[all-commits] [llvm/llvm-project] e1ddc3: [libc++] Move __libcpp_timespec_t into namespace s...
Alexey Bataev via All-commits
all-commits at lists.llvm.org
Wed Jan 31 10:08:31 PST 2024
Branch: refs/heads/users/alexey-bataev/spr/ttiriscvimprove-costs-for-fixed-vector-whole-reg-extractinsert
Home: https://github.com/llvm/llvm-project
Commit: e1ddc3331210957cec2569cef79021fa69363ab1
https://github.com/llvm/llvm-project/commit/e1ddc3331210957cec2569cef79021fa69363ab1
Author: Louis Dionne <ldionne.2 at gmail.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M libcxx/include/__thread/support.h
M libcxx/include/__thread/support/c11.h
M libcxx/include/__thread/support/pthread.h
M libcxx/include/__thread/support/windows.h
Log Message:
-----------
[libc++] Move __libcpp_timespec_t into namespace std (#80004)
It was previously defined outside of namespace std for apparently no
good reason.
Commit: 97d72839301e6fd005fb258322b96bd46086daa1
https://github.com/llvm/llvm-project/commit/97d72839301e6fd005fb258322b96bd46086daa1
Author: Cyndy Ishida <cyndy_ishida at apple.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M llvm/include/llvm/TextAPI/Symbol.h
Log Message:
-----------
[TextAPI] Fix -Wdocumentation error, NFC
Commit: f2a78e68eee53646327f71c475c7f18a28b7f576
https://github.com/llvm/llvm-project/commit/f2a78e68eee53646327f71c475c7f18a28b7f576
Author: Joseph Huber <huberjn at outlook.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M clang/docs/HIPSupport.rst
M clang/lib/Basic/Targets/AMDGPU.cpp
M clang/test/CodeGenOpenCL/builtins-amdgcn-wave64.cl
M clang/test/Preprocessor/predefined-arch-macros.c
Log Message:
-----------
[AMDGPU] Do not emit arch dependent macros with unspecified cpu (#80035)
Summary:
Currently, the AMDGPU toolchain accepts not passing `-mcpu` as a means
to create a sort of "generic" IR. The resulting IR will not contain any
target dependent attributes and can then be inserted into another
program via `-mlink-builtin-bitcode` to inherit its attributes.
However, there are a handful of macros that can leak incorrect
information when compiling for an unspecified architecture. Currently,
things like the wavefront size will default to 64, which is actually
variable. We should not expose these macros unless it is known.
Commit: 5470ea4e36d47ed09595517854f0fa07ca91e16f
https://github.com/llvm/llvm-project/commit/5470ea4e36d47ed09595517854f0fa07ca91e16f
Author: Joseph Huber <huberjn at outlook.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M libc/src/__support/GPU/amdgpu/utils.h
M libc/src/__support/GPU/generic/utils.h
M libc/src/__support/GPU/nvptx/utils.h
M libc/src/__support/RPC/rpc.h
M libc/utils/gpu/server/rpc_server.h
Log Message:
-----------
[libc] Change the starting port index to use the SMID (#79200)
Summary:
The RPC interface uses several ports to provide parallel access. Right
now we begin the search at the beginning, which heavily contests the
early ports. Using the SMID allows us to stagger the starting index
based off of the cluster identifier that is executing the current warp.
Multiple warps can share an SM, but it will guaruntee that the
contention for the low indices is lower.
This also increases the maximum port size to around 4096, this is
because 512 isn't enough to cover the full hardare parallelism needed to
guarantee this doesdn't deadlock.
Commit: 626fe71fa5ed79cbd41b7b29582560d7adb1220e
https://github.com/llvm/llvm-project/commit/626fe71fa5ed79cbd41b7b29582560d7adb1220e
Author: Joseph Huber <huberjn at outlook.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M clang/test/Preprocessor/predefined-arch-macros.c
Log Message:
-----------
[Clang] Fix test failing on systems without ROCm installed
Summary:
Forgot to specify `-nogpulib` which makes this test look for ROCm.
Commit: 85a847fd1d639a0e7d5319b17e994ea157be6046
https://github.com/llvm/llvm-project/commit/85a847fd1d639a0e7d5319b17e994ea157be6046
Author: Konstantin Varlamov <varconsteq at gmail.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M libcxx/test/libcxx/atomics/atomics.align/align.pass.cpp
M libcxx/test/libcxx/atomics/atomics.types.generic/atomics.types.float/lockfree.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/assign.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/compare_exchange_strong.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/compare_exchange_weak.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/ctor.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/exchange.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/fetch_add.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/fetch_sub.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/load.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/lockfree.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/notify_all.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/notify_one.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/operator.float.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/operator.minus_equals.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/operator.plus_equals.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/store.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/wait.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.req/atomic_compare_exchange_strong.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.req/atomic_compare_exchange_strong_explicit.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.req/atomic_compare_exchange_weak.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.req/atomic_compare_exchange_weak_explicit.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.req/atomic_exchange.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.req/atomic_exchange_explicit.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.req/atomic_init.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.req/atomic_is_lock_free.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.req/atomic_load.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.req/atomic_load_explicit.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.req/atomic_store.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.req/atomic_store_explicit.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.wait/atomic_notify_all.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.wait/atomic_notify_one.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.wait/atomic_wait.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.wait/atomic_wait_explicit.pass.cpp
M libcxx/test/support/atomic_helpers.h
M libcxx/utils/libcxx/test/features.py
Log Message:
-----------
[libc++] Simplify features for detecting atomics' support. (#75553)
`non-lockfree-atomics` is very similar to `has-64-bit-atomics`; to
simplify, we can have uniform features for atomic types of
increasing sizes (`has-128-bit-atomics`, `has-256-bit-atomics`, etc.).
`is-lockfree-runtime-function` feature was a workaround for the partial
support for large atomic types on older versions of macOS (see
https://reviews.llvm.org/D91911). While we still support macOS 10.14,
conceptually it's simpler to check for support for all the atomic
functionality inside the `has-*-atomics` features, and the workaround is
no longer worth the maintenance cost.
Commit: 6fecfbc7b62f54bd633e83c22630d7c2a3e5741e
https://github.com/llvm/llvm-project/commit/6fecfbc7b62f54bd633e83c22630d7c2a3e5741e
Author: Joseph Huber <huberjn at outlook.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M clang/lib/Basic/Targets/AMDGPU.cpp
Log Message:
-----------
[AMDGPU] Correctly exclude the HIP host from arch macros
Summary:
This logic was wrong and accidentally appling to OpenCL.
Commit: 733b86d3ff8087f1e267c23eb315bb16e3c6c953
https://github.com/llvm/llvm-project/commit/733b86d3ff8087f1e267c23eb315bb16e3c6c953
Author: Chelsea Cassanova <chelsea_cassanova at apple.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M lldb/include/lldb/Core/DebuggerEvents.h
M lldb/include/lldb/Core/Progress.h
M lldb/source/Core/DebuggerEvents.cpp
M lldb/source/Core/Progress.cpp
Log Message:
-----------
[lldb][progress] Correctly check total for deterministic progress (#79912)
The `total` parameter for the constructor for Progress was changed to a
std::optional in https://github.com/llvm/llvm-project/pull/77547. It was originally set to 1 to indicate non-determinisitic progress, but this commit changes this. First, `UINT64_MAX` will again be used for non-deterministic progress, and `Progress` now has a static variable set to this value so that we can use this instead of a magic number.
The member variable `m_total` could be changed to a std::optional as
well, but this means that the `ProgressEventData::GetTotal()` (which is
used for the public API) would
either need to return a std::optional value or it would return some
specific integer to represent non-deterministic progress if `m_total` is
std::nullopt.
Commit: 1d3300d5027c95c84b335f6adfca7e49cae45bb2
https://github.com/llvm/llvm-project/commit/1d3300d5027c95c84b335f6adfca7e49cae45bb2
Author: Peiming Liu <36770114+PeimingLiu at users.noreply.github.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M mlir/lib/Dialect/SparseTensor/Transforms/Utils/SparseTensorLevel.cpp
M mlir/lib/Dialect/SparseTensor/Transforms/Utils/SparseTensorLevel.h
Log Message:
-----------
[mlir][sparse] use shared value storage between wrapped iterator and the wrapper. (#80046)
Commit: 235f1e74fe240e414718c64d05bafc01d34c32cb
https://github.com/llvm/llvm-project/commit/235f1e74fe240e414718c64d05bafc01d34c32cb
Author: Jinsong Ji <jinsong.ji at intel.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M clang/include/clang/Basic/Builtins.td
Log Message:
-----------
[Clang] Fix typo in __fprintf_chk Prototype (#80012)
An extra int was copied.
Commit: 30b9140c148923e31a6dbcb2202ef3908481bb29
https://github.com/llvm/llvm-project/commit/30b9140c148923e31a6dbcb2202ef3908481bb29
Author: Craig Topper <craig.topper at sifive.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M llvm/test/MC/RISCV/rv32zbb-only-valid.s
M llvm/test/MC/RISCV/rv32zbb-valid.s
M llvm/test/MC/RISCV/rv64zbb-valid.s
M llvm/test/MC/RISCV/rv64zbkb-valid.s
Log Message:
-----------
[RISCV] Minor cleanup to rori MC layer testing. NFC
rv32zbb-valid.s tests rv64 and rv32. rv32zbb-only-valid.s only tests rv32.
The rori tests in rv32zbb-only-valid.s produce the same result for rv32 and
rv64 so its better to test them in rv32zbb-valid.s.
Remove a now redundant test case from rv64zbb-valid.s.
Add a missing rori test with imm >= 32 to rv64zbkb-valid.s.
Commit: 6a21e00e397648141ed36aae4bd958efa09908f3
https://github.com/llvm/llvm-project/commit/6a21e00e397648141ed36aae4bd958efa09908f3
Author: Shilei Tian <i at tianshilei.me>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M llvm/lib/Target/AMDGPU/AsmParser/AMDGPUAsmParser.cpp
A llvm/test/MC/AMDGPU/writelane_m0.s
A llvm/test/MachineVerifier/writelane_m0.mir
Log Message:
-----------
[AMDGPU][AsmParser] Allow `v_writelane_b32` to use SGPR and M0 as source operands at the same time (#78827)
Currently the asm parser takes `v_writelane_b32 v1, s13, m0` as illegal
instruction for pre-gfx11 because it uses two constant buses while the
hardware
can only allow one. However, based on the comment of
`AMDGPUInstructionSelector::selectWritelane`,
it is allowed to have M0 as lane selector and a SGPR used as SRC0
because the
lane selector doesn't count as a use of constant bus. In fact, codegen
can already
generate this form, but this inconsistency is not exposed because the
validation
of constant bus limitation only happens when paring an assembly but we
don't have
a test case when both SGPR and M0 used as source operands for the
instruction.
Commit: d8b61d716899736c7f0444d1b18b8e1a536c3472
https://github.com/llvm/llvm-project/commit/d8b61d716899736c7f0444d1b18b8e1a536c3472
Author: Aiden Grossman <agrossman154 at yahoo.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M llvm/docs/CommandGuide/llvm-exegesis.rst
A llvm/test/tools/llvm-exegesis/X86/latency/middle-half.s
M llvm/tools/llvm-exegesis/lib/BenchmarkResult.h
M llvm/tools/llvm-exegesis/lib/CMakeLists.txt
A llvm/tools/llvm-exegesis/lib/ResultAggregator.cpp
A llvm/tools/llvm-exegesis/lib/ResultAggregator.h
M llvm/tools/llvm-exegesis/lib/SnippetRepetitor.cpp
M llvm/tools/llvm-exegesis/llvm-exegesis.cpp
M llvm/unittests/tools/llvm-exegesis/CMakeLists.txt
A llvm/unittests/tools/llvm-exegesis/ResultAggregatorTest.cpp
Log Message:
-----------
[llvm-exegesis] Add middle half repetition mode (#77020)
This patch adds two new repetition modes to llvm-exegesis, particularly
loop and duplicate repetition modes of what I am terming the middle half
repetition mode. The middle half repetition mode essentially runs each
measurement twice, one with twice the number of iterations of the other.
These two measurements are then agregated by taking their difference.
This subtracts away any setup/overhead that is unrelated to the code in
the snippet, providing more accurate results.
Using this mode on a couple toy examples, I am able to get exact
(integer) throughput values on all of them in contrast to the default
duplicate/loop repetition modes which show a little bit of noise on the
snippet value.
Commit: 58e8c072aa4ebb11dfab13ed00fa8d61e408516c
https://github.com/llvm/llvm-project/commit/58e8c072aa4ebb11dfab13ed00fa8d61e408516c
Author: Shilei Tian <i at tianshilei.me>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M llvm/test/MachineVerifier/writelane_m0.mir
Log Message:
-----------
[FIX] Require AMDGPU target in test case `llvm/test/MachineVerifier/writelane_m0.mir`
Commit: 0dd0cbd324ad13dd7b91edf69a2ca66a6a208c80
https://github.com/llvm/llvm-project/commit/0dd0cbd324ad13dd7b91edf69a2ca66a6a208c80
Author: erichkeane <ekeane at nvidia.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M clang/include/clang/Basic/OpenACCKinds.h
M clang/lib/Parse/ParseOpenACC.cpp
A clang/test/ParserOpenACC/parse-wait-clause.c
Log Message:
-----------
[OpenACC] Implement 'wait' clause parsing.
The 'wait' clause is parsed the same way as the 'wait' construct, so
this jsut differs to that function.
Commit: 66ef6900f9f3aa4fab9f6e36af04f775948cdf9d
https://github.com/llvm/llvm-project/commit/66ef6900f9f3aa4fab9f6e36af04f775948cdf9d
Author: erichkeane <ekeane at nvidia.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M clang/lib/Parse/ParseOpenACC.cpp
M clang/test/ParserOpenACC/parse-clauses.c
Log Message:
-----------
[OpenACC] Better recover during clause parsing
Previously we gave up immediately and just escaped. Instead, skip to
the next close paren and see if we can continue parsing the next clause
instead.
Commit: aa88a09fbc6428fa3c74e2027b0f329d89c332bd
https://github.com/llvm/llvm-project/commit/aa88a09fbc6428fa3c74e2027b0f329d89c332bd
Author: LLVM GN Syncbot <llvmgnsyncbot at gmail.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M llvm/utils/gn/secondary/llvm/tools/llvm-exegesis/lib/BUILD.gn
M llvm/utils/gn/secondary/llvm/unittests/tools/llvm-exegesis/BUILD.gn
Log Message:
-----------
[gn build] Port d8b61d716899
Commit: a385c379f8694f42d1efb88bb8c5a53fccb6a664
https://github.com/llvm/llvm-project/commit/a385c379f8694f42d1efb88bb8c5a53fccb6a664
Author: Yitzhak Mandelbaum <ymand at users.noreply.github.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M clang/lib/Analysis/FlowSensitive/TypeErasedDataflowAnalysis.cpp
Log Message:
-----------
[clang][dataflow] Drop block-relative cap on worklist iterations. (#80033)
As per the FIXME, this cap never really served its purpose. This patch
simplifies to a single, caller-specified, absolute cap.
Commit: 576c4dfa067fa767818a0d80c7072a64c221384e
https://github.com/llvm/llvm-project/commit/576c4dfa067fa767818a0d80c7072a64c221384e
Author: michaelrj-google <71531609+michaelrj-google at users.noreply.github.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M libc/config/linux/x86_64/entrypoints.txt
Log Message:
-----------
[libc] disable epoll_pwait2 due to breakage (#80051)
It appears that sys_epoll_pwait2 isn't always available, so we need to
add some sort of condition to enable it. This patch disables it until
that happens.
Commit: 2c5a0d392592982bb9c73cbc10c64390b9045873
https://github.com/llvm/llvm-project/commit/2c5a0d392592982bb9c73cbc10c64390b9045873
Author: Yitzhak Mandelbaum <ymand at users.noreply.github.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M clang/include/clang/Analysis/Analyses/PostOrderCFGView.h
M clang/unittests/Analysis/CFGTest.cpp
M clang/unittests/Analysis/FlowSensitive/LoggerTest.cpp
Log Message:
-----------
[clang][CFG] Change child order in Reverse Post Order (RPO) iteration. (#80030)
The CFG orders the blocks of loop bodies before those of loop successors
(both numerically, and in the successor order of the loop condition
block). So, RPO necessarily reverses that order, placing the loop
successor *before* the loop body. For many analyses, particularly those
that converge to a fixpoint, this results in potentially significant
extra work, because loop successors will necessarily need to be
reconsidered once the algorithm has reached a fixpoint on the loop body.
This definition of CFG graph traits reverses the order of children, so
that loop bodies will come first in an RPO. Then, the algorithm can
fully evaluate the loop and only then consider successor blocks.
Commit: 0fa4463e93dca275ee80fd85120e33ccc9f22c5e
https://github.com/llvm/llvm-project/commit/0fa4463e93dca275ee80fd85120e33ccc9f22c5e
Author: Valentin Clement (バレンタイン クレメン) <clementval at gmail.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M flang/lib/Semantics/resolve-directives.cpp
M flang/test/Semantics/OpenACC/acc-loop.f90
Log Message:
-----------
[flang][openacc] Check trip count invariance with other IVs (#79906)
2.9.1 The trip count for all loops associated with the collapse clause
must be computable and invariant in all the loops.
This patch checks that iteration range of loops part of a collapse nest
does not depend on outer loops induction variables.
The check is also applied to combined construct with a loop.
Commit: d9423398ea129e229b20ba42dfe4326e620129b5
https://github.com/llvm/llvm-project/commit/d9423398ea129e229b20ba42dfe4326e620129b5
Author: Valentin Clement <clementval at gmail.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M flang/lib/Semantics/resolve-directives.cpp
M flang/test/Semantics/OpenACC/acc-loop.f90
Log Message:
-----------
Revert "[flang][openacc] Check trip count invariance with other IVs (#79906)"
This reverts commit 0fa4463e93dca275ee80fd85120e33ccc9f22c5e.
Breaks buildbot https://lab.llvm.org/buildbot/#/builders/268/builds/7155
Commit: 9b91c54d9bd3227a49e146c055fb0165567f7f8d
https://github.com/llvm/llvm-project/commit/9b91c54d9bd3227a49e146c055fb0165567f7f8d
Author: Fangrui Song <i at maskray.me>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M llvm/lib/Transforms/Instrumentation/MemorySanitizer.cpp
M llvm/test/Instrumentation/MemorySanitizer/msan_asm_conservative.ll
Log Message:
-----------
[msan] Unpoison indirect outputs for userspace using memset for large operands (#79924)
Modify #77393 to clear shadow memory using `llvm.memset.*` when the size
is large, similar to `shouldUseBZeroPlusStoresToInitialize` in clang for
`-ftrivial-auto-var-init=`. The intrinsic, if lowered to libcall, will
use the msan interceptor.
The instruction selector lowers a `StoreInst` to multiple stores, not
utilizing `memset`. When the size is large (e.g.
`store { [100 x i32] } zeroinitializer, ptr %12, align 1`), the
generated code will be long (and `CodeGenPrepare::optimizeInst` will
even crash for a huge size).
```
// Test stack size
template <class T>
void DoNotOptimize(const T& var) { // deprecated by https://github.com/google/benchmark/pull/1493
asm volatile("" : "+m"(const_cast<T&>(var)));
}
int main() {
using LargeArray = std::array<int, 1000000>;
auto large_stack = []() { DoNotOptimize(LargeArray()); };
/////// CodeGenPrepare::optimizeInst triggers an assertion failure when creating an integer type with a bit width>2**23
large_stack();
}
```
Commit: 648560062af8deb4e6478130deb1dd8fa62929a8
https://github.com/llvm/llvm-project/commit/648560062af8deb4e6478130deb1dd8fa62929a8
Author: Fangrui Song <i at maskray.me>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M compiler-rt/lib/dfsan/dfsan_custom.cpp
M compiler-rt/lib/dfsan/done_abilist.txt
M compiler-rt/lib/dfsan/libc_ubuntu1404_abilist.txt
Log Message:
-----------
[dfsan] Wrap glibc 2.38 __isoc23_* functions (#79958)
Fix #79283: `test/dfsan/custom.cpp` has undefined symbol linker errors
on glibc 2.38 due to lack of wrappers for `__isoc23_strtol` and
`__isoc23_scanf` family functions.
Implement these wrappers as aliases to existing wrappers, similar to
https://reviews.llvm.org/D158943 for other sanitizers.
`strtol` in a user program, whether or not `_ISOC2X_SOURCE` is defined,
uses the C23 semantics (`strtol("0b1", 0, 0)` => 1), when
`libclang_rt.dfsan.a` is built on glibc 2.38+.
Commit: a356e6ccada87d6bfc4513fba4b1a682305e094a
https://github.com/llvm/llvm-project/commit/a356e6ccada87d6bfc4513fba4b1a682305e094a
Author: PiJoules <6019989+PiJoules at users.noreply.github.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M llvm/include/llvm/CodeGen/TargetLowering.h
M llvm/lib/CodeGen/SelectionDAG/LegalizeIntegerTypes.cpp
M llvm/lib/CodeGen/SelectionDAG/TargetLowering.cpp
A llvm/test/CodeGen/Thumb/smul_fix.ll
A llvm/test/CodeGen/Thumb/smul_fix_sat.ll
A llvm/test/CodeGen/Thumb/umul_fix.ll
A llvm/test/CodeGen/Thumb/umul_fix_sat.ll
Log Message:
-----------
[SelectionDAG] Expand fixed point multiplication into libcall (#79352)
32-bit ARMv6 with thumb doesn't support MULHS/MUL_LOHI as legal/custom
nodes during expansion which will cause fixed point multiplication of
_Accum types to fail with fixed point arithmetic. Prior to this, we just
happen to use fixed point multiplication on platforms that happen to
support these MULHS/MUL_LOHI.
This patch attempts to check if the multiplication can be done via
libcalls, which are provided by the arm runtime. These libcall attempts
are made elsewhere, so this patch refactors that libcall logic into its
own functions and the fixed point expansion calls and reuses that logic.
Commit: 404af14f92b8b7318ab3d34bd65d800c0bde1e10
https://github.com/llvm/llvm-project/commit/404af14f92b8b7318ab3d34bd65d800c0bde1e10
Author: Maksim Levental <maksim.levental at gmail.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M mlir/include/mlir-c/BuiltinTypes.h
M mlir/lib/Bindings/Python/IRTypes.cpp
M mlir/lib/CAPI/IR/BuiltinTypes.cpp
M mlir/python/mlir/dialects/_ods_common.py
M mlir/python/mlir/dialects/memref.py
M mlir/python/mlir/dialects/transform/structured.py
M mlir/test/python/dialects/memref.py
Log Message:
-----------
[mlir][python] enable memref.subview (#79393)
Commit: 24923214e7845acc0e2f56f13e08ee519eba8303
https://github.com/llvm/llvm-project/commit/24923214e7845acc0e2f56f13e08ee519eba8303
Author: Schrodinger ZHU Yifan <yifanzhu at rochester.edu>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M libc/config/linux/aarch64/entrypoints.txt
M libc/config/linux/riscv/entrypoints.txt
M libc/config/linux/x86_64/entrypoints.txt
M libc/spec/linux.td
M libc/spec/posix.td
M libc/src/sys/mman/CMakeLists.txt
M libc/src/sys/mman/linux/CMakeLists.txt
A libc/src/sys/mman/linux/mlock.cpp
A libc/src/sys/mman/linux/mlock2.cpp
A libc/src/sys/mman/linux/mlockall.cpp
A libc/src/sys/mman/linux/munlock.cpp
A libc/src/sys/mman/linux/munlockall.cpp
A libc/src/sys/mman/mlock.h
A libc/src/sys/mman/mlock2.h
A libc/src/sys/mman/mlockall.h
A libc/src/sys/mman/munlock.h
A libc/src/sys/mman/munlockall.h
M libc/test/src/sys/mman/linux/CMakeLists.txt
M libc/test/src/sys/mman/linux/mincore_test.cpp
A libc/test/src/sys/mman/linux/mlock_test.cpp
Log Message:
-----------
[libc] implement mlock/mlock2/munlock/mlockall/munlockall (#79645)
fixes #79336
Co-authored-by: Sirui Mu <msrlancern at gmail.com>
Commit: 75ea78ab677f8357aa14fd4c0aff5d551a4ff8aa
https://github.com/llvm/llvm-project/commit/75ea78ab677f8357aa14fd4c0aff5d551a4ff8aa
Author: Felipe de Azevedo Piovezan <fpiovezan at apple.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M llvm/include/llvm/DebugInfo/DWARF/DWARFAcceleratorTable.h
M llvm/lib/DebugInfo/DWARF/DWARFAcceleratorTable.cpp
Log Message:
-----------
[DebugNames] Compare TableEntry names more efficiently (#79759)
TableEntry names are pointers into the string table section, and
accessing their
length requires a search for `\0`. However, 99% of the time we only need
to
compare the name against some other other, and such a comparison will
fail as
early as the first character.
