; CHECK64-NEXT: andb $8, %al
+; CHECK64-NEXT: je .LBB3_2
+; CHECK64-NEXT: # %bb.3: # %exit2
; CHECK64-NEXT: xorl %eax, %eax
; CHECK64-NEXT: retq
-; CHECK64-NEXT: .LBB3_1: # %exit
+; CHECK64-NEXT: .LBB3_2: # %exit
; CHECK64-NEXT: movb $1, %al
; CHECK64-NEXT: retq
entry:
@@ -292,7 +284,7 @@ define i64 @test_two_live_flags(ptr %foo0, i64 %bar0, i64 %baz0, ptr %foo1, i64
; CHECK32-NEXT: movl {{[0-9]+}}(%esp), %ecx
; CHECK32-NEXT: movl {{[0-9]+}}(%esp), %esi
; CHECK32-NEXT: lock cmpxchg8b (%esi)
-; CHECK32-NEXT: sete {{[-0-9]+}}(%e{{[sb]}}p) # 1-byte Folded Spill
+; CHECK32-NEXT: setne {{[-0-9]+}}(%e{{[sb]}}p) # 1-byte Folded Spill
; CHECK32-NEXT: movl {{[0-9]+}}(%esp), %eax
; CHECK32-NEXT: movl %ebp, %edx
; CHECK32-NEXT: movl %edi, %ecx
@@ -300,15 +292,17 @@ define i64 @test_two_live_flags(ptr %foo0, i64 %bar0, i64 %baz0, ptr %foo1, i64
; CHECK32-NEXT: movl {{[0-9]+}}(%esp), %esi
; CHECK32-NEXT: lock cmpxchg8b (%esi)
; CHECK32-NEXT: sete %al
-; CHECK32-NEXT: andb {{[-0-9]+}}(%e{{[sb]}}p), %al # 1-byte Folded Reload
-; CHECK32-NEXT: cmpb $1, %al
-; CHECK32-NEXT: jne .LBB5_3
-; CHECK32-NEXT: # %bb.1: # %t
+; CHECK32-NEXT: cmpb $0, {{[-0-9]+}}(%e{{[sb]}}p) # 1-byte Folded Reload
+; CHECK32-NEXT: jne .LBB5_4
+; CHECK32-NEXT: # %bb.1: # %entry
+; CHECK32-NEXT: testb %al, %al
+; CHECK32-NEXT: je .LBB5_4
+; CHECK32-NEXT: # %bb.2: # %t
; CHECK32-NEXT: movl $42, %eax
-; CHECK32-NEXT: jmp .LBB5_2
-; CHECK32-NEXT: .LBB5_3: # %f
+; CHECK32-NEXT: jmp .LBB5_3
+; CHECK32-NEXT: .LBB5_4: # %f
; CHECK32-NEXT: xorl %eax, %eax
-; CHECK32-NEXT: .LBB5_2: # %t
+; CHECK32-NEXT: .LBB5_3: # %t
; CHECK32-NEXT: xorl %edx, %edx
; CHECK32-NEXT: addl $4, %esp
; CHECK32-NEXT: popl %esi
@@ -321,17 +315,19 @@ define i64 @test_two_live_flags(ptr %foo0, i64 %bar0, i64 %baz0, ptr %foo1, i64
; CHECK64: # %bb.0: # %entry
; CHECK64-NEXT: movq %rsi, %rax
; CHECK64-NEXT: lock cmpxchgq %rdx, (%rdi)
-; CHECK64-NEXT: sete %dl
+; CHECK64-NEXT: setne %dl
; CHECK64-NEXT: movq %r8, %rax
; CHECK64-NEXT: lock cmpxchgq %r9, (%rcx)
; CHECK64-NEXT: sete %al
-; CHECK64-NEXT: andb %dl, %al
-; CHECK64-NEXT: cmpb $1, %al
-; CHECK64-NEXT: jne .LBB5_2
-; CHECK64-NEXT: # %bb.1: # %t
+; CHECK64-NEXT: testb %dl, %dl
+; CHECK64-NEXT: jne .LBB5_3
+; CHECK64-NEXT: # %bb.1: # %entry
+; CHECK64-NEXT: testb %al, %al
+; CHECK64-NEXT: je .LBB5_3
+; CHECK64-NEXT: # %bb.2: # %t
; CHECK64-NEXT: movl $42, %eax
; CHECK64-NEXT: retq
-; CHECK64-NEXT: .LBB5_2: # %f
+; CHECK64-NEXT: .LBB5_3: # %f
; CHECK64-NEXT: xorl %eax, %eax
; CHECK64-NEXT: retq
entry:
@@ -357,6 +353,7 @@ define i1 @asm_clobbering_flags(ptr %mem) nounwind {
; CHECK32-NEXT: testl %edx, %edx
; CHECK32-NEXT: setg %al
; CHECK32-NEXT: #APP
+; CHECK32-NOT: rep
; CHECK32-NEXT: bsfl %edx, %edx
; CHECK32-NEXT: #NO_APP
; CHECK32-NEXT: movl %edx, (%ecx)
@@ -368,6 +365,7 @@ define i1 @asm_clobbering_flags(ptr %mem) nounwind {
; CHECK64-NEXT: testl %ecx, %ecx
; CHECK64-NEXT: setg %al
; CHECK64-NEXT: #APP
+; CHECK64-NOT: rep
; CHECK64-NEXT: bsfl %ecx, %ecx
; CHECK64-NEXT: #NO_APP
; CHECK64-NEXT: movl %ecx, (%rdi)
diff --git a/llvm/test/CodeGen/X86/pr33747.ll b/llvm/test/CodeGen/X86/pr33747.ll
index c8ba2b2e3a7909..e261486dd59246 100644
--- a/llvm/test/CodeGen/X86/pr33747.ll
+++ b/llvm/test/CodeGen/X86/pr33747.ll
@@ -5,19 +5,18 @@ define void @PR33747(ptr nocapture) {
; CHECK-LABEL: PR33747:
; CHECK: # %bb.0:
; CHECK-NEXT: movl 24(%rdi), %eax
-; CHECK-NEXT: leal 1(%rax), %ecx
-; CHECK-NEXT: cmpl $3, %ecx
-; CHECK-NEXT: setb %cl
; CHECK-NEXT: testl %eax, %eax
-; CHECK-NEXT: setne %al
-; CHECK-NEXT: testb %cl, %al
-; CHECK-NEXT: je .LBB0_2
-; CHECK-NEXT: .p2align 4, 0x90
-; CHECK-NEXT: .LBB0_1: # =>This Inner Loop Header: Depth=1
-; CHECK-NEXT: jmp .LBB0_1
+; CHECK-NEXT: je .LBB0_3
+; CHECK-NEXT: # %bb.1:
+; CHECK-NEXT: incl %eax
+; CHECK-NEXT: cmpl $3, %eax
+; CHECK-NEXT: jae .LBB0_3
; CHECK-NEXT: .p2align 4, 0x90
; CHECK-NEXT: .LBB0_2: # =>This Inner Loop Header: Depth=1
; CHECK-NEXT: jmp .LBB0_2
+; CHECK-NEXT: .p2align 4, 0x90
+; CHECK-NEXT: .LBB0_3: # =>This Inner Loop Header: Depth=1
+; CHECK-NEXT: jmp .LBB0_3
%2 = getelementptr inbounds i32, ptr %0, i64 6
%3 = load i32, ptr %2, align 4
%4 = add i32 %3, 1
diff --git a/llvm/test/CodeGen/X86/pr37025.ll b/llvm/test/CodeGen/X86/pr37025.ll
index 8ac28d6286a607..a758ddc91541bc 100644
--- a/llvm/test/CodeGen/X86/pr37025.ll
+++ b/llvm/test/CodeGen/X86/pr37025.ll
@@ -18,13 +18,11 @@ define void @test_dec_select(ptr nocapture %0, ptr readnone %1) {
; CHECK-LABEL: test_dec_select:
; CHECK: # %bb.0:
; CHECK-NEXT: lock decq (%rdi)
-; CHECK-NEXT: sete %al
-; CHECK-NEXT: testq %rsi, %rsi
-; CHECK-NEXT: setne %cl
-; CHECK-NEXT: andb %al, %cl
-; CHECK-NEXT: cmpb $1, %cl
-; CHECK-NEXT: je func2 # TAILCALL
+; CHECK-NEXT: jne .LBB0_2
; CHECK-NEXT: # %bb.1:
+; CHECK-NEXT: testq %rsi, %rsi
+; CHECK-NEXT: jne func2 # TAILCALL
+; CHECK-NEXT: .LBB0_2:
; CHECK-NEXT: retq
%3 = atomicrmw sub ptr %0, i64 1 seq_cst
%4 = icmp eq i64 %3, 1
@@ -46,11 +44,11 @@ define void @test_dec_select_commute(ptr nocapture %0, ptr readnone %1) {
; CHECK-NEXT: lock decq (%rdi)
; CHECK-NEXT: sete %al
; CHECK-NEXT: testq %rsi, %rsi
-; CHECK-NEXT: setne %cl
-; CHECK-NEXT: andb %al, %cl
-; CHECK-NEXT: cmpb $1, %cl
-; CHECK-NEXT: je func2 # TAILCALL
+; CHECK-NEXT: je .LBB1_2
; CHECK-NEXT: # %bb.1:
+; CHECK-NEXT: testb %al, %al
+; CHECK-NEXT: jne func2 # TAILCALL
+; CHECK-NEXT: .LBB1_2:
; CHECK-NEXT: retq
%3 = atomicrmw sub ptr %0, i64 1 seq_cst
%4 = icmp eq i64 %3, 1
@@ -71,13 +69,12 @@ define void @test_dec_and(ptr nocapture %0, ptr readnone %1) {
; CHECK: # %bb.0:
; CHECK-NEXT: lock decq (%rdi)
; CHECK-NEXT: sete %al
-; CHECK-NEXT: notb %al
; CHECK-NEXT: testq %rsi, %rsi
-; CHECK-NEXT: sete %cl
-; CHECK-NEXT: orb %al, %cl
-; CHECK-NEXT: testb $1, %cl
-; CHECK-NEXT: je func2 # TAILCALL
+; CHECK-NEXT: je .LBB2_2
; CHECK-NEXT: # %bb.1:
+; CHECK-NEXT: testb %al, %al
+; CHECK-NEXT: jne func2 # TAILCALL
+; CHECK-NEXT: .LBB2_2:
; CHECK-NEXT: retq
%3 = atomicrmw sub ptr %0, i64 1 seq_cst
%4 = icmp eq i64 %3, 1
@@ -97,14 +94,11 @@ define void @test_dec_and_commute(ptr nocapture %0, ptr readnone %1) {
; CHECK-LABEL: test_dec_and_commute:
; CHECK: # %bb.0:
; CHECK-NEXT: lock decq (%rdi)
-; CHECK-NEXT: sete %al
-; CHECK-NEXT: notb %al
-; CHECK-NEXT: testq %rsi, %rsi
-; CHECK-NEXT: sete %cl
-; CHECK-NEXT: orb %al, %cl
-; CHECK-NEXT: testb $1, %cl
-; CHECK-NEXT: je func2 # TAILCALL
+; CHECK-NEXT: jne .LBB3_2
; CHECK-NEXT: # %bb.1:
+; CHECK-NEXT: testq %rsi, %rsi
+; CHECK-NEXT: jne func2 # TAILCALL
+; CHECK-NEXT: .LBB3_2:
; CHECK-NEXT: retq
%3 = atomicrmw sub ptr %0, i64 1 seq_cst
%4 = icmp eq i64 %3, 1
diff --git a/llvm/test/CodeGen/X86/pr38795.ll b/llvm/test/CodeGen/X86/pr38795.ll
index f64c70e8fc79a4..03629a353d84dc 100644
--- a/llvm/test/CodeGen/X86/pr38795.ll
+++ b/llvm/test/CodeGen/X86/pr38795.ll
@@ -25,126 +25,141 @@ define dso_local void @fn() {
; CHECK-NEXT: xorl %ebx, %ebx
; CHECK-NEXT: # implicit-def: $ecx
; CHECK-NEXT: # implicit-def: $edi
-; CHECK-NEXT: # implicit-def: $dh
; CHECK-NEXT: # implicit-def: $al
; CHECK-NEXT: # kill: killed $al
+; CHECK-NEXT: # implicit-def: $al
; CHECK-NEXT: # implicit-def: $ebp
; CHECK-NEXT: jmp .LBB0_1
; CHECK-NEXT: .p2align 4, 0x90
-; CHECK-NEXT: .LBB0_15: # %for.inc
-; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
-; CHECK-NEXT: movb %dl, {{[-0-9]+}}(%e{{[sb]}}p) # 1-byte Spill
+; CHECK-NEXT: .LBB0_16: # in Loop: Header=BB0_1 Depth=1
+; CHECK-NEXT: movb %al, {{[-0-9]+}}(%e{{[sb]}}p) # 1-byte Spill
+; CHECK-NEXT: movb %dh, %al
; CHECK-NEXT: .LBB0_1: # %for.cond
; CHECK-NEXT: # =>This Loop Header: Depth=1
-; CHECK-NEXT: # Child Loop BB0_19 Depth 2
-; CHECK-NEXT: testb %bl, %bl
-; CHECK-NEXT: jne .LBB0_3
-; CHECK-NEXT: # %bb.2: # %if.then
+; CHECK-NEXT: # Child Loop BB0_22 Depth 2
+; CHECK-NEXT: movb %al, {{[-0-9]+}}(%e{{[sb]}}p) # 1-byte Spill
+; CHECK-NEXT: cmpb $8, %al
+; CHECK-NEXT: ja .LBB0_3
+; CHECK-NEXT: # %bb.2: # %for.cond
; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
-; CHECK-NEXT: movb %dh, {{[-0-9]+}}(%e{{[sb]}}p) # 1-byte Spill
-; CHECK-NEXT: movl $.str, (%esp)
-; CHECK-NEXT: calll printf
-; CHECK-NEXT: # implicit-def: $eax
-; CHECK-NEXT: movzbl {{[-0-9]+}}(%e{{[sb]}}p), %edx # 1-byte Folded Reload
-; CHECK-NEXT: testl %edi, %edi
-; CHECK-NEXT: jne .LBB0_10
-; CHECK-NEXT: jmp .LBB0_6
-; CHECK-NEXT: .p2align 4, 0x90
-; CHECK-NEXT: .LBB0_3: # %if.end
+; CHECK-NEXT: testb %bl, %bl
+; CHECK-NEXT: je .LBB0_3
+; CHECK-NEXT: # %bb.4: # %if.end
; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
; CHECK-NEXT: movl %ecx, %eax
; CHECK-NEXT: cltd
; CHECK-NEXT: idivl a
-; CHECK-NEXT: movl %ecx, %edx
+; CHECK-NEXT: movl %eax, %esi
+; CHECK-NEXT: movb %cl, %dh
; CHECK-NEXT: movl $0, h
-; CHECK-NEXT: movb {{[-0-9]+}}(%e{{[sb]}}p), %dh # 1-byte Reload
-; CHECK-NEXT: cmpb $8, %dh
-; CHECK-NEXT: jg .LBB0_7
-; CHECK-NEXT: # %bb.4: # %if.then13
+; CHECK-NEXT: movzbl {{[-0-9]+}}(%e{{[sb]}}p), %eax # 1-byte Folded Reload
+; CHECK-NEXT: cmpb $8, %al
+; CHECK-NEXT: jg .LBB0_8
+; CHECK-NEXT: # %bb.5: # %if.then13
; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
-; CHECK-NEXT: movl %eax, %esi
; CHECK-NEXT: movl $.str, (%esp)
-; CHECK-NEXT: movb %dl, {{[-0-9]+}}(%e{{[sb]}}p) # 1-byte Spill
+; CHECK-NEXT: movb %dh, {{[-0-9]+}}(%e{{[sb]}}p) # 1-byte Spill
; CHECK-NEXT: calll printf
; CHECK-NEXT: movb {{[-0-9]+}}(%e{{[sb]}}p), %dh # 1-byte Reload
-; CHECK-NEXT: movb {{[-0-9]+}}(%e{{[sb]}}p), %dl # 1-byte Reload
; CHECK-NEXT: testb %bl, %bl
; CHECK-NEXT: movl %esi, %ecx
; CHECK-NEXT: # implicit-def: $eax
-; CHECK-NEXT: movb %dh, {{[-0-9]+}}(%e{{[sb]}}p) # 1-byte Spill
-; CHECK-NEXT: jne .LBB0_15
+; CHECK-NEXT: movb {{[-0-9]+}}(%e{{[sb]}}p), %dl # 1-byte Reload
+; CHECK-NEXT: movb %dl, {{[-0-9]+}}(%e{{[sb]}}p) # 1-byte Spill
+; CHECK-NEXT: movb %dh, %dl
+; CHECK-NEXT: je .LBB0_6
+; CHECK-NEXT: jmp .LBB0_18
; CHECK-NEXT: .p2align 4, 0x90
-; CHECK-NEXT: # %bb.5: # %for.cond35
+; CHECK-NEXT: .LBB0_3: # %if.then
+; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
+; CHECK-NEXT: movl $.str, (%esp)
+; CHECK-NEXT: calll printf
+; CHECK-NEXT: # implicit-def: $eax
+; CHECK-NEXT: movzbl {{[-0-9]+}}(%e{{[sb]}}p), %edx # 1-byte Folded Reload
+; CHECK-NEXT: .LBB0_6: # %for.cond35
; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
; CHECK-NEXT: testl %edi, %edi
-; CHECK-NEXT: je .LBB0_6
-; CHECK-NEXT: .LBB0_10: # %af
+; CHECK-NEXT: je .LBB0_7
+; CHECK-NEXT: .LBB0_11: # %af
; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
; CHECK-NEXT: testb %bl, %bl
-; CHECK-NEXT: jne .LBB0_11
-; CHECK-NEXT: .LBB0_16: # %if.end39
+; CHECK-NEXT: jne .LBB0_12
+; CHECK-NEXT: .LBB0_19: # %if.end39
; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
; CHECK-NEXT: testl %eax, %eax
-; CHECK-NEXT: je .LBB0_18
-; CHECK-NEXT: # %bb.17: # %if.then41
+; CHECK-NEXT: je .LBB0_21
+; CHECK-NEXT: # %bb.20: # %if.then41
; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
; CHECK-NEXT: movl $0, {{[0-9]+}}(%esp)
; CHECK-NEXT: movl $fn, {{[0-9]+}}(%esp)
; CHECK-NEXT: movl $.str, (%esp)
; CHECK-NEXT: calll printf
-; CHECK-NEXT: .LBB0_18: # %for.end46
+; CHECK-NEXT: .LBB0_21: # %for.end46
; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
+; CHECK-NEXT: # implicit-def: $al
; CHECK-NEXT: # implicit-def: $dh
-; CHECK-NEXT: # implicit-def: $dl
; CHECK-NEXT: # implicit-def: $ebp
-; CHECK-NEXT: jmp .LBB0_19
+; CHECK-NEXT: jmp .LBB0_22
; CHECK-NEXT: .p2align 4, 0x90
-; CHECK-NEXT: .LBB0_7: # %if.end21
+; CHECK-NEXT: .LBB0_8: # %if.end21
; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
; CHECK-NEXT: # implicit-def: $ebp
-; CHECK-NEXT: jmp .LBB0_8
+; CHECK-NEXT: jmp .LBB0_9
; CHECK-NEXT: .p2align 4, 0x90
-; CHECK-NEXT: .LBB0_6: # in Loop: Header=BB0_1 Depth=1
+; CHECK-NEXT: .LBB0_7: # in Loop: Header=BB0_1 Depth=1
; CHECK-NEXT: xorl %edi, %edi
-; CHECK-NEXT: movb {{[-0-9]+}}(%e{{[sb]}}p), %dh # 1-byte Reload
+; CHECK-NEXT: movb %dl, %dh
+; CHECK-NEXT: movzbl {{[-0-9]+}}(%e{{[sb]}}p), %eax # 1-byte Folded Reload
; CHECK-NEXT: .p2align 4, 0x90
-; CHECK-NEXT: .LBB0_19: # %for.cond47
+; CHECK-NEXT: .LBB0_22: # %for.cond47
; CHECK-NEXT: # Parent Loop BB0_1 Depth=1
; CHECK-NEXT: # => This Inner Loop Header: Depth=2
; CHECK-NEXT: testb %bl, %bl
-; CHECK-NEXT: jne .LBB0_19
-; CHECK-NEXT: .LBB0_8: # %ae
+; CHECK-NEXT: jne .LBB0_22
+; CHECK-NEXT: # %bb.23: # %for.cond47
+; CHECK-NEXT: # in Loop: Header=BB0_22 Depth=2
+; CHECK-NEXT: jne .LBB0_22
+; CHECK-NEXT: .LBB0_9: # %ae
; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
; CHECK-NEXT: testb %bl, %bl
-; CHECK-NEXT: jne .LBB0_9
-; CHECK-NEXT: # %bb.12: # %if.end26
+; CHECK-NEXT: jne .LBB0_10
+; CHECK-NEXT: # %bb.13: # %if.end26
; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
; CHECK-NEXT: xorl %ecx, %ecx
-; CHECK-NEXT: testb %dh, %dh
-; CHECK-NEXT: je .LBB0_15
-; CHECK-NEXT: # %bb.13: # %if.end26
+; CHECK-NEXT: testb %al, %al
+; CHECK-NEXT: je .LBB0_14
+; CHECK-NEXT: # %bb.15: # %if.end26
; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
; CHECK-NEXT: testl %ebp, %ebp
-; CHECK-NEXT: jne .LBB0_15
-; CHECK-NEXT: # %bb.14: # %if.then31
+; CHECK-NEXT: jne .LBB0_16
+; CHECK-NEXT: # %bb.17: # %if.then31
; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
; CHECK-NEXT: xorl %ecx, %ecx
+; CHECK-NEXT: movb %al, {{[-0-9]+}}(%e{{[sb]}}p) # 1-byte Spill
; CHECK-NEXT: xorl %ebp, %ebp
-; CHECK-NEXT: jmp .LBB0_15
+; CHECK-NEXT: .LBB0_18: # %for.inc
+; CHECK-NEXT: # in Loop: Header=BB0_1 Depth=1
+; CHECK-NEXT: movb %dh, %al
+; CHECK-NEXT: jmp .LBB0_1
; CHECK-NEXT: .p2align 4, 0x90
-; CHECK-NEXT: .LBB0_9: # in Loop: Header=BB0_1 Depth=1
+; CHECK-NEXT: .LBB0_10: # in Loop: Header=BB0_1 Depth=1
; CHECK-NEXT: # implicit-def: $eax
; CHECK-NEXT: testb %bl, %bl
-; CHECK-NEXT: je .LBB0_16
-; CHECK-NEXT: .LBB0_11: # in Loop: Header=BB0_1 Depth=1
+; CHECK-NEXT: je .LBB0_19
+; CHECK-NEXT: .LBB0_12: # in Loop: Header=BB0_1 Depth=1
; CHECK-NEXT: # implicit-def: $edi
; CHECK-NEXT: # implicit-def: $cl
; CHECK-NEXT: # kill: killed $cl
; CHECK-NEXT: # implicit-def: $dl
; CHECK-NEXT: # implicit-def: $ebp
; CHECK-NEXT: testl %edi, %edi
-; CHECK-NEXT: jne .LBB0_10
-; CHECK-NEXT: jmp .LBB0_6
+; CHECK-NEXT: jne .LBB0_11
+; CHECK-NEXT: jmp .LBB0_7
+; CHECK-NEXT: .p2align 4, 0x90
+; CHECK-NEXT: .LBB0_14: # in Loop: Header=BB0_1 Depth=1
+; CHECK-NEXT: movb %al, {{[-0-9]+}}(%e{{[sb]}}p) # 1-byte Spill
+; CHECK-NEXT: movb %dh, %al
+; CHECK-NEXT: jmp .LBB0_1
entry:
br label %for.cond
diff --git a/llvm/test/CodeGen/X86/setcc-logic.ll b/llvm/test/CodeGen/X86/setcc-logic.ll
index c98aae7fbf4059..3faa493ebccd0d 100644
--- a/llvm/test/CodeGen/X86/setcc-logic.ll
+++ b/llvm/test/CodeGen/X86/setcc-logic.ll
@@ -132,12 +132,15 @@ return:
define i32 @all_sign_bits_clear_branch(i32 %P, i32 %Q) nounwind {
; CHECK-LABEL: all_sign_bits_clear_branch:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: orl %esi, %edi
-; CHECK-NEXT: js .LBB9_2
-; CHECK-NEXT: # %bb.1: # %bb1
+; CHECK-NEXT: testl %edi, %edi
+; CHECK-NEXT: js .LBB9_3
+; CHECK-NEXT: # %bb.1: # %entry
+; CHECK-NEXT: testl %esi, %esi
+; CHECK-NEXT: js .LBB9_3
+; CHECK-NEXT: # %bb.2: # %bb1
; CHECK-NEXT: movl $4, %eax
; CHECK-NEXT: retq
-; CHECK-NEXT: .LBB9_2: # %return
+; CHECK-NEXT: .LBB9_3: # %return
; CHECK-NEXT: movl $192, %eax
; CHECK-NEXT: retq
entry:
@@ -156,13 +159,15 @@ return:
define i32 @all_bits_set_branch(i32 %P, i32 %Q) nounwind {
; CHECK-LABEL: all_bits_set_branch:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: andl %esi, %edi
; CHECK-NEXT: cmpl $-1, %edi
-; CHECK-NEXT: jne .LBB10_2
-; CHECK-NEXT: # %bb.1: # %bb1
+; CHECK-NEXT: jne .LBB10_3
+; CHECK-NEXT: # %bb.1: # %entry
+; CHECK-NEXT: cmpl $-1, %esi
+; CHECK-NEXT: jne .LBB10_3
+; CHECK-NEXT: # %bb.2: # %bb1
; CHECK-NEXT: movl $4, %eax
; CHECK-NEXT: retq
-; CHECK-NEXT: .LBB10_2: # %return
+; CHECK-NEXT: .LBB10_3: # %return
; CHECK-NEXT: movl $192, %eax
; CHECK-NEXT: retq
entry:
@@ -181,12 +186,15 @@ return:
define i32 @all_sign_bits_set_branch(i32 %P, i32 %Q) nounwind {
; CHECK-LABEL: all_sign_bits_set_branch:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: testl %esi, %edi
-; CHECK-NEXT: jns .LBB11_2
-; CHECK-NEXT: # %bb.1: # %bb1
+; CHECK-NEXT: testl %edi, %edi
+; CHECK-NEXT: jns .LBB11_3
+; CHECK-NEXT: # %bb.1: # %entry
+; CHECK-NEXT: testl %esi, %esi
+; CHECK-NEXT: jns .LBB11_3
+; CHECK-NEXT: # %bb.2: # %bb1
; CHECK-NEXT: movl $4, %eax
; CHECK-NEXT: retq
-; CHECK-NEXT: .LBB11_2: # %return
+; CHECK-NEXT: .LBB11_3: # %return
; CHECK-NEXT: movl $192, %eax
; CHECK-NEXT: retq
entry:
@@ -230,14 +238,17 @@ return:
define i32 @any_sign_bits_set_branch(i32 %P, i32 %Q) nounwind {
; CHECK-LABEL: any_sign_bits_set_branch:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: orl %esi, %edi
-; CHECK-NEXT: jns .LBB13_2
-; CHECK-NEXT: # %bb.1: # %bb1
-; CHECK-NEXT: movl $4, %eax
-; CHECK-NEXT: retq
-; CHECK-NEXT: .LBB13_2: # %return
+; CHECK-NEXT: testl %edi, %edi
+; CHECK-NEXT: js .LBB13_2
+; CHECK-NEXT: # %bb.1: # %entry
+; CHECK-NEXT: testl %esi, %esi
+; CHECK-NEXT: js .LBB13_2
+; CHECK-NEXT: # %bb.3: # %return
; CHECK-NEXT: movl $192, %eax
; CHECK-NEXT: retq
+; CHECK-NEXT: .LBB13_2: # %bb1
+; CHECK-NEXT: movl $4, %eax
+; CHECK-NEXT: retq
entry:
%a = icmp slt i32 %P, 0
%b = icmp slt i32 %Q, 0
@@ -254,15 +265,17 @@ return:
define i32 @any_bits_clear_branch(i32 %P, i32 %Q) nounwind {
; CHECK-LABEL: any_bits_clear_branch:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: andl %esi, %edi
; CHECK-NEXT: cmpl $-1, %edi
-; CHECK-NEXT: je .LBB14_2
-; CHECK-NEXT: # %bb.1: # %bb1
-; CHECK-NEXT: movl $4, %eax
-; CHECK-NEXT: retq
-; CHECK-NEXT: .LBB14_2: # %return
+; CHECK-NEXT: jne .LBB14_2
+; CHECK-NEXT: # %bb.1: # %entry
+; CHECK-NEXT: cmpl $-1, %esi
+; CHECK-NEXT: jne .LBB14_2
+; CHECK-NEXT: # %bb.3: # %return
; CHECK-NEXT: movl $192, %eax
; CHECK-NEXT: retq
+; CHECK-NEXT: .LBB14_2: # %bb1
+; CHECK-NEXT: movl $4, %eax
+; CHECK-NEXT: retq
entry:
%a = icmp ne i32 %P, -1
%b = icmp ne i32 %Q, -1
@@ -279,14 +292,17 @@ return:
define i32 @any_sign_bits_clear_branch(i32 %P, i32 %Q) nounwind {
; CHECK-LABEL: any_sign_bits_clear_branch:
; CHECK: # %bb.0: # %entry
-; CHECK-NEXT: testl %esi, %edi
-; CHECK-NEXT: js .LBB15_2
-; CHECK-NEXT: # %bb.1: # %bb1
-; CHECK-NEXT: movl $4, %eax
-; CHECK-NEXT: retq
-; CHECK-NEXT: .LBB15_2: # %return
+; CHECK-NEXT: testl %edi, %edi
+; CHECK-NEXT: jns .LBB15_2
+; CHECK-NEXT: # %bb.1: # %entry
+; CHECK-NEXT: testl %esi, %esi
+; CHECK-NEXT: jns .LBB15_2
+; CHECK-NEXT: # %bb.3: # %return
; CHECK-NEXT: movl $192, %eax
; CHECK-NEXT: retq
+; CHECK-NEXT: .LBB15_2: # %bb1
+; CHECK-NEXT: movl $4, %eax
+; CHECK-NEXT: retq
entry:
%a = icmp sgt i32 %P, -1
%b = icmp sgt i32 %Q, -1
diff --git a/llvm/test/CodeGen/X86/swifterror.ll b/llvm/test/CodeGen/X86/swifterror.ll
index 1489b0295e9356..75252309790b1b 100644
--- a/llvm/test/CodeGen/X86/swifterror.ll
+++ b/llvm/test/CodeGen/X86/swifterror.ll
@@ -1259,7 +1259,12 @@ entry:
define swiftcc void @dont_crash_on_new_isel_blocks(ptr nocapture swifterror, i1, ptr) {
; CHECK-APPLE-LABEL: dont_crash_on_new_isel_blocks:
; CHECK-APPLE: ## %bb.0: ## %entry
+; CHECK-APPLE-NEXT: xorl %eax, %eax
+; CHECK-APPLE-NEXT: testb %al, %al
+; CHECK-APPLE-NEXT: jne LBB15_2
+; CHECK-APPLE-NEXT: ## %bb.1: ## %entry
; CHECK-APPLE-NEXT: testb $1, %dil
+; CHECK-APPLE-NEXT: LBB15_2: ## %cont
; CHECK-APPLE-NEXT: pushq %rax
; CHECK-APPLE-NEXT: .cfi_def_cfa_offset 16
; CHECK-APPLE-NEXT: callq *%rax
@@ -1285,7 +1290,12 @@ define swiftcc void @dont_crash_on_new_isel_blocks(ptr nocapture swifterror, i1,
;
; CHECK-i386-LABEL: dont_crash_on_new_isel_blocks:
; CHECK-i386: ## %bb.0: ## %entry
+; CHECK-i386-NEXT: xorl %eax, %eax
+; CHECK-i386-NEXT: testb %al, %al
+; CHECK-i386-NEXT: jne LBB15_2
+; CHECK-i386-NEXT: ## %bb.1: ## %entry
; CHECK-i386-NEXT: testb $1, 8(%esp)
+; CHECK-i386-NEXT: LBB15_2: ## %cont
; CHECK-i386-NEXT: jmpl *%eax ## TAILCALL
entry:
%3 = or i1 false, %1
diff --git a/llvm/test/CodeGen/X86/tail-dup-merge-loop-headers.ll b/llvm/test/CodeGen/X86/tail-dup-merge-loop-headers.ll
index 8d84e887d3f279..9cd37315181209 100644
--- a/llvm/test/CodeGen/X86/tail-dup-merge-loop-headers.ll
+++ b/llvm/test/CodeGen/X86/tail-dup-merge-loop-headers.ll
@@ -91,97 +91,116 @@ define i32 @loop_shared_header(ptr %exe, i32 %exesz, i32 %headsize, i32 %min, i3
; CHECK-NEXT: pushq %rbp
; CHECK-NEXT: pushq %r15
; CHECK-NEXT: pushq %r14
+; CHECK-NEXT: pushq %r13
; CHECK-NEXT: pushq %r12
; CHECK-NEXT: pushq %rbx
+; CHECK-NEXT: pushq %rax
; CHECK-NEXT: movl $1, %ebx
; CHECK-NEXT: xorl %eax, %eax
; CHECK-NEXT: testb %al, %al
-; CHECK-NEXT: jne .LBB1_12
+; CHECK-NEXT: jne .LBB1_24
; CHECK-NEXT: # %bb.1: # %if.end19
-; CHECK-NEXT: movl (%rax), %r12d
-; CHECK-NEXT: leal (,%r12,4), %ebp
-; CHECK-NEXT: movl %ebp, %r15d
+; CHECK-NEXT: movl %esi, %ebp
+; CHECK-NEXT: movq %rdi, %r15
+; CHECK-NEXT: movl (%rax), %r13d
+; CHECK-NEXT: leal (,%r13,4), %ebx
+; CHECK-NEXT: movl %ebx, %r12d
; CHECK-NEXT: movl $1, %esi
-; CHECK-NEXT: movq %r15, %rdi
+; CHECK-NEXT: movq %r12, %rdi
; CHECK-NEXT: callq cli_calloc at PLT
+; CHECK-NEXT: testl %ebp, %ebp
+; CHECK-NEXT: je .LBB1_23
+; CHECK-NEXT: # %bb.2: # %if.end19
+; CHECK-NEXT: testl %r13d, %r13d
+; CHECK-NEXT: je .LBB1_23
+; CHECK-NEXT: # %bb.3: # %if.end19
; CHECK-NEXT: movq %rax, %r14
-; CHECK-NEXT: movb $1, %al
+; CHECK-NEXT: xorl %eax, %eax
; CHECK-NEXT: testb %al, %al
-; CHECK-NEXT: jne .LBB1_12
-; CHECK-NEXT: # %bb.2: # %if.end50
+; CHECK-NEXT: jne .LBB1_23
+; CHECK-NEXT: # %bb.4: # %if.end19
+; CHECK-NEXT: cmpq %r15, %r14
+; CHECK-NEXT: jb .LBB1_23
+; CHECK-NEXT: # %bb.5: # %if.end50
; CHECK-NEXT: movq %r14, %rdi
-; CHECK-NEXT: movq %r15, %rdx
+; CHECK-NEXT: movq %r12, %rdx
; CHECK-NEXT: callq memcpy at PLT
-; CHECK-NEXT: cmpl $4, %ebp
-; CHECK-NEXT: jb .LBB1_19
-; CHECK-NEXT: # %bb.3: # %shared_preheader
+; CHECK-NEXT: cmpl $4, %ebx
+; CHECK-NEXT: jb .LBB1_26
+; CHECK-NEXT: # %bb.6: # %shared_preheader
; CHECK-NEXT: movb $32, %cl
; CHECK-NEXT: xorl %eax, %eax
-; CHECK-NEXT: jmp .LBB1_4
+; CHECK-NEXT: jmp .LBB1_8
; CHECK-NEXT: .p2align 4, 0x90
-; CHECK-NEXT: .LBB1_15: # %merge_predecessor_split
-; CHECK-NEXT: # in Loop: Header=BB1_4 Depth=1
+; CHECK-NEXT: .LBB1_7: # %merge_predecessor_split
+; CHECK-NEXT: # in Loop: Header=BB1_8 Depth=1
; CHECK-NEXT: movb $32, %cl
-; CHECK-NEXT: .LBB1_4: # %outer_loop_header
+; CHECK-NEXT: .LBB1_8: # %outer_loop_header
; CHECK-NEXT: # =>This Loop Header: Depth=1
-; CHECK-NEXT: # Child Loop BB1_8 Depth 2
-; CHECK-NEXT: testl %r12d, %r12d
-; CHECK-NEXT: je .LBB1_5
+; CHECK-NEXT: # Child Loop BB1_9 Depth 2
+; CHECK-NEXT: testl %r13d, %r13d
+; CHECK-NEXT: je .LBB1_16
; CHECK-NEXT: .p2align 4, 0x90
-; CHECK-NEXT: .LBB1_8: # %shared_loop_header
-; CHECK-NEXT: # Parent Loop BB1_4 Depth=1
+; CHECK-NEXT: .LBB1_9: # %shared_loop_header
+; CHECK-NEXT: # Parent Loop BB1_8 Depth=1
; CHECK-NEXT: # => This Inner Loop Header: Depth=2
; CHECK-NEXT: testq %r14, %r14
-; CHECK-NEXT: jne .LBB1_18
-; CHECK-NEXT: # %bb.9: # %inner_loop_body
-; CHECK-NEXT: # in Loop: Header=BB1_8 Depth=2
+; CHECK-NEXT: jne .LBB1_25
+; CHECK-NEXT: # %bb.10: # %inner_loop_body
+; CHECK-NEXT: # in Loop: Header=BB1_9 Depth=2
; CHECK-NEXT: testb %al, %al
-; CHECK-NEXT: je .LBB1_8
-; CHECK-NEXT: # %bb.10: # %if.end96.i
-; CHECK-NEXT: # in Loop: Header=BB1_4 Depth=1
-; CHECK-NEXT: cmpl $3, %r12d
-; CHECK-NEXT: jae .LBB1_11
-; CHECK-NEXT: # %bb.13: # %if.end287.i
-; CHECK-NEXT: # in Loop: Header=BB1_4 Depth=1
+; CHECK-NEXT: je .LBB1_9
+; CHECK-NEXT: # %bb.11: # %if.end96.i
+; CHECK-NEXT: # in Loop: Header=BB1_8 Depth=1
+; CHECK-NEXT: cmpl $3, %r13d
+; CHECK-NEXT: jae .LBB1_20
+; CHECK-NEXT: # %bb.12: # %if.end287.i
+; CHECK-NEXT: # in Loop: Header=BB1_8 Depth=1
; CHECK-NEXT: testb %al, %al
; CHECK-NEXT: # implicit-def: $cl
-; CHECK-NEXT: jne .LBB1_4
-; CHECK-NEXT: # %bb.14: # %if.end308.i
-; CHECK-NEXT: # in Loop: Header=BB1_4 Depth=1
+; CHECK-NEXT: jne .LBB1_8
+; CHECK-NEXT: # %bb.13: # %if.end308.i
+; CHECK-NEXT: # in Loop: Header=BB1_8 Depth=1
; CHECK-NEXT: testb %al, %al
-; CHECK-NEXT: je .LBB1_15
-; CHECK-NEXT: # %bb.16: # %if.end335.i
-; CHECK-NEXT: # in Loop: Header=BB1_4 Depth=1
+; CHECK-NEXT: je .LBB1_7
+; CHECK-NEXT: # %bb.14: # %if.end335.i
+; CHECK-NEXT: # in Loop: Header=BB1_8 Depth=1
; CHECK-NEXT: xorl %ecx, %ecx
; CHECK-NEXT: testb %cl, %cl
-; CHECK-NEXT: jne .LBB1_4
-; CHECK-NEXT: # %bb.17: # %merge_other
-; CHECK-NEXT: # in Loop: Header=BB1_4 Depth=1
+; CHECK-NEXT: jne .LBB1_8
+; CHECK-NEXT: # %bb.15: # %merge_other
+; CHECK-NEXT: # in Loop: Header=BB1_8 Depth=1
; CHECK-NEXT: # implicit-def: $cl
-; CHECK-NEXT: jmp .LBB1_4
-; CHECK-NEXT: .LBB1_5: # %while.cond.us1412.i
+; CHECK-NEXT: jmp .LBB1_8
+; CHECK-NEXT: .LBB1_23:
+; CHECK-NEXT: movl $1, %ebx
+; CHECK-NEXT: jmp .LBB1_24
+; CHECK-NEXT: .LBB1_16: # %while.cond.us1412.i
; CHECK-NEXT: xorl %eax, %eax
; CHECK-NEXT: testb %al, %al
-; CHECK-NEXT: jne .LBB1_7
-; CHECK-NEXT: # %bb.6: # %while.cond.us1412.i
+; CHECK-NEXT: movl $1, %ebx
+; CHECK-NEXT: jne .LBB1_18
+; CHECK-NEXT: # %bb.17: # %while.cond.us1412.i
; CHECK-NEXT: decb %cl
-; CHECK-NEXT: jne .LBB1_12
-; CHECK-NEXT: .LBB1_7: # %if.end41.us1436.i
-; CHECK-NEXT: .LBB1_11: # %if.then99.i
+; CHECK-NEXT: jne .LBB1_24
+; CHECK-NEXT: .LBB1_18: # %if.end41.us1436.i
+; CHECK-NEXT: .LBB1_20: # %if.then99.i
; CHECK-NEXT: movq .str.6 at GOTPCREL(%rip), %rdi
; CHECK-NEXT: xorl %ebx, %ebx
; CHECK-NEXT: xorl %eax, %eax
; CHECK-NEXT: callq cli_dbgmsg at PLT
-; CHECK-NEXT: .LBB1_12: # %cleanup
+; CHECK-NEXT: .LBB1_24: # %cleanup
; CHECK-NEXT: movl %ebx, %eax
+; CHECK-NEXT: addq $8, %rsp
; CHECK-NEXT: popq %rbx
; CHECK-NEXT: popq %r12
+; CHECK-NEXT: popq %r13
; CHECK-NEXT: popq %r14
; CHECK-NEXT: popq %r15
; CHECK-NEXT: popq %rbp
; CHECK-NEXT: retq
-; CHECK-NEXT: .LBB1_18: # %wunpsect.exit.thread.loopexit389
-; CHECK-NEXT: .LBB1_19: # %wunpsect.exit.thread.loopexit391
+; CHECK-NEXT: .LBB1_25: # %wunpsect.exit.thread.loopexit389
+; CHECK-NEXT: .LBB1_26: # %wunpsect.exit.thread.loopexit391
entry:
%0 = load i32, ptr undef, align 4
%mul = shl nsw i32 %0, 2
diff --git a/llvm/test/CodeGen/X86/tail-opts.ll b/llvm/test/CodeGen/X86/tail-opts.ll
index d9ab2f7d1f5fb6..d54110d1fa8119 100644
--- a/llvm/test/CodeGen/X86/tail-opts.ll
+++ b/llvm/test/CodeGen/X86/tail-opts.ll
@@ -300,9 +300,10 @@ define fastcc void @c_expand_expr_stmt(ptr %expr) nounwind {
; CHECK-NEXT: cmpl $23, %ecx
; CHECK-NEXT: jne .LBB3_9
; CHECK-NEXT: .LBB3_16: # %lvalue_p.exit4
+; CHECK-NEXT: testb %al, %al
+; CHECK-NEXT: jne .LBB3_9
+; CHECK-NEXT: # %bb.17: # %lvalue_p.exit4
; CHECK-NEXT: testb %bl, %bl
-; CHECK-NEXT: sete %cl
-; CHECK-NEXT: orb %al, %cl
entry:
%tmp4 = load i8, ptr null, align 8 ; <i8> [#uses=3]
switch i8 %tmp4, label %bb3 [
diff --git a/llvm/test/CodeGen/X86/tailcall-extract.ll b/llvm/test/CodeGen/X86/tailcall-extract.ll
index aff6146198c899..7a6c75c44ca7dd 100644
--- a/llvm/test/CodeGen/X86/tailcall-extract.ll
+++ b/llvm/test/CodeGen/X86/tailcall-extract.ll
@@ -6,7 +6,7 @@
; containing call. And later tail call can be generated.
; CHECK-LABEL: test1:
-; CHECK: jne foo # TAILCALL
+; CHECK: je foo # TAILCALL
; CHECK: jmp bar # TAILCALL
; OPT-LABEL: test1
@@ -48,8 +48,8 @@ exit:
; can't be duplicated.
; CHECK-LABEL: test2:
-; CHECK: callq foo
; CHECK: callq bar
+; CHECK: callq foo
; OPT-LABEL: test2
; OPT: if.then.i:
@@ -93,7 +93,7 @@ exit:
; offset, so the exit block can still be duplicated, and tail call generated.
; CHECK-LABEL: test3:
-; CHECK: jne qux # TAILCALL
+; CHECK: je qux # TAILCALL
; CHECK: jmp baz # TAILCALL
; OPT-LABEL: test3
@@ -136,8 +136,8 @@ exit:
; block can't be duplicated.
; CHECK-LABEL: test4:
-; CHECK: callq qux
; CHECK: callq baz
+; CHECK: callq qux
; OPT-LABEL: test4
; OPT: if.then.i:
diff --git a/llvm/test/CodeGen/X86/test-shrink-bug.ll b/llvm/test/CodeGen/X86/test-shrink-bug.ll
index 953a0d65c5386c..ed43cabbdaee11 100644
--- a/llvm/test/CodeGen/X86/test-shrink-bug.ll
+++ b/llvm/test/CodeGen/X86/test-shrink-bug.ll
@@ -48,39 +48,37 @@ define dso_local void @fail(i16 %a, <2 x i8> %b) {
; CHECK-X86: ## %bb.0:
; CHECK-X86-NEXT: subl $12, %esp
; CHECK-X86-NEXT: .cfi_def_cfa_offset 16
-; CHECK-X86-NEXT: movzwl {{[0-9]+}}(%esp), %eax
+; CHECK-X86-NEXT: movzwl {{[0-9]+}}(%esp), %ecx
; CHECK-X86-NEXT: cmpb $123, {{[0-9]+}}(%esp)
-; CHECK-X86-NEXT: setne %cl
-; CHECK-X86-NEXT: testl $263, %eax ## imm = 0x107
-; CHECK-X86-NEXT: setne %al
-; CHECK-X86-NEXT: testb %cl, %al
-; CHECK-X86-NEXT: jne LBB1_2
-; CHECK-X86-NEXT: ## %bb.1: ## %yes
-; CHECK-X86-NEXT: addl $12, %esp
-; CHECK-X86-NEXT: retl
-; CHECK-X86-NEXT: LBB1_2: ## %no
+; CHECK-X86-NEXT: sete %al
+; CHECK-X86-NEXT: testl $263, %ecx ## imm = 0x107
+; CHECK-X86-NEXT: je LBB1_3
+; CHECK-X86-NEXT: ## %bb.1:
+; CHECK-X86-NEXT: testb %al, %al
+; CHECK-X86-NEXT: jne LBB1_3
+; CHECK-X86-NEXT: ## %bb.2: ## %no
; CHECK-X86-NEXT: calll _bar
+; CHECK-X86-NEXT: LBB1_3: ## %yes
; CHECK-X86-NEXT: addl $12, %esp
; CHECK-X86-NEXT: retl
;
; CHECK-X64-LABEL: fail:
; CHECK-X64: # %bb.0:
+; CHECK-X64-NEXT: testl $263, %edi # imm = 0x107
+; CHECK-X64-NEXT: je .LBB1_3
+; CHECK-X64-NEXT: # %bb.1:
; CHECK-X64-NEXT: pslld $8, %xmm0
; CHECK-X64-NEXT: pcmpeqb {{\.?LCPI[0-9]+_[0-9]+}}(%rip), %xmm0
; CHECK-X64-NEXT: pextrw $1, %xmm0, %eax
-; CHECK-X64-NEXT: xorb $1, %al
-; CHECK-X64-NEXT: testl $263, %edi # imm = 0x107
-; CHECK-X64-NEXT: setne %cl
-; CHECK-X64-NEXT: testb %al, %cl
-; CHECK-X64-NEXT: jne .LBB1_2
-; CHECK-X64-NEXT: # %bb.1: # %yes
-; CHECK-X64-NEXT: retq
-; CHECK-X64-NEXT: .LBB1_2: # %no
+; CHECK-X64-NEXT: testb $1, %al
+; CHECK-X64-NEXT: jne .LBB1_3
+; CHECK-X64-NEXT: # %bb.2: # %no
; CHECK-X64-NEXT: pushq %rax
; CHECK-X64-NEXT: .cfi_def_cfa_offset 16
; CHECK-X64-NEXT: callq bar at PLT
; CHECK-X64-NEXT: popq %rax
; CHECK-X64-NEXT: .cfi_def_cfa_offset 8
+; CHECK-X64-NEXT: .LBB1_3: # %yes
; CHECK-X64-NEXT: retq
%1 = icmp eq <2 x i8> %b, <i8 40, i8 123>
%2 = extractelement <2 x i1> %1, i32 1
diff --git a/llvm/test/CodeGen/X86/x86-shrink-wrap-unwind.ll b/llvm/test/CodeGen/X86/x86-shrink-wrap-unwind.ll
index 3349d31cad4b97..b9e490888d9bfc 100644
--- a/llvm/test/CodeGen/X86/x86-shrink-wrap-unwind.ll
+++ b/llvm/test/CodeGen/X86/x86-shrink-wrap-unwind.ll
@@ -181,40 +181,38 @@ define zeroext i1 @segmentedStack(ptr readonly %vk1, ptr readonly %vk2, i64 %key
; CHECK-LABEL: segmentedStack:
; CHECK: ## %bb.0:
; CHECK-NEXT: cmpq %gs:816, %rsp
-; CHECK-NEXT: jbe LBB3_6
+; CHECK-NEXT: jbe LBB3_7
; CHECK-NEXT: LBB3_1: ## %entry
; CHECK-NEXT: pushq %rax
; CHECK-NEXT: .cfi_def_cfa_offset 16
-; CHECK-NEXT: testq %rdi, %rdi
-; CHECK-NEXT: sete %al
-; CHECK-NEXT: testq %rsi, %rsi
-; CHECK-NEXT: sete %cl
-; CHECK-NEXT: orb %al, %cl
; CHECK-NEXT: movq %rdi, %rax
; CHECK-NEXT: orq %rsi, %rax
; CHECK-NEXT: sete %al
-; CHECK-NEXT: testb %cl, %cl
-; CHECK-NEXT: jne LBB3_4
-; CHECK-NEXT: ## %bb.2: ## %if.end4.i
+; CHECK-NEXT: testq %rdi, %rdi
+; CHECK-NEXT: je LBB3_5
+; CHECK-NEXT: ## %bb.2: ## %entry
+; CHECK-NEXT: testq %rsi, %rsi
+; CHECK-NEXT: je LBB3_5
+; CHECK-NEXT: ## %bb.3: ## %if.end4.i
; CHECK-NEXT: movq 8(%rdi), %rdx
; CHECK-NEXT: cmpq 8(%rsi), %rdx
-; CHECK-NEXT: jne LBB3_5
-; CHECK-NEXT: ## %bb.3: ## %land.rhs.i.i
+; CHECK-NEXT: jne LBB3_6
+; CHECK-NEXT: ## %bb.4: ## %land.rhs.i.i
; CHECK-NEXT: movq (%rsi), %rsi
; CHECK-NEXT: movq (%rdi), %rdi
; CHECK-NEXT: callq _memcmp
; CHECK-NEXT: testl %eax, %eax
; CHECK-NEXT: sete %al
-; CHECK-NEXT: LBB3_4: ## %__go_ptr_strings_equal.exit
+; CHECK-NEXT: LBB3_5: ## %__go_ptr_strings_equal.exit
; CHECK-NEXT: ## kill: def $al killed $al killed $eax
; CHECK-NEXT: popq %rcx
; CHECK-NEXT: retq
-; CHECK-NEXT: LBB3_5:
+; CHECK-NEXT: LBB3_6:
; CHECK-NEXT: xorl %eax, %eax
; CHECK-NEXT: ## kill: def $al killed $al killed $eax
; CHECK-NEXT: popq %rcx
; CHECK-NEXT: retq
-; CHECK-NEXT: LBB3_6:
+; CHECK-NEXT: LBB3_7:
; CHECK-NEXT: movl $8, %r10d
; CHECK-NEXT: movl $0, %r11d
; CHECK-NEXT: callq ___morestack
@@ -224,43 +222,41 @@ define zeroext i1 @segmentedStack(ptr readonly %vk1, ptr readonly %vk2, i64 %key
; NOCOMPACTUNWIND-LABEL: segmentedStack:
; NOCOMPACTUNWIND: # %bb.0:
; NOCOMPACTUNWIND-NEXT: cmpq %fs:112, %rsp
-; NOCOMPACTUNWIND-NEXT: jbe .LBB3_6
+; NOCOMPACTUNWIND-NEXT: jbe .LBB3_7
; NOCOMPACTUNWIND-NEXT: .LBB3_1: # %entry
; NOCOMPACTUNWIND-NEXT: pushq %rax
; NOCOMPACTUNWIND-NEXT: .cfi_def_cfa_offset 16
-; NOCOMPACTUNWIND-NEXT: testq %rdi, %rdi
-; NOCOMPACTUNWIND-NEXT: sete %al
-; NOCOMPACTUNWIND-NEXT: testq %rsi, %rsi
-; NOCOMPACTUNWIND-NEXT: sete %cl
-; NOCOMPACTUNWIND-NEXT: orb %al, %cl
; NOCOMPACTUNWIND-NEXT: movq %rdi, %rax
; NOCOMPACTUNWIND-NEXT: orq %rsi, %rax
; NOCOMPACTUNWIND-NEXT: sete %al
-; NOCOMPACTUNWIND-NEXT: testb %cl, %cl
-; NOCOMPACTUNWIND-NEXT: jne .LBB3_4
-; NOCOMPACTUNWIND-NEXT: # %bb.2: # %if.end4.i
+; NOCOMPACTUNWIND-NEXT: testq %rdi, %rdi
+; NOCOMPACTUNWIND-NEXT: je .LBB3_5
+; NOCOMPACTUNWIND-NEXT: # %bb.2: # %entry
+; NOCOMPACTUNWIND-NEXT: testq %rsi, %rsi
+; NOCOMPACTUNWIND-NEXT: je .LBB3_5
+; NOCOMPACTUNWIND-NEXT: # %bb.3: # %if.end4.i
; NOCOMPACTUNWIND-NEXT: movq 8(%rdi), %rdx
; NOCOMPACTUNWIND-NEXT: cmpq 8(%rsi), %rdx
-; NOCOMPACTUNWIND-NEXT: jne .LBB3_5
-; NOCOMPACTUNWIND-NEXT: # %bb.3: # %land.rhs.i.i
+; NOCOMPACTUNWIND-NEXT: jne .LBB3_6
+; NOCOMPACTUNWIND-NEXT: # %bb.4: # %land.rhs.i.i
; NOCOMPACTUNWIND-NEXT: movq (%rsi), %rsi
; NOCOMPACTUNWIND-NEXT: movq (%rdi), %rdi
; NOCOMPACTUNWIND-NEXT: callq memcmp at PLT
; NOCOMPACTUNWIND-NEXT: testl %eax, %eax
; NOCOMPACTUNWIND-NEXT: sete %al
-; NOCOMPACTUNWIND-NEXT: .LBB3_4: # %__go_ptr_strings_equal.exit
+; NOCOMPACTUNWIND-NEXT: .LBB3_5: # %__go_ptr_strings_equal.exit
; NOCOMPACTUNWIND-NEXT: # kill: def $al killed $al killed $eax
; NOCOMPACTUNWIND-NEXT: popq %rcx
; NOCOMPACTUNWIND-NEXT: .cfi_def_cfa_offset 8
; NOCOMPACTUNWIND-NEXT: retq
-; NOCOMPACTUNWIND-NEXT: .LBB3_5:
+; NOCOMPACTUNWIND-NEXT: .LBB3_6:
; NOCOMPACTUNWIND-NEXT: .cfi_def_cfa_offset 16
; NOCOMPACTUNWIND-NEXT: xorl %eax, %eax
; NOCOMPACTUNWIND-NEXT: # kill: def $al killed $al killed $eax
; NOCOMPACTUNWIND-NEXT: popq %rcx
; NOCOMPACTUNWIND-NEXT: .cfi_def_cfa_offset 8
; NOCOMPACTUNWIND-NEXT: retq
-; NOCOMPACTUNWIND-NEXT: .LBB3_6:
+; NOCOMPACTUNWIND-NEXT: .LBB3_7:
; NOCOMPACTUNWIND-NEXT: movl $8, %r10d
; NOCOMPACTUNWIND-NEXT: movl $0, %r11d
; NOCOMPACTUNWIND-NEXT: callq __morestack
>From 58b44c8102afb0e76d1cb70d4a5d089f70d2f657 Mon Sep 17 00:00:00 2001
From: Jacques Pienaar <jpienaar at google.com>
Date: Sun, 3 Mar 2024 05:56:56 -0800
Subject: [PATCH 389/406] Reapply "Reapply "[mlir-query] Add function
extraction feature to mlir-query""
Fix ASAN by erasing the op extracted post printing.
This reverts commit 732a5cba8c739ed40a7280b5d74ca717910c2c4c.
---
.../include/mlir/Query/Matcher/ErrorBuilder.h | 7 +-
.../mlir/Query/Matcher/MatchersInternal.h | 7 ++
mlir/lib/Query/CMakeLists.txt | 1 +
mlir/lib/Query/Matcher/Diagnostics.cpp | 10 +++
mlir/lib/Query/Matcher/Parser.cpp | 67 +++++++++++++--
mlir/lib/Query/Matcher/Parser.h | 18 +++--
mlir/lib/Query/Matcher/RegistryManager.cpp | 15 +++-
mlir/lib/Query/Matcher/RegistryManager.h | 1 +
mlir/lib/Query/Query.cpp | 81 ++++++++++++++++++-
mlir/test/mlir-query/function-extraction.mlir | 19 +++++
10 files changed, 209 insertions(+), 17 deletions(-)
create mode 100644 mlir/test/mlir-query/function-extraction.mlir
diff --git a/mlir/include/mlir/Query/Matcher/ErrorBuilder.h b/mlir/include/mlir/Query/Matcher/ErrorBuilder.h
index 1073daed8703f5..08f1f415cbd3e5 100644
--- a/mlir/include/mlir/Query/Matcher/ErrorBuilder.h
+++ b/mlir/include/mlir/Query/Matcher/ErrorBuilder.h
@@ -37,8 +37,12 @@ enum class ErrorType {
None,
// Parser Errors
+ ParserChainedExprInvalidArg,
+ ParserChainedExprNoCloseParen,
+ ParserChainedExprNoOpenParen,
ParserFailedToBuildMatcher,
ParserInvalidToken,
+ ParserMalformedChainedExpr,
ParserNoCloseParen,
ParserNoCode,
ParserNoComma,
@@ -50,9 +54,10 @@ enum class ErrorType {
// Registry Errors
RegistryMatcherNotFound,
+ RegistryNotBindable,
RegistryValueNotFound,
RegistryWrongArgCount,
- RegistryWrongArgType
+ RegistryWrongArgType,
};
void addError(Diagnostics *error, SourceRange range, ErrorType errorType,
diff --git a/mlir/include/mlir/Query/Matcher/MatchersInternal.h b/mlir/include/mlir/Query/Matcher/MatchersInternal.h
index 67455be592393b..117f7d4edef9e3 100644
--- a/mlir/include/mlir/Query/Matcher/MatchersInternal.h
+++ b/mlir/include/mlir/Query/Matcher/MatchersInternal.h
@@ -63,8 +63,15 @@ class DynMatcher {
bool match(Operation *op) const { return implementation->match(op); }
+ void setFunctionName(StringRef name) { functionName = name.str(); };
+
+ bool hasFunctionName() const { return !functionName.empty(); };
+
+ StringRef getFunctionName() const { return functionName; };
+
private:
llvm::IntrusiveRefCntPtr<MatcherInterface> implementation;
+ std::string functionName;
};
} // namespace mlir::query::matcher
diff --git a/mlir/lib/Query/CMakeLists.txt b/mlir/lib/Query/CMakeLists.txt
index 817583e94c5222..7ecbf6e628b318 100644
--- a/mlir/lib/Query/CMakeLists.txt
+++ b/mlir/lib/Query/CMakeLists.txt
@@ -6,6 +6,7 @@ add_mlir_library(MLIRQuery
${MLIR_MAIN_INCLUDE_DIR}/mlir/Query
LINK_LIBS PUBLIC
+ MLIRFuncDialect
MLIRQueryMatcher
)
diff --git a/mlir/lib/Query/Matcher/Diagnostics.cpp b/mlir/lib/Query/Matcher/Diagnostics.cpp
index 10468dbcc53067..2a137e8fdfab0d 100644
--- a/mlir/lib/Query/Matcher/Diagnostics.cpp
+++ b/mlir/lib/Query/Matcher/Diagnostics.cpp
@@ -38,6 +38,8 @@ static llvm::StringRef errorTypeToFormatString(ErrorType type) {
return "Incorrect type for arg $0. (Expected = $1) != (Actual = $2)";
case ErrorType::RegistryValueNotFound:
return "Value not found: $0";
+ case ErrorType::RegistryNotBindable:
+ return "Matcher does not support binding.";
case ErrorType::ParserStringError:
return "Error parsing string token: <$0>";
@@ -57,6 +59,14 @@ static llvm::StringRef errorTypeToFormatString(ErrorType type) {
return "Unexpected end of code.";
case ErrorType::ParserOverloadedType:
return "Input value has unresolved overloaded type: $0";
+ case ErrorType::ParserMalformedChainedExpr:
+ return "Period not followed by valid chained call.";
+ case ErrorType::ParserChainedExprInvalidArg:
+ return "Missing/Invalid argument for the chained call.";
+ case ErrorType::ParserChainedExprNoCloseParen:
+ return "Missing ')' for the chained call.";
+ case ErrorType::ParserChainedExprNoOpenParen:
+ return "Missing '(' for the chained call.";
case ErrorType::ParserFailedToBuildMatcher:
return "Failed to build matcher: $0.";
diff --git a/mlir/lib/Query/Matcher/Parser.cpp b/mlir/lib/Query/Matcher/Parser.cpp
index 30eb4801fc03c1..3609e24f9939f7 100644
--- a/mlir/lib/Query/Matcher/Parser.cpp
+++ b/mlir/lib/Query/Matcher/Parser.cpp
@@ -26,12 +26,17 @@ struct Parser::TokenInfo {
text = newText;
}
+ // Known identifiers.
+ static const char *const ID_Extract;
+
llvm::StringRef text;
TokenKind kind = TokenKind::Eof;
SourceRange range;
VariantValue value;
};
+const char *const Parser::TokenInfo::ID_Extract = "extract";
+
class Parser::CodeTokenizer {
public:
// Constructor with matcherCode and error
@@ -298,6 +303,36 @@ bool Parser::parseIdentifierPrefixImpl(VariantValue *value) {
return parseMatcherExpressionImpl(nameToken, openToken, ctor, value);
}
+bool Parser::parseChainedExpression(std::string &argument) {
+ // Parse the parenthesized argument to .extract("foo")
+ // Note: EOF is handled inside the consume functions and would fail below when
+ // checking token kind.
+ const TokenInfo openToken = tokenizer->consumeNextToken();
+ const TokenInfo argumentToken = tokenizer->consumeNextTokenIgnoreNewlines();
+ const TokenInfo closeToken = tokenizer->consumeNextTokenIgnoreNewlines();
+
+ if (openToken.kind != TokenKind::OpenParen) {
+ error->addError(openToken.range, ErrorType::ParserChainedExprNoOpenParen);
+ return false;
+ }
+
+ if (argumentToken.kind != TokenKind::Literal ||
+ !argumentToken.value.isString()) {
+ error->addError(argumentToken.range,
+ ErrorType::ParserChainedExprInvalidArg);
+ return false;
+ }
+
+ if (closeToken.kind != TokenKind::CloseParen) {
+ error->addError(closeToken.range, ErrorType::ParserChainedExprNoCloseParen);
+ return false;
+ }
+
+ // If all checks passed, extract the argument and return true.
+ argument = argumentToken.value.getString();
+ return true;
+}
+
// Parse the arguments of a matcher
bool Parser::parseMatcherArgs(std::vector<ParserValue> &args, MatcherCtor ctor,
const TokenInfo &nameToken, TokenInfo &endToken) {
@@ -364,13 +399,34 @@ bool Parser::parseMatcherExpressionImpl(const TokenInfo &nameToken,
return false;
}
+ std::string functionName;
+ if (tokenizer->peekNextToken().kind == TokenKind::Period) {
+ tokenizer->consumeNextToken();
+ TokenInfo chainCallToken = tokenizer->consumeNextToken();
+ if (chainCallToken.kind == TokenKind::CodeCompletion) {
+ addCompletion(chainCallToken, MatcherCompletion("extract(\"", "extract"));
+ return false;
+ }
+
+ if (chainCallToken.kind != TokenKind::Ident ||
+ chainCallToken.text != TokenInfo::ID_Extract) {
+ error->addError(chainCallToken.range,
+ ErrorType::ParserMalformedChainedExpr);
+ return false;
+ }
+
+ if (chainCallToken.text == TokenInfo::ID_Extract &&
+ !parseChainedExpression(functionName))
+ return false;
+ }
+
if (!ctor)
return false;
// Merge the start and end infos.
SourceRange matcherRange = nameToken.range;
matcherRange.end = endToken.range.end;
- VariantMatcher result =
- sema->actOnMatcherExpression(*ctor, matcherRange, args, error);
+ VariantMatcher result = sema->actOnMatcherExpression(
+ *ctor, matcherRange, functionName, args, error);
if (result.isNull())
return false;
*value = result;
@@ -470,9 +526,10 @@ Parser::RegistrySema::lookupMatcherCtor(llvm::StringRef matcherName) {
}
VariantMatcher Parser::RegistrySema::actOnMatcherExpression(
- MatcherCtor ctor, SourceRange nameRange, llvm::ArrayRef<ParserValue> args,
- Diagnostics *error) {
- return RegistryManager::constructMatcher(ctor, nameRange, args, error);
+ MatcherCtor ctor, SourceRange nameRange, llvm::StringRef functionName,
+ llvm::ArrayRef<ParserValue> args, Diagnostics *error) {
+ return RegistryManager::constructMatcher(ctor, nameRange, functionName, args,
+ error);
}
std::vector<ArgKind> Parser::RegistrySema::getAcceptedCompletionTypes(
diff --git a/mlir/lib/Query/Matcher/Parser.h b/mlir/lib/Query/Matcher/Parser.h
index f049af34e9c907..58968023022d56 100644
--- a/mlir/lib/Query/Matcher/Parser.h
+++ b/mlir/lib/Query/Matcher/Parser.h
@@ -64,10 +64,9 @@ class Parser {
// Process a matcher expression. The caller takes ownership of the Matcher
// object returned.
- virtual VariantMatcher
- actOnMatcherExpression(MatcherCtor ctor, SourceRange nameRange,
- llvm::ArrayRef<ParserValue> args,
- Diagnostics *error) = 0;
+ virtual VariantMatcher actOnMatcherExpression(
+ MatcherCtor ctor, SourceRange nameRange, llvm::StringRef functionName,
+ llvm::ArrayRef<ParserValue> args, Diagnostics *error) = 0;
// Look up a matcher by name in the matcher name found by the parser.
virtual std::optional<MatcherCtor>
@@ -93,10 +92,11 @@ class Parser {
std::optional<MatcherCtor>
lookupMatcherCtor(llvm::StringRef matcherName) override;
- VariantMatcher actOnMatcherExpression(MatcherCtor ctor,
- SourceRange nameRange,
- llvm::ArrayRef<ParserValue> args,
- Diagnostics *error) override;
+ VariantMatcher actOnMatcherExpression(MatcherCtor Ctor,
+ SourceRange NameRange,
+ StringRef functionName,
+ ArrayRef<ParserValue> Args,
+ Diagnostics *Error) override;
std::vector<ArgKind> getAcceptedCompletionTypes(
llvm::ArrayRef<std::pair<MatcherCtor, unsigned>> context) override;
@@ -153,6 +153,8 @@ class Parser {
Parser(CodeTokenizer *tokenizer, const Registry &matcherRegistry,
const NamedValueMap *namedValues, Diagnostics *error);
+ bool parseChainedExpression(std::string &argument);
+
bool parseExpressionImpl(VariantValue *value);
bool parseMatcherArgs(std::vector<ParserValue> &args, MatcherCtor ctor,
diff --git a/mlir/lib/Query/Matcher/RegistryManager.cpp b/mlir/lib/Query/Matcher/RegistryManager.cpp
index 01856aa8ffa67f..8c9197f4d00981 100644
--- a/mlir/lib/Query/Matcher/RegistryManager.cpp
+++ b/mlir/lib/Query/Matcher/RegistryManager.cpp
@@ -132,8 +132,19 @@ RegistryManager::getMatcherCompletions(llvm::ArrayRef<ArgKind> acceptedTypes,
VariantMatcher RegistryManager::constructMatcher(
MatcherCtor ctor, internal::SourceRange nameRange,
- llvm::ArrayRef<ParserValue> args, internal::Diagnostics *error) {
- return ctor->create(nameRange, args, error);
+ llvm::StringRef functionName, llvm::ArrayRef<ParserValue> args,
+ internal::Diagnostics *error) {
+ VariantMatcher out = ctor->create(nameRange, args, error);
+ if (functionName.empty() || out.isNull())
+ return out;
+
+ if (std::optional<DynMatcher> result = out.getDynMatcher()) {
+ result->setFunctionName(functionName);
+ return VariantMatcher::SingleMatcher(*result);
+ }
+
+ error->addError(nameRange, internal::ErrorType::RegistryNotBindable);
+ return {};
}
} // namespace mlir::query::matcher
diff --git a/mlir/lib/Query/Matcher/RegistryManager.h b/mlir/lib/Query/Matcher/RegistryManager.h
index 5f2867261225e7..e2026e97f83dcb 100644
--- a/mlir/lib/Query/Matcher/RegistryManager.h
+++ b/mlir/lib/Query/Matcher/RegistryManager.h
@@ -61,6 +61,7 @@ class RegistryManager {
static VariantMatcher constructMatcher(MatcherCtor ctor,
internal::SourceRange nameRange,
+ llvm::StringRef functionName,
ArrayRef<ParserValue> args,
internal::Diagnostics *error);
};
diff --git a/mlir/lib/Query/Query.cpp b/mlir/lib/Query/Query.cpp
index 5c42e5a5f0a116..7fdbbd181234b6 100644
--- a/mlir/lib/Query/Query.cpp
+++ b/mlir/lib/Query/Query.cpp
@@ -8,6 +8,8 @@
#include "mlir/Query/Query.h"
#include "QueryParser.h"
+#include "mlir/Dialect/Func/IR/FuncOps.h"
+#include "mlir/IR/IRMapping.h"
#include "mlir/Query/Matcher/MatchFinder.h"
#include "mlir/Query/QuerySession.h"
#include "mlir/Support/LogicalResult.h"
@@ -34,6 +36,70 @@ static void printMatch(llvm::raw_ostream &os, QuerySession &qs, Operation *op,
"\"" + binding + "\" binds here");
}
+// TODO: Extract into a helper function that can be reused outside query
+// context.
+static Operation *extractFunction(std::vector<Operation *> &ops,
+ MLIRContext *context,
+ llvm::StringRef functionName) {
+ context->loadDialect<func::FuncDialect>();
+ OpBuilder builder(context);
+
+ // Collect data for function creation
+ std::vector<Operation *> slice;
+ std::vector<Value> values;
+ std::vector<Type> outputTypes;
+
+ for (auto *op : ops) {
+ // Return op's operands are propagated, but the op itself isn't needed.
+ if (!isa<func::ReturnOp>(op))
+ slice.push_back(op);
+
+ // All results are returned by the extracted function.
+ outputTypes.insert(outputTypes.end(), op->getResults().getTypes().begin(),
+ op->getResults().getTypes().end());
+
+ // Track all values that need to be taken as input to function.
+ values.insert(values.end(), op->getOperands().begin(),
+ op->getOperands().end());
+ }
+
+ // Create the function
+ FunctionType funcType =
+ builder.getFunctionType(ValueRange(values), outputTypes);
+ auto loc = builder.getUnknownLoc();
+ func::FuncOp funcOp = func::FuncOp::create(loc, functionName, funcType);
+
+ builder.setInsertionPointToEnd(funcOp.addEntryBlock());
+
+ // Map original values to function arguments
+ IRMapping mapper;
+ for (const auto &arg : llvm::enumerate(values))
+ mapper.map(arg.value(), funcOp.getArgument(arg.index()));
+
+ // Clone operations and build function body
+ std::vector<Operation *> clonedOps;
+ std::vector<Value> clonedVals;
+ for (Operation *slicedOp : slice) {
+ Operation *clonedOp =
+ clonedOps.emplace_back(builder.clone(*slicedOp, mapper));
+ clonedVals.insert(clonedVals.end(), clonedOp->result_begin(),
+ clonedOp->result_end());
+ }
+ // Add return operation
+ builder.create<func::ReturnOp>(loc, clonedVals);
+
+ // Remove unused function arguments
+ size_t currentIndex = 0;
+ while (currentIndex < funcOp.getNumArguments()) {
+ if (funcOp.getArgument(currentIndex).use_empty())
+ funcOp.eraseArgument(currentIndex);
+ else
+ ++currentIndex;
+ }
+
+ return funcOp;
+}
+
Query::~Query() = default;
mlir::LogicalResult InvalidQuery::run(llvm::raw_ostream &os,
@@ -65,9 +131,22 @@ mlir::LogicalResult QuitQuery::run(llvm::raw_ostream &os,
mlir::LogicalResult MatchQuery::run(llvm::raw_ostream &os,
QuerySession &qs) const {
+ Operation *rootOp = qs.getRootOp();
int matchCount = 0;
std::vector<Operation *> matches =
- matcher::MatchFinder().getMatches(qs.getRootOp(), matcher);
+ matcher::MatchFinder().getMatches(rootOp, matcher);
+
+ // An extract call is recognized by considering if the matcher has a name.
+ // TODO: Consider making the extract more explicit.
+ if (matcher.hasFunctionName()) {
+ auto functionName = matcher.getFunctionName();
+ Operation *function =
+ extractFunction(matches, rootOp->getContext(), functionName);
+ os << "\n" << *function << "\n\n";
+ function->erase();
+ return mlir::success();
+ }
+
os << "\n";
for (Operation *op : matches) {
os << "Match #" << ++matchCount << ":\n\n";
diff --git a/mlir/test/mlir-query/function-extraction.mlir b/mlir/test/mlir-query/function-extraction.mlir
new file mode 100644
index 00000000000000..a783f65c6761bc
--- /dev/null
+++ b/mlir/test/mlir-query/function-extraction.mlir
@@ -0,0 +1,19 @@
+// RUN: mlir-query %s -c "m hasOpName(\"arith.mulf\").extract(\"testmul\")" | FileCheck %s
+
+// CHECK: func.func @testmul({{.*}}) -> (f32, f32, f32) {
+// CHECK: %[[MUL0:.*]] = arith.mulf {{.*}} : f32
+// CHECK: %[[MUL1:.*]] = arith.mulf {{.*}}, %[[MUL0]] : f32
+// CHECK: %[[MUL2:.*]] = arith.mulf {{.*}} : f32
+// CHECK-NEXT: return %[[MUL0]], %[[MUL1]], %[[MUL2]] : f32, f32, f32
+
+func.func @mixedOperations(%a: f32, %b: f32, %c: f32) -> f32 {
+ %sum0 = arith.addf %a, %b : f32
+ %sub0 = arith.subf %sum0, %c : f32
+ %mul0 = arith.mulf %a, %sub0 : f32
+ %sum1 = arith.addf %b, %c : f32
+ %mul1 = arith.mulf %sum1, %mul0 : f32
+ %sub2 = arith.subf %mul1, %a : f32
+ %sum2 = arith.addf %mul1, %b : f32
+ %mul2 = arith.mulf %sub2, %sum2 : f32
+ return %mul2 : f32
+}
>From 3ca73e03aaf516ed10df2ec79f92f73d9216c884 Mon Sep 17 00:00:00 2001
From: Jacques Pienaar <jpienaar at google.com>
Date: Sun, 3 Mar 2024 06:46:30 -0800
Subject: [PATCH 390/406] [mlir-query] Attempt to fix gcc7 build
I haven't tested via gcc7, but this should address the error reported.
---
mlir/lib/Query/Query.cpp | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/mlir/lib/Query/Query.cpp b/mlir/lib/Query/Query.cpp
index 7fdbbd181234b6..944aae52528aa7 100644
--- a/mlir/lib/Query/Query.cpp
+++ b/mlir/lib/Query/Query.cpp
@@ -65,7 +65,7 @@ static Operation *extractFunction(std::vector<Operation *> &ops,
// Create the function
FunctionType funcType =
- builder.getFunctionType(ValueRange(values), outputTypes);
+ builder.getFunctionType(TypeRange(values), outputTypes);
auto loc = builder.getUnknownLoc();
func::FuncOp funcOp = func::FuncOp::create(loc, functionName, funcType);
>From 03f150bb5688be72ae4dfb43fbe6795aae493e6d Mon Sep 17 00:00:00 2001
From: Mark de Wever <koraq at xs4all.nl>
Date: Sun, 3 Mar 2024 16:18:35 +0100
Subject: [PATCH 391/406] Removes arcanist and Phabricator information.
(#82115)
Removes old arcanist configuration files and documentation of
Phabricator. This only removes the data that seems save to remove.
---
.arcconfig | 8 -
.arclint | 15 -
llvm/docs/Contributing.rst | 9 +-
llvm/docs/DeveloperPolicy.rst | 4 +-
llvm/docs/Phabricator.rst | 441 ------------------
llvm/docs/Phabricator_premerge_results.png | Bin 28229 -> 0 bytes
llvm/docs/Phabricator_premerge_unit_tests.png | Bin 25929 -> 0 bytes
llvm/docs/UserGuides.rst | 1 -
utils/arcanist/clang-format.sh | 68 ---
9 files changed, 6 insertions(+), 540 deletions(-)
delete mode 100644 .arcconfig
delete mode 100644 .arclint
delete mode 100644 llvm/docs/Phabricator.rst
delete mode 100644 llvm/docs/Phabricator_premerge_results.png
delete mode 100644 llvm/docs/Phabricator_premerge_unit_tests.png
delete mode 100755 utils/arcanist/clang-format.sh
diff --git a/.arcconfig b/.arcconfig
deleted file mode 100644
index e200298f603e5e..00000000000000
--- a/.arcconfig
+++ /dev/null
@@ -1,8 +0,0 @@
-{
- "phabricator.uri" : "https://reviews.llvm.org/",
- "repository.callsign" : "G",
- "conduit_uri" : "https://reviews.llvm.org/",
- "base": "git:HEAD^",
- "arc.land.onto.default": "main",
- "arc.land.onto": ["main"]
-}
diff --git a/.arclint b/.arclint
deleted file mode 100644
index 27d838eb153f2a..00000000000000
--- a/.arclint
+++ /dev/null
@@ -1,15 +0,0 @@
-{
- "linters": {
- "clang-format": {
- "type": "script-and-regex",
- "script-and-regex.script": "bash utils/arcanist/clang-format.sh",
- "script-and-regex.regex": "/^(?P<severity>[[:alpha:]]+)\n(?P<message>[^\n]+)\n(====|(?P<line>\\d),(?P<char>\\d)\n(?P<original>.*)>>>>\n(?P<replacement>.*)<<<<\n)$/s",
- "include": [
- "(\\.(cc|cpp|h)$)"
- ],
- "exclude": [
- "(^clang/test/)"
- ]
- }
- }
-}
diff --git a/llvm/docs/Contributing.rst b/llvm/docs/Contributing.rst
index 05521684517524..dc8be93463cec1 100644
--- a/llvm/docs/Contributing.rst
+++ b/llvm/docs/Contributing.rst
@@ -89,10 +89,9 @@ in order to update the last commit with all pending changes.
``clang/tools/clang-format/git-clang-format``.
The LLVM project has migrated to GitHub Pull Requests as its review process.
-We still have an active :ref:`Phabricator <phabricator-reviews>`
-instance for the duration of the migration. If you want to contribute to LLVM
-now, please use GitHub. For more information about the workflow of using GitHub
-Pull Requests see our :ref:`GitHub <github-reviews>` documentation.
+For more information about the workflow of using GitHub Pull Requests see our
+:ref:`GitHub <github-reviews>` documentation. We still have an read-only
+`LLVM's Phabricator <https://reviews.llvm.org>`_ instance.
To make sure the right people see your patch, please select suitable reviewers
and add them to your patch when requesting a review. Suitable reviewers are the
@@ -185,5 +184,5 @@ of LLVM's high-level design, as well as its internals:
.. _clang-format-diff.py: https://reviews.llvm.org/source/llvm-github/browse/main/clang/tools/clang-format/clang-format-diff.py
.. _git-clang-format: https://reviews.llvm.org/source/llvm-github/browse/main/clang/tools/clang-format/git-clang-format
.. _LLVM's GitHub: https://github.com/llvm/llvm-project
-.. _LLVM's Phabricator (deprecated): https://reviews.llvm.org/
+.. _LLVM's Phabricator (read-only): https://reviews.llvm.org/
.. _LLVM's Open Projects page: https://llvm.org/OpenProjects.html#what
diff --git a/llvm/docs/DeveloperPolicy.rst b/llvm/docs/DeveloperPolicy.rst
index 19b8ddb5245fc3..5d3731d761a3d6 100644
--- a/llvm/docs/DeveloperPolicy.rst
+++ b/llvm/docs/DeveloperPolicy.rst
@@ -129,8 +129,8 @@ awareness of. For such changes, the following should be done:
.. warning::
- Phabricator is deprecated and will be switched to read-only mode in October
- 2023, for new code contributions use :ref:`GitHub Pull Requests <github-reviews>`.
+ Phabricator is deprecated is available in read-only mode,
+ for new code contributions use :ref:`GitHub Pull Requests <github-reviews>`.
This section contains old information that needs to be updated.
* When performing the code review for the change, please add any applicable
diff --git a/llvm/docs/Phabricator.rst b/llvm/docs/Phabricator.rst
deleted file mode 100644
index 057e5e0a140709..00000000000000
--- a/llvm/docs/Phabricator.rst
+++ /dev/null
@@ -1,441 +0,0 @@
-.. _phabricator-reviews:
-
-=============================
-Code Reviews with Phabricator
-=============================
-
-.. warning::
-
- Phabricator is deprecated and will be switched to read-only mode in October
- 2023, for new code contributions use :ref:`GitHub Pull Requests <github-reviews>`.
-
-
-.. contents::
- :local:
-
-
-If you prefer to use a web user interface for code reviews, you can now submit
-your patches for Clang and LLVM at `LLVM's Phabricator`_ instance.
-
-While Phabricator is a useful tool for some, the relevant -commits mailing list
-is the system of record for all LLVM code review. The mailing list should be
-added as a subscriber on all reviews, and Phabricator users should be prepared
-to respond to free-form comments in mail sent to the commits list.
-
-Sign up
--------
-
-To get started with Phabricator, navigate to `https://reviews.llvm.org`_ and
-click the power icon in the top right. You can register with a GitHub account,
-a Google account, or you can create your own profile.
-
-Make *sure* that the email address registered with Phabricator is subscribed
-to the relevant -commits mailing list. If you are not subscribed to the commit
-list, all mail sent by Phabricator on your behalf will be held for moderation.
-
-Note that if you use your git user name as Phabricator user name,
-Phabricator will automatically connect your submits to your Phabricator user in
-the `Code Repository Browser`_.
-
-Requesting a review via the command line
-----------------------------------------
-
-Phabricator has a tool called *Arcanist* to upload patches from
-the command line. To get you set up, follow the
-`Arcanist Quick Start`_ instructions.
-
-You can learn more about how to use arc to interact with
-Phabricator in the `Arcanist User Guide`_.
-The basic way of creating a revision for the current commit in your local
-repository is to run:
-
-::
-
- arc diff HEAD~
-
-
-Sometime you may want to create a draft revision to show the proof of concept
-or for experimental purposes, In that case you can use the `--draft` option. It
-will create a new draft revision. The good part is: it will not send mail to
-llvm-commit mailing list, patch reviewers, and all other subscribers, buildbot
-will also run on every patch update:
-
-::
-
- arc diff --draft HEAD~
-
-
-If you later update your commit message, you need to add the `--verbatim`
-option to have `arc` update the description on Phabricator:
-
-::
-
- arc diff --edit --verbatim
-
-
-.. _phabricator-request-review-web:
-
-Requesting a review via the web interface
------------------------------------------
-
-The tool to create and review patches in Phabricator is called
-*Differential*.
-
-Note that you can upload patches created through git, but using `arc` on the
-command line (see previous section) is preferred: it adds more metadata to
-Phabricator which are useful for the pre-merge testing system and for
-propagating attribution on commits when someone else has to push it for you.
-
-To make reviews easier, please always include **as much context as
-possible** with your diff! Don't worry, Phabricator
-will automatically send a diff with a smaller context in the review
-email, but having the full file in the web interface will help the
-reviewer understand your code.
-
-To get a full diff, use one of the following commands (or just use Arcanist
-to upload your patch):
-
-* ``git show HEAD -U999999 > mypatch.patch``
-* ``git diff -U999999 @{u} > mypatch.patch``
-* ``git diff HEAD~1 -U999999 > mypatch.patch``
-
-Before uploading your patch, please make sure it is formatted properly, as
-described in :ref:`How to Submit a Patch <format patches>`.
-
-To upload a new patch:
-
-* Click *Differential*.
-* Click *+ Create Diff*.
-* Paste the text diff or browse to the patch file. Leave this first Repository
- field blank. (We'll fill in the Repository later, when sending the review.)
- Click *Create Diff*.
-* Leave the drop down on *Create a new Revision...* and click *Continue*.
-* Enter a descriptive title and summary. The title and summary are usually
- in the form of a :ref:`commit message <commit messages>`.
-* Add reviewers (see below for advice). (If you set the Repository field
- correctly, llvm-commits or cfe-commits will be subscribed automatically;
- otherwise, you will have to manually subscribe them.)
-* In the Repository field, enter "rG LLVM Github Monorepo".
-* Click *Save*.
-
-To submit an updated patch:
-
-* Click *Differential*.
-* Click *+ Create Diff*.
-* Paste the updated diff or browse to the updated patch file. Click *Create Diff*.
-* Select the review you want to from the *Attach To* dropdown and click
- *Continue*.
-* Leave the Repository field blank. (We previously filled out the Repository
- for the review request.)
-* Add comments about the changes in the new diff. Click *Save*.
-
-Choosing reviewers: You typically pick one or two people as initial reviewers.
-This choice is not crucial, because you are merely suggesting and not requiring
-them to participate. Many people will see the email notification on cfe-commits
-or llvm-commits, and if the subject line suggests the patch is something they
-should look at, they will.
-
-.. _creating-a-patch-series:
-
-Creating a patch series
------------------------
-
-Chaining reviews together requires some manual work. There are two ways to do it
-(these are also described `here <https://moz-conduit.readthedocs.io/en/latest/arcanist-user.html#series-of-commits>`_
-along with some screenshots of what to expect).
-
-.. _using-the-web-interface:
-
-Using the web interface
-^^^^^^^^^^^^^^^^^^^^^^^
-
-This assumes that you've already created a Phabricator review for each commit,
-using `arc` or the web interface.
-
-* Go to what will be the last review in the series (the most recent).
-* Click "Edit Related Revisions" then "Edit Parent Revisions".
-* This will open a dialog where you will enter the patch number of the parent patch
- (or patches). The patch number is of the form D<number> and you can find it by
- looking at the URL for the review e.g. reviews.llvm/org/D12345.
-* Click "Save Parent Revisions" after entering them.
-* You should now see a "Stack" tab in the "Revision Contents" section of the web
- interface, showing the parent patch that you added.
-
-Repeat this with each previous review until you reach the first in the series. This
-one won't have a parent since it's the start of the series.
-
-If you prefer to start with the first in the series and go forward, you can use the
-"Edit Child Revisions" option instead.
-
-.. _using-patch-summaries:
-
-Using patch summaries
-^^^^^^^^^^^^^^^^^^^^^
-
-This applies to new and existing reviews, uploaded with `arc` or the web interface.
-
-* Upload the first review and note its patch number, either with the web interface
- or `arc`.
-* For each commit after that, add the following line to the commit message or patch
- summary: "Depends on D<num>", where "<num>" is the patch number of the previous review.
- This must be entirely on its own line, with a blank line before it.
- For example::
-
- [llvm] Example commit
-
- Depends on D12345
-
-* If you want a single review to have multiple parent reviews then
- add more with "and", for example: "Depends on D12344 and D12345".
-* Upload the commit with the web interface or `arc`
- (``arc diff --verbatim`` to update an existing review).
-* You will see a "Stack" tab in the "Revision Contents" section of the review
- in the web interface, showing the parent review.
-* Repeat these steps until you've uploaded or updated all the patches in
- your series.
-
-When you push the patches, please remove the "Depends on" lines from the
-commit messages, since they add noise and duplicate git's implicit ordering.
-
-One frequently used workflow for creating a series of patches using patch summaries
-is based on git's rebasing. These steps assume that you have a series of commits that
-you have not posted for review, but can be adapted to update existing reviews.
-
-* git interactive rebase back to the first commit you want to upload for review::
-
- git rebase -i HEAD~<number of commits you have written>
-
-* Mark all commits for editing by changing "pick" to "edit" in the instructions
- git shows.
-* Start the rebase (usually by writing and closing the instructions).
-* For the first commit:
-
- - Upload the current commit for a review (with ``arc diff`` or the web
- interface).
-
- - Continue to the next commit with ``git rebase --continue``
-
-* For the rest:
-
- - Add the "Depends on..." line using ``git commit --amend``
-
- - Upload for review.
-
- - Continue the rebase.
-
-* Once the rebase is complete, you've created your patch series.
-
-.. _finding-potential-reviewers:
-
-Finding potential reviewers
----------------------------
-
-Here are a couple of ways to pick the initial reviewer(s):
-
-* Use ``git blame`` and the commit log to find names of people who have
- recently modified the same area of code that you are modifying.
-* Look in CODE_OWNERS.TXT to see who might be responsible for that area.
-* If you've discussed the change on a dev list, the people who participated
- might be appropriate reviewers.
-
-Even if you think the code owner is the busiest person in the world, it's still
-okay to put them as a reviewer. Being the code owner means they have accepted
-responsibility for making sure the review happens.
-
-Reviewing code with Phabricator
--------------------------------
-
-Phabricator allows you to add inline comments as well as overall comments
-to a revision. To add an inline comment, select the lines of code you want
-to comment on by clicking and dragging the line numbers in the diff pane.
-When you have added all your comments, scroll to the bottom of the page and
-click the Submit button.
-
-You can add overall comments in the text box at the bottom of the page.
-When you're done, click the Submit button.
-
-Phabricator has many useful features, for example allowing you to select
-diffs between different versions of the patch as it was reviewed in the
-*Revision Update History*. Most features are self descriptive - explore, and
-if you have a question, drop by on #llvm in IRC to get help.
-
-Note that as e-mail is the system of reference for code reviews, and some
-people prefer it over a web interface, we do not generate automated mail
-when a review changes state, for example by clicking "Accept Revision" in
-the web interface. Thus, please type LGTM into the comment box to accept
-a change from Phabricator.
-
-.. _pre-merge-testing:
-
-Pre-merge testing
------------------
-
-The pre-merge tests are a continuous integration (CI) workflow. The workflow
-checks the patches uploaded to Phabricator before a user merges them to the main
-branch - thus the term *pre-merge testing*.
-
-When a user uploads a patch to Phabricator, Phabricator triggers the checks and
-then displays the results. This way bugs in a patch are contained during the
-code review stage and do not pollute the main branch.
-
-Our goal with pre-merge testing is to report most true problems while strongly
-minimizing the number of false positive reports. Our goal is that problems
-reported are always actionable. If you notice a false positive, please report
-it so that we can identify the cause.
-
-If you notice issues or have an idea on how to improve pre-merge checks, please
-`create a new issue <https://github.com/google/llvm-premerge-checks/issues/new>`_
-or give a ❤️ to an existing one.
-
-Requirements
-^^^^^^^^^^^^
-
-To get a patch on Phabricator tested, the build server must be able to apply the
-patch to the checked out git repository. Please make sure that either:
-
-* You set a git hash as ``sourceControlBaseRevision`` in Phabricator which is
- available on the GitHub repository,
-* **or** you define the dependencies of your patch in Phabricator,
-* **or** your patch can be applied to the main branch.
-
-Only then can the build server apply the patch locally and run the builds and
-tests.
-
-Accessing build results
-^^^^^^^^^^^^^^^^^^^^^^^
-Phabricator will automatically trigger a build for every new patch you upload or
-modify. Phabricator shows the build results at the top of the entry. Clicking on
-the links (in the red box) will show more details:
-
- .. image:: Phabricator_premerge_results.png
-
-The CI will compile and run tests, run clang-format and clang-tidy on lines
-changed.
-
-If a unit test failed, this is shown below the build status. You can also expand
-the unit test to see the details:
-
- .. image:: Phabricator_premerge_unit_tests.png
-
-Opting Out
-^^^^^^^^^^
-
-In case you want to opt-out entirely of pre-merge testing, add yourself to the
-`OPT OUT project <https://reviews.llvm.org/project/view/83/>`_. If you decide
-to opt-out, please let us know why, so we might be able to improve in the future.
-
-Operational Details
-^^^^^^^^^^^^^^^^^^^
-
-The code responsible for running the pre-merge flow can be found in the `external
-repository <https://github.com/google/llvm-premerge-checks>`_. For enhancement
-ideas and most bugs, please file an issue on said repository. For immediate
-operational problems, the point of contact is
-`Mikhail Goncharov <mailto:goncharo at google.com>`_.
-
-Background on the pre-merge infrastructure can be found in `this 2020 DevMeeting
-talk <https://llvm.org/devmtg/2020-09/slides/Goncharov-Pre-merge_checks.pdf>`_
-
-Committing a change
--------------------
-
-Once a patch has been reviewed and approved on Phabricator it can then be
-committed to trunk. If you do not have commit access, someone has to
-commit the change for you (with attribution). It is sufficient to add
-a comment to the approved review indicating you cannot commit the patch
-yourself. If you have commit access, there are multiple workflows to commit the
-change. Whichever method you follow it is recommended that your commit message
-ends with the line:
-
-::
-
- Differential Revision: <URL>
-
-where ``<URL>`` is the URL for the code review, starting with
-``https://reviews.llvm.org/``.
-
-This allows people reading the version history to see the review for
-context. This also allows Phabricator to detect the commit, close the
-review, and add a link from the review to the commit.
-
-Note that if you use the Arcanist tool the ``Differential Revision`` line will
-be added automatically. If you don't want to use Arcanist, you can add the
-``Differential Revision`` line (as the last line) to the commit message
-yourself.
-
-Using the Arcanist tool can simplify the process of committing reviewed code as
-it will retrieve reviewers, the ``Differential Revision``, etc from the review
-and place it in the commit message. You may also commit an accepted change
-directly using ``git push``, per the section in the :ref:`getting started
-guide <commit_from_git>`.
-
-Note that if you commit the change without using Arcanist and forget to add the
-``Differential Revision`` line to your commit message then it is recommended
-that you close the review manually. In the web UI, under "Leap Into Action" put
-the git revision number in the Comment, set the Action to "Close Revision" and
-click Submit. Note the review must have been Accepted first.
-
-Committing someone's change from Phabricator
-^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
-
-On a clean Git repository on an up to date ``main`` branch run the
-following (where ``<Revision>`` is the Phabricator review number):
-
-::
-
- arc patch D<Revision>
-
-
-This will create a new branch called ``arcpatch-D<Revision>`` based on the
-current ``main`` and will create a commit corresponding to ``D<Revision>`` with a
-commit message derived from information in the Phabricator review.
-
-Check you are happy with the commit message and amend it if necessary.
-For example, ensure the 'Author' property of the commit is set to the original author.
-You can use a command to correct the author property if it is incorrect:
-
-::
-
- git commit --amend --author="John Doe <jdoe at llvm.org>"
-
-Then, make sure the commit is up-to-date, and commit it. This can be done by running
-the following:
-
-::
-
- git pull --rebase https://github.com/llvm/llvm-project.git main
- git show # Ensure the patch looks correct.
- ninja check-$whatever # Rerun the appropriate tests if needed.
