<table border="1" cellspacing="0" cellpadding="8">
<tr>
<th>Issue</th>
<td>
<a href=https://github.com/llvm/llvm-project/issues/82484>82484</a>
</td>
</tr>
<tr>
<th>Summary</th>
<td>
[Optimization] [Load-Store-Vectorizer][Cuda&AMDGPU] Cannot vectorize "load instr" after loop unroll with atomic fadd
</td>
</tr>
<tr>
<th>Labels</th>
<td>
</td>
</tr>
<tr>
<th>Assignees</th>
<td>
</td>
</tr>
<tr>
<th>Reporter</th>
<td>
hlyix
</td>
</tr>
</table>
<pre>
Here is Cuda file
```
__global__ void testAtomic(int* __restrict__ address, int* __restrict__ dst, int n) {
#pragma unroll 4
for (int i = 0; i < n; i++) {
atomicAdd(&address[i], dst[i]);
}
}
```
IR stop before "load-store-vectorizer"
```
; Function Attrs: mustprogress nofree norecurse nounwind
define dso_local void @_Z10testAtomicPiS_i(i32 addrspace(1)* noalias nocapture %address, i32 addrspace(4)* noalias nocapture readonly %dst, i32 %n) local_unnamed_addr #0 {
entry:
%cmp7 = icmp sgt i32 %n, 0
br i1 %cmp7, label %for.body.preheader, label %for.cond.cleanup
for.body.preheader: ; preds = %entry
%0 = add nsw i32 %n, -1
%xtraiter = and i32 %n, 3
%1 = icmp ult i32 %0, 3
br i1 %1, label %for.cond.cleanup.loopexit.unr-lcssa, label %for.body.preheader.new
for.body.preheader.new: ; preds = %for.body.preheader
%unroll_iter = and i32 %n, -4
%scevgep26 = getelementptr i32, i32 addrspace(1)* %address, i64 2
%scevgep32 = getelementptr i32, i32 addrspace(4)* %dst, i64 2
br label %for.body
for.cond.cleanup.loopexit.unr-lcssa.loopexit: ; preds = %for.body
br label %for.cond.cleanup.loopexit.unr-lcssa
for.cond.cleanup.loopexit.unr-lcssa: ; preds = %for.cond.cleanup.loopexit.unr-lcssa.loopexit, %for.body.preheader
%i.08.unr = phi i32 [ 0, %for.body.preheader ], [ %inc.3, %for.cond.cleanup.loopexit.unr-lcssa.loopexit ]
%lcmp.mod.not = icmp eq i32 %xtraiter, 0
br i1 %lcmp.mod.not, label %for.cond.cleanup, label %for.body.epil.preheader
for.body.epil.preheader: ; preds = %for.cond.cleanup.loopexit.unr-lcssa
%2 = sext i32 %i.08.unr to i64
%scevgep = getelementptr i32, i32 addrspace(4)* %dst, i64 %2
%scevgep23 = getelementptr i32, i32 addrspace(1)* %address, i64 %2
br label %for.body.epil