This commit adds a method to the interface of TableEntry so that such a
comparison can be done without extracting the full name. It saves 10% in
the
time (1250ms -> 1100 ms) to evaluate the following expression.
```
lldb \
--batch \
-o "b CodeGenFunction::GenerateCode" \
-o run \
-o "expr Fn" \
-- \
clang++ -c -g test.cpp -o /dev/null &> output
```
Commit: e5cebec521a7cf86ff21dedb8a2c96b3f8331c9d
https://github.com/llvm/llvm-project/commit/e5cebec521a7cf86ff21dedb8a2c96b3f8331c9d
Author: jkorous-apple <32549412+jkorous-apple at users.noreply.github.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M clang/lib/Analysis/UnsafeBufferUsage.cpp
Log Message:
-----------
[-Wunsafe-buffer-usage] Fix AST matcher of UUCAddAssignGadget (#79392)
We are not interested in nonpointers being added to.
Commit: bb770f0df53eee91a803b2829808d82279f7b577
https://github.com/llvm/llvm-project/commit/bb770f0df53eee91a803b2829808d82279f7b577
Author: yronglin <yronglin777 at gmail.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M clang/include/clang/AST/TextNodeDumper.h
M clang/lib/AST/TextNodeDumper.cpp
M clang/test/AST/ast-dump-for-range-lifetime.cpp
M clang/test/Import/cxx-default-init-expr/test.cpp
Log Message:
-----------
[Clang] Dump the rewritten sub-expressions in CXXDefaultArgExpr/CXXDefaultInitExpr (#80001)
This patch dump the rewritten sub-expressions in `CXXDefaultArgExpr` and
`CXXDefaultInitExpr`.
This machinery is useful for checking whether the materialized
temporaries is lifetime-extended in the sub-AST of `CXXDefaultArgExpr`
(`CXXDefaultInitExpr` has not been lifetime extendend now).
Signed-off-by: yronglin <yronglin777 at gmail.com>
Commit: 2f490f924647aa0724bab49cb390d4423fc9fc03
https://github.com/llvm/llvm-project/commit/2f490f924647aa0724bab49cb390d4423fc9fc03
Author: Valentin Clement <clementval at gmail.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M flang/lib/Semantics/resolve-directives.cpp
M flang/test/Semantics/OpenACC/acc-loop.f90
Log Message:
-----------
[flang][openacc] Check trip count invariance with other IVs (#79906)
2.9.1 The trip count for all loops associated with the collapse clause must be
computable and invariant in all the loops.
This patch checks that loops part of a collapse nest does not depends on outer
loops induction variables.
The check is also applied to combined construct with a loop.
Commit: 16c15b5f84836d81084e9987701ca011da5a864f
https://github.com/llvm/llvm-project/commit/16c15b5f84836d81084e9987701ca011da5a864f
Author: Nick Desaulniers <nickdesaulniers at users.noreply.github.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M libc/test/src/sys/mman/linux/mlock_test.cpp
Log Message:
-----------
[libc] disable mlockall w/ MCL_ONFAULT (#80075)
I suspect this is a bug in linux 4.19, as the test passes as written on
my
linux 6.5 machine.
Let's revisit this after the build bots are upgraded.
Link: #80073
Commit: 7847e44594aa932c0a5f5d2cd15940d2a815c059
https://github.com/llvm/llvm-project/commit/7847e44594aa932c0a5f5d2cd15940d2a815c059
Author: Michael Spencer <bigcheesegs at gmail.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M clang/include/clang/Basic/DiagnosticSerializationKinds.td
M clang/include/clang/Basic/FileManager.h
M clang/include/clang/Lex/HeaderSearch.h
M clang/include/clang/Lex/HeaderSearchOptions.h
M clang/include/clang/Serialization/ASTBitCodes.h
M clang/include/clang/Serialization/ASTReader.h
M clang/include/clang/Serialization/ASTWriter.h
M clang/include/clang/Serialization/ModuleFile.h
M clang/include/clang/Tooling/DependencyScanning/DependencyScanningFilesystem.h
M clang/include/clang/Tooling/DependencyScanning/DependencyScanningService.h
M clang/lib/Basic/FileManager.cpp
M clang/lib/Frontend/CompilerInvocation.cpp
M clang/lib/Lex/HeaderSearch.cpp
M clang/lib/Serialization/ASTReader.cpp
M clang/lib/Serialization/ASTWriter.cpp
M clang/lib/Tooling/DependencyScanning/DependencyScanningFilesystem.cpp
M clang/lib/Tooling/DependencyScanning/DependencyScanningWorker.cpp
M clang/lib/Tooling/DependencyScanning/ModuleDepCollector.cpp
A clang/test/ClangScanDeps/optimize-vfs-edgecases.m
A clang/test/ClangScanDeps/optimize-vfs-leak.m
A clang/test/ClangScanDeps/optimize-vfs-pch.m
A clang/test/ClangScanDeps/optimize-vfs.m
M clang/tools/clang-scan-deps/ClangScanDeps.cpp
M llvm/include/llvm/Support/VirtualFileSystem.h
M llvm/lib/Support/VirtualFileSystem.cpp
M llvm/unittests/Support/VirtualFileSystemTest.cpp
Log Message:
-----------
[clang][DependencyScanner] Remove unused -ivfsoverlay files (#73734)
`-ivfsoverlay` files are unused when building most modules. Enable
removing them by,
* adding a way to visit the filesystem tree with extensible RTTI to
access each `RedirectingFileSystem`.
* Adding tracking to `RedirectingFileSystem` to record when it
actually redirects a file access.
* Storing this information in each PCM.
Usage tracking is only enabled when iterating over the source manager
and affecting modulemaps. Here each path is stated to cause an access.
During scanning these stats all hit the cache.
Commit: 86cd2fbdfe67d70a7fe061ed5d3a644f50f070f5
https://github.com/llvm/llvm-project/commit/86cd2fbdfe67d70a7fe061ed5d3a644f50f070f5
Author: jkorous-apple <32549412+jkorous-apple at users.noreply.github.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M clang/test/SemaCXX/warn-unsafe-buffer-usage-fixits-pointer-access.cpp
Log Message:
-----------
[-Wunsafe-buffer-usage][NFC] Add testcase for non-unsafe pointer (#80076)
This adds a missing CHECK-NOT directive for an existing test case.
Commit: c8c3fe70ae09a48408ee15a256e52a4624e0291c
https://github.com/llvm/llvm-project/commit/c8c3fe70ae09a48408ee15a256e52a4624e0291c
Author: Jacek Caban <jacek at codeweavers.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M lld/COFF/DLL.cpp
M lld/test/COFF/imports.test
M lld/test/COFF/pdb-publics-import.test
Log Message:
-----------
[LLD][COFF] Align import directory chunk. (#80014)
The loader can usually handle an unaligned import dir chunk, but It's not
optimal and it's not what MSVC link.exe does.
Windows refuses to load ARM64X binaries with unaligned import directory.
aarch64 and arm64ec imports are shared in such binaries as much as
possible. As long as they use the same set of functions from given import
directory, both the directory and import addresses chunk are just shared.
When used set of functions differs, ARM64X dynamic relocations are used
to modify import dir to point to different names and import addresses for
its EC view. I suspect that the loader expects some alignment on ARM64X
dynamic relocation offset and may not be the case when relocated import
dir is not aligned.
Commit: 8b38970811086b09752a5909d0c17de4d0cd04c3
https://github.com/llvm/llvm-project/commit/8b38970811086b09752a5909d0c17de4d0cd04c3
Author: Katherine Rasmussen <krasmussen at lbl.gov>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M flang/docs/Intrinsics.md
M flang/lib/Evaluate/intrinsics.cpp
M flang/lib/Semantics/check-call.cpp
A flang/test/Semantics/image_index01.f90
A flang/test/Semantics/image_index02.f90
Log Message:
-----------
[flang] Add image_index to list of intrinsics and add tests (#79519)
Add image_index to the list of intrinsic functions and add additional
check on its args in check-call.cpp. Add two semantics tests for
image_index.
Commit: 4effff21fb2f3462e06fcbd7812562f4771b0487
https://github.com/llvm/llvm-project/commit/4effff21fb2f3462e06fcbd7812562f4771b0487
Author: Kai Sasaki <lewuathe at gmail.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M mlir/lib/Conversion/ComplexToStandard/ComplexToStandard.cpp
M mlir/test/Conversion/ComplexToStandard/convert-to-standard.mlir
M mlir/test/Conversion/ComplexToStandard/full-conversion.mlir
M mlir/test/Integration/Dialect/Complex/CPU/correctness.mlir
Log Message:
-----------
[mlir][complex] Prevent underflow in complex.abs (#79786)
The previous PR was not correct on the way to handle the negative value.
It is necessary to take the absolute value of the given real (or
imaginary) part to be multiplied with the sqrt part.
See: https://github.com/llvm/llvm-project/pull/76316
Commit: b21a2f9365b6c5fd464a97be5dfe7085742870ef
https://github.com/llvm/llvm-project/commit/b21a2f9365b6c5fd464a97be5dfe7085742870ef
Author: Michael Spencer <bigcheesegs at gmail.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M clang/lib/Tooling/DependencyScanning/DependencyScanningWorker.cpp
A clang/test/ClangScanDeps/missing-vfs.m
Log Message:
-----------
[clang][scan-deps] Stop scanning if any scanning setup emits an error.
Without this scanning will continue and later hit an assert that the
number of `RedirectingFileSystem`s matches the number of -ivfsoverlay
arguments.
Commit: c806d8c7e948f01405be4ea344d883f066f8ae59
https://github.com/llvm/llvm-project/commit/c806d8c7e948f01405be4ea344d883f066f8ae59
Author: rmarker <37921131+rmarker at users.noreply.github.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M clang/docs/tools/dump_format_style.py
Log Message:
-----------
[clang-format] Explicitly open DOC_FILE with utf-8 in dump_format_style.py (#79805)
The dump_format_style.py script generates the clang-format style options
documentation.
There was an issue where the script could include spurious characters in
the output when run in windows. It appears that it wasn't defaulting to
the correct encoding when reading the input.
This has been addressed by explicitly setting the encoding when opening
the file.
Commit: b91bba89edfb25d011e1f2366cda5dec605c87f6
https://github.com/llvm/llvm-project/commit/b91bba89edfb25d011e1f2366cda5dec605c87f6
Author: Jakub Kuderski <jakub at nod-labs.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M mlir/include/mlir/Conversion/MemRefToSPIRV/MemRefToSPIRV.h
M mlir/lib/Conversion/GPUToSPIRV/GPUToSPIRVPass.cpp
M mlir/lib/Conversion/MemRefToSPIRV/MapMemRefStorageClassPass.cpp
Log Message:
-----------
[mlir][spirv] Use `AttrTypeReplacer` in map-memref-storage-class. NFC. (#80055)
Keep the conversion target to allow for checking if the op is legal.
Commit: d783933bc910ac005e18928d22b6c10c4fe8d6f6
https://github.com/llvm/llvm-project/commit/d783933bc910ac005e18928d22b6c10c4fe8d6f6
Author: Yaraslau <yaraslau.tamashevich at gmail.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
A clang/test/ClangScanDeps/empty.cpp
M clang/tools/clang-scan-deps/ClangScanDeps.cpp
Log Message:
-----------
[clang-scan-deps] Fix check for empty `Compilation` (#75545)
Closes https://github.com/llvm/llvm-project/issues/64144
Instead of checking for `nullptr` we need to ensure that `JobList` is
not empty to proceed
Commit: 2abcbbd96ad731b05fae970a0abb23cda784dddd
https://github.com/llvm/llvm-project/commit/2abcbbd96ad731b05fae970a0abb23cda784dddd
Author: Maksim Panchenko <maks at fb.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M bolt/include/bolt/Core/BinaryContext.h
M bolt/include/bolt/Utils/CommandLineOpts.h
M bolt/lib/Profile/DataAggregator.cpp
M bolt/lib/Rewrite/LinuxKernelRewriter.cpp
M bolt/lib/Rewrite/RewriteInstance.cpp
M bolt/lib/Utils/CommandLineOpts.cpp
M bolt/test/X86/linux-orc.s
Log Message:
-----------
[BOLT] Detect Linux kernel based on ELF program headers (#80086)
Check if program header addresses fall into the kernel space to detect a
Linux kernel binary on x86-64.
Delete opts::LinuxKernelMode and use BinaryContext::IsLinuxKernel
instead.
Commit: b4d832c77dcba4136132559a5183883cf064389d
https://github.com/llvm/llvm-project/commit/b4d832c77dcba4136132559a5183883cf064389d
Author: Carl Peto <carl.peto at me.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M clang/include/clang/Sema/Sema.h
M clang/lib/Parse/ParseExpr.cpp
M clang/lib/Parse/ParseObjc.cpp
M clang/lib/Sema/SemaDecl.cpp
Log Message:
-----------
[clang] Improved isSimpleTypeSpecifier (#79037)
- Sema::isSimpleTypeSpecifier return true for _Bool in c99 (currently
returns false for _Bool, regardless of C dialect). (Fixes #72203)
- replace the logic with a check for simple types and a proper check for
a valid keyword in the appropriate dialect
Co-authored-by: Carl Peto <CPeto at becrypt.com>
Commit: c761b4a5e4cc003a2c850898e1dc67d2637cfb0c
https://github.com/llvm/llvm-project/commit/c761b4a5e4cc003a2c850898e1dc67d2637cfb0c
Author: Billy Laws <blaws05 at gmail.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M llvm/lib/Target/AArch64/AArch64ISelLowering.cpp
M llvm/test/CodeGen/AArch64/arm64ec-varargs.ll
M llvm/test/CodeGen/AArch64/vararg-tallcall.ll
Log Message:
-----------
[AArch64] Fix variadic tail-calls on ARM64EC (#79774)
ARM64EC varargs calls expect that x4 = sp at entry, special handling is
needed to ensure this with tail calls since they occur after the
epilogue and the x4 write happens before.
I tried going through AArch64MachineFrameLowering for this, hoping to
avoid creating the dummy object but this was the best I could do since
the stack info that uses isn't populated at this stage,
CreateFixedObject also explicitly forbids 0 sized objects.
Commit: 1a17f2beb9cd1f5bbaa64502ab5c02ff74c199a4
https://github.com/llvm/llvm-project/commit/1a17f2beb9cd1f5bbaa64502ab5c02ff74c199a4
Author: Congcong Cai <congcongcai0907 at 163.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/Target/WebAssembly/WebAssemblyTargetMachine.cpp
A llvm/test/CodeGen/WebAssembly/disable-feature.ll
Log Message:
-----------
[WebAssembly] avoid to use explicit disabled feature
In `CoalesceFeaturesAndStripAtomics`, feature string is converted to FeatureBitset and back to feature string. It will lose information about explicit diasbled features.
Commit: c43fda3efcbf5b16e611473cf03c88381237f50f
https://github.com/llvm/llvm-project/commit/c43fda3efcbf5b16e611473cf03c88381237f50f
Author: Congcong Cai <congcongcai0907 at 163.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/Target/WebAssembly/WebAssemblyTargetMachine.cpp
R llvm/test/CodeGen/WebAssembly/disable-feature.ll
Log Message:
-----------
Revert "[WebAssembly] avoid to use explicit disabled feature"
This reverts commit 1a17f2beb9cd1f5bbaa64502ab5c02ff74c199a4.
Commit: ff4636a4ab00b633c15eb3942c26126ceb2662e6
https://github.com/llvm/llvm-project/commit/ff4636a4ab00b633c15eb3942c26126ceb2662e6
Author: Oskar Wirga <10386631+oskarwirga at users.noreply.github.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M llvm/include/llvm/CodeGen/LivePhysRegs.h
M llvm/include/llvm/CodeGen/MachineBasicBlock.h
M llvm/lib/CodeGen/BranchFolding.cpp
M llvm/lib/Target/AArch64/AArch64FrameLowering.cpp
M llvm/lib/Target/AArch64/AArch64InstrInfo.cpp
M llvm/lib/Target/ARM/ARMLowOverheadLoops.cpp
M llvm/lib/Target/PowerPC/PPCExpandAtomicPseudoInsts.cpp
M llvm/lib/Target/PowerPC/PPCFrameLowering.cpp
M llvm/lib/Target/SystemZ/SystemZFrameLowering.cpp
M llvm/lib/Target/X86/X86FrameLowering.cpp
M llvm/test/CodeGen/SystemZ/branch-folder-hoist-livein.mir
M llvm/test/CodeGen/Thumb2/LowOverheadLoops/spillingmove.mir
Log Message:
-----------
Refactor recomputeLiveIns to converge on added MachineBasicBlocks (#79940)
This is a fix for the regression seen in
https://github.com/llvm/llvm-project/pull/79498
> Currently, the way that recomputeLiveIns works is that it will
recompute the livein registers for that MachineBasicBlock but it matters
what order you call recomputeLiveIn which can result in incorrect
register allocations down the line.
Now we do not recompute the entire CFG but we do ensure that the newly
added MBB do reach convergence.
Commit: c19436eec1c236cbe622c04e33f35f1f9478fa15
https://github.com/llvm/llvm-project/commit/c19436eec1c236cbe622c04e33f35f1f9478fa15
Author: Kohei Yamaguchi <fix7211 at gmail.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M mlir/lib/Conversion/SPIRVToLLVM/SPIRVToLLVM.cpp
Log Message:
-----------
[mlir][spirv] Fix a crash of typeConverter with non supported type (#79955)
Fixes a crash in the `convert-to-spirv-llvm` pass caused by unsupported
types (e.g. `spirv.matrix` ). This PR fixes it by checking the converted type.
Fixes #60017
Commit: 7155c1ef658b66132f15bf1406e84e68eed3358f
https://github.com/llvm/llvm-project/commit/7155c1ef658b66132f15bf1406e84e68eed3358f
Author: Joseph Huber <huberjn at outlook.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M clang/include/clang/Basic/DiagnosticDriverKinds.td
M clang/lib/Basic/Targets/NVPTX.cpp
M clang/lib/Basic/Targets/NVPTX.h
M clang/lib/Driver/ToolChains/Cuda.cpp
M clang/test/Driver/cuda-cross-compiling.c
M clang/test/Preprocessor/predefined-arch-macros.c
Log Message:
-----------
[NVPTX] Allow compiling LLVM-IR without `-march` set (#79873)
Summary:
The NVPTX tools require an architecture to be used, however if we are
creating generic LLVM-IR we should be able to leave it unspecified. This
will result in the `target-cpu` attributes not being set on the
functions so it can be changed when linked into code. This allows the
standalone `--target=nvptx64-nvidia-cuda` toolchain to create LLVM-IR
simmilar to how CUDA's deviceRTL looks from C/C++
Commit: ab70ac605e784c630122b27c5971fde68e80bd1b
https://github.com/llvm/llvm-project/commit/ab70ac605e784c630122b27c5971fde68e80bd1b
Author: Younan Zhang <zyn7109 at gmail.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M clang/docs/ReleaseNotes.rst
M clang/lib/AST/DeclTemplate.cpp
M clang/lib/Sema/SemaConcept.cpp
M clang/test/SemaTemplate/concepts-out-of-line-def.cpp
Log Message:
-----------
[concepts] Push a CurContext before substituting into out-of-line constraints for comparison (#79985)
Commit: fa3307eb3f47b0bd574fc754934f98c0f27e4e36
https://github.com/llvm/llvm-project/commit/fa3307eb3f47b0bd574fc754934f98c0f27e4e36
Author: Karthika Devi C <quic_kartc at quicinc.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M polly/lib/Analysis/ScopBuilder.cpp
A polly/test/ScopInfo/reduction_different_index.ll
A polly/test/ScopInfo/reduction_different_index1.ll
Log Message:
-----------
[polly] Make reduction detection checks more robust - part 1 (#75297)
Existing reduction detection algorithm does two types of memory checks
before marking a load store pair as reduction.
First is to check if load and store are pointing to the same memory. This
check right now detects the following case as reduction. sum[0] = sum[1]
+ A[i]
This is because the check compares only base of the memory addresses
involved and not their indices. This patch addresses this issue and
introduces some debug prints. Added couple of test cases to verify the
functionality of patch as well.
Commit: 9179d87abce8e92c0bf30bc1ee1c17e17e362bc0
https://github.com/llvm/llvm-project/commit/9179d87abce8e92c0bf30bc1ee1c17e17e362bc0
Author: Craig Topper <craig.topper at sifive.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M llvm/lib/Target/RISCV/RISCVISelLowering.cpp
M llvm/lib/Target/RISCV/RISCVISelLowering.h
Log Message:
-----------
[RISCV] Remove unused RISCVISD opcodes. NFC
These were left behind after fb94c6491a114ebd5815b1d42665a8f6bcd9d639
Commit: 150ab99583e252a809b94f89da2576a1fc808297
https://github.com/llvm/llvm-project/commit/150ab99583e252a809b94f89da2576a1fc808297
Author: Shengchen Kan <shengchen.kan at intel.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/Target/X86/X86InstrInfo.h
Log Message:
-----------
[X86][NFC] Add documentation for methods in X86InstrInfo.h
Address RKSimon's comment in 2960656eb909b5361ce2c3f641ee341769076ab7
Commit: c12f30c7ffedb2338d64d8f98a76ae56c497cfbb
https://github.com/llvm/llvm-project/commit/c12f30c7ffedb2338d64d8f98a76ae56c497cfbb
Author: Ben Shi <2283975856 at qq.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M clang/lib/StaticAnalyzer/Checkers/StdLibraryFunctionsChecker.cpp
M clang/test/Analysis/errno-stdlibraryfunctions.c
Log Message:
-----------
[clang][analyzer] Improve modeling of 'realpath' in StdLibraryFunctionsChecker (#79939)
Commit: 8e77390c065fafeca220937e28f7d2ecc1a9ef15
https://github.com/llvm/llvm-project/commit/8e77390c065fafeca220937e28f7d2ecc1a9ef15
Author: Shengchen Kan <shengchen.kan at intel.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/Target/X86/X86InstrAVX512.td
M llvm/lib/Target/X86/X86InstrFoldTables.cpp
M llvm/lib/Target/X86/X86InstrFoldTables.h
M llvm/lib/Target/X86/X86InstrInfo.cpp
M llvm/lib/Target/X86/X86InstrInfo.h
M llvm/test/CodeGen/X86/vector-interleaved-load-i16-stride-7.ll
M llvm/test/CodeGen/X86/vector-interleaved-store-i16-stride-5.ll
M llvm/test/CodeGen/X86/vector-interleaved-store-i8-stride-8.ll
Log Message:
-----------
[X86][CodeGen] Support folding memory broadcast in X86InstrInfo::foldMemoryOperandImpl (#79761)
Commit: a034e65e972175a2465deacb8c78bc7efc99bd23
https://github.com/llvm/llvm-project/commit/a034e65e972175a2465deacb8c78bc7efc99bd23
Author: Yingwei Zheng <dtcxzyw2333 at gmail.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/Transforms/Scalar/CorrelatedValuePropagation.cpp
M llvm/test/Transforms/CorrelatedValuePropagation/basic.ll
A llvm/test/Transforms/CorrelatedValuePropagation/switch.ll
Log Message:
-----------
[CVP] Check whether the default case is reachable (#79993)
This patch eliminates unreachable default cases using context-sensitive
range information.