- git push https://github.com/llvm/llvm-project.git HEAD:main
-
-
-Abandoning a change
--------------------
-
-If you decide you should not commit the patch, you should explicitly abandon
-the review so that reviewers don't think it is still open. In the web UI,
-scroll to the bottom of the page where normally you would enter an overall
-comment. In the drop-down Action list, which defaults to "Comment," you should
-select "Abandon Revision" and then enter a comment explaining why. Click the
-Submit button to finish closing the review.
-
-Status
-------
-
-Please let us know whether you like it and what could be improved! We're still
-working on setting up a bug tracker, but you can email klimek-at-google-dot-com
-and chandlerc-at-gmail-dot-com and CC the llvm-dev mailing list with questions
-until then. We also could use help implementing improvements. This sadly is
-really painful and hard because the Phabricator codebase is in PHP and not as
-testable as you might like. However, we've put exactly what we're deploying up
-on an `llvm-reviews GitHub project`_ where folks can hack on it and post pull
-requests. We're looking into what the right long-term hosting for this is, but
-note that it is a derivative of an existing open source project, and so not
-trivially a good fit for an official LLVM project.
-
-.. _LLVM's Phabricator: https://reviews.llvm.org
-.. _`https://reviews.llvm.org`: https://reviews.llvm.org
-.. _Code Repository Browser: https://reviews.llvm.org/diffusion/
-.. _Arcanist Quick Start: https://secure.phabricator.com/book/phabricator/article/arcanist_quick_start/
-.. _Arcanist User Guide: https://secure.phabricator.com/book/phabricator/article/arcanist/
-.. _llvm-reviews GitHub project: https://github.com/r4nt/llvm-reviews/
diff --git a/llvm/docs/Phabricator_premerge_results.png b/llvm/docs/Phabricator_premerge_results.png
deleted file mode 100644
index ce55f231148b5fdce97559b2836c57e73d4e6c81..0000000000000000000000000000000000000000
GIT binary patch
literal 0
HcmV?d00001
literal 28229
zcmbrlWk6iZvNlWz1WO1`@WCAd1a}A?BokbN2Y0t%2`+;>!QI`1!{F}jHn__-Is2S@
z at 7{;^*9Qw`&1$Qz>aMPOs#c(aoWvVsd}J6Hm^V_AAAvA1aPrXmGQ?NV|Btjny)ZDy
z<0hh_3R0q?00mnsBNKB&7#PXGm^cK*C^ej(<*RH?b(j~lzc_apzekUV#-V0lfP_Q>
zNl61{Vt%6&qR^40hwK0Xd@{)abYvN- at 33O@QUJa_4X8Ngc?Sp#x<;1=N3(82cT3Ei
zSBp-NxT~QX1el<=GBg9<v0-|#41&q-o4?tdAbnVPFZ2>yNGP?2p+>bA@$K7J0fR$c
z)mI)ciHQ)^Pn)+_kf%agn>sxX7zMKSK0+2=%vBD9kTU-aa~K8o039!}8tb4&G-Vu8
zcru2RwFx{=&aS at kkZ$>&k7CZ`MMyBI1A2kL7l0&yr#dPxcAqG!(2RQ9Dhk?=*i6cx
zz73kCxU;a))+y~HkuD~MHX at 9F$b0 at 9dG0SyAVIa*v at YqGlTSM1Kdx4T{qc%op0*2b
zmSYo06BauV at eERF0I&&>I+*y9I>Z$E!nWUL7|yuIPsRtL;64tsY8<4z2NTB1N0?iP
ze>-N#J${I<;F}%DQ`-viAU9U4;uEP+3F=K^0W*v)w1CdPC8YHj_MdK_Wat at l|0KcW
z0k56+rq{o-O3<MQjF=q8zIGct+^62>|8k$}dGl#@&RkpZdy&(W=7Z)7eWqM4Ic0*M
z`|G^8n2f==Ms9tV7)E~JwR*fq)>bZRU=0TWce0&Xhau#BDE2!6FaXByCH^sdO&ijT
zcagcJ<)tF#64;+!>|RluBh-8015+sNR}H50S at rojnD-7=#$oOA-n(~*`D@$mYR$dq
zQ^H at Jhk6>|+h$#1^3t~4Z>M@$Dqg0uhcKdV4qT6XdHWgw>yrL@!kc3RfvOEQe-OP6
zRz9m=2<=sd5T7dY%y$G<Z^R;)!r!kHV1n9E%MhZyrL7SszOS!Pe1qL?6SIb2fT<N?
zc81CN`mPB^e}zB(I{*>kGk`7&byw&|1h)aoD5+B~F7gkubY~hQX at 9r~IQ2IcK0)bv
zd9Qg8Cq)EBjnjii*z*t?5Z;Jnju7myh4}Q9u@=D-{8oNXWYi{XjnxDv=U=(P$3?RA
zDz07Wn57QA1#$Vin=b7=EV0B3ETrt9F)_9D9U3decXTged at z1ZWgvg1%%fA}FMyv6
zZ14qTXlDrgD*r~8_ at hRsG2`XP=r;}?lxCb}Y^@(9!kihrBTgf}J1pm%ui-NTS$gWe
z#>aDgqBDZef%)Q--<{m8*?q3}g9TEqT0}SXZr|@sTetprSz(z*`Ca*&84mNej)=Tr
z9jg;ITU?x)@521S-PkLat6{55E0*g&Y)DQhnoyT;AV1~XP>u;sD6ccGmG3R?+3w+l
zy}wFYllq}^`NjAh`gQo>w9B@?*Y(Mh{6N)!o*7`$`KA-7$A7|lLVCg&_;HM!I|?WA
zI_n|}IEFN)GzQqkR0}j0zoeoDQEpglkZ*9D@}FuT`|Eu?$)ZrGpq;0wj+Tk;i4M0_
z<d)&iA(XI8(X7|ZT(GEDIfZi(b at _1*yy3gSxcPF*xv4{kh82R<gsqBfhTV at nL~~9b
zLJ!2Y!0Nza!>*+xR%*)O%JBQb3OrR>quHb<0yboQ_$c=IB7aGd!vXW+{ROLoDqf*^
z(SV}d7bc)U$wDz-PDYkqDMlu!5LjZXEmjZ&WCt1+80A^2 at aNCv-nyht@pbbZH8Gy;
zZ7-%?30t%z=HjaqD-;VCs~lGH$S$hzYkB0lM%|LXsrr%7O%{rckMM!XtSPyaZ`nb>
z&2#lW>I`Dmo at kVao>=(dt%;*an3;*$jTut)rHR&<YkqOTVSY+Zvqqzmo8r%c^^%V1
z*<w54ZEjir?sUTuX%nI<7A at ID7_Gn~;YG_uB!2zoZ_S~uZ(PIA18?mgupSm~4{!Bf
z at w_5^RrqG_^$`Ka>)juG9nC*devpKOgzANI5U}HgzAMCI3q1?j4<SiZ_{8_A;#0w=
zqeMN~-JIQ=J6WrQ-$tlLe3iD9Nn2(0ncU0ntuDi`1F+lhKJZE?w~W0wuY(DLd4h#y
zl)zuXp|P^DrA4ocFp3=29n?K49m|Hw1k4}W#QUg5j51||2MILTG- at pB54CuMQqmTA
z8jTvKFSjl=?_OTML{<EW_Hz*R5LJgLg-|T)A}mwxm7J6uw%migp(~dM{X+p;_bk{Y
z<&1k<o+*rJmWf*H(Yo4N)`@?Qr((pJ)M<6qU)0jolA+eu66loZ2D%GB0>0IH8!Hjh
zgDLMJA7)&=&Gv(qJk%!Sq#rydv*9qe?^_#ug%9B%i4Jd-|0Q2r3bLxQN`UAK^0z9s
z^0cyeAv`HPTD*w=p8h at M#lt5?sw6cqA&Nb+Cgu$KN7SI#bSSPE<~R(<mPp>Bu%eFs
ze6QJGWBYOVd%riDDJhd!?Os(|HOAG&^=GEjIsed3rRVU`n1bC_ZDX|e>a+Ie`Ap)E
zNgri0=Jhx9G4xIK1v+m#aeAcJi`J$(7XzjPwtG0KS1|N23NX8I at 0gY<ow-Iy%K_z9
zfhV8^%IR2BhCx+V&xCu{sfsUB at mVujnNm8cy3nod%*s|z<`Qx^xCHk6eX?<|6=J(s
z*R^0wYf0NhOP+6;-w2d&A#TE0l4;>=4SC{W1QfF#in^-aMxOVD%!K^-<ZcAq!t(|J
zv_{G`-CT}NiGS6X3DFGN_RU4HQz2t01(Tj&*x1#ul0`I7P=O#6zT8LLo7^NSokd(R
zh4J*ghw3IZw%~qa7f%<#Vv$n4Qd6DcM%RwL-|Qjm2-6~FQPVZ0<2rGzmd?#jw~22$
z-|P~2E`Dn+cV2IlEl*NEtv;RJe(SOQq^0Gp>7AGERk^>_4;fuPYlST7)fz6xTKOlp
z?~6@|QHtr*RMcue{oeXHMnYAaZN9&BRQJ$^dVu;ntR;n**DMG-_$=tBqyK^Fg6zCj
z-Q8lUp<7AJOq}8o<x$K*Ozf*T4hY*!t^RTxtG1d|y^4#dzfo6g(AzuiJ1df7J_Vh8
zB{jvH8;Qs8mk1AUIh65~VhG!b`?=50tp`?z(sl$VmCY1!mAv at LxX6kF^LFzb3X1s)
zT<qP5G^z6m_+y<9rfkyI2QP3g5C{|rg5<tqf-r}@<ZkOB1|xl!U(UZ=w7z=;+9bL*
zl%bny&T>t4nt?caIIohC_{Nvk=4@|^HfPDV?T2I1RJdE4V`dVUd0a>#?aoPMhnrm!
z!J>!YITFpFM*CX*&k|Rg>0p)8Ypwc;zMUrP$-}*RGp6Yw&0HO;hE?axa`3PH^HS8-
z)Fa0O%cfoX%A44;;@DJw{^DAGOP!{5yX}6htwn<7U(Ng;qaH6G0w2a+47K$(hq#qO
zwinWz%N|L$bXUp!B`Cw$NmL$;ZZ&)-KD&C37?<r!ZA2l69{j>>4fc9sO at 4|#t=dQ!
zs+>cgkF?A5%&bji_7u1mxz<}V{4I#}^!cQJW0Kj+`EisThm+%8{oM6*aH at 9CD!i%E
zYg&L<;PKjH>n`xEKgp!vlzWEP-aX;n&1`27a~*TGj%;g<JId{)HLIO1uot5|CmRMC
z&srK8#wrZZz(qWY8t?<alsY;&{%Y_ZH=gP^%~{+{K8YNrdjCbhDI5Uq#yR~BOb0D(
z at O3+X?n7Bhiupablh(0 at tzJ?#-~(+!vU~83crq=F&K)&1bs`mYt1@}l5<>dnLr7{G
zD?c~PLGI*NFA2))#=&n7f*03Uc%PKMzI_yU!fXt~8Ki^#;03jE^$b;|jAUhD=%DwA
zFt9H$U|vG+UO<0gewx6*{p%hEh6?%#1M?E}0|o*5i2?mnNQeDTDV%)z%m3WNl>MnF
z{6$ns3i|m)-`3F3((ap;J;ucr9}EnvfQh22y{had9(^kdCS3z7JwqmE3+q2kVECMQ
zptlx=_PPLP3v)|59%p{Cf7RfD-v4>bOa}N at 6?-#&GF4dxfT)$NA%KJFJ=1$K0b~FG
zz-Mb<!~^^&{_p0{Z~SE6?Cq_2n3<iNoS2;0n5=A#nOV5GxtZUyGPANWLTfPExmeok
zIx||@k^j}nfBN}oXs2&$Vr_3?WeNDxudbezgFQbP*`I;_=jSgv4V_K?cO*- at e@_cK
zLFPXt%q&drnV)NBZ({WSX!fV%uV(+6*I&c&{ppNH!Nl3nT<xQY1(d5$(gavIIr#oH
z%zu^qFQI?6RI)R)6}7T}HnbP`U$OkV@&7ISXTyIDsrrA0WO>i_f5-ekMgOPipE>Zz
z+nPX!)BVFl0Tw>y|9bZC`h3iPIQ)M&{+Bra^%N>k0c1Yr|5+OX$VF_1mM}0vFj60d
z6`fxkq#(G5P80Nypt}V(PcFHY0w?K;@fox4i}8!63S^7NGE7xy#b^ui)T^(S+&Y(7
zK!{|*7*A)s({9c6_4QXj5T!hG(>92Vo3`DD-K<h{Qn$Hnj_wfnu&FQrFP^;`;T8^-
zHf5hJgFck~zJ{a&_k5|f(D${#ms|s6&-WZe?T#S%9qyT{?Zt~AYSfkY!Os<bhoeb7
zCi;I+ivTU;`rg6tJVEKs?M}}Q_#KWA&Dtr#c(B11tkMLzDctA6AjHsX9>#pWqX0R$
zwT9ne8~M%@@?>h`*|z!n|6-$qB1XH^{q+fj=$;}52JA_vu8o8&OZfBC(5CmUv$W|P
zJj{2#x$a- at k=MjfNNzZ6TZ3!wivs+zK2^_+drSQs at 0`_O-y?f>zbNilGhA;H%Uwg#
zbogr1{t=c!=$VVfU+80#S#l6{fQ^VsO8lv*HQ}@M0BGpN9r?~8S<jYIpd}$G at C6Q5
z4wpy4AVvJw#YHJ}(n(8(^Q>S32BC84+?w5<k$R5*$r$O*Ygp(g|J^I}Nv9Dkmb~8C
zf!)Egbjd-fvIz=+e`Xndhtp&8=9J at eIlnGnXgDM?k|TZv*Z=bA=dYvrM%)4+ES>nf
z$LkZ!di$Hig_d>9uI82XXS*Sb`tD}Hv6WZsy&N7D5rJlg4pp&INmSL*4BC?YF^o($
zshjt#7xE`3_4J{8)3JJDrzmisT{c`*_!#ep7IZ|+nyZEN?&=zTkEvzblQE_J>ZGKk
zEV&pF+wFcP$W$J~$$C%a7B{ajuL&PeYAj1C85`SfnID)NZBnqzZD$ZO#fZ;c41Pwq
zP at Y&(dDB$#vG_$D%(BX)E^t#A1{v6P?8g?VR)6+<uqg54^C&=~l#5m%!KC_>9-hPj
z8EZ${`|xz2?=7hZNyRHYVF)13izD?=KRLOG(sD!X%VTNn(`t3wT3b!+FohEtfX<|y
zQGclHu#r1_`&lWBMhQi$rM`2<=PV%aOI5QG;`4Usz98T<oIdgemb*)t%omjNDIRh6
zfhZ at HN(xyetId?gW9hhRo!(wqe5s~0%yu62xxMW8`Qr4B1Z8upnD-QN>Tud>^u|2+
zXZ>Y^3-18`S!k~GaUf<-Swf_ON2}`~STp+nK}@tzbTGA%93ER%6c0ot&MUSgGPJ)P
zZmm!7sU$WkcbHZsPTpWWR?BvC?~Rt>4-A1dS|@_K+nJ^Px%`-VwZ`p0OlnY0s9-b;
zrcv*#U0l_LR6kZ<jN34~T7zCnm at F(fvOwB8U$G_nV98B#%3|i%yn4NB)R9bPxS33U
zbe}<AMKxV&p92yyGDy?P5ED@(5QFOVq*G(c%Cm~p`<n!yf5EYx{7c<e?G)_moyagl
zpY*Z-6IfkXCV>DIpJ+)Wg1#8`pk}v*?<lRnTxr^TV9p4omGk11GR?R#<48Nwg4 at D+
zJ-C2fV`JxJ{I=fG5~mQO4sCVz=*VU>T<|H<ZkyQ*9ijY-br_H2R?9xYz1VZB3GEQ6
zNg0ee!iHc~9V!OQ)-&O at ISpxp-x~ixB6(|X^1<5eN;4(Upbr!P(Gq;H+c`$kI_!9B
zDmgpWMIi*AOC(@g5f*ytZ%fkPF)!hG#7)CqpcDb5MBcAR^HP=%<_*YP+ji3N#OEB`
zjHfBNjNE*7!z~fQmTK{N#{@<K^8gj4Jb3d&xzdp$jtgArB(<)K%4)5nYZ<--Ep&C}
z&PY at Ao>xcUN8cWMH1%k=^Bo)KE|;|DR4yP9)A?|%FYt@;hju?C3`w8s6CGMP)tava
z23fE1#sV}5gJl#FfMV4e5hurrv{3}Px?yI~BNYxk0v;qDM$aB&0kd%0h0Z>8<X~mX
z5kK_23#FW&{glQ>I^c8irTzrj9s#MiA<;&NL4Uk<5YABUS(#x)k_iIQLT3q&q*Iee
zwKa&(1-Ls>lfT6NZRKj+p4cn$zjW&#E%*ucGgIn-M%kwx?vv)b1!TB2v25gQvXtX)
z#>UN&$fz|4382=}O-52OpiMpN at h4=@m^7!~WcaM&TOS<}AC9o;)d6ot4JQ-eVs9$?
zg9&igme-Le;taP$@}{Ee!ok`)U at m*RfKbpzyw(J+I`sTSnecOmpZByJpuZCn at iiKA
zh{X?^(BdE&EP9$va10u_g at eq-yhuRXFJknSru}Qql!^Q=(%RLTLyhcoP<KRcJ5~H*
zIc}4lvp?3t?L1SV#Nb5aw#oXJJCF0hA+Nw%@f at 92MZi~;R5oMgejhP<_zd})qJ)jx
zP>qJB6HU9c!$r33v*hO_yD~_Hw%y|Oy^ESM+4JbCiLA at E6<f}7pq>cr9gWT6nz}#s
zSugBM5-Heft#Z<1fDnVGOPN0l<}>G5gwQ#K_4R=ZZ477O_>e at xX5e^g(-!QX4P1**
zLnh?|SISXlQAecv>e<H8m}Tain4967FP}Z>Bmu5y>CPDZTY=3K&z|hE(1Wsx>e!v(
z+1}3qLMIfi1DI}7&u!l0L_`HX7ul5?)n^5_Bm8|$>O7wM67(z!+0oOTPZQhD%AZ&8
zzA#-;J1p`Cl+O{?W=1A-vcc}Xt^e$-GZ3Km+^Bx)jLfryO at I8p)@KGg+yi=U<$rt&
zdsJdSKK;}}-=+HFIntr$JmHJD&Zy+wFWq(Cc0$iipggH<lb}`$R;ZRJ?tMAhbF&aK
zhuSa{HA8$ovd^)11p_(@CS5(!XD2Zu4dt$Ric471b0oG=LX8;B_D+%KX^Vj}cZTPT
zkn=gRzRN(@M4ext|Ff!6j~+@@xx*H><#S}ch=VQ(8zfAW=aq``AJb}oz;5ALvY4PN
zVhw`|=Xu3f{Kur5O4zP at R^*z{1<^_QiQ!qB6iwrgDOt=mZ1b!sSqEJYfim%`0nc#~
zPy;m<F*J-**QuV{K-PgUU6}vB1&k;QpxMahLwpU&l^0zOms8ofd-zU`QPiy`_afZ4
z>*;gEjdI at E_%tN2^l4q;O0!;wXu|NHZ1Ua_hb{^Gq;kmv$nBt;;p1BM?KXsR-*A2E
z!S?BQhormDzU-l(y|gDGn at ovz<ECr&w1RElQX%lJClr(m2GWk%`9I=a4zo1sbyU2Z
zrr73uLiWR%pYZyvYw`$2-9Ic8c<V5$^wUZef=7);gnXq+dgiE!l{v_7+#GtK&=WO%
zZ_jI2qlM_O>~3=nD*cdDr*+l*tuzLt5xQB3=e9X!;iXk{IH7g=J3OgKDYnoizGuXI
z3{}l*0GtTfL)uF(p+|CmZ`Arz{s5=vy6qCH>s_O}bJX9(0<irfOwH8Mf@&hSu-;3p
zpBKZiL<oi_6`^BJz09^-3!5|~JuSY}n{%P_wqxTJJIgt@?C$3SG?1T}2w~bbz=okE
zW<y(--u4nD1B+IC*1XT?H^$3KvmRS=@dY(FL|d at EC@g_=YC!7PAeZr89bV>y;N3H9
zgi;fmtp~k?B4x77*fhj1sGQwJeA$qsL{ufqvp$W}lO0B%ds+){|Lr5BHw1Nav*1cJ
zp|BG#s~fvQCJDd({3dDz?Z$OWz=aSiqcn35_qy$N^GbHRoev|HMgNJHXiLEApB_nD
zA=%1f0lrb==+CwlfkO)2_Uj7Ebz-$flW+#@7AaQ;OZ4oQ-){Td)?6+tuo#my1g~}i
zE7$C%nWgW(LUc*{YbnESA(szA33YQ{<`jo1ANFx;a0XKZ5+)cE)G)e(&6=+=sAcK4
zBCMhnRyT2J at PHIm9502lwRagnbW-m7%^uqx2IGNAr;fkRr`#l%mt(3WI%*NUlZND_
z?P(Jkvj_H6h1VK2s>W-_C}a9>#sgP<&p+ogOmSG{w{S^+W0ND4pwwovx-S?X%aE2k
zk&JDd8(BESrBpzoxdc@{a`ih!8#f_rmGjWOJ)tg1@^~M%H%ovC`G@{!@`P#*?I*$}
zbbiTXnqP{g>gvJNkB_nNmEjQngokM_+s8HbYBc*O+iVo6Ojk(Wqd<(dFO~GonApbN
zg@)}>yOLBYU!eQwntop-V<sOGGKdn)30`_hy)n8 at 4I<StH5n_5-55xf^6~L8oNB_h
z-MCicKZ3on?cGjmVQ#!4ic;Elk{-(nG%T#};kN15^B#lT^#N&~G{&k%-C)h4pQa8Y
z+^+5~&h{n>7_h-Okt-`-7t^FSg939a66-zJ!?2h^5 at BgP%!e8r5q$L(d&aVl9+8 at L
z&RXKAH*=(Rbt4~=%0zG7H6>RBfLcgcT@|?#4lVAS^6?Fkq{-={iT-SoAh at Fn^CzX7
zj2~hjPn&FX!n97JmPoKG1UPdscnh#4smuKG3&JdimCvEeiPAyZAa=jyQmd5DYGK?$
z)=FoIF8N((!@hruVY#3%5)S9lD`~JP_vCf>4w*&H!I($VR7rA+K!zWF01uiCU?s%l
zGZ07>#@xJ31S%p9+$>agaj1Vn)rwo at NRH`REWi&31)A|0Zf%|2Hb^YO&W&{?n(&w?
zbN at V0Ih0qrxSOa9dHPi$?(HDEJ$GYp4O*WXvtGt)+Q~Zr;t0+1O*CH1F_|dS=HfW6
zD93!z<>U68BxBm_i}-X=8;#Wu5}B4D8QsDwy;E1+E8J?<Jo=yq;lKVR#gdTzu}Uxv
ziHjtzkIX}mi6L;k2b+&N1*2I`yOH|opqVT_cQh?78iO0i?H=ZU#z*>hz3r at zr22S%
z-|ZMq6pRcj(Bf%(QxG?xcAVy^IVw^g13)Lsq<+ZvkJ?j`mg=$<t9C9o>R{SDJy9g)
zcO^@zC5eDTT9e8??W#&=ao7^<cV5lEul`ot_J&5Sq7&Hg at x@8QCb>TKa9pG3Tl*AI
z3I6K3&sPuq81JrC86OuZjz{$ux1y-!vxJri*K#`X?-gmjd_3LmV+sg7jSCt+-LQ%9
zTq0NUTxy at Ry`I4{^Wrd{rCwU{1kvi_YrXZ*EWQo4 at 3||%F|gfqw^aJYc5si3>PZ*Z
z{9w3Ifyr8?i*9lA-QVHyQy-<n*ftKDV?oPA at ki4aOJ$nM*z+5p>XdA0$-W5I$mrpy
zZr8WeL@@y`KX;XV;C3EW;UH|K)e`8%El9puTNp&R9a9}hIvd#bqzfn-_LTss)nj<%
z6`4lx(6V%*eY6hU_B`_xxLF4yS6n66-j{cgIWE>eNgn0jiX*#Y6sZc}+BGS)qy??Q
zs{G=iWHl+ at JQ%zaKT(iSwG`4!Xm~8D=@#Bfw!o!S%WyuGx-p-sKy;n|HlXZ{J+ddj
zo+Z_Fz$z3dVC^I#GVl&jhCSFInsTv_j<ib)g|YW#Ewk4$eev=TCD^Tn5uP<Sf@;0i
zY_)UA?RdYTQk at Ggw=-_iqW~pd#9XA^4zLpqKK!NCa7q{X%7R=wBy)SG|DWFIu{b8w
z8Woq9pRl)FDD~>gJF%;(Q>alS&DW_-OjeqrC_C;=rY&xYA+OvROp!&QL<o0Q=Z&Ei
z#owK2`1Qf$xTJ<oxNKIV*2D1Xab5j-=gGp%WT~!ZqTsV!*A?RE6s5S3IwCn`&_)as
zQIh0Z=dhOI2v=wPM<h&1zD?vWSIzyv3RO?+0mn2?%Us8_ooxs6aY-HW-r`8WhWm1>
zuOoMVDO^0%Nd)h*#hr6~t at cr@bXCi&8(+Ul!x>)_M&I1B6$D5!Hw?z031%HmEZ!Rb
zE&*>9;R;wOG9_u&T?l=h^%lEwH(VT5417_;1lR>pPv~_AWK-J{MyIKyVomseN7H6?
z9PyUarzmZFF~#y)%YC4(IK0e<_IiLP^W)HjG77SRV`-F50gVdDeUlDDW^&zLVleiC
z)h%spE}7aF=~CmV54`*x-N7t8z-EP44+}cc)yN+)>P}W>krvXzb)ymyLW*@BL_nPS
ztc(o5 at wXt0!`pD?0!ltI<p=p2Y at 5XJzY$DEQ^9k#uY6D#KL7AkS6r5e&?HY-_D#?j
zGLy;b3>qwU3(qRRZ{>Ejd|*|prhK#YOM{4#kgjDrhHInWE at b;e^6$3v at zx(dV{1?<
z`f6wVmK|OM5!mn{pTcsXZf#v(?X{bW3;15l>|Fld`J}2bWc0W5NvfNNOIA&t&_bPw
z8lv$h$S+MQ21@{Uh0%nP<?=~P0k(`J>t>=aOu4VbCrm_6>rI>3Bbs20EQSOI7J&-G
zazZP&JM}^%$!*d<D4VuumGE3q(O1U<0kR!^CQ7*aMAlqs1I9#o#{ShX-6aPqi9`xu
z;WzR6oCWtGe|>&ki?%Mz0OT at j?|B5Dk#=CFr&{oQqy?shl7dPn1zz28fH|*&22ZoG
zO-wnXvF5gNESe;maY(eLn$6eO*8Fp;F7tInzsU8<<Lm3x at k*Gi%e}kAosmiv!r!9w
z9~9#n#8>PcE5r(t(0jKhw~;Wh8eP$<PHQ$9&hqza;%sltu&6{UeX98oSS+^I<uLxj
zyYvPQYVbi`ti^v7SQ+xIqrc`ZRc-h0mo$o`cL2(S;6o6?yJEKASsed2>z!L}J<e{s
ziN(-gbYjs)3+7_5<$zBo=j}(Ps-!;(izG*N_g8c#qm6fR{APSb8(g6%>;oSZS>mFG
zvx&wG1)i8XUfECl)_wZyZ8DtNnz5Fa%o6m&?Nb6-{<Yxih@{$PO8wgpwjE%yu`J~&
z%2mp9kCU-bSQYXtSBC<Bm5JR4(|*vZgyH5%oNc}^18UZRNz_i-8|E^LQcFOxPMT6b
zDfwh&nF3Uj2c7!Nq}{!7{V7J#w#*`F74$4UpM7Xv;-*WP4fS>^XFGgWRcIr7dBh$`
z3Pb7`q`SJ7$K2b&(P<qnl17+~+;5m~`&h-(-G3dM4L|IB^o|0g-G%23 at Vf+3)C3sk
zD!Ipf$|tG~HYR%y at kSAt>JbHaW4~dLHplcsKgTZlBs)pSEz?t?Du7vr5!7p!Tn%>r
zyNBhSM=b=7$}@fx7hrKHzyd;E$|wvk8!<&5sIh%RL6?b`N}03O-?*NwupM+Xdn(mz
zq)e(I8u0;lfjKFPC8VX+Bc+jXd$WDJ<q~TYl=Dstr;a8Zq_LR+0Zyz=tN1o5mbeLQ
zYB+g)pdVW2)bg<(dxX at QJ>ziH(d^)nJTxk8YVQS%6Ix1Cr)+g}X6}QwkC<ZUvBsTN
zsT6Azg_AH!bVQtmB7kraV)w7%Xqxkj1Zq+nvKfJd)%HNf?r_07ZkIv%o^Qe~ov&Dq
z)}2pkx`433c8F-;=zYoc(^(>RM#jReiQk6kUY%+_jYGXTT at DNprA7ynHeByt)gf9a
z^Ipx!NX69oz}b*B%}{K)a!14W-s*F1g78s1zozKQq4}XrV6!Mu71eYivuIexgA<1l
z*cs>$r|yJLK5fn4HUR~Kzy5UbP8#U<ot|{I+>NKxMV?=9mbZ8cnPEZnblcZX|D^3C
zURkO};VUZzru3tN3lRe>1F&%sd5IZ6YbX(zv|{LeP4H2r8K2|;Bg!R-2AZRLgpCr1
z|HGrTdi6p*wF&R+Slv~(Zj$e;Bob;*fXkz{H$&#ijTX0>Pi61A)wABiVIJf~i5|x5
zQyjFt+(++Z^R^xn?h+I>UCOE%NPS8(-A_(FZK9FFpa#Vb?nyUP<!@wd!_Ss#IyxTm
z7l7MC5gJ#M1<a5 at K^ESTE4FM`kV*A;VZzv9!D2>Fx>sPH>X_4tr<%QZx at t4!2xQY*
zqK?C!cj1;Rv!!J4cKOb<ciGbZYp^VoB7I}nW-(0FXELh{v=<p(3tqAQf@?ls3)i+x
zd9~)VUSr$e?&J>ss*t-^R0(Ab)2^B(s_#ogP{BNqep!owNP`HYky+No-$!FmWun<(
z3)k2&LzPsbQHh>upaj|Dd1rYh#S3+v%B*i%%Ei91P7fxr)Yo_l3z7mD4|U6zSRAj*
zIqnbO^iUaWmWUhVG)z8}r0do3Vfrh;>9r4=8WVI93g1UT{VP*2`n+SvRa;#ey$A5H
zMPD;1yzJn*@(U%Sxh^irfE3u&D!;9q+n&V@;{Ul-{MY%ZmM at u)GxH2BqDNwSk;Z%F
z0KwQ-A!B4jrdy+y;*f_j;bp&hbVozh+;9o2QDss8%A5$Dx#-aoQ$qe8&A5Mp{?Pab
z*VV(zRGz&#&tZCCu`{uRSUheA5}z{fieDblHw>z(PV4XUa<wh`)eh2Ea)alNok*Cf
zrvo%1(I{|xb6dI+#7{rHeGVfR%_m{LyhJnfnc(OQsMeEv`;x(7 at T#3R?XsuURU-Ab
zM~ecJC~Z4E&gz{t<a;3s&fX|DDI$H%2|HZXarf!5P1#ZyXOsK<U0JeC=c|JO7HRYS
z)*XlMd(?9d9K>#inI+uuCC#ke{BCDYhsiH_hKBQuC_6uEgq?<5y8HtV48Vs?dYcjn
zbP?@Qs=C_PX+EvwBwGr$hgEMvEY?v?^KRXn4<Z+*@<VrX$&30Bc;<{{T^(5JX^#03
zR|N!FbW`W*%XLH!`m_o+EPjt7vG$$*!40$j>%5K%hEJn71-Jegoge1;u+mA#k}4T+
zdiI{z6#O~0+4F?>?;up${vS0rEr>8$g3xdMv7``Ch9(}O<+#)-3 at 6~quw*(7I3G<7
zIHS5u at Ca&wE6YR$D!;vZ;h72Pow56y#tf*3`{sgSw|!Y1{+bCrflb}VzU6X=YX=4{
zYG*_qLG-Kg2Qr~i3Vd0dM(Mv94d at hTQ`BTWZ_2p-PTGIq!cK!fIM(Tbt@%H8{a;_1
zp+V|C8FGV{&z7<zK*6_ozD7cV=Q?kb`D2KVA<q71tiK at wLZ7Ihh#}Q5Q;+!H2>$m#
z$76rc+z%og&xK_v(4zhTCw-OR at _#tje+|*};l)*)rT3erQ8*Ei)c$3eslIXJX8T}F
z31H4As_dXm-0%t7<jckVoZ5lJR*?cFI@(QXY>>C$J(bmFF9l=L)SE9(H+vQp#!pDQ
z3%_jQYkZ-u^!|{j?a8TwR3b$=R&Sgr^!&lj3EgpC&(Cn%J#y#+@%h#@c7=wCeogyt
zSdS12U9Z8&ed<L<LW;C#MBV>YS6`1*5*hnYt29 at WN8N?IJvzPmaLVVT28FXIp-y^S
z1tm%#bS>JRIf^uPHGACKKSogt|2jPxAn6{6hFa&vSG5ORG@*NwBN+olF7y<_KG$Pe
zzZ<9SkLBLSGS0u1UOr;%pvN%0dh413+Wm<G4lDfG$$6Yg5tt^~Z_Gp`i!vFD&)v^`
zh*0<G)*+V9Bgb6Vb1X-Sak3yb?)C0CPjRaWm`Sb7I>8<?CPysjNhTPQO!H>n3veM&
zgq>qq>M7U at 4LY*w4n(|n=?+a#2be4#Y0v_>TF-Z;e%D#>Kb}G8e#<|#q)=KNB~RTA
z$pMm!udSMsxm?77S&~%j%lQ}ukM(D927?WZYy11u at Tc3cZ}%s#oSeWaQI!oUCE9UH
zW*ot_wc%KdKq1ps6|FTIZ!{zamEu_%iSU$IKP1dv-bwmh)}h;f+7~Y{%KpUEV<lfV
z%Vpt&lmB#Q3{T^Wyhyt2 at 2}?F5WHCb#FwvFl2?HxMNw~S<f6+;EvGfoE_FiYlC4zv
zwo8X`t(G1=>r<dl!(fNRuw)D0td{B1UvSiLc13B$$kKjK)?~$twI_<U+jmbrFDf3}
znP%;6!b9>WzX%MR)vymQNkQX67}y*;MRhjo($>~x0%<2buy`Z6m5K$bbK30t&7nz-
zy*DUvhRfdMAYK*Jt{IIck5m-JDWAQKvFyUr_bV<sgD&0NMbRVOF@>BV8o$D7A=f+i
zFzj9>REY10T8|3nnwX%`mFVwnLTU}}#jo*4Wc%Y7Ni}LAk-CC%BZH(~;F`q>btKxT
zp0{84L<pz&J;%PdUgDM1cZHM41E?$(n!boXjL0Ja<u~V-L^mgP?exmDnjI_86*Cmx
zP-eXU=k5~v2*tz$5sTj`aCkO3gBZ<T at nh81#YS)n-t&E7G$jE?v>cv42;vrjd?n<;
z--#_YN|rqm8m+4pOM&X9(?#!sgjO<pSj~=*xovKJI+c_$Romud!lRYoK+DYt>P=Fy
zAIh6_Dt#*a5TjQ!jr%bTPrh^9dI+is6lf{&0V!2V#P_ at QW5X?L#jD4FP*0QfFx(4X
z<TXY=PXANvBNRQ8Ho4Y)ldn({fbsUeDh9<bp}QYsIM}^d0YyGs&UXS0`Xj^ztTZ($
zjO0q^okw+21>)Kfskdr;(tb!zvy)RA`WOHyHE8W(7tbjALrq5SX$!)`Hz8g0215&7
zr`z{l&}0y;78CNH;mHv}n=;_h_1uG+hXyOlg(guH>ariZGbQ!Vga}5)dB?bA&$Pm>
zD5NN(Z#L`UyZW6S<S{j!YBhQ(2a8Us&CFLsQ$&I%PK?PR1pJbxTP`v!1bph3M}iFV
zP6tsG(#O8mz+!2a-Nkj8KUo&`I};L*z*rtAc6g=nd;4$bztA~3RF~ck&Z1nrgM9^u
z6hKNXuM_Ru&zNEJkl0Xs_m)^X9Ya3kyiHIj_>DEa%PECw8Uh?2YejL7i?kxQ<7qM$
z-EpkJFi2Rrc-e4}Eo}oFCA$K$T^)1SW%=3^=5Xpccnady=h<wDl!eZeyf2C}@((=u
z!#@8HHm^S5l51)*>#<T-q<o0e8}|iyV~|urK6zYL1qulTlcEs<LWFvSeX3zgNT6vX
z)daQGZouwylPus(Mg!A=hBikrS0!b1S73c}Y}cODAmL{ALqBQ7&IC_fCuXLAX51+)
zIt<bjh9pt+WVh(k&(j`={>8=cx at T1J{AF(yExBPwHxaATBZgE0S^W^(Q-k|vL&eU!
zQZe5T{n$H?FTEyn#26YK_QOJ+41W-Ey8;{UqG^>r-CjJZ52Mc=pEMU1akRum<qj3h
zu+utdw>0Ulk29z>sBbZ=7A)nvfw=8n?Jm`)U@@T0y*W6IF>BCpNv*%hl3o8b-&D+?
zdF;8^_#|{i(vAc?$?%8fN=%w at Mx(@cwfAZ-A_O79Mb_FHVP;yTv6mR5%R3&$pz64n
z6l(-wGo~*(vl>a}&iCB?cLEanpMY9MXNHLjgW_9a?qZxG`RZ(h&eyGOkIa1dbz+2E
z?&|e=6cLw<1bOfUy~VsO6_Ay__ZDPA=F66hhJ8VUbM0_GD4uh*1<Vjddh$PTA49^J
z$v%eS(Tyz1BJmKL;V1flK-<+d_WT=1HMJVkBsh2kHSp1_7h%^y4uUk6h{*C+3!n7b
z$jBNU{=B68sK$b8epkSJ3E{|eaqwi^3#B=*=w^Qula%RfiQX?jygA`TS|--JYe@}F
zXE%D!es}~Nz7(EEd6oLYweRtZ7WdKD at YA>f9|LrK&LqM~H1z$_F}50v({$A*@^l~`
zlvMnnm_iQquBc7AM?}9Up6cb#Q+USJD`j6tZB0)5ByJO&qTS?5l4rB+`!XurAi{X>
zcc>EtjX^_fp2b?NO3;*@FdSxpdRs=O(-Voo<AD^2%Z4m79;1gr5A7qds;_2)y=>#7
z(8zDzc&6f?EvXONdbFA}X*H6<h5 at u_>JbN%{xE*g+)-UY$lD35Y79Xo%XPGUQPktH
zjCJAXkP7x&)p|WVj}7L(8E4SEtpG%5C=vY^b|_e6<K5$8oGYBu196^~T~7aiU>tZy
zH$~^0;?<FcU)*^=a6`>q?&o1TVJAkXrdkPHM5x9Uc#7y}mQ+XCZ&~KTcmlABl}aq#
zbQLxdzW6~%Kn at gQmp-bk=$}1PF&JPzi}n{~y=hp?HT`W_ZX58;P5j2LMTNq!-GH at 5
znHlLb6Aw{zjMPxHT2Z@{3^vMUyH;?QzfO8Zk%A!+Whaj}JJQFus at -jSo%7oznRKXU
zXz|!n0Bri`*h`C~-3ngEquQYN#ZS|!>ebhZgBpZHSr?T!DfaJGGDiuyEBaR;4ZAXM
z5&rLN4jbYki^CBKgZ)-YXunX!(Z%$edaq?+=u5}YWSkur+Gex%7w1JE%v9^V^0F#V
z{r%u%rubXf)e%DD(Ms at ZG5Y+?1<E?JMnfIyDZaKAqMYQ(8vhfruM9q@*kP1(bME}E
zs1?p<a9fsOhxMNzrw}YU>9PAJdZao7K`~OB7?pNYoqBxR5SPuunq--JT?bv4Y)T^t
z#8=7mUZeEui4`+xO<$<S5{O>H=r?R_JTf853EXhCESjTd;&E;Tp(I%vySw~KYWcB_
zjDpg9MIFb2#_L)lJ3Lj6uk#!G+D-<=K_0M$@zqI}l9lpHY`DS4F1sQA1}Vs|=iNF~
z at owZe6V#2<=Q3urG?In5gx{-WE#y~lW6LR^vdF&%qpGG=eH&NuBxIL*)Z!wVMVI4j
zvfSmdHYtxoQ*`Vug0C=!kREdQvX;rQfJjAF at R``q<c|upVh50>XeBF+n5&k4+ at a|$
z$78}JLT(*K%jNj^nR~6P$<dZly3^eAf`88$tTxf|)btf`qd26^Rh!TSVo*-ptWI92
zK;S{)6$307j{Cx_49eD?2iGRMSBsLHII)V|4<95^SnG!WE7FWk3ROO2RT(yFoqTFd
z=9!LHTppJo964K~;Vi9>tT|^9<5x^zou{J7a)}k-IzxS954LL5f}*h2lUj>Z<JY#(
z9&M4vUNAI1<=FB2h(|Iz7*~ObI97~x?N^a%r4|%gtkcf=q6~}XQgg(IRUow>8iLg+
zEc`TzkTp1uD!KL%$)L6`6hVWWS*={Ei<dUX3B|`5qzPZ>F{{XJhQyf4z*DWv3I77V
zgvV$V4lhQrJ|IUiANb8%s&PH<nh<dh1(yi%3!1N{l=y2bL>6&Y6b-Fbq9R5O0B~bC
zPKL*c!~hG$?t@?aIfn-II{t~YXA++Xh*q~<O*-~N{-*>EiBL+_S9!%@<ql<$D>;5z
zzJRTC!5R(5`NH7q_jyj|Gql)o)RG$M2Xp#1Y5j52YjkiZgyy5KS-!Q;{F=k=b*B0!
zj6#8i4t2H2MCkEj*)>heoPSg!U}!q`$1>2o5hy4r-S<+}>XuDq=5-_)brD0^j3w_G
zF5ts1CNHuHDDl-{6fC4)&%LK4s5uyqCEHX&o7Qp*&rr`h|J at j4?;c}^Thb53#_Y?~
z4^qECBR5(lrd=2nhCRY+)t0&LQ#<^91#nn(bLke*EWxj;O{1ggy-JlW`RB9D^F_uq
z4^w@$9HAL!1&oSi7Zq`FwU)RgV$P}P1~_Yjjgw&iz4>6x39yFf7SWTuoSTlKu<mrf
zZ_lIc{;zPtbJv!2*;@+YF=_a42g={@hI>_lN(^ydxt(|F!t{XvFH6Sv2H-?B)EmM$
zq}Bl}MEU^XH3s4DLh6|{_k$U*^<>BNey9O&Bxl0jO)-^y`hD3_v%7F3<MXvFpmfb;
zs|od0FcctD%yoQ&$E({AWOthBen0A_em~Q^oqm6=?<H02GccD!A}%*J?EfB^W&Nly
z>%6p6{-qil-4A=-pp=P09iKffbN!b+gk7-_nbZ=6AyS~=t|WbsnC=LrGcjbA75uU5
zEz;{ohewgLGu(f=vUSpcA&;l;xnal<Xm-?O(6)`Dp9_m0jN^n<RuLyz;tFe&f*LHB
zjB2kQHDSkGrzUZ^!op<xG at A4XuG6NvpO!Zi76l-_F}lJqcM54MDhnu=opC`ZXE~@g
z)R>wyOM?+KX~>GhQ83>Z;!05Q$_nxY&2rFBI7IB(E#4N3Ec)hsZZStPDRm6?F6{FU
zRyiNywEiNjT}}pXe;+Z+*1ZQPJA1rU`QbjTwN_x$!4H4*KEN1u)nK8r*qt<|jy?=c
zB$nw`3*In=I`~m7KP{NilO!+28JOq%p8V%k)LVk8F}=XJX$wX^0|gwa<+n$_KE{Vk
zxkAfgG73nnE1 at o6J=4$b0+m7<trko2GGrENK9u2)3^9TFKm3p_gVSpVHJs2xN_9$0
zv!ypHwh9{3RwujMj=|Bhr^}|QituKmM(MWb?MJ-&-SSaT+vuk$xK6d)AZKzBT-QVX
zcYX^UP?X(_;QcFw?Dv<y(v#Z+yxmN5Q>t+t3l<$w=?bHwK+EL0ibKjk)6Jqhr}=W7
z{jMXjOB6 at OAW5IP?<@I6xOkZYMOqP7OL#rK9iwFS{HUDEnwLw>cj_}NYs2wp8Eb^R
zg75|LjDZ;Hnr#_t3GV+$NfR3QlP+d7KrSKtEIJW{SVxyyhvR*U?Eo5lHuox`ElCcF
zog at i}9+3Qfihsc&ZDy2c9QfO2ho~fSuq<&x3cCj^PS%8Y|E at cOX1(mxw}s05Z!7_D
zi;=!5b)Ld|`D_*+02y)QlmZ!WhEDO7s;#v%!Q}X_dVn1C^lZaVNuR at h{wwzc28tuK
zUp<#e4o#8z3#CA<d^TH368gHr^55gn|C6x(zppE(Ao9iJ+MXP-BOxO>W;<uaAR)ev
zMtFSd;KpgW0HRkZowwknp^*$rJCBwKC!QbVv=s2To!|-`K|fsI7Q;xzLqoeJQ&Q`J
zhi!3s=sY`s$CYkS-Z)vOzSU}H;mCq!ke^&!xc&OYbNi`9!FRL_RJhDv>h`VVa(wm<
zvhDQb-- at Ec`BEiy*l7-1nnCnm!uwyes2K>0&@3mFtJIM_QPmCfkRzZKD2}YsVv*#~
zTsS<nBj7M$hIq{^+>URYm2N=9=rs$Lv+n>mI!PrB2O)wuz1LD~2UBOzT=hja)R at 9)
z%bCHR!Tj;Z=sA+=h<T@`!`S+LCwT$W8Ff$Mt0eZP-!Hv(Cm{&=8m%#pH#JvRwvZ(c
zvlbhlF5?IJmI%m?5DrTuoNRIl`KjTer(N7rlkqUy;}IKZ6<C|i{gUOr?P4B+TIUcL
zZ`mZL{@Ugr;^{xuGyd2PPJR1Zj6Lv~fU7GtuifE6D2~v<$5^qHWWu%uHfH2O!U;u}
z-C6GJt0Yrr6pwM*Y}^(@AWS%em<kd#KcQ6;cs*vnCgI){`+43yz0Uj4EsxIoSIp};
z2#T$_bbX(7AD}3^x at 9qWv?5WnaSXnGwKVQ~?nMaLXFdQq(!T;%uqA2YJ4;#zOgJ}Y
ze0p+-4tX~vfsETvJ#IV{x9Ikkr}*jfqWW0gBZ3^5oBqA$7^LEQSqU}x&7F<UN@)oi
ze+V4u=0SZhtLFe(!iOWbdiR^ekZY5QNDKZj1u~?uTCI5v2%}EDHiy+BV`~Tr6 at BbL
zH1ej5)RS;#=hUs??~F}baW%R4G&2i7>hf5aA`=`2O{T#l_6VrIh0;L^Wk%3mv-?#F
z-P&p--2j{O`UQGG!A*ECA|{n2fMhB^e<`jXJ- at r+f3VHb04SdM?StCEUXpOz_%^6Y
zokQq84Q}R8;dmTvx4|gOyt!%FvgL3vnieFpHGr3;I_h(()bq4!E-$}bg5zL19WjhQ
zU1`BIQO!20dpZFPUrmae%-%;STnylXRZ5~NjhT^gK;k}=ePLR6*-F9k6i{dkv|oHM
zR&!xo at wD>UJ0>U+niNm<6O|<H(W5nTqYs2%+jTbJ(ig at 1Q~SC*lt5+ALsiDd*LQR3
za66V6msvX!uM($M!eP03D!4Z=vwVJQHi%;=RbON2axRZ#$zy|jIN8e0qDnWKU5A&4
zv(|(Ocge%}khj3ta+xdqn at eVDp+uePYdj9+Ry$b&FT$KTa0}<wD^epzDC)P?6K>p6
zJlsK$d)R2G!P4Yfv)SJ0SS`@+ufowJ at Iyr)<7)KkI2C=VPP3V0_6(Ajwi-IWQ^+kS
zm&|pl^z%u|-*&i_`ty<D9B1l!9?|*lg|~J at ZdcH3<UPN*?QgHewTS<t-#E~$!{7LB
zypsa3A{9Z=0L|4b!*W+3n}mx=t8D<(+><LXKzVp;V*DV9CfLFRA`@fv at Z*)49<nHY
z0+8 at SvqQq+iTuLnrOmHPbmHC*GHIWt4LsVFw?#K8csJ>uh7uTpv2gDxq>?2KYHY4<
z(2tOz4*%!joj-6(B@^6N8y~n}baEvc6<}KGB_H)>fAk0$a*_J+^bC+P=v~)2i(3st
zh1C=KL%1gc&k7I at y^Fkhllfj1 at Ouy;L)!b^#b7?HdFmF;ZYZUdA%(ZPW~rmE+Dv<_
zy63COctPMNl_Q+1Bf*G%Y_KGRSSP5lv9apgq8Pr{Y2<*$aj7G-dc%$rBjKPTlROOy
z$`1klR#1@|tH0 at V-MfpkQjpMt!_9TzctNZ7sZ<9Ki2KW{gk$h)i<q<Dcaxh*r3 at ZE
z1Z|Q^k5IeERMT=SPngJLwCLB-I_DyS^iO7i>5Cw2TAG))j><WYn9vtXUfzE03dROy
zNnx1jGAQ+9InJ}(8W8>gx%;cQD_jqa7ICXaD>V>Oh>D7mMtYzy?0!p?*|_4Kr^1)*
z6g~%KPkdgnD-<&A?NSYm<?1J8t7x at K+&!0pXqM)4g+t12H$7>yX{(s!oZ%Ssjyuzw
zGS>E)@$8F{&0wq{E4sru+NFdJ3HknwlaA_d<qq at 2i%(MPt#MT*d<I)2Ui(}W`r;nc
z&Q1e;qi*`qypH!(uL*A}?=QiKQYk#y068%ztXXBKm>rbuz)}~aRH`gImMcTQP9+xy
zZ%3`MTq=)06*FsxYcf=Z{}T6neTawzujnI at s<byHTwF*H0mjyL?ecbiVztJ(F{@XL
z=2)eh1b?d0)17)V*rL<<QYGci45cdUFmb=(3${+v{PpWF!iU0(%I}X3Hx0$Ewd;Gf
z*Zw!lH6EqVmpMKw-`8p*fk;nVhY9*}L-$N=Y=7w0il}+4y1i&0Nq at 0;-spJUi&W0(
zR3_Q6{ZiTZ56tb^+!70YkAU}nq3(83|FCMXuQ1hX-6rgIcgN2A7R_I!cqyxuvp|Wq
zbjkbjmUjzmb!#G%eS5K_vivy?Zh6|8zN7Jbefymc_gs}>Zq|t;<MlmY_&(vo?N9O+
zyEcL~c0Uuu5f3*n#;%x=uq&J?uRB!2QKjRDmnX0KmYP;uPCThTFEd{Yv|rH+u(dv3
z<`${ds<kq2_QysL_e;P3oZ*MMY*N+pAIGpf6oye=Z$8AXiCOmRol>xjY|4UCwykpT
z*YDyQxP{Cw3+<yZ at J?kKDDn;OCPnF at 55D9M^V;l%{6W!zi4I%#ig9Tn%^I at P9T`i6
zJCpKVSoLnxdb2h<o1}m|i*~_^@|A)|NBBdWD1JAbd9o?90Q{QvACZBr93pLbiodFG
zL__YlTo;>)nZM*pn>43<dgvgA4Ty`Qv^tHRbshEZ5=jZykcK=8?)kIRO%$jp0nn;%
zGa75izBdkU%kFF7`m{a>$ooW7O3y2&sm*iBIUex<_Bk!tn2IH$5ttc*05li3HJRGq
zn6%2};=ILPe}q##`1-ri=}8xxddtZqqsR&R`gYOAK%~;G2j|#a>LJpMK0_L<83H2b
z87_lTa2WULLpt$Tk(5VsdS^Rf{_uB_N!X{75aLlC&v$bgI85548a0Pg`ll+wo}^s%
z*BSK~b^_62GRplg*o`rJP-8~P5x&U~F<7!1N|RXf)_5dA-_w7%*IsOm&X>mOEoSg;
zdx?a at uiEqkb$MvDD)PcQUVurDg_0AS>X*kX^`Fd^Bwu+6Dl^A_W&B{d2JsOCX!d`7
zIC~GM%AQPZ{&~K33`S-Az+2}S14TZ!22=AG6AskOW-jNK9PFy|d}$D`*gHq?*tb;j
zuRb#}eh?baxE_|~&)F(&*iq#!oHDQASl?-8K^Cq<eC<xbn--{qwgsRnQVy1&Xqrb8
z`igY9GfMs-_h)56qY9!w-W=uk)aj0+&Q?OuDzcwe((GIB^1CdoDBBlXA*GP@=^}0~
z6wOIjdkDa{bw8*3La5>5U4|I$K;?;mzPqZur~yk6%<+)$j%uq-qi0&r6Q3%T{JWfl
zB!5i4?bQyL2W{VZdGc2~T`X&gZTJX2%jlHS7l)HlKTz+L0ciKd3u_SvgG5DbXehh;
z%o=^kc<Wix*%hw8AUk%Lkq}~rxf9E|92Nd2=hRG3o?Fd#9$ijoALZSRptc63Ol<L}
z8X9WoFw$0|!AbjEcDeg3=(f`53f0c<TF%nalGSLUO(9Jx(_=jVlHB^JO+_iAI_K at b
zw(?8=d>gMM#U{r3vhsH5``4yV9>cnx9Z8(-9LM)iSFK;@;vrrH$z5{X_%Yi*YKgxE
zv`iHqL9bG>4`JWncFm3aA1vnoZn>3Y2)0zh`-G6<Ng0voU^xUsLlB!G4xU1GGoNA!
zA7hNnFnskLDoAJLrPkD_C at IIE0K+|rzy!*42;P`UB&mM4eOQ5i($Cfay%P&n;SZlt
z&Y?i7pN2rwYt at pK(*Li$^NMP!ZJ at MZfFK|NB=p_{LPtP)uL`0_FQExa2WiqIRH at Rt
zASfL~dhbnX(p%_N5JK-|4qscp|9mrRF6Lq`<|Zp^WhE!)<UQ|s&)(18`DyA+PMRG|
zw?1*TLW8lZ^$PT%BQsNWS6Y|xZ8zWR6CoR8U%8786)jK;iSY^nm!YT)fv-=wDGvtP
zqEQ8DODnx$eTk8}wx_r|;k|6N&Tw%t5v2$V1c83E3)^ufrZPwp0p6L+foidUWlA93
zpJA#1w8pv;w}K1JofU7a#Si|5h}FDY881O^Hd)`wUpc&d`HBa<CnZzvj^amzyZP0e
z%3&)><_{*~>y`a%yuwzkSy8(@Z%T+ZlGgcIyv)j|ky}&==|F;D!g7C{jFF#GAnwZt
z=Q~q*x;3esRu_mkMZd_oDqXH-0QQ3L)OrtV8eOT?ShURCi5Jfi8?c%k9dX-sI|mo4
z5HdZwj}>Q+Zj2T$1aW;|Vksl-^WFvZkP%`Hm)dt3y>mvrx?H;$?3yKisC+gXdV#3G
zJHwH}ix)W&CEb4Lb5Wy+^Loz3CMW4K3&zl?nphkFg5gp%2+AA512po at 2$*Dl4N8-r
z$Vei6=5q~Ww<l`Ut^;U_EfY8m9^~spmY98ye^Az(|6<!nWf at tc63yqK$??Q<|2aDc
zZ-)KPr*cKDIJ0emhgNz9bImmta|;_{BA;RU8odlm_oQHx<<2>h$cI at lJk>PuoK*&2
zN$Ud5oR5$mUbEt333{^6+M3#;^AmPET?KSju3vso2kEq4OMFwEbTY}-lkXtf_4
zjf3enK;fycm(W2kRzDC9++#shF>%R at n{v*MPc^HoF5ZmpN3IENtgUj?wO;DaJB5LK
zap!p4u*Qm~^NTvIm(-FtmS}NhL_1umpSq=gyEt{+^xWsFPr*y?s6?16<#66!zUb)D
zeH#c4_ebGtgQX7qoT1TM^<wUOve<9%%c~J67(<IRHWaW;{VjD=b?945SI3G(fU8oL
z_}|JJBn9kmkkp<%=v2tKgAP)*fH7`rz$a!YI=^?j)_xlizTGj?H^Y`nn+W69SERUg
zi}vMB7r at hPjmgwIEcdaVZM)c{ENI~1ho^Y4YBRPvF3J%?O9F6KJ)-i*gdvdmSp>#|
zLdN%ZDNDnwdQV;|Tb95sc1b*7peXpvtz8BKVf;%i8>Alwc(2T&2WF!yFeZZDl8J$1
zcj4!?PTSLp?XwlM34-3Xca@^jzBi8*DwmkMRP#7?8c&u9_O?yM*4Cj=hx$9mQZF9~
z1G3#M%)jYJCKnFL7k=B9J at 14F73y*%`K4M-`VE!iMe`UnLiHH6k?mUakWRaH8(;8i
zU5>X=+#irNrJGI{-^~a+XY&ko-W-r+cLm8Yt>XKvH043L6eFgj#Gy0Va8ooCj7iH&
zzE%HY`nn)eC=7&yRbA?qC-;F)lFWUT0jc>uUxU-C0WTD at nhZ`&CpyoyPd1cOv8u2P
zLbTpnQNERcRsEEVeny>1K=PK1_)x- at 9=K4#WlKDlLm?Fy-Zb-jd&7x&Z+Ng9`LZM8
zkJ8?-FRUk8&or`(REG&4MJUBEN3p!>$5nytXO7&r>&4fv5A*NfB!mtpT2;@t5Q6F$
zTBcZZhP>W<P2+!Q(#LI3%YRme7K$CLye@*|#C7Pg96thYV!}eaVu|k&`qNk28S6P|
zE0NkhKU%$;&R2cWn{*smdE^VnQtupGW6qot>#UzTI)6UU^yeIZ$?wy(`~+&1z!^k5
zS>LcrRjV;i=)51_L5`0KvElV$w%NB2f5;!bYXB+`02`KA`jNhQ=H(+ at -nk}R?|z=?
z{EST0vv8IJXORTmtt}JdaOWzy35$+X_)Sju)j!1O*Ko-b_V*L=h$SX85^RlrUFlGk
zP}QQ*2ecWaP?kV at M3{2EzAVud{X2}pHJu(KfA#Bywr21HKOa(x>?MMHOSV*ccV4O-
zhITVeR55f)@ubVUI2B3<pKD|o3s}AKgU)%tQp1}{I-Pu|Es1cLU}FycR;?^}8 at lPi
zasqpBJTzZWs4D|qKbR2edjwMtb3BS*QT?F4%{4$$w91<lD<{KSaq<8}=|l|zRcF*I
zevfUT|55%t`ylYayTJ(K8e{#XU?F;l at jQAQt(0eyxOuE0cb9Y7PUUz+jkw!l0}oVW
zRa9Xu at IAk!q*mXoK6LC(CuK5<Vy)zkbZUI#ZF$Ra?p}kWp^n$q at 0VCa<IV?2w}g+<
z2%i`-(m_E;7WgHvTunr?GcJOxogi#fv2&3EB_}&ep-m>WE<HW}7K23=x4K8N-SV=j
zvy(wzn7rjZ4W|EPA^E<a>!5v?-wH9|qRza5Uv;pyxSIqdhov#Zi{GYG^iW6T1#t+s
z{EmOmD6;8_*jnvw0i6OmF>+!jMxZFjmS#5;K6<-=sN6?SC!Q`q&=ss0J|V6bOAM8L
z+&<)RP~&h|hvoFpTG6NAezu75*<t?LoVo;+7w0c8Z{vm-F)K at U+Il_v7XM&80#T*K
z_Mv<O*I}^HuX`v6VWCQ3cwz>JOs(gPd}!R3$l+IkS9Y at yqLp#%w!_Nltggp#H1dz5
z<@R&d2Q(g6$UIq+hqCi!5mdjSoAk&D=N0`+M3l5<*tt+6|7x>L$%S1{>-)ytN>MzL
zvQ_{T%XLk`mR?{J+SjV|kKS$^<)%|pIRE9Bb~$~vB*qFuq<;r7`swM}+0XM}xdoW9
z?`>DCi{`BtLtlLS^)P&hyNsyu1QWX=VQbn*_~6}8(j_dP=RqaI+2%y%2GR0$!nA>4
zL{}y%ILh||mc+L~`$c=1o<@@aOdp!&1SgE>U_|Q27ikxegt`e7>X*zn8?_qiz(t9=
zj;$Jsma^uNV9kd=$8{DWUM^*)2^Zg5?4JM9jq+cT-m~pvOCDr4&&ChMKX6FC!;izv
z6*KSXhe7JLP6}r0L|c4KOYPeL at -CsQ$$*a7+qFs)`;bK{ifG$kH&_O&Vpoy1o7Px%
zt+Zcww!Hy6=*{n;^LbU%w`{E25QB*5(Geh1!)CCrUbuh2MKJ2z(${>^tVh4u8I0or
zg7#(j=lLsx-$a34*mp>YzB872vvG{&s~W|o#l~Pi`Vin^<`gKgN(w%8qJA~-9AnVq
z&OWbZA=QKlwQjUSxcgSp(ikM!H~K!5DTWf)9Z`-z(d5O-!`(5|JjZrFB&F|Hmiqf*
z;OV=-`<{OERJz=Tqv801u+w?8KdgH)UD0-Ejj2{*r(0B`A(p;;&&0q+bq$*4R6J1c
zBadSeV$_bvMPV^arik>eBs=RJtW}f~cK$Hx&C42iEZgV-S2qqel9#X#3psTiQBz3A
z$x2^Ek$QG%YK{4=`lGDs6YNJ3iS=IN;!ZC9{kskRZ(9<tCE`*@{b{rV(w@*W&Ekb&
zq&s^K&<6<GiMXQ1p$d>YyW3qJFB*;`-q5UGS7`V|E_p!Goxtw>vp>Ojh=9LknLr32
zJL4uP-euST)6RZFMk*){Gc_!iAIs@@c`M`w$^2nin5jjvj$H0=mRPpp6Pm=)iYxR$
z(>FF%sq{9q>C!9KKangm#a-8ZwfVHw+QyCQq$d>NZYBmn(N5SueP!^o9XY_^<e1A%
zlM5Tkmcci$=!j10EPA4_&v$-bFx*%oVqE;>K4{@~F}dOd2c{IO59vcCES(OqU(Lfs
z`y at i6BH_3+JnB;gP5t!7#+W2w2#mdTD}|=Yf?MhKbKEZRB^-6;=e8W3^Wxg at ua=BX
z*Iz&1ue1y-_!gOkIIQ0E-ic7>?<Lq4EoKy5I&Tp(3l7;G(%AZh0P%dzb&=rFb(@7k
z>q^ACGht?MrdwJ}pi_Mz)VTdLk1kIHd at T!Vjj5*13nzi>yM>o_5{OW=Y?#GPwO}~F
z-j_hyGVk!H?AYR78mBhm_uNT5E%+#=;!ytnfoz`x%3I<-4=ggop-c})-feA&-J#Dd
zD4e{Q+IZpp11n}5CB&8K2Z9Nb{on}}d-e5Mr(D~+=_Kvx&29|Iw3f~0Shh}z!2^EB
zB~Jr*2WrG<>~p_Pi{qFuAVYT=O at m+uSjAGVv74BLCT+B{{w+lG^TEbmhenrCku|OT
z@`2`e+Nm1uYc9T95O)U5{0q?|LH9xvEm|r4Ru5Aysd9h&;9dAQlXebJXiH<xdZ6Am
z7A>Ss&zcK*bb#HO)KJrQ&JQp*VmXi>@OJ?n!mEPye~i{&hZM(|CRbF4!-H$BZdCoL
zb+mZoRl_pP{m%m>H?v*Fq+2f*y`=RidVM>Rfp~TvCZ!j%v$;r<u=lW5DAJMyK at XH{
z2%Jdb3_*wpSd^MrHulM8>!sdaTm at m*ItSZMh*Rf1F6dNttFgGG?y|UpDkyW+)mr@<
z$_O?GEh3Nc?N2PmE<bE=8Fi#_S(=au-c0~4&t_qj9<{1Yx~ybS9tg9Zia9E;STlXr
z><@WUMWrVz^_ioXbNifg^2NjYKqlFYsl(ei`N53ZwDUCETzip+!J=3`MgCvq-8dhh
zeUC%CY|iWvFjj|VK<yxU`j2yOTM;wN2CL&UA42f6ulBNZVf38J$S1q#H&<Z%5u<kt
z(0h}GKL#@9X at i`CI$R2_z1S+|3X1D66PT^F&esZe$BI%6USh at ZkOUV%23;|}TG1xM
zTg+624TDNk9h|)l4^CGtY8~&Q5rleA7sVLlowN0j#_QWRl_vbK>os>fJ=&O<bvh_E
zp~G{fwr;bDP%ta^9f)X3R%`3)u8uTya|&`nF4az7dIpUrXkE?_>FlEl(-*urn{oDo
zZMyLW$&amxP9$@ikLN-^UHQqgeiMjr;V2hOKf!$)&@kZJ;69vgG0LLNHOX9ln}lk5
zptj6)s*-ByOzzspVq`7quXJ-}bn~i=#U~BJwcXn?*D4R$Ji0BSB>7q1i%LCxnRsn*
zxz84a!0?hKX<HxYf&HN8rJly9vYC;6*Gl3=n>%r3I#b!W^<ZOy$fS3LzE=C4B~9;u
z<LkRptfK1Qa<x=!RPab>ejVJ7x37{;#lFBmDi)XfmFA+X#lr;px^`x{>OBaI_cI3s
zk2~U=VA at +8q<<W!w+UGTRA*cF=i(Y`glUde at 1;|Cv|@jtm_<%nb*)>tdAU#WkZ%RK
zh83Q=j;Se_x*pZY&$TTP%~n&+RE?A9p-t+~8M<G(S2Cn#P$y1pegXFV;?ak{Ks?Du
zH>h`_cpK#$h0I%@cODhb(2hw!cI_^i1jK5FHUp_u5s8>N&*zLUqqtCd!r5W_x-cp9
zkJz+hoki2G2V)f<o!p42u;D5WjO|e&w(qW+LT&jvuWptFlE0XN&z=ywrWC_&7e<FX
zf`EC1vwM^Hz}|_9^XA}B%5l;=Ko2ZfR$-9w#rw7UfBARK;%M8Irs+7Se>W)KGB+o(
zcoHbmhG3Jf_NrfKi%0w(PX}DWc?|3yd&?LtU&;T?!<76*d-KJ31}Il3Bxy7C?lqwq
zyde3X-NSo8fMn;vKW^dgPySDO#|)#JpSiP<pbTR&-p?mkvzm<FM!&t{do5$|vol-|
z=pu5i!vkSpeA|uru(v*FT6fynm!p<Wo<ks<>2*=B*vfYs9lfn6gs0JRdO?8P7ne_q
z4+Z8YFbxUx_YeN^#VCvnA4~c-qnCgVI5-3!J4zYh^!7hCV;@PBYrE)+F*f=hGb&xk
zJ{5Q3d8wOQInu4(ufcmU9Qb%D^qLP1^!aJFBIgYwoz7oK<o(&=p+PNvw8(5 at spZwZ
zBmn>2ZP;YV@?Iy&{t!7}@DrHOACVt7EWcs*Nc2P|3U8_DT%g#J#7qkTwvZsZ7bub%
z%5)}iuX}~@bL<o+?Rws~3Am8dQ;IuE8<B9vsx at v->qN7tLG#6-$f9X4cDaz{1iCrr
zad++DYyKA@))VD2MnL*W<LuxUBU1>;(D+)vQFO~(WRzZ2!=dxnObqiMZ;PYv8%ujp
zJ#XsO at 2gJ}^Fdv;MT=RzP)gtoFUuTc_L&MhEp_|m!)v->`7Mzrt-YN`KII!+;XfJo
z%v3-g&ZK-uLrMhx)!_Xo`FdJGGj%32fGF(SwZq%OrV^E at B2rjSzqRAbM7kEbr%PKQ
zyqDwZye8T-zPEV1Ry`*hjx&bOXhw^e!ef8zmA<_AG*@B2n41P*%<sD*)4{U%440zY
zf)72mGs9^3WO4WsxQt>5BpwR at 2rEGr$8qD<)a)C()9;6+?whu!<`>*L0AHYS-$?lk
zpPVW1P$m6J;?=?e0O2m@(46;tUCLSc(v+aH*%T2Iyz at cWra1MX$Dpww&)D#XwL()D
z?GwE2!rayM8Q1*aAO*G=3a!o)%-1OfzYSbp#T!WKDR*hqgzSHsg;XxTn}v_HQ_T8P
zrQim;e>#N&IF%i(`r~;9GU8VHT)kfVcx4mDjdrPOAB6QZi>K~$r1+R1?>Ol<I;N#Q
zm%arZ_%FL~D)Y0==78CCOBOmiF+<UG$>Y0J;+&V~-V7z2Jke`O`_U|}ciq`71l~~y
z7LS~l#DlP~tW;tEv%0(C9Df;5Ltmm{AfBq5S2$j^nrGDxXJt7|uaY6c%jDaZY`$Ej
ziHP?nKigJp8Pd_gPvVGdE%3LP at Q6^qlIt=Xsd6p%qF(*zk>Elo;Vo)_jN_TIN;v-Q
zjHeYQ%$Qbvo%-PDw1QCE;e|?dt5T22;inf7dqdtU5S`br(lovu>D$|X9>!km8t-`e
zsieBmbE-V+^%hc-Ew-$j at 69ibv`9G^VCH=<TB-9kXywN{4w>}fgtq^@uR&{<=(!|6
z$=iV;0VK%?lWdS)-m<-s-=3}ITD*?m5;@Z0Q2S3WuQfSSKZ#IR*7tc&kn=0$JVLoJ
zle0uIJ?LcBbubjP*#3?I@`yIm?UO1KAjg=kmZvkxoRyCW+t0BUw=*#YKLk#h`2I9q
zy?qDtUGq*FpPoDBqX-AnuM(D$f;U-^u(MMwr38U+N?}KR)epk#&zLWBO^QI>_g92p
zZzU%{U34!|&+;w}51-g1bM at A1eVKu!RQ`(Pr_M9qIxEtBVmY3jSAV=cJ!J9rm7bW-
zP^=EG$E?ZE0%TOFd7qi>_Z26JrgL<hbT6!kbzz!%BZI~bIKjlc{OCzcq}eROX9d7o
zN?#A6_U1Oid99A5`^2Ah9t>saVX?lKaLru<MCE4IcZ(Pfn*iNE6>bf`F0RGvy{>*Y
zyfUCeMDHB-QMe1|H=NZ?=4Q^vOCxpJ>|-jq%<uS|t-786^kIP<x1`;FyFGOw0SI_$
z{}9j&X7+7pRQH$V at pHR|Ctj$TSGD9Y?p|NR%Mtq1ZG%wrF0Z&CA(l$)F&e-dircW$
z`eDm6S!VH-!=xcF*O=X!G^ympiEX!K-oM#BI`NXXcK1q`AAjK0t2>jl%-wfT`B|jz
z0P(@d)9lMf_stz8nKAD!`8qYTwx502F(Xz?sD><T#a=A&Jbf&It*J@=IK{JYa~tU_
zIcA5<9_VW-W+Pbc9*h~P(qbVK-qGWT2L3>yh7;WuLdI+HJ;SsTAaZ6mJ*W~u(#i>T
zQ*13uQ8hK(YcFQ;X)wE6WV)P<y28lse^!CUy^FEPt9irNmpn4=JXfIec&h3p^ULAv
zyQ9!mB40o_ at cT3{>YS0b*5<`tY_hlCjW(41oaiP7K+Ukx(rVGl#Rr1&K$PGMe1LEB
zv}yJnfXuUMQQu{lAd}1rsCz;j2928enw&XHYmAQ)C2y=(LEo<*ZR_2(Rl6+D9~u6h
z1$ce45Lp-Z`{ff$B(&xs_mue&v#Hf#G-M at nSV|{p`B9P_rp8My{5W<sm6ahUsjWu8
zWs(!g1m_W at U_6gwD(H0(K1MMFXaF3hzm0HgRMf3_6H`fjvdSK6E+3;Nu2KAuf*yGf
zru8G8M*<J`**N4i{DDadgkt50%8q#0EaC30>4nf$-DNUi&r|?0QSaiear+s9+^J>K
zDKmQ-y6dL=+93w8Jghbez})f(xsI%^NDLE<LTh*u?@68Q-m=ofj8`cjs4n?XTWiEc
zci>pz+*!he at q|^g&!eftQO}61)0XE_41$j1ij`kWouxZ^ASj4nmLVi%+TDQs-$s6G
z94XLF57w7|HCdS=9uNTbCv`$}`_p{#ba(pph?w-GcM|7&c;4GaEZ^laHI8CEnR`an
zQV%ru!$DdlBueJW#4(sO<73Yy0Ie9zY at L!CK3FOG<v%ZZinO&rx{Ywg;{9c$Bl>4P
zXtXmMw>1jS)O=ZF#_Uy^@8b5VEwL)(5tP+6-&!?*C|0I<;t#o5?-jr8(dUcZHTs{2
zHVR%`nN2s4IiNa+T2?$+Y4Gx__>2h(nu{gI8S<5hcL*nw075<NA5kr09TR9+JfgIU
zpH$X97KuN(#VOYvBs7?9Zb~NcGSKBR32+QqH9uwGQXLf8V#UKC1hn_=alM#yz#<Fo
zK+u5i+JBRJVgS@{US_dRT})NG2Nmj;>DW!<vM107?CYrjNVwv7oCu*wAE}q%cGEhK
zyQ7LI3AcTGAl}csP)W11Tw|+Kk8LyG(TE06l;y%Av2J2b9_h!3Q?f)F26t8-wxHYW
z3|acJ5%BiEjpM)28d~WpszwY(h!lEUnXbQ|T+W#Cz at bE_UTU?mKM}vqPo0`zetav;
z_Kh7;k6GQVg*M5}8g>@#ohher`_IMd%mGuj)#`r2PXP{+3Lk?<9T_JF_NKkJ{5{El
zWTpxgtS+bXOuPRpm1CxCJV(G%jUFO26H=%Fe~w_Nr0-8z<FGPl7nGX4sq}L?_9hcr
zwy>gB<z-!1`aZh(aeLB`7W!SyG<$=}m^p$hUygN}x6^rwKX0YcF@*<*K;BS;3a@}_
z$r4r5CjSUhEhgob3}~XCR4<W_zgK#aKVa70ua2faQ>__d?)hJ29FLU2HvsLP`|=MP
z8OhVVrjL6yQ<W1XLQ?YoXnAxl9p)>gh#9jhgG%|E91!vM_>t#dX${M4%TE3f^sE+O
zEsje7<8g*%D;VQ_$$(^=P{$a<4W#H at Qiylbb}fI-BLF8by=Z<8YE?~%e|*3x6dZ?0
zqySTgHZsg&?v<JK=Pp(*4 at zl7MP}rH=|xP((1}GpS3}kA5cd`=x)#Q%yz(#=rPx)3
zSD>pz0p{UmQ8Gcs==8K!T{X<0QGQ+(;XmWcd at 0P{n;1bYQpCaa3aDUhp=)uJ<pFcW
zX|>qwidy4 at uX(U(CA#}uQW)-nX9Q(40ru&JTrHGxv7zwoB0`iU&%|2yqzWyt0%61P
zF(DEzgHf1G59zp_7V8%dZ^#6(>2$eyg7r*gS9c|~(Q;a;rnk%D2C2>FZt`#UD4FbN
zwOg{|Nv2Ik6lm=tN$0!Z8<;lrsPTTm017-x0%qCYh>ZQksy}UP-j+>;pkah%Q{=u)
z=g{-a|03dS%^FO+rxU7*P7)riT*6)XxuQZ_GUGX8drR{+OzaGI7{|%l!ur=(CQhPv
zntE%Opg~jF?91VgLB(Yz-yUs>?Y}!s^3s5h0UA|;ssZLYJwzPyV5 at L|;61UF-i=J9
zr#jE<GXKZweGb4($iz)D%eBxPqu>tv=I79-C6d%$;f_Qs10yDcwi+5zRw9*F#ru`0
z33i3Z^wMqNEW3OoaO#vrGkEJx%%9>5ImlfuB<qSV=iuki4M~)jW}W?Ag6%#BDD1 at m
z`cQJu0&@Npb=@hlQndI++UiX%d$QVluFz%d`yj#wAz5MB$V6IT^TA=Jqy<a&wKNR@
zjeOloVxY;kLik1;X#e3skVCC-WuSmbJ?YlM`c7Kuf?08n#+N4v#bG=e7>2)(aQ;8q
zBb%QoT+X4~<?@NEV3w3|rqtN&0_exoV($TF_j at Hf)=I{>(l=DpGd2r$)(S_>k-9Be
zD86<OC_hb=o;>}wlmVS`BFRM5D2tPbl$6w~9^=8fl0?8zKtuDbr8$DZ;B>wQwzQQK
zDqzwS{+EOWZ+&?IwT0jp$Ta2s+80ERw2=J+<0^`3COH9?c0Z*=+7^|nPy;vGM5a!c
zAx_46E;xkx8UJo3Dt2p$!78kBYwy2?QOKW)#cZJ}jl%z?i}@W$pID7_pOLv={2w;v
zAA0cS3FIXZTb3nP7Wl6T at Xr)8gy<%={I2Xf&wmFi|6qb;$$=12RA4mTzrG60sX$VD
zvC#3+Z(IC3A02hmnD^<Unasbw3TzNaY6}%m{(EodC!kn{@a6r<fA4k#HV7oO``P~g
zF8_6G|KI(U-#*)AEY_n0FbqnfuKs@?X6;YWe+Xx|S4RU;R_bpt-8Gw4tQpnPG3LMB
z#{G?m&$^*QR5P3<_wAWFYEU#gBRVbYRh}K^ADTcxLL3`~tgF8*KmUZ=fk%LEzZFUZ
zX8EJyord!r3ui^Uv<o(HTdPuP{@6k=Qt-Fs)IXc^L|2`0nZ2MZ3HsN8%(%00)70v0
zJ<0p8iWKe*w~zUVKIrfB;<r!vzx?LrYe91KEIRK0dcc*wb<6nqJktsvD*WaTE0p9^
KWs9ZZi2ngVU9)Ha
diff --git a/llvm/docs/Phabricator_premerge_unit_tests.png b/llvm/docs/Phabricator_premerge_unit_tests.png
deleted file mode 100644
index fc2088550227d386a4d10c3d47b82890a19142c9..0000000000000000000000000000000000000000
GIT binary patch
literal 0
HcmV?d00001
literal 25929
zcmcG#byS<p*EZUgmKJYtE0ka at 7Tl#RDHJd6(Bkf{?L%=ZP$Xz^4 at H6nE$;5_5L^Sn
zzVMv$`~EoZdDnaX_|95cnOo)_*?VTszOLC5`dLvL51SJE(W6IrGM~UIj~-#Tp|59O
zJVF1PUP+Il6Ab4MGHNegyqH^2T1MYexO~)dQMEU7asTRM`pDeQ-qw`e+1Sa{)Xv$$
z-sKRZS^UwX*N<et at 6|j~_ZGbMh>?vFcLIZZ9BhC7v{Zz at eo^23QA7FVFS&-y)ySvO
zQo6Cpd6rHn+qh~OXRqY5vt;Mwo7gIuSteU6Yf2ql4Z;T25bO`{-#I*c|M}oepY2yN
zQZq>4676dz?UydcC@=97kM>vM8AA=`n>>|=xBUaMOAC_dc0PKPz_aW3{NJl+%ABN!
zi!Wb4aXm(-Eq{L+J at oKfAYI4PhZi`KVOS3-X%I2dL&}ExmgynYB3F at rNdIvDcLkJ>
zl at 8Bm+V5;1a9s?5c^@(#eXayxn?zNQ$#JEKoHcg(`Gb&;lleF~CBOe$xnxgoSV=*1
zX0ERnbFZ#&{er3DEk-x!;oX;#?~f6*NgEu_$p&FF#(PxcEgLBhWpZYI|E}Fl_W$1a
zlncr5hfFk#zP`SZkpgF4Vne4$k%Z?@`YJ9iE)EXto_t>(q$>aN?jaXJ+Gc`Ad1Q-w
zdRZiF+pp{7-S*A~CA5aWrmB9(4ZbGjkVXAanDxTK0!^i9Hz;^UD_qp9uO1FR%mYLi
zDGrr<_sgs4>orN`8}@HDh7|b~Yhy$Vo7hg-2O1KiKQ)HPGg-%cc|>qa)2hS336Xan
zd*T$e^VRDdcj@}&Mj~$#>1m^U*`43>2PH(~Je0{6ckCDJ5KOb!jqan_cuUKpAkHp$
zpX)!w&R!)nvmBR4Qut^wtQ|30TK=oVWk-Q;)MKOnDzatG_EC1y=KO*%<cc`1`6Rj~
zDt-pD at p3j<NFX1U<A3qKdeVE$U!0b^72}D{g!hG+^;VhpagXPP8P1u(-QIp&{91mv
zPsZ)BlwmknJb+Tx at 2D{>89>xttZ}nu+OhqiQTsmeqRwH*-Y`vp0y32L^ZsuC8MMZ_
z*1MMx-QaH_A($3ltg at 3z1DQ`KsT13S>aZex^?iNKaIkDU{sL%W`S-|<CBuu`i|b~C
zLt&>?cYptxwYkIg#Jj^_lE-CD$TY at k_ZnPqj@ap at zn`A$so~90DV}5{x7jTs<#4Lx
zaw7e(md0<bqnToL>2{xIQPuX4L)wjYTv^^=YOL?v%@GXF>AUJP7oxd8o(%#F-J6)U
z0_d=Tt1wf~DV>iMzh8o+ffa6X3by#Zn$b;-(Q}uxs&XalG`DIms0kONrkA}=6a2nA
z_+U*1o&-KA|JLn8i-}f`T+-~Dyo>g9!}}{)+O(0ICI6m#6e`~gvpyt5G~H`A?uRZ#
zI4>`gme27`Pil~>k{7OmwYd9g*84vez6G_{J~f$e_#9zd!NAri3+m~UdaqTzwV?cY
z>08^{Tg!p%_p}`iJYn63cY+Pkrq96bO9gh^F<skFO5|Z0c|hQuj&&<cL!;ctcAeUp
zT_FdSmpjE!uGbC*k55gXbhJV}=Nb~=gFv9Z=Ng$dhO(0PB_t(gcyiXQVu`K)AND>{
zTz=~nPPC4`OcP6UX-kK)D+jl9w8g+&GuFgfYbt|9M2h%yCs1F4PiM?|iq?XpUQ#)8
zv&c}_yFtcVF9wu=pWfuao0)64cKg*;I_*gF{5?_fx2lGx<a*qcH%l!o+y3$$ZQ@}w
zKT!wG9B=>mr;z_XIf_i?Ruei0IAGdlL9I7dDty;nd|`hnX{1~n`sOfP;Pg}ZX3A1z
zswij=Iw<B1MCwQ~&-83Tr~e3hLD`kvJC5U|!>M$HD&mIp%Y{Y{=I;VDalx~{YWx#{
zC%zY5yE%;J1bLd{?k6Py{Sr<ClP_n^mU?HVJeNUJ;pb{MjwHT)BA=Hoj}2^bl%_7Q
z4g9qaTvB=$JTu4+`z$Q?NIj%Ee9lclnpv>~1iltjcUxQ1QGJxf(PaLyS(XRs8?_F1
zav+e_7dex??#rB`Q)jR2Y{_ZxD;o5WVB&<8i@{BYny;mXNxGITAW2Qvr`tVL4IjzL
zi4aL?eg`fCJkDE$%I7<keCvN$%wqN*Z8V<V%;nNa-0sDH;nv7lJk7tonqc>>?j^yx
zKfIc#2ygaWX^ibCyE}iL`N2y5Y9zXuv-55<pv*I_e4AkDTHSFQByl_WcLl<mE~Za^
z<V$B)xr|zoxVv7DFY_In(i4rIdt-J83qyRQ)2%6=FdrmI6NGTxQ|$&T8F>Hj_jN{^
zKWDjYaa{`er7f~(Hh(OI(#$ZefwSqK-h4QYoR7#34K8Vh^Ayn03zfBU*({v;+4N0d
z8tn)0+w34vt0vh%#1$Wlb&TB9Mzg=`PLOo_RJzMr3Uor3$Ng;5{kxz`d4XW~+WEqB
zaSn-|Q?K-p>1Tbf>=F$L`D!$O&dD7HgI*5=->cU$_w6 at lcV-CZA2j?m^c%VFpQF-*
zCqsSG&lhQ~mzvqi?nK>{vght^YzLlv7vIh9cXlTfMlV{%)?wL6`di3`3q`-+FYl+G
zFI6ktEqtdu?GWX^ZKf at Cq7eG{vX<#Xf**s#ey{V=Np5n)-Y$b~CASu*lSBFLO;<C@
z_`7lcsXdgK?0zk7shQsG{)_I9vgMnNRaWAPKV0{E3Wl`$4a2q8P;XNM$NaU`mm48;
zJz;S|kx%aPfz;G*g*^_XJ<Vk^PVs(cKEa^J1kq+I%L9Q<__G%#1ynH=NS%?GpggAZ
zP5gTW2Iq1{;G`lVuXf)w0Z*udy+QJ*df>4gc#)$OfgCh=Gxbc{Sro8jx?PE*RqaLt
z0Q69oKBr2o(<X9t5Mx^PhUr(eNZf>e6Vb<SZK(AG4a1Zw1)CD5hydl^m4>`I#^)!}
zebX}hk;OyLi-o*ykQtKco at Pe`mGoq!cd)$htj?|6P8<r#xrvcteF~sis~KpDmjBn!
zWgmm3*hEr}Ka9X@#?}j$RmC>6pWvaVK$n6TL)3>Bl)>K5G254vLAeb3r>6y=u)1BN
zhNzp$WpGbr(?4gY?CUf&ZY$l~7z<lUq%MMN_Xh&$T5oa!4dEWBfg9(EA at N3|rr)(C
zwaI#NIF#ns&)p2g3`YU>4O+8w__)Vpi&iTqJ2x8dTm0F~BBiiHUJz$U_*ZXJJ#PJ*
z(w2ac{ha$S6r#kX4PXVX*3sNe&U<+)fFodhJk@*pL2d5tu0+Zsw0_FGq64|%l~~%1
zu+8b7aPxZuuSuN)__4$!yCa4Eh%!k{(@qPd?`?*@nJr0cia;l%(aQ<@X at w{Mg?6gj
zQ5?)+(S|1=1`K`zXTK-na&d;dTmIA;)PQKCm?{=2fX|pj at apE5!LtqLw9X6}0|c<n
z-RFcqYnD|@uG77Ovpm?;FwDF&CaSKa1qq67dk4LS_d9GiGqjotKGIj0lk<tvtVn+Y
zpUu^0 at 89Ei`rcxdWpYclMJ(vQ@*Rg<?f&Rb;iHbw$5{Q?=ljf`{cUN&#*{FJ*Qrd~
z_2D|1=DEHd at ufXM?YWAp@$t+l`}ovJPYt1Xop$50i{sSl=hlI6E_-})#a%urf}2n$
z$Y?;FODTVI!<>62J3!ff;Hp^Ih<K4EAzg&k(dBhTl*dNyFc(I;T>1?vcAy at y>Rc$z
zf}aO^F}uTuI?NJU(QTp~gz2f%-m-|?J2ds$5B#!6(7xAHxpp)PcDr;gTUj<Ndb)I?
zeIR~kdK8geT)I23MaD}jd^_f>xa7^Z%BcCZCs<mXcc}q3uD-lNb$5{v<Br9bR=K}>
z&=m0H!A;0J9tQTz*DXHL4gH3R`J<%NA&a+Dk93Q&Nu};^?8g6Aa`<ghvuWV<(c6>O
z6GCaoH{22XTfcS2Ul<rU*ymaP>$HNJJAW>%PciCmpV8ik)Rk$xJR0bzZgb`$O=I7F
zS?tzKT1HJh$!)N3Z?}3?6|SEtXJ374k^ZIzPlqa9HBR4cnYI~p;ZVr~(<`;yHq-kH
zlzf#x`G~ce$*Q!@Cv%?HyeZhG;^%_K57sb6VxMCYs(t26Xi&w8-60-TfOj}PY23XL
zfwu^t?`K-J*1L8c9x%J<GtH7Mucw05sh`T?InL6IZLJ3gwdM8>Ok}RBo?p0D;TrhY
z*$$p`?uOP;mmP{91)41qEHL?hHkEWuEIrI(gnmHSfr<{Y1I^^PT8r1c#g)yUfg(>{
zQl_Mw6qUC9P5tY0jZ7_=;z*_6w-ZVqnUOvb!9p)Z%Z_}olrQy_61NAz9Sctmx0ddr
z_9gr)%O-uekhPlrq-)%E6~^s46N>~m)}PRF>(lS*w|hrk&#!lp(l2o{XxoKN0V}8k
z!9}l5Gz>Fs91FG<bN=?>D~pKAOp_5#Bd>4z{`q#VHiKU?tnZOG{rW|S0mbhIp(h(8
zL_bx0j>kRsRaTOo`Lx?10dGDS-X!dgoZVC;hXIL<xAsWuxsCKg=G5#99kH|;3xK)n
zqpfWUttlB1rzv~yB`S{c)ALoOot)!9P9>!-QHI;p(yLS+O*<;R>6MKU(`|>LWo0h(
zKvR>PiWR*XNCcI0TW(73_}tI(vVw4MRM at vyN|;K=E6K*B<6p;^=IYh#+){@QHu#@Z
zc)oYoAM+nO5loyDf8o1AYKTM*-Y+YZt0Df_WVStJo|36G*}30iyV*{ZmO#AL)y(hC
z4`};Dela?lwM6WT+_fsK5fxYA5b<R$$9VKe6q+X()<c0S1w`;zTt{HMvK?UG3=f50
z_g6FFhhmeEZT>`rz6 at S@(iRZ at Psh;hx at l{^%v=A<n(x%2l51IJIL|Rd%s?swibcBy
z)Z&JMoUd_p0I$27x9f~XN=b#Wxx?{RJ6Qi|uaSE5?6Fb-H8%Fxi7tPXL5ug*Fp$;P
zeP~>cOl=&Le&{T4>OHN!n_{n;RaR#BI*D(U9_wKH;*4V0I@<jX?V3cmD*L{58Btrr
zo%UqRuN~py<Zdy|D*r7lbJr2}vFNu5^zO^N^4%K>h#{ev;1whK6M2)cDI*j#<bpAI
zk|Z*k{a>Va<WbpvO-1{j;0~4)9s8J-wK(`RzwcZ8#4SF09xuP=-4N-e1rgl6+KB$;
zC)Is4e;c)`c*Yam=1Pw)ax7R`zLGP{69g&QFP!TAFG$H(n&1I{dW_=@SEYZtt8IC+
zDK=rxSG=@|Z+L^2_oJhvcmD#?XqdJ}C9YU%Bp>t*JU4$zu+QqI7%P7T%JPs)bdQ0s
z2Twty3*x_ZX<U%Vvp8HO$KdWdOPc)vcaOAEc)A+va&tGmQhH44m&!$7k_VN;NZ`E(
z+xo!*|3cqyU6g$ll?(F+?!?iQsc-&;%l{)7{$shMytr7J5h{qT<<W8s*FN!>zLf-#
z<HKzWJqB|xT1NjTLH2)8dddY_>Ofeb|LswO-JV+4@>cd-oD$`S=HoM_A at 7FE{d{rM
z^+;a1YH2{akM-8PH`N2GZ^8BYr7FMGAy+-?hWuHWdHDgNkrk%*n(Sv}c4A~^W_}Gk
z9F7Fcprk&Y!!8J6#Y%=_)862q+L at O#-XaRQ6�#_Gy|oN8T|f5c~&zVEI6__if(7
z{PKi2cs#|>J5zqQ%0XeBn=0%3cfVru#ZV?Q4T&ZHXnI0Vb}WeX$8q;k_T6MDVfS;?
zXJ#NJIp=~n;hmQxj(zT*<f}Ii!a5kuPBj{B`PKsl^KxGH at SZ6rB8LpAdBKgB1I%L9
z;`bAoyS<O5s7N+mMNA=FQ%XSlBHCm9;i8G9-gaYpSjtNJcg-r{vdOq5+0sXOuJ?e~
zbtxgJ>*paM@)#Ik-gmcokBI;~)=|`gDXOI#+B*%VN_%<|njd_O7t4Jq_@>}mJE@*2
z)q%&-O_!RC(rQN+RL=y<(UAKQL2cKGTZT3mTv-y*-5Vx9Frjl8shbi0Ydrl15e=z2
z**(Sz2fGR}D at _6{C;YG3uEV~({~IpihH|_zr0%sT_uysEzo6- at UHNlhEz(pu0b at L!
zZo*l}VV`wBqHO-M&kBMX3Jl3uto?c8=bIGqiSqI<GQ*R7ux<4{y81_2!^RM!s7|lK
ztlI?);EiYqgI}LUzq=tN|5PY0yMi7ZH3~D3(YopVXi!OJt8*|^O{^IO_uuB2&>ytr
z9?*xG!R~Dim*cs_=lNW1l|WrY=i6}a_JclwADA;S!|xGRk|wrmdx$-g(@)W2=y}!B
zM$m&j@(6;mObDfT4a{2__vbmTUOiu+jydRm-Yn)^SyG&PNQhXg_YRpQ*uT2VOo{W6
z_pOx7h_bzvo~@I(zeqh#{helLNMs`6(&Yc;%XWhVx+5(ZIBz#iQcaA2Ba^gZ at IhA#
z+2)>c^NMx0rx*Aa?H=vTN4-vSDW}_8myf%cSN#Ena2*fS=`T5HXSMgc9}`kp9}1EG
z5GF(+(*nF-V;&`p#>(27Io)SOkRs1_vliIuN9Uga#Xvc!qBqZId540E;XVpvf6Nly
z<$6P at 4CF`!!#}cd5i)ZD%AaH<1o<1*R%q3=^ex8H{VQlvmHr;wX-v^;(VF|^t8oxV
z9IRc8(<Q!t)Y|49<*kkA{RU)AI@&a*d&2qso(<PAZ}IhPvpDOvDWiehltg2DLP$c1
z+Qv;K at 7AYkGuT)Sy$LD)gQ041DmhyaQw8aNR&Ew;G2hIB(Bby|(ZKNay_HnTNad4j
zk1Z_Ap#5X?tkMkcjOyw!koEhQ1oh?~3t&YBA+{ObQC^cDkd-x|JlWLrBQNK$L<@nq
z{kENU`9IqI at 0w$1ts=jgb7^R3 at N#l;wxnR9EG_ahc!woK$Fwz`boPc>w2Uvgmt|}}
zSOZSH=#Dpep#qWheih9bJotCk-<n-bH{LBBH9yCU=+wR6^bBA6!qb9;Tq*-DQaXvr
zCC2W)H~GyY9(qFXShVWJgRuU;Glc&!UjH4%I9+A<dZu7v2>ighJv!=6atqs`cTfF~
zas5uT@$mfr2kKJH=&jj)7f7tquW#7 at xLK7zai2xv?liF(E_9b7Vu;!&ORPV%{(&O!