for.body.epil: ; preds = %for.body.epil.preheader, %for.body.epil
%lsr.iv24 = phi i32 addrspace(1)* [ %scevgep23, %for.body.epil.preheader ], [ %scevgep25, %for.body.epil ]
%lsr.iv = phi i32 addrspace(4)* [ %scevgep, %for.body.epil.preheader ], [ %scevgep22, %for.body.epil ]
%epil.iter = phi i32 [ %epil.iter.sub, %for.body.epil ], [ %xtraiter, %for.body.epil.preheader ]
%3 = load i32, i32 addrspace(4)* %lsr.iv, align 4, !tbaa !7
%4 = atomicrmw add i32 addrspace(1)* %lsr.iv24, i32 %3 seq_cst, align 4
%epil.iter.sub = add nsw i32 %epil.iter, -1
%scevgep22 = getelementptr i32, i32 addrspace(4)* %lsr.iv, i64 1
%scevgep25 = getelementptr i32, i32 addrspace(1)* %lsr.iv24, i64 1
%epil.iter.cmp.not = icmp eq i32 %epil.iter.sub, 0
br i1 %epil.iter.cmp.not, label %for.cond.cleanup.loopexit, label %for.body.epil, !llvm.loop !11
for.cond.cleanup.loopexit: ; preds = %for.body.epil
br label %for.cond.cleanup
for.cond.cleanup: ; preds = %for.cond.cleanup.loopexit, %for.cond.cleanup.loopexit.unr-lcssa, %entry
ret void
for.body: ; preds = %for.body, %for.body.preheader.new
%lsr.iv33 = phi i32 addrspace(4)* [ %scevgep34, %for.body ], [ %scevgep32, %for.body.preheader.new ]
%lsr.iv27 = phi i32 addrspace(1)* [ %scevgep28, %for.body ], [ %scevgep26, %for.body.preheader.new ]
%i.08 = phi i32 [ 0, %for.body.preheader.new ], [ %inc.3, %for.body ]
%scevgep30 = getelementptr i32, i32 addrspace(1)* %lsr.iv27, i64 -2
%scevgep35 = getelementptr i32, i32 addrspace(4)* %lsr.iv33, i64 -2
%5 = load i32, i32 addrspace(4)* %scevgep35, align 4, !tbaa !7
%6 = atomicrmw add i32 addrspace(1)* %scevgep30, i32 %5 seq_cst, align 4
%scevgep31 = getelementptr i32, i32 addrspace(1)* %lsr.iv27, i64 -1
%scevgep37 = getelementptr i32, i32 addrspace(4)* %lsr.iv33, i64 -1
%7 = load i32, i32 addrspace(4)* %scevgep37, align 4, !tbaa !7
%8 = atomicrmw add i32 addrspace(1)* %scevgep31, i32 %7 seq_cst, align 4
%9 = load i32, i32 addrspace(4)* %lsr.iv33, align 4, !tbaa !7
%10 = atomicrmw add i32 addrspace(1)* %lsr.iv27, i32 %9 seq_cst, align 4
%scevgep29 = getelementptr i32, i32 addrspace(1)* %lsr.iv27, i64 1
%scevgep36 = getelementptr i32, i32 addrspace(4)* %lsr.iv33, i64 1