Commit: 5d7a0a734a0073ed2237606558d7616923ff50c2
https://github.com/llvm/llvm-project/commit/5d7a0a734a0073ed2237606558d7616923ff50c2
Author: Kazu Hirata <kazu at google.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M llvm/lib/Target/X86/X86InstrInfo.cpp
Log Message:
-----------
[X86] Use a range-based for loop (NFC)
Commit: eef6485ac1bffb6adf0b25ff4a117aa1590e70d0
https://github.com/llvm/llvm-project/commit/eef6485ac1bffb6adf0b25ff4a117aa1590e70d0
Author: Kazu Hirata <kazu at google.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M llvm/lib/Target/AMDGPU/R600OptimizeVectorRegisters.cpp
Log Message:
-----------
[AMDGPU] Use llvm::all_of (NFC)
Commit: 2699c1d7007ea8001bfaae50de01ff33791ce958
https://github.com/llvm/llvm-project/commit/2699c1d7007ea8001bfaae50de01ff33791ce958
Author: Kazu Hirata <kazu at google.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M clang-tools-extra/clang-tidy/bugprone/ReservedIdentifierCheck.cpp
Log Message:
-----------
[clang-tidy] Use StringRef::starts_with (NFC)
Commit: 292b508ebaa653073d9ce12156c93f5a0cf67680
https://github.com/llvm/llvm-project/commit/292b508ebaa653073d9ce12156c93f5a0cf67680
Author: Kazu Hirata <kazu at google.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M llvm/lib/Target/AMDGPU/AsmParser/AMDGPUAsmParser.cpp
Log Message:
-----------
[AMDGPU] Use StringRef::consume_front (NFC)
Commit: 8a98091162841fabc3816f3f29380c930ccbcab5
https://github.com/llvm/llvm-project/commit/8a98091162841fabc3816f3f29380c930ccbcab5
Author: Craig Topper <craig.topper at sifive.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M llvm/lib/Target/RISCV/RISCVInstrInfo.td
M llvm/test/CodeGen/RISCV/or-is-add.ll
M llvm/test/CodeGen/RISCV/rv64-legal-i32/rv64zba.ll
M llvm/test/CodeGen/RISCV/rv64zba.ll
Log Message:
-----------
[RISCV] Use disjoint flag in or_is_add.
Commit: f2816ff60c7dae0347beba9b11154b33e6311059
https://github.com/llvm/llvm-project/commit/f2816ff60c7dae0347beba9b11154b33e6311059
Author: Yingwei Zheng <dtcxzyw2333 at gmail.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/Transforms/InstCombine/InstCombineAndOrXor.cpp
M llvm/test/Transforms/InstCombine/and-or-icmps.ll
M llvm/test/Transforms/InstCombine/and-or-not.ll
M llvm/test/Transforms/InstCombine/and-xor-or.ll
M llvm/test/Transforms/InstCombine/or-xor.ll
M llvm/test/Transforms/InstCombine/or.ll
Log Message:
-----------
[InstCombine] Simplify and/or by replacing operands with constants (#77231)
This patch tries to simplify `X | Y` by replacing occurrences of `Y` in
`X` with 0. Similarly, it tries to simplify `X & Y` by replacing
occurrences of `Y` in `X` with -1.
Alive2: https://alive2.llvm.org/ce/z/cNjDTR
Note: As the current implementation is too conservative in the one-use
checks, I cannot remove other existing hard-coded simplifications if
they involves more than two instructions (e.g, `A & ~(A ^ B) --> A &
B`).
Compile-time impact:
http://llvm-compile-time-tracker.com/compare.php?from=a085402ef54379758e6c996dbaedfcb92ad222b5&to=9d655c6685865ffce0ad336fed81228f3071bd03&stat=instructions%3Au
|stage1-O3|stage1-ReleaseThinLTO|stage1-ReleaseLTO-g|stage1-O0-g|stage2-O3|stage2-O0-g|stage2-clang|
|--|--|--|--|--|--|--|
|+0.01%|-0.00%|+0.00%|-0.02%|+0.01%|+0.02%|-0.01%|
Fixes #76554.
Commit: 5bb99edcb6726e5dcc20d2236ef51b11c248acb9
https://github.com/llvm/llvm-project/commit/5bb99edcb6726e5dcc20d2236ef51b11c248acb9
Author: Timm Baeder <tbaeder at redhat.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M clang/lib/AST/Interp/ByteCodeExprGen.cpp
M clang/lib/AST/Interp/ByteCodeExprGen.h
M clang/lib/AST/Interp/Descriptor.cpp
M clang/lib/AST/Interp/Descriptor.h
M clang/lib/AST/Interp/Interp.cpp
M clang/lib/AST/Interp/Interp.h
M clang/lib/AST/Interp/InterpFrame.cpp
M clang/lib/AST/Interp/Opcodes.td
M clang/lib/AST/Interp/Pointer.cpp
M clang/lib/AST/Interp/Pointer.h
M clang/lib/AST/Interp/Program.cpp
M clang/test/AST/Interp/cxx11.cpp
M clang/test/AST/Interp/cxx17.cpp
M clang/test/AST/Interp/cxx23.cpp
M clang/test/AST/Interp/literals.cpp
M clang/unittests/AST/Interp/Descriptor.cpp
Log Message:
-----------
[clang][Interp] Add inline descriptor to global variables (#72892)
Some time ago, I did a similar patch for local variables.
Initializing global variables can fail as well:
```c++
constexpr int a = 1/0;
static_assert(a == 0);
```
... would succeed in the new interpreter, because we never saved the
fact that `a` has not been successfully initialized.
Commit: 6f35f1d7c137f5733b7035444397bcdace5c9df1
https://github.com/llvm/llvm-project/commit/6f35f1d7c137f5733b7035444397bcdace5c9df1
Author: Piggy <piggynl at outlook.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M .git-blame-ignore-revs
Log Message:
-----------
[NFC] Update .git-blame-ignore-revs for compiler-rt builtins (#79803)
The three commits from "[RFC] compiler-rt builtins cleanup and
refactoring" rewrote lots of code in compiler-rt builtins.
- 082b89b: [builtins] Reformat builtins with clang-format
- 0ba22f5: [builtins] Use single line C++/C99 comment style
- 84da0e1: [builtins] Use aliases for function redirects
Commit: 95947465024e865a4a671e94902db40d250f0601
https://github.com/llvm/llvm-project/commit/95947465024e865a4a671e94902db40d250f0601
Author: Piggy <piggynl at outlook.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M .github/new-prs-labeler.yml
Log Message:
-----------
[NFC] Add compiler-rt:* to .github/new-prs-labeler.yml (#79872)
After this change, all current compiler-rt:* labels on GitHub are
covered.
Commit: c83ec847ac9d06fb4ad85ce3bc50d7a6b122ead2
https://github.com/llvm/llvm-project/commit/c83ec847ac9d06fb4ad85ce3bc50d7a6b122ead2
Author: martinboehme <mboehme at google.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M clang/lib/Analysis/FlowSensitive/DataflowEnvironment.cpp
Log Message:
-----------
[clang][dataflow] Extend debug output for `Environment`. (#79982)
* Print `ReturnLoc`, `ReturnVal`, and `ThisPointeeLoc` if applicable.
* For entries in `LocToVal` that correspond to declarations, print the
names
of the declarations next to them.
I've removed the FIXME because all relevant fields are now being dumped.
I'm
not sure we actually need the capability for the caller to specify which
fields
to dump, so I've simply deleted this part of the comment.
Some examples of the output:


Commit: 3564666fe19217e3d6d3d98dd182553fc8d50e6f
https://github.com/llvm/llvm-project/commit/3564666fe19217e3d6d3d98dd182553fc8d50e6f
Author: Changpeng Fang <changpeng.fang at amd.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M llvm/test/Analysis/UniformityAnalysis/AMDGPU/intrinsics.ll
M llvm/test/CodeGen/AMDGPU/llvm.amdgcn.wmma_64.ll
M llvm/test/CodeGen/AMDGPU/wmma-gfx12-w32-f16-f32-matrix-modifiers.ll
M llvm/test/CodeGen/AMDGPU/wmma-gfx12-w32-imm.ll
M llvm/test/CodeGen/AMDGPU/wmma-gfx12-w32-iu-modifiers.ll
M llvm/test/CodeGen/AMDGPU/wmma-gfx12-w32-swmmac-index_key.ll
M llvm/test/CodeGen/AMDGPU/wmma-gfx12-w32.ll
M llvm/test/CodeGen/AMDGPU/wmma-gfx12-w64-f16-f32-matrix-modifiers.ll
M llvm/test/CodeGen/AMDGPU/wmma-gfx12-w64-imm.ll
M llvm/test/CodeGen/AMDGPU/wmma-gfx12-w64-iu-modifiers.ll
M llvm/test/CodeGen/AMDGPU/wmma-gfx12-w64-swmmac-index_key.ll
M llvm/test/CodeGen/AMDGPU/wmma-gfx12-w64.ll
M llvm/test/CodeGen/AMDGPU/wmma_modifiers.ll
M llvm/test/CodeGen/AMDGPU/wmma_multiple_32.ll
M llvm/test/CodeGen/AMDGPU/wmma_multiple_64.ll
Log Message:
-----------
[AMDGPU]: Fix type signatures for wmma intrinsics, NFC (#80087)
Make the wmma intrinsic type signatures to be canonical. We need
a type signature as long as the type is not fixed. However, when an
argument's type matches a previous argument's type, we do not need the
signature for this argument.
This patch fixes three general cases:
1. add missing signatures
2. remove signatures for matching arguments
3. reorer the signatures -- return type signature should always appear
first
Commit: ee01a2c3996f9647f3158f5acdb921a6ede94dc1
https://github.com/llvm/llvm-project/commit/ee01a2c3996f9647f3158f5acdb921a6ede94dc1
Author: Tianlan Zhou <bobby825 at 126.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M clang-tools-extra/clangd/InlayHints.cpp
M clang/docs/ReleaseNotes.rst
M clang/lib/AST/ExprConstant.cpp
M clang/lib/CodeGen/CGExpr.cpp
M clang/lib/Sema/SemaChecking.cpp
M clang/lib/Sema/SemaOverload.cpp
A clang/test/AST/ast-dump-static-operators.cpp
M clang/test/CodeGenCXX/cxx2b-static-call-operator.cpp
M clang/test/CodeGenCXX/cxx2b-static-subscript-operator.cpp
A clang/test/SemaCXX/cxx2b-static-operator.cpp
Log Message:
-----------
[clang] static operators should evaluate object argument (reland) (#80108)
This re-applies 30155fc0 with a fix for clangd.
### Description
clang don't evaluate the object argument of `static operator()` and
`static operator[]` currently, for example:
```cpp
#include <iostream>
struct Foo {
static int operator()(int x, int y) {
std::cout << "Foo::operator()" << std::endl;
return x + y;
}
static int operator[](int x, int y) {
std::cout << "Foo::operator[]" << std::endl;
return x + y;
}
};
Foo getFoo() {
std::cout << "getFoo()" << std::endl;
return {};
}
int main() {
std::cout << getFoo()(1, 2) << std::endl;
std::cout << getFoo()[1, 2] << std::endl;
}
```
`getFoo()` is expected to be called, but clang don't call it currently
(17.0.6). This PR fixes this issue.
Fixes #67976, reland #68485.
### Walkthrough
- **clang/lib/Sema/SemaOverload.cpp**
- **`Sema::CreateOverloadedArraySubscriptExpr` &
`Sema::BuildCallToObjectOfClassType`**
Previously clang generate `CallExpr` for static operators, ignoring the
object argument. In this PR `CXXOperatorCallExpr` is generated for
static operators instead, with the object argument as the first
argument.
- **`TryObjectArgumentInitialization`**
`const` / `volatile` objects are allowed for static methods, so that we
can call static operators on them.
- **clang/lib/CodeGen/CGExpr.cpp**
- **`CodeGenFunction::EmitCall`**
CodeGen changes for `CXXOperatorCallExpr` with static operators: emit
and ignore the object argument first, then emit the operator call.
- **clang/lib/AST/ExprConstant.cpp**
- **`ExprEvaluatorBase::handleCallExpr`**
Evaluation of static operators in constexpr also need some small changes
to work, so that the arguments won't be out of position.
- **clang/lib/Sema/SemaChecking.cpp**
- **`Sema::CheckFunctionCall`**
Code for argument checking also need to be modify, or it will fail the
test `clang/test/SemaCXX/overloaded-operator-decl.cpp`.
- **clang-tools-extra/clangd/InlayHints.cpp**
- **`InlayHintVisitor::VisitCallExpr`**
Now that the `CXXOperatorCallExpr` for static operators also have object
argument, we should also take care of this situation in clangd.
### Tests
- **Added:**
- **clang/test/AST/ast-dump-static-operators.cpp**
Verify the AST generated for static operators.
- **clang/test/SemaCXX/cxx2b-static-operator.cpp**
Static operators should be able to be called on const / volatile
objects.
- **Modified:**
- **clang/test/CodeGenCXX/cxx2b-static-call-operator.cpp**
- **clang/test/CodeGenCXX/cxx2b-static-subscript-operator.cpp**
Matching the new CodeGen.
### Documentation
- **clang/docs/ReleaseNotes.rst**
Update release notes.
---------
Co-authored-by: Shafik Yaghmour <shafik at users.noreply.github.com>
Co-authored-by: cor3ntin <corentinjabot at gmail.com>
Co-authored-by: Aaron Ballman <aaron at aaronballman.com>
Commit: 82324bc991401aecc4d743d4993b6c68dd60a615
https://github.com/llvm/llvm-project/commit/82324bc991401aecc4d743d4993b6c68dd60a615
Author: martinboehme <mboehme at google.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M clang/lib/Analysis/FlowSensitive/HTMLLogger.cpp
Log Message:
-----------
[clang][dataflow] In the CFG visualization, mark converged blocks. (#79999)
Here's an example of the output:
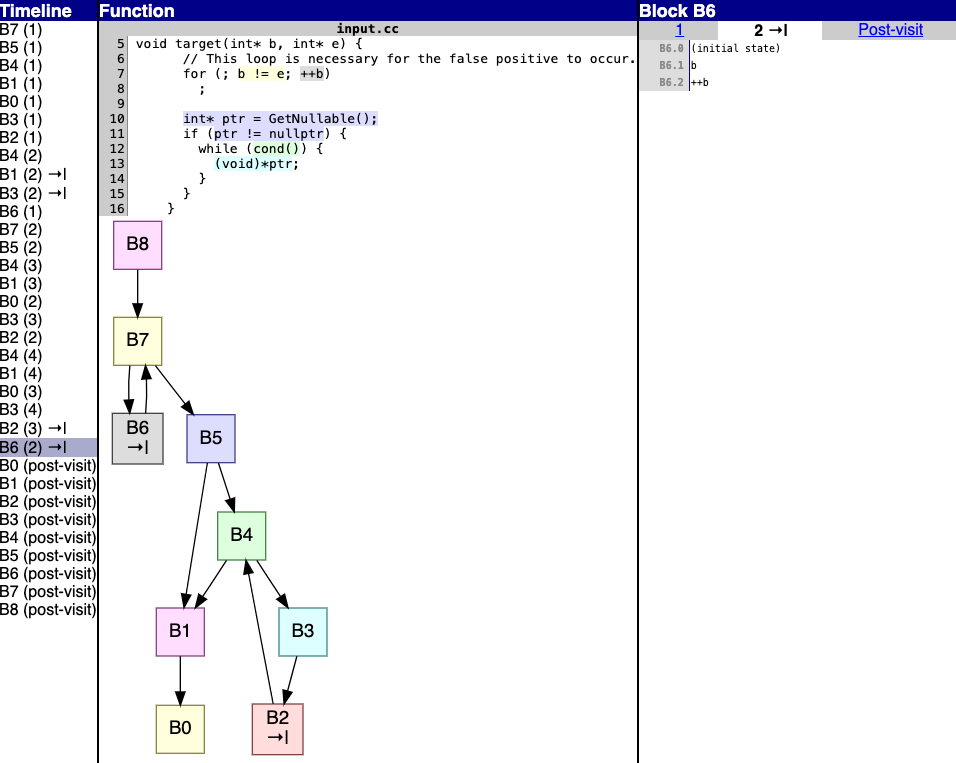
Commit: b49b3ddd828192f0b3ef43762ab832b085ac95c4
https://github.com/llvm/llvm-project/commit/b49b3ddd828192f0b3ef43762ab832b085ac95c4
Author: Kazu Hirata <kazu at google.com>
Date: 2024-01-30 (Tue, 30 Jan 2024)
Changed paths:
M llvm/include/llvm/ADT/SmallPtrSet.h
Log Message:
-----------
[ADT] Use a constexpr version of llvm::bit_ceil (NFC) (#79709)
This patch replaces the template trick with a constexpr function that
is more readable. Once C++20 is available in our code base, we can
remove the constexpr function in favor of std::bit_ceil.
Commit: f292f90bc2ec2c1ec4306027e17877bb4603d8d2
https://github.com/llvm/llvm-project/commit/f292f90bc2ec2c1ec4306027e17877bb4603d8d2
Author: Yingwei Zheng <dtcxzyw2333 at gmail.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/Transforms/InstCombine/InstCombineSelect.cpp
M llvm/test/Transforms/InstCombine/fabs.ll
Log Message:
-----------
[InstCombine] Fold select with signbit idiom into fabs (#76342)
This patch folds:
```
((bitcast X to int) <s 0 ? -X : X) -> fabs(X)
((bitcast X to int) >s -1 ? X : -X) -> fabs(X)
((bitcast X to int) <s 0 ? X : -X) -> -fabs(X)
((bitcast X to int) >s -1 ? -X : X) -> -fabs(X)
```
Alive2: https://alive2.llvm.org/ce/z/rGepow
Commit: d71831a2172e4cf7c3f3540c472ce2aeb14d4505
https://github.com/llvm/llvm-project/commit/d71831a2172e4cf7c3f3540c472ce2aeb14d4505
Author: Chuanqi Xu <yedeng.yd at linux.alibaba.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M clang/test/Interpreter/cxx20-modules.cppm
Log Message:
-----------
[NFC] [clang-repl] Fix test failures due to incosistent target settings
See https://github.com/llvm/llvm-project/pull/79261 for details.
It shows that clang-repl uses a different target triple with clang so that it
may be problematic if the calng-repl reads the generated BMI from clang
in a different target triple.
While the underlying issue is not easy to fix, this patch tries to make
this test green to not bother developers.
Commit: dc5dca1d0118a826459026cfe5819f3f83b599ed
https://github.com/llvm/llvm-project/commit/dc5dca1d0118a826459026cfe5819f3f83b599ed
Author: Chia <sun1011jacobi at gmail.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/Target/RISCV/RISCVISelLowering.cpp
M llvm/test/CodeGen/RISCV/rvv/vector-interleave.ll
A llvm/test/CodeGen/RISCV/rvv/vwadd-mask-sdnode.ll
Log Message:
-----------
[RISCV][Isel] Remove redundant vmerge for the scalable vwadd(u).wv (#80079)
Similar to #78403, but for scalable `vwadd(u).wv`, given that #76785 is recommited.
### Code
```
define <vscale x 8 x i64> @vwadd_wv_mask_v8i32(<vscale x 8 x i32> %x, <vscale x 8 x i64> %y) {
%mask = icmp slt <vscale x 8 x i32> %x, shufflevector (<vscale x 8 x i32> insertelement (<vscale x 8 x i32> poison, i32 42, i64 0), <vscale x 8 x i32> poison, <vscale x 8 x i32> zeroinitializer)
%a = select <vscale x 8 x i1> %mask, <vscale x 8 x i32> %x, <vscale x 8 x i32> zeroinitializer
%sa = sext <vscale x 8 x i32> %a to <vscale x 8 x i64>
%ret = add <vscale x 8 x i64> %sa, %y
ret <vscale x 8 x i64> %ret
}
```
### Before this patch
[Compiler Explorer](https://godbolt.org/z/xsoa5xPrd)
```
vwadd_wv_mask_v8i32:
li a0, 42
vsetvli a1, zero, e32, m4, ta, ma
vmslt.vx v0, v8, a0
vmv.v.i v12, 0
vmerge.vvm v24, v12, v8, v0
vwadd.wv v8, v16, v24
ret
```
### After this patch
```
vwadd_wv_mask_v8i32:
li a0, 42
vsetvli a1, zero, e32, m4, ta, ma
vmslt.vx v0, v8, a0
vsetvli zero, zero, e32, m4, tu, mu
vwadd.wv v16, v16, v8, v0.t
vmv8r.v v8, v16
ret
```
Commit: db49319264d6d2b6f9f7b345495d543210c2cfe3
https://github.com/llvm/llvm-project/commit/db49319264d6d2b6f9f7b345495d543210c2cfe3
Author: Matthias Springer <me at m-sp.org>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M mlir/lib/Dialect/MemRef/IR/MemRefOps.cpp
M mlir/test/Dialect/GPU/decompose-memrefs.mlir
M mlir/test/Dialect/MemRef/fold-memref-alias-ops.mlir
M mlir/test/Dialect/MemRef/invalid.mlir
M mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_rewrite_sort_coo.mlir
Log Message:
-----------
[mlir][memref] `memref.subview`: Verify result strides (#79865)
The `memref.subview` verifier currently checks result shape, element
type, memory space and offset of the result type. However, the strides
of the result type are currently not verified. This commit adds
verification of result strides for non-rank reducing ops and fixes
invalid IR in test cases.
Verification of result strides for ops with rank reductions is more
complex (and there could be multiple possible result types). That is
left for a separate commit.
Also refactor the implementation a bit:
* If `computeMemRefRankReductionMask` could not compute the dropped
dimensions, there must be something wrong with the op. Return
`FailureOr` instead of `std::optional`.
* `isRankReducedMemRefType` did much more than just checking whether the
op has rank reductions or not. Inline the implementation into the
verifier and add better comments.
* `produceSubViewErrorMsg` does not have to be templatized.
Commit: f8525030004f907cd108e7c18df255a6d3b23124
https://github.com/llvm/llvm-project/commit/f8525030004f907cd108e7c18df255a6d3b23124
Author: Jay Foad <jay.foad at amd.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/CodeGen/RegisterClassInfo.cpp
Log Message:
-----------
[CodeGen] Don't include aliases in RegisterClassInfo::IgnoreCSRForAllocOrder (#80015)
Previously we called ignoreCSRForAllocationOrder on every alias of every
CSR which was expensive on targets like AMDGPU which define a very large
number of overlapping register tuples.
On such targets it is simpler and faster to call
ignoreCSRForAllocationOrder once for every physical register.
Differential Revision: https://reviews.llvm.org/D146735
Commit: 96c907dbcebdfbc88f73e097270d171bb83ec3cf
https://github.com/llvm/llvm-project/commit/96c907dbcebdfbc88f73e097270d171bb83ec3cf
Author: Matthias Springer <me at m-sp.org>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M mlir/lib/Dialect/MemRef/IR/MemRefOps.cpp
M mlir/test/Dialect/GPU/decompose-memrefs.mlir
M mlir/test/Dialect/MemRef/fold-memref-alias-ops.mlir
M mlir/test/Dialect/MemRef/invalid.mlir
M mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_rewrite_sort_coo.mlir
Log Message:
-----------
Revert "[mlir][memref] `memref.subview`: Verify result strides" (#80116)
Reverts llvm/llvm-project#79865
I think there is a bug in the stride computation in
`SubViewOp::inferResultType`. (Was already there before this change.)
Reverting this commit for now and updating the original pull request
with a fix and more test cases.
Commit: 64a849a52e08827e889be22ed3ceafe62cd03793
https://github.com/llvm/llvm-project/commit/64a849a52e08827e889be22ed3ceafe62cd03793
Author: Timm Baeder <tbaeder at redhat.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M clang/lib/AST/Interp/ByteCodeEmitter.cpp
M clang/lib/AST/Interp/ByteCodeExprGen.cpp
M clang/lib/AST/Interp/Disasm.cpp
M clang/lib/AST/Interp/IntegralAP.h
M clang/lib/AST/Interp/Interp.h
M clang/lib/AST/Interp/Opcodes.td
M clang/test/AST/Interp/intap.cpp
Log Message:
-----------
[clang][Interp] Support arbitrary precision constants (#79747)
Add (de)serialization support for them, like we do for Floating values.