zb7nZG`Z~_5KM+Nmb6 at dwdn^}YNBmHIA`+?rahu%IG>y->Uls^{a;H^BF=w+>*qr8a
z52<hYpiH_aM{ucox^Bw5<+P?E((}1;?YTL!8W3|Aw?yrkH*Avm(oAQmusyETzl5TO
zDZkr+_t at rWw@ZV at f-%cL;g;$!_xa6o$dHm^^Uujy%N{|rt)!9Vi8FFiACMlTs9hNn
z)}Phf7ceu?$R;ndt`9J{y}TW|JGnFWzuG=rQU(AldF~Ilg5O?T`_G(S46SZ=>o$w{
z<Xd($0*H5 at HU+m%YCmUlob}(w7{~&FRvhq?e8dPObrT^%CK%N@@~iaTc%a`zH0^ru
zT#RIgliqd-=gClA#f#jubG5#dsJp8(stHM2FHmBmqxQ{YO1XJ;-AmWIogqfXqFgjZ
zm{&x5E#q`*sEUk)&Y?QXu$9gut(~~tKR-h+B9FN--ZE(#Alu3k8_!1rY5hk!05Q;8
z_aTz|y#cxVLs%YUkUK?}uiD^L)C9Xup3c3Bh!CJJC+0Ka-PKoqN}>Ys->Ye^`^|Cn
zWgoZ8(S6+jE{ZF&RaKLxHc2}n<IX`s1OUKYI4Td9yTA80Wf$_DEAm6vbPy9R6GNYq
zRrI~pxS1zC%_y6hf5o&mM>|5CqHGFmn&T&(_x1AiNa^T+S>pQd;eu|V<KIIV?BER$
zxkPF6^LnVP at BP_7@BkL{z$74?JW+6quhB$=cK<>auhQ;r)xRo6A$lJH_%>>$oUjFA
zHns%iRrBMY_ed)s-oQtN%?q2yhNX4YYjv*+E8I?;C^=%U=PuP|#zrgX6LosF3h(cN
zF8d^CIPAA`o+;h#MdF?Q=tP}0-d}5H<|)0_|8uuNYpZP{5Fqys3|^h)+yRYQVOPsa
zJ_Vcf4q97jpzMF)-fB~<6pLzIC~l-8f8hd at +a?Hl_YC}I?GDS8OD(W*GVZeK>dIU<
zlvt?M!iV-;psZ}Z`(KQ|Lzh~6JdxEMWlyz;02DeBGHkbF6HrCMXN9B<*JsqZ%Nq2J
z6Y)!OC4-YGU`38HX11A))|Y^ow<7QXo__zcq9&mwXQAQ~lP*JbFG9db?)cbH_4Tc{
z?oeg3r2)Cr44KP$$=TG9=WbMjpNjFajh-KBfB4c7 at 7xOE4?FBl<P&S;kAf3 at xMyxj
z9>03LMeV=uayuZ}hS-|ihl<|XL~0_6dxa8l5}7Y<&$?EQ)nLXa+7Wgu9lia6X@(Qd
zcG+7t!l<pa!*2SacA=MmLT6u<SBf`kj%STG1e8Lk%XMX{9``9MafyP7a~J%w=}70k
zi!|#6k}aT>^}O!P76m;`xo}bX)mr>s`dw^B+AqPOt26cc*ZRB6*BrMyR-mphO?$l?
zyPN<%il_tDn~gw at SFBpKyhqvH=~JC*5T_~hB=vaL|1NCjX8kX+INZNBA0966*$j7c
zE^3Ru+awc at yJA#Um6V%`2N`;b*QHQz2HN}WQ1xxS5aH8ta%wz}KV)!yZCjksZ3+Hp
ze6H at b!tC$gc(^{a=(ASp32M9^RI;%~(_rCBih=k3$_RpcC*KV?t=Rs1g$-BUwJSzI
zj89K0-}Am$76rP;xaWM#g$h(e#5J9B?O{{KMf}tyUK{GU%;z*>I%9P%I~<;4i(HXx
z`lvt->pHJNh~}p7%X5w5jN7c!LNX0T)@PJ3)K23S{yhn7Zsuo&fPdM*-|?DFj|)qQ
zD_$f71U4rO>XJP7Zmyk$BSQOPRuvVj)9`qBXNG^NvCmvped~__K`PIdCqPuc$~<14
z!w%qIW|Nk!6ky}o#V!WvD4c6lRY@%YsN=vO{o0nvdufJDg=)%Y&bQyf$TxSAkNa$?
zY}$2mvx_mI^y;I-Q;0BYncud={nU`q(*bj^FSJ<uxhBxsd~4$Itt?d*P5lC!6l_>m
z=o}B|yD`z>Dxs{~{O5w*9+)+Nq1|^nAKi at LNuoNO6}s<3-id+ILM-lLJ9=X1Rpjf2
zwm{?>e$%I8hCiTymoaoZ_E+AF;nB@&Oj8RU=Z!drwbIQ{kZ<Ye%ArIwHh>(PQXb!_
zW<(ur2x!E4oY<M*N6*8Tl>PwlmHxP2jx4DuUG<+eepDP8YCP{m`rjRt`6IIjPUO6o
zF01+l&l2Z+l|@ixN9Bx8X9P~1^&I+ijD%i+Y%ixY7hVJDTod$*tOc-1{7y-D8eT}Y
zSGuE8qBi)Dgsw%_(G_9(ciE(^JWj2u^$7QI-*JcYv|{`+8`s8ttfjwud5RPNki}1e
zBlI?!b)j<gznS&N%;ViawrOi`UlYn1&K4|>pU=<_mExdwt!FuQy5AoVx;T@=RP_zB
z&XPH=0jzG<NTv<T(1MzZi#Ns7LV~lh{8Z`}li=Pfe8P&kf+{9L at KeDvE0+NiVN{Lr
z<1$(tkK1X~xFS$Rs>nbavHUI~zt{I`G*m at k`rEGV(Azb2s4SN!hx)Df;KcWkb>}6y
zBP>d6vsmp2+pkHRdV|X)7~%!>aeXd$0tUBh>S5XjsJn!qjNlT>GSt|{A{I^!-+pnq
zw`FlkD%u!>*fS$=gpJIVl{DQVGc{l1A6I9bY-B!IWGDrB2Lo_)XY|xNvW at m!e`iLY
z%9nvhBt+&z;S}&K03egtd<Mf2kzj9-O4(3h8FnM=!R)KD#$#|TPy7As`?qZ~Gd70D
z=YW}y&8X}_CGqQp$_(rqV<H3JuRCHr+>nq at f!kxV*_dzLp#$nLppm>dvxBctr`^Oz
zg`q6vTeh3GSjuzjc*(r=;?Lbj2F^Zmc7-O-364?-%Pf2GxHE*ptTU?XqV1SUF5vDU
zySuE_os9TemaV4vWm@#2)0XHtuR5p4l%Dt+sM5+fNo)hN7N6Rqq_I2 at JuCrOHWwx)
zO(>NK4<LyKDyk_&eajSNicu#;@1^w^K_Rb!z?jHsSITTJV>7O=I46G?^VM&`;F9jW
z!uy_c1KZ0Ar5NfpAT!XsCIec6C#ZF6^sPC6W>hRlvB~;yu>|y70zIf%D)2wwib>rT
zgB1OT&5`4i9rl4Dult at p`WCz(pOaL7u_UG$>tp&Y<dX#>FFtvX+F3O!ILGTAf?l(O
zDIymb900M|_fHa)ocd<hOccT31;o5?{xhsGS)#NAyQ`j2_RgSwcmIp6W=!9+IER(}
z-FZIijrn{Vr;A+u4Xbu|wM-Y;&)};=c at gAS_}(Gb=vxzp2tDBTxN{?T5)Aeo*k3Oq
zi~;Yxn>BkivK%Q=zi9T|!i3OlfA3CW$?=|6a%)k^*+7h?Z(-*{@+^bjMLtapPWnmQ
zc;tZQzME}j#^^~{sWe;QMdIN`;t$Z(wkes=gv6=WgqlvR^Aqc<5R)@SukEBNSib#V
z_$8wolz%kso`MEM!zW}iF*>f!G+=r at mXY8`@yBTDRXcjv9leHpcb*bZDGoZ3GY_V{
zwT`0H$p23)z|8f~9Cm1k{Kw|fo^fqIw;GrAd)DK=zq|YT3kn+$T0b{iMVoQaEKkQ2
zGIjr}mGa_!{Z~_?$h-5ft*BCiF^dTgF^QV$@K4*qbBeF4D`D^aW{TH%g#)C_hqt{%
z?9<~ngYw9E>lY1xz#S;#>OVZN#B~}a$iUXqQBA at p{%OA{oA4|`pjQFyv8uvAp!MUn
zoq7arP(A<H=!?JrRPSPtIB-;t<2p{N!a7t;hFBzCKZDwO{0wmJdLTB-pfW(gWi;z9
z<C_hQ{>0`M&xz0f1X%9^?V;;mxOut2KB_PGl;SxH_ST>;0{=i*z(u_}Tm$47gHuph
zF|o%NN9o#AY&nny&MEY#FGs|7*rl3_ZmiZ9+q$CnF(EFB?x)J1D@&fCwc40wi{jeJ
zKA)el_M(&!EZt{7*usyCtN5SiqT?_ix at QPWTMz(?T-ngR5n2W<O=Jj5b9VI?_CU8R
z1jRCOo<AEhn;flyB;>*$oWy_f9YdrZ9pBL+X at M!lwcvKy6q|YXyVq_T)kn+bml5WF
zBSd?bU>~u5F>#oxwIXZii)!|!6zOqY3 at cr_*Pgcl0xi${@8^#WX#J6U`IsV8zw;L_
z?=~&d at c7&`a_{%ECCDQ_95)o$H(PyA at xI0x8+w*U;Hy>dx)I6=Y}!(y%|ML}^QMsb
z*P>S-6)CT$xtbwB=Kd|}U*e$1jM*_ywS`fN_tp&SzfZhaN<G at Brs(;D?!=gm4wVv{
zE-X<Z!cGpc2aB)j=O7{NaJOJLCWF}{DM#kef7Ea!{AXR;EsPAEP0x`R`iLBDsB_~|
zq~q_V&BjDqx6ZJxAvavpoZu};F*GJj#M3EH>v*&`SyMtZWre{hZI_bnkkT-xsbWVf
zayyq?GbZn9d!s2=Ogy1}Ux$L|OjhAIC_}AISVR=ot_=|o)UM|lJ(y`%?Mov*Y^reC
z>Bc5Ry5Gln(=$q3zV5=Z0jd?P=j)dimO)Dxv%7Mg<HvOl%5}BxJIlr-lu^w7=5{v+
zj02&$j%9}1#4mn1n>XK`r5fl at jey4Ow^1@*D!IPyNO8q at sKw7Qo;}!c>i<oBmg$wG
z%J%q0r7%)D_QtHCK4wYpseg#3*LRj37-r`~XMRKk$(-}GQ1g=kcY|p02&X(IZllnS
z*drQ`Pd5+m{}0Bz{C9{pqH*c5sNLnoN$S}@QesLB6{=Dt;TOaTWqzip^kVU$E|h%J
zh7QYwFxiCY&ccs}s3V8qpGJ$i^{hK}V(*XVZW-AeZ51%h>hb=h(;Yjd%-Qlcorl#Y
z;3YA4T%aM-x9dl5yBjCQzJA%?>tF-KbZa|0KULL)q!|obybdDI&!y71k_#!IXTJJ1
zsM^X`?aUNcYPG;5v6gGBZTc#$G>Wy!*O|Cd3|S1KvL$}lTXQ0qdwIY#TA(_pz9Srw
zdZ%^rtl~U;mUvrGF!ADKK3uBoO*~aKdiV8F{~HD>WJ2YVQA(Wj1<bo&!($M6imWmZ
z{ZuR-y8z=97ytB^a4Hk7USHg^471k#5fZW$`iYtt-qFnMJ2Vl)o-7!rJ8l;L!@h6c
zpUM8N+M<rdPxsx-iZASYIaPzSouPrQKdgPZ_Wue!>gPmPN4neKG3Q3BU~FqFX=;Y(
zsM~dus&|^AayfbD-?KcNm%XlGNmcfYCIBOC?*~;FppS$QXq48d7vV{XQ5V9TjBH5y
zaj0!0^PqpGAH=7N#*9v7uj at 2_itG;*STSl|W65#%|2lZa4FCX?Oej&z=zJ}{fx)B;
zx<Q-Pk?1Y#kSUm3@{bE6;M@!ip at JtQff=|e>@r`a!%G33;y(uKsRnjR(a}==CFV9+
z?%Yga-<YvPP~9wm(As*`l7r^JqtAIsP10m|2m$mOY`Tr_K7dsw@?Q9&j(>eH((1I_
z2~sDl3`nGO?XA;UoVMh3$)kQl;u+k*?#O7=z6x#lg`pE5vr0z7PRrKoRj^5xE}oi0
zDtnW~Ux;asTyZ_0*udN(sU>}2WzCY}o8ab%TpSjJCWpqL9xtc<ex2c~jch_-+M)Yv
zbdE<g%V430REt~@B0it`H$%R5iR<A(#CPTYA<*l;8}$DrQmkQNE1gG;M&_**9ne$j
zL&VfFriCza;+T>?X5cTL?gzaCd!L6Y-TTmyYCPwo&q&T$$ym)fC?6hrJpJD-{GTGv
z{`&@P2JA`ctcGIyZA*F|e2>0MtrFm}99mreRjH0%`k;G9=5IHs0RW0H0w1 at W*!<3Z
zF<NGt!u604ol_#B%9I1~mu-=9xdOE^;SR1dJ<pqFPq#22rN;N;KVwo=tZJ{{*sW3x
zGWnk!hgRr5J|^jk9YwGS1YiG{TF+--WM=YpZMeB8F24Pn*<LB&0UTXtqWQdQ#*jYW
zzJ7DDGNfmUNI$c_Vc_epR`E6&>W<_qVQ0Q7PIYYD7;J;LX)s|Q($p2_4j0A6I_ZXl
zgjn}0DafM6(%Z#kAX8EtQBYCSAwy)kb-FCuR1{;LhT@;^%m&H{3$3~=6H`?QCDuD@
zLvP}!k!;fb`+J$~?duOe<6MO?M6tWGgGK+M2+wm;51-{{u>=6Ay;m at i&Vbt4H5u)E
zb9k4+Sr#K5pFVW*?JYw>a%JX)QQ@@MumZ0mAjZ5Me<&(-U3IPbH!+>HMum}F$6o=`
zQ~|+S&IGH&$D?XG1J65|3ij*`f7!ojkjJU1A6UolSJy9y!|W2mQ+nws)$!JbonJ2a
zV{vx(aa3_M&S9oWW-h1NE2ZMNlBn=g;!{j9ck9F9L{m*J4u1EUn{~GOfYVaVahOeu
z=+3J%o>NzL?;8r^*tPWBBiCo<(7x&e+{E%Axx%*)%?9 at ZGb_hOY-onrx5c`*vKJDl
z^v1O2ZFk6z4?Kmxx)-`S)CvR$u?D6pk!S0Da#en;Qc8B9p+<|dFcpQ^#BEmY!PF`8
z(2({6Wv&$iBgv1Qg+>aAib~A*<J=`|HmbE#<KB^(Ec;r8QcE283pBKX9$GenP5CXn
zOHotqJLhiU{3Up?gn+4>K{O?22{hV^SLR}g4vp1r63YK={k2L{#&^HF2N;7VVy3V&
zE_44z-DUyS>)Sh`7*VFUlwGaOa!@i#5t*ZP_0)OOBfD|9fTV|be9_`(X=L<8GQ(rq
z;{T^v_gsjHkS%R0zD5<U%SsjL5M`(C>E>LA)hk28XzuX7+Hi=v6)2DO$f>9B7n-mg
z&-R{GWib%}gxDesC{{TT8nm;TgVR(ZGSHW>YKvC^YsT?}P1$Tb#h;BCfXAtS&SPk*
z+fIiK-tHagZHU#X&BH30arne$@$+FzdLs6JFp>(b-PRUOEChXPzu_2EzPB8j+MwyT
zAFYPmtksk{P~243)%)l=>S)LWhlV80e4WcU`qCAgug?5xYw`fQu};9zw6GA5PQ++^
zpu<wA!<GpsMM at 15ABHdjB|T-GO8b2B)W_N=C`|i1UrO_=#8jVnB-c-X!4Y!Z^?0&e
z$1v$TofgkIuGF5E8TQD~i};t8<8RGb at d7&3l&znezYm(7FG(%dX9^<sZib~`n8vvr
zDzkdtEV|R%+9ynYEI9n*=+4h?DKB20lD)x}uS`4iW+FDSUAa4k2;k@%ufWktCE5XQ
z58Dr(QgQb*fbg17xHI|24uVl(5voG2Op}W;R`o&(nkk<3zX#ueKX`Wcl5Z>zrKgAW
zXLpq9Q`6&wYj1$~-~p=MmMARO{Lm0`k>-$ix&yRLI2hPQM-b!ID~c8CHOnyac;k-z
z*G1UkZkf{$ZF;PkMA263PA($9v`}v9s|%JcSvK*K9)?s*qr8#TdVqW9TV}yd$AJzC
zAx2v!Bl2?h=}CvvE)^c at 78~RyB{#vA+6CvuAbv?+7qefV(P{P*+?Y at vK+H%xPxS at S
zeFHz$Vr at XcRiwyqmSghGc!b+Mp7lQm42Qv8lwSS5Uq&_J^#EQ{Zw6 at 1?HwZ*SFFq`
zGNHY%Pm$Hk$=km|jX!@;sz-HJw8Rj3+TKnO2CP-|sK`?xf4X830suSX!75Jndj|WP
zaIbKCYdfPLk6ZqUsxF;&ajrQZO77U9=;T at Yv&Dv<INPCH#P52cZ7j_u4p8H)>)HiO
zk!{IuWqQQt<A<EOXUt87ua!jnO{;1PO~zd&t<U2OjC;dUe?4A|eT(}-F-B%=&@Os`
z&NOuEDhfzgFWmu8Q(|)njaJ>vRkP^sbJp2+<)dhDvkiX<I2Hx$)>x((+DfTpit>ve
zRo7WLXU=X at IkV<(oQsX(>1xQFKYOl%vx~v+f&67c?C?Fs{rRl3D?}zAN0bn_7fSBw
z&|tXV#H)HXSWt0`U^3|0NM|9HvR&F>0p8}ebyXCt33w1}M8lqK0M$#33d%w@#mY at -
zG$F|ztd;g$s)?QU^O>VTvsG0<Z2g*6U3qYcxkrP!uA<ZA_6DV9jX|3EXQn;uD#leo
zJ8<(WK)PBUCkY?LCn;O at h5-5b(ckVz4w(u6lziZ4plg*gDG-iLRTsVP`Pu3-H4SwS
z4UZ-!I=(p?9@{=j9{*UHZcX?%E!5*+QqhbUq*d7(x6dI_4yqiru2fmyZWK2#?IS$K
z>q2hCd)ng?s=9k>cxBH`rm;}SrB(+pC)avMYxk at n#eo&4hK)f3(}tUkzVNL=5UYrc
zVjxAX&8K<0+&_%SqdR<b7^-w4`&cTZXp&t1L!Fg+l}aZe1<TN{S+;Oz(@N%Dc|B7D
zjpFOcAD<!Rh)<)-8%(IxswW)0{H?0;di%$>LZ%11w}Ie1j%1={R;dzJv3iNhQ65E0
zYrE$)=lJ0SRb+tU<auB72?LQ2reKrT(IK!qqqf}fRt~F!*9 at 8+_Bd}u8p`-N-D<zh
zz|74sAjKlB$6Y2>1QF3Ld7XRhd&T>*@%u-VoD(!kMJXPlvG4 at XB5;F~cS%Z!M_RRc
z7DnL}A7{0<2;chVcpaEgbfuHmjG1N!VgW5N at 1CuXlO~MQ;^tmtt?^cJ@!_OhybK6{
zM6#wkjNnGrb at 9Oe;V(Is_QM(rR&=Hfx#9O4I>bjna3{<!_86hT#3LzWa?GqOskCoE
zEM>{|0!EY~Af^@Xnv~#7aZqDJ8hubi8s;^PA5;B{wRJkQYrSgIroX=us#BceGJA10
zt^)+d#U#2pt_$A at _STS^TKP-{%@GL%?#g|np;PkE;<l<&5%TzHs+|x5m<iX))G{$<
zHTw90+i6T+o!<Z_2(xn95^4lh(Kn^7UD%i;o*d~@l?7jLzg0Eo1S~C1uPm?GDuIDY
zw9gF3bLhQ|z(6`{deYgSNiYBx)8MqScVpj|UOBOMU=!}x>0wC|C2$TrHedNiX)=SP
zfbLX(r)g;Scx>EkJG|u6QTo}_rOWz3JMKmlIH=XUIwc<&lDV(E(leh1FVgX}JTIh2
zE&m9K(x9s0jLFm(%l=#!9`b2#XDwEJq&FDXPF!kJz at HO0!8Fu^XJy8__i`_Ftsy!w
z|8LjWm6->=fm1?=jk)*q)}jSn?(->6u50<ybn?y|fuwd!AlH)C0`Oc{=yF$?!Ic=m
zr!d~wRl4rzoq<>WA?7m!Ay$V`OgF<ipVX>w3T{Q<q7g85K=V^kXh;ZiX`Z$AO&k}Y
z at 61Zuj@1m5 at o!jV?%!c8f&``|T^(pmxM+YW8(_EamnsFoQ9<2SEa*nH=PF<>!IA4F
zRwy|$tr8bNX47M4YsrE!w{(US=9)jo0uyaZ@~X!RYb}1Q?JeNW1qfxlP_yJz at HOZ1
zcHnIOo)_lm=>8?Ndr{eDkCTuBT}$xfH+VEoyn<GFW6?+_$nMCCP6L?camZPN+39)+
zWr~!cSz!VK-9hdv?TKsE8e~?)DTIH;lA>1WyA*#3cRWu{gIyhU(opx?>6KsA=S7Xu
zOGm8!6kJbqFdw$30Y*%FZ=7<`=ow$!t!Z~u*03dTXDdNCYpR)d0lfLIx3CpFxED$$
zvxq)ciQe^i8m+P_-CTw3T&PPC5iZQ|$q+UdyjrQbD&o|$AF+nxGbIpG;4#Iy`3rZH
zoo8 at bt_TIh{4k2iMG3aabJq*@s0gH8BRnEwy3JOC*y(Cc{>r4J$am#tDV8xeNc+Nh
zROjO$t#Ni>^vF5}Gn_>%67pQ=JZZ`-m?!?T>81&eD4P>{FGH0v!Mb-^Ioe0!=r=~8
zm2la?Tq`gkz^BJPZRkSpw{3HobfgssS6Demumr$C&e;cE(LIbF6~#X(%=8o`_(gRO
z)v->hJL@~cZsI&Ovk5f_(tbDB#VepC2?dH2zo&tVO~&L__vi4?Q&Pj%l6Du at G)|s+
zFKzq!^tWf0zD>ZUAfu(l0?c at O&6 at JNowScvpO2g79WZh`>SGGWw?k)0>^9dQ$+gcX
z_c*jwm^$wIN<#|@52gjU$5=Yb%c<6Zqw!4n^9=*t^D_%rZjt4kWnv>wsVuC>jqFHj
zy7_)(M|%^Md at n@2Q54fIVJ7r~E&vYRkE<9!owZl!fIw+ldw4^=oA|IFWuM4{cd(|Y
zr3rw|l(MlGxA5?{2l7$Tv at keGU!lEV*|EWdnt4mt81HG>!}P!Z=tOCSW=9@);Yfq^
z<l+_;5gxmLGCyA(O++rxvsC{w&o8u>cl)#v(J-vc!~}#Q5Fw8!xQxfC>}iufGjJo$
z$HXn*9;~&+xl@?_d(O6arJJBfKMVN9o4vaZe!PO$1ivNk2-}ZaPXz0o#|&L$Kr`x!
zkMd;!SL+Y2iI}bl(}bI#1>p4>HSrxJ#_syTw6=CBGY|?b3UyUU8mgmiG{e~qV{sJ)
z0P-70xNEU+Cj!s$<uI6=iOm10H{)`{uG8(dihqlgKd!PP<==KSDLc{#0$=vvrUjf*
z(x!tsc+`t^_v7WnA_EbMh51A=T68s*^|R9o;2=bp#&h??(5dO#Bf+#q2Dgh7)sMv{
zOukc}-Fab}>Qo`0G*zt~9OKY_Q7qW1i}1KqJrdQr9_ at -uu<Vo5^#B45rbfh+ku=S*
z%(K^>FMEhr2ZiyJz`_b+%XrPzm5n*C at FJ-Jj**f2)hZ$hqDF*nVi|vo-Ty`@obK<D
zB at KZ>KMBwE{I*0e0h at BG+rVH3l}o{Dvf{ZQ(yVfAfd)(j`tVC}*#x{6ayZy9Vo?zz
z6owfNQ$(>&>_O>Fx?2{C%-r at NOYhbYiZM3Tahc`iY0TW?>WXg0wQ<qjN_AdGGn5UA
zBJ*p~w8*@A%spZ!DQ6gjd6mkV%KnwXE3&Tr>9jw_$bqMd3;;@AJa$n41?8@=?fyQ~
zb}vz&K=M_jbrXm2Vad<yQoPEyGOQM>1HsQZu_BBXpEKFoUXf%f{aD(EcBH=81!Tn@
zfa-J3v9Tgg6#8W5Q$Cgqe<Xpa$@2PqiRmYZCChckom&0BxrsQv at Es_2T)ME+auB#b
zMEkkf<?@?zy*(d<$EYSS)8?aIdwYPc(bAX0*#2MbdQ?N(>>~%`2Fd9Li^k(f7efh%
z9*5cwXgI%nD{z;hS|;9Em{BM^gq*7Eh>ylSBXVaB_e0?Qdf{}Nw4us)){Ch6g~}&;
zWKeudS&{0RkPt_$TC3cD3g+~Lv at erMAllE7B*);A&($sgDG>!9^@}p#f01qhC1$&d
zQivM<1~-45CZPD|M9(5E>rr<XmCj7e&aaL(Rb_RCI1SY|9%ir@^2PQyf3q<~(jiBw
z3wpQ{5jAn(y<QV!ZJ#zUHW19N&^McrB+c+EP)fn?YtQ!42S{=%5rV@=UQ~!pM@;mK
zP1j_GEE{4KJzL0gL%Ib_{7f%a#+^hGNWwZK+gz&sl&wW76!+wqg1+wEPTILu at l7=j
zuyugFm$U}uG+CoF#8QFPUqga4Qh2|VBIHqb>to;&<K@|9%Ty84w{2O7A!^ajtfX9d
znaA?i9bBv~`9ll_{Ajk2%b^s`3IG^OpXU>XdwEDz1EnnG%-kK2rkNW%h0?5h6dG*5
z6t8;-N`kHYR(9HCtTNj{R&l)}d#&%y{V*a+MLO1^KT(jX`y-Z{WG6ditcK)$x?c{2
z8)Of4%gFMU<AyeB+Tf8 at g4d$FRrN4Rq%X0D+RO=wC}Jw(z}@n^#xgBoZxkkD+O3Ra
z)~Or#U9uuYls$}-7HZ=rVCqt(MKWUPJLT5rKagLaB$?(OrXR7a9b-SxS?Sv{LXQYu
zrlE!bZDIN~B3E|~D||E8gV+KGFVb3>&mCZ0$i(_CdtAzlQ_Iu1C~`FEb+EPF!LTy$
zrs<;Fe52Q1e*bLMcA+fy8`jayGUJG?P>*&Ms)r;&aD_8+2GOgE&kvFd>8yP%YJ@&h
z*RpSM630_?PM!TizjBA4d6-r?L4j+fbyVZ0S6-}fH+c2gSE>a0i$`DNM&oIP42tN3
zK5f%9anBM-2rerJpifaQJN_<XFCB{#zaJFz!t~TR=rM at KR#a8bqqrUDo~|82#)y$`
zh0-1!Jqr2{lhyX>zX^5XlJHy`C`@cx%u6Zu$Vq>4`r4vf%u6(XThFf2CKNf4;yM==
zoz~0NEum{ow6`mI;QlRh?<jHW*{N@?&2?ZIzMiv+XR?3H9J!AvDu2teTt#^IqVhHL
zY}=fXU#>w~^m|O1*xgWS`ju=Q`Y7L+T0+&_8|tTHhDKI}Y61hXA~O;9eWf4a;o9?N
zBmLwCRq4G|Z9 at 0r8M@-u2ETo_S3RK|B8;~m4(diZ${v+nJB at 9H@Ga>ldS8Cl7z~W<
z!)sJDIEW3kcW6q%<8 at q6rm{dtAscr%=WEqQHnxQ~U71i}RmQ=Ci3#d1av1ZBIn8bt
z>m$x&69^So`Z}+A#WM%1<dVaMMdIDXfn-`~!vwdz?q)eT+1+cgO;${E+X6A)qxG5a
z4Mvg$=;H&o8q2Q?Xi(r!5*n~6l61 at JzdtQe`KHC*BHyx4MqC?&OmUV#`CJD|K4)Qg
z?7VMo=|rSdHH7z5_eO)%Antl7TR`;5LU1*+CIqD&^KN5}w^Y1$isni;{jI}YZ7}uH
z{wx*M;;U+IWe;TUwteKzNKsr<k;YTcX~GyN|LJAV*<O~9Ywml}Wxkun99AV6(Ij&R
zL!WC<E7yXzO)61ofry0LV<|4$r!*^6?lu}dQev4?o{oD7mkxnf`4`m*qzJJ at Po?Xh
zeO^KB(zQ$T0ZeIuLiK%!yqTgEGK53&$tnW6(}@oL@!2JDH4Uyq9z+;aiKKPtvn7Km
zDsB5 at 50#}|(TrV`E$i*!Ql*z&VAqtHDX*-it-qhU&#zixG4Bd at zJ(6V<XWgHYSD$<
z3Y1VC;cM5BS)MauIRUkWR|k5%JpPwtn>?J4`T55)ru at xmF9V1&xfZPkwSUzhr>awM
zK9l^1{p(b6pupkHq`vx8J(zKCHsK|iXdHoqi&mAe)rjxTg^%QlsSdg5u^f=?TXFqo
zW;~4rulAB|9u^K89s8`*aeZi`<BC{nr;qjgTVF>V#W)|+zo%FrrV^@S%4fdXZX|0?
znlhKR3s>bhM{XJ3iiR<cn+=_xzzlBDVOSY=1?2AR&9mYjr$;GjwfwGDPWg+UR<Bt3
z1L2_sE0>EZW%|3fAKNw4r=2Gbue3l3!W^&qSa!E<T=kCkwK76$gqIAwHZA-_LihFB
z#dx{- at 1(vKTCQLcB!pZB_0xZhM7d#P#Lu%ZST5&Hh*!7s6;>)Hx+RB at dz-37^h$!;
zYe at 1<<6V+MLLjfIZ?On8vK56ib9XtNP{uuE-IE}zc4ty)w&W}ApHSgz54-G`koI&*
z>u7rp#lE+8JOHkW<%09?gG6kvrha-O<Xs5>F<N!}in*L{3ssW>c?IbC5^Pcv3?6{U
z2<-(ilTG|r*3QhZZOkCq at 56#65ZE~gGBOQ;hlE at r&cv)za#sgg(ndao#n0I_W!Rc{
zB+p7|l=q}D8a0x>k<Yi*?NP|=Q4nQbtXE*9D;oI3@~f*0WWiN=aXCxx&%WHSPd;d}
zyqC}kzLx#uzB2q?QtLwwtFo?{N`gmQ9Nop{)Xg*=SYY(R%u at dc3ZKf|+&Hdtod_<Z
zGZ>pG%2+pPDn3 at Uvl0=(ZDt(OM|{0_>Bm~!E2v(wGrF_W{#_?1KF}5$X>>K~%zO%U
zhfykMKgZt)ZO9TR)(fHIc4Pu_Cwp{G`u#&owt1ai=T}@Rnx1FJ2LP-QR at eooh`wKN
z>_5{T>TJ6nOiBGTNAK!BY^g)8zK0)wq+%tDmHjd<lqbn#g;i7GOdjklU0(jaFD5SJ
zl^?9Wdoid;1aF<`YgeP)Eomi{#bp`V0;vZ6{aLEyF&*0kTvJm_3x&DIF8bsE3=_RM
zn`P$APNJ9Gc7 at i>_z!+m(&ln`5AC=GX8#m8C;!n4<N6*)P~>W;EYPby(k2pJUUxK|
zDW$*+Qn#JWi7jupevcUo{7)<Z>)2RWvOIYG52qJeQw6%Vc86;sz1)@9d{RKdAuL_m
z9Y^aNIq%#*ZO#+J(ToSPGjV~*G`7KGv-Z$5fwK>&V^^xE!?&CRHEZYkUX2S`c-8?@
zP29c14k(AmWDRBkql@#iJeuw|D~>)MI<BLRcKgubl;=KBHa-}giFCyLyrcaMrV}qw
zI^@9iVEG+-?`cN1?F*Os_-v+RaVEb2>y}kwC|&2G{r=`V$c&i9aDn9R<)L`f-+t&y
zx8-;jk1WiD-jUd89ew1wm}3lH_QH__0I-(uLFB<j%j795B1GcEwe7jb8V79kfQZ6w
zQJwkO4z7wnN$PhhK<A~D&8WpVw}>t(m45I3PB9bxf52d{@OkF1c`CRjT%qjoe*9m2
zB+040FP$SM{Lj8MiObsAT?zH!tKxODVj;{9yW=wXC1=;sPFKy*)5!2u_op&v9ffZr
z>F-8;)%AA^X8CHj{?Lp#(x3|^ww;b*4l?lRpW4XPgxk$GO@?mFfv822%RYs;<a)WL
zzlZ!`9Zm>Y6HEwMFS at jSY#NN5!0fa;qFK0=;z+L3eyJJnTHV3SAr6*huL~wHoARUY
zl+*pG-W|li;1P<eE*)DLW-dWt<c8ctV9P;Fm!>!S2!|rQo}&srrU1+H%jDjhzS=4#
zj>)TtI-YsMSi~$vLw%?T2MrK6@)X%L*N18*i^bUPz9OZy00CF|>aGWi8r^Vx{gZh2
z_b#Siq34>PM~RJzM?+>Xkr%G5cT8mW at QkgS{J`EUJ&-$$tYl`n$1O2qI#GKEHZzaW
z%~T at NbU1TWX3%D~2RdDBS~wj~j89{5M^C5fUH#Qn`VQVIa at AdLvk+fR`(xVyh5nai
zOZ=j#ZC)Sk&d~6bc2BE(f73fiRC01MO*A&CJvQdppw2hzy at s>zkWI6#3K`4`D)YiU
zZ)K2Mrnzxob}jT%kq%j|M73e|O()aTEk&eoyg*FPdciF5PA at _>j(~LhAcFteKx6R>
zu!)N`TNWUax=qvtunZfOTUf(j_Rrb4#50iun^>`mxNXMXhFyLV001;0i4%w>J~}nC
z65&`ifhy|smE-gWugy4x8t#}ML4+zXI0S84^Qb5qUd(4EGn{OGfQ<-r?rLOZ9md#A
zSI8ED1b^yi(f(<L=QCt~!<lao8BQ<mlNZ)sj(Pc2$?QU$1F2TdX?4w^3D^O>5>HTn
z<^R8GyUU<Dp0z>X2X_q)0TNtKumiz^1_<t+1b26rK=9!1?(P=cT~5#w+&TEcdHLVF
zTl?Os-KyOW`>ktgrfRx-s=J at x^fTkMa{fQW);u%fe~PV^0EI+EYMaFTe=xPVI||2q
zQ6Zu7ejC>MW*B(ArELo*hBx_E!(An{S8d*ynzXU;44czIE at -`{?}rXO|7q%)Xnr5p
zTxZxI6@^6f`q7qp6DuCX-rLY16*frC;gW1t$lGSKR{A<(SP0yPML$Y#-%RsAw<}7S
zx?-uyNHLM)H|sK4j|g at 6ogoe1V+W;>DN>DE@^F41m{rH?!hbKmld6(#;!tIMQ}8sY
z2LshR?BS-inJYY2k<`Af_MXROr}zphTaCbo(oi)1K_eWd-A>bzDLJ6s-p_YN#XVi2
z+3TRc<l&=CA6&Qn)7_hr1L at xLQnfNE<}+L}?au4iwdXd%&SP<7J7bzvza5<!F0&K4
z+*RD9Za<n^xx_21WM%2dy&}%VEPJ$`<bUAbHnf?i-h6A<Az$*iOK%iEc3k(}{mY8L
zLpG?Y65<C<J%|+i8U#0l++O7Ba2VW=g`&bpAcoq2J3AZ7$Qb)ep<u7O1@=rA<6PxQ
z>-<wR_Z=1*6Y$-%eU503Egv7p0LRxFtKWn4Mo~O8YgCws#~i>P1s_kI9}`IIpp7>=
zUMD<WH*znI0J3UeUj2bKAY&$j=jyv8Yn(p)u<3r{mWZneT56pOl-%uSUALuU&29{L
z-;_|`z_FV<iIqO`89KojXG5S7!C!MEIT<nTFc*Z&7|#s2*t~*a7K7#|o#a^^R*ntB
zDTNav;OY8dp8-I=aL3XD!1NJ$XSj~)BECZA^9S6C8qBde%%R$f{-3pXXn=&lw$zYQ
zo)OoKiWYkBw)<Ut1j39%&og^|qwZBJGiB0lbuymK_zl~c46FInC}{&91rAK{ddxm%
z0&eneg*5<xT9R-Oa?b1lV<^MV)qc`X4jv^#Hn!$D$lZQ?nKLO=9`hix((fV1rH$Z;
zH*OChjheC?OQ57BMgbvKBWfhvYr*Grw6&eG2?6UzIjf3VQE`NZnY at 8<;kHMqEtOGg
zAr$|`y#gdX-<hH>8anpNdkJ at 7*9PRwEGsnxCCmAFLEtC7OT at WxdOE<O`C?f7I&K1I
zCve|j`ETLO<O+aVvgaI66b+EOmoKb;J|L7K(ZnihLejtuP%jcoSqoo}^J|%7F--)e
z-*_`5YJs%fSLw2(vRgTt-<Rq8=x+q>*8L5C-=4CwHnM4u5g<W&zP%>!j*lexIy(!q
zr7wq(X<Uv1$3AapM^l%@D1N$vKNG2=E|%&uW at VUB_7^bjqk)0bU_adS_JJBZz#q|J
z;h}6>)(NZr=IYY}O>x&JsE6Q0Mm5*;+3CW5-D&20izy9?=(TT^qqPST(cMC3-Hh%c
z2Wr9Fbr4HD4#T;{7MRKrHxuV&ueHH1HuJ1rgxvyt4BMN0=$#*>`w5;vJ#mkTU(b%=
z3eZDcdn|qP6j4)~JpFnd3A%ag{;=)1bp#edqtIv+kJp}`H@|Tg!iZkKIdB4Z2^Pa+
zSC9edK~#-MR(1Q*Z=E`N+jID|YuG?YO1dZPGVcNIuWj|jiOx7V at 2j1F^wpzgXk=kw
z!BRW8XocU`=P93nF!^9GOqzwzntK?586YO{RaJG<^URkBqVkEq!D^V)+%3HQI-bDA
zf18GH;qFO|<ZI-DJl(k_7nKTMcOTv;Gfxd*cA{v0=8lI$!~!|~a~`CwC}Lt+eX3(`
z;14XnerG~mT0d7BYF%F01esNlEwi(q8QUf*n^WhJ%!&^9R>&j41i56B{V2)55Ox?b
zb|Tcb438$egr-Ct7Qm-#;^KZgle3}}KV~~BHIn at 6ZUADd=b-zu^O*e6!%+wpXaU|=
zcx#^{d+ZZgyE#VYvkLAXkO_6ZSDDpVp{+gkjI(1NS1%l`%{2(E>hVlLrKh6Y>d$xa
z9O#d;iUwyFB<&@?SJCJ(Pz>Qj4krfEg?T}-v3nyJ#3Pp5tXvMbHBfX>Tpz!7JQ=_D
z`))4Jc{Ab~RjJriF~X!m&=xO+EgGVnd;vA=Q)<zqxeUsL0OD$T@~acOobx42Pd|it
zF_38L$+5CXU+ia!ifzAei8VcR=m(b!7g+HDdRHr6uJ<teWMijK_0hTeroCw!w%$PJ
zEQF_SHcq*N4IRBCMfI|D^PF|)a{m7LOpPgeb-xIstk^2c;lfHgtJ4Hfy9=(Ia|>S1
zR|7{QybAIeWy7VK>Z at 4e6;d*v>52kt+FD-MkyO~9O1ZSdM=QvDg&MAHLg0bN`0^T!
zEzG|XD>sCkSl&~6W>UUm(Zy0IR(CfOss@}@5wlp_S5*F{0DHct+APKNIbDj&iyzf`
zpjD4DVG^#Xec++)tDCWRA2MrrPH^?vtzD~ZI2Ix;c{n~wpOEKGZ_bM(iIPQ^=f|LK
z_-n8<CWf|Y;dGtnHb?^>_|Td>Ix+#Dqr at 5e^)q74A(}*UH#x);P|*017>D|5cEZfW
z3Xo(Jd=>(r-Zn%tim9tZ=7&GnBTKUd at veDi2GXAEhUe#Pylx(`?kOW#Z{8<{JIlJe
zCfK<Nxj2iULLS<4yDsO0#9!;aBS>l)*DJ5=EsFhqLZb=NCgfxT25o0vqx-jT@&Zlw
zO<+G5xzzER1rY6bBZ#>SoMUK2fLucIdX5j0HTRpqFIG4xyyJJFo-9MJTT`9Jm=%$w
z+TVTy9A;py at A)8!UbP2xZ<KP!N^FUtx9!0LZd;dlToh&tQ#K#BxfXRw*0>(>xvmb5
z6f{ZvKZxuVayehT{UF2}nwsrA*c*+jbu(1a-%d|7i*AxUd#bBJ#H?OC!CqD;LxZ3i
zAmqn`y>ymBoh4fyt9L_KSU63RSyNpeMf#Z%hW$RP!)piyMdqhip+X^?gURHZ=#R*i
zycY1$7Tu_T?~J$1+S`he`Xhr~d|FY_y4kQWfS54U6fniPf4~FV4Sm)e{X&PyGr{}Z
z-g;o_r0Qc(c0qIZh<|aK+21m|yef$E+Hu%sCS!ZSp+DErVqX-|QU|=-_iY9ayQ)^k
zn4>rMxh+>dSr~l_$ZxMaVNifsh!5<FRyF(dUi++U8gtngE at -RuuJ(`3_YU5MN=C1c
zoV2|COPAQ#VSqt>srTt{Elc3}N{ujOq8OCjxrNe9q91c{^tQQJTh*b at P;po-ca#OF
zb$s%8N;))+k3a;FnA#?&Fr+&!k>l7QFP64zl;_mGyH-ykFmmX$xmA{4!3D_1>N<}6
zLgM(lPw6cADGa}mg$d%z&im(ro^s8qk&D^Nqm%8ej9Nr>AWyQP*6Hb~JMy%wk&8S#
zmU;LnhF8e4t`wY<Q`h6QX&>JL?Mr{BLo=dITuMfs&XYlzg#z(@8?ufLsf({k5F0(A
zTix#~>zaHMiEkCRbz(UFi+%-1Cyu4SB&z-45*za;hP}6)nJ_~}rZl7Zk>V)h{(Psg
z at +2x@%a?XkjZ97bba at 1&RCK2dgtxH7QMIJ+aZQwff>{h7ws>;*LYB(f8o-w()w#Zt
zOa-2y<JC1nLr_=%wge|6LVD5;t|V%Y^Px=_S`%5+ko(1TSH`8SVU>4&VG|w;RG)MI
z*pz`cHKvVY!{XVQO1};>|JaSyN#Sb_0nmkgerU1ul49$z+bREPC8QeXnwyZ9pYM{A
zOt6a~V>++pWHMlB2YbtqEc<D;GyBlR<F+kN=V&@V8md(Yuafq0PNW-`RfWp&h%-}L
zCmyo+k-M<dds0QO>w`V4Dcy+4!l^gZZwA6k_^Y?a<;t)5b75wAIiE*^d{080HfhHk
zel+#kjpXc)lnt|ZU;R&azDK+XW at X_WLO5Nih$RhN#4IkNkEyTOqw*t#vpu=(&GeG~
zrrbXom&ktGWn=p(c{+B7(k<0_<u+*~x2$*#I!E2*_8>H7S-U6T0l5Ss+?0zj3Ecuc
z at n@_oj`3hO#85#x==yojhOu(i<w&Q3G_yPxMe`DkYQ at e%Pi|=QvZ!*xtd0+zzVHRZ
zV3o0vp<wC{^`z4w7(XA<kCT)HeNSb`8st0*@k82d*{w`~&{vaH-N_bA(ZcV!)h3+p
zRnlh3<j{?cz at PGY-yyf=KZ=Aj7Q3B>MpPTR=c9Pg_P(ro*sU)r`Q18MVoy?OHPYCx
zZiby!`SG#(J#21o=-#<;PE(OQ?@cP$^+b_vLD_~^dM>xqW3L9w at 4WV+^PnS at L*qL|
zmv(0bls#)}!j*O%-XM-WjL1e;$+7gY&19Pn`5Rnllw<H;>LCG29W*<fxbOI=e%R3-
z1n(%2;=Xsu-3~6_>wgQF&FrT2BU+%M#HT>DL;mL^MEC&F+Zd^<cGKp?NZTHB*2OoW
zy2BED8pB)|0ix8nsKGDh=20VUQ=Zzrx}nF647mTggqnhjc7XPOTb_S;7I}gFg&62y
z`Q!*(xLEpmJ}R`sfXkQzc8p}t1HwQP)1qTvZmnaxqaFETg$_5tixX3aZC}{gHV#d<
z<+G)yQ94^+x8U>hGmgm8$($>W0*PV)rF*RX{(;*`cZtm)q at iHtwSls7?iy~+q^&9x
zg!aiPsJxCf2r|Z38>EJpoa}B5MWXqhFTVM1Du$n)`e937ur9-bvjtWdTI)S5P|7Tl
z9bi at Po3Edw_!vC5I1YY(cQ5tq;kWdwI;M4{_F>(2AzEobxNM}Ra at lY<+xbfP?cFy|
z8kqCxq6N at yzz&Bt3qBBL0m%$CGE(KLKPsj2{xwMpye7hQ{;CnW(q%ZU0}*+I;}4v=
zvzE`5TT##6CvU%8iw`rKEQCdRXhQ=GDY_tYyuw^2*{NIVQbEif^|YEchPOM}hSmky
ze_&0;G-|c#bK{+Me%?T6!7);kG$AyHV$u)(W>J8BO&eheSKM9vm-cvbOv}aUDdwpg
zEL8AlvUswe9LZTSnHkna2}323W#`qewOHRKt>1jS{T;U(aU?%6p(z}#fGrH!qK|S5
z9(Qsv1SRdeHinO?I9-p)#(O*CJguBg)MoN`B)XEiO)+od?q*GvV_55=U{Q8M-x)MQ
zbO!L$jG|2BHCYr-6lfuVkkgUqBv_Q&N~)sW>Me9vHq*}iH`Bix!+ut{iuvW1w{S0T
zieqQ_=fkwX3I63#nw_`4)egWtJ9?5aB0ar&y+fm)U&>EsX$uxt)+EyLP;AkC+;cpn
zAsLx?5LR;@-<O5xp>&Qtto#@%%I7;AebF2-wSL~G$4Elhi?f{den7_{I~$vWkBg6c
zBLe>KI`DauOB~(bzrKB_>pfgfUAS;{qrKH!XJ_=aDDCF!oMINv>F3(|8RN`J2&c$r
zgXi?Iaq#gEN!_0(m;)0~9n&tjuapX`k*$t^+Px1Y&x)y&jgr0ii3BERmH7gE<X;eZ
zv{r|gbST=amfcodF-Sl4F*i&GD3vbOjlLJcfDH3K9o at 5r<5Y%Pj1gahu&_`gf?y$;
zc(SRfQV;KU2Pe{d-sAveegP!tVr7--r!esQ5okH~k54Hskn^k!Ot#FHSp9!_ohct{
zh)C(GX&WiS<7#HaP_76mPk+5K$u{KfqQpdmXqmk%moCehnV3-r5A=BDUn&E>HXtpi
z?}}4lv9T+Dku$Swu5L?$pX;=tIr2^zVQY7u>F?p4y+D91sHdab!<rS$$;mIZKW>fU
zb5%*OaLqdy8UMYLn0Ds?9lvdd(v{KcBDuqce@|N at 0^(JbbWJqizW-iY;W|hJ6l9i`
zu+B1&rVK2UX62fFLIWhKdY|-0xA(f0xr)-XP(Jl#`E>TA!Bcaux$<gxcBVkPuJaQD
zL?tQ}G437{Dyv55)75_%Ug13MN5BJ$fz?c5^2zMNw&ZbNw7=Pj{wk;lv{KgvUmfF4
zK`+qn^Yn;*hp9>xZ50|em}kKFSDVNi2iauO#xNZ#n?a6yx-nuyVg&D}iNQ(6^|+?^
zqmC$C(<~2e%@hfoZP=C3`sXOK7-UDR%%aZM&udkT+lzZ*GmOrOnsUyUG;Tv30qO^8
zTMM(>V91XwU$^AfJiBAW8vZ~0{R_VO1$q?6X;;BucZU+29|8Q`U85QJ_RiM=2pdtF
zay~W+vNr8%MjMO(F*SfW6Z7k8F7D$O4 at msc-)cR at HmMF}fZE{@k70)TCGh^C$eTR(
z1LeA_YC};=m&6SbT`O~vR~IR|F~>%ZST^bPJ+0GPV)z$D at C!Ndm(m34b1}<r@&hB_
znJ>2{<Atm(b*=dyl?8pP%I9*cJG~Xy?z4s6TPz={$zG%Vj=%Q0hQlRq1g!#T3;zgL
z^Hz=wX8*dBfwqLAATj6H+-#Qqw1&RvxXG2CJHi)bV%y;XAz<{FK~J->MRR4%5IcID
zPSFrwrwsjuror-Jv(q)lJ at 7&rh#Vp^%R7)@*zOQ0dAsL at 6QUQ@NWW~At;b<t$v%Q8
z at d@A``FL3LIB;rr+=`W~XoFLc(YjmaQQLhoq`x3RGMDH{)A`y-RZrl0Vg=O6nOwpr
z&51ppxb}7z;XCoFv$3xbuBr<ieGmo*!B5)D7y?xXqpmn43CM8e(9LSmB^f{v(`2ET
z?{%7-4Er(HNY5ILIc1i}YdBmasHoExm-SngJfdu`8)|7$h*$U}5gfORb+LK=t>|o7
zU4DLPiT|UU at B;yP)*&hJB$$W%BkJkt%?9ZcadC=aXd6Re9Sg5Kg at kXEU*^C?R_tj{
zRDENz0-aZ%q)A4(Rmop-|Lj)q9k94oSUWH)ShL>Mt?gv+NN$}rs|mzQT9R0M<CWjt
z;dd^+^!;K`-aNr(OKPu8XV2|X(m6&zOE;69{<!wRAkWfK{b$y>f#xzX7)ZW<Hh<z3
zL(zs at epTV8H{9*WWymy+(<DsB%bk2+?4nx}bCI-5e#hibjVeIq(`<<n<O})k&3S;S
zJylu*I@*Q+d8XarN^G)|L#Y}bSpCXHX4au-OS3y!K?L`CQ|aoj1ISZ*bnH&L`Vs)Z
zRP$cn`cXw%oZvNA#5HUvG`~U&@8M0cF)btn(AuZIt%LImk*WPLT%N89y9p<9SHJR?
z+%2{xwf`&;x6WF#XF>SU4%dlmwYl;PfckE6-^xYak}QuAzTx#9U<>~$$ocQ$S|CV`
zn?&pe$`3yvPuygSuC9Ajt+V!2`DVFo at KOGbdv8qS^z>l}BF%)>7S3W8Pcg<`oTi7e
z*UM!@=^|+qm9_4uduqIp%%CZybKeTATD}=Bh-)x7EG?6B_IrptSmrT;G*7x1!~b-o
z(l6tgt){@S!{T?U)&g}?x(nmYC+|9p3~*^Cvo*mYO%gwg*QbpRt`bnUx|16S!v+^P
ziEt$WzrsY|yuk5MTv1VG>fFI!QT=7BU=uMnZ3=o_8kwIWtQ4tMspfe6q~xy@=OnRs
z*&_Y64ZP02n$qF=zM&m>TtjP12Dw`_T!H|fmF>L|m6)T*&PVK<%_n&d#|Oo${0ccS
zb;$ggRo{(EN&N0^7$n8u<`zAg&`y!jakQDtuK^j?14PT`N2>6V;s2Wm5_{Fkv(#Tx
z02B&?<CFb=f*CBv>a+p(dP4O{S6~gjH^TZpPGJG)3NAwK|3Dp3x3R-rPoXLVc^{L9
z*k=IYY_d}7wzjK at 1E4~nMuc-_3%uH?<(=eCuI0&+={cyXV$_`f#odkQUjjQ&f~gP?
z<ZUn-MFK{2r9u|6>3PT1ci)PO6pqc+0_w&+U4Op`_73;>@Jf8gMGjF!C)isdSuyv{
z1H>@g>;10e5*@+ZA3V&(e?$?K(%4GhU|0>u3-)l=%b at x5q`7Ps at FHefhs35<qODNf
zT<&IA=Z~DVB|WLf2Q6lfhGBMNX4lI&)yLiSqKP67e88OG#4J~uwhm709WgMv#K`ZA
z=7A%~JL=$kZ!4uJYtt~OB9pf6nETW(@a0b-U!?+)|K#{Yc=Wxy@!P{Szl;FJBolL_
zA;#Y`=t*(G`$=Rv5t46<2h-`c>!z6GUKW3)<2$;posffl^&6m)D;$We*pp1oI)}v!
z2tgjmo$D#(YcS25AXBXn6YY>KEsgK}e-J^5N#%ub1=}PEG-JM6m;h>a1^!=#%^!!@
zfs|TC7T4Zp(!AF)TZDbW@)g5R=5s3+WVj}qQ{{yNzd$c)$9MjTK8*1Ggvq=FT1O|&
z2>t|w3*>>g*B5DA^w|FNip7p^8#7UZg{YZ!+W|(e0i;y-Q9i-kfayt at +4|-8<A<50
zi`}xPz*$|B|5UrR$6J3RD(LZH$`!&i5ifXq)*rHgYLZB%1voHOJ=}jxOYu9qh7x3I
z0SoU6zQIh)S$-LsNgj+=8&6$fMv)(d*O_adi%o at w1}0g_C;ibqo(V#43j15v{r95!
zt at pUVcHjrH90T5`8<BrYTHJAZ&s&NS7<T3IH|777$*4;*>Qqb28VDKp@~`SWzZAo<
zjm)@OPdRJP;yu~gMH~eeUlBrN5+fJYFu32N+kG<L%eU8|6cT%VFCNd!p9zTf{LVKW
zWTjB;iVD2>WF1OF^{C0p<q!+{?n5#HO8&GZ`~k|X$V(|dRDb-uPbN(*$a^AxXJvv8
zNF2!!7Od|lF2(84<E{+~0_mBzP at Z`a?fQCtIAFA at Xr^$~HvUf6{@lEDrHe)12|^Ni
z*orHvu^xK!Bhnr4J|L%`^9(6(c)9)Dm2~UpxwHwJ9rMz84kO>04$tBAMu;dMrg8fe
z6d)cz+$7-YX^YJza)22Iphir35(J>;*7Td~>evv1q6pUiq-p1B at q?7z__#lkb_~_i
z!#{R7RhwLsn)>vAGb93tVj?wJekaig4{kal%vYAll`(@0CR!Z<4;LRcB-q_(;^7L}
zDmot-O{zdvo$Ff<b{823{yS@#)M4$&^hX3Oq|Skhj?2FvTV)xF1L_>3&IFwX!_Ta8
zCt?FtOb;6t55Eu8XE{_e0<#z;mae!70S+Fv7P?r|nBteQN_so211KQZZT^kaVqYKS
z^;4nrIJZR_z~*R%^zg7e3V|#={%Zv_gaR0EXsgg&6p*2pUGUWRYdvg6XH{W88hV2<
zl4BNN#_AE}@MSQrg2GlwJW>0})?8l^1m_T8pS1&Y1l--d4(Gue0#om!^9|et{`kU@
z at v;ptZxnqs*}uHdEsk`r8PGuFG=EoJ>yg6hWq=sxTb27NP;(PnzG$L9!@snJAW)A_
z+{2jDsIvwOjD(zQ;czw0cJo7UxVaglk*IdzP`h at 1E5y1rQ&OMH*;b>Xt`iIYP#Ak>
zu at pqM-yHwP>7&$7kI%#1`0MY`C1qxYvq(kyYR}pq;Q>AEB*qE45gd{b=P9G1Q~LGF
zG;5SlTy#lomm3+~a|S79f_0rFaR)VS3P^tN!1;45aeLcokJxKE`Q9d6utD2h#c>LT
zN4CPHM-xtSyqL$i#LHX&TG_s5zB~oht;dRW-R6lD==pWnP!k^dLcQn`lv`;)wkM)Z
zpZP)HN$v~qn~Q at apnS&R=u#L at ba*cc!w|9e{DNIR>Pb5XtEnSQ8m4m+IjUn|CkIZ@
zV}47~=4Hh$fBb5=h%Nv8BR~bwTuN0dy%J6g7)rIwD=PE;HNfJu!NO1D0_}bS+c4x0
zciOkAk?WRFhK0~nCw195eQ3MP)+8}0GiDpu!SHdj`)DB<q9a4s%>VFhpwRxs-YP;u
z_3xKL!$f;-z_OOs-+f!Fhp;)HWu^0X<uBVE`OTNl7<7_Ok^Bc4m^O?|JnQ7<7P)`M
zF$u-#%C-JeoxJOk>p3?^eB?c<iny=Lb9Ny30FY3(jvqXqvX1WA{&|p{)F;)*uI<Z+
zGVpAH)+n&+_?VJ=wS<#a!N*t&;|eEa<+QL!3A52jGjRO|4Ggo1h at WWiQ8x=Klu4UI
zYO4xJ(vZqDT>3gjAQZ1!<69Urm!T3qIk`AfQ}DsCB|#2>S at m1AQ_fbGO6sUey819_
zvO+~*BSA6{bG7qiS4(y|ZR%>JxQ{9!D^hcp&j%Q0d9FTvpJzGu`*$S>@2_LHQG3{w
z8li_5r8gIvl7$(&hApr^(yr4#-)ou>iB2}5sz5LaOsgCvp#9Yo^k;@M?}LW7HePyi
z6igSuppaUi8$Vx67rM$+*-Tje&}IuP=L^rDE7?{R;oP){u(UzwtgJ-HNhq4t!N3qT
z{F=V+F}*9R>M$Ek at S*D(5WWSH60k*amoZ_ho`%nfPY}upz=nUx>$YR2{t<Mv|6&^}
zE1;?Api)&{OTSWjuyLbMoMu$Bg~3$hy>+!;*(5{H@*0}FPu{9yV38FP5@%z}5iPwO
zEssifl!a^F`e?*nZ)t!*S^WCc$9PIT(0k)kf3jeOG*vIVv)5O*Ut^D%%aV_RRE at q(
z+^rTqlo${BX5KE!i7|IhgE?E at DYea#z20|9x_he5pB66Tk)I5nQdGi<EOy+*H6?7?
z)=<(p?kw<(O#e!h_oMR4;aG3y+S at ld=Kn+<dEr04K)Hy(D<M=a4OnnF1g&(*nA-n~
z+K at U*gFd4o0)D at scgwb+(Zrq;V<hge+9{Crri&ANnghJLN{G_+HD$X5<a6UY>7g}4
z5sRu19hsI8!rN>C=)?-yA&ytV2p-<*+R5Dg;FuZYFW>@2;{=tW+1-l9?KEO%BKs+1
z?x!CE!czd=n*NKu)^pPl*6s3~0IY8S3>?nx_(c6U@{VaYJ9y!I60TVE6Ff}W;l!{W
zGF$V;(b+{YR1_|<tDvs;)^-;Ou~%RePvuLm15NTPqy1|l&weulO}h?u>pn5!COQgp
z+e!;{(-V9JwpT`b5TzV?&X^{PcbPiD?gm0z-2ag`YTTQE{~J^LKUv%VkK<S0Fe;D@
zI?+D<8~Sij{YZvc>Hk#;MEH%AcTE3p<+~S}V&&RYSi@@!0szQJDo9j`eGU9CEWPe^
diff --git a/llvm/docs/UserGuides.rst b/llvm/docs/UserGuides.rst
index 6fb61f2d3a2526..2eeb076192033b 100644
--- a/llvm/docs/UserGuides.rst
+++ b/llvm/docs/UserGuides.rst
@@ -57,7 +57,6 @@ intermediate LLVM representation.
JITLink
NewPassManager
NVPTXUsage
- Phabricator
Passes
ReportingGuide
ResponseGuide
diff --git a/utils/arcanist/clang-format.sh b/utils/arcanist/clang-format.sh
deleted file mode 100755
index c8ae017fe751a4..00000000000000
--- a/utils/arcanist/clang-format.sh
+++ /dev/null
@@ -1,68 +0,0 @@
-#!/bin/bash
-
-set -euo pipefail
-
-# "script-and-regex.regex": "/^(?P<severity>.*?)\n(?P<message>.*?)\n(?P<line>\\d),(?P<char>\\d)(\n(?P<original>.*?)>>>>\n(?P<replacement>.*?)<<<<?)$/s",
-
-# Arcanist linter that invokes clang-format via clang/tools/clang-format/clang-format-diff.py
-# stdout from this script is parsed into a regex and used by Arcanist.
-# https://secure.phabricator.com/book/phabricator/article/arcanist_lint_script_and_regex/
-
-# To skip running all linters when creating/updating a diff, use `arc diff --nolint`.
-
-# advice severity level is completely non-disruptive.
-# switch to warning or error if you want to prompt the user.
-if ! hash clang-format >/dev/null; then
- echo "advice"
- echo "clang-format not found in user’s local PATH; not linting file."
- echo "===="
- exit 0
-fi
-if ! git rev-parse --git-dir >/dev/null; then
- echo "advice"
- echo "not in git repostitory; not linting file."
- echo "===="
- exit 0
-fi
-
-src_file="${1}"
-original_file="$(mktemp)"
-formatted_file="$(mktemp)"
-readonly src_file
-readonly original_file
-readonly formatted_file
-cp -p "${src_file}" "${original_file}"
-cp -p "${src_file}" "${formatted_file}"
-
-cleanup() {
- rc=$?
- rm -f "${formatted_file}" "${original_file}"
- exit ${rc}
-}
-trap 'cleanup' INT HUP QUIT TERM EXIT
-
-# Arcanist can filter out lint messages for unchanged lines, but for that, we
-# need to generate line by line lint messages. Instead, we generate one lint
-# message on line 1, char 1 with file content edited using clang-format-diff.py
-#
-# We do not use git-clang-format because it wants to modify the index,
-# and arc is already holding the lock.
-#
-# We do not look for clang-format-diff or clang-format-diff.py in the PATH
-# because whether/how these are installed differs between distributions,
-# and we have an executable copy in the tree anyway.
-arc_base_commit=$(arc which --show-base)
-git diff-index -U0 "${arc_base_commit}" "${src_file}" \
- | clang/tools/clang-format/clang-format-diff.py -style file -i -p1
-
-cp -p "${src_file}" "${formatted_file}"
-cp -p "${original_file}" "${src_file}"
-if ! diff -q "${src_file}" "${formatted_file}" > /dev/null ; then
- echo "autofix"
- echo "clang-format suggested style edits found:"
- echo "1,1" # line,char of start of replacement.
- cat "${src_file}"
- echo ">>>>"
- cat "${formatted_file}"
- echo "<<<<"
-fi
>From 5f058398ab7a6c2cf3555daf190d3d13d68f78f5 Mon Sep 17 00:00:00 2001
From: David Green <david.green at arm.com>
Date: Sun, 3 Mar 2024 16:56:21 +0000
Subject: [PATCH 392/406] [ARM] Mark AESD and AESE instructions as commutative.
Similar to #83390, this marks AESD and AESE as commutative, as the logic of the
instructions starts as a XOR between the two operands.
---
llvm/lib/Target/ARM/ARMInstrNEON.td | 2 ++
llvm/test/CodeGen/ARM/aes-erratum-fix.ll | 44 ++++++++++++------------
llvm/test/CodeGen/ARM/aes.ll | 41 ++++++++++++++++++++++
3 files changed, 65 insertions(+), 22 deletions(-)
create mode 100644 llvm/test/CodeGen/ARM/aes.ll
diff --git a/llvm/lib/Target/ARM/ARMInstrNEON.td b/llvm/lib/Target/ARM/ARMInstrNEON.td
index f160c031d843a9..21a5817252aeaa 100644
--- a/llvm/lib/Target/ARM/ARMInstrNEON.td
+++ b/llvm/lib/Target/ARM/ARMInstrNEON.td
@@ -7362,8 +7362,10 @@ let PostEncoderMethod = "NEONThumb2DataIPostEncoder",
}
let Predicates = [HasV8, HasAES] in {
+let isCommutable = 1 in {
def AESD : AES2Op<"d", 0, 1, int_arm_neon_aesd>;
def AESE : AES2Op<"e", 0, 0, int_arm_neon_aese>;
+}
def AESIMC : AES<"imc", 1, 1, int_arm_neon_aesimc>;
def AESMC : AES<"mc", 1, 0, int_arm_neon_aesmc>;
}
diff --git a/llvm/test/CodeGen/ARM/aes-erratum-fix.ll b/llvm/test/CodeGen/ARM/aes-erratum-fix.ll
index 17d1ca65430aff..43c403fe6d64df 100644
--- a/llvm/test/CodeGen/ARM/aes-erratum-fix.ll
+++ b/llvm/test/CodeGen/ARM/aes-erratum-fix.ll
@@ -49,8 +49,8 @@ define arm_aapcs_vfpcc void @aese_via_call1(ptr %0) nounwind {
; CHECK-FIX-NEXT: bl get_input
; CHECK-FIX-NEXT: vorr q0, q0, q0
; CHECK-FIX-NEXT: vld1.64 {d16, d17}, [r4]
-; CHECK-FIX-NEXT: aese.8 q0, q8
-; CHECK-FIX-NEXT: aesmc.8 q8, q0
+; CHECK-FIX-NEXT: aese.8 q8, q0
+; CHECK-FIX-NEXT: aesmc.8 q8, q8
; CHECK-FIX-NEXT: vst1.64 {d16, d17}, [r4]
; CHECK-FIX-NEXT: pop {r4, pc}
%2 = call arm_aapcs_vfpcc <16 x i8> @get_input()
@@ -70,8 +70,8 @@ define arm_aapcs_vfpcc void @aese_via_call2(half %0, ptr %1) nounwind {
; CHECK-FIX-NEXT: bl get_inputf16
; CHECK-FIX-NEXT: vorr q0, q0, q0
; CHECK-FIX-NEXT: vld1.64 {d16, d17}, [r4]
-; CHECK-FIX-NEXT: aese.8 q0, q8
-; CHECK-FIX-NEXT: aesmc.8 q8, q0
+; CHECK-FIX-NEXT: aese.8 q8, q0
+; CHECK-FIX-NEXT: aesmc.8 q8, q8
; CHECK-FIX-NEXT: vst1.64 {d16, d17}, [r4]
; CHECK-FIX-NEXT: pop {r4, pc}
%3 = call arm_aapcs_vfpcc <16 x i8> @get_inputf16(half %0)
@@ -91,8 +91,8 @@ define arm_aapcs_vfpcc void @aese_via_call3(float %0, ptr %1) nounwind {
; CHECK-FIX-NEXT: bl get_inputf32
; CHECK-FIX-NEXT: vorr q0, q0, q0
; CHECK-FIX-NEXT: vld1.64 {d16, d17}, [r4]
-; CHECK-FIX-NEXT: aese.8 q0, q8
-; CHECK-FIX-NEXT: aesmc.8 q8, q0
+; CHECK-FIX-NEXT: aese.8 q8, q0
+; CHECK-FIX-NEXT: aesmc.8 q8, q8
; CHECK-FIX-NEXT: vst1.64 {d16, d17}, [r4]
; CHECK-FIX-NEXT: pop {r4, pc}
%3 = call arm_aapcs_vfpcc <16 x i8> @get_inputf32(float %0)
@@ -123,10 +123,10 @@ define arm_aapcs_vfpcc void @aese_once_via_ptr(ptr %0, ptr %1) nounwind {
define arm_aapcs_vfpcc <16 x i8> @aese_once_via_val(<16 x i8> %0, <16 x i8> %1) nounwind {
; CHECK-FIX-LABEL: aese_once_via_val:
; CHECK-FIX: @ %bb.0:
-; CHECK-FIX-NEXT: vorr q1, q1, q1
; CHECK-FIX-NEXT: vorr q0, q0, q0
-; CHECK-FIX-NEXT: aese.8 q1, q0
-; CHECK-FIX-NEXT: aesmc.8 q0, q1
+; CHECK-FIX-NEXT: vorr q1, q1, q1
+; CHECK-FIX-NEXT: aese.8 q0, q1
+; CHECK-FIX-NEXT: aesmc.8 q0, q0
; CHECK-FIX-NEXT: bx lr
%3 = call <16 x i8> @llvm.arm.neon.aese(<16 x i8> %1, <16 x i8> %0)
%4 = call <16 x i8> @llvm.arm.neon.aesmc(<16 x i8> %3)
@@ -142,8 +142,8 @@ define arm_aapcs_vfpcc void @aese_twice_via_ptr(ptr %0, ptr %1) nounwind {
; CHECK-FIX-NEXT: aesmc.8 q8, q9
; CHECK-FIX-NEXT: vst1.64 {d16, d17}, [r1]
; CHECK-FIX-NEXT: vld1.64 {d18, d19}, [r0]
-; CHECK-FIX-NEXT: aese.8 q8, q9
-; CHECK-FIX-NEXT: aesmc.8 q8, q8
+; CHECK-FIX-NEXT: aese.8 q9, q8
+; CHECK-FIX-NEXT: aesmc.8 q8, q9
; CHECK-FIX-NEXT: vst1.64 {d16, d17}, [r1]
; CHECK-FIX-NEXT: bx lr
%3 = load <16 x i8>, ptr %1, align 8
@@ -2202,8 +2202,8 @@ define arm_aapcs_vfpcc void @aesd_via_call1(ptr %0) nounwind {
; CHECK-FIX-NEXT: bl get_input
; CHECK-FIX-NEXT: vorr q0, q0, q0
; CHECK-FIX-NEXT: vld1.64 {d16, d17}, [r4]
-; CHECK-FIX-NEXT: aesd.8 q0, q8
-; CHECK-FIX-NEXT: aesimc.8 q8, q0
+; CHECK-FIX-NEXT: aesd.8 q8, q0
+; CHECK-FIX-NEXT: aesimc.8 q8, q8
; CHECK-FIX-NEXT: vst1.64 {d16, d17}, [r4]
; CHECK-FIX-NEXT: pop {r4, pc}
%2 = call arm_aapcs_vfpcc <16 x i8> @get_input()
@@ -2223,8 +2223,8 @@ define arm_aapcs_vfpcc void @aesd_via_call2(half %0, ptr %1) nounwind {
; CHECK-FIX-NEXT: bl get_inputf16
; CHECK-FIX-NEXT: vorr q0, q0, q0
; CHECK-FIX-NEXT: vld1.64 {d16, d17}, [r4]
-; CHECK-FIX-NEXT: aesd.8 q0, q8
-; CHECK-FIX-NEXT: aesimc.8 q8, q0
+; CHECK-FIX-NEXT: aesd.8 q8, q0
+; CHECK-FIX-NEXT: aesimc.8 q8, q8
; CHECK-FIX-NEXT: vst1.64 {d16, d17}, [r4]
; CHECK-FIX-NEXT: pop {r4, pc}
%3 = call arm_aapcs_vfpcc <16 x i8> @get_inputf16(half %0)
@@ -2244,8 +2244,8 @@ define arm_aapcs_vfpcc void @aesd_via_call3(float %0, ptr %1) nounwind {
; CHECK-FIX-NEXT: bl get_inputf32
; CHECK-FIX-NEXT: vorr q0, q0, q0
; CHECK-FIX-NEXT: vld1.64 {d16, d17}, [r4]
-; CHECK-FIX-NEXT: aesd.8 q0, q8
-; CHECK-FIX-NEXT: aesimc.8 q8, q0
+; CHECK-FIX-NEXT: aesd.8 q8, q0
+; CHECK-FIX-NEXT: aesimc.8 q8, q8
; CHECK-FIX-NEXT: vst1.64 {d16, d17}, [r4]
; CHECK-FIX-NEXT: pop {r4, pc}
%3 = call arm_aapcs_vfpcc <16 x i8> @get_inputf32(float %0)
@@ -2276,10 +2276,10 @@ define arm_aapcs_vfpcc void @aesd_once_via_ptr(ptr %0, ptr %1) nounwind {
define arm_aapcs_vfpcc <16 x i8> @aesd_once_via_val(<16 x i8> %0, <16 x i8> %1) nounwind {
; CHECK-FIX-LABEL: aesd_once_via_val:
; CHECK-FIX: @ %bb.0:
-; CHECK-FIX-NEXT: vorr q1, q1, q1
; CHECK-FIX-NEXT: vorr q0, q0, q0
-; CHECK-FIX-NEXT: aesd.8 q1, q0
-; CHECK-FIX-NEXT: aesimc.8 q0, q1
+; CHECK-FIX-NEXT: vorr q1, q1, q1
+; CHECK-FIX-NEXT: aesd.8 q0, q1
+; CHECK-FIX-NEXT: aesimc.8 q0, q0
; CHECK-FIX-NEXT: bx lr
%3 = call <16 x i8> @llvm.arm.neon.aesd(<16 x i8> %1, <16 x i8> %0)
%4 = call <16 x i8> @llvm.arm.neon.aesimc(<16 x i8> %3)
@@ -2295,8 +2295,8 @@ define arm_aapcs_vfpcc void @aesd_twice_via_ptr(ptr %0, ptr %1) nounwind {
; CHECK-FIX-NEXT: aesimc.8 q8, q9
; CHECK-FIX-NEXT: vst1.64 {d16, d17}, [r1]
; CHECK-FIX-NEXT: vld1.64 {d18, d19}, [r0]
-; CHECK-FIX-NEXT: aesd.8 q8, q9
-; CHECK-FIX-NEXT: aesimc.8 q8, q8
+; CHECK-FIX-NEXT: aesd.8 q9, q8
+; CHECK-FIX-NEXT: aesimc.8 q8, q9
; CHECK-FIX-NEXT: vst1.64 {d16, d17}, [r1]
; CHECK-FIX-NEXT: bx lr
%3 = load <16 x i8>, ptr %1, align 8
diff --git a/llvm/test/CodeGen/ARM/aes.ll b/llvm/test/CodeGen/ARM/aes.ll
new file mode 100644
index 00000000000000..6dc606ebab64de
--- /dev/null
+++ b/llvm/test/CodeGen/ARM/aes.ll
@@ -0,0 +1,41 @@
+; NOTE: Assertions have been autogenerated by utils/update_llc_test_checks.py UTC_ARGS: --version 4
+; RUN: llc %s -o - -mtriple=armv8-none-eabi -mattr=+aes | FileCheck %s
+
+declare <16 x i8> @llvm.arm.neon.aese(<16 x i8> %d, <16 x i8> %k)
+declare <16 x i8> @llvm.arm.neon.aesd(<16 x i8> %d, <16 x i8> %k)
+
+define arm_aapcs_vfpcc <16 x i8> @aese(<16 x i8> %a, <16 x i8> %b) {
+; CHECK-LABEL: aese:
+; CHECK: @ %bb.0:
+; CHECK-NEXT: aese.8 q0, q1
+; CHECK-NEXT: bx lr
+ %r = call <16 x i8> @llvm.arm.neon.aese(<16 x i8> %a, <16 x i8> %b)
+ ret <16 x i8> %r
+}
+
+define arm_aapcs_vfpcc <16 x i8> @aese_c(<16 x i8> %a, <16 x i8> %b) {
+; CHECK-LABEL: aese_c:
+; CHECK: @ %bb.0:
+; CHECK-NEXT: aese.8 q0, q1
+; CHECK-NEXT: bx lr
+ %r = call <16 x i8> @llvm.arm.neon.aese(<16 x i8> %b, <16 x i8> %a)
+ ret <16 x i8> %r
+}
+
+define arm_aapcs_vfpcc <16 x i8> @aesd(<16 x i8> %a, <16 x i8> %b) {
+; CHECK-LABEL: aesd:
+; CHECK: @ %bb.0:
+; CHECK-NEXT: aesd.8 q0, q1
+; CHECK-NEXT: bx lr
+ %r = call <16 x i8> @llvm.arm.neon.aesd(<16 x i8> %a, <16 x i8> %b)
+ ret <16 x i8> %r
+}
+
+define arm_aapcs_vfpcc <16 x i8> @aesd_c(<16 x i8> %a, <16 x i8> %b) {
+; CHECK-LABEL: aesd_c:
+; CHECK: @ %bb.0:
+; CHECK-NEXT: aesd.8 q0, q1
+; CHECK-NEXT: bx lr
+ %r = call <16 x i8> @llvm.arm.neon.aesd(<16 x i8> %b, <16 x i8> %a)
+ ret <16 x i8> %r
+}
>From 0c89427b99f6f6d7c217c70ff880ca097340f9a4 Mon Sep 17 00:00:00 2001
From: Mark de Wever <koraq at xs4all.nl>
Date: Sun, 3 Mar 2024 17:58:08 +0100
Subject: [PATCH 393/406] Reland "[clang][modules] Print library module
manifest path." (#82160)
This implements a way for the compiler to find the modules.json
associated with the C++23 Standard library modules.
This is based on a discussion in SG15. At the moment no Standard library
installs this manifest. #75741 adds this feature in libc++.
This reverts commit 82f424f766be00b037a706a835d0a0663a2680f1.
Disables the tests on non-X86 platforms as suggested.
---
clang/include/clang/Driver/Driver.h | 10 +++++
clang/include/clang/Driver/Options.td | 3 ++
clang/lib/Driver/Driver.cpp | 44 +++++++++++++++++++
...les-print-library-module-manifest-path.cpp | 40 +++++++++++++++++
4 files changed, 97 insertions(+)
create mode 100644 clang/test/Driver/modules-print-library-module-manifest-path.cpp
diff --git a/clang/include/clang/Driver/Driver.h b/clang/include/clang/Driver/Driver.h
index 73cf326101ffd5..f145ddc05bd9d6 100644
--- a/clang/include/clang/Driver/Driver.h
+++ b/clang/include/clang/Driver/Driver.h
@@ -620,6 +620,16 @@ class Driver {
// FIXME: This should be in CompilationInfo.
std::string GetProgramPath(StringRef Name, const ToolChain &TC) const;
+ /// Lookup the path to the Standard library module manifest.
+ ///
+ /// \param C - The compilation.
+ /// \param TC - The tool chain for additional information on
+ /// directories to search.
+ //
+ // FIXME: This should be in CompilationInfo.
+ std::string GetStdModuleManifestPath(const Compilation &C,
+ const ToolChain &TC) const;
+
/// HandleAutocompletions - Handle --autocomplete by searching and printing
/// possible flags, descriptions, and its arguments.
void HandleAutocompletions(StringRef PassedFlags) const;
diff --git a/clang/include/clang/Driver/Options.td b/clang/include/clang/Driver/Options.td
index bef38738fde82e..3e857f4e6faf87 100644
--- a/clang/include/clang/Driver/Options.td
+++ b/clang/include/clang/Driver/Options.td
@@ -5364,6 +5364,9 @@ def print_resource_dir : Flag<["-", "--"], "print-resource-dir">,
def print_search_dirs : Flag<["-", "--"], "print-search-dirs">,
HelpText<"Print the paths used for finding libraries and programs">,
Visibility<[ClangOption, CLOption]>;
+def print_std_module_manifest_path : Flag<["-", "--"], "print-library-module-manifest-path">,
+ HelpText<"Print the path for the C++ Standard library module manifest">,
+ Visibility<[ClangOption, CLOption]>;
def print_targets : Flag<["-", "--"], "print-targets">,
HelpText<"Print the registered targets">,
Visibility<[ClangOption, CLOption]>;
diff --git a/clang/lib/Driver/Driver.cpp b/clang/lib/Driver/Driver.cpp
index 00e14071a4afec..d7fbb127fed2dd 100644
--- a/clang/lib/Driver/Driver.cpp
+++ b/clang/lib/Driver/Driver.cpp
@@ -2197,6 +2197,12 @@ bool Driver::HandleImmediateArgs(const Compilation &C) {
return false;
}
+ if (C.getArgs().hasArg(options::OPT_print_std_module_manifest_path)) {
+ llvm::outs() << GetStdModuleManifestPath(C, C.getDefaultToolChain())
+ << '\n';
+ return false;
+ }
+
if (C.getArgs().hasArg(options::OPT_print_runtime_dir)) {
if (std::optional<std::string> RuntimePath = TC.getRuntimePath())
llvm::outs() << *RuntimePath << '\n';
@@ -6169,6 +6175,44 @@ std::string Driver::GetProgramPath(StringRef Name, const ToolChain &TC) const {
return std::string(Name);
}
+std::string Driver::GetStdModuleManifestPath(const Compilation &C,
+ const ToolChain &TC) const {
+ std::string error = "<NOT PRESENT>";
+
+ switch (TC.GetCXXStdlibType(C.getArgs())) {
+ case ToolChain::CST_Libcxx: {
+ std::string lib = GetFilePath("libc++.so", TC);
+
+ // Note when there are multiple flavours of libc++ the module json needs to
+ // look at the command-line arguments for the proper json.
+ // These flavours do not exist at the moment, but there are plans to
+ // provide a variant that is built with sanitizer instrumentation enabled.
+
+ // For example
+ // StringRef modules = [&] {
+ // const SanitizerArgs &Sanitize = TC.getSanitizerArgs(C.getArgs());
+ // if (Sanitize.needsAsanRt())
+ // return "modules-asan.json";
+ // return "modules.json";
+ // }();
+
+ SmallString<128> path(lib.begin(), lib.end());
+ llvm::sys::path::remove_filename(path);
+ llvm::sys::path::append(path, "modules.json");
+ if (TC.getVFS().exists(path))
+ return static_cast<std::string>(path);
+
+ return error;
+ }
+
+ case ToolChain::CST_Libstdcxx:
+ // libstdc++ does not provide Standard library modules yet.
+ return error;
+ }
+
+ return error;
+}
+
std::string Driver::GetTemporaryPath(StringRef Prefix, StringRef Suffix) const {
SmallString<128> Path;
std::error_code EC = llvm::sys::fs::createTemporaryFile(Prefix, Suffix, Path);
diff --git a/clang/test/Driver/modules-print-library-module-manifest-path.cpp b/clang/test/Driver/modules-print-library-module-manifest-path.cpp
new file mode 100644
index 00000000000000..95bcc59ae23c2a
--- /dev/null
+++ b/clang/test/Driver/modules-print-library-module-manifest-path.cpp
@@ -0,0 +1,40 @@
+// Test that -print-library-module-manifest-path finds the correct file.
+
+// FIXME: Enable on all platforms.
+
+// REQUIRES: x86-registered-target
+
+// RUN: rm -rf %t && split-file %s %t && cd %t
+// RUN: mkdir -p %t/Inputs/usr/lib/x86_64-linux-gnu
+// RUN: touch %t/Inputs/usr/lib/x86_64-linux-gnu/libc++.so
+
+// RUN: %clang -print-library-module-manifest-path \
+// RUN: -stdlib=libc++ \
+// RUN: --sysroot=%t/Inputs \
+// RUN: --target=x86_64-linux-gnu 2>&1 \
+// RUN: | FileCheck libcxx-no-module-json.cpp
+
+// RUN: touch %t/Inputs/usr/lib/x86_64-linux-gnu/modules.json
+// RUN: %clang -print-library-module-manifest-path \
+// RUN: -stdlib=libc++ \
+// RUN: --sysroot=%t/Inputs \
+// RUN: --target=x86_64-linux-gnu 2>&1 \
+// RUN: | FileCheck libcxx.cpp
+
+// RUN: %clang -print-library-module-manifest-path \
+// RUN: -stdlib=libstdc++ \
+// RUN: --sysroot=%t/Inputs \
+// RUN: --target=x86_64-linux-gnu 2>&1 \
+// RUN: | FileCheck libstdcxx.cpp
+
+//--- libcxx-no-module-json.cpp
+
+// CHECK: <NOT PRESENT>
+
+//--- libcxx.cpp
+
+// CHECK: {{.*}}/Inputs/usr/lib/x86_64-linux-gnu{{/|\\}}modules.json
+
+//--- libstdcxx.cpp
+
+// CHECK: <NOT PRESENT>
>From 55357160d0e151c32f86e1d6683b4bddbb706aa1 Mon Sep 17 00:00:00 2001
From: Nikolas Klauser <nikolasklauser at berlin.de>
Date: Sun, 3 Mar 2024 18:26:57 +0100
Subject: [PATCH 394/406] [libc++] Use GCC type traits builtins for remove_cv
and remove_cvref (#81386)
They have been added recently to GCC without support for mangling. This
patch uses them in structs and adds aliases to these structs instead of
the builtins directly.
---
libcxx/include/__type_traits/remove_cv.h | 11 +++--------
libcxx/include/__type_traits/remove_cvref.h | 15 ++++++++++-----
2 files changed, 13 insertions(+), 13 deletions(-)
diff --git a/libcxx/include/__type_traits/remove_cv.h b/libcxx/include/__type_traits/remove_cv.h
index c4bf612794bd55..8e1c0433643235 100644
--- a/libcxx/include/__type_traits/remove_cv.h
+++ b/libcxx/include/__type_traits/remove_cv.h
@@ -19,22 +19,17 @@
_LIBCPP_BEGIN_NAMESPACE_STD
-#if __has_builtin(__remove_cv) && !defined(_LIBCPP_COMPILER_GCC)
template <class _Tp>
struct remove_cv {
using type _LIBCPP_NODEBUG = __remove_cv(_Tp);
};
+#if defined(_LIBCPP_COMPILER_GCC)
template <class _Tp>
-using __remove_cv_t = __remove_cv(_Tp);
+using __remove_cv_t = typename remove_cv<_Tp>::type;
#else
template <class _Tp>
-struct _LIBCPP_TEMPLATE_VIS remove_cv {
- typedef __remove_volatile_t<__remove_const_t<_Tp> > type;
-};
-
-template <class _Tp>
-using __remove_cv_t = __remove_volatile_t<__remove_const_t<_Tp> >;
+using __remove_cv_t = __remove_cv(_Tp);
#endif // __has_builtin(__remove_cv)
#if _LIBCPP_STD_VER >= 14
diff --git a/libcxx/include/__type_traits/remove_cvref.h b/libcxx/include/__type_traits/remove_cvref.h
index e8e8745ab09609..55f894dbd1d815 100644
--- a/libcxx/include/__type_traits/remove_cvref.h
+++ b/libcxx/include/__type_traits/remove_cvref.h
@@ -20,21 +20,26 @@
_LIBCPP_BEGIN_NAMESPACE_STD
-#if __has_builtin(__remove_cvref) && !defined(_LIBCPP_COMPILER_GCC)
+#if defined(_LIBCPP_COMPILER_GCC)
template <class _Tp>
-using __remove_cvref_t _LIBCPP_NODEBUG = __remove_cvref(_Tp);
+struct __remove_cvref_gcc {
+ using type = __remove_cvref(_Tp);
+};
+
+template <class _Tp>
+using __remove_cvref_t _LIBCPP_NODEBUG = typename __remove_cvref_gcc<_Tp>::type;
#else
template <class _Tp>
-using __remove_cvref_t _LIBCPP_NODEBUG = __remove_cv_t<__libcpp_remove_reference_t<_Tp> >;
+using __remove_cvref_t _LIBCPP_NODEBUG = __remove_cvref(_Tp);
#endif // __has_builtin(__remove_cvref)
template <class _Tp, class _Up>
-struct __is_same_uncvref : _IsSame<__remove_cvref_t<_Tp>, __remove_cvref_t<_Up> > {};
+using __is_same_uncvref = _IsSame<__remove_cvref_t<_Tp>, __remove_cvref_t<_Up> >;
#if _LIBCPP_STD_VER >= 20
template <class _Tp>
struct remove_cvref {
- using type _LIBCPP_NODEBUG = __remove_cvref_t<_Tp>;
+ using type _LIBCPP_NODEBUG = __remove_cvref(_Tp);
};
template <class _Tp>
>From 0c90e8837a9e5f27985ccaf85120083db9e1b43e Mon Sep 17 00:00:00 2001
From: Nikolas Klauser <nikolasklauser at berlin.de>
Date: Sun, 3 Mar 2024 18:15:00 +0100
Subject: [PATCH 395/406] [libc++][NFC] Replace _ALIGNAS_TYPE with alignas in
iostream.cpp
---
libcxx/src/iostream.cpp | 36 ++++++++++++++----------------------
1 file changed, 14 insertions(+), 22 deletions(-)
diff --git a/libcxx/src/iostream.cpp b/libcxx/src/iostream.cpp
index bb49e265ba0ef5..c5ad77a0191608 100644
--- a/libcxx/src/iostream.cpp
+++ b/libcxx/src/iostream.cpp
@@ -21,74 +21,67 @@
_LIBCPP_BEGIN_NAMESPACE_STD
-_ALIGNAS_TYPE(istream)
-_LIBCPP_EXPORTED_FROM_ABI char cin[sizeof(istream)]
+alignas(istream) _LIBCPP_EXPORTED_FROM_ABI char cin[sizeof(istream)]
#if defined(_LIBCPP_ABI_MICROSOFT) && defined(__clang__)
__asm__("?cin@" _LIBCPP_ABI_NAMESPACE_STR "@std@@3V?$basic_istream at DU?$char_traits at D@" _LIBCPP_ABI_NAMESPACE_STR
"@std@@@12 at A")
#endif
;
-_ALIGNAS_TYPE(__stdinbuf<char>) static char __cin[sizeof(__stdinbuf<char>)];
+alignas(__stdinbuf<char>) static char __cin[sizeof(__stdinbuf<char>)];
static mbstate_t mb_cin;
#ifndef _LIBCPP_HAS_NO_WIDE_CHARACTERS
-_ALIGNAS_TYPE(wistream)
-_LIBCPP_EXPORTED_FROM_ABI char wcin[sizeof(wistream)]
+alignas(wistream) _LIBCPP_EXPORTED_FROM_ABI char wcin[sizeof(wistream)]
# if defined(_LIBCPP_ABI_MICROSOFT) && defined(__clang__)
__asm__("?wcin@" _LIBCPP_ABI_NAMESPACE_STR "@std@@3V?$basic_istream at _WU?$char_traits at _W@" _LIBCPP_ABI_NAMESPACE_STR
"@std@@@12 at A")
# endif
;
-_ALIGNAS_TYPE(__stdinbuf<wchar_t>) static char __wcin[sizeof(__stdinbuf<wchar_t>)];
+alignas(__stdinbuf<wchar_t>) static char __wcin[sizeof(__stdinbuf<wchar_t>)];
static mbstate_t mb_wcin;
#endif // _LIBCPP_HAS_NO_WIDE_CHARACTERS
-_ALIGNAS_TYPE(ostream)
-_LIBCPP_EXPORTED_FROM_ABI char cout[sizeof(ostream)]
+alignas(ostream) _LIBCPP_EXPORTED_FROM_ABI char cout[sizeof(ostream)]
#if defined(_LIBCPP_ABI_MICROSOFT) && defined(__clang__)
__asm__("?cout@" _LIBCPP_ABI_NAMESPACE_STR "@std@@3V?$basic_ostream at DU?$char_traits at D@" _LIBCPP_ABI_NAMESPACE_STR
"@std@@@12 at A")
#endif
;
-_ALIGNAS_TYPE(__stdoutbuf<char>) static char __cout[sizeof(__stdoutbuf<char>)];
+alignas(__stdoutbuf<char>) static char __cout[sizeof(__stdoutbuf<char>)];
static mbstate_t mb_cout;
#ifndef _LIBCPP_HAS_NO_WIDE_CHARACTERS
-_ALIGNAS_TYPE(wostream)
-_LIBCPP_EXPORTED_FROM_ABI char wcout[sizeof(wostream)]
+alignas(wostream) _LIBCPP_EXPORTED_FROM_ABI char wcout[sizeof(wostream)]
# if defined(_LIBCPP_ABI_MICROSOFT) && defined(__clang__)
__asm__("?wcout@" _LIBCPP_ABI_NAMESPACE_STR "@std@@3V?$basic_ostream at _WU?$char_traits at _W@" _LIBCPP_ABI_NAMESPACE_STR
"@std@@@12 at A")
# endif
;
-_ALIGNAS_TYPE(__stdoutbuf<wchar_t>) static char __wcout[sizeof(__stdoutbuf<wchar_t>)];
+alignas(__stdoutbuf<wchar_t>) static char __wcout[sizeof(__stdoutbuf<wchar_t>)];
static mbstate_t mb_wcout;
#endif // _LIBCPP_HAS_NO_WIDE_CHARACTERS
-_ALIGNAS_TYPE(ostream)
-_LIBCPP_EXPORTED_FROM_ABI char cerr[sizeof(ostream)]
+alignas(ostream) _LIBCPP_EXPORTED_FROM_ABI char cerr[sizeof(ostream)]
#if defined(_LIBCPP_ABI_MICROSOFT) && defined(__clang__)
__asm__("?cerr@" _LIBCPP_ABI_NAMESPACE_STR "@std@@3V?$basic_ostream at DU?$char_traits at D@" _LIBCPP_ABI_NAMESPACE_STR
"@std@@@12 at A")
#endif
;
-_ALIGNAS_TYPE(__stdoutbuf<char>) static char __cerr[sizeof(__stdoutbuf<char>)];
+alignas(__stdoutbuf<char>) static char __cerr[sizeof(__stdoutbuf<char>)];
static mbstate_t mb_cerr;
#ifndef _LIBCPP_HAS_NO_WIDE_CHARACTERS
-_ALIGNAS_TYPE(wostream)
-_LIBCPP_EXPORTED_FROM_ABI char wcerr[sizeof(wostream)]
+alignas(wostream) _LIBCPP_EXPORTED_FROM_ABI char wcerr[sizeof(wostream)]
# if defined(_LIBCPP_ABI_MICROSOFT) && defined(__clang__)
__asm__("?wcerr@" _LIBCPP_ABI_NAMESPACE_STR "@std@@3V?$basic_ostream at _WU?$char_traits at _W@" _LIBCPP_ABI_NAMESPACE_STR
"@std@@@12 at A")
# endif
;
-_ALIGNAS_TYPE(__stdoutbuf<wchar_t>) static char __wcerr[sizeof(__stdoutbuf<wchar_t>)];
+alignas(__stdoutbuf<wchar_t>) static char __wcerr[sizeof(__stdoutbuf<wchar_t>)];
static mbstate_t mb_wcerr;
#endif // _LIBCPP_HAS_NO_WIDE_CHARACTERS
-_ALIGNAS_TYPE(ostream)
-_LIBCPP_EXPORTED_FROM_ABI char clog[sizeof(ostream)]
+alignas(ostream) _LIBCPP_EXPORTED_FROM_ABI char clog[sizeof(ostream)]
#if defined(_LIBCPP_ABI_MICROSOFT) && defined(__clang__)
__asm__("?clog@" _LIBCPP_ABI_NAMESPACE_STR "@std@@3V?$basic_ostream at DU?$char_traits at D@" _LIBCPP_ABI_NAMESPACE_STR
"@std@@@12 at A")
@@ -96,8 +89,7 @@ _LIBCPP_EXPORTED_FROM_ABI char clog[sizeof(ostream)]
;
#ifndef _LIBCPP_HAS_NO_WIDE_CHARACTERS
-_ALIGNAS_TYPE(wostream)
-_LIBCPP_EXPORTED_FROM_ABI char wclog[sizeof(wostream)]
+alignas(wostream) _LIBCPP_EXPORTED_FROM_ABI char wclog[sizeof(wostream)]
# if defined(_LIBCPP_ABI_MICROSOFT) && defined(__clang__)
__asm__("?wclog@" _LIBCPP_ABI_NAMESPACE_STR "@std@@3V?$basic_ostream at _WU?$char_traits at _W@" _LIBCPP_ABI_NAMESPACE_STR
"@std@@@12 at A")
>From 33de5a316caa3c9b07ee1ccc7fbc3434247ff787 Mon Sep 17 00:00:00 2001
From: Nikolas Klauser <nikolasklauser at berlin.de>
Date: Sun, 3 Mar 2024 20:45:17 +0100
Subject: [PATCH 396/406] [libc++] Rename __fwd/hash.h to __fwd/functional.h
and add reference_wrapper (#81445)
We forward declare `reference_wrapper` in multiple places already. This
moves the declaration to the canonical place and removes unnecessary
includes of `__functional/reference_wrapper.h`.