%11 = load i32, i32 addrspace(4)* %scevgep36, align 4, !tbaa !7
%12 = atomicrmw add i32 addrspace(1)* %scevgep29, i32 %11 seq_cst, align 4
%inc.3 = add nuw i32 %i.08, 4
%scevgep28 = getelementptr i32, i32 addrspace(1)* %lsr.iv27, i64 4
%scevgep34 = getelementptr i32, i32 addrspace(4)* %lsr.iv33, i64 4
%niter.ncmp.3.not = icmp eq i32 %unroll_iter, %inc.3
br i1 %niter.ncmp.3.not, label %for.cond.cleanup.loopexit.unr-lcssa.loopexit, label %for.body, !llvm.loop !13
}
; Function Attrs: nofree nosync nounwind readnone speculatable willreturn
declare i32 @llvm.ctlz.i32(i32, i1 immarg) #1
; Function Attrs: nounwind
attributes #0 = { mustprogress nofree norecurse nounwind "frame-pointer"="all" "min-legal-vector-width"="0" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="sm_80" "target-features"="+ptx72,+sm_80" }
attributes #1 = { nofree nosync nounwind readnone speculatable willreturn }
attributes #2 = { nounwind }
!llvm.module.flags = !{!0, !1, !2, !3}
!nvvm.annotations = !{!4}
!llvm.ident = !{!5, !6}
!0 = !{i32 2, !"SDK Version", [2 x i32] [i32 11, i32 2]}
!1 = !{i32 1, !"wchar_size", i32 4}
!2 = !{i32 4, !"nvvm-reflect-ftz", i32 0}
!3 = !{i32 7, !"frame-pointer", i32 2}
!4 = distinct !{null, !"kernel", i32 1}
!5 = !{!"clang version 13.0.1 (git@git.nevint.com:allspark/llvm_nio.git 89e15cca5f53247b91fb2acf5806047d54c3027e)"}
!6 = !{!"clang version 3.8.0 (tags/RELEASE_380/final)"}
!7 = !{!8, !8, i64 0}
!8 = !{!"int", !9, i64 0}
!9 = !{!"omnipotent char", !10, i64 0}
!10 = !{!"Simple C++ TBAA"}
!11 = distinct !{!11, !12}
!12 = !{!"llvm.loop.unroll.disable"}
!13 = distinct !{!13, !14, !12}
!14 = !{!"llvm.loop.mustprogress"}
```
after `opt -mtriple=amdgcn -debug test.ll -passes="load-store-vectorizer" -S`
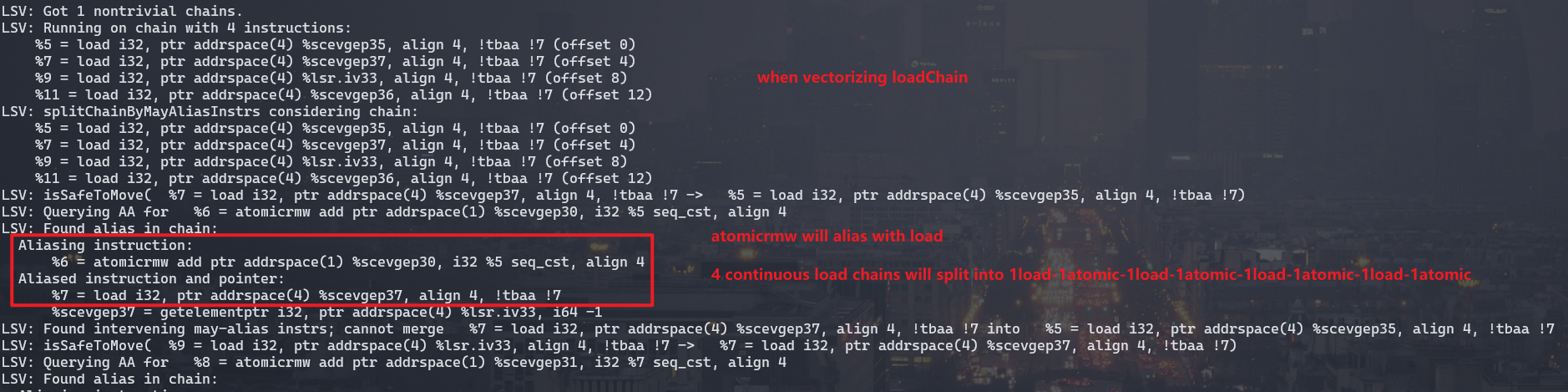
And I found that the alias analyzer considers seq_cst atomicrmw operations to be aliased with any pointer.
but for this situation
```
for (int i = 0; i < n; i += 4) {
atomicAdd(&address[i], dst[i]);
atomicAdd(&address[i+1], dst[i+1]);
atomicAdd(&address[i+2], dst[i+2]);
atomicAdd(&address[i+3], dst[i+3]);
}
```
We can pre-load operand 2 for vectorization.