Commit: d439f3640b6261f372c614afced7bac321af2958
https://github.com/llvm/llvm-project/commit/d439f3640b6261f372c614afced7bac321af2958
Author: jinchen62 <49575973+jinchen62 at users.noreply.github.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M mlir/include/mlir/Dialect/Linalg/TransformOps/LinalgTransformOps.td
M mlir/lib/Dialect/Linalg/TransformOps/LinalgTransformOps.cpp
M mlir/test/Dialect/Linalg/tile-to-forall.mlir
Log Message:
-----------
Add support of param type for transform.structured.tile_using_forall (#72097)
Make transform.structured.tile_using_forall be able to take param type
tile sizes.
Examples:
```
%tile_sizes = transform.param.constant 16 : i64 -> !transform.param<i64>
transform.structured.tile_using_forall %matmul tile_sizes [%tile_sizes : !transform.param<i64>, 32] ( mapping = [#gpu.block<x>, #gpu.block<y>] ) : (!transform.any_op) -> (!transform.any_op, !transform.any_op)
```
```
%c10 = transform.param.constant 10 : i64 -> !transform.any_param
%c20 = transform.param.constant 20 : i64 -> !transform.any_param
%tile_sizes = transform.merge_handles %c10, %c20 : !transform.any_param
transform.structured.tile_using_forall %matmul tile_sizes *(%tile_sizes : !transform.any_param) ( mapping = [#gpu.block<x>, #gpu.block<y>] ) : (!transform.any_op) -> (!transform.any_op, !transform.any_op)
```
Commit: dd736661826e215ac70ff3a4a4ccd75bda0c5ccd
https://github.com/llvm/llvm-project/commit/dd736661826e215ac70ff3a4a4ccd75bda0c5ccd
Author: Sander de Smalen <sander.desmalen at arm.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/Target/AArch64/AArch64ExpandPseudoInsts.cpp
M llvm/lib/Target/AArch64/AArch64ISelLowering.cpp
M llvm/lib/Target/AArch64/AArch64ISelLowering.h
M llvm/lib/Target/AArch64/AArch64RegisterInfo.cpp
M llvm/lib/Target/AArch64/AArch64SMEInstrInfo.td
M llvm/test/CodeGen/AArch64/sme-disable-gisel-fisel.ll
A llvm/test/CodeGen/AArch64/sme-pstate-sm-changing-call-disable-coalescing.ll
M llvm/test/CodeGen/AArch64/sme-streaming-body.ll
M llvm/test/CodeGen/AArch64/sme-streaming-compatible-interface.ll
M llvm/test/CodeGen/AArch64/sme-streaming-interface.ll
M llvm/test/CodeGen/AArch64/sme-streaming-mode-changing-call-disable-stackslot-scavenging.ll
Log Message:
-----------
[SME] Stop RA from coalescing COPY instructions that transcend beyond smstart/smstop. (#78294)
This patch introduces a 'COALESCER_BARRIER' which is a pseudo node that
expands to
a 'nop', but which stops the register allocator from coalescing a COPY
node when
its use/def crosses a SMSTART or SMSTOP instruction.
For example:
%0:fpr64 = COPY killed $d0
undef %2.dsub:zpr = COPY %0 // <- Do not coalesce this COPY
ADJCALLSTACKDOWN 0, 0
MSRpstatesvcrImm1 1, 0, csr_aarch64_smstartstop, implicit-def dead $d0
$d0 = COPY killed %0
BL @use_f64, csr_aarch64_aapcs
If the COPY would be coalesced, that would lead to:
$d0 = COPY killed %0
being replaced by:
$d0 = COPY killed %2.dsub
which means the whole ZPR reg would be live upto the call, causing the
MSRpstatesvcrImm1 (smstop) to spill/reload the ZPR register:
str q0, [sp] // 16-byte Folded Spill
smstop sm
ldr z0, [sp] // 16-byte Folded Reload
bl use_f64
which would be incorrect for two reasons:
1. The program may load more data than it has allocated.
2. If there are other SVE objects on the stack, the compiler might use
the
'mul vl' addressing modes to access the spill location.
By disabling the coalescing, we get the desired results:
str d0, [sp, #8] // 8-byte Folded Spill
smstop sm
ldr d0, [sp, #8] // 8-byte Folded Reload
bl use_f64
Commit: 89f87c387627150d342722b79c78cea2311cddf7
https://github.com/llvm/llvm-project/commit/89f87c387627150d342722b79c78cea2311cddf7
Author: Yingwei Zheng <dtcxzyw2333 at gmail.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/docs/RISCVUsage.rst
M llvm/docs/ReleaseNotes.rst
M llvm/lib/Support/RISCVISAInfo.cpp
M llvm/lib/Target/RISCV/RISCVFeatures.td
M llvm/lib/Target/RISCV/RISCVInstrInfoZa.td
M llvm/lib/Target/RISCV/RISCVSchedRocket.td
M llvm/lib/Target/RISCV/RISCVSchedSiFive7.td
M llvm/lib/Target/RISCV/RISCVSchedSiFiveP400.td
M llvm/lib/Target/RISCV/RISCVSchedSyntacoreSCR1.td
M llvm/lib/Target/RISCV/RISCVSchedule.td
M llvm/test/CodeGen/RISCV/attributes.ll
A llvm/test/MC/RISCV/rvzabha-invalid.s
A llvm/test/MC/RISCV/rvzabha-valid.s
A llvm/test/MC/RISCV/rvzabha-zacas-valid.s
M llvm/unittests/Support/RISCVISAInfoTest.cpp
Log Message:
-----------
[RISCV][MC] Add MC layer support for the experimental zabha extension (#80005)
This patch implements the zabha (Byte and Halfword Atomic Memory
Operations) v1.0-rc1 extension.
See also https://github.com/riscv/riscv-zabha/blob/v1.0-rc1/zabha.adoc.
Commit: 488f88b844739fb8dac6a05799a1e1ec450c0ad9
https://github.com/llvm/llvm-project/commit/488f88b844739fb8dac6a05799a1e1ec450c0ad9
Author: srcarroll <50210727+srcarroll at users.noreply.github.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M mlir/include/mlir/Dialect/Linalg/TransformOps/LinalgMatchOps.td
M mlir/lib/Dialect/Linalg/TransformOps/LinalgMatchOps.cpp
M mlir/test/Dialect/Linalg/match-ops-interpreter.mlir
M mlir/test/Dialect/Linalg/match-ops-invalid.mlir
Log Message:
-----------
[mlir][transform] Add elementwise criteria to `match.structured.body` (#79626)
As far as I am aware, there is no simple way to match on elementwise
ops. I propose to add an `elementwise` criteria to the
`match.structured.body` op. Although my only hesitation is that
elementwise is not only determined by the body, but also the indexing
maps. So if others find this too awkward, I can implement a separate
match op instead.
Commit: 95ef8e386823717efeb2b7b1d02bfbb28473cccc
https://github.com/llvm/llvm-project/commit/95ef8e386823717efeb2b7b1d02bfbb28473cccc
Author: Cullen Rhodes <cullen.rhodes at arm.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M mlir/include/mlir/Dialect/ArmSME/IR/ArmSMEIntrinsicOps.td
M mlir/include/mlir/Dialect/ArmSME/IR/ArmSMEOps.td
M mlir/include/mlir/Dialect/ArmSME/Transforms/Passes.h
M mlir/include/mlir/Dialect/ArmSME/Transforms/Passes.td
M mlir/include/mlir/Dialect/ArmSME/Transforms/Transforms.h
M mlir/lib/Conversion/ArmSMEToLLVM/ArmSMEToLLVM.cpp
M mlir/lib/Dialect/ArmSME/Transforms/CMakeLists.txt
A mlir/lib/Dialect/ArmSME/Transforms/OuterProductFusion.cpp
M mlir/test/Conversion/ArmSMEToLLVM/arm-sme-to-llvm.mlir
M mlir/test/Dialect/ArmSME/invalid.mlir
A mlir/test/Dialect/ArmSME/outer-product-fusion.mlir
M mlir/test/Dialect/ArmSME/roundtrip.mlir
A mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-outerproduct-f16f16f32.mlir
M mlir/test/Target/LLVMIR/arm-sme.mlir
Log Message:
-----------
[mlir][ArmSME] Support 2-way widening outer products (#78975)
This patch introduces support for 2-way widening outer products. This
enables the fusion of 2 'arm_sme.outerproduct' operations that are
chained via the accumulator into a 2-way widening outer product
operation.
Changes:
- Add 'llvm.aarch64.sme.[us]mop[as].za32' intrinsics for 2-way variants.
These map to instruction variants added in SME2 and use different
intrinsics. Intrinsics are already implemented for widening variants
from SME1.
- Adds the following operations:
- fmopa_2way, fmops_2way
- smopa_2way, smops_2way
- umopa_2way, umops_2way
- Implements conversions for the above ops to intrinsics in
ArmSMEToLLVM.
- Adds a pass 'arm-sme-outer-product-fusion' that fuses
'arm_sme.outerproduct' operations.
For a detailed description of these operations see the
'arm_sme.fmopa_2way' description.
The reason for introducing many operations rather than one is the
signed/unsigned variants can't be distinguished with types (e.g., ui16,
si16) since 'arith.extui' and 'arith.extsi' only support signless
integers. A single operation would require this information and an
attribute (for example) for the sign doesn't feel right if
floating-point types are also supported where this wouldn't apply.
Furthermore, the SME FP8 extensions (FEAT_SME_F8F16, FEAT_SME_F8F32)
introduce FMOPA 2-way (FP8 to FP16) and 4-way (FP8 to FP32) variants but
no subtract variant. Whilst these are not supported in this patch, it
felt simpler to have separate ops for add/subtract given this.
Commit: 88610b79510983d7838e4f97411d5a2ac1f8fee8
https://github.com/llvm/llvm-project/commit/88610b79510983d7838e4f97411d5a2ac1f8fee8
Author: Benjamin Maxwell <benjamin.maxwell at arm.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M mlir/lib/Dialect/Vector/Transforms/LowerVectorTranspose.cpp
M mlir/test/Dialect/Vector/vector-transpose-lowering.mlir
Log Message:
-----------
[mlir][vector] Disable transpose -> shuffle lowering for scalable vectors (#79979)
vector.shuffle is not supported for scalable vectors (outside of splats)
Commit: ce7cc723b9d51ad9c741bbaeecb5e008b2b81338
https://github.com/llvm/llvm-project/commit/ce7cc723b9d51ad9c741bbaeecb5e008b2b81338
Author: Matthias Springer <springerm at google.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M mlir/lib/Dialect/MemRef/IR/MemRefOps.cpp
M mlir/lib/Dialect/MemRef/Transforms/ExpandStridedMetadata.cpp
M mlir/test/Dialect/GPU/decompose-memrefs.mlir
M mlir/test/Dialect/MemRef/fold-memref-alias-ops.mlir
M mlir/test/Dialect/MemRef/invalid.mlir
M mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_rewrite_sort_coo.mlir
Log Message:
-----------
[mlir][memref] `memref.subview`: Verify result strides
The `memref.subview` verifier currently checks result shape, element type, memory space and offset of the result type. However, the strides of the result type are currently not verified. This commit adds verification of result strides for non-rank reducing ops and fixes invalid IR in test cases.
Verification of result strides for ops with rank reductions is more complex (and there could be multiple possible result types). That is left for a separate commit.
Also refactor the implementation a bit:
* If `computeMemRefRankReductionMask` could not compute the dropped dimensions, there must be something wrong with the op. Return `FailureOr` instead of `std::optional`.
* `isRankReducedMemRefType` did much more than just checking whether the op has rank reductions or not. Inline the implementation into the verifier and add better comments.
* `produceSubViewErrorMsg` does not have to be templatized.
* Fix comment and add additional assert to `ExpandStridedMetadata.cpp`, to make sure that the memref.subview verifier is in sync with the memref.subview -> memref.reinterpret_cast lowering.
Note: This change is identical to #79865, but with a fixed comment and an additional assert in `ExpandStridedMetadata.cpp`. (I reverted #79865 in #80116, but the implementation was actually correct, just the comment in `ExpandStridedMetadata.cpp` was confusing.)
Commit: db1fbd65eb5cec0eb8ac0bd0cc38c88dda1babf7
https://github.com/llvm/llvm-project/commit/db1fbd65eb5cec0eb8ac0bd0cc38c88dda1babf7
Author: Nikita Popov <npopov at redhat.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/test/Transforms/BDCE/invalidate-assumptions.ll
Log Message:
-----------
[BDCE] Add tests for #80113 (NFC)
Commit: 44ba4c732b60f4e3ab83703e4c83b35f91c4eb13
https://github.com/llvm/llvm-project/commit/44ba4c732b60f4e3ab83703e4c83b35f91c4eb13
Author: David Spickett <david.spickett at linaro.org>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
A .github/workflows/merged-prs.yml
M llvm/utils/git/github-automation.py
Log Message:
-----------
[GitHub][workflows] Add buildbot information comment to first merged PR from a new contributor (#78292)
This change adds a comment to the first PR from a new contributor that
is merged, which tells them what to expect post merge from the build
bots.
How they will be notified, where to ask questions, that you're more
likely to be reverted than in other projects, etc. The information
overlaps with, and links to
https://llvm.org/docs/MyFirstTypoFix.html#myfirsttypofix-issues-after-landing-your-pr.
So that users who simply read the email are still aware, and know where
to follow up if they do get reports.
To do this, I have added a hidden HTML comment to the new contributor
greeting comment. This workflow will look for that to tell if the author
of the PR was a new contributor at the time they opened the merge. It
has to be done this way because as soon as the PR is merged, they are by
GitHub's definition no longer a new contributor and I suspect that their
author association will be "contributor" instead.
I cannot 100% confirm that without a whole lot of effort and probably
breaking GitHub's terms of service, but it's fairly cheap to work around
anyway. It seems rare / almost impossible to reopen a PR in llvm at
least, but in case it does happen the buildbot info comment has its own
hidden HTML comment. If we find this we will not post another copy of
the same information.
Commit: 24a804101b67676aa9fa7f1097043ddd9e2ac1b6
https://github.com/llvm/llvm-project/commit/24a804101b67676aa9fa7f1097043ddd9e2ac1b6
Author: Timm Baeder <tbaeder at redhat.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/include/llvm/Support/raw_ostream.h
M llvm/lib/Support/Process.cpp
M llvm/lib/Support/Unix/Process.inc
M llvm/lib/Support/Windows/Process.inc
Log Message:
-----------
[llvm][Support] Support bright colors in raw_ostream (#80017)
Commit: b210cbbd0eb8ef7cd2735e99570474e6e53ee00b
https://github.com/llvm/llvm-project/commit/b210cbbd0eb8ef7cd2735e99570474e6e53ee00b
Author: Nikita Popov <npopov at redhat.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/Transforms/Scalar/BDCE.cpp
M llvm/test/Transforms/BDCE/invalidate-assumptions.ll
Log Message:
-----------
[BDCE] Fix clearing of poison-generating flags
If the demanded bits of an instruction are full, we don't have to
recurse to its users, but we may still have to clear flags on the
instruction itself.
Fixes https://github.com/llvm/llvm-project/issues/80113.
Commit: da784a25557e29996bd33638d51d569ddf989faf
https://github.com/llvm/llvm-project/commit/da784a25557e29996bd33638d51d569ddf989faf
Author: Matthias Springer <me at m-sp.org>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M mlir/include/mlir/IR/Block.h
M mlir/include/mlir/IR/PatternMatch.h
M mlir/lib/IR/Block.cpp
M mlir/lib/IR/PatternMatch.cpp
M mlir/test/Transforms/test-strict-pattern-driver.mlir
M mlir/test/lib/Dialect/Test/TestPatterns.cpp
Log Message:
-----------
[mlir][IR] Add `RewriterBase::moveBlockBefore` and fix bug in `moveOpBefore` (#79579)
This commit adds a new method to the rewriter API: `moveBlockBefore`.
This op is utilized by `inlineRegionBefore` and covered by dialect
conversion test cases.
Also fixes a bug in `moveOpBefore`, where the previous op location was
not passed correctly. Adds a test case to
`test-strict-pattern-driver.mlir`.
Commit: 942cc9a222343d18339d08516166cfe94445fd13
https://github.com/llvm/llvm-project/commit/942cc9a222343d18339d08516166cfe94445fd13
Author: Jay Foad <jay.foad at amd.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/CodeGen/RegisterClassInfo.cpp
Log Message:
-----------
Revert "[CodeGen] Don't include aliases in RegisterClassInfo::IgnoreCSRForAllocOrder (#80015)"
This reverts commit f8525030004f907cd108e7c18df255a6d3b23124.
It was supposed to speed things up but llvm-compile-time-tracker.com
showed a slight slow down.
Commit: 50e80e06d1d4d1de200a3b349fcdd0dd0d0eb66d
https://github.com/llvm/llvm-project/commit/50e80e06d1d4d1de200a3b349fcdd0dd0d0eb66d
Author: Yingwei Zheng <dtcxzyw2333 at gmail.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/include/llvm/Analysis/ValueTracking.h
M llvm/lib/Analysis/InstructionSimplify.cpp
M llvm/lib/Analysis/ValueTracking.cpp
M llvm/lib/Transforms/InstCombine/InstCombineCalls.cpp
A llvm/test/Analysis/ValueTracking/powi-nneg.ll
M llvm/test/CodeGen/Thumb2/mve-vmaxnma-commute.ll
M llvm/test/Transforms/InstCombine/copysign-fneg-fabs.ll
M llvm/test/Transforms/InstSimplify/floating-point-arithmetic-strictfp.ll
Log Message:
-----------
[ValueTracking] Merge `cannotBeOrderedLessThanZeroImpl` into `computeKnownFPClass` (#76360)
This patch merges the logic of `cannotBeOrderedLessThanZeroImpl` into
`computeKnownFPClass` to improve the signbit inference.
---------
Co-authored-by: Matt Arsenault <arsenm2 at gmail.com>
Commit: c2c650f62e15ca2444e1a938fdf869c84535ef16
https://github.com/llvm/llvm-project/commit/c2c650f62e15ca2444e1a938fdf869c84535ef16
Author: Jay Foad <jay.foad at amd.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/Target/AMDGPU/SIISelLowering.cpp
M llvm/test/CodeGen/AMDGPU/global-constant.ll
M llvm/test/CodeGen/AMDGPU/llvm.memcpy.ll
M llvm/test/CodeGen/AMDGPU/rel32.ll
Log Message:
-----------
[AMDGPU] Stop combining arbitrary offsets into PAL relocs (#80034)
PAL uses ELF REL (not RELA) relocations which can only store a 32-bit
addend in the instruction, even for reloc types like R_AMDGPU_ABS32_HI
which require the upper 32 bits of a 64-bit address calculation to be
correct. This means that it is not safe to fold an arbitrary offset into
a GlobalAddressSDNode, so stop doing that.
In practice this is mostly a problem for small negative offsets which do
not work as expected because PAL treats the 32-bit addend as unsigned.
Commit: 0217d2e089afba8ca33330713787521ba52a1056
https://github.com/llvm/llvm-project/commit/0217d2e089afba8ca33330713787521ba52a1056
Author: David Spickett <david.spickett at linaro.org>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M clang/docs/HIPSupport.rst
Log Message:
-----------
[clang][AMDGPU] Remove trialing whitespace in doc
Added by f2a78e68eee53646327f71c475c7f18a28b7f576.
Wouldn't normally bother but it's showing up in some CI checks,
just want to reduce the noise.
Commit: 78e0cca135076154abab21eadd146dc1dfd3549f
https://github.com/llvm/llvm-project/commit/78e0cca135076154abab21eadd146dc1dfd3549f
Author: Robert Konicar <robert.konicar at trailofbits.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M mlir/lib/Rewrite/PatternApplicator.cpp
Log Message:
-----------
[mlir] Fix debug output for passes that modify top-level operation. (#80022)
Make it so that when the top-level (root) operation itself is being
modified, it is also used as the root for debug output in
PatternApplicator.
Fix #80021
Commit: e624648bd903208a92d8edbecbfa92085d1c34dc
https://github.com/llvm/llvm-project/commit/e624648bd903208a92d8edbecbfa92085d1c34dc
Author: Simon Camphausen <simon.camphausen at iml.fraunhofer.de>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M mlir/include/mlir/Dialect/EmitC/IR/EmitC.td
M mlir/lib/Target/Cpp/TranslateToCpp.cpp
M mlir/test/Dialect/EmitC/ops.mlir
A mlir/test/Target/Cpp/verbatim.mlir
Log Message:
-----------
[mlir][EmitC] Add `verbatim` op (#79584)
The `verbatim` operation produces no results and the value is emitted as
is followed by a line break ('\n' character) during translation.
Note: Use with caution. This operation can have arbitrary effects on the
semantics of the emitted code. Use semantically more meaningful
operations whenever possible. Additionally this op is *NOT* intended to
be used to inject large snippets of code.
This operation can be used in situations where a more suitable operation
is not yet implemented in the dialect or where preprocessor directives
interfere with the structure of the code.
Co-authored-by: Marius Brehler <marius.brehler at iml.fraunhofer.de>
Commit: 5a07774fe11b560652b15776ff6477ba17b6cae0
https://github.com/llvm/llvm-project/commit/5a07774fe11b560652b15776ff6477ba17b6cae0
Author: Vyacheslav Levytskyy <89994100+VyacheslavLevytskyy at users.noreply.github.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/Target/SPIRV/SPIRVBuiltins.cpp
M llvm/lib/Target/SPIRV/SPIRVCallLowering.cpp
M llvm/lib/Target/SPIRV/SPIRVGlobalRegistry.cpp
M llvm/lib/Target/SPIRV/SPIRVGlobalRegistry.h
A llvm/test/CodeGen/SPIRV/pointers/custom-kernel-arg-type.ll
Log Message:
-----------
[SPIR-V] Improve how lowering of formal arguments in SPIR-V Backend interprets a value of 'kernel_arg_type' (#78730)
The goal of this PR is to tolerate differences between description of
formal arguments by function metadata (represented by "kernel_arg_type")
and LLVM actual parameter types. A compiler may use "kernel_arg_type" of
function metadata fields to encode detailed type information, whereas
LLVM IR may utilize for an actual parameter a more general type, in
particular, opaque pointer type. This PR proposes to resolve this by a
fallback to LLVM actual parameter types during the lowering of formal
function arguments in cases when the type can't be created by string
content of "kernel_arg_type", i.e., when "kernel_arg_type" contains a
type unknown for the SPIR-V Backend.
An example of the issue manifestation is
https://github.com/KhronosGroup/SPIRV-LLVM-Translator/blob/main/test/transcoding/KernelArgTypeInOpString.ll,
where a compiler generates for the following kernel function detailed
`kernel_arg_type` info in a form of `!{!"image_kernel_data*", !"myInt",
!"struct struct_name*"}`, and in LLVM IR same arguments are referred to
as `@foo(ptr addrspace(1) %in, i32 %out, ptr addrspace(1) %outData)`.
Both definitions are correct, and the resulting LLVM IR is correct, but
lowering stage of SPIR-V Backend fails to generate SPIR-V type.
```
typedef int myInt;
typedef struct {
int width;
int height;
} image_kernel_data;
struct struct_name {
int i;
int y;
};
void kernel foo(__global image_kernel_data* in,
__global struct struct_name *outData,
myInt out) {}
```
```
define spir_kernel void @foo(ptr addrspace(1) %in, i32 %out, ptr addrspace(1) %outData) ... !kernel_arg_type !7 ... {
entry:
ret void
}
...
!7 = !{!"image_kernel_data*", !"myInt", !"struct struct_name*"}
```
The PR changes a contract of `SPIRVType *getArgSPIRVType(...)` in a way
that it may return `nullptr` to signal that the metadata string content
is not recognized, so corresponding comments are added and a couple of
checks for `nullptr` are inserted where appropriate.
Commit: 53b9d479d5a4d31d2b4a57af7640c0747100a59d
https://github.com/llvm/llvm-project/commit/53b9d479d5a4d31d2b4a57af7640c0747100a59d
Author: Simon Pilgrim <llvm-dev at redking.me.uk>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/test/CodeGen/X86/i256-add.ll
Log Message:
-----------
[X86] i256-add - replace i386 triple X32 check prefixes with X86 and add gnux32 triple tests
Commit: 8d450b47ba28748edfe975b35ab603bd43688d9b
https://github.com/llvm/llvm-project/commit/8d450b47ba28748edfe975b35ab603bd43688d9b
Author: Simon Pilgrim <llvm-dev at redking.me.uk>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/test/CodeGen/X86/mmx-arith.ll
Log Message:
-----------
[X86] mmx-arith.ll - replace X32 check prefixes with X86 + strip cfi noise
We try to only use X32 for gnux32 triple tests.