---
libcxx/include/CMakeLists.txt | 2 +-
libcxx/include/__filesystem/path.h | 3 +--
libcxx/include/__functional/bind.h | 1 +
libcxx/include/__functional/hash.h | 2 +-
libcxx/include/__functional/identity.h | 2 +-
libcxx/include/__fwd/{hash.h => functional.h} | 9 ++++++---
libcxx/include/__thread/id.h | 2 +-
libcxx/include/__thread/support/pthread.h | 1 -
libcxx/include/__type_traits/is_reference_wrapper.h | 4 +---
libcxx/include/__type_traits/unwrap_ref.h | 7 +------
libcxx/include/experimental/propagate_const | 2 +-
libcxx/include/filesystem | 1 +
libcxx/include/libcxx.imp | 2 +-
libcxx/include/module.modulemap.in | 2 +-
libcxx/include/optional | 2 +-
libcxx/include/type_traits | 2 +-
libcxx/test/libcxx/transitive_includes/cxx23.csv | 1 -
libcxx/test/libcxx/transitive_includes/cxx26.csv | 1 -
libcxx/utils/generate_iwyu_mapping.py | 2 --
19 files changed, 20 insertions(+), 28 deletions(-)
rename libcxx/include/__fwd/{hash.h => functional.h} (77%)
diff --git a/libcxx/include/CMakeLists.txt b/libcxx/include/CMakeLists.txt
index cafd8c6e00d968..459b077087e2b5 100644
--- a/libcxx/include/CMakeLists.txt
+++ b/libcxx/include/CMakeLists.txt
@@ -431,7 +431,7 @@ set(files
__fwd/bit_reference.h
__fwd/complex.h
__fwd/fstream.h
- __fwd/hash.h
+ __fwd/functional.h
__fwd/ios.h
__fwd/istream.h
__fwd/mdspan.h
diff --git a/libcxx/include/__filesystem/path.h b/libcxx/include/__filesystem/path.h
index 8c7d426f7a6f4f..9ffc90ada5e716 100644
--- a/libcxx/include/__filesystem/path.h
+++ b/libcxx/include/__filesystem/path.h
@@ -14,9 +14,8 @@
#include <__algorithm/replace_copy.h>
#include <__availability>
#include <__config>
-#include <__functional/hash.h>
#include <__functional/unary_function.h>
-#include <__fwd/hash.h>
+#include <__fwd/functional.h>
#include <__iterator/back_insert_iterator.h>
#include <__iterator/iterator_traits.h>
#include <__type_traits/decay.h>
diff --git a/libcxx/include/__functional/bind.h b/libcxx/include/__functional/bind.h
index 19e7d82155ec97..8a0e3b7ffa5840 100644
--- a/libcxx/include/__functional/bind.h
+++ b/libcxx/include/__functional/bind.h
@@ -13,6 +13,7 @@
#include <__config>
#include <__functional/invoke.h>
#include <__functional/weak_result_type.h>
+#include <__fwd/functional.h>
#include <__type_traits/decay.h>
#include <__type_traits/is_reference_wrapper.h>
#include <__type_traits/is_void.h>
diff --git a/libcxx/include/__functional/hash.h b/libcxx/include/__functional/hash.h
index ff22055d6915e4..a466c837038f8d 100644
--- a/libcxx/include/__functional/hash.h
+++ b/libcxx/include/__functional/hash.h
@@ -12,7 +12,7 @@
#include <__config>
#include <__functional/invoke.h>
#include <__functional/unary_function.h>
-#include <__fwd/hash.h>
+#include <__fwd/functional.h>
#include <__tuple/sfinae_helpers.h>
#include <__type_traits/is_copy_constructible.h>
#include <__type_traits/is_default_constructible.h>
diff --git a/libcxx/include/__functional/identity.h b/libcxx/include/__functional/identity.h
index 7fbfc6c6249b65..b7be367bd5eed7 100644
--- a/libcxx/include/__functional/identity.h
+++ b/libcxx/include/__functional/identity.h
@@ -11,7 +11,7 @@
#define _LIBCPP___FUNCTIONAL_IDENTITY_H
#include <__config>
-#include <__functional/reference_wrapper.h>
+#include <__fwd/functional.h>
#include <__type_traits/integral_constant.h>
#include <__utility/forward.h>
diff --git a/libcxx/include/__fwd/hash.h b/libcxx/include/__fwd/functional.h
similarity index 77%
rename from libcxx/include/__fwd/hash.h
rename to libcxx/include/__fwd/functional.h
index af9eca876a1047..32c9ef33e453b1 100644
--- a/libcxx/include/__fwd/hash.h
+++ b/libcxx/include/__fwd/functional.h
@@ -6,8 +6,8 @@
//
//===---------------------------------------------------------------------===//
-#ifndef _LIBCPP___FWD_HASH_H
-#define _LIBCPP___FWD_HASH_H
+#ifndef _LIBCPP___FWD_FUNCTIONAL_H
+#define _LIBCPP___FWD_FUNCTIONAL_H
#include <__config>
@@ -20,6 +20,9 @@ _LIBCPP_BEGIN_NAMESPACE_STD
template <class>
struct _LIBCPP_TEMPLATE_VIS hash;
+template <class>
+class _LIBCPP_TEMPLATE_VIS reference_wrapper;
+
_LIBCPP_END_NAMESPACE_STD
-#endif // _LIBCPP___FWD_HASH_H
+#endif // _LIBCPP___FWD_FUNCTIONAL_H
diff --git a/libcxx/include/__thread/id.h b/libcxx/include/__thread/id.h
index d5aef3f860ce27..6db0ccbfe569b6 100644
--- a/libcxx/include/__thread/id.h
+++ b/libcxx/include/__thread/id.h
@@ -12,7 +12,7 @@
#include <__compare/ordering.h>
#include <__config>
-#include <__fwd/hash.h>
+#include <__fwd/functional.h>
#include <__fwd/ostream.h>
#include <__thread/support.h>
diff --git a/libcxx/include/__thread/support/pthread.h b/libcxx/include/__thread/support/pthread.h
index d8e3f938ddf629..e194e5c68ad339 100644
--- a/libcxx/include/__thread/support/pthread.h
+++ b/libcxx/include/__thread/support/pthread.h
@@ -14,7 +14,6 @@
#include <__chrono/convert_to_timespec.h>
#include <__chrono/duration.h>
#include <__config>
-#include <__fwd/hash.h>
#include <ctime>
#include <errno.h>
#include <pthread.h>
diff --git a/libcxx/include/__type_traits/is_reference_wrapper.h b/libcxx/include/__type_traits/is_reference_wrapper.h
index b638e7046b71ca..310a910040e8be 100644
--- a/libcxx/include/__type_traits/is_reference_wrapper.h
+++ b/libcxx/include/__type_traits/is_reference_wrapper.h
@@ -10,6 +10,7 @@
#define _LIBCPP___TYPE_TRAITS_IS_REFERENCE_WRAPPER_H
#include <__config>
+#include <__fwd/functional.h>
#include <__type_traits/integral_constant.h>
#include <__type_traits/remove_cv.h>
@@ -19,9 +20,6 @@
_LIBCPP_BEGIN_NAMESPACE_STD
-template <class _Tp>
-class _LIBCPP_TEMPLATE_VIS reference_wrapper;
-
template <class _Tp>
struct __is_reference_wrapper_impl : public false_type {};
template <class _Tp>
diff --git a/libcxx/include/__type_traits/unwrap_ref.h b/libcxx/include/__type_traits/unwrap_ref.h
index 5fed08f7ddda1a..6bd74550f30921 100644
--- a/libcxx/include/__type_traits/unwrap_ref.h
+++ b/libcxx/include/__type_traits/unwrap_ref.h
@@ -10,6 +10,7 @@
#define _LIBCPP___TYPE_TRAITS_UNWRAP_REF_H
#include <__config>
+#include <__fwd/functional.h>
#include <__type_traits/decay.h>
#if !defined(_LIBCPP_HAS_NO_PRAGMA_SYSTEM_HEADER)
@@ -23,17 +24,11 @@ struct __unwrap_reference {
typedef _LIBCPP_NODEBUG _Tp type;
};
-template <class _Tp>
-class reference_wrapper;
-
template <class _Tp>
struct __unwrap_reference<reference_wrapper<_Tp> > {
typedef _LIBCPP_NODEBUG _Tp& type;
};
-template <class _Tp>
-struct decay;
-
#if _LIBCPP_STD_VER >= 20
template <class _Tp>
struct unwrap_reference : __unwrap_reference<_Tp> {};
diff --git a/libcxx/include/experimental/propagate_const b/libcxx/include/experimental/propagate_const
index 8c2ceb9def3357..43648015fe80ed 100644
--- a/libcxx/include/experimental/propagate_const
+++ b/libcxx/include/experimental/propagate_const
@@ -108,7 +108,7 @@
*/
#include <__functional/operations.h>
-#include <__fwd/hash.h>
+#include <__fwd/functional.h>
#include <__type_traits/conditional.h>
#include <__type_traits/decay.h>
#include <__type_traits/enable_if.h>
diff --git a/libcxx/include/filesystem b/libcxx/include/filesystem
index b344ed468082e8..eff7dff4a45512 100644
--- a/libcxx/include/filesystem
+++ b/libcxx/include/filesystem
@@ -564,6 +564,7 @@ inline constexpr bool std::ranges::enable_view<std::filesystem::recursive_direct
#if !defined(_LIBCPP_REMOVE_TRANSITIVE_INCLUDES) && _LIBCPP_STD_VER <= 20
# include <concepts>
# include <cstdlib>
+# include <cstring>
# include <iosfwd>
# include <new>
# include <system_error>
diff --git a/libcxx/include/libcxx.imp b/libcxx/include/libcxx.imp
index eeeae39ca101d9..cdbb0a63fc0eae 100644
--- a/libcxx/include/libcxx.imp
+++ b/libcxx/include/libcxx.imp
@@ -426,7 +426,7 @@
{ include: [ "<__fwd/bit_reference.h>", "private", "<vector>", "public" ] },
{ include: [ "<__fwd/complex.h>", "private", "<complex>", "public" ] },
{ include: [ "<__fwd/fstream.h>", "private", "<iosfwd>", "public" ] },
- { include: [ "<__fwd/hash.h>", "private", "<functional>", "public" ] },
+ { include: [ "<__fwd/functional.h>", "private", "<functional>", "public" ] },
{ include: [ "<__fwd/ios.h>", "private", "<iosfwd>", "public" ] },
{ include: [ "<__fwd/istream.h>", "private", "<iosfwd>", "public" ] },
{ include: [ "<__fwd/mdspan.h>", "private", "<mdspan>", "public" ] },
diff --git a/libcxx/include/module.modulemap.in b/libcxx/include/module.modulemap.in
index 219906aa9a5668..b247f97c1804d9 100644
--- a/libcxx/include/module.modulemap.in
+++ b/libcxx/include/module.modulemap.in
@@ -1365,7 +1365,7 @@ module std_private_functional_hash [system] {
export std_private_type_traits_underlying_type
export std_private_utility_pair
}
-module std_private_functional_hash_fwd [system] { header "__fwd/hash.h" }
+module std_private_functional_fwd [system] { header "__fwd/functional.h" }
module std_private_functional_identity [system] { header "__functional/identity.h" }
module std_private_functional_invoke [system] {
header "__functional/invoke.h"
diff --git a/libcxx/include/optional b/libcxx/include/optional
index 9e4f0fff2f4a7a..99bfd0dd900d3a 100644
--- a/libcxx/include/optional
+++ b/libcxx/include/optional
@@ -186,8 +186,8 @@ namespace std {
#include <__exception/exception.h>
#include <__functional/hash.h>
#include <__functional/invoke.h>
-#include <__functional/reference_wrapper.h>
#include <__functional/unary_function.h>
+#include <__fwd/functional.h>
#include <__memory/addressof.h>
#include <__memory/construct_at.h>
#include <__tuple/sfinae_helpers.h>
diff --git a/libcxx/include/type_traits b/libcxx/include/type_traits
index 0037c426560e6f..54c8abec340c4d 100644
--- a/libcxx/include/type_traits
+++ b/libcxx/include/type_traits
@@ -418,7 +418,7 @@ namespace std
*/
#include <__config>
-#include <__fwd/hash.h> // This is https://llvm.org/PR56938
+#include <__fwd/functional.h> // This is https://llvm.org/PR56938
#include <__type_traits/add_const.h>
#include <__type_traits/add_cv.h>
#include <__type_traits/add_lvalue_reference.h>
diff --git a/libcxx/test/libcxx/transitive_includes/cxx23.csv b/libcxx/test/libcxx/transitive_includes/cxx23.csv
index 49b3ac265487d7..ce11a358fc3e27 100644
--- a/libcxx/test/libcxx/transitive_includes/cxx23.csv
+++ b/libcxx/test/libcxx/transitive_includes/cxx23.csv
@@ -178,7 +178,6 @@ experimental/utility utility
filesystem compare
filesystem cstddef
filesystem cstdint
-filesystem cstring
filesystem ctime
filesystem iomanip
filesystem limits
diff --git a/libcxx/test/libcxx/transitive_includes/cxx26.csv b/libcxx/test/libcxx/transitive_includes/cxx26.csv
index 49b3ac265487d7..ce11a358fc3e27 100644
--- a/libcxx/test/libcxx/transitive_includes/cxx26.csv
+++ b/libcxx/test/libcxx/transitive_includes/cxx26.csv
@@ -178,7 +178,6 @@ experimental/utility utility
filesystem compare
filesystem cstddef
filesystem cstdint
-filesystem cstring
filesystem ctime
filesystem iomanip
filesystem limits
diff --git a/libcxx/utils/generate_iwyu_mapping.py b/libcxx/utils/generate_iwyu_mapping.py
index 6eb2c6095bf1e7..8ab7b86299edca 100644
--- a/libcxx/utils/generate_iwyu_mapping.py
+++ b/libcxx/utils/generate_iwyu_mapping.py
@@ -34,8 +34,6 @@ def IWYU_mapping(header: str) -> typing.Optional[typing.List[str]]:
return ["atomic", "mutex", "semaphore", "thread"]
elif header == "__tree":
return ["map", "set"]
- elif header == "__fwd/hash.h":
- return ["functional"]
elif header == "__fwd/pair.h":
return ["utility"]
elif header == "__fwd/subrange.h":
>From 09b34b998d9d84fa4740c1f2821699250fc318cb Mon Sep 17 00:00:00 2001
From: Aiden Grossman <agrossman154 at yahoo.com>
Date: Sun, 3 Mar 2024 11:47:44 -0800
Subject: [PATCH 397/406] [Github] Make CI container build more reliable
(#83707)
---
.github/workflows/build-ci-container.yml | 6 +++++-
1 file changed, 5 insertions(+), 1 deletion(-)
diff --git a/.github/workflows/build-ci-container.yml b/.github/workflows/build-ci-container.yml
index 3f2bf57eb85088..28fc7de2ee0654 100644
--- a/.github/workflows/build-ci-container.yml
+++ b/.github/workflows/build-ci-container.yml
@@ -77,14 +77,18 @@ jobs:
cp ./.github/workflows/containers/github-action-ci/storage.conf ~/.config/containers/storage.conf
podman info
+ # Download the container image into /mnt/podman rather than
+ # $GITHUB_WORKSPACE to avoid space limitations on the default drive
+ # and use the permissions setup for /mnt/podman.
- name: Download stage1-toolchain
uses: actions/download-artifact at v4
with:
name: stage1-toolchain
+ path: /mnt/podman
- name: Load stage1-toolchain
run: |
- podman load -i stage1-toolchain.tar
+ podman load -i /mnt/podman/stage1-toolchain.tar
- name: Build Container
working-directory: ./.github/workflows/containers/github-action-ci/
>From 5105f1551b4bc800f564e7c105fc95e2c51f1239 Mon Sep 17 00:00:00 2001
From: LLVM GN Syncbot <llvmgnsyncbot at gmail.com>
Date: Sun, 3 Mar 2024 19:51:44 +0000
Subject: [PATCH 398/406] [gn build] Port 33de5a316caa
---
llvm/utils/gn/secondary/libcxx/include/BUILD.gn | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/llvm/utils/gn/secondary/libcxx/include/BUILD.gn b/llvm/utils/gn/secondary/libcxx/include/BUILD.gn
index 4d02f99e3fca26..5ba0d04b47452e 100644
--- a/llvm/utils/gn/secondary/libcxx/include/BUILD.gn
+++ b/llvm/utils/gn/secondary/libcxx/include/BUILD.gn
@@ -509,7 +509,7 @@ if (current_toolchain == default_toolchain) {
"__fwd/bit_reference.h",
"__fwd/complex.h",
"__fwd/fstream.h",
- "__fwd/hash.h",
+ "__fwd/functional.h",
"__fwd/ios.h",
"__fwd/istream.h",
"__fwd/mdspan.h",
>From 2435dcd83a32c63aef91c82cb19b08604ba96b64 Mon Sep 17 00:00:00 2001
From: Florian Hahn <flo at fhahn.com>
Date: Sun, 3 Mar 2024 21:48:58 +0000
Subject: [PATCH 399/406] [VPlan] Add initial pattern match implementation for
VPInstruction. (#80563)
Add an initial version of a pattern match for VPValues and recipes,
starting with VPInstruction.
PR: https://github.com/llvm/llvm-project/pull/80563
---
llvm/lib/Transforms/Vectorize/VPlan.cpp | 10 +-
.../Transforms/Vectorize/VPlanPatternMatch.h | 136 ++++++++++++++++++
.../Transforms/Vectorize/VPlanTransforms.cpp | 22 +--
3 files changed, 148 insertions(+), 20 deletions(-)
create mode 100644 llvm/lib/Transforms/Vectorize/VPlanPatternMatch.h
diff --git a/llvm/lib/Transforms/Vectorize/VPlan.cpp b/llvm/lib/Transforms/Vectorize/VPlan.cpp
index 4aeab6fc619988..9768e4b7aa0a8a 100644
--- a/llvm/lib/Transforms/Vectorize/VPlan.cpp
+++ b/llvm/lib/Transforms/Vectorize/VPlan.cpp
@@ -19,6 +19,7 @@
#include "VPlan.h"
#include "VPlanCFG.h"
#include "VPlanDominatorTree.h"
+#include "VPlanPatternMatch.h"
#include "llvm/ADT/PostOrderIterator.h"
#include "llvm/ADT/STLExtras.h"
#include "llvm/ADT/SmallVector.h"
@@ -46,6 +47,7 @@
#include <vector>
using namespace llvm;
+using namespace llvm::VPlanPatternMatch;
namespace llvm {
extern cl::opt<bool> EnableVPlanNativePath;
@@ -569,11 +571,9 @@ static bool hasConditionalTerminator(const VPBasicBlock *VPBB) {
}
const VPRecipeBase *R = &VPBB->back();
- auto *VPI = dyn_cast<VPInstruction>(R);
- bool IsCondBranch =
- isa<VPBranchOnMaskRecipe>(R) ||
- (VPI && (VPI->getOpcode() == VPInstruction::BranchOnCond ||
- VPI->getOpcode() == VPInstruction::BranchOnCount));
+ bool IsCondBranch = isa<VPBranchOnMaskRecipe>(R) ||
+ match(R, m_BranchOnCond(m_VPValue())) ||
+ match(R, m_BranchOnCount(m_VPValue(), m_VPValue()));
(void)IsCondBranch;
if (VPBB->getNumSuccessors() >= 2 ||
diff --git a/llvm/lib/Transforms/Vectorize/VPlanPatternMatch.h b/llvm/lib/Transforms/Vectorize/VPlanPatternMatch.h
new file mode 100644
index 00000000000000..b90c588b607564
--- /dev/null
+++ b/llvm/lib/Transforms/Vectorize/VPlanPatternMatch.h
@@ -0,0 +1,136 @@
+//===- VPlanPatternMatch.h - Match on VPValues and recipes ------*- C++ -*-===//
+//
+// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
+// See https://llvm.org/LICENSE.txt for license information.
+// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
+//
+//===----------------------------------------------------------------------===//
+//
+// This file provides a simple and efficient mechanism for performing general
+// tree-based pattern matches on the VPlan values and recipes, based on
+// LLVM's IR pattern matchers.
+//
+// Currently it provides generic matchers for unary and binary VPInstructions,
+// and specialized matchers like m_Not, m_ActiveLaneMask, m_BranchOnCond,
+// m_BranchOnCount to match specific VPInstructions.
+// TODO: Add missing matchers for additional opcodes and recipes as needed.
+//
+//===----------------------------------------------------------------------===//
+
+#ifndef LLVM_TRANSFORM_VECTORIZE_VPLANPATTERNMATCH_H
+#define LLVM_TRANSFORM_VECTORIZE_VPLANPATTERNMATCH_H
+
+#include "VPlan.h"
+
+namespace llvm {
+namespace VPlanPatternMatch {
+
+template <typename Val, typename Pattern> bool match(Val *V, const Pattern &P) {
+ return const_cast<Pattern &>(P).match(V);
+}
+
+template <typename Class> struct class_match {
+ template <typename ITy> bool match(ITy *V) { return isa<Class>(V); }
+};
+
+/// Match an arbitrary VPValue and ignore it.
+inline class_match<VPValue> m_VPValue() { return class_match<VPValue>(); }
+
+template <typename Class> struct bind_ty {
+ Class *&VR;
+
+ bind_ty(Class *&V) : VR(V) {}
+
+ template <typename ITy> bool match(ITy *V) {
+ if (auto *CV = dyn_cast<Class>(V)) {
+ VR = CV;
+ return true;
+ }
+ return false;
+ }
+};
+
+/// Match a VPValue, capturing it if we match.
+inline bind_ty<VPValue> m_VPValue(VPValue *&V) { return V; }
+
+template <typename Op0_t, unsigned Opcode> struct UnaryVPInstruction_match {
+ Op0_t Op0;
+
+ UnaryVPInstruction_match(Op0_t Op0) : Op0(Op0) {}
+
+ bool match(const VPValue *V) {
+ auto *DefR = V->getDefiningRecipe();
+ return DefR && match(DefR);
+ }
+
+ bool match(const VPRecipeBase *R) {
+ auto *DefR = dyn_cast<VPInstruction>(R);
+ if (!DefR || DefR->getOpcode() != Opcode)
+ return false;
+ assert(DefR->getNumOperands() == 1 &&
+ "recipe with matched opcode does not have 1 operands");
+ return Op0.match(DefR->getOperand(0));
+ }
+};
+
+template <typename Op0_t, typename Op1_t, unsigned Opcode>
+struct BinaryVPInstruction_match {
+ Op0_t Op0;
+ Op1_t Op1;
+
+ BinaryVPInstruction_match(Op0_t Op0, Op1_t Op1) : Op0(Op0), Op1(Op1) {}
+
+ bool match(const VPValue *V) {
+ auto *DefR = V->getDefiningRecipe();
+ return DefR && match(DefR);
+ }
+
+ bool match(const VPRecipeBase *R) {
+ auto *DefR = dyn_cast<VPInstruction>(R);
+ if (!DefR || DefR->getOpcode() != Opcode)
+ return false;
+ assert(DefR->getNumOperands() == 2 &&
+ "recipe with matched opcode does not have 2 operands");
+ return Op0.match(DefR->getOperand(0)) && Op1.match(DefR->getOperand(1));
+ }
+};
+
+template <unsigned Opcode, typename Op0_t>
+inline UnaryVPInstruction_match<Op0_t, Opcode>
+m_VPInstruction(const Op0_t &Op0) {
+ return UnaryVPInstruction_match<Op0_t, Opcode>(Op0);
+}
+
+template <unsigned Opcode, typename Op0_t, typename Op1_t>
+inline BinaryVPInstruction_match<Op0_t, Op1_t, Opcode>
+m_VPInstruction(const Op0_t &Op0, const Op1_t &Op1) {
+ return BinaryVPInstruction_match<Op0_t, Op1_t, Opcode>(Op0, Op1);
+}
+
+template <typename Op0_t>
+inline UnaryVPInstruction_match<Op0_t, VPInstruction::Not>
+m_Not(const Op0_t &Op0) {
+ return m_VPInstruction<VPInstruction::Not>(Op0);
+}
+
+template <typename Op0_t>
+inline UnaryVPInstruction_match<Op0_t, VPInstruction::BranchOnCond>
+m_BranchOnCond(const Op0_t &Op0) {
+ return m_VPInstruction<VPInstruction::BranchOnCond>(Op0);
+}
+
+template <typename Op0_t, typename Op1_t>
+inline BinaryVPInstruction_match<Op0_t, Op1_t, VPInstruction::ActiveLaneMask>
+m_ActiveLaneMask(const Op0_t &Op0, const Op1_t &Op1) {
+ return m_VPInstruction<VPInstruction::ActiveLaneMask>(Op0, Op1);
+}
+
+template <typename Op0_t, typename Op1_t>
+inline BinaryVPInstruction_match<Op0_t, Op1_t, VPInstruction::BranchOnCount>
+m_BranchOnCount(const Op0_t &Op0, const Op1_t &Op1) {
+ return m_VPInstruction<VPInstruction::BranchOnCount>(Op0, Op1);
+}
+} // namespace VPlanPatternMatch
+} // namespace llvm
+
+#endif
diff --git a/llvm/lib/Transforms/Vectorize/VPlanTransforms.cpp b/llvm/lib/Transforms/Vectorize/VPlanTransforms.cpp
index 9c3f35112b592f..9d6deb802e2090 100644
--- a/llvm/lib/Transforms/Vectorize/VPlanTransforms.cpp
+++ b/llvm/lib/Transforms/Vectorize/VPlanTransforms.cpp
@@ -16,6 +16,7 @@
#include "VPlanAnalysis.h"
#include "VPlanCFG.h"
#include "VPlanDominatorTree.h"
+#include "VPlanPatternMatch.h"
#include "llvm/ADT/PostOrderIterator.h"
#include "llvm/ADT/STLExtras.h"
#include "llvm/ADT/SetVector.h"
@@ -26,8 +27,6 @@
using namespace llvm;
-using namespace llvm::PatternMatch;
-
void VPlanTransforms::VPInstructionsToVPRecipes(
VPlanPtr &Plan,
function_ref<const InductionDescriptor *(PHINode *)>
@@ -486,6 +485,7 @@ static void removeDeadRecipes(VPlan &Plan) {
[](VPValue *V) { return V->getNumUsers(); }))
continue;
+ using namespace llvm::PatternMatch;
// Having side effects keeps R alive, but do remove conditional assume
// instructions as their conditions may be flattened.
auto *RepR = dyn_cast<VPReplicateRecipe>(&R);
@@ -595,15 +595,6 @@ static void removeRedundantExpandSCEVRecipes(VPlan &Plan) {
}
}
-static bool canSimplifyBranchOnCond(VPInstruction *Term) {
- VPInstruction *Not = dyn_cast<VPInstruction>(Term->getOperand(0));
- if (!Not || Not->getOpcode() != VPInstruction::Not)
- return false;
-
- VPInstruction *ALM = dyn_cast<VPInstruction>(Not->getOperand(0));
- return ALM && ALM->getOpcode() == VPInstruction::ActiveLaneMask;
-}
-
void VPlanTransforms::optimizeForVFAndUF(VPlan &Plan, ElementCount BestVF,
unsigned BestUF,
PredicatedScalarEvolution &PSE) {
@@ -611,15 +602,16 @@ void VPlanTransforms::optimizeForVFAndUF(VPlan &Plan, ElementCount BestVF,
assert(Plan.hasUF(BestUF) && "BestUF is not available in Plan");
VPBasicBlock *ExitingVPBB =
Plan.getVectorLoopRegion()->getExitingBasicBlock();
- auto *Term = dyn_cast<VPInstruction>(&ExitingVPBB->back());
+ auto *Term = &ExitingVPBB->back();
// Try to simplify the branch condition if TC <= VF * UF when preparing to
// execute the plan for the main vector loop. We only do this if the
// terminator is:
// 1. BranchOnCount, or
// 2. BranchOnCond where the input is Not(ActiveLaneMask).
- if (!Term || (Term->getOpcode() != VPInstruction::BranchOnCount &&
- (Term->getOpcode() != VPInstruction::BranchOnCond ||
- !canSimplifyBranchOnCond(Term))))
+ using namespace llvm::VPlanPatternMatch;
+ if (!match(Term, m_BranchOnCount(m_VPValue(), m_VPValue())) &&
+ !match(Term,
+ m_BranchOnCond(m_Not(m_ActiveLaneMask(m_VPValue(), m_VPValue())))))
return;
Type *IdxTy =
>From 3dd6750027cd168fce5fd9894b0bac0739652cf5 Mon Sep 17 00:00:00 2001
From: David Majnemer <david.majnemer at gmail.com>
Date: Fri, 1 Mar 2024 17:19:48 +0000
Subject: [PATCH 400/406] [AArch64] Add more complete support for BF16
We can use a small amount of integer arithmetic to round FP32 to BF16
and extend BF16 to FP32.
While a number of operations still require promotion, this can be
reduced for some rather simple operations like abs, copysign, fneg but
these can be done in a follow-up.
A few neat optimizations are implemented:
- round-inexact-to-odd is used for F64 to BF16 rounding.
- quieting signaling NaNs for f32 -> bf16 tries to detect if a prior
operation makes it unnecessary.
---
llvm/include/llvm/CodeGen/TargetLowering.h | 5 +-
llvm/include/llvm/CodeGen/ValueTypes.h | 7 +
.../Target/AArch64/AArch64ISelLowering.cpp | 290 ++++++++----
llvm/lib/Target/AArch64/AArch64ISelLowering.h | 3 +
.../lib/Target/AArch64/AArch64InstrFormats.td | 2 +-
llvm/lib/Target/AArch64/AArch64InstrInfo.td | 37 ++
.../GISel/AArch64PostLegalizerLowering.cpp | 8 +-
.../Analysis/CostModel/AArch64/reduce-fadd.ll | 8 +-
.../GlobalISel/lower-neon-vector-fcmp.mir | 7 +-
.../implicitly-set-zero-high-64-bits.ll | 5 +-
.../AArch64/neon-compare-instructions.ll | 126 ++---
.../AArch64/round-fptosi-sat-scalar.ll | 102 ++++
llvm/test/CodeGen/AArch64/vector-fcopysign.ll | 439 ++++++++++++++++++
13 files changed, 842 insertions(+), 197 deletions(-)
diff --git a/llvm/include/llvm/CodeGen/TargetLowering.h b/llvm/include/llvm/CodeGen/TargetLowering.h
index f2e00aab8d5da2..0438abc7c3061a 100644
--- a/llvm/include/llvm/CodeGen/TargetLowering.h
+++ b/llvm/include/llvm/CodeGen/TargetLowering.h
@@ -1573,13 +1573,14 @@ class TargetLoweringBase {
assert((VT.isInteger() || VT.isFloatingPoint()) &&
"Cannot autopromote this type, add it with AddPromotedToType.");
+ uint64_t VTBits = VT.getScalarSizeInBits();
MVT NVT = VT;
do {
NVT = (MVT::SimpleValueType)(NVT.SimpleTy+1);
assert(NVT.isInteger() == VT.isInteger() && NVT != MVT::isVoid &&
"Didn't find type to promote to!");
- } while (!isTypeLegal(NVT) ||
- getOperationAction(Op, NVT) == Promote);
+ } while (VTBits >= NVT.getScalarSizeInBits() || !isTypeLegal(NVT) ||
+ getOperationAction(Op, NVT) == Promote);
return NVT;
}
diff --git a/llvm/include/llvm/CodeGen/ValueTypes.h b/llvm/include/llvm/CodeGen/ValueTypes.h
index 1e0356ee69ff52..b66c66d1bfc45a 100644
--- a/llvm/include/llvm/CodeGen/ValueTypes.h
+++ b/llvm/include/llvm/CodeGen/ValueTypes.h
@@ -107,6 +107,13 @@ namespace llvm {
return changeExtendedVectorElementType(EltVT);
}
+ /// Return a VT for a type whose attributes match ourselves with the
+ /// exception of the element type that is chosen by the caller.
+ EVT changeElementType(EVT EltVT) const {
+ EltVT = EltVT.getScalarType();
+ return isVector() ? changeVectorElementType(EltVT) : EltVT;
+ }
+
/// Return the type converted to an equivalently sized integer or vector
/// with integer element type. Similar to changeVectorElementTypeToInteger,
/// but also handles scalars.
diff --git a/llvm/lib/Target/AArch64/AArch64ISelLowering.cpp b/llvm/lib/Target/AArch64/AArch64ISelLowering.cpp
index 7f80e877cb2406..475c73c3588dbc 100644
--- a/llvm/lib/Target/AArch64/AArch64ISelLowering.cpp
+++ b/llvm/lib/Target/AArch64/AArch64ISelLowering.cpp
@@ -368,8 +368,7 @@ AArch64TargetLowering::AArch64TargetLowering(const TargetMachine &TM,
addDRTypeForNEON(MVT::v1i64);
addDRTypeForNEON(MVT::v1f64);
addDRTypeForNEON(MVT::v4f16);
- if (Subtarget->hasBF16())
- addDRTypeForNEON(MVT::v4bf16);
+ addDRTypeForNEON(MVT::v4bf16);
addQRTypeForNEON(MVT::v4f32);
addQRTypeForNEON(MVT::v2f64);
@@ -378,8 +377,7 @@ AArch64TargetLowering::AArch64TargetLowering(const TargetMachine &TM,
addQRTypeForNEON(MVT::v4i32);
addQRTypeForNEON(MVT::v2i64);
addQRTypeForNEON(MVT::v8f16);
- if (Subtarget->hasBF16())
- addQRTypeForNEON(MVT::v8bf16);
+ addQRTypeForNEON(MVT::v8bf16);
}
if (Subtarget->hasSVEorSME()) {
@@ -403,11 +401,9 @@ AArch64TargetLowering::AArch64TargetLowering(const TargetMachine &TM,
addRegisterClass(MVT::nxv4f32, &AArch64::ZPRRegClass);
addRegisterClass(MVT::nxv2f64, &AArch64::ZPRRegClass);
- if (Subtarget->hasBF16()) {
- addRegisterClass(MVT::nxv2bf16, &AArch64::ZPRRegClass);
- addRegisterClass(MVT::nxv4bf16, &AArch64::ZPRRegClass);
- addRegisterClass(MVT::nxv8bf16, &AArch64::ZPRRegClass);
- }
+ addRegisterClass(MVT::nxv2bf16, &AArch64::ZPRRegClass);
+ addRegisterClass(MVT::nxv4bf16, &AArch64::ZPRRegClass);
+ addRegisterClass(MVT::nxv8bf16, &AArch64::ZPRRegClass);
if (Subtarget->useSVEForFixedLengthVectors()) {
for (MVT VT : MVT::integer_fixedlen_vector_valuetypes())
@@ -437,9 +433,11 @@ AArch64TargetLowering::AArch64TargetLowering(const TargetMachine &TM,
setOperationAction(ISD::GlobalTLSAddress, MVT::i64, Custom);
setOperationAction(ISD::SETCC, MVT::i32, Custom);
setOperationAction(ISD::SETCC, MVT::i64, Custom);
+ setOperationAction(ISD::SETCC, MVT::bf16, Custom);
setOperationAction(ISD::SETCC, MVT::f16, Custom);
setOperationAction(ISD::SETCC, MVT::f32, Custom);
setOperationAction(ISD::SETCC, MVT::f64, Custom);
+ setOperationAction(ISD::STRICT_FSETCC, MVT::bf16, Custom);
setOperationAction(ISD::STRICT_FSETCC, MVT::f16, Custom);
setOperationAction(ISD::STRICT_FSETCC, MVT::f32, Custom);
setOperationAction(ISD::STRICT_FSETCC, MVT::f64, Custom);
@@ -463,7 +461,7 @@ AArch64TargetLowering::AArch64TargetLowering(const TargetMachine &TM,
setOperationAction(ISD::SELECT_CC, MVT::i32, Custom);
setOperationAction(ISD::SELECT_CC, MVT::i64, Custom);
setOperationAction(ISD::SELECT_CC, MVT::f16, Custom);
- setOperationAction(ISD::SELECT_CC, MVT::bf16, Expand);
+ setOperationAction(ISD::SELECT_CC, MVT::bf16, Custom);
setOperationAction(ISD::SELECT_CC, MVT::f32, Custom);
setOperationAction(ISD::SELECT_CC, MVT::f64, Custom);
setOperationAction(ISD::BR_JT, MVT::Other, Custom);
@@ -539,12 +537,16 @@ AArch64TargetLowering::AArch64TargetLowering(const TargetMachine &TM,
setOperationAction(ISD::STRICT_UINT_TO_FP, MVT::i32, Custom);
setOperationAction(ISD::STRICT_UINT_TO_FP, MVT::i64, Custom);
setOperationAction(ISD::STRICT_UINT_TO_FP, MVT::i128, Custom);
- if (Subtarget->hasFPARMv8())
+ if (Subtarget->hasFPARMv8()) {
setOperationAction(ISD::FP_ROUND, MVT::f16, Custom);
+ setOperationAction(ISD::FP_ROUND, MVT::bf16, Custom);
+ }
setOperationAction(ISD::FP_ROUND, MVT::f32, Custom);
setOperationAction(ISD::FP_ROUND, MVT::f64, Custom);
- if (Subtarget->hasFPARMv8())
+ if (Subtarget->hasFPARMv8()) {
setOperationAction(ISD::STRICT_FP_ROUND, MVT::f16, Custom);
+ setOperationAction(ISD::STRICT_FP_ROUND, MVT::bf16, Custom);
+ }
setOperationAction(ISD::STRICT_FP_ROUND, MVT::f32, Custom);
setOperationAction(ISD::STRICT_FP_ROUND, MVT::f64, Custom);
@@ -678,6 +680,7 @@ AArch64TargetLowering::AArch64TargetLowering(const TargetMachine &TM,
setOperationAction(ISD::FCOPYSIGN, MVT::f16, Custom);
else
setOperationAction(ISD::FCOPYSIGN, MVT::f16, Promote);
+ setOperationAction(ISD::FCOPYSIGN, MVT::bf16, Promote);
for (auto Op : {ISD::FREM, ISD::FPOW, ISD::FPOWI,
ISD::FCOS, ISD::FSIN, ISD::FSINCOS,
@@ -690,9 +693,12 @@ AArch64TargetLowering::AArch64TargetLowering(const TargetMachine &TM,
setOperationAction(Op, MVT::f16, Promote);
setOperationAction(Op, MVT::v4f16, Expand);
setOperationAction(Op, MVT::v8f16, Expand);
+ setOperationAction(Op, MVT::bf16, Promote);
+ setOperationAction(Op, MVT::v4bf16, Expand);
+ setOperationAction(Op, MVT::v8bf16, Expand);
}
- if (!Subtarget->hasFullFP16()) {
+ auto LegalizeNarrowFP = [this](MVT ScalarVT) {
for (auto Op :
{ISD::SETCC, ISD::SELECT_CC,
ISD::BR_CC, ISD::FADD, ISD::FSUB,
@@ -708,60 +714,69 @@ AArch64TargetLowering::AArch64TargetLowering(const TargetMachine &TM,
ISD::STRICT_FROUND, ISD::STRICT_FTRUNC, ISD::STRICT_FROUNDEVEN,
ISD::STRICT_FMINNUM, ISD::STRICT_FMAXNUM, ISD::STRICT_FMINIMUM,
ISD::STRICT_FMAXIMUM})
- setOperationAction(Op, MVT::f16, Promote);
+ setOperationAction(Op, ScalarVT, Promote);
// Round-to-integer need custom lowering for fp16, as Promote doesn't work
// because the result type is integer.
for (auto Op : {ISD::LROUND, ISD::LLROUND, ISD::LRINT, ISD::LLRINT,
ISD::STRICT_LROUND, ISD::STRICT_LLROUND, ISD::STRICT_LRINT,
ISD::STRICT_LLRINT})
- setOperationAction(Op, MVT::f16, Custom);
+ setOperationAction(Op, ScalarVT, Custom);
// promote v4f16 to v4f32 when that is known to be safe.
- setOperationPromotedToType(ISD::FADD, MVT::v4f16, MVT::v4f32);
- setOperationPromotedToType(ISD::FSUB, MVT::v4f16, MVT::v4f32);
- setOperationPromotedToType(ISD::FMUL, MVT::v4f16, MVT::v4f32);
- setOperationPromotedToType(ISD::FDIV, MVT::v4f16, MVT::v4f32);
-
- setOperationAction(ISD::FABS, MVT::v4f16, Expand);
- setOperationAction(ISD::FNEG, MVT::v4f16, Expand);
- setOperationAction(ISD::FROUND, MVT::v4f16, Expand);
- setOperationAction(ISD::FROUNDEVEN, MVT::v4f16, Expand);
- setOperationAction(ISD::FMA, MVT::v4f16, Expand);
- setOperationAction(ISD::SETCC, MVT::v4f16, Custom);
- setOperationAction(ISD::BR_CC, MVT::v4f16, Expand);
- setOperationAction(ISD::SELECT, MVT::v4f16, Expand);
- setOperationAction(ISD::SELECT_CC, MVT::v4f16, Expand);
- setOperationAction(ISD::FTRUNC, MVT::v4f16, Expand);
- setOperationAction(ISD::FCOPYSIGN, MVT::v4f16, Expand);
- setOperationAction(ISD::FFLOOR, MVT::v4f16, Expand);
- setOperationAction(ISD::FCEIL, MVT::v4f16, Expand);
- setOperationAction(ISD::FRINT, MVT::v4f16, Expand);
- setOperationAction(ISD::FNEARBYINT, MVT::v4f16, Expand);
- setOperationAction(ISD::FSQRT, MVT::v4f16, Expand);
-
- setOperationAction(ISD::FABS, MVT::v8f16, Expand);
- setOperationAction(ISD::FADD, MVT::v8f16, Expand);
- setOperationAction(ISD::FCEIL, MVT::v8f16, Expand);
- setOperationAction(ISD::FCOPYSIGN, MVT::v8f16, Expand);
- setOperationAction(ISD::FDIV, MVT::v8f16, Expand);
- setOperationAction(ISD::FFLOOR, MVT::v8f16, Expand);
- setOperationAction(ISD::FMA, MVT::v8f16, Expand);
- setOperationAction(ISD::FMUL, MVT::v8f16, Expand);
- setOperationAction(ISD::FNEARBYINT, MVT::v8f16, Expand);
- setOperationAction(ISD::FNEG, MVT::v8f16, Expand);
- setOperationAction(ISD::FROUND, MVT::v8f16, Expand);
- setOperationAction(ISD::FROUNDEVEN, MVT::v8f16, Expand);
- setOperationAction(ISD::FRINT, MVT::v8f16, Expand);
- setOperationAction(ISD::FSQRT, MVT::v8f16, Expand);
- setOperationAction(ISD::FSUB, MVT::v8f16, Expand);
- setOperationAction(ISD::FTRUNC, MVT::v8f16, Expand);
- setOperationAction(ISD::SETCC, MVT::v8f16, Expand);
- setOperationAction(ISD::BR_CC, MVT::v8f16, Expand);
- setOperationAction(ISD::SELECT, MVT::v8f16, Expand);
- setOperationAction(ISD::SELECT_CC, MVT::v8f16, Expand);
- setOperationAction(ISD::FP_EXTEND, MVT::v8f16, Expand);
+ auto V4Narrow = MVT::getVectorVT(ScalarVT, 4);
+ setOperationPromotedToType(ISD::FADD, V4Narrow, MVT::v4f32);
+ setOperationPromotedToType(ISD::FSUB, V4Narrow, MVT::v4f32);
+ setOperationPromotedToType(ISD::FMUL, V4Narrow, MVT::v4f32);
+ setOperationPromotedToType(ISD::FDIV, V4Narrow, MVT::v4f32);
+
+ setOperationAction(ISD::FABS, V4Narrow, Expand);
+ setOperationAction(ISD::FNEG, V4Narrow, Expand);
+ setOperationAction(ISD::FROUND, V4Narrow, Expand);
+ setOperationAction(ISD::FROUNDEVEN, V4Narrow, Expand);
+ setOperationAction(ISD::FMA, V4Narrow, Expand);
+ setOperationAction(ISD::SETCC, V4Narrow, Custom);
+ setOperationAction(ISD::BR_CC, V4Narrow, Expand);
+ setOperationAction(ISD::SELECT, V4Narrow, Expand);
+ setOperationAction(ISD::SELECT_CC, V4Narrow, Expand);
+ setOperationAction(ISD::FTRUNC, V4Narrow, Expand);
+ setOperationAction(ISD::FCOPYSIGN, V4Narrow, Expand);
+ setOperationAction(ISD::FFLOOR, V4Narrow, Expand);
+ setOperationAction(ISD::FCEIL, V4Narrow, Expand);
+ setOperationAction(ISD::FRINT, V4Narrow, Expand);
+ setOperationAction(ISD::FNEARBYINT, V4Narrow, Expand);
+ setOperationAction(ISD::FSQRT, V4Narrow, Expand);
+
+ auto V8Narrow = MVT::getVectorVT(ScalarVT, 8);
+ setOperationAction(ISD::FABS, V8Narrow, Expand);
+ setOperationAction(ISD::FADD, V8Narrow, Expand);
+ setOperationAction(ISD::FCEIL, V8Narrow, Expand);
+ setOperationAction(ISD::FCOPYSIGN, V8Narrow, Expand);
+ setOperationAction(ISD::FDIV, V8Narrow, Expand);
+ setOperationAction(ISD::FFLOOR, V8Narrow, Expand);
+ setOperationAction(ISD::FMA, V8Narrow, Expand);
+ setOperationAction(ISD::FMUL, V8Narrow, Expand);
+ setOperationAction(ISD::FNEARBYINT, V8Narrow, Expand);
+ setOperationAction(ISD::FNEG, V8Narrow, Expand);
+ setOperationAction(ISD::FROUND, V8Narrow, Expand);
+ setOperationAction(ISD::FROUNDEVEN, V8Narrow, Expand);
+ setOperationAction(ISD::FRINT, V8Narrow, Expand);
+ setOperationAction(ISD::FSQRT, V8Narrow, Expand);
+ setOperationAction(ISD::FSUB, V8Narrow, Expand);
+ setOperationAction(ISD::FTRUNC, V8Narrow, Expand);
+ setOperationAction(ISD::SETCC, V8Narrow, Expand);
+ setOperationAction(ISD::BR_CC, V8Narrow, Expand);
+ setOperationAction(ISD::SELECT, V8Narrow, Expand);
+ setOperationAction(ISD::SELECT_CC, V8Narrow, Expand);
+ setOperationAction(ISD::FP_EXTEND, V8Narrow, Expand);
+ };
+
+ if (!Subtarget->hasFullFP16()) {
+ LegalizeNarrowFP(MVT::f16);
}
+ LegalizeNarrowFP(MVT::bf16);
+ setOperationAction(ISD::FP_ROUND, MVT::v4f32, Custom);
+ setOperationAction(ISD::FP_ROUND, MVT::v4bf16, Custom);
// AArch64 has implementations of a lot of rounding-like FP operations.
for (auto Op :
@@ -886,6 +901,7 @@ AArch64TargetLowering::AArch64TargetLowering(const TargetMachine &TM,
setOperationAction(ISD::STORE, MVT::v32i8, Custom);
setOperationAction(ISD::STORE, MVT::v16i16, Custom);
setOperationAction(ISD::STORE, MVT::v16f16, Custom);
+ setOperationAction(ISD::STORE, MVT::v16bf16, Custom);
setOperationAction(ISD::STORE, MVT::v8i32, Custom);
setOperationAction(ISD::STORE, MVT::v8f32, Custom);
setOperationAction(ISD::STORE, MVT::v4f64, Custom);
@@ -897,6 +913,7 @@ AArch64TargetLowering::AArch64TargetLowering(const TargetMachine &TM,
setOperationAction(ISD::LOAD, MVT::v32i8, Custom);
setOperationAction(ISD::LOAD, MVT::v16i16, Custom);
setOperationAction(ISD::LOAD, MVT::v16f16, Custom);
+ setOperationAction(ISD::LOAD, MVT::v16bf16, Custom);
setOperationAction(ISD::LOAD, MVT::v8i32, Custom);
setOperationAction(ISD::LOAD, MVT::v8f32, Custom);
setOperationAction(ISD::LOAD, MVT::v4f64, Custom);
@@ -931,6 +948,7 @@ AArch64TargetLowering::AArch64TargetLowering(const TargetMachine &TM,
// AArch64 does not have floating-point extending loads, i1 sign-extending
// load, floating-point truncating stores, or v2i32->v2i16 truncating store.
for (MVT VT : MVT::fp_valuetypes()) {
+ setLoadExtAction(ISD::EXTLOAD, VT, MVT::bf16, Expand);
setLoadExtAction(ISD::EXTLOAD, VT, MVT::f16, Expand);
setLoadExtAction(ISD::EXTLOAD, VT, MVT::f32, Expand);
setLoadExtAction(ISD::EXTLOAD, VT, MVT::f64, Expand);
@@ -939,13 +957,13 @@ AArch64TargetLowering::AArch64TargetLowering(const TargetMachine &TM,
for (MVT VT : MVT::integer_valuetypes())
setLoadExtAction(ISD::SEXTLOAD, VT, MVT::i1, Expand);
- setTruncStoreAction(MVT::f32, MVT::f16, Expand);
- setTruncStoreAction(MVT::f64, MVT::f32, Expand);
- setTruncStoreAction(MVT::f64, MVT::f16, Expand);
- setTruncStoreAction(MVT::f128, MVT::f80, Expand);
- setTruncStoreAction(MVT::f128, MVT::f64, Expand);
- setTruncStoreAction(MVT::f128, MVT::f32, Expand);
- setTruncStoreAction(MVT::f128, MVT::f16, Expand);
+ for (MVT WideVT : MVT::fp_valuetypes()) {
+ for (MVT NarrowVT : MVT::fp_valuetypes()) {
+ if (WideVT.getScalarSizeInBits() > NarrowVT.getScalarSizeInBits()) {
+ setTruncStoreAction(WideVT, NarrowVT, Expand);
+ }
+ }
+ }
if (Subtarget->hasFPARMv8()) {
setOperationAction(ISD::BITCAST, MVT::i16, Custom);
@@ -1553,7 +1571,7 @@ AArch64TargetLowering::AArch64TargetLowering(const TargetMachine &TM,
setOperationAction(ISD::VECREDUCE_SEQ_FADD, VT, Custom);
}
- if (!Subtarget->isNeonAvailable()) {
+ if (!Subtarget->isNeonAvailable()) {// TODO(majnemer)
setTruncStoreAction(MVT::v2f32, MVT::v2f16, Custom);
setTruncStoreAction(MVT::v4f32, MVT::v4f16, Custom);
setTruncStoreAction(MVT::v8f32, MVT::v8f16, Custom);
@@ -1652,6 +1670,7 @@ AArch64TargetLowering::AArch64TargetLowering(const TargetMachine &TM,
setOperationAction(ISD::FLDEXP, MVT::f64, Custom);
setOperationAction(ISD::FLDEXP, MVT::f32, Custom);
setOperationAction(ISD::FLDEXP, MVT::f16, Custom);
+ setOperationAction(ISD::FLDEXP, MVT::bf16, Custom);
}
PredictableSelectIsExpensive = Subtarget->predictableSelectIsExpensive();
@@ -2451,6 +2470,7 @@ const char *AArch64TargetLowering::getTargetNodeName(unsigned Opcode) const {
MAKE_CASE(AArch64ISD::FCMP)
MAKE_CASE(AArch64ISD::STRICT_FCMP)
MAKE_CASE(AArch64ISD::STRICT_FCMPE)
+ MAKE_CASE(AArch64ISD::FCVTXN)
MAKE_CASE(AArch64ISD::SME_ZA_LDR)
MAKE_CASE(AArch64ISD::SME_ZA_STR)
MAKE_CASE(AArch64ISD::DUP)
@@ -3181,7 +3201,7 @@ static SDValue emitStrictFPComparison(SDValue LHS, SDValue RHS, const SDLoc &dl,
const bool FullFP16 = DAG.getSubtarget<AArch64Subtarget>().hasFullFP16();
- if (VT == MVT::f16 && !FullFP16) {
+ if ((VT == MVT::f16 && !FullFP16) || VT == MVT::bf16) {
LHS = DAG.getNode(ISD::STRICT_FP_EXTEND, dl, {MVT::f32, MVT::Other},
{Chain, LHS});
RHS = DAG.getNode(ISD::STRICT_FP_EXTEND, dl, {MVT::f32, MVT::Other},
@@ -3201,7 +3221,7 @@ static SDValue emitComparison(SDValue LHS, SDValue RHS, ISD::CondCode CC,
if (VT.isFloatingPoint()) {
assert(VT != MVT::f128);
- if (VT == MVT::f16 && !FullFP16) {
+ if ((VT == MVT::f16 && !FullFP16) || VT == MVT::bf16) {
LHS = DAG.getNode(ISD::FP_EXTEND, dl, MVT::f32, LHS);
RHS = DAG.getNode(ISD::FP_EXTEND, dl, MVT::f32, RHS);
VT = MVT::f32;
@@ -3309,7 +3329,8 @@ static SDValue emitConditionalComparison(SDValue LHS, SDValue RHS,
if (LHS.getValueType().isFloatingPoint()) {
assert(LHS.getValueType() != MVT::f128);
- if (LHS.getValueType() == MVT::f16 && !FullFP16) {
+ if ((LHS.getValueType() == MVT::f16 && !FullFP16) ||
+ LHS.getValueType() == MVT::bf16) {
LHS = DAG.getNode(ISD::FP_EXTEND, DL, MVT::f32, LHS);
RHS = DAG.getNode(ISD::FP_EXTEND, DL, MVT::f32, RHS);
}
@@ -4009,16 +4030,73 @@ SDValue AArch64TargetLowering::LowerFP_EXTEND(SDValue Op,
SDValue AArch64TargetLowering::LowerFP_ROUND(SDValue Op,
SelectionDAG &DAG) const {
- if (Op.getValueType().isScalableVector())
+ EVT VT = Op.getValueType();
+ if (VT.isScalableVector())
return LowerToPredicatedOp(Op, DAG, AArch64ISD::FP_ROUND_MERGE_PASSTHRU);
bool IsStrict = Op->isStrictFPOpcode();
SDValue SrcVal = Op.getOperand(IsStrict ? 1 : 0);
EVT SrcVT = SrcVal.getValueType();
+ bool Trunc = Op.getConstantOperandVal(IsStrict ? 2 : 1) == 1;
if (useSVEForFixedLengthVectorVT(SrcVT, !Subtarget->isNeonAvailable()))
return LowerFixedLengthFPRoundToSVE(Op, DAG);
+ // Expand cases where the result type is BF16 but we don't have hardware
+ // instructions to lower it.
+ if (VT.getScalarType() == MVT::bf16 &&
+ !((Subtarget->hasNEON() || Subtarget->hasSME()) &&
+ Subtarget->hasBF16())) {
+ SDLoc dl(Op);
+ SDValue Narrow = SrcVal;
+ SDValue NaN;
+ EVT I32 = SrcVT.changeElementType(MVT::i32);
+ EVT F32 = SrcVT.changeElementType(MVT::f32);
+ if (SrcVT.getScalarType() == MVT::f32) {
+ bool NeverSNaN = DAG.isKnownNeverSNaN(Narrow);
+ Narrow = DAG.getNode(ISD::BITCAST, dl, I32, Narrow);
+ if (!NeverSNaN) {
+ // Set the quiet bit.
+ NaN = DAG.getNode(ISD::OR, dl, I32, Narrow,
+ DAG.getConstant(0x400000, dl, I32));
+ }
+ } else if (SrcVT.getScalarType() == MVT::f64) {
+ Narrow = DAG.getNode(AArch64ISD::FCVTXN, dl, F32, Narrow);
+ Narrow = DAG.getNode(ISD::BITCAST, dl, I32, Narrow);
+ } else {
+ return SDValue();
+ }
+ if (!Trunc) {
+ SDValue One = DAG.getConstant(1, dl, I32);
+ SDValue Lsb = DAG.getNode(ISD::SRL, dl, I32, Narrow,
+ DAG.getShiftAmountConstant(16, I32, dl));
+ Lsb = DAG.getNode(ISD::AND, dl, I32, Lsb, One);
+ SDValue RoundingBias =
+ DAG.getNode(ISD::ADD, dl, I32, DAG.getConstant(0x7fff, dl, I32), Lsb);
+ Narrow = DAG.getNode(ISD::ADD, dl, I32, Narrow, RoundingBias);
+ }
+
+ // Don't round if we had a NaN, we don't want to turn 0x7fffffff into
+ // 0x80000000.
+ if (NaN) {
+ SDValue IsNaN = DAG.getSetCC(
+ dl, getSetCCResultType(DAG.getDataLayout(), *DAG.getContext(), SrcVT),
+ SrcVal, SrcVal, ISD::SETUO);
+ Narrow = DAG.getSelect(dl, I32, IsNaN, NaN, Narrow);
+ }
+
+ // Now that we have rounded, shift the bits into position.
+ Narrow = DAG.getNode(ISD::SRL, dl, I32, Narrow,
+ DAG.getShiftAmountConstant(16, I32, dl));
+ if (VT.isVector()) {
+ EVT I16 = I32.changeVectorElementType(MVT::i16);
+ Narrow = DAG.getNode(ISD::TRUNCATE, dl, I16, Narrow);
+ return DAG.getNode(ISD::BITCAST, dl, VT, Narrow);
+ }
+ Narrow = DAG.getNode(ISD::BITCAST, dl, F32, Narrow);
+ return DAG.getTargetExtractSubreg(AArch64::hsub, dl, VT, Narrow);
+ }
+
if (SrcVT != MVT::f128) {
// Expand cases where the input is a vector bigger than NEON.
if (useSVEForFixedLengthVectorVT(SrcVT))
@@ -4054,8 +4132,8 @@ SDValue AArch64TargetLowering::LowerVectorFP_TO_INT(SDValue Op,
unsigned NumElts = InVT.getVectorNumElements();
// f16 conversions are promoted to f32 when full fp16 is not supported.
- if (InVT.getVectorElementType() == MVT::f16 &&
- !Subtarget->hasFullFP16()) {
+ if ((InVT.getVectorElementType() == MVT::f16 && !Subtarget->hasFullFP16()) ||
+ InVT.getVectorElementType() == MVT::bf16) {
MVT NewVT = MVT::getVectorVT(MVT::f32, NumElts);
SDLoc dl(Op);
if (IsStrict) {
@@ -4128,7 +4206,8 @@ SDValue AArch64TargetLowering::LowerFP_TO_INT(SDValue Op,
return LowerVectorFP_TO_INT(Op, DAG);
// f16 conversions are promoted to f32 when full fp16 is not supported.
- if (SrcVal.getValueType() == MVT::f16 && !Subtarget->hasFullFP16()) {
+ if ((SrcVal.getValueType() == MVT::f16 && !Subtarget->hasFullFP16()) ||
+ SrcVal.getValueType() == MVT::bf16) {
SDLoc dl(Op);
if (IsStrict) {
SDValue Ext =
@@ -4175,15 +4254,16 @@ AArch64TargetLowering::LowerVectorFP_TO_INT_SAT(SDValue Op,
EVT SrcElementVT = SrcVT.getVectorElementType();
// In the absence of FP16 support, promote f16 to f32 and saturate the result.
- if (SrcElementVT == MVT::f16 &&
- (!Subtarget->hasFullFP16() || DstElementWidth > 16)) {
+ if ((SrcElementVT == MVT::f16 &&
+ (!Subtarget->hasFullFP16() || DstElementWidth > 16)) ||
+ SrcElementVT == MVT::bf16) {
MVT F32VT = MVT::getVectorVT(MVT::f32, SrcVT.getVectorNumElements());
SrcVal = DAG.getNode(ISD::FP_EXTEND, SDLoc(Op), F32VT, SrcVal);
SrcVT = F32VT;
SrcElementVT = MVT::f32;
SrcElementWidth = 32;
} else if (SrcElementVT != MVT::f64 && SrcElementVT != MVT::f32 &&
- SrcElementVT != MVT::f16)
+ SrcElementVT != MVT::f16 && SrcElementVT != MVT::bf16)
return SDValue();
SDLoc DL(Op);
@@ -4236,10 +4316,11 @@ SDValue AArch64TargetLowering::LowerFP_TO_INT_SAT(SDValue Op,
assert(SatWidth <= DstWidth && "Saturation width cannot exceed result width");
// In the absence of FP16 support, promote f16 to f32 and saturate the result.
- if (SrcVT == MVT::f16 && !Subtarget->hasFullFP16()) {
+ if ((SrcVT == MVT::f16 && !Subtarget->hasFullFP16()) || SrcVT == MVT::bf16) {
SrcVal = DAG.getNode(ISD::FP_EXTEND, SDLoc(Op), MVT::f32, SrcVal);
SrcVT = MVT::f32;
- } else if (SrcVT != MVT::f64 && SrcVT != MVT::f32 && SrcVT != MVT::f16)
+ } else if (SrcVT != MVT::f64 && SrcVT != MVT::f32 && SrcVT != MVT::f16 &&
+ SrcVT != MVT::bf16)
return SDValue();
SDLoc DL(Op);
@@ -4358,17 +4439,17 @@ SDValue AArch64TargetLowering::LowerINT_TO_FP(SDValue Op,
SDValue SrcVal = Op.getOperand(IsStrict ? 1 : 0);
// f16 conversions are promoted to f32 when full fp16 is not supported.
- if (Op.getValueType() == MVT::f16 && !Subtarget->hasFullFP16()) {
+ if ((Op.getValueType() == MVT::f16 && !Subtarget->hasFullFP16()) || Op.getValueType() == MVT::bf16) {
SDLoc dl(Op);
if (IsStrict) {
SDValue Val = DAG.getNode(Op.getOpcode(), dl, {MVT::f32, MVT::Other},
{Op.getOperand(0), SrcVal});
return DAG.getNode(
- ISD::STRICT_FP_ROUND, dl, {MVT::f16, MVT::Other},
+ ISD::STRICT_FP_ROUND, dl, {Op.getValueType(), MVT::Other},
{Val.getValue(1), Val.getValue(0), DAG.getIntPtrConstant(0, dl)});
}
return DAG.getNode(
- ISD::FP_ROUND, dl, MVT::f16,
+ ISD::FP_ROUND, dl, Op.getValueType(),
DAG.getNode(Op.getOpcode(), dl, MVT::f32, SrcVal),
DAG.getIntPtrConstant(0, dl));
}
@@ -6100,6 +6181,7 @@ static SDValue LowerFLDEXP(SDValue Op, SelectionDAG &DAG) {
switch (Op.getSimpleValueType().SimpleTy) {
default:
return SDValue();
+ case MVT::bf16:
case MVT::f16:
X = DAG.getNode(ISD::FP_EXTEND, DL, MVT::f32, X);
[[fallthrough]];
@@ -6416,7 +6498,8 @@ SDValue AArch64TargetLowering::LowerOperation(SDValue Op,
case ISD::LLROUND:
case ISD::LRINT:
case ISD::LLRINT: {
- assert(Op.getOperand(0).getValueType() == MVT::f16 &&
+ assert((Op.getOperand(0).getValueType() == MVT::f16 ||
+ Op.getOperand(0).getValueType() == MVT::bf16) &&
"Expected custom lowering of rounding operations only for f16");
SDLoc DL(Op);
SDValue Ext = DAG.getNode(ISD::FP_EXTEND, DL, MVT::f32, Op.getOperand(0));
@@ -6426,7 +6509,8 @@ SDValue AArch64TargetLowering::LowerOperation(SDValue Op,
case ISD::STRICT_LLROUND:
case ISD::STRICT_LRINT:
case ISD::STRICT_LLRINT: {
- assert(Op.getOperand(1).getValueType() == MVT::f16 &&
+ assert((Op.getOperand(1).getValueType() == MVT::f16 ||
+ Op.getOperand(1).getValueType() == MVT::bf16) &&
"Expected custom lowering of rounding operations only for f16");
SDLoc DL(Op);
SDValue Ext = DAG.getNode(ISD::STRICT_FP_EXTEND, DL, {MVT::f32, MVT::Other},
@@ -9459,8 +9543,8 @@ SDValue AArch64TargetLowering::LowerSETCC(SDValue Op, SelectionDAG &DAG) const {
}
// Now we know we're dealing with FP values.
- assert(LHS.getValueType() == MVT::f16 || LHS.getValueType() == MVT::f32 ||
- LHS.getValueType() == MVT::f64);
+ assert(LHS.getValueType() == MVT::bf16 || LHS.getValueType() == MVT::f16 ||
+ LHS.getValueType() == MVT::f32 || LHS.getValueType() == MVT::f64);
// If that fails, we'll need to perform an FCMP + CSEL sequence. Go ahead
// and do the comparison.
@@ -9547,7 +9631,8 @@ SDValue AArch64TargetLowering::LowerSELECT_CC(ISD::CondCode CC, SDValue LHS,
}
// Also handle f16, for which we need to do a f32 comparison.
- if (LHS.getValueType() == MVT::f16 && !Subtarget->hasFullFP16()) {
+ if ((LHS.getValueType() == MVT::f16 && !Subtarget->hasFullFP16()) ||
+ LHS.getValueType() == MVT::bf16) {
LHS = DAG.getNode(ISD::FP_EXTEND, dl, MVT::f32, LHS);
RHS = DAG.getNode(ISD::FP_EXTEND, dl, MVT::f32, RHS);
}
@@ -10306,6 +10391,7 @@ bool AArch64TargetLowering::isFPImmLegal(const APFloat &Imm, EVT VT,
IsLegal = AArch64_AM::getFP64Imm(ImmInt) != -1 || Imm.isPosZero();
else if (VT == MVT::f32)
IsLegal = AArch64_AM::getFP32Imm(ImmInt) != -1 || Imm.isPosZero();
+ // TODO(majnemer): double check this...
else if (VT == MVT::f16 || VT == MVT::bf16)
IsLegal =
(Subtarget->hasFullFP16() && AArch64_AM::getFP16Imm(ImmInt) != -1) ||
@@ -14161,11 +14247,30 @@ SDValue AArch64TargetLowering::LowerVSETCC(SDValue Op,
return DAG.getSExtOrTrunc(Cmp, dl, Op.getValueType());
}
+ // Lower isnan(x) | isnan(never-nan) to x != x.
+ // Lower !isnan(x) & !isnan(never-nan) to x == x.
+ if (CC == ISD::SETUO || CC == ISD::SETO) {
+ bool OneNaN = false;
+ if (LHS == RHS) {
+ OneNaN = true;
+ } else if (DAG.isKnownNeverNaN(RHS)) {
+ OneNaN = true;
+ RHS = LHS;
+ } else if (DAG.isKnownNeverNaN(LHS)) {
+ OneNaN = true;
+ LHS = RHS;
+ }
+ if (OneNaN) {
+ CC = CC == ISD::SETUO ? ISD::SETUNE : ISD::SETOEQ;
+ }
+ }
+
const bool FullFP16 = DAG.getSubtarget<AArch64Subtarget>().hasFullFP16();
// Make v4f16 (only) fcmp operations utilise vector instructions
// v8f16 support will be a litle more complicated
- if (!FullFP16 && LHS.getValueType().getVectorElementType() == MVT::f16) {
+ if ((!FullFP16 && LHS.getValueType().getVectorElementType() == MVT::f16) ||
+ LHS.getValueType().getVectorElementType() == MVT::bf16) {
if (LHS.getValueType().getVectorNumElements() == 4) {
LHS = DAG.getNode(ISD::FP_EXTEND, dl, MVT::v4f32, LHS);
RHS = DAG.getNode(ISD::FP_EXTEND, dl, MVT::v4f32, RHS);
@@ -14177,7 +14282,8 @@ SDValue AArch64TargetLowering::LowerVSETCC(SDValue Op,
}
assert((!FullFP16 && LHS.getValueType().getVectorElementType() != MVT::f16) ||
- LHS.getValueType().getVectorElementType() != MVT::f128);
+ LHS.getValueType().getVectorElementType() != MVT::bf16 ||
+ LHS.getValueType().getVectorElementType() != MVT::f128);
// Unfortunately, the mapping of LLVM FP CC's onto AArch64 CC's isn't totally
// clean. Some of them require two branches to implement.
@@ -24684,7 +24790,8 @@ static void ReplaceAddWithADDP(SDNode *N, SmallVectorImpl<SDValue> &Results,
if (!VT.is256BitVector() ||
(VT.getScalarType().isFloatingPoint() &&
!N->getFlags().hasAllowReassociation()) ||
- (VT.getScalarType() == MVT::f16 && !Subtarget->hasFullFP16()))
+ (VT.getScalarType() == MVT::f16 && !Subtarget->hasFullFP16()) ||
+ VT.getScalarType() == MVT::bf16)
return;
SDValue X = N->getOperand(0);
@@ -25736,6 +25843,8 @@ bool AArch64TargetLowering::shouldConvertFpToSat(unsigned Op, EVT FPVT,
// legalize.
if (FPVT == MVT::v8f16 && !Subtarget->hasFullFP16())
return false;
+ if (FPVT == MVT::v8bf16)
+ return false;
return TargetLowering::shouldConvertFpToSat(Op, FPVT, VT);
}
@@ -25928,6 +26037,8 @@ static EVT getContainerForFixedLengthVector(SelectionDAG &DAG, EVT VT) {
return EVT(MVT::nxv4i32);
case MVT::i64:
return EVT(MVT::nxv2i64);
+ case MVT::bf16:
+ return EVT(MVT::nxv8bf16);
case MVT::f16:
return EVT(MVT::nxv8f16);
case MVT::f32:
@@ -25967,6 +26078,7 @@ static SDValue getPredicateForFixedLengthVector(SelectionDAG &DAG, SDLoc &DL,
break;
case MVT::i16:
case MVT::f16:
+ case MVT::bf16:
MaskVT = MVT::nxv8i1;
break;
case MVT::i32:
diff --git a/llvm/lib/Target/AArch64/AArch64ISelLowering.h b/llvm/lib/Target/AArch64/AArch64ISelLowering.h
index c1fe76c07cba87..68341c199e0a2a 100644
--- a/llvm/lib/Target/AArch64/AArch64ISelLowering.h
+++ b/llvm/lib/Target/AArch64/AArch64ISelLowering.h
@@ -249,6 +249,9 @@ enum NodeType : unsigned {
FCMLEz,
FCMLTz,
+ // Round wide FP to narrow FP with inexact results to odd.
+ FCVTXN,
+
// Vector across-lanes addition
// Only the lower result lane is defined.
SADDV,
diff --git a/llvm/lib/Target/AArch64/AArch64InstrFormats.td b/llvm/lib/Target/AArch64/AArch64InstrFormats.td
index 7f8856db6c6e61..091db559a33708 100644
--- a/llvm/lib/Target/AArch64/AArch64InstrFormats.td
+++ b/llvm/lib/Target/AArch64/AArch64InstrFormats.td
@@ -7547,7 +7547,7 @@ class BaseSIMDCmpTwoScalar<bit U, bits<2> size, bits<2> size2, bits<5> opcode,
let mayRaiseFPException = 1, Uses = [FPCR] in
class SIMDInexactCvtTwoScalar<bits<5> opcode, string asm>
: I<(outs FPR32:$Rd), (ins FPR64:$Rn), asm, "\t$Rd, $Rn", "",
- [(set (f32 FPR32:$Rd), (int_aarch64_sisd_fcvtxn (f64 FPR64:$Rn)))]>,
+ [(set (f32 FPR32:$Rd), (AArch64fcvtxn (f64 FPR64:$Rn)))]>,
Sched<[WriteVd]> {
bits<5> Rd;
bits<5> Rn;
diff --git a/llvm/lib/Target/AArch64/AArch64InstrInfo.td b/llvm/lib/Target/AArch64/AArch64InstrInfo.td
index 52137c1f4065bc..c153bb3f0145bc 100644
--- a/llvm/lib/Target/AArch64/AArch64InstrInfo.td
+++ b/llvm/lib/Target/AArch64/AArch64InstrInfo.td
@@ -756,6 +756,11 @@ def AArch64fcmgtz: SDNode<"AArch64ISD::FCMGTz", SDT_AArch64fcmpz>;
def AArch64fcmlez: SDNode<"AArch64ISD::FCMLEz", SDT_AArch64fcmpz>;
def AArch64fcmltz: SDNode<"AArch64ISD::FCMLTz", SDT_AArch64fcmpz>;
+def AArch64fcvtxn_n: SDNode<"AArch64ISD::FCVTXN", SDTFPRoundOp>;
+def AArch64fcvtxn: PatFrags<(ops node:$Rn),
+ [(f32 (int_aarch64_sisd_fcvtxn (f64 node:$Rn))),
+ (f32 (AArch64fcvtxn_n (f64 node:$Rn)))]>;
+
def AArch64bici: SDNode<"AArch64ISD::BICi", SDT_AArch64vecimm>;
def AArch64orri: SDNode<"AArch64ISD::ORRi", SDT_AArch64vecimm>;
@@ -1276,6 +1281,9 @@ def BFMLALTIdx : SIMDBF16MLALIndex<1, "bfmlalt", int_aarch64_neon_bfmlalt>;
def BFCVTN : SIMD_BFCVTN;
def BFCVTN2 : SIMD_BFCVTN2;
+def : Pat<(v4bf16 (any_fpround (v4f32 V128:$Rn))),
+ (EXTRACT_SUBREG (BFCVTN V128:$Rn), dsub)>;
+
// Vector-scalar BFDOT:
// The second source operand of the 64-bit variant of BF16DOTlane is a 128-bit
// register (the instruction uses a single 32-bit lane from it), so the pattern
@@ -1296,6 +1304,8 @@ def : Pat<(v2f32 (int_aarch64_neon_bfdot
let Predicates = [HasNEONorSME, HasBF16] in {
def BFCVT : BF16ToSinglePrecision<"bfcvt">;
+// Round FP32 to BF16.
+def : Pat<(bf16 (any_fpround (f32 FPR32:$Rn))), (BFCVT $Rn)>;
}
// ARMv8.6A AArch64 matrix multiplication
@@ -4648,6 +4658,22 @@ let Predicates = [HasFullFP16] in {
//===----------------------------------------------------------------------===//
defm FCVT : FPConversion<"fcvt">;
+// Helper to get bf16 into fp32.
+def cvt_bf16_to_fp32 :
+ OutPatFrag<(ops node:$Rn),
+ (f32 (COPY_TO_REGCLASS
+ (i32 (UBFMWri
+ (i32 (COPY_TO_REGCLASS (INSERT_SUBREG (f32 (IMPLICIT_DEF)),
+ node:$Rn, hsub), GPR32)),
+ (i64 (i32shift_a (i64 16))),
+ (i64 (i32shift_b (i64 16))))),
+ FPR32))>;
+// Pattern for bf16 -> fp32.
+def : Pat<(f32 (any_fpextend (bf16 FPR16:$Rn))),
+ (cvt_bf16_to_fp32 FPR16:$Rn)>;
+// Pattern for bf16 -> fp64.
+def : Pat<(f64 (any_fpextend (bf16 FPR16:$Rn))),
+ (FCVTDSr (f32 (cvt_bf16_to_fp32 FPR16:$Rn)))>;
//===----------------------------------------------------------------------===//
// Floating point single operand instructions.
@@ -5002,6 +5028,9 @@ defm FCVTNU : SIMDTwoVectorFPToInt<1,0,0b11010, "fcvtnu",int_aarch64_neon_fcvtnu
defm FCVTN : SIMDFPNarrowTwoVector<0, 0, 0b10110, "fcvtn">;
def : Pat<(v4i16 (int_aarch64_neon_vcvtfp2hf (v4f32 V128:$Rn))),
(FCVTNv4i16 V128:$Rn)>;
+//def : Pat<(concat_vectors V64:$Rd,
+// (v4bf16 (any_fpround (v4f32 V128:$Rn)))),
+// (FCVTNv8bf16 (INSERT_SUBREG (IMPLICIT_DEF), V64:$Rd, dsub), V128:$Rn)>;
def : Pat<(concat_vectors V64:$Rd,
(v4i16 (int_aarch64_neon_vcvtfp2hf (v4f32 V128:$Rn)))),
(FCVTNv8i16 (INSERT_SUBREG (IMPLICIT_DEF), V64:$Rd, dsub), V128:$Rn)>;
@@ -5686,6 +5715,11 @@ defm USQADD : SIMDTwoScalarBHSDTied< 1, 0b00011, "usqadd",
def : Pat<(v1i64 (AArch64vashr (v1i64 V64:$Rn), (i32 63))),
(CMLTv1i64rz V64:$Rn)>;
+// Round FP64 to BF16.
+let Predicates = [HasNEONorSME, HasBF16] in
+def : Pat<(bf16 (any_fpround (f64 FPR64:$Rn))),
+ (BFCVT (FCVTXNv1i64 $Rn))>;
+
def : Pat<(v1i64 (int_aarch64_neon_fcvtas (v1f64 FPR64:$Rn))),
(FCVTASv1i64 FPR64:$Rn)>;
def : Pat<(v1i64 (int_aarch64_neon_fcvtau (v1f64 FPR64:$Rn))),
@@ -7698,6 +7732,9 @@ def : Pat<(v4i32 (anyext (v4i16 V64:$Rn))), (USHLLv4i16_shift V64:$Rn, (i32 0))>
def : Pat<(v2i64 (sext (v2i32 V64:$Rn))), (SSHLLv2i32_shift V64:$Rn, (i32 0))>;
def : Pat<(v2i64 (zext (v2i32 V64:$Rn))), (USHLLv2i32_shift V64:$Rn, (i32 0))>;
def : Pat<(v2i64 (anyext (v2i32 V64:$Rn))), (USHLLv2i32_shift V64:$Rn, (i32 0))>;
+// Vector bf16 -> fp32 is implemented morally as a zext + shift.
+def : Pat<(v4f32 (any_fpextend (v4bf16 V64:$Rn))),
+ (USHLLv4i16_shift V64:$Rn, (i32 16))>;
// Also match an extend from the upper half of a 128 bit source register.
def : Pat<(v8i16 (anyext (v8i8 (extract_high_v16i8 (v16i8 V128:$Rn)) ))),
(USHLLv16i8_shift V128:$Rn, (i32 0))>;
diff --git a/llvm/lib/Target/AArch64/GISel/AArch64PostLegalizerLowering.cpp b/llvm/lib/Target/AArch64/GISel/AArch64PostLegalizerLowering.cpp
index 9bc5815ae05371..5a8031641ae099 100644
--- a/llvm/lib/Target/AArch64/GISel/AArch64PostLegalizerLowering.cpp
+++ b/llvm/lib/Target/AArch64/GISel/AArch64PostLegalizerLowering.cpp
@@ -1022,13 +1022,17 @@ void applyLowerVectorFCMP(MachineInstr &MI, MachineRegisterInfo &MRI,
bool Invert = false;
AArch64CC::CondCode CC, CC2 = AArch64CC::AL;
- if (Pred == CmpInst::Predicate::FCMP_ORD && IsZero) {
+ if ((Pred == CmpInst::Predicate::FCMP_ORD ||
+ Pred == CmpInst::Predicate::FCMP_UNO) &&
+ IsZero) {
// The special case "fcmp ord %a, 0" is the canonical check that LHS isn't
// NaN, so equivalent to a == a and doesn't need the two comparisons an
// "ord" normally would.
+ // Similarly, "fcmp uno %a, 0" is the canonical check that LHS is NaN and is
+ // thus equivalent to a != a.
RHS = LHS;
IsZero = false;
- CC = AArch64CC::EQ;
+ CC = Pred == CmpInst::Predicate::FCMP_ORD ? AArch64CC::EQ : AArch64CC::NE;
} else
changeVectorFCMPPredToAArch64CC(Pred, CC, CC2, Invert);
diff --git a/llvm/test/Analysis/CostModel/AArch64/reduce-fadd.ll b/llvm/test/Analysis/CostModel/AArch64/reduce-fadd.ll
index 954a836e44f283..a68c21f7943432 100644
--- a/llvm/test/Analysis/CostModel/AArch64/reduce-fadd.ll
+++ b/llvm/test/Analysis/CostModel/AArch64/reduce-fadd.ll
@@ -13,7 +13,7 @@ define void @strict_fp_reductions() {
; CHECK-NEXT: Cost Model: Found an estimated cost of 28 for instruction: %fadd_v8f32 = call float @llvm.vector.reduce.fadd.v8f32(float 0.000000e+00, <8 x float> undef)
; CHECK-NEXT: Cost Model: Found an estimated cost of 6 for instruction: %fadd_v2f64 = call double @llvm.vector.reduce.fadd.v2f64(double 0.000000e+00, <2 x double> undef)
; CHECK-NEXT: Cost Model: Found an estimated cost of 12 for instruction: %fadd_v4f64 = call double @llvm.vector.reduce.fadd.v4f64(double 0.000000e+00, <4 x double> undef)
-; CHECK-NEXT: Cost Model: Found an estimated cost of 12 for instruction: %fadd_v4f8 = call bfloat @llvm.vector.reduce.fadd.v4bf16(bfloat 0xR0000, <4 x bfloat> undef)
+; CHECK-NEXT: Cost Model: Found an estimated cost of 18 for instruction: %fadd_v4f8 = call bfloat @llvm.vector.reduce.fadd.v4bf16(bfloat 0xR0000, <4 x bfloat> undef)
; CHECK-NEXT: Cost Model: Found an estimated cost of 20 for instruction: %fadd_v4f128 = call fp128 @llvm.vector.reduce.fadd.v4f128(fp128 undef, <4 x fp128> undef)
; CHECK-NEXT: Cost Model: Found an estimated cost of 0 for instruction: ret void
;
@@ -24,7 +24,7 @@ define void @strict_fp_reductions() {
; FP16-NEXT: Cost Model: Found an estimated cost of 28 for instruction: %fadd_v8f32 = call float @llvm.vector.reduce.fadd.v8f32(float 0.000000e+00, <8 x float> undef)
; FP16-NEXT: Cost Model: Found an estimated cost of 6 for instruction: %fadd_v2f64 = call double @llvm.vector.reduce.fadd.v2f64(double 0.000000e+00, <2 x double> undef)
; FP16-NEXT: Cost Model: Found an estimated cost of 12 for instruction: %fadd_v4f64 = call double @llvm.vector.reduce.fadd.v4f64(double 0.000000e+00, <4 x double> undef)
-; FP16-NEXT: Cost Model: Found an estimated cost of 12 for instruction: %fadd_v4f8 = call bfloat @llvm.vector.reduce.fadd.v4bf16(bfloat 0xR0000, <4 x bfloat> undef)
+; FP16-NEXT: Cost Model: Found an estimated cost of 18 for instruction: %fadd_v4f8 = call bfloat @llvm.vector.reduce.fadd.v4bf16(bfloat 0xR0000, <4 x bfloat> undef)
; FP16-NEXT: Cost Model: Found an estimated cost of 20 for instruction: %fadd_v4f128 = call fp128 @llvm.vector.reduce.fadd.v4f128(fp128 undef, <4 x fp128> undef)
; FP16-NEXT: Cost Model: Found an estimated cost of 0 for instruction: ret void
;
@@ -72,7 +72,7 @@ define void @fast_fp_reductions() {
; CHECK-NEXT: Cost Model: Found an estimated cost of 5 for instruction: %fadd_v4f64_reassoc = call reassoc double @llvm.vector.reduce.fadd.v4f64(double 0.000000e+00, <4 x double> undef)
; CHECK-NEXT: Cost Model: Found an estimated cost of 9 for instruction: %fadd_v7f64 = call fast double @llvm.vector.reduce.fadd.v7f64(double 0.000000e+00, <7 x double> undef)
; CHECK-NEXT: Cost Model: Found an estimated cost of 15 for instruction: %fadd_v9f64_reassoc = call reassoc double @llvm.vector.reduce.fadd.v9f64(double 0.000000e+00, <9 x double> undef)
-; CHECK-NEXT: Cost Model: Found an estimated cost of 6 for instruction: %fadd_v4f8 = call reassoc bfloat @llvm.vector.reduce.fadd.v4bf16(bfloat 0xR8000, <4 x bfloat> undef)
+; CHECK-NEXT: Cost Model: Found an estimated cost of 10 for instruction: %fadd_v4f8 = call reassoc bfloat @llvm.vector.reduce.fadd.v4bf16(bfloat 0xR8000, <4 x bfloat> undef)
; CHECK-NEXT: Cost Model: Found an estimated cost of 12 for instruction: %fadd_v4f128 = call reassoc fp128 @llvm.vector.reduce.fadd.v4f128(fp128 undef, <4 x fp128> undef)
; CHECK-NEXT: Cost Model: Found an estimated cost of 0 for instruction: ret void
;
@@ -95,7 +95,7 @@ define void @fast_fp_reductions() {
; FP16-NEXT: Cost Model: Found an estimated cost of 5 for instruction: %fadd_v4f64_reassoc = call reassoc double @llvm.vector.reduce.fadd.v4f64(double 0.000000e+00, <4 x double> undef)
; FP16-NEXT: Cost Model: Found an estimated cost of 9 for instruction: %fadd_v7f64 = call fast double @llvm.vector.reduce.fadd.v7f64(double 0.000000e+00, <7 x double> undef)
; FP16-NEXT: Cost Model: Found an estimated cost of 15 for instruction: %fadd_v9f64_reassoc = call reassoc double @llvm.vector.reduce.fadd.v9f64(double 0.000000e+00, <9 x double> undef)
-; FP16-NEXT: Cost Model: Found an estimated cost of 6 for instruction: %fadd_v4f8 = call reassoc bfloat @llvm.vector.reduce.fadd.v4bf16(bfloat 0xR8000, <4 x bfloat> undef)
+; FP16-NEXT: Cost Model: Found an estimated cost of 10 for instruction: %fadd_v4f8 = call reassoc bfloat @llvm.vector.reduce.fadd.v4bf16(bfloat 0xR8000, <4 x bfloat> undef)
; FP16-NEXT: Cost Model: Found an estimated cost of 12 for instruction: %fadd_v4f128 = call reassoc fp128 @llvm.vector.reduce.fadd.v4f128(fp128 undef, <4 x fp128> undef)
; FP16-NEXT: Cost Model: Found an estimated cost of 0 for instruction: ret void
;
diff --git a/llvm/test/CodeGen/AArch64/GlobalISel/lower-neon-vector-fcmp.mir b/llvm/test/CodeGen/AArch64/GlobalISel/lower-neon-vector-fcmp.mir
index 8f01c009c4967a..1f5fb892df5820 100644
--- a/llvm/test/CodeGen/AArch64/GlobalISel/lower-neon-vector-fcmp.mir
+++ b/llvm/test/CodeGen/AArch64/GlobalISel/lower-neon-vector-fcmp.mir
@@ -321,18 +321,15 @@ body: |
bb.0:
liveins: $q0, $q1
- ; Should be inverted. Needs two compares.
; CHECK-LABEL: name: uno_zero
; CHECK: liveins: $q0, $q1
; CHECK-NEXT: {{ $}}
; CHECK-NEXT: %lhs:_(<2 x s64>) = COPY $q0
- ; CHECK-NEXT: [[FCMGEZ:%[0-9]+]]:_(<2 x s64>) = G_FCMGEZ %lhs
- ; CHECK-NEXT: [[FCMLTZ:%[0-9]+]]:_(<2 x s64>) = G_FCMLTZ %lhs
- ; CHECK-NEXT: [[OR:%[0-9]+]]:_(<2 x s64>) = G_OR [[FCMLTZ]], [[FCMGEZ]]
+ ; CHECK-NEXT: [[FCMEQ:%[0-9]+]]:_(<2 x s64>) = G_FCMEQ %lhs, %lhs(<2 x s64>)
; CHECK-NEXT: [[C:%[0-9]+]]:_(s64) = G_CONSTANT i64 -1
; CHECK-NEXT: [[BUILD_VECTOR:%[0-9]+]]:_(<2 x s64>) = G_BUILD_VECTOR [[C]](s64), [[C]](s64)
- ; CHECK-NEXT: [[XOR:%[0-9]+]]:_(<2 x s64>) = G_XOR [[OR]], [[BUILD_VECTOR]]
+ ; CHECK-NEXT: [[XOR:%[0-9]+]]:_(<2 x s64>) = G_XOR [[FCMEQ]], [[BUILD_VECTOR]]
; CHECK-NEXT: $q0 = COPY [[XOR]](<2 x s64>)
; CHECK-NEXT: RET_ReallyLR implicit $q0
%lhs:_(<2 x s64>) = COPY $q0
diff --git a/llvm/test/CodeGen/AArch64/implicitly-set-zero-high-64-bits.ll b/llvm/test/CodeGen/AArch64/implicitly-set-zero-high-64-bits.ll
index a949eaac5cfa29..adde5429a6d93d 100644
--- a/llvm/test/CodeGen/AArch64/implicitly-set-zero-high-64-bits.ll
+++ b/llvm/test/CodeGen/AArch64/implicitly-set-zero-high-64-bits.ll
@@ -187,10 +187,7 @@ entry:
define <8 x bfloat> @insertzero_v4bf16(<4 x bfloat> %a) {
; CHECK-LABEL: insertzero_v4bf16:
; CHECK: // %bb.0: // %entry
-; CHECK-NEXT: movi d4, #0000000000000000
-; CHECK-NEXT: movi d5, #0000000000000000
-; CHECK-NEXT: movi d6, #0000000000000000
-; CHECK-NEXT: movi d7, #0000000000000000
+; CHECK-NEXT: fmov d0, d0
; CHECK-NEXT: ret
entry:
%shuffle.i = shufflevector <4 x bfloat> %a, <4 x bfloat> zeroinitializer, <8 x i32> <i32 0, i32 1, i32 2, i32 3, i32 4, i32 5, i32 6, i32 7>
diff --git a/llvm/test/CodeGen/AArch64/neon-compare-instructions.ll b/llvm/test/CodeGen/AArch64/neon-compare-instructions.ll
index 765c81e26e13ca..632b6b32625022 100644
--- a/llvm/test/CodeGen/AArch64/neon-compare-instructions.ll
+++ b/llvm/test/CodeGen/AArch64/neon-compare-instructions.ll
@@ -3057,55 +3057,34 @@ define <2 x i64> @fcmonez2xdouble(<2 x double> %A) {
ret <2 x i64> %tmp4
}
-; ORD with zero = OLT | OGE
+; ORD A, zero = EQ A, A
define <2 x i32> @fcmordz2xfloat(<2 x float> %A) {
-; CHECK-SD-LABEL: fcmordz2xfloat:
-; CHECK-SD: // %bb.0:
-; CHECK-SD-NEXT: fcmge v1.2s, v0.2s, #0.0
-; CHECK-SD-NEXT: fcmlt v0.2s, v0.2s, #0.0
-; CHECK-SD-NEXT: orr v0.8b, v0.8b, v1.8b
-; CHECK-SD-NEXT: ret
-;
-; CHECK-GI-LABEL: fcmordz2xfloat:
-; CHECK-GI: // %bb.0:
-; CHECK-GI-NEXT: fcmeq v0.2s, v0.2s, v0.2s
-; CHECK-GI-NEXT: ret
+; CHECK-LABEL: fcmordz2xfloat:
+; CHECK: // %bb.0:
+; CHECK-NEXT: fcmeq v0.2s, v0.2s, v0.2s
+; CHECK-NEXT: ret
%tmp3 = fcmp ord <2 x float> %A, zeroinitializer
%tmp4 = sext <2 x i1> %tmp3 to <2 x i32>
ret <2 x i32> %tmp4
}
-; ORD with zero = OLT | OGE
+; ORD A, zero = EQ A, A
define <4 x i32> @fcmordz4xfloat(<4 x float> %A) {
-; CHECK-SD-LABEL: fcmordz4xfloat:
-; CHECK-SD: // %bb.0:
-; CHECK-SD-NEXT: fcmge v1.4s, v0.4s, #0.0
-; CHECK-SD-NEXT: fcmlt v0.4s, v0.4s, #0.0
-; CHECK-SD-NEXT: orr v0.16b, v0.16b, v1.16b
-; CHECK-SD-NEXT: ret
-;
-; CHECK-GI-LABEL: fcmordz4xfloat:
-; CHECK-GI: // %bb.0:
-; CHECK-GI-NEXT: fcmeq v0.4s, v0.4s, v0.4s
-; CHECK-GI-NEXT: ret
+; CHECK-LABEL: fcmordz4xfloat:
+; CHECK: // %bb.0:
+; CHECK-NEXT: fcmeq v0.4s, v0.4s, v0.4s
+; CHECK-NEXT: ret
%tmp3 = fcmp ord <4 x float> %A, zeroinitializer
%tmp4 = sext <4 x i1> %tmp3 to <4 x i32>
ret <4 x i32> %tmp4
}
-; ORD with zero = OLT | OGE
+; ORD A, zero = EQ A, A
define <2 x i64> @fcmordz2xdouble(<2 x double> %A) {
-; CHECK-SD-LABEL: fcmordz2xdouble:
-; CHECK-SD: // %bb.0:
-; CHECK-SD-NEXT: fcmge v1.2d, v0.2d, #0.0
-; CHECK-SD-NEXT: fcmlt v0.2d, v0.2d, #0.0
-; CHECK-SD-NEXT: orr v0.16b, v0.16b, v1.16b
-; CHECK-SD-NEXT: ret
-;
-; CHECK-GI-LABEL: fcmordz2xdouble:
-; CHECK-GI: // %bb.0:
-; CHECK-GI-NEXT: fcmeq v0.2d, v0.2d, v0.2d
-; CHECK-GI-NEXT: ret
+; CHECK-LABEL: fcmordz2xdouble:
+; CHECK: // %bb.0:
+; CHECK-NEXT: fcmeq v0.2d, v0.2d, v0.2d
+; CHECK-NEXT: ret
%tmp3 = fcmp ord <2 x double> %A, zeroinitializer
%tmp4 = sext <2 x i1> %tmp3 to <2 x i64>
ret <2 x i64> %tmp4
@@ -3331,13 +3310,11 @@ define <2 x i64> @fcmunez2xdouble(<2 x double> %A) {
ret <2 x i64> %tmp4
}
-; UNO with zero = !ORD = !(OLT | OGE)
+; UNO A, zero = !(ORD A, zero) = !(EQ A, A)
define <2 x i32> @fcmunoz2xfloat(<2 x float> %A) {
; CHECK-LABEL: fcmunoz2xfloat:
; CHECK: // %bb.0:
-; CHECK-NEXT: fcmge v1.2s, v0.2s, #0.0
-; CHECK-NEXT: fcmlt v0.2s, v0.2s, #0.0
-; CHECK-NEXT: orr v0.8b, v0.8b, v1.8b
+; CHECK-NEXT: fcmeq v0.2s, v0.2s, v0.2s
; CHECK-NEXT: mvn v0.8b, v0.8b
; CHECK-NEXT: ret
%tmp3 = fcmp uno <2 x float> %A, zeroinitializer
@@ -3345,13 +3322,11 @@ define <2 x i32> @fcmunoz2xfloat(<2 x float> %A) {
ret <2 x i32> %tmp4
}
-; UNO with zero = !ORD = !(OLT | OGE)
+; UNO A, zero = !(ORD A, zero) = !(EQ A, A)
define <4 x i32> @fcmunoz4xfloat(<4 x float> %A) {
; CHECK-LABEL: fcmunoz4xfloat:
; CHECK: // %bb.0:
-; CHECK-NEXT: fcmge v1.4s, v0.4s, #0.0
-; CHECK-NEXT: fcmlt v0.4s, v0.4s, #0.0
-; CHECK-NEXT: orr v0.16b, v0.16b, v1.16b
+; CHECK-NEXT: fcmeq v0.4s, v0.4s, v0.4s
; CHECK-NEXT: mvn v0.16b, v0.16b
; CHECK-NEXT: ret
%tmp3 = fcmp uno <4 x float> %A, zeroinitializer
@@ -3359,13 +3334,11 @@ define <4 x i32> @fcmunoz4xfloat(<4 x float> %A) {
ret <4 x i32> %tmp4
}
-; UNO with zero = !ORD = !(OLT | OGE)
+; UNO A, zero = !(ORD A, zero) = !(EQ A, A)
define <2 x i64> @fcmunoz2xdouble(<2 x double> %A) {
; CHECK-LABEL: fcmunoz2xdouble:
; CHECK: // %bb.0:
-; CHECK-NEXT: fcmge v1.2d, v0.2d, #0.0
-; CHECK-NEXT: fcmlt v0.2d, v0.2d, #0.0
-; CHECK-NEXT: orr v0.16b, v0.16b, v1.16b
+; CHECK-NEXT: fcmeq v0.2d, v0.2d, v0.2d
; CHECK-NEXT: mvn v0.16b, v0.16b
; CHECK-NEXT: ret
%tmp3 = fcmp uno <2 x double> %A, zeroinitializer
@@ -4133,51 +4106,30 @@ define <2 x i64> @fcmonez2xdouble_fast(<2 x double> %A) {
}
define <2 x i32> @fcmordz2xfloat_fast(<2 x float> %A) {
-; CHECK-SD-LABEL: fcmordz2xfloat_fast:
-; CHECK-SD: // %bb.0:
-; CHECK-SD-NEXT: fcmge v1.2s, v0.2s, #0.0
-; CHECK-SD-NEXT: fcmlt v0.2s, v0.2s, #0.0
-; CHECK-SD-NEXT: orr v0.8b, v0.8b, v1.8b
-; CHECK-SD-NEXT: ret
-;
-; CHECK-GI-LABEL: fcmordz2xfloat_fast:
-; CHECK-GI: // %bb.0:
-; CHECK-GI-NEXT: fcmeq v0.2s, v0.2s, v0.2s
-; CHECK-GI-NEXT: ret
+; CHECK-LABEL: fcmordz2xfloat_fast:
+; CHECK: // %bb.0:
+; CHECK-NEXT: fcmeq v0.2s, v0.2s, v0.2s
+; CHECK-NEXT: ret
%tmp3 = fcmp fast ord <2 x float> %A, zeroinitializer
%tmp4 = sext <2 x i1> %tmp3 to <2 x i32>
ret <2 x i32> %tmp4
}
define <4 x i32> @fcmordz4xfloat_fast(<4 x float> %A) {
-; CHECK-SD-LABEL: fcmordz4xfloat_fast:
-; CHECK-SD: // %bb.0:
-; CHECK-SD-NEXT: fcmge v1.4s, v0.4s, #0.0
-; CHECK-SD-NEXT: fcmlt v0.4s, v0.4s, #0.0
-; CHECK-SD-NEXT: orr v0.16b, v0.16b, v1.16b
-; CHECK-SD-NEXT: ret
-;
-; CHECK-GI-LABEL: fcmordz4xfloat_fast:
-; CHECK-GI: // %bb.0:
-; CHECK-GI-NEXT: fcmeq v0.4s, v0.4s, v0.4s
-; CHECK-GI-NEXT: ret
+; CHECK-LABEL: fcmordz4xfloat_fast:
+; CHECK: // %bb.0:
+; CHECK-NEXT: fcmeq v0.4s, v0.4s, v0.4s
+; CHECK-NEXT: ret
%tmp3 = fcmp fast ord <4 x float> %A, zeroinitializer
%tmp4 = sext <4 x i1> %tmp3 to <4 x i32>
ret <4 x i32> %tmp4
}
define <2 x i64> @fcmordz2xdouble_fast(<2 x double> %A) {
-; CHECK-SD-LABEL: fcmordz2xdouble_fast:
-; CHECK-SD: // %bb.0:
-; CHECK-SD-NEXT: fcmge v1.2d, v0.2d, #0.0
-; CHECK-SD-NEXT: fcmlt v0.2d, v0.2d, #0.0
-; CHECK-SD-NEXT: orr v0.16b, v0.16b, v1.16b
-; CHECK-SD-NEXT: ret
-;
-; CHECK-GI-LABEL: fcmordz2xdouble_fast:
-; CHECK-GI: // %bb.0:
-; CHECK-GI-NEXT: fcmeq v0.2d, v0.2d, v0.2d
-; CHECK-GI-NEXT: ret
+; CHECK-LABEL: fcmordz2xdouble_fast:
+; CHECK: // %bb.0:
+; CHECK-NEXT: fcmeq v0.2d, v0.2d, v0.2d
+; CHECK-NEXT: ret
%tmp3 = fcmp fast ord <2 x double> %A, zeroinitializer
%tmp4 = sext <2 x i1> %tmp3 to <2 x i64>
ret <2 x i64> %tmp4
@@ -4466,9 +4418,7 @@ define <2 x i64> @fcmunez2xdouble_fast(<2 x double> %A) {
define <2 x i32> @fcmunoz2xfloat_fast(<2 x float> %A) {
; CHECK-LABEL: fcmunoz2xfloat_fast:
; CHECK: // %bb.0:
-; CHECK-NEXT: fcmge v1.2s, v0.2s, #0.0
-; CHECK-NEXT: fcmlt v0.2s, v0.2s, #0.0
-; CHECK-NEXT: orr v0.8b, v0.8b, v1.8b
+; CHECK-NEXT: fcmeq v0.2s, v0.2s, v0.2s
; CHECK-NEXT: mvn v0.8b, v0.8b
; CHECK-NEXT: ret
%tmp3 = fcmp fast uno <2 x float> %A, zeroinitializer
@@ -4479,9 +4429,7 @@ define <2 x i32> @fcmunoz2xfloat_fast(<2 x float> %A) {
define <4 x i32> @fcmunoz4xfloat_fast(<4 x float> %A) {
; CHECK-LABEL: fcmunoz4xfloat_fast:
; CHECK: // %bb.0:
-; CHECK-NEXT: fcmge v1.4s, v0.4s, #0.0
-; CHECK-NEXT: fcmlt v0.4s, v0.4s, #0.0
-; CHECK-NEXT: orr v0.16b, v0.16b, v1.16b
+; CHECK-NEXT: fcmeq v0.4s, v0.4s, v0.4s
; CHECK-NEXT: mvn v0.16b, v0.16b
; CHECK-NEXT: ret
%tmp3 = fcmp fast uno <4 x float> %A, zeroinitializer
@@ -4492,9 +4440,7 @@ define <4 x i32> @fcmunoz4xfloat_fast(<4 x float> %A) {
define <2 x i64> @fcmunoz2xdouble_fast(<2 x double> %A) {
; CHECK-LABEL: fcmunoz2xdouble_fast:
; CHECK: // %bb.0:
-; CHECK-NEXT: fcmge v1.2d, v0.2d, #0.0
-; CHECK-NEXT: fcmlt v0.2d, v0.2d, #0.0
-; CHECK-NEXT: orr v0.16b, v0.16b, v1.16b
+; CHECK-NEXT: fcmeq v0.2d, v0.2d, v0.2d
; CHECK-NEXT: mvn v0.16b, v0.16b
; CHECK-NEXT: ret
%tmp3 = fcmp fast uno <2 x double> %A, zeroinitializer
diff --git a/llvm/test/CodeGen/AArch64/round-fptosi-sat-scalar.ll b/llvm/test/CodeGen/AArch64/round-fptosi-sat-scalar.ll
index 4f23df1d168197..ec7548e1e65410 100644
--- a/llvm/test/CodeGen/AArch64/round-fptosi-sat-scalar.ll
+++ b/llvm/test/CodeGen/AArch64/round-fptosi-sat-scalar.ll
@@ -4,6 +4,54 @@
; Round towards minus infinity (fcvtms).