```
for (int i = 0; i < n; i += 4) {
// we can vectorize these 4 instr first
int a = dst[i];
int a1 = dst[i+1];
int a2 = dst[i+2];
int a3 = dst[i+3];
atomicAdd(&address[i], a);
atomicAdd(&address[i+1], a1);
atomicAdd(&address[i+2], a2);
atomicAdd(&address[i+3], a3);
}
```
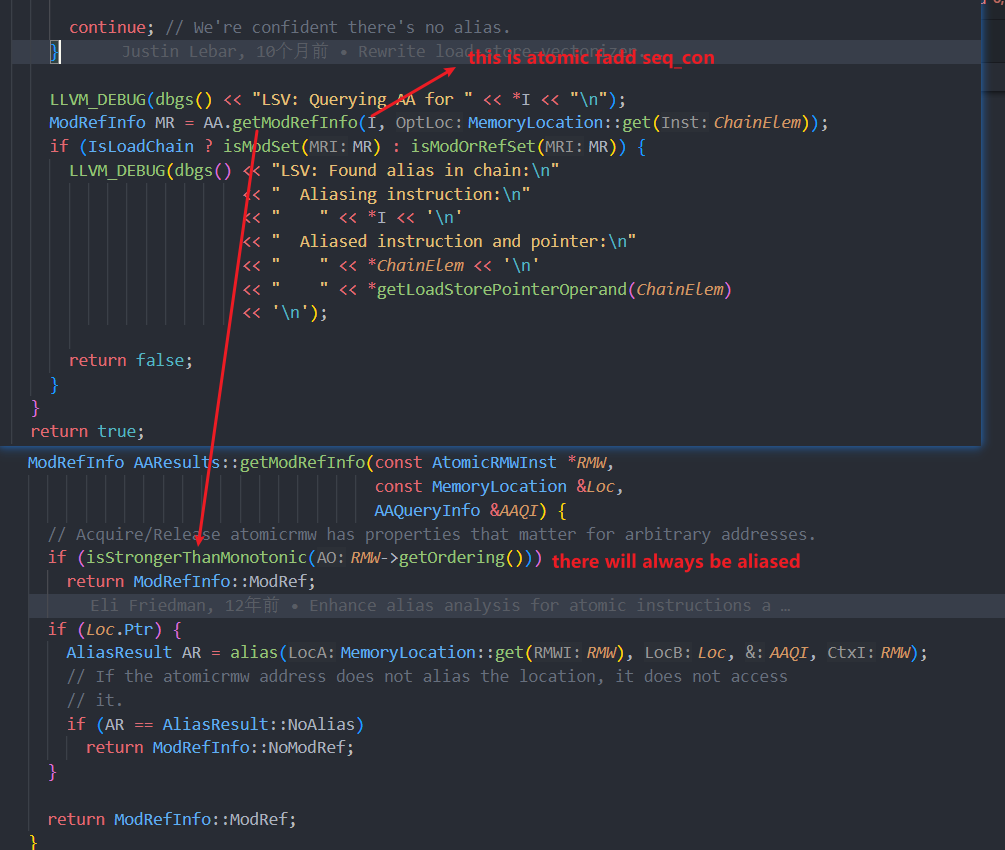
I just modify some code in:
file: llvm/lib/Transforms/Vectorize/LoadStoreVectorizer.cpp
function: isSafeToMove
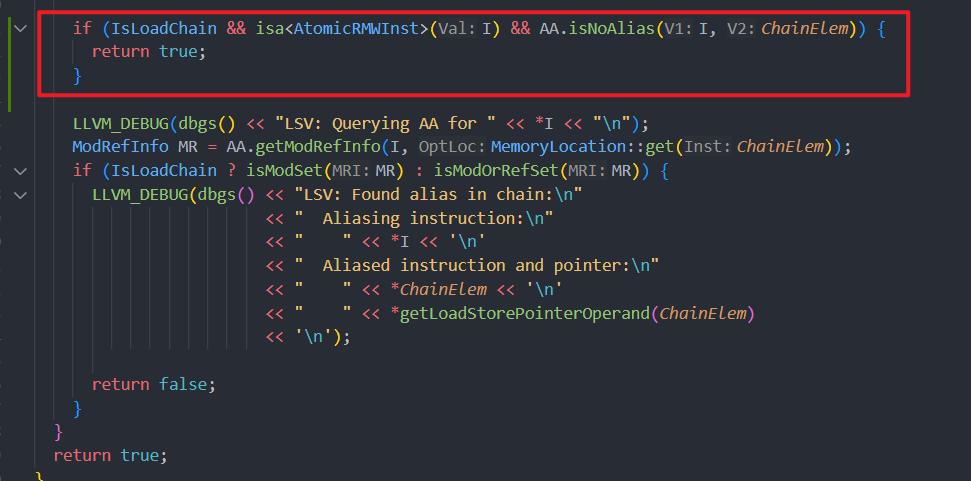
Then I get result below:
```
; Function Attrs: mustprogress nofree norecurse nounwind
define dso_local void @_Z10testAtomicPiS_i(ptr addrspace(1) noalias nocapture %address, ptr addrspace(4) noalias nocapture readonly %dst, i32 %n) local_unnamed_addr #0 {
entry:
%cmp7 = icmp sgt i32 %n, 0
br i1 %cmp7, label %for.body.preheader, label %for.cond.cleanup
for.body.preheader: ; preds = %entry
%0 = add nsw i32 %n, -1
%xtraiter = and i32 %n, 3
%1 = icmp ult i32 %0, 3
br i1 %1, label %for.cond.cleanup.loopexit.unr-lcssa, label %for.body.preheader.new
for.body.preheader.new: ; preds = %for.body.preheader
%unroll_iter = and i32 %n, -4
%scevgep26 = getelementptr i32, ptr addrspace(1) %address, i64 2
%scevgep32 = getelementptr i32, ptr addrspace(4) %dst, i64 2
br label %for.body
for.cond.cleanup.loopexit.unr-lcssa.loopexit: ; preds = %for.body
br label %for.cond.cleanup.loopexit.unr-lcssa
for.cond.cleanup.loopexit.unr-lcssa: ; preds = %for.cond.cleanup.loopexit.unr-lcssa.loopexit, %for.body.preheader
%i.08.unr = phi i32 [ 0, %for.body.preheader ], [ %inc.3, %for.cond.cleanup.loopexit.unr-lcssa.loopexit ]
%lcmp.mod.not = icmp eq i32 %xtraiter, 0
br i1 %lcmp.mod.not, label %for.cond.cleanup, label %for.body.epil.preheader