Commit: 00a68171085dbf7f02ec8ddad6240d90ba6d7286
https://github.com/llvm/llvm-project/commit/00a68171085dbf7f02ec8ddad6240d90ba6d7286
Author: Simon Pilgrim <llvm-dev at redking.me.uk>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/test/CodeGen/X86/v4f32-immediate.ll
Log Message:
-----------
[X86] v4f32-immediate.ll - replace X32 check prefixes with X86
We try to only use X32 for gnux32 triple tests.
Commit: 929503ead36bd954a2fa9ca4338d12d8ddd607ff
https://github.com/llvm/llvm-project/commit/929503ead36bd954a2fa9ca4338d12d8ddd607ff
Author: Simon Pilgrim <llvm-dev at redking.me.uk>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/test/CodeGen/X86/v2f32.ll
Log Message:
-----------
[X86] v2f32.ll - replace X32 check prefixes with X86 (and add common CHECK prefix)
We try to only use X32 for gnux32 triple tests.
Commit: 3f5fcb59ae582ebfbe3f23050d90f86a2cb76eb0
https://github.com/llvm/llvm-project/commit/3f5fcb59ae582ebfbe3f23050d90f86a2cb76eb0
Author: Simon Pilgrim <llvm-dev at redking.me.uk>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/tools/llvm-exegesis/lib/ResultAggregator.cpp
Log Message:
-----------
Fix MSVC "not all control paths return a value" warning. NFC.
Commit: b4370140b4467eddc42e7b8075959c692daaf3e8
https://github.com/llvm/llvm-project/commit/b4370140b4467eddc42e7b8075959c692daaf3e8
Author: Dominik Adamski <dominik.adamski at amd.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/Frontend/OpenMP/OMPIRBuilder.cpp
A mlir/test/Target/LLVMIR/omptarget-teams-llvm.mlir
Log Message:
-----------
[OpenMPIRBuilder] Do not call host runtime for GPU teams codegen (#79984)
Patch ensures that host runtime functions are not called for handling
OpenMP teams clause on the device.
GPU code for pragma `omp target teams distribute parallel do` will
require only one call to OpenMP loop-worksharing GPU runtime. Support
for it will be added later.
This patch does not include changes required for handling `omp target
teams` for the host side.
Commit: cb6240d247b3419dea29eb99261171ea239b1c5c
https://github.com/llvm/llvm-project/commit/cb6240d247b3419dea29eb99261171ea239b1c5c
Author: Nikita Popov <npopov at redhat.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/Transforms/Scalar/BDCE.cpp
M llvm/test/Transforms/BDCE/invalidate-assumptions.ll
Log Message:
-----------
[BDCE] Also drop poison-generating metadata
The comment was incorrect: !range also applies to calls, and we
do need to drop it in some cases.
Commit: 5cc87b424be87db4247f34ae5477be8b09a573e9
https://github.com/llvm/llvm-project/commit/5cc87b424be87db4247f34ae5477be8b09a573e9
Author: Nikita Popov <npopov at redhat.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/AsmParser/LLParser.cpp
A llvm/test/Assembler/incomplete-ir-declarations.ll
Log Message:
-----------
[AsmParser] Add missing globals declarations in incomplete IR mode (#79855)
If `-allow-incomplete-ir` is enabled, automatically insert declarations
for missing globals.
If a global is only used in calls with the same function type, insert a
function declaration with that type.
Otherwise, insert a dummy i8 global. The fallback case could be extended
with various heuristics (e.g. we could look at load/store types), but
I've chosen to keep it simple for now, because I'm unsure to what degree
this would really useful without more experience. I expect that in most
cases the declaration type doesn't really matter (note that the type of
an external global specifies a *minimum* size only, not a precise size).
This is a followup to https://github.com/llvm/llvm-project/pull/78421.
Commit: a74e9ce5dc5cc746bd625b0ef20524a90a073375
https://github.com/llvm/llvm-project/commit/a74e9ce5dc5cc746bd625b0ef20524a90a073375
Author: SunilKuravinakop <98882378+SunilKuravinakop at users.noreply.github.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M clang/include/clang/AST/OpenMPClause.h
M clang/include/clang/AST/RecursiveASTVisitor.h
M clang/include/clang/Basic/DiagnosticSemaKinds.td
M clang/include/clang/Sema/Sema.h
M clang/lib/AST/OpenMPClause.cpp
M clang/lib/AST/StmtProfile.cpp
M clang/lib/CodeGen/CGStmtOpenMP.cpp
M clang/lib/Parse/ParseOpenMP.cpp
M clang/lib/Sema/SemaOpenMP.cpp
M clang/lib/Sema/TreeTransform.h
M clang/lib/Serialization/ASTReader.cpp
M clang/lib/Serialization/ASTWriter.cpp
M clang/test/OpenMP/atomic_ast_print.cpp
M clang/test/OpenMP/atomic_messages.cpp
M clang/tools/libclang/CIndex.cpp
M flang/lib/Semantics/check-omp-structure.cpp
M llvm/include/llvm/Frontend/OpenMP/OMP.td
Log Message:
-----------
[OpenMP] atomic compare weak : Parser & AST support (#79475)
This is a support for " #pragma omp atomic compare weak". It has Parser
& AST support for now.
---------
Authored-by: Sunil Kuravinakop <kuravina at pe28vega.us.cray.com>
Commit: 3abf55a68caefd45042c27b73a658c638afbbb8b
https://github.com/llvm/llvm-project/commit/3abf55a68caefd45042c27b73a658c638afbbb8b
Author: Sander de Smalen <sander.desmalen at arm.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/Target/AArch64/AArch64TargetTransformInfo.cpp
M llvm/test/Transforms/Inline/AArch64/sme-pstatesm-attrs.ll
Log Message:
-----------
[AArch64][SME] Fix inlining bug introduced in #78703 (#79994)
Calling a `__arm_locally_streaming` function from a function that
is not a streaming-SVE function would lead to incorrect inlining.
The issue didn't surface because the tests were not testing what
they were supposed to test.
Commit: d309261d05cf173e6a18b20be986877fd87fe4f3
https://github.com/llvm/llvm-project/commit/d309261d05cf173e6a18b20be986877fd87fe4f3
Author: Nashe Mncube <nashe.mncube at arm.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/IR/Instructions.cpp
A llvm/test/Transforms/InstCombine/bitcast-bfloat-half-mixing.ll
Log Message:
-----------
[llvm][InstCombine] bitcast bfloat half castpair bug (#79832)
Miscompilation arises due to instruction combining of cast pairs of the
type `bitcast bfloat to half` + `<FPOp> bfloat to half` or `bitcast half
to bfloat` + `<FPOp half to bfloat`. For example `bitcast bfloat to
half`+`fpext half to double` or `bitcast bfloat to half`+`fpext bfloat
to double` respectively reduce to `fpext bfloat to double` and `fpext
half to double`. This is an incorrect conversion as it assumes the
representation of `bfloat` and `half` are equivalent due to having the
same width. As a consequence miscompilation arises.
Fixes #61984
Commit: d55d72e931bab77a3d1265cf03f4da7858a49478
https://github.com/llvm/llvm-project/commit/d55d72e931bab77a3d1265cf03f4da7858a49478
Author: Billy Laws <blaws05 at gmail.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/test/tools/llvm-rc/windres-prefix.test
M llvm/tools/llvm-rc/llvm-rc.cpp
Log Message:
-----------
[llvm-rc] Support ARM64EC resource generation (#78908)
This is already supported in llvm-cvtres, so only a small change is
needed.
Commit: d74619abb53bc9c5680f83bb1dead9c65135ecc6
https://github.com/llvm/llvm-project/commit/d74619abb53bc9c5680f83bb1dead9c65135ecc6
Author: Billy Laws <blaws05 at gmail.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M clang/lib/Driver/ToolChains/MinGW.cpp
M clang/test/Driver/mingw.cpp
Log Message:
-----------
[clang] [MinGW] Handle linking ARM64EC code (#78912)
Commit: 042800a4dd79375ec0895c8959a43c86149232f3
https://github.com/llvm/llvm-project/commit/042800a4dd79375ec0895c8959a43c86149232f3
Author: Benjamin Maxwell <benjamin.maxwell at arm.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M mlir/include/mlir/Dialect/ArmSME/Transforms/Passes.h
M mlir/include/mlir/Dialect/ArmSME/Transforms/Passes.td
M mlir/include/mlir/Dialect/ArmSME/Utils/Utils.h
M mlir/lib/Dialect/ArmSME/IR/Utils.cpp
M mlir/lib/Dialect/ArmSME/Transforms/CMakeLists.txt
A mlir/lib/Dialect/ArmSME/Transforms/VectorLegalization.cpp
A mlir/test/Dialect/ArmSME/vector-legalization.mlir
A mlir/test/Integration/Dialect/Linalg/CPU/ArmSME/multi-tile-matmul.mlir
A mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-multi-tile-transpose.mlir
Log Message:
-----------
[mlir][ArmSME] Add initial SME vector legalization pass (#79152)
This adds a new pass (`-arm-sme-vector-legalization`) which legalizes
vector operations so that they can be lowered to ArmSME. This initial
patch adds decomposition for `vector.outerproduct`,
`vector.transfer_read`, and `vector.transfer_write` when they operate on
vector types larger than a single SME tile. For example, a [8]x[8]xf32
outer product would be decomposed into four [4]x[4]xf32 outer products,
which could then be lowered to ArmSME. These three ops have been picked
as supporting them alone allows lowering matmuls that use all ZA
accumulators to ArmSME.
For it to be possible to legalize a vector type it has to be a multiple
of an SME tile size, but other than that any shape can be used. E.g.
`vector<[8]x[8]xf32>`, `vector<[4]x[16]xf32>`, `vector<[16]x[4]xf32>`
can all be lowered to four `vector<[4]x[4]xf32>` operations.
In future, this pass will be extended with more SME-specific rewrites to
legalize unrolling the reduction dimension of matmuls (which is not
type-decomposition), which is why the pass has quite a general name.
Commit: 912cdd2179783b67926d53adc77c12148076ddb2
https://github.com/llvm/llvm-project/commit/912cdd2179783b67926d53adc77c12148076ddb2
Author: Simon Pilgrim <llvm-dev at redking.me.uk>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/CodeGen/SelectionDAG/SelectionDAG.cpp
Log Message:
-----------
[DAG] AddNodeIDCustom - call ShuffleVectorSDNode::getMask once instead of repeated getMaskElt calls.
Use a simpler for-range loop to append all shuffle mask elements
Commit: a82ca1cd1b57671ce5ddbed63c6418f6841fe71d
https://github.com/llvm/llvm-project/commit/a82ca1cd1b57671ce5ddbed63c6418f6841fe71d
Author: Simon Pilgrim <llvm-dev at redking.me.uk>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/test/CodeGen/X86/insertps-from-constantpool.ll
Log Message:
-----------
[X86] insertps-from-constantpool.ll - replace X32 check prefixes with X86 and expose address math
We try to only use X32 for gnux32 triple tests.
Use no_x86_scrub_mem_shuffle so the test shows updated shuffle intermediate and the +4 offset into the constant pool vector entry
Commit: e4af212f967027430b4b313d2cca51888601547b
https://github.com/llvm/llvm-project/commit/e4af212f967027430b4b313d2cca51888601547b
Author: Simon Pilgrim <llvm-dev at redking.me.uk>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/test/CodeGen/X86/divrem.ll
Log Message:
-----------
[X86] divrem.ll - replace X32 check prefixes with X86
We try to only use X32 for gnux32 triple tests.
Commit: ed11f255a89f6eb3713a3d4f2b241317a41be40c
https://github.com/llvm/llvm-project/commit/ed11f255a89f6eb3713a3d4f2b241317a41be40c
Author: Simon Pilgrim <llvm-dev at redking.me.uk>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/test/CodeGen/X86/divide-by-constant.ll
Log Message:
-----------
[X86] divide-by-constant.ll - replace X32 check prefixes with X86
We try to only use X32 for gnux32 triple tests.
Commit: 824d073fb654891dc31523f6b68f49818cfaf40a
https://github.com/llvm/llvm-project/commit/824d073fb654891dc31523f6b68f49818cfaf40a
Author: Simon Pilgrim <llvm-dev at redking.me.uk>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/test/CodeGen/X86/fold-vector-sext-crash2.ll
M llvm/test/CodeGen/X86/fold-vector-sext-zext.ll
Log Message:
-----------
[X86] fold-vector-sext - replace X32 check prefixes with X86
We try to only use X32 for gnux32 triple tests.
Commit: 1d8c8f11699ef03e8cc299245a16b2bd141b2ba7
https://github.com/llvm/llvm-project/commit/1d8c8f11699ef03e8cc299245a16b2bd141b2ba7
Author: Simon Pilgrim <llvm-dev at redking.me.uk>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/test/CodeGen/X86/cfguard-checks-funclet.ll
M llvm/test/CodeGen/X86/cfguard-checks.ll
M llvm/test/CodeGen/X86/cfguard-module-flag.ll
M llvm/test/CodeGen/X86/cfguard-x86-vectorcall.ll
Log Message:
-----------
[X86] cfguard - replace X32 check prefixes with X86
We try to only use X32 for gnux32 triple tests.
Commit: 648eb7c1415afb818b45782e1f2758a1f7677496
https://github.com/llvm/llvm-project/commit/648eb7c1415afb818b45782e1f2758a1f7677496
Author: Simon Pilgrim <llvm-dev at redking.me.uk>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/test/CodeGen/X86/divrem8_ext.ll
Log Message:
-----------
[X86] divrem8_ext.ll - replace X32 check prefixes with X86
We try to only use X32 for gnux32 triple tests.
Commit: cf828aee2460058db5dacb1523797fe787486f4d
https://github.com/llvm/llvm-project/commit/cf828aee2460058db5dacb1523797fe787486f4d
Author: Rin Dobrescu <irina.dobrescu at arm.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/Target/AArch64/AArch64ISelLowering.cpp
M llvm/test/CodeGen/AArch64/avoid-pre-trunc.ll
A llvm/test/CodeGen/AArch64/concat-vector-add-combine.ll
Log Message:
-----------
[AArch64] Convert concat(uhadd(a,b), uhadd(c,d)) to uhadd(concat(a,c), concat(b,d)) (#79464)
We can convert concat(v4i16 uhadd(a,b), v4i16 uhadd(c,d)) to v8i16
uhadd(concat(a,c), concat(b,d)), which can lead to further
simplifications.
Commit: e3c9327bc493286bf420d1520df8217ae559f5c3
https://github.com/llvm/llvm-project/commit/e3c9327bc493286bf420d1520df8217ae559f5c3
Author: Shengchen Kan <shengchen.kan at intel.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/Target/X86/X86InstrInfo.cpp
M llvm/lib/Target/X86/X86InstrSSE.td
M llvm/test/CodeGen/X86/matrix-multiply.ll
M llvm/test/CodeGen/X86/vector-interleaved-store-i8-stride-8.ll
Log Message:
-----------
[X86][CodeGen] Set isReMaterializable = 1 for AVX broadcast load
Broadcast of a single float should not be any slower than
loading 32B using vmovaps. So remat it can help reduce
register spill when there is big register pressure.
Commit: f96e85b9494f549976fac3947756e6da1fcc572b
https://github.com/llvm/llvm-project/commit/f96e85b9494f549976fac3947756e6da1fcc572b
Author: Mariusz Sikora <mariusz.sikora at amd.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M clang/test/CodeGenOpenCL/builtins-amdgcn-gfx12-err.cl
Log Message:
-----------
[AMDGPU][GFX12] Add tests for unsupported builtins (#78729)
__builtin_amdgcn_mfma* and __builtin_amdgcn_smfmac*
Commit: d9e875dcc13359f2a399b04e7c54bf70c0306a89
https://github.com/llvm/llvm-project/commit/d9e875dcc13359f2a399b04e7c54bf70c0306a89
Author: XinWang10 <108658776+XinWang10 at users.noreply.github.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/Target/X86/X86InstrMisc.td
M llvm/lib/Target/X86/X86InstrSSE.td
A llvm/test/MC/Disassembler/X86/apx/lzcnt.txt
A llvm/test/MC/Disassembler/X86/apx/popcnt.txt
A llvm/test/MC/Disassembler/X86/apx/tzcnt.txt
A llvm/test/MC/X86/apx/lzcnt-att.s
A llvm/test/MC/X86/apx/lzcnt-intel.s
A llvm/test/MC/X86/apx/popcnt-att.s
A llvm/test/MC/X86/apx/popcnt-intel.s
A llvm/test/MC/X86/apx/tzcnt-att.s
A llvm/test/MC/X86/apx/tzcnt-intel.s
M llvm/test/TableGen/x86-fold-tables.inc
Log Message:
-----------
[X86][MC] Support encoding/decoding for APX variant LZCNT/TZCNT/POPCNT instructions (#79954)
Two variants: promoted legacy, NF (no flags update).
The syntax of NF instructions is aligned with GNU binutils.
https://sourceware.org/pipermail/binutils/2023-September/129545.html
Commit: 817d0cb4856236e16c7065fc37fbdd97a3ca67e0
https://github.com/llvm/llvm-project/commit/817d0cb4856236e16c7065fc37fbdd97a3ca67e0
Author: Yingwei Zheng <dtcxzyw2333 at gmail.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/Transforms/InstCombine/InstCombineCompares.cpp
M llvm/test/Transforms/InstCombine/fcmp-select.ll
M llvm/test/Transforms/InstCombine/icmp-select.ll
Log Message:
-----------
[InstCombine] Simplify commutative compares of symmetric pairs (#80134)
Fixes #78038.
Commit: 9536a6286e470960601d269a4bd478927aceea61
https://github.com/llvm/llvm-project/commit/9536a6286e470960601d269a4bd478927aceea61
Author: Florian Hahn <flo at fhahn.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/Transforms/Vectorize/VPlanTransforms.cpp
M llvm/test/Transforms/LoopVectorize/X86/interleaved-accesses-hoist-load-across-store.ll
M llvm/test/Transforms/LoopVectorize/X86/pr36524.ll
M llvm/test/Transforms/LoopVectorize/cast-induction.ll
M llvm/test/Transforms/LoopVectorize/float-induction.ll
M llvm/test/Transforms/LoopVectorize/induction-multiple-uses-in-same-instruction.ll
M llvm/test/Transforms/LoopVectorize/induction-unroll-novec.ll
M llvm/test/Transforms/LoopVectorize/iv_outside_user.ll
M llvm/test/Transforms/LoopVectorize/optimal-epilog-vectorization.ll
M llvm/test/Transforms/LoopVectorize/runtime-check-needed-but-empty.ll
M llvm/test/Transforms/LoopVectorize/single-value-blend-phis.ll
M llvm/test/Transforms/LoopVectorize/uniform_across_vf_induction2.ll
M llvm/test/Transforms/LoopVectorize/vect-phiscev-sext-trunc.ll
Log Message:
-----------
[VPlan] Preserve original induction order when creating scalar steps.
Update createScalarIVSteps to take an insert point as parameter. This
ensures that the inserted scalar steps are in the same order as the
recipes they replace (vs in reverse order as currently). This helps to
reduce the diff for follow-up changes.
Commit: ab874268f636bdfc83b567429ca2d2483f7cc831
https://github.com/llvm/llvm-project/commit/ab874268f636bdfc83b567429ca2d2483f7cc831
Author: Joel Wee <joelwee at google.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M utils/bazel/llvm-project-overlay/mlir/BUILD.bazel
Log Message:
-----------
Fix after #79152
Commit: c672b342c3b6ae70a0b25852e3ce3bcadd684b11
https://github.com/llvm/llvm-project/commit/c672b342c3b6ae70a0b25852e3ce3bcadd684b11
Author: Matthias Springer <me at m-sp.org>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M mlir/lib/IR/PatternMatch.cpp
M mlir/test/Dialect/Affine/simplify-structures.mlir
M mlir/test/Transforms/test-strict-pattern-driver.mlir
M mlir/test/lib/Dialect/Test/TestPatterns.cpp
Log Message:
-----------
[mlir][IR] Send missing notifications when inlining a block (#79593)
When a block is inlined into another block, the nested operations are
moved into another block and the `notifyOperationInserted` callback
should be triggered. This commit adds the missing notifications for:
* `RewriterBase::inlineBlockBefore`
* `RewriterBase::mergeBlocks`
Commit: 7e45cfda8f75e44f23eee7622a31c04841df888e
https://github.com/llvm/llvm-project/commit/7e45cfda8f75e44f23eee7622a31c04841df888e
Author: Joel Wee <joelwee at google.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M utils/bazel/llvm-project-overlay/mlir/BUILD.bazel
Log Message:
-----------
[mlir] Fix ab874268f636bdfc83b567429ca2d2483f7cc831
Commit: 121a0ef0bbc1a69760b69391b387e2efda0ad922
https://github.com/llvm/llvm-project/commit/121a0ef0bbc1a69760b69391b387e2efda0ad922
Author: Simon Camphausen <simon.camphausen at iml.fraunhofer.de>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M mlir/include/mlir/Dialect/EmitC/IR/EmitC.td
Log Message:
-----------
[mlir][EmitC] Remove unused attribute from verbatim op (#80142)
The uses of the attribute were removed in code review of #79584, but
it's definition was inadvertently kept.
Commit: cec24f0d7efc206e329890821e92a4b25c550885
https://github.com/llvm/llvm-project/commit/cec24f0d7efc206e329890821e92a4b25c550885
Author: Florian Hahn <flo at fhahn.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/Transforms/Vectorize/VPlanTransforms.cpp
M llvm/test/Transforms/LoopVectorize/PowerPC/optimal-epilog-vectorization.ll
Log Message:
-----------
[VPlan] Update stale test after 9536a6286, fix formatting.
Commit: c2675ba91aa22e7530465f027fbd853c05b95192
https://github.com/llvm/llvm-project/commit/c2675ba91aa22e7530465f027fbd853c05b95192
Author: Matthias Springer <me at m-sp.org>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M mlir/lib/IR/PatternMatch.cpp
M mlir/lib/Transforms/Utils/DialectConversion.cpp
M mlir/test/Transforms/test-strict-pattern-driver.mlir
M mlir/test/lib/Dialect/Test/TestPatterns.cpp
Log Message:
-----------
[mlir][IR] Send missing notification when splitting a block (#79597)
When a block is split with `RewriterBase::splitBlock`, a
`notifyBlockInserted` notification, followed by
`notifyOperationInserted` notifications (for moving over the operations
into the new block) should be sent. This commit adds those
notifications.
Commit: de75e5079ae1d4894c918fd452e468fb6a888be1
https://github.com/llvm/llvm-project/commit/de75e5079ae1d4894c918fd452e468fb6a888be1
Author: Alfie Richards <156316945+AlfieRichardsArm at users.noreply.github.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/Target/ARM/ARMExpandPseudoInsts.cpp
M llvm/lib/Target/ARM/ARMISelDAGToDAG.cpp
M llvm/lib/Target/ARM/ARMInstrNEON.td
M llvm/test/CodeGen/ARM/arm-vlddup-update.ll
M llvm/test/CodeGen/ARM/arm-vlddup.ll
M llvm/test/CodeGen/ARM/bf16-intrinsics-ld-st.ll
Log Message:
-----------
[ARM][NEON] Add constraint to vld2 Odd/Even Pseudo instructions. (#79287)
This ensures the odd/even pseudo instructions are allocated to the same
register range.
This fixes #71763
Commit: e538486e90539096e7851d0deba4ea9ed94fced2
https://github.com/llvm/llvm-project/commit/e538486e90539096e7851d0deba4ea9ed94fced2
Author: Zahira Ammarguellat <zahira.ammarguellat at intel.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M clang/lib/Driver/ToolChains/Clang.cpp
M clang/test/Driver/range.c
Log Message:
-----------
[Driver] Fix erroneous warning for -fcx-limited-range and -fcx-fortran-rules. (#79821)
The options `-fcx-limited-range` and `-fcx-fortran-rules` were added in
_https://github.com/llvm/llvm-project/pull/70244_
The code adding the options introduced an erroneous warning.