+define i32 @testmswbf(bfloat %a) {
+; CHECK-LABEL: testmswbf:
+; CHECK: // %bb.0: // %entry
+; CHECK-NEXT: // kill: def $h0 killed $h0 def $s0
+; CHECK-NEXT: fmov w9, s0
+; CHECK-NEXT: mov w8, #32767 // =0x7fff
+; CHECK-NEXT: lsl w9, w9, #16
+; CHECK-NEXT: fmov s0, w9
+; CHECK-NEXT: frintm s0, s0
+; CHECK-NEXT: fmov w9, s0
+; CHECK-NEXT: ubfx w10, w9, #16, #1
+; CHECK-NEXT: add w8, w9, w8
+; CHECK-NEXT: add w8, w10, w8
+; CHECK-NEXT: lsr w8, w8, #16
+; CHECK-NEXT: lsl w8, w8, #16
+; CHECK-NEXT: fmov s0, w8
+; CHECK-NEXT: fcvtzs w0, s0
+; CHECK-NEXT: ret
+entry:
+ %r = call bfloat @llvm.floor.bf16(bfloat %a) nounwind readnone
+ %i = call i32 @llvm.fptosi.sat.i32.bf16(bfloat %r)
+ ret i32 %i
+}
+
+define i64 @testmsxbf(bfloat %a) {
+; CHECK-LABEL: testmsxbf:
+; CHECK: // %bb.0: // %entry
+; CHECK-NEXT: // kill: def $h0 killed $h0 def $s0
+; CHECK-NEXT: fmov w9, s0
+; CHECK-NEXT: mov w8, #32767 // =0x7fff
+; CHECK-NEXT: lsl w9, w9, #16
+; CHECK-NEXT: fmov s0, w9
+; CHECK-NEXT: frintm s0, s0
+; CHECK-NEXT: fmov w9, s0
+; CHECK-NEXT: ubfx w10, w9, #16, #1
+; CHECK-NEXT: add w8, w9, w8
+; CHECK-NEXT: add w8, w10, w8
+; CHECK-NEXT: lsr w8, w8, #16
+; CHECK-NEXT: lsl w8, w8, #16
+; CHECK-NEXT: fmov s0, w8
+; CHECK-NEXT: fcvtzs x0, s0
+; CHECK-NEXT: ret
+entry:
+ %r = call bfloat @llvm.floor.bf16(bfloat %a) nounwind readnone
+ %i = call i64 @llvm.fptosi.sat.i64.bf16(bfloat %r)
+ ret i64 %i
+}
+
define i32 @testmswh(half %a) {
; CHECK-CVT-LABEL: testmswh:
; CHECK-CVT: // %bb.0: // %entry
@@ -90,6 +138,54 @@ entry:
; Round towards plus infinity (fcvtps).
+define i32 @testpswbf(bfloat %a) {
+; CHECK-LABEL: testpswbf:
+; CHECK: // %bb.0: // %entry
+; CHECK-NEXT: // kill: def $h0 killed $h0 def $s0
+; CHECK-NEXT: fmov w9, s0
+; CHECK-NEXT: mov w8, #32767 // =0x7fff
+; CHECK-NEXT: lsl w9, w9, #16
+; CHECK-NEXT: fmov s0, w9
+; CHECK-NEXT: frintp s0, s0
+; CHECK-NEXT: fmov w9, s0
+; CHECK-NEXT: ubfx w10, w9, #16, #1
+; CHECK-NEXT: add w8, w9, w8
+; CHECK-NEXT: add w8, w10, w8
+; CHECK-NEXT: lsr w8, w8, #16
+; CHECK-NEXT: lsl w8, w8, #16
+; CHECK-NEXT: fmov s0, w8
+; CHECK-NEXT: fcvtzs w0, s0
+; CHECK-NEXT: ret
+entry:
+ %r = call bfloat @llvm.ceil.bf16(bfloat %a) nounwind readnone
+ %i = call i32 @llvm.fptosi.sat.i32.bf16(bfloat %r)
+ ret i32 %i
+}
+
+define i64 @testpsxbf(bfloat %a) {
+; CHECK-LABEL: testpsxbf:
+; CHECK: // %bb.0: // %entry
+; CHECK-NEXT: // kill: def $h0 killed $h0 def $s0
+; CHECK-NEXT: fmov w9, s0
+; CHECK-NEXT: mov w8, #32767 // =0x7fff
+; CHECK-NEXT: lsl w9, w9, #16
+; CHECK-NEXT: fmov s0, w9
+; CHECK-NEXT: frintp s0, s0
+; CHECK-NEXT: fmov w9, s0
+; CHECK-NEXT: ubfx w10, w9, #16, #1
+; CHECK-NEXT: add w8, w9, w8
+; CHECK-NEXT: add w8, w10, w8
+; CHECK-NEXT: lsr w8, w8, #16
+; CHECK-NEXT: lsl w8, w8, #16
+; CHECK-NEXT: fmov s0, w8
+; CHECK-NEXT: fcvtzs x0, s0
+; CHECK-NEXT: ret
+entry:
+ %r = call bfloat @llvm.ceil.bf16(bfloat %a) nounwind readnone
+ %i = call i64 @llvm.fptosi.sat.i64.bf16(bfloat %r)
+ ret i64 %i
+}
+
define i32 @testpswh(half %a) {
; CHECK-CVT-LABEL: testpswh:
; CHECK-CVT: // %bb.0: // %entry
@@ -346,6 +442,8 @@ entry:
ret i64 %i
}
+declare i32 @llvm.fptosi.sat.i32.bf16 (bfloat)
+declare i64 @llvm.fptosi.sat.i64.bf16 (bfloat)
declare i32 @llvm.fptosi.sat.i32.f16 (half)
declare i64 @llvm.fptosi.sat.i64.f16 (half)
declare i32 @llvm.fptosi.sat.i32.f32 (float)
@@ -353,6 +451,10 @@ declare i64 @llvm.fptosi.sat.i64.f32 (float)
declare i32 @llvm.fptosi.sat.i32.f64 (double)
declare i64 @llvm.fptosi.sat.i64.f64 (double)
+declare bfloat @llvm.floor.bf16(bfloat) nounwind readnone
+declare bfloat @llvm.ceil.bf16(bfloat) nounwind readnone
+declare bfloat @llvm.trunc.bf16(bfloat) nounwind readnone
+declare bfloat @llvm.round.bf16(bfloat) nounwind readnone
declare half @llvm.floor.f16(half) nounwind readnone
declare half @llvm.ceil.f16(half) nounwind readnone
declare half @llvm.trunc.f16(half) nounwind readnone
diff --git a/llvm/test/CodeGen/AArch64/vector-fcopysign.ll b/llvm/test/CodeGen/AArch64/vector-fcopysign.ll
index c7134508883b11..d01ca881545c02 100644
--- a/llvm/test/CodeGen/AArch64/vector-fcopysign.ll
+++ b/llvm/test/CodeGen/AArch64/vector-fcopysign.ll
@@ -477,4 +477,443 @@ define <8 x half> @test_copysign_v8f16_v8f32(<8 x half> %a, <8 x float> %b) #0 {
declare <8 x half> @llvm.copysign.v8f16(<8 x half> %a, <8 x half> %b) #0
+;============ v4bf16
+
+define <4 x bfloat> @test_copysign_v4bf16_v4bf16(<4 x bfloat> %a, <4 x bfloat> %b) #0 {
+; CHECK-LABEL: test_copysign_v4bf16_v4bf16:
+; CHECK: ; %bb.0:
+; CHECK-NEXT: ; kill: def $d1 killed $d1 def $q1
+; CHECK-NEXT: ; kill: def $d0 killed $d0 def $q0
+; CHECK-NEXT: mov h3, v1[1]
+; CHECK-NEXT: mov h4, v0[1]
+; CHECK-NEXT: fmov w8, s1
+; CHECK-NEXT: mov h5, v1[2]
+; CHECK-NEXT: mov h6, v0[2]
+; CHECK-NEXT: fmov w11, s0
+; CHECK-NEXT: mvni.4s v2, #128, lsl #24
+; CHECK-NEXT: mov h1, v1[3]
+; CHECK-NEXT: mov h0, v0[3]
+; CHECK-NEXT: lsl w8, w8, #16
+; CHECK-NEXT: fmov w9, s3
+; CHECK-NEXT: lsl w11, w11, #16
+; CHECK-NEXT: fmov w10, s4
+; CHECK-NEXT: fmov s7, w8
+; CHECK-NEXT: fmov w8, s5
+; CHECK-NEXT: lsl w9, w9, #16
+; CHECK-NEXT: lsl w10, w10, #16
+; CHECK-NEXT: lsl w8, w8, #16
+; CHECK-NEXT: fmov s3, w9
+; CHECK-NEXT: fmov s4, w10
+; CHECK-NEXT: fmov w9, s6
+; CHECK-NEXT: fmov w10, s1
+; CHECK-NEXT: bit.16b v3, v4, v2
+; CHECK-NEXT: lsl w9, w9, #16
+; CHECK-NEXT: fmov s4, w11
+; CHECK-NEXT: fmov w11, s0
+; CHECK-NEXT: fmov s0, w8
+; CHECK-NEXT: lsl w10, w10, #16
+; CHECK-NEXT: fmov s1, w9
+; CHECK-NEXT: bif.16b v4, v7, v2
+; CHECK-NEXT: fmov w8, s3
+; CHECK-NEXT: lsl w11, w11, #16
+; CHECK-NEXT: bif.16b v1, v0, v2
+; CHECK-NEXT: fmov s5, w11
+; CHECK-NEXT: lsr w8, w8, #16
+; CHECK-NEXT: fmov w9, s4
+; CHECK-NEXT: fmov s4, w10
+; CHECK-NEXT: fmov s3, w8
+; CHECK-NEXT: fmov w8, s1
+; CHECK-NEXT: mov.16b v1, v2
+; CHECK-NEXT: lsr w9, w9, #16
+; CHECK-NEXT: bsl.16b v1, v5, v4
+; CHECK-NEXT: fmov s0, w9
+; CHECK-NEXT: lsr w8, w8, #16
+; CHECK-NEXT: fmov s2, w8
+; CHECK-NEXT: mov.h v0[1], v3[0]
+; CHECK-NEXT: fmov w8, s1
+; CHECK-NEXT: lsr w8, w8, #16
+; CHECK-NEXT: mov.h v0[2], v2[0]
+; CHECK-NEXT: fmov s1, w8
+; CHECK-NEXT: mov.h v0[3], v1[0]
+; CHECK-NEXT: ; kill: def $d0 killed $d0 killed $q0
+; CHECK-NEXT: ret
+ %r = call <4 x bfloat> @llvm.copysign.v4bf16(<4 x bfloat> %a, <4 x bfloat> %b)
+ ret <4 x bfloat> %r
+}
+
+define <4 x bfloat> @test_copysign_v4bf16_v4f32(<4 x bfloat> %a, <4 x float> %b) #0 {
+; CHECK-LABEL: test_copysign_v4bf16_v4f32:
+; CHECK: ; %bb.0:
+; CHECK-NEXT: movi.4s v2, #127, msl #8
+; CHECK-NEXT: movi.4s v3, #1
+; CHECK-NEXT: ; kill: def $d0 killed $d0 def $q0
+; CHECK-NEXT: ushr.4s v4, v1, #16
+; CHECK-NEXT: fmov w9, s0
+; CHECK-NEXT: mov h5, v0[2]
+; CHECK-NEXT: mov h6, v0[3]
+; CHECK-NEXT: add.4s v2, v1, v2
+; CHECK-NEXT: and.16b v3, v4, v3
+; CHECK-NEXT: fcmeq.4s v4, v1, v1
+; CHECK-NEXT: orr.4s v1, #64, lsl #16
+; CHECK-NEXT: lsl w9, w9, #16
+; CHECK-NEXT: add.4s v2, v3, v2
+; CHECK-NEXT: mov h3, v0[1]
+; CHECK-NEXT: bit.16b v1, v2, v4
+; CHECK-NEXT: fmov w8, s3
+; CHECK-NEXT: lsl w8, w8, #16
+; CHECK-NEXT: shrn.4h v2, v1, #16
+; CHECK-NEXT: mvni.4s v1, #128, lsl #24
+; CHECK-NEXT: fmov s3, w8
+; CHECK-NEXT: fmov w8, s5
+; CHECK-NEXT: fmov s5, w9
+; CHECK-NEXT: mov h4, v2[1]
+; CHECK-NEXT: mov h0, v2[2]
+; CHECK-NEXT: fmov w11, s2
+; CHECK-NEXT: mov h2, v2[3]
+; CHECK-NEXT: lsl w8, w8, #16
+; CHECK-NEXT: lsl w11, w11, #16
+; CHECK-NEXT: fmov w10, s4
+; CHECK-NEXT: fmov w9, s0
+; CHECK-NEXT: fmov s0, w8
+; CHECK-NEXT: fmov w8, s2
+; CHECK-NEXT: lsl w10, w10, #16
+; CHECK-NEXT: lsl w9, w9, #16
+; CHECK-NEXT: lsl w8, w8, #16
+; CHECK-NEXT: fmov s4, w10
+; CHECK-NEXT: fmov w10, s6
+; CHECK-NEXT: fmov s2, w9
+; CHECK-NEXT: bif.16b v3, v4, v1
+; CHECK-NEXT: fmov s4, w11
+; CHECK-NEXT: bit.16b v2, v0, v1
+; CHECK-NEXT: lsl w10, w10, #16
+; CHECK-NEXT: bit.16b v4, v5, v1
+; CHECK-NEXT: fmov s5, w8
+; CHECK-NEXT: fmov w9, s3
+; CHECK-NEXT: fmov w8, s2
+; CHECK-NEXT: fmov w11, s4
+; CHECK-NEXT: fmov s4, w10
+; CHECK-NEXT: lsr w9, w9, #16
+; CHECK-NEXT: lsr w8, w8, #16
+; CHECK-NEXT: fmov s3, w9
+; CHECK-NEXT: lsr w11, w11, #16
+; CHECK-NEXT: bsl.16b v1, v4, v5
+; CHECK-NEXT: fmov s2, w8
+; CHECK-NEXT: fmov s0, w11
+; CHECK-NEXT: fmov w8, s1
+; CHECK-NEXT: mov.h v0[1], v3[0]
+; CHECK-NEXT: lsr w8, w8, #16
+; CHECK-NEXT: mov.h v0[2], v2[0]
+; CHECK-NEXT: fmov s1, w8
+; CHECK-NEXT: mov.h v0[3], v1[0]
+; CHECK-NEXT: ; kill: def $d0 killed $d0 killed $q0
+; CHECK-NEXT: ret
+ %tmp0 = fptrunc <4 x float> %b to <4 x bfloat>
+ %r = call <4 x bfloat> @llvm.copysign.v4bf16(<4 x bfloat> %a, <4 x bfloat> %tmp0)
+ ret <4 x bfloat> %r
+}
+
+define <4 x bfloat> @test_copysign_v4bf16_v4f64(<4 x bfloat> %a, <4 x double> %b) #0 {
+; CHECK-LABEL: test_copysign_v4bf16_v4f64:
+; CHECK: ; %bb.0:
+; CHECK-NEXT: ; kill: def $d0 killed $d0 def $q0
+; CHECK-NEXT: fmov w8, s0
+; CHECK-NEXT: mov h4, v0[1]
+; CHECK-NEXT: mov h5, v0[2]
+; CHECK-NEXT: mov d3, v1[1]
+; CHECK-NEXT: fcvt s1, d1
+; CHECK-NEXT: mov h0, v0[3]
+; CHECK-NEXT: lsl w8, w8, #16
+; CHECK-NEXT: fmov w9, s4
+; CHECK-NEXT: mvni.4s v4, #128, lsl #24
+; CHECK-NEXT: fmov s6, w8
+; CHECK-NEXT: fmov w8, s5
+; CHECK-NEXT: fcvt s3, d3
+; CHECK-NEXT: fmov w10, s0
+; CHECK-NEXT: lsl w9, w9, #16
+; CHECK-NEXT: bit.16b v1, v6, v4
+; CHECK-NEXT: lsl w8, w8, #16
+; CHECK-NEXT: mov d6, v2[1]
+; CHECK-NEXT: fmov s7, w9
+; CHECK-NEXT: fcvt s2, d2
+; CHECK-NEXT: lsl w10, w10, #16
+; CHECK-NEXT: fmov s5, w8
+; CHECK-NEXT: fmov w8, s1
+; CHECK-NEXT: mov.16b v1, v4
+; CHECK-NEXT: bit.16b v3, v7, v4
+; CHECK-NEXT: bsl.16b v1, v5, v2
+; CHECK-NEXT: lsr w8, w8, #16
+; CHECK-NEXT: fcvt s2, d6
+; CHECK-NEXT: fmov w9, s3
+; CHECK-NEXT: fmov s5, w10
+; CHECK-NEXT: fmov s0, w8
+; CHECK-NEXT: fmov w8, s1
+; CHECK-NEXT: mov.16b v1, v4
+; CHECK-NEXT: lsr w9, w9, #16
+; CHECK-NEXT: fmov s3, w9
+; CHECK-NEXT: bsl.16b v1, v5, v2
+; CHECK-NEXT: lsr w8, w8, #16
+; CHECK-NEXT: mov.h v0[1], v3[0]
+; CHECK-NEXT: fmov s2, w8
+; CHECK-NEXT: fmov w8, s1
+; CHECK-NEXT: mov.h v0[2], v2[0]
+; CHECK-NEXT: lsr w8, w8, #16
+; CHECK-NEXT: fmov s1, w8
+; CHECK-NEXT: mov.h v0[3], v1[0]
+; CHECK-NEXT: ; kill: def $d0 killed $d0 killed $q0
+; CHECK-NEXT: ret
+ %tmp0 = fptrunc <4 x double> %b to <4 x bfloat>
+ %r = call <4 x bfloat> @llvm.copysign.v4bf16(<4 x bfloat> %a, <4 x bfloat> %tmp0)
+ ret <4 x bfloat> %r
+}
+
+declare <4 x bfloat> @llvm.copysign.v4bf16(<4 x bfloat> %a, <4 x bfloat> %b) #0
+
+;============ v8bf16
+
+define <8 x bfloat> @test_copysign_v8bf16_v8bf16(<8 x bfloat> %a, <8 x bfloat> %b) #0 {
+; CHECK-LABEL: test_copysign_v8bf16_v8bf16:
+; CHECK: ; %bb.0:
+; CHECK-NEXT: fmov w8, s1
+; CHECK-NEXT: mov h2, v1[1]
+; CHECK-NEXT: mov h4, v0[1]
+; CHECK-NEXT: fmov w9, s0
+; CHECK-NEXT: mov h6, v1[2]
+; CHECK-NEXT: mov h7, v0[2]
+; CHECK-NEXT: mvni.4s v3, #128, lsl #24
+; CHECK-NEXT: mov h5, v1[3]
+; CHECK-NEXT: mov h16, v0[3]
+; CHECK-NEXT: lsl w8, w8, #16
+; CHECK-NEXT: mov h17, v1[4]
+; CHECK-NEXT: lsl w9, w9, #16
+; CHECK-NEXT: fmov w10, s4
+; CHECK-NEXT: mov h4, v0[4]
+; CHECK-NEXT: fmov s18, w8
+; CHECK-NEXT: fmov w8, s2
+; CHECK-NEXT: fmov w11, s7
+; CHECK-NEXT: fmov s2, w9
+; CHECK-NEXT: lsl w9, w10, #16
+; CHECK-NEXT: fmov w10, s6
+; CHECK-NEXT: lsl w8, w8, #16
+; CHECK-NEXT: fmov s7, w9
+; CHECK-NEXT: bif.16b v2, v18, v3
+; CHECK-NEXT: lsl w9, w11, #16
+; CHECK-NEXT: fmov s6, w8
+; CHECK-NEXT: lsl w8, w10, #16
+; CHECK-NEXT: fmov w10, s5
+; CHECK-NEXT: fmov w11, s16
+; CHECK-NEXT: fmov s16, w9
+; CHECK-NEXT: mov h18, v0[5]
+; CHECK-NEXT: fmov s5, w8
+; CHECK-NEXT: bit.16b v6, v7, v3
+; CHECK-NEXT: fmov w8, s2
+; CHECK-NEXT: lsl w9, w10, #16
+; CHECK-NEXT: lsl w10, w11, #16
+; CHECK-NEXT: mov h7, v1[5]
+; CHECK-NEXT: bit.16b v5, v16, v3
+; CHECK-NEXT: fmov s16, w10
+; CHECK-NEXT: fmov w10, s4
+; CHECK-NEXT: mov.16b v4, v3
+; CHECK-NEXT: fmov w11, s6
+; CHECK-NEXT: fmov s6, w9
+; CHECK-NEXT: fmov w9, s17
+; CHECK-NEXT: lsr w8, w8, #16
+; CHECK-NEXT: lsr w11, w11, #16
+; CHECK-NEXT: fmov s2, w8
+; CHECK-NEXT: lsl w8, w9, #16
+; CHECK-NEXT: bsl.16b v4, v16, v6
+; CHECK-NEXT: lsl w9, w10, #16
+; CHECK-NEXT: fmov w10, s5
+; CHECK-NEXT: fmov s6, w11
+; CHECK-NEXT: fmov s5, w8
+; CHECK-NEXT: lsr w8, w10, #16
+; CHECK-NEXT: fmov w10, s7
+; CHECK-NEXT: mov.h v2[1], v6[0]
+; CHECK-NEXT: fmov s6, w9
+; CHECK-NEXT: fmov w9, s18
+; CHECK-NEXT: fmov s7, w8
+; CHECK-NEXT: fmov w8, s4
+; CHECK-NEXT: mov h4, v1[6]
+; CHECK-NEXT: lsl w10, w10, #16
+; CHECK-NEXT: mov h1, v1[7]
+; CHECK-NEXT: lsl w9, w9, #16
+; CHECK-NEXT: bit.16b v5, v6, v3
+; CHECK-NEXT: mov h6, v0[6]
+; CHECK-NEXT: mov.h v2[2], v7[0]
+; CHECK-NEXT: fmov s7, w10
+; CHECK-NEXT: lsr w8, w8, #16
+; CHECK-NEXT: fmov s16, w9
+; CHECK-NEXT: fmov w9, s4
+; CHECK-NEXT: mov h0, v0[7]
+; CHECK-NEXT: fmov w10, s6
+; CHECK-NEXT: bit.16b v7, v16, v3
+; CHECK-NEXT: fmov s16, w8
+; CHECK-NEXT: fmov w8, s5
+; CHECK-NEXT: lsl w9, w9, #16
+; CHECK-NEXT: lsl w10, w10, #16
+; CHECK-NEXT: lsr w8, w8, #16
+; CHECK-NEXT: mov.h v2[3], v16[0]
+; CHECK-NEXT: fmov s5, w9
+; CHECK-NEXT: fmov w9, s1
+; CHECK-NEXT: fmov s4, w8
+; CHECK-NEXT: fmov w8, s7
+; CHECK-NEXT: lsl w9, w9, #16
+; CHECK-NEXT: mov.h v2[4], v4[0]
+; CHECK-NEXT: fmov s4, w10
+; CHECK-NEXT: fmov w10, s0
+; CHECK-NEXT: lsr w8, w8, #16
+; CHECK-NEXT: fmov s1, w9
+; CHECK-NEXT: fmov s0, w8
+; CHECK-NEXT: bif.16b v4, v5, v3
+; CHECK-NEXT: lsl w10, w10, #16
+; CHECK-NEXT: fmov s5, w10
+; CHECK-NEXT: mov.h v2[5], v0[0]
+; CHECK-NEXT: mov.16b v0, v3
+; CHECK-NEXT: fmov w8, s4
+; CHECK-NEXT: bsl.16b v0, v5, v1
+; CHECK-NEXT: lsr w8, w8, #16
+; CHECK-NEXT: fmov s1, w8
+; CHECK-NEXT: fmov w8, s0
+; CHECK-NEXT: mov.h v2[6], v1[0]
+; CHECK-NEXT: lsr w8, w8, #16
+; CHECK-NEXT: fmov s0, w8
+; CHECK-NEXT: mov.h v2[7], v0[0]
+; CHECK-NEXT: mov.16b v0, v2
+; CHECK-NEXT: ret
+ %r = call <8 x bfloat> @llvm.copysign.v8bf16(<8 x bfloat> %a, <8 x bfloat> %b)
+ ret <8 x bfloat> %r
+}
+
+define <8 x bfloat> @test_copysign_v8bf16_v8f32(<8 x bfloat> %a, <8 x float> %b) #0 {
+; CHECK-LABEL: test_copysign_v8bf16_v8f32:
+; CHECK: ; %bb.0:
+; CHECK-NEXT: movi.4s v3, #127, msl #8
+; CHECK-NEXT: movi.4s v4, #1
+; CHECK-NEXT: ushr.4s v5, v1, #16
+; CHECK-NEXT: fcmeq.4s v7, v1, v1
+; CHECK-NEXT: fmov w9, s0
+; CHECK-NEXT: add.4s v6, v1, v3
+; CHECK-NEXT: and.16b v5, v5, v4
+; CHECK-NEXT: orr.4s v1, #64, lsl #16
+; CHECK-NEXT: lsl w9, w9, #16
+; CHECK-NEXT: add.4s v5, v5, v6
+; CHECK-NEXT: ushr.4s v6, v2, #16
+; CHECK-NEXT: and.16b v4, v6, v4
+; CHECK-NEXT: mov h6, v0[2]
+; CHECK-NEXT: bit.16b v1, v5, v7
+; CHECK-NEXT: add.4s v7, v2, v3
+; CHECK-NEXT: mov h5, v0[1]
+; CHECK-NEXT: fcmeq.4s v3, v2, v2
+; CHECK-NEXT: orr.4s v2, #64, lsl #16
+; CHECK-NEXT: shrn.4h v1, v1, #16
+; CHECK-NEXT: add.4s v4, v4, v7
+; CHECK-NEXT: fmov w8, s5
+; CHECK-NEXT: mov h7, v0[3]
+; CHECK-NEXT: mov h5, v0[4]
+; CHECK-NEXT: mov h16, v1[1]
+; CHECK-NEXT: fmov w10, s1
+; CHECK-NEXT: lsl w8, w8, #16
+; CHECK-NEXT: bsl.16b v3, v4, v2
+; CHECK-NEXT: mov h4, v1[2]
+; CHECK-NEXT: mov h17, v1[3]
+; CHECK-NEXT: mvni.4s v2, #128, lsl #24
+; CHECK-NEXT: fmov s1, w9
+; CHECK-NEXT: fmov w9, s6
+; CHECK-NEXT: lsl w10, w10, #16
+; CHECK-NEXT: fmov s6, w8
+; CHECK-NEXT: fmov w8, s7
+; CHECK-NEXT: fmov w11, s16
+; CHECK-NEXT: fmov s7, w10
+; CHECK-NEXT: fmov w10, s4
+; CHECK-NEXT: mov.16b v4, v2
+; CHECK-NEXT: lsl w9, w9, #16
+; CHECK-NEXT: lsl w8, w8, #16
+; CHECK-NEXT: shrn.4h v3, v3, #16
+; CHECK-NEXT: lsl w11, w11, #16
+; CHECK-NEXT: bif.16b v1, v7, v2
+; CHECK-NEXT: fmov s16, w8
+; CHECK-NEXT: fmov s7, w11
+; CHECK-NEXT: bsl.16b v4, v6, v7
+; CHECK-NEXT: fmov s7, w9
+; CHECK-NEXT: lsl w9, w10, #16
+; CHECK-NEXT: fmov w10, s17
+; CHECK-NEXT: mov h6, v0[5]
+; CHECK-NEXT: lsl w8, w10, #16
+; CHECK-NEXT: fmov w10, s1
+; CHECK-NEXT: fmov s1, w9
+; CHECK-NEXT: lsr w9, w10, #16
+; CHECK-NEXT: fmov w10, s4
+; CHECK-NEXT: fmov s4, w8
+; CHECK-NEXT: bif.16b v7, v1, v2
+; CHECK-NEXT: fmov w8, s5
+; CHECK-NEXT: mov h5, v3[1]
+; CHECK-NEXT: fmov s1, w9
+; CHECK-NEXT: fmov w9, s3
+; CHECK-NEXT: lsr w10, w10, #16
+; CHECK-NEXT: bit.16b v4, v16, v2
+; CHECK-NEXT: lsl w8, w8, #16
+; CHECK-NEXT: fmov s16, w10
+; CHECK-NEXT: lsl w9, w9, #16
+; CHECK-NEXT: fmov w10, s7
+; CHECK-NEXT: mov h7, v0[6]
+; CHECK-NEXT: mov h0, v0[7]
+; CHECK-NEXT: mov.h v1[1], v16[0]
+; CHECK-NEXT: fmov s16, w8
+; CHECK-NEXT: fmov w8, s6
+; CHECK-NEXT: fmov s6, w9
+; CHECK-NEXT: fmov w9, s5
+; CHECK-NEXT: lsr w10, w10, #16
+; CHECK-NEXT: lsl w8, w8, #16
+; CHECK-NEXT: lsl w9, w9, #16
+; CHECK-NEXT: bit.16b v6, v16, v2
+; CHECK-NEXT: fmov s16, w10
+; CHECK-NEXT: fmov w10, s4
+; CHECK-NEXT: fmov s5, w8
+; CHECK-NEXT: fmov w8, s7
+; CHECK-NEXT: fmov s7, w9
+; CHECK-NEXT: mov h4, v3[2]
+; CHECK-NEXT: mov h3, v3[3]
+; CHECK-NEXT: mov.h v1[2], v16[0]
+; CHECK-NEXT: lsr w10, w10, #16
+; CHECK-NEXT: fmov w9, s6
+; CHECK-NEXT: lsl w8, w8, #16
+; CHECK-NEXT: bif.16b v5, v7, v2
+; CHECK-NEXT: fmov s16, w10
+; CHECK-NEXT: fmov w10, s4
+; CHECK-NEXT: fmov s4, w8
+; CHECK-NEXT: lsr w9, w9, #16
+; CHECK-NEXT: mov.h v1[3], v16[0]
+; CHECK-NEXT: fmov w8, s5
+; CHECK-NEXT: lsl w10, w10, #16
+; CHECK-NEXT: fmov s6, w9
+; CHECK-NEXT: fmov w9, s0
+; CHECK-NEXT: fmov s5, w10
+; CHECK-NEXT: fmov w10, s3
+; CHECK-NEXT: lsr w8, w8, #16
+; CHECK-NEXT: mov.h v1[4], v6[0]
+; CHECK-NEXT: lsl w9, w9, #16
+; CHECK-NEXT: fmov s0, w8
+; CHECK-NEXT: bif.16b v4, v5, v2
+; CHECK-NEXT: lsl w10, w10, #16
+; CHECK-NEXT: fmov s3, w9
+; CHECK-NEXT: fmov s5, w10
+; CHECK-NEXT: mov.h v1[5], v0[0]
+; CHECK-NEXT: mov.16b v0, v2
+; CHECK-NEXT: fmov w8, s4
+; CHECK-NEXT: bsl.16b v0, v3, v5
+; CHECK-NEXT: lsr w8, w8, #16
+; CHECK-NEXT: fmov s2, w8
+; CHECK-NEXT: fmov w8, s0
+; CHECK-NEXT: mov.h v1[6], v2[0]
+; CHECK-NEXT: lsr w8, w8, #16
+; CHECK-NEXT: fmov s0, w8
+; CHECK-NEXT: mov.h v1[7], v0[0]
+; CHECK-NEXT: mov.16b v0, v1
+; CHECK-NEXT: ret
+ %tmp0 = fptrunc <8 x float> %b to <8 x bfloat>
+ %r = call <8 x bfloat> @llvm.copysign.v8bf16(<8 x bfloat> %a, <8 x bfloat> %tmp0)
+ ret <8 x bfloat> %r
+}
+
+declare <8 x bfloat> @llvm.copysign.v8bf16(<8 x bfloat> %a, <8 x bfloat> %b) #0
+
attributes #0 = { nounwind }
>From b29301cd40441b5eb8cef9356429fb081e6b6a72 Mon Sep 17 00:00:00 2001
From: Po-yao Chang <poyaoc97 at gmail.com>
Date: Mon, 4 Mar 2024 08:05:01 +0800
Subject: [PATCH 401/406] [libc++][format] Handle range-underlying-spec
(#81914)
An immediate colon signifeis that the range-format-spec contains only
range-underlying-spec.
This patch allows this code to compile and run:
```c++
std::println("{::<<9?}", std::span<const char>{"Hello", sizeof "Hello"});
```
---
.../include/__format/parser_std_format_spec.h | 22 ++++++++----------
.../format.functions.tests.h | 13 ++++-------
.../vector.bool.fmt/format.functions.tests.h | 1 -
.../format.functions.tests.h | 15 ------------
.../format.functions.tests.h | 23 +++++--------------
.../format.functions.tests.h | 2 --
.../format.functions.tests.h | 19 ++++-----------
.../format.tuple/format.functions.tests.h | 5 ----
8 files changed, 24 insertions(+), 76 deletions(-)
diff --git a/libcxx/include/__format/parser_std_format_spec.h b/libcxx/include/__format/parser_std_format_spec.h
index 370b28a22bba77..a4b47abff40dc5 100644
--- a/libcxx/include/__format/parser_std_format_spec.h
+++ b/libcxx/include/__format/parser_std_format_spec.h
@@ -355,10 +355,10 @@ class _LIBCPP_TEMPLATE_VIS __parser {
_LIBCPP_HIDE_FROM_ABI constexpr typename _ParseContext::iterator __parse(_ParseContext& __ctx, __fields __fields) {
auto __begin = __ctx.begin();
auto __end = __ctx.end();
- if (__begin == __end || *__begin == _CharT('}'))
+ if (__begin == __end || *__begin == _CharT('}') || (__fields.__use_range_fill_ && *__begin == _CharT(':')))
return __begin;
- if (__parse_fill_align(__begin, __end, __fields.__use_range_fill_) && __begin == __end)
+ if (__parse_fill_align(__begin, __end) && __begin == __end)
return __begin;
if (__fields.__sign_) {
@@ -574,12 +574,10 @@ class _LIBCPP_TEMPLATE_VIS __parser {
return false;
}
- _LIBCPP_HIDE_FROM_ABI constexpr void __validate_fill_character(_CharT __fill, bool __use_range_fill) {
+ _LIBCPP_HIDE_FROM_ABI constexpr void __validate_fill_character(_CharT __fill) {
// The forbidden fill characters all code points formed from a single code unit, thus the
// check can be omitted when more code units are used.
- if (__use_range_fill && (__fill == _CharT('{') || __fill == _CharT(':')))
- std::__throw_format_error("The fill option contains an invalid value");
- else if (__fill == _CharT('{'))
+ if (__fill == _CharT('{'))
std::__throw_format_error("The fill option contains an invalid value");
}
@@ -590,7 +588,7 @@ class _LIBCPP_TEMPLATE_VIS __parser {
# ifndef _LIBCPP_HAS_NO_WIDE_CHARACTERS
|| (same_as<_CharT, wchar_t> && sizeof(wchar_t) == 2)
# endif
- _LIBCPP_HIDE_FROM_ABI constexpr bool __parse_fill_align(_Iterator& __begin, _Iterator __end, bool __use_range_fill) {
+ _LIBCPP_HIDE_FROM_ABI constexpr bool __parse_fill_align(_Iterator& __begin, _Iterator __end) {
_LIBCPP_ASSERT_VALID_ELEMENT_ACCESS(
__begin != __end,
"when called with an empty input the function will cause "
@@ -606,7 +604,7 @@ class _LIBCPP_TEMPLATE_VIS __parser {
// The forbidden fill characters all are code points encoded
// in one code unit, thus the check can be omitted when more
// code units are used.
- __validate_fill_character(*__begin, __use_range_fill);
+ __validate_fill_character(*__begin);
std::copy_n(__begin, __code_units, std::addressof(__fill_.__data[0]));
__begin += __code_units + 1;
@@ -623,7 +621,7 @@ class _LIBCPP_TEMPLATE_VIS __parser {
# ifndef _LIBCPP_HAS_NO_WIDE_CHARACTERS
template <contiguous_iterator _Iterator>
requires(same_as<_CharT, wchar_t> && sizeof(wchar_t) == 4)
- _LIBCPP_HIDE_FROM_ABI constexpr bool __parse_fill_align(_Iterator& __begin, _Iterator __end, bool __use_range_fill) {
+ _LIBCPP_HIDE_FROM_ABI constexpr bool __parse_fill_align(_Iterator& __begin, _Iterator __end) {
_LIBCPP_ASSERT_VALID_ELEMENT_ACCESS(
__begin != __end,
"when called with an empty input the function will cause "
@@ -632,7 +630,7 @@ class _LIBCPP_TEMPLATE_VIS __parser {
if (!__unicode::__is_scalar_value(*__begin))
std::__throw_format_error("The fill option contains an invalid value");
- __validate_fill_character(*__begin, __use_range_fill);
+ __validate_fill_character(*__begin);
__fill_.__data[0] = *__begin;
__begin += 2;
@@ -651,14 +649,14 @@ class _LIBCPP_TEMPLATE_VIS __parser {
# else // _LIBCPP_HAS_NO_UNICODE
// range-fill and tuple-fill are identical
template <contiguous_iterator _Iterator>
- _LIBCPP_HIDE_FROM_ABI constexpr bool __parse_fill_align(_Iterator& __begin, _Iterator __end, bool __use_range_fill) {
+ _LIBCPP_HIDE_FROM_ABI constexpr bool __parse_fill_align(_Iterator& __begin, _Iterator __end) {
_LIBCPP_ASSERT_VALID_ELEMENT_ACCESS(
__begin != __end,
"when called with an empty input the function will cause "
"undefined behavior by evaluating data not in the input");
if (__begin + 1 != __end) {
if (__parse_alignment(*(__begin + 1))) {
- __validate_fill_character(*__begin, __use_range_fill);
+ __validate_fill_character(*__begin);
__fill_.__data[0] = *__begin;
__begin += 2;
diff --git a/libcxx/test/std/containers/container.adaptors/container.adaptors.format/format.functions.tests.h b/libcxx/test/std/containers/container.adaptors/container.adaptors.format/format.functions.tests.h
index 05de1bb12dfa5a..f4a1307d30daed 100644
--- a/libcxx/test/std/containers/container.adaptors/container.adaptors.format/format.functions.tests.h
+++ b/libcxx/test/std/containers/container.adaptors/container.adaptors.format/format.functions.tests.h
@@ -35,8 +35,10 @@ void test_char_default(TestFunction check, ExceptionTest check_exception, auto&&
// when one is present there is no escaping,
check(SV("[H, e, l, l, o]"), SV("{::}"), input);
+ check(SV("[H, e, l, l, o]"), SV("{::<}"), input);
// unless forced by the type specifier.
check(SV("['H', 'e', 'l', 'l', 'o']"), SV("{::?}"), input);
+ check(SV("['H', 'e', 'l', 'l', 'o']"), SV("{::<?}"), input);
// ***** underlying has no format-spec
@@ -53,7 +55,6 @@ void test_char_default(TestFunction check, ExceptionTest check_exception, auto&&
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -153,7 +154,6 @@ void test_char_string(TestFunction check, ExceptionTest check_exception, auto&&
check_exception("The format string contains an invalid escape sequence", SV("{:}<s}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<s}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<s}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-s}"), input);
@@ -177,6 +177,7 @@ void test_char_string(TestFunction check, ExceptionTest check_exception, auto&&
// *** type ***
check_exception("Type m requires a pair or a tuple with two elements", SV("{:m}"), input);
+ check_exception("The type option contains an invalid value for a character formatting argument", SV("{::<s}"), input);
// ***** Only underlying has a format-spec
check_exception("Type s and an underlying format specification can't be used together", SV("{:s:}"), input);
@@ -206,7 +207,7 @@ void test_char_escaped_string(TestFunction check, ExceptionTest check_exception,
check_exception("The format string contains an invalid escape sequence", SV("{:}<?s}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<?s}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<?s}"), input);
+ check_exception("The format specifier should consume the input or end with a '}'", SV("{::<?s}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-?s}"), input);
@@ -324,7 +325,6 @@ void test_bool(TestFunction check, ExceptionTest check_exception, auto&& input)
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -440,7 +440,6 @@ void test_int(TestFunction check, ExceptionTest check_exception, auto&& input) {
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -550,7 +549,6 @@ void test_floating_point(TestFunction check, ExceptionTest check_exception, auto
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -688,7 +686,6 @@ void test_pointer(TestFunction check, ExceptionTest check_exception, auto&& inpu
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -798,7 +795,6 @@ void test_string(TestFunction check, ExceptionTest check_exception, auto&& input
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -910,7 +906,6 @@ void test_status(TestFunction check, ExceptionTest check_exception, auto&& input
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
diff --git a/libcxx/test/std/containers/sequences/vector.bool/vector.bool.fmt/format.functions.tests.h b/libcxx/test/std/containers/sequences/vector.bool/vector.bool.fmt/format.functions.tests.h
index e6f8164c536421..8be3d9ab274a61 100644
--- a/libcxx/test/std/containers/sequences/vector.bool/vector.bool.fmt/format.functions.tests.h
+++ b/libcxx/test/std/containers/sequences/vector.bool/vector.bool.fmt/format.functions.tests.h
@@ -34,7 +34,6 @@ void format_test_vector_bool(TestFunction check, ExceptionTest check_exception,
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
diff --git a/libcxx/test/std/utilities/format/format.range/format.range.fmtmap/format.functions.tests.h b/libcxx/test/std/utilities/format/format.range/format.range.fmtmap/format.functions.tests.h
index 2716f461895c8d..3ebaa054f0cabc 100644
--- a/libcxx/test/std/utilities/format/format.range/format.range.fmtmap/format.functions.tests.h
+++ b/libcxx/test/std/utilities/format/format.range/format.range.fmtmap/format.functions.tests.h
@@ -45,7 +45,6 @@ void test_char(TestFunction check, ExceptionTest check_exception) {
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -87,7 +86,6 @@ void test_char(TestFunction check, ExceptionTest check_exception) {
check(SV("{__'a': 'A'___, __'b': 'B'___, __'c': 'C'___}"), SV("{::_^{}}"), input, 13);
check(SV("{#####'a': 'A', #####'b': 'B', #####'c': 'C'}"), SV("{::#>{}}"), input, 13);
- check_exception("The fill option contains an invalid value", SV("{:::<}"), input);
check_exception("The format string contains an invalid escape sequence", SV("{::}<}"), input);
check_exception("The fill option contains an invalid value", SV("{::{<}"), input);
@@ -157,7 +155,6 @@ void test_char_to_wchar(TestFunction check, ExceptionTest check_exception) {
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -198,7 +195,6 @@ void test_char_to_wchar(TestFunction check, ExceptionTest check_exception) {
check(SV("{__'a': 'A'___, __'b': 'B'___, __'c': 'C'___}"), SV("{::_^{}}"), input, 13);
check(SV("{#####'a': 'A', #####'b': 'B', #####'c': 'C'}"), SV("{::#>{}}"), input, 13);
- check_exception("The fill option contains an invalid value", SV("{:::<}"), input);
check_exception("The format string contains an invalid escape sequence", SV("{::}<}"), input);
check_exception("The fill option contains an invalid value", SV("{::{<}"), input);
@@ -267,7 +263,6 @@ void test_bool(TestFunction check, ExceptionTest check_exception) {
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -308,7 +303,6 @@ void test_bool(TestFunction check, ExceptionTest check_exception) {
check(SV("{_false: 0_, _true: 42_, _true: 1__}"), SV("{::_^{}}"), input, 10);
check(SV("{##false: 0, ##true: 42, ###true: 1}"), SV("{::#>{}}"), input, 10);
- check_exception("The fill option contains an invalid value", SV("{:::<}"), input);
check_exception("The format string contains an invalid escape sequence", SV("{::}<}"), input);
check_exception("The fill option contains an invalid value", SV("{::{<}"), input);
@@ -369,7 +363,6 @@ void test_int(TestFunction check, ExceptionTest check_exception, auto&& input) {
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -410,7 +403,6 @@ void test_int(TestFunction check, ExceptionTest check_exception, auto&& input) {
check(SV("{_-42: 42__, __1: -1___, _42: -42__}"), SV("{::_^{}}"), input, 10);
check(SV("{###-42: 42, #####1: -1, ###42: -42}"), SV("{::#>{}}"), input, 10);
- check_exception("The fill option contains an invalid value", SV("{:::<}"), input);
check_exception("The format string contains an invalid escape sequence", SV("{::}<}"), input);
check_exception("The fill option contains an invalid value", SV("{::{<}"), input);
@@ -478,7 +470,6 @@ void test_floating_point(TestFunction check, ExceptionTest check_exception) {
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -519,7 +510,6 @@ void test_floating_point(TestFunction check, ExceptionTest check_exception) {
check(SV("{_-42: 42__, __1: -1___}"), SV("{::_^{}}"), input, 10);
check(SV("{###-42: 42, #####1: -1}"), SV("{::#>{}}"), input, 10);
- check_exception("The fill option contains an invalid value", SV("{:::<}"), input);
check_exception("The format string contains an invalid escape sequence", SV("{::}<}"), input);
check_exception("The fill option contains an invalid value", SV("{::{<}"), input);
@@ -582,7 +572,6 @@ void test_pointer(TestFunction check, ExceptionTest check_exception) {
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:#}"), input);
@@ -621,7 +610,6 @@ void test_pointer(TestFunction check, ExceptionTest check_exception) {
check(SV("{__0x0: 0x0___}"), SV("{::_^{}}"), input, 13);
check(SV("{#####0x0: 0x0}"), SV("{::#>{}}"), input, 13);
- check_exception("The fill option contains an invalid value", SV("{:::<}"), input);
check_exception("The format string contains an invalid escape sequence", SV("{::}<}"), input);
check_exception("The fill option contains an invalid value", SV("{::{<}"), input);
@@ -685,7 +673,6 @@ void test_string(TestFunction check, ExceptionTest check_exception) {
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:#}"), input);
@@ -724,7 +711,6 @@ void test_string(TestFunction check, ExceptionTest check_exception) {
check(SV(R"({__"hello": "HELLO"___, __"world": "WORLD"___})"), SV("{::_^{}}"), input, 21);
check(SV(R"({#####"hello": "HELLO", #####"world": "WORLD"})"), SV("{::#>{}}"), input, 21);
- check_exception("The fill option contains an invalid value", SV("{:::<}"), input);
check_exception("The format string contains an invalid escape sequence", SV("{::}<}"), input);
check_exception("The fill option contains an invalid value", SV("{::{<}"), input);
@@ -788,7 +774,6 @@ void test_status(TestFunction check, ExceptionTest check_exception) {
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
diff --git a/libcxx/test/std/utilities/format/format.range/format.range.fmtset/format.functions.tests.h b/libcxx/test/std/utilities/format/format.range/format.range.fmtset/format.functions.tests.h
index a4d8c2d34c333f..5a0c89ecccfff7 100644
--- a/libcxx/test/std/utilities/format/format.range/format.range.fmtset/format.functions.tests.h
+++ b/libcxx/test/std/utilities/format/format.range/format.range.fmtset/format.functions.tests.h
@@ -34,8 +34,10 @@ void test_char_default(TestFunction check, ExceptionTest check_exception) {
check(SV("{'a', 'b', 'c'}^42"), SV("{:}^42"), input);
// when one is present there is no escaping,
check(SV("{a, b, c}"), SV("{::}"), input);
+ check(SV("{a, b, c}"), SV("{::<}"), input);
// unless forced by the type specifier.
check(SV("{'a', 'b', 'c'}"), SV("{::?}"), input);
+ check(SV("{'a', 'b', 'c'}"), SV("{::<?}"), input);
// ***** underlying has no format-spec
@@ -52,7 +54,6 @@ void test_char_default(TestFunction check, ExceptionTest check_exception) {
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -156,7 +157,6 @@ void test_char_string(TestFunction check, [[maybe_unused]] ExceptionTest check_e
check_exception("The format string contains an invalid escape sequence", SV("{:}<s}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<s}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<s}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-s}"), input);
@@ -180,6 +180,7 @@ void test_char_string(TestFunction check, [[maybe_unused]] ExceptionTest check_e
// *** type ***
check_exception("Type m requires a pair or a tuple with two elements", SV("{:m}"), input);
+ check_exception("The type option contains an invalid value for a character formatting argument", SV("{::<s}"), input);
// ***** Only underlying has a format-spec
check_exception("Type s and an underlying format specification can't be used together", SV("{:s:}"), input);
@@ -215,7 +216,7 @@ void test_char_escaped_string(TestFunction check, [[maybe_unused]] ExceptionTest
check_exception("The format string contains an invalid escape sequence", SV("{:}<?s}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<?s}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<?s}"), input);
+ check_exception("The format specifier should consume the input or end with a '}'", SV("{::<?s}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-?s}"), input);
@@ -271,8 +272,10 @@ void test_char_to_wchar(TestFunction check, ExceptionTest check_exception) {
check(SV("{'a', 'b', 'c'}^42"), SV("{:}^42"), input);
// when one is present there is no escaping,
check(SV("{a, b, c}"), SV("{::}"), input);
+ check(SV("{a, b, c}"), SV("{::<}"), input);
// unless forced by the type specifier.
check(SV("{'a', 'b', 'c'}"), SV("{::?}"), input);
+ check(SV("{'a', 'b', 'c'}"), SV("{::<?}"), input);
// ***** underlying has no format-spec
@@ -289,7 +292,6 @@ void test_char_to_wchar(TestFunction check, ExceptionTest check_exception) {
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -405,7 +407,6 @@ void test_bool(TestFunction check, ExceptionTest check_exception) {
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -512,7 +513,6 @@ void test_bool_multiset(TestFunction check, ExceptionTest check_exception) {
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -621,7 +621,6 @@ void test_int(TestFunction check, ExceptionTest check_exception, auto&& input) {
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -730,7 +729,6 @@ void test_floating_point(TestFunction check, ExceptionTest check_exception, auto
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -868,7 +866,6 @@ void test_pointer(TestFunction check, ExceptionTest check_exception, auto&& inpu
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:#}"), input);
@@ -978,7 +975,6 @@ void test_string(TestFunction check, ExceptionTest check_exception, auto&& input
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:#}"), input);
@@ -1091,7 +1087,6 @@ void test_status(TestFunction check, ExceptionTest check_exception) {
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -1160,7 +1155,6 @@ void test_pair_tuple(TestFunction check, ExceptionTest check_exception, auto&& i
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -1202,7 +1196,6 @@ void test_pair_tuple(TestFunction check, ExceptionTest check_exception, auto&& i
check(SV("{_(1, 'a')__, _(42, '*')_}"), SV("{::_^{}}"), input, 11);
check(SV("{###(1, 'a'), ##(42, '*')}"), SV("{::#>{}}"), input, 11);
- check_exception("The fill option contains an invalid value", SV("{:::<}"), input);
check_exception("The format string contains an invalid escape sequence", SV("{::}<}"), input);
check_exception("The fill option contains an invalid value", SV("{::{<}"), input);
@@ -1284,7 +1277,6 @@ void test_tuple_int(TestFunction check, ExceptionTest check_exception) {
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -1325,7 +1317,6 @@ void test_tuple_int(TestFunction check, ExceptionTest check_exception) {
check(SV("{_(42)__, _(99)__}"), SV("{::_^{}}"), input, 7);
check(SV("{###(42), ###(99)}"), SV("{::#>{}}"), input, 7);
- check_exception("The fill option contains an invalid value", SV("{:::<}"), input);
check_exception("The format string contains an invalid escape sequence", SV("{::}<}"), input);
check_exception("The fill option contains an invalid value", SV("{::{<}"), input);
@@ -1394,7 +1385,6 @@ void test_tuple_int_int_int(TestFunction check, ExceptionTest check_exception) {
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -1435,7 +1425,6 @@ void test_tuple_int_int_int(TestFunction check, ExceptionTest check_exception) {
check(SV("{_(1, 10, 100)_, _(42, 99, 0)__}"), SV("{::_^{}}"), input, 14);
check(SV("{##(1, 10, 100), ###(42, 99, 0)}"), SV("{::#>{}}"), input, 14);
- check_exception("The fill option contains an invalid value", SV("{:::<}"), input);
check_exception("The format string contains an invalid escape sequence", SV("{::}<}"), input);
check_exception("The fill option contains an invalid value", SV("{::{<}"), input);
diff --git a/libcxx/test/std/utilities/format/format.range/format.range.fmtstr/format.functions.tests.h b/libcxx/test/std/utilities/format/format.range/format.range.fmtstr/format.functions.tests.h
index 5d899d75d30fc4..261431c7124453 100644
--- a/libcxx/test/std/utilities/format/format.range/format.range.fmtstr/format.functions.tests.h
+++ b/libcxx/test/std/utilities/format/format.range/format.range.fmtstr/format.functions.tests.h
@@ -137,7 +137,6 @@ void test_range_string(TestFunction check, ExceptionTest check_exception, auto&&
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -327,7 +326,6 @@ void test_range_debug_string(TestFunction check, ExceptionTest check_exception,
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
diff --git a/libcxx/test/std/utilities/format/format.range/format.range.formatter/format.functions.tests.h b/libcxx/test/std/utilities/format/format.range/format.range.formatter/format.functions.tests.h
index 917791f7358a07..78b067e8cffa9c 100644
--- a/libcxx/test/std/utilities/format/format.range/format.range.formatter/format.functions.tests.h
+++ b/libcxx/test/std/utilities/format/format.range/format.range.formatter/format.functions.tests.h
@@ -39,8 +39,10 @@ void test_char_default(TestFunction check, ExceptionTest check_exception, auto&&
// when one is present there is no escaping,
check(SV("[H, e, l, l, o]"), SV("{::}"), input);
+ check(SV("[H, e, l, l, o]"), SV("{::<}"), input);
// unless forced by the type specifier.
check(SV("['H', 'e', 'l', 'l', 'o']"), SV("{::?}"), input);
+ check(SV("['H', 'e', 'l', 'l', 'o']"), SV("{::<?}"), input);
// ***** underlying has no format-spec
@@ -57,7 +59,6 @@ void test_char_default(TestFunction check, ExceptionTest check_exception, auto&&
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -157,7 +158,6 @@ void test_char_string(TestFunction check, ExceptionTest check_exception, auto&&
check_exception("The format string contains an invalid escape sequence", SV("{:}<s}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<s}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<s}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-s}"), input);
@@ -181,6 +181,7 @@ void test_char_string(TestFunction check, ExceptionTest check_exception, auto&&
// *** type ***
check_exception("Type m requires a pair or a tuple with two elements", SV("{:m}"), input);
+ check_exception("The type option contains an invalid value for a character formatting argument", SV("{::<s}"), input);
// ***** Only underlying has a format-spec
check_exception("Type s and an underlying format specification can't be used together", SV("{:s:}"), input);
@@ -210,7 +211,7 @@ void test_char_escaped_string(TestFunction check, ExceptionTest check_exception,
check_exception("The format string contains an invalid escape sequence", SV("{:}<?s}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<?s}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<?s}"), input);
+ check_exception("The format specifier should consume the input or end with a '}'", SV("{::<?s}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-?s}"), input);
@@ -315,7 +316,6 @@ void test_bool(TestFunction check, ExceptionTest check_exception) {
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -423,7 +423,6 @@ void test_int(TestFunction check, ExceptionTest check_exception, auto&& input) {
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -534,7 +533,6 @@ void test_floating_point(TestFunction check, ExceptionTest check_exception, auto
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -673,7 +671,6 @@ void test_pointer(TestFunction check, ExceptionTest check_exception, auto&& inpu
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:#}"), input);
@@ -782,7 +779,6 @@ void test_string(TestFunction check, ExceptionTest check_exception, auto&& input
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:#}"), input);
@@ -895,7 +891,6 @@ void test_status(TestFunction check, ExceptionTest check_exception) {
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -978,7 +973,6 @@ void test_pair_tuple(TestFunction check, ExceptionTest check_exception, auto&& i
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -1019,7 +1013,6 @@ void test_pair_tuple(TestFunction check, ExceptionTest check_exception, auto&& i
check(SV("[_(1, 'a')__, _(42, '*')_]"), SV("{::_^{}}"), input, 11);
check(SV("[###(1, 'a'), ##(42, '*')]"), SV("{::#>{}}"), input, 11);
- check_exception("The fill option contains an invalid value", SV("{:::<}"), input);
check_exception("The format string contains an invalid escape sequence", SV("{::}<}"), input);
check_exception("The fill option contains an invalid value", SV("{::{<}"), input);
@@ -1098,7 +1091,6 @@ void test_tuple_int(TestFunction check, ExceptionTest check_exception) {
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -1138,7 +1130,6 @@ void test_tuple_int(TestFunction check, ExceptionTest check_exception) {
check(SV("[_(42)__, _(99)__]"), SV("{::_^{}}"), input, 7);
check(SV("[###(42), ###(99)]"), SV("{::#>{}}"), input, 7);
- check_exception("The fill option contains an invalid value", SV("{:::<}"), input);
check_exception("The format string contains an invalid escape sequence", SV("{::}<}"), input);
check_exception("The fill option contains an invalid value", SV("{::{<}"), input);
@@ -1203,7 +1194,6 @@ void test_tuple_int_int_int(TestFunction check, ExceptionTest check_exception) {
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -1243,7 +1233,6 @@ void test_tuple_int_int_int(TestFunction check, ExceptionTest check_exception) {
check(SV("[_(42, 99, 0)__, _(1, 10, 100)_]"), SV("{::_^{}}"), input, 14);
check(SV("[###(42, 99, 0), ##(1, 10, 100)]"), SV("{::#>{}}"), input, 14);
- check_exception("The fill option contains an invalid value", SV("{:::<}"), input);
check_exception("The format string contains an invalid escape sequence", SV("{::}<}"), input);
check_exception("The fill option contains an invalid value", SV("{::{<}"), input);
diff --git a/libcxx/test/std/utilities/format/format.tuple/format.functions.tests.h b/libcxx/test/std/utilities/format/format.tuple/format.functions.tests.h
index dc57693469fec4..e26d2dfaf6806c 100644
--- a/libcxx/test/std/utilities/format/format.tuple/format.functions.tests.h
+++ b/libcxx/test/std/utilities/format/format.tuple/format.functions.tests.h
@@ -46,7 +46,6 @@ void test_tuple_or_pair_int_int(TestFunction check, ExceptionTest check_exceptio
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -95,7 +94,6 @@ void test_tuple_or_pair_int_string(TestFunction check, ExceptionTest check_excep
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -187,7 +185,6 @@ void test_tuple_int(TestFunction check, ExceptionTest check_exception) {
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -238,7 +235,6 @@ void test_tuple_int_string_color(TestFunction check, ExceptionTest check_excepti
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
@@ -313,7 +309,6 @@ void test_nested(TestFunction check, ExceptionTest check_exception, Nested&& inp
check_exception("The format string contains an invalid escape sequence", SV("{:}<}"), input);
check_exception("The fill option contains an invalid value", SV("{:{<}"), input);
- check_exception("The fill option contains an invalid value", SV("{::<}"), input);
// *** sign ***
check_exception("The format specifier should consume the input or end with a '}'", SV("{:-}"), input);
>From 5f058aa211995d2f0df2a0e063532832569cb7a8 Mon Sep 17 00:00:00 2001
From: Lu Weining <luweining at loongson.cn>
Date: Mon, 4 Mar 2024 08:38:52 +0800
Subject: [PATCH 402/406] [LoongArch] Override
LoongArchTargetLowering::getExtendForAtomicCmpSwapArg (#83656)
This patch aims to solve Firefox issue:
https://bugzilla.mozilla.org/show_bug.cgi?id=1882301
Similar to 616289ed2922. Currently LoongArch uses an ll.[wd]/sc.[wd]
loop for ATOMIC_CMP_XCHG. Because the comparison in the loop is
full-width (i.e. the `bne` instruction), we must sign extend the input
comparsion argument.
Note that LoongArch ISA manual V1.1 has introduced compare-and-swap
instructions. We would change the implementation (return `ANY_EXTEND`)
when we support them.
---
.../LoongArch/LoongArchISelLowering.cpp | 5 +
.../Target/LoongArch/LoongArchISelLowering.h | 2 +
.../LoongArch/atomicrmw-uinc-udec-wrap.ll | 120 +++++++------
.../ir-instruction/atomic-cmpxchg.ll | 25 +--
.../LoongArch/ir-instruction/atomicrmw-fp.ll | 160 +++++++++---------
5 files changed, 159 insertions(+), 153 deletions(-)
diff --git a/llvm/lib/Target/LoongArch/LoongArchISelLowering.cpp b/llvm/lib/Target/LoongArch/LoongArchISelLowering.cpp
index 3324dd2e8fc217..c8e955a23336d7 100644
--- a/llvm/lib/Target/LoongArch/LoongArchISelLowering.cpp
+++ b/llvm/lib/Target/LoongArch/LoongArchISelLowering.cpp
@@ -4963,3 +4963,8 @@ bool LoongArchTargetLowering::hasAndNotCompare(SDValue Y) const {
return !isa<ConstantSDNode>(Y);
}
+
+ISD::NodeType LoongArchTargetLowering::getExtendForAtomicCmpSwapArg() const {
+ // TODO: LAMCAS will use amcas{_DB,}.[bhwd] which does not require extension.
+ return ISD::SIGN_EXTEND;
+}
diff --git a/llvm/lib/Target/LoongArch/LoongArchISelLowering.h b/llvm/lib/Target/LoongArch/LoongArchISelLowering.h
index 72182623b2c3dd..9e9ac0b8269291 100644
--- a/llvm/lib/Target/LoongArch/LoongArchISelLowering.h
+++ b/llvm/lib/Target/LoongArch/LoongArchISelLowering.h
@@ -206,6 +206,8 @@ class LoongArchTargetLowering : public TargetLowering {
return ISD::SIGN_EXTEND;
}
+ ISD::NodeType getExtendForAtomicCmpSwapArg() const override;
+
Register getRegisterByName(const char *RegName, LLT VT,
const MachineFunction &MF) const override;
bool mayBeEmittedAsTailCall(const CallInst *CI) const override;
diff --git a/llvm/test/CodeGen/LoongArch/atomicrmw-uinc-udec-wrap.ll b/llvm/test/CodeGen/LoongArch/atomicrmw-uinc-udec-wrap.ll
index b0f29ee790885d..b84c1093eb75f2 100644
--- a/llvm/test/CodeGen/LoongArch/atomicrmw-uinc-udec-wrap.ll
+++ b/llvm/test/CodeGen/LoongArch/atomicrmw-uinc-udec-wrap.ll
@@ -25,15 +25,16 @@ define i8 @atomicrmw_uinc_wrap_i8(ptr %ptr, i8 %val) {
; LA64-NEXT: andi $a5, $a5, 255
; LA64-NEXT: sll.w $a5, $a5, $a3
; LA64-NEXT: and $a6, $a2, $a4
-; LA64-NEXT: or $a6, $a6, $a5
+; LA64-NEXT: or $a5, $a6, $a5
+; LA64-NEXT: addi.w $a6, $a2, 0
; LA64-NEXT: .LBB0_3: # %atomicrmw.start
; LA64-NEXT: # Parent Loop BB0_1 Depth=1
; LA64-NEXT: # => This Inner Loop Header: Depth=2
-; LA64-NEXT: ll.w $a5, $a0, 0
-; LA64-NEXT: bne $a5, $a2, .LBB0_5
+; LA64-NEXT: ll.w $a2, $a0, 0
+; LA64-NEXT: bne $a2, $a6, .LBB0_5
; LA64-NEXT: # %bb.4: # %atomicrmw.start
; LA64-NEXT: # in Loop: Header=BB0_3 Depth=2
-; LA64-NEXT: move $a7, $a6
+; LA64-NEXT: move $a7, $a5
; LA64-NEXT: sc.w $a7, $a0, 0
; LA64-NEXT: beqz $a7, .LBB0_3
; LA64-NEXT: b .LBB0_6
@@ -42,11 +43,9 @@ define i8 @atomicrmw_uinc_wrap_i8(ptr %ptr, i8 %val) {
; LA64-NEXT: dbar 20
; LA64-NEXT: .LBB0_6: # %atomicrmw.start
; LA64-NEXT: # in Loop: Header=BB0_1 Depth=1
-; LA64-NEXT: addi.w $a6, $a2, 0
-; LA64-NEXT: move $a2, $a5
-; LA64-NEXT: bne $a5, $a6, .LBB0_1
+; LA64-NEXT: bne $a2, $a6, .LBB0_1
; LA64-NEXT: # %bb.2: # %atomicrmw.end
-; LA64-NEXT: srl.w $a0, $a5, $a3
+; LA64-NEXT: srl.w $a0, $a2, $a3
; LA64-NEXT: ret
%result = atomicrmw uinc_wrap ptr %ptr, i8 %val seq_cst
ret i8 %result
@@ -77,15 +76,16 @@ define i16 @atomicrmw_uinc_wrap_i16(ptr %ptr, i16 %val) {
; LA64-NEXT: bstrpick.d $a5, $a5, 15, 0
; LA64-NEXT: sll.w $a5, $a5, $a3
; LA64-NEXT: and $a6, $a2, $a4
-; LA64-NEXT: or $a6, $a6, $a5
+; LA64-NEXT: or $a5, $a6, $a5
+; LA64-NEXT: addi.w $a6, $a2, 0
; LA64-NEXT: .LBB1_3: # %atomicrmw.start
; LA64-NEXT: # Parent Loop BB1_1 Depth=1
; LA64-NEXT: # => This Inner Loop Header: Depth=2
-; LA64-NEXT: ll.w $a5, $a0, 0
-; LA64-NEXT: bne $a5, $a2, .LBB1_5
+; LA64-NEXT: ll.w $a2, $a0, 0
+; LA64-NEXT: bne $a2, $a6, .LBB1_5
; LA64-NEXT: # %bb.4: # %atomicrmw.start
; LA64-NEXT: # in Loop: Header=BB1_3 Depth=2
-; LA64-NEXT: move $a7, $a6
+; LA64-NEXT: move $a7, $a5
; LA64-NEXT: sc.w $a7, $a0, 0
; LA64-NEXT: beqz $a7, .LBB1_3
; LA64-NEXT: b .LBB1_6
@@ -94,11 +94,9 @@ define i16 @atomicrmw_uinc_wrap_i16(ptr %ptr, i16 %val) {
; LA64-NEXT: dbar 20
; LA64-NEXT: .LBB1_6: # %atomicrmw.start
; LA64-NEXT: # in Loop: Header=BB1_1 Depth=1
-; LA64-NEXT: addi.w $a6, $a2, 0
-; LA64-NEXT: move $a2, $a5
-; LA64-NEXT: bne $a5, $a6, .LBB1_1
+; LA64-NEXT: bne $a2, $a6, .LBB1_1
; LA64-NEXT: # %bb.2: # %atomicrmw.end
-; LA64-NEXT: srl.w $a0, $a5, $a3
+; LA64-NEXT: srl.w $a0, $a2, $a3
; LA64-NEXT: ret
%result = atomicrmw uinc_wrap ptr %ptr, i16 %val seq_cst
ret i16 %result
@@ -107,37 +105,36 @@ define i16 @atomicrmw_uinc_wrap_i16(ptr %ptr, i16 %val) {
define i32 @atomicrmw_uinc_wrap_i32(ptr %ptr, i32 %val) {
; LA64-LABEL: atomicrmw_uinc_wrap_i32:
; LA64: # %bb.0:
-; LA64-NEXT: ld.w $a3, $a0, 0
-; LA64-NEXT: addi.w $a2, $a1, 0
+; LA64-NEXT: ld.w $a2, $a0, 0
+; LA64-NEXT: addi.w $a1, $a1, 0
; LA64-NEXT: .p2align 4, , 16
; LA64-NEXT: .LBB2_1: # %atomicrmw.start
; LA64-NEXT: # =>This Loop Header: Depth=1
; LA64-NEXT: # Child Loop BB2_3 Depth 2
-; LA64-NEXT: addi.w $a4, $a3, 0
-; LA64-NEXT: sltu $a1, $a4, $a2
-; LA64-NEXT: xori $a1, $a1, 1
-; LA64-NEXT: addi.d $a5, $a3, 1
-; LA64-NEXT: masknez $a5, $a5, $a1
+; LA64-NEXT: addi.w $a3, $a2, 0
+; LA64-NEXT: sltu $a4, $a3, $a1
+; LA64-NEXT: xori $a4, $a4, 1
+; LA64-NEXT: addi.d $a2, $a2, 1
+; LA64-NEXT: masknez $a4, $a2, $a4
; LA64-NEXT: .LBB2_3: # %atomicrmw.start
; LA64-NEXT: # Parent Loop BB2_1 Depth=1
; LA64-NEXT: # => This Inner Loop Header: Depth=2
-; LA64-NEXT: ll.w $a1, $a0, 0
-; LA64-NEXT: bne $a1, $a3, .LBB2_5
+; LA64-NEXT: ll.w $a2, $a0, 0
+; LA64-NEXT: bne $a2, $a3, .LBB2_5
; LA64-NEXT: # %bb.4: # %atomicrmw.start
; LA64-NEXT: # in Loop: Header=BB2_3 Depth=2
-; LA64-NEXT: move $a6, $a5
-; LA64-NEXT: sc.w $a6, $a0, 0
-; LA64-NEXT: beqz $a6, .LBB2_3
+; LA64-NEXT: move $a5, $a4
+; LA64-NEXT: sc.w $a5, $a0, 0
+; LA64-NEXT: beqz $a5, .LBB2_3
; LA64-NEXT: b .LBB2_6
; LA64-NEXT: .LBB2_5: # %atomicrmw.start
; LA64-NEXT: # in Loop: Header=BB2_1 Depth=1
; LA64-NEXT: dbar 20
; LA64-NEXT: .LBB2_6: # %atomicrmw.start
; LA64-NEXT: # in Loop: Header=BB2_1 Depth=1
-; LA64-NEXT: move $a3, $a1
-; LA64-NEXT: bne $a1, $a4, .LBB2_1
+; LA64-NEXT: bne $a2, $a3, .LBB2_1
; LA64-NEXT: # %bb.2: # %atomicrmw.end
-; LA64-NEXT: move $a0, $a1
+; LA64-NEXT: move $a0, $a2
; LA64-NEXT: ret
%result = atomicrmw uinc_wrap ptr %ptr, i32 %val seq_cst
ret i32 %result
@@ -209,15 +206,16 @@ define i8 @atomicrmw_udec_wrap_i8(ptr %ptr, i8 %val) {
; LA64-NEXT: andi $a6, $a6, 255
; LA64-NEXT: sll.w $a6, $a6, $a3
; LA64-NEXT: and $a7, $a2, $a4
-; LA64-NEXT: or $a7, $a7, $a6
+; LA64-NEXT: or $a6, $a7, $a6
+; LA64-NEXT: addi.w $a7, $a2, 0
; LA64-NEXT: .LBB4_3: # %atomicrmw.start
; LA64-NEXT: # Parent Loop BB4_1 Depth=1
; LA64-NEXT: # => This Inner Loop Header: Depth=2
-; LA64-NEXT: ll.w $a6, $a0, 0
-; LA64-NEXT: bne $a6, $a2, .LBB4_5
+; LA64-NEXT: ll.w $a2, $a0, 0
+; LA64-NEXT: bne $a2, $a7, .LBB4_5
; LA64-NEXT: # %bb.4: # %atomicrmw.start
; LA64-NEXT: # in Loop: Header=BB4_3 Depth=2
-; LA64-NEXT: move $t0, $a7
+; LA64-NEXT: move $t0, $a6
; LA64-NEXT: sc.w $t0, $a0, 0
; LA64-NEXT: beqz $t0, .LBB4_3
; LA64-NEXT: b .LBB4_6
@@ -226,11 +224,9 @@ define i8 @atomicrmw_udec_wrap_i8(ptr %ptr, i8 %val) {
; LA64-NEXT: dbar 20
; LA64-NEXT: .LBB4_6: # %atomicrmw.start
; LA64-NEXT: # in Loop: Header=BB4_1 Depth=1
-; LA64-NEXT: addi.w $a7, $a2, 0
-; LA64-NEXT: move $a2, $a6
-; LA64-NEXT: bne $a6, $a7, .LBB4_1
+; LA64-NEXT: bne $a2, $a7, .LBB4_1
; LA64-NEXT: # %bb.2: # %atomicrmw.end
-; LA64-NEXT: srl.w $a0, $a6, $a3
+; LA64-NEXT: srl.w $a0, $a2, $a3
; LA64-NEXT: ret
%result = atomicrmw udec_wrap ptr %ptr, i8 %val seq_cst
ret i8 %result
@@ -266,15 +262,16 @@ define i16 @atomicrmw_udec_wrap_i16(ptr %ptr, i16 %val) {
; LA64-NEXT: bstrpick.d $a6, $a6, 15, 0
; LA64-NEXT: sll.w $a6, $a6, $a3
; LA64-NEXT: and $a7, $a2, $a4
-; LA64-NEXT: or $a7, $a7, $a6
+; LA64-NEXT: or $a6, $a7, $a6
+; LA64-NEXT: addi.w $a7, $a2, 0
; LA64-NEXT: .LBB5_3: # %atomicrmw.start
; LA64-NEXT: # Parent Loop BB5_1 Depth=1
; LA64-NEXT: # => This Inner Loop Header: Depth=2
-; LA64-NEXT: ll.w $a6, $a0, 0
-; LA64-NEXT: bne $a6, $a2, .LBB5_5
+; LA64-NEXT: ll.w $a2, $a0, 0
+; LA64-NEXT: bne $a2, $a7, .LBB5_5
; LA64-NEXT: # %bb.4: # %atomicrmw.start
; LA64-NEXT: # in Loop: Header=BB5_3 Depth=2
-; LA64-NEXT: move $t0, $a7
+; LA64-NEXT: move $t0, $a6
; LA64-NEXT: sc.w $t0, $a0, 0
; LA64-NEXT: beqz $t0, .LBB5_3
; LA64-NEXT: b .LBB5_6
@@ -283,11 +280,9 @@ define i16 @atomicrmw_udec_wrap_i16(ptr %ptr, i16 %val) {
; LA64-NEXT: dbar 20
; LA64-NEXT: .LBB5_6: # %atomicrmw.start
; LA64-NEXT: # in Loop: Header=BB5_1 Depth=1
-; LA64-NEXT: addi.w $a7, $a2, 0
-; LA64-NEXT: move $a2, $a6
-; LA64-NEXT: bne $a6, $a7, .LBB5_1
+; LA64-NEXT: bne $a2, $a7, .LBB5_1
; LA64-NEXT: # %bb.2: # %atomicrmw.end
-; LA64-NEXT: srl.w $a0, $a6, $a3
+; LA64-NEXT: srl.w $a0, $a2, $a3
; LA64-NEXT: ret
%result = atomicrmw udec_wrap ptr %ptr, i16 %val seq_cst
ret i16 %result
@@ -296,22 +291,22 @@ define i16 @atomicrmw_udec_wrap_i16(ptr %ptr, i16 %val) {
define i32 @atomicrmw_udec_wrap_i32(ptr %ptr, i32 %val) {
; LA64-LABEL: atomicrmw_udec_wrap_i32:
; LA64: # %bb.0:
-; LA64-NEXT: ld.w $a4, $a0, 0
+; LA64-NEXT: ld.w $a2, $a0, 0
; LA64-NEXT: addi.w $a3, $a1, 0
; LA64-NEXT: .p2align 4, , 16
; LA64-NEXT: .LBB6_1: # %atomicrmw.start
; LA64-NEXT: # =>This Loop Header: Depth=1
; LA64-NEXT: # Child Loop BB6_3 Depth 2
-; LA64-NEXT: addi.w $a5, $a4, 0
-; LA64-NEXT: sltu $a2, $a3, $a5
-; LA64-NEXT: addi.d $a6, $a4, -1
-; LA64-NEXT: masknez $a6, $a6, $a2
-; LA64-NEXT: maskeqz $a2, $a1, $a2
-; LA64-NEXT: or $a2, $a2, $a6
-; LA64-NEXT: sltui $a6, $a5, 1
-; LA64-NEXT: masknez $a2, $a2, $a6
-; LA64-NEXT: maskeqz $a6, $a1, $a6
-; LA64-NEXT: or $a6, $a6, $a2
+; LA64-NEXT: addi.w $a4, $a2, 0
+; LA64-NEXT: sltu $a5, $a3, $a4
+; LA64-NEXT: addi.d $a2, $a2, -1
+; LA64-NEXT: masknez $a2, $a2, $a5
+; LA64-NEXT: maskeqz $a5, $a1, $a5
+; LA64-NEXT: or $a2, $a5, $a2
+; LA64-NEXT: sltui $a5, $a4, 1
+; LA64-NEXT: masknez $a2, $a2, $a5
+; LA64-NEXT: maskeqz $a5, $a1, $a5
+; LA64-NEXT: or $a5, $a5, $a2
; LA64-NEXT: .LBB6_3: # %atomicrmw.start
; LA64-NEXT: # Parent Loop BB6_1 Depth=1
; LA64-NEXT: # => This Inner Loop Header: Depth=2
@@ -319,17 +314,16 @@ define i32 @atomicrmw_udec_wrap_i32(ptr %ptr, i32 %val) {
; LA64-NEXT: bne $a2, $a4, .LBB6_5
; LA64-NEXT: # %bb.4: # %atomicrmw.start
; LA64-NEXT: # in Loop: Header=BB6_3 Depth=2
-; LA64-NEXT: move $a7, $a6
-; LA64-NEXT: sc.w $a7, $a0, 0
-; LA64-NEXT: beqz $a7, .LBB6_3
+; LA64-NEXT: move $a6, $a5
+; LA64-NEXT: sc.w $a6, $a0, 0
+; LA64-NEXT: beqz $a6, .LBB6_3
; LA64-NEXT: b .LBB6_6
; LA64-NEXT: .LBB6_5: # %atomicrmw.start
; LA64-NEXT: # in Loop: Header=BB6_1 Depth=1
; LA64-NEXT: dbar 20
; LA64-NEXT: .LBB6_6: # %atomicrmw.start
; LA64-NEXT: # in Loop: Header=BB6_1 Depth=1
-; LA64-NEXT: move $a4, $a2
-; LA64-NEXT: bne $a2, $a5, .LBB6_1
+; LA64-NEXT: bne $a2, $a4, .LBB6_1
; LA64-NEXT: # %bb.2: # %atomicrmw.end
; LA64-NEXT: move $a0, $a2
; LA64-NEXT: ret
diff --git a/llvm/test/CodeGen/LoongArch/ir-instruction/atomic-cmpxchg.ll b/llvm/test/CodeGen/LoongArch/ir-instruction/atomic-cmpxchg.ll
index 417c865f6383ff..31ecec6ea8051b 100644
--- a/llvm/test/CodeGen/LoongArch/ir-instruction/atomic-cmpxchg.ll
+++ b/llvm/test/CodeGen/LoongArch/ir-instruction/atomic-cmpxchg.ll
@@ -69,6 +69,7 @@ define void @cmpxchg_i16_acquire_acquire(ptr %ptr, i16 %cmp, i16 %val) nounwind
define void @cmpxchg_i32_acquire_acquire(ptr %ptr, i32 %cmp, i32 %val) nounwind {
; LA64-LABEL: cmpxchg_i32_acquire_acquire:
; LA64: # %bb.0:
+; LA64-NEXT: addi.w $a1, $a1, 0
; LA64-NEXT: .LBB2_1: # =>This Inner Loop Header: Depth=1
; LA64-NEXT: ll.w $a3, $a0, 0
; LA64-NEXT: bne $a3, $a1, .LBB2_3
@@ -172,6 +173,7 @@ define void @cmpxchg_i16_acquire_monotonic(ptr %ptr, i16 %cmp, i16 %val) nounwin
define void @cmpxchg_i32_acquire_monotonic(ptr %ptr, i32 %cmp, i32 %val) nounwind {
; LA64-LABEL: cmpxchg_i32_acquire_monotonic:
; LA64: # %bb.0:
+; LA64-NEXT: addi.w $a1, $a1, 0
; LA64-NEXT: .LBB6_1: # =>This Inner Loop Header: Depth=1
; LA64-NEXT: ll.w $a3, $a0, 0
; LA64-NEXT: bne $a3, $a1, .LBB6_3
@@ -279,9 +281,10 @@ define i16 @cmpxchg_i16_acquire_acquire_reti16(ptr %ptr, i16 %cmp, i16 %val) nou
define i32 @cmpxchg_i32_acquire_acquire_reti32(ptr %ptr, i32 %cmp, i32 %val) nounwind {
; LA64-LABEL: cmpxchg_i32_acquire_acquire_reti32:
; LA64: # %bb.0:
+; LA64-NEXT: addi.w $a3, $a1, 0
; LA64-NEXT: .LBB10_1: # =>This Inner Loop Header: Depth=1
-; LA64-NEXT: ll.w $a3, $a0, 0
-; LA64-NEXT: bne $a3, $a1, .LBB10_3
+; LA64-NEXT: ll.w $a1, $a0, 0
+; LA64-NEXT: bne $a1, $a3, .LBB10_3
; LA64-NEXT: # %bb.2: # in Loop: Header=BB10_1 Depth=1
; LA64-NEXT: move $a4, $a2
; LA64-NEXT: sc.w $a4, $a0, 0
@@ -290,7 +293,7 @@ define i32 @cmpxchg_i32_acquire_acquire_reti32(ptr %ptr, i32 %cmp, i32 %val) nou
; LA64-NEXT: .LBB10_3:
; LA64-NEXT: dbar 20
; LA64-NEXT: .LBB10_4:
-; LA64-NEXT: move $a0, $a3
+; LA64-NEXT: move $a0, $a1
; LA64-NEXT: ret
%tmp = cmpxchg ptr %ptr, i32 %cmp, i32 %val acquire acquire
%res = extractvalue { i32, i1 } %tmp, 0
@@ -396,6 +399,7 @@ define i1 @cmpxchg_i16_acquire_acquire_reti1(ptr %ptr, i16 %cmp, i16 %val) nounw
define i1 @cmpxchg_i32_acquire_acquire_reti1(ptr %ptr, i32 %cmp, i32 %val) nounwind {
; LA64-LABEL: cmpxchg_i32_acquire_acquire_reti1:
; LA64: # %bb.0:
+; LA64-NEXT: addi.w $a1, $a1, 0
; LA64-NEXT: .LBB14_1: # =>This Inner Loop Header: Depth=1
; LA64-NEXT: ll.w $a3, $a0, 0
; LA64-NEXT: bne $a3, $a1, .LBB14_3
@@ -407,8 +411,7 @@ define i1 @cmpxchg_i32_acquire_acquire_reti1(ptr %ptr, i32 %cmp, i32 %val) nounw
; LA64-NEXT: .LBB14_3:
; LA64-NEXT: dbar 20
; LA64-NEXT: .LBB14_4:
-; LA64-NEXT: addi.w $a0, $a1, 0
-; LA64-NEXT: xor $a0, $a3, $a0
+; LA64-NEXT: xor $a0, $a3, $a1
; LA64-NEXT: sltui $a0, $a0, 1
; LA64-NEXT: ret
%tmp = cmpxchg ptr %ptr, i32 %cmp, i32 %val acquire acquire
@@ -506,6 +509,7 @@ define void @cmpxchg_i16_monotonic_monotonic(ptr %ptr, i16 %cmp, i16 %val) nounw
define void @cmpxchg_i32_monotonic_monotonic(ptr %ptr, i32 %cmp, i32 %val) nounwind {
; LA64-LABEL: cmpxchg_i32_monotonic_monotonic:
; LA64: # %bb.0:
+; LA64-NEXT: addi.w $a1, $a1, 0
; LA64-NEXT: .LBB18_1: # =>This Inner Loop Header: Depth=1
; LA64-NEXT: ll.w $a3, $a0, 0
; LA64-NEXT: bne $a3, $a1, .LBB18_3
@@ -613,9 +617,10 @@ define i16 @cmpxchg_i16_monotonic_monotonic_reti16(ptr %ptr, i16 %cmp, i16 %val)
define i32 @cmpxchg_i32_monotonic_monotonic_reti32(ptr %ptr, i32 %cmp, i32 %val) nounwind {
; LA64-LABEL: cmpxchg_i32_monotonic_monotonic_reti32:
; LA64: # %bb.0:
+; LA64-NEXT: addi.w $a3, $a1, 0
; LA64-NEXT: .LBB22_1: # =>This Inner Loop Header: Depth=1
-; LA64-NEXT: ll.w $a3, $a0, 0
-; LA64-NEXT: bne $a3, $a1, .LBB22_3
+; LA64-NEXT: ll.w $a1, $a0, 0
+; LA64-NEXT: bne $a1, $a3, .LBB22_3
; LA64-NEXT: # %bb.2: # in Loop: Header=BB22_1 Depth=1
; LA64-NEXT: move $a4, $a2
; LA64-NEXT: sc.w $a4, $a0, 0
@@ -624,7 +629,7 @@ define i32 @cmpxchg_i32_monotonic_monotonic_reti32(ptr %ptr, i32 %cmp, i32 %val)
; LA64-NEXT: .LBB22_3:
; LA64-NEXT: dbar 1792
; LA64-NEXT: .LBB22_4:
-; LA64-NEXT: move $a0, $a3
+; LA64-NEXT: move $a0, $a1
; LA64-NEXT: ret
%tmp = cmpxchg ptr %ptr, i32 %cmp, i32 %val monotonic monotonic
%res = extractvalue { i32, i1 } %tmp, 0
@@ -730,6 +735,7 @@ define i1 @cmpxchg_i16_monotonic_monotonic_reti1(ptr %ptr, i16 %cmp, i16 %val) n
define i1 @cmpxchg_i32_monotonic_monotonic_reti1(ptr %ptr, i32 %cmp, i32 %val) nounwind {
; LA64-LABEL: cmpxchg_i32_monotonic_monotonic_reti1:
; LA64: # %bb.0:
+; LA64-NEXT: addi.w $a1, $a1, 0
; LA64-NEXT: .LBB26_1: # =>This Inner Loop Header: Depth=1
; LA64-NEXT: ll.w $a3, $a0, 0
; LA64-NEXT: bne $a3, $a1, .LBB26_3
@@ -741,8 +747,7 @@ define i1 @cmpxchg_i32_monotonic_monotonic_reti1(ptr %ptr, i32 %cmp, i32 %val) n
; LA64-NEXT: .LBB26_3:
; LA64-NEXT: dbar 1792
; LA64-NEXT: .LBB26_4:
-; LA64-NEXT: addi.w $a0, $a1, 0
-; LA64-NEXT: xor $a0, $a3, $a0
+; LA64-NEXT: xor $a0, $a3, $a1
; LA64-NEXT: sltui $a0, $a0, 1
; LA64-NEXT: ret
%tmp = cmpxchg ptr %ptr, i32 %cmp, i32 %val monotonic monotonic
diff --git a/llvm/test/CodeGen/LoongArch/ir-instruction/atomicrmw-fp.ll b/llvm/test/CodeGen/LoongArch/ir-instruction/atomicrmw-fp.ll
index 589360823b1488..4d8160d7080340 100644
--- a/llvm/test/CodeGen/LoongArch/ir-instruction/atomicrmw-fp.ll
+++ b/llvm/test/CodeGen/LoongArch/ir-instruction/atomicrmw-fp.ll
@@ -16,6 +16,7 @@ define float @float_fadd_acquire(ptr %p) nounwind {
; LA64F-NEXT: fadd.s $fa2, $fa0, $fa1
; LA64F-NEXT: movfr2gr.s $a1, $fa2
; LA64F-NEXT: movfr2gr.s $a2, $fa0
+; LA64F-NEXT: addi.w $a2, $a2, 0
; LA64F-NEXT: .LBB0_3: # %atomicrmw.start
; LA64F-NEXT: # Parent Loop BB0_1 Depth=1
; LA64F-NEXT: # => This Inner Loop Header: Depth=2
@@ -33,8 +34,7 @@ define float @float_fadd_acquire(ptr %p) nounwind {
; LA64F-NEXT: .LBB0_6: # %atomicrmw.start
; LA64F-NEXT: # in Loop: Header=BB0_1 Depth=1
; LA64F-NEXT: movgr2fr.w $fa0, $a3
-; LA64F-NEXT: addi.w $a1, $a2, 0
-; LA64F-NEXT: bne $a3, $a1, .LBB0_1
+; LA64F-NEXT: bne $a3, $a2, .LBB0_1
; LA64F-NEXT: # %bb.2: # %atomicrmw.end
; LA64F-NEXT: ret
;
@@ -51,6 +51,7 @@ define float @float_fadd_acquire(ptr %p) nounwind {
; LA64D-NEXT: fadd.s $fa2, $fa0, $fa1
; LA64D-NEXT: movfr2gr.s $a1, $fa2
; LA64D-NEXT: movfr2gr.s $a2, $fa0
+; LA64D-NEXT: addi.w $a2, $a2, 0
; LA64D-NEXT: .LBB0_3: # %atomicrmw.start
; LA64D-NEXT: # Parent Loop BB0_1 Depth=1
; LA64D-NEXT: # => This Inner Loop Header: Depth=2
@@ -68,8 +69,7 @@ define float @float_fadd_acquire(ptr %p) nounwind {
; LA64D-NEXT: .LBB0_6: # %atomicrmw.start
; LA64D-NEXT: # in Loop: Header=BB0_1 Depth=1
; LA64D-NEXT: movgr2fr.w $fa0, $a3
-; LA64D-NEXT: addi.w $a1, $a2, 0
-; LA64D-NEXT: bne $a3, $a1, .LBB0_1
+; LA64D-NEXT: bne $a3, $a2, .LBB0_1
; LA64D-NEXT: # %bb.2: # %atomicrmw.end
; LA64D-NEXT: ret
%v = atomicrmw fadd ptr %p, float 1.0 acquire, align 4
@@ -90,6 +90,7 @@ define float @float_fsub_acquire(ptr %p) nounwind {
; LA64F-NEXT: fadd.s $fa2, $fa0, $fa1
; LA64F-NEXT: movfr2gr.s $a1, $fa2
; LA64F-NEXT: movfr2gr.s $a2, $fa0
+; LA64F-NEXT: addi.w $a2, $a2, 0
; LA64F-NEXT: .LBB1_3: # %atomicrmw.start
; LA64F-NEXT: # Parent Loop BB1_1 Depth=1
; LA64F-NEXT: # => This Inner Loop Header: Depth=2
@@ -107,8 +108,7 @@ define float @float_fsub_acquire(ptr %p) nounwind {
; LA64F-NEXT: .LBB1_6: # %atomicrmw.start
; LA64F-NEXT: # in Loop: Header=BB1_1 Depth=1
; LA64F-NEXT: movgr2fr.w $fa0, $a3
-; LA64F-NEXT: addi.w $a1, $a2, 0
-; LA64F-NEXT: bne $a3, $a1, .LBB1_1
+; LA64F-NEXT: bne $a3, $a2, .LBB1_1
; LA64F-NEXT: # %bb.2: # %atomicrmw.end
; LA64F-NEXT: ret
;
@@ -125,6 +125,7 @@ define float @float_fsub_acquire(ptr %p) nounwind {
; LA64D-NEXT: fadd.s $fa2, $fa0, $fa1
; LA64D-NEXT: movfr2gr.s $a1, $fa2
; LA64D-NEXT: movfr2gr.s $a2, $fa0
+; LA64D-NEXT: addi.w $a2, $a2, 0
; LA64D-NEXT: .LBB1_3: # %atomicrmw.start
; LA64D-NEXT: # Parent Loop BB1_1 Depth=1
; LA64D-NEXT: # => This Inner Loop Header: Depth=2
@@ -142,8 +143,7 @@ define float @float_fsub_acquire(ptr %p) nounwind {
; LA64D-NEXT: .LBB1_6: # %atomicrmw.start
; LA64D-NEXT: # in Loop: Header=BB1_1 Depth=1
; LA64D-NEXT: movgr2fr.w $fa0, $a3
-; LA64D-NEXT: addi.w $a1, $a2, 0
-; LA64D-NEXT: bne $a3, $a1, .LBB1_1
+; LA64D-NEXT: bne $a3, $a2, .LBB1_1
; LA64D-NEXT: # %bb.2: # %atomicrmw.end
; LA64D-NEXT: ret
%v = atomicrmw fsub ptr %p, float 1.0 acquire, align 4
@@ -165,6 +165,7 @@ define float @float_fmin_acquire(ptr %p) nounwind {
; LA64F-NEXT: fmin.s $fa2, $fa2, $fa1
; LA64F-NEXT: movfr2gr.s $a1, $fa2
; LA64F-NEXT: movfr2gr.s $a2, $fa0
+; LA64F-NEXT: addi.w $a2, $a2, 0
; LA64F-NEXT: .LBB2_3: # %atomicrmw.start
; LA64F-NEXT: # Parent Loop BB2_1 Depth=1
; LA64F-NEXT: # => This Inner Loop Header: Depth=2
@@ -182,8 +183,7 @@ define float @float_fmin_acquire(ptr %p) nounwind {
; LA64F-NEXT: .LBB2_6: # %atomicrmw.start
; LA64F-NEXT: # in Loop: Header=BB2_1 Depth=1
; LA64F-NEXT: movgr2fr.w $fa0, $a3
-; LA64F-NEXT: addi.w $a1, $a2, 0
-; LA64F-NEXT: bne $a3, $a1, .LBB2_1
+; LA64F-NEXT: bne $a3, $a2, .LBB2_1
; LA64F-NEXT: # %bb.2: # %atomicrmw.end
; LA64F-NEXT: ret
;
@@ -201,6 +201,7 @@ define float @float_fmin_acquire(ptr %p) nounwind {
; LA64D-NEXT: fmin.s $fa2, $fa2, $fa1
; LA64D-NEXT: movfr2gr.s $a1, $fa2