for.body.epil.preheader: ; preds = %for.cond.cleanup.loopexit.unr-lcssa
%2 = sext i32 %i.08.unr to i64
%scevgep = getelementptr i32, ptr addrspace(4) %dst, i64 %2
%scevgep23 = getelementptr i32, ptr addrspace(1) %address, i64 %2
br label %for.body.epil
for.body.epil: ; preds = %for.body.epil, %for.body.epil.preheader
%lsr.iv24 = phi ptr addrspace(1) [ %scevgep23, %for.body.epil.preheader ], [ %scevgep25, %for.body.epil ]
%lsr.iv = phi ptr addrspace(4) [ %scevgep, %for.body.epil.preheader ], [ %scevgep22, %for.body.epil ]
%epil.iter = phi i32 [ %epil.iter.sub, %for.body.epil ], [ %xtraiter, %for.body.epil.preheader ]
%3 = load i32, ptr addrspace(4) %lsr.iv, align 4, !tbaa !7
%4 = atomicrmw add ptr addrspace(1) %lsr.iv24, i32 %3 seq_cst, align 4
%epil.iter.sub = add nsw i32 %epil.iter, -1
%scevgep22 = getelementptr i32, ptr addrspace(4) %lsr.iv, i64 1
%scevgep25 = getelementptr i32, ptr addrspace(1) %lsr.iv24, i64 1
%epil.iter.cmp.not = icmp eq i32 %epil.iter.sub, 0
br i1 %epil.iter.cmp.not, label %for.cond.cleanup.loopexit, label %for.body.epil, !llvm.loop !11
for.cond.cleanup.loopexit: ; preds = %for.body.epil
br label %for.cond.cleanup
for.cond.cleanup: ; preds = %for.cond.cleanup.loopexit, %for.cond.cleanup.loopexit.unr-lcssa, %entry
ret void
for.body: ; preds = %for.body, %for.body.preheader.new
%lsr.iv33 = phi ptr addrspace(4) [ %scevgep34, %for.body ], [ %scevgep32, %for.body.preheader.new ]
%lsr.iv27 = phi ptr addrspace(1) [ %scevgep28, %for.body ], [ %scevgep26, %for.body.preheader.new ]
%i.08 = phi i32 [ 0, %for.body.preheader.new ], [ %inc.3, %for.body ]
%scevgep30 = getelementptr i32, ptr addrspace(1) %lsr.iv27, i64 -2
%scevgep35 = getelementptr i32, ptr addrspace(4) %lsr.iv33, i64 -2