`$ clang -c -fcx-limited-range t1.c`
`clang: warning: overriding '' option with '-fcx-limited-range'
[-Woverriding-option]`
and
`$ clang -c -fcx-fortran-rules t1.c`
`clang: warning: overriding '' option with '-fcx-fortran-rules'
[-Woverriding-option]`
The warning doesn't make sense. This patch removes it.
Commit: 4f32f5d5720fbef06672714a62376f236a36aef5
https://github.com/llvm/llvm-project/commit/4f32f5d5720fbef06672714a62376f236a36aef5
Author: Nikita Popov <npopov at redhat.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/include/llvm/Analysis/AliasAnalysis.h
M llvm/include/llvm/Analysis/BasicAliasAnalysis.h
M llvm/lib/Analysis/BasicAliasAnalysis.cpp
M llvm/lib/Transforms/Scalar/JumpThreading.cpp
M llvm/test/Transforms/JumpThreading/pr79175.ll
Log Message:
-----------
[AA][JumpThreading] Don't use DomTree for AA in JumpThreading (#79294)
JumpThreading may perform AA queries while the dominator tree is not up
to date, which may result in miscompilations.
Fix this by adding a new AAQI option to disable the use of the dominator
tree in BasicAA.
Fixes https://github.com/llvm/llvm-project/issues/79175.
Commit: 74bf0b1cd9dde53b2df08966bcf2f91d4909ccd6
https://github.com/llvm/llvm-project/commit/74bf0b1cd9dde53b2df08966bcf2f91d4909ccd6
Author: Guray Ozen <guray.ozen at gmail.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M mlir/lib/Dialect/GPU/Pipelines/GPUToNVVMPipeline.cpp
A mlir/test/Dialect/GPU/test-nvvm-pipeline.mlir
Log Message:
-----------
[mlir] Lower math dialect later in gpu-lower-to-nvvm-pipeline (#78556)
This PR moves lowering of math dialect later in the pipeline. Because
math dialect is lowered correctly by `createConvertGpuOpsToNVVMOps` for
GPU target, and it needs to run it first.
Commit: 9bf4e54ef42d907ae7550f36fa518f14fa97af6f
https://github.com/llvm/llvm-project/commit/9bf4e54ef42d907ae7550f36fa518f14fa97af6f
Author: Andrey Ali Khan Bolshakov <32954549+bolshakov-a at users.noreply.github.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M clang/lib/Sema/SemaTemplate.cpp
M clang/test/CoverageMapping/templates.cpp
Log Message:
-----------
[clang] Represent array refs as `TemplateArgument::Declaration` (#80050)
This returns (probably temporarily) array-referring NTTP behavior to
which was prior to #78041 because ~~I'm fed up~~ have no time to fix
regressions.
Commit: b7738e275dc097f224d00434253b485288a6caff
https://github.com/llvm/llvm-project/commit/b7738e275dc097f224d00434253b485288a6caff
Author: Quentin Dian <dianqk at dianqk.net>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/CodeGen/MIRPrinter.cpp
M llvm/test/CodeGen/AArch64/GlobalISel/uaddo-8-16-bits.mir
M llvm/test/CodeGen/AArch64/regalloc-last-chance-recolor-with-split.mir
M llvm/test/CodeGen/AArch64/tail-dup-redundant-phi.mir
M llvm/test/CodeGen/AMDGPU/GlobalISel/legalize-trap.mir
M llvm/test/CodeGen/ARM/constant-island-movwt.mir
A llvm/test/CodeGen/MIR/X86/unreachable-block-print.mir
M llvm/test/CodeGen/X86/statepoint-invoke-ra-enter-at-end.mir
M llvm/test/CodeGen/X86/statepoint-invoke-ra-remove-back-copies.mir
M llvm/test/CodeGen/X86/statepoint-vreg-invoke.ll
Log Message:
-----------
[MIRPrinter] Don't print space when there is no successor (#80143)
Extra space causes the checks generated by update_mir_test_checks to be
unavailable.
```
# NOTE: Assertions have been autogenerated by utils/update_mir_test_checks.py UTC_ARGS: --version 4
# RUN: llc -mtriple=x86_64-- -o - %s -run-pass=none -verify-machineinstrs -simplify-mir | FileCheck %s
---
name: foo
body: |
; CHECK-LABEL: name: foo
; CHECK: bb.0:
; CHECK-NEXT: successors:
; CHECK-NEXT: {{ $}}
; CHECK-NEXT: {{ $}}
; CHECK-NEXT: bb.1:
; CHECK-NEXT: RET 0, $eax
bb.0:
successors:
bb.1:
RET 0, $eax
...
```
The failure log is as follows:
```
llvm/test/CodeGen/MIR/X86/unreachable-block-print.mir:9:16: error: CHECK-NEXT: is on the same line as previous match
; CHECK-NEXT: {{ $}}
^
<stdin>:21:13: note: 'next' match was here
successors:
^
<stdin>:21:13: note: previous match ended here
successors:
```
Commit: 70fb96a28678c488326a135fe298175b9a3a7657
https://github.com/llvm/llvm-project/commit/70fb96a28678c488326a135fe298175b9a3a7657
Author: Benjamin Kramer <benny.kra at googlemail.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M mlir/lib/Conversion/ComplexToStandard/ComplexToStandard.cpp
M mlir/test/Conversion/ComplexToStandard/convert-to-standard.mlir
M mlir/test/Conversion/ComplexToStandard/full-conversion.mlir
M mlir/test/Integration/Dialect/Complex/CPU/correctness.mlir
Log Message:
-----------
Revert "[mlir][complex] Prevent underflow in complex.abs (#79786)"
This reverts commit 4effff21fb2f3462e06fcbd7812562f4771b0487. It makes
`complex.abs(-1)` return `-1`.
Commit: 4679132a85c6c4cced2a71ef6422b793ae39598c
https://github.com/llvm/llvm-project/commit/4679132a85c6c4cced2a71ef6422b793ae39598c
Author: jeanPerier <jperier at nvidia.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M flang/include/flang/Runtime/io-api.h
M flang/lib/Lower/CallInterface.cpp
M flang/lib/Lower/IO.cpp
M flang/runtime/io-api.cpp
A flang/test/Lower/io-asynchronous.f90
M flang/test/Lower/io-statement-1.f90
Log Message:
-----------
[flang] Lower ASYNCHRONOUS variables and IO statements (#80008)
Finish plugging-in ASYNCHRONOUS IO in lowering (GetAsynchronousId was
not used yet).
Add a runtime implementation for GetAsynchronousId (only the signature
was defined). Always return zero since flang runtime "fakes"
asynchronous IO (data transfer are always complete, see
flang/docs/IORuntimeInternals.md).
Update all runtime integer argument and results for IDs to use the
AsynchronousId int alias for consistency.
In lowering, asynchronous attribute is added on the hlfir.declare of
ASYNCHRONOUS variable, but nothing else is done. This is OK given the
synchronous aspects of flang IO, but it would be safer to treat these
variable as volatile (prevent code motion of related store/loads) since
the asynchronous data change can also be done by C defined user
procedure (see 18.10.4 Asynchronous communication). Flang lowering
anyway does not give enough info for LLVM to do such code motions (the
variables that are passed in a call are not given the noescape
attribute, so LLVM will assume any later opaque call may modify the
related data and would not move load/stores of such variables
before/after calls even if it could from a pure Fortran point of view
without ASYNCHRONOUS).
Commit: 47df391296fcf8fe430e1ff6f797e5d7cfd41ca4
https://github.com/llvm/llvm-project/commit/47df391296fcf8fe430e1ff6f797e5d7cfd41ca4
Author: Timm Baeder <tbaeder at redhat.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M clang/lib/AST/Interp/ByteCodeExprGen.h
M clang/lib/AST/Interp/Context.h
M clang/lib/AST/Interp/Interp.cpp
M clang/lib/AST/Interp/InterpBuiltin.cpp
M clang/test/AST/Interp/functions.cpp
M clang/test/SemaCXX/builtin-std-move.cpp
Log Message:
-----------
[clang][Interp] Handle std::move etc. builtins (#70772)
Commit: 6e6aa44c7d14b37a12e40c6b36478045d6004a0a
https://github.com/llvm/llvm-project/commit/6e6aa44c7d14b37a12e40c6b36478045d6004a0a
Author: Erich Keane <ekeane at nvidia.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M clang/docs/ReleaseNotes.rst
M clang/lib/Sema/SemaTemplateInstantiate.cpp
R clang/test/SemaTemplate/default-parm-init.cpp
Log Message:
-----------
Revert "[Clang][Sema] fix outline member function template with defau… (#80144)
…lt align crash (#78400)"
This reverts commit 7b3389980ddbd84f72ccc4776889c67519cc2c14.
A regression was discovered here:
https://github.com/llvm/llvm-project/pull/78400
and the author requested a revert to give time to review.
Commit: 31fc0a12e1552e6bcea63ae740f284eaf74f4c17
https://github.com/llvm/llvm-project/commit/31fc0a12e1552e6bcea63ae740f284eaf74f4c17
Author: Boian Petkantchin <boian.petkantchin at amd.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M mlir/docs/Dialects/Mesh.md
M mlir/include/mlir/Dialect/Mesh/IR/CMakeLists.txt
M mlir/include/mlir/Dialect/Mesh/IR/MeshBase.td
A mlir/include/mlir/Dialect/Mesh/IR/MeshDialect.h
M mlir/include/mlir/Dialect/Mesh/IR/MeshOps.h
M mlir/include/mlir/Dialect/Mesh/IR/MeshOps.td
M mlir/include/mlir/InitAllDialects.h
M mlir/lib/Dialect/Mesh/IR/CMakeLists.txt
M mlir/lib/Dialect/Mesh/IR/MeshOps.cpp
M mlir/lib/Dialect/Mesh/Transforms/ShardingPropagation.cpp
M mlir/lib/Dialect/Mesh/Transforms/Spmdization.cpp
M mlir/lib/Dialect/Mesh/Transforms/Transforms.cpp
M mlir/test/Dialect/Mesh/invalid.mlir
M mlir/test/Dialect/Mesh/ops.mlir
M mlir/test/lib/Dialect/Mesh/TestProcessMultiIndexOpLowering.cpp
M mlir/test/lib/Dialect/Mesh/TestSimplifications.cpp
Log Message:
-----------
[mlir][mesh] Refactoring code organization, tests and docs (#79606)
* Split out `MeshDialect.h` form `MeshOps.h` that defines the dialect
class. Reduces include clutter if you care only about the dialect and
not the ops.
* Expose functions `getMesh` and `collectiveProcessGroupSize`. There
functions are useful for outside users of the dialect.
* Remove unused code.
* Remove examples and tests of mesh.shard attribute in tensor encoding.
Per the decision that Spmdization would be performed on sharding
annotations and there will be no tensors with sharding specified in the
type.
For more info see this RFC comment:
https://discourse.llvm.org/t/rfc-sharding-framework-design-for-device-mesh/73533/81
Commit: 1bab570e9b82a68089348a3bca388d297a72f60f
https://github.com/llvm/llvm-project/commit/1bab570e9b82a68089348a3bca388d297a72f60f
Author: Shimin Cui <scui at ca.ibm.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/Target/PowerPC/PPCMergeStringPool.cpp
M llvm/test/CodeGen/PowerPC/mergeable-string-pool-large.ll
M llvm/test/CodeGen/PowerPC/mergeable-string-pool.ll
Log Message:
-----------
Move the PowerPC/PPCMergeStringPool work to initializer (#77352)
Currently, the `PPCMergeStringPool` merges the global variable after the
`AsmPrinter` initializer adds the global variables to its symbol list.
This is to move the merging work of `PPCMergeStringPool` to its
initializer, just like what GlobalMerge does, to avoid adding merged
global variables to the `AsmPrinter` symbol lis.
Commit: c651b2b0d9d1393fb5191ac3acfe96e5ecc94bbc
https://github.com/llvm/llvm-project/commit/c651b2b0d9d1393fb5191ac3acfe96e5ecc94bbc
Author: AdityaK <1894981+hiraditya at users.noreply.github.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/cmake/modules/LLVMExternalProjectUtils.cmake
Log Message:
-----------
Fix: CMake Error at cmake/modules/LLVMExternalProjectUtils.cmake:86 (is_msvc_triple) (#80071)
Adding quotes around the `${target_triple}`
Fix: #78530
Commit: 8d1b1c9b97de557299e8148a79d756c1e8d9b7eb
https://github.com/llvm/llvm-project/commit/8d1b1c9b97de557299e8148a79d756c1e8d9b7eb
Author: Sam McCall <sam.mccall at gmail.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M clang/include/clang/AST/ASTNodeTraverser.h
M clang/include/clang/AST/JSONNodeDumper.h
M clang/include/clang/AST/TextNodeDumper.h
M clang/include/clang/AST/TypeLoc.h
M clang/lib/AST/ASTDumper.cpp
M clang/lib/AST/ASTTypeTraits.cpp
M clang/lib/AST/JSONNodeDumper.cpp
M clang/lib/AST/TextNodeDumper.cpp
A clang/unittests/AST/ASTDumperTest.cpp
M clang/unittests/AST/CMakeLists.txt
Log Message:
-----------
[AST] Add dump() method to TypeLoc (#65484)
The ability to dump AST nodes is important to ad-hoc debugging, and
the fact this doesn't work with TypeLoc nodes is an obvious missing
feature in e.g. clang-query (`set output dump` simply does nothing).
Having TypeLoc::dump(), and enabling DynTypedNode::dump() for such nodes
seems like a clear win.
It looks like this:
```
int main(int argc, char **argv);
FunctionProtoTypeLoc <test.cc:3:1, col:31> 'int (int, char **)' cdecl
|-ParmVarDecl 0x30071a8 <col:10, col:14> col:14 argc 'int'
| `-BuiltinTypeLoc <col:10> 'int'
|-ParmVarDecl 0x3007250 <col:20, col:27> col:27 argv 'char **'
| `-PointerTypeLoc <col:20, col:26> 'char **'
| `-PointerTypeLoc <col:20, col:25> 'char *'
| `-BuiltinTypeLoc <col:20> 'char'
`-BuiltinTypeLoc <col:1> 'int'
```
It dumps the lexically nested tree of type locs.
This often looks similar to how types are dumped, but unlike types
we don't look at desugaring e.g. typedefs, as their underlying types
are not lexically spelled here.
---
Less clear is exactly when to include these nodes in existing text AST
dumps rooted at (TranslationUnit)Decls.
These already omit supported nodes sometimes, e.g. NestedNameSpecifiers
are often mentioned but not recursively dumped.
TypeLocs are a more extreme case: they're ~always more verbose
than the current AST dump.
So this patch punts on that, TypeLocs are only ever printed recursively
as part of a TypeLoc::dump() call.
It would also be nice to be able to invoke `clang` to dump a typeloc
somehow, like `clang -cc1 -ast-dump`. But I don't know exactly what the
best verison of that is, so this patch doesn't do it.
---
There are similar (less critical!) nodes: TemplateArgumentLoc etc,
these also don't have dump() functions today and are obvious extensions.
I suspect that we should add these, and Loc nodes should dump each other
(e.g. the ElaboratedTypeLoc `vector<int>::iterator` should dump
the NestedNameSpecifierLoc `vector<int>::`, which dumps the
TemplateSpecializationTypeLoc `vector<int>::` etc).
Maybe this generalizes further to a "full syntactic dump" mode, where
even Decls and Stmts would print the TypeLocs they lexically contain.
But this may be more complex than useful.
---
While here, ConceptReference JSON dumping must be implemented. It's not
totally clear to me why this implementation wasn't required before but
is now...
Commit: 88418460502c524de1f1b014316eb5d603c3758f
https://github.com/llvm/llvm-project/commit/88418460502c524de1f1b014316eb5d603c3758f
Author: Sjoerd Meijer <smeijer at nvidia.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/Target/AArch64/AArch64InstrInfo.cpp
M llvm/test/CodeGen/AArch64/arm64-ldp-cluster.ll
M llvm/test/CodeGen/AArch64/zext-to-tbl.ll
Log Message:
-----------
[AArch64] MI Scheduler LDP combine follow up (#79003)
This is a follow up of 75d820dcdd86, adding more opcodes to the combine
target hook enabling more LDP creation.
Patch co-authored by Cameron McInally.
Commit: e33dc6b0282fb28d5289490981ad57d97d83db42
https://github.com/llvm/llvm-project/commit/e33dc6b0282fb28d5289490981ad57d97d83db42
Author: Aaron Ballman <aaron at aaronballman.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M clang/docs/ReleaseNotes.rst
Log Message:
-----------
Add a release note for TypeLoc::dump() support; NFC
This amends 8d1b1c9b97de557299e8148a79d756c1e8d9b7eb which added the
functionality the release note refers to.
Commit: 5d7d89de31ad017a91204988cacc2f0ff69d47da
https://github.com/llvm/llvm-project/commit/5d7d89de31ad017a91204988cacc2f0ff69d47da
Author: David Green <david.green at arm.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/Target/AArch64/AArch64InstrInfo.td
M llvm/test/CodeGen/AArch64/arm64-csel.ll
Log Message:
-----------
[AArch64] Use add_and_or_is_add for CSINC (#79552)
Adds or add-like-or's of 1 can both be turned into csinc, which can help
fold more instructions into a csinc.
Commit: 32c00485f1e896d472549324218878ba6444f4f6
https://github.com/llvm/llvm-project/commit/32c00485f1e896d472549324218878ba6444f4f6
Author: Timm Baeder <tbaeder at redhat.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M clang/lib/AST/Interp/ByteCodeExprGen.cpp
M clang/lib/AST/Interp/Pointer.h
M clang/test/AST/Interp/complex.cpp
Log Message:
-----------
[clang][Interp] Handle casts between complex types (#79269)
Just handle this like two primtive casts.
Commit: dfd5a64da4b76db1ec557ff31e1d64dd7e9eebe5
https://github.com/llvm/llvm-project/commit/dfd5a64da4b76db1ec557ff31e1d64dd7e9eebe5
Author: Timm Bäder <tbaeder at redhat.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M clang/lib/AST/Interp/ByteCodeExprGen.cpp
Log Message:
-----------
[clang][Interp] Remove wrong * operator
classifyComplexElementType used to return a std::optional, seems like
this was left in a PR and not re-tested.
This broke build bots, e.g.
https://lab.llvm.org/buildbot/#/builders/68/builds/67930
Commit: f2df4bfe54cd4161b7a2d89a0bc5dc69e747b01e
https://github.com/llvm/llvm-project/commit/f2df4bfe54cd4161b7a2d89a0bc5dc69e747b01e
Author: Nikita Popov <npopov at redhat.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/include/llvm/AsmParser/LLParser.h
A llvm/include/llvm/AsmParser/NumberedValues.h
M llvm/include/llvm/AsmParser/SlotMapping.h
M llvm/lib/AsmParser/LLParser.cpp
M llvm/lib/CodeGen/MIRParser/MIParser.cpp
A llvm/test/Assembler/skip-value-numbers-globals.ll
M llvm/test/Assembler/skip-value-numbers-invalid.ll
M llvm/unittests/AsmParser/AsmParserTest.cpp
Log Message:
-----------
[AsmParser] Support non-consecutive global value numbers (#80013)
https://github.com/llvm/llvm-project/pull/78171 added support for
non-consecutive local value numbers. This extends the support for global
value numbers (for globals and functions).
This means that it is now possible to delete an unnamed global
definition/declaration without breaking the IR.
This is a lot less common than unnamed local values, but it seems like
something we should support for consistency. (Unnamed globals are used a
lot in Rust though.)
Commit: 0cd83486c0a0973e2242926c7cc3ef561021e3b2
https://github.com/llvm/llvm-project/commit/0cd83486c0a0973e2242926c7cc3ef561021e3b2
Author: LLVM GN Syncbot <llvmgnsyncbot at gmail.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/utils/gn/secondary/clang/unittests/AST/BUILD.gn
Log Message:
-----------
[gn build] Port 8d1b1c9b97de
Commit: 5c2da289d2514e35708832fed41501d136cc3cb0
https://github.com/llvm/llvm-project/commit/5c2da289d2514e35708832fed41501d136cc3cb0
Author: Paul Semel <semelpaul at gmail.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M clang/lib/Analysis/FlowSensitive/Transfer.cpp
M clang/unittests/Analysis/FlowSensitive/TransferTest.cpp
Log Message:
-----------
[clang][dataflow] fix assert in `Environment::getResultObjectLocation` (#79608)
When calling `Environment::getResultObjectLocation` with a
CXXOperatorCallExpr that is a prvalue, we just hit an assert because no
record was ever created.
---------
Co-authored-by: martinboehme <mboehme at google.com>
Commit: bd8bec27e25022b07ec7044654cd6a1efcd9704f
https://github.com/llvm/llvm-project/commit/bd8bec27e25022b07ec7044654cd6a1efcd9704f
Author: Daniel Chen <cdchen at ca.ibm.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M flang/lib/Lower/Bridge.cpp
M flang/lib/Lower/CallInterface.cpp
M flang/lib/Optimizer/Builder/IntrinsicCall.cpp
M flang/test/Lower/HLFIR/procedure-pointer.f90
Log Message:
-----------
[Flang] Support NULL(procptr): null intrinsic that has procedure pointer argument. (#80072)
This PR adds support for NULL intrinsic to have a procedure pointer
argument.
Commit: e34fd2e193686f8a98504b58c12d966ce14b4209
https://github.com/llvm/llvm-project/commit/e34fd2e193686f8a98504b58c12d966ce14b4209
Author: Jay Foad <jay.foad at amd.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/CodeGen/RegisterClassInfo.cpp
Log Message:
-----------
[CodeGen] Simplify RegisterClassInfo BitVector comparisons. NFC.
Commit: baf1b19763ff41d991ac80275bbbff54859c6e7c
https://github.com/llvm/llvm-project/commit/baf1b19763ff41d991ac80275bbbff54859c6e7c
Author: Jay Foad <jay.foad at amd.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/CodeGen/RegisterClassInfo.cpp
Log Message:
-----------
[CodeGen] Use regunits instead of MCRegUnitIterator in RegisterClassInfo. NFC.
Commit: 98dbc688de90cd7019dad32356b466a896b0d2ff
https://github.com/llvm/llvm-project/commit/98dbc688de90cd7019dad32356b466a896b0d2ff
Author: Benjamin Kramer <benny.kra at googlemail.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M mlir/lib/Dialect/GPU/Pipelines/GPUToNVVMPipeline.cpp
R mlir/test/Dialect/GPU/test-nvvm-pipeline.mlir
Log Message:
-----------
Revert "[mlir] Lower math dialect later in gpu-lower-to-nvvm-pipeline (#78556)"
This reverts commit 74bf0b1cd9dde53b2df08966bcf2f91d4909ccd6. The test
always fails.
| mlir/test/Dialect/GPU/test-nvvm-pipeline.mlir:23:16: error: CHECK-PTX: expected string not found in input
| // CHECK-PTX: __nv_expf
https://lab.llvm.org/buildbot/#/builders/61/builds/53789
Commit: 2907c63311bfdeb4c2a09e858b969893a3dd35cc
https://github.com/llvm/llvm-project/commit/2907c63311bfdeb4c2a09e858b969893a3dd35cc
Author: Rin Dobrescu <irina.dobrescu at arm.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/Target/AArch64/AArch64ISelLowering.cpp
M llvm/test/CodeGen/AArch64/avoid-pre-trunc.ll
R llvm/test/CodeGen/AArch64/concat-vector-add-combine.ll
Log Message:
-----------
Revert "[AArch64] Convert concat(uhadd(a,b), uhadd(c,d)) to uhadd(concat(a,c), concat(b,d))" (#80157)
Reverts llvm/llvm-project#79464 while figuring out why the tests are
failing.