; LA64D-NEXT: movfr2gr.s $a2, $fa0
+; LA64D-NEXT: addi.w $a2, $a2, 0
; LA64D-NEXT: .LBB2_3: # %atomicrmw.start
; LA64D-NEXT: # Parent Loop BB2_1 Depth=1
; LA64D-NEXT: # => This Inner Loop Header: Depth=2
@@ -218,8 +219,7 @@ define float @float_fmin_acquire(ptr %p) nounwind {
; LA64D-NEXT: .LBB2_6: # %atomicrmw.start
; LA64D-NEXT: # in Loop: Header=BB2_1 Depth=1
; LA64D-NEXT: movgr2fr.w $fa0, $a3
-; LA64D-NEXT: addi.w $a1, $a2, 0
-; LA64D-NEXT: bne $a3, $a1, .LBB2_1
+; LA64D-NEXT: bne $a3, $a2, .LBB2_1
; LA64D-NEXT: # %bb.2: # %atomicrmw.end
; LA64D-NEXT: ret
%v = atomicrmw fmin ptr %p, float 1.0 acquire, align 4
@@ -241,6 +241,7 @@ define float @float_fmax_acquire(ptr %p) nounwind {
; LA64F-NEXT: fmax.s $fa2, $fa2, $fa1
; LA64F-NEXT: movfr2gr.s $a1, $fa2
; LA64F-NEXT: movfr2gr.s $a2, $fa0
+; LA64F-NEXT: addi.w $a2, $a2, 0
; LA64F-NEXT: .LBB3_3: # %atomicrmw.start
; LA64F-NEXT: # Parent Loop BB3_1 Depth=1
; LA64F-NEXT: # => This Inner Loop Header: Depth=2
@@ -258,8 +259,7 @@ define float @float_fmax_acquire(ptr %p) nounwind {
; LA64F-NEXT: .LBB3_6: # %atomicrmw.start
; LA64F-NEXT: # in Loop: Header=BB3_1 Depth=1
; LA64F-NEXT: movgr2fr.w $fa0, $a3
-; LA64F-NEXT: addi.w $a1, $a2, 0
-; LA64F-NEXT: bne $a3, $a1, .LBB3_1
+; LA64F-NEXT: bne $a3, $a2, .LBB3_1
; LA64F-NEXT: # %bb.2: # %atomicrmw.end
; LA64F-NEXT: ret
;
@@ -277,6 +277,7 @@ define float @float_fmax_acquire(ptr %p) nounwind {
; LA64D-NEXT: fmax.s $fa2, $fa2, $fa1
; LA64D-NEXT: movfr2gr.s $a1, $fa2
; LA64D-NEXT: movfr2gr.s $a2, $fa0
+; LA64D-NEXT: addi.w $a2, $a2, 0
; LA64D-NEXT: .LBB3_3: # %atomicrmw.start
; LA64D-NEXT: # Parent Loop BB3_1 Depth=1
; LA64D-NEXT: # => This Inner Loop Header: Depth=2
@@ -294,8 +295,7 @@ define float @float_fmax_acquire(ptr %p) nounwind {
; LA64D-NEXT: .LBB3_6: # %atomicrmw.start
; LA64D-NEXT: # in Loop: Header=BB3_1 Depth=1
; LA64D-NEXT: movgr2fr.w $fa0, $a3
-; LA64D-NEXT: addi.w $a1, $a2, 0
-; LA64D-NEXT: bne $a3, $a1, .LBB3_1
+; LA64D-NEXT: bne $a3, $a2, .LBB3_1
; LA64D-NEXT: # %bb.2: # %atomicrmw.end
; LA64D-NEXT: ret
%v = atomicrmw fmax ptr %p, float 1.0 acquire, align 4
@@ -694,6 +694,7 @@ define float @float_fadd_release(ptr %p) nounwind {
; LA64F-NEXT: fadd.s $fa2, $fa0, $fa1
; LA64F-NEXT: movfr2gr.s $a1, $fa2
; LA64F-NEXT: movfr2gr.s $a2, $fa0
+; LA64F-NEXT: addi.w $a2, $a2, 0
; LA64F-NEXT: .LBB8_3: # %atomicrmw.start
; LA64F-NEXT: # Parent Loop BB8_1 Depth=1
; LA64F-NEXT: # => This Inner Loop Header: Depth=2
@@ -711,8 +712,7 @@ define float @float_fadd_release(ptr %p) nounwind {
; LA64F-NEXT: .LBB8_6: # %atomicrmw.start
; LA64F-NEXT: # in Loop: Header=BB8_1 Depth=1
; LA64F-NEXT: movgr2fr.w $fa0, $a3
-; LA64F-NEXT: addi.w $a1, $a2, 0
-; LA64F-NEXT: bne $a3, $a1, .LBB8_1
+; LA64F-NEXT: bne $a3, $a2, .LBB8_1
; LA64F-NEXT: # %bb.2: # %atomicrmw.end
; LA64F-NEXT: ret
;
@@ -729,6 +729,7 @@ define float @float_fadd_release(ptr %p) nounwind {
; LA64D-NEXT: fadd.s $fa2, $fa0, $fa1
; LA64D-NEXT: movfr2gr.s $a1, $fa2
; LA64D-NEXT: movfr2gr.s $a2, $fa0
+; LA64D-NEXT: addi.w $a2, $a2, 0
; LA64D-NEXT: .LBB8_3: # %atomicrmw.start
; LA64D-NEXT: # Parent Loop BB8_1 Depth=1
; LA64D-NEXT: # => This Inner Loop Header: Depth=2
@@ -746,8 +747,7 @@ define float @float_fadd_release(ptr %p) nounwind {
; LA64D-NEXT: .LBB8_6: # %atomicrmw.start
; LA64D-NEXT: # in Loop: Header=BB8_1 Depth=1
; LA64D-NEXT: movgr2fr.w $fa0, $a3
-; LA64D-NEXT: addi.w $a1, $a2, 0
-; LA64D-NEXT: bne $a3, $a1, .LBB8_1
+; LA64D-NEXT: bne $a3, $a2, .LBB8_1
; LA64D-NEXT: # %bb.2: # %atomicrmw.end
; LA64D-NEXT: ret
%v = atomicrmw fadd ptr %p, float 1.0 release, align 4
@@ -768,6 +768,7 @@ define float @float_fsub_release(ptr %p) nounwind {
; LA64F-NEXT: fadd.s $fa2, $fa0, $fa1
; LA64F-NEXT: movfr2gr.s $a1, $fa2
; LA64F-NEXT: movfr2gr.s $a2, $fa0
+; LA64F-NEXT: addi.w $a2, $a2, 0
; LA64F-NEXT: .LBB9_3: # %atomicrmw.start
; LA64F-NEXT: # Parent Loop BB9_1 Depth=1
; LA64F-NEXT: # => This Inner Loop Header: Depth=2
@@ -785,8 +786,7 @@ define float @float_fsub_release(ptr %p) nounwind {
; LA64F-NEXT: .LBB9_6: # %atomicrmw.start
; LA64F-NEXT: # in Loop: Header=BB9_1 Depth=1
; LA64F-NEXT: movgr2fr.w $fa0, $a3
-; LA64F-NEXT: addi.w $a1, $a2, 0
-; LA64F-NEXT: bne $a3, $a1, .LBB9_1
+; LA64F-NEXT: bne $a3, $a2, .LBB9_1
; LA64F-NEXT: # %bb.2: # %atomicrmw.end
; LA64F-NEXT: ret
;
@@ -803,6 +803,7 @@ define float @float_fsub_release(ptr %p) nounwind {
; LA64D-NEXT: fadd.s $fa2, $fa0, $fa1
; LA64D-NEXT: movfr2gr.s $a1, $fa2
; LA64D-NEXT: movfr2gr.s $a2, $fa0
+; LA64D-NEXT: addi.w $a2, $a2, 0
; LA64D-NEXT: .LBB9_3: # %atomicrmw.start
; LA64D-NEXT: # Parent Loop BB9_1 Depth=1
; LA64D-NEXT: # => This Inner Loop Header: Depth=2
@@ -820,8 +821,7 @@ define float @float_fsub_release(ptr %p) nounwind {
; LA64D-NEXT: .LBB9_6: # %atomicrmw.start
; LA64D-NEXT: # in Loop: Header=BB9_1 Depth=1
; LA64D-NEXT: movgr2fr.w $fa0, $a3
-; LA64D-NEXT: addi.w $a1, $a2, 0
-; LA64D-NEXT: bne $a3, $a1, .LBB9_1
+; LA64D-NEXT: bne $a3, $a2, .LBB9_1
; LA64D-NEXT: # %bb.2: # %atomicrmw.end
; LA64D-NEXT: ret
%v = atomicrmw fsub ptr %p, float 1.0 release, align 4
@@ -843,6 +843,7 @@ define float @float_fmin_release(ptr %p) nounwind {
; LA64F-NEXT: fmin.s $fa2, $fa2, $fa1
; LA64F-NEXT: movfr2gr.s $a1, $fa2
; LA64F-NEXT: movfr2gr.s $a2, $fa0
+; LA64F-NEXT: addi.w $a2, $a2, 0
; LA64F-NEXT: .LBB10_3: # %atomicrmw.start
; LA64F-NEXT: # Parent Loop BB10_1 Depth=1
; LA64F-NEXT: # => This Inner Loop Header: Depth=2
@@ -860,8 +861,7 @@ define float @float_fmin_release(ptr %p) nounwind {
; LA64F-NEXT: .LBB10_6: # %atomicrmw.start
; LA64F-NEXT: # in Loop: Header=BB10_1 Depth=1
; LA64F-NEXT: movgr2fr.w $fa0, $a3
-; LA64F-NEXT: addi.w $a1, $a2, 0
-; LA64F-NEXT: bne $a3, $a1, .LBB10_1
+; LA64F-NEXT: bne $a3, $a2, .LBB10_1
; LA64F-NEXT: # %bb.2: # %atomicrmw.end
; LA64F-NEXT: ret
;
@@ -879,6 +879,7 @@ define float @float_fmin_release(ptr %p) nounwind {
; LA64D-NEXT: fmin.s $fa2, $fa2, $fa1
; LA64D-NEXT: movfr2gr.s $a1, $fa2
; LA64D-NEXT: movfr2gr.s $a2, $fa0
+; LA64D-NEXT: addi.w $a2, $a2, 0
; LA64D-NEXT: .LBB10_3: # %atomicrmw.start
; LA64D-NEXT: # Parent Loop BB10_1 Depth=1
; LA64D-NEXT: # => This Inner Loop Header: Depth=2
@@ -896,8 +897,7 @@ define float @float_fmin_release(ptr %p) nounwind {
; LA64D-NEXT: .LBB10_6: # %atomicrmw.start
; LA64D-NEXT: # in Loop: Header=BB10_1 Depth=1
; LA64D-NEXT: movgr2fr.w $fa0, $a3
-; LA64D-NEXT: addi.w $a1, $a2, 0
-; LA64D-NEXT: bne $a3, $a1, .LBB10_1
+; LA64D-NEXT: bne $a3, $a2, .LBB10_1
; LA64D-NEXT: # %bb.2: # %atomicrmw.end
; LA64D-NEXT: ret
%v = atomicrmw fmin ptr %p, float 1.0 release, align 4
@@ -919,6 +919,7 @@ define float @float_fmax_release(ptr %p) nounwind {
; LA64F-NEXT: fmax.s $fa2, $fa2, $fa1
; LA64F-NEXT: movfr2gr.s $a1, $fa2
; LA64F-NEXT: movfr2gr.s $a2, $fa0
+; LA64F-NEXT: addi.w $a2, $a2, 0
; LA64F-NEXT: .LBB11_3: # %atomicrmw.start
; LA64F-NEXT: # Parent Loop BB11_1 Depth=1
; LA64F-NEXT: # => This Inner Loop Header: Depth=2
@@ -936,8 +937,7 @@ define float @float_fmax_release(ptr %p) nounwind {
; LA64F-NEXT: .LBB11_6: # %atomicrmw.start
; LA64F-NEXT: # in Loop: Header=BB11_1 Depth=1
; LA64F-NEXT: movgr2fr.w $fa0, $a3
-; LA64F-NEXT: addi.w $a1, $a2, 0
-; LA64F-NEXT: bne $a3, $a1, .LBB11_1
+; LA64F-NEXT: bne $a3, $a2, .LBB11_1
; LA64F-NEXT: # %bb.2: # %atomicrmw.end
; LA64F-NEXT: ret
;
@@ -955,6 +955,7 @@ define float @float_fmax_release(ptr %p) nounwind {
; LA64D-NEXT: fmax.s $fa2, $fa2, $fa1
; LA64D-NEXT: movfr2gr.s $a1, $fa2
; LA64D-NEXT: movfr2gr.s $a2, $fa0
+; LA64D-NEXT: addi.w $a2, $a2, 0
; LA64D-NEXT: .LBB11_3: # %atomicrmw.start
; LA64D-NEXT: # Parent Loop BB11_1 Depth=1
; LA64D-NEXT: # => This Inner Loop Header: Depth=2
@@ -972,8 +973,7 @@ define float @float_fmax_release(ptr %p) nounwind {
; LA64D-NEXT: .LBB11_6: # %atomicrmw.start
; LA64D-NEXT: # in Loop: Header=BB11_1 Depth=1
; LA64D-NEXT: movgr2fr.w $fa0, $a3
-; LA64D-NEXT: addi.w $a1, $a2, 0
-; LA64D-NEXT: bne $a3, $a1, .LBB11_1
+; LA64D-NEXT: bne $a3, $a2, .LBB11_1
; LA64D-NEXT: # %bb.2: # %atomicrmw.end
; LA64D-NEXT: ret
%v = atomicrmw fmax ptr %p, float 1.0 release, align 4
@@ -1372,6 +1372,7 @@ define float @float_fadd_acq_rel(ptr %p) nounwind {
; LA64F-NEXT: fadd.s $fa2, $fa0, $fa1
; LA64F-NEXT: movfr2gr.s $a1, $fa2
; LA64F-NEXT: movfr2gr.s $a2, $fa0
+; LA64F-NEXT: addi.w $a2, $a2, 0
; LA64F-NEXT: .LBB16_3: # %atomicrmw.start
; LA64F-NEXT: # Parent Loop BB16_1 Depth=1
; LA64F-NEXT: # => This Inner Loop Header: Depth=2
@@ -1389,8 +1390,7 @@ define float @float_fadd_acq_rel(ptr %p) nounwind {
; LA64F-NEXT: .LBB16_6: # %atomicrmw.start
; LA64F-NEXT: # in Loop: Header=BB16_1 Depth=1
; LA64F-NEXT: movgr2fr.w $fa0, $a3
-; LA64F-NEXT: addi.w $a1, $a2, 0
-; LA64F-NEXT: bne $a3, $a1, .LBB16_1
+; LA64F-NEXT: bne $a3, $a2, .LBB16_1
; LA64F-NEXT: # %bb.2: # %atomicrmw.end
; LA64F-NEXT: ret
;
@@ -1407,6 +1407,7 @@ define float @float_fadd_acq_rel(ptr %p) nounwind {
; LA64D-NEXT: fadd.s $fa2, $fa0, $fa1
; LA64D-NEXT: movfr2gr.s $a1, $fa2
; LA64D-NEXT: movfr2gr.s $a2, $fa0
+; LA64D-NEXT: addi.w $a2, $a2, 0
; LA64D-NEXT: .LBB16_3: # %atomicrmw.start
; LA64D-NEXT: # Parent Loop BB16_1 Depth=1
; LA64D-NEXT: # => This Inner Loop Header: Depth=2
@@ -1424,8 +1425,7 @@ define float @float_fadd_acq_rel(ptr %p) nounwind {
; LA64D-NEXT: .LBB16_6: # %atomicrmw.start
; LA64D-NEXT: # in Loop: Header=BB16_1 Depth=1
; LA64D-NEXT: movgr2fr.w $fa0, $a3
-; LA64D-NEXT: addi.w $a1, $a2, 0
-; LA64D-NEXT: bne $a3, $a1, .LBB16_1
+; LA64D-NEXT: bne $a3, $a2, .LBB16_1
; LA64D-NEXT: # %bb.2: # %atomicrmw.end
; LA64D-NEXT: ret
%v = atomicrmw fadd ptr %p, float 1.0 acq_rel, align 4
@@ -1446,6 +1446,7 @@ define float @float_fsub_acq_rel(ptr %p) nounwind {
; LA64F-NEXT: fadd.s $fa2, $fa0, $fa1
; LA64F-NEXT: movfr2gr.s $a1, $fa2
; LA64F-NEXT: movfr2gr.s $a2, $fa0
+; LA64F-NEXT: addi.w $a2, $a2, 0
; LA64F-NEXT: .LBB17_3: # %atomicrmw.start
; LA64F-NEXT: # Parent Loop BB17_1 Depth=1
; LA64F-NEXT: # => This Inner Loop Header: Depth=2
@@ -1463,8 +1464,7 @@ define float @float_fsub_acq_rel(ptr %p) nounwind {
; LA64F-NEXT: .LBB17_6: # %atomicrmw.start
; LA64F-NEXT: # in Loop: Header=BB17_1 Depth=1
; LA64F-NEXT: movgr2fr.w $fa0, $a3
-; LA64F-NEXT: addi.w $a1, $a2, 0
-; LA64F-NEXT: bne $a3, $a1, .LBB17_1
+; LA64F-NEXT: bne $a3, $a2, .LBB17_1
; LA64F-NEXT: # %bb.2: # %atomicrmw.end
; LA64F-NEXT: ret
;
@@ -1481,6 +1481,7 @@ define float @float_fsub_acq_rel(ptr %p) nounwind {
; LA64D-NEXT: fadd.s $fa2, $fa0, $fa1
; LA64D-NEXT: movfr2gr.s $a1, $fa2
; LA64D-NEXT: movfr2gr.s $a2, $fa0
+; LA64D-NEXT: addi.w $a2, $a2, 0
; LA64D-NEXT: .LBB17_3: # %atomicrmw.start
; LA64D-NEXT: # Parent Loop BB17_1 Depth=1
; LA64D-NEXT: # => This Inner Loop Header: Depth=2
@@ -1498,8 +1499,7 @@ define float @float_fsub_acq_rel(ptr %p) nounwind {
; LA64D-NEXT: .LBB17_6: # %atomicrmw.start
; LA64D-NEXT: # in Loop: Header=BB17_1 Depth=1
; LA64D-NEXT: movgr2fr.w $fa0, $a3
-; LA64D-NEXT: addi.w $a1, $a2, 0
-; LA64D-NEXT: bne $a3, $a1, .LBB17_1
+; LA64D-NEXT: bne $a3, $a2, .LBB17_1
; LA64D-NEXT: # %bb.2: # %atomicrmw.end
; LA64D-NEXT: ret
%v = atomicrmw fsub ptr %p, float 1.0 acq_rel, align 4
@@ -1521,6 +1521,7 @@ define float @float_fmin_acq_rel(ptr %p) nounwind {
; LA64F-NEXT: fmin.s $fa2, $fa2, $fa1
; LA64F-NEXT: movfr2gr.s $a1, $fa2
; LA64F-NEXT: movfr2gr.s $a2, $fa0
+; LA64F-NEXT: addi.w $a2, $a2, 0
; LA64F-NEXT: .LBB18_3: # %atomicrmw.start
; LA64F-NEXT: # Parent Loop BB18_1 Depth=1
; LA64F-NEXT: # => This Inner Loop Header: Depth=2
@@ -1538,8 +1539,7 @@ define float @float_fmin_acq_rel(ptr %p) nounwind {
; LA64F-NEXT: .LBB18_6: # %atomicrmw.start
; LA64F-NEXT: # in Loop: Header=BB18_1 Depth=1
; LA64F-NEXT: movgr2fr.w $fa0, $a3
-; LA64F-NEXT: addi.w $a1, $a2, 0
-; LA64F-NEXT: bne $a3, $a1, .LBB18_1
+; LA64F-NEXT: bne $a3, $a2, .LBB18_1
; LA64F-NEXT: # %bb.2: # %atomicrmw.end
; LA64F-NEXT: ret
;
@@ -1557,6 +1557,7 @@ define float @float_fmin_acq_rel(ptr %p) nounwind {
; LA64D-NEXT: fmin.s $fa2, $fa2, $fa1
; LA64D-NEXT: movfr2gr.s $a1, $fa2
; LA64D-NEXT: movfr2gr.s $a2, $fa0
+; LA64D-NEXT: addi.w $a2, $a2, 0
; LA64D-NEXT: .LBB18_3: # %atomicrmw.start
; LA64D-NEXT: # Parent Loop BB18_1 Depth=1
; LA64D-NEXT: # => This Inner Loop Header: Depth=2
@@ -1574,8 +1575,7 @@ define float @float_fmin_acq_rel(ptr %p) nounwind {
; LA64D-NEXT: .LBB18_6: # %atomicrmw.start
; LA64D-NEXT: # in Loop: Header=BB18_1 Depth=1
; LA64D-NEXT: movgr2fr.w $fa0, $a3
-; LA64D-NEXT: addi.w $a1, $a2, 0
-; LA64D-NEXT: bne $a3, $a1, .LBB18_1
+; LA64D-NEXT: bne $a3, $a2, .LBB18_1
; LA64D-NEXT: # %bb.2: # %atomicrmw.end
; LA64D-NEXT: ret
%v = atomicrmw fmin ptr %p, float 1.0 acq_rel, align 4
@@ -1597,6 +1597,7 @@ define float @float_fmax_acq_rel(ptr %p) nounwind {
; LA64F-NEXT: fmax.s $fa2, $fa2, $fa1
; LA64F-NEXT: movfr2gr.s $a1, $fa2
; LA64F-NEXT: movfr2gr.s $a2, $fa0
+; LA64F-NEXT: addi.w $a2, $a2, 0
; LA64F-NEXT: .LBB19_3: # %atomicrmw.start
; LA64F-NEXT: # Parent Loop BB19_1 Depth=1
; LA64F-NEXT: # => This Inner Loop Header: Depth=2
@@ -1614,8 +1615,7 @@ define float @float_fmax_acq_rel(ptr %p) nounwind {
; LA64F-NEXT: .LBB19_6: # %atomicrmw.start
; LA64F-NEXT: # in Loop: Header=BB19_1 Depth=1
; LA64F-NEXT: movgr2fr.w $fa0, $a3
-; LA64F-NEXT: addi.w $a1, $a2, 0
-; LA64F-NEXT: bne $a3, $a1, .LBB19_1
+; LA64F-NEXT: bne $a3, $a2, .LBB19_1
; LA64F-NEXT: # %bb.2: # %atomicrmw.end
; LA64F-NEXT: ret
;
@@ -1633,6 +1633,7 @@ define float @float_fmax_acq_rel(ptr %p) nounwind {
; LA64D-NEXT: fmax.s $fa2, $fa2, $fa1
; LA64D-NEXT: movfr2gr.s $a1, $fa2
; LA64D-NEXT: movfr2gr.s $a2, $fa0
+; LA64D-NEXT: addi.w $a2, $a2, 0
; LA64D-NEXT: .LBB19_3: # %atomicrmw.start
; LA64D-NEXT: # Parent Loop BB19_1 Depth=1
; LA64D-NEXT: # => This Inner Loop Header: Depth=2
@@ -1650,8 +1651,7 @@ define float @float_fmax_acq_rel(ptr %p) nounwind {
; LA64D-NEXT: .LBB19_6: # %atomicrmw.start
; LA64D-NEXT: # in Loop: Header=BB19_1 Depth=1
; LA64D-NEXT: movgr2fr.w $fa0, $a3
-; LA64D-NEXT: addi.w $a1, $a2, 0
-; LA64D-NEXT: bne $a3, $a1, .LBB19_1
+; LA64D-NEXT: bne $a3, $a2, .LBB19_1
; LA64D-NEXT: # %bb.2: # %atomicrmw.end
; LA64D-NEXT: ret
%v = atomicrmw fmax ptr %p, float 1.0 acq_rel, align 4
@@ -2074,6 +2074,7 @@ define float @float_fadd_seq_cst(ptr %p) nounwind {
; LA64F-NEXT: fadd.s $fa2, $fa0, $fa1
; LA64F-NEXT: movfr2gr.s $a1, $fa2
; LA64F-NEXT: movfr2gr.s $a2, $fa0
+; LA64F-NEXT: addi.w $a2, $a2, 0
; LA64F-NEXT: .LBB24_3: # %atomicrmw.start
; LA64F-NEXT: # Parent Loop BB24_1 Depth=1
; LA64F-NEXT: # => This Inner Loop Header: Depth=2
@@ -2091,8 +2092,7 @@ define float @float_fadd_seq_cst(ptr %p) nounwind {
; LA64F-NEXT: .LBB24_6: # %atomicrmw.start
; LA64F-NEXT: # in Loop: Header=BB24_1 Depth=1
; LA64F-NEXT: movgr2fr.w $fa0, $a3
-; LA64F-NEXT: addi.w $a1, $a2, 0
-; LA64F-NEXT: bne $a3, $a1, .LBB24_1
+; LA64F-NEXT: bne $a3, $a2, .LBB24_1
; LA64F-NEXT: # %bb.2: # %atomicrmw.end
; LA64F-NEXT: ret
;
@@ -2109,6 +2109,7 @@ define float @float_fadd_seq_cst(ptr %p) nounwind {
; LA64D-NEXT: fadd.s $fa2, $fa0, $fa1
; LA64D-NEXT: movfr2gr.s $a1, $fa2
; LA64D-NEXT: movfr2gr.s $a2, $fa0
+; LA64D-NEXT: addi.w $a2, $a2, 0
; LA64D-NEXT: .LBB24_3: # %atomicrmw.start
; LA64D-NEXT: # Parent Loop BB24_1 Depth=1
; LA64D-NEXT: # => This Inner Loop Header: Depth=2
@@ -2126,8 +2127,7 @@ define float @float_fadd_seq_cst(ptr %p) nounwind {
; LA64D-NEXT: .LBB24_6: # %atomicrmw.start
; LA64D-NEXT: # in Loop: Header=BB24_1 Depth=1
; LA64D-NEXT: movgr2fr.w $fa0, $a3
-; LA64D-NEXT: addi.w $a1, $a2, 0
-; LA64D-NEXT: bne $a3, $a1, .LBB24_1
+; LA64D-NEXT: bne $a3, $a2, .LBB24_1
; LA64D-NEXT: # %bb.2: # %atomicrmw.end
; LA64D-NEXT: ret
%v = atomicrmw fadd ptr %p, float 1.0 seq_cst, align 4
@@ -2148,6 +2148,7 @@ define float @float_fsub_seq_cst(ptr %p) nounwind {
; LA64F-NEXT: fadd.s $fa2, $fa0, $fa1
; LA64F-NEXT: movfr2gr.s $a1, $fa2
; LA64F-NEXT: movfr2gr.s $a2, $fa0
+; LA64F-NEXT: addi.w $a2, $a2, 0
; LA64F-NEXT: .LBB25_3: # %atomicrmw.start
; LA64F-NEXT: # Parent Loop BB25_1 Depth=1
; LA64F-NEXT: # => This Inner Loop Header: Depth=2
@@ -2165,8 +2166,7 @@ define float @float_fsub_seq_cst(ptr %p) nounwind {
; LA64F-NEXT: .LBB25_6: # %atomicrmw.start
; LA64F-NEXT: # in Loop: Header=BB25_1 Depth=1
; LA64F-NEXT: movgr2fr.w $fa0, $a3
-; LA64F-NEXT: addi.w $a1, $a2, 0
-; LA64F-NEXT: bne $a3, $a1, .LBB25_1
+; LA64F-NEXT: bne $a3, $a2, .LBB25_1
; LA64F-NEXT: # %bb.2: # %atomicrmw.end
; LA64F-NEXT: ret
;
@@ -2183,6 +2183,7 @@ define float @float_fsub_seq_cst(ptr %p) nounwind {
; LA64D-NEXT: fadd.s $fa2, $fa0, $fa1
; LA64D-NEXT: movfr2gr.s $a1, $fa2
; LA64D-NEXT: movfr2gr.s $a2, $fa0
+; LA64D-NEXT: addi.w $a2, $a2, 0
; LA64D-NEXT: .LBB25_3: # %atomicrmw.start
; LA64D-NEXT: # Parent Loop BB25_1 Depth=1
; LA64D-NEXT: # => This Inner Loop Header: Depth=2
@@ -2200,8 +2201,7 @@ define float @float_fsub_seq_cst(ptr %p) nounwind {
; LA64D-NEXT: .LBB25_6: # %atomicrmw.start
; LA64D-NEXT: # in Loop: Header=BB25_1 Depth=1
; LA64D-NEXT: movgr2fr.w $fa0, $a3
-; LA64D-NEXT: addi.w $a1, $a2, 0
-; LA64D-NEXT: bne $a3, $a1, .LBB25_1
+; LA64D-NEXT: bne $a3, $a2, .LBB25_1
; LA64D-NEXT: # %bb.2: # %atomicrmw.end
; LA64D-NEXT: ret
%v = atomicrmw fsub ptr %p, float 1.0 seq_cst, align 4
@@ -2223,6 +2223,7 @@ define float @float_fmin_seq_cst(ptr %p) nounwind {
; LA64F-NEXT: fmin.s $fa2, $fa2, $fa1
; LA64F-NEXT: movfr2gr.s $a1, $fa2
; LA64F-NEXT: movfr2gr.s $a2, $fa0
+; LA64F-NEXT: addi.w $a2, $a2, 0
; LA64F-NEXT: .LBB26_3: # %atomicrmw.start
; LA64F-NEXT: # Parent Loop BB26_1 Depth=1
; LA64F-NEXT: # => This Inner Loop Header: Depth=2
@@ -2240,8 +2241,7 @@ define float @float_fmin_seq_cst(ptr %p) nounwind {
; LA64F-NEXT: .LBB26_6: # %atomicrmw.start
; LA64F-NEXT: # in Loop: Header=BB26_1 Depth=1
; LA64F-NEXT: movgr2fr.w $fa0, $a3
-; LA64F-NEXT: addi.w $a1, $a2, 0
-; LA64F-NEXT: bne $a3, $a1, .LBB26_1
+; LA64F-NEXT: bne $a3, $a2, .LBB26_1
; LA64F-NEXT: # %bb.2: # %atomicrmw.end
; LA64F-NEXT: ret
;
@@ -2259,6 +2259,7 @@ define float @float_fmin_seq_cst(ptr %p) nounwind {
; LA64D-NEXT: fmin.s $fa2, $fa2, $fa1
; LA64D-NEXT: movfr2gr.s $a1, $fa2
; LA64D-NEXT: movfr2gr.s $a2, $fa0
+; LA64D-NEXT: addi.w $a2, $a2, 0
; LA64D-NEXT: .LBB26_3: # %atomicrmw.start
; LA64D-NEXT: # Parent Loop BB26_1 Depth=1
; LA64D-NEXT: # => This Inner Loop Header: Depth=2
@@ -2276,8 +2277,7 @@ define float @float_fmin_seq_cst(ptr %p) nounwind {
; LA64D-NEXT: .LBB26_6: # %atomicrmw.start
; LA64D-NEXT: # in Loop: Header=BB26_1 Depth=1
; LA64D-NEXT: movgr2fr.w $fa0, $a3
-; LA64D-NEXT: addi.w $a1, $a2, 0
-; LA64D-NEXT: bne $a3, $a1, .LBB26_1
+; LA64D-NEXT: bne $a3, $a2, .LBB26_1
; LA64D-NEXT: # %bb.2: # %atomicrmw.end
; LA64D-NEXT: ret
%v = atomicrmw fmin ptr %p, float 1.0 seq_cst, align 4
@@ -2299,6 +2299,7 @@ define float @float_fmax_seq_cst(ptr %p) nounwind {
; LA64F-NEXT: fmax.s $fa2, $fa2, $fa1
; LA64F-NEXT: movfr2gr.s $a1, $fa2
; LA64F-NEXT: movfr2gr.s $a2, $fa0
+; LA64F-NEXT: addi.w $a2, $a2, 0
; LA64F-NEXT: .LBB27_3: # %atomicrmw.start
; LA64F-NEXT: # Parent Loop BB27_1 Depth=1
; LA64F-NEXT: # => This Inner Loop Header: Depth=2
@@ -2316,8 +2317,7 @@ define float @float_fmax_seq_cst(ptr %p) nounwind {
; LA64F-NEXT: .LBB27_6: # %atomicrmw.start
; LA64F-NEXT: # in Loop: Header=BB27_1 Depth=1
; LA64F-NEXT: movgr2fr.w $fa0, $a3
-; LA64F-NEXT: addi.w $a1, $a2, 0
-; LA64F-NEXT: bne $a3, $a1, .LBB27_1
+; LA64F-NEXT: bne $a3, $a2, .LBB27_1
; LA64F-NEXT: # %bb.2: # %atomicrmw.end
; LA64F-NEXT: ret
;
@@ -2335,6 +2335,7 @@ define float @float_fmax_seq_cst(ptr %p) nounwind {
; LA64D-NEXT: fmax.s $fa2, $fa2, $fa1
; LA64D-NEXT: movfr2gr.s $a1, $fa2
; LA64D-NEXT: movfr2gr.s $a2, $fa0
+; LA64D-NEXT: addi.w $a2, $a2, 0
; LA64D-NEXT: .LBB27_3: # %atomicrmw.start
; LA64D-NEXT: # Parent Loop BB27_1 Depth=1
; LA64D-NEXT: # => This Inner Loop Header: Depth=2
@@ -2352,8 +2353,7 @@ define float @float_fmax_seq_cst(ptr %p) nounwind {
; LA64D-NEXT: .LBB27_6: # %atomicrmw.start
; LA64D-NEXT: # in Loop: Header=BB27_1 Depth=1
; LA64D-NEXT: movgr2fr.w $fa0, $a3
-; LA64D-NEXT: addi.w $a1, $a2, 0
-; LA64D-NEXT: bne $a3, $a1, .LBB27_1
+; LA64D-NEXT: bne $a3, $a2, .LBB27_1
; LA64D-NEXT: # %bb.2: # %atomicrmw.end
; LA64D-NEXT: ret
%v = atomicrmw fmax ptr %p, float 1.0 seq_cst, align 4
@@ -2752,6 +2752,7 @@ define float @float_fadd_monotonic(ptr %p) nounwind {
; LA64F-NEXT: fadd.s $fa2, $fa0, $fa1
; LA64F-NEXT: movfr2gr.s $a1, $fa2
; LA64F-NEXT: movfr2gr.s $a2, $fa0
+; LA64F-NEXT: addi.w $a2, $a2, 0
; LA64F-NEXT: .LBB32_3: # %atomicrmw.start
; LA64F-NEXT: # Parent Loop BB32_1 Depth=1
; LA64F-NEXT: # => This Inner Loop Header: Depth=2
@@ -2769,8 +2770,7 @@ define float @float_fadd_monotonic(ptr %p) nounwind {
; LA64F-NEXT: .LBB32_6: # %atomicrmw.start
; LA64F-NEXT: # in Loop: Header=BB32_1 Depth=1
; LA64F-NEXT: movgr2fr.w $fa0, $a3
-; LA64F-NEXT: addi.w $a1, $a2, 0
-; LA64F-NEXT: bne $a3, $a1, .LBB32_1
+; LA64F-NEXT: bne $a3, $a2, .LBB32_1
; LA64F-NEXT: # %bb.2: # %atomicrmw.end
; LA64F-NEXT: ret
;
@@ -2787,6 +2787,7 @@ define float @float_fadd_monotonic(ptr %p) nounwind {
; LA64D-NEXT: fadd.s $fa2, $fa0, $fa1
; LA64D-NEXT: movfr2gr.s $a1, $fa2
; LA64D-NEXT: movfr2gr.s $a2, $fa0
+; LA64D-NEXT: addi.w $a2, $a2, 0
; LA64D-NEXT: .LBB32_3: # %atomicrmw.start
; LA64D-NEXT: # Parent Loop BB32_1 Depth=1
; LA64D-NEXT: # => This Inner Loop Header: Depth=2
@@ -2804,8 +2805,7 @@ define float @float_fadd_monotonic(ptr %p) nounwind {
; LA64D-NEXT: .LBB32_6: # %atomicrmw.start
; LA64D-NEXT: # in Loop: Header=BB32_1 Depth=1
; LA64D-NEXT: movgr2fr.w $fa0, $a3
-; LA64D-NEXT: addi.w $a1, $a2, 0
-; LA64D-NEXT: bne $a3, $a1, .LBB32_1
+; LA64D-NEXT: bne $a3, $a2, .LBB32_1
; LA64D-NEXT: # %bb.2: # %atomicrmw.end
; LA64D-NEXT: ret
%v = atomicrmw fadd ptr %p, float 1.0 monotonic, align 4
@@ -2826,6 +2826,7 @@ define float @float_fsub_monotonic(ptr %p) nounwind {
; LA64F-NEXT: fadd.s $fa2, $fa0, $fa1
; LA64F-NEXT: movfr2gr.s $a1, $fa2
; LA64F-NEXT: movfr2gr.s $a2, $fa0
+; LA64F-NEXT: addi.w $a2, $a2, 0
; LA64F-NEXT: .LBB33_3: # %atomicrmw.start
; LA64F-NEXT: # Parent Loop BB33_1 Depth=1
; LA64F-NEXT: # => This Inner Loop Header: Depth=2
@@ -2843,8 +2844,7 @@ define float @float_fsub_monotonic(ptr %p) nounwind {
; LA64F-NEXT: .LBB33_6: # %atomicrmw.start
; LA64F-NEXT: # in Loop: Header=BB33_1 Depth=1
; LA64F-NEXT: movgr2fr.w $fa0, $a3
-; LA64F-NEXT: addi.w $a1, $a2, 0
-; LA64F-NEXT: bne $a3, $a1, .LBB33_1
+; LA64F-NEXT: bne $a3, $a2, .LBB33_1
; LA64F-NEXT: # %bb.2: # %atomicrmw.end
; LA64F-NEXT: ret
;
@@ -2861,6 +2861,7 @@ define float @float_fsub_monotonic(ptr %p) nounwind {
; LA64D-NEXT: fadd.s $fa2, $fa0, $fa1
; LA64D-NEXT: movfr2gr.s $a1, $fa2
; LA64D-NEXT: movfr2gr.s $a2, $fa0
+; LA64D-NEXT: addi.w $a2, $a2, 0
; LA64D-NEXT: .LBB33_3: # %atomicrmw.start
; LA64D-NEXT: # Parent Loop BB33_1 Depth=1
; LA64D-NEXT: # => This Inner Loop Header: Depth=2
@@ -2878,8 +2879,7 @@ define float @float_fsub_monotonic(ptr %p) nounwind {
; LA64D-NEXT: .LBB33_6: # %atomicrmw.start
; LA64D-NEXT: # in Loop: Header=BB33_1 Depth=1
; LA64D-NEXT: movgr2fr.w $fa0, $a3
-; LA64D-NEXT: addi.w $a1, $a2, 0
-; LA64D-NEXT: bne $a3, $a1, .LBB33_1
+; LA64D-NEXT: bne $a3, $a2, .LBB33_1
; LA64D-NEXT: # %bb.2: # %atomicrmw.end
; LA64D-NEXT: ret
%v = atomicrmw fsub ptr %p, float 1.0 monotonic, align 4
@@ -2901,6 +2901,7 @@ define float @float_fmin_monotonic(ptr %p) nounwind {
; LA64F-NEXT: fmin.s $fa2, $fa2, $fa1
; LA64F-NEXT: movfr2gr.s $a1, $fa2
; LA64F-NEXT: movfr2gr.s $a2, $fa0
+; LA64F-NEXT: addi.w $a2, $a2, 0
; LA64F-NEXT: .LBB34_3: # %atomicrmw.start
; LA64F-NEXT: # Parent Loop BB34_1 Depth=1
; LA64F-NEXT: # => This Inner Loop Header: Depth=2
@@ -2918,8 +2919,7 @@ define float @float_fmin_monotonic(ptr %p) nounwind {
; LA64F-NEXT: .LBB34_6: # %atomicrmw.start
; LA64F-NEXT: # in Loop: Header=BB34_1 Depth=1
; LA64F-NEXT: movgr2fr.w $fa0, $a3
-; LA64F-NEXT: addi.w $a1, $a2, 0
-; LA64F-NEXT: bne $a3, $a1, .LBB34_1
+; LA64F-NEXT: bne $a3, $a2, .LBB34_1
; LA64F-NEXT: # %bb.2: # %atomicrmw.end
; LA64F-NEXT: ret
;
@@ -2937,6 +2937,7 @@ define float @float_fmin_monotonic(ptr %p) nounwind {
; LA64D-NEXT: fmin.s $fa2, $fa2, $fa1
; LA64D-NEXT: movfr2gr.s $a1, $fa2
; LA64D-NEXT: movfr2gr.s $a2, $fa0
+; LA64D-NEXT: addi.w $a2, $a2, 0
; LA64D-NEXT: .LBB34_3: # %atomicrmw.start
; LA64D-NEXT: # Parent Loop BB34_1 Depth=1
; LA64D-NEXT: # => This Inner Loop Header: Depth=2
@@ -2954,8 +2955,7 @@ define float @float_fmin_monotonic(ptr %p) nounwind {
; LA64D-NEXT: .LBB34_6: # %atomicrmw.start
; LA64D-NEXT: # in Loop: Header=BB34_1 Depth=1
; LA64D-NEXT: movgr2fr.w $fa0, $a3
-; LA64D-NEXT: addi.w $a1, $a2, 0
-; LA64D-NEXT: bne $a3, $a1, .LBB34_1
+; LA64D-NEXT: bne $a3, $a2, .LBB34_1
; LA64D-NEXT: # %bb.2: # %atomicrmw.end
; LA64D-NEXT: ret
%v = atomicrmw fmin ptr %p, float 1.0 monotonic, align 4
@@ -2977,6 +2977,7 @@ define float @float_fmax_monotonic(ptr %p) nounwind {
; LA64F-NEXT: fmax.s $fa2, $fa2, $fa1
; LA64F-NEXT: movfr2gr.s $a1, $fa2
; LA64F-NEXT: movfr2gr.s $a2, $fa0
+; LA64F-NEXT: addi.w $a2, $a2, 0
; LA64F-NEXT: .LBB35_3: # %atomicrmw.start
; LA64F-NEXT: # Parent Loop BB35_1 Depth=1
; LA64F-NEXT: # => This Inner Loop Header: Depth=2
@@ -2994,8 +2995,7 @@ define float @float_fmax_monotonic(ptr %p) nounwind {
; LA64F-NEXT: .LBB35_6: # %atomicrmw.start
; LA64F-NEXT: # in Loop: Header=BB35_1 Depth=1
; LA64F-NEXT: movgr2fr.w $fa0, $a3
-; LA64F-NEXT: addi.w $a1, $a2, 0
-; LA64F-NEXT: bne $a3, $a1, .LBB35_1
+; LA64F-NEXT: bne $a3, $a2, .LBB35_1
; LA64F-NEXT: # %bb.2: # %atomicrmw.end
; LA64F-NEXT: ret
;
@@ -3013,6 +3013,7 @@ define float @float_fmax_monotonic(ptr %p) nounwind {
; LA64D-NEXT: fmax.s $fa2, $fa2, $fa1
; LA64D-NEXT: movfr2gr.s $a1, $fa2
; LA64D-NEXT: movfr2gr.s $a2, $fa0
+; LA64D-NEXT: addi.w $a2, $a2, 0
; LA64D-NEXT: .LBB35_3: # %atomicrmw.start
; LA64D-NEXT: # Parent Loop BB35_1 Depth=1
; LA64D-NEXT: # => This Inner Loop Header: Depth=2
@@ -3030,8 +3031,7 @@ define float @float_fmax_monotonic(ptr %p) nounwind {
; LA64D-NEXT: .LBB35_6: # %atomicrmw.start
; LA64D-NEXT: # in Loop: Header=BB35_1 Depth=1
; LA64D-NEXT: movgr2fr.w $fa0, $a3
-; LA64D-NEXT: addi.w $a1, $a2, 0
-; LA64D-NEXT: bne $a3, $a1, .LBB35_1
+; LA64D-NEXT: bne $a3, $a2, .LBB35_1
; LA64D-NEXT: # %bb.2: # %atomicrmw.end
; LA64D-NEXT: ret
%v = atomicrmw fmax ptr %p, float 1.0 monotonic, align 4
>From 8d1046ae49fdf7585f70cfbb35bcfc46725d9b29 Mon Sep 17 00:00:00 2001
From: Chen Zheng <czhengsz at cn.ibm.com>
Date: Mon, 4 Mar 2024 09:37:11 +0800
Subject: [PATCH 403/406] [PowerPC] adjust cost for extract i64 from vector on
P9 and above (#82963)
https://godbolt.org/z/Ma347Tx1W
---
llvm/lib/Target/PowerPC/PPCTargetTransformInfo.cpp | 10 ++++------
.../CostModel/PowerPC/insert_extract-inseltpoison.ll | 4 ++--
llvm/test/Analysis/CostModel/PowerPC/insert_extract.ll | 4 ++--
3 files changed, 8 insertions(+), 10 deletions(-)
diff --git a/llvm/lib/Target/PowerPC/PPCTargetTransformInfo.cpp b/llvm/lib/Target/PowerPC/PPCTargetTransformInfo.cpp
index 48274e8835381f..7adf1adcc64768 100644
--- a/llvm/lib/Target/PowerPC/PPCTargetTransformInfo.cpp
+++ b/llvm/lib/Target/PowerPC/PPCTargetTransformInfo.cpp
@@ -716,12 +716,10 @@ InstructionCost PPCTTIImpl::getVectorInstrCost(unsigned Opcode, Type *Val,
} else if (ISD == ISD::EXTRACT_VECTOR_ELT) {
// It's an extract. Maybe we can do a cheap move-from VSR.
unsigned EltSize = Val->getScalarSizeInBits();
- if (EltSize == 64) {
- // FIXME: no need to worry about endian, P9 has both mfvsrd/mfvsrld.
- unsigned MfvsrdIndex = ST->isLittleEndian() ? 1 : 0;
- if (Index == MfvsrdIndex)
- return 1;
- } else if (EltSize == 32) {
+ // P9 has both mfvsrd and mfvsrld for 64 bit integer.
+ if (EltSize == 64 && Index != -1U)
+ return 1;
+ else if (EltSize == 32) {
unsigned MfvsrwzIndex = ST->isLittleEndian() ? 2 : 1;
if (Index == MfvsrwzIndex)
return 1;
diff --git a/llvm/test/Analysis/CostModel/PowerPC/insert_extract-inseltpoison.ll b/llvm/test/Analysis/CostModel/PowerPC/insert_extract-inseltpoison.ll
index e85e6f0ab08961..9894fb95f69230 100644
--- a/llvm/test/Analysis/CostModel/PowerPC/insert_extract-inseltpoison.ll
+++ b/llvm/test/Analysis/CostModel/PowerPC/insert_extract-inseltpoison.ll
@@ -147,11 +147,11 @@ define void @vexti64(<2 x i64> %p1) {
;
; CHECK-P9BE-LABEL: 'vexti64'
; CHECK-P9BE-NEXT: Cost Model: Found an estimated cost of 1 for instruction: %i1 = extractelement <2 x i64> %p1, i32 0
-; CHECK-P9BE-NEXT: Cost Model: Found an estimated cost of 2 for instruction: %i2 = extractelement <2 x i64> %p1, i32 1
+; CHECK-P9BE-NEXT: Cost Model: Found an estimated cost of 1 for instruction: %i2 = extractelement <2 x i64> %p1, i32 1
; CHECK-P9BE-NEXT: Cost Model: Found an estimated cost of 0 for instruction: ret void
;
; CHECK-P9LE-LABEL: 'vexti64'
-; CHECK-P9LE-NEXT: Cost Model: Found an estimated cost of 2 for instruction: %i1 = extractelement <2 x i64> %p1, i32 0
+; CHECK-P9LE-NEXT: Cost Model: Found an estimated cost of 1 for instruction: %i1 = extractelement <2 x i64> %p1, i32 0
; CHECK-P9LE-NEXT: Cost Model: Found an estimated cost of 1 for instruction: %i2 = extractelement <2 x i64> %p1, i32 1
; CHECK-P9LE-NEXT: Cost Model: Found an estimated cost of 0 for instruction: ret void
;
diff --git a/llvm/test/Analysis/CostModel/PowerPC/insert_extract.ll b/llvm/test/Analysis/CostModel/PowerPC/insert_extract.ll
index fda6a4ae51fc2c..0c2ed5cb96b970 100644
--- a/llvm/test/Analysis/CostModel/PowerPC/insert_extract.ll
+++ b/llvm/test/Analysis/CostModel/PowerPC/insert_extract.ll
@@ -172,11 +172,11 @@ define void @vexti64(<2 x i64> %p1) {
;
; CHECK-P9BE-LABEL: 'vexti64'
; CHECK-P9BE-NEXT: Cost Model: Found an estimated cost of 1 for instruction: %i1 = extractelement <2 x i64> %p1, i32 0
-; CHECK-P9BE-NEXT: Cost Model: Found an estimated cost of 2 for instruction: %i2 = extractelement <2 x i64> %p1, i32 1
+; CHECK-P9BE-NEXT: Cost Model: Found an estimated cost of 1 for instruction: %i2 = extractelement <2 x i64> %p1, i32 1
; CHECK-P9BE-NEXT: Cost Model: Found an estimated cost of 0 for instruction: ret void
;
; CHECK-P9LE-LABEL: 'vexti64'
-; CHECK-P9LE-NEXT: Cost Model: Found an estimated cost of 2 for instruction: %i1 = extractelement <2 x i64> %p1, i32 0
+; CHECK-P9LE-NEXT: Cost Model: Found an estimated cost of 1 for instruction: %i1 = extractelement <2 x i64> %p1, i32 0
; CHECK-P9LE-NEXT: Cost Model: Found an estimated cost of 1 for instruction: %i2 = extractelement <2 x i64> %p1, i32 1
; CHECK-P9LE-NEXT: Cost Model: Found an estimated cost of 0 for instruction: ret void
;
>From 61c283db4be0c8ff1832afa754a9a6b45dcf2b06 Mon Sep 17 00:00:00 2001
From: Yeting Kuo <46629943+yetingk at users.noreply.github.com>
Date: Mon, 4 Mar 2024 09:41:16 +0800
Subject: [PATCH 404/406] [ScalarizeMaskedMemIntrin] Use pointer alignment from
pointer of masked.compressstore/expandload. (#83519)
Previously we used Align(1) for all scalarized load/stores from
masked.compressstore/expandload.
For targets not supporting unaligned accesses, it make backend need to
split
aligned large width loads/stores to byte loads/stores.
To solve this performance issue, this patch preserves the alignment of
base
pointer after scalarizing.
---
.../Scalar/ScalarizeMaskedMemIntrin.cpp | 18 +-
.../rvv/fixed-vectors-compressstore-fp.ll | 1079 ++++++++++++++++
.../rvv/fixed-vectors-compressstore-int.ll | 986 +++++++++++++++
.../RISCV/rvv/fixed-vectors-expandload-fp.ll | 1107 +++++++++++++++++
.../RISCV/rvv/fixed-vectors-expandload-int.ll | 1000 +++++++++++++++
5 files changed, 4186 insertions(+), 4 deletions(-)
create mode 100644 llvm/test/CodeGen/RISCV/rvv/fixed-vectors-compressstore-fp.ll
create mode 100644 llvm/test/CodeGen/RISCV/rvv/fixed-vectors-compressstore-int.ll
create mode 100644 llvm/test/CodeGen/RISCV/rvv/fixed-vectors-expandload-fp.ll
create mode 100644 llvm/test/CodeGen/RISCV/rvv/fixed-vectors-expandload-int.ll
diff --git a/llvm/lib/Transforms/Scalar/ScalarizeMaskedMemIntrin.cpp b/llvm/lib/Transforms/Scalar/ScalarizeMaskedMemIntrin.cpp
index c01d03f6447240..f362dc5708b799 100644
--- a/llvm/lib/Transforms/Scalar/ScalarizeMaskedMemIntrin.cpp
+++ b/llvm/lib/Transforms/Scalar/ScalarizeMaskedMemIntrin.cpp
@@ -627,6 +627,7 @@ static void scalarizeMaskedExpandLoad(const DataLayout &DL, CallInst *CI,
Value *Ptr = CI->getArgOperand(0);
Value *Mask = CI->getArgOperand(1);
Value *PassThru = CI->getArgOperand(2);
+ Align Alignment = CI->getParamAlign(0).valueOrOne();
auto *VecType = cast<FixedVectorType>(CI->getType());
@@ -644,6 +645,10 @@ static void scalarizeMaskedExpandLoad(const DataLayout &DL, CallInst *CI,
// The result vector
Value *VResult = PassThru;
+ // Adjust alignment for the scalar instruction.
+ const Align AdjustedAlignment =
+ commonAlignment(Alignment, EltTy->getPrimitiveSizeInBits() / 8);
+
// Shorten the way if the mask is a vector of constants.
// Create a build_vector pattern, with loads/poisons as necessary and then
// shuffle blend with the pass through value.
@@ -659,7 +664,7 @@ static void scalarizeMaskedExpandLoad(const DataLayout &DL, CallInst *CI,
} else {
Value *NewPtr =
Builder.CreateConstInBoundsGEP1_32(EltTy, Ptr, MemIndex);
- InsertElt = Builder.CreateAlignedLoad(EltTy, NewPtr, Align(1),
+ InsertElt = Builder.CreateAlignedLoad(EltTy, NewPtr, AdjustedAlignment,
"Load" + Twine(Idx));
ShuffleMask[Idx] = Idx;
++MemIndex;
@@ -713,7 +718,7 @@ static void scalarizeMaskedExpandLoad(const DataLayout &DL, CallInst *CI,
CondBlock->setName("cond.load");
Builder.SetInsertPoint(CondBlock->getTerminator());
- LoadInst *Load = Builder.CreateAlignedLoad(EltTy, Ptr, Align(1));
+ LoadInst *Load = Builder.CreateAlignedLoad(EltTy, Ptr, AdjustedAlignment);
Value *NewVResult = Builder.CreateInsertElement(VResult, Load, Idx);
// Move the pointer if there are more blocks to come.
@@ -755,6 +760,7 @@ static void scalarizeMaskedCompressStore(const DataLayout &DL, CallInst *CI,
Value *Src = CI->getArgOperand(0);
Value *Ptr = CI->getArgOperand(1);
Value *Mask = CI->getArgOperand(2);
+ Align Alignment = CI->getParamAlign(1).valueOrOne();
auto *VecType = cast<FixedVectorType>(Src->getType());
@@ -767,6 +773,10 @@ static void scalarizeMaskedCompressStore(const DataLayout &DL, CallInst *CI,
Type *EltTy = VecType->getElementType();
+ // Adjust alignment for the scalar instruction.
+ const Align AdjustedAlignment =
+ commonAlignment(Alignment, EltTy->getPrimitiveSizeInBits() / 8);
+
unsigned VectorWidth = VecType->getNumElements();
// Shorten the way if the mask is a vector of constants.
@@ -778,7 +788,7 @@ static void scalarizeMaskedCompressStore(const DataLayout &DL, CallInst *CI,
Value *OneElt =
Builder.CreateExtractElement(Src, Idx, "Elt" + Twine(Idx));
Value *NewPtr = Builder.CreateConstInBoundsGEP1_32(EltTy, Ptr, MemIndex);
- Builder.CreateAlignedStore(OneElt, NewPtr, Align(1));
+ Builder.CreateAlignedStore(OneElt, NewPtr, AdjustedAlignment);
++MemIndex;
}
CI->eraseFromParent();
@@ -824,7 +834,7 @@ static void scalarizeMaskedCompressStore(const DataLayout &DL, CallInst *CI,
Builder.SetInsertPoint(CondBlock->getTerminator());
Value *OneElt = Builder.CreateExtractElement(Src, Idx);
- Builder.CreateAlignedStore(OneElt, Ptr, Align(1));
+ Builder.CreateAlignedStore(OneElt, Ptr, AdjustedAlignment);
// Move the pointer if there are more blocks to come.
Value *NewPtr;
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-compressstore-fp.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-compressstore-fp.ll
new file mode 100644
index 00000000000000..52c52921e7e1d2
--- /dev/null
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-compressstore-fp.ll
@@ -0,0 +1,1079 @@
+; NOTE: Assertions have been autogenerated by utils/update_llc_test_checks.py UTC_ARGS: --version 4
+; RUN: llc -mtriple=riscv32 -mattr=+m,+v,+f,+d,+zfh,+zvfh -verify-machineinstrs < %s | FileCheck %s --check-prefixes=RV32
+; RUN: llc -mtriple=riscv64 -mattr=+m,+v,+f,+d,+zfh,+zvfh -verify-machineinstrs < %s | FileCheck %s --check-prefixes=RV64
+
+declare void @llvm.masked.compressstore.v1f16(<1 x half>, ptr, <1 x i1>)
+define void @compressstore_v1f16(ptr %base, <1 x half> %v, <1 x i1> %mask) {
+; RV32-LABEL: compressstore_v1f16:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetvli a1, zero, e8, mf8, ta, ma
+; RV32-NEXT: vfirst.m a1, v0
+; RV32-NEXT: bnez a1, .LBB0_2
+; RV32-NEXT: # %bb.1: # %cond.store
+; RV32-NEXT: vsetivli zero, 1, e16, mf4, ta, ma
+; RV32-NEXT: vse16.v v8, (a0)
+; RV32-NEXT: .LBB0_2: # %else
+; RV32-NEXT: ret
+;
+; RV64-LABEL: compressstore_v1f16:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetvli a1, zero, e8, mf8, ta, ma
+; RV64-NEXT: vfirst.m a1, v0
+; RV64-NEXT: bnez a1, .LBB0_2
+; RV64-NEXT: # %bb.1: # %cond.store
+; RV64-NEXT: vsetivli zero, 1, e16, mf4, ta, ma
+; RV64-NEXT: vse16.v v8, (a0)
+; RV64-NEXT: .LBB0_2: # %else
+; RV64-NEXT: ret
+ call void @llvm.masked.compressstore.v1f16(<1 x half> %v, ptr align 2 %base, <1 x i1> %mask)
+ ret void
+}
+
+declare void @llvm.masked.compressstore.v2f16(<2 x half>, ptr, <2 x i1>)
+define void @compressstore_v2f16(ptr %base, <2 x half> %v, <2 x i1> %mask) {
+; RV32-LABEL: compressstore_v2f16:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV32-NEXT: vmv.x.s a1, v0
+; RV32-NEXT: andi a2, a1, 1
+; RV32-NEXT: bnez a2, .LBB1_3
+; RV32-NEXT: # %bb.1: # %else
+; RV32-NEXT: andi a1, a1, 2
+; RV32-NEXT: bnez a1, .LBB1_4
+; RV32-NEXT: .LBB1_2: # %else2
+; RV32-NEXT: ret
+; RV32-NEXT: .LBB1_3: # %cond.store
+; RV32-NEXT: vsetivli zero, 1, e16, mf4, ta, ma
+; RV32-NEXT: vse16.v v8, (a0)
+; RV32-NEXT: addi a0, a0, 2
+; RV32-NEXT: andi a1, a1, 2
+; RV32-NEXT: beqz a1, .LBB1_2
+; RV32-NEXT: .LBB1_4: # %cond.store1
+; RV32-NEXT: vsetivli zero, 1, e16, mf4, ta, ma
+; RV32-NEXT: vslidedown.vi v8, v8, 1
+; RV32-NEXT: vse16.v v8, (a0)
+; RV32-NEXT: ret
+;
+; RV64-LABEL: compressstore_v2f16:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV64-NEXT: vmv.x.s a1, v0
+; RV64-NEXT: andi a2, a1, 1
+; RV64-NEXT: bnez a2, .LBB1_3
+; RV64-NEXT: # %bb.1: # %else
+; RV64-NEXT: andi a1, a1, 2
+; RV64-NEXT: bnez a1, .LBB1_4
+; RV64-NEXT: .LBB1_2: # %else2
+; RV64-NEXT: ret
+; RV64-NEXT: .LBB1_3: # %cond.store
+; RV64-NEXT: vsetivli zero, 1, e16, mf4, ta, ma
+; RV64-NEXT: vse16.v v8, (a0)
+; RV64-NEXT: addi a0, a0, 2
+; RV64-NEXT: andi a1, a1, 2
+; RV64-NEXT: beqz a1, .LBB1_2
+; RV64-NEXT: .LBB1_4: # %cond.store1
+; RV64-NEXT: vsetivli zero, 1, e16, mf4, ta, ma
+; RV64-NEXT: vslidedown.vi v8, v8, 1
+; RV64-NEXT: vse16.v v8, (a0)
+; RV64-NEXT: ret
+ call void @llvm.masked.compressstore.v2f16(<2 x half> %v, ptr align 2 %base, <2 x i1> %mask)
+ ret void
+}
+
+declare void @llvm.masked.compressstore.v4f16(<4 x half>, ptr, <4 x i1>)
+define void @compressstore_v4f16(ptr %base, <4 x half> %v, <4 x i1> %mask) {
+; RV32-LABEL: compressstore_v4f16:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV32-NEXT: vmv.x.s a1, v0
+; RV32-NEXT: andi a2, a1, 1
+; RV32-NEXT: bnez a2, .LBB2_5
+; RV32-NEXT: # %bb.1: # %else
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: bnez a2, .LBB2_6
+; RV32-NEXT: .LBB2_2: # %else2
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: bnez a2, .LBB2_7
+; RV32-NEXT: .LBB2_3: # %else5
+; RV32-NEXT: andi a1, a1, 8
+; RV32-NEXT: bnez a1, .LBB2_8
+; RV32-NEXT: .LBB2_4: # %else8
+; RV32-NEXT: ret
+; RV32-NEXT: .LBB2_5: # %cond.store
+; RV32-NEXT: vsetivli zero, 1, e16, mf2, ta, ma
+; RV32-NEXT: vse16.v v8, (a0)
+; RV32-NEXT: addi a0, a0, 2
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: beqz a2, .LBB2_2
+; RV32-NEXT: .LBB2_6: # %cond.store1
+; RV32-NEXT: vsetivli zero, 1, e16, mf2, ta, ma
+; RV32-NEXT: vslidedown.vi v9, v8, 1
+; RV32-NEXT: vse16.v v9, (a0)
+; RV32-NEXT: addi a0, a0, 2
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: beqz a2, .LBB2_3
+; RV32-NEXT: .LBB2_7: # %cond.store4
+; RV32-NEXT: vsetivli zero, 1, e16, mf2, ta, ma
+; RV32-NEXT: vslidedown.vi v9, v8, 2
+; RV32-NEXT: vse16.v v9, (a0)
+; RV32-NEXT: addi a0, a0, 2
+; RV32-NEXT: andi a1, a1, 8
+; RV32-NEXT: beqz a1, .LBB2_4
+; RV32-NEXT: .LBB2_8: # %cond.store7
+; RV32-NEXT: vsetivli zero, 1, e16, mf2, ta, ma
+; RV32-NEXT: vslidedown.vi v8, v8, 3
+; RV32-NEXT: vse16.v v8, (a0)
+; RV32-NEXT: ret
+;
+; RV64-LABEL: compressstore_v4f16:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV64-NEXT: vmv.x.s a1, v0
+; RV64-NEXT: andi a2, a1, 1
+; RV64-NEXT: bnez a2, .LBB2_5
+; RV64-NEXT: # %bb.1: # %else
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: bnez a2, .LBB2_6
+; RV64-NEXT: .LBB2_2: # %else2
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: bnez a2, .LBB2_7
+; RV64-NEXT: .LBB2_3: # %else5
+; RV64-NEXT: andi a1, a1, 8
+; RV64-NEXT: bnez a1, .LBB2_8
+; RV64-NEXT: .LBB2_4: # %else8
+; RV64-NEXT: ret
+; RV64-NEXT: .LBB2_5: # %cond.store
+; RV64-NEXT: vsetivli zero, 1, e16, mf2, ta, ma
+; RV64-NEXT: vse16.v v8, (a0)
+; RV64-NEXT: addi a0, a0, 2
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: beqz a2, .LBB2_2
+; RV64-NEXT: .LBB2_6: # %cond.store1
+; RV64-NEXT: vsetivli zero, 1, e16, mf2, ta, ma
+; RV64-NEXT: vslidedown.vi v9, v8, 1
+; RV64-NEXT: vse16.v v9, (a0)
+; RV64-NEXT: addi a0, a0, 2
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: beqz a2, .LBB2_3
+; RV64-NEXT: .LBB2_7: # %cond.store4
+; RV64-NEXT: vsetivli zero, 1, e16, mf2, ta, ma
+; RV64-NEXT: vslidedown.vi v9, v8, 2
+; RV64-NEXT: vse16.v v9, (a0)
+; RV64-NEXT: addi a0, a0, 2
+; RV64-NEXT: andi a1, a1, 8
+; RV64-NEXT: beqz a1, .LBB2_4
+; RV64-NEXT: .LBB2_8: # %cond.store7
+; RV64-NEXT: vsetivli zero, 1, e16, mf2, ta, ma
+; RV64-NEXT: vslidedown.vi v8, v8, 3
+; RV64-NEXT: vse16.v v8, (a0)
+; RV64-NEXT: ret
+ call void @llvm.masked.compressstore.v4f16(<4 x half> %v, ptr align 2 %base, <4 x i1> %mask)
+ ret void
+}
+
+declare void @llvm.masked.compressstore.v8f16(<8 x half>, ptr, <8 x i1>)
+define void @compressstore_v8f16(ptr %base, <8 x half> %v, <8 x i1> %mask) {
+; RV32-LABEL: compressstore_v8f16:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV32-NEXT: vmv.x.s a1, v0
+; RV32-NEXT: andi a2, a1, 1
+; RV32-NEXT: bnez a2, .LBB3_9
+; RV32-NEXT: # %bb.1: # %else
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: bnez a2, .LBB3_10
+; RV32-NEXT: .LBB3_2: # %else2
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: bnez a2, .LBB3_11
+; RV32-NEXT: .LBB3_3: # %else5
+; RV32-NEXT: andi a2, a1, 8
+; RV32-NEXT: bnez a2, .LBB3_12
+; RV32-NEXT: .LBB3_4: # %else8
+; RV32-NEXT: andi a2, a1, 16
+; RV32-NEXT: bnez a2, .LBB3_13
+; RV32-NEXT: .LBB3_5: # %else11
+; RV32-NEXT: andi a2, a1, 32
+; RV32-NEXT: bnez a2, .LBB3_14
+; RV32-NEXT: .LBB3_6: # %else14
+; RV32-NEXT: andi a2, a1, 64
+; RV32-NEXT: bnez a2, .LBB3_15
+; RV32-NEXT: .LBB3_7: # %else17
+; RV32-NEXT: andi a1, a1, -128
+; RV32-NEXT: bnez a1, .LBB3_16
+; RV32-NEXT: .LBB3_8: # %else20
+; RV32-NEXT: ret
+; RV32-NEXT: .LBB3_9: # %cond.store
+; RV32-NEXT: vsetivli zero, 1, e16, m1, ta, ma
+; RV32-NEXT: vse16.v v8, (a0)
+; RV32-NEXT: addi a0, a0, 2
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: beqz a2, .LBB3_2
+; RV32-NEXT: .LBB3_10: # %cond.store1
+; RV32-NEXT: vsetivli zero, 1, e16, m1, ta, ma
+; RV32-NEXT: vslidedown.vi v9, v8, 1
+; RV32-NEXT: vse16.v v9, (a0)
+; RV32-NEXT: addi a0, a0, 2
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: beqz a2, .LBB3_3
+; RV32-NEXT: .LBB3_11: # %cond.store4
+; RV32-NEXT: vsetivli zero, 1, e16, m1, ta, ma
+; RV32-NEXT: vslidedown.vi v9, v8, 2
+; RV32-NEXT: vse16.v v9, (a0)
+; RV32-NEXT: addi a0, a0, 2
+; RV32-NEXT: andi a2, a1, 8
+; RV32-NEXT: beqz a2, .LBB3_4
+; RV32-NEXT: .LBB3_12: # %cond.store7
+; RV32-NEXT: vsetivli zero, 1, e16, m1, ta, ma
+; RV32-NEXT: vslidedown.vi v9, v8, 3
+; RV32-NEXT: vse16.v v9, (a0)
+; RV32-NEXT: addi a0, a0, 2
+; RV32-NEXT: andi a2, a1, 16
+; RV32-NEXT: beqz a2, .LBB3_5
+; RV32-NEXT: .LBB3_13: # %cond.store10
+; RV32-NEXT: vsetivli zero, 1, e16, m1, ta, ma
+; RV32-NEXT: vslidedown.vi v9, v8, 4
+; RV32-NEXT: vse16.v v9, (a0)
+; RV32-NEXT: addi a0, a0, 2
+; RV32-NEXT: andi a2, a1, 32
+; RV32-NEXT: beqz a2, .LBB3_6
+; RV32-NEXT: .LBB3_14: # %cond.store13
+; RV32-NEXT: vsetivli zero, 1, e16, m1, ta, ma
+; RV32-NEXT: vslidedown.vi v9, v8, 5
+; RV32-NEXT: vse16.v v9, (a0)
+; RV32-NEXT: addi a0, a0, 2
+; RV32-NEXT: andi a2, a1, 64
+; RV32-NEXT: beqz a2, .LBB3_7
+; RV32-NEXT: .LBB3_15: # %cond.store16
+; RV32-NEXT: vsetivli zero, 1, e16, m1, ta, ma
+; RV32-NEXT: vslidedown.vi v9, v8, 6
+; RV32-NEXT: vse16.v v9, (a0)
+; RV32-NEXT: addi a0, a0, 2
+; RV32-NEXT: andi a1, a1, -128
+; RV32-NEXT: beqz a1, .LBB3_8
+; RV32-NEXT: .LBB3_16: # %cond.store19
+; RV32-NEXT: vsetivli zero, 1, e16, m1, ta, ma
+; RV32-NEXT: vslidedown.vi v8, v8, 7
+; RV32-NEXT: vse16.v v8, (a0)
+; RV32-NEXT: ret
+;
+; RV64-LABEL: compressstore_v8f16:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV64-NEXT: vmv.x.s a1, v0
+; RV64-NEXT: andi a2, a1, 1
+; RV64-NEXT: bnez a2, .LBB3_9
+; RV64-NEXT: # %bb.1: # %else
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: bnez a2, .LBB3_10
+; RV64-NEXT: .LBB3_2: # %else2
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: bnez a2, .LBB3_11
+; RV64-NEXT: .LBB3_3: # %else5
+; RV64-NEXT: andi a2, a1, 8
+; RV64-NEXT: bnez a2, .LBB3_12
+; RV64-NEXT: .LBB3_4: # %else8
+; RV64-NEXT: andi a2, a1, 16
+; RV64-NEXT: bnez a2, .LBB3_13
+; RV64-NEXT: .LBB3_5: # %else11
+; RV64-NEXT: andi a2, a1, 32
+; RV64-NEXT: bnez a2, .LBB3_14
+; RV64-NEXT: .LBB3_6: # %else14
+; RV64-NEXT: andi a2, a1, 64
+; RV64-NEXT: bnez a2, .LBB3_15
+; RV64-NEXT: .LBB3_7: # %else17
+; RV64-NEXT: andi a1, a1, -128
+; RV64-NEXT: bnez a1, .LBB3_16
+; RV64-NEXT: .LBB3_8: # %else20
+; RV64-NEXT: ret
+; RV64-NEXT: .LBB3_9: # %cond.store
+; RV64-NEXT: vsetivli zero, 1, e16, m1, ta, ma
+; RV64-NEXT: vse16.v v8, (a0)
+; RV64-NEXT: addi a0, a0, 2
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: beqz a2, .LBB3_2
+; RV64-NEXT: .LBB3_10: # %cond.store1
+; RV64-NEXT: vsetivli zero, 1, e16, m1, ta, ma
+; RV64-NEXT: vslidedown.vi v9, v8, 1
+; RV64-NEXT: vse16.v v9, (a0)
+; RV64-NEXT: addi a0, a0, 2
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: beqz a2, .LBB3_3
+; RV64-NEXT: .LBB3_11: # %cond.store4
+; RV64-NEXT: vsetivli zero, 1, e16, m1, ta, ma
+; RV64-NEXT: vslidedown.vi v9, v8, 2
+; RV64-NEXT: vse16.v v9, (a0)
+; RV64-NEXT: addi a0, a0, 2
+; RV64-NEXT: andi a2, a1, 8
+; RV64-NEXT: beqz a2, .LBB3_4
+; RV64-NEXT: .LBB3_12: # %cond.store7
+; RV64-NEXT: vsetivli zero, 1, e16, m1, ta, ma
+; RV64-NEXT: vslidedown.vi v9, v8, 3
+; RV64-NEXT: vse16.v v9, (a0)
+; RV64-NEXT: addi a0, a0, 2
+; RV64-NEXT: andi a2, a1, 16
+; RV64-NEXT: beqz a2, .LBB3_5
+; RV64-NEXT: .LBB3_13: # %cond.store10
+; RV64-NEXT: vsetivli zero, 1, e16, m1, ta, ma
+; RV64-NEXT: vslidedown.vi v9, v8, 4
+; RV64-NEXT: vse16.v v9, (a0)
+; RV64-NEXT: addi a0, a0, 2
+; RV64-NEXT: andi a2, a1, 32
+; RV64-NEXT: beqz a2, .LBB3_6
+; RV64-NEXT: .LBB3_14: # %cond.store13
+; RV64-NEXT: vsetivli zero, 1, e16, m1, ta, ma
+; RV64-NEXT: vslidedown.vi v9, v8, 5
+; RV64-NEXT: vse16.v v9, (a0)
+; RV64-NEXT: addi a0, a0, 2
+; RV64-NEXT: andi a2, a1, 64
+; RV64-NEXT: beqz a2, .LBB3_7
+; RV64-NEXT: .LBB3_15: # %cond.store16
+; RV64-NEXT: vsetivli zero, 1, e16, m1, ta, ma
+; RV64-NEXT: vslidedown.vi v9, v8, 6
+; RV64-NEXT: vse16.v v9, (a0)
+; RV64-NEXT: addi a0, a0, 2
+; RV64-NEXT: andi a1, a1, -128
+; RV64-NEXT: beqz a1, .LBB3_8
+; RV64-NEXT: .LBB3_16: # %cond.store19
+; RV64-NEXT: vsetivli zero, 1, e16, m1, ta, ma
+; RV64-NEXT: vslidedown.vi v8, v8, 7
+; RV64-NEXT: vse16.v v8, (a0)
+; RV64-NEXT: ret
+ call void @llvm.masked.compressstore.v8f16(<8 x half> %v, ptr align 2 %base, <8 x i1> %mask)
+ ret void
+}
+
+declare void @llvm.masked.compressstore.v1f32(<1 x float>, ptr, <1 x i1>)
+define void @compressstore_v1f32(ptr %base, <1 x float> %v, <1 x i1> %mask) {
+; RV32-LABEL: compressstore_v1f32:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetvli a1, zero, e8, mf8, ta, ma
+; RV32-NEXT: vfirst.m a1, v0
+; RV32-NEXT: bnez a1, .LBB4_2
+; RV32-NEXT: # %bb.1: # %cond.store
+; RV32-NEXT: vsetivli zero, 1, e32, mf2, ta, ma
+; RV32-NEXT: vse32.v v8, (a0)
+; RV32-NEXT: .LBB4_2: # %else
+; RV32-NEXT: ret
+;
+; RV64-LABEL: compressstore_v1f32:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetvli a1, zero, e8, mf8, ta, ma
+; RV64-NEXT: vfirst.m a1, v0
+; RV64-NEXT: bnez a1, .LBB4_2
+; RV64-NEXT: # %bb.1: # %cond.store
+; RV64-NEXT: vsetivli zero, 1, e32, mf2, ta, ma
+; RV64-NEXT: vse32.v v8, (a0)
+; RV64-NEXT: .LBB4_2: # %else
+; RV64-NEXT: ret
+ call void @llvm.masked.compressstore.v1f32(<1 x float> %v, ptr align 4 %base, <1 x i1> %mask)
+ ret void
+}
+
+declare void @llvm.masked.compressstore.v2f32(<2 x float>, ptr, <2 x i1>)
+define void @compressstore_v2f32(ptr %base, <2 x float> %v, <2 x i1> %mask) {
+; RV32-LABEL: compressstore_v2f32:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV32-NEXT: vmv.x.s a1, v0
+; RV32-NEXT: andi a2, a1, 1
+; RV32-NEXT: bnez a2, .LBB5_3
+; RV32-NEXT: # %bb.1: # %else
+; RV32-NEXT: andi a1, a1, 2
+; RV32-NEXT: bnez a1, .LBB5_4
+; RV32-NEXT: .LBB5_2: # %else2
+; RV32-NEXT: ret
+; RV32-NEXT: .LBB5_3: # %cond.store
+; RV32-NEXT: vsetivli zero, 1, e32, mf2, ta, ma
+; RV32-NEXT: vse32.v v8, (a0)
+; RV32-NEXT: addi a0, a0, 4
+; RV32-NEXT: andi a1, a1, 2
+; RV32-NEXT: beqz a1, .LBB5_2
+; RV32-NEXT: .LBB5_4: # %cond.store1
+; RV32-NEXT: vsetivli zero, 1, e32, mf2, ta, ma
+; RV32-NEXT: vslidedown.vi v8, v8, 1
+; RV32-NEXT: vse32.v v8, (a0)
+; RV32-NEXT: ret
+;
+; RV64-LABEL: compressstore_v2f32:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV64-NEXT: vmv.x.s a1, v0
+; RV64-NEXT: andi a2, a1, 1
+; RV64-NEXT: bnez a2, .LBB5_3
+; RV64-NEXT: # %bb.1: # %else
+; RV64-NEXT: andi a1, a1, 2
+; RV64-NEXT: bnez a1, .LBB5_4
+; RV64-NEXT: .LBB5_2: # %else2
+; RV64-NEXT: ret
+; RV64-NEXT: .LBB5_3: # %cond.store
+; RV64-NEXT: vsetivli zero, 1, e32, mf2, ta, ma
+; RV64-NEXT: vse32.v v8, (a0)
+; RV64-NEXT: addi a0, a0, 4
+; RV64-NEXT: andi a1, a1, 2
+; RV64-NEXT: beqz a1, .LBB5_2
+; RV64-NEXT: .LBB5_4: # %cond.store1
+; RV64-NEXT: vsetivli zero, 1, e32, mf2, ta, ma
+; RV64-NEXT: vslidedown.vi v8, v8, 1
+; RV64-NEXT: vse32.v v8, (a0)
+; RV64-NEXT: ret
+ call void @llvm.masked.compressstore.v2f32(<2 x float> %v, ptr align 4 %base, <2 x i1> %mask)
+ ret void
+}
+
+declare void @llvm.masked.compressstore.v4f32(<4 x float>, ptr, <4 x i1>)
+define void @compressstore_v4f32(ptr %base, <4 x float> %v, <4 x i1> %mask) {
+; RV32-LABEL: compressstore_v4f32:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV32-NEXT: vmv.x.s a1, v0
+; RV32-NEXT: andi a2, a1, 1
+; RV32-NEXT: bnez a2, .LBB6_5
+; RV32-NEXT: # %bb.1: # %else
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: bnez a2, .LBB6_6
+; RV32-NEXT: .LBB6_2: # %else2
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: bnez a2, .LBB6_7
+; RV32-NEXT: .LBB6_3: # %else5
+; RV32-NEXT: andi a1, a1, 8
+; RV32-NEXT: bnez a1, .LBB6_8
+; RV32-NEXT: .LBB6_4: # %else8
+; RV32-NEXT: ret
+; RV32-NEXT: .LBB6_5: # %cond.store
+; RV32-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; RV32-NEXT: vse32.v v8, (a0)
+; RV32-NEXT: addi a0, a0, 4
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: beqz a2, .LBB6_2
+; RV32-NEXT: .LBB6_6: # %cond.store1
+; RV32-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; RV32-NEXT: vslidedown.vi v9, v8, 1
+; RV32-NEXT: vse32.v v9, (a0)
+; RV32-NEXT: addi a0, a0, 4
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: beqz a2, .LBB6_3
+; RV32-NEXT: .LBB6_7: # %cond.store4
+; RV32-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; RV32-NEXT: vslidedown.vi v9, v8, 2
+; RV32-NEXT: vse32.v v9, (a0)
+; RV32-NEXT: addi a0, a0, 4
+; RV32-NEXT: andi a1, a1, 8
+; RV32-NEXT: beqz a1, .LBB6_4
+; RV32-NEXT: .LBB6_8: # %cond.store7
+; RV32-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; RV32-NEXT: vslidedown.vi v8, v8, 3
+; RV32-NEXT: vse32.v v8, (a0)
+; RV32-NEXT: ret
+;
+; RV64-LABEL: compressstore_v4f32:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV64-NEXT: vmv.x.s a1, v0
+; RV64-NEXT: andi a2, a1, 1
+; RV64-NEXT: bnez a2, .LBB6_5
+; RV64-NEXT: # %bb.1: # %else
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: bnez a2, .LBB6_6
+; RV64-NEXT: .LBB6_2: # %else2
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: bnez a2, .LBB6_7
+; RV64-NEXT: .LBB6_3: # %else5
+; RV64-NEXT: andi a1, a1, 8
+; RV64-NEXT: bnez a1, .LBB6_8
+; RV64-NEXT: .LBB6_4: # %else8
+; RV64-NEXT: ret
+; RV64-NEXT: .LBB6_5: # %cond.store
+; RV64-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; RV64-NEXT: vse32.v v8, (a0)
+; RV64-NEXT: addi a0, a0, 4
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: beqz a2, .LBB6_2
+; RV64-NEXT: .LBB6_6: # %cond.store1
+; RV64-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; RV64-NEXT: vslidedown.vi v9, v8, 1
+; RV64-NEXT: vse32.v v9, (a0)
+; RV64-NEXT: addi a0, a0, 4
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: beqz a2, .LBB6_3
+; RV64-NEXT: .LBB6_7: # %cond.store4
+; RV64-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; RV64-NEXT: vslidedown.vi v9, v8, 2
+; RV64-NEXT: vse32.v v9, (a0)
+; RV64-NEXT: addi a0, a0, 4
+; RV64-NEXT: andi a1, a1, 8
+; RV64-NEXT: beqz a1, .LBB6_4
+; RV64-NEXT: .LBB6_8: # %cond.store7
+; RV64-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; RV64-NEXT: vslidedown.vi v8, v8, 3
+; RV64-NEXT: vse32.v v8, (a0)
+; RV64-NEXT: ret
+ call void @llvm.masked.compressstore.v4f32(<4 x float> %v, ptr align 4 %base, <4 x i1> %mask)
+ ret void
+}
+
+declare void @llvm.masked.compressstore.v8f32(<8 x float>, ptr, <8 x i1>)
+define void @compressstore_v8f32(ptr %base, <8 x float> %v, <8 x i1> %mask) {
+; RV32-LABEL: compressstore_v8f32:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV32-NEXT: vmv.x.s a1, v0
+; RV32-NEXT: andi a2, a1, 1
+; RV32-NEXT: bnez a2, .LBB7_9
+; RV32-NEXT: # %bb.1: # %else
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: bnez a2, .LBB7_10
+; RV32-NEXT: .LBB7_2: # %else2
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: bnez a2, .LBB7_11
+; RV32-NEXT: .LBB7_3: # %else5
+; RV32-NEXT: andi a2, a1, 8
+; RV32-NEXT: bnez a2, .LBB7_12
+; RV32-NEXT: .LBB7_4: # %else8
+; RV32-NEXT: andi a2, a1, 16
+; RV32-NEXT: bnez a2, .LBB7_13
+; RV32-NEXT: .LBB7_5: # %else11
+; RV32-NEXT: andi a2, a1, 32
+; RV32-NEXT: bnez a2, .LBB7_14
+; RV32-NEXT: .LBB7_6: # %else14
+; RV32-NEXT: andi a2, a1, 64
+; RV32-NEXT: bnez a2, .LBB7_15
+; RV32-NEXT: .LBB7_7: # %else17
+; RV32-NEXT: andi a1, a1, -128
+; RV32-NEXT: bnez a1, .LBB7_16
+; RV32-NEXT: .LBB7_8: # %else20
+; RV32-NEXT: ret
+; RV32-NEXT: .LBB7_9: # %cond.store
+; RV32-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; RV32-NEXT: vse32.v v8, (a0)
+; RV32-NEXT: addi a0, a0, 4
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: beqz a2, .LBB7_2
+; RV32-NEXT: .LBB7_10: # %cond.store1
+; RV32-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; RV32-NEXT: vslidedown.vi v10, v8, 1
+; RV32-NEXT: vse32.v v10, (a0)
+; RV32-NEXT: addi a0, a0, 4
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: beqz a2, .LBB7_3
+; RV32-NEXT: .LBB7_11: # %cond.store4
+; RV32-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; RV32-NEXT: vslidedown.vi v10, v8, 2
+; RV32-NEXT: vse32.v v10, (a0)
+; RV32-NEXT: addi a0, a0, 4
+; RV32-NEXT: andi a2, a1, 8
+; RV32-NEXT: beqz a2, .LBB7_4
+; RV32-NEXT: .LBB7_12: # %cond.store7
+; RV32-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; RV32-NEXT: vslidedown.vi v10, v8, 3
+; RV32-NEXT: vse32.v v10, (a0)
+; RV32-NEXT: addi a0, a0, 4
+; RV32-NEXT: andi a2, a1, 16
+; RV32-NEXT: beqz a2, .LBB7_5
+; RV32-NEXT: .LBB7_13: # %cond.store10
+; RV32-NEXT: vsetivli zero, 1, e32, m2, ta, ma
+; RV32-NEXT: vslidedown.vi v10, v8, 4
+; RV32-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; RV32-NEXT: vse32.v v10, (a0)
+; RV32-NEXT: addi a0, a0, 4
+; RV32-NEXT: andi a2, a1, 32
+; RV32-NEXT: beqz a2, .LBB7_6
+; RV32-NEXT: .LBB7_14: # %cond.store13
+; RV32-NEXT: vsetivli zero, 1, e32, m2, ta, ma
+; RV32-NEXT: vslidedown.vi v10, v8, 5
+; RV32-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; RV32-NEXT: vse32.v v10, (a0)
+; RV32-NEXT: addi a0, a0, 4
+; RV32-NEXT: andi a2, a1, 64
+; RV32-NEXT: beqz a2, .LBB7_7
+; RV32-NEXT: .LBB7_15: # %cond.store16
+; RV32-NEXT: vsetivli zero, 1, e32, m2, ta, ma
+; RV32-NEXT: vslidedown.vi v10, v8, 6
+; RV32-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; RV32-NEXT: vse32.v v10, (a0)
+; RV32-NEXT: addi a0, a0, 4
+; RV32-NEXT: andi a1, a1, -128
+; RV32-NEXT: beqz a1, .LBB7_8
+; RV32-NEXT: .LBB7_16: # %cond.store19
+; RV32-NEXT: vsetivli zero, 1, e32, m2, ta, ma
+; RV32-NEXT: vslidedown.vi v8, v8, 7
+; RV32-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; RV32-NEXT: vse32.v v8, (a0)
+; RV32-NEXT: ret
+;
+; RV64-LABEL: compressstore_v8f32:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV64-NEXT: vmv.x.s a1, v0
+; RV64-NEXT: andi a2, a1, 1
+; RV64-NEXT: bnez a2, .LBB7_9
+; RV64-NEXT: # %bb.1: # %else
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: bnez a2, .LBB7_10
+; RV64-NEXT: .LBB7_2: # %else2
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: bnez a2, .LBB7_11
+; RV64-NEXT: .LBB7_3: # %else5
+; RV64-NEXT: andi a2, a1, 8
+; RV64-NEXT: bnez a2, .LBB7_12
+; RV64-NEXT: .LBB7_4: # %else8
+; RV64-NEXT: andi a2, a1, 16
+; RV64-NEXT: bnez a2, .LBB7_13
+; RV64-NEXT: .LBB7_5: # %else11
+; RV64-NEXT: andi a2, a1, 32
+; RV64-NEXT: bnez a2, .LBB7_14
+; RV64-NEXT: .LBB7_6: # %else14
+; RV64-NEXT: andi a2, a1, 64
+; RV64-NEXT: bnez a2, .LBB7_15
+; RV64-NEXT: .LBB7_7: # %else17
+; RV64-NEXT: andi a1, a1, -128
+; RV64-NEXT: bnez a1, .LBB7_16
+; RV64-NEXT: .LBB7_8: # %else20
+; RV64-NEXT: ret
+; RV64-NEXT: .LBB7_9: # %cond.store
+; RV64-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; RV64-NEXT: vse32.v v8, (a0)
+; RV64-NEXT: addi a0, a0, 4
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: beqz a2, .LBB7_2
+; RV64-NEXT: .LBB7_10: # %cond.store1
+; RV64-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; RV64-NEXT: vslidedown.vi v10, v8, 1
+; RV64-NEXT: vse32.v v10, (a0)
+; RV64-NEXT: addi a0, a0, 4
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: beqz a2, .LBB7_3
+; RV64-NEXT: .LBB7_11: # %cond.store4
+; RV64-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; RV64-NEXT: vslidedown.vi v10, v8, 2
+; RV64-NEXT: vse32.v v10, (a0)
+; RV64-NEXT: addi a0, a0, 4
+; RV64-NEXT: andi a2, a1, 8
+; RV64-NEXT: beqz a2, .LBB7_4
+; RV64-NEXT: .LBB7_12: # %cond.store7
+; RV64-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; RV64-NEXT: vslidedown.vi v10, v8, 3
+; RV64-NEXT: vse32.v v10, (a0)
+; RV64-NEXT: addi a0, a0, 4
+; RV64-NEXT: andi a2, a1, 16
+; RV64-NEXT: beqz a2, .LBB7_5
+; RV64-NEXT: .LBB7_13: # %cond.store10
+; RV64-NEXT: vsetivli zero, 1, e32, m2, ta, ma
+; RV64-NEXT: vslidedown.vi v10, v8, 4
+; RV64-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; RV64-NEXT: vse32.v v10, (a0)
+; RV64-NEXT: addi a0, a0, 4
+; RV64-NEXT: andi a2, a1, 32
+; RV64-NEXT: beqz a2, .LBB7_6
+; RV64-NEXT: .LBB7_14: # %cond.store13
+; RV64-NEXT: vsetivli zero, 1, e32, m2, ta, ma
+; RV64-NEXT: vslidedown.vi v10, v8, 5
+; RV64-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; RV64-NEXT: vse32.v v10, (a0)
+; RV64-NEXT: addi a0, a0, 4
+; RV64-NEXT: andi a2, a1, 64
+; RV64-NEXT: beqz a2, .LBB7_7
+; RV64-NEXT: .LBB7_15: # %cond.store16
+; RV64-NEXT: vsetivli zero, 1, e32, m2, ta, ma
+; RV64-NEXT: vslidedown.vi v10, v8, 6
+; RV64-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; RV64-NEXT: vse32.v v10, (a0)
+; RV64-NEXT: addi a0, a0, 4
+; RV64-NEXT: andi a1, a1, -128
+; RV64-NEXT: beqz a1, .LBB7_8
+; RV64-NEXT: .LBB7_16: # %cond.store19
+; RV64-NEXT: vsetivli zero, 1, e32, m2, ta, ma
+; RV64-NEXT: vslidedown.vi v8, v8, 7
+; RV64-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; RV64-NEXT: vse32.v v8, (a0)
+; RV64-NEXT: ret
+ call void @llvm.masked.compressstore.v8f32(<8 x float> %v, ptr align 4 %base, <8 x i1> %mask)
+ ret void
+}
+
+declare void @llvm.masked.compressstore.v1f64(<1 x double>, ptr, <1 x i1>)
+define void @compressstore_v1f64(ptr %base, <1 x double> %v, <1 x i1> %mask) {
+; RV32-LABEL: compressstore_v1f64:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetvli a1, zero, e8, mf8, ta, ma
+; RV32-NEXT: vfirst.m a1, v0
+; RV32-NEXT: bnez a1, .LBB8_2
+; RV32-NEXT: # %bb.1: # %cond.store
+; RV32-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV32-NEXT: vse64.v v8, (a0)
+; RV32-NEXT: .LBB8_2: # %else
+; RV32-NEXT: ret
+;
+; RV64-LABEL: compressstore_v1f64:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetvli a1, zero, e8, mf8, ta, ma
+; RV64-NEXT: vfirst.m a1, v0
+; RV64-NEXT: bnez a1, .LBB8_2
+; RV64-NEXT: # %bb.1: # %cond.store
+; RV64-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV64-NEXT: vse64.v v8, (a0)
+; RV64-NEXT: .LBB8_2: # %else
+; RV64-NEXT: ret
+ call void @llvm.masked.compressstore.v1f64(<1 x double> %v, ptr align 8 %base, <1 x i1> %mask)
+ ret void
+}
+
+declare void @llvm.masked.compressstore.v2f64(<2 x double>, ptr, <2 x i1>)
+define void @compressstore_v2f64(ptr %base, <2 x double> %v, <2 x i1> %mask) {
+; RV32-LABEL: compressstore_v2f64:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV32-NEXT: vmv.x.s a1, v0
+; RV32-NEXT: andi a2, a1, 1
+; RV32-NEXT: bnez a2, .LBB9_3
+; RV32-NEXT: # %bb.1: # %else
+; RV32-NEXT: andi a1, a1, 2
+; RV32-NEXT: bnez a1, .LBB9_4
+; RV32-NEXT: .LBB9_2: # %else2
+; RV32-NEXT: ret
+; RV32-NEXT: .LBB9_3: # %cond.store
+; RV32-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV32-NEXT: vse64.v v8, (a0)
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a1, a1, 2
+; RV32-NEXT: beqz a1, .LBB9_2
+; RV32-NEXT: .LBB9_4: # %cond.store1
+; RV32-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV32-NEXT: vslidedown.vi v8, v8, 1
+; RV32-NEXT: vse64.v v8, (a0)
+; RV32-NEXT: ret
+;
+; RV64-LABEL: compressstore_v2f64:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV64-NEXT: vmv.x.s a1, v0
+; RV64-NEXT: andi a2, a1, 1
+; RV64-NEXT: bnez a2, .LBB9_3
+; RV64-NEXT: # %bb.1: # %else
+; RV64-NEXT: andi a1, a1, 2
+; RV64-NEXT: bnez a1, .LBB9_4
+; RV64-NEXT: .LBB9_2: # %else2
+; RV64-NEXT: ret
+; RV64-NEXT: .LBB9_3: # %cond.store
+; RV64-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV64-NEXT: vse64.v v8, (a0)
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a1, a1, 2
+; RV64-NEXT: beqz a1, .LBB9_2
+; RV64-NEXT: .LBB9_4: # %cond.store1
+; RV64-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV64-NEXT: vslidedown.vi v8, v8, 1
+; RV64-NEXT: vse64.v v8, (a0)
+; RV64-NEXT: ret
+ call void @llvm.masked.compressstore.v2f64(<2 x double> %v, ptr align 8 %base, <2 x i1> %mask)
+ ret void
+}
+
+declare void @llvm.masked.compressstore.v4f64(<4 x double>, ptr, <4 x i1>)
+define void @compressstore_v4f64(ptr %base, <4 x double> %v, <4 x i1> %mask) {
+; RV32-LABEL: compressstore_v4f64:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV32-NEXT: vmv.x.s a1, v0
+; RV32-NEXT: andi a2, a1, 1
+; RV32-NEXT: bnez a2, .LBB10_5
+; RV32-NEXT: # %bb.1: # %else
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: bnez a2, .LBB10_6
+; RV32-NEXT: .LBB10_2: # %else2
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: bnez a2, .LBB10_7
+; RV32-NEXT: .LBB10_3: # %else5
+; RV32-NEXT: andi a1, a1, 8
+; RV32-NEXT: bnez a1, .LBB10_8
+; RV32-NEXT: .LBB10_4: # %else8
+; RV32-NEXT: ret
+; RV32-NEXT: .LBB10_5: # %cond.store
+; RV32-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV32-NEXT: vse64.v v8, (a0)
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: beqz a2, .LBB10_2
+; RV32-NEXT: .LBB10_6: # %cond.store1
+; RV32-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV32-NEXT: vslidedown.vi v10, v8, 1
+; RV32-NEXT: vse64.v v10, (a0)
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: beqz a2, .LBB10_3
+; RV32-NEXT: .LBB10_7: # %cond.store4
+; RV32-NEXT: vsetivli zero, 1, e64, m2, ta, ma
+; RV32-NEXT: vslidedown.vi v10, v8, 2
+; RV32-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV32-NEXT: vse64.v v10, (a0)
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a1, a1, 8
+; RV32-NEXT: beqz a1, .LBB10_4
+; RV32-NEXT: .LBB10_8: # %cond.store7
+; RV32-NEXT: vsetivli zero, 1, e64, m2, ta, ma
+; RV32-NEXT: vslidedown.vi v8, v8, 3
+; RV32-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV32-NEXT: vse64.v v8, (a0)
+; RV32-NEXT: ret
+;
+; RV64-LABEL: compressstore_v4f64:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV64-NEXT: vmv.x.s a1, v0
+; RV64-NEXT: andi a2, a1, 1
+; RV64-NEXT: bnez a2, .LBB10_5
+; RV64-NEXT: # %bb.1: # %else
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: bnez a2, .LBB10_6
+; RV64-NEXT: .LBB10_2: # %else2
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: bnez a2, .LBB10_7
+; RV64-NEXT: .LBB10_3: # %else5
+; RV64-NEXT: andi a1, a1, 8
+; RV64-NEXT: bnez a1, .LBB10_8
+; RV64-NEXT: .LBB10_4: # %else8
+; RV64-NEXT: ret
+; RV64-NEXT: .LBB10_5: # %cond.store
+; RV64-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV64-NEXT: vse64.v v8, (a0)
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: beqz a2, .LBB10_2
+; RV64-NEXT: .LBB10_6: # %cond.store1
+; RV64-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV64-NEXT: vslidedown.vi v10, v8, 1
+; RV64-NEXT: vse64.v v10, (a0)
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: beqz a2, .LBB10_3
+; RV64-NEXT: .LBB10_7: # %cond.store4
+; RV64-NEXT: vsetivli zero, 1, e64, m2, ta, ma
+; RV64-NEXT: vslidedown.vi v10, v8, 2
+; RV64-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV64-NEXT: vse64.v v10, (a0)
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a1, a1, 8
+; RV64-NEXT: beqz a1, .LBB10_4
+; RV64-NEXT: .LBB10_8: # %cond.store7
+; RV64-NEXT: vsetivli zero, 1, e64, m2, ta, ma
+; RV64-NEXT: vslidedown.vi v8, v8, 3
+; RV64-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV64-NEXT: vse64.v v8, (a0)
+; RV64-NEXT: ret
+ call void @llvm.masked.compressstore.v4f64(<4 x double> %v, ptr align 8 %base, <4 x i1> %mask)
+ ret void
+}
+
+declare void @llvm.masked.compressstore.v8f64(<8 x double>, ptr, <8 x i1>)
+define void @compressstore_v8f64(ptr %base, <8 x double> %v, <8 x i1> %mask) {
+; RV32-LABEL: compressstore_v8f64:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV32-NEXT: vmv.x.s a1, v0
+; RV32-NEXT: andi a2, a1, 1
+; RV32-NEXT: bnez a2, .LBB11_11
+; RV32-NEXT: # %bb.1: # %else
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: bnez a2, .LBB11_12
+; RV32-NEXT: .LBB11_2: # %else2
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: bnez a2, .LBB11_13
+; RV32-NEXT: .LBB11_3: # %else5
+; RV32-NEXT: andi a2, a1, 8
+; RV32-NEXT: beqz a2, .LBB11_5
+; RV32-NEXT: .LBB11_4: # %cond.store7