%5 = load <4 x i32>, ptr addrspace(4) %scevgep35, align 4, !tbaa !7
%6 = extractelement <4 x i32> %5, i32 0
%7 = extractelement <4 x i32> %5, i32 1
%8 = extractelement <4 x i32> %5, i32 2
%9 = extractelement <4 x i32> %5, i32 3
%10 = atomicrmw add ptr addrspace(1) %scevgep30, i32 %6 seq_cst, align 4
%scevgep31 = getelementptr i32, ptr addrspace(1) %lsr.iv27, i64 -1
%11 = atomicrmw add ptr addrspace(1) %scevgep31, i32 %7 seq_cst, align 4
%12 = atomicrmw add ptr addrspace(1) %lsr.iv27, i32 %8 seq_cst, align 4
%scevgep29 = getelementptr i32, ptr addrspace(1) %lsr.iv27, i64 1
%13 = atomicrmw add ptr addrspace(1) %scevgep29, i32 %9 seq_cst, align 4
%inc.3 = add nuw i32 %i.08, 4
%scevgep28 = getelementptr i32, ptr addrspace(1) %lsr.iv27, i64 4
%scevgep34 = getelementptr i32, ptr addrspace(4) %lsr.iv33, i64 4
%niter.ncmp.3.not = icmp eq i32 %unroll_iter, %inc.3
br i1 %niter.ncmp.3.not, label %for.cond.cleanup.loopexit.unr-lcssa.loopexit, label %for.body, !llvm.loop !13
}
```
we can fully vectorize load operation.
I would like to ask whether this modification is feasible or it might lead to unknown runtime issues?
</pre>
<img width="1px" height="1px" alt="" src="http://email.email.llvm.org/o/eJzsW19v4zYS_zTKCyFBIiVLfsiDnWzuimtxRXevB9yLQUuUzS5FqiQVb_bTH0j9tSw7sjfbHnpZBOs_mhkOZ34cDodjrBTdcULunWjtRI93uNJ7Ie_37IV-uduK7OX-70QSQBV4qDIMcsqI4z86_spZ-M2f_bjZ7JjYYrbZgGdBM6CJ0istCpo6MKFcO3AFNhtJlJY01ZsNwFkmiVIOfABTjzOlm0eAO3AJnHhdDwSAA1Ep8a7AoOJSMAbC9kkuJKiHAxQ46BH4Dlrbtw-A27cOXNu_I4EAYKvpKsscmDhw0eoWrakTPRo9jDrtp6WDWlYnfmys0b05Nkv9_w-_AKVFCbYkF5IAB0ImcOYqLSRxn0mqhaRfiXQgHHJNijKzeKp4qqngYKW1VA5agaJSupRiZ7QGXOSSEMCFJGkllXlX8QPlWS0hIznlBGRKbJhIMav95YT-5j