Commit: 6720e3af253e458db56a018950065c27872b3c62
https://github.com/llvm/llvm-project/commit/6720e3af253e458db56a018950065c27872b3c62
Author: Benjamin Kramer <benny.kra at googlemail.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M utils/bazel/llvm-project-overlay/mlir/BUILD.bazel
Log Message:
-----------
[bazel] Port 31fc0a12e1552e6bcea63ae740f284eaf74f4c17
Commit: d04ae1b15ff3064e9fb43a3a15f43285d4ee7998
https://github.com/llvm/llvm-project/commit/d04ae1b15ff3064e9fb43a3a15f43285d4ee7998
Author: David Green <david.green at arm.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/lib/Target/AArch64/AArch64InstrInfo.td
M llvm/test/CodeGen/AArch64/arm64-csel.ll
M llvm/test/CodeGen/AArch64/shift-accumulate.ll
Log Message:
-----------
[AArch64] Use DAG->isAddLike in add_and_or_is_add (#79563)
This allows it to work with disjoint or's as well as computing the known
bits.
Commit: b929be2d12a291412f726f2df54934803343fa29
https://github.com/llvm/llvm-project/commit/b929be2d12a291412f726f2df54934803343fa29
Author: Jinsong Ji <jinsong.ji at intel.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M clang/test/Interpreter/cxx20-modules.cppm
Log Message:
-----------
[Clang][test] Add fPIC when building shared library (#80065)
Fix linking error: "ld: error: can't create dynamic relocation
R_X86_64_64 against local symbol in readonly segment; recompile object
files with -fPIC or pass '-Wl,-z,notext' to allow text relocations in
the output"
Commit: 16c4843d3263050b359733a05e86cc4a09361aed
https://github.com/llvm/llvm-project/commit/16c4843d3263050b359733a05e86cc4a09361aed
Author: Benjamin Kramer <benny.kra at googlemail.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M utils/bazel/llvm-project-overlay/mlir/BUILD.bazel
Log Message:
-----------
[bazel] Add missing header file for 31fc0a12e1552e6bcea63ae740f284eaf74f4c17
Commit: 8241106bf30fa74f27e324ba23c42a3503ab5707
https://github.com/llvm/llvm-project/commit/8241106bf30fa74f27e324ba23c42a3503ab5707
Author: Min-Yih Hsu <min.hsu at sifive.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M llvm/test/tools/llvm-exegesis/X86/analysis-epsilons.test
M llvm/tools/llvm-exegesis/lib/Analysis.cpp
Log Message:
-----------
[Exegesis] Print epsilon value in the sched model inconsistency report (#80080)
Since I've formatted the epsilon value, I don't think it's necessary to
escape it.
Commit: 08c0eb183a9ca2983d20f5a5f366df44f199d287
https://github.com/llvm/llvm-project/commit/08c0eb183a9ca2983d20f5a5f366df44f199d287
Author: Michael Buch <michaelbuch12 at gmail.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M lldb/source/Plugins/Language/CPlusPlus/LibCxxMap.cpp
M lldb/source/Plugins/Language/CPlusPlus/LibCxxUnorderedMap.cpp
M lldb/source/Plugins/Language/CPlusPlus/LibCxxVector.cpp
Log Message:
-----------
[lldb][DataFormatter][NFC] Use GetFirstValueOfLibCXXCompressedPair throughout formatters (#80133)
This avoids duplicating the logic to get the first
element of a libc++ `__compressed_pair`. This will
be useful in supporting upcoming changes to the layout
of `__compressed_pair`.
Drive-by changes:
* Renamed `m_item` to `size_node` for readability;
`m_item` suggests it's a member variable, which it
is not.
Commit: 57c66b35a885b571f9897d75d18f1d974c29e533
https://github.com/llvm/llvm-project/commit/57c66b35a885b571f9897d75d18f1d974c29e533
Author: Jason Molenda <jmolenda at apple.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
A lldb/include/lldb/Breakpoint/WatchpointAlgorithms.h
M lldb/include/lldb/lldb-enumerations.h
M lldb/packages/Python/lldbsuite/test/concurrent_base.py
M lldb/source/Breakpoint/CMakeLists.txt
M lldb/source/Breakpoint/Watchpoint.cpp
A lldb/source/Breakpoint/WatchpointAlgorithms.cpp
M lldb/source/Breakpoint/WatchpointResource.cpp
M lldb/source/Commands/CommandObjectWatchpoint.cpp
M lldb/source/Plugins/Process/Utility/StopInfoMachException.cpp
M lldb/source/Plugins/Process/gdb-remote/ProcessGDBRemote.cpp
M lldb/source/Target/StopInfo.cpp
M lldb/test/API/functionalities/watchpoint/large-watchpoint/TestLargeWatchpoint.py
A lldb/test/API/functionalities/watchpoint/unaligned-large-watchpoint/Makefile
A lldb/test/API/functionalities/watchpoint/unaligned-large-watchpoint/TestUnalignedLargeWatchpoint.py
A lldb/test/API/functionalities/watchpoint/unaligned-large-watchpoint/main.c
M lldb/unittests/Breakpoint/CMakeLists.txt
A lldb/unittests/Breakpoint/WatchpointAlgorithmsTests.cpp
Log Message:
-----------
[lldb] Add support for large watchpoints in lldb (#79962)
This patch is the next piece of work in my Large Watchpoint proposal,
https://discourse.llvm.org/t/rfc-large-watchpoint-support-in-lldb/72116
This patch breaks a user's watchpoint into one or more
WatchpointResources which reflect what the hardware registers can cover.
This means we can watch objects larger than 8 bytes, and we can watched
unaligned address ranges. On a typical 64-bit target with 4 watchpoint
registers you can watch 32 bytes of memory if the start address is
doubleword aligned.
Additionally, if the remote stub implements AArch64 MASK style
watchpoints (e.g. debugserver on Darwin), we can watch any power-of-2
size region of memory up to 2GB, aligned to that same size.
I updated the Watchpoint constructor and CommandObjectWatchpoint to
create a CompilerType of Array<UInt8> when the size of the watched
region is greater than pointer-size and we don't have a variable type to
use. For pointer-size and smaller, we can display the watched granule as
an integer value; for larger-than-pointer-size we will display as an
array of bytes.
I have `watchpoint list` now print the WatchpointResources used to
implement the watchpoint.
I added a WatchpointAlgorithm class which has a top-level static method
that takes an enum flag mask WatchpointHardwareFeature and a user
address and size, and returns a vector of WatchpointResources covering
the request. It does not take into account the number of watchpoint
registers the target has, or the number still available for use. Right
now there is only one algorithm, which monitors power-of-2 regions of
memory. For up to pointer-size, this is what Intel hardware supports.
AArch64 Byte Address Select watchpoints can watch any number of
contiguous bytes in a pointer-size memory granule, that is not currently
supported so if you ask to watch bytes 3-5, the algorithm will watch the
entire doubleword (8 bytes). The newly default "modify" style means we
will silently ignore modifications to bytes outside the watched range.
I've temporarily skipped TestLargeWatchpoint.py for all targets. It was
only run on Darwin when using the in-tree debugserver, which was a proxy
for "debugserver supports MASK watchpoints". I'll be adding the
aforementioned feature flag from the stub and enabling full mask
watchpoints when a debugserver with that feature is enabled, and
re-enable this test.
I added a new TestUnalignedLargeWatchpoint.py which only has one test
but it's a great one, watching a 22-byte range that is unaligned and
requires four 8-byte watchpoints to cover.
I also added a unit test, WatchpointAlgorithmsTests, which has a number
of simple tests against WatchpointAlgorithms::PowerOf2Watchpoints. I
think there's interesting possible different approaches to how we cover
these; I note in the unit test that a user requesting a watch on address
0x12e0 of 120 bytes will be covered by two watchpoints today, a
128-bytes at 0x1280 and at 0x1300. But it could be done with a 16-byte
watchpoint at 0x12e0 and a 128-byte at 0x1300, which would have fewer
false positives/private stops. As we try refining this one, it's helpful
to have a collection of tests to make sure things don't regress.
I tested this on arm64 macOS, (genuine) x86_64 macOS, and AArch64
Ubuntu. I have not modifed the Windows process plugins yet, I might try
that as a standalone patch, I'd be making the change blind, but the
necessary changes (see ProcessGDBRemote::EnableWatchpoint) are pretty
small so it might be obvious enough that I can change it and see what
the Windows CI thinks.
There isn't yet a packet (or a qSupported feature query) for the gdb
remote serial protocol stub to communicate its watchpoint capabilities
to lldb. I'll be doing that in a patch right after this is landed,
having debugserver advertise its capability of AArch64 MASK watchpoints,
and have ProcessGDBRemote add eWatchpointHardwareArmMASK to
WatchpointAlgorithms so we can watch larger than 32-byte requests on
Darwin.
I haven't yet tackled WatchpointResource *sharing* by multiple
Watchpoints. This is all part of the goal, especially when we may be
watching a larger memory range than the user requested, if they then add
another watchpoint next to their first request, it may be covered by the
same WatchpointResource (hardware watchpoint register). Also one "read"
watchpoint and one "write" watchpoint on the same memory granule need to
be handled, making the WatchpointResource cover all requests.
As WatchpointResources aren't shared among multiple Watchpoints yet,
there's no handling of running the conditions/commands/etc on multiple
Watchpoints when their shared WatchpointResource is hit. The goal beyond
"large watchpoint" is to unify (much more) the Watchpoint and Breakpoint
behavior and commands. I have a feeling I may be slowly chipping away at
this for a while.
rdar://108234227
Commit: 1689f41ebec8e414a0374c8a835dfe484a1baea5
https://github.com/llvm/llvm-project/commit/1689f41ebec8e414a0374c8a835dfe484a1baea5
Author: Alexey Bataev <a.bataev at outlook.com>
Date: 2024-01-31 (Wed, 31 Jan 2024)
Changed paths:
M .git-blame-ignore-revs
M .github/new-prs-labeler.yml
A .github/workflows/merged-prs.yml
M bolt/include/bolt/Core/BinaryContext.h
M bolt/include/bolt/Utils/CommandLineOpts.h
M bolt/lib/Profile/DataAggregator.cpp
M bolt/lib/Rewrite/LinuxKernelRewriter.cpp
M bolt/lib/Rewrite/RewriteInstance.cpp
M bolt/lib/Utils/CommandLineOpts.cpp
M bolt/test/X86/linux-orc.s
M clang-tools-extra/clang-tidy/bugprone/ReservedIdentifierCheck.cpp
M clang-tools-extra/clangd/InlayHints.cpp
M clang/docs/HIPSupport.rst
M clang/docs/ReleaseNotes.rst
M clang/docs/tools/dump_format_style.py
M clang/include/clang/AST/ASTNodeTraverser.h
M clang/include/clang/AST/JSONNodeDumper.h
M clang/include/clang/AST/OpenMPClause.h
M clang/include/clang/AST/RecursiveASTVisitor.h
M clang/include/clang/AST/TextNodeDumper.h
M clang/include/clang/AST/TypeLoc.h
M clang/include/clang/Analysis/Analyses/PostOrderCFGView.h
M clang/include/clang/Basic/Builtins.td
M clang/include/clang/Basic/DiagnosticDriverKinds.td
M clang/include/clang/Basic/DiagnosticSemaKinds.td
M clang/include/clang/Basic/DiagnosticSerializationKinds.td
M clang/include/clang/Basic/FileManager.h
M clang/include/clang/Basic/OpenACCKinds.h
M clang/include/clang/Lex/HeaderSearch.h
M clang/include/clang/Lex/HeaderSearchOptions.h
M clang/include/clang/Sema/Sema.h
M clang/include/clang/Serialization/ASTBitCodes.h
M clang/include/clang/Serialization/ASTReader.h
M clang/include/clang/Serialization/ASTWriter.h
M clang/include/clang/Serialization/ModuleFile.h
M clang/include/clang/Tooling/DependencyScanning/DependencyScanningFilesystem.h
M clang/include/clang/Tooling/DependencyScanning/DependencyScanningService.h
M clang/lib/AST/ASTDumper.cpp
M clang/lib/AST/ASTTypeTraits.cpp
M clang/lib/AST/DeclTemplate.cpp
M clang/lib/AST/ExprConstant.cpp
M clang/lib/AST/Interp/ByteCodeEmitter.cpp
M clang/lib/AST/Interp/ByteCodeExprGen.cpp
M clang/lib/AST/Interp/ByteCodeExprGen.h
M clang/lib/AST/Interp/Context.h
M clang/lib/AST/Interp/Descriptor.cpp
M clang/lib/AST/Interp/Descriptor.h
M clang/lib/AST/Interp/Disasm.cpp
M clang/lib/AST/Interp/IntegralAP.h
M clang/lib/AST/Interp/Interp.cpp
M clang/lib/AST/Interp/Interp.h
M clang/lib/AST/Interp/InterpBuiltin.cpp
M clang/lib/AST/Interp/InterpFrame.cpp
M clang/lib/AST/Interp/Opcodes.td
M clang/lib/AST/Interp/Pointer.cpp
M clang/lib/AST/Interp/Pointer.h
M clang/lib/AST/Interp/Program.cpp
M clang/lib/AST/JSONNodeDumper.cpp
M clang/lib/AST/OpenMPClause.cpp
M clang/lib/AST/StmtProfile.cpp
M clang/lib/AST/TextNodeDumper.cpp
M clang/lib/Analysis/FlowSensitive/DataflowEnvironment.cpp
M clang/lib/Analysis/FlowSensitive/HTMLLogger.cpp
M clang/lib/Analysis/FlowSensitive/Transfer.cpp
M clang/lib/Analysis/FlowSensitive/TypeErasedDataflowAnalysis.cpp
M clang/lib/Analysis/UnsafeBufferUsage.cpp
M clang/lib/Basic/FileManager.cpp
M clang/lib/Basic/Targets/AMDGPU.cpp
M clang/lib/Basic/Targets/NVPTX.cpp
M clang/lib/Basic/Targets/NVPTX.h
M clang/lib/CodeGen/CGExpr.cpp
M clang/lib/CodeGen/CGStmtOpenMP.cpp
M clang/lib/Driver/ToolChains/Clang.cpp
M clang/lib/Driver/ToolChains/Cuda.cpp
M clang/lib/Driver/ToolChains/MinGW.cpp
M clang/lib/Frontend/CompilerInvocation.cpp
M clang/lib/Lex/HeaderSearch.cpp
M clang/lib/Parse/ParseExpr.cpp
M clang/lib/Parse/ParseObjc.cpp
M clang/lib/Parse/ParseOpenACC.cpp
M clang/lib/Parse/ParseOpenMP.cpp
M clang/lib/Sema/SemaChecking.cpp
M clang/lib/Sema/SemaConcept.cpp
M clang/lib/Sema/SemaDecl.cpp
M clang/lib/Sema/SemaOpenMP.cpp
M clang/lib/Sema/SemaOverload.cpp
M clang/lib/Sema/SemaTemplate.cpp
M clang/lib/Sema/SemaTemplateInstantiate.cpp
M clang/lib/Sema/TreeTransform.h
M clang/lib/Serialization/ASTReader.cpp
M clang/lib/Serialization/ASTWriter.cpp
M clang/lib/StaticAnalyzer/Checkers/StdLibraryFunctionsChecker.cpp
M clang/lib/Tooling/DependencyScanning/DependencyScanningFilesystem.cpp
M clang/lib/Tooling/DependencyScanning/DependencyScanningWorker.cpp
M clang/lib/Tooling/DependencyScanning/ModuleDepCollector.cpp
M clang/test/AST/Interp/complex.cpp
M clang/test/AST/Interp/cxx11.cpp
M clang/test/AST/Interp/cxx17.cpp
M clang/test/AST/Interp/cxx23.cpp
M clang/test/AST/Interp/functions.cpp
M clang/test/AST/Interp/intap.cpp
M clang/test/AST/Interp/literals.cpp
M clang/test/AST/ast-dump-for-range-lifetime.cpp
A clang/test/AST/ast-dump-static-operators.cpp
M clang/test/Analysis/errno-stdlibraryfunctions.c
A clang/test/ClangScanDeps/empty.cpp
A clang/test/ClangScanDeps/missing-vfs.m
A clang/test/ClangScanDeps/optimize-vfs-edgecases.m
A clang/test/ClangScanDeps/optimize-vfs-leak.m
A clang/test/ClangScanDeps/optimize-vfs-pch.m
A clang/test/ClangScanDeps/optimize-vfs.m
M clang/test/CodeGenCXX/cxx2b-static-call-operator.cpp
M clang/test/CodeGenCXX/cxx2b-static-subscript-operator.cpp
M clang/test/CodeGenOpenCL/builtins-amdgcn-gfx12-err.cl
M clang/test/CodeGenOpenCL/builtins-amdgcn-wave64.cl
M clang/test/CoverageMapping/templates.cpp
M clang/test/Driver/cuda-cross-compiling.c
M clang/test/Driver/mingw.cpp
M clang/test/Driver/range.c
M clang/test/Import/cxx-default-init-expr/test.cpp
M clang/test/Interpreter/cxx20-modules.cppm
M clang/test/OpenMP/atomic_ast_print.cpp
M clang/test/OpenMP/atomic_messages.cpp
M clang/test/ParserOpenACC/parse-clauses.c
A clang/test/ParserOpenACC/parse-wait-clause.c
M clang/test/Preprocessor/predefined-arch-macros.c
M clang/test/SemaCXX/builtin-std-move.cpp
A clang/test/SemaCXX/cxx2b-static-operator.cpp
M clang/test/SemaCXX/warn-unsafe-buffer-usage-fixits-pointer-access.cpp
M clang/test/SemaTemplate/concepts-out-of-line-def.cpp
R clang/test/SemaTemplate/default-parm-init.cpp
M clang/tools/clang-scan-deps/ClangScanDeps.cpp
M clang/tools/libclang/CIndex.cpp
A clang/unittests/AST/ASTDumperTest.cpp
M clang/unittests/AST/CMakeLists.txt
M clang/unittests/AST/Interp/Descriptor.cpp
M clang/unittests/Analysis/CFGTest.cpp
M clang/unittests/Analysis/FlowSensitive/LoggerTest.cpp
M clang/unittests/Analysis/FlowSensitive/TransferTest.cpp
M compiler-rt/lib/dfsan/dfsan_custom.cpp
M compiler-rt/lib/dfsan/done_abilist.txt
M compiler-rt/lib/dfsan/libc_ubuntu1404_abilist.txt
M flang/docs/Intrinsics.md
M flang/include/flang/Runtime/io-api.h
M flang/lib/Evaluate/intrinsics.cpp
M flang/lib/Lower/Bridge.cpp
M flang/lib/Lower/CallInterface.cpp
M flang/lib/Lower/IO.cpp
M flang/lib/Optimizer/Builder/IntrinsicCall.cpp
M flang/lib/Semantics/check-call.cpp
M flang/lib/Semantics/check-omp-structure.cpp
M flang/lib/Semantics/resolve-directives.cpp
M flang/runtime/io-api.cpp
M flang/test/Lower/HLFIR/procedure-pointer.f90
A flang/test/Lower/io-asynchronous.f90
M flang/test/Lower/io-statement-1.f90
M flang/test/Semantics/OpenACC/acc-loop.f90
A flang/test/Semantics/image_index01.f90
A flang/test/Semantics/image_index02.f90
M libc/config/linux/aarch64/entrypoints.txt
M libc/config/linux/riscv/entrypoints.txt
M libc/config/linux/x86_64/entrypoints.txt
M libc/spec/linux.td
M libc/spec/posix.td
M libc/src/__support/GPU/amdgpu/utils.h
M libc/src/__support/GPU/generic/utils.h
M libc/src/__support/GPU/nvptx/utils.h
M libc/src/__support/RPC/rpc.h
M libc/src/sys/mman/CMakeLists.txt
M libc/src/sys/mman/linux/CMakeLists.txt
A libc/src/sys/mman/linux/mlock.cpp
A libc/src/sys/mman/linux/mlock2.cpp
A libc/src/sys/mman/linux/mlockall.cpp
A libc/src/sys/mman/linux/munlock.cpp
A libc/src/sys/mman/linux/munlockall.cpp
A libc/src/sys/mman/mlock.h
A libc/src/sys/mman/mlock2.h
A libc/src/sys/mman/mlockall.h
A libc/src/sys/mman/munlock.h
A libc/src/sys/mman/munlockall.h
M libc/test/src/sys/mman/linux/CMakeLists.txt
M libc/test/src/sys/mman/linux/mincore_test.cpp
A libc/test/src/sys/mman/linux/mlock_test.cpp
M libc/utils/gpu/server/rpc_server.h
M libcxx/include/__thread/support.h
M libcxx/include/__thread/support/c11.h
M libcxx/include/__thread/support/pthread.h
M libcxx/include/__thread/support/windows.h
M libcxx/test/libcxx/atomics/atomics.align/align.pass.cpp
M libcxx/test/libcxx/atomics/atomics.types.generic/atomics.types.float/lockfree.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/assign.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/compare_exchange_strong.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/compare_exchange_weak.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/ctor.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/exchange.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/fetch_add.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/fetch_sub.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/load.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/lockfree.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/notify_all.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/notify_one.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/operator.float.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/operator.minus_equals.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/operator.plus_equals.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/store.pass.cpp
M libcxx/test/std/atomics/atomics.types.generic/atomics.types.float/wait.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.req/atomic_compare_exchange_strong.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.req/atomic_compare_exchange_strong_explicit.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.req/atomic_compare_exchange_weak.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.req/atomic_compare_exchange_weak_explicit.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.req/atomic_exchange.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.req/atomic_exchange_explicit.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.req/atomic_init.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.req/atomic_is_lock_free.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.req/atomic_load.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.req/atomic_load_explicit.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.req/atomic_store.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.req/atomic_store_explicit.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.wait/atomic_notify_all.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.wait/atomic_notify_one.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.wait/atomic_wait.pass.cpp
M libcxx/test/std/atomics/atomics.types.operations/atomics.types.operations.wait/atomic_wait_explicit.pass.cpp
M libcxx/test/support/atomic_helpers.h
M libcxx/utils/libcxx/test/features.py
M lld/COFF/DLL.cpp
M lld/test/COFF/imports.test
M lld/test/COFF/pdb-publics-import.test
A lldb/include/lldb/Breakpoint/WatchpointAlgorithms.h
M lldb/include/lldb/Core/DebuggerEvents.h
M lldb/include/lldb/Core/Progress.h
M lldb/include/lldb/lldb-enumerations.h
M lldb/packages/Python/lldbsuite/test/concurrent_base.py
M lldb/source/Breakpoint/CMakeLists.txt
M lldb/source/Breakpoint/Watchpoint.cpp
A lldb/source/Breakpoint/WatchpointAlgorithms.cpp
M lldb/source/Breakpoint/WatchpointResource.cpp
M lldb/source/Commands/CommandObjectWatchpoint.cpp
M lldb/source/Core/DebuggerEvents.cpp
M lldb/source/Core/Progress.cpp
M lldb/source/Plugins/Language/CPlusPlus/LibCxxMap.cpp
M lldb/source/Plugins/Language/CPlusPlus/LibCxxUnorderedMap.cpp
M lldb/source/Plugins/Language/CPlusPlus/LibCxxVector.cpp
M lldb/source/Plugins/Process/Utility/StopInfoMachException.cpp
M lldb/source/Plugins/Process/gdb-remote/ProcessGDBRemote.cpp
M lldb/source/Target/StopInfo.cpp
M lldb/test/API/functionalities/watchpoint/large-watchpoint/TestLargeWatchpoint.py
A lldb/test/API/functionalities/watchpoint/unaligned-large-watchpoint/Makefile
A lldb/test/API/functionalities/watchpoint/unaligned-large-watchpoint/TestUnalignedLargeWatchpoint.py
A lldb/test/API/functionalities/watchpoint/unaligned-large-watchpoint/main.c
M lldb/unittests/Breakpoint/CMakeLists.txt
A lldb/unittests/Breakpoint/WatchpointAlgorithmsTests.cpp
M llvm/cmake/modules/LLVMExternalProjectUtils.cmake
M llvm/docs/CommandGuide/llvm-exegesis.rst
M llvm/docs/RISCVUsage.rst
M llvm/docs/ReleaseNotes.rst
M llvm/include/llvm/ADT/SmallPtrSet.h
M llvm/include/llvm/Analysis/AliasAnalysis.h
M llvm/include/llvm/Analysis/BasicAliasAnalysis.h
M llvm/include/llvm/Analysis/ValueTracking.h
M llvm/include/llvm/AsmParser/LLParser.h
A llvm/include/llvm/AsmParser/NumberedValues.h
M llvm/include/llvm/AsmParser/SlotMapping.h
M llvm/include/llvm/CodeGen/LivePhysRegs.h
M llvm/include/llvm/CodeGen/MachineBasicBlock.h
M llvm/include/llvm/CodeGen/TargetLowering.h
M llvm/include/llvm/DebugInfo/DWARF/DWARFAcceleratorTable.h
M llvm/include/llvm/Frontend/OpenMP/OMP.td
M llvm/include/llvm/Support/VirtualFileSystem.h
M llvm/include/llvm/Support/raw_ostream.h
M llvm/include/llvm/TextAPI/Symbol.h
M llvm/lib/Analysis/BasicAliasAnalysis.cpp
M llvm/lib/Analysis/InstructionSimplify.cpp
M llvm/lib/Analysis/ValueTracking.cpp
M llvm/lib/AsmParser/LLParser.cpp
M llvm/lib/CodeGen/BranchFolding.cpp
M llvm/lib/CodeGen/MIRParser/MIParser.cpp
M llvm/lib/CodeGen/MIRPrinter.cpp
M llvm/lib/CodeGen/RegisterClassInfo.cpp
M llvm/lib/CodeGen/SelectionDAG/LegalizeIntegerTypes.cpp
M llvm/lib/CodeGen/SelectionDAG/SelectionDAG.cpp
M llvm/lib/CodeGen/SelectionDAG/TargetLowering.cpp
M llvm/lib/DebugInfo/DWARF/DWARFAcceleratorTable.cpp
M llvm/lib/Frontend/OpenMP/OMPIRBuilder.cpp
M llvm/lib/IR/Instructions.cpp
M llvm/lib/Support/Process.cpp
M llvm/lib/Support/RISCVISAInfo.cpp
M llvm/lib/Support/Unix/Process.inc
M llvm/lib/Support/VirtualFileSystem.cpp
M llvm/lib/Support/Windows/Process.inc
M llvm/lib/Target/AArch64/AArch64ExpandPseudoInsts.cpp
M llvm/lib/Target/AArch64/AArch64FrameLowering.cpp
M llvm/lib/Target/AArch64/AArch64ISelLowering.cpp
M llvm/lib/Target/AArch64/AArch64ISelLowering.h
M llvm/lib/Target/AArch64/AArch64InstrInfo.cpp
M llvm/lib/Target/AArch64/AArch64InstrInfo.td
M llvm/lib/Target/AArch64/AArch64RegisterInfo.cpp
M llvm/lib/Target/AArch64/AArch64SMEInstrInfo.td
M llvm/lib/Target/AArch64/AArch64TargetTransformInfo.cpp
M llvm/lib/Target/AMDGPU/AsmParser/AMDGPUAsmParser.cpp
M llvm/lib/Target/AMDGPU/R600OptimizeVectorRegisters.cpp
M llvm/lib/Target/AMDGPU/SIISelLowering.cpp
M llvm/lib/Target/ARM/ARMExpandPseudoInsts.cpp
M llvm/lib/Target/ARM/ARMISelDAGToDAG.cpp
M llvm/lib/Target/ARM/ARMInstrNEON.td
M llvm/lib/Target/ARM/ARMLowOverheadLoops.cpp
M llvm/lib/Target/PowerPC/PPCExpandAtomicPseudoInsts.cpp
M llvm/lib/Target/PowerPC/PPCFrameLowering.cpp
M llvm/lib/Target/PowerPC/PPCMergeStringPool.cpp
M llvm/lib/Target/RISCV/RISCVFeatures.td
M llvm/lib/Target/RISCV/RISCVISelLowering.cpp
M llvm/lib/Target/RISCV/RISCVISelLowering.h
M llvm/lib/Target/RISCV/RISCVInstrInfo.td
M llvm/lib/Target/RISCV/RISCVInstrInfoZa.td
M llvm/lib/Target/RISCV/RISCVSchedRocket.td
M llvm/lib/Target/RISCV/RISCVSchedSiFive7.td
M llvm/lib/Target/RISCV/RISCVSchedSiFiveP400.td
M llvm/lib/Target/RISCV/RISCVSchedSyntacoreSCR1.td
M llvm/lib/Target/RISCV/RISCVSchedule.td
M llvm/lib/Target/RISCV/RISCVTargetTransformInfo.cpp
M llvm/lib/Target/SPIRV/SPIRVBuiltins.cpp
M llvm/lib/Target/SPIRV/SPIRVCallLowering.cpp
M llvm/lib/Target/SPIRV/SPIRVGlobalRegistry.cpp
M llvm/lib/Target/SPIRV/SPIRVGlobalRegistry.h
M llvm/lib/Target/SystemZ/SystemZFrameLowering.cpp
M llvm/lib/Target/X86/X86FrameLowering.cpp
M llvm/lib/Target/X86/X86InstrAVX512.td
M llvm/lib/Target/X86/X86InstrFoldTables.cpp
M llvm/lib/Target/X86/X86InstrFoldTables.h
M llvm/lib/Target/X86/X86InstrInfo.cpp
M llvm/lib/Target/X86/X86InstrInfo.h
M llvm/lib/Target/X86/X86InstrMisc.td
M llvm/lib/Target/X86/X86InstrSSE.td
M llvm/lib/Transforms/InstCombine/InstCombineAndOrXor.cpp
M llvm/lib/Transforms/InstCombine/InstCombineCalls.cpp
M llvm/lib/Transforms/InstCombine/InstCombineCompares.cpp
M llvm/lib/Transforms/InstCombine/InstCombineSelect.cpp
M llvm/lib/Transforms/Instrumentation/MemorySanitizer.cpp
M llvm/lib/Transforms/Scalar/BDCE.cpp
M llvm/lib/Transforms/Scalar/CorrelatedValuePropagation.cpp
M llvm/lib/Transforms/Scalar/JumpThreading.cpp
M llvm/lib/Transforms/Vectorize/VPlanTransforms.cpp
M llvm/test/Analysis/CostModel/RISCV/shuffle-extract_subvector.ll
M llvm/test/Analysis/CostModel/RISCV/shuffle-insert_subvector.ll
M llvm/test/Analysis/CostModel/RISCV/shuffle-interleave.ll
M llvm/test/Analysis/UniformityAnalysis/AMDGPU/intrinsics.ll
A llvm/test/Analysis/ValueTracking/powi-nneg.ll
A llvm/test/Assembler/incomplete-ir-declarations.ll
A llvm/test/Assembler/skip-value-numbers-globals.ll
M llvm/test/Assembler/skip-value-numbers-invalid.ll
M llvm/test/CodeGen/AArch64/GlobalISel/uaddo-8-16-bits.mir
M llvm/test/CodeGen/AArch64/arm64-csel.ll
M llvm/test/CodeGen/AArch64/arm64-ldp-cluster.ll
M llvm/test/CodeGen/AArch64/arm64ec-varargs.ll
M llvm/test/CodeGen/AArch64/regalloc-last-chance-recolor-with-split.mir
M llvm/test/CodeGen/AArch64/shift-accumulate.ll
M llvm/test/CodeGen/AArch64/sme-disable-gisel-fisel.ll
A llvm/test/CodeGen/AArch64/sme-pstate-sm-changing-call-disable-coalescing.ll
M llvm/test/CodeGen/AArch64/sme-streaming-body.ll
M llvm/test/CodeGen/AArch64/sme-streaming-compatible-interface.ll
M llvm/test/CodeGen/AArch64/sme-streaming-interface.ll
M llvm/test/CodeGen/AArch64/sme-streaming-mode-changing-call-disable-stackslot-scavenging.ll
M llvm/test/CodeGen/AArch64/tail-dup-redundant-phi.mir
M llvm/test/CodeGen/AArch64/vararg-tallcall.ll
M llvm/test/CodeGen/AArch64/zext-to-tbl.ll
M llvm/test/CodeGen/AMDGPU/GlobalISel/legalize-trap.mir
M llvm/test/CodeGen/AMDGPU/global-constant.ll
M llvm/test/CodeGen/AMDGPU/llvm.amdgcn.wmma_64.ll
M llvm/test/CodeGen/AMDGPU/llvm.memcpy.ll
M llvm/test/CodeGen/AMDGPU/rel32.ll
M llvm/test/CodeGen/AMDGPU/wmma-gfx12-w32-f16-f32-matrix-modifiers.ll
M llvm/test/CodeGen/AMDGPU/wmma-gfx12-w32-imm.ll
M llvm/test/CodeGen/AMDGPU/wmma-gfx12-w32-iu-modifiers.ll
M llvm/test/CodeGen/AMDGPU/wmma-gfx12-w32-swmmac-index_key.ll
M llvm/test/CodeGen/AMDGPU/wmma-gfx12-w32.ll
M llvm/test/CodeGen/AMDGPU/wmma-gfx12-w64-f16-f32-matrix-modifiers.ll
M llvm/test/CodeGen/AMDGPU/wmma-gfx12-w64-imm.ll
M llvm/test/CodeGen/AMDGPU/wmma-gfx12-w64-iu-modifiers.ll
M llvm/test/CodeGen/AMDGPU/wmma-gfx12-w64-swmmac-index_key.ll
M llvm/test/CodeGen/AMDGPU/wmma-gfx12-w64.ll
M llvm/test/CodeGen/AMDGPU/wmma_modifiers.ll
M llvm/test/CodeGen/AMDGPU/wmma_multiple_32.ll
M llvm/test/CodeGen/AMDGPU/wmma_multiple_64.ll
M llvm/test/CodeGen/ARM/arm-vlddup-update.ll
M llvm/test/CodeGen/ARM/arm-vlddup.ll
M llvm/test/CodeGen/ARM/bf16-intrinsics-ld-st.ll
M llvm/test/CodeGen/ARM/constant-island-movwt.mir
A llvm/test/CodeGen/MIR/X86/unreachable-block-print.mir
M llvm/test/CodeGen/PowerPC/mergeable-string-pool-large.ll
M llvm/test/CodeGen/PowerPC/mergeable-string-pool.ll
M llvm/test/CodeGen/RISCV/attributes.ll
M llvm/test/CodeGen/RISCV/or-is-add.ll
M llvm/test/CodeGen/RISCV/rv64-legal-i32/rv64zba.ll
M llvm/test/CodeGen/RISCV/rv64zba.ll
M llvm/test/CodeGen/RISCV/rvv/vector-interleave.ll
A llvm/test/CodeGen/RISCV/rvv/vwadd-mask-sdnode.ll
A llvm/test/CodeGen/SPIRV/pointers/custom-kernel-arg-type.ll
M llvm/test/CodeGen/SystemZ/branch-folder-hoist-livein.mir
A llvm/test/CodeGen/Thumb/smul_fix.ll
A llvm/test/CodeGen/Thumb/smul_fix_sat.ll
A llvm/test/CodeGen/Thumb/umul_fix.ll
A llvm/test/CodeGen/Thumb/umul_fix_sat.ll
M llvm/test/CodeGen/Thumb2/LowOverheadLoops/spillingmove.mir
M llvm/test/CodeGen/Thumb2/mve-vmaxnma-commute.ll
M llvm/test/CodeGen/X86/cfguard-checks-funclet.ll
M llvm/test/CodeGen/X86/cfguard-checks.ll
M llvm/test/CodeGen/X86/cfguard-module-flag.ll
M llvm/test/CodeGen/X86/cfguard-x86-vectorcall.ll
M llvm/test/CodeGen/X86/divide-by-constant.ll
M llvm/test/CodeGen/X86/divrem.ll
M llvm/test/CodeGen/X86/divrem8_ext.ll
M llvm/test/CodeGen/X86/fold-vector-sext-crash2.ll
M llvm/test/CodeGen/X86/fold-vector-sext-zext.ll
M llvm/test/CodeGen/X86/i256-add.ll
M llvm/test/CodeGen/X86/insertps-from-constantpool.ll
M llvm/test/CodeGen/X86/matrix-multiply.ll
M llvm/test/CodeGen/X86/mmx-arith.ll
M llvm/test/CodeGen/X86/statepoint-invoke-ra-enter-at-end.mir
M llvm/test/CodeGen/X86/statepoint-invoke-ra-remove-back-copies.mir
M llvm/test/CodeGen/X86/statepoint-vreg-invoke.ll
M llvm/test/CodeGen/X86/v2f32.ll
M llvm/test/CodeGen/X86/v4f32-immediate.ll
M llvm/test/CodeGen/X86/vector-interleaved-load-i16-stride-7.ll
M llvm/test/CodeGen/X86/vector-interleaved-store-i16-stride-5.ll
M llvm/test/CodeGen/X86/vector-interleaved-store-i8-stride-8.ll
M llvm/test/Instrumentation/MemorySanitizer/msan_asm_conservative.ll
A llvm/test/MC/AMDGPU/writelane_m0.s
A llvm/test/MC/Disassembler/X86/apx/lzcnt.txt
A llvm/test/MC/Disassembler/X86/apx/popcnt.txt
A llvm/test/MC/Disassembler/X86/apx/tzcnt.txt
M llvm/test/MC/RISCV/rv32zbb-only-valid.s
M llvm/test/MC/RISCV/rv32zbb-valid.s
M llvm/test/MC/RISCV/rv64zbb-valid.s
M llvm/test/MC/RISCV/rv64zbkb-valid.s
A llvm/test/MC/RISCV/rvzabha-invalid.s
A llvm/test/MC/RISCV/rvzabha-valid.s
A llvm/test/MC/RISCV/rvzabha-zacas-valid.s
A llvm/test/MC/X86/apx/lzcnt-att.s
A llvm/test/MC/X86/apx/lzcnt-intel.s
A llvm/test/MC/X86/apx/popcnt-att.s
A llvm/test/MC/X86/apx/popcnt-intel.s
A llvm/test/MC/X86/apx/tzcnt-att.s
A llvm/test/MC/X86/apx/tzcnt-intel.s
A llvm/test/MachineVerifier/writelane_m0.mir
M llvm/test/TableGen/x86-fold-tables.inc
M llvm/test/Transforms/BDCE/invalidate-assumptions.ll
M llvm/test/Transforms/CorrelatedValuePropagation/basic.ll
A llvm/test/Transforms/CorrelatedValuePropagation/switch.ll
M llvm/test/Transforms/Inline/AArch64/sme-pstatesm-attrs.ll
M llvm/test/Transforms/InstCombine/and-or-icmps.ll
M llvm/test/Transforms/InstCombine/and-or-not.ll
M llvm/test/Transforms/InstCombine/and-xor-or.ll
A llvm/test/Transforms/InstCombine/bitcast-bfloat-half-mixing.ll
M llvm/test/Transforms/InstCombine/copysign-fneg-fabs.ll
M llvm/test/Transforms/InstCombine/fabs.ll
M llvm/test/Transforms/InstCombine/fcmp-select.ll
M llvm/test/Transforms/InstCombine/icmp-select.ll
M llvm/test/Transforms/InstCombine/or-xor.ll
M llvm/test/Transforms/InstCombine/or.ll
M llvm/test/Transforms/InstSimplify/floating-point-arithmetic-strictfp.ll
M llvm/test/Transforms/JumpThreading/pr79175.ll
M llvm/test/Transforms/LoopVectorize/PowerPC/optimal-epilog-vectorization.ll
M llvm/test/Transforms/LoopVectorize/X86/interleaved-accesses-hoist-load-across-store.ll
M llvm/test/Transforms/LoopVectorize/X86/pr36524.ll
M llvm/test/Transforms/LoopVectorize/cast-induction.ll
M llvm/test/Transforms/LoopVectorize/float-induction.ll
M llvm/test/Transforms/LoopVectorize/induction-multiple-uses-in-same-instruction.ll
M llvm/test/Transforms/LoopVectorize/induction-unroll-novec.ll
M llvm/test/Transforms/LoopVectorize/iv_outside_user.ll
M llvm/test/Transforms/LoopVectorize/optimal-epilog-vectorization.ll
M llvm/test/Transforms/LoopVectorize/runtime-check-needed-but-empty.ll
M llvm/test/Transforms/LoopVectorize/single-value-blend-phis.ll
M llvm/test/Transforms/LoopVectorize/uniform_across_vf_induction2.ll
M llvm/test/Transforms/LoopVectorize/vect-phiscev-sext-trunc.ll
M llvm/test/tools/llvm-exegesis/X86/analysis-epsilons.test
A llvm/test/tools/llvm-exegesis/X86/latency/middle-half.s
M llvm/test/tools/llvm-rc/windres-prefix.test
M llvm/tools/llvm-exegesis/lib/Analysis.cpp
M llvm/tools/llvm-exegesis/lib/BenchmarkResult.h
M llvm/tools/llvm-exegesis/lib/CMakeLists.txt
A llvm/tools/llvm-exegesis/lib/ResultAggregator.cpp
A llvm/tools/llvm-exegesis/lib/ResultAggregator.h
M llvm/tools/llvm-exegesis/lib/SnippetRepetitor.cpp
M llvm/tools/llvm-exegesis/llvm-exegesis.cpp
M llvm/tools/llvm-rc/llvm-rc.cpp
M llvm/unittests/AsmParser/AsmParserTest.cpp
M llvm/unittests/Support/RISCVISAInfoTest.cpp
M llvm/unittests/Support/VirtualFileSystemTest.cpp
M llvm/unittests/tools/llvm-exegesis/CMakeLists.txt
A llvm/unittests/tools/llvm-exegesis/ResultAggregatorTest.cpp
M llvm/utils/git/github-automation.py
M llvm/utils/gn/secondary/clang/unittests/AST/BUILD.gn
M llvm/utils/gn/secondary/llvm/tools/llvm-exegesis/lib/BUILD.gn
M llvm/utils/gn/secondary/llvm/unittests/tools/llvm-exegesis/BUILD.gn
M mlir/docs/Dialects/Mesh.md
M mlir/include/mlir-c/BuiltinTypes.h
M mlir/include/mlir/Conversion/MemRefToSPIRV/MemRefToSPIRV.h
M mlir/include/mlir/Dialect/ArmSME/IR/ArmSMEIntrinsicOps.td
M mlir/include/mlir/Dialect/ArmSME/IR/ArmSMEOps.td
M mlir/include/mlir/Dialect/ArmSME/Transforms/Passes.h
M mlir/include/mlir/Dialect/ArmSME/Transforms/Passes.td
M mlir/include/mlir/Dialect/ArmSME/Transforms/Transforms.h
M mlir/include/mlir/Dialect/ArmSME/Utils/Utils.h
M mlir/include/mlir/Dialect/EmitC/IR/EmitC.td
M mlir/include/mlir/Dialect/Linalg/TransformOps/LinalgMatchOps.td
M mlir/include/mlir/Dialect/Linalg/TransformOps/LinalgTransformOps.td
M mlir/include/mlir/Dialect/Mesh/IR/CMakeLists.txt
M mlir/include/mlir/Dialect/Mesh/IR/MeshBase.td
A mlir/include/mlir/Dialect/Mesh/IR/MeshDialect.h
M mlir/include/mlir/Dialect/Mesh/IR/MeshOps.h
M mlir/include/mlir/Dialect/Mesh/IR/MeshOps.td
M mlir/include/mlir/IR/Block.h
M mlir/include/mlir/IR/PatternMatch.h
M mlir/include/mlir/InitAllDialects.h
M mlir/lib/Bindings/Python/IRTypes.cpp
M mlir/lib/CAPI/IR/BuiltinTypes.cpp
M mlir/lib/Conversion/ArmSMEToLLVM/ArmSMEToLLVM.cpp
M mlir/lib/Conversion/GPUToSPIRV/GPUToSPIRVPass.cpp
M mlir/lib/Conversion/MemRefToSPIRV/MapMemRefStorageClassPass.cpp
M mlir/lib/Conversion/SPIRVToLLVM/SPIRVToLLVM.cpp
M mlir/lib/Dialect/ArmSME/IR/Utils.cpp
M mlir/lib/Dialect/ArmSME/Transforms/CMakeLists.txt
A mlir/lib/Dialect/ArmSME/Transforms/OuterProductFusion.cpp
A mlir/lib/Dialect/ArmSME/Transforms/VectorLegalization.cpp
M mlir/lib/Dialect/Linalg/TransformOps/LinalgMatchOps.cpp
M mlir/lib/Dialect/Linalg/TransformOps/LinalgTransformOps.cpp
M mlir/lib/Dialect/MemRef/IR/MemRefOps.cpp
M mlir/lib/Dialect/MemRef/Transforms/ExpandStridedMetadata.cpp
M mlir/lib/Dialect/Mesh/IR/CMakeLists.txt
M mlir/lib/Dialect/Mesh/IR/MeshOps.cpp
M mlir/lib/Dialect/Mesh/Transforms/ShardingPropagation.cpp
M mlir/lib/Dialect/Mesh/Transforms/Spmdization.cpp
M mlir/lib/Dialect/Mesh/Transforms/Transforms.cpp
M mlir/lib/Dialect/SparseTensor/Transforms/Utils/SparseTensorLevel.cpp
M mlir/lib/Dialect/SparseTensor/Transforms/Utils/SparseTensorLevel.h
M mlir/lib/Dialect/Vector/Transforms/LowerVectorTranspose.cpp
M mlir/lib/IR/Block.cpp
M mlir/lib/IR/PatternMatch.cpp
M mlir/lib/Rewrite/PatternApplicator.cpp
M mlir/lib/Target/Cpp/TranslateToCpp.cpp
M mlir/lib/Transforms/Utils/DialectConversion.cpp
M mlir/python/mlir/dialects/_ods_common.py
M mlir/python/mlir/dialects/memref.py
M mlir/python/mlir/dialects/transform/structured.py
M mlir/test/Conversion/ArmSMEToLLVM/arm-sme-to-llvm.mlir
M mlir/test/Dialect/Affine/simplify-structures.mlir
M mlir/test/Dialect/ArmSME/invalid.mlir
A mlir/test/Dialect/ArmSME/outer-product-fusion.mlir
M mlir/test/Dialect/ArmSME/roundtrip.mlir
A mlir/test/Dialect/ArmSME/vector-legalization.mlir
M mlir/test/Dialect/EmitC/ops.mlir
M mlir/test/Dialect/GPU/decompose-memrefs.mlir
M mlir/test/Dialect/Linalg/match-ops-interpreter.mlir
M mlir/test/Dialect/Linalg/match-ops-invalid.mlir
M mlir/test/Dialect/Linalg/tile-to-forall.mlir
M mlir/test/Dialect/MemRef/fold-memref-alias-ops.mlir
M mlir/test/Dialect/MemRef/invalid.mlir
M mlir/test/Dialect/Mesh/invalid.mlir
M mlir/test/Dialect/Mesh/ops.mlir
M mlir/test/Dialect/Vector/vector-transpose-lowering.mlir
A mlir/test/Integration/Dialect/Linalg/CPU/ArmSME/multi-tile-matmul.mlir
M mlir/test/Integration/Dialect/SparseTensor/CPU/sparse_rewrite_sort_coo.mlir
A mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-multi-tile-transpose.mlir
A mlir/test/Integration/Dialect/Vector/CPU/ArmSME/test-outerproduct-f16f16f32.mlir
A mlir/test/Target/Cpp/verbatim.mlir
M mlir/test/Target/LLVMIR/arm-sme.mlir
A mlir/test/Target/LLVMIR/omptarget-teams-llvm.mlir
M mlir/test/Transforms/test-strict-pattern-driver.mlir
M mlir/test/lib/Dialect/Mesh/TestProcessMultiIndexOpLowering.cpp
M mlir/test/lib/Dialect/Mesh/TestSimplifications.cpp
M mlir/test/lib/Dialect/Test/TestPatterns.cpp
M mlir/test/python/dialects/memref.py
M polly/lib/Analysis/ScopBuilder.cpp
A polly/test/ScopInfo/reduction_different_index.ll
A polly/test/ScopInfo/reduction_different_index1.ll
M utils/bazel/llvm-project-overlay/mlir/BUILD.bazel
Log Message:
-----------
Rebase, address comments
Created using spr 1.3.5
Compare: https://github.com/llvm/llvm-project/compare/cfd0dcfa1f5f...1689f41ebec8
More information about the All-commits
mailing list