+; RV32-NEXT: vsetivli zero, 1, e64, m2, ta, ma
+; RV32-NEXT: vslidedown.vi v12, v8, 3
+; RV32-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV32-NEXT: vse64.v v12, (a0)
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: .LBB11_5: # %else8
+; RV32-NEXT: addi sp, sp, -320
+; RV32-NEXT: .cfi_def_cfa_offset 320
+; RV32-NEXT: sw ra, 316(sp) # 4-byte Folded Spill
+; RV32-NEXT: sw s0, 312(sp) # 4-byte Folded Spill
+; RV32-NEXT: .cfi_offset ra, -4
+; RV32-NEXT: .cfi_offset s0, -8
+; RV32-NEXT: addi s0, sp, 320
+; RV32-NEXT: .cfi_def_cfa s0, 0
+; RV32-NEXT: andi sp, sp, -64
+; RV32-NEXT: andi a2, a1, 16
+; RV32-NEXT: bnez a2, .LBB11_14
+; RV32-NEXT: # %bb.6: # %else11
+; RV32-NEXT: andi a2, a1, 32
+; RV32-NEXT: bnez a2, .LBB11_15
+; RV32-NEXT: .LBB11_7: # %else14
+; RV32-NEXT: andi a2, a1, 64
+; RV32-NEXT: bnez a2, .LBB11_16
+; RV32-NEXT: .LBB11_8: # %else17
+; RV32-NEXT: andi a1, a1, -128
+; RV32-NEXT: beqz a1, .LBB11_10
+; RV32-NEXT: .LBB11_9: # %cond.store19
+; RV32-NEXT: mv a1, sp
+; RV32-NEXT: vsetivli zero, 8, e64, m4, ta, ma
+; RV32-NEXT: vse64.v v8, (a1)
+; RV32-NEXT: fld fa5, 56(sp)
+; RV32-NEXT: fsd fa5, 0(a0)
+; RV32-NEXT: .LBB11_10: # %else20
+; RV32-NEXT: addi sp, s0, -320
+; RV32-NEXT: lw ra, 316(sp) # 4-byte Folded Reload
+; RV32-NEXT: lw s0, 312(sp) # 4-byte Folded Reload
+; RV32-NEXT: addi sp, sp, 320
+; RV32-NEXT: ret
+; RV32-NEXT: .LBB11_11: # %cond.store
+; RV32-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV32-NEXT: vse64.v v8, (a0)
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: beqz a2, .LBB11_2
+; RV32-NEXT: .LBB11_12: # %cond.store1
+; RV32-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV32-NEXT: vslidedown.vi v12, v8, 1
+; RV32-NEXT: vse64.v v12, (a0)
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: beqz a2, .LBB11_3
+; RV32-NEXT: .LBB11_13: # %cond.store4
+; RV32-NEXT: vsetivli zero, 1, e64, m2, ta, ma
+; RV32-NEXT: vslidedown.vi v12, v8, 2
+; RV32-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV32-NEXT: vse64.v v12, (a0)
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a2, a1, 8
+; RV32-NEXT: bnez a2, .LBB11_4
+; RV32-NEXT: j .LBB11_5
+; RV32-NEXT: .LBB11_14: # %cond.store10
+; RV32-NEXT: addi a2, sp, 192
+; RV32-NEXT: vsetivli zero, 8, e64, m4, ta, ma
+; RV32-NEXT: vse64.v v8, (a2)
+; RV32-NEXT: fld fa5, 224(sp)
+; RV32-NEXT: fsd fa5, 0(a0)
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a2, a1, 32
+; RV32-NEXT: beqz a2, .LBB11_7
+; RV32-NEXT: .LBB11_15: # %cond.store13
+; RV32-NEXT: addi a2, sp, 128
+; RV32-NEXT: vsetivli zero, 8, e64, m4, ta, ma
+; RV32-NEXT: vse64.v v8, (a2)
+; RV32-NEXT: fld fa5, 168(sp)
+; RV32-NEXT: fsd fa5, 0(a0)
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a2, a1, 64
+; RV32-NEXT: beqz a2, .LBB11_8
+; RV32-NEXT: .LBB11_16: # %cond.store16
+; RV32-NEXT: addi a2, sp, 64
+; RV32-NEXT: vsetivli zero, 8, e64, m4, ta, ma
+; RV32-NEXT: vse64.v v8, (a2)
+; RV32-NEXT: fld fa5, 112(sp)
+; RV32-NEXT: fsd fa5, 0(a0)
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a1, a1, -128
+; RV32-NEXT: bnez a1, .LBB11_9
+; RV32-NEXT: j .LBB11_10
+;
+; RV64-LABEL: compressstore_v8f64:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV64-NEXT: vmv.x.s a1, v0
+; RV64-NEXT: andi a2, a1, 1
+; RV64-NEXT: bnez a2, .LBB11_11
+; RV64-NEXT: # %bb.1: # %else
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: bnez a2, .LBB11_12
+; RV64-NEXT: .LBB11_2: # %else2
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: bnez a2, .LBB11_13
+; RV64-NEXT: .LBB11_3: # %else5
+; RV64-NEXT: andi a2, a1, 8
+; RV64-NEXT: beqz a2, .LBB11_5
+; RV64-NEXT: .LBB11_4: # %cond.store7
+; RV64-NEXT: vsetivli zero, 1, e64, m2, ta, ma
+; RV64-NEXT: vslidedown.vi v12, v8, 3
+; RV64-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV64-NEXT: vse64.v v12, (a0)
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: .LBB11_5: # %else8
+; RV64-NEXT: addi sp, sp, -320
+; RV64-NEXT: .cfi_def_cfa_offset 320
+; RV64-NEXT: sd ra, 312(sp) # 8-byte Folded Spill
+; RV64-NEXT: sd s0, 304(sp) # 8-byte Folded Spill
+; RV64-NEXT: .cfi_offset ra, -8
+; RV64-NEXT: .cfi_offset s0, -16
+; RV64-NEXT: addi s0, sp, 320
+; RV64-NEXT: .cfi_def_cfa s0, 0
+; RV64-NEXT: andi sp, sp, -64
+; RV64-NEXT: andi a2, a1, 16
+; RV64-NEXT: bnez a2, .LBB11_14
+; RV64-NEXT: # %bb.6: # %else11
+; RV64-NEXT: andi a2, a1, 32
+; RV64-NEXT: bnez a2, .LBB11_15
+; RV64-NEXT: .LBB11_7: # %else14
+; RV64-NEXT: andi a2, a1, 64
+; RV64-NEXT: bnez a2, .LBB11_16
+; RV64-NEXT: .LBB11_8: # %else17
+; RV64-NEXT: andi a1, a1, -128
+; RV64-NEXT: beqz a1, .LBB11_10
+; RV64-NEXT: .LBB11_9: # %cond.store19
+; RV64-NEXT: mv a1, sp
+; RV64-NEXT: vsetivli zero, 8, e64, m4, ta, ma
+; RV64-NEXT: vse64.v v8, (a1)
+; RV64-NEXT: fld fa5, 56(sp)
+; RV64-NEXT: fsd fa5, 0(a0)
+; RV64-NEXT: .LBB11_10: # %else20
+; RV64-NEXT: addi sp, s0, -320
+; RV64-NEXT: ld ra, 312(sp) # 8-byte Folded Reload
+; RV64-NEXT: ld s0, 304(sp) # 8-byte Folded Reload
+; RV64-NEXT: addi sp, sp, 320
+; RV64-NEXT: ret
+; RV64-NEXT: .LBB11_11: # %cond.store
+; RV64-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV64-NEXT: vse64.v v8, (a0)
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: beqz a2, .LBB11_2
+; RV64-NEXT: .LBB11_12: # %cond.store1
+; RV64-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV64-NEXT: vslidedown.vi v12, v8, 1
+; RV64-NEXT: vse64.v v12, (a0)
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: beqz a2, .LBB11_3
+; RV64-NEXT: .LBB11_13: # %cond.store4
+; RV64-NEXT: vsetivli zero, 1, e64, m2, ta, ma
+; RV64-NEXT: vslidedown.vi v12, v8, 2
+; RV64-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV64-NEXT: vse64.v v12, (a0)
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a2, a1, 8
+; RV64-NEXT: bnez a2, .LBB11_4
+; RV64-NEXT: j .LBB11_5
+; RV64-NEXT: .LBB11_14: # %cond.store10
+; RV64-NEXT: addi a2, sp, 192
+; RV64-NEXT: vsetivli zero, 8, e64, m4, ta, ma
+; RV64-NEXT: vse64.v v8, (a2)
+; RV64-NEXT: fld fa5, 224(sp)
+; RV64-NEXT: fsd fa5, 0(a0)
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a2, a1, 32
+; RV64-NEXT: beqz a2, .LBB11_7
+; RV64-NEXT: .LBB11_15: # %cond.store13
+; RV64-NEXT: addi a2, sp, 128
+; RV64-NEXT: vsetivli zero, 8, e64, m4, ta, ma
+; RV64-NEXT: vse64.v v8, (a2)
+; RV64-NEXT: fld fa5, 168(sp)
+; RV64-NEXT: fsd fa5, 0(a0)
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a2, a1, 64
+; RV64-NEXT: beqz a2, .LBB11_8
+; RV64-NEXT: .LBB11_16: # %cond.store16
+; RV64-NEXT: addi a2, sp, 64
+; RV64-NEXT: vsetivli zero, 8, e64, m4, ta, ma
+; RV64-NEXT: vse64.v v8, (a2)
+; RV64-NEXT: fld fa5, 112(sp)
+; RV64-NEXT: fsd fa5, 0(a0)
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a1, a1, -128
+; RV64-NEXT: bnez a1, .LBB11_9
+; RV64-NEXT: j .LBB11_10
+ call void @llvm.masked.compressstore.v8f64(<8 x double> %v, ptr align 8 %base, <8 x i1> %mask)
+ ret void
+}
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-compressstore-int.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-compressstore-int.ll
new file mode 100644
index 00000000000000..eb0096dbfba6de
--- /dev/null
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-compressstore-int.ll
@@ -0,0 +1,986 @@
+; NOTE: Assertions have been autogenerated by utils/update_llc_test_checks.py UTC_ARGS: --version 4
+; RUN: llc -mtriple=riscv32 -mattr=+m,+v -verify-machineinstrs < %s | FileCheck %s --check-prefixes=CHECK,RV32
+; RUN: llc -mtriple=riscv64 -mattr=+m,+v -verify-machineinstrs < %s | FileCheck %s --check-prefixes=CHECK,RV64
+
+declare void @llvm.masked.compressstore.v1i8(<1 x i8>, ptr, <1 x i1>)
+define void @compressstore_v1i8(ptr %base, <1 x i8> %v, <1 x i1> %mask) {
+; CHECK-LABEL: compressstore_v1i8:
+; CHECK: # %bb.0:
+; CHECK-NEXT: vsetvli a1, zero, e8, mf8, ta, ma
+; CHECK-NEXT: vfirst.m a1, v0
+; CHECK-NEXT: bnez a1, .LBB0_2
+; CHECK-NEXT: # %bb.1: # %cond.store
+; CHECK-NEXT: vsetivli zero, 1, e8, mf8, ta, ma
+; CHECK-NEXT: vse8.v v8, (a0)
+; CHECK-NEXT: .LBB0_2: # %else
+; CHECK-NEXT: ret
+ call void @llvm.masked.compressstore.v1i8(<1 x i8> %v, ptr %base, <1 x i1> %mask)
+ ret void
+}
+
+declare void @llvm.masked.compressstore.v2i8(<2 x i8>, ptr, <2 x i1>)
+define void @compressstore_v2i8(ptr %base, <2 x i8> %v, <2 x i1> %mask) {
+; CHECK-LABEL: compressstore_v2i8:
+; CHECK: # %bb.0:
+; CHECK-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; CHECK-NEXT: vmv.x.s a1, v0
+; CHECK-NEXT: andi a2, a1, 1
+; CHECK-NEXT: bnez a2, .LBB1_3
+; CHECK-NEXT: # %bb.1: # %else
+; CHECK-NEXT: andi a1, a1, 2
+; CHECK-NEXT: bnez a1, .LBB1_4
+; CHECK-NEXT: .LBB1_2: # %else2
+; CHECK-NEXT: ret
+; CHECK-NEXT: .LBB1_3: # %cond.store
+; CHECK-NEXT: vsetivli zero, 1, e8, mf8, ta, ma
+; CHECK-NEXT: vse8.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 1
+; CHECK-NEXT: andi a1, a1, 2
+; CHECK-NEXT: beqz a1, .LBB1_2
+; CHECK-NEXT: .LBB1_4: # %cond.store1
+; CHECK-NEXT: vsetivli zero, 1, e8, mf8, ta, ma
+; CHECK-NEXT: vslidedown.vi v8, v8, 1
+; CHECK-NEXT: vse8.v v8, (a0)
+; CHECK-NEXT: ret
+ call void @llvm.masked.compressstore.v2i8(<2 x i8> %v, ptr %base, <2 x i1> %mask)
+ ret void
+}
+
+declare void @llvm.masked.compressstore.v4i8(<4 x i8>, ptr, <4 x i1>)
+define void @compressstore_v4i8(ptr %base, <4 x i8> %v, <4 x i1> %mask) {
+; CHECK-LABEL: compressstore_v4i8:
+; CHECK: # %bb.0:
+; CHECK-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; CHECK-NEXT: vmv.x.s a1, v0
+; CHECK-NEXT: andi a2, a1, 1
+; CHECK-NEXT: bnez a2, .LBB2_5
+; CHECK-NEXT: # %bb.1: # %else
+; CHECK-NEXT: andi a2, a1, 2
+; CHECK-NEXT: bnez a2, .LBB2_6
+; CHECK-NEXT: .LBB2_2: # %else2
+; CHECK-NEXT: andi a2, a1, 4
+; CHECK-NEXT: bnez a2, .LBB2_7
+; CHECK-NEXT: .LBB2_3: # %else5
+; CHECK-NEXT: andi a1, a1, 8
+; CHECK-NEXT: bnez a1, .LBB2_8
+; CHECK-NEXT: .LBB2_4: # %else8
+; CHECK-NEXT: ret
+; CHECK-NEXT: .LBB2_5: # %cond.store
+; CHECK-NEXT: vsetivli zero, 1, e8, mf4, ta, ma
+; CHECK-NEXT: vse8.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 1
+; CHECK-NEXT: andi a2, a1, 2
+; CHECK-NEXT: beqz a2, .LBB2_2
+; CHECK-NEXT: .LBB2_6: # %cond.store1
+; CHECK-NEXT: vsetivli zero, 1, e8, mf4, ta, ma
+; CHECK-NEXT: vslidedown.vi v9, v8, 1
+; CHECK-NEXT: vse8.v v9, (a0)
+; CHECK-NEXT: addi a0, a0, 1
+; CHECK-NEXT: andi a2, a1, 4
+; CHECK-NEXT: beqz a2, .LBB2_3
+; CHECK-NEXT: .LBB2_7: # %cond.store4
+; CHECK-NEXT: vsetivli zero, 1, e8, mf4, ta, ma
+; CHECK-NEXT: vslidedown.vi v9, v8, 2
+; CHECK-NEXT: vse8.v v9, (a0)
+; CHECK-NEXT: addi a0, a0, 1
+; CHECK-NEXT: andi a1, a1, 8
+; CHECK-NEXT: beqz a1, .LBB2_4
+; CHECK-NEXT: .LBB2_8: # %cond.store7
+; CHECK-NEXT: vsetivli zero, 1, e8, mf4, ta, ma
+; CHECK-NEXT: vslidedown.vi v8, v8, 3
+; CHECK-NEXT: vse8.v v8, (a0)
+; CHECK-NEXT: ret
+ call void @llvm.masked.compressstore.v4i8(<4 x i8> %v, ptr %base, <4 x i1> %mask)
+ ret void
+}
+
+declare void @llvm.masked.compressstore.v8i8(<8 x i8>, ptr, <8 x i1>)
+define void @compressstore_v8i8(ptr %base, <8 x i8> %v, <8 x i1> %mask) {
+; CHECK-LABEL: compressstore_v8i8:
+; CHECK: # %bb.0:
+; CHECK-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; CHECK-NEXT: vmv.x.s a1, v0
+; CHECK-NEXT: andi a2, a1, 1
+; CHECK-NEXT: bnez a2, .LBB3_9
+; CHECK-NEXT: # %bb.1: # %else
+; CHECK-NEXT: andi a2, a1, 2
+; CHECK-NEXT: bnez a2, .LBB3_10
+; CHECK-NEXT: .LBB3_2: # %else2
+; CHECK-NEXT: andi a2, a1, 4
+; CHECK-NEXT: bnez a2, .LBB3_11
+; CHECK-NEXT: .LBB3_3: # %else5
+; CHECK-NEXT: andi a2, a1, 8
+; CHECK-NEXT: bnez a2, .LBB3_12
+; CHECK-NEXT: .LBB3_4: # %else8
+; CHECK-NEXT: andi a2, a1, 16
+; CHECK-NEXT: bnez a2, .LBB3_13
+; CHECK-NEXT: .LBB3_5: # %else11
+; CHECK-NEXT: andi a2, a1, 32
+; CHECK-NEXT: bnez a2, .LBB3_14
+; CHECK-NEXT: .LBB3_6: # %else14
+; CHECK-NEXT: andi a2, a1, 64
+; CHECK-NEXT: bnez a2, .LBB3_15
+; CHECK-NEXT: .LBB3_7: # %else17
+; CHECK-NEXT: andi a1, a1, -128
+; CHECK-NEXT: bnez a1, .LBB3_16
+; CHECK-NEXT: .LBB3_8: # %else20
+; CHECK-NEXT: ret
+; CHECK-NEXT: .LBB3_9: # %cond.store
+; CHECK-NEXT: vsetivli zero, 1, e8, mf2, ta, ma
+; CHECK-NEXT: vse8.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 1
+; CHECK-NEXT: andi a2, a1, 2
+; CHECK-NEXT: beqz a2, .LBB3_2
+; CHECK-NEXT: .LBB3_10: # %cond.store1
+; CHECK-NEXT: vsetivli zero, 1, e8, mf2, ta, ma
+; CHECK-NEXT: vslidedown.vi v9, v8, 1
+; CHECK-NEXT: vse8.v v9, (a0)
+; CHECK-NEXT: addi a0, a0, 1
+; CHECK-NEXT: andi a2, a1, 4
+; CHECK-NEXT: beqz a2, .LBB3_3
+; CHECK-NEXT: .LBB3_11: # %cond.store4
+; CHECK-NEXT: vsetivli zero, 1, e8, mf2, ta, ma
+; CHECK-NEXT: vslidedown.vi v9, v8, 2
+; CHECK-NEXT: vse8.v v9, (a0)
+; CHECK-NEXT: addi a0, a0, 1
+; CHECK-NEXT: andi a2, a1, 8
+; CHECK-NEXT: beqz a2, .LBB3_4
+; CHECK-NEXT: .LBB3_12: # %cond.store7
+; CHECK-NEXT: vsetivli zero, 1, e8, mf2, ta, ma
+; CHECK-NEXT: vslidedown.vi v9, v8, 3
+; CHECK-NEXT: vse8.v v9, (a0)
+; CHECK-NEXT: addi a0, a0, 1
+; CHECK-NEXT: andi a2, a1, 16
+; CHECK-NEXT: beqz a2, .LBB3_5
+; CHECK-NEXT: .LBB3_13: # %cond.store10
+; CHECK-NEXT: vsetivli zero, 1, e8, mf2, ta, ma
+; CHECK-NEXT: vslidedown.vi v9, v8, 4
+; CHECK-NEXT: vse8.v v9, (a0)
+; CHECK-NEXT: addi a0, a0, 1
+; CHECK-NEXT: andi a2, a1, 32
+; CHECK-NEXT: beqz a2, .LBB3_6
+; CHECK-NEXT: .LBB3_14: # %cond.store13
+; CHECK-NEXT: vsetivli zero, 1, e8, mf2, ta, ma
+; CHECK-NEXT: vslidedown.vi v9, v8, 5
+; CHECK-NEXT: vse8.v v9, (a0)
+; CHECK-NEXT: addi a0, a0, 1
+; CHECK-NEXT: andi a2, a1, 64
+; CHECK-NEXT: beqz a2, .LBB3_7
+; CHECK-NEXT: .LBB3_15: # %cond.store16
+; CHECK-NEXT: vsetivli zero, 1, e8, mf2, ta, ma
+; CHECK-NEXT: vslidedown.vi v9, v8, 6
+; CHECK-NEXT: vse8.v v9, (a0)
+; CHECK-NEXT: addi a0, a0, 1
+; CHECK-NEXT: andi a1, a1, -128
+; CHECK-NEXT: beqz a1, .LBB3_8
+; CHECK-NEXT: .LBB3_16: # %cond.store19
+; CHECK-NEXT: vsetivli zero, 1, e8, mf2, ta, ma
+; CHECK-NEXT: vslidedown.vi v8, v8, 7
+; CHECK-NEXT: vse8.v v8, (a0)
+; CHECK-NEXT: ret
+ call void @llvm.masked.compressstore.v8i8(<8 x i8> %v, ptr %base, <8 x i1> %mask)
+ ret void
+}
+
+declare void @llvm.masked.compressstore.v1i16(<1 x i16>, ptr, <1 x i1>)
+define void @compressstore_v1i16(ptr %base, <1 x i16> %v, <1 x i1> %mask) {
+; CHECK-LABEL: compressstore_v1i16:
+; CHECK: # %bb.0:
+; CHECK-NEXT: vsetvli a1, zero, e8, mf8, ta, ma
+; CHECK-NEXT: vfirst.m a1, v0
+; CHECK-NEXT: bnez a1, .LBB4_2
+; CHECK-NEXT: # %bb.1: # %cond.store
+; CHECK-NEXT: vsetivli zero, 1, e16, mf4, ta, ma
+; CHECK-NEXT: vse16.v v8, (a0)
+; CHECK-NEXT: .LBB4_2: # %else
+; CHECK-NEXT: ret
+ call void @llvm.masked.compressstore.v1i16(<1 x i16> %v, ptr align 2 %base, <1 x i1> %mask)
+ ret void
+}
+
+declare void @llvm.masked.compressstore.v2i16(<2 x i16>, ptr, <2 x i1>)
+define void @compressstore_v2i16(ptr %base, <2 x i16> %v, <2 x i1> %mask) {
+; CHECK-LABEL: compressstore_v2i16:
+; CHECK: # %bb.0:
+; CHECK-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; CHECK-NEXT: vmv.x.s a1, v0
+; CHECK-NEXT: andi a2, a1, 1
+; CHECK-NEXT: bnez a2, .LBB5_3
+; CHECK-NEXT: # %bb.1: # %else
+; CHECK-NEXT: andi a1, a1, 2
+; CHECK-NEXT: bnez a1, .LBB5_4
+; CHECK-NEXT: .LBB5_2: # %else2
+; CHECK-NEXT: ret
+; CHECK-NEXT: .LBB5_3: # %cond.store
+; CHECK-NEXT: vsetivli zero, 1, e16, mf4, ta, ma
+; CHECK-NEXT: vse16.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 2
+; CHECK-NEXT: andi a1, a1, 2
+; CHECK-NEXT: beqz a1, .LBB5_2
+; CHECK-NEXT: .LBB5_4: # %cond.store1
+; CHECK-NEXT: vsetivli zero, 1, e16, mf4, ta, ma
+; CHECK-NEXT: vslidedown.vi v8, v8, 1
+; CHECK-NEXT: vse16.v v8, (a0)
+; CHECK-NEXT: ret
+ call void @llvm.masked.compressstore.v2i16(<2 x i16> %v, ptr align 2 %base, <2 x i1> %mask)
+ ret void
+}
+
+declare void @llvm.masked.compressstore.v4i16(<4 x i16>, ptr, <4 x i1>)
+define void @compressstore_v4i16(ptr %base, <4 x i16> %v, <4 x i1> %mask) {
+; CHECK-LABEL: compressstore_v4i16:
+; CHECK: # %bb.0:
+; CHECK-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; CHECK-NEXT: vmv.x.s a1, v0
+; CHECK-NEXT: andi a2, a1, 1
+; CHECK-NEXT: bnez a2, .LBB6_5
+; CHECK-NEXT: # %bb.1: # %else
+; CHECK-NEXT: andi a2, a1, 2
+; CHECK-NEXT: bnez a2, .LBB6_6
+; CHECK-NEXT: .LBB6_2: # %else2
+; CHECK-NEXT: andi a2, a1, 4
+; CHECK-NEXT: bnez a2, .LBB6_7
+; CHECK-NEXT: .LBB6_3: # %else5
+; CHECK-NEXT: andi a1, a1, 8
+; CHECK-NEXT: bnez a1, .LBB6_8
+; CHECK-NEXT: .LBB6_4: # %else8
+; CHECK-NEXT: ret
+; CHECK-NEXT: .LBB6_5: # %cond.store
+; CHECK-NEXT: vsetivli zero, 1, e16, mf2, ta, ma
+; CHECK-NEXT: vse16.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 2
+; CHECK-NEXT: andi a2, a1, 2
+; CHECK-NEXT: beqz a2, .LBB6_2
+; CHECK-NEXT: .LBB6_6: # %cond.store1
+; CHECK-NEXT: vsetivli zero, 1, e16, mf2, ta, ma
+; CHECK-NEXT: vslidedown.vi v9, v8, 1
+; CHECK-NEXT: vse16.v v9, (a0)
+; CHECK-NEXT: addi a0, a0, 2
+; CHECK-NEXT: andi a2, a1, 4
+; CHECK-NEXT: beqz a2, .LBB6_3
+; CHECK-NEXT: .LBB6_7: # %cond.store4
+; CHECK-NEXT: vsetivli zero, 1, e16, mf2, ta, ma
+; CHECK-NEXT: vslidedown.vi v9, v8, 2
+; CHECK-NEXT: vse16.v v9, (a0)
+; CHECK-NEXT: addi a0, a0, 2
+; CHECK-NEXT: andi a1, a1, 8
+; CHECK-NEXT: beqz a1, .LBB6_4
+; CHECK-NEXT: .LBB6_8: # %cond.store7
+; CHECK-NEXT: vsetivli zero, 1, e16, mf2, ta, ma
+; CHECK-NEXT: vslidedown.vi v8, v8, 3
+; CHECK-NEXT: vse16.v v8, (a0)
+; CHECK-NEXT: ret
+ call void @llvm.masked.compressstore.v4i16(<4 x i16> %v, ptr align 2 %base, <4 x i1> %mask)
+ ret void
+}
+
+declare void @llvm.masked.compressstore.v8i16(<8 x i16>, ptr, <8 x i1>)
+define void @compressstore_v8i16(ptr %base, <8 x i16> %v, <8 x i1> %mask) {
+; CHECK-LABEL: compressstore_v8i16:
+; CHECK: # %bb.0:
+; CHECK-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; CHECK-NEXT: vmv.x.s a1, v0
+; CHECK-NEXT: andi a2, a1, 1
+; CHECK-NEXT: bnez a2, .LBB7_9
+; CHECK-NEXT: # %bb.1: # %else
+; CHECK-NEXT: andi a2, a1, 2
+; CHECK-NEXT: bnez a2, .LBB7_10
+; CHECK-NEXT: .LBB7_2: # %else2
+; CHECK-NEXT: andi a2, a1, 4
+; CHECK-NEXT: bnez a2, .LBB7_11
+; CHECK-NEXT: .LBB7_3: # %else5
+; CHECK-NEXT: andi a2, a1, 8
+; CHECK-NEXT: bnez a2, .LBB7_12
+; CHECK-NEXT: .LBB7_4: # %else8
+; CHECK-NEXT: andi a2, a1, 16
+; CHECK-NEXT: bnez a2, .LBB7_13
+; CHECK-NEXT: .LBB7_5: # %else11
+; CHECK-NEXT: andi a2, a1, 32
+; CHECK-NEXT: bnez a2, .LBB7_14
+; CHECK-NEXT: .LBB7_6: # %else14
+; CHECK-NEXT: andi a2, a1, 64
+; CHECK-NEXT: bnez a2, .LBB7_15
+; CHECK-NEXT: .LBB7_7: # %else17
+; CHECK-NEXT: andi a1, a1, -128
+; CHECK-NEXT: bnez a1, .LBB7_16
+; CHECK-NEXT: .LBB7_8: # %else20
+; CHECK-NEXT: ret
+; CHECK-NEXT: .LBB7_9: # %cond.store
+; CHECK-NEXT: vsetivli zero, 1, e16, m1, ta, ma
+; CHECK-NEXT: vse16.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 2
+; CHECK-NEXT: andi a2, a1, 2
+; CHECK-NEXT: beqz a2, .LBB7_2
+; CHECK-NEXT: .LBB7_10: # %cond.store1
+; CHECK-NEXT: vsetivli zero, 1, e16, m1, ta, ma
+; CHECK-NEXT: vslidedown.vi v9, v8, 1
+; CHECK-NEXT: vse16.v v9, (a0)
+; CHECK-NEXT: addi a0, a0, 2
+; CHECK-NEXT: andi a2, a1, 4
+; CHECK-NEXT: beqz a2, .LBB7_3
+; CHECK-NEXT: .LBB7_11: # %cond.store4
+; CHECK-NEXT: vsetivli zero, 1, e16, m1, ta, ma
+; CHECK-NEXT: vslidedown.vi v9, v8, 2
+; CHECK-NEXT: vse16.v v9, (a0)
+; CHECK-NEXT: addi a0, a0, 2
+; CHECK-NEXT: andi a2, a1, 8
+; CHECK-NEXT: beqz a2, .LBB7_4
+; CHECK-NEXT: .LBB7_12: # %cond.store7
+; CHECK-NEXT: vsetivli zero, 1, e16, m1, ta, ma
+; CHECK-NEXT: vslidedown.vi v9, v8, 3
+; CHECK-NEXT: vse16.v v9, (a0)
+; CHECK-NEXT: addi a0, a0, 2
+; CHECK-NEXT: andi a2, a1, 16
+; CHECK-NEXT: beqz a2, .LBB7_5
+; CHECK-NEXT: .LBB7_13: # %cond.store10
+; CHECK-NEXT: vsetivli zero, 1, e16, m1, ta, ma
+; CHECK-NEXT: vslidedown.vi v9, v8, 4
+; CHECK-NEXT: vse16.v v9, (a0)
+; CHECK-NEXT: addi a0, a0, 2
+; CHECK-NEXT: andi a2, a1, 32
+; CHECK-NEXT: beqz a2, .LBB7_6
+; CHECK-NEXT: .LBB7_14: # %cond.store13
+; CHECK-NEXT: vsetivli zero, 1, e16, m1, ta, ma
+; CHECK-NEXT: vslidedown.vi v9, v8, 5
+; CHECK-NEXT: vse16.v v9, (a0)
+; CHECK-NEXT: addi a0, a0, 2
+; CHECK-NEXT: andi a2, a1, 64
+; CHECK-NEXT: beqz a2, .LBB7_7
+; CHECK-NEXT: .LBB7_15: # %cond.store16
+; CHECK-NEXT: vsetivli zero, 1, e16, m1, ta, ma
+; CHECK-NEXT: vslidedown.vi v9, v8, 6
+; CHECK-NEXT: vse16.v v9, (a0)
+; CHECK-NEXT: addi a0, a0, 2
+; CHECK-NEXT: andi a1, a1, -128
+; CHECK-NEXT: beqz a1, .LBB7_8
+; CHECK-NEXT: .LBB7_16: # %cond.store19
+; CHECK-NEXT: vsetivli zero, 1, e16, m1, ta, ma
+; CHECK-NEXT: vslidedown.vi v8, v8, 7
+; CHECK-NEXT: vse16.v v8, (a0)
+; CHECK-NEXT: ret
+ call void @llvm.masked.compressstore.v8i16(<8 x i16> %v, ptr align 2 %base, <8 x i1> %mask)
+ ret void
+}
+
+declare void @llvm.masked.compressstore.v1i32(<1 x i32>, ptr, <1 x i1>)
+define void @compressstore_v1i32(ptr %base, <1 x i32> %v, <1 x i1> %mask) {
+; CHECK-LABEL: compressstore_v1i32:
+; CHECK: # %bb.0:
+; CHECK-NEXT: vsetvli a1, zero, e8, mf8, ta, ma
+; CHECK-NEXT: vfirst.m a1, v0
+; CHECK-NEXT: bnez a1, .LBB8_2
+; CHECK-NEXT: # %bb.1: # %cond.store
+; CHECK-NEXT: vsetivli zero, 1, e32, mf2, ta, ma
+; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: .LBB8_2: # %else
+; CHECK-NEXT: ret
+ call void @llvm.masked.compressstore.v1i32(<1 x i32> %v, ptr align 4 %base, <1 x i1> %mask)
+ ret void
+}
+
+declare void @llvm.masked.compressstore.v2i32(<2 x i32>, ptr, <2 x i1>)
+define void @compressstore_v2i32(ptr %base, <2 x i32> %v, <2 x i1> %mask) {
+; CHECK-LABEL: compressstore_v2i32:
+; CHECK: # %bb.0:
+; CHECK-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; CHECK-NEXT: vmv.x.s a1, v0
+; CHECK-NEXT: andi a2, a1, 1
+; CHECK-NEXT: bnez a2, .LBB9_3
+; CHECK-NEXT: # %bb.1: # %else
+; CHECK-NEXT: andi a1, a1, 2
+; CHECK-NEXT: bnez a1, .LBB9_4
+; CHECK-NEXT: .LBB9_2: # %else2
+; CHECK-NEXT: ret
+; CHECK-NEXT: .LBB9_3: # %cond.store
+; CHECK-NEXT: vsetivli zero, 1, e32, mf2, ta, ma
+; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 4
+; CHECK-NEXT: andi a1, a1, 2
+; CHECK-NEXT: beqz a1, .LBB9_2
+; CHECK-NEXT: .LBB9_4: # %cond.store1
+; CHECK-NEXT: vsetivli zero, 1, e32, mf2, ta, ma
+; CHECK-NEXT: vslidedown.vi v8, v8, 1
+; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: ret
+ call void @llvm.masked.compressstore.v2i32(<2 x i32> %v, ptr align 4 %base, <2 x i1> %mask)
+ ret void
+}
+
+declare void @llvm.masked.compressstore.v4i32(<4 x i32>, ptr, <4 x i1>)
+define void @compressstore_v4i32(ptr %base, <4 x i32> %v, <4 x i1> %mask) {
+; CHECK-LABEL: compressstore_v4i32:
+; CHECK: # %bb.0:
+; CHECK-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; CHECK-NEXT: vmv.x.s a1, v0
+; CHECK-NEXT: andi a2, a1, 1
+; CHECK-NEXT: bnez a2, .LBB10_5
+; CHECK-NEXT: # %bb.1: # %else
+; CHECK-NEXT: andi a2, a1, 2
+; CHECK-NEXT: bnez a2, .LBB10_6
+; CHECK-NEXT: .LBB10_2: # %else2
+; CHECK-NEXT: andi a2, a1, 4
+; CHECK-NEXT: bnez a2, .LBB10_7
+; CHECK-NEXT: .LBB10_3: # %else5
+; CHECK-NEXT: andi a1, a1, 8
+; CHECK-NEXT: bnez a1, .LBB10_8
+; CHECK-NEXT: .LBB10_4: # %else8
+; CHECK-NEXT: ret
+; CHECK-NEXT: .LBB10_5: # %cond.store
+; CHECK-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 4
+; CHECK-NEXT: andi a2, a1, 2
+; CHECK-NEXT: beqz a2, .LBB10_2
+; CHECK-NEXT: .LBB10_6: # %cond.store1
+; CHECK-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; CHECK-NEXT: vslidedown.vi v9, v8, 1
+; CHECK-NEXT: vse32.v v9, (a0)
+; CHECK-NEXT: addi a0, a0, 4
+; CHECK-NEXT: andi a2, a1, 4
+; CHECK-NEXT: beqz a2, .LBB10_3
+; CHECK-NEXT: .LBB10_7: # %cond.store4
+; CHECK-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; CHECK-NEXT: vslidedown.vi v9, v8, 2
+; CHECK-NEXT: vse32.v v9, (a0)
+; CHECK-NEXT: addi a0, a0, 4
+; CHECK-NEXT: andi a1, a1, 8
+; CHECK-NEXT: beqz a1, .LBB10_4
+; CHECK-NEXT: .LBB10_8: # %cond.store7
+; CHECK-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; CHECK-NEXT: vslidedown.vi v8, v8, 3
+; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: ret
+ call void @llvm.masked.compressstore.v4i32(<4 x i32> %v, ptr align 4 %base, <4 x i1> %mask)
+ ret void
+}
+
+declare void @llvm.masked.compressstore.v8i32(<8 x i32>, ptr, <8 x i1>)
+define void @compressstore_v8i32(ptr %base, <8 x i32> %v, <8 x i1> %mask) {
+; CHECK-LABEL: compressstore_v8i32:
+; CHECK: # %bb.0:
+; CHECK-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; CHECK-NEXT: vmv.x.s a1, v0
+; CHECK-NEXT: andi a2, a1, 1
+; CHECK-NEXT: bnez a2, .LBB11_9
+; CHECK-NEXT: # %bb.1: # %else
+; CHECK-NEXT: andi a2, a1, 2
+; CHECK-NEXT: bnez a2, .LBB11_10
+; CHECK-NEXT: .LBB11_2: # %else2
+; CHECK-NEXT: andi a2, a1, 4
+; CHECK-NEXT: bnez a2, .LBB11_11
+; CHECK-NEXT: .LBB11_3: # %else5
+; CHECK-NEXT: andi a2, a1, 8
+; CHECK-NEXT: bnez a2, .LBB11_12
+; CHECK-NEXT: .LBB11_4: # %else8
+; CHECK-NEXT: andi a2, a1, 16
+; CHECK-NEXT: bnez a2, .LBB11_13
+; CHECK-NEXT: .LBB11_5: # %else11
+; CHECK-NEXT: andi a2, a1, 32
+; CHECK-NEXT: bnez a2, .LBB11_14
+; CHECK-NEXT: .LBB11_6: # %else14
+; CHECK-NEXT: andi a2, a1, 64
+; CHECK-NEXT: bnez a2, .LBB11_15
+; CHECK-NEXT: .LBB11_7: # %else17
+; CHECK-NEXT: andi a1, a1, -128
+; CHECK-NEXT: bnez a1, .LBB11_16
+; CHECK-NEXT: .LBB11_8: # %else20
+; CHECK-NEXT: ret
+; CHECK-NEXT: .LBB11_9: # %cond.store
+; CHECK-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: addi a0, a0, 4
+; CHECK-NEXT: andi a2, a1, 2
+; CHECK-NEXT: beqz a2, .LBB11_2
+; CHECK-NEXT: .LBB11_10: # %cond.store1
+; CHECK-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; CHECK-NEXT: vslidedown.vi v10, v8, 1
+; CHECK-NEXT: vse32.v v10, (a0)
+; CHECK-NEXT: addi a0, a0, 4
+; CHECK-NEXT: andi a2, a1, 4
+; CHECK-NEXT: beqz a2, .LBB11_3
+; CHECK-NEXT: .LBB11_11: # %cond.store4
+; CHECK-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; CHECK-NEXT: vslidedown.vi v10, v8, 2
+; CHECK-NEXT: vse32.v v10, (a0)
+; CHECK-NEXT: addi a0, a0, 4
+; CHECK-NEXT: andi a2, a1, 8
+; CHECK-NEXT: beqz a2, .LBB11_4
+; CHECK-NEXT: .LBB11_12: # %cond.store7
+; CHECK-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; CHECK-NEXT: vslidedown.vi v10, v8, 3
+; CHECK-NEXT: vse32.v v10, (a0)
+; CHECK-NEXT: addi a0, a0, 4
+; CHECK-NEXT: andi a2, a1, 16
+; CHECK-NEXT: beqz a2, .LBB11_5
+; CHECK-NEXT: .LBB11_13: # %cond.store10
+; CHECK-NEXT: vsetivli zero, 1, e32, m2, ta, ma
+; CHECK-NEXT: vslidedown.vi v10, v8, 4
+; CHECK-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; CHECK-NEXT: vse32.v v10, (a0)
+; CHECK-NEXT: addi a0, a0, 4
+; CHECK-NEXT: andi a2, a1, 32
+; CHECK-NEXT: beqz a2, .LBB11_6
+; CHECK-NEXT: .LBB11_14: # %cond.store13
+; CHECK-NEXT: vsetivli zero, 1, e32, m2, ta, ma
+; CHECK-NEXT: vslidedown.vi v10, v8, 5
+; CHECK-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; CHECK-NEXT: vse32.v v10, (a0)
+; CHECK-NEXT: addi a0, a0, 4
+; CHECK-NEXT: andi a2, a1, 64
+; CHECK-NEXT: beqz a2, .LBB11_7
+; CHECK-NEXT: .LBB11_15: # %cond.store16
+; CHECK-NEXT: vsetivli zero, 1, e32, m2, ta, ma
+; CHECK-NEXT: vslidedown.vi v10, v8, 6
+; CHECK-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; CHECK-NEXT: vse32.v v10, (a0)
+; CHECK-NEXT: addi a0, a0, 4
+; CHECK-NEXT: andi a1, a1, -128
+; CHECK-NEXT: beqz a1, .LBB11_8
+; CHECK-NEXT: .LBB11_16: # %cond.store19
+; CHECK-NEXT: vsetivli zero, 1, e32, m2, ta, ma
+; CHECK-NEXT: vslidedown.vi v8, v8, 7
+; CHECK-NEXT: vsetivli zero, 1, e32, m1, ta, ma
+; CHECK-NEXT: vse32.v v8, (a0)
+; CHECK-NEXT: ret
+ call void @llvm.masked.compressstore.v8i32(<8 x i32> %v, ptr align 4 %base, <8 x i1> %mask)
+ ret void
+}
+
+declare void @llvm.masked.compressstore.v1i64(<1 x i64>, ptr, <1 x i1>)
+define void @compressstore_v1i64(ptr %base, <1 x i64> %v, <1 x i1> %mask) {
+; RV32-LABEL: compressstore_v1i64:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetvli a1, zero, e8, mf8, ta, ma
+; RV32-NEXT: vfirst.m a1, v0
+; RV32-NEXT: bnez a1, .LBB12_2
+; RV32-NEXT: # %bb.1: # %cond.store
+; RV32-NEXT: li a1, 32
+; RV32-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV32-NEXT: vsrl.vx v9, v8, a1
+; RV32-NEXT: vmv.x.s a1, v9
+; RV32-NEXT: vmv.x.s a2, v8
+; RV32-NEXT: sw a2, 0(a0)
+; RV32-NEXT: sw a1, 4(a0)
+; RV32-NEXT: .LBB12_2: # %else
+; RV32-NEXT: ret
+;
+; RV64-LABEL: compressstore_v1i64:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetvli a1, zero, e8, mf8, ta, ma
+; RV64-NEXT: vfirst.m a1, v0
+; RV64-NEXT: bnez a1, .LBB12_2
+; RV64-NEXT: # %bb.1: # %cond.store
+; RV64-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV64-NEXT: vse64.v v8, (a0)
+; RV64-NEXT: .LBB12_2: # %else
+; RV64-NEXT: ret
+ call void @llvm.masked.compressstore.v1i64(<1 x i64> %v, ptr align 8 %base, <1 x i1> %mask)
+ ret void
+}
+
+declare void @llvm.masked.compressstore.v2i64(<2 x i64>, ptr, <2 x i1>)
+define void @compressstore_v2i64(ptr %base, <2 x i64> %v, <2 x i1> %mask) {
+; RV32-LABEL: compressstore_v2i64:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV32-NEXT: vmv.x.s a1, v0
+; RV32-NEXT: andi a2, a1, 1
+; RV32-NEXT: bnez a2, .LBB13_3
+; RV32-NEXT: # %bb.1: # %else
+; RV32-NEXT: andi a1, a1, 2
+; RV32-NEXT: bnez a1, .LBB13_4
+; RV32-NEXT: .LBB13_2: # %else2
+; RV32-NEXT: ret
+; RV32-NEXT: .LBB13_3: # %cond.store
+; RV32-NEXT: li a2, 32
+; RV32-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV32-NEXT: vsrl.vx v9, v8, a2
+; RV32-NEXT: vmv.x.s a2, v9
+; RV32-NEXT: vmv.x.s a3, v8
+; RV32-NEXT: sw a3, 0(a0)
+; RV32-NEXT: sw a2, 4(a0)
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a1, a1, 2
+; RV32-NEXT: beqz a1, .LBB13_2
+; RV32-NEXT: .LBB13_4: # %cond.store1
+; RV32-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV32-NEXT: vslidedown.vi v8, v8, 1
+; RV32-NEXT: li a1, 32
+; RV32-NEXT: vsrl.vx v9, v8, a1
+; RV32-NEXT: vmv.x.s a1, v9
+; RV32-NEXT: vmv.x.s a2, v8
+; RV32-NEXT: sw a2, 0(a0)
+; RV32-NEXT: sw a1, 4(a0)
+; RV32-NEXT: ret
+;
+; RV64-LABEL: compressstore_v2i64:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV64-NEXT: vmv.x.s a1, v0
+; RV64-NEXT: andi a2, a1, 1
+; RV64-NEXT: bnez a2, .LBB13_3
+; RV64-NEXT: # %bb.1: # %else
+; RV64-NEXT: andi a1, a1, 2
+; RV64-NEXT: bnez a1, .LBB13_4
+; RV64-NEXT: .LBB13_2: # %else2
+; RV64-NEXT: ret
+; RV64-NEXT: .LBB13_3: # %cond.store
+; RV64-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV64-NEXT: vse64.v v8, (a0)
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a1, a1, 2
+; RV64-NEXT: beqz a1, .LBB13_2
+; RV64-NEXT: .LBB13_4: # %cond.store1
+; RV64-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV64-NEXT: vslidedown.vi v8, v8, 1
+; RV64-NEXT: vse64.v v8, (a0)
+; RV64-NEXT: ret
+ call void @llvm.masked.compressstore.v2i64(<2 x i64> %v, ptr align 8 %base, <2 x i1> %mask)
+ ret void
+}
+
+declare void @llvm.masked.compressstore.v4i64(<4 x i64>, ptr, <4 x i1>)
+define void @compressstore_v4i64(ptr %base, <4 x i64> %v, <4 x i1> %mask) {
+; RV32-LABEL: compressstore_v4i64:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV32-NEXT: vmv.x.s a1, v0
+; RV32-NEXT: andi a2, a1, 1
+; RV32-NEXT: bnez a2, .LBB14_5
+; RV32-NEXT: # %bb.1: # %else
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: bnez a2, .LBB14_6
+; RV32-NEXT: .LBB14_2: # %else2
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: bnez a2, .LBB14_7
+; RV32-NEXT: .LBB14_3: # %else5
+; RV32-NEXT: andi a1, a1, 8
+; RV32-NEXT: bnez a1, .LBB14_8
+; RV32-NEXT: .LBB14_4: # %else8
+; RV32-NEXT: ret
+; RV32-NEXT: .LBB14_5: # %cond.store
+; RV32-NEXT: li a2, 32
+; RV32-NEXT: vsetivli zero, 1, e64, m2, ta, ma
+; RV32-NEXT: vsrl.vx v10, v8, a2
+; RV32-NEXT: vmv.x.s a2, v10
+; RV32-NEXT: vmv.x.s a3, v8
+; RV32-NEXT: sw a3, 0(a0)
+; RV32-NEXT: sw a2, 4(a0)
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: beqz a2, .LBB14_2
+; RV32-NEXT: .LBB14_6: # %cond.store1
+; RV32-NEXT: vsetivli zero, 1, e64, m2, ta, ma
+; RV32-NEXT: vslidedown.vi v10, v8, 1
+; RV32-NEXT: li a2, 32
+; RV32-NEXT: vsrl.vx v12, v10, a2
+; RV32-NEXT: vmv.x.s a2, v12
+; RV32-NEXT: vmv.x.s a3, v10
+; RV32-NEXT: sw a3, 0(a0)
+; RV32-NEXT: sw a2, 4(a0)
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: beqz a2, .LBB14_3
+; RV32-NEXT: .LBB14_7: # %cond.store4
+; RV32-NEXT: vsetivli zero, 1, e64, m2, ta, ma
+; RV32-NEXT: vslidedown.vi v10, v8, 2
+; RV32-NEXT: li a2, 32
+; RV32-NEXT: vsrl.vx v12, v10, a2
+; RV32-NEXT: vmv.x.s a2, v12
+; RV32-NEXT: vmv.x.s a3, v10
+; RV32-NEXT: sw a3, 0(a0)
+; RV32-NEXT: sw a2, 4(a0)
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a1, a1, 8
+; RV32-NEXT: beqz a1, .LBB14_4
+; RV32-NEXT: .LBB14_8: # %cond.store7
+; RV32-NEXT: vsetivli zero, 1, e64, m2, ta, ma
+; RV32-NEXT: vslidedown.vi v8, v8, 3
+; RV32-NEXT: li a1, 32
+; RV32-NEXT: vsrl.vx v10, v8, a1
+; RV32-NEXT: vmv.x.s a1, v10
+; RV32-NEXT: vmv.x.s a2, v8
+; RV32-NEXT: sw a2, 0(a0)
+; RV32-NEXT: sw a1, 4(a0)
+; RV32-NEXT: ret
+;
+; RV64-LABEL: compressstore_v4i64:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV64-NEXT: vmv.x.s a1, v0
+; RV64-NEXT: andi a2, a1, 1
+; RV64-NEXT: bnez a2, .LBB14_5
+; RV64-NEXT: # %bb.1: # %else
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: bnez a2, .LBB14_6
+; RV64-NEXT: .LBB14_2: # %else2
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: bnez a2, .LBB14_7
+; RV64-NEXT: .LBB14_3: # %else5
+; RV64-NEXT: andi a1, a1, 8
+; RV64-NEXT: bnez a1, .LBB14_8
+; RV64-NEXT: .LBB14_4: # %else8
+; RV64-NEXT: ret
+; RV64-NEXT: .LBB14_5: # %cond.store
+; RV64-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV64-NEXT: vse64.v v8, (a0)
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: beqz a2, .LBB14_2
+; RV64-NEXT: .LBB14_6: # %cond.store1
+; RV64-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV64-NEXT: vslidedown.vi v10, v8, 1
+; RV64-NEXT: vse64.v v10, (a0)
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: beqz a2, .LBB14_3
+; RV64-NEXT: .LBB14_7: # %cond.store4
+; RV64-NEXT: vsetivli zero, 1, e64, m2, ta, ma
+; RV64-NEXT: vslidedown.vi v10, v8, 2
+; RV64-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV64-NEXT: vse64.v v10, (a0)
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a1, a1, 8
+; RV64-NEXT: beqz a1, .LBB14_4
+; RV64-NEXT: .LBB14_8: # %cond.store7
+; RV64-NEXT: vsetivli zero, 1, e64, m2, ta, ma
+; RV64-NEXT: vslidedown.vi v8, v8, 3
+; RV64-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV64-NEXT: vse64.v v8, (a0)
+; RV64-NEXT: ret
+ call void @llvm.masked.compressstore.v4i64(<4 x i64> %v, ptr align 8 %base, <4 x i1> %mask)
+ ret void
+}
+
+declare void @llvm.masked.compressstore.v8i64(<8 x i64>, ptr, <8 x i1>)
+define void @compressstore_v8i64(ptr %base, <8 x i64> %v, <8 x i1> %mask) {
+; RV32-LABEL: compressstore_v8i64:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV32-NEXT: vmv.x.s a1, v0
+; RV32-NEXT: andi a2, a1, 1
+; RV32-NEXT: bnez a2, .LBB15_9
+; RV32-NEXT: # %bb.1: # %else
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: bnez a2, .LBB15_10
+; RV32-NEXT: .LBB15_2: # %else2
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: bnez a2, .LBB15_11
+; RV32-NEXT: .LBB15_3: # %else5
+; RV32-NEXT: andi a2, a1, 8
+; RV32-NEXT: bnez a2, .LBB15_12
+; RV32-NEXT: .LBB15_4: # %else8
+; RV32-NEXT: andi a2, a1, 16
+; RV32-NEXT: bnez a2, .LBB15_13
+; RV32-NEXT: .LBB15_5: # %else11
+; RV32-NEXT: andi a2, a1, 32
+; RV32-NEXT: bnez a2, .LBB15_14
+; RV32-NEXT: .LBB15_6: # %else14
+; RV32-NEXT: andi a2, a1, 64
+; RV32-NEXT: bnez a2, .LBB15_15
+; RV32-NEXT: .LBB15_7: # %else17
+; RV32-NEXT: andi a1, a1, -128
+; RV32-NEXT: bnez a1, .LBB15_16
+; RV32-NEXT: .LBB15_8: # %else20
+; RV32-NEXT: ret
+; RV32-NEXT: .LBB15_9: # %cond.store
+; RV32-NEXT: li a2, 32
+; RV32-NEXT: vsetivli zero, 1, e64, m4, ta, ma
+; RV32-NEXT: vsrl.vx v12, v8, a2
+; RV32-NEXT: vmv.x.s a2, v12
+; RV32-NEXT: vmv.x.s a3, v8
+; RV32-NEXT: sw a3, 0(a0)
+; RV32-NEXT: sw a2, 4(a0)
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: beqz a2, .LBB15_2
+; RV32-NEXT: .LBB15_10: # %cond.store1
+; RV32-NEXT: vsetivli zero, 1, e64, m4, ta, ma
+; RV32-NEXT: vslidedown.vi v12, v8, 1
+; RV32-NEXT: li a2, 32
+; RV32-NEXT: vsrl.vx v16, v12, a2
+; RV32-NEXT: vmv.x.s a2, v16
+; RV32-NEXT: vmv.x.s a3, v12
+; RV32-NEXT: sw a3, 0(a0)
+; RV32-NEXT: sw a2, 4(a0)
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: beqz a2, .LBB15_3
+; RV32-NEXT: .LBB15_11: # %cond.store4
+; RV32-NEXT: vsetivli zero, 1, e64, m4, ta, ma
+; RV32-NEXT: vslidedown.vi v12, v8, 2
+; RV32-NEXT: li a2, 32
+; RV32-NEXT: vsrl.vx v16, v12, a2
+; RV32-NEXT: vmv.x.s a2, v16
+; RV32-NEXT: vmv.x.s a3, v12
+; RV32-NEXT: sw a3, 0(a0)
+; RV32-NEXT: sw a2, 4(a0)
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a2, a1, 8
+; RV32-NEXT: beqz a2, .LBB15_4
+; RV32-NEXT: .LBB15_12: # %cond.store7
+; RV32-NEXT: vsetivli zero, 1, e64, m4, ta, ma
+; RV32-NEXT: vslidedown.vi v12, v8, 3
+; RV32-NEXT: li a2, 32
+; RV32-NEXT: vsrl.vx v16, v12, a2
+; RV32-NEXT: vmv.x.s a2, v16
+; RV32-NEXT: vmv.x.s a3, v12
+; RV32-NEXT: sw a3, 0(a0)
+; RV32-NEXT: sw a2, 4(a0)
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a2, a1, 16
+; RV32-NEXT: beqz a2, .LBB15_5
+; RV32-NEXT: .LBB15_13: # %cond.store10
+; RV32-NEXT: vsetivli zero, 1, e64, m4, ta, ma
+; RV32-NEXT: vslidedown.vi v12, v8, 4
+; RV32-NEXT: li a2, 32
+; RV32-NEXT: vsrl.vx v16, v12, a2
+; RV32-NEXT: vmv.x.s a2, v16
+; RV32-NEXT: vmv.x.s a3, v12
+; RV32-NEXT: sw a3, 0(a0)
+; RV32-NEXT: sw a2, 4(a0)
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a2, a1, 32
+; RV32-NEXT: beqz a2, .LBB15_6
+; RV32-NEXT: .LBB15_14: # %cond.store13
+; RV32-NEXT: vsetivli zero, 1, e64, m4, ta, ma
+; RV32-NEXT: vslidedown.vi v12, v8, 5
+; RV32-NEXT: li a2, 32
+; RV32-NEXT: vsrl.vx v16, v12, a2
+; RV32-NEXT: vmv.x.s a2, v16
+; RV32-NEXT: vmv.x.s a3, v12
+; RV32-NEXT: sw a3, 0(a0)
+; RV32-NEXT: sw a2, 4(a0)
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a2, a1, 64
+; RV32-NEXT: beqz a2, .LBB15_7
+; RV32-NEXT: .LBB15_15: # %cond.store16
+; RV32-NEXT: vsetivli zero, 1, e64, m4, ta, ma
+; RV32-NEXT: vslidedown.vi v12, v8, 6
+; RV32-NEXT: li a2, 32
+; RV32-NEXT: vsrl.vx v16, v12, a2
+; RV32-NEXT: vmv.x.s a2, v16
+; RV32-NEXT: vmv.x.s a3, v12
+; RV32-NEXT: sw a3, 0(a0)
+; RV32-NEXT: sw a2, 4(a0)
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a1, a1, -128
+; RV32-NEXT: beqz a1, .LBB15_8
+; RV32-NEXT: .LBB15_16: # %cond.store19
+; RV32-NEXT: vsetivli zero, 1, e64, m4, ta, ma
+; RV32-NEXT: vslidedown.vi v8, v8, 7
+; RV32-NEXT: li a1, 32
+; RV32-NEXT: vsrl.vx v12, v8, a1
+; RV32-NEXT: vmv.x.s a1, v12
+; RV32-NEXT: vmv.x.s a2, v8
+; RV32-NEXT: sw a2, 0(a0)
+; RV32-NEXT: sw a1, 4(a0)
+; RV32-NEXT: ret
+;
+; RV64-LABEL: compressstore_v8i64:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV64-NEXT: vmv.x.s a1, v0
+; RV64-NEXT: andi a2, a1, 1
+; RV64-NEXT: bnez a2, .LBB15_11
+; RV64-NEXT: # %bb.1: # %else
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: bnez a2, .LBB15_12
+; RV64-NEXT: .LBB15_2: # %else2
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: bnez a2, .LBB15_13
+; RV64-NEXT: .LBB15_3: # %else5
+; RV64-NEXT: andi a2, a1, 8
+; RV64-NEXT: beqz a2, .LBB15_5
+; RV64-NEXT: .LBB15_4: # %cond.store7
+; RV64-NEXT: vsetivli zero, 1, e64, m2, ta, ma
+; RV64-NEXT: vslidedown.vi v12, v8, 3
+; RV64-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV64-NEXT: vse64.v v12, (a0)
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: .LBB15_5: # %else8
+; RV64-NEXT: addi sp, sp, -320
+; RV64-NEXT: .cfi_def_cfa_offset 320
+; RV64-NEXT: sd ra, 312(sp) # 8-byte Folded Spill
+; RV64-NEXT: sd s0, 304(sp) # 8-byte Folded Spill
+; RV64-NEXT: .cfi_offset ra, -8
+; RV64-NEXT: .cfi_offset s0, -16
+; RV64-NEXT: addi s0, sp, 320
+; RV64-NEXT: .cfi_def_cfa s0, 0
+; RV64-NEXT: andi sp, sp, -64
+; RV64-NEXT: andi a2, a1, 16
+; RV64-NEXT: bnez a2, .LBB15_14
+; RV64-NEXT: # %bb.6: # %else11
+; RV64-NEXT: andi a2, a1, 32
+; RV64-NEXT: bnez a2, .LBB15_15
+; RV64-NEXT: .LBB15_7: # %else14
+; RV64-NEXT: andi a2, a1, 64
+; RV64-NEXT: bnez a2, .LBB15_16
+; RV64-NEXT: .LBB15_8: # %else17
+; RV64-NEXT: andi a1, a1, -128
+; RV64-NEXT: beqz a1, .LBB15_10
+; RV64-NEXT: .LBB15_9: # %cond.store19
+; RV64-NEXT: mv a1, sp
+; RV64-NEXT: vsetivli zero, 8, e64, m4, ta, ma
+; RV64-NEXT: vse64.v v8, (a1)
+; RV64-NEXT: ld a1, 56(sp)
+; RV64-NEXT: sd a1, 0(a0)
+; RV64-NEXT: .LBB15_10: # %else20
+; RV64-NEXT: addi sp, s0, -320
+; RV64-NEXT: ld ra, 312(sp) # 8-byte Folded Reload
+; RV64-NEXT: ld s0, 304(sp) # 8-byte Folded Reload
+; RV64-NEXT: addi sp, sp, 320
+; RV64-NEXT: ret
+; RV64-NEXT: .LBB15_11: # %cond.store
+; RV64-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV64-NEXT: vse64.v v8, (a0)
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: beqz a2, .LBB15_2
+; RV64-NEXT: .LBB15_12: # %cond.store1
+; RV64-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV64-NEXT: vslidedown.vi v12, v8, 1
+; RV64-NEXT: vse64.v v12, (a0)
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: beqz a2, .LBB15_3
+; RV64-NEXT: .LBB15_13: # %cond.store4
+; RV64-NEXT: vsetivli zero, 1, e64, m2, ta, ma
+; RV64-NEXT: vslidedown.vi v12, v8, 2
+; RV64-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV64-NEXT: vse64.v v12, (a0)
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a2, a1, 8
+; RV64-NEXT: bnez a2, .LBB15_4
+; RV64-NEXT: j .LBB15_5
+; RV64-NEXT: .LBB15_14: # %cond.store10
+; RV64-NEXT: addi a2, sp, 192
+; RV64-NEXT: vsetivli zero, 8, e64, m4, ta, ma
+; RV64-NEXT: vse64.v v8, (a2)
+; RV64-NEXT: ld a2, 224(sp)
+; RV64-NEXT: sd a2, 0(a0)
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a2, a1, 32
+; RV64-NEXT: beqz a2, .LBB15_7
+; RV64-NEXT: .LBB15_15: # %cond.store13
+; RV64-NEXT: addi a2, sp, 128
+; RV64-NEXT: vsetivli zero, 8, e64, m4, ta, ma
+; RV64-NEXT: vse64.v v8, (a2)
+; RV64-NEXT: ld a2, 168(sp)
+; RV64-NEXT: sd a2, 0(a0)
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a2, a1, 64
+; RV64-NEXT: beqz a2, .LBB15_8
+; RV64-NEXT: .LBB15_16: # %cond.store16
+; RV64-NEXT: addi a2, sp, 64
+; RV64-NEXT: vsetivli zero, 8, e64, m4, ta, ma
+; RV64-NEXT: vse64.v v8, (a2)
+; RV64-NEXT: ld a2, 112(sp)
+; RV64-NEXT: sd a2, 0(a0)
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a1, a1, -128
+; RV64-NEXT: bnez a1, .LBB15_9
+; RV64-NEXT: j .LBB15_10
+ call void @llvm.masked.compressstore.v8i64(<8 x i64> %v, ptr align 8 %base, <8 x i1> %mask)
+ ret void
+}
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-expandload-fp.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-expandload-fp.ll
new file mode 100644
index 00000000000000..48e820243c9578
--- /dev/null
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-expandload-fp.ll
@@ -0,0 +1,1107 @@
+; NOTE: Assertions have been autogenerated by utils/update_llc_test_checks.py UTC_ARGS: --version 4
+; RUN: llc -mtriple=riscv32 -mattr=+m,+v,+f,+d,+zfh,+zvfh -verify-machineinstrs < %s | FileCheck %s --check-prefixes=RV32
+; RUN: llc -mtriple=riscv64 -mattr=+m,+v,+f,+d,+zfh,+zvfh -verify-machineinstrs < %s | FileCheck %s --check-prefixes=RV64
+
+declare <1 x half> @llvm.masked.expandload.v1f16(ptr, <1 x i1>, <1 x half>)
+define <1 x half> @expandload_v1f16(ptr %base, <1 x half> %src0, <1 x i1> %mask) {
+; RV32-LABEL: expandload_v1f16:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetvli a1, zero, e8, mf8, ta, ma
+; RV32-NEXT: vfirst.m a1, v0
+; RV32-NEXT: bnez a1, .LBB0_2
+; RV32-NEXT: # %bb.1: # %cond.load
+; RV32-NEXT: vsetivli zero, 1, e16, mf4, ta, ma
+; RV32-NEXT: vle16.v v8, (a0)
+; RV32-NEXT: .LBB0_2: # %else
+; RV32-NEXT: ret
+;
+; RV64-LABEL: expandload_v1f16:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetvli a1, zero, e8, mf8, ta, ma
+; RV64-NEXT: vfirst.m a1, v0
+; RV64-NEXT: bnez a1, .LBB0_2
+; RV64-NEXT: # %bb.1: # %cond.load
+; RV64-NEXT: vsetivli zero, 1, e16, mf4, ta, ma
+; RV64-NEXT: vle16.v v8, (a0)
+; RV64-NEXT: .LBB0_2: # %else
+; RV64-NEXT: ret
+ %res = call <1 x half> @llvm.masked.expandload.v1f16(ptr align 2 %base, <1 x i1> %mask, <1 x half> %src0)
+ ret <1 x half>%res
+}
+
+declare <2 x half> @llvm.masked.expandload.v2f16(ptr, <2 x i1>, <2 x half>)
+define <2 x half> @expandload_v2f16(ptr %base, <2 x half> %src0, <2 x i1> %mask) {
+; RV32-LABEL: expandload_v2f16:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV32-NEXT: vmv.x.s a1, v0
+; RV32-NEXT: andi a2, a1, 1
+; RV32-NEXT: bnez a2, .LBB1_3
+; RV32-NEXT: # %bb.1: # %else
+; RV32-NEXT: andi a1, a1, 2
+; RV32-NEXT: bnez a1, .LBB1_4
+; RV32-NEXT: .LBB1_2: # %else2
+; RV32-NEXT: ret
+; RV32-NEXT: .LBB1_3: # %cond.load
+; RV32-NEXT: flh fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 2, e16, m2, tu, ma
+; RV32-NEXT: vfmv.s.f v8, fa5
+; RV32-NEXT: addi a0, a0, 2
+; RV32-NEXT: andi a1, a1, 2
+; RV32-NEXT: beqz a1, .LBB1_2
+; RV32-NEXT: .LBB1_4: # %cond.load1
+; RV32-NEXT: flh fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 2, e16, mf4, ta, ma
+; RV32-NEXT: vfmv.s.f v9, fa5
+; RV32-NEXT: vslideup.vi v8, v9, 1
+; RV32-NEXT: ret
+;
+; RV64-LABEL: expandload_v2f16:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV64-NEXT: vmv.x.s a1, v0
+; RV64-NEXT: andi a2, a1, 1
+; RV64-NEXT: bnez a2, .LBB1_3
+; RV64-NEXT: # %bb.1: # %else
+; RV64-NEXT: andi a1, a1, 2
+; RV64-NEXT: bnez a1, .LBB1_4
+; RV64-NEXT: .LBB1_2: # %else2
+; RV64-NEXT: ret
+; RV64-NEXT: .LBB1_3: # %cond.load
+; RV64-NEXT: flh fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 2, e16, m2, tu, ma
+; RV64-NEXT: vfmv.s.f v8, fa5
+; RV64-NEXT: addi a0, a0, 2
+; RV64-NEXT: andi a1, a1, 2
+; RV64-NEXT: beqz a1, .LBB1_2
+; RV64-NEXT: .LBB1_4: # %cond.load1
+; RV64-NEXT: flh fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 2, e16, mf4, ta, ma
+; RV64-NEXT: vfmv.s.f v9, fa5
+; RV64-NEXT: vslideup.vi v8, v9, 1
+; RV64-NEXT: ret
+ %res = call <2 x half> @llvm.masked.expandload.v2f16(ptr align 2 %base, <2 x i1> %mask, <2 x half> %src0)
+ ret <2 x half>%res
+}
+
+declare <4 x half> @llvm.masked.expandload.v4f16(ptr, <4 x i1>, <4 x half>)
+define <4 x half> @expandload_v4f16(ptr %base, <4 x half> %src0, <4 x i1> %mask) {
+; RV32-LABEL: expandload_v4f16:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV32-NEXT: vmv.x.s a1, v0
+; RV32-NEXT: andi a2, a1, 1
+; RV32-NEXT: bnez a2, .LBB2_5
+; RV32-NEXT: # %bb.1: # %else
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: bnez a2, .LBB2_6
+; RV32-NEXT: .LBB2_2: # %else2
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: bnez a2, .LBB2_7
+; RV32-NEXT: .LBB2_3: # %else6
+; RV32-NEXT: andi a1, a1, 8
+; RV32-NEXT: bnez a1, .LBB2_8
+; RV32-NEXT: .LBB2_4: # %else10
+; RV32-NEXT: ret
+; RV32-NEXT: .LBB2_5: # %cond.load
+; RV32-NEXT: flh fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 4, e16, m2, tu, ma
+; RV32-NEXT: vfmv.s.f v8, fa5
+; RV32-NEXT: addi a0, a0, 2
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: beqz a2, .LBB2_2
+; RV32-NEXT: .LBB2_6: # %cond.load1
+; RV32-NEXT: flh fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 2, e16, mf2, tu, ma
+; RV32-NEXT: vfmv.s.f v9, fa5
+; RV32-NEXT: vslideup.vi v8, v9, 1
+; RV32-NEXT: addi a0, a0, 2
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: beqz a2, .LBB2_3
+; RV32-NEXT: .LBB2_7: # %cond.load5
+; RV32-NEXT: flh fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 3, e16, mf2, tu, ma
+; RV32-NEXT: vfmv.s.f v9, fa5
+; RV32-NEXT: vslideup.vi v8, v9, 2
+; RV32-NEXT: addi a0, a0, 2
+; RV32-NEXT: andi a1, a1, 8
+; RV32-NEXT: beqz a1, .LBB2_4
+; RV32-NEXT: .LBB2_8: # %cond.load9
+; RV32-NEXT: flh fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 4, e16, mf2, ta, ma
+; RV32-NEXT: vfmv.s.f v9, fa5
+; RV32-NEXT: vslideup.vi v8, v9, 3
+; RV32-NEXT: ret
+;
+; RV64-LABEL: expandload_v4f16:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV64-NEXT: vmv.x.s a1, v0
+; RV64-NEXT: andi a2, a1, 1
+; RV64-NEXT: bnez a2, .LBB2_5
+; RV64-NEXT: # %bb.1: # %else
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: bnez a2, .LBB2_6
+; RV64-NEXT: .LBB2_2: # %else2
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: bnez a2, .LBB2_7
+; RV64-NEXT: .LBB2_3: # %else6
+; RV64-NEXT: andi a1, a1, 8
+; RV64-NEXT: bnez a1, .LBB2_8
+; RV64-NEXT: .LBB2_4: # %else10
+; RV64-NEXT: ret
+; RV64-NEXT: .LBB2_5: # %cond.load
+; RV64-NEXT: flh fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 4, e16, m2, tu, ma
+; RV64-NEXT: vfmv.s.f v8, fa5
+; RV64-NEXT: addi a0, a0, 2
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: beqz a2, .LBB2_2
+; RV64-NEXT: .LBB2_6: # %cond.load1
+; RV64-NEXT: flh fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 2, e16, mf2, tu, ma
+; RV64-NEXT: vfmv.s.f v9, fa5
+; RV64-NEXT: vslideup.vi v8, v9, 1
+; RV64-NEXT: addi a0, a0, 2
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: beqz a2, .LBB2_3
+; RV64-NEXT: .LBB2_7: # %cond.load5
+; RV64-NEXT: flh fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 3, e16, mf2, tu, ma
+; RV64-NEXT: vfmv.s.f v9, fa5
+; RV64-NEXT: vslideup.vi v8, v9, 2
+; RV64-NEXT: addi a0, a0, 2
+; RV64-NEXT: andi a1, a1, 8
+; RV64-NEXT: beqz a1, .LBB2_4
+; RV64-NEXT: .LBB2_8: # %cond.load9
+; RV64-NEXT: flh fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 4, e16, mf2, ta, ma
+; RV64-NEXT: vfmv.s.f v9, fa5
+; RV64-NEXT: vslideup.vi v8, v9, 3
+; RV64-NEXT: ret
+ %res = call <4 x half> @llvm.masked.expandload.v4f16(ptr align 2 %base, <4 x i1> %mask, <4 x half> %src0)
+ ret <4 x half>%res
+}
+
+declare <8 x half> @llvm.masked.expandload.v8f16(ptr, <8 x i1>, <8 x half>)
+define <8 x half> @expandload_v8f16(ptr %base, <8 x half> %src0, <8 x i1> %mask) {
+; RV32-LABEL: expandload_v8f16:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV32-NEXT: vmv.x.s a1, v0
+; RV32-NEXT: andi a2, a1, 1
+; RV32-NEXT: bnez a2, .LBB3_9
+; RV32-NEXT: # %bb.1: # %else
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: bnez a2, .LBB3_10
+; RV32-NEXT: .LBB3_2: # %else2
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: bnez a2, .LBB3_11
+; RV32-NEXT: .LBB3_3: # %else6
+; RV32-NEXT: andi a2, a1, 8
+; RV32-NEXT: bnez a2, .LBB3_12
+; RV32-NEXT: .LBB3_4: # %else10
+; RV32-NEXT: andi a2, a1, 16
+; RV32-NEXT: bnez a2, .LBB3_13
+; RV32-NEXT: .LBB3_5: # %else14
+; RV32-NEXT: andi a2, a1, 32
+; RV32-NEXT: bnez a2, .LBB3_14
+; RV32-NEXT: .LBB3_6: # %else18
+; RV32-NEXT: andi a2, a1, 64
+; RV32-NEXT: bnez a2, .LBB3_15
+; RV32-NEXT: .LBB3_7: # %else22
+; RV32-NEXT: andi a1, a1, -128
+; RV32-NEXT: bnez a1, .LBB3_16
+; RV32-NEXT: .LBB3_8: # %else26
+; RV32-NEXT: ret
+; RV32-NEXT: .LBB3_9: # %cond.load
+; RV32-NEXT: flh fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 8, e16, m2, tu, ma
+; RV32-NEXT: vfmv.s.f v8, fa5
+; RV32-NEXT: addi a0, a0, 2
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: beqz a2, .LBB3_2
+; RV32-NEXT: .LBB3_10: # %cond.load1
+; RV32-NEXT: flh fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 2, e16, m1, tu, ma
+; RV32-NEXT: vfmv.s.f v9, fa5
+; RV32-NEXT: vslideup.vi v8, v9, 1
+; RV32-NEXT: addi a0, a0, 2
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: beqz a2, .LBB3_3
+; RV32-NEXT: .LBB3_11: # %cond.load5
+; RV32-NEXT: flh fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 3, e16, m1, tu, ma
+; RV32-NEXT: vfmv.s.f v9, fa5
+; RV32-NEXT: vslideup.vi v8, v9, 2
+; RV32-NEXT: addi a0, a0, 2
+; RV32-NEXT: andi a2, a1, 8
+; RV32-NEXT: beqz a2, .LBB3_4
+; RV32-NEXT: .LBB3_12: # %cond.load9
+; RV32-NEXT: flh fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 4, e16, m1, tu, ma
+; RV32-NEXT: vfmv.s.f v9, fa5
+; RV32-NEXT: vslideup.vi v8, v9, 3
+; RV32-NEXT: addi a0, a0, 2
+; RV32-NEXT: andi a2, a1, 16
+; RV32-NEXT: beqz a2, .LBB3_5
+; RV32-NEXT: .LBB3_13: # %cond.load13
+; RV32-NEXT: flh fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 5, e16, m1, tu, ma
+; RV32-NEXT: vfmv.s.f v9, fa5
+; RV32-NEXT: vslideup.vi v8, v9, 4
+; RV32-NEXT: addi a0, a0, 2
+; RV32-NEXT: andi a2, a1, 32
+; RV32-NEXT: beqz a2, .LBB3_6
+; RV32-NEXT: .LBB3_14: # %cond.load17
+; RV32-NEXT: flh fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 6, e16, m1, tu, ma
+; RV32-NEXT: vfmv.s.f v9, fa5
+; RV32-NEXT: vslideup.vi v8, v9, 5
+; RV32-NEXT: addi a0, a0, 2
+; RV32-NEXT: andi a2, a1, 64
+; RV32-NEXT: beqz a2, .LBB3_7
+; RV32-NEXT: .LBB3_15: # %cond.load21
+; RV32-NEXT: flh fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 7, e16, m1, tu, ma
+; RV32-NEXT: vfmv.s.f v9, fa5
+; RV32-NEXT: vslideup.vi v8, v9, 6
+; RV32-NEXT: addi a0, a0, 2
+; RV32-NEXT: andi a1, a1, -128
+; RV32-NEXT: beqz a1, .LBB3_8
+; RV32-NEXT: .LBB3_16: # %cond.load25
+; RV32-NEXT: flh fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 8, e16, m1, ta, ma
+; RV32-NEXT: vfmv.s.f v9, fa5
+; RV32-NEXT: vslideup.vi v8, v9, 7
+; RV32-NEXT: ret
+;
+; RV64-LABEL: expandload_v8f16:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV64-NEXT: vmv.x.s a1, v0
+; RV64-NEXT: andi a2, a1, 1
+; RV64-NEXT: bnez a2, .LBB3_9
+; RV64-NEXT: # %bb.1: # %else
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: bnez a2, .LBB3_10
+; RV64-NEXT: .LBB3_2: # %else2
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: bnez a2, .LBB3_11
+; RV64-NEXT: .LBB3_3: # %else6
+; RV64-NEXT: andi a2, a1, 8
+; RV64-NEXT: bnez a2, .LBB3_12
+; RV64-NEXT: .LBB3_4: # %else10
+; RV64-NEXT: andi a2, a1, 16
+; RV64-NEXT: bnez a2, .LBB3_13
+; RV64-NEXT: .LBB3_5: # %else14
+; RV64-NEXT: andi a2, a1, 32
+; RV64-NEXT: bnez a2, .LBB3_14
+; RV64-NEXT: .LBB3_6: # %else18
+; RV64-NEXT: andi a2, a1, 64
+; RV64-NEXT: bnez a2, .LBB3_15
+; RV64-NEXT: .LBB3_7: # %else22
+; RV64-NEXT: andi a1, a1, -128
+; RV64-NEXT: bnez a1, .LBB3_16
+; RV64-NEXT: .LBB3_8: # %else26
+; RV64-NEXT: ret
+; RV64-NEXT: .LBB3_9: # %cond.load
+; RV64-NEXT: flh fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 8, e16, m2, tu, ma
+; RV64-NEXT: vfmv.s.f v8, fa5
+; RV64-NEXT: addi a0, a0, 2
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: beqz a2, .LBB3_2
+; RV64-NEXT: .LBB3_10: # %cond.load1
+; RV64-NEXT: flh fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 2, e16, m1, tu, ma
+; RV64-NEXT: vfmv.s.f v9, fa5
+; RV64-NEXT: vslideup.vi v8, v9, 1
+; RV64-NEXT: addi a0, a0, 2
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: beqz a2, .LBB3_3
+; RV64-NEXT: .LBB3_11: # %cond.load5
+; RV64-NEXT: flh fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 3, e16, m1, tu, ma
+; RV64-NEXT: vfmv.s.f v9, fa5
+; RV64-NEXT: vslideup.vi v8, v9, 2
+; RV64-NEXT: addi a0, a0, 2
+; RV64-NEXT: andi a2, a1, 8
+; RV64-NEXT: beqz a2, .LBB3_4
+; RV64-NEXT: .LBB3_12: # %cond.load9
+; RV64-NEXT: flh fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 4, e16, m1, tu, ma
+; RV64-NEXT: vfmv.s.f v9, fa5
+; RV64-NEXT: vslideup.vi v8, v9, 3
+; RV64-NEXT: addi a0, a0, 2
+; RV64-NEXT: andi a2, a1, 16
+; RV64-NEXT: beqz a2, .LBB3_5
+; RV64-NEXT: .LBB3_13: # %cond.load13
+; RV64-NEXT: flh fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 5, e16, m1, tu, ma
+; RV64-NEXT: vfmv.s.f v9, fa5
+; RV64-NEXT: vslideup.vi v8, v9, 4
+; RV64-NEXT: addi a0, a0, 2
+; RV64-NEXT: andi a2, a1, 32
+; RV64-NEXT: beqz a2, .LBB3_6
+; RV64-NEXT: .LBB3_14: # %cond.load17
+; RV64-NEXT: flh fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 6, e16, m1, tu, ma
+; RV64-NEXT: vfmv.s.f v9, fa5
+; RV64-NEXT: vslideup.vi v8, v9, 5
+; RV64-NEXT: addi a0, a0, 2
+; RV64-NEXT: andi a2, a1, 64
+; RV64-NEXT: beqz a2, .LBB3_7
+; RV64-NEXT: .LBB3_15: # %cond.load21
+; RV64-NEXT: flh fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 7, e16, m1, tu, ma
+; RV64-NEXT: vfmv.s.f v9, fa5
+; RV64-NEXT: vslideup.vi v8, v9, 6
+; RV64-NEXT: addi a0, a0, 2
+; RV64-NEXT: andi a1, a1, -128
+; RV64-NEXT: beqz a1, .LBB3_8
+; RV64-NEXT: .LBB3_16: # %cond.load25
+; RV64-NEXT: flh fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 8, e16, m1, ta, ma
+; RV64-NEXT: vfmv.s.f v9, fa5
+; RV64-NEXT: vslideup.vi v8, v9, 7
+; RV64-NEXT: ret
+ %res = call <8 x half> @llvm.masked.expandload.v8f16(ptr align 2 %base, <8 x i1> %mask, <8 x half> %src0)
+ ret <8 x half>%res
+}
+
+declare <1 x float> @llvm.masked.expandload.v1f32(ptr, <1 x i1>, <1 x float>)
+define <1 x float> @expandload_v1f32(ptr %base, <1 x float> %src0, <1 x i1> %mask) {
+; RV32-LABEL: expandload_v1f32:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetvli a1, zero, e8, mf8, ta, ma
+; RV32-NEXT: vfirst.m a1, v0
+; RV32-NEXT: bnez a1, .LBB4_2
+; RV32-NEXT: # %bb.1: # %cond.load
+; RV32-NEXT: vsetivli zero, 1, e32, mf2, ta, ma
+; RV32-NEXT: vle32.v v8, (a0)
+; RV32-NEXT: .LBB4_2: # %else
+; RV32-NEXT: ret
+;
+; RV64-LABEL: expandload_v1f32:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetvli a1, zero, e8, mf8, ta, ma
+; RV64-NEXT: vfirst.m a1, v0
+; RV64-NEXT: bnez a1, .LBB4_2
+; RV64-NEXT: # %bb.1: # %cond.load
+; RV64-NEXT: vsetivli zero, 1, e32, mf2, ta, ma
+; RV64-NEXT: vle32.v v8, (a0)
+; RV64-NEXT: .LBB4_2: # %else
+; RV64-NEXT: ret
+ %res = call <1 x float> @llvm.masked.expandload.v1f32(ptr align 4 %base, <1 x i1> %mask, <1 x float> %src0)
+ ret <1 x float>%res
+}
+
+declare <2 x float> @llvm.masked.expandload.v2f32(ptr, <2 x i1>, <2 x float>)
+define <2 x float> @expandload_v2f32(ptr %base, <2 x float> %src0, <2 x i1> %mask) {
+; RV32-LABEL: expandload_v2f32:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV32-NEXT: vmv.x.s a1, v0
+; RV32-NEXT: andi a2, a1, 1
+; RV32-NEXT: bnez a2, .LBB5_3
+; RV32-NEXT: # %bb.1: # %else
+; RV32-NEXT: andi a1, a1, 2
+; RV32-NEXT: bnez a1, .LBB5_4
+; RV32-NEXT: .LBB5_2: # %else2
+; RV32-NEXT: ret
+; RV32-NEXT: .LBB5_3: # %cond.load
+; RV32-NEXT: flw fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 2, e32, m4, tu, ma
+; RV32-NEXT: vfmv.s.f v8, fa5
+; RV32-NEXT: addi a0, a0, 4
+; RV32-NEXT: andi a1, a1, 2
+; RV32-NEXT: beqz a1, .LBB5_2
+; RV32-NEXT: .LBB5_4: # %cond.load1
+; RV32-NEXT: flw fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 2, e32, mf2, ta, ma
+; RV32-NEXT: vfmv.s.f v9, fa5
+; RV32-NEXT: vslideup.vi v8, v9, 1
+; RV32-NEXT: ret
+;
+; RV64-LABEL: expandload_v2f32:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV64-NEXT: vmv.x.s a1, v0
+; RV64-NEXT: andi a2, a1, 1
+; RV64-NEXT: bnez a2, .LBB5_3
+; RV64-NEXT: # %bb.1: # %else
+; RV64-NEXT: andi a1, a1, 2
+; RV64-NEXT: bnez a1, .LBB5_4
+; RV64-NEXT: .LBB5_2: # %else2
+; RV64-NEXT: ret
+; RV64-NEXT: .LBB5_3: # %cond.load
+; RV64-NEXT: flw fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 2, e32, m4, tu, ma
+; RV64-NEXT: vfmv.s.f v8, fa5
+; RV64-NEXT: addi a0, a0, 4
+; RV64-NEXT: andi a1, a1, 2
+; RV64-NEXT: beqz a1, .LBB5_2
+; RV64-NEXT: .LBB5_4: # %cond.load1
+; RV64-NEXT: flw fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 2, e32, mf2, ta, ma
+; RV64-NEXT: vfmv.s.f v9, fa5
+; RV64-NEXT: vslideup.vi v8, v9, 1
+; RV64-NEXT: ret
+ %res = call <2 x float> @llvm.masked.expandload.v2f32(ptr align 4 %base, <2 x i1> %mask, <2 x float> %src0)
+ ret <2 x float>%res
+}
+
+declare <4 x float> @llvm.masked.expandload.v4f32(ptr, <4 x i1>, <4 x float>)
+define <4 x float> @expandload_v4f32(ptr %base, <4 x float> %src0, <4 x i1> %mask) {
+; RV32-LABEL: expandload_v4f32:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV32-NEXT: vmv.x.s a1, v0
+; RV32-NEXT: andi a2, a1, 1
+; RV32-NEXT: bnez a2, .LBB6_5
+; RV32-NEXT: # %bb.1: # %else
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: bnez a2, .LBB6_6
+; RV32-NEXT: .LBB6_2: # %else2
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: bnez a2, .LBB6_7
+; RV32-NEXT: .LBB6_3: # %else6
+; RV32-NEXT: andi a1, a1, 8
+; RV32-NEXT: bnez a1, .LBB6_8
+; RV32-NEXT: .LBB6_4: # %else10
+; RV32-NEXT: ret
+; RV32-NEXT: .LBB6_5: # %cond.load
+; RV32-NEXT: flw fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 4, e32, m4, tu, ma
+; RV32-NEXT: vfmv.s.f v8, fa5
+; RV32-NEXT: addi a0, a0, 4
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: beqz a2, .LBB6_2
+; RV32-NEXT: .LBB6_6: # %cond.load1
+; RV32-NEXT: flw fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 2, e32, m1, tu, ma
+; RV32-NEXT: vfmv.s.f v9, fa5
+; RV32-NEXT: vslideup.vi v8, v9, 1
+; RV32-NEXT: addi a0, a0, 4
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: beqz a2, .LBB6_3
+; RV32-NEXT: .LBB6_7: # %cond.load5
+; RV32-NEXT: flw fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 3, e32, m1, tu, ma
+; RV32-NEXT: vfmv.s.f v9, fa5
+; RV32-NEXT: vslideup.vi v8, v9, 2
+; RV32-NEXT: addi a0, a0, 4
+; RV32-NEXT: andi a1, a1, 8
+; RV32-NEXT: beqz a1, .LBB6_4
+; RV32-NEXT: .LBB6_8: # %cond.load9
+; RV32-NEXT: flw fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; RV32-NEXT: vfmv.s.f v9, fa5
+; RV32-NEXT: vslideup.vi v8, v9, 3
+; RV32-NEXT: ret
+;
+; RV64-LABEL: expandload_v4f32:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV64-NEXT: vmv.x.s a1, v0
+; RV64-NEXT: andi a2, a1, 1
+; RV64-NEXT: bnez a2, .LBB6_5
+; RV64-NEXT: # %bb.1: # %else
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: bnez a2, .LBB6_6
+; RV64-NEXT: .LBB6_2: # %else2
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: bnez a2, .LBB6_7
+; RV64-NEXT: .LBB6_3: # %else6
+; RV64-NEXT: andi a1, a1, 8
+; RV64-NEXT: bnez a1, .LBB6_8
+; RV64-NEXT: .LBB6_4: # %else10
+; RV64-NEXT: ret
+; RV64-NEXT: .LBB6_5: # %cond.load
+; RV64-NEXT: flw fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 4, e32, m4, tu, ma
+; RV64-NEXT: vfmv.s.f v8, fa5
+; RV64-NEXT: addi a0, a0, 4
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: beqz a2, .LBB6_2
+; RV64-NEXT: .LBB6_6: # %cond.load1
+; RV64-NEXT: flw fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 2, e32, m1, tu, ma
+; RV64-NEXT: vfmv.s.f v9, fa5
+; RV64-NEXT: vslideup.vi v8, v9, 1
+; RV64-NEXT: addi a0, a0, 4
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: beqz a2, .LBB6_3
+; RV64-NEXT: .LBB6_7: # %cond.load5
+; RV64-NEXT: flw fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 3, e32, m1, tu, ma
+; RV64-NEXT: vfmv.s.f v9, fa5
+; RV64-NEXT: vslideup.vi v8, v9, 2
+; RV64-NEXT: addi a0, a0, 4
+; RV64-NEXT: andi a1, a1, 8
+; RV64-NEXT: beqz a1, .LBB6_4
+; RV64-NEXT: .LBB6_8: # %cond.load9
+; RV64-NEXT: flw fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; RV64-NEXT: vfmv.s.f v9, fa5
+; RV64-NEXT: vslideup.vi v8, v9, 3
+; RV64-NEXT: ret
+ %res = call <4 x float> @llvm.masked.expandload.v4f32(ptr align 4 %base, <4 x i1> %mask, <4 x float> %src0)
+ ret <4 x float>%res
+}
+
+declare <8 x float> @llvm.masked.expandload.v8f32(ptr, <8 x i1>, <8 x float>)
+define <8 x float> @expandload_v8f32(ptr %base, <8 x float> %src0, <8 x i1> %mask) {
+; RV32-LABEL: expandload_v8f32:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV32-NEXT: vmv.x.s a1, v0
+; RV32-NEXT: andi a2, a1, 1
+; RV32-NEXT: bnez a2, .LBB7_9
+; RV32-NEXT: # %bb.1: # %else
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: bnez a2, .LBB7_10
+; RV32-NEXT: .LBB7_2: # %else2
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: bnez a2, .LBB7_11
+; RV32-NEXT: .LBB7_3: # %else6
+; RV32-NEXT: andi a2, a1, 8
+; RV32-NEXT: bnez a2, .LBB7_12
+; RV32-NEXT: .LBB7_4: # %else10
+; RV32-NEXT: andi a2, a1, 16
+; RV32-NEXT: bnez a2, .LBB7_13
+; RV32-NEXT: .LBB7_5: # %else14
+; RV32-NEXT: andi a2, a1, 32
+; RV32-NEXT: bnez a2, .LBB7_14
+; RV32-NEXT: .LBB7_6: # %else18
+; RV32-NEXT: andi a2, a1, 64
+; RV32-NEXT: bnez a2, .LBB7_15
+; RV32-NEXT: .LBB7_7: # %else22
+; RV32-NEXT: andi a1, a1, -128
+; RV32-NEXT: bnez a1, .LBB7_16
+; RV32-NEXT: .LBB7_8: # %else26
+; RV32-NEXT: ret
+; RV32-NEXT: .LBB7_9: # %cond.load
+; RV32-NEXT: flw fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 8, e32, m4, tu, ma
+; RV32-NEXT: vfmv.s.f v8, fa5
+; RV32-NEXT: addi a0, a0, 4
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: beqz a2, .LBB7_2
+; RV32-NEXT: .LBB7_10: # %cond.load1
+; RV32-NEXT: flw fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 2, e32, m1, tu, ma
+; RV32-NEXT: vfmv.s.f v10, fa5
+; RV32-NEXT: vslideup.vi v8, v10, 1
+; RV32-NEXT: addi a0, a0, 4
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: beqz a2, .LBB7_3
+; RV32-NEXT: .LBB7_11: # %cond.load5
+; RV32-NEXT: flw fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 3, e32, m1, tu, ma
+; RV32-NEXT: vfmv.s.f v10, fa5
+; RV32-NEXT: vslideup.vi v8, v10, 2
+; RV32-NEXT: addi a0, a0, 4
+; RV32-NEXT: andi a2, a1, 8
+; RV32-NEXT: beqz a2, .LBB7_4
+; RV32-NEXT: .LBB7_12: # %cond.load9
+; RV32-NEXT: flw fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 4, e32, m1, tu, ma
+; RV32-NEXT: vfmv.s.f v10, fa5
+; RV32-NEXT: vslideup.vi v8, v10, 3
+; RV32-NEXT: addi a0, a0, 4
+; RV32-NEXT: andi a2, a1, 16
+; RV32-NEXT: beqz a2, .LBB7_5
+; RV32-NEXT: .LBB7_13: # %cond.load13
+; RV32-NEXT: flw fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 5, e32, m2, tu, ma
+; RV32-NEXT: vfmv.s.f v10, fa5
+; RV32-NEXT: vslideup.vi v8, v10, 4
+; RV32-NEXT: addi a0, a0, 4
+; RV32-NEXT: andi a2, a1, 32
+; RV32-NEXT: beqz a2, .LBB7_6
+; RV32-NEXT: .LBB7_14: # %cond.load17
+; RV32-NEXT: flw fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 6, e32, m2, tu, ma
+; RV32-NEXT: vfmv.s.f v10, fa5
+; RV32-NEXT: vslideup.vi v8, v10, 5
+; RV32-NEXT: addi a0, a0, 4
+; RV32-NEXT: andi a2, a1, 64
+; RV32-NEXT: beqz a2, .LBB7_7
+; RV32-NEXT: .LBB7_15: # %cond.load21
+; RV32-NEXT: flw fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 7, e32, m2, tu, ma
+; RV32-NEXT: vfmv.s.f v10, fa5
+; RV32-NEXT: vslideup.vi v8, v10, 6
+; RV32-NEXT: addi a0, a0, 4
+; RV32-NEXT: andi a1, a1, -128
+; RV32-NEXT: beqz a1, .LBB7_8
+; RV32-NEXT: .LBB7_16: # %cond.load25
+; RV32-NEXT: flw fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 8, e32, m2, ta, ma
+; RV32-NEXT: vfmv.s.f v10, fa5
+; RV32-NEXT: vslideup.vi v8, v10, 7
+; RV32-NEXT: ret
+;
+; RV64-LABEL: expandload_v8f32:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV64-NEXT: vmv.x.s a1, v0
+; RV64-NEXT: andi a2, a1, 1
+; RV64-NEXT: bnez a2, .LBB7_9
+; RV64-NEXT: # %bb.1: # %else
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: bnez a2, .LBB7_10
+; RV64-NEXT: .LBB7_2: # %else2
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: bnez a2, .LBB7_11
+; RV64-NEXT: .LBB7_3: # %else6
+; RV64-NEXT: andi a2, a1, 8
+; RV64-NEXT: bnez a2, .LBB7_12
+; RV64-NEXT: .LBB7_4: # %else10
+; RV64-NEXT: andi a2, a1, 16
+; RV64-NEXT: bnez a2, .LBB7_13
+; RV64-NEXT: .LBB7_5: # %else14
+; RV64-NEXT: andi a2, a1, 32
+; RV64-NEXT: bnez a2, .LBB7_14
+; RV64-NEXT: .LBB7_6: # %else18
+; RV64-NEXT: andi a2, a1, 64
+; RV64-NEXT: bnez a2, .LBB7_15
+; RV64-NEXT: .LBB7_7: # %else22
+; RV64-NEXT: andi a1, a1, -128
+; RV64-NEXT: bnez a1, .LBB7_16
+; RV64-NEXT: .LBB7_8: # %else26
+; RV64-NEXT: ret
+; RV64-NEXT: .LBB7_9: # %cond.load
+; RV64-NEXT: flw fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 8, e32, m4, tu, ma
+; RV64-NEXT: vfmv.s.f v8, fa5
+; RV64-NEXT: addi a0, a0, 4
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: beqz a2, .LBB7_2
+; RV64-NEXT: .LBB7_10: # %cond.load1
+; RV64-NEXT: flw fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 2, e32, m1, tu, ma
+; RV64-NEXT: vfmv.s.f v10, fa5
+; RV64-NEXT: vslideup.vi v8, v10, 1
+; RV64-NEXT: addi a0, a0, 4
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: beqz a2, .LBB7_3
+; RV64-NEXT: .LBB7_11: # %cond.load5
+; RV64-NEXT: flw fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 3, e32, m1, tu, ma
+; RV64-NEXT: vfmv.s.f v10, fa5
+; RV64-NEXT: vslideup.vi v8, v10, 2
+; RV64-NEXT: addi a0, a0, 4
+; RV64-NEXT: andi a2, a1, 8
+; RV64-NEXT: beqz a2, .LBB7_4
+; RV64-NEXT: .LBB7_12: # %cond.load9
+; RV64-NEXT: flw fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 4, e32, m1, tu, ma
+; RV64-NEXT: vfmv.s.f v10, fa5
+; RV64-NEXT: vslideup.vi v8, v10, 3
+; RV64-NEXT: addi a0, a0, 4
+; RV64-NEXT: andi a2, a1, 16
+; RV64-NEXT: beqz a2, .LBB7_5
+; RV64-NEXT: .LBB7_13: # %cond.load13
+; RV64-NEXT: flw fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 5, e32, m2, tu, ma
+; RV64-NEXT: vfmv.s.f v10, fa5
+; RV64-NEXT: vslideup.vi v8, v10, 4
+; RV64-NEXT: addi a0, a0, 4
+; RV64-NEXT: andi a2, a1, 32
+; RV64-NEXT: beqz a2, .LBB7_6
+; RV64-NEXT: .LBB7_14: # %cond.load17
+; RV64-NEXT: flw fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 6, e32, m2, tu, ma
+; RV64-NEXT: vfmv.s.f v10, fa5
+; RV64-NEXT: vslideup.vi v8, v10, 5
+; RV64-NEXT: addi a0, a0, 4
+; RV64-NEXT: andi a2, a1, 64
+; RV64-NEXT: beqz a2, .LBB7_7
+; RV64-NEXT: .LBB7_15: # %cond.load21
+; RV64-NEXT: flw fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 7, e32, m2, tu, ma
+; RV64-NEXT: vfmv.s.f v10, fa5
+; RV64-NEXT: vslideup.vi v8, v10, 6
+; RV64-NEXT: addi a0, a0, 4
+; RV64-NEXT: andi a1, a1, -128
+; RV64-NEXT: beqz a1, .LBB7_8
+; RV64-NEXT: .LBB7_16: # %cond.load25
+; RV64-NEXT: flw fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 8, e32, m2, ta, ma
+; RV64-NEXT: vfmv.s.f v10, fa5
+; RV64-NEXT: vslideup.vi v8, v10, 7
+; RV64-NEXT: ret
+ %res = call <8 x float> @llvm.masked.expandload.v8f32(ptr align 4 %base, <8 x i1> %mask, <8 x float> %src0)
+ ret <8 x float>%res
+}
+
+declare <1 x double> @llvm.masked.expandload.v1f64(ptr, <1 x i1>, <1 x double>)
+define <1 x double> @expandload_v1f64(ptr %base, <1 x double> %src0, <1 x i1> %mask) {
+; RV32-LABEL: expandload_v1f64:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetvli a1, zero, e8, mf8, ta, ma
+; RV32-NEXT: vfirst.m a1, v0
+; RV32-NEXT: bnez a1, .LBB8_2
+; RV32-NEXT: # %bb.1: # %cond.load
+; RV32-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV32-NEXT: vle64.v v8, (a0)
+; RV32-NEXT: .LBB8_2: # %else
+; RV32-NEXT: ret
+;
+; RV64-LABEL: expandload_v1f64:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetvli a1, zero, e8, mf8, ta, ma
+; RV64-NEXT: vfirst.m a1, v0
+; RV64-NEXT: bnez a1, .LBB8_2
+; RV64-NEXT: # %bb.1: # %cond.load
+; RV64-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV64-NEXT: vle64.v v8, (a0)
+; RV64-NEXT: .LBB8_2: # %else
+; RV64-NEXT: ret
+ %res = call <1 x double> @llvm.masked.expandload.v1f64(ptr align 8 %base, <1 x i1> %mask, <1 x double> %src0)
+ ret <1 x double>%res
+}
+
+declare <2 x double> @llvm.masked.expandload.v2f64(ptr, <2 x i1>, <2 x double>)
+define <2 x double> @expandload_v2f64(ptr %base, <2 x double> %src0, <2 x i1> %mask) {
+; RV32-LABEL: expandload_v2f64:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV32-NEXT: vmv.x.s a1, v0
+; RV32-NEXT: andi a2, a1, 1
+; RV32-NEXT: bnez a2, .LBB9_3
+; RV32-NEXT: # %bb.1: # %else
+; RV32-NEXT: andi a1, a1, 2
+; RV32-NEXT: bnez a1, .LBB9_4
+; RV32-NEXT: .LBB9_2: # %else2
+; RV32-NEXT: ret
+; RV32-NEXT: .LBB9_3: # %cond.load
+; RV32-NEXT: fld fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 2, e64, m8, tu, ma
+; RV32-NEXT: vfmv.s.f v8, fa5
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a1, a1, 2
+; RV32-NEXT: beqz a1, .LBB9_2
+; RV32-NEXT: .LBB9_4: # %cond.load1
+; RV32-NEXT: fld fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 2, e64, m1, ta, ma
+; RV32-NEXT: vfmv.s.f v9, fa5
+; RV32-NEXT: vslideup.vi v8, v9, 1
+; RV32-NEXT: ret
+;
+; RV64-LABEL: expandload_v2f64:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV64-NEXT: vmv.x.s a1, v0
+; RV64-NEXT: andi a2, a1, 1
+; RV64-NEXT: bnez a2, .LBB9_3
+; RV64-NEXT: # %bb.1: # %else
+; RV64-NEXT: andi a1, a1, 2
+; RV64-NEXT: bnez a1, .LBB9_4
+; RV64-NEXT: .LBB9_2: # %else2
+; RV64-NEXT: ret
+; RV64-NEXT: .LBB9_3: # %cond.load
+; RV64-NEXT: fld fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 2, e64, m8, tu, ma
+; RV64-NEXT: vfmv.s.f v8, fa5
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a1, a1, 2
+; RV64-NEXT: beqz a1, .LBB9_2
+; RV64-NEXT: .LBB9_4: # %cond.load1
+; RV64-NEXT: fld fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 2, e64, m1, ta, ma
+; RV64-NEXT: vfmv.s.f v9, fa5
+; RV64-NEXT: vslideup.vi v8, v9, 1
+; RV64-NEXT: ret
+ %res = call <2 x double> @llvm.masked.expandload.v2f64(ptr align 8 %base, <2 x i1> %mask, <2 x double> %src0)
+ ret <2 x double>%res
+}
+
+declare <4 x double> @llvm.masked.expandload.v4f64(ptr, <4 x i1>, <4 x double>)
+define <4 x double> @expandload_v4f64(ptr %base, <4 x double> %src0, <4 x i1> %mask) {
+; RV32-LABEL: expandload_v4f64:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV32-NEXT: vmv.x.s a1, v0
+; RV32-NEXT: andi a2, a1, 1
+; RV32-NEXT: bnez a2, .LBB10_5
+; RV32-NEXT: # %bb.1: # %else
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: bnez a2, .LBB10_6
+; RV32-NEXT: .LBB10_2: # %else2
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: bnez a2, .LBB10_7
+; RV32-NEXT: .LBB10_3: # %else6
+; RV32-NEXT: andi a1, a1, 8
+; RV32-NEXT: bnez a1, .LBB10_8
+; RV32-NEXT: .LBB10_4: # %else10
+; RV32-NEXT: ret
+; RV32-NEXT: .LBB10_5: # %cond.load
+; RV32-NEXT: fld fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 4, e64, m8, tu, ma
+; RV32-NEXT: vfmv.s.f v8, fa5
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: beqz a2, .LBB10_2
+; RV32-NEXT: .LBB10_6: # %cond.load1
+; RV32-NEXT: fld fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 2, e64, m1, tu, ma
+; RV32-NEXT: vfmv.s.f v10, fa5
+; RV32-NEXT: vslideup.vi v8, v10, 1
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: beqz a2, .LBB10_3
+; RV32-NEXT: .LBB10_7: # %cond.load5
+; RV32-NEXT: fld fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 3, e64, m2, tu, ma
+; RV32-NEXT: vfmv.s.f v10, fa5
+; RV32-NEXT: vslideup.vi v8, v10, 2
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a1, a1, 8
+; RV32-NEXT: beqz a1, .LBB10_4
+; RV32-NEXT: .LBB10_8: # %cond.load9
+; RV32-NEXT: fld fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 4, e64, m2, ta, ma
+; RV32-NEXT: vfmv.s.f v10, fa5
+; RV32-NEXT: vslideup.vi v8, v10, 3
+; RV32-NEXT: ret
+;
+; RV64-LABEL: expandload_v4f64:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV64-NEXT: vmv.x.s a1, v0
+; RV64-NEXT: andi a2, a1, 1
+; RV64-NEXT: bnez a2, .LBB10_5
+; RV64-NEXT: # %bb.1: # %else
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: bnez a2, .LBB10_6
+; RV64-NEXT: .LBB10_2: # %else2
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: bnez a2, .LBB10_7
+; RV64-NEXT: .LBB10_3: # %else6
+; RV64-NEXT: andi a1, a1, 8
+; RV64-NEXT: bnez a1, .LBB10_8
+; RV64-NEXT: .LBB10_4: # %else10
+; RV64-NEXT: ret
+; RV64-NEXT: .LBB10_5: # %cond.load
+; RV64-NEXT: fld fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 4, e64, m8, tu, ma
+; RV64-NEXT: vfmv.s.f v8, fa5
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: beqz a2, .LBB10_2
+; RV64-NEXT: .LBB10_6: # %cond.load1
+; RV64-NEXT: fld fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 2, e64, m1, tu, ma
+; RV64-NEXT: vfmv.s.f v10, fa5
+; RV64-NEXT: vslideup.vi v8, v10, 1
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: beqz a2, .LBB10_3
+; RV64-NEXT: .LBB10_7: # %cond.load5
+; RV64-NEXT: fld fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 3, e64, m2, tu, ma
+; RV64-NEXT: vfmv.s.f v10, fa5
+; RV64-NEXT: vslideup.vi v8, v10, 2
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a1, a1, 8
+; RV64-NEXT: beqz a1, .LBB10_4
+; RV64-NEXT: .LBB10_8: # %cond.load9
+; RV64-NEXT: fld fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 4, e64, m2, ta, ma
+; RV64-NEXT: vfmv.s.f v10, fa5
+; RV64-NEXT: vslideup.vi v8, v10, 3
+; RV64-NEXT: ret
+ %res = call <4 x double> @llvm.masked.expandload.v4f64(ptr align 8 %base, <4 x i1> %mask, <4 x double> %src0)
+ ret <4 x double>%res
+}
+
+declare <8 x double> @llvm.masked.expandload.v8f64(ptr, <8 x i1>, <8 x double>)
+define <8 x double> @expandload_v8f64(ptr %base, <8 x double> %src0, <8 x i1> %mask) {
+; RV32-LABEL: expandload_v8f64:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV32-NEXT: vmv.x.s a1, v0
+; RV32-NEXT: andi a2, a1, 1
+; RV32-NEXT: bnez a2, .LBB11_9
+; RV32-NEXT: # %bb.1: # %else
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: bnez a2, .LBB11_10
+; RV32-NEXT: .LBB11_2: # %else2
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: bnez a2, .LBB11_11
+; RV32-NEXT: .LBB11_3: # %else6
+; RV32-NEXT: andi a2, a1, 8
+; RV32-NEXT: bnez a2, .LBB11_12
+; RV32-NEXT: .LBB11_4: # %else10
+; RV32-NEXT: andi a2, a1, 16
+; RV32-NEXT: bnez a2, .LBB11_13
+; RV32-NEXT: .LBB11_5: # %else14
+; RV32-NEXT: andi a2, a1, 32
+; RV32-NEXT: bnez a2, .LBB11_14
+; RV32-NEXT: .LBB11_6: # %else18
+; RV32-NEXT: andi a2, a1, 64
+; RV32-NEXT: bnez a2, .LBB11_15
+; RV32-NEXT: .LBB11_7: # %else22
+; RV32-NEXT: andi a1, a1, -128
+; RV32-NEXT: bnez a1, .LBB11_16
+; RV32-NEXT: .LBB11_8: # %else26
+; RV32-NEXT: ret
+; RV32-NEXT: .LBB11_9: # %cond.load
+; RV32-NEXT: fld fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 8, e64, m8, tu, ma
+; RV32-NEXT: vfmv.s.f v8, fa5
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: beqz a2, .LBB11_2
+; RV32-NEXT: .LBB11_10: # %cond.load1
+; RV32-NEXT: fld fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 2, e64, m1, tu, ma
+; RV32-NEXT: vfmv.s.f v12, fa5
+; RV32-NEXT: vslideup.vi v8, v12, 1
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: beqz a2, .LBB11_3
+; RV32-NEXT: .LBB11_11: # %cond.load5
+; RV32-NEXT: fld fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 3, e64, m2, tu, ma
+; RV32-NEXT: vfmv.s.f v12, fa5
+; RV32-NEXT: vslideup.vi v8, v12, 2
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a2, a1, 8
+; RV32-NEXT: beqz a2, .LBB11_4
+; RV32-NEXT: .LBB11_12: # %cond.load9
+; RV32-NEXT: fld fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 4, e64, m2, tu, ma
+; RV32-NEXT: vfmv.s.f v12, fa5
+; RV32-NEXT: vslideup.vi v8, v12, 3
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a2, a1, 16
+; RV32-NEXT: beqz a2, .LBB11_5
+; RV32-NEXT: .LBB11_13: # %cond.load13
+; RV32-NEXT: fld fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 5, e64, m4, tu, ma
+; RV32-NEXT: vfmv.s.f v12, fa5
+; RV32-NEXT: vslideup.vi v8, v12, 4
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a2, a1, 32
+; RV32-NEXT: beqz a2, .LBB11_6
+; RV32-NEXT: .LBB11_14: # %cond.load17
+; RV32-NEXT: fld fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 6, e64, m4, tu, ma
+; RV32-NEXT: vfmv.s.f v12, fa5
+; RV32-NEXT: vslideup.vi v8, v12, 5
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a2, a1, 64
+; RV32-NEXT: beqz a2, .LBB11_7
+; RV32-NEXT: .LBB11_15: # %cond.load21
+; RV32-NEXT: fld fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 7, e64, m4, tu, ma
+; RV32-NEXT: vfmv.s.f v12, fa5
+; RV32-NEXT: vslideup.vi v8, v12, 6
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a1, a1, -128
+; RV32-NEXT: beqz a1, .LBB11_8
+; RV32-NEXT: .LBB11_16: # %cond.load25
+; RV32-NEXT: fld fa5, 0(a0)
+; RV32-NEXT: vsetivli zero, 8, e64, m4, ta, ma
+; RV32-NEXT: vfmv.s.f v12, fa5
+; RV32-NEXT: vslideup.vi v8, v12, 7
+; RV32-NEXT: ret
+;
+; RV64-LABEL: expandload_v8f64:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV64-NEXT: vmv.x.s a1, v0
+; RV64-NEXT: andi a2, a1, 1
+; RV64-NEXT: bnez a2, .LBB11_9
+; RV64-NEXT: # %bb.1: # %else
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: bnez a2, .LBB11_10
+; RV64-NEXT: .LBB11_2: # %else2
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: bnez a2, .LBB11_11
+; RV64-NEXT: .LBB11_3: # %else6
+; RV64-NEXT: andi a2, a1, 8
+; RV64-NEXT: bnez a2, .LBB11_12
+; RV64-NEXT: .LBB11_4: # %else10
+; RV64-NEXT: andi a2, a1, 16
+; RV64-NEXT: bnez a2, .LBB11_13
+; RV64-NEXT: .LBB11_5: # %else14
+; RV64-NEXT: andi a2, a1, 32
+; RV64-NEXT: bnez a2, .LBB11_14
+; RV64-NEXT: .LBB11_6: # %else18
+; RV64-NEXT: andi a2, a1, 64
+; RV64-NEXT: bnez a2, .LBB11_15
+; RV64-NEXT: .LBB11_7: # %else22
+; RV64-NEXT: andi a1, a1, -128
+; RV64-NEXT: bnez a1, .LBB11_16
+; RV64-NEXT: .LBB11_8: # %else26
+; RV64-NEXT: ret
+; RV64-NEXT: .LBB11_9: # %cond.load
+; RV64-NEXT: fld fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 8, e64, m8, tu, ma
+; RV64-NEXT: vfmv.s.f v8, fa5
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: beqz a2, .LBB11_2
+; RV64-NEXT: .LBB11_10: # %cond.load1
+; RV64-NEXT: fld fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 2, e64, m1, tu, ma
+; RV64-NEXT: vfmv.s.f v12, fa5
+; RV64-NEXT: vslideup.vi v8, v12, 1
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: beqz a2, .LBB11_3
+; RV64-NEXT: .LBB11_11: # %cond.load5
+; RV64-NEXT: fld fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 3, e64, m2, tu, ma
+; RV64-NEXT: vfmv.s.f v12, fa5
+; RV64-NEXT: vslideup.vi v8, v12, 2
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a2, a1, 8
+; RV64-NEXT: beqz a2, .LBB11_4
+; RV64-NEXT: .LBB11_12: # %cond.load9
+; RV64-NEXT: fld fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 4, e64, m2, tu, ma
+; RV64-NEXT: vfmv.s.f v12, fa5
+; RV64-NEXT: vslideup.vi v8, v12, 3
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a2, a1, 16
+; RV64-NEXT: beqz a2, .LBB11_5
+; RV64-NEXT: .LBB11_13: # %cond.load13
+; RV64-NEXT: fld fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 5, e64, m4, tu, ma
+; RV64-NEXT: vfmv.s.f v12, fa5
+; RV64-NEXT: vslideup.vi v8, v12, 4
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a2, a1, 32
+; RV64-NEXT: beqz a2, .LBB11_6
+; RV64-NEXT: .LBB11_14: # %cond.load17
+; RV64-NEXT: fld fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 6, e64, m4, tu, ma
+; RV64-NEXT: vfmv.s.f v12, fa5
+; RV64-NEXT: vslideup.vi v8, v12, 5
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a2, a1, 64
+; RV64-NEXT: beqz a2, .LBB11_7
+; RV64-NEXT: .LBB11_15: # %cond.load21
+; RV64-NEXT: fld fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 7, e64, m4, tu, ma
+; RV64-NEXT: vfmv.s.f v12, fa5
+; RV64-NEXT: vslideup.vi v8, v12, 6
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a1, a1, -128
+; RV64-NEXT: beqz a1, .LBB11_8
+; RV64-NEXT: .LBB11_16: # %cond.load25
+; RV64-NEXT: fld fa5, 0(a0)
+; RV64-NEXT: vsetivli zero, 8, e64, m4, ta, ma
+; RV64-NEXT: vfmv.s.f v12, fa5
+; RV64-NEXT: vslideup.vi v8, v12, 7
+; RV64-NEXT: ret
+ %res = call <8 x double> @llvm.masked.expandload.v8f64(ptr align 8 %base, <8 x i1> %mask, <8 x double> %src0)
+ ret <8 x double>%res
+}
diff --git a/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-expandload-int.ll b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-expandload-int.ll
new file mode 100644
index 00000000000000..d6aca55fbde59d
--- /dev/null
+++ b/llvm/test/CodeGen/RISCV/rvv/fixed-vectors-expandload-int.ll
@@ -0,0 +1,1000 @@
+; NOTE: Assertions have been autogenerated by utils/update_llc_test_checks.py UTC_ARGS: --version 4
+; RUN: llc -mtriple=riscv32 -mattr=+m,+v -verify-machineinstrs < %s | FileCheck %s --check-prefixes=CHECK,RV32
+; RUN: llc -mtriple=riscv64 -mattr=+m,+v -verify-machineinstrs < %s | FileCheck %s --check-prefixes=CHECK,RV64
+
+declare <1 x i8> @llvm.masked.expandload.v1i8(ptr, <1 x i1>, <1 x i8>)
+define <1 x i8> @expandload_v1i8(ptr %base, <1 x i8> %src0, <1 x i1> %mask) {
+; CHECK-LABEL: expandload_v1i8:
+; CHECK: # %bb.0:
+; CHECK-NEXT: vsetvli a1, zero, e8, mf8, ta, ma
+; CHECK-NEXT: vfirst.m a1, v0
+; CHECK-NEXT: bnez a1, .LBB0_2
+; CHECK-NEXT: # %bb.1: # %cond.load
+; CHECK-NEXT: vsetivli zero, 1, e8, mf8, ta, ma
+; CHECK-NEXT: vle8.v v8, (a0)
+; CHECK-NEXT: .LBB0_2: # %else
+; CHECK-NEXT: ret
+ %res = call <1 x i8> @llvm.masked.expandload.v1i8(ptr %base, <1 x i1> %mask, <1 x i8> %src0)
+ ret <1 x i8>%res
+}
+
+declare <2 x i8> @llvm.masked.expandload.v2i8(ptr, <2 x i1>, <2 x i8>)
+define <2 x i8> @expandload_v2i8(ptr %base, <2 x i8> %src0, <2 x i1> %mask) {
+; CHECK-LABEL: expandload_v2i8:
+; CHECK: # %bb.0:
+; CHECK-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; CHECK-NEXT: vmv.x.s a1, v0
+; CHECK-NEXT: andi a2, a1, 1
+; CHECK-NEXT: bnez a2, .LBB1_3
+; CHECK-NEXT: # %bb.1: # %else
+; CHECK-NEXT: andi a1, a1, 2
+; CHECK-NEXT: bnez a1, .LBB1_4
+; CHECK-NEXT: .LBB1_2: # %else2
+; CHECK-NEXT: ret
+; CHECK-NEXT: .LBB1_3: # %cond.load
+; CHECK-NEXT: lbu a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 2, e8, m1, tu, ma
+; CHECK-NEXT: vmv.s.x v8, a2
+; CHECK-NEXT: addi a0, a0, 1
+; CHECK-NEXT: andi a1, a1, 2
+; CHECK-NEXT: beqz a1, .LBB1_2
+; CHECK-NEXT: .LBB1_4: # %cond.load1
+; CHECK-NEXT: lbu a0, 0(a0)
+; CHECK-NEXT: vsetivli zero, 2, e8, mf8, ta, ma
+; CHECK-NEXT: vmv.s.x v9, a0
+; CHECK-NEXT: vslideup.vi v8, v9, 1
+; CHECK-NEXT: ret
+ %res = call <2 x i8> @llvm.masked.expandload.v2i8(ptr %base, <2 x i1> %mask, <2 x i8> %src0)
+ ret <2 x i8>%res
+}
+
+declare <4 x i8> @llvm.masked.expandload.v4i8(ptr, <4 x i1>, <4 x i8>)
+define <4 x i8> @expandload_v4i8(ptr %base, <4 x i8> %src0, <4 x i1> %mask) {
+; CHECK-LABEL: expandload_v4i8:
+; CHECK: # %bb.0:
+; CHECK-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; CHECK-NEXT: vmv.x.s a1, v0
+; CHECK-NEXT: andi a2, a1, 1
+; CHECK-NEXT: bnez a2, .LBB2_5
+; CHECK-NEXT: # %bb.1: # %else
+; CHECK-NEXT: andi a2, a1, 2
+; CHECK-NEXT: bnez a2, .LBB2_6
+; CHECK-NEXT: .LBB2_2: # %else2
+; CHECK-NEXT: andi a2, a1, 4
+; CHECK-NEXT: bnez a2, .LBB2_7
+; CHECK-NEXT: .LBB2_3: # %else6
+; CHECK-NEXT: andi a1, a1, 8
+; CHECK-NEXT: bnez a1, .LBB2_8
+; CHECK-NEXT: .LBB2_4: # %else10
+; CHECK-NEXT: ret
+; CHECK-NEXT: .LBB2_5: # %cond.load
+; CHECK-NEXT: lbu a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 4, e8, m1, tu, ma
+; CHECK-NEXT: vmv.s.x v8, a2
+; CHECK-NEXT: addi a0, a0, 1
+; CHECK-NEXT: andi a2, a1, 2
+; CHECK-NEXT: beqz a2, .LBB2_2
+; CHECK-NEXT: .LBB2_6: # %cond.load1
+; CHECK-NEXT: lbu a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 2, e8, mf4, tu, ma
+; CHECK-NEXT: vmv.s.x v9, a2
+; CHECK-NEXT: vslideup.vi v8, v9, 1
+; CHECK-NEXT: addi a0, a0, 1
+; CHECK-NEXT: andi a2, a1, 4
+; CHECK-NEXT: beqz a2, .LBB2_3
+; CHECK-NEXT: .LBB2_7: # %cond.load5
+; CHECK-NEXT: lbu a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 3, e8, mf4, tu, ma
+; CHECK-NEXT: vmv.s.x v9, a2
+; CHECK-NEXT: vslideup.vi v8, v9, 2
+; CHECK-NEXT: addi a0, a0, 1
+; CHECK-NEXT: andi a1, a1, 8
+; CHECK-NEXT: beqz a1, .LBB2_4
+; CHECK-NEXT: .LBB2_8: # %cond.load9
+; CHECK-NEXT: lbu a0, 0(a0)
+; CHECK-NEXT: vsetivli zero, 4, e8, mf4, ta, ma
+; CHECK-NEXT: vmv.s.x v9, a0
+; CHECK-NEXT: vslideup.vi v8, v9, 3
+; CHECK-NEXT: ret
+ %res = call <4 x i8> @llvm.masked.expandload.v4i8(ptr %base, <4 x i1> %mask, <4 x i8> %src0)
+ ret <4 x i8>%res
+}
+
+declare <8 x i8> @llvm.masked.expandload.v8i8(ptr, <8 x i1>, <8 x i8>)
+define <8 x i8> @expandload_v8i8(ptr %base, <8 x i8> %src0, <8 x i1> %mask) {
+; CHECK-LABEL: expandload_v8i8:
+; CHECK: # %bb.0:
+; CHECK-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; CHECK-NEXT: vmv.x.s a1, v0
+; CHECK-NEXT: andi a2, a1, 1
+; CHECK-NEXT: bnez a2, .LBB3_9
+; CHECK-NEXT: # %bb.1: # %else
+; CHECK-NEXT: andi a2, a1, 2
+; CHECK-NEXT: bnez a2, .LBB3_10
+; CHECK-NEXT: .LBB3_2: # %else2
+; CHECK-NEXT: andi a2, a1, 4
+; CHECK-NEXT: bnez a2, .LBB3_11
+; CHECK-NEXT: .LBB3_3: # %else6
+; CHECK-NEXT: andi a2, a1, 8
+; CHECK-NEXT: bnez a2, .LBB3_12
+; CHECK-NEXT: .LBB3_4: # %else10
+; CHECK-NEXT: andi a2, a1, 16
+; CHECK-NEXT: bnez a2, .LBB3_13
+; CHECK-NEXT: .LBB3_5: # %else14
+; CHECK-NEXT: andi a2, a1, 32
+; CHECK-NEXT: bnez a2, .LBB3_14
+; CHECK-NEXT: .LBB3_6: # %else18
+; CHECK-NEXT: andi a2, a1, 64
+; CHECK-NEXT: bnez a2, .LBB3_15
+; CHECK-NEXT: .LBB3_7: # %else22
+; CHECK-NEXT: andi a1, a1, -128
+; CHECK-NEXT: bnez a1, .LBB3_16
+; CHECK-NEXT: .LBB3_8: # %else26
+; CHECK-NEXT: ret
+; CHECK-NEXT: .LBB3_9: # %cond.load
+; CHECK-NEXT: lbu a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 8, e8, m1, tu, ma
+; CHECK-NEXT: vmv.s.x v8, a2
+; CHECK-NEXT: addi a0, a0, 1
+; CHECK-NEXT: andi a2, a1, 2
+; CHECK-NEXT: beqz a2, .LBB3_2
+; CHECK-NEXT: .LBB3_10: # %cond.load1
+; CHECK-NEXT: lbu a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 2, e8, mf2, tu, ma
+; CHECK-NEXT: vmv.s.x v9, a2
+; CHECK-NEXT: vslideup.vi v8, v9, 1
+; CHECK-NEXT: addi a0, a0, 1
+; CHECK-NEXT: andi a2, a1, 4
+; CHECK-NEXT: beqz a2, .LBB3_3
+; CHECK-NEXT: .LBB3_11: # %cond.load5
+; CHECK-NEXT: lbu a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 3, e8, mf2, tu, ma
+; CHECK-NEXT: vmv.s.x v9, a2
+; CHECK-NEXT: vslideup.vi v8, v9, 2
+; CHECK-NEXT: addi a0, a0, 1
+; CHECK-NEXT: andi a2, a1, 8
+; CHECK-NEXT: beqz a2, .LBB3_4
+; CHECK-NEXT: .LBB3_12: # %cond.load9
+; CHECK-NEXT: lbu a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 4, e8, mf2, tu, ma
+; CHECK-NEXT: vmv.s.x v9, a2
+; CHECK-NEXT: vslideup.vi v8, v9, 3
+; CHECK-NEXT: addi a0, a0, 1
+; CHECK-NEXT: andi a2, a1, 16
+; CHECK-NEXT: beqz a2, .LBB3_5
+; CHECK-NEXT: .LBB3_13: # %cond.load13
+; CHECK-NEXT: lbu a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 5, e8, mf2, tu, ma
+; CHECK-NEXT: vmv.s.x v9, a2
+; CHECK-NEXT: vslideup.vi v8, v9, 4
+; CHECK-NEXT: addi a0, a0, 1
+; CHECK-NEXT: andi a2, a1, 32
+; CHECK-NEXT: beqz a2, .LBB3_6
+; CHECK-NEXT: .LBB3_14: # %cond.load17
+; CHECK-NEXT: lbu a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 6, e8, mf2, tu, ma
+; CHECK-NEXT: vmv.s.x v9, a2
+; CHECK-NEXT: vslideup.vi v8, v9, 5
+; CHECK-NEXT: addi a0, a0, 1
+; CHECK-NEXT: andi a2, a1, 64
+; CHECK-NEXT: beqz a2, .LBB3_7
+; CHECK-NEXT: .LBB3_15: # %cond.load21
+; CHECK-NEXT: lbu a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 7, e8, mf2, tu, ma
+; CHECK-NEXT: vmv.s.x v9, a2
+; CHECK-NEXT: vslideup.vi v8, v9, 6
+; CHECK-NEXT: addi a0, a0, 1
+; CHECK-NEXT: andi a1, a1, -128
+; CHECK-NEXT: beqz a1, .LBB3_8
+; CHECK-NEXT: .LBB3_16: # %cond.load25
+; CHECK-NEXT: lbu a0, 0(a0)
+; CHECK-NEXT: vsetivli zero, 8, e8, mf2, ta, ma
+; CHECK-NEXT: vmv.s.x v9, a0
+; CHECK-NEXT: vslideup.vi v8, v9, 7
+; CHECK-NEXT: ret
+ %res = call <8 x i8> @llvm.masked.expandload.v8i8(ptr %base, <8 x i1> %mask, <8 x i8> %src0)
+ ret <8 x i8>%res
+}
+
+declare <1 x i16> @llvm.masked.expandload.v1i16(ptr, <1 x i1>, <1 x i16>)
+define <1 x i16> @expandload_v1i16(ptr %base, <1 x i16> %src0, <1 x i1> %mask) {
+; CHECK-LABEL: expandload_v1i16:
+; CHECK: # %bb.0:
+; CHECK-NEXT: vsetvli a1, zero, e8, mf8, ta, ma
+; CHECK-NEXT: vfirst.m a1, v0
+; CHECK-NEXT: bnez a1, .LBB4_2
+; CHECK-NEXT: # %bb.1: # %cond.load
+; CHECK-NEXT: vsetivli zero, 1, e16, mf4, ta, ma
+; CHECK-NEXT: vle16.v v8, (a0)
+; CHECK-NEXT: .LBB4_2: # %else
+; CHECK-NEXT: ret
+ %res = call <1 x i16> @llvm.masked.expandload.v1i16(ptr align 2 %base, <1 x i1> %mask, <1 x i16> %src0)
+ ret <1 x i16>%res
+}
+
+declare <2 x i16> @llvm.masked.expandload.v2i16(ptr, <2 x i1>, <2 x i16>)
+define <2 x i16> @expandload_v2i16(ptr %base, <2 x i16> %src0, <2 x i1> %mask) {
+; CHECK-LABEL: expandload_v2i16:
+; CHECK: # %bb.0:
+; CHECK-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; CHECK-NEXT: vmv.x.s a1, v0
+; CHECK-NEXT: andi a2, a1, 1
+; CHECK-NEXT: bnez a2, .LBB5_3
+; CHECK-NEXT: # %bb.1: # %else
+; CHECK-NEXT: andi a1, a1, 2
+; CHECK-NEXT: bnez a1, .LBB5_4
+; CHECK-NEXT: .LBB5_2: # %else2
+; CHECK-NEXT: ret
+; CHECK-NEXT: .LBB5_3: # %cond.load
+; CHECK-NEXT: lh a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 2, e16, m2, tu, ma
+; CHECK-NEXT: vmv.s.x v8, a2
+; CHECK-NEXT: addi a0, a0, 2
+; CHECK-NEXT: andi a1, a1, 2
+; CHECK-NEXT: beqz a1, .LBB5_2
+; CHECK-NEXT: .LBB5_4: # %cond.load1
+; CHECK-NEXT: lh a0, 0(a0)
+; CHECK-NEXT: vsetivli zero, 2, e16, mf4, ta, ma
+; CHECK-NEXT: vmv.s.x v9, a0
+; CHECK-NEXT: vslideup.vi v8, v9, 1
+; CHECK-NEXT: ret
+ %res = call <2 x i16> @llvm.masked.expandload.v2i16(ptr align 2 %base, <2 x i1> %mask, <2 x i16> %src0)
+ ret <2 x i16>%res
+}
+
+declare <4 x i16> @llvm.masked.expandload.v4i16(ptr, <4 x i1>, <4 x i16>)
+define <4 x i16> @expandload_v4i16(ptr %base, <4 x i16> %src0, <4 x i1> %mask) {
+; CHECK-LABEL: expandload_v4i16:
+; CHECK: # %bb.0:
+; CHECK-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; CHECK-NEXT: vmv.x.s a1, v0
+; CHECK-NEXT: andi a2, a1, 1
+; CHECK-NEXT: bnez a2, .LBB6_5
+; CHECK-NEXT: # %bb.1: # %else
+; CHECK-NEXT: andi a2, a1, 2
+; CHECK-NEXT: bnez a2, .LBB6_6
+; CHECK-NEXT: .LBB6_2: # %else2
+; CHECK-NEXT: andi a2, a1, 4
+; CHECK-NEXT: bnez a2, .LBB6_7
+; CHECK-NEXT: .LBB6_3: # %else6
+; CHECK-NEXT: andi a1, a1, 8
+; CHECK-NEXT: bnez a1, .LBB6_8
+; CHECK-NEXT: .LBB6_4: # %else10
+; CHECK-NEXT: ret
+; CHECK-NEXT: .LBB6_5: # %cond.load
+; CHECK-NEXT: lh a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 4, e16, m2, tu, ma
+; CHECK-NEXT: vmv.s.x v8, a2
+; CHECK-NEXT: addi a0, a0, 2
+; CHECK-NEXT: andi a2, a1, 2
+; CHECK-NEXT: beqz a2, .LBB6_2
+; CHECK-NEXT: .LBB6_6: # %cond.load1
+; CHECK-NEXT: lh a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 2, e16, mf2, tu, ma
+; CHECK-NEXT: vmv.s.x v9, a2
+; CHECK-NEXT: vslideup.vi v8, v9, 1
+; CHECK-NEXT: addi a0, a0, 2
+; CHECK-NEXT: andi a2, a1, 4
+; CHECK-NEXT: beqz a2, .LBB6_3
+; CHECK-NEXT: .LBB6_7: # %cond.load5
+; CHECK-NEXT: lh a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 3, e16, mf2, tu, ma
+; CHECK-NEXT: vmv.s.x v9, a2
+; CHECK-NEXT: vslideup.vi v8, v9, 2
+; CHECK-NEXT: addi a0, a0, 2
+; CHECK-NEXT: andi a1, a1, 8
+; CHECK-NEXT: beqz a1, .LBB6_4
+; CHECK-NEXT: .LBB6_8: # %cond.load9
+; CHECK-NEXT: lh a0, 0(a0)
+; CHECK-NEXT: vsetivli zero, 4, e16, mf2, ta, ma
+; CHECK-NEXT: vmv.s.x v9, a0
+; CHECK-NEXT: vslideup.vi v8, v9, 3
+; CHECK-NEXT: ret
+ %res = call <4 x i16> @llvm.masked.expandload.v4i16(ptr align 2 %base, <4 x i1> %mask, <4 x i16> %src0)
+ ret <4 x i16>%res
+}
+
+declare <8 x i16> @llvm.masked.expandload.v8i16(ptr, <8 x i1>, <8 x i16>)
+define <8 x i16> @expandload_v8i16(ptr %base, <8 x i16> %src0, <8 x i1> %mask) {
+; CHECK-LABEL: expandload_v8i16:
+; CHECK: # %bb.0:
+; CHECK-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; CHECK-NEXT: vmv.x.s a1, v0
+; CHECK-NEXT: andi a2, a1, 1
+; CHECK-NEXT: bnez a2, .LBB7_9
+; CHECK-NEXT: # %bb.1: # %else
+; CHECK-NEXT: andi a2, a1, 2
+; CHECK-NEXT: bnez a2, .LBB7_10
+; CHECK-NEXT: .LBB7_2: # %else2
+; CHECK-NEXT: andi a2, a1, 4
+; CHECK-NEXT: bnez a2, .LBB7_11
+; CHECK-NEXT: .LBB7_3: # %else6
+; CHECK-NEXT: andi a2, a1, 8
+; CHECK-NEXT: bnez a2, .LBB7_12
+; CHECK-NEXT: .LBB7_4: # %else10
+; CHECK-NEXT: andi a2, a1, 16
+; CHECK-NEXT: bnez a2, .LBB7_13
+; CHECK-NEXT: .LBB7_5: # %else14
+; CHECK-NEXT: andi a2, a1, 32
+; CHECK-NEXT: bnez a2, .LBB7_14
+; CHECK-NEXT: .LBB7_6: # %else18
+; CHECK-NEXT: andi a2, a1, 64
+; CHECK-NEXT: bnez a2, .LBB7_15
+; CHECK-NEXT: .LBB7_7: # %else22
+; CHECK-NEXT: andi a1, a1, -128
+; CHECK-NEXT: bnez a1, .LBB7_16
+; CHECK-NEXT: .LBB7_8: # %else26
+; CHECK-NEXT: ret
+; CHECK-NEXT: .LBB7_9: # %cond.load
+; CHECK-NEXT: lh a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 8, e16, m2, tu, ma
+; CHECK-NEXT: vmv.s.x v8, a2
+; CHECK-NEXT: addi a0, a0, 2
+; CHECK-NEXT: andi a2, a1, 2
+; CHECK-NEXT: beqz a2, .LBB7_2
+; CHECK-NEXT: .LBB7_10: # %cond.load1
+; CHECK-NEXT: lh a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 2, e16, m1, tu, ma
+; CHECK-NEXT: vmv.s.x v9, a2
+; CHECK-NEXT: vslideup.vi v8, v9, 1
+; CHECK-NEXT: addi a0, a0, 2
+; CHECK-NEXT: andi a2, a1, 4
+; CHECK-NEXT: beqz a2, .LBB7_3
+; CHECK-NEXT: .LBB7_11: # %cond.load5
+; CHECK-NEXT: lh a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 3, e16, m1, tu, ma
+; CHECK-NEXT: vmv.s.x v9, a2
+; CHECK-NEXT: vslideup.vi v8, v9, 2
+; CHECK-NEXT: addi a0, a0, 2
+; CHECK-NEXT: andi a2, a1, 8
+; CHECK-NEXT: beqz a2, .LBB7_4
+; CHECK-NEXT: .LBB7_12: # %cond.load9
+; CHECK-NEXT: lh a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 4, e16, m1, tu, ma
+; CHECK-NEXT: vmv.s.x v9, a2
+; CHECK-NEXT: vslideup.vi v8, v9, 3
+; CHECK-NEXT: addi a0, a0, 2
+; CHECK-NEXT: andi a2, a1, 16
+; CHECK-NEXT: beqz a2, .LBB7_5
+; CHECK-NEXT: .LBB7_13: # %cond.load13
+; CHECK-NEXT: lh a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 5, e16, m1, tu, ma
+; CHECK-NEXT: vmv.s.x v9, a2
+; CHECK-NEXT: vslideup.vi v8, v9, 4
+; CHECK-NEXT: addi a0, a0, 2
+; CHECK-NEXT: andi a2, a1, 32
+; CHECK-NEXT: beqz a2, .LBB7_6
+; CHECK-NEXT: .LBB7_14: # %cond.load17
+; CHECK-NEXT: lh a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 6, e16, m1, tu, ma
+; CHECK-NEXT: vmv.s.x v9, a2
+; CHECK-NEXT: vslideup.vi v8, v9, 5
+; CHECK-NEXT: addi a0, a0, 2
+; CHECK-NEXT: andi a2, a1, 64
+; CHECK-NEXT: beqz a2, .LBB7_7
+; CHECK-NEXT: .LBB7_15: # %cond.load21
+; CHECK-NEXT: lh a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 7, e16, m1, tu, ma
+; CHECK-NEXT: vmv.s.x v9, a2
+; CHECK-NEXT: vslideup.vi v8, v9, 6
+; CHECK-NEXT: addi a0, a0, 2
+; CHECK-NEXT: andi a1, a1, -128
+; CHECK-NEXT: beqz a1, .LBB7_8
+; CHECK-NEXT: .LBB7_16: # %cond.load25
+; CHECK-NEXT: lh a0, 0(a0)
+; CHECK-NEXT: vsetivli zero, 8, e16, m1, ta, ma
+; CHECK-NEXT: vmv.s.x v9, a0
+; CHECK-NEXT: vslideup.vi v8, v9, 7
+; CHECK-NEXT: ret
+ %res = call <8 x i16> @llvm.masked.expandload.v8i16(ptr align 2 %base, <8 x i1> %mask, <8 x i16> %src0)
+ ret <8 x i16>%res
+}
+
+declare <1 x i32> @llvm.masked.expandload.v1i32(ptr, <1 x i1>, <1 x i32>)
+define <1 x i32> @expandload_v1i32(ptr %base, <1 x i32> %src0, <1 x i1> %mask) {
+; CHECK-LABEL: expandload_v1i32:
+; CHECK: # %bb.0:
+; CHECK-NEXT: vsetvli a1, zero, e8, mf8, ta, ma
+; CHECK-NEXT: vfirst.m a1, v0
+; CHECK-NEXT: bnez a1, .LBB8_2
+; CHECK-NEXT: # %bb.1: # %cond.load
+; CHECK-NEXT: vsetivli zero, 1, e32, mf2, ta, ma
+; CHECK-NEXT: vle32.v v8, (a0)
+; CHECK-NEXT: .LBB8_2: # %else
+; CHECK-NEXT: ret
+ %res = call <1 x i32> @llvm.masked.expandload.v1i32(ptr align 4 %base, <1 x i1> %mask, <1 x i32> %src0)
+ ret <1 x i32>%res
+}
+
+declare <2 x i32> @llvm.masked.expandload.v2i32(ptr, <2 x i1>, <2 x i32>)
+define <2 x i32> @expandload_v2i32(ptr %base, <2 x i32> %src0, <2 x i1> %mask) {
+; CHECK-LABEL: expandload_v2i32:
+; CHECK: # %bb.0:
+; CHECK-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; CHECK-NEXT: vmv.x.s a1, v0
+; CHECK-NEXT: andi a2, a1, 1
+; CHECK-NEXT: bnez a2, .LBB9_3
+; CHECK-NEXT: # %bb.1: # %else
+; CHECK-NEXT: andi a1, a1, 2
+; CHECK-NEXT: bnez a1, .LBB9_4
+; CHECK-NEXT: .LBB9_2: # %else2
+; CHECK-NEXT: ret
+; CHECK-NEXT: .LBB9_3: # %cond.load
+; CHECK-NEXT: lw a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 2, e32, m4, tu, ma
+; CHECK-NEXT: vmv.s.x v8, a2
+; CHECK-NEXT: addi a0, a0, 4
+; CHECK-NEXT: andi a1, a1, 2
+; CHECK-NEXT: beqz a1, .LBB9_2
+; CHECK-NEXT: .LBB9_4: # %cond.load1
+; CHECK-NEXT: lw a0, 0(a0)
+; CHECK-NEXT: vsetivli zero, 2, e32, mf2, ta, ma
+; CHECK-NEXT: vmv.s.x v9, a0
+; CHECK-NEXT: vslideup.vi v8, v9, 1
+; CHECK-NEXT: ret
+ %res = call <2 x i32> @llvm.masked.expandload.v2i32(ptr align 4 %base, <2 x i1> %mask, <2 x i32> %src0)
+ ret <2 x i32>%res
+}
+
+declare <4 x i32> @llvm.masked.expandload.v4i32(ptr, <4 x i1>, <4 x i32>)
+define <4 x i32> @expandload_v4i32(ptr %base, <4 x i32> %src0, <4 x i1> %mask) {
+; CHECK-LABEL: expandload_v4i32:
+; CHECK: # %bb.0:
+; CHECK-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; CHECK-NEXT: vmv.x.s a1, v0
+; CHECK-NEXT: andi a2, a1, 1
+; CHECK-NEXT: bnez a2, .LBB10_5
+; CHECK-NEXT: # %bb.1: # %else
+; CHECK-NEXT: andi a2, a1, 2
+; CHECK-NEXT: bnez a2, .LBB10_6
+; CHECK-NEXT: .LBB10_2: # %else2
+; CHECK-NEXT: andi a2, a1, 4
+; CHECK-NEXT: bnez a2, .LBB10_7
+; CHECK-NEXT: .LBB10_3: # %else6
+; CHECK-NEXT: andi a1, a1, 8
+; CHECK-NEXT: bnez a1, .LBB10_8
+; CHECK-NEXT: .LBB10_4: # %else10
+; CHECK-NEXT: ret
+; CHECK-NEXT: .LBB10_5: # %cond.load
+; CHECK-NEXT: lw a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 4, e32, m4, tu, ma
+; CHECK-NEXT: vmv.s.x v8, a2
+; CHECK-NEXT: addi a0, a0, 4
+; CHECK-NEXT: andi a2, a1, 2
+; CHECK-NEXT: beqz a2, .LBB10_2
+; CHECK-NEXT: .LBB10_6: # %cond.load1
+; CHECK-NEXT: lw a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 2, e32, m1, tu, ma
+; CHECK-NEXT: vmv.s.x v9, a2
+; CHECK-NEXT: vslideup.vi v8, v9, 1
+; CHECK-NEXT: addi a0, a0, 4
+; CHECK-NEXT: andi a2, a1, 4
+; CHECK-NEXT: beqz a2, .LBB10_3
+; CHECK-NEXT: .LBB10_7: # %cond.load5
+; CHECK-NEXT: lw a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 3, e32, m1, tu, ma
+; CHECK-NEXT: vmv.s.x v9, a2
+; CHECK-NEXT: vslideup.vi v8, v9, 2
+; CHECK-NEXT: addi a0, a0, 4
+; CHECK-NEXT: andi a1, a1, 8
+; CHECK-NEXT: beqz a1, .LBB10_4
+; CHECK-NEXT: .LBB10_8: # %cond.load9
+; CHECK-NEXT: lw a0, 0(a0)
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, ta, ma
+; CHECK-NEXT: vmv.s.x v9, a0
+; CHECK-NEXT: vslideup.vi v8, v9, 3
+; CHECK-NEXT: ret
+ %res = call <4 x i32> @llvm.masked.expandload.v4i32(ptr align 4 %base, <4 x i1> %mask, <4 x i32> %src0)
+ ret <4 x i32>%res
+}
+
+declare <8 x i32> @llvm.masked.expandload.v8i32(ptr, <8 x i1>, <8 x i32>)
+define <8 x i32> @expandload_v8i32(ptr %base, <8 x i32> %src0, <8 x i1> %mask) {
+; CHECK-LABEL: expandload_v8i32:
+; CHECK: # %bb.0:
+; CHECK-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; CHECK-NEXT: vmv.x.s a1, v0
+; CHECK-NEXT: andi a2, a1, 1
+; CHECK-NEXT: bnez a2, .LBB11_9
+; CHECK-NEXT: # %bb.1: # %else
+; CHECK-NEXT: andi a2, a1, 2
+; CHECK-NEXT: bnez a2, .LBB11_10
+; CHECK-NEXT: .LBB11_2: # %else2
+; CHECK-NEXT: andi a2, a1, 4
+; CHECK-NEXT: bnez a2, .LBB11_11
+; CHECK-NEXT: .LBB11_3: # %else6
+; CHECK-NEXT: andi a2, a1, 8
+; CHECK-NEXT: bnez a2, .LBB11_12
+; CHECK-NEXT: .LBB11_4: # %else10
+; CHECK-NEXT: andi a2, a1, 16
+; CHECK-NEXT: bnez a2, .LBB11_13
+; CHECK-NEXT: .LBB11_5: # %else14
+; CHECK-NEXT: andi a2, a1, 32
+; CHECK-NEXT: bnez a2, .LBB11_14
+; CHECK-NEXT: .LBB11_6: # %else18
+; CHECK-NEXT: andi a2, a1, 64
+; CHECK-NEXT: bnez a2, .LBB11_15
+; CHECK-NEXT: .LBB11_7: # %else22
+; CHECK-NEXT: andi a1, a1, -128
+; CHECK-NEXT: bnez a1, .LBB11_16
+; CHECK-NEXT: .LBB11_8: # %else26
+; CHECK-NEXT: ret
+; CHECK-NEXT: .LBB11_9: # %cond.load
+; CHECK-NEXT: lw a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 8, e32, m4, tu, ma
+; CHECK-NEXT: vmv.s.x v8, a2
+; CHECK-NEXT: addi a0, a0, 4
+; CHECK-NEXT: andi a2, a1, 2
+; CHECK-NEXT: beqz a2, .LBB11_2
+; CHECK-NEXT: .LBB11_10: # %cond.load1
+; CHECK-NEXT: lw a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 2, e32, m1, tu, ma
+; CHECK-NEXT: vmv.s.x v10, a2
+; CHECK-NEXT: vslideup.vi v8, v10, 1
+; CHECK-NEXT: addi a0, a0, 4
+; CHECK-NEXT: andi a2, a1, 4
+; CHECK-NEXT: beqz a2, .LBB11_3
+; CHECK-NEXT: .LBB11_11: # %cond.load5
+; CHECK-NEXT: lw a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 3, e32, m1, tu, ma
+; CHECK-NEXT: vmv.s.x v10, a2
+; CHECK-NEXT: vslideup.vi v8, v10, 2
+; CHECK-NEXT: addi a0, a0, 4
+; CHECK-NEXT: andi a2, a1, 8
+; CHECK-NEXT: beqz a2, .LBB11_4
+; CHECK-NEXT: .LBB11_12: # %cond.load9
+; CHECK-NEXT: lw a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 4, e32, m1, tu, ma
+; CHECK-NEXT: vmv.s.x v10, a2
+; CHECK-NEXT: vslideup.vi v8, v10, 3
+; CHECK-NEXT: addi a0, a0, 4
+; CHECK-NEXT: andi a2, a1, 16
+; CHECK-NEXT: beqz a2, .LBB11_5
+; CHECK-NEXT: .LBB11_13: # %cond.load13
+; CHECK-NEXT: lw a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 5, e32, m2, tu, ma
+; CHECK-NEXT: vmv.s.x v10, a2
+; CHECK-NEXT: vslideup.vi v8, v10, 4
+; CHECK-NEXT: addi a0, a0, 4
+; CHECK-NEXT: andi a2, a1, 32
+; CHECK-NEXT: beqz a2, .LBB11_6
+; CHECK-NEXT: .LBB11_14: # %cond.load17
+; CHECK-NEXT: lw a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 6, e32, m2, tu, ma
+; CHECK-NEXT: vmv.s.x v10, a2
+; CHECK-NEXT: vslideup.vi v8, v10, 5
+; CHECK-NEXT: addi a0, a0, 4
+; CHECK-NEXT: andi a2, a1, 64
+; CHECK-NEXT: beqz a2, .LBB11_7
+; CHECK-NEXT: .LBB11_15: # %cond.load21
+; CHECK-NEXT: lw a2, 0(a0)
+; CHECK-NEXT: vsetivli zero, 7, e32, m2, tu, ma
+; CHECK-NEXT: vmv.s.x v10, a2
+; CHECK-NEXT: vslideup.vi v8, v10, 6
+; CHECK-NEXT: addi a0, a0, 4
+; CHECK-NEXT: andi a1, a1, -128
+; CHECK-NEXT: beqz a1, .LBB11_8
+; CHECK-NEXT: .LBB11_16: # %cond.load25
+; CHECK-NEXT: lw a0, 0(a0)
+; CHECK-NEXT: vsetivli zero, 8, e32, m2, ta, ma
+; CHECK-NEXT: vmv.s.x v10, a0
+; CHECK-NEXT: vslideup.vi v8, v10, 7
+; CHECK-NEXT: ret
+ %res = call <8 x i32> @llvm.masked.expandload.v8i32(ptr align 4 %base, <8 x i1> %mask, <8 x i32> %src0)
+ ret <8 x i32>%res
+}
+
+declare <1 x i64> @llvm.masked.expandload.v1i64(ptr, <1 x i1>, <1 x i64>)
+define <1 x i64> @expandload_v1i64(ptr %base, <1 x i64> %src0, <1 x i1> %mask) {
+; RV32-LABEL: expandload_v1i64:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetvli a1, zero, e8, mf8, ta, ma
+; RV32-NEXT: vfirst.m a1, v0
+; RV32-NEXT: bnez a1, .LBB12_2
+; RV32-NEXT: # %bb.1: # %cond.load
+; RV32-NEXT: addi sp, sp, -16
+; RV32-NEXT: .cfi_def_cfa_offset 16
+; RV32-NEXT: lw a1, 4(a0)
+; RV32-NEXT: lw a0, 0(a0)
+; RV32-NEXT: sw a1, 12(sp)
+; RV32-NEXT: sw a0, 8(sp)
+; RV32-NEXT: addi a0, sp, 8
+; RV32-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV32-NEXT: vlse64.v v8, (a0), zero
+; RV32-NEXT: addi sp, sp, 16
+; RV32-NEXT: .LBB12_2: # %else
+; RV32-NEXT: ret
+;
+; RV64-LABEL: expandload_v1i64:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetvli a1, zero, e8, mf8, ta, ma
+; RV64-NEXT: vfirst.m a1, v0
+; RV64-NEXT: bnez a1, .LBB12_2
+; RV64-NEXT: # %bb.1: # %cond.load
+; RV64-NEXT: vsetivli zero, 1, e64, m1, ta, ma
+; RV64-NEXT: vle64.v v8, (a0)
+; RV64-NEXT: .LBB12_2: # %else
+; RV64-NEXT: ret
+ %res = call <1 x i64> @llvm.masked.expandload.v1i64(ptr align 8 %base, <1 x i1> %mask, <1 x i64> %src0)
+ ret <1 x i64>%res
+}
+
+declare <2 x i64> @llvm.masked.expandload.v2i64(ptr, <2 x i1>, <2 x i64>)
+define <2 x i64> @expandload_v2i64(ptr %base, <2 x i64> %src0, <2 x i1> %mask) {
+; RV32-LABEL: expandload_v2i64:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV32-NEXT: vmv.x.s a1, v0
+; RV32-NEXT: andi a2, a1, 1
+; RV32-NEXT: bnez a2, .LBB13_3
+; RV32-NEXT: # %bb.1: # %else
+; RV32-NEXT: andi a1, a1, 2
+; RV32-NEXT: bnez a1, .LBB13_4
+; RV32-NEXT: .LBB13_2: # %else2
+; RV32-NEXT: ret
+; RV32-NEXT: .LBB13_3: # %cond.load
+; RV32-NEXT: lw a2, 0(a0)
+; RV32-NEXT: lw a3, 4(a0)
+; RV32-NEXT: vsetivli zero, 2, e32, m1, tu, ma
+; RV32-NEXT: vslide1down.vx v8, v8, a2
+; RV32-NEXT: vslide1down.vx v8, v8, a3
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a1, a1, 2
+; RV32-NEXT: beqz a1, .LBB13_2
+; RV32-NEXT: .LBB13_4: # %cond.load1
+; RV32-NEXT: lw a1, 0(a0)
+; RV32-NEXT: lw a0, 4(a0)
+; RV32-NEXT: vsetivli zero, 2, e32, m1, ta, ma
+; RV32-NEXT: vslide1down.vx v9, v8, a1
+; RV32-NEXT: vslide1down.vx v9, v9, a0
+; RV32-NEXT: vsetivli zero, 2, e64, m1, ta, ma
+; RV32-NEXT: vslideup.vi v8, v9, 1
+; RV32-NEXT: ret
+;
+; RV64-LABEL: expandload_v2i64:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV64-NEXT: vmv.x.s a1, v0
+; RV64-NEXT: andi a2, a1, 1
+; RV64-NEXT: bnez a2, .LBB13_3
+; RV64-NEXT: # %bb.1: # %else
+; RV64-NEXT: andi a1, a1, 2
+; RV64-NEXT: bnez a1, .LBB13_4
+; RV64-NEXT: .LBB13_2: # %else2
+; RV64-NEXT: ret
+; RV64-NEXT: .LBB13_3: # %cond.load
+; RV64-NEXT: ld a2, 0(a0)
+; RV64-NEXT: vsetivli zero, 2, e64, m8, tu, ma
+; RV64-NEXT: vmv.s.x v8, a2
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a1, a1, 2
+; RV64-NEXT: beqz a1, .LBB13_2
+; RV64-NEXT: .LBB13_4: # %cond.load1
+; RV64-NEXT: ld a0, 0(a0)
+; RV64-NEXT: vsetivli zero, 2, e64, m1, ta, ma
+; RV64-NEXT: vmv.s.x v9, a0
+; RV64-NEXT: vslideup.vi v8, v9, 1
+; RV64-NEXT: ret
+ %res = call <2 x i64> @llvm.masked.expandload.v2i64(ptr align 8 %base, <2 x i1> %mask, <2 x i64> %src0)
+ ret <2 x i64>%res
+}
+
+declare <4 x i64> @llvm.masked.expandload.v4i64(ptr, <4 x i1>, <4 x i64>)
+define <4 x i64> @expandload_v4i64(ptr %base, <4 x i64> %src0, <4 x i1> %mask) {
+; RV32-LABEL: expandload_v4i64:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV32-NEXT: vmv.x.s a1, v0
+; RV32-NEXT: andi a2, a1, 1
+; RV32-NEXT: bnez a2, .LBB14_5
+; RV32-NEXT: # %bb.1: # %else
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: bnez a2, .LBB14_6
+; RV32-NEXT: .LBB14_2: # %else2
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: bnez a2, .LBB14_7
+; RV32-NEXT: .LBB14_3: # %else6
+; RV32-NEXT: andi a1, a1, 8
+; RV32-NEXT: bnez a1, .LBB14_8
+; RV32-NEXT: .LBB14_4: # %else10
+; RV32-NEXT: ret
+; RV32-NEXT: .LBB14_5: # %cond.load
+; RV32-NEXT: lw a2, 0(a0)
+; RV32-NEXT: lw a3, 4(a0)
+; RV32-NEXT: vsetivli zero, 2, e32, m1, tu, ma
+; RV32-NEXT: vslide1down.vx v8, v8, a2
+; RV32-NEXT: vslide1down.vx v8, v8, a3
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: beqz a2, .LBB14_2
+; RV32-NEXT: .LBB14_6: # %cond.load1
+; RV32-NEXT: lw a2, 0(a0)
+; RV32-NEXT: lw a3, 4(a0)
+; RV32-NEXT: vsetivli zero, 2, e32, m1, ta, ma
+; RV32-NEXT: vslide1down.vx v10, v8, a2
+; RV32-NEXT: vslide1down.vx v10, v10, a3
+; RV32-NEXT: vsetivli zero, 2, e64, m1, tu, ma
+; RV32-NEXT: vslideup.vi v8, v10, 1
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: beqz a2, .LBB14_3
+; RV32-NEXT: .LBB14_7: # %cond.load5
+; RV32-NEXT: lw a2, 0(a0)
+; RV32-NEXT: lw a3, 4(a0)
+; RV32-NEXT: vsetivli zero, 2, e32, m2, ta, ma
+; RV32-NEXT: vslide1down.vx v10, v8, a2
+; RV32-NEXT: vslide1down.vx v10, v10, a3
+; RV32-NEXT: vsetivli zero, 3, e64, m2, tu, ma
+; RV32-NEXT: vslideup.vi v8, v10, 2
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a1, a1, 8
+; RV32-NEXT: beqz a1, .LBB14_4
+; RV32-NEXT: .LBB14_8: # %cond.load9
+; RV32-NEXT: lw a1, 0(a0)
+; RV32-NEXT: lw a0, 4(a0)
+; RV32-NEXT: vsetivli zero, 2, e32, m2, ta, ma
+; RV32-NEXT: vslide1down.vx v10, v8, a1
+; RV32-NEXT: vslide1down.vx v10, v10, a0
+; RV32-NEXT: vsetivli zero, 4, e64, m2, ta, ma
+; RV32-NEXT: vslideup.vi v8, v10, 3
+; RV32-NEXT: ret
+;
+; RV64-LABEL: expandload_v4i64:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV64-NEXT: vmv.x.s a1, v0
+; RV64-NEXT: andi a2, a1, 1
+; RV64-NEXT: bnez a2, .LBB14_5
+; RV64-NEXT: # %bb.1: # %else
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: bnez a2, .LBB14_6
+; RV64-NEXT: .LBB14_2: # %else2
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: bnez a2, .LBB14_7
+; RV64-NEXT: .LBB14_3: # %else6
+; RV64-NEXT: andi a1, a1, 8
+; RV64-NEXT: bnez a1, .LBB14_8
+; RV64-NEXT: .LBB14_4: # %else10
+; RV64-NEXT: ret
+; RV64-NEXT: .LBB14_5: # %cond.load
+; RV64-NEXT: ld a2, 0(a0)
+; RV64-NEXT: vsetivli zero, 4, e64, m8, tu, ma
+; RV64-NEXT: vmv.s.x v8, a2
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: beqz a2, .LBB14_2
+; RV64-NEXT: .LBB14_6: # %cond.load1
+; RV64-NEXT: ld a2, 0(a0)
+; RV64-NEXT: vsetivli zero, 2, e64, m1, tu, ma
+; RV64-NEXT: vmv.s.x v10, a2
+; RV64-NEXT: vslideup.vi v8, v10, 1
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: beqz a2, .LBB14_3
+; RV64-NEXT: .LBB14_7: # %cond.load5
+; RV64-NEXT: ld a2, 0(a0)
+; RV64-NEXT: vsetivli zero, 3, e64, m2, tu, ma
+; RV64-NEXT: vmv.s.x v10, a2
+; RV64-NEXT: vslideup.vi v8, v10, 2
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a1, a1, 8
+; RV64-NEXT: beqz a1, .LBB14_4
+; RV64-NEXT: .LBB14_8: # %cond.load9
+; RV64-NEXT: ld a0, 0(a0)
+; RV64-NEXT: vsetivli zero, 4, e64, m2, ta, ma
+; RV64-NEXT: vmv.s.x v10, a0
+; RV64-NEXT: vslideup.vi v8, v10, 3
+; RV64-NEXT: ret
+ %res = call <4 x i64> @llvm.masked.expandload.v4i64(ptr align 8 %base, <4 x i1> %mask, <4 x i64> %src0)
+ ret <4 x i64>%res
+}
+
+declare <8 x i64> @llvm.masked.expandload.v8i64(ptr, <8 x i1>, <8 x i64>)
+define <8 x i64> @expandload_v8i64(ptr %base, <8 x i64> %src0, <8 x i1> %mask) {
+; RV32-LABEL: expandload_v8i64:
+; RV32: # %bb.0:
+; RV32-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV32-NEXT: vmv.x.s a1, v0
+; RV32-NEXT: andi a2, a1, 1
+; RV32-NEXT: bnez a2, .LBB15_9
+; RV32-NEXT: # %bb.1: # %else
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: bnez a2, .LBB15_10
+; RV32-NEXT: .LBB15_2: # %else2
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: bnez a2, .LBB15_11
+; RV32-NEXT: .LBB15_3: # %else6
+; RV32-NEXT: andi a2, a1, 8
+; RV32-NEXT: bnez a2, .LBB15_12
+; RV32-NEXT: .LBB15_4: # %else10
+; RV32-NEXT: andi a2, a1, 16
+; RV32-NEXT: bnez a2, .LBB15_13
+; RV32-NEXT: .LBB15_5: # %else14
+; RV32-NEXT: andi a2, a1, 32
+; RV32-NEXT: bnez a2, .LBB15_14
+; RV32-NEXT: .LBB15_6: # %else18
+; RV32-NEXT: andi a2, a1, 64
+; RV32-NEXT: bnez a2, .LBB15_15
+; RV32-NEXT: .LBB15_7: # %else22
+; RV32-NEXT: andi a1, a1, -128
+; RV32-NEXT: bnez a1, .LBB15_16
+; RV32-NEXT: .LBB15_8: # %else26
+; RV32-NEXT: ret
+; RV32-NEXT: .LBB15_9: # %cond.load
+; RV32-NEXT: lw a2, 0(a0)
+; RV32-NEXT: lw a3, 4(a0)
+; RV32-NEXT: vsetivli zero, 2, e32, m1, tu, ma
+; RV32-NEXT: vslide1down.vx v8, v8, a2
+; RV32-NEXT: vslide1down.vx v8, v8, a3
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a2, a1, 2
+; RV32-NEXT: beqz a2, .LBB15_2
+; RV32-NEXT: .LBB15_10: # %cond.load1
+; RV32-NEXT: lw a2, 0(a0)
+; RV32-NEXT: lw a3, 4(a0)
+; RV32-NEXT: vsetivli zero, 2, e32, m1, ta, ma
+; RV32-NEXT: vslide1down.vx v12, v8, a2
+; RV32-NEXT: vslide1down.vx v12, v12, a3
+; RV32-NEXT: vsetivli zero, 2, e64, m1, tu, ma
+; RV32-NEXT: vslideup.vi v8, v12, 1
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a2, a1, 4
+; RV32-NEXT: beqz a2, .LBB15_3
+; RV32-NEXT: .LBB15_11: # %cond.load5
+; RV32-NEXT: lw a2, 0(a0)
+; RV32-NEXT: lw a3, 4(a0)
+; RV32-NEXT: vsetivli zero, 2, e32, m2, ta, ma
+; RV32-NEXT: vslide1down.vx v12, v8, a2
+; RV32-NEXT: vslide1down.vx v12, v12, a3
+; RV32-NEXT: vsetivli zero, 3, e64, m2, tu, ma
+; RV32-NEXT: vslideup.vi v8, v12, 2
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a2, a1, 8
+; RV32-NEXT: beqz a2, .LBB15_4
+; RV32-NEXT: .LBB15_12: # %cond.load9
+; RV32-NEXT: lw a2, 0(a0)
+; RV32-NEXT: lw a3, 4(a0)
+; RV32-NEXT: vsetivli zero, 2, e32, m2, ta, ma
+; RV32-NEXT: vslide1down.vx v12, v8, a2
+; RV32-NEXT: vslide1down.vx v12, v12, a3
+; RV32-NEXT: vsetivli zero, 4, e64, m2, tu, ma
+; RV32-NEXT: vslideup.vi v8, v12, 3
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a2, a1, 16
+; RV32-NEXT: beqz a2, .LBB15_5
+; RV32-NEXT: .LBB15_13: # %cond.load13
+; RV32-NEXT: lw a2, 0(a0)
+; RV32-NEXT: lw a3, 4(a0)
+; RV32-NEXT: vsetivli zero, 2, e32, m4, ta, ma
+; RV32-NEXT: vslide1down.vx v12, v8, a2
+; RV32-NEXT: vslide1down.vx v12, v12, a3
+; RV32-NEXT: vsetivli zero, 5, e64, m4, tu, ma
+; RV32-NEXT: vslideup.vi v8, v12, 4
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a2, a1, 32
+; RV32-NEXT: beqz a2, .LBB15_6
+; RV32-NEXT: .LBB15_14: # %cond.load17
+; RV32-NEXT: lw a2, 0(a0)
+; RV32-NEXT: lw a3, 4(a0)
+; RV32-NEXT: vsetivli zero, 2, e32, m4, ta, ma
+; RV32-NEXT: vslide1down.vx v12, v8, a2
+; RV32-NEXT: vslide1down.vx v12, v12, a3
+; RV32-NEXT: vsetivli zero, 6, e64, m4, tu, ma
+; RV32-NEXT: vslideup.vi v8, v12, 5
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a2, a1, 64
+; RV32-NEXT: beqz a2, .LBB15_7
+; RV32-NEXT: .LBB15_15: # %cond.load21
+; RV32-NEXT: lw a2, 0(a0)
+; RV32-NEXT: lw a3, 4(a0)
+; RV32-NEXT: vsetivli zero, 2, e32, m4, ta, ma
+; RV32-NEXT: vslide1down.vx v12, v8, a2
+; RV32-NEXT: vslide1down.vx v12, v12, a3
+; RV32-NEXT: vsetivli zero, 7, e64, m4, tu, ma
+; RV32-NEXT: vslideup.vi v8, v12, 6
+; RV32-NEXT: addi a0, a0, 8
+; RV32-NEXT: andi a1, a1, -128
+; RV32-NEXT: beqz a1, .LBB15_8
+; RV32-NEXT: .LBB15_16: # %cond.load25
+; RV32-NEXT: lw a1, 0(a0)
+; RV32-NEXT: lw a0, 4(a0)
+; RV32-NEXT: vsetivli zero, 2, e32, m4, ta, ma
+; RV32-NEXT: vslide1down.vx v12, v8, a1
+; RV32-NEXT: vslide1down.vx v12, v12, a0
+; RV32-NEXT: vsetivli zero, 8, e64, m4, ta, ma
+; RV32-NEXT: vslideup.vi v8, v12, 7
+; RV32-NEXT: ret
+;
+; RV64-LABEL: expandload_v8i64:
+; RV64: # %bb.0:
+; RV64-NEXT: vsetivli zero, 1, e8, m1, ta, ma
+; RV64-NEXT: vmv.x.s a1, v0
+; RV64-NEXT: andi a2, a1, 1
+; RV64-NEXT: bnez a2, .LBB15_9
+; RV64-NEXT: # %bb.1: # %else
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: bnez a2, .LBB15_10
+; RV64-NEXT: .LBB15_2: # %else2
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: bnez a2, .LBB15_11
+; RV64-NEXT: .LBB15_3: # %else6
+; RV64-NEXT: andi a2, a1, 8
+; RV64-NEXT: bnez a2, .LBB15_12
+; RV64-NEXT: .LBB15_4: # %else10
+; RV64-NEXT: andi a2, a1, 16
+; RV64-NEXT: bnez a2, .LBB15_13
+; RV64-NEXT: .LBB15_5: # %else14
+; RV64-NEXT: andi a2, a1, 32
+; RV64-NEXT: bnez a2, .LBB15_14
+; RV64-NEXT: .LBB15_6: # %else18
+; RV64-NEXT: andi a2, a1, 64
+; RV64-NEXT: bnez a2, .LBB15_15
+; RV64-NEXT: .LBB15_7: # %else22
+; RV64-NEXT: andi a1, a1, -128
+; RV64-NEXT: bnez a1, .LBB15_16
+; RV64-NEXT: .LBB15_8: # %else26
+; RV64-NEXT: ret
+; RV64-NEXT: .LBB15_9: # %cond.load
+; RV64-NEXT: ld a2, 0(a0)
+; RV64-NEXT: vsetivli zero, 8, e64, m8, tu, ma
+; RV64-NEXT: vmv.s.x v8, a2
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a2, a1, 2
+; RV64-NEXT: beqz a2, .LBB15_2
+; RV64-NEXT: .LBB15_10: # %cond.load1
+; RV64-NEXT: ld a2, 0(a0)
+; RV64-NEXT: vsetivli zero, 2, e64, m1, tu, ma
+; RV64-NEXT: vmv.s.x v12, a2
+; RV64-NEXT: vslideup.vi v8, v12, 1
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a2, a1, 4
+; RV64-NEXT: beqz a2, .LBB15_3
+; RV64-NEXT: .LBB15_11: # %cond.load5
+; RV64-NEXT: ld a2, 0(a0)
+; RV64-NEXT: vsetivli zero, 3, e64, m2, tu, ma
+; RV64-NEXT: vmv.s.x v12, a2
+; RV64-NEXT: vslideup.vi v8, v12, 2
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a2, a1, 8
+; RV64-NEXT: beqz a2, .LBB15_4
+; RV64-NEXT: .LBB15_12: # %cond.load9
+; RV64-NEXT: ld a2, 0(a0)
+; RV64-NEXT: vsetivli zero, 4, e64, m2, tu, ma
+; RV64-NEXT: vmv.s.x v12, a2
+; RV64-NEXT: vslideup.vi v8, v12, 3
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a2, a1, 16
+; RV64-NEXT: beqz a2, .LBB15_5
+; RV64-NEXT: .LBB15_13: # %cond.load13
+; RV64-NEXT: ld a2, 0(a0)
+; RV64-NEXT: vsetivli zero, 5, e64, m4, tu, ma
+; RV64-NEXT: vmv.s.x v12, a2
+; RV64-NEXT: vslideup.vi v8, v12, 4
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a2, a1, 32
+; RV64-NEXT: beqz a2, .LBB15_6
+; RV64-NEXT: .LBB15_14: # %cond.load17
+; RV64-NEXT: ld a2, 0(a0)
+; RV64-NEXT: vsetivli zero, 6, e64, m4, tu, ma
+; RV64-NEXT: vmv.s.x v12, a2
+; RV64-NEXT: vslideup.vi v8, v12, 5
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a2, a1, 64
+; RV64-NEXT: beqz a2, .LBB15_7
+; RV64-NEXT: .LBB15_15: # %cond.load21
+; RV64-NEXT: ld a2, 0(a0)
+; RV64-NEXT: vsetivli zero, 7, e64, m4, tu, ma
+; RV64-NEXT: vmv.s.x v12, a2
+; RV64-NEXT: vslideup.vi v8, v12, 6
+; RV64-NEXT: addi a0, a0, 8
+; RV64-NEXT: andi a1, a1, -128
+; RV64-NEXT: beqz a1, .LBB15_8
+; RV64-NEXT: .LBB15_16: # %cond.load25
+; RV64-NEXT: ld a0, 0(a0)
+; RV64-NEXT: vsetivli zero, 8, e64, m4, ta, ma
+; RV64-NEXT: vmv.s.x v12, a0
+; RV64-NEXT: vslideup.vi v8, v12, 7
+; RV64-NEXT: ret
+ %res = call <8 x i64> @llvm.masked.expandload.v8i64(ptr align 8 %base, <8 x i1> %mask, <8 x i64> %src0)
+ ret <8 x i64>%res
+}
>From 9606655fbb03b1cf1c69d624c7320630e85f33e6 Mon Sep 17 00:00:00 2001
From: Matthias Springer <me at m-sp.org>
Date: Mon, 4 Mar 2024 11:09:39 +0900
Subject: [PATCH 405/406] [mlir][Transforms] Fix use-after-free when accessing
replaced block args (#83646)
This commit fixes a bug in a dialect conversion. Currently, when a block
is replaced via a signature conversion, the block is erased during the
"commit" phase. This is problematic because the block arguments may
still be referenced internal data structures of the dialect conversion
(`mapping`). Blocks should be treated same as ops: they should be erased
during the "cleanup" phase.
Note: The test case fails without this fix when running with ASAN, but
may pass when running without ASAN.
---
.../Transforms/Utils/DialectConversion.cpp | 30 ++++++++++++-------
mlir/test/Transforms/test-legalizer.mlir | 12 ++++++++
mlir/test/lib/Dialect/Test/TestOps.td | 4 +--
3 files changed, 34 insertions(+), 12 deletions(-)
diff --git a/mlir/lib/Transforms/Utils/DialectConversion.cpp b/mlir/lib/Transforms/Utils/DialectConversion.cpp
index ffdb442033d323..b4284ce8be8a1b 100644
--- a/mlir/lib/Transforms/Utils/DialectConversion.cpp
+++ b/mlir/lib/Transforms/Utils/DialectConversion.cpp
@@ -207,13 +207,13 @@ class IRRewrite {
/// Roll back the rewrite. Operations may be erased during rollback.
virtual void rollback() = 0;
- /// Commit the rewrite. Operations may be unlinked from their blocks during
- /// the commit phase, but they must not be erased yet. This is because
- /// internal dialect conversion state (such as `mapping`) may still be using
- /// them. Operations must be erased during cleanup.
+ /// Commit the rewrite. Operations/blocks may be unlinked during the commit
+ /// phase, but they must not be erased yet. This is because internal dialect
+ /// conversion state (such as `mapping`) may still be using them. Operations/
+ /// blocks must be erased during cleanup.
virtual void commit() {}
- /// Cleanup operations. Cleanup is called after commit.
+ /// Cleanup operations/blocks. Cleanup is called after commit.
virtual void cleanup() {}
Kind getKind() const { return kind; }
@@ -280,9 +280,9 @@ class CreateBlockRewrite : public BlockRewrite {
};
/// Erasure of a block. Block erasures are partially reflected in the IR. Erased
-/// blocks are immediately unlinked, but only erased when the rewrite is
-/// committed. This makes it easier to rollback a block erasure: the block is
-/// simply inserted into its original location.
+/// blocks are immediately unlinked, but only erased during cleanup. This makes
+/// it easier to rollback a block erasure: the block is simply inserted into its
+/// original location.
class EraseBlockRewrite : public BlockRewrite {
public:
EraseBlockRewrite(ConversionPatternRewriterImpl &rewriterImpl, Block *block,
@@ -295,7 +295,8 @@ class EraseBlockRewrite : public BlockRewrite {
}
~EraseBlockRewrite() override {
- assert(!block && "rewrite was neither rolled back nor committed");
+ assert(!block &&
+ "rewrite was neither rolled back nor committed/cleaned up");
}
void rollback() override {
@@ -310,7 +311,7 @@ class EraseBlockRewrite : public BlockRewrite {
block = nullptr;
}
- void commit() override {
+ void cleanup() override {
// Erase the block.
assert(block && "expected block");
assert(block->empty() && "expected empty block");
@@ -438,6 +439,8 @@ class BlockTypeConversionRewrite : public BlockRewrite {
void commit() override;
+ void cleanup() override;
+
void rollback() override;
private:
@@ -985,7 +988,9 @@ void BlockTypeConversionRewrite::commit() {
rewriterImpl.mapping.lookupOrDefault(castValue, origArg.getType()));
}
}
+}
+void BlockTypeConversionRewrite::cleanup() {
assert(origBlock->empty() && "expected empty block");
origBlock->dropAllDefinedValueUses();
delete origBlock;
@@ -1483,6 +1488,11 @@ void ConversionPatternRewriterImpl::notifyBlockInserted(
Block *block, Region *previous, Region::iterator previousIt) {
assert(!wasOpReplaced(block->getParentOp()) &&
"attempting to insert into a region within a replaced/erased op");
+ LLVM_DEBUG({
+ logger.startLine() << "** Insert Block into : '"
+ << block->getParentOp()->getName() << "'("
+ << block->getParentOp() << ")\n";
+ });
if (!previous) {
// This is a newly created block.
diff --git a/mlir/test/Transforms/test-legalizer.mlir b/mlir/test/Transforms/test-legalizer.mlir
index 62d776cd7573ee..ccdc9fe78ea0d3 100644
--- a/mlir/test/Transforms/test-legalizer.mlir
+++ b/mlir/test/Transforms/test-legalizer.mlir
@@ -346,3 +346,15 @@ func.func @test_properties_rollback() {
{modify_inplace}
"test.return"() : () -> ()
}
+
+// -----
+
+// CHECK: func.func @use_of_replaced_bbarg(
+// CHECK-SAME: %[[arg0:.*]]: f64)
+// CHECK: "test.valid"(%[[arg0]])
+func.func @use_of_replaced_bbarg(%arg0: i64) {
+ %0 = "test.op_with_region_fold"(%arg0) ({
+ "foo.op_with_region_terminator"() : () -> ()
+ }) : (i64) -> (i64)
+ "test.invalid"(%0) : (i64) -> ()
+}
diff --git a/mlir/test/lib/Dialect/Test/TestOps.td b/mlir/test/lib/Dialect/Test/TestOps.td
index 91ce0af9cd7fd5..dfd2f21a5ea249 100644
--- a/mlir/test/lib/Dialect/Test/TestOps.td
+++ b/mlir/test/lib/Dialect/Test/TestOps.td
@@ -1270,8 +1270,8 @@ def TestOpWithRegionFoldNoMemoryEffect : TEST_Op<
// Op for testing folding of outer op with inner ops.
def TestOpWithRegionFold : TEST_Op<"op_with_region_fold"> {
- let arguments = (ins I32:$operand);
- let results = (outs I32);
+ let arguments = (ins AnyType:$operand);
+ let results = (outs AnyType);
let regions = (region SizedRegion<1>:$region);
let hasFolder = 1;
}
>From 2c59864b78c17249373032cc10b960c3ad5a16da Mon Sep 17 00:00:00 2001
From: Matthias Springer <springerm at google.com>
Date: Mon, 4 Mar 2024 08:51:09 +0000
Subject: [PATCH 406/406] [mlir][Transforms][NFC] Simplify
`BlockTypeConversionRewrite`
---
.../Transforms/Utils/DialectConversion.cpp | 84 +++++++++----------
1 file changed, 40 insertions(+), 44 deletions(-)
diff --git a/mlir/lib/Transforms/Utils/DialectConversion.cpp b/mlir/lib/Transforms/Utils/DialectConversion.cpp
index b4284ce8be8a1b..f5cddc4ecd0277 100644
--- a/mlir/lib/Transforms/Utils/DialectConversion.cpp
+++ b/mlir/lib/Transforms/Utils/DialectConversion.cpp
@@ -439,8 +439,6 @@ class BlockTypeConversionRewrite : public BlockRewrite {
void commit() override;
- void cleanup() override;
-
void rollback() override;
private:
@@ -788,24 +786,27 @@ struct ConversionPatternRewriterImpl : public RewriterBase::Listener {
/// block is returned containing the new arguments. Returns `block` if it did
/// not require conversion.
FailureOr<Block *> convertBlockSignature(
- Block *block, const TypeConverter *converter,
+ ConversionPatternRewriter &rewriter, Block *block,
+ const TypeConverter *converter,
TypeConverter::SignatureConversion *conversion = nullptr);
/// Convert the types of non-entry block arguments within the given region.
LogicalResult convertNonEntryRegionTypes(
- Region *region, const TypeConverter &converter,
+ ConversionPatternRewriter &rewriter, Region *region,
+ const TypeConverter &converter,
ArrayRef<TypeConverter::SignatureConversion> blockConversions = {});
/// Apply a signature conversion on the given region, using `converter` for
/// materializations if not null.
Block *
- applySignatureConversion(Region *region,
+ applySignatureConversion(ConversionPatternRewriter &rewriter, Region *region,
TypeConverter::SignatureConversion &conversion,
const TypeConverter *converter);
/// Convert the types of block arguments within the given region.
FailureOr<Block *>
- convertRegionTypes(Region *region, const TypeConverter &converter,
+ convertRegionTypes(ConversionPatternRewriter &rewriter, Region *region,
+ const TypeConverter &converter,
TypeConverter::SignatureConversion *entryConversion);
/// Apply the given signature conversion on the given block. The new block
@@ -815,7 +816,8 @@ struct ConversionPatternRewriterImpl : public RewriterBase::Listener {
/// translate between the origin argument types and those specified in the
/// signature conversion.
Block *applySignatureConversion(
- Block *block, const TypeConverter *converter,
+ ConversionPatternRewriter &rewriter, Block *block,
+ const TypeConverter *converter,
TypeConverter::SignatureConversion &signatureConversion);
//===--------------------------------------------------------------------===//
@@ -990,24 +992,8 @@ void BlockTypeConversionRewrite::commit() {
}
}
-void BlockTypeConversionRewrite::cleanup() {
- assert(origBlock->empty() && "expected empty block");
- origBlock->dropAllDefinedValueUses();
- delete origBlock;
- origBlock = nullptr;
-}
-
void BlockTypeConversionRewrite::rollback() {
- // Drop all uses of the new block arguments and replace uses of the new block.
- for (int i = block->getNumArguments() - 1; i >= 0; --i)
- block->getArgument(i).dropAllUses();
block->replaceAllUsesWith(origBlock);
-
- // Move the operations back the original block, move the original block back
- // into its original location and the delete the new block.
- origBlock->getOperations().splice(origBlock->end(), block->getOperations());
- block->getParent()->getBlocks().insert(Region::iterator(block), origBlock);
- eraseBlock(block);
}
LogicalResult BlockTypeConversionRewrite::materializeLiveConversions(
@@ -1223,10 +1209,11 @@ bool ConversionPatternRewriterImpl::wasOpReplaced(Operation *op) const {
// Type Conversion
FailureOr<Block *> ConversionPatternRewriterImpl::convertBlockSignature(
- Block *block, const TypeConverter *converter,
+ ConversionPatternRewriter &rewriter, Block *block,
+ const TypeConverter *converter,
TypeConverter::SignatureConversion *conversion) {
if (conversion)
- return applySignatureConversion(block, converter, *conversion);
+ return applySignatureConversion(rewriter, block, converter, *conversion);
// If a converter wasn't provided, and the block wasn't already converted,
// there is nothing we can do.
@@ -1235,35 +1222,39 @@ FailureOr<Block *> ConversionPatternRewriterImpl::convertBlockSignature(
// Try to convert the signature for the block with the provided converter.
if (auto conversion = converter->convertBlockSignature(block))
- return applySignatureConversion(block, converter, *conversion);
+ return applySignatureConversion(rewriter, block, converter, *conversion);
return failure();
}
Block *ConversionPatternRewriterImpl::applySignatureConversion(
- Region *region, TypeConverter::SignatureConversion &conversion,
+ ConversionPatternRewriter &rewriter, Region *region,
+ TypeConverter::SignatureConversion &conversion,
const TypeConverter *converter) {
if (!region->empty())
- return *convertBlockSignature(®ion->front(), converter, &conversion);
+ return *convertBlockSignature(rewriter, ®ion->front(), converter,
+ &conversion);
return nullptr;
}
FailureOr<Block *> ConversionPatternRewriterImpl::convertRegionTypes(
- Region *region, const TypeConverter &converter,
+ ConversionPatternRewriter &rewriter, Region *region,
+ const TypeConverter &converter,
TypeConverter::SignatureConversion *entryConversion) {
regionToConverter[region] = &converter;
if (region->empty())
return nullptr;
- if (failed(convertNonEntryRegionTypes(region, converter)))
+ if (failed(convertNonEntryRegionTypes(rewriter, region, converter)))
return failure();
- FailureOr<Block *> newEntry =
- convertBlockSignature(®ion->front(), &converter, entryConversion);
+ FailureOr<Block *> newEntry = convertBlockSignature(
+ rewriter, ®ion->front(), &converter, entryConversion);
return newEntry;
}
LogicalResult ConversionPatternRewriterImpl::convertNonEntryRegionTypes(
- Region *region, const TypeConverter &converter,
+ ConversionPatternRewriter &rewriter, Region *region,
+ const TypeConverter &converter,
ArrayRef<TypeConverter::SignatureConversion> blockConversions) {
regionToConverter[region] = &converter;
if (region->empty())
@@ -1284,16 +1275,18 @@ LogicalResult ConversionPatternRewriterImpl::convertNonEntryRegionTypes(
: const_cast<TypeConverter::SignatureConversion *>(
&blockConversions[blockIdx++]);
- if (failed(convertBlockSignature(&block, &converter, blockConversion)))
+ if (failed(convertBlockSignature(rewriter, &block, &converter,
+ blockConversion)))
return failure();
}
return success();
}
Block *ConversionPatternRewriterImpl::applySignatureConversion(
- Block *block, const TypeConverter *converter,
+ ConversionPatternRewriter &rewriter, Block *block,
+ const TypeConverter *converter,
TypeConverter::SignatureConversion &signatureConversion) {
- MLIRContext *ctx = eraseRewriter.getContext();
+ MLIRContext *ctx = rewriter.getContext();
// If no arguments are being changed or added, there is nothing to do.
unsigned origArgCount = block->getNumArguments();
@@ -1303,11 +1296,8 @@ Block *ConversionPatternRewriterImpl::applySignatureConversion(
// Split the block at the beginning to get a new block to use for the updated
// signature.
- Block *newBlock = block->splitBlock(block->begin());
+ Block *newBlock = rewriter.splitBlock(block, block->begin());
block->replaceAllUsesWith(newBlock);
- // Unlink the block, but do not erase it yet, so that the change can be rolled
- // back.
- block->getParent()->getBlocks().remove(block);
// Map all new arguments to the location of the argument they originate from.
SmallVector<Location> newLocs(convertedTypes.size(),
@@ -1383,6 +1373,11 @@ Block *ConversionPatternRewriterImpl::applySignatureConversion(
appendRewrite<BlockTypeConversionRewrite>(newBlock, block, argInfo,
converter);
+
+ // Erase the old block. (It is just unlinked for now and will be erased during
+ // cleanup.)
+ rewriter.eraseBlock(block);
+
return newBlock;
}
@@ -1590,7 +1585,7 @@ Block *ConversionPatternRewriter::applySignatureConversion(
assert(!impl->wasOpReplaced(region->getParentOp()) &&
"attempting to apply a signature conversion to a block within a "
"replaced/erased op");
- return impl->applySignatureConversion(region, conversion, converter);
+ return impl->applySignatureConversion(*this, region, conversion, converter);
}
FailureOr<Block *> ConversionPatternRewriter::convertRegionTypes(
@@ -1599,7 +1594,7 @@ FailureOr<Block *> ConversionPatternRewriter::convertRegionTypes(
assert(!impl->wasOpReplaced(region->getParentOp()) &&
"attempting to apply a signature conversion to a block within a "
"replaced/erased op");
- return impl->convertRegionTypes(region, converter, entryConversion);
+ return impl->convertRegionTypes(*this, region, converter, entryConversion);
}
LogicalResult ConversionPatternRewriter::convertNonEntryRegionTypes(
@@ -1608,7 +1603,8 @@ LogicalResult ConversionPatternRewriter::convertNonEntryRegionTypes(
assert(!impl->wasOpReplaced(region->getParentOp()) &&
"attempting to apply a signature conversion to a block within a "
"replaced/erased op");
- return impl->convertNonEntryRegionTypes(region, converter, blockConversions);
+ return impl->convertNonEntryRegionTypes(*this, region, converter,
+ blockConversions);
}
void ConversionPatternRewriter::replaceUsesOfBlockArgument(BlockArgument from,
@@ -2102,7 +2098,7 @@ LogicalResult OperationLegalizer::legalizePatternBlockRewrites(
// If the region of the block has a type converter, try to convert the block
// directly.
if (auto *converter = impl.regionToConverter.lookup(block->getParent())) {
- if (failed(impl.convertBlockSignature(block, converter))) {
+ if (failed(impl.convertBlockSignature(rewriter, block, converter))) {
LLVM_DEBUG(logFailure(impl.logger, "failed to convert types of moved "
"block"));
return failure();
More information about the llvm-branch-commits
mailing list