-B37vtZ_pxQ40xEbS-UiVOiQOTwBgArgAXmFFsRktxqSs7rWjo1BFfeJZPEpwJzl6MgNbtCJpP1vNWyU3FOS5ItjEiDQL83oGEa_nioFWPjygtytgCgKZFCdRODyQ-AL-l3EpAg5bePGF4S5j5IhfSM-j3Skn2BGfGOaPHqeCZlzKCeVUOPTTBiizILvwzXi0lyZRV2oFRPad-Qr59gLMMcHU4mowbDMi-aImpJrKm5tkRJRoQBr11KtZZxz8i66wTXJy7x4QoyReqvYpLl6VK4VdM6XFyuGwxS4FWp3aZMG4_qTocbM4awG0DhQMjlZLnHSnhwlLuiCaMFITrUkvDM4XgFvkjnC9CAE_kmlHnyg17uS38BzKNG05sObbeK_7ovmqReNau5wZ9zeHX6XPWtbPnAR9eRQP1_MSwWvnlntZQiNbAP8sNmmhvqIwEnnpoQDxXOyumV4SlRekVIvO40P2yI7-32GwX7XRoGnJfjkGTi46UlI3NM1p1I5IbfTOYcI19Rb50gaXzhRYG3APaZr1862oxo55KhegtVvdQ9tRitAY8a9nLYWxk-xEwe8E1kJT06DMMjxA9OYcav50VpuSeRX3LFU1xjaFtNTqrTzipz03awBnaWEFd9B8u-eFDT1Xbs8L6gYer8hVtew1qvJnkbgZ8a-MZIszojoOwHirQW4zNazwQXPu8TlNlcbCZwAUEt0gZ5FIIKPL7Jq2XTDvghO2MeaaSjY7gKOkYeuimNdwbwSy1CbHRTUv4yADHgvuZmsh6JiafoOU0MJ_ImZclnQ_TjfsZey4stfkQBLO21gsZ5uXYM2e_v6TB66ntGQ3O2mZ-hjlOkyXR9iwzFYovRuGz-UCfqA6iHUJXxjsUjgaYDnHoJMQd6TEZeWF87V6QzNIFLq7RxezuV2RZnYTzmVan2cmWjvxviQdxGw_ciWwBXRFqTiIYQpOio2s2hE6PeXvC4ro9oTPgYFOILm8KLUvwNjYPJkTHb2Pzoej4FpvH82ye3GbzYGDz-LLNl9enELUdXlc-8G_KIuKB8stZgIHLNwHMFF6uOK9fwMtQchDcgpfFTJPDmwBjPnc2D4LLRrfBs0_ZqsPw1GVYpjyUvImHpoJF-CYeGkrmNsviJs1C5xK2Qe2n2UfqPWWctY1lXVvaupzHTaZwaFwivlDI7Wq36oWnXeHWlki54ASokqQVwxpvGQEHypgkupK8reymDEtSmyT0rRapZl89a_6kdUIAaFFgubNVcIiCOVoNC8hYa0m3lSaqKcSabCpezyxCAwfCXOKCuKWgXNdVb_ToQIgZc8wpAsKCcpeRHWZNcdw90EzvO0K_IePC1RKXJeU7t8ADAi0r0tAojdPPbimFriVtqzwn0lX0K-nIk4ZWY7kj2k3Lqnukik3iHz_OCdaVJKqjceC61F9iY1wHrnuO1t_H9go6e93o63OC4UBwa-oR5BpkFiKrGPFyhndtLhw48dqBQZO0BUHz2qSkAeolwYA_Pxce5lxobGAyEhEOSe1wNCNcHxM1tYVgcaqhP6A0QG5VcCD8-PgP8CuRigruNAWBaA3BFxteokfzyXAE3W5rvh2qE4xkB73sQ7rHctPCouE_mgscMYc9s7GIK0nOSKrdXH8diPCHItBIRNyLOFkS3RQG_HVozajSlKe6EcQrxno5n4nkhA0EBEMB0bEbHAhThvkOPNdWBQHyfM_EyWRHtRP6O6o9Tp4p114qCgetMGOqxPKzA5-MbzecCm9HNUiWJIjSFEd5hGAYb5dBvoU4zaPEX_hhnEVhinwYExvwj-a0eEUl5CWebzTSeKcc-PTLhx8_rD5-2CCzyp5yyjE7FRofC20OPfWr2V2OvJKcaGAvJFvgLSeZlidMouC0FNpg3WCpF1CvqhMJR0hvAE6LkhHwUN9Sgk_r1Wo0sQbCIwjUhYJmtGN6eDJItzl59Z7pZVSZEDMeCZ0bCbUjhdNDhheGHO4RRwNO3XXi3NbyFr4oNXALLWnJiIMecZHtUg7cjGyrnb1p9hgDbomVIqqOyefuV4H7cXyhCgMTNwq8I_ZMmuy1Ls2u58AnBz7tqN5XW4v-GvLNi9lSfiOpduCTGVYbaKJgEUYQLR34BGMUBiEK3AjHWzdcJIG7XJLATaIsy7MI58EiM7AdKLLiGfgB5KLiGdB7rIHeE1DflWKO2ctXIkEquKIZkarNCAeZpSiJbAKyFmDb8JIMHKjeA8xfQBNdvO858RAtoziLly6Mw4Ub5outuwzI0k3iRQwR9vOtOWodTXxbaXtzr_dUAUV1ZWcxiYs5V_zArB70aOLz8Jb_1iv-y90BcB2M2NtvrhABT0TAsYiL_OiEH52ocG6l_ZuAFHNQSuLaE5BFEc8AtJZu1471iPfWLgEmuzdYA4dai26pGuwrAkJAudIS5FQq3TOZkXAdnXqfDa1tCYIjisYtJ1RwRAUnqdCICg2p5gIM34QrHMwHQgskDK8aqsUPRmeaWyZ7WsBvldKgEBnNX4ASBQGpyAigvGvFsM1CaAXa6EG3Dnz6JDFXuZCFCRy_tg534NOPAmcfTcTuvpReWjbV57w5kxhxVH3EOfkkfhLP5HuGMpKE0F-GyA1QFLshTgM3SQh2gzgm-TZM_GCbjELZpz3h4Adz-AWSqIppsCVMHDqLjC35RzfzmLP4-Gj_aifPmCmcZvrT2njeu3jeu3jO15wmIf-tLTyTS-K9f-e9f-e9f-eGpXJ9887MRf29O3cu94ac3tb2nTvTE_iT2namXfT_27NzDrLf2rBzDrX_Y906r0__-ladWVN_79N579P5Ln06MwLcH9OkMyfs_5U7dF4JAze351wOWa_35jjoIWzukdCHSwJvatEhZl9KW7WPB7OK9JdFPWt8Hevw_Jhcxzq0yfI61qPD6FR3yTmHTzUjLb65GWk2vAbbTHOjcp3aM_t5zjWAzNKzlp5clD6j32auTY5aYtD1NjlqWbnQJvQdGlbmTvHKbpW5QeWv3KoyVfltivV5xdjLoGTfXx8MLwuaWvFBVCwDjH4m5giJ1Wdw2BO9J82tj60i09RyAqpATrCiW0aAkIBqUNDdXgNGcGa4K_6ZiwMHsuKaFgRQpSqiHPRUD3aX3aNsiZb4jtwHsZ9EQRSG6G5_n_pbP17kSZRsUwJjf5GGUbaM4zwNUxKh5R29hz4MfWjSORRD5EGShlmKEhgukqUPIyf0SYEp86zVhNzd2bHvExgm4Z01sWp_SCvvbYl5W-2UE_qMKq16Nk01sz-5_WepadHcrzQtDD8KnLm2EO72lXCz00brhyrDDlysfnr828__MuQPtg1j4ITm6rO-N3EgBPUdqnVw82vZ-jrQLm2Q4yy7qyS7v7pg3hgdPtm5_zcAAP__XgN